
html_url stringlengths 48 51 | title stringlengths 5 268 | comments stringlengths 70 51.8k | body stringlengths 0 29.8k | comment_length int64 16 1.52k | text stringlengths 164 54.1k | embeddings list |
|---|---|---|---|---|---|---|
https://github.com/huggingface/datasets/issues/649 | Inconsistent behavior in map | Thanks for reporting !
This issue must have appeared when we refactored type inference in `nlp`
By default the library tries to keep the same feature types when applying `map` but apparently it has troubles with nested structures. I'll try to fix that next week | I'm observing inconsistent behavior when applying .map(). This happens specifically when I'm incrementally adding onto a feature that is a nested dictionary. Here's a simple example that reproduces the problem.
```python
import datasets
# Dataset with a single feature called 'field' consisting of two examples
d... | 45 | Inconsistent behavior in map
I'm observing inconsistent behavior when applying .map(). This happens specifically when I'm incrementally adding onto a feature that is a nested dictionary. Here's a simple example that reproduces the problem.
```python
import datasets
# Dataset with a single feature called 'field... | [
0.3283728361129761,
-0.29242926836013794,
-0.07196908444166183,
0.08141161501407623,
-0.07207603007555008,
-0.20643611252307892,
0.06377099454402924,
0.01955341547727585,
0.20414860546588898,
-0.005322565790265799,
0.292031854391098,
0.5868220329284668,
0.20928767323493958,
0.1178400889039... |
https://github.com/huggingface/datasets/issues/647 | Cannot download dataset_info.json | Thanks for reporting !
We should add support for servers without internet connection indeed
I'll do that early next week | I am running my job on a cloud server where does not provide for connections from the standard compute nodes to outside resources. Hence, when I use `dataset.load_dataset()` to load data, I got an error like this:
```
ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/text... | 20 | Cannot download dataset_info.json
I am running my job on a cloud server where does not provide for connections from the standard compute nodes to outside resources. Hence, when I use `dataset.load_dataset()` to load data, I got an error like this:
```
ConnectionError: Couldn't reach https://storage.googleapis.com... | [
-0.2581687569618225,
0.024374015629291534,
-0.059488825500011444,
0.2031504511833191,
0.07885235548019409,
0.12885922193527222,
0.09597357362508774,
0.2360108494758606,
0.19916659593582153,
0.07956844568252563,
0.14541971683502197,
0.23831741511821747,
0.24385590851306915,
0.18965159356594... |
https://github.com/huggingface/datasets/issues/647 | Cannot download dataset_info.json | Right now the recommended way is to create the dataset on a server with internet connection and then to save it and copy the serialized dataset to the server without internet connection. | I am running my job on a cloud server where does not provide for connections from the standard compute nodes to outside resources. Hence, when I use `dataset.load_dataset()` to load data, I got an error like this:
```
ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/text... | 32 | Cannot download dataset_info.json
I am running my job on a cloud server where does not provide for connections from the standard compute nodes to outside resources. Hence, when I use `dataset.load_dataset()` to load data, I got an error like this:
```
ConnectionError: Couldn't reach https://storage.googleapis.com... | [
-0.27391406893730164,
0.05753080174326897,
-0.03478340804576874,
0.18709026277065277,
0.09355483949184418,
0.18032506108283997,
0.09542029350996017,
0.2747621238231659,
0.08295506983995438,
0.08681366592645645,
0.11729244142770767,
0.24106425046920776,
0.20684388279914856,
0.19720005989074... |
https://github.com/huggingface/datasets/issues/647 | Cannot download dataset_info.json | #652 should allow you to load text/json/csv/pandas datasets without an internet connection **IF** you've the dataset script locally.
Example:
If you have `datasets/text/text.py` locally, then you can do `load_dataset("./datasets/text", data_files=...)` | I am running my job on a cloud server where does not provide for connections from the standard compute nodes to outside resources. Hence, when I use `dataset.load_dataset()` to load data, I got an error like this:
```
ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/text... | 30 | Cannot download dataset_info.json
I am running my job on a cloud server where does not provide for connections from the standard compute nodes to outside resources. Hence, when I use `dataset.load_dataset()` to load data, I got an error like this:
```
ConnectionError: Couldn't reach https://storage.googleapis.com... | [
-0.27912092208862305,
0.05780753865838051,
-0.04657016322016716,
0.18359866738319397,
0.1229124367237091,
0.18686698377132416,
0.15476639568805695,
0.27119529247283936,
0.20814108848571777,
0.041916850954294205,
0.048986177891492844,
0.25967976450920105,
0.2826952338218689,
0.1925580650568... |
https://github.com/huggingface/datasets/issues/643 | Caching processed dataset at wrong folder | Thanks for reporting !
It uses a temporary file to write the data.
However it looks like the temporary file is not placed in the right directory during the processing | Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length')
dataset = ... | 30 | Caching processed dataset at wrong folder
Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncati... | [
-0.0562821589410305,
0.17550331354141235,
-0.04873058199882507,
0.39088553190231323,
-0.03564663231372833,
-0.05728090554475784,
0.27607792615890503,
-0.024446925148367882,
0.04081207513809204,
0.15739357471466064,
0.05064784362912178,
0.17668680846691132,
0.0519225150346756,
0.36383640766... |
https://github.com/huggingface/datasets/issues/643 | Caching processed dataset at wrong folder | Well actually I just tested and the temporary file is placed in the same directory, so it should work as expected.
Which version of `datasets` are you using ? | Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length')
dataset = ... | 29 | Caching processed dataset at wrong folder
Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncati... | [
-0.0980261042714119,
0.18809330463409424,
-0.028087064623832703,
0.3890114426612854,
-0.015298697166144848,
-0.011468087323009968,
0.3272339999675751,
-0.009628405794501305,
0.033867016434669495,
0.22865672409534454,
0.005427843425422907,
0.22752989828586578,
0.027003666386008263,
0.359607... |
https://github.com/huggingface/datasets/issues/643 | Caching processed dataset at wrong folder | It looks like a pyarrow issue with google colab.
