
branch_name stringclasses 149 values | text stringlengths 23 89.3M | directory_id stringlengths 40 40 | languages listlengths 1 19 | num_files int64 1 11.8k | repo_language stringclasses 38 values | repo_name stringlengths 6 114 | revision_id stringlengths 40 40 | snapshot_id stringlengths 40 40 |
|---|---|---|---|---|---|---|---|---|
refs/heads/master | <repo_name>dayamll/Twitter<file_sep>/js/app.js
window.onload = begin;
function begin() {
var tweetArea = document.getElementById('tweet-area');
var tweetBtn = document.getElementById('tweet-btn');
var messages = document.getElementById('messages');
var count = document.getElementById('count');
var MAXCHARACTERS = 140;
tweetBtn.addEventListener('click', message);
tweetArea.addEventListener('keyup', changeText);
function message(event) {
event.preventDefault();
// if (tweetArea.value) {
if (tweetArea.value != '') {
var div = document.createElement('div');
var tweet = document.createElement('span');
// agrega formato de hora
tweet.innerHTML = tweetArea.value + '<i> Publicado: ' + moment().format('hh:mm') + '</i>';
tweet.classList.add('tweet');
div.classList.add('nuevo-mensaje');
tweetArea.value = '';
tweetArea.focus();
div.appendChild(tweet);
messages.insertBefore(div, messages.firstElementChild);
tweetArea.value = '';
tweetArea.focus();
} else {
event.target.disabled = true;
}
}
function changeText(event) {
// si no existe, se asigna MAX
// si existe se habilita el boton y se resta el max con la longitud
if (event.target.value != '') {
tweetBtnActive(true);
var writtenChars = event.target.value.length;
var total = MAXCHARACTERS - writtenChars;
count.textContent = total;
changeColor(total);
checkEnters(event);
// checkLong(event);
/* if (event.keyCode === 13)
event.target.rows = event.target.rows + 1; */
} else {
tweetBtnActive(false);
count.textContent = MAXCHARACTERS;
}
}
function changeColor(total) {
// if(total < 0) {
// tweetBtnActive(false);
// count.classList.add('red');
// count.classList.remove('orangered', 'greenyellow', 'seagreen');
// return;
// }
switch (true) {
case (total < 0): // cuando se supera el max
tweetBtnActive(false);
count.classList.add('red');
count.classList.remove('orangered', 'greenyellow', 'seagreen');
break;
case (total <= 10): // a 10 chars del max
count.classList.add('orangered');
count.classList.remove('red', 'greenyellow', 'seagreen');
break;
case (total <= 20): // a 20 chars del max
count.classList.add('greenyellow');
count.classList.remove('red', 'orangered', 'seagreen');
break;
default:
count.classList.add('seagreen');
count.classList.remove('red', 'orangered', 'greenyellow');
}
}
// habilita el boton de tweet
function tweetBtnActive(centinel) {
tweetBtn.disabled = !centinel;
}
// verifica las filas del textarea, si sobrepasa
// se agrega una fila más, sino se elimina
function checkEnters(event) {
// var text = event.target.value.split('');
// var count = 0;
// for (var i = 0; i < text.length; i++)
// if (text[i] === '\n')
// count++;
// if (count)
// event.target.rows = count + 2;
if (event.keyCode === 13) {
event.target.style.height = "5px";
event.target.style.height = (event.target.scrollHeight) + "px";
// event.target.rows = event.target.rows + 2;
// console.log(event.target.rows)
}
}
// agrega filas si el cociente entre los caracteres y las columnas del
// textarea, es menor a las filas del textarea actuales
function checkLong(event) {
if ((event.target.value.length / event.target.cols) < event.target.rows)
event.target.rows = (event.target.value.length / event.target.cols) + 2;
}
} | feed954b45d16b23e214304d212580fe2ec06888 | [
"JavaScript"
] | 1 | JavaScript | dayamll/Twitter | 6e5d2df2a18f3475d5ec95f0b2bec087a917ec8d | 2e2421c39b8f3b6577313309c6489990ee3ac400 |
refs/heads/master | <repo_name>ibarria0/ExData_Plotting1<file_sep>/run.R
#For mis amigos out there:
Sys.setlocale("LC_TIME", "en_US.utf8")
source('plot1.R')
source('plot2.R')
source('plot3.R')
source('plot4.R')
<file_sep>/plot3.R
#read data
h <- read.csv2('household_power_consumption.txt', header=TRUE, colClasses = c(rep("character",9)),comment.char = "?" )
h$datetime <- strptime(paste(h$Date, h$Time), "%d/%m/%Y %H:%M:%S")
df <- subset(h, datetime >= as.POSIXct("2007-02-01") & datetime < as.POSIXct("2007-02-03"))
df[3:9] <- lapply(df[3:9], as.numeric)
#plot3
png('plot3.png', width=640, height=640)
with(df, {
plot(datetime, Sub_metering_1,type='n',ylab="Energy sub metering", xlab="")
lines(datetime, Sub_metering_1, type="l", col="black")
lines(datetime, Sub_metering_2, type="l", col="red")
lines(datetime, Sub_metering_3, type="l", col="blue")
legend("topright", legend = c('Sub_metering_1','Sub_metering_2', 'Sub_metering_3'), lty = c(1,1), lwd=c(2.5,2.5), box.lwd = 0, col = c('black','red','blue'))
}
)
dev.off()
<file_sep>/plot1.R
#read data
h <- read.csv2('household_power_consumption.txt', header=TRUE, colClasses = c(rep("character",9)),comment.char = "?" )
h$datetime <- strptime(paste(h$Date, h$Time), "%d/%m/%Y %H:%M:%S")
df <- subset(h, datetime >= as.POSIXct("2007-02-01") & datetime < as.POSIXct("2007-02-03"))
df[3:9] <- lapply(df[3:9], as.numeric)
#plot1
png('plot1.png', width=640, height=640)
with(df, hist(Global_active_power, col='red', main = "Global Active Power", xlab= "Global Active Power (kilowatts)"))
dev.off()
| 4ce9f681c7353df50d75199a4e9f5f1104a207ae | [
"R"
] | 3 | R | ibarria0/ExData_Plotting1 | 406164320f2ef81d741eae15326b639a9f5b3cfc | 729032e9c512ca8d5dee9cd04751217ad3a9a099 |
refs/heads/master | <file_sep><!DOCTYPE html>
<html>
<head>
<title>Protótipo 01 - teste com WebSockets</title>
</head>
<body>
<p>Teste de comunicação em tempo real.</p>
<ul>
<li>Abra essa mesma página em outra guia (ou <a href="/" target="_blank">clique aqui</a>).</li>
<li>Na outra página aberta, clique no botão enviar.</li>
<li>Volte para a primeira página e o resultado estará abaixo.</li>
<li>Cada página recebe a informação do botão da outra.</li>
</ul>
<button>Enviar</button>
<hr>
<div id="infoServerToCli"></div>
<script src="/socket.io/socket.io.js"></script>
<script>
var io = io();
var infoReceived = [];
io.on('infoServerToCli',function(data){
document.querySelector('#infoServerToCli').innerHTML += 'informação recebida: '+ data.textData +'<br>';
});
document.querySelector('button').onclick = function(e){
e.preventDefault();
io.emit('infoCliToServer',{textData:new Date()});
};
</script>
</body>
</html> <file_sep># cafecomlucas.github.io
Projetos pessoais e Portfólio
<file_sep>var app = require('./config/express')();
var http = require('http').Server(app);
var io = require('socket.io')(http);
app.set('io', io);
io.sockets.on('connection',function(client){
client.on('infoCliToServer',function(data){
client.broadcast.emit('infoServerToCli',data);
});
});
http.listen(process.env.PORT || 3000,function(){
console.log("servidor rodando...");
}); <file_sep>var app = require('./config/express')();
var http = require('http').Server(app);
var io = require('socket.io')(http);
io.sockets.on('connection',function(client){
var idCli = 'x';
client.on('sendPlayer',function(data){
client.broadcast.emit('receivePlayer',data);
});
client.on('sendConnectionOn',function(){
idCli = new Date().getTime().toString(16);
console.log('cliente ' + idCli + ' entrou');
client.emit('receiveConnectionOn',{id:new Date().getTime().toString(16)});
});
client.on('disconnect',function(){
console.log('cliente '+ idCli +' saiu');
client.broadcast.emit('infoServerToCliDisconnect',{id:idCli});
});
});
http.listen(process.env.PORT || 3000,function(){
console.log("servidor rodando...");
}); | fe70822822ee23ae6eafee1eac83a916bcf60118 | [
"Markdown",
"JavaScript",
"HTML"
] | 4 | HTML | cafecomlucas/cafecomlucas.github.io | c99067ebc6f9036c0de1a05f624537f9165283b1 | 9aada93960d5b31eb3893d8d3eeb2fd65fff0d1f |
refs/heads/master | <file_sep>package ch.helsana.web;
import java.util.Random;
/**
* Created by hkfq4 on 07.02.2017.
*/
public class Start {
//psvm shortcut für main Class
public static void main(String[] args) {
System.out.println("Hellooooo");
long millis = new java.util.Date().getTime();
System.out.println("Millis: " + millis);
int a = 0;
for(int i = 0; i < 100; i++){
a = a + 1;
System.out.println(a);
}
System.out.println("Zähler: " + a);
long millis1 = new java.util.Date().getTime();
System.out.println("Millis: " + millis1);
long millis2 = new java.util.Date().getTime();
System.out.println("Millis: " + millis2);
Random randomGenerator = new Random();
//for (int idx = 1; idx <= 10; ++idx){
int randomInt = randomGenerator.nextInt(1000);
System.out.println("Generated : " + randomInt);
//}
}
}
<file_sep>package ch.helsana.web;
import ch.helsana.web.hib.entities.Books;
import ch.helsana.web.hib.init.HibernateUtil;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
/**
* Created by hkfq4 on 07.02.2017.
*/
public class DemoThird {
public static void main(String[] args) {
SessionFactory sessionFactory = HibernateUtil.getSessionFactory();
Session session = sessionFactory.openSession();
session.beginTransaction();
Books book = (Books) session.get(Books.class, 3);
book.setIsbn("N 123456");
book.setTitle("NEU Der zame Hai.");
book.setYear(2018);
session.update(book);
session.getTransaction().commit();
session.close();
}
}
<file_sep>package ch.helsana.web.hib.entities;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
/**
* Created by hkfq4 on 07.02.2017.
*/
@Entity
@Table
public class Books {
@Id
//@GeneratedValue
private int id;
private String isbn;
private String title;
private Integer year;
public Books() {};
public Books(int id, String isbn, String title, int year) {
this.id = id;
this.isbn = isbn;
this.title = title;
this.year = year;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getIsbn() {
return isbn;
}
public void setIsbn(String isbn) {
this.isbn = isbn;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public Integer getYear() {
return year;
}
public void setYear(Integer year) {
this.year = year;
}
}
| 30362fa9ec5fad0f9bd0dd1f1d5184da76433505 | [
"Java"
] | 3 | Java | Ziitlos/hibernate | 8dff300ba09e7afb5996c6b25326d8989239cb0f | 955e39aa932b6b734a57d016375e22b461c02f1c |
refs/heads/master | <file_sep>package com.github.ryanrupert.UnixLogger;
class Main {
public static void main(String args[]){
Logger logger = Logger.create();
logger.crit("critical message");
logger.notice("notice message");
logger.debug("debug message");
}
}
<file_sep># Unix Logger
This is a Log4j2 custom logger that has the same log levels as the Unix logging standard as per RFC5424.
Look at license.html for the licenses for the libraries used in this project.
<file_sep>package com.github.ryanrupert.UnixLogger;
import java.io.Serializable;
import org.apache.logging.log4j.Level;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Marker;
import org.apache.logging.log4j.message.Message;
import org.apache.logging.log4j.message.MessageFactory;
import org.apache.logging.log4j.spi.AbstractLogger;
import org.apache.logging.log4j.spi.ExtendedLoggerWrapper;
/**
* Custom Logger interface with convenience methods for
* the EMERG, ALERT, CRIT, ERROR, WARNING, NOTICE, INFO and DEBUG custom log levels.
*/
public final class Logger implements Serializable {
private static final long serialVersionUID = 685727341505000L;
private final ExtendedLoggerWrapper logger;
private static final String FQCN = Logger.class.getName();
private static final Level EMERG = Level.forName("EMERG", 50);
private static final Level ALERT = Level.forName("ALERT", 100);
private static final Level CRIT = Level.forName("CRIT", 150);
private static final Level ERROR = Level.forName("ERROR", 200);
private static final Level WARNING = Level.forName("WARNING", 250);
private static final Level NOTICE = Level.forName("NOTICE", 300);
private static final Level INFO = Level.forName("INFO", 350);
private static final Level DEBUG = Level.forName("DEBUG", 400);
private Logger(final org.apache.logging.log4j.Logger logger) {
this.logger = new ExtendedLoggerWrapper((AbstractLogger) logger, logger.getName(), logger.getMessageFactory());
}
/**
* Returns a custom Logger with the name of the calling class.
*
* @return The custom Logger for the calling class.
*/
public static Logger create() {
final org.apache.logging.log4j.Logger wrapped = LogManager.getLogger();
return new Logger(wrapped);
}
/**
* Returns a custom Logger using the fully qualified name of the Class as
* the Logger name.
*
* @param loggerName The Class whose name should be used as the Logger name.
* If null it will default to the calling class.
* @return The custom Logger.
*/
public static Logger create(final Class<?> loggerName) {
final org.apache.logging.log4j.Logger wrapped = LogManager.getLogger(loggerName);
return new Logger(wrapped);
}
/**
* Returns a custom Logger using the fully qualified name of the Class as
* the Logger name.
*
* @param loggerName The Class whose name should be used as the Logger name.
* If null it will default to the calling class.
* @param messageFactory The message factory is used only when creating a
* logger, subsequent use does not change the logger but will log
* a warning if mismatched.
* @return The custom Logger.
*/
public static Logger create(final Class<?> loggerName, final MessageFactory factory) {
final org.apache.logging.log4j.Logger wrapped = LogManager.getLogger(loggerName, factory);
return new Logger(wrapped);
}
/**
* Returns a custom Logger using the fully qualified class name of the value
* as the Logger name.
*
* @param value The value whose class name should be used as the Logger
* name. If null the name of the calling class will be used as
* the logger name.
* @return The custom Logger.
*/
public static Logger create(final Object value) {
final org.apache.logging.log4j.Logger wrapped = LogManager.getLogger(value);
return new Logger(wrapped);
}
/**
* Returns a custom Logger using the fully qualified class name of the value
* as the Logger name.
*
* @param value The value whose class name should be used as the Logger
* name. If null the name of the calling class will be used as
* the logger name.
* @param messageFactory The message factory is used only when creating a
* logger, subsequent use does not change the logger but will log
* a warning if mismatched.
* @return The custom Logger.
*/
public static Logger create(final Object value, final MessageFactory factory) {
final org.apache.logging.log4j.Logger wrapped = LogManager.getLogger(value, factory);
return new Logger(wrapped);
}
/**
* Returns a custom Logger with the specified name.
*
* @param name The logger name. If null the name of the calling class will
* be used.
* @return The custom Logger.
*/
public static Logger create(final String name) {
final org.apache.logging.log4j.Logger wrapped = LogManager.getLogger(name);
return new Logger(wrapped);
}
/**
* Returns a custom Logger with the specified name.
*
* @param name The logger name. If null the name of the calling class will
* be used.
* @param messageFactory The message factory is used only when creating a
* logger, subsequent use does not change the logger but will log
* a warning if mismatched.
* @return The custom Logger.
*/
public static Logger create(final String name, final MessageFactory factory) {
final org.apache.logging.log4j.Logger wrapped = LogManager.getLogger(name, factory);
return new Logger(wrapped);
}
/**
* Logs a message with the specific Marker at the {@code EMERG} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
*/
public void emerg(final Marker marker, final Message msg) {
logger.logIfEnabled(FQCN, EMERG, marker, msg, (Throwable) null);
}
/**
* Logs a message with the specific Marker at the {@code EMERG} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void emerg(final Marker marker, final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, EMERG, marker, msg, t);
}
/**
* Logs a message object with the {@code EMERG} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void emerg(final Marker marker, final Object message) {
logger.logIfEnabled(FQCN, EMERG, marker, message, (Throwable) null);
}
/**
* Logs a message at the {@code EMERG} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void emerg(final Marker marker, final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, EMERG, marker, message, t);
}
/**
* Logs a message object with the {@code EMERG} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void emerg(final Marker marker, final String message) {
logger.logIfEnabled(FQCN, EMERG, marker, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code EMERG} level.
*
* @param marker the marker data specific to this log statement
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void emerg(final Marker marker, final String message, final Object... params) {
logger.logIfEnabled(FQCN, EMERG, marker, message, params);
}
/**
* Logs a message at the {@code EMERG} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void emerg(final Marker marker, final String message, final Throwable t) {
logger.logIfEnabled(FQCN, EMERG, marker, message, t);
}
/**
* Logs the specified Message at the {@code EMERG} level.
*
* @param msg the message string to be logged
*/
public void emerg(final Message msg) {
logger.logIfEnabled(FQCN, EMERG, null, msg, (Throwable) null);
}
/**
* Logs the specified Message at the {@code EMERG} level.
*
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void emerg(final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, EMERG, null, msg, t);
}
/**
* Logs a message object with the {@code EMERG} level.
*
* @param message the message object to log.
*/
public void emerg(final Object message) {
logger.logIfEnabled(FQCN, EMERG, null, message, (Throwable) null);
}
/**
* Logs a message at the {@code EMERG} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void emerg(final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, EMERG, null, message, t);
}
/**
* Logs a message object with the {@code EMERG} level.
*
* @param message the message object to log.
*/
public void emerg(final String message) {
logger.logIfEnabled(FQCN, EMERG, null, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code EMERG} level.
*
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void emerg(final String message, final Object... params) {
logger.logIfEnabled(FQCN, EMERG, null, message, params);
}
/**
* Logs a message at the {@code EMERG} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void emerg(final String message, final Throwable t) {
logger.logIfEnabled(FQCN, EMERG, null, message, t);
}
/**
* Logs a message with the specific Marker at the {@code ALERT} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
*/
public void alert(final Marker marker, final Message msg) {
logger.logIfEnabled(FQCN, ALERT, marker, msg, (Throwable) null);
}
/**
* Logs a message with the specific Marker at the {@code ALERT} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void alert(final Marker marker, final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, ALERT, marker, msg, t);
}
/**
* Logs a message object with the {@code ALERT} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void alert(final Marker marker, final Object message) {
logger.logIfEnabled(FQCN, ALERT, marker, message, (Throwable) null);
}
/**
* Logs a message at the {@code ALERT} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void alert(final Marker marker, final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, ALERT, marker, message, t);
}
/**
* Logs a message object with the {@code ALERT} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void alert(final Marker marker, final String message) {
logger.logIfEnabled(FQCN, ALERT, marker, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code ALERT} level.
*
* @param marker the marker data specific to this log statement
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void alert(final Marker marker, final String message, final Object... params) {
logger.logIfEnabled(FQCN, ALERT, marker, message, params);
}
/**
* Logs a message at the {@code ALERT} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void alert(final Marker marker, final String message, final Throwable t) {
logger.logIfEnabled(FQCN, ALERT, marker, message, t);
}
/**
* Logs the specified Message at the {@code ALERT} level.
*
* @param msg the message string to be logged
*/
public void alert(final Message msg) {
logger.logIfEnabled(FQCN, ALERT, null, msg, (Throwable) null);
}
/**
* Logs the specified Message at the {@code ALERT} level.
*
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void alert(final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, ALERT, null, msg, t);
}
/**
* Logs a message object with the {@code ALERT} level.
*
* @param message the message object to log.
*/
public void alert(final Object message) {
logger.logIfEnabled(FQCN, ALERT, null, message, (Throwable) null);
}
/**
* Logs a message at the {@code ALERT} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void alert(final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, ALERT, null, message, t);
}
/**
* Logs a message object with the {@code ALERT} level.
*
* @param message the message object to log.
*/
public void alert(final String message) {
logger.logIfEnabled(FQCN, ALERT, null, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code ALERT} level.
*
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void alert(final String message, final Object... params) {
logger.logIfEnabled(FQCN, ALERT, null, message, params);
}
/**
* Logs a message at the {@code ALERT} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void alert(final String message, final Throwable t) {
logger.logIfEnabled(FQCN, ALERT, null, message, t);
}
/**
* Logs a message with the specific Marker at the {@code CRIT} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
*/
public void crit(final Marker marker, final Message msg) {
logger.logIfEnabled(FQCN, CRIT, marker, msg, (Throwable) null);
}
/**
* Logs a message with the specific Marker at the {@code CRIT} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void crit(final Marker marker, final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, CRIT, marker, msg, t);
}
/**
* Logs a message object with the {@code CRIT} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void crit(final Marker marker, final Object message) {
logger.logIfEnabled(FQCN, CRIT, marker, message, (Throwable) null);
}
/**
* Logs a message at the {@code CRIT} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void crit(final Marker marker, final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, CRIT, marker, message, t);
}
/**
* Logs a message object with the {@code CRIT} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void crit(final Marker marker, final String message) {
logger.logIfEnabled(FQCN, CRIT, marker, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code CRIT} level.
*
* @param marker the marker data specific to this log statement
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void crit(final Marker marker, final String message, final Object... params) {
logger.logIfEnabled(FQCN, CRIT, marker, message, params);
}
/**
* Logs a message at the {@code CRIT} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void crit(final Marker marker, final String message, final Throwable t) {
logger.logIfEnabled(FQCN, CRIT, marker, message, t);
}
/**
* Logs the specified Message at the {@code CRIT} level.
*
* @param msg the message string to be logged
*/
public void crit(final Message msg) {
logger.logIfEnabled(FQCN, CRIT, null, msg, (Throwable) null);
}
/**
* Logs the specified Message at the {@code CRIT} level.
*
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void crit(final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, CRIT, null, msg, t);
}
/**
* Logs a message object with the {@code CRIT} level.
*
* @param message the message object to log.
*/
public void crit(final Object message) {
logger.logIfEnabled(FQCN, CRIT, null, message, (Throwable) null);
}
/**
* Logs a message at the {@code CRIT} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void crit(final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, CRIT, null, message, t);
}
/**
* Logs a message object with the {@code CRIT} level.
*
* @param message the message object to log.
*/
public void crit(final String message) {
logger.logIfEnabled(FQCN, CRIT, null, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code CRIT} level.
*
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void crit(final String message, final Object... params) {
logger.logIfEnabled(FQCN, CRIT, null, message, params);
}
/**
* Logs a message at the {@code CRIT} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void crit(final String message, final Throwable t) {
logger.logIfEnabled(FQCN, CRIT, null, message, t);
}
/**
* Logs a message with the specific Marker at the {@code ERROR} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
*/
public void error(final Marker marker, final Message msg) {
logger.logIfEnabled(FQCN, ERROR, marker, msg, (Throwable) null);
}
/**
* Logs a message with the specific Marker at the {@code ERROR} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void error(final Marker marker, final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, ERROR, marker, msg, t);
}
/**
* Logs a message object with the {@code ERROR} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void error(final Marker marker, final Object message) {
logger.logIfEnabled(FQCN, ERROR, marker, message, (Throwable) null);
}
/**
* Logs a message at the {@code ERROR} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void error(final Marker marker, final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, ERROR, marker, message, t);
}
/**
* Logs a message object with the {@code ERROR} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void error(final Marker marker, final String message) {
logger.logIfEnabled(FQCN, ERROR, marker, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code ERROR} level.
*
* @param marker the marker data specific to this log statement
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void error(final Marker marker, final String message, final Object... params) {
logger.logIfEnabled(FQCN, ERROR, marker, message, params);
}
/**
* Logs a message at the {@code ERROR} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void error(final Marker marker, final String message, final Throwable t) {
logger.logIfEnabled(FQCN, ERROR, marker, message, t);
}
/**
* Logs the specified Message at the {@code ERROR} level.
*
* @param msg the message string to be logged
*/
public void error(final Message msg) {
logger.logIfEnabled(FQCN, ERROR, null, msg, (Throwable) null);
}
/**
* Logs the specified Message at the {@code ERROR} level.
*
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void error(final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, ERROR, null, msg, t);
}
/**
* Logs a message object with the {@code ERROR} level.
*
* @param message the message object to log.
*/
public void error(final Object message) {
logger.logIfEnabled(FQCN, ERROR, null, message, (Throwable) null);
}
/**
* Logs a message at the {@code ERROR} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void error(final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, ERROR, null, message, t);
}
/**
* Logs a message object with the {@code ERROR} level.
*
* @param message the message object to log.
*/
public void error(final String message) {
logger.logIfEnabled(FQCN, ERROR, null, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code ERROR} level.
*
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void error(final String message, final Object... params) {
logger.logIfEnabled(FQCN, ERROR, null, message, params);
}
/**
* Logs a message at the {@code ERROR} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void error(final String message, final Throwable t) {
logger.logIfEnabled(FQCN, ERROR, null, message, t);
}
/**
* Logs a message with the specific Marker at the {@code WARNING} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
*/
public void warning(final Marker marker, final Message msg) {
logger.logIfEnabled(FQCN, WARNING, marker, msg, (Throwable) null);
}
/**
* Logs a message with the specific Marker at the {@code WARNING} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void warning(final Marker marker, final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, WARNING, marker, msg, t);
}
/**
* Logs a message object with the {@code WARNING} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void warning(final Marker marker, final Object message) {
logger.logIfEnabled(FQCN, WARNING, marker, message, (Throwable) null);
}
/**
* Logs a message at the {@code WARNING} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void warning(final Marker marker, final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, WARNING, marker, message, t);
}
/**
* Logs a message object with the {@code WARNING} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void warning(final Marker marker, final String message) {
logger.logIfEnabled(FQCN, WARNING, marker, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code WARNING} level.
*
* @param marker the marker data specific to this log statement
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void warning(final Marker marker, final String message, final Object... params) {
logger.logIfEnabled(FQCN, WARNING, marker, message, params);
}
/**
* Logs a message at the {@code WARNING} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void warning(final Marker marker, final String message, final Throwable t) {
logger.logIfEnabled(FQCN, WARNING, marker, message, t);
}
/**
* Logs the specified Message at the {@code WARNING} level.
*
* @param msg the message string to be logged
*/
public void warning(final Message msg) {
logger.logIfEnabled(FQCN, WARNING, null, msg, (Throwable) null);
}
/**
* Logs the specified Message at the {@code WARNING} level.
*
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void warning(final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, WARNING, null, msg, t);
}
/**
* Logs a message object with the {@code WARNING} level.
*
* @param message the message object to log.
*/
public void warning(final Object message) {
logger.logIfEnabled(FQCN, WARNING, null, message, (Throwable) null);
}
/**
* Logs a message at the {@code WARNING} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void warning(final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, WARNING, null, message, t);
}
/**
* Logs a message object with the {@code WARNING} level.
*
* @param message the message object to log.
*/
public void warning(final String message) {
logger.logIfEnabled(FQCN, WARNING, null, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code WARNING} level.
*
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void warning(final String message, final Object... params) {
logger.logIfEnabled(FQCN, WARNING, null, message, params);
}
/**
* Logs a message at the {@code WARNING} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void warning(final String message, final Throwable t) {
logger.logIfEnabled(FQCN, WARNING, null, message, t);
}
/**
* Logs a message with the specific Marker at the {@code NOTICE} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
*/
public void notice(final Marker marker, final Message msg) {
logger.logIfEnabled(FQCN, NOTICE, marker, msg, (Throwable) null);
}
/**
* Logs a message with the specific Marker at the {@code NOTICE} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void notice(final Marker marker, final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, NOTICE, marker, msg, t);
}
/**
* Logs a message object with the {@code NOTICE} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void notice(final Marker marker, final Object message) {
logger.logIfEnabled(FQCN, NOTICE, marker, message, (Throwable) null);
}
/**
* Logs a message at the {@code NOTICE} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void notice(final Marker marker, final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, NOTICE, marker, message, t);
}
/**
* Logs a message object with the {@code NOTICE} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void notice(final Marker marker, final String message) {
logger.logIfEnabled(FQCN, NOTICE, marker, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code NOTICE} level.
*
* @param marker the marker data specific to this log statement
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void notice(final Marker marker, final String message, final Object... params) {
logger.logIfEnabled(FQCN, NOTICE, marker, message, params);
}
/**
* Logs a message at the {@code NOTICE} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void notice(final Marker marker, final String message, final Throwable t) {
logger.logIfEnabled(FQCN, NOTICE, marker, message, t);
}
/**
* Logs the specified Message at the {@code NOTICE} level.
*
* @param msg the message string to be logged
*/
public void notice(final Message msg) {
logger.logIfEnabled(FQCN, NOTICE, null, msg, (Throwable) null);
}
/**
* Logs the specified Message at the {@code NOTICE} level.
*
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void notice(final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, NOTICE, null, msg, t);
}
/**
* Logs a message object with the {@code NOTICE} level.
*
* @param message the message object to log.
*/
public void notice(final Object message) {
logger.logIfEnabled(FQCN, NOTICE, null, message, (Throwable) null);
}
/**
* Logs a message at the {@code NOTICE} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void notice(final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, NOTICE, null, message, t);
}
/**
* Logs a message object with the {@code NOTICE} level.
*
* @param message the message object to log.
*/
public void notice(final String message) {
logger.logIfEnabled(FQCN, NOTICE, null, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code NOTICE} level.
*
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void notice(final String message, final Object... params) {
logger.logIfEnabled(FQCN, NOTICE, null, message, params);
}
/**
* Logs a message at the {@code NOTICE} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void notice(final String message, final Throwable t) {
logger.logIfEnabled(FQCN, NOTICE, null, message, t);
}
/**
* Logs a message with the specific Marker at the {@code INFO} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
*/
public void info(final Marker marker, final Message msg) {
logger.logIfEnabled(FQCN, INFO, marker, msg, (Throwable) null);
}
/**
* Logs a message with the specific Marker at the {@code INFO} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void info(final Marker marker, final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, INFO, marker, msg, t);
}
/**
* Logs a message object with the {@code INFO} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void info(final Marker marker, final Object message) {
logger.logIfEnabled(FQCN, INFO, marker, message, (Throwable) null);
}
/**
* Logs a message at the {@code INFO} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void info(final Marker marker, final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, INFO, marker, message, t);
}
/**
* Logs a message object with the {@code INFO} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void info(final Marker marker, final String message) {
logger.logIfEnabled(FQCN, INFO, marker, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code INFO} level.
*
* @param marker the marker data specific to this log statement
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void info(final Marker marker, final String message, final Object... params) {
logger.logIfEnabled(FQCN, INFO, marker, message, params);
}
/**
* Logs a message at the {@code INFO} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void info(final Marker marker, final String message, final Throwable t) {
logger.logIfEnabled(FQCN, INFO, marker, message, t);
}
/**
* Logs the specified Message at the {@code INFO} level.
*
* @param msg the message string to be logged
*/
public void info(final Message msg) {
logger.logIfEnabled(FQCN, INFO, null, msg, (Throwable) null);
}
/**
* Logs the specified Message at the {@code INFO} level.
*
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void info(final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, INFO, null, msg, t);
}
/**
* Logs a message object with the {@code INFO} level.
*
* @param message the message object to log.
*/
public void info(final Object message) {
logger.logIfEnabled(FQCN, INFO, null, message, (Throwable) null);
}
/**
* Logs a message at the {@code INFO} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void info(final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, INFO, null, message, t);
}
/**
* Logs a message object with the {@code INFO} level.
*
* @param message the message object to log.
*/
public void info(final String message) {
logger.logIfEnabled(FQCN, INFO, null, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code INFO} level.
*
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void info(final String message, final Object... params) {
logger.logIfEnabled(FQCN, INFO, null, message, params);
}
/**
* Logs a message at the {@code INFO} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void info(final String message, final Throwable t) {
logger.logIfEnabled(FQCN, INFO, null, message, t);
}
/**
* Logs a message with the specific Marker at the {@code DEBUG} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
*/
public void debug(final Marker marker, final Message msg) {
logger.logIfEnabled(FQCN, DEBUG, marker, msg, (Throwable) null);
}
/**
* Logs a message with the specific Marker at the {@code DEBUG} level.
*
* @param marker the marker data specific to this log statement
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void debug(final Marker marker, final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, DEBUG, marker, msg, t);
}
/**
* Logs a message object with the {@code DEBUG} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void debug(final Marker marker, final Object message) {
logger.logIfEnabled(FQCN, DEBUG, marker, message, (Throwable) null);
}
/**
* Logs a message at the {@code DEBUG} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void debug(final Marker marker, final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, DEBUG, marker, message, t);
}
/**
* Logs a message object with the {@code DEBUG} level.
*
* @param marker the marker data specific to this log statement
* @param message the message object to log.
*/
public void debug(final Marker marker, final String message) {
logger.logIfEnabled(FQCN, DEBUG, marker, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code DEBUG} level.
*
* @param marker the marker data specific to this log statement
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void debug(final Marker marker, final String message, final Object... params) {
logger.logIfEnabled(FQCN, DEBUG, marker, message, params);
}
/**
* Logs a message at the {@code DEBUG} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param marker the marker data specific to this log statement
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void debug(final Marker marker, final String message, final Throwable t) {
logger.logIfEnabled(FQCN, DEBUG, marker, message, t);
}
/**
* Logs the specified Message at the {@code DEBUG} level.
*
* @param msg the message string to be logged
*/
public void debug(final Message msg) {
logger.logIfEnabled(FQCN, DEBUG, null, msg, (Throwable) null);
}
/**
* Logs the specified Message at the {@code DEBUG} level.
*
* @param msg the message string to be logged
* @param t A Throwable or null.
*/
public void debug(final Message msg, final Throwable t) {
logger.logIfEnabled(FQCN, DEBUG, null, msg, t);
}
/**
* Logs a message object with the {@code DEBUG} level.
*
* @param message the message object to log.
*/
public void debug(final Object message) {
logger.logIfEnabled(FQCN, DEBUG, null, message, (Throwable) null);
}
/**
* Logs a message at the {@code DEBUG} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void debug(final Object message, final Throwable t) {
logger.logIfEnabled(FQCN, DEBUG, null, message, t);
}
/**
* Logs a message object with the {@code DEBUG} level.
*
* @param message the message object to log.
*/
public void debug(final String message) {
logger.logIfEnabled(FQCN, DEBUG, null, message, (Throwable) null);
}
/**
* Logs a message with parameters at the {@code DEBUG} level.
*
* @param message the message to log; the format depends on the message factory.
* @param params parameters to the message.
* @see #getMessageFactory()
*/
public void debug(final String message, final Object... params) {
logger.logIfEnabled(FQCN, DEBUG, null, message, params);
}
/**
* Logs a message at the {@code DEBUG} level including the stack trace of
* the {@link Throwable} {@code t} passed as parameter.
*
* @param message the message to log.
* @param t the exception to log, including its stack trace.
*/
public void debug(final String message, final Throwable t) {
logger.logIfEnabled(FQCN, DEBUG, null, message, t);
}
}
<file_sep>rootProject.name = 'RyanLogger'
<file_sep>plugins {
id 'java'
id 'com.palantir.git-version' version '0.12.3'
}
group 'io.github.ryanrupert'
version '1.0-SNAPSHOT'
sourceCompatibility = 1.8
repositories {
mavenCentral()
}
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.12'
compile group: 'org.apache.logging.log4j', name: 'log4j-api', version: '2.1'
compile group: 'org.apache.logging.log4j', name: 'log4j-core', version: '2.1'
}
task releaseJar(type: Jar) {
manifest {
attributes (
'Main-Class': 'io.github.ryanrupert.MainProgram',
'Implementation-Version' : gitVersion()
)
}
archiveName('UnixLogger-' + gitVersion() + '.jar')
from {
configurations.compile.collect { it.isDirectory() ? it : zipTree(it)}
configurations.runtimeClasspath.collect { it.isDirectory() ? it : zipTree(it)}
}
with jar
} | 40f7b76e817750563d80b64e59d9e1cbb98a355f | [
"Markdown",
"Java",
"Gradle"
] | 5 | Java | ryanrupert/UnixLogger | 03b4b9ac0b3524d3f756d8a2a51ab8438f5caaea | a89a440757b3f28f8fd210a12fd103707376bdf0 |
refs/heads/master | <file_sep>using System.Collections;
using System.Collections.Generic;
using System.Diagnostics;
using UnityEditor;
using UnityEngine;
using UnityEngine.UI;
using UnityEngine.XR.ARFoundation;
using UnityEngine.XR.ARSubsystems;
[RequireComponent(typeof(ARSessionOrigin))]
[RequireComponent(typeof(ARRaycastManager))]
public class ARTapPlaceObject : MonoBehaviour
{
public GameObject gameObjectToInstantiate;
private ARRaycastManager _aRRaycastManager;
ARSessionOrigin SessionOrigin;
private int Isspawned = 0;
private GameObject spawnedObject;
private Vector2 touchposition;
//public Button ReloadButton;
static List<ARRaycastHit> hits = new List<ARRaycastHit>();
[SerializeField]
[Tooltip("A transform which should be made to appear to be at the touch point.")]
Transform m_Content;
/// <summary>
/// A transform which should be made to appear to be at the touch point.
/// </summary>
public Transform content
{
get { return m_Content; }
set { m_Content = value; }
}
[SerializeField]
[Tooltip("The rotation the content should appear to have.")]
Quaternion m_Rotation;
/// <summary>
/// The rotation the content should appear to have.
/// </summary>
public Quaternion rotation
{
get { return m_Rotation; }
set
{
m_Rotation = value;
if (SessionOrigin != null)
SessionOrigin.MakeContentAppearAt(content, content.transform.position, m_Rotation);
}
}
private void Awake()
{
SessionOrigin = GetComponent<ARSessionOrigin>();
_aRRaycastManager = GetComponent<ARRaycastManager>();
SessionOrigin.transform.localScale = Vector3.one * 50;
//ReloadButton.onClick.AddListener(replaceMap);
}
public bool TryGetTouchPosition(out Vector2 touchposition)
{
if (Input.touchCount > 0)
{
touchposition = Input.GetTouch(0).position;
return true;
}
touchposition = default;
return false;
}
public void replaceMap()
{
//SessionOrigin.MakeContentAppearAt(content, new Vector3(content.position.x + 1000, content.position.y, content.position.z), m_Rotation);
if (GameObject.Find("All_Objects").transform.childCount != 0)
{
int maxchild = GameObject.Find("All_Objects").transform.childCount;
for (int i = 0; i != maxchild; i++)
{
Destroy(GameObject.Find("All_Objects").transform.GetChild(i));
}
}
Destroy(spawnedObject);
Isspawned = 0;
}
// Update is called once per frame
void Update()
{
if (!TryGetTouchPosition(out Vector2 touchposition))
return;
if (_aRRaycastManager.Raycast(touchposition, hits, trackableTypes:TrackableType.PlaneWithinPolygon))
{
var hitpose = hits[0].pose;
if (Isspawned == 0)
{
Isspawned = 1;
spawnedObject = (GameObject)Instantiate(gameObjectToInstantiate, new Vector3(hitpose.position.x, hitpose.position.y + 1, hitpose.position.z), m_Rotation, GameObject.Find("Offset").transform);
SessionOrigin.MakeContentAppearAt(content, hitpose.position, m_Rotation);
GameObject.Find("GameHandler").GetComponent<WaveSpawner>().Start();
}
//spawnedObject = Instantiate(gameObjectToInstantiate, hitpose.position, hitpose.rotation);
//SessionOrigin.MakeContentAppearAt(content, hitpose.position, rotation);
//spawnedObject = 1;
/*else
{
spawnedObject.transform.position = hitpose.position;
spawnedObject.transform.rotation = hitpose.rotation;
}*/
}
}
}
<file_sep>using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UIElements;
using UnityEngine.EventSystems;
public class Node : MonoBehaviour
{
public Color hoverColor;
private Color startColor;
public Vector3 positionOffset;
public GameObject turret;
public GameObject node;
public GameObject Shop;
public GameObject Level_up;
private Renderer rend;
BuildManager buildmanager;
// Start is called before the first frame update
void Start()
{
rend = GetComponent<Renderer>();
startColor = rend.material.color;
buildmanager = BuildManager.instance;
}
// Update is called once per frame
void OnMouseDown()
{
if (EventSystem.current.IsPointerOverGameObject())
return;
if (BuildManager.instance.ShopParent.childCount >= 1)
{
for (int i = 0; i != BuildManager.instance.ShopParent.childCount ; i++)
{
Destroy(BuildManager.instance.ShopParent.GetChild(i).gameObject);
}
}
GameObject Prefab;
if (turret == null)
Prefab = Shop;
else
Prefab = Level_up;
GameObject clone = Instantiate(Prefab);
clone.transform.position = node.transform.position + new Vector3(0, 5.5f, 10);
clone.transform.SetParent(BuildManager.instance.ShopParent);
clone.GetComponentInChildren<Shop>().positionOffset = positionOffset;
clone.GetComponentInChildren<Shop>().nodeposition = transform.position;
clone.GetComponentInChildren<Shop>().actualObject = clone;
clone.GetComponentInChildren<Shop>().node = transform.gameObject;
}
void OnMouseEnter()
{
rend.material.color = hoverColor;
}
void OnMouseExit()
{
rend.material.color = startColor;
}
}
<file_sep>using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
public class Enemy : MonoBehaviour
{
public float speed;
public float starthp;
private float hp;
public Image Healthbar;
private GameObject gameHandler;
private Transform target;
private int wavepointIndex = 0;
void Start () {
target = Waypoints.points[0];
hp = starthp;
gameHandler = GameObject.Find("GameHandler");
}
void Update () {
Vector3 dir = target.position - transform.position;
transform.Translate(dir.normalized * speed * Time.deltaTime, Space.World);
if (Vector3.Distance(transform.position, target.position) <= 0.4f) {
GetNextWaypoint();
}
}
void GetNextWaypoint() {
if (wavepointIndex >= Waypoints.points.Length - 1) {
gameHandler.GetComponent<WaveSpawner>().hp -= 1;
Destroy(gameObject);
return;
}
wavepointIndex++;
target = Waypoints.points[wavepointIndex];
}
public void Hit(float power) {
hp -= power;
Healthbar.fillAmount = hp / starthp;
if (hp <= 0) {
gameHandler.GetComponent<WaveSpawner>().money = gameHandler.GetComponent<WaveSpawner>().money + ( (power + hp) / 2) + 10;
Destroy(gameObject);
} else {
gameHandler.GetComponent<WaveSpawner>().money = gameHandler.GetComponent<WaveSpawner>().money + ( power / 2);
}
}
public void MultWave(int w) {
hp += (float)(hp * (w * 0.1));
}
}
<file_sep>using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.EventSystems;
public class Shop : MonoBehaviour
{
BuildManager buildmanager;
private GameObject turret;
public GameObject actualObject;
public GameObject node;
public Vector3 positionOffset;
public Vector3 nodeposition;
private GameObject gameHandler;
private float money;
void Start()
{
buildmanager = BuildManager.instance;
gameHandler = GameObject.Find("GameHandler");
money = gameHandler.GetComponent<WaveSpawner>().money;
}
void Update()
{
money = gameHandler.GetComponent<WaveSpawner>().money;
}
public void Create_Turret()
{
if (node.GetComponent<Node>().turret != null || money < 70) return;
buildmanager.SetTurretToBuild(buildmanager.TurretPrefab);
if (buildmanager.GetTurretToBuild() == null) return;
GameObject turretToBuild = BuildManager.instance.GetTurretToBuild();
turret = (GameObject)Instantiate(turretToBuild, nodeposition + positionOffset, node.transform.rotation);
turret.transform.SetParent(BuildManager.instance.ParentElement);
node.GetComponent<Node>().turret = turret;
gameHandler.GetComponent<WaveSpawner>().money -= 70;
Destroy(actualObject);
}
public void Create_Missile()
{
if (node.GetComponent<Node>().turret != null || money < 70) return;
buildmanager.SetTurretToBuild(buildmanager.MissilePrefab);
if (buildmanager.GetTurretToBuild() == null) return;
GameObject turretToBuild = BuildManager.instance.GetTurretToBuild();
turret = (GameObject)Instantiate(turretToBuild, nodeposition + new Vector3(0, 0.1f, 0), node.transform.rotation);
turret.transform.SetParent(BuildManager.instance.ParentElement);
node.GetComponent<Node>().turret = turret;
gameHandler.GetComponent<WaveSpawner>().money -= 70;
Destroy(actualObject);
}
public void Create_Laser()
{
if (node.GetComponent<Node>().turret != null || money < 70) return;
buildmanager.SetTurretToBuild(buildmanager.LaserPrefab);
if (buildmanager.GetTurretToBuild() == null) return;
GameObject turretToBuild = BuildManager.instance.GetTurretToBuild();
turret = (GameObject)Instantiate(turretToBuild, nodeposition + new Vector3(0, 0.1f, 0), node.transform.rotation);
turret.transform.SetParent(BuildManager.instance.ParentElement);
node.GetComponent<Node>().turret = turret;
gameHandler.GetComponent<WaveSpawner>().money -= 70;
Destroy(actualObject);
}
public GameObject get_turret()
{
return turret;
}
public void Level_Up()
{
if (money < 50) return;
gameHandler.GetComponent<WaveSpawner>().money -= 50;
node.GetComponent<Node>().turret.GetComponent<Turret>().lvl_up();
}
public void Destroy_Shop()
{
Destroy(actualObject);
}
}
<file_sep>using System.Collections;
using System.Collections.Generic;
// using System.Diagnostics.PerformanceData;
using UnityEngine;
using UnityEngine.UI;
public class WaveSpawner : MonoBehaviour
{
[Header("Enemy Type")]
public Transform NormalEnemy;
public Transform TankEnemy;
public Transform SpeedEnemy;
public Transform FastAsFuckBoiEnemy;
[Header("Start")]
public Transform SpawnPoint;
[Header("Settings")]
public Transform ParentElement;
public GameObject End;
public float Time_btw_waves = 5f;
private float countdow = 2f;
private List<List<int>> waves = new List<List<int>>();
private Dictionary<EnemyType, Transform> dict = new Dictionary<EnemyType, Transform>();
public float hp = 25f;
public Text HP;
public Text WaveCountdownTest;
private int Waveindex = -1;
[Header("Money")]
public float money = 300;
public Text MoneyDisplay;
[Header("Wave")]
public Text WaveDisplay;
private int wave;
public void Start () {
dict.Add(EnemyType.Normal, NormalEnemy);
dict.Add(EnemyType.Tank, TankEnemy);
dict.Add(EnemyType.Speed, SpeedEnemy);
dict.Add(EnemyType.FastAsFuckBoi, FastAsFuckBoiEnemy);
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 });
waves.Add(new List<int> { 0, 0, 1, 1, 1, 1, 1, 1 });
waves.Add(new List<int> { 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3 });
waves.Add(new List<int> { 2, 2, 2, 2, 2, 1, 1, 1 });
waves.Add(new List<int> { 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0 });
waves.Add(new List<int> {
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1
});
}
void Update()
{
if (countdow <= 0f && Waveindex + 1 < waves.Count)
{
if (hp > 0)
StartCoroutine(SpawnWave());
else if (hp <= 0)
End.SetActive(true);
}
if (GameObject.FindGameObjectsWithTag("Enemy").Length != 0)
{
countdow = Time_btw_waves;
}
countdow -= Time.deltaTime;
if (WaveCountdownTest != null)
WaveCountdownTest.text = Mathf.Round(countdow).ToString();
if (MoneyDisplay != null)
MoneyDisplay.text = money.ToString();
if (WaveDisplay != null)
WaveDisplay.text = (Waveindex + 1).ToString() + " / " + waves.Count.ToString();
if (HP != null)
HP.text = hp.ToString();
}
IEnumerator SpawnWave()
{
Waveindex++;
foreach (EnemyType type in waves[Waveindex]) {
SpawnEnemy(type);
yield return new WaitForSeconds(0.5f);
}
}
void SpawnEnemy(EnemyType type)
{
Transform Enemy = Instantiate(dict[type], SpawnPoint.position, SpawnPoint.rotation);
Enemy.localScale = new Vector3(1, 1, 1);
Enemy.gameObject.GetComponent<Enemy>().MultWave(Waveindex);
Enemy.SetParent(ParentElement);
}
}
<file_sep># Augmented-Bloons
AR Defense Game
<file_sep>enum EnemyType {
Normal,
Tank,
Speed,
FastAsFuckBoi
}
| 19a2e1b31f5386e0b82c43595aebf9997e4ca89b | [
"Markdown",
"C#"
] | 7 | C# | UgoSantoro/Augmented-Bloons | 2c356447ede3b8f18e8e6bcd03c81eb7396fb34c | bf29f601fac5832e83e0d2e6a6f955bceeb53e4f |
refs/heads/master | <file_sep>import random
def getGuess(randNum):
while True:
print('\n', 'What is my number? ', end='')
guess = input()
if guess.isalpha():
print("You can only input numbers.")
elif int(guess) < randNum:
print("Your guess is SMALLER than my number!")
elif int(guess) > randNum:
print("Your guess is BIGGER than my number!")
else:
return int(guess)
def playAgain():
print('\n', 'Do you want to play again? (yes or no)')
return input().lower().startswith('y')
def startGame():
print('''
___
|__ \\
/ /
|_|
(_) What is my number (1-1000)''')
randNum = random.randrange(0, 1001)
gameIsDone = False
return randNum, gameIsDone
randNum, gameIsDone = startGame()
while True:
guess = getGuess(randNum)
if guess == randNum:
print("You Won! The number is indeed: ", guess)
gameIsDone = True
if gameIsDone:
if playAgain():
randNum, gameIsDone = startGame()
else:
break
<file_sep>What is my number?
==================
©Copyright 2017 <NAME>
Command line interface, What is my number? game in Python.
```
___ _ _ _ _ __ __ ____ _____ ____
|__ \ | \ | | | | | | | \/ | | __ ) | ____| | _ \
/ / | \| | | | | | | |\/| | | _ \ | _| | |_) |
|_| | |\ | | |_| | | | | | | |_) | | |___ | _ <
(_) |_| \_| \___/ |_| |_| |____/ |_____| |_| \_\
#######################################################
# any bugs please report to #
# https://github.com/mannguyen0107 #
# All rights reserved! #
#######################################################
```
###Setup
1. Git or download this program.
2. Run this program in Python3. Using ``python3 guessnumber.py``
---
©Copyright 2017 <NAME>, bugs please report to https://github.com/mannguyen0107
<file_sep>import random
hangmanpics = ['''
+---+
| |
|
|
|
|
=========''','''
+---+
| |
O |
|
|
|
=========''','''
+---+
| |
O |
| |
|
|
=========''','''
+---+
| |
O |
/| |
|
|
=========''','''
+---+
| |
O |
/|\ |
|
|
=========''','''
+---+
| |
O |
/|\ |
/ |
|
=========''','''
+---+
| |
O |
/|\ |
/ \ |
|
=========''']
def strike(text):
result = text + '\u0336'
return result
def getRandWord(wordList):
randWord = wordList[random.randrange(len(wordList))]
return list(randWord)
def genDashLines(word):
dash = ' - ' * len(word)
return dash.split()
def getGuess(alreadyGuessed):
while True:
print('\n', 'Guess a letter: ', end='')
guess = input().lower()
if len(guess) != 1:
print("Please enter a single letter.")
elif guess in alreadyGuessed:
print("You already guessed that letter. Try again.")
elif not (guess.isalpha()):
print("Please enter a LETTER.")
else:
return guess
def displayBoard(hangmanpics, missedLetters, correctLetters, secretWord, alphabet, dashLines):
alreadyGuessed = missedLetters + correctLetters
print(hangmanpics[len(missedLetters)])
for i in range(len(alphabet)):
if alphabet[i] in alreadyGuessed:
alphabet[i] = strike(char[i])
for i in range(len(alphabet)):
if i < 12:
print(alphabet[i], end=' ')
elif i == 12:
print(alphabet[i], "\n")
elif i > 12:
print(alphabet[i], end=' ')
for i in range(len(alphabet)):
if char[i] in alreadyGuessed:
char[i] = strike(char[i])
# print(alphabet, "\n")
print("\n\n", dashLines)
def playAgain():
print('\n', 'Do you want to play again? (yes or no)')
return input().lower().startswith('y')
def startGame():
secretWord = getRandWord(words)
dashLines = genDashLines(secretWord)
missedLetters = ""
correctLetters = ""
alphabet = "a b c d e f g h i j k l m n o p q r s t u v w x y z"
char = alphabet.split()
gameIsDone = False
return (secretWord, dashLines, missedLetters, correctLetters, char, gameIsDone)
# Get all words into a list
wordsList = open('words.txt', 'r')
words = wordsList.read().lower().split()
print("H A N G M A N")
secretWord, dashLines, missedLetters, correctLetters, char, gameIsDone = startGame()
print(secretWord)
while True:
displayBoard(hangmanpics, missedLetters, correctLetters, secretWord, char, dashLines)
guess = getGuess(missedLetters + correctLetters)
if guess in secretWord:
correctLetters += guess
for i in range(len(secretWord)):
if guess == secretWord[i]:
dashLines[i] = guess
foundAllLetters = True
for i in range(len(secretWord)):
if secretWord[i] not in correctLetters:
foundAllLetters = False
break
if foundAllLetters:
print('\n', 'You Won! The word is indeed: ', end = '')
print('[', ''.join(secretWord), ']')
gameIsDone = True
else:
missedLetters += guess
if len(missedLetters) == len(hangmanpics) - 1:
displayBoard(hangmanpics, missedLetters, correctLetters, secretWord, char, dashLines)
print('\n', 'You FAILED! The word was: ', end = '')
print('[', ''.join(secretWord), ']')
gameIsDone = True
if gameIsDone:
if playAgain():
secretWord, dashLines, missedLetters, correctLetters, char, gameIsDone = startGame()
else:
break
| 9dc8714f53229e29e46ea54a11baad41a0f3057e | [
"Markdown",
"Python"
] | 3 | Python | mannguyen0107/pyproject | 984c1eb9b574486af093443547c53dddb7ae6bcf | e39d693a27410dcc98a8ac1cde56653d02e1e9b8 |
refs/heads/master | <file_sep>import MovieList from './MoviList'
import React, { Component } from 'react';
import { Layout, Menu} from 'antd';
// const { SubMenu } = Menu;
import{Link,Route} from 'react-router-dom'
const { Content, Sider } = Layout;
export default class MovieContainer extends Component{
render(){
return(
<Layout style={{ padding: '24px 0', background: '#fff' }}>
<Sider width={200} style={{ background: '#fff' }}>
<Menu
mode="inline"
defaultSelectedKeys={['1']}
defaultOpenKeys={['sub1']}
style={{ height: '100%' }}
>
<Menu.Item key="1"> <Link to='/movie/in_theaters/1'>正上演</Link></Menu.Item>
<Menu.Item key="2"><Link to='/movie/coming_soon/1'>即将演</Link></Menu.Item>
<Menu.Item key="3"><Link to='/movie/top250/1'>top260</Link></Menu.Item>
</Menu>
</Sider>
<Content style={{ padding: '0 24px', minHeight: 280 }}>
<Route path='/movie/:type/:currentPage' render={ (props)=> <MovieList {...props}/> }></Route>
</Content>
</Layout>
)
}
}<file_sep>import React, { Component } from 'react';
import CalendarHotel from './Calendar'
import styles from './app.scss';
// import { createForm } from 'rc-form';
import { Form, Row, Col, Input, Button,DatePicker,Modal,Upload, Icon,Checkbox } from 'antd';
const { RangePicker } = DatePicker;
class App extends Component {
state = {
expand: false,
visible: false
};
handleSearch = e => {
e.preventDefault();
this.props.form.validateFields((err, values) => {
console.log('Received values of form: ', values);
});
};
handleReset = () => {
this.props.form.resetFields();
};
showModal = () => {
this.setState({
visible: true,
});
};
handleOk = e => {
console.log(e);
this.setState({
visible: false,
});
};
handleCancel = e => {
console.log(e);
this.setState({
visible: false,
});
};
plainOptions = ['Apple', 'Pear', 'Orange'];
onChange=(checkedValues)=> {
console.log('checked = ', checkedValues);
}
render() {
const { getFieldDecorator } = this.props.form;
const formItemLayout = {
labelCol: {
xs: { span:4 },
sm: { span: 4 },
},
wrapperCol: {
xs: { span: 8 },
sm: { span: 12 },
},
};
return (
<Form className="ant-advanced-search-form" onSubmit={this.handleSearch} >
<Form.Item label={"名称"} {...formItemLayout} >
{getFieldDecorator("userName", {
rules: [
{
required: true,
message: 'Input something!',
},
],
})(<Input placeholder="placeholder" />)}
</Form.Item>
<Form.Item label="选择" {...formItemLayout} >
{getFieldDecorator('range-picker', {
rules: [
{ type: 'array', required: true,
message: 'Please select time!' }
],
})(<RangePicker />)}
</Form.Item>
<Form.Item label="属性" {...formItemLayout} >
{getFieldDecorator('roomProperty', {
initialValue:['Apple','Pear'],
rules: [
{ required: true,
message: '请选择' }
],
})(
<Checkbox.Group options={this.plainOptions} onChange={this.onChange} />
)}
</Form.Item>
<Form.Item label="房态设置" {...formItemLayout} >
{getFieldDecorator('roomStatus', {
rules: [
{ required: true,
message: '请设置' }
],
})(
<div>
<Button onClick={this.showModal}>
<Icon type="setting" /> 设置
</Button>
</div>
)}
</Form.Item>
<Form.Item label="房态&价格" {...formItemLayout} >
{getFieldDecorator('roomStatusAndPrice', {
rules: [
{ required: true,
message: '请设置' }
],
})(
<CalendarHotel></CalendarHotel>
)}
</Form.Item>
<div className={styles.priceBtn}>价格的的多少</div>
<Form.Item label="上传图片" {...formItemLayout} >
{getFieldDecorator('upLoadPicture', {
rules: [
{ type: 'array', required: true,
message: 'Please select time!' }
],
})(
<div>
<Upload >
<Button>
<Icon type="upload" /> Upload
</Button>
</Upload>
</div>
)}
</Form.Item>
<Row>
<Col span={24} style={{ textAlign: 'center' }}>
<Button type="primary " htmlType="submit">
确认
</Button>
<Button style={{ marginLeft: 8 }} onClick={this.handleReset}>
取消
</Button>
{/* <a style={{ marginLeft: 8, fontSize: 12 }}>
Collapse <Icon type={this.state.expand ? 'up' : 'down'} />
</a> */}
</Col>
</Row>
<div>
<Modal
title="房态设置"
visible={this.state.visible}
onOk={this.handleOk}
onCancel={this.handleCancel}
>
</Modal>
</div>
</Form>
);
}
}
export default Form.create({ name: 'advanced_search' })(App);
<file_sep>import React, { Component } from 'react';
// import fetchJsonp from 'fetch-jsonp'
// import MovieBox from './MovieBox'
// import { Pagination } from 'antd';
export default class MovieList extends Component {
constructor(props) {
super(props)
this.state = {
}
console.log(props);
}
render(){
return(
<div>11</div>
)
}
} | 8c7911a505489f17005c8bf8f9c7ba8d57aaa76a | [
"JavaScript"
] | 3 | JavaScript | laoxiu666/wensihaihui | e5e05e84d248c2bd7c95d00c6bbc0c150702193e | e1e16c657d5142c9d01a2407ef33d47967e6fb19 |
refs/heads/master | <repo_name>binary-cleric/gatsby_blog<file_sep>/src/components/sidebar.jsx
import React from 'react'
import Link from 'gatsby-link'
import styled from 'styled-components'
const Sidebar = () => (
<h1>
</h1>
)
export default Sidebar
| ea8606dff4474453ee8d4a273c52a4b1c01aa782 | [
"JavaScript"
] | 1 | JavaScript | binary-cleric/gatsby_blog | 8de494625486f5779485ab7ff865b79e4ecfb349 | c29ae91448ad719eef5ed63a3cc87639791df201 |
refs/heads/master | <file_sep># help here: https://docs.djangoproject.com/en/2.1/howto/custom-template-tags/
from pytz import all_timezones
from django import template
from django.utils.safestring import mark_safe
from crontrack.models import JobEvent
register = template.Library()
# Create a dropdown containing all the valid timezones
@register.simple_tag
def timezone_selector(my_timezone):
result = '<input type="text" name="timezone" list="timezoneList" id="timezoneSelector" placeholder="Country/City" '
result += f'value="{my_timezone}">'
result += '<datalist id="timezoneList">'
for tz in all_timezones:
result += f'<option value="{tz}">'
return mark_safe(result + '</datalist>')
# Count a user's number of unseen events
@register.simple_tag
def unseen_event_count(user):
return user.all_accessible(JobEvent).filter(seen=False).count()<file_sep>// Requires JSCookie
// Set up jQuery AJAX to include CSRF tokens
// more info here: https://docs.djangoproject.com/en/2.1/ref/csrf/#ajax
var csrfToken = Cookies.get('csrftoken');
function csrfSafeMethod(method) {
// these HTTP methods do not require CSRF protection
return (/^(GET|HEAD|OPTIONS|TRACE)$/.test(method));
}
function setToken(xhr, settings) {
if (!csrfSafeMethod(settings.type) && !this.crossDomain) {
xhr.setRequestHeader("X-CSRFToken", csrfToken);
}
}
function quickAjax(obj) {
if (obj.success === undefined) {
obj.success = () => {};
}
if (obj.url === undefined) {
obj.url = $(location).attr('href');
}
$.ajax({
beforeSend: setToken,
type: 'POST',
url: obj.url,
data: obj.data,
dataType: 'json',
success: obj.success
});
}<file_sep># CronTrack
[CronTrack](https://crontrack.com) is an open-source Django app for logging Cron jobs and keeping track of when they don't complete on time.
One problem with having a lot of Cron jobs running continuously is that there isn't an easy way to tell when your jobs aren't completing successfully. You could have them notify you when they succeed, but that just leads to spam, and doesn't address the real problem. Ideally, you'd want to be notified only when your attention is required, i.e. when the job isn't completing successfully. Enter CronTrack, which was created to solve this exact problem.
## Usage
You can input jobs either individually or in groups. Given the Cron schedule string (e.g. "30 9 * * 1-5") and a time window for the job to complete in, CronTrack will calculate the next run time and send you an email/text message (configurable) if the job doesn't complete on time. This is accomplished by having you add an API call to your program being run by the job to notify CronTrack when the job completes. If CronTrack doesn't receive a notification in time, it will send you an alert.
## Notifying CronTrack
The API call can be sent by pinging the URL `https://crontrack.com/p/UUID_FOR_THE_JOB/` with a regular GET request. The simplest way of doing this is probably using cURL, and including something like this in your crontab:
```bash
30 9 * * 1-5 ubuntu /PATH/TO/YOUR_SCRIPT && curl https://crontrack.com/p/UUID_FOR_THE_JOB/
```
## Support for Teams
You can create custom teams which allow you to share jobs between multiple users. When you create a job or group of jobs, you can select a team to associate it with, and all members of that team will be able to view and edit it. By default, all members of the team will also be alerted by CronTrack when jobs fail to run on time, but members can disable alerts for teams individually.
<file_sep>import os
from django.apps import AppConfig
from django.conf import settings
class CronTrackConfig(AppConfig):
name = 'crontrack'
def ready(self):
from .background import JobMonitor
# Only run the monitor in the main thread
if settings.JOB_MONITOR_ON and os.environ.get('RUN_MAIN') == 'true':
monitor = JobMonitor(threaded=True)<file_sep>import logging
import random
from datetime import timedelta
from io import StringIO
from django.core.management import call_command
from django.core.management.base import CommandError
from django.test import TestCase, SimpleTestCase
from django.utils import timezone
from .background import JobMonitor
from .models import Job, User, Team, TeamMembership
logging.disable(logging.INFO)
class JobTestCase(SimpleTestCase):
def test_failing(self):
false_cases = (
Job(last_failed=timezone.now()),
Job(next_run=timezone.now()+timedelta(seconds=1)),
Job(next_run=timezone.now()),
)
for job in false_cases:
self.assertEqual(job.failing, False)
true_cases = (
Job(next_run=timezone.now()-timedelta(seconds=1), last_notified=None),
Job(next_run=timezone.now()-timedelta(minutes=1), last_notified=timezone.now()-timedelta(minutes=2)),
)
for job in true_cases:
self.assertEqual(job.failing, True)
class JobMonitorTestCase(TestCase):
def test_validation(self):
self.assertRaises(ValueError, JobMonitor, time_limit=0)
self.assertRaises(ValueError, JobMonitor, time_limit=-5)
def test_stopping(self):
monitor = JobMonitor()
monitor.stop()
self.assertEqual(monitor.running, False)
monitor = JobMonitor(time_limit=JobMonitor.WAIT_INTERVAL, threaded=False)
self.assertEqual(monitor.running, False)
monitor = JobMonitor(time_limit=JobMonitor.WAIT_INTERVAL+1, threaded=True)
self.assertEqual(monitor.running, True)
monitor.stop()
self.assertEqual(monitor.running, False)
class UserTestCase(TestCase):
def setup(self):
users = {
'alice': User.objects.create(username='alice'),
'bob': User.objects.create(username='bob'),
'carl': User.objects.create(username='carl'),
}
teams = (
Team.objects.create(name='generic name', creator=users['alice']),
Team.objects.create(name='the sequel', creator=users['bob']),
Team.objects.create(name='headless chicken', creator=None),
)
TeamMembership.objects.create(user=users['alice'], team=teams[0])
TeamMembership.objects.create(user=users['bob'], team=teams[0])
TeamMembership.objects.create(user=users['bob'], team=team[1])
for i in range(10):
Job.objects.create(user=random.choice(users), team=random.choice(teams))
def test_job_access(self):
for user in User.objects.all():
my_jobs = user.all_accessible(Job)
for job in Job.objects.all():
self.assertEqual(user.can_access(job), job in my_jobs)
<file_sep>from django.urls import path, include, reverse_lazy
from django.contrib.auth import views as auth_views
from . import views
app_name = 'crontrack'
urlpatterns = [
path('', views.index, name='index'),
path('dashboard/', views.dashboard, name='dashboard'),
path('dashboard/<int:per_page>/', views.dashboard, name='dashboard'),
path('viewjobs/', views.view_jobs, name='view_jobs'),
path('addjob/', views.add_job, name='add_job'),
path('editjob/', views.edit_job, name='edit_job'),
path('editgroup/', views.edit_group, name='edit_group'),
path('deletegroup/', views.delete_group, name='delete_group'),
path('deletejob/', views.delete_job, name='delete_job'),
path('teams/', views.teams, name='teams'),
path('p/<uuid:id>/', views.notify_job, name='notify_job'),
path('accounts/profile/', views.profile, name='profile'),
path('accounts/register/', views.RegisterView.as_view(), name='register'),
path('accounts/delete/', views.delete_account, name='delete_account'),
path('accounts/login/', auth_views.LoginView.as_view(), name='login'),
path('accounts/logout/', auth_views.LogoutView.as_view(), name='logout'),
path(
'accounts/password_change/',
auth_views.PasswordChangeView.as_view(success_url=reverse_lazy('crontrack:password_change_done')),
name='password_change',
),
path('accounts/password_change/done/', auth_views.PasswordChangeDoneView.as_view(), name='password_change_done'),
path(
'accounts/password_reset/',
auth_views.PasswordResetView.as_view(success_url=reverse_lazy('crontrack:password_reset_done')),
name='password_reset',
),
path('accounts/password_reset/done/', auth_views.PasswordResetDoneView.as_view(), name='password_reset_done'),
path(
'accounts/reset/<uidb64>/<token>/',
auth_views.PasswordResetConfirmView.as_view(success_url=reverse_lazy('crontrack:password_reset_complete')),
name='password_reset_confirm',
),
path('accounts/reset/done/', auth_views.PasswordResetCompleteView.as_view(), name='password_reset_complete'),
#path('accounts/', include('django.contrib.auth.urls')),
]<file_sep># Background Tasks (main loop logic for job notification handling)
import time
import threading
import logging
from datetime import datetime, timedelta
from croniter import croniter
from twilio.base.exceptions import TwilioRestException
from twilio.rest import Client
from django.core import mail
from django.conf import settings
from django.utils import timezone
from django.utils.html import strip_tags
from django.template.loader import render_to_string
from .models import Job, JobAlert, JobEvent, User, TeamMembership
logger = logging.getLogger(__name__)
class JobMonitor:
WAIT_INTERVAL = 60 # seconds for time.sleep()
def __init__(self, time_limit=None, threaded=True):
self.time_limit = time_limit # maximum time to run for in seconds
if time_limit is not None and time_limit <= 0:
raise ValueError("Time limit must be a positive number of seconds or None")
self.start_time = timezone.now()
self.running = True
if threaded:
logger.debug(f"Starting JobMonitor on a separate thread with time limit '{time_limit}'")
self.t = threading.Thread(target=self.monitor_loop, name='JobMonitorThread', daemon=True)
self.t.start()
else:
logger.debug(f"Starting JobMonitor on main thread with time limit '{time_limit}'")
self.t = None
self.monitor_loop()
def stop(self):
logger.debug("Stopping JobMonitor")
self.running = False
def monitor_loop(self):
while self.running:
logger.debug(f"Starting monitor loop at {timezone.now()}")
for job in Job.objects.all():
# Set now to a constant time for this iteration
now = timezone.now()
# Calculate the next scheduled run time + time window
run_by = job.next_run + timedelta(minutes=job.time_window)
# If this run time is in the future, check if we need to issue a warning, then move on
if run_by > now:
if job.failing and not JobEvent.objects.filter(job=job, type=JobEvent.WARNING).exists():
JobEvent.objects.create(job=job, type=JobEvent.WARNING, time=job.next_run)
logger.debug(f"Warning created: job {job} is failing")
continue
# Change to local time (for alerts / calculating next run time)
timezone.activate(job.user.timezone)
# Check if a notification was not received in the time window
if job.last_notified is None or not (job.next_run <= job.last_notified <= run_by):
# Error condition: the job did not send a notification
logger.debug(f"Alert! Job: {job} failed to notify in the time window")
# Check if the job has already failed to avoid sending multiple notifications
if job.failed:
logger.debug(f"Skipped sending another alert for continually failing job {job}")
else:
# Try alerting users in the relevant team
if job.team is None:
users = (job.user,)
else:
users = job.team.user_set.all()
for user in users:
if user not in job.alerted_users.all():
# Send an alert if it's our first
JobAlert.objects.create(user=user, job=job, last_alert=now)
self.alert_user(user, job)
else:
# Otherwise, decide whether to skip alerting based on the user's alert_buffer setting
buffer_time = timedelta(minutes=user.alert_buffer)
last_alert = JobAlert.objects.get(job=job, user=user).last_alert
if now > last_alert + buffer_time:
self.alert_user(user, job)
else:
logger.debug(f"Skipped alerting user '{user}' of failed job {job}")
job.last_failed = now
JobEvent.objects.create(job=job, type=JobEvent.FAILURE, time=now)
# Calculate the new next run time
job.next_run = croniter(job.schedule_str, timezone.localtime(now)).get_next(datetime)
job.save()
# Check if we're due to stop running
if self.time_limit is not None:
next_iteration = timezone.now() + timedelta(seconds=self.WAIT_INTERVAL)
stop_time = self.start_time + timedelta(seconds=self.time_limit)
if next_iteration > stop_time:
self.stop()
break
time.sleep(self.WAIT_INTERVAL)
def alert_user(self, user, job):
# Skip alerting if the user has alerts disabled (either globally or just for this team)
if user.alert_method == User.NO_ALERTS:
logger.debug(f"Not alerting user '{user}' as they have all alerts disabled")
return
if job.team is None:
alerts_on = user.personal_alerts_on
else:
alerts_on = TeamMembership.objects.get(user=user, team=job.team).alerts_on
if not alerts_on:
logger.debug(f"Not alerting user '{user}' as they have alerts for team '{job.team}' disabled")
return
# Either send an email or text based on user preferences
context = {'job': job, 'user': user, 'protocol': settings.SITE_PROTOCOL, 'domain': settings.SITE_DOMAIN}
if user.alert_method == User.EMAIL:
logger.debug(f"Sending user '{user}' an email at {user.email}")
subject = f"[CronTrack] ALERT: Job '{job.name}' failed to notify in time"
message = render_to_string('crontrack/email/alertuser.html', context)
user.email_user(subject, strip_tags(message), html_message=message)
else:
logger.debug(f"Sending user '{user}' an SMS at {user.phone}")
message = render_to_string('crontrack/sms/alertuser.txt', context)
client = Client(settings.TWILIO_ACCOUNT_SID, settings.TWILIO_AUTH_TOKEN)
try:
client.messages.create(body=message, to=str(user.phone), from_=settings.TWILIO_FROM_NUMBER)
except TwilioRestException:
logger.exception(f"Failed to send user '{user.username}' an SMS at {user.phone}")
JobAlert.objects.get(job=job, user=user).last_alert = timezone.now()
job.save()<file_sep>{% extends 'crontrack/base.html' %}
{% block title %}Password changed{% endblock %}
{% block content %}
<div class="hcenter">
<div class="center">
<h3>Password changed</h3>
<p class="successMessage">Your password has been successfully changed.</p>
</div>
{% endblock content %}<file_sep>from datetime import timedelta
import uuid
from django.contrib.auth.models import AbstractUser
from django.core.exceptions import FieldError
from django.db import models
from django.db.models import Q
from django.template.defaultfilters import date, time
from django.utils import timezone
from phonenumber_field.modelfields import PhoneNumberField
from timezone_field import TimeZoneField
class JobManager(models.Manager):
def running(self):
return self.get_queryset().filter(last_failed__isnull=True)
def failed(self):
return self.get_queryset().filter(last_failed__isnull=False)
class Job(models.Model):
id = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False)
schedule_str = models.CharField('cron schedule string', max_length=100)
name = models.CharField(max_length=50)
description = models.CharField(max_length=200, blank=True, default='')
time_window = models.PositiveIntegerField('time window (minutes)', default=0)
next_run = models.DateTimeField('next time to run')
last_failed = models.DateTimeField('last time job failed to notify', null=True, blank=True)
last_notified = models.DateTimeField('last time notification received', null=True, blank=True)
user = models.ForeignKey('User', models.CASCADE)
group = models.ForeignKey('JobGroup', models.CASCADE, null=True, blank=True)
team = models.ForeignKey('Team', models.SET_NULL, null=True, blank=True)
alerted_users = models.ManyToManyField('User', through='JobAlert', related_name='job_alert_set')
objects = JobManager()
def __str__(self):
return f"({self.team}) {self.user}'s {self.name}: '{self.schedule_str}'"
@property
def failed(self):
return bool(self.last_failed)
@property
def failing(self):
# Checks if next_run has passed and a notification was not received, but it is still within the time window
# Note: requires the job monitor to update last_failed to work correctly
return (
not self.failed and
self.next_run < timezone.now() and
(self.last_notified is None or self.last_notified < self.next_run)
)
class JobGroup(models.Model):
name = models.CharField(max_length=50)
description = models.CharField(max_length=200, blank=True, default='')
user = models.ForeignKey('User', models.CASCADE)
team = models.ForeignKey('Team', models.SET_NULL, null=True, blank=True)
def __str__(self):
return f"({self.team}) {self.user}'s {self.name}"
class JobAlert(models.Model):
job = models.ForeignKey('Job', models.CASCADE)
user = models.ForeignKey('User', models.CASCADE)
last_alert = models.DateTimeField('last time alert sent', null=True, blank=True)
class JobEvent(models.Model):
FAILURE = 'F'
WARNING = 'W'
TYPE_CHOICES = (
(FAILURE, 'Failure'),
(WARNING, 'Warning'),
)
job = models.ForeignKey('Job', models.CASCADE, related_name='events')
type = models.CharField(max_length=1, choices=TYPE_CHOICES, default=FAILURE)
time = models.DateTimeField()
seen = models.BooleanField(default=False)
class Meta:
ordering = ['-time']
class User(AbstractUser):
EMAIL = 'E'
SMS = 'T'
NO_ALERTS = 'N'
ALERT_METHOD_CHOICES = (
(EMAIL, 'Email'),
(SMS, 'SMS'),
(NO_ALERTS, 'No alerts'),
)
timezone = TimeZoneField(default='UTC')
alert_method = models.CharField(max_length=1, choices=ALERT_METHOD_CHOICES, default=NO_ALERTS)
alert_buffer = models.IntegerField('time to wait between alerts (min)', default=1440)
personal_alerts_on = models.BooleanField('alerts on for jobs without a team', default=True)
phone = PhoneNumberField(blank=True)
email = models.EmailField(unique=True, max_length=100)
teams = models.ManyToManyField('Team', through='TeamMembership')
# Check if this user has access to an instance of a model (either Job or JobGroup)
def can_access(self, instance):
return instance.user == self or instance.team in self.teams.all()
# Get all instances of a model this user has access to
def all_accessible(self, model):
try:
return model.objects.filter(Q(user=self) | Q(team__in=self.teams.all()))
except FieldError:
# The model is connected to the user indirectly e.g. through a job like JobEvent
return model.objects.filter(Q(job__user=self) | Q(job__team__in=self.teams.all()))
class Team(models.Model):
name = models.CharField(max_length=50)
creator = models.ForeignKey('User', models.CASCADE)
def __str__(self):
return self.name
class TeamMembership(models.Model):
user = models.ForeignKey('User', models.CASCADE)
team = models.ForeignKey('Team', models.CASCADE)
alerts_on = models.BooleanField(default=True)<file_sep># Generated by Django 2.1.7 on 2019-02-22 06:18
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('crontrack', '0005_auto_20190222_1454'),
]
operations = [
migrations.AddField(
model_name='jobevent',
name='seen',
field=models.BooleanField(default=False),
),
migrations.AddField(
model_name='jobevent',
name='type',
field=models.CharField(choices=[('F', 'Failure')], default='F', max_length=1),
),
]
<file_sep># Generated by Django 2.1.5 on 2019-01-27 05:57
from django.conf import settings
import django.contrib.auth.models
import django.contrib.auth.validators
import django.core.validators
from django.db import migrations, models
import django.db.models.deletion
import django.utils.timezone
import phonenumber_field.modelfields
import timezone_field.fields
import uuid
class Migration(migrations.Migration):
initial = True
dependencies = [
('auth', '0009_alter_user_last_name_max_length'),
]
operations = [
migrations.CreateModel(
name='User',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('password', models.CharField(max_length=128, verbose_name='password')),
('last_login', models.DateTimeField(blank=True, null=True, verbose_name='last login')),
('is_superuser', models.BooleanField(default=False, help_text='Designates that this user has all permissions without explicitly assigning them.', verbose_name='superuser status')),
('username', models.CharField(error_messages={'unique': 'A user with that username already exists.'}, help_text='Required. 150 characters or fewer. Letters, digits and @/./+/-/_ only.', max_length=150, unique=True, validators=[django.contrib.auth.validators.UnicodeUsernameValidator()], verbose_name='username')),
('first_name', models.CharField(blank=True, max_length=30, verbose_name='first name')),
('last_name', models.CharField(blank=True, max_length=150, verbose_name='last name')),
('is_staff', models.BooleanField(default=False, help_text='Designates whether the user can log into this admin site.', verbose_name='staff status')),
('is_active', models.BooleanField(default=True, help_text='Designates whether this user should be treated as active. Unselect this instead of deleting accounts.', verbose_name='active')),
('date_joined', models.DateTimeField(default=django.utils.timezone.now, verbose_name='date joined')),
('timezone', timezone_field.fields.TimeZoneField(default='UTC')),
('alert_method', models.CharField(choices=[('E', 'Email'), ('T', 'SMS'), ('N', 'No alerts')], default='N', max_length=1)),
('alert_buffer', models.IntegerField(default=1440, verbose_name='time to wait between alerts (min)')),
('personal_alerts_on', models.BooleanField(default=True, verbose_name='alerts on for jobs without a user group')),
('phone', phonenumber_field.modelfields.PhoneNumberField(blank=True, max_length=128)),
('email', models.EmailField(blank=True, max_length=100, null=True, unique=True)),
('groups', models.ManyToManyField(blank=True, help_text='The groups this user belongs to. A user will get all permissions granted to each of their groups.', related_name='user_set', related_query_name='user', to='auth.Group', verbose_name='groups')),
],
options={
'verbose_name': 'user',
'verbose_name_plural': 'users',
'abstract': False,
},
managers=[
('objects', django.contrib.auth.models.UserManager()),
],
),
migrations.CreateModel(
name='Job',
fields=[
('id', models.UUIDField(default=uuid.uuid4, editable=False, primary_key=True, serialize=False)),
('schedule_str', models.CharField(max_length=100, verbose_name='cron schedule string')),
('name', models.CharField(max_length=50)),
('time_window', models.IntegerField(default=0, validators=[django.core.validators.MinValueValidator(0)], verbose_name='time window (minutes)')),
('next_run', models.DateTimeField(verbose_name='next time to run')),
('last_notified', models.DateTimeField(blank=True, null=True, verbose_name='last time notification received')),
('description', models.CharField(blank=True, default='', max_length=200)),
],
),
migrations.CreateModel(
name='JobAlert',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('last_alert', models.DateTimeField(blank=True, null=True, verbose_name='last time alert sent')),
('job', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='crontrack.Job')),
('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),
],
),
migrations.CreateModel(
name='JobGroup',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('name', models.CharField(max_length=50)),
('description', models.CharField(blank=True, default='', max_length=200)),
('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),
],
),
migrations.CreateModel(
name='UserGroup',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('name', models.CharField(max_length=50)),
('creator', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),
],
),
migrations.CreateModel(
name='UserGroupMembership',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('alerts_on', models.BooleanField(default=True)),
('group', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='crontrack.UserGroup')),
('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),
],
),
migrations.AddField(
model_name='jobgroup',
name='user_group',
field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, to='crontrack.UserGroup'),
),
migrations.AddField(
model_name='job',
name='alerted_users',
field=models.ManyToManyField(related_name='job_alert_set', through='crontrack.JobAlert', to=settings.AUTH_USER_MODEL),
),
migrations.AddField(
model_name='job',
name='group',
field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, to='crontrack.JobGroup'),
),
migrations.AddField(
model_name='job',
name='user',
field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),
),
migrations.AddField(
model_name='job',
name='user_group',
field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, to='crontrack.UserGroup'),
),
migrations.AddField(
model_name='user',
name='user_groups',
field=models.ManyToManyField(through='crontrack.UserGroupMembership', to='crontrack.UserGroup'),
),
migrations.AddField(
model_name='user',
name='user_permissions',
field=models.ManyToManyField(blank=True, help_text='Specific permissions for this user.', related_name='user_set', related_query_name='user', to='auth.Permission', verbose_name='user permissions'),
),
]
<file_sep># Generated by Django 2.1.7 on 2019-02-16 01:24
from django.conf import settings
from django.db import migrations, models
import django.db.models.deletion
class Migration(migrations.Migration):
dependencies = [
('crontrack', '0002_auto_20190127_1657'),
]
operations = [
# manually edited to stop Django unneccessarily deleting models
migrations.RenameField(
model_name='job',
old_name='user_group',
new_name='team',
),
migrations.RenameField(
model_name='jobgroup',
old_name='user_group',
new_name='team',
),
migrations.RenameField(
model_name='user',
old_name='user_groups',
new_name='teams',
),
migrations.AlterField(
model_name='user',
name='personal_alerts_on',
field=models.BooleanField(default=True, verbose_name='alerts on for jobs without a team'),
),
migrations.RenameModel(
old_name='UserGroup',
new_name='Team',
),
migrations.RenameField(
model_name='usergroupmembership',
old_name='group',
new_name='team'
),
migrations.RenameModel(
old_name='UserGroupMembership',
new_name='TeamMembership',
),
]
<file_sep># Generated by Django 2.1.7 on 2019-02-18 06:58
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('crontrack', '0003_rename_user_groups'),
]
operations = [
migrations.AddField(
model_name='job',
name='last_failed',
field=models.DateTimeField(blank=True, null=True, verbose_name='last time job failed to notify'),
),
]
<file_sep># Generated by Django 2.1.7 on 2019-02-22 04:54
from django.db import migrations, models
import django.db.models.deletion
class Migration(migrations.Migration):
dependencies = [
('crontrack', '0004_job_last_failed'),
]
operations = [
migrations.CreateModel(
name='JobEvent',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('time', models.DateTimeField()),
],
),
migrations.AlterField(
model_name='job',
name='time_window',
field=models.PositiveIntegerField(default=0, verbose_name='time window (minutes)'),
),
migrations.AddField(
model_name='jobevent',
name='job',
field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='events', to='crontrack.Job'),
),
]
<file_sep>{% extends 'crontrack/email/emailbase.html' %}
{% block message %}
<p>Your job '{{ job.name }}' {% if job.team %}from team '{{ job.team }}' {% endif %}has failed to notify CronTrack in time.
<br>Details below.</p>
<table class="form">
<tr><th>Job group </th><td>{{ job.group|default:'Ungrouped' }}</td></tr>
<tr><th>Cron schedule string </th><td>{{ job.schedule_str }}</td></tr>
<tr><th>Scheduled run time </th><td>{{ job.next_run }}</td></tr>
<tr><th>Time window </th><td>{{ job.time_window }} minutes</td></tr>
</table>
{% url 'crontrack:view_jobs' as jobs_url %}
<p>Go to <a href="{{ protocol }}://{{ domain }}{{ jobs_url }}">{{ protocol }}://{{ domain }}{{ jobs_url }}</a> for more details.</p>
{% endblock %}<file_sep>import os
from django.urls import reverse_lazy
# Production settings
# for reference: https://docs.djangoproject.com/en/2.1/howto/deployment/checklist/
DEBUG = False
JOB_MONITOR_ON = True # Whether to run the job alert monitor
SITE_PROTOCOL = 'https'
SITE_DOMAIN = 'crontrack.com'
ALLOWED_HOSTS = [SITE_DOMAIN, f'www.{SITE_DOMAIN}']
CSRF_COOKIE_SECURE = True
SESSION_COOKIE_SECURE = True
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
AUTH_USER_MODEL = 'crontrack.User'
# Login / logout
LOGIN_URL = reverse_lazy('crontrack:login')
LOGIN_REDIRECT_URL = reverse_lazy('crontrack:view_jobs')
LOGOUT_REDIRECT_URL = reverse_lazy('crontrack:index')
# Email
DEFAULT_FROM_EMAIL = '<EMAIL>'
# Logging
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console': {
'class': 'logging.StreamHandler',
'formatter': 'simple',
},
},
'loggers': {
'crontrack.views': {
'handlers': ['console'],
'level': os.getenv('DJANGO_LOG_LEVEL', 'DEBUG'),
},
'crontrack.background': {
'handlers': ['console'],
'level': os.getenv('DJANGO_LOG_LEVEL', 'DEBUG'),
},
},
'formatters': {
'simple': {
'format': '[{levelname}] {message}',
'style': '{',
},
},
}
# Application definition
INSTALLED_APPS = [
'anymail', # https://github.com/anymail/django-anymail
'phonenumber_field', # https://github.com/stefanfoulis/django-phonenumber-field
'timezone_field', # https://github.com/mfogel/django-timezone-field
'crontrack.apps.CronTrackConfig',
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
ROOT_URLCONF = 'crontrack_site.urls'
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
WSGI_APPLICATION = 'crontrack_site.wsgi.application'
# Password validation
# https://docs.djangoproject.com/en/2.1/ref/settings/#auth-password-validators
AUTH_PASSWORD_VALIDATORS = [
{
'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
},
]
# Internationalization
# https://docs.djangoproject.com/en/2.1/topics/i18n/
LANGUAGE_CODE = 'en-us'
TIME_ZONE = 'UTC'
USE_I18N = True
USE_L10N = True
USE_TZ = True
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/2.1/howto/static-files/
STATIC_URL = '/static/'
STATIC_ROOT = os.path.join(BASE_DIR, 'crontrack', 'staticfiles')
# Import all local settings
from .local_settings import *<file_sep>from django.core.management.base import BaseCommand, CommandError
from crontrack.background import JobMonitor
class Command(BaseCommand):
help = "Start the job monitor."
def add_arguments(self, parser):
parser.add_argument(
'--run-for', '-s',
type=int,
default=None,
dest='run-for',
help="Time to run for in seconds. Defaults to forever.",
)
def handle(self, *args, **options):
try:
monitor = JobMonitor(options['run-for'])
except ValueError as e:
raise CommandError(str(e))<file_sep>Babel>=2.6.0
certifi>=2018.11.29
chardet>=3.0.4
croniter>=0.3.26
Django>=2.1.7
django-anymail>=5.0
django-phonenumber-field>=2.1.0
django-timezone-field>=3.0
gunicorn>=19.9.0
idna>=2.8
mysqlclient>=1.3.14
phonenumberslite>=8.10.3
PyJWT>=1.7.1
PySocks>=1.6.8
python-dateutil>=2.7.5
pytz>=2018.7
requests>=2.21.0
six>=1.12.0
twilio>=6.23.1
urllib3>=1.24.2
<file_sep># TODO: move more forms into this implementation (?)
from django import forms
from django.contrib.auth.forms import UserCreationForm
from timezone_field import TimeZoneFormField
from phonenumber_field.formfields import PhoneNumberField
from .models import User
class RegisterForm(UserCreationForm):
class Meta:
model = User
fields = ('email', 'username', '<PASSWORD>', '<PASSWORD>')
class ProfileForm(forms.Form):
timezone = TimeZoneFormField(label='Timezone', initial='UTC')
alert_method = forms.ChoiceField(
label='Alert method',
widget=forms.RadioSelect,
choices=User.ALERT_METHOD_CHOICES,
)
email = forms.EmailField(label='Email address', required=False)
full_phone = PhoneNumberField(label='Phone number', required=False)
alert_buffer = forms.IntegerField()<file_sep>import logging
import math
import re
from datetime import datetime
from itertools import chain
import pytz
from croniter import croniter, CroniterBadCronError # see https://pypi.org/project/croniter/#usage
from django.conf import settings
from django.contrib.auth import authenticate, login, logout
from django.contrib.auth.decorators import login_required
from django.core.exceptions import ValidationError
from django.db import transaction
from django.http import HttpResponseRedirect, JsonResponse
from django.shortcuts import render
from django.urls import reverse, reverse_lazy
from django.utils import timezone
from django.views import generic
from django.views.decorators.csrf import csrf_exempt
from .forms import ProfileForm, RegisterForm
from .models import Job, JobGroup, JobAlert, JobEvent, User, Team, TeamMembership
logger = logging.getLogger(__name__)
def index(request):
return render(request, 'crontrack/index.html')
def notify_job(request, id):
# Update job's last_notified, last_failed, and next_run
job = Job.objects.get(pk=id)
job.last_notified = timezone.now()
job.last_failed = None
now = timezone.localtime(timezone.now(), job.user.timezone)
job.next_run = croniter(job.schedule_str, now).get_next(datetime)
job.save()
# Delete the JobEvent warning(s)
JobEvent.objects.filter(job=job, type=JobEvent.WARNING).delete()
logger.debug(f"Notified for job '{job}' at {job.last_notified}")
return JsonResponse({'success_message': "Job notified successfully."})
@login_required
def dashboard(request, per_page=20):
if request.is_ajax():
for id in request.POST['ids'].split(','):
if id.isdigit():
event = JobEvent.objects.get(pk=id)
event.seen = True
event.save()
return JsonResponse({})
else:
timezone.activate(request.user.timezone)
events = request.user.all_accessible(JobEvent)
pages = [events[i*per_page:(i+1)*per_page] for i in range(math.ceil(events.count() / per_page))]
context = {
'pages': pages,
'per_page': per_page,
'size_options': (10, 20, 50, 100),
}
return render(request, 'crontrack/dashboard.html', context)
@login_required
def view_jobs(request):
timezone.activate(request.user.timezone)
context = {
'teams': [{'id': 'All', 'job_groups': [], 'empty': True}],
'protocol': settings.SITE_PROTOCOL,
'domain': settings.SITE_DOMAIN,
'tab': request.COOKIES.get('tab', None),
}
for team in chain((None,), request.user.teams.all()):
ungrouped = (get_job_group(request.user, None, team),)
grouped = (get_job_group(request.user, g, team) for g in request.user.all_accessible(JobGroup))
if team is None:
id = None
else:
id = team.id
job_groups = [group for group in chain(ungrouped, grouped) if group is not None]
empty = not any(group['jobs'] for group in job_groups)
context['teams'].append({'id': id, 'job_groups': job_groups, 'empty': empty})
context['teams'][0]['job_groups'] += job_groups
context['teams'][0]['empty'] = empty and context['teams'][0]['empty']
return render(request, 'crontrack/viewjobs.html', context)
@login_required
def add_job(request):
context = {'tab': request.COOKIES.get('tab', None)}
if request.method == 'POST':
context['prefill'] = request.POST
# Logic to add the job
try:
now = datetime.now(tz=pytz.timezone(request.POST['timezone']))
# Determine which team we're adding to
if request.POST['team'] == 'None':
team = None
else:
team = Team.objects.get(pk=request.POST['team'])
if team not in request.user.teams.all():
team = None
logger.warning(f"User {request.user} tried to access a team they're not in: {team}")
# Check if we're adding a group
if request.POST['type'] == 'group':
with transaction.atomic():
group = JobGroup(
user=request.user,
name=request.POST['name'],
description=request.POST['description'],
team=team,
)
group.full_clean()
logger.debug(f'Adding new group: {group}')
group.save()
job_name = '[unnamed job]'
for line in request.POST['group_schedule'].split('\n'):
# Check if line is empty or starts with whitespace, and skip
if not line or line[0] in (' ', '\t', '\r'):
continue
# Interpret the line as a job name if it starts with '#'
if line[0] == '#':
job_name = line[1:].strip()
continue
# Otherwise, process the line as a Cron schedule string
schedule_str = ' '.join(line.split(' ')[:5])
time_window = int(request.POST['time_window'])
if time_window < 0:
raise ValueError
job = Job(
user=request.user,
name=job_name,
schedule_str=schedule_str,
time_window=time_window,
next_run=croniter(schedule_str, now).get_next(datetime),
group=group,
team=team,
)
job.full_clean()
logger.debug(f'Adding new job: {job}')
job.save()
else:
# We didn't get any jobs
raise ValueError("no valid jobs entered")
# Group added successfully, open it up for editing
context = {'group': get_job_group(request.user, group, team)}
return render(request, 'crontrack/editgroup.html', context)
# Otherwise, just add the single job
else:
time_window = int(request.POST['time_window'])
if time_window < 0:
raise ValueError
job = Job(
user=request.user,
name=request.POST['name'],
schedule_str=request.POST['schedule_str'],
time_window=time_window,
description=request.POST['description'],
next_run=croniter(request.POST['schedule_str'], now).get_next(datetime),
team=team,
)
job.full_clean()
logger.debug(f'Adding new job: {job}')
job.save()
return HttpResponseRedirect(reverse('crontrack:view_jobs'))
except KeyError:
context['error_message'] = "missing required field(s)"
except (CroniterBadCronError, IndexError):
context['error_message'] = "invalid cron schedule string"
except ValueError as e:
if str(e) == "no valid jobs entered":
context['error_message'] = str(e)
else:
context['error_message'] = "invalid time window"
except ValidationError:
# TODO: replace this with form validation
context['error_message'] = "invalid data in one or more field(s)"
return render(request, 'crontrack/addjob.html', context)
@login_required
def edit_job(request):
if request.method == 'POST':
job = Job.objects.get(pk=request.POST['job'])
if 'edited' in request.POST:
# Edit the job
context = {'prefill': request.POST}
if request.user.can_access(job):
try:
with transaction.atomic():
job.name = request.POST['name']
job.schedule_str = request.POST['schedule_str']
job.time_window = request.POST['time_window']
job.description = request.POST['description']
now = timezone.localtime(timezone.now(), request.user.timezone)
job.next_run = croniter(job.schedule_str, now).get_next(datetime)
job.full_clean()
job.save()
except CroniterBadCronError:
context['error_message'] = "invalid cron schedule string"
except ValueError:
context['error_message'] = "please enter a valid whole number for the time window"
except ValidationError:
context['error_message'] = "invalid data entered in one or more fields"
else:
if 'save_reset' in request.POST:
# Reset all status fields (notification and fail timestamps)
job.last_notified = None
job.last_failed = None
job.save()
return HttpResponseRedirect(reverse('crontrack:view_jobs'))
else:
logger.warning("User {user} tried to edit job {job} without permission")
# ^ copied code feels bad. TODO: draw this out into a helper function (or just use a form)
return render(request, 'crontrack/editjob.html', context)
else:
return render(request, 'crontrack/editjob.html', {'job': job})
else:
return render(request, 'crontrack/editjob.html')
@login_required
def edit_group(request):
if request.method == 'POST' and request.user.is_authenticated and 'group' in request.POST:
timezone.activate(request.user.timezone)
context = {
'group': get_job_group(request.user, request.POST['group'], request.POST['team']),
'team': request.POST['team'],
}
if 'edited' in request.POST:
# Submission after editing the group
# Process the edit then return to view all jobs
# Find team
if request.POST['team'] == 'None':
team = None
else:
team = Team.objects.get(pk=request.POST['team'])
# Rename the job group / modify its description
if request.POST['group'] == 'None':
group = None
else:
try:
group = JobGroup.objects.get(pk=request.POST['group'])
if not request.user.can_access(group):
logger.warning(f"User {request.user} tried to modify job group {group} without permission")
return render(request, 'crontrack/editgroup.html')
with transaction.atomic():
group.name = request.POST['group_name']
group.description = request.POST['description']
group.full_clean()
group.save()
except ValidationError:
context['error_message'] = f"invalid group name/description"
return render(request, 'crontrack/editgroup.html', context)
# Modify the jobs in the group
pattern = re.compile(r'^([0-9a-z\-]+)__name')
try:
for key in request.POST:
match = pattern.match(key)
if match:
with transaction.atomic():
job_id = match.group(1)
# Check if we're adding a new job (with a single number for its temporary ID)
if job_id.isdigit():
job = Job(user=request.user, group=group, team=team)
# Otherwise, find the existing job to edit
else:
job = Job.objects.get(id=job_id)
if not request.user.can_access(job):
logger.warning(f"User {request.user} tried to access job {job} without permission")
return render(request, 'crontrack/editgroup.html')
job.name = request.POST[f'{job_id}__name']
job.schedule_str = request.POST[f'{job_id}__schedule_str']
job.time_window = int(request.POST[f'{job_id}__time_window'])
job.description = request.POST[f'{job_id}__description']
now = timezone.localtime(timezone.now())
job.next_run = croniter(job.schedule_str, now).get_next(datetime)
job.full_clean()
job.save()
except CroniterBadCronError:
context['error_message'] = "invalid cron schedule string"
except ValueError:
context['error_message'] = "please enter a valid whole number for the time window"
except ValidationError:
context['error_message'] = "invalid data entered in one or more fields"
else:
return HttpResponseRedirect(reverse('crontrack:view_jobs'))
return render(request, 'crontrack/editgroup.html', context)
else:
# First view of page with group to edit
return render(request, 'crontrack/editgroup.html', context)
return render(request, 'crontrack/editgroup.html')
@login_required
def delete_group(request):
if request.method == 'POST' and request.user.is_authenticated and 'group' in request.POST:
try:
group = JobGroup.objects.get(pk=request.POST['group'])
if request.user.can_access(group):
group.delete()
else:
logger.warning(f"User {request.user} tried to delete job group {group} without permission")
except JobGroup.DoesNotExist:
logger.exception(f"Tried to delete job group with id '{request.POST['group']}' and it didn't exist")
return HttpResponseRedirect(reverse('crontrack:view_jobs'))
# Delete job with AJAX
@login_required
def delete_job(request):
# Delete job and return to editing job/job group
if request.method == 'POST' and request.user.is_authenticated and 'itemID' in request.POST:
try:
job = Job.objects.get(pk=request.POST['itemID'])
if request.user.can_access(job):
job.delete()
else:
logger.warning(f"User {request.user} tried to delete job {job} without permission")
return JsonResponse({})
except ValidationError:
# This was a newly created job and the ID wasn't a valid UUID
pass
data = {'itemID': request.POST['itemID']}
return JsonResponse(data)
return HttpResponseRedirect(reverse('crontrack:view_jobs'))
@login_required
def teams(request):
context = {}
if request.method == 'POST' and 'type' in request.POST:
if request.POST['type'] == 'create_team':
try:
with transaction.atomic():
team = Team(name=request.POST.get('team_name'), creator=request.user)
team.full_clean()
team.save()
TeamMembership.objects.create(user=request.user, team=team)
except ValidationError:
context['error_message'] = 'invalid team name'
elif request.POST['type'] == 'delete_team':
Team.objects.get(pk=request.POST['team_id']).delete()
elif request.POST['type'] == 'toggle_alerts':
if request.POST['team_id'] == 'None':
request.user.personal_alerts_on = request.POST['alerts_on'] == 'true'
request.user.save()
else:
team = Team.objects.get(pk=request.POST['team_id'])
membership = TeamMembership.objects.get(team=team, user=request.user)
membership.alerts_on = request.POST['alerts_on'] == 'true'
membership.save()
else:
try:
user = User.objects.get(username=request.POST['username'])
team = Team.objects.get(pk=request.POST['team_id'])
except User.DoesNotExist:
context['error_message'] = f"no user found with username '{request.POST['username']}'"
else:
if request.POST['type'] == 'add_user':
# Is it okay to add users to teams without them having a say?
# TODO: consider sending a popup etc. to the other user to confirm before adding them
TeamMembership.objects.create(user=user, team=team)
context['success_message'] = f"User '{user}' successfully added to team '{team}'"
elif request.POST['type'] == 'remove_user':
if user.id == team.creator.id:
context['error_message'] = "a team's creator cannot be removed from their own team"
else:
TeamMembership.objects.get(user=user, team=team).delete()
context['success_message'] = f"User '{user}' successfully removed from team '{team}'"
if request.is_ajax():
return JsonResponse({})
else:
context['membership_alerts'] = {
m.team.id for m in TeamMembership.objects.filter(user=request.user) if m.alerts_on
}
return render(request, 'crontrack/teams.html', context)
@login_required
def profile(request):
context = {}
if request.method == 'POST' and request.user.is_authenticated:
form = ProfileForm(request.POST)
if form.is_valid():
# Update profile settings
request.user.timezone = form.cleaned_data['timezone']
request.user.alert_method = form.cleaned_data['alert_method']
request.user.alert_buffer = form.cleaned_data['alert_buffer']
request.user.email = form.cleaned_data['email']
request.user.phone = form.cleaned_data['full_phone']
request.user.save()
context['success_message'] = "Account settings updated."
else:
context['prefill'] = {'alert_method': form.data['alert_method']}
else:
form = ProfileForm()
context['form'] = form
return render(request, 'registration/profile.html', context)
def delete_account(request):
context = {}
if request.method == 'POST' and request.user.is_authenticated:
logger.debug(f"Deleting user account '{request.user}'")
request.user.delete()
logout(request)
context['success_message'] = "Account successfully deleted."
return render(request, 'registration/deleteaccount.html', context)
class RegisterView(generic.CreateView):
form_class = RegisterForm
success_url = reverse_lazy('crontrack:profile')
template_name = 'registration/register.html'
def form_valid(self, form):
valid = super(RegisterView, self).form_valid(form)
username, password = form.cleaned_data.get('username'), form.cleaned_data.get('<PASSWORD>')
new_user = authenticate(username=username, password=<PASSWORD>)
login(self.request, new_user)
return valid
# --- HELPER FUNCTIONS ---
# Gets a user's job group information with their corresponding jobs
def get_job_group(user, job_group, team):
# Try to convert the team to an object
if type(team) == str:
if team == 'None':
team = None
elif team.isdigit():
# team is an ID rather than an object
team = Team.objects.get(pk=team)
# Check if we're looking at a real job group or the 'Ungrouped' group
if job_group is None or job_group == 'None':
jobs = Job.objects.filter(group__isnull=True)
id = None
name = 'Ungrouped'
description = ''
if team is None:
jobs = jobs.filter(user=user, team__isnull=True)
else:
jobs = jobs.filter(team=team)
# Skip showing the 'Ungrouped' group if it's empty
if not jobs:
return None
else:
# Try to convert the job group to an object
if type(job_group) == str and job_group.isdigit():
# Group is an ID rather than an object
job_group = JobGroup.objects.get(pk=job_group)
# Discard if the JobGroup's team doesn't match the given team
if (team != job_group.team) or (job_group.team is None and user != job_group.user):
return None
jobs = Job.objects.filter(group=job_group.id)
id = job_group.id
name = job_group.name
description = job_group.description
return {'id': id, 'name': name, 'description': description, 'jobs': jobs, 'team': team} | 9068d59cb38b96497b5e51ad7b2b0e20c898cc17 | [
"HTML",
"JavaScript",
"Markdown",
"Python",
"Text"
] | 20 | Python | Arch199/crontrack | 67faf4a8c6e866c1a38855dec68f9f43ba558100 | 91d86ff3b9021d0ad39a821f5dc5d6060a9c48d0 |
refs/heads/master | <file_sep><?php
/* Template Name: Sample template */
get_header(); ?>
<?php
while ( have_posts() ) : the_post();
get_template_part( 'template-contents/content', 'page' );
endwhile; // End of the loop.
