
code stringlengths 5 1M | repo_name stringlengths 5 109 | path stringlengths 6 208 | language stringclasses 1 value | license stringclasses 15 values | size int64 5 1M |
|---|---|---|---|---|---|
package com.github.rshindo.playchat.repository
import java.time.ZoneId
import java.util.Date
import javax.inject.Singleton
import com.github.rshindo.playchat.entity.Channel
import com.github.rshindo.playchat.json.{Channel => ChannelJson}
import scalikejdbc.DB
/**
* Created by shindo on 2016/12/18.
*/
@Singleton
class ChannelRepository {
def findAll(): List[ChannelJson] = {
val channelList = DB readOnly { implicit session =>
Channel.findAll()
}
channelList.map { c => ChannelJson(
channelId = c.channelId,
title = c.title,
insertDate = Date.from(c.insertDate.atZone(ZoneId.systemDefault()).toInstant)
)
}
}
def create(title: String): ChannelJson = {
val channel = DB autoCommit { implicit session =>
Channel.create(title)
}
ChannelJson(
channelId = channel.channelId,
title = channel.title,
insertDate = Date.from(channel.insertDate.atZone(ZoneId.systemDefault()).toInstant)
)
}
}
| rshindo/play-chat | play-chat-server/app/com/github/rshindo/playchat/repository/ChannelRepository.scala | Scala | mit | 986 |
package com.statigories.switchboard.common.providers
import com.statigories.switchboard.common.FromMap
import org.scalatest.{FlatSpec, Matchers}
class SystemPropertyConfigProviderTest extends FlatSpec with Matchers {
case class TestClass(foo: String, bar: Int, baz: Option[BigDecimal]) {
val dummyProperty = "should not break"
}
object TestClassProvider extends SystemPropertyConfigProvider[TestClass]
object TestClass extends FromMap[TestClass] {
override implicit def fromMap(map: Map[String, String]): TestClass = TestClass(
foo = get("foo", map),
bar = Integer.parseInt(get("bar", map)),
baz = getOpt("baz", map).map(s => BigDecimal(s))
)
}
"#getConfig" should "return None when the config is missing" in {
TestClassProvider.getConfig() shouldBe None
}
it should "return the populated TestClass when the config is provided" in {
System.setProperty("foo", "abcd")
System.setProperty("bar", "1234")
System.setProperty("baz", "10.5")
TestClassProvider.getConfig() shouldBe Some(TestClass(
foo = "abcd",
bar = 1234,
baz = Some(BigDecimal(10.5))
))
}
it should "return the populated TestClass even when optional properties are missing" in {
System.setProperty("foo", "abcd")
System.setProperty("bar", "1234")
System.clearProperty("baz")
TestClassProvider.getConfig() shouldBe Some(TestClass(
foo = "abcd",
bar = 1234,
baz = None
))
}
"#cleanupName" should "work without a prefix" in {
TestClassProvider.cleanupName(None, "apiKey") shouldBe "apiKey"
}
it should "include the prefix when given" in {
TestClassProvider.cleanupName(Some("prefix"), "apiKey") shouldBe "prefix.apiKey"
}
}
| statigories/switchboard | src/test/scala/com/statigories/switchboard/common/providers/SystemPropertyConfigProviderTest.scala | Scala | mit | 1,741 |
/*
* Copyright 2020 Precog Data
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package quasar.impl.destinations
import slamdata.Predef._
import quasar.ConditionMatchers
import quasar.Qspec
import quasar.api.destination.{
DestinationError,
DestinationName,
DestinationRef,
DestinationType
}
import quasar.contrib.scalaz.MonadState_
import monocle.Lens
import monocle.macros.Lenses
import scalaz.std.anyVal._
import scalaz.syntax.monad._
import scalaz.{IMap, ISet, State}
final class MockDestinationsSpec extends Qspec with ConditionMatchers {
import MockDestinationsSpec._
type M[A] = State[RunState[Int, String], A]
implicit def monadRunningState: MonadState_[M, MockDestinations.State[Int, String]] =
MonadState_.zoom[M](runStateMockState[Int, String])
implicit def monadIndex: MonadState_[M, Int] =
MonadState_.zoom[M][RunState[Int, String], Int](RunState.currentIndex)
val mockType = DestinationType("mock", 1)
val unsupportedType = DestinationType("unsupported", 1337)
def freshId: M[Int] =
MonadState_[M, Int].modify(_ + 1) >> MonadState_[M, Int].get
def lastId: M[Int] =
MonadState_[M, Int].get
val supportedSet = ISet.singleton(mockType)
val destinations =
MockDestinations[Int, String, M](freshId, supportedSet)
val testRef: DestinationRef[String] =
DestinationRef(mockType, DestinationName("mock-name"), "foo")
val unsupportedRef: DestinationRef[String] =
DestinationRef(unsupportedType, DestinationName("unsupported-name"), "bar")
def run[A](act: M[A]): A =
act.eval(initial[Int, String])
"adds a destination" >> {
val (addStatus, retrieved) =
run(for {
addStatus <- destinations.addDestination(testRef)
newId <- lastId
retrieved <- destinations.destinationRef(newId)
} yield (addStatus, retrieved))
addStatus must be_\/-
retrieved must be_\/-(testRef)
}
"verifies name uniqueness on creation" >> {
val (add1, add2) =
run(for {
add1 <- destinations.addDestination(testRef)
add2 <- destinations.addDestination(testRef)
} yield (add1, add2))
add1 must be_\/-
add2 must be_-\/(DestinationError.destinationNameExists(testRef.name))
}
"verifies name uniqueness on replace" >> {
val testRef2 = DestinationRef.name.set(DestinationName("mock-2"))(testRef)
val testRef3 = DestinationRef.name.set(DestinationName("mock-2"))(testRef)
val replace =
run(for {
_ <- destinations.addDestination(testRef)
addId <- lastId
_ <- destinations.addDestination(testRef2)
replace <- destinations.replaceDestination(addId, testRef3)
} yield replace)
replace must beAbnormal(DestinationError.destinationNameExists(testRef2.name))
}
"allows replacement with the same name" >> {
val testRef2 = DestinationRef.config.set("modified")(testRef)
val (replaceStatus, replaced) =
run(for {
_ <- destinations.addDestination(testRef)
addId <- lastId
replaceStatus <- destinations.replaceDestination(addId, testRef2)
replaced <- destinations.destinationRef(addId)
} yield (replaceStatus, replaced))
replaceStatus must beNormal
replaced must be_\/-(testRef2)
}
"errors on unsupported when replacing" >> {
val testRef2 = DestinationRef.kind.set(unsupportedType)(testRef)
val (replaceStatus, replaced) =
run(for {
_ <- destinations.addDestination(testRef)
addId <- lastId
replaceStatus <- destinations.replaceDestination(addId, testRef2)
replaced <- destinations.destinationRef(addId)
} yield (replaceStatus, replaced))
replaceStatus must beAbnormal(DestinationError.destinationUnsupported(unsupportedType, supportedSet))
replaced must be_\/-(testRef)
}
"errors on unsupported" >> {
run(destinations.addDestination(unsupportedRef)) must be_-\/(
DestinationError.destinationUnsupported(unsupportedType, supportedSet))
}
}
object MockDestinationsSpec {
@Lenses
case class RunState[I, C](running: IMap[I, DestinationRef[C]], errored: IMap[I, Exception], currentIndex: Int)
def initial[I, C]: RunState[I, C] =
RunState(IMap.empty, IMap.empty, 0)
def runStateMockState[I, C]: Lens[RunState[I, C], MockDestinations.State[I, C]] =
Lens[RunState[I, C], MockDestinations.State[I, C]](runState =>
MockDestinations.State(runState.running, runState.errored))(mockState => (rs =>
rs.copy(
running = mockState.running,
errored = mockState.errored)))
}
| quasar-analytics/quasar | impl/src/test/scala/quasar/impl/destinations/MockDestinationsSpec.scala | Scala | apache-2.0 | 5,068 |
package com.wuyuntao.aeneas.cli
import com.typesafe.config.ConfigFactory
import com.wuyuntao.aeneas.migration.Migrator
import scopt.OptionParser
object CliApp extends App {
val parser = new OptionParser[CliConfig]("aeneas-cli") {
head("aeneas-cli", "0.0.1")
help("help")
.text("Print usage text")
cmd("migrate").
action { (o, c) => c.copy(migrate = new MigrateConfig()) }.
children(
opt[String]('i', "input-jar-path")
.action { (o, c) => c.copy(migrate = c.migrate.copy(inputJarPath = o)) },
opt[Long]('v', "migrate-to-version")
.action { (o, c) => c.copy(migrate = c.migrate.copy(version = o)) })
}
parser.parse(args, CliConfig()) match {
case Some(config) =>
if (config.migrate != null) {
migrate(config.migrate)
}
case None =>
}
def migrate(config: MigrateConfig) = {
val config = ConfigFactory.load();
val migrator = Migrator(config.getConfig("aeneas.migration"))
migrator.migrate()
}
} | wuyuntao/Aeneas | aeneas-cli/src/main/scala/com/wuyuntao/aeneas/cli/CliApp.scala | Scala | apache-2.0 | 1,018 |
/**
* Copyright 2015 Thomson Reuters
*
* Licensed under the Apache License, Version 2.0 (the “License”); you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
* an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
*
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package cmwell.tools.data.helpers
import akka.actor.ActorSystem
import akka.stream.ActorMaterializer
import com.typesafe.config.ConfigFactory
import org.scalatest.{BeforeAndAfterAll, Matchers, _}
import scala.concurrent.Await
import scala.concurrent.duration._
trait BaseStreamSpec extends FlatSpec with Matchers with BeforeAndAfterAll {
protected implicit val system = {
def config = ConfigFactory.parseString(s"akka.stream.materializer.auto-fusing=$autoFusing")
.withFallback(ConfigFactory.load())
ActorSystem("default", config)
}
protected implicit val mat = ActorMaterializer()
override protected def afterAll() = {
Await.ready(system.terminate(), 42.seconds)
super.afterAll()
}
protected def autoFusing: Boolean
}
| thomsonreuters/CM-Well | server/cmwell-data-tools/src/test/scala/cmwell/tools/data/helpers/BaseStreamSpec.scala | Scala | apache-2.0 | 1,378 |
package com.bio4j.release.generic
import com.bio4j.model._
import scala.compat.java8.OptionConverters._
import bio4j.data.uniprot._
case object conversions {
def statusToDatasets(status: Status): UniProtGraph.Datasets =
status match {
case Reviewed => UniProtGraph.Datasets.swissProt
case Unreviewed => UniProtGraph.Datasets.trEMBL
}
def proteinExistenceToExistenceEvidence(prEx: ProteinExistence): UniProtGraph.ExistenceEvidence =
prEx match {
case EvidenceAtProteinLevel => UniProtGraph.ExistenceEvidence.proteinLevel
case EvidenceAtTranscriptLevel => UniProtGraph.ExistenceEvidence.transcriptLevel
case InferredFromHomology => UniProtGraph.ExistenceEvidence.homologyInferred
case Predicted => UniProtGraph.ExistenceEvidence.predicted
case Uncertain => UniProtGraph.ExistenceEvidence.uncertain
}
def organelleToGeneLocation(org: Organelle): UniProtGraph.GeneLocations =
org match {
case Apicoplast => UniProtGraph.GeneLocations.apicoplast
case Chloroplast => UniProtGraph.GeneLocations.chloroplast
case OrganellarChromatophore => UniProtGraph.GeneLocations.organellar_chromatophore
case Cyanelle => UniProtGraph.GeneLocations.cyanelle
case Hydrogenosome => UniProtGraph.GeneLocations.hydrogenosome
case Mitochondrion => UniProtGraph.GeneLocations.mitochondrion
case NonPhotosyntheticPlastid => UniProtGraph.GeneLocations.non_photosynthetic_plastid
case Nucleomorph => UniProtGraph.GeneLocations.nucleomorph
case Plasmid(_) => UniProtGraph.GeneLocations.plasmid
case Plastid => UniProtGraph.GeneLocations.plastid
}
def featureKeyToFeatureType(ftKey: FeatureKey): UniProtGraph.FeatureTypes =
ftKey match {
case INIT_MET => UniProtGraph.FeatureTypes.initiatorMethionine
case SIGNAL => UniProtGraph.FeatureTypes.signalPeptide
case PROPEP => UniProtGraph.FeatureTypes.propeptide
case TRANSIT => UniProtGraph.FeatureTypes.transitPeptide
case CHAIN => UniProtGraph.FeatureTypes.chain
case PEPTIDE => UniProtGraph.FeatureTypes.peptide
case TOPO_DOM => UniProtGraph.FeatureTypes.topologicalDomain
case TRANSMEM => UniProtGraph.FeatureTypes.transmembraneRegion
case INTRAMEM => UniProtGraph.FeatureTypes.intramembraneRegion
case DOMAIN => UniProtGraph.FeatureTypes.domain
case REPEAT => UniProtGraph.FeatureTypes.repeat
case CA_BIND => UniProtGraph.FeatureTypes.calciumBindingRegion
case ZN_FING => UniProtGraph.FeatureTypes.zincFingerRegion
case DNA_BIND => UniProtGraph.FeatureTypes.DNABindingRegion
case NP_BIND => UniProtGraph.FeatureTypes.nucleotidePhosphateBindingRegion
case REGION => UniProtGraph.FeatureTypes.regionOfInterest
case COILED => UniProtGraph.FeatureTypes.coiledCoilRegion
case MOTIF => UniProtGraph.FeatureTypes.shortSequenceMotif
case COMPBIAS => UniProtGraph.FeatureTypes.compositionallyBiasedRegion
case ACT_SITE => UniProtGraph.FeatureTypes.activeSite
case METAL => UniProtGraph.FeatureTypes.metalIonBindingSite
case BINDING => UniProtGraph.FeatureTypes.bindingSite
case SITE => UniProtGraph.FeatureTypes.site
case NON_STD => UniProtGraph.FeatureTypes.nonstandardAminoAcid
case MOD_RES => UniProtGraph.FeatureTypes.modifiedResidue
case LIPID => UniProtGraph.FeatureTypes.lipidMoietyBindingRegion
case CARBOHYD => UniProtGraph.FeatureTypes.glycosylationSite
case DISULFID => UniProtGraph.FeatureTypes.disulfideBond
case CROSSLNK => UniProtGraph.FeatureTypes.crosslink
case VAR_SEQ => UniProtGraph.FeatureTypes.spliceVariant
case VARIANT => UniProtGraph.FeatureTypes.sequenceVariant
case MUTAGEN => UniProtGraph.FeatureTypes.mutagenesisSite
case UNSURE => UniProtGraph.FeatureTypes.unsureResidue
case CONFLICT => UniProtGraph.FeatureTypes.sequenceConflict
case NON_CONS => UniProtGraph.FeatureTypes.nonConsecutiveResidues
case NON_TER => UniProtGraph.FeatureTypes.nonTerminalResidue
case HELIX => UniProtGraph.FeatureTypes.helix
case STRAND => UniProtGraph.FeatureTypes.strand
case TURN => UniProtGraph.FeatureTypes.turn
}
// TODO implement this
def featureFromAsInt(from: String): Int =
???
// TODO implement this
def featureToAsInt(to: String): Int =
???
def commentTopic(c: Comment): UniProtGraph.CommentTopics =
c match {
case Isoform(_,_,_) => UniProtGraph.CommentTopics.alternativeProducts
case Allergen(_) => UniProtGraph.CommentTopics.allergen
case BiophysicochemicalProperties(_) => UniProtGraph.CommentTopics.biophysicochemicalProperties
case Biotechnology(_) => UniProtGraph.CommentTopics.biotechnology
case CatalyticActivity(_) => UniProtGraph.CommentTopics.catalyticActivity
case Caution(_) => UniProtGraph.CommentTopics.caution
case Cofactor(_) => UniProtGraph.CommentTopics.cofactor
case DevelopmentalStage(_) => UniProtGraph.CommentTopics.developmentalStage
case Disease(_) => UniProtGraph.CommentTopics.disease
case DisruptionPhenotype(_) => UniProtGraph.CommentTopics.disruptionPhenotype
case Domain(_) => UniProtGraph.CommentTopics.domain
case EnzymeRegulation(_) => UniProtGraph.CommentTopics.enzymeRegulation
case Function(_) => UniProtGraph.CommentTopics.function
case Induction(_) => UniProtGraph.CommentTopics.induction
case Interaction(_) => UniProtGraph.CommentTopics.interaction
case MassSpectrometry(_) => UniProtGraph.CommentTopics.massSpectrometry
case Miscellaneous(_) => UniProtGraph.CommentTopics.miscellaneous
case Pathway(_) => UniProtGraph.CommentTopics.pathway
case Pharmaceutical(_) => UniProtGraph.CommentTopics.pharmaceutical
case Polymorphism(_) => UniProtGraph.CommentTopics.polymorphism
case PTM(_) => UniProtGraph.CommentTopics.PTM
case RNAEditing(_) => UniProtGraph.CommentTopics.RNAEditing
case SequenceCaution(_) => UniProtGraph.CommentTopics.sequenceCaution
case Similarity(_) => UniProtGraph.CommentTopics.similarity
case SubcellularLocation(_) => UniProtGraph.CommentTopics.subcellularLocation
case Subunit(_) => UniProtGraph.CommentTopics.subunit
case TissueSpecificity(_) => UniProtGraph.CommentTopics.tissueSpecificity
case ToxicDose(_) => UniProtGraph.CommentTopics.toxicDose
case WebResource(_) => UniProtGraph.CommentTopics.onlineInformation
}
val stringToGeneLocation: String => UniProtGraph.GeneLocations =
{
case "apicoplast" => UniProtGraph.GeneLocations.apicoplast
case "chloroplast" => UniProtGraph.GeneLocations.chloroplast
case "organellar chromatophore" => UniProtGraph.GeneLocations.organellar_chromatophore
case "cyanelle" => UniProtGraph.GeneLocations.cyanelle
case "hydrogenosome" => UniProtGraph.GeneLocations.hydrogenosome
case "mitochondrion" => UniProtGraph.GeneLocations.mitochondrion
case "non-photosynthetic plastid" => UniProtGraph.GeneLocations.non_photosynthetic_plastid
case "nucleomorph" => UniProtGraph.GeneLocations.nucleomorph
case "plasmid" => UniProtGraph.GeneLocations.plasmid
case "plastid" => UniProtGraph.GeneLocations.plastid
case _ => UniProtGraph.GeneLocations.chromosome
}
val stringToKeywordCategory: String => Option[UniProtGraph.KeywordCategories] =
{
case "Biological process" => Some(UniProtGraph.KeywordCategories.biologicalProcess)
case "Cellular component" => Some(UniProtGraph.KeywordCategories.cellularComponent)
case "Coding sequence diversity" => Some(UniProtGraph.KeywordCategories.codingSequenceDiversity)
case "Developmental stage" => Some(UniProtGraph.KeywordCategories.developmentalStage)
case "Disease" => Some(UniProtGraph.KeywordCategories.disease)
case "Domain" => Some(UniProtGraph.KeywordCategories.domain)
case "Ligand" => Some(UniProtGraph.KeywordCategories.ligand)
case "Molecular function" => Some(UniProtGraph.KeywordCategories.molecularFunction)
case "PTM" => Some(UniProtGraph.KeywordCategories.PTM)
case "Technical term" => Some(UniProtGraph.KeywordCategories.technicalTerm)
case _ => None
}
}
| bio4j/bio4j-data-import | src/main/scala/uniprot/conversions.scala | Scala | agpl-3.0 | 9,383 |
/**
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package kafka.producer
import async.{CallbackHandler, EventHandler}
import kafka.serializer.Encoder
import kafka.utils._
import java.util.Properties
import kafka.cluster.{Partition, Broker}
import java.util.concurrent.atomic.AtomicBoolean
import kafka.common.{NoBrokersForPartitionException, InvalidPartitionException}
import kafka.api.ProducerRequest
class Producer[K,V](config: ProducerConfig,
partitioner: Partitioner[K],
producerPool: ProducerPool[V],
populateProducerPool: Boolean,
private var brokerPartitionInfo: BrokerPartitionInfo) /* for testing purpose only. Applications should ideally */
/* use the other constructor*/
extends Logging {
private val hasShutdown = new AtomicBoolean(false)
private val random = new java.util.Random
// check if zookeeper based auto partition discovery is enabled
private val zkEnabled = Utils.propertyExists(config.zkConnect)
if(brokerPartitionInfo == null) {
zkEnabled match {
case true =>
val zkProps = new Properties()
zkProps.put("zk.connect", config.zkConnect)
zkProps.put("zk.sessiontimeout.ms", config.zkSessionTimeoutMs.toString)
zkProps.put("zk.connectiontimeout.ms", config.zkConnectionTimeoutMs.toString)
zkProps.put("zk.synctime.ms", config.zkSyncTimeMs.toString)
brokerPartitionInfo = new ZKBrokerPartitionInfo(new ZKConfig(zkProps), producerCbk)
case false =>
brokerPartitionInfo = new ConfigBrokerPartitionInfo(config)
}
}
// pool of producers, one per broker
if(populateProducerPool) {
val allBrokers = brokerPartitionInfo.getAllBrokerInfo
allBrokers.foreach(b => producerPool.addProducer(new Broker(b._1, b._2.host, b._2.host, b._2.port)))
}
/**
* This constructor can be used when all config parameters will be specified through the
* ProducerConfig object
* @param config Producer Configuration object
*/
def this(config: ProducerConfig) = this(config, Utils.getObject(config.partitionerClass),
new ProducerPool[V](config, Utils.getObject(config.serializerClass)), true, null)
/**
* This constructor can be used to provide pre-instantiated objects for all config parameters
* that would otherwise be instantiated via reflection. i.e. encoder, partitioner, event handler and
* callback handler. If you use this constructor, encoder, eventHandler, callback handler and partitioner
* will not be picked up from the config.
* @param config Producer Configuration object
* @param encoder Encoder used to convert an object of type V to a kafka.message.Message. If this is null it
* throws an InvalidConfigException
* @param eventHandler the class that implements kafka.producer.async.IEventHandler[T] used to
* dispatch a batch of produce requests, using an instance of kafka.producer.SyncProducer. If this is null, it
* uses the DefaultEventHandler
* @param cbkHandler the class that implements kafka.producer.async.CallbackHandler[T] used to inject
* callbacks at various stages of the kafka.producer.AsyncProducer pipeline. If this is null, the producer does
* not use the callback handler and hence does not invoke any callbacks
* @param partitioner class that implements the kafka.producer.Partitioner[K], used to supply a custom
* partitioning strategy on the message key (of type K) that is specified through the ProducerData[K, T]
* object in the send API. If this is null, producer uses DefaultPartitioner
*/
def this(config: ProducerConfig,
encoder: Encoder[V],
eventHandler: EventHandler[V],
cbkHandler: CallbackHandler[V],
partitioner: Partitioner[K]) =
this(config, if(partitioner == null) new DefaultPartitioner[K] else partitioner,
new ProducerPool[V](config, encoder, eventHandler, cbkHandler), true, null)
/**
* Sends the data, partitioned by key to the topic using either the
* synchronous or the asynchronous producer
* @param producerData the producer data object that encapsulates the topic, key and message data
*/
def send(producerData: ProducerData[K,V]*) {
zkEnabled match {
case true => zkSend(producerData: _*)
case false => configSend(producerData: _*)
}
}
private def zkSend(producerData: ProducerData[K,V]*) {
val producerPoolRequests = producerData.map { pd =>
var brokerIdPartition: Option[Partition] = None
var brokerInfoOpt: Option[Broker] = None
var numRetries: Int = 0
while(numRetries <= config.zkReadRetries && brokerInfoOpt.isEmpty) {
if(numRetries > 0) {
info("Try #" + numRetries + " ZK producer cache is stale. Refreshing it by reading from ZK again")
brokerPartitionInfo.updateInfo
}
val topicPartitionsList = getPartitionListForTopic(pd)
val totalNumPartitions = topicPartitionsList.length
val partitionId = getPartition(pd.getKey, totalNumPartitions)
brokerIdPartition = Some(topicPartitionsList(partitionId))
brokerInfoOpt = brokerPartitionInfo.getBrokerInfo(brokerIdPartition.get.brokerId)
numRetries += 1
}
brokerInfoOpt match {
case Some(brokerInfo) =>
debug("Sending message to broker " + brokerInfo.host + ":" + brokerInfo.port +
" on partition " + brokerIdPartition.get.partId)
case None =>
throw new NoBrokersForPartitionException("Invalid Zookeeper state. Failed to get partition for topic: " +
pd.getTopic + " and key: " + pd.getKey)
}
producerPool.getProducerPoolData(pd.getTopic,
new Partition(brokerIdPartition.get.brokerId, brokerIdPartition.get.partId),
pd.getData)
}
producerPool.send(producerPoolRequests: _*)
}
private def configSend(producerData: ProducerData[K,V]*) {
val producerPoolRequests = producerData.map { pd =>
// find the broker partitions registered for this topic
val topicPartitionsList = getPartitionListForTopic(pd)
val totalNumPartitions = topicPartitionsList.length
val randomBrokerId = random.nextInt(totalNumPartitions)
val brokerIdPartition = topicPartitionsList(randomBrokerId)
val brokerInfo = brokerPartitionInfo.getBrokerInfo(brokerIdPartition.brokerId).get
debug("Sending message to broker " + brokerInfo.host + ":" + brokerInfo.port +
" on a randomly chosen partition")
val partition = ProducerRequest.RandomPartition
debug("Sending message to broker " + brokerInfo.host + ":" + brokerInfo.port + " on a partition " +
brokerIdPartition.partId)
producerPool.getProducerPoolData(pd.getTopic,
new Partition(brokerIdPartition.brokerId, partition),
pd.getData)
}
producerPool.send(producerPoolRequests: _*)
}
private def getPartitionListForTopic(pd: ProducerData[K,V]): Seq[Partition] = {
debug("Getting the number of broker partitions registered for topic: " + pd.getTopic)
val topicPartitionsList = brokerPartitionInfo.getBrokerPartitionInfo(pd.getTopic).toSeq
debug("Broker partitions registered for topic: " + pd.getTopic + " = " + topicPartitionsList)
val totalNumPartitions = topicPartitionsList.length
if(totalNumPartitions == 0) throw new NoBrokersForPartitionException("Partition = " + pd.getKey)
topicPartitionsList
}
/**
* Retrieves the partition id and throws an InvalidPartitionException if
* the value of partition is not between 0 and numPartitions-1
* @param key the partition key
* @param numPartitions the total number of available partitions
* @returns the partition id
*/
private def getPartition(key: K, numPartitions: Int): Int = {
if(numPartitions <= 0)
throw new InvalidPartitionException("Invalid number of partitions: " + numPartitions +
"\\n Valid values are > 0")
val partition = if(key == null) random.nextInt(numPartitions)
else partitioner.partition(key , numPartitions)
if(partition < 0 || partition >= numPartitions)
throw new InvalidPartitionException("Invalid partition id : " + partition +
"\\n Valid values are in the range inclusive [0, " + (numPartitions-1) + "]")
partition
}
/**
* Callback to add a new producer to the producer pool. Used by ZKBrokerPartitionInfo
* on registration of new broker in zookeeper
* @param bid the id of the broker
* @param host the hostname of the broker
* @param port the port of the broker
*/
private def producerCbk(bid: Int, host: String, port: Int) = {
if(populateProducerPool) producerPool.addProducer(new Broker(bid, host, host, port))
else debug("Skipping the callback since populateProducerPool = false")
}
/**
* Close API to close the producer pool connections to all Kafka brokers. Also closes
* the zookeeper client connection if one exists
*/
def close() = {
val canShutdown = hasShutdown.compareAndSet(false, true)
if(canShutdown) {
producerPool.close
brokerPartitionInfo.close
}
}
}
| piavlo/operations-debs-kafka | core/src/main/scala/kafka/producer/Producer.scala | Scala | apache-2.0 | 9,978 |
package im.actor.server.push
import java.nio.ByteBuffer
import scala.annotation.tailrec
import scala.concurrent._
import scala.concurrent.duration._
import akka.actor._
import akka.pattern.ask
import akka.util.Timeout
import com.esotericsoftware.kryo.serializers.TaggedFieldSerializer.{ Tag ⇒ KryoTag }
import com.google.android.gcm.server.{ Sender ⇒ GCMSender }
import slick.dbio.DBIO
import im.actor.api.rpc.UpdateBox
import im.actor.api.rpc.messaging.UpdateMessage
import im.actor.api.rpc.peers.Peer
import im.actor.api.{ rpc ⇒ api }
import im.actor.server.models.sequence
import im.actor.server.sequence.SeqState
import im.actor.server.{ models, persist ⇒ p }
object SeqUpdatesManager {
@SerialVersionUID(1L)
private[push] case class Envelope(authId: Long, payload: Message)
private[push] sealed trait Message
@SerialVersionUID(1L)
private[push] case object GetSequenceState extends Message
@SerialVersionUID(1L)
private[push] case class PushUpdate(
header: Int,
serializedData: Array[Byte],
userIds: Set[Int],
groupIds: Set[Int],
pushText: Option[String],
originPeer: Option[Peer],
isFat: Boolean
) extends Message
@SerialVersionUID(1L)
private[push] case class PushUpdateGetSequenceState(
header: Int,
serializedData: Array[Byte],
userIds: Set[Int],
groupIds: Set[Int],
pushText: Option[String],
originPeer: Option[Peer],
isFat: Boolean
) extends Message
@SerialVersionUID(1L)
private[push] case class Subscribe(consumer: ActorRef) extends Message
@SerialVersionUID(1L)
private[push] case class SubscribeAck(consumer: ActorRef) extends Message
@SerialVersionUID(1L)
private[push] case class PushCredentialsUpdated(credsOpt: Option[models.push.PushCredentials]) extends Message
@SerialVersionUID(1L)
case class UpdateReceived(update: UpdateBox)
type Sequence = Int
// TODO: configurable
private val OperationTimeout = Timeout(30.seconds)
def getSeqState(authId: Long)(implicit region: SeqUpdatesManagerRegion, ec: ExecutionContext): DBIO[SeqState] = {
for {
seqstate ← DBIO.from(region.ref.ask(Envelope(authId, GetSequenceState))(OperationTimeout).mapTo[SeqState])
} yield seqstate
}
def persistAndPushUpdate(
authId: Long,
header: Int,
serializedData: Array[Byte],
userIds: Set[Int],
groupIds: Set[Int],
pushText: Option[String],
originPeer: Option[Peer],
isFat: Boolean
)(implicit region: SeqUpdatesManagerRegion, ec: ExecutionContext): DBIO[SeqState] = {
DBIO.from(pushUpdateGetSeqState(authId, header, serializedData, userIds, groupIds, pushText, originPeer, isFat))
}
def persistAndPushUpdateF(
authId: Long,
header: Int,
serializedData: Array[Byte],
userIds: Set[Int],
groupIds: Set[Int],
pushText: Option[String],
originPeer: Option[Peer],
isFat: Boolean
)(implicit region: SeqUpdatesManagerRegion, ec: ExecutionContext): Future[SeqState] = {
pushUpdateGetSeqState(authId, header, serializedData, userIds, groupIds, pushText, originPeer, isFat)
}
def persistAndPushUpdate(authId: Long, update: api.Update, pushText: Option[String], isFat: Boolean = false)(implicit region: SeqUpdatesManagerRegion, ec: ExecutionContext): DBIO[SeqState] = {
val header = update.header
val serializedData = update.toByteArray
val (userIds, groupIds) = updateRefs(update)
persistAndPushUpdate(authId, header, serializedData, userIds, groupIds, pushText, getOriginPeer(update), isFat)
}
def persistAndPushUpdateF(authId: Long, update: api.Update, pushText: Option[String], isFat: Boolean = false)(implicit region: SeqUpdatesManagerRegion, ec: ExecutionContext): Future[SeqState] = {
val header = update.header
val serializedData = update.toByteArray
val (userIds, groupIds) = updateRefs(update)
persistAndPushUpdateF(authId, header, serializedData, userIds, groupIds, pushText, getOriginPeer(update), isFat)
}
def persistAndPushUpdates(authIds: Set[Long], update: api.Update, pushText: Option[String], isFat: Boolean = false)(implicit region: SeqUpdatesManagerRegion, ec: ExecutionContext): DBIO[Seq[SeqState]] = {
val header = update.header
val serializedData = update.toByteArray
val (userIds, groupIds) = updateRefs(update)
persistAndPushUpdates(authIds, header, serializedData, userIds, groupIds, pushText, getOriginPeer(update), isFat)
}
def persistAndPushUpdatesF(authIds: Set[Long], update: api.Update, pushText: Option[String], isFat: Boolean = false)(implicit region: SeqUpdatesManagerRegion, ec: ExecutionContext): Future[Seq[SeqState]] = {
val header = update.header
val serializedData = update.toByteArray
val (userIds, groupIds) = updateRefs(update)
persistAndPushUpdatesF(authIds, header, serializedData, userIds, groupIds, pushText, getOriginPeer(update), isFat)
}
def persistAndPushUpdates(
authIds: Set[Long],
header: Int,
serializedData: Array[Byte],
userIds: Set[Int],
groupIds: Set[Int],
pushText: Option[String],
originPeer: Option[Peer],
isFat: Boolean
)(implicit region: SeqUpdatesManagerRegion, ec: ExecutionContext): DBIO[Seq[SeqState]] =
DBIO.sequence(authIds.toSeq map (persistAndPushUpdate(_, header, serializedData, userIds, groupIds, pushText, originPeer, isFat)))
def persistAndPushUpdatesF(
authIds: Set[Long],
header: Int,
serializedData: Array[Byte],
userIds: Set[Int],
groupIds: Set[Int],
pushText: Option[String],
originPeer: Option[Peer],
isFat: Boolean
)(implicit region: SeqUpdatesManagerRegion, ec: ExecutionContext): Future[Seq[SeqState]] =
Future.sequence(authIds.toSeq map (persistAndPushUpdateF(_, header, serializedData, userIds, groupIds, pushText, originPeer, isFat)))
def broadcastClientAndUsersUpdate(
userIds: Set[Int],
update: api.Update,
pushText: Option[String],
isFat: Boolean = false
)(implicit
region: SeqUpdatesManagerRegion,
ec: ExecutionContext,
client: api.AuthorizedClientData): DBIO[(SeqState, Seq[SeqState])] =
broadcastClientAndUsersUpdate(client.userId, client.authId, userIds, update, pushText, isFat)
def broadcastClientAndUsersUpdate(
clientUserId: Int,
clientAuthId: Long,
userIds: Set[Int],
update: api.Update,
pushText: Option[String],
isFat: Boolean
)(implicit
region: SeqUpdatesManagerRegion,
ec: ExecutionContext): DBIO[(SeqState, Seq[SeqState])] = {
val header = update.header
val serializedData = update.toByteArray
val (refUserIds, refGroupIds) = updateRefs(update)
val originPeer = getOriginPeer(update)
for {
authIds ← p.AuthId.findIdByUserIds(userIds + clientUserId)
seqstates ← DBIO.sequence(
authIds.view
.filterNot(_ == clientAuthId)
.map(persistAndPushUpdate(_, header, serializedData, refUserIds, refGroupIds, pushText, originPeer, isFat))
)
seqstate ← persistAndPushUpdate(clientAuthId, header, serializedData, refUserIds, refGroupIds, pushText, originPeer, isFat)
} yield (seqstate, seqstates)
}
def broadcastOtherDevicesUpdate(userId: Int, currentAuthId: Long, update: api.Update, pushText: Option[String], isFat: Boolean = false)(
implicit
region: SeqUpdatesManagerRegion,
ec: ExecutionContext
): DBIO[SeqState] = {
val header = update.header
val serializedData = update.toByteArray
val (userIds, groupIds) = updateRefs(update)
val originPeer = getOriginPeer(update)
for {
otherAuthIds ← p.AuthId.findIdByUserId(userId).map(_.view.filter(_ != currentAuthId))
_ ← DBIO.sequence(otherAuthIds map (authId ⇒ persistAndPushUpdate(authId, header, serializedData, userIds, groupIds, pushText, originPeer, isFat)))
seqstate ← persistAndPushUpdate(currentAuthId, header, serializedData, userIds, groupIds, pushText, originPeer, isFat)
} yield seqstate
}
def notifyUserUpdate(userId: Int, exceptAuthId: Long, update: api.Update, pushText: Option[String], isFat: Boolean = false)(
implicit
region: SeqUpdatesManagerRegion,
ec: ExecutionContext
): DBIO[Seq[SeqState]] = {
val header = update.header
val serializedData = update.toByteArray
val (userIds, groupIds) = updateRefs(update)
val originPeer = getOriginPeer(update)
notifyUserUpdate(userId, exceptAuthId, header, serializedData, userIds, groupIds, pushText, originPeer, isFat)
}
def notifyUserUpdate(
userId: Int,
exceptAuthId: Long,
header: Int,
serializedData: Array[Byte],
userIds: Set[Int],
groupIds: Set[Int],
pushText: Option[String],
originPeer: Option[Peer],
isFat: Boolean
)(implicit
region: SeqUpdatesManagerRegion,
ec: ExecutionContext) = {
for {
otherAuthIds ← p.AuthId.findIdByUserId(userId).map(_.view.filter(_ != exceptAuthId))
seqstates ← DBIO.sequence(otherAuthIds map (authId ⇒ persistAndPushUpdate(authId, header, serializedData, userIds, groupIds, pushText, originPeer, isFat)))
} yield seqstates
}
def notifyClientUpdate(update: api.Update, pushText: Option[String], isFat: Boolean = false)(
implicit
region: SeqUpdatesManagerRegion,
client: api.AuthorizedClientData,
ec: ExecutionContext
): DBIO[Seq[SeqState]] = {
val header = update.header
val serializedData = update.toByteArray
val (userIds, groupIds) = updateRefs(update)
val originPeer = getOriginPeer(update)
notifyClientUpdate(header, serializedData, userIds, groupIds, pushText, originPeer, isFat)
}
def notifyClientUpdate(
header: Int,
serializedData: Array[Byte],
userIds: Set[Int],
groupIds: Set[Int],
pushText: Option[String],
originPeer: Option[Peer],
isFat: Boolean
)(implicit
region: SeqUpdatesManagerRegion,
client: api.AuthorizedClientData,
ec: ExecutionContext) = {
notifyUserUpdate(client.userId, client.authId, header, serializedData, userIds, groupIds, pushText, originPeer, isFat)
}
def setPushCredentials(authId: Long, creds: models.push.PushCredentials)(implicit region: SeqUpdatesManagerRegion): Unit = {
region.ref ! Envelope(authId, PushCredentialsUpdated(Some(creds)))
}
def deletePushCredentials(authId: Long)(implicit region: SeqUpdatesManagerRegion): Unit = {
region.ref ! Envelope(authId, PushCredentialsUpdated(None))
}
def getDifference(authId: Long, timestamp: Long, maxSizeInBytes: Long)(implicit ec: ExecutionContext): DBIO[(Vector[models.sequence.SeqUpdate], Boolean)] = {
def run(state: Long, acc: Vector[models.sequence.SeqUpdate], currentSize: Long): DBIO[(Vector[models.sequence.SeqUpdate], Boolean)] = {
p.sequence.SeqUpdate.findAfter(authId, state).flatMap { updates ⇒
if (updates.isEmpty) {
DBIO.successful(acc → false)
} else {
val (newAcc, newSize, allFit) = append(updates.toVector, currentSize, maxSizeInBytes, acc)
if (allFit) {
newAcc.lastOption match {
case Some(u) ⇒ run(u.timestamp, newAcc, newSize)
case None ⇒ DBIO.successful(acc → false)
}
} else {
DBIO.successful(newAcc → true)
}
}
}
}
run(timestamp, Vector.empty[sequence.SeqUpdate], 0L)
}
private def append(updates: Vector[sequence.SeqUpdate], currentSize: Long, maxSizeInBytes: Long, updateAcc: Vector[sequence.SeqUpdate]): (Vector[sequence.SeqUpdate], Long, Boolean) = {
@tailrec
def run(updLeft: Vector[sequence.SeqUpdate], acc: Vector[sequence.SeqUpdate], currSize: Long): (Vector[sequence.SeqUpdate], Long, Boolean) = {
updLeft match {
case h +: t ⇒
val newSize = currSize + h.serializedData.length
if (newSize > maxSizeInBytes) {
(acc, currSize, false)
} else {
run(t, acc :+ h, newSize)
}
case Vector() ⇒ (acc, currSize, true)
}
}
run(updates, updateAcc, currentSize)
}
def updateRefs(update: api.Update): (Set[Int], Set[Int]) = {
def peerRefs(peer: api.peers.Peer): (Set[Int], Set[Int]) = {
if (peer.`type` == api.peers.PeerType.Private) {
(Set(peer.id), Set.empty)
} else {
(Set.empty, Set(peer.id))
}
}
val empty = (Set.empty[Int], Set.empty[Int])
def singleUser(userId: Int): (Set[Int], Set[Int]) = (Set(userId), Set.empty)
def singleGroup(groupId: Int): (Set[Int], Set[Int]) = (Set.empty, Set(groupId))
def users(userIds: Seq[Int]): (Set[Int], Set[Int]) = (userIds.toSet, Set.empty)
update match {
case _: api.misc.UpdateConfig ⇒ empty
case _: api.configs.UpdateParameterChanged ⇒ empty
case api.messaging.UpdateChatClear(peer) ⇒ (Set.empty, Set(peer.id))
case api.messaging.UpdateChatDelete(peer) ⇒ (Set.empty, Set(peer.id))
case api.messaging.UpdateMessage(peer, senderUserId, _, _, _) ⇒
val refs = peerRefs(peer)
refs.copy(_1 = refs._1 + senderUserId)
case api.messaging.UpdateMessageDelete(peer, _) ⇒ peerRefs(peer)
case api.messaging.UpdateMessageRead(peer, _, _) ⇒ peerRefs(peer)
case api.messaging.UpdateMessageReadByMe(peer, _) ⇒ peerRefs(peer)
case api.messaging.UpdateMessageReceived(peer, _, _) ⇒ peerRefs(peer)
case api.messaging.UpdateMessageSent(peer, _, _) ⇒ peerRefs(peer)
case api.messaging.UpdateMessageContentChanged(peer, _, _) ⇒ peerRefs(peer)
case api.messaging.UpdateMessageDateChanged(peer, _, _) ⇒ peerRefs(peer)
case api.groups.UpdateGroupAvatarChanged(groupId, userId, _, _, _) ⇒ (Set(userId), Set(groupId))
case api.groups.UpdateGroupInvite(groupId, inviteUserId, _, _) ⇒ (Set(inviteUserId), Set(groupId))
case api.groups.UpdateGroupMembersUpdate(groupId, members) ⇒ (members.map(_.userId).toSet ++ members.map(_.inviterUserId).toSet, Set(groupId)) // TODO: #perf use foldLeft
case api.groups.UpdateGroupTitleChanged(groupId, userId, _, _, _) ⇒ (Set(userId), Set(groupId))
case api.groups.UpdateGroupUserInvited(groupId, userId, inviterUserId, _, _) ⇒ (Set(userId, inviterUserId), Set(groupId))
case api.groups.UpdateGroupUserKick(groupId, userId, kickerUserId, _, _) ⇒ (Set(userId, kickerUserId), Set(groupId))
case api.groups.UpdateGroupUserLeave(groupId, userId, _, _) ⇒ (Set(userId), Set(groupId))
case api.groups.UpdateGroupAboutChanged(groupId, _) ⇒ singleGroup(groupId)
case api.groups.UpdateGroupTopicChanged(groupId, _, userId, _, _) ⇒ (Set(userId), Set(groupId))
case api.contacts.UpdateContactRegistered(userId, _, _, _) ⇒ singleUser(userId)
case api.contacts.UpdateContactsAdded(userIds) ⇒ users(userIds)
case api.contacts.UpdateContactsRemoved(userIds) ⇒ users(userIds)
case api.users.UpdateUserAvatarChanged(userId, _) ⇒ singleUser(userId)
case api.users.UpdateUserContactsChanged(userId, _) ⇒ singleUser(userId)
case api.users.UpdateUserLocalNameChanged(userId, _) ⇒ singleUser(userId)
case api.users.UpdateUserNameChanged(userId, _) ⇒ singleUser(userId)
case api.users.UpdateUserNickChanged(userId, _) ⇒ singleUser(userId)
case api.users.UpdateUserAboutChanged(userId, _) ⇒ singleUser(userId)
case api.weak.UpdateGroupOnline(groupId, _) ⇒ singleGroup(groupId)
case api.weak.UpdateTyping(peer, userId, _) ⇒
val refs = peerRefs(peer)
refs.copy(_1 = refs._1 + userId)
case api.weak.UpdateUserLastSeen(userId, _) ⇒ singleUser(userId)
case api.weak.UpdateUserOffline(userId) ⇒ singleUser(userId)
case api.weak.UpdateUserOnline(userId) ⇒ singleUser(userId)
case api.calls.UpdateCallRing(user, _) ⇒ singleUser(user.id)
case api.calls.UpdateCallEnd(_) ⇒ empty
}
}
def bytesToTimestamp(bytes: Array[Byte]): Long = {
if (bytes.isEmpty) {
0L
} else {
ByteBuffer.wrap(bytes).getLong
}
}
def timestampToBytes(timestamp: Long): Array[Byte] = {
ByteBuffer.allocate(java.lang.Long.BYTES).putLong(timestamp).array()
}
private[push] def subscribe(authId: Long, consumer: ActorRef)(implicit region: SeqUpdatesManagerRegion, ec: ExecutionContext, timeout: Timeout): Future[Unit] = {
region.ref.ask(Envelope(authId, Subscribe(consumer))).mapTo[SubscribeAck].map(_ ⇒ ())
}
private def pushUpdateGetSeqState(
authId: Long,
header: Int,
serializedData: Array[Byte],
userIds: Set[Int],
groupIds: Set[Int],
pushText: Option[String],
originPeer: Option[Peer],
isFat: Boolean
)(implicit region: SeqUpdatesManagerRegion): Future[SeqState] = {
region.ref.ask(Envelope(authId, PushUpdateGetSequenceState(header, serializedData, userIds, groupIds, pushText, originPeer, isFat)))(OperationTimeout).mapTo[SeqState]
}
private def pushUpdate(
authId: Long,
header: Int,
serializedData: Array[Byte],
userIds: Set[Int],
groupIds: Set[Int],
pushText: Option[String],
originPeer: Option[Peer],
isFat: Boolean
)(implicit region: SeqUpdatesManagerRegion): Unit = {
region.ref ! Envelope(authId, PushUpdate(header, serializedData, userIds, groupIds, pushText, originPeer, isFat))
}
def getOriginPeer(update: api.Update): Option[Peer] = {
update match {
case u: UpdateMessage ⇒ Some(u.peer)
case _ ⇒ None
}
}
}
| chieryw/actor-platform | actor-server/actor-push/src/main/scala/im/actor/server/push/SeqUpdatesManager.scala | Scala | mit | 18,589 |
package som
import java.util.Arrays
import java.util.Comparator
class Vector[E <: AnyRef](size: Int) {
def this() = this(50)
var storage: Array[AnyRef] = new Array[AnyRef](size)
var firstIdx: Int = 0
var lastIdx: Int = 0
def at(idx: Int): E = {
if (idx >= storage.length) {
return null.asInstanceOf[E]
}
storage(idx).asInstanceOf[E]
}
def atPut(idx: Int, value: E): Unit = {
if (idx >= storage.length) {
var newLength = storage.length
while (newLength <= idx) {
newLength *= 2
}
storage = Arrays.copyOf(storage, newLength)
}
storage(idx) = value
if (lastIdx < idx + 1) {
lastIdx = idx + 1
}
}
def append(elem: E): Unit = {
if (lastIdx >= storage.length) {
// Need to expand capacity first
storage = Arrays.copyOf(storage, 2 * storage.length)
}
storage(lastIdx) = elem
lastIdx += 1
}
def isEmpty(): Boolean = lastIdx == firstIdx
def forEach(f: E => Unit): Unit =
(firstIdx until lastIdx).foreach { i =>
f(storage(i).asInstanceOf[E])
}
def hasSome(f: E => Boolean): Boolean = {
(firstIdx until lastIdx).foreach { i =>
if (f(storage(i).asInstanceOf[E])) {
return true
}
}
false
}
def getOne(f: E => Boolean): E = {
(firstIdx until lastIdx).foreach { i =>
val e = storage(i).asInstanceOf[E]
if (f(e)) {
return e
}
}
null.asInstanceOf[E]
}
def first(): E = {
if (isEmpty()) {
return null.asInstanceOf[E]
}
return storage(firstIdx).asInstanceOf[E]
}
def removeFirst(): E = {
if (isEmpty()) {
return null.asInstanceOf[E]
}
firstIdx += 1
return storage(firstIdx - 1).asInstanceOf[E]
}
def remove(obj: E): Boolean = {
val newArray = new Array[AnyRef](capacity())
val newLast = Array(0)
val found = Array(false)
forEach { it =>
if (it == obj) {
found(0) = true
} else {
newArray(newLast(0)) = it
newLast(0) += 1
}
}
storage = newArray
lastIdx = newLast(0)
firstIdx = 0
return found(0)
}
def removeAll(): Unit = {
firstIdx = 0
lastIdx = 0
storage = new Array[AnyRef](storage.length)
}
def size(): Int = lastIdx - firstIdx
def capacity(): Int = storage.length
}
object Vector {
def `with`[E <: AnyRef](elem: E): Vector[E] = {
val v = new Vector[E](1)
v.append(elem)
v
}
}
| cedricviaccoz/scala-native | benchmarks/src/main/scala/som/Vector.scala | Scala | bsd-3-clause | 2,488 |
trait Semigroup[T] {
def (lhs: T).append(rhs: T): T
def (lhs: Int).appendS(rhs: T): T = ???
}
object Semigroup {
implicit object stringAppend extends Semigroup[String] {
override def (lhs: String).append(rhs: String): String = lhs + rhs
}
implicit def sumSemigroup[N](implicit N: Numeric[N]): Semigroup[N] = new {
override def (lhs: N).append(rhs: N): N = N.plus(lhs, rhs)
def (lhs: Int).appendS(rhs: N): N = ??? // N.plus(lhs, rhs)
}
}
object Main {
import Semigroup.sumSemigroup // this is not sufficient
def f1 = {
println(1 appendS 2) // error This should give the following error message:
/*
21 | println(1 appendS 2)
| ^^^^^^^^^
|value appendS is not a member of Int.
|An extension method was tried, but could not be fully constructed:
|
| Semigroup.sumSemigroup[Any](/* ambiguous */implicitly[Numeric[Any]]).appendS()
one error found
*/
}
} | som-snytt/dotty | tests/neg/i5773.scala | Scala | apache-2.0 | 917 |
/*
* Copyright 2017 Datamountaineer.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.datamountaineer.streamreactor.connect.coap.connection
import java.io.FileInputStream
import java.net.{ConnectException, InetAddress, InetSocketAddress, URI}
import java.security.cert.Certificate
import java.security.{KeyStore, PrivateKey}
import com.datamountaineer.streamreactor.connect.coap.configs.{CoapConstants, CoapSetting}
import com.typesafe.scalalogging.slf4j.StrictLogging
import org.apache.kafka.common.config.ConfigException
import org.eclipse.californium.core.coap.CoAP
import org.eclipse.californium.core.CoapClient
import org.eclipse.californium.core.network.CoapEndpoint
import org.eclipse.californium.core.network.config.NetworkConfig
import org.eclipse.californium.scandium.DTLSConnector
import org.eclipse.californium.scandium.config.DtlsConnectorConfig
import org.eclipse.californium.scandium.dtls.cipher.CipherSuite
import org.eclipse.californium.scandium.dtls.pskstore.InMemoryPskStore
/**
* Created by andrew@datamountaineer.com on 27/12/2016.
* stream-reactor
*/
object DTLSConnectionFn extends StrictLogging {
def apply(setting: CoapSetting): CoapClient = {
val configUri = new URI(setting.uri)
val uri: URI = configUri.getHost match {
case CoapConstants.COAP_DISCOVER_IP4 => discoverServer(CoapConstants.COAP_DISCOVER_IP4_ADDRESS, configUri)
case CoapConstants.COAP_DISCOVER_IP6 => discoverServer(CoapConstants.COAP_DISCOVER_IP6_ADDRESS, configUri)
case _ => configUri
}
val client: CoapClient = new CoapClient(uri)
val addr = new InetSocketAddress(InetAddress.getByName(setting.bindHost), setting.bindPort)
val builder = new DtlsConnectorConfig.Builder
builder.setAddress(addr)
if (uri.getScheme.equals(CoAP.COAP_SECURE_URI_SCHEME)) {
//Use SSL
if (setting.identity.isEmpty) {
val keyStore = KeyStore.getInstance("JKS")
val inKey = new FileInputStream(setting.keyStoreLoc)
keyStore.load(inKey, setting.keyStorePass.value().toCharArray())
inKey.close()
val trustStore = KeyStore.getInstance("JKS")
val inTrust = new FileInputStream(setting.trustStoreLoc)
trustStore.load(inTrust, setting.trustStorePass.value().toCharArray())
inTrust.close()
val certificates: Array[Certificate] = setting.certs.map(c => trustStore.getCertificate(c))
val privateKey = keyStore.getKey(setting.chainKey, setting.keyStorePass.value().toCharArray).asInstanceOf[PrivateKey]
val certChain = keyStore.getCertificateChain(setting.chainKey)
builder.setIdentity(privateKey, certChain, true)
builder.setTrustStore(certificates)
} else {
val psk = new InMemoryPskStore()
psk.setKey(setting.identity, setting.secret.value().getBytes())
psk.addKnownPeer(addr, setting.identity, setting.secret.value().getBytes())
builder.setPskStore(psk)
if (setting.privateKey.isDefined) {
builder.setSupportedCipherSuites(Array[CipherSuite](CipherSuite.TLS_PSK_WITH_AES_128_CCM_8, CipherSuite.TLS_PSK_WITH_AES_128_CBC_SHA256))
builder.setIdentity(setting.privateKey.get, setting.publicKey.get)
}
}
client.setEndpoint(new CoapEndpoint(new DTLSConnector(builder.build()), NetworkConfig.getStandard))
}
client.setURI(s"${setting.uri}/${setting.target}")
}
/**
* Discover servers on the local network
* and return the first one
*
* @param address The multicast address (ip4 or ip6)
* @param uri The original URI
* @return A new URI of the server
**/
def discoverServer(address: String, uri: URI): URI = {
val client = new CoapClient(s"${uri.getScheme}://$address:${uri.getPort.toString}/.well-known/core")
client.useNONs()
val response = client.get()
if (response != null) {
logger.info(s"Discovered Server ${response.advanced().getSource.toString}.")
new URI(uri.getScheme,
uri.getUserInfo,
response.advanced().getSource.getHostName,
response.advanced().getSourcePort,
uri.getPath,
uri.getQuery,
uri.getFragment)
} else {
logger.error(s"Unable to find any servers on local network with multicast address $address.")
throw new ConnectException(s"Unable to find any servers on local network with multicast address $address.")