For some reason this code increases the disk usage of google colab while it actually writes into google drive:
```python
import pyarrow as pa
stream = pa.OSFile("/content/drive/My Drive/path/to/file.arrow", "wb")
writer = pa.RecordBatchStreamWriter(stream, schem... | Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length')
dataset = ... | 74 | Caching processed dataset at wrong folder
Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncati... | [
0.021420380100607872,
0.2508094012737274,
-0.004486151970922947,
0.4046228229999542,
-0.059329528361558914,
-0.09766606241464615,
0.30059489607810974,
0.005136273335665464,
-0.2152586579322815,
0.1271965503692627,
-0.04512887820601463,
0.338610976934433,
0.10689070075750351,
0.293411642313... |
https://github.com/huggingface/datasets/issues/643 | Caching processed dataset at wrong folder | Actually I did more tests it doesn't >.<
I'll let you know if I find a way to fix that | Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length')
dataset = ... | 20 | Caching processed dataset at wrong folder
Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncati... | [
-0.1001969650387764,
0.18694111704826355,
-0.019980235025286674,
0.4581356942653656,
-0.04149489477276802,
-0.03286156803369522,
0.3107515275478363,
0.013784495182335377,
0.006922826170921326,
0.19623656570911407,
0.015261154621839523,
0.28122299909591675,
0.05301002413034439,
0.4453213810... |
https://github.com/huggingface/datasets/issues/643 | Caching processed dataset at wrong folder | Actually I also have the issue when writing a regular text file
```python
f = open("/content/drive/My Drive/path/to/file", "w")
f.write(("a"*511 + "\n") * ((1 << 30) // 512)) # 1GiB
f.close()
```
Is that supposed to happen ? | Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length')
dataset = ... | 37 | Caching processed dataset at wrong folder
Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncati... | [
-0.08096189051866531,
0.15093392133712769,
-0.004716146737337112,
0.4641735851764679,
-0.007445428520441055,
-0.08379004895687103,
0.37827715277671814,
-0.01606561988592148,
-0.0122855044901371,
0.15142348408699036,
0.022320708259940147,
0.20403529703617096,
0.12372244894504547,
0.45949253... |
https://github.com/huggingface/datasets/issues/643 | Caching processed dataset at wrong folder | The code you wrote should write a 1GB file in the Google Drive folder. Doesn't it? | Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length')
dataset = ... | 16 | Caching processed dataset at wrong folder
Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncati... | [
-0.0446968711912632,
0.1795121431350708,
-0.04743406921625137,
0.4067888557910919,
-0.03534688428044319,
-0.015860600396990776,
0.31329286098480225,
0.026928385719656944,
-0.0032724780030548573,
0.21246232092380524,
0.05278339982032776,
0.23325659334659576,
0.017306488007307053,
0.46836292... |
https://github.com/huggingface/datasets/issues/643 | Caching processed dataset at wrong folder | I could check it and as you say as I write to te Drive disk the colab disk also increases... | Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length')
dataset = ... | 20 | Caching processed dataset at wrong folder
Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncati... | [
-0.09090021252632141,
0.08981800824403763,
-0.03479202091693878,
0.49087175726890564,
-0.06337086856365204,
-0.027062326669692993,
0.267678827047348,
0.004958819597959518,
0.024215418845415115,
0.22792339324951172,
-0.014806761406362057,
0.2577185034751892,
0.0650782436132431,
0.4686146080... |
https://github.com/huggingface/datasets/issues/643 | Caching processed dataset at wrong folder | To reproduce it:
```bash
!df -h | grep sda1
```
```python
f = open("/content/drive/My Drive/test_to_remove.txt", "w")
f.write(("a"*511 + "\n") * ((1 << 30) // 512)) # 1GiB
f.write(("a"*511 + "\n") * ((1 << 30) // 512)) # 1GiB
f.close()
```
```bash
!ls -lh /content/drive/My\ Drive/test_to_remove.txt
!df... | Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length')
dataset = ... | 56 | Caching processed dataset at wrong folder
Hi guys, I run this on my Colab (PRO):
```python
from datasets import load_dataset
dataset = load_dataset('text', data_files='/content/corpus.txt', cache_dir='/content/drive/My Drive', split='train')
def encode(examples):
return tokenizer(examples['text'], truncati... | [
-0.08412285894155502,
0.19454526901245117,
-0.01632627286016941,
0.45931336283683777,
-0.0439053513109684,
-0.07286731898784637,
0.38594329357147217,
0.03055381588637829,
0.033721063286066055,
0.20726576447486877,
-0.0354527123272419,
0.28437313437461853,
0.047132790088653564,
0.4058024287... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | Not sure what could cause that on the `datasets` side. Could this be a `Trainer` issue ? cc @julien-c @sgugger ? | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 21 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | There was a memory leak issue fixed recently in master. You should install from source and see if it fixes your problem. | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 22 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | @lhoestq @sgugger Thanks for your comments. I have install from source code as you told, but the problem is still there.
To reproduce the issue, just replace [these lines](https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_language_modeling.py#L241-L258) with:
(load_dataset and Da... | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 80 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | Same here. Pre-training on wikitext-103 to do some test. At the end of the training it takes 32GB of RAM + ~30GB of SWAP. I installed dataset==1.1.0, not built from source. I will try uninstalling and building from source when it finish. | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 42 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | This seems to be on the `transformers` library side.
If you have more informations (pip env) or even better, a colab reproducing the error we can investigate. | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 27 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | It seems like it's solved with freshed versions of transformers. I have tried to replicate the error doing a fresh pip install transformers & datasets on colab and the error doesn't continue. On colab it keeps stable on 5GB! (Y)
Edit: **Thanks for your great work**. Have a good day. | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 50 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | @gaceladri witch version transformers and datasets are you using now? I want to try again. Thanks. | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 16 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | It's happening to me again. After 4 hours of pre-training, my ram memory gets full and the kernel dies. I am using the last transformers version as today. 4.4.0 and the last version of datasets 1.2.1, both installed from master. The memory consumption keeps increasing. | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 45 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | Thanks for the investigation @gaceladri
Apparently this happens when `num_workers>0` and has to do with objects being copied-on-write.
Did you try setting num_workers to 0 @gaceladri ?
If the issue doesn't happen with `num_workers=0` then this would confirm that it's indeed related to this python/pytorch issue.
... | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 114 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | Hmmm so this might come from another issue...
Since it doesn't seem to be related to multiprocessing it should be easier to investigate though.
Do you have some ideas @gaceladri ? | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 31 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | @lhoestq I looked quickly to a previously spoted bug in my env wandb /sdk/interface/interface.py, because sometimes when I load the dataset I got a multiprocessing error at line 510 in wandb...interface.py
This bug is reported here https://github.com/huggingface/datasets/issues/847
```
--------------------------... | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 396 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | @lhoestq But despite this, I got lost into the [class Dataset()](https://huggingface.co/docs/datasets/_modules/datasets/arrow_dataset.html#Dataset) reading the pyarrow files.
Edit: but you should be rigth, that it does not have to be related to multiprocessing since it keeps happening when `num_workers=0` | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 37 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | Or maybe wandb uses multiprocessing ? One process for wandb logging and one for actual training ? If this is the case then even setting `num_workers=0` would cause the process to be forked for wandb and therefore cause the memory issue. | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 41 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | @lhoestq could be, but if we set wandb to false this should not happen. I am going to try. | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 19 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | @lhoestq It keeps happening. I have uninstalled wandb from my env, setted `%env WANDB_DISABLED=true` on my notebook, and commented this func:
```
def get_available_reporting_integrations():
integrations = []
if is_azureml_available():
integrations.append("azure_ml")
if is_comet_available():
... | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 65 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | Thanks for checking @gaceladri . Let's investigate the single process setting then.
