
text stringlengths 8 6.05M |
|---|
#!/bin/env python3
# Search algorithms
#from . import map_utils as utils
import heapq
def backtracking(parents, agent_cord, goal_cord):
path = [goal_cord]
while path[-1] != agent_cord:
path.append(parents[path[-1]])
path.reverse()
return path
def manhattan_heuristic_function(agent_cord, goal_cord):
return abs(agent_cord[0] - goal_cord[0]) + abs(agent_cord[1] - goal_cord[1])
def a_star_search(the_map, agent_cord, goal_cord, is_ghost=False):
parents = {}
explored = []
frontier = []
h_start = manhattan_heuristic_function(agent_cord, goal_cord)
heapq.heappush(frontier, (h_start, (h_start, agent_cord)))
while True:
if not frontier:
return None
current = heapq.heappop(frontier)
if current[1][1] in explored:
continue
explored.append(current[1][1])
if current[1][1] == goal_cord:
for p in parents:
parents[p] = parents[p][0]
return backtracking(parents, agent_cord, goal_cord)
adjacents = the_map.get_adjacents(current[1][1], not is_ghost)
for adj in adjacents:
if adj not in explored:
current_path_cost = current[0] - manhattan_heuristic_function(current[1][1], goal_cord)
h_adj = manhattan_heuristic_function(adj, goal_cord)
adjacent_priority = current_path_cost + 1 + h_adj
heapq.heappush(frontier, (adjacent_priority, (h_adj, adj)))
if adj not in parents or parents[adj][1] > adjacent_priority:
parents[adj] = [current[1][1], adjacent_priority]
# Unnecessary search
def breadth_first_search(the_map, agent_cord, goal_cord):
parents = {}
explored = []
frontier = [agent_cord]
while True:
if not frontier:
return None
current = frontier.pop(0)
if current in explored:
continue
explored.append(current)
if current == goal_cord:
return backtracking(parents, agent_cord, goal_cord)
adjacents = the_map.get_adjacents(current[1])
for adj in adjacents:
if adj not in explored and adj not in frontier:
frontier.append(adj)
parents[adj] = current |
'''
FileServer is a library with a file-like interface for reading and writing,
most of which is exposed by the BundleRPCServer for calling remotely.
The core method that opens files handles, open_file, is NOT exposed as an RPC
method for security reasons. Instead, alternate methods for opening files (such
as open_temp_file) are exposed by this class. These methods all return a file
uuid, which is like a Unix file descriptor.
The other methods, such as read_file, write_file, and close_file, are exposed
as RPC methods. These methods take a file uuid in addition to their regular
arguments, and they perform the requested operation on the file handle
corresponding to that uuid.
'''
import os
import tempfile
import uuid
import xmlrpclib
from codalab.lib import path_util
class FileServer(object):
def __init__(self):
# Keep a dictionary mapping file uuids to open file handles and a
# dictionary mapping temporary file's file uuids to their absolute paths.
self.file_paths = {}
self.file_handles = {}
self.delete_file_paths = {}
def open_temp_file(self, name):
'''
Open a new temp file with given |name| for writing and return a file
uuid identifying it. Put the file in a temporary directory so the file
can have the desired name.
'''
base_path = tempfile.mkdtemp('-file_server_open_temp_file')
path = os.path.join(base_path, name)
file_uuid = uuid.uuid4().hex
self.file_paths[file_uuid] = path
self.file_handles[file_uuid] = open(path, 'wb')
self.delete_file_paths[file_uuid] = base_path
return file_uuid
def manage_handle(self, handle):
'''
Take a handle to manage and return a file uuid identifying it.
'''
file_uuid = uuid.uuid4().hex
self.file_handles[file_uuid] = handle
return file_uuid
def read_file(self, file_uuid, num_bytes=None):
'''
Read up to num_bytes from the given file uuid. Return an empty buffer
if and only if this file handle is at EOF.
'''
file_handle = self.file_handles[file_uuid]
return xmlrpclib.Binary(file_handle.read(num_bytes))
def write_file(self, file_uuid, buffer):
'''
Write data from the given binary data buffer to the file uuid.
'''
file_handle = self.file_handles[file_uuid]
file_handle.write(buffer.data)
def close_file(self, file_uuid):
'''
Close the given file uuid.
'''
file_handle = self.file_handles[file_uuid]
file_handle.close()
def finalize_file(self, file_uuid):
'''
Remove the record from the file server.
'''
self.file_paths.pop(file_uuid, None)
self.file_handles.pop(file_uuid, None)
path = self.delete_file_paths.pop(file_uuid, None)
if path:
path_util.remove(path)
|
#!/usr/bin/python
import numpy as np
import pylab as py
from COMMON import grav, light, hub0, yr, mpc, msun, week, h0, omm, omv
import COMMON as CM
from Formulas_AjithEtAl2008 import apar, bpar, cpar, xpar, ypar, zpar, kpar
import Formulas_AjithEtAl2008 as A8
from scipy import interpolate
factor=1.
detector='ALIGO'
tobs=0.05
mch=1.
m=mch*2.**(1./5.)
nu=1./4.
mtot=2.*m
fbins=1000
finteg=100
z=np.array([2.])
zall=np.linspace(0.01,20.,100)
snrall=np.zeros(len(zall))
def htilde_f(nu, mtot, z, lumdist, fvec):
''''''
mch=nu**(3./5.)*mtot
fmer=A8.f_mer(nu, mtot)*1./(1.+z)
frin=A8.f_rin(nu, mtot)*1./(1.+z)
fcut=A8.f_cut(nu, mtot)*1./(1.+z)
fsig=A8.f_sig(nu, mtot)*1./(1.+z)
camp=CM.htilde_f(mch, z, lumdist, fmer)
aeff=np.zeros(np.shape(fvec))
selecti=(fvec<fmer)
aeff[selecti]+=A8.aeff_low(fvec[selecti], fmer, camp)
selecti=(fvec>=fmer)&(fvec<frin)
aeff[selecti]+=A8.aeff_mid(fvec[selecti], fmer, camp)
selecti=(fvec>=frin)&(fvec<fcut)
aeff[selecti]+=A8.aeff_upp(fvec[selecti], fmer, frin, fsig, camp)
return aeff
def snr_mat_f(mchvec, reds, lum_dist, fmin, fmax, fvec, finteg, tobs, sn_f):
''''''
mch_fmat=np.transpose(np.tile(mchvec, (len(reds), len(fvec), finteg, 1) ), axes=(0,3,1,2))
z_fmat=np.transpose(np.tile(reds, (len(mchvec), len(fvec), finteg, 1) ),axes=(3,0,1,2))
f_fmat=np.transpose(np.tile(fvec, (len(reds), len(mchvec), finteg, 1) ), axes=(0,1,3,2))
finteg_fmat=np.transpose(np.tile(np.arange(finteg), (len(reds), len(mchvec), len(fvec), 1) ), axes=(0,1,2,3))
stshape=np.shape(z_fmat) #Standard shape of all matrices that I will use.
DL_fmat=np.transpose(np.tile(lum_dist, (len(mchvec), len(fvec), finteg, 1) ),axes=(3,0,1,2)) #Luminosity distance in Mpc.
flim_fmat=A8.f_cut(1./4., 2.*mch_fmat*2.**(1./5.))*1./(1.+z_fmat) #The symmetric mass ratio is 1/4, since I assume equal masses.
flim_det=np.maximum(np.minimum(fmax, flim_fmat), fmin) #The isco frequency limited to the detector window.
tlim_fmat=CM.tafter(mch_fmat, f_fmat, flim_fmat, z_fmat)
#By construction, f_mat cannot be smaller than fmin or larger than fmax (which are the limits imposed by the detector).
fmin_fmat=np.minimum(f_fmat, flim_det) #I impose that the minimum frequency cannot be larger than the fisco.
fmaxobs_fmat=flim_det.copy()
#fmaxobs_fmat=fmin_fmat.copy()
fmaxobs_fmat[tobs<tlim_fmat]=CM.fafter(mch_fmat[tobs<tlim_fmat], z_fmat[tobs<tlim_fmat], f_fmat[tobs<tlim_fmat], tobs)
fmax_fmat=np.minimum(fmaxobs_fmat, flim_det) #The maximum frequency (after an observation tobs) cannot exceed fisco or the maximum frequency of the detector.
integconst=(np.log10(fmax_fmat)-np.log10(fmin_fmat))*1./(finteg-1)
finteg_fmat=fmin_fmat*10**(integconst*finteg_fmat)
sn_vec=sn_f(fvec)##########
sn_fmat=sn_f(finteg_fmat) #Noise spectral density.
#htilde_fmat=A8.htilde_f(1./4., 2.*mch_fmat*2**(1./5.), z_fmat, DL_fmat, f_fmat)
htilde_fmat=A8.htilde_f(1./4., 2.*mch_fmat*2**(1./5.), z_fmat, DL_fmat, finteg_fmat)
#py.loglog(finteg_fmat[0,0,:,0],htilde_fmat[0,0,:,0]**2.)
#py.loglog(finteg_fmat[0,0,:,0],sn_fmat[0,0,:,0])
snrsq_int_fmat=4.*htilde_fmat**2./sn_fmat #Integrand of the S/N square.
snrsq_int_m_fmat=0.5*(snrsq_int_fmat[:,:,:,1:]+snrsq_int_fmat[:,:,:,:-1]) #Integrand at the arithmetic mean of the infinitesimal intervals.
df_fmat=np.diff(finteg_fmat, axis=3) #Infinitesimal intervals.
snr_full_fmat=np.sqrt(np.sum(snrsq_int_m_fmat*df_fmat,axis=3)) #S/N as a function of redshift, mass and frequency.
fopt=fvec[np.argmax(snr_full_fmat, axis=2)] #Frequency at which the S/N is maximum, for each pixel of redshift and mass.
snr_opt=np.amax(snr_full_fmat, axis=2) #Maximum S/N at each pixel of redshift and mass.
snr_min=snr_full_fmat[:,:,0]
return snr_opt
for zeti in xrange(len(zall)):
z=np.array([zall[zeti]])
DL=CM.comdist(z)*(1.+z) #Luminosity distance in Mpc.
fvecd, sn=CM.detector_f(detector, factor)
sn_f=interpolate.interp1d(fvecd,sn)
fmin=min(fvecd)*1.000001
fmax=max(fvecd)*0.99999
fvec=np.logspace(np.log10(fmin), np.log10(fmax), fbins)
sred=sn_f(fvec)
htilde=htilde_f(nu, mtot, z, DL, fvec)
integrand=4.*htilde**2./sred
#py.loglog(fvec,integrand)
snr=np.sqrt(np.trapz(integrand,fvec))
snrmat=snr_mat_f(np.array([mch]), z, DL, fmin, fmax, fvec, finteg, tobs, sn_f)
snrall[zeti]=snrmat
py.ion()
#py.loglog(fvec, htilde**2.)
#py.loglog(fvec,sred)
py.loglog(zall, snrall)
raw_input('enter')
integrand=4.*htilde**2./sred
#py.loglog(fvec,integrand)
snr=np.sqrt(np.trapz(integrand,fvec))
snrmat=snr_mat_f(np.array([mch]), z, DL, fmin, fmax, fvec, finteg, tobs, sn_f)
print snr
print snrmat
print np.sqrt(np.sum(integrand[:-1]*np.diff(fvec)))
exit()
mvec=np.logspace(-11.,1.,100) #Vector of total mass.
nueq=1./4. #nu for equal masses.
fmervec=A8.f_mer(nueq, mvec)
frinvec=A8.f_rin(nueq,mvec)
flsovec=CM.felso(mvec*0.5, mvec*0.5)
#print fmervec*1./flsovec
#print frinvec*1./flsovec
#py.loglog(mvec, flsovec)
#py.loglog(mvec, fmervec)
#py.loglog(mvec, frinvec)
#raw_input('enter')
xmat=np.tile(xpar, (len(fvec),1))
ymat=np.tile(xpar, (len(fvec),1))
zmat=np.tile(xpar, (len(fvec),1))
kmat=np.tile(kpar, (len(fvec),1))
fmat=np.transpose(np.tile(fvec, (len(xpar),1)),axes=(1,0))
nu=A8.nu_f(m1,m2)
mtot=m1+m2
mch=CM.mchirp(m1, m2)
t0=0.017
phi0=0.
#pvec=phase_eff(nu, mtot, t0, phi0, fmat, xmat, ymat, zmat, kmat)
pvec=A8.phase_eff(nu, mtot, t0, phi0, fvec)
pvecold=CM.phase_f(mch, 0., 0., fvec)
fmer=A8.f_mer(nu, mtot)
frin=A8.f_rin(nu, mtot)
fcut=A8.f_cut(nu, mtot)
fsig=A8.f_sig(nu, mtot)
flso=CM.felso(m1,m2)
print
print fmer
print flso
py.ion()
fcomp=1.*flso
#tmer=tafter(nu, mtot, t0, xmat, ymat, zmat, kmat, fmer, fmat)
tmer=abs(A8.tafter(nu, mtot, t0, fcomp, fvec))###########
#Compare this to the typical (inspiral only) calculation.
#tmerold=np.zeros(len(fvec))
#tmerold[fvec<flso]=CM.tafter(mch, fvec, flso, 0)
tmerold=CM.tafter(mch, fvec, fcomp, 0)
#tcoalold=np.zeros(len(fvec))
print
py.clf()
py.loglog(fvec, tmer*1.8)
py.loglog(fvec, tmerold)
raw_input('enter')
py.clf()
py.subplot(2,1,1)
py.loglog(fvec, abs(pvec))
#py.loglog(fvec, abs(pvecold))
py.subplot(2,1,2)
fvec_low=np.zeros(len(fvec))
fvec_mid=np.zeros(len(fvec))
fvec_upp=np.zeros(len(fvec))
fvec_low[fvec<fmer]=fvec[fvec<fmer]
fvec_mid[(fmer<=fvec)&(fvec<frin)]=fvec[(fmer<=fvec)&(fvec<frin)]
fvec_upp[(frin<=fvec)&(fvec<fcut)]=fvec[(frin<=fvec)&(fvec<fcut)]
camp=A8.c_amp(nu, mtot, dist, fmer)
alow=np.zeros(len(fvec))
amid=np.zeros(len(fvec))
aupp=np.zeros(len(fvec))
alow[fvec_low>0]=A8.aeff_low(fvec_low[fvec_low>0], fmer, camp)
amid[fvec_mid>0]=A8.aeff_mid(fvec_mid[fvec_mid>0], fmer, camp)
aupp[fvec_upp>0]=A8.aeff_upp(fvec_upp[fvec_upp>0], fmer, frin, fsig, camp)
aeff=alow+amid+aupp
wave=aeff*np.cos(pvec)
#py.plot(fvec, wave)
py.loglog(fvec, aeff)
#py.plot(fvec, pvec)
raw_input('enter')
|
#build watershed image set
#last update 4/23/2014
import urllib
widList = [1, 2, 3, 4, 5, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 76, 77, 78, 79, 80, 81, 82, 83, 84]
# 75 was deleted due to a change in the watershed dataset
for wid in widList:
fileTemplate = "C:/OSGeo4w/apps/watershed/output/wshd_" + str(wid) + ".png"
urlTemplate = "http://127.0.0.1:8080/cgi-bin/mapserv.exe?map=/OSGeo4w/apps/watershed/mapfiles/ws-new-images.map&mode=map&wid=" + str(wid)
urllib.urlretrieve(urlTemplate,fileTemplate)
print "Done" |
from flask import Flask, g, render_template, request, send_from_directory
from sounds import controller as c_sounds
from sounds.model import sounds_dir
from helpers import languages
import sqlite3
import os
app = Flask(__name__)
@app.route('/', methods=['GET'])
def index():
return render_template('index.html', languages=languages.sort_by_value())
@app.route('/sounds', methods=['POST'])
@app.route('/sounds/<idd>', methods=['GET'])
def sounds(idd=None):
if request.method == 'GET':
return c_sounds.get_sound(idd)
elif request.method == 'POST':
return c_sounds.create()
@app.route('/results', methods=['GET'])
def results():
if request.method == 'GET':
return render_template('results.html')
@app.route('/static/sounds/<path:filename>', methods=['GET'])
def download_sound(filename):
return send_from_directory(sounds_dir, filename.encode('utf-8'), as_attachment=True)
current_dir = os.path.abspath(os.path.dirname(__file__))
DATABASE = os.path.join(current_dir, 'sounds.db')
def connect_db():
return sqlite3.connect(DATABASE)
def get_db():
db = getattr(g, 'db', None)
if db is None:
db = g._database = connect_db()
return db
@app.before_request
def before_request():
g.db = get_db()
@app.teardown_appcontext
def close_connection(exception):
db = getattr(g, 'db', None)
if db is not None:
db.close()
if __name__ == '__main__':
app.run(debug=True)
|
#!/usr/bin/env python3
import sys
import math
try:
fp= open("input.txt","r")
fuel= 0
part1_fuel=0
lines= fp.readlines()
for l in lines:
try:
i= int(l.strip())
new_fuel= math.floor(i/3)-2
fuel+= new_fuel
part1_fuel+= new_fuel
while new_fuel >= 9:
new_fuel= math.floor(new_fuel/3)-2
fuel+= new_fuel
except Exception as e:
print(str(e)+" Unexpected non int " + l)
sys.exit()
print(part1_fuel,fuel)
finally:
fp.close()
|
from PIL import Image
from scipy import misc
from keras.constraints import maxnorm
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, Dropout, MaxPooling2D
import matplotlib.image as mpimg
import numpy as np
import tensorflow as tf
import cv2
import os
"""
Data collection and preprocessing
"""
# An array containing the possible classifications
class_names = ['drawings', 'engraving', 'iconography', 'painting', 'sculpture']
# Collects image data and label pairs from a specified directory
def collect_data(img_dir):
x = []
y = []
class_count = 0
classes = os.listdir(img_dir)
for image_class in classes:
imgs = os.listdir(img_dir + "\\" + image_class)
for image in imgs:
img = cv2.imread(img_dir + "\\" + image_class + "\\" + image)
img = cv2.resize(img, (64,64))
x.append(img)
y.append(class_count)
class_count += 1
return [x,y]
# Raw training data parsed from images
training_data = collect_data("Images")
train_x = training_data[0]
train_y = training_data[1]
# Final numpy arrays for training
training_images = np.array(train_x) / 255.0
training_labels = np.array(train_y)
# Raw testing data parsed from images
testing_data = collect_data("Validation_Images")
test_x = testing_data[0]
test_y = testing_data[1]
# Final numpy arrays for testing
testing_images = np.array(test_x)
testing_labels = np.array(test_y)
# Prints shape of training data
print("Shape of training data:")
print(training_images.shape)
print(training_labels.shape)
"""
Keras model creation, data training, and testing
"""
# Creates a location to save training checkpoints along with the model
cp_path = "Trained_Model\\cp.ckpt"
cp_dir = os.path.dirname(cp_path)
# Establishes the checkpoint callback for saving the model in parts
cp_callback = tf.keras.callbacks.ModelCheckpoint(cp_path, save_weights_only=True, verbose=1)
# Creates a Sequential tensorflow neural network under the keras framework
model = Sequential()
# Adding layers to the model
model.add(Conv2D(32, (3, 3), input_shape=(64, 64, 3), padding='same', activation='relu', kernel_constraint=maxnorm(3)))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', kernel_constraint=maxnorm(3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu', kernel_constraint=maxnorm(3)))
model.add(Dense(5, activation='softmax'))
# Compiles the model together, the last step to establishing the neural network
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Trains the values
model.fit(training_images, training_labels, epochs=10, batch_size=32, shuffle=True, callbacks=[cp_callback])
# Evaluates the testing samples
test_loss, test_acc = model.evaluate(testing_images, testing_labels, verbose=0)
print("Test accuracy:", test_acc)
print("Test loss:", test_loss)
predictions = model.predict(testing_images)
print(predictions[0])
print(class_names[np.argmax(predictions[0])])
print("Saving model to 'Trained_Model\\model.h5'")
model.save("Trained_Model\\model.h5")
print("Done!") |
from flask import Blueprint, redirect, render_template, url_for, flash, session, request
from .__init__ import db
roles = Blueprint('roles', __name__, template_folder='templates', static_folder='static')
@roles.route('/roles/edit')
def editRoles():
if not session:
return redirect(url_for('auth.login'))
cur = db.connection.cursor()
cur.execute('call getProfile(%s)', [session['id']])
profileInfo = cur.fetchone()
if profileInfo[5] != "Administrativo":
flash('No se tienen los permisos suficientes para acceder a esta página', 'alert')
return redirect(url_for('main.index'))
cur.execute('call getRoleless')
roleless = cur.fetchall()
cur.close()
return render_template('rolesEdit.html',roleless=roleless, search='')
@roles.route('/roles/edit', methods=['POST'])
def editRolesPost():
print(session)
cedula = request.form['cedula']
cur = db.connection.cursor()
cur.execute('call getRolelessSearch(%s)', [cedula])
roleless = cur.fetchall()
cur.close()
return render_template('rolesEdit.html',roleless=roleless, search=cedula, session=session)
@roles.route('/roles/giveRole')
def giveRole():
if not session:
return redirect(url_for('auth.login'))
cedula = request.args.get('cedula')
cur = db.connection.cursor()
cur.execute('call getProfile(%s)', [cedula])
profileInfo = cur.fetchone()
return render_template('giveRole.html', profileInfo=profileInfo)
@roles.route('/roles/giveRole', methods=['POST'])
def giveRolePost():
cedula = request.args.get('cedula')
rol = request.form['rol']
cur = db.connection.cursor()
cur.execute('call giveRole(%s,%s)', [cedula,rol])
db.connection.commit()
cur.close()
return redirect(url_for('roles.roleFiller',cedula=cedula, rol=rol))
@roles.route('/roles/roleFiller')
def roleFiller():
if not session:
return redirect(url_for('auth.login'))
cedula = request.args.get('cedula')
rol = request.args.get('rol')
cur = db.connection.cursor()
cur.execute('select nombre from perfiles where cedula = %s', [cedula])
nombre = cur.fetchone()
# Queries para el médico Especialidades y Horarios
if rol == 'Médico':
cur.execute('call getEspec()')
especialidades = cur.fetchall()
cur.execute('call getSchedule()')
horarios = cur.fetchall()
cur.close()
return render_template('roleFiller.html', cedula=cedula, nombre=nombre, rol=rol, especialidades=especialidades, horarios=horarios)
elif rol == 'Enfermero' or rol == 'Ingeniero' or rol == 'Servicios' or rol == 'Administrativo':
cur.execute('call getSchedule()')
horarios = cur.fetchall()
cur.close()
return render_template('roleFiller.html', cedula=cedula, nombre=nombre, rol=rol, horarios=horarios)
elif rol == 'Paciente':
cur.execute('select * from EPS')
eps = cur.fetchall()
cur.close()
return render_template('roleFiller.html', cedula=cedula, nombre=nombre, rol=rol, eps=eps)
# This literally, should never happen, if so, be scared.
return render_template('roleFiller.html', cedula=cedula, rol=rol)
@roles.route('/roles/roleFiller', methods=['POST'])
def roleFillerPost():
cedula = request.args.get('cedula')
print(cedula)
cur = db.connection.cursor()
if request.args.get('rol') == 'Médico':
especialidad = request.form['especialidad']
horario = request.form['horario']
cur.execute('call getMedicProfile(%s)',[cedula])
doubleChecker = cur.fetchall()
if len(doubleChecker) != 0:
cur.execute('update medico set idEspecialidad=%s, idHorario=%s where cedula==%s', [especialidad,horario,cedula])
flash('Médico actualizado correctamente', 'ok')
else:
cur.execute('insert into medico (cedula,idEspecialidad,idHorario) values (%s,%s,%s)',[cedula,especialidad,horario])
flash('Médico creado correctamente', 'ok')
db.connection.commit()
elif request.args.get('rol') == 'Enfermero':
horario = request.form['horario']
cur.execute('call getNurseProfile(%s)',[cedula])
doubleChecker = cur.fetchall()
if len(doubleChecker) != 0:
cur.execute('update enfermeras set idHorario = %s where cedula = %s', [horario,cedula])
flash('Enfermero actualizado correctamente', 'ok')
else:
cur.execute('insert into enfermeras (cedula, idHorario) values (%s,%s)', [cedula,horario])
flash('Enfermero creado correctamente', 'ok')
db.connection.commit()
elif request.args.get('rol') == 'Ingeniero':
horario = request.form['horario']
cur.execute('call getEngieProfile(%s)',[cedula])
doubleChecker = cur.fetchall()
if len(doubleChecker) != 0:
flash('Ingeniero actualizado correctamente', 'ok')
cur.execute('update ingenieros set idHorario = %s where cedula = %s', [horario,cedula])
else:
flash('Ingeniero creado correctamente', 'ok')
cur.execute('insert into ingenieros (cedula, idHorario) values (%s,%s)', [cedula,horario])
db.connection.commit()
elif request.args.get('rol') == 'Servicios':
horario = request.form['horario']
cur.execute('call getSerGenProfile(%s)',[cedula])
doubleChecker = cur.fetchall()
if len(doubleChecker) != 0:
cur.execute('update serviciosGenerales set idHorario = %s where cedula = %s', [horario,cedula])
flash('Personal de servicios generales actualizado correctamente', 'ok')
else:
cur.execute('insert into serviciosGenerales (cedula, idHorario) values (%s,%s)', [cedula,horario])
flash('Personal de servicios generales creado correctamente', 'ok')
db.connection.commit()
elif request.args.get('rol') == 'Administrativo':
horario = request.form['horario']
area = request.form['area']
cur.execute('call getAdminProfile(%s)',[cedula])
doubleChecker = cur.fetchall()
if len(doubleChecker) != 0:
cur.execute('update administrativos set idHorario = %s where cedula = %s', [horario,cedula])
flash('Administrativo actualizado correctamente', 'ok')
else:
cur.execute('insert into administrativos (cedula, idHorario,areaAsig) values (%s,%s,%s)', [cedula,horario,area])
flash('Administrativo creado correctamente', 'ok')
db.connection.commit()
elif request.args.get('rol') == 'Paciente':
eps = request.form['eps']
peso = request.form['peso']
cur.execute('call getPatientProfile(%s)',[cedula])
doubleChecker = cur.fetchall()
if len(doubleChecker) != 0:
cur.execute('update pacientes set idEPS = %s, peso = %s where cedula = %s', [eps,peso,cedula])
flash('Paciente actualizado correctamente', 'ok')
else:
cur.execute('insert into pacientes (cedula,idEPS,peso) values (%s,%s,%s)', [cedula,eps,peso])
flash('Paciente creado correctamente', 'ok')
db.connection.commit()
cur.execute('select * from historialMedico where idHistorial = %s', [cedula])
historialMedico = cur.fetchone()
if historialMedico == None:
cur.execute('insert into historialMedico (idHistorial,fechaSubida) values (%s, curdate())',[cedula])
cur.execute('update pacientes set idHistorial = %s where cedula = %s', [cedula, cedula])
db.connection.commit()
return redirect(url_for('roles.editRoles')) |
from bitstring import ConstBitStream, ReadError
from .reporter import Reporter
# How many updates we want, 100 would be every percentage. 4 would be every 25%.
UPDATES = 100
def read(config, file_name):
"""
Read binary file into an array of unsigned integers.