}
}
}
| CodeSmell/stream-reactor | kafka-connect-coap/src/main/scala/com/datamountaineer/streamreactor/connect/coap/connection/DTLSConnectionFn.scala | Scala | apache-2.0 | 4,935 |
package io.github.tailhq.dynaml.graphics.charts.repl
import io.github.tailhq.dynaml.graphics.charts.Highcharts._
import org.scalatest.Matchers
import org.scalatest.FunSuite
/**
* User: austin
* Date: 12/15/14
*/
class HighchartsReplTest extends FunSuite with Matchers {
test("Pie repl") {
disableOpenWindow // prevents server from starting
pie(1 to 4).toJson should be(
"""{"series":[""" +
"""{"data":[{"x":0,"y":1},{"x":1,"y":2},{"x":2,"y":3},{"x":3,"y":4}],"type":"pie"}],""" +
""""exporting":{"filename":"chart"},""" +
""""yAxis":[{"title":{"text":""}}],""" +
""""plotOptions":{},""" +
""""credits":{"href":"","text":""},""" +
""""chart":{"zoomType":"xy"},""" +
""""title":{"text":""},""" +
""""xAxis":[{"title":{"text":""}}]}"""
)
}
}
| mandar2812/DynaML | dynaml-core/src/test/scala/io/github/tailhq/dynaml/graphics/charts/repl/HighchartsReplTest.scala | Scala | apache-2.0 | 835 |
package models.db
import com.ponkotuy.data.master
import scalikejdbc._
import tool.{EquipIconType, EquipType}
import util.scalikejdbc.BulkInsert._
case class MasterSlotItem(
id: Int,
name: String,
typ: Array[Int],
power: Int,
torpedo: Int,
bomb: Int,
antiair: Int,
antisub: Int,
search: Int,
hit: Int,
length: Int,
rare: Int,
info: String) {
def save()(implicit session: DBSession = MasterSlotItem.autoSession): MasterSlotItem = MasterSlotItem.save(this)(session)
def destroy()(implicit session: DBSession = MasterSlotItem.autoSession): Unit = MasterSlotItem.destroy(this)(session)
/** typのうち3番目の値より。種別 */
def category: Option[EquipType] = typ.lift(2).flatMap(EquipType.fromInt)
/** typeの4番目の値より。アイコン色の元となっている種別 */
def iconType: Option[EquipIconType] = typ.lift(3).flatMap(EquipIconType.fromInt)
}
object MasterSlotItem extends SQLSyntaxSupport[MasterSlotItem] {
override val tableName = "master_slot_item"
override val columns = Seq("id", "name", "typ", "power", "torpedo", "bomb", "antiAir", "antiSub", "search", "hit", "length", "rare", "info")
def apply(msi: SyntaxProvider[MasterSlotItem])(rs: WrappedResultSet): MasterSlotItem = apply(msi.resultName)(rs)
def apply(msi: ResultName[MasterSlotItem])(rs: WrappedResultSet): MasterSlotItem = new MasterSlotItem(
id = rs.int(msi.id),
name = rs.string(msi.name),
typ = rs.string(msi.typ).split(',').map(_.toInt),
power = rs.int(msi.power),
torpedo = rs.int(msi.torpedo),
bomb = rs.int(msi.bomb),
antiair = rs.int(msi.antiair),
antisub = rs.int(msi.antisub),
search = rs.int(msi.search),
hit = rs.int(msi.hit),
length = rs.int(msi.length),
rare = rs.int(msi.rare),
info = rs.string(msi.info)
)
val msi = MasterSlotItem.syntax("msi")
override val autoSession = AutoSession
def find(id: Int)(implicit session: DBSession = autoSession): Option[MasterSlotItem] = {
withSQL {
select.from(MasterSlotItem as msi).where.eq(msi.id, id)
}.map(MasterSlotItem(msi.resultName)).single().apply()
}
def findAll()(implicit session: DBSession = autoSession): List[MasterSlotItem] = {
withSQL(select.from(MasterSlotItem as msi)).map(MasterSlotItem(msi.resultName)).list().apply()
}
def countAll()(implicit session: DBSession = autoSession): Long = {
withSQL(select(sqls"count(1)").from(MasterSlotItem as msi)).map(rs => rs.long(1)).single().apply().get
}
def findAllBy(where: SQLSyntax)(implicit session: DBSession = autoSession): List[MasterSlotItem] = {
withSQL {
select.from(MasterSlotItem as msi).where.append(sqls"${where}")
}.map(MasterSlotItem(msi.resultName)).list().apply()
}
def findAllName()(implicit session: DBSession = autoSession): List[String] = withSQL {
select(msi.name).from(MasterSlotItem as msi)
}.map(_.string(1)).list().apply()
def findIn(items: Seq[Int])(implicit session: DBSession = autoSession): List[MasterSlotItem] = {
items match {
case Seq() => Nil
case _ =>
withSQL {
select.from(MasterSlotItem as msi)
.where.in(msi.id, items)
}.map(MasterSlotItem(msi.resultName)).list().apply()
}
}
def countBy(where: SQLSyntax)(implicit session: DBSession = autoSession): Long = {
withSQL {
select(sqls"count(1)").from(MasterSlotItem as msi).where.append(sqls"${where}")
}.map(_.long(1)).single().apply().get
}
def create(
id: Int,
name: String,
typ: List[Int],
power: Int,
torpedo: Int,
bomb: Int,
antiair: Int,
antisub: Int,
search: Int,
hit: Int,
length: Int,
rare: Int,
info: String)(implicit session: DBSession = autoSession): MasterSlotItem = {
withSQL {
insert.into(MasterSlotItem).columns(
column.id,
column.name,
column.typ,
column.power,
column.torpedo,
column.bomb,
column.antiair,
column.antisub,
column.search,
column.hit,
column.length,
column.rare,
column.info
).values(
id,
name,
typ.mkString(","),
power,
torpedo,
bomb,
antiair,
antisub,
search,
hit,
length,
rare,
info
)
}.update().apply()
MasterSlotItem(
id = id,
name = name,
typ = typ.toArray,
power = power,
torpedo = torpedo,
bomb = bomb,
antiair = antiair,
antisub = antisub,
search = search,
hit = hit,
length = length,
rare = rare,
info = info)
}
def bulkInsert(xs: Seq[master.MasterSlotItem])(implicit session: DBSession = autoSession): Seq[MasterSlotItem] = {
applyUpdate {
insert.into(MasterSlotItem)
.columns(column.id, column.name, column.typ,
column.power, column.torpedo, column.bomb, column.antiair, column.antisub,
column.search, column.hit, column.length, column.rare, column.info)
.multiValues(xs.map(_.id), xs.map(_.name), xs.map(_.typ.mkString(",")),
xs.map(_.power), xs.map(_.torpedo), xs.map(_.bomb), xs.map(_.antiAir), xs.map(_.antiSub),
xs.map(_.search), xs.map(_.hit), xs.map(_.length), xs.map(_.rare), xs.map(_.info))
}
xs.map { x =>
MasterSlotItem(x.id, x.name, x.typ.toArray, x.power, x.torpedo, x.bomb, x.antiAir, x.antiSub,
x.search, x.hit, x.length, x.rare, x.info)
}
}
def save(entity: MasterSlotItem)(implicit session: DBSession = autoSession): MasterSlotItem = {
withSQL {
update(MasterSlotItem).set(
column.id -> entity.id,
column.name -> entity.name,
column.typ -> entity.typ.mkString(","),
column.power -> entity.power,
column.torpedo -> entity.torpedo,
column.bomb -> entity.bomb,
column.antiair -> entity.antiair,
column.antisub -> entity.antisub,
column.search -> entity.search,
column.hit -> entity.hit,
column.length -> entity.length,
column.rare -> entity.rare,
column.info -> entity.info
).where.eq(column.id, entity.id)
}.update().apply()
entity
}
def destroy(entity: MasterSlotItem)(implicit session: DBSession = autoSession): Unit = {
withSQL {
delete.from(MasterSlotItem).where.eq(column.id, entity.id)
}.update().apply()
}
def deleteAll()(implicit session: DBSession = autoSession): Unit = applyUpdate {
delete.from(MasterSlotItem)
}
}
| kxbmap/MyFleetGirls | server/app/models/db/MasterSlotItem.scala | Scala | mit | 6,600 |
/*
* MIT License
*
* Copyright (c) 2017 Enrique González Rodrigo
* Permission is hereby granted, free of charge, to any person obtaining a copy of this
* software and associated documentation files (the "Software"), to deal in the Software
* without restriction, including without limitation the rights to use, copy, modify,
* merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit
* persons to whom the Software is furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in all copies or
* substantial portions of the Software.
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING
* BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
* NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
* DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
*/
package com.enriquegrodrigo.spark.crowd.methods
import com.enriquegrodrigo.spark.crowd.types._
import com.enriquegrodrigo.spark.crowd.utils.Functions
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.mllib.optimization._
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.mllib.linalg.{Vector,Vectors}
import scala.util.Random
/**
* Provides functions for transforming an annotation dataset into
* a standard label dataset using the RaykarBinary algorithm
*
* This algorithm only works with [[types.BinaryAnnotation]] datasets. There are versions for the
* [[types.MulticlassAnnotation]] ([[RaykarMulti]]) and [[types.RealAnnotation]] ([[RaykarCont]]).
*
* It will return a [[types.RaykarBinaryModel]] with information about the estimation of the
* ground truth for each example, the annotator precision estimation of the model, the weights of the
* logistic regression model learned and the log-likelihood of the model.
*
* The next example can be found in the examples folders. In it, the user may also find an example
* of how to add prior confidence on the annotators.
*
* @example
* {{{
* import com.enriquegrodrigo.spark.crowd.methods.RaykarBinary
* import com.enriquegrodrigo.spark.crowd.types._
*
* sc.setCheckpointDir("checkpoint")
*
* val exampleFile = "data/binary-data.parquet"
* val annFile = "data/binary-ann.parquet"
*
* val exampleData = spark.read.parquet(exampleFile)
* val annData = spark.read.parquet(annFile).as[BinaryAnnotation]
*
* //Applying the learning algorithm
* val mode = RaykarBinary(exampleData, annData)
*
* //Get MulticlassLabel with the class predictions
* val pred = mode.getMu().as[BinarySoftLabel]
*
* //Annotator precision matrices
* val annprec = mode.getAnnotatorPrecision()
*
* //Annotator likelihood
* val like = mode.getLogLikelihood()
* }}}
* @author enrique.grodrigo
* @version 0.1.5
* @see Raykar, Vikas C., et al. "Learning from crowds." Journal of Machine
* Learning Research 11.Apr (2010): 1297-1322.
*
*/
object RaykarBinary {
/****************************************************/
/****************** CASE CLASSES ********************/
/****************************************************/
/**
* Case class for the RaykarBinary partial model
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class RaykarBinaryPartialModel(dataset: DataFrame, annotatorData: Dataset[BinaryAnnotation],
mu: Dataset[BinarySoftLabel], dataStatistics: Dataset[RaykarBinaryStatistics],
params: Broadcast[RaykarBinaryParams], logLikelihood: Double,
improvement: Double, nAnnotators: Int, nFeatures: Int) {
def modify(nDataset: DataFrame =dataset,
nAnnotatorData: Dataset[BinaryAnnotation] =annotatorData,
nMu: Dataset[BinarySoftLabel] =mu,
nDataStatistics: Dataset[RaykarBinaryStatistics] = dataStatistics,
nParams: Broadcast[RaykarBinaryParams] =params,
nLogLikelihood: Double =logLikelihood,
nImprovement: Double =improvement,
nNAnnotators: Int =nAnnotators,
nNFeatures: Int =nFeatures) =
new RaykarBinaryPartialModel(nDataset, nAnnotatorData, nMu, nDataStatistics,
nParams, nLogLikelihood, nImprovement, nNAnnotators, nNFeatures)
}
/**
* Estimation of a y b for an example
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class RaykarBinaryStatistics(example: Long, a: Double, b: Double)
/**
* Case class for storing RaykarBinary parameters
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class RaykarBinaryParams(alpha: Array[Double], beta: Array[Double], w: Array[Double],
a: Array[Array[Double]], b: Array[Array[Double]], wp: Array[Array[Double]])
/**
* Case class that stores annotations with class probability estimation
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class RaykarBinaryPartial(example: Long, annotator: Int, value: Int, mu: Double)
/**
* Stores the logistic predictions
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class LogisticPrediction(example: Long, p: Double)
/**
* Stores annotators parameters
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class AnnotatorParameters(example: Long, a: Double, b: Double)
/**
* Stores the parameters for the label estimation
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class FullParameters(example: Long, p:Double, a: Double, b: Double)
/**
* Stores the ground truth estimation
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class MuEstimation(example: Long, mu:Double)
/**
* Stores the parameters with the estimation of the ground truth label
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class ParameterWithEstimation(example: Long, mu:Double, a: Double, b: Double, p: Double)
/**
* Stores the value of an annotator parameter
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class ParamValue(annotator: Long, value:Double)
/**
* Stores data for parameter calculation
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class ParamCalc(annotator: Long, num: Double, denom:Double)
/**
* Stores partial estimations of a and b in the statistics aggregator
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] case class RaykarBinaryStatisticsAggregatorBuffer(a: Double, b: Double)
/****************************************************/
/****************** AGGREGATORS ********************/
/****************************************************/
/**
* Aggregator for obtaining a and b estimation for each example
*
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] class RaykarBinaryStatisticsAggregator(params: Broadcast[RaykarBinaryParams])
extends Aggregator[RaykarBinaryPartial, RaykarBinaryStatisticsAggregatorBuffer, (Double,Double)] {
def zero: RaykarBinaryStatisticsAggregatorBuffer = RaykarBinaryStatisticsAggregatorBuffer(1,1) //Binary
def reduce(b: RaykarBinaryStatisticsAggregatorBuffer, a: RaykarBinaryPartial) : RaykarBinaryStatisticsAggregatorBuffer = {
//Likelihood of an annotation
val alphaValue = params.value.alpha(a.annotator)
val alphaTerm = if (a.value == 1) alphaValue else 1-alphaValue
val betaValue = params.value.beta(a.annotator)
val betaTerm = if (a.value == 0) betaValue else 1-betaValue
RaykarBinaryStatisticsAggregatorBuffer(b.a * alphaTerm, b.b * betaTerm)
}
def merge(b1: RaykarBinaryStatisticsAggregatorBuffer, b2: RaykarBinaryStatisticsAggregatorBuffer) : RaykarBinaryStatisticsAggregatorBuffer = {
RaykarBinaryStatisticsAggregatorBuffer(b1.a * b2.a, b1.b*b2.b)
}
def finish(reduction: RaykarBinaryStatisticsAggregatorBuffer) = {
//Likelihood of an example annotations given class is 1 or 0
(reduction.a,reduction.b)
}
def bufferEncoder: Encoder[RaykarBinaryStatisticsAggregatorBuffer] = Encoders.product[RaykarBinaryStatisticsAggregatorBuffer]
def outputEncoder: Encoder[(Double,Double)] = Encoders.product[(Double,Double)]
}
/****************************************************/
/******************** GRADIENT **********************/
/****************************************************/
/**
* Computes the logistic function for a data point
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] def computeSigmoid(x: Array[Double], w: Array[Double]): Double = {
val vectMult = x.zip(w).map{case (x,w) => x*w}
Functions.sigmoid(vectMult.sum)
}
/**
* Computes the negative likelihood of a point (loss)
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] def computePointLoss(mui: Double, pi: Double, ai: Double, bi: Double): Double = {
val mulaipi = ai*pi
val mulbipi = bi*(1-pi)
-(Functions.prodlog(mui,mulaipi) + Functions.prodlog((1-mui),mulbipi))
}
/**
* Matrix multiplication
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] def matMult (mat: Array[Array[Double]], v: Array[Double]): Array[Double] = {
mat.map(mv => mv.zip(v).map{ case (x,y) => x*y }.reduce(_ + _))
}
/**
* Computes the gradient for the SGD algorithm
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] class RaykarBinaryGradient(params: Broadcast[RaykarBinaryParams]) extends Gradient {
override def compute(data: Vector, label: Double, weights: Vector, cumGradient:Vector): Double = {
val w = weights.toArray
val s: Array[Double] = data.toArray
//First 2 columns are special parameters
val a = s(0)
val b = s(1)
// The data point
val x = s.drop(2)
//Gradient calculation
val sigm = computeSigmoid(x,w)
val innerPart = label-sigm
val sumTerm = x.map(_ * innerPart)
val cumGradientArray = cumGradient.toDense.values
cumGradient.foreachActive({ case (i,gi) => cumGradientArray(i) += sumTerm(i) })
//Point loss
val loss = computePointLoss(label,sigm,a,b)
loss
}
}
/**
* Computes updater for the SGD algorithm.
* Adds the regularization priors.
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] class RaykarBinaryUpdater(priors: Broadcast[RaykarBinaryParams]) extends Updater {
def compute(weightsOld:Vector, gradient: Vector, stepSize: Double, iter: Int, regParam: Double) = {
val regTerm = matMult(priors.value.wp, weightsOld.toArray) //Regularization with prior weights
val stepS = stepSize/scala.math.sqrt(iter) //Atenuates step size
//Full update
val fullGradient = gradient.toArray.zip(regTerm).map{case (g,t) => g - t}
val newWeights = weightsOld.toArray.zip(fullGradient).map{ case (wold,fg) => wold + stepS*fg }
val newVector = Vectors.dense(newWeights)
(newVector, 0) //Second parameter is not used
}
}
/****************************************************/
/******************** METHODS **********************/
/****************************************************/
/**
* Applies the learning algorithm
*
* @param dataset the dataset with feature vectors (spark ``Dataframe``).
* @param annDataset the dataset with the annotations (spark Dataset of [[types.BinaryAnnotation]]).
* @param emIters number of iterations for the EM algorithm
* @param emThreshold logLikelihood variability threshold for the EM algorithm
* @param gradIters maximum number of iterations for the GradientDescent algorithm
* @param gradThreshold threshold for the log likelihood variability for the gradient descent algorithm
* @param gradLearning learning rate for the gradient descent algorithm
* @param a_prior prior (Beta distribution hyperparameters) for the estimation
* of the probability that an annotator correctly classifias positive instances
* @param b_prior prior (Beta distribution hyperparameters) for the estimation
* of the probability that an annotator correctly classify as negative instances
* @param w_prior prior for the weights of the logistic regression model
* @return [[com.enriquegrodrigo.spark.crowd.types.RaykarBinaryModel]]
* @author enrique.grodrigo
* @version 0.1.5
*/
def apply(dataset: DataFrame, annDataset: Dataset[BinaryAnnotation], eMIters: Int = 5,
eMThreshold: Double = 0.001, gradIters: Int = 100,
gradThreshold: Double = 0.1, gradLearning: Double = 0.1,
a_prior: Option[Array[Array[Double]]]= None,
b_prior: Option[Array[Array[Double]]]= None,
w_prior: Option[Array[Array[Double]]]= None): RaykarBinaryModel = {
import dataset.sparkSession.implicits._
val datasetFixed = dataset.withColumn("comenriquegrodrigotempindependent", lit(1))
val initialModel = initialization(datasetFixed, annDataset, a_prior, b_prior, w_prior)
val secondModel = step(gradIters, gradThreshold, gradLearning)(initialModel,0)
val fixed = secondModel.modify(nImprovement=1)
//Loop until any of the conditions met
val l = Stream.range(1,eMIters).scanLeft(fixed)(step(gradIters, gradThreshold, gradLearning))
.takeWhile( (model) => model.improvement > eMThreshold )
.last
val preparedDataset = l.mu.select($"example", $"value").distinct()
new RaykarBinaryModel(preparedDataset.as[BinarySoftLabel], l.params.value.alpha, l.params.value.beta, l.params.value.w)
}
/**
* Initialize the parameters.
* First ground truth estimation is done using the majority voting algorithm
*
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] def initialization(dataset: DataFrame, annotatorData: Dataset[BinaryAnnotation],
a_prior: Option[Array[Array[Double]]], b_prior: Option[Array[Array[Double]]],
w_prior: Option[Array[Array[Double]]]): RaykarBinaryPartialModel = {
val sc = dataset.sparkSession.sparkContext
import dataset.sparkSession.implicits._
val annCached = annotatorData.cache()
val datasetCached = dataset.cache()
val nFeatures = datasetCached.take(1)(0).length - 1 //example
val nAnnotators = annCached.select($"annotator").distinct().count().toInt
//Prepare priors. If no prior is provided, suppose a uniform prior for annotators
val ap = a_prior match {
case Some(arr) => arr
case None => Array.fill(nAnnotators,2)(2.0)
}
val bp = b_prior match {
case Some(arr) => arr
case None => Array.fill(nAnnotators,2)(2.0)
}
//For weights, suppose a diagonal matrix as prior (for all but the independent term)
val wp: Array[Array[Double]] = w_prior match {
case Some(arr) => arr
case None => Array.tabulate(nFeatures,nFeatures){ case (x,y) => if (x == y) (if (x==0) 0 else 1) else 0 }
}
val mu = MajorityVoting.transformSoftBinary(annCached)
val placeholderStatistics = Seq(RaykarBinaryStatistics(0,0,0)).toDS()
RaykarBinaryPartialModel(dataset, //Training data
annotatorData, //Annotation data
mu, //Ground truth estimation
placeholderStatistics, //Parameters a and b for each example
sc.broadcast(
new RaykarBinaryParams(Array.fill(nAnnotators)(-1), //Alpha
Array.fill(nAnnotators)(-1), //Beta
Array.fill(nFeatures)(-1), //Logistic weights
ap, bp, wp //Alpha, beta and weight priors
)
),
0, //Neg-loglikelihood
0, //Improvement
nAnnotators.toInt, //Number of annotators
nFeatures.toInt //Number of features in the training data
)
}
/**
* M step of the EM algorithm.
*
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] def mStep(model: RaykarBinaryPartialModel, gradIters: Int, gradThreshold: Double, gradLearning: Double): RaykarBinaryPartialModel = {
import model.dataset.sparkSession.implicits._
val sc = model.dataset.sparkSession.sparkContext
/**
* Prepares row to be used by the SGD algorithm
*/
def convertRowRDD(r: Row, names: Array[String]): (Double,Vector) = {
val s: Seq[Double] = r.toSeq.map( x =>
x match {
case d: Double => d
case d: Int => d.toDouble
})
val a_index = names.indexOf("comenriquegrodrigotempa")
val a_val = s(a_index)
val b_index = names.indexOf("comenriquegrodrigotempb")
val b_val = s(b_index)
val mu_index = names.indexOf("comenriquegrodrigotempmu")
val mu_val = s(mu_index)
val indep_index = names.indexOf("comenriquegrodrigotempindependent")
val indep_val = s(indep_index)
val featureVector = s.zip(names).filter( { case (x,name) => name != "comenriquegrodrigotempa" &&
name != "comenriquegrodrigotempb" &&
name != "comenriquegrodrigotempindependent" &&
name != "comenriquegrodrigotempmu"})
.map( { case (x,name) => x })
val nAr = Array(a_val, b_val, indep_val) ++ featureVector
val vect = Vectors.dense(nAr)
val result = (mu_val, vect)
result
}
//Annotations dataset with ground truth estimation
val joinedData = model.annotatorData.joinWith(model.mu, model.annotatorData.col("example") === model.mu.col("example"))
.as[(BinaryAnnotation,BinarySoftLabel)]
.map(x => RaykarBinaryPartial(x._1.example, x._1.annotator.toInt, x._1.value, x._2.value))
.as[RaykarBinaryPartial]
.cache()
//Annotator alpha estimation (reliability of predicting positive cases)
val p = model.params
val alpha = Array.ofDim[Double](model.nAnnotators.toInt)
val denomsalpha = joinedData.groupBy(col("annotator"))
.agg(sum(col("mu")) as "denom")
val numsalpha = joinedData.groupBy(col("annotator"))
.agg(sum(col("mu") * col("value")) as "num")
val alphad = numsalpha.as("n").join(denomsalpha.as("d"),
$"n.annotator" === $"d.annotator")
.select(col("n.annotator") as "annotator", col("num"), col("denom"))
.as[ParamCalc]
.map{case ParamCalc(ann,num,denom) => ParamValue(ann, (num + p.value.a(ann.toInt)(0) - 1)/(denom + p.value.a(ann.toInt).sum - 2)) }
alphad.collect.foreach((pv: ParamValue) => alpha(pv.annotator.toInt) = pv.value)
//Annotator beta estimation (reliability of predicting negative cases)
val beta = Array.ofDim[Double](model.nAnnotators.toInt)
val denomsbeta = joinedData.groupBy("annotator")
.agg(sum(lit(1) - col("mu")) as "denom")
val numsbeta = joinedData.groupBy(col("annotator"))
.agg(sum((lit(1)-col("mu")) *(lit(1)-col("value"))) as "num")
val betad = numsbeta.as("n").join(denomsbeta.as("d"),
$"n.annotator" === $"d.annotator")
.select(col("n.annotator") as "annotator", col("num"), col("denom"))
.as[ParamCalc]
.map{case ParamCalc(ann,num,denom) => ParamValue(ann,(num + p.value.b(ann.toInt)(0) - 1)/(denom + p.value.b(ann.toInt).sum - 2))}
betad.collect().foreach((pv: ParamValue) => beta(pv.annotator.toInt) = pv.value)
//Saving parameters for the model and broadcasting them
val annParam = sc.broadcast(RaykarBinaryParams(alpha=alpha, beta=beta, w=model.params.value.w,
model.params.value.a, model.params.value.b, model.params.value.wp))
//Obtains a and b for each example
val aggregator = new RaykarBinaryStatisticsAggregator(annParam)
val dataStatistics = joinedData.groupByKey(_.example)
.agg(aggregator.toColumn)
.map(x => RaykarBinaryStatistics(x._1, x._2._1, x._2._2))
//Renames a and b, joining with full training data.
val statsFixed = dataStatistics.toDF().withColumnRenamed("a", "comenriquegrodrigotempa")
.withColumnRenamed("b", "comenriquegrodrigotempb")
val withPar = model.dataset.as('d).join(statsFixed, "example")
// Renames mu column and adds it to full data
val withMuRenamed = model.mu.toDF().withColumnRenamed("value","comenriquegrodrigotempmu")
val withMu = withPar.join(withMuRenamed,"example").drop("example")
val colNames = withMu.columns
//Prepares data for SGT
val d1 = withMu.map(x => convertRowRDD(x,colNames))
val finalData = d1.as[(Double,Vector)]
val optiData = finalData.rdd
//Stochastic gradient descent process
val grad = new RaykarBinaryGradient(annParam)
val updater = new RaykarBinaryUpdater(annParam)
val rand = new Random(0) //First weight estimation is random
val initialWeights = Vectors.dense(Array.tabulate(model.nFeatures)(x => rand.nextDouble()))
val opt = GradientDescent.runMiniBatchSGD(optiData,grad,updater,gradLearning,gradIters,0,1,initialWeights,gradThreshold)._1
val optWeights = opt.toArray
//Saving results in the partial model
val param = sc.broadcast(RaykarBinaryParams(alpha=alpha, beta=beta, w=optWeights,
model.params.value.a, model.params.value.b, model.params.value.wp))
model.modify(nDataStatistics=dataStatistics.cache(), nParams=param)
}
/**
* Obtains the logistic prediction for a data point.
*
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] def computeP(params : Broadcast[RaykarBinaryParams])(r: Row): LogisticPrediction = {
val w = params.value.w
//Converts number data to double
val s: Seq[Double] = r.toSeq.map( x =>
x match {
case d: Double => d
case d: Int => d.toDouble
case d: Long => d.toDouble
})
val exampleId = s.head.toLong
val x = s.tail.toArray
LogisticPrediction(exampleId, computeSigmoid(x,w.toArray))
}
/**
* Estimates the ground truth.
*
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] def estimateMu(params: FullParameters): BinarySoftLabel = {
val a: Double = params.a
val b: Double = params.b
val p: Double = params.p
BinarySoftLabel(params.example,(a * p)/(a*p + b*(1-p)))
}
/**
* E step for the EM algorithm.
*
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] def eStep(model: RaykarBinaryPartialModel): RaykarBinaryPartialModel = {
import model.dataset.sparkSession.implicits._
val p = model.dataset.map(computeP(model.params)).as[LogisticPrediction]
//Estimates ground truth value
val allParams = p.joinWith(model.dataStatistics, p.col("example") === model.dataStatistics.col("example"))
.as[(LogisticPrediction, RaykarBinaryStatistics)]
.map( x => FullParameters(x._1.example, x._1.p, x._2.a, x._2.b))
.as[FullParameters]
val mu = allParams.map(estimateMu(_)).as[BinarySoftLabel]
model.modify(nMu = mu)
}
/**
* Log likelihood calculation.
*
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] def logLikelihood(model: RaykarBinaryPartialModel): RaykarBinaryPartialModel = {
import model.dataset.sparkSession.implicits._
val p = model.dataset.map(computeP(model.params)).as[LogisticPrediction]
//Obtains log-likelihood for the iteration
val allParams = p.joinWith(model.dataStatistics, p.col("example") === model.dataStatistics.col("example"))
.as[(LogisticPrediction, RaykarBinaryStatistics)]
.map( x => FullParameters(x._1.example, x._1.p, x._2.a, x._2.b) )
.as[FullParameters]
val temp = model.mu.joinWith(allParams, model.mu.col("example") === allParams.col("example"))
.as[(BinarySoftLabel,FullParameters)]
.map(x => ParameterWithEstimation(x._1.example,x._1.value,x._2.a, x._2.b, x._2.p))
val logLikelihood = temp.as[ParameterWithEstimation].map( { case ParameterWithEstimation(example,mu,a,b,p) => computePointLoss(mu,a,b,p) } ).reduce(_ + _)
model.modify(nLogLikelihood=logLikelihood, nImprovement=(model.logLikelihood-logLikelihood))
}
/**
* Full EM iteration.
*
* @author enrique.grodrigo
* @version 0.1
*/
private[spark] def step(gradIters: Int, gradThreshold: Double, gradLearning: Double)(model: RaykarBinaryPartialModel, i: Int): RaykarBinaryPartialModel = {
import model.dataset.sparkSession.implicits._
val m = mStep(model, gradIters, gradThreshold, gradLearning)
val e = eStep(m)
val result = logLikelihood(e)
result
}
}
| enriquegrodrigo/spark-crowd | spark-crowd/src/main/scala/com/enriquegrodrigo/spark/crowd/methods/RaykarBinary.scala | Scala | mit | 25,774 |
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.table.planner.plan.batch.table
import org.apache.flink.api.scala._
import org.apache.flink.table.api.TableException
import org.apache.flink.table.api.scala._
import org.apache.flink.table.planner.utils.{TableTestBase, TableTestUtil}
import org.hamcrest.Matchers.containsString
import org.junit.Test
import java.sql.Timestamp
class TemporalTableJoinTest extends TableTestBase {
val util: TableTestUtil = batchTestUtil()
val orders = util.addDataStream[(Long, String, Timestamp)](
"Orders", 'o_amount, 'o_currency, 'rowtime)
val ratesHistory = util.addDataStream[(String, Int, Timestamp)](
"RatesHistory", 'currency, 'rate, 'rowtime)
val rates = ratesHistory.createTemporalTableFunction('rowtime, 'currency)
util.addFunction("Rates", rates)
@Test
def testSimpleJoin(): Unit = {
expectedException.expect(classOf[TableException])
expectedException.expectMessage("Cannot generate a valid execution plan for the given query")
val result = orders
.as('o_amount, 'o_currency, 'o_rowtime)
.joinLateral(rates('o_rowtime), 'currency === 'o_currency)
.select("o_amount * rate").as("rate")
util.verifyPlan(result)
}
@Test
def testUncorrelatedJoin(): Unit = {
expectedException.expect(classOf[TableException])
expectedException.expectMessage(
containsString("Cannot generate a valid execution plan"))
val result = orders
.as('o_amount, 'o_currency, 'o_rowtime)
.joinLateral(
rates(java.sql.Timestamp.valueOf("2016-06-27 10:10:42.123")),
'o_currency === 'currency)
.select("o_amount * rate")
util.verifyPlan(result)
}
}
| bowenli86/flink | flink-table/flink-table-planner-blink/src/test/scala/org/apache/flink/table/planner/plan/batch/table/TemporalTableJoinTest.scala | Scala | apache-2.0 | 2,471 |
package com.github.swwjf.ws
import com.github.swwjf.errorhandling.WSException
import org.springframework.beans.BeanUtils
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.dao.DataIntegrityViolationException
import org.springframework.stereotype.Service
import org.springframework.transaction.annotation.Transactional
import scala.collection.JavaConversions._
import scala.compat.java8.OptionConverters.RichOptionalGeneric
@Service
class InfoService @Autowired()(infoRepository: InfoRepository) {
def fetchAllInformation(): List[InfoResponseDTO] = {
def jpaToResponse(jpa: InfoJPA): InfoResponseDTO = {
val response = InfoResponseDTO(
createdDate = jpa.createdData.toString,
updatedDate = Option(jpa.updatedDate).map(_.toString).orNull
)
BeanUtils.copyProperties(jpa, response)
response
}
infoRepository
.findAll()
.map(jpaToResponse)
.toList
}
def saveInfo(infoRequestDTO: InfoRequestDTO): Unit = {
def requestToJPA(request: InfoRequestDTO): InfoJPA = {
val jpa = new InfoJPA
BeanUtils.copyProperties(request, jpa)
jpa
}
try {
infoRepository.save(requestToJPA(infoRequestDTO))
} catch {
case e: DataIntegrityViolationException => throw new WSException("Invalid/duplicate label")
}
}
@Transactional
def updateInfo(info: InfoRequestDTO): Unit = {
val infoJPA = infoRepository
.findOneByLabel(info.label)
.asScala
.getOrElse(throw new WSException(s"Failed to find info by label ${info.label}"))
infoJPA.setMainDetails(info.mainDetails)
infoJPA.setComments(info.comments)
}
} | andrei-l/scala-webapp-with-java-frameworks | webservices/src/main/scala/com/github/swwjf/ws/InfoService.scala | Scala | mit | 1,683 |
/*
* Shadowsocks - A shadowsocks client for Android
* Copyright (C) 2014 <max.c.lv@gmail.com>
*
* This program is free software: you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation, either version 3 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program. If not, see <http://www.gnu.org/licenses/>.
*
*
* ___====-_ _-====___
* _--^^^#####// \\\\#####^^^--_
* _-^##########// ( ) \\\\##########^-_
* -############// |\\^^/| \\\\############-
* _/############// (@::@) \\\\############\\_
* /#############(( \\\\// ))#############\\
* -###############\\\\ (oo) //###############-
* -#################\\\\ / VV \\ //#################-
* -###################\\\\/ \\//###################-
* _#/|##########/\\######( /\\ )######/\\##########|\\#_
* |/ |#/\\#/\\#/\\/ \\#/\\##\\ | | /##/\\#/ \\/\\#/\\#/\\#| \\|
* ` |/ V V ` V \\#\\| | | |/#/ V ' V V \\| '
* ` ` ` ` / | | | | \\ ' ' ' '
* ( | | | | )
* __\\ | | | | /__
* (vvv(VVV)(VVV)vvv)
*
* HERE BE DRAGONS
*
*/
package com.github.shadowsocks
import android.os.{Handler, RemoteCallbackList}
import com.github.shadowsocks.aidl.{Config, IShadowsocksService, IShadowsocksServiceCallback}
import com.github.shadowsocks.utils.{Path, State}
import java.io.{IOException, FileNotFoundException, FileReader, BufferedReader}
import android.util.Log
import android.app.Notification
import android.content.Context
trait BaseService {
@volatile private var state = State.INIT
@volatile private var callbackCount = 0
final val callbacks = new RemoteCallbackList[IShadowsocksServiceCallback]
protected val binder = new IShadowsocksService.Stub {
override def getMode: Int = {
getServiceMode
}
override def getState: Int = {
state
}
override def unregisterCallback(cb: IShadowsocksServiceCallback) {
if (cb != null ) {
callbacks.unregister(cb)
callbackCount -= 1
}
if (callbackCount == 0 && state != State.CONNECTING && state != State.CONNECTED) {
stopBackgroundService()
}
}
override def registerCallback(cb: IShadowsocksServiceCallback) {
if (cb != null) {
callbacks.register(cb)
callbackCount += 1
}
}
override def stop() {
if (state != State.CONNECTING && state != State.STOPPING) {
stopRunner()
}
}
override def start(config: Config) {
if (state != State.CONNECTING && state != State.STOPPING) {
startRunner(config)
}
}
}
def stopBackgroundService()
def startRunner(config: Config)
def stopRunner()
def getServiceMode: Int
def getTag: String
def getContext: Context
def getCallbackCount(): Int = {
callbackCount
}
def getState(): Int = {
state
}
def changeState(s: Int) {
changeState(s, null)
}
protected def changeState(s: Int, msg: String) {
val handler = new Handler(getContext.getMainLooper)
handler.post(new Runnable {
override def run() {
if (state != s) {
if (callbackCount > 0) {
val n = callbacks.beginBroadcast()
for (i <- 0 to n - 1) {
try {
callbacks.getBroadcastItem(i).stateChanged(s, msg)
} catch {
case _: Exception => // Ignore
}
}
callbacks.finishBroadcast()
}
state = s
}
}
})
}
def initSoundVibrateLights(notification: Notification) {
notification.sound = null
}
}
| azraelrabbit/shadowsocks-android | src/main/scala/com/github/shadowsocks/BaseService.scala | Scala | gpl-3.0 | 4,282 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.ml.linalg
import breeze.linalg.{DenseVector => BDV, SparseVector => BSV}
import org.apache.spark.ml.SparkMLFunSuite
/**
* Test Breeze vector conversions.
*/
class BreezeVectorConversionSuite extends SparkMLFunSuite {
val arr = Array(0.1, 0.2, 0.3, 0.4)
val n = 20
val indices = Array(0, 3, 5, 10, 13)
val values = Array(0.1, 0.5, 0.3, -0.8, -1.0)
test("dense to breeze") {
val vec = Vectors.dense(arr)
assert(vec.asBreeze === new BDV[Double](arr))
}
test("sparse to breeze") {
val vec = Vectors.sparse(n, indices, values)
assert(vec.asBreeze === new BSV[Double](indices, values, n))
}
test("dense breeze to vector") {
val breeze = new BDV[Double](arr)
val vec = Vectors.fromBreeze(breeze).asInstanceOf[DenseVector]
assert(vec.size === arr.length)
assert(vec.values.eq(arr), "should not copy data")
}
test("sparse breeze to vector") {
val breeze = new BSV[Double](indices, values, n)
val vec = Vectors.fromBreeze(breeze).asInstanceOf[SparseVector]
assert(vec.size === n)
assert(vec.indices.eq(indices), "should not copy data")
assert(vec.values.eq(values), "should not copy data")
}
test("sparse breeze with partially-used arrays to vector") {
val activeSize = 3
val breeze = new BSV[Double](indices, values, activeSize, n)
val vec = Vectors.fromBreeze(breeze).asInstanceOf[SparseVector]
assert(vec.size === n)
assert(vec.indices === indices.slice(0, activeSize))
assert(vec.values === values.slice(0, activeSize))
}
}
| bravo-zhang/spark | mllib-local/src/test/scala/org/apache/spark/ml/linalg/BreezeVectorConversionSuite.scala | Scala | apache-2.0 | 2,360 |
package predict4s.sgp
/*
* The traits/classes here are used to compare our results with those from Vallado's software, using the same variable names as in Vallado.
*/
trait Initl[F] {
def satn: Int
def ecco : F
def epoch : F
def inclo : F
def no : F
// outputs :
def ainv : F ; def ao : F ; def cosio : F ; def cosio2 : F
def eccsq : F ; def omeosq : F ; def rp : F ; def rteosq : F ;
def sinio : F ; def gsto : F ;
}
trait Sgp4Init[F] {
def satn: Int; def yr : Int ; def bstar : F; def ecco : F; def epoch : F; def argpo : F;
def inclo : F ; def mo : F ;
// in and out variables
def no : F ;
// outputs :
def isimp : Int ; def method : Char ; def aycof : F ;
def con41 : F ; def cc1 : F ; def cc4 : F ;
def cc5 : F ; def d2 : F ; def d3 : F ; def d4 : F ; def delmo : F;
def eta : F ; def argpdot : F ; def omgcof : F;
def sinmao : F ; def t2cof : F ; def t3cof : F ;
def t4cof : F ; def t5cof : F ; def gsto : F ; def x1mth2 : F ; def x7thm1 : F ; def xlcof : F ;
def xmcof : F ; def mdot : F ; def nodecf : F ; def nodedt : F ;
// in and outputs from deep space satellites :
def t : F ; def nodeo : F ;
}
//trait Sgp4Vars[F] extends Initl[F] with Sgp4Init[F]
trait PosVel[F] {
def error: Int; def x : F; def y : F; def z: F; def xdot: F ; def ydot : F; def zdot: F;
}
trait Sgp4Near[F] extends Initl[F] with PosVel[F] {
def xno : F ;
def atime: F;
def satn: Int; def yr : Int ; def bstar : F; def ecco : F; def epoch : F; def argpo : F;
def inclo : F ; def mo : F ;
// in and out variables
def no : F ;
// outputs :
def isimp : Int ; def method : Char ;
def cc1 : F ; def cc4 : F ;
def cc5 : F ; def d2 : F ; def d3 : F ; def d4 : F ;
def eta : F ; def argpdot : F ; def omgcof : F;
def sinmao : F ; def t2cof : F ; def t3cof : F ;
def t4cof : F ; def t5cof : F ; def gsto : F ; def x1mth2 : F ; def x7thm1 : F ;
def xmcof : F ; def mdot : F ; def nodecf : F ; def nodedt : F ;
// in and outputs from deep space satellites :
def t : F ; def nodeo : F ;
// def xli : F;
// def xni: F;
}
| pleira/SGP4Extensions | tests/src/test/scala/predict4s/sgp/Initl.scala | Scala | apache-2.0 | 2,597 |
package com.mz.training.common.services
import java.util.UUID
import akka.actor.{Actor, ActorContext, ActorLogging, ActorRef, PoisonPill, Props}
import akka.pattern._
import akka.util.Timeout
import com.mz.training.common.messages.UnsupportedOperation
import com.mz.training.common._
import com.mz.training.common.services.pagination.GetAllPaginationActor
import com.mz.training.domains.EntityId
import com.typesafe.config.Config
import scala.concurrent.duration._
import scala.concurrent.{Future, Promise}
import scala.util.{Failure, Success}
/**
* Created by zemi on 12/06/16.
*/
abstract class AbstractDomainServiceActor[E <: EntityId](repositoryBuilder:(ActorContext) => ActorRef)
extends Actor with ActorLogging {
import scala.concurrent.ExecutionContext.Implicits.global
protected val sysConfig: Config = context.system.settings.config
protected implicit val timeout: Timeout =
DurationInt(sysConfig.getInt("akka.actor.timeout.domain.services")).millisecond
val repository = repositoryBuilder(context)
context.watch(repository)
override def receive: Receive = {
case c:Create[E] => create(c.entity) pipeTo sender
case FindById(id) => findById(id) pipeTo sender
case d:Delete[E] => delete(d.entity) pipeTo sender
case DeleteById(id) => delete(id) pipeTo sender
case u:Update[E] => update(u.entity) pipeTo sender
case msg:GetAllPagination[E] => getAllPagination(msg) pipeTo sender
case GetAll => getAll pipeTo sender
case _ => sender ! UnsupportedOperation
}
/**
* List all entities from DB
* TODO: add pagination
* @return
*/
protected def getAll: Future[Found[E]] = {
log.info(s"${getClass.getCanonicalName} getAll ->")
(repository ? repositories.SelectAll).mapTo[List[E]].map(result => {
log.info("findUserById - success!")
Found(result)
})
}
/**
* List all entities from DB pagination
* TODO: add pagination
* @return
*/
protected def getAllPagination(msg:GetAllPagination[E]): Future[GetAllPaginationResult[E]] = {
log.info(s"${getClass.getCanonicalName} getAllPagination ->")
val actRef = Future {
context.actorOf(GetAllPaginationActor.props[E](repository),
s"GetAllPaginationActor-${UUID.randomUUID.toString}")
}
actRef.flatMap(getAllPagActRef => executeAndCleanUpAct(getAllPagActRef ? msg)(getAllPagActRef)
.mapTo[GetAllPaginationResult[E]])
}
/**
* Create
*
* @param entity
* @return
*/
protected def create(entity: E): Future[Created] = {
log.info(s"${getClass.getCanonicalName} create ->")
(repository ? repositories.Insert(entity)).mapTo[repositories.Inserted].map(result => {
log.info("createUser - success!")
Created(result.id)
})
}
/**
* Find entity by id
*
* @param id
* @return
*/
protected def findById(id: Long): Future[Found[E]] = {
log.info(s"${getClass.getCanonicalName} findById ->")
(repository ? repositories.SelectById(id)).mapTo[Option[E]].map(result => {
log.info("findUserById - success!")
result match {
case s:Some[E] => Found[E](List(s.get))
case None => Found(Nil)
}
})
}
/**
* Delete entity
*
* @param entity - Entity to delete
* @return Future[UserDeleted]
*/
protected def delete(entity: E): Future[Deleted] = {
log.info(s"${getClass.getCanonicalName} delete ->")
(repository ? repositories.Delete(entity.id)).mapTo[Boolean].map(result => {
log.info("User delete success!")
Deleted()
})
}
/**
* Delete by id
* @param id - id of entity
* @return
*/
protected def delete(id: Long): Future[Deleted] = {
log.info(s"${getClass.getCanonicalName} delete ->")
(repository ? repositories.Delete(id)).mapTo[Boolean].map(result => {
log.info("User delete success!")
Deleted()
})
}
/**
* Update entity
*
* @param entity
* @return
*/
protected def update(entity: E): Future[UpdateResult[E]] = {
log.info(s"${getClass.getCanonicalName} update ->")
(repository ? repositories.Update(entity)).mapTo[Boolean].map(result => {
if (result) Updated(entity)
else NotUpdated(entity)
})
}
/**
* execute action and clean up actor
* @param execute - execution function
* @param actor - actor to terminate after execution
* @tparam R - Type of result
* @return Future of execution
*/
protected def executeAndCleanUpAct[R](execute: => Future[R])(actor: ActorRef): Future[R] = {
execute.andThen {
case Success(s) => {
destroyActors(Some(actor))
s
}
case Failure(e) => {
destroyActors(Some(actor))
e
}
}
}
/**
* send message PoinsonPill to the actor
* @param actor - ActorRef to be terminated
*/
def destroyActors(actor: Option[ActorRef]): Unit = {
actor.foreach(actor => actor ! PoisonPill)
}
@throws[Exception](classOf[Exception])
override def postStop(): Unit = {
log.debug("Actor stop")
super.postStop()
}
}
| michalzeman/angular2-training | akka-http-server/src/main/scala/com/mz/training/common/services/AbstractDomainServiceActor.scala | Scala | mit | 5,103 |
package sbt
import org.scalacheck._
import Prop._
import TaskGen._
import Task._
object TaskRunnerCircularTest extends Properties("TaskRunner Circular")
{
property("Catches circular references") = forAll(MaxTasksGen, MaxWorkersGen) { checkCircularReferences _ }
property("Allows references to completed tasks") = forAllNoShrink(MaxTasksGen, MaxWorkersGen) { allowedReference _ }
final def allowedReference(intermediate: Int, workers: Int) =
{
val top = task(intermediate).named("top")
def iterate(tk: Task[Int]): Task[Int] =
tk flatMap { t =>
if(t <= 0)
top
else
iterate(task(t-1).named((t-1).toString) )
}
try { checkResult(tryRun(iterate(top), true, workers), intermediate) }
catch { case i: Incomplete if cyclic(i) => ("Unexpected cyclic exception: " + i) |: false }
}
final def checkCircularReferences(intermediate: Int, workers: Int) =
{
lazy val top = iterate(task(intermediate).named("bottom"), intermediate)
def iterate(tk: Task[Int], i: Int): Task[Int] =
tk flatMap { t =>
if(t <= 0)
top
else
iterate(task(t-1).named((t-1).toString), i-1)
}
try { tryRun(top, true, workers); false }
catch { case i: Incomplete => cyclic(i) }
}
def cyclic(i: Incomplete) = Incomplete.allExceptions(i).exists(_.isInstanceOf[Execute[Task]#CyclicException[_]])
} | xeno-by/old-scalameta-sbt | tasks/standard/src/test/scala/TaskRunnerCircular.scala | Scala | bsd-3-clause | 1,325 |
package com.faacets.qalg
package impl
import scala.{specialized => sp}
import scala.annotation.tailrec
import spire.algebra._
import spire.syntax.cfor._
import spire.syntax.field._
import algebra._
import indup.algebra._
object MatSparse0 {/*
@inline def feedTo[M, @sp(Double, Long) A](m: M, b: MatBuilder[_, A])(implicit M: MatBuild[M, A]): Unit = {
import M._
cforRange(0 until nRows(m)) { r =>
cforRange(0 until nCols(m)) { c =>
b.add(r, c, apply(m, r, c))
}
}
}
@inline def plus[M, @sp(Double, Long) A](x: M, y: M)(implicit M: MatRing[M, A]): M = {
import M._
val nR = nRows(x)
require(nR == nRows(y))
val nC = nCols(x)
require(nC == nCols(y))
val b = builder(nR, nC, storageSize(x))
cforRange(0 until nR) { r =>
cforRange(0 until nC) { c =>
b.add(r, c, apply(x, r, c) + apply(y, r, c))
}
}
b.result()
}
@inline def minus[M, @sp(Double, Long) A](x: M, y: M)(implicit M: MatRing[M, A]): M = {
import M._
val nR = nRows(x)
require(nR == nRows(y))
val nC = nCols(x)
require(nC == nCols(y))
val b = builder(nR, nC, storageSize(x))
cforRange(0 until nR) { r =>
cforRange(0 until nC) { c =>
b.add(r, c, apply(x, r, c) - apply(y, r, c))
}
}
b.result()
}
@inline def negate[M, @sp(Double, Long) A](m: M)(implicit M: MatRing[M, A]): M = {
import M._
val nR = nRows(m)
val nC = nCols(m)
val b = builder(nR, nC, storageSize(m))
cforRange(0 until nR) { r =>
cforRange(0 until nC) { c =>
b.add(r, c, -apply(m, r, c))
}
}
b.result()
}
@inline def timesl[M, @sp(Double, Long) A](a: A, m: M)(implicit M: MatRing[M, A]): M = {
import M._
val nR = nRows(m)
val nC = nCols(m)
val b = builder(nR, nC, storageSize(m))
cforRange(0 until nR) { r =>
cforRange(0 until nC) { c =>
b.add(r, c, a * apply(m, r, c))
}
}
b.result()
}
@inline def timesr[M, @sp(Double, Long) A](m: M, a: A)(implicit M: MatRing[M, A]): M = {
import M._
val nR = nRows(m)
val nC = nCols(m)
val b = builder(nR, nC, storageSize(m))
cforRange(0 until nR) { r =>
cforRange(0 until nC) { c =>
b.add(r, c, apply(m, r, c) * a)
}
}
b.result()
}
@inline def divr[M, @sp(Double, Long) A](m: M, a: A)(implicit M: MatField[M, A]): M = {
import M._
val nR = nRows(m)
val nC = nCols(m)
val b = builder(nR, nC, storageSize(m))
cforRange(0 until nR) { r =>
cforRange(0 until nC) { c =>
b.add(r, c, apply(m, r, c) / a)
}
}
b.result()
}*/
}
| denisrosset/qalg | core/src/main/scala/qalg/impl/MatSparse0.scala | Scala | mit | 2,651 |
/*
* MUSIT is a museum database to archive natural and cultural history data.