If you have some sort of colab notebook with a minimal code example that shows this behavior feel free to share it @gaceladri so that we can play around with it to find what causes this. Otherwise I'll probably try to reproduce on my s... | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 60 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | @lhoestq sure. Here you have https://colab.research.google.com/drive/1ba09ZOpyHGAOQLcsxiQAHRXl10qnMU5o?usp=sharing let me know if the link works and it reproduces the issue. To me, it reproduces the issue, since if you start the training the ram memory keeps increasing.
Let me know. Thanks! | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 39 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | Could the bug be comming from tokenizers?
I got this warning at the terminal from my jupyter notebook:
```
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `to... | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 63 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | I've never experienced memory issues with tokenizers so I don't know
Cc @n1t0 are you aware of any issue that would cause memory to keep increasing when the tokenizer is used in the Data Collator for language modeling ? | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 39 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | @lhoestq Thanks for pointing to n1t0, just to clarify. That warning was doing fine-tuning, without collator:
```
from datasets import load_dataset, load_metric
import numpy as np
GLUE_TASKS = [
"cola",
"mnli",
"mnli-mm",
"mrpc",
"qnli",
"qqp",
"rte",
"sst2",
"stsb",
... | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 468 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | Thanks for sharing your results.
So you still had the issue for fine-tuning ?
And the issue still appears with a bare-bone dataset from an arrow file... | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 27 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/633 | Load large text file for LM pre-training resulting in OOM | Yes, on both cases. Fine-tuning a pre-trained model and pre-training from scratch with a local arrow file already pre-processed. | I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(DataCollatorForLanguageModeling):
"""
Data collator u... | 19 | Load large text file for LM pre-training resulting in OOM
I tried to pretrain Longformer using transformers and datasets. But I got OOM issues with loading a large text file. My script is almost like this:
```python
from datasets import load_dataset
@dataclass
class DataCollatorForDatasetsLanguageModeling(Dat... | [
-0.6339288353919983,
-0.4775370955467224,
0.010693461634218693,
0.2986351549625397,
0.3600475490093231,
-0.1518251597881317,
0.5567325949668884,
0.373805969953537,
0.010882685892283916,
0.010719516314566135,
-0.12959282100200653,
-0.1828002631664276,
-0.26698461174964905,
-0.16209015250205... |
https://github.com/huggingface/datasets/issues/630 | Text dataset not working with large files | Basically ~600MB txt files(UTF-8) * 59.
contents like ```안녕하세요, 이것은 예제로 한번 말해보는 텍스트입니다. 그냥 이렇다고요.<|endoftext|>\n```
Also, it gets stuck for a loooong time at ```Testing the mapped function outputs```, for more than 12 hours(currently ongoing) | ```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_t... | 36 | Text dataset not working with large files
```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir... | [
-0.4925664961338043,
-0.2310243397951126,
-0.11986424028873444,
0.2836015224456787,
0.46635642647743225,
-0.07350162416696548,
0.30536797642707825,
0.5961021780967712,
-0.11382581293582916,
0.046165186911821365,
-0.062419772148132324,
-0.030404802411794662,
-0.10334186255931854,
0.31017917... |
https://github.com/huggingface/datasets/issues/630 | Text dataset not working with large files | It gets stuck while doing `.map()` ? Are you using multiprocessing ?
If you could provide a code snippet it could be very useful | ```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_t... | 24 | Text dataset not working with large files
```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir... | [
-0.4925664961338043,
-0.2310243397951126,
-0.11986424028873444,
0.2836015224456787,
0.46635642647743225,
-0.07350162416696548,
0.30536797642707825,
0.5961021780967712,
-0.11382581293582916,
0.046165186911821365,
-0.062419772148132324,
-0.030404802411794662,
-0.10334186255931854,
0.31017917... |
https://github.com/huggingface/datasets/issues/630 | Text dataset not working with large files | From transformers/examples/language-modeling/run-language-modeling.py :
```
def get_dataset(
args: DataTrainingArguments,
tokenizer: PreTrainedTokenizer,
evaluate: bool = False,
cache_dir: Optional[str] = None,
):
file_path = args.eval_data_file if evaluate else args.train_data_file
if ... | ```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_t... | 71 | Text dataset not working with large files
```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir... | [
-0.4925664961338043,
-0.2310243397951126,
-0.11986424028873444,
0.2836015224456787,
0.46635642647743225,
-0.07350162416696548,
0.30536797642707825,
0.5961021780967712,
-0.11382581293582916,
0.046165186911821365,
-0.062419772148132324,
-0.030404802411794662,
-0.10334186255931854,
0.31017917... |
https://github.com/huggingface/datasets/issues/630 | Text dataset not working with large files | I am not able to reproduce on my side :/
Could you send the version of `datasets` and `pyarrow` you're using ?
Could you try to update the lib and try again ?
Or do you think you could try to reproduce it on google colab ? | ```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_t... | 47 | Text dataset not working with large files
```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir... | [
-0.4925664961338043,
-0.2310243397951126,
-0.11986424028873444,
0.2836015224456787,
0.46635642647743225,
-0.07350162416696548,
0.30536797642707825,
0.5961021780967712,
-0.11382581293582916,
0.046165186911821365,
-0.062419772148132324,
-0.030404802411794662,
-0.10334186255931854,
0.31017917... |
https://github.com/huggingface/datasets/issues/630 | Text dataset not working with large files | Huh, weird. It's fixed on my side too.
But now ```Caching processed dataset``` is taking forever - how can I disable it? Any flags? | ```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_t... | 24 | Text dataset not working with large files
```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir... | [
-0.4925664961338043,
-0.2310243397951126,
-0.11986424028873444,
0.2836015224456787,
0.46635642647743225,
-0.07350162416696548,
0.30536797642707825,
0.5961021780967712,
-0.11382581293582916,
0.046165186911821365,
-0.062419772148132324,
-0.030404802411794662,
-0.10334186255931854,
0.31017917... |
https://github.com/huggingface/datasets/issues/630 | Text dataset not working with large files | Right after `Caching processed dataset`, your function is applied to the dataset and there's a progress bar that shows how much time is left. How much time does it take for you ?
Also caching isn't supposed to slow down your processing. But if you still want to disable it you can do `.map(..., load_from_cache_file=F... | ```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_t... | 55 | Text dataset not working with large files
```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir... | [
-0.4925664961338043,
-0.2310243397951126,
-0.11986424028873444,
0.2836015224456787,
0.46635642647743225,
-0.07350162416696548,
0.30536797642707825,
0.5961021780967712,
-0.11382581293582916,
0.046165186911821365,
-0.062419772148132324,
-0.030404802411794662,
-0.10334186255931854,
0.31017917... |
https://github.com/huggingface/datasets/issues/630 | Text dataset not working with large files | Ah, it’s much faster now(Takes around 15~20min).