?>
<p>hello world</p>
<?php get_footer();<file_sep><?php
/**
* Functions which enhance the theme by hooking into WordPress
*
* @package RWP
*/
function rwp_custom_nav_class( $classes, $item ) {
//$classes = array("nav__link2");
foreach ($classes as $key => $class) {
if(strpos($class, 'menu-item') !== false) {
unset($classes[$key]);
}
switch ($class) {
case 'menu-item':
$classes[$key] = 'menu__item';
break;
case 'menu-item-has-children':
$classes[$key] = 'menu__item--has-children';
break;
case 'current-menu-item':
$classes[$key] = 'menu__item--current';
break;
case 'current-menu-parent':
$classes[$key] = 'menu__item--current-parent';
break;
case 'menu-item-home':
$classes[$key] = 'menu__item--home';
break;
default:
unset($classes[$key]);
break;
}
}
return $classes;
}
function rwp_remove_nav_id($id, $item, $args) {
return "";
}
function my_nav_menu_submenu_css_class( $classes ) {
$classes = array('menu', 'menu--submenu');
return $classes;
}
add_filter( 'nav_menu_submenu_css_class', 'my_nav_menu_submenu_css_class' );
add_filter( 'nav_menu_css_class' , 'rwp_custom_nav_class' , 10, 2 );
add_filter('nav_menu_item_id', 'rwp_remove_nav_id', 10, 3);
add_filter( 'get_custom_logo', 'rwp_custom_logo' );
function rwp_custom_logo() {
$custom_logo_id = get_theme_mod( 'custom_logo' );
$html = sprintf( '<img src="%1$s" class="logo" alt="'.get_bloginfo().'">',
wp_get_attachment_image_url( $custom_logo_id, 'full', false)
);
return $html;
}
if(function_exists ('acf_add_options_page')) {
acf_add_options_page(array(
'menu_title' => 'Homepage',
'menu_slug' => 'homepage-settings',
'position' => 4,
'redirect' => true
));
acf_add_options_sub_page(array(
'page_title' => 'Slider',
'menu_title' => 'Slider',
'parent_slug' => 'homepage-settings',
'menu_slug' => 'slider-settings'
));
}
<file_sep>const webpack = require('webpack'),
HtmlWebpackPlugin = require('html-webpack-plugin'),
ExtractTextPlugin = require('extract-text-webpack-plugin'),
path = require('path'),
autoprefixer = require('autoprefixer');
module.exports = {
entry: {
'app': path.resolve(__dirname, '../../') + '/dev/main.ts',
},
resolve: {
extensions: ['.ts', '.js']
},
module: {
rules: [
{ test: /\.ts?$/, use: "awesome-typescript-loader"},
{ test: /\.(png|jpe?g|gif|svg|ico)$/,
loader: 'file-loader?name=images/[name].[ext]' },
{ test: /\.(|woff|woff2|ttf|eot)$/,
loader: 'file-loader?name=fonts/[name].[ext]' },
{ test: /\.css$/, use: ExtractTextPlugin.extract(
[{loader: 'css-loader', options: {sourceMap: true, importLoaders: 1} },
{loader: 'postcss-loader', options: {sourceMap: true, ident: 'postcss', plugins: (loader) => [autoprefixer()]} } ])
},
{ test: /\.scss$/, use: ExtractTextPlugin.extract(
[{loader: 'css-loader', options: {sourceMap: true, importLoaders: 1} },
{loader: 'postcss-loader', options: {sourceMap: true, ident: 'postcss', plugins: (loader) => [autoprefixer()]} },
{loader: 'sass-loader', options: {sourceMap: true, importLoaders: 1} } ])
},
{ enforce: "pre", test: /\.js$/, loader: "source-map-loader" },
{
test: /\.html$/,
loader: 'html-loader'
},
]
},
plugins: [
new webpack.optimize.CommonsChunkPlugin({
name: ['app']
}),
]
}<file_sep><?php
/**
* RWP Class: The main class of theme
*
* @author <NAME>
* @since 1.0.0
* @package RWP
*/
if ( ! defined( 'ABSPATH' ) ) {
exit;
}
class RWP {
function __construct() {
add_action( 'after_setup_theme', array( $this, 'setup' ) );
add_action( 'wp_enqueue_scripts', array( $this, 'scripts' ), 10 );
add_filter( 'body_class', array( $this, 'body_classes' ) );
add_action( 'widgets_init', array( $this, 'widgets_init' ) );
}
public function setup() {
load_theme_textdomain( 'RWP', get_template_directory() . '/languages' );
add_theme_support( 'automatic-feed-links' );
add_theme_support( 'title-tag' );
add_theme_support( 'post-thumbnails' );
add_theme_support( 'custom-logo', array() );
register_nav_menus( array(
'primary' => __( 'Primary Menu', 'RWP' ),
) );
add_theme_support( 'html5', array(
'search-form',
'comment-form',
'comment-list',
'gallery',
'caption',
) );
add_theme_support( 'customize-selective-refresh-widgets' );
}
public function scripts() {
/**
* Styles
*/
wp_enqueue_style( 'rwp-style', get_template_directory_uri() . '/assets/app.css');
/**
* Fonts
*/
$google_fonts = apply_filters( 'rwp_google_font_families', array(
'lato' => 'Lato:300,400,400i,700,700i,900',
'merriweather' => 'Merriweather:400i',
) );
$query_args = array(
'family' => implode( '|', $google_fonts ),
'subset' => urlencode( 'latin,latin-ext' ),
);
$fonts_url = add_query_arg( $query_args, 'https://fonts.googleapis.com/css' );
wp_enqueue_style( 'rwp-fonts', $fonts_url, array(), null );
/**
* Scripts
*/
wp_enqueue_script( 'rwp-script', get_template_directory_uri() . '/assets/app.js', null, '', true);
}
public function widgets_init() {
$sidebar_args['banner-1'] = array(
'name' => __( 'Banner 1', 'RWP' ),
'id' => 'banner-1',
'description' => ''
);
$sidebar_args['banner-2'] = array(
'name' => __( 'Banner 2', 'RWP' ),
'id' => 'banner-2',
'description' => __( '', 'RWP' ),
);
$sidebar_args['banner-3'] = array(
'name' => __( 'Banner 3', 'RWP' ),
'id' => 'banner-3',
'description' => __( '', 'RWP' ),
);
foreach ( $sidebar_args as $sidebar => $args ) {
$widget_tags = array(
'before_widget' => '<div id="%1$s" class="widget %2$s">',
'after_widget' => '</div>',
'before_title' => '<span class="gamma widget-title">',
'after_title' => '</span>'
);
$filter_hook = sprintf( 'rwp_%s_widget_tags', $sidebar );
$widget_tags = apply_filters( $filter_hook, $widget_tags );
if ( is_array( $widget_tags ) ) {
register_sidebar( $args + $widget_tags );
}
}
}
public function body_classes( $classes ) {
// Adds a class of hfeed to non-singular pages.
$classes[] = 'rwp';
return $classes;
}
}
return new RWP();
?><file_sep><?php
/**
* Template part for displaying posts
*
* @link https://developer.wordpress.org/themes/basics/template-hierarchy/
*
* @package RWP
*/
?>
<main id="post-<?=the_ID()?>" <?php post_class(); ?>>
<header class="page__header">
<div class="container">
<?php the_title( '<h2 class="page__title">', '</h2>' ); ?>
</div>
</header>
<section class="page__content">
<div class="container">
<?php
the_content();
?>
</div>
</section>
</main>
<file_sep><?php
/**
* RWP functions and definitions
*
* @link https://developer.wordpress.org/themes/basics/theme-functions/
*
* @package RWP
*/
$rwp = (object) array(
'main' => require 'inc/rwp-class.php',
'customizer' => require 'inc/customizer/customizer.php',
);
require get_template_directory() . '/inc/template-tags.php';
require get_template_directory() . '/inc/theme-configure.php';
<file_sep><?php
/**
*
* @package RWP
*
*/
get_header(); ?>
<?php
get_template_part( 'template-contents/content', 'none' );
?>
<?php
get_footer();
<file_sep><?php
/**
*
* @package RWP
*
*/
?>
<h3>Lorem ipsum</h3>
<file_sep><?php
/**
* Custom template tags for this theme
*
* Eventually, some of the functionality here could be replaced by core features.
*
* @package RWP
*/
class WPSE_78121_Sublevel_Walker extends Walker_Nav_Menu
{
function start_lvl( &$output, $depth = 0, $args = array() ) {
$indent = str_repeat("\t", $depth);
$output .= "\n$indent<div class='menu--submenu-wrapper'><ul class='menu--submenu'>\n";
}
function end_lvl( &$output, $depth = 0, $args = array() ) {
$indent = str_repeat("\t", $depth);
$output .= "$indent</ul></div>\n";
}
}
function rwp_nav($nav_args) {
$args = array(
'container' => 'div',
'menu_class' => 'menu',
'walker' => new WPSE_78121_Sublevel_Walker
);
if(is_string($nav_args)) {
$args['theme_location'] = $nav_args;
} else {
$args = array_merge($args, $nav_args) ;
}
wp_nav_menu( $args );
}
function image($file_dir) {
return get_template_directory_uri() .'/assets/images/'. $file_dir;
}
<file_sep>RWP
===
Starter wordpress theme for developers.
<file_sep>const webpack = require('webpack'),
webpackMerge = require('webpack-merge'),
ExtractTextPlugin = require('extract-text-webpack-plugin'),
commonConfig = require('./webpack.comm.js'),
path = require('path'),
ImageminPlugin = require('imagemin-webpack-plugin').default,
CopyWebpackPlugin = require('copy-webpack-plugin');;
const ENV = process.env.NODE_ENV = process.env.ENV = 'production';
module.exports = webpackMerge(commonConfig, {
devtool: 'source-map',
output: {
path: path.resolve(__dirname, '../../') + '/assets',
publicPath: '',
filename: '[name].js',
chunkFilename: '[id].chunk.js'
},
plugins: [
new webpack.optimize.UglifyJsPlugin({
sourceMap: true,
mangle: {
keep_fnames: true
}
}),
new ExtractTextPlugin('[name].css'),
new webpack.DefinePlugin({
'process.env': {
'ENV': JSON.stringify(ENV)
}
}),
new CopyWebpackPlugin([{
from: path.resolve(__dirname, '../../') + '/dev/images',
to: path.resolve(__dirname, '../../') + '/assets/images'
}]),
new ImageminPlugin({ test: /\.(jpe?g|png|gif|svg)$/i })
]
});
<file_sep>
<footer>
<a href="<?php echo esc_url( __( 'https://wordpress.org/', 'RWP' ) ); ?>"><?php
printf( esc_html__( 'Proudly powered by %s', 'RWP' ), 'WordPress' );
?></a>
</footer>
<?php wp_footer(); ?>
</body>
</html>
<file_sep><?php
/**
* RWP Theme Customizer
*
* @package RWP
*/
/**
* Add postMessage support for site title and description for the Theme Customizer.
*
* @param WP_Customize_Manager $wp_customize Theme Customizer object.
*/
class RWP_Customizer {
public function __construct() {
add_action( 'customize_register', array( $this, 'customize_register' ), 10 );
add_action( 'customize_preview_init', array( $this, 'customize_js' ) );
}
public function customize_register($wp_customize) {
$wp_customize->get_setting( 'blogname' )->transport = 'postMessage';
$wp_customize->get_setting( 'blogdescription' )->transport = 'postMessage';
$wp_customize->get_setting( 'header_textcolor' )->transport = 'postMessage';
if ( isset( $wp_customize->selective_refresh ) ) {
$wp_customize->selective_refresh->add_partial( 'blogname', array(
'selector' => '.site-title a',
'render_callback' => array($this, 'get_blog_name'),
) );
$wp_customize->selective_refresh->add_partial( 'blogdescription', array(
'selector' => '.site-description',
'render_callback' => array($this, 'get_blog_description'),
) );
}
}
function customize_js() {
wp_enqueue_script( 'RWP-customizer', get_template_directory_uri() . '/inc/customizer/customizer.js', array( 'customize-preview' ), '20151215', true );
}
function get_blog_name() {
the_custom_logo();
bloginfo( 'name' );
}
function get_blog_description() {
bloginfo( 'description' );
}
}
return new RWP_Customizer(); | f473f0882af72479223a7d9dd8143320a8008394 | [
"JavaScript",
"Markdown",
"PHP"
] | 13 | PHP | mateuszszmytko/raa-wordpress-theme | 75cb7af33606699e4eba70ec563b8bb5aaeed7d8 | caa067c57341203805df833771754668f32b7968 |
refs/heads/master | <file_sep>package org.bytecodeandcode.spring.jms;
import javax.jms.ConnectionFactory;
import javax.jms.Destination;
import javax.jms.Topic;
import org.apache.activemq.command.ActiveMQTopic;
import org.bytecodeandcode.spring.jms.properties.jms.AdditionalJmsProperties;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.jms.annotation.EnableJms;
import org.springframework.jms.config.DefaultJmsListenerContainerFactory;
import org.springframework.jms.core.JmsTemplate;
@SpringBootApplication
@ComponentScan(basePackages = {"org.bytecodeandcode.spring"})
@EnableJms
public class Application {
public static final String TOPIC_NAME = "person.status.topic";
public static final String QUEUE_NAME = "person.status.queue";
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public Topic topic() {
ActiveMQTopic activeMQTopic = new ActiveMQTopic(TOPIC_NAME);
return activeMQTopic;
}
/*@Bean
public Queue queue() {
return new ActiveMQQueue(QUEUE_NAME);
}*/
@Bean
public DefaultJmsListenerContainerFactory containerFactory(ConnectionFactory connectionFactory,
AdditionalJmsProperties additionalJmsProperties) {
DefaultJmsListenerContainerFactory factory = new DefaultJmsListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setConcurrency("1");
factory.setClientId(additionalJmsProperties.getClientId());
factory.setPubSubDomain(true);
factory.setSubscriptionDurable(true);
return factory;
}
@Bean
public JmsTemplate jmsTemplate(ConnectionFactory connectionFactory, Destination destination) {
JmsTemplate jmsTemplate = new JmsTemplate(connectionFactory);
jmsTemplate.setDefaultDestination(destination);
return jmsTemplate;
}
}
<file_sep>/**
*
*/
package org.bytecodeandcode.spring.jms;
import static org.hamcrest.CoreMatchers.containsString;
import static org.hamcrest.Matchers.not;
import static org.junit.Assert.assertThat;
import org.apache.commons.lang3.RandomStringUtils;
import org.bytecodeandcode.spring.batch.persistence.domain.Person;
import org.bytecodeandcode.spring.jms.producer.Producer;
import org.junit.Rule;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.OutputCapture;
import org.springframework.boot.test.SpringApplicationConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
/**
* @author Carl
*
*/
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(Application.class)
public class ApplicationIT {
@Rule
public OutputCapture outputCapture = new OutputCapture();
@Autowired private Producer producer;
@Test
public void testPushAndPull() throws InterruptedException {
// Build person
Person person = new Person();
person.setFirstName(getRandomChars());
person.setLastName(getRandomChars());
person.setPersonId(2l);
producer.send(person, "human");
Thread.sleep(2000);
assertThat(outputCapture.toString(), not(containsString("Received:")));
producer.send(person, "person");
Thread.sleep(5000);
assertThat(outputCapture.toString(), containsString("Received:"));
assertThat(outputCapture.toString(), containsString(person.getFirstName()));
}
private String getRandomChars() {
return RandomStringUtils.randomAlphabetic(5);
}
}
<file_sep><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.bytecodeandcode.spring</groupId>
<artifactId>spring-jms-pubsub</artifactId>
<name>Spring JMS Publish and Subscribe</name>
<parent>
<groupId>org.bytecodeandcode</groupId>
<artifactId>parent-bytecodeandcode</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<dependencies>
<dependency>
<groupId>org.bytecodeandcode.spring.batch</groupId>
<artifactId>spring-batch-persistence</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jms</artifactId>
</dependency>
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-broker</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
</project><file_sep># spring-jms-pubsub
A small example of using JMS with Pub Sub<file_sep>package org.bytecodeandcode.spring.jms.properties.jms;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Component
@ConfigurationProperties(prefix = "spring.jms.additional")
public class AdditionalJmsProperties {
private String clientId;
public String getClientId() {
return clientId;
}
public void setClientId(String clientId) {
this.clientId = clientId;
}
}
<file_sep>package org.bytecodeandcode.spring.jms.consumer;
import org.bytecodeandcode.spring.batch.persistence.domain.Person;
import org.bytecodeandcode.spring.jms.Application;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.jms.annotation.JmsListener;
import org.springframework.stereotype.Component;
@Component
public class Consumer {
private static Logger logger = LoggerFactory.getLogger(Consumer.class);
@JmsListener(
destination = Application.TOPIC_NAME
, selector = "REQUEST_TYPE = 'person' AND PERSON_ID = 2"
, subscription = "test.subscriber"
, id = "client.test.id"
, containerFactory = "containerFactory"
)
public void receiveStatus(Person person) {
logger.info("Received: " + person);
}
}
| 98f69c56eb487a4e918989558d9505445a165801 | [
"Markdown",
"Java",
"Maven POM"
] | 6 | Java | carlmdavid/spring-jms-pubsub | 5862826da20f77d51974c8579bf7d56a38e9765e | 44b983b5ba567ff94ca971fb54bcc54747161778 |
refs/heads/master | <file_sep>import React, { useContext } from 'react';
import { Context as TimerContext } from './state/TimerContext';
import Timer from './timers/Timer';
import Menu from './menu/Menu';
import Interval from './timers/Interval';
import EveryMinuteOnTheMinute from './timers/EveryMinuteOnTheMinute';
import AsManyRoundsAsPossible from './timers/AsManyRoundsAsPossible';
function App() {
const { state: { timer } } = useContext(TimerContext);
let timerToDisplay = <Timer />;
if (timer === 'STOP_WATCH') {
timerToDisplay = <Timer />;
} else if (timer === 'EMOM') {
timerToDisplay = <EveryMinuteOnTheMinute />;
} else if (timer === 'AMRAP') {
timerToDisplay = <AsManyRoundsAsPossible />;
} else if (timer === 'INTERVAL') {
timerToDisplay = <Interval />;
}
return (
<>
{timerToDisplay}
<Menu />
</>
);
}
export default App;
<file_sep>import React, { useState, useEffect } from 'react';
import CountDown from '../shared/CountDown';
import AmrapSlider from '../shared/AmrapSlider';
import Grid from '@material-ui/core/Grid';
import { makeStyles } from '@material-ui/core/styles';
import Button from '@material-ui/core/Button';
const useStyles = makeStyles(theme => ({
clock: {
// border: '1px solid white',
width: '100vw',
fontSize: '10rem',
[theme.breakpoints.down('md')]: {
fontSize: '5rem',
},
fontWeight: '100',
color: 'white',
textAlign: 'center',
textShadow: '0 0 20px rgba(10, 175, 230, 1), 0 0 20px rgba(10, 175, 230, 0)',
},
timeLabel: {
fontSize: '1rem',
},
button: {
margin: theme.spacing(0, 2),
}
}));
function AsManyRoundsAsPossible() {
const classes = useStyles();
const [amrap, setAMRAP] = useState(0);
const [clockRunning, setClockRunning] = useState(false);
const [countDownRunning, setCountDownRunning] = useState(false);
const [countDown, setCountDown] = useState(10);
const [minutes, setMinutes] = useState(0);
const [seconds, setSeconds] = useState(0);
const setSliderAndMinutes = (value) => {
setAMRAP(value);
setMinutes(value);
setSeconds(0);
setClockRunning(false);
if (countDownRunning === true) {
setCountDownRunning(false);
}
}
const startClock = () => {
if (countDownRunning === true || amrap === 0) {
return;
}
// If the clock is paused/stopped at 00:00:00
if (minutes > 0 && seconds === 0 && clockRunning === false) {
setCountDownRunning(true)
setCountDown(10);
setClockRunning(true)
} else {
setClockRunning(true);
}
}
const stopClock = () => {
setClockRunning(false);
setCountDownRunning(false);
}
const reset = () => {
setSeconds(0);
setMinutes(amrap);
setCountDown(false);
setClockRunning(false);
}
const tMinus = <CountDown countDown={countDown} setCountDown={setCountDown} />;
const formattedMinutesString = `${minutes.toString().padStart(2, '0')}`;
const formattedSecondsString = `${seconds.toString().padStart(2, '0')}`;
const clock = (
<>
<Grid justify="center" alignItems="flex-end" direction="column" xs={4} item container>
<Grid item>{formattedMinutesString}</Grid>
<Grid justify="center" item container>
<Grid className={classes.timeLabel} item>Minutes</Grid>
</Grid>
</Grid>
<Grid justify="center" direction="column" xs={4} item container>
<Grid item>:</Grid>
</Grid>
<Grid justify="center" alignItems="flex-start" direction="column" xs={4} item container>
<Grid item>{formattedSecondsString}</Grid>
<Grid justify="center" item container>
<Grid className={classes.timeLabel} item>Seconds</Grid>
</Grid>
</Grid>
</>
);
useEffect(() => {
const clockLogic = () => {
if (clockRunning === true) {
if (seconds === 0) {
// Time is up so don't do anything
if (minutes === 0) {
setClockRunning(false);
setAMRAP(0);
return;
}
setMinutes(minutes => minutes - 1);
setSeconds(59);
} else {
setSeconds(secs => secs - 1);
}
}
}
let clockInterval = null;
if (countDown === 0) {
clockInterval = setInterval(clockLogic, 1000);
}
return () => clearInterval(clockInterval);
}, [seconds, minutes, countDown, clockRunning]);
return (
<>
<Grid className={classes.clock} container>
<Grid justify="center" xs={12} item container>{countDownRunning === true && countDown > 0 ? tMinus : clock}</Grid>
<Grid justify="center" item container>
<Grid item><Button className={classes.button} onClick={startClock}>Start</Button></Grid>
<Grid item><Button className={classes.button} onClick={stopClock}>Stop</Button></Grid>
<Grid item><Button className={classes.button} onClick={reset}>Reset</Button></Grid>
</Grid>
</Grid>
<Grid justify="center" alignContent="center" container>
<Grid item>
<AmrapSlider amrap={amrap} setAMRAP={setSliderAndMinutes} />
</Grid>
</Grid>
</>
);
}
export default AsManyRoundsAsPossible;
<file_sep>import React from 'react';
import { makeStyles } from '@material-ui/core/styles';
import Input from '@material-ui/core/Input';
import InputLabel from '@material-ui/core/InputLabel';
import FormControl from '@material-ui/core/FormControl';
import NativeSelect from '@material-ui/core/NativeSelect';
const useStyles = makeStyles(theme => ({
formControl: {
margin: theme.spacing(1),
minWidth: '23vw',
[theme.breakpoints.down('md')]: {
width: '80vw',
}
},
}));
const ITEM_HEIGHT = 48;
const ITEM_PADDING_TOP = 8;
const MenuProps = {
PaperProps: {
style: {
maxHeight: ITEM_HEIGHT * 4.5 + ITEM_PADDING_TOP,
width: 250,
},
},
};
const minutes = ['One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight',];
function MultipleSelect({ min, setMin }) {
const classes = useStyles();
const handleChange = (event) => setMin(event.target.value);
let selectLabel;
switch(min) {
case 'One':
selectLabel = 'Every 1 Minute On The Minute';
break;
case 'Two':
selectLabel = 'Every 2 Minutes On The 2 Minutes';
break;
case 'Three':
selectLabel = 'Every 3 Minutes On The 3 Minutes';
break;
case 'Four':
selectLabel = 'Every 4 Minutes On The 4 Minutes';
break;
case 'Five':
selectLabel = 'Every 5 Minutes On The 5 Minutes';
break;
case 'Six':
selectLabel = 'Every 6 Minutes On The 6 Minutes';
break;
case 'Seven':
selectLabel = 'Every 7 Minutes On The 7 Minutes';
break;
case 'Eight':
selectLabel = 'Every 8 Minutes On The 8 Minutes';
break;
default:
break;
}
const menuItems = minutes.map((minute) => (
<option key={minute} value={minute}>
{minute}
</option>
));
return (
<FormControl className={classes.formControl}>
<InputLabel id="multipleSelectLabel">{selectLabel}</InputLabel>
<NativeSelect
value={min}
onChange={handleChange}
input={<Input id="select-multiple-chip" />}
MenuProps={MenuProps}
>
{menuItems}
</NativeSelect>
</FormControl>
);
}
export default MultipleSelect;
<file_sep>import React from 'react';
import InputLabel from '@material-ui/core/InputLabel';
import FormHelperText from '@material-ui/core/FormHelperText';
import FormControl from '@material-ui/core/FormControl';
import NativeSelect from '@material-ui/core/NativeSelect';
import Grid from '@material-ui/core/Grid';
import { makeStyles } from '@material-ui/core/styles';
const useStyles = makeStyles(theme => ({
formControl: {
margin: theme.spacing(1),
width: '50vw',
[theme.breakpoints.down('md')]: {
width: '80vw'
}
},
title: {
alignText: 'center',
}
}));
function IntervalSetter({ workRest, setWorkRest, mins, setMins, secs, setSecs }) {
const classes = useStyles();
const handleWorkRestChange = event => setWorkRest(event.target.value);
const handleMinsChange = event => {
console.log(typeof event.target.value);
console.log(event.target.value);
setMins(event.target.value)
};
const handleSecsChange = event => {
console.log(event.target.value)
setSecs(event.target.value)
};
const minuteOptions = [];
for (let minOpt = 0; minOpt <= 10; minOpt++) {
minuteOptions.push(<option key={minOpt} value={minOpt}>{minOpt}</option>)
}
const secondOptions = [];
for (let secOpt = 0; secOpt < 60; secOpt++) {
if (secOpt % 5 === 0) {
secondOptions.push(<option key={secOpt} value={secOpt}>{secOpt}</option>);
}
}
return (
<>
<Grid className={classes.gridItem} item>
<FormControl className={classes.formControl}>
<InputLabel>Choose what you would like to set</InputLabel>
<NativeSelect
value={workRest}
onChange={handleWorkRestChange}
>
<option value={'WORK'}>Work Time</option>
<option value={'REST'}>Rest Time</option>
</NativeSelect>
<FormHelperText>{workRest} is ready to be set</FormHelperText>
</FormControl>
</Grid>
<Grid className={classes.gridItem} item>
<FormControl className={classes.formControl}>
<InputLabel>Set Minutes</InputLabel>
<NativeSelect
value={mins}
onChange={handleMinsChange}
>
{minuteOptions}
</NativeSelect>
<FormHelperText>Minutes for {workRest}</FormHelperText>
</FormControl>
</Grid>
<Grid item>
<FormControl className={classes.formControl}>
<InputLabel>Set Seconds</InputLabel>
<NativeSelect
value={secs}
onChange={handleSecsChange}
>
{secondOptions}
</NativeSelect>
<FormHelperText>Seconds for {workRest}</FormHelperText>
</FormControl>
</Grid>
</>
);
}
export default IntervalSetter;
<file_sep>import React, { useEffect, useState, useCallback } from 'react';
import Grid from '@material-ui/core/Grid';
import { makeStyles } from '@material-ui/core/styles';
const useStyles = makeStyles({
timeLabel: {
fontSize: '1rem',
},
});
function CountDown({ countDown, setCountDown }) {
const classes = useStyles();
const [countDownLabel, setCountDownLabel] = useState('');
const memoizedSetCountDown = useCallback(() => setCountDown(cntDwn => cntDwn - 1), [setCountDown]);
useEffect(() => {
let countDownInterval = setInterval(memoizedSetCountDown, 1000);
setCountDownLabel(`${countDown.toString().padStart(2, '0')}`);
if (countDown === 0) {
clearInterval(countDownInterval);
setCountDownLabel('');
}
return () => clearInterval(countDownInterval);
}, [countDown, memoizedSetCountDown]);
return (
<Grid justify="center" alignItems="center" direction="column" xs={4} item container>
<Grid item>{countDownLabel}</Grid>
<Grid justify="center" item container>
<Grid className={classes.timeLabel} item>Countdown</Grid>
</Grid>
</Grid>
);
}
export default CountDown;
<file_sep>import React, { useState, useContext } from 'react';
import { Context as TimerContext } from '../state/TimerContext';
import { makeStyles } from '@material-ui/core/styles';
import SpeedDial from '@material-ui/lab/SpeedDial';
import SpeedDialIcon from '@material-ui/lab/SpeedDialIcon';
import SpeedDialAction from '@material-ui/lab/SpeedDialAction';
import DirectionsRunIcon from '@material-ui/icons/DirectionsRun';
import FitnessCenterIcon from '@material-ui/icons/FitnessCenter';
import RepeatIcon from '@material-ui/icons/Repeat';
import TimerIcon from '@material-ui/icons/Timer';
const useStyles = makeStyles((theme) => ({
root: {
position: 'absolute',
right: 0,
bottom: 0,
height: 380,
transform: 'translateZ(0px)',
flexGrow: 1,
},
speedDial: {
position: 'absolute',
bottom: theme.spacing(2),
right: theme.spacing(2),
},
}));
const actions = [
{ icon: <RepeatIcon />, name: 'EMOM', timerType: 'EMOM' },
{ icon: <DirectionsRunIcon />, name: 'Interval', timerType: 'INTERVAL' },
{ icon: <FitnessCenterIcon />, name: 'AMRAP', timerType: 'AMRAP' },
{ icon: <TimerIcon />, name: 'StopWatch', timerType: 'TIMER' },
];
export default function Menu() {
const classes = useStyles();
const { setTimer } = useContext(TimerContext);
const [open, setOpen] = useState(false);
const handleOpen = () => {
setOpen(true);
};
const handleClose = () => {
setOpen(false);
};
const selectTimer = (type) => {
setTimer(type);
handleClose()
}
return (
<div className={classes.root}>
<SpeedDial
ariaLabel="Set timer type"
className={classes.speedDial}
icon={<SpeedDialIcon />}
onClose={handleClose}
onOpen={handleOpen}
open={open}
>
{actions.map((action) => (
<SpeedDialAction
key={action.name}
icon={action.icon}
tooltipTitle={action.name}
tooltipOpen
onClick={() => selectTimer(action.timerType)}
/>
))}
</SpeedDial>
</div>
);
}<file_sep>import createDataContext from './createDataContext';
const timerReducer = (state, action) => {
switch (action.type) {
case 'SET_TIMER':
return {
...state,
timer: action.timerType,
};
default:
return state;
}
};
const setTimer = (dispatch) => (timerType) => dispatch({ type: 'SET_TIMER', timerType });
export const { Provider, Context } = createDataContext(
timerReducer,
{
setTimer,
},
{
timer: 'STOP_WATCH',
},
);<file_sep>import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import { MuiThemeProvider } from '@material-ui/core';
import Theme from './theme/theme';
import { CssBaseline } from '@material-ui/core';
import StateProviders from './state/StateProviders';
const app = (
<MuiThemeProvider theme={Theme}>
<CssBaseline />
<StateProviders>
<App />
</StateProviders>
</MuiThemeProvider>
);
ReactDOM.render(app, document.getElementById('root'));
<file_sep>import React, { useState, useEffect, useReducer } from 'react';
import CountDown from '../shared/CountDown';
import IntervalSetter from '../shared/IntervalSetter';
import Button from '@material-ui/core/Button';
import Grid from '@material-ui/core/Grid';
import { makeStyles } from '@material-ui/core/styles';
const initialState = {
workRestDropDown: 'WORK',
workSettingMinutes: 0, // this value will be coming in as a string - must be converted to number
workSettingSeconds: 0, // this value will be coming in as a string - must be converted to number
restSettingMinutes: 0, // this value will be coming in as a string - must be converted to number
restSettingSeconds: 0, // this value will be coming in as a string - must be converted to number
workClockRunning: false,
restClockRunning: false,
countDownRunning: false,
countDown: 10,
rounds: 0,
workClockMins: 0,
workClockSecs: 0,
restClockMins: 0,
restClockSecs: 0,
};
function intervalReducer(state, action) {
switch (action.type) {
case 'SET_WORK_REST_DROP_DOWN':
return {
...state,
workRestDropDown: action.payload,
};
case 'SET_WORK_SETTING_MINS':
return {
...state,
workSettingMinutes: action.payload,
};
case 'SET_WORK_SETTING_SECS':
return {
...state,
workSettingSeconds: action.payload,
};
case 'SET_REST_SETTING_MINS':
return {
...state,
restSettingMinutes: action.payload,
};
case 'SET_REST_SETTING_SECS':
return {
...state,
restSettingSeconds: action.payload,
};
case 'SET_WORK_CLOCK_RUNNING':
return {
...state,
workClockRunning: action.payload,
};
case 'SET_REST_CLOCK_RUNNING':
return {
...state,
restClockRunning: action.payload,
};
case 'SET_COUNTDOWN_RUNNING':
return {
...state,
countDownRunning: action.payload,
};
case 'SET_ROUNDS':
return {
...state,
rounds: action.payload,
};
case 'INCREMENT_ROUNDS':
return {
...state,
rounds: state.rounds + 1,
};
case 'SET_WORK_CLOCK_MINS':
return {
...state,
workClockMins: action.payload,
};
case 'DECREMENT_WORK_CLOCK_MINS':
return {
...state,
workClockMins: state.workClockMins - 1,
};
case 'DECREMENT_WORK_CLOCK_SECS':
return {
...state,
workClockSecs: state.workClockSecs - 1,
};
case 'SET_WORK_CLOCK_SECS':
return {
...state,
workClockSecs: action.payload,
};
case 'SET_REST_CLOCK_MINS':
return {
...state,
restClockMins: action.payload,
};
case 'SET_REST_CLOCK_SECS':
return {
...state,
restClockSecs: action.payload,
};
case 'DECREMENT_REST_CLOCK_MINS':
return {
...state,
restClockMins: state.restClockMins - 1,
};
case 'DECREMENT_REST_CLOCK_SECS':
return {
...state,
restClockSecs: state.restClockSecs - 1,
};
default:
throw new Error();
}
}
const useStyles = makeStyles(theme => ({
clock: {
// border: '1px solid white',
width: '100vw',
fontSize: '10rem',
[theme.breakpoints.down('md')]: {
fontSize: '5rem',
},
fontWeight: '100',
color: 'white',
textAlign: 'center',
textShadow: '0 0 20px rgba(10, 175, 230, 1), 0 0 20px rgba(10, 175, 230, 0)',
},
restClock: {
color: 'red',
},
rounds: {
fontSize: '5rem',
margin: theme.spacing(0, 0, 6, 0),
[theme.breakpoints.down('md')]: {
fontSize: '2rem',
}
},
gridItem: {
alignSelf: 'center',
},
button: {
margin: theme.spacing(0, 2),
},
timeLabel: {
fontSize: '1rem',
},
restSignal: {
testTransform: 'capitalize',
fontSize: '1rem',
},
}));
function Interval() {
const classes = useStyles();
const [countDown, setCountDown] = useState(10);
const [state, dispatch] = useReducer(intervalReducer, initialState);
const {
workRestDropDown,
workSettingMinutes,
workSettingSeconds,
restSettingMinutes,
restSettingSeconds,
workClockRunning,
restClockRunning,
countDownRunning,
rounds,
workClockMins,
workClockSecs,
restClockMins,
restClockSecs,
} = state;
const dispatchNewState = (type, payload) => dispatch({ type, payload });
const initiateMins = (value) => {
if (workRestDropDown === 'WORK') {
dispatchNewState('SET_WORK_SETTING_MINS', value);
dispatchNewState('SET_WORK_CLOCK_MINS', parseInt(value));
} else {
dispatchNewState('SET_REST_SETTING_MINS', value);
dispatchNewState('SET_REST_CLOCK_MINS', parseInt(value));
}
}
const initiateSecs = (value) => {
if (workRestDropDown === 'WORK') {
dispatchNewState('SET_WORK_SETTING_SECS', value);
dispatchNewState('SET_WORK_CLOCK_SECS', parseInt(value));
} else {
dispatchNewState('SET_REST_SETTING_SECS', value);
dispatchNewState('SET_REST_CLOCK_SECS', parseInt(value));
}
}
const startClock = () => {
if ((workSettingMinutes === 0 && workSettingSeconds === 0) ||(restSettingMinutes === 0 && restSettingSeconds === 0)) {
return;
}
// If the clock is paused/stopped at 00:00:00
if ((workClockMins === parseInt(workSettingMinutes) && workClockSecs === parseInt(workSettingSeconds)) && workClockRunning === false) {
dispatchNewState('SET_COUNTDOWN_RUNNING', true);
setCountDown(10);
dispatchNewState('SET_WORK_CLOCK_RUNNING', true);
} else {
dispatchNewState('SET_WORK_CLOCK_RUNNING', true);
}
}
const stopClock = () => {
if (countDownRunning === true) {
dispatchNewState('SET_COUNTDOWN_RUNNING', false);
}
if (workClockRunning === true) {
dispatchNewState('SET_WORK_CLOCK_RUNNING', false);
}
if (restClockRunning === true) {
dispatchNewState('SET_REST_CLOCK_RUNNING', false);
}
dispatchNewState('SET_REST_CLOCK_MINS', parseInt(restSettingMinutes));
dispatchNewState('SET_REST_CLOCK_SECS', parseInt(restSettingSeconds));
};
const reset = () => {
dispatchNewState('SET_WORK_CLOCK_MINS', parseInt(workSettingMinutes));
dispatchNewState('SET_WORK_CLOCK_SECS', parseInt(workSettingSeconds));
dispatchNewState('SET_REST_CLOCK_MINS', parseInt(restSettingMinutes));
dispatchNewState('SET_REST_CLOCK_SECS', parseInt(restSettingSeconds));
dispatchNewState('SET_ROUNDS', 0);
dispatchNewState('SET_WORK_CLOCK_RUNNING', false);
}
let roundsStyled = (
<Grid className={classes.rounds} item>Completed Rounds: {rounds}</Grid>
);
const tMinus = <CountDown countDown={countDown} setCountDown={setCountDown} />;
const formattedWorkMinutesString = `${workClockMins.toString().padStart(2, '0')}`;
const formattedWorkSecondsString = `${workClockSecs.toString().padStart(2, '0')}`;
const formattedRestMinutesString = `${restClockMins.toString().padStart(2, '0')}`;
const formattedRestSecondsString = `${restClockSecs.toString().padStart(2, '0')}`;
let minutesToDisplay;
let secondsToDisplay;
if (restClockRunning === true) {
minutesToDisplay = formattedRestMinutesString;
secondsToDisplay = formattedRestSecondsString;
} else {
minutesToDisplay = formattedWorkMinutesString;
secondsToDisplay = formattedWorkSecondsString;
}
const clock = (
<>
<Grid justify="center" alignItems="flex-end" direction="column" xs={4} item container>
<Grid item>{minutesToDisplay}</Grid>
<Grid justify="center" item container>
<Grid className={classes.timeLabel} item>Minutes</Grid>
</Grid>
</Grid>
<Grid justify="center" alignItems="center" direction="column" xs={4} item container>
<Grid item>:</Grid>
</Grid>
<Grid justify="center" alignItems="flex-start" direction="column" xs={4} item container>
<Grid item>{secondsToDisplay}</Grid>
<Grid justify="center" item container>
<Grid className={classes.timeLabel} item>Seconds</Grid>
</Grid>
</Grid>
</>
);
const intervalSetterComponent = (
<IntervalSetter
workRest={workRestDropDown}
setWorkRest={(setting) => dispatchNewState('SET_WORK_REST_DROP_DOWN', setting)}
mins={workRestDropDown === 'WORK' ? workSettingMinutes : restSettingMinutes}
setMins={initiateMins}
secs={workRestDropDown === 'WORK' ? workSettingSeconds : restSettingSeconds}
setSecs={initiateSecs}
/>
);
const intervalRunning = workClockRunning || restClockRunning;
useEffect(() => {
const clockLogic = () => {
if (workClockRunning === true) {
if (workClockSecs === 0) {
// Interval is complete if next if is true
if (workClockMins === 0) {
// set rest clock running to true and reset the work clock to the top of the interval add 1 to rounds
dispatchNewState('SET_REST_CLOCK_RUNNING', true);
dispatchNewState('SET_WORK_CLOCK_RUNNING', false);
dispatchNewState('SET_WORK_CLOCK_MINS', workSettingMinutes);
dispatchNewState('SET_WORK_CLOCK_SECS', workSettingSeconds);
dispatchNewState('INCREMENT_ROUNDS');
return;
}
dispatchNewState('SET_WORK_CLOCK_SECS', 59);
dispatchNewState('DECREMENT_WORK_CLOCK_MINS');
} else {
dispatchNewState('DECREMENT_WORK_CLOCK_SECS');
}
} else {
// rest clock logic (use logic from above)
if (restClockSecs === 0) {
if (restClockMins === 0) {
dispatchNewState('SET_WORK_CLOCK_RUNNING', true);
dispatchNewState('SET_REST_CLOCK_RUNNING', false);
dispatchNewState('SET_REST_CLOCK_MINS', restSettingMinutes);
dispatchNewState('SET_REST_CLOCK_SECS', restSettingSeconds);
return;
}
dispatchNewState('SET_REST_CLOCK_SECS', 59);
dispatchNewState('DECREMENT_REST_CLOCK_MINS');
} else {
dispatchNewState('DECREMENT_REST_CLOCK_SECS');
}
}
}
let clockInterval = null;
if (countDown === 0) {
clockInterval = setInterval(clockLogic, 1000);
}
return () => clearInterval(clockInterval);
}, [countDown,
workClockSecs,
workClockMins,
workClockRunning,
workSettingMinutes,
workSettingSeconds,
restClockSecs,
restClockMins,
restSettingMinutes,
restSettingSeconds,
restClockRunning]);
let restClockStyles = '';
if (restClockRunning === true) {
restClockStyles = classes.restClock;
}
return (
<>
<Grid className={classes.clock} container>
<Grid justify="center" className={restClockStyles} xs={12} item container>
{countDownRunning === true && countDown > 0 ? tMinus : clock}
</Grid>
<Grid justify="center" item container>
<Grid item>
<Button className={classes.button} onClick={startClock}>Start</Button>
</Grid>
<Grid item>
<Button className={classes.button} onClick={stopClock}>Stop</Button>
</Grid>
<Grid item>
<Button className={classes.button} onClick={reset}>Reset</Button>
</Grid>
</Grid>
</Grid>
<Grid justify="center" alignItems="center" container>
<Grid item>
{intervalRunning ? roundsStyled : intervalSetterComponent}
</Grid>
</Grid>
</>
);
}
export default Interval;
| 3bfe2ce65f8c4399286d8d07d2d4b23821f62954 | [
"JavaScript"
] | 9 | JavaScript | ryandiaz1087/GYM-TIMER | cb30b29ff4dfbd43ba652ae64781ce5399e1c6a1 | 74a6739cae3a6b814a4ee1e68153d03bded0f9b6 |
refs/heads/master | <repo_name>pudans/Sunshine<file_sep>/app/src/main/java/sunshine/udacity/pudans/sunshine/Day.java
package sunshine.udacity.pudans.sunshine;
import android.content.Context;
import android.database.Cursor;
import android.database.sqlite.SQLiteDatabase;
import android.os.Parcel;
import android.os.Parcelable;
import android.text.format.Time;
import org.json.JSONArray;
import org.json.JSONException;
import org.json.JSONObject;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Locale;
import java.util.TimeZone;
/**
* Created by Константин on 13.04.2015.
*/
public class Day implements Parcelable {
public long date;
public String dateString;
public Temp temp;
public double pressure;
public int humidity;
public Weather weather;
public double speed;
public int deg;
public int clouds;
Day (JSONObject day) throws JSONException {
this.date = day.getLong("dt");
SimpleDateFormat sdf = new SimpleDateFormat("EEE dd MMM");
sdf.setTimeZone(TimeZone.getTimeZone("GMT+3"));
this.dateString = sdf.format(date*1000L);
this.temp = new Temp(day.getJSONObject("temp"));
this.pressure = day.getDouble("pressure");
this.humidity = day.getInt("humidity");
this.weather = new Weather(day.getJSONArray("weather").getJSONObject(0));
this.speed = day.getDouble("speed");
this.deg = day.getInt("deg");
this.clouds = day.getInt("clouds");
}
Day (Cursor cursor) {
this.date = cursor.getLong(cursor.getColumnIndex("date"));
SimpleDateFormat sdf = new SimpleDateFormat("EEE dd MMM");
sdf.setTimeZone(TimeZone.getTimeZone("GMT+3"));
this.dateString = sdf.format(date*1000L);
this.temp = new Temp(
cursor.getInt(cursor.getColumnIndex("tempDay")),
cursor.getInt(cursor.getColumnIndex("tempMin")),
cursor.getInt(cursor.getColumnIndex("tempMax")),
cursor.getInt(cursor.getColumnIndex("tempNight")),
cursor.getInt(cursor.getColumnIndex("tempEve")),
cursor.getInt(cursor.getColumnIndex("tempMorn"))
);
this.pressure = cursor.getDouble(cursor.getColumnIndex("pressure"));
this.humidity = cursor.getInt(cursor.getColumnIndex("humidity"));
this.weather = new Weather(
cursor.getString(cursor.getColumnIndex("weatherMain")),
cursor.getString(cursor.getColumnIndex("weatherDescription")),
cursor.getString(cursor.getColumnIndex("weatherIcon"))
);
this.speed = cursor.getDouble(cursor.getColumnIndex("speed"));
this.deg = cursor.getInt(cursor.getColumnIndex("deg"));
this.clouds = cursor.getInt(cursor.getColumnIndex("clouds"));
}
Day(Parcel parcel) {
this.date = parcel.readLong();
SimpleDateFormat sdf = new SimpleDateFormat("EEE dd MMM");
sdf.setTimeZone(TimeZone.getTimeZone("GMT+3"));
this.dateString = sdf.format(date*1000L);
int[] input1 = new int[9];
parcel.readIntArray(input1);
this.humidity = input1[0];
this.deg = input1[1];
this.clouds = input1[2];
this.temp = new Temp(input1[3], input1[4], input1[5], input1[6], input1[7], input1[8]);
double[] input2 = new double[2];
parcel.readDoubleArray(input2);
this.pressure = input2[0];
this.speed = input2[1];
String[] input3 = new String[3];
parcel.readStringArray(input3);
this.weather = new Weather(input3[0], input3[1], input3[2]);
}
public static ArrayList<Day> getAllDays(String JSONStr) throws JSONException {
final String OWM_LIST = "list";
ArrayList<Day> days = new ArrayList<Day>();
JSONObject data = new JSONObject(JSONStr);
JSONArray jsdays = data.getJSONArray(OWM_LIST);
for (int i=0;i<jsdays.length();i++)
days.add(new Day(jsdays.getJSONObject(i)));
return days;
}
public static ArrayList<Day> getAllDays(Cursor cursor) {
ArrayList<Day> days = new ArrayList<Day>();
cursor.moveToFirst();
do {
days.add(new Day(cursor));
} while (cursor.moveToNext());
cursor.close();
return days;
}
@Override
public int describeContents() {
return 0;
}
@Override
public void writeToParcel(Parcel parcel, int i) {
parcel.writeLong(date);
parcel.writeIntArray(new int[]{humidity, deg, clouds, temp.day, temp.min, temp.max, temp.night, temp.eve, temp.morn});
parcel.writeDoubleArray(new double[] {pressure, speed});
parcel.writeStringArray(new String[] {weather.main, weather.description, weather.icon});
}
public static final Parcelable.Creator<Day> CREATOR = new Parcelable.Creator<Day>() {
@Override
public Day createFromParcel(Parcel source) {
return new Day(source);
}
@Override
public Day[] newArray(int size) {
return new Day[size];
}
};
public class Temp {
public int day;
public int min;
public int max;
public int night;
public int eve;
public int morn;
Temp (double day, double min, double max, double night, double eve, double morn) {
this.day = (int) Math.round(day);
this.min = (int) Math.round(min);
this.max = (int) Math.round(max);
this.night = (int) Math.round(night);
this.eve = (int) Math.round(eve);
this.morn = (int) Math.round(morn);
}
Temp (JSONObject temp) throws JSONException {
this.day = (int) Math.round(temp.getDouble("day"));
this.min = (int) Math.round(temp.getDouble("min"));
this.max = (int) Math.round(temp.getDouble("max"));
this.night = (int) Math.round(temp.getDouble("night"));
this.eve = (int) Math.round(temp.getDouble("eve"));
this.morn = (int) Math.round(temp.getDouble("morn"));
}
}
public class Weather {
public String main;
public String description;
public String icon;
Weather (String main, String description, String icon) {
this.main = main;
this.description = description;
this.icon = icon;
}
Weather (JSONObject weather) throws JSONException{
this.main = weather.getString("main");
this.description = weather.getString("description");
this.icon = weather.getString("icon");
}
}
}
<file_sep>/app/src/main/java/sunshine/udacity/pudans/sunshine/TaskToGetWeather.java
package sunshine.udacity.pudans.sunshine;
import android.net.Uri;
import android.os.AsyncTask;
import android.util.Log;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
/**
* Created by Константин on 13.04.2015.
*/
public class TaskToGetWeather extends AsyncTask<Void,Void,String> {
public final String LOGS = "Sunshine";
private String ZIP;
private int METERS;
private int DAYS;
TaskToGetWeather(String ZIP, int METERS, int DAYS) {
this.ZIP = ZIP;
this.METERS = METERS;
this.DAYS = DAYS;
}
@Override
protected String doInBackground(Void... voids) {
HttpURLConnection urlConnection = null;
BufferedReader reader = null;
String forecastJsonStr = null;
try {
String BASE_URL = "http://api.openweathermap.org/data/2.5/forecast/daily";
String QUERY_URL = "q";
String FORMAT = "mode";
String UNITS = "units";
//String DAYS = "cnt";
Uri uri = Uri.parse(BASE_URL)
.buildUpon()
.appendQueryParameter(QUERY_URL, ZIP)
.appendQueryParameter(FORMAT,"json")
.appendQueryParameter(UNITS,"metric")
.appendQueryParameter("cnt", DAYS+"")
.build();
URL url = new URL(uri.toString());
urlConnection = (HttpURLConnection) url.openConnection();
urlConnection.setRequestMethod("GET");
urlConnection.connect();
InputStream inputStream = urlConnection.getInputStream();
StringBuffer buffer = new StringBuffer();
if (inputStream == null)
return null;
reader = new BufferedReader(new InputStreamReader(inputStream));
String line;
while ((line = reader.readLine()) != null) {
buffer.append(line + "\n");
}
if (buffer.length() == 0) {
return null;
}
forecastJsonStr = buffer.toString();
} catch (IOException e) {
Log.e(LOGS, "Error IOException: ", e);
return null;
} finally{
if (urlConnection != null) {
urlConnection.disconnect();
}
if (reader != null) {
try {
reader.close();
} catch (final IOException e) {
Log.e("PlaceholderFragment", "Error closing stream", e);
Log.e(LOGS, "Error IOException: ", e);
}
}
}
return forecastJsonStr;
}
}<file_sep>/app/src/main/java/sunshine/udacity/pudans/sunshine/WeatherListAdapter.java
package sunshine.udacity.pudans.sunshine;
import android.animation.ValueAnimator;
import android.content.Context;
import android.content.Intent;
import android.graphics.Bitmap;
import android.graphics.BitmapFactory;
import android.os.AsyncTask;
import android.support.v7.widget.CardView;
import android.text.format.Time;
import android.view.View;
import android.view.ViewGroup;
import android.widget.BaseAdapter;
import android.widget.Button;
import android.widget.ImageView;
import android.widget.LinearLayout;
import android.widget.TextView;
import android.widget.Toast;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.Date;
/**
* Created by Константин on 13.04.2015.
*/
public class WeatherListAdapter extends BaseAdapter {
private ArrayList<Day> days;
private Context context;
WeatherListAdapter(Context context) {
this.context = context;
days = new ArrayList<Day>();
}
@Override
public int getCount() {
return days.size();
}
@Override
public Object getItem(int i) {
return days.get(i);
}
@Override
public long getItemId(int i) {
return 0;
}
@Override
public View getView(final int i, View rootView, ViewGroup viewGroup) {
final Day day = days.get(i);
if (rootView == null)
rootView = View.inflate(context,R.layout.weather_list_item,null);
final LinearLayout ll_detail = (LinearLayout)rootView.findViewById(R.id.weather_list_item_detail_ll);
ll_detail.setVisibility(View.GONE);
((TextView)rootView.findViewById(R.id.weather_list_item_detail_wind)).setText(day.speed+" м/с");
((TextView)rootView.findViewById(R.id.weather_list_item_detail_pressure)).setText(day.pressure+" hpa");
((TextView)rootView.findViewById(R.id.weather_list_item_detail_humidity)).setText(day.humidity+"%");
CardView cardView = (CardView)rootView.findViewById(R.id.weather_list_item_card_view);
cardView.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
if (ll_detail.getVisibility() == View.GONE) {
ll_detail.setVisibility(View.VISIBLE);
}
else
ll_detail.setVisibility(View.GONE);
}
});
final StringBuilder str = new StringBuilder();
if (day.temp.max>0) str.append("+");
str.append(day.temp.max);
str.append("\u00B0");
str.append("..");
if (day.temp.min>0) str.append("+");
str.append(day.temp.min);
str.append("\u00B0");
((TextView)rootView.findViewById(R.id.weather_list_item_tv1)).setText(str.toString() + " "+day.weather.main);
long dateNow = System.currentTimeMillis();
long dateWeather = day.date*1000;
long halfDay = 1000*60*60*12;
if (dateNow - halfDay > dateWeather)
((TextView)rootView.findViewById(R.id.weather_list_item_tv2)).setText("Вчера");
else if (dateNow + halfDay > dateWeather)
((TextView)rootView.findViewById(R.id.weather_list_item_tv2)).setText("Сегодня");
else if (dateNow + 3*halfDay > dateWeather)
((TextView)rootView.findViewById(R.id.weather_list_item_tv2)).setText("Завтра");
else
((TextView)rootView.findViewById(R.id.weather_list_item_tv2)).setText(day.dateString);
final ImageView img = (ImageView)rootView.findViewById(R.id.weather_list_item_img);
new AsyncTask<ImageView,Void,ImageView>() {
Bitmap bt;
@Override
protected ImageView doInBackground(ImageView... imageViews) {
try {
bt = BitmapFactory.decodeStream(new URL("http://openweathermap.org/img/w/" + day.weather.icon + ".png").openConnection().getInputStream());
} catch (IOException e) {
e.printStackTrace();
}
return imageViews[0];
}
@Override
protected void onPostExecute(ImageView img) {
img.setImageBitmap(bt);
}
}.execute(img);
((TextView) rootView.findViewById(R.id.weather_list_item_detail_temp_morn)).setText(day.temp.morn+"°");
((TextView) rootView.findViewById(R.id.weather_list_item_detail_temp_day)).setText(day.temp.day+"°");
((TextView) rootView.findViewById(R.id.weather_list_item_detail_temp_eve)).setText(day.temp.eve+"°");
((TextView) rootView.findViewById(R.id.weather_list_item_detail_temp_night)).setText(day.temp.night+"°");
rootView.findViewById(R.id.weather_list_item_detail_share).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Intent sendIntent = new Intent();
sendIntent.setAction(Intent.ACTION_SEND);
sendIntent.putExtra(Intent.EXTRA_TEXT, day.dateString + " " + str.toString() + " " + day.weather.description);
sendIntent.setType("text/plain");
context.startActivity(sendIntent);
}
});
rootView.findViewById(R.id.weather_list_item_img_more).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
context.startActivity(new Intent(context,DetailActivity.class).putExtra("DAY",day));
}
});
return rootView;
}
public void notifyDataSetChanged(ArrayList<Day> days) {
this.days = days;
this.notifyDataSetChanged();
}
}
<file_sep>/app/src/main/java/sunshine/udacity/pudans/sunshine/SettingsActivity.java
package sunshine.udacity.pudans.sunshine;
import android.app.Dialog;
import android.content.Context;
import android.content.DialogInterface;
import android.content.Intent;
import android.content.SharedPreferences;
import android.os.Bundle;
import android.support.v7.app.ActionBarActivity;
import android.support.v7.widget.Toolbar;
import android.view.Menu;
import android.view.MenuItem;
import android.view.View;
import android.view.ViewGroup;
import android.widget.AdapterView;
import android.widget.BaseAdapter;
import android.widget.EditText;
import android.widget.ListView;
import android.widget.NumberPicker;
import android.widget.SimpleAdapter;
import android.widget.TextView;
import com.alertdialogpro.AlertDialogPro;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.zip.Inflater;
/**
* Created by Константин on 19.04.2015.
*/
public class SettingsActivity extends ActionBarActivity {
SettingsAdapter adapter;
String[] titles;
static private String ZIP;
static private int METERS;
static private int DAYS;
@Override
protected void onCreate(Bundle save) {
super.onCreate(save);
setContentView(R.layout.activity_settings);
loadSettings();
Toolbar toolbar = (Toolbar) findViewById(R.id.toolbar);
setSupportActionBar(toolbar);
getSupportActionBar().setDisplayHomeAsUpEnabled(true);
//getWindow().setNavigationBarColor(getResources().getColor(R.color.main_color));
titles = new String[] { "Местоположение",
"Метрическая система",
"Количество дней"};
adapter = new SettingsAdapter(this,titles,getSubTitles());
ListView settingsList = (ListView) findViewById(R.id.settings_listview);
settingsList.setAdapter(adapter);
settingsList.setOnItemClickListener(new AdapterView.OnItemClickListener() {
@Override
public void onItemClick(AdapterView<?> adapterView, View view, int position, long l) {
getSettingsDialog(position).show();
}
});
}
private String[] getSubTitles() {
String[] subtitles = new String[titles.length];
subtitles[0] = "Индекс: "+ZIP;
if (METERS == 0) subtitles[1] = "Нормальная"; else subtitles[1] = "Забугорная";
subtitles[2] = DAYS+"";
return subtitles;
}
private AlertDialogPro.Builder getSettingsDialog(int id) {
final AlertDialogPro.Builder dialog = new AlertDialogPro.Builder(this);
dialog.setTitle(titles[id]);
switch (id) {
case 0: {
final EditText ed = new EditText(this);
ed.setText(ZIP);
dialog.setView(ed);
dialog.setNegativeButton("Отмена", null);
dialog.setPositiveButton("OK", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
ZIP = ed.getText().toString();
adapter.notifyDataSetChanged(getSubTitles());
}
});
}
break;
case 1: {
dialog.setSingleChoiceItems(new String[]{"Нормальная", "Забугорная"}, METERS, new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
METERS = i;
}
});
dialog.setNegativeButton("Отмена", null);
dialog.setPositiveButton("OK", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
adapter.notifyDataSetChanged(getSubTitles());
}
});
}
break;
case 2: {
final NumberPicker np = new NumberPicker(this);
np.setWrapSelectorWheel(false);
np.setDescendantFocusability(NumberPicker.FOCUS_BLOCK_DESCENDANTS);
np.setMinValue(1);
np.setMaxValue(16);
np.setValue(DAYS);
dialog.setView(np);
dialog.setNegativeButton("Отмена", null);
dialog.setPositiveButton("OK", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
DAYS = np.getValue();
adapter.notifyDataSetChanged(getSubTitles());
}
});
}
break;
}
return dialog;
}
@Override
public boolean onOptionsItemSelected(MenuItem item) {
if (item.getItemId() == android.R.id.home) {
onBackPressed();
return true;
}
else
return super.onOptionsItemSelected(item);
}
@Override
public void onDestroy() {
super.onDestroy();
saveSettings();
}
private void loadSettings() {
SharedPreferences sPref = getSharedPreferences("SETTINGS",MODE_PRIVATE);
ZIP = sPref.getString("ZIP","143090");
METERS = sPref.getInt("METERS", 0);
DAYS = sPref.getInt("DAYS", 7);
}
private void saveSettings() {
SharedPreferences sPref = getSharedPreferences("SETTINGS",MODE_PRIVATE);
SharedPreferences.Editor ed = sPref.edit();
ed.putString("ZIP",ZIP);
ed.putInt("METERS",METERS);
ed.putInt("DAYS",DAYS);
ed.apply();
}
private class SettingsAdapter extends BaseAdapter {
private Context context;
private String[] titles;
private String[] subtitles;
public SettingsAdapter(Context context, String[] titles, String[] subtitles) {
this.context = context;
this.titles = titles;
this.subtitles = subtitles;
}
@Override
public int getCount() {
return titles.length;
}
@Override
public Object getItem(int i) {
return titles[i];
}
@Override
public long getItemId(int i) {
return i;
}
@Override
public View getView(int position, View view, ViewGroup viewGroup) {
if (view == null)
view = View.inflate(context, android.R.layout.simple_list_item_2, null);
((TextView)view.findViewById(android.R.id.text1)).setText(titles[position]);
((TextView)view.findViewById(android.R.id.text2)).setText(subtitles[position]);
return view;
}
public void notifyDataSetChanged(String[] subtitles) {
this.subtitles = subtitles;
notifyDataSetChanged();
}
}
}
| b4339c246d049a1250cf3486347259962044790f | [
"Java"
] | 4 | Java | pudans/Sunshine | 3b64df9e606ce147ea50ec9697fa64bf476952cc | 1713ba427a91807431d357e0952ff067ef8e1fef |
refs/heads/master | <file_sep>CREATE TABLE "PROGRAMMEUR" (
"ID" INTEGER NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1),
"MATRICULE" VARCHAR(5),
"NOM" VARCHAR(25),
"PRENOM" VARCHAR(25),
"ADRESSE" VARCHAR(150),
"PSEUDO" VARCHAR(20) ,
"RESPONSABLE" VARCHAR(30) ,
"HOBBY" VARCHAR(30) ,
"DATE_NAISS" DATE ,
"DATE_EMB" DATE ,
CONSTRAINT primary_key_programmeur PRIMARY KEY (ID)
);
INSERT INTO PROGRAMMEUR(MATRICULE,NOM,PRENOM,ADRESSE,PSEUDO,RESPONSABLE,HOBBY,DATE_NAISS,DATE_EMB) VALUES
('17542','Galois','Evariste','2 avenue Groupes','evagal','<NAME>','Salsa','1993-02-23','1994-02-23'),
('17543','Simpson','Bart','2 rue Casimir','bsimp','<NAME>','Voyages','1995-02-23','1994-02-23'),
('17544','Cantor','Georg','3 impasse Infini','plus_infini','<NAME>','Peinture','2009-02-23','1994-02-23'),
('17545','Turing','Alan','4 ruelle Enigma','robot20','<NAME>','Maquettes','1994-02-23','1999-02-23'),
('17546','Gauss','<NAME>','6 rue des Transformations','cfgg4','<NAME>','Boxe','1989-02-23','1994-02-23'),
('17547','Pascal','Blaise','39 bvd de Port-Royal','clermont','<NAME>','Cinéma','1939-02-23','1994-02-23'),
('17548','Euler','Leonhard','140 avenue Complexe','elga33','<NAME>','Cuisine','1959-02-23','1994-02-23'),
('17549','Woodpecker','Woody','2 rue du Bois','ww715','<NAME>','Randonnée','1949-02-23','1994-02-23'),
('17550','Brown','Charlie','2 allée BD','cb14','<NAME>','Philatélie','1969-02-23','1994-02-23');<file_sep><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<!-- NewPage -->
<html lang="fr">
<head>
<!-- Generated by javadoc (1.8.0_202) on Mon Oct 21 15:00:13 CEST 2019 -->
<title>ViewAbstract</title>
<meta name="date" content="2019-10-21">
<link rel="stylesheet" type="text/css" href="../../../stylesheet.css" title="Style">
<script type="text/javascript" src="../../../script.js"></script>
</head>
<body>
<script type="text/javascript"><!--
try {
if (location.href.indexOf('is-external=true') == -1) {
parent.document.title="ViewAbstract";
}
}
catch(err) {
}
//-->
var methods = {"i0":10,"i1":10};
var tabs = {65535:["t0","All Methods"],2:["t2","Instance Methods"],8:["t4","Concrete Methods"]};
var altColor = "altColor";
var rowColor = "rowColor";
var tableTab = "tableTab";
var activeTableTab = "activeTableTab";
</script>
<noscript>
<div>JavaScript is disabled on your browser.</div>
</noscript>
<!-- ========= START OF TOP NAVBAR ======= -->
<div class="topNav"><a name="navbar.top">
<!-- -->
</a>
<div class="skipNav"><a href="#skip.navbar.top" title="Skip navigation links">Skip navigation links</a></div>
<a name="navbar.top.firstrow">
<!-- -->
</a>
<ul class="navList" title="Navigation">
<li><a href="../../../overview-summary.html">Overview</a></li>
<li><a href="package-summary.html">Package</a></li>
<li class="navBarCell1Rev">Class</li>
<li><a href="package-tree.html">Tree</a></li>
<li><a href="../../../deprecated-list.html">Deprecated</a></li>
<li><a href="../../../index-files/index-1.html">Index</a></li>
<li><a href="../../../help-doc.html">Help</a></li>
</ul>
</div>
<div class="subNav">
<ul class="navList">
<li><a href="../../../fr/kerroue_dehoux/view/View.html" title="class in fr.kerroue_dehoux.view"><span class="typeNameLink">Prev Class</span></a></li>
<li>Next Class</li>
</ul>
<ul class="navList">
<li><a href="../../../index.html?fr/kerroue_dehoux/view/ViewAbstract.html" target="_top">Frames</a></li>
<li><a href="ViewAbstract.html" target="_top">No Frames</a></li>
</ul>
<ul class="navList" id="allclasses_navbar_top">
<li><a href="../../../allclasses-noframe.html">All Classes</a></li>
</ul>
<div>
<script type="text/javascript"><!--
allClassesLink = document.getElementById("allclasses_navbar_top");
if(window==top) {
allClassesLink.style.display = "block";
}
else {
allClassesLink.style.display = "none";
}
//-->
</script>
</div>
<div>
<ul class="subNavList">
<li>Summary: </li>
<li><a href="#nested.classes.inherited.from.class.javax.swing.JFrame">Nested</a> | </li>
<li><a href="#field.summary">Field</a> | </li>
<li><a href="#constructor.summary">Constr</a> | </li>
<li><a href="#method.summary">Method</a></li>
</ul>
<ul class="subNavList">
<li>Detail: </li>
<li><a href="#field.detail">Field</a> | </li>
<li><a href="#constructor.detail">Constr</a> | </li>
<li><a href="#method.detail">Method</a></li>
</ul>
</div>
<a name="skip.navbar.top">
<!-- -->
</a></div>
<!-- ========= END OF TOP NAVBAR ========= -->
<!-- ======== START OF CLASS DATA ======== -->
<div class="header">
<div class="subTitle">fr.kerroue_dehoux.view</div>
<h2 title="Class ViewAbstract" class="title">Class ViewAbstract</h2>
</div>
<div class="contentContainer">
<ul class="inheritance">
<li>java.lang.Object</li>
<li>
<ul class="inheritance">
<li>java.awt.Component</li>
<li>
<ul class="inheritance">
<li>java.awt.Container</li>
<li>
<ul class="inheritance">
<li>java.awt.Window</li>
<li>
<ul class="inheritance">
<li>java.awt.Frame</li>
<li>
<ul class="inheritance">
<li>javax.swing.JFrame</li>
<li>
<ul class="inheritance">
<li>fr.kerroue_dehoux.view.ViewAbstract</li>
</ul>
</li>
</ul>
</li>
</ul>
</li>
</ul>
</li>
</ul>
</li>
</ul>
</li>
</ul>
<div class="description">
<ul class="blockList">
<li class="blockList">
<dl>
<dt>All Implemented Interfaces:</dt>
<dd>java.awt.image.ImageObserver, java.awt.MenuContainer, java.io.Serializable, javax.accessibility.Accessible, javax.swing.RootPaneContainer, javax.swing.WindowConstants</dd>
</dl>
<dl>
<dt>Direct Known Subclasses:</dt>
<dd><a href="../../../fr/kerroue_dehoux/view/View.html" title="class in fr.kerroue_dehoux.view">View</a></dd>
</dl>
<hr>
<br>
<pre>public abstract class <span class="typeNameLabel">ViewAbstract</span>
extends javax.swing.JFrame</pre>
<dl>
<dt><span class="seeLabel">See Also:</span></dt>
<dd><a href="../../../serialized-form.html#fr.kerroue_dehoux.view.ViewAbstract">Serialized Form</a></dd>
</dl>
</li>
</ul>
</div>
<div class="summary">
<ul class="blockList">
<li class="blockList">
<!-- ======== NESTED CLASS SUMMARY ======== -->
<ul class="blockList">
<li class="blockList"><a name="nested.class.summary">
<!-- -->
</a>
<h3>Nested Class Summary</h3>
<ul class="blockList">
<li class="blockList"><a name="nested.classes.inherited.from.class.javax.swing.JFrame">
<!-- -->
</a>
<h3>Nested classes/interfaces inherited from class javax.swing.JFrame</h3>
<code>javax.swing.JFrame.AccessibleJFrame</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="nested.classes.inherited.from.class.java.awt.Frame">
<!-- -->
</a>
<h3>Nested classes/interfaces inherited from class java.awt.Frame</h3>
<code>java.awt.Frame.AccessibleAWTFrame</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="nested.classes.inherited.from.class.java.awt.Window">
<!-- -->
</a>
<h3>Nested classes/interfaces inherited from class java.awt.Window</h3>
<code>java.awt.Window.AccessibleAWTWindow, java.awt.Window.Type</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="nested.classes.inherited.from.class.java.awt.Container">
<!-- -->
</a>
<h3>Nested classes/interfaces inherited from class java.awt.Container</h3>
<code>java.awt.Container.AccessibleAWTContainer</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="nested.classes.inherited.from.class.java.awt.Component">
<!-- -->
</a>
<h3>Nested classes/interfaces inherited from class java.awt.Component</h3>
<code>java.awt.Component.AccessibleAWTComponent, java.awt.Component.BaselineResizeBehavior, java.awt.Component.BltBufferStrategy, java.awt.Component.FlipBufferStrategy</code></li>
</ul>
</li>
</ul>
<!-- =========== FIELD SUMMARY =========== -->
<ul class="blockList">
<li class="blockList"><a name="field.summary">
<!-- -->
</a>
<h3>Field Summary</h3>
<table class="memberSummary" border="0" cellpadding="3" cellspacing="0" summary="Field Summary table, listing fields, and an explanation">
<caption><span>Fields</span><span class="tabEnd"> </span></caption>
<tr>
<th class="colFirst" scope="col">Modifier and Type</th>
<th class="colLast" scope="col">Field and Description</th>
</tr>
<tr class="altColor">
<td class="colFirst"><code>private javax.swing.JMenu</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#actionCategory">actionCategory</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JMenuItem</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#addMenuButton">addMenuButton</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JLabel</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#address">address</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JTextField</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#addressField">addressField</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JMenuItem</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#allMenuButton">allMenuButton</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) java.awt.image.BufferedImage</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#background">background</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JButton</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#cancelButton">cancelButton</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>protected javax.swing.JPanel</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#contentPanel">contentPanel</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JLabel</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#dateBirth">dateBirth</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JTextField</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#dateBirthDayField">dateBirthDayField</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JComboBox</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#dateBirthMonthField">dateBirthMonthField</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JTextField</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#dateBirthYearField">dateBirthYearField</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JLabel</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#dateHiring">dateHiring</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JTextField</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#dateHiringDayField">dateHiringDayField</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JComboBox</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#dateHiringMonthField">dateHiringMonthField</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JTextField</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#dateHiringYearField">dateHiringYearField</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JMenuItem</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#deleteMenuButton">deleteMenuButton</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>private javax.swing.JMenu</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#displayCategory">displayCategory</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JTextArea</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#displayZoneProgrammers">displayZoneProgrammers</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JMenuItem</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#editMenuButton">editMenuButton</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JLabel</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#firstName">firstName</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JTextField</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#firstNameField">firstNameField</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JLabel</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#hobby">hobby</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JTextField</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#hobbyField">hobbyField</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JLabel</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#id">id</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JTextField</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#idField">idField</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JLabel</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#lastName">lastName</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JTextField</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#lastNameField">lastNameField</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>private javax.swing.JMenuBar</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#menuBar">menuBar</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JLabel</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#nickname">nickname</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JTextField</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#nicknameField">nicknameField</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>private javax.swing.JMenu</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#programmerCategory">programmerCategory</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JMenuItem</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#quitMenuButton">quitMenuButton</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JButton</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#resetButton">resetButton</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JLabel</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#responsible">responsible</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JTextField</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#responsibleField">responsibleField</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JScrollPane</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#scroll">scroll</a></span></code> </td>
</tr>
<tr class="rowColor">
<td class="colFirst"><code>(package private) javax.swing.JButton</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#searchButton">searchButton</a></span></code> </td>
</tr>
<tr class="altColor">
<td class="colFirst"><code>(package private) javax.swing.JButton</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#validateButton">validateButton</a></span></code> </td>
</tr>
</table>
<ul class="blockList">
<li class="blockList"><a name="fields.inherited.from.class.javax.swing.JFrame">
<!-- -->
</a>
<h3>Fields inherited from class javax.swing.JFrame</h3>
<code>accessibleContext, EXIT_ON_CLOSE, rootPane, rootPaneCheckingEnabled</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="fields.inherited.from.class.java.awt.Frame">
<!-- -->
</a>
<h3>Fields inherited from class java.awt.Frame</h3>
<code>CROSSHAIR_CURSOR, DEFAULT_CURSOR, E_RESIZE_CURSOR, HAND_CURSOR, ICONIFIED, MAXIMIZED_BOTH, MAXIMIZED_HORIZ, MAXIMIZED_VERT, MOVE_CURSOR, N_RESIZE_CURSOR, NE_RESIZE_CURSOR, NORMAL, NW_RESIZE_CURSOR, S_RESIZE_CURSOR, SE_RESIZE_CURSOR, SW_RESIZE_CURSOR, TEXT_CURSOR, W_RESIZE_CURSOR, WAIT_CURSOR</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="fields.inherited.from.class.java.awt.Component">
<!-- -->
</a>
<h3>Fields inherited from class java.awt.Component</h3>
<code>BOTTOM_ALIGNMENT, CENTER_ALIGNMENT, LEFT_ALIGNMENT, RIGHT_ALIGNMENT, TOP_ALIGNMENT</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="fields.inherited.from.class.javax.swing.WindowConstants">
<!-- -->
</a>
<h3>Fields inherited from interface javax.swing.WindowConstants</h3>
<code>DISPOSE_ON_CLOSE, DO_NOTHING_ON_CLOSE, HIDE_ON_CLOSE</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="fields.inherited.from.class.java.awt.image.ImageObserver">
<!-- -->
</a>
<h3>Fields inherited from interface java.awt.image.ImageObserver</h3>
<code>ABORT, ALLBITS, ERROR, FRAMEBITS, HEIGHT, PROPERTIES, SOMEBITS, WIDTH</code></li>
</ul>
</li>
</ul>
<!-- ======== CONSTRUCTOR SUMMARY ======== -->
<ul class="blockList">
<li class="blockList"><a name="constructor.summary">
<!-- -->
</a>
<h3>Constructor Summary</h3>
<table class="memberSummary" border="0" cellpadding="3" cellspacing="0" summary="Constructor Summary table, listing constructors, and an explanation">
<caption><span>Constructors</span><span class="tabEnd"> </span></caption>
<tr>
<th class="colOne" scope="col">Constructor and Description</th>
</tr>
<tr class="altColor">
<td class="colOne"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#ViewAbstract--">ViewAbstract</a></span>()</code> </td>
</tr>
</table>
</li>
</ul>
<!-- ========== METHOD SUMMARY =========== -->
<ul class="blockList">
<li class="blockList"><a name="method.summary">
<!-- -->
</a>
<h3>Method Summary</h3>
<table class="memberSummary" border="0" cellpadding="3" cellspacing="0" summary="Method Summary table, listing methods, and an explanation">
<caption><span id="t0" class="activeTableTab"><span>All Methods</span><span class="tabEnd"> </span></span><span id="t2" class="tableTab"><span><a href="javascript:show(2);">Instance Methods</a></span><span class="tabEnd"> </span></span><span id="t4" class="tableTab"><span><a href="javascript:show(8);">Concrete Methods</a></span><span class="tabEnd"> </span></span></caption>
<tr>
<th class="colFirst" scope="col">Modifier and Type</th>
<th class="colLast" scope="col">Method and Description</th>
</tr>
<tr id="i0" class="altColor">
<td class="colFirst"><code>(package private) void</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#generateAlert-java.lang.String-">generateAlert</a></span>(java.lang.String message)</code>
<div class="block">Generate an alert to the user</div>
</td>
</tr>
<tr id="i1" class="rowColor">
<td class="colFirst"><code>(package private) boolean</code></td>
<td class="colLast"><code><span class="memberNameLink"><a href="../../../fr/kerroue_dehoux/view/ViewAbstract.html#handleClose--">handleClose</a></span>()</code>
<div class="block">Display an alert to confirm program exit</div>
</td>
</tr>
</table>
<ul class="blockList">
<li class="blockList"><a name="methods.inherited.from.class.javax.swing.JFrame">
<!-- -->
</a>
<h3>Methods inherited from class javax.swing.JFrame</h3>
<code>addImpl, createRootPane, frameInit, getAccessibleContext, getContentPane, getDefaultCloseOperation, getGlassPane, getGraphics, getJMenuBar, getLayeredPane, getRootPane, getTransferHandler, isDefaultLookAndFeelDecorated, isRootPaneCheckingEnabled, paramString, processWindowEvent, remove, repaint, setContentPane, setDefaultCloseOperation, setDefaultLookAndFeelDecorated, setGlassPane, setIconImage, setJMenuBar, setLayeredPane, setLayout, setRootPane, setRootPaneCheckingEnabled, setTransferHandler, update</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="methods.inherited.from.class.java.awt.Frame">
<!-- -->
</a>
<h3>Methods inherited from class java.awt.Frame</h3>
<code>addNotify, getCursorType, getExtendedState, getFrames, getIconImage, getMaximizedBounds, getMenuBar, getState, getTitle, isResizable, isUndecorated, remove, removeNotify, setBackground, setCursor, setExtendedState, setMaximizedBounds, setMenuBar, setOpacity, setResizable, setShape, setState, setTitle, setUndecorated</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="methods.inherited.from.class.java.awt.Window">
<!-- -->
</a>
<h3>Methods inherited from class java.awt.Window</h3>
<code>addPropertyChangeListener, addPropertyChangeListener, addWindowFocusListener, addWindowListener, addWindowStateListener, applyResourceBundle, applyResourceBundle, createBufferStrategy, createBufferStrategy, dispose, getBackground, getBufferStrategy, getFocusableWindowState, getFocusCycleRootAncestor, getFocusOwner, getFocusTraversalKeys, getIconImages, getInputContext, getListeners, getLocale, getModalExclusionType, getMostRecentFocusOwner, getOpacity, getOwnedWindows, getOwner, getOwnerlessWindows, getShape, getToolkit, getType, getWarningString, getWindowFocusListeners, getWindowListeners, getWindows, getWindowStateListeners, hide, isActive, isAlwaysOnTop, isAlwaysOnTopSupported, isAutoRequestFocus, isFocusableWindow, isFocusCycleRoot, isFocused, isLocationByPlatform, isOpaque, isShowing, isValidateRoot, pack, paint, postEvent, processEvent, processWindowFocusEvent, processWindowStateEvent, removeWindowFocusListener, removeWindowListener, removeWindowStateListener, reshape, setAlwaysOnTop, setAutoRequestFocus, setBounds, setBounds, setCursor, setFocusableWindowState, setFocusCycleRoot, setIconImages, setLocation, setLocation, setLocationByPlatform, setLocationRelativeTo, setMinimumSize, setModalExclusionType, setSize, setSize, setType, setVisible, show, toBack, toFront</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="methods.inherited.from.class.java.awt.Container">
<!-- -->
</a>
<h3>Methods inherited from class java.awt.Container</h3>
<code>add, add, add, add, add, addContainerListener, applyComponentOrientation, areFocusTraversalKeysSet, countComponents, deliverEvent, doLayout, findComponentAt, findComponentAt, getAlignmentX, getAlignmentY, getComponent, getComponentAt, getComponentAt, getComponentCount, getComponents, getComponentZOrder, getContainerListeners, getFocusTraversalPolicy, getInsets, getLayout, getMaximumSize, getMinimumSize, getMousePosition, getPreferredSize, insets, invalidate, isAncestorOf, isFocusCycleRoot, isFocusTraversalPolicyProvider, isFocusTraversalPolicySet, layout, list, list, locate, minimumSize, paintComponents, preferredSize, print, printComponents, processContainerEvent, remove, removeAll, removeContainerListener, setComponentZOrder, setFocusTraversalKeys, setFocusTraversalPolicy, setFocusTraversalPolicyProvider, setFont, transferFocusDownCycle, validate, validateTree</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="methods.inherited.from.class.java.awt.Component">
<!-- -->
</a>
<h3>Methods inherited from class java.awt.Component</h3>
<code>action, add, addComponentListener, addFocusListener, addHierarchyBoundsListener, addHierarchyListener, addInputMethodListener, addKeyListener, addMouseListener, addMouseMotionListener, addMouseWheelListener, bounds, checkImage, checkImage, coalesceEvents, contains, contains, createImage, createImage, createVolatileImage, createVolatileImage, disable, disableEvents, dispatchEvent, enable, enable, enableEvents, enableInputMethods, firePropertyChange, firePropertyChange, firePropertyChange, firePropertyChange, firePropertyChange, firePropertyChange, firePropertyChange, firePropertyChange, firePropertyChange, getBaseline, getBaselineResizeBehavior, getBounds, getBounds, getColorModel, getComponentListeners, getComponentOrientation, getCursor, getDropTarget, getFocusListeners, getFocusTraversalKeysEnabled, getFont, getFontMetrics, getForeground, getGraphicsConfiguration, getHeight, getHierarchyBoundsListeners, getHierarchyListeners, getIgnoreRepaint, getInputMethodListeners, getInputMethodRequests, getKeyListeners, getLocation, getLocation, getLocationOnScreen, getMouseListeners, getMouseMotionListeners, getMousePosition, getMouseWheelListeners, getName, getParent, getPeer, getPropertyChangeListeners, getPropertyChangeListeners, getSize, getSize, getTreeLock, getWidth, getX, getY, gotFocus, handleEvent, hasFocus, imageUpdate, inside, isBackgroundSet, isCursorSet, isDisplayable, isDoubleBuffered, isEnabled, isFocusable, isFocusOwner, isFocusTraversable, isFontSet, isForegroundSet, isLightweight, isMaximumSizeSet, isMinimumSizeSet, isPreferredSizeSet, isValid, isVisible, keyDown, keyUp, list, list, list, location, lostFocus, mouseDown, mouseDrag, mouseEnter, mouseExit, mouseMove, mouseUp, move, nextFocus, paintAll, prepareImage, prepareImage, printAll, processComponentEvent, processFocusEvent, processHierarchyBoundsEvent, processHierarchyEvent, processInputMethodEvent, processKeyEvent, processMouseEvent, processMouseMotionEvent, processMouseWheelEvent, removeComponentListener, removeFocusListener, removeHierarchyBoundsListener, removeHierarchyListener, removeInputMethodListener, removeKeyListener, removeMouseListener, removeMouseMotionListener, removeMouseWheelListener, removePropertyChangeListener, removePropertyChangeListener, repaint, repaint, repaint, requestFocus, requestFocus, requestFocusInWindow, requestFocusInWindow, resize, resize, revalidate, setComponentOrientation, setDropTarget, setEnabled, setFocusable, setFocusTraversalKeysEnabled, setForeground, setIgnoreRepaint, setLocale, setMaximumSize, setName, setPreferredSize, show, size, toString, transferFocus, transferFocusBackward, transferFocusUpCycle</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="methods.inherited.from.class.java.lang.Object">
<!-- -->
</a>
<h3>Methods inherited from class java.lang.Object</h3>
<code>clone, equals, finalize, getClass, hashCode, notify, notifyAll, wait, wait, wait</code></li>
</ul>
<ul class="blockList">
<li class="blockList"><a name="methods.inherited.from.class.java.awt.MenuContainer">
<!-- -->
</a>
<h3>Methods inherited from interface java.awt.MenuContainer</h3>
<code>getFont, postEvent</code></li>
</ul>
</li>
</ul>
</li>
</ul>
</div>
<div class="details">
<ul class="blockList">
<li class="blockList">
<!-- ============ FIELD DETAIL =========== -->
<ul class="blockList">
<li class="blockList"><a name="field.detail">
<!-- -->
</a>
<h3>Field Detail</h3>
<a name="menuBar">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>menuBar</h4>
<pre>private javax.swing.JMenuBar menuBar</pre>
</li>
</ul>
<a name="programmerCategory">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>programmerCategory</h4>
<pre>private javax.swing.JMenu programmerCategory</pre>
</li>
</ul>
<a name="displayCategory">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>displayCategory</h4>
<pre>private javax.swing.JMenu displayCategory</pre>
</li>
</ul>
<a name="actionCategory">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>actionCategory</h4>
<pre>private javax.swing.JMenu actionCategory</pre>
</li>
</ul>
<a name="addMenuButton">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>addMenuButton</h4>
<pre>javax.swing.JMenuItem addMenuButton</pre>
</li>
</ul>
<a name="editMenuButton">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>editMenuButton</h4>
<pre>javax.swing.JMenuItem editMenuButton</pre>
</li>
</ul>
<a name="deleteMenuButton">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>deleteMenuButton</h4>
<pre>javax.swing.JMenuItem deleteMenuButton</pre>
</li>
</ul>
<a name="allMenuButton">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>allMenuButton</h4>
<pre>javax.swing.JMenuItem allMenuButton</pre>
</li>
</ul>
<a name="quitMenuButton">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>quitMenuButton</h4>
<pre>javax.swing.JMenuItem quitMenuButton</pre>
</li>
</ul>
<a name="id">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>id</h4>
<pre>javax.swing.JLabel id</pre>
</li>
</ul>
<a name="lastName">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>lastName</h4>
<pre>javax.swing.JLabel lastName</pre>
</li>
</ul>
<a name="firstName">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>firstName</h4>
<pre>javax.swing.JLabel firstName</pre>
</li>
</ul>
<a name="address">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>address</h4>
<pre>javax.swing.JLabel address</pre>
</li>
</ul>
<a name="nickname">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>nickname</h4>
<pre>javax.swing.JLabel nickname</pre>
</li>
</ul>
<a name="responsible">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>responsible</h4>
<pre>javax.swing.JLabel responsible</pre>
</li>
</ul>
<a name="dateBirth">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>dateBirth</h4>
<pre>javax.swing.JLabel dateBirth</pre>
</li>
</ul>
<a name="hobby">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>hobby</h4>
<pre>javax.swing.JLabel hobby</pre>
</li>
</ul>
<a name="dateHiring">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>dateHiring</h4>
<pre>javax.swing.JLabel dateHiring</pre>
</li>
</ul>
<a name="idField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>idField</h4>
<pre>javax.swing.JTextField idField</pre>
</li>
</ul>
<a name="lastNameField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>lastNameField</h4>
<pre>javax.swing.JTextField lastNameField</pre>
</li>
</ul>
<a name="firstNameField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>firstNameField</h4>
<pre>javax.swing.JTextField firstNameField</pre>
</li>
</ul>
<a name="addressField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>addressField</h4>
<pre>javax.swing.JTextField addressField</pre>
</li>
</ul>
<a name="nicknameField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>nicknameField</h4>
<pre>javax.swing.JTextField nicknameField</pre>
</li>
</ul>
<a name="responsibleField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>responsibleField</h4>
<pre>javax.swing.JTextField responsibleField</pre>
</li>
</ul>
<a name="dateBirthDayField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>dateBirthDayField</h4>
<pre>javax.swing.JTextField dateBirthDayField</pre>
</li>
</ul>
<a name="dateBirthYearField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>dateBirthYearField</h4>
<pre>javax.swing.JTextField dateBirthYearField</pre>
</li>
</ul>
<a name="hobbyField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>hobbyField</h4>
<pre>javax.swing.JTextField hobbyField</pre>
</li>
</ul>
<a name="dateHiringDayField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>dateHiringDayField</h4>
<pre>javax.swing.JTextField dateHiringDayField</pre>
</li>
</ul>
<a name="dateHiringYearField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>dateHiringYearField</h4>
<pre>javax.swing.JTextField dateHiringYearField</pre>
</li>
</ul>
<a name="dateBirthMonthField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>dateBirthMonthField</h4>
<pre>javax.swing.JComboBox dateBirthMonthField</pre>
</li>
</ul>
<a name="dateHiringMonthField">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>dateHiringMonthField</h4>
<pre>javax.swing.JComboBox dateHiringMonthField</pre>
</li>
</ul>
<a name="searchButton">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>searchButton</h4>
<pre>javax.swing.JButton searchButton</pre>
</li>
</ul>
<a name="resetButton">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>resetButton</h4>
<pre>javax.swing.JButton resetButton</pre>
</li>
</ul>
<a name="validateButton">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>validateButton</h4>
<pre>javax.swing.JButton validateButton</pre>
</li>
</ul>
<a name="cancelButton">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>cancelButton</h4>
<pre>javax.swing.JButton cancelButton</pre>
</li>
</ul>
<a name="displayZoneProgrammers">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>displayZoneProgrammers</h4>
<pre>javax.swing.JTextArea displayZoneProgrammers</pre>
</li>
</ul>
<a name="scroll">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>scroll</h4>
<pre>javax.swing.JScrollPane scroll</pre>
</li>
</ul>
<a name="contentPanel">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>contentPanel</h4>
<pre>protected javax.swing.JPanel contentPanel</pre>
</li>
</ul>
<a name="background">
<!-- -->
</a>
<ul class="blockListLast">
<li class="blockList">
<h4>background</h4>
<pre>java.awt.image.BufferedImage background</pre>
</li>
</ul>
</li>
</ul>
<!-- ========= CONSTRUCTOR DETAIL ======== -->
<ul class="blockList">
<li class="blockList"><a name="constructor.detail">
<!-- -->
</a>
<h3>Constructor Detail</h3>
<a name="ViewAbstract--">
<!-- -->
</a>
<ul class="blockListLast">
<li class="blockList">
<h4>ViewAbstract</h4>
<pre>ViewAbstract()</pre>
</li>
</ul>
</li>
</ul>
<!-- ============ METHOD DETAIL ========== -->
<ul class="blockList">
<li class="blockList"><a name="method.detail">
<!-- -->
</a>
<h3>Method Detail</h3>
<a name="handleClose--">
<!-- -->
</a>
<ul class="blockList">
<li class="blockList">
<h4>handleClose</h4>
<pre>boolean handleClose()</pre>
<div class="block">Display an alert to confirm program exit</div>
<dl>
<dt><span class="returnLabel">Returns:</span></dt>
<dd>boolean which is the choice of the user</dd>
</dl>
</li>
</ul>
<a name="generateAlert-java.lang.String-">
<!-- -->
</a>
<ul class="blockListLast">
<li class="blockList">
<h4>generateAlert</h4>
<pre>void generateAlert(java.lang.String message)</pre>
<div class="block">Generate an alert to the user</div>
<dl>
<dt><span class="paramLabel">Parameters:</span></dt>
<dd><code>message</code> - will be displayed</dd>
</dl>
</li>
</ul>
</li>
</ul>
</li>
</ul>
</div>
</div>
<!-- ========= END OF CLASS DATA ========= -->
<!-- ======= START OF BOTTOM NAVBAR ====== -->
<div class="bottomNav"><a name="navbar.bottom">
<!-- -->
</a>
<div class="skipNav"><a href="#skip.navbar.bottom" title="Skip navigation links">Skip navigation links</a></div>
<a name="navbar.bottom.firstrow">
<!-- -->
</a>
<ul class="navList" title="Navigation">
<li><a href="../../../overview-summary.html">Overview</a></li>
<li><a href="package-summary.html">Package</a></li>
<li class="navBarCell1Rev">Class</li>
<li><a href="package-tree.html">Tree</a></li>
<li><a href="../../../deprecated-list.html">Deprecated</a></li>
<li><a href="../../../index-files/index-1.html">Index</a></li>
<li><a href="../../../help-doc.html">Help</a></li>
</ul>
</div>
<div class="subNav">
<ul class="navList">
<li><a href="../../../fr/kerroue_dehoux/view/View.html" title="class in fr.kerroue_dehoux.view"><span class="typeNameLink">Prev Class</span></a></li>
<li>Next Class</li>
</ul>
<ul class="navList">
<li><a href="../../../index.html?fr/kerroue_dehoux/view/ViewAbstract.html" target="_top">Frames</a></li>
<li><a href="ViewAbstract.html" target="_top">No Frames</a></li>
</ul>
<ul class="navList" id="allclasses_navbar_bottom">
<li><a href="../../../allclasses-noframe.html">All Classes</a></li>
</ul>
<div>
<script type="text/javascript"><!--
allClassesLink = document.getElementById("allclasses_navbar_bottom");
if(window==top) {
allClassesLink.style.display = "block";
}
else {
allClassesLink.style.display = "none";
}
//-->
</script>
</div>
<div>
<ul class="subNavList">
<li>Summary: </li>
<li><a href="#nested.classes.inherited.from.class.javax.swing.JFrame">Nested</a> | </li>
<li><a href="#field.summary">Field</a> | </li>
<li><a href="#constructor.summary">Constr</a> | </li>
<li><a href="#method.summary">Method</a></li>
</ul>
<ul class="subNavList">
<li>Detail: </li>
<li><a href="#field.detail">Field</a> | </li>
<li><a href="#constructor.detail">Constr</a> | </li>
<li><a href="#method.detail">Method</a></li>
</ul>
</div>
<a name="skip.navbar.bottom">
<!-- -->
</a></div>
<!-- ======== END OF BOTTOM NAVBAR ======= -->
</body>
</html>
<file_sep>package fr.kerroue_dehoux;
import fr.kerroue_dehoux.view.View;
import fr.kerroue_dehoux.view.ViewAbstract;
public class Start {
public static void main(String[] args) {
ViewAbstract view = new View();