* Copyright (C) 2016 MUSIT Norway, part of www.uio.no (University of Oslo)
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation; either version 2 of the License,
* or any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License along
* with this program; if not, write to the Free Software Foundation, Inc.,
* 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
*/
package models.storage.nodes
import play.api.libs.json.{Format, Json}
// FIXME Fields are required according to requirements
case class EnvironmentAssessment(
relativeHumidity: Option[Boolean],
temperature: Option[Boolean],
lightingCondition: Option[Boolean],
preventiveConservation: Option[Boolean]
)
object EnvironmentAssessment {
lazy val empty = EnvironmentAssessment(None, None, None, None)
implicit val format: Format[EnvironmentAssessment] =
Json.format[EnvironmentAssessment]
}
| kpmeen/musit | service_storagefacility/app/models/storage/nodes/EnvironmentAssessment.scala | Scala | gpl-2.0 | 1,379 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package reforest.rf.feature
import reforest.rf.RFCategoryInfo
/**
* An utility to retrieve how must be large a data structure to contain the information relative to a given feature
*/
trait RFFeatureSizer extends Serializable {
/**
* It return the size requested by the given feature
*
* @param featureId a feature index
* @return the minimum size required to store information for the feature (it considers the number of bins, the number of
* possible values for the feature, the missing values, the number of classes in the dataset)
*/
def getSize(featureId: Int): Int
/**
* Starting from a bin number it returns the bin number when the number of bins is less that the number of bins stored in the static data
*
* @param featureId the feature identifier
* @param value the bin value
* @return the shrinked bin value
*/
def getShrinkedValue(featureId: Int, value: Int): Int
/**
* It is the reverse function of getShrinkedValue
*
* @param featureId the feature identifer
* @param value the bin value
* @return the de-shrinked bin value
*/
def getDeShrinkedValue(featureId: Int, value: Int): Int
}
/**
* A feature sizer specialized for each feature
*
* @param splitNumberMap a map containing the possible discretized values of each feature. Each value is <= number of configured bin
* @param numClasses the number of classes in the dataset
* @param categoricalFeatureInfo the information about categorical features
*/
class RFFeatureSizerSpecialized(splitNumberMap: scala.collection.Map[Int, Int],
numClasses: Int,
categoricalFeatureInfo: RFCategoryInfo) extends RFFeatureSizer {
override def getSize(featureId: Int): Int = {
if (categoricalFeatureInfo.isCategorical(featureId))
(categoricalFeatureInfo.getArity(featureId) + 1) * numClasses
else
(splitNumberMap(featureId) + 2) * numClasses
}
override def getShrinkedValue(featureId: Int, value: Int): Int = value
override def getDeShrinkedValue(featureId: Int, value: Int): Int = value
}
class RFFeatureSizerSpecializedModelSelection(splitNumberMap: scala.collection.Map[Int, Int],
numClasses: Int,
categoricalFeatureInfo: RFCategoryInfo,
binNumberShrinked: Int,
binNumberMax: Int) extends RFFeatureSizer {
override def getSize(featureId: Int): Int = {
if (categoricalFeatureInfo.isCategorical(featureId))
(categoricalFeatureInfo.getArity(featureId) + 1) * numClasses
else {
val splitNumberFeature = splitNumberMap(featureId)
if (splitNumberFeature <= binNumberShrinked)
(splitNumberFeature + 2) * numClasses
else {
(binNumberShrinked + 2) * numClasses
}
}
}
override def getShrinkedValue(featureId: Int, value: Int): Int = {
if (binNumberShrinked >= binNumberMax) {
value
} else {
if (value == 0) {
value
} else {
val binnumberfeature = splitNumberMap(featureId) + 1
if (binnumberfeature <= binNumberShrinked) {
value
} else {
math.min(binNumberShrinked, math.max(1, (value / (binnumberfeature / binNumberShrinked.toDouble)).toInt))
}
}
}
}
override def getDeShrinkedValue(featureId: Int, value: Int): Int = {
if (binNumberShrinked >= binNumberMax) {
value
} else {
val binNumberFeature = splitNumberMap(featureId) + 1
if (binNumberFeature <= binNumberShrinked) {
value
} else {
Math.min(binNumberFeature, value * (binNumberFeature / binNumberShrinked.toDouble).toInt)
}
}
}
}
/**
* A simple feature sizer that assign the size for each feature equal to the number of configured bin
*
* @param binNumber the number of configured bin
* @param numClasses the number of classes in the dataset
* @param categoricalFeatureInfo the information about categorical features
*/
class RFFeatureSizerSimple(binNumber: Int, numClasses: Int, categoricalFeatureInfo: RFCategoryInfo) extends RFFeatureSizer {
override def getSize(featureId: Int): Int = {
if (categoricalFeatureInfo.isCategorical(featureId))
(categoricalFeatureInfo.getArity(featureId) + 1) * numClasses
else
(binNumber + 1) * numClasses
}
override def getShrinkedValue(featureId: Int, value: Int): Int = value
override def getDeShrinkedValue(featureId: Int, value: Int): Int = value
}
class RFFeatureSizerSimpleModelSelection(binNumber: Int, numClasses: Int, categoricalFeatureInfo: RFCategoryInfo, binNumberShrinked: Int) extends RFFeatureSizer {
override def getSize(featureId: Int): Int = {
if (categoricalFeatureInfo.isCategorical(featureId))
(categoricalFeatureInfo.getArity(featureId) + 1) * numClasses
else {
if (binNumber <= binNumberShrinked)
(binNumber + 1) * numClasses
else {
(binNumberShrinked + 1) * numClasses
}
}
}
override def getShrinkedValue(featureId: Int, value: Int): Int = {
if (binNumber <= binNumberShrinked || value == 0) {
value
} else {
Math.min(binNumberShrinked, Math.max(1, (value / (binNumber / binNumberShrinked.toDouble)).toInt))
}
}
override def getDeShrinkedValue(featureId: Int, value: Int): Int = {
if (binNumber <= binNumberShrinked) {
value
} else {
Math.min(binNumber, value * (binNumber / binNumberShrinked.toDouble).toInt)
}
}
} | alessandrolulli/reforest | src/main/scala/reforest/rf/feature/RFFeatureSizer.scala | Scala | apache-2.0 | 6,683 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.streaming.ui
import java.util.TimeZone
import java.util.concurrent.TimeUnit
import org.scalatest.Matchers
import org.apache.spark.SparkFunSuite
import org.apache.spark.ui.{UIUtils => SparkUIUtils}
class UIUtilsSuite extends SparkFunSuite with Matchers{
test("shortTimeUnitString") {
assert("ns" === UIUtils.shortTimeUnitString(TimeUnit.NANOSECONDS))
assert("us" === UIUtils.shortTimeUnitString(TimeUnit.MICROSECONDS))
assert("ms" === UIUtils.shortTimeUnitString(TimeUnit.MILLISECONDS))
assert("sec" === UIUtils.shortTimeUnitString(TimeUnit.SECONDS))
assert("min" === UIUtils.shortTimeUnitString(TimeUnit.MINUTES))
assert("hrs" === UIUtils.shortTimeUnitString(TimeUnit.HOURS))
assert("days" === UIUtils.shortTimeUnitString(TimeUnit.DAYS))
}
test("normalizeDuration") {
verifyNormalizedTime(900, TimeUnit.MILLISECONDS, 900)
verifyNormalizedTime(1.0, TimeUnit.SECONDS, 1000)
verifyNormalizedTime(1.0, TimeUnit.MINUTES, 60 * 1000)
verifyNormalizedTime(1.0, TimeUnit.HOURS, 60 * 60 * 1000)
verifyNormalizedTime(1.0, TimeUnit.DAYS, 24 * 60 * 60 * 1000)
}
private def verifyNormalizedTime(
expectedTime: Double, expectedUnit: TimeUnit, input: Long): Unit = {
val (time, unit) = UIUtils.normalizeDuration(input)
time should be (expectedTime +- 1E-6)
unit should be (expectedUnit)
}
test("convertToTimeUnit") {
verifyConvertToTimeUnit(60.0 * 1000 * 1000 * 1000, 60 * 1000, TimeUnit.NANOSECONDS)
verifyConvertToTimeUnit(60.0 * 1000 * 1000, 60 * 1000, TimeUnit.MICROSECONDS)
verifyConvertToTimeUnit(60 * 1000, 60 * 1000, TimeUnit.MILLISECONDS)
verifyConvertToTimeUnit(60, 60 * 1000, TimeUnit.SECONDS)
verifyConvertToTimeUnit(1, 60 * 1000, TimeUnit.MINUTES)
verifyConvertToTimeUnit(1.0 / 60, 60 * 1000, TimeUnit.HOURS)
verifyConvertToTimeUnit(1.0 / 60 / 24, 60 * 1000, TimeUnit.DAYS)
}
private def verifyConvertToTimeUnit(
expectedTime: Double, milliseconds: Long, unit: TimeUnit): Unit = {
val convertedTime = UIUtils.convertToTimeUnit(milliseconds, unit)
convertedTime should be (expectedTime +- 1E-6)
}
test("formatBatchTime") {
val tzForTest = TimeZone.getTimeZone("America/Los_Angeles")
val batchTime = 1431637480452L // Thu May 14 14:04:40 PDT 2015
assert("2015/05/14 14:04:40" ===
SparkUIUtils.formatBatchTime(batchTime, 1000, timezone = tzForTest))
assert("2015/05/14 14:04:40.452" ===
SparkUIUtils.formatBatchTime(batchTime, 999, timezone = tzForTest))
assert("14:04:40" ===
SparkUIUtils.formatBatchTime(batchTime, 1000, false, timezone = tzForTest))
assert("14:04:40.452" ===
SparkUIUtils.formatBatchTime(batchTime, 999, false, timezone = tzForTest))
}
}
| ConeyLiu/spark | streaming/src/test/scala/org/apache/spark/streaming/ui/UIUtilsSuite.scala | Scala | apache-2.0 | 3,570 |
package at.fh.swengb.resifo_android
/**
* Created by niki on 05.02.2017.
*/
import android.content.Context
import android.view.LayoutInflater
import android.view.View
import android.view.ViewGroup
import android.widget.TextView
import scala.collection.JavaConversions._
import java.util.List
class CustomAdapter(var context: Context, var listPerson: List[Person]) extends android.widget.BaseAdapter {
var inflter: LayoutInflater = null
inflter = (LayoutInflater.from(context))
def getCount: Int = {
return listPerson.size
}
def getItemId(i: Int): Long = {
return i
}
def getView(i: Int, view: View, viewGroup: ViewGroup): View = {
var viewVar:View = view
if (view == null) {
viewVar = inflter.inflate(R.layout.activity_list_eintrag, null)
}
val viewName: TextView = viewVar.findViewById(R.id.textViewListName).asInstanceOf[TextView]
val viewAddress: TextView = viewVar.findViewById(R.id.textViewListAddress).asInstanceOf[TextView]
val viewPhone: TextView = viewVar.findViewById(R.id.textViewListPhone).asInstanceOf[TextView]
val person: Person = listPerson.get(i)
viewName.setText(person.firstName + " " + person.secondName)
viewAddress.setText(person.dateOfBirth)
viewPhone.setText(person.sex)
return view
}
override def getItem(position: Int): AnyRef =
return listPerson.get(position)
}
| x-qlusive/resifo-android | app/src/main/scala/at/fh/swengb/resifo_android/CustomAdapter.scala | Scala | apache-2.0 | 1,384 |
// Databricks notebook source
// MAGIC %md
// MAGIC ScaDaMaLe Course [site](https://lamastex.github.io/scalable-data-science/sds/3/x/) and [book](https://lamastex.github.io/ScaDaMaLe/index.html)
// COMMAND ----------
// MAGIC %md
// MAGIC # Why Apache Spark?
// MAGIC
// MAGIC * [Apache Spark: A Unified Engine for Big Data Processing](https://cacm.acm.org/magazines/2016/11/209116-apache-spark/fulltext) By Matei Zaharia, Reynold S. Xin, Patrick Wendell, Tathagata Das, Michael Armbrust, Ankur Dave, Xiangrui Meng, Josh Rosen, Shivaram Venkataraman, Michael J. Franklin, Ali Ghodsi, Joseph Gonzalez, Scott Shenker, Ion Stoica
// MAGIC Communications of the ACM, Vol. 59 No. 11, Pages 56-65
// MAGIC 10.1145/2934664
// MAGIC
// MAGIC [](https://player.vimeo.com/video/185645796)
// MAGIC
// MAGIC Right-click the above image-link, open in a new tab and watch the video (4 minutes) or read about it in the Communications of the ACM in the frame below or from the link above.
// MAGIC
// MAGIC **Key Insights from [Apache Spark: A Unified Engine for Big Data Processing](https://cacm.acm.org/magazines/2016/11/209116-apache-spark/fulltext) **
// MAGIC
// MAGIC - A simple programming model can capture streaming, batch, and interactive workloads and enable new applications that combine them.
// MAGIC - Apache Spark applications range from finance to scientific data processing and combine libraries for SQL, machine learning, and graphs.
// MAGIC - In six years, Apache Spark has grown to 1,000 contributors and thousands of deployments.
// MAGIC
// MAGIC 
// COMMAND ----------
//This allows easy embedding of publicly available information into any other notebook
//Example usage:
// displayHTML(frameIt("https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation#Topics_in_LDA",250))
def frameIt( u:String, h:Int ) : String = {
"""<iframe
src=""""+ u+""""
width="95%" height="""" + h + """">
<p>
<a href="http://spark.apache.org/docs/latest/index.html">
Fallback link for browsers that, unlikely, don't support frames
</a>
</p>
</iframe>"""
}
displayHTML(frameIt("https://cacm.acm.org/magazines/2016/11/209116-apache-spark/fulltext",600))
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC Spark 3.0 is the latest version now (20200918) and it should be seen as the latest step in the evolution of tools in the big data ecosystem as summarized in [https://towardsdatascience.com/what-is-big-data-understanding-the-history-32078f3b53ce](https://towardsdatascience.com/what-is-big-data-understanding-the-history-32078f3b53ce):
// MAGIC
// MAGIC 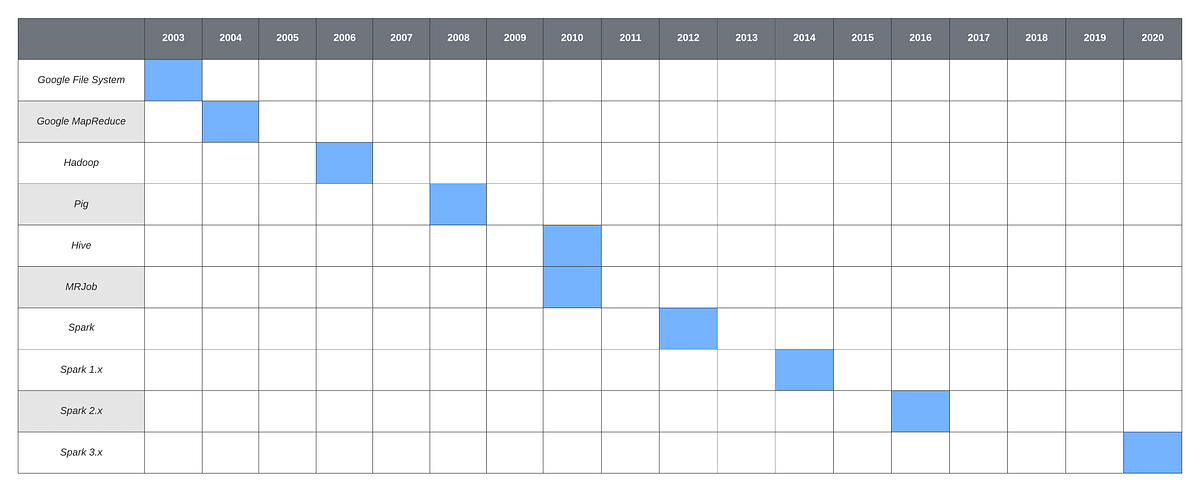
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC ## Alternatives to Apache Spark
// MAGIC
// MAGIC There are several alternatives to Apache Spark, but none of them have the penetration and community of Spark as of 2021.
// MAGIC
// MAGIC For real-time streaming operations [Apache Flink](https://flink.apache.org/) is competitive. See [Apache Flink vs Spark – Will one overtake the other?](https://www.projectpro.io/article/apache-flink-vs-spark-will-one-overtake-the-other/282#toc-7) for a July 2021 comparison. Most scalable data science and engineering problems faced by several major industries in Sweden today are routinely solved using tools in the ecosystem around Apache Spark. Therefore, we will focus on Apache Spark here which still holds [the world record for 10TB or 10,000 GB sort](http://www.tpc.org/tpcds/results/tpcds_perf_results5.asp?spm=a2c65.11461447.0.0.626f184fy7PwOU&resulttype=all) by [Alibaba cloud](https://www.alibabacloud.com/blog/alibaba-cloud-e-mapreduce-sets-world-record-again-on-tpc-ds-benchmark_596195) in 06/17/2020.
// COMMAND ----------
// MAGIC %md
// MAGIC ## The big data problem
// MAGIC
// MAGIC **Hardware, distributing work, handling failed and slow machines**
// MAGIC
// MAGIC Let us recall and appreciate the following:
// MAGIC
// MAGIC * The Big Data Problem
// MAGIC * Many routine problems today involve dealing with "big data", operationally, this is a dataset that is larger than a few TBs and thus won't fit into a single commodity computer like a powerful desktop or laptop computer.
// MAGIC
// MAGIC * Hardware for Big Data
// MAGIC * The best single commodity computer can not handle big data as it has limited hard-disk and memory
// MAGIC * Thus, we need to break the data up into lots of commodity computers that are networked together via cables to communicate instructions and data between them - this can be thought of as *a cloud*
// MAGIC * How to distribute work across a cluster of commodity machines?
// MAGIC * We need a software-level framework for this.
// MAGIC * How to deal with failures or slow machines?
// MAGIC * We also need a software-level framework for this.
// MAGIC
// COMMAND ----------
// MAGIC %md
// MAGIC ## Key Papers
// MAGIC
// MAGIC * Key Historical Milestones
// MAGIC * 1956-1979: [Stanford, MIT, CMU, and other universities develop set/list operations in LISP, Prolog, and other languages for parallel processing](https://en.wikipedia.org/wiki/Lisp_(programming_language))
// MAGIC * 2004: **READ**: [Google's MapReduce: Simplified Data Processing on Large Clusters, by Jeffrey Dean and Sanjay Ghemawat](https://research.google/pubs/pub62/)
// MAGIC * 2006: [Yahoo!'s Apache Hadoop, originating from the Yahoo!’s Nutch Project, Doug Cutting - wikipedia](https://en.wikipedia.org/wiki/Apache_Hadoop)
// MAGIC * 2009: [Cloud computing with Amazon Web Services Elastic MapReduce](https://aws.amazon.com/emr/), a Hadoop version modified for Amazon Elastic Cloud Computing (EC2) and Amazon Simple Storage System (S3), including support for Apache Hive and Pig.
// MAGIC * 2010: **READ**: [The Hadoop Distributed File System, by Konstantin Shvachko, Hairong Kuang, Sanjay Radia, and Robert Chansler. IEEE MSST](https://dx.doi.org/10.1109/MSST.2010.5496972)
// MAGIC * Apache Spark Core Papers
// MAGIC * 2012: **READ**: [Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker and Ion Stoica. NSDI](https://www.usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf)
// MAGIC * 2016: [Apache Spark: A Unified Engine for Big Data Processing](https://cacm.acm.org/magazines/2016/11/209116-apache-spark/fulltext) By Matei Zaharia, Reynold S. Xin, Patrick Wendell, Tathagata Das, Michael Armbrust, Ankur Dave, Xiangrui Meng, Josh Rosen, Shivaram Venkataraman, Michael J. Franklin, Ali Ghodsi, Joseph Gonzalez, Scott Shenker, Ion Stoica , Communications of the ACM, Vol. 59 No. 11, Pages 56-65, 10.1145/2934664
// MAGIC
// MAGIC 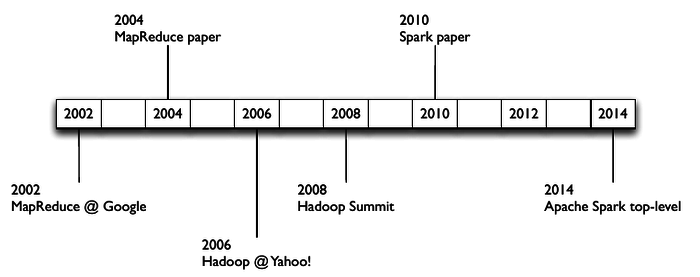
// MAGIC
// MAGIC * A lot has happened since 2014 to improve efficiency of Spark and embed more into the big data ecosystem
// MAGIC - See [Introducing Apache Spark 3.0 | Matei Zaharia and Brooke Wenig | Keynote Spark + AI Summit 2020](https://www.youtube.com/watch?v=p4PkA2huzVc).
// MAGIC
// MAGIC * More research papers on Spark are available from here:
// MAGIC - [https://databricks.com/resources?_sft_resource_type=research-papers](https://databricks.com/resources?_sft_resource_type=research-papers)
// COMMAND ----------
// MAGIC %md
// MAGIC ## MapReduce and Apache Spark.
// MAGIC
// MAGIC MapReduce as we will see shortly in action is a framework for distributed fault-tolerant computing over a fault-tolerant distributed file-system, such as Google File System or open-source Hadoop for storage.
// MAGIC
// MAGIC * Unfortunately, Map Reduce is bounded by Disk I/O and can be slow
// MAGIC * especially when doing a sequence of MapReduce operations requirinr multiple Disk I/O operations
// MAGIC * Apache Spark can use Memory instead of Disk to speed-up MapReduce Operations
// MAGIC * Spark Versus MapReduce - the speed-up is orders of magnitude faster
// MAGIC * SUMMARY
// MAGIC * Spark uses memory instead of disk alone and is thus fater than Hadoop MapReduce
// MAGIC * Spark's resilience abstraction is by RDD (resilient distributed dataset)
// MAGIC * RDDs can be recovered upon failures from their *lineage graphs*, the recipes to make them starting from raw data
// MAGIC * Spark supports a lot more than MapReduce, including streaming, interactive in-memory querying, etc.
// MAGIC * Spark demonstrated an unprecedented sort of 1 petabyte (1,000 terabytes) worth of data in 234 minutes running on 190 Amazon EC2 instances (in 2015).
// MAGIC * Spark expertise corresponds to the highest Median Salary in the US (~ 150K)
// COMMAND ----------
// MAGIC %md
// MAGIC ***
// MAGIC ***
// MAGIC
// MAGIC **Next let us get everyone to login to databricks** (or another Spark platform) to get our hands dirty with some Spark code!
// MAGIC
// MAGIC ***
// MAGIC *** | lamastex/scalable-data-science | _sds/3/x/db/000_1-sds-3-x/001_whySpark.scala | Scala | unlicense | 9,408 |
import scala.tools.partest.Util.ArrayDeep
object Test extends App {
Test1
Test2
}
class Foo[T](x: T)
trait Bar[T] { def f: T }
object Test1 extends TestUtil {
print(())
print(true)
print('a')
print(1)
print("abc")
print('abc)
println()
print(List(()))
print(List(true))
print(List(1))
print(List("abc"))
print(List('abc))
println()
//print(Array(())) //Illegal class name "[V" in class file Test$
print(Array(true))
print(Array('a'))
print(Array(1))
print(Array("abc"))
print(Array('abc))
println()
print(((), ()))
print((true, false))
print((1, 2))
print(("abc", "xyz"))
print(('abc, 'xyz))
println()
// Disabled: should these work? changing the inference for objects from
// "object Test" to "Test.type" drags in a singleton manifest which for
// some reason leads to serialization failure.
// print(Test)
// print(List)
println()
print(new Foo(2))
print(new Foo(List(2)))
print(new Foo(new Foo(2)))
print(new Foo(List(new Foo(2))))
println()
print(new Bar[String] { def f = "abc" })
println()
}
object Test2 {
import Marshal._
println("()="+load[Unit](dump(())))
println("true="+load[Boolean](dump(true)))
println("a="+load[Char](dump('a')))
println("1="+load[Int](dump(1)))
println("'abc="+load[Symbol](dump('abc)))
println()
println("List(())="+load[List[Unit]](dump(List(()))))
println("List(true)="+load[List[Boolean]](dump(List(true))))
println("List('abc)="+load[List[Symbol]](dump(List('abc))))
println()
def loadArray[T](x: Array[Byte])(implicit m: reflect.Manifest[Array[T]]) =
load[Array[T]](x)(m).deep.toString
println("Array()="+loadArray[Int](dump(Array(): Array[Int])))
println("Array(true)="+loadArray[Boolean](dump(Array(true))))
println("Array(a)="+loadArray[Char](dump(Array('a'))))
println("Array(1)="+loadArray[Int](dump(Array(1))))
println()
println("((),())="+load[(Unit, Unit)](dump(((), ()))))
println("(true,false)="+load[(Boolean, Boolean)](dump((true, false))))
println()
println("List(List(1), List(2))="+load[List[List[Int]]](dump(List(List(1), List(2)))))
println()
println("Array(Array(1), Array(2))="+loadArray[Array[Int]](dump(Array(Array(1), Array(2)))))
println()
}
object Marshal {
import java.io._
import scala.reflect.ClassTag
def dump[A](o: A)(implicit t: ClassTag[A]): Array[Byte] = {
val ba = new ByteArrayOutputStream(512)
val out = new ObjectOutputStream(ba)
out.writeObject(t)
out.writeObject(o)
out.close()
ba.toByteArray()
}
@throws(classOf[IOException])
@throws(classOf[ClassCastException])
@throws(classOf[ClassNotFoundException])
def load[A](buffer: Array[Byte])(implicit expected: ClassTag[A]): A = {
val in = new ObjectInputStream(new ByteArrayInputStream(buffer))
val found = in.readObject.asInstanceOf[ClassTag[_]]
try {
found.runtimeClass.asSubclass(expected.runtimeClass)
in.readObject.asInstanceOf[A]
} catch {
case _: ClassCastException =>
in.close()
throw new ClassCastException("type mismatch;"+
"\\n found : "+found+
"\\n required: "+expected)
}
}
}
trait TestUtil {
import java.io._
def write[A](o: A): Array[Byte] = {
val ba = new ByteArrayOutputStream(512)
val out = new ObjectOutputStream(ba)
out.writeObject(o)
out.close()
ba.toByteArray()
}
def read[A](buffer: Array[Byte]): A = {
val in = new ObjectInputStream(new ByteArrayInputStream(buffer))
in.readObject().asInstanceOf[A]
}
import scala.reflect._
def print[T](x: T)(implicit m: Manifest[T]): Unit = {
val m1: Manifest[T] = read(write(m))
val x1 = x.toString.replaceAll("@[0-9a-z]+$", "")
println("x="+x1+", m="+m1)
}
}
| scala/scala | test/files/jvm/manifests-old.scala | Scala | apache-2.0 | 3,768 |
/*
* Scala (https://www.scala-lang.org)
*
* Copyright EPFL and Lightbend, Inc.
*
* Licensed under Apache License 2.0
* (http://www.apache.org/licenses/LICENSE-2.0).
*
* See the NOTICE file distributed with this work for
* additional information regarding copyright ownership.
*/
package scala.tools.nsc.tasty.bridge
import scala.tools.tasty.TastyName
import scala.tools.nsc.tasty.TastyUniverse
/**This layer handles encoding of [[TastyName]] to [[symbolTable.Name]], escaping any specially handled names.
* Also contains definitions of names for handling special compiler internal symbols from TASTy.
*/
trait NameOps { self: TastyUniverse =>
import self.{symbolTable => u}
import TastyName._
private def encodeAsTermName(tastyName: TastyName): u.TermName = tastyName match {
case Empty => u.termNames.EMPTY
case Constructor => u.nme.CONSTRUCTOR
case EmptyPkg => u.nme.EMPTY_PACKAGE_NAME
case Root => u.nme.ROOT
case WildcardName() => u.nme.WILDCARD
case name => u.TermName(name.encoded)
}
private def encodeAsTypeName(tastyName: TypeName): u.TypeName = tastyName match {
case RepeatedClass => u.tpnme.REPEATED_PARAM_CLASS_NAME
case name => encodeAsTermName(name.toTermName).toTypeName
}
def encodeTypeName(name: TypeName): u.TypeName = encodeAsTypeName(name)
def encodeTermName(name: TastyName): u.TermName = encodeAsTermName(name.stripSignedPart)
def encodeTastyName(name: TastyName): u.Name = name match {
case name: TypeName => encodeTypeName(name)
case name => encodeTermName(name)
}
object tpnme {
final val Or: String = "|"
final val And: String = "&"
final val AnyKind: String = "AnyKind"
final val TupleCons: String = "*:"
final val Tuple: String = "Tuple"
final val Matchable: String = "Matchable"
val ContextFunctionN = raw"ContextFunction(\\d+)".r
val FunctionN = raw"Function(\\d+)".r
final val ErrorType: TypeName = TastyName.SimpleName("<error>").toTypeName
}
}
| scala/scala | src/compiler/scala/tools/nsc/tasty/bridge/NameOps.scala | Scala | apache-2.0 | 2,065 |
/**
* Licensed to Big Data Genomics (BDG) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The BDG licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.bdgenomics.services
import org.scalatest.FunSuite
class TypedLocationTestSuite extends FunSuite {
test("can parse a straightforward path alright") {
val tl = TypedLocation("name", "location", "/foo/bar")
assert(tl.scheme === "file")
assert(tl.fullPath === "/foo/bar")
}
test("can parse a classpath:// URI correctly") {
val tl = TypedLocation("name", "location", "classpath://test_config.yml")
assert(tl.name === "name")
assert(tl.locationType === "location")
assert(tl.location === "classpath://test_config.yml")
assert(tl.scheme === "classpath")
assert(tl.bucketName === "test_config.yml")
assert(tl.keyName === "")
}
test("can parse a file:// URI correctly") {
val tl = TypedLocation("name", "location", "file://path1/path2")
assert(tl.name === "name")
assert(tl.locationType === "location")
assert(tl.location === "file://path1/path2")
assert(tl.scheme === "file")
assert(tl.bucketName === "path1")
assert(tl.keyName === "path2")
assert(tl.fullPath === "/path1/path2")
}
test("can parse an s3:// URI correctly") {
val tl = TypedLocation("name", "location", "s3://path1/path2")
assert(tl.name === "name")
assert(tl.locationType === "location")
assert(tl.location === "s3://path1/path2")
assert(tl.scheme === "s3")
assert(tl.bucketName === "path1")
assert(tl.keyName === "path2")
}
}
| bigdatagenomics/bdg-services | bdgs-core/src/test/scala/org/bdgenomics/services/TypedLocationTestSuite.scala | Scala | apache-2.0 | 2,213 |
package com.rzethon.marsexp
import akka.http.scaladsl.marshalling.ToResponseMarshallable.apply
import akka.http.scaladsl.model.HttpMethods._
import akka.http.scaladsl.model.HttpResponse
import akka.http.scaladsl.model.StatusCode.int2StatusCode
import akka.http.scaladsl.model.headers._
import akka.http.scaladsl.server.Directive.addByNameNullaryApply
import akka.http.scaladsl.server.Directives._
import akka.http.scaladsl.server.{Directive0, Route}
trait CorsSupport {
private def addAccessControlHeaders(): Directive0 = {
mapResponseHeaders { headers =>
`Access-Control-Allow-Origin`.* +:
`Access-Control-Allow-Credentials`(true) +:
`Access-Control-Allow-Headers`("Authorization", "Content-Type", "X-Requested-With") +:
headers
}
}
private def preflightRequestHandler: Route = options {
complete(HttpResponse(200).withHeaders(
`Access-Control-Allow-Methods`(OPTIONS, POST, PUT, GET, DELETE)
)
)
}
def corsHandler(r: Route) = addAccessControlHeaders() {
preflightRequestHandler ~ r
}
} | bmagrys/rzethon-mars-exped-stream | backend/src/main/scala/com/rzethon/marsexp/CorsSupport.scala | Scala | mit | 1,063 |
package argonaut
import Data._
import org.scalacheck._
import org.specs2._, org.specs2.specification._, execute.Result
import org.specs2.matcher._
import scalaz._, Scalaz._
import Argonaut._
import java.io.File
object JsonFilesSpecification extends Specification with ScalaCheck {
def find = new File(getClass.getResource("/data").toURI).listFiles.toList
case class JsonFile(file: File)
implicit def JsonFileArbitrary: Arbitrary[JsonFile] =
Arbitrary(Gen.oneOf(find.map(JsonFile)))
def is = s2""" Predefined files can print and get same result" ! ${propNoShrink(test)} """
val test: JsonFile => Result =
jsonfile => {
val string = scala.io.Source.fromFile(jsonfile.file).mkString
val parsed = string.parseOption
val json = parsed.getOrElse(sys.error("could not parse json file [" + jsonfile + "]"))
json.nospaces.parseOption must beSome(json)
json.spaces2.parseOption must beSome(json)
json.spaces4.parseOption must beSome(json)
}
}
| julien-truffaut/argonaut | src/test/scala/argonaut/JsonFilesSpecification.scala | Scala | bsd-3-clause | 997 |
// scalastyle:off line.size.limit
/*
* Ported by Alistair Johnson from
* https://github.com/gwtproject/gwt/blob/master/user/test/com/google/gwt/emultest/java/math/BigIntegerConvertTest.java
*/
// scalastyle:on line.size.limit
package org.scalajs.testsuite.javalib.math
import java.math.BigInteger
import org.scalajs.jasminetest.JasmineTest
object BigIntegerConvertTest extends JasmineTest {
describe("BigIntegerConvertTest") {
it("testDoubleValueNegative1") {
val a = "-27467238945"
val result = -2.7467238945E10
val aNumber = new BigInteger(a).doubleValue()
expect(aNumber).toEqual(result)
}
it("testDoubleValueNegative2") {
val a = "-2746723894572364578265426346273456972"
val result = -2.7467238945723645E36
val aNumber = new BigInteger(a).doubleValue()
expect(aNumber).toEqual(result)
}
it("testDoubleValueNegativeInfinity1") {
val a = "-274672389457236457826542634627345697228374687236476867674746" +
"2342342342342342342342323423423423423423426767456345745293762384756" +
"2384756345634568456345689345683475863465786485764785684564576348756" +
"7384567845678658734587364576745683475674576345786348576847567846578" +
"3456702897830296720476846578634576384567845678346573465786457863"
val aNumber = new BigInteger(a).doubleValue()
expect(aNumber).toEqual(Double.NegativeInfinity)
}
it("testDoubleValueNegativeInfinity2") {
val a = Array[Byte](-1, -1, -1, -1, -1, -1, -1, -8, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
val aSign = -1
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(Double.NegativeInfinity)
}
it("testDoubleValueNegMantissaIsZero") {
val a = Array[Byte](-128, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
val aSign = -1
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(-8.98846567431158E307)
}
it("testDoubleValueNegMaxValue") {
val a = Array[Byte](0, -1, -1, -1, -1, -1, -1, -8, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1)
val aSign = -1
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(-Double.MaxValue)
}
it("testDoubleValueNegNotRounded") {
val a = Array[Byte](-128, 1, 2, 3, 4, 5, -128, 23, 1, -3, -5)
val aSign = -1
val result = -1.5474726438794828E26
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(result)
}
it("testDoubleValueNegRounded1") {
val a = Array[Byte](-128, 1, 2, 3, 4, 5, 60, 23, 1, -3, -5)
val aSign = -1
val result = -1.54747264387948E26
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(result)
}
it("testDoubleValueNegRounded2") {
val a = Array[Byte](-128, 1, 2, 3, 4, 5, 36, 23, 1, -3, -5)
val aSign = -1
val result = -1.547472643879479E26
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(result)
}
it("testDoubleValuePositive1") {
val a = "27467238945"
val result = 2.7467238945E10
val aNumber = new BigInteger(a).doubleValue()
expect(aNumber).toEqual(result)
}
it("testDoubleValuePositive2") {
val a = "2746723894572364578265426346273456972"
val result = 2.7467238945723645E36
val aNumber = new BigInteger(a).doubleValue()
expect(aNumber).toEqual(result)
}
it("testDoubleValuePositiveInfinity1") {
val a = Array[Byte](-1, -1, -1, -1, -1, -1, -1, -8, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
val aSign = 1
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(Double.PositiveInfinity)
}
it("testDoubleValuePositiveInfinity2") {
val a = "2746723894572364578265426346273456972283746872364768676747462" +
"3423423423423423423423234234234234234234267674563457452937623847562" +
"3847563456345684563456893456834758634657864857647856845645763487567" +
"3845678456786587345873645767456834756745763457863485768475678465783" +
"456702897830296720476846578634576384567845678346573465786457863"
val aNumber = new BigInteger(a).doubleValue()
expect(aNumber).toEqual(Double.PositiveInfinity)
}
it("testDoubleValuePosMantissaIsZero") {
val a = Array[Byte](-128, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
val aSign = 1
val result = 8.98846567431158E307
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(result)
}
it("testDoubleValuePosMaxValue") {
val a = Array[Byte](0, -1, -1, -1, -1, -1, -1, -8, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1)
val aSign = 1
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(Double.MaxValue)
}
it("testDoubleValuePosNotRounded") {
val a = Array[Byte](-128, 1, 2, 3, 4, 5, -128, 23, 1, -3, -5)
val aSign = 1
val result = 1.5474726438794828E26
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(result)
}
it("testDoubleValuePosRounded1") {
val a = Array[Byte](-128, 1, 2, 3, 4, 5, 60, 23, 1, -3, -5)
val aSign = 1
val result = 1.54747264387948E26
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(result)
}
it("testDoubleValuePosRounded2") {
val a = Array[Byte](-128, 1, 2, 3, 4, 5, 36, 23, 1, -3, -5)
val aSign = 1
val result = 1.547472643879479E26
val aNumber = new BigInteger(aSign, a).doubleValue()
expect(aNumber).toEqual(result)
}
it("testDoubleValueZero") {
val a = "0"
val result = 0.0
val aNumber = new BigInteger(a).doubleValue()
expect(aNumber).toEqual(result)
}
// To test that it works with strict floats, do:
// > set scalaJSSemantics in testSuite ~= { _.withStrictFloats(true) }
when("strict-floats").
it("testFloatValueBug2482") {
val a = "2147483649"
val result = 2.14748365E9f
val aNumber = new BigInteger(a).floatValue()
val delta = 0
expect(Math.abs(aNumber - result)).toEqual(delta)
}
it("testFloatValueNearNegMaxValue") {
val a = Array[Byte](0, -1, -1, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
val aSign = -1
val aNumber:Float = new BigInteger(aSign, a).floatValue()
val result = -3.4028235e38
val delta = 1e31
expect(Math.abs(aNumber - result)).toBeLessThan(delta)
}
it("testFloatValueNearPosMaxValue") {
val a = Array[Byte](0, -1, -1, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
val aSign = 1
val aNumber = new BigInteger(aSign, a).floatValue()
val result = 3.4028235e38
val delta = 1e31
expect(Math.abs(aNumber - result)).toBeLessThan(delta)
}
it("testFloatValueNegative1") {
val a = "-27467238"
val result = -2.7467238E7f
val aNumber = new BigInteger(a).floatValue()
val delta = 1
expect(Math.abs(aNumber - result)).toBeLessThan(delta)
}
it("testFloatValueNegative2") {
val a = "-27467238945723645782"
val result = -2.7467239E19f
val aNumber = new BigInteger(a).floatValue()
val delta = 1e12
expect(aNumber - result).toBeLessThan(delta)
}
it("testFloatValueNegativeInfinity1") {
val a = "-274672389457236457826542634627345697228374687236476867674746" +
"2342342342342342342342323423423423423423426767456345745293762384756" +
"2384756345634568456345689345683475863465786485764785684564576348756" +
"7384567845678658734587364576745683475674576345786348576847567846578" +
"3456702897830296720476846578634576384567845678346573465786457863"
val aNumber = new BigInteger(a).floatValue()
expect(aNumber).toEqual(Float.NegativeInfinity)
}
xit("testFloatValueNegativeInfinity2") {
val a = Array[Byte](0, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1)
val aSign = -1
val aNumber = new BigInteger(aSign, a).floatValue()
expect(aNumber).toEqual(Float.NegativeInfinity)
}
xit("testFloatValueNegMantissaIsZero") {
val a = Array[Byte](1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
val aSign = -1
val aNumber = new BigInteger(aSign, a).floatValue()
expect(aNumber).toEqual(Float.NegativeInfinity)
}
it("testFloatValueNegNotRounded") {
val a = Array[Byte](-128, 1, 2, 3, 4, 5, 60, 23, 1, -3, -5)
val aSign = -1
val result = -1.5474726E26f
val aNumber = new BigInteger(aSign, a).floatValue()
val delta = 1e19
expect(aNumber - result).toBeLessThan(delta)
}
it("testFloatValueNegRounded1") {
val a = Array[Byte](-128, 1, -1, -4, 4, 5, 60, 23, 1, -3, -5)
val aSign = -1
val result = -1.5475195E26f
val aNumber = new BigInteger(aSign, a).floatValue()
val delta = 1e19
expect(aNumber - result).toBeLessThan(delta)
}
it("testFloatValueNegRounded2") {
val a = Array[Byte](-128, 1, 2, -128, 4, 5, 60, 23, 1, -3, -5)
val aSign = -1
val result = -1.5474728E26f
val aNumber = new BigInteger(aSign, a).floatValue()
val delta = 1e19
expect(aNumber - result).toBeLessThan(delta)
}
xit("testFloatValuePastNegMaxValue") {
val a = Array[Byte](0, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1)
val aSign = -1
val aNumber = new BigInteger(aSign, a).floatValue()
expect(aNumber).toEqual(Float.NegativeInfinity)
}
xit("testFloatValuePastPosMaxValue") {
val a = Array[Byte](0, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1)
val aSign = 1
val aNumber = new BigInteger(aSign, a).floatValue()
expect(aNumber).toEqual(Float.PositiveInfinity)
}
it("testFloatValuePositive1") {
val a = "27467238"
val result = 2.7467238E7f
val aNumber = new BigInteger(a).floatValue()
expect(aNumber).toEqual(result)
}
it("testFloatValuePositive2") {
val a = "27467238945723645782"
val result = 2.7467239E19f
val aNumber = new BigInteger(a).floatValue()
val delta = 1e12
expect(aNumber - result).toBeLessThan(delta)
}
xit("testFloatValuePositiveInfinity1") {
val a = Array[Byte](0, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1)
val aSign = 1
val aNumber: Float = new BigInteger(aSign, a).floatValue()
expect(aNumber).toEqual(Float.PositiveInfinity)
}
it("testFloatValuePositiveInfinity2") {
val a = "274672389457236457826542634627345697228374687236476867674746234" +
"23423423423423423423234234234234234234267674563457452937623847562384" +
"75634563456845634568934568347586346578648576478568456457634875673845" +
"67845678658734587364576745683475674576345786348576847567846578345670" +
"2897830296720476846578634576384567845678346573465786457863"
val aNumber = new BigInteger(a).floatValue()
expect(aNumber).toEqual(Float.PositiveInfinity)
}
it("testFloatValuePosMantissaIsZero") {
val a = Array[Byte](-128, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
val aSign = 1
val result = 1.7014118E38f
val aNumber = new BigInteger(aSign, a).floatValue()
val delta = 1e31
expect(aNumber - result).toBeLessThan(delta)
}
it("testFloatValuePosNotRounded") {
val a = Array[Byte](-128, 1, 2, 3, 4, 5, 60, 23, 1, -3, -5)
val aSign = 1
val result = 1.5474726E26f
val aNumber = new BigInteger(aSign, a).floatValue()
val delta = 1e19
expect(aNumber - result).toBeLessThan(delta)
}
it("testFloatValuePosRounded1") {
val a = Array[Byte](-128, 1, -1, -4, 4, 5, 60, 23, 1, -3, -5)
val aSign = 1
val result = 1.5475195E26f
val aNumber = new BigInteger(aSign, a).floatValue()
val delta = 1e19
expect(aNumber - result).toBeLessThan(delta)
}
it("testFloatValuePosRounded2") {
val a = Array[Byte](-128, 1, 2, -128, 4, 5, 60, 23, 1, -3, -5)
val aSign = 1
val result = 1.5474728E26f
val aNumber = new BigInteger(aSign, a).floatValue()
val delta = 1e19
expect(aNumber - result).toBeLessThan(delta)
}
it("testFloatValueZero") {
val a = "0"
val result = 0.0f
val aNumber = new BigInteger(a).floatValue()
expect(aNumber).toEqual(result)
}
it("testIntValueNegative1") {
val aBytes = Array[Byte](12, 56, 100, -2, -76, -128, 45, 91, 3)
val sign = -1
val resInt = 2144511229
val aNumber = new BigInteger(sign, aBytes).intValue()
expect(aNumber).toEqual(resInt)
}
it("testIntValueNegative2") {
val aBytes = Array[Byte](-12, 56, 100)
val result = -771996
val aNumber = new BigInteger(aBytes).intValue()
expect(aNumber).toEqual(result)
}
it("testIntValueNegative3") {
val aBytes = Array[Byte](12, 56, 100, -2, -76, 127, 45, 91, 3)
val sign = -1
val resInt = -2133678851
val aNumber = new BigInteger(sign, aBytes).intValue()
expect(aNumber).toEqual(resInt)
}
it("testIntValuePositive1") {
val aBytes = Array[Byte](12, 56, 100, -2, -76, 89, 45, 91, 3)
val resInt = 1496144643
val aNumber = new BigInteger(aBytes).intValue()
expect(aNumber).toEqual(resInt)
}
it("testIntValuePositive2") {
val aBytes = Array[Byte](12, 56, 100)
val resInt = 800868
val aNumber = new BigInteger(aBytes).intValue()
expect(aNumber).toEqual(resInt)
}
it("testIntValuePositive3") {
val aBytes = Array[Byte](56, 13, 78, -12, -5, 56, 100)
val sign = 1
val resInt = -184862620
val aNumber = new BigInteger(sign, aBytes).intValue()
expect(aNumber).toEqual(resInt)
}
it("testLongValueNegative1") {
val aBytes = Array[Byte](12, -1, 100, -2, -76, -128, 45, 91, 3)
val result = -43630045168837885L
val aNumber = new BigInteger(aBytes).longValue()
expect(aNumber).toEqual(result)
}
it("testLongValueNegative2") {
val aBytes = Array[Byte](-12, 56, 100, 45, -101, 45, 98)
val result = -3315696807498398L
val aNumber = new BigInteger(aBytes).longValue()
expect(aNumber).toEqual(result)
}
it("testLongValuePositive1") {
val aBytes = Array[Byte](12, 56, 100, -2, -76, 89, 45, 91, 3, 120, -34, -12, 45, 98)
val result = 3268209772258930018L
val aNumber = new BigInteger(aBytes).longValue()
expect(aNumber).toEqual(result)
}
it("testLongValuePositive2") {
val aBytes = Array[Byte](12, 56, 100, 18, -105, 34, -18, 45)
val result = 880563758158769709L
val aNumber = new BigInteger(aBytes).longValue()
expect(aNumber).toEqual(result)
}
it("testValueOfIntegerMax") {
val longVal = Int.MaxValue
val aNumber = BigInteger.valueOf(longVal)
val rBytes = Array[Byte](127, -1, -1, -1)
var resBytes = Array.ofDim[Byte](rBytes.length)
resBytes = aNumber.toByteArray()
for (i <- 0 until resBytes.length) {
expect(resBytes(i)).toEqual(rBytes(i))
}
expect(aNumber.signum()).toEqual(1)
}
it("testValueOfIntegerMin") {
val longVal = Int.MinValue
val aNumber = BigInteger.valueOf(longVal)
val rBytes = Array[Byte](-128, 0, 0, 0)
var resBytes = Array.ofDim[Byte](rBytes.length)
resBytes = aNumber.toByteArray()
for (i <- 0 until resBytes.length) {
expect(resBytes(i)).toEqual(rBytes(i))
}
expect(aNumber.signum()).toEqual(-1)
}
it("testValueOfLongMax") {
val longVal = Long.MaxValue
val aNumber = BigInteger.valueOf(longVal)
val rBytes = Array[Byte](127, -1, -1, -1, -1, -1, -1, -1)
var resBytes = Array.ofDim[Byte](rBytes.length)
resBytes = aNumber.toByteArray()
for (i <- 0 until resBytes.length) {
expect(resBytes(i)).toEqual(rBytes(i))
}
expect(aNumber.signum()).toEqual(1)
}
it("testValueOfLongMin") {
val longVal = Long.MinValue
val aNumber = BigInteger.valueOf(longVal)
val rBytes = Array[Byte](-128, 0, 0, 0, 0, 0, 0, 0)
var resBytes = Array.ofDim[Byte](rBytes.length)
resBytes = aNumber.toByteArray()
for (i <- 0 until resBytes.length) {
expect(resBytes(i)).toEqual(rBytes(i))
}
expect(aNumber.signum()).toEqual(-1)
}
it("testValueOfLongNegative1") {
val longVal = -268209772258930018L
val aNumber = BigInteger.valueOf(longVal)
val rBytes = Array[Byte](-4, 71, 32, -94, 23, 55, -46, -98)
var resBytes = Array.ofDim[Byte](rBytes.length)
resBytes = aNumber.toByteArray()
for (i <- 0 until resBytes.length) {
expect(resBytes(i)).toEqual(rBytes(i))
}
expect(aNumber.signum()).toEqual(-1)
}
it("testValueOfLongNegative2") {
val longVal = -58930018L
val aNumber = BigInteger.valueOf(longVal)
val rBytes = Array[Byte](-4, 124, -52, -98)
var resBytes = Array.ofDim[Byte](rBytes.length)
resBytes = aNumber.toByteArray()
for (i <- 0 until resBytes.length) {
expect(resBytes(i)).toEqual(rBytes(i))
}
expect(aNumber.signum()).toEqual(-1)
}
it("testValueOfLongPositive1") {
val longVal = 268209772258930018L
val aNumber = BigInteger.valueOf(longVal)
val rBytes = Array[Byte](3, -72, -33, 93, -24, -56, 45, 98)
var resBytes = Array.ofDim[Byte](rBytes.length)
resBytes = aNumber.toByteArray()
for (i <- 0 until resBytes.length) {
expect(resBytes(i)).toEqual(rBytes(i))
}
expect(aNumber.signum()).toEqual(1)
}
it("testValueOfLongPositive2") {
val longVal = 58930018L
val aNumber = BigInteger.valueOf(longVal)
val rBytes = Array[Byte](3, -125, 51, 98)
var resBytes = Array.ofDim[Byte](rBytes.length)
resBytes = aNumber.toByteArray()
for (i <- 0 until resBytes.length) {
expect(resBytes(i)).toEqual(rBytes(i))
}
expect(aNumber.signum()).toEqual(1)
}
it("testValueOfLongZero") {
val longVal = 0L
val aNumber = BigInteger.valueOf(longVal)
val rBytes = Array[Byte](0)
var resBytes = Array.ofDim[Byte](rBytes.length)
resBytes = aNumber.toByteArray()
for (i <- 0 until resBytes.length) {
expect(resBytes(i)).toEqual(rBytes(i))
}
expect(aNumber.signum()).toEqual(0)
}
}
}
| renyaoxiang/scala-js | test-suite/src/test/scala/org/scalajs/testsuite/javalib/math/BigIntegerConvertTest.scala | Scala | bsd-3-clause | 21,183 |
package example
import common._
object Lists {
/**
* This method computes the sum of all elements in the list xs. There are
* multiple techniques that can be used for implementing this method, and
* you will learn during the class.
*
* For this example assignment you can use the following methods in class
* `List`:
*
* - `xs.isEmpty: Boolean` returns `true` if the list `xs` is empty
* - `xs.head: Int` returns the head element of the list `xs`. If the list
* is empty an exception is thrown
* - `xs.tail: List[Int]` returns the tail of the list `xs`, i.e. the the
* list `xs` without its `head` element
*
* ''Hint:'' instead of writing a `for` or `while` loop, think of a recursive
* solution.
*
* @param xs A list of natural numbers
* @return The sum of all elements in `xs`
*/
def sum(xs: List[Int]): Int = {
def sumIter(current: Int, rest: List[Int]): Int =
if (rest.isEmpty)
current
else
sumIter(current + rest.head, rest.tail)
sumIter(0, xs)
}
/**
* This method returns the largest element in a list of integers. If the
* list `xs` is empty it throws a `java.util.NoSuchElementException`.
*
* You can use the same methods of the class `List` as mentioned above.
*
* ''Hint:'' Again, think of a recursive solution instead of using looping
* constructs. You might need to define an auxiliary method.
*
* @param xs A list of natural numbers
* @return The largest element in `xs`
* @throws java.util.NoSuchElementException if `xs` is an empty list
*/
def max(xs: List[Int]): Int = {
def maxIter(current: Int, rest: List[Int]): Int =
if (rest.isEmpty)
current
else if (rest.head > current)
maxIter(rest.head, rest.tail)
else
maxIter(current, rest.tail)
if (xs.isEmpty)
throw new java.util.NoSuchElementException()
else
maxIter(Int.MinValue, xs)
}
}
| elkorn/MOOCs | scala1/example/src/main/scala/example/Lists.scala | Scala | mit | 1,975 |
package com.seanshubin.schulze.server
import scala.util.Random
class RandomnessImpl(random:Random) extends Randomness {
def shuffle[T](target:Seq[T]):Seq[T] = random.shuffle(target)
}
| SeanShubin/schulze | server/src/main/scala/com/seanshubin/schulze/server/RandomnessImpl.scala | Scala | unlicense | 188 |
/*
* Licensed to STRATIO (C) under one or more contributor license agreements.
* See the NOTICE file distributed with this work for additional information
* regarding copyright ownership. The STRATIO (C) licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*/
package com.stratio.connector.sparksql.core
import com.stratio.connector.commons.Loggable
import com.stratio.crossdata.common.exceptions.InitializationException
import com.typesafe.config.{Config, ConfigFactory}
import org.apache.spark.sql.SQLContext
import scala.util.Try
import scala.xml.{Elem, XML}
object `package`{
type SparkSQLContext = SQLContext with Catalog
}
object providers {
val providers: Array[String] = SparkSQLConnector.providersFromConfig
def providerByName(name: String): Provider = {
val clazz = Class.forName(name + "$")
clazz.getField("MODULE$").get(clazz).asInstanceOf[Provider]
}
lazy val all: Array[Provider] = providers.map(providerByName)
/*
def all: Array[Provider] = providers.map(providerByName)
*/
def manifests = all.map(_.manifest)
def apply(name: String): Option[Provider] = {
all.map(p => p.name -> p).toMap.get(name)
}
}
/**
* Provides an accessor to SQLContext catalog.