BTW, any way to set default tensor output as plain tensors with distributed training? The ragged tensors are incompatible with tpustrategy :( | ```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_t... | 29 | Text dataset not working with large files
```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir... | [
-0.4925664961338043,
-0.2310243397951126,
-0.11986424028873444,
0.2836015224456787,
0.46635642647743225,
-0.07350162416696548,
0.30536797642707825,
0.5961021780967712,
-0.11382581293582916,
0.046165186911821365,
-0.062419772148132324,
-0.030404802411794662,
-0.10334186255931854,
0.31017917... |
https://github.com/huggingface/datasets/issues/630 | Text dataset not working with large files | > Ah, it’s much faster now(Takes around 15~20min).
Glad to see that it's faster now. What did you change exactly ?
> BTW, any way to set default tensor output as plain tensors with distributed training? The ragged tensors are incompatible with tpustrategy :(
Oh I didn't know about that. Feel free to open an is... | ```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_t... | 92 | Text dataset not working with large files
```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir... | [
-0.4925664961338043,
-0.2310243397951126,
-0.11986424028873444,
0.2836015224456787,
0.46635642647743225,
-0.07350162416696548,
0.30536797642707825,
0.5961021780967712,
-0.11382581293582916,
0.046165186911821365,
-0.062419772148132324,
-0.030404802411794662,
-0.10334186255931854,
0.31017917... |
https://github.com/huggingface/datasets/issues/630 | Text dataset not working with large files | >>> Glad to see that it's faster now. What did you change exactly ?
I don't know, it just worked...? Sorry I couldn't be more helpful.
Setting with numpy array is a great idea! Thanks. | ```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_t... | 35 | Text dataset not working with large files
```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir... | [
-0.4925664961338043,
-0.2310243397951126,
-0.11986424028873444,
0.2836015224456787,
0.46635642647743225,
-0.07350162416696548,
0.30536797642707825,
0.5961021780967712,
-0.11382581293582916,
0.046165186911821365,
-0.062419772148132324,
-0.030404802411794662,
-0.10334186255931854,
0.31017917... |
https://github.com/huggingface/datasets/issues/625 | dtype of tensors should be preserved | Indeed we convert tensors to list to be able to write in arrow format. Because of this conversion we lose the dtype information. We should add the dtype detection when we do type inference. However it would require a bit of refactoring since currently the conversion happens before the type inference..
And then for y... | After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-required-that-input-and-hidden-for-gru-... | 156 | dtype of tensors should be preserved
After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-... | [
-0.11343368142843246,
-0.22111479938030243,
-0.00971086323261261,
0.20730525255203247,
0.5532286763191223,
0.17301316559314728,
0.5313701033592224,
0.1225806325674057,
0.15048260986804962,
-0.06653967499732971,
-0.08439911901950836,
0.24571456015110016,
-0.11755148321390152,
-0.17514538764... |
https://github.com/huggingface/datasets/issues/625 | dtype of tensors should be preserved | If the arrow format is basically lists, why is the intermediate step to numpy necessary? I am a bit confused about that part.
Thanks for your suggestion. as I have currently implemented this, I cast to torch.Tensor in my collate_fn to save disk space (so I do not have to save padded tensors to max_len but can pad up... | After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-required-that-input-and-hidden-for-gru-... | 89 | dtype of tensors should be preserved
After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-... | [
-0.11343368142843246,
-0.22111479938030243,
-0.00971086323261261,
0.20730525255203247,
0.5532286763191223,
0.17301316559314728,
0.5313701033592224,
0.1225806325674057,
0.15048260986804962,
-0.06653967499732971,
-0.08439911901950836,
0.24571456015110016,
-0.11755148321390152,
-0.17514538764... |
https://github.com/huggingface/datasets/issues/625 | dtype of tensors should be preserved | I'm glad you managed to figure something out :)
Casting from arrow to numpy can be 100x faster than casting from arrow to list.
This is because arrow has an integration with numpy that allows it to instantiate numpy arrays with zero-copy from arrow.
On the other hand to create python lists it is slow since it has ... | After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-required-that-input-and-hidden-for-gru-... | 70 | dtype of tensors should be preserved
After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-... | [
-0.11343368142843246,
-0.22111479938030243,
-0.00971086323261261,
0.20730525255203247,
0.5532286763191223,
0.17301316559314728,
0.5313701033592224,
0.1225806325674057,
0.15048260986804962,
-0.06653967499732971,
-0.08439911901950836,
0.24571456015110016,
-0.11755148321390152,
-0.17514538764... |
https://github.com/huggingface/datasets/issues/625 | dtype of tensors should be preserved | I encountered a simliar issue: `datasets` converted my float numpy array to `torch.float64` tensors, while many pytorch operations require `torch.float32` inputs and it's very troublesome.
I tried @lhoestq 's solution, but since it's mixed with the preprocess function, it's not very intuitive.
I just want to sh... | After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-required-that-input-and-hidden-for-gru-... | 96 | dtype of tensors should be preserved
After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-... | [
-0.11343368142843246,
-0.22111479938030243,
-0.00971086323261261,
0.20730525255203247,
0.5532286763191223,
0.17301316559314728,
0.5313701033592224,
0.1225806325674057,
0.15048260986804962,
-0.06653967499732971,
-0.08439911901950836,
0.24571456015110016,
-0.11755148321390152,
-0.17514538764... |
https://github.com/huggingface/datasets/issues/625 | dtype of tensors should be preserved | Reopening since @bhavitvyamalik started looking into it !
Also I'm posting here a function that could be helpful to support preserving the dtype of tensors.
It's used to build a pyarrow array out of a numpy array and:
- it doesn't convert the numpy array to a python list
- it keeps the precision of the numpy ar... | After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-required-that-input-and-hidden-for-gru-... | 206 | dtype of tensors should be preserved
After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-... | [
-0.11343368142843246,
-0.22111479938030243,
-0.00971086323261261,
0.20730525255203247,
0.5532286763191223,
0.17301316559314728,
0.5313701033592224,
0.1225806325674057,
0.15048260986804962,
-0.06653967499732971,
-0.08439911901950836,
0.24571456015110016,
-0.11755148321390152,
-0.17514538764... |
https://github.com/huggingface/datasets/issues/625 | dtype of tensors should be preserved | @lhoestq Have you thought about this further?
We have a use case where we're attempting to load data containing numpy arrays using the `datasets` library.
When using one of the "standard" methods (`[Value(...)]` or `Sequence()`) we see ~200 samples processed per second during the call to `_prepare_split`. This sl... | After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-required-that-input-and-hidden-for-gru-... | 239 | dtype of tensors should be preserved
After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-... | [
-0.11343368142843246,
-0.22111479938030243,
-0.00971086323261261,
0.20730525255203247,
0.5532286763191223,
0.17301316559314728,
0.5313701033592224,
0.1225806325674057,
0.15048260986804962,
-0.06653967499732971,
-0.08439911901950836,
0.24571456015110016,
-0.11755148321390152,
-0.17514538764... |
https://github.com/huggingface/datasets/issues/625 | dtype of tensors should be preserved | Hi !