:param config: dict - Config values from the config file.
:param file_name: string - The file we read from, using bitstream.
"""
# Get bit length, default to 1 byte.
bit_length = int(config.get('bits', 8))
print("Reading file {} - Splitting up in chunks of {} bits.".format(file_name, bit_length))
stream = ConstBitStream(filename=file_name)
print("Starting to read...")
reporter = Reporter(int(len(stream) / bit_length), updates=UPDATES)
return _read_read(stream, bit_length, reporter)
# return _read_cut(stream, bit_length)
def _read_cut(stream, bit_length, reporter):
"""
Testing showed that this is 3 times slower than using read. Shame.
"""
result = []
for chunk in stream.cut(bit_length):
if chunk is None:
break
result.append(chunk.uint)
reporter.report(len(result))
return result
def _read_read(stream, bit_length, reporter):
"""
Currently the faster way of reading.
"""
bform = 'uint:{}'.format(bit_length)
result = []
while True:
try:
result.append(stream.read(bform))
reporter.report(len(result))
except ReadError:
break
return result
|
# coding=utf-8
from django.core.management.base import BaseCommand, CommandError
from mulan.models import Order, OrderHistory
class Command(BaseCommand):
def handle(self, *args, **options):
if OrderHistory.objects.count() == 0:
for order in Order.objects.all():
order_history = OrderHistory( original_order = order,
created = order.created,
money = order.calc_order_total())
order_history.save() |
# -*- coding: utf-8 -*-
"""
Define image properties
@author: peter
"""
import cv2
import numpy as np
class png_gray(object):
def __init__(self, image_path, isPositive ):
self.image = cv2.imread( image_path )[:,:,0]
self.integral = self.integral_image(self.image)
self.isPositive = isPositive
# Get the integrated image to speed up region summations in later steps
def integral_image(self, image : np.ndarray ):
if type(image) != np.ndarray:
raise TypeError("Input must be numpy.ndarray")
return image.cumsum(axis=0).cumsum(axis=1) |
import sys
import string
import logging
from util import mapper_logfile
logging.basicConfig(filename=mapper_logfile, format='%(message)s',
level=logging.INFO, filemode='w')
def mapper():
'''
For this exercise, compute the average value of the ENTRIESn_hourly column
for different weather types. Weather type will be defined based on the
combination of the columns fog and rain (which are boolean values).
For example, one output of our reducer would be the average hourly entries
across all hours when it was raining but not foggy.
Each line of input will be a row from our final Subway-MTA dataset in csv format.
You can check out the input csv file and its structure below:
https://s3.amazonaws.com/content.udacity-data.com/courses/ud359/turnstile_data_master_with_weather.csv
Note that this is a comma-separated file.
This mapper should PRINT (not return) the weather type as the key (use the
given helper function to format the weather type correctly) and the number in
the ENTRIESn_hourly column as the value. They should be separated by a tab.
For example: 'fog-norain\t12345'
Since you are printing the output of your program, printing a debug
statement will interfere with the operation of the grader. Instead,
use the logging module, which we've configured to log to a file printed
when you click "Test Run". For example:
logging.info("My debugging message")
Note that, unlike print, logging.info will take only a single argument.
So logging.info("my message") will work, but logging.info("my","message") will not.
'''
# Takes in variables indicating whether it is foggy and/or rainy and
# returns a formatted key that you should output. The variables passed in
# can be booleans, ints (0 for false and 1 for true) or floats (0.0 for
# false and 1.0 for true), but the strings '0.0' and '1.0' will not work,
# so make sure you convert these values to an appropriate type before
# calling the function.
def format_key(fog, rain):
return '{}fog-{}rain'.format(
'' if fog else 'no',
'' if rain else 'no'
)
first = True
for line in sys.stdin:
data = line.strip().split(",")
if first == True:
first = False
continue
if len(data) != 22:
continue
print "{0}\t{1}".format(format_key(float(data[14]), float(data[15])), data[6])
mapper()
from util import reducer_logfile
logging.basicConfig(filename=reducer_logfile, format='%(message)s',
level=logging.INFO, filemode='w')
def reducer():
'''
Given the output of the mapper for this assignment, the reducer should
print one row per weather type, along with the average value of
ENTRIESn_hourly for that weather type, separated by a tab. You can assume
that the input to the reducer will be sorted by weather type, such that all
entries corresponding to a given weather type will be grouped together.
In order to compute the average value of ENTRIESn_hourly, you'll need to
keep track of both the total riders per weather type and the number of
hours with that weather type. That's why we've initialized the variable
riders and num_hours below. Feel free to use a different data structure in
your solution, though.
An example output row might look like this:
'fog-norain\t1105.32467557'
Since you are printing the output of your program, printing a debug
statement will interfere with the operation of the grader. Instead,
use the logging module, which we've configured to log to a file printed
when you click "Test Run". For example:
logging.info("My debugging message")
Note that, unlike print, logging.info will take only a single argument.
So logging.info("my message") will work, but logging.info("my","message") will not.
'''
riders = 0 # The number of total riders for this key
num_hours = 0 # The number of hours with this key
old_key = None
dist_counts = {}
for line in sys.stdin:
data = line.strip().split("\t")
if len(data) != 2:
continue
k,v = data
if k in dist_counts.keys():
dist_counts[k][0] += float(v)
dist_counts[k][1] += 1.0
else:
dist_counts[k] = [float(v),1.0]
for key in dist_counts.keys():
print "{0}\t{1}".format( key, dist_counts[key][0]/dist_counts[key][1])
reducer()
import sys
import string
import logging
from util import mapper_logfile
logging.basicConfig(filename=mapper_logfile, format='%(message)s',
level=logging.INFO, filemode='w')
def mapper():
"""
In this exercise, for each turnstile unit, you will determine the date and time
(in the span of this data set) at which the most people entered through the unit.
The input to the mapper will be the final Subway-MTA dataset, the same as
in the previous exercise. You can check out the csv and its structure below:
https://s3.amazonaws.com/content.udacity-data.com/courses/ud359/turnstile_data_master_with_weather.csv
For each line, the mapper should return the UNIT, ENTRIESn_hourly, DATEn, and
TIMEn columns, separated by tabs. For example:
'R001\t100000.0\t2011-05-01\t01:00:00'
Since you are printing the output of your program, printing a debug
statement will interfere with the operation of the grader. Instead,
use the logging module, which we've configured to log to a file printed
when you click "Test Run". For example:
logging.info("My debugging message")
Note that, unlike print, logging.info will take only a single argument.
So logging.info("my message") will work, but logging.info("my","message") will not.
"""
first = True
for line in sys.stdin:
data = line.strip().split(",")
if first == True:
first = False
continue
if len(data) != 22:
continue
print "{0}\t{1}\t{2}\t{3}".format(data[1], data[6], data[2], data[3])
mapper()
import sys
import logging
from util import reducer_logfile
logging.basicConfig(filename=reducer_logfile, format='%(message)s',
level=logging.INFO, filemode='w')
def reducer():
'''
Write a reducer that will compute the busiest date and time (that is, the
date and time with the most entries) for each turnstile unit. Ties should
be broken in favor of datetimes that are later on in the month of May. You
may assume that the contents of the reducer will be sorted so that all entries
corresponding to a given UNIT will be grouped together.
The reducer should print its output with the UNIT name, the datetime (which
is the DATEn followed by the TIMEn column, separated by a single space), and
the number of entries at this datetime, separated by tabs.
For example, the output of the reducer should look like this:
R001 2011-05-11 17:00:00 31213.0
R002 2011-05-12 21:00:00 4295.0
R003 2011-05-05 12:00:00 995.0
R004 2011-05-12 12:00:00 2318.0
R005 2011-05-10 12:00:00 2705.0
R006 2011-05-25 12:00:00 2784.0
R007 2011-05-10 12:00:00 1763.0
R008 2011-05-12 12:00:00 1724.0
R009 2011-05-05 12:00:00 1230.0
R010 2011-05-09 18:00:00 30916.0
...
...
Since you are printing the output of your program, printing a debug
statement will interfere with the operation of the grader. Instead,
use the logging module, which we've configured to log to a file printed
when you click "Test Run". For example:
logging.info("My debugging message")
Note that, unlike print, logging.info will take only a single argument.
So logging.info("my message") will work, but logging.info("my","message") will not.
'''
max_entries = 0
old_key = None
datetime = ''
dist_counts = {}
for line in sys.stdin:
data = line.strip().split("\t")
if len(data) != 4:
continue
k = data[0]
if k in dist_counts.keys():
if float(data[1]) >= dist_counts[k][0]:
dist_counts[k][0] = float(data[1])
dist_counts[k][1] = data[2]
dist_counts[k][2] = data[3]
else:
dist_counts[k] = [float(data[1]), data[2], data[3]]
for key in dist_counts.keys():
logging.info("{0}\t{1} {2}\t{3}".format( key, dist_counts[key][1], dist_counts[key][2], dist_counts[key][0]))
print "{0}\t{1} {2}\t{3}".format( key, dist_counts[key][1], dist_counts[key][2], dist_counts[key][0])
reducer()
|
from django.db import models
from django.contrib.auth.models import AbstractUser
# Create your models here.
############################PARA LA TABLA USUARIO EN LA BASE DE DATOS###############################
class User(AbstractUser): #A partir de ahora la tabla de usuarios para la autenticacion es esta (User) y el dia de mañana puedo añadir mas campos. #Luego en los settings de le da permiso. AUTH_USER_MODEL = 'users.User' <-- ('nombreDeLaAPP.nombreDeLaClase')
nacionalidad = models.CharField(max_length = 30, null = False, blank=True)
bio = models.CharField(max_length = 250, null = False, blank=True)
face = models.CharField(max_length = 100, null = False, blank=True)
wapp = models.CharField(max_length = 100, null = False, blank=True)
web = models.CharField(max_length = 100, null = False, blank=True)
avatar = models.ImageField('Foto de Perfil', upload_to='avatar', blank=True, null=True)
fechaModif = models.DateTimeField(auto_now=True)
fecha_creacion = models.DateField('Fecha de creación', auto_now_add = True) #auto_now = False es para que no modifique su fecha si se llega a actualizar
def __str__(self):
return self.username
|
# encoding=utf8
"""
Author: 'jdwang'
Date: 'create date: 2017-01-13'; 'last updated date: 2017-01-13'
Email: '383287471@qq.com'
Describe:
"""
from __future__ import print_function
from regex_extracting.extracting.common.regex_base import RegexBase
__version__ = '1.3'
class Brand(RegexBase):
name = '品牌'
def __init__(self, sentence):
# 要处理的输入句子
self.sentence = sentence
# region 1 初始化正则表达式
# 描述正则表达式
self.statement_regexs = [
'品牌|牌'
]
# 值正则表达式
self.value_regexs = [
'诺基亚|nokia|Nokia|NOKIA|三星|SAMSUNG|samsung|Samsung|苹果|HTC|htc|华为|联想|lenovo|Lenovo|LENOVO|\
步步高|酷派|金立|魅族|黑莓|天语|摩托罗拉|OPPO|oppo|经纬|飞利浦|小米|中兴|云台|LG|lg|TCL|tcl|华硕|海信|\
长虹|海尔|康佳|夏新|纽曼|亿通|乐派|七喜|阿尔法|富士通|Yahoo|谷歌|卡西欧|优派|技嘉|惠普|多普达|东芝|爱国者|\
明基|万利达|戴尔|中天|夏普|索尼|努比亚|锤子|LG|lg|小辣椒',
'随意|随便|都可以|其他|别的',
'好一点',
'好',
]
# endregion
super(Brand, self).__int__()
self.regex_process()
if __name__ == '__main__':
price = Brand(u'三星、诺基亚')
for info_meta_data in price.info_meta_data_list:
print('-' * 80)
print(unicode(info_meta_data))
|
import os
import sys
from src.tcp import read_request, handle_request, write_response
from src.tcp.tcp_server import create_server_socket, accept_connection
def serve_client(client_socket, cid):
child_pid = os.fork()
if child_pid:
client_socket.close()
return child_pid
request = read_request(client_socket)
if request is None:
print(f"Client #{cid} disconnected.")
return
response = handle_request(request)
write_response(client_socket, response, cid)
os._exit(0)
def reap_children(active_children):
for child_pid in active_children.copy():
child_pid, _ = os.waitpid(child_pid, os.WNOHANG)
if child_pid:
active_children.discard(child_pid)
def run_server(port=53210):
server_socket = create_server_socket(port)
cid = 0
active_children = set()
while True:
client_socket = accept_connection(server_socket, cid)
child_id = serve_client(client_socket, cid)
active_children.add(child_id)
reap_children(active_children)
cid += 1
if __name__ == '__main__':
run_server(port=int(sys.argv[1]))
|
#!/usr/bin/python
import fractions
den = 1
nom = 1
for i in range(1, 10):
for j in range(1, i):
for k in range(1, j):
if (k * 10 + i) * j == k * (i * 10 + j):
den *= j
nom *= k
print(den / fractions.gcd(nom, den))
|
from MSLLib.MSL import run
run("""
COM This is a simple calculator
COM Take user input for the math
GET math Type the math equasion you want to solve:
COM Calculate the equasion and store it in the "$&maths" variable
CAL outmath $&math
COM Print the equasion and the answer
PRL $&math = $&outmath!
""") |
../../Integrate-Exp-Data.py |
from room import Room
from secrets import Secrets
from decision import Decision
from challenge import Challenge
from randomiser import Random
import yaml, os
class Scenario(object):
def __init__(self, name, image=None, text = None):
self.rooms = {}
self.name = name
self.image = image
self.text = text
self.starts = []
import inflection
self.title = inflection.titleize(name)
def add_room(self, room):
self.rooms[room.name] = room
def room(self, room):
return self.rooms[room]
def add_start(self, name):
self.starts.append(self.rooms[name])
@staticmethod
def from_data():
data = yaml.load(open(os.path.join(
os.path.dirname(os.path.dirname(__file__)),
'scenario','data.yaml')))
scenario = Scenario(data['name'],
data.get('image'),
data.get('text'))
for name, roomd in data['rooms'].items():
room= Room(name,
roomd.get('text'),
roomd.get('title'),
roomd.get('image', scenario.image)
)
scenario.add_room(room)
for name in data['start']:
scenario.add_start(name)
for name, roomd in data['rooms'].items():
room = scenario.room(name)
if 'exits' in roomd:
obstacle = Decision(
roomd['exits']
)
if 'cards' in roomd:
obstacle = Challenge(
roomd['success'],
roomd['fail'],
roomd['cards'],
roomd.get('timer',5),
roomd.get('boni',[])
)
if 'requirements' in roomd:
obstacle = Secrets(
roomd['success'],
roomd['fail'],
roomd['requirements'],
roomd.get('special',{}),
roomd.get('failtext',""),
roomd.get('failcontinue',"")
)
if 'random' in roomd:
obstacle = Random(
roomd['prompt'],
roomd['random']
)
room.add_obstacle(obstacle)
return scenario
scenario = Scenario.from_data() |
from string import join
from datetime import datetime
def get_between(string, sep1, sep2):
tmp = string.split(sep1)[1]
return tmp.split(sep2)[0]
ids = file('ids.txt', 'r')
names = file('titles.txt', 'r')
times = file('times.txt', 'r')
outf = file('edges.csv', 'w')
for iline in ids:
nameline = names.readline()
timeline = times.readline()
lines = (iline, nameline, timeline)
_id, _name, timestr = [get_between(l, '>', '<') for l in lines]
dttime = (datetime.strptime(timestr, '%Y-%m-%dT%H:%M:%SZ'))
_time = dttime.strftime('%s')
combline = join([_id, _name, _time, '\n'], ',')
outf.write(combline)
[f.close() for f in (ids, names, outf)]
|
from folium import Marker
from sunnyday import Weather
from geopy.distance import geodesic
from geopy.geocoders import Nominatim
class Address:
def __init__(self, area, zone, city, country='India'):
self.area = area
self.zone = zone
self.city = city
self.country = country
def coord(self):
nom = Nominatim(user_agent="Mozilla/5.0")
address = f"{self.area+', '+self.zone+', '+self.city+', '+self.country}"
loc = nom.geocode(address)
return loc
class GeoLoc(Marker):
def __init__(self, lat, long):
# Inheriting the parent(Marker) class
super().__init__(location=[lat, long])
self.lat = lat
self.long = long
def weather(self):
# Calculates the weather
weather = Weather(apikey="586f3825fb98b38d0c5719a3f11dc995", lat=self.lat, lon=self.long)
return weather.next_12h_simplified()
# Calculates the distance
def distance(loc1, loc2):
return geodesic(loc1, loc2)
|
# coding=utf-8
import os
import sys
import unittest
from time import sleep
from selenium import webdriver
from selenium.common.exceptions import NoAlertPresentException, NoSuchElementException
sys.path.append(os.environ.get('PY_DEV_HOME'))
from webTest_pro.common.initData import init
from webTest_pro.common.model.baseActionAdd import user_login, \
add_cfg_jpks
from webTest_pro.common.model.baseActionDel import del_cfg_jpks
from webTest_pro.common.model.baseActionSearch import search_cfg_jpks
from webTest_pro.common.model.baseActionModify import update_ExcellentClassroom
from webTest_pro.common.logger import logger, T_INFO
reload(sys)
sys.setdefaultencoding("utf-8")
loginInfo = init.loginInfo
hdk_lesson_cfgs = [{'name': u'互动课模板'}, {'name': u'互动_课模板480p'}]
jp_lesson_cfgs = [{'name': u'精品课'}, {'name': u'精品_课480p'}]
conference_cfgs = [{'name': u'会议'}, {'name': u'会_议480p'}]
speaker_lesson_cfgs = [{'name': u'主讲下课'}, {'name': u'主讲_下课_1'}]
listener_lesson_cfgs = [{'name': u'听讲下课'}, {'name': u'听讲_下课_1'}]
excellentClassroomData = [{'name': '720PP', 'searchName': u'精品_课480p'},
{'name': u'720精品_课480p', 'searchName': '720PP'}]
class jpkCfgsMgr(unittest.TestCase):
''''精品课模板管理'''
def setUp(self):
if init.execEnv['execType'] == 'local':
T_INFO(logger,"\nlocal exec testcase")
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(8)
self.verificationErrors = []
self.accept_next_alert = True
T_INFO(logger,"start tenantmanger...")
else:
T_INFO(logger,"\nremote exec testcase")
browser = webdriver.DesiredCapabilities.CHROME
self.driver = webdriver.Remote(command_executor=init.execEnv['remoteUrl'], desired_capabilities=browser)
self.driver.implicitly_wait(8)
self.verificationErrors = []
self.accept_next_alert = True
T_INFO(logger,"start tenantmanger...")
def tearDown(self):
self.driver.quit()
self.assertEqual([], self.verificationErrors)
T_INFO(logger,"tenantmanger end!")
def test_add_cfg_jpks(self):
'''添加精品课模板'''
print "exec:test_add_cfg_jpks..."
driver = self.driver
user_login(driver, **loginInfo)
for jp_lesson_cfg in jp_lesson_cfgs:
add_cfg_jpks(driver, **jp_lesson_cfg)
self.assertEqual(u"添加成功!", driver.find_element_by_css_selector(".layui-layer-content").text)
sleep(0.5)
print "exec:test_add_cfg_jpks success."
def test_bsearch_cfg_jpks(self):
'''查询精品课模板信息'''
print "exec:test_search_cfg_jpks"
driver = self.driver
user_login(driver, **loginInfo)
for jp_lesson_cfg in jp_lesson_cfgs:
search_cfg_jpks(driver, **jp_lesson_cfg)
self.assertEqual(jp_lesson_cfg['name'],
driver.find_element_by_xpath("//table[@id='excellentclassroomtable']/tbody/tr/td[3]").text)
print "exec: test_search_cfg_jpks success."
sleep(0.5)
def test_bupdate_cfg_jpks(self):
'''修改精品课模板信息'''
print "exec:test_bupdate_cfg_jpks"
driver = self.driver
user_login(driver, **loginInfo)
for jp_lesson_cfg in excellentClassroomData:
update_ExcellentClassroom(driver, **jp_lesson_cfg)
print "exec: test_bupdate_cfg_jpks success."
sleep(0.5)
def test_del_cfg_jpks(self):
'''删除精品课模板_确定'''
print "exec:test_del_cfg_jpks..."
driver = self.driver
user_login(driver, **loginInfo)
for jp_lesson_cfg in jp_lesson_cfgs:
del_cfg_jpks(driver, **jp_lesson_cfg)
sleep(1.5)
self.assertEqual(u"删除成功!", driver.find_element_by_css_selector(".layui-layer-content").text)
sleep(0.5)
print "exec:test_del_cfg_jpks success."
def is_element_present(self, how, what):
try:
self.driver.find_element(by=how, value=what)
except NoSuchElementException as e:
return False
return True
def is_alert_present(self):
try:
self.driver.switch_to_alert()
except NoAlertPresentException as e:
return False
return True
def close_alert_and_get_its_text(self):
try:
alert = self.driver.switch_to_alert()
alert_text = alert.text
if self.accept_next_alert:
alert.accept()
else:
alert.dismiss()
return alert_text
finally:
self.accept_next_alert = True
if __name__ == '__main__':
unittest.main()
|
# coding: utf-8
# # Tools for visualizing data
#
# This notebook is a "tour" of just a few of the data visualization capabilities available to you in Python. It focuses on two packages: [Bokeh](https://blog.modeanalytics.com/python-data-visualization-libraries/) for creating _interactive_ plots and _[Seaborn]_ for creating "static" (or non-interactive) plots. The former is really where the ability to develop _programmatic_ visualizations, that is, code that generates graphics, really shines. But the latter is important in printed materials and reports. So, both techniques should be a core part of your toolbox.
#
# With that, let's get started!
#
# > **Note 1.** Since visualizations are not amenable to autograding, this notebook is more of a demo of what you can do. It doesn't require you to write any code on your own. However, we strongly encourage you to spend some time experimenting with the basic methods here and generate some variations on your own. Once you start, you'll find it's more than a little fun!
# >
# > **Note 2.** Though designed for R programs, Hadley Wickham has an [excellent description of many of the principles in this notebook](http://r4ds.had.co.nz/data-visualisation.html).