*/
trait Catalog {
_: SQLContext =>
def getCatalog = catalog
}
/**
* Configuration stuff related to SparkSQLConnector.
*/
trait Configuration extends Constants{
_: Loggable =>
// References to 'connector-application'
val connectorConfig: Try[Config] = {
val input = Option(getClass.getClassLoader.getResourceAsStream(
ConfigurationFileConstant))
Try(input.fold {
val message = s"Sorry, unable to find [${
ConfigurationFileConstant
}]"
logger.error(message)
throw new InitializationException(message)
}(_ => ConfigFactory.load(ConfigurationFileConstant)))
}
// References to 'SparkSQLConnector'
val connectorConfigFile: Try[Elem] =
Try(XML.load(
getClass.getClassLoader.getResourceAsStream(ConnectorConfigFile)))
}
trait Constants {
// Constants
val ActorSystemName = "SparkSQLConnectorSystem"
val ConfigurationFileConstant = "connector-application.conf"
val SparkMaster = "spark.master"
val SparkHome = "spark.home"
val SparkDriverMemory = "spark.driver.memory"
val SparkExecutorMemory = "spark.executor.memory"
val SparkTaskCPUs = "spark.task.cpus"
val SparkJars = "jars"
val MethodNotSupported = "Not supported yet"
val SparkSQLConnectorJobConstant = "SparkSQLConnectorJob"
val Spark = "spark"
val SparkCoresMax = "spark.cores.max"
val ConnectorConfigFile = "SparkSQLConnector.xml"
val ConnectorName = "ConnectorName"
val DataStoreName = "DataStoreName"
val SQLContext = "SQLContext"
val HIVEContext = "HiveContext"
val CountApproxTimeout = "connector.count-approx-timeout"
val QueryExecutorsAmount = "connector.query-executors.size"
val SQLContextType = "connector.sql-context-type"
val ProvidersInUse = "datastore.providers"
val AsyncStoppable = "connector.async-stoppable"
val ChunkSize = "connector.query-executors.chunk-size"
val CatalogTableSeparator = "_"
} | Stratio/stratio-connector-sparkSQL | connector-sparksql/src/main/scala/com/stratio/connector/sparksql/core/package.scala | Scala | apache-2.0 | 3,651 |
/* Copyright 2009-2018 EPFL, Lausanne */
package inox
package solvers
package unrolling
import utils._
import scala.collection.mutable.{Set => MutableSet, Map => MutableMap}
/** Incrementally unfolds equality relations between types for which the
* SMT notion of equality is not relevant.
*
* @see [[ast.Definitions.ADTSort.equality]] for such a case of equality
*/
trait EqualityTemplates { self: Templates =>
import context._
import program._
import program.trees._
import program.symbols._
import equalityManager._
private val checking: MutableSet[TypedADTSort] = MutableSet.empty
private val unrollCache: MutableMap[Type, Boolean] = MutableMap.empty
def unrollEquality(tpe: Type): Boolean = unrollCache.getOrElse(tpe, {
val res = tpe match {
case adt: ADTType =>
val sort = adt.getSort
sort.hasEquality || (!checking(sort) && {
checking += sort
sort.constructors.exists(c => c.fields.exists(vd => unrollEquality(vd.getType)))
})
case BooleanType() | UnitType() | CharType() | IntegerType() |
RealType() | StringType() | (_: BVType) | (_: TypeParameter) => false
case NAryType(tpes, _) => tpes.exists(unrollEquality)
}
unrollCache(tpe) = res
res
})
def equalitySymbol(tpe: Type): (Variable, Encoded) = {
typeSymbols.cached(tpe) {
val v = Variable.fresh("eq" + tpe, FunctionType(Seq(tpe, tpe), BooleanType()))
v -> encodeSymbol(v)
}
}
private[unrolling] def mkEqualities(
blocker: Encoded,
tpe: Type,
e1: Encoded,
e2: Encoded,
register: Boolean = true
): (Encoded, Clauses) = {
if (!unrollEquality(tpe)) (mkEquals(e1, e2), Seq())
else if (register) (registerEquality(blocker, tpe, e1, e2), Seq())
else {
val app = mkApp(equalitySymbol(tpe)._2, FunctionType(Seq(tpe, tpe), BooleanType()), Seq(e1, e2))
(app, Seq(mkImplies(mkAnd(blocker, mkEquals(e1, e2)), app)))
}
}
class EqualityTemplate private(val tpe: Type, val contents: TemplateContents) extends Template {
def instantiate(aVar: Encoded, e1: Encoded, e2: Encoded): Clauses = {
instantiate(aVar, Seq(Left(e1), Left(e2)))
}
override protected def instantiate(substMap: Map[Encoded, Arg]): Clauses = {
val clauses = Template.instantiate(
contents.clauses, contents.blockers, contents.applications, contents.matchers,
Map.empty, substMap)
// register equalities (WILL NOT lead to any [[instantiate]] calls)
val substituter = mkSubstituter(substMap.mapValues(_.encoded))
for ((b, eqs) <- contents.equalities; bp = substituter(b); equality <- eqs) {
registerEquality(bp, equality.substitute(substituter))
}
clauses
}
}
object EqualityTemplate {
private val cache: MutableMap[Type, EqualityTemplate] = MutableMap.empty
def apply(tpe: Type): EqualityTemplate = cache.getOrElse(tpe, {
val (f, fT) = equalitySymbol(tpe)
val args @ Seq(e1, e2) = Seq("e1", "e2").map(s => Variable.fresh(s, tpe))
val argsT = args.map(encodeSymbol)
val pathVar = Variable.fresh("b", BooleanType(), true)
val pathVarT = encodeSymbol(pathVar)
val tmplClauses = mkClauses(pathVar, Equals(Application(f, args), tpe match {
case adt: ADTType =>
val sort = adt.getSort
if (sort.hasEquality) {
sort.equality.get.applied(args)
} else {
orJoin(sort.constructors.map { tcons =>
val instCond = and(isCons(e1, tcons.id), isCons(e2, tcons.id))
val fieldConds = tcons.fields.map(vd => Equals(ADTSelector(e1, vd.id), ADTSelector(e2, vd.id)))
andJoin(instCond +: fieldConds)
})
}
case TupleType(tps) =>
andJoin(tps.indices.map(i => Equals(TupleSelect(e1, i + 1), TupleSelect(e2, i + 1))))
case _ => throw new InternalSolverError(s"Why does $tpe require equality unrolling!?")
}), (args zip argsT).toMap + (f -> fT) + (pathVar -> encodeSymbol(pathVar)))
val (contents, _) = Template.contents(
pathVar -> pathVarT, args zip argsT, tmplClauses,
substMap = Map(f -> fT), optApp = Some(fT -> FunctionType(Seq(tpe, tpe), BooleanType()))
)
val res = new EqualityTemplate(tpe, contents)
cache(tpe) = res
res
})
}
def instantiateEquality(blocker: Encoded, equality: Equality): Clauses = {
val Equality(tpe, e1, e2) = equality
val clauses = new scala.collection.mutable.ListBuffer[Encoded]
if (!instantiated(tpe)((blocker, e1, e2))) {
val eqBlocker = eqBlockers.get(equality) match {
case Some(eqBlocker) =>
eqBlocker
case None =>
val eqBlocker = encodeSymbol(Variable.fresh("q", BooleanType(), true))
eqBlockers += equality -> eqBlocker
clauses ++= EqualityTemplate(tpe).instantiate(eqBlocker, e1, e2)
val (_, f) = equalitySymbol(tpe)
val ft = FunctionType(Seq(tpe, tpe), BooleanType())
// congruence is transitive
for ((tb, te1, te2) <- instantiated(tpe); cond = mkAnd(eqBlocker, tb)) {
if (e2 == te1) {
clauses += mkImplies(
mkAnd(cond, mkApp(f, ft, Seq(e1, e2)), mkApp(f, ft, Seq(e2, te2))),
mkApp(f, ft, Seq(e1, te2))
)
instantiated += tpe -> (instantiated(tpe) + ((cond, e1, te2)))
}
if (te2 == e1) {
clauses += mkImplies(
mkAnd(cond, mkApp(f, ft, Seq(te1, te2)), mkApp(f, ft, Seq(te2, e2))),
mkApp(f, ft, Seq(te1, e2))
)
instantiated += tpe -> (instantiated(tpe) + ((cond, te1, e2)))
}
}
// congruence is commutative
clauses += mkImplies(eqBlocker, mkEquals(mkApp(f, ft, Seq(e1, e2)), mkApp(f, ft, Seq(e2, e1))))
instantiated += tpe -> (instantiated(tpe) + ((eqBlocker, e1, e2)) + ((eqBlocker, e2, e1)))
clauses += mkImplies(mkEquals(e1, e2), mkApp(f, ft, Seq(e1, e2)))
eqBlocker
}
if (eqBlocker != blocker) {
registerImplication(blocker, eqBlocker)
clauses += mkImplies(blocker, eqBlocker)
}
reporter.debug("Unrolling equality behind " + equality + " (" + clauses.size + ")")
for (cl <- clauses) {
reporter.debug(" . " + cl)
}
}
clauses.toSeq
}
def registerEquality(blocker: Encoded, tpe: Type, e1: Encoded, e2: Encoded): Encoded = {
registerEquality(blocker, Equality(tpe, e1, e2))
}
def registerEquality(blocker: Encoded, equality: Equality): Encoded = {
val tpe = equality.tpe
val gen = nextGeneration(currentGeneration)
val notBlocker = mkNot(blocker)
equalityInfos.get(blocker) match {
case Some((exGen, origGen, _, exEqs)) =>
val minGen = gen min exGen
equalityInfos += blocker -> (minGen, origGen, notBlocker, exEqs + equality)
case None =>
equalityInfos += blocker -> (gen, gen, notBlocker, Set(equality))
}
mkApp(equalitySymbol(tpe)._2, FunctionType(Seq(tpe, tpe), BooleanType()), Seq(equality.e1, equality.e2))
}
private[unrolling] object equalityManager extends Manager {
private[EqualityTemplates] val eqBlockers = new IncrementalMap[Equality, Encoded]()
private[EqualityTemplates] val typeSymbols = new IncrementalMap[Type, (Variable, Encoded)]
private[EqualityTemplates] val equalityInfos = new IncrementalMap[Encoded, (Int, Int, Encoded, Set[Equality])]
private[EqualityTemplates] val instantiated = new IncrementalMap[Type, Set[(Encoded, Encoded, Encoded)]].withDefaultValue(Set.empty)
val incrementals: Seq[IncrementalState] = Seq(eqBlockers, typeSymbols, equalityInfos, instantiated)
def unrollGeneration: Option[Int] =
if (equalityInfos.isEmpty) None
else Some(equalityInfos.values.map(_._1).min)
def satisfactionAssumptions: Seq[Encoded] = equalityInfos.map(_._2._3).toSeq
def refutationAssumptions: Seq[Encoded] = Seq.empty
def promoteBlocker(b: Encoded): Boolean = {
if (equalityInfos contains b) {
val (_, origGen, notB, eqs) = equalityInfos(b)
equalityInfos += b -> (currentGeneration, origGen, notB, eqs)
true
} else {
false
}
}
def unroll: Clauses = if (equalityInfos.isEmpty) Seq.empty else {
val newClauses = new scala.collection.mutable.ListBuffer[Encoded]
val eqBlockers = equalityInfos.filter(_._2._1 <= currentGeneration).toSeq.map(_._1)
val newEqInfos = eqBlockers.flatMap(id => equalityInfos.get(id).map(id -> _))
equalityInfos --= eqBlockers
for ((blocker, (gen, _, _, eqs)) <- newEqInfos; e <- eqs) {
newClauses ++= instantiateEquality(blocker, e)
}
reporter.debug("Unrolling equalities (" + newClauses.size + ")")
for (cl <- newClauses) {
reporter.debug(" . " + cl)
}
newClauses.toSeq
}
}
}
| romac/inox | src/main/scala/inox/solvers/unrolling/EqualityTemplates.scala | Scala | apache-2.0 | 9,032 |
/***********************************************************************
* Copyright (c) 2013-2022 Commonwealth Computer Research, Inc.
* All rights reserved. This program and the accompanying materials
* are made available under the terms of the Apache License, Version 2.0
* which accompanies this distribution and is available at
* http://www.opensource.org/licenses/apache2.0.php.
***********************************************************************/
package org.locationtech.geomesa.utils.iterators
import org.junit.runner.RunWith
import org.specs2.mock.Mockito
import org.specs2.mutable.Specification
import org.specs2.runner.JUnitRunner
@RunWith(classOf[JUnitRunner])
class InfiniteIteratorTest extends Specification with Mockito {
"stop after" should {
import InfiniteIterator._
"delegate until stop" >> {
val end = mock[Iterator[String]]
end.hasNext throws new IllegalArgumentException("You should have stopped.")
end.next throws new IllegalArgumentException("You should have stopped.")
val delegate = Iterator("A", "B") ++ end
val result: Iterator[String] = delegate.stopAfter(_ == "B")
result.hasNext must beTrue
result.next() mustEqual "A"
result.hasNext must beTrue
result.next() mustEqual "B"
result.hasNext must beFalse
result.next() must throwA[NoSuchElementException]
}
"or the iterator is exhausted" >> {
val delegate = Iterator("A", "B", "C")
val result: Iterator[String] = delegate.stopAfter(_ == "D")
result.hasNext must beTrue
result.next() mustEqual "A"
result.hasNext must beTrue
result.next() mustEqual "B"
result.hasNext must beTrue
result.next() mustEqual "C"
result.hasNext must beFalse
result.next() must throwA[NoSuchElementException]
}
}
}
| locationtech/geomesa | geomesa-utils/src/test/scala/org/locationtech/geomesa/utils/iterators/InfiniteIteratorTest.scala | Scala | apache-2.0 | 1,849 |
package ncreep.figi
import language.experimental.macros
import reflect.macros.blackbox.Context
import reflect.api._
import ncreep.figi._
/** Use [[Figi.makeConf]] to produce configuration instances.
*
* Assuming proper implicits in scope:
* {{{
* trait Foo { def a: Int; val b: String }
* val config = getConfig ...
* val foo: Foo = Figi.makeConf[Foo](config)
*
* println(foo.a)
* println(foo.b)
* }}}
*
* More examples in [[ncreep.figi.FigiSpecs]]
*/
object Figi {
/** Implements a config trait of the given type. */
def makeConf[A](cnf: InstanceWithConf[_, _ <: Conf[_, _]]): A = macro Macros.makeConfImpl[A]
/** Wrapper object for macros to be hidden from the API.
* Using this, as macro methods cannot be marked `private`.
*/
private[figi] object Macros {
def makeConfImpl[A](c: Context)(cnf: c.Expr[InstanceWithConf[_, _ <: Conf[_, _]]])(implicit tag: c.WeakTypeTag[A]): c.Expr[A] = {
new Helper[c.type](c) {
def tpe = tag.tpe
def conf = cnf
// when writing just Vector() the macro misbehaves when not finding implicit
// converters, go figure...
def prefix = c.universe.reify(collection.immutable.Vector())
}.res
}
}
private abstract class Helper[C <: Context](val c: C) { helper =>
def tpe: c.Type // The type of the trait being implemented
def conf: c.Expr[InstanceWithConf[_, _ <: Conf[_, _]]]
def prefix: c.Expr[ConfNames]
import c.universe._
/** Applies `tp1` as a type constructor to `tp2` produce a `Type` instance (`tp1[tp2]`).
* `tp1` is assumed to be applied to `Nothing` at this stage.
*/
def applyType(tp1: Type, tp2: Type): Type = {
// must be a cleaner way to apply a type
val appliedType = tp1 match { case TypeRef(p, s, _) => internal.typeRef(p, s, List(tp2)) }
appliedType
}
/** @return true if the an implicit instance of tpe is in scope. */
def hasImplicitValue(tpe: Type): Boolean = c.inferImplicitValue(tpe) != EmptyTree
/** @return true if the an implicit instance of tp1[tp2] is in scope. */
def hasImplicitValue(tp1: Type, tp2: Type): Boolean = hasImplicitValue(applyType(tp1, tp2))
def isImplicitlyConfChainer(tpe: Type): Boolean =
tpe <:< typeOf[ConfChainer] || hasImplicitValue(typeOf[IsConfChainer[Nothing]], tpe)
// ugly hack to get the type currently used as a converter, there must be a better way...
// using intermediate 'val cnf' to ensure that a stable identifier is used to obtain the type (no idea why it breaks at times)
def converterType(tpe: Type) = c.typecheck(q"{ val cnf = $conf; ???.asInstanceOf[cnf.confTypeClass.CC[$tpe]] }").tpe
def hasImplicitConverter(tpe: Type): Boolean = hasImplicitValue(converterType(tpe))
def abort(msg: String) = c.abort(c.enclosingPosition, msg)
val impls: Iterable[Tree] = for {
mem <- tpe.members
if mem.isMethod
//TODO avoid using internal Scala implementation (currently not in the public API)
meth = mem.asInstanceOf[reflect.internal.Symbols$MethodSymbol]
if meth.isDeferred
name = meth.name.decoded
termName = TermName(name)
t = meth.returnType.asInstanceOf[Type]
(isConfChainer, hasConverter) = (isImplicitlyConfChainer(t), hasImplicitConverter(t))
} yield {
//TODO this error should be emitted after checking for too many arguments, as it may be irrelevant in that case
if (!isConfChainer && !hasConverter) abort(s"No implicit instance of ${q"${converterType(t).dealias}"} found to convert the result of method $name")
val confName = q"$prefix :+ $name"
val getter: Tree =
// creating chaining invocation
if (isConfChainer) {
// generating inner invocation on the fly, this way there's no need
// to expose another macro method in the API
new Helper[c.type](c) {
def tpe = t
def conf = helper.conf
def prefix = c.Expr(confName)
}.res.tree
} else q"$conf.confTypeClass.get[$t]($conf.config, $confName)"
if (meth.isStable) { // val
q"val $termName = $getter"
} else { // def
def nullaryDef = q"def $termName = $getter"
mem.typeSignature match {
case NullaryMethodType(_) => nullaryDef
case MethodType(Nil, _) => nullaryDef
case MethodType(arg :: Nil, _) => {
val argType = arg.typeSignature
val argName = TermName("arg")
if (argType weak_<:< t)
q"def $termName($argName: ${arg.typeSignature}) = $conf.confTypeClass.getWithDefault[$t]($conf.config, $confName, $argName)"
else abort(s"Type mismatch in default configuration argument for method $name, $argType does not (weakly) conform to $t")
}
case _ => abort(s"Too many arguments in method ${name}")
}
}
}
val typeName = TypeName(tpe.typeSymbol.name.encodedName.toString)
// for some reason the quasiquote does not handle the empty case making: new typeName ()
val impl = if (impls.isEmpty) q"new $typeName {}" else q"new $typeName {..$impls}"
val res = c.Expr(impl)
}
} | ncreep/figi | macros/src/main/scala/ncreep/figi/Figi.scala | Scala | bsd-2-clause | 5,317 |
package com.avsystem.commons
package mongo
import java.nio.ByteBuffer
import com.avsystem.commons.serialization.{InputAndSimpleInput, InputMetadata, OutputAndSimpleOutput, TypeMarker}
import org.bson.BsonType
import org.bson.types.{Decimal128, ObjectId}
object ObjectIdMarker extends TypeMarker[ObjectId]
object Decimal128Marker extends TypeMarker[Decimal128]
object BsonTypeMetadata extends InputMetadata[BsonType]
trait BsonInput extends Any with InputAndSimpleInput {
def readObjectId(): ObjectId
def readDecimal128(): Decimal128
protected def bsonType: BsonType
override def readMetadata[T](metadata: InputMetadata[T]): Opt[T] =
metadata match {
case BsonTypeMetadata => bsonType.opt
case _ => Opt.Empty
}
override def readCustom[T](typeMarker: TypeMarker[T]): Opt[T] =
typeMarker match {
case ObjectIdMarker => readObjectId().opt
case Decimal128Marker => readDecimal128().opt
case _ => Opt.Empty
}
}
object BsonInput {
def bigDecimalFromBytes(bytes: Array[Byte]): BigDecimal = {
val buf = ByteBuffer.wrap(bytes)
val unscaledBytes = new Array[Byte](bytes.length - Integer.BYTES)
buf.get(unscaledBytes)
val unscaled = BigInt(unscaledBytes)
val scale = buf.getInt
BigDecimal(unscaled, scale)
}
}
trait BsonOutput extends Any with OutputAndSimpleOutput {
def writeObjectId(objectId: ObjectId): Unit
def writeDecimal128(decimal128: Decimal128): Unit
override def keepsMetadata(metadata: InputMetadata[_]): Boolean =
BsonTypeMetadata == metadata
override def writeCustom[T](typeMarker: TypeMarker[T], value: T): Boolean =
typeMarker match {
case ObjectIdMarker => writeObjectId(value); true
case Decimal128Marker => writeDecimal128(value); true
case _ => false
}
}
object BsonOutput {
def bigDecimalBytes(bigDecimal: BigDecimal): Array[Byte] = {
val unscaledBytes = bigDecimal.bigDecimal.unscaledValue.toByteArray
ByteBuffer.allocate(unscaledBytes.length + Integer.BYTES).put(unscaledBytes).putInt(bigDecimal.scale).array
}
}
| AVSystem/scala-commons | commons-mongo/jvm/src/main/scala/com/avsystem/commons/mongo/BsonInputOutput.scala | Scala | mit | 2,072 |
package org.apache.predictionio.examples.experimental.trimapp
import org.apache.predictionio.controller.LServing
class Serving
extends LServing[Query, PredictedResult] {
override
def serve(query: Query,
predictedResults: Seq[PredictedResult]): PredictedResult = {
predictedResults.head
}
}
| alex9311/PredictionIO | examples/experimental/scala-parallel-trim-app/src/main/scala/Serving.scala | Scala | apache-2.0 | 309 |
/*
* Copyright (C) 2009-2018 Lightbend Inc. <https://www.lightbend.com>
*/
package play.it.http
import play.api.http.HttpErrorHandler
import play.api.mvc._
import play.api.routing.Router
import play.api.test.PlaySpecification
import play.api.{ Application, ApplicationLoader, BuiltInComponentsFromContext, Environment }
import play.it.test.{ ApplicationFactories, ApplicationFactory, EndpointIntegrationSpecification, OkHttpEndpointSupport }
import scala.concurrent.Future
class HttpFiltersSpec extends PlaySpecification
with EndpointIntegrationSpecification with ApplicationFactories with OkHttpEndpointSupport {
"Play http filters" should {
val appFactory: ApplicationFactory = new ApplicationFactory {
override def create(): Application = {
val components = new BuiltInComponentsFromContext(
ApplicationLoader.Context.create(Environment.simple())) {
import play.api.mvc.Results._
import play.api.routing.sird
import play.api.routing.sird._
override lazy val router: Router = Router.from {
case sird.GET(p"/") => Action { Ok("Done!") }
case sird.GET(p"/error") => Action { Ok("Done!") }
case sird.GET(p"/invalid") => Action { Ok("Done!") }
}
override lazy val httpFilters: Seq[EssentialFilter] = Seq(
// A non-essential filter that throws an exception
new Filter {
override def mat = materializer
override def apply(f: RequestHeader => Future[Result])(rh: RequestHeader): Future[Result] = {
if (rh.path.contains("invalid")) {
throw new RuntimeException("INVALID")
}
f(rh)
}
},
new EssentialFilter {
// an essential filter returning an action that throws before returning an accumulator
def apply(next: EssentialAction) = EssentialAction { rh =>
if (rh.path.contains("error")) {
throw new RuntimeException("ERROR")
}
next(rh)
}
}
)
override lazy val httpErrorHandler: HttpErrorHandler = new HttpErrorHandler {
override def onServerError(request: RequestHeader, exception: Throwable) = {
Future(InternalServerError(exception.getMessage))
}
override def onClientError(request: RequestHeader, statusCode: Int, message: String) = {
Future(InternalServerError(message))
}
}
}
components.application
}
}
"send exceptions from Filters to the HttpErrorHandler" in appFactory.withAllOkHttpEndpoints { endpoint =>
val request = new okhttp3.Request.Builder()
.url(endpoint.endpoint.pathUrl("/error"))
.get()
.build()
val response = endpoint.client.newCall(request).execute()
response.code must_== 500
response.body.string must_== "ERROR"
}
"send exceptions from EssentialFilters to the HttpErrorHandler" in appFactory.withAllOkHttpEndpoints { endpoint =>
val request = new okhttp3.Request.Builder()
.url(endpoint.endpoint.pathUrl("/invalid"))
.get()
.build()
val response = endpoint.client.newCall(request).execute()
response.code must_== 500
response.body.string must_== "INVALID"
}
}
}
| Shenker93/playframework | framework/src/play-integration-test/src/test/scala/play/it/http/HttpFiltersSpec.scala | Scala | apache-2.0 | 3,439 |
package org.scalatra
import org.scalatra.test.scalatest.ScalatraFunSuite
import skinny.micro.{ SkinnyMicroFilter, SkinnyMicroServlet, UrlGeneratorSupport }
import skinny.micro.routing.Route
import skinny.micro.util.UrlGenerator
class UrlGeneratorContextTestServlet extends SkinnyMicroServlet with UrlGeneratorSupport {
val servletRoute: Route = get("/foo") { url(servletRoute) }
}
class UrlGeneratorContextTestFilter extends SkinnyMicroFilter {
val filterRoute: Route = get("/filtered/foo") {
UrlGenerator.url(filterRoute)
}
}
class UrlGeneratorSupportTest extends ScalatraFunSuite {
addServlet(new UrlGeneratorContextTestServlet, "/*")
addServlet(new UrlGeneratorContextTestServlet, "/servlet-path/*")
addServlet(new UrlGeneratorContextTestServlet, "/filtered/*")
addFilter(new UrlGeneratorContextTestFilter, "/*")
test("Url of a servlet mounted on /*") {
get("/foo") {
body should equal("/foo")
}
}
test("Url of a servlet mounted on /servlet-path/*") {
get("/servlet-path/foo") {
body should equal("/servlet-path/foo")
}
}
test("Url of a filter does not duplicate the servlet path") {
get("/filtered/foo") {
body should equal("/filtered/foo")
}
}
}
class UrlGeneratorNonRootContextSupportTest extends ScalatraFunSuite {
override def contextPath = "/context"
addServlet(new UrlGeneratorContextTestServlet, "/*")
addServlet(new UrlGeneratorContextTestServlet, "/servlet-path/*")
addServlet(new UrlGeneratorContextTestServlet, "/filtered/*")
addFilter(new UrlGeneratorContextTestFilter, "/*")
test("Url of a servlet mounted on /*") {
get("/context/foo") {
body should equal("/context/foo")
}
}
test("Url of a servlet mounted on /servlet-path/*") {
get("/context/servlet-path/foo") {
body should equal("/context/servlet-path/foo")
}
}
test("Url of a filter does not duplicate the servlet path") {
get("/context/filtered/foo") {
body should equal("/context/filtered/foo")
}
}
}
| xerial/skinny-micro | micro/src/test/scala/org/scalatra/UrlGeneratorSupportTest.scala | Scala | bsd-2-clause | 2,024 |
package scalaxy.fx
import scala.language.implicitConversions
import scala.language.experimental.macros
import scala.reflect.ClassTag
import javafx.beans.value._
/** Meant to be imported by (package) objects that want to expose change listener macros. */
private[fx] trait ObservableValueExtensions
{
/** Methods on observable values */
implicit def observableValuesExtensions[T](value: ObservableValue[T]) = new
{
// /** Add change listener to the observable value using a function
// * that takes the new value.
// */
// def onChange[V <: T](f: V => Unit): Unit =
// macro impl.ObservableValueExtensionMacros.onChangeFunction[V]
/** Add change listener to the observable value using a function
* that takes the old value and the new value.
*/
def onChangeWithValues[V <: T](f: (V, V) => Unit): Unit =
macro impl.ObservableValueExtensionMacros.onChangeFunction2[V]
/** Add change listener to the observable value using a block (passed `by name`). */
def onChange(block: Unit): Unit =
macro impl.ObservableValueExtensionMacros.onChangeBlock[Any]
/** Add invalidation listener using a block (passed `by name`) */
def onInvalidate(block: Unit): Unit =
macro impl.ObservableValueExtensionMacros.onInvalidate[Any]
}
}
| nativelibs4java/Scalaxy | Fx/src/main/scala/scalaxy/fx/ObservableValueExtensions.scala | Scala | bsd-3-clause | 1,306 |
package com.arcusys.valamis.web.configuration.ioc
import com.escalatesoft.subcut.inject.Injectable
trait InjectableFactory extends Injectable {
implicit val bindingModule = Configuration
}
| igor-borisov/valamis | valamis-portlets/src/main/scala/com/arcusys/valamis/web/configuration/ioc/InjectableFactory.scala | Scala | gpl-3.0 | 193 |
/*
* naiveIncompleteMatchingAlgorithm.scala
*
*/
package at.logic.gapt.language.hol.algorithms
import at.logic.gapt.expr._
object NaiveIncompleteMatchingAlgorithm {
def matchTerm( term: LambdaExpression, posInstance: LambdaExpression ): Option[Substitution] =
matchTerm( term, posInstance, freeVariables( posInstance ) )
// restrictedDomain: variables to be treated as constants.
def matchTerm( term: LambdaExpression, posInstance: LambdaExpression, restrictedDomain: List[Var] ): Option[Substitution] =
holMatch( term, posInstance )( restrictedDomain )
def holMatch( s: LambdaExpression, t: LambdaExpression )( implicit restrictedDomain: List[Var] ): Option[Substitution] =
( s, t ) match {
case ( App( s_1, s_2 ), App( t_1, t_2 ) ) => merge( holMatch( s_1, t_1 ), holMatch( s_2, t_2 ) )
case ( s: Var, t: LambdaExpression ) if !restrictedDomain.contains( s ) && s.exptype == t.exptype => Some( Substitution( s, t ) )
case ( v1: Var, v2: Var ) if v1 == v2 => Some( Substitution() )
case ( v1: Var, v2: Var ) if v1 != v2 => None
case ( c1: Const, c2: Const ) if c1 == c2 => Some( Substitution() )
case ( Abs( v1, e1 ), Abs( v2, e2 ) ) => holMatch( e1, e2 ) //TODO: add sub v2 <- v1 on e2 and check
case _ => None
}
def merge( s1: Option[Substitution], s2: Option[Substitution] ): Option[Substitution] = ( s1, s2 ) match {
case ( Some( ss1 ), Some( ss2 ) ) => {
if ( !ss1.map.forall( s1 =>
ss2.map.forall( s2 =>
s1._1 != s2._1 || s1._2 == s2._2 ) ) )
None
else {
val new_list = ss2.map.filter( s2 => ss1.map.forall( s1 => s1._1 != s2._1 ) )
Some( Substitution( ss1.map ++ new_list ) )
}
}
case ( None, _ ) => None
case ( _, None ) => None
}
}
| gisellemnr/gapt | src/main/scala/at/logic/gapt/language/hol/algorithms/NaiveIncompleteMatchingAlgorithm.scala | Scala | gpl-3.0 | 1,798 |
package gitbucket.core.model
import gitbucket.core.util.DatabaseConfig
import com.github.takezoe.slick.blocking.BlockingJdbcProfile
trait Profile {
val profile: BlockingJdbcProfile
import profile.blockingApi._
/**
* java.util.Date Mapped Column Types
*/
implicit val dateColumnType = MappedColumnType.base[java.util.Date, java.sql.Timestamp](
d => new java.sql.Timestamp(d.getTime),
t => new java.util.Date(t.getTime)
)
/**
* Extends Column to add conditional condition
*/
implicit class RichColumn(c1: Rep[Boolean]){
def &&(c2: => Rep[Boolean], guard: => Boolean): Rep[Boolean] = if(guard) c1 && c2 else c1
}
/**
* Returns system date.
*/
def currentDate = new java.util.Date()
}
trait ProfileProvider { self: Profile =>
lazy val profile = DatabaseConfig.slickDriver
}
trait CoreProfile extends ProfileProvider with Profile
with AccessTokenComponent
with AccountComponent
with ActivityComponent
with CollaboratorComponent
with CommitCommentComponent
with CommitStatusComponent
with GroupMemberComponent
with IssueComponent
with IssueCommentComponent
with IssueLabelComponent
with LabelComponent
with MilestoneComponent
with PullRequestComponent
with RepositoryComponent
with SshKeyComponent
with WebHookComponent
with WebHookEventComponent
with ProtectedBranchComponent
with DeployKeyComponent
object Profile extends CoreProfile
| shiena/gitbucket | src/main/scala/gitbucket/core/model/Profile.scala | Scala | apache-2.0 | 1,431 |
package sample
import org.junit.Before
import org.slf4j.Logger
import org.slf4j.LoggerFactory
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.test.web.servlet._
import org.springframework.test.web.servlet.request.MockMvcRequestBuilders._
import org.springframework.test.web.servlet.result.MockMvcResultMatchers._
import org.springframework.test.web.servlet.setup.MockMvcBuilders
import org.springframework.web.context.WebApplicationContext
import sample.context.Timestamper
import sample.model.BusinessDayHandler
import sample.model.DataFixtures
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder
import org.springframework.web.util.UriComponentsBuilder
import org.hamcrest.Matcher
import org.springframework.web.util.UriComponents
import org.springframework.http.MediaType
import org.springframework.test.context.ActiveProfiles
/**
* Spring コンテナを用いた Web 検証サポートクラス。
* <p>Controller に対する URL 検証はこちらを利用して下さい。
* <p>本クラスを継承したテストクラスを作成後、以下のアノテーションを付与してください。
* <pre>
* {@literal @}RunWith(SpringRunner.class)
* {@literal @}WebMvcTest([テスト対象クラス].class)
* </pre>
* <p>{@literal @}WebMvcTest 利用時は標準で {@literal @}Component や {@literal @}Service 等の
* コンポーネントはインスタンス化されないため、必要に応じて {@literal @}MockBean などを利用して代替するようにしてください。
*/
@ActiveProfiles(Array("testweb"))
abstract class ControllerSpecSupport {
protected val logger: Logger = LoggerFactory.getLogger("ControllerTest")
@Autowired
protected var mvc: MockMvc = _
protected val mockTime: Timestamper = Timestamper();
protected val mockBusinessDay: BusinessDayHandler = new BusinessDayHandler { time = mockTime }
protected val fixtures: DataFixtures =
new DataFixtures {
encoder = new BCryptPasswordEncoder()
businessDay = mockBusinessDay
}
def uri(path: String): String = s"${prefix}${path}"
def uriBuilder(path: String): UriComponentsBuilder =
UriComponentsBuilder.fromUriString(uri(path));
def prefix: String = "/"
/** Get 要求を投げて結果を検証します。 */
def performGet(path: String, expects: JsonExpects): ResultActions =
performGet(uriBuilder(path).build(), expects)
def performGet(uri: UriComponents, expects: JsonExpects): ResultActions =
perform(
get(uri.toUriString()).accept(MediaType.APPLICATION_JSON),
expects.expects.toList)
/** Get 要求 ( JSON ) を投げて結果を検証します。 */
def performJsonGet(path: String, content: String, expects: JsonExpects): ResultActions =
performJsonGet(uriBuilder(path).build(), content, expects)
def performJsonGet(uri: UriComponents, content: String, expects: JsonExpects): ResultActions =
perform(
get(uri.toUriString()).contentType(MediaType.APPLICATION_JSON).content(content).accept(MediaType.APPLICATION_JSON),
expects.expects.toList)
/** Post 要求を投げて結果を検証します。 */
def performPost(path: String, expects: JsonExpects): ResultActions =
performPost(uriBuilder(path).build(), expects)
def performPost(uri: UriComponents, expects: JsonExpects): ResultActions =
perform(
post(uri.toUriString()).accept(MediaType.APPLICATION_JSON),
expects.expects.toList)
/** Post 要求 ( JSON ) を投げて結果を検証します。 */
def performJsonPost(path: String, content: String, expects: JsonExpects): ResultActions =
performJsonPost(uriBuilder(path).build(), content, expects)
def performJsonPost(uri: UriComponents, content: String, expects: JsonExpects): ResultActions =
perform(
post(uri.toUriString()).contentType(MediaType.APPLICATION_JSON).content(content).accept(MediaType.APPLICATION_JSON),
expects.expects.toList)
def perform(req: RequestBuilder, expects: Seq[ResultMatcher]): ResultActions = {
var result = mvc.perform(req)
expects.foreach(result.andExpect)
result
}
}
/** JSON 検証をビルダー形式で可能にします */
class JsonExpects {
var expects = scala.collection.mutable.ListBuffer[ResultMatcher]();
def value(key: String, expectedValue: Any): JsonExpects = {
this.expects += jsonPath(key).value(expectedValue)
this
}
def matcher[T](key: String, matcher: Matcher[T]): JsonExpects = {
this.expects += jsonPath(key).value(matcher)
this
}
def empty(key: String): JsonExpects = {
this.expects += jsonPath(key).isEmpty()
this
}
def notEmpty(key: String): JsonExpects = {
this.expects += jsonPath(key).isNotEmpty()
this
}
def array(key: String): JsonExpects = {
this.expects += jsonPath(key).isArray()
this
}
def map(key: String): JsonExpects = {
this.expects += jsonPath(key).isMap()
this
}
}
object JsonExpects {
// 200 OK
def success(): JsonExpects = {
var v = new JsonExpects()
v.expects += status().isOk()
v
}
// 400 Bad Request
def failure(): JsonExpects = {
var v = new JsonExpects()
v.expects += status().isBadRequest()
v
}
}
| jkazama/sample-boot-scala | src/test/scala/sample/ControllerSpecSupport.scala | Scala | mit | 5,266 |
package com.twitter.querulous.sql
import java.sql._
import java.util.Properties
import com.mysql.jdbc.exceptions.jdbc4.CommunicationsException
import java.net.SocketException
import com.twitter.querulous.query.DestroyableConnection
import org.apache.commons.dbcp.TesterConnection
import java.util.concurrent.Executor
class FakeConnection(val url: String, val info: Properties, val user: String, val passwd: String)
extends TesterConnection(user, passwd) with DestroyableConnection {
private[sql] val host: String = FakeConnection.host(url)
private[this] val properties: Properties = FakeConnection.properties(url, info)
private[this] var destroyed: Boolean = false
FakeConnection.checkAliveness(host)
FakeConnection.checkTimeout(host, properties)
def destroy() {
this.close()
this.destroyed = true
}
@throws(classOf[SQLException])
override def createStatement(): Statement = {
checkOpen()
new FakeStatement(this);
}
@throws(classOf[SQLException])
override def prepareStatement(sql: String): PreparedStatement = {
checkOpen()
new FakePreparedStatement(this, sql)
}
@throws(classOf[SQLException])
override protected def checkOpen() {
if (this.isClosed) {
throw new SQLException("Connection has been closed")
}
try {
FakeConnection.checkAliveness(host)
} catch {
case e: CommunicationsException => {
this.close()
throw e
}
case e => throw e
}
}
def setSchema(schema: String): Unit = ???
def getSchema: String = ???
def abort(executor: Executor): Unit = ???
def setNetworkTimeout(executor: Executor, milliseconds: Int): Unit = ???
def getNetworkTimeout: Int = ???
}
object FakeConnection {
def host(url: String): String = {
if (url == null || url == "") {
""
} else {
url.indexOf('?') match {
case -1 => url.substring(FakeDriver.DRIVER_NAME.length + 3)
case _ => url.substring(FakeDriver.DRIVER_NAME.length + 3, url.indexOf('?'))
}
}
}
def properties(url: String, info: Properties): Properties = {
url.indexOf('?') match {
case -1 => info
case _ => {
val newInfo = new Properties(info)
url.substring(url.indexOf('?') + 1).split("&") foreach {nameVal =>
nameVal.split("=").toList match {
case Nil =>
case n :: Nil =>
case n :: v :: _ => newInfo.put(n, v)
}
}
newInfo
}
}
}
@throws(classOf[CommunicationsException])
def checkAliveness(host: String) {
if (FakeContext.isServerDown(host)) {
throw new CommunicationsException(null, 0, 0, new Exception("Communication link failure"))
}
}
@throws(classOf[CommunicationsException])
def checkAliveness(conn: FakeConnection) {
if (FakeContext.isServerDown(conn.host)) {
// real driver mark the connection as closed when running into communication problem too
conn.close()
throw new CommunicationsException(null, 0, 0, new Exception("Communication link failure"))
}
}
@throws(classOf[SocketException])
def checkTimeout(host: String, properties: Properties) {
val connectTimeoutInMillis: Long = properties match {
case null => 0L
case _ => properties.getProperty("connectTimeout", "0").toLong
}
val timeTakenToOpenConnInMiills = FakeContext.getTimeTakenToOpenConn(host).toMillis
if (timeTakenToOpenConnInMiills > connectTimeoutInMillis) {
Thread.sleep(connectTimeoutInMillis)
throw new SocketException("Connection timeout")
} else {
Thread.sleep(timeTakenToOpenConnInMiills)
}
}
}
| kievbs/querulous210 | src/test/scala/com/twitter/querulous/sql/FakeConnection.scala | Scala | apache-2.0 | 3,649 |
package io.livingston.ditto.thrift
import java.util.Base64
import com.twitter.finagle.thrift.{Protocols, ThriftClientRequest}
import com.twitter.finagle.{ListeningServer, Service, Thrift}
import com.twitter.util.{Await, Future}
import com.typesafe.scalalogging.LazyLogging
import io.livingston.ditto.Latency
import org.apache.thrift.transport.TMemoryInputTransport
import scala.util.Try
case class CallRecord(msg: String, request: String, response: String)
object CallRecord {
private def base64(bytes: Array[Byte]): String = Base64.getEncoder.encodeToString(bytes)
def apply(msg: String, request: Array[Byte], response: Array[Byte]): CallRecord = {
CallRecord(msg, base64(request), base64(response))
}
}
object ThriftTrainer extends App with LazyLogging {
val trainer = new ThriftTrainer(8080, 8081)
trainer.start()
sys.addShutdownHook {
println("Begin Config File")
println("---\n" + trainer.conf)
println("End Config File")
trainer.close()
}
Await.ready(trainer.server.get)
}
class ThriftTrainer(servicePort: Int, listenPort: Int) {
val client = Thrift.client.newClient(s":$servicePort").toService
type Msg = String
var trainedResponses = Map.empty[Msg, ThriftEndpoint]
val service = new Service[Array[Byte], Array[Byte]] {
def apply(request: Array[Byte]): Future[Array[Byte]] = {
client(new ThriftClientRequest(request, false)).map { response =>
val inputTransport = new TMemoryInputTransport(response)
val thriftRequest = Protocols.binaryFactory().getProtocol(inputTransport)
Try {
val msg = thriftRequest.readMessageBegin()
trainedResponses.synchronized {
trainedResponses = trainedResponses + (msg.name -> ThriftEndpoint(msg.name, response.toList, Latency()))
}
}
response
}
}
}
var server: Option[ListeningServer] = None
def start() = server = Option(Thrift.server.serve(s":$listenPort", service))
def conf: String = {
import net.jcazevedo.moultingyaml._
import ThriftResponsesProtocol._
ThriftResponses(List(ThriftServerConfig(servicePort, trainedResponses.values.toList))).toYaml.prettyPrint
}
def close(): Unit = Await.all(client.close(), server.get.close())
}
| scottlivingston/ditto | ditto-thrift/src/main/scala/io/livingston/ditto/thrift/ThriftTrainer.scala | Scala | mit | 2,256 |
package org.jetbrains.plugins.scala.lang.adjustTypes
import com.intellij.psi.PsiNamedElement
import com.intellij.testFramework.fixtures.LightCodeInsightFixtureTestCase
import org.jetbrains.plugins.scala.extensions.{PsiElementExt, PsiNamedElementExt}
import org.jetbrains.plugins.scala.lang.psi.ScalaPsiUtil
import org.junit.Assert
/**
* @author Nikolay.Tropin
*/
class StaticJavaTest extends LightCodeInsightFixtureTestCase {
def testStaticJava(): Unit = {
val file = myFixture.addFileToProject("TestStatic.java",
"""public class TestStatic {
|
| public static int staticField = 0;
|
| public static int staticMethod() {
| return 1;
| }
|
| enum Enum {
| A1;
|
| public static String enumStaticField = "";
| public String enumField = "";
|
| enum Enum2 {
| B1;
| }
| }
|
| interface Interface {
| String interfaceField = "";
| }
|
| class Inner {
| public int innerField = 1;
|
| public static int innerStaticField = 2; //compile error
| }
|
| public static class StaticInner {
| public int staticClassField = 1;
|
| public static int staticClassStaticField = 2;
| }
|}""".stripMargin.replace("\\r", ""))
val hasStablePaths = file.depthFirst().collect {
case named: PsiNamedElement if ScalaPsiUtil.hasStablePath(named) => named.name
}
Assert.assertEquals(hasStablePaths.toSet,
Set("TestStatic", "staticField", "staticMethod", "Enum", "A1", "enumStaticField", "Enum2", "B1",
"Interface", "interfaceField", "StaticInner", "staticClassStaticField"))
}
}
| loskutov/intellij-scala | test/org/jetbrains/plugins/scala/lang/adjustTypes/StaticJavaTest.scala | Scala | apache-2.0 | 1,898 |
package com.github.apuex.akka.gen.dao.mysql
import com.github.apuex.akka.gen.util._
import com.github.apuex.akka.gen.util.TextNode._
import scala.xml.Node
class MySqlDaoGenerator(xml: Node) {
def generate(): Unit = {
var dependency = Dependency(xml)
xml.filter(x => x.label == "entity")
.foreach(x => {
generateDao(x, dependency)
})
}
def generateDao(entity: Node, dependency: Dependency): Unit = {
var content: String =
s"""
${dependency.imports}|
@Singleton
class ${text(entity.attribute("name"))} @Inject() (${dependency.daoDefs}) {
}
""".stripMargin
}
}
| apuex/akka-model-gen | src/main/scala/com/github/apuex/akka/gen/dao/mysql/MySqlDaoGenerator.scala | Scala | gpl-3.0 | 615 |
package scala.pickling
package runtime
import scala.collection.mutable
import scala.collection.concurrent.TrieMap
object GlobalRegistry {
val picklerMap: mutable.Map[String, FastTypeTag[_] => Pickler[_]] =
new TrieMap[String, FastTypeTag[_] => Pickler[_]]
val unpicklerMap: mutable.Map[String, Unpickler[_]] =
new TrieMap[String, Unpickler[_]]
}
| phaller/pickling | core/src/main/scala/scala/pickling/runtime/GlobalRegistry.scala | Scala | bsd-3-clause | 361 |
package com.seanshubin.utility.duration.format
import com.seanshubin.utility.duration.format.DurationFormat.{MillisecondsFormat, MillisecondsFormatPadded}
import org.scalatest.FunSuite
class MillisecondsFormatTest extends FunSuite {
test("parse") {
assertParse("0", "0")
assertParse("1 day", "86,400,000")
assertParse("5 seconds", "5,000")
assertParse("2 days", "172,800,000")
assertParse("5 minutes", "300,000")
assertParse("10 hours", "36,000,000")
assertParse("1 second", "1,000")
assertParse("1 millisecond", "1")
assertParse("500 milliseconds", "500")
assertParse("55 minutes", "3,300,000")
assertParse("22", "22")
assertParse("1 day 5 hours 2 minutes 1 second 123 milliseconds", "104,521,123")
assertParse("2 Days 1 Hour 1 Minute 53 Seconds 1 Millisecond", "176,513,001")
assertParse("32 days 5 hours", "2,782,800,000")
assertParse("1 day 2 hours 1 day", "180,000,000")
assertParse("1 hour 2 days 1 hours", "180,000,000")
assertParse("25 days", "2,160,000,000")
assertParse("9223372036854775807", "9,223,372,036,854,775,807")
assertParse("9223372036854775807 milliseconds", "9,223,372,036,854,775,807")
assertParse("106751991167 days 7 hours 12 minutes 55 seconds 807 milliseconds", "9,223,372,036,854,775,807")
}
test("parse trims whitespace") {
assert(MillisecondsFormat.parse(" 1 minute ") === 60000)
}
test("back and forth") {
assertBackAndForth("1 day 10 hours 17 minutes 36 seconds 789 milliseconds")
assertBackAndForth("1 day 10 hours 36 seconds 789 milliseconds")
assertBackAndForth("10 hours 17 minutes 36 seconds 789 milliseconds")
assertBackAndForth("1 day 10 hours 17 minutes 36 seconds")
assertBackAndForth("17 minutes")
assertBackAndForth("789 milliseconds")
assertBackAndForth("1 day 5 hours 2 minutes 1 second 123 milliseconds")
assertBackAndForth("2 days 1 hour 1 minute 53 seconds 1 millisecond")
assertBackAndForth("25 days")
assertBackAndForth("0 milliseconds")
}
test("error message") {
assertErrorMessage("1 foo", """'foo' does not match a valid time unit (milliseconds, seconds, minutes, hours, days)""")
assertErrorMessage("1 SecondsA", """'SecondsA' does not match a valid time unit (milliseconds, seconds, minutes, hours, days)""")
assertErrorMessage("a 1 foo", """'a 1 foo' does not match a valid pattern: \\d+\\s+[a-zA-Z]+(?:\\s+\\d+\\s+[a-zA-Z]+)*""")
assertErrorMessage("1 foo 3", """'1 foo 3' does not match a valid pattern: \\d+\\s+[a-zA-Z]+(?:\\s+\\d+\\s+[a-zA-Z]+)*""")
assertErrorMessage("seconds", """'seconds' does not match a valid pattern: \\d+\\s+[a-zA-Z]+(?:\\s+\\d+\\s+[a-zA-Z]+)*""")
assertErrorMessage("1 foo 2 bar", """'foo' does not match a valid time unit (milliseconds, seconds, minutes, hours, days)""")
}
test("order should not matter for parsing") {
assert(MillisecondsFormat.parse("12 seconds 34 milliseconds") === 12034)
assert(MillisecondsFormat.parse("34 milliseconds 12 seconds") === 12034)
}
test("duplicates get added together") {
assert(MillisecondsFormat.parse("12 seconds 34 milliseconds 2 seconds") === 14034)
}
test("aligned") {
assertAligned(0, "0 milliseconds")
assertAligned(1, " 1 millisecond ")
assertAligned(2, " 2 milliseconds")
assertAligned(10, " 10 milliseconds")
assertAligned(100, "100 milliseconds")
assertAligned(999, "999 milliseconds")
assertAligned(9223372036310399999L, "106751991160 days 23 hours 59 minutes 59 seconds 999 milliseconds")
assertAligned(90061001, "1 day 1 hour 1 minute 1 second 1 millisecond ")
assertAligned(180122002, "2 days 2 hours 2 minutes 2 seconds 2 milliseconds")
}
def assertParse(verbose: String, expected: String) {
val parsed: Long = MillisecondsFormat.parse(verbose)
val actual = f"$parsed%,d"
assert(expected === actual)
}
def assertBackAndForth(verbose: String) {
val parsed: Long = MillisecondsFormat.parse(verbose)
val formatted = MillisecondsFormat.format(parsed)
assert(verbose === formatted)
}
def assertErrorMessage(verbose: String, expected: String) {
try {
MillisecondsFormat.parse(verbose)
fail(s"Expected '$verbose' to throw an exception during parsing")
} catch {
case ex: Exception =>
assert(ex.getMessage === expected)
}
}
def assertAligned(milliseconds: Long, expected: String): Unit = {
val actual = MillisecondsFormatPadded.format(milliseconds)
assert(actual === expected)
}
}
| SeanShubin/utility | duration-format/src/test/scala/com/seanshubin/utility/duration/format/MillisecondsFormatTest.scala | Scala | unlicense | 4,537 |
package com.sksamuel.scrimage.filter
import com.sksamuel.scrimage.ImmutableImage
import org.scalatest.{BeforeAndAfter, FunSuite, OneInstancePerTest}
class SnowFilterTest extends FunSuite with BeforeAndAfter with OneInstancePerTest {
val original = ImmutableImage.fromStream(getClass.getResourceAsStream("/bird_small.png"))
test("snow filter output matches expected") {
val expected = ImmutableImage.fromStream(getClass.getResourceAsStream("/com/sksamuel/scrimage/filters/bird_small_snow.png"))
val actual = original.filter(new SnowFilter())
assert(actual === expected)
}
}
| sksamuel/scrimage | scrimage-filters/src/test/scala/com/sksamuel/scrimage/filter/SnowFilterTest.scala | Scala | apache-2.0 | 595 |
package org.eoin
import org.eoin.Chapter11._
import org.junit.Test
import org.scalacheck.{Arbitrary, Gen}
import org.scalatest.Matchers._
import org.scalatest.junit.JUnitSuite
import org.scalatest.prop.GeneratorDrivenPropertyChecks
import scala.language.higherKinds
/**
* Created by eoin.parker on 11/10/16.