It would be awesome to achieve this speed for numpy arrays !
For now we have to use `encode_nested_example` to convert numpy arrays to python lists since pyarrow doesn't support multidimensional numpy arrays (only 1D).
Maybe let's start a new PR from your PR @bhavitvyamalik (idk why we didn't answer your PR... | After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-required-that-input-and-hidden-for-gru-... | 185 | dtype of tensors should be preserved
After switching to `datasets` my model just broke. After a weekend of debugging, the issue was that my model could not handle the double that the Dataset provided, as it expected a float (but didn't give a warning, which seems a [PyTorch issue](https://discuss.pytorch.org/t/is-it-... | [
-0.11343368142843246,
-0.22111479938030243,
-0.00971086323261261,
0.20730525255203247,
0.5532286763191223,
0.17301316559314728,
0.5313701033592224,
0.1225806325674057,
0.15048260986804962,
-0.06653967499732971,
-0.08439911901950836,
0.24571456015110016,
-0.11755148321390152,
-0.17514538764... |
https://github.com/huggingface/datasets/issues/623 | Custom feature types in `load_dataset` from CSV | Currently `csv` doesn't support the `features` attribute (unlike `json`).
What you can do for now is cast the features using the in-place transform `cast_`
```python
from datasets import load_dataset
dataset = load_dataset('csv', data_files=file_dict, delimiter=';', column_names=['text', 'label'])
dataset.cast... | I am trying to load a local file with the `load_dataset` function and I want to predefine the feature types with the `features` argument. However, the types are always the same independent of the value of `features`.
I am working with the local files from the emotion dataset. To get the data you can use the followi... | 38 | Custom feature types in `load_dataset` from CSV
I am trying to load a local file with the `load_dataset` function and I want to predefine the feature types with the `features` argument. However, the types are always the same independent of the value of `features`.
I am working with the local files from the emotio... | [
0.08020298182964325,
-0.2782895267009735,
-0.05317900702357292,
0.35092276334762573,
0.3172289729118347,
-0.19431033730506897,
0.5701338052749634,
0.11138428747653961,
0.4461255967617035,
0.025330763310194016,
0.094744473695755,
0.31617772579193115,
-0.09191006422042847,
0.3901153802871704... |
https://github.com/huggingface/datasets/issues/623 | Custom feature types in `load_dataset` from CSV | Hi @lhoestq we've tried out your suggestion but are now running into the following error:
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-163-81ffd5ac18c9> in <module>
----> 1 dataset.cast_(... | I am trying to load a local file with the `load_dataset` function and I want to predefine the feature types with the `features` argument. However, the types are always the same independent of the value of `features`.
I am working with the local files from the emotion dataset. To get the data you can use the followi... | 168 | Custom feature types in `load_dataset` from CSV
I am trying to load a local file with the `load_dataset` function and I want to predefine the feature types with the `features` argument. However, the types are always the same independent of the value of `features`.
I am working with the local files from the emotio... | [
0.08020298182964325,
-0.2782895267009735,
-0.05317900702357292,
0.35092276334762573,
0.3172289729118347,
-0.19431033730506897,
0.5701338052749634,
0.11138428747653961,
0.4461255967617035,
0.025330763310194016,
0.094744473695755,
0.31617772579193115,
-0.09191006422042847,
0.3901153802871704... |
https://github.com/huggingface/datasets/issues/623 | Custom feature types in `load_dataset` from CSV | In general, I don't think there is any hard reason we don't allow to use `features` in the csv script, right @lhoestq?
Should I add it? | I am trying to load a local file with the `load_dataset` function and I want to predefine the feature types with the `features` argument. However, the types are always the same independent of the value of `features`.
I am working with the local files from the emotion dataset. To get the data you can use the followi... | 26 | Custom feature types in `load_dataset` from CSV
I am trying to load a local file with the `load_dataset` function and I want to predefine the feature types with the `features` argument. However, the types are always the same independent of the value of `features`.
I am working with the local files from the emotio... | [
0.08020298182964325,
-0.2782895267009735,
-0.05317900702357292,
0.35092276334762573,
0.3172289729118347,
-0.19431033730506897,
0.5701338052749634,
0.11138428747653961,
0.4461255967617035,
0.025330763310194016,
0.094744473695755,
0.31617772579193115,
-0.09191006422042847,
0.3901153802871704... |
https://github.com/huggingface/datasets/issues/623 | Custom feature types in `load_dataset` from CSV | > In general, I don't think there is any hard reason we don't allow to use `features` in the csv script, right @lhoestq?
>
> Should I add it?
Sure let's add it. Setting the convert options should do the job
> Hi @lhoestq we've tried out your suggestion but are now running into the following error:
>
> ```
... | I am trying to load a local file with the `load_dataset` function and I want to predefine the feature types with the `features` argument. However, the types are always the same independent of the value of `features`.
I am working with the local files from the emotion dataset. To get the data you can use the followi... | 136 | Custom feature types in `load_dataset` from CSV
I am trying to load a local file with the `load_dataset` function and I want to predefine the feature types with the `features` argument. However, the types are always the same independent of the value of `features`.
I am working with the local files from the emotio... | [
0.08020298182964325,
-0.2782895267009735,
-0.05317900702357292,
0.35092276334762573,
0.3172289729118347,
-0.19431033730506897,
0.5701338052749634,
0.11138428747653961,
0.4461255967617035,
0.025330763310194016,
0.094744473695755,
0.31617772579193115,
-0.09191006422042847,
0.3901153802871704... |
https://github.com/huggingface/datasets/issues/623 | Custom feature types in `load_dataset` from CSV | PR is open for the `ValueError: Target schema's field names are not matching the table's field names` error.
I'm adding the features parameter to csv | I am trying to load a local file with the `load_dataset` function and I want to predefine the feature types with the `features` argument. However, the types are always the same independent of the value of `features`.
I am working with the local files from the emotion dataset. To get the data you can use the followi... | 25 | Custom feature types in `load_dataset` from CSV
I am trying to load a local file with the `load_dataset` function and I want to predefine the feature types with the `features` argument. However, the types are always the same independent of the value of `features`.
I am working with the local files from the emotio... | [
0.08020298182964325,
-0.2782895267009735,
-0.05317900702357292,
0.35092276334762573,
0.3172289729118347,
-0.19431033730506897,
0.5701338052749634,
0.11138428747653961,
0.4461255967617035,
0.025330763310194016,
0.094744473695755,
0.31617772579193115,
-0.09191006422042847,
0.3901153802871704... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | @thomwolf Sure. I'll try downgrading to 3.7 now even though Arrow say they support >=3.5.