}
}
<file_sep># SoftwareManagementProgrammers
- **Project type :** School Project
- **Description :** Software to manage users (programmers) from a database
- **Language(s) :** Java, SQL
## Who made this ?
* <NAME>
* <NAME>
<file_sep>package fr.kerroue_dehoux.utils;
public class Constants {
// Connection
public static String CLASS_DRIVER = "org.apache.derby.jdbc.EmbeddedDriver";
public static String URL_DB = "jdbc:derby:LSI_L3_JAVA";
public static String USER_DB = "adm";
public static String PASS_DB = "adm";
// Requests
public static String SELECT_ALL = "SELECT * FROM PROGRAMMEUR";
public static String INSERT_PROGRAMMER = "INSERT INTO PROGRAMMEUR (MATRICULE, NOM, PRENOM, ADRESSE, PSEUDO, RESPONSABLE, HOBBY, DATE_NAISS, DATE_EMB) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)";
public static String DELETE_PROGRAMMER = "DELETE FROM PROGRAMMEUR WHERE MATRICULE = ?";
public static String UPDATE_PROGRAMMER = "UPDATE PROGRAMMEUR SET MATRICULE = ?, NOM = ?, PRENOM = ?, ADRESSE = ?, PSEUDO = ?, RESPONSABLE = ?, HOBBY = ?, DATE_NAISS = ?, DATE_EMB = ? WHERE MATRICULE = ?";
public static String SELECT_PROGRAMMER = "SELECT * FROM PROGRAMMEUR WHERE MATRICULE = ?";
}
<file_sep>package fr.kerroue_dehoux.view;
import fr.kerroue_dehoux.data.ActionDBImpl;
import fr.kerroue_dehoux.model.ProgrammerBean;
import javax.imageio.ImageIO;
import javax.swing.*;
import javax.swing.border.EmptyBorder;
import java.awt.*;
import java.awt.event.ActionEvent;
import java.io.IOException;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.time.LocalDate;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class View extends ViewAbstract {
// Type of the view (1 : add, 2 : edit, 3 : delete)
private int type;
// Panels
private JPanel drawListProgrammers;
private JPanel drawInfoProgrammer;
private JPanel defaultPanel;
// Database connection
private ActionDBImpl dt;
//InfoPanel
private JPanel headerPanel;
private JPanel bodyPanel;
private JPanel footerPanel;
private GridBagConstraints constraints = new GridBagConstraints();
private List<ProgrammerBean> list = new ArrayList<>();
public View() {
super();
try {
background = ImageIO.read(getClass().getResourceAsStream("/images/background.jpg"));
} catch (IOException e) {
e.printStackTrace();
}
// Creating the connection
dt = new ActionDBImpl();
// Creating the JPanels
drawListProgrammers = new JPanel();
drawInfoProgrammer = new JPanel(new GridBagLayout());
defaultPanel = new JPanel() {
@Override
public void paintComponent(Graphics g) {
super.paintComponent(g); // paint the background image and scale it to fill the entire space
g.drawImage(background, this.getWidth() / 2 - background.getWidth() / 2, this.getHeight() / 2 - background.getHeight() / 2, null);
}
};
// Creating the parts of programmer information view
headerPanel = new JPanel(new GridBagLayout());
bodyPanel = new JPanel(new GridBagLayout());
footerPanel = new JPanel(new GridBagLayout());
// Setting header properties
headerPanel.setBackground(Color.DARK_GRAY);
headerPanel.setBorder(new EmptyBorder(6, 6, 6, 6));
// ID Label
id = new JLabel("Matricule");
id.setForeground(Color.white);
constraints.anchor = GridBagConstraints.LINE_START;
constraints.gridx = 0;
constraints.gridy = 0;
constraints.weightx = 0;
constraints.weighty = 1;
constraints.ipadx = 10;
headerPanel.add(id, constraints);
// ID Text field
idField = new JTextField("0");
constraints.gridx = 1;
constraints.gridy = 0;
constraints.weightx = 1;
constraints.weighty = 1;
constraints.ipadx = 120;
headerPanel.add(idField, constraints);
// Adding headerPanel
constraints.anchor = GridBagConstraints.PAGE_START;
constraints.fill = GridBagConstraints.HORIZONTAL;
constraints.gridy = 0;
constraints.gridx = 0;
constraints.gridheight = 0;
constraints.gridwidth = 3;
drawInfoProgrammer.add(headerPanel, constraints);
// Creating new GridBagConstraints
constraints = new GridBagConstraints();
constraints.weighty = 1;
constraints.insets = new Insets(10, 10, 10, 10);
constraints.anchor = GridBagConstraints.LINE_START;
// Last name
lastName = new JLabel("Nom");
constraints.gridx = 0;
constraints.gridy = 0;
constraints.weightx = 0;
bodyPanel.add(lastName, constraints);
lastNameField = new JTextField("");
lastNameField.setColumns(10);
constraints.anchor = GridBagConstraints.LINE_START;
constraints.gridx = 1;
constraints.gridy = 0;
constraints.weightx = 1;
bodyPanel.add(lastNameField, constraints);
// First name
firstName = new JLabel("Prénom");
constraints.anchor = GridBagConstraints.LINE_START;
constraints.gridx = 2;
constraints.gridy = 0;
constraints.weightx = 0;
constraints.ipadx = 0;
bodyPanel.add(firstName, constraints);
firstNameField = new JTextField("");
firstNameField.setColumns(10);
constraints.anchor = GridBagConstraints.LINE_START;
constraints.gridx = 3;
constraints.gridy = 0;
constraints.weightx = 1;
bodyPanel.add(firstNameField, constraints);
// Address
address = new JLabel("Adresse");
constraints.gridx = 0;
constraints.gridy = 1;
constraints.weightx = 0;
constraints.ipadx = 0;
constraints.anchor = GridBagConstraints.LINE_START;
bodyPanel.add(address, constraints);
addressField = new JTextField("");
addressField.setColumns(10);
constraints.gridx = 1;
constraints.gridy = 1;
constraints.weightx = 1;
constraints.anchor = GridBagConstraints.LINE_START;
bodyPanel.add(addressField, constraints);
// Nickname
nickname = new JLabel("Pseudo");
constraints.gridx = 2;
constraints.gridy = 1;
constraints.weightx = 0;
constraints.anchor = GridBagConstraints.LINE_START;
bodyPanel.add(nickname, constraints);
nicknameField = new JTextField("");
nicknameField.setColumns(10);
constraints.gridx = 3;
constraints.gridy = 1;
constraints.weightx = 1;
bodyPanel.add(nicknameField, constraints);
// Responsible
responsible = new JLabel("Responsable");
constraints.gridx = 0;
constraints.gridy = 2;
bodyPanel.add(responsible, constraints);
responsibleField = new JTextField("");
responsibleField.setColumns(10);
constraints.gridx = 1;
constraints.gridy = 2;
bodyPanel.add(responsibleField, constraints);
// Birth date
dateBirth = new JLabel("Date de Naissance");
constraints.gridx = 2;
constraints.gridy = 2;
bodyPanel.add(dateBirth, constraints);
// Birth date (day)
dateBirthDayField = new JTextField("");
dateBirthDayField.setToolTipText("jour");
dateBirthDayField.setColumns(5);
constraints.gridx = 3;
constraints.gridy = 2;
constraints.weightx = 1;
bodyPanel.add(dateBirthDayField, constraints);
// Birth date (month)
dateBirthMonthField = new JComboBox<>(new String[]{"01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12"});
constraints.gridx = 4;
constraints.gridy = 2;
constraints.ipadx = 0;
constraints.weightx = 0;
bodyPanel.add(dateBirthMonthField, constraints);
// Birth date (year)
dateBirthYearField = new JTextField("");
dateBirthYearField.setToolTipText("annéee");
dateBirthYearField.setColumns(5);
constraints.gridx = 5;
constraints.gridy = 2;
constraints.weightx = 1;
bodyPanel.add(dateBirthYearField, constraints);
// Hobby
hobby = new JLabel("Hobby");
constraints.gridx = 0;
constraints.gridy = 3;
constraints.weightx = 0;
bodyPanel.add(hobby, constraints);
hobbyField = new JTextField("");
hobbyField.setColumns(10);
constraints.gridx = 1;
constraints.gridy = 3;
constraints.weightx = 1;
bodyPanel.add(hobbyField, constraints);
// Date of Hiring
dateHiring = new JLabel("Date Embauche");
constraints.gridx = 2;
constraints.gridy = 3;
constraints.weightx = 0;
bodyPanel.add(dateHiring, constraints);
// Date of Hiring (day)
dateHiringDayField = new JTextField("");
dateHiringDayField.setColumns(5);
constraints.gridx = 3;
constraints.gridy = 3;
bodyPanel.add(dateHiringDayField, constraints);
// Date of Hiring (Month)
dateHiringMonthField = new JComboBox<>(new String[]{"01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12"});
constraints.gridx = 4;
constraints.gridy = 3;
constraints.ipadx = 0;
bodyPanel.add(dateHiringMonthField, constraints);
// Date of Hiring (Year)
dateHiringYearField = new JTextField("");
dateHiringYearField.setColumns(5);
constraints.gridx = 5;
constraints.gridy = 3;
bodyPanel.add(dateHiringYearField, constraints);
// Adding bodyPanel
constraints.anchor = GridBagConstraints.CENTER;
constraints.gridy = 1;
constraints.gridx = 0;
constraints.gridheight = 4;
constraints.gridwidth = 6;
constraints.weightx = 1;
constraints.weighty = 1;
drawInfoProgrammer.add(bodyPanel, constraints);
//Footer elements
constraints = new GridBagConstraints();
constraints.anchor = GridBagConstraints.CENTER;
constraints.gridx = 0;
constraints.gridy = 0;
constraints.ipadx = 10;
constraints.ipady = 2;
constraints.insets = new Insets(3, 3, 3, 3);
// Search button
searchButton = new JButton("Rechercher");
footerPanel.add(searchButton, constraints);
constraints.anchor = GridBagConstraints.CENTER;
constraints.gridx = 1;
constraints.gridy = 0;
// Reset button
resetButton = new JButton("Réinitialiser");
footerPanel.add(resetButton, constraints);
constraints.anchor = GridBagConstraints.CENTER;
constraints.gridx = 2;
constraints.gridy = 0;
// Validate button
validateButton = new JButton("Valider");
footerPanel.add(validateButton, constraints);
constraints.anchor = GridBagConstraints.CENTER;
constraints.gridx = 3;
constraints.gridy = 0;
// Cancel button
cancelButton = new JButton("Annuler");
footerPanel.add(cancelButton, constraints);
// Adding footerPanel
constraints.anchor = GridBagConstraints.PAGE_END;
constraints.fill = GridBagConstraints.HORIZONTAL;
constraints.gridy = 2;
constraints.gridx = 0;
constraints.gridheight = 1;
constraints.gridwidth = 4;
constraints.weightx = 1;
constraints.weighty = 1;
drawInfoProgrammer.add(footerPanel, constraints);
// Adding programmer list scroll
drawListProgrammers.add(scroll);
// Setting listener on allMenuButton
allMenuButton.setAction(new AbstractAction("Tous") {
@Override
public void actionPerformed(ActionEvent e) {
fillAndDisplayProgrammers(dt.fetchAllProgrammers());
// Switch content to all programmer view
switchContent(1);
}
});
// Setting listener on addMenuButton
addMenuButton.setAction(new AbstractAction("Ajouter") {
@Override
public void actionPerformed(ActionEvent e) {
// Set type to 1 (add programmer)
setType(1);
// Switch content to programmer information view
switchContent(2);
}
});
// Setting listener on editMenuButton
editMenuButton.setAction(new AbstractAction("Modifier") {
@Override
public void actionPerformed(ActionEvent e) {
// Set type to 2 (edit programmer)
setType(2);
// Switch content to programmer information view
switchContent(2);
}
});
// Setting listener on deleteMenuButton
deleteMenuButton.setAction(new AbstractAction("Supprimer") {
@Override
public void actionPerformed(ActionEvent e) {
// Set type to 2 (delete programmer)
setType(3);
// Switch content to programmer information view
switchContent(2);
}
});
// Setting listener on cancelButton
cancelButton.setAction(new AbstractAction("Annuler") {
@Override
public void actionPerformed(ActionEvent e) {
// Switch content to homepage
switchContent(0);
}
});
// Listening on-click event on search button
searchButton.addActionListener(e -> {
// Creating a new programmer
ProgrammerBean temp = dt.selectProgrammer(idField.getText());
// If the programmer was not successfully created
if(temp == null){
generateAlert("Programmeur non trouvé en base de données.");
} else {
// Enable fields
switchFields(true);
// Fill fields with programmer information
fillFields(temp);
if(type == 2)
validateButton.setEnabled(true);
}
});
// Listening on-click event on reset button
resetButton.addActionListener(e -> setEmptyFields());
// Listening on-click event on reset button
validateButton.addActionListener(e -> {
boolean result;
// If type = 3 (removing)
if(type == 3){
// If id field is set
if(!idField.getText().isEmpty()){
result = dt.removeProgrammer(new ProgrammerBean(Integer.parseInt(idField.getText())));
if (result)
generateAlert("Suppression réussie");
else
generateAlert("Erreur lors de la suppression");
}
else
generateAlert("Matricule incorrect !");
}
// If type = 1 (add) or 2 (edit) and some fields are empty
else if((type == 1 || type == 2) && Arrays.stream(bodyPanel.getComponents()).filter(c -> c instanceof JTextField).anyMatch(c -> ((JTextField) c).getText().isEmpty())
){
generateAlert("Certains champs sont incorrects !");
} else {
if(type == 1 || type == 2){
// Creating the programmer
int id = Integer.parseInt(idField.getText());
String lastName = lastNameField.getText();
String firstName = firstNameField.getText();
String address = addressField.getText();
String nickname = nicknameField.getText();
String responsible = responsibleField.getText();
String hobby = hobbyField.getText();
LocalDate dateBirth = LocalDate.of(Integer.parseInt(dateBirthYearField.getText()), dateBirthMonthField.getSelectedIndex()+1, Integer.parseInt(dateBirthDayField.getText()));
LocalDate dateHiring = LocalDate.of(Integer.parseInt(dateHiringYearField.getText()), dateHiringMonthField.getSelectedIndex()+1, Integer.parseInt(dateHiringDayField.getText()));
ProgrammerBean programmerBean = new ProgrammerBean(id, lastName, firstName, address, nickname, responsible, hobby, dateBirth, dateHiring);
// If type = 1 (add)
if(type == 1){
result = dt.addProgrammer(programmerBean);
if (result)
generateAlert("Insertion réussie");
else
generateAlert("Erreur lors de l'inscription");
// If type = 2 (edit)
} else {
result = dt.updateProgrammer(programmerBean);
if (result)
generateAlert("Mise à jour réussie");
else
generateAlert("Erreur lors de la mise à jour");
}
}
}
});
// Set quitMenuButton listener
quitMenuButton.setAction(new AbstractAction("Quitter") {
@Override
public void actionPerformed(ActionEvent e) {
if(handleClose()) {
dt.free();
System.exit(0);
}
}
});
contentPanel.add(defaultPanel, "default");
contentPanel.add(drawInfoProgrammer, "info");
contentPanel.add(drawListProgrammers, "list");
}
/**
* Switch the view depending on the option parameter
* @param option : 1 for homepage, 2 for programmers list, 3 for information panel
*/
private void switchContent(int option) {
if(option == 0)
((CardLayout)this.contentPanel.getLayout()).show(this.contentPanel, "default");
else if (option == 1)
((CardLayout)this.contentPanel.getLayout()).show(this.contentPanel, "list");
else
((CardLayout)this.contentPanel.getLayout()).show(this.contentPanel, "info");
// Reset fields
setEmptyFields();
}
/**
* Fill the programmer list and display them
* @param result : ResultSet from the database
*/
private void fillAndDisplayProgrammers(ResultSet result) {
// Clearing programmers list
list.clear();
try {
while (result.next()) {
// Getting programmer information
int id = result.getInt("MATRICULE");
String last_name = result.getString("NOM");
String first_name = result.getString("PRENOM");
String address = result.getString("ADRESSE");
String nickname = result.getString("PSEUDO");
String responsible = result.getString("RESPONSABLE");
String hobby = result.getString("HOBBY");
LocalDate date_birth = result.getDate("DATE_NAISS").toLocalDate();
LocalDate date_hiring = result.getDate("DATE_EMB").toLocalDate();
// Creating the programmer
ProgrammerBean programmerBean = new ProgrammerBean(id, last_name, first_name, address, nickname, responsible, hobby, date_birth, date_hiring);
// Adding the programmer to the list
list.add(programmerBean);
}
// Refreshing content
displayZoneProgrammers.setText("");
list.forEach(p -> displayZoneProgrammers.append(p.toString() + "\n"));
displayZoneProgrammers.repaint();
} catch (SQLException exception) {
System.err.println("Erreur lors du traitement");
}
}
/**
* Filling the fields with programmer information
* @param p : Programmer
*/
private void fillFields(ProgrammerBean p){
lastNameField.setText(p.getLastName());
firstNameField.setText(p.getFirstName());
addressField.setText(p.getAddress());
nicknameField.setText(p.getNickname());
responsibleField.setText(p.getResponsible());
hobbyField.setText(p.getHobby());
dateBirthDayField.setText(String.valueOf(p.getDateBirth().getDayOfMonth()));
dateBirthMonthField.setSelectedIndex(p.getDateBirth().getMonthValue()-1);
dateBirthYearField.setText(String.valueOf(p.getDateBirth().getYear()));
dateHiringDayField.setText(String.valueOf(p.getDateHiring().getDayOfMonth()));
dateHiringMonthField.setSelectedIndex(p.getDateHiring().getMonthValue()-1);
dateHiringYearField.setText(String.valueOf(p.getDateHiring().getYear()));
}
/**
* Set fields empty and id to 0
*/
private void setEmptyFields(){
Arrays.stream(this.getComponents()).filter(c -> c instanceof JTextField).forEach(c -> ((JTextField) c).setText(""));
dateBirthMonthField.setSelectedIndex(0);
dateHiringMonthField.setSelectedIndex(0);
}
/**
* Setting the type of the view and switch fields
* @param type : 1 = Add, 2 = Edit, 3 = Delete
*/
private void setType(int type){
// Setting type
this.type = type;
// Type 1 = Add
if(this.type == 1){
this.searchButton.setEnabled(false);
this.resetButton.setEnabled(true);
this.validateButton.setEnabled(true);
this.switchFields(true);
// Type 2 = Edit
} else if (this.type == 2){
this.searchButton.setEnabled(true);
this.resetButton.setEnabled(false);
this.validateButton.setEnabled(false);
this.switchFields(false);
// Type 3 = Delete
} else {
this.searchButton.setEnabled(false);
this.resetButton.setEnabled(false);
this.validateButton.setEnabled(true);
this.switchFields(false);
}
// Refreshing the view
repaint();
}
/**
* Switch the property of fields (enabled or disabled)
* @param value : true or false
*/
private void switchFields(boolean value){
Arrays.stream(this.getComponents()).filter(c -> c instanceof JTextField).forEach(c -> c.setEnabled(value));
}
}
<file_sep>package fr.kerroue_dehoux.view;
import javax.swing.*;
import java.awt.*;
import java.awt.event.WindowAdapter;
import java.awt.event.WindowEvent;
import java.awt.image.BufferedImage;
public abstract class ViewAbstract extends JFrame {
private JMenuBar menuBar = new JMenuBar();
private JMenu programmerCategory;
private JMenu displayCategory;
private JMenu actionCategory;
JMenuItem addMenuButton;
JMenuItem editMenuButton;
JMenuItem deleteMenuButton;
JMenuItem allMenuButton;
JMenuItem quitMenuButton;
JLabel id;
JLabel lastName;
JLabel firstName;
JLabel address;
JLabel nickname;
JLabel responsible;
JLabel dateBirth;
JLabel hobby;
JLabel dateHiring;
JTextField idField;
JTextField lastNameField;
JTextField firstNameField;
JTextField addressField;
JTextField nicknameField;
JTextField responsibleField;
JTextField dateBirthDayField;
JTextField dateBirthYearField;
JTextField hobbyField;
JTextField dateHiringDayField;
JTextField dateHiringYearField;
JComboBox dateBirthMonthField;
JComboBox dateHiringMonthField;
JButton searchButton;
JButton resetButton;
JButton validateButton;
JButton cancelButton;
JTextArea displayZoneProgrammers;
JScrollPane scroll;
protected JPanel contentPanel;
BufferedImage background;
ViewAbstract() {
// Creating the view
super("Projet Java - KERROUÉ et DEHOUX");
setSize(800, 450);
setLocationRelativeTo(null);
setDefaultCloseOperation(WindowConstants.DO_NOTHING_ON_CLOSE);
try {
UIManager.setLookAndFeel("com.sun.java.swing.plaf.windows.WindowsLookAndFeel");
SwingUtilities.updateComponentTreeUI(this);
} catch (ClassNotFoundException | InstantiationException | IllegalAccessException | UnsupportedLookAndFeelException e) {
e.printStackTrace();
}
addWindowListener(new WindowAdapter() {
@Override
public void windowClosing(WindowEvent e) {
if(handleClose()) {
System.exit(0);
}
}
});
// Creating the JPanel
contentPanel = new JPanel(new CardLayout());
// Creating menu items
programmerCategory = new JMenu("Programmeur");
addMenuButton = new JMenuItem();
editMenuButton = new JMenuItem();
deleteMenuButton = new JMenuItem();
displayCategory = new JMenu("Afficher");
allMenuButton = new JMenuItem();
displayCategory.add(allMenuButton);
programmerCategory.add(displayCategory);
programmerCategory.add(addMenuButton);
programmerCategory.add(editMenuButton);
programmerCategory.add(deleteMenuButton);
// Creating menu bar
actionCategory = new JMenu("Action");
quitMenuButton = new JMenuItem();
actionCategory.add(quitMenuButton);
// Adding category to menuBar
menuBar.add(programmerCategory);
menuBar.add(actionCategory);
setJMenuBar(menuBar);
displayZoneProgrammers = new JTextArea(15, 75);
displayZoneProgrammers.setFont(displayZoneProgrammers.getFont().deriveFont(16f));
displayZoneProgrammers.setEnabled(true);
scroll = new JScrollPane(displayZoneProgrammers);
add(contentPanel);
setVisible(true);
}
/**
* Display an alert to confirm program exit
* @return boolean which is the choice of the user
*/
boolean handleClose() {
int option = JOptionPane.showConfirmDialog(null, "Voulez-vous vraiment quitter ?", "Attention", JOptionPane.YES_NO_OPTION, JOptionPane.QUESTION_MESSAGE);
return option == JOptionPane.YES_OPTION;
}
/**
* Generate an alert to the user
* @param message will be displayed
*/
void generateAlert(String message){
JOptionPane.showMessageDialog(null, message, "Attention", JOptionPane.ERROR_MESSAGE);
}
}
| a3a9ea789b4e06d7ce3e15655fa8bca69db73a39 | [
"Java",
"SQL",
"HTML",
"Markdown"
] | 7 | SQL | skerroue/softwareManagementProgrammers | b7d6969a6b3a346e6f037a680b2fe45d10d384d1 | 656f7e7302966a33bc688faa61faadbbb642134f |
refs/heads/master | <repo_name>jswordfish/Jay-Emart<file_sep>/EMartV2.Buisnesslayer/Services/ProductService.cs
using EMartV2.BuisnessLayer.Interfaces;
using EMartV2.DataLayer.Interfaces;
using EMartV2.Models.ProductModels;
using System;
using System.Threading.Tasks;
namespace EMartV2.BuisnessLayer.Services
{
public class ProductService : IProductService
{
private readonly IProductRepository _productRepository;
public ProductService(IProductRepository productRepository)
{
_productRepository = productRepository;
}
public async Task<Product> CreateProductAsync(Product product)
{
try
{
var productDto = new Product { Name = product.Name };
return await _productRepository.CreateProductAsync(productDto);
}
catch (Exception ex)
{
throw ex;
}
}
public async Task<Product> GetProductByIdAsync(int id)
{
try
{
return await _productRepository.GetProductByIdAsync(id);
}
catch (Exception ex)
{
throw (ex);
}
}
}
}
<file_sep>/EMartv2.Tests/ProductTests.cs
using EMartV2.BuisnessLayer.Interfaces;
using EMartV2.BuisnessLayer.Services;
using EMartV2.DataLayer.Interfaces;
using EMartV2.Models.ProductModels;
using NSubstitute;
using Xunit;
namespace EMartv2.Tests
{
public class ProductTests
{
private readonly IProductService _service;
private readonly IProductRepository _repository = Substitute.For<IProductRepository>();
public ProductTests()
{
_service = new ProductService(_repository);
}
[Fact]
public async void CreateProductAsync_ShouldReturnProduct_WhenDataIsValid()
{
// Arrange
var productName = "Ps4";
var productTest = new Product { Name = productName };
_repository.CreateProductAsync(Arg.Any<Product>()).Returns(productTest);
// Act
var product = await _service.CreateProductAsync(productTest);
// Assert
Assert.IsType<Product>(product);
Assert.Equal("Ps4", product.Name);
}
[Fact]
public async void GetProductById_ShouldReturnProduct_WhenDataIsValid()
{
// Arrange
var productId = 1;
var productName = "Computer";
var productTest = new Product { Id = productId, Name = productName };
_repository.GetProductByIdAsync(productId).Returns(productTest);
// Act
var product = await _service.GetProductByIdAsync(productId);
// Assert
Assert.Equal(productId, product.Id);
Assert.Equal(productName, product.Name);
}
}
}
<file_sep>/EMartV2.Buisnesslayer/Interfaces/IProductService.cs
using EMartV2.Models.ProductModels;
using System.Threading.Tasks;
namespace EMartV2.BuisnessLayer.Interfaces
{
public interface IProductService
{
Task<Product> CreateProductAsync(Product product);
Task<Product> GetProductByIdAsync(int id);
}
}
<file_sep>/EMartV2.DataLayer/Repositories/ProductRepository.cs
using EMartV2.DataLayer.Interfaces;
using EMartV2.Models.ProductModels;
using Microsoft.EntityFrameworkCore;
using System;
using System.Threading.Tasks;
namespace EMartV2.DataLayer.Repositories
{
public class ProductRepository : IProductRepository
{
private readonly EMartContext _context;
public ProductRepository(EMartContext context)
{
_context = context;
}
public async Task<Product> CreateProductAsync(Product product)
{
try
{
await _context.Products.AddAsync(product);
var result = await _context.SaveChangesAsync();
if (result > 0)
return product;
else
return null;
}
catch (Exception ex)
{
throw (ex);
}
}
public async Task<Product> GetProductByIdAsync(int id)
{
try
{
var prdouct = await _context.Products.FirstOrDefaultAsync(x => x.Id == id);
return prdouct;
}
catch (Exception ex)
{
throw (ex);
}
}
}
}
<file_sep>/EMartV2.DataLayer/Interfaces/IProductRepository.cs
using EMartV2.Models.ProductModels;
using System.Threading.Tasks;
namespace EMartV2.DataLayer.Interfaces
{
public interface IProductRepository
{
Task<Product> CreateProductAsync(Product product);
Task<Product> GetProductByIdAsync(int id);
}
}
<file_sep>/EMartV2.DataLayer/EMartContext.cs
using EMartV2.Models.ProductModels;
using Microsoft.EntityFrameworkCore;
using System;
using System.Collections.Generic;
using System.Text;
namespace EMartV2.DataLayer
{
public class EMartContext : DbContext
{
public EMartContext(DbContextOptions options) : base(options)
{
}
protected override void OnModelCreating(ModelBuilder builder)
{
base.OnModelCreating(builder);
builder.Entity<Product>().HasKey(pf => pf.Id);
builder.Entity<Product>().Property(pf => pf.Name).HasMaxLength(100);
}
public DbSet<Product> Products { get; set; }
}
}
| 53cf311e1708e7d9ede5713fb333b9ac2ebc5938 | [
"C#"
] | 6 | C# | jswordfish/Jay-Emart | 734b00fef4ef227429658af003206c2cc99c19b3 | 8030f70573dd20d787c6b862e4ae7adf69fde475 |
refs/heads/master | <repo_name>KuzinVadym/ui_demo<file_sep>/js/components/Archive/index.js
import React from 'react';
import uniqid from '../../utils/uniqid'
import style from "./archive.css";
let Archive = ({data}) => {
return (
<div className={style.archive_base}>
<div className={style.archive_img_div}>
<img className={style.archive_img} src={`../../../img/${data.image}`} alt={data.title} />
</div>
<div className={style.archive_content}>
<div className={style.archive_title}>
{data.title}
</div>
<div className={style.content_short}>
{data.content_short}
</div>
</div>
</div>
)
}
export default Archive;<file_sep>/js/components/Archives/index.js
import React from 'react';
import uniqid from '../../utils/uniqid'
import Archive from '../Archive';
import style from "./archives.css";
let Archives = ({archives}) => {
return (
<div className={style.archives}>
{archives.map(archive => <Archive key={uniqid()} data={archive} />)}
</div>
)
}
export default Archives;<file_sep>/js/actions/tabs.js
import { SELECT_TAB } from '../constants/ActionTypes'
export function selectTab(value){
return{
type: SELECT_TAB,
value: value
}
}<file_sep>/js/containers/Archives/index.js
import { connect } from 'react-redux';
import Archives from '../../components/Archives'
const mapStateToProps = (state) => ({
archives: state.archives.archives
})
const mapDispatchToProps = (dispatch) => ({
})
export default connect(mapStateToProps, mapDispatchToProps)(Archives)<file_sep>/js/components/Tab/index.js
import React from 'react';
import style from "./tab.css";
let Tab = ({name, index, selectedIndex, onSelect, children}) => {
return (
<div className={style.tab} onClick={() => (onSelect) ? onSelect() : console.log('add listener first!')}>
{(index == selectedIndex)
? <div className={style.selected_tab}>
{name}
</div>
: <div className={style.unselected_tab}>
{name}
</div>
}
</div>
)
}
export default Tab;<file_sep>/js/components/Tabs/index.js
import React from 'react';
import uniqid from '../../utils/uniqid';
import style from './tabs.css';
let Tabs = ({selectedIndex, onSelect, children}) => {
return (
<div className={style.tabs_base}>
<div className={style.tabs_lables}>
{children.map((child, index) => {
const select = onSelect.bind(null, index);
return React.cloneElement(child, {key: uniqid(), index: index, selectedIndex: selectedIndex, onSelect: select})
})}
</div>
<div className={style.tabs_content_holder}>
{children[selectedIndex].props.children}
</div>
</div>
)
}
export default Tabs;<file_sep>/js/reducers/topics.js
import { } from '../constants/ActionTypes';
const initialState = {
topics: [
{name: 'HTML Techniques', quantity: 4},
{name: 'CSS Styling', quantity: 32},
{name: 'Flash Tutorials', quantity: 2},
{name: 'Web Miscellanea', quantity: 19},
{name: 'Site News', quantity: 6},
{name: 'Web Development', quantity: 8}
]
};
export default function topics(state = initialState, action) {
switch (action.type) {
default:
return state;
}
}<file_sep>/js/components/TabContent/index.js
import React from 'react';
let TabContent = ({children}) => {
return (
<div>
{children}
</div>
)
}
export default TabContent;<file_sep>/js/components/Base/index.js
import React from 'react';
import Tabs from '../Tabs';
import Tab from '../Tab';
import TabContent from '../TabContent';
import Topics from '../../containers/Topics';
import Archives from '../../containers/Archives';
import Pages from '../../containers/Pages';
import style from "./base.css";
let Base = ({selectedTab, selectTab}) => {
return (
<div className={style.base}>
<div className={style.title}>
Browse Site <span className={style.title_warning}>SELECT A TAB</span>
</div>
<Tabs selectedIndex={selectedTab} onSelect={selectTab}>
<Tab name="TOPICS" >
<TabContent>
<Topics/>
</TabContent>
</Tab>
<Tab name="ARCHIVES" >
<TabContent>
<Archives />
</TabContent>
</Tab>
<Tab name="PAGES" >
<TabContent>
<Pages />
</TabContent>
</Tab>
</Tabs>
</div>
)
}
export default Base;<file_sep>/js/constants/ActionTypes.js
// TABS
export const SELECT_TAB = 'SELECT_TAB';<file_sep>/js/components/Topics/index.js
import React from 'react';
import uniqid from '../../utils/uniqid'
import Topic from '../Topic';
import style from "./topics.css";
let Topics = ({topics}) => {
if (!topics) return null;
return (
<div className={style.topics}>
{ topics.map(topic => <Topic key={uniqid()} data={topic} />)}
</div>
)
}
export default Topics;<file_sep>/js/reducers/index.js
import { combineReducers } from 'redux';
import tabs from './tabs';
import topics from './topics';
import archives from './archives';
export default combineReducers({
tabs,
topics,
archives
})<file_sep>/js/components/Pages/index.js
import React from 'react';
import style from "./pages.css";
let Pages = ({}) => {
return (
<div className={style.pages}>
<img src={`../../../img/ogq2o.jpg`} />
</div>
)
}
export default Pages;<file_sep>/README.md
1. yarn install/ npm i
2. yarn start/ npm run start
| 3fa6b69b52f84ebba36c02ec94c638f37e6288c6 | [
"JavaScript",
"Markdown"
] | 14 | JavaScript | KuzinVadym/ui_demo | f1638f101bd08ea97c2dda32fe73e8351602cb16 | e3ee9587741d24bd5f8e4c0b0b95e17d51109062 |
refs/heads/master | <repo_name>pip-services-infrastructure/pip-clients-locks-node<file_sep>/obj/src/version1/LocksHttpClientV1.d.ts
import { LockV1 } from './LockV1';
import { CommandableHttpClient } from 'pip-services3-rpc-node';
import { FilterParams, PagingParams, DataPage } from 'pip-services3-commons-node';
import { ILocksClientV1 } from './ILocksClientV1';
export declare class LocksHttpClientV1 extends CommandableHttpClient implements ILocksClientV1 {
private _clientId;
constructor();
setClientId(client_id: string): void;
getLocks(correlationId: string, filter: FilterParams, paging: PagingParams, callback: (err: any, page: DataPage<LockV1>) => void): void;
getLockById(correlationId: string, key: string, callback: (err: any, job: LockV1) => void): void;
tryAcquireLock(correlationId: string, key: string, ttl: number, callback: (err: any, result: boolean) => void): void;
acquireLock(correlationId: string, key: string, ttl: number, timeout: number, callback: (err: any) => void): void;
releaseLock(correlationId: string, key: string, callback: (err: any) => void): void;
private fixLock;
}
<file_sep>/src/lock/HttpLock.ts
import { AbstractLock } from "./AbstractLock";
import { LocksHttpClientV1 } from "../version1/LocksHttpClientV1";
export class HttpLock extends AbstractLock {
public constructor() {
super(new LocksHttpClientV1());
}
}<file_sep>/obj/src/version1/ILocksClientV1.d.ts
import { DataPage } from 'pip-services3-commons-node';
import { FilterParams } from 'pip-services3-commons-node';
import { PagingParams } from 'pip-services3-commons-node';
import { LockV1 } from './LockV1';
export interface ILocksClientV1 {
setClientId(client_id: string): any;
getLocks(correlationId: string, filter: FilterParams, paging: PagingParams, callback: (err: any, page: DataPage<LockV1>) => void): void;
getLockById(correlationId: string, key: string, callback: (err: any, job: LockV1) => void): void;
tryAcquireLock(correlationId: string, key: string, ttl: number, callback: (err: any, result: boolean) => void): void;
acquireLock(correlationId: string, key: string, ttl: number, timeout: number, callback: (err: any) => void): void;
releaseLock(correlationId: string, key: string, callback: (err: any) => void): void;
}
<file_sep>/test/version1/SearchHttpClientV1.test.ts
let assert = require('chai').assert;
let async = require('async');
import { Descriptor, IdGenerator } from 'pip-services3-commons-node';
import { ConfigParams } from 'pip-services3-commons-node';
import { References } from 'pip-services3-commons-node';
import { ConsoleLogger, LogLevel } from 'pip-services3-components-node';
import { LocksMemoryPersistence } from 'pip-services-locks-node';
import { LocksController } from 'pip-services-locks-node';
import { LocksHttpServiceV1 } from 'pip-services-locks-node';
import { ILocksClientV1 } from '../../src/version1/ILocksClientV1';
import { LocksHttpClientV1 } from '../../src/version1/LocksHttpClientV1';
import { LocksClientFixtureV1 } from './LocksClientFixtureV1';
var httpConfig = ConfigParams.fromTuples(
"connection.protocol", "http",
"connection.host", "localhost",
"connection.port", 3000
);
suite('LocksHttpServiceV1', () => {
let service: LocksHttpServiceV1;
let client: LocksHttpClientV1;
let fixture: LocksClientFixtureV1;
setup((done) => {
let logger = new ConsoleLogger();
logger.setLevel(LogLevel.None);
let persistence = new LocksMemoryPersistence();
let controller = new LocksController();
let client_id = IdGenerator.nextLong();
let admin_id = IdGenerator.nextLong();
service = new LocksHttpServiceV1();
service.configure(httpConfig);
let references: References = References.fromTuples(
new Descriptor('pip-services', 'logger', 'console', 'default', '1.0'), logger,
new Descriptor('pip-services-locks', 'persistence', 'memory', 'default', '1.0'), persistence,
new Descriptor('pip-services-locks', 'controller', 'default', 'default', '1.0'), controller,
new Descriptor('pip-services-locks', 'service', 'http', 'default', '1.0'), service
);
controller.setReferences(references);
controller.configure(ConfigParams.fromTuples(
'options.release_own_locks_only', true,
'options.release_admin_id', admin_id
));
service.setReferences(references);
client = new LocksHttpClientV1();
client.setReferences(references);
client.configure(httpConfig);
fixture = new LocksClientFixtureV1(client, client_id, admin_id);
service.open(null, (err) => {
client.open(null, done);
});
});
teardown((done) => {
client.close(null, (err) => {
service.close(null, done);
});
});
test('TryAcquireLock', (done) => {
fixture.testTryAcquireLock(done);
});
test('AcquireLock', (done) => {
fixture.testAcquireLock(done);
});
});
<file_sep>/obj/src/lock/AbstractLock.d.ts
import { Lock } from "pip-services3-components-node";
import { ILocksClientV1 } from "../version1/ILocksClientV1";
import { ConfigParams } from "pip-services3-commons-node";
export declare class AbstractLock extends Lock {
protected _client: ILocksClientV1;
constructor(client: ILocksClientV1);
configure(config: ConfigParams): void;
tryAcquireLock(correlationId: string, key: string, ttl: number, callback: (err: any, result: boolean) => void): void;
releaseLock(correlationId: string, key: string, callback?: (err: any) => void): void;
}
<file_sep>/src/version1/LocksNullClientV1.ts
import { FilterParams } from 'pip-services3-commons-node';
import { PagingParams } from 'pip-services3-commons-node';
import { DataPage } from 'pip-services3-commons-node';
import { ILocksClientV1 } from './ILocksClientV1';
import { LockV1 } from './LockV1';
export class LocksNullClientV1 implements ILocksClientV1 {
private _clientId: string;
constructor(config?: any) { }
public setClientId(client_id: string) {
this._clientId = client_id;
}
public getLocks(correlationId: string, filter: FilterParams, paging: PagingParams,
callback: (err: any, page: DataPage<LockV1>) => void): void {
callback(null, new DataPage<LockV1>());
}
public getLockById(correlationId: string, key: string,
callback: (err: any, job: LockV1) => void): void {
callback(null, null);
}
public tryAcquireLock(correlationId: string, key: string, ttl: number,
callback: (err: any, result: boolean) => void): void {
callback(null, null);
}
public acquireLock(correlationId: string, key: string, ttl: number, timeout: number,
callback: (err: any) => void): void {
callback(null);
}
public releaseLock(correlationId: string, key: string,
callback: (err: any) => void): void {
callback(null);
}
}
<file_sep>/test/version1/SearchDirectClientV1.test.ts
let assert = require('chai').assert;
let async = require('async');
import { Descriptor, IdGenerator } from 'pip-services3-commons-node';
import { ConfigParams } from 'pip-services3-commons-node';
import { References } from 'pip-services3-commons-node';
import { ConsoleLogger, LogLevel } from 'pip-services3-components-node';
import { LocksMemoryPersistence } from 'pip-services-locks-node';
import { LocksController } from 'pip-services-locks-node';
import { ILocksClientV1 } from '../../src/version1/ILocksClientV1';
import { LocksDirectClientV1 } from '../../src/version1/LocksDirectClientV1';
import { LocksClientFixtureV1 } from './LocksClientFixtureV1';
suite('LocksDirectClientV1', () => {
let client: LocksDirectClientV1;
let fixture: LocksClientFixtureV1;
setup((done) => {
let logger = new ConsoleLogger();
logger.setLevel(LogLevel.None);
let persistence = new LocksMemoryPersistence();
let controller = new LocksController();
let client_id = IdGenerator.nextLong();
let admin_id = IdGenerator.nextLong();
let references: References = References.fromTuples(
new Descriptor('pip-services-commons', 'logger', 'console', 'default', '1.0'), logger,
new Descriptor('pip-services-locks', 'persistence', 'memory', 'default', '1.0'), persistence,
new Descriptor('pip-services-locks', 'controller', 'default', 'default', '1.0'), controller,
);
controller.setReferences(references);
controller.configure(ConfigParams.fromTuples(
'options.release_own_locks_only', true,
'options.release_admin_id', admin_id
));
client = new LocksDirectClientV1();
client.setReferences(references);
fixture = new LocksClientFixtureV1(client, client_id, admin_id);
client.open(null, done);
});
teardown((done) => {
client.close(null, done);
});
test('TryAcquireLock', (done) => {
fixture.testTryAcquireLock(done);
});
test('AcquireLock', (done) => {
fixture.testAcquireLock(done);
});
});
<file_sep>/obj/src/lock/DirectLock.d.ts
import { AbstractLock } from "./AbstractLock";
export declare class DirectLock extends AbstractLock {
constructor();
}
<file_sep>/src/index.ts
export * from './version1';
export { LocksClientFactory } from './build/LocksClientFactory';<file_sep>/src/version1/ILocksClientV1.ts
import { DataPage, SortParams } from 'pip-services3-commons-node';
import { FilterParams } from 'pip-services3-commons-node';
import { PagingParams } from 'pip-services3-commons-node';
import { LockV1 } from './LockV1';
export interface ILocksClientV1 {
// Set client id
setClientId(client_id: string);
// Get list of all locks
getLocks(correlationId: string, filter: FilterParams, paging: PagingParams,
callback: (err: any, page: DataPage<LockV1>) => void): void;
// Get lock by key
getLockById(correlationId: string, key: string,
callback: (err: any, job: LockV1) => void): void;
// Makes a single attempt to acquire a lock by its key
tryAcquireLock(correlationId: string, key: string, ttl: number,
callback: (err: any, result: boolean) => void): void;
// Makes multiple attempts to acquire a lock by its key within give time interval
acquireLock(correlationId: string, key: string, ttl: number, timeout: number,
callback: (err: any) => void): void;
// Releases prevously acquired lock by its key
releaseLock(correlationId: string, key: string,
callback: (err: any) => void): void;
}
<file_sep>/obj/src/version1/LocksNullClientV1.d.ts
import { FilterParams } from 'pip-services3-commons-node';
import { PagingParams } from 'pip-services3-commons-node';
import { DataPage } from 'pip-services3-commons-node';
import { ILocksClientV1 } from './ILocksClientV1';
import { LockV1 } from './LockV1';
export declare class LocksNullClientV1 implements ILocksClientV1 {
private _clientId;
constructor(config?: any);
setClientId(client_id: string): void;
getLocks(correlationId: string, filter: FilterParams, paging: PagingParams, callback: (err: any, page: DataPage<LockV1>) => void): void;
getLockById(correlationId: string, key: string, callback: (err: any, job: LockV1) => void): void;
tryAcquireLock(correlationId: string, key: string, ttl: number, callback: (err: any, result: boolean) => void): void;
acquireLock(correlationId: string, key: string, ttl: number, timeout: number, callback: (err: any) => void): void;
releaseLock(correlationId: string, key: string, callback: (err: any) => void): void;
}
<file_sep>/src/build/LocksClientFactory.ts
import { Descriptor } from 'pip-services3-commons-node';
import { Factory } from 'pip-services3-components-node';
import { LocksNullClientV1 } from '../version1/LocksNullClientV1';
import { LocksDirectClientV1 } from '../version1/LocksDirectClientV1';
import { LocksHttpClientV1 } from '../version1/LocksHttpClientV1';
import { DirectLock } from '../lock/DirectLock';
import { HttpLock } from '../lock/HttpLock';
export class LocksClientFactory extends Factory {
public static Descriptor: Descriptor = new Descriptor('pip-services-locks', 'factory', 'default', 'default', '1.0');
public static DirectLockDescriptor = new Descriptor('pip-services-locks', 'lock', 'direct', 'default', '1.0');
public static HttpLockDescriptor = new Descriptor('pip-services-locks', 'lock', 'http', 'default', '1.0');
public static NullClientV1Descriptor = new Descriptor('pip-services-locks', 'client', 'null', 'default', '1.0');
public static DirectClientV1Descriptor = new Descriptor('pip-services-locks', 'client', 'direct', 'default', '1.0');
public static HttpClientV1Descriptor = new Descriptor('pip-services-locks', 'client', 'http', 'default', '1.0');
constructor() {
super();
this.registerAsType(LocksClientFactory.DirectLockDescriptor, DirectLock);
this.registerAsType(LocksClientFactory.HttpLockDescriptor, HttpLock);
this.registerAsType(LocksClientFactory.NullClientV1Descriptor, LocksNullClientV1);
this.registerAsType(LocksClientFactory.DirectClientV1Descriptor, LocksDirectClientV1);
this.registerAsType(LocksClientFactory.HttpClientV1Descriptor, LocksHttpClientV1);
}
}
<file_sep>/obj/src/version1/LocksDirectClientV1.d.ts
import { ILocksClientV1 } from './ILocksClientV1';
import { DirectClient } from 'pip-services3-rpc-node';
import { LockV1 } from './LockV1';
export declare class LocksDirectClientV1 extends DirectClient<any> implements ILocksClientV1 {
private _clientId;
constructor();
setClientId(client_id: string): void;
getLocks(correlationId: string, filter: any, paging: any, callback: (err: any, page: any) => void): void;
getLockById(correlationId: string, key: string, callback: (err: any, lock: LockV1) => void): void;
tryAcquireLock(correlationId: string, key: string, ttl: number, callback: (err: any, result: boolean) => void): void;
acquireLock(correlationId: string, key: string, ttl: number, timeout: number, callback: (err: any) => void): void;
releaseLock(correlationId: string, key: string, callback: (err: any) => void): void;
}
<file_sep>/src/version1/LocksDirectClientV1.ts
import { ILocksClientV1 } from './ILocksClientV1';
import { DirectClient } from 'pip-services3-rpc-node';
import { Descriptor, IdGenerator } from 'pip-services3-commons-node';
import { LockV1 } from './LockV1';
export class LocksDirectClientV1 extends DirectClient<any> implements ILocksClientV1 {
private _clientId: string;
public constructor() {
super();
this._dependencyResolver.put('controller', new Descriptor('pip-services-locks', 'controller', '*', '*', '1.0'));
this._clientId = IdGenerator.nextLong();
}
public setClientId(client_id: string) {
this._clientId = client_id;
}
public getLocks(correlationId: string, filter: any, paging: any, callback: (err: any, page: any) => void): void {
let timing = this.instrument(correlationId, 'locks.get_locks');
this._controller.getLocks(correlationId, filter, paging, (err, page) => {
timing.endTiming();
callback(err, page);
});
}
public getLockById(correlationId: string, key: string, callback: (err: any, lock: LockV1) => void): void {
let timing = this.instrument(correlationId, 'locks.get_lock_by_id');
this._controller.getLockById(correlationId, key, (err, result) => {
timing.endTiming();
callback(err, result);
});
}
public tryAcquireLock(correlationId: string, key: string, ttl: number, callback: (err: any, result: boolean) => void): void {
let timing = this.instrument(correlationId, 'locks.try_acquire_lock');
this._controller.tryAcquireLock(correlationId, key, ttl, this._clientId, (err, result) => {
timing.endTiming();
callback(err, result);
});
}
public acquireLock(correlationId: string, key: string, ttl: number, timeout: number, callback: (err: any) => void): void {
let timing = this.instrument(correlationId, 'locks.acquire_lock');
this._controller.acquireLock(correlationId, key, ttl, timeout, this._clientId, (err) => {
timing.endTiming();
callback(err);
});
}
public releaseLock(correlationId: string, key: string, callback: (err: any) => void): void {
let timing = this.instrument(correlationId, 'locks.release_lock');
this._controller.releaseLock(correlationId, key, this._clientId, (err) => {
timing.endTiming();
callback(err);
});
}
}<file_sep>/test/version1/LocksClientFixtureV1.ts
let _ = require('lodash');
let async = require('async');
let assert = require('chai').assert;
import { IdGenerator } from 'pip-services3-commons-node';
import { ILocksClientV1 } from '../../src/version1/ILocksClientV1';
let LOCK1: string = "lock_1";
let LOCK2: string = "lock_2";
let LOCK3: string = "lock_3";
export class LocksClientFixtureV1 {
private _client: ILocksClientV1;
private _clientId: string;
private _adminId: string;
constructor(client: ILocksClientV1, clientId: string, adminId: string) {
this._client = client;
this._clientId = clientId;
this._adminId = adminId;
}
public testTryAcquireLock(done) {
async.series([
// Try to acquire lock for the first time
(callback) => {
this._client.tryAcquireLock(null, LOCK1, 3000, (err, result) => {
assert.isNull(err || null);
assert.isTrue(result);
callback();
});
},
// Try to acquire lock for the second time
(callback) => {
this._client.tryAcquireLock(null, LOCK1, 3000, (err, result) => {
assert.isNull(err || null);
assert.isFalse(result);
callback();
});
},
// Release the lock
(callback) => {
this._client.releaseLock(null, LOCK1, callback);
},
// Try to acquire lock for the third time
(callback) => {
this._client.tryAcquireLock(null, LOCK1, 3000, (err, result) => {
assert.isNull(err || null);
assert.isTrue(result);
callback();
});
},
// Release the lock
(callback) => {
this._client.releaseLock(null, LOCK1, callback);
},
// Try to acquire lock for the fourth time
(callback) => {
this._client.tryAcquireLock(null, LOCK1, 4000, (err, result) => {
assert.isNull(err || null);
assert.isTrue(result);
callback();
});
},
// Try to release the lock with wrong client id
(callback) => {
this._client.setClientId(IdGenerator.nextLong());
this._client.releaseLock(null, LOCK1, (err) => {
assert.isNotNull(err || null); // should get an error
callback();
});
},
// Try to acquire lock to check it still exist
(callback) => {
this._client.setClientId(this._clientId);
this._client.tryAcquireLock(null, LOCK1, 4000, (err, result) => {
assert.isNull(err || null);
assert.isFalse(result);
callback();
});
},
// Release the lock with admin id
(callback) => {
this._client.setClientId(this._adminId);
this._client.releaseLock(null, LOCK1, (err) => {
assert.isNull(err || null);
callback();
});
},
// Try to acquire lock to check it not exist
(callback) => {
this._client.setClientId(this._adminId);
this._client.tryAcquireLock(null, LOCK1, 4000, (err, result) => {
assert.isNull(err || null);
assert.isTrue(result);
callback();
});
},
// Release the lock
(callback) => {
this._client.releaseLock(null, LOCK1, callback);
},
], done);
}
public testAcquireLock(done) {
async.series([
// Acquire lock for the first time
(callback) => {
this._client.acquireLock(null, LOCK2, 3000, 1000, (err) => {
assert.isNull(err || null);
callback();
});
},
// Acquire lock for the second time
(callback) => {
this._client.acquireLock(null, LOCK2, 3000, 1000, (err) => {
assert.isNotNull(err || null);
callback();
});
},
// Release the lock
(callback) => {
this._client.releaseLock(null, LOCK2, callback)
},
// Acquire lock for the third time
(callback) => {
this._client.acquireLock(null, LOCK2, 3000, 1000, (err) => {
assert.isNull(err || null);
callback();
});
},
// Release the lock
(callback) => {
this._client.releaseLock(null, LOCK2, callback)
},
], done);
}
}
<file_sep>/obj/src/lock/HttpLock.d.ts
import { AbstractLock } from "./AbstractLock";
export declare class HttpLock extends AbstractLock {
constructor();
}
<file_sep>/doc/ClientApiVersion1.md
Node.js client API for Locks microservice is a thin layer on the top of
communication protocols. It hides details related to specific protocol implementation
and provides high-level API to access the microservice for simple and productive development.
* [ILocksClientV1 interface](#interface)
- [getLocks()](#operation1)
- [getLockById()](#operation2)
- [tryAcquireLock()](#operation3)
- [acquireLock()](#operation4)
- [releaseLock()](#operation5)
* [LocksHttpClientV1 class](#client_http)
* [LocksDirectClientV1 class](#client_direct)
* [LocksNullClientV1 class](#client_null)
## <a name="interface"></a> ILocksClientV1 interface
If you are using Typescript, you can use ILocksClientV1 as a common interface across all client implementations.
If you are using plain typescript, you shall not worry about ILocksClientV1 interface. You can just expect that
all methods defined in this interface are implemented by all client classes.
```typescript
interface ILocksClientV1 {
getLocks(correlationId: string, filter: FilterParams, paging: PagingParams, callback: (err: any, result: DataPage<LockV1>) => void): void;
getLockById(correlationId: string, key: string, callback: (err: any, result: LockV1) => void): void;
tryAcquireLock(correlationId: string, key: string, ttl: number, callback: (err: any, result: boolean) => void): void;
acquireLock(correlationId: string, key: string, ttl: number, timeout: number, callback: (err: any) => void): void;
releaseLock(correlationId: string, key: string, callback: (err: any) => void): void;
}
```
### <a name="operation1"></a> getLocks(correlationId, filter, paging, callback)
Get list of all locks
**Arguments:**
- correlationId: string - id that uniquely identifies transaction
- filter: FilterParams - filter parameters
- paging: PagingParams - paging parameters
**Returns:**
- err: Error - occured error or null for success
- result: DataPage<LockV1> - Page with retrieved locks
### <a name="operation2"></a> getLockById(correlationId, key, callback)
Get lock by key
**Arguments:**
- correlationId: string - id that uniquely identifies transaction
- key: string - a unique lock key
**Returns:**
- err: Error - occured error or null for success
- result: LockV1 - finded lock
### <a name="operation3"></a> tryAcquireLock(correlationId, key, ttl, callback)
Makes a single attempt to acquire a lock by its key
**Arguments:**
- correlationId: string - id that uniquely identifies transaction
- key: string - a unique lock key to acquire
- ttl: number - a lock timeout (time to live) in milliseconds
**Returns:**
- err: Error - occured error or null for success
- result: boolean - lock result
### <a name="operation4"></a> acquireLock(correlationId, key, ttl, timeout, callback)
Makes multiple attempts to acquire a lock by its key within give time interval
**Arguments:**
- correlationId: string - id that uniquely identifies transaction
- key: string - a unique lock key to acquire
- ttl: number - a lock timeout (time to live) in milliseconds
- timeout: number - a lock acquisition timeout
**Returns:**
- err: Error - occured error or null for success
### <a name="operation5"></a> releaseLock(correlationId, key, callback)
Releases prevously acquired lock by its key
**Arguments:**
- correlationId: string - id that uniquely identifies transaction
- key: string - a unique lock key to release
**Returns:**
- err: Error - occured error or null for success
## <a name="client_http"></a> LocksHttpClientV1 class
LocksHttpClientV1 is a client that implements HTTP protocol
```typescript
class LocksHttpClientV1 extends CommandableHttpClient implements ILocksClientV1 {
constructor(config?: any);
setReferences(references);
open(correlationId, callback);
close(correlationId, callback);
getLocks(correlationId: string, filter: FilterParams, paging: PagingParams, callback: (err: any, result: DataPage<LockV1>) => void): void;
getLockById(correlationId: string, key: string, callback: (err: any, result: LockV1) => void): void;
tryAcquireLock(correlationId: string, key: string, ttl: number, callback: (err: any, result: boolean) => void): void;
acquireLock(correlationId: string, key: string, ttl: number, timeout: number, callback: (err: any) => void): void;
releaseLock(correlationId: string, key: string, callback: (err: any) => void): void;
}
```
**Constructor config properties:**
- connection: object -HTTP transport configuration options
- protocol: string -HTTP protocol - 'http' or 'https'(default is 'http')
- host: string -IP address / hostname binding(default is '0.0.0.0')
- port: number - HTTP port number
## <a name="client_http"></a> LocksDirectClientV1 class
LocksDirectClientV1 is a dummy client calls controller from the same container.
It can be used in monolytic deployments.
```typescript
class LocksDirectClientV1 extends DirectClient<any> implements ILocksClientV1 {
constructor();
setReferences(references);
open(correlationId, callback);
close(correlationId, callback);
getLocks(correlationId: string, filter: FilterParams, paging: PagingParams, callback: (err: any, result: DataPage<LockV1>) => void): void;
getLockById(correlationId: string, key: string, callback: (err: any, result: LockV1) => void): void;
tryAcquireLock(correlationId: string, key: string, ttl: number, callback: (err: any, result: boolean) => void): void;
acquireLock(correlationId: string, key: string, ttl: number, timeout: number, callback: (err: any) => void): void;
releaseLock(correlationId: string, key: string, callback: (err: any) => void): void;
}
```
## <a name="client_http"></a> LocksNullClientV1 class
LocksNullClientV1 is a dummy client that mimics the real client but doesn't call a microservice.
It can be useful in testing scenarios to cut dependencies on external microservices.
```typescript
class LocksNullClientV1 implements ILocksClientV1 {
constructor();
getLocks(correlationId: string, filter: FilterParams, paging: PagingParams, callback: (err: any, result: DataPage<LockV1>) => void): void;
getLockById(correlationId: string, key: string, callback: (err: any, result: LockV1) => void): void;
tryAcquireLock(correlationId: string, key: string, ttl: number, callback: (err: any, result: boolean) => void): void;
acquireLock(correlationId: string, key: string, ttl: number, timeout: number, callback: (err: any) => void): void;
releaseLock(correlationId: string, key: string, callback: (err: any) => void): void;
}
```
<file_sep>/src/lock/AbstractLock.ts
import { ILock, Lock } from "pip-services3-components-node";
import { ILocksClientV1 } from "../version1/ILocksClientV1";
import { ConfigParams, IdGenerator } from "pip-services3-commons-node";
export class AbstractLock extends Lock
{
protected _client: ILocksClientV1;
public constructor(client: ILocksClientV1) {
super();
this._client = client;
}
public configure(config: ConfigParams): void {
super.configure(config);
let clientId = config.getAsStringWithDefault("options.client_id", null);
if (clientId) this._client.setClientId(clientId);
}
public tryAcquireLock(correlationId: string, key: string, ttl: number,
callback: (err: any, result: boolean) => void): void {
this._client.tryAcquireLock(correlationId, key, ttl, callback);
}
public releaseLock(correlationId: string, key: string,
callback?: (err: any) => void): void {
this._client.releaseLock(correlationId, key, callback);
}
}<file_sep>/src/lock/DirectLock.ts
import { AbstractLock } from "./AbstractLock";
import { LocksDirectClientV1 } from "../version1/LocksDirectClientV1";
export class DirectLock extends AbstractLock {
public constructor() {
super(new LocksDirectClientV1());
}
}<file_sep>/obj/src/version1/LockV1.d.ts
export declare class LockV1 {
id: string;
client_id: string;
created: Date;
expire_time: Date;
}
<file_sep>/src/version1/LockV1Schema.ts
import { ObjectSchema } from 'pip-services3-commons-node';
import { TypeCode } from 'pip-services3-commons-node';
export class LockV1Schema extends ObjectSchema {
constructor() {
super();
this.withRequiredProperty('key', TypeCode.String);
this.withRequiredProperty('client_id', TypeCode.String);
this.withRequiredProperty('created', TypeCode.DateTime);
this.withRequiredProperty('expire_time', TypeCode.DateTime);
}
}<file_sep>/obj/src/version1/index.d.ts
export { LockV1 } from './LockV1';
export { LockV1Schema } from './LockV1Schema';
export { ILocksClientV1 } from './ILocksClientV1';
export { LocksHttpClientV1 } from './LocksHttpClientV1';
export { LocksDirectClientV1 } from './LocksDirectClientV1';
export { LocksNullClientV1 } from './LocksNullClientV1';
<file_sep>/src/version1/LocksHttpClientV1.ts
let _ = require('lodash');
import { LockV1 } from './LockV1';
import { CommandableHttpClient } from 'pip-services3-rpc-node';
import { DateTimeConverter, FilterParams, PagingParams, DataPage, SortParams, IdGenerator } from 'pip-services3-commons-node';
import { ILocksClientV1 } from './ILocksClientV1';
export class LocksHttpClientV1 extends CommandableHttpClient implements ILocksClientV1 {
private _clientId: string;
public constructor() {
super('v1/locks');
this._clientId = IdGenerator.nextLong();
}
public setClientId(client_id: string) {
this._clientId = client_id;
}
public getLocks(correlationId: string, filter: FilterParams, paging: PagingParams, callback: (err: any, page: DataPage<LockV1>) => void): void {
this.callCommand(
'get_records',
correlationId,
{
filter: filter,
paging: paging
},
(err, page) => {
if (page == null || page.data.length == 0) {
callback(err, page);
return;
}
page.data = _.map(page.data, (record) => this.fixLock(record));
callback(err, page);
}
);
}
public getLockById(correlationId: string, key: string, callback: (err: any, job: LockV1) => void): void {
this.callCommand(
'get_lock_by_id',
correlationId,
{
key: key
},
(err, lock) => {
callback(err, this.fixLock(lock));
}
);
}
public tryAcquireLock(correlationId: string, key: string, ttl: number, callback: (err: any, result: boolean) => void): void {
this.callCommand(
'try_acquire_lock',
correlationId,
{
key: key,
ttl: ttl,
client_id: this._clientId
},
(err, result) => {
callback(err, result == 'true');
}
);
}
public acquireLock(correlationId: string, key: string, ttl: number, timeout: number, callback: (err: any) => void): void {
this.callCommand(
'acquire_lock',
correlationId,
{
key: key,
ttl: ttl,
timeout: timeout,
client_id: this._clientId
},
(err) => {
callback(err);
}
);
}
public releaseLock(correlationId: string, key: string, callback: (err: any) => void): void {
this.callCommand(
'release_lock',
correlationId,
{
key: key,
client_id: this._clientId
},
(err) => {
callback(err);
}
);
}
private fixLock(lock: LockV1): LockV1 {
if (lock == null) return null;
lock.created = DateTimeConverter.toNullableDateTime(lock.created);
lock.expire_time = DateTimeConverter.toNullableDateTime(lock.expire_time);
return lock;
}
}<file_sep>/README.md
# pip-clients-locks-node
Client SDK for distributed locks microservices for Pip.Services in Node.js
| 281539273eb63a7dcdc0686a9101a4988c20b2e1 | [
"Markdown",
"TypeScript"
] | 24 | TypeScript | pip-services-infrastructure/pip-clients-locks-node | 4ffa0e50d1c5d18cc5f32e4c8e90d22de832ebd6 | daa35ead9f095945245dd740841b8c56a1426bc4 |
refs/heads/master | <file_sep>package com.asniie.utils;
import android.util.Log;
/*
* Created by XiaoWei on 2019/1/9.
*/
public class LogUtil {
public static String TAG = "LogUtil";
public static void debug(Object obj) {
if (obj instanceof Throwable) {
Throwable throwable = (Throwable) obj;
throwable.printStackTrace();
} else {
Log.i(TAG, format(obj));
}
}
private static String format(Object obj) {
if (obj == null) {
return "你传入了一个Null";
}
return String.valueOf(obj);
}
}
<file_sep>package com.asniie.utils.sql.interceptors;
import com.asniie.utils.sql.exception.DataBaseException;
import java.lang.reflect.Type;
import java.util.ArrayList;
import java.util.List;
/*
* Created by XiaoWei on 2019/1/10.
*/
public final class InterceptorChain {
private static final List<Interceptor> mInterceptorsors = new ArrayList<>(10);
private InterceptorChain() {
}
static {
addInterceptor(new LogInterceptor());
}
public static void addInterceptor(Interceptor interceptor) {
mInterceptorsors.add(interceptor);
}
public static boolean removeInterceptor(Interceptor interceptor) {
return mInterceptorsors.remove(interceptor);
}
public static Interceptor removeInterceptor(int index) {
return mInterceptorsors.remove(index);
}
public static Object intercept(String[] sqls, Interceptor.ExecType type, Type returnType) throws DataBaseException {
Object object = null;
for (Interceptor interceptor : mInterceptorsors) {
if (object == null) {
object = interceptor.intercept(sqls, type, returnType);
}
}
return object;
}
}
<file_sep>package com.asniie.library.librarys;
import android.Manifest;
import android.content.pm.PackageManager;
import android.os.Build;
import android.os.Bundle;
import android.support.annotation.NonNull;
import android.support.v4.app.ActivityCompat;
import android.support.v4.content.ContextCompat;
import android.support.v7.app.AppCompatActivity;
import android.widget.TextView;
import android.widget.Toast;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
this.requestPermission();
TextView view = findViewById(R.id.tv);
SQLiteAPI api = AndroidSQLite.create(SQLiteAPI.class);
api.createTable();
String names[] = {"小玲", "小辉", "小红", "小马", "大明"};
List<Person> persons = new ArrayList<>(15);
Random random = new Random();
int n = random.nextInt(20) + 1;
for (int i = 0; i < 10; i++) {
Person person = new Person();
person.setAge(random.nextInt(12) + 15);
person.setId(random.nextInt(1000));
person.setName(names[random.nextInt(4)]);
persons.add(person);
}
Teacher teacher = initTeacher();
Student student = new Student();
student.setId(100);
student.setAge(30);
int count = api.insertStudents(persons, teacher.getStudents());
view.setText(String.format("插入数据:%d条,\n通过Teacher查询Student:\n%s", count,api.queryStudentByTeacher(teacher, new int[]{25, 26, 27, 28, 29, 30}, 5)));
api.queryById(100);
Person person = new Person();
person.setAge(18);
person.setId(1);
person.setName("小明");
api.insert(person, student);
}
private Teacher initTeacher() {
Teacher teacher = new Teacher();
List<Student> students = new ArrayList<>();
Map<String, Book> books = new HashMap<>();
String keys[] = new String[]{"热爱", "喜欢", "看过"};
for (int i = 0; i < 10; i++) {
Student student = new Student();
student.setId(12358 + i);
student.setName("小玲");
student.setAge(25 + i);
students.add(student);
Book book = new Book();
book.setName("《三国演义》");
book.setPrice(35.5);
books.put(keys[i % 3], book);
}
teacher.setStudents(students);
teacher.setBooks(books);
return teacher;
}
private void requestPermission() {
// 版本判断。当手机系统大于 23 时,才有必要去判断权限是否获取
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.M) {
String[] permissions = {Manifest.permission.WRITE_EXTERNAL_STORAGE, Manifest.permission.READ_EXTERNAL_STORAGE};
// 检查该权限是否已经获取
int i = ContextCompat.checkSelfPermission(this, permissions[0]);
// 权限是否已经 授权 GRANTED---授权 DINIED---拒绝
if (i != PackageManager.PERMISSION_GRANTED) {
// 如果没有授予该权限,就去提示用户请求
ActivityCompat.requestPermissions(this, permissions, 321);
}
}
}
@Override
public void onRequestPermissionsResult(int requestCode, @NonNull String[] permissions, @NonNull int[] grantResults) {
if (requestCode == 321) {
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.M) {
if (grantResults[0] != PackageManager.PERMISSION_GRANTED) {
// 判断用户是否 点击了不再提醒。(检测该权限是否还可以申请)
boolean shouldRequest = shouldShowRequestPermissionRationale(permissions[0]);
if (!shouldRequest) {
// 提示用户去应用设置界面手动开启权限
requestPermission();
} else {
finish();
}
} else {
Toast.makeText(this, "权限获取成功", Toast.LENGTH_SHORT).show();
}
}
}
}
}
<file_sep>package com.asniie.library.librarys;
import android.database.Cursor;
import android.database.sqlite.SQLiteDatabase;
import android.os.Environment;
import com.asniie.utils.LogUtil;
import com.asniie.utils.sql.SqlEscape;
import com.asniie.utils.sql.core.ObjectFactory;
import com.asniie.utils.sql.exception.DataBaseException;
import com.asniie.utils.sql.interceptors.AbstractInterceptor;
import com.asniie.utils.sql.interceptors.InterceptorChain;
import java.io.File;
import java.io.IOException;
import java.lang.reflect.Method;
import java.lang.reflect.Type;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/*
* Created by XiaoWei on 2019/1/10.
*/
public final class AndroidSQLite extends AbstractInterceptor {
static {
InterceptorChain.addInterceptor(new AndroidSQLite());
}
private AndroidSQLite() {
}
public static <T> T create(Class<T> clazz) {
return ObjectFactory.create(clazz);
}
@Override
public Object intercept(String[] sqls, ExecType type, Type returnType) throws DataBaseException {
SQLiteDatabase database = connect("database.db");
Object object = null;
if (type == ExecType.QUERY) {
for (String sql : sqls) {
if (sql != null) {
object = query(database, sql, returnType);
}
}
} else {
int count = 0;
database.beginTransaction();
for (String sql : sqls) {
if (sql != null) {
int code = update(database, sql);
if (code == 0) {
count = 0;
break;
} else {
count += code;
}
}
}
if (count != 0) {
database.setTransactionSuccessful();
}
database.endTransaction();
object = count;
}
if (database != null && database.isOpen()) {
database.close();
}
return TypeConverter.convert(object, returnType);
}
private int executeSql(SQLiteDatabase db, String sql) throws Exception {
int count = 0;
Method method = SQLiteDatabase.class.getDeclaredMethod("executeSql", String.class, Object[].class);
if (method != null) {
method.setAccessible(true);
count = (int) method.invoke(db, sql, null);
}
return count;
}
private int update(SQLiteDatabase database, String sql) {
try {
return executeSql(database, sql);
} catch (Exception e) {
LogUtil.debug(e);
//database.execSQL(Update);
return 0;
}
}
private Object query(SQLiteDatabase database, String sql, Type returnType) {
Cursor cursor = database.rawQuery(sql, null);
List<Map<String, Object>> array = new ArrayList<>();
cursor.moveToFirst();
while (!cursor.isAfterLast()) {
Map<String, Object> map = new HashMap<>();
int columnCount = cursor.getColumnCount();
for (int i = 0; i < columnCount; i++) {
int type = cursor.getType(i);
String key = cursor.getColumnName(i);
switch (type) {
case Cursor.FIELD_TYPE_STRING:
map.put(key, SqlEscape.unescape(cursor.getString(i)));
break;
case Cursor.FIELD_TYPE_INTEGER:
map.put(key, cursor.getInt(i));
break;
case Cursor.FIELD_TYPE_FLOAT:
map.put(key, cursor.getFloat(i));
break;
case Cursor.FIELD_TYPE_NULL:
map.put(key, null);
break;
case Cursor.FIELD_TYPE_BLOB:
break;
}
}
array.add(map);
cursor.moveToNext();
}
cursor.close();
return array;
}
private SQLiteDatabase connect(String path) throws DataBaseException {
File file = new File(Environment.getExternalStorageDirectory(), path);
if (!file.exists()) {
file.getParentFile().mkdirs();
try {
file.createNewFile();
} catch (IOException e) {
throw new DataBaseException(e);
}
}
return SQLiteDatabase.openOrCreateDatabase(file.getAbsolutePath(), null);
}
}
<file_sep>package com.asniie.utils.sql.core;
/*
* Created by XiaoWei on 2019/1/13.
*/
import com.asniie.utils.sql.exception.ExpParseException;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
public final class ExpReader extends StringReader {
private StringBuilder mBuilder = new StringBuilder();
private int level = 0;
private boolean isExp = false;
public ExpReader(String src) {
super(src);
}
private String value() {
String str = mBuilder.toString();
mBuilder.delete(0, mBuilder.length());
return str.trim().length() > 0 ? str : null;
}
public String[] peek() {
List<String> mList = new ArrayList<>(10);
try {
int buf;
while ((buf = read()) != -1) {
char ch = (char) buf;
switch (buf) {
case '$':
mark(0);
if (read() == '{') {
isExp = true;
level++;
}
mBuilder.append(ch);
reset();
break;
case '.':
if (isExp) {
mBuilder.append(ch);
} else {
String value = value();
if (value != null) {
mList.add(value);
}
}
break;
case '}':
level--;
isExp = level > 0;
mBuilder.append(ch);
if (!isExp) {
String value = value();
if (value != null) {
mList.add(value);
}
}
break;
default:
mBuilder.append(ch);
break;
}
}
String value = value();
if (value != null) {
mList.add(value);
}
} catch (IOException e) {
throw new ExpParseException(e);
}
return mList.toArray(new String[]{});
}
}
| 49c1ac99d9fe20f489719fb7145a0391f085235c | [
"Java"
] | 5 | Java | AsnIIe/SQLiteUtil | 44eeca064be6d272dce500ebfefbaebb256e9c65 | 80adbfe0408ae5f362020d2946e32ec5873f24e1 |
refs/heads/master | <file_sep>package app.com.itsomobiledev.rmanacmol.rssfeedcontentaggregator.util;
import android.content.Context;
import android.content.SharedPreferences;
import java.text.SimpleDateFormat;
import java.util.Calendar;
/**
* Created by renzmanacmol on 9/9/15.
*/
public class Utils {
private final static String PREF_NAME = "pre_contentaggregator";
public static void saveBooleanPref(Context context, String key, boolean value) {
SharedPreferences.Editor prefs = context.getSharedPreferences(PREF_NAME, Context.MODE_PRIVATE).edit();
prefs.putBoolean(key, value);
prefs.apply();
}
public static boolean getBooleanPref(Context context, String tblName) {
SharedPreferences prefs = context.getSharedPreferences(PREF_NAME, Context.MODE_PRIVATE);
return prefs.getBoolean(tblName, false);
}
public static void saveBooleanPref2(Context context, String key, boolean value) {
SharedPreferences.Editor prefs = context.getSharedPreferences(PREF_NAME, Context.MODE_PRIVATE).edit();
prefs.putBoolean(key, value);
prefs.apply();
}
public static boolean getBooleanPref2(Context context, String tblName) {
SharedPreferences prefs = context.getSharedPreferences(PREF_NAME, Context.MODE_PRIVATE);
return prefs.getBoolean(tblName, true);
}
public static String getCurrentDateTime(String format) {
return new SimpleDateFormat(format).format(Calendar.getInstance().getTime());
}
}
<file_sep>package app.com.itsomobiledev.rmanacmol.rssfeedcontentaggregator.drawer_activity;
import app.com.itsomobiledev.rmanacmol.rssfeedcontentaggregator.util.BaseDrawerActivity;
import app.com.itsomobiledev.rmanacmol.rssfeedcontentaggregator.R;
/**
* Created by renzmanacmol on 24/02/2016.
*/
public class WeatherActivity extends BaseDrawerActivity {
@Override
protected String toolbarTitle() {
return "Weather Forecast";
}
@Override
protected int selectedMenuItem() {
return R.id.nav_mysubscription;
}
@Override
protected int navigationViewId() {
return R.id.nav_view;
}
@Override
protected int drawerLayoutId() {
return R.id.drawerLayout;
}
@Override
protected int toolbarId() {
return R.id.toolbar;
}
@Override
protected int contentViewId() {
return R.layout.drawer_subscription_activity;
}
}
| 90897458f420aaa443db75f2e94be916ca442a4e | [
"Java"
] | 2 | Java | rmanacmol/RSSFeedContentAggregator | 5eb3f749916f645c0b506e737e47699e6e715b6a | fa563970e791850d569a696b1610bb7a4bf99c14 |
refs/heads/master | <repo_name>kpyrkosz/databases_final_project<file_sep>/src/api_command_handler.cpp
#include <api_command_handler.hpp>
#include <iostream>
#include <api_support.hpp>
#include <api_upvote.hpp>
#include <api_actions.hpp>
#include <api_projects.hpp>
#include <api_votes.hpp>
#include <api_trolls.hpp>
api_command_handler::api_command_handler(database_executor& db)
: command_handler(db)
{
}
abstract_api::pointer api_command_handler::from_input_line(const std::string& input_line)
{
nlohmann::json command_data = nlohmann::json::parse(input_line);
if(command_data.size() != 1)
throw std::invalid_argument("Every line should contain exactly one json object");
const std::string& api_name = command_data.begin().key();
//maybe should've used some hashmap
if (api_name == "support")
return std::make_unique<api_support>(command_data[api_name], db_, true);
if (api_name == "protest")
return std::make_unique<api_support>(command_data[api_name], db_, false);
if (api_name == "upvote")
return std::make_unique<api_upvote>(command_data[api_name], db_, true);
if (api_name == "downvote")
return std::make_unique<api_upvote>(command_data[api_name], db_, false);
if (api_name == "actions")
return std::make_unique<api_actions>(command_data[api_name], db_);
if (api_name == "projects")
return std::make_unique<api_projects>(command_data[api_name], db_);
if (api_name == "votes")
return std::make_unique<api_votes>(command_data[api_name], db_);
if (api_name == "trolls")
return std::make_unique<api_trolls>(command_data[api_name], db_);
nlohmann::json error_json;
error_json["status"] = "ERROR";
error_json["debug"] = "No handler for api: " + api_name;
std::cout << error_json << std::endl;
return abstract_api::pointer();
}
<file_sep>/inc/query_result.hpp
#pragma once
#include <string>
#include <libpq-fe.h>
//raii
//encapsulates the result of query
class query_result
{
PGresult* res_;
public:
query_result(PGresult* res);
~query_result();
unsigned tuple_count();
unsigned column_count();
bool is_null(int row, int col);
std::string get_as_string(int row, int col);
bool get_as_boolean(int row, int col);
unsigned get_as_number(int row, int col);
std::string column_name(int col);
};<file_sep>/inc/init_command_handler.hpp
#pragma once
#include <command_handler.hpp>
class init_command_handler
: public command_handler
{
public:
init_command_handler(database_executor& db);
virtual abstract_api::pointer from_input_line(const std::string& input_line) override;
};<file_sep>/inc/api_upvote.hpp
#pragma once
#include <abstract_api.hpp>
class api_upvote
: public abstract_api
{
unsigned timestamp_;
unsigned member_;
std::string password_;
unsigned action_;
bool is_upvote_or_downvote_;
public:
api_upvote(nlohmann::json& data, database_executor& db, bool is_upvote_or_downvote);
virtual void handle() override;
};<file_sep>/src/api_actions.cpp
#include <api_actions.hpp>
#include <cassert>
#include <iostream>
api_actions::api_actions(nlohmann::json& data, database_executor& db)
: abstract_api(data, db),
timestamp_(fetch_number("timestamp")),
member_(fetch_number("member")),
password_(fetch_string("password")),
type_(fetch_string("type", &is_type_set_)),
project_(fetch_number("project", &is_project_set_)),
authority_(fetch_number("authority", &is_authority_set_))
{
if (is_type_set_ && type_ != "support" && type_ != "protest")
throw std::invalid_argument("Type has been set, but not to protest or support");
if (is_project_set_ && is_authority_set_)
throw std::invalid_argument("You cannot set both project and authority at the same time");
}
void api_actions::handle()
{
//sprawdz czy czlonek jest liderem
auto query_res = db_.exec_query_variadic("SELECT id FROM leader WHERE id = $1", { std::to_string(member_) });
//jesli nie, konczymy bledem
if (query_res->tuple_count() == 0)
throw std::runtime_error("Member is not a leader");
//sprawdz czy haslo jest ok
query_res = db_.exec_query_variadic("SELECT id, last_activity FROM member WHERE id = $1 AND password_hash = crypt($2, password_hash)",
{
std::to_string(member_),
password_
});
if (query_res->tuple_count() == 0)
throw std::runtime_error("User exists but password is wrong");
assert(query_res->column_count() == 2);
assert(query_res->column_name(0) == "id");
assert(query_res->column_name(1) == "last_activity");
//czy zamrozony
if (timestamp_ - 31556926 > query_res->get_as_number(0, 1))
throw std::runtime_error("User is frozen");
//i cyk kwerenda
std::string built_query = "SELECT action_id, is_support, project, authority, COUNT(is_upvote) FILTER (WHERE is_upvote) AS upvotes, "
"COUNT(is_upvote) FILTER (WHERE NOT is_upvote) AS downvotes FROM action JOIN project ON(project = project_id) "
"JOIN vote USING (action_id)";
if (is_type_set_ || is_project_set_ || is_authority_set_)
built_query += " WHERE";
if (is_type_set_)
{
built_query += (type_ == "support" ? " is_support = TRUE" : " is_support = FALSE");
if (is_project_set_ || is_authority_set_)
built_query += " AND";
}
if (is_project_set_)
built_query += " project = " + std::to_string(project_);
else if (is_authority_set_)
built_query += " authority = " + std::to_string(authority_);
built_query += " GROUP BY action_id, is_support, project, authority ORDER BY action_id";
query_res = db_.exec_query(built_query);
assert(query_res->column_count() == 6);
assert(query_res->column_name(0) == "action_id");
assert(query_res->column_name(1) == "is_support");
assert(query_res->column_name(2) == "project");
assert(query_res->column_name(3) == "authority");
assert(query_res->column_name(4) == "upvotes");
assert(query_res->column_name(5) == "downvotes");
//aktualizacja timestampa ostatniej akcji uzytkownika
db_.exec_query_variadic("UPDATE member SET last_activity = $2 WHERE id = $1", { std::to_string(member_), std::to_string(timestamp_) });
//wypisz dzejsona z danymi
nlohmann::json action_confirmation;
action_confirmation["status"] = "OK";
for (unsigned i = 0; i < query_res->tuple_count(); ++i)
{
// <action> <type> <project> <authority> <upvotes> <downvotes>
action_confirmation["data"][i] =
{
query_res->get_as_number(i, 0),
query_res->get_as_boolean(i, 1) ? "support" : "protest",
query_res->get_as_number(i, 2),
query_res->get_as_number(i, 3),
query_res->get_as_number(i, 4),
query_res->get_as_number(i, 5),
};
}
std::cout << action_confirmation << std::endl;
}
<file_sep>/inc/command_handler.hpp
#pragma once
#include <database_executor.hpp>
#include <abstract_api.hpp>
class command_handler
{
protected:
database_executor& db_;
command_handler(database_executor& db)
: db_(db) {}
public:
virtual abstract_api::pointer from_input_line(const std::string& input_line) = 0;
virtual ~command_handler() = default;
};<file_sep>/src/api_projects.cpp
#include <api_projects.hpp>
#include <cassert>
#include <iostream>
api_projects::api_projects(nlohmann::json& data, database_executor& db)
: abstract_api(data, db),
timestamp_(fetch_number("timestamp")),
member_(fetch_number("member")),
password_(fetch_string("password")),
authority_(fetch_number("authority", &is_authority_set_))
{
}
void api_projects::handle()
{
//sprawdz czy czlonek jest liderem
auto query_res = db_.exec_query_variadic("SELECT id FROM leader WHERE id = $1", { std::to_string(member_) });
//jesli nie, konczymy bledem
if (query_res->tuple_count() == 0)
throw std::runtime_error("Member is not a leader");
//sprawdz czy haslo jest ok
query_res = db_.exec_query_variadic("SELECT id, last_activity FROM member WHERE id = $1 AND password_hash = crypt($2, password_hash)", { std::to_string(member_), password_ });
if (query_res->tuple_count() == 0)
throw std::runtime_error("User exists but password is wrong");
assert(query_res->column_count() == 2);
assert(query_res->column_name(0) == "id");
assert(query_res->column_name(1) == "last_activity");
//czy zamrozony
if (timestamp_ - 31556926 > query_res->get_as_number(0, 1))
throw std::runtime_error("User is frozen");
//i cyk kwerenda
std::string built_query = "SELECT * FROM project";
if (is_authority_set_)
built_query += " WHERE authority = " + std::to_string(authority_);
query_res = db_.exec_query(built_query);
assert(query_res->column_count() == 2);
assert(query_res->column_name(0) == "project_id");
assert(query_res->column_name(1) == "authority");
//aktualizacja timestampa ostatniej akcji uzytkownika
db_.exec_query_variadic("UPDATE member SET last_activity = $2 WHERE id = $1", { std::to_string(member_), std::to_string(timestamp_) });
//wypisz dzejsona z danymi
nlohmann::json action_confirmation;
action_confirmation["status"] = "OK";
for (unsigned i = 0; i < query_res->tuple_count(); ++i)
{
// <project> <authority>
action_confirmation["data"][i] =
{
query_res->get_as_number(i, 0),
query_res->get_as_number(i, 1)
};
}
std::cout << action_confirmation << std::endl;
}
<file_sep>/src/api_trolls.cpp
#include <api_trolls.hpp>
#include <cassert>
#include <iostream>
api_trolls::api_trolls(nlohmann::json& data, database_executor& db)
: abstract_api(data, db),
timestamp_(fetch_number("timestamp"))
{
}
void api_trolls::handle()
{
auto query_res = db_.exec_query_variadic("SELECT member_id, SUM(upvotes) AS upvote_sum, SUM(downvotes) AS downvote_sum, "
"is_member_active(member_id, $1) AS active FROM action "
"GROUP BY member_id ORDER BY (SUM(downvotes) - SUM(upvotes)) DESC, member_id", {std::to_string(timestamp_)});
assert(query_res->column_count() == 4);
assert(query_res->column_name(0) == "member_id");
assert(query_res->column_name(1) == "upvote_sum");
assert(query_res->column_name(2) == "downvote_sum");
assert(query_res->column_name(3) == "active");
//wypisz dzejsona z danymi
nlohmann::json action_confirmation;
action_confirmation["status"] = "OK";
for (unsigned i = 0; i < query_res->tuple_count(); ++i)
{
// <member> <upvotes> <downvotes> <active>
action_confirmation["data"][i] =
{
query_res->get_as_number(i, 0),
query_res->get_as_number(i, 1),
query_res->get_as_number(i, 2),
query_res->get_as_boolean(i, 3) ? "true" : "false"
};
}
std::cout << action_confirmation << std::endl;
}
<file_sep>/src/main.cpp
#include <nlohmann/json.hpp>
#include <database_executor.hpp>
#include <command_handler.hpp>
#include <init_command_handler.hpp>
#include <api_command_handler.hpp>
#include <iostream>
#include <string>
int main(int argc, char** argv)
{
try
{
//first line has to be "open" command
std::string input_line;
std::getline(std::cin, input_line);
nlohmann::json db_init_args = nlohmann::json::parse(input_line);
if (db_init_args["open"].empty())
throw std::invalid_argument("First line should be \"open\" command");
database_executor db{ db_init_args["open"]["database"], db_init_args["open"]["login"], db_init_args["open"]["password"] };
nlohmann::json confirmation;
confirmation["status"] = "OK";
confirmation["debug"] = "opening DB connection succeed";
std::cout << confirmation << std::endl;
//instantiation of concrete factory used to translate jsons to command handlers
std::unique_ptr<command_handler> handler;
if (argc >= 2 && argv[1] == std::string("--init"))
handler = std::make_unique<init_command_handler>(db);
else
handler = std::make_unique<api_command_handler>(db);
//reading line after line
while (std::getline(std::cin, input_line))
{
try
{
//try to translate json to handler
auto api = handler->from_input_line(input_line);
//if succesfull, execute associated handler
if (api)
api->handle();
}
catch (const std::exception& e)
{
nlohmann::json error_json;
error_json["status"] = "ERROR";
error_json["debug"] = e.what();
std::cout << error_json << std::endl;
}
}
}
catch (const std::exception& e)
{
nlohmann::json error_json;
error_json["status"] = "ERROR";
error_json["debug"] = e.what();
std::cout << error_json << std::endl;
return 1;
}
return 0;
}
<file_sep>/inc/api_trolls.hpp
#pragma once
#include <abstract_api.hpp>
class api_trolls
: public abstract_api
{
unsigned timestamp_;
public:
api_trolls(nlohmann::json& data, database_executor& db);
virtual void handle() override;
};<file_sep>/src/api_upvote.cpp
#include <api_upvote.hpp>
#include <cassert>
#include <iostream>
api_upvote::api_upvote(nlohmann::json& data, database_executor& db, bool is_upvote_or_downvote)
: abstract_api(data, db),
timestamp_(fetch_number("timestamp")),
member_(fetch_number("member")),
password_(fetch_string("<PASSWORD>")),
action_(fetch_number("action")),
is_upvote_or_downvote_(is_upvote_or_downvote)
{
}
void api_upvote::handle()
{
//sprawdz czy czlonek istnieje
auto query_res = db_.exec_query_variadic("SELECT id FROM member WHERE id = $1", { std::to_string(member_) });
//jesli nie, dodaj
if (query_res->tuple_count() == 0)
db_.exec_query_variadic("INSERT INTO member(id, password_hash, last_activity) VALUES($1, crypt($2, gen_salt('bf')), $3)",
{
std::to_string(member_),
password_,
std::to_string(timestamp_)
});
else
{
//jesli tak, sprawdz czy haslo jest ok
query_res = db_.exec_query_variadic("SELECT id, last_activity FROM member WHERE id = $1 AND password_hash = crypt($2, password_hash)", { std::to_string(member_), password_ });
if (query_res->tuple_count() == 0)
throw std::runtime_error("User exists but password is wrong");
assert(query_res->column_count() == 2);
assert(query_res->column_name(0) == "id");
assert(query_res->column_name(1) == "last_activity");
//jesli tak, czy zamrozony
if (timestamp_ - 31556926 > query_res->get_as_number(0, 1))
throw std::runtime_error("User is frozen");
}
//czy akcja istnieje?
query_res = db_.exec_query_variadic("SELECT action_id FROM action WHERE action_id = $1", { std::to_string(action_) });
if (query_res->tuple_count() == 0)
throw std::runtime_error("Action does not exist");
//czy ten czlonek juz glosowal?
query_res = db_.exec_query_variadic("SELECT voter_id FROM vote WHERE voter_id = $1 AND action_id = $2",
{
std::to_string(member_),
std::to_string(action_)
});
if (query_res->tuple_count() != 0)
{
assert(query_res->column_count() == 1);
throw std::runtime_error("Already voted before");
}
//wstawiamy nowa krotke do tablicy vote
db_.exec_query_variadic("INSERT INTO vote(voter_id, action_id, voting_time, is_upvote) "
"VALUES($1, $2, $3, $4)",
{
std::to_string(member_),
std::to_string(action_),
std::to_string(timestamp_),
is_upvote_or_downvote_ ? "TRUE" : "FALSE"
});
//aktualizujemy liczniki glosow w tabeli akcji
if(is_upvote_or_downvote_)
db_.exec_query_variadic("UPDATE action SET upvotes = upvotes + 1 "
"WHERE action_id = $1", { std::to_string(action_) });
else
db_.exec_query_variadic("UPDATE action SET downvotes = downvotes + 1 "
"WHERE action_id = $1", { std::to_string(action_) });
//aktualizacja timestampa ostatniej akcji uzytkownika
db_.exec_query_variadic("UPDATE member SET last_activity = $2 WHERE id = $1", { std::to_string(member_), std::to_string(timestamp_) });
//wypisz dzejsona
nlohmann::json action_confirmation;
action_confirmation["status"] = "OK";
std::cout << action_confirmation << std::endl;
}
<file_sep>/src/init_leader.cpp
#include <init_leader.hpp>
#include <cassert>
#include <iostream>
init_leader::init_leader(nlohmann::json& data, database_executor& db)
: abstract_api(data, db),
timestamp_(fetch_number("timestamp")),
member_(fetch_number("member")),
password_(fetch_string("password"))
{
if (password_.empty())
throw std::invalid_argument("Leader's password cannot be empty");
if (password_.size() > 128)
throw std::invalid_argument("Leader's password cannot be longer that 128 chars");
}
void init_leader::handle()
{
auto res = db_.exec_query_variadic("SELECT make_leader($1, $2, $3)",
{
std::to_string(member_),
password_,
std::to_string(timestamp_)
});
nlohmann::json insertion_confirmation;
insertion_confirmation["status"] = "OK";
std::cout << insertion_confirmation << std::endl;
}
<file_sep>/inc/api_support.hpp
#pragma once
#include <abstract_api.hpp>
class api_support
: public abstract_api
{
unsigned timestamp_;
unsigned member_;
std::string password_;
unsigned action_;
unsigned project_;
bool authority_present_;
unsigned authority_;
bool is_support_or_protest_;
public:
api_support(nlohmann::json& data, database_executor& db, bool is_support_or_protest);
virtual void handle() override;
};<file_sep>/README.md
# Final project for the databases university class
The project is an implementation of a facade over database, which task is to properly handle requests given as JSON objects, store and fetch information during run.
The full specification (in polish language) is given [here](https://github.com/KoncepcyjnyMiliarder/databases_final_project/blob/master/lecturers_specification.md).
Program is written in object oriented, modern style C++, compiles and runs both on Windows and Linux.
## Requirements
+ c++11 compiler
+ installed PostgreSQL database
+ pgcrypto extension
## How to use?
For convenience, create `build` directory, run `cmake`, then `make`. As specified in the task, first run the program with --init argument.
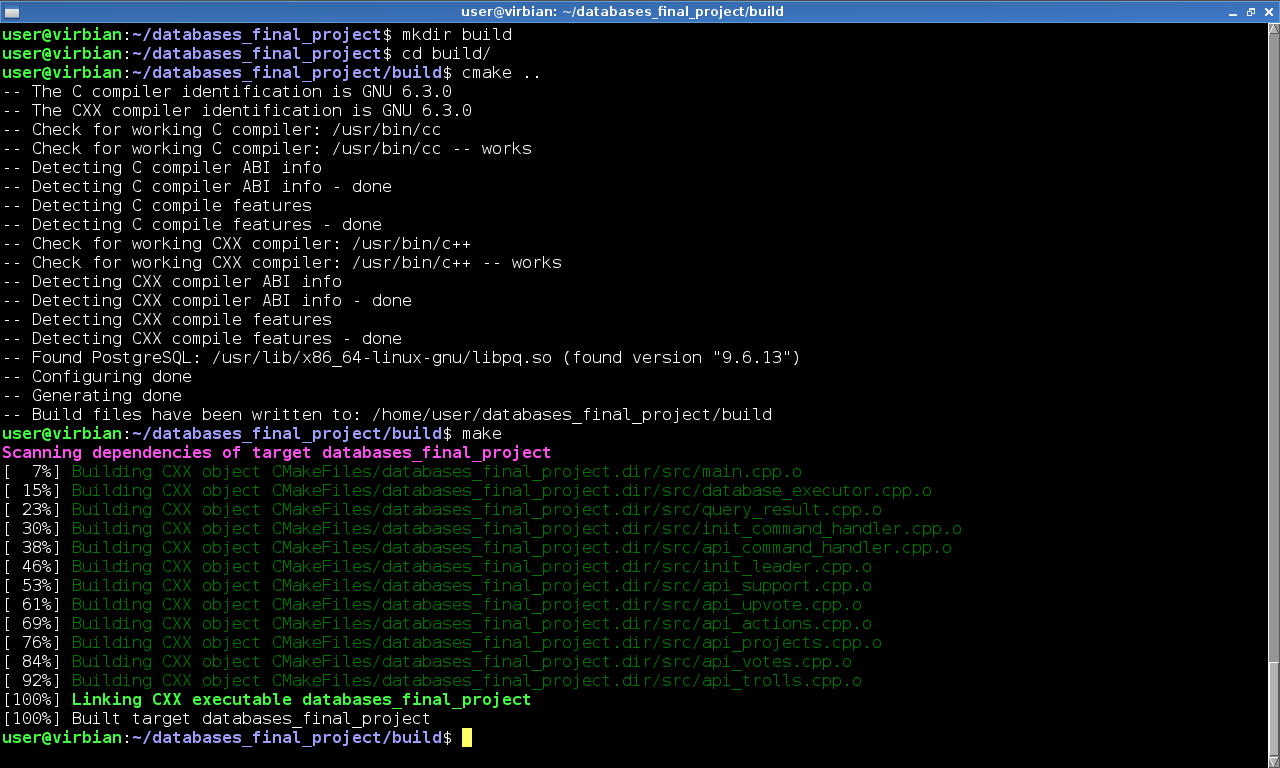
From now on, you can use the executable to give orders to the system.
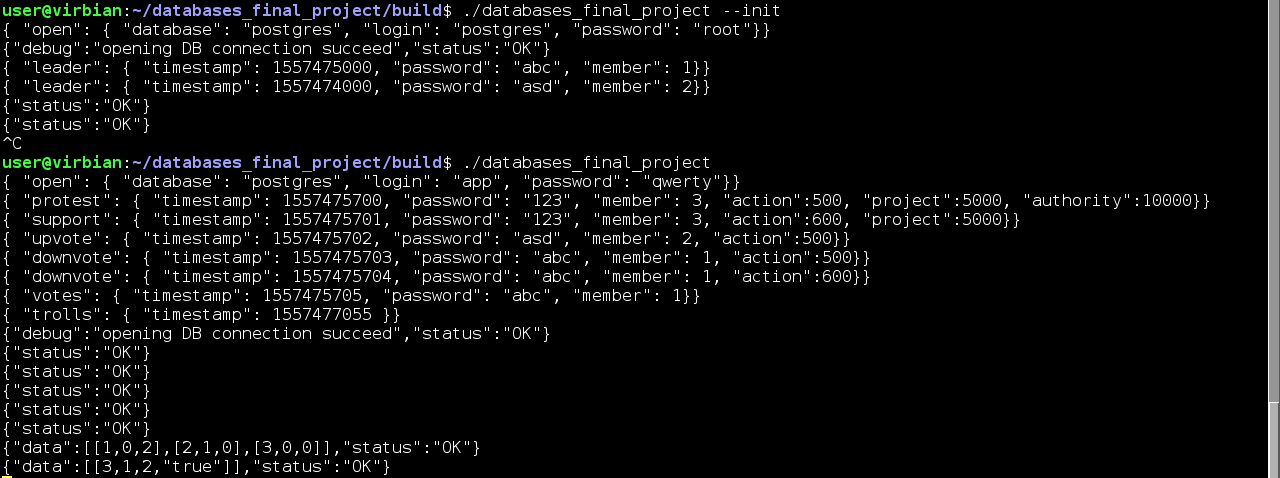
## Implementation details
### Code
Abstract factory pattern is at the very core of the application. The two modes of run (`init` and standard) are completely separated by being implemented in two unrelated factories. The product is a instance of class responsible for handling a particular request. Every request handler is encapsulated in one class. The main loop of the program operates on abstract commands, which makes it very easy to add next handlers without modifying existing parts of code.
### Underlying database structure
E-R diagram for PostgreSQL database:
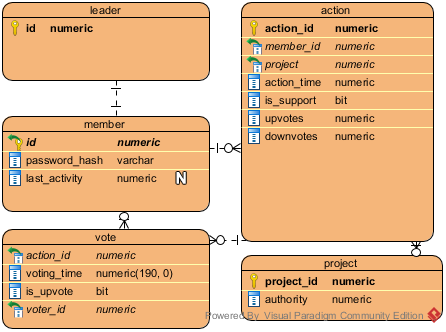
<file_sep>/resources/drop.sql
--usuniecie starych danych jesli istnieja
DROP OWNED BY app CASCADE;
DROP USER IF EXISTS app;
DROP TABLE IF EXISTS vote CASCADE;
DROP TABLE IF EXISTS action CASCADE;
DROP TABLE IF EXISTS project CASCADE;
DROP TABLE IF EXISTS leader CASCADE;
DROP TABLE IF EXISTS member CASCADE;<file_sep>/inc/abstract_api.hpp
#pragma once
#include <nlohmann/json.hpp>
#include <database_executor.hpp>
#include <memory>
class abstract_api
{
nlohmann::json& data_;
protected:
database_executor& db_;
/*welll not the cleanest way with that raw bool pointer, but as a protected helper method it should do...*/
inline unsigned fetch_number(const std::string& key_name, bool* optional = nullptr)
{
auto iter = data_.find(key_name);
if (iter == data_.end())
{
if (optional)
{
*optional = false;
return 0;
}
throw std::invalid_argument("Expected " + key_name + " in json");
}
if (!iter->is_number())
throw std::invalid_argument("Expected " + key_name + " to be number");
if (optional)
*optional = true;
return iter->get<unsigned>();
}
inline std::string fetch_string(const std::string& key_name, bool* optional = nullptr)
{
auto iter = data_.find(key_name);
if (iter == data_.end())
{
if (optional)
{
*optional = false;
return {};
}
throw std::invalid_argument("Expected " + key_name + " in json");
}
if (!iter->is_string())
throw std::invalid_argument("Expected " + key_name + " to be string");
if (optional)
*optional = true;
return iter->get<std::string>();
}
public:
using pointer = std::unique_ptr<abstract_api>;
abstract_api(nlohmann::json& data, database_executor& db)
: data_(data), db_(db) {}
virtual ~abstract_api() = default;
virtual void handle() = 0;
};<file_sep>/inc/database_executor.hpp
#pragma once
#include <string>
#include <libpq-fe.h>
#include <query_result.hpp>
#include <memory>
#include <vector>
//serves as a wrapper around the low level C psql library
class database_executor
{
PGconn* connection_;
public:
database_executor(const std::string& database, const std::string& login, const std::string& password);
std::unique_ptr<query_result> exec_query(const std::string& query);
std::unique_ptr<query_result> exec_query_variadic(const std::string& query, const std::vector<std::string>& args);
~database_executor();
};<file_sep>/src/api_support.cpp
#include <api_support.hpp>
#include <cassert>
#include <iostream>
api_support::api_support(nlohmann::json& data, database_executor& db, bool is_support_or_protest)
: abstract_api(data, db),
timestamp_(fetch_number("timestamp")),
member_(fetch_number("member")),
password_(fetch_string("password")),
action_(fetch_number("action")),
project_(fetch_number("project")),
authority_(fetch_number("authority", &authority_present_)),
is_support_or_protest_(is_support_or_protest)
{
}
void api_support::handle()
{
//sprawdz czy czlonek istnieje
auto query_res = db_.exec_query_variadic("SELECT id FROM member WHERE id = $1", { std::to_string(member_) });
//jesli nie, dodaj
if(query_res->tuple_count() == 0)
db_.exec_query_variadic("INSERT INTO member(id, password_hash, last_activity) VALUES($1, crypt($2, gen_salt('bf')), $3)",
{
std::to_string(member_),
password_,
std::to_string(timestamp_)
});
else
{
//jesli tak, sprawdz czy haslo jest ok
query_res = db_.exec_query_variadic("SELECT id, last_activity FROM member WHERE id = $1 AND password_hash = crypt($2, password_hash)",
{
std::to_string(member_),
password_
});
if (query_res->tuple_count() == 0)
throw std::runtime_error("User exists but password is wrong");
assert(query_res->column_count() == 2);
assert(query_res->column_name(0) == "id");
assert(query_res->column_name(1) == "last_activity");
//jesli tak, czy zamrozony
if(timestamp_ - 31556926 > query_res->get_as_number(0, 1))
throw std::runtime_error("User is frozen");
}
//czy project bylo juz dodane?
query_res = db_.exec_query_variadic("SELECT project_id FROM project WHERE project_id = $1", { std::to_string(project_)});
if (query_res->tuple_count() == 0)
{
if (authority_present_)
db_.exec_query_variadic("INSERT INTO project(project_id, authority) VALUES($1, $2)",
{
std::to_string(project_),
std::to_string(authority_)
});
else
throw std::runtime_error("Project does not exist and authority was not set");
}
//wstawiamy nowa krotke do tablicy actions
db_.exec_query_variadic("INSERT INTO action(action_id, member_id, project, action_time, is_support) "
"VALUES($1, $2, $3, $4, $5)",
{
std::to_string(action_),
std::to_string(member_),
std::to_string(project_),
std::to_string(timestamp_),
is_support_or_protest_ ? "TRUE" : "FALSE"
});
//na koniec apdejtnij mu stampa
db_.exec_query_variadic("UPDATE member SET last_activity = $2 WHERE id = $1", { std::to_string(member_), std::to_string(timestamp_) });
//wypisz dzejsona
nlohmann::json action_confirmation;
action_confirmation["status"] = "OK";
std::cout << action_confirmation << std::endl;
}
<file_sep>/inc/api_actions.hpp
#pragma once
#include <abstract_api.hpp>
class api_actions
: public abstract_api
{
unsigned timestamp_;
unsigned member_;
std::string password_;
bool is_type_set_;
std::string type_;
bool is_project_set_;
unsigned project_;
bool is_authority_set_;
unsigned authority_;
public:
api_actions(nlohmann::json& data, database_executor& db);
virtual void handle() override;
};<file_sep>/src/api_votes.cpp
#include <api_votes.hpp>
#include <cassert>
#include <iostream>
api_votes::api_votes(nlohmann::json& data, database_executor& db)
: abstract_api(data, db),
timestamp_(fetch_number("timestamp")),
member_(fetch_number("member")),
password_(fetch_string("password")),
project_(fetch_number("project", &is_project_set_)),
action_(fetch_number("action", &is_action_set_))
{
if (is_project_set_ && is_action_set_)
throw std::invalid_argument("You cannot set both project and action at the same time");
}
void api_votes::handle()
{
//sprawdz czy czlonek jest liderem
auto query_res = db_.exec_query_variadic("SELECT id FROM leader WHERE id = $1", { std::to_string(member_) });
//jesli nie, konczymy bledem
if (query_res->tuple_count() == 0)
throw std::runtime_error("Member is not a leader");
//sprawdz czy haslo jest ok
query_res = db_.exec_query_variadic("SELECT id, last_activity FROM member WHERE id = $1 AND password_hash = crypt($2, password_hash)", { std::to_string(member_), password_ });
if (query_res->tuple_count() == 0)
throw std::runtime_error("User exists but password is wrong");
assert(query_res->column_count() == 2);
assert(query_res->column_name(0) == "id");
assert(query_res->column_name(1) == "last_activity");
//czy zamrozony
if (timestamp_ - 31556926 > query_res->get_as_number(0, 1))
throw std::runtime_error("User is frozen");
//i cyk kwerenda
if (is_action_set_)
query_res = db_.exec_query_variadic("SELECT member.id, COUNT(is_upvote) FILTER (WHERE is_upvote AND action_id = $1) AS upvotes, "
"COUNT(is_upvote) FILTER (WHERE NOT is_upvote AND action_id = $1) AS downvotes FROM member "
"LEFT JOIN vote ON(voter_id = member.id) "
"GROUP BY member.id ORDER BY member.id", { std::to_string(action_) });
else if (is_project_set_)
query_res = db_.exec_query_variadic("SELECT member.id, COUNT(is_upvote) FILTER (WHERE is_upvote AND project = $1) AS upvotes, "
"COUNT(is_upvote) FILTER (WHERE NOT is_upvote AND project = $1) AS downvotes FROM member "
"LEFT JOIN vote ON(voter_id = member.id) LEFT JOIN action USING(action_id) "
"GROUP BY member.id ORDER BY member.id", { std::to_string(project_) });
else
query_res = db_.exec_query("SELECT member.id, COUNT(is_upvote) FILTER (WHERE is_upvote) AS upvotes, "
"COUNT(is_upvote) FILTER (WHERE NOT is_upvote) AS downvotes FROM member "
"LEFT JOIN vote ON(voter_id = member.id) GROUP BY member.id ORDER BY member.id");
assert(query_res->column_count() == 3);
assert(query_res->column_name(0) == "id");
assert(query_res->column_name(1) == "upvotes");
assert(query_res->column_name(2) == "downvotes");
//aktualizacja timestampa ostatniej akcji uzytkownika
db_.exec_query_variadic("UPDATE member SET last_activity = $2 WHERE id = $1", { std::to_string(member_), std::to_string(timestamp_) });
//wypisz dzejsona z danymi
nlohmann::json action_confirmation;
action_confirmation["status"] = "OK";
for (unsigned i = 0; i < query_res->tuple_count(); ++i)
{
// <member> <upvotes> <downvotes>
action_confirmation["data"][i] =
{
query_res->get_as_number(i, 0),
query_res->get_as_number(i, 1),
query_res->get_as_number(i, 2)
};
}
std::cout << action_confirmation << std::endl;
}
<file_sep>/src/init_command_handler.cpp
#include <init_command_handler.hpp>
#include <iostream>
#include <fstream>
#include <sstream>
#include <init_leader.hpp>
init_command_handler::init_command_handler(database_executor& db)
: command_handler(db)
{
//check is init.sql file is accessible
std::ifstream filein("resources/init.sql");
if (!filein)
throw std::runtime_error("resources/init.sql - file is missing");
//execute init.sql
std::stringstream ss;
ss << filein.rdbuf();
try
{
db.exec_query(ss.str());
}
catch (const std::exception& e)
{
throw std::runtime_error(std::string("init.sql - execution failed, error msg: ") + e.what());
}
}
abstract_api::pointer init_command_handler::from_input_line(const std::string& input_line)
{
nlohmann::json command_data = nlohmann::json::parse(input_line);
if(command_data.size() != 1)
throw std::invalid_argument("Every line should contain exactly one json object");
const std::string& api_name = command_data.begin().key();
if (api_name == "leader")
return std::make_unique<init_leader>(command_data[api_name], db_);
nlohmann::json error_json;
error_json["status"] = "ERROR";
error_json["debug"] = "No handler for api: " + api_name;
std::cout << error_json << std::endl;
return abstract_api::pointer();
}
<file_sep>/CMakeLists.txt
cmake_minimum_required(VERSION 3.0)
project(databases_final_project)
set(CMAKE_CXX_STANDARD 14)
find_package(PostgreSQL REQUIRED)
set(SOURCES
src/main.cpp
src/database_executor.cpp
src/query_result.cpp
src/init_command_handler.cpp
src/api_command_handler.cpp
src/init_leader.cpp
src/api_support.cpp
src/api_upvote.cpp
src/api_actions.cpp
src/api_projects.cpp
src/api_votes.cpp
src/api_trolls.cpp
)
set(INCLUDES
inc/database_executor.hpp
inc/query_result.hpp
inc/command_handler.hpp
inc/init_command_handler.hpp
inc/api_command_handler.hpp
inc/abstract_api.hpp
inc/init_leader.hpp
inc/api_support.hpp
inc/api_upvote.hpp
inc/api_actions.hpp
inc/api_projects.hpp
inc/api_votes.hpp
inc/api_trolls.hpp
)
add_executable(${PROJECT_NAME} ${SOURCES} ${INCLUDES})
if(MSVC)
target_compile_options(${PROJECT_NAME} PRIVATE /W4)
else()
target_compile_options(${PROJECT_NAME} PRIVATE -Wall -Wextra -pedantic)
endif()
target_include_directories(${PROJECT_NAME} PRIVATE
inc
third_party
${PostgreSQL_INCLUDE_DIRS}
)
target_link_libraries(${PROJECT_NAME} PRIVATE
${PostgreSQL_LIBRARIES}
)
add_custom_command(
TARGET ${PROJECT_NAME} POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_directory
${CMAKE_CURRENT_SOURCE_DIR}/resources
${CMAKE_CURRENT_BINARY_DIR}/resources
)
<file_sep>/inc/api_command_handler.hpp
#pragma once
#include <command_handler.hpp>
class api_command_handler
: public command_handler
{
public:
api_command_handler(database_executor& db);
virtual abstract_api::pointer from_input_line(const std::string& input_line) override;
};<file_sep>/src/query_result.cpp
#include <query_result.hpp>
#include <stdexcept>
query_result::query_result(PGresult* res)
: res_(res)
{
auto status = PQresultStatus(res_);
if (status != PGRES_COMMAND_OK && status != PGRES_TUPLES_OK)
{
std::runtime_error to_throw(PQresultErrorMessage(res_));
PQclear(res_);
throw to_throw; //woohoo i've never done something like that before
}
}
query_result::~query_result()
{
PQclear(res_);
}
unsigned query_result::tuple_count()
{
return PQntuples(res_);
}
unsigned query_result::column_count()
{
return PQnfields(res_);
}
bool query_result::is_null(int row, int col)
{
return PQgetisnull(res_, row, col);
}
std::string query_result::get_as_string(int row, int col)
{
return PQgetvalue(res_, row, col);
}
bool query_result::get_as_boolean(int row, int col)
{
return PQgetvalue(res_, row, col)[0] == 't';
}
unsigned query_result::get_as_number(int row, int col)
{
return std::stoi(PQgetvalue(res_, row, col));
}
std::string query_result::column_name(int col)
{
return PQfname(res_, col);
}
<file_sep>/src/database_executor.cpp
#include <database_executor.hpp>
#include <iostream>
#include <stdexcept>
#include <algorithm>
database_executor::database_executor(const std::string& database, const std::string& login, const std::string& password)
{
connection_ = PQsetdbLogin("localhost", //default host
nullptr, //default port
nullptr, //default optons
nullptr, //default debug output
database.c_str(),
login.c_str(),
password.c_str());
if (PQstatus(connection_) != ConnStatusType::CONNECTION_OK)
throw std::runtime_error(PQerrorMessage(connection_));
}
std::unique_ptr<query_result> database_executor::exec_query(const std::string& query)
{
return std::make_unique<query_result>(PQexec(connection_, query.c_str()));
}
std::unique_ptr<query_result> database_executor::exec_query_variadic(const std::string& query, const std::vector<std::string>& args)
{
std::vector<const char*> args_as_raw(args.size());
std::transform(args.begin(), args.end(), args_as_raw.begin(), [](const std::string & arg)
{
return arg.c_str();
});
return std::make_unique<query_result>(PQexecParams(connection_,
query.c_str(), //"If parameters are used, they are referred to in the command string as $1, $2, etc."
static_cast<int>(args.size()),
nullptr, //"If paramTypes is NULL [..] the server infers a data type"
args_as_raw.data(),
nullptr, //"It is ignored for null parameters and text-format parameters"
nullptr, //"If the array pointer is null then all parameters are presumed to be text strings"
0)); //"Specify zero to obtain results in text format"
}
database_executor::~database_executor()
{
PQfinish(connection_);
}
| 9258ee9f7b5bf6477b682b4fd8a335a389bce651 | [
"Markdown",
"SQL",
"CMake",
"C++"
] | 25 | C++ | kpyrkosz/databases_final_project | ed4e1636c78a873ee327c305e62a66edefc37e44 | e8c2562e08480c1012ee97131a8b7723169ebced |
refs/heads/master | <file_sep>using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ConsoleApplication5
{
class Program
{
void op(int[] n)
{
int max = n[0];
int min = n[0];
int sum = 0;
for (int i = 0; i < n.Length; i++)
{
if (n[i] >= max) max = n[i];
if (n[i] <= min) min = n[i];
sum += n[i];
}
double avg = sum / n.Length;
Console.WriteLine("MAX:" + max + " MIN:" + min + " SUM:" + sum + " AVG:" + avg);
}
static void Main(string[] args)
{
Program p=new Program();
string s = "";
int[] a = new int[5];
for (int i = 0; i < 5; i++)
{
s = Console.ReadLine();
a[i] = Int32.Parse(s);
}
p.op(a);
Console.ReadLine();
}
}
}
<file_sep>using System;
using System.Threading;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ConsoleApplication5
{
class Program
{
static void Main(string[] args)
{
Program p=new Program();
OrderService os = new OrderService();
int a = Convert.ToInt32(Console.ReadLine());
while (a != 0)
{
try
{
switch (a)
{
case 1:
os.AddOrder();
break;
case 2:
os.searchatID(1);
break;
case 3:
os.changeatID(2);
break;
}
}
catch (NotExistException e)
{
Console.WriteLine("NOT FOUND!");
}
finally
{
a = Convert.ToInt32(Console.ReadLine());
}
}
}
}
}
class Order
{
private static int ID = 1;
private string name;
private string goods;
private int quantity;
public Order(string n,string g,int q) { name = n; goods = g; quantity = q; }
public int getID() { return ID; }
public string getname() { return name; }
public string getgoods() { return goods; }
public int getquantity() { return quantity; }
public void setname(string n) { name = n; }
public void setgoods(string n) { goods = n; }
public void setquantity(int n) { quantity = n; }
}
class OrderService
{
private List<Order> l;
public OrderService() { l = new List<Order>(); }
public void AddOrder()
{
string name = Console.ReadLine();
string goods = Console.ReadLine();
int quantity = Convert.ToInt32(Console.ReadLine());
Order order = new Order(name,goods,quantity);
l.Add(order);
/////////////////////////////////////////////
}
public void deletebyID(int n)
{
if (l.RemoveAll(delegate (Order order) { return order.getID().Equals(n); }) == 0)
throw (new NotExistException("NOT FOUND OBJ!"));
}
public void searchatname(string n)
{
List<Order> find = l.FindAll(delegate (Order order) { return order.getname().Equals(n); });
if (find == null)
throw (new NotExistException("NOT FOUND OBJ!"));
foreach (Order or in find)
{
Console.WriteLine(or.getID() + " " + or.getname() + " " + or.getquantity());
}
}
public void searchatgoods(string n)
{
List<Order> find = l.FindAll(delegate (Order order) { return order.getgoods().Equals(n); });
if (find == null)
throw (new NotExistException("NOT FOUND OBJ!"));
foreach (Order or in find)
{
Console.WriteLine(or.getID() + " " + or.getname() + " " + or.getquantity());
}
}
public void searchatID(int n)
{
List<Order> find = l.FindAll(delegate (Order order) { return order.getID().Equals(n); });
if (find == null)
throw (new NotExistException("NOT FOUND OBJ!"));
foreach (Order or in find)
{
Console.WriteLine(or.getID() + " " + or.getname() + " " + or.getquantity());
}
}
public void changeatID(int n)
{
Order find = l.Find(delegate (Order order) { return order.getID().Equals(n); });
if (find == null)
throw (new NotExistException("NOT FOUND OBJ!"));
find.setname(Console.ReadLine());
find.setgoods(Console.ReadLine());
find.setquantity(Convert.ToInt32(Console.ReadLine()));
}
}
public class NotExistException: ApplicationException
{
public NotExistException(string message): base(message)
{
}
}
public class OpFailException : ApplicationException
{
public OpFailException(string message): base(message)
{
}
}
<file_sep>using System;
using System.Threading;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ConsoleApplication5
{
class Program
{
public static void CallToChildThread()
{
Console.WriteLine("BIBIBIBIBIBIBIBI!!!!!!!!!");
}
static void Main(string[] args)
{
Program p=new Program();
int a=Convert.ToInt32(Console.ReadLine());
ThreadStart childref = new ThreadStart(CallToChildThread);
Thread childth = new Thread(childref);
Thread.Sleep(a);
childth.Start();
Console.ReadLine();
}
}
}
<file_sep>using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ConsoleApplication5
{
class Program
{
void op(int n)
{
for (int i = 2; i < n / 2; i++)
{
if (n % i == 0)
{
Console.WriteLine(i + "");
n = n / i;
i = 1;
}
}
if (n != 1)
{
Console.WriteLine(n + "");
}
}
static void Main(string[] args)
{
Program p=new Program();
string s = "";
int a = 0;
s = Console.ReadLine();
a = Int32.Parse(s);
p.op(a);
Console.ReadLine();
}
}
}
| 782c1a2da9d75f6c00f03a36d40e8247b5ca6d87 | [
"C#"
] | 4 | C# | zyck321/C- | 14e8ccec08be6e9ef3014a60f83e223b16e96081 | d7e504bfa82cde2a99b0ef27b3e000bff1bfb7c3 |
refs/heads/master | <file_sep>package com.sm.flyrect;
import android.content.Context;
import android.graphics.Canvas;
import android.graphics.Color;
import android.graphics.Paint;
import android.graphics.Rect;
import android.util.Log;
import android.view.SurfaceHolder;
import android.view.SurfaceView;
public class DrawView extends SurfaceView implements SurfaceHolder.Callback {
private DrawThread drawThread;
Paint p;
Rect rect;
Rect canvasRect;
/**
* Current height of the surface/canvas.
*
* @see #setSurfaceSize
*/
private int mCanvasHeight = 1;
/**
* Current width of the surface/canvas.