*/
class Chapter11TestSuite extends JUnitSuite with GeneratorDrivenPropertyChecks {
def associativeLaw[M[_],A,B,C] (m:Monad[M])
(implicit arbMA: Arbitrary[M[A]],
arbFunc1: Arbitrary[A => M[B]], arbFunc2: Arbitrary[B => M[C]]) = {
forAll (minSuccessful(1000)) { (ma: M[A], f:A=>M[B], g:B=>M[C]) =>
val x1 = m.flatMap(ma)(f)
val x2 = m.flatMap(x1)(g) // f then g
val y1 = (a:A) => m.flatMap(f(a))(g)
val y2 = m.flatMap(ma)(y1) // g then f
x2 should equal(y2)
}
}
// def zeroElement[A] (m:Monoid[A]) (implicit arbA: Arbitrary[A]) = {
// forAll (minSuccessful(1000)) { (a:A) =>
// //println(a)
// m.op (a, m.zero) should be (a)
// m.op (m.zero, a) should be (a)
//
// }
// }
@Test def exercise3SequenceTraverse : Unit = {
val findFn = (s:String) => s.find(_.isWhitespace)
val foundYesNoFn = findFn andThen( _.isDefined)
val mapFn = findFn andThen {_.map { Character.getNumericValue(_) }}
val om = exercise1.optionMonad
forAll { (los:List[Option[String]]) =>
val referenceResult = {
val fs = los.filter { _.isDefined } map {_.get}
if (fs.size == 0 ) None else Some (fs)
}
val ourResult = om.sequence(los)
//ourResult should be (referenceResult)
}
forAll { (ls:List[String]) =>
val referenceResult = {
val fs = ls.filter { foundYesNoFn }
if (fs.size == 0 ) None else Some (fs)
}
val ourResult = om.traverse(ls) { mapFn }
//ourResult should be (referenceResult)
}
}
@Test def exercise7Expansions : Unit = {
exercise7.genOrderExpanded.sample map {println}
exercise7.genOrder2Expanded.sample map {println}
}
@Test def exercise8MonadAssociativity: Unit = {
implicit val flatMapFnGenner1 : Arbitrary [Int => Option[Double]] = Arbitrary {
val func = (i:Int) => {
val s = Arbitrary.arbitrary[Double].sample
s map {_ + i}
}
Gen.const(func)
}
implicit val flatMapFnGenner2 : Arbitrary [Double => Option[String]] = Arbitrary {
val func = (d:Double) => {
val s = Arbitrary.arbitrary[String].sample
s map {_ + d}
}
Gen.const(func)
}
implicit val optionIntGenner : Arbitrary [Option[Int]] = Arbitrary {
val int = new java.util.Random().nextInt()
if (int % 2 == 0) Some(int) else None
}
associativeLaw[Option, Int, Double, String] ( exercise1.optionMonad ) (optionIntGenner, flatMapFnGenner1, flatMapFnGenner2)
}
@Test def exercise19IdMonad: Unit = {
import exercise19._
val x = "elephants!"
val id1 = Id(3.14159)
val id2 = Id("eoin")
// try to pimp in the map/flatMap, for the for-yield
implicit class IdAsMonad[A] (val id: Id[A]) extends Monad[Id] {
override def unit[A](a: => A): Id[A] = Id(a)
override def flatMap[A, B](ma: Id[A])(f: (A) => Id[B]): Id[B] = f(ma.value)
}
// def doTest(implicit mi: Monad[Id]) = {
// //val imp = implicitly[Monad[Id]]
// val mid1 = mi.unit(id1)
// val mid2 = mi.unit(id2)
// val id3 = for {
// v1 <- id1
// v2 <- id2
// v3 = s"$v2 $v1 :: $x"
// } yield v3.length
//id3 map println
}
@Test def exercise20StateMonad: Unit = {
import exercise20._
val sti = stateMonad[String]
val a = sti.unit(10)
val a1 = a.run("eoin321")
val b = a.get.run("eoin")
val c = sti.replicateM(5, a)
val d = c.run("eoin")
val a2 = sti.unit(1.23)
val e = sti.map2(a,a2)((i,d) => Math.pow(d,i))
val f = e.run("asdf")
val h = sti.sequence(List.fill(10){ sti.unit(new java.util.Random().nextDouble()) } )
val i =h.run("qwerty")
println("done")
}
} | eoinparker/FunctionalProgrammingRedBook | src/test/scala/org/eoin/Chapter11TestSuite.scala | Scala | mit | 4,216 |
package com.github.rbobin.playjsonmatch.processors
import com.github.rbobin.playjsonmatch.FailureMessages
import play.api.libs.json.JsValue
object AnyValueProcessor extends SimpleProcessor {
override val regex = "\\\\*".r
override def doMatch(maybeJsValue: Option[JsValue]) =
maybeJsValue match {
case Some(_) => success
case _ => fail(FailureMessages("wasNotAnything"))
}
}
| rbobin/play-json-match | src/main/scala/com/github/rbobin/playjsonmatch/processors/AnyValueProcessor.scala | Scala | mit | 400 |
object Test extends App {
Api.foo
} | som-snytt/dotty | tests/disabled/macro/run/macro-term-declared-in-annotation/Test_3.scala | Scala | apache-2.0 | 37 |
/**
* Copyright 2009 Google Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS-IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package net.appjet.oui;
import java.text.SimpleDateFormat;
import java.io.{File, FileWriter, StringWriter, PrintWriter};
import java.util.Date;
import java.util.concurrent.{ConcurrentLinkedQueue, ConcurrentHashMap, CopyOnWriteArraySet};
import java.util.concurrent.atomic.AtomicInteger;
import scala.util.Sorting;
import scala.ref.WeakReference;
import scala.collection.mutable.{Map, HashMap};
import scala.collection.jcl.{SetWrapper, Conversions};
import net.sf.json.{JSONObject, JSONArray};
import org.mozilla.javascript.{Scriptable, Context};
import Util.iteratorToRichIterator;
import scala.collection.jcl.Conversions._;
trait LoggablePropertyBag {
def date: Date;
def `type`: String = value("type").asInstanceOf[String];
def json: String;
def tabDelimited: String;
def keys: Array[String];
def value(k: String): Any;
}
class LoggableFromScriptable(
scr: Scriptable,
extra: Option[scala.collection.Map[String, String]])
extends LoggablePropertyBag {
def this(scr: Scriptable) = this(scr, None);
if (extra.isDefined) {
for ((k, v) <- extra.get if (! scr.has(k, scr))) {
scr.put(k, scr, v);
}
}
val keys =
scr.getIds()
.map(_.asInstanceOf[String])
.filter(scr.get(_, scr) != Context.getUndefinedValue());
Sorting.quickSort(keys);
if (! scr.has("date", scr)) {
scr.put("date", scr, System.currentTimeMillis());
}
val date = new Date(scr.get("date", scr).asInstanceOf[Number].longValue);
val json = FastJSON.stringify(scr);
val tabDelimited = GenericLoggerUtils.dateString(date) + "\\t" +
keys.filter("date" != _).map(value(_)).mkString("\\t");
def value(k: String) = {
scr.get(k, scr);
}
}
class LoggableFromMap[T](
map: scala.collection.Map[String, T],
extra: Option[scala.collection.Map[String, String]])
extends LoggablePropertyBag {
def this(map: scala.collection.Map[String, T]) = this(map, None);
val keys = map.keys.collect.toArray ++
extra.map(_.keys.collect.toArray).getOrElse(Array[String]());
Sorting.quickSort(keys);
def fillJson(json: JSONObject,
map: scala.collection.Map[String, T]): JSONObject = {
for ((k, v) <- map) {
v match {
case b: Boolean => json.put(k, b);
case d: Double => json.put(k, d);
case i: Int => json.put(k, i);
case l: Long => json.put(k, l);
case m: java.util.Map[_,_] => json.put(k, m);
case m: scala.collection.Map[String,T] =>
json.put(k, fillJson(new JSONObject(), m));
case c: java.util.Collection[_] => json.put(k, c);
case o: Object => json.put(k, o);
case _ => {};
}
}
json;
}
val json0 = fillJson(new JSONObject(), map);
if (extra.isDefined) {
for ((k, v) <- extra.get if (! json0.has(k))) {
json0.put(k, v);
}
}
if (! json0.has("date")) {
json0.put("date", System.currentTimeMillis());
}
val date = new Date(json0.getLong("date"));
val json = json0.toString;
val tabDelimited =
GenericLoggerUtils.dateString(date) + "\\t" +
keys.filter("date" != _).map(value(_)).mkString("\\t");
def value(k: String) = {
map.orElse(extra.getOrElse(Map[String, Any]()))(k);
}
}
class LoggableFromJson(val json: String) extends LoggablePropertyBag {
val obj = JSONObject.fromObject(json);
val date = new Date(obj.getLong("date"));
val keys = obj.keys().map(String.valueOf(_)).collect.toArray;
// FIXME: is now not sorted in any particular order.
def value(k: String) = obj.get(k);
val tabDelimited =
GenericLoggerUtils.dateString(date) + "\\t"+
keys.filter("date" != _).map(value(_)).mkString("\\t");
}
object GenericLoggerUtils {
lazy val df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSSZ");
def dateString(date: Date) = df.format(date);
var extraPropertiesFunction: Option[() => Map[String, String]] = None;
def setExtraPropertiesFunction(f: () => Map[String, String]) {
extraPropertiesFunction = Some(() => {
try {
f();
} catch {
case e => withoutExtraProperties {
exceptionlog(e);
Map[String, String]();
}
}
});
}
def getExtraProperties: Option[Map[String, String]] = {
if (shouldGetExtraProperties) {
withoutExtraProperties(extraPropertiesFunction.map(_()));
} else {
None;
}
}
val registeredWranglers =
new ConcurrentHashMap[String, SetWrapper[WeakReference[LogWrangler]]];
def registerWrangler(name: String, wrangler: LogWrangler) {
wranglers(name) += wrangler.ref;
}
def clearWrangler(name: String, wrangler: LogWrangler) {
wranglers(name) -= wrangler.ref;
}
def wranglers(name: String) = {
if (! registeredWranglers.containsKey(name)) {
val set1 = Conversions.convertSet(
new CopyOnWriteArraySet[WeakReference[LogWrangler]]);
val set2 = registeredWranglers.putIfAbsent(
name, set1);
if (set2 == null) {
set1
} else {
set2
}
} else {
registeredWranglers.get(name);
}
}
def tellWranglers(name: String, lpb: LoggablePropertyBag) {
for (w <- wranglers(name)) {
w.get.foreach(_.tell(lpb));
if (! w.isValid) {
wranglers(name) -= w;
}
}
}
val shouldGetExtraProperties_var =
new NoninheritedDynamicVariable[Boolean](true);
def withoutExtraProperties[E](block: => E): E = {
shouldGetExtraProperties_var.withValue(false)(block);
}
def shouldGetExtraProperties = shouldGetExtraProperties_var.value;
}
class GenericLogger(path: String, logName: String, rotateDaily: Boolean) {
val queue = new ConcurrentLinkedQueue[LoggablePropertyBag];
var loggerThread: Thread = null;
var currentLogDay:Date = null;
var logWriter: FileWriter = null;
var logBase = config.logDir;
def setLogBase(p: String) { logBase = p }
var echoToStdOut = false;
def setEchoToStdOut(e: Boolean) {
echoToStdOut = e;
}
def stdOutPrefix = logName+": "
def initLogWriter(logDay: Date) {
currentLogDay = logDay;
// if rotating, log filename is logBase/[path/]logName/logName-<date>.jslog
// otherwise, log filename is logBase/[path/]logName.jslog
var fileName =
if (rotateDaily) {
val df = new SimpleDateFormat("yyyy-MM-dd");
logName + "/" + logName + "-" + df.format(logDay) + ".jslog";
} else {
logName + ".jslog";
}
if (path != null && path.length > 0) {
fileName = path + "/" + fileName;
}
val f = new File(logBase+"/"+fileName);
if (! f.getParentFile.exists) {
f.getParentFile().mkdirs();
}
logWriter = new FileWriter(f, true);
}
def rotateIfNecessary(messageDate: Date) {
if (rotateDaily) {
if (!((messageDate.getYear == currentLogDay.getYear) &&
(messageDate.getMonth == currentLogDay.getMonth) &&
(messageDate.getDate == currentLogDay.getDate))) {
logWriter.flush();
logWriter.close();
initLogWriter(messageDate);
}
}
}
def flush() {
flush(java.lang.Integer.MAX_VALUE);
}
def close() {
logWriter.close();
}
def flush(n: Int) = synchronized {
var count = 0;
while (count < n && ! queue.isEmpty()) {
val lpb = queue.poll();
rotateIfNecessary(lpb.date);
logWriter.write(lpb.json+"\\n");
if (echoToStdOut)
print(lpb.tabDelimited.split("\\n").mkString(stdOutPrefix, "\\n"+stdOutPrefix, "\\n"));
count += 1;
}
if (count > 0) {
logWriter.flush();
}
count;
}
def start() {
initLogWriter(new Date());
loggerThread = new Thread("GenericLogger "+logName) {
this.setDaemon(true);
override def run() {
while (true) {
if (queue.isEmpty()) {
Thread.sleep(500);
} else {
flush(1000);
}
}
}
}
main.loggers += this;
loggerThread.start();
}
def log(lpb: LoggablePropertyBag) {
if (loggerThread != null) {
queue.offer(lpb);
GenericLoggerUtils.tellWranglers(logName, lpb);
}
}
def logObject(scr: Scriptable) {
log(new LoggableFromScriptable(
scr, GenericLoggerUtils.getExtraProperties));
}
def log[T](m: scala.collection.Map[String, T]) {
log(new LoggableFromMap(
m, GenericLoggerUtils.getExtraProperties));
}
def log(s: String) {
log(Map("message" -> s));
}
def apply(s: String) {
log(s);
}
def apply(scr: Scriptable) {
logObject(scr);
}
def apply[T](m: scala.collection.Map[String, T]) {
log(m);
}
}
object profiler extends GenericLogger("backend", "profile", false) {
def apply(id: String, op: String, method: String, path: String, countAndNanos: (Long, Long)) {
if (loggerThread != null)
log(id+":"+op+":"+method+":"+path+":"+
Math.round(countAndNanos._2/1000)+
(if (countAndNanos._1 > 1) ":"+countAndNanos._1 else ""));
}
// def apply(state: RequestState, op: String, nanos: long) {
// apply(state.requestId, op, state.req.getMethod(), state.req.getRequestURI(), nanos);
// }
def time =
System.nanoTime();
// thread-specific stuff.
val map = new ThreadLocal[HashMap[String, Any]] {
override def initialValue = new HashMap[String, Any];
}
val idGen = new java.util.concurrent.atomic.AtomicLong(0);
val id = new ThreadLocal[Long] {
override def initialValue = idGen.getAndIncrement();
}
def reset() = {
map.remove();
id.remove();
}
def record(key: String, time: Long) {
map.get()(key) = (1L, time);
}
def recordCumulative(key: String, time: Long) {
map.get()(key) = map.get().getOrElse(key, (0L, 0L)) match {
case (count: Long, time0: Long) => (count+1, time0+time);
case _ => { } // do nothing, but maybe shoud error.
}
}
def print() {
for ((k, t) <- map.get()) {
profiler(""+id.get(), k, "/", "/", t match {
case (count: Long, time0: Long) => (count, time0);
case _ => (-1L, -1L);
});
}
}
def printTiming[E](name: String)(block: => E): E = {
val startTime = time;
val r = block;
val endTime = time;
println(name+": "+((endTime - startTime)/1000)+" us.");
r;
}
}
object eventlog extends GenericLogger("backend", "server-events", true) {
start();
}
object streaminglog extends GenericLogger("backend", "streaming-events", true) {
start();
}
object exceptionlog extends GenericLogger("backend", "exceptions", true) {
def apply(e: Throwable) {
val s = new StringWriter;
e.printStackTrace(new PrintWriter(s));
log(Map(
"description" -> e.toString(),
"trace" -> s.toString()));
}
echoToStdOut = config.devMode
override def stdOutPrefix = "(exlog): ";
start();
}
// object dprintln extends GenericLogger("backend", "debug", true) {
// echoToStdOut = config.devMode;
// }
class STFULogger extends org.mortbay.log.Logger {
def debug(m: String, a0: Object, a1: Object) { }
def debug(m: String, t: Throwable) { }
def getLogger(m: String) = { this }
def info(m: String, a0: Object, a2: Object) { }
def isDebugEnabled() = { false }
def setDebugEnabled(t: Boolean) { }
def warn(m: String, a0: Object, a1: Object) { }
def warn(m: String, t: Throwable) { }
}
case class Percentile(count: Int, p50: Int, p90: Int, p95: Int, p99: Int, max: Int);
object cometlatencies {
var latencies = new java.util.concurrent.ConcurrentLinkedQueue[Int];
def register(t: Int) = latencies.offer(t);
var loggerThread: Thread = null;
var lastCount: Option[Map[String, Int]] = None;
var lastStats: Option[Percentile] = None;
def start() {
loggerThread = new Thread("latencies logger") {
this.setDaemon(true);
override def run() {
while(true) {
Thread.sleep(60*1000); // every minute
try {
val oldLatencies = latencies;
latencies = new java.util.concurrent.ConcurrentLinkedQueue[Int];
val latArray = oldLatencies.toArray().map(_.asInstanceOf[int]);
Sorting.quickSort(latArray);
def pct(p: Int) =
if (latArray.length > 0)
latArray(Math.floor((p/100.0)*latArray.length).toInt);
else
0;
def s(a: Any) = String.valueOf(a);
lastStats = Some(Percentile(latArray.length,
pct(50), pct(90), pct(95), pct(99),
if (latArray.length > 0) latArray.last else 0));
eventlog.log(Map(
"type" -> "streaming-message-latencies",
"count" -> s(lastStats.get.count),
"p50" -> s(lastStats.get.p50),
"p90" -> s(lastStats.get.p90),
"p95" -> s(lastStats.get.p95),
"p99" -> s(lastStats.get.p99),
"max" -> s(lastStats.get.max)));
lastCount = Some({
val c = Class.forName("net.appjet.ajstdlib.Comet$");
c.getDeclaredMethod("connectionStatus")
.invoke(c.getDeclaredField("MODULE$").get(null))
}.asInstanceOf[Map[String, Int]]);
eventlog.log(
Map("type" -> "streaming-connection-count") ++
lastCount.get.elements.map(p => (p._1, String.valueOf(p._2))));
} catch {
case e: Exception => {
exceptionlog(e);
}
}
}
}
}
loggerThread.start();
}
start();
}
object executionlatencies extends GenericLogger("backend", "latency", true) {
start();
def time = System.currentTimeMillis();
}
abstract class LogWrangler {
def tell(lpb: LoggablePropertyBag);
def tell(json: String) { tell(new LoggableFromJson(json)); }
lazy val ref = new WeakReference(this);
def watch(logName: String) {
GenericLoggerUtils.registerWrangler(logName, this);
}
}
// you probably want to subclass this, or at least set data.
class FilterWrangler(
`type`: String,
filter: LoggablePropertyBag => Boolean,
field: String) extends LogWrangler {
def tell(lpb: LoggablePropertyBag) {
if ((`type` == null || lpb.`type` == `type`) &&
(filter == null || filter(lpb))) {
val entry = lpb.value(field);
data(lpb.date, entry);
}
}
var data: (Date, Any) => Unit = null;
def setData(data0: (Date, Any) => Unit) {
data = data0;
}
}
class TopNWrangler(n: Int, `type`: String,
filter: LoggablePropertyBag => Boolean,
field: String)
extends FilterWrangler(`type`, filter, field) {
val entries = new ConcurrentHashMap[String, AtomicInteger]();
def sortedEntries = {
Sorting.stableSort(
convertMap(entries).toSeq,
(p1: (String, AtomicInteger), p2: (String, AtomicInteger)) =>
p1._2.get() > p2._2.get());
}
def count = {
(convertMap(entries) :\\ 0) { (x, y) => x._2.get() + y }
}
def topNItems(n: Int): Array[(String, Int)] =
sortedEntries.take(n).map(p => (p._1, p._2.get())).toArray;
def topNItems: Array[(String, Int)] = topNItems(n);
data = (date: Date, value: Any) => {
val entry = value.asInstanceOf[String];
val i =
if (! entries.containsKey(entry)) {
val newInt = new AtomicInteger(0);
val oldInt = entries.putIfAbsent(entry, newInt);
if (oldInt == null) { newInt } else { oldInt }
} else {
entries.get(entry);
}
i.incrementAndGet();
}
}
| lgadi/ethelect | infrastructure/net.appjet.oui/logging.scala | Scala | apache-2.0 | 16,034 |
/*
* Happy Melly Teller
* Copyright (C) 2013 - 2015, Happy Melly http://www.happymelly.com
*
* This file is part of the Happy Melly Teller.
*
* Happy Melly Teller is free software: you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation, either version 3 of the License, or
* (at your option) any later version.
*
* Happy Melly Teller is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with Happy Melly Teller. If not, see <http://www.gnu.org/licenses/>.
*
* If you have questions concerning this license or the applicable additional
* terms, you may contact by email Sergey Kotlov, sergey.kotlov@happymelly.com or
* in writing Happy Melly One, Handelsplein 37, Rotterdam, The Netherlands, 3071 PR
*/
package models.core.payment
import com.stripe.Stripe
import com.stripe.exception._
import com.stripe.model._
import models.Person
import scala.collection.JavaConversions._
class RequestException(msg: String, logMsg: Option[String] = None) extends RuntimeException(msg) {
def log: Option[String] = logMsg
}
/**
* Wrapper around stripe.CardException
*
* @param msg Human-readable message
* @param code Unique error code
* @param param Optional parameter
*/
case class PaymentException(msg: String, code: String, param: String) extends RuntimeException(msg)
/**
* Contains the logic required for working with payment gateway
*/
class GatewayWrapper(apiKey: String) {
/**
* Creates new coupon
* @param coupon Coupon
*/
def createCoupon(coupon: models.core.Coupon) = stripeCall {
val params = Map(
"id" -> coupon.code,
"duration" -> "once",
"percent_off" -> Int.box(coupon.discount)
)
com.stripe.model.Coupon.create(params)
}
/**
* Cancels subscriptions
*
* @param customerId Customer
*/
def cancel(customerId: String) = stripeCall {
val subscriptions = com.stripe.model.Customer.retrieve(customerId).getSubscriptions.getData
subscriptions.foreach(_.cancel(Map[String, AnyRef]()))
}
/**
* Charges user's card using Stripe
*
* @param sum Amount to be charged
* @param payer User object
* @param token Stripe token for a single session
* @return Returns Stripe JSON response
*/
def charge(sum: Int, payer: Person, token: Option[String]) = stripeCall {
val params = Map("amount" -> Int.box(sum * 100),
"currency" -> "eur",
"card" -> token.getOrElse(""),
"description" -> Payment.DESC,
"receipt_email" -> payer.email)
com.stripe.model.Charge.create(params)
}
/**
* Charges user's card using Stripe
*
* @param sum Amount to be charged
* @param email Payer's email
* @param token Stripe token for a single session
* @return Returns Stripe JSON response
*/
def charge(sum: Float, email: String, desc: String, token: String) = stripeCall {
val params = Map("amount" -> Int.box((sum * 100).toInt),
"currency" -> "eur",
"card" -> token,
"description" -> desc,
"receipt_email" -> email)
com.stripe.model.Charge.create(params)
}
/**
* Creates a new customer and subscribes him/her to the given plan
*
* @param customerName Name of the customer
* @param customerId Internal id of the customer
* @param payerEmail Email of the person who pays
* @param plan Plan identifier
* @param token Card token
* @param coupon Coupon with discount
* @return Returns customer identifier and credit card info
*/
def customer(customerName: String,
customerId: Long,
payerEmail: String,
plan: String,
token: String,
coupon: Option[String] = None): (String, CreditCard) = stripeCall {
val params = Map(
"description" -> "Customer %s (id = %s) ".format(customerName, customerId),
"email" -> payerEmail,
"source" -> token)
val customer = com.stripe.model.Customer.create(params)
try {
val subscriptionParams = Map("plan" -> plan, "tax_percent" -> Payment.TAX_PERCENT_AMOUNT.toString)
val withCoupon = coupon match {
case None => subscriptionParams
case Some(value) => subscriptionParams + ("coupon" -> value)
}
customer.createSubscription(withCoupon)
(customer.getId, creditCard(customer))
} catch {
case e: StripeException =>
customer.delete()
throw e
}
}
/**
* Deletes a coupon
* @param couponId Coupon id
*/
def deleteCoupon(couponId: String) = stripeCall {
val coupon = com.stripe.model.Coupon.retrieve(couponId)
coupon.delete()
}
/**
* Returns a list of invoices for the given customer
*
* @param customerId Customer
* @return
*/
def invoices(customerId: String): List[String] = stripeCall {
Invoice.all(Map("customer" -> customerId)).getData.map(_.getId).toList
}
/**
* Retrieves plan or creates a plan if the required one doesn't exist
*
* @param fee Plan amount
* @return Returns plan identifier
*/
def plan(fee: Int): String = stripeCall {
val amount = fee * 100
val params = Map[String, AnyRef]("limit" -> 100.asInstanceOf[AnyRef])
val plans = Plan.all(params).getData
val plan = plans.
find(p ⇒ p.getCurrency == "eur" && p.getAmount == amount).
getOrElse {
val params = Map("amount" -> Int.box(amount),
"interval" -> "year",
"currency" -> "eur",
"name" -> Payment.DESC,
"id" -> "custom_%s".format(fee))
Plan.create(params)
}
plan.getId
}
/**
* Creates new subscription for the given customer
* @param customerId Customer identifier
* @param fee Subscription amount
*/
def subscribe(customerId: String, fee: BigDecimal) = stripeCall {
val customer = com.stripe.model.Customer.retrieve(customerId)
val planId = plan(fee.intValue())
customer.createSubscription(Map("plan" -> planId, "tax_percent" -> Payment.TAX_PERCENT_AMOUNT.toString))
}
/**
* Creates new subscription for the given customer
* @param customerId Customer identifier
* @param newPlan Plan identifier
*/
def changeSubscription(customerId: String, newPlan: String) = stripeCall {
val customer = com.stripe.model.Customer.retrieve(customerId)
val subscriptions = customer.getSubscriptions.getData
if (subscriptions.isEmpty) {
customer.createSubscription(Map("plan" -> newPlan, "tax_percent" -> Payment.TAX_PERCENT_AMOUNT.toString))
} else {
val subscription = subscriptions.head
subscription.update(Map("plan" -> newPlan, "prorate" -> true.toString))
}
}
/**
* Deletes old cards and add a new one to the given customer
*
* @param customerId Customer identifier
* @param cardToken New card token
* @param cards Old cards
* @return New card data
*/
def updateCards(customerId: String, cardToken: String, cards: Seq[CreditCard]): CreditCard = stripeCall {
val customer = com.stripe.model.Customer.retrieve(customerId)
val remoteCards = customer.getCards
cards.foreach { card =>
remoteCards.retrieve(card.remoteId).delete()
}
val card = customer.createCard(cardToken)
customer.setDefaultCard(card.getId)
CreditCard(None, 0, card.getId, card.getBrand, card.getLast4, card.getExpMonth, card.getExpYear)
}
protected def stripeCall[A](f: => A) = {
try {
Stripe.apiKey = apiKey
f
} catch {
case e: CardException ⇒
throw new PaymentException(codeToMsg(e.getCode), e.getCode, e.getParam)
case e: InvalidRequestException ⇒
throw new RequestException("error.payment.invalid_request", Some(e.toString))
case e: AuthenticationException ⇒
throw new RequestException("error.payment.authorisation")
case e: APIConnectionException ⇒
throw new RequestException("error.payment.api.connection", Some(e.toString))
case e: APIException ⇒
throw new RequestException("error.payment.api", Some(e.toString))
}
}
protected def codeToMsg(code: String): String = code match {
case "card_declined" ⇒ "error.payment.card_declined"
case "incorrect_cvc" ⇒ "error.payment.incorrect_cvc"
case "expired_card" ⇒ "error.payment.expired_card"
case "processing_error" ⇒ "error.payment.processing_error"
case _ ⇒ "error.payment.unexpected_error"
}
/**
* Returns default credit card info
*
* @param customer Stripe customer object
*/
protected def creditCard(customer: com.stripe.model.Customer): CreditCard = {
val card = customer.getCards.retrieve(customer.getDefaultCard)
CreditCard(None, 0, card.getId, card.getBrand, card.getLast4, card.getExpMonth, card.getExpYear)
}
}
| HappyMelly/teller | app/models/core/payment/GatewayWrapper.scala | Scala | gpl-3.0 | 9,107 |
package com.github.okapies.finagle.gntp.protocol
import java.net.URI
import com.twitter.naggati.Encoder
import com.github.okapies.finagle.gntp._
object GntpRequestCodec extends GntpMessageCodec[Request] {
import util.GntpBoolean._
import GntpConstants._
import GntpConstants.RequestMessageType._
import Header._
val encode: Encoder[Request] = new GntpRequestEncoder
protected def decode(ctx: GntpMessageContext): AnyRef = ctx.messageType match {
case REGISTER => decodeRegister(ctx)
case NOTIFY => decodeNotify(ctx)
case SUBSCRIBE => decodeSubscribe(ctx)
case _ => // invalid message type
throw new GntpProtocolException(
ErrorCode.UNKNOWN_PROTOCOL,
"The message type is invalid: " + ctx.messageType)
}
@throws(classOf[GntpProtocolException])
private def decodeRegister(ctx: GntpMessageContext): Request = {
// required
val appName = ctx.toRequiredHeader(APPLICATION_NAME)
val types = ctx.toNotificationTypes
val appIcon = ctx.toIcon(APPLICATION_ICON)
Register(
Application(appName, types, appIcon),
ctx.unhandledHeaders, ctx.encryption, ctx.authorization)
}
@throws(classOf[GntpProtocolException])
private def decodeNotify(ctx: GntpMessageContext): Request = {
import Notify._
// required
val appName = ctx.toRequiredHeader(APPLICATION_NAME)
val name = ctx.toRequiredHeader(NOTIFICATION_NAME)
val title = ctx.toRequiredHeader(NOTIFICATION_TITLE)
// optional
val id = ctx.toOptionalHeader(NOTIFICATION_ID)
val text = ctx.toOptionalHeader(NOTIFICATION_TEXT).getOrElse(DEFAULT_TEXT)
val sticky = ctx.toOptionalHeader(NOTIFICATION_STICKY).map {
parseBoolean _
}.getOrElse(DEFAULT_STICKY)
val priority = ctx.toOptionalHeader(NOTIFICATION_PRIORITY).map {
v => Priority(v.toInt)
}.getOrElse(DEFAULT_PRIORITY)
val icon = ctx.toIcon(NOTIFICATION_ICON)
val coalescingId = ctx.toOptionalHeader(NOTIFICATION_COALESCING_ID)
val callback = ctx.toOptionalHeader(NOTIFICATION_CALLBACK_TARGET) match {
case Some(target) => Some(UrlCallback(new URI(target)))
case None => ctx.toOptionalHeader(NOTIFICATION_CALLBACK_CONTEXT) match {
case Some(cbCtx) =>
val cbCtxType = ctx.toRequiredHeader(NOTIFICATION_CALLBACK_CONTEXT_TYPE)
Some(SocketCallback(cbCtx, cbCtxType))
case None => None
}
}
Notify(
appName, name,
id,
title, text, icon, sticky, priority,
coalescingId, callback,
ctx.unhandledHeaders, ctx.encryption, ctx.authorization)
}
@throws(classOf[GntpProtocolException])
private def decodeSubscribe(ctx: GntpMessageContext): Request = {
// required
val id = ctx.toRequiredHeader(SUBSCRIBER_ID)
val name = ctx.toRequiredHeader(SUBSCRIBER_NAME)
// optional
val port = ctx.toOptionalHeader(SUBSCRIBER_PORT).map {
_.toInt
}.getOrElse(DEFAULT_GNTP_PORT)
Subscribe(id, name, port, ctx.unhandledHeaders, ctx.encryption, ctx.authorization)
}
}
| okapies/finagle-gntp | src/main/scala/com/github/okapies/finagle/gntp/protocol/GntpRequestCodec.scala | Scala | bsd-2-clause | 3,040 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.carbondata.mv.rewrite
import org.apache.spark.sql.Row
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
import org.apache.spark.sql.execution.datasources.LogicalRelation
import org.apache.spark.sql.test.util.QueryTest
import org.scalatest.BeforeAndAfterAll
class MVCoalesceTestCase extends QueryTest with BeforeAndAfterAll {
override def beforeAll(): Unit = {
drop()
sql("create table coalesce_test_main(id int,name string,height int,weight int) " +
"using carbondata")
sql("insert into coalesce_test_main select 1,'tom',170,130")
sql("insert into coalesce_test_main select 2,'tom',170,120")
sql("insert into coalesce_test_main select 3,'lily',160,100")
}
def drop(): Unit = {
sql("drop table if exists coalesce_test_main")
}
test("test mv table with coalesce expression on sql not on mv and less groupby cols") {
sql("drop materialized view if exists coalesce_test_main_mv")
sql("create materialized view coalesce_test_main_mv as " +
"select sum(id) as sum_id,name as myname,weight from coalesce_test_main group by name,weight")
sql("refresh materialized view coalesce_test_main_mv")
val frame = sql("select coalesce(sum(id),0) as sumid,name from coalesce_test_main group by name")
assert(TestUtil.verifyMVDataMap(frame.queryExecution.optimizedPlan, "coalesce_test_main_mv"))
checkAnswer(frame, Seq(Row(3, "tom"), Row(3, "lily")))
sql("drop materialized view if exists coalesce_test_main_mv")
}
test("test mv table with coalesce expression less groupby cols") {
sql("drop materialized view if exists coalesce_test_main_mv")
val exception: Exception = intercept[UnsupportedOperationException] {
sql("create materialized view coalesce_test_main_mv as " +
"select coalesce(sum(id),0) as sum_id,name as myname,weight from coalesce_test_main group by name,weight")
sql("refresh materialized view coalesce_test_main_mv")
}
assert("MV doesn't support Coalesce".equals(exception.getMessage))
val frame = sql("select coalesce(sum(id),0) as sumid,name from coalesce_test_main group by name")
assert(!TestUtil.verifyMVDataMap(frame.queryExecution.optimizedPlan, "coalesce_test_main_mv"))
checkAnswer(frame, Seq(Row(3, "tom"), Row(3, "lily")))
sql("drop materialized view if exists coalesce_test_main_mv")
}
test("test mv table with coalesce expression in other expression") {
sql("drop materialized view if exists coalesce_test_main_mv")
sql("create materialized view coalesce_test_main_mv as " +
"select sum(coalesce(id,0)) as sum_id,name as myname,weight from coalesce_test_main group by name,weight")
sql("refresh materialized view coalesce_test_main_mv")
val frame = sql("select sum(coalesce(id,0)) as sumid,name from coalesce_test_main group by name")
assert(TestUtil.verifyMVDataMap(frame.queryExecution.optimizedPlan, "coalesce_test_main_mv"))
checkAnswer(frame, Seq(Row(3, "tom"), Row(3, "lily")))
sql("drop materialized view if exists coalesce_test_main_mv")
}
override def afterAll(): Unit ={
drop
}
}
object TestUtil {
def verifyMVDataMap(logicalPlan: LogicalPlan, dataMapName: String): Boolean = {
val tables = logicalPlan collect {
case l: LogicalRelation => l.catalogTable.get
}
tables.exists(_.identifier.table.equalsIgnoreCase(dataMapName+"_table"))
}
} | jackylk/incubator-carbondata | mv/core/src/test/scala/org/apache/carbondata/mv/rewrite/MVCoalesceTestCase.scala | Scala | apache-2.0 | 4,223 |
package com.twitter.finatra.http.filters
import com.twitter.finagle.http.Request
import com.twitter.finagle.http.filter.StatsFilter
import com.twitter.finatra.filters.MergedFilter
import javax.inject.Inject
class CommonFilters @Inject()(
a: AccessLoggingFilter,
b: HttpResponseFilter,
c: StatsFilter[Request],
d: ExceptionMappingFilter)
extends MergedFilter(a, b, c, d)
| kaushik94/finatra | http/src/main/scala/com/twitter/finatra/http/filters/CommonFilters.scala | Scala | apache-2.0 | 382 |
/*
Copyright 2012 Twitter, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package com.twitter.scalding {
import cascading.operation._
import cascading.tuple._
import cascading.flow._
import cascading.pipe.assembly.AggregateBy
import com.twitter.chill.MeatLocker
import scala.collection.JavaConverters._
import com.twitter.algebird.{ Semigroup, StatefulSummer, SummingWithHitsCache, AdaptiveCache }
import com.twitter.scalding.mathematics.Poisson
import serialization.Externalizer
import scala.util.Try
trait ScaldingPrepare[C] extends Operation[C] {
abstract override def prepare(flowProcess: FlowProcess[_], operationCall: OperationCall[C]): Unit = {
RuntimeStats.addFlowProcess(flowProcess)
super.prepare(flowProcess, operationCall)
}
}
class FlatMapFunction[S, T](@transient fn: S => TraversableOnce[T], fields: Fields,
conv: TupleConverter[S], set: TupleSetter[T])
extends BaseOperation[Any](fields) with Function[Any] with ScaldingPrepare[Any] {
val lockedFn = Externalizer(fn)
/**
* Private helper to get at the function that this FlatMapFunction wraps
*/
private[scalding] def getFunction = fn
def operate(flowProcess: FlowProcess[_], functionCall: FunctionCall[Any]): Unit = {
lockedFn.get(conv(functionCall.getArguments)).foreach { arg: T =>
val this_tup = set(arg)
functionCall.getOutputCollector.add(this_tup)
}
}
}
class MapFunction[S, T](@transient fn: S => T, fields: Fields,
conv: TupleConverter[S], set: TupleSetter[T])
extends BaseOperation[Any](fields) with Function[Any] with ScaldingPrepare[Any] {
val lockedFn = Externalizer(fn)
def operate(flowProcess: FlowProcess[_], functionCall: FunctionCall[Any]): Unit = {
val res = lockedFn.get(conv(functionCall.getArguments))
functionCall.getOutputCollector.add(set(res))
}
}
/*
The IdentityFunction puts empty nodes in the cascading graph. We use these to nudge the cascading planner
in some edge cases.
*/
object IdentityFunction
extends BaseOperation[Any](Fields.ALL) with Function[Any] with ScaldingPrepare[Any] {
def operate(flowProcess: FlowProcess[_], functionCall: FunctionCall[Any]): Unit = {
functionCall.getOutputCollector.add(functionCall.getArguments)
}
}
class CleanupIdentityFunction(@transient fn: () => Unit)
extends BaseOperation[Any](Fields.ALL) with Function[Any] with ScaldingPrepare[Any] {
val lockedEf = Externalizer(fn)
def operate(flowProcess: FlowProcess[_], functionCall: FunctionCall[Any]): Unit = {
functionCall.getOutputCollector.add(functionCall.getArguments)
}
override def cleanup(flowProcess: FlowProcess[_], operationCall: OperationCall[Any]): Unit = {
Try.apply(lockedEf.get).foreach(_())
}
}
class CollectFunction[S, T](@transient fn: PartialFunction[S, T], fields: Fields,
conv: TupleConverter[S], set: TupleSetter[T])
extends BaseOperation[Any](fields) with Function[Any] with ScaldingPrepare[Any] {
val lockedFn = Externalizer(fn)
def operate(flowProcess: FlowProcess[_], functionCall: FunctionCall[Any]): Unit = {
val partialfn = lockedFn.get
val args = conv(functionCall.getArguments)
if (partialfn.isDefinedAt(args)) {
functionCall.getOutputCollector.add(set(partialfn(args)))
}
}
}
/**
* An implementation of map-side combining which is appropriate for associative and commutative functions
* If a cacheSize is given, it is used, else we query
* the config for cascading.aggregateby.threshold (standard cascading param for an equivalent case)
* else we use a default value of 100,000
*
* This keeps a cache of keys up to the cache-size, summing values as keys collide
* On eviction, or completion of this Operation, the key-value pairs are put into outputCollector.
*
* This NEVER spills to disk and generally never be a performance penalty. If you have
* poor locality in the keys, you just don't get any benefit but little added cost.
*
* Note this means that you may still have repeated keys in the output even on a single mapper
* since the key space may be so large that you can't fit all of them in the cache at the same
* time.
*
* You can use this with the Fields-API by doing:
* {{{
* val msr = new MapsideReduce(Semigroup.from(fn), 'key, 'value, None)
* // MUST map onto the same key,value space (may be multiple fields)
* val mapSideReduced = pipe.eachTo(('key, 'value) -> ('key, 'value)) { _ => msr }
* }}}
* That said, this is equivalent to AggregateBy, and the only value is that it is much simpler than AggregateBy.
* AggregateBy assumes several parallel reductions are happening, and thus has many loops, and array lookups
* to deal with that. Since this does many fewer allocations, and has a smaller code-path it may be faster for
* the typed-API.
*/
object MapsideReduce {
val COUNTER_GROUP = "MapsideReduce"
}
class MapsideReduce[V](
@transient commutativeSemigroup: Semigroup[V],
keyFields: Fields, valueFields: Fields,
cacheSize: Option[Int])(implicit conv: TupleConverter[V], set: TupleSetter[V])
extends BaseOperation[MapsideCache[Tuple, V]](Fields.join(keyFields, valueFields))
with Function[MapsideCache[Tuple, V]]
with ScaldingPrepare[MapsideCache[Tuple, V]] {
val boxedSemigroup = Externalizer(commutativeSemigroup)
override def prepare(flowProcess: FlowProcess[_], operationCall: OperationCall[MapsideCache[Tuple, V]]): Unit = {
//Set up the context:
implicit val sg: Semigroup[V] = boxedSemigroup.get
val cache = MapsideCache[Tuple, V](cacheSize, flowProcess)
operationCall.setContext(cache)
}
@inline
private def add(evicted: Option[Map[Tuple, V]], functionCall: FunctionCall[MapsideCache[Tuple, V]]): Unit = {
// Use iterator and while for optimal performance (avoid closures/fn calls)
if (evicted.isDefined) {
// Don't use pattern matching in performance-critical code
@SuppressWarnings(Array("org.brianmckenna.wartremover.warts.OptionPartial"))
val it = evicted.get.iterator
val tecol = functionCall.getOutputCollector
while (it.hasNext) {
val (key, value) = it.next
// Safe to mutate this key as it is evicted from the map
key.addAll(set(value))
tecol.add(key)
}
}
}
override def operate(flowProcess: FlowProcess[_], functionCall: FunctionCall[MapsideCache[Tuple, V]]): Unit = {
val cache = functionCall.getContext
val keyValueTE = functionCall.getArguments
// Have to keep a copy of the key tuple because cascading will modify it
val key = keyValueTE.selectEntry(keyFields).getTupleCopy
val value = conv(keyValueTE.selectEntry(valueFields))
val evicted = cache.put(key, value)
add(evicted, functionCall)
}
override def flush(flowProcess: FlowProcess[_], operationCall: OperationCall[MapsideCache[Tuple, V]]): Unit = {
// Docs say it is safe to do this cast:
// http://docs.cascading.org/cascading/2.1/javadoc/cascading/operation/Operation.html#flush(cascading.flow.FlowProcess, cascading.operation.OperationCall)
val functionCall = operationCall.asInstanceOf[FunctionCall[MapsideCache[Tuple, V]]]
val cache = functionCall.getContext
add(cache.flush, functionCall)
}
override def cleanup(flowProcess: FlowProcess[_], operationCall: OperationCall[MapsideCache[Tuple, V]]): Unit = {
// The cache may be large, but super sure we drop any reference to it ASAP
// probably overly defensive, but it's super cheap.
operationCall.setContext(null)
}
}
class TypedMapsideReduce[K, V](
@transient fn: TupleEntry => TraversableOnce[(K, V)],
@transient commutativeSemigroup: Semigroup[V],
sourceFields: Fields,
keyFields: Fields, valueFields: Fields,
cacheSize: Option[Int])(implicit setKV: TupleSetter[(K, V)])
extends BaseOperation[MapsideCache[K, V]](Fields.join(keyFields, valueFields))
with Function[MapsideCache[K, V]]
with ScaldingPrepare[MapsideCache[K, V]] {
val boxedSemigroup = Externalizer(commutativeSemigroup)
val lockedFn = Externalizer(fn)
override def prepare(flowProcess: FlowProcess[_], operationCall: OperationCall[MapsideCache[K, V]]): Unit = {
//Set up the context:
implicit val sg: Semigroup[V] = boxedSemigroup.get
val cache = MapsideCache[K, V](cacheSize, flowProcess)
operationCall.setContext(cache)
}
// Don't use pattern matching in a performance-critical section
@SuppressWarnings(Array("org.brianmckenna.wartremover.warts.OptionPartial"))
@inline
private def add(evicted: Option[Map[K, V]], functionCall: FunctionCall[MapsideCache[K, V]]): Unit = {
// Use iterator and while for optimal performance (avoid closures/fn calls)
if (evicted.isDefined) {
val it = evicted.get.iterator
val tecol = functionCall.getOutputCollector
while (it.hasNext) {
val (key, value) = it.next
// Safe to mutate this key as it is evicted from the map
tecol.add(setKV(key, value))
}
}
}
import scala.collection.mutable.{ Map => MMap }
private[this] class CollectionBackedMap[K, V](val backingMap: MMap[K, V]) extends Map[K, V] with java.io.Serializable {
def get(key: K) = backingMap.get(key)
def iterator = backingMap.iterator
def +[B1 >: V](kv: (K, B1)) = backingMap.toMap + kv
def -(key: K) = backingMap.toMap - key
}
// Don't use pattern matching in a performance-critical section
@SuppressWarnings(Array("org.brianmckenna.wartremover.warts.OptionPartial"))
private[this] def mergeTraversableOnce[K, V: Semigroup](items: TraversableOnce[(K, V)]): Map[K, V] = {
val mutable = scala.collection.mutable.OpenHashMap[K, V]() // Scala's OpenHashMap seems faster than Java and Scala's HashMap Impl's
val innerIter = items.toIterator
while (innerIter.hasNext) {
val (k, v) = innerIter.next
val oldVOpt: Option[V] = mutable.get(k)
// sorry for the micro optimization here: avoiding a closure
val newV: V = if (oldVOpt.isEmpty) v else Semigroup.plus(oldVOpt.get, v)
mutable.update(k, newV)
}
new CollectionBackedMap(mutable)
}
override def operate(flowProcess: FlowProcess[_], functionCall: FunctionCall[MapsideCache[K, V]]): Unit = {
val cache = functionCall.getContext
implicit val sg = boxedSemigroup.get
val res: Map[K, V] = mergeTraversableOnce(lockedFn.get(functionCall.getArguments))
val evicted = cache.putAll(res)
add(evicted, functionCall)
}
override def flush(flowProcess: FlowProcess[_], operationCall: OperationCall[MapsideCache[K, V]]): Unit = {
// Docs say it is safe to do this cast:
// http://docs.cascading.org/cascading/2.1/javadoc/cascading/operation/Operation.html#flush(cascading.flow.FlowProcess, cascading.operation.OperationCall)
val functionCall = operationCall.asInstanceOf[FunctionCall[MapsideCache[K, V]]]
val cache = functionCall.getContext
add(cache.flush, functionCall)
}
override def cleanup(flowProcess: FlowProcess[_], operationCall: OperationCall[MapsideCache[K, V]]): Unit = {
// The cache may be large, but super sure we drop any reference to it ASAP
// probably overly defensive, but it's super cheap.
operationCall.setContext(null)
}
}
sealed trait MapsideCache[K, V] {
def flush: Option[Map[K, V]]
def put(key: K, value: V): Option[Map[K, V]]
def putAll(key: Map[K, V]): Option[Map[K, V]]
}
object MapsideCache {
val DEFAULT_CACHE_SIZE = 100000
val SIZE_CONFIG_KEY = AggregateBy.AGGREGATE_BY_THRESHOLD
val ADAPTIVE_CACHE_KEY = "scalding.mapsidecache.adaptive"
private def getCacheSize(fp: FlowProcess[_]): Int =
Option(fp.getStringProperty(SIZE_CONFIG_KEY))
.filterNot { _.isEmpty }
.map { _.toInt }
.getOrElse(DEFAULT_CACHE_SIZE)
def apply[K, V: Semigroup](cacheSize: Option[Int], flowProcess: FlowProcess[_]): MapsideCache[K, V] = {
val size = cacheSize.getOrElse{ getCacheSize(flowProcess) }
val adaptive = Option(flowProcess.getStringProperty(ADAPTIVE_CACHE_KEY)).isDefined
if (adaptive)
new AdaptiveMapsideCache(flowProcess, new AdaptiveCache(size))
else
new SummingMapsideCache(flowProcess, new SummingWithHitsCache(size))
}
}
class SummingMapsideCache[K, V](flowProcess: FlowProcess[_], summingCache: SummingWithHitsCache[K, V])
extends MapsideCache[K, V] {
private[this] val misses = CounterImpl(flowProcess, StatKey(MapsideReduce.COUNTER_GROUP, "misses"))
private[this] val hits = CounterImpl(flowProcess, StatKey(MapsideReduce.COUNTER_GROUP, "hits"))
private[this] val evictions = CounterImpl(flowProcess, StatKey(MapsideReduce.COUNTER_GROUP, "evictions"))
def flush = summingCache.flush
// Don't use pattern matching in performance-critical code
@SuppressWarnings(Array("org.brianmckenna.wartremover.warts.OptionPartial"))
def put(key: K, value: V): Option[Map[K, V]] = {
val (curHits, evicted) = summingCache.putWithHits(Map(key -> value))
misses.increment(1 - curHits)
hits.increment(curHits)
if (evicted.isDefined)
evictions.increment(evicted.get.size)
evicted
}
// Don't use pattern matching in a performance-critical section
@SuppressWarnings(Array("org.brianmckenna.wartremover.warts.OptionPartial"))
def putAll(kvs: Map[K, V]): Option[Map[K, V]] = {
val (curHits, evicted) = summingCache.putWithHits(kvs)
misses.increment(kvs.size - curHits)
hits.increment(curHits)
if (evicted.isDefined)
evictions.increment(evicted.get.size)
evicted
}
}
class AdaptiveMapsideCache[K, V](flowProcess: FlowProcess[_], adaptiveCache: AdaptiveCache[K, V])
extends MapsideCache[K, V] {
private[this] val misses = CounterImpl(flowProcess, StatKey(MapsideReduce.COUNTER_GROUP, "misses"))
private[this] val hits = CounterImpl(flowProcess, StatKey(MapsideReduce.COUNTER_GROUP, "hits"))
private[this] val capacity = CounterImpl(flowProcess, StatKey(MapsideReduce.COUNTER_GROUP, "capacity"))
private[this] val sentinel = CounterImpl(flowProcess, StatKey(MapsideReduce.COUNTER_GROUP, "sentinel"))
private[this] val evictions = CounterImpl(flowProcess, StatKey(MapsideReduce.COUNTER_GROUP, "evictions"))
def flush = adaptiveCache.flush
// Don't use pattern matching in performance-critical code
@SuppressWarnings(Array("org.brianmckenna.wartremover.warts.OptionPartial"))
def put(key: K, value: V) = {
val (stats, evicted) = adaptiveCache.putWithStats(Map(key -> value))
misses.increment(1 - stats.hits)
hits.increment(stats.hits)
capacity.increment(stats.cacheGrowth)
sentinel.increment(stats.sentinelGrowth)
if (evicted.isDefined)
evictions.increment(evicted.get.size)
evicted
}
// Don't use pattern matching in a performance-critical section
@SuppressWarnings(Array("org.brianmckenna.wartremover.warts.OptionPartial"))
def putAll(kvs: Map[K, V]): Option[Map[K, V]] = {
val (stats, evicted) = adaptiveCache.putWithStats(kvs)
misses.increment(kvs.size - stats.hits)
hits.increment(stats.hits)
capacity.increment(stats.cacheGrowth)
sentinel.increment(stats.sentinelGrowth)
if (evicted.isDefined)
evictions.increment(evicted.get.size)
evicted
}
}
/*
* BaseOperation with support for context
*/
abstract class SideEffectBaseOperation[C](
@transient bf: => C, // begin function returns a context
@transient ef: C => Unit, // end function to clean up context object
fields: Fields) extends BaseOperation[C](fields) with ScaldingPrepare[C] {
val lockedBf = Externalizer(() => bf)
val lockedEf = Externalizer(ef)
override def prepare(flowProcess: FlowProcess[_], operationCall: OperationCall[C]): Unit = {
operationCall.setContext(lockedBf.get.apply)
}
override def cleanup(flowProcess: FlowProcess[_], operationCall: OperationCall[C]): Unit = {
lockedEf.get(operationCall.getContext)
}
}
/*
* A map function that allows state object to be set up and tear down.
*/
class SideEffectMapFunction[S, C, T](
bf: => C, // begin function returns a context
@transient fn: (C, S) => T, // function that takes a context and a tuple and generate a new tuple
ef: C => Unit, // end function to clean up context object
fields: Fields,
conv: TupleConverter[S],
set: TupleSetter[T]) extends SideEffectBaseOperation[C](bf, ef, fields) with Function[C] {
val lockedFn = Externalizer(fn)
override def operate(flowProcess: FlowProcess[_], functionCall: FunctionCall[C]): Unit = {
val context = functionCall.getContext
val s = conv(functionCall.getArguments)
val res = lockedFn.get(context, s)
functionCall.getOutputCollector.add(set(res))
}
}
/*
* A flatmap function that allows state object to be set up and tear down.