Linux (Ubuntu 18.04) - Python 3.8
======================
Package - Version
---------------------
certifi 2020.6.20
chardet 3.0.4
click 7.1.2
datasets 1.0.1
di... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 194 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | Downgrading to 3.7 does not help. Here is a dummy text file:
```text
Verzekering weigert vaker te betalen
Bedrijven van verzekeringen erkennen steeds minder arbeidsongevallen .
In 2012 weigerden de bedrijven te betalen voor 21.055 ongevallen op het werk .
Dat is 11,8 % van alle ongevallen op het werk .
Nog nooi... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 120 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | @banunitte Please do not post screenshots in the future but copy-paste your code and the errors. That allows others to copy-and-paste your code and test it. You may also want to provide the Python version that you are using. | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 39 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | I have the same problem on Linux of the script crashing with a CSV error. This may be caused by 'CRLF', when changed 'CRLF' to 'LF', the problem solved. | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 29 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | I pushed a fix for `pyarrow.lib.ArrowInvalid: CSV parse error`. Let me know if you still have this issue.
Not sure about the windows one yet | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 25 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | To complete what @lhoestq is saying, I think that to use the new version of the `text` processing script (which is on master right now) you need to either specify the version of the script to be the `master` one or to install the lib from source (in which case it uses the `master` version of the script by default):
``... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 107 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | 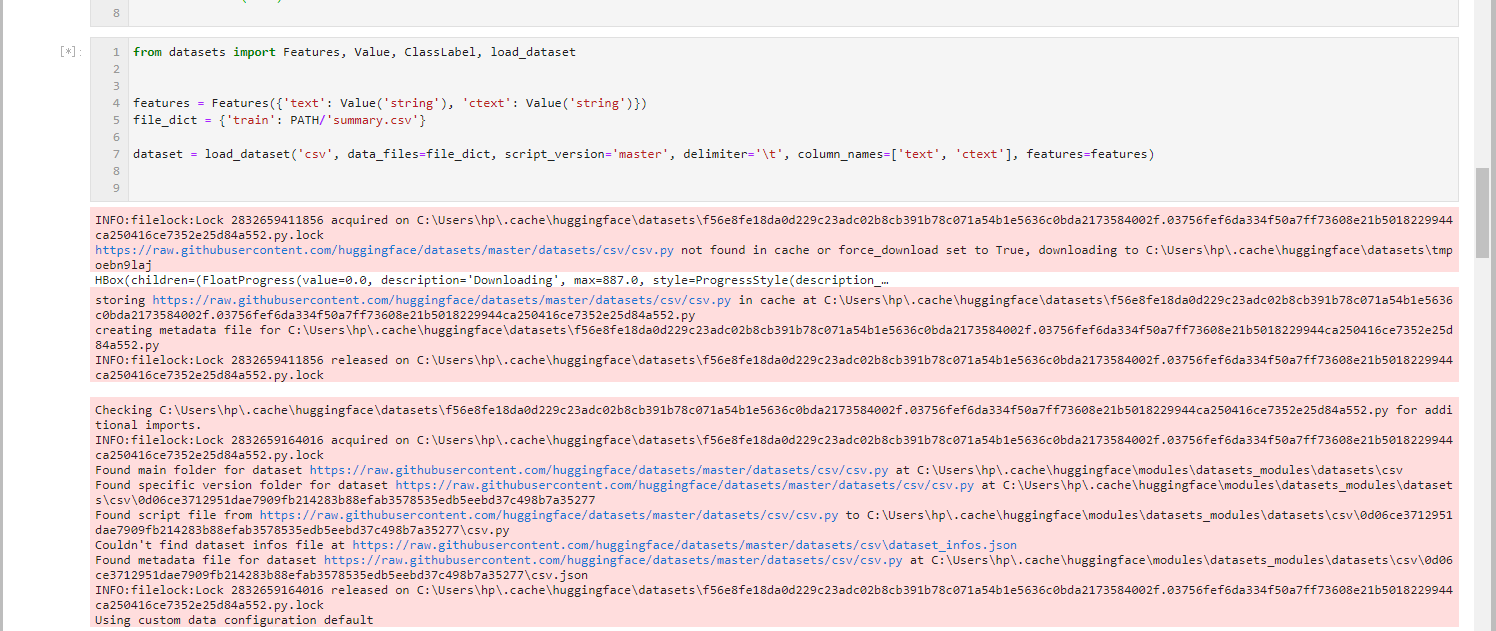
win10, py3.6
```
from datasets import Features, Value, ClassLabel, load_dataset
features = Features({'text': Value('string'), 'ctext': Value('string')})
file_dict = {'train': PATH/'summary.csv'}
... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 31 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | ```python
Traceback` (most recent call last):
File "main.py", line 281, in <module>
main()
File "main.py", line 190, in main
train_data, test_data = data_factory(
File "main.py", line 129, in data_factory
train_data = load_dataset('text',
File "/home/me/Downloads/datasets/src/datasets/load.... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 135 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | > 
> win10, py3.6
>
> ```
> from datasets import Features, Value, ClassLabel, load_dataset
>
>
> features = Features({'text': Value('string'), 'ctext': Value('string')})
> file_dict = {'train': PATH/... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 184 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | > To complete what @lhoestq is saying, I think that to use the new version of the `text` processing script (which is on master right now) you need to either specify the version of the script to be the `master` one or to install the lib from source (in which case it uses the `master` version of the script by default):
... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 206 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | Hi @raruidol
To fix the RAM issue you'll need to shard your text files into smaller files (see https://github.com/huggingface/datasets/issues/610#issuecomment-691672919 for example)
I'm not sure why you're having the csv error on linux.
Do you think you could to to reproduce it on google colab for example ?
Or s... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 59 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | @lhoestq
The crash message shows up when loading the dataset:
```
print('Loading corpus...')
files = glob.glob('corpora/shards/*')
-> dataset = load_dataset('text', script_version='master', data_files=files)
print('Corpus loaded.')
```
And this is the exact message:
```
Traceback (most recent call last)... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 207 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | I tested on google colab which is also linux using this code:
- first download an arbitrary text file
```bash
wget https://raw.githubusercontent.com/abisee/cnn-dailymail/master/url_lists/all_train.txt
```
- then run
```python
from datasets import load_dataset
d = load_dataset("text", data_files="all_train.t... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 156 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | Update: also tested the above code in a docker container from [jupyter/minimal-notebook](https://hub.docker.com/r/jupyter/minimal-notebook/) (based on ubuntu) and still not able to reproduce | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 21 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | It looks like with your text input file works without any problem. I have been doing some experiments this morning with my input files and I'm almost certain that the crash is caused by some unexpected pattern in the files. However, I've not been able to spot the main cause of it. What I find strange is that this same ... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 92 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | Under the hood it does