# ## Part 0: Downloading some data to visualize
#
# For the demos in this notebook, we'll need the Iris dataset. The following code cell downloads it for you.
# In[1]:
import requests
import os
import hashlib
import io
def download(file, url_suffix=None, checksum=None):
if url_suffix is None:
url_suffix = file
if not os.path.exists(file):
url = 'https://cse6040.gatech.edu/datasets/{}'.format(url_suffix)
print("Downloading: {} ...".format(url))
r = requests.get(url)
with open(file, 'w', encoding=r.encoding) as f:
f.write(r.text)
if checksum is not None:
with io.open(file, 'r', encoding='utf-8', errors='replace') as f:
body = f.read()
body_checksum = hashlib.md5(body.encode('utf-8')).hexdigest()
assert body_checksum == checksum, "Downloaded file '{}' has incorrect checksum: '{}' instead of '{}'".format(file, body_checksum, checksum)
print("'{}' is ready!".format(file))
datasets = {'iris.csv': ('tidy', 'd1175c032e1042bec7f974c91e4a65ae'),
'tips.csv': ('seaborn-data', 'ee24adf668f8946d4b00d3e28e470c82'),
'anscombe.csv': ('seaborn-data', '2c824795f5d51593ca7d660986aefb87'),
'titanic.csv': ('seaborn-data', '56f29cc0b807cb970a914ed075227f94')
}
for filename, (category, checksum) in datasets.items():
download(filename, url_suffix='{}/{}'.format(category, filename), checksum=checksum)
print("\n(All data appears to be ready.)")
# # Part 1: Bokeh and the Grammar of Graphics ("lite")
#
# Let's start with some methods for creating an interactive visualization in Python and Jupyter, based on the [Bokeh](https://bokeh.pydata.org/en/latest/) package. It generates JavaScript-based visualizations, which you can then run in a web browser, without you having to know or write any JS yourself. The web-friendly aspect of Bokeh makes it an especially good package for creating interactive visualizations in a Jupyter notebook, since it's also browser-based.
#
# The design and use of Bokeh is based on Leland Wilkinson's Grammar of Graphics (GoG).
#
# > If you've encountered GoG ideas before, it was probably when using the best known implementation of GoG, namely, Hadley Wickham's R package, [ggplot2](http://ggplot2.org/).
# ## Setup
#
# Here are the modules we'll need for this notebook:
# In[2]:
from IPython.display import display, Markdown
import pandas as pd
import bokeh
# Bokeh is designed to output HTML, which you can then embed in any website. To embed Bokeh output into a Jupyter notebook, we need to do the following:
# In[3]:
from bokeh.io import output_notebook
from bokeh.io import show
output_notebook ()
# ## Philosophy: Grammar of Graphics
#
# [The Grammar of Graphics](http://www.springer.com.prx.library.gatech.edu/us/book/9780387245447) is an idea of Leland Wilkinson. Its basic idea is that the way most people think about visualizing data is ad hoc and unsystematic, whereas there exists in fact a "formal language" for describing visual displays.
#
# The reason why this idea is important and powerful in the context of our course is that it makes visualization more systematic, thereby making it easier to create those visualizations through code.
#
# The high-level concept is simple:
# 1. Start with a (tidy) data set.
# 2. Transform it into a new (tidy) data set.
# 3. Map variables to geometric objects (e.g., bars, points, lines) or other aesthetic "flourishes" (e.g., color).
# 4. Rescale or transform the visual coordinate system.
# 5. Render and enjoy!
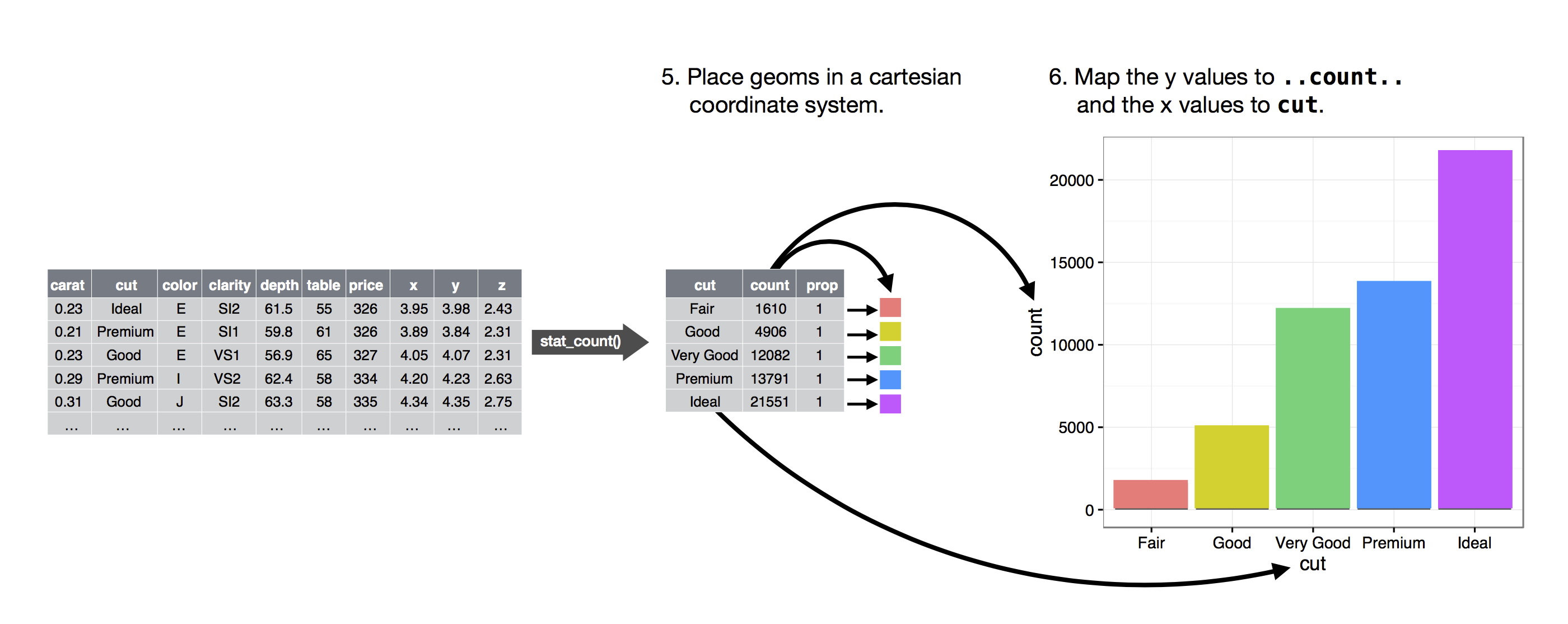
# 
#
# > This image is "liberated" from: http://r4ds.had.co.nz/data-visualisation.html
# ## HoloViews
#
# Before seeing Bokeh directly, let's start with an easier way to take advantage of Bokeh, which is through a higher-level interface known as [HoloViews](http://holoviews.org/). HoloViews provides a simplified interface suitable for "canned" charts.
#
# To see it in action, let's load the Iris data set and study relationships among its variables, such as petal length vs. petal width.
#
# The cells below demonstrate histograms, simple scatter plots, and box plots. However, there is a much larger gallery of options: http://holoviews.org/reference/index.html
# In[4]:
flora = pd.read_csv ('iris.csv')
display (flora.head ())
# In[5]:
from bokeh.io import show
import holoviews as hv
import numpy as np
hv.extension('bokeh')
# ### 1. Histogram
#
# * The Histogram(f, e) can takes two arguments, frequencies and edges (bin boundaries).
# * These can easily be created using numpy's histogram function as illustrated below.
# * The plot is interactive and comes with a bunch of tools. You can customize these tools as well; for your many options, see http://bokeh.pydata.org/en/latest/docs/user_guide/tools.html.
#
# > You may see some warnings appear in a pink-shaded box. You can ignore these. They are caused by some slightly older version of the Bokeh library that is running on Vocareum.
# In[6]:
frequencies, edges = np.histogram(flora['petal width'], bins = 5)
hv.Histogram(frequencies, edges, label = 'Histogram')
# A user can interact with the chart above using the tools shown on the right-hand side. Indeed, you can select or customize these tools! You'll see an example below.
# ### 2. ScatterPlot
# In[7]:
hv.Scatter(flora[['petal width','sepal length']],label = 'Scatter plot')
# ### 3. BoxPlot
# In[8]:
hv.BoxWhisker(flora['sepal length'], label = "Box whiskers plot")
# ## Mid-level charts: the Plotting interface
#
# Beyond the canned methods above, Bokeh provides a "mid-level" interface that more directly exposes the grammar of graphics methodology for constructing visual displays.
#
# The basic procedure is
# * Create a blank canvas by calling `bokeh.plotting.figure`
# * Add glyphs, which are geometric shapes.
#
# > For a full list of glyphs, refer to the methods of `bokeh.plotting.figure`: http://bokeh.pydata.org/en/latest/docs/reference/plotting.html
# In[9]:
from bokeh.plotting import figure
# Create a canvas with a specific set of tools for the user:
TOOLS = 'pan,box_zoom,wheel_zoom,lasso_select,save,reset,help'
p = figure(width=500, height=500, tools=TOOLS)
print(p)
# In[10]:
# Add one or more glyphs
p.triangle(x=flora['petal width'], y=flora['petal length'])
# In[11]:
show(p)
# **Using data from Pandas.** Here is another way to do the same thing, but using a Pandas data frame as input.
# In[12]:
from bokeh.models import ColumnDataSource
data=ColumnDataSource(flora)
p=figure()
p.triangle(source=data, x='petal width', y='petal length')
show(p)
# **Color maps.** Let's make a map that assigns each unique species its own color. Incidentally, there are many choices of colors! http://bokeh.pydata.org/en/latest/docs/reference/palettes.html
# In[13]:
# Determine the unique species
unique_species = flora['species'].unique()
print(unique_species)
# In[14]:
# Map each species with a unique color
from bokeh.palettes import brewer
color_map = dict(zip(unique_species, brewer['Dark2'][len(unique_species)]))
print(color_map)
# In[15]:
# Create data sources for each species
data_sources = {}
for s in unique_species:
data_sources[s] = ColumnDataSource(flora[flora['species']==s])
# Now we can more programmatically generate the same plot as above, but use a unique color for each species.
# In[16]:
p = figure()
for s in unique_species:
p.triangle(source=data_sources[s], x='petal width', y='petal length', color=color_map[s])
show(p)
# That's just a quick tour of what you can do with Bokeh. We will incorporate it into some of our future labs. At this point, we'd encourage you to experiment with the code cells above and try generating your own variations!
# # Part 2: Static visualizations using Seaborn
#
# Parts of this lab are taken from publicly available Seaborn tutorials.
# http://seaborn.pydata.org/tutorial/distributions.html
#
# They were adapted for use in this notebook by [Shang-Tse Chen at Georgia Tech](https://www.cc.gatech.edu/~schen351).
# In[17]:
import seaborn as sns
# The following Jupyter "magic" command forces plots to appear inline
# within the notebook.
get_ipython().magic('matplotlib inline')
# When dealing with a set of data, often the first thing we want to do is get a sense for how the variables are distributed. Here, we will look at some of the tools in seborn for examining univariate and bivariate distributions.
#
# ### Plotting univariate distributions
# distplot() function will draw a histogram and fit a kernel density estimate
# In[18]:
import numpy as np
x = np.random.normal(size=100)
sns.distplot(x)
# ## Plotting bivariate distributions
#
# The easiest way to visualize a bivariate distribution in seaborn is to use the jointplot() function, which creates a multi-panel figure that shows both the bivariate (or joint) relationship between two variables along with the univariate (or marginal) distribution of each on separate axes.
# In[19]:
mean, cov = [0, 1], [(1, .5), (.5, 1)]
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=["x", "y"])
# **Basic scatter plots.** The most familiar way to visualize a bivariate distribution is a scatterplot, where each observation is shown with point at the x and y values. You can draw a scatterplot with the matplotlib plt.scatter function, and it is also the default kind of plot shown by the jointplot() function:
# In[20]:
sns.jointplot(x="x", y="y", data=df)
# **Hexbin plots.** The bivariate analogue of a histogram is known as a “hexbin” plot, because it shows the counts of observations that fall within hexagonal bins. This plot works best with relatively large datasets. It’s availible through the matplotlib plt.hexbin function and as a style in jointplot()
# In[21]:
sns.jointplot(x="x", y="y", data=df, kind="hex")
# **Kernel density estimation.** It is also posible to use the kernel density estimation procedure described above to visualize a bivariate distribution. In seaborn, this kind of plot is shown with a contour plot and is available as a style in jointplot()
# In[22]:
sns.jointplot(x="x", y="y", data=df, kind="kde")
# ## Visualizing pairwise relationships in a dataset
# To plot multiple pairwise bivariate distributions in a dataset, you can use the pairplot() function. This creates a matrix of axes and shows the relationship for each pair of columns in a DataFrame. by default, it also draws the univariate distribution of each variable on the diagonal Axes:
# In[23]:
sns.pairplot(flora)
# In[24]:
# We can add colors to different species
sns.pairplot(flora, hue="species")
# ### Visualizing linear relationships
# In[25]:
tips = pd.read_csv("tips.csv")
tips.head()
# We can use the function `regplot` to show the linear relationship between total_bill and tip.
# It also shows the 95% confidence interval.
# In[26]:
sns.regplot(x="total_bill", y="tip", data=tips)
# ### Visualizing higher order relationships
# In[27]:
anscombe = pd.read_csv("anscombe.csv")
sns.regplot(x="x", y="y", data=anscombe[anscombe["dataset"] == "II"])
# The plot clearly shows that this is not a good model.
# Let's try to fit a polynomial regression model with degree 2.
# In[28]:
sns.regplot(x="x", y="y", data=anscombe[anscombe["dataset"] == "II"], order=2)
# **Strip plots.** This is similar to scatter plot but used when one variable is categorical.
# In[29]:
sns.stripplot(x="day", y="total_bill", data=tips)
# **Box plots.**
# In[30]:
sns.boxplot(x="day", y="total_bill", hue="time", data=tips)
# **Bar plots.**
# In[31]:
titanic = pd.read_csv("titanic.csv")
sns.barplot(x="sex", y="survived", hue="class", data=titanic)
# **Fin!** That ends this tour of basic plotting functionality available to you in Python. It only scratches the surface of what is possible. We'll explore more advanced features in future labs, but in the meantime, we encourage you to play with the code in this notebook and try to generate your own visualizations of datasets you care about!
#
# Although this notebook did not require you to write any code, go ahead and "submit" it for grading. You'll effectively get "free points" for doing so: the code cell below gives it to you.
# In[33]:
# Test cell: `freebie_test`
assert True
|
import loader
import pyautogui
import time
import json
import os
import distutils.dir_util
pyautogui.FAILSAFE = True
def main():
generateFiles()
generateFileProperties()
createSave()
def generateFiles():
try:
distutils.dir_util.mkpath(pathing('SaveGames'))
return False
except FileExistsError:
pass
def createSave():
try:
saveFile = False
i = 0
while False:
try:
with open(pathing('SaveGames') + f'/save{i}.json', 'w+') as f:
x = {"Pass": 0, "Cookies": 0, "Buildings": 0}
json.dump(x, f)
except FileExistsError:
i += 1
except FileExistsError:
x = pyautogui.confirm('A save file exists. Delete and reset?')
if x == 'OK':
pass
else:
print('done')
def generateFileProperties():
loader.writeLine('cookieMaker2.py properties:', 'endWOinput', 0.1)
loader.writeLine(f'File ----------> : {__file__}', 'endWOinput')
loader.writeLine(f'Access time ---> : {time.ctime(os.path.getatime(__file__))}', 'endWOinput')
loader.writeLine(f'Modified time -> : {time.ctime(os.path.getmtime(__file__))}', 'endWOinput')
loader.writeLine(f'Change time ---> : {time.ctime(os.path.getctime(__file__))}', 'endWOinput')
loader.writeLine('File size -----> : ', 'endWOinput')
loader.writeLine(f'In bytes ------> : {os.path.getsize(__file__)}', 'endWOinput')
loader.writeLine(f'In kilobytes --> : {os.path.getsize(__file__) / 1000}', 'endWOinput')
loader.writeLine(f'In megabytes --> : {os.path.getsize(__file__) / 1000000}', 'endWOinput')
loader.writeLine(f'In gigabytes --> : {os.path.getsize(__file__) / 1000000000}', 'endWOinput')
loader.writeLine(f'In terabytes --> : {os.path.getsize(__file__) / 1000000000000}', 'endWOinput')
loader.writeLine(f'In petabytes --> : {os.path.getsize(__file__) / 100000000000000}', 'endWOinput')
def pathing(option):
if option == 'dirPath':
dir_path = os.path.dirname(os.path.realpath(__file__))
return dir_path
elif option == 'SaveGames':
dir_path = os.path.dirname(os.path.realpath(__file__))
savePath = dir_path + '/SaveGames'
return savePath
if __name__ == '__main__':
main()
|
#!/usr/bin/python3
'''
DBStorage schema using SQLAlchemy and MySQL
'''
import pymongo
from pymongo import MongoClient
from models.base_model import BaseModel
import models
import os
class DBStorage:
'''
Main database storage class
'''
__collection = None
__client = None
def __init__(self):
'''
Instantiation of a database storage class
'''
self.database = os.environ.get('MONGODB_URL')
self.__client = MongoClient(self.database)
def all(self, cls=None):
'''
Queries database for specified classes
Parameters:
cls (object): the class to query
Return:
a dictionary of objects of the corresponding cls
'''
to_query = []
new_dict = {}
results = []
if cls is not None:
# Set the database collection to query
self.new(cls)
# Queries the database collection for __class__ equivalency.
# If there are matches, it loops and appends to results array.
for dic in self.__collection.find({"__class__": cls.__name__}):
results.append(models.classes[cls.__name__](**dic))
for row in results:
key = row.__class__.__name__ + '.' + row.id
new_dict[key] = row
else:
for key, value in models.classes.items():
try:
# Sets the database collection to query
self.new(value)
# If the query returns something, the class is
# appended to an array
if self.__collection.find_one({"__class__": key}):
to_query.append(models.classes[key])
except BaseException:
continue
for classes in to_query:
# Set the database collection to query
self.new(classes)
# For every object with the classname associated with the
# collection, append to the results array
for dic in self.__collection.find(
{"__class__": classes.__name__}):
results.append(models.classes[classes.__name__](**dic))
for row in results:
key = row.__class__.__name__ + '.' + row.id
new_dict[key] = row
return new_dict
def new(self, obj):
'''
Sets the MongoDB collection
Parameters:
obj (object): the object to refer to for database
table/collection
'''
self.__collection = eval("self._DBStorage__client.AdventureUs.{}"
.format(obj.collection), {"__builtins__": {}},
{'self': self})
def save(self, obj):
'''
Saves an object to MongoDB or updates it if it exists
'''
self.new(obj)
# Checks if the MongoDB _id is present:
# if not, the object is not in the database
if hasattr(obj, "_id"):
self.__collection.update_one({"id": obj.id},
{"$set": obj.to_dict_mongoid()})
else:
self.__collection.insert_one(obj.to_dict())
def delete(self, obj=None):
'''
Deletes a specified object from the database
Parameters:
obj (object): the object to delete
'''
self.new(obj)
self.__collection.delete_one({"id": obj.id})
def reload(self):
'''
Restarts the database engine session
'''
def get(self, cls, id):
'''
Gets a single instance of a particular object based on id and class
Parameters:
cls (string): the class of the object to get
id (string): the id of the object to get
'''
if cls not in models.classes.keys():
return None
self.new(models.classes[cls])
obj = self.__collection.find_one({"id": id})
if obj is None:
return None
return models.classes[cls](**obj)
def get_user(self, username):
'''
Gets a single instance of a user based on username
Parameters:
username (string): the username to pull from the database
'''
self.new(models.User)
obj = self.__collection.find_one({"username": username})
if obj is None:
return None
return models.User(**obj)
def count(self, cls=None):
'''
Counts the number of a specific class in storage or all objects
if cls variable is None
Parameters:
cls (string): the class of the objects to count
'''
count_dict = {}
if cls is None:
count_dict = self.all()
else:
if cls in models.classes.keys():
count_dict = self.all(models.classes[cls])
return len(count_dict)
|
import flask
from flask import render_template
from helpers import json_method
from standalone import get_queue_and_start
app = flask.Flask(__name__)
logger = app.logger
queue = None
@app.route('/')
def index():
global queue
if queue is None:
queue = get_queue_and_start()
return render_template('home.html')
@app.route('/move')
@json_method
def move():
messages = []
while queue.qsize() > 0:
messages.append(queue.get())
return messages
if __name__ == '__main__':
app.run()
|
n=int(input())
f=1
for x in range (n,1,-1):
f*=x
print(f)
|
from time import sleep
from enum import Enum
import napari
import numpy as np
import psygnal
from napari.qt.threading import thread_worker
BOARD_SIZE = 14
INITIAL_SNAKE_LENGTH = 4
class Direction(Enum):
UP = (-1, 0)
DOWN = (1, 0)
LEFT = (0, -1)
RIGHT = (0, 1)
class Snake:
board_update = psygnal.Signal()
nom = psygnal.Signal()
def __init__(self):
self.length = INITIAL_SNAKE_LENGTH
self.direction = Direction.DOWN
self.board = np.zeros((BOARD_SIZE, BOARD_SIZE), dtype=int)
start_position = self._random_empty_board_position
self._head_position = start_position
self.board[start_position] = 1
self.tail = self.board.copy()
self.food = np.zeros_like(self.board)
self.food[self._random_empty_board_position] = 1
def update(self):
self._head_position = self._next_head_position
if self.on_food:
self.length += 1
self._update_food()
self.nom.emit()
self.tail[self.tail > 0] += 1
self.tail[self.tail > self.length] = 0
self.tail[self._head_position] = 1
self.board = self.tail > 0
self.board_update.emit()
def _update_food(self):
self.food = np.zeros_like(self.food)
self.food[self._random_empty_board_position] = 1
@property
def direction(self):
"""not synchronised with velocity"""
return self._direction
@direction.setter
def direction(self, value: Direction):
self._velocity_ = value.value
self._direction = value
@property
def about_to_self_collide(self):
if self._next_board_value == 1:
return True
else:
return False
@property
def on_food(self):
if self.food[self._head_position] == 1:
return True
else:
return False
@property
def _head_position(self):
return self._head_position_
@_head_position.setter
def _head_position(self, value):
self._head_position_ = tuple(value)
@property
def _velocity(self):
return self._velocity_
@property
def _random_empty_board_position(self):
idx = np.where(self.board == 0)
n_idx = len(idx[0])
random_idx = np.random.randint(0, n_idx - 1, 1)
return int(idx[0][random_idx]), int(idx[1][random_idx])
@property
def _next_head_position(self):
next_position = np.array(self._head_position) + np.array(self._velocity)
next_position[next_position > (BOARD_SIZE - 1)] = 0
next_position[next_position < 0] = BOARD_SIZE - 1
return tuple(next_position)
@property
def _next_board_value(self):
return int(self.board[self._next_head_position])
viewer = napari.Viewer()
snake = Snake()
outline = np.ones((BOARD_SIZE + 2, BOARD_SIZE + 2))
outline[1:-1, 1:-1] = 0
outline_layer = viewer.add_image(outline, blending='additive', colormap='blue', translate=(-1, -1))
board_layer = viewer.add_image(snake.board, blending='additive')
food_layer = viewer.add_image(snake.food, blending='additive', colormap='red')
viewer.text_overlay.visible = True
@snake.board_update.connect
def on_board_update():
viewer.text_overlay.text = f'Score: {snake.length - INITIAL_SNAKE_LENGTH}'
board_layer.data = snake.board
food_layer.data = snake.food
@snake.nom.connect
def nom():
print('nom')
viewer.text_overlay.text = 'nom nom nom'
@viewer.bind_key('w')
def up(event=None):
snake.direction = Direction.UP
@viewer.bind_key('s')
def down(event=None):
snake.direction = Direction.DOWN
@viewer.bind_key('a')
def left(event=None):
snake.direction = Direction.LEFT
@viewer.bind_key('d')
def right(event=None):
snake.direction = Direction.RIGHT
@thread_worker(connect={"yielded": snake.update})
def update_in_background():
while True:
sleep(1/10)
if snake.about_to_self_collide:
print('game over!')
sleep(1)
snake.__init__()
yield
worker = update_in_background()
napari.run()
|
import os
from PIL import Image
def argumanetation(path, name):
label = name[-7:]
id = str(int(name[:-7])+300)
newName = id + label
img = Image.open(path+name)
img = img.transpose(Image.ROTATE_90) # rotation 90
#img = img.transpose(Image.ROTATE_180) # rotation 180
#img = img.transpose(Image.ROTATE_270) # rotation 270
# img.show("img/rotateImg.png")
img.save(path+newName)
def mirror(path, name):
label = name[-7:]
id = str(int(name[:-7])+600)
newName = id + label
img = Image.open(path+name)
img.transpose(Image.FLIP_LEFT_RIGHT).save(path+newName)
path = "./dataAndLabel/"
fileNames = os.listdir(path)
errorNames = ['117b33.jpg', '16b44.jpg', '171b55.jpg', '218g32.jpg', '254b11.jpg', '256b22.jpg', '267g23.jpg', '295g13.jpg', '37s23.jpg', '43g23.jpg', '56s23.jpg', '8g14.jpg']
rightNames = set(fileNames).difference(set(errorNames))
for name in rightNames:
# argumanetation(path, name)
mirror(path, name)
|
from django.core.cache.backends import memcached
class MemcachedCache(memcached.MemcachedCache):
def _get_memcache_timeout(self, timeout):
"""Override _get_memcache_timeout so that it accepts 0."""
if timeout == 0: return 0
else: return super(MemcachedCache, self)._get_memcache_timeout(timeout)
|
import socket
def create_command_socket(host, port):
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((host, port))
sock.listen(1)
return sock
def create_data_socket(client):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
print("Connecting to client " + client.address[0] + ":" + str(client.address[1]) + " on dataport " + str(client.data_port))
sock.connect((client.address[0], client.data_port))
return sock
|
import os
import smtplib, ssl
def send_confirmation_email(receiver_email, alumni_uuid):
port = 465 # For SSL
smtp_server = "smtp.gmail.com"
sender_email = os.getenv('SENDER_EMAIL')
password = os.getenv('EMAIL_ACCOUNT_PASSWORD')
confirmation_link = f"https://alumni-frontend.herokuapp.com/confirm/{alumni_uuid}/"
message = f"""Subject: NaUKMA Alumni service
Please, follow the link to finish your registration in NaUKMA alumni service {confirmation_link} ."""
context = ssl.create_default_context()
with smtplib.SMTP_SSL(smtp_server, port, context=context) as server:
server.login(sender_email, password)
server.sendmail(sender_email, receiver_email, message)
return
|
"""Define the command-line interface for the iterator program."""
import typer
from factorialmaker import display
from factorialmaker import factorial
def main(
# TODO: Add a typer option parameter for the --iterative command-line argument
# TODO: Set the default value of this argument to be False
# TODO: Add a typer option parameter for the "--number" command-line argument
# TODO: set the min of this to be 1, the max to be 20, and the default to be 5
):
"""Compute sequence of factorial numbers with iteration or recursion."""