*
* @see #setSurfaceSize
*/
private int mCanvasWidth = 1;
public DrawView(Context context) {
super(context);
getHolder().addCallback(this);
p = new Paint();
rect = new Rect();
canvasRect = new Rect();
}
@Override
public void surfaceCreated(SurfaceHolder holder) {
drawThread = new DrawThread(getHolder());
drawThread.setRunning(true);
drawThread.start();
}
@Override
public void surfaceChanged(SurfaceHolder holder, int format, int width,
int height) {
//drawThread.setSurfaceSize(width, height);
}
@Override
public void surfaceDestroyed(SurfaceHolder holder) {
boolean retry = true;
drawThread.setRunning(false);
while (retry) {
try {
drawThread.join();
retry = false;
} catch (InterruptedException e) {
}
}
}
class DrawThread extends Thread {
private boolean running = false;
private SurfaceHolder surfaceHolder;
long prevTime;
public DrawThread(SurfaceHolder surfaceHolder) {
this.surfaceHolder = surfaceHolder;
// сохраняем текущее время
prevTime = System.currentTimeMillis();
rect.set(250, 300, 350, 400);
Log.i("Surf", "Surf Change "+mCanvasWidth+" high "+mCanvasHeight);
canvasRect.set(0, 0, mCanvasWidth, mCanvasHeight);
}
public void setSurfaceSize(int width, int height) {
// synchronized to make sure these all change atomically
synchronized (surfaceHolder) {
mCanvasWidth = width;
mCanvasHeight = height;
Log.i("SurfSize", "Surf Change "+mCanvasWidth+" high "+mCanvasHeight);
// don't forget to resize the background image
//mBackgroundImage = mBackgroundImage.createScaledBitmap(
// mBackgroundImage, width, height, true);
}
}
public void setRunning(boolean running) {
this.running = running;
}
// Рисовачь
// TODO Implement
private void doDraw(Canvas canvas) {
canvas.drawColor(Color.CYAN);
// настройка кисти
// красный цвет
p.setColor(Color.RED);
// толщина линии = 10
p.setStrokeWidth(10);
p.setStyle(Paint.Style.STROKE);
// настройка объекта Rect;
// левая верхняя точка (250,300), нижняя правая (350,500)
Paint test = new Paint();
test.setColor(Color.WHITE);
test.setStrokeWidth(15);
test.setStyle(Paint.Style.STROKE);
canvas.drawRect(rect, p);
canvas.drawRect(canvasRect, test);
}
// Обновляет позиции
// TODO Implement method
private void updatePhysics() {
int dx = 15;
int dy = 15;
rect.offset(dx, dy);
// if (rect.intersects(rect, canvasRect)) {
// Log.v("coll", "its workiing");
//
// }
//canvas.drawRect(rect, p);
}
@Override
public void run() {
Canvas canvas;
while (running) {
long now = System.currentTimeMillis();
long elapsedTime = now - prevTime;
if (elapsedTime > 1000){
prevTime = now;
//updatePhysics();
rect.offset(-10, -10);
if (rect.intersect(canvasRect)){
rect.offset(15, 15);
}
}
canvas = null;
try {
canvas = surfaceHolder.lockCanvas(null);
if (canvas == null)
continue;
// TODO implement update() and draw()
//canvas.drawRect(canvasRect, p);
doDraw(canvas);
//updatePhysics(canvas);
} finally {
if (canvas != null) {
surfaceHolder.unlockCanvasAndPost(canvas);
}
}
}
}
}
public Object getThread() {
// TODO Auto-generated method stub
return drawThread;
}
public void pause() {
// TODO Implement
// synchronized (mSurfaceHolder) {
// if (mMode == STATE_RUNNING) setState(STATE_PAUSE);
// }
}
public int getmCanvasHeight() {
return mCanvasHeight;
}
public void setmCanvasHeight(int mCanvasHeight) {
this.mCanvasHeight = mCanvasHeight;
}
public int getmCanvasWidth() {
return mCanvasWidth;
}
public void setmCanvasWidth(int mCanvasWidth) {
this.mCanvasWidth = mCanvasWidth;
}
}
| 311b3b8478520202a165f42ee8c777fdd800b877 | [
"Java"
] | 1 | Java | Grishman/Flyrect | 01571ac43398b1fd188339c439f235a0ad203220 | da2a92bd28e5cc8bd83e762a0fb0ddb0f6178390 |
refs/heads/master | <repo_name>fantianyun/fly<file_sep>/Fly/src/main/java/com/fty/service/JdbcTmplUserService.java
package com.fty.service;
import com.fty.entity.User;
import java.util.List;
public interface JdbcTmplUserService {
public User getUser(long id);
public List<User> findUsers(String userName,String note);
public int inserUser(User user);
public int updateUser(User user);
public int deleteUser(long id);
}
<file_sep>/Fly/pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.fty</groupId>
<artifactId>Fly</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<mysql.version>5.1.47</mysql.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.2.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jooq</artifactId>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>fluent-hc</artifactId>
<version>4.5.7</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-dbcp2 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.8.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.56</version>
</dependency>
<dependency>
<groupId>org.jooq</groupId>
<artifactId>jooq</artifactId>
<version>3.11.9</version>
</dependency>
<dependency>
<groupId>org.jooq</groupId>
<artifactId>jooq-meta</artifactId>
<version>3.11.9</version>
</dependency>
<dependency>
<groupId>org.jooq</groupId>
<artifactId>jooq-codegen</artifactId>
<version>3.11.9</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--<dependency>-->
<!--<groupId>org.springframework.boot</groupId>-->
<!--<artifactId>spring-boot-starter-security</artifactId>-->
<!--</dependency>-->
<!--<dependency>-->
<!--<groupId>org.springframework.boot</groupId>-->
<!--<artifactId>spring-boot-starter-data-jpa</artifactId>-->
<!--</dependency>-->
<!-- https://mvnrepository.com/artifact/org.mybatis.spring.boot/mybatis-spring-boot-starter -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.1.4.RELEASE</version>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/com.itextpdf/itextpdf -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13</version>
</dependency>
<dependency>
<groupId>org.xhtmlrenderer</groupId>
<artifactId>core-renderer</artifactId>
<version>R8</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
</dependencies>
<build>
<resources>
<resource>
<directory>src/main/java</directory>
<filtering>true</filtering>
<includes>
<include>**/*.xml</include>
<include>**/*.html</include>
</includes>
<excludes>
<exclude>**/*.java</exclude>
</excludes>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.yml</include>
<include>**/*.xml</include>
</includes>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>gensrc/main/java</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.jooq</groupId>
<artifactId>jooq-codegen-maven</artifactId>
<version>${jooq.version}</version>
<!-- The plugin should hook into the generate goal -->
<executions>
<execution>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
<!-- Manage the plugin's dependency. In this example, we'll use a MySQL database -->
<dependencies>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>
<!-- Specify the plugin configuration.
The configuration format is the same as for the standalone code generator -->
<configuration>
<!--可选值 TRACE DEBUG INFO WARN ERROR FATAL-->
<logging>DEBUG</logging>
<jdbc>
<driver>com.mysql.jdbc.Driver</driver>
<url>jdbc:mysql://localhost:3306/smallProgram</url>
<user>root</user>
<password><PASSWORD></password>
</jdbc>
<generator>
<database>
<name>org.jooq.meta.mysql.MySQLDatabase</name>
<includes>.*</includes>
<!--<excludes>tmp_.*|wf_.*|rpt_.*</excludes>-->
<!--测试-->
<inputSchema>smallprogram</inputSchema>
</database>
<strategy>
<matchers>
<tables>
<table>
<expression>^(.*)$</expression>
<tableClass>
<transform>PASCAL</transform>
<expression>$1</expression>
</tableClass>
<recordClass>
<transform>PASCAL</transform>
<expression>$1_P_O</expression>
</recordClass>
</table>
</tables>
</matchers>
</strategy>
<target>
<packageName>com.fty.jooq.domain</packageName>
<directory>${basedir}/gensrc/main/java</directory>
</target>
<generate>
<records>false</records>
<javaTimeTypes>true</javaTimeTypes>
</generate>
</generator>
</configuration>
</plugin>
</plugins>
</build>
</project><file_sep>/Fly/src/main/java/com/fty/config/WxConfig.java
package com.fty.config;
import org.springframework.stereotype.Component;
@Component
public class WxConfig {
public static final String AppID = "wxab8a4466ceff329d";
public static final String AppSecret = "c8a3b4ed3f1b3fa71428782e1f7b98ce";
//通过code获取sessionKey地址
public static final String url = "https://api.weixin.qq.com/sns/jscode2session?appid=%s&secret=%s&js_code=%s&grant_type=authorization_code";
}
<file_sep>/Fly/src/main/java/com/fty/entity/Reader.java
package com.fty.entity;
public class Reader {
}
<file_sep>/Fly/src/main/java/com/fty/service/impl/MyBatisUserServiceImpl.java
package com.fty.service.impl;
import com.fty.entity.User;
import com.fty.service.MyBatisUserService;
import com.fty.service.mybatisInterface.MybatisUserDao;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Isolation;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
@Service
public class MyBatisUserServiceImpl implements MyBatisUserService {
@Autowired
private MybatisUserDao mybatisUserDao = null;
@Override
@Transactional(isolation = Isolation.READ_COMMITTED,timeout = 1)
public User getUser(long id) {
return mybatisUserDao.getUser(id);
}
@Override
@Transactional(isolation = Isolation.READ_COMMITTED,timeout = 1)
public int insertUser(User user) {
return mybatisUserDao.insertUser(user);
}
@Override
public List<User> getUsers(String userName, String note) {
return mybatisUserDao.getUsers(userName,note);
}
}
<file_sep>/Fly/src/test/java/com/fty/SubPizza.java
package com.fty;
import java.util.Objects;
public class SubPizza extends Pizza {
public enum Size{
SMALL,MEDIUM,LARGE
}
private final Size size;
SubPizza(Builder builder) {
super(builder);
size = builder.size;
}
public static class Builder extends Pizza.Builder<Builder>{
private final Size size;
public Builder(Size size){
this.size = Objects.requireNonNull(size);
}
@Override
Pizza build() {
return new SubPizza(this);
}
@Override
protected Builder self() {
return this;
}
}
@Override
public void print(){
System.out.println(toppings);
System.out.println(size);
}
}
<file_sep>/Fly/src/main/java/com/fty/service/mybatisInterface/MybatisUserDao.java
package com.fty.service.mybatisInterface;
import com.fty.entity.User;
import org.apache.ibatis.annotations.Param;
import org.springframework.stereotype.Repository;
import java.util.List;
import java.util.Map;
@Repository
public interface MybatisUserDao {
User getUser(long id);
int insertUser(User user);
List<User> getUsers(String userName,String note);
}
<file_sep>/Fly/src/main/java/com/fty/service/ClassService.java
package com.fty.service;
import com.fty.jooq.domain.tables.MallClass;
import org.jooq.DSLContext;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Map;
@Component
public class ClassService {
private DSLContext dsl;
@Autowired
public ClassService(DSLContext dsl) {
this.dsl = dsl;
}
/**
* FTY 获取分类数据
* @return
*/
public List<Map<String, Object>> getClassData() {
MallClass C = MallClass.MALL_CLASS;
//Result<Record3<Integer, String, String>> list = dsl.select(c.CLASS_ID,c.CLASS_IMG_URL,c.CLASS_NAME).from(c).orderBy(c.SORT).fetch();
List<Map<String, Object>> aaa = dsl.select(C.CLASS_ID, C.CLASS_NAME, C.IMG_URL).from(C).fetchMaps();
return aaa;
}
}
<file_sep>/Fly/src/test/java/com/fty/UtilityClass.java
package com.fty;
public class UtilityClass {
private UtilityClass() {
throw new AssertionError();
}
public static void main(String[] args) {
System.out.println(new UtilityClass());
Math.abs(1);
}
}
<file_sep>/Fly/src/main/java/com/fty/util/PdfExportService.java
package com.fty.util;
import com.lowagie.text.Document;
import com.lowagie.text.pdf.PdfWriter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.Map;
public interface PdfExportService {
public void make(Map<String ,Object> model, Document document, PdfWriter writer, HttpServletRequest request, HttpServletResponse response);
}
<file_sep>/Fly/src/main/java/com/fty/controller/Validator.java
package com.fty.controller;
import org.springframework.stereotype.Controller;
import org.springframework.validation.Errors;
import org.springframework.validation.FieldError;
import org.springframework.validation.ObjectError;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.validation.Valid;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Controller
public class Validator {
@RequestMapping(value = "/valid/validate")
@ResponseBody
public Map<String,Object> validate(@Valid @RequestBody com.fty.entity.Validator vp, Errors errors){
Map<String,Object> errMap = new HashMap<>();
List<ObjectError> oes = errors.getAllErrors();
for(ObjectError oe : oes){
String key = null;
String msg = null;
if(oe instanceof FieldError){
FieldError fe = (FieldError) oe;
key = fe.getField();
}else {
key = oe.getObjectName();
}
msg = oe.getDefaultMessage();
errMap.put(key,msg);
}
return errMap;
}
}
<file_sep>/Fly/src/main/java/com/fty/enumeration/SexEnum.java
package com.fty.enumeration;
public enum SexEnum {
MALE(1,"男"),FEMALE(2,"女");
private int id;
private String name;
SexEnum(int id , String name){
this.id = id;
this.name = name;
}
public static SexEnum getEnumById(int id){
for(SexEnum sex : SexEnum.values()){
if(sex.getId() == id){
return sex;
}
}
return null;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
| 25a59895ca25770db5ac2091d069b19520f93af0 | [
"Java",
"Maven POM"
] | 12 | Java | fantianyun/fly | df0291961993c5176014ad1f0f87fa365c1331f5 | 774f3fb6b0cee4fe92ce5cc2340d5d480691f600 |
refs/heads/master | <file_sep><!DOCTYPE HTML>
<head>
<title>Categories</title>
<link rel="shortcut icon" href="images/title.PNG">
<link href="css/style.css" rel="stylesheet" type="text/css" media="all" />
</head>
<body>
<div class="header">
<div class="wrap">
<div class="logo">
<a href="index.php"><img src="images/logo.png" title="logo" /></a>
</div>
<div class="top-menu">
<div class="top-nav">
<ul>
<li><a href="categories.php">RECENT UPLOADS</a></li>
<li><a href="contact.html">Contact</a></li>
</ul>
</div>
<div class="search">
<form>
<input type="text" class="textbox" value="Search:" onfocus="this.value = '';" onblur="if (this.value == '') {this.value = 'Search';}">
<input type="submit" value=" " />
</form>
</div>
<div class="clear"> </div>
</div>
<div class="clear"> </div>
</div>
</div>
<div class="clear"> </div>
<div class="main-content">
<div class="wrap">
<div class="left-sidebar">
<div class="sidebar-boxs">
<div class="clear"> </div>
<div class="type-videos">
<h3>Categories</h3>
<ul>
<li><a href="JAVA.html">JAVA.</a></li>
<li><a href="DE.html">Digital Electronics.</a></li>
<li><a href="COMI.html">Computer Organization & Microprocessor Interfacing.</a></li>
<li><a href="snt.html">Statical & Numerical Techniques.</a></li>
<li><a href="DSA1.html">DATA Stucture & Algorithm</a></li>
<li><a href="DC.html">Data Communication</a></li>
<li><a href="DBMS.html">DataBase Management System</a></li>
<li><a href="CN.html">Computer Networks</a></li>
<li><a href="Avdwebtech.html">Advanced Web Technologies</a></li>
</ul>
</div>
</div>
</div>
<div class="right-content">
<div class="right-content-heading">
<div class="right-content-heading-left">
<h3>Latest Categories of videos</h3>
</div>
<div class="right-content-heading-right">
<div class="social-icons">
<ul>
<li>
<a class="facebook" href="#" target="_blank"> </a>
</li>
<li>
<a class="twitter" href="#" target="_blank"></a>
</li>
<li>
<a class="googleplus" href="#" target="_blank"></a>
</li>
<li>
<a class="pinterest" href="#" target="_blank"></a>
</li>
<li>
<a class="dribbble" href="#" target="_blank"></a>
</li>
<li>
<a class="vimeo" href="#" target="_blank"></a>
</li>
</ul>
</div>
</div>
<div class="clear"> </div>
</div>
<div class="content-grids">
<?php
include("dbconfig.php");
?>
<!doctype html>
<html>
<head>
<style>
video{
float: left;
border:1px solid black;
}
body{
font: 14px sans-serif;
background-image: url(https://static.wixstatic.com/media/11062b_4b7c9a8e48334d5aad2fd274fddba3bc~mv2.jpg/v1/fill/w_480,h_320,al_c,q_80,usm_0.66_1.00_0.01,blur_2/11062b_4b7c9a8e48334d5aad2fd274fddba3bc~mv2.jpg);
background-size: cover;
background-repeat: no-repeat;
background-position: center center;
object-position: 50% 50%;
}
.wrapper{
width: 350px;
padding: 20px;
border: 1px solid black;
margin: auto;
}
</style>
</head>
<body>
<?php
$fetchVideos = mysqli_query($con, "SELECT * FROM videos ORDER BY id DESC");
while($row = mysqli_fetch_assoc($fetchVideos)){
$location = $row['location'];
echo "<div>";
echo "<video src='".$location."' controls width='465px' height='300px' >";
echo "</div>";
}
?>
</div>
</div>
<div class="clear"> </div>
</div>
</div>
<div class="clear"> </div>
</div>
</div>
<div class="clear"> </div>
</body>
</html><file_sep><?php
include("dbconfig.php");
?>
<!doctype html>
<html>
<head>
<style>
video{
float: left;
border:1px solid black;
}
body{
font: 14px sans-serif;
background-image: url(https://static.wixstatic.com/media/11062b_4b7c9a8e48334d5aad2fd274fddba3bc~mv2.jpg/v1/fill/w_480,h_320,al_c,q_80,usm_0.66_1.00_0.01,blur_2/11062b_4b7c9a8e48334d5aad2fd274fddba3bc~mv2.jpg);
background-size: cover;
background-repeat: no-repeat;
background-position: center center;
object-position: 50% 50%;
}
.wrapper{
width: 350px;
padding: 20px;
border-right: 1px solid black;
border-bottom: 1px solid black;
border-left: 1px solid black;
margin: auto;
}
.logo{
border: 1px solid black;
}
</style>
</head>
<body>
<div class="logo">
<a href="adminindex.php"><img src="images/logo.png" title="logo" /></a>
</div>
<?php
$fetchVideos = mysqli_query($con, "SELECT * FROM videos ORDER BY id DESC");
while($row = mysqli_fetch_assoc($fetchVideos)){
$location = $row['location'];
echo "<div>";
echo "<video src='".$location."' controls width='426.7px' height='300px' >";
echo "</div>";
}
?>
</body>
</html>
<file_sep><!doctype html>
<html>
<head>
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.css">
<style type="text/css">
body{
font: 14px sans-serif;
background-image: url(https://static.wixstatic.com/media/11062b_4b7c9a8e48334d5aad2fd274fddba3bc~mv2.jpg/v1/fill/w_480,h_320,al_c,q_80,usm_0.66_1.00_0.01,blur_2/11062b_4b7c9a8e48334d5aad2fd274fddba3bc~mv2.jpg);
background-size: cover;
background-repeat: no-repeat;
background-position: center center;
object-position: 50% 50%;
}
.logo{
border: 1px solid black;
}
.wrapper{
width: 350px;
padding: 20px;
border-right: 1px solid black;
border-bottom: 1px solid black;
border-left: 1px solid black;
margin: auto;
}
p{
border: 1px solid black;
align: justify;
}
</style>
<?php
include("dbconfig.php");
if(isset($_POST['but_upload'])){
$maxsize = 99999999999;
$name = $_FILES['file']['name'];
$target_dir = "videos/";
$target_file = $target_dir . $_FILES["file"]["name"];
$videoFileType = strtolower(pathinfo($target_file,PATHINFO_EXTENSION));
$extensions_arr = array("mp4","avi","3gp","mov","mpeg","docx","mkv");
if( in_array($videoFileType,$extensions_arr) ){
if(($_FILES['file']['size'] >= $maxsize) || ($_FILES["file"]["size"] == 0)) {
echo "File too large. File must be less than 5MB.";
}else{
if(move_uploaded_file($_FILES['file']['tmp_name'],$target_file)){
$query = "INSERT INTO videos(name,location) VALUES('".$name."','".$target_file."')";
mysqli_query($con,$query);
echo "Upload successfully.";
}
}
}else{
echo "Invalid file extension.";
}
}
?>
</head>
<body>
<div class="logo">
<a href="adminlogin.php"><img src="images/logo.png" title="logo" /></a>
</div>
<div class="wrapper">
<form method="post" action="" enctype='multipart/form-data'>
Select the file you want to upload: <br><br> <input type='file' name='file' /><br><br>
<p> These are the allowed extensions: "mp4","avi","3gp","mov","mpeg","docx","mkv". Please select from this only.</p><br>
<input type='submit' value='Upload' name='but_upload'>
<br><br><br><br><br><br>
</form>
</div>
</body>
</html>
| 6dbbe91255bbac5531a923fce4e3c6378a4d1790 | [
"PHP"
] | 3 | PHP | Aakash200/Videosontips | b4bacd190f5dbc4a2c78749531d40e024f49593b | 7b098761ac7354a73421fb4fa4db46a379107635 |
refs/heads/master | <file_sep>termblox
========
A simplistic, yet fun and challenging combiner/merger game for *nix terminals.
Requirements
------------
- Node.js
- NPM
Install
-------
```bash
npm install termblox --global
```
License
-------
MIT @ 2017 - <NAME><file_sep>"use strict";
class TerminalFrame {
/**
* @param {Terminal} terminal The terminal class.
*/
constructor(terminal) {
/**
* @private
*/
this._terminal = terminal;
}
/**
* Draws the outer frame of the terminal.
*/
drawFrame() {
const term = this._terminal,
width = term.getWidth(),
height = term.getHeight();
let chars = '',
i;
// generate the top and bottom frames
for (i = 1; i < width - 1; i++) {
chars += TerminalFrame.FRAME_SYMBOLS.HORIZONTAL;
}
term
// print the top frame
.move(2, 0)
.print(chars)
// print the bottom frame
.move(2, height)
.print(chars)
;
const sideChar = TerminalFrame.FRAME_SYMBOLS.VERTICAL;
// print the left and right frames
for (i = 2; i < height; i++) {
term
// left frame
.move(0, i)
.print(sideChar)
// right frame
.move(width - 1, i)
.print(sideChar)
;
}
// draw corners
term
// top left
.move(0, 0)
.print(TerminalFrame.FRAME_SYMBOLS.TOP_LEFT_CORNER)
// top right
.move(width, 0)
.print(TerminalFrame.FRAME_SYMBOLS.TOP_RIGHT_CORNER)
// bottom left
.move(0, height)
.print(TerminalFrame.FRAME_SYMBOLS.BOTTOM_LEFT_CORNER)
// bottom right
.move(width, height)
.print(TerminalFrame.FRAME_SYMBOLS.BOTTOM_RIGHT_CORNER)
;
}
}
/**
* @typedef {Object}
*/
TerminalFrame.FRAME_SYMBOLS = {
/**
* @type {string}
*/
TOP_LEFT_CORNER: '█',
/**
* @type {string}
*/
TOP_RIGHT_CORNER: '█',
/**
/**
* @type {string}
*/
BOTTOM_LEFT_CORNER: '█',
/**
* @type {string}
*/
BOTTOM_RIGHT_CORNER: '█',
/**
* @type {string}
*/
HORIZONTAL: '█',
/**
* @type {string}
*/
VERTICAL: '██',
};
module.exports = TerminalFrame;<file_sep>"use strict";
const fs = require('fs'),
path = require('path');
const tracer = require('tracer');
/**
* @class
*/
const Logger = {
/**
* Initializes the logger.
*
* @param {string} logPath The path of the log file.
*/
init: (logPath) => {
const file = path.normalize(logPath + '/log.txt');
// delete the log file
fs.writeFileSync(file, '');
const _logger = tracer.console({
transport: (data) => {
fs.appendFile(
file,
data.rawoutput + '\n',
(error) => {
if (error) {
throw error;
}
}
);
}
});
// after initialization, assign the actual logger function of tracer
// to properly display file names and lines
Logger.log = _logger.log;
},
/**
* Logs the given message.
*
* @param {string} message The message to log.
*/
log: null,
};
module.exports = Logger;<file_sep>#!/usr/bin/env node
"use strict";
const Game = require('./Game');
Game.init();
Game.start();
Game.exit(); | 9a11ac28f7d6ed3d1647e0ef5bc110d211944b3f | [
"Markdown",
"JavaScript"
] | 4 | Markdown | termbrix/termblox | da5fae01feb16a820d26e11322b84d6734161b1e | 977ace781d5be9e3562b7862736b0537eaf59e1f |
refs/heads/main | <repo_name>keremdadak/Mvc-Stock-Project<file_sep>/Controllers/CategoryController.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.Mvc;
using MvcStok.Models.Entity;
using PagedList;
using PagedList.Mvc;
namespace MvcStok.Controllers
{
public class CategoryController : Controller
{
// GET: Category
MvcDbStokEntities db = new MvcDbStokEntities();
public ActionResult Index(int sayfa = 1)
{
// var degerler = db.tbl_Category.ToList();
var degerler = db.tbl_Category.ToList().ToPagedList(sayfa,10);
return View(degerler);
}
[HttpGet]
public ActionResult NewCategory()
{
return View();
}
[HttpPost]
public ActionResult NewCategory(tbl_Category p1)
{
if (!ModelState.IsValid) {
return View("NewCategory");
}
db.tbl_Category.Add(p1);
db.SaveChanges();
return RedirectToAction("Index");
}
public ActionResult DeleteCategory(int id)
{
var kategori = db.tbl_Category.Find(id);
db.tbl_Category.Remove(kategori);
db.SaveChanges();
return RedirectToAction("Index");
}
public ActionResult CategoryGet(int id)
{
var ctgr = db.tbl_Category.Find(id);
return View("CategoryGet",ctgr);
}
public ActionResult CategoryUpdate(tbl_Category p1)
{
var ctgr = db.tbl_Category.Find(p1.Category_ID);
ctgr.Category_Name = p1.Category_Name;
db.SaveChanges();
return RedirectToAction("Index");
}
}
}<file_sep>/Controllers/ProductController.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.Mvc;
using MvcStok.Models.Entity;
using PagedList;
using PagedList.Mvc;
namespace MvcStok.Controllers
{
public class ProductController : Controller
{
// GET: Product
MvcDbStokEntities db = new MvcDbStokEntities();
public ActionResult Index()
{
var degerler = db.tbl_Product.ToList();
return View(degerler);
}
[HttpGet]
public ActionResult NewProduct()
{
List<SelectListItem> degerler = (from i in db.tbl_Category.ToList()
select new SelectListItem {
Text=i.Category_Name,
Value=i.Category_ID.ToString()
}).ToList();
ViewBag.dgr = degerler;
return View();
}
[HttpPost]
public ActionResult NewProduct(tbl_Product p1)
{
var ktg = db.tbl_Category.Where(m=>m.Category_ID==p1.tbl_Category.Category_ID).FirstOrDefault();
p1.tbl_Category = ktg;
db.tbl_Product.Add(p1);
db.SaveChanges();
return RedirectToAction("Index");
}
public ActionResult DeleteProduct(int id)
{
var product = db.tbl_Product.Find(id);
db.tbl_Product.Remove(product);
db.SaveChanges();
return RedirectToAction("Index");
}
public ActionResult ProductGet(int id)
{
var product = db.tbl_Product.Find(id);
List<SelectListItem> degerler = (from i in db.tbl_Category.ToList()
select new SelectListItem
{
Text = i.Category_Name,
Value = i.Category_ID.ToString()
}).ToList();
ViewBag.dgr = degerler;
return View("ProductGet", product);
}
public ActionResult ProductUpdate(tbl_Product p1)
{
var pupdt = db.tbl_Product.Find(p1.Product_ID);
pupdt.Product_Name = p1.Product_Name;
pupdt.Product_Brand = p1.Product_Brand;
// pupdt.Product_Category = p1.Product_Category;
var ktg = db.tbl_Category.Where(m => m.Category_ID == p1.tbl_Category.Category_ID).FirstOrDefault();
pupdt.Product_Category = ktg.Category_ID;
pupdt.Product_Price = p1.Product_Price;
pupdt.Product_Stock = p1.Product_Stock;
db.SaveChanges();
return RedirectToAction("Index");
}
}
}<file_sep>/Controllers/SellingController.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.Mvc;
using MvcStok.Models.Entity;
namespace MvcStok.Controllers
{
public class SellingController : Controller
{
MvcDbStokEntities db = new MvcDbStokEntities();
// GET: Selling
public ActionResult Index()
{
return View();
}
[HttpGet]
public ActionResult NewSelling()
{
return View();
}
[HttpPost]
public ActionResult NewSelling(tbl_Selling p)
{
db.tbl_Selling.Add(p);
db.SaveChanges();
return View("Index");
}
public ActionResult SellingTable()
{
var degerler = db.tbl_Selling.ToList();
return View(degerler);
}
public ActionResult DeleteSelling(int id)
{
var selldelete = db.tbl_Selling.Find(id);
db.tbl_Selling.Remove(selldelete);
db.SaveChanges();
return RedirectToAction("Index");
}
}
}<file_sep>/README.md
# Mvc Stock Project
It is a weak application in design, but it is a simple stock keeping site that you can use if you adapt and make the design for yourself.
<file_sep>/Controllers/CustomerController.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.Mvc;
using MvcStok.Models.Entity;
namespace MvcStok.Controllers
{
public class CustomerController : Controller
{
// GET: Customer
MvcDbStokEntities db = new MvcDbStokEntities();
public ActionResult Index(string p)
{
var degerler = from d in db.tbl_Customers select d;
if (!string.IsNullOrEmpty(p))
{
degerler = degerler.Where(m => m.Customer_Name.Contains(p));
}
return View(degerler.ToList());
//var degerler = db.tbl_Customers.ToList();
//return View(degerler);
}
[HttpGet]
public ActionResult NewCustomer()
{
return View();
}
[HttpPost]
public ActionResult NewCustomer(tbl_Customers p1)
{
if (!ModelState.IsValid) {
return View("NewCustomer");
}
db.tbl_Customers.Add(p1);
db.SaveChanges();
return RedirectToAction("Index");
}
public ActionResult DeleteCustomer(int id)
{
var customer = db.tbl_Customers.Find(id);
db.tbl_Customers.Remove(customer);
db.SaveChanges();
return RedirectToAction("Index");
}
public ActionResult CustomerGet(int id)
{
var custmr = db.tbl_Customers.Find(id);
return View("CustomerGet",custmr);
}
public ActionResult CustomerUpdate(tbl_Customers p1)
{
var cstmr = db.tbl_Customers.Find(p1.Customer_ID);
cstmr.Customer_Name = p1.Customer_Name;
cstmr.Customer_Surname = p1.Customer_Surname;
db.SaveChanges();
return RedirectToAction("Index");
}
}
} | c09bfcb5a8494a7c32c5ac38a1069f21e60826d7 | [
"Markdown",
"C#"
] | 5 | C# | keremdadak/Mvc-Stock-Project | 456321f96c0dec78e8efb23462e9803e86f43352 | 5fbd18b7c1ba6457e404a38b369e5cbb351e9772 |
refs/heads/master | <file_sep>#code for Hello World
print ("Hello World")
<file_sep># Contributing
## How to Contribute
This repository is built for the purpose of encouraging your contributions, big or small. **All** changes are considered, as long as they do not complicate the process for others.
That said, suggested ways to contribute include:
### Your name on the readme.md
* Fork the project.
* Add your name to the readme.md using this example;
```
### My Name
- Description about me
- [![twitter-alt][twitter-img]](https://twitter.com/example)
[![github-alt][github-img]](https://github.com/example)
```
* Commit and send a pull request. Bonus points for correctly named branches.
### A code sample
* Fork the project.
* Create a code sample under `/code` named <yourname>.<language-file-extension>. I.e. `lukeoliff.js`, `lukeoliff.php`
* Create a working hello world example inside your file.
* Commit and send a pull request. Bonus points for correctly named branches.
### Anything else
* Fork the project.
* Make your change.
* Commit and send a pull request. Bonus points for correctly named branches.
## Code of Conduct
Please note that this project is released with a [Contributor Code of Conduct](CODE_OF_CONDUCT.md). By participating in this project you agree to abide by its terms.
| 097ad6d70d5ae407e850bbcce5f7c84a3d347fd6 | [
"Markdown",
"Python"
] | 2 | Python | savinabeysooriya/hacktoberfest-2018 | aed94a710a2b433eaf5644a0e136d92a21903276 | 95bd907e87fd2c8a160cf7198dddef4b5471ef05 |
refs/heads/master | <file_sep>import React, { Component } from 'react';
import './Card.css'
function Card(props) {
return (
<div className="MemeCard">
<img src={props.url} alt={props.name} />
<p>{props.name}</p>
</div>
);
}
export default Card; | 5bf5807c83b12aabb87005e455f5e76b824556e3 | [
"JavaScript"
] | 1 | JavaScript | silberov/MemeApp | 05a91a5b722f9977e06dbfd05146ce96f21f2510 | 9bf82b685ca8ac04ed139526420bf1007a766901 |
refs/heads/main | <repo_name>J-16/Design-Pattern<file_sep>/simUDuck/src/DuckProperties/NoFly.java
package DuckProperties;
import DuckPropertiesInterface.Flyable;
public class NoFly implements Flyable {
@Override
public void fly() {
System.out.println("Doesn't Flyyyyyy");
}
}
<file_sep>/simUDuck/src/Materials/RubberDuck.java
package Materials;
import DuckProperties.NoFly;
import DuckProperties.noQuack;
import DuckPropertiesInterface.Flyable;
import DuckPropertiesInterface.Quackable;
import duck.Duck;
public class RubberDuck extends Duck{
public RubberDuck(){
super(new NoFly(), new noQuack());
}
@Override
public void display() {
System.out.println("Looks like Rubber Duck");
}
}
<file_sep>/Head First Design Pattern/Intro to Design/WeatherMonitoring/src/SubjectInterface/Subject.java
package SubjectInterface;
import ObservableInterface.Observer;
public interface Subject extends Observer {
void registerObserver(Observer observer);
void removeObserver(Observer observer);
void notifyObserver();
}
<file_sep>/simUDuck/Readme.md
#SimUDuck
Intro to design pattern [Head First Design Patten].<file_sep>/simUDuck/src/Materials/decoyDuck.java
package Materials;
import DuckProperties.NoFly;
import DuckProperties.noQuack;
import duck.Duck;
public class decoyDuck extends Duck{
public decoyDuck(){
super(new NoFly(),new noQuack());
}
@Override
public void display() {
System.out.println("Looks like decoy Duck");
}
}
<file_sep>/simUDuck/src/Ducks/MallardDuck.java
package Ducks;
import DuckProperties.Fly;
import DuckProperties.Quack;
import duck.Duck;
public class MallardDuck extends Duck {
public MallardDuck(){
super(new Fly(), new Quack());
}
public void display(){
System.out.println("Looks like real MallarDuck");
}
}
<file_sep>/simUDuck/src/duck/Duck.java
package duck;
import DuckPropertiesInterface.Flyable;
import DuckPropertiesInterface.Quackable;
public abstract class Duck {
//QUACK AND FLY ARE MOVED TO INTERFACE AS NOT ALL DUCKS QUACKS AND FLIES.
Flyable flyable;
Quackable quackable;
public Duck(){ }
public Duck(Flyable flyable, Quackable quackable){
this.flyable = flyable;
this.quackable = quackable;
}
public void setFlyable(Flyable flyable) {
this.flyable = flyable;
}
public void setQuackable(Quackable quackable) {
this.quackable = quackable;
}
public void swim(){
System.out.println("Swimming");
}
public void fly(){
flyable.fly();
}
public void quack(){
quackable.quack();
}
public abstract void display();
}
| 22ca2d611e7d86419adbdc0c602d4482cdce5b15 | [
"Markdown",
"Java"
] | 7 | Java | J-16/Design-Pattern | 8c761b0f8421c8f8986d5b660fcffd471331c3ec | c8764e313daa66cf619b1420dc86b890e51456e5 |
refs/heads/develop | <repo_name>CarstenFrommhold/great_expectations<file_sep>/docs/guides/validation/checkpoints/components_how_to_create_a_new_checkpoint/_a_edit_the_configuration.mdx
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
The sample Checkpoint configuration in your Jupyter Notebook will utilize the `SimpleCheckpoint` class, which takes care of some defaults.
To update this configuration to suit your environment, you will need to replace the names `my_datasource`, `my_data_connector`, `MyDataAsset` and `my_suite` with the respective <TechnicalTag tag="datasource" text="Datasource" />, <TechnicalTag tag="data_connector" text="Data Connector" />, <TechnicalTag tag="data_asset" text="Data Asset" />, and <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> names you have configured in your `great_expectations.yml`.
```yaml title="Example YAML configuration, as a Python string"
config = """
name: my_checkpoint # This is populated by the CLI.
config_version: 1
class_name: SimpleCheckpoint
validations:
- batch_request:
datasource_name: my_datasource # Update this value.
data_connector_name: my_data_connector # Update this value.
data_asset_name: MyDataAsset # Update this value.
data_connector_query:
index: -1
expectation_suite_name: my_suite # Update this value.
"""
```
This is the minimum required to configure a Checkpoint that will run the Expectation Suite `my_suite` against the Data Asset `MyDataAsset`.
See [How to configure a new Checkpoint using test_yaml_config](../how_to_configure_a_new_checkpoint_using_test_yaml_config.md) for advanced configuration options.
<file_sep>/docs/tutorials/getting_started/tutorial_version_snippet.mdx
```
great_expectations, version 0.15.34
```<file_sep>/tests/data_context/cloud_data_context/test_checkpoint_crud.py
import copy
from typing import Callable, Tuple, Type
from unittest import mock
import pytest
from great_expectations.data_context.cloud_constants import GXCloudRESTResource
from great_expectations.data_context.data_context.abstract_data_context import (
AbstractDataContext,
)
from great_expectations.data_context.data_context.base_data_context import (
BaseDataContext,
)
from great_expectations.data_context.data_context.cloud_data_context import (
CloudDataContext,
)
from great_expectations.data_context.data_context.data_context import DataContext
from great_expectations.data_context.types.base import (
CheckpointConfig,
DataContextConfig,
GXCloudConfig,
checkpointConfigSchema,
)
from great_expectations.data_context.types.resource_identifiers import GXCloudIdentifier
from tests.data_context.conftest import MockResponse
@pytest.fixture
def checkpoint_id() -> str:
return "c83e4299-6188-48c6-83b7-f6dce8ad4ab5"
@pytest.fixture
def validation_ids() -> Tuple[str, str]:
validation_id_1 = "v8764797-c486-4104-a764-1f2bf9630ee1"
validation_id_2 = "vd0185a8-11c2-11ed-861d-0242ac120002"
return validation_id_1, validation_id_2
@pytest.fixture
def checkpoint_config_with_ids(
checkpoint_config: dict, checkpoint_id: str, validation_ids: Tuple[str, str]
) -> dict:
validation_id_1, validation_id_2 = validation_ids
updated_checkpoint_config = copy.deepcopy(checkpoint_config)
updated_checkpoint_config["id"] = checkpoint_id
updated_checkpoint_config["validations"][0]["id"] = validation_id_1
updated_checkpoint_config["validations"][1]["id"] = validation_id_2
return updated_checkpoint_config
@pytest.fixture
def mocked_post_response(
mock_response_factory: Callable, checkpoint_id: str, validation_ids: Tuple[str, str]
) -> Callable[[], MockResponse]:
validation_id_1, validation_id_2 = validation_ids
def _mocked_post_response(*args, **kwargs):
return mock_response_factory(
{
"data": {
"id": checkpoint_id,
"validations": [
{"id": validation_id_1},
{"id": validation_id_2},
],
}
},
201,
)
return _mocked_post_response
@pytest.fixture
def mocked_put_response(
mock_response_factory: Callable, checkpoint_id: str, validation_ids: Tuple[str, str]
) -> Callable[[], MockResponse]:
def _mocked_put_response(*args, **kwargs):
return mock_response_factory(
{},
204,
)
return _mocked_put_response
@pytest.fixture
def mocked_get_response(
mock_response_factory: Callable,
checkpoint_config_with_ids: dict,
checkpoint_id: str,
) -> Callable[[], MockResponse]:
def _mocked_get_response(*args, **kwargs):
created_by_id = "c06ac6a2-52e0-431e-b878-9df624edc8b8"
organization_id = "046fe9bc-c85b-4e95-b1af-e4ce36ba5384"
return mock_response_factory(
{
"data": {
"attributes": {
"checkpoint_config": checkpoint_config_with_ids,
"created_at": "2022-08-02T17:55:45.107550",
"created_by_id": created_by_id,
"deleted": False,
"deleted_at": None,
"desc": None,
"name": "oss_test_checkpoint",
"organization_id": f"{organization_id}",
"updated_at": "2022-08-02T17:55:45.107550",
},
"id": checkpoint_id,
"links": {
"self": f"/organizations/{organization_id}/checkpoints/{checkpoint_id}"
},
"type": "checkpoint",
},
},
200,
)
return _mocked_get_response
@pytest.mark.cloud
@pytest.mark.integration
@pytest.mark.parametrize(
"data_context_fixture_name,data_context_type",
[
# In order to leverage existing fixtures in parametrization, we provide
# their string names and dynamically retrieve them using pytest's built-in
# `request` fixture.
# Source: https://stackoverflow.com/a/64348247
pytest.param(
"empty_base_data_context_in_cloud_mode",
BaseDataContext,
id="BaseDataContext",
),
pytest.param("empty_data_context_in_cloud_mode", DataContext, id="DataContext"),
pytest.param(
"empty_cloud_data_context", CloudDataContext, id="CloudDataContext"
),
],
)
def test_cloud_backed_data_context_add_checkpoint(
data_context_fixture_name: str,
data_context_type: Type[AbstractDataContext],
checkpoint_id: str,
validation_ids: Tuple[str, str],
checkpoint_config: dict,
mocked_post_response: Callable[[], MockResponse],
mocked_get_response: Callable[[], MockResponse],
ge_cloud_base_url: str,
ge_cloud_organization_id: str,
request,
) -> None:
"""
All Cloud-backed contexts (DataContext, BaseDataContext, and CloudDataContext) should save to a Cloud-backed CheckpointStore when calling `add_checkpoint`.
When saving, it should use the id from the response to create the checkpoint.
"""
context = request.getfixturevalue(data_context_fixture_name)
# Make sure the fixture has the right configuration
assert isinstance(context, data_context_type)
assert context.ge_cloud_mode
validation_id_1, validation_id_2 = validation_ids
with mock.patch(
"requests.Session.post", autospec=True, side_effect=mocked_post_response
) as mock_post, mock.patch(
"requests.Session.get", autospec=True, side_effect=mocked_get_response
) as mock_get:
checkpoint = context.add_checkpoint(**checkpoint_config)
# Round trip through schema to mimic updates made during store serialization process
expected_checkpoint_config = checkpointConfigSchema.dump(
CheckpointConfig(**checkpoint_config)
)
mock_post.assert_called_with(
mock.ANY, # requests.Session object
f"{ge_cloud_base_url}/organizations/{ge_cloud_organization_id}/checkpoints",
json={
"data": {
"type": "checkpoint",
"attributes": {
"checkpoint_config": expected_checkpoint_config,
"organization_id": ge_cloud_organization_id,
},
},
},
)
mock_get.assert_called_with(
mock.ANY, # requests.Session object
f"{ge_cloud_base_url}/organizations/{ge_cloud_organization_id}/checkpoints/{checkpoint_id}",
params={"name": checkpoint_config["name"]},
)
assert checkpoint.ge_cloud_id == checkpoint_id
assert checkpoint.config.ge_cloud_id == checkpoint_id
assert checkpoint.config.validations[0]["id"] == validation_id_1
assert checkpoint.validations[0]["id"] == validation_id_1
assert checkpoint.config.validations[1]["id"] == validation_id_2
assert checkpoint.validations[1]["id"] == validation_id_2
@pytest.mark.cloud
@pytest.mark.integration
@pytest.mark.parametrize(
"data_context_fixture_name,data_context_type",
[
# In order to leverage existing fixtures in parametrization, we provide
# their string names and dynamically retrieve them using pytest's built-in
# `request` fixture.
# Source: https://stackoverflow.com/a/64348247
pytest.param(
"empty_base_data_context_in_cloud_mode",
BaseDataContext,
id="BaseDataContext",
),
pytest.param("empty_data_context_in_cloud_mode", DataContext, id="DataContext"),
pytest.param(
"empty_cloud_data_context", CloudDataContext, id="CloudDataContext"
),
],
)
def test_add_checkpoint_updates_existing_checkpoint_in_cloud_backend(
data_context_fixture_name: str,
data_context_type: Type[AbstractDataContext],
checkpoint_config: dict,
checkpoint_id: str,
mocked_post_response: Callable[[], MockResponse],
mocked_put_response: Callable[[], MockResponse],
mocked_get_response: Callable[[], MockResponse],
ge_cloud_base_url: str,
ge_cloud_organization_id: str,
request,
) -> None:
context = request.getfixturevalue(data_context_fixture_name)
# Make sure the fixture has the right configuration
assert isinstance(context, data_context_type)
assert context.ge_cloud_mode
with mock.patch(
"requests.Session.post", autospec=True, side_effect=mocked_post_response
) as mock_post, mock.patch(
"requests.Session.put", autospec=True, side_effect=mocked_put_response
) as mock_put, mock.patch(
"requests.Session.get", autospec=True, side_effect=mocked_get_response
) as mock_get:
checkpoint_1 = context.add_checkpoint(**checkpoint_config)
checkpoint_2 = context.add_checkpoint(
ge_cloud_id=checkpoint_1.ge_cloud_id, **checkpoint_config
)
# Round trip through schema to mimic updates made during store serialization process
expected_checkpoint_config = checkpointConfigSchema.dump(
CheckpointConfig(**checkpoint_config)
)
# Called during creation of `checkpoint_1`
mock_post.assert_called_once_with(
mock.ANY, # requests.Session object
f"{ge_cloud_base_url}/organizations/{ge_cloud_organization_id}/checkpoints",
json={
"data": {
"type": "checkpoint",
"attributes": {
"checkpoint_config": expected_checkpoint_config,
"organization_id": ge_cloud_organization_id,
},
},
},
)
# Always called by store after POST and PATCH calls
assert mock_get.call_count == 2
mock_get.assert_called_with(
mock.ANY, # requests.Session object
f"{ge_cloud_base_url}/organizations/{ge_cloud_organization_id}/checkpoints/{checkpoint_id}",
params={"name": checkpoint_config["name"]},
)
expected_checkpoint_config["ge_cloud_id"] = checkpoint_id
# Called during creation of `checkpoint_2` (which is `checkpoint_1` but updated)
mock_put.assert_called_once_with(
mock.ANY, # requests.Session object
f"{ge_cloud_base_url}/organizations/{ge_cloud_organization_id}/checkpoints/{checkpoint_id}",
json={
"data": {
"type": "checkpoint",
"attributes": {
"checkpoint_config": expected_checkpoint_config,
"organization_id": ge_cloud_organization_id,
},
"id": checkpoint_id,
},
},
)
assert checkpoint_1.ge_cloud_id == checkpoint_2.ge_cloud_id
@pytest.mark.xfail(
reason="GX Cloud E2E tests are currently failing due to a schema issue with DataContextVariables; xfailing for purposes of the 0.15.20 release",
run=True,
strict=True,
)
@pytest.mark.e2e
@pytest.mark.cloud
@mock.patch("great_expectations.data_context.DataContext._save_project_config")
def test_cloud_backed_data_context_add_checkpoint_e2e(
mock_save_project_config: mock.MagicMock,
checkpoint_config: dict,
) -> None:
context = DataContext(ge_cloud_mode=True)
checkpoint = context.add_checkpoint(**checkpoint_config)
ge_cloud_id = checkpoint.ge_cloud_id
checkpoint_stored_in_cloud = context.get_checkpoint(ge_cloud_id=ge_cloud_id)
assert checkpoint.ge_cloud_id == checkpoint_stored_in_cloud.ge_cloud_id
assert (
checkpoint.config.to_json_dict()
== checkpoint_stored_in_cloud.config.to_json_dict()
)
@pytest.fixture
def checkpoint_names_and_ids() -> Tuple[Tuple[str, str], Tuple[str, str]]:
checkpoint_name_1 = "Test Checkpoint 1"
checkpoint_id_1 = "9db8721d-52e3-4263-90b3-ddb83a7aca04"
checkpoint_name_2 = "Test Checkpoint 2"
checkpoint_id_2 = "88972771-1774-4e7c-b76a-0c30063bea55"
checkpoint_1 = (checkpoint_name_1, checkpoint_id_1)
checkpoint_2 = (checkpoint_name_2, checkpoint_id_2)
return checkpoint_1, checkpoint_2
@pytest.fixture
def mock_get_all_checkpoints_json(
checkpoint_names_and_ids: Tuple[Tuple[str, str], Tuple[str, str]]
) -> dict:
checkpoint_1, checkpoint_2 = checkpoint_names_and_ids
checkpoint_name_1, checkpoint_id_1 = checkpoint_1
checkpoint_name_2, checkpoint_id_2 = checkpoint_2
mock_json = {
"data": [
{
"attributes": {
"checkpoint_config": {
"action_list": [],
"batch_request": {},
"class_name": "Checkpoint",
"config_version": 1.0,
"evaluation_parameters": {},
"module_name": "great_expectations.checkpoint",
"name": checkpoint_name_1,
"profilers": [],
"run_name_template": None,
"runtime_configuration": {},
"template_name": None,
"validations": [
{
"batch_request": {
"data_asset_name": "my_data_asset",
"data_connector_name": "my_data_connector",
"data_connector_query": {"index": 0},
"datasource_name": "data__dir",
},
"expectation_suite_name": "raw_health.critical",
}
],
},
"class_name": "Checkpoint",
"created_by_id": "329eb0a6-6559-4221-8b27-131a9185118d",
"default_validation_id": None,
"id": checkpoint_id_1,
"name": checkpoint_name_1,
"organization_id": "77eb8b08-f2f4-40b1-8b41-50e7fbedcda3",
},
"id": checkpoint_id_1,
"type": "checkpoint",
},
{
"attributes": {
"checkpoint_config": {
"action_list": [],
"batch_request": {},
"class_name": "Checkpoint",
"config_version": 1.0,
"evaluation_parameters": {},
"module_name": "great_expectations.checkpoint",
"name": checkpoint_name_2,
"profilers": [],
"run_name_template": None,
"runtime_configuration": {},
"template_name": None,
"validations": [
{
"batch_request": {
"data_asset_name": "my_data_asset",
"data_connector_name": "my_data_connector",
"data_connector_query": {"index": 0},
"datasource_name": "data__dir",
},
"expectation_suite_name": "raw_health.critical",
}
],
},
"class_name": "Checkpoint",
"created_by_id": "329eb0a6-6559-4221-8b27-131a9185118d",
"default_validation_id": None,
"id": checkpoint_id_2,
"name": checkpoint_name_2,
"organization_id": "77eb8b08-f2f4-40b1-8b41-50e7fbedcda3",
},
"id": checkpoint_id_2,
"type": "checkpoint",
},
]
}
return mock_json
@pytest.mark.unit
@pytest.mark.cloud
def test_list_checkpoints(
empty_ge_cloud_data_context_config: DataContextConfig,
ge_cloud_config: GXCloudConfig,
checkpoint_names_and_ids: Tuple[Tuple[str, str], Tuple[str, str]],
mock_get_all_checkpoints_json: dict,
) -> None:
project_path_name = "foo/bar/baz"
context = BaseDataContext(
project_config=empty_ge_cloud_data_context_config,
context_root_dir=project_path_name,
ge_cloud_config=ge_cloud_config,
ge_cloud_mode=True,
)
checkpoint_1, checkpoint_2 = checkpoint_names_and_ids
checkpoint_name_1, checkpoint_id_1 = checkpoint_1
checkpoint_name_2, checkpoint_id_2 = checkpoint_2
with mock.patch("requests.Session.get", autospec=True) as mock_get:
mock_get.return_value = mock.Mock(
status_code=200, json=lambda: mock_get_all_checkpoints_json
)
checkpoints = context.list_checkpoints()
assert checkpoints == [
GXCloudIdentifier(
resource_type=GXCloudRESTResource.CHECKPOINT,
ge_cloud_id=checkpoint_id_1,
resource_name=checkpoint_name_1,
),
GXCloudIdentifier(
resource_type=GXCloudRESTResource.CHECKPOINT,
ge_cloud_id=checkpoint_id_2,
resource_name=checkpoint_name_2,
),
]
<file_sep>/docs/guides/expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md
---
title: How to create and edit Expectations with instant feedback from a sample Batch of data
---
import Preface from './components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_preface.mdx'
import UseTheCliToBeginTheInteractiveProcessOfCreatingExpectations from './components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_use_the_cli_to_begin_the_interactive_process_of_creating_expectations.mdx'
import SpecifyADatasourceIfMultipleAreAvailable from './components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_specify_a_datasource_if_multiple_are_available.mdx'
import SpecifyTheNameOfYourNewExpectationSuite from './components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_specify_the_name_of_your_new_expectation_suite.mdx'
import ContinueTheWorkflowWithinAJupyterNotebook from './components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_continue_the_workflow_within_a_jupyter_notebook.mdx'
import Congrats from './components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_congrats.mdx'
import OptionalEditAnExistingExpectationSuiteInInteractiveMode from './components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_optional_edit_an_existing_expectation_suite_in_interactive_mode.mdx'
import OptionalProfileYourDataToGenerateExpectationsThenEditThemInInteractiveMode from './components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_optional_profile_your_data_to_generate_expectations_then_edit_them_in_interactive_mode.mdx'
import SaveABatchRequestToReuseWhenEditingAnExpectationSuiteInInteractiveMode from './components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_save_a_batch_request_to_reuse_when_editing_an_expectation_suite_in_interactive_mode.mdx'
import UseTheBuiltInHelpToReviewTheCliSSuiteNewOptionalFlags from './components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_use_the_builtin_help_to_review_the_clis_suite_new_optional_flags.mdx'
<Preface />
## Steps
### 1. Use the CLI to begin the interactive process of creating Expectations
<UseTheCliToBeginTheInteractiveProcessOfCreatingExpectations />
### 2. Specify a Datasource (if multiple are available)
<SpecifyADatasourceIfMultipleAreAvailable />
### 3. Specify the name of your new Expectation Suite
<SpecifyTheNameOfYourNewExpectationSuite />
### 4. Continue the workflow within a Jupyter Notebook
<ContinueTheWorkflowWithinAJupyterNotebook />
<Congrats />
## Optional alternative Interactive Mode workflows
### 1. (Optional) Edit an existing Expectation Suite in Interactive Mode
<OptionalEditAnExistingExpectationSuiteInInteractiveMode />
### 2. (Optional) Profile your data to generate Expectations, then edit them in Interactive Mode.
<OptionalProfileYourDataToGenerateExpectationsThenEditThemInInteractiveMode />
## Additional tips and tricks
### 1. Save a Batch Request to reuse when editing an Expectation Suite in Interactive Mode
<SaveABatchRequestToReuseWhenEditingAnExpectationSuiteInInteractiveMode />
### 2. Use the built-in help to review the CLI's `suite new` optional flags
<UseTheBuiltInHelpToReviewTheCliSSuiteNewOptionalFlags />
<file_sep>/docs/deployment_patterns/reference_architecture_overview.md
---
title: Reference Architectures
---
## Overview
In this section of the documentation you will find our guides on how to work with third party products and services alongside Great Expectations.
Some of these guides were written by the teams who maintain those products, though many were written by the Great Expectations team as well.
For those who are interested, we have [a guide on how to contribute integration documentation](../integrations/contributing_integration.md). If you have a third party product or service that you would like to collaborate on building an integration for, please reach out to us on [Slack](https://greatexpectations.io/slack).
<file_sep>/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/metrics/__init__.py
# Make sure to include any Metrics your want exported below!
from .data_profiler_metrics.data_profiler_profile_diff import DataProfilerProfileDiff
from .data_profiler_metrics.data_profiler_profile_metric_provider import (
DataProfilerProfileMetricProvider,
)
from .data_profiler_metrics.data_profiler_profile_numeric_columns import (
DataProfilerProfileNumericColumns,
)
from .data_profiler_metrics.data_profiler_profile_percent_diff import (
DataProfilerProfilePercentDiff,
)
from .data_profiler_metrics.data_profiler_profile_report import (
DataProfilerProfileReport,
)
<file_sep>/tests/integration/docusaurus/reference/core_concepts/checkpoints_and_actions.py
import os
from ruamel import yaml
import great_expectations as ge
from great_expectations.core.batch import BatchRequest
from great_expectations.core.expectation_validation_result import (
ExpectationSuiteValidationResult,
)
from great_expectations.core.run_identifier import RunIdentifier
from great_expectations.data_context.types.base import CheckpointConfig
from great_expectations.data_context.types.resource_identifiers import (
ValidationResultIdentifier,
)
yaml = yaml.YAML(typ="safe")
context = ge.get_context()
# Add datasource for all tests
datasource_yaml = """
name: taxi_datasource
class_name: Datasource
module_name: great_expectations.datasource
execution_engine:
module_name: great_expectations.execution_engine
class_name: PandasExecutionEngine
data_connectors:
default_inferred_data_connector_name:
class_name: InferredAssetFilesystemDataConnector
base_directory: ../data/
default_regex:
group_names:
- data_asset_name
pattern: (.*)\\.csv
default_runtime_data_connector_name:
class_name: RuntimeDataConnector
batch_identifiers:
- default_identifier_name
"""
context.test_yaml_config(datasource_yaml)
context.add_datasource(**yaml.load(datasource_yaml))
assert [ds["name"] for ds in context.list_datasources()] == ["taxi_datasource"]
context.create_expectation_suite("my_expectation_suite")
context.create_expectation_suite("my_other_expectation_suite")
# Add a Checkpoint
checkpoint_yaml = """
name: test_checkpoint
config_version: 1
class_name: Checkpoint
run_name_template: "%Y-%M-foo-bar-template"
validations:
- batch_request:
datasource_name: taxi_datasource
data_connector_name: default_inferred_data_connector_name
data_asset_name: yellow_tripdata_sample_2019-01
expectation_suite_name: my_expectation_suite
action_list:
- name: <ACTION NAME FOR STORING VALIDATION RESULTS>
action:
class_name: StoreValidationResultAction
- name: <ACTION NAME FOR STORING EVALUATION PARAMETERS>
action:
class_name: StoreEvaluationParametersAction
- name: <ACTION NAME FOR UPDATING DATA DOCS>
action:
class_name: UpdateDataDocsAction
"""
context.add_checkpoint(**yaml.load(checkpoint_yaml))
assert context.list_checkpoints() == ["test_checkpoint"]
results = context.run_checkpoint(checkpoint_name="test_checkpoint")
assert results.success is True
run_id_type = type(results.run_id)
assert run_id_type == RunIdentifier
validation_result_id_type_set = {type(k) for k in results.run_results.keys()}
assert len(validation_result_id_type_set) == 1
validation_result_id_type = next(iter(validation_result_id_type_set))
assert validation_result_id_type == ValidationResultIdentifier
validation_result_id = results.run_results[[k for k in results.run_results.keys()][0]]
assert (
type(validation_result_id["validation_result"]) == ExpectationSuiteValidationResult
)
assert isinstance(results.checkpoint_config, CheckpointConfig)
typed_results = {
"run_id": run_id_type,
"run_results": {
validation_result_id_type: {
"validation_result": type(validation_result_id["validation_result"]),
"actions_results": {
"<ACTION NAME FOR STORING VALIDATION RESULTS>": {
"class": "StoreValidationResultAction"
}
},
}
},
"checkpoint_config": CheckpointConfig,
"success": True,
}
# <snippet>
results = {
"run_id": RunIdentifier,
"run_results": {
ValidationResultIdentifier: {
"validation_result": ExpectationSuiteValidationResult,
"actions_results": {
"<ACTION NAME FOR STORING VALIDATION RESULTS>": {
"class": "StoreValidationResultAction"
}
},
}
},
"checkpoint_config": CheckpointConfig,
"success": True,
}
# </snippet>
assert typed_results == results
# A few different Checkpoint examples
os.environ["VAR"] = "ge"
batch_request = BatchRequest(
datasource_name="taxi_datasource",
data_connector_name="default_inferred_data_connector_name",
data_asset_name="yellow_tripdata_sample_2019-01",
)
validator = context.get_validator(
batch_request=batch_request, expectation_suite_name="my_expectation_suite"
)
validator.expect_table_row_count_to_be_between(
min_value={"$PARAMETER": "GT_PARAM", "$PARAMETER.GT_PARAM": 0},
max_value={"$PARAMETER": "LT_PARAM", "$PARAMETER.LT_PARAM": 1000000},
)
validator.save_expectation_suite(discard_failed_expectations=False)
validator = context.get_validator(
batch_request=batch_request, expectation_suite_name="my_other_expectation_suite"
)
validator.expect_table_row_count_to_be_between(
min_value={"$PARAMETER": "GT_PARAM", "$PARAMETER.GT_PARAM": 0},
max_value={"$PARAMETER": "LT_PARAM", "$PARAMETER.LT_PARAM": 1000000},
)
validator.save_expectation_suite(discard_failed_expectations=False)
# <snippet>
no_nesting = f"""
name: my_checkpoint
config_version: 1
class_name: Checkpoint
run_name_template: "%Y-%M-foo-bar-template-$VAR"
validations:
- batch_request:
datasource_name: taxi_datasource
data_connector_name: default_inferred_data_connector_name
data_asset_name: yellow_tripdata_sample_2019-01
expectation_suite_name: my_expectation_suite
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
evaluation_parameters:
GT_PARAM: 1000
LT_PARAM: 50000
runtime_configuration:
result_format:
result_format: BASIC
partial_unexpected_count: 20
"""
# </snippet>
context.add_checkpoint(**yaml.load(no_nesting))
# <snippet>
results = context.run_checkpoint(checkpoint_name="my_checkpoint")
# </snippet>
assert results.success is True
assert (
list(results.run_results.items())[0][1]["validation_result"]["results"][0][
"expectation_config"
]["kwargs"]["max_value"]
== 50000
)
assert (
list(results.run_results.items())[0][1]["validation_result"]["results"][0][
"expectation_config"
]["kwargs"]["min_value"]
== 1000
)
# <snippet>
nesting_with_defaults = """
name: my_checkpoint
config_version: 1
class_name: Checkpoint
run_name_template: "%Y-%M-foo-bar-template-$VAR"
validations:
- batch_request:
datasource_name: taxi_datasource
data_connector_name: default_inferred_data_connector_name
data_asset_name: yellow_tripdata_sample_2019-01
- batch_request:
datasource_name: taxi_datasource
data_connector_name: default_inferred_data_connector_name
data_asset_name: yellow_tripdata_sample_2019-02
expectation_suite_name: my_expectation_suite
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
evaluation_parameters:
GT_PARAM: 1000
LT_PARAM: 50000
runtime_configuration:
result_format:
result_format: BASIC
partial_unexpected_count: 20
"""
# </snippet>
context.add_checkpoint(**yaml.load(nesting_with_defaults))
# <snippet>
results = context.run_checkpoint(checkpoint_name="my_checkpoint")
# </snippet>
assert results.success is True
# <snippet>
first_validation_result = list(results.run_results.items())[0][1]["validation_result"]
second_validation_result = list(results.run_results.items())[1][1]["validation_result"]
first_expectation_suite = first_validation_result["meta"]["expectation_suite_name"]
first_data_asset = first_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
second_expectation_suite = second_validation_result["meta"]["expectation_suite_name"]
second_data_asset = second_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
assert first_expectation_suite == "my_expectation_suite"
assert first_data_asset == "yellow_tripdata_sample_2019-01"
assert second_expectation_suite == "my_expectation_suite"
assert second_data_asset == "yellow_tripdata_sample_2019-02"
# </snippet>
# <snippet>
documentation_results = """
print(first_expectation_suite)
my_expectation_suite
print(first_data_asset)
yellow_tripdata_sample_2019-01
print(second_expectation_suite)
my_expectation_suite
print(second_data_asset)
yellow_tripdata_sample_2019-02
"""
# </snippet>
# <snippet>
keys_passed_at_runtime = """
name: my_base_checkpoint
config_version: 1
class_name: Checkpoint
run_name_template: "%Y-%M-foo-bar-template-$VAR"
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
evaluation_parameters:
GT_PARAM: 1000
LT_PARAM: 50000
runtime_configuration:
result_format:
result_format: BASIC
partial_unexpected_count: 20
"""
# </snippet>
context.add_checkpoint(**yaml.load(keys_passed_at_runtime))
# <snippet>
results = context.run_checkpoint(
checkpoint_name="my_base_checkpoint",
validations=[
{
"batch_request": {
"datasource_name": "taxi_datasource",
"data_connector_name": "default_inferred_data_connector_name",
"data_asset_name": "yellow_tripdata_sample_2019-01",
},
"expectation_suite_name": "my_expectation_suite",
},
{
"batch_request": {
"datasource_name": "taxi_datasource",
"data_connector_name": "default_inferred_data_connector_name",
"data_asset_name": "yellow_tripdata_sample_2019-02",
},
"expectation_suite_name": "my_other_expectation_suite",
},
],
)
# </snippet>
assert results.success is True
# <snippet>
first_validation_result = list(results.run_results.items())[0][1]["validation_result"]
second_validation_result = list(results.run_results.items())[1][1]["validation_result"]
first_expectation_suite = first_validation_result["meta"]["expectation_suite_name"]
first_data_asset = first_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
second_expectation_suite = second_validation_result["meta"]["expectation_suite_name"]
second_data_asset = second_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
assert first_expectation_suite == "my_expectation_suite"
assert first_data_asset == "yellow_tripdata_sample_2019-01"
assert second_expectation_suite == "my_other_expectation_suite"
assert second_data_asset == "yellow_tripdata_sample_2019-02"
# </snippet>
# <snippet>
documentation_results = """
print(first_expectation_suite)
my_expectation_suite
print(first_data_asset)
yellow_tripdata_sample_2019-01
print(second_expectation_suite)
my_other_expectation_suite
print(second_data_asset)
yellow_tripdata_sample_2019-02
"""
# </snippet>
context.create_expectation_suite("my_expectation_suite", overwrite_existing=True)
context.create_expectation_suite("my_other_expectation_suite", overwrite_existing=True)
# <snippet>
using_template = """
name: my_checkpoint
config_version: 1
class_name: Checkpoint
template_name: my_base_checkpoint
validations:
- batch_request:
datasource_name: taxi_datasource
data_connector_name: default_inferred_data_connector_name
data_asset_name: yellow_tripdata_sample_2019-01
expectation_suite_name: my_expectation_suite
- batch_request:
datasource_name: taxi_datasource
data_connector_name: default_inferred_data_connector_name
data_asset_name: yellow_tripdata_sample_2019-02
expectation_suite_name: my_other_expectation_suite
"""
# </snippet>
context.add_checkpoint(**yaml.load(using_template))
# <snippet>
results = context.run_checkpoint(checkpoint_name="my_checkpoint")
# </snippet>
assert results.success is True
# <snippet>
first_validation_result = list(results.run_results.items())[0][1]["validation_result"]
second_validation_result = list(results.run_results.items())[1][1]["validation_result"]
first_expectation_suite = first_validation_result["meta"]["expectation_suite_name"]
first_data_asset = first_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
second_expectation_suite = second_validation_result["meta"]["expectation_suite_name"]
second_data_asset = second_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
assert first_expectation_suite == "my_expectation_suite"
assert first_data_asset == "yellow_tripdata_sample_2019-01"
assert second_expectation_suite == "my_other_expectation_suite"
assert second_data_asset == "yellow_tripdata_sample_2019-02"
# </snippet>
# <snippet>
documentation_results = """
print(first_expectation_suite)
my_expectation_suite
print(first_data_asset)
yellow_tripdata_sample_2019-01"
print(second_expectation_suite)
my_other_expectation_suite
print(second_data_asset)
yellow_tripdata_sample_2019-02
"""
# </snippet>
# <snippet>
using_simple_checkpoint = """
name: my_checkpoint
config_version: 1
class_name: SimpleCheckpoint
validations:
- batch_request:
datasource_name: taxi_datasource
data_connector_name: default_inferred_data_connector_name
data_asset_name: yellow_tripdata_sample_2019-01
expectation_suite_name: my_expectation_suite
site_names: all
slack_webhook: <YOUR SLACK WEBHOOK URL>
notify_on: failure
notify_with: all
"""
# </snippet>
using_simple_checkpoint = using_simple_checkpoint.replace(
"<YOUR SLACK WEBHOOK URL>", "https://hooks.slack.com/foo/bar"
)
context.add_checkpoint(**yaml.load(using_simple_checkpoint))
# <snippet>
results = context.run_checkpoint(checkpoint_name="my_checkpoint")
# </snippet>
assert results.success is True
validation_result = list(results.run_results.items())[0][1]["validation_result"]
# <snippet>
expectation_suite = validation_result["meta"]["expectation_suite_name"]
data_asset = validation_result["meta"]["active_batch_definition"]["data_asset_name"]
assert expectation_suite == "my_expectation_suite"
assert data_asset == "yellow_tripdata_sample_2019-01"
# </snippet>
# <snippet>
documentation_results: str = """
print(expectation_suite)
my_expectation_suite
"""
# </snippet>
# <snippet>
equivalent_using_checkpoint = """
name: my_checkpoint
config_version: 1
class_name: Checkpoint
validations:
- batch_request:
datasource_name: taxi_datasource
data_connector_name: default_inferred_data_connector_name
data_asset_name: yellow_tripdata_sample_2019-01
expectation_suite_name: my_expectation_suite
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
- name: send_slack_notification
action:
class_name: SlackNotificationAction
slack_webhook: <YOUR SLACK WEBHOOK URL>
notify_on: failure
notify_with: all
renderer:
module_name: great_expectations.render.renderer.slack_renderer
class_name: SlackRenderer
"""
# </snippet>
equivalent_using_checkpoint = equivalent_using_checkpoint.replace(
"<YOUR SLACK WEBHOOK URL>", "https://hooks.slack.com/foo/bar"
)
context.add_checkpoint(**yaml.load(equivalent_using_checkpoint))
# <snippet>
results = context.run_checkpoint(checkpoint_name="my_checkpoint")
# </snippet>
assert results.success is True
validation_result = list(results.run_results.items())[0][1]["validation_result"]
# <snippet>
expectation_suite = validation_result["meta"]["expectation_suite_name"]
data_asset = validation_result["meta"]["active_batch_definition"]["data_asset_name"]
assert expectation_suite == "my_expectation_suite"
assert data_asset == "yellow_tripdata_sample_2019-01"
# </snippet>
# <snippet>
documentation_results: str = """
print(expectation_suite)
my_expectation_suite
print(data_asset)
yellow_tripdata_sample_2019-01"
"""
# </snippet>
<file_sep>/tests/integration/docusaurus/miscellaneous/migration_guide_postgresql_v2_api.py
import os
from ruamel import yaml
import great_expectations as ge
CONNECTION_STRING = "postgresql+psycopg2://postgres:@localhost/test_ci"
# This utility is not for general use. It is only to support testing.
from tests.test_utils import load_data_into_test_database
load_data_into_test_database(
table_name="titanic",
csv_path="./data/Titanic.csv",
connection_string=CONNECTION_STRING,
load_full_dataset=True,
)
context = ge.get_context()
# parse great_expectations.yml for comparison
great_expectations_yaml_file_path = os.path.join(
context.root_directory, "great_expectations.yml"
)
with open(great_expectations_yaml_file_path) as f:
great_expectations_yaml = yaml.safe_load(f)
actual_datasource = great_expectations_yaml["datasources"]
# expected Datasource
expected_existing_datasource_yaml = r"""
my_postgres_datasource:
class_name: SqlAlchemyDatasource
module_name: great_expectations.datasource
data_asset_type:
module_name: great_expectations.dataset
class_name: SqlAlchemyDataset
connection_string: postgresql+psycopg2://postgres:@localhost/test_ci
"""
assert actual_datasource == yaml.safe_load(expected_existing_datasource_yaml)
actual_validation_operators = great_expectations_yaml["validation_operators"]
# expected Validation Operators
expected_existing_validation_operators_yaml = """
action_list_operator:
class_name: ActionListValidationOperator
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
"""
assert actual_validation_operators == yaml.safe_load(
expected_existing_validation_operators_yaml
)
# check that checkpoint contains the right configuration
# parse great_expectations.yml for comparison
checkpoint_yaml_file_path = os.path.join(
context.root_directory, "checkpoints/test_v2_checkpoint.yml"
)
with open(checkpoint_yaml_file_path) as f:
actual_checkpoint_yaml = yaml.safe_load(f)
expected_checkpoint_yaml = """
name: test_v2_checkpoint
config_version:
module_name: great_expectations.checkpoint
class_name: LegacyCheckpoint
validation_operator_name: action_list_operator
batches:
- batch_kwargs:
query: SELECT * from public.titanic
datasource: my_postgres_datasource
expectation_suite_names:
- Titanic.profiled
"""
assert actual_checkpoint_yaml == yaml.safe_load(expected_checkpoint_yaml)
# run checkpoint
results = context.run_checkpoint(checkpoint_name="test_v2_checkpoint")
assert results["success"] is True
<file_sep>/docs/guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_amazon_s3.md
---
title: How to configure a Validation Result Store in Amazon S3
---
import Preface from './components_how_to_configure_a_validation_result_store_in_amazon_s3/_preface.mdx'
import ConfigureBotoToConnectToTheAmazonSBucketWhereValidationResultsWillBeStored from './components/_install_boto3_with_pip.mdx'
import VerifyYourAwsCredentials from './components/_verify_aws_credentials_are_configured_properly.mdx'
import IdentifyYourDataContextValidationResultsStore from './components_how_to_configure_a_validation_result_store_in_amazon_s3/_identify_your_data_context_validation_results_store.mdx'
import UpdateYourConfigurationFileToIncludeANewStoreForValidationResultsOnS from './components_how_to_configure_a_validation_result_store_in_amazon_s3/_update_your_configuration_file_to_include_a_new_store_for_validation_results_on_s.mdx'
import CopyExistingValidationResultsToTheSBucketThisStepIsOptional from './components_how_to_configure_a_validation_result_store_in_amazon_s3/_copy_existing_validation_results_to_the_s_bucket_this_step_is_optional.mdx'
import ConfirmThatTheNewValidationResultsStoreHasBeenAddedByRunningGreatExpectationsStoreList from './components_how_to_configure_a_validation_result_store_in_amazon_s3/_confirm_that_the_new_validation_results_store_has_been_added_by_running_great_expectations_store_list.mdx'
import ConfirmThatTheValidationsResultsStoreHasBeenCorrectlyConfigured from './components_how_to_configure_a_validation_result_store_in_amazon_s3/_confirm_that_the_validations_results_store_has_been_correctly_configured.mdx'
import Congrats from '../components/_congrats.mdx'
<Preface />
## Steps
### 1. Install boto3 to your local environment
<ConfigureBotoToConnectToTheAmazonSBucketWhereValidationResultsWillBeStored />
### 2. Verify that your AWS credentials are properly configured
<VerifyYourAwsCredentials />
### 3. Identify your Data Context Validation Results Store
<IdentifyYourDataContextValidationResultsStore />
### 4. Update your configuration file to include a new Store for Validation Results on S3
<UpdateYourConfigurationFileToIncludeANewStoreForValidationResultsOnS />
### 5. Confirm that the new Validation Results Store has been properly added
<ConfirmThatTheNewValidationResultsStoreHasBeenAddedByRunningGreatExpectationsStoreList />
### 6. Copy existing Validation results to the S3 bucket (This step is optional)
<CopyExistingValidationResultsToTheSBucketThisStepIsOptional />
### 7. Confirm that the Validations Results Store has been correctly configured
<ConfirmThatTheValidationsResultsStoreHasBeenCorrectlyConfigured />
<Congrats/>
You have configured your Validation Results Store to exist in your S3 bucket!<file_sep>/docs/guides/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_a_filesystem.md
---
title: How to host and share Data Docs on a filesystem
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '/docs/term_tags/_tag.mdx';
This guide will explain how to host and share <TechnicalTag relative="../../../" tag="data_docs" text="Data Docs" /> on a filesystem.
<Prerequisites>
- [Set up a working deployment of Great Expectations.](../../../tutorials/getting_started/tutorial_overview.md)
</Prerequisites>
## Steps
### 1. Review defaults and change if desired.
Filesystem-hosted Data Docs are configured by default for Great Expectations deployments created using great_expectations init. To create additional Data Docs sites, you may re-use the default Data Docs configuration below. You may replace ``local_site`` with your own site name, or leave the default.
```yaml
data_docs_sites:
local_site: # this is a user-selected name - you may select your own
class_name: SiteBuilder
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/data_docs/local_site/ # this is the default path but can be changed as required
site_index_builder:
class_name: DefaultSiteIndexBuilder
```
### 2. Test that your configuration is correct by building the site
Use the following <TechnicalTag relative="../../../" tag="cli" text="CLI" /> command: ``great_expectations docs build --site-name local_site``. If successful, the CLI will open your newly built Data Docs site and provide the path to the index page.
```bash
> great_expectations docs build --site-name local_site
The following Data Docs sites will be built:
- local_site: file:///great_expectations/uncommitted/data_docs/local_site/index.html
Would you like to proceed? [Y/n]: Y
Building Data Docs...
Done building Data Docs
```
## Additional notes
- To share the site, you can zip the directory specified under the ``base_directory`` key in your site configuration and distribute as desired.
## Additional resources
- <TechnicalTag tag="data_docs" text="Data Docs"/>
<file_sep>/docs/guides/setup/installation/components_local/_verify_ge_install_succeeded.mdx
<!--
-->
import VersionSnippet from '../../../../tutorials/getting_started/tutorial_version_snippet.mdx'
You can confirm that installation worked by running:
```console title="Terminal command"
great_expectations --version
```
This should return something like:
<VersionSnippet /><file_sep>/docs/terms/_batches_and_batch_requests.mdx
### Batches and Batch Requests: Design Motivation
You do not generally need to access the metadata that Great Expectations uses to define a Batch.
Typically, a user need specify only the Batch Request. The Batch Request will describe what data Great
Expectations should fetch, including the name of the Data Asset and other identifiers (see more detail below).
A **Batch Definition** includes all the information required to precisely identify a set of data from the external data
source that should be translated into a Batch. One or more BatchDefinitions are always *returned* from the Datasource,
as a result of processing the Batch Request. A Batch Definition includes several key components:
* **Batch Identifiers**: contains information that uniquely identifies a specific batch from the Data Asset, such as the
delivery date or query time.
* **Engine Passthrough**: contains information that will be passed directly to the Execution Engine as part of the Batch
Spec.
* **Sample Definition**: contains information about sampling or limiting done on the Data Asset to create a Batch.
:::info Best practice
We recommend that you make every Data Asset Name **unique** in your Data Context configuration. Even though a Batch
Definition includes the Data Connector Name and Datasource Name, choosing a unique Data Asset name makes it
easier to navigate quickly through Data Docs and ensures your logical data assets are not confused with any particular
view of them provided by an Execution Engine.
:::
A **Batch Spec** is an Execution Engine-specific description of the Batch. The Data Connector is responsible for working
with the Execution Engine to translate the Batch Definition into a spec that enables Great Expectations to access the
data using that Execution Engine.
Finally, the **BatchMarkers** are additional pieces of metadata that can be useful to understand reproducibility, such
as the time the batch was constructed, or hash of an in-memory DataFrame.
### Batches and Batch Requests: A full journey
Let's follow the outline in this diagram to follow the journey from BatchRequest to Batch list:

1. A Datasource's `get_batch_list_from_batch_request` method is passed a BatchRequest.
* A BatchRequest can include `data_connector_query` params with values relative to the latest Batch (e.g. the "latest" slice).
Conceptually, this enables "fetch the latest Batch" behavior. It is the key thing that differentiates
a BatchRequest, which does NOT necessarily uniquely identify the Batch(es) to be fetched, from a
BatchDefinition.
* The BatchRequest can also include a section called `batch_spec_passthrough` to make it easy to directly
communicate parameters to a specific Execution Engine.
* When resolved, the BatchRequest may point to many BatchDefinitions and Batches.
* BatchRequests can be defined as dictionaries, or by instantiating a BatchRequest object.
```python file=../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L76-L89
```
2. The Datasource finds the Data Connector indicated by the BatchRequest, and uses it to obtain a BatchDefinition list.
```python
DataSource.get_batch_list_from_batch_request(batch_request=batch_request)
```
* A BatchDefinition resolves any ambiguity in BatchRequest to uniquely identify a single Batch to be
fetched. BatchDefinitions are Datasource -- and Execution Engine -- agnostic. That means that its parameters may depend on
the configuration of the Datasource, but they do not otherwise depend on the specific Data Connector type (e.g.
filesystem, SQL, etc.) or Execution Engine being used to instantiate Batches.
```yaml
BatchDefinition
datasource: str
data_connector: str
data_asset_name: str
batch_identifiers:
** contents depend on the configuration of the DataConnector **
** provides a persistent, unique identifier for the Batch within the context of the Data Asset **
```
3. The Datasource then requests that the Data Connector transform the BatchDefinition list into BatchData, BatchSpec, and BatchMarkers.
4. When the Data Connector receives this request, it first builds the BatchSpec, then calls its Execution Engine to create BatchData and BatchMarkers.
* A `BatchSpec` is a set of specific instructions for the Execution Engine to fetch specific data; it is the
ExecutionEngine-specific version of the BatchDefinition. For example, a `BatchSpec` could include the path to files,
information about headers, or other configuration required to ensure the data is loaded properly for validation.
* Batch Markers are metadata that can be used to calculate performance characteristics, ensure reproducibility of Validation Results, and provide indicators of the state of the underlying data system.
5. After the Data Connector returns the BatchSpec, BatchData, and BatchMarkers, the Datasource builds and returns a list of Batches.
<file_sep>/great_expectations/experimental/datasources/config.py
"""POC for loading config."""
from __future__ import annotations
import logging
from pprint import pformat as pf
from typing import Dict, Type
from pydantic import validator
from great_expectations.experimental.datasources.experimental_base_model import (
ExperimentalBaseModel,
)
from great_expectations.experimental.datasources.interfaces import Datasource
from great_expectations.experimental.datasources.sources import _SourceFactories
LOGGER = logging.getLogger(__name__)
class GxConfig(ExperimentalBaseModel):
"""Represents the full new-style/experimental configuration file."""
datasources: Dict[str, Datasource]
@validator("datasources", pre=True)
@classmethod
def _load_datasource_subtype(cls, v: Dict[str, dict]):
LOGGER.info(f"Loading 'datasources' ->\n{pf(v, depth=2)}")
loaded_datasources: Dict[str, Datasource] = {}
# TODO (kilo59): catch key errors
for ds_name, config in v.items():
ds_type_name: str = config["type"]
ds_type: Type[Datasource] = _SourceFactories.type_lookup[ds_type_name]
LOGGER.debug(f"Instantiating '{ds_name}' as {ds_type}")
datasource = ds_type(**config)
loaded_datasources[datasource.name] = datasource
# TODO: move this to a different 'validator' method
# attach the datasource to the nested assets, avoiding recursion errors
for asset in datasource.assets.values():
asset._datasource = datasource
LOGGER.info(f"Loaded 'datasources' ->\n{repr(loaded_datasources)}")
return loaded_datasources
<file_sep>/docs/guides/connecting_to_your_data/how_to_configure_a_runtimedataconnector.md
---
title: How to configure a RuntimeDataConnector
---
import Prerequisites from '../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
This guide demonstrates how to configure a RuntimeDataConnector and only applies to the V3 (Batch Request) API. A `RuntimeDataConnector` allows you to specify a <TechnicalTag tag="batch" text="Batch" /> using a Runtime <TechnicalTag tag="batch_request" text="Batch Request" />, which is used to create a Validator. A <TechnicalTag tag="validator" text="Validator" /> is the key object used to create <TechnicalTag tag="expectation" text="Expectations" /> and <TechnicalTag tag="validation" text="Validate" /> datasets.
<Prerequisites>
- [Understand the basics of Datasources in the V3 (Batch Request) API](../../terms/datasource.md)
- Learned how to configure a [Data Context using test_yaml_config](../setup/configuring_data_contexts/how_to_configure_datacontext_components_using_test_yaml_config.md)
</Prerequisites>
A RuntimeDataConnector is a special kind of [Data Connector](../../terms/datasource.md) that enables you to use a RuntimeBatchRequest to provide a [Batch's](../../terms/batch.md) data directly at runtime. The RuntimeBatchRequest can wrap an in-memory dataframe, a filepath, or a SQL query, and must include batch identifiers that uniquely identify the data (e.g. a `run_id` from an AirFlow DAG run). The batch identifiers that must be passed in at runtime are specified in the RuntimeDataConnector's configuration.
## Steps
### 1. Instantiate your project's DataContext
Import these necessary packages and modules:
<Tabs
groupId="yaml-or-python"
defaultValue='yaml'
values={[
{label: 'YAML', value:'yaml'},
{label: 'Python', value:'python'},
]}>
<TabItem value="yaml">
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py#L4-L5
```
</TabItem>
<TabItem value="python">
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py#L2-L5
```
</TabItem>
</Tabs>
### 2. Set up a Datasource
All of the examples below assume you’re testing configuration using something like:
<Tabs
groupId="yaml-or-python"
defaultValue='yaml'
values={[
{label: 'YAML', value:'yaml'},
{label: 'Python', value:'python'},
]}>
<TabItem value="yaml">
```python
datasource_yaml = """
name: taxi_datasource
class_name: Datasource
execution_engine:
class_name: PandasExecutionEngine
data_connectors:
<DATACONNECTOR NAME GOES HERE>:
<DATACONNECTOR CONFIGURATION GOES HERE>
"""
context.test_yaml_config(yaml_config=datasource_config)
```
</TabItem>
<TabItem value="python">
```python
datasource_config = {
"name": "taxi_datasource",
"class_name": "Datasource",
"module_name": "great_expectations.datasource",
"execution_engine": {
"module_name": "great_expectations.execution_engine",
"class_name": "PandasExecutionEngine",
},
"data_connectors": {
"<DATACONNECTOR NAME GOES HERE>": {
"<DATACONNECTOR CONFIGURATION GOES HERE>"
},
},
}
context.test_yaml_config(yaml.dump(datasource_config))
```
</TabItem>
</Tabs>
If you’re not familiar with the `test_yaml_config` method, please check out: [How to configure Data Context components using test_yaml_config](../setup/configuring_data_contexts/how_to_configure_datacontext_components_using_test_yaml_config.md)
### 3. Add a RuntimeDataConnector to a Datasource configuration
This basic configuration can be used in multiple ways depending on how the `RuntimeBatchRequest` is configured:
<Tabs
groupId="yaml-or-python"
defaultValue='yaml'
values={[
{label: 'YAML', value:'yaml'},
{label: 'Python', value:'python'},
]}>
<TabItem value="yaml">
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py#L10-L22
```
</TabItem>
<TabItem value="python">
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py#L27-L41
```
</TabItem>
</Tabs>
Once the RuntimeDataConnector is configured you can add your <TechnicalTag tag="datasource" text="Datasource" /> using:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py#L49-L49
```
#### Example 1: RuntimeDataConnector for access to file-system data:
At runtime, you would get a Validator from the <TechnicalTag tag="data_context" text="Data Context" /> by first defining a `RuntimeBatchRequest` with the `path` to your data defined in `runtime_parameters`:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py#L50-L57
```
Next, you would pass that request into `context.get_validator`:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py#L64-L68
```
### Example 2: RuntimeDataConnector that uses an in-memory DataFrame
At runtime, you would get a Validator from the Data Context by first defining a `RuntimeBatchRequest` with the DataFrame passed into `batch_data` in `runtime_parameters`:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py#L1-L1
```
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py#L80-L80
```
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py#L83-L92
```
Next, you would pass that request into `context.get_validator`:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py#L94-L98
```
### Additional Notes
To view the full script used in this page, see it on GitHub:
- [how_to_configure_a_runtimedataconnector.py](https://github.com/great-expectations/great_expectations/tree/develop/tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py)
<file_sep>/docs/terms/datasource.md
---
title: Datasource
id: datasource
hoverText: Provides a standard API for accessing and interacting with data from a wide variety of source systems.
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import ConnectHeader from '/docs/images/universal_map/_um_connect_header.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
import ValidateHeader from '/docs/images/universal_map/_um_validate_header.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
<UniversalMap setup='inactive' connect='active' create='active' validate='active'/>
### Definition
A Datasource provides a standard API for accessing and interacting with data from a wide variety of source systems.
### Features and promises
Datasources provide a unified API across multiple backends: the Datasource API remains the same for PostgreSQL, CSV Filesystems, and all other supported data backends.
:::note Important:
Datasources do not modify your data.
:::
### Relationship to other objects
Datasources function by bringing together a way of interacting with Data (an <TechnicalTag relative="../" tag="execution_engine" text="Execution Engine" />) with a way of accessing that data (a <TechnicalTag relative="../" tag="data_connector" text="Data Connector." />). <TechnicalTag relative="../" tag="batch_request" text="Batch Requests" /> utilize Datasources in order to return a <TechnicalTag relative="../" tag="batch" text="Batch" /> of data.
## Use Cases
<ConnectHeader/>
When connecting to data the Datasource is your primary tool. At this stage, you will create Datasources to define how Great Expectations can find and access your <TechnicalTag relative="../" tag="data_asset" text="Data Assets" />. Under the hood, each Datasource must have an Execution Engine and one or more Data Connectors configured. Once a Datasource is configured you will be able to operate with the Datasource's API rather than needing a different API for each possible data backend you may be working with.
<CreateHeader/>
When creating <TechnicalTag relative="../" tag="expectation" text="Expectations" /> you will use your Datasources to obtain <TechnicalTag relative="../" tag="batch" text="Batches" /> for <TechnicalTag relative="../" tag="profiler" text="Profilers" /> to analyze. Datasources also provide Batches for <TechnicalTag relative="../" tag="expectation_suite" text="Expectation Suites" />, such as when you use [the interactive workflow](../guides/expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md) to create new Expectations.
<ValidateHeader/>
Datasources are also used to obtain Batches for <TechnicalTag relative="../" tag="validator" text="Validators" /> to run against when you are validating data.
## Features
### Unified API
Datasources support connecting to a variety of different data backends. No matter which source data system you employ, the Datasource's API will remain the same.
### No Unexpected Modifications
Datasources do not modify your data during profiling or validation, but they may create temporary artifacts to optimize computing Metrics and Validation. This behaviour can be configured at the Data Connector level.
### API Basics
### How to access
You will typically only access your Datasource directly through Python code, which can be executed from a script, a Python console, or a Jupyter Notebook. To access a Datasource all you need is a <TechnicalTag relative="../" tag="data_context" text="Data Context" /> and the name of the Datasource you want to access, as shown below:
```python title="Python console:"
import great_expectations as ge
context = ge.get_context()
datasource = context.get_datasource("my_datasource_name")
```
### How to create and configure
Creating a Datasource is quick and easy, and can be done from the <TechnicalTag relative="../" tag="cli" text="CLI" /> or through Python code. Configuring the Datasource may differ between backends, according to the given backend's requirements, but the process of creating one will remain the same.
To create a new Datasource through the CLI, run `great_expectations datasource new`.
To create a new Datasource through Python code, obtain a data context and call its `add_datasource` method.
Advanced users may also create a Datasource directly through a YAML config file.
For detailed instructions on how to create Datasources that are configured for various backends, see [our documentation on Connecting to Data](../guides/connecting_to_your_data/index.md).
<file_sep>/great_expectations/execution_engine/bundled_metric_configuration.py
from dataclasses import asdict, dataclass
from typing import Any
from great_expectations.core.util import convert_to_json_serializable
from great_expectations.types import DictDot
from great_expectations.validator.metric_configuration import MetricConfiguration
@dataclass(frozen=True)
class BundledMetricConfiguration(DictDot):
"""
BundledMetricConfiguration is a "dataclass" object, which holds components required for bundling metric computation.
"""
metric_configuration: MetricConfiguration
metric_fn: Any
compute_domain_kwargs: dict
accessor_domain_kwargs: dict
metric_provider_kwargs: dict
def to_dict(self) -> dict:
"""Returns: this BundledMetricConfiguration as a dictionary"""
return asdict(self)
def to_json_dict(self) -> dict:
"""Returns: this BundledMetricConfiguration as a JSON dictionary"""
return convert_to_json_serializable(data=self.to_dict())
<file_sep>/requirements.txt
altair>=4.0.0,<5
Click>=7.1.2
colorama>=0.4.3
cryptography>=3.2
importlib-metadata>=1.7.0 # (included in Python 3.8 by default.)
Ipython>=7.16.3
ipywidgets>=7.5.1
jinja2>=2.10
jsonpatch>=1.22
jsonschema>=2.5.1,<=4.7.2
makefun>=1.7.0,<2
marshmallow>=3.7.1,<4.0.0
mistune>=0.8.4
nbformat>=5.0
notebook>=6.4.10
numpy>=1.18.5
packaging
pandas>=1.1.0
pydantic>=1.0,<2.0
pyparsing>=2.4
python-dateutil>=2.8.1
pytz>=2021.3
requests>=2.20
ruamel.yaml>=0.16,<0.17.18
scipy>=0.19.0
tqdm>=4.59.0
typing-extensions>=3.10.0.0 # Leverage type annotations from recent Python releases
tzlocal>=1.2
urllib3>=1.25.4,<1.27
<file_sep>/tests/data_context/cloud_data_context/test_expectation_suite_crud.py
from typing import Callable, NamedTuple
from unittest import mock
import pytest
from great_expectations.core.expectation_suite import ExpectationSuite
from great_expectations.data_context.cloud_constants import GXCloudRESTResource
from great_expectations.data_context.data_context.base_data_context import (
BaseDataContext,
)
from great_expectations.data_context.types.base import DataContextConfig, GXCloudConfig
from great_expectations.data_context.types.resource_identifiers import GXCloudIdentifier
from great_expectations.exceptions.exceptions import DataContextError
from tests.data_context.conftest import MockResponse
class SuiteIdentifierTuple(NamedTuple):
id: str
name: str
@pytest.fixture
def suite_1() -> SuiteIdentifierTuple:
id = "9db8721d-52e3-4263-90b3-ddb83a7aca04"
name = "Test Suite 1"
return SuiteIdentifierTuple(id=id, name=name)
@pytest.fixture
def suite_2() -> SuiteIdentifierTuple:
id = "88972771-1774-4e7c-b76a-0c30063bea55"
name = "Test Suite 2"
return SuiteIdentifierTuple(id=id, name=name)
@pytest.fixture
def mock_get_all_suites_json(
suite_1: SuiteIdentifierTuple,
suite_2: SuiteIdentifierTuple,
) -> dict:
mock_json = {
"data": [
{
"attributes": {
"clause_id": None,
"created_at": "2022-03-02T19:34:00.687921",
"created_by_id": "934e0898-6a5c-4ffd-9125-89381a46d191",
"deleted": False,
"deleted_at": None,
"organization_id": "77eb8b08-f2f4-40b1-8b41-50e7fbedcda3",
"rendered_data_doc_id": None,
"suite": {
"data_asset_type": None,
"expectation_suite_name": suite_1.name,
"expectations": [
{
"expectation_type": "expect_column_to_exist",
"ge_cloud_id": "c8a239a6-fb80-4f51-a90e-40c38dffdf91",
"kwargs": {"column": "infinities"},
"meta": {},
},
],
"ge_cloud_id": suite_1.id,
"meta": {"great_expectations_version": "0.15.19"},
},
"updated_at": "2022-08-18T18:34:17.561984",
},
"id": suite_1.id,
"type": "expectation_suite",
},
{
"attributes": {
"clause_id": None,
"created_at": "2022-03-02T19:34:00.687921",
"created_by_id": "934e0898-6a5c-4ffd-9125-89381a46d191",
"deleted": False,
"deleted_at": None,
"organization_id": "77eb8b08-f2f4-40b1-8b41-50e7fbedcda3",
"rendered_data_doc_id": None,
"suite": {
"data_asset_type": None,
"expectation_suite_name": suite_2.name,
"expectations": [
{
"expectation_type": "expect_column_to_exist",
"ge_cloud_id": "c8a239a6-fb80-4f51-a90e-40c38dffdf91",
"kwargs": {"column": "infinities"},
"meta": {},
},
],
"ge_cloud_id": suite_2.id,
"meta": {"great_expectations_version": "0.15.19"},
},
"updated_at": "2022-08-18T18:34:17.561984",
},
"id": suite_2.id,
"type": "expectation_suite",
},
]
}
return mock_json
@pytest.fixture
def mocked_post_response(
mock_response_factory: Callable,
suite_1: SuiteIdentifierTuple,
) -> Callable[[], MockResponse]:
suite_id = suite_1.id
def _mocked_post_response(*args, **kwargs):
return mock_response_factory(
{
"data": {
"id": suite_id,
}
},
201,
)
return _mocked_post_response
@pytest.fixture
def mocked_get_response(
mock_response_factory: Callable,
suite_1: SuiteIdentifierTuple,
) -> Callable[[], MockResponse]:
suite_id = suite_1.id
def _mocked_get_response(*args, **kwargs):
return mock_response_factory(
{
"data": {
"attributes": {
"clause_id": "3199e1eb-3f68-473a-aca5-5e12324c3b92",
"created_at": "2021-12-02T16:53:31.015139",
"created_by_id": "67dce9ed-9c41-4607-9f22-15c14cc82ac0",
"deleted": False,
"deleted_at": None,
"organization_id": "c8f9f2d0-fb5c-464b-bcc9-8a45b8144f44",
"rendered_data_doc_id": None,
"suite": {
"data_asset_type": None,
"expectation_suite_name": "my_mock_suite",
"expectations": [
{
"expectation_type": "expect_column_to_exist",
"ge_cloud_id": "869771ee-a728-413d-96a6-8efc4dc70318",
"kwargs": {"column": "infinities"},
"meta": {},
},
],
"ge_cloud_id": suite_id,
},
},
"id": suite_id,
}
},
200,
)
return _mocked_get_response
@pytest.fixture
def mock_list_expectation_suite_names() -> mock.MagicMock:
"""
Expects a return value to be set within the test function.
"""
with mock.patch(
"great_expectations.data_context.data_context.cloud_data_context.CloudDataContext.list_expectation_suite_names",
) as mock_method:
yield mock_method
@pytest.fixture
def mock_list_expectation_suites() -> mock.MagicMock:
"""
Expects a return value to be set within the test function.
"""
with mock.patch(
"great_expectations.data_context.data_context.cloud_data_context.CloudDataContext.list_expectation_suites",
) as mock_method:
yield mock_method
@pytest.fixture
def mock_expectations_store_has_key() -> mock.MagicMock:
"""
Expects a return value to be set within the test function.
"""
with mock.patch(
"great_expectations.data_context.store.expectations_store.ExpectationsStore.has_key",
) as mock_method:
yield mock_method
@pytest.mark.unit
@pytest.mark.cloud
def test_list_expectation_suites(
empty_ge_cloud_data_context_config: DataContextConfig,
ge_cloud_config: GXCloudConfig,
suite_1: SuiteIdentifierTuple,
suite_2: SuiteIdentifierTuple,
mock_get_all_suites_json: dict,
) -> None:
project_path_name = "foo/bar/baz"
context = BaseDataContext(
project_config=empty_ge_cloud_data_context_config,
context_root_dir=project_path_name,
ge_cloud_config=ge_cloud_config,
ge_cloud_mode=True,
)
with mock.patch("requests.Session.get", autospec=True) as mock_get:
mock_get.return_value = mock.Mock(
status_code=200, json=lambda: mock_get_all_suites_json
)
suites = context.list_expectation_suites()
assert suites == [
GXCloudIdentifier(
resource_type=GXCloudRESTResource.EXPECTATION_SUITE,
ge_cloud_id=suite_1.id,
resource_name=suite_1.name,
),
GXCloudIdentifier(
resource_type=GXCloudRESTResource.EXPECTATION_SUITE,
ge_cloud_id=suite_2.id,
resource_name=suite_2.name,
),
]
@pytest.mark.unit
@pytest.mark.cloud
def test_create_expectation_suite_saves_suite_to_cloud(
empty_base_data_context_in_cloud_mode: BaseDataContext,
mocked_post_response: Callable[[], MockResponse],
mock_list_expectation_suite_names: mock.MagicMock,
) -> None:
context = empty_base_data_context_in_cloud_mode
suite_name = "my_suite"
existing_suite_names = []
with mock.patch(
"requests.Session.post", autospec=True, side_effect=mocked_post_response
):
mock_list_expectation_suite_names.return_value = existing_suite_names
suite = context.create_expectation_suite(suite_name)
assert suite.ge_cloud_id is not None
@pytest.mark.unit
@pytest.mark.cloud
def test_create_expectation_suite_overwrites_existing_suite(
empty_base_data_context_in_cloud_mode: BaseDataContext,
mock_list_expectation_suite_names: mock.MagicMock,
mock_list_expectation_suites: mock.MagicMock,
suite_1: SuiteIdentifierTuple,
) -> None:
context = empty_base_data_context_in_cloud_mode
suite_name = suite_1.name
existing_suite_names = [suite_name]
suite_id = suite_1.id
with mock.patch(
"great_expectations.data_context.data_context.cloud_data_context.CloudDataContext.expectations_store"
):
mock_list_expectation_suite_names.return_value = existing_suite_names
mock_list_expectation_suites.return_value = [
GXCloudIdentifier(
resource_type=GXCloudRESTResource.EXPECTATION,
ge_cloud_id=suite_id,
resource_name=suite_name,
)
]
suite = context.create_expectation_suite(
expectation_suite_name=suite_name, overwrite_existing=True
)
assert suite.ge_cloud_id == suite_id
@pytest.mark.unit
@pytest.mark.cloud
def test_create_expectation_suite_namespace_collision_raises_error(
empty_base_data_context_in_cloud_mode: BaseDataContext,
mock_list_expectation_suite_names: mock.MagicMock,
) -> None:
context = empty_base_data_context_in_cloud_mode
suite_name = "my_suite"
existing_suite_names = [suite_name]
with pytest.raises(DataContextError) as e:
mock_list_expectation_suite_names.return_value = existing_suite_names
context.create_expectation_suite(suite_name)
assert f"expectation_suite '{suite_name}' already exists" in str(e.value)
@pytest.mark.unit
@pytest.mark.cloud
def test_delete_expectation_suite_deletes_suite_in_cloud(
empty_base_data_context_in_cloud_mode: BaseDataContext,
suite_1: SuiteIdentifierTuple,
mock_expectations_store_has_key: mock.MagicMock,
) -> None:
context = empty_base_data_context_in_cloud_mode
suite_id = suite_1.id
with mock.patch("requests.Session.delete", autospec=True) as mock_delete:
mock_expectations_store_has_key.return_value = True
context.delete_expectation_suite(ge_cloud_id=suite_id)
mock_expectations_store_has_key.assert_called_once_with(
GXCloudIdentifier(GXCloudRESTResource.EXPECTATION_SUITE, ge_cloud_id=suite_id)
)
assert mock_delete.call_args[1]["json"] == {
"data": {
"type": GXCloudRESTResource.EXPECTATION_SUITE,
"id": suite_id,
"attributes": {"deleted": True},
}
}
@pytest.mark.unit
@pytest.mark.cloud
def test_delete_expectation_suite_nonexistent_suite_raises_error(
empty_base_data_context_in_cloud_mode: BaseDataContext,
suite_1: SuiteIdentifierTuple,
mock_expectations_store_has_key: mock.MagicMock,
) -> None:
context = empty_base_data_context_in_cloud_mode
suite_id = suite_1.id
with pytest.raises(DataContextError) as e:
mock_expectations_store_has_key.return_value = False
context.delete_expectation_suite(ge_cloud_id=suite_id)
mock_expectations_store_has_key.assert_called_once_with(
GXCloudIdentifier(GXCloudRESTResource.EXPECTATION_SUITE, ge_cloud_id=suite_id)
)
assert f"expectation_suite with id {suite_id} does not exist" in str(e.value)
@pytest.mark.unit
@pytest.mark.cloud
def test_get_expectation_suite_retrieves_suite_from_cloud(
empty_base_data_context_in_cloud_mode: BaseDataContext,
suite_1: SuiteIdentifierTuple,
mocked_get_response: Callable[[], MockResponse],
mock_expectations_store_has_key: mock.MagicMock,
) -> None:
context = empty_base_data_context_in_cloud_mode
suite_id = suite_1.id
with mock.patch(
"requests.Session.get", autospec=True, side_effect=mocked_get_response
):
mock_expectations_store_has_key.return_value = True
suite = context.get_expectation_suite(ge_cloud_id=suite_id)
mock_expectations_store_has_key.assert_called_once_with(
GXCloudIdentifier(GXCloudRESTResource.EXPECTATION_SUITE, ge_cloud_id=suite_id)
)
assert str(suite.ge_cloud_id) == str(suite_id)
@pytest.mark.unit
@pytest.mark.cloud
def test_get_expectation_suite_nonexistent_suite_raises_error(
empty_base_data_context_in_cloud_mode: BaseDataContext,
mock_expectations_store_has_key: mock.MagicMock,
) -> None:
context = empty_base_data_context_in_cloud_mode
suite_id = "abc123"
with pytest.raises(DataContextError) as e:
mock_expectations_store_has_key.return_value = False
context.get_expectation_suite(ge_cloud_id=suite_id)
mock_expectations_store_has_key.assert_called_once_with(
GXCloudIdentifier(GXCloudRESTResource.EXPECTATION_SUITE, ge_cloud_id=suite_id)
)
assert f"expectation_suite with id {suite_id} not found" in str(e.value)
@pytest.mark.unit
@pytest.mark.cloud
def test_save_expectation_suite_saves_suite_to_cloud(
empty_base_data_context_in_cloud_mode: BaseDataContext,
mocked_post_response: Callable[[], MockResponse],
) -> None:
context = empty_base_data_context_in_cloud_mode
suite_name = "my_suite"
suite_id = None
suite = ExpectationSuite(suite_name, ge_cloud_id=suite_id)
assert suite.ge_cloud_id is None
with mock.patch(
"requests.Session.post", autospec=True, side_effect=mocked_post_response
):
context.save_expectation_suite(suite)
assert suite.ge_cloud_id is not None
@pytest.mark.unit
@pytest.mark.cloud
def test_save_expectation_suite_overwrites_existing_suite(
empty_base_data_context_in_cloud_mode: BaseDataContext,
suite_1: SuiteIdentifierTuple,
) -> None:
context = empty_base_data_context_in_cloud_mode
suite_name = suite_1.name
suite_id = suite_1.id
suite = ExpectationSuite(suite_name, ge_cloud_id=suite_id)
with mock.patch(
"requests.Session.put", autospec=True, return_value=mock.Mock(status_code=405)
) as mock_put, mock.patch("requests.Session.patch", autospec=True) as mock_patch:
context.save_expectation_suite(suite)
expected_suite_json = {
"data_asset_type": None,
"expectation_suite_name": suite_name,
"expectations": [],
"ge_cloud_id": suite_id,
}
actual_put_suite_json = mock_put.call_args[1]["json"]["data"]["attributes"]["suite"]
actual_put_suite_json.pop("meta")
assert actual_put_suite_json == expected_suite_json
actual_patch_suite_json = mock_patch.call_args[1]["json"]["data"]["attributes"][
"suite"
]
assert actual_patch_suite_json == expected_suite_json
@pytest.mark.unit
@pytest.mark.cloud
def test_save_expectation_suite_no_overwrite_namespace_collision_raises_error(
empty_base_data_context_in_cloud_mode: BaseDataContext,
mock_expectations_store_has_key: mock.MagicMock,
mock_list_expectation_suite_names: mock.MagicMock,
) -> None:
context = empty_base_data_context_in_cloud_mode
suite_name = "my_suite"
suite_id = None
suite = ExpectationSuite(suite_name, ge_cloud_id=suite_id)
existing_suite_names = [suite_name]
with pytest.raises(DataContextError) as e:
mock_expectations_store_has_key.return_value = False
mock_list_expectation_suite_names.return_value = existing_suite_names
context.save_expectation_suite(
expectation_suite=suite, overwrite_existing=False
)
assert f"expectation_suite '{suite_name}' already exists" in str(e.value)
@pytest.mark.unit
@pytest.mark.cloud
def test_save_expectation_suite_no_overwrite_id_collision_raises_error(
empty_base_data_context_in_cloud_mode: BaseDataContext,
suite_1: SuiteIdentifierTuple,
mock_expectations_store_has_key: mock.MagicMock,
) -> None:
context = empty_base_data_context_in_cloud_mode
suite_name = "my_suite"
suite_id = suite_1.id
suite = ExpectationSuite(suite_name, ge_cloud_id=suite_id)
with pytest.raises(DataContextError) as e:
mock_expectations_store_has_key.return_value = True
context.save_expectation_suite(
expectation_suite=suite, overwrite_existing=False
)
mock_expectations_store_has_key.assert_called_once_with(
GXCloudIdentifier(
GXCloudRESTResource.EXPECTATION_SUITE,
ge_cloud_id=suite_id,
resource_name=suite_name,
)
)
assert f"expectation_suite with GE Cloud ID {suite_id} already exists" in str(
e.value
)
<file_sep>/docs/terms/data_context.md
---
title: Data Context
id: data_context
hoverText: The primary entry point for a Great Expectations deployment, with configurations and methods for all supporting components.