*/
class SideEffectFlatMapFunction[S, C, T](
bf: => C, // begin function returns a context
@transient fn: (C, S) => TraversableOnce[T], // function that takes a context and a tuple, returns TraversableOnce of T
ef: C => Unit, // end function to clean up context object
fields: Fields,
conv: TupleConverter[S],
set: TupleSetter[T]) extends SideEffectBaseOperation[C](bf, ef, fields) with Function[C] {
val lockedFn = Externalizer(fn)
override def operate(flowProcess: FlowProcess[_], functionCall: FunctionCall[C]): Unit = {
val context = functionCall.getContext
val s = conv(functionCall.getArguments)
lockedFn.get(context, s) foreach { t => functionCall.getOutputCollector.add(set(t)) }
}
}
class FilterFunction[T](@transient fn: T => Boolean, conv: TupleConverter[T])
extends BaseOperation[Any] with Filter[Any] with ScaldingPrepare[Any] {
val lockedFn = Externalizer(fn)
def isRemove(flowProcess: FlowProcess[_], filterCall: FilterCall[Any]) = {
!lockedFn.get(conv(filterCall.getArguments))
}
}
// All the following are operations for use in GroupBuilder
class FoldAggregator[T, X](@transient fn: (X, T) => X, @transient init: X, fields: Fields,
conv: TupleConverter[T], set: TupleSetter[X])
extends BaseOperation[X](fields) with Aggregator[X] with ScaldingPrepare[X] {
val lockedFn = Externalizer(fn)
private val lockedInit = MeatLocker(init)
def initCopy = lockedInit.copy
def start(flowProcess: FlowProcess[_], call: AggregatorCall[X]): Unit = {
call.setContext(initCopy)
}
def aggregate(flowProcess: FlowProcess[_], call: AggregatorCall[X]): Unit = {
val left = call.getContext
val right = conv(call.getArguments)
call.setContext(lockedFn.get(left, right))
}
def complete(flowProcess: FlowProcess[_], call: AggregatorCall[X]): Unit = {
emit(flowProcess, call)
}
def emit(flowProcess: FlowProcess[_], call: AggregatorCall[X]): Unit = {
call.getOutputCollector.add(set(call.getContext))
}
}
/*
* fields are the declared fields of this aggregator
*/
class MRMAggregator[T, X, U](
@transient inputFsmf: T => X,
@transient inputRfn: (X, X) => X,
@transient inputMrfn: X => U,
fields: Fields, conv: TupleConverter[T], set: TupleSetter[U])
extends BaseOperation[Tuple](fields) with Aggregator[Tuple] with ScaldingPrepare[Tuple] {
val fsmf = Externalizer(inputFsmf)
val rfn = Externalizer(inputRfn)
val mrfn = Externalizer(inputMrfn)
// The context is a singleton Tuple, which is mutable so
// we don't have to allocate at every step of the loop:
def start(flowProcess: FlowProcess[_], call: AggregatorCall[Tuple]): Unit = {
call.setContext(null)
}
def extractArgument(call: AggregatorCall[Tuple]): X = fsmf.get(conv(call.getArguments))
def aggregate(flowProcess: FlowProcess[_], call: AggregatorCall[Tuple]): Unit = {
val arg = extractArgument(call)
val ctx = call.getContext
if (ctx == null) {
// Initialize the context, this is the only allocation done by this loop.
val newCtx = Tuple.size(1)
newCtx.set(0, arg.asInstanceOf[AnyRef])
call.setContext(newCtx)
} else {
// Mutate the context:
val oldValue = ctx.getObject(0).asInstanceOf[X]
val newValue = rfn.get(oldValue, arg)
ctx.set(0, newValue.asInstanceOf[AnyRef])
}
}
def complete(flowProcess: FlowProcess[_], call: AggregatorCall[Tuple]): Unit = {
val ctx = call.getContext
if (null != ctx) {
val lastValue = ctx.getObject(0).asInstanceOf[X]
// Make sure to drop the reference to the lastValue as soon as possible (it may be big)
call.setContext(null)
call.getOutputCollector.add(set(mrfn.get(lastValue)))
} else {
throw new Exception("MRMAggregator completed without any args")
}
}
}
/**
* This handles the mapReduceMap work on the map-side of the operation. The code below
* attempts to be optimal with respect to memory allocations and performance, not functional
* style purity.
*/
abstract class FoldFunctor[X](fields: Fields) extends AggregateBy.Functor {
// Extend these three methods:
def first(args: TupleEntry): X
def subsequent(oldValue: X, newArgs: TupleEntry): X
def finish(lastValue: X): Tuple
override final def getDeclaredFields = fields
/*
* It's important to keep all state in the context as Cascading seems to
* reuse these objects, so any per instance state might give unexpected
* results.
*/
override final def aggregate(flowProcess: FlowProcess[_], args: TupleEntry, context: Tuple) = {
var nextContext: Tuple = null
val newContextObj = if (context == null) {
// First call, make a new mutable tuple to reduce allocations:
nextContext = Tuple.size(1)
first(args)
} else {
//We are updating
val oldValue = context.getObject(0).asInstanceOf[X]
nextContext = context
subsequent(oldValue, args)
}
nextContext.set(0, newContextObj.asInstanceOf[AnyRef])
//Return context for reuse next time:
nextContext
}
override final def complete(flowProcess: FlowProcess[_], context: Tuple) = {
if (context == null) {
throw new Exception("FoldFunctor completed with any aggregate calls")
} else {
val res = context.getObject(0).asInstanceOf[X]
// Make sure we remove the ref to the context ASAP:
context.set(0, null)
finish(res)
}
}
}
/**
* This handles the mapReduceMap work on the map-side of the operation. The code below
* attempts to be optimal with respect to memory allocations and performance, not functional
* style purity.
*/
class MRMFunctor[T, X](
@transient inputMrfn: T => X,
@transient inputRfn: (X, X) => X,
fields: Fields,
conv: TupleConverter[T], set: TupleSetter[X])
extends FoldFunctor[X](fields) {
val mrfn = Externalizer(inputMrfn)
val rfn = Externalizer(inputRfn)
override def first(args: TupleEntry): X = mrfn.get(conv(args))
override def subsequent(oldValue: X, newArgs: TupleEntry) = {
val right = mrfn.get(conv(newArgs))
rfn.get(oldValue, right)
}
override def finish(lastValue: X) = set(lastValue)
}
/**
* MapReduceMapBy Class
*/
class MRMBy[T, X, U](arguments: Fields,
middleFields: Fields,
declaredFields: Fields,
mfn: T => X,
rfn: (X, X) => X,
mfn2: X => U,
startConv: TupleConverter[T],
midSet: TupleSetter[X],
midConv: TupleConverter[X],
endSet: TupleSetter[U]) extends AggregateBy(
arguments,
new MRMFunctor[T, X](mfn, rfn, middleFields, startConv, midSet),
new MRMAggregator[X, X, U](args => args, rfn, mfn2, declaredFields, midConv, endSet))
class BufferOp[I, T, X](
@transient init: I,
@transient inputIterfn: (I, Iterator[T]) => TraversableOnce[X],
fields: Fields, conv: TupleConverter[T], set: TupleSetter[X])
extends BaseOperation[Any](fields) with Buffer[Any] with ScaldingPrepare[Any] {
val iterfn = Externalizer(inputIterfn)
private val lockedInit = MeatLocker(init)
def initCopy = lockedInit.copy
def operate(flowProcess: FlowProcess[_], call: BufferCall[Any]): Unit = {
val oc = call.getOutputCollector
val in = call.getArgumentsIterator.asScala.map { entry => conv(entry) }
iterfn.get(initCopy, in).foreach { x => oc.add(set(x)) }
}
}
/*
* A buffer that allows state object to be set up and tear down.
*/
class SideEffectBufferOp[I, T, C, X](
@transient init: I,
bf: => C, // begin function returns a context
@transient inputIterfn: (I, C, Iterator[T]) => TraversableOnce[X],
ef: C => Unit, // end function to clean up context object
fields: Fields,
conv: TupleConverter[T],
set: TupleSetter[X]) extends SideEffectBaseOperation[C](bf, ef, fields) with Buffer[C] {
val iterfn = Externalizer(inputIterfn)
private val lockedInit = MeatLocker(init)
def initCopy = lockedInit.copy
def operate(flowProcess: FlowProcess[_], call: BufferCall[C]): Unit = {
val context = call.getContext
val oc = call.getOutputCollector
val in = call.getArgumentsIterator.asScala.map { entry => conv(entry) }
iterfn.get(initCopy, context, in).foreach { x => oc.add(set(x)) }
}
}
class SampleWithReplacement(frac: Double, val seed: Int = new java.util.Random().nextInt) extends BaseOperation[Poisson]()
with Function[Poisson] with ScaldingPrepare[Poisson] {
override def prepare(flowProcess: FlowProcess[_], operationCall: OperationCall[Poisson]): Unit = {
super.prepare(flowProcess, operationCall)
val p = new Poisson(frac, seed)
operationCall.setContext(p);
}
def operate(flowProcess: FlowProcess[_], functionCall: FunctionCall[Poisson]): Unit = {
val r = functionCall.getContext.nextInt
for (i <- 0 until r)
functionCall.getOutputCollector().add(Tuple.NULL)
}
}
/** In the typed API every reduce operation is handled by this Buffer */
class TypedBufferOp[K, V, U](
conv: TupleConverter[K],
convV: TupleConverter[V],
@transient reduceFn: (K, Iterator[V]) => Iterator[U],
valueField: Fields)
extends BaseOperation[Any](valueField) with Buffer[Any] with ScaldingPrepare[Any] {
val reduceFnSer = Externalizer(reduceFn)
def operate(flowProcess: FlowProcess[_], call: BufferCall[Any]): Unit = {
val oc = call.getOutputCollector
val key = conv(call.getGroup)
val values = call.getArgumentsIterator
.asScala
.map(convV(_))
// Avoiding a lambda here
val resIter = reduceFnSer.get(key, values)
while (resIter.hasNext) {
val tup = Tuple.size(1)
tup.set(0, resIter.next)
oc.add(tup)
}
}
}
}
| cchepelov/scalding | scalding-core/src/main/scala/com/twitter/scalding/Operations.scala | Scala | apache-2.0 | 27,826 |
package at.logic.gapt.examples.tip.prod
import at.logic.gapt.expr._
import at.logic.gapt.formats.ClasspathInputFile
import at.logic.gapt.formats.tip.TipSmtParser
import at.logic.gapt.proofs.gaptic._
import at.logic.gapt.proofs.{ Ant, Sequent }
import at.logic.gapt.provers.viper.aip.AnalyticInductionProver
object prop_29 extends TacticsProof {
val bench = TipSmtParser.fixupAndParse( ClasspathInputFile( "tip/prod/prop_29.smt2", getClass ) )
ctx = bench.ctx
val sequent = bench.toSequent.zipWithIndex.map {
case ( f, Ant( i ) ) => s"h$i" -> f
case ( f, _ ) => "goal" -> f
}
val dca_goal = hof"!xs (xs = nil ∨ xs = cons(head(xs), tail(xs)))"
val dca = (
( "" -> hof"∀x0 ∀x1 head(cons(x0, x1)) = x0" ) +:
( "" -> hof"∀x0 ∀x1 tail(cons(x0, x1)) = x1" ) +:
Sequent() :+ ( "" -> dca_goal )
)
val dca_proof = AnalyticInductionProver.singleInduction( dca, hov"xs:list" )
val lemma_11_goal = hof"!xs !y !zs append(append(xs, cons(y,nil)), zs) = append(xs, cons(y,zs))"
val lemma_11 = (
( "" -> hof"∀y append(nil, y) = y" ) +:
( "" -> hof"∀z ∀xs ∀y append(cons(z, xs), y) = cons(z, append(xs, y))" ) +:
Sequent() :+ ( "" -> lemma_11_goal )
)
val lemma_11_proof = AnalyticInductionProver.singleInduction( lemma_11, hov"xs:list" )
val cong_3_goal = hof"!xs !ys rev(qrev(xs,ys)) = append(rev(ys), xs)"
val cong_3 = (
( "" -> hof"∀y append(nil, y) = y" ) +:
( "" -> hof"∀z ∀xs ∀y append(cons(z, xs), y) = cons(z, append(xs, y))" ) +:
( "" -> hof"rev(nil) = nil" ) +:
( "" -> hof"∀y ∀xs rev(cons(y, xs)) = append(rev(xs), cons(y, nil))" ) +:
( "" -> hof"∀y qrev(nil, y) = y" ) +:
( "" -> hof"∀z ∀xs ∀y qrev(cons(z, xs), y) = qrev(xs, cons(z, y))" ) +:
( "lemma_11" -> lemma_11_goal ) +:
( "dca" -> dca_goal ) +:
Sequent() :+ ( "" -> cong_3_goal )
)
val cong_3_proof = AnalyticInductionProver.singleInduction( cong_3, hov"xs:list" )
val proof = Lemma( sequent ) {
cut( "dca", dca_goal ); insert( dca_proof )
cut( "lemma_11", lemma_11_goal ); insert( lemma_11_proof )
cut( "cong_3", cong_3_goal ); insert( cong_3_proof )
escargot
}
}
| gebner/gapt | examples/tip/prod/prop_29.scala | Scala | gpl-3.0 | 2,198 |
/*
* EMWithBPTest.scala
* Tests for the EM algorithm
*
* Created By: Michael Howard (mhoward@cra.com)
* Creation Date: Jun 6, 2013
*
* Copyright 2013 Avrom J. Pfeffer and Charles River Analytics, Inc.
* See http://www.cra.com or email figaro@cra.com for information.
*
* See http://www.github.com/p2t2/figaro for a copy of the software license.
*/
package com.cra.figaro.test.algorithm.learning
import org.scalatest.Matchers
import org.scalatest.{ PrivateMethodTester, WordSpec }
import com.cra.figaro.algorithm._
import com.cra.figaro.algorithm.factored._
import com.cra.figaro.algorithm.sampling._
import com.cra.figaro.algorithm.learning._
import com.cra.figaro.library.atomic.continuous._
import com.cra.figaro.library.atomic.discrete.Binomial
import com.cra.figaro.library.compound._
import com.cra.figaro.language._
import com.cra.figaro.language.Universe._
import com.cra.figaro.util._
import com.cra.figaro.util.random
import scala.math.abs
import java.io._
import com.cra.figaro.test.tags.NonDeterministic
class EMWithBPTest extends WordSpec with PrivateMethodTester with Matchers {
"Expectation Maximization with belief propagation" when
{
"when provided a termination criteria based on sufficient statistics magnitudes" should {
"exit before reaching the maximum iterations" in {
val universe = Universe.createNew
val b = Beta(2, 2)
val terminationCriteria = EMTerminationCriteria.sufficientStatisticsMagnitude(0.05)
for (i <- 1 to 7) {
val f = Flip(b)
f.observe(true)
}
for (i <- 1 to 3) {
val f = Flip(b)
f.observe(false)
}
val algorithm = EMWithBP(terminationCriteria, 10, b)(universe)
algorithm.start
val result = b.MAPValue
algorithm.kill
result should be(0.6666 +- 0.01)
}
}
"used to estimate a Beta parameter" should
{
"detect bias after a large enough number of trials" in
{
val universe = Universe.createNew
val b = Beta(2, 2)
for (i <- 1 to 7) {
val f = Flip(b)
f.observe(true)
}
for (i <- 1 to 3) {
val f = Flip(b)
f.observe(false)
}
val algorithm = EMWithBP(15, 10, b)(universe)
algorithm.start
val result = b.MAPValue
algorithm.kill
result should be(0.6666 +- 0.01)
}
"take the prior concentration parameters into account" in
{
val universe = Universe.createNew
val b = Beta(3.0, 7.0)
for (i <- 1 to 7) {
val f = Flip(b)
f.observe(true)
}
for (i <- 1 to 3) {
val f = Flip(b)
f.observe(false)
}
val algorithm = EMWithBP(15, 10, b)(universe)
algorithm.start
val result = b.MAPValue
algorithm.kill
result should be(0.50 +- 0.01)
}
"learn the bias from observations of binomial elements" in {
val universe = Universe.createNew
val b = Beta(2, 2)
val b1 = Binomial(7, b)
b1.observe(6)
val b2 = Binomial(3, b)
b2.observe(1)
val algorithm = EMWithBP(15, 10, b)(universe)
algorithm.start
val result = b.MAPValue
algorithm.kill
result should be(0.6666 +- 0.01)
}
}
"correctly use a uniform prior" in {
val universe = Universe.createNew
val b = Beta(1, 1)
val b1 = Binomial(7, b)
b1.observe(6)
val b2 = Binomial(3, b)
b2.observe(1)
val algorithm = EMWithBP(15, 10, b)(universe)
algorithm.start
val result = b.MAPValue
algorithm.kill
result should be(0.7 +- 0.01)
}
"used to estimate a Dirichlet parameter with two concentration parameters" should
{
"detect bias after a large enough number of trials" in
{
val universe = Universe.createNew
val b = Dirichlet(2, 2)
for (i <- 1 to 7) {
val f = Select(b, true, false)
f.observe(true)
}
for (i <- 1 to 3) {
val f = Select(b, true, false)
f.observe(false)
}
val algorithm = EMWithBP(15, 10, b)(universe)
algorithm.start
val result = b.MAPValue
algorithm.kill
result(0) should be(0.6666 +- 0.01)
}
"take the prior concentration parameters into account" in
{
val universe = Universe.createNew
val b = Dirichlet(3, 7)
for (i <- 1 to 7) {
val f = Select(b, true, false)
f.observe(true)
}
for (i <- 1 to 3) {
val f = Select(b, true, false)
f.observe(false)
}
val algorithm = EMWithBP(15, 10, b)(universe)
algorithm.start
val result = b.MAPValue
algorithm.kill
result(0) should be(0.50 +- 0.01)
}
}
"used to estimate a Dirichlet parameter with three concentration parameters" should
{
"calculate sufficient statistics in the correct order for long lists of concentration parameters" in
{
val universe = Universe.createNew
val alphas = Seq[Double](0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476, 0.0476)
val d = Dirichlet(alphas: _*)
val outcomes = List(2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23)
val outcome = Select(d, outcomes: _*)
val algorithm = EMWithBP(5, 10, d)
algorithm.start
val result = d.MAPValue
algorithm.kill
result(0) should be(0.04 +- 0.01)
result(1) should be(0.04 +- 0.01)
result(2) should be(0.04 +- 0.01)
result(3) should be(0.04 +- 0.01)
result(4) should be(0.04 +- 0.01)
result(5) should be(0.04 +- 0.01)
result(6) should be(0.04 +- 0.01)
result(7) should be(0.04 +- 0.01)
result(8) should be(0.04 +- 0.01)
result(9) should be(0.04 +- 0.01)
result(10) should be(0.04 +- 0.01)
result(11) should be(0.04 +- 0.01)
result(12) should be(0.04 +- 0.01)
result(13) should be(0.04 +- 0.01)
result(14) should be(0.04 +- 0.01)
result(15) should be(0.04 +- 0.01)
result(16) should be(0.04 +- 0.01)
result(17) should be(0.04 +- 0.01)
result(18) should be(0.04 +- 0.01)
result(19) should be(0.04 +- 0.01)
result(20) should be(0.04 +- 0.01)
result(21) should be(0.04 +- 0.01)
}
"calculate sufficient statistics in the correct order for long lists of concentration parameters, taking into account a condition" in
{
val universe = Universe.createNew
val alphas = Seq[Double](1.0476, 1.0476, 1.0476, 1.0476, 1.0476)
val d = Dirichlet(alphas: _*)
val outcomes = List(2, 3, 4, 5, 6)
for (i <- 1 to 10) {
val outcome = Select(d, outcomes: _*)
outcome.addCondition(x => x >= 3 && x <= 6)
}
val algorithm = EMWithBP(2, 10, d)
algorithm.start
val result = d.MAPValue
algorithm.kill
result(0) should be(0.0 +- 0.01)
result(1) should be(0.25 +- 0.01)
result(2) should be(0.25 +- 0.01)
result(3) should be(0.25 +- 0.01)
result(4) should be(0.25 +- 0.01)
}
"detect bias after a large enough number of trials" in
{
val universe = Universe.createNew
val b = Dirichlet(2, 2, 2)
val outcomes = List(1, 2, 3)
val errorTolerance = 0.01
for (i <- 1 to 8) {
val f = Select(b, outcomes: _*)
f.observe(1)
}
for (i <- 1 to 6) {
val f = Select(b, outcomes: _*)
f.observe(2)
}
for (i <- 1 to 2) {
val f = Select(b, outcomes: _*)
f.observe(3)
}
val algorithm = EMWithBP(15, 10, b)(universe)
algorithm.start
val result = b.MAPValue
algorithm.kill
//9/19
result(0) should be(0.47 +- errorTolerance)
//7/19
result(1) should be(0.36 +- errorTolerance)
//3/19
result(2) should be(0.15 +- errorTolerance)
}
"take the prior concentration parameters into account" in
{
val universe = Universe.createNew
val b = Dirichlet(2.0, 3.0, 2.0)
val outcomes = List(1, 2, 3)
for (i <- 1 to 3) {
val f2 = Select(b, outcomes: _*)
f2.observe(1)
}
for (i <- 1 to 2) {
val f3 = Select(b, outcomes: _*)
f3.observe(2)
}
for (i <- 1 to 3) {
val f1 = Select(b, outcomes: _*)
f1.observe(3)
}
val algorithm = EMWithBP(3, 10, b)(universe)
algorithm.start
val result = b.MAPValue
algorithm.kill
result(0) should be(0.33 +- 0.01)
result(1) should be(0.33 +- 0.01)
result(2) should be(0.33 +- 0.01)
}
"correctly use a uniform prior" in
{
val universe = Universe.createNew
val b = Dirichlet(1.0, 1.0, 1.0)
val outcomes = List(1, 2, 3)
for (i <- 1 to 3) {
val f2 = Select(b, outcomes: _*)
f2.observe(1)
}
for (i <- 1 to 3) {
val f3 = Select(b, outcomes: _*)
f3.observe(2)
}
for (i <- 1 to 3) {
val f1 = Select(b, outcomes: _*)
f1.observe(3)
}
val algorithm = EMWithBP(3, 10, b)(universe)
algorithm.start
val result = b.MAPValue
algorithm.kill
result(0) should be(0.33 +- 0.01)
result(1) should be(0.33 +- 0.01)
result(2) should be(0.33 +- 0.01)
}
}
"used to estimate multiple parameters" should
{
"leave parameters having no observations unchanged" in
{
val universe = Universe.createNew
val d = Dirichlet(2.0, 4.0, 2.0)
val b = Beta(2.0, 2.0)
val outcomes = List(1, 2, 3)
for (i <- 1 to 4) {
val f2 = Select(d, outcomes: _*)
f2.observe(1)
}
for (i <- 1 to 2) {
val f3 = Select(d, outcomes: _*)
f3.observe(2)
}
for (i <- 1 to 4) {
val f1 = Select(d, outcomes: _*)
f1.observe(3)
}
val algorithm = EMWithBP(100, 10, d, b)(universe)
algorithm.start
val result = d.MAPValue
algorithm.kill
result(0) should be(0.33 +- 0.01)
result(1) should be(0.33 +- 0.01)
result(2) should be(0.33 +- 0.01)
val betaResult = b.MAPValue
betaResult should be(0.5)
}
"correctly estimate all parameters with observations" in
{
val universe = Universe.createNew
val d = Dirichlet(2.0, 3.0, 2.0)
val b = Beta(3.0, 7.0)
val outcomes = List(1, 2, 3)
for (i <- 1 to 3) {
val f2 = Select(d, outcomes: _*)
f2.observe(1)
}
for (i <- 1 to 2) {
val f3 = Select(d, outcomes: _*)
f3.observe(2)
}
for (i <- 1 to 3) {
val f1 = Select(d, outcomes: _*)
f1.observe(3)
}
for (i <- 1 to 7) {
val f = Flip(b)
f.observe(true)
}
for (i <- 1 to 3) {
val f = Flip(b)
f.observe(false)
}
val algorithm = EMWithBP(5, 10, b, d)(universe)
algorithm.start
val result = d.MAPValue
result(0) should be(0.33 +- 0.01)
result(1) should be(0.33 +- 0.01)
result(2) should be(0.33 +- 0.01)
val betaResult = b.MAPValue
betaResult should be(0.5 +- 0.01)
}
}
val observationProbability = 0.7
val trainingSetSize = 100
val testSetSize = 100
val minScale = 10
val maxScale = 10
val scaleStep = 2
abstract class Parameters(val universe: Universe) {
val b1: Element[Double]
val b2: Element[Double]
val b3: Element[Double]
val b4: Element[Double]
val b5: Element[Double]
val b6: Element[Double]
val b7: Element[Double]
val b8: Element[Double]
val b9: Element[Double]
}
val trueB1 = 0.1
val trueB2 = 0.2
val trueB3 = 0.3
val trueB4 = 0.4
val trueB5 = 0.5
val trueB6 = 0.6
val trueB7 = 0.7
val trueB8 = 0.8
val trueB9 = 0.9
val trueUniverse = new Universe
object TrueParameters extends Parameters(trueUniverse) {
val b1 = Constant(trueB1)("b1", universe)
val b2 = Constant(trueB2)("b2", universe)
val b3 = Constant(trueB3)("b3", universe)
val b4 = Constant(trueB4)("b4", universe)
val b5 = Constant(trueB5)("b5", universe)
val b6 = Constant(trueB6)("b6", universe)
val b7 = Constant(trueB7)("b7", universe)
val b8 = Constant(trueB8)("b8", universe)
val b9 = Constant(trueB9)("b9", universe)
}
class LearnableParameters(universe: Universe) extends Parameters(universe) {
val b1 = Beta(1, 1)("b1", universe)
val b2 = Beta(1, 1)("b2", universe)
val b3 = Beta(1, 1)("b3", universe)
val b4 = Beta(1, 1)("b4", universe)
val b5 = Beta(1, 1)("b5", universe)
val b6 = Beta(1, 1)("b6", universe)
val b7 = Beta(1, 1)("b7", universe)
val b8 = Beta(1, 1)("b8", universe)
val b9 = Beta(1, 1)("b9", universe)
}
var id = 0
class Model(val parameters: Parameters, flipConstructor: (Element[Double], String, Universe) => Flip) {
id += 1
val universe = parameters.universe
val x = flipConstructor(parameters.b1, "x_" + id, universe)
val f2 = flipConstructor(parameters.b2, "f2_" + id, universe)
val f3 = flipConstructor(parameters.b3, "f3_" + id, universe)
val f4 = flipConstructor(parameters.b4, "f4_" + id, universe)
val f5 = flipConstructor(parameters.b5, "f5_" + id, universe)
val f6 = flipConstructor(parameters.b6, "f6_" + id, universe)
val f7 = flipConstructor(parameters.b7, "f7_" + id, universe)
val f8 = flipConstructor(parameters.b8, "f8_" + id, universe)
val f9 = flipConstructor(parameters.b9, "f9_" + id, universe)
val y = If(x, f2, f3)("y_" + id, universe)
val z = If(x, f4, f5)("z_" + id, universe)
val w = CPD(y, z, (true, true) -> f6, (true, false) -> f7,
(false, true) -> f8, (false, false) -> f9)("w_" + id, universe)
}
def normalFlipConstructor(parameter: Element[Double], name: String, universe: Universe) = new CompoundFlip(name, parameter, universe)
def learningFlipConstructor(parameter: Element[Double], name: String, universe: Universe) = {
parameter match {
case p: AtomicBeta => new ParameterizedFlip(name, p, universe)
case _ => throw new IllegalArgumentException("Not a beta parameter")
}
}
object TrueModel extends Model(TrueParameters, normalFlipConstructor)
case class Datum(x: Boolean, y: Boolean, z: Boolean, w: Boolean)
def generateDatum(): Datum = {
val model = TrueModel
Forward(model.universe)
Datum(model.x.value, model.y.value, model.z.value, model.w.value)
}
def observe(model: Model, datum: Datum) {
if (random.nextDouble() < observationProbability) model.x.observe(datum.x)
if (random.nextDouble() < observationProbability) model.y.observe(datum.y)
if (random.nextDouble() < observationProbability) model.z.observe(datum.z)
if (random.nextDouble() < observationProbability) model.w.observe(datum.w)
}
var nextSkip = 0
def predictionAccuracy(model: Model, datum: Datum): Double = {
model.x.unobserve()
model.y.unobserve()
model.z.unobserve()
model.w.unobserve()
val result = nextSkip match {
case 0 =>
model.y.observe(datum.y)
model.z.observe(datum.z)
model.w.observe(datum.w)
val alg = VariableElimination(model.x)(model.universe)
alg.start()
alg.probability(model.x, datum.x)
case 1 =>
model.x.observe(datum.x)
model.z.observe(datum.z)
model.w.observe(datum.w)
val alg = VariableElimination(model.y)(model.universe)
alg.start()
alg.probability(model.y, datum.y)
case 2 =>
model.x.observe(datum.x)
model.y.observe(datum.y)
model.w.observe(datum.w)
val alg = VariableElimination(model.z)(model.universe)
alg.start()
alg.probability(model.z, datum.z)
case 3 =>
model.x.observe(datum.x)
model.y.observe(datum.y)
model.z.observe(datum.z)
val alg = VariableElimination(model.w)(model.universe)
alg.start()
alg.probability(model.w, datum.w)
}
nextSkip = (nextSkip + 1) % 4
result
}
def parameterError(model: Model): Double = {
val parameters = model.parameters
(abs(parameters.b1.value - trueB1) + abs(parameters.b2.value - trueB2) + abs(parameters.b3.value - trueB3) +
abs(parameters.b4.value - trueB4) + abs(parameters.b5.value - trueB5) + abs(parameters.b6.value - trueB6) +
abs(parameters.b7.value - trueB7) + abs(parameters.b8.value - trueB8) + abs(parameters.b9.value - trueB9)) / 9.0
}
def assessModel(model: Model, testSet: Seq[Datum]): (Double, Double) = {
val paramErr = parameterError(model)
nextSkip = 0
var totalPredictionAccuracy = 0.0
for (datum <- testSet) (totalPredictionAccuracy += predictionAccuracy(model, datum))
val predAcc = totalPredictionAccuracy / testSet.length
(paramErr, predAcc)
}
def train(trainingSet: List[Datum], parameters: Parameters, algorithmCreator: Parameters => Algorithm, valueGetter: (Algorithm, Element[Double]) => Double,
flipConstructor: (Element[Double], String, Universe) => Flip): (Model, Double) = {
for (datum <- trainingSet) observe(new Model(parameters, flipConstructor), datum)
val time0 = System.currentTimeMillis()
val algorithm = algorithmCreator(parameters)
algorithm.start()
val resultUniverse = new Universe
def extractParameter(parameter: Element[Double], name: String) =
{
parameter match {
case b: AtomicBeta =>
{
Constant(valueGetter(algorithm, parameter))(name, resultUniverse)
}
case _ => Constant(valueGetter(algorithm, parameter))(name, resultUniverse)
}
}
val learnedParameters = new Parameters(resultUniverse) {
val b1 = extractParameter(parameters.b1, "b1"); b1.generate()
val b2 = extractParameter(parameters.b2, "b2"); b2.generate()
val b3 = extractParameter(parameters.b3, "b3"); b3.generate()
val b4 = extractParameter(parameters.b4, "b4"); b4.generate()
val b5 = extractParameter(parameters.b5, "b5"); b5.generate()
val b6 = extractParameter(parameters.b6, "b6"); b6.generate()
val b7 = extractParameter(parameters.b7, "b7"); b7.generate()
val b8 = extractParameter(parameters.b8, "b8"); b8.generate()
val b9 = extractParameter(parameters.b9, "b9"); b9.generate()
}
algorithm.kill()
val time1 = System.currentTimeMillis()
val totalTime = (time1 - time0) / 1000.0
println("Training time: " + totalTime + " seconds")
(new Model(learnedParameters, normalFlipConstructor), totalTime)
}
"derive parameters within a reasonable accuracy for random data" taggedAs (NonDeterministic) in
{
val numEMIterations = 5
val testSet = List.fill(testSetSize)(generateDatum())
val trainingSet = List.fill(trainingSetSize)(generateDatum())
def learner(parameters: Parameters): Algorithm = {
parameters match {
case ps: LearnableParameters => EMWithBP(numEMIterations, 10, ps.b1, ps.b2, ps.b3, ps.b4, ps.b5, ps.b6, ps.b7, ps.b8, ps.b9)(parameters.universe)
case _ => throw new IllegalArgumentException("Not learnable parameters")
}
}
def parameterGetter(algorithm: Algorithm, parameter: Element[Double]): Double = {
parameter match {
case p: Parameter[Double] => {
p.MAPValue
}
case _ => throw new IllegalArgumentException("Not a learnable parameter")
}
}
val (trueParamErr, truePredAcc) = assessModel(TrueModel, testSet)
val (learnedModel, learningTime) = train(trainingSet, new LearnableParameters(new Universe), learner, parameterGetter, learningFlipConstructor)
val (learnedParamErr, learnedPredAcc) = assessModel(learnedModel, testSet)
println(learnedParamErr)
println(learnedPredAcc)
learnedParamErr should be(0.00 +- 0.12)
learnedPredAcc should be(truePredAcc +- 0.12)
}
}
} | agarbuno/figaro | Figaro/src/test/scala/com/cra/figaro/test/algorithm/learning/EMWithBPTest.scala | Scala | bsd-3-clause | 23,336 |
package au.com.dius.pact.provider
import au.com.dius.pact.model.Request
object ServiceInvokeRequest {
def apply(url: String, request: Request):Request = {
val r = request.copy
r.setPath(s"$url${request.getPath}")
r
}
}
| Fitzoh/pact-jvm | pact-jvm-provider/src/main/scala/au/com/dius/pact/provider/ServiceInvokeRequest.scala | Scala | apache-2.0 | 237 |
/*
* Copyright 2015 Rik van der Kleij
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.powertuple.intellij.haskell.view
import java.io.File
import com.intellij.openapi.actionSystem.{AnAction, AnActionEvent}
import com.intellij.openapi.module.ModuleManager
import com.intellij.openapi.progress.{ProgressIndicator, ProgressManager, Task}
import com.intellij.openapi.project.Project
import com.intellij.openapi.roots.{ModifiableRootModel, ModuleRootModificationUtil, OrderRootType}
import com.intellij.openapi.util.io.FileUtil
import com.intellij.openapi.vfs.VfsUtil
import com.intellij.util.Consumer
import com.powertuple.intellij.haskell.HaskellNotificationGroup
import com.powertuple.intellij.haskell.external.{GhcModiManager, ExternalProcess}
import com.powertuple.intellij.haskell.settings.HaskellSettingsState
import com.powertuple.intellij.haskell.util.HaskellProjecUtil
import scala.collection.JavaConversions._
class AddDependencies extends AnAction {
private val libName = "ideaHaskellLib"
private val PackageInCabalConfigPattern = """.* ([\\w\\-]+)\\s*==\\s*([\\d\\.]+),?""".r
private val initialProgressStep = 0.1
override def update(e: AnActionEvent): Unit = e.getPresentation.setEnabledAndVisible(HaskellProjecUtil.isHaskellProject(e.getProject))
override def actionPerformed(e: AnActionEvent): Unit = {
HaskellSettingsState.getCabalPath match {
case Some(cabalPath) =>
val project = e.getProject
ProgressManager.getInstance().run(new Task.Backgroundable(project, "Downloading Haskell package sources and adding them as source libraries to module") {
def run(progressIndicator: ProgressIndicator) {
val libPath = new File(project.getBasePath + File.separator + libName)
FileUtil.delete(libPath)
FileUtil.createDirectory(libPath)
ExternalProcess.getProcessOutput(project.getBasePath, cabalPath, Seq("freeze"))
readCabalConfig(project, cabalPath).map(cl => getHaskellPackages(cl)).foreach(packages => {
progressIndicator.setFraction(initialProgressStep)
downloadHaskellPackageSources(project, cabalPath, packages, progressIndicator)
progressIndicator.setFraction(0.9)
addDependenciesAsLibrariesToModule(project, packages, libPath.getAbsolutePath)
})
GhcModiManager.doRestart(project)
}
})
case None => HaskellNotificationGroup.notifyError("Could not download sources because path to Cabal is not set")
}
}
private def readCabalConfig(project: Project, cabalPath: String): Option[Seq[String]] = {
try {
Option(FileUtil.loadLines(project.getBasePath + File.separator + "cabal.config"))
} catch {
case e: Exception =>
HaskellNotificationGroup.notifyError(s"Could not read cabal.config file. Error: ${e.getMessage}")
None
}
}
private def getHaskellPackages(cabalConfigLines: Seq[String]) = {
cabalConfigLines.flatMap {
case PackageInCabalConfigPattern(name, version) => Option(HaskellPackage(name, version, s"$name-$version"))
case x => HaskellNotificationGroup.notifyWarning(s"Could not determine package for line [$x] in cabal.config file"); None
}
}
private def downloadHaskellPackageSources(project: Project, cabalPath: String, haskellPackages: Seq[HaskellPackage], progressIndicator: ProgressIndicator) {
val step = 0.8 / haskellPackages.size
var progressFraction = initialProgressStep
haskellPackages.foreach { p =>
val fullName = p.name + "-" + p.version
ExternalProcess.getProcessOutput(project.getBasePath, cabalPath, Seq("get", "-d", libName, fullName))
ExternalProcess.getProcessOutput(project.getBasePath, cabalPath, Seq("sandbox", "add-source", libName + File.separator + fullName))
progressFraction = progressFraction + step
progressIndicator.setFraction(progressFraction)
}
}
private def getUrlByPath(path: String): String = {
VfsUtil.getUrlForLibraryRoot(new File(path))
}
private def addDependenciesAsLibrariesToModule(project: Project, haskellPackages: Seq[HaskellPackage], libPath: String) {
ModuleManager.getInstance(project).getModules.headOption match {
case Some(m) =>
ModuleRootModificationUtil.updateModel(m, new Consumer[ModifiableRootModel] {
override def consume(t: ModifiableRootModel): Unit = {
val libraryTable = t.getModuleLibraryTable
libraryTable.getLibraries.foreach(l => libraryTable.removeLibrary(l))
haskellPackages.foreach { hp =>
val library = libraryTable.createLibrary(hp.name)
val model = library.getModifiableModel
model.addRoot(getUrlByPath(libPath + File.separator + hp.fileName), OrderRootType.SOURCES)
model.commit()
}
}
})
case None => HaskellNotificationGroup.notifyWarning("Could not add packages as libraries because not Haskell module defined in project")
}
}
case class HaskellPackage(name: String, version: String, fileName: String)
}
| epost/intellij-haskell | src/com/powertuple/intellij/haskell/view/AddDependencies.scala | Scala | apache-2.0 | 5,634 |
/* Copyright (C) 2008-2014 University of Massachusetts Amherst.
This file is part of "FACTORIE" (Factor graphs, Imperative, Extensible)
http://factorie.cs.umass.edu, http://github.com/factorie
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
package cc.factorie.db.mongo
import cc.factorie.util.Cubbie
import com.mongodb.{MongoClient, Mongo}
/**
* This class shows some example usage of cubbies and mongo serialization and querying.
*/
object CubbieMongoTest {
import MongoCubbieImplicits._
import MongoCubbieConverter._
def main(args: Array[String]) {
class Person extends Cubbie {
val name = StringSlot("name")
val age = IntSlot("age")
val address = CubbieSlot("address", () => new Address)
val hobbies = StringListSlot("hobbies")
val spouse = RefSlot("spouse", () => new Person)
val children = InverseSlot("children", (p: Person) => p.father)
val father = RefSlot("father", () => new Person)
}
class Address extends Cubbie {
val street = StringSlot("street")
val zip = StringSlot("zip")
}
val address = new Address
address.street := "Mass Ave."
val james = new Person
val laura = new Person
val kid = new Person
james.name := "James"
james.id = 1
james.age := 50
james.hobbies := Seq("photography", "soccer")
james.address := address
laura.name := "Laura"
laura.id = 2
laura.age := 20
laura.hobbies := Seq("James")
laura.address := address
kid.name := "Kid"
kid.id = 3
//reference attributes
james.spouse ::= laura
laura.spouse ::= james
kid.father ::= james
//calling apply on a slot without parameters returns the value of the slot.
println("apply method calls")
println(james.age())
//calling apply with a parameter sets the slot to the given value and returns the cubbie.
println(kid.age(10))
val mongoConn = new MongoClient("localhost", 27017)
val mongoDB = mongoConn.getDB("mongocubbie-test")
val coll = mongoDB.getCollection("persons")
coll.drop()
val persons = new MongoCubbieCollection(coll, () => new Person, (p: Person) => Seq(Seq(p.name))) with LazyCubbieConverter[Person]
persons += james
persons += laura
persons += kid
//find all persons with name = "James" and set their name slot to "Jamie"
persons.update(_.name.set("James"), _.name.update("Jamie"))
//iterate over all persons in the collection
for (p <- persons) {
println(p._map)
}
//find all people with age == 50 but only return their age and name slots.
val queryResult = persons.query(_.age(50), _.age.select.name.select)
// val queryResult = persons.query(_.age.set(50))
for (p <- queryResult) {
println(p._map)
}
//test a delta update, laura turns 21 and is also interested in Rick!
val updatedLaura = new Person
updatedLaura.id = 2
updatedLaura.age := 21
updatedLaura.hobbies := Seq("James", "Rick!")
updatedLaura.address := address
updatedLaura.spouse ::= james
//todo: this seems to not keep the name (= attribute not set in updated cubbie)
persons.updateDelta(laura, updatedLaura)
println(persons.mkString("\n"))
//test batch id query
println("****")
println(persons.query(_.hobbies.contains("James")).mkString("\n"))
println(persons.query(_.idsIn(Seq(1, 2))).mkString("\n"))
println(persons.query(_.idIs(1)).mkString("\n"))
//the graph loader loads a graph rooted around "james" by incrementally and recursively instantiating
//the spouse of every person in the graph.
implicit val refs = GraphLoader.load(Seq(james), {
case p: Person => Seq(p.spouse in persons)
})
//the calls below use the implicit refs object returned by the graph loader to do dereferencing.
println("James' spouse")
println(james.spouse.deref)
println("James' spouse's spouse")
println(james.spouse.deref.spouse.deref)
//same as above, but with both inverse and ref slots.
val index = GraphLoader.load2(Seq(kid), {
case p: Person => Seq(p.children of persons, p.father of persons)
})
println("Index:")
println(index)
println(james.children.value2(index))
//ref slots need a Refs object (mapping from IDs to cubbies) and inv slots an inverter.
println(james.children.value(GraphLoader.toInverter(index)))
println(kid.father.deref(GraphLoader.toRefs(index)))
println("Test Index 2")
val index2 = GraphLoader.load2(Seq(james), {
case p: Person => Seq(p.children of persons)
})
println(james.children.value(GraphLoader.toInverter(index2)))
println(kid.father.deref(GraphLoader.toRefs(index2)))
//or with fancy deref implicits
// import DerefImplicits._
// println(james.spouse-->spouse-->name.value)
kid.name := "Kid 2"
//more experimental stuff from here on:
implicit val inverter = new CachedFunction(new LazyInverter(Map(manifest[Person] -> Seq(james, laura, kid))))
println(james.children.value)
val mongoInverter = new CachedFunction(new LazyMongoInverter(Map(manifest[Person] -> persons)))
println(james.children.value(mongoInverter))
val indexedInverter = new CachedFunction(new IndexedLazyInverter(Map(manifest[Person] -> Seq(james, laura, kid))))
println(james.children.value(indexedInverter))
//in memory caching
implicit val indexer = new Indexer({
case p: Person => Seq(p.name, p.age)
})
//these :=! calls inform the indexer of changes
james.age :=! 51
james.name :=! "Jamison"
println(indexer.index)
}
}
| iesl/fuse_ttl | src/factorie-factorie_2.11-1.1/src/main/scala/cc/factorie/db/mongo/CubbieMongoTest.scala | Scala | apache-2.0 | 6,142 |
package org.jetbrains.plugins.scala.lang.refactoring.util
import com.intellij.openapi.util.TextRange
import com.intellij.psi._
import com.intellij.psi.util.PsiTreeUtil
import org.jetbrains.plugins.scala.ScalaBundle
import org.jetbrains.plugins.scala.extensions.ResolvesTo
import org.jetbrains.plugins.scala.lang.psi.ScalaPsiUtil
import org.jetbrains.plugins.scala.lang.psi.api.base.patterns.{ScBindingPattern, ScCaseClause}
import org.jetbrains.plugins.scala.lang.psi.api.expr.{ScForBinding, ScGenerator}
import org.jetbrains.plugins.scala.lang.psi.api.statements._
import org.jetbrains.plugins.scala.lang.psi.api.statements.params.{ScClassParameter, ScParameter}
import org.jetbrains.plugins.scala.lang.psi.api.toplevel.typedef.{ScClass, ScMember, ScTypeDefinition}
import org.jetbrains.plugins.scala.lang.psi.impl.ScalaPsiElementFactory
import org.jetbrains.plugins.scala.lang.refactoring.util.ScalaRefactoringUtil._
/**
* User: Alexander Podkhalyuzin
* Date: 24.06.2008
*/
object ScalaVariableValidator {
def empty = new ScalaVariableValidator(null, true, null, null)
def apply(file: PsiFile, element: PsiElement, occurrences: Seq[TextRange]): ScalaVariableValidator = {
val container = enclosingContainer(commonParent(file, occurrences))
val containerOne = enclosingContainer(element)
new ScalaVariableValidator(element, occurrences.isEmpty, container, containerOne)
}
}
class ScalaVariableValidator(selectedElement: PsiElement, noOccurrences: Boolean, enclosingContainerAll: PsiElement, enclosingOne: PsiElement)
extends ScalaValidator(selectedElement, noOccurrences, enclosingContainerAll, enclosingOne) {
protected override def findConflictsImpl(name: String, allOcc: Boolean): Seq[(PsiNamedElement, String)] = { //returns declaration and message
val container = enclosingContainer(allOcc)
if (container == null) return Seq.empty
val builder = Seq.newBuilder[(PsiNamedElement, String)]
builder ++= validateDown(container, name, allOcc)
builder ++= validateReference(selectedElement, name)
var cl = container
while (cl != null && !cl.isInstanceOf[ScTypeDefinition]) cl = cl.getParent
if (cl != null) {
cl match {
case x: ScTypeDefinition =>
for (member <- x.membersWithSynthetic) {
member match {
case x: ScVariable => for (el <- x.declaredElements if el.name == name)
builder += ((el, messageForMember(el.name)))
case x: ScValue => for (el <- x.declaredElements if el.name == name)
builder += ((el, messageForMember(el.name)))
case _ =>
}
}
for (function <- x.functions; if function.name == name) {
builder += ((x, messageForMember(function.name)))
}
x match {
case scClass: ScClass =>
for {
constructor <- scClass.constructor
parameter <- constructor.parameters
if parameter.name == name
} {
builder += ((parameter, messageForClassParameter(parameter.name)))
}
case _ =>
}
}
}
builder.result()
}
private def validateReference(context: PsiElement, name: String): Seq[(PsiNamedElement, String)] = {
ScalaPsiElementFactory.createExpressionFromText(name, context) match {
case ResolvesTo(elem@ScalaPsiUtil.inNameContext(nameCtx)) =>
val message = nameCtx match {
case _: ScClassParameter => messageForClassParameter(name)
case _: ScParameter => messageForParameter(name)
case m: ScMember if m.isLocal =>
if (m.getTextOffset < context.getTextOffset) messageForLocal(name)
else ""
case _: ScCaseClause | _: ScGenerator | _: ScForBinding => messageForLocal(name)
case _: PsiMember => messageForMember(name)
case _ => ""
}
if (message != "") Seq((elem, message))
else Seq.empty
case _ => Seq.empty
}
}
private def validateDown(element: PsiElement, name: String, allOcc: Boolean): Seq[(PsiNamedElement, String)] = {
val container = enclosingContainer(allOcc)
val builder = Seq.newBuilder[(PsiNamedElement, String)]
for (child <- element.getChildren) {
child match {
case x: ScClassParameter if x.name == name =>
builder += ((x, messageForClassParameter(x.name)))
case x: ScParameter if x.name == name =>
builder += ((x, messageForParameter(x.name)))
case x: ScFunctionDefinition if x.name == name =>
builder += (if (x.isLocal) (x, messageForLocal(x.name)) else (x, messageForMember(x.name)))
case x: ScBindingPattern if x.name == name =>
builder += (if (x.isClassMember) (x, messageForMember(x.name)) else (x, messageForLocal(x.name)))
case _ =>
}
}
if (element != container)
for (child <- element.getChildren) {
builder ++= validateDown(child, name, allOcc)
}
else {
var from = {
var parent: PsiElement = if (allOcc) {
selectedElement //todo:
} else {
selectedElement
}
if (PsiTreeUtil.isAncestor(container, parent, true))
while (parent.getParent != null && parent.getParent != container) parent = parent.getParent
else parent = container.getFirstChild
parent
}
var fromDoubles = from.getPrevSibling
var i = 0
while (fromDoubles != null) {
i = i + 1
fromDoubles match {
case x: ScVariableDefinition =>
val elems = x.declaredElements
for (elem <- elems; if elem.name == name)
builder += (if (x.isLocal) (elem, messageForLocal(elem.name)) else (elem, messageForMember(elem.name)))
case x: ScPatternDefinition =>
val elems = x.declaredElements
for (elem <- elems; if elem.name == name)
builder += (if (x.isLocal) (elem, messageForLocal(elem.name)) else (elem, messageForMember(elem.name)))
case _ =>
}
fromDoubles = fromDoubles.getPrevSibling
}
while (from != null) {
builder ++= validateDown(from, name, allOcc)
from = from.getNextSibling
}
}
builder.result()
}
private def messageForMember(name: String) = ScalaBundle.message("introduced.variable.will.conflict.with.field", name)
private def messageForLocal(name: String) = ScalaBundle.message("introduced.variable.will.conflict.with.local", name)
private def messageForParameter(name: String) = ScalaBundle.message("introduced.variable.will.conflict.with.parameter", name)
private def messageForClassParameter(name: String) = ScalaBundle.message("introduced.variable.will.conflict.with.class.parameter", name)
}
| JetBrains/intellij-scala | scala/scala-impl/src/org/jetbrains/plugins/scala/lang/refactoring/util/ScalaVariableValidator.scala | Scala | apache-2.0 | 6,842 |
package modules.computation
import org.scalatestplus.play._
import play.api._
import play.api.inject.guice.GuiceApplicationBuilder
import scala.collection.mutable.ListBuffer
/**
* Tests the modules.computation.Pixel class
*/
class ClusterizerTest extends PlaySpec {
// We need to instance a guice application to load test resources
val application: Application = new GuiceApplicationBuilder()
.configure("some.configuration" -> "value")
.build()
"The Clusterizer loader" must {
"loads correctly a custom generated image" in {
val clusterizer = new Clusterizer(
application.getFile("test/resources/simpleForestDiff.png"))
clusterizer.width mustBe 20
clusterizer.height mustBe 20
}
"loads correctly a real sample image" in {
// Not throwing anything is enough for this test.
val clusterizer = new Clusterizer(
application.getFile("test/resources/realSampleForestDiff.png"))
}
}
"The Clusterizer util" must {
// Create a clusterizer instance for this test set
val clusterizer = new Clusterizer(
application.getFile("test/resources/simpleForestDiff.png"))
"get the pixels matching the threshold" in {
// The test sample contains 18 pixels matching the threshold
val expectedPixels = List[Pixel](
Pixel(1, 1, 0xff0000),
Pixel(2, 1, 0xff0000),
Pixel(1, 2, 0xc80000),
Pixel(2, 2, 0xcd0000),
Pixel(13, 8, 0xc80000),
Pixel(14, 8, 0xff0000),
Pixel(15, 8, 0xc80000),
Pixel(13, 9, 0xff0000),
Pixel(14, 9, 0xff0000),
Pixel(15, 9, 0xff0000),
Pixel(13, 10, 0xff0000),
Pixel(14, 10, 0xc80000),
Pixel(15, 10, 0xff0000),
Pixel(7, 17, 0xff0000),
Pixel(8, 17, 0xff0000),
Pixel(5, 18, 0xff0000),
Pixel(6, 18, 0xff0000),
Pixel(7, 18, 0xff0000)
)
clusterizer.clusters.size mustBe expectedPixels.size
/**
* Utility to check if expected pixels match computed pixels.
*
* @param expected expected pixels
* @param actual actual pixels
* @return true if expected pixels are all in the actual list of pixels.
*/
def checkPixels(expected: List[Pixel], actual: ListBuffer[Pixel]
): Boolean =
expected match {
case Nil => true
case pixel::tail => {
actual must contain (pixel)
checkPixels(tail, actual)
}
}
checkPixels(expectedPixels, clusterizer.clusters.map(_.pixels.head))
}
"clusterize correctly the test image" in {
val expectedClusters = ListBuffer[Cluster](
Cluster(List[Pixel](
Pixel(1, 1, 0xff0000),
Pixel(2, 1, 0xff0000),
Pixel(1, 2, 0xc80000),
Pixel(2, 2, 0xcd0000)
)),
Cluster(List[Pixel](
Pixel(13, 8, 0xc80000),
Pixel(14, 8, 0xff0000),
Pixel(15, 8, 0xc80000),
Pixel(13, 9, 0xff0000),
Pixel(14, 9, 0xff0000),
Pixel(15, 9, 0xff0000),
Pixel(13, 10, 0xff0000),
Pixel(14, 10, 0xc80000),
Pixel(15, 10, 0xff0000)
)),
Cluster(List[Pixel](
Pixel(7, 17, 0xff0000),
Pixel(8, 17, 0xff0000),
Pixel(5, 18, 0xff0000),
Pixel(6, 18, 0xff0000),
Pixel(7, 18, 0xff0000)
))
)
val clusters = clusterizer.clusterize()
clusters.size mustBe expectedClusters.size
/**
* Check expected clusters are matching computed clusters
*
* @param expected expected clusters
* @param actual computed clusters
* @return true if the expected clusters are contained in the computed
* clusters.