```python
import pyarrow as pa
import pyarrow.csv
# Use csv reader from Pyarrow with one column for text files
# To force the one-column setting, we set an arbitrary character
# that is not in text files as delimiter, such as \b or \v.
# The bell character, \b, was used to make beeps b... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 107 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | Could you try with `\a` instead of `\b` ? It looks like the bell character is \a in python and not \b | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 22 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | I was just exploring if the crash was happening in every shard or not, and which shards were generating the error message. With \b I got the following list of shards crashing:
```
Errors on files: ['corpora/shards/shard_0069', 'corpora/shards/shard_0043', 'corpora/shards/shard_0014', 'corpora/shards/shard_0032', '... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 205 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | Hmmm I was expecting it to work with \a, not sure why they appear in your text files though | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 19 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | Hi @lhoestq, is there any input length restriction which was not before the update of the nlp library? | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 18 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | No we never set any input length restriction on our side (maybe arrow but I don't think so) | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 18 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | @lhoestq Can you ever be certain that a delimiter character is not present in a plain text file? In other formats (e.g. CSV) , rules are set of what is allowed and what isn't so that it actually constitutes a CSV file. In a text file you basically have "anything goes", so I don't think you can ever be entirely sure tha... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 118 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | Okay, I have splitted the crashing shards into individual sentences and some examples of the inputs that are causing the crashes are the following ones:
_4. DE L’ORGANITZACIÓ ESTAMENTAL A L’ORGANITZACIÓ EN CLASSES A mesura que es desenvolupava un sistema econòmic capitalista i naixia una classe burgesa cada vegada... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 949 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | So we're using the csv reader to read text files because arrow doesn't have a text reader.
To workaround the fact that text files are just csv with one column, we want to set a delimiter that doesn't appear in text files.
Until now I thought that it would do the job but unfortunately it looks like even characters lik... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 289 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | > Okay, I have splitted the crashing shards into individual sentences and some examples of the inputs that are causing the crashes are the following ones
Thanks for digging into it !
Characters like \a or \b are not shown when printing the text, so as it is I can't tell if it contains unexpected characters.
Mayb... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 178 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | That's true, It was my error printing the text that way. Maybe as a workaround, I can force all my input samples to have "\b" at the end? | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 28 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/622 | load_dataset for text files not working | > That's true, It was my error printing the text that way. Maybe as a workaround, I can force all my input samples to have "\b" at the end?
I don't think it would work since we only want one column, and "\b" is set to be the delimiter between two columns, so it will raise the same issue again. Pyarrow would think th... | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that ... | 96 | load_dataset for text files not working
Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loa... | [
-0.2746652662754059,
-0.40205711126327515,
0.017560521140694618,
0.3872528374195099,
0.2696422040462494,
-0.03866121172904968,
0.3188883066177368,
-0.05435652658343315,
0.4263594448566437,
-0.05804874375462532,
0.0659719780087471,
0.1455249786376953,
-0.15576301515102386,
0.274200469255447... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | It seems that I ran into the same problem
```
def tokenize(cols, example):
for in_col, out_col in cols.items():
example[out_col] = hf_tokenizer.convert_tokens_to_ids(hf_tokenizer.tokenize(example[in_col]))
return example
cola = datasets.load_dataset('glue', 'cola')
tokenized_cola = cola.map(partial(token... | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 121 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.40427714586257935,
-0.07616442441940308,
0.0068099601194262505,
0.14667057991027832,
0.1475026160478592,
-0.18960437178611755,
0.3224092721939087,
0.3429277539253235,
0.13417468965053558,
0.1369510293006897,
0.036748602986335754,
0.3943179249763489,
-0.40547284483909607,
0.3103386461734... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | same problem.
`encoded_dataset = core_data.map(lambda examples: tokenizer(examples["query"], examples["document"], padding=True, truncation='longest_first', return_tensors="pt", max_length=384), num_proc=16, keep_in_memory=True)`
it outputs:
```
Set __getitem__(key) output type to python objects for ['document', 'i... | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 301 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.38126274943351746,
-0.15998250246047974,
-0.02571856789290905,
0.2450912743806839,
0.13851642608642578,
-0.1244138702750206,
0.22778403759002686,
0.35518354177474976,
0.09710746258497238,
0.16505464911460876,
0.09049484878778458,
0.47809362411499023,
-0.43798744678497314,
0.322587817907... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | Thanks for reporting.
Which tokenizers are you using ? What platform are you on ? Can you tell me which version of datasets and pyarrow you're using ? @timothyjlaurent @richarddwang @HuangLianzhe
Also if you're able to reproduce the issue on google colab that would be very helpful.
I tried to run your code ... | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 64 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.4514070451259613,
-0.018355974927544594,
-0.018717370927333832,
0.25396937131881714,
0.15917818248271942,
-0.16415101289749146,
0.2910158634185791,
0.3014788329601288,
-0.0354783833026886,
0.14610999822616577,
0.04826456680893898,
0.48891711235046387,
-0.43166738748550415,
0.33583301305... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | Hi, Sorry that I forgot to see what my version was.
But after updating datasets to master (editable install), and latest pyarrow.
It works now ~ | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 26 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.42622387409210205,
-0.02808404713869095,
-0.030707653611898422,
0.1988402158021927,
0.133143812417984,
-0.13753530383110046,
0.3073055148124695,
0.3333304524421692,
-0.006456186529248953,
0.12903739511966705,
0.028643429279327393,
0.43688303232192993,
-0.41073766350746155,
0.29677429795... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | Sorry, I just noticed this.
I'm running this on MACOS the version of datasets I'm was 1.0.0 but I've also tried it on 1.0.2. `pyarrow==1.0.1`, Python 3.6
Consider this code:
```python
loader_path = str(Path(__file__).parent / "prodigy_dataset_builder.py")
ds = load_dataset(
loader_path, name=... | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 289 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.39023688435554504,
-0.05921122804284096,
-0.034988999366760254,
0.21786300837993622,
0.1645163893699646,
-0.12629367411136627,
0.29201728105545044,
0.27592822909355164,
0.012660840526223183,
0.15889140963554382,
0.027785759419202805,
0.5151470303535461,
-0.46636784076690674,
0.193190231... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | #659 should fix the `KeyError` issue. It was due to the formatting not getting updated the right way | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 18 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.35121315717697144,
-0.18554289638996124,
-0.019590524956583977,
0.2103060632944107,
0.13818581402301788,
-0.16708415746688843,
0.279554158449173,
0.3684959411621094,
0.08157967776060104,
0.10868801176548004,
0.08891010284423828,
0.38034188747406006,
-0.4003903269767761,
0.40012577176094... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | Also maybe @n1t0 knows why setting `TOKENIZERS_PARALLELISM=true` creates deadlock issues when calling `map` with multiprocessing ? | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 16 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.4357653260231018,
-0.10919728875160217,
-0.04172855243086815,
0.21217754483222961,
0.06955541670322418,
-0.1265099048614502,
0.25464877486228943,
0.33281418681144714,
0.1938222050666809,
0.12194409221410751,
0.11606427282094955,
0.4567500352859497,
-0.40930232405662537,
0.28846937417984... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | @lhoestq
Thanks for taking a look. I pulled the master but I still see the key error.