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import SetupHeader from '/docs/images/universal_map/_um_setup_header.mdx'
import ConnectHeader from '/docs/images/universal_map/_um_connect_header.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
import ValidateHeader from '/docs/images/universal_map/_um_validate_header.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
import RelevantApiLinks from './data_context__api_links.mdx'
<UniversalMap setup='active' connect='active' create='active' validate='active'/>
## Overview
### Definition
A Data Context is the primary entry point for a Great Expectations deployment, with configurations and methods for all supporting components.
### Features and promises
As the primary entry point for all of Great Expectations' APIs, the Data Context provides convenience methods for accessing common objects based on untyped input or common defaults. It also provides the ability to easily handle configuration of its own top-level components, and the configs and data necessary to back up your Data Context itself can be stored in a variety of ways. It doesn’t matter how you instantiate your `DataContext`, or store its configs: once you have the `DataContext` in memory, it will always behave in the same way.
### Relationships to other objects
Your Data Context will provide you with methods to configure your Stores, plugins, and Data Docs. It will also provide the methods needed to create, configure, and access your <TechnicalTag relative="../" tag="datasource" text="Datasources" />, <TechnicalTag relative="../" tag="expectation" text="Expectations" />, <TechnicalTag relative="../" tag="profiler" text="Profilers" />, and <TechnicalTag relative="../" tag="checkpoint" text="Checkpoints" />. In addition to all of that, it will internally manage your <TechnicalTag relative="../" tag="metric" text="Metrics" />, <TechnicalTag relative="../" tag="validation_result" text="Validation Results" />, and the contents of your <TechnicalTag relative="../" tag="data_docs" text="Data Docs" /> for you!
## Use Cases

<SetupHeader/>
During Setup you will initialize a Data Context. For instructions on how to do this, please see our [Setup Overview: Initialize a Data Context](../guides/setup/setup_overview.md#3-initialize-a-data-context) documentation. For more information on configuring a newly initialized Data Context, please see our [guides for configuring your Data Context](../guides/setup/index.md#data-contexts).
You can also use the Data Context to manage optional configurations for your Stores, Plugins, and Data Docs. For information on configuring Stores, please check out our [guides for configuring stores](../guides/setup/index.md#stores). For Data Docs, please reference our [guides on configuring Data Docs](../guides/setup/index.md#data-docs).
<ConnectHeader/>
When connecting to Data, your Data Context will be used to create and configure Datasources. For more information on how to create and configure Datasources, please see our [overview documentation for the Connect to Data step](../guides/connecting_to_your_data/connect_to_data_overview.md), as well as our [how-to guides for connecting to data](../guides/connecting_to_your_data/index.md).
<CreateHeader/>
When creating Expectations, your Data Context will be used to create <TechnicalTag relative="../" tag="expectation_suite" text="Expectation Suites" /> and Expectations, as well as save them to an <TechnicalTag relative="../" tag="expectation_store" text="Expectations Store" />. The Data Context also provides your starting point for creating Profilers, and will manage the Metrics and Validation Results involved in running a Profiler automatically. Finally, the Data Context will manage the content of your Data Docs (displaying such things as the Validation Results and Expectations generated by a Profiler) for you. For more information on creating Expectations, please see our [overview documentation for the Create Expectations step](../guides/expectations/create_expectations_overview.md), as well as our [how-to guides for creating Expectations](../guides/expectations/index.md).
<ValidateHeader/>
When Validating data, the Data Context provides your entry point for creating, configuring, saving, and accessing Checkpoints. For more information on using your Data Context to create a Checkpoint, please see our [overview documentation for the Validate Data step](../guides/validation/validate_data_overview.md).
Additionally, it continues to manage all the same behind the scenes activity involved in using Metrics, saving Validation Results, and creating the contents of your Data Docs for you.
## Features
### Access to APIs
The Data Context provides a primary entry point to all of Great Expectations' APIs. Your Data Context will provide convenience methods for accessing common objects. While internal workflows of Great Expectations are strongly typed, the convenience methods available from the Data Context are exceptions, allowing access based on untyped input or common defaults.
#### Configuration management
The Data Context makes it easy to manage configuration of its own top-level components. It includes basic CRUD operations for all of the core components for a Great Expectations deployment (Datasources, Expectation Suites, Checkpoints) and provides access and default integrations with Data Docs, your Stores, Plugins, etc. It also provides convenience methods such as `test_yaml_config()` for testing configurations. For more information on configuring Data Context components and the `test_yaml_config()` method, please see our guide on [how to configure DataContext components using test_yaml_config](../guides/setup/configuring_data_contexts/how_to_configure_datacontext_components_using_test_yaml_config.md).
#### Component management and config storage
The Data Context doesn't just give you convenient ways to access and configure components. It also provides the ability to *create* top-level components such as Datasources, Checkpoints, and Expectation Suites and manage where the information about those components is stored.
In the Getting Started Tutorial, everything was created locally and stored. This is a simple way to get started with Great Expectations. For production deployments, however, you'll probably want to swap out some of the components that were used in the Getting Started Tutorial for others that correspond to your source data systems and production environment. This may include storing information about those components in something other than your local environment. You can see several soup-to-nuts examples of how to do this for specific environments and source data systems in the [Reference Architecture guides](../deployment_patterns/index.md).
If the exact deployment pattern you want to follow isn't documented in a Reference Architecture, you can see details for configuring specific components that component's related how-to guides.
### Great Expectations Cloud compatability
Because your Data Context contains the entirety of your Great Expectations project, Great Expectations Cloud can reference it to permit seamless upgrading from open source Great Expectations to Great Expectations Cloud.
## API basics
### Instantiating a DataContext
As a Great Expectations user, once you have created a Data Context, you will almost always start future work either by using <TechnicalTag relative="../" tag="cli" text="CLI" /> commands from your Data Context's root folder, or by instantiating a `DataContext` in Python:
```python title="Python code"
import great_expectations as ge
context = ge.get_context()
```
Alternatively, you might call:
```python title="Python code"
import great_expectations as ge
context = ge.get_context(filepath=”something”)
```
If you’re using Great Expectations Cloud, you’d call:
```python title="Python code"
import great_expectations as ge
context = ge.get_context(API_KEY=”something”)
```
That’s it! You now have access to all the goodness of a DataContext.
### Interactively testing configurations from your Data Context
Especially during the beginning of a Great Expecations project, it is often incredibly useful to rapidly iterate over
configurations of key Data Context components. The `test_yaml_config()` feature makes that easy.
`test_yaml_config()` is a convenience method for configuring the moving parts of a Great Expectations deployment. It
allows you to quickly test out configs for Datasources, Checkpoints, and each type of Store (ExpectationStores,
ValidationResultStores, and MetricsStores). For many deployments of Great Expectations, these components (plus
Expectations) are the only ones you'll need.
Here's a typical example:
```python title="Python code"
config = """
class_name: Datasource
execution_engine:
class_name: PandasExecutionEngine
data_connectors:
my_data_connector:
class_name: InferredAssetFilesystemDataConnector
base_directory: {data_base_directory}
glob_directive: "*/*.csv"
default_regex:
pattern: (.+)/(.+)\\.csv
group_names:
- data_asset_name
- partition
"""
my_context.test_yaml_config(
config=config
)
```
Running `test_yaml_config()` will show some feedback on the configuration. The helpful output can include any result
from the "self check" of an artifact produced using that configuration. You should note, however, that `test_yaml_config()` never overwrites the underlying configuration. If you make edits in the course of your work, you will have to explicitly save the configuration before running `test_yaml_config()`.
For more detailed guidance on using the `test_yaml_config()` method, please see our guide on [how to configure DataContext components using test_yaml_config](../guides/setup/configuring_data_contexts/how_to_configure_datacontext_components_using_test_yaml_config.md).
### Relevant API documentation (links)
<RelevantApiLinks/>
## More details
### Design motivations
#### Untyped inputs
The code standards for Great Expectations strive for strongly typed inputs. However, the Data Context's convenience functions are a noted exception to this standard. For example, to get a Batch with typed input, you would call:
```python title="Python code"
from great_expectations.core.batch import BatchRequest
batch_request = BatchRequest(
datasource_name="my_azure_datasource",
data_connector_name="default_inferred_data_connector_name",
data_asset_name="<YOUR_DATA_ASSET_NAME>",
)
context.get_batch(
batch_request=batch_request
)
```
However, we can take some of the friction out of that process by allowing untyped inputs:
```python title="Python code"
context.get_batch(
datasource_name="my_azure_datasource",
data_connector_name="default_inferred_data_connector_name",
data_asset_name="<YOUR_DATA_ASSET_NAME>",
)
```
In this example, the `get_batch()` method takes on the responsibility for inferring your intended types, and passing it through to the correct internal methods.
This distinction around untyped inputs reflects an important architecture decision within the Great Expectations codebase: “Internal workflows are strongly typed, but we make exceptions for a handful of convenience methods on the `DataContext`.”
Stronger type-checking allows the building of cleaner code, with stronger guarantees and a better understanding of error states. It also allows us to take advantage of tools like static type checkers, cyclometric complexity analysis, etc.
However, requiring typed inputs creates a steep learning curve for new users. For example, the first method above can be intimidating if you haven’t done a deep dive on exactly what a `BatchRequest` is. It also requires you to know that a Batch Request is imported from `great_expectations.core.batch`.
Allowing untyped inputs makes it possible to get started much more quickly in Great Expectations. However, the risk is that untyped inputs will lead to confusion. To head off that risk, we follow the following principles:
1. Type inference is conservative. If inferring types would require guessing, the method will instead throw an error.
2. We raise informative errors, to help users zero in on alternative input that does not require guessing to infer.
<file_sep>/docs/guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_on_a_filesystem.md
---
title: How to configure a Validation Result store on a filesystem
---
import Prerequisites from '../../../guides/connecting_to_your_data/components/prerequisites.jsx';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
By default, <TechnicalTag tag="validation_result" text="Validation Results" /> are stored in the ``uncommitted/validations/`` directory. Since Validation Results may include examples of data (which could be sensitive or regulated) they should not be committed to a source control system. This guide will help you configure a new storage location for Validation Results on your filesystem.
This guide will explain how to use an <TechnicalTag tag="action" text="Action" /> to update <TechnicalTag tag="data_docs" text="Data Docs" /> sites with new Validation Results from <TechnicalTag tag="checkpoint" text="Checkpoint" /> runs.
<Prerequisites>
- [Configured a Data Context](../../../tutorials/getting_started/tutorial_setup.md).
- [Configured an Expectation Suite ](../../../tutorials/getting_started/tutorial_create_expectations.md).
- [Configured a Checkpoint](../../../guides/validation/checkpoints/how_to_create_a_new_checkpoint.md).
- Determined a new storage location where you would like to store Validation Results. This can either be a local path, or a path to a secure network filesystem.
</Prerequisites>
## Steps
### 1. Configure a new folder on your filesystem where Validation Results will be stored
Create a new folder where you would like to store your Validation Results, and move your existing Validation Results over to the new location. In our case, the name of the Validation Result is ``npi_validations`` and the path to our new storage location is ``shared_validations/``.
```bash
# in the great_expectations/ folder
mkdir shared_validations
mv uncommitted/validations/npi_validations/ uncommitted/shared_validations/
```
### 2. Identify your Data Context Validation Results Store
As with other <TechnicalTag tag="store" text="Stores" />, you can find your <TechnicalTag tag="validation_result_store" text="Validation Results Store" /> by using your <TechnicalTag tag="data_context" text="Data Context" />. In your ``great_expectations.yml``, look for the following lines. The configuration tells Great Expectations to look for Validation Results in a Store called ``validations_store``. The ``base_directory`` for ``validations_store`` is set to ``uncommitted/validations/`` by default.
```yaml
validations_store_name: validations_store
stores:
validations_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
```
### 3. Update your configuration file to include a new store for Validation results on your filesystem
In the example below, Validation Results Store is being set to ``shared_validations_filesystem_store``, but it can be any name you like. Also, the ``base_directory`` is being set to ``uncommitted/shared_validations/``, but it can be set to any path accessible by Great Expectations.
```yaml
validations_store_name: shared_validations_filesystem_store
stores:
shared_validations_filesystem_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/shared_validations/
```
### 4. Confirm that the location has been updated by running ``great_expectations store list``
Notice the output contains two Validation Result Stores: the original ``validations_store`` and the ``shared_validations_filesystem_store`` we just configured. This is ok, since Great Expectations will look for Validation Results in the ``uncommitted/shared_validations/`` folder as long as we set the ``validations_store_name`` variable to ``shared_validations_filesystem_store``. The config for ``validations_store`` can be removed if you would like.
```bash
great_expectations store list
- name: validations_store
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
- name: shared_validations_filesystem_store
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/shared_validations/
```
### 5. Confirm that the Validation Results Store has been correctly configured
Run a [Checkpoint](../../../tutorials/getting_started/tutorial_validate_data.md) to store results in the new Validation Results Store on in your new location then visualize the results by re-building [Data Docs](../../../terms/data_docs.md).
<file_sep>/docs/terms/plugin.md
---
id: plugin
title: Plugin
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
<UniversalMap setup='active' connect='active' create='active' validate='active'/>
## Overview
### Definition
Plugins extend Great Expectations' components and/or functionality.
### Features and promises
Python files that are placed in the `plugins` directory in your project (which is created automatically when you initialize your <TechnicalTag relative="../" tag="data_context" text="Data Context" />) can be used to extend Great Expectations. Modules added there can be referenced in configuration files or imported directly in Python interpreters, scripts, or Jupyter Notebooks. If you contribute a feature to Great Expectations, implementing it as a Plugin will allow you to start using that feature even before it has been merged into the open source Great Expectations code base and included in a new release.
### Relationships to other objects
Due to their nature as extensions of Great Expectations, it can be generally said that any given Plugin can interact with any other object in Great Expectations that it is written to interact with. However, best practices are to not interact with any objects not needed to achieve the Plugin's purpose.
## Use cases
<UniversalMap setup='active' connect='active' create='active' validate='active'/>
Plugins can be relevant to any point in the process of working with Great Expectations, depending on what any given Plugin is meant to do or extend. Developing a Plugin is a process that exists outside the standard four-step workflow for using Great Expectations. However, you can generally expect to actually *use* a Plugin in the same step as whatever object it is extending would be used, and to configure a Plugin in the same step as you would configure whatever object is extended by the Plugin.
## Features
### Versatility and customization
Plugins can be anything from entirely custom code to subclasses inheriting from existing Great Expectations classes. This versatility allows you to extend and tailor Great Expectations to your specific needs. The use of Plugins can also allow you to implement features that have been submitted to Great Expectations but not yet integrated into the code base. For instance, if you contributed code for a new feature to Great Expectations, you could implement it in your production environment as a plugin even if it had not yet been merged into the official Great Expectations code base and released as a new version.
### Component specific functionality
Because Plugins often extend the functionality of existing Greate Expectations components, it is impossible to classify all of their potential features in a few generic statements. In general, best practices are to include thorough documentation if you are developing or contributing code for use as a Plugin. If you are using code that was created by someone else, you will have to reference their documentation (and possibly their code itself) in order to determine the features of that specific Plugin.
## API basics
The API of any given Plugin is determined by the individual or team that created it. That said, if the Plugin is extending an existing Great Expectations component, then best practices are for the Plugin's API to mirror that of the object it extends as closely as possible.
### Importing
Any Plugin dropped into the `plugins` folder can be imported with a standard Python import statement. In some cases, this will be all you need to do in order to make use of the Plugin's functionality. For example, a <TechnicalTag relative="../" tag="custom_expectation" text="Custom Expectation" /> Plugin could be imported and used the same as any other Expectation in the [interactive process for creating Expectations](../guides/expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md).
### Configuration
If a Plugin can't be directly used from an import, it can typically be used by editing the relevant configuration file to reference it. This typically involves setting the `module_name` for an object to the module name of the Plugin (as you would type it in an import statement) and the `class_name` for that same object to the class name that is implemented in the Plugin file.
For example, say you created a Plugin to extend the functionality of a <TechnicalTag relative="../" tag="data_connector" text="Data Connector" /> so that it works with a specific source data system that otherwise wouldn't be supported in Great Expectations. In this example, you have created `my_custom_data_connector.py` that implements the class `MyCustomDataConnector`. To use that Plugin in place of a standard Data Connector, you would edit the configuration for the corresponding <TechnicalTag relative="../" tag="datasource" text="Datasource" /> in your `great_expectations.yml` file to contain an entry like the following:
```yaml
datasources:
my_datasource:
execution_engine:
class_name: SqlAlchemyExecutionEngine
module_name: great_expectations.execution_engine
connection_string: ${my_connection_string}
data_connectors:
my_custom_data_connector:
class_name: MyCustomDataConnector
module_name: my_custom_data_connector
```
<file_sep>/docs/tutorials/getting_started/tutorial_review.md
---
title: 'Review and next steps'
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '/docs/term_tags/_tag.mdx';
<UniversalMap setup='active' connect='active' create='active' validate='active'/>
:::note Prerequisites
- Completed [Step 4: Validate Data](./tutorial_validate_data.md) of this tutorial.
:::
### Review
In this tutorial we've taken you through the four steps you need to be able to perform to use Great Expectations.
Let's review each of these steps and take a look at the important concepts and features we used.
<table class="borderless">
<tr>
<td><img src={require('../../images/universal_map/Gear-active.png').default} alt="Setup" /></td>
<td>
<h3>Step 1: Setup</h3>
<p>
You installed Great Expectations and initialized your Data Context.
</p>
</td>
</tr>
</table>
- **<TechnicalTag relative="../../" tag="data_context" text="Data Context" />**: The folder structure that contains the entirety of your Great Expectations project. It is also the entry point for accessing all the primary methods for creating elements of your project, configuring those elements, and working with the metadata for your project.
- **<TechnicalTag relative="../../" tag="cli" text="CLI" />**: The Command Line Interface for Great Expectations. The CLI provides helpful utilities for deploying and configuring Data Contexts, as well as a few other convenience methods.
<table class="borderless">
<tr>
<td><img src={require('../../images/universal_map/Outlet-active.png').default} alt="Connect to Data" /></td>
<td>
<h3>Step 2: Connect to Data</h3>
<p>You created and configured your Datasource.</p>
</td>
</tr>
</table>
- **<TechnicalTag relative="../../" tag="datasource" text="Datasource" />**: An object that brings together a way of interacting with data (an Execution Engine) and a way of accessing that data (a Data Connector). Datasources are used to obtain Batches for Validators, Expectation Suites, and Profilers.
- **Jupyter Notebooks**: These notebooks are launched by some processes in the CLI. They provide useful boilerplate code for everything from configuring a new Datasource to building an Expectation Suite to running a Checkpoint.
<table class="borderless">
<tr>
<td><img src={require('../../images/universal_map/Flask-active.png').default} alt="Create Expectations" /></td>
<td>
<h3>Step 3: Create Expectations</h3>
<p>You used the automatic Profiler to build an Expectation Suite.</p>
</td>
</tr>
</table>
- **<TechnicalTag relative="../../" tag="expectation_suite" text="Expectation Suite" />**: A collection of Expectations.
- **<TechnicalTag relative="../../" tag="expectation" text="Expectations" />**: A verifiable assertion about data. Great Expectations is a framework for defining Expectations and running them against your data. In the tutorial's example, we asserted that NYC taxi rides should have a minimum of one passenger. When we ran that Expectation against our second set of data Great Expectations reported back that some records in the new data indicated a ride with zero passengers, which failed to meet this Expectation.
- **<TechnicalTag relative="../../" tag="profiler" text="Profiler" />**: A tool that automatically generates Expectations from a <TechnicalTag relative="../../" tag="batch" text="Batch" /> of data.
<table class="borderless">
<tr>
<td><img src={require('../../images/universal_map/Checkmark-active.png').default} alt="Validate Data" /></td>
<td>
<h3>Step 4: Validate Data</h3>
<p>You created a Checkpoint which you used to validate new data. You then viewed the Validation Results in Data Docs.</p>
</td>
</tr>
</table>
- **<TechnicalTag relative="../../" tag="checkpoint" text="Checkpoint" />**: An object that uses a Validator to run an Expectation Suite against a batch of data. Running a Checkpoint produces Validation Results for the data it was run on.
- **<TechnicalTag relative="../../" tag="validation_result" text="Validation Results" />**: A report generated from an Expectation Suite being run against a batch of data. The Validation Result itself is in JSON and is rendered as Data Docs.
- **<TechnicalTag relative="../../" tag="data_docs" text="Data Docs" />**: Human readable documentation that describes Expectations for data and its Validation Results. Data docs can be generated both from Expectation Suites (describing our Expectations for the data) and also from Validation Results (describing if the data meets those Expectations).
### Going forward
Your specific use case will no doubt differ from that of our tutorial. However, the four steps you'll need to perform in order to get Great Expectations working for you will be the same. Setup, connect to data, create Expectations, and validate data. That's all there is to it! As long as you can perform these four steps you can have Great Expectations working to validate data for you.
For those who only need to know the basics in order to make Great Expectations work our documentation include an Overview reference for each step.
For those who prefer working from examples, we have "How to" guides which show working examples of how to configure objects from Great Expectations according to specific use cases. You can find these in the table of contents under the category that corresponds to when you would need to do so. Or, if you want a broad overview of the options for customizing your deployment we also provide a [reference document on ways to customize your deployment](../../reference/customize_your_deployment.md).
<file_sep>/docs/guides/expectations/components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_preface.mdx
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide will take you through the process of creating <TechnicalTag tag="expectation" text="Expectations" /> in Interactive Mode. The term "Interactive Mode" denotes the fact that you are interacting with your data as you work. In other words, you have access to a <TechnicalTag tag="datasource" text="Datasource" /> and can specify a <TechnicalTag tag="batch" text="Batch" /> of data to be used to create Expectations against. Working in interactive mode will not edit your data: you are only using it to run your Expectations against.
<Prerequisites>
- [Configured a Data Context](../../../tutorials/getting_started/tutorial_setup.md).
- [Created a Datasource](../../../tutorials/getting_started/tutorial_connect_to_data.md).
</Prerequisites>
<file_sep>/docs/guides/setup/setup_overview.md
---
title: "Setup: Overview"
---
# [](./setup_overview.md) Setup: Overview
import TechnicalTag from '/docs/term_tags/_tag.mdx';
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
<!--Use 'inactive' or 'active' to indicate which Universal Map steps this term has a use case within.-->
<UniversalMap setup='active' connect='inactive' create='inactive' validate='inactive'/>
<!-- Only keep one of the 'To best understand this document' lines. For processes like the Universal Map steps, use the first one. For processes like the Architecture Reviews, use the second one. -->
:::note Prerequisites
- Completing [Step 1: Setup](../../tutorials/getting_started/tutorial_setup.md) of the Getting Started tutorial is recommended.
:::
Getting started with Great Expectations is quick and easy. Once you have completed setup for your production deployment, you will have access to all of the features of Great Expectations from a single entry point: Your <TechnicalTag relative="../" tag="data_context" text="Data Context" />. You will also have your <TechnicalTag relative="../" tag="store" text="Stores" /> and <TechnicalTag relative="../" tag="data_docs" text="Data Docs" /> configured in the manner most suitable for your project's purposes.
### The alternative to manual Setup
If you're not interested in managing your own configuration or infrastructure then Great Expectations Cloud may be of interest to you. You can learn more about Great Expectations Cloud — our fully managed SaaS offering — by signing up for [our weekly cloud workshop!](https://greatexpectations.io/cloud) You’ll get to see our newest features and apply for our private Alpha program!
## The Setup process
<!-- Brief outline of what the process entails. -->
Setup entails ensuring your system is prepared to run Great Expectations, installing Great Expectations itself, and initializing your deployment. Optionally, you can also tweak the configuration of some components, such as Stores and Data Docs. We'll look at each of these things in sequence.
Note: configuration of <TechnicalTag relative="../" tag="datasource" text="Datasources" />, <TechnicalTag relative="../" tag="expectation_suite" text="Expectation Suites" />, and <TechnicalTag relative="../" tag="checkpoint" text="Checkpoints" /> will be handled separately. We consider those to be configuration of components after your main Great Expectations deployment is set up.
<!-- The following subsections should be repeated as necessary. They should give a high level map of the things that need to be done or optionally can be done in this process, preferably in the order that they should be addressed (assuming there is one). If the process crosses multiple steps of the Universal Map, use the <SetupHeader> <ConnectHeader> <CreateHeader> and <ValidateHeader> tags to indicate which Universal Map step the subsections fall under. -->
### 1. System Dependencies
The first thing to take care of is making sure your work environment has the utilities you need to install and run Great Expectations. These include a working Python install (version 3.7 or greater), the ability to pip install Python packages, an internet connection, and a browser so that you can use Jupyter notebooks. Best practices are to use a virtual environment for your project's workspace.
If you are having trouble with any of these, our documentation on <TechnicalTag relative="../" tag="supporting_resource" text="Supporting Resources" /> will direct you to more information and helpful tutorials.
### 2. Installation
Installing Great Expectations is a simple pip command. From the terminal, execute:
```markup title="Terminal command:"
pip install great_expectations
```
Running this command in an environment configured to accept Python pip install commands will handle the entire installation process for Great Expectations and its dependencies.
See our [guides for the installation process](./index.md#installation) for more information.
### 3. Initialize a Data Context
Your Data Context contains the entirety of your Great Expectations project and provides the entry point for all of the primary methods you will use to configure and interact with Great Expectations. At every step in your use of Great Expectations, the Data Context provides easy access to the key elements you will need to interact with. Furthermore, the Data Context will internally manage various classes so that you don't have to. Because of this, once you have completed the configurations in your Setup there will be relatively few objects you will need to manage to get Great Expectations working for you.
That's why the first thing you'll do once you've installed Great Expectations will be to initialize your Data Context.

Initializing your Data Context is another one-line command. Simply go to the root folder for your project and execute:
```markdown title="Terminal command:"
great_expectations init
```
Running this command will initialize your Data Context in the directory that the command is run from. It will create the folder structure a Data Context requires to organize your project.
See our [guides for configuring your Data Context](./index.md#data-contexts) for more information.
### 4. Optional Configurations
Once your Data Context is initialized, you'll be all set to start using Great Expectations. However, there are a few things that are configured by default to operate locally which you may want to configure to be hosted elsewhere. We include these optional configurations in our Setup instructions. Using the Data Context, you can easily create and test your configurations.
#### Stores
Stores are the locations where your Data Context stores information about your <TechnicalTag relative="../" tag="expectation" text="Expectations" />, your <TechnicalTag relative="../" tag="validation_result" text="Validation Results" />, and your <TechnicalTag relative="../" tag="metric" text="Metrics" />. By default, these are stored locally. But you can reconfigure them to work with a variety of backends.
See our [guides for configuring Stores](./index.md#stores) for more information.
#### Data Docs
Data Docs provide human readable renderings of your Expectation Suites and Validation Results. As with Stores, these are built locally by default. However, you can configure them to be hosted and shared in a variety of different ways.
See our [guides on configuring Data Docs](./index.md#data-docs) for more information.
#### Plugins
Python files are treated as <TechnicalTag relative="../" tag="plugin" text="Plugins" /> if they are in the `plugins` directory in your project (which is created automatically when you initialize your Data Context) can be used to extend Great Expectations. If you have <TechnicalTag relative="../" tag="custom_expectation" text="Custom Expectations" /> or other extensions to Great Expectations that you wish to use as Plugins in your deployment of Great Expectations, you should include them in the `plugins` directory.
## Wrapping up
That's all there is to the Setup step. Once you have your Data Context initialized you will almost always start from your Data Context (as illustrated below) for everything else you do through Great Expectations.
```markdown title="Python code:"
import great_expectations as ge
context = ge.get_context()
```
From here you will move on to the next step of working with Great Expectations: Connecting to Data.
<file_sep>/docs/guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.md
---
title: How to configure an Expectation Store to use GCS
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
By default, newly <TechnicalTag tag="profiling" text="Profiled" /> <TechnicalTag tag="expectation" text="Expectations" /> are stored as <TechnicalTag tag="expectation_suite" text="Expectation Suites" /> in JSON format in the ``expectations/`` subdirectory of your ``great_expectations/`` folder. This guide will help you configure Great Expectations to store them in a Google Cloud Storage (GCS) bucket.
<Prerequisites>
- [Configured a Data Context](../../../tutorials/getting_started/tutorial_setup.md).
- [Configured an Expectations Suite](../../../tutorials/getting_started/tutorial_create_expectations.md).
- Configured a Google Cloud Platform (GCP) [service account](https://cloud.google.com/iam/docs/service-accounts) with credentials that can access the appropriate GCP resources, which include Storage Objects.
- Identified the GCP project, GCS bucket, and prefix where Expectations will be stored.
</Prerequisites>
## Steps
### 1. Configure your GCP credentials
Check that your environment is configured with the appropriate authentication credentials needed to connect to the GCS bucket where Expectations will be stored.
The Google Cloud Platform documentation describes how to verify your [authentication for the Google Cloud API](https://cloud.google.com/docs/authentication/getting-started), which includes:
1. Creating a Google Cloud Platform (GCP) service account,
2. Setting the ``GOOGLE_APPLICATION_CREDENTIALS`` environment variable,
3. Verifying authentication by running a simple [Google Cloud Storage client](https://cloud.google.com/storage/docs/reference/libraries) library script.
### 2. Identify your Data Context Expectations Store
In your ``great_expectations.yml``, look for the following lines. The configuration tells Great Expectations to look for Expectations in a <TechnicalTag tag="store" text="Store" /> called ``expectations_store``. The ``base_directory`` for ``expectations_store`` is set to ``expectations/`` by default.
```yaml file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.py#L38-L45
```
### 3. Update your configuration file to include a new store for Expectations on GCS
In our case, the name is set to ``expectations_GCS_store``, but it can be any name you like. We also need to make some changes to the ``store_backend`` settings. The ``class_name`` will be set to ``TupleGCSStoreBackend``, ``project`` will be set to your GCP project, ``bucket`` will be set to the address of your GCS bucket, and ``prefix`` will be set to the folder on GCS where Expectation files will be located.
:::warning
If you are also storing [Validations in GCS](./how_to_configure_a_validation_result_store_in_gcs.md) or [DataDocs in GCS](../configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.md), please ensure that the ``prefix`` values are disjoint and one is not a substring of the other.
:::
```yaml file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.py#L53-L62
```
### 4. Copy existing Expectation JSON files to the GCS bucket (This step is optional)
One way to copy Expectations into GCS is by using the ``gsutil cp`` command, which is part of the Google Cloud SDK. The following example will copy one Expectation, ``my_expectation_suite`` from a local folder to the GCS bucket. Information on other ways to copy Expectation JSON files, like the Cloud Storage browser in the Google Cloud Console, can be found in the [Documentation for Google Cloud](https://cloud.google.com/storage/docs/uploading-objects).
```bash file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.py#L106
```
```bash file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.py#L137
```
### 5. Confirm that the new Expectations store has been added
Run the following:
```bash file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.py#L144
```
Only the active Stores will be listed. Great Expectations will look for Expectations in GCS as long as we set the ``expectations_store_name`` variable to ``expectations_GCS_store``, and the config for ``expectations_store`` can be removed if you would like.
```bash file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.py#L155-L161
```
### 6. Confirm that Expectations can be accessed from GCS
To do this, run the following:
```bash file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.py#L171
```
If you followed Step 4, the output should include the Expectation we copied to GCS: ``my_expectation_suite``. If you did not copy Expectations to the new Store, you will see a message saying no Expectations were found.
```bash file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.py#L182-L183
```
## Additional Notes
To view the full script used in this page, see it on GitHub:
- [how_to_configure_an_expectation_store_in_gcs.py](https://github.com/great-expectations/great_expectations/tree/develop/tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.py)
<file_sep>/great_expectations/execution_engine/sqlalchemy_execution_engine.py
from __future__ import annotations
import copy
import datetime
import hashlib
import logging
import math
import os
import random
import re
import string
import traceback
import warnings
from pathlib import Path
from typing import (
TYPE_CHECKING,
Any,
Callable,
Dict,
Iterable,
List,
Optional,
Tuple,
Union,
cast,
)
from great_expectations._version import get_versions # isort:skip
__version__ = get_versions()["version"] # isort:skip
from great_expectations.core.usage_statistics.events import UsageStatsEvents
from great_expectations.core.util import convert_to_json_serializable
from great_expectations.execution_engine.bundled_metric_configuration import (
BundledMetricConfiguration,
)
from great_expectations.execution_engine.split_and_sample.sqlalchemy_data_sampler import (
SqlAlchemyDataSampler,
)
from great_expectations.execution_engine.split_and_sample.sqlalchemy_data_splitter import (
SqlAlchemyDataSplitter,
)
from great_expectations.validator.computed_metric import MetricValue
del get_versions # isort:skip
from great_expectations.core import IDDict
from great_expectations.core.batch import BatchMarkers, BatchSpec
from great_expectations.core.batch_spec import (
RuntimeQueryBatchSpec,
SqlAlchemyDatasourceBatchSpec,
)
from great_expectations.data_context.types.base import ConcurrencyConfig
from great_expectations.exceptions import (
DatasourceKeyPairAuthBadPassphraseError,
ExecutionEngineError,
GreatExpectationsError,
InvalidBatchSpecError,
InvalidConfigError,
)
from great_expectations.exceptions import exceptions as ge_exceptions
from great_expectations.execution_engine import ExecutionEngine
from great_expectations.execution_engine.execution_engine import (
MetricDomainTypes,
SplitDomainKwargs,
)
from great_expectations.execution_engine.sqlalchemy_batch_data import (
SqlAlchemyBatchData,
)
from great_expectations.execution_engine.sqlalchemy_dialect import GESqlDialect
from great_expectations.expectations.row_conditions import (
RowCondition,
RowConditionParserType,
parse_condition_to_sqlalchemy,
)
from great_expectations.util import (
filter_properties_dict,
get_sqlalchemy_selectable,
get_sqlalchemy_url,
import_library_module,
import_make_url,
)
from great_expectations.validator.metric_configuration import MetricConfiguration
logger = logging.getLogger(__name__)
try:
import sqlalchemy as sa
make_url = import_make_url()
except ImportError:
sa = None
try:
from sqlalchemy.engine import Dialect, Row
from sqlalchemy.exc import OperationalError
from sqlalchemy.sql import Selectable
from sqlalchemy.sql.elements import (
BooleanClauseList,
Label,
TextClause,
quoted_name,
)
from sqlalchemy.sql.selectable import Select, TextualSelect
except ImportError:
BooleanClauseList = None
DefaultDialect = None
Dialect = None
Label = None
OperationalError = None
reflection = None
Row = None
Select = None
Selectable = None
TextClause = None
TextualSelect = None
quoted_name = None
try:
import psycopg2 # noqa: F401
import sqlalchemy.dialects.postgresql.psycopg2 as sqlalchemy_psycopg2 # noqa: F401
except (ImportError, KeyError):
sqlalchemy_psycopg2 = None
try:
import sqlalchemy_redshift.dialect
except ImportError:
sqlalchemy_redshift = None
try:
import sqlalchemy_dremio.pyodbc
if sa:
sa.dialects.registry.register(
GESqlDialect.DREMIO, "sqlalchemy_dremio.pyodbc", "dialect"
)
except ImportError:
sqlalchemy_dremio = None
try:
import snowflake.sqlalchemy.snowdialect
if sa:
# Sometimes "snowflake-sqlalchemy" fails to self-register in certain environments, so we do it explicitly.
# (see https://stackoverflow.com/questions/53284762/nosuchmoduleerror-cant-load-plugin-sqlalchemy-dialectssnowflake)
sa.dialects.registry.register(
GESqlDialect.SNOWFLAKE, "snowflake.sqlalchemy", "dialect"
)
except (ImportError, KeyError, AttributeError):
snowflake = None
_BIGQUERY_MODULE_NAME = "sqlalchemy_bigquery"
try:
import sqlalchemy_bigquery as sqla_bigquery
sa.dialects.registry.register(
GESqlDialect.BIGQUERY, _BIGQUERY_MODULE_NAME, "dialect"
)
bigquery_types_tuple = None
except ImportError:
try:
# noinspection PyUnresolvedReferences
import pybigquery.sqlalchemy_bigquery as sqla_bigquery
# deprecated-v0.14.7
warnings.warn(
"The pybigquery package is obsolete and its usage within Great Expectations is deprecated as of v0.14.7. "
"As support will be removed in v0.17, please transition to sqlalchemy-bigquery",
DeprecationWarning,
)
_BIGQUERY_MODULE_NAME = "pybigquery.sqlalchemy_bigquery"
# Sometimes "pybigquery.sqlalchemy_bigquery" fails to self-register in Azure (our CI/CD pipeline) in certain cases, so we do it explicitly.
# (see https://stackoverflow.com/questions/53284762/nosuchmoduleerror-cant-load-plugin-sqlalchemy-dialectssnowflake)
sa.dialects.registry.register(
GESqlDialect.BIGQUERY, _BIGQUERY_MODULE_NAME, "dialect"
)
try:
getattr(sqla_bigquery, "INTEGER")
bigquery_types_tuple = None
except AttributeError:
# In older versions of the pybigquery driver, types were not exported, so we use a hack
logger.warning(
"Old pybigquery driver version detected. Consider upgrading to 0.4.14 or later."
)
from collections import namedtuple
BigQueryTypes = namedtuple("BigQueryTypes", sorted(sqla_bigquery._type_map)) # type: ignore[misc] # expect List/tuple, _type_map unknown
bigquery_types_tuple = BigQueryTypes(**sqla_bigquery._type_map)
except (ImportError, AttributeError):
sqla_bigquery = None
bigquery_types_tuple = None
pybigquery = None
try:
import teradatasqlalchemy.dialect
import teradatasqlalchemy.types as teradatatypes
except ImportError:
teradatasqlalchemy = None
teradatatypes = None
if TYPE_CHECKING:
import sqlalchemy as sa
from sqlalchemy.engine import Engine as SaEngine
def _get_dialect_type_module(dialect):
"""Given a dialect, returns the dialect type, which is defines the engine/system that is used to communicates
with the database/database implementation. Currently checks for RedShift/BigQuery dialects"""
if dialect is None:
logger.warning(
"No sqlalchemy dialect found; relying in top-level sqlalchemy types."
)
return sa
try:
# Redshift does not (yet) export types to top level; only recognize base SA types
if isinstance(dialect, sqlalchemy_redshift.dialect.RedshiftDialect):
# noinspection PyUnresolvedReferences
return dialect.sa
except (TypeError, AttributeError):
pass
# Bigquery works with newer versions, but use a patch if we had to define bigquery_types_tuple
try:
if (
isinstance(
dialect,
sqla_bigquery.BigQueryDialect,
)
and bigquery_types_tuple is not None
):
return bigquery_types_tuple
except (TypeError, AttributeError):
pass
# Teradata types module
try:
if (
issubclass(
dialect,
teradatasqlalchemy.dialect.TeradataDialect,
)
and teradatatypes is not None
):
return teradatatypes
except (TypeError, AttributeError):
pass
return dialect
class SqlAlchemyExecutionEngine(ExecutionEngine):
# noinspection PyUnusedLocal
def __init__( # noqa: C901 - 17
self,
name: Optional[str] = None,
credentials: Optional[dict] = None,
data_context: Optional[Any] = None,
engine: Optional[SaEngine] = None,
connection_string: Optional[str] = None,
url: Optional[str] = None,
batch_data_dict: Optional[dict] = None,
create_temp_table: bool = True,
concurrency: Optional[ConcurrencyConfig] = None,
**kwargs, # These will be passed as optional parameters to the SQLAlchemy engine, **not** the ExecutionEngine
) -> None:
"""Builds a SqlAlchemyExecutionEngine, using a provided connection string/url/engine/credentials to access the
desired database. Also initializes the dialect to be used and configures usage statistics.
Args:
name (str): \
The name of the SqlAlchemyExecutionEngine
credentials: \
If the Execution Engine is not provided, the credentials can be used to build the Execution
Engine. If the Engine is provided, it will be used instead
data_context (DataContext): \
An object representing a Great Expectations project that can be used to access Expectation
Suites and the Project Data itself
engine (Engine): \
A SqlAlchemy Engine used to set the SqlAlchemyExecutionEngine being configured, useful if an
Engine has already been configured and should be reused. Will override Credentials
if provided.
connection_string (string): \
If neither the engines nor the credentials have been provided, a connection string can be used
to access the data. This will be overridden by both the engine and credentials if those are
provided.
url (string): \
If neither the engines, the credentials, nor the connection_string have been provided,
a url can be used to access the data. This will be overridden by all other configuration
options if any are provided.
concurrency (ConcurrencyConfig): Concurrency config used to configure the sqlalchemy engine.
"""
super().__init__(name=name, batch_data_dict=batch_data_dict)
self._name = name
self._credentials = credentials
self._connection_string = connection_string
self._url = url
self._create_temp_table = create_temp_table
os.environ["SF_PARTNER"] = "great_expectations_oss"
if engine is not None:
if credentials is not None:
logger.warning(
"Both credentials and engine were provided during initialization of SqlAlchemyExecutionEngine. "
"Ignoring credentials."
)
self.engine = engine
else:
if data_context is None or data_context.concurrency is None:
concurrency = ConcurrencyConfig()
else:
concurrency = data_context.concurrency
concurrency.add_sqlalchemy_create_engine_parameters(kwargs) # type: ignore[union-attr]
if credentials is not None:
self.engine = self._build_engine(credentials=credentials, **kwargs)
elif connection_string is not None:
self.engine = sa.create_engine(connection_string, **kwargs)
elif url is not None:
parsed_url = make_url(url)
self.drivername = parsed_url.drivername
self.engine = sa.create_engine(url, **kwargs)
else:
raise InvalidConfigError(
"Credentials or an engine are required for a SqlAlchemyExecutionEngine."
)
# these are two backends where temp_table_creation is not supported we set the default value to False.
if self.dialect_name in [
GESqlDialect.TRINO,
GESqlDialect.AWSATHENA, # WKS 202201 - AWS Athena currently doesn't support temp_tables.
]:
self._create_temp_table = False
# Get the dialect **for purposes of identifying types**
if self.dialect_name in [
GESqlDialect.POSTGRESQL,
GESqlDialect.MYSQL,
GESqlDialect.SQLITE,
GESqlDialect.ORACLE,
GESqlDialect.MSSQL,
]:
# These are the officially included and supported dialects by sqlalchemy
self.dialect_module = import_library_module(
module_name=f"sqlalchemy.dialects.{self.engine.dialect.name}"
)
elif self.dialect_name == GESqlDialect.SNOWFLAKE:
self.dialect_module = import_library_module(
module_name="snowflake.sqlalchemy.snowdialect"
)
elif self.dialect_name == GESqlDialect.DREMIO:
# WARNING: Dremio Support is experimental, functionality is not fully under test
self.dialect_module = import_library_module(
module_name="sqlalchemy_dremio.pyodbc"
)
elif self.dialect_name == GESqlDialect.REDSHIFT:
self.dialect_module = import_library_module(
module_name="sqlalchemy_redshift.dialect"
)
elif self.dialect_name == GESqlDialect.BIGQUERY:
self.dialect_module = import_library_module(
module_name=_BIGQUERY_MODULE_NAME
)
elif self.dialect_name == GESqlDialect.TERADATASQL:
# WARNING: Teradata Support is experimental, functionality is not fully under test
self.dialect_module = import_library_module(
module_name="teradatasqlalchemy.dialect"
)
else:
self.dialect_module = None
# <WILL> 20210726 - engine_backup is used by the snowflake connector, which requires connection and engine
# to be closed and disposed separately. Currently self.engine can refer to either a Connection or Engine,
# depending on the backend. This will need to be cleaned up in an upcoming refactor, so that Engine and
# Connection can be handled separately.
self._engine_backup = None
if self.engine and self.dialect_name in [
GESqlDialect.SQLITE,
GESqlDialect.MSSQL,
GESqlDialect.SNOWFLAKE,
GESqlDialect.MYSQL,
]:
self._engine_backup = self.engine
# sqlite/mssql temp tables only persist within a connection so override the engine
self.engine = self.engine.connect()
if (
self._engine_backup.dialect.name.lower() == GESqlDialect.SQLITE
and not isinstance(self._engine_backup, sa.engine.base.Connection)
):
raw_connection = self._engine_backup.raw_connection()
raw_connection.create_function("sqrt", 1, lambda x: math.sqrt(x))
raw_connection.create_function(
"md5",
2,
lambda x, d: hashlib.md5(str(x).encode("utf-8")).hexdigest()[
-1 * d :
],
)
# Send a connect event to provide dialect type
if data_context is not None and getattr(
data_context, "_usage_statistics_handler", None
):
handler = data_context._usage_statistics_handler
handler.send_usage_message(
event=UsageStatsEvents.EXECUTION_ENGINE_SQLALCHEMY_CONNECT,
event_payload={
"anonymized_name": handler.anonymizer.anonymize(self.name),
"sqlalchemy_dialect": self.engine.name,
},
success=True,
)
# Gather the call arguments of the present function (and add the "class_name"), filter out the Falsy values,
# and set the instance "_config" variable equal to the resulting dictionary.
self._config = {
"name": name,
"credentials": credentials,
"data_context": data_context,
"engine": engine,
"connection_string": connection_string,
"url": url,
"batch_data_dict": batch_data_dict,
"module_name": self.__class__.__module__,
"class_name": self.__class__.__name__,
}
self._config.update(kwargs)
filter_properties_dict(properties=self._config, clean_falsy=True, inplace=True)
self._data_splitter = SqlAlchemyDataSplitter(dialect=self.dialect_name)
self._data_sampler = SqlAlchemyDataSampler()
@property
def credentials(self) -> Optional[dict]:
return self._credentials
@property
def connection_string(self) -> Optional[str]:
return self._connection_string
@property
def url(self) -> Optional[str]:
return self._url
@property
def dialect(self) -> Dialect:
return self.engine.dialect
@property
def dialect_name(self) -> str:
"""Retrieve the string name of the engine dialect in lowercase e.g. "postgresql".
Returns:
String representation of the sql dialect.
"""
return self.engine.dialect.name.lower()
def _build_engine(self, credentials: dict, **kwargs) -> "sa.engine.Engine":
"""
Using a set of given credentials, constructs an Execution Engine , connecting to a database using a URL or a
private key path.
"""
# Update credentials with anything passed during connection time
drivername = credentials.pop("drivername")
schema_name = credentials.pop("schema_name", None)
if schema_name is not None:
logger.warning(
"schema_name specified creating a URL with schema is not supported. Set a default "
"schema on the user connecting to your database."
)
create_engine_kwargs = kwargs
connect_args = credentials.pop("connect_args", None)
if connect_args:
create_engine_kwargs["connect_args"] = connect_args
if "private_key_path" in credentials:
options, create_engine_kwargs = self._get_sqlalchemy_key_pair_auth_url(
drivername, credentials
)
else:
options = get_sqlalchemy_url(drivername, **credentials)
self.drivername = drivername
engine = sa.create_engine(options, **create_engine_kwargs)
return engine
@staticmethod
def _get_sqlalchemy_key_pair_auth_url(
drivername: str,
credentials: dict,
) -> Tuple["sa.engine.url.URL", dict]:
"""
Utilizing a private key path and a passphrase in a given credentials dictionary, attempts to encode the provided
values into a private key. If passphrase is incorrect, this will fail and an exception is raised.
Args:
drivername(str) - The name of the driver class
credentials(dict) - A dictionary of database credentials used to access the database
Returns:
a tuple consisting of a url with the serialized key-pair authentication, and a dictionary of engine kwargs.
"""
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives import serialization
private_key_path = credentials.pop("private_key_path")
private_key_passphrase = credentials.pop("private_key_passphrase")
with Path(private_key_path).expanduser().resolve().open(mode="rb") as key:
try:
p_key = serialization.load_pem_private_key(
key.read(),
password=private_key_passphrase.encode()
if private_key_passphrase
else None,
backend=default_backend(),
)
except ValueError as e:
if "incorrect password" in str(e).lower():
raise DatasourceKeyPairAuthBadPassphraseError(
datasource_name="SqlAlchemyDatasource",
message="Decryption of key failed, was the passphrase incorrect?",
) from e
else:
raise e
pkb = p_key.private_bytes(
encoding=serialization.Encoding.DER,
format=serialization.PrivateFormat.PKCS8,
encryption_algorithm=serialization.NoEncryption(),
)
credentials_driver_name = credentials.pop("drivername", None)
create_engine_kwargs = {"connect_args": {"private_key": pkb}}
return (
get_sqlalchemy_url(drivername or credentials_driver_name, **credentials),
create_engine_kwargs,
)
def get_domain_records( # noqa: C901 - 24
self,
domain_kwargs: dict,
) -> Selectable:
"""
Uses the given domain kwargs (which include row_condition, condition_parser, and ignore_row_if directives) to
obtain and/or query a batch. Returns in the format of an SqlAlchemy table/column(s) object.
Args:
domain_kwargs (dict) - A dictionary consisting of the domain kwargs specifying which data to obtain
Returns:
An SqlAlchemy table/column(s) (the selectable object for obtaining data on which to compute)
"""
data_object: SqlAlchemyBatchData
batch_id: Optional[str] = domain_kwargs.get("batch_id")
if batch_id is None:
# We allow no batch id specified if there is only one batch
if self.batch_manager.active_batch_data:
data_object = cast(
SqlAlchemyBatchData, self.batch_manager.active_batch_data
)
else:
raise GreatExpectationsError(
"No batch is specified, but could not identify a loaded batch."
)
else:
if batch_id in self.batch_manager.batch_data_cache:
data_object = cast(
SqlAlchemyBatchData, self.batch_manager.batch_data_cache[batch_id]
)
else:
raise GreatExpectationsError(
f"Unable to find batch with batch_id {batch_id}"
)
selectable: Selectable
if "table" in domain_kwargs and domain_kwargs["table"] is not None:
# TODO: Add logic to handle record_set_name once implemented
# (i.e. multiple record sets (tables) in one batch
if domain_kwargs["table"] != data_object.selectable.name:
# noinspection PyProtectedMember
selectable = sa.Table(
domain_kwargs["table"],
sa.MetaData(),
schema=data_object._schema_name,
)
else:
selectable = data_object.selectable
elif "query" in domain_kwargs:
raise ValueError(
"query is not currently supported by SqlAlchemyExecutionEngine"
)
else:
selectable = data_object.selectable
"""
If a custom query is passed, selectable will be TextClause and not formatted
as a subquery wrapped in "(subquery) alias". TextClause must first be converted
to TextualSelect using sa.columns() before it can be converted to type Subquery
"""
if TextClause and isinstance(selectable, TextClause):
selectable = selectable.columns().subquery()
# Filtering by row condition.
if (
"row_condition" in domain_kwargs
and domain_kwargs["row_condition"] is not None
):
condition_parser = domain_kwargs["condition_parser"]
if condition_parser == "great_expectations__experimental__":
parsed_condition = parse_condition_to_sqlalchemy(
domain_kwargs["row_condition"]
)
selectable = (
sa.select([sa.text("*")])
.select_from(selectable)
.where(parsed_condition)
)
else:
raise GreatExpectationsError(
"SqlAlchemyExecutionEngine only supports the great_expectations condition_parser."
)
# Filtering by filter_conditions
filter_conditions: List[RowCondition] = domain_kwargs.get(
"filter_conditions", []
)
# For SqlAlchemyExecutionEngine only one filter condition is allowed
if len(filter_conditions) == 1:
filter_condition = filter_conditions[0]
assert (
filter_condition.condition_type == RowConditionParserType.GE
), "filter_condition must be of type GE for SqlAlchemyExecutionEngine"
selectable = (
sa.select([sa.text("*")])
.select_from(selectable)
.where(parse_condition_to_sqlalchemy(filter_condition.condition))
)
elif len(filter_conditions) > 1:
raise GreatExpectationsError(
"SqlAlchemyExecutionEngine currently only supports a single filter condition."
)
if "column" in domain_kwargs:
return selectable
# Filtering by ignore_row_if directive
if (
"column_A" in domain_kwargs
and "column_B" in domain_kwargs
and "ignore_row_if" in domain_kwargs
):
if cast(
SqlAlchemyBatchData, self.batch_manager.active_batch_data
).use_quoted_name:
# Checking if case-sensitive and using appropriate name
# noinspection PyPep8Naming
column_A_name = quoted_name(domain_kwargs["column_A"], quote=True)
# noinspection PyPep8Naming
column_B_name = quoted_name(domain_kwargs["column_B"], quote=True)
else:
# noinspection PyPep8Naming
column_A_name = domain_kwargs["column_A"]
# noinspection PyPep8Naming
column_B_name = domain_kwargs["column_B"]
ignore_row_if = domain_kwargs["ignore_row_if"]
if ignore_row_if == "both_values_are_missing":
selectable = get_sqlalchemy_selectable(
sa.select([sa.text("*")])
.select_from(get_sqlalchemy_selectable(selectable))
.where(
sa.not_(
sa.and_(
sa.column(column_A_name) == None, # noqa: E711
sa.column(column_B_name) == None, # noqa: E711
)
)
)
)
elif ignore_row_if == "either_value_is_missing":
selectable = get_sqlalchemy_selectable(
sa.select([sa.text("*")])
.select_from(get_sqlalchemy_selectable(selectable))
.where(
sa.not_(
sa.or_(
sa.column(column_A_name) == None, # noqa: E711
sa.column(column_B_name) == None, # noqa: E711
)
)
)
)
else:
if ignore_row_if not in ["neither", "never"]:
raise ValueError(
f'Unrecognized value of ignore_row_if ("{ignore_row_if}").'
)
if ignore_row_if == "never":
# deprecated-v0.13.29
warnings.warn(
f"""The correct "no-action" value of the "ignore_row_if" directive for the column pair case is \
"neither" (the use of "{ignore_row_if}" is deprecated as of v0.13.29 and will be removed in v0.16). Please use \
"neither" moving forward.
""",
DeprecationWarning,
)
return selectable
if "column_list" in domain_kwargs and "ignore_row_if" in domain_kwargs:
if cast(
SqlAlchemyBatchData, self.batch_manager.active_batch_data
).use_quoted_name:
# Checking if case-sensitive and using appropriate name
column_list = [
quoted_name(domain_kwargs[column_name], quote=True)
for column_name in domain_kwargs["column_list"]
]
else:
column_list = domain_kwargs["column_list"]
ignore_row_if = domain_kwargs["ignore_row_if"]
if ignore_row_if == "all_values_are_missing":
selectable = get_sqlalchemy_selectable(
sa.select([sa.text("*")])
.select_from(get_sqlalchemy_selectable(selectable))
.where(
sa.not_(
sa.and_(
*(
sa.column(column_name) == None # noqa: E711
for column_name in column_list
)
)
)
)
)
elif ignore_row_if == "any_value_is_missing":
selectable = get_sqlalchemy_selectable(
sa.select([sa.text("*")])
.select_from(get_sqlalchemy_selectable(selectable))
.where(
sa.not_(
sa.or_(
*(
sa.column(column_name) == None # noqa: E711
for column_name in column_list
)
)
)
)
)
else:
if ignore_row_if != "never":
raise ValueError(
f'Unrecognized value of ignore_row_if ("{ignore_row_if}").'
)
return selectable
return selectable
def get_compute_domain(
self,
domain_kwargs: dict,
domain_type: Union[str, MetricDomainTypes],
accessor_keys: Optional[Iterable[str]] = None,
) -> Tuple[Selectable, dict, dict]:
"""Uses a given batch dictionary and domain kwargs to obtain a SqlAlchemy column object.
Args:
domain_kwargs (dict) - A dictionary consisting of the domain kwargs specifying which data to obtain
domain_type (str or MetricDomainTypes) - an Enum value indicating which metric domain the user would
like to be using, or a corresponding string value representing it. String types include "identity",
"column", "column_pair", "table" and "other". Enum types include capitalized versions of these from the
class MetricDomainTypes.
accessor_keys (str iterable) - keys that are part of the compute domain but should be ignored when
describing the domain and simply transferred with their associated values into accessor_domain_kwargs.
Returns:
SqlAlchemy column
"""
split_domain_kwargs: SplitDomainKwargs = self._split_domain_kwargs(
domain_kwargs, domain_type, accessor_keys
)
selectable: Selectable = self.get_domain_records(domain_kwargs=domain_kwargs)
return selectable, split_domain_kwargs.compute, split_domain_kwargs.accessor
def _split_column_metric_domain_kwargs( # type: ignore[override] # ExecutionEngine method is static
self,
domain_kwargs: dict,
domain_type: MetricDomainTypes,
) -> SplitDomainKwargs:
"""Split domain_kwargs for column domain types into compute and accessor domain kwargs.
Args:
domain_kwargs: A dictionary consisting of the domain kwargs specifying which data to obtain
domain_type: an Enum value indicating which metric domain the user would
like to be using.
Returns:
compute_domain_kwargs, accessor_domain_kwargs split from domain_kwargs
The union of compute_domain_kwargs, accessor_domain_kwargs is the input domain_kwargs
"""
assert (
domain_type == MetricDomainTypes.COLUMN
), "This method only supports MetricDomainTypes.COLUMN"
compute_domain_kwargs: dict = copy.deepcopy(domain_kwargs)
accessor_domain_kwargs: dict = {}
if "column" not in compute_domain_kwargs:
raise ge_exceptions.GreatExpectationsError(
"Column not provided in compute_domain_kwargs"
)
# Checking if case-sensitive and using appropriate name
if cast(
SqlAlchemyBatchData, self.batch_manager.active_batch_data
).use_quoted_name:
accessor_domain_kwargs["column"] = quoted_name(
compute_domain_kwargs.pop("column"), quote=True
)
else:
accessor_domain_kwargs["column"] = compute_domain_kwargs.pop("column")
return SplitDomainKwargs(compute_domain_kwargs, accessor_domain_kwargs)
def _split_column_pair_metric_domain_kwargs( # type: ignore[override] # ExecutionEngine method is static
self,
domain_kwargs: dict,
domain_type: MetricDomainTypes,
) -> SplitDomainKwargs:
"""Split domain_kwargs for column pair domain types into compute and accessor domain kwargs.
Args:
domain_kwargs: A dictionary consisting of the domain kwargs specifying which data to obtain
domain_type: an Enum value indicating which metric domain the user would
like to be using.
Returns:
compute_domain_kwargs, accessor_domain_kwargs split from domain_kwargs
The union of compute_domain_kwargs, accessor_domain_kwargs is the input domain_kwargs
"""
assert (
domain_type == MetricDomainTypes.COLUMN_PAIR
), "This method only supports MetricDomainTypes.COLUMN_PAIR"
compute_domain_kwargs: dict = copy.deepcopy(domain_kwargs)
accessor_domain_kwargs: dict = {}
if not (
"column_A" in compute_domain_kwargs and "column_B" in compute_domain_kwargs
):
raise ge_exceptions.GreatExpectationsError(
"column_A or column_B not found within compute_domain_kwargs"
)
# Checking if case-sensitive and using appropriate name
if cast(
SqlAlchemyBatchData, self.batch_manager.active_batch_data
).use_quoted_name:
accessor_domain_kwargs["column_A"] = quoted_name(
compute_domain_kwargs.pop("column_A"), quote=True
)
accessor_domain_kwargs["column_B"] = quoted_name(
compute_domain_kwargs.pop("column_B"), quote=True
)
else:
accessor_domain_kwargs["column_A"] = compute_domain_kwargs.pop("column_A")
accessor_domain_kwargs["column_B"] = compute_domain_kwargs.pop("column_B")
return SplitDomainKwargs(compute_domain_kwargs, accessor_domain_kwargs)
def _split_multi_column_metric_domain_kwargs( # type: ignore[override] # ExecutionEngine method is static
self,
domain_kwargs: dict,
domain_type: MetricDomainTypes,
) -> SplitDomainKwargs:
"""Split domain_kwargs for multicolumn domain types into compute and accessor domain kwargs.
Args:
domain_kwargs: A dictionary consisting of the domain kwargs specifying which data to obtain
domain_type: an Enum value indicating which metric domain the user would
like to be using.
Returns:
compute_domain_kwargs, accessor_domain_kwargs split from domain_kwargs
The union of compute_domain_kwargs, accessor_domain_kwargs is the input domain_kwargs
"""
assert (
domain_type == MetricDomainTypes.MULTICOLUMN
), "This method only supports MetricDomainTypes.MULTICOLUMN"
compute_domain_kwargs: dict = copy.deepcopy(domain_kwargs)
accessor_domain_kwargs: dict = {}
if "column_list" not in domain_kwargs:
raise GreatExpectationsError("column_list not found within domain_kwargs")
column_list = compute_domain_kwargs.pop("column_list")
if len(column_list) < 2:
raise GreatExpectationsError("column_list must contain at least 2 columns")
# Checking if case-sensitive and using appropriate name
if cast(
SqlAlchemyBatchData, self.batch_manager.active_batch_data
).use_quoted_name:
accessor_domain_kwargs["column_list"] = [
quoted_name(column_name, quote=True) for column_name in column_list
]
else:
accessor_domain_kwargs["column_list"] = column_list
return SplitDomainKwargs(compute_domain_kwargs, accessor_domain_kwargs)
def resolve_metric_bundle(
self,
metric_fn_bundle: Iterable[BundledMetricConfiguration],
) -> Dict[Tuple[str, str, str], MetricValue]:
"""For every metric in a set of Metrics to resolve, obtains necessary metric keyword arguments and builds
bundles of the metrics into one large query dictionary so that they are all executed simultaneously. Will fail
if bundling the metrics together is not possible.
Args:
metric_fn_bundle (Iterable[BundledMetricConfiguration]): \
"BundledMetricConfiguration" contains MetricProvider's MetricConfiguration (its unique identifier),
its metric provider function (the function that actually executes the metric), and arguments to pass
to metric provider function (dictionary of metrics defined in registry and corresponding arguments).
Returns:
A dictionary of "MetricConfiguration" IDs and their corresponding now-queried (fully resolved) values.
"""
resolved_metrics: Dict[Tuple[str, str, str], MetricValue] = {}
res: List[Row]
# We need a different query for each domain (where clause).
queries: Dict[Tuple[str, str, str], dict] = {}
query: dict
domain_id: Tuple[str, str, str]
bundled_metric_configuration: BundledMetricConfiguration
for bundled_metric_configuration in metric_fn_bundle:
metric_to_resolve: MetricConfiguration = (
bundled_metric_configuration.metric_configuration
)
metric_fn: Any = bundled_metric_configuration.metric_fn
compute_domain_kwargs: dict = (
bundled_metric_configuration.compute_domain_kwargs
)
if not isinstance(compute_domain_kwargs, IDDict):
compute_domain_kwargs = IDDict(compute_domain_kwargs)
domain_id = compute_domain_kwargs.to_id()
if domain_id not in queries:
queries[domain_id] = {
"select": [],
"metric_ids": [],
"domain_kwargs": compute_domain_kwargs,
}
if self.engine.dialect.name == "clickhouse":
queries[domain_id]["select"].append(
metric_fn.label(
metric_to_resolve.metric_name.join(
random.choices(string.ascii_lowercase, k=4)
)
)
)
else:
queries[domain_id]["select"].append(
metric_fn.label(metric_to_resolve.metric_name)
)
queries[domain_id]["metric_ids"].append(metric_to_resolve.id)
for query in queries.values():
domain_kwargs: dict = query["domain_kwargs"]
selectable: Selectable = self.get_domain_records(
domain_kwargs=domain_kwargs
)
assert len(query["select"]) == len(query["metric_ids"])
try:
"""
If a custom query is passed, selectable will be TextClause and not formatted
as a subquery wrapped in "(subquery) alias". TextClause must first be converted
to TextualSelect using sa.columns() before it can be converted to type Subquery
"""
if TextClause and isinstance(selectable, TextClause):
sa_query_object = sa.select(query["select"]).select_from(
selectable.columns().subquery()
)
elif (Select and isinstance(selectable, Select)) or (
TextualSelect and isinstance(selectable, TextualSelect)
):
sa_query_object = sa.select(query["select"]).select_from(
selectable.subquery()
)
else:
sa_query_object = sa.select(query["select"]).select_from(selectable)
logger.debug(f"Attempting query {str(sa_query_object)}")
res = self.engine.execute(sa_query_object).fetchall()
logger.debug(
f"""SqlAlchemyExecutionEngine computed {len(res[0])} metrics on domain_id \
{IDDict(domain_kwargs).to_id()}"""
)
except OperationalError as oe:
exception_message: str = "An SQL execution Exception occurred. "
exception_traceback: str = traceback.format_exc()
exception_message += f'{type(oe).__name__}: "{str(oe)}". Traceback: "{exception_traceback}".'
logger.error(exception_message)
raise ExecutionEngineError(message=exception_message)
assert (
len(res) == 1
), "all bundle-computed metrics must be single-value statistics"
assert len(query["metric_ids"]) == len(
res[0]
), "unexpected number of metrics returned"
idx: int
metric_id: Tuple[str, str, str]
for idx, metric_id in enumerate(query["metric_ids"]):
# Converting SQL query execution results into JSON-serializable format produces simple data types,
# amenable for subsequent post-processing by higher-level "Metric" and "Expectation" layers.
resolved_metrics[metric_id] = convert_to_json_serializable(
data=res[0][idx]
)
return resolved_metrics
def close(self) -> None:
"""
Note: Will 20210729
This is a helper function that will close and dispose Sqlalchemy objects that are used to connect to a database.
Databases like Snowflake require the connection and engine to be instantiated and closed separately, and not
doing so has caused problems with hanging connections.
Currently the ExecutionEngine does not support handling connections and engine separately, and will actually
override the engine with a connection in some cases, obfuscating what object is used to actually used by the
ExecutionEngine to connect to the external database. This will be handled in an upcoming refactor, which will
allow this function to eventually become:
self.connection.close()
self.engine.dispose()
More background can be found here: https://github.com/great-expectations/great_expectations/pull/3104/
"""
if self._engine_backup:
self.engine.close()
self._engine_backup.dispose()
else:
self.engine.dispose()
def _get_splitter_method(self, splitter_method_name: str) -> Callable:
"""Get the appropriate splitter method from the method name.
Args:
splitter_method_name: name of the splitter to retrieve.
Returns:
splitter method.
"""
return self._data_splitter.get_splitter_method(splitter_method_name)
def execute_split_query(self, split_query: Selectable) -> List[Row]:
"""Use the execution engine to run the split query and fetch all of the results.
Args:
split_query: Query to be executed as a sqlalchemy Selectable.
Returns:
List of row results.
"""
if self.dialect_name == "awsathena":
# Note: Athena does not support casting to string, only to varchar
# but sqlalchemy currently generates a query as `CAST(colname AS STRING)` instead
# of `CAST(colname AS VARCHAR)` with other dialects.
split_query = str(
split_query.compile(self.engine, compile_kwargs={"literal_binds": True})
)
pattern = re.compile(r"(CAST\(EXTRACT\(.*?\))( AS STRING\))", re.IGNORECASE)
split_query = re.sub(pattern, r"\1 AS VARCHAR)", split_query)
return self.engine.execute(split_query).fetchall()
def get_data_for_batch_identifiers(
self, table_name: str, splitter_method_name: str, splitter_kwargs: dict
) -> List[dict]:
"""Build data used to construct batch identifiers for the input table using the provided splitter config.
Sql splitter configurations yield the unique values that comprise a batch by introspecting your data.
Args:
table_name: Table to split.
splitter_method_name: Desired splitter method to use.
splitter_kwargs: Dict of directives used by the splitter method as keyword arguments of key=value.
Returns:
List of dicts of the form [{column_name: {"key": value}}]
"""
return self._data_splitter.get_data_for_batch_identifiers(
execution_engine=self,
table_name=table_name,
splitter_method_name=splitter_method_name,
splitter_kwargs=splitter_kwargs,
)
def _build_selectable_from_batch_spec(
self, batch_spec: BatchSpec
) -> Union[Selectable, str]:
if "splitter_method" in batch_spec:
splitter_fn: Callable = self._get_splitter_method(
splitter_method_name=batch_spec["splitter_method"]
)
split_clause = splitter_fn(
batch_identifiers=batch_spec["batch_identifiers"],
**batch_spec["splitter_kwargs"],
)
else:
if self.dialect_name == GESqlDialect.SQLITE:
split_clause = sa.text("1 = 1")
else:
split_clause = sa.true()
table_name: str = batch_spec["table_name"]
sampling_method: Optional[str] = batch_spec.get("sampling_method")
if sampling_method is not None:
if sampling_method in [
"_sample_using_limit",
"sample_using_limit",
"_sample_using_random",
"sample_using_random",
]:
sampler_fn = self._data_sampler.get_sampler_method(sampling_method)
return sampler_fn(
execution_engine=self,
batch_spec=batch_spec,
where_clause=split_clause,
)
else:
sampler_fn = self._data_sampler.get_sampler_method(sampling_method)
return (
sa.select("*")
.select_from(
sa.table(table_name, schema=batch_spec.get("schema_name", None))
)
.where(
sa.and_(
split_clause,
sampler_fn(batch_spec),
)
)
)
return (
sa.select("*")
.select_from(
sa.table(table_name, schema=batch_spec.get("schema_name", None))
)
.where(split_clause)
)
def get_batch_data_and_markers(
self, batch_spec: BatchSpec
) -> Tuple[Any, BatchMarkers]:
if not isinstance(
batch_spec, (SqlAlchemyDatasourceBatchSpec, RuntimeQueryBatchSpec)
):
raise InvalidBatchSpecError(
f"""SqlAlchemyExecutionEngine accepts batch_spec only of type SqlAlchemyDatasourceBatchSpec or
RuntimeQueryBatchSpec (illegal type "{str(type(batch_spec))}" was received).
"""
)
batch_data: Optional[SqlAlchemyBatchData] = None
batch_markers = BatchMarkers(
{
"ge_load_time": datetime.datetime.now(datetime.timezone.utc).strftime(
"%Y%m%dT%H%M%S.%fZ"
)
}
)
source_schema_name: str = batch_spec.get("schema_name", None)
source_table_name: str = batch_spec.get("table_name", None)
temp_table_schema_name: Optional[str] = batch_spec.get("temp_table_schema_name")
if batch_spec.get("bigquery_temp_table"):
# deprecated-v0.15.3
warnings.warn(
"BigQuery tables that are created as the result of a query are no longer created as "
"permanent tables. Thus, a named permanent table through the `bigquery_temp_table`"
"parameter is not required. The `bigquery_temp_table` parameter is deprecated as of"
"v0.15.3 and will be removed in v0.18.",
DeprecationWarning,
)
create_temp_table: bool = batch_spec.get(
"create_temp_table", self._create_temp_table
)
if isinstance(batch_spec, RuntimeQueryBatchSpec):
# query != None is already checked when RuntimeQueryBatchSpec is instantiated
query: str = batch_spec.query
batch_spec.query = "SQLQuery"
batch_data = SqlAlchemyBatchData(
execution_engine=self,
query=query,
temp_table_schema_name=temp_table_schema_name,
create_temp_table=create_temp_table,
source_table_name=source_table_name,
source_schema_name=source_schema_name,
)
elif isinstance(batch_spec, SqlAlchemyDatasourceBatchSpec):
selectable: Union[Selectable, str] = self._build_selectable_from_batch_spec(
batch_spec=batch_spec
)
batch_data = SqlAlchemyBatchData(
execution_engine=self,
selectable=selectable,
create_temp_table=create_temp_table,
source_table_name=source_table_name,
source_schema_name=source_schema_name,
)
return batch_data, batch_markers
<file_sep>/great_expectations/expectations/metrics/util.py
import logging
import re
import warnings
from typing import Any, Dict, List, Optional
import numpy as np
from dateutil.parser import parse
from packaging import version
from great_expectations.execution_engine.sqlalchemy_dialect import GESqlDialect
from great_expectations.execution_engine.util import check_sql_engine_dialect
from great_expectations.util import get_sqlalchemy_inspector
try:
import psycopg2 # noqa: F401
import sqlalchemy.dialects.postgresql.psycopg2 as sqlalchemy_psycopg2
except (ImportError, KeyError):
sqlalchemy_psycopg2 = None
try:
import snowflake
except ImportError:
snowflake = None
try:
import sqlalchemy as sa
from sqlalchemy.dialects import registry
from sqlalchemy.engine import Engine, reflection
from sqlalchemy.engine.interfaces import Dialect
from sqlalchemy.exc import OperationalError
from sqlalchemy.sql import Insert, Select, TableClause
from sqlalchemy.sql.elements import (
BinaryExpression,
ColumnElement,
Label,
TextClause,
literal,
)
from sqlalchemy.sql.operators import custom_op
except ImportError:
sa = None
registry = None
Engine = None
reflection = None
Dialect = None
Insert = None
Select = None
BinaryExpression = None
ColumnElement = None
Label = None
TableClause = None
TextClause = None
literal = None
custom_op = None
OperationalError = None
try:
import sqlalchemy_redshift
except ImportError:
sqlalchemy_redshift = None
logger = logging.getLogger(__name__)
try:
import sqlalchemy_dremio.pyodbc
registry.register("dremio", "sqlalchemy_dremio.pyodbc", "dialect")
except ImportError:
sqlalchemy_dremio = None
try:
import trino
except ImportError:
trino = None
_BIGQUERY_MODULE_NAME = "sqlalchemy_bigquery"
try:
import sqlalchemy_bigquery as sqla_bigquery
registry.register("bigquery", _BIGQUERY_MODULE_NAME, "BigQueryDialect")
bigquery_types_tuple = None
except ImportError:
try:
import pybigquery.sqlalchemy_bigquery as sqla_bigquery
# deprecated-v0.14.7
warnings.warn(
"The pybigquery package is obsolete and its usage within Great Expectations is deprecated as of v0.14.7. "
"As support will be removed in v0.17, please transition to sqlalchemy-bigquery",
DeprecationWarning,
)
_BIGQUERY_MODULE_NAME = "pybigquery.sqlalchemy_bigquery"
# Sometimes "pybigquery.sqlalchemy_bigquery" fails to self-register in Azure (our CI/CD pipeline) in certain cases, so we do it explicitly.
# (see https://stackoverflow.com/questions/53284762/nosuchmoduleerror-cant-load-plugin-sqlalchemy-dialectssnowflake)
registry.register("bigquery", _BIGQUERY_MODULE_NAME, "dialect")
try:
getattr(sqla_bigquery, "INTEGER")
bigquery_types_tuple = None
except AttributeError:
# In older versions of the pybigquery driver, types were not exported, so we use a hack
logger.warning(
"Old pybigquery driver version detected. Consider upgrading to 0.4.14 or later."
)
from collections import namedtuple
BigQueryTypes = namedtuple("BigQueryTypes", sorted(sqla_bigquery._type_map))
bigquery_types_tuple = BigQueryTypes(**sqla_bigquery._type_map)
except ImportError:
sqla_bigquery = None
bigquery_types_tuple = None
pybigquery = None
namedtuple = None
try:
import teradatasqlalchemy.dialect
import teradatasqlalchemy.types as teradatatypes
except ImportError:
teradatasqlalchemy = None
teradatatypes = None
def get_dialect_regex_expression(column, regex, dialect, positive=True):
try:
# postgres
if issubclass(dialect.dialect, sa.dialects.postgresql.dialect):
if positive:
return BinaryExpression(column, literal(regex), custom_op("~"))
else:
return BinaryExpression(column, literal(regex), custom_op("!~"))
except AttributeError:
pass
try:
# redshift
# noinspection PyUnresolvedReferences
if hasattr(dialect, "RedshiftDialect") or issubclass(
dialect.dialect, sqlalchemy_redshift.dialect.RedshiftDialect
):
if positive:
return BinaryExpression(column, literal(regex), custom_op("~"))
else:
return BinaryExpression(column, literal(regex), custom_op("!~"))
except (
AttributeError,
TypeError,
): # TypeError can occur if the driver was not installed and so is None
pass
try:
# MySQL
if issubclass(dialect.dialect, sa.dialects.mysql.dialect):
if positive:
return BinaryExpression(column, literal(regex), custom_op("REGEXP"))
else:
return BinaryExpression(column, literal(regex), custom_op("NOT REGEXP"))
except AttributeError:
pass
try:
# Snowflake
if issubclass(
dialect.dialect,
snowflake.sqlalchemy.snowdialect.SnowflakeDialect,
):
if positive:
return BinaryExpression(column, literal(regex), custom_op("RLIKE"))
else:
return BinaryExpression(column, literal(regex), custom_op("NOT RLIKE"))
except (
AttributeError,
TypeError,
): # TypeError can occur if the driver was not installed and so is None
pass
try:
# Bigquery
if hasattr(dialect, "BigQueryDialect"):
if positive:
return sa.func.REGEXP_CONTAINS(column, literal(regex))
else:
return sa.not_(sa.func.REGEXP_CONTAINS(column, literal(regex)))
except (
AttributeError,
TypeError,
): # TypeError can occur if the driver was not installed and so is None
logger.debug(
"Unable to load BigQueryDialect dialect while running get_dialect_regex_expression in expectations.metrics.util",
exc_info=True,
)
pass
try:
# Trino
if isinstance(dialect, trino.sqlalchemy.dialect.TrinoDialect):
if positive:
return sa.func.regexp_like(column, literal(regex))
else:
return sa.not_(sa.func.regexp_like(column, literal(regex)))
except (
AttributeError,
TypeError,
): # TypeError can occur if the driver was not installed and so is None
pass
try:
# Dremio
if hasattr(dialect, "DremioDialect"):
if positive:
return sa.func.REGEXP_MATCHES(column, literal(regex))
else:
return sa.not_(sa.func.REGEXP_MATCHES(column, literal(regex)))
except (
AttributeError,
TypeError,
): # TypeError can occur if the driver was not installed and so is None
pass
try:
# Teradata
if issubclass(dialect.dialect, teradatasqlalchemy.dialect.TeradataDialect):
if positive:
return sa.func.REGEXP_SIMILAR(column, literal(regex), literal("i")) == 1
else:
return sa.func.REGEXP_SIMILAR(column, literal(regex), literal("i")) == 0
except (AttributeError, TypeError):
pass
try:
# sqlite
# regex_match for sqlite introduced in sqlalchemy v1.4
if issubclass(dialect.dialect, sa.dialects.sqlite.dialect) and version.parse(
sa.__version__
) >= version.parse("1.4"):
if positive:
return column.regexp_match(literal(regex))
else:
return sa.not_(column.regexp_match(literal(regex)))
else:
logger.debug(
"regex_match is only enabled for sqlite when SQLAlchemy version is >= 1.4",
exc_info=True,
)
pass
except AttributeError:
pass
return None
def _get_dialect_type_module(dialect=None):
if dialect is None:
logger.warning(
"No sqlalchemy dialect found; relying in top-level sqlalchemy types."
)
return sa
try:
# Redshift does not (yet) export types to top level; only recognize base SA types
# noinspection PyUnresolvedReferences
if isinstance(dialect, sqlalchemy_redshift.dialect.RedshiftDialect):
return dialect.sa
except (TypeError, AttributeError):
pass
# Bigquery works with newer versions, but use a patch if we had to define bigquery_types_tuple
try:
if (
isinstance(
dialect,
sqla_bigquery.BigQueryDialect,
)
and bigquery_types_tuple is not None
):
return bigquery_types_tuple
except (TypeError, AttributeError):
pass
# Teradata types module
try:
if (
issubclass(
dialect,
teradatasqlalchemy.dialect.TeradataDialect,
)
and teradatatypes is not None
):
return teradatatypes
except (TypeError, AttributeError):
pass
return dialect
def attempt_allowing_relative_error(dialect):
# noinspection PyUnresolvedReferences
detected_redshift: bool = (
sqlalchemy_redshift is not None
and check_sql_engine_dialect(
actual_sql_engine_dialect=dialect,
candidate_sql_engine_dialect=sqlalchemy_redshift.dialect.RedshiftDialect,
)
)
# noinspection PyTypeChecker
detected_psycopg2: bool = (
sqlalchemy_psycopg2 is not None
and check_sql_engine_dialect(
actual_sql_engine_dialect=dialect,
candidate_sql_engine_dialect=sqlalchemy_psycopg2.PGDialect_psycopg2,
)
)
return detected_redshift or detected_psycopg2
def is_column_present_in_table(
engine: Engine,
table_selectable: Select,
column_name: str,
schema_name: Optional[str] = None,
) -> bool:
all_columns_metadata: Optional[
List[Dict[str, Any]]
] = get_sqlalchemy_column_metadata(
engine=engine, table_selectable=table_selectable, schema_name=schema_name
)
# Purposefully do not check for a NULL "all_columns_metadata" to insure that it must never happen.
column_names: List[str] = [col_md["name"] for col_md in all_columns_metadata]
return column_name in column_names
def get_sqlalchemy_column_metadata(
engine: Engine, table_selectable: Select, schema_name: Optional[str] = None
) -> Optional[List[Dict[str, Any]]]:
try:
columns: List[Dict[str, Any]]
inspector: reflection.Inspector = get_sqlalchemy_inspector(engine)
try:
# if a custom query was passed
if isinstance(table_selectable, TextClause):
if hasattr(table_selectable, "selected_columns"):
columns = table_selectable.selected_columns.columns
else:
columns = table_selectable.columns().columns
else:
columns = inspector.get_columns(
table_selectable,
schema=schema_name,
)
except (
KeyError,
AttributeError,
sa.exc.NoSuchTableError,
sa.exc.ProgrammingError,
):
# we will get a KeyError for temporary tables, since
# reflection will not find the temporary schema
columns = column_reflection_fallback(
selectable=table_selectable,
dialect=engine.dialect,
sqlalchemy_engine=engine,
)
# Use fallback because for mssql and trino reflection mechanisms do not throw an error but return an empty list
if len(columns) == 0:
columns = column_reflection_fallback(
selectable=table_selectable,
dialect=engine.dialect,
sqlalchemy_engine=engine,
)
return columns
except AttributeError as e:
logger.debug(f"Error while introspecting columns: {str(e)}")
return None
def column_reflection_fallback(
selectable: Select, dialect: Dialect, sqlalchemy_engine: Engine
) -> List[Dict[str, str]]:
"""If we can't reflect the table, use a query to at least get column names."""
col_info_dict_list: List[Dict[str, str]]
# noinspection PyUnresolvedReferences
if dialect.name.lower() == "mssql":
# Get column names and types from the database
# Reference: https://dataedo.com/kb/query/sql-server/list-table-columns-in-database
tables_table_clause: TableClause = sa.table(
"tables",
sa.column("object_id"),
sa.column("schema_id"),
sa.column("name"),
schema="sys",
).alias("sys_tables_table_clause")
tables_table_query: Select = (
sa.select(
[
tables_table_clause.c.object_id.label("object_id"),
sa.func.schema_name(tables_table_clause.c.schema_id).label(
"schema_name"
),
tables_table_clause.c.name.label("table_name"),
]
)
.select_from(tables_table_clause)
.alias("sys_tables_table_subquery")
)
columns_table_clause: TableClause = sa.table(
"columns",
sa.column("object_id"),
sa.column("user_type_id"),
sa.column("column_id"),
sa.column("name"),
sa.column("max_length"),
sa.column("precision"),
schema="sys",
).alias("sys_columns_table_clause")
columns_table_query: Select = (
sa.select(
[
columns_table_clause.c.object_id.label("object_id"),
columns_table_clause.c.user_type_id.label("user_type_id"),
columns_table_clause.c.column_id.label("column_id"),
columns_table_clause.c.name.label("column_name"),
columns_table_clause.c.max_length.label("column_max_length"),
columns_table_clause.c.precision.label("column_precision"),
]
)
.select_from(columns_table_clause)
.alias("sys_columns_table_subquery")
)
types_table_clause: TableClause = sa.table(
"types",
sa.column("user_type_id"),
sa.column("name"),
schema="sys",
).alias("sys_types_table_clause")
types_table_query: Select = (
sa.select(
[
types_table_clause.c.user_type_id.label("user_type_id"),
types_table_clause.c.name.label("column_data_type"),
]
)
.select_from(types_table_clause)
.alias("sys_types_table_subquery")
)
inner_join_conditions: BinaryExpression = sa.and_(
*(tables_table_query.c.object_id == columns_table_query.c.object_id,)
)
outer_join_conditions: BinaryExpression = sa.and_(
*(
columns_table_query.columns.user_type_id
== types_table_query.columns.user_type_id,
)
)
col_info_query: Select = (
sa.select(
[
tables_table_query.c.schema_name,
tables_table_query.c.table_name,
columns_table_query.c.column_id,
columns_table_query.c.column_name,
types_table_query.c.column_data_type,
columns_table_query.c.column_max_length,
columns_table_query.c.column_precision,
]
)
.select_from(
tables_table_query.join(
right=columns_table_query,
onclause=inner_join_conditions,
isouter=False,
).join(
right=types_table_query,
onclause=outer_join_conditions,
isouter=True,
)
)
.where(tables_table_query.c.table_name == selectable.name)
.order_by(
tables_table_query.c.schema_name.asc(),
tables_table_query.c.table_name.asc(),
columns_table_query.c.column_id.asc(),
)
)
col_info_tuples_list: List[tuple] = sqlalchemy_engine.execute(
col_info_query
).fetchall()
# type_module = _get_dialect_type_module(dialect=dialect)
col_info_dict_list: List[Dict[str, str]] = [
{
"name": column_name,
# "type": getattr(type_module, column_data_type.upper())(),
"type": column_data_type.upper(),
}
for schema_name, table_name, column_id, column_name, column_data_type, column_max_length, column_precision in col_info_tuples_list
]
elif dialect.name.lower() == "trino":
try:
table_name = selectable.name
except AttributeError:
table_name = selectable
if str(table_name).lower().startswith("select"):
rx = re.compile(r"^.* from ([\S]+)", re.I)
match = rx.match(str(table_name).replace("\n", ""))
if match:
table_name = match.group(1)
schema_name = sqlalchemy_engine.dialect.default_schema_name
tables_table: sa.Table = sa.Table(
"tables",
sa.MetaData(),
schema="information_schema",
)
tables_table_query: Select = (
sa.select(
[
sa.column("table_schema").label("schema_name"),
sa.column("table_name").label("table_name"),
]
)
.select_from(tables_table)
.alias("information_schema_tables_table")
)
columns_table: sa.Table = sa.Table(
"columns",
sa.MetaData(),
schema="information_schema",
)
columns_table_query: Select = (
sa.select(
[
sa.column("column_name").label("column_name"),
sa.column("table_name").label("table_name"),
sa.column("table_schema").label("schema_name"),
sa.column("data_type").label("column_data_type"),
]
)
.select_from(columns_table)
.alias("information_schema_columns_table")
)
conditions = sa.and_(
*(
tables_table_query.c.table_name == columns_table_query.c.table_name,
tables_table_query.c.schema_name == columns_table_query.c.schema_name,
)
)
col_info_query: Select = (
sa.select(
[
tables_table_query.c.schema_name,
tables_table_query.c.table_name,
columns_table_query.c.column_name,
columns_table_query.c.column_data_type,
]
)
.select_from(
tables_table_query.join(
right=columns_table_query, onclause=conditions, isouter=False
)
)
.where(
sa.and_(
*(
tables_table_query.c.table_name == table_name,
tables_table_query.c.schema_name == schema_name,
)
)
)
.order_by(
tables_table_query.c.schema_name.asc(),
tables_table_query.c.table_name.asc(),
columns_table_query.c.column_name.asc(),
)
.alias("column_info")
)
col_info_tuples_list: List[tuple] = sqlalchemy_engine.execute(
col_info_query
).fetchall()
# type_module = _get_dialect_type_module(dialect=dialect)
col_info_dict_list: List[Dict[str, str]] = [
{
"name": column_name,
"type": column_data_type.upper(),
}
for schema_name, table_name, column_name, column_data_type in col_info_tuples_list
]
else:
# if a custom query was passed
if isinstance(selectable, TextClause):
query: TextClause = selectable
else:
if dialect.name.lower() == GESqlDialect.REDSHIFT:
# Redshift needs temp tables to be declared as text
query: Select = (
sa.select([sa.text("*")]).select_from(sa.text(selectable)).limit(1)
)
else:
query: Select = (
sa.select([sa.text("*")]).select_from(selectable).limit(1)
)
result_object = sqlalchemy_engine.execute(query)
# noinspection PyProtectedMember
col_names: List[str] = result_object._metadata.keys
col_info_dict_list = [{"name": col_name} for col_name in col_names]
return col_info_dict_list
def parse_value_set(value_set):
parsed_value_set = [
parse(value) if isinstance(value, str) else value for value in value_set
]
return parsed_value_set
def get_dialect_like_pattern_expression(column, dialect, like_pattern, positive=True):
dialect_supported: bool = False
try:
# Bigquery
if hasattr(dialect, "BigQueryDialect"):
dialect_supported = True
except (
AttributeError,
TypeError,
): # TypeError can occur if the driver was not installed and so is None
pass
if hasattr(dialect, "dialect"):
if issubclass(
dialect.dialect,
(
sa.dialects.sqlite.dialect,
sa.dialects.postgresql.dialect,
sa.dialects.mysql.dialect,
sa.dialects.mssql.dialect,
),
):
dialect_supported = True
try:
if hasattr(dialect, "RedshiftDialect"):
dialect_supported = True
except (AttributeError, TypeError):
pass
try:
# noinspection PyUnresolvedReferences
if isinstance(dialect, sqlalchemy_redshift.dialect.RedshiftDialect):
dialect_supported = True
except (AttributeError, TypeError):
pass
try:
# noinspection PyUnresolvedReferences
if isinstance(dialect, trino.sqlalchemy.dialect.TrinoDialect):
dialect_supported = True
except (AttributeError, TypeError):
pass
try:
if hasattr(dialect, "SnowflakeDialect"):
dialect_supported = True
except (AttributeError, TypeError):
pass
try:
if hasattr(dialect, "DremioDialect"):
dialect_supported = True
except (AttributeError, TypeError):
pass
try:
if issubclass(dialect.dialect, teradatasqlalchemy.dialect.TeradataDialect):
dialect_supported = True
except (AttributeError, TypeError):
pass
if dialect_supported:
try:
if positive:
return column.like(literal(like_pattern))
else:
return sa.not_(column.like(literal(like_pattern)))
except AttributeError:
pass
return None
def validate_distribution_parameters(distribution, params):
"""Ensures that necessary parameters for a distribution are present and that all parameters are sensical.
If parameters necessary to construct a distribution are missing or invalid, this function raises ValueError\
with an informative description. Note that 'loc' and 'scale' are optional arguments, and that 'scale'\
must be positive.
Args:
distribution (string): \
The scipy distribution name, e.g. normal distribution is 'norm'.
params (dict or list): \
The distribution shape parameters in a named dictionary or positional list form following the scipy \
cdf argument scheme.
params={'mean': 40, 'std_dev': 5} or params=[40, 5]
Exceptions:
ValueError: \
With an informative description, usually when necessary parameters are omitted or are invalid.
"""
norm_msg = (
"norm distributions require 0 parameters and optionally 'mean', 'std_dev'."
)
beta_msg = "beta distributions require 2 positive parameters 'alpha', 'beta' and optionally 'loc', 'scale'."
gamma_msg = "gamma distributions require 1 positive parameter 'alpha' and optionally 'loc','scale'."
# poisson_msg = "poisson distributions require 1 positive parameter 'lambda' and optionally 'loc'."
uniform_msg = (
"uniform distributions require 0 parameters and optionally 'loc', 'scale'."
)
chi2_msg = "chi2 distributions require 1 positive parameter 'df' and optionally 'loc', 'scale'."
expon_msg = (
"expon distributions require 0 parameters and optionally 'loc', 'scale'."
)
if distribution not in [
"norm",
"beta",
"gamma",
"poisson",
"uniform",
"chi2",
"expon",
]:
raise AttributeError(f"Unsupported distribution provided: {distribution}")
if isinstance(params, dict):
# `params` is a dictionary
if params.get("std_dev", 1) <= 0 or params.get("scale", 1) <= 0:
raise ValueError("std_dev and scale must be positive.")
# alpha and beta are required and positive
if distribution == "beta" and (
params.get("alpha", -1) <= 0 or params.get("beta", -1) <= 0
):
raise ValueError(f"Invalid parameters: {beta_msg}")
# alpha is required and positive
elif distribution == "gamma" and params.get("alpha", -1) <= 0:
raise ValueError(f"Invalid parameters: {gamma_msg}")
# lambda is a required and positive
# elif distribution == 'poisson' and params.get('lambda', -1) <= 0:
# raise ValueError("Invalid parameters: %s" %poisson_msg)
# df is necessary and required to be positive
elif distribution == "chi2" and params.get("df", -1) <= 0:
raise ValueError(f"Invalid parameters: {chi2_msg}:")
elif isinstance(params, tuple) or isinstance(params, list):
scale = None
# `params` is a tuple or a list
if distribution == "beta":
if len(params) < 2:
raise ValueError(f"Missing required parameters: {beta_msg}")
if params[0] <= 0 or params[1] <= 0:
raise ValueError(f"Invalid parameters: {beta_msg}")
if len(params) == 4:
scale = params[3]
elif len(params) > 4:
raise ValueError(f"Too many parameters provided: {beta_msg}")
elif distribution == "norm":
if len(params) > 2:
raise ValueError(f"Too many parameters provided: {norm_msg}")
if len(params) == 2:
scale = params[1]
elif distribution == "gamma":
if len(params) < 1:
raise ValueError(f"Missing required parameters: {gamma_msg}")
if len(params) == 3:
scale = params[2]
if len(params) > 3:
raise ValueError(f"Too many parameters provided: {gamma_msg}")
elif params[0] <= 0:
raise ValueError(f"Invalid parameters: {gamma_msg}")
# elif distribution == 'poisson':
# if len(params) < 1:
# raise ValueError("Missing required parameters: %s" %poisson_msg)
# if len(params) > 2:
# raise ValueError("Too many parameters provided: %s" %poisson_msg)
# elif params[0] <= 0:
# raise ValueError("Invalid parameters: %s" %poisson_msg)
elif distribution == "uniform":
if len(params) == 2:
scale = params[1]
if len(params) > 2:
raise ValueError(f"Too many arguments provided: {uniform_msg}")
elif distribution == "chi2":
if len(params) < 1:
raise ValueError(f"Missing required parameters: {chi2_msg}")
elif len(params) == 3:
scale = params[2]
elif len(params) > 3:
raise ValueError(f"Too many arguments provided: {chi2_msg}")
if params[0] <= 0:
raise ValueError(f"Invalid parameters: {chi2_msg}")
elif distribution == "expon":
if len(params) == 2:
scale = params[1]
if len(params) > 2:
raise ValueError(f"Too many arguments provided: {expon_msg}")
if scale is not None and scale <= 0:
raise ValueError("std_dev and scale must be positive.")
else:
raise ValueError(
"params must be a dict or list, or use ge.dataset.util.infer_distribution_parameters(data, distribution)"
)
return
def _scipy_distribution_positional_args_from_dict(distribution, params):
"""Helper function that returns positional arguments for a scipy distribution using a dict of parameters.
See the `cdf()` function here https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.beta.html#Methods\
to see an example of scipy's positional arguments. This function returns the arguments specified by the \
scipy.stat.distribution.cdf() for that distribution.
Args:
distribution (string): \
The scipy distribution name.
params (dict): \
A dict of named parameters.
Raises:
AttributeError: \
If an unsupported distribution is provided.
"""
params["loc"] = params.get("loc", 0)
if "scale" not in params:
params["scale"] = 1
if distribution == "norm":
return params["mean"], params["std_dev"]
elif distribution == "beta":
return params["alpha"], params["beta"], params["loc"], params["scale"]
elif distribution == "gamma":
return params["alpha"], params["loc"], params["scale"]
# elif distribution == 'poisson':
# return params['lambda'], params['loc']
elif distribution == "uniform":
return params["min"], params["max"]
elif distribution == "chi2":
return params["df"], params["loc"], params["scale"]
elif distribution == "expon":
return params["loc"], params["scale"]
def is_valid_continuous_partition_object(partition_object):
"""Tests whether a given object is a valid continuous partition object. See :ref:`partition_object`.
:param partition_object: The partition_object to evaluate
:return: Boolean
"""
if (
(partition_object is None)
or ("weights" not in partition_object)
or ("bins" not in partition_object)
):
return False
if "tail_weights" in partition_object:
if len(partition_object["tail_weights"]) != 2:
return False
comb_weights = partition_object["tail_weights"] + partition_object["weights"]
else:
comb_weights = partition_object["weights"]
## TODO: Consider adding this check to migrate to the tail_weights structure of partition objects
# if (partition_object['bins'][0] == -np.inf) or (partition_object['bins'][-1] == np.inf):
# return False
# Expect one more bin edge than weight; all bin edges should be monotonically increasing; weights should sum to one
return (
(len(partition_object["bins"]) == (len(partition_object["weights"]) + 1))
and np.all(np.diff(partition_object["bins"]) > 0)
and np.allclose(np.sum(comb_weights), 1.0)
)
<file_sep>/docs/guides/connecting_to_your_data/datasource_configuration/sql_components/_section_add_a_dictionary_as_the_value_of_the_data_connectors_key.mdx
import PartAddADictionaryAsTheValueOfTheDataConnectorsKey from '../components/_part_add_a_dictionary_as_the_value_of_the_data_connectors_key.mdx'
<PartAddADictionaryAsTheValueOfTheDataConnectorsKey />
Your current configuration should look like:
```python
datasource_config: dict = {
"name": "my_datasource_name",
"class_name": "Datasource",
"module_name": "great_expectations.datasource",
"execution_engine": {
"class_name": "SqlAlchemyExecutionEngine",
"module_name": "great_expectations.execution_engine",
"connection_string": CONNECTION_STRING,
},
"data_connectors": {}
}
```<file_sep>/docs/tutorials/getting_started/tutorial_setup.md
---
title: 'Tutorial, Step 1: Setup'
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '/docs/term_tags/_tag.mdx';
import VersionSnippet from './tutorial_version_snippet.mdx'
<UniversalMap setup='active' connect='inactive' create='inactive' validate='inactive'/>
:::note Prerequisites
In order to work with Great Expectations, you will need:
- A working Python install
- The ability to pip install for Python
- Note: A best practice would be to do this in a virtual environment!
- A working Git install
- A working internet browser install (for viewing Data Docs in steps 3 and 4).
If you need assistance with setting up any of these utilities, we have links to their documentation on our page for <TechnicalTag relative="../../" tag="supporting_resource" text="supporting resources" />.
:::
### Setting up the tutorial data
The first thing we'll need is a copy of the data that this tutorial will work with. Fortunately, we've already put that data into a convenient repository that you can clone to your machine.
Clone the [ge_tutorials](https://github.com/superconductive/ge_tutorials) repository to download the data. This repository also contains directories with the final versions of the tutorial, which you can use for reference.
To clone the repository and go into the directory you'll be working from, start from your working directory and enter the following commands into your terminal:
```console
git clone https://github.com/superconductive/ge_tutorials
cd ge_tutorials
```
The repository you cloned contains several directories with final versions for this and our other tutorials. The final version for this tutorial is located in the `getting_started_tutorial_final_v3_api` folder. You can use the final version as a reference or to explore a complete deployment of Great Expectations, but **you do not need it for this tutorial**.
### Install Great Expectations and dependencies
Great Expectations requires Python 3 and can be installed using pip. If you haven’t already, install Great Expectations by running:
```bash
pip install great_expectations
```
You can confirm that installation worked by running
```bash
great_expectations --version
```
This should return something like:
<VersionSnippet />
For detailed installation instructions, see [How to install Great Expectations locally](../../guides/setup/installation/local.md).
<details>
<summary>Other deployment patterns</summary>
<div>
<p>
This tutorial deploys Great Expectations locally. Note that other options (e.g. running Great Expectations on an EMR Cluster) are also available. You can find more information in the [Reference Architectures](../../deployment_patterns/index.md) section of the documentation.
</p>
</div>
</details>
### Create a Data Context
In Great Expectations, your <TechnicalTag relative="../../" tag="data_context" text="Data Context" /> manages your project configuration, so let’s go and create a Data Context for our tutorial project!
When you installed Great Expectations, you also installed the Great Expectations command line interface (<TechnicalTag relative="../../" tag="cli" text="CLI" />). It provides helpful utilities for deploying and configuring Data Contexts, plus a few other convenience methods.
To initialize your Great Expectations deployment for the project, run this command in the terminal from the `ge_tutorials` directory:
```console
great_expectations init
```
You should see this:
```console
Using v3 (Batch Request) API
___ _ ___ _ _ _
/ __|_ _ ___ __ _| |_ | __|_ ___ __ ___ __| |_ __ _| |_(_)___ _ _ ___
| (_ | '_/ -_) _` | _| | _|\ \ / '_ \/ -_) _| _/ _` | _| / _ \ ' \(_-<
\___|_| \___\__,_|\__| |___/_\_\ .__/\___\__|\__\__,_|\__|_\___/_||_/__/
|_|
~ Always know what to expect from your data ~
Let's create a new Data Context to hold your project configuration.
Great Expectations will create a new directory with the following structure:
great_expectations
|-- great_expectations.yml
|-- expectations
|-- checkpoints
|-- plugins
|-- .gitignore
|-- uncommitted
|-- config_variables.yml
|-- data_docs
|-- validations
OK to proceed? [Y/n]: <press Enter>
```
When you see the prompt, press enter to continue. Great Expectations will build out the directory structure and configuration files it needs for you to proceed. All of these together are your Data Context.
:::note
Your Data Context will contain the entirety of your Great Expectations project. It is also the entry point for accessing all of the primary methods for creating elements of your project, configuring those elements, and working with the metadata for your project. That is why the first thing you do when working with Great Expectations is to initialize a Data Context!
[You can follow this link to read more about Data Contexts.](../../terms/data_context.md)
:::
<details>
<summary>About the <code>great_expectations</code> directory structure</summary>
<div>
<p>
After running the <code>init</code> command, your <code>great_expectations</code> directory will contain all of the important components of a local Great Expectations deployment. This is what the directory structure looks like
</p>
<ul>
<li><code>great_expectations.yml</code> contains the main configuration of your deployment.</li>
<li>
The `expectations` directory stores all your <TechnicalTag relative="../../" tag="expectation" text="Expectations" /> as JSON files. If you want to store them somewhere else, you can change that later.
</li>
<li>The <code>plugins/</code> directory holds code for any custom plugins you develop as part of your deployment.</li>
<li>The <code>uncommitted/</code> directory contains files that shouldn’t live in version control. It has a .gitignore configured to exclude all its contents from version control. The main contents of the directory are:
<ul>
<li><code>uncommitted/config_variables.yml</code>, which holds sensitive information, such as database credentials and other secrets.</li>
<li><code>uncommitted/data_docs</code>, which contains Data Docs generated from Expectations, Validation Results, and other metadata.</li>
<li><code>uncommitted/validations</code>, which holds Validation Results generated by Great Expectations.</li>
</ul>
</li>
</ul>
</div>
</details>
Congratulations, that's all there is to Step 1: Setup with Great Expectations. You've finished the first step! Let's move on to [Step 2: Connect to Data](./tutorial_connect_to_data.md)
<file_sep>/tests/data_context/cloud_data_context/test_include_rendered_content.py
from unittest import mock
import pandas as pd
import pytest
from great_expectations.core import (
ExpectationConfiguration,
ExpectationSuite,
ExpectationValidationResult,
)
from great_expectations.core.batch import RuntimeBatchRequest
from great_expectations.data_context.cloud_constants import GXCloudRESTResource
from great_expectations.data_context.types.refs import GXCloudResourceRef
from great_expectations.render import RenderedAtomicContent
from great_expectations.validator.validator import Validator
@pytest.mark.cloud
@pytest.mark.integration
@pytest.mark.parametrize(
"data_context_fixture_name",
[
# In order to leverage existing fixtures in parametrization, we provide
# their string names and dynamically retrieve them using pytest's built-in
# `request` fixture.
# Source: https://stackoverflow.com/a/64348247
pytest.param(
"empty_base_data_context_in_cloud_mode",
id="BaseDataContext",
),
pytest.param("empty_data_context_in_cloud_mode", id="DataContext"),
pytest.param("empty_cloud_data_context", id="CloudDataContext"),
],
)
def test_cloud_backed_data_context_save_expectation_suite_include_rendered_content(
data_context_fixture_name: str,
request,
) -> None:
"""
All Cloud-backed contexts (DataContext, BaseDataContext, and CloudDataContext) should save an ExpectationSuite
with rendered_content by default.