*/
def checkClusters(expected: ListBuffer[Cluster],
actual: ListBuffer[Cluster]
): Boolean = {
if (expected.isEmpty)
return true
actual must contain (expected.head)
checkClusters(expected.tail, actual)
}
checkClusters(expectedClusters, clusters)
}
}
}
| ArchangelX360/EnvironmentalEventsDetector | backend/test/modules/computation/ClusterizerTest.scala | Scala | mit | 4,175 |
package com.besuikerd.autologistics.common.lib.util
import java.awt.Toolkit
import java.awt.datatransfer._
import java.io.IOException
object ClipBoard {
val systemClipboard = Toolkit.getDefaultToolkit.getSystemClipboard
val clipboardOwner:ClipboardOwner = new ClipboardOwner {
override def lostOwnership(clipboard: Clipboard, contents: Transferable): Unit = {}
}
def set(value:String): Unit ={
systemClipboard.setContents(new StringSelection(value), clipboardOwner)
}
def get(): Option[String] ={
val transferable = systemClipboard.getContents(null)
if(transferable != null && transferable.isDataFlavorSupported(DataFlavor.stringFlavor)){
try{
Some(transferable.getTransferData(DataFlavor.stringFlavor).toString)
} catch{case e:IOException => None}
} else None
}
}
| besuikerd/AutoLogistics | src/main/scala/com/besuikerd/autologistics/common/lib/util/ClipBoard.scala | Scala | gpl-2.0 | 823 |
package com.ldaniels528.broadway.server
import java.io.{File, FilenameFilter}
import akka.actor.{Actor, ActorRef, ActorSystem, Props}
import akka.routing.RoundRobinPool
import com.ldaniels528.broadway.core.actors.file.ArchivingActor
import com.ldaniels528.broadway.core.narrative.{Anthology, AnthologyParser}
import com.ldaniels528.broadway.core.resources._
import com.ldaniels528.broadway.core.util.FileHelper._
import com.ldaniels528.broadway.server.ServerConfig._
import com.ldaniels528.broadway.server.http.ServerContext
import com.ldaniels528.commons.helpers.OptionHelper._
import com.ldaniels528.commons.helpers.PropertiesHelper._
import org.slf4j.LoggerFactory
import scala.collection.concurrent.TrieMap
import scala.reflect.ClassTag
/**
* Server Config
* @author Lawrence Daniels <lawrence.daniels@gmail.com>
*/
case class ServerConfig(props: java.util.Properties, httpInfo: Option[HttpInfo]) {
private lazy val logger = LoggerFactory.getLogger(getClass)
implicit val system = ActorSystem(props.getOrElse("broadway.actor.system", "BroadwaySystem"))
private val actorCache = TrieMap[String, ActorRef]()
// create the system actors
lazy val archivingActor = prepareActor(id = "$archivingActor", new ArchivingActor(this))
/**
* Prepares a new actor for execution within the narrative
* @param actor the given [[Actor]]
* @param parallelism the number of actors to create
* @tparam T the actor type
* @return an [[akka.actor.ActorRef]]
*/
def prepareActor[T <: Actor : ClassTag](id: String, actor: => T, parallelism: Int = 1) = {
actorCache.getOrElseUpdate(id, {
logger.info(s"Creating actor '$id' ($parallelism instances)...")
system.actorOf(Props(actor).withRouter(RoundRobinPool(nrOfInstances = parallelism)))
})
}
def getRootDirectory = new File(props.asOpt[String](BaseDir).orDie(s"Required property '$BaseDir' is missing"))
def getAnthologiesDirectory = new File(getRootDirectory, "anthologies")
def getArchiveDirectory = new File(getRootDirectory, "archive")
def getCompletedDirectory = new File(getRootDirectory, "completed")
def getFailedDirectory = new File(getRootDirectory, "failed")
def getIncomingDirectory = new File(getRootDirectory, "incoming")
def getWorkDirectory = new File(getRootDirectory, "work")
/**
* Initializes the environment based on this configuration
*/
def init() = {
// ensure all directories exist
Seq(
getArchiveDirectory, getCompletedDirectory, getFailedDirectory,
getIncomingDirectory, getAnthologiesDirectory, getWorkDirectory) foreach ensureExistence
// load the anthologies
val anthologies = loadAnthologies(getAnthologiesDirectory)
// return the server context
new ServerContext(this, anthologies)
}
/**
* Loads all anthologies from the given directory
* @param directory the given directory
* @return the collection of successfully parsed [[Anthology]] objects
*/
private def loadAnthologies(directory: File): Seq[Anthology] = {
logger.info(s"Searching for narrative configuration files in '${directory.getAbsolutePath}'...")
val xmlFile = directory.listFiles(new FilenameFilter {
override def accept(dir: File, name: String): Boolean = name.toLowerCase.endsWith(".xml")
})
xmlFile.toSeq flatMap (f => AnthologyParser.parse(FileResource(f.getAbsolutePath)))
}
}
/**
* Server Config Singleton
* @author Lawrence Daniels <lawrence.daniels@gmail.com>
*/
object ServerConfig {
private val BaseDir = "broadway.directories.base"
/**
* Loads the default server configuration
* @return the default server configuration
*/
def apply(): Option[ServerConfig] = apply(ClasspathResource("/broadway-config.xml"))
/**
* Loads the server configuration from the given resource
* @return the server configuration
*/
def apply(resource: ReadableResource): Option[ServerConfig] = ServerConfigParser.parse(resource)
case class HttpInfo(host: String, port: Int)
} | ldaniels528/shocktrade-broadway-server | src/main/scala/com/ldaniels528/broadway/server/ServerConfig.scala | Scala | apache-2.0 | 4,002 |
package com.avsystem.commons
package misc
import com.avsystem.commons.annotation.positioned
import com.avsystem.commons.meta._
import com.avsystem.commons.serialization.{GenCaseInfo, GenCodec, GenParamInfo, GenUnionInfo, name}
trait GenCodecStructure[T] {
def codec: GenCodec[T]
def structure: GenStructure[T]
}
abstract class HasGenCodecStructure[T](
implicit macroInstances: MacroInstances[Unit, GenCodecStructure[T]]) {
implicit val genCodec: GenCodec[T] = macroInstances((), this).codec
implicit val genStructure: GenStructure[T] = macroInstances((), this).structure
}
sealed trait GenStructure[T] extends TypedMetadata[T] {
def repr: String
}
object GenStructure extends AdtMetadataCompanion[GenStructure]
case class GenField[T](
@infer ts: TypeString[T],
@infer codec: GenCodec[T],
@composite info: GenParamInfo[T]
) extends TypedMetadata[T] {
def rawName: String = info.rawName
def repr: String = s"[$info.flags]${info.annotName.fold("")(n => s"<${n.name}> ")}$ts"
}
@positioned(positioned.here) case class GenUnion[T](
@composite info: GenUnionInfo[T],
@multi @adtCaseMetadata cases: Map[String, GenCase[_]]
) extends GenStructure[T] {
def repr: String = cases.iterator.map {
case (name, gr) => s"case $name:${gr.repr}"
}.mkString(s"[${info.flags}]\n", "\n", "")
}
sealed trait GenCase[T] extends TypedMetadata[T] {
def repr: String
def info: GenCaseInfo[T]
def sealedParents: List[GenSealedParent[_]]
}
case class GenSealedParent[T](
@infer repr: TypeString[T]
) extends TypedMetadata[T]
@positioned(positioned.here) case class GenCustomCase[T](
@composite info: GenCaseInfo[T],
@multi @adtCaseSealedParentMetadata sealedParents: List[GenSealedParent[_]],
@checked @infer structure: GenStructure.Lazy[T]
) extends GenCase[T] {
def repr: String = structure.value.repr
}
@positioned(positioned.here) case class GenRecord[T](
@composite info: GenCaseInfo[T],
@multi @adtParamMetadata fields: Map[String, GenField[_]],
@multi @adtCaseSealedParentMetadata sealedParents: List[GenSealedParent[_]]
) extends GenCase[T] with GenStructure[T] {
def repr(indent: Int): String = fields.iterator.map {
case (name, gf) => s"${" " * indent}$name: ${gf.repr}"
}.mkString(s"[${info.flags}]\n", "\n", "")
def repr: String = repr(0)
}
@positioned(positioned.here) case class GenSingleton[T](
@composite info: GenCaseInfo[T],
@checked @infer valueOf: ValueOf[T],
@multi @adtCaseSealedParentMetadata sealedParents: List[GenSealedParent[_]]
) extends GenCase[T] with GenStructure[T] {
def repr: String = valueOf.value.toString
}
@allowUnorderedSubtypes
case class GenUnorderedUnion[T](
@composite info: GenUnionInfo[T],
@multi @adtCaseMetadata cases: Map[String, GenCase[_]]
) extends TypedMetadata[T]
object GenUnorderedUnion extends AdtMetadataCompanion[GenUnorderedUnion] {
materialize[Option[String]]
}
sealed trait Being
object Being extends HasGenCodecStructure[Being]
sealed trait MaterialBeing extends Being
case class Person(name: String, @name("raw_age") age: Int) extends MaterialBeing
object Person extends HasGenCodecStructure[Person]
case class Galaxy(name: String, distance: Long) extends MaterialBeing
class Peculiarity extends Being
object Peculiarity {
implicit val codec: GenCodec[Peculiarity] = null
implicit val structure: GenStructure[Peculiarity] = null
}
case object God extends Being
| AVSystem/scala-commons | commons-core/src/test/scala/com/avsystem/commons/misc/AdtMetadataTest.scala | Scala | mit | 3,400 |
package unfiltered.jetty
object Https {
/** bind to the given port for any host */
def apply(port: Int): Https = Https(port, "0.0.0.0")
/** bind to a the loopback interface only */
def local(port: Int) = Https(port, "127.0.0.1")
/** bind to any available port on the loopback interface */
def anylocal = local(unfiltered.util.Port.any)
}
case class Https(port: Int, host: String) extends Server with Ssl {
val url = "http://%s:%d/" format (host, port)
def sslPort = port
sslConn.setHost(host)
}
/** Provides ssl support for Servers. This trait only requires a x509 keystore cert.
* A keyStore, keyStorePassword are required and default to using the system property values
* "jetty.ssl.keyStore" and "jetty.ssl.keyStorePassword" respectively.
* For added trust store support, mix in the Trusted trait */
trait Ssl { self: Server =>
import org.eclipse.jetty.server.ssl.SslSocketConnector
def tryProperty(name: String) = System.getProperty(name) match {
case null => error("required system property not set %s" format name)
case prop => prop
}
def sslPort: Int
val sslMaxIdleTime = 90000
val sslHandshakeTimeout = 120000
lazy val keyStore = tryProperty("jetty.ssl.keyStore")
lazy val keyStorePassword = tryProperty("jetty.ssl.keyStorePassword")
val sslConn = new SslSocketConnector()
sslConn.setPort(sslPort)
sslConn.setKeystore(keyStore)
sslConn.setKeyPassword(keyStorePassword)
sslConn.setMaxIdleTime(sslMaxIdleTime)
sslConn.setHandshakeTimeout(sslHandshakeTimeout)
underlying.addConnector(sslConn)
}
/** Provides truststore support to an Ssl supported Server
* A trustStore and trustStorePassword are required and default
* to the System property values "jetty.ssl.trustStore" and
* "jetty.ssl.trustStorePassword" respectively */
trait Trusted { self: Ssl =>
lazy val trustStore = tryProperty("jetty.ssl.trustStore")
lazy val trustStorePassword = tryProperty("jetty.ssl.trustStorePassword")
sslConn.setTruststore(trustStore)
sslConn.setTrustPassword(trustStorePassword)
}
| softprops/Unfiltered | jetty/src/main/scala/secured.scala | Scala | mit | 2,062 |
package scoverage
import sbt._
object ScoverageKeys {
// format: off
lazy val coverageEnabled = settingKey[Boolean](
"controls whether code instrumentation is enabled or not"
)
lazy val coverageReport = taskKey[Unit]("run report generation")
lazy val coverageAggregate = taskKey[Unit]("aggregate reports from subprojects")
lazy val coverageExcludedPackages = settingKey[String]("regex for excluded packages")
lazy val coverageExcludedFiles = settingKey[String]("regex for excluded file paths")
lazy val coverageHighlighting = settingKey[Boolean]("enables range positioning for highlighting")
lazy val coverageOutputCobertura = settingKey[Boolean]("enables cobertura XML report generation")
lazy val coverageOutputXML = settingKey[Boolean]("enables xml report generation")
lazy val coverageOutputHTML = settingKey[Boolean]("enables html report generation")
lazy val coverageOutputDebug = settingKey[Boolean]("turn on the debug report")
lazy val coverageOutputTeamCity = settingKey[Boolean]("turn on teamcity reporting")
lazy val coverageScalacPluginVersion = settingKey[String]("version of scalac-scoverage-plugin to use")
lazy val coverageDataDir = settingKey[File]("directory where the measurements and report files will be stored")
// format: on
@deprecated("Use coverageMinimumStmtTotal instead", "v1.8.0")
lazy val coverageMinimum =
settingKey[Double]("see coverageMinimumStmtTotal")
lazy val coverageMinimumStmtTotal =
settingKey[Double]("scoverage minimum coverage: statement total")
lazy val coverageMinimumBranchTotal =
settingKey[Double]("scoverage minimum coverage: branch total")
lazy val coverageMinimumStmtPerPackage =
settingKey[Double]("scoverage minimum coverage: statement per package")
lazy val coverageMinimumBranchPerPackage =
settingKey[Double]("scoverage minimum coverage: branch per package")
lazy val coverageMinimumStmtPerFile =
settingKey[Double]("scoverage minimum coverage: statement per file")
lazy val coverageMinimumBranchPerFile =
settingKey[Double]("scoverage minimum coverage: branch per file")
lazy val coverageFailOnMinimum =
settingKey[Boolean]("if coverage is less than minimum then fail build")
}
| scoverage/sbt-scoverage | src/main/scala/scoverage/ScoverageKeys.scala | Scala | apache-2.0 | 2,225 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.execution.datasources.parquet
import org.apache.spark.sql.Row
import org.apache.spark.sql.test.SharedSQLContext
class ParquetProtobufCompatibilitySuite extends ParquetCompatibilityTest with SharedSQLContext {
test("unannotated array of primitive type") {
checkAnswer(readResourceParquetFile("old-repeated-int.parquet"), Row(Seq(1, 2, 3)))
}
test("unannotated array of struct") {
checkAnswer(
readResourceParquetFile("old-repeated-message.parquet"),
Row(
Seq(
Row("First inner", null, null),
Row(null, "Second inner", null),
Row(null, null, "Third inner"))))
checkAnswer(
readResourceParquetFile("proto-repeated-struct.parquet"),
Row(
Seq(
Row("0 - 1", "0 - 2", "0 - 3"),
Row("1 - 1", "1 - 2", "1 - 3"))))
checkAnswer(
readResourceParquetFile("proto-struct-with-array-many.parquet"),
Seq(
Row(
Seq(
Row("0 - 0 - 1", "0 - 0 - 2", "0 - 0 - 3"),
Row("0 - 1 - 1", "0 - 1 - 2", "0 - 1 - 3"))),
Row(
Seq(
Row("1 - 0 - 1", "1 - 0 - 2", "1 - 0 - 3"),
Row("1 - 1 - 1", "1 - 1 - 2", "1 - 1 - 3"))),
Row(
Seq(
Row("2 - 0 - 1", "2 - 0 - 2", "2 - 0 - 3"),
Row("2 - 1 - 1", "2 - 1 - 2", "2 - 1 - 3")))))
}
test("struct with unannotated array") {
checkAnswer(
readResourceParquetFile("proto-struct-with-array.parquet"),
Row(10, 9, Seq.empty, null, Row(9), Seq(Row(9), Row(10))))
}
test("unannotated array of struct with unannotated array") {
checkAnswer(
readResourceParquetFile("nested-array-struct.parquet"),
Seq(
Row(2, Seq(Row(1, Seq(Row(3))))),
Row(5, Seq(Row(4, Seq(Row(6))))),
Row(8, Seq(Row(7, Seq(Row(9)))))))
}
test("unannotated array of string") {
checkAnswer(
readResourceParquetFile("proto-repeated-string.parquet"),
Seq(
Row(Seq("hello", "world")),
Row(Seq("good", "bye")),
Row(Seq("one", "two", "three"))))
}
}
| chenc10/Spark-PAF | sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetProtobufCompatibilitySuite.scala | Scala | apache-2.0 | 2,909 |
// Copyright (C) 2019 MapRoulette contributors (see CONTRIBUTORS.md).
// Licensed under the Apache License, Version 2.0 (see LICENSE).
package org.maproulette.jobs
import java.util.Calendar
import akka.actor.{ActorRef, ActorSystem}
import javax.inject.{Inject, Named}
import org.maproulette.Config
import org.maproulette.jobs.SchedulerActor.RunJob
import org.slf4j.LoggerFactory
import play.api.{Application, Logger}
import scala.concurrent.ExecutionContext
import scala.concurrent.duration._
/**
* @author cuthbertm
* @author davis_20
*/
class Scheduler @Inject() (
val system: ActorSystem,
@Named("scheduler-actor") val schedulerActor: ActorRef,
val config: Config
)(implicit application: Application, ec: ExecutionContext) {
private val logger = LoggerFactory.getLogger(this.getClass)
schedule("cleanLocks", "Cleaning locks", 1.minute, Config.KEY_SCHEDULER_CLEAN_LOCKS_INTERVAL)
schedule(
"cleanClaimLocks",
"Cleaning review claim locks",
1.minute,
Config.KEY_SCHEDULER_CLEAN_CLAIM_LOCKS_INTERVAL
)
schedule(
"runChallengeSchedules",
"Running challenge Schedules",
1.minute,
Config.KEY_SCHEDULER_RUN_CHALLENGE_SCHEDULES_INTERVAL
)
schedule(
"updateLocations",
"Updating locations",
1.minute,
Config.KEY_SCHEDULER_UPDATE_LOCATIONS_INTERVAL
)
schedule(
"cleanOldTasks",
"Cleaning old tasks",
1.minute,
Config.KEY_SCHEDULER_CLEAN_TASKS_INTERVAL
)
schedule(
"cleanExpiredVirtualChallenges",
"Cleaning up expired Virtual Challenges",
1.minute,
Config.KEY_SCHEDULER_CLEAN_VC_INTEVAL
)
schedule(
"OSMChangesetMatcher",
"Matches OSM changesets to tasks",
1.minute,
Config.KEY_SCHEDULER_OSM_MATCHER_INTERVAL
)
schedule(
"cleanDeleted",
"Deleting Project/Challenges",
1.minute,
Config.KEY_SCHEDULER_CLEAN_DELETED
)
schedule(
"KeepRightUpdate",
"Updating KeepRight Challenges",
1.minute,
Config.KEY_SCHEDULER_KEEPRIGHT
)
schedule(
"rebuildChallengesLeaderboard",
"Rebuilding Challenges Leaderboard",
1.minute,
Config.KEY_SCHEDULER_CHALLENGES_LEADERBOARD
)
schedule(
"sendImmediateNotificationEmails",
"Sending Immediate Notification Emails",
1.minute,
Config.KEY_SCHEDULER_NOTIFICATION_IMMEDIATE_EMAIL_INTERVAL
)
scheduleAtTime(
"sendDigestNotificationEmails",
"Sending Notification Email Digests",
config.getValue(Config.KEY_SCHEDULER_NOTIFICATION_DIGEST_EMAIL_START),
Config.KEY_SCHEDULER_NOTIFICATION_DIGEST_EMAIL_INTERVAL
)
// Run the rebuild of the country leaderboard at
scheduleAtTime(
"rebuildCountryLeaderboard",
"Rebuilding Country Leaderboard",
config.getValue(Config.KEY_SCHEDULER_COUNTRY_LEADERBOARD_START),
Config.KEY_SCHEDULER_COUNTRY_LEADERBOARD
)
// Run the user metrics snapshot at
scheduleAtTime(
"snapshotUserMetrics",
"Snapshotting User Metrics",
config.getValue(Config.KEY_SCHEDULER_SNAPSHOT_USER_METRICS_START),
Config.KEY_SCHEDULER_SNAPSHOT_USER_METRICS
)
// Run the challenge snapshots at
scheduleAtTime(
"snapshotChallenges",
"Snapshotting Challenges",
config.getValue(Config.KEY_SCHEDULER_SNAPSHOT_CHALLENGES_START),
Config.KEY_SCHEDULER_SNAPSHOT_CHALLENGES_INTERVAL
)
/**
* Conditionally schedules message event to start at an initial time and run every duration
*
* @param name The message name sent to the SchedulerActor
* @param action The action this job is performing for logging
* @param initialRunTime String time in format "00:00:00"
* @param intervalKey Configuration key that, when set, will enable periodic scheduled messages
*/
def scheduleAtTime(
name: String,
action: String,
initialRunTime: Option[String],
intervalKey: String
): Unit = {
initialRunTime match {
case Some(initialRunTime) =>
val timeValues = initialRunTime.split(":")
val c = Calendar.getInstance()
c.set(Calendar.HOUR_OF_DAY, timeValues(0).toInt)
c.set(Calendar.MINUTE, timeValues(1).toInt)
c.set(Calendar.SECOND, timeValues(2).toInt)
c.set(Calendar.MILLISECOND, 0)
if (c.getTimeInMillis() < System.currentTimeMillis()) {
c.add(Calendar.DATE, 1)
}
val msBeforeStart = c.getTimeInMillis() - System.currentTimeMillis()
logger.debug("Scheduling " + action + " to run in " + msBeforeStart + "ms.")
schedule(name, action, msBeforeStart.milliseconds, intervalKey)
case _ => logger.error("Invalid start time given for " + action + "!")
}
}
/**
* Conditionally schedules message event when configured with a valid duration
*
* @param name The message name sent to the SchedulerActor
* @param action The action this job is performing for logging
* @param initialDelay FiniteDuration until the initial message is sent
* @param intervalKey Configuration key that, when set, will enable periodic scheduled messages
*/
def schedule(
name: String,
action: String,
initialDelay: FiniteDuration,
intervalKey: String
): Unit = {
config.withFiniteDuration(intervalKey) { interval =>
this.system.scheduler
.schedule(initialDelay, interval, this.schedulerActor, RunJob(name, action))
logger.info(s"$action every $interval")
}
}
}
| Crashfreak/maproulette2 | app/org/maproulette/jobs/Scheduler.scala | Scala | apache-2.0 | 5,446 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.ml.feature
import scala.util.Random
import org.apache.hadoop.fs.Path
import org.apache.spark.annotation.Since
import org.apache.spark.ml.linalg._
import org.apache.spark.ml.param._
import org.apache.spark.ml.param.shared.HasSeed
import org.apache.spark.ml.util._
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.StructType
/**
* Params for [[BucketedRandomProjectionLSH]].
*/
private[ml] trait BucketedRandomProjectionLSHParams extends Params {
/**
* The length of each hash bucket, a larger bucket lowers the false negative rate. The number of
* buckets will be `(max L2 norm of input vectors) / bucketLength`.
*
*
* If input vectors are normalized, 1-10 times of pow(numRecords, -1/inputDim) would be a
* reasonable value
* @group param
*/
val bucketLength: DoubleParam = new DoubleParam(this, "bucketLength",
"the length of each hash bucket, a larger bucket lowers the false negative rate.",
ParamValidators.gt(0))
/** @group getParam */
final def getBucketLength: Double = $(bucketLength)
}
/**
* Model produced by [[BucketedRandomProjectionLSH]], where multiple random vectors are stored. The
* vectors are normalized to be unit vectors and each vector is used in a hash function:
* `h_i(x) = floor(r_i.dot(x) / bucketLength)`
* where `r_i` is the i-th random unit vector. The number of buckets will be `(max L2 norm of input
* vectors) / bucketLength`.
*
* @param randMatrix A matrix with each row representing a hash function.
*/
@Since("2.1.0")
class BucketedRandomProjectionLSHModel private[ml](
override val uid: String,
private[ml] val randMatrix: Matrix)
extends LSHModel[BucketedRandomProjectionLSHModel] with BucketedRandomProjectionLSHParams {
private[ml] def this(uid: String, randUnitVectors: Array[Vector]) = {
this(uid, Matrices.fromVectors(randUnitVectors))
}
private[ml] def randUnitVectors: Array[Vector] = randMatrix.rowIter.toArray
/** @group setParam */
@Since("2.4.0")
override def setInputCol(value: String): this.type = super.set(inputCol, value)
/** @group setParam */
@Since("2.4.0")
override def setOutputCol(value: String): this.type = super.set(outputCol, value)
@Since("2.1.0")
override protected[ml] def hashFunction(elems: Vector): Array[Vector] = {
val hashVec = new DenseVector(Array.ofDim[Double](randMatrix.numRows))
BLAS.gemv(1.0 / $(bucketLength), randMatrix, elems, 0.0, hashVec)
// TODO: Output vectors of dimension numHashFunctions in SPARK-18450
hashVec.values.map(h => Vectors.dense(h.floor))
}
@Since("2.1.0")
override protected[ml] def keyDistance(x: Vector, y: Vector): Double = {
Math.sqrt(Vectors.sqdist(x, y))
}
@Since("2.1.0")
override protected[ml] def hashDistance(x: Array[Vector], y: Array[Vector]): Double = {
// Since it's generated by hashing, it will be a pair of dense vectors.
var distance = Double.MaxValue
var i = 0
while (i < x.length) {
val vx = x(i).toArray
val vy = y(i).toArray
var j = 0
var d = 0.0
while (j < vx.length && d < distance) {
val diff = vx(j) - vy(j)
d += diff * diff
j += 1
}
if (d == 0) return 0.0
if (d < distance) distance = d
i += 1
}
distance
}
@Since("2.1.0")
override def copy(extra: ParamMap): BucketedRandomProjectionLSHModel = {
val copied = new BucketedRandomProjectionLSHModel(uid, randMatrix).setParent(parent)
copyValues(copied, extra)
}
@Since("2.1.0")
override def write: MLWriter = {
new BucketedRandomProjectionLSHModel.BucketedRandomProjectionLSHModelWriter(this)
}
@Since("3.0.0")
override def toString: String = {
s"BucketedRandomProjectionLSHModel: uid=$uid, numHashTables=${$(numHashTables)}"
}
}
/**
* This [[BucketedRandomProjectionLSH]] implements Locality Sensitive Hashing functions for
* Euclidean distance metrics.
*
* The input is dense or sparse vectors, each of which represents a point in the Euclidean
* distance space. The output will be vectors of configurable dimension. Hash values in the
* same dimension are calculated by the same hash function.
*
* References:
*
* 1. <a href="https://en.wikipedia.org/wiki/Locality-sensitive_hashing#Stable_distributions">
* Wikipedia on Stable Distributions</a>
*
* 2. Wang, Jingdong et al. "Hashing for similarity search: A survey." arXiv preprint
* arXiv:1408.2927 (2014).
*/
@Since("2.1.0")
class BucketedRandomProjectionLSH(override val uid: String)
extends LSH[BucketedRandomProjectionLSHModel]
with BucketedRandomProjectionLSHParams with HasSeed {
@Since("2.1.0")
override def setInputCol(value: String): this.type = super.setInputCol(value)
@Since("2.1.0")
override def setOutputCol(value: String): this.type = super.setOutputCol(value)
@Since("2.1.0")
override def setNumHashTables(value: Int): this.type = super.setNumHashTables(value)
@Since("2.1.0")
def this() = this(Identifiable.randomUID("brp-lsh"))
/** @group setParam */
@Since("2.1.0")
def setBucketLength(value: Double): this.type = set(bucketLength, value)
/** @group setParam */
@Since("2.1.0")
def setSeed(value: Long): this.type = set(seed, value)
@Since("2.1.0")
override protected[this] def createRawLSHModel(
inputDim: Int): BucketedRandomProjectionLSHModel = {
val rng = new Random($(seed))
val localNumHashTables = $(numHashTables)
val values = Array.fill(localNumHashTables * inputDim)(rng.nextGaussian)
var i = 0
while (i < localNumHashTables) {
val offset = i * inputDim
val norm = BLAS.javaBLAS.dnrm2(inputDim, values, offset, 1)
if (norm != 0) BLAS.javaBLAS.dscal(inputDim, 1.0 / norm, values, offset, 1)
i += 1
}
val randMatrix = new DenseMatrix(localNumHashTables, inputDim, values, true)
new BucketedRandomProjectionLSHModel(uid, randMatrix)
}
@Since("2.1.0")
override def transformSchema(schema: StructType): StructType = {
SchemaUtils.checkColumnType(schema, $(inputCol), new VectorUDT)
validateAndTransformSchema(schema)
}
@Since("2.1.0")
override def copy(extra: ParamMap): this.type = defaultCopy(extra)
}
@Since("2.1.0")
object BucketedRandomProjectionLSH extends DefaultParamsReadable[BucketedRandomProjectionLSH] {
@Since("2.1.0")
override def load(path: String): BucketedRandomProjectionLSH = super.load(path)
}
@Since("2.1.0")
object BucketedRandomProjectionLSHModel extends MLReadable[BucketedRandomProjectionLSHModel] {
@Since("2.1.0")
override def read: MLReader[BucketedRandomProjectionLSHModel] = {
new BucketedRandomProjectionLSHModelReader
}
@Since("2.1.0")
override def load(path: String): BucketedRandomProjectionLSHModel = super.load(path)
private[BucketedRandomProjectionLSHModel] class BucketedRandomProjectionLSHModelWriter(
instance: BucketedRandomProjectionLSHModel) extends MLWriter {
// TODO: Save using the existing format of Array[Vector] once SPARK-12878 is resolved.
private case class Data(randUnitVectors: Matrix)
override protected def saveImpl(path: String): Unit = {
DefaultParamsWriter.saveMetadata(instance, path, sc)
val data = Data(instance.randMatrix)
val dataPath = new Path(path, "data").toString
sparkSession.createDataFrame(Seq(data)).repartition(1).write.parquet(dataPath)
}
}
private class BucketedRandomProjectionLSHModelReader
extends MLReader[BucketedRandomProjectionLSHModel] {
/** Checked against metadata when loading model */
private val className = classOf[BucketedRandomProjectionLSHModel].getName
override def load(path: String): BucketedRandomProjectionLSHModel = {
val metadata = DefaultParamsReader.loadMetadata(path, sc, className)
val dataPath = new Path(path, "data").toString
val data = sparkSession.read.parquet(dataPath)
val Row(randMatrix: Matrix) = MLUtils.convertMatrixColumnsToML(data, "randUnitVectors")
.select("randUnitVectors")
.head()
val model = new BucketedRandomProjectionLSHModel(metadata.uid, randMatrix)
metadata.getAndSetParams(model)
model
}
}
}
| maropu/spark | mllib/src/main/scala/org/apache/spark/ml/feature/BucketedRandomProjectionLSH.scala | Scala | apache-2.0 | 9,044 |
package com.mentatlabs.nsa
package scalac
package dsl
package experimental
trait ScalacYNooptimiseDSL
extends ScalacExperimentalDSL {
object Ynooptimise {
val unary_- = options.ScalacYNooptimise
}
}
| mentat-labs/sbt-nsa | nsa-dsl/src/main/scala/com/mentatlabs/nsa/scalac/dsl/experimental/private/ScalacYNooptimiseDSL.scala | Scala | bsd-3-clause | 213 |
package controllers
import auth.AuthState
import connectors.AuthConnector
import javax.inject.Inject
import play.api.mvc.{Action, AnyContent, Controller, Request}
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Future
class AuthController @Inject()(authConnector: AuthConnector) extends Controller {
def authenticate = Action.async { request: Request[AnyContent] =>
val gitCode: Option[String] = request.getQueryString("code")
val state: Option[String] = request.session.get("state")
(gitCode, state) match {
case (Some(code), Some(stateValue)) => implicit val s = AuthState(stateValue)
authConnector.authExchange(code).flatMap {
case Right(token) =>
Future(Redirect(
routes
.ReleaseNoteController
.getReleases("ZDevelop94", "RNG-GitHubAPI"))
.withSession("OAuth" -> token.access_token))
case Left(e) => println(s"Failure!! Cause: ${e.getCause}")
Future(Redirect(routes.HomeController.index()))
}
case (Some(_), None) => println("State not found from session, REDIRECTING To Home page")
Future(Redirect(routes.HomeController.index()))
case (None, Some(_)) => println("code not included in query string, REDIRECTING To Home page")
Future(Redirect(routes.HomeController.index()))
}
}
} | ZDevelop94/RNG-GitHubAPI | app/controllers/AuthController.scala | Scala | apache-2.0 | 1,471 |
package com.lookout.borderpatrol.sessionx
import com.lookout.borderpatrol.test._
class SessionSpec extends BorderPatrolSuite {
import sessionx.helpers._
behavior of "Session"
it should "expire" in {
Session(sessionid.next, 1).expired should be(false)
Session(sessionid.expired, 1).expired should be(true)
}
it should "have a decent toString method" in {
val session = sessions.create(1)
session.toString() should be(s"Session(${session.id}, ${session.data})")
}
it should "be the same object in memory when equal" in {
val id = sessionid.next
val data = "session"
Session(id, data) shouldBe Session(id, data)
Session(id, "session1") should not be Session(id, "session2")
// generate unique ids, but same data
sessions.create(data) should not be sessions.create(data)
}
}
| tejom/borderpatrol | core/src/test/scala/com/lookout/borderpatrol/test/sessionx/SessionSpec.scala | Scala | mit | 835 |
package vultura.factor.generation
import org.specs2.Specification
import org.specs2.matcher.{MatchResult, Matcher}
import org.specs2.specification.core.SpecStructure
import vultura.factor.Problem
import scala.util.Random
/**
* Created by thomas on 02.01.17.
*/
class SingletonParameterizationTest extends Specification {
override def is: SpecStructure =
s2"""magnetize some problems and see if the result is as expected
|add singleton potentials to 2x1 grid without singleton potentials ${checkSmallLatticeWO}
|add singleton potentials to 2x1 grid with singleton potentials ${checkSmallLatticeWith}
|""".stripMargin
def checkSmallLatticeWO: MatchResult[Problem] =
identityMagnetization(smallLattice).problem must containFactors(1, Array(0d,1d,1d,2d))
def checkSmallLatticeWith: MatchResult[Problem] =
identityMagnetization(smallLatticeWithSingletons).problem must containFactors(2,Array(0d,1d))
/** Magnetize with energy 0,1,2,… .*/
def identityMagnetization[L](lps: LabeledProblemStructure[L]): LabeledProblem[L] =
SingletonParameterization{(_: L, n: Int) => Generator.only((0 until n).toArray.map(_.toDouble))}.parameterize(lps).generate(new Random(0))
/** Just a small lattice 1x2. */
def smallLattice: LabeledProblemStructure[IndexedSeq[Int]] = FixedDomainsSize(2).addDomains(graph.lattice((2,false))).withSeed(0)
def smallLatticeWithSingletons: LabeledProblemStructure[IndexedSeq[Int]] = smallLattice.addSingletons(_ => true)
/** Check for the presence of factors with the specified values. */
def containFactors(count: Int, values: Array[Double]): Matcher[Problem] =
be_==(count) ^^ ((p:Problem) => p.factors.map(_.values).count(f => f.deep == values.deep))
}
| ziggystar/vultura-factor | src/test/scala/vultura/factor/generation/SingletonParameterizationTest.scala | Scala | mit | 1,746 |
package org.jetbrains.plugins.scala.codeInsight.intention.booleans
import com.intellij.codeInsight.intention.PsiElementBaseIntentionAction
import com.intellij.openapi.editor.Editor
import com.intellij.openapi.project.Project
import com.intellij.psi.{PsiDocumentManager, PsiElement}
import org.jetbrains.plugins.scala.extensions._
import org.jetbrains.plugins.scala.lang.psi.api.expr.{ScParenthesisedExpr, ScReturnStmt}
import org.jetbrains.plugins.scala.lang.psi.impl.ScalaPsiElementFactory.createExpressionFromText
import org.jetbrains.plugins.scala.lang.psi.types.result.Typeable
import org.jetbrains.plugins.scala.project.ProjectContext
/**
* @author Ksenia.Sautina
* @since 6/29/12
*/
class ExpandBooleanIntention extends PsiElementBaseIntentionAction {
import ExpandBooleanIntention._
def isAvailable(project: Project, editor: Editor, element: PsiElement): Boolean =
findReturnParent(element).filter { statement =>
val range = statement.getTextRange
val offset = editor.getCaretModel.getOffset
range.getStartOffset <= offset && offset <= range.getEndOffset
}.collect {
case ScReturnStmt(Typeable(scType)) => scType.canonicalText
}.contains("Boolean")
override def invoke(project: Project, editor: Editor, element: PsiElement): Unit = {
val statement = findReturnParent(element).filter(_.isValid)
.getOrElse(return)
val expressionText = statement match {
case ScReturnStmt(ScParenthesisedExpr(ElementText(text))) => text
case ScReturnStmt(ElementText(text)) => text
case _ => return
}
val start = statement.getTextRange.getStartOffset
inWriteAction {
implicit val context: ProjectContext = project
val replacement = createExpressionFromText(s"if ($expressionText) { return true } else { return false }")
statement.replaceExpression(replacement, removeParenthesis = true)
editor.getCaretModel.moveToOffset(start)
PsiDocumentManager.getInstance(project).commitDocument(editor.getDocument)
}
}
override def getText: String = "Expand boolean use to 'if else'"
def getFamilyName: String = FamilyName
}
object ExpandBooleanIntention {
val FamilyName = "Expand Boolean"
private def findReturnParent(element: PsiElement): Option[ScReturnStmt] =
element.parentOfType(classOf[ScReturnStmt], strict = false)
}
| triplequote/intellij-scala | scala/scala-impl/src/org/jetbrains/plugins/scala/codeInsight/intention/booleans/ExpandBooleanIntention.scala | Scala | apache-2.0 | 2,357 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.executor
import java.lang.Long.{MAX_VALUE => LONG_MAX_VALUE}
import java.util.concurrent.{ConcurrentHashMap, TimeUnit}
import java.util.concurrent.atomic.{AtomicLong, AtomicLongArray}
import scala.collection.mutable.HashMap
import org.apache.spark.internal.Logging
import org.apache.spark.memory.MemoryManager
import org.apache.spark.metrics.ExecutorMetricType
import org.apache.spark.util.{ThreadUtils, Utils}
/**
* A class that polls executor metrics, and tracks their peaks per task and per stage.
* Each executor keeps an instance of this class.
* The poll method polls the executor metrics, and is either run in its own thread or
* called by the executor's heartbeater thread, depending on configuration.
* The class keeps two ConcurrentHashMaps that are accessed (via its methods) by the
* executor's task runner threads concurrently with the polling thread. One thread may
* update one of these maps while another reads it, so the reading thread may not get
* the latest metrics, but this is ok.
* We track executor metric peaks per stage, as well as per task. The per-stage peaks
* are sent in executor heartbeats. That way, we get incremental updates of the metrics
* as the tasks are running, and if the executor dies we still have some metrics. The
* per-task peaks are sent in the task result at task end. These are useful for short
* tasks. If there are no heartbeats during the task, we still get the metrics polled
* for the task.
*
* @param memoryManager the memory manager used by the executor.
* @param pollingInterval the polling interval in milliseconds.
*/
private[spark] class ExecutorMetricsPoller(
memoryManager: MemoryManager,
pollingInterval: Long,
executorMetricsSource: Option[ExecutorMetricsSource]) extends Logging {
type StageKey = (Int, Int)
// Task Count and Metric Peaks
private[executor] case class TCMP(count: AtomicLong, peaks: AtomicLongArray)
// Map of (stageId, stageAttemptId) to (count of running tasks, executor metric peaks)
private[executor] val stageTCMP = new ConcurrentHashMap[StageKey, TCMP]
// Map of taskId to executor metric peaks
private val taskMetricPeaks = new ConcurrentHashMap[Long, AtomicLongArray]
private val poller =
if (pollingInterval > 0) {
Some(ThreadUtils.newDaemonSingleThreadScheduledExecutor("executor-metrics-poller"))
} else {
None
}
/**
* Function to poll executor metrics.
* On start, if pollingInterval is positive, this is scheduled to run at that interval.
* Otherwise, this is called by the reportHeartBeat function defined in Executor and passed
* to its Heartbeater.
*/
def poll(): Unit = {
// Note: Task runner threads may update stageTCMP or read from taskMetricPeaks concurrently
// with this function via calls to methods of this class.
// get the latest values for the metrics
val latestMetrics = ExecutorMetrics.getCurrentMetrics(memoryManager)
executorMetricsSource.foreach(_.updateMetricsSnapshot(latestMetrics))
def updatePeaks(metrics: AtomicLongArray): Unit = {
(0 until metrics.length).foreach { i =>
metrics.getAndAccumulate(i, latestMetrics(i), math.max)
}
}
// for each active stage, update the peaks
stageTCMP.forEachValue(LONG_MAX_VALUE, v => updatePeaks(v.peaks))
// for each running task, update the peaks
taskMetricPeaks.forEachValue(LONG_MAX_VALUE, updatePeaks)
}
/** Starts the polling thread. */
def start(): Unit = {
poller.foreach { exec =>
val pollingTask: Runnable = () => Utils.logUncaughtExceptions(poll())
exec.scheduleAtFixedRate(pollingTask, 0L, pollingInterval, TimeUnit.MILLISECONDS)
}
}
/**
* Called by TaskRunner#run.
*/
def onTaskStart(taskId: Long, stageId: Int, stageAttemptId: Int): Unit = {
// Put an entry in taskMetricPeaks for the task.
taskMetricPeaks.put(taskId, new AtomicLongArray(ExecutorMetricType.numMetrics))
// Put a new entry in stageTCMP for the stage if there isn't one already.
// Increment the task count.
val countAndPeaks = stageTCMP.computeIfAbsent((stageId, stageAttemptId),
_ => TCMP(new AtomicLong(0), new AtomicLongArray(ExecutorMetricType.numMetrics)))
val stageCount = countAndPeaks.count.incrementAndGet()
logDebug(s"stageTCMP: ($stageId, $stageAttemptId) -> $stageCount")
}
/**
* Called by TaskRunner#run. It should only be called if onTaskStart has been called with
* the same arguments.
*/
def onTaskCompletion(taskId: Long, stageId: Int, stageAttemptId: Int): Unit = {
// Decrement the task count.
def decrementCount(stage: StageKey, countAndPeaks: TCMP): TCMP = {
val countValue = countAndPeaks.count.decrementAndGet()
assert(countValue >= 0, "task count shouldn't below 0")
logDebug(s"stageTCMP: (${stage._1}, ${stage._2}) -> " + countValue)
countAndPeaks
}
stageTCMP.computeIfPresent((stageId, stageAttemptId), decrementCount)
// Remove the entry from taskMetricPeaks for the task.
taskMetricPeaks.remove(taskId)
}
/**
* Called by TaskRunner#run.
*/
def getTaskMetricPeaks(taskId: Long): Array[Long] = {
// If this is called with an invalid taskId or a valid taskId but the task was killed and
// onTaskStart was therefore not called, then we return an array of zeros.
val currentPeaks = taskMetricPeaks.get(taskId) // may be null
val metricPeaks = new Array[Long](ExecutorMetricType.numMetrics) // initialized to zeros
if (currentPeaks != null) {
ExecutorMetricType.metricToOffset.foreach { case (_, i) =>
metricPeaks(i) = currentPeaks.get(i)
}
}
metricPeaks
}
/**
* Called by the reportHeartBeat function defined in Executor and passed to its Heartbeater.
* It resets the metric peaks in stageTCMP before returning the executor updates.
* Thus, the executor updates contains the per-stage metric peaks since the last heartbeat
* (the last time this method was called).
*/
def getExecutorUpdates(): HashMap[StageKey, ExecutorMetrics] = {
val executorUpdates = new HashMap[StageKey, ExecutorMetrics]
def getUpdateAndResetPeaks(k: StageKey, v: TCMP): TCMP = {
executorUpdates.put(k, new ExecutorMetrics(v.peaks))
TCMP(v.count, new AtomicLongArray(ExecutorMetricType.numMetrics))
}
stageTCMP.replaceAll(getUpdateAndResetPeaks)
def removeIfInactive(k: StageKey, v: TCMP): TCMP = {
if (v.count.get == 0) {
logDebug(s"removing (${k._1}, ${k._2}) from stageTCMP")
null
} else {
v
}
}
// Remove the entry from stageTCMP if the task count reaches zero.
executorUpdates.foreach { case (k, _) =>
stageTCMP.computeIfPresent(k, removeIfInactive)
}
executorUpdates
}
/** Stops the polling thread. */
def stop(): Unit = {
poller.foreach { exec =>
exec.shutdown()
exec.awaitTermination(10, TimeUnit.SECONDS)
}
}
}
| ueshin/apache-spark | core/src/main/scala/org/apache/spark/executor/ExecutorMetricsPoller.scala | Scala | apache-2.0 | 7,806 |
/*
* Copyright (c) 2012, TU Berlin
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
* * Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of the TU Berlin nor the
* names of its contributors may be used to endorse or promote products
* derived from this software without specific prior written permission.
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
* ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
* WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
* DISCLAIMED. IN NO EVENT SHALL TU Berlin BE LIABLE FOR ANY
* DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
* (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
* LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
* ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
* SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*
* */
package de.tuberlin.uebb.sl2.impl
import scala.language.implicitConversions
import de.tuberlin.uebb.sl2.modules._
import java.io.ByteArrayOutputStream
import java.io.PrintStream
import scala.util.parsing.combinator.syntactical.StandardTokenParsers
import scala.util.parsing.combinator.Parsers
import scala.util.parsing.combinator.RegexParsers
import scala.collection.mutable.Stack
import scala.collection.mutable.Queue
import scala.util.parsing.combinator.Parsers
import org.scalatest.time.Milliseconds
import scala.util.matching.Regex
import org.kiama.output.PrettyPrinter
import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ListBuffer
import scala.language.postfixOps
/**
* Parser implementation module based on scala's combinators
*/
trait CombinatorParser extends RegexParsers with Parsers with Parser with Syntax with Errors with Lexic {
def parseAst(in: String): Either[Error, AST] = {
lines = buildLineIndex(in)
try {
parseAll(parseTopLevel, new ParserString(in)) match {
case Success(result, _) => Right(result)
case failure: NoSuccess =>
// println("Parser Error: " + failure.toString)
Left(convertError(failure)) // HERE IS WHERE THE EXCEPTIONS GET THROWN!