# display the debugging output for the program's command-line arguments
typer.echo("")
typer.echo(
f"Calculating {number}! and returning all numbers in the computation of {number}! 🛫"
)
typer.echo("")
typer.echo(
f" Should I use an iterative function? {display.convert_bool_to_answer(iterative)}"
)
typer.echo("")
# compute the sequence of factorial numbers and the value of number! using iteration
if iterative is True:
typer.echo(" Here is the output from the iterative function.")
typer.echo("")
# TODO: call the factorial.factorial_iterative function for the provided number
# TODO: make sure to collect the tuple output that contains the computed
# factorial ordered pair and the list of computed factorials in ordered pairs
# TODO: refer to the test cases to learn more about the output format
# TODO: make sure to reformat this function call using the Black code formatter
# developed by the Python software foundation
# use different approaches to display the result of the computation
display.display_factorial_list(computed_factorials, " ")
display.display_factorial_unpack(computed_factorials, " ")
# TODO: Also display the computed factorial pair as the last output
typer.echo("")
# display a final message and some extra spacing
typer.echo("Wow, computing factorial numbers is demanding! 😂")
typer.echo("")
if __name__ == "__main__":
typer.run(main)
|
# Generated by Django 2.2.4 on 2019-08-24 10:46
from django.db import migrations, models
import django.db.models.deletion
class Migration(migrations.Migration):
initial = True
dependencies = [
('residents', '0001_initial'),
]
operations = [
migrations.CreateModel(
name='IPCamera',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('url', models.CharField(max_length=255)),
('type', models.CharField(choices=[('EF', 'Entry Front Camera'), ('EB', 'Entry Back Camera'), ('IC', 'IC Camera'), ('XF', 'Exit Front Camera'), ('XB', 'Exit Back Camera'), ('FC', 'Face Camera')], default='EF', max_length=2)),
('area', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='residents.Area')),
('community', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='residents.Community')),
],
options={
'verbose_name_plural': 'IP Camera Settings',
},
),
migrations.CreateModel(
name='Boomgate',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('url', models.CharField(max_length=255)),
('type', models.CharField(choices=[('E', 'Entry Boomgate'), ('X', 'Exit Boomgate')], default='E', max_length=2)),
('area', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='residents.Area')),
('community', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='residents.Community')),
],
options={
'verbose_name_plural': 'Boomgate Settings',
},
),
]
|
def solution(N, stages):
answer = []
player = len(stages)
for i in range(1, N + 1):
if player == 0:
answer.append([i, 0.0])
else:
answer.append([i, stages.count(i) / player])
player -= stages.count(i)
answer.sort(key=lambda x: -x[1])
return [answer[i][0] for i in range(len(answer))] |
# Copyright (C) 2012-2013 Claudio Guarnieri.
# Copyright (C) 2014-2018 Cuckoo Foundation.
# This file is part of Cuckoo Sandbox - http://www.cuckoosandbox.org
# See the file 'docs/LICENSE' for copying permission.
def has_com_exports(exports):
com_exports = [
"DllInstall",
"DllCanUnloadNow",
"DllGetClassObject",
"DllRegisterServer",
"DllUnregisterServer",
]
for name in com_exports:
if name not in exports:
return False
return True
def choose_package(file_type, file_name, exports):
"""Choose analysis package due to file type and file extension.
@param file_type: file type.
@param file_name: file name.
@return: package name or None.
"""
if not file_type:
return None
file_name = file_name.lower()
if "DLL" in file_type:
if file_name.endswith(".cpl"):
return "cpl"
elif has_com_exports(exports):
return "com"
else:
return "dll"
elif "PE32" in file_type or "MS-DOS" in file_type:
return "exe"
elif "PDF" in file_type or file_name.endswith(".pdf"):
return "pdf"
elif file_name.endswith(".pub"):
return "pub"
elif "Hangul (Korean) Word Processor File 5.x" in file_type or file_name.endswith(".hwp"):
return "hwp"
elif "Rich Text Format" in file_type or \
"Microsoft Word" in file_type or \
"Microsoft Office Word" in file_type or \
file_name.endswith((".doc", ".docx", ".rtf", ".docm")):
return "doc"
elif "Microsoft Office Excel" in file_type or \
"Microsoft Excel" in file_type or \
file_name.endswith((".xls", ".xlsx", ".xlt", ".xlsm", ".iqy", ".slk")):
return "xls"
elif "Microsoft Office PowerPoint" in file_type or \
"Microsoft PowerPoint" in file_type or \
file_name.endswith((".ppt", ".pptx", ".pps", ".ppsx", ".pptm", ".potm", ".potx", ".ppsm")):
return "ppt"
elif file_name.endswith(".jar"):
return "jar"
elif file_name.endswith(".hta"):
return "hta"
elif "Zip" in file_type:
return "zip"
elif file_name.endswith((".py", ".pyc")) or "Python script" in file_type:
return "python"
elif file_name.endswith(".vbs"):
return "vbs"
elif file_name.endswith(".js"):
return "js"
elif file_name.endswith(".jse"):
return "jse"
elif file_name.endswith(".msi"):
return "msi"
elif file_name.endswith(".ps1"):
return "ps1"
elif file_name.endswith((".wsf", ".wsc")):
return "wsf"
elif "HTML" in file_type or file_name.endswith((".htm", ".html", ".hta", ".mht", ".mhtml", ".url")):
return "ie"
else:
return "generic"
|
import numpy as np
import pandas as pd
import re
import tkinter as tk
df = pd.read_html('data.html', header=0, encoding='utf-8')[0]
gk = {}
dl = {}
dc = {}
dr = {}
dm = {}
mc = {}
ml = {}
mr = {}
aml = {}
amr = {}
amc = {}
fs = {}
ts = {}
for i in range(len(df)):
player = df.iloc[i]
pos = player['Position']
dl_match = re.search(r"\bD[/\w]*\s?\(.{0,3}L.*\)", pos)
dr_match = re.search(r"\bD[/\w]*\s?\(.{0,3}R.*\)", pos)
dc_match = re.search(r"\bD\s?\(.{0,3}C.*\)", pos)
dm_match = re.search(r"\bDM.*", pos)
mc_match = re.search(r"\bM[/\w]*\s?\(.{0,3}C.*\)", pos)
ml_match = re.search(r"\bM[/\w]*\s?\(.{0,3}L.*\)", pos)
mr_match = re.search(r"\bM[/\w]*\s?\(.{0,3}R.*\)", pos)
aml_match = re.search(r"\bAM\s?\(.{0,3}L.*\)", pos)
amr_match = re.search(r"\bAM\s?\(.{0,3}R.*\)", pos)
amc_match = re.search(r"\bAM\s?\(.{0,3}C.*\)", pos)
st_match = re.search(r"\bST.*", pos)
if pos == 'GK':
weights = [0.12, 0.12, 0.10, 0.09]
attributes = [player['Han'], player['Ref'], player['Dec'], player['Agi']]
rating = round(np.dot(weights, attributes) * 1 / sum(weights), 2)
gk[player['Name']] = rating
if dl_match or dr_match:
weights = [0.15, 0.14, 0.13, 0.11, 0.07, 0.07, 0.07]
attributes = [player['Acc'], player['Pos'], player['Dec'], player['Pac'],
player['Tck'], player['Cnt'], player['Agi']]
rating = round(np.dot(weights, attributes) * 1 / sum(weights), 2)
if dl_match:
dl[player['Name']] = rating
if dr_match:
dr[player['Name']] = rating
if dc_match:
weights = [0.13, 0.10, 0.10, 0.09, 0.08, 0.08, 0.08]
attributes = [player['Dec'], player['Pos'], player['Mar'], player['Acc'],
player['Jum'], player['Str'], player['Pac']]
rating = round(np.dot(weights, attributes) * 1 / sum(weights), 2)
dc[player['Name']] = rating
if dm_match:
weights = [0.12, 0.11, 0.10, 0.08, 0.07, 0.07]
attributes = [player['Acc'], player['Dec'], player['Tck'], player['Pac'],
player['Str'], player['Agi']]
rating = round(np.dot(weights, attributes) * 1 / sum(weights), 2)
dm[player['Name']] = rating
if mc_match:
weights = [0.12, 0.11, 0.10, 0.10, 0.07, 0.07]
attributes = [player['Acc'], player['Vis'], player['Pas'], player['Pac'],
player['Dec'], player['Agi']]
rating = round(np.dot(weights, attributes) * 1 / sum(weights), 2)
mc[player['Name']] = rating
if ml_match or mr_match:
weights = [0.26, 0.20, 0.07]
attributes = [player['Acc'], player['Pac'], player['Agi']]
rating = round(np.dot(weights, attributes) * 1 / sum(weights), 2)
if ml_match:
ml[player['Name']] = rating
if mr_match:
mr[player['Name']] = rating
if aml_match or amr_match:
weights = [0.28, 0.28, 0.07]
attributes = [player['Acc'], player['Pac'], player['Dri']]
rating = round(np.dot(weights, attributes) * 1 / sum(weights), 2)
if aml_match:
aml[player['Name']] = rating
if amr_match:
amr[player['Name']] = rating
if amc_match:
weights = [0.23, 0.13, 0.09]
attributes = [player['Acc'], player['Pac'], player['Vis']]
rating = round(np.dot(weights, attributes) * 1 / sum(weights), 2)
amc[player['Name']] = rating
if st_match:
weigths_fs = [0.24, 0.17, 0.08]
weigths_ts = [0.17, 0.13, 0.12, 0.10]
attributes_fs = [player['Acc'], player['Pac'], player['Fin']]
attributes_ts = [player['Acc'], player['Hea'], player['Jum'], player['Pac']]
rating_fs = round(np.dot(weigths_fs, attributes_fs) * 1 / sum(weigths_fs), 2)
rating_ts = round(np.dot(weigths_ts, attributes_ts) * 1 / sum(weigths_ts), 2)
fs[player['Name']] = rating_fs
ts[player['Name']] = rating_ts
gk = dict(sorted(gk.items(), key=lambda item: item[1], reverse=True)) # sort the dictionary
dl = dict(sorted(dl.items(), key=lambda item: item[1], reverse=True))
dr = dict(sorted(dr.items(), key=lambda item: item[1], reverse=True))
dc = dict(sorted(dc.items(), key=lambda item: item[1], reverse=True))
dm = dict(sorted(dm.items(), key=lambda item: item[1], reverse=True))
mc = dict(sorted(mc.items(), key=lambda item: item[1], reverse=True))
ml = dict(sorted(ml.items(), key=lambda item: item[1], reverse=True))
mr = dict(sorted(mr.items(), key=lambda item: item[1], reverse=True))
aml = dict(sorted(aml.items(), key=lambda item: item[1], reverse=True))
amr = dict(sorted(amr.items(), key=lambda item: item[1], reverse=True))
amc = dict(sorted(amc.items(), key=lambda item: item[1], reverse=True))
fs = dict(sorted(fs.items(), key=lambda item: item[1], reverse=True))
ts = dict(sorted(ts.items(), key=lambda item: item[1], reverse=True))
def on_selection(event):
position = None
choice = list_box.curselection()[0]
if choice == 0:
position = gk.items()
elif choice == 1:
position = dc.items()
elif choice == 2:
position = dl.items()
elif choice == 3:
position = dr.items()
elif choice == 4:
position = dm.items()
elif choice == 5:
position = mc.items()
elif choice == 6:
position = ml.items()
elif choice == 7:
position = mr.items()
elif choice == 8:
position = aml.items()
elif choice == 9:
position = amr.items()
elif choice == 10:
position = amc.items()
elif choice == 11:
position = fs.items()
elif choice == 12:
position = ts.items()
string = ""
for name, value in position:
string += name + " " + str(value)
string += "\n"
text_box.delete('1.0', 'end')
text_box.insert('1.0', string)
root = tk.Tk()
root.title("Player ratings")
text_box = tk.Text(height=15)
text_box.grid(row=0, column=0)
list_box = tk.Listbox(height=15)
list_box.insert(1, "GK")
list_box.insert(2, "DC")
list_box.insert(3, "DL")
list_box.insert(4, "DR")
list_box.insert(5, "DM")
list_box.insert(6, "MC")
list_box.insert(7, "ML")
list_box.insert(8, "MR")
list_box.insert(9, "AML")
list_box.insert(10, "AMR")
list_box.insert(11, "AMC")
list_box.insert(12, "FS")
list_box.insert(13, "TS")
list_box.bind('<<ListboxSelect>>', on_selection)
list_box.grid(row=0, column=1)
root.mainloop()
|
from django.dispatch import Signal
badge_awarded = Signal(providing_args=["badge"])
|
# shell utilities
import shutil
shutil.copyfile('old', 'new')
shutil.move('old', 'new')
|
from __future__ import unicode_literals
__version__ = '2019.03.01'
|
import unittest
from katas.kyu_7.two_to_one import longest
class LongestTestCase(unittest.TestCase):
def test_equals(self):
self.assertEqual(longest('aretheyhere', 'yestheyarehere'), 'aehrsty')
def test_equals_2(self):
self.assertEqual(longest(
'loopingisfunbutdangerous', 'lessdangerousthancoding'),
'abcdefghilnoprstu')
def test_equals_3(self):
self.assertEqual(longest('inmanylanguages', 'theresapairoffunctions'),
'acefghilmnoprstuy')
|
"""Utilities available to other modules."""
import typing as t
import pandas as pd
def get_metadata(
num_train_episodes: int, artificial: bool, num_base_models: int = 4
) -> t.Tuple[pd.DataFrame, pd.DataFrame]:
metadata_path = (
f"metadata/metafeatures_{num_train_episodes}"
f"{'_artificial' if artificial else ''}.csv"
)
data = pd.read_csv(metadata_path, index_col=0)
X = data.iloc[:, :-num_base_models]
y = data.iloc[:, -num_base_models:]
return X, y
def binsearch(y):
if isinstance(y, pd.DataFrame):
y = y.values
start = 0
ind = y.shape[0]
end = y.shape[0] - 1
while start <= end:
middle = start + (end - start) // 2
if pd.isna(y[middle, :]).all():
ind = middle
end = middle - 1
else:
start = middle + 1
return ind
|
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'dashboard/$', views.dashboard, name="user_dash"),
url(r'dashboard/admin/$', views.dashboard_admin, name="user_dash_admin"),
url(r'user/new/$', views.user_new, name="user_user_new"),
url(r'user/create/$', views.create_new, name="user_create_new"),
# url(r'user/edit/$', views.user_edit, name="user_user_edit"),
# url(r'user/edit/(?P<user_id>\d+)/$', views.admin_edit, name="user_admin_edit"),
# url(r'user/delete/$', views.user_delete, name="user_user_delete"),
url(r'profile/(?P<user_id>\d+)/$', views.profile, name="user_profile"),
url(r'message/(?P<user_id>\d+)/$', views.message, name="user_message"),
url(r'comment/(?P<message_id>\d+)/(?P<user_id>\d+)/$', views.comment, name="user_comment"),
url(r'message/delete/(?P<message_id>\d+)/$', views.d_message, name="user_dmessage"),
# url(r'comment/delete/(?P<comment_id>\d+)/$', views.d_comment, name="user_dcomment"),
] |
from ipwhois import IPWhois
obj = IPWhois('16.58.214.142')
res1 = obj.lookup_whois()
print(res1)
res2 = obj.lookup_rdap()
print(res2)
|
from .common import assert_dataservice_processor_data
def test_bills():
assert_dataservice_processor_data("bills", "bills",
[{'id': 5, 'kns_num': 1, 'name': 'חוק שכר חברי הכנסת, התש"ט-1949'},
{'id': 20, 'kns_num': 7, 'name': 'חוק מקצועות רפואיים (אגרות), התשל"א-1971'},
{'id': 15752, 'kns_num': 16, 'name': 'חוק רשות הספנות והנמלים, התשס"ד-2004'}])
def test_bill_names():
assert_dataservice_processor_data("bills", "bill-names",
[{'id': 1, 'bill_id': 135664,
'name': 'הצעת חוק בתי דין רבניים (קיום פסקי דין של גירושין) (תיקון - הרחבת אמצעי האכיפה כנגד סרבן גט), התשס"ו-2006'},
{'id': 2, 'bill_id': 143609,
'name': 'חוק הביטוח הלאומי (תיקון מס\' 87), התשס"ו-2006'},
{'id': 3, 'bill_id': 142356,
'name': 'הצעת חוק חופש המידע (תיקון מס\' 5), התשס"ז-2007'}])
|
# -*- coding:utf-8 -*-
import sqlite3
import re
import requests
# 去重列表
medicine_name_list = []
# 药物ID
medicine_id = [0]
# 获取疾病大类例如:肝炎的子链接
def get_sub_url():
html = requests.get('http://www.a-hospital.com/w/%E8%A1%A5%E9%93%81%E5%92%8C%E8%A1%A5%E7%A1%92%E7%9A%84%E8%8D%AF%E5%93%81%E5%88%97%E8%A1%A8')
li = re.findall(r'药品百科([\s|\S]*?)世界卫生', html.text)
list2 = []
li2 = re.findall(r'<li><a href=\"([\s|\S]*?)\" title=', li[0])
for i in li2:
list2.append('http://www.a-hospital.com'+i)
return list2
# 创建表
def create_table(cursor1):
# 名称,适应症,禁忌,用法,不良反应,注意
# cursor1.execute('''CREATE TABLE DRUG
# (ID INT PRIMARY KEY NOT NULL,
# NAME TEXT,
# INDICATIONS TEXT,
# CONTRAINDICATIONS TEXT,
# DOSAGE TEXT,
# ADVERSEREACTIONS TEXT,
# COMPOSITION TEXT,
# PRECAUTIONS TEXT);''')
cursor1.execute('''CREATE TABLE MEDICINE
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
INDICATIONS TEXT);''')
# 清空表
def delete_items(cursor1):
cursor1.execute("DELETE FROM MEDICINE")
# 添加某个疾病的药物
def add(url, cursor1):
html = requests.get(url)
li = re.findall(r'<li>([\s|\S]*?)</li>', html.text)
list2 = []
for i in li:
a = re.sub(r'<[\s|\S]*?>', '', i).split('\n\n')
list2.append(a)
print('----')
for item in list2:
if len(item) == 2 and item[0] not in medicine_name_list:
print(item)
medicine_name = item[0]
medicine_name_list.append(medicine_name)
disease_name = item[1]
cursor1.execute("insert into MEDICINE(ID,NAME,INDICATIONS) values(?, ?, ?)", (medicine_id[0], medicine_name, disease_name))
medicine_id[0] += 1
# 添加所有条
def add_all(cursor1):
delete_items(cursor1)
for sub_url in get_sub_url():
try:
add(sub_url,cursor1)
except Exception as e:
print(e)
def show_table(cursor1):
cursor1.execute("select * from MEDICINE")
# cursor1.execute("select * from MEDICINE where INDICATIONS like '%牙龈出血%'")
values = cursor1.fetchall()
for i in values:
print(i)
if __name__ == '__main__':
conn = sqlite3.connect('medicine.db')
cursor = conn.cursor()
show_table(cursor)
cursor.close()
conn.commit()
conn.close()
|
vocales = "aeiou"
for vocal in vocales:
print(vocal.upper()) |
DAEMON_VERSION='2.0'
SOCKET_PATH='/tmp/pywalfox_socket'
PYWAL_COLORS_PATH='~/.cache/wal/colors'
LOG_FILE='daemon.log'
LOG_FILE_COUNT=1
LOG_FILE_MAX_SIZE=1000*200 # 0.2 mb
BG_LIGHT_MODIFIER=35
ACTIONS = {
'VERSION': 'debug:version',
'OUTPUT': 'debug:output',
'COLORS': 'action:colors',
'INVALID_ACTION': 'action:invalid',
'CSS_ENABLE': 'css:enable',
'CSS_DISABLE': 'css:disable',
}
|
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 7 20:13:26 2018
@author: user
倍數總和計算
"""
a=int(input())
b=int(input())
c=[]
j=0
sum=0
while a <= b:
if (a % 4 == 0) or (a % 9 == 0):
c.append(a)
sum=sum+a
a=a+1
for i in c:
j=j+1
print("{:<4}".format(i),end="")
if j % 10 == 0:
print("")
print("")
print(len(c))
print(sum) |
import numpy as np
import pandas as pd
class Analyze():
def __init__(self,Draft):
self.draft = Draft
self.teams = Draft.teams
self.roster_spots = {'RB':2.5,'WR':2.5,'TE':1,'QB':1,'DEF':0,'K':0} #Used by the draft analysis tool. Doesn't deal with flex players yet, so I'm sticking in 2.5s for RB and WR. Not going to try to analyze kickers and def. Assuming always at replacement value.