"""
context = request.getfixturevalue(data_context_fixture_name)
ge_cloud_id = "d581305a-cdce-483b-84ba-5c673d2ce009"
cloud_ref = GXCloudResourceRef(
resource_type=GXCloudRESTResource.EXPECTATION_SUITE,
ge_cloud_id=ge_cloud_id,
url="foo/bar/baz",
)
with mock.patch(
"great_expectations.data_context.store.gx_cloud_store_backend.GXCloudStoreBackend.list_keys"
), mock.patch(
"great_expectations.data_context.store.gx_cloud_store_backend.GXCloudStoreBackend._set",
return_value=cloud_ref,
):
expectation_suite: ExpectationSuite = context.create_expectation_suite(
"test_suite"
)
expectation_suite.expectations.append(
ExpectationConfiguration(
expectation_type="expect_table_row_count_to_equal", kwargs={"value": 10}
)
)
assert expectation_suite.expectations[0].rendered_content is None
with mock.patch(
"great_expectations.data_context.store.gx_cloud_store_backend.GXCloudStoreBackend.list_keys"
), mock.patch(
"great_expectations.data_context.store.gx_cloud_store_backend.GXCloudStoreBackend._update"
) as mock_update:
context.save_expectation_suite(
expectation_suite,
)
# remove dynamic great_expectations version
mock_update.call_args[1]["value"].pop("meta")
mock_update.assert_called_with(
ge_cloud_id=ge_cloud_id,
value={
"expectations": [
{
"meta": {},
"kwargs": {"value": 10},
"expectation_type": "expect_table_row_count_to_equal",
"rendered_content": [
{
"value": {
"schema": {
"type": "com.superconductive.rendered.string"
},
"params": {
"value": {
"schema": {"type": "number"},
"value": 10,
}
},
"template": "Must have exactly $value rows.",
"header": None,
},
"name": "atomic.prescriptive.summary",
"value_type": "StringValueType",
}
],
}
],
"ge_cloud_id": ge_cloud_id,
"data_asset_type": None,
"expectation_suite_name": "test_suite",
},
)
# TODO: ACB - Enable this test after merging fixes in PRs 5778 and 5763
@pytest.mark.cloud
@pytest.mark.integration
@pytest.mark.xfail(strict=True, reason="Remove xfail on merge of PRs 5778 and 5763")
@pytest.mark.parametrize(
"data_context_fixture_name",
[
# In order to leverage existing fixtures in parametrization, we provide
# their string names and dynamically retrieve them using pytest's built-in
# `request` fixture.
# Source: https://stackoverflow.com/a/64348247
pytest.param(
"cloud_base_data_context_in_cloud_mode_with_datasource_pandas_engine",
id="BaseDataContext",
),
pytest.param(
"cloud_data_context_in_cloud_mode_with_datasource_pandas_engine",
id="DataContext",
),
pytest.param(
"cloud_data_context_with_datasource_pandas_engine",
id="CloudDataContext",
),
],
)
def test_cloud_backed_data_context_expectation_validation_result_include_rendered_content(
data_context_fixture_name: str,
request,
) -> None:
"""
All Cloud-backed contexts (DataContext, BaseDataContext, and CloudDataContext) should save an ExpectationValidationResult
with rendered_content by default.
"""
context = request.getfixturevalue(data_context_fixture_name)
df = pd.DataFrame([1, 2, 3, 4, 5])
batch_request = RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="my_data_asset",
runtime_parameters={"batch_data": df},
batch_identifiers={"default_identifier_name": "my_id"},
)
with mock.patch(
"great_expectations.data_context.store.gx_cloud_store_backend.GXCloudStoreBackend.list_keys"
), mock.patch(
"great_expectations.data_context.store.gx_cloud_store_backend.GXCloudStoreBackend._set"
):
validator: Validator = context.get_validator(
batch_request=batch_request,
create_expectation_suite_with_name="test_suite",
)
expectation_validation_result: ExpectationValidationResult = (
validator.expect_table_row_count_to_equal(value=10)
)
for result in expectation_validation_result.results:
for rendered_content in result.rendered_content:
assert isinstance(rendered_content, RenderedAtomicContent)
for expectation_configuration in expectation_validation_result.expectation_config:
for rendered_content in expectation_configuration.rendered_content:
assert isinstance(rendered_content, RenderedAtomicContent)
<file_sep>/docs/guides/setup/configuring_metadata_stores/components/_install_boto3_with_pip.mdx
Python interacts with AWS through the `boto3` library. Great Expectations makes use of this library in the background when working with AWS. Therefore, although you will not need to use `boto3` directly, you will need to have it installed into your virtual environment.
You can do this with the pip command:
```bash title="Terminal command"
python -m pip install boto3
```
or
```bash title="Terminal command"
python3 -m pip install boto3
```
For more detailed instructions on how to set up [boto3](https://github.com/boto/boto3) with AWS, and information on how you can use `boto3` from within Python, please reference [boto3's documentation site](https://boto3.amazonaws.com/v1/documentation/api/latest/index.html).
<file_sep>/great_expectations/data_context/store/datasource_store.py
from __future__ import annotations
import copy
from typing import List, Optional, Union
from great_expectations.core.data_context_key import (
DataContextKey,
DataContextVariableKey,
)
from great_expectations.core.serializer import AbstractConfigSerializer
from great_expectations.data_context.store.store import Store
from great_expectations.data_context.store.store_backend import StoreBackend
from great_expectations.data_context.types.base import (
DatasourceConfig,
datasourceConfigSchema,
)
from great_expectations.data_context.types.refs import GXCloudResourceRef
from great_expectations.data_context.types.resource_identifiers import GXCloudIdentifier
from great_expectations.util import filter_properties_dict
class DatasourceStore(Store):
"""
A DatasourceStore manages Datasources for the DataContext.
"""
_key_class = DataContextVariableKey
def __init__(
self,
serializer: AbstractConfigSerializer,
store_name: Optional[str] = None,
store_backend: Optional[dict] = None,
runtime_environment: Optional[dict] = None,
) -> None:
self._schema = datasourceConfigSchema
self._serializer = serializer
super().__init__(
store_backend=store_backend,
runtime_environment=runtime_environment,
store_name=store_name, # type: ignore[arg-type]
)
# Gather the call arguments of the present function (include the "module_name" and add the "class_name"), filter
# out the Falsy values, and set the instance "_config" variable equal to the resulting dictionary.
self._config = {
"store_backend": store_backend,
"runtime_environment": runtime_environment,
"store_name": store_name,
"module_name": self.__class__.__module__,
"class_name": self.__class__.__name__,
}
filter_properties_dict(properties=self._config, clean_falsy=True, inplace=True)
def list_keys(self) -> List[str]: # type: ignore[override]
"""
See parent 'Store.list_keys()' for more information
"""
keys_without_store_backend_id: List[str] = list(
filter(
lambda k: k != StoreBackend.STORE_BACKEND_ID_KEY,
self._store_backend.list_keys(),
)
)
return keys_without_store_backend_id
def remove_key(self, key: Union[DataContextVariableKey, GXCloudIdentifier]) -> None:
"""
See parent `Store.remove_key()` for more information
"""
return self._store_backend.remove_key(key.to_tuple())
def serialize(self, value: DatasourceConfig) -> Union[str, dict, DatasourceConfig]:
"""
See parent 'Store.serialize()' for more information
"""
return self._serializer.serialize(value)
def deserialize(self, value: Union[dict, DatasourceConfig]) -> DatasourceConfig:
"""
See parent 'Store.deserialize()' for more information
"""
# When using the InlineStoreBackend, objects are already converted to their respective config types.
if isinstance(value, DatasourceConfig):
return value
elif isinstance(value, dict):
return self._schema.load(value)
else:
return self._schema.loads(value)
def ge_cloud_response_json_to_object_dict(self, response_json: dict) -> dict:
"""
This method takes full json response from GE cloud and outputs a dict appropriate for
deserialization into a GE object
"""
datasource_ge_cloud_id: str = response_json["data"]["id"]
datasource_config_dict: dict = response_json["data"]["attributes"][
"datasource_config"
]
datasource_config_dict["ge_cloud_id"] = datasource_ge_cloud_id
return datasource_config_dict
def retrieve_by_name(self, datasource_name: str) -> DatasourceConfig:
"""Retrieves a DatasourceConfig persisted in the store by it's given name.
Args:
datasource_name: The name of the Datasource to retrieve.
Returns:
The DatasourceConfig persisted in the store that is associated with the given
input datasource_name.
Raises:
ValueError if a DatasourceConfig is not found.
"""
datasource_key: Union[
DataContextVariableKey, GXCloudIdentifier
] = self.store_backend.build_key(name=datasource_name)
if not self.has_key(datasource_key): # noqa: W601
raise ValueError(
f"Unable to load datasource `{datasource_name}` -- no configuration found or invalid configuration."
)
datasource_config: DatasourceConfig = copy.deepcopy(self.get(datasource_key)) # type: ignore[assignment]
return datasource_config
def delete(self, datasource_config: DatasourceConfig) -> None:
"""Deletes a DatasourceConfig persisted in the store using its config.
Args:
datasource_config: The config of the Datasource to delete.
"""
self.remove_key(self._build_key_from_config(datasource_config))
def _build_key_from_config( # type: ignore[override]
self, datasource_config: DatasourceConfig
) -> Union[GXCloudIdentifier, DataContextVariableKey]:
return self.store_backend.build_key(
name=datasource_config.name,
id=datasource_config.id,
)
def set_by_name(
self, datasource_name: str, datasource_config: DatasourceConfig
) -> None:
"""Persists a DatasourceConfig in the store by a given name.
Args:
datasource_name: The name of the Datasource to update.
datasource_config: The config object to persist using the StoreBackend.
"""
datasource_key: DataContextVariableKey = self._determine_datasource_key(
datasource_name=datasource_name
)
self.set(datasource_key, datasource_config)
def set( # type: ignore[override]
self, key: Union[DataContextKey, None], value: DatasourceConfig, **_: dict
) -> DatasourceConfig:
"""Create a datasource config in the store using a store_backend-specific key.
Args:
key: Optional key to use when setting value.
value: DatasourceConfig set in the store at the key provided or created from the DatasourceConfig attributes.
**_: kwargs will be ignored but accepted to align with the parent class.
Returns:
DatasourceConfig retrieved from the DatasourceStore.
"""
if not key:
key = self._build_key_from_config(value)
# Make two separate requests to set and get in order to obtain any additional
# values that may have been added to the config by the StoreBackend (i.e. object ids)
ref: Optional[Union[bool, GXCloudResourceRef]] = super().set(key, value)
if ref and isinstance(ref, GXCloudResourceRef):
key.ge_cloud_id = ref.ge_cloud_id # type: ignore[attr-defined]
return_value: DatasourceConfig = self.get(key) # type: ignore[assignment]
if not return_value.name and isinstance(key, DataContextVariableKey):
# Setting the name in the config is currently needed to handle adding the name to v2 datasource
# configs and can be refactored (e.g. into `get()`)
return_value.name = key.resource_name
return return_value
def update_by_name(
self, datasource_name: str, datasource_config: DatasourceConfig
) -> None:
"""Updates a DatasourceConfig that already exists in the store.
Args:
datasource_name: The name of the Datasource to retrieve.
datasource_config: The config object to persist using the StoreBackend.
Raises:
ValueError if a DatasourceConfig is not found.
"""
datasource_key: DataContextVariableKey = self._determine_datasource_key(
datasource_name=datasource_name
)
if not self.has_key(datasource_key): # noqa: W601
raise ValueError(
f"Unable to load datasource `{datasource_name}` -- no configuration found or invalid configuration."
)
self.set_by_name(
datasource_name=datasource_name, datasource_config=datasource_config
)
def _determine_datasource_key(self, datasource_name: str) -> DataContextVariableKey:
datasource_key = DataContextVariableKey(
resource_name=datasource_name,
)
return datasource_key
<file_sep>/docs/terms/evaluation_parameter.md
---
id: evaluation_parameter
title: Evaluation Parameter
hoverText: A dynamic value used during Validation of an Expectation which is populated by evaluating simple expressions or by referencing previously generated metrics.
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
import ValidateHeader from '/docs/images/universal_map/_um_validate_header.mdx';
<UniversalMap setup='inactive' connect='inactive' create='active' validate='active'/>
## Overview
### Definition
An Evaluation Parameter is a dynamic value used during <TechnicalTag relative="../" tag="validation" text="Validation" /> of an <TechnicalTag relative="../" tag="expectation" text="Expectation" /> which is populated by evaluating simple expressions or by referencing previously generated <TechnicalTag relative="../" tag="metric" text="Metrics" />.
### Features and promises
You can use Evaluation Parameters to configure Expectations to use dynamic values, such as a value from a previous step in a pipeline or a date relative to today. Evaluation Parameters can be simple expressions such as math expressions or the current date, or reference Metrics generated from a previous Validation run. During interactive development, you can even provide a temporary value that should be used during the initial evaluation of the Expectation.
### Relationship to other objects
Evaluation Parameters are used in Expectations when Validating data. <TechnicalTag relative="../" tag="checkpoint" text="Checkpoints" /> use <TechnicalTag relative="../" tag="action" text="Actions" /> to store Evaluation Parameters in the <TechnicalTag relative="../" tag="evaluation_parameter_store" text="Evaluation Parameter Store" />.
## Use cases
<CreateHeader/>
When creating Expectations based on introspection of Data, it can be useful to reference the results of a previous Expectation Suite's Validation. To do this, you would use an `URN` directing to an Evaluation Parameter store. An example of this might look something like the following:
```python title="Python code"
eval_param_urn = 'urn:great_expectations:validations:my_expectation_suite_1:expect_table_row_count_to_be_between.result.observed_value'
downstream_batch.expect_table_row_count_to_equal(
value={
'$PARAMETER': eval_param_urn, # this is the actual parameter we're going to use in the validation
}
)
```
The core of this is a `$PARAMETER : URN` pair. When Great Expectations encounters a `$PARAMETER` flag during validation, it will replace the `URN` with a value retrieved from an Evaluation Parameter Store or Metrics Store.
If you do not have a previous Expectation Suite's Validation Results to reference, however, you can instead provide Evaluation Parameters with a temporary initial value. For example, the interactive method of creating Expectations is based on Validating Expectations against a previous run of the same Expectation Suite. Since a previous run has not been performed when Expectations are being created, Evaluation Parameters cannot reference a past Validation and will require a temporary value instead. This will allow you to test Expectations that are meant to rely on values from previous Validation runs before you have actually used them to Validate data.
Say you are creating additional expectations for the data that you used in the [Getting Started Tutorial](../tutorials/getting_started/tutorial_overview.md). (You have completed the Getting Started Tutorial, right?) You want to create an expression that asserts that the row count for each Validation remains the same as the previous `upstream_row_count`, but since there is no previous `upstream_row_count` you need to provide a value that matches what the Expectation you are creating will find.
To do so, you would first edit your existing (or create a new) Expectation Suite using the CLI. This will open a Jupyter Notebook. After running the first cell, you will have access to a Validator object named `validator` that you can use to add new Expectations to the Expectation Suite.
The Expectation you will want to add to solve the above problem is the `expect_table_row_count_to_equal` Expectation, and this Expectation uses an evaluation parameter: `upstream_row_count`. Therefore, when using the validator to add the `expect_table_row_count_to_equal` Expectation you will have to define the parameter in question (`upstream_row_count`) by assigning it to the `$PARAMETER` value in a dictionary. Then, you would provide the temporary value for that parameter by setting it as the value of the `$PARAMETER.<parameter_in_question>` key in the same dictionary. Or, in this case, the `$PARAMETER.upstream_row_count`.
For an example of this, see below:
```python title="Python code"
validator.expect_table_row_count_to_equal(
value={"$PARAMETER": "upstream_row_count", "$PARAMETER.upstream_row_count": 10000},
result_format={'result_format': 'BOOLEAN_ONLY'}
)
```
This will return `{'success': True}`.
An alternative method of defining the temporary value for an Evaluation Parameter is the `set_evaluation_parameter()` method, as shown below:
```python title="Python code"
validator.set_evaluation_parameter("upstream_row_count", 10000)
validator.expect_table_row_count_to_equal(
value={"$PARAMETER": "upstream_row_count"},
result_format={'result_format': 'BOOLEAN_ONLY'}
)
```
This will also return `{'success': True}`.
Additionally, if the Evaluation Parameter's value is set in this way, you do not need to set it again (or define it alongside the use of the `$PARAMETER` key) for future Expectations that you create with this Validator.
It is also possible for advanced users to create Expectations using Evaluation Parameters by turning off interactive evaluation and adding the Expectation configuration directly to the Expectation Suite. For more information on this, see our guide on [how to create and edit Expectations based on domain knowledge without inspecting data directly](../guides/expectations/how_to_create_and_edit_expectations_based_on_domain_knowledge_without_inspecting_data_directly.md).
More typically, when validating Expectations, you will provide Evaluation Parameters that are only available at runtime.
<ValidateHeader/>
Evaluation Parameters that are configured as part of a Checkpoint's Expectations will be used without further interaction from you. Additionally, Evaluation Parameters will be stored by having the `StoreEvaluationParametersAction` subclass of the `ValidationAction` class defined in a Checkpoint configuration's `action_list`.
However, if you wish to provide specific values for Evaluation Parameters when running a Checkpoint (for instance, when you are testing a newly configured Checkpoint) you can do so by either defining the value of the Evaluation Parameter as an environment variable, or by passing the Evaluation Parameter value in as a dictionary assigned to the named parameter `evaluation_parameters` in the Data Context's `run_checkpoint()` method.
For example, say you have a Checkpoint named `my_checkpoint` that is configured to use the Evaluation Parameter `upstream_row_count`. To associate this Evaluation Parameter with an environment variable, you would edit the Checkpoint's configuration like this:
```yaml title="YAML configuration"
name: my_checkpoint
...
evaluation_parameters:
upstream_row_count: $MY_ENV_VAR
```
If you would rather pass the value of the Environment Variable `upstream_row_count` in as a dictionary when the Checkpoint is run, you can do so like this:
```python title="Python code"
import great_expectations as ge
test_row_count = 10000
context = ge.get_context()
context.run_checkpoint(`my_checkpoint`, evaluation_parameters={"upstream_row_count":test_row_count})
```
## Features
### Dynamic values
Evaluation Parameters are defined by expressions that are evaluated at run time and replaced with the corresponding values. These expressions can include such things as:
- Values from previous Validation runs, such as the number of rows in a previous Validation.
- Values modified by basic arithmatic, such as a percentage of rows in a previous Validation.
- Temporal values, such as "now" or "timedelta."
- Complex values, such as lists.
:::note
Although complex values like lists can be used as the value of an Evaluation Parameter, you cannot currently combine complex values with arithmetic expressions.
:::
## API basics
### How to create
An Evaluation Parameter is defined when an Expectation is created. The Evaluation Parameter at that point will be a reference, either indicating a Metric from the results of a previous Validation, or an expression which will be evaluated prior to a Validation being run on the Expectation Suite.
The Evaluation Parameter references take the form of a dictionary with the `$PARAMETER` key. The value for this key will be directions to the desired Metric or the Evaluation Parameter's expression. In either case, it will be evaluated at run time and replaced with the value described by the reference dictionary's value. If the reference is pointing to a previous Validation's Metrics, it will be in the form of a `$PARAMETER`: `URN` pair, rather than a `$PARAMETER`: `expression` pair.
To store Evaluation Parameters, define a `StoreEvaluationParametersAction` subclass of the `ValidationAction` class in a Checkpoint configuration's `action_list`, and run that Checkpoint.
It is also possible to [dynamically load Evaluation Parameters from a database](../guides/expectations/advanced/how_to_dynamically_load_evaluation_parameters_from_a_database.md).
### Evaluation Parameter expressions
Evaluation Parameters can include basic arithmetic and temporal expressions. For example, we might want to specify that a new table's row count should be between 90 - 110 % of an upstream table's row count (or a count from a previous run). Evaluation parameters support basic arithmetic expressions to accomplish that goal:
```python title="Python code"
validator.set_evaluation_parameter("upstream_row_count", 10000)
validator.expect_table_row_count_to_be_between(
min_value={"$PARAMETER": "trunc(upstream_row_count * 0.9)"},
max_value={"$PARAMETER": "trunc(upstream_row_count * 1.1)"},
result_format={'result_format': 'BOOLEAN_ONLY'}
)
```
This will return `{'success': True}`.
We can also use the temporal expressions "now" and "timedelta". This example states that we expect values for the "load_date" column to be within the last week.
```python title="Python code"
validator.expect_column_values_to_be_greater_than(
column="load_date",
min_value={"$PARAMETER": "now() - timedelta(weeks=1)"}
)
```
Evaluation Parameters are not limited to simple values, for example you could include a list as a parameter value. Going back to our taxi data, let's say that we know there are only two types of accepted payment: Cash or Credit Card, which are represented by a 1 or a 2 in the `payment_type` column. We could verify that these are the only values present by using a list, as shown below:
```python title="Python code"
validator.set_evaluation_parameter("runtime_values", [1,2])
validator.expect_column_values_to_be_in_set(
"payment_type",
value_set={"$PARAMETER": "runtime_values"}
)
```
This Expectation will fail (the NYC taxi data allows for four types of payments), and now we are aware that what we thought we knew about the `payment_type` column wasn't accurate, and that now we need to research what those other two payment types are!
:::note
- You cannot currently combine complex values with arithmetic expressions.
:::
<file_sep>/great_expectations/data_context/data_context/file_data_context.py
import logging
from typing import Optional
from great_expectations.data_context.data_context.abstract_data_context import (
AbstractDataContext,
)
from great_expectations.data_context.data_context_variables import (
DataContextVariableSchema,
FileDataContextVariables,
)
from great_expectations.data_context.types.base import (
DataContextConfig,
datasourceConfigSchema,
)
from great_expectations.datasource.datasource_serializer import (
YAMLReadyDictDatasourceConfigSerializer,
)
logger = logging.getLogger(__name__)
class FileDataContext(AbstractDataContext):
"""
Extends AbstractDataContext, contains only functionality necessary to hydrate state from disk.
TODO: Most of the functionality in DataContext will be refactored into this class, and the current DataContext
class will exist only for backwards-compatibility reasons.
"""
GE_YML = "great_expectations.yml"
def __init__(
self,
project_config: DataContextConfig,
context_root_dir: str,
runtime_environment: Optional[dict] = None,
) -> None:
"""FileDataContext constructor
Args:
project_config (DataContextConfig): Config for current DataContext
context_root_dir (Optional[str]): location to look for the ``great_expectations.yml`` file. If None,
searches for the file based on conventions for project subdirectories.
runtime_environment (Optional[dict]): a dictionary of config variables that override both those set in
config_variables.yml and the environment
"""
self._context_root_directory = context_root_dir
self._project_config = self._apply_global_config_overrides(
config=project_config
)
super().__init__(runtime_environment=runtime_environment)
def _init_datasource_store(self) -> None:
from great_expectations.data_context.store.datasource_store import (
DatasourceStore,
)
store_name: str = "datasource_store" # Never explicitly referenced but adheres
# to the convention set by other internal Stores
store_backend: dict = {
"class_name": "InlineStoreBackend",
"resource_type": DataContextVariableSchema.DATASOURCES,
}
runtime_environment: dict = {
"root_directory": self.root_directory,
"data_context": self,
# By passing this value in our runtime_environment,
# we ensure that the same exact context (memory address and all) is supplied to the Store backend
}
datasource_store = DatasourceStore(
store_name=store_name,
store_backend=store_backend,
runtime_environment=runtime_environment,
serializer=YAMLReadyDictDatasourceConfigSerializer(
schema=datasourceConfigSchema
),
)
self._datasource_store = datasource_store
@property
def root_directory(self) -> Optional[str]:
"""The root directory for configuration objects in the data context; the location in which
``great_expectations.yml`` is located.
Why does this exist in AbstractDataContext? CloudDataContext and FileDataContext both use it
"""
return self._context_root_directory
def _init_variables(self) -> FileDataContextVariables:
variables = FileDataContextVariables(
config=self._project_config,
config_provider=self.config_provider,
data_context=self, # type: ignore[arg-type]
)
return variables
<file_sep>/docs/guides/expectations/index.md
---
title: "Create Expectations: Index"
---
# [](./create_expectations_overview.md) Create Expectations: Index
## Core skills
- [How to create and edit Expectations based on domain knowledge, without inspecting data directly](../../guides/expectations/how_to_create_and_edit_expectations_based_on_domain_knowledge_without_inspecting_data_directly.md)
- [How to create and edit Expectations with the User Configurable Profiler](../../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md)
- [How to create and edit Expectations with instant feedback from a sample Batch of data](../../guides/expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md)
- [How to configure notebooks generated by suite-edit](../../guides/miscellaneous/how_to_configure_notebooks_generated_by_suite_edit.md)
## Configuring Profilers
- [How to create a new Expectation Suite using Rule Based Profilers](../../guides/expectations/advanced/how_to_create_a_new_expectation_suite_using_rule_based_profilers.md)
- [How to create a new Expectation Suite by profiling from a jsonschema file](../../guides/expectations/advanced/how_to_create_a_new_expectation_suite_by_profiling_from_a_jsonschema_file.md)
## Advanced skills
- [How to create Expectations that span multiple Batches using Evaluation Parameters](../../guides/expectations/advanced/how_to_create_expectations_that_span_multiple_batches_using_evaluation_parameters.md)
- [How to dynamically load evaluation parameters from a database](../../guides/expectations/advanced/how_to_dynamically_load_evaluation_parameters_from_a_database.md)
- [How to compare two tables with the UserConfigurableProfiler](../../guides/expectations/advanced/how_to_compare_two_tables_with_the_user_configurable_profiler.md)
## Creating Custom Expectations
- [Overview](../../guides/expectations/creating_custom_expectations/overview.md)
- [How to create a Custom Column Aggregate Expectation](../../guides/expectations/creating_custom_expectations/how_to_create_custom_column_aggregate_expectations.md)
- [How to create a Custom Column Map Expectation](../../guides/expectations/creating_custom_expectations/how_to_create_custom_column_map_expectations.md)
- [How to create a Custom Table Expectation](../../guides/expectations/creating_custom_expectations/how_to_create_custom_table_expectations.md)
- [How to create a Custom Column Pair Map Expectation](../../guides/expectations/creating_custom_expectations/how_to_create_custom_column_pair_map_expectations.md)
- [How to create a Custom Multicolumn Map Expectation](../../guides/expectations/creating_custom_expectations/how_to_create_custom_multicolumn_map_expectations.md)
- [How to create a Custom Regex-Based Column Map Expectation](../../guides/expectations/creating_custom_expectations/how_to_create_custom_regex_based_column_map_expectations.md)
- [How to create a Custom Set-Based Column Map Expectation](../../guides/expectations/creating_custom_expectations/how_to_create_custom_set_based_column_map_expectations.md)
- [How to create a Custom Query Expectation](../../guides/expectations/creating_custom_expectations/how_to_create_custom_query_expectations.md)
- [How to create custom parameterized Expectations](../../guides/expectations/creating_custom_expectations/how_to_create_custom_parameterized_expectations.md)
- [How to use a Custom Expectation](../../guides/expectations/creating_custom_expectations/how_to_use_custom_expectations.md)
### Adding Features to Custom Expectations
- [How to add comments to Expectations and display them in Data Docs](../../guides/expectations/advanced/how_to_add_comments_to_expectations_and_display_them_in_data_docs.md)
- [How to create example cases for a Custom Expectation](../../guides/expectations/features_custom_expectations/how_to_add_example_cases_for_an_expectation.md)
- [How to add input validation and type checking for a Custom Expectation](../../guides/expectations/features_custom_expectations/how_to_add_input_validation_for_an_expectation.md)
- [How to add Spark support for Custom Expectations](../../guides/expectations/features_custom_expectations/how_to_add_spark_support_for_an_expectation.md)
- [How to add SQLAlchemy support for Custom Expectations](../../guides/expectations/features_custom_expectations/how_to_add_sqlalchemy_support_for_an_expectation.md)
<file_sep>/pyproject.toml
[build-system]
requires = ["setuptools", "wheel"]
# uncomment to enable pep517 after versioneer problem is fixed.
# https://github.com/python-versioneer/python-versioneer/issues/193
# build-backend = "setuptools.build_meta"
[tool.black]
extend_excludes = '''(docs/.*|tests/.*.fixture|.*.ge_store_backend_id)'''
[tool.isort]
profile = "black"
skip_gitignore = true
extend_skip_glob = ['venv/*', 'docs/*']
[tool.mypy]
python_version = "3.7"
plugins = ["pydantic.mypy"]
files = [
"great_expectations",
# "contrib" # ignore entire `contrib` package
]
warn_unused_configs = true
ignore_missing_imports = true
# TODO: change this to 'normal' once we have 'full' type coverage
follow_imports = 'silent'
warn_redundant_casts = true
show_error_codes = true
exclude = [
# If pattern should always be excluded add comment explaining why
'_version\.py', # generated by `versioneer`
'v012', # legacy code
# #################################################################################
# TODO: complete typing for the following modules and remove from exclude list
# number is the current number of typing errors for the excluded pattern
'checkpoint/actions\.py', # 18
'checkpoint/checkpoint\.py', # 22
'checkpoint/configurator\.py', # 2
'checkpoint/types/checkpoint_result\.py', # 34
'checkpoint/util\.py', # 5
'cli/batch_request\.py', # 11
'cli/checkpoint\.py', # 9
'cli/cli\.py', # 10
'cli/datasource\.py', # 12
'cli/docs\.py', # 1
'cli/project\.py', # 5
'cli/python_subprocess\.py', # 6
'cli/store\.py', # 2
'cli/suite\.py', # 24
'cli/toolkit\.py', # 27
'cli/upgrade_helpers/upgrade_helper_v11\.py', # 59
'cli/upgrade_helpers/upgrade_helper_v13\.py', # 17
'cli/util\.py', # 1
'core/batch\.py', # 29
'core/expectation_configuration\.py', # 21
'core/expectation_diagnostics', # 20
'core/expectation_validation_result\.py', # 9
'core/usage_statistics/anonymizers/action_anonymizer\.py', # 1
'core/usage_statistics/anonymizers/anonymizer\.py', # 6
'core/usage_statistics/anonymizers/base\.py', # 8
'core/usage_statistics/anonymizers/batch_anonymizer\.py', # 10
'core/usage_statistics/anonymizers/batch_request_anonymizer\.py', # 16
'core/usage_statistics/anonymizers/checkpoint_anonymizer\.py', # 16
'core/usage_statistics/anonymizers/data_connector_anonymizer\.py', # 3
'core/usage_statistics/anonymizers/data_docs_anonymizer\.py', # 5
'core/usage_statistics/anonymizers/datasource_anonymizer\.py', # 9
'core/usage_statistics/anonymizers/expectation_anonymizer\.py', # 6
'core/usage_statistics/anonymizers/profiler_anonymizer\.py', # 2
'core/usage_statistics/anonymizers/store_anonymizer\.py', # 6
'core/usage_statistics/anonymizers/store_backend_anonymizer\.py', # 5
'core/usage_statistics/anonymizers/validation_operator_anonymizer\.py', # 5
'core/usage_statistics/usage_statistics\.py', # 19
'core/usage_statistics/util\.py', # 2
'core/util\.py', # 18
'dataset/sparkdf_dataset\.py', # 3
'dataset/sqlalchemy_dataset\.py', # 16
'datasource/data_connector/configured_asset_sql_data_connector\.py', # 47
'execution_engine/split_and_sample/data_splitter\.py', # 6
'execution_engine/split_and_sample/pandas_data_sampler\.py', # 16
'execution_engine/split_and_sample/sparkdf_data_sampler\.py', # 11
'execution_engine/split_and_sample/sparkdf_data_splitter\.py', # 4
'execution_engine/split_and_sample/sqlalchemy_data_sampler\.py', # 10
'execution_engine/split_and_sample/sqlalchemy_data_splitter\.py', # 22
'expectations/core/expect_column_', # 214
'expectations/core/expect_compound_columns_to_be_unique\.py', # 3
'expectations/core/expect_multicolumn_sum_to_equal\.py', # 4
'expectations/core/expect_multicolumn_values_to_be_unique\.py', # 3
'expectations/core/expect_select_column_values_to_be_unique_within_record\.py', # 3
'expectations/core/expect_table_column', # 25
'expectations/core/expect_table_row_count_to', # 5
'expectations/metrics/column_aggregate_metrics/column_', # 21
'expectations/metrics/map_metric_provider\.py', # 57
'expectations/metrics/metric_provider\.py', # 12
'expectations/metrics/query_metrics/query_column_pair\.py', # 9
'expectations/metrics/query_metrics/query_column\.py', # 7
'expectations/metrics/util\.py', # 11
'expectations/regex_based_column_map_expectation\.py', # 3
'expectations/registry\.py', # 19
'expectations/row_conditions\.py', # 4
'expectations/set_based_column_map_expectation\.py', # 3
'expectations/validation_handlers\.py', # 1
'render/renderer/checkpoint_new_notebook_renderer\.py', # 9
'render/renderer/column_section_renderer\.py', # 1
'render/renderer/content_block/bullet_list_content_block\.py', # 1
'render/renderer/content_block/content_block\.py', # 5
'render/renderer/content_block/exception_list_content_block\.py', # 4
'render/renderer/content_block/validation_results_table_content_block\.py', # 2
'render/renderer/datasource_new_notebook_renderer\.py', # 4
'render/renderer/notebook_renderer\.py', # 2
'render/renderer/page_renderer\.py', # 10
'render/renderer/profiling_results_overview_section_renderer\.py', # 2
'render/renderer/site_builder\.py', # 3
'render/renderer/slack_renderer\.py', # 9
'render/renderer/suite_edit_notebook_renderer\.py', # 7
'render/renderer/suite_scaffold_notebook_renderer\.py', # 7
'render/renderer/v3/suite_edit_notebook_renderer\.py', # 11
'render/renderer/v3/suite_profile_notebook_renderer\.py', # 4
'render/util\.py', # 2
'render/view/view\.py', # 11
'rule_based_profiler/attributed_resolved_metrics\.py', # 4
'rule_based_profiler/builder\.py', # 4
'rule_based_profiler/config/base\.py', # 13
'rule_based_profiler/data_assistant_result/data_assistant_result\.py', # 71
'rule_based_profiler/data_assistant_result/onboarding_data_assistant_result\.py', # 1
'rule_based_profiler/data_assistant_result/plot_components\.py', # 12
'rule_based_profiler/data_assistant/data_assistant_dispatcher\.py', # 3
'rule_based_profiler/data_assistant/data_assistant_runner\.py', # 10
'rule_based_profiler/data_assistant/data_assistant\.py', # 15
'rule_based_profiler/domain_builder/categorical_column_domain_builder\.py', # 18
'rule_based_profiler/domain_builder/column_domain_builder\.py',
'rule_based_profiler/domain_builder/column_pair_domain_builder\.py', # 4
'rule_based_profiler/domain_builder/domain_builder\.py', # 5
'rule_based_profiler/domain_builder/map_metric_column_domain_builder\.py', # 8
'rule_based_profiler/domain_builder/multi_column_domain_builder\.py', # 4
'rule_based_profiler/domain_builder/table_domain_builder\.py', # 1
'rule_based_profiler/estimators/bootstrap_numeric_range_estimator\.py', # 8
'rule_based_profiler/estimators/exact_numeric_range_estimator\.py', # 3
'rule_based_profiler/estimators/kde_numeric_range_estimator\.py', # 7
'rule_based_profiler/estimators/numeric_range_estimator\.py', # 1
'rule_based_profiler/estimators/quantiles_numeric_range_estimator\.py', # 5
'rule_based_profiler/expectation_configuration_builder', # 13
'rule_based_profiler/helpers/cardinality_checker\.py', # 9
'rule_based_profiler/helpers/simple_semantic_type_filter\.py', # 7
'rule_based_profiler/helpers/util\.py', # 53
'rule_based_profiler/parameter_builder/histogram_single_batch_parameter_builder\.py', # 7
'rule_based_profiler/parameter_builder/mean_table_columns_set_match_multi_batch_parameter_builder\.py', # 2
'rule_based_profiler/parameter_builder/mean_unexpected_map_metric_multi_batch_parameter_builder\.py', # 19
'rule_based_profiler/parameter_builder/metric_multi_batch_parameter_builder\.py', # 15
'rule_based_profiler/parameter_builder/metric_single_batch_parameter_builder\.py', # 3
'rule_based_profiler/parameter_builder/numeric_metric_range_multi_batch_parameter_builder\.py', # 27
'rule_based_profiler/parameter_builder/parameter_builder\.py', # 40
'rule_based_profiler/parameter_builder/partition_parameter_builder\.py', # 9
'rule_based_profiler/parameter_builder/regex_pattern_string_parameter_builder\.py', # 21
'rule_based_profiler/parameter_builder/simple_date_format_string_parameter_builder\.py', # 20
'rule_based_profiler/parameter_builder/value_counts_single_batch_parameter_builder\.py', # 3
'rule_based_profiler/parameter_builder/value_set_multi_batch_parameter_builder\.py', # 2
'rule_based_profiler/parameter_container\.py', # 7
'rule_based_profiler/rule_based_profiler_result\.py', # 1
'rule_based_profiler/rule_based_profiler\.py', # 40
'rule_based_profiler/rule/rule.py', # 5
'validation_operators/types/validation_operator_result\.py', # 35
'validation_operators/validation_operators\.py', # 16
'validator/exception_info\.py', # 1
'validator/validator\.py', # 54
]
[tool.pydantic-mypy]
# https://pydantic-docs.helpmanual.io/mypy_plugin/#plugin-settings
init_typed = true
warn_required_dynamic_aliases = true
warn_untyped_fields = true
[tool.pytest.ini_options]
filterwarnings = [
# This warning is common during testing where we intentionally use a COMPLETE format even in cases that would
# be potentially overly resource intensive in standard operation
"ignore:Setting result format to COMPLETE for a SqlAlchemyDataset:UserWarning",
# This deprecation warning was fixed in moto release 1.3.15, and the filter should be removed once we migrate
# to that minimum version
"ignore:Using or importing the ABCs:DeprecationWarning:moto.cloudformation.parsing",
# This deprecation warning comes from getsentry/responses, a mocking utility for requests. It is a dependency in moto.
"ignore:stream argument is deprecated. Use stream parameter in request directly:DeprecationWarning",
]
junit_family="xunit2"
markers = [
"base_data_context: mark test as being relevant to BaseDataContext, which will be removed during refactor",
"cloud: mark test as being relevant to Great Expectations Cloud.",
"docs: mark a test as a docs test.",
"e2e: mark test as an E2E test.",
"external_sqldialect: mark test as requiring install of an external sql dialect.",
"integration: mark test as an integration test.",
"slow: mark tests taking longer than 1 second.",
"unit: mark a test as a unit test.",
"v2_api: mark test as specific to the v2 api (e.g. pre Data Connectors)",
]
testpaths = "tests"
# use `pytest-mock` drop-in replacement for `unittest.mock`
# https://pytest-mock.readthedocs.io/en/latest/configuration.html#use-standalone-mock-package
mock_use_standalone_module = false
<file_sep>/tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py
"""Example Script: How to create an Expectation Suite with the Onboarding Data Assistant
This example script is intended for use in documentation on how to use an Onboarding Data Assistant to create
an Expectation Suite.
Assert statements are included to ensure that if the behaviour shown in this script breaks it will not pass
tests and will be updated. These statements can be ignored by users.
Comments with the tags `<snippet>` and `</snippet>` are used to ensure that if this script is updated
the snippets that are specified for use in documentation are maintained. These comments can be ignored by users.
--documentation--
https://docs.greatexpectations.io/docs/guides/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant
"""
import great_expectations as ge
from great_expectations.checkpoint import SimpleCheckpoint
from great_expectations.core.batch import BatchRequest
from great_expectations.core.yaml_handler import YAMLHandler
yaml = YAMLHandler()
context: ge.DataContext = ge.get_context()
# Configure your datasource (if you aren't using one that already exists)
# <snippet>
datasource_config = {
"name": "taxi_multi_batch_datasource",
"class_name": "Datasource",
"module_name": "great_expectations.datasource",
"execution_engine": {
"module_name": "great_expectations.execution_engine",
"class_name": "PandasExecutionEngine",
},
"data_connectors": {
"inferred_data_connector_all_years": {
"class_name": "InferredAssetFilesystemDataConnector",
"base_directory": "<PATH_TO_YOUR_DATA_HERE>",
"default_regex": {
"group_names": ["data_asset_name", "year", "month"],
"pattern": "(yellow_tripdata_sample)_(\\d.*)-(\\d.*)\\.csv",
},
},
},
}
# </snippet>
# Please note this override is only to provide good UX for docs and tests.
# In normal usage you'd set your path directly in the yaml above.
datasource_config["data_connectors"]["inferred_data_connector_all_years"][
"base_directory"
] = "../data/"
context.test_yaml_config(yaml.dump(datasource_config))
# add_datasource only if it doesn't already exist in our configuration
try:
context.get_datasource(datasource_config["name"])
except ValueError:
context.add_datasource(**datasource_config)
# Prepare an Expectation Suite
# <snippet>
expectation_suite_name = "my_onboarding_assistant_suite"
expectation_suite = context.create_expectation_suite(
expectation_suite_name=expectation_suite_name, overwrite_existing=True
)
# </snippet>
# Prepare a Batch Request
# <snippet>
multi_batch_all_years_batch_request: BatchRequest = BatchRequest(
datasource_name="taxi_multi_batch_datasource",
data_connector_name="inferred_data_connector_all_years",
data_asset_name="yellow_tripdata_sample",
)
# </snippet>
# Run the Onboarding Assistant
# <snippet>
exclude_column_names = [
"VendorID",
"pickup_datetime",
"dropoff_datetime",
"RatecodeID",
"PULocationID",
"DOLocationID",
"payment_type",
"fare_amount",
"extra",
"mta_tax",
"tip_amount",
"tolls_amount",
"improvement_surcharge",
"congestion_surcharge",
]
# </snippet>
# <snippet>
data_assistant_result = context.assistants.onboarding.run(
batch_request=multi_batch_all_years_batch_request,
exclude_column_names=exclude_column_names,
)
# </snippet>
# Save your Expectation Suite
# <snippet>
expectation_suite = data_assistant_result.get_expectation_suite(
expectation_suite_name=expectation_suite_name
)
# </snippet>
# <snippet>
context.save_expectation_suite(
expectation_suite=expectation_suite, discard_failed_expectations=False
)
# </snippet>
# Use a SimpleCheckpoint to verify that your new Expectation Suite works.
# <snippet>
checkpoint_config = {
"class_name": "SimpleCheckpoint",
"validations": [
{
"batch_request": multi_batch_all_years_batch_request,
"expectation_suite_name": expectation_suite_name,
}
],
}
# </snippet>
# <snippet>
checkpoint = SimpleCheckpoint(
f"yellow_tripdata_sample_{expectation_suite_name}",
context,
**checkpoint_config,
)
checkpoint_result = checkpoint.run()
assert checkpoint_result["success"] is True
# </snippet>
# If you are using code from this script as part of a Jupyter Notebook, uncommenting and running the
# following lines will open your Data Docs for the `checkpoint`'s results:
# context.build_data_docs()
# validation_result_identifier = checkpoint_result.list_validation_result_identifiers()[0]
# context.open_data_docs(resource_identifier=validation_result_identifier)
# <snippet>
data_assistant_result.plot_metrics()
# </snippet>
# <snippet>
data_assistant_result.metrics_by_domain
# </snippet>
# <snippet>
data_assistant_result.plot_expectations_and_metrics()
# </snippet>
# <snippet>
data_assistant_result.show_expectations_by_domain_type()
# </snippet>
# <snippet>
data_assistant_result.show_expectations_by_expectation_type()
# </snippet>
<file_sep>/great_expectations/render/renderer_configuration.py
from dataclasses import dataclass, field
from typing import Union
from great_expectations.core import (
ExpectationConfiguration,
ExpectationValidationResult,
)
@dataclass(frozen=True)
class RendererConfiguration:
"""Configuration object built for each renderer."""
configuration: Union[ExpectationConfiguration, None]
result: Union[ExpectationValidationResult, None]
language: str = "en"
runtime_configuration: dict = field(default_factory=dict)
kwargs: dict = field(init=False)
include_column_name: bool = field(init=False)
styling: Union[dict, None] = field(init=False)
def __post_init__(self) -> None:
kwargs: dict
if self.configuration:
kwargs = self.configuration.kwargs
elif self.result and self.result.expectation_config:
kwargs = self.result.expectation_config.kwargs
else:
kwargs = {}
object.__setattr__(self, "kwargs", kwargs)
include_column_name: bool = True
styling: Union[dict, None] = None
if self.runtime_configuration:
include_column_name = (
False
if self.runtime_configuration.get("include_column_name") is False
else True
)
styling = self.runtime_configuration.get("styling")
object.__setattr__(self, "include_column_name", include_column_name)
object.__setattr__(self, "styling", styling)
<file_sep>/docs/terms/cli.md
---
title: CLI (Command Line Interface)
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
import SetupHeader from '/docs/images/universal_map/_um_setup_header.mdx'
import ConnectHeader from '/docs/images/universal_map/_um_connect_header.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
import ValidateHeader from '/docs/images/universal_map/_um_validate_header.mdx';
<UniversalMap setup='active' connect='active' create='active' validate='active'/>
## Overview
### Definition
CLI stands for Command Line Interface.
### Features and promises
The CLI provides useful convenience functions covering all the steps of working with Great Expectations. CLI commands consist of a noun indicating what you want to operate on, and a verb indicating the operation to perform. All CLI commands have help documentation that can be accessed by including the `--help` option after the command. Running `great_expectations` without any additional arguments or `great_expectations --help` will display a list of the available commands.
### Relationship to other objects
The CLI provides commands for performing operations on your Great Expectations deployment, as well as on <TechnicalTag relative="../" tag="checkpoint" text="Checkpoints" />, <TechnicalTag relative="../" tag="datasource" text="Datasources" />, <TechnicalTag relative="../" tag="data_docs" text="Data Docs" />, <TechnicalTag relative="../" tag="store" text="Stores" />, and <TechnicalTag relative="../" tag="expectation_suite" text="Expectation Suites" />.
You will usually also initialize your <TechnicalTag relative="../" tag="data_context" text="Data Context" /> through the CLI.
Most CLI commands will either execute entirely in the terminal, or will open Jupyter Notebooks with boilerplate code and additional commentary to help you accomplish a task that requires more complicated configuration.
## Use cases
<UniversalMap setup='active' connect='active' create='active' validate='active'/>
The CLI provides functionality at every stage in your use of Great Expectations. What commands you'll want to execute, however, will differ from step to step.
<SetupHeader/>
Every Great Expectations project starts with initializing your Data Context, which is typically done with the command:
```bash title="Terminal command"
great_expectations init
```
You can also utilize the project commands to check config files for validity and help with migrations when updating versions of Great Expectations. You can read about these commands in the CLI with the command:
```bash title="Terminal command"
great_expectations project --help
```
<ConnectHeader/>
To assist with connecting to data, the CLI provides commands for creating, listing, and deleting Datasources. You can read about these commands in the CLI with the command:
```bash title="Terminal command"
great_expectations datasource --help
```
<CreateHeader/>
To assist you in creating Expectation Suites, the CLI provides commands for listing available suites, creating new empty suites, creating new suites with scaffolding, editing existing suites, and deleting expectation suites. You can read about these commands in the CLI with the command:
```bash title="Terminal command"
great_expectations suite --help
```
<ValidateHeader/>
To assist you in Validating your data, the CLI provides commands for listing existing Checkpoints, running an existing Checkpoint, creating new Checkpoints, and creating Python scripts that will run a Checkpoint. You can read about these commands in the CLI with the command:
```bash title="Terminal command"
great_expectations checkpoint --help
```
There are also commands available through the CLI for building, deleting, and listing your available Data Docs. You can read about these commands in the CLI with the command:
```bash title="Terminal command"
great_expectations docs --help
```
## Features
### Convenience commands
The CLI provides commands that will list, create, delete, or edit almost anything you may want to list, create, delete, or edit in Great Expectations. If the CLI does not perform the operation directly in the terminal, it will provide you with a Jupyter Notebook that has the necessary code boilerplate and contextual notes to get you started on the process.
## API basics
For an in-depth guide on using the CLI, see [our document on how to use the Great Expectations CLI](../guides/miscellaneous/how_to_use_the_great_expectations_cli.md) or read the CLI documentation directly using the following command:
```bash title="Terminal command"
great_expectations --help
```
<file_sep>/tests/cli/v012/test_validation_operator.py
import json
import os
import pytest
from click.testing import CliRunner
from great_expectations import DataContext
from great_expectations.cli.v012 import cli
from tests.cli.utils import escape_ansi
from tests.cli.v012.utils import (
VALIDATION_OPERATORS_DEPRECATION_MESSAGE,
assert_no_logging_messages_or_tracebacks,
)
def test_validation_operator_run_interactive_golden_path(
caplog, data_context_simple_expectation_suite, filesystem_csv_2
):
"""
Interactive mode golden path - pass an existing suite name and an existing validation
operator name, select an existing file.
"""
not_so_empty_data_context = data_context_simple_expectation_suite
root_dir = not_so_empty_data_context.root_directory
os.mkdir(os.path.join(root_dir, "uncommitted"))
runner = CliRunner(mix_stderr=False)
csv_path = os.path.join(filesystem_csv_2, "f1.csv")
result = runner.invoke(
cli,
[
"validation-operator",
"run",
"-d",
root_dir,
"--name",
"default",
"--suite",
"default",
],
input=f"{csv_path}\n",
catch_exceptions=False,
)
stdout = result.stdout
assert "Validation failed" in stdout
assert result.exit_code == 1
assert_no_logging_messages_or_tracebacks(caplog, result)
def test_validation_operator_run_interactive_pass_non_existing_expectation_suite(
caplog,
data_context_parameterized_expectation_suite_no_checkpoint_store,
filesystem_csv_2,
):
"""
Interactive mode: pass an non-existing suite name and an existing validation
operator name, select an existing file.
"""
not_so_empty_data_context = (
data_context_parameterized_expectation_suite_no_checkpoint_store
)
root_dir = not_so_empty_data_context.root_directory
os.mkdir(os.path.join(root_dir, "uncommitted"))
runner = CliRunner(mix_stderr=False)
csv_path = os.path.join(filesystem_csv_2, "f1.csv")
result = runner.invoke(
cli,
[
"validation-operator",
"run",
"-d",
root_dir,
"--name",
"default",
"--suite",
"this.suite.does.not.exist",
],
input=f"{csv_path}\n",
catch_exceptions=False,
)
stdout = result.stdout
assert "Could not find a suite named" in stdout
assert result.exit_code == 1
assert_no_logging_messages_or_tracebacks(caplog, result)
def test_validation_operator_run_interactive_pass_non_existing_operator_name(
caplog,
data_context_parameterized_expectation_suite_no_checkpoint_store,
filesystem_csv_2,
):
"""
Interactive mode: pass an non-existing suite name and an existing validation
operator name, select an existing file.
"""
not_so_empty_data_context = (
data_context_parameterized_expectation_suite_no_checkpoint_store
)
root_dir = not_so_empty_data_context.root_directory
os.mkdir(os.path.join(root_dir, "uncommitted"))
runner = CliRunner(mix_stderr=False)
csv_path = os.path.join(filesystem_csv_2, "f1.csv")
result = runner.invoke(
cli,
[
"validation-operator",
"run",
"-d",
root_dir,
"--name",
"this_val_op_does_not_exist",
"--suite",
"my_dag_node.default",
],
input=f"{csv_path}\n",
catch_exceptions=False,
)
stdout = result.stdout
assert "Could not find a validation operator" in stdout
assert result.exit_code == 1
assert_no_logging_messages_or_tracebacks(caplog, result)
def test_validation_operator_run_noninteractive_golden_path(
caplog, data_context_simple_expectation_suite, filesystem_csv_2
):
"""
Non-nteractive mode golden path - use the --validation_config_file argument to pass the path
to a valid validation config file
"""
not_so_empty_data_context = data_context_simple_expectation_suite
root_dir = not_so_empty_data_context.root_directory
os.mkdir(os.path.join(root_dir, "uncommitted"))
csv_path = os.path.join(filesystem_csv_2, "f1.csv")
validation_config = {
"validation_operator_name": "default",
"batches": [
{
"batch_kwargs": {
"path": csv_path,
"datasource": "mydatasource",
"reader_method": "read_csv",
},
"expectation_suite_names": ["default"],
}
],
}
validation_config_file_path = os.path.join(
root_dir, "uncommitted", "validation_config_1.json"
)
with open(validation_config_file_path, "w") as f:
json.dump(validation_config, f)
runner = CliRunner(mix_stderr=False)
result = runner.invoke(
cli,
[
"validation-operator",
"run",
"-d",
root_dir,
"--validation_config_file",
validation_config_file_path,
],
catch_exceptions=False,
)
stdout = result.stdout
assert "Validation failed" in stdout
assert result.exit_code == 1
assert_no_logging_messages_or_tracebacks(caplog, result)
def test_validation_operator_run_noninteractive_validation_config_file_does_not_exist(
caplog,
data_context_parameterized_expectation_suite_no_checkpoint_store,
filesystem_csv_2,
):
"""
Non-nteractive mode. Use the --validation_config_file argument to pass the path
to a validation config file that does not exist.
"""
not_so_empty_data_context = (
data_context_parameterized_expectation_suite_no_checkpoint_store
)
root_dir = not_so_empty_data_context.root_directory
os.mkdir(os.path.join(root_dir, "uncommitted"))
validation_config_file_path = os.path.join(
root_dir, "uncommitted", "validation_config_1.json"
)
runner = CliRunner(mix_stderr=False)
result = runner.invoke(
cli,
[
"validation-operator",
"run",
"-d",
root_dir,
"--validation_config_file",
validation_config_file_path,
],
catch_exceptions=False,
)
stdout = result.stdout
assert "Failed to process the --validation_config_file argument" in stdout
assert result.exit_code == 1
assert_no_logging_messages_or_tracebacks(caplog, result)
def test_validation_operator_run_noninteractive_validation_config_file_does_is_misconfigured(
caplog,
data_context_parameterized_expectation_suite_no_checkpoint_store,
filesystem_csv_2,
):
"""
Non-nteractive mode. Use the --validation_config_file argument to pass the path
to a validation config file that is misconfigured - one of the batches does not
have expectation_suite_names attribute
"""
not_so_empty_data_context = (
data_context_parameterized_expectation_suite_no_checkpoint_store
)
root_dir = not_so_empty_data_context.root_directory
os.mkdir(os.path.join(root_dir, "uncommitted"))
csv_path = os.path.join(filesystem_csv_2, "f1.csv")
validation_config = {
"validation_operator_name": "default",
"batches": [
{
"batch_kwargs": {
"path": csv_path,
"datasource": "mydatasource",
"reader_method": "read_csv",
},
"wrong_attribute_expectation_suite_names": ["my_dag_node.default1"],
}
],
}
validation_config_file_path = os.path.join(
root_dir, "uncommitted", "validation_config_1.json"
)
with open(validation_config_file_path, "w") as f:
json.dump(validation_config, f)
runner = CliRunner(mix_stderr=False)
result = runner.invoke(
cli,
[
"validation-operator",
"run",
"-d",
root_dir,
"--validation_config_file",
validation_config_file_path,
],
catch_exceptions=False,
)
stdout = result.stdout
assert (
"is misconfigured: Each batch must have a list of expectation suite names"
in stdout
)
assert result.exit_code == 1
assert_no_logging_messages_or_tracebacks(caplog, result)
def test_validation_operator_list_with_one_operator(caplog, empty_data_context):
project_dir = empty_data_context.root_directory
context = DataContext(project_dir)
context.create_expectation_suite("a.warning")
def test_validation_operator_list_with_zero_validation_operators(
caplog, empty_data_context
):
project_dir = empty_data_context.root_directory
context = DataContext(project_dir)
context._project_config.validation_operators = {}
context._save_project_config()
runner = CliRunner(mix_stderr=False)
result = runner.invoke(
cli,
f"validation-operator list -d {project_dir}",
catch_exceptions=False,
)
assert result.exit_code == 0
assert "No Validation Operators found" in result.output
assert_no_logging_messages_or_tracebacks(
my_caplog=caplog,
click_result=result,
allowed_deprecation_message=VALIDATION_OPERATORS_DEPRECATION_MESSAGE,
)
@pytest.mark.slow # 1.03s
def test_validation_operator_list_with_one_validation_operator(
caplog, filesystem_csv_data_context_with_validation_operators
):
project_dir = filesystem_csv_data_context_with_validation_operators.root_directory
runner = CliRunner(mix_stderr=False)
expected_result = """Heads up! This feature is Experimental. It may change. Please give us your feedback!
1 Validation Operator found:
- name: action_list_operator
class_name: ActionListValidationOperator
action_list: store_validation_result (StoreValidationResultAction) => store_evaluation_params (StoreEvaluationParametersAction) => update_data_docs (UpdateDataDocsAction)"""
result = runner.invoke(
cli,
f"validation-operator list -d {project_dir}",
catch_exceptions=False,
)
assert result.exit_code == 0
# _capture_ansi_codes_to_file(result)
assert escape_ansi(result.output).strip() == expected_result.strip()
assert_no_logging_messages_or_tracebacks(
my_caplog=caplog,
click_result=result,
allowed_deprecation_message=VALIDATION_OPERATORS_DEPRECATION_MESSAGE,
)
@pytest.mark.slow # 1.53s
def test_validation_operator_list_with_multiple_validation_operators(
caplog, filesystem_csv_data_context_with_validation_operators
):
project_dir = filesystem_csv_data_context_with_validation_operators.root_directory
runner = CliRunner(mix_stderr=False)
context = DataContext(project_dir)
context.add_validation_operator(
"my_validation_operator",
{
"class_name": "WarningAndFailureExpectationSuitesValidationOperator",
"action_list": [
{
"name": "store_validation_result",
"action": {"class_name": "StoreValidationResultAction"},
},
{
"name": "store_evaluation_params",
"action": {"class_name": "StoreEvaluationParametersAction"},
},
{
"name": "update_data_docs",
"action": {"class_name": "UpdateDataDocsAction"},
},
],
"base_expectation_suite_name": "new-years-expectations",
"slack_webhook": "https://hooks.slack.com/services/dummy",
},
)
context._save_project_config()
expected_result = """Heads up! This feature is Experimental. It may change. Please give us your feedback!
2 Validation Operators found:
- name: action_list_operator
class_name: ActionListValidationOperator
action_list: store_validation_result (StoreValidationResultAction) => store_evaluation_params (StoreEvaluationParametersAction) => update_data_docs (UpdateDataDocsAction)
- name: my_validation_operator
class_name: WarningAndFailureExpectationSuitesValidationOperator
action_list: store_validation_result (StoreValidationResultAction) => store_evaluation_params (StoreEvaluationParametersAction) => update_data_docs (UpdateDataDocsAction)
base_expectation_suite_name: new-years-expectations
slack_webhook: https://hooks.slack.com/services/dummy"""
result = runner.invoke(
cli,
f"validation-operator list -d {project_dir}",
catch_exceptions=False,
)
assert result.exit_code == 0
assert escape_ansi(result.output).strip() == expected_result.strip()
assert_no_logging_messages_or_tracebacks(
my_caplog=caplog,
click_result=result,
allowed_deprecation_message=VALIDATION_OPERATORS_DEPRECATION_MESSAGE,
)
<file_sep>/tasks.py
"""
PyInvoke developer task file
https://www.pyinvoke.org/
These tasks can be run using `invoke <NAME>` or `inv <NAME>` from the project root.
To show all available tasks `invoke --list`
To show task help page `invoke <NAME> --help`
"""
import json
import os
import pathlib
import shutil
import invoke
from scripts import check_type_hint_coverage
try:
from tests.integration.usage_statistics import usage_stats_utils
is_ge_installed: bool = True
except ModuleNotFoundError:
is_ge_installed = False
_CHECK_HELP_DESC = "Only checks for needed changes without writing back. Exit with error code if changes needed."
_EXCLUDE_HELP_DESC = "Exclude files or directories"
_PATH_HELP_DESC = "Target path. (Default: .)"
@invoke.task(
help={
"check": _CHECK_HELP_DESC,
"exclude": _EXCLUDE_HELP_DESC,
"path": _PATH_HELP_DESC,
}
)
def sort(ctx, path=".", check=False, exclude=None):
"""Sort module imports."""
cmds = ["isort", path]
if check:
cmds.append("--check-only")
if exclude:
cmds.extend(["--skip", exclude])
ctx.run(" ".join(cmds), echo=True)
@invoke.task(
help={
"check": _CHECK_HELP_DESC,
"exclude": _EXCLUDE_HELP_DESC,
"path": _PATH_HELP_DESC,
"sort": "Disable import sorting. Runs by default.",
}
)
def fmt(ctx, path=".", sort_=True, check=False, exclude=None):
"""
Run code formatter.
"""
if sort_:
sort(ctx, path, check=check, exclude=exclude)
cmds = ["black", path]
if check:
cmds.append("--check")
if exclude:
cmds.extend(["--exclude", exclude])
ctx.run(" ".join(cmds), echo=True)
@invoke.task(help={"path": _PATH_HELP_DESC})
def lint(ctx, path="."):
"""Run code linter"""
cmds = ["flake8", path, "--statistics"]
ctx.run(" ".join(cmds), echo=True)
@invoke.task(help={"path": _PATH_HELP_DESC})
def upgrade(ctx, path="."):
"""Run code syntax upgrades."""
cmds = ["pyupgrade", path, "--py3-plus"]
ctx.run(" ".join(cmds))
@invoke.task(
help={
"all_files": "Run hooks against all files, not just the current changes.",
"diff": "Show the diff of changes on hook failure.",
"sync": "Re-install the latest git hooks.",
}
)
def hooks(ctx, all_files=False, diff=False, sync=False):
"""Run and manage pre-commit hooks."""
cmds = ["pre-commit", "run"]
if diff:
cmds.append("--show-diff-on-failure")
if all_files:
cmds.extend(["--all-files"])
else:
# used in CI - runs faster and only checks files that have changed
cmds.extend(["--from-ref", "origin/HEAD", "--to-ref", "HEAD"])
ctx.run(" ".join(cmds))
if sync:
print(" Re-installing hooks ...")
ctx.run(" ".join(["pre-commit", "uninstall"]), echo=True)
ctx.run(" ".join(["pre-commit", "install"]), echo=True)
@invoke.task(aliases=["type-cov"]) # type: ignore
def type_coverage(ctx):
"""
Check total type-hint coverage compared to `develop`.
"""
try:
check_type_hint_coverage.main()
except AssertionError as err:
raise invoke.Exit(
message=f"{err}\n\n See {check_type_hint_coverage.__file__}", code=1
)
@invoke.task(
aliases=["types"],
iterable=["packages"],
help={
"packages": "One or more `great_expectatations` sub-packages to type-check with mypy.",
"install-types": "Automatically install any needed types from `typeshed`.",
"daemon": "Run mypy in daemon mode with faster analysis."
" The daemon will be started and re-used for subsequent calls."
" For detailed usage see `dmypy --help`.",
"clear-cache": "Clear the local mypy cache directory.",
},
)
def type_check(
ctx,
packages,
install_types=False,
pretty=False,
warn_unused_ignores=False,
daemon=False,
clear_cache=False,
report=False,
):
"""Run mypy static type-checking on select packages."""
if clear_cache:
mypy_cache = pathlib.Path(".mypy_cache")
print(f" Clearing {mypy_cache} ... ", end="")
try:
shutil.rmtree(mypy_cache)
print("✅"),
except FileNotFoundError as exc:
print(f"❌\n {exc}")
if daemon:
bin = "dmypy run --"
else:
bin = "mypy"
ge_pkgs = [f"great_expectations.{p}" for p in packages]
cmds = [
bin,
*ge_pkgs,
]
if install_types:
cmds.extend(["--install-types", "--non-interactive"])
if daemon:
# see related issue https://github.com/python/mypy/issues/9475
cmds.extend(["--follow-imports=normal"])
if report:
cmds.extend(["--txt-report", "type_cov", "--html-report", "type_cov"])
if pretty:
cmds.extend(["--pretty"])
if warn_unused_ignores:
cmds.extend(["--warn-unused-ignores"])
# use pseudo-terminal for colorized output
ctx.run(" ".join(cmds), echo=True, pty=True)
@invoke.task(aliases=["get-stats"])
def get_usage_stats_json(ctx):
"""
Dump usage stats event examples to json file
"""
if not is_ge_installed:
raise invoke.Exit(
message="This invoke task requires Great Expecations to be installed in the environment. Please try again.",
code=1,
)
events = usage_stats_utils.get_usage_stats_example_events()
version = usage_stats_utils.get_gx_version()
outfile = f"v{version}_example_events.json"
with open(outfile, "w") as f:
json.dump(events, f)
print(f"File written to '{outfile}'.")
@invoke.task(pre=[get_usage_stats_json], aliases=["move-stats"])
def mv_usage_stats_json(ctx):
"""
Use databricks-cli lib to move usage stats event examples to dbfs:/
"""
version = usage_stats_utils.get_gx_version()
outfile = f"v{version}_example_events.json"
cmd = "databricks fs cp --overwrite {0} dbfs:/schemas/{0}"
cmd = cmd.format(outfile)
ctx.run(cmd)
print(f"'{outfile}' copied to dbfs.")
UNIT_TEST_DEFAULT_TIMEOUT: float = 2.0
@invoke.task(
aliases=["test"],
help={
"unit": "Runs tests marked with the 'unit' marker. Default behavior.",
"integration": "Runs integration tests and exclude unit-tests. By default only unit tests are run.",
"ignore-markers": "Don't exclude any test by not passing any markers to pytest.",
"slowest": "Report on the slowest n number of tests",
"ci": "execute tests assuming a CI environment. Publish XML reports for coverage reporting etc.",
"timeout": f"Fails unit-tests if calls take longer than this value. Default {UNIT_TEST_DEFAULT_TIMEOUT} seconds",
"html": "Create html coverage report",
"package": "Run tests on a specific package. Assumes there is a `tests/<PACKAGE>` directory of the same name.",
"full-cov": "Show coverage report on the entire `great_expectations` package regardless of `--package` param.",
},
)
def tests(
ctx,
unit=True,
integration=False,
ignore_markers=False,
ci=False,
html=False,
cloud=True,
slowest=5,
timeout=UNIT_TEST_DEFAULT_TIMEOUT,
package=None,
full_cov=False,
):
"""
Run tests. Runs unit tests by default.
Use `invoke tests -p=<TARGET_PACKAGE>` to run tests on a particular package and measure coverage (or lack thereof).
"""
markers = []
if integration:
markers += ["integration"]
unit = False
markers += ["unit" if unit else "not unit"]
marker_text = " and ".join(markers)
cov_param = "--cov=great_expectations"
if package and not full_cov:
cov_param += f"/{package.replace('.', '/')}"
cmds = [
"pytest",
f"--durations={slowest}",
cov_param,
"--cov-report term",
"-vv",
]
if not ignore_markers:
cmds += ["-m", f"'{marker_text}'"]
if unit and not ignore_markers:
try:
import pytest_timeout # noqa: F401
cmds += [f"--timeout={timeout}"]
except ImportError:
print("`pytest-timeout` is not installed, cannot use --timeout")
if cloud:
cmds += ["--cloud"]
if ci:
cmds += ["--cov-report", "xml"]
if html:
cmds += ["--cov-report", "html"]
if package:
cmds += [f"tests/{package.replace('.', '/')}"] # allow `foo.bar`` format
ctx.run(" ".join(cmds), echo=True, pty=True)
PYTHON_VERSION_DEFAULT: float = 3.8
@invoke.task(
help={
"name": "Docker image name.",
"tag": "Docker image tag.",
"build": "If True build the image, otherwise run it. Defaults to False.",
"detach": "Run container in background and print container ID. Defaults to False.",
"py": f"version of python to use. Default is {PYTHON_VERSION_DEFAULT}",
"cmd": "Command for docker image. Default is bash.",
}
)
def docker(
ctx,
name="gx38local",
tag="latest",
build=False,
detach=False,
cmd="bash",
py=PYTHON_VERSION_DEFAULT,
):
"""
Build or run gx docker image.
"""
filedir = os.path.realpath(os.path.dirname(os.path.realpath(__file__)))
curdir = os.path.realpath(os.getcwd())
if filedir != curdir:
raise invoke.Exit(
"The docker task must be invoked from the same directory as the task.py file at the top of the repo.",
code=1,
)
cmds = ["docker"]
if build:
cmds.extend(
[
"buildx",
"build",
"-f",
"docker/Dockerfile.tests",
f"--tag {name}:{tag}",
*[
f"--build-arg {arg}"
for arg in ["SOURCE=local", f"PYTHON_VERSION={py}"]
],
".",
]
)
else:
cmds.append("run")
if detach:
cmds.append("--detach")
cmds.extend(
[
"-it",
"--rm",
"--mount",
f"type=bind,source={filedir},target=/great_expectations",
"-w",
"/great_expectations",
f"{name}:{tag}",
f"{cmd}",
]
)
ctx.run(" ".join(cmds), echo=True, pty=True)
<file_sep>/tests/core/usage_statistics/test_usage_stats_schema.py
import json
import jsonschema
import pytest
from great_expectations.core.usage_statistics.events import UsageStatsEvents
from great_expectations.core.usage_statistics.schemas import (
anonymized_batch_request_schema,
anonymized_batch_schema,
anonymized_checkpoint_run_schema,
anonymized_cli_new_ds_choice_payload_schema,
anonymized_cli_suite_expectation_suite_payload_schema,
anonymized_datasource_schema,
anonymized_datasource_sqlalchemy_connect_payload_schema,
anonymized_get_or_edit_or_save_expectation_suite_payload_schema,
anonymized_init_payload_schema,
anonymized_legacy_profiler_build_suite_payload_schema,
anonymized_rule_based_profiler_run_schema,
anonymized_run_validation_operator_payload_schema,
anonymized_test_yaml_config_payload_schema,
anonymized_usage_statistics_record_schema,
cloud_migrate_schema,
empty_payload_schema,
)
from great_expectations.data_context.util import file_relative_path
from tests.integration.usage_statistics.test_usage_statistics_messages import (
valid_usage_statistics_messages,
)
def test_comprehensive_list_of_messages():
"""Ensure that we have a comprehensive set of tests for known messages, by
forcing a manual update to this list when a message is added or removed, and
reminding the developer to add or remove the associate test."""
valid_message_list = list(valid_usage_statistics_messages.keys())
# NOTE: If you are changing the expected valid message list below, you need
# to also update one or more tests below!
assert set(valid_message_list) == {
"cli.checkpoint.delete",
"cli.checkpoint.list",
"cli.checkpoint.new",
"cli.checkpoint.run",
"cli.checkpoint.script",
"cli.datasource.delete",
"cli.datasource.list",
"cli.datasource.new",
"cli.datasource.profile",
"cli.docs.build",
"cli.docs.clean",
"cli.docs.list",
"cli.init.create",
"cli.new_ds_choice",
"cli.project.check_config",
"cli.project.upgrade",
"cli.store.list",
"cli.suite.delete",
"cli.suite.demo",
"cli.suite.edit",
"cli.suite.list",
"cli.suite.new",
"cli.suite.scaffold",
"cli.validation_operator.list",
"cli.validation_operator.run",
"data_asset.validate",
"data_context.__init__",
"data_context.add_datasource",
"data_context.get_batch_list",
"data_context.build_data_docs",
"data_context.open_data_docs",
"data_context.run_checkpoint",
"data_context.save_expectation_suite",
"data_context.test_yaml_config",
"data_context.run_validation_operator",
"datasource.sqlalchemy.connect",
"execution_engine.sqlalchemy.connect",
"checkpoint.run",
"expectation_suite.add_expectation",
"legacy_profiler.build_suite",
"profiler.run",
"data_context.run_profiler_on_data",
"data_context.run_profiler_with_dynamic_arguments",
"profiler.result.get_expectation_suite",
"data_assistant.result.get_expectation_suite",
"cloud_migrator.migrate",
}
# Note: "cli.project.upgrade" has no base event, only .begin and .end events
assert set(valid_message_list) == set(
UsageStatsEvents.get_all_event_names_no_begin_end_events()
+ ["cli.project.upgrade"]
)
def test_init_message():
usage_stats_records_messages = [
"data_context.__init__",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
# non-empty payload
jsonschema.validate(
message["event_payload"],
anonymized_init_payload_schema,
)
def test_data_asset_validate_message():
usage_stats_records_messages = [
"data_asset.validate",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
# non-empty payload
jsonschema.validate(
message["event_payload"],
anonymized_batch_schema,
)
def test_data_context_add_datasource_message():
usage_stats_records_messages = [
"data_context.add_datasource",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
# non-empty payload
jsonschema.validate(
message["event_payload"],
anonymized_datasource_schema,
)
def test_data_context_get_batch_list_message():
usage_stats_records_messages = [
"data_context.get_batch_list",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
anonymized_batch_request_schema,
)
def test_checkpoint_run_message():
usage_stats_records_messages = [
"checkpoint.run",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
anonymized_checkpoint_run_schema,
)
def test_run_validation_operator_message():
usage_stats_records_messages = ["data_context.run_validation_operator"]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
anonymized_run_validation_operator_payload_schema,
)
def test_legacy_profiler_build_suite_message():
usage_stats_records_messages = [
"legacy_profiler.build_suite",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
anonymized_legacy_profiler_build_suite_payload_schema,
)
def test_data_context_save_expectation_suite_message():
usage_stats_records_messages = [
"data_context.save_expectation_suite",
"profiler.result.get_expectation_suite",
"data_assistant.result.get_expectation_suite",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
anonymized_get_or_edit_or_save_expectation_suite_payload_schema,
)
def test_datasource_sqlalchemy_connect_message():
usage_stats_records_messages = [
"datasource.sqlalchemy.connect",
"execution_engine.sqlalchemy.connect",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
anonymized_datasource_sqlalchemy_connect_payload_schema,
)
def test_cli_data_asset_validate():
usage_stats_records_messages = [
"data_asset.validate",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
def test_cli_new_ds_choice_message():
usage_stats_records_messages = [
"cli.new_ds_choice",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# non-empty payload
jsonschema.validate(
message["event_payload"],
anonymized_cli_new_ds_choice_payload_schema,
)
def test_cli_suite_new_message():
usage_stats_records_messages = [
"cli.suite.new",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
anonymized_cli_suite_expectation_suite_payload_schema,
)
def test_cli_suite_edit_message():
usage_stats_records_messages = [
"cli.suite.edit",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
anonymized_cli_suite_expectation_suite_payload_schema,
)
@pytest.mark.slow # 2.42s
def test_test_yaml_config_messages():
usage_stats_records_messages = [
"data_context.test_yaml_config",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
# record itself
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
anonymized_test_yaml_config_payload_schema,
)
def test_usage_stats_empty_payload_messages():
usage_stats_records_messages = [
"data_context.build_data_docs",
"data_context.open_data_docs",
"data_context.run_checkpoint",
"data_context.run_profiler_on_data",
"data_context.run_profiler_with_dynamic_arguments",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
empty_payload_schema,
)
def test_usage_stats_expectation_suite_messages():
usage_stats_records_messages = [
"expectation_suite.add_expectation",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
empty_payload_schema,
)
@pytest.mark.slow # 5.20s
def test_usage_stats_cli_payload_messages():
usage_stats_records_messages = [
"cli.checkpoint.delete",
"cli.checkpoint.list",
"cli.checkpoint.new",
"cli.checkpoint.run",
"cli.checkpoint.script",
"cli.datasource.delete",
"cli.datasource.list",
"cli.datasource.new",
"cli.datasource.profile",
"cli.docs.build",
"cli.docs.clean",
"cli.docs.list",
"cli.init.create",
"cli.project.check_config",
"cli.project.upgrade",
"cli.store.list",
"cli.suite.delete",
"cli.suite.demo",
"cli.suite.list",
"cli.suite.new",
"cli.suite.scaffold",
"cli.validation_operator.list",
"cli.validation_operator.run",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
def test_rule_based_profiler_run_message():
usage_stats_records_messages = [
"profiler.run",
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
anonymized_rule_based_profiler_run_schema,
)
def test_cloud_migrate_event():
usage_stats_records_messages = [
UsageStatsEvents.CLOUD_MIGRATE,
]
for message_type in usage_stats_records_messages:
for message in valid_usage_statistics_messages[message_type]:
jsonschema.validate(
message,
anonymized_usage_statistics_record_schema,
)
jsonschema.validate(
message["event_payload"],
cloud_migrate_schema,
)
def test_usage_stats_schema_in_codebase_is_up_to_date() -> None:
path: str = file_relative_path(
__file__,
"../../../great_expectations/core/usage_statistics/usage_statistics_record_schema.json",
)
with open(path) as f:
contents: dict = json.load(f)
assert contents == anonymized_usage_statistics_record_schema
<file_sep>/docs/guides/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.md
---
title: How to get one or more Batches of data from a configured Datasource
---
import Prerequisites from '../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide will help you load a <TechnicalTag tag="batch" text="Batch" /> for validation using an active <TechnicalTag tag="data_connector" text="Data Connector" />. For guides on loading batches of data from specific <TechnicalTag tag="datasource" text="Datasources" /> using a Data Connector see the [Datasource specific guides in the "Connecting to your data" section](./index.md).
A <TechnicalTag tag="validator" text="Validator" /> knows how to <TechnicalTag tag="validation" text="Validate" /> a particular Batch of data on a particular <TechnicalTag tag="execution_engine" text="Execution Engine" /> against a particular <TechnicalTag tag="expectation_suite" text="Expectation Suite" />. In interactive mode, the Validator can store and update an Expectation Suite while conducting Data Discovery or Exploratory Data Analysis.
<Prerequisites>
- [Configured and loaded a Data Context](../../tutorials/getting_started/tutorial_setup.md)
- [Configured a Datasource and Data Connector](../../terms/datasource.md)
</Prerequisites>
## Steps: Loading one or more Batches of data
To load one or more `Batch(es)`, the steps you will take are the same regardless of the type of `Datasource` or `Data Connector` you have set up. To learn more about `Datasources`, `Data Connectors` and `Batch(es)` see our [Datasources Guide](../../terms/datasource.md).
### 1. Construct a BatchRequest
:::note
As outlined in the `Datasource` and `Data Connector` docs mentioned above, this `Batch Request` must reference a previously configured `Datasource` and `Data Connector`.
:::
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py#L39-L44
```
Since a `BatchRequest` can return multiple `Batch(es)`, you can optionally provide additional parameters to filter the retrieved `Batch(es)`. See [Datasources Guide](../../terms/datasource.md) for more info on filtering besides `batch_filter_parameters` and `limit` including custom filter functions and sampling. The example `BatchRequest`s below shows several non-exhaustive possibilities.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py#L54-L64
```
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py#L71-L80
```
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py#L87-L101
```
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py#L108-L121
```
You may also wish to list available batches to verify that your `BatchRequest` is retrieving the correct `Batch(es)`, or to see which are available. You can use `context.get_batch_list()` for this purpose by passing it your `BatchRequest`:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py#L129
```
### 2. Get access to your Batches via a Validator
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py#L131-L137
```
### 3. Check your data
You can check that the `Batch(es)` that were loaded into your `Validator` are what you expect by running:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py#L138
```
You can also check that the first few lines of the `Batch(es)` you loaded into your `Validator` are what you expect by running:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py#L140
```
Now that you have a `Validator`, you can use it to create `Expectations` or validate the data.
To view the full script used in this page, see it on GitHub:
- [how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/docusaurus/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py)
<file_sep>/docs/terms/batch_request.md
---
title: "Batch Request"
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
import BatchesAndBatchRequests from './_batches_and_batch_requests.mdx';
import ConnectHeader from '/docs/images/universal_map/_um_connect_header.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
import ValidateHeader from '/docs/images/universal_map/_um_validate_header.mdx';
<UniversalMap setup='inactive' connect='active' create='active' validate='active'/>
## Overview
### Definition
A Batch Request is provided to a <TechnicalTag relative="../" tag="datasource" text="Datasource" /> in order to create a <TechnicalTag relative="../" tag="batch" text="Batch" />.
### Features and promises
A Batch Request contains all the necessary details to query the appropriate underlying data. The relationship between a Batch Request and the data returned as a Batch is guaranteed. If a Batch Request identifies multiple Batches that fit the criteria of the user provided `batch_identifiers`, the Batch Request will return all of the matching Batches.
### Relationship to other objects
A Batch Request is always used when Great Expectations builds a Batch. The Batch Request includes a "query" for a Datasource's <TechnicalTag relative="../" tag="data_connector" text="Data Connector" /> to describe the data to include in the Batch. Any time you interact with something that requires a Batch of Data (such as a <TechnicalTag relative="../" tag="profiler" text="Profiler" />, <TechnicalTag relative="../" tag="checkpoint" text="Checkpoint" />, or <TechnicalTag relative="../" tag="validator" text="Validator" />) you will use a Batch Request and Datasource to create the Batch that is used.
## Use cases
<ConnectHeader/>
Since a Batch Request is necessary in order to get a Batch from a Datasource, all of our guides on how to connect to specific source data systems include a section on using a Batch Request to test that your Datasource is properly configured. These sections also serve as examples on how to define a Batch Request for a Datasource that is configured for a given source data system.
You can find these guides in our documentation on [how to connect to data](../guides/connecting_to_your_data/index.md).
<CreateHeader/>
If you are using a Profiler or the interactive method of creating Expectations, you will need to provide a Batch of data for the Profiler to analyze or your manually defined Expectations to test against. For both of these processes, you will therefore need a Batch Request to get the Batch.
For more information, see:
- [Our how-to guide on the interactive process for creating Expectations](../guides/expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md)
- [Our how-to guide on using a Profiler to generate Expectations](../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md)
<ValidateHeader/>
When <TechnicalTag relative="../" tag="validation" text="Validating" /> data with a Checkpoint, you will need to provide one or more Batch Requests and one or more <TechnicalTag relative="../" tag="expectation_suite" text="Expectation Suites" />. You can do this at runtime, or by defining Batch Request and Expectation Suite pairs in advance, in the Checkpoint's configuration.
For more information on setting up Batch Request/Expectation Suite pairs in a Checkpoint's configuration, see:
- [Our guide on how to add data or suites to a Checkpoint](../guides/validation/checkpoints/how_to_add_validations_data_or_suites_to_a_checkpoint.md)
- [Our guide on how to configure a new Checkpoint using `test_yaml_config(...)`](../guides/validation/checkpoints/how_to_configure_a_new_checkpoint_using_test_yaml_config.md)
When passing `RuntimeBatchRequest`s to a Checkpoint, you will not be pairing Expectation Suites with Batch Requests. Instead, when you provide `RuntimeBatchRequest`s to a Checkpoint, it will run all of its configured Expectation Suites against each of the `RuntimeBatchRequest`s that are passed in.
For examples of how to pass `RuntimeBatchRequest`s to a Checkpoint, see the examples used to test your Datasource configurations in [our documentation on how to connect to data](../guides/connecting_to_your_data/index.md). `RuntimeBatchRequest`s are typically used when you need to pass in a DataFrame at runtime.
For a good example if you don't have a specific source data system in mind right now, check out [Example 2 of our guide on how to pass an in memory dataframe to a Checkpoint](../guides/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.md#example-2-pass-a-complete-runtimebatchrequest-at-runtime).
## Features
### Guaranteed relationships
The relationship between a Batch and the Batch Request that generated it is guaranteed. A Batch Request includes all of the information necessary to identify a specific Batch or Batches.
Batches are always built using a Batch Request. When the Batch is built, additional metadata is included, one of which is a Batch Definition. The Batch Definition directly corresponds to the Batch Request that was used to create the Batch.
## API basics
### How to access
You will rarely need to access an existing Batch Request. Instead, you will often find yourself defining a Batch Request in a configuration file, or passing in parameters to create a Batch Request which you will then pass to a Datasource. Once you receive a Batch back, it is unlikely you will need to reference to the Batch Request that generated it. Indeed, if the Batch Request was part of a configuration, Great Expectations will simply initialize a new copy rather than load an existing one when the Batch Request is needed.
### How to create
Batch Requests are instances of either a `RuntimeBatchRequest` or a `BatchRequest`
A `BatchRequest` can be defined by passing a dictionary with the necessary parameters when a `BatchRequest` is initialized, like so:
```python title="Python code
from great_expectations.core.batch import BatchRequest
batch_request_parameters = {
'datasource_name': 'getting_started_datasource',
'data_connector_name': 'default_inferred_data_connector_name',
'data_asset_name': 'yellow_tripdata_sample_2019-01.csv',
'limit': 1000
}
batch_request=BatchRequest(**batch_request_parameters)
```
Regardless of the source data system that the Datasource being referenced by a Batch Request is associated with, the parameters for initializing a Batch Request will remain the same. Great Expectations will handle translating that information into a query appropriate for the source data system behind the scenes.
A `RuntimeBatchRequest` will need a Datasource that has been configured with a `RuntimeDataConnector`. You will then use a `RuntimeBatchRequest` to specify the Batch that you will be working with.
For more information and examples regarding setting up a Datasource for use with `RuntimeBatchRequest`s, see:
- [Our guide on how to configure a `RuntimeDataConnector`](../guides/connecting_to_your_data/how_to_configure_a_runtimedataconnector.md)
## More Details
<BatchesAndBatchRequests/>
### RuntimeDataConnector and RuntimeBatchRequest
A Runtime Data Connector is a special kind of Data Connector that supports easy integration with Pipeline Runners where
the data is already available as a reference that needs only a lightweight wrapper to track validations. Runtime Data
Connectors are used alongside a special kind of Batch Request class called a `RuntimeBatchRequest`. Instead of serving
as a description of what data Great Expectations should fetch, a Runtime Batch Request serves as a wrapper for data that
is passed in at runtime (as an in-memory dataframe, file/S3 path, or SQL query), with user-provided identifiers for
uniquely identifying the data.
In a Batch Definition produced by a Runtime Data Connector, the `batch_identifiers` come directly from the Runtime Batch
Request and serve as a persistent, unique identifier for the data included in the Batch. By relying on
user-provided `batch_identifiers`, we allow the definition of the specific batch's identifiers to happen at runtime, for
example using a run_id from an Airflow DAG run. The specific runtime batch_identifiers to be expected are controlled in
the Runtime Data Connector configuration. Using that configuration creates a control plane for governance-minded
engineers who want to enforce some level of consistency between validations.
<file_sep>/docs/guides/setup/installation/components_local/_preface.mdx
<!--
---Import---
import Preface from './_preface.mdx'
<Preface />
---Header---
preface
-->
This guide will help you Install Great Expectations locally for use with Python.
:::caution Prerequisites
This guide assumes you have:
- Installed a supported version of Python. (As of this writing, Great Expectations supports versions 3.7 through 3.9 of Python. For details on how to download and install Python on your platform, please see [Python's documentation](https://www.python.org/doc/) and [download site](https://www.python.org/downloads/)s.)
:::
:::note
- Great Expectations is developed and tested on macOS and Linux Ubuntu. Installation for Windows users may vary from the steps listed below. If you have questions, feel free to reach out to the community on our [Slack channel](https://greatexpectationstalk.slack.com/join/shared_invite/<KEY>#/shared-invite/email).
- If you have the Mac M1, you may need to follow the instructions in this blog post: [Installing Great Expectations on a Mac M1](https://greatexpectations.io/blog/m-one-mac-instructions/).
:::
<file_sep>/reqs/requirements-dev-bigquery.txt
gcsfs>=0.5.1
google-cloud-secret-manager>=1.0.0
google-cloud-storage>=1.28.0
sqlalchemy-bigquery>=1.3.0
<file_sep>/tests/test_fixtures/configuration_for_testing_v2_v3_migration/postgresql/v2/running_checkpoint.sh
great_expectations --v2-api checkpoint run test_v2_checkpoint
<file_sep>/docs/terms/data_assistant.md
---
id: data_assistant
title: Data Assistant
---
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
<UniversalMap setup='inactive' connect='inactive' create='active' validate='inactive'/>
## Overview
### Definition
A Data Assistant is a utility that asks questions about your data, gathering information to describe what is observed, and then presents <TechnicalTag tag="metric" text="Metrics" /> and proposes <TechnicalTag tag="expectation" text="Expectations" /> based on the answers.
### Features and promises
Data Assistants allow you to introspect multiple <TechnicalTag tag="batch" text="Batches" /> and create an <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> from the aggregated Metrics of those Batches. They provide convenient, visual representations of the generated Expectations to assist with identifying outliers in the corresponding parameters. They are convenient to access from your <TechnicalTag tag="data_context" text="Data Context" />, and provide an excellent starting point for building Expectations or performing initial data exploration.
### Relationships to other objects
A Data Assistant implements a pre-configured <TechnicalTag tag="profiler" text="Rule Based Profiler" /> in order to gather Metrics and propose an Expectation Suite based on the introspection of the Batch or Batches contained in a provided <TechnicalTag tag="batch_request" text="Batch Request" />.
## Use cases
<CreateHeader/>
Data Assistants are an ideal starting point for creating your Expectations. If you are working with data that you are not familiar with, a Data Assistant can give you an overview by introspecting it and generating a series of relevant Expectations using estimated parameters for you to review. If you use the `"flag_outliers"` value for the `estimation` parameter your generated Expectations will have parameters that disregard values that the Data Assistant identifies as outliers. Using the Data Assistant's `plot_metrics()` method will then give you a graphical representation of the generated Expectations. This will further assist you in spotting outliers in your data when reviewing the Data Assistant's results.
Even when working with data that you are familiar with and know is good, a Data Assistant can use the `"exact"` value for the `estimation` parameter to provide comprehensive Expectations that exactly reflect the values found in the provided data.
## Features
### Easy profiling
Data Assistants implement pre-configured Rule-Based Profilers under the hood, but also provide extended functionality. They are easily accessible: You can call them directly from your Data Context. This ensures that they will always provide a quick, simple entry point to creating Expectations and <TechnicalTag tag="profiling" text="Profiling" /> your data. However, the rules implemented by a Data Assistant are also fully exposed in the parameters for its `run(...)` method. This means that while you can use a Data Assistant easily out of the box, you can also customize it behavior to take advantage of the domain knowledge possessed by subject-matter experts.
### Multi-Batch introspection
Data Assistants leverage the ability to process multiple Batches from a single Batch Request to provide a representative analysis of the provided data. With previous Profilers you would only be able to introspect a single Batch at a time. This meant that the Expectation Suite generated would only reflect a single Batch. If you had many Batches of data that you wanted to build inter-related Expectations for, you would have needed to run each Batch individually and then manually compare and update the Expectation parameters that were generated. With a Data Assistant, that process is automated. You can provide a Data Assistant multiple Batches and get back Expectations that have parameters based on, for instance, the mean or median value of a column on a per-Batch basis.
### Visual plots for Metrics
When working in a Jupyter Notebook you can use the `plot_metrics()` method of a Data Assistant's result object to generate a visual representation of your Expectations, the values that were assigned to their parameters, and the Metrics that informed those values. This assists in exploratory data analysis and fine-tuning your Expectations, while providing complete transparency into the information used by the Data Assistant to build your Expectations.
## API basics
Data Assistants can be easily accessed from your Data Context. In a Jupyter Notebook, you can enter `context.assistants.` and use code completion to select the Data Assistant you wish to use. All Data Assistants have a `run(...)` method that takes in a Batch Request and numerous optional parameters, the results of which can be loaded into an Expectation Suite for future use.
The Onboarding Data Assistant is an ideal starting point for working with Data Assistants. It can be accessed from `context.assistants.onboarding`, or from the <TechnicalTag tag="cli" text="CLI" /> command `great_expectations suite new --profile`.
:::note For more information on the Onboarding Data Assistant, see the guide:
- [How to create an Expectation Suite with the Onboarding Data Assistant](../guides/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.md)
:::
### Configuration
Data Assistants come pre-configured! All you need to provide is a Batch Request, and some optional parameters in the Data Assistant's `run(...)` method.
## More details
### Design motivation
Data Assistants were designed to make creating Expectations easier for users of Great Expectations. A Data Assistant will help solve the problem of "where to start" when working with a large, new, or complex dataset by greedily asking questions according to a set theme and then building a list of all the relevant Metrics that it can determine from the answers to those questions. Branching question paths ensure that additional relevant Metrics are gathered on the groundwork of the earlier questions asked. The result is a comprehensive gathering of Metrics that can then be saved, reviewed as graphical plots, or used by the Data Assistant to generate a set of proposed Expectations.
### Additional documentation
Data Assistants are multi-batch aware out of the box. However, not every use case requires multiple Batches. For more information on when it is best to work with either a single Batch or multiple Batches of data in a Batch Request, please see the following guide:
- [How to choose between working with a single or multiple Batches of data](../guides/connecting_to_your_data/how_to_choose_between_working_with_a_single_or_multiple_batches_of_data.md)
To take advantage of the multi-batch awareness of Data Assistants, your <TechnicalTag tag="datasource" text="Datasources" /> need to be configured so that you can acquire multiple Batches in a single Batch Request. For guidance on how to configure your Datasources to be capable of returning multiple Batches, please see the following documentation that matches the Datasource type you are working with:
- [How to configure a Pandas Datasource](../guides/connecting_to_your_data/datasource_configuration/how_to_configure_a_pandas_datasource.md)
- [How to configure a Spark Datasource](../guides/connecting_to_your_data/datasource_configuration/how_to_configure_a_spark_datasource.md)
- [How to configure a SQL Datasource](../guides/connecting_to_your_data/datasource_configuration/how_to_configure_a_sql_datasource.md)
For guidance on how to request multiple Batches in a single Batch Request, please see the guide:
- [How to get one or more Batches of data from a configured Datasource](../guides/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.md)
For an overview of working with the Onboarding Data Assistant, please see the guide:
- [How to create an Expectation Suite with the Onboarding Data Assistant](../guides/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.md)<file_sep>/great_expectations/data_context/store/profiler_store.py
import random
import uuid
from typing import Union
from great_expectations.data_context.cloud_constants import GXCloudRESTResource
from great_expectations.data_context.store.configuration_store import ConfigurationStore
from great_expectations.data_context.types.resource_identifiers import (
ConfigurationIdentifier,
GXCloudIdentifier,
)
from great_expectations.rule_based_profiler.config import RuleBasedProfilerConfig
class ProfilerStore(ConfigurationStore):
"""
A ProfilerStore manages Profilers for the DataContext.
"""
_configuration_class = RuleBasedProfilerConfig
def serialization_self_check(self, pretty_print: bool) -> None:
"""
Fufills the abstract method defined by the parent class.
See `ConfigurationStore` for more details.
"""
test_profiler_name = f"profiler_{''.join([random.choice(list('0123456789ABCDEF')) for _ in range(20)])}"
test_profiler_configuration = RuleBasedProfilerConfig(
name=test_profiler_name,
config_version=1.0,
rules={},
)
test_key: Union[GXCloudIdentifier, ConfigurationIdentifier]
if self.ge_cloud_mode:
test_key = self.key_class( # type: ignore[assignment,call-arg]
resource_type=GXCloudRESTResource.PROFILER,
ge_cloud_id=str(uuid.uuid4()),
)
else:
test_key = self.key_class(configuration_key=test_profiler_name) # type: ignore[assignment,call-arg]
if pretty_print:
print(f"Attempting to add a new test key {test_key} to Profiler store...")
self.set(key=test_key, value=test_profiler_configuration)
if pretty_print:
print(f"\tTest key {test_key} successfully added to Profiler store.\n")
print(
f"Attempting to retrieve the test value associated with key {test_key} from Profiler store..."
)
test_value = self.get(key=test_key)
if pretty_print:
print(
f"\tTest value successfully retrieved from Profiler store: {test_value}\n"
)
print(f"Cleaning up test key {test_key} and value from Profiler store...")
test_value = self.remove_key(key=test_key)
if pretty_print:
print(
f"\tTest key and value successfully removed from Profiler store: {test_value}\n"
)
def ge_cloud_response_json_to_object_dict(self, response_json: dict) -> dict:
"""
This method takes full json response from GE cloud and outputs a dict appropriate for
deserialization into a GE object
"""
ge_cloud_profiler_id = response_json["data"]["id"]
profiler_config_dict = response_json["data"]["attributes"]["profiler"]
profiler_config_dict["id"] = ge_cloud_profiler_id
return profiler_config_dict
<file_sep>/docs/deployment_patterns/index.md
---
title: "Reference Architectures: Index"
---
- [Deploying Great Expectations in a hosted environment without file system or CLI](../deployment_patterns/how_to_instantiate_a_data_context_hosted_environments.md)
- [How to Use Great Expectations in Databricks](../deployment_patterns/how_to_use_great_expectations_in_databricks.md)
- [How to Use Great Expectations with Google Cloud Platform and BigQuery](../deployment_patterns/how_to_use_great_expectations_with_google_cloud_platform_and_bigquery.md)
- [How to instantiate a Data Context on an EMR Spark cluster](../deployment_patterns/how_to_instantiate_a_data_context_on_an_emr_spark_cluster.md)
- [How to Use Great Expectations with Airflow](../deployment_patterns/how_to_use_great_expectations_with_airflow.md)
- [How to Use Great Expectations in Flyte](../deployment_patterns/how_to_use_great_expectations_in_flyte.md)
- [How to use Great Expectations in Deepnote](../deployment_patterns/how_to_use_great_expectations_in_deepnote.md)
- [How to Use Great Expectations with Meltano](../deployment_patterns/how_to_use_great_expectations_with_meltano.md)
- [How to Use Great Expectations with YData-Synthetic](./how_to_use_great_expectations_with_ydata_synthetic.md)
- [Integrating ZenML With Great Expectations](../integrations/integration_zenml.md)
<file_sep>/assets/partners/anthonydb/just_connect.py
import sqlalchemy as sa
connection = "mssql://sa:BK72nEAoI72CSWmP@db:1433/integration?driver=ODBC+Driver+17+for+SQL+Server&charset=utf&autocommit=true"
e = sa.create_engine(connection)
results = e.execute("SELECT TOP 10 * from dbo.taxi_data").fetchall()
for r in results:
print(r)
print("finish")
<file_sep>/docs/terms/batch.md
---
title: Batch
id: batch
hoverText: A selection of records from a Data Asset.
---
import BatchesAndBatchRequests from './_batches_and_batch_requests.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import ValidateHeader from '/docs/images/universal_map/_um_validate_header.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
<UniversalMap setup='inactive' connect='inactive' create='active' validate='active'/>
## Overview
### Definition
A Batch is a selection of records from a <TechnicalTag relative="../" tag="data_asset" text="Data Asset" />.
### Features and promises
A Batch provides a consistent interface for describing specific data from any <TechnicalTag relative="../" tag="datasource" text="Datasource" />, to support building <TechnicalTag relative="../" tag="metric" text="Metrics" />, <TechnicalTag relative="../" tag="validation" text="Validation" />, and <TechnicalTag relative="../" tag="profiling" text="Profiling" />.
### Relationship to other objects
A Batch is generated by providing a <TechnicalTag relative="../" tag="batch_request" text="Batch Request" /> to a Datasource. It provides a reference to interact with the data through the Datasource and adds metadata to precisely identify the specific data included in the Batch.
<TechnicalTag relative="../" tag="profiler" text="Profilers" /> use Batches to generate Metrics and potential <TechnicalTag relative="../" tag="expectation" text="Expectations" /> based on the data. Batches make it possible for the Profiler to compare data over time and sample from large datasets to improve performance.
Metrics are always associated with a Batch of data. The identifier for the Batch is the primary way that Great Expectations identifies what data to use when computing a Metric and how to store that Metric.
Batches are also used by <TechnicalTag relative="../" tag="validator" text="Validators" /> when they run an Expectation Suite against data.
## Use Cases
<CreateHeader/>
When creating Expectations interactively, a <TechnicalTag relative="../" tag="validator" text="Validator" /> needs access to a specific Batch of data against which to check Expectations. The [how to guide on interactively creating expectations](../guides/expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md) covers using a Batch in this use case.
Our in-depth guide on [how to create and edit expectations with a profiler](../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md) covers how to specify which Batches of data should be used when using Great Expectations to generate statistics and candidate Expectations for your data.
<ValidateHeader/>
During Validation, a <TechnicalTag relative="../" tag="checkpoint" text="Checkpoint" /> will check a Batch of data against Expectations from an <TechnicalTag relative="../" tag="expectation_suite" text="Expectation Suite" />. You must specify a Batch Request or provide a Batch of data at runtime for the Checkpoint to run.
## Features
### Consistent Interface for Describing Specific Data from any Datasource
A Batch is always part of a Data Asset. The Data Asset is sliced into Batches to correspond to the specification you define in a Data Connector, allowing you to define Batches of a Data Asset based on times from the data, pipeline runs, or the time of a Validation.
A Batch is always built using a Batch Request. The Batch Request includes a "query" for the Data Connector to describe the data that will be included in the Batch. The query makes it possible to create a Batch Request for the most recent Batch of data without defining the specific timeframe, for example.
Once a Datasource identifies the specific data that will be included in a Batch based on the Batch Request, it creates a reference to the data, and adds metadata including a Batch Definition, Batch Spec, and Batch Markers. That additional metadata is how Great Expectations identifies the Batch when accessing or storing Metrics.
## API Basics
### How to access
You will typically not need to access a Batch directly. Instead, you will pass it to a Great Expectations object such as a Profiler, Validator, or Checkpoint, which will then do something in response to the Batch's data.
### How to create
The `BatchRequest` object is the primary API used to construct Batches. It is provided to the `get_validator` method on DataContext.
- For more information, see [our documentation on Batch Requests](./batch_request.md).
:::note
Instantiating a Batch does not necessarily “fetch” the data by immediately running a query or pulling data into memory. Instead, think of a Batch as a wrapper that includes the information that you will need to fetch the right data when it’s time to Validate.
:::
## More details
### Batches: Design Motivation
Batches are designed to be "MECE" -- mutually exclusive and collectively exhaustive partitions of Data Assets. However, in many cases the same *underlying data* could be present in multiple batches, for example if an analyst runs an analysis against an entire table of data each day, with only a fraction of new records being added.
Consequently, the best way to understand what "makes a Batch a Batch" is the act of attending to it. Once you have defined how a Datasource's data should be sliced (even if that is to define a single slice containing all of the data in the Datasource), you have determined what makes those particular Batches "a Batch." The Batch is the fundamental unit that Great Expectations will validate and about which it will collect metrics.
<BatchesAndBatchRequests/>
<file_sep>/great_expectations/expectations/metrics/column_aggregate_metrics/column_max.py
import warnings
from dateutil.parser import parse
from great_expectations.execution_engine import (
PandasExecutionEngine,
SparkDFExecutionEngine,
SqlAlchemyExecutionEngine,
)
from great_expectations.execution_engine.sparkdf_execution_engine import (
apply_dateutil_parse,
)
from great_expectations.expectations.metrics.column_aggregate_metric_provider import (
ColumnAggregateMetricProvider,
column_aggregate_partial,
column_aggregate_value,
)
from great_expectations.expectations.metrics.import_manager import F, sa
class ColumnMax(ColumnAggregateMetricProvider):
metric_name = "column.max"
value_keys = ("parse_strings_as_datetimes",)
@column_aggregate_value(engine=PandasExecutionEngine)
def _pandas(cls, column, **kwargs):
parse_strings_as_datetimes: bool = (
kwargs.get("parse_strings_as_datetimes") or False
)
if parse_strings_as_datetimes:
# deprecated-v0.13.41
warnings.warn(
"""The parameter "parse_strings_as_datetimes" is deprecated as of v0.13.41 in \
v0.16. As part of the V3 API transition, we've moved away from input transformation. For more information, \
please see: https://greatexpectations.io/blog/why_we_dont_do_transformations_for_expectations/
""",
DeprecationWarning,
)
try:
temp_column = column.map(parse)
except TypeError:
temp_column = column
return temp_column.max()
else:
return column.max()
@column_aggregate_partial(engine=SqlAlchemyExecutionEngine)
def _sqlalchemy(cls, column, **kwargs):
parse_strings_as_datetimes: bool = (
kwargs.get("parse_strings_as_datetimes") or False
)
if parse_strings_as_datetimes:
# deprecated-v0.13.41
warnings.warn(
"""The parameter "parse_strings_as_datetimes" is deprecated as of v0.13.41 in \
v0.16. As part of the V3 API transition, we've moved away from input transformation. For more information, \
please see: https://greatexpectations.io/blog/why_we_dont_do_transformations_for_expectations/
""",
DeprecationWarning,
)
return sa.func.max(column)
@column_aggregate_partial(engine=SparkDFExecutionEngine)
def _spark(cls, column, **kwargs):
parse_strings_as_datetimes: bool = (
kwargs.get("parse_strings_as_datetimes") or False
)
if parse_strings_as_datetimes:
# deprecated-v0.13.41
warnings.warn(
"""The parameter "parse_strings_as_datetimes" is deprecated as of v0.13.41 in \
v0.16. As part of the V3 API transition, we've moved away from input transformation. For more information, \
please see: https://greatexpectations.io/blog/why_we_dont_do_transformations_for_expectations/
""",
DeprecationWarning,
)
try:
column = apply_dateutil_parse(column=column)
except TypeError:
pass
return F.max(column)
<file_sep>/great_expectations/rule_based_profiler/data_assistant/__init__.py
from .data_assistant import DataAssistant
from .onboarding_data_assistant import OnboardingDataAssistant
from .volume_data_assistant import VolumeDataAssistant
<file_sep>/docs/guides/setup/configuring_metadata_stores/components_how_to_configure_a_validation_result_store_in_amazon_s3/_confirm_that_the_validations_results_store_has_been_correctly_configured.mdx
[Run a Checkpoint](../../../../tutorials/getting_started/tutorial_validate_data.md) to store results in the new Validation Results Store on S3 then visualize the results by [re-building Data Docs](../../../../terms/data_docs.md).
<file_sep>/docs/guides/setup/configuring_metadata_stores/components_how_to_configure_a_validation_result_store_in_amazon_s3/_confirm_that_the_new_validation_results_store_has_been_added_by_running_great_expectations_store_list.mdx
You can verify that your Stores are properly configured by running the command:
```bash title="Terminal command"
great_expectations store list
```
This will list the currently configured Stores that Great Expectations has access to. If you added a new S3 Validation Results Store, the output should include the following `ValidationStore` entries:
```bash title="Terminal output"
- name: validations_store
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
- name: validations_S3_store
class_name: ValidationsStore
store_backend:
class_name: TupleS3StoreBackend
bucket: '<your_s3_bucket_name>'
prefix: '<your_s3_bucket_folder_name>'
```
Notice the output contains two Validation Results Stores: the original ``validations_store`` on the local filesystem and the ``validations_S3_store`` we just configured. This is ok, since Great Expectations will look for Validation Results on the S3 bucket as long as we set the ``validations_store_name`` variable to ``validations_S3_store``.