}
} catch {
case err: Error => Left(err)
case e: Throwable =>
val baos = new ByteArrayOutputStream()
e.printStackTrace(new PrintStream(baos))
Left(ParseError("UNEXPECTED ERROR: " + e.getMessage() + "\n" + baos.toString, AttributeImpl(NoLocation))) // TODO Use Attribute
}
}
def parseExpr(in: String): Either[Error, Expr] = {
try {
parseAll(expr, new ParserString(in)) match {
case Success(result, _) => Right(result)
case failure: NoSuccess => Left(scala.sys.error(failure.msg))
}
} catch {
case err: Error => Left(err)
case e: Throwable =>
val baos = new ByteArrayOutputStream()
e.printStackTrace(new PrintStream(baos))
Left(ParseError("UNEXPECTED ERROR: " + e.getMessage() + "\n" + baos.toString, AttributeImpl(NoLocation))) // TODO: Fix this
}
}
var fileName = ""
//contains the offsets where a line starts
//in the input, which is currently parsed
private var lines: Array[Int] = Array()
private def buildLineIndex(s: CharSequence): Array[Int] = {
val lines = new ArrayBuffer[Int]
lines += 0
for (i <- 0 until s.length)
if (s.charAt(i) == '\n') lines += (i + 1)
lines += s.length
lines.toArray
}
private def offsetToPosition(off: Int): Position =
{
if (lines.length < 1) return Position(-1, -1)
var min = 0
var max = lines.length - 1
while (min + 1 < max) {
val mid = (max + min) / 2
if (off < lines(mid))
max = mid
else
min = mid
}
Position(min + 1, off - lines(min) + 1)
}
//ignore whitespace and comments between parsers
override protected val whiteSpace = """(\s|--.*|(?m)\{-(\*(?!/)|[^*])*-\})+""".r
private def parseTopLevel: Parser[AST] = rep(makeImport | makeDataDef | makeFunctionDef | makeFunctionSig | makeFunctionDefExtern | makeError) ^^
{ _.foldLeft(emptyProgram: AST)((z, f) => f(z)) }
private def makeImport: Parser[AST => AST] = (importDef | importExternDef | importDefError) ^^ { i =>
(a: AST) =>
a match {
case m: Program => m.copy(imports = i :: m.imports)
}
}
private def makeDataDef: Parser[AST => AST] = (dataDef | dataDefError) ^^ { d =>
(a: AST) =>
a match {
case m: Program => m.copy(dataDefs = d :: m.dataDefs)
}
}
def makeFunctionDef: Parser[AST => AST] = (functionDef | binaryOpDef | funDefError) ^^ { x =>
(a: AST) =>
a match {
case m: Program => m.copy(functionDefs = updateMap(x._1, x._2, m.functionDefs))
}
}
def makeFunctionSig: Parser[AST => AST] = (functionSig | funSigError) ^^ { x =>
(a: AST) =>
a match {
case m: Program => m.copy(signatures = m.signatures + x)
}
}
def makeFunctionDefExtern: Parser[AST => AST] = (functionDefExtern | funDefExternError) ^^ { x =>
(a: AST) =>
a match {
case m: Program => m.copy(functionDefsExtern = m.functionDefsExtern + x)
}
}
def makeError: Parser[AST => AST] = anyToken ^^@ {
case (a, found) => throw ParseError("unexpected token: " + quote(found) + "; expected top level definition", a)
}
private def updateMap[T](s: String, t: T, m: Map[String, List[T]]) = m + (s -> (t :: m.get(s).getOrElse(Nil)))
private def importDef: Parser[Import] =
importLex ~> string ~ asLex ~ checkedModuleIde ^^@ {
case (a, name ~ _ ~ mod) => QualifiedImport(name.value, mod, a)
}
private def importExternDef: Parser[Import] =
importLex ~ externLex ~> string ^^@ {
case (a, name) => ExternImport(name.value, a)
}
private def functionDef: Parser[(VarName, FunctionDef)] =
defLex ~> varRegex ~ rep(pat) ~ not(opRegex) ~ expect(funEqLex) ~ expr ^^@ {
case (a, v ~ ps ~ _ ~ _ ~ e) => (v, FunctionDef(ps, e, a))
}
private def binaryOpDef: Parser[(VarName, FunctionDef)] =
defLex ~> rep1(pat) ~ opRegex ~ rep1(pat) ~ expect(funEqLex) ~ expr ^^@ {
case (a, p1 ~ op ~ p2 ~ _ ~ e) => (op, FunctionDef(p1 ++ p2, e, a))
}
private def functionDefExtern: Parser[(VarName, FunctionDefExtern)] =
defLex ~ externLex ~> (varRegex|opRegex) ~ expect(funEqLex) ~ jsRegex ^^@ {
case (a, v ~ _ ~ js) => (v, FunctionDefExtern(js, a))
}
private def dataDef: Parser[DataDef] = (
publicLex ~> dataLex ~> externLex ~> checkedTypeIde ~ rep(varRegex) ^^@
{ case (a, t ~ tvs) => DataDef(t, tvs, List(), PublicModifier, a) }
| dataLex ~> externLex ~> checkedTypeIde ~ rep(varRegex) ^^@
{ case (a, t ~ tvs) => DataDef(t, tvs, List(), DefaultModifier, a) }
| publicLex ~> dataLex ~> checkedTypeIde ~ rep(varRegex) ~ expect(funEqLex) ~ rep1sep(conDef, dataSepLex) ^^@
{ case (a, t ~ tvs ~ _ ~ cs) => DataDef(t, tvs, cs, PublicModifier, a) }
| dataLex ~> checkedTypeIde ~ rep(varRegex) ~ expect(funEqLex) ~ rep1sep(conDef, dataSepLex) ^^@
{ case (a, t ~ tvs ~ _ ~ cs) => DataDef(t, tvs, cs, DefaultModifier, a) })
private def functionSig: Parser[Tuple2[VarName, FunctionSig]] = (
publicLex ~> funLex ~> expect(varRegex|opRegex, "variable or operator name") ~ expect(typeLex) ~ parseType ^^@ { case (a, v ~ _ ~ t) => (v, FunctionSig(t, PublicModifier, a)) }
| funLex ~> expect(varRegex|opRegex, "variable or operator name") ~ expect(typeLex) ~ parseType ^^@ { case (a, v ~ _ ~ t) => (v, FunctionSig(t, DefaultModifier, a)) } )
private def expr: Parser[Expr] = binop
private def simpleexpr: Parser[Expr] = app
private def app: Parser[Expr] = chainl1(stmt, stmt <~ not(eqRegex), success(()) ^^ (_ => ((x: Expr, y: Expr) => App(x, y, mergeAttributes(x, y)))))
private def stmt: Parser[Expr] = (
conditional
| lambda
| caseParser
| let
| javaScript
| parentheses
| exVar | exCon | string | real | num | char | badStmt)
private def conditional: Parser[Conditional] = ifLex ~> expr ~ expect(thenLex) ~ expr ~ expect(elseLex) ~ expr ^^@ { case (a, c ~ _ ~ e1 ~ _ ~ e2) => Conditional(c, e1, e2, a) }
private def lambda: Parser[Lambda] = lambdaLex ~> rep(pat) ~ dotLex ~ expr ^^@ { case (a, p ~ _ ~ e) => Lambda(p, e, a) }
private def caseParser: Parser[Case] = caseLex ~> expr ~ rep1(alt) ^^@ { case (a, e ~ as) => Case(e, as, a) }
private def let: Parser[Let] = letLex ~> rep1(localDef) ~ expect(inLex) ~ expr ^^@ { case (a, lds ~ _ ~ e) => Let(lds, e, a) }
private def javaScript: Parser[Expr] = ((jsOpenLex ~> """(?:(?!\|\}).)*""".r <~ jsCloseLex) ~ (typeLex ~> parseType?)) ^^@ { case (a, s ~ t) => JavaScript(s, t, a) }
private def parentheses: Parser[Expr] = "(" ~> expr <~ closeBracket(")")
private def string: Parser[ConstString] = """"(\\"|[^"])*"""".r ^^@ { (a, s: String) => ConstString(s.substring(1, s.length() - 1), a) }
private def num: Parser[ConstInt] = """-?\d+""".r ^^@ { case (a, d) => ConstInt(d.toInt, a) }
private def real: Parser[ConstReal] = """-?(\d+\.\d*|\.\d+)([Ee]-?\d+)?""".r ^^@ {
case (a, d) => ConstReal(d.toDouble, a)
}
private def char: Parser[ConstChar] = """\'.\'""".r ^^@ { (a, s: String) => ConstChar(s.apply(1), a) }
private def exVar: Parser[ExVar] = qualVar | unqualVar
private def exCon: Parser[ExCon] = qualCon | unqualCon
private def unqualVar: Parser[ExVar] = varRegex ^^@ { (a, s) => ExVar(Syntax.Var(s), a) }
private def unqualCon: Parser[ExCon] = consRegex ~ not(".") ^^@ { case (a, s~_) => ExCon(Syntax.ConVar(s), a) }
private def qualVar: Parser[ExVar] = moduleRegex ~ "." ~ varRegex ^^@ { case (a, m~_~s) => ExVar(Syntax.Var(s,m), a) }
private def qualCon: Parser[ExCon] = moduleRegex ~ "." ~ consRegex ^^@ { case (a, m~_~s) => ExCon(Syntax.ConVar(s,m), a) }
private def localDef: Parser[LetDef] = varRegex ~ funEqLex ~ expr ^^@ { case (a, v ~ _ ~ e) => LetDef(v, e, a) }
private def alt: Parser[Alternative] = ofLex ~ ppat ~ expect(thenLex) ~ expr ^^@ { case (a, _ ~ p ~ _ ~ e) => Alternative(p, e, a) }
private def cons: Parser[ASTType] = consRegex ^^@ { (a, s) => TyExpr(Syntax.TConVar(s), Nil, a) }
private def qualCons: Parser[ASTType] = moduleRegex ~ "." ~ checkedConsIde ^^@ { case (a, m~_~s) => TyExpr(Syntax.TConVar(s,m), Nil, a) }
private def conElem: Parser[ASTType] =
typeVar | qualCons | cons | "(" ~> parseType <~ closeBracket(")") //| not(dataSepLex) ~> unexpectedIn("data constructor definition")
private def conDef: Parser[ConstructorDef] = consRegex ~ rep(conElem) ^^@ { case (a, c ~ ts) => ConstructorDef(c, ts, a) }
// //Parse Types
private def parseType: Parser[ASTType] =
baseType ~ (arrowLex ~> rep1sep(baseType, arrowLex)).? ^^@ {
case (a, t1 ~ None) => t1; case (a, t1 ~ Some(ts)) => FunTy(t1 :: ts, a)
}
private def typeVar: Parser[TyVar] = varRegex ^^@ {
(a, t) => TyVar(t, a)
}
private def typeExpr: Parser[TyExpr] =
typeCon ~ rep(baseType) ^^@ {
case (a, t ~ ts) => TyExpr(t, ts, a)
}
private def baseType: Parser[ASTType] = typeVar | typeExpr | "(" ~> (parseType) <~ closeBracket(")")
private def typeArg: Parser[ASTType] = simpleType | typeVar | "(" ~> parseType <~ closeBracket(")")
private def simpleType: Parser[ASTType] = typeCon ^^@ {
(a, t) => TyExpr(t, List(), a)
}
private def typeCon: Parser[Syntax.TConVar] = qualTCon | unqualTCon
private def qualTCon: Parser[Syntax.TConVar] = moduleRegex ~ "." ~ typeRegex ^^ {
case m~_~t => Syntax.TConVar(t, m)
}
private def unqualTCon: Parser[Syntax.TConVar] = typeRegex ~ not(".") ^^ { case t~_ => Syntax.TConVar(t)}
//Parse Pattern
private def ppat: Parser[Pattern] = patVar | patQualExpr | patExpr
private def pat: Parser[Pattern] = patVar | patQualCons | patCons | "(" ~> (patQualExpr | patExpr) <~ closeBracket(")")
private def patVar: Parser[PatternVar] = varRegex ^^@ {
(a, s) => PatternVar(s, a)
}
private def patCons: Parser[Pattern] = consRegex ^^@ {
(a, c) => PatternExpr(Syntax.ConVar(c), Nil, a)
}
private def patQualCons: Parser[Pattern] = moduleRegex ~ "." ~ consRegex ^^@ {
case (a, m ~ _ ~ c) => PatternExpr(Syntax.ConVar(c, m), Nil, a)
}
private def patExpr: Parser[Pattern] = consRegex ~ rep(pat) ^^@ {
case (a, c ~ pp) => PatternExpr(Syntax.ConVar(c), pp, a)
}
private def patQualExpr: Parser[Pattern] = moduleRegex ~ "." ~ consRegex ~ rep(pat) ^^@ {
case (a, m ~ _ ~ c ~ pp) => PatternExpr(Syntax.ConVar(c, m), pp, a)
}
private def consRegex: Parser[String] = not(keyword) ~> """[A-Z][a-zA-Z0-9]*""".r ^^ { case s: String => s }
private def typeRegex: Parser[String] = not(keyword) ~> """[A-Z][a-zA-Z0-9]*""".r ^^ { case s: String => s }
private def moduleRegex: Parser[String] = not(keyword) ~> """[A-Z][a-zA-Z0-9]*""".r ^^ { case s: String => s }
private def varRegex: Parser[String] = """[a-z][a-zA-Z0-9]*""".r ^^ { case s: String => s }
private def opRegex: Parser[String] = not(eqRegex) ~> """[!§%&/=\?\+\*#\-\<\>|]+""".r ^^ { case s: String => s }
private def eqRegex: Parser[String] = """=(?![!§%&/=\?\+\*#\-:\<\>|])""".r ^^ { case s: String => s }
private def keyword: Parser[String] = keywords.mkString("", "|", "").r
private def jsRegex = jsOpenLex ~> """(?:(?!\|\}).|\n|\r)*""".r <~ jsCloseLex ^^ { case s: String => s }
private def anyToken = keyword | consRegex | varRegex | eqRegex | jsOpenLex | jsCloseLex | """^[ \t\n]""".r
//Qualified things
private def unqualBinop: Parser[ExVar] =
opRegex ^^@ { (a, s) => ExVar(Syntax.Var(s), a)}
private def qualBinop: Parser[ExVar] =
moduleRegex ~ "." ~ opRegex ^^@ {case (a, m ~ _ ~ s) => ExVar(Syntax.Var(s, m), a)}
//Shunting-yard algorithm
private def binop: Parser[Expr] = simpleexpr ~ rep((unqualBinop | qualBinop) ~ simpleexpr) ^^ {
case x ~ xs =>
var input = new Queue ++= (x :: (xs.flatMap({ case a ~ b => List(a, b) }))) //TODO
val out: Stack[Expr] = new Stack
val ops: Stack[Expr] = new Stack
var isOp = false
while (!input.isEmpty) {
val o1 = input.dequeue
if (isOp) {
while (!ops.isEmpty && prec(o1) <= prec(ops.head)) {
clearStack(out, ops)
}
ops.push(o1)
} else {
out.push(o1.asInstanceOf[Expr])
}
isOp = !isOp
}
while (!ops.isEmpty) clearStack(out, ops)
if (out.size != 1) failure("OutputStack should have only one value")
out.pop
}
// Parse errors
private def closeBracket(bracket: String): Parser[String] =
bracket | bracketError(bracket) ^^ {case s: String => s}
private def bracketError(expected: String): Parser[String] =
(")" | "]" | "}" | jsCloseLex | funLex | defLex | importLex | dataLex | publicLex | externLex | anyToken) ^^@ {
case (a, found) => throw ParseError("unbalanced parentheses: " + quote(expected) + " expected but " + quote(found) + " found.", a)
}
private def expect(expected: String): Parser[String] =
expected | wrongToken(expected)
private def expect(parser: Parser[String], description: String): Parser[String] =
parser | wrongTokenType(description) ^^ {case s: String => s}
private def wrongToken(expected: String): Parser[String] =
anyToken ^^@ {
case (a, found) => throw ParseError("unexpected token: "+ quote(expected) + " expected but " + quote(found) + " found.", a)
}
private def checkedVarIde: Parser[String] =
varRegex | wrongTokenType("lower case identifier")
private def checkedModuleIde: Parser[String] =
moduleRegex | wrongTokenType("module identifier") ^^ {case s: String => s}
private def checkedTypeIde: Parser[String] =
typeRegex | wrongTokenType("type identifier") ^^ {case s: String => s}
private def checkedConsIde: Parser[String] =
consRegex | wrongTokenType("constructor identifier") ^^ {case s: String => s}
private def wrongTokenType(expected: String): Parser[String] = anyToken ^^@ {
case (a, found) => throw ParseError(expected + " expected but " + quote(found) + " found.", a)
}
private def importDefError: Parser[Import] =
importLex ~> anyToken ^^@ {
case (a, found) => throw ParseError("malformed import declaration: " + quote(found) + " unexpected.", a)
}
private def dataDefError: Parser[DataDef] =
(publicLex?) ~> dataLex ~> anyToken ^^@ {
case (a, found) => throw ParseError("malformed data declaration: " + quote(found) + " unexpected.", a)
}
private def funSigError: Parser[Tuple2[VarName, FunctionSig]] =
(publicLex?) ~> funLex ~> anyToken ^^@ {
case (a, found) => throw ParseError("malformed function signature: " + quote(found) + " unexpected.", a)
}
private def funDefError: Parser[(VarName, FunctionDef)] =
defLex ~> not(externLex) ~> anyToken ^^@ {
case (a, found) => throw ParseError("malformed function definition: " + quote(found) + " unexpected.", a)
}
private def funDefExternError: Parser[(VarName, FunctionDefExtern)] =
defLex ~> externLex ~> anyToken ^^@ {
case (a, found) => throw ParseError("malformed extern function definition: " + quote(found) + " unexpected.", a)
}
private def badStmt: Parser[Expr] = "." ~> anyToken ^^@ {
case (a, found) => throw ParseError("unexpected qualification operator before " + quote(found) + ".", a)
} // TODO add here!
private def clearStack(out: Stack[Expr], ops: Stack[Expr]) =
{
val o2 = ops.pop
val a = out.pop
val b = out.pop
val att1 = mergeAttributes(b, o2)
val att2 = mergeAttributes(b, a)
out.push(App(App(o2, b, att1), a, att2))
}
private def prec(op: Any): Int = op match {
case ExVar(Syntax.Var(`gtLex`, _), a) => 1
case ExVar(Syntax.Var(`ltLex`, _), a) => 1
case ExVar(Syntax.Var(`leLex`, _), a) => 1
case ExVar(Syntax.Var(`eqLex`, _), a) => 1
case ExVar(Syntax.Var(`neLex`, _), a) => 1
case ExVar(Syntax.Var(`geLex`, _), a) => 1
case ExVar(Syntax.Var(`bindLex`, _), a) => 1
case ExVar(Syntax.Var(`bindNRLex`, _), a) => 1
case ExVar(Syntax.Var(`addLex`, _), a) => 2
case ExVar(Syntax.Var(`subLex`, _), a) => 2
case ExVar(Syntax.Var(`mulLex`, _), a) => 3
case ExVar(Syntax.Var(`divLex`, _), a) => 3
case _ => 0
}
private def mergeAttributes(a: Expr, b: Expr): Attribute = {
val aat = attribute(a)
val bat = attribute(b)
if (aat.isInstanceOf[AttributeImpl] && bat.isInstanceOf[AttributeImpl]) {
val to = bat.asInstanceOf[AttributeImpl].location.asInstanceOf[FileLocation].to
val from = aat.asInstanceOf[AttributeImpl].location.asInstanceOf[FileLocation].from
val file = aat.asInstanceOf[AttributeImpl].location.asInstanceOf[FileLocation].file
return new AttributeImpl(new FileLocation(file, from, to))
} else
return EmptyAttribute
}
private def convertError(ns: NoSuccess) = ns match {
case NoSuccess(msg, in1) =>
val pos = offsetToPosition(in1.offset)
val attr = AttributeImpl(FileLocation(fileName, pos, pos))
throw ParseError(msg, attr)
}
private implicit def parser2Attributed[T](p: Parser[T]): AttributedParser[T] = new AttributedParser(p)
private implicit def regexAttributed(p: Regex): AttributedParser[String] = new AttributedParser(regex(p))
private class AttributedParser[T](p: Parser[T]) {
def ^^@[U](f: (Attribute, T) => U): Parser[U] = Parser { in =>
val source = in.source
val offset = in.offset
val start = handleWhiteSpace(source, offset)
val inwo = in.drop(start - offset)
p(inwo) match {
case Success(t, in1) =>
{
val from = offsetToPosition(start)
val to = offsetToPosition(in1.offset)
val att = AttributeImpl(FileLocation(fileName, from, to))
Success(f(att, t), in1)
}
/*
case Error(msg, in1) =>
{
val from = offsetToPosition(start)
val to = offsetToPosition(in1.offset)
val att = AttributeImpl(FileLocation(fileName, from, to))
throw ParseError("From CombinatorParser: " + msg, att)
}
*/
case ns: NoSuccess => ns
}
}
}
}
| mzuber/simple-language | src/main/scala/impl/CombinatorParser.scala | Scala | bsd-3-clause | 20,898 |
/*
* Copyright 2018 Han van Venrooij
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.irundaia.util
import java.nio.file.Path
package object extensions {
implicit class RichPath (p: Path) {
def withExtension(extension: String): Path = p.resolveSibling(p.toString.replaceAll("""(.*)\\.\\w+""", s"$$1.$extension"))
}
}
| irundaia/sbt-sassify | src/main/scala/org/irundaia/util/extensions/package.scala | Scala | apache-2.0 | 852 |
/*
* Copyright 2011-2018 GatlingCorp (http://gatling.io)
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package io.gatling.core.check.extractor.jsonpath
import io.gatling.commons.validation._
import io.gatling.core.config.GatlingConfiguration
import io.gatling.core.util.cache.Cache
import io.gatling.jsonpath.JsonPath
class JsonPaths(implicit configuration: GatlingConfiguration) {
private val jsonPathCache = {
def compile(expression: String): Validation[JsonPath] = JsonPath.compile(expression) match {
case Left(error) => error.reason.failure
case Right(path) => path.success
}
Cache.newConcurrentLoadingCache(configuration.core.extract.jsonPath.cacheMaxCapacity, compile)
}
def extractAll[X: JsonFilter](json: Any, expression: String): Validation[Iterator[X]] =
compileJsonPath(expression).map(_.query(json).collect(JsonFilter[X].filter))
def compileJsonPath(expression: String): Validation[JsonPath] = jsonPathCache.get(expression)
}
| wiacekm/gatling | gatling-core/src/main/scala/io/gatling/core/check/extractor/jsonpath/JsonPaths.scala | Scala | apache-2.0 | 1,496 |
object Test {
def main(args: Array[String]): Unit = {
new foo.bar.Foo
new foo.Foo
new Foo
}
}
package foo {
package bar {
class Foo {
new Object {
println(this.getClass) // Foo$$anon$1
}
new Object {
println(this.getClass) // Foo$$anon$2
}
}
}
class Foo {
new Object {
println(this.getClass) // Foo$$anon$1
}
}
}
class Foo {
new Object {
println(this.getClass) // Foo$$anon$1
}
}
| som-snytt/dotty | tests/run/i2964e.scala | Scala | apache-2.0 | 477 |
/*
* @author Philip Stutz
* @author Sara Magliacane
*
* Copyright 2014 University of Zurich & VU University Amsterdam
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
*/
package com.signalcollect.admm.optimizers
import breeze.linalg.DenseVector
import breeze.optimize.DiffFunction
import breeze.optimize.minimize
class LinearConstraintOptimizer(
setId: Int,
val comparator: String,
constant: Double,
zIndices: Array[Int],
stepSize: Double = 1.0,
initialZmap: Map[Int, Double],
coefficientMatrix: Array[Double],
val tolerance: Double = 0.0) extends OptimizerBase(setId, constant, zIndices, stepSize, initialZmap, coefficientMatrix) {
def basicFunction = {
new Function1[DenseVector[Double], Double] {
def apply(d: DenseVector[Double]) = {
val coeffsDotX = coeffs.dot(d)
if (comparator == "leq" && coeffsDotX > constant
|| comparator == "geq" && coeffsDotX < constant
|| comparator == "eq" && coeffsDotX != constant) {
// If the constraint is broken, check how much.
val absDiff = math.abs(coeffsDotX - constant)
// Under a certain tolerance, ignore the violation.
if (tolerance >= 0 && absDiff <= tolerance) {
0.0
} else {
Double.MaxValue
}
} else {
0.0
}
}
}
}
def evaluateAtEfficient(someX: Array[Double]): Double = {
basicFunction(DenseVector(someX))
}
/**
* Adaptation of Stephen Bach's solver.
*
* Objective of the form:
* 0 if coeffs^T * x CMP constant,
* infinity otherwise,
* where CMP is ==, >=, or <=
* All coeffs must be non-zero.
*/
def optimizeEfficient(
consensusAssignments: Array[Double]) {
setZ(consensusAssignments)
val newXIfNoLoss = z - (y / stepSize)
val total = coeffs.dot(newXIfNoLoss)
x = newXIfNoLoss
if ((comparator == "leq" && total > constant)
|| (comparator == "geq" && total < constant)
|| (comparator == "eq" && total != constant)) {
// If the constraint is broken, check how much.
// val absDiff = math.abs(total - constant)
// // Under a certain tolerance, ignore the violation.
// if (tolerance >= 0 && absDiff <= tolerance) {
// return
// }
if (x.length == 1) {
x(0) = constant / coeffs(0)
return
}
// Project x onto coeffsDotX == constant plane.
var distance = -constant / length
distance += x.dot(unitNormalVector)
x = x - (unitNormalVector * distance)
}
}
override def toString = s"LinearConstraintOptimizer(x=$x, y=$y, z=$z, coeffs=$coeffs, constant=$constant, zIndices=${zIndices.mkString("[", ",", "]")})"
}
| uzh/fox | src/main/scala/com/signalcollect/admm/optimizers/LinearConstraintOptimizer.scala | Scala | apache-2.0 | 3,270 |
import sbt._
import sbt.Keys._
import com.typesafe.sbt.SbtMultiJvm
import com.typesafe.sbt.SbtMultiJvm.MultiJvmKeys.MultiJvm
import com.typesafe.sbt.SbtScalariform
import com.typesafe.sbt.SbtScalariform.ScalariformKeys
object Build extends sbt.Build {
lazy val root = Project("spray-socketio-root", file("."))
.aggregate(examples, socketio)
.settings(basicSettings: _*)
.settings(Formatting.settings: _*)
.settings(Formatting.buildFileSettings: _*)
.settings(noPublishing: _*)
lazy val socketio = Project("spray-socketio", file("spray-socketio"))
.settings(basicSettings: _*)
.settings(Formatting.settings: _*)
.settings(releaseSettings: _*)
.settings(libraryDependencies ++= Dependencies.all)
.settings(SbtMultiJvm.multiJvmSettings ++ multiJvmSettings: _*)
.settings(unmanagedSourceDirectories in Test += baseDirectory.value / "multi-jvm/scala")
.configs(MultiJvm)
lazy val examples = Project("spray-socketio-examples", file("examples"))
.aggregate(sprayBenchmark, sprayServer)
.settings(exampleSettings: _*)
lazy val sprayBenchmark = Project("spray-socketio-examples-benchmark", file("examples/socketio-benchmark"))
.settings(exampleSettings: _*)
.settings(libraryDependencies += Dependencies.akka_persistence_cassandra)
.settings(Formatting.settings: _*)
.settings(Packaging.bench_settings: _*)
.dependsOn(socketio)
lazy val sprayServer = Project("spray-socketio-examples-server", file("examples/socketio-server"))
.settings(exampleSettings: _*)
.settings(libraryDependencies += Dependencies.akka_persistence_cassandra)
.settings(Formatting.settings: _*)
.dependsOn(socketio)
lazy val basicSettings = Seq(
organization := "com.wandoulabs.akka",
version := "0.2.0-SNAPSHOT",
scalaVersion := "2.11.6",
// no more scala-2.10.x @see https://github.com/milessabin/shapeless/issues/63
//crossScalaVersions := Seq("2.10.4", "2.11.5"),
scalacOptions ++= Seq("-unchecked", "-deprecation"),
resolvers ++= Seq(
"Sonatype OSS Releases" at "https://oss.sonatype.org/content/repositories/releases",
"Sonatype OSS Snapshots" at "https://oss.sonatype.org/content/repositories/snapshots",
"Typesafe repo" at "http://repo.typesafe.com/typesafe/releases/",
"spray" at "http://repo.spray.io",
"spray nightly" at "http://nightlies.spray.io/",
"krasserm at bintray" at "http://dl.bintray.com/krasserm/maven"))
lazy val exampleSettings = basicSettings ++ noPublishing
lazy val releaseSettings = Seq(
publishTo := {
val nexus = "https://oss.sonatype.org/"
if (version.value.trim.endsWith("SNAPSHOT"))
Some("snapshots" at nexus + "content/repositories/snapshots")
else
Some("releases" at nexus + "service/local/staging/deploy/maven2")
},
publishMavenStyle := true,
publishArtifact in Test := false,
pomIncludeRepository := { (repo: MavenRepository) => false },
pomExtra := (
<url>https://github.com/wandoulabs/spray-socketio</url>
<licenses>
<license>
<name>The Apache Software License, Version 2.0</name>
<url>http://www.apache.org/licenses/LICENSE-2.0.txt</url>
<distribution>repo</distribution>
</license>
</licenses>
<scm>
<url>git@github.com:wandoulabs/spray-socketio.git</url>
<connection>scm:git:git@github.com:wandoulabs/spray-socketio.git</connection>
</scm>
<developers>
<developer>
<id>dcaoyuan</id>
<name>Caoyuan DENG</name>
<email>dcaoyuan@gmail.com</email>
</developer>
<developer>
<id>cowboy129</id>
<name>Xingrun CHEN</name>
<email>cowboy129@gmail.com</email>
</developer>
</developers>))
def multiJvmSettings = Seq(
// make sure that MultiJvm test are compiled by the default test compilation
compile in MultiJvm <<= (compile in MultiJvm) triggeredBy (compile in Test),
// disable parallel tests
parallelExecution in Test := false,
// make sure that MultiJvm tests are executed by the default test target,
// and combine the results from ordinary test and multi-jvm tests
executeTests in Test <<= (executeTests in Test, executeTests in MultiJvm) map {
case (testResults, multiNodeResults) =>
val overall =
if (testResults.overall.id < multiNodeResults.overall.id)
multiNodeResults.overall
else
testResults.overall
Tests.Output(overall,
testResults.events ++ multiNodeResults.events,
testResults.summaries ++ multiNodeResults.summaries)
})
lazy val noPublishing = Seq(
publish := (),
publishLocal := (),
// required until these tickets are closed https://github.com/sbt/sbt-pgp/issues/42,
// https://github.com/sbt/sbt-pgp/issues/36
publishTo := None)
}
object Dependencies {
val SPRAY_VERSION = "1.3.3"
val AKKA_VERSION = "2.3.11"
val spray_websocket = "com.wandoulabs.akka" %% "spray-websocket" % "0.1.5-SNAPSHOT"
val spray_can = "io.spray" %% "spray-can" % SPRAY_VERSION
val spray_json = "io.spray" %% "spray-json" % "1.3.1"
val akka_actor = "com.typesafe.akka" %% "akka-actor" % AKKA_VERSION
val akka_contrib = "com.typesafe.akka" %% "akka-contrib" % AKKA_VERSION
val akka_stream = "com.typesafe.akka" %% "akka-stream-experimental" % "1.0-RC4"
val parboiled = "org.parboiled" %% "parboiled" % "2.0.1"
val akka_testkit = "com.typesafe.akka" %% "akka-testkit" % AKKA_VERSION % Test
val akka_multinode_testkit = "com.typesafe.akka" %% "akka-multi-node-testkit" % AKKA_VERSION % "test"
val scalatest = "org.scalatest" %% "scalatest" % "2.2.4" % Test
val scalaspecs = "org.specs2" %% "specs2-core" % "2.3.13" % Test
val apache_math = "org.apache.commons" % "commons-math3" % "3.2" // % Test
val caliper = "com.google.caliper" % "caliper" % "0.5-rc1" % Test
val akka_persistence_cassandra = "com.github.krasserm" %% "akka-persistence-cassandra" % "0.3.6" % Runtime
val kafka = "org.apache.kafka" %% "kafka" % "0.8.2.1" excludeAll (
ExclusionRule(organization = "com.sun.jdmk"),
ExclusionRule(organization = "com.sun.jmx"),
ExclusionRule(organization = "log4j"),
ExclusionRule(organization = "org.slf4j"),
ExclusionRule(organization = "javax.jms"))
val logback = "ch.qos.logback" % "logback-classic" % "1.0.13"
val akka_slf4j = "com.typesafe.akka" %% "akka-slf4j" % AKKA_VERSION
val all = Seq(spray_websocket, spray_can, spray_json, akka_actor, akka_contrib, akka_stream, parboiled, akka_testkit, akka_multinode_testkit, scalatest, scalaspecs, apache_math, caliper, logback, akka_slf4j, kafka)
}
object Formatting {
import com.typesafe.sbt.SbtScalariform
import com.typesafe.sbt.SbtScalariform.ScalariformKeys
import ScalariformKeys._
val BuildConfig = config("build") extend Compile
val BuildSbtConfig = config("buildsbt") extend Compile
// invoke: build:scalariformFormat
val buildFileSettings: Seq[Setting[_]] = SbtScalariform.noConfigScalariformSettings ++
inConfig(BuildConfig)(SbtScalariform.configScalariformSettings) ++
inConfig(BuildSbtConfig)(SbtScalariform.configScalariformSettings) ++ Seq(
scalaSource in BuildConfig := baseDirectory.value / "project",
scalaSource in BuildSbtConfig := baseDirectory.value,
includeFilter in (BuildConfig, format) := ("*.scala": FileFilter),
includeFilter in (BuildSbtConfig, format) := ("*.sbt": FileFilter),
format in BuildConfig := {
val x = (format in BuildSbtConfig).value
(format in BuildConfig).value
},
ScalariformKeys.preferences in BuildConfig := formattingPreferences,
ScalariformKeys.preferences in BuildSbtConfig := formattingPreferences)
val settings = SbtScalariform.scalariformSettings ++ Seq(
ScalariformKeys.preferences in Compile := formattingPreferences,
ScalariformKeys.preferences in Test := formattingPreferences)
val formattingPreferences = {
import scalariform.formatter.preferences._
FormattingPreferences()
.setPreference(RewriteArrowSymbols, false)
.setPreference(AlignParameters, true)
.setPreference(AlignSingleLineCaseStatements, true)
.setPreference(DoubleIndentClassDeclaration, true)
.setPreference(IndentSpaces, 2)
}
}
object Packaging {
import com.typesafe.sbt.SbtNativePackager._
import com.typesafe.sbt.packager.Keys._
import com.typesafe.sbt.packager.archetypes._
val bench_settings = packagerSettings ++ deploymentSettings ++
packageArchetype.java_application ++ Seq(
mainClass in Compile := Some("spray.contrib.socketio.examples.benchmark.SocketIOTestClusterServer"),
name := "bench_cluster",
NativePackagerKeys.packageName := "bench_cluster",
bashScriptConfigLocation := Some("${app_home}/../conf/jvmopts"),
bashScriptExtraDefines += """addJava "-Dconfig.file=${app_home}/../conf/cluster.conf"""")
}
| chamsiin1982/spray-socketio | project/Build.scala | Scala | apache-2.0 | 9,010 |
package org.moe.runtime.nativeobjects
import org.moe.runtime._
import org.scalatest.FunSuite
import org.scalatest.BeforeAndAfter
class MoeNumObjectTestSuite extends FunSuite with BeforeAndAfter {
var r : MoeRuntime = _
before {
r = new MoeRuntime()
r.bootstrap()
}
test("... simple Float object") {
val o = r.NativeObjects.getNum(10.5)
assert(o.getNativeValue === 10.5)
assert(o.isTrue)
assert(!o.isFalse)
assert(!o.isUndef)
}
test("... simple Float object with class") {
val o = r.NativeObjects.getNum(10.5)
assert(o.getAssociatedClass.get === r.getCoreClassFor("Num").get)
}
test("... false Float object") {
val o = r.NativeObjects.getNum(0.0)
assert(o.getNativeValue === 0.0)
assert(!o.isTrue)
assert(o.isFalse)
assert(!o.isUndef)
}
test("... increment") {
val o = r.NativeObjects.getNum(0.5)
o.increment(r)
assert(o.unboxToDouble.get === 1.5)
}
test("... decrement") {
val o = r.NativeObjects.getNum(2.3)
o.decrement(r)
assert(o.unboxToDouble.get === 1.2999999999999998)
}
test("... add") {
val o = r.NativeObjects.getNum(2.5)
val x = o.add(r, r.NativeObjects.getNum(2.5))
assert(x.isInstanceOf("Num"))
assert(x.unboxToDouble.get === 5.0)
assert(o.unboxToDouble.get === 2.5)
}
test("... subtract") {
val o = r.NativeObjects.getNum(3.3)
val x = o.subtract(r, r.NativeObjects.getNum(2.5))
assert(x.isInstanceOf("Num"))
assert(x.unboxToDouble.get === 0.7999999999999998)
assert(o.unboxToDouble.get === 3.3)
}
test("... multiply") {
val o = r.NativeObjects.getNum(2.2)
val x = o.multiply(r, r.NativeObjects.getNum(2.5))
assert(x.isInstanceOf("Num"))
assert(x.unboxToDouble.get === 5.5)
assert(o.unboxToDouble.get === 2.2)
}
test("... divide") {
val o = r.NativeObjects.getNum(4.3)
val x = o.divide(r, r.NativeObjects.getNum(5.1))
assert(x.isInstanceOf("Num"))
assert(x.unboxToDouble.get === 0.8431372549019608 )
assert(o.unboxToDouble.get === 4.3)
}
test("... modulo") {
val o = r.NativeObjects.getNum(10.5)
val x = o.modulo(r, r.NativeObjects.getNum(3.3))
assert(x.isInstanceOf("Int"))
assert(x.unboxToDouble.get === 1)
assert(o.unboxToDouble.get === 10.5)
}
test("... pow") {
val o = r.NativeObjects.getNum(10.4)
val x = o.pow(r, r.NativeObjects.getNum(3.5))
assert(x.isInstanceOf("Num"))
assert(x.unboxToDouble.get === 3627.5773999128405)
assert(o.unboxToDouble.get === 10.4)
}
// equal_to
test("... equal_to (true)") {
val o = r.NativeObjects.getNum(10.5)
val x = o.equal_to(r, r.NativeObjects.getNum(10.5))
assert(x.isInstanceOf("Bool"))
assert(x.isTrue)
}
test("... equal_to (false)") {
val o = r.NativeObjects.getNum(10.5)
val x = o.equal_to(r, r.NativeObjects.getNum(5.5))
assert(x.isInstanceOf("Bool"))
assert(x.isFalse)
}
// not_equal_to
test("... not_equal_to (false)") {
val o = r.NativeObjects.getNum(10.2)
val x = o.not_equal_to(r, r.NativeObjects.getNum(10.2))
assert(x.isInstanceOf("Bool"))
assert(x.isFalse)
}
test("... not_equal_to (true)") {
val o = r.NativeObjects.getNum(10.3)
val x = o.not_equal_to(r, r.NativeObjects.getNum(5.5))
assert(x.isInstanceOf("Bool"))
assert(x.isTrue)
}
}
| MoeOrganization/moe | src/test/scala/org/moe/runtime/nativeobjects/MoeNumObjectTestSuite.scala | Scala | mit | 3,367 |
import sbt._
import Keys._
object Build extends Build {
lazy val solicitorSettings = Defaults.defaultSettings ++ Seq(
crossScalaVersions := Seq("2.10.4"),
scalaVersion <<= (crossScalaVersions) { versions => versions.head },
scalacOptions ++= Seq("-unchecked", "-deprecation", "-feature"),
publishTo := Some(Resolver.file("file", new File("/Users/gphat/src/mvn-repo/releases"))),
resolvers ++= Seq(
"spray repo" at "http://repo.spray.io",
"Typesafe Repository" at "http://repo.typesafe.com/typesafe/releases/"
),
libraryDependencies ++= Seq(
"org.clapper" %% "grizzled-slf4j" % "1.0.1",
"org.specs2" %% "specs2" % "1.14" % "test",
"org.slf4j" % "slf4j-simple" % "1.7.5" % "test"
)
)
lazy val root = Project(
id = "solicitor",
base = file("core"),
settings = solicitorSettings ++ Seq(
description := "Core Solicitor",
version := "1.0"
)
)
lazy val http = Project(
id = "solicitor-http",
base = file("http"),
settings = solicitorSettings ++ Seq(
description := "HTTP Config Backend",
version := "1.0",
libraryDependencies ++= Seq(
"com.typesafe.akka" %% "akka-actor" % "2.3.0",
"io.spray" % "spray-can" % "1.3.0",
"io.spray" % "spray-client" % "1.3.0"
)
)
) dependsOn(
root
)
lazy val consul = Project(
id = "solicitor-consul",
base = file("consul"),
settings = solicitorSettings ++ Seq(
description := "Consul KV Backend",
version := "1.0",
libraryDependencies ++= Seq(
"commons-codec" % "commons-codec" % "1.9",
"io.spray" %% "spray-json" % "1.2.6"
)
)
) dependsOn(
http
)
lazy val typesafe = Project(
id = "solicitor-typesafe",
base = file("typesafe"),
settings = solicitorSettings ++ Seq(
description := "Typesafe Config Backend",
version := "1.0",
libraryDependencies ++= Seq(
"com.typesafe" % "config" % "1.2.0"
)
)
) dependsOn(
root
)
lazy val zk = Project(
id = "solicitor-zk",
base = file("zk"),
settings = solicitorSettings ++ Seq(
description := "Zookeeper Backend",
version := "1.0",
libraryDependencies ++= Seq(
"org.apache.curator" % "curator-recipes" % "2.4.2"
)
)
) dependsOn(
root
)
}
| gphat/solicitor | project/Build.scala | Scala | mit | 2,362 |
package org.precompiler.spark101.helloworld
/**
*
* @author Richard Li
*/
class MockConnection {
def close(): Unit = {
println("Connection closed")
}
}
| precompiler/spark-101 | learning-spark/src/main/scala/org/precompiler/spark101/helloworld/MockConnection.scala | Scala | apache-2.0 | 167 |
package chapter24
/**
* 24.11 배열
*
* 스칼라 컬렉션에서 배열은 특별하다. 자바 배열과 일대일로 대응한다. 스칼라 Array[Int]는 자바
* int[]으로 표현할 수 있다는 뜻이다. 하지만 동시에 자바 쪽의 같은 배열에 비해 훨씬 많은 기능을 제공한다.
*
* - 1. 스칼라 배열은 제네릭 하다. Array[T]
* - 2. 스칼라 배열은 스칼라 시퀀스와 호환 가능하다. Array[T]를 Seq[T]가 필요한 곳에 넘길 수 있다.
* - 3. 스칼라 배열은 모든 시퀀스의 연산을 지원한다.
*/
object c24_i11 extends App {
val a1 = Array(1,2,3) //> a1 : Array[Int] = Array(1, 2, 3)
val a2 = a1 map (_ * 3) //> a2 : Array[Int] = Array(3, 6, 9)
val a3 = a2 filter ( _ % 2 != 0) //> a3 : Array[Int] = Array(3, 9)
a3.reverse //> res0: Array[Int] = Array(9, 3)
/*
* 스칼라 배열을 자바 배열과 마찬가지로 표현한다는 사실을 생각해볼 때, 어떻게 이런 추가 기능을
* 스칼라에서 지원할 수 있을까 신기할 것이다. 스칼라 2.8부터는 배열은 결코 시퀀스인 척하지 않는다.
* 네이티브 배열을 표현하는 데이터 타입이 Seq의 하위 타입이 아니기 때문에 실제로 그럴 수도 없다.
* 배열을 scala.coleciton.mutable.WrappedArray 클래스로 바꿔주는 암시적
* 감싸기 변환이 존재한다. WrappedArray는 Seq의 서브 클래스다.
*
* Array 에서 WrappedArray로의 암시적 변환이 있어서 배열이 시퀀스 역할을 하며, 반대방향으로
* 가기위해서는 Traversable에 있는 toArray 메소드를 사용할 수 있다.
*/
val seq: Seq[Int] = a1 //> seq : Seq[Int] = WrappedArray(1, 2, 3)
val a4: Array[Int] = seq.toArray //> a4 : Array[Int] = Array(1, 2, 3)
a1 eq a4 //> res1: Boolean = true
/*
* seq는 WrappedArray이며 reverse도 WrappedArray로 돌려준다. 이게 논리적이다.
*/
seq.reverse //> res2: Seq[Int] = WrappedArray(3, 2, 1)
val ops: collection.mutable.ArrayOps[Int] = a1 //> ops : scala.collection.mutable.ArrayOps[Int] = [I(1, 2, 3)
ops.reverse //> res3: Array[Int] = Array(3, 2, 1)
/*
* 반면 ArrayOps의 reverse는 Seq가 아니고 Array이다. ArrayOps를 이처럼 쓰지는 않는다.
* 보통은 a1.reverse 와 같이 배열에 대해 Seq메소드를 직접 호출한다.
*
* ArrayOps 객체는 암시적 변환에 의해 자동 삽입된다.
*/
a1.reverse //> res4: Array[Int] = Array(3, 2, 1)
// 실제 다음이 자동 적용된 것이다.
intArrayOps(a1).reverse //> res5: Array[Int] = Array(3, 2, 1)
/*
* 이제 드는 의문은 어떻게 컴파일러가 앞의 코드를 보고 WrappedArray 대신 intArrayOps를 선택하느냐다.
* 전자는 Predef 객체, 후자는 prefer 슈퍼클래스인 scala.LowPriorityImplicits에 들어있다.
* 서브클래스의 암시는 슈퍼클래스의 암시보다 더 우선적으로 쓰인다.
*
* 이제 배열이 시퀀스와 호환 가능한 이유와 배열이 모든 시퀀스 연산을 지원할 수 있는 이유를 알았다. 그렇다면 자바에서는
* T[]가 불가능한데 스칼라에서는 Array[T]가 가능한 이유는 무엇일까?
*
* 실행시점에서 자바의 여덟가지 원시 타입 배열 똔느 객체의 배열이 될 수 있는데, 이 모두를 꿰뚫는 공통 실행 시점 타입은
* AnyRef(=java.lang.Object)뿐이다. 따라서 스칼라는 Array[T]를 AnyRef의 배열로 변환한다.
*
* 제네릭 배열 타입을 표현하는 것 뿐만 아니라 만들어낼 방법도 필요하다.
*
* 타입 파마리터 T에 연관된 실제 타입은 실행 시점에 지워진다.
*/
/*
def evenElems[T](xs: Vector[T]): Array[T] = {
val arr = new Array[T]((xs.length + 1) / 2) // cannot find class tag for element type T
for (i <- 0 until xs.length by 2)
arr(i / 2) = xs(i)
arr
}
*/
/*
* 여기서 필요한 건 evenElems의 실제 타입 파라미터가 어떤 것이 될 수 있는지에 대한 런타임 힌트를 컴파일러에게 제공하는 것이다.
* scala.reflect.ClassManifest의 형태를 취한다. 클래스 매니페스트는 해당 타입의 루트 슈퍼클래스가
* 어떤 것이 될지를 설명하는 타입기술자(type descriptor)객체다. 클래스 매니페스트 대신에 scala.reflect.Manifest
* 라는 전체 매니페스트도 있다. 이는 어떤 타입의 모든 측면을 기술하는데, 배열을 생성할 때는 클래스 매니페스트만 필요하다.
*
* 스칼라 컴파일러는 지시에 따라 클래스 매니페스트를 만들어서 전달하는 코드를 자동으로 생성하는데 지시라는 말은
* 암시적 파라미터로 요청한다는 뜻이다.
* def evenElems[T](xs: Vector[T])(implicit m: ClassManifest[T]): Array[T] = ...
*
* 컨텍스트 바운드를 사용해 더 짧은 문법을 쓸 수도 있다. 타입 파라미터 뒤에 콜론과 클래스 이름을 추가하면 된다.
* 2.10.0 이후로 ClassManifest 대신에 scala.reflect.ClassTag을 쓰고 있다.
*
* 컴파일러가 Array[T]를 만들 때 타입 파라미터 T에 대한 클래스 매니페스트를 찾을 것이다.
*/
def evenElems[T: scala.reflect.ClassTag](xs: Vector[T]): Array[T] = {
val arr = new Array[T]((xs.length + 1) / 2) // cannot find class tag for element type T
for (i <- 0 until xs.length by 2)
arr(i / 2) = xs(i)
arr
} //> evenElems: [T](xs: Vector[T])(implicit evidence$2: scala.reflect.ClassTag[T
//| ])Array[T]
evenElems(Vector(1,2,3,4,5)) //> res6: Array[Int] = Array(1, 3, 5)
evenElems(Vector("this","is","a","test","run")) //> res7: Array[String] = Array(this, a, run)
/*
* 제네릭 배열 생성 시에는 클래스 매니페스트가 필요하다. 가장 쉬운 방법은 컨텍스트 바운드를 사용해 타입 파라미터를 선언하는 것이다.
*/
} | seraekim/srkim-lang-scala | src/main/java/chapter24/c24_i11.scala | Scala | bsd-3-clause | 6,429 |
/*
* Copyright (c) 2006-2007, AIOTrade Computing Co. and Contributors
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* o Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
*
* o Redistributions in binary form must reproduce the above copyright notice,
* this list of conditions and the following disclaimer in the documentation
* and/or other materials provided with the distribution.
*
* o Neither the name of AIOTrade Computing Co. nor the names of
* its contributors may be used to endorse or promote products derived
* from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
* AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO,
* THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
* PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
* CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
* EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
* PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS;
* OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY,
* WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR
* OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE,
* EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
package org.aiotrade.lib.indicator.basic
import org.aiotrade.lib.indicator.Indicator
/**
*
* @author Caoyuan Deng
*/
class MTMIndicator extends Indicator {
sname = "MTM"
lname = "Momentum"
val period = Factor("Period", 12)
val periodSmooth = Factor("Period Smoothing", 6)
val mtm = TVar[Double]("MTM", Plot.Line)
val mtm_ma = TVar[Double]("MTM_MA", Plot.Line)
protected def compute(fromIdx: Int, size: Int) {
var i = fromIdx
while (i < size) {
mtm(i) = mtm(i, C, period)
mtm_ma(i) = ma(i, mtm, periodSmooth)
i += 1
}
}
}
| wandoulabs/wandou-math | wandou-indicator-basic/src/main/scala/org/aiotrade/lib/indicator/basic/MTMIndicator.scala | Scala | apache-2.0 | 2,268 |
package org.jetbrains.sbt
import java.io.File
import javax.swing.Icon
import com.intellij.openapi.project.Project
import org.jetbrains.annotations.NotNull
import org.jetbrains.plugins.scala.buildinfo.BuildInfo
import org.jetbrains.plugins.scala.icons.Icons
/**
* @author Pavel Fatin
*/
object Sbt {
val Name = "sbt"
val FileExtension = "sbt"
val FileDescription = "sbt files"
val BuildFile = "build.sbt"
val PropertiesFile = "build.properties"
val PluginsFile = "plugins.sbt"
val ProjectDirectory = "project"
val TargetDirectory = "target"
val ModulesDirectory = ".idea/modules"
val ProjectDescription = "sbt project"
val ProjectLongDescription = "Project backed by sbt"
val BuildModuleSuffix = "-build"
val BuildModuleName = "sbt module"
val BuildModuleDescription = "sbt modules are used to mark content roots and to provide libraries for sbt project definitions"
val BuildLibraryName = "sbt-and-plugins"
val UnmanagedLibraryName = "unmanaged-jars"
val UnmanagedSourcesAndDocsName = "unmanaged-sources-and-docs"
val DefinitionHolderClasses = Seq("sbt.Plugin", "sbt.Build")
// this should be in sync with sbt.BuildUtil.baseImports
val DefaultImplicitImports = Seq("sbt._", "Process._", "Keys._", "dsl._")
val LatestVersion: String = BuildInfo.sbtLatestVersion
val Latest_0_13: String = BuildInfo.sbtLatest_0_13
lazy val Icon: Icon = Icons.SBT
lazy val FileIcon: Icon = Icons.SBT_FILE
def isProjectDefinitionFile(project: Project, file: File): Boolean = {
val baseDir = new File(project.getBasePath)
val projectDir = baseDir / Sbt.ProjectDirectory
file.getName == Sbt.BuildFile && file.isUnder(baseDir) ||
isSbtFile(file.getName) && file.isUnder(baseDir) ||
file.getName.endsWith(".scala") && file.isUnder(projectDir)
}
def isSbtFile(@NotNull filename: String): Boolean = filename.endsWith(s".${Sbt.FileExtension}")
}
| triplequote/intellij-scala | scala/scala-impl/src/org/jetbrains/sbt/Sbt.scala | Scala | apache-2.0 | 1,925 |
package view
import service.RequestCache
import twirl.api.Html
import util.StringUtil
trait AvatarImageProvider { self: RequestCache =>
/**
* Returns <img> which displays the avatar icon.
* Looks up Gravatar if avatar icon has not been configured in user settings.
*/
protected def getAvatarImageHtml(userName: String, size: Int,
mailAddress: String = "", tooltip: Boolean = false)(implicit context: app.Context): Html = {
val src = getAccountByUserName(userName).map { account =>
if(account.image.isEmpty){
s"""http://www.gravatar.com/avatar/${StringUtil.md5(account.mailAddress)}?s=${size}"""
} else {
s"""${context.path}/${userName}/_avatar"""
}
} getOrElse {
if(mailAddress.nonEmpty){
s"""http://www.gravatar.com/avatar/${StringUtil.md5(mailAddress)}?s=${size}"""
} else {
s"""${context.path}/${userName}/_avatar"""
}
}
if(tooltip){
Html(s"""<img src="${src}" class="avatar" style="width: ${size}px; height: ${size}px;" data-toggle="tooltip" title="${userName}"/>""")
} else {
Html(s"""<img src="${src}" class="avatar" style="width: ${size}px; height: ${size}px;" />""")
}
}
} | kxbmap/gitbucket | src/main/scala/view/AvatarImageProvider.scala | Scala | apache-2.0 | 1,216 |
package org.jetbrains.plugins.scala
package annotator
package quickfix
import com.intellij.codeInsight.intention.IntentionAction
import com.intellij.openapi.editor.Editor
import com.intellij.openapi.project.Project
import com.intellij.psi.PsiFile
import org.jetbrains.plugins.scala.lang.psi.api.base.ScLiteral
import org.jetbrains.plugins.scala.lang.psi.impl.ScalaPsiElementFactory
class AddLToLongLiteralFix(literal: ScLiteral) extends IntentionAction {
val getText: String = "add L to Long number"
def getFamilyName: String = "Change ScLiteral"
def startInWriteAction: Boolean = true
def isAvailable(project: Project, editor: Editor, file: PsiFile): Boolean = literal.isValid && literal.getManager.isInProject(file)
def invoke(project: Project, editor: Editor, file: PsiFile): Unit = {
if (!literal.isValid) return
val psi = ScalaPsiElementFactory.createExpressionFromText(literal.getText + "L", literal.getManager)
literal.replace(psi)
}
}
| triggerNZ/intellij-scala | src/org/jetbrains/plugins/scala/annotator/quickfix/AddLToLongLiteralFix.scala | Scala | apache-2.0 | 974 |
package collins.models
import org.squeryl.PrimitiveTypeMode._
import org.squeryl.annotations.Column
import org.squeryl.dsl.ast.BinaryOperatorNodeLogicalBoolean
import org.squeryl.dsl.ast.LogicalBoolean
import play.api.libs.json.Json
import collins.models.asset.AssetView
import collins.models.cache.Cache
import collins.models.conversions.IpmiFormat
import collins.models.shared.AddressPool
import collins.models.shared.IpAddressStorage
import collins.models.shared.IpAddressable
import collins.models.shared.Page
import collins.models.shared.PageParams
import collins.util.CryptoCodec
import collins.util.IpAddress
import collins.util.config.IpmiConfig
case class IpmiInfo(
@Column("ASSET_ID") assetId: Long,
username: String,
password: String,
gateway: Long,
address: Long,
netmask: Long,
id: Long = 0) extends IpAddressable {
override def validate() {
super.validate()
List(username, password).foreach { s =>
require(s != null && s.length > 0, "Username and Password must not be empty")
}
}
def toJsValue() = Json.toJson(this)
override def asJson: String = toJsValue.toString
override def compare(z: Any): Boolean = {
if (z == null)
return false
val ar = z.asInstanceOf[AnyRef]
if (!ar.getClass.isAssignableFrom(this.getClass))
false
else {
val other = ar.asInstanceOf[IpmiInfo]
this.assetId == other.assetId && this.gateway == other.gateway &&
this.netmask == other.netmask && this.username == other.username && this.password == other.password
}
}
def decryptedPassword(): String = IpmiInfo.decrypt(password)
def withExposedCredentials(exposeCredentials: Boolean = false) = {
if (exposeCredentials) {
this.copy(password = decryptedPassword())
} else {
this.copy(username = "********", password = "********")
}
}
}
object IpmiInfo extends IpAddressStorage[IpmiInfo] with IpAddressKeys[IpmiInfo] {
import org.squeryl.PrimitiveTypeMode._
def storageName = "IpmiInfo"
val tableDef = table[IpmiInfo]("ipmi_info")
on(tableDef)(i => declare(
i.id is (autoIncremented, primaryKey),
i.assetId is (unique),
i.address is (unique),
i.gateway is (indexed),
i.netmask is (indexed)))
def createForAsset(asset: Asset): IpmiInfo = inTransaction {
val assetId = asset.id
val username = getUsername(asset)
val password = generateEncryptedPassword()
createWithRetry(10) { attempt =>
val (gateway, address, netmask) = getNextAvailableAddress()(None)
val ipmiInfo = IpmiInfo(
assetId, username, password, gateway, address, netmask)
tableDef.insert(ipmiInfo)
}
}
def encryptPassword(pass: String): String = {
CryptoCodec.withKeyFromFramework.Encode(pass)
}
type IpmiQuerySeq = Seq[Tuple2[Enum, String]]
def findAssetsByIpmi(page: PageParams, ipmi: IpmiQuerySeq, finder: AssetFinder): Page[AssetView] = {
def whereClause(assetRow: Asset, ipmiRow: IpmiInfo) = {
where(
assetRow.id === ipmiRow.assetId and
finder.asLogicalBoolean(assetRow) and
collectParams(ipmi, ipmiRow))
}
inTransaction {
log {
val results = from(Asset.tableDef, tableDef)((assetRow, ipmiRow) =>
whereClause(assetRow, ipmiRow)
select (assetRow)).page(page.offset, page.size).toList
val totalCount = from(Asset.tableDef, tableDef)((assetRow, ipmiRow) =>
whereClause(assetRow, ipmiRow)
compute (count))
Page(results, page.page, page.offset, totalCount)
}
}
}
override def get(i: IpmiInfo): IpmiInfo = Cache.get(findByIdKey(i.id), inTransaction {
tableDef.lookup(i.id).get
})
type Enum = Enum.Value
object Enum extends Enumeration(1) {
val IpmiAddress = Value("IPMI_ADDRESS")
val IpmiUsername = Value("IPMI_USERNAME")
val IpmiPassword = Value("IPMI_PASSWORD")
val IpmiGateway = Value("IPMI_GATEWAY")
val IpmiNetmask = Value("IPMI_NETMASK")
}
def decrypt(password: String) = {
logger.debug("Decrypting %s".format(password))
CryptoCodec.withKeyFromFramework.Decode(password).getOrElse("")
}
protected def getPasswordLength(): Int = IpmiConfig.passwordLength
protected def generateEncryptedPassword(): String = {
val length = getPasswordLength()
CryptoCodec.withKeyFromFramework.Encode(CryptoCodec.randomString(length))
}
protected def getUsername(asset: Asset): String = {
IpmiConfig.genUsername(asset)
}
override protected def getConfig()(implicit scope: Option[String]): Option[AddressPool] = {
IpmiConfig.get.flatMap(_.defaultPool)
}
// Converts our query parameters to fragments and parameters for a query
private[this] def collectParams(ipmi: Seq[Tuple2[Enum, String]], ipmiRow: IpmiInfo): LogicalBoolean = {
import Enum._
val results: Seq[LogicalBoolean] = ipmi.map {
case (enum, value) =>
enum match {
case IpmiAddress =>
(ipmiRow.address === IpAddress.toLong(value))
case IpmiUsername =>
(ipmiRow.username === value)
case IpmiGateway =>
(ipmiRow.gateway === IpAddress.toLong(value))
case IpmiNetmask =>
(ipmiRow.netmask === IpAddress.toLong(value))
case e =>
throw new Exception("Unhandled IPMI tag: %s".format(e))
}
}
results.reduceRight((a, b) => new BinaryOperatorNodeLogicalBoolean(a, b, "and"))
}
}
| discordianfish/collins | app/collins/models/IpmiInfo.scala | Scala | apache-2.0 | 5,469 |
Subsets and Splits
Filtered Scala Code Snippets
The query filters and retrieves a sample of code snippets that meet specific criteria, providing a basic overview of the dataset's content without revealing deeper insights.