self.roster_size = Draft.roster_size -2 #Subtracting 2 for kickers and def
self.replacement_level = self.replacement_level_rank()
self.first_pick_PAR = 5 #how many points above replacement the first pick will get you. This is just used to level set and make the Points above replacement at the right order of magnitude
self.trade_value = 0.5 #you can get 50% of a player's utility value if you trade them, so it might be worthwhile to draft an 8th WR if they're good value
self.vol =0.25
def replacement_level_rank(self):
return round(self.teams*(self.roster_size)*0.9)
#translate ranking into points above replacement
def pick_to_PAR(self,pick):
rv = self.replacement_level
fpv = self.first_pick_PAR
k = np.log(0.99)
PAR =exponential(pick, fpv, rv, k)
PAR = max(PAR,0)
return PAR
#make a guess on what % of the season the player will be on your starting roster (and thus provide utility)
# this is without taking into consideration the other players you drafted, and is only based on their rank
def prob_startable(self,pick):
PAR = self.pick_to_PAR(pick)
marginal = self.pick_to_PAR(sum(self.roster_spots.values())*self.teams)
util = exponential_2(PAR, self.first_pick_PAR, 0.95,marginal,0.45)
return util
#This works in tandem with the previous function to determine how likely an additional player is to make the active roster, taking into consideration ateam's other draft picks
def roster_utility(self,position,r):
roster = self.draft.get_roster(r)
spots = self.roster_spots[position]
util = 0
for pick in roster.loc[roster.Position==position,'Pick']:
util += self.prob_startable(pick)
try: roster_utility = logistic(util,spots-1,0.85,spots,0.2)
except: roster_utility = 0
return roster_utility
#retuns a dictionary of how to adjust a player's rank for each positon
def utility(self,r):
util = {}
for position in self.roster_spots.keys():
roster_utility = self.roster_utility(position,r)
trade_utility = (1-roster_utility)*self.trade_value
utility = roster_utility+trade_utility
util[position] = round(utility,2)
return util
#get the upside of a set of players given their average and standard deviation
""" def upsideIndicator(avg: pd.Series,stdev: pd.Series):
avgArr = avg.reshape(-1,1)
stdevArr = stdev.reshape(-1,1)
upsideRaw = pow(stdevArr,2)/avgArr
model = LinearRegression()
model.fit(avgArr,upsideRaw)
exp = model.predict(avgArr)
upside = upsideRaw-exp
upside = upside.reshape(-1)
upside= (upside/np.linalg.norm(upside)*100).round()
return pd.Series(upside,index=avg.index).rename('Upside') """
#some math functions used for the stats above
def logistic(x,x1,y1,x2,y2):
g1 = np.log(y1/(1-y1))
g2 = np.log(y2/(1-y2))
b = (g2-g1)/(x2-x1)
a = g1-b*x1
return np.exp(a+b*x)/(1+np.exp(a+b*x))
def exponential(x,y_intercept,x_intercept,k):
return -y_intercept*np.exp(k*x_intercept)/(np.exp(k*x_intercept)-1)*np.exp(k*(x-x_intercept-1))+y_intercept/(np.exp(k*x_intercept)-1)+y_intercept
def exponential_2(x,x1,y1,x2,y2):
k=np.log(y2/y1)/(x2-x1)
a = y1/np.exp(k*x1)
return a*np.exp(k*x)
|
import os
from .common import *
DEBUG = True
INTERNAL_IPS = ['127.0.0.1']
INSTALLED_APPS += (
'debug_toolbar',
)
MIDDLEWARE_CLASSES += (
'debug_toolbar.middleware.DebugToolbarMiddleware',
)
DATABASES = {
'default': {
'ENGINE': 'django.contrib.gis.db.backends.postgis',
'NAME': os.environ.get('DJANGO_DB_NAME', 'postgres'),
'USER': os.environ.get('DJANGO_DB_USER', 'postgres'),
'PASSWORD': os.environ.get('DJANGO_DB_PASSWORD', ''),
'HOST': os.environ.get('DJANGO_DB_HOST', '127.0.0.1'),
'PORT': os.environ.get('DJANGO_DB_PORT', '5432'),
}
}
# DATABASES = {
# 'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
# }
# }
|
from contextlib import nullcontext
class Node:
def __init__(self,value=None):
self.value=value
self.next=None
class SlinkedList:
def __init__(self):
self.head=None
self.tail=None
def __iter__(self):
node=self.head
while node:
yield node
node=node.next
def insert(self,value,location):
Newnode=Node(value)
if self.head==None:
self.tail=Newnode
self.head=Newnode
elif location==0:
Newnode.next=self.head
self.head=Newnode
elif location ==-1:
Newnode.next=None
self.tail.next=Newnode
self.tail=Newnode
else:
temp=self.head
index=0
while index < location-1:
temp=temp.next
index+=1
Nextnode=temp.next
temp.next=Newnode
Newnode.next=Nextnode
if temp==self.tail:
self.tail=Newnode
def transverse(self):
node=self.head
while node is not None:
print(node.value)
node=node.next
def search(self,val):
node=self.head
while node is not None:
if node.value==val:
print("yeet")
node=node.next
def delete(self,location):
if location==0:
if self.head==self.tail:
self.head=None
self.tail=None
else:
self.head=self.head.next
elif location==-1:
if self.head==self.tail:
self.head=None
self.tail=None
else:
node=self.head
while node is not None:
if node.next==self.tail:
break
node=node.next
node.next=None
self.tail=node
else:
temp=self.head
index=1
# here we have taken one location back of the current node
while index<location-1:
temp=temp.next
index+=1
nextnode=temp.next
temp.next=nextnode.next
singleLinkedList=SlinkedList()
singleLinkedList.insert(1,1)
singleLinkedList.insert(2,-1)
singleLinkedList.insert(3,-1)
singleLinkedList.insert(4,-1)
print([i.value for i in singleLinkedList])
singleLinkedList.transverse()
singleLinkedList.search(2)
singleLinkedList.delete(3)
print([i.value for i in singleLinkedList])
|
from flask import Flask, request, render_template
from wordcloud import WordCloud
import tempfile
app = Flask(__name__)
def display_cloud(raw_text):
# do some escaping or something, right?
print(raw_text)
wc = WordCloud().generate(raw_text)
fname = tempfile.NamedTemporaryFile(suffix=".png", delete=False, dir="static")
wc.to_file(fname.name)
base_name = "static/" + fname.name.split("/")[-1]
return render_template('show_cloud.html', image=base_name)
@app.route('/', methods=['GET', 'POST'])
def word_cloud():
if request.method == 'POST':
return display_cloud(request.form['raw_text'])
else:
return render_template('input.html')
if __name__ == "__main__":
app.run(debug=True)
|
from examples.instrument import generate_experiment_kwargs
from examples.development.variants import TOTAL_STEPS_PER_UNIVERSE_DOMAIN_TASK
from morphing_agents.mujoco.ant.elements import LEG
from ray import tune
import argparse
import importlib
import ray
import multiprocessing
import tensorflow as tf
BAD_DESIGN = [
LEG(x=-0.01752557260248648,
y=-0.044383452339044505,
z=0.035900934167950344,
a=-176.4195801607484,
b=116.68176744690157,
c=35.268085280820344,
hip_upper=11.19603545382594,
hip_lower=-49.46392195321905,
thigh_upper=51.0657131726093,
thigh_lower=-14.615106012390918,
ankle_upper=74.57176333327824,
ankle_lower=56.473702804353934,
hip_size=0.29823093428061825,
thigh_size=0.29646611375533083,
ankle_size=0.6441347845016865),
LEG(x=0.03496779544477463,
y=0.07108504122970247,
z=-0.03569704198856287,
a=55.64648224655676,
b=34.441818144624534,
c=128.52145488754383,
hip_upper=2.765140451501311,
hip_lower=-7.805535509168628,
thigh_upper=16.581956331053753,
thigh_lower=-16.643597452043643,
ankle_upper=118.82753177520526,
ankle_lower=17.41881784645519,
hip_size=0.34530722883833775,
thigh_size=0.23448506603466768,
ankle_size=0.6420048202696035),
LEG(x=-0.032470586985765534,
y=-0.04473449397619514,
z=-0.04842402058229145,
a=-147.23479919574032,
b=-89.35407443045268,
c=-6.695254247948668,
hip_upper=39.55393812599064,
hip_lower=-53.067012630493096,
thigh_upper=57.65507028195125,
thigh_lower=-16.087327083146604,
ankle_upper=84.64298937095785,
ankle_lower=56.113804601571054,
hip_size=0.22588675560970153,
thigh_size=0.286648206672234,
ankle_size=0.5973884071392149),
LEG(x=0.05334992704907848,
y=-0.0879241340931864,
z=0.004781725263273515,
a=-160.96831368893146,
b=-46.40782597864799,
c=-144.58495413419965,
hip_upper=7.979335068756887,
hip_lower=-33.96012769698596,
thigh_upper=21.344848783389082,
thigh_lower=-39.90798896053889,
ankle_upper=118.97687622111908,
ankle_lower=26.683489542854673,
hip_size=0.1588388652402842,
thigh_size=0.18433120777152506,
ankle_size=0.5539785875000842)]
if __name__ == '__main__':
parser = argparse.ArgumentParser('EvaluateAntDesign')
parser.add_argument('--local-dir',
type=str,
default='./data')
parser.add_argument('--num-samples',
type=int,
default=1)
parser.add_argument('--num-parallel',
type=int,
default=1)
args = parser.parse_args()
TOTAL_STEPS_PER_UNIVERSE_DOMAIN_TASK[
'gym']['MorphingAnt']['v0'] = 3000000
def run_example(example_module_name, example_argv, local_mode=False):
"""Run example locally, potentially parallelizing across cpus/gpus."""
example_module = importlib.import_module(example_module_name)
example_args = example_module.get_parser().parse_args(example_argv)
variant_spec = example_module.get_variant_spec(example_args)
trainable_class = example_module.get_trainable_class(example_args)
experiment_kwargs = generate_experiment_kwargs(variant_spec, example_args)
experiment_kwargs['config'][
'environment_params'][
'training'][
'kwargs'][
'fixed_design'] = BAD_DESIGN
experiment_kwargs['config'][
'environment_params'][
'training'][
'kwargs'][
'expose_design'] = False
ray.init(
num_cpus=example_args.cpus,
num_gpus=example_args.gpus,
resources=example_args.resources or {},
local_mode=local_mode,
include_webui=example_args.include_webui,
temp_dir=example_args.temp_dir)
tune.run(
trainable_class,
**experiment_kwargs,
with_server=example_args.with_server,
server_port=example_args.server_port,
scheduler=None,
reuse_actors=True)
num_cpus = multiprocessing.cpu_count()
num_gpus = len(tf.config.list_physical_devices('GPU'))
run_example('examples.development', (
'--algorithm', 'SAC',
'--universe', 'gym',
'--domain', 'MorphingAnt',
'--task', 'v0',
'--exp-name', f'bad-design',
'--checkpoint-frequency', '10',
'--mode=local',
'--local-dir', args.local_dir,
'--num-samples', f'{args.num_samples}',
'--cpus', f'{num_cpus}',
'--gpus', f'{num_gpus}',
'--server-port', '9032',
'--trial-cpus', f'{num_cpus // args.num_parallel}',
'--trial-gpus', f'{num_gpus / args.num_parallel}'))
|
from enums import Direction, State, Symbol
def encode_number(s):
inputs = []
for c in s:
for rep in c:
inputs.append(Symbol.by_rep(rep))
return inputs
def encode(s):
inputs = []
for c in s:
for rep in str(ord(c)):
inputs.append(Symbol.by_rep(rep))
inputs.append(Symbol.by_rep("d"))
return inputs
def display(inputs):
print([i.name[4] for i in inputs], sep=",")
|
# 卡最后一个样例的时间md
N = int(input())
W = list(map(int, input().split()))
s = set()
for i in range(N):
for item in s.copy():
if abs(W[i] - item):
s.add(abs(W[i] - item))
if abs(W[i] + item):
s.add(abs(W[i] + item))
s.add(W[i])
print(len(s))
|
from weather_ui import WeatherUi
from weather_api import WeatherApi
from datetime import datetime as dt
from config import data
import logging
class Comparator:
def __init__(self, logger):
self.logger = logger
self.weather_ui = WeatherUi(logger)
self.weather_api = WeatherApi(logger)
self.result = dict()
def get_temp_comparision(self, cities, variance):
self.logger.info('Starting weather details comparision from UI and API')
temp_from_ui = self.weather_ui.get_weather_details(cities)
temp_from_api = self.weather_api.get_weather_details(cities)
for ct in cities:
res = abs(float(temp_from_ui.get(ct, 0)) - float(temp_from_api.get(ct, 0)))
if res < variance:
self.result[ct] = True
else:
self.result[ct] = False
return self.result
if __name__ == '__main__':
today = dt.today().strftime("%Y-%m-%d")
fmt = '%(asctime)-8s %(process)-4s %(message)s'
logging.basicConfig(filename='weather_compare_{}.log'.format(today), level='INFO', filemode='w', format=fmt)
logger = logging.getLogger()
cities = data['city']
variance = data['variance']
comp = Comparator(logger)
result = comp.get_temp_comparision(cities, variance)
logger.info("result {}".format(result))
print(result)
|
# import dependancies
import scrape_mars.py, pymongo
from flask import (
Flask,
render_template,
jsonify,
request,
redirect)
# constants
WIP = "wip<br/>rip"
APP = Flask(__name__)
CONN = 'mongodb://localhost:27017'
CLIENT = pymongo.MongoClient(CONN)
DB = CLIENT.marsdb
# define functions
def storescrape(i):
""" takes the output of scrape, stores it in our pymongo database """
# format:
# result
# news
# title
# p
# featured_image_url
# mars_weather
# table
# hemisphere_image_urls
# title
# img_url
return WIP
def getscrape():
"""return last scrape from database"""
return [{"wip": "rip"}]
# define routes
@APP.route("/")
def index():
return render_template("index.html", js = getscrape(), src = "index.js")
@APP.route("/scrape")
def reload():
scrape_mars.storescrape(scrape_mars.scrape())
return index()
@APP.route("/api")
def api():
return jsonify(getscrape())
# start application
if __name__ == "__main__":
APP.run(debug = True) |
def get_characters_between(start, end):
string = ""
start = ord(start)
end = ord(end)
for character in range(start + 1, end):
string += (chr(character) + " ")
return string
chr_1 = input()
chr_2 = input()
print(get_characters_between(chr_1, chr_2)) |
# Generated by Django 3.0.3 on 2021-05-03 19:39
import django.core.validators
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('ticketingsystem', '0004_auto_20210420_2004'),
]
operations = [
migrations.CreateModel(
name='inventoryItem',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('itemName', models.CharField(max_length=150, verbose_name='Item Name')),
('itemType', models.CharField(choices=[('Mobile Phone', 'Mobile Phone'), ('Laptop', 'Laptop'), ('Desktop', 'Desktop'), ('Games Console', 'Games Console'), ('Tablet', 'Tablet'), ('Smart device', 'Smart Device'), ('Monitor', 'Monitor'), ('Peripherals', 'Peripherals'), ('Component', 'Component'), ('Accessory', 'Accessory'), ('Software', 'Software'), ('Other', 'Other')], max_length=50, verbose_name='Item Type')),
('quantityInStock', models.IntegerField(verbose_name='In Stock')),
('price', models.DecimalField(decimal_places=2, max_digits=9, verbose_name='Price')),
('orderLink', models.URLField(blank=True, verbose_name='Order Link')),
('lastOrdered', models.DateTimeField(auto_now=True, verbose_name='Last Ordered On')),
],
),
migrations.AlterField(
model_name='customer',
name='address',
field=models.TextField(blank=True, verbose_name='Address'),
),
migrations.AlterField(
model_name='customer',
name='email',
field=models.EmailField(blank=True, max_length=254, null=True, verbose_name='Email Address'),
),
migrations.AlterField(
model_name='customer',
name='firstName',
field=models.CharField(max_length=50, verbose_name='First Name'),
),
migrations.AlterField(
model_name='customer',
name='lastName',
field=models.CharField(max_length=50, verbose_name='Last Name'),
),
migrations.AlterField(
model_name='customer',
name='number',
field=models.CharField(max_length=11, validators=[django.core.validators.RegexValidator(message="Phone number must be 11 digits format '00000000000'", regex='^\\d{11}$')], verbose_name='Phone Number'),
),
]
|
#!/usr/bin/env python
"""
prep-cub.py
Process the CUB metadata into something saner
"""
import pandas as pd
import numpy as np
train_sel = pd.read_csv('./data/cub/train_test_split.txt', sep=' ', header=None)
train_sel = np.array(train_sel[1].astype('bool'))
meta = pd.read_csv('./data/cub/images.txt', sep=' ', header=None)
meta.columns = ('id', 'fname')
meta['train'] = train_sel
meta.to_csv('./data/cub/meta.tsv', sep='\t', header=False, index=False)
|
#!/usr/bin/env python3
from gender_bias import Document
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('document', help="document to analyze")
parser.add_argument('-s', help="list sentences", action='store_true')
parser.add_argument('-w', help="list words", action='store_true')
parser.add_argument('-ws', help="list words (stemmed)", action='store_true')
parser.add_argument('-c', help="list categories", action='store_true')
if __name__ == "__main__":
options = parser.parse_args()
text = Document(options.document)
if options.s:
print("\n".join(text.sentences()))
if options.w:
print(text.words())
if options.ws:
print(text.stemmed_words())
if options.c:
for type, words in text.words_by_part_of_speech().items():
print(type, words)
|
# environment
def setup():
size(800, 500)
background(255)
stroke(0)
strokeWeight(1)
noFill()
# general axis references (not used for curve control points)
alist = [0, 100, 200, 300, 400, 500, 600, 700, 800]
# right eyebrow
strokeWeight(2)
curve(0, 400, alist[4], alist[2], alist[5], alist[1]+85, 500, 200)
# left eyebrow
strokeWeight(2)
curve(565, 290, alist[3]+60, alist[2]+03, alist[3], alist[2]+05, 310, 210)
# nose
strokeWeight(1)
curve(445, 0, alist[3]+72, alist[2]+60, alist[4], alist[2]+80, 300, 318)
# silhouette
strokeWeight(1)
curve(390, 300, alist[3]+70, alist[3]+30, alist[4]+35, alist[3]+30, 640, 130)
curve(350, -95, alist[2]+95, alist[1]+95, alist[3]+70, alist[3]+30, 400, 350)
curve(340, 410, alist[4]+35, alist[3]+30, alist[4]+90, alist[2]+70, 590, 150)
curve(340, 410, alist[4]+90, alist[2]+70, alist[5]+10, alist[1]+70, 495, 150)
# hair
strokeWeight(1)
curve(-900, 390, alist[3]+85, alist[0]+90, alist[5], alist[4]+50, 600, 600)
curve(-500, 405, alist[3]+85, alist[0]+95, alist[5]+05, alist[4]+50, 600, 600)
curve(-1300, 405, alist[3]+85, alist[0]+85, alist[5]+35, alist[4]+50, 1000, 600)
curve(-800, 405, alist[3]+89, alist[0]+80, alist[5]+50, alist[4]+10, 400, 400)
curve(1200, 390, alist[3]+70, alist[0]+90, alist[3], alist[4]+25, 600, 600)
curve(800, 390, alist[3]+70, alist[0]+95, alist[2]+50, alist[4], 300, 600)
curve(1200, 390, alist[3]+70, alist[0]+85, alist[3], alist[4]+40, 50, 600)
# neck
strokeWeight(1)
curve(250, 300, alist[3]+48, alist[3]+05, alist[3]+65, alist[4], 300, 425)
curve(500, 305, alist[4]+60, alist[3]+05, alist[4]+60, alist[4], 500, 550)
# mouth
strokeWeight(1)
curve(370, 310, alist[3]+65, alist[3]+05, alist[4]+25, alist[2]+97, 600, 160)
curve(370, 310, alist[3]+65, alist[3]+05, alist[4]+25, alist[2]+97, 600, 230)
# eyeball right
strokeWeight(1)
curve(400, 200, alist[4]+9, alist[2]+19, alist[4]+87, alist[2]+12, 700, 90)
# eyeball left
strokeWeight(1)
curve(360, 220, alist[3]+60, alist[2]+20, alist[3]+10, alist[2]+18, 190, 125)
# movement
def draw():
# mouth axis references (mouth movement only, used for curve control points)
mlist = [370, 310, 365, 305, 425, 297, 600, 100]
if mouseX >= mlist[2]-20 and mouseX <= mlist[4]+20 and mouseY >= mlist[5]-40 and mouseY <= mlist[3]+40:
stroke(0)
strokeWeight(0)
curve(mlist[0], mlist[1], mlist[2], mlist[3], mlist[4], mlist[5], mlist[6], mlist[7])
curve(mlist[0], mlist[1], mlist[2], mlist[3], mlist[4], mlist[5], mlist[6], mlist[7]-150)
stroke(255)
strokeWeight(0)
curve(mlist[0], mlist[1], mlist[2], mlist[3], mlist[4], mlist[5], mlist[6], mlist[7]-100)
else:
stroke(255)
curve(mlist[0], mlist[1], mlist[2], mlist[3], mlist[4], mlist[5], mlist[6], mlist[7])
curve(mlist[0], mlist[1], mlist[2], mlist[3], mlist[4], mlist[5], mlist[6], mlist[7]-150)
stroke(0)
strokeWeight(0)
curve(mlist[0], mlist[1], mlist[2], mlist[3], mlist[4], mlist[5], mlist[6], mlist[7]-100)
# eye movement axis reference (not used for curve control points in curve, eye movement only)
elist = [0, 100, 200, 300, 400, 500]
if mouseY > elist[2]:
# eyeball right
stroke(235)
strokeWeight(2)
curve(200, 410, elist[4]+9, elist[2]+19, elist[4]+87, elist[2]+12, 492, 200)
# eyeball left
stroke(235)
strokeWeight(2)
curve(515, 300, elist[3]+60, elist[2]+20, elist[3]+10, elist[2]+18, 350, 210)
else:
# right eyeball
stroke(0)
strokeWeight(1.5)
curve(200, 410, elist[4]+9, elist[2]+19, elist[4]+87, elist[2]+12, 492, 200)
# left eyeball
stroke(0)
strokeWeight(1.5)
curve(515, 300, elist[3]+60, elist[2]+20, elist[3]+10, elist[2]+18, 350, 210)
|
import random
print("안녕하세요. 시간표마법사입니다")
print("먼저 자신의 정보를 작성해주세요")
print("="*40)
name=str(input("이름을 입력하세요:"))
student_number=str(input("학번을 입력하세요:"))
print("="*40)
while True:
print("메뉴를 선택해주세요.\n1. 개설 강좌 목록 \n2. 시간표 생성\n3. 수강신청 예상인원\n4. 시스템종료")
choice_one=int(input('선택:'))
print('='*40)
if choice_one==1:
print('개설강좌목록 \n1. 전공\n2. 교양')
print('(메뉴로 돌아가고 싶다면 "0"을 눌러주세요)')
choice_two=int(input("선택하세요:"))
print('='*40)
if choice_two==1:
f=open('major_all.txt','r',encoding='UTF8')
major_txt=f.read()
print(major_txt)
f.close()
elif choice_two==2:
f=open('liberal_all.txt','r',encoding='UTF8')
liberal_txt=f.read()
print(liberal_txt)
f.close()
elif choice_two==0:
print('이전 화면으로 돌아갑니다')
print('='*40)
elif choice_one==2:
print('먼저',name,"학생의 희망사항을 입력하세요")
print('='*40)
major_number=int(input("몇 개의 전공수업을 들으시나요?:"))
print('-'*40)
liberal_number=int(input("몇 개의 교양수업을 들으시나요?:"))
print('-'*40)
print("온라인 수업을 희망하시나요?")
online_option=str(input("희망하신다면 'Y', 희망하지 않는다면 'N'을 입력해주세요:"))
print('-'*40)
if online_option=='Y':
online_number=int(input("몇 개의 온라인 수업을 들으시나요:"))
print('-'*40)
print(name,"학생의 총 학점은",(major_number+liberal_number+online_number)*3,'학점입니다.')
print('-'*40)
i=1
major_subject=[]
while i<=major_number:
major_subject.append(input("희망하는 전공 과목을 하나씩 입력하세요:"))
i=i+1
print('-'*40)
print(name,'학생이 희망하는 전공 과목은',major_subject,'입니다.')
print('-'*40)
j=1
liberal_subject=[]
while j<=liberal_number:
liberal_subject.append(input("희망하는 교양 과목을 하나씩 입력하세요:"))
j=j+1
print('-'*40)
print(name,"학생이 희망하는 교양 과목은",liberal_subject,'입니다')
print('-'*40)
k=1
online_subject=[]
while k<=online_number:
online_subject.append(input("희망하는 온라인 과목을 하나씩 입력하세요:"))
k=k+1
print('-'*40)
print(name,'학생이 희망하는 온라인 과목은',online_subject,'입니다')
print('-'*40)
print('아래의 표를 보고 희망하는 시간대를 띄어쓰기로 구분하여 입력해주세요')
print('ex. 1 2 13 15')
f=open('timetable.txt','r',encoding='UTF8')
timetable_txt=f.read()
print(timetable_txt)
f.close()
print('-'*40)
hope_timetable=list(input('입력하세요:').split())
print(hope_timetable)
print('='*40)
print(name,'학생의 희망하는 시간대는 ',list(hope_timetable))
print('-'*40)
while True:
subject_all=major_subject+liberal_subject
random.shuffle(subject_all)
random.shuffle(hope_timetable)
real_timetable=dict(zip(hope_timetable,subject_all))
sorted(real_timetable.items(),key=lambda item: item[0])
print(name,'학생의 시간표입니다')
for key,value in sorted(real_timetable.items()):
print(key,"시간대의 과목은",value,'입니다.')
print("온라인 수업은",online_subject,"입니다")
print('-'*40)
print("더 만들고 싶다면 'Y', 그만 만들고 싶다면 'N'을 입력해주세요")
choice=str(input("입력하세요:"))
print('-'*40)
if choice=="Y":
continue
elif choice=='N':
break
elif online_option=='N':
print(name,"학생의 총 학점은",(major_number+liberal_number)*3,"학점입니다.")
print('-'*40)
i=1
major_subject=[]
while i<=major_number:
major_subject.append(input("희망하는 전공 과목을 하나씩 입력하세요:"))
i=i+1
print('-'*40)
print(name,'학생이 희망하는 전공 과목은',major_subject,'입니다.')
print('-'*40)
j=1
liberal_subject=[]
while j<=liberal_number:
liberal_subject.append(input("희망하는 교양 과목을 하나씩 입력하세요:"))
j=j+1
print('-'*40)
print(name,"학생이 희망하는 교양 과목은",liberal_subject,'입니다')
print('-'*40)
print('아래의 표를 보고 희망하는 시간대를 띄어쓰기로 구분하여 입력해주세요')
print('ex. 1 2 13 15')
f=open('timetable.txt','r',encoding='UTF8')
timetable_txt=f.read()
print(timetable_txt)
f.close()
print('-'*40)
hope_timetable=list(input('입력하세요:').split())
print(hope_timetable)
print('='*40)
print(name,'학생의 희망하는 시간대는 ',list(hope_timetable))
print('-'*40)
while True:
subject_all=major_subject+liberal_subject
random.shuffle(subject_all)
random.shuffle(hope_timetable)
real_timetable=dict(zip(hope_timetable,subject_all))
sorted(real_timetable.items(),key=lambda item: item[0])
print(name,'학생의 시간표입니다')
for key,value in sorted(real_timetable.items()):
print(key,"시간대의 과목은",value,'입니다.')