Additional options are available for a more fine-grained customization of the TupleS3StoreBackend.
```yaml title="File contents: great_expectations.yml"
class_name: ValidationsStore
store_backend:
class_name: TupleS3StoreBackend
bucket: '<your_s3_bucket_name>'
prefix: '<your_s3_bucket_folder_name>'
boto3_options:
endpoint_url: ${S3_ENDPOINT} # Uses the S3_ENDPOINT environment variable to determine which endpoint to use.
region_name: '<your_aws_region_name>'
```
<file_sep>/contrib/experimental/great_expectations_experimental/expectations/expect_column_values_to_be_hexadecimal.py
"""
This is a template for creating custom ColumnMapExpectations.
For detailed instructions on how to use it, please see:
https://docs.greatexpectations.io/docs/guides/expectations/creating_custom_expectations/how_to_create_custom_column_map_expectations
"""
from typing import Optional
from great_expectations.core.expectation_configuration import ExpectationConfiguration
from great_expectations.execution_engine import PandasExecutionEngine
from great_expectations.expectations.expectation import ColumnMapExpectation
from great_expectations.expectations.metrics import (
ColumnMapMetricProvider,
column_condition_partial,
)
# This class defines a Metric to support your Expectation.
# For most ColumnMapExpectations, the main business logic for calculation will live in this class.
class ColumnValuesToBeHexadecimal(ColumnMapMetricProvider):
# This is the id string that will be used to reference your metric.
condition_metric_name = "column_values.is_hexadecimal"
filter_column_isnull = False
# This method implements the core logic for the PandasExecutionEngine
@column_condition_partial(engine=PandasExecutionEngine)
def _pandas(cls, column, **kwargs):
def is_hex(x):
if not x:
return False
if x is None:
return False
if not isinstance(x, str):
return False
try:
int(x, 16)
return True
except ValueError:
return False
return column.apply(is_hex)
# This method defines the business logic for evaluating your metric when using a SqlAlchemyExecutionEngine
# @column_condition_partial(engine=SqlAlchemyExecutionEngine)
# def _sqlalchemy(cls, column, _dialect, **kwargs):
# raise NotImplementedError
# This method defines the business logic for evaluating your metric when using a SparkDFExecutionEngine
# @column_condition_partial(engine=SparkDFExecutionEngine)
# def _spark(cls, column, **kwargs):
# raise NotImplementedError
# This class defines the Expectation itself
class ExpectColumnValuesToBeHexadecimal(ColumnMapExpectation):
"""This expectation checks if the column values are valid hexadecimals"""
# These examples will be shown in the public gallery.
# They will also be executed as unit tests for your Expectation.
examples = [
{
"data": {
"a": ["3", "aa", "ba", "5A", "60F", "Gh"],
"b": ["Verify", "String", "3Z", "X", "yy", "sun"],
"c": ["0", "BB", "21D", "ca", "20", "1521D"],
"d": ["c8", "ffB", "11x", "apple", "ran", "woven"],
"e": ["a8", "21", 2.0, "1B", "4AA", "31"],
"f": ["a8", "41", "ca", 46, "4AA", "31"],
"g": ["a8", "41", "ca", "", "0", "31"],
"h": ["a8", "41", "ca", None, "0", "31"],
},
"tests": [
{
"title": "positive_test_with_mostly",
"include_in_gallery": True,
"exact_match_out": False,
"in": {"column": "a", "mostly": 0.6},
"out": {
"success": True,
"unexpected_index_list": [5],
"unexpected_list": ["Gh"],
},
},
{
"title": "negative_test_without_mostly",
"include_in_gallery": True,
"exact_match_out": False,
"in": {"column": "b"},
"out": {
"success": False,
"unexpected_index_list": [0, 1, 2, 3, 4, 5],
"unexpected_list": ["Verify", "String", "3Z", "X", "yy", "sun"],
},
},
{
"title": "positive_test_without_mostly",
"include_in_gallery": True,
"exact_match_out": False,
"in": {"column": "c"},
"out": {
"success": True,
"unexpected_index_list": [],
"unexpected_list": [],
},
},
{
"title": "negative_test_with_mostly",
"include_in_gallery": True,
"exact_match_out": False,
"in": {"column": "d", "mostly": 0.6},
"out": {
"success": False,
"unexpected_index_list": [2, 3, 4, 5],
"unexpected_list": ["11x", "apple", "ran", "woven"],
},
},
{
"title": "negative_test_with_float",
"include_in_gallery": True,
"exact_match_out": False,
"in": {"column": "e"},
"out": {
"success": False,
"unexpected_index_list": [2],
"unexpected_list": [2.0],
},
},
{
"title": "negative_test_with_int",
"include_in_gallery": True,
"exact_match_out": False,
"in": {"column": "f"},
"out": {
"success": False,
"unexpected_index_list": [3],
"unexpected_list": [46],
},
},
{
"title": "negative_test_with_empty_value",
"include_in_gallery": True,
"exact_match_out": False,
"in": {"column": "g"},
"out": {
"success": False,
"unexpected_index_list": [3],
"unexpected_list": [""],
},
},
{
"title": "negative_test_with_none_value",
"include_in_gallery": True,
"exact_match_out": False,
"in": {"column": "h"},
"out": {
"success": False,
"unexpected_index_list": [3],
"unexpected_list": [None],
},
},
],
}
]
# This is the id string of the Metric used by this Expectation.
# For most Expectations, it will be the same as the `condition_metric_name` defined in your Metric class above.
map_metric = "column_values.is_hexadecimal"
# This is a list of parameter names that can affect whether the Expectation evaluates to True or False
success_keys = ("mostly",)
# This dictionary contains default values for any parameters that should have default values
default_kwarg_values = {}
def validate_configuration(
self, configuration: Optional[ExpectationConfiguration]
) -> None:
"""
Validates that a configuration has been set, and sets a configuration if it has yet to be set. Ensures that
necessary configuration arguments have been provided for the validation of the expectation.
Args:
configuration (OPTIONAL[ExpectationConfiguration]): \
An optional Expectation Configuration entry that will be used to configure the expectation
Returns:
None. Raises InvalidExpectationConfigurationError if the config is not validated successfully
"""
super().validate_configuration(configuration)
if configuration is None:
configuration = self.configuration
# # Check other things in configuration.kwargs and raise Exceptions if needed
# try:
# assert (
# ...
# ), "message"
# assert (
# ...
# ), "message"
# except AssertionError as e:
# raise InvalidExpectationConfigurationError(str(e))
# This object contains metadata for display in the public Gallery
library_metadata = {
"maturity": "experimental",
"tags": ["experimental"], # Tags for this Expectation in the Gallery
"contributors": [ # Github handles for all contributors to this Expectation.
"@andrewsx", # Don't forget to add your github handle here!
],
}
if __name__ == "__main__":
ExpectColumnValuesToBeHexadecimal().print_diagnostic_checklist()
<file_sep>/docs/guides/expectations/create_expectations_overview.md
---
title: "Create Expectations: Overview"
---
# [](./create_expectations_overview.md) Create Expectations: Overview
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
<!--Use 'inactive' or 'active' to indicate which Universal Map steps this term has a use case within.-->
<UniversalMap setup='inactive' connect='inactive' create='active' validate='inactive'/>
:::note Prerequisites
- Completing [Step 3: Create Expectations](../../tutorials/getting_started/tutorial_create_expectations.md) of the Getting Started tutorial is recommended.
:::
Creating <TechnicalTag tag="expectation" text="Expectations" /> is an integral part of Great Expectations. By the end of this step, you will have created an <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> containing one or more Expectations which you will use when you <TechnicalTag tag="validation" text="Validate" /> data.
## The Create Expectations process
There are a few workflows you can potentially follow when creating Expectations. These workflows represent various ways of creating Expectations, although they converge in the end when you will save and test those Expectations.

Of the four potential ways to create Expectations illustrated above, two are recommended in particular.
The first recommended workflow of those illustrated above is the **interactive workflow.** In this workflow, you will be working in a Python interpreter or Jupyter notebook. You will use a <TechnicalTag tag="validator" text="Validator" /> and call expectations as methods on it to define Expectations in an Expectation Suite, and when you have finished you will save that Expectation Suite into your <TechnicalTag tag="expectation_store" text="Expectation Store" />. A more thorough overview of this workflow, and a link to an in-depth guide on it, can be found in this document's section on [creating Expectations interactively](#creating-expectations-interactively).
The second recommended workflow is the **Data Assistant workflow.** In this workflow, you will use a <TechnicalTag tag="data_assistant" text="Data Assistant" /> to generate Expectations based on some input data. You may then preview the metrics that these Expectations are based on. Finally, you save can the generated Expectations as an Expectation Suite in an Expectation Store. A more thorough overview of this workflow, and a link to an in-depth guide on it, can be found in this document's section on [creating Expectations with Data Assistants](#creating-expectations-with-data-assistants).
The third workflow, which is for advanced users, is to **manually define your Expectations** by writing their configurations. This workflow does not require source data to work against, but does require a deep understanding of the configurations available for Expectations. We will forgo discussion of it in this document, and focus on the two recommended workflows. If for some reason you must use this workflow, we do provide an in-depth guide to it in our documentation on [how to create and edit expectations based on domain knowledge without inspecting data directly](./how_to_create_and_edit_expectations_based_on_domain_knowledge_without_inspecting_data_directly.md).
Some advanced users have also taken advantage of the fourth workflow, and have **written custom methods** that allow them to generate Expectations based on the metadata associated with their source data systems. This process for creating Expectations is outside the scope of this overview, and will not be discussed in depth here. However, if it is something you are interested in pursuing, you are encouraged to [reach out to us on Slack](https://greatexpectations.io/slack).
When following one of the first two workflows, once you have saved your Expectation Suite it is advised that you test it by validating your Expectations against the <TechnicalTag tag="batch" text="Batch" /> or Batches of data against which you created them. This process is the same in either workflow, since at this point you will be using a saved Expectation Suite and each of the prior workflows ends with the saving of your Expectation Suite. Instructions for this will be detailed in this document's section on [testing your Expectation Suite](#testing-your-expectation-suite).
### Creating Expectations interactively
When using the interactive method of creating Expectations, you will start as you always do with your <TechnicalTag tag="data_context" text="Data Context" />. In this case, you will want to navigate to your Data Context's root directory in your terminal, where you will use the <TechnicalTag tag="cli" text="CLI" /> to launch a Jupyter Notebook which will contain scaffolding to assist you in the process. You can even provide flags such as `--profile` which will allow you to enter into the interactive workflow after using a Profiler to generate and prepopulate your Expectation Suite.
We provide an in-depth guide to using the CLI (and what flags are available to you) for interactively creating Expectations in our guide on [how to create and edit Expectations with instant feedback from a sample batch of data](./how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md).
### Creating Expectations with Data Assistants
As with creating Expectations interactively, you will start with your Data Context. However, in this case you will be working in a Python environment, so you will need to load or create your Data Context as an instantiated object. Next, you will create a Batch Request to specify the data you would like to <TechnicalTag tag="profiling" text="Profile" /> with your Data Assistant. Once you have a <TechnicalTag tag="batch_request" text="Batch Request" /> configured you will use it as the input for the run method of your Data Assistant, which can be accessed from your Data Context object. Once the Data Assistant has run, you will be able to review the results as well as save the generated Expectations to an empty Expectation Suite.
The Data Assistant we recommend using for new data is the Onboarding Data Assistant. We provide an in-depth guide to this in our documentation on [how to create an Expectation Suite with the Onboarding Data Assistant](./data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.md).
### Testing your Expectation Suite
Once you have created your Expectation Suite and saved it, you may wish to test it. The simplest way to do this is to Validate some data against it. You can do this using a `SimpleCheckpoint` as demonstrated in the [optional step on running validation, saving your suite, and building Data Docs](./how_to_create_and_edit_expectations_with_a_profiler.md#6-optional-running-validation-saving-your-suite-and-building-data-docs) of our [how to create and edit Expectations with a Profiler](./how_to_create_and_edit_expectations_with_a_profiler.md) documentation. Or you can just move on to [Step 4: Validate Data.](../validation/validate_data_overview.md)
### Editing a saved Expectation Suite
It may be that you have saved an Expectation Suite that you wish to go back to and edit. The simplest way to do this is to use the CLI. You can use the command:
```markdown title="Terminal command"
great_expectations suite edit NAME_OF_YOUR_SUITE_HERE
```
This will open a Jupyter Notebook that contains the configurations for each of that Expectation Suite's Expectations in their own cells. You can edit these cells and then run them to generate Expectations in a new Expectation Suite. Once your edited version of the Expectations have been created in their own Expectation Suite, you can save that Expectation Suite over the pre-existing one, or save it as a new suite altogether.
## Wrapping up
At this point you have created an Expectation Suite, saved it to your Expectation Store, and are ready to use it in a <TechnicalTag tag="checkpoint" text="Checkpoint" /> in the Validate Data step! If you wish, you can check your Expectation Store where you will see a json file that contains your Expectation Suite. You won't ever have to manually edit it, but you can view its contents if you are curious about how the Expectations are configured or if you simply want to verify that it is there. You can also see the Expectation Suites that you have saved by using the CLI command:
```markdown title="Terminal command"
great_expectations suite list
```
This command will list all the saved Expectation Suites in your Data Context.
As long as you have a saved Expectation Suite with which to work, you'll be all set to move on to [Step 4: Validate Data.](../validation/validate_data_overview.md)
<file_sep>/reqs/requirements-dev-all-contrib-expectations.txt
# aequitas # This depends on old versions of Flask (0.12.2) and sqlalchemy (1.1.1)
arxiv
barcodenumber
blockcypher
coinaddrvalidator
cryptoaddress
cryptocompare
dataprofiler
disposable_email_domains
dnspython
edtf_validate
ephem
geonamescache
geopandas
geopy
global-land-mask
gtin
holidays
ipwhois
isbnlib
langid>=1.1.6
pgeocode
phonenumbers
price_parser
primefac
pwnedpasswords
py-moneyed
pydnsbl
pygeos
pyogrio
python-geohash
python-stdnum
pyvat
rtree
schwifty
scikit-learn
shapely
simple_icd_10
sklearn
sympy
tensorflow
timezonefinder
us
user_agents
uszipcode
yahoo_fin
zipcodes
<file_sep>/docs/guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md
---
title: How to create and edit Expectations with the User Configurable Profiler
---
import Prerequisites from '../../guides/connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide will help you create a new <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> by profiling your data with the User Configurable <TechnicalTag tag="profiler" text="Profiler" />.
<Prerequisites>
- [Configured a Data Context](../../tutorials/getting_started/tutorial_setup.md).
- Configured a [Datasource](../../tutorials/getting_started/tutorial_connect_to_data.md)
</Prerequisites>
:::note
The User Configurable Profiler makes it easier to produce a new Expectation Suite by building out a bunch of <TechnicalTag tag="expectation" text="Expectations" /> for your data.
These Expectations are deliberately over-fitted on your data e.g. if your table has 10,000 rows, the Profiler will produce an Expectation with the following config:
```json
{
"expectation_type": "expect_table_row_count_to_be_between",
"kwargs": {
"min_value": 10000,
"max_value": 10000
},
"meta": {}
}
```
Thus, the intention is for this Expectation Suite to be edited and updated to better suit your specific use case - it is not specifically intended to be used as is.
:::
:::note
You can access this same functionality from the Great Expectations <TechnicalTag tag="cli" text="CLI" /> by running
```console
great_expectations suite new --profile rule_based_profiler
```
If you go that route, you can follow along in the resulting Jupyter Notebook instead of using this guide.
:::
## Steps
### 1. Load or create your Data Context
Load an on-disk <TechnicalTag tag="data_context" text="Data Context" /> via:
```python
from great_expectations.data_context.data_context import DataContext
context = DataContext(
context_root_dir='path/to/my/context/root/directory/great_expectations'
)
```
Alternatively, [you can instantiate a Data Context without a .yml file](../setup/configuring_data_contexts/how_to_instantiate_a_data_context_without_a_yml_file.md)
### 2. Set your expectation_suite_name and create your Batch Request
The <TechnicalTag tag="batch_request" text="Batch Request" /> specifies which <TechnicalTag tag="batch" text="Batch" /> of data you would like to <TechnicalTag tag="profiling" text="Profile" /> in order to create your Expectation Suite. We will pass it into a <TechnicalTag tag="validator" text="Validator" /> in the next step.
```python
expectation_suite_name = "insert_the_name_of_your_suite_here"
batch_request = {
"datasource_name": "my_datasource",
"data_connector_name": "default_inferred_data_connector_name",
"data_asset_name": "yellow_tripdata_sample_2020-05.csv",
}
```
### 3. Instantiate your Validator
We use a Validator to access and interact with your data. We will be passing the Validator to our Profiler in the next step.
```python
from great_expectations.core.batch import BatchRequest
validator = context.get_validator(
batch_request=BatchRequest(**batch_request),
expectation_suite_name=expectation_suite_name
)
```
After you get your Validator, you can call `validator.head()` to confirm that it contains the data that you expect.
### 4. Instantiate a UserConfigurableProfiler
Next, we instantiate a UserConfigurableProfiler, passing in the Validator with our data
```python
from great_expectations.profile.user_configurable_profiler import UserConfigurableProfiler
profiler = UserConfigurableProfiler(profile_dataset=validator)
```
### 5. Use the profiler to build a suite
Once we have our Profiler set up with our Batch, we call `profiler.build_suite()`. This will print a list of all the Expectations created by column, and return the Expectation Suite object.
```python
suite = profiler.build_suite()
```
### 6. (Optional) Running validation, saving your suite, and building Data Docs
If you'd like, you can <TechnicalTag tag="validation" text="Validate" /> your data with the new Expectation Suite, save your Expectation Suite, and build <TechnicalTag tag="data_docs" text="Data Docs" /> to take a closer look at the output
```python
from great_expectations.checkpoint.checkpoint import SimpleCheckpoint
# Review and save our Expectation Suite
print(validator.get_expectation_suite(discard_failed_expectations=False))
validator.save_expectation_suite(discard_failed_expectations=False)
# Set up and run a Simple Checkpoint for ad hoc validation of our data
checkpoint_config = {
"class_name": "SimpleCheckpoint",
"validations": [
{
"batch_request": batch_request,
"expectation_suite_name": expectation_suite_name,
}
],
}
checkpoint = SimpleCheckpoint(
f"{validator.active_batch_definition.data_asset_name}_{expectation_suite_name}", context, **checkpoint_config
)
checkpoint_result = checkpoint.run()
# Build Data Docs
context.build_data_docs()
# Get the only validation_result_identifier from our SimpleCheckpoint run, and open Data Docs to that page
validation_result_identifier = checkpoint_result.list_validation_result_identifiers()[0]
context.open_data_docs(resource_identifier=validation_result_identifier)
```
And you're all set!
## Optional Parameters
The UserConfigurableProfiler can take a few different parameters to further hone the results. These parameters are:
- **excluded_expectations**: List\[str\] - Specifies Expectation types which you want to exclude from the Expectation Suite
- **ignored_columns**: List\[str\] - Columns for which you do not want to build Expectations (i.e. if you have metadata columns which might not be the same between tables
- **not_null_only**: Bool - By default, each column is evaluated for nullity. If the column values contain fewer than 50% null values, then the Profiler will add `expect_column_values_to_not_be_null`; if greater than 50% it will add `expect_column_values_to_be_null`. If `not_null_only` is set to True, the Profiler will add a `not_null` Expectation irrespective of the percent nullity (and therefore will not add an `expect_column_values_to_be_null`)
- **primary_or_compound_key**: List\[str\] - This allows you to specify one or more columns in list form as a primary or compound key, and will add `expect_column_values_to_be_unique` or `expect_compound_column_values_to_be_unique`
- **table_expectations_only**: Bool - If True, this will only create table-level Expectations (i.e. ignoring all columns). Table-level Expectations include `expect_table_row_count_to_equal` and `expect_table_columns_to_match_ordered_list`
- **value_set_threshold**: str: Specify a value from the following ordered list - "none", "one", "two", "very_few", "few", "many", "very_many", "unique". When the Profiler runs, each column is profiled for cardinality. This threshold determines the greatest cardinality for which to add `expect_column_values_to_be_in_set`. For example, if `value_set_threshold` is set to "unique", it will add a value_set Expectation for every included column. If set to "few", it will add a value_set expectation for columns whose cardinality is one of "one", "two", "very_few" or "few". The default value here is "many". For the purposes of comparing whether two tables are identical, it might make the most sense to set this to "unique".
- **semantic_types_dict**: Dict\[str, List\[str\]\]. Described in more detail below.
If you would like to make use of these parameters, you can specify them while instantiating your Profiler.
```python
excluded_expectations = ["expect_column_quantile_values_to_be_between"]
ignored_columns = ['comment', 'acctbal', 'mktsegment', 'name', 'nationkey', 'phone']
not_null_only = True
table_expectations_only = False
value_set_threshold = "unique"
validator = context.get_validator(
batch_request=BatchRequest(**batch_request),
expectation_suite_name=expectation_suite_name
)
profiler = UserConfigurableProfiler(
profile_dataset=validator,
excluded_expectations=excluded_expectations,
ignored_columns=ignored_columns,
not_null_only=not_null_only,
table_expectations_only=table_expectations_only,
value_set_threshold=value_set_threshold)
suite = profiler.build_suite()
```
**Once you have instantiated a Profiler with parameters specified, you must re-instantiate the Profiler if you wish to change any of the parameters.**
### Semantic Types Dictionary Configuration
The Profiler is fairly rudimentary - if it detects that a column is numeric, it will create numeric Expectations (e.g. ``expect_column_mean_to_be_between``). But if you are storing foreign keys or primary keys as integers, then you may not want numeric Expectations on these columns. This is where the semantic_types dictionary comes in.
The available semantic types that can be specified in the UserConfigurableProfiler are "numeric", "value_set", and "datetime". The Expectations created for each of these types is below. You can pass in a dictionary where the keys are the semantic types, and the values are lists of columns of those semantic types.
When you pass in a `semantic_types_dict`, the Profiler will still create table-level expectations, and will create certain expectations for all columns (around nullity and column proportions of unique values). It will then only create semantic-type-specific Expectations for those columns specified in the semantic_types dict.
```python
semantic_types_dict = {
"numeric": ["acctbal"],
"value_set": ["nationkey","mktsegment", 'custkey', 'name', 'address', 'phone', "acctbal"]
}
validator = context.get_validator(
batch_request=BatchRequest(**batch_request),
expectation_suite_name=expectation_suite_name
)
profiler = UserConfigurableProfiler(
profile_dataset=validator,
semantic_types_dict=semantic_types_dict
)
suite = profiler.build_suite()
```
These are the Expectations added when using a `semantics_type_dict`:
**Table Expectations:**
- [`expect_table_row_count_to_be_between`](https://greatexpectations.io/expectations/expect_table_row_count_to_be_between)
- [`expect_table_columns_to_match_ordered_list`](https://greatexpectations.io/expectations/expect_table_columns_to_match_ordered_list)
**Expectations added for all included columns**
- [`expect_column_value_to_not_be_null`](https://greatexpectations.io/expectations/expect_column_values_to_not_be_null) (if a column consists of more than 50% null values, this will instead add [`expect_column_values_to_be_null`](https://greatexpectations.io/expectations/expect_column_values_to_be_null))
- [`expect_column_proportion_of_unique_values_to_be_between`](https://greatexpectations.io/expectations/expect_column_proportion_of_unique_values_to_be_between)
- [`expect_column_values_to_be_in_type_list`](https://greatexpectations.io/expectations/expect_column_values_to_be_in_type_list)
**Value set Expectations**
- [`expect_column_values_to_be_in_set`](https://greatexpectations.io/expectations/expect_column_values_to_be_in_set)
**Datetime Expectations**
- [`expect_column_values_to_be_between`](https://greatexpectations.io/expectations/expect_column_values_to_be_between)
**Numeric Expectations**
- [`expect_column_min_to_be_between`](https://greatexpectations.io/expectations/expect_column_min_to_be_between)
- [`expect_column_max_to_be_between`](https://greatexpectations.io/expectations/expect_column_max_to_be_between)
- [`expect_column_mean_to_be_between`](https://greatexpectations.io/expectations/expect_column_mean_to_be_between)
- [`expect_column_median_to_be_between`](https://greatexpectations.io/expectations/expect_column_median_to_be_between)
- [`expect_column_quantile_values_to_be_between`](https://greatexpectations.io/expectations/expect_column_quantile_values_to_be_between)
**Other Expectations**
- [`expect_column_values_to_be_unique`](https://greatexpectations.io/expectations/expect_column_values_to_be_unique) (if a single key is specified for `primary_or_compound_key`)
- [`expect_compound_columns_to_be_unique`](https://greatexpectations.io/expectations/expect_compound_columns_to_be_unique) (if a compound key is specified for `primary_or_compound_key`)
<file_sep>/docs/deployment_patterns/how_to_use_great_expectations_in_aws_glue.md
---
title: How to Use Great Expectations in AWS Glue
---
import Prerequisites from './components/deployment_pattern_prerequisites.jsx'
import Congratulations from '../guides/connecting_to_your_data/components/congratulations.md'
This Guide demonstrates how to set up, initialize and run validations against your data on AWS Glue Spark Job.
We will cover case with RuntimeDataConnector and use S3 as metadata store.
### 0. Pre-requirements
- Configure great_expectations.yaml and upload to your S3 bucket or generate it dynamically from code
```yaml file=../../tests/integration/docusaurus/deployment_patterns/aws_glue_deployment_patterns_great_expectations.yaml#L1-L67
```
### 1. Install Great Expectations
You need to add to your AWS Glue Spark Job Parameters to install great expectations module. Glue at least v2
```bash
— additional-python-modules great_expectations
```
Then import necessary libs:
```python file=../../tests/integration/docusaurus/deployment_patterns/aws_glue_deployment_patterns.py#L1-L13
```
### 2. Set up Great Expectations
Here we initialize a Spark and Glue, and read great_expectations.yaml
```python file=../../tests/integration/docusaurus/deployment_patterns/aws_glue_deployment_patterns.py#L15-L22
```
### 3. Connect to your data
```python file=../../tests/integration/docusaurus/deployment_patterns/aws_glue_deployment_patterns.py#L24-L43
```
### 4. Create Expectations
```python file=../../tests/integration/docusaurus/deployment_patterns/aws_glue_deployment_patterns.py#L45-L62
```
### 5. Validate your data
```python file=../../tests/integration/docusaurus/deployment_patterns/aws_glue_deployment_patterns.py#L64-L78
```
### 6. Congratulations!
Your data docs built on S3 and you can see index.html at the bucket
<details>
<summary>This documentation has been contributed by <NAME> from Provectus</summary>
<div>
<p>
Our links:
</p>
<ul>
<li> <a href="https://www.linkedin.com/in/bogdan-volodarskiy-652498108/">Author's Linkedin</a> </li>
<li> <a href="https://medium.com/@bvolodarskiy">Author's Blog</a> </li>
<li> <a href="https://provectus.com/">About Provectus</a> </li>
<li> <a href="https://provectus.com/data-quality-assurance/">About Provectus Data QA Expertise</a> </li>
</ul>
</div>
</details>
<file_sep>/docs/guides/connecting_to_your_data/cloud/s3/components_pandas/_save_the_datasource_configuration_to_your_datacontext.mdx
import TabItem from '@theme/TabItem';
import Tabs from '@theme/Tabs';
Save the configuration into your `DataContext` by using the `add_datasource()` function.
<Tabs
groupId="yaml-or-python"
defaultValue='yaml'
values={[
{label: 'YAML', value:'yaml'},
{label: 'Python', value:'python'},
]}>
<TabItem value="yaml">
```python file=../../../../../../tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/inferred_and_runtime_yaml_example.py#L41
```
</TabItem>
<TabItem value="python">
```python file=../../../../../../tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/inferred_and_runtime_python_example.py#L42
```
</TabItem>
</Tabs>
<file_sep>/docs/deployment_patterns/how_to_use_great_expectations_in_emr_serverless.md
---
title: How to Use Great Expectations in EMR Serverless
---
import Prerequisites from './components/deployment_pattern_prerequisites.jsx'
import Congratulations from '../guides/connecting_to_your_data/components/congratulations.md'
This Guide demonstrates how to set up, initialize and run validations against your data on AWS EMR Serverless.
We will cover case with RuntimeDataConnector and use S3 as metadata store.
### 0. Pre-requirements
- Configure great_expectations.yaml and upload to your S3 bucket or generate it dynamically from code, notice critical moment, that you need to add endpoint_url to data_doc section
```yaml file=../../tests/integration/docusaurus/deployment_patterns/aws_emr_serverless_deployment_patterns_great_expectations.yaml#L1-L68
```
### 1. Install Great Expectations
Create a Dockerfile and build it to generate virtualenv archive and upload this tar.gz output to S3 bucket.
At requirements.txt you should have great_expectations package and everything else what you want to install
```dockerfile
FROM --platform=linux/amd64 amazonlinux:2 AS base
RUN yum install -y python3
ENV VIRTUAL_ENV=/opt/venv
RUN python3 -m venv $VIRTUAL_ENV
ENV PATH="$VIRTUAL_ENV/bin:$PATH"
COPY ./requirements.txt /
RUN python3 -m pip install --upgrade pip && \
python3 -m pip install -r requirements.txt --no-cache-dir
RUN mkdir /output && venv-pack -o /output/pyspark_ge.tar.gz
FROM scratch AS export
COPY --from=base /output/pyspark_ge.tar.gz /
```
When you will configure a job, it's necessary to define additional params to Spark properties:
```bash
--conf spark.archives=s3://bucket/folder/pyspark_ge.tar.gz#environment
--conf spark.emr-serverless.driverEnv.PYSPARK_DRIVER_PYTHON=./environment/bin/python
--conf spark.emr-serverless.driverEnv.PYSPARK_PYTHON=./environment/bin/python
--conf spark.emr-serverless.executorEnv.PYSPARK_PYTHON=./environment/bin/python
--conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory
```
Then import necessary libs:
```python file=../../tests/integration/docusaurus/deployment_patterns/aws_emr_serverless_deployment_patterns.py#L1-L11
```
### 2. Set up Great Expectations
Here we initialize a Spark, and read great_expectations.yaml
```python file=../../tests/integration/docusaurus/deployment_patterns/aws_emr_serverless_deployment_patterns.py#L13-L26
```
### 3. Connect to your data
```python file=../../tests/integration/docusaurus/deployment_patterns/aws_emr_serverless_deployment_patterns.py#L27-L48
```
### 4. Create Expectations
```python file=../../tests/integration/docusaurus/deployment_patterns/aws_emr_serverless_deployment_patterns.py#L50-L68
```
### 5. Validate your data
```python file=../../tests/integration/docusaurus/deployment_patterns/aws_emr_serverless_deployment_patterns.py#L70-L111
```
### 6. Congratulations!
Your data docs built on S3 and you can see index.html at the bucket
<details>
<summary>This documentation has been contributed by <NAME> from Provectus</summary>
<div>
<p>
Our links:
</p>
<ul>
<li> <a href="https://www.linkedin.com/in/bogdan-volodarskiy-652498108/">Author's Linkedin</a> </li>
<li> <a href="https://medium.com/@bvolodarskiy">Author's Blog</a> </li>
<li> <a href="https://provectus.com/">About Provectus</a> </li>
<li> <a href="https://provectus.com/data-quality-assurance/">About Provectus Data QA Expertise</a> </li>
</ul>
</div>
</details><file_sep>/great_expectations/core/http.py
import requests
from requests.adapters import HTTPAdapter, Retry
from great_expectations import __version__
DEFAULT_TIMEOUT = 20
class _TimeoutHTTPAdapter(HTTPAdapter):
# https://stackoverflow.com/a/62044100
# Session-wide timeouts are not supported by requests
# but are discussed in detail here: https://github.com/psf/requests/issues/3070
def __init__(self, *args, **kwargs) -> None:
self.timeout = kwargs.pop("timeout", DEFAULT_TIMEOUT)
super().__init__(*args, **kwargs)
def send(self, request: requests.PreparedRequest, **kwargs) -> requests.Response: # type: ignore[override]
kwargs["timeout"] = kwargs.get("timeout", self.timeout)
return super().send(request, **kwargs)
def create_session(
access_token: str,
retry_count: int = 5,
backoff_factor: float = 1.0,
timeout: int = DEFAULT_TIMEOUT,
) -> requests.Session:
session = requests.Session()
session = _update_headers(session=session, access_token=access_token)
session = _mount_adapter(
session=session,
timeout=timeout,
retry_count=retry_count,
backoff_factor=backoff_factor,
)
return session
def _update_headers(session: requests.Session, access_token: str) -> requests.Session:
headers = {
"Content-Type": "application/vnd.api+json",
"Authorization": f"Bearer {access_token}",
"Gx-Version": __version__,
}
session.headers.update(headers)
return session
def _mount_adapter(
session: requests.Session, timeout: int, retry_count: int, backoff_factor: float
) -> requests.Session:
retries = Retry(total=retry_count, backoff_factor=backoff_factor)
adapter = _TimeoutHTTPAdapter(timeout=timeout, max_retries=retries)
for protocol in ("http://", "https://"):
session.mount(protocol, adapter)
return session
<file_sep>/docs/guides/setup/configuring_data_contexts/components_how_to_configure_a_new_data_context_with_the_cli/_preface.mdx
<!--
---Import---
import Preface from './_preface.mdx'
<Preface />
---Header---
preface
-->
import TechnicalTag from '/docs/term_tags/_tag.mdx';
import Prerequisites from '../../../connecting_to_your_data/components/prerequisites.jsx'
<Prerequisites>
- [Configured a Data Context](../../../../tutorials/getting_started/tutorial_setup.md)
</Prerequisites>
<file_sep>/tests/data_context/datasource/test_data_context_datasource_runtime_data_connector_sqlalchemy_execution_engine.py
from typing import Dict, List
import pytest
import great_expectations
import great_expectations.exceptions as ge_exceptions
from great_expectations import DataContext
from great_expectations.core.batch import Batch, RuntimeBatchRequest
from great_expectations.core.yaml_handler import YAMLHandler
from great_expectations.validator.validator import Validator
yaml = YAMLHandler()
####################################
# Tests with data passed in as query
####################################
def test_get_batch_successful_specification_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
batch_list: List[Batch] = context.get_batch_list(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers={"default_identifier_name": "identifier_name"},
)
)
assert len(batch_list) == 1
assert isinstance(batch_list[0], Batch)
def test_get_batch_successful_specification_sqlalchemy_engine_named_asset(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
batch_identifiers: Dict[str, int] = {"day": 1, "month": 12}
batch_list: List[Batch] = context.get_batch_list(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="asset_a",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers=batch_identifiers,
)
)
assert len(batch_list) == 1
assert isinstance(batch_list[0], Batch)
batch_1: Batch = batch_list[0]
assert batch_1.batch_definition.batch_identifiers == batch_identifiers
def test_get_batch_successful_specification_pandas_engine_named_asset_two_batch_requests(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
batch_identifiers: Dict[str, int] = {"day": 1, "month": 12}
batch_list: List[Batch] = context.get_batch_list(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="asset_a",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers=batch_identifiers,
)
)
assert len(batch_list) == 1
assert isinstance(batch_list[0], Batch)
batch_1: Batch = batch_list[0]
assert batch_1.batch_definition.batch_identifiers == batch_identifiers
batch_identifiers: Dict[str, int] = {"day": 2, "month": 12}
batch_list: List[Batch] = context.get_batch_list(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="asset_a",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers=batch_identifiers,
)
)
assert len(batch_list) == 1
assert isinstance(batch_list[0], Batch)
batch_2: Batch = batch_list[0]
assert batch_2.batch_definition.batch_identifiers == batch_identifiers
def test_get_batch_ambiguous_parameter_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
"""
What does this test and why?
get_batch_list() requires batch_request to be passed in a named parameter. This test passes in a batch_request
as an unnamed parameter, which will raise a GreatExpectationsTypeError
"""
context = data_context_with_datasource_sqlalchemy_engine
# raised by get_batch_list()
with pytest.raises(ge_exceptions.GreatExpectationsTypeError):
batch_list: List[Batch] = context.get_batch_list(
RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers={"default_identifier_name": "identifier_name"},
)
)
def test_get_batch_failed_specification_type_error_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context = data_context_with_datasource_sqlalchemy_engine
# raised by _validate_runtime_batch_request_specific_init_parameters() in RuntimeBatchRequest.__init__()
with pytest.raises(TypeError):
batch_list: List[Batch] = context.get_batch_list(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name=1, # wrong data_type
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers={"default_identifier_name": "identifier_name"},
)
)
def test_get_batch_failed_specification_no_batch_identifier_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context = data_context_with_datasource_sqlalchemy_engine
# raised by _validate_runtime_batch_request_specific_init_parameters() in RuntimeBatchRequest.__init__()
with pytest.raises(TypeError):
# batch_identifiers missing (set to None)
batch_list: List[Batch] = context.get_batch_list(
RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers=None,
)
)
# raised by _validate_runtime_batch_request_specific_init_parameters() in RuntimeBatchRequest.__init__()
with pytest.raises(TypeError):
# batch_identifiers missing (omitted)
batch_list: List[Batch] = context.get_batch_list(
RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
)
)
def test_get_batch_failed_specification_no_runtime_parameters_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context = data_context_with_datasource_sqlalchemy_engine
# raised by _validate_runtime_batch_request_specific_init_parameters() in RuntimeBatchRequest.__init__()
with pytest.raises(TypeError):
# runtime_parameters missing (None)
batch_list: List[Batch] = context.get_batch_list(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters=None,
batch_identifiers={"default_identifier_name": "identifier_name"},
)
)
# raised by _validate_runtime_batch_request_specific_init_parameters() in RuntimeBatchRequest.__init__()
with pytest.raises(TypeError):
# runtime_parameters missing (omitted)
batch_list: List[Batch] = context.get_batch_list(
RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
batch_identifiers={"default_identifier_name": "identifier_name"},
)
)
def test_get_batch_failed_specification_incorrect_batch_spec_passthrough_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context = data_context_with_datasource_sqlalchemy_engine
# raised by _validate_runtime_batch_request_specific_init_parameters() in RuntimeBatchRequest.__init__()
with pytest.raises(TypeError):
# incorrect batch_spec_passthrough, which should be a dict
batch_list: List[Batch] = context.get_batch_list(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers={"default_identifier_name": "identifier_name"},
batch_spec_passthrough=1,
)
)
def test_get_batch_failed_specification_wrong_runtime_parameters_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context = data_context_with_datasource_sqlalchemy_engine
# raised by _validate_runtime_parameters() in RuntimeDataConnector
with pytest.raises(
great_expectations.exceptions.exceptions.InvalidBatchRequestError
):
# runtime_parameters are not configured in the DataConnector
batch_list: List[Batch] = context.get_batch_list(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={"i_dont_exist": "i_dont_either"},
batch_identifiers={"default_identifier_name": "identifier_name"},
)
)
def test_get_validator_successful_specification_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context = data_context_with_datasource_sqlalchemy_engine
context.create_expectation_suite("my_expectations")
# Successful specification using a RuntimeBatchRequest
my_validator: Validator = context.get_validator(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers={"default_identifier_name": "identifier_name"},
),
expectation_suite_name="my_expectations",
)
assert isinstance(my_validator, Validator)
def test_get_validator_ambiguous_parameter_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
"""
What does this test and why?
get_batch_list() requires batch_request to be passed in a named parameter. This test passes in a batch_request
as an unnamed parameter, which will raise a GreatExpectationsTypeError
"""
context: DataContext = data_context_with_datasource_sqlalchemy_engine
context.create_expectation_suite("my_expectations")
# raised by get_batch_list() in DataContext
with pytest.raises(ge_exceptions.GreatExpectationsTypeError):
batch_list: List[Batch] = context.get_validator(
RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers={"default_identifier_name": "identifier_name"},
),
expectation_suite_name="my_expectations",
)
def test_get_validator_wrong_type_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
context.create_expectation_suite("my_expectations")
# raised by _validate_runtime_batch_request_specific_init_parameters() in RuntimeBatchRequest.__init__()
# data_connector_name should be a dict not an int
with pytest.raises(TypeError):
validator: Validator = context.get_validator(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name=1,
data_asset_name="default_data_asset_name",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers={"default_identifier_name": "identifier_name"},
),
expectation_suite_name="my_expectations",
)
def test_get_validator_failed_specification_no_batch_identifier_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
context.create_expectation_suite("my_expectations")
# raised by _validate_runtime_batch_request_specific_init_parameters() in RuntimeBatchRequest.__init__()
# batch_identifiers should not be None
with pytest.raises(TypeError):
validator: Validator = context.get_validator(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers=None,
),
expectation_suite_name="my_expectations",
)
# batch_identifiers should not be omitted
with pytest.raises(TypeError):
validator: Validator = context.get_validator(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
),
expectation_suite_name="my_expectations",
)
def test_get_validator_failed_specification_incorrect_batch_spec_passthrough_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
context.create_expectation_suite("my_expectations")
# raised by _validate_runtime_batch_request_specific_init_parameters() in RuntimeBatchRequest.__init__()
with pytest.raises(TypeError):
# incorrect batch_spec_passthrough, which should be a dict
validator: Validator = context.get_validator(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers={"default_identifier_name": "identifier_name"},
batch_spec_passthrough=1,
),
expectation_suite_name="my_expectations",
)
def test_get_validator_failed_specification_no_runtime_parameters_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
context.create_expectation_suite("my_expectations")
with pytest.raises(TypeError):
# runtime_parameters should not be None
batch_list: List[Batch] = context.get_validator(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters=None,
batch_identifiers={"default_identifier_name": "identifier_name"},
),
expectation_suite_name="my_expectations",
)
# raised by _validate_runtime_batch_request_specific_init_parameters() in RuntimeBatchRequest.__init__()
with pytest.raises(TypeError):
# runtime_parameters missing (omitted)
batch_list: List[Batch] = context.get_validator(
RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
batch_identifiers={"default_identifier_name": "identifier_name"},
)
)
def test_get_validator_wrong_runtime_parameters_sqlalchemy_engine(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
context.create_expectation_suite("my_expectations")
# raised by _validate_runtime_parameters() in RuntimeDataConnector
with pytest.raises(
great_expectations.exceptions.exceptions.InvalidBatchRequestError
):
# runtime_parameters are not configured in the DataConnector
validator: Validator = context.get_validator(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="default_data_asset_name",
runtime_parameters={"i_dont_exist": "i_dont_either"},
batch_identifiers={"default_identifier_name": "identifier_name"},
),
expectation_suite_name="my_expectations",
)
def test_get_validator_successful_specification_sqlalchemy_engine_named_asset(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
batch_identifiers: Dict[str, int] = {"day": 1, "month": 12}
context.create_expectation_suite("my_expectations")
# Successful specification using a RuntimeBatchRequest
my_validator: Validator = context.get_validator(
batch_request=RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="asset_a",
runtime_parameters={
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
batch_identifiers=batch_identifiers,
),
expectation_suite_name="my_expectations",
)
assert isinstance(my_validator, Validator)
assert (
my_validator.active_batch.batch_definition.batch_identifiers
== batch_identifiers
)
<file_sep>/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/tests/expectations/metrics/test_core.py
import os
import dataprofiler as dp
import pandas as pd
# noinspection PyUnresolvedReferences
import contrib.capitalone_dataprofiler_expectations.capitalone_dataprofiler_expectations.metrics.data_profiler_metrics
from great_expectations.self_check.util import build_pandas_engine
from great_expectations.validator.metric_configuration import MetricConfiguration
from tests.expectations.test_util import get_table_columns_metric
test_root_path = os.path.dirname(
os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
)
def test_data_profiler_column_profile_report_metric_pd():
engine = build_pandas_engine(
pd.DataFrame(
{
"VendorID": [
"<NAME>",
"<NAME>",
"<NAME>",
"<NAME>",
"<NAME>",
"<NAME>",
"<NAME>",
"<NAME>",
]
}
)
)
profile_path = os.path.join(
test_root_path,
"data_profiler_files",
"profile.pkl",
)
metrics: dict = {}
table_columns_metric: MetricConfiguration
results: dict
table_columns_metric, results = get_table_columns_metric(engine=engine)
metrics.update(results)
desired_metric = MetricConfiguration(
metric_name="data_profiler.column_profile_report",
metric_domain_kwargs={"column": "VendorID"},
metric_value_kwargs={
"profile_path": profile_path,
},
metric_dependencies={
"table.columns": table_columns_metric,
},
)
results = engine.resolve_metrics(
metrics_to_resolve=(desired_metric,), metrics=metrics
)
metrics.update(results)
profile = dp.Profiler.load(profile_path)
assert (
results[desired_metric.id]["column_name"]
== profile.report()["data_stats"][0]["column_name"]
)
assert (
results[desired_metric.id]["data_type"]
== profile.report()["data_stats"][0]["data_type"]
)
assert (
results[desired_metric.id]["categorical"]
== profile.report()["data_stats"][0]["categorical"]
)
assert (
results[desired_metric.id]["order"]
== profile.report()["data_stats"][0]["order"]
)
assert (
results[desired_metric.id]["samples"]
== profile.report()["data_stats"][0]["samples"]
)
<file_sep>/great_expectations/expectations/metrics/query_metric_provider.py
import logging
from great_expectations.expectations.metrics.metric_provider import MetricProvider
logger = logging.getLogger(__name__)
class QueryMetricProvider(MetricProvider):
"""Base class for all Query Metrics.
Query Metric classes inheriting from QueryMetricProvider *must* have the following attributes set:
1. `metric_name`: the name to use. Metric Name must be globally unique in
a great_expectations installation.
1. `domain_keys`: a tuple of the *keys* used to determine the domain of the
metric
2. `value_keys`: a tuple of the *keys* used to determine the value of
the metric.
In some cases, subclasses of MetricProvider, such as QueryMetricProvider, will already
have correct values that may simply be inherited by Metric classes.
"""
domain_keys = ("batch_id", "row_condition", "condition_parser")
<file_sep>/docs/guides/setup/installation/hosted_environment.md
---
title: How to install Great Expectations in a hosted environment
---
import NextSteps from '/docs/guides/setup/components/install_nextsteps.md'
import Congratulations from '/docs/guides/setup/components/install_congrats.md'
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
Great Expectations can be deployed in environments such as Databricks, AWS EMR, Google Cloud Composer, and others. These environments do not always have a typical file system where Great Expectations can be installed. This guide will provide tool-specific resources to successfully install Great Expectations in a hosted environment.
## Install Great Expectations
The following guides provide instructions for installing Great Expectations in the hosted environment of your choice:
- [How to Use Great Expectations in Databricks](https://docs.greatexpectations.io/docs/deployment_patterns/how_to_use_great_expectations_in_databricks)
- [How to instantiate a Data Context on an EMR Spark cluster](https://docs.greatexpectations.io/docs/deployment_patterns/how_to_instantiate_a_data_context_on_an_emr_spark_cluster)
<file_sep>/assets/docker/starburst/docker-compose.yml
version: '3.2'
services:
starburst_db:
image: starburstdata/starburst-enterprise:373-e
ports:
- "8088:8080"
<file_sep>/docs/integrations/contributing_integration.md
---
title: How to write integration documentation
---
### Introduction
As the data stack ecosystem grows and expands in usage and tooling, so does the need to integrate with 3rd party
products or services. As drivers and ushers
of [Great Expectations](https://greatexpectations.io), we want to make the process to integrating with Great Expectations
as low friction as possible. We are committed to work and iterate in the process and greatly value any feedback you may have.
The aim of this document is to provide guidance for vendors or community partners which wish to integrate with us as to
how to write documentation for said integration and to establish a sense of uniformity and consistency.
With all having been said, let's delve into actionable steps.
## Steps
### 0. Reach out to our Developer Relations team
Before you embark in this journey, drop by and introduce yourself in the #integrations channel in our [Great Expectations Slack](https://greatexpectationstalk.slack.com)
to let us know. We're big believers of building strong relationships with ecosystem partners. And thus we believe
opening communication channels early in the process is essential.
### 1. Copy the template
Create a copy of `integration_template.md` and name it `integration_<my_product>.md`. This file is located in `great_expectations/docs/integrations/` directory.
This file is in markdown format and supports basic [docusaurus admonitions](https://docusaurus.io/docs/markdown-features/admonitions).
### 2. Add to index
In the same directory as above, there is a file named `index.md`. In it add an entry matching the pattern in place of the first entry.
:::info
(Optional) Live-test the document
Sometimes is easier to author a document while getting a full visual representation of it. To this end, you can locally install our documentation stack as follows:
1. Navigate to the top level directory you cloned (i.e. `great_expectations`).
2. Install `yarn` (via homebrew or other package manager)
3. Run `yarn` and wait for dependency setup to finish.
4. Run `yarn start`. This will open a browser window with the docs site.
5. The document you're authoring should be visible by expanding the left side nav bar 'Integrations' menu.
This document will refresh every time you make changes and save the file (assuming the `yarn` process is still running).
:::
### 3. Fill in the `info` admonition at the top of the template
Populating this section is a key requirement for acceptance into our integration docs. At a glance it should provide ownership,
support and other important information.
It's important to recognize who created an integration, as well as to make clear to the users of the integration
where to turn to if they have questions or need assistance. Further, you should include information on where to raise
potential issues about the documentation itself.
### 4. Introduction content
In this section, ideally, you will set expectations (no pun intended) with the user, what problem the integration is solving,
what use case it enables, and what the desired outcome is.
### 5. Technical background
In some cases, it is necessary to provide a detailed technical background about the integration as well as important
technical considerations as well as possible trade-offs and shortcomings with the integration.
### 6. Dev loops unlocked by integration
This should be a more direct, concise and less hand-wavy version of the introduction. It should also foreshadow the content
in Usages section.
### 7. Usages
This section will be where the substance and nitty-gritty of your documentation is written. You should put a lot of
technical emphasis in this section and making sure you stay focused in fleshing out and explaining users how this integration
facilitates or enables a dev loop or use case with relevant and replicatable examples (see [template](../integrations/integration_template.md) for suggested format and structure).
### 8. Further discussion
This section is comprised of four subsections. They are:
- **Things to consider**: is where you would describe to the user important considerations, caveats, trade-offs, extensibility, applicability, etc.
- **When things don't work**:, should at the very least point your users where to seek support. Ideally, however, you can provide some basic trouble-shooting.
- **FAQs**: as this subsection's namesake hints, here is where you will document common questions, issues and pitfalls (and answers thereto)
- **Additional resources**: is optional, but here is where you would place links to external tutorials, videos, etc.
### 9. Before submitting PR
Once you believe your documentation is ready to be submitted for review and consideration, reach out to anyone in our
Developer Relations team in [the #integrations channel](https://greatexpectationstalk.slack.com/archives/C037YCYNF1Q) in our [Great Expectations Slack](https://greatexpectationstalk.slack.com)
to let us know.
### 10. Getting assistance
If you have any questions about the format, structure, process or any non-Great Expectations-specific questions, use [the channel mentioned above](https://greatexpectationstalk.slack.com).
For any technical questions, feel free to post in the [#support channel](https://greatexpectationstalk.slack.com/archives/CUTCNHN82) or reach out directly to one of developer advocates for expedited turn-around.<file_sep>/docs/integrations/integration_datahub.md
---
title: Integrating DataHub With Great Expectations
authors:
name: <NAME>, <NAME>, <NAME>
url: https://datahubproject.io
---
:::info
* Maintained By: DataHub
* Status: Beta
* Support/Contact: https://slack.datahubproject.io/
:::
### Introduction
This integration allows you to push the results of running Expectations into DataHub (https://datahubproject.io/). DataHub is a metadata platform which enables search & discovery, federated governance, and data observability for the Modern Data Stack.
### Technical background
There is a custom Action named `DataHubValidationAction` which allows you to view Expectation Results inside of DataHub.
:::note Prerequisites
- Create a [Great Expectations Checkpoint](https://docs.greatexpectations.io/docs/terms/checkpoint)
- [Deploy an instance of DataHub](https://datahubproject.io/docs/quickstart)
:::
`DataHubValidationAction` pushes Expectations metadata to DataHub. This includes
- **Expectation Details**: Details of assertions (i.e. Expectation) set on a Dataset (Table). Expectation set on a dataset in GE aligns with `AssertionInfo` aspect in DataHub. `AssertionInfo` captures the dataset and dataset fields on which assertion is applied, along with its scope, type and parameters.
- **Expectation Results**: Evaluation results for an assertion tracked over time.
Validation Result for an Expectation in GE align with `AssertionRunEvent` aspect in DataHub. `AssertionRunEvent` captures the time at which Validation was run, Batch(subset) of dataset on which it was run, the success status along with other result fields.
### Dev loops unlocked by integration
* View dataset and column level Expectations set on a dataset
* View time-series history of Expectation's outcome (pass/fail)
* View current health status of dataset
### Setup
Install the required dependency in your Great Expectations environment.
```shell
pip install 'acryl-datahub[great-expectations]'
```
## Usage
:::tip
Stand up and take a breath
:::
#### 1. Ingest the metadata from source data platform into DataHub
For example, if you have GE Checkpoint that runs Expectations on a BigQuery dataset, then first
ingest the respective dataset into DataHub using [BigQuery](https://datahubproject.io/docs/generated/ingestion/sources/bigquery#module-bigquery) metadata ingestion source recipe.
```bash
datahub ingest -c recipe.yaml
```
You should be able to see the dataset in DataHub UI.
#### 2. Update GE Checkpoint Configurations
Add `DataHubValidationAction` in `action_list` of your Great Expectations Checkpoint. For more details on setting action_list, see [the configuration section of the GE Actions reference entry](https://docs.greatexpectations.io/docs/terms/action#configuration)
```yml
action_list:
- name: datahub_action
action:
module_name: datahub.integrations.great_expectations.action
class_name: DataHubValidationAction
server_url: http://localhost:8080 #DataHub server url
```
**Configuration options:**
- `server_url` (required): URL of DataHub GMS endpoint
- `env` (optional, defaults to "PROD"): Environment to use in namespace when constructing dataset URNs.
- `platform_instance_map` (optional): Platform instance mapping to use when constructing dataset URNs. Maps the GE 'data source' name to a platform instance on DataHub. e.g. `platform_instance_map: { "datasource_name": "warehouse" }`
- `graceful_exceptions` (defaults to true): If set to true, most runtime errors in the lineage backend will be suppressed and will not cause the overall Checkpoint to fail. Note that configuration issues will still throw exceptions.
- `token` (optional): Bearer token used for authentication.
- `timeout_sec` (optional): Per-HTTP request timeout.
- `retry_status_codes` (optional): Retry HTTP request also on these status codes.
- `retry_max_times` (optional): Maximum times to retry if HTTP request fails. The delay between retries is increased exponentially.
- `extra_headers` (optional): Extra headers which will be added to the datahub request.
- `parse_table_names_from_sql` (defaults to false): The integration can use an SQL parser to try to parse the datasets being asserted. This parsing is disabled by default, but can be enabled by setting `parse_table_names_from_sql: True`. The parser is based on the [`sqllineage`](https://pypi.org/project/sqllineage/) package.
#### 3. Run the GE checkpoint
```bash
great_expectations checkpoint run my_checkpoint #replace my_checkpoint with your checkpoint name
```
#### 4. Hurray!
The Validation Results would show up in Validation tab on Dataset page in DataHub UI.
## Further discussion
### Things to consider
Currently this integration only supports v3 API Datasources using `SqlAlchemyExecutionEngine`.
This integration does not support
- v2 Datasources such as `SqlAlchemyDataset`
- v3 Datasources using an Execution Engine other than `SqlAlchemyExecutionEngine` (Spark, Pandas)
- Cross-dataset Expectations (those involving > 1 table)
### When things don't work
- Follow [Debugging](https://datahubproject.io/docs/metadata-ingestion/integration_docs/great-expectations/#debugging) section to see what went wrong!
- Feel free to ping us on [DataHub Slack](https://slack.datahubproject.io/)!
### Other resources
- [Demo](https://www.loom.com/share/d781c9f0b270477fb5d6b0c26ef7f22d) of Great Expectations Datahub Integration in action
- DataHub [Metadata Ingestion Sources](https://datahubproject.io/docs/metadata-ingestion)<file_sep>/great_expectations/data_context/data_context/cloud_data_context.py
from __future__ import annotations
import logging
import os
from typing import TYPE_CHECKING, Dict, List, Mapping, Optional, Union, cast
import requests
import great_expectations.exceptions as ge_exceptions
from great_expectations import __version__
from great_expectations.core import ExpectationSuite
from great_expectations.core.config_provider import (
_CloudConfigurationProvider,
_ConfigurationProvider,
)
from great_expectations.core.serializer import JsonConfigSerializer
from great_expectations.core.usage_statistics.events import UsageStatsEvents
from great_expectations.core.usage_statistics.usage_statistics import (
save_expectation_suite_usage_statistics,
usage_statistics_enabled_method,
)
from great_expectations.data_context.cloud_constants import (
CLOUD_DEFAULT_BASE_URL,
GXCloudEnvironmentVariable,
GXCloudRESTResource,
)
from great_expectations.data_context.data_context.abstract_data_context import (
AbstractDataContext,
)
from great_expectations.data_context.data_context_variables import (
CloudDataContextVariables,
)
from great_expectations.data_context.types.base import (
DEFAULT_USAGE_STATISTICS_URL,
DataContextConfig,
DataContextConfigDefaults,
GXCloudConfig,
datasourceConfigSchema,
)
from great_expectations.data_context.types.refs import GXCloudResourceRef
from great_expectations.data_context.types.resource_identifiers import (
ConfigurationIdentifier,
GXCloudIdentifier,
)
from great_expectations.data_context.util import instantiate_class_from_config
from great_expectations.exceptions.exceptions import DataContextError
from great_expectations.render.renderer.site_builder import SiteBuilder
from great_expectations.rule_based_profiler.rule_based_profiler import RuleBasedProfiler
if TYPE_CHECKING:
from great_expectations.checkpoint.checkpoint import Checkpoint
logger = logging.getLogger(__name__)
class CloudDataContext(AbstractDataContext):
"""
Subclass of AbstractDataContext that contains functionality necessary to hydrate state from cloud
"""
def __init__(
self,
project_config: Optional[Union[DataContextConfig, Mapping]] = None,
context_root_dir: Optional[str] = None,
runtime_environment: Optional[dict] = None,
ge_cloud_base_url: Optional[str] = None,
ge_cloud_access_token: Optional[str] = None,
ge_cloud_organization_id: Optional[str] = None,
) -> None:
"""
CloudDataContext constructor
Args:
project_config (DataContextConfig): config for CloudDataContext
runtime_environment (dict): a dictionary of config variables that override both those set in
config_variables.yml and the environment
ge_cloud_config (GeCloudConfig): GeCloudConfig corresponding to current CloudDataContext
"""
self._ge_cloud_mode = True # property needed for backward compatibility
self._ge_cloud_config = self.get_ge_cloud_config(
ge_cloud_base_url=ge_cloud_base_url,
ge_cloud_access_token=ge_cloud_access_token,
ge_cloud_organization_id=ge_cloud_organization_id,
)
self._context_root_directory = self.determine_context_root_directory(
context_root_dir
)
if project_config is None:
project_config = self.retrieve_data_context_config_from_ge_cloud(
ge_cloud_config=self._ge_cloud_config,
)
project_data_context_config: DataContextConfig = (
CloudDataContext.get_or_create_data_context_config(project_config)
)
self._project_config = self._apply_global_config_overrides(
config=project_data_context_config
)
super().__init__(
runtime_environment=runtime_environment,
)
def _register_providers(self, config_provider: _ConfigurationProvider) -> None:
"""
To ensure that Cloud credentials are accessible downstream, we want to ensure that
we register a CloudConfigurationProvider.
Note that it is registered last as it takes the highest precedence.
"""
super()._register_providers(config_provider)
config_provider.register_provider(
_CloudConfigurationProvider(self._ge_cloud_config)
)
@classmethod
def is_ge_cloud_config_available(
cls,
ge_cloud_base_url: Optional[str] = None,
ge_cloud_access_token: Optional[str] = None,
ge_cloud_organization_id: Optional[str] = None,
) -> bool:
"""
Helper method called by gx.get_context() method to determine whether all the information needed
to build a ge_cloud_config is available.
If provided as explicit arguments, ge_cloud_base_url, ge_cloud_access_token and
ge_cloud_organization_id will use runtime values instead of environment variables or conf files.
If any of the values are missing, the method will return False. It will return True otherwise.
Args:
ge_cloud_base_url: Optional, you may provide this alternatively via
environment variable GE_CLOUD_BASE_URL or within a config file.
ge_cloud_access_token: Optional, you may provide this alternatively
via environment variable GE_CLOUD_ACCESS_TOKEN or within a config file.
ge_cloud_organization_id: Optional, you may provide this alternatively
via environment variable GE_CLOUD_ORGANIZATION_ID or within a config file.
Returns:
bool: Is all the information needed to build a ge_cloud_config is available?
"""
ge_cloud_config_dict = cls._get_ge_cloud_config_dict(
ge_cloud_base_url=ge_cloud_base_url,
ge_cloud_access_token=ge_cloud_access_token,
ge_cloud_organization_id=ge_cloud_organization_id,
)
for key, val in ge_cloud_config_dict.items():
if not val:
return False
return True
@classmethod
def determine_context_root_directory(cls, context_root_dir: Optional[str]) -> str:
if context_root_dir is None:
context_root_dir = os.getcwd()
logger.info(
f'context_root_dir was not provided - defaulting to current working directory "'
f'{context_root_dir}".'
)
return os.path.abspath(os.path.expanduser(context_root_dir))
@classmethod
def retrieve_data_context_config_from_ge_cloud(
cls, ge_cloud_config: GXCloudConfig
) -> DataContextConfig:
"""
Utilizes the GeCloudConfig instantiated in the constructor to create a request to the Cloud API.
Given proper authorization, the request retrieves a data context config that is pre-populated with
GE objects specific to the user's Cloud environment (datasources, data connectors, etc).
Please note that substitution for ${VAR} variables is performed in GE Cloud before being sent
over the wire.
:return: the configuration object retrieved from the Cloud API
"""
base_url = ge_cloud_config.base_url
organization_id = ge_cloud_config.organization_id
ge_cloud_url = (
f"{base_url}/organizations/{organization_id}/data-context-configuration"
)
headers = {
"Content-Type": "application/vnd.api+json",
"Authorization": f"Bearer {ge_cloud_config.access_token}",
"Gx-Version": __version__,
}
response = requests.get(ge_cloud_url, headers=headers)
if response.status_code != 200:
raise ge_exceptions.GXCloudError(
f"Bad request made to GE Cloud; {response.text}"
)
config = response.json()
return DataContextConfig(**config)
@classmethod
def get_ge_cloud_config(
cls,
ge_cloud_base_url: Optional[str] = None,
ge_cloud_access_token: Optional[str] = None,
ge_cloud_organization_id: Optional[str] = None,
) -> GXCloudConfig:
"""
Build a GeCloudConfig object. Config attributes are collected from any combination of args passed in at
runtime, environment variables, or a global great_expectations.conf file (in order of precedence).
If provided as explicit arguments, ge_cloud_base_url, ge_cloud_access_token and
ge_cloud_organization_id will use runtime values instead of environment variables or conf files.
Args:
ge_cloud_base_url: Optional, you may provide this alternatively via
environment variable GE_CLOUD_BASE_URL or within a config file.
ge_cloud_access_token: Optional, you may provide this alternatively
via environment variable GE_CLOUD_ACCESS_TOKEN or within a config file.
ge_cloud_organization_id: Optional, you may provide this alternatively
via environment variable GE_CLOUD_ORGANIZATION_ID or within a config file.
Returns:
GeCloudConfig
Raises:
GeCloudError if a GE Cloud variable is missing
"""
ge_cloud_config_dict = cls._get_ge_cloud_config_dict(
ge_cloud_base_url=ge_cloud_base_url,
ge_cloud_access_token=ge_cloud_access_token,
ge_cloud_organization_id=ge_cloud_organization_id,
)
missing_keys = []
for key, val in ge_cloud_config_dict.items():
if not val:
missing_keys.append(key)
if len(missing_keys) > 0:
missing_keys_str = [f'"{key}"' for key in missing_keys]
global_config_path_str = [
f'"{path}"' for path in super().GLOBAL_CONFIG_PATHS
]
raise DataContextError(
f"{(', ').join(missing_keys_str)} arg(s) required for ge_cloud_mode but neither provided nor found in "
f"environment or in global configs ({(', ').join(global_config_path_str)})."
)
base_url = ge_cloud_config_dict[GXCloudEnvironmentVariable.BASE_URL]
assert base_url is not None
access_token = ge_cloud_config_dict[GXCloudEnvironmentVariable.ACCESS_TOKEN]
organization_id = ge_cloud_config_dict[
GXCloudEnvironmentVariable.ORGANIZATION_ID
]
return GXCloudConfig(
base_url=base_url,
access_token=access_token,
organization_id=organization_id,
)
@classmethod
def _get_ge_cloud_config_dict(
cls,
ge_cloud_base_url: Optional[str] = None,
ge_cloud_access_token: Optional[str] = None,
ge_cloud_organization_id: Optional[str] = None,
) -> Dict[GXCloudEnvironmentVariable, Optional[str]]:
ge_cloud_base_url = (
ge_cloud_base_url
or CloudDataContext._get_global_config_value(
environment_variable=GXCloudEnvironmentVariable.BASE_URL,
conf_file_section="ge_cloud_config",
conf_file_option="base_url",
)
or CLOUD_DEFAULT_BASE_URL
)
ge_cloud_organization_id = (
ge_cloud_organization_id
or CloudDataContext._get_global_config_value(
environment_variable=GXCloudEnvironmentVariable.ORGANIZATION_ID,
conf_file_section="ge_cloud_config",
conf_file_option="organization_id",
)
)
ge_cloud_access_token = (
ge_cloud_access_token
or CloudDataContext._get_global_config_value(
environment_variable=GXCloudEnvironmentVariable.ACCESS_TOKEN,
conf_file_section="ge_cloud_config",
conf_file_option="access_token",
)
)
return {
GXCloudEnvironmentVariable.BASE_URL: ge_cloud_base_url,
GXCloudEnvironmentVariable.ORGANIZATION_ID: ge_cloud_organization_id,
GXCloudEnvironmentVariable.ACCESS_TOKEN: ge_cloud_access_token,
}
def _init_datasource_store(self) -> None:
from great_expectations.data_context.store.datasource_store import (
DatasourceStore,
)
from great_expectations.data_context.store.gx_cloud_store_backend import (
GXCloudStoreBackend,
)
store_name: str = "datasource_store" # Never explicitly referenced but adheres
# to the convention set by other internal Stores
store_backend: dict = {"class_name": GXCloudStoreBackend.__name__}
runtime_environment: dict = {
"root_directory": self.root_directory,
"ge_cloud_credentials": self.ge_cloud_config.to_dict(), # type: ignore[union-attr]
"ge_cloud_resource_type": GXCloudRESTResource.DATASOURCE,
"ge_cloud_base_url": self.ge_cloud_config.base_url, # type: ignore[union-attr]
}
datasource_store = DatasourceStore(
store_name=store_name,
store_backend=store_backend,
runtime_environment=runtime_environment,
serializer=JsonConfigSerializer(schema=datasourceConfigSchema),
)
self._datasource_store = datasource_store
def list_expectation_suite_names(self) -> List[str]:
"""
Lists the available expectation suite names. If in ge_cloud_mode, a list of
GE Cloud ids is returned instead.
"""
return [suite_key.resource_name for suite_key in self.list_expectation_suites()] # type: ignore[union-attr]
@property
def ge_cloud_config(self) -> Optional[GXCloudConfig]:
return self._ge_cloud_config
@property
def ge_cloud_mode(self) -> bool:
return self._ge_cloud_mode
def _init_variables(self) -> CloudDataContextVariables:
ge_cloud_base_url: str = self._ge_cloud_config.base_url
ge_cloud_organization_id: str = self._ge_cloud_config.organization_id # type: ignore[assignment]
ge_cloud_access_token: str = self._ge_cloud_config.access_token
variables = CloudDataContextVariables(
config=self._project_config,
config_provider=self.config_provider,
ge_cloud_base_url=ge_cloud_base_url,
ge_cloud_organization_id=ge_cloud_organization_id,
ge_cloud_access_token=ge_cloud_access_token,
)
return variables
def _construct_data_context_id(self) -> str:
"""
Choose the id of the currently-configured expectations store, if available and a persistent store.
If not, it should choose the id stored in DataContextConfig.
Returns:
UUID to use as the data_context_id
"""
# if in ge_cloud_mode, use ge_cloud_organization_id
return self.ge_cloud_config.organization_id # type: ignore[return-value,union-attr]
def get_config_with_variables_substituted(
self, config: Optional[DataContextConfig] = None
) -> DataContextConfig:
"""
Substitute vars in config of form ${var} or $(var) with values found in the following places,
in order of precedence: ge_cloud_config (for Data Contexts in GE Cloud mode), runtime_environment,
environment variables, config_variables, or ge_cloud_config_variable_defaults (allows certain variables to
be optional in GE Cloud mode).
"""
if not config:
config = self.config
substitutions: dict = self.config_provider.get_values()
ge_cloud_config_variable_defaults = {
"plugins_directory": self._normalize_absolute_or_relative_path(
path=DataContextConfigDefaults.DEFAULT_PLUGINS_DIRECTORY.value
),
"usage_statistics_url": DEFAULT_USAGE_STATISTICS_URL,
}
for config_variable, value in ge_cloud_config_variable_defaults.items():
if substitutions.get(config_variable) is None:
logger.info(
f'Config variable "{config_variable}" was not found in environment or global config ('
f'{self.GLOBAL_CONFIG_PATHS}). Using default value "{value}" instead. If you would '
f"like to "
f"use a different value, please specify it in an environment variable or in a "
f"great_expectations.conf file located at one of the above paths, in a section named "
f'"ge_cloud_config".'
)
substitutions[config_variable] = value
return DataContextConfig(**self.config_provider.substitute_config(config))
def create_expectation_suite(
self,
expectation_suite_name: str,
overwrite_existing: bool = False,
**kwargs: Optional[dict],
) -> ExpectationSuite:
"""Build a new expectation suite and save it into the data_context expectation store.
Args:
expectation_suite_name: The name of the expectation_suite to create
overwrite_existing (boolean): Whether to overwrite expectation suite if expectation suite with given name
already exists.
Returns:
A new (empty) expectation suite.
"""
if not isinstance(overwrite_existing, bool):
raise ValueError("Parameter overwrite_existing must be of type BOOL")
expectation_suite = ExpectationSuite(
expectation_suite_name=expectation_suite_name, data_context=self
)
existing_suite_names = self.list_expectation_suite_names()
ge_cloud_id: Optional[str] = None
if expectation_suite_name in existing_suite_names and not overwrite_existing:
raise ge_exceptions.DataContextError(
f"expectation_suite '{expectation_suite_name}' already exists. If you would like to overwrite this "
"expectation_suite, set overwrite_existing=True."
)
elif expectation_suite_name in existing_suite_names and overwrite_existing:
identifiers: Optional[
Union[List[str], List[GXCloudIdentifier]]
] = self.list_expectation_suites()
if identifiers:
for ge_cloud_identifier in identifiers:
if isinstance(ge_cloud_identifier, GXCloudIdentifier):
ge_cloud_identifier_tuple = ge_cloud_identifier.to_tuple()
name: str = ge_cloud_identifier_tuple[2]
if name == expectation_suite_name:
ge_cloud_id = ge_cloud_identifier_tuple[1]
expectation_suite.ge_cloud_id = ge_cloud_id
key = GXCloudIdentifier(
resource_type=GXCloudRESTResource.EXPECTATION_SUITE,
ge_cloud_id=ge_cloud_id,
)
response: Union[bool, GXCloudResourceRef] = self.expectations_store.set(key, expectation_suite, **kwargs) # type: ignore[func-returns-value]
if isinstance(response, GXCloudResourceRef):
expectation_suite.ge_cloud_id = response.ge_cloud_id
return expectation_suite
def delete_expectation_suite(
self,
expectation_suite_name: Optional[str] = None,
ge_cloud_id: Optional[str] = None,
) -> bool:
"""Delete specified expectation suite from data_context expectation store.
Args:
expectation_suite_name: The name of the expectation_suite to create
Returns:
True for Success and False for Failure.
"""
key = GXCloudIdentifier(
resource_type=GXCloudRESTResource.EXPECTATION_SUITE,
ge_cloud_id=ge_cloud_id,
)
if not self.expectations_store.has_key(key): # noqa: W601
raise ge_exceptions.DataContextError(
f"expectation_suite with id {ge_cloud_id} does not exist."
)
return self.expectations_store.remove_key(key)
def get_expectation_suite(
self,
expectation_suite_name: Optional[str] = None,
include_rendered_content: Optional[bool] = None,
ge_cloud_id: Optional[str] = None,
) -> ExpectationSuite:
"""Get an Expectation Suite by name or GE Cloud ID
Args:
expectation_suite_name (str): The name of the Expectation Suite
include_rendered_content (bool): Whether or not to re-populate rendered_content for each
ExpectationConfiguration.
ge_cloud_id (str): The GE Cloud ID for the Expectation Suite.
Returns:
An existing ExpectationSuite
"""
key = GXCloudIdentifier(
resource_type=GXCloudRESTResource.EXPECTATION_SUITE,
ge_cloud_id=ge_cloud_id,
)
if not self.expectations_store.has_key(key): # noqa: W601
raise ge_exceptions.DataContextError(
f"expectation_suite with id {ge_cloud_id} not found"
)
expectations_schema_dict: dict = cast(dict, self.expectations_store.get(key))
if include_rendered_content is None:
include_rendered_content = (
self._determine_if_expectation_suite_include_rendered_content()
)
# create the ExpectationSuite from constructor
expectation_suite = ExpectationSuite(
**expectations_schema_dict, data_context=self
)
if include_rendered_content:
expectation_suite.render()
return expectation_suite
@usage_statistics_enabled_method(
event_name=UsageStatsEvents.DATA_CONTEXT_SAVE_EXPECTATION_SUITE,
args_payload_fn=save_expectation_suite_usage_statistics,
)
def save_expectation_suite(
self,
expectation_suite: ExpectationSuite,
expectation_suite_name: Optional[str] = None,
overwrite_existing: bool = True,
include_rendered_content: Optional[bool] = None,
**kwargs: Optional[dict],
) -> None:
"""Save the provided expectation suite into the DataContext.
Args:
expectation_suite: The suite to save.
expectation_suite_name: The name of this Expectation Suite. If no name is provided, the name will be read
from the suite.
overwrite_existing: Whether to overwrite the suite if it already exists.
include_rendered_content: Whether to save the prescriptive rendered content for each expectation.
Returns:
None
"""
id = (
str(expectation_suite.ge_cloud_id)
if expectation_suite.ge_cloud_id
else None
)
key = GXCloudIdentifier(
resource_type=GXCloudRESTResource.EXPECTATION_SUITE,
ge_cloud_id=id,
resource_name=expectation_suite.expectation_suite_name,
)
if not overwrite_existing:
self._validate_suite_unique_constaints_before_save(key)
self._evaluation_parameter_dependencies_compiled = False
include_rendered_content = (
self._determine_if_expectation_suite_include_rendered_content(
include_rendered_content=include_rendered_content
)
)
if include_rendered_content:
expectation_suite.render()
response = self.expectations_store.set(key, expectation_suite, **kwargs) # type: ignore[func-returns-value]
if isinstance(response, GXCloudResourceRef):
expectation_suite.ge_cloud_id = response.ge_cloud_id
def _validate_suite_unique_constaints_before_save(
self, key: GXCloudIdentifier
) -> None:
ge_cloud_id = key.ge_cloud_id
if ge_cloud_id:
if self.expectations_store.has_key(key): # noqa: W601
raise ge_exceptions.DataContextError(
f"expectation_suite with GE Cloud ID {ge_cloud_id} already exists. "
f"If you would like to overwrite this expectation_suite, set overwrite_existing=True."
)
suite_name = key.resource_name
existing_suite_names = self.list_expectation_suite_names()
if suite_name in existing_suite_names:
raise ge_exceptions.DataContextError(
f"expectation_suite '{suite_name}' already exists. If you would like to overwrite this "
"expectation_suite, set overwrite_existing=True."
)
@property
def root_directory(self) -> Optional[str]:
"""The root directory for configuration objects in the data context; the location in which
``great_expectations.yml`` is located.
Why does this exist in AbstractDataContext? CloudDataContext and FileDataContext both use it
"""
return self._context_root_directory
def add_checkpoint(
self,
name: str,
config_version: Optional[Union[int, float]] = None,
template_name: Optional[str] = None,
module_name: Optional[str] = None,
class_name: Optional[str] = None,
run_name_template: Optional[str] = None,
expectation_suite_name: Optional[str] = None,
batch_request: Optional[dict] = None,
action_list: Optional[List[dict]] = None,
evaluation_parameters: Optional[dict] = None,
runtime_configuration: Optional[dict] = None,
validations: Optional[List[dict]] = None,
profilers: Optional[List[dict]] = None,
# Next two fields are for LegacyCheckpoint configuration
validation_operator_name: Optional[str] = None,
batches: Optional[List[dict]] = None,
# the following four arguments are used by SimpleCheckpoint
site_names: Optional[Union[str, List[str]]] = None,
slack_webhook: Optional[str] = None,
notify_on: Optional[str] = None,
notify_with: Optional[Union[str, List[str]]] = None,
ge_cloud_id: Optional[str] = None,
expectation_suite_ge_cloud_id: Optional[str] = None,
default_validation_id: Optional[str] = None,
) -> Checkpoint:
"""
See `AbstractDataContext.add_checkpoint` for more information.
"""
from great_expectations.checkpoint.checkpoint import Checkpoint
checkpoint: Checkpoint = Checkpoint.construct_from_config_args(
data_context=self,
checkpoint_store_name=self.checkpoint_store_name, # type: ignore[arg-type]
name=name,
config_version=config_version,
template_name=template_name,
module_name=module_name,
class_name=class_name,
run_name_template=run_name_template,
expectation_suite_name=expectation_suite_name,
batch_request=batch_request,
action_list=action_list,
evaluation_parameters=evaluation_parameters,
runtime_configuration=runtime_configuration,
validations=validations,
profilers=profilers,
# Next two fields are for LegacyCheckpoint configuration
validation_operator_name=validation_operator_name,
batches=batches,
# the following four arguments are used by SimpleCheckpoint
site_names=site_names,
slack_webhook=slack_webhook,
notify_on=notify_on,
notify_with=notify_with,
ge_cloud_id=ge_cloud_id,
expectation_suite_ge_cloud_id=expectation_suite_ge_cloud_id,
default_validation_id=default_validation_id,
)
checkpoint_config = self.checkpoint_store.create(
checkpoint_config=checkpoint.config
)
checkpoint = Checkpoint.instantiate_from_config_with_runtime_args(
checkpoint_config=checkpoint_config, data_context=self # type: ignore[arg-type]
)
return checkpoint
def list_checkpoints(self) -> Union[List[str], List[ConfigurationIdentifier]]:
return self.checkpoint_store.list_checkpoints(ge_cloud_mode=self.ge_cloud_mode)
def list_profilers(self) -> Union[List[str], List[ConfigurationIdentifier]]:
return RuleBasedProfiler.list_profilers(
profiler_store=self.profiler_store, ge_cloud_mode=self.ge_cloud_mode
)
def _init_site_builder_for_data_docs_site_creation(
self, site_name: str, site_config: dict
) -> SiteBuilder:
"""
Note that this explicitly overriding the `AbstractDataContext` helper method called
in `self.build_data_docs()`.
The only difference here is the inclusion of `ge_cloud_mode` in the `runtime_environment`
used in `SiteBuilder` instantiation.
"""
site_builder: SiteBuilder = instantiate_class_from_config(
config=site_config,
runtime_environment={
"data_context": self,
"root_directory": self.root_directory,
"site_name": site_name,
"ge_cloud_mode": self.ge_cloud_mode,
},
config_defaults={
"module_name": "great_expectations.render.renderer.site_builder"
},
)
return site_builder
def _determine_key_for_profiler_save(
self, name: str, id: Optional[str]
) -> Union[ConfigurationIdentifier, GXCloudIdentifier]:
"""
Note that this explicitly overriding the `AbstractDataContext` helper method called
in `self.save_profiler()`.
The only difference here is the creation of a Cloud-specific `GXCloudIdentifier`
instead of the usual `ConfigurationIdentifier` for `Store` interaction.
"""
return GXCloudIdentifier(
resource_type=GXCloudRESTResource.PROFILER, ge_cloud_id=id
)
<file_sep>/docs/guides/validation/advanced/how_to_validate_data_with_an_in_memory_checkpoint.md
---
title: How to Validate data with an in-memory Checkpoint
---
import Prerequisites from '../../../guides/connecting_to_your_data/components/prerequisites.jsx';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
import Tabs from '@theme/Tabs'
import TabItem from '@theme/TabItem'
This guide will demonstrate how to Validate data using a Checkpoint that is configured and run entirely in-memory. This workflow is appropriate for environments or workflows where a user does not want to or cannot use a Checkpoint Store, e.g. in a [hosted environment](../../../deployment_patterns/how_to_instantiate_a_data_context_hosted_environments.md).
<Prerequisites>
- Have a Data Context
- Have an Expectation Suite
- Have a Datasource
- Have a basic understanding of Checkpoints
</Prerequisites>
:::note
Reading our guide on [Deploying Great Expectations in a hosted environment without file system or CLI](../../../deployment_patterns/how_to_instantiate_a_data_context_hosted_environments.md) is recommended for guidance on the setup, connecting to data, and creating expectations steps that take place prior to this process.
:::
## Steps
### 1. Import the necessary modules
The recommended method for creating a Checkpoint is to use the CLI to open a Jupyter Notebook which contains code scaffolding to assist you with the process. Since that option is not available (this guide is assuming that your need for an in-memory Checkpoint is due to being unable to use the CLI or access a filesystem) you will have to provide that scaffolding yourself.
In the script that you are defining and executing your Checkpoint in, enter the following code:
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_python_configured_in_memory_checkpoint.py#L6-L8
```
Importing `great_expectations` will give you access to your Data Context, while we will configure an instance of the `Checkpoint` class as our in-memory Checkpoint.
If you are planning to use a YAML string to configure your in-memory Checkpoint you will also need to import `yaml` from `ruamel`:
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_yaml_configured_in_memory_checkpoint.py#L4-L5
```
You will also need to initialize `yaml.YAML(...)`:
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_yaml_configured_in_memory_checkpoint.py#L21
```
### 2. Initialize your Data Context
In the previous section you imported `great_expectations` in order to get access to your Data Context. The line of code that does this is:
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_python_configured_in_memory_checkpoint.py#L26
```
Checkpoints require a Data Context in order to access necessary Stores from which to retrieve Expectation Suites and store Validation Results and Metrics, so you will pass `context` in as a parameter when you initialize your `Checkpoint` class later.
### 3. Define your Checkpoint configuration
In addition to a Data Context, you will need a configuration with which to initialize your Checkpoint. This configuration can be in the form of a YAML string or a Python dictionary, The following examples show configurations that are equivalent to the one used by the Getting Started Tutorial.
Normally, a Checkpoint configuration will include the keys `class_name` and `module_name`. These are used by Great Expectations to identify the class of Checkpoint that should be initialized with a given configuration. Since we are initializing an instance of the `Checkpoint` class directly we don't need the configuration to indicate the class of Checkpoint to be initialized. Therefore, these two keys will be left out of our configuration.
<Tabs
defaultValue="python_dict"
values={[
{label: 'Python Dictionary', value: 'python_dict'},
{label: 'YAML String', value: 'yaml_str'},
]}>
<TabItem value="python_dict">
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_python_configured_in_memory_checkpoint.py#L60-L90
```
</TabItem>
<TabItem value="yaml_str">
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_yaml_configured_in_memory_checkpoint.py#L61-L83
```
</TabItem>
</Tabs>
When you are tailoring the configuration for your own purposes, you will want to replace the Batch Request and Expectation Suite under the `validations` key with your own values. You can further edit the configuration to add additional Batch Request and Expectation Suite entries under the `validations` key. Alternatively, you can even replace this configuration entirely and build one from scratch. If you choose to build a configuration from scratch, or to further modify the examples provided above, you may wish to reference [our documentation on Checkpoint configurations](../../../terms/checkpoint.md#checkpoint-configuration) as you do.
### 4. Initialize your Checkpoint
Once you have your Data Context and Checkpoint configuration you will be able to initialize a `Checkpoint` instance in memory. There is a minor variation in how you do so, depending on whether you are using a Python dictionary or a YAML string for your configuration.
<Tabs
defaultValue="python_dict"
values={[
{label: 'Python Dictionary', value: 'python_dict'},
{label: 'YAML String', value: 'yaml_str'},
]}>
<TabItem value="python_dict">
If you are using a Python dictionary as your configuration, you will need to unpack it as parameters for the `Checkpoint` object's initialization. This can be done with the code:
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_python_configured_in_memory_checkpoint.py#L96
```
</TabItem>
<TabItem value="yaml_str">
If you are using a YAML string as your configuration, you will need to convert it into a dictionary and unpack it as parameters for the `Checkpoint` object's initialization. This can be done with the code:
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_yaml_configured_in_memory_checkpoint.py#L89
```
</TabItem>
</Tabs>
### 5. Run your Checkpoint
Congratulations! You now have an initialized `Checkpoint` object in memory. You can now use it's `run(...)` method to Validate your data as specified in the configuration.
This will be done with the line:
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_yaml_configured_in_memory_checkpoint.py#L94
```
Congratulations! Your script is now ready to be run. Each time you run it, it will initialize and run a Checkpoint in memory, rather than retrieving a Checkpoint configuration from a Checkpoint Store.
### 6. Check your Data Docs
Once you have run your script you can verify that it has worked by checking your Data Docs for new results.
## Notes
To view the full example scripts used in this documentation, see:
- [how_to_validate_data_with_a_yaml_configured_in_memory_checkpoint.py](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_python_configured_in_memory_checkpoint.py)
- [how_to_validate_data_with_a_python_configured_in_memory_checkpoint.py](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_python_configured_in_memory_checkpoint.py)<file_sep>/tests/data_context/store/test_ge_cloud_store_backend.py
import pytest
from great_expectations.data_context.cloud_constants import (
CLOUD_DEFAULT_BASE_URL,
GXCloudRESTResource,
)
from great_expectations.data_context.store.ge_cloud_store_backend import (
GeCloudStoreBackend,
)
from great_expectations.data_context.store.gx_cloud_store_backend import (
GXCloudStoreBackend,
)
@pytest.mark.cloud
@pytest.mark.unit
def test_ge_cloud_store_backend_is_alias_of_gx_cloud_store_backend(
ge_cloud_access_token: str,
) -> None:
ge_cloud_base_url = CLOUD_DEFAULT_BASE_URL
ge_cloud_credentials = {
"access_token": ge_cloud_access_token,
"organization_id": "51379b8b-86d3-4fe7-84e9-e1a52f4a414c",
}
backend = GeCloudStoreBackend(
ge_cloud_base_url=ge_cloud_base_url,
ge_cloud_credentials=ge_cloud_credentials,
ge_cloud_resource_type=GXCloudRESTResource.CHECKPOINT,
)
assert isinstance(backend, GXCloudStoreBackend)
<file_sep>/docs/guides/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.md
---
title: How to create an Expectation Suite with the Onboarding Data Assistant
---
import Prerequisites from '../../../guides/connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide demonstrates how to use the Onboarding Data Assistant to Profile your data and automate the generation of an
Expectation Suite, which you can then adjust to be suited for your specific needs.
:::note
This process mirrors that of the Jupyter Notebook that is created when you run the following CLI command:
```terminal
great_expectations suite new --profile
```
:::
<Prerequisites>
- A [configured Data Context](../../../tutorials/getting_started/tutorial_setup.md).
- The knowledge to [configure and save a Datasource](../../connecting_to_your_data/connect_to_data_overview.md).
- The knowledge to [configure and save a Batch Request](../../connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.md).
</Prerequisites>
## Steps
### 1. Prepare your Batch Request
Data Assistants excel at automating the Profiling process across multiple Batches. Therefore, for this guide you will
be using a Batch Request that covers multiple Batches. For the purposes of this demo, the Datasource that our Batch
Request queries will consist of a sample of the New York taxi trip data.
This is the configuration that you will use for your `Datasource`:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L27-L45
```
And this is the configuration that you will use for your `BatchRequest`:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L76-L80
```
:::caution
The Onboarding Data Assistant will run a high volume of queries against your `Datasource`. Data Assistant performance
can vary significantly depending on the number of Batches, count of records per Batch, and network latency. It is
recommended that you start with a smaller `BatchRequest` if you find that Data Assistant runtimes are too long.
:::
### 2. Prepare a new Expectation Suite
Preparing a new Expectation Suite is done with the Data Context's `create_expectation_suite(...)` method, as seen in
this code example:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L66-L70
```
### 3. Run the Onboarding Data Assistant
Running a Data Assistant is as simple as calling the `run(...)` method for the appropriate assistant.
That said, there are numerous parameters available for the `run(...)` method of the Onboarding Data Assistant. For
instance, the `exclude_column_names` parameter allows you to provide a list columns that should not be Profiled.
For this guide, you will exclude the following columns:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L86-L101
```
The following code shows how to run the Onboarding Assistant. In this code block, `context` is an instance of your Data Context.
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L105-L108
```
:::note
If you consider your `BatchRequest` data valid, and want to produce Expectations with ranges that are identical to the
data in the `BatchRequest`, there is no need to alter the command above. You will be using the default `estimation` parameter (`"exact"`).
If you want to identify potential outliers in your `BatchRequest` data, pass `estimation="flag_outliers"` to the `run(...)` method.
:::
:::note
The Onboarding Data Assistant `run(...)` method can accept other parameters in addition to `exclude_column_names` such
as `include_column_names`, `include_column_name_suffixes`, and `cardinality_limit_mode`.
For a description of the available parameters please see this docstring [here](https://github.com/great-expectations/great_expectations/blob/develop/great_expectations/rule_based_profiler/data_assistant/onboarding_data_assistant.py#L44).
:::
### 4. Save your Expectation Suite
Once you have executed the Onboarding Data Assistant's `run(...)` method and generated Expectations for your data, you
need to load them into your Expectation Suite and save them. You will do this by using the Data Assistant result:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L114-L116
```
And once the Expectation Suite has been retrieved from the Data Assistant result, you can save it like so:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L120-L122
```
### 5. Test your Expectation Suite with a `SimpleCheckpoint`
To verify that your Expectation Suite is working, you can use a `SimpleCheckpoint`. First, you will configure one to
operate with the Expectation Suite and Batch Request that you have already defined:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L128-L136
```
Once you have our `SimpleCheckpoint`'s configuration defined, you can instantiate a `SimpleCheckpoint` and run it. You
can check the `"success"` key of the `SimpleCheckpoint`'s results to verify that your Expectation Suite worked.
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L140-L147
```
### 6. Plot and inspect the Data Assistant's calculated Metrics and produced Expectations
To see Batch-level visualizations of Metrics computed by the Onboarding Data Assistant run:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L159
```

:::note
Hovering over a data point will provide more information about the Batch and its calculated Metric value in a tooltip.
:::
To see all Metrics computed by the Onboarding Data Assistant run:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L163
```
To plot the Expectations produced, and the associated Metrics calculated by the Onboarding Data Assistant run:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L167
```

:::note
If no Expectation was produced by the Data Assistant for a given Metric, neither the Expectation nor the Metric will be visualized by the `plot_expectations_and_metrics()` method.
:::
To see the Expectations produced and grouped by Domain run:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L171
```
To see the Expectations produced and grouped by Expectation type run:
```python file=../../../../tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py#L175
```
### 7. (Optional) Edit your Expectation Suite, save, and test again.
The Onboarding Data Assistant will create as many applicable Expectations as it can for the permitted columns. This
provides a solid base for analyzing your data, but may exceed your needs. It is also possible that you may possess
some domain knowledge that is not reflected in the data that was sampled for the Profiling process. In either of these
(or any other) cases, you can edit your Expectation Suite to more closely suite your needs.
To edit an existing Expectation Suite (such as the one that you just created and saved with the Onboarding Data
Assistant) you need only execute the following console command:
```markdown title="Terminal command"
great_expectations suite edit NAME_OF_YOUR_SUITE_HERE
```
This will open a Jupyter Notebook that will permit you to review, edit, and save changes to the specified Expectation
Suite.
## Additional Information
:::note Example Code
To view the full script used for example code on this page, see it on GitHub:
- [how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py)
:::
<file_sep>/great_expectations/experimental/context.py
from __future__ import annotations
import logging
import pathlib
from pprint import pformat as pf
from typing import TYPE_CHECKING, ClassVar, Dict, Optional, Union
from pydantic import DirectoryPath, validate_arguments
from great_expectations.experimental.datasources.config import GxConfig
from great_expectations.experimental.datasources.sources import _SourceFactories
if TYPE_CHECKING:
from great_expectations.experimental.datasources.interfaces import Datasource
LOGGER = logging.getLogger(__name__)
class DataContext:
"""
NOTE: this is just a scaffold for exploring and iterating on our experimental datasource prototype
this will be formalized and tested prior to release.
Use `great_expectations.get_context()` for a real DataContext.
"""
_context: ClassVar[Optional[DataContext]] = None
_config: ClassVar[Optional[GxConfig]] = None # (kilo59) should this live here?
_datasources: Dict[str, Datasource]
root_directory: Union[DirectoryPath, str, None]
@classmethod
def get_context(
cls,
context_root_dir: Optional[DirectoryPath] = None,
_config_file: str = "config.yaml", # for ease of use during POC
) -> DataContext:
if not cls._context:
cls._context = DataContext(context_root_dir=context_root_dir)
assert cls._context
if cls._context.root_directory:
# load config and add/instantiate Datasources & Assets
config_path = pathlib.Path(cls._context.root_directory) / _config_file
cls._config = GxConfig.parse_yaml(config_path)
for ds_name, datasource in cls._config.datasources.items():
LOGGER.info(f"Loaded '{ds_name}' from config")
cls._context._attach_datasource_to_context(datasource)
# TODO: add assets?
return cls._context
@validate_arguments
def __init__(self, context_root_dir: Optional[DirectoryPath] = None) -> None:
self.root_directory = context_root_dir
self._sources: _SourceFactories = _SourceFactories(self)
self._datasources: Dict[str, Datasource] = {}
LOGGER.info(f"4a. Available Factories - {self._sources.factories}")
LOGGER.debug(f"4b. `type_lookup` mapping ->\n{pf(self._sources.type_lookup)}")
@property
def sources(self) -> _SourceFactories:
return self._sources
def _attach_datasource_to_context(self, datasource: Datasource) -> None:
self._datasources[datasource.name] = datasource
def get_datasource(self, datasource_name: str) -> Datasource:
# NOTE: this same method exists on AbstractDataContext
# TODO (kilo59): implement as __getitem__ ?
try:
return self._datasources[datasource_name]
except KeyError as exc:
raise LookupError(
f"'{datasource_name}' not found. Available datasources are {list(self._datasources.keys())}"
) from exc
def get_context(
context_root_dir: Optional[DirectoryPath] = None, **kwargs
) -> DataContext:
"""Experimental get_context placeholder function."""
LOGGER.info(f"3. Getting context {context_root_dir or ''}")
context = DataContext.get_context(context_root_dir=context_root_dir, **kwargs)
return context
<file_sep>/docs/guides/setup/configuring_metadata_stores/components_how_to_configure_a_validation_result_store_in_amazon_s3/_update_your_configuration_file_to_include_a_new_store_for_validation_results_on_s.mdx
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
You can manually add a Validation Results Store by adding the configuration below to the `stores` section of your `great_expectations.yml` file:
```yaml title="File contents: great_expectations.yml"
stores:
validations_S3_store:
class_name: ValidationsStore
store_backend:
class_name: TupleS3StoreBackend
bucket: '<your_s3_bucket_name>'
prefix: '<your_s3_bucket_folder_name>'
```
To make the Store work with S3, you will need to make some changes from the default ``store_backend`` settings, as has been done in the above example. The ``class_name`` will be set to ``TupleS3StoreBackend``, ``bucket`` will be set to the address of your S3 bucket, and ``prefix`` will be set to the folder in your S3 bucket where Validation results will be located.
For the example above, note that the new Store's name is set to ``validations_S3_store``. This can be any name you like, as long as you also update the value of the `validations_store_name` key to match the new Store's name.
```yaml title="File contents: great_expectations.yml"
validations_store_name: validations_S3_store
```
This update to the value of the `validations_store_name` key will tell Great Expectations to use the new Store for Validation Results.
:::caution
If you are also storing <TechnicalTag tag="expectation" text="Expectations" /> in S3 ([How to configure an Expectation store to use Amazon S3](../how_to_configure_an_expectation_store_in_amazon_s3.md)), or DataDocs in S3 ([How to host and share Data Docs on Amazon S3](../../configuring_data_docs/how_to_host_and_share_data_docs_on_amazon_s3.md)), then please ensure that the ``prefix`` values are disjoint and one is not a substring of the other.
:::
<file_sep>/contrib/experimental/great_expectations_experimental/expectations/expect_column_values_to_be_valid_arn.py
"""
This is a template for creating custom RegexBasedColumnMapExpectations.
For detailed instructions on how to use it, please see:
https://docs.greatexpectations.io/docs/guides/expectations/creating_custom_expectations/how_to_create_custom_regex_based_column_map_expectations
"""
from typing import Dict, Optional
from great_expectations.core.expectation_configuration import ExpectationConfiguration
from great_expectations.exceptions.exceptions import (
InvalidExpectationConfigurationError,
)
from great_expectations.expectations.regex_based_column_map_expectation import (
RegexBasedColumnMapExpectation,
RegexColumnMapMetricProvider,
)
class ExpectColumnValuesToBeValidArn(RegexBasedColumnMapExpectation):
"""Expect values in this column to be a valid amazon arn."""
# These values will be used to configure the metric created by your expectation
regex_camel_name = "AmazonResourceName"
regex = "^arn:(?P<Partition>[^:\n]*):(?P<Service>[^:\n]*):(?P<Region>[^:\n]*):(?P<AccountID>[^:\n]*):(?P<Ignore>(?P<ResourceType>[^:\/\n]*)[:\/])?(?P<Resource>.*)$"
semantic_type_name_plural = "arns"
# These examples will be shown in the public gallery.
# They will also be executed as unit tests for your Expectation.
examples = [
{
"data": {
"valid_arns": [
"arn:aws:s3:::my-bucket/my-object",
"arn:partition:service:region:account-id:resource",
],
"invalid_alphanumeric": [
"apz8",
"bubba:arn:123",
],
"invalid_arn": [
"arn:aws:::::::my-bucket/my-object",
"arn::::",
],
"empty": ["", None],
},
"tests": [
{
"title": "basic_positive_test",
"exact_match_out": False,
"include_in_gallery": True,
"in": {"column": "valid_arns"},
"out": {
"success": True,
},
},
{
"title": "basic_negative_test",
"exact_match_out": False,
"include_in_gallery": True,
"in": {"column": "invalid_alphanumeric", "mostly": 1},
"out": {
"success": False,
},
},
{
"title": "invalid_non_alphanumeric",
"exact_match_out": False,
"include_in_gallery": True,
"in": {"column": "invalid_arn", "mostly": 1},
"out": {
"success": False,
},
},
{
"title": "empty",
"exact_match_out": False,
"include_in_gallery": True,
"in": {"column": "empty", "mostly": 1},
"out": {
"success": False,
},
},
],
}
]
# Here your regex is used to create a custom metric for this expectation
map_metric = RegexBasedColumnMapExpectation.register_metric(
regex_camel_name=regex_camel_name,
regex_=regex,
)
# This object contains metadata for display in the public Gallery
library_metadata = {
"maturity": "experimental",
"tags": [
"amazon",
"arn",
"expectation",
], # Tags for this Expectation in the Gallery
"contributors": [ # Github handles for all contributors to this Expectation.
"@rdodev", # Don't forget to add your github handle here!