```
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
#0: 100%|█████████████████... | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 299 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.4438698887825012,
-0.16750483214855194,
-0.040071651339530945,
0.17160919308662415,
0.08894600719213486,
-0.11882494390010834,
0.20784609019756317,
0.3421577215194702,
0.11804810911417007,
0.15760400891304016,
0.13065357506275177,
0.4856553077697754,
-0.43620991706848145,
0.278643250465... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | The parallelism is automatically disabled on `tokenizers` when the process gets forked, while we already used the parallelism capabilities of a tokenizer. We have to do it in order to avoid having the process hang, because we cannot safely fork a multithreaded process (cf https://github.com/huggingface/tokenizers/issue... | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 75 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.4698334336280823,
-0.167496457695961,
-0.014036889187991619,
0.1800086349248886,
0.08544354140758514,
-0.19053849577903748,
0.2459651678800583,
0.27562928199768066,
0.10163681209087372,
0.17267414927482605,
0.09160729497671127,
0.4495115876197815,
-0.3661406636238098,
0.2278045862913131... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | > Thanks for taking a look. I pulled the master but I still see the key error.
I am no longer able to get the error since #659 was merged. Not sure why you still have it @timothyjlaurent
Maybe it is a cache issue ? Could you try to use `load_from_cache_file=False` in your `.map()` calls ? | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 56 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.4314344525337219,
-0.12447061389684677,
-0.02134542167186737,
0.22684937715530396,
0.12996482849121094,
-0.10097521543502808,
0.216061532497406,
0.4109106957912445,
0.06116877496242523,
0.10985521227121353,
0.019463028758764267,
0.4327993094921112,
-0.3604692220687866,
0.377241402864456... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | > The parallelism is automatically disabled on `tokenizers` when the process gets forked, while we already used the parallelism capabilities of a tokenizer. We have to do it in order to avoid having the process hang, because we cannot safely fork a multithreaded process (cf [huggingface/tokenizers#187](https://github.c... | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 140 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.4756867587566376,
-0.1844158172607422,
-0.01699610985815525,
0.20499153435230255,
0.08199292421340942,
-0.18161141872406006,
0.21128854155540466,
0.2972385585308075,
0.1219882145524025,
0.15598495304584503,
0.07838442176580429,
0.445144921541214,
-0.38646453619003296,
0.2127691060304641... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | Hmmm I pulled the latest commit, `b93c5517f70a480533a44e0c42638392fd53d90`, and I'm still seeing both the hanging and the key error. | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 18 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.3769075274467468,
-0.19042794406414032,
-0.03744109347462654,
0.12037250399589539,
0.055316098034381866,
-0.14881914854049683,
0.25110864639282227,
0.3369266390800476,
0.14734947681427002,
0.1732962429523468,
0.10614566504955292,
0.4089754819869995,
-0.4025796055793762,
0.33076846599578... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | Hi @timothyjlaurent
The hanging fix just got merged, that why you still had it.
For the key error it's possible that the code you ran reused cached datasets from where the KeyError bug was still there.
Could you try to clear your cache or make sure that it doesn't reuse cached data with `.map(..., load_from_cac... | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 63 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.3729742467403412,
-0.18595226109027863,
-0.0339064747095108,
0.12920668721199036,
0.09803550690412521,
-0.13251110911369324,
0.2636091113090515,
0.4240575134754181,
0.13913197815418243,
0.1339375376701355,
0.04652804136276245,
0.4665992558002472,
-0.3696383833885193,
0.44662076234817505... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | Hi @lhoestq ,
Thanks for letting me know about the update.
So I don't think it's the caching - because hashing mechanism isn't stable for me -- but that's a different issue. In any case I `rm -rf ~/.cache/huggingface` to make a clean slate.
I synced with master and I see the key error has gone away, I tried w... | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 174 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.3455716073513031,
-0.1244763731956482,
-0.00994644220918417,
0.2436581701040268,
0.13264867663383484,
-0.10858847945928574,
0.20911861956119537,
0.38427087664604187,
0.12759779393672943,
0.055418193340301514,
0.06508693844079971,
0.288519024848938,
-0.416008323431015,
0.3402270972728729... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | Thanks for reporting.
I'm going to fix that and add a test case so that it doesn't happen again :)
I'll let you know when it's done
In the meantime if you could make a google colab that reproduces the issue it would be helpful ! @timothyjlaurent | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 47 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.4121118187904358,
-0.14065226912498474,
-0.03324824571609497,
0.25470882654190063,
0.15278391540050507,
-0.15756738185882568,
0.30053991079330444,
0.284224271774292,
0.12205137312412262,
0.1786370724439621,
0.10574256628751755,
0.4333913326263428,
-0.450995534658432,
0.4070863127708435,... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | Thanks @timothyjlaurent ! I just merged a fix on master. I also checked your notebook and it looks like it's working now.
I added some tests to make sure it works as expected now :) | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 35 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.4193553924560547,
-0.10714110732078552,
-0.03926026448607445,
0.21476900577545166,
0.14587751030921936,
-0.159807950258255,
0.26043838262557983,
0.3937075138092041,
0.09895414859056473,
0.15138639509677887,
0.019559968262910843,
0.450470894575119,
-0.36374038457870483,
0.439867943525314... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | Great, @lhoestq . I'm trying to verify in the colab:
changed
```
!pip install datasets
```
to
```
!pip install git+https://github.com/huggingface/datasets@master
```
But I'm still seeing the error - I wonder why? | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 32 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.44166722893714905,
-0.1638825237751007,
-0.03336871787905693,
0.27265530824661255,
0.13985955715179443,
-0.14885394275188446,
0.2888735234737396,
0.24280470609664917,
0.12334556132555008,
0.210349440574646,
0.01985969766974449,
0.5049683451652527,
-0.3794000744819641,
0.366486132144928,... |
https://github.com/huggingface/datasets/issues/620 | map/filter multiprocessing raises errors and corrupts datasets | It works on my side @timothyjlaurent on google colab.
Did you try to uninstall datasets first, before updating it to master's version ? | After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_ds_dict["test"]
rel_ds_dict = rel_ds.train_test_split(test_si... | 23 | map/filter multiprocessing raises errors and corrupts datasets
After upgrading to the 1.0 started seeing errors in my data loading script after enabling multiprocessing.
```python
...
ner_ds_dict = ner_ds.train_test_split(test_size=test_pct, shuffle=True, seed=seed)
ner_ds_dict["validation"] = ner_d... | [
-0.43540459871292114,
-0.02133144438266754,
-0.03790339082479477,
0.26032906770706177,
0.10330444574356079,
-0.052439745515584946,
0.2046663463115692,
0.3077462613582611,
0.0026611851062625647,
0.1889890879392624,
0.02980169653892517,
0.42504259943962097,
-0.47574469447135925,
0.3481319248... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.