print('='*40)
print("더 만들고 싶다면 'Y', 그만 만들고 싶다면 'N'을 입력해주세요")
choice=str(input("입력하세요:"))
print('-'*40)
if choice=="Y":
continue
elif choice=='N':
break
elif choice_one==3:
print("예상 수강신청 인원 \n1. 전공\n2. 교양")
choice_three=int(input("선택:"))
print('='*40)
while True:
if choice_three>=1 and choice_three<3:
major_subject=str(input("과목을 입력하세요:"))
print('='*40)
print('"',major_subject,'"','의 예상 수강 신청 인원은',random.randint(1,100+(choice_three-1)*30),'명입니다')
print('='*40)
print("다른 과목도 궁금하다면 'Y', 메뉴로 돌아가고 싶다면 'N'을 입력해주세요")
a=str(input('입력하세요:'))
print('='*40)
if a=='Y':
continue
elif a=="N":
break
else:
print('오류가 발생했습니다.')
print("다시 입력해주세요")
print('='*40)
break
elif choice_one==4:
print(name,'님 이용해주셔서 감사합니다')
print('='*40)
break
else:
print('오류가 발생했습니다.')
print('다시 입력해주세요')
print('='*40)
|
# -*- coding: utf-8 -*-
#
# Copyright 2016 Ramil Nugmanov <stsouko@live.ru>
# This file is part of MODtools.
#
# MODtools is free software; you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as published by
# the Free Software Foundation; either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
#
# You should have received a copy of the GNU Affero General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston,
# MA 02110-1301, USA.
#
import sys
import operator
import pandas as pd
from collections import defaultdict
from functools import reduce
from CGRtools.files.SDFrw import SDFread
from CGRtools.files.RDFrw import RDFread
class Descriptorchain(object):
def __init__(self, *args):
"""
chaining multiple descriptor generators.
concatenate X vectors and merge AD
:param args: set of generators or set of list[generator, consider their AD {True|False}]
"""
if isinstance(args[0], tuple):
self.__generators = args
else:
self.__generators = [(x, True) for x in args]
def setworkpath(self, workpath):
for gen, _ in self.__generators:
if hasattr(gen, 'setworkpath'):
gen.setworkpath(workpath)
def get(self, structures, **kwargs):
"""
:param structures: opened structure file or stringio
:param kwargs: generators specific arguments
:return: dict(X=DataFrame, AD=Series, Y=Series, BOX=Series, structures=DataFrame)
"""
res = defaultdict(list)
def merge_wrap(x, y):
return pd.merge(x, y, how='outer', left_index=True, right_index=True)
for gen, ad in self.__generators:
for k, v in gen.get(structures, **kwargs).items():
res[k].append(v)
res['BOX'].append(pd.Series(ad, index=res['X'][-1].columns))
structures.seek(0)
res['X'] = reduce(merge_wrap, res['X'])
res['AD'] = reduce(operator.and_, sorted(res['AD'], key=lambda x: len(x.index), reverse=True))
# на данный момент не придумано как поступать с мультицентровостью. пока свойство просто дублируется.
res['Y'] = sorted(res['Y'], key=lambda x: len(x.index), reverse=True)[0]
res['BOX'] = pd.concat(res['BOX'])
if 'structures' in res:
res['structures'] = reduce(merge_wrap, res['structures'])
return dict(res)
class Propertyextractor(object):
def __init__(self, name):
self.__name = name
def get_property(self, meta, marks=None):
"""
for marked atom property can named property_name.1-2-3 - where 1-2-3 sorted marked atoms.
for correct work NEED in rdf mapping started from 1 without breaks.
or used common property with key property_name
:param meta: dict of data
:param marks: list of marked atoms
:return: float property or None
"""
tmp = marks and meta.get('%s.%s' % (self.__name,
'-'.join(str(x) for x in sorted(marks)))) or meta.get(self.__name)
return float(tmp) if tmp else None
class Descriptorsdict(Propertyextractor):
def __init__(self, data=None, s_option=None, is_reaction=False, ):
Propertyextractor.__init__(self, s_option)
self.__is_reaction = is_reaction
self.__extention = data
self.__extheader = self.__prepareextheader(data)
@staticmethod
def setworkpath(_):
return None
@staticmethod
def __prepareextheader(data):
"""
:param data: dict
:return: list of strings. descriptors header
"""
tmp = []
for i, j in data.items():
if j:
tmp.extend(j['value'].columns)
else:
tmp.append(i)
return tmp
def __parsefile(self, structures):
"""
parse SDF or RDF on known keys-headers.
:param structures: opened file
:return: DataFrame of descriptors. indexes is the numbers of structures in file, columns - names of descriptors
"""
extblock = []
props = []
reader = RDFread(structures) if self.__is_reaction else SDFread(structures)
for i in reader.read():
meta = i['meta'] if self.__is_reaction else i.graph['meta']
tmp = []
for key, value in meta.items():
if key in self.__extention:
data = self.__extention[key]['value'].loc[self.__extention[key]['key'] == value] if \
self.__extention[key] else pd.DataFrame([{key: float(value)}])
if not data.empty:
data.index = [0]
tmp.append(data)
extblock.append(pd.concat(tmp, axis=1) if tmp else pd.DataFrame([{}]))
props.append(self.get_property(meta))
res = pd.DataFrame(pd.concat(extblock), columns=self.__extheader)
res.index = pd.Index(range(len(res.index)), name='structure')
prop = pd.Series(props, name='Property', index=res.index)
return res, prop
def __parseadditions0(self, **kwargs):
extblock = []
for i, j in kwargs.items():
if i in self.__extention:
for n, k in enumerate(j) if isinstance(j, list) else j.items():
data = self.__extention[i]['value'].loc[self.__extention[i]['key'] == k] if \
self.__extention[i] else pd.DataFrame([{i: k}])
if not data.empty:
data.index = [0]
if len(extblock) > n:
extblock[n].append(data)
else:
extblock.extend([[] for _ in range(n - len(extblock))] + [[data]])
res = pd.DataFrame(pd.concat([pd.concat(x, axis=1) if x else pd.DataFrame([{}]) for x in extblock]),
columns=self.__extheader)
res.index = pd.Index(range(len(res.index)), name='structure')
return res
def __parseadditions1(self, **kwargs):
tmp = []
for i, j in kwargs.items():
if i in self.__extention:
data = self.__extention[i]['value'].loc[self.__extention[i]['key'] == j] if \
self.__extention[i] else pd.DataFrame([{i: j}])
if not data.empty:
data.index = [0]
tmp.append(data)
return pd.DataFrame(pd.concat(tmp, axis=1) if tmp else pd.DataFrame([{}]), columns=self.__extheader,
index=pd.Index([0], name='structure'))
def get(self, structures=None, **kwargs):
if kwargs.get('parsesdf'):
extblock, prop = self.__parsefile(structures)
structures.seek(0) # ad-hoc for rereading
elif all(isinstance(x, list) or isinstance(x, dict) for y, x in kwargs.items() if y in self.__extention):
extblock = self.__parseadditions0(**kwargs)
prop = pd.Series(index=extblock.index)
elif not any(isinstance(x, list) or isinstance(x, dict) for y, x in kwargs.items() if y in self.__extention):
extblock = self.__parseadditions1(**kwargs)
prop = pd.Series(index=extblock.index)
else:
print('WHAT DO YOU WANT? use correct extentions params', file=sys.stderr)
return False
return dict(X=extblock, AD=-extblock.isnull().any(axis=1), Y=prop)
|
class Mensaje:
def __init__(self, id_vecino, mensaje):
self.id_vecino = id_vecino
self.mensaje = mensaje
def getId(self):
return self.id_vecino
def getMensaje(self):
return self.mensaje |
import numpy as np
from control.matlab import *
import matplotlib.pyplot as plt
from control_self import *
## Inputs for the simulation and unit conversion:
m = 1600 ## mass of the vehicle, in kgs
kdash = 0.072 ##k' = k/(a*b) - 1
wb = 2.747 ##wheelbase in metres
a = wb * 600 / m ##distance from CG to front axle in m
b = wb * 1000 / m ##distance from CG to rear axle in m
mf = m * b / (a+b) ##mass on front axle, kg
mr = m * a / (a+b)
DF = 6 ##front corenering compliance in deg/g
DR = 3
IZZ = (kdash+1) * m * a * b ## yaw moment of inertia of the vehicle, in kg m^2
CF = 57.3 * mf * 9.81 / DF ## Front tire cornering stiffness, input in N/deg, gets converted to N/rad
CR = 57.3 * mr * 9.81 / DR ## Same as above, for rear tires
u = 100 / 3.6 ## vehicle forward velocity in m/s
SR = 16 ##degrees of steer wheel angle per degree of wheel angle. Assumed constant
### Note: CF and CR can also be considered as effective front and rear
### cornering compliances, according to the paper by Bundorf and Leffert
## Computation area
D1 = m * u * IZZ
D2 = (IZZ * (CF+CR)) + (m * (a**2 * CF + b**2 * CR))
D3 = ((a+b)**2 * CF * CR / u) + (m * u * (b * CR - a * CF))
denom = np.array([D1,D2,D3])
### Yaw velocity numerator
N1 = a * m * u * CF
N2 = (a+b) * CF * CR
yawn = np.array([N1,N2])
yawan = np.array([N1,N2,0])
### Sideslip angle numerator
N3 = IZZ * CF
N4 = (CF * CR * (b**2 + a * b) / u) - a * m * u * CF
betan = np.array([N3,N4])
dbetan = np.array([N3,N4,0])
### Lateral acceleration numerator
N5 = u * IZZ * CF
N6 = CF * CR * (b**2 + a * b)
N7 = (a+b) * CF * CR * u
ayn = np.array([N5,N6,N7])
### transfer functions
yawvtxy = tf(yawn, denom) ##yaw velocity to steer
betatxy = tf(betan, denom) ##sideslip by steer
sstxy = tf(ayn, denom) ##lateral acceleration by steer
betagtxy = tf(betan, ayn) ##sideslip by lateral acceleration
yawatxy = tf(yawan, denom) ##yaw acceleration to steer
dbetatxy = tf(dbetan, denom) ##sideslip velocity by steer
### Steer function
t=np.linspace(0,2,21)
tmid = 1.5 ##point about which the step function is symmetric
hw=1 ##half width of steer function duration
pwr=31.8 ##steer velocity in deg/sec
swamp= 20 ##degrees of steering wheel angle
steerdeg=(-2/np.pi*np.arctan(np.abs((t-tmid)/hw)**pwr)+1)*swamp ##in degrees
steer = steerdeg / 57.3
## Responses and plots
r = lsim(yawvtxy,steer / SR ,t) ##yaw response wrt wheel angle
beta = lsim(betatxy, steer / SR, t) ##beta response wrt wheel angle
ay = lsim(sstxy, steer / SR ,t)
rd = lsim(yawatxy, steer / SR , t) ##yaw acceleration response wrt wheel angle
betad = lsim(dbetatxy, steer / SR, t)
r = r[0]
beta = beta[0]
ay = ay[0]
rd = rd[0]
betad = betad[0]
mag,phase,w = bode(yawvtxy)
mag = np.squeeze(mag)
w = np.squeeze(w)
mag1,phase1,w1 = bode(betagtxy, Plot=False)
mag1 = np.squeeze(mag1)
w1 = np.squeeze(w1)
mag2,phase2,w2 = bode(sstxy, Plot=False)
mag2 = np.squeeze(mag2)
w2 = np.squeeze(w2)
mag3,phase3,w3 = bode(yawatxy, Plot=False)
mag3 = np.squeeze(mag3)
w3 = np.squeeze(w3)
print(w)
## Outputs
### steady state gains
yawvss = N2 / D3 ##steady state yaw velocity gain rad/s/rad of WA
betass = N4 / D3 ##steady state sideslip angle gain rad/rad of WA
ayss = N7 / D3 ##steady state lateral acceleration gain ms^-2/rad
ss = betass / ayss ##steady state sideslip gain rad/ms^-2
ayssg = ayss / 9.807 / 57.3 ##steady state lateral acceleration gain g's/deg
steeringsens = ayssg * 100 / SR ##steering sensitivity. g's per 100 deg
yaw_bw = bandwidth(mag,w)
beta_bw = bandwidth(mag1,w1)
ay_bw = bandwidth(mag2,w2)
R_BW = yaw_bw/(2*np.pi) ##in Hertz
TAU_R = 2/yaw_bw ##in seconds
B_BW = beta_bw/(2*np.pi)##in Hertz
TAU_B = 2/beta_bw ##in seconds
AY_BW = ay_bw/(2*np.pi) ##in Hertz
TAU_AY = 2/ay_bw ##in seconds
print(TAU_AY)
wn=damp(yawvtxy)[0]
z=damp(yawvtxy)[1]
WN = wn[0] / (2*np.pi) ##first natural frequency in Hertz
ZETA = z[0] ##damping ratio
yawv_p2ss= ((np.max(r)/r[-1])-1)*100 ##yaw velocity peak to steady state ratio
###ayssg is steering sensitivity in terms of g's per 1 deg wheel angle
###ayss is steering sensitivity in terms of ms^-2 per radian wheel angle
fig1, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2)
fig1.suptitle('Frequency Domain Plots')
ax1.plot(w/2/np.pi,mag*100/SR,'b-')
ax1.set_xlim((0,4))
ax1.grid()
ax1.set_ylabel('Yaw velocity Gain (deg / sec / 100 deg SWA)')
ax1.legend('Theory')
ax2.plot(w1/2/np.pi,mag1 * 57.3 * 9.807,'b-')
ax2.set_xlim((0,4))
ax2.grid()
ax2.set_ylabel('Sideslip Gain')
ax2.legend('Theory')
ax3.plot(w2/2/np.pi,mag2* 100/ 57.3 /SR /9.807,'b-')
ax3.set_xlim((0,4))
ax3.grid()
ax3.set_ylabel('Lateral acceleration Gain (gs per 100 deg SWA)')
ax3.legend('Theory')
ax4.plot(w/2/np.pi,mag3*100/SR,'b-')
ax4.set_xlim((0,4))
ax4.grid()
ax4.set_ylabel('Yaw acceleratoin (deg / sec^2 / 100 deg SWA)')
ax4.legend('Theory')
fig1.show()
### Time plots
fig2, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2)
fig2.suptitle('Time Domain Plots')
ax1.plot(t, r * 180 / np.pi, 'k')
ax1.grid()
ax1.set_xlabel('Time (s)')
ax1.set_ylabel('Yaw velocity (deg/sec)')
ax2.plot(t,beta * 180 / np.pi , 'r')
ax2.grid()
ax2.set_xlabel('Time (s)')
ax2.set_ylabel('Sideslip angle (deg)')
ax3.plot(t,ay / 9.807 , 'b')
ax3.grid()
ax3.set_xlabel('Time (s)')
ax3.set_ylabel('Lateral acceleration (g)')
ax4.plot(t ,steerdeg, 'y')
ax4.grid()
ax4.set_xlabel('Time (s)')
ax4.set_ylabel('Steer (deg)')
plt.show()
|
import argparse
import datetime as dt
import json
import logging
import os
import sys
import traceback
import numpy as np
import pandas as pd
import requests
import calculateCalibrationConstant
import Configurator
import Scripts.plotFitResults as plotFitResults
import vdmDriverII
from postvdm import PostOutput
def RunAnalysis(name, luminometer, fit, corr='noCorr', automation_folder='Automation/'):
"""Runs vdm driver without correction and with beam beam correction,
then calculates the calibration constant ant plots the results in pdfs
You need to have already made the configuration files in automation_folder + '/autoconfigs'
name : the name of the analysis folder (fill number and datetimes from the beginning and ending of the scan pair)
automation_folder : the relative path to folder with your dipfiles, autoconfigs and Analysed_Data folders
"""
def LogInfo(message):
print(message)
logging.info('\n\t' + dt.datetime.now().strftime('%y%m%d%H%M%S') +
'\n\tFile ' + name + '\n\t' + message)
try:
beambeamsource = 'noCorr_' if 'Background' not in corr else 'Background_'
if 'BeamBeam' in corr:
# LogInfo(beambeamsource + ' ' + luminometer + fit + ' START')
fitresults,calibration = vdmDriverII.DriveVdm(automation_folder + 'autoconfigs/' + name + '/' +
luminometer + beambeamsource + fit + '_driver.json')
# LogInfo('CALIBRATION CONST ' + luminometer + fit + ' START')
# calibration = calculateCalibrationConstant.CalculateCalibrationConstant(
# automation_folder + 'autoconfigs/' + name + '/' + luminometer + beambeamsource + fit + '_calibrationConst.json')
# LogInfo(corr + ' ' + luminometer + fit + ' START')
fitresults,calibration = vdmDriverII.DriveVdm(automation_folder + 'autoconfigs/' + name + '/' +
luminometer + corr + '_' + fit + '_driver.json')
# LogInfo('CALIBRATION CONST ' + luminometer + fit + ' START')
# calibration = calculateCalibrationConstant.CalculateCalibrationConstant(
# automation_folder + 'autoconfigs/' + name + '/' + luminometer + corr + '_' + fit + '_calibrationConst.json')
# these just take up space in emittance scans. If you need them the configurations are still made
# LogInfo('PLOT FIT ' + luminometer + fit + ' START')
# plotFitResults.PlotFit(automation_folder + 'autoconfigs/' + name + '/' +
# luminometer + corr + '_' + fit + '_plotFit.json')
config = json.load(open(automation_folder + 'autoconfigs/' + name + '/' +
luminometer + beambeamsource + fit + '_driver.json'))
fill = config['Fill']
time = config['makeScanFileConfig']['ScanTimeWindows'][0][0]
fitresults = pd.DataFrame(fitresults[1:], columns=fitresults[0])
calibration = pd.DataFrame(calibration[1:], columns=calibration[0])
#LogInfo(luminometer + fit + ' END')
return fitresults, calibration
except (KeyboardInterrupt, SystemExit):
raise
except:
raise
message = 'Error analysing data!\n' + traceback.format_exc()
print(message)
logging.error('\n\t' + dt.datetime.now().strftime('%y%m%d%H%M%S') +
'\n\tFile ' + name + '\n' + message)
if (__name__ == '__main__'):
'''Should just be the above method runnable from console, but is not tested'''
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--name', help='name of new analysis folder')
parser.add_argument('-l', '--luminometer')
parser.add_argument('-f', '--fit')
parser.add_argument('-c', '--corr')
parser.add_argument('-a', '--automation_folder')
args = parser.parse_args()
# if not os.path.exists(args.automation_folder + '/Analysed_Data/' + args.name + '/Logs/'):
# os.makedirs(args.automation_folder + '/Analysed_Data/' + args.name + '/Logs/')
# logging.basicConfig(filename=args.automation_folder + '/Analysed_Data/' + args.name +
# "/Logs/run_" + args.luminometer + '.log', level=logging.DEBUG)
# logging.info('name: ' + args.name)
# logging.info('luminometer: ' + args.luminometer)
# logging.info('fit: ' + args.fit)
# logging.info('corr: ' + args.corr)
# logging.info('automation_folder: ' + args.automation_folder)
RunAnalysis(args.name, args.luminometer, args.fit,
args.corr, args.automation_folder)
|
class Solution:
def uncommonFromSentences(self, s1: str, s2: str) -> List[str]:
dic = {}
l1, l2 = s1.split(' '), s2.split(' ')
for item in l1:
if item not in dic:
dic[item] = 1
else:
dic[item] += 1
for item in l2:
if item not in dic:
dic[item] = 1
else:
dic[item] += 1
res = []
for k, v in dic.items():
if v == 1:
res.append(k)
return res
|
space=" "
firstName=input("What is your first name? ")
lastName=input("What is your last name? ")
location=input("What is your current location? ")
age=input("What is your age? ")
print("Hi"+space+firstName+space+lastName+"."+space+"You are in"+space+location+space+"and you are"+space+age+space+"years old") |
#2048.py
#write a program that will open the game at https://play2048.co/ and keep sending up right down left keystrokes to autoamtically play the game
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
browser = webdriver.Firefox()
browser.get('https://play2048.co/')
keySend = browser.find_element_by_tag_name('html')
while True:
keySend.send_keys(Keys.UP)
time.sleep(.1)
keySend.send_keys(Keys.RIGHT)
time.sleep(.1)
keySend.send_keys(Keys.DOWN)
time.sleep(.1)
keySend.send_keys(Keys.LEFT)
time.sleep(.1)
|
class student:
def __init__(a,name,age):
a.name=name
a.age=age
def say_age(self):
print(self.age)
s1=student('sdfg',18)
#s1.say_age()
#student.say_age(s1)
class math:
pass
#print(dir(math))
#print(dir(student))
#print(dir(s1))
#print(s1.__dir__())
print(isinstance(s1,math)) |
# Write a Python file that uploads an image to your
# Twitter account. Make sure to use the
# hashtags #UMSI-206 #Proj3 in the tweet.
# You will demo this live for grading.
print("""No output necessary although you
can print out a success/failure message if you want to.""")
import tweepy
import nltk
import requests
import requests_oauthlib
access_token = "2721234898-yZ2dGB6nPo21ia09dUEtjblp7Q53Fh3usIimTto"
access_token_secret = "F8wmByokRFtHqCRECeD6MCELfMSGQIL0pASsjq5Reygmo"
consumer_key = "juxL77LAY5gXuuel5bayXM0v1"
consumer_secret = "ehsLrBNgQsjB4ySzSiuJ1bvaitS5om96WQDo8VBmJivuQHLBnD" #all my twitter access codes
auth = tweepy.OAuthHandler(consumer_key,consumer_secret) #putting my twitter consumer_key and consumer_secret into the twitter api to get access to my twitter account
auth.set_access_token(access_token,access_token_secret) #authenticating access to my twitter account with the access_token and the access_secret_token
api = tweepy.API(auth) #using the tweepy module
img = "/Users/robertbracci/desktop/project3/SI206/friends.jpg"
api.update_with_media(img, status="#UMSI-206 #Proj3") #posting the photo from my desktop to twitter with the hashtag #UMSI-206 #Proj3
print("Posted")
|
from flask import g
import sqlite3
import os
import errno
import time
insert_query = 'INSERT INTO sounds (lang, text, path, created, accessed) values (?, ?, ?, ?, ?)'
select_path_query = 'SELECT * FROM sounds WHERE path = ?'
select_idd_query = 'SELECT * FROM sounds WHERE id = ?'
update_idd_query = 'UPDATE sounds SET accessed = ? WHERE id = ?'
select_lang_text_query = 'SELECT * FROM sounds WHERE lang = ? AND text = ?'
# returns id of new sound
def insert_sound(lang, text, path):
timestamp = int(time.time())
cur = g.db.execute(insert_query, [lang, text, path, timestamp, timestamp])
g.db.commit()
sound = get_sound_by_path(path)
return sound[0]
def get_sound_by_path(path):
cur = g.db.execute(select_path_query, [path])
return cur.fetchone()
def get_sound_by_id(idd):
timestamp = int(time.time())
g.db.execute(update_idd_query, [timestamp, idd])
g.db.commit()
cur = g.db.execute(select_idd_query, [idd])
return cur.fetchone()
def sound_exists(lang, text):
cur = g.db.execute(select_lang_text_query, [lang, text])
res = cur.fetchone()
return res is not None
def get_sound_by_lang_text_pair(lang, text):
cur = g.db.execute(select_lang_text_query, [lang, text])
return cur.fetchone()
sound_path = 'static/sounds/%(lang)s/%(text)s.mp3'
# get absolute path to sounds directory
current_dir = os.path.dirname(__file__)
sounds_dir = os.path.join(current_dir, '../static/sounds')
sounds_dir = os.path.abspath(sounds_dir)
def save_sound(lang, text, sound):
pathText = "".join( map(to_file_path, text) )
lang_dir = os.path.join(sounds_dir, lang)
sound_path = os.path.join(lang_dir, '%s.mp3' % pathText)
create_dir_if_not_exists(os.path.dirname(sound_path))
f = open(sound_path, 'w')
f.write(sound)
f.close()
return sound_path
def to_file_path(c):
switcher = {
' ': '_',
'/': '-',
}
return switcher.get(c, c)
def create_dir_if_not_exists(path):
try:
os.makedirs(path)
except OSError as exception:
if exception.errno != errno.EEXIST:
raise
|
import pandas as pd
import numpy as np
# in-memory modelling
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
if __name__ == '__main__':
X_train = pd.read_csv('X_train.csv')
X_val = pd.read_csv('X_val.csv')
X_test = pd.read_csv('X_test.csv')
y_train = pd.read_csv('y_train.csv')
y_val = pd.read_csv('y_val.csv')
y_test = pd.read_csv('y_test.csv')
items = pd.read_csv("items.csv",
).set_index("item_nbr")
# in-memory lightgbm baseline
print("Training and predicting models...")
params = {
'num_leaves': 2**5 - 1,
'objective': 'regression_l2',
'max_depth': 8,
'min_data_in_leaf': 50,
'learning_rate': 0.05,
'feature_fraction': 0.75,
'bagging_fraction': 0.75,
'bagging_freq': 1,
'metric': 'l2',
'num_threads': 4
}
MAX_ROUNDS = 1000
val_pred = []
test_pred = []
cate_vars = []
for i in range(2):
print("=" * 50)
print("Step %d" % (i+1))
print("=" * 50)
dtrain = lgb.Dataset(
X_train, label=y_train[:, i],
categorical_feature=cate_vars,
weight=pd.concat([items["perishable"]] * 4) * 0.25 + 1
)
dval = lgb.Dataset(
X_val, label=y_val[:, i], reference=dtrain,
weight=items["perishable"] * 0.25 + 1,
categorical_feature=cate_vars)
bst = lgb.train(
params, dtrain, num_boost_round=MAX_ROUNDS,
valid_sets=[dtrain, dval], early_stopping_rounds=50, verbose_eval=50
)
print("\n".join(("%s: %.2f" % x) for x in sorted(
zip(X_train.columns, bst.feature_importance("gain")),
key=lambda x: x[1], reverse=True
)))
val_pred.append(bst.predict(
X_val, num_iteration=bst.best_iteration or MAX_ROUNDS))
test_pred.append(bst.predict(
X_test, num_iteration=bst.best_iteration or MAX_ROUNDS))
print("Baseline LightGBM test rmse:", np.sqrt(mean_squared_error(
y_test[:, 0], np.array(test_pred).transpose()[:, 0]))) |
# Python Substrate Interface Library
#
# Copyright 2018-2021 Stichting Polkascan (Polkascan Foundation).
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from substrateinterface import SubstrateInterface
from test import settings
class SubscriptionsTestCase(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.substrate = SubstrateInterface(
url=settings.POLKADOT_NODE_URL
)
def test_query_subscription(self):
def subscription_handler(obj, update_nr, subscription_id):
return {'update_nr': update_nr, 'subscription_id': subscription_id}
result = self.substrate.query("System", "Events", [], subscription_handler=subscription_handler)
self.assertEqual(result['update_nr'], 0)
self.assertIsNotNone(result['subscription_id'])
def test_subscribe_storage_multi(self):
def subscription_handler(storage_key, updated_obj, update_nr, subscription_id):
return {'update_nr': update_nr, 'subscription_id': subscription_id}
storage_keys = [
self.substrate.create_storage_key(
"System", "Account", ["5GrwvaEF5zXb26Fz9rcQpDWS57CtERHpNehXCPcNoHGKutQY"]
),
self.substrate.create_storage_key(
"System", "Account", ["5FHneW46xGXgs5mUiveU4sbTyGBzmstUspZC92UhjJM694ty"]
)
]
result = self.substrate.subscribe_storage(
storage_keys=storage_keys, subscription_handler=subscription_handler
)
self.assertEqual(result['update_nr'], 0)
self.assertIsNotNone(result['subscription_id'])
def test_subscribe_new_heads(self):
def block_subscription_handler(obj, update_nr, subscription_id):
return obj['header']['number']
result = self.substrate.subscribe_block_headers(block_subscription_handler, finalized_only=True)
self.assertGreater(result, 0)
if __name__ == '__main__':
unittest.main()
|
from flask import request, jsonify
from werkzeug.security import generate_password_hash
import re
import json
from ..models.models import Users, get_all_users
def register_user():
"""This method handles the registration of a new user"""
data = request.json
given_data = {
"username": data.get("username"),
"email": data.get("email"),
"password": data.get("password"),
"confirm_password": data.get("confirm_password"),
"role": data.get("role")
}
if not all(
[data.get('username'),
data.get('email'),
data.get('password'),
data.get('confirm_password')]
):
return jsonify({'error': 'Missing field/s'}), 400
try:
int(given_data["username"])
return jsonify({"error": "username cannot be an integer"}), 400
except:
pass
if given_data["username"] is not None and given_data["username"].strip() == "":
return jsonify({"error": "Required field/s Missing"}), 400
if given_data["email"] is not None and given_data["email"].strip() == "":
return jsonify({"error": "Required field/s Missing"}), 400
if given_data["password"] is not None and given_data["password"].strip() == "":
return jsonify({"error": "Required field/s Missing"}), 400
if given_data["confirm_password"] is not None and given_data["confirm_password"].strip(
) == "":
return jsonify({"error": "Required field/s Missing"}), 400
if given_data["role"] is None:
given_data["role"] = "user"
if not re.match(r"[^@]+@[^@]+\.[^@]+", given_data["email"]):
return jsonify({"error": "Invalid email"}), 400
if given_data["password"] != given_data["confirm_password"]:
return jsonify({"error": "Your passwords do not match!"}), 400
if len(given_data["password"]) < 5:
return jsonify({"error": "Password too short!"}), 400
else:
new_user = Users(
given_data["username"],
given_data["email"],
generate_password_hash(given_data["password"], method='sha256'),
given_data["role"]
)
all_users = get_all_users()
for user in all_users:
if user["username"] == new_user.username:
return jsonify({"error": "Username already taken!"}), 409
elif user["email"] == new_user.email:
return jsonify({"error": "Email already exists!"}), 409
new_user.create_user()
return jsonify({"message": "Registration Successfull"}), 201
|
import cv2
import time
import numpy as np
#计算程序执行时间的装饰器
def time_test(fn):
def _wrapper(*args, **kwargs):
start = time.clock()
location = fn(*args, **kwargs)
print ("%s() cost %s second" % (fn.__name__, time.clock() - start))
return location
return _wrapper
@time_test
def img_choose(img_name, threshold = [80, 110]):
deep_img = cv2.imread(img_name, 0)
region = (threshold[0] < deep_img) & (deep_img < threshold[1])
#region = np.zeros(deep_img.shape, dtype = 'bool')
#region[threshold[0] < deep_img & deep_img < threshold[1]] = True
shape = deep_img.shape
height = np.arange(0, shape[0], 1)
width = np.arange(0, shape[1], 1)
location = [int(shape[0]/2), int(shape[1]/2), int(shape[0]/2), int(shape[1]/2)] #top-left, bottom_right
for h in height:
for w in width:
if(region[h, w]):
if(h < location[0] and region[h - 2 : h + 2, w - 2 : w + 2].all()): location[0] = h
if(w < location[1] and region[h - 2 : h + 2, w - 2 : w + 2].all()): location[1] = w
if(h > location[2] and region[h - 2 : h + 2, w - 2 : w + 2].all()): location[2] = h
if(w > location[3] and region[h - 2 : h + 2, w - 2 : w + 2].all()): location[3] = w
return location #return top-left', bottom_right' coordinate
if __name__ == '__main__':
location = img_choose('614994183907944461.jpg', [70, 110])
print(location) |
a=int(input("ENTER 1 : "))
b=int(input("ENTER 2 : "))
degit=0
while a>0 and b>0:
if a%10==b%10:
degit+=1
a//=10
b//=10
print(degit)
|
# Ryan Spies
# 3/28/13
# Python 2.6.5
# This script converts .MAP and .MAT files into simple tab delimited text
# files for use in matlab
#!!!!!!!!!!! Units left in inches and degrees F !!!!!!!!!!!!!!!!!!!!!!!
#!!!!!!!!!!! Data must be 6 hour time steps !!!!!!!!!!!!!!!!!!!!!!
import os
import datetime
os.chdir("../..")
maindir = os.getcwd()
######################## User Input Section ############################
path = os.getcwd()
rfc = 'MBRFC_FY2017'
variable = 'MAP'
map_dir = maindir + '\\Calibration_NWS\\' + rfc[:5] + os.sep + rfc + '\\datacards\\Forcings\\MAP\\Bighorn\\'
output_dir = maindir + '\\Calibration_NWS\\' + rfc[:5] + os.sep + rfc + '\\datacards\\Forcings\\' + variable +'\\' + variable + '_single_column\\'
###################### End User Input ##################################
# give directory of original RFC MAP/MAT files
rfc_files = os.listdir(map_dir)
#rfc_files=['notg1']
for basin_file in rfc_files:
basin_files = os.listdir(map_dir + basin_file)
for files in basin_files:
variable = variable[:3]
# locate only .mat and .map files
if files[-5:] == variable + '06' or files[-3:] == variable:
basin = files.split('.')[0]
basin_title = str.upper(basin)
#var = files[-5:]
print basin_title + ' : ' + variable
if files[-5:]== variable + '06':
variable = variable + '06'
# enter file locations for old and new files
file1 = map_dir + basin_file + '\\' + files
fw = open(output_dir + '\\' + basin_title + '_' + variable + '.txt','w')
fg = open(file1,'r')
for each in fg:
if each[:20] == '$ PERIOD OF RECORD=':
start_year = int(each[23:27]); start_mn = int(each[20:22]); begin = start_year
end_year = int(each[-5:-1]); end_mn = int(each[-8:-6])
fg.close()
break
years = []
while start_year <= end_year:
years.append(start_year)
start_year += 1
count_time = 0
count_out = 0
count_years = 0
for yr_num in years:
count_years += 1
if yr_num == begin:
timestamp = datetime.datetime(yr_num,start_mn,1,6)
else:
timestamp = datetime.datetime(yr_num,1,1,6)
hours6 = datetime.timedelta(hours=6)
print yr_num
# process data for specified years
# start = datetime.datetime(start_year,start_mn,1,0)
# end = datetime.datetime(end_year,end_mn+1,1,0)
# print start
# print end
# count_out = 0
# count_time = 0
# hours6 = datetime.timedelta(hours=6)
# timestamp = start
# while timestamp <= end:
# print timestamp
# load the RFC data file
fg = open(file1,'r')
count = 0
for each in fg:
if count > 6:
spl = each.split()
# data format for years prior to 2000
if len(spl) == 8 or len(spl) == 6 or len(spl) == 4:
#mn = int(spl[0])
mnyr = spl[0]
yr = mnyr[-2:]
if int(yr) <= 20: #change format for years >= 2010
yr = '20' + yr
else:
yr = '19' + yr
mn = mnyr[:-2]
if yr == str(yr_num) and mn == str(timestamp.month):
for num in spl:
if len(num) > 4:
# write output file in column format
fw.write(str(timestamp) + '\t')
fw.write(str(num) + '\n')
timestamp = (timestamp + hours6)
count_out += 1
count_time += 1
# data format for years 2000+
elif len(spl) == 9 or len(spl) == 7 or len(spl) == 5:
#mn = int(spl[0])
yr = spl[1]
mn = spl[0]
if len(yr) == 1:
yr = '0' + yr
yr = '20' + yr
if yr == str(yr_num) and mn == str(timestamp.month):
for num in spl:
if len(num) > 4:
# write output file in column format
fw.write(str(timestamp) + '\t')
fw.write(str(num) + '\n')
timestamp = (timestamp + hours6)
count_out += 1
count_time += 1
else:
timestamp = (timestamp + hours6)
count_time += 1
print '### Caution: data not found -> ' + str(timestamp)
count += 1
fg.close()
fw.close()
print 'timesteps:\t' + str(count_time)
print 'output: \t' + str(count_out)
print 'Finito!!!'
|
import PyPDF2
pdf_file = PyPDF2.PdfFileReader('super.pdf', 'rb')
watermark = PyPDF2.PdfFileReader('wtr.pdf', 'rb')
output = PyPDF2.PdfFileWriter()
for i in range(pdf_file.getNumPages()):
page = pdf_file.getPage(i)
page.mergePage(watermark.getPage(0))
output.addPage(page)
with open('edited.pdf', 'wb') as file1:
output.write(file1)
# with open('edited.pdf', 'wb') as new_pdf:
##writer = PyPDF2.PdfFileWriter()
# writer.addPage(merged)
|
# -*- coding: utf-8 -*-
from datetime import datetime
import pytz
from django.contrib.auth import get_user_model
from django.core.mail import EmailMessage
from progress_analyzer.helpers.helper_classes import ProgressReport
def str_to_dt(dt_str):
if dt_str:
return datetime.strptime(dt_str,"%Y-%m-%d")
else:
return None
def stringfy_error_objects(username,error_objs):
error_str = """User '{}' has the following negative values - \n""".format(username)
for obj in error_objs:
estr = "Summary Type: {} | Field Name: {} | Duration: {} | Value: {}\n"
estr = estr.format(
obj['summary'],obj['field'], obj['duration'], obj['value']
)
error_str += estr
return error_str
def prepare_report(users_having_negative_pa,for_date,check_start_time,check_end_time):
file_name = "pa-log-{}.txt".format(check_start_time.strftime("%Y-%m-%dT%H:%M"))
fh = open(file_name,'+a')
fh.write("Check Start Time: {}\n".format(check_start_time.isoformat()))
fh.write("Check End Time: {}\n".format(check_end_time.isoformat()))
fh.write("PA Report is for: {}\n".format(for_date))
fh.write("\n\n")
for username,error_objs in users_having_negative_pa.items():
error_str = stringfy_error_objects(username,error_objs)
fh.write(error_str)
fh.write("\n\n")
fh.close()
return fh
def check_negative_numbers(pa_data):
# ignore custom ranges
fields_with_negative_number = []
for summary_type,summary_data in pa_data['summary'].items():
for field_type, field_data in summary_data.items():
for duration_type, avg_data in field_data.items():
if ((type(avg_data) is int or type(avg_data) is float)
and avg_data < 0
# Stress level can be -1 so ignore it
and not field_type == "garmin_stress_lvl"):
# negative number detected
error_obj = {
"summary":summary_type,
"field":field_type,
"duration":duration_type,
"value":avg_data
}
fields_with_negative_number.append(error_obj)
return fields_with_negative_number
def send_email(report, recipients):
# recipients is a list of all recipients
if recipients and report:
with open(report.name,'r') as fh:
mail = EmailMessage()
mail.subject = "Negative Number Alert | Hourly Logs"
mail.body = ""
mail.to = recipients
mail.attach(fh.name, fh.read(), "text/plain")
mail.send()
def generate_incorrect_pa_report(recipients,for_date=None):
check_start_time = pytz.utc.localize(datetime.utcnow())
if not for_date:
for_date = pytz.utc.localize(datetime.utcnow())
else:
for_date = str_to_dt(for_date)
users_having_negative_pa = {}
for user in get_user_model().objects.all():
query_params = {"date":for_date.strftime("%Y-%m-%d")}
pa_data = ProgressReport(user,query_params).get_progress_report()
meta = check_negative_numbers(pa_data)
if meta:
users_having_negative_pa[user.username] = meta
check_end_time = pytz.utc.localize(datetime.utcnow())
if users_having_negative_pa:
report = prepare_report(users_having_negative_pa,for_date,
check_start_time, check_end_time)
send_email(report,recipients) |
def main():
print("Syötä kilpailijan nimi ja pistemäärä. Lopeta syöttämällä tyhjä rivi.")
rivi = "a"
dict = {}
summadict = {}
nimilista = []
while rivi != "":
rivi = input("")
if rivi == "":
break
nimi, numero = rivi.split(" ")
numero = str(numero)
if nimi not in dict:
dict[nimi] = numero
elif nimi in dict:
dict[nimi] += " "+numero
numero = int(numero)
if nimi not in summadict:
summadict[nimi] = numero
elif nimi in summadict:
summadict[nimi] += numero
print("Kilpailijoiden pistetilanne:")
for x in sorted(dict):
print(x, dict[x], "=", summadict[x])
main() |
import functools
print("We have three helpful functions; filter(), map() y reduce()")
print("All of them receive a function and one or more secuences (depending of the number of paramaters that the function receive)")
def return_some_prime_numbers(x): return x%2!=0 and x%3!=0
print("For a function like this 'def return_some_prime_numbers(x): return x%2!=0 and x%3!=0' we can use the next call: filter(return_some_prime_numbers,range(2,25))")
result=filter(return_some_prime_numbers,range(2,25))
print(list(result))
print("The map() function help us to execute one task to all the elements contained into a list")
print("If we want to know the cube for each element into a list, we can create a function like this: def return_cube(x): return x**3")
def return_cube(x): return x**3
print("And then, call it using something like this: map(return_cube,range(1,11))")
result=map(return_cube,range(1,11))
print(list(result))
print("reduce() is another function, it take the first two elements into the sequence, execute the operation for them, and then execute the function again taking the result for the previous operation and the next value into the sequence")
print("If we want to sum all the numbers from 0 to 10, we can create a function that sum two numbers like this: def sum(x,y): return x+y")
def sum(x,y): return x+y
print("Now we can call it with an expresion like this: functools.reduce(sum,range(1,11))")
result=functools.reduce(sum,range(1,11))
print(result)
print("We can also apply operations without the previous mentioned functions, this kind of implementation al call LC's, example:")
print("We can create a sequence like this: fruits=['fresa ',' uva ',' durazno'] and apply the function strip() to each element with the next instriction: [fruit.strip() for fruit in fruits] -> the brackets are mandatory")
fruits=['fresa ',' uva ',' durazno']
result=[fruit.strip() for fruit in fruits]
print(result)
print("We can also delete elements from a sequence, using the reserved word: 'del', from the previous sequence:",result)
print("We can delete an element, for example, using a this call: del result[1], we wll delete the second element into the sequence")
del result[1]
print(result)
|
# -*- coding: utf-8 -*-
"""
Created on Wed Apr 10 21:34:02 2019
@author: My
"""
# Import libraries
# math library
import numpy as np
# visualization library
%matplotlib inline
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('png2x','pdf')
import matplotlib.pyplot as plt
# machine learning library
from sklearn.linear_model import LogisticRegression
# 3d visualization
from mpl_toolkits.mplot3d import axes3d
# computational time
import time
import os
os.chdir('C:/Users/My/Desktop')
df = np.loadtxt('all_out_mat.csv', delimiter=',')
# number of training data
n = df.shape[0] #YOUR CODE HERE
print('Number of training data=',n)
# print
print(df[:10,:])
print(df.shape)
print(df.dtype)
from sklearn.model_selection import train_test_split
data, test = train_test_split(df, test_size=0.2)
#%%
# number of training data
n = data.shape[0]
print('Number of training data=',n)
# print
print(data[:10,:])
print(data.shape)
print(data.dtype)
# plot
x1 = data[:,0] # feature 1
x2 = data[:,1] # feature 2
idx_class0 = (data[:,3]==0) # index of class0
idx_class1 = (data[:,3]==1) # index of class1
plt.figure(1,figsize=(6,6))
plt.scatter(x1[idx_class0], x2[idx_class0], s=60, c='r', marker='+', label='bad')
plt.scatter(x1[idx_class1], x2[idx_class1], s=30, c='b', marker='o', label='good')
plt.title('Training data')
plt.legend()
plt.show()
#%%
# sigmoid function
def sigmoid(z):
sigmoid_f = 1 / (1 + np.exp(-z))
return sigmoid_f
# predictive function definition
def f_pred(X,w):
p = sigmoid(X.dot(w))
return p
# loss function definition
def loss_logreg(y_pred,y):
n = len(y)
loss = -1/n* ( y.T.dot(np.log(y_pred)) + (1-y).T.dot(np.log(1-y_pred)) )
return loss
# gradient function definition
def grad_loss(y_pred,y,X):
n = len(y)
grad = 2/n* X.T.dot(y_pred-y)
return grad
# gradient descent function definition
def grad_desc(X, y , w_init, tau, max_iter):
L_iters = np.zeros([max_iter]) # record the loss values
w = w_init # initialization
for i in range(max_iter): # loop over the iterations
y_pred = f_pred(X,w) # linear predicition function
grad_f = grad_loss(y_pred,y,X) # gradient of the loss
w = w - tau* grad_f # update rule of gradient descent
L_iters[i] = loss_logreg(y_pred,y) # save the current loss value
return w, L_iters
#%%
# construct the data matrix X, and label vector y
n = data.shape[0]
X = np.ones([n,6])
X[:,1:3] = data[:,0:2]
X[:,3] = data[:,0]**2
X[:,4] = data[:,1]**2
X[:,5] = data[:,0]*data[:,1]
print(X.shape)
y = data[:,3][:,None] # label
print(y.shape)
# run gradient descent algorithm
start = time.time()
w_init = np.array([0,0,0,0,0,0])[:,None]
tau = 1e-1; max_iter = 5000
w, L_iters = grad_desc(X,y,w_init,tau,max_iter)
print('Time=',time.time() - start)
print(L_iters[-1])
print(w)
# compute values p(x) for multiple data points x
x1_min, x1_max = X[:,1].min(), X[:,1].max() # min and max of grade 1
x2_min, x2_max = X[:,2].min(), X[:,2].max() # min and max of grade 2
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max)) # create meshgrid
X2 = np.ones([np.prod(xx1.shape),6])
X2[:,1] = xx1.reshape(-1)
X2[:,2] = xx2.reshape(-1)
X2[:,3] = xx1.reshape(-1)**2
X2[:,4] = xx2.reshape(-1)**2
X2[:,5] = xx1.reshape(-1)*xx2.reshape(-1)
p = f_pred(X2,w)
p = p.reshape(xx1.shape)
# plot
plt.figure(4,figsize=(6,6))
plt.scatter(x1[idx_class0], x2[idx_class0], s=60, c='r', marker='+', label='Class0')
plt.scatter(x1[idx_class1], x2[idx_class1], s=30, c='b', marker='o', label='Class1')
plt.contour(xx1, xx2, p, [0.5], linewidths=2, colors='k')
plt.legend()
plt.title('Decision boundary (quadratic)')
plt.show() |
# -*- coding: utf-8 -*-
class BinNode(object):
def __init__(self, value, left_child=None, right_child=None):
self.lChild = left_child
self.rChild = right_child
self.value = value
def addLeft(self, lChild):
self.lChild = lChild
def addRight(self, rChild):
self.rChild = rChild
def add(self, child):
if self.lChild is None:
self.lChild = child
elif self.rChild is None:
self.rChild = child
else:
raise Exception("Couldn't add the third child")
def headTraverse(self, ret):
ret.append(self.value)
if self.lChild:
self.lChild.headTraverse(ret)
if self.rChild:
self.rChild.headTraverse(ret)
def midTraverse(self, ret):
if self.lChild:
self.lChild.midTraverse(ret)
ret.append(self.value)
if self.rChild:
self.rChild.midTraverse(ret)
def rearTraverse(self, ret):
if self.lChild:
self.lChild.rearTraverse(ret)
if self.rChild:
self.rChild.rearTraverse(ret)
ret.append(self.value)
class TriNode(BinNode):
def __init__(self, value, root, left_child=None, right_child=None, ):
super(TriNode, self).__init__(value, left_child, right_child)
self.root = root
def buildTree(nums):
if nums is 0:
return None
tmp = nums
root = BinNode(0)
nums -= 1
layer = [root] * 2
while nums:
new = BinNode(tmp-nums)
layer.pop(0).add(new)
layer.append(new)
layer.append(new)
nums-=1
return root
nums = 10
root = buildTree(nums)
ret = []
root.headTraverse(ret)
print(ret)
ret = []
root.midTraverse(ret)
print(ret)
ret = []
root.rearTraverse(ret)
print(ret)
"""
0
/ \
1 2
/ \ / \
3 4 5 6
/ \ / \ / \ / \
7 8 9 10
"""
|
"""Given a array of numbers, output the array like this:
a1 <= a2 >= a3 <= a4 >= a5...
"""
import unittest
def print_list(alist):
out = ''
for i in range(len(alist)):
if i > 0:
out += (' <' if i % 2 else ' >') + '= '
out += str(alist[i])
return out
class OutputTest(unittest.TestCase):
def setUp(self):
self.array = range(1, 5 + 1)
def test_output(self):
output = print_list(self.array)
self.assertEqual(output, '1 <= 2 >= 3 <= 4 >= 5')
if __name__ == '__main__':
unittest.main()
|
# function 定义
# 无参定义
def say_hello():
"""函数定义"""
print("hello dear.")
say_hello() # 函数调用
# 带有参数的定义
def get_max(a, b): # 形参(形式参数)
if a > b:
print(a)
else:
print(b)
get_max(3, 5) # 传递实参,与形参位置对应,个数也与形参相对应,会按顺序传参(位置参数)
get_max(b=5, a=12) # 关键字参数调用,这里就可以与参数顺序无关了
# 默认参数
def get_square(num, lo=2):
print(num**lo)
# get_square(5)
# get_square(4, 3)
# 可变长参数
def get_sum(*num):
"""可变长参数函数"""
summ = 0
for i in num:
summ += i
return summ
print(get_sum(1, 2, 3, 4, 5, 6, 7, 8, 9))
def print_alpha(*args):
"""可变长参数
:param args: 代表可以传入多个参数
"""
for i in args:
print(i)
print_alpha("a", "b", "c")
# list1 = [1,2,3,4,5]
# print(sum(list1))
# print(set("abc").issubset(set("aabccd")))
|
# CD to DAPPER folder
from IPython import get_ipython
IP = get_ipython()
if IP.magic("pwd").endswith('tutorials'):
IP.magic("cd ..")
elif IP.magic("pwd").endswith('DA and the Dynamics of Ensemble Based Forecasting'):
IP.magic("cd ../..")
else:
assert IP.magic("pwd").endswith("DAPPER")
# Load DAPPER
from common import *
# Load answers
from tutorials.resources.answers import answers, show_answer
# Load widgets
from ipywidgets import *
import markdown
|
# SPDX-License-Identifier: BSD-2-Clause
import time
import sys
import traceback
import socket
import struct
import threading
import curses
import atexit
try:
import RPi.GPIO as gpio
except:
pierr = "Rpi.GPIO not loaded"
try:
import audiodev
import audiospeex
except:
print('cannot load audiodev.so and audiospeex.so, please set the PYTHONPATH')
traceback.print_exc()
sys.exit(-1)
class radiopeer():
#os.system('clear')
def __init__(self):
self.__parent = super(radiopeer, self)
self._loopthread = False
self._rqueue = []
self._squeue = []
self._timec = 0
self._packlag = 0
self._remotepacklag = 0
self._thispeer_ipin = None
self._thispeer_portin = None
self._sockin = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # UDP
self._sockout = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # UDP
self._upsample = None
self._downsample = None
self._enc = None
self._dec = None
self._to_peer_port = None
self._peerip = None
self._cardname = 'default'
self._stimeout = 0
self._stimeout_ct = True
self._isbase = True
self._statsndpack = " "
self._statrecvpack = " "
self._pttstate = "OFF"
self._pttstaterec = 0
self._recbuffer = 0
self._buffcontrol = True
self._stdscr = curses.initscr()
self._lock = threading.RLock()
self.termcolor = False
self._screenrefresh = 0
self.pttpin = 0
self._soundbuff = []
self._databuff = []
self._gateip = None
def startout(self):
self._loopthread = True
self.__ctrdev(1)
self._stdscr.nodelay(1)
self.__raspberryconf()
self._sockin.bind((self._thispeer_ipin, self._thispeer_portin))
g = threading.Thread(target=self.__getpacks, args=())
g.setDaemon(True)
g.start()
r = threading.Thread(target=self.__sendpacks, args=())
r.setDaemon(True)
r.start()
s = threading.Thread(target=self.__statscreen, args=())
s.setDaemon(True)
s.start()
y = threading.Thread(target=self.__getkeyboard, args=())
y.setDaemon(True)
y.start()
if self._gateip != None:
v = threading.Thread(target=self.__sndip2gate, args=())
v.setDaemon(True)
v.start()
def __sndip2gate(self):
while self._loopthread == True:
data = 'HELLO GATE-'
if self._isbase == True:
data = data + 'BASE'
else:
data = data + 'REMOTE'
data = data.encode('utf-8')
self._sockout.sendto(data, (self._gateip, self._to_peer_port))
time.sleep(10)
def gateip(self, gateip):
self._gateip = gateip
def getcardinfo(self):
d1 = audiodev.get_api_name()
d2 = audiodev.get_devices()
print("API name: "+str(d1))
print("Sound devices: "+str(d2))
def __raspberryconf(self):
if self.pttpin != 0 and self._isbase:
gpio.setmode(gpio.BCM)
gpio.setup(self.pttpin, gpio.OUT) # PTT
gpio.output(self.pttpin, False)
def __getkeyboard(self):
while self._loopthread == True:
#stdscr = curses.initscr()
self._lock.acquire()
curses.noecho()
self._stdscr.keypad(1)
key = self._stdscr.getch()
if not self._isbase:
if key == 80 or key == 112:
if self._pttstate == "ON":
self._pttstate = "OFF"
else:
self._pttstate = "ON"
if key == 101:
if self.pttpin != 0 and self._isbase:
gpio.output(self.pttpin, False)
gpio.cleanup()
curses.echo()
curses.endwin()
self._loopthread = False
#os.kill(os.getppid(), signal.SIGKILL)
curses.flushinp()
self._lock.release()
time.sleep(0.1)
def __statscreen(self):
while self._loopthread == True:
tt = int(time.time())
if tt - self._screenrefresh > 5:
self._stdscr.clear()
self._stdscr.refresh()
self._screenrefresh = tt
mode = "Remote"
if self._isbase:
mode = "Base"
# https://stackoverflow.com/questions/18551558/how-to-use-terminal-color-palette-with-curses
if self.termcolor == True:
curses.start_color()
curses.init_pair(1, 254, 0)
cl1 = curses.color_pair(1)
curses.init_pair(2, 227, 0)
cl2 = curses.color_pair(2)
curses.init_pair(3, 46, 0)
cl3 = curses.color_pair(3)
curses.init_pair(4, 111, 0)
cl4 = curses.color_pair(4)
curses.init_pair(5, 196, 0)
cl5 = curses.color_pair(5)
curses.init_pair(6, 172, 0)
cl6 = curses.color_pair(6)
else:
cl1 = 0
cl2 = 0
cl3 = 0
cl4 = 0
cl5 = 0
cl6 = 0
lline = "-"*60
# maker color disponible: export TERM='xterm-256color'
try:
self._stdscr.addstr(0, 0, "(P)", cl6)
self._stdscr.addstr(0, 3, "TT switch", cl1)
self._stdscr.addstr(0, 14, "(E)", cl6)
self._stdscr.addstr(0, 17, "xit", cl1)
self._stdscr.addstr(1, 0, lline, cl4)
self._stdscr.addstr(2, 0, "Mode:" , cl1)
self._stdscr.clrtoeol()
self._stdscr.addstr(2, 8, mode, cl3)
self._stdscr.clrtoeol()
self._stdscr.addstr(3, 0, lline, cl4)
self._stdscr. clrtoeol()
self._stdscr.addstr(4, 0, "Status:", cl1)
self._stdscr.clrtoeol()
self._stdscr.addstr(4, 8, "Listening on", cl1)
self._stdscr.addstr(4, 21, self._thispeer_ipin + ":" + str(self._thispeer_portin), cl3)
self._stdscr.clrtoeol()
self._stdscr.addstr(4, 44, "To Port:", cl1)
self._stdscr.clrtoeol()
self._stdscr.addstr(4, 53, str(self._to_peer_port), cl3)
self._stdscr.clrtoeol()
self._stdscr.addstr(5, 0, "Peer:", cl1)
self._stdscr.clrtoeol()
self._stdscr.addstr(5, 6, str(self._peerip), cl3)
self._stdscr.clrtoeol()
self._stdscr.addstr(5, 23, "Lag:", cl1)
self._stdscr.clrtoeol()
self._stdscr.addstr(5, 28, str(self._packlag), cl3)
self._stdscr.clrtoeol()
self._stdscr.addstr(5, 35, "Remote Lag:", cl1)
self._stdscr.clrtoeol()
self._stdscr.addstr(5, 47, str(self._remotepacklag), cl3)
self._stdscr.clrtoeol()
self._stdscr.addstr(6, 0, lline, cl4)
self._stdscr.clrtoeol()
self._stdscr.addstr(7, 0, "Send: ", cl1)
self._stdscr.clrtoeol()
self._stdscr.addstr(7, 6, self._statsndpack, cl2)
self._stdscr.clrtoeol()
self._stdscr.addstr(7, 11, "Receive:", cl1)
self._stdscr.clrtoeol()
self._stdscr.addstr(7, 20, self._statrecvpack, cl2)
if self._buffcontrol == True and self._stimeout_ct == False:
self._stdscr.addstr(7, 35, "Buffering ...", cl5)
self._stdscr.clrtoeol()
self._stdscr.clrtoeol()
self._stdscr.addstr(8, 0, lline, cl4)
self._stdscr.clrtoeol()
if not self._isbase:
self._stdscr.addstr(9, 0, "PTT:", cl1)
if self._pttstate == "ON":
tc = cl5
else:
tc = cl3
self._stdscr.addstr(9, 5, self._pttstate, tc)
self._stdscr.clrtoeol()
self._stdscr.addstr(10, 0, lline, cl4)
self._stdscr.move(12,0)
else:
self._stdscr.move(10, 0)
if pierr != None and self._isbase:
self._stdscr.addstr(13, 0, "Warning: " + pierr, cl5)
except:
pass
time.sleep(0.05)
def setcardname(self, card):
self._cardname = card
def thispeer(self, thispeer_ip, thispeer_port, to_peer_port):
self._thispeer_ipin = thispeer_ip
self._thispeer_portin = thispeer_port
self._to_peer_port = to_peer_port
def getbaseon(self, peerip):
self._peerip = peerip
self._isbase = False
def __sendpacks(self):
while self._loopthread == True:
self.__timeoutcheck()
pl = len(self._squeue)
if pl == 26 and self._isbase == False or pl == 26 and self._stimeout_ct == False:
packtime = int(time.time())
self._squeue.append(packtime)
if self._pttstate == "ON":
pttstate = 1
else:
pttstate = 0
self._squeue.append(pttstate)
self._squeue.append(self._packlag)
try:
packer = struct.Struct('38s ' * 26 + 'I' + 'I' + 'I')
packed_data = packer.pack(*self._squeue)
self._sockout.sendto(packed_data, (self._peerip, self._to_peer_port))
except:
pass
self._squeue = []
if self._statsndpack == " ":
self._statsndpack = "X"
else:
self._statsndpack = " "
elif len(self._squeue) > 26:
self._statsndpack = " "
self._peerip = None
self._squeue = []
def __timeoutcheck(self):
time.sleep(0.01) # Avoid hog CPU
if int(time.time()) - self._stimeout > 2:
self._stimeout_ct = True
self._statrecvpack = " "
self._packlag = 0
else:
self._stimeout_ct = False
def __getpacks(self):
while self._loopthread == True:
try:
data, addr = self._sockin.recvfrom(1024) # buffer size is 1024 bytes
self._stimeout = int(time.time())
if self._peerip is None:
self._peerip = addr[0]
unpacker = struct.Struct('38s ' * 26 + 'I' + 'I' + 'I')
ntq = unpacker.unpack(data)
for fragment in ntq:
self._rqueue.append(fragment)
self.__packprocs()
if self._statrecvpack == " ":
self._statrecvpack = "X"
else:
self._statrecvpack = " "
except:
pass
def __ctrdev(self, ct):
if ct == 1:
audiodev.open(output=self._cardname, input=self._cardname,
format="l16", sample_rate=48000, frame_duration=20,
output_channels=2, input_channels=1, flags=0x01, callback=self.__datainout)
if ct == 0:
audiodev.close()
def defbuffer(self, buff):
self._recbuffer = buff * 50
def __packprocs(self):
if len(self._rqueue) > self._recbuffer and self._buffcontrol == True:
self._buffcontrol = False
if len(self._rqueue) != 0 and self._buffcontrol == False:
while len(self._rqueue) > 0:
for x in range(0, 26):
self._soundbuff.append(self._rqueue.pop(0))
for x in range(26, 29):
self._databuff.append(self._rqueue.pop(0))
def __getparams(self):
self._timec = self._timec + 1
if self._timec == 26:
self._timec = 0
self._packlag = int(time.time()) - self._databuff.pop(0)
pttstate = self._databuff.pop(0)
self._remotepacklag = self._databuff.pop(0)
if pttstate == 1 and self._pttstaterec == 0:
self._pttstaterec = 1
gpio.output(self.pttpin, True)
elif pttstate == 0 and self._pttstaterec == 1:
self._pttstaterec = 0
gpio.output(self.pttpin, False)
def __uglywave(self):
res = b''
pt = 0
for y in range(0, 320):
pt = pt + 1
if pt > 76:
uu = 0
pt = 0
else:
uu = 125
ba = bytes([uu])
res = res + ba
return res
def __datainout(self, fragment, timestamp, userdata):
fragout1, self._downsample = audiospeex.resample(fragment, input_rate=48000, output_rate=8000, state=self._downsample)
#fragout1 = self.__uglywave()
fragout2, self._enc = audiospeex.lin2speex(fragout1, sample_rate=8000, state=self._enc)
self._squeue.append(fragout2)
try:
if len(self._soundbuff) != 0:
self.__getparams()
fragin1 = self._soundbuff.pop(0)
fragin3, self._dec = audiospeex.speex2lin(fragin1, sample_rate=8000, state=self._dec)
fragin4, self._upsample = audiospeex.resample(fragin3, input_rate=8000, output_rate=48000, state=self._upsample)
fragin5 = fragin4 + fragin4 # create stereo
return fragin5
else:
fragment = b'\x00' * 3840 # silence sample at output_rate=48000
self._buffcontrol = True
if self.pttpin !=0 and self._isbase:
gpio.output(self.pttpin, False)
return fragment
except:
pass
def close(self):
audiodev.close()
self._loopthread = False
@atexit.register
def _results():
print ("EXIT")
gpio.output(self.pttpin, False)
gpio.cleanup()
curses.endwin()
|
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# removeAcentos.py
#
# Copyright 2015 Cristian <cristian@cristian>
import sys
import libplnbsi
"""
Remover acentos de um texto
Exemplo: python3 removeAcentos.py <arquivo original> <arquivo sem acentos>
"""
def main():
PARAMETROS = 3
copiaArquivo = ""
if len(sys.argv) == PARAMETROS:
arquivo = open(sys.argv[1], 'r')
for texto in arquivo.readlines():
copiaArquivo += libplnbsi.removeAcento(texto)
#
novoArquivo = open(sys.argv[2], 'w')
novoArquivo.write(copiaArquivo)
novoArquivo.close()
arquivo.close()
else:
print("\nA função precisa receber dois parâmetros!\n")
#
return 0
if __name__ == '__main__':
main()
|
from django.contrib import admin
from media.models import *
admin.site.register(MediaType)
#class TagInline(admin.TabularInline):
# model = Tag
#admin.site.register(Tag, TagInline)
class MediaAdmin(admin.ModelAdmin):
model = Media
fields = ('is_featured', 'name', 'short_description', 'description', 'views', 'expires', 'upload_date', 'visibility', 'user', 'filesize', 'members', 'vendors', 'employees', 'contractors', 'file', 'duration', 'retention','mediatype', 'is_360', 'uuid')
search_fields = ['short_description', 'name']
# inlines = [
# TagInline,
# ]
admin.site.register(Media, MediaAdmin)
admin.site.register(Groups)
admin.site.register(Category)
class TagAdmin(admin.ModelAdmin):
search_fields = ['name']
admin.site.register(Tag, TagAdmin)
admin.site.register(UserProfile)
|
from . import temp_views as views
from rest_framework.routers import DefaultRouter
from django.urls import path, include
from . import api_view
router = DefaultRouter()
router.register(r"", api_view.StakeViewSet, basename="Stake")
app_name = "daru_wheel"
urlpatterns = [
path("stake", include(router.urls)),
path("", views.spin, name="spin"),
path("spin_it", views.spin_it, name="spin_it"),
path("spin", views.daru_spin, name="daru_spin"),
]
|
'''
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
enumerate(sequence, [start=0])
sequence – 一个序列、迭代器或其他支持迭代对象。
'''
'''
常规方法很容易想到,用内外两层循环即可
更加有效的方法是利用 HashMap存储 nums数组的值-索引
'''
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
dict = {}
result = []
for i , num in enumerate(nums):
div = target - num
if (div) in dict:
result.append(i)
result.append(dict[div])
return result
dict[num] = i
return result |
'''
@Description: In User Settings Edit
@Author: your name
@Date: 2019-08-19 20:11:09
@LastEditTime: 2019-09-06 15:27:05
@LastEditors: Please set LastEditors
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from layers import GraphConvolution,GConv
class GCNencoder(nn.Module):
def __init__(self, nfeat, z, dropout, nver):
super(GCNencoder, self).__init__()
self.nver = nver
self.nfeat = nfeat
self.gc1 = GraphConvolution(nfeat, 3*nfeat)
self.gc2 = GraphConvolution(3*nfeat, int(4*nfeat))
self.bn1 = nn.BatchNorm2d(1)
self.fc = nn.Linear(int(4*nver*nfeat), z)
self.dropout = dropout
def forward(self, l, n, adj):
out = torch.cat((l,n),3)
out = torch.tanh(self.bn1(self.gc1(out, adj)))
out = F.dropout(out, self.dropout, training=self.training)
out = torch.tanh(self.gc2(out, adj))
out = F.dropout(out, self.dropout, training=self.training)
out = out.view(-1, int(4*self.nver*self.nfeat))
out = self.fc(out)
return out
class GCNdecoder(nn.Module):
def __init__(self, nfeat, z, dropout, nver):
super(GCNdecoder, self).__init__()
self.nver = nver
self.nfeat = nfeat
self.fc = nn.Linear(z, int(4*nver*nfeat))
self.bnfc = nn.BatchNorm1d(int(4*nver*nfeat))
self.gc1 = GraphConvolution(int(4*nfeat+3), 3*nfeat)
self.bn1 = nn.BatchNorm2d(1)
self.gc2 = GraphConvolution(3*nfeat, int(nfeat/2))
self.dropout = dropout
def forward(self, z , n, adj):
out = self.fc(z)
out = torch.tanh(self.bnfc(out))
out = out.view(-1, 1, self.nver, int(4*self.nfeat))
out = torch.cat((out,n),3)
out = torch.tanh(self.bn1(self.gc1(out, adj)))
out = F.dropout(out, self.dropout, training=self.training)
out = torch.tanh(self.gc2(out, adj))
return out
class GCNcolorDecoder(nn.Module):
def __init__(self, nfeat, z, dropout, nver):
super(GCNcolorDecoder, self).__init__()
self.nver = nver
self.nfeat = nfeat
self.fc = nn.Linear(z, int(4*nver*nfeat))
self.bnfc = nn.BatchNorm1d(int(4*nver*nfeat))
self.gc1 = GraphConvolution(int(4*nver*nfeat)+3, int(3*nfeat))
self.bn1 = nn.BatchNorm2d(1)
self.gc2 = GraphConvolution(int(3*nfeat), 1)
self.dropout = dropout
def forward(self, z , n, adj):
out = self.fc(z)
out = torch.tanh(self.bnfc(out))
out = out.view(-1, 1, self.nver, int(4*self.nfeat))
out = torch.cat((out,n),3)
out = torch.tanh(self.bn1(self.gc1(out, adj)))
out = F.dropout(out, self.dropout, training=self.training)
out = torch.tanh(self.gc2(out, adj))
return out
class GAE(nn.Module):
def __init__(self, encoder, decoder):
super(GAE, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, l1, n1, adj1, n2, adj2):
z = self.encoder(l1, n1, adj1)
# if adj2 is not None:
# adj2 = adj2.permute(0, 1, 3, 2)
recons = self.decoder(z, n2, adj2)
return recons
class Discriminator(nn.Module):
def __init__(self, nfeat, nver, dropout):
super(Discriminator, self).__init__()
self.nver = nver
self.nfeat = nfeat
self.gc1 = GraphConvolution(nfeat, 2*nfeat)
self.gc2 = GraphConvolution(2*nfeat, 3*nfeat)
self.bn1 = nn.BatchNorm2d(1)
self.fc1 = nn.Linear(3*nver*nfeat, 1024)
self.fc2 = nn.Linear(1024, 1)
self.dropout = dropout
def forward(self,x1,adj1):
out1 = torch.tanh(self.bn1(self.gc1(x1, adj1)))
out1 = F.dropout(out1, self.dropout, training=self.training)
out1 = torch.tanh(self.gc2(out1, adj1))
out1 = F.dropout(out1, self.dropout, training=self.training)
out1 = out1.view(-1, int(3*self.nver*self.nfeat))
out1 = self.fc1(out1)
out1 = self.fc2(out1)
out1 = torch.sigmoid(out1)
return out1
class LSDiscriminator(nn.Module):
def __init__(self, nfeat, nver, dropout):
super(LSDiscriminator, self).__init__()
self.nver = nver
self.nfeat = nfeat
self.gc1 = GraphConvolution(nfeat, 2*nfeat)
self.bn1 = nn.BatchNorm2d(1)
self.gc2 = GraphConvolution(2*nfeat, 3*nfeat)
self.bn2 = nn.BatchNorm2d(1)
self.fc1 = nn.Linear(3*nver*nfeat, 1024)
self.bn3 = nn.BatchNorm1d(1024)
self.fc2 = nn.Linear(1024, 1)
self.dropout = dropout
def forward(self,x1,adj1):
out1 = torch.tanh(self.bn1(self.gc1(x1, adj1)))
out1 = F.dropout(out1, self.dropout, training=self.training)
out1 = torch.tanh(self.bn2(self.gc2(out1, adj1)))
out1 = F.dropout(out1, self.dropout, training=self.training)
out1 = out1.view(-1, int(3*self.nver*self.nfeat))
out1 = self.bn3(self.fc1(out1))
out1 = self.fc2(out1)
return out1
class ZDiscriminator(nn.Module):
def __init__(self, z,dropout):
super(ZDiscriminator, self).__init__()
self.z = z
self.fc1 = nn.Linear(self.z, self.z)
self.bn1 = nn.BatchNorm1d(self.z)
self.fc2 = nn.Linear(self.z, self.z)
self.bn2 = nn.BatchNorm1d(self.z)
self.fc3 = nn.Linear(self.z, self.z)
self.bn3 = nn.BatchNorm1d(self.z)
self.fc4 = nn.Linear(self.z, 1)
self.dropout = dropout
def forward(self,x1):
x1 = x1.view(-1, self.z)
out1 = torch.tanh(self.bn1(self.fc1(x1)))
out1 = F.dropout(out1, self.dropout, training=self.training)
out1 = torch.tanh(self.bn2(self.fc2(out1)))
out1 = F.dropout(out1, self.dropout, training=self.training)
out1 = torch.tanh(self.bn3(self.fc3(out1)))
out1 = F.dropout(out1, self.dropout, training=self.training)
out1 = self.fc4(out1)
out1 = torch.sigmoid(out1)
return out1
|
# Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
from __future__ import annotations
import pytest
from pants_release.changelog import Category, Entry, format_notes
@pytest.mark.parametrize("category", [*(c for c in Category if c is not Category.Internal), None])
def test_format_notes(category: None | Category) -> None:
entries = [Entry(category=category, text="some entry")]
heading = "Uncategorized" if category is None else category.heading()
formatted = format_notes(entries)
# we're testing the exact formatting, so no softwrap/dedent:
assert (
formatted
== f"""\
## {heading}
some entry"""
)
|
"""
BFS Algorithm - Iterative
"""
#graph to be explored, implemented using dictionary
g = {'A':['B','C','E'], 'B':['D','E'], 'E':['A','B','D'], 'D':['B','E'], 'C':['A','F','G'], 'F':['C'], 'G':['C']}
#function that visits all nodes of a graph using BFS (Iterative) approach
def BFS(graph,start):
queue = [start] #add nodes yet to be checked
explored = [] #add nodes already checked
while queue: #execute while loop until the list "queue" is empty
node=queue.pop(0) #gets first element of the list "queue"
if node not in explored:
explored.append(node) #add node to the list "explored"
neighbours = graph[node] #assign neighbours of the node
for n in neighbours:
queue.append(n) #adds neighbours of the node to the list "queue"
return explored
print(BFS(g,'A'))
|
for number in range(10):
print("send email", number+1, (number+1)*".")
|
import re
# Download the Data
! wget -O gdp_data.txt 'https://www.cia.gov/library/publications/the-world-factbook/rankorder/rawdata_2001.txt' |
"""Sengled Bulb Integration."""
import asyncio
import logging
_LOGGER = logging.getLogger(__name__)
class Switch:
def __init__(
self,
api,
device_mac,
friendly_name,
state,
device_model,
accesstoken,
country,
):
_LOGGER.debug("SengledApi: Switch " + friendly_name + " initializing.")
self._api = api
self._device_mac = device_mac
self._friendly_name = friendly_name
self._state = state
self._avaliable = True
self._just_changed_state = False
self._device_model = device_model
self._accesstoken = accesstoken
self._country = country
async def async_turn_on(self):
_LOGGER.debug("Switch " + self._friendly_name + " turning on.")
url = (
"https://"
+ self._country
+ "-elements.cloud.sengled.com/zigbee/device/deviceSetOnOff.json"
)
payload = {"deviceUuid": self._device_mac, "onoff": "1"}
loop = asyncio.get_running_loop()
loop.create_task(self._api.async_do_request(url, payload, self._accesstoken))
self._state = True
self._just_changed_state = True
async def async_turn_off(self):
_LOGGER.debug("Switch " + self._friendly_name + " turning off.")
url = (
"https://"
+ self._country
+ "-elements.cloud.sengled.com/zigbee/device/deviceSetOnOff.json"
)
payload = {"deviceUuid": self._device_mac, "onoff": "0"}
loop = asyncio.get_running_loop()
loop.create_task(self._api.async_do_request(url, payload, self._accesstoken))
self._state = False
self._just_changed_state = True
def is_on(self):
return self._state
async def async_update(self):
_LOGGER.debug("Switch " + self._friendly_name + " updating.")
if self._just_changed_state:
self._just_changed_state = False
else:
url = (
"https://element.cloud.sengled.com/zigbee/device/getDeviceDetails.json"
)
payload = {}
data = await self._api.async_do_request(url, payload, self._accesstoken)
_LOGGER.debug("Switch " + self._friendly_name + " updating.")
for item in data["deviceInfos"]:
for items in item["lampInfos"]:
self._friendly_name = items["attributes"]["name"]
self._state = (
True if int(items["attributes"]["onoff"]) == 1 else False
)
self._avaliable = (
False if int(items["attributes"]["isOnline"]) == 0 else True
)
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.