],
}
if __name__ == "__main__":
ExpectColumnValuesToBeValidArn().print_diagnostic_checklist()
<file_sep>/tests/rule_based_profiler/parameter_builder/test_mean_unexpected_map_metric_multi_batch_parameter_builder.py
from typing import Any, Dict, List, Optional
import numpy as np
import pytest
from great_expectations import DataContext
from great_expectations.core.metric_domain_types import MetricDomainTypes
from great_expectations.rule_based_profiler.config import ParameterBuilderConfig
from great_expectations.rule_based_profiler.domain import Domain
from great_expectations.rule_based_profiler.helpers.util import (
get_parameter_value_and_validate_return_type,
)
from great_expectations.rule_based_profiler.parameter_builder import (
MeanUnexpectedMapMetricMultiBatchParameterBuilder,
MetricMultiBatchParameterBuilder,
ParameterBuilder,
)
from great_expectations.rule_based_profiler.parameter_container import (
DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
ParameterContainer,
ParameterNode,
)
from tests.rule_based_profiler.conftest import ATOL, RTOL
@pytest.mark.integration
def test_instantiation_mean_unexpected_map_metric_multi_batch_parameter_builder(
bobby_columnar_table_multi_batch_deterministic_data_context,
):
data_context: DataContext = (
bobby_columnar_table_multi_batch_deterministic_data_context
)
# noinspection PyUnusedLocal
parameter_builder: ParameterBuilder = (
MeanUnexpectedMapMetricMultiBatchParameterBuilder(
name="my_name",
map_metric_name="column_values.nonnull",
total_count_parameter_builder_name="my_total_count",
data_context=data_context,
)
)
@pytest.mark.integration
def test_instantiation_mean_unexpected_map_metric_multi_batch_parameter_builder_required_arguments_absent(
bobby_columnar_table_multi_batch_deterministic_data_context,
):
data_context: DataContext = (
bobby_columnar_table_multi_batch_deterministic_data_context
)
with pytest.raises(TypeError) as excinfo:
# noinspection PyUnusedLocal,PyArgumentList
parameter_builder: ParameterBuilder = (
MeanUnexpectedMapMetricMultiBatchParameterBuilder(
name="my_name",
map_metric_name="column_values.nonnull",
data_context=data_context,
)
)
assert (
"__init__() missing 1 required positional argument: 'total_count_parameter_builder_name'"
in str(excinfo.value)
)
with pytest.raises(TypeError) as excinfo:
# noinspection PyUnusedLocal,PyArgumentList
parameter_builder: ParameterBuilder = (
MeanUnexpectedMapMetricMultiBatchParameterBuilder(
name="my_name",
total_count_parameter_builder_name="my_total_count",
data_context=data_context,
)
)
assert (
"__init__() missing 1 required positional argument: 'map_metric_name'"
in str(excinfo.value)
)
@pytest.mark.integration
@pytest.mark.slow # 1.56s
def test_mean_unexpected_map_metric_multi_batch_parameter_builder_bobby_numeric_dependencies_evaluated_separately(
bobby_columnar_table_multi_batch_deterministic_data_context,
):
data_context: DataContext = (
bobby_columnar_table_multi_batch_deterministic_data_context
)
batch_request: dict = {
"datasource_name": "taxi_pandas",
"data_connector_name": "monthly",
"data_asset_name": "my_reports",
}
my_total_count_metric_multi_batch_parameter_builder: MetricMultiBatchParameterBuilder = MetricMultiBatchParameterBuilder(
name="my_total_count",
metric_name="table.row_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
single_batch_mode=False,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
data_context=data_context,
)
my_null_count_metric_multi_batch_parameter_builder: MetricMultiBatchParameterBuilder = MetricMultiBatchParameterBuilder(
name="my_null_count",
metric_name="column_values.nonnull.unexpected_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
single_batch_mode=False,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
data_context=data_context,
)
mean_unexpected_map_metric_multi_batch_parameter_builder: ParameterBuilder = (
MeanUnexpectedMapMetricMultiBatchParameterBuilder(
name="my_passenger_count_values_not_null_mean_unexpected_map_metric",
map_metric_name="column_values.nonnull",
total_count_parameter_builder_name="my_total_count",
null_count_parameter_builder_name="my_null_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
evaluation_parameter_builder_configs=None,
data_context=data_context,
)
)
metric_domain_kwargs: dict = {"column": "passenger_count"}
domain = Domain(
domain_type=MetricDomainTypes.COLUMN,
domain_kwargs=metric_domain_kwargs,
rule_name="my_rule",
)
variables: Optional[ParameterContainer] = None
parameter_container = ParameterContainer(parameter_nodes=None)
parameters: Dict[str, ParameterContainer] = {
domain.id: parameter_container,
}
my_total_count_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
my_null_count_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
mean_unexpected_map_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
expected_parameter_value: float = 0.0
parameter_node: ParameterNode = get_parameter_value_and_validate_return_type(
domain=domain,
parameter_reference=mean_unexpected_map_metric_multi_batch_parameter_builder.json_serialized_fully_qualified_parameter_name,
expected_return_type=None,
variables=variables,
parameters=parameters,
)
rtol: float = RTOL
atol: float = 5.0e-1 * ATOL
np.testing.assert_allclose(
actual=parameter_node.value,
desired=expected_parameter_value,
rtol=rtol,
atol=atol,
err_msg=f"Actual value of {parameter_node.value} differs from expected value of {expected_parameter_value} by more than {atol + rtol * abs(parameter_node.value)} tolerance.",
)
@pytest.mark.integration
@pytest.mark.slow # 1.58s
def test_mean_unexpected_map_metric_multi_batch_parameter_builder_bobby_numeric_dependencies_evaluated_in_parameter_builder(
bobby_columnar_table_multi_batch_deterministic_data_context,
):
data_context: DataContext = (
bobby_columnar_table_multi_batch_deterministic_data_context
)
batch_request: dict = {
"datasource_name": "taxi_pandas",
"data_connector_name": "monthly",
"data_asset_name": "my_reports",
}
my_total_count_metric_multi_batch_parameter_builder_config = ParameterBuilderConfig(
module_name="great_expectations.rule_based_profiler.parameter_builder",
class_name="MetricMultiBatchParameterBuilder",
name="my_total_count",
metric_name="table.row_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
)
my_null_count_metric_multi_batch_parameter_builder_config = ParameterBuilderConfig(
module_name="great_expectations.rule_based_profiler.parameter_builder",
class_name="MetricMultiBatchParameterBuilder",
name="my_null_count",
metric_name="column_values.nonnull.unexpected_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
)
evaluation_parameter_builder_configs: Optional[List[ParameterBuilderConfig]] = [
my_total_count_metric_multi_batch_parameter_builder_config,
my_null_count_metric_multi_batch_parameter_builder_config,
]
mean_unexpected_map_metric_multi_batch_parameter_builder: ParameterBuilder = (
MeanUnexpectedMapMetricMultiBatchParameterBuilder(
name="my_passenger_count_values_not_null_mean_unexpected_map_metric",
map_metric_name="column_values.nonnull",
total_count_parameter_builder_name="my_total_count",
null_count_parameter_builder_name="my_null_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
evaluation_parameter_builder_configs=evaluation_parameter_builder_configs,
data_context=data_context,
)
)
metric_domain_kwargs: dict = {"column": "passenger_count"}
domain = Domain(
domain_type=MetricDomainTypes.COLUMN,
domain_kwargs=metric_domain_kwargs,
rule_name="my_rule",
)
variables: Optional[ParameterContainer] = None
parameter_container = ParameterContainer(parameter_nodes=None)
parameters: Dict[str, ParameterContainer] = {
domain.id: parameter_container,
}
mean_unexpected_map_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
expected_parameter_value: float = 0.0
parameter_node: ParameterNode = get_parameter_value_and_validate_return_type(
domain=domain,
parameter_reference=mean_unexpected_map_metric_multi_batch_parameter_builder.json_serialized_fully_qualified_parameter_name,
expected_return_type=None,
variables=variables,
parameters=parameters,
)
rtol: float = RTOL
atol: float = 5.0e-1 * ATOL
np.testing.assert_allclose(
actual=parameter_node.value,
desired=expected_parameter_value,
rtol=rtol,
atol=atol,
err_msg=f"Actual value of {parameter_node.value} differs from expected value of {expected_parameter_value} by more than {atol + rtol * abs(parameter_node.value)} tolerance.",
)
@pytest.mark.integration
@pytest.mark.slow # 1.58s
def test_mean_unexpected_map_metric_multi_batch_parameter_builder_bobby_numeric_dependencies_evaluated_mixed(
bobby_columnar_table_multi_batch_deterministic_data_context,
):
data_context: DataContext = (
bobby_columnar_table_multi_batch_deterministic_data_context
)
batch_request: dict = {
"datasource_name": "taxi_pandas",
"data_connector_name": "monthly",
"data_asset_name": "my_reports",
}
my_total_count_metric_multi_batch_parameter_builder_config = ParameterBuilderConfig(
module_name="great_expectations.rule_based_profiler.parameter_builder",
class_name="MetricMultiBatchParameterBuilder",
name="my_total_count",
metric_name="table.row_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
)
my_null_count_metric_multi_batch_parameter_builder: MetricMultiBatchParameterBuilder = MetricMultiBatchParameterBuilder(
name="my_null_count",
metric_name="column_values.nonnull.unexpected_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
single_batch_mode=False,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
data_context=data_context,
)
evaluation_parameter_builder_configs: Optional[List[ParameterBuilderConfig]] = [
my_total_count_metric_multi_batch_parameter_builder_config,
]
mean_unexpected_map_metric_multi_batch_parameter_builder: ParameterBuilder = (
MeanUnexpectedMapMetricMultiBatchParameterBuilder(
name="my_passenger_count_values_not_null_mean_unexpected_map_metric",
map_metric_name="column_values.nonnull",
total_count_parameter_builder_name="my_total_count",
null_count_parameter_builder_name="my_null_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
evaluation_parameter_builder_configs=evaluation_parameter_builder_configs,
data_context=data_context,
)
)
metric_domain_kwargs: dict = {"column": "passenger_count"}
domain = Domain(
domain_type=MetricDomainTypes.COLUMN,
domain_kwargs=metric_domain_kwargs,
rule_name="my_rule",
)
variables: Optional[ParameterContainer] = None
parameter_container = ParameterContainer(parameter_nodes=None)
parameters: Dict[str, ParameterContainer] = {
domain.id: parameter_container,
}
my_null_count_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
mean_unexpected_map_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
expected_parameter_value: float = 0.0
parameter_node: ParameterNode = get_parameter_value_and_validate_return_type(
domain=domain,
parameter_reference=mean_unexpected_map_metric_multi_batch_parameter_builder.json_serialized_fully_qualified_parameter_name,
expected_return_type=None,
variables=variables,
parameters=parameters,
)
rtol: float = RTOL
atol: float = 5.0e-1 * ATOL
np.testing.assert_allclose(
actual=parameter_node.value,
desired=expected_parameter_value,
rtol=rtol,
atol=atol,
err_msg=f"Actual value of {parameter_node.value} differs from expected value of {expected_parameter_value} by more than {atol + rtol * abs(parameter_node.value)} tolerance.",
)
@pytest.mark.integration
@pytest.mark.slow # 1.58s
def test_mean_unexpected_map_metric_multi_batch_parameter_builder_bobby_datetime_dependencies_evaluated_separately(
bobby_columnar_table_multi_batch_deterministic_data_context,
):
data_context: DataContext = (
bobby_columnar_table_multi_batch_deterministic_data_context
)
batch_request: dict = {
"datasource_name": "taxi_pandas",
"data_connector_name": "monthly",
"data_asset_name": "my_reports",
}
my_total_count_metric_multi_batch_parameter_builder: MetricMultiBatchParameterBuilder = MetricMultiBatchParameterBuilder(
name="my_total_count",
metric_name="table.row_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
single_batch_mode=False,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
data_context=data_context,
)
my_null_count_metric_multi_batch_parameter_builder: MetricMultiBatchParameterBuilder = MetricMultiBatchParameterBuilder(
name="my_null_count",
metric_name="column_values.nonnull.unexpected_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
single_batch_mode=False,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
data_context=data_context,
)
mean_unexpected_map_metric_multi_batch_parameter_builder: ParameterBuilder = (
MeanUnexpectedMapMetricMultiBatchParameterBuilder(
name="my_pickup_datetime_count_values_unique_mean_unexpected_map_metric",
map_metric_name="column_values.nonnull",
total_count_parameter_builder_name="my_total_count",
null_count_parameter_builder_name="my_null_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
evaluation_parameter_builder_configs=None,
data_context=data_context,
)
)
metric_domain_kwargs: dict = {"column": "pickup_datetime"}
domain = Domain(
domain_type=MetricDomainTypes.COLUMN,
domain_kwargs=metric_domain_kwargs,
rule_name="my_rule",
)
variables: Optional[ParameterContainer] = None
parameter_container = ParameterContainer(parameter_nodes=None)
parameters: Dict[str, ParameterContainer] = {
domain.id: parameter_container,
}
my_total_count_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
my_null_count_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
mean_unexpected_map_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
expected_parameter_value: float = 3.89e-3
parameter_node: ParameterNode = get_parameter_value_and_validate_return_type(
domain=domain,
parameter_reference=mean_unexpected_map_metric_multi_batch_parameter_builder.json_serialized_fully_qualified_parameter_name,
expected_return_type=None,
variables=variables,
parameters=parameters,
)
rtol: float = RTOL
atol: float = 5.0e-1 * ATOL
np.testing.assert_allclose(
actual=parameter_node.value,
desired=expected_parameter_value,
rtol=rtol,
atol=atol,
err_msg=f"Actual value of {parameter_node.value} differs from expected value of {expected_parameter_value} by more than {atol + rtol * abs(parameter_node.value)} tolerance.",
)
@pytest.mark.integration
@pytest.mark.slow # 1.58s
def test_mean_unexpected_map_metric_multi_batch_parameter_builder_bobby_datetime_dependencies_evaluated_in_parameter_builder(
bobby_columnar_table_multi_batch_deterministic_data_context,
):
data_context: DataContext = (
bobby_columnar_table_multi_batch_deterministic_data_context
)
batch_request: dict = {
"datasource_name": "taxi_pandas",
"data_connector_name": "monthly",
"data_asset_name": "my_reports",
}
my_total_count_metric_multi_batch_parameter_builder_config = ParameterBuilderConfig(
module_name="great_expectations.rule_based_profiler.parameter_builder",
class_name="MetricMultiBatchParameterBuilder",
name="my_total_count",
metric_name="table.row_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
)
my_null_count_metric_multi_batch_parameter_builder_config = ParameterBuilderConfig(
module_name="great_expectations.rule_based_profiler.parameter_builder",
class_name="MetricMultiBatchParameterBuilder",
name="my_null_count",
metric_name="column_values.nonnull.unexpected_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
)
evaluation_parameter_builder_configs: Optional[List[ParameterBuilderConfig]] = [
my_total_count_metric_multi_batch_parameter_builder_config,
my_null_count_metric_multi_batch_parameter_builder_config,
]
mean_unexpected_map_metric_multi_batch_parameter_builder: ParameterBuilder = (
MeanUnexpectedMapMetricMultiBatchParameterBuilder(
name="my_pickup_datetime_count_values_unique_mean_unexpected_map_metric",
map_metric_name="column_values.nonnull",
total_count_parameter_builder_name="my_total_count",
null_count_parameter_builder_name="my_null_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
evaluation_parameter_builder_configs=evaluation_parameter_builder_configs,
data_context=data_context,
)
)
metric_domain_kwargs: dict = {"column": "pickup_datetime"}
domain = Domain(
domain_type=MetricDomainTypes.COLUMN,
domain_kwargs=metric_domain_kwargs,
rule_name="my_rule",
)
variables: Optional[ParameterContainer] = None
parameter_container = ParameterContainer(parameter_nodes=None)
parameters: Dict[str, ParameterContainer] = {
domain.id: parameter_container,
}
mean_unexpected_map_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
expected_parameter_value: float = 3.89e-3
parameter_node: ParameterNode = get_parameter_value_and_validate_return_type(
domain=domain,
parameter_reference=mean_unexpected_map_metric_multi_batch_parameter_builder.json_serialized_fully_qualified_parameter_name,
expected_return_type=None,
variables=variables,
parameters=parameters,
)
rtol: float = RTOL
atol: float = 5.0e-1 * ATOL
np.testing.assert_allclose(
actual=parameter_node.value,
desired=expected_parameter_value,
rtol=rtol,
atol=atol,
err_msg=f"Actual value of {parameter_node.value} differs from expected value of {expected_parameter_value} by more than {atol + rtol * abs(parameter_node.value)} tolerance.",
)
@pytest.mark.integration
@pytest.mark.slow # 1.65s
def test_mean_unexpected_map_metric_multi_batch_parameter_builder_bobby_datetime_dependencies_evaluated_mixed(
bobby_columnar_table_multi_batch_deterministic_data_context,
):
data_context: DataContext = (
bobby_columnar_table_multi_batch_deterministic_data_context
)
batch_request: dict = {
"datasource_name": "taxi_pandas",
"data_connector_name": "monthly",
"data_asset_name": "my_reports",
}
my_total_count_metric_multi_batch_parameter_builder: MetricMultiBatchParameterBuilder = MetricMultiBatchParameterBuilder(
name="my_total_count",
metric_name="table.row_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
single_batch_mode=False,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
data_context=data_context,
)
my_null_count_metric_multi_batch_parameter_builder_config = ParameterBuilderConfig(
module_name="great_expectations.rule_based_profiler.parameter_builder",
class_name="MetricMultiBatchParameterBuilder",
name="my_null_count",
metric_name="column_values.nonnull.unexpected_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
)
evaluation_parameter_builder_configs: Optional[List[ParameterBuilderConfig]] = [
my_null_count_metric_multi_batch_parameter_builder_config,
]
mean_unexpected_map_metric_multi_batch_parameter_builder: ParameterBuilder = (
MeanUnexpectedMapMetricMultiBatchParameterBuilder(
name="my_pickup_datetime_count_values_unique_mean_unexpected_map_metric",
map_metric_name="column_values.nonnull",
total_count_parameter_builder_name="my_total_count",
null_count_parameter_builder_name="my_null_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
evaluation_parameter_builder_configs=evaluation_parameter_builder_configs,
data_context=data_context,
)
)
metric_domain_kwargs: dict = {"column": "pickup_datetime"}
domain = Domain(
domain_type=MetricDomainTypes.COLUMN,
domain_kwargs=metric_domain_kwargs,
rule_name="my_rule",
)
variables: Optional[ParameterContainer] = None
parameter_container = ParameterContainer(parameter_nodes=None)
parameters: Dict[str, ParameterContainer] = {
domain.id: parameter_container,
}
my_total_count_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
mean_unexpected_map_metric_multi_batch_parameter_builder.build_parameters(
domain=domain,
variables=variables,
parameters=parameters,
batch_request=batch_request,
)
expected_parameter_value: float = 3.89e-3
parameter_node: ParameterNode = get_parameter_value_and_validate_return_type(
domain=domain,
parameter_reference=mean_unexpected_map_metric_multi_batch_parameter_builder.json_serialized_fully_qualified_parameter_name,
expected_return_type=None,
variables=variables,
parameters=parameters,
)
rtol: float = RTOL
atol: float = 5.0e-1 * ATOL
np.testing.assert_allclose(
actual=parameter_node.value,
desired=expected_parameter_value,
rtol=rtol,
atol=atol,
err_msg=f"Actual value of {parameter_node.value} differs from expected value of {expected_parameter_value} by more than {atol + rtol * abs(parameter_node.value)} tolerance.",
)
@pytest.mark.integration
def test_mean_unexpected_map_metric_multi_batch_parameter_builder_bobby_check_serialized_keys_no_evaluation_parameter_builder_configs(
bobby_columnar_table_multi_batch_deterministic_data_context,
):
data_context: DataContext = (
bobby_columnar_table_multi_batch_deterministic_data_context
)
mean_unexpected_map_metric_multi_batch_parameter_builder: ParameterBuilder = (
MeanUnexpectedMapMetricMultiBatchParameterBuilder(
name="my_pickup_datetime_count_values_unique_mean_unexpected_map_metric",
map_metric_name="column_values.nonnull",
total_count_parameter_builder_name="my_total_count",
null_count_parameter_builder_name="my_null_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
evaluation_parameter_builder_configs=None,
data_context=data_context,
)
)
# Note: "evaluation_parameter_builder_configs" is not one of "ParameterBuilder" formal property attributes.
assert set(
mean_unexpected_map_metric_multi_batch_parameter_builder.to_json_dict().keys()
) == {
"class_name",
"module_name",
"name",
"map_metric_name",
"total_count_parameter_builder_name",
"null_count_parameter_builder_name",
"metric_domain_kwargs",
"metric_value_kwargs",
"evaluation_parameter_builder_configs",
}
@pytest.mark.integration
def test_mean_unexpected_map_metric_multi_batch_parameter_builder_bobby_check_serialized_keys_with_evaluation_parameter_builder_configs(
bobby_columnar_table_multi_batch_deterministic_data_context,
):
data_context: DataContext = (
bobby_columnar_table_multi_batch_deterministic_data_context
)
my_total_count_metric_multi_batch_parameter_builder_config = ParameterBuilderConfig(
module_name="great_expectations.rule_based_profiler.parameter_builder",
class_name="MetricMultiBatchParameterBuilder",
name="my_total_count",
metric_name="table.row_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
)
my_null_count_metric_multi_batch_parameter_builder_config = ParameterBuilderConfig(
module_name="great_expectations.rule_based_profiler.parameter_builder",
class_name="MetricMultiBatchParameterBuilder",
name="my_null_count",
metric_name="column_values.nonnull.unexpected_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
enforce_numeric_metric=False,
replace_nan_with_zero=False,
reduce_scalar_metric=True,
evaluation_parameter_builder_configs=None,
)
evaluation_parameter_builder_configs: Optional[List[ParameterBuilderConfig]] = [
my_total_count_metric_multi_batch_parameter_builder_config,
my_null_count_metric_multi_batch_parameter_builder_config,
]
mean_unexpected_map_metric_multi_batch_parameter_builder: ParameterBuilder = (
MeanUnexpectedMapMetricMultiBatchParameterBuilder(
name="my_pickup_datetime_count_values_unique_mean_unexpected_map_metric",
map_metric_name="column_values.nonnull",
total_count_parameter_builder_name="my_total_count",
null_count_parameter_builder_name="my_null_count",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
evaluation_parameter_builder_configs=evaluation_parameter_builder_configs,
data_context=data_context,
)
)
# Note: "evaluation_parameter_builder_configs" is not one of "ParameterBuilder" formal property attributes.
assert set(
mean_unexpected_map_metric_multi_batch_parameter_builder.to_json_dict().keys()
) == {
"class_name",
"module_name",
"name",
"map_metric_name",
"total_count_parameter_builder_name",
"null_count_parameter_builder_name",
"metric_domain_kwargs",
"metric_value_kwargs",
"evaluation_parameter_builder_configs",
}
<file_sep>/great_expectations/experimental/datasources/sources.py
from __future__ import annotations
import logging
from typing import TYPE_CHECKING, Callable, Dict, List, Type, Union
from typing_extensions import ClassVar
from great_expectations.experimental.datasources.type_lookup import TypeLookup
if TYPE_CHECKING:
from great_expectations.data_context import DataContext as GXDataContext
from great_expectations.experimental.datasources.context import DataContext
from great_expectations.experimental.datasources.interfaces import (
DataAsset,
Datasource,
)
SourceFactoryFn = Callable[..., "Datasource"]
LOGGER = logging.getLogger(__name__)
class TypeRegistrationError(TypeError):
pass
class _SourceFactories:
"""
Contains a collection of datasource factory methods in the format `.add_<TYPE_NAME>()`
Contains a `.type_lookup` dict-like two way mapping between previously registered `Datasource`
or `DataAsset` types and a simplified name for those types.
"""
# TODO (kilo59): split DataAsset & Datasource lookups
type_lookup: ClassVar = TypeLookup()
__source_factories: ClassVar[Dict[str, SourceFactoryFn]] = {}
_data_context: Union[DataContext, GXDataContext]
def __init__(self, data_context: Union[DataContext, GXDataContext]):
self._data_context = data_context
@classmethod
def register_types_and_ds_factory(
cls,
ds_type: Type[Datasource],
factory_fn: SourceFactoryFn,
) -> None:
"""
Add/Register a datasource factory function and all related `Datasource`,
`DataAsset` and `ExecutionEngine` types.
Creates mapping table between the `DataSource`/`DataAsset` classes and their
declared `type` string.
Example
-------
An `.add_pandas()` pandas factory method will be added to `context.sources`.
>>> class PandasDatasource(Datasource):
>>> type: str = 'pandas'`
>>> asset_types = [FileAsset]
>>> execution_engine: PandasExecutionEngine
"""
# TODO: check that the name is a valid python identifier (and maybe that it is snake_case?)
ds_type_name = ds_type.__fields__["type"].default
if not ds_type_name:
raise TypeRegistrationError(
f"`{ds_type.__name__}` is missing a `type` attribute with an assigned string value"
)
# rollback type registrations if exception occurs
with cls.type_lookup.transaction() as type_lookup:
# TODO: We should namespace the asset type to the datasource so different datasources can reuse asset types.
cls._register_assets(ds_type, asset_type_lookup=type_lookup)
cls._register_datasource_and_factory_method(
ds_type,
factory_fn=factory_fn,
ds_type_name=ds_type_name,
datasource_type_lookup=type_lookup,
)
@classmethod
def _register_datasource_and_factory_method(
cls,
ds_type: Type[Datasource],
factory_fn: SourceFactoryFn,
ds_type_name: str,
datasource_type_lookup: TypeLookup,
) -> str:
"""
Register the `Datasource` class and add a factory method for the class on `sources`.
The method name is pulled from the `Datasource.type` attribute.
"""
method_name = f"add_{ds_type_name}"
LOGGER.info(
f"2a. Registering {ds_type.__name__} as {ds_type_name} with {method_name}() factory"
)
pre_existing = cls.__source_factories.get(method_name)
if pre_existing:
raise TypeRegistrationError(
f"'{ds_type_name}' - `sources.{method_name}()` factory already exists",
)
datasource_type_lookup[ds_type] = ds_type_name
LOGGER.info(f"'{ds_type_name}' added to `type_lookup`")
cls.__source_factories[method_name] = factory_fn
return ds_type_name
@classmethod
def _register_assets(cls, ds_type: Type[Datasource], asset_type_lookup: TypeLookup):
asset_types: List[Type[DataAsset]] = ds_type.asset_types
if not asset_types:
LOGGER.warning(
f"No `{ds_type.__name__}.asset_types` have be declared for the `Datasource`"
)
for t in asset_types:
try:
asset_type_name = t.__fields__["type"].default
if asset_type_name is None:
raise TypeError(
f"{t.__name__} `type` field must be assigned and cannot be `None`"
)
LOGGER.info(
f"2b. Registering `DataAsset` `{t.__name__}` as {asset_type_name}"
)
asset_type_lookup[t] = asset_type_name
except (AttributeError, KeyError, TypeError) as bad_field_exc:
raise TypeRegistrationError(
f"No `type` field found for `{ds_type.__name__}.asset_types` -> `{t.__name__}` unable to register asset type",
) from bad_field_exc
@property
def factories(self) -> List[str]:
return list(self.__source_factories.keys())
def __getattr__(self, attr_name: str):
try:
ds_constructor = self.__source_factories[attr_name]
def wrapped(name: str, **kwargs):
datasource = ds_constructor(name=name, **kwargs)
# TODO (bdirks): _attach_datasource_to_context to the AbstractDataContext class
self._data_context._attach_datasource_to_context(datasource)
return datasource
return wrapped
except KeyError:
raise AttributeError(f"No factory {attr_name} in {self.factories}")
def __dir__(self) -> List[str]:
"""Preserves autocompletion for dynamic attributes."""
return [*self.factories, *super().__dir__()]
<file_sep>/docs/deployment_patterns/how_to_use_great_expectations_in_deepnote.md
---
title: How to use Great Expectations in Deepnote
---
import Prerequisites from './components/deployment_pattern_prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
_This piece of documentation was authored by [<NAME>](https://www.linkedin.com/in/allan-campopiano-703394120)._
This guide will help you get started with Great Expectations on Deepnote. You will learn how to validate columns in a Pandas DataFrame,
host your data docs, and schedule a pipeline job.
All of this will be accomplished from within a single, [ready-to-use notebook](https://deepnote.com/project/Reduce-Pipeline-Debt-With-Great-Expectations-d78cwK3GRYKU7AAl9fO7lg/%2Fnotebook.ipynb/#00000-85c6538f-6aaa-427b-9eda-29fdacf56457),
with no prerequisites beyond signing up for a [free Deepnote account](https://deepnote.com/)!
### Benefits of Great Expectations in Deepnote
Deepnote provides a "click and play" notebook platform that integrates perfectly with Great Expectations.
You can read all about it in [this blog post](https://deepnote.com/blog/how-not-to-draw-an-owl-cky1yda1c784x0b30j4ktcok7)!
Here are some of the notable benefits:
- Great Expectation's features are demonstrated in a [single notebook](https://deepnote.com/project/Reduce-Pipeline-Debt-With-Great-Expectations-d78cwK3GRYKU7AAl9fO7lg/%2Fnotebook.ipynb/#00000-85c6538f-6aaa-427b-9eda-29fdacf56457) (no terminal needed)
- Data Docs can be [hosted publicly on Deepnote](https://docs.deepnote.com/environment/incoming-connections) (no need to host them yourself)
- [Deepnote scheduling](https://docs.deepnote.com/features/scheduling) allows you to experience Great Expectations as part of a pipeline
These benefits make Deepnote one of the easiest and fastest ways to get started with Great Expectations.
## Steps
### 1. Begin by importing Great Expectations
Since Great Expectations can be listed in Deepnote's `requirements.txt`, it will be installed automatically. You can read more about package installation [here](https://docs.deepnote.com/environment/python-requirements).
This lets us import the required libraries right away.
```python
import pandas as pd
import numpy as np
import great_expectations as ge
from great_expectations.data_context.types.base import (
DataContextConfig,
DatasourceConfig,
FilesystemStoreBackendDefaults,
)
from great_expectations.data_context import BaseDataContext
from great_expectations.checkpoint import SimpleCheckpoint
from great_expectations.core.batch import RuntimeBatchRequest
```
### 2. Initialize Great Expectations
The following cell creates a Great Expectations folder in the filesystem
which will hold all of the forthcoming project configurations. Note that if this folder already exists, Great Expectations gracefully allows us to continue.
```bash
!great_expectations --yes --v3-api init
```
### 3. Validate a Pandas DataFrame
In practice, this is where you would bring in your own data; however, for the sake of a placeholder,
a DataFrame with random values is created. The Expectations we set later on this data may pass or fail.
:::note
Replace the randomly created DataFrame below with your own datasource.
:::
```python
import pandas as pd
products = np.random.choice(
[
"camera",
"phone",
"computer",
"speaker",
"TV",
"cable",
"movie",
"guitar",
"printer",
],
size=5,
)
quantities = np.random.choice(list(range(10)) + [None], size=5)
dates = np.random.choice(pd.date_range(start="2020-12-30", end="2021-01-08"), size=5)
df = pd.DataFrame({"products": products, "quantities": quantities, "dates": dates})
df.show()
```

### 4. Define Expectations
Expectations can be defined directly on a Pandas DataFrame using `ge.from_pandas(df)`.
We're defining three Expectations on our DataFrame:
1. The `products` column must contain unique values
2. The `quantities` column cannot contain null values
3. The `dates` column must have dates between January 1st and January 8th
These Expectations together form an <TechnicalTag tag="expectation_suite" text="Expectation Suite"/> that will be validated against our data.
:::tip
Replace the sample Expectations below with those that relate to your data.
You can see all the Expectations available in the [gallery](https://greatexpectations.io/expectations).
:::
```python
df = ge.from_pandas(df)
# ~30% chance of passing
df.expect_column_values_to_be_unique("products") # ~30% chance of passing
# ~60% chance of passing
df.expect_column_values_to_not_be_null("quantities") # ~60% chance of passing
# ~60% chance of passing
df.expect_column_values_to_be_between(
"dates", "2021-01-01", "2021-01-8", parse_strings_as_datetimes=True
);
```
### 5. Set project configurations
Before we can validate our expectations against our data, we need to tell Great Expectations more about our project's configuration.
Great Expectations keeps track of many configurations with a <TechnicalTag tag="data_context" text="Data Context"/>.
These configurations are used to manage aspects of your project behind the scenes.
:::info
There's a lot going on here, but for the sake of this guide we don't need to worry about the full details.
To learn more, visit the [Great Expectations docs](https://docs.greatexpectations.io/docs/).
:::
```python
data_context_config = DataContextConfig(
datasources={
"my_datasource": DatasourceConfig(
class_name="Datasource",
module_name="great_expectations.datasource",
execution_engine={
"class_name": "PandasExecutionEngine",
"module_name": "great_expectations.execution_engine",
},
data_connectors={
"default_runtime_data_connector_name": {
"class_name": "RuntimeDataConnector",
"batch_identifiers": ["default_identifier_name"],
}
},
)
},
store_backend_defaults=FilesystemStoreBackendDefaults(
root_directory="/work/great_expectations"
),
)
context = BaseDataContext(project_config=data_context_config)
context.save_expectation_suite(
expectation_suite_name="my_expectation_suite",
expectation_suite=df.get_expectation_suite(discard_failed_expectations=False),
);
```
### 6. Setting up a Batch and Checkpoint
In order to populate the documentation (<TechnicalTag tag="data_docs" text="Data Docs"/>) for our tests,
we need to set up at least one <TechnicalTag tag="batch" text="Batch"/> and a <TechnicalTag tag="checkpoint" text="Checkpoint"/>.
A Batch is a pairing of data and metadata to be validated. A Checkpoint is a bundle of at least:
- One Batch (the data to be validated)
- One Expectation Suite (our Expectations for that data)
- One <TechnicalTag tag="action" text="Action"/> (saving our validation results, rebuilding Data Docs, sending a Slack notification, etc.)
In the cell below, one Batch is constructed from our DataFrame with a <TechnicalTag tag="batch_request" text="RuntimeBatchRequest"/>.
We then create a Checkpoint, and pass in our `batch_request`.
When we execute this code, our Expectation Suite is run against our data, validating whether that data meets our
Expectations or not. The results are then persisted temporarily until we build our Data Docs.
```python
batch_request = RuntimeBatchRequest(
datasource_name="my_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="df",
runtime_parameters={"batch_data": df},
batch_identifiers={"default_identifier_name": "df"},
)
checkpoint_config = {
"name": "my_checkpoint",
"config_version": 1,
"class_name": "SimpleCheckpoint",
"expectation_suite_name": "my_expectation_suite",
}
context.add_checkpoint(**checkpoint_config)
results = context.run_checkpoint(
checkpoint_name="my_checkpoint",
validations=[{"batch_request": batch_request}],
run_id="my_run_id",
)
```
### 7. Build the documentation
Our Data Docs can now be generated and served (thanks to [Deepnote Tunneling](https://docs.deepnote.com/environment/incoming-connections)!) by running the next cell.
```python
context.build_data_docs();
# Uncomment this line to serve up the documentation
#!python -m http.server 8080 --directory great_expectations/uncommitted/data_docs/local_site
```
When served, the Data Docs site provides the details of each <TechnicalTag tag="validation" text="Validation"/> we've run and Expectation Suite we've created.
For example, the following image shows a run where three Expectations were validated against our DataFrame and two of them failed.

<div style={{"text-align":"center"}}>
<p style={{"color":"#8784FF","font-size":"1.4em"}}><b>
Congratulations!<br/>🎉 You've successfully deployed Great Expectations on Deepnote! 🎉
</b></p>
</div>
## Summary
Deepnote integrates perfectly with Great Expectations, allowing documentation to be hosted and notebooks to be scheduled. Please visit [Deepnote](https://deepnote.com/)
to learn more about how to bring tools, teams, and workflows together.
<file_sep>/docs/guides/expectations/advanced/how_to_create_expectations_that_span_multiple_batches_using_evaluation_parameters.md
---
title: How to create Expectations that span multiple Batches using Evaluation Parameters
---
import Prerequisites from '../../../guides/connecting_to_your_data/components/prerequisites.jsx';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide will help you create <TechnicalTag tag="expectation" text="Expectations" /> that span multiple <TechnicalTag tag="batch" text="Batches" /> of data using <TechnicalTag tag="evaluation_parameter" text="Evaluation Parameters" /> (see also <TechnicalTag tag="evaluation_parameter_store" text="Evaluation Parameter Stores" />). This pattern is useful for things like verifying that row counts between tables stay consistent.
<Prerequisites>
- Configured a <TechnicalTag tag="data_context" text="Data Context" />.
- Configured a <TechnicalTag tag="datasource" text="Datasource" /> (or several Datasources) with at least two <TechnicalTag tag="data_asset" text="Data Assets" /> and understand the basics of <TechnicalTag tag="batch_request" text="Batch Requests" />.
- Also created <TechnicalTag tag="expectation_suite" text="Expectations Suites" /> for those Data Assets.
- Have a working Evaluation Parameter store. (The default in-memory <TechnicalTag tag="store" text="Store" /> from ``great_expectations init`` can work for this.)
- Have a working <TechnicalTag tag="checkpoint" text="Checkpoint" />
</Prerequisites>
## Steps
In a notebook,
### 1. Import great_expectations and instantiate your Data Context
```python
import great_expectations as ge
context = ge.DataContext()
```
### 2. Instantiate two Validators, one for each Data Asset
We'll call one of these <TechnicalTag tag="validator" text="Validators" /> the *upstream* Validator and the other the *downstream* Validator. Evaluation Parameters will allow us to use <TechnicalTag tag="validation_result" text="Validation Results" /> from the upstream Validator as parameters passed into Expectations on the downstream.
It's common (but not required) for both Batch Requests to have the same Datasource and <TechnicalTag tag="data_connector" text="Data Connector" />.
```python
batch_request_1 = BatchRequest(
datasource_name="my_datasource",
data_connector_name="my_data_connector",
data_asset_name="my_data_asset_1"
)
upstream_validator = context.get_validator(batch_request=batch_request_1, expectation_suite_name="my_expectation_suite_1")
batch_request_2 = BatchRequest(
datasource_name="my_datasource",
data_connector_name="my_data_connector",
data_asset_name="my_data_asset_2"
)
downstream_validator = context.get_validator(batch_request=batch_request_2, expectation_suite_name="my_expectation_suite_2")
```
### 3. Disable interactive evaluation for the downstream Validator
```python
downstream_validator.interactive_evaluation = False
```
Disabling interactive evaluation allows you to declare an Expectation even when it cannot be evaluated immediately.
### 4. Define an Expectation using an Evaluation Parameter on the downstream Validator
```python
eval_param_urn = 'urn:great_expectations:validations:my_expectation_suite_1:expect_table_row_count_to_be_between.result.observed_value'
downstream_validator.expect_table_row_count_to_equal(
value={
'$PARAMETER': eval_param_urn, # this is the actual parameter we're going to use in the validation
}
)
```
The core of this is a ``$PARAMETER : URN`` pair. When Great Expectations encounters a ``$PARAMETER`` flag during <TechnicalTag tag="validation" text="Validation" />, it will replace the ``URN`` with a value retrieved from an Evaluation Parameter Store or <TechnicalTag tag="metric_store" text="Metrics Store" /> (see also [How to configure a MetricsStore](../../../guides/setup/configuring_metadata_stores/how_to_configure_a_metricsstore.md)).
This declaration above includes two ``$PARAMETERS``. The first is the real parameter that will be used after the Expectation Suite is stored and deployed in a Validation Operator. The second parameter supports immediate evaluation in the notebook.
When executed in the notebook, this Expectation will generate a Validation Result. Most values will be missing, since interactive evaluation was disabled.
```python
{
"result": {},
"success": null,
"meta": {},
"exception_info": {
"raised_exception": false,
"exception_traceback": null,
"exception_message": null
}
}
```
:::warning
Your URN must be exactly correct in order to work in production. Unfortunately, successful execution at this stage does not guarantee that the URN is specified correctly and that the intended parameters will be available when executed later.
:::
### 5. Save your Expectation Suite
```python
downstream_validator.save_expectation_suite(discard_failed_expectations=False)
```
This step is necessary because your ``$PARAMETER`` will only function properly when invoked within a Validation operation with multiple Validators. The simplest way to execute such an operation is through a :ref:`Validation Operator <reference__core_concepts__validation__validation_operator>`, and Validation Operators are configured to load Expectation Suites from <TechnicalTag tag="expectation_store" text="Expectation Stores" />, not memory.
### 6. Execute an existing Checkpoint
You can do this within your notebook by running ``context.run_checkpoint``.
```python
results = context.run_checkpoint(
checkpoint_name="my_checkpoint"
)
```
### 7. Rebuild Data Docs and review results in docs
You can do this within your notebook by running:
```python
context.build_data_docs()
```
You can also execute from the command line with:
```bash
great_expectations docs build
```
Once your <TechnicalTag tag="data_docs" text="Data Docs" /> rebuild, open them in a browser and navigate to the page for the new Validation Result.
If your Evaluation Parameter was executed successfully, you'll see something like this:

If it encountered an error, you'll see something like this. The most common problem is a mis-specified URN name.

<file_sep>/tests/cli/test_batch_request.py
from unittest import mock
from great_expectations.cli.batch_request import (
_get_data_asset_name_from_data_connector,
)
@mock.patch("great_expectations.cli.batch_request.BaseDatasource")
@mock.patch("great_expectations.cli.batch_request._get_user_response")
def test_get_data_asset_name_from_data_connector_default_path(
mock_user_input, mock_datasource
):
mock_datasource.get_available_data_asset_names.return_value = {
"my_data_connector": ["a", "b", "c", "d", "e"]
}
mock_user_input.side_effect = ["4"] # Immediately select my asset
data_asset_name = _get_data_asset_name_from_data_connector(
mock_datasource, "my_data_connector", "my message prompt"
)
assert data_asset_name == "d"
@mock.patch("great_expectations.cli.batch_request.BaseDatasource")
@mock.patch("great_expectations.cli.batch_request._get_user_response")
def test_get_data_asset_name_from_data_connector_pagination(
mock_user_input, mock_datasource
):
mock_datasource.get_available_data_asset_names.return_value = {
"my_data_connector": [f"my_file{n}" for n in range(200)]
}
mock_user_input.side_effect = [
"l", # Select listing/pagination option
"n", # Go to page 2 of my data asset listing
"n", # Go to page 3 of my data asset listing
"34", # Select the 34th option in page 3
]
data_asset_name = _get_data_asset_name_from_data_connector(
mock_datasource, "my_data_connector", "my message prompt"
)
assert data_asset_name == "my_file128"
@mock.patch("great_expectations.cli.batch_request.BaseDatasource")
@mock.patch("great_expectations.cli.batch_request._get_user_response")
def test_get_data_asset_name_from_data_connector_with_search(
mock_user_input, mock_datasource
):
files = [f"my_file{n}" for n in range(200)]
target_file = "my_file2021-12-30"
files.append(target_file)
mock_datasource.get_available_data_asset_names.return_value = {
"my_data_connector": files
}
mock_user_input.side_effect = [
"s", # Select search option
"my_file20", # Filter listing
r"my_file\d{4}-\d{2}-\d{2}", # Use regex to isolate one file with date format
"1", # Select the 1st and only option
]
data_asset_name = _get_data_asset_name_from_data_connector(
mock_datasource, "my_data_connector", "my message prompt"
)
assert data_asset_name == target_file
<file_sep>/tests/checkpoint/test_checkpoint.py
import logging
import os
import pickle
import unittest
from typing import List, Optional, Union
from unittest import mock
import pandas as pd
import pytest
from ruamel.yaml.comments import CommentedMap
import great_expectations as ge
import great_expectations.exceptions as ge_exceptions
from great_expectations.checkpoint import Checkpoint, LegacyCheckpoint
from great_expectations.checkpoint.types.checkpoint_result import CheckpointResult
from great_expectations.core import ExpectationSuiteValidationResult
from great_expectations.core.batch import BatchRequest, RuntimeBatchRequest
from great_expectations.core.config_peer import ConfigOutputModes
from great_expectations.core.expectation_validation_result import (
ExpectationValidationResult,
)
from great_expectations.core.util import get_or_create_spark_application
from great_expectations.core.yaml_handler import YAMLHandler
from great_expectations.data_context.data_context.data_context import DataContext
from great_expectations.data_context.types.base import (
CheckpointConfig,
CheckpointValidationConfig,
checkpointConfigSchema,
)
from great_expectations.data_context.types.resource_identifiers import (
ConfigurationIdentifier,
ValidationResultIdentifier,
)
from great_expectations.render import RenderedAtomicContent
from great_expectations.util import (
deep_filter_properties_iterable,
filter_properties_dict,
)
yaml = YAMLHandler()
logger = logging.getLogger(__name__)
def test_checkpoint_raises_typeerror_on_incorrect_data_context():
with pytest.raises(TypeError):
Checkpoint(name="my_checkpoint", data_context="foo", config_version=1)
def test_checkpoint_with_no_config_version_has_no_action_list(empty_data_context):
checkpoint: Checkpoint = Checkpoint(
name="foo", data_context=empty_data_context, config_version=None
)
assert checkpoint.action_list == []
def test_checkpoint_with_config_version_has_action_list(empty_data_context):
checkpoint: Checkpoint = Checkpoint(
"foo", empty_data_context, config_version=1, action_list=[{"foo": "bar"}]
)
obs = checkpoint.action_list
assert isinstance(obs, list)
assert obs == [{"foo": "bar"}]
@mock.patch(
"great_expectations.core.usage_statistics.usage_statistics.UsageStatisticsHandler.emit"
)
def test_basic_checkpoint_config_validation(
mock_emit,
empty_data_context_stats_enabled,
caplog,
capsys,
):
context: DataContext = empty_data_context_stats_enabled
yaml_config_erroneous: str
config_erroneous: CommentedMap
checkpoint_config: Union[CheckpointConfig, dict]
checkpoint: Checkpoint
yaml_config_erroneous = """
name: misconfigured_checkpoint
unexpected_property: UNKNOWN_PROPERTY_VALUE
"""
config_erroneous = yaml.load(yaml_config_erroneous)
with pytest.raises(TypeError):
# noinspection PyUnusedLocal
checkpoint_config = CheckpointConfig(**config_erroneous)
with pytest.raises(KeyError):
# noinspection PyUnusedLocal
checkpoint: Checkpoint = context.test_yaml_config(
yaml_config=yaml_config_erroneous,
name="my_erroneous_checkpoint",
)
assert mock_emit.call_count == 1
# noinspection PyUnresolvedReferences
expected_events: List[unittest.mock._Call]
# noinspection PyUnresolvedReferences
actual_events: List[unittest.mock._Call]
expected_events = [
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"diagnostic_info": ["__class_name_not_provided__"]},
"success": False,
}
),
]
actual_events = mock_emit.call_args_list
assert actual_events == expected_events
yaml_config_erroneous = """
config_version: 1
"""
config_erroneous = yaml.load(yaml_config_erroneous)
with pytest.raises(ge_exceptions.InvalidConfigError):
# noinspection PyUnusedLocal
checkpoint_config = CheckpointConfig.from_commented_map(
commented_map=config_erroneous
)
with pytest.raises(KeyError):
# noinspection PyUnusedLocal
checkpoint: Checkpoint = context.test_yaml_config(
yaml_config=yaml_config_erroneous,
name="my_erroneous_checkpoint",
)
assert mock_emit.call_count == 2
expected_events = [
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"diagnostic_info": ["__class_name_not_provided__"]},
"success": False,
}
),
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"diagnostic_info": ["__class_name_not_provided__"]},
"success": False,
}
),
]
actual_events = mock_emit.call_args_list
assert actual_events == expected_events
with pytest.raises(ge_exceptions.InvalidConfigError):
# noinspection PyUnusedLocal
checkpoint: Checkpoint = context.test_yaml_config(
yaml_config=yaml_config_erroneous,
name="my_erroneous_checkpoint",
class_name="Checkpoint",
)
assert mock_emit.call_count == 3
expected_events = [
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"diagnostic_info": ["__class_name_not_provided__"]},
"success": False,
}
),
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"diagnostic_info": ["__class_name_not_provided__"]},
"success": False,
}
),
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"parent_class": "Checkpoint"},
"success": False,
}
),
]
actual_events = mock_emit.call_args_list
assert actual_events == expected_events
yaml_config_erroneous = """
config_version: 1
name: my_erroneous_checkpoint
class_name: Checkpoint
"""
# noinspection PyUnusedLocal
checkpoint: Checkpoint = context.test_yaml_config(
yaml_config=yaml_config_erroneous,
name="my_erroneous_checkpoint",
class_name="Checkpoint",
)
captured = capsys.readouterr()
assert any(
[
'Your current Checkpoint configuration has an empty or missing "validations" attribute'
in message
for message in [caplog.text, captured.out]
]
)
assert any(
[
'Your current Checkpoint configuration has an empty or missing "action_list" attribute'
in message
for message in [caplog.text, captured.out]
]
)
assert mock_emit.call_count == 4
# Substitute anonymized name since it changes for each run
anonymized_name_0 = mock_emit.call_args_list[3][0][0]["event_payload"][
"anonymized_name"
]
expected_events = [
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"diagnostic_info": ["__class_name_not_provided__"]},
"success": False,
}
),
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"diagnostic_info": ["__class_name_not_provided__"]},
"success": False,
}
),
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"parent_class": "Checkpoint"},
"success": False,
}
),
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {
"anonymized_name": anonymized_name_0,
"parent_class": "Checkpoint",
},
"success": True,
}
),
]
actual_events = mock_emit.call_args_list
assert actual_events == expected_events
assert len(context.list_checkpoints()) == 0
context.add_checkpoint(**yaml.load(yaml_config_erroneous))
assert len(context.list_checkpoints()) == 1
yaml_config: str = """
name: my_checkpoint
config_version: 1
class_name: Checkpoint
validations: []
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
"""
expected_checkpoint_config: dict = {
"name": "my_checkpoint",
"config_version": 1.0,
"class_name": "Checkpoint",
"module_name": "great_expectations.checkpoint",
"action_list": [
{
"name": "store_validation_result",
"action": {"class_name": "StoreValidationResultAction"},
},
{
"name": "store_evaluation_params",
"action": {"class_name": "StoreEvaluationParametersAction"},
},
{
"name": "update_data_docs",
"action": {"class_name": "UpdateDataDocsAction"},
},
],
}
config: CommentedMap = yaml.load(yaml_config)
checkpoint_config = CheckpointConfig(**config)
checkpoint: Checkpoint = Checkpoint(
data_context=context,
**filter_properties_dict(
properties=checkpoint_config.to_json_dict(),
delete_fields={"class_name", "module_name"},
clean_falsy=True,
),
)
assert (
filter_properties_dict(
properties=checkpoint.self_check()["config"],
clean_falsy=True,
)
== expected_checkpoint_config
)
assert (
filter_properties_dict(
properties=checkpoint.get_config(mode=ConfigOutputModes.DICT),
clean_falsy=True,
)
== expected_checkpoint_config
)
checkpoint: Checkpoint = context.test_yaml_config(
yaml_config=yaml_config,
name="my_checkpoint",
)
assert (
filter_properties_dict(
properties=checkpoint.self_check()["config"],
clean_falsy=True,
)
== expected_checkpoint_config
)
assert (
filter_properties_dict(
properties=checkpoint.get_config(mode=ConfigOutputModes.DICT),
clean_falsy=True,
)
== expected_checkpoint_config
)
assert mock_emit.call_count == 5
# Substitute anonymized name since it changes for each run
anonymized_name_1 = mock_emit.call_args_list[4][0][0]["event_payload"][
"anonymized_name"
]
expected_events = [
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"diagnostic_info": ["__class_name_not_provided__"]},
"success": False,
}
),
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"diagnostic_info": ["__class_name_not_provided__"]},
"success": False,
}
),
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {"parent_class": "Checkpoint"},
"success": False,
}
),
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {
"anonymized_name": anonymized_name_0,
"parent_class": "Checkpoint",
},
"success": True,
}
),
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {
"anonymized_name": anonymized_name_1,
"parent_class": "Checkpoint",
},
"success": True,
}
),
]
actual_events = mock_emit.call_args_list
assert actual_events == expected_events
assert len(context.list_checkpoints()) == 1
context.add_checkpoint(**yaml.load(yaml_config))
assert len(context.list_checkpoints()) == 2
context.create_expectation_suite(expectation_suite_name="my_expectation_suite")
with pytest.raises(
ge_exceptions.DataContextError,
match=r'Checkpoint "my_checkpoint" must contain either a batch_request or validations.',
):
# noinspection PyUnusedLocal
result: CheckpointResult = context.run_checkpoint(
checkpoint_name=checkpoint.name,
)
context.delete_checkpoint(name="my_erroneous_checkpoint")
context.delete_checkpoint(name="my_checkpoint")
assert len(context.list_checkpoints()) == 0
@mock.patch(
"great_expectations.core.usage_statistics.usage_statistics.UsageStatisticsHandler.emit"
)
def test_checkpoint_configuration_no_nesting_using_test_yaml_config(
mock_emit,
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
monkeypatch,
):
monkeypatch.setenv("VAR", "test")
monkeypatch.setenv("MY_PARAM", "1")
monkeypatch.setenv("OLD_PARAM", "2")
checkpoint: Checkpoint
data_context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
yaml_config: str = """
name: my_fancy_checkpoint
config_version: 1
class_name: Checkpoint
run_name_template: "%Y-%M-foo-bar-template-$VAR"
validations:
- batch_request:
datasource_name: my_datasource
data_connector_name: my_special_data_connector
data_asset_name: users
data_connector_query:
index: -1
expectation_suite_name: users.delivery
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
evaluation_parameters:
param1: "$MY_PARAM"
param2: 1 + "$OLD_PARAM"
runtime_configuration:
result_format:
result_format: BASIC
partial_unexpected_count: 20
"""
expected_checkpoint_config: dict = {
"name": "my_fancy_checkpoint",
"config_version": 1.0,
"class_name": "Checkpoint",
"module_name": "great_expectations.checkpoint",
"validations": [
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {
"index": -1,
},
},
"expectation_suite_name": "users.delivery",
"action_list": [
{
"name": "store_validation_result",
"action": {"class_name": "StoreValidationResultAction"},
},
{
"name": "store_evaluation_params",
"action": {"class_name": "StoreEvaluationParametersAction"},
},
{
"name": "update_data_docs",
"action": {"class_name": "UpdateDataDocsAction"},
},
],
},
],
"evaluation_parameters": {"param1": "1", "param2": '1 + "2"'},
"runtime_configuration": {
"result_format": {
"result_format": "BASIC",
"partial_unexpected_count": 20,
}
},
"template_name": None,
"run_name_template": "%Y-%M-foo-bar-template-test",
"expectation_suite_name": None,
"batch_request": None,
"action_list": [],
"profilers": [],
}
checkpoint: Checkpoint = data_context.test_yaml_config(
yaml_config=yaml_config,
name="my_fancy_checkpoint",
)
assert filter_properties_dict(
properties=checkpoint.get_config(mode=ConfigOutputModes.DICT),
clean_falsy=True,
) == filter_properties_dict(
properties=expected_checkpoint_config,
clean_falsy=True,
)
# Test usage stats messages
assert mock_emit.call_count == 1
# Substitute current anonymized name since it changes for each run
anonymized_checkpoint_name = mock_emit.call_args_list[0][0][0]["event_payload"][
"anonymized_name"
]
# noinspection PyUnresolvedReferences
expected_events: List[unittest.mock._Call] = [
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {
"anonymized_name": anonymized_checkpoint_name,
"parent_class": "Checkpoint",
},
"success": True,
}
),
]
# noinspection PyUnresolvedReferences
actual_events: List[unittest.mock._Call] = mock_emit.call_args_list
assert actual_events == expected_events
assert len(data_context.list_checkpoints()) == 0
data_context.add_checkpoint(**yaml.load(yaml_config))
assert len(data_context.list_checkpoints()) == 1
data_context.create_expectation_suite(expectation_suite_name="users.delivery")
result: CheckpointResult = data_context.run_checkpoint(
checkpoint_name=checkpoint.name,
)
assert len(result.list_validation_results()) == 1
assert len(data_context.validations_store.list_keys()) == 1
assert result.success
data_context.delete_checkpoint(name="my_fancy_checkpoint")
assert len(data_context.list_checkpoints()) == 0
@pytest.mark.slow # 1.74s
def test_checkpoint_configuration_nesting_provides_defaults_for_most_elements_test_yaml_config(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
monkeypatch,
):
monkeypatch.setenv("VAR", "test")
monkeypatch.setenv("MY_PARAM", "1")
monkeypatch.setenv("OLD_PARAM", "2")
checkpoint: Checkpoint
data_context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
yaml_config: str = """
name: my_fancy_checkpoint
config_version: 1
class_name: Checkpoint
run_name_template: "%Y-%M-foo-bar-template-$VAR"
validations:
- batch_request:
datasource_name: my_datasource
data_connector_name: my_special_data_connector
data_asset_name: users
data_connector_query:
index: -1
- batch_request:
datasource_name: my_datasource
data_connector_name: my_other_data_connector
data_asset_name: users
data_connector_query:
index: -2
expectation_suite_name: users.delivery
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
evaluation_parameters:
param1: "$MY_PARAM"
param2: 1 + "$OLD_PARAM"
runtime_configuration:
result_format:
result_format: BASIC
partial_unexpected_count: 20
"""
expected_checkpoint_config: dict = {
"name": "my_fancy_checkpoint",
"config_version": 1.0,
"class_name": "Checkpoint",
"module_name": "great_expectations.checkpoint",
"validations": [
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {
"index": -1,
},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector",
"data_asset_name": "users",
"data_connector_query": {
"index": -2,
},
}
},
],
"expectation_suite_name": "users.delivery",
"action_list": [
{
"name": "store_validation_result",
"action": {"class_name": "StoreValidationResultAction"},
},
{
"name": "store_evaluation_params",
"action": {"class_name": "StoreEvaluationParametersAction"},
},
{
"name": "update_data_docs",
"action": {"class_name": "UpdateDataDocsAction"},
},
],
"evaluation_parameters": {"param1": "1", "param2": '1 + "2"'},
"runtime_configuration": {
"result_format": {"result_format": "BASIC", "partial_unexpected_count": 20}
},
"template_name": None,
"run_name_template": "%Y-%M-foo-bar-template-test",
"batch_request": None,
"profilers": [],
}
checkpoint: Checkpoint = data_context.test_yaml_config(
yaml_config=yaml_config,
name="my_fancy_checkpoint",
)
assert filter_properties_dict(
properties=checkpoint.get_config(mode=ConfigOutputModes.DICT),
clean_falsy=True,
) == filter_properties_dict(
properties=expected_checkpoint_config,
clean_falsy=True,
)
assert len(data_context.list_checkpoints()) == 0
data_context.add_checkpoint(**yaml.load(yaml_config))
assert len(data_context.list_checkpoints()) == 1
data_context.create_expectation_suite(expectation_suite_name="users.delivery")
result: CheckpointResult = data_context.run_checkpoint(
checkpoint_name=checkpoint.name,
)
assert len(result.list_validation_results()) == 2
assert len(data_context.validations_store.list_keys()) == 2
assert result.success
data_context.delete_checkpoint(name="my_fancy_checkpoint")
assert len(data_context.list_checkpoints()) == 0
@mock.patch(
"great_expectations.core.usage_statistics.usage_statistics.UsageStatisticsHandler.emit"
)
def test_checkpoint_configuration_using_RuntimeDataConnector_with_Airflow_test_yaml_config(
mock_emit,
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
checkpoint: Checkpoint
data_context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
yaml_config: str = """
name: airflow_checkpoint
config_version: 1
class_name: Checkpoint
validations:
- batch_request:
datasource_name: my_datasource
data_connector_name: my_runtime_data_connector
data_asset_name: IN_MEMORY_DATA_ASSET
expectation_suite_name: users.delivery
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
"""
expected_checkpoint_config: dict = {
"name": "airflow_checkpoint",
"config_version": 1.0,
"class_name": "Checkpoint",
"module_name": "great_expectations.checkpoint",
"validations": [
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "IN_MEMORY_DATA_ASSET",
}
}
],
"expectation_suite_name": "users.delivery",
"action_list": [
{
"name": "store_validation_result",
"action": {"class_name": "StoreValidationResultAction"},
},
{
"name": "store_evaluation_params",
"action": {"class_name": "StoreEvaluationParametersAction"},
},
{
"name": "update_data_docs",
"action": {"class_name": "UpdateDataDocsAction"},
},
],
"template_name": None,
"run_name_template": None,
"batch_request": None,
"evaluation_parameters": {},
"runtime_configuration": {},
"profilers": [],
}
checkpoint: Checkpoint = data_context.test_yaml_config(
yaml_config=yaml_config,
name="airflow_checkpoint",
)
assert filter_properties_dict(
properties=checkpoint.get_config(mode=ConfigOutputModes.DICT),
clean_falsy=True,
) == filter_properties_dict(
properties=expected_checkpoint_config,
clean_falsy=True,
)
assert len(data_context.list_checkpoints()) == 0
data_context.add_checkpoint(**yaml.load(yaml_config))
assert len(data_context.list_checkpoints()) == 1
data_context.create_expectation_suite(expectation_suite_name="users.delivery")
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
result: CheckpointResult = data_context.run_checkpoint(
checkpoint_name=checkpoint.name,
batch_request={
"runtime_parameters": {
"batch_data": test_df,
},
"batch_identifiers": {
"airflow_run_id": 1234567890,
},
},
run_name="airflow_run_1234567890",
)
assert len(result.list_validation_results()) == 1
assert len(data_context.validations_store.list_keys()) == 1
assert result.success
assert mock_emit.call_count == 6
# noinspection PyUnresolvedReferences
expected_events: List[unittest.mock._Call] = [
mock.call(
{
"event": "data_context.test_yaml_config",
"event_payload": {
"anonymized_name": "f563d9aa1604e16099bb7dff7b203319",
"parent_class": "Checkpoint",
},
"success": True,
},
),
mock.call(
{
"event": "data_context.get_batch_list",
"event_payload": {
"anonymized_batch_request_required_top_level_properties": {
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
"anonymized_data_connector_name": "d52d7bff3226a7f94dd3510c1040de78",
"anonymized_data_asset_name": "556e8c06239d09fc66f424eabb9ca491",
},
"batch_request_optional_top_level_keys": [
"batch_identifiers",
"runtime_parameters",
],
"runtime_parameters_keys": ["batch_data"],
},
"success": True,
},
),
mock.call(
{
"event": "data_asset.validate",
"event_payload": {
"anonymized_batch_kwarg_keys": [],
"anonymized_expectation_suite_name": "6a04fc37da0d43a4c21429f6788d2cff",
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
},
"success": True,
}
),
mock.call(
{
"event": "data_context.build_data_docs",
"event_payload": {},
"success": True,
}
),
mock.call(
{
"event": "checkpoint.run",
"event_payload": {
"anonymized_name": "f563d9aa1604e16099bb7dff7b203319",
"config_version": 1.0,
"anonymized_expectation_suite_name": "6a04fc37da0d43a4c21429f6788d2cff",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
"anonymized_validations": [
{
"anonymized_batch_request": {
"anonymized_batch_request_required_top_level_properties": {
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
"anonymized_data_connector_name": "d52d7bff3226a7f94dd3510c1040de78",
"anonymized_data_asset_name": "556e8c06239d09fc66f424eabb9ca491",
},
"batch_request_optional_top_level_keys": [
"batch_identifiers",
"runtime_parameters",
],
"runtime_parameters_keys": ["batch_data"],
},
"anonymized_expectation_suite_name": "6a04fc37da0d43a4c21429f6788d2cff",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
},
],
},
"success": True,
},
),
mock.call(
{
"event": "data_context.run_checkpoint",
"event_payload": {},
"success": True,
}
),
]
# noinspection PyUnresolvedReferences
actual_events: List[unittest.mock._Call] = mock_emit.call_args_list
assert actual_events == expected_events
data_context.delete_checkpoint(name="airflow_checkpoint")
assert len(data_context.list_checkpoints()) == 0
@pytest.mark.slow # 1.75s
def test_checkpoint_configuration_warning_error_quarantine_test_yaml_config(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
monkeypatch,
):
monkeypatch.setenv("GE_ENVIRONMENT", "my_ge_environment")
checkpoint: Checkpoint
data_context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
yaml_config: str = """
name: airflow_users_node_3
config_version: 1
class_name: Checkpoint
batch_request:
datasource_name: my_datasource
data_connector_name: my_special_data_connector
data_asset_name: users
data_connector_query:
index: -1
validations:
- expectation_suite_name: users.warning # runs the top-level action list against the top-level batch_request
- expectation_suite_name: users.error # runs the locally-specified action_list union the top level action-list against the top-level batch_request
action_list:
- name: quarantine_failed_data
action:
class_name: CreateQuarantineData
- name: advance_passed_data
action:
class_name: CreatePassedData
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
evaluation_parameters:
environment: $GE_ENVIRONMENT
tolerance: 0.01
runtime_configuration:
result_format:
result_format: BASIC
partial_unexpected_count: 20
"""
mock_create_quarantine_data = mock.MagicMock()
mock_create_quarantine_data.run.return_value = True
ge.validation_operators.CreateQuarantineData = mock_create_quarantine_data
mock_create_passed_data = mock.MagicMock()
mock_create_passed_data.run.return_value = True
ge.validation_operators.CreatePassedData = mock_create_passed_data
expected_checkpoint_config: dict = {
"name": "airflow_users_node_3",
"config_version": 1.0,
"class_name": "Checkpoint",
"module_name": "great_expectations.checkpoint",
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {
"index": -1,
},
},
"validations": [
{"expectation_suite_name": "users.warning"},
{
"expectation_suite_name": "users.error",
"action_list": [
{
"name": "quarantine_failed_data",
"action": {"class_name": "CreateQuarantineData"},
},
{
"name": "advance_passed_data",
"action": {"class_name": "CreatePassedData"},
},
],
},
],
"action_list": [
{
"name": "store_validation_result",
"action": {"class_name": "StoreValidationResultAction"},
},
{
"name": "store_evaluation_params",
"action": {"class_name": "StoreEvaluationParametersAction"},
},
{
"name": "update_data_docs",
"action": {"class_name": "UpdateDataDocsAction"},
},
],
"evaluation_parameters": {
"environment": "my_ge_environment",
"tolerance": 0.01,
},
"runtime_configuration": {
"result_format": {"result_format": "BASIC", "partial_unexpected_count": 20}
},
"template_name": None,
"run_name_template": None,
"expectation_suite_name": None,
"profilers": [],
}
checkpoint: Checkpoint = data_context.test_yaml_config(
yaml_config=yaml_config,
name="airflow_users_node_3",
)
assert filter_properties_dict(
properties=checkpoint.get_config(mode=ConfigOutputModes.DICT),
clean_falsy=True,
) == filter_properties_dict(
properties=expected_checkpoint_config,
clean_falsy=True,
)
assert len(data_context.list_checkpoints()) == 0
data_context.add_checkpoint(**yaml.load(yaml_config))
assert len(data_context.list_checkpoints()) == 1
data_context.create_expectation_suite(expectation_suite_name="users.warning")
data_context.create_expectation_suite(expectation_suite_name="users.error")
result: CheckpointResult = data_context.run_checkpoint(
checkpoint_name=checkpoint.name,
)
assert len(result.list_validation_results()) == 2
assert len(data_context.validations_store.list_keys()) == 2
assert result.success
data_context.delete_checkpoint(name="airflow_users_node_3")
assert len(data_context.list_checkpoints()) == 0
@pytest.mark.slow # 3.10s
def test_checkpoint_configuration_template_parsing_and_usage_test_yaml_config(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
monkeypatch,
):
monkeypatch.setenv("VAR", "test")
monkeypatch.setenv("MY_PARAM", "1")
monkeypatch.setenv("OLD_PARAM", "2")
checkpoint: Checkpoint
yaml_config: str
expected_checkpoint_config: dict
result: CheckpointResult
data_context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
yaml_config = """
name: my_base_checkpoint
config_version: 1
class_name: Checkpoint
run_name_template: "%Y-%M-foo-bar-template-$VAR"
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
evaluation_parameters:
param1: "$MY_PARAM"
param2: 1 + "$OLD_PARAM"
runtime_configuration:
result_format:
result_format: BASIC
partial_unexpected_count: 20
"""
expected_checkpoint_config = {
"name": "my_base_checkpoint",
"config_version": 1.0,
"class_name": "Checkpoint",
"module_name": "great_expectations.checkpoint",
"template_name": None,
"run_name_template": "%Y-%M-foo-bar-template-test",
"expectation_suite_name": None,
"batch_request": None,
"action_list": [
{
"name": "store_validation_result",
"action": {"class_name": "StoreValidationResultAction"},
},
{
"name": "store_evaluation_params",
"action": {"class_name": "StoreEvaluationParametersAction"},
},
{
"name": "update_data_docs",
"action": {"class_name": "UpdateDataDocsAction"},
},
],
"evaluation_parameters": {"param1": "1", "param2": '1 + "2"'},
"runtime_configuration": {
"result_format": {"result_format": "BASIC", "partial_unexpected_count": 20}
},
"validations": [],
"profilers": [],
}
checkpoint: Checkpoint = data_context.test_yaml_config(
yaml_config=yaml_config,
name="my_base_checkpoint",
)
assert filter_properties_dict(
properties=checkpoint.get_config(mode=ConfigOutputModes.DICT),
clean_falsy=True,
) == filter_properties_dict(
properties=expected_checkpoint_config,
clean_falsy=True,
)
assert len(data_context.list_checkpoints()) == 0
data_context.add_checkpoint(**yaml.load(yaml_config))
assert len(data_context.list_checkpoints()) == 1
with pytest.raises(
ge_exceptions.DataContextError,
match=r'Checkpoint "my_base_checkpoint" must contain either a batch_request or validations.',
):
# noinspection PyUnusedLocal
result: CheckpointResult = data_context.run_checkpoint(
checkpoint_name=checkpoint.name,
)
data_context.create_expectation_suite(expectation_suite_name="users.delivery")
result = data_context.run_checkpoint(
checkpoint_name="my_base_checkpoint",
validations=[
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {
"index": -1,
},
},
"expectation_suite_name": "users.delivery",
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector",
"data_asset_name": "users",
"data_connector_query": {
"index": -2,
},
},
"expectation_suite_name": "users.delivery",
},
],
)
assert len(result.list_validation_results()) == 2
assert len(data_context.validations_store.list_keys()) == 2
assert result.success
yaml_config = """
name: my_fancy_checkpoint
config_version: 1
class_name: Checkpoint
template_name: my_base_checkpoint
validations:
- batch_request:
datasource_name: my_datasource
data_connector_name: my_special_data_connector
data_asset_name: users
data_connector_query:
index: -1
- batch_request:
datasource_name: my_datasource
data_connector_name: my_other_data_connector
data_asset_name: users
data_connector_query:
index: -2
expectation_suite_name: users.delivery
"""
expected_checkpoint_config = {
"name": "my_fancy_checkpoint",
"config_version": 1.0,
"class_name": "Checkpoint",
"module_name": "great_expectations.checkpoint",
"template_name": "my_base_checkpoint",
"validations": [
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {
"index": -1,
},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector",
"data_asset_name": "users",
"data_connector_query": {
"index": -2,
},
}
},
],
"expectation_suite_name": "users.delivery",
"run_name_template": None,
"batch_request": None,
"action_list": [],
"evaluation_parameters": {},
"runtime_configuration": {},
"profilers": [],
}
checkpoint: Checkpoint = data_context.test_yaml_config(
yaml_config=yaml_config,
name="my_fancy_checkpoint",
)
assert filter_properties_dict(
properties=checkpoint.get_config(mode=ConfigOutputModes.DICT),
clean_falsy=True,
) == filter_properties_dict(
properties=expected_checkpoint_config,
clean_falsy=True,
)
assert len(data_context.list_checkpoints()) == 1
data_context.add_checkpoint(**yaml.load(yaml_config))
assert len(data_context.list_checkpoints()) == 2
result: CheckpointResult = data_context.run_checkpoint(
checkpoint_name=checkpoint.name,
)
assert len(result.list_validation_results()) == 2
assert len(data_context.validations_store.list_keys()) == 4
assert result.success
data_context.delete_checkpoint(name="my_base_checkpoint")
data_context.delete_checkpoint(name="my_fancy_checkpoint")
assert len(data_context.list_checkpoints()) == 0
@pytest.mark.slow # 1.05s
def test_legacy_checkpoint_instantiates_and_produces_a_validation_result_when_run(
filesystem_csv_data_context_with_validation_operators,
):
rad_datasource = list(
filter(
lambda element: element["name"] == "rad_datasource",
filesystem_csv_data_context_with_validation_operators.list_datasources(),
)
)[0]
base_directory = rad_datasource["batch_kwargs_generators"]["subdir_reader"][
"base_directory"
]
batch_kwargs: dict = {
"path": base_directory + "/f1.csv",
"datasource": "rad_datasource",
"reader_method": "read_csv",
}
checkpoint_config_dict: dict = {
"name": "my_checkpoint",
"validation_operator_name": "action_list_operator",
"batches": [
{"batch_kwargs": batch_kwargs, "expectation_suite_names": ["my_suite"]}
],
}
checkpoint: LegacyCheckpoint = LegacyCheckpoint(
data_context=filesystem_csv_data_context_with_validation_operators,
**checkpoint_config_dict,
)
with pytest.raises(
ge_exceptions.DataContextError, match=r"expectation_suite .* not found"
):
checkpoint.run()
assert (
len(
filesystem_csv_data_context_with_validation_operators.validations_store.list_keys()
)
== 0
)
filesystem_csv_data_context_with_validation_operators.create_expectation_suite(
"my_suite"
)
# noinspection PyUnusedLocal
result = checkpoint.run()
assert (
len(
filesystem_csv_data_context_with_validation_operators.validations_store.list_keys()
)
== 1
)
@pytest.mark.slow # 1.25s
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
# add checkpoint config
checkpoint_config = CheckpointConfig(
name="my_checkpoint",
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
validations=[
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
}
}
],
)
checkpoint_config_key = ConfigurationIdentifier(
configuration_key=checkpoint_config.name
)
context.checkpoint_store.set(key=checkpoint_config_key, value=checkpoint_config)
checkpoint: Checkpoint = context.get_checkpoint(checkpoint_config.name)
with pytest.raises(
ge_exceptions.DataContextError, match=r"expectation_suite .* not found"
):
checkpoint.run()
assert len(context.validations_store.list_keys()) == 0
context.create_expectation_suite("my_expectation_suite")
result = checkpoint.run()
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
@pytest.mark.integration
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_with_checkpoint_name_in_meta_when_run(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
checkpoint_name: str = "test_checkpoint_name"
# add checkpoint config
checkpoint_config = CheckpointConfig(
name=checkpoint_name,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
],
validations=[
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
}
}
],
)
checkpoint_config_key = ConfigurationIdentifier(
configuration_key=checkpoint_config.name
)
context.checkpoint_store.set(key=checkpoint_config_key, value=checkpoint_config)
checkpoint: Checkpoint = context.get_checkpoint(checkpoint_config.name)
assert len(context.validations_store.list_keys()) == 0
context.create_expectation_suite("my_expectation_suite")
result: CheckpointResult = checkpoint.run()
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
validation_result_identifier: ValidationResultIdentifier = (
context.validations_store.list_keys()[0]
)
validation_result: ExpectationSuiteValidationResult = context.validations_store.get(
validation_result_identifier
)
assert "checkpoint_name" in validation_result.meta
assert validation_result.meta["checkpoint_name"] == checkpoint_name
@pytest.mark.slow # 1.15s
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_batch_request_object(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
# add checkpoint config
batch_request: dict = {
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
}
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
validations=[{"batch_request": batch_request}],
)
with pytest.raises(
ge_exceptions.DataContextError, match=r"expectation_suite .* not found"
):
checkpoint.run()
assert len(context.validations_store.list_keys()) == 0
context.create_expectation_suite("my_expectation_suite")
result = checkpoint.run()
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_object_pandasdf(
data_context_with_datasource_pandas_engine,
):
context: DataContext = data_context_with_datasource_pandas_engine
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "test_df",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
with pytest.raises(
ge_exceptions.DataContextError, match=r"expectation_suite .* not found"
):
checkpoint.run(validations=[{"batch_request": runtime_batch_request}])
assert len(context.validations_store.list_keys()) == 0
context.create_expectation_suite("my_expectation_suite")
result = checkpoint.run(validations=[{"batch_request": runtime_batch_request}])
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_object_sparkdf(
data_context_with_datasource_spark_engine, spark_session
):
context: DataContext = data_context_with_datasource_spark_engine
pandas_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
test_df = spark_session.createDataFrame(pandas_df)
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "test_df",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
with pytest.raises(
ge_exceptions.DataContextError, match=r"expectation_suite .* not found"
):
# noinspection PyUnusedLocal
result = checkpoint.run(validations=[{"batch_request": runtime_batch_request}])
assert len(context.validations_store.list_keys()) == 0
context.create_expectation_suite("my_expectation_suite")
result = checkpoint.run(validations=[{"batch_request": runtime_batch_request}])
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
@mock.patch(
"great_expectations.core.usage_statistics.usage_statistics.UsageStatisticsHandler.emit"
)
@pytest.mark.slow # 1.31s
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_batch_request_object_multi_validation_pandasdf(
mock_emit,
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
sa,
):
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
batch_request: dict = {
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
}
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "test_df",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"batch_data": test_df},
}
)
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
with pytest.raises(
ge_exceptions.DataContextError, match=r"expectation_suite .* not found"
):
# noinspection PyUnusedLocal
result = checkpoint.run(
validations=[
{"batch_request": runtime_batch_request},
{"batch_request": batch_request},
]
)
assert mock_emit.call_count == 1
# noinspection PyUnresolvedReferences
expected_events: List[unittest.mock._Call] = [
mock.call(
{
"event_payload": {
"anonymized_name": "d7e22c0913c0cb83d528d2a7ad097f2b",
"config_version": 1,
"anonymized_run_name_template": "131f67e5ea07d59f2bc5376234f7f9f2",
"anonymized_expectation_suite_name": "295722d0683963209e24034a79235ba6",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
"anonymized_validations": [
{
"anonymized_batch_request": {
"anonymized_batch_request_required_top_level_properties": {
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
"anonymized_data_connector_name": "d52d7bff3226a7f94dd3510c1040de78",
"anonymized_data_asset_name": "7e60092b1b9b96327196fdba39029b9e",
},
"batch_request_optional_top_level_keys": [
"batch_identifiers",
"runtime_parameters",
],
"runtime_parameters_keys": ["batch_data"],
},
"anonymized_expectation_suite_name": "295722d0683963209e24034a79235ba6",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
},
{
"anonymized_batch_request": {
"anonymized_batch_request_required_top_level_properties": {
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
"anonymized_data_connector_name": "af09acd176f54642635a8a2975305437",
"anonymized_data_asset_name": "38b9086d45a8746d014a0d63ad58e331",
}
},
"anonymized_expectation_suite_name": "295722d0683963209e24034a79235ba6",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
},
],
},
"event": "checkpoint.run",
"success": False,
}
)
]
actual_events: List[unittest.mock._Call] = mock_emit.call_args_list
assert actual_events == expected_events
assert len(context.validations_store.list_keys()) == 0
context.create_expectation_suite("my_expectation_suite")
# noinspection PyUnusedLocal
result = checkpoint.run(
validations=[
{"batch_request": runtime_batch_request},
{"batch_request": batch_request},
]
)
assert len(context.validations_store.list_keys()) == 2
assert result["success"]
assert mock_emit.call_count == 8
# noinspection PyUnresolvedReferences
expected_events: List[unittest.mock._Call] = [
mock.call(
{
"event_payload": {
"anonymized_name": "d7e22c0913c0cb83d528d2a7ad097f2b",
"config_version": 1,
"anonymized_run_name_template": "131f67e5ea07d59f2bc5376234f7f9f2",
"anonymized_expectation_suite_name": "295722d0683963209e24034a79235ba6",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
"anonymized_validations": [
{
"anonymized_batch_request": {
"anonymized_batch_request_required_top_level_properties": {
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
"anonymized_data_connector_name": "d52d7bff3226a7f94dd3510c1040de78",
"anonymized_data_asset_name": "7e60092b1b9b96327196fdba39029b9e",
},
"batch_request_optional_top_level_keys": [
"batch_identifiers",
"runtime_parameters",
],
"runtime_parameters_keys": ["batch_data"],
},
"anonymized_expectation_suite_name": "295722d0683963209e24034a79235ba6",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
},
{
"anonymized_batch_request": {
"anonymized_batch_request_required_top_level_properties": {
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
"anonymized_data_connector_name": "af09acd176f54642635a8a2975305437",
"anonymized_data_asset_name": "38b9086d45a8746d014a0d63ad58e331",
},
},
"anonymized_expectation_suite_name": "295722d0683963209e24034a79235ba6",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
},
],
},
"event": "checkpoint.run",
"success": False,
}
),
mock.call(
{
"event_payload": {
"anonymized_batch_request_required_top_level_properties": {
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
"anonymized_data_connector_name": "d52d7bff3226a7f94dd3510c1040de78",
"anonymized_data_asset_name": "7e60092b1b9b96327196fdba39029b9e",
},
"batch_request_optional_top_level_keys": [
"batch_identifiers",
"runtime_parameters",
],
"runtime_parameters_keys": ["batch_data"],
},
"event": "data_context.get_batch_list",
"success": True,
}
),
mock.call(
{
"event": "data_asset.validate",
"event_payload": {
"anonymized_batch_kwarg_keys": [],
"anonymized_expectation_suite_name": "295722d0683963209e24034a79235ba6",
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
},
"success": True,
}
),
mock.call(
{
"event_payload": {},
"event": "data_context.build_data_docs",
"success": True,
}
),
mock.call(
{
"event_payload": {
"anonymized_batch_request_required_top_level_properties": {
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
"anonymized_data_connector_name": "af09acd176f54642635a8a2975305437",
"anonymized_data_asset_name": "38b9086d45a8746d014a0d63ad58e331",
}
},
"event": "data_context.get_batch_list",
"success": True,
}
),
mock.call(
{
"event": "data_asset.validate",
"event_payload": {
"anonymized_batch_kwarg_keys": [],
"anonymized_expectation_suite_name": "295722d0683963209e24034a79235ba6",
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
},
"success": True,
}
),
mock.call(
{
"event_payload": {},
"event": "data_context.build_data_docs",
"success": True,
}
),
mock.call(
{
"event_payload": {
"anonymized_name": "d7e22c0913c0cb83d528d2a7ad097f2b",
"config_version": 1,
"anonymized_run_name_template": "131f67e5ea07d59f2bc5376234f7f9f2",
"anonymized_expectation_suite_name": "295722d0683963209e24034a79235ba6",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
"anonymized_validations": [
{
"anonymized_batch_request": {
"anonymized_batch_request_required_top_level_properties": {
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
"anonymized_data_connector_name": "d52d7bff3226a7f94dd3510c1040de78",
"anonymized_data_asset_name": "7e60092b1b9b96327196fdba39029b9e",
},
"batch_request_optional_top_level_keys": [
"batch_identifiers",
"runtime_parameters",
],
"runtime_parameters_keys": ["batch_data"],
},
"anonymized_expectation_suite_name": "295722d0683963209e24034a79235ba6",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
},
{
"anonymized_batch_request": {
"anonymized_batch_request_required_top_level_properties": {
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
"anonymized_data_connector_name": "af09acd176f54642635a8a2975305437",
"anonymized_data_asset_name": "38b9086d45a8746d014a0d63ad58e331",
},
},
"anonymized_expectation_suite_name": "295722d0683963209e24034a79235ba6",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
},
],
},
"event": "checkpoint.run",
"success": True,
}
),
]
# noinspection PyUnresolvedReferences
actual_events: List[unittest.mock._Call] = mock_emit.call_args_list
assert actual_events == expected_events
# Since there are two validations, confirming there should be two "data_asset.validate" events
num_data_asset_validate_events = 0
for event in actual_events:
if event[0][0]["event"] == "data_asset.validate":
num_data_asset_validate_events += 1
assert num_data_asset_validate_events == 2
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_batch_request_object_multi_validation_sparkdf(
data_context_with_datasource_spark_engine,
spark_session,
):
context: DataContext = data_context_with_datasource_spark_engine
pandas_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
test_df_1 = spark_session.createDataFrame(pandas_df)
pandas_df: pd.DataFrame = pd.DataFrame(data={"col1": [5, 6], "col2": [7, 8]})
test_df_2 = spark_session.createDataFrame(pandas_df)
# RuntimeBatchRequest with a DataFrame
runtime_batch_request_1: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "test_df_1",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df_1},
}
)
# RuntimeBatchRequest with a DataFrame
runtime_batch_request_2: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "test_df_2",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df_2},
}
)
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
with pytest.raises(
ge_exceptions.DataContextError, match=r"expectation_suite .* not found"
):
# noinspection PyUnusedLocal
result = checkpoint.run(
validations=[
{"batch_request": runtime_batch_request_1},
{"batch_request": runtime_batch_request_2},
]
)
assert len(context.validations_store.list_keys()) == 0
context.create_expectation_suite("my_expectation_suite")
# noinspection PyUnusedLocal
result = checkpoint.run(
validations=[
{"batch_request": runtime_batch_request_1},
{"batch_request": runtime_batch_request_2},
]
)
assert len(context.validations_store.list_keys()) == 2
assert result["success"]
@pytest.mark.slow # 1.08s
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_single_runtime_batch_request_query_in_validations(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
validations=[{"batch_request": runtime_batch_request}],
)
result = checkpoint.run()
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_multiple_runtime_batch_request_query_in_validations(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query 1
batch_request_1 = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
}
)
# RuntimeBatchRequest with a query 2
batch_request_2 = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 5"
},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
validations=[
{"batch_request": batch_request_1},
{"batch_request": batch_request_2},
],
)
result = checkpoint.run()
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_raise_error_when_run_when_missing_batch_request_and_validations(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
with pytest.raises(
ge_exceptions.CheckpointError,
match='Checkpoint "my_checkpoint" must contain either a batch_request or validations.',
):
checkpoint.run()
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_query_in_top_level_batch_request(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
batch_request=runtime_batch_request,
)
result = checkpoint.run()
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_batch_data_in_top_level_batch_request_pandas(
data_context_with_datasource_pandas_engine,
):
context: DataContext = data_context_with_datasource_pandas_engine
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(batch_request=runtime_batch_request)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_batch_data_in_top_level_batch_request_spark(
data_context_with_datasource_spark_engine,
spark_session,
):
context: DataContext = data_context_with_datasource_spark_engine
pandas_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
test_df = spark_session.createDataFrame(pandas_df)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(batch_request=runtime_batch_request)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
@pytest.mark.slow # 1.09s
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_path_in_top_level_batch_request_pandas(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
data_path: str = os.path.join(
context.datasources["my_datasource"]
.data_connectors["my_basic_data_connector"]
.base_directory,
"Titanic_19120414_1313.csv",
)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"path": data_path},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
batch_request=runtime_batch_request,
)
result = checkpoint.run()
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_path_in_top_level_batch_request_spark(
titanic_spark_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_spark_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
data_path: str = os.path.join(
context.datasources["my_datasource"]
.data_connectors["my_basic_data_connector"]
.base_directory,
"Titanic_19120414_1313.csv",
)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"path": data_path},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
batch_request=runtime_batch_request,
)
result = checkpoint.run()
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_config_substitution_simple(
titanic_pandas_data_context_with_v013_datasource_stats_enabled_with_checkpoints_v1_with_templates,
monkeypatch,
):
monkeypatch.setenv("GE_ENVIRONMENT", "my_ge_environment")
monkeypatch.setenv("VAR", "test")
monkeypatch.setenv("MY_PARAM", "1")
monkeypatch.setenv("OLD_PARAM", "2")
context: DataContext = titanic_pandas_data_context_with_v013_datasource_stats_enabled_with_checkpoints_v1_with_templates
simplified_checkpoint_config = CheckpointConfig(
name="my_simplified_checkpoint",
config_version=1,
template_name="my_simple_template_checkpoint",
expectation_suite_name="users.delivery",
validations=[
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -1},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -2},
}
},
],
)
simplified_checkpoint: Checkpoint = Checkpoint(
data_context=context,
**filter_properties_dict(
properties=simplified_checkpoint_config.to_json_dict(),
delete_fields={"class_name", "module_name"},
clean_falsy=True,
),
)
# template only
expected_substituted_checkpoint_config_template_only: CheckpointConfig = (
CheckpointConfig(
name="my_simplified_checkpoint",
config_version=1.0,
run_name_template="%Y-%M-foo-bar-template-test",
expectation_suite_name="users.delivery",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
evaluation_parameters={
"environment": "my_ge_environment",
"tolerance": 1.0e-2,
"aux_param_0": "1",
"aux_param_1": "1 + 1",
},
runtime_configuration={
"result_format": {
"result_format": "BASIC",
"partial_unexpected_count": 20,
}
},
validations=[
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -1},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -2},
}
},
],
)
)
substituted_config_template_only: dict = (
simplified_checkpoint.get_substituted_config()
)
assert deep_filter_properties_iterable(
properties=substituted_config_template_only,
clean_falsy=True,
) == deep_filter_properties_iterable(
properties=expected_substituted_checkpoint_config_template_only.to_json_dict(),
clean_falsy=True,
)
# make sure operation is idempotent
simplified_checkpoint.get_substituted_config()
assert deep_filter_properties_iterable(
properties=substituted_config_template_only,
clean_falsy=True,
) == deep_filter_properties_iterable(
properties=expected_substituted_checkpoint_config_template_only.to_json_dict(),
clean_falsy=True,
)
# template and runtime kwargs
expected_substituted_checkpoint_config_template_and_runtime_kwargs = (
CheckpointConfig(
name="my_simplified_checkpoint",
config_version=1,
run_name_template="runtime_run_template",
expectation_suite_name="runtime_suite_name",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "MyCustomStoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs_deluxe",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
evaluation_parameters={
"environment": "runtime-my_ge_environment",
"tolerance": 1.0e-2,
"aux_param_0": "runtime-1",
"aux_param_1": "1 + 1",
"new_runtime_eval_param": "bloopy!",
},
runtime_configuration={
"result_format": {
"result_format": "BASIC",
"partial_unexpected_count": 999,
"new_runtime_config_key": "bleepy!",
}
},
validations=[
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -1},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -2},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector_2",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -3},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector_3",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -4},
}
},
],
)
)
substituted_config_template_and_runtime_kwargs = (
simplified_checkpoint.get_substituted_config(
runtime_kwargs={
"expectation_suite_name": "runtime_suite_name",
"validations": [
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector_2",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -3},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector_3",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -4},
}
},
],
"run_name_template": "runtime_run_template",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "MyCustomStoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": None,
},
{
"name": "update_data_docs_deluxe",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"evaluation_parameters": {
"environment": "runtime-$GE_ENVIRONMENT",
"tolerance": 1.0e-2,
"aux_param_0": "runtime-$MY_PARAM",
"aux_param_1": "1 + $MY_PARAM",
"new_runtime_eval_param": "bloopy!",
},
"runtime_configuration": {
"result_format": {
"result_format": "BASIC",
"partial_unexpected_count": 999,
"new_runtime_config_key": "bleepy!",
}
},
}
)
)
assert deep_filter_properties_iterable(
properties=substituted_config_template_and_runtime_kwargs,
clean_falsy=True,
) == deep_filter_properties_iterable(
properties=expected_substituted_checkpoint_config_template_and_runtime_kwargs.to_json_dict(),
clean_falsy=True,
)
def test_newstyle_checkpoint_config_substitution_nested(
titanic_pandas_data_context_with_v013_datasource_stats_enabled_with_checkpoints_v1_with_templates,
monkeypatch,
):
monkeypatch.setenv("GE_ENVIRONMENT", "my_ge_environment")
monkeypatch.setenv("VAR", "test")
monkeypatch.setenv("MY_PARAM", "1")
monkeypatch.setenv("OLD_PARAM", "2")
context: DataContext = titanic_pandas_data_context_with_v013_datasource_stats_enabled_with_checkpoints_v1_with_templates
nested_checkpoint_config = CheckpointConfig(
name="my_nested_checkpoint",
config_version=1,
template_name="my_nested_checkpoint_template_2",
expectation_suite_name="users.delivery",
validations=[
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -1},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -2},
}
},
],
)
nested_checkpoint: Checkpoint = Checkpoint(
data_context=context,
**filter_properties_dict(
properties=nested_checkpoint_config.to_json_dict(),
delete_fields={"class_name", "module_name"},
clean_falsy=True,
),
)
# template only
expected_nested_checkpoint_config_template_only = CheckpointConfig(
name="my_nested_checkpoint",
config_version=1,
run_name_template="%Y-%M-foo-bar-template-test-template-2",
expectation_suite_name="users.delivery",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "MyCustomStoreEvaluationParametersActionTemplate2",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
{
"name": "new_action_from_template_2",
"action": {"class_name": "Template2SpecialAction"},
},
],
evaluation_parameters={
"environment": "my_ge_environment",
"tolerance": 1.0e-2,
"aux_param_0": "1",
"aux_param_1": "1 + 1",
"template_1_key": 456,
},
runtime_configuration={
"result_format": "BASIC",
"partial_unexpected_count": 20,
"template_1_key": 123,
},
validations=[
{
"batch_request": {
"datasource_name": "my_datasource_template_1",
"data_connector_name": "my_special_data_connector_template_1",
"data_asset_name": "users_from_template_1",
"data_connector_query": {"partition_index": -999},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -1},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -2},
}
},
],
)
substituted_config_template_only = nested_checkpoint.get_substituted_config()
assert deep_filter_properties_iterable(
properties=substituted_config_template_only,
clean_falsy=True,
) == deep_filter_properties_iterable(
properties=expected_nested_checkpoint_config_template_only.to_json_dict(),
clean_falsy=True,
)
# make sure operation is idempotent
nested_checkpoint.get_substituted_config()
assert deep_filter_properties_iterable(
properties=substituted_config_template_only,
clean_falsy=True,
) == deep_filter_properties_iterable(
properties=expected_nested_checkpoint_config_template_only.to_json_dict(),
clean_falsy=True,
)
# runtime kwargs with new checkpoint template name passed at runtime
expected_nested_checkpoint_config_template_and_runtime_template_name = (
CheckpointConfig(
name="my_nested_checkpoint",
config_version=1,
template_name="my_nested_checkpoint_template_3",
run_name_template="runtime_run_template",
expectation_suite_name="runtime_suite_name",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "MyCustomRuntimeStoreEvaluationParametersAction",
},
},
{
"name": "new_action_from_template_2",
"action": {"class_name": "Template2SpecialAction"},
},
{
"name": "new_action_from_template_3",
"action": {"class_name": "Template3SpecialAction"},
},
{
"name": "update_data_docs_deluxe_runtime",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
evaluation_parameters={
"environment": "runtime-my_ge_environment",
"tolerance": 1.0e-2,
"aux_param_0": "runtime-1",
"aux_param_1": "1 + 1",
"template_1_key": 456,
"template_3_key": 123,
"new_runtime_eval_param": "bloopy!",
},
runtime_configuration={
"result_format": "BASIC",
"partial_unexpected_count": 999,
"template_1_key": 123,
"template_3_key": "bloopy!",
"new_runtime_config_key": "bleepy!",
},
validations=[
{
"batch_request": {
"datasource_name": "my_datasource_template_1",
"data_connector_name": "my_special_data_connector_template_1",
"data_asset_name": "users_from_template_1",
"data_connector_query": {"partition_index": -999},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -1},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -2},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector_2_runtime",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -3},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector_3_runtime",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -4},
}
},
],
)
)
substituted_config_template_and_runtime_kwargs = nested_checkpoint.get_substituted_config(
runtime_kwargs={
"expectation_suite_name": "runtime_suite_name",
"template_name": "my_nested_checkpoint_template_3",
"validations": [
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector_2_runtime",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -3},
}
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector_3_runtime",
"data_asset_name": "users",
"data_connector_query": {"partition_index": -4},
}
},
],
"run_name_template": "runtime_run_template",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "MyCustomRuntimeStoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": None,
},
{
"name": "update_data_docs_deluxe_runtime",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"evaluation_parameters": {
"environment": "runtime-$GE_ENVIRONMENT",
"tolerance": 1.0e-2,
"aux_param_0": "runtime-$MY_PARAM",
"aux_param_1": "1 + $MY_PARAM",
"new_runtime_eval_param": "bloopy!",
},
"runtime_configuration": {
"result_format": "BASIC",
"partial_unexpected_count": 999,
"new_runtime_config_key": "bleepy!",
},
}
)
assert deep_filter_properties_iterable(
properties=substituted_config_template_and_runtime_kwargs,
clean_falsy=True,
) == deep_filter_properties_iterable(
properties=expected_nested_checkpoint_config_template_and_runtime_template_name.to_json_dict(),
clean_falsy=True,
)
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_query_in_checkpoint_run(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(batch_request=runtime_batch_request)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_batch_data_in_checkpoint_run_pandas(
data_context_with_datasource_pandas_engine,
):
context: DataContext = data_context_with_datasource_pandas_engine
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(batch_request=runtime_batch_request)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_batch_data_in_checkpoint_run_spark(
data_context_with_datasource_spark_engine,
):
context: DataContext = data_context_with_datasource_spark_engine
pandas_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
test_df = get_or_create_spark_application().createDataFrame(pandas_df)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(batch_request=runtime_batch_request)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_validations_query_in_checkpoint_run(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(validations=[{"batch_request": runtime_batch_request}])
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_validations_batch_data_in_checkpoint_run_pandas(
data_context_with_datasource_pandas_engine,
):
context: DataContext = data_context_with_datasource_pandas_engine
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(validations=[{"batch_request": runtime_batch_request}])
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_validations_batch_data_in_checkpoint_run_spark(
data_context_with_datasource_spark_engine,
):
context: DataContext = data_context_with_datasource_spark_engine
pandas_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
test_df = get_or_create_spark_application().createDataFrame(pandas_df)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(validations=[{"batch_request": runtime_batch_request}])
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
@pytest.mark.slow # 1.11s
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_path_in_checkpoint_run_pandas(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
data_path: str = os.path.join(
context.datasources["my_datasource"]
.data_connectors["my_basic_data_connector"]
.base_directory,
"Titanic_19120414_1313.csv",
)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"path": data_path},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(batch_request=runtime_batch_request)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_path_in_checkpoint_run_spark(
titanic_spark_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_spark_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
data_path: str = os.path.join(
context.datasources["my_datasource"]
.data_connectors["my_basic_data_connector"]
.base_directory,
"Titanic_19120414_1313.csv",
)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"path": data_path},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(batch_request=runtime_batch_request)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_path_in_checkpoint_run_pandas(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
data_path: str = os.path.join(
context.datasources["my_datasource"]
.data_connectors["my_basic_data_connector"]
.base_directory,
"Titanic_19120414_1313.csv",
)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"path": data_path},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(validations=[{"batch_request": runtime_batch_request}])
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_validations_path_in_checkpoint_run_spark(
titanic_spark_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_spark_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
data_path: str = os.path.join(
context.datasources["my_datasource"]
.data_connectors["my_basic_data_connector"]
.base_directory,
"Titanic_19120414_1313.csv",
)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"path": data_path},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(validations=[{"batch_request": runtime_batch_request}])
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_query_in_context_run_checkpoint(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint", batch_request=runtime_batch_request
)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_batch_data_in_context_run_checkpoint_pandas(
data_context_with_datasource_pandas_engine,
):
context: DataContext = data_context_with_datasource_pandas_engine
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint", batch_request=runtime_batch_request
)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_batch_data_in_context_run_checkpoint_spark(
data_context_with_datasource_spark_engine,
):
context: DataContext = data_context_with_datasource_spark_engine
pandas_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
test_df = get_or_create_spark_application().createDataFrame(pandas_df)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint", batch_request=runtime_batch_request
)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_validations_query_in_context_run_checkpoint(
data_context_with_datasource_sqlalchemy_engine, sa
):
context: DataContext = data_context_with_datasource_sqlalchemy_engine
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {
"query": "SELECT * from table_partitioned_by_date_column__A LIMIT 10"
},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint",
validations=[{"batch_request": runtime_batch_request}],
)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_validations_batch_data_in_context_run_checkpoint_pandas(
data_context_with_datasource_pandas_engine,
):
context: DataContext = data_context_with_datasource_pandas_engine
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint",
validations=[{"batch_request": runtime_batch_request}],
)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_validations_batch_data_in_context_run_checkpoint_spark(
data_context_with_datasource_spark_engine,
):
context: DataContext = data_context_with_datasource_spark_engine
pandas_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
test_df = get_or_create_spark_application().createDataFrame(pandas_df)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint",
validations=[{"batch_request": runtime_batch_request}],
)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
@pytest.mark.slow # 1.18s
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_path_in_context_run_checkpoint_pandas(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
data_path: str = os.path.join(
context.datasources["my_datasource"]
.data_connectors["my_basic_data_connector"]
.base_directory,
"Titanic_19120414_1313.csv",
)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"path": data_path},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint", batch_request=runtime_batch_request
)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_path_in_context_run_checkpoint_spark(
titanic_spark_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_spark_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
data_path: str = os.path.join(
context.datasources["my_datasource"]
.data_connectors["my_basic_data_connector"]
.base_directory,
"Titanic_19120414_1313.csv",
)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"path": data_path},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint", batch_request=runtime_batch_request
)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_batch_request_path_in_context_run_checkpoint_pandas(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
data_path: str = os.path.join(
context.datasources["my_datasource"]
.data_connectors["my_basic_data_connector"]
.base_directory,
"Titanic_19120414_1313.csv",
)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"path": data_path},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint",
validations=[{"batch_request": runtime_batch_request}],
)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_validation_result_when_run_runtime_validations_path_in_context_run_checkpoint_spark(
titanic_spark_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_spark_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
data_path: str = os.path.join(
context.datasources["my_datasource"]
.data_connectors["my_basic_data_connector"]
.base_directory,
"Titanic_19120414_1313.csv",
)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a query
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"path": data_path},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint",
validations=[{"batch_request": runtime_batch_request}],
)
assert len(context.validations_store.list_keys()) == 1
assert result["success"]
def test_newstyle_checkpoint_instantiates_and_produces_a_printable_validation_result_with_batch_data(
data_context_with_datasource_pandas_engine,
):
context: DataContext = data_context_with_datasource_pandas_engine
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint: Checkpoint = Checkpoint(
name="my_checkpoint",
data_context=context,
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
)
result = checkpoint.run(batch_request=runtime_batch_request)
assert type(repr(result)) == str
def test_newstyle_checkpoint_instantiates_and_produces_a_runtime_parameters_error_contradictory_batch_request_in_checkpoint_yml_and_checkpoint_run(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
data_path: str = os.path.join(
context.datasources["my_datasource"]
.data_connectors["my_basic_data_connector"]
.base_directory,
"Titanic_19120414_1313.csv",
)
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a path
# Using typed object instead of dictionary, expected by "add_checkpoint()", on purpose to insure that checks work.
batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"path": data_path},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"batch_request": batch_request,
}
context.add_checkpoint(**checkpoint_config)
checkpoint: Checkpoint = context.get_checkpoint(name="my_checkpoint")
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "Titanic_19120414_1313.csv",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"batch_data": test_df},
}
)
with pytest.raises(
ge_exceptions.exceptions.InvalidBatchRequestError,
match=r"The runtime_parameters dict must have one \(and only one\) of the following keys: 'batch_data', 'query', 'path'.",
):
checkpoint.run(batch_request=runtime_batch_request)
@pytest.mark.slow # 1.75s
def test_newstyle_checkpoint_instantiates_and_produces_a_correct_validation_result_batch_request_in_checkpoint_yml_and_checkpoint_run(
titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation,
sa,
):
context: DataContext = titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
batch_request: dict = {
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
}
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "test_df",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"batch_request": batch_request,
}
context.add_checkpoint(**checkpoint_config)
checkpoint: Checkpoint = context.get_checkpoint(name="my_checkpoint")
result = checkpoint.run()
assert not result["success"]
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"evaluated_expectations"
]
== 1
)
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"successful_expectations"
]
== 0
)
result = checkpoint.run(batch_request=runtime_batch_request)
assert result["success"]
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"evaluated_expectations"
]
== 1
)
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"successful_expectations"
]
== 1
)
@pytest.mark.slow # 2.35s
def test_newstyle_checkpoint_instantiates_and_produces_a_correct_validation_result_validations_in_checkpoint_yml_and_checkpoint_run(
titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation,
sa,
):
context: DataContext = titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
batch_request: dict = {
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
}
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "test_df",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"validations": [{"batch_request": batch_request}],
}
context.add_checkpoint(**checkpoint_config)
checkpoint: Checkpoint = context.get_checkpoint(name="my_checkpoint")
result = checkpoint.run()
assert result["success"] is False
assert len(result.run_results.values()) == 1
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"evaluated_expectations"
]
== 1
)
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"successful_expectations"
]
== 0
)
result = checkpoint.run(validations=[{"batch_request": runtime_batch_request}])
assert result["success"] is False
assert len(result.run_results.values()) == 2
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"evaluated_expectations"
]
== 1
)
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"successful_expectations"
]
== 0
)
assert (
list(result.run_results.values())[1]["validation_result"]["statistics"][
"evaluated_expectations"
]
== 1
)
assert (
list(result.run_results.values())[1]["validation_result"]["statistics"][
"successful_expectations"
]
== 1
)
@pytest.mark.slow # 1.91s
def test_newstyle_checkpoint_instantiates_and_produces_a_correct_validation_result_batch_request_in_checkpoint_yml_and_context_run_checkpoint(
titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation,
sa,
):
context: DataContext = titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
batch_request: dict = {
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
}
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "test_df",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"batch_request": batch_request,
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(checkpoint_name="my_checkpoint")
assert result["success"] is False
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"evaluated_expectations"
]
== 1
)
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"successful_expectations"
]
== 0
)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint", batch_request=runtime_batch_request
)
assert result["success"]
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"evaluated_expectations"
]
== 1
)
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"successful_expectations"
]
== 1
)
@pytest.mark.slow # 2.46s
def test_newstyle_checkpoint_instantiates_and_produces_a_correct_validation_result_validations_in_checkpoint_yml_and_context_run_checkpoint(
titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation,
sa,
):
context: DataContext = titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
# add checkpoint config
batch_request: dict = {
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
}
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "my_runtime_data_connector",
"data_asset_name": "test_df",
"batch_identifiers": {
"pipeline_stage_name": "core_processing",
"airflow_run_id": 1234567890,
},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"validations": [{"batch_request": batch_request}],
}
context.add_checkpoint(**checkpoint_config)
result = context.run_checkpoint(checkpoint_name="my_checkpoint")
assert result["success"] is False
assert len(result.run_results.values()) == 1
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"evaluated_expectations"
]
== 1
)
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"successful_expectations"
]
== 0
)
result = context.run_checkpoint(
checkpoint_name="my_checkpoint",
validations=[{"batch_request": runtime_batch_request}],
)
assert result["success"] is False
assert len(result.run_results.values()) == 2
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"evaluated_expectations"
]
== 1
)
assert (
list(result.run_results.values())[0]["validation_result"]["statistics"][
"successful_expectations"
]
== 0
)
assert (
list(result.run_results.values())[1]["validation_result"]["statistics"][
"evaluated_expectations"
]
== 1
)
assert (
list(result.run_results.values())[1]["validation_result"]["statistics"][
"successful_expectations"
]
== 1
)
def test_newstyle_checkpoint_does_not_pass_dataframes_via_batch_request_into_checkpoint_store(
data_context_with_datasource_pandas_engine,
):
context: DataContext = data_context_with_datasource_pandas_engine
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"batch_request": batch_request,
}
with pytest.raises(
ge_exceptions.InvalidConfigError,
match='batch_data found in batch_request cannot be saved to CheckpointStore "checkpoint_store"',
):
context.add_checkpoint(**checkpoint_config)
def test_newstyle_checkpoint_does_not_pass_dataframes_via_validations_into_checkpoint_store(
data_context_with_datasource_pandas_engine,
):
context: DataContext = data_context_with_datasource_pandas_engine
test_df: pd.DataFrame = pd.DataFrame(data={"col1": [1, 2], "col2": [3, 4]})
# create expectation suite
context.create_expectation_suite("my_expectation_suite")
# RuntimeBatchRequest with a DataFrame
runtime_batch_request: RuntimeBatchRequest = RuntimeBatchRequest(
**{
"datasource_name": "my_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "default_data_asset_name",
"batch_identifiers": {"default_identifier_name": "test_identifier"},
"runtime_parameters": {"batch_data": test_df},
}
)
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"validations": [{"batch_request": runtime_batch_request}],
}
with pytest.raises(
ge_exceptions.InvalidConfigError,
match='batch_data found in validations cannot be saved to CheckpointStore "checkpoint_store"',
):
context.add_checkpoint(**checkpoint_config)
@pytest.mark.slow # 1.19s
def test_newstyle_checkpoint_result_can_be_pickled(
titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation,
sa,
):
context: DataContext = titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation
batch_request: dict = {
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
}
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"batch_request": batch_request,
}
context.add_checkpoint(**checkpoint_config)
checkpoint: Checkpoint = context.get_checkpoint(name="my_checkpoint")
result: CheckpointResult = checkpoint.run()
assert isinstance(pickle.dumps(result), bytes)
@pytest.mark.integration
@pytest.mark.slow # 1.19s
def test_newstyle_checkpoint_result_validations_include_rendered_content(
titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation,
sa,
):
context: DataContext = titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation
batch_request: dict = {
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
}
include_rendered_content: bool = True
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"validations": [
{
"batch_request": batch_request,
"include_rendered_content": include_rendered_content,
}
],
}
context.add_checkpoint(**checkpoint_config)
checkpoint: Checkpoint = context.get_checkpoint(name="my_checkpoint")
result: CheckpointResult = checkpoint.run()
validation_result_identifier: ValidationResultIdentifier = (
result.list_validation_result_identifiers()[0]
)
expectation_validation_result: ExpectationValidationResult = result.run_results[
validation_result_identifier
]["validation_result"]
for result in expectation_validation_result.results:
for rendered_content in result.rendered_content:
assert isinstance(rendered_content, RenderedAtomicContent)
@pytest.mark.integration
@pytest.mark.slow # 1.22s
def test_newstyle_checkpoint_result_validations_include_rendered_content_data_context_variable(
titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation,
sa,
):
context: DataContext = titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation
batch_request: dict = {
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
}
context.include_rendered_content.globally = True
# add checkpoint config
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"validations": [
{
"batch_request": batch_request,
}
],
}
context.add_checkpoint(**checkpoint_config)
checkpoint: Checkpoint = context.get_checkpoint(name="my_checkpoint")
result: CheckpointResult = checkpoint.run()
validation_result_identifier: ValidationResultIdentifier = (
result.list_validation_result_identifiers()[0]
)
expectation_validation_result: ExpectationValidationResult = result.run_results[
validation_result_identifier
]["validation_result"]
for result in expectation_validation_result.results:
for rendered_content in result.rendered_content:
assert isinstance(rendered_content, RenderedAtomicContent)
@pytest.mark.integration
@pytest.mark.cloud
@pytest.mark.parametrize(
"checkpoint_config,expected_validation_id",
[
pytest.param(
CheckpointConfig(
name="my_checkpoint",
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
],
validations=[
CheckpointValidationConfig(
batch_request={
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
},
),
],
),
None,
id="no ids",
),
pytest.param(
CheckpointConfig(
name="my_checkpoint",
config_version=1,
default_validation_id="7e2bb5c9-cdbe-4c7a-9b2b-97192c55c95b",
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
batch_request={
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
},
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
],
validations=[],
),
"7e2bb5c9-cdbe-4c7a-9b2b-97192c55c95b",
id="default validation id",
),
pytest.param(
CheckpointConfig(
name="my_checkpoint",
config_version=1,
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
],
validations=[
CheckpointValidationConfig(
id="f22601d9-00b7-4d54-beb6-605d87a74e40",
batch_request={
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
},
),
],
),
"f22601d9-00b7-4d54-beb6-605d87a74e40",
id="nested validation id",
),
pytest.param(
CheckpointConfig(
name="my_checkpoint",
config_version=1,
default_validation_id="7e2bb5c9-cdbe-4c7a-9b2b-97192c55c95b",
run_name_template="%Y-%M-foo-bar-template",
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
],
validations=[
CheckpointValidationConfig(
id="f22601d9-00b7-4d54-beb6-605d87a74e40",
batch_request={
"datasource_name": "my_datasource",
"data_connector_name": "my_basic_data_connector",
"data_asset_name": "Titanic_1911",
},
),
],
),
"f22601d9-00b7-4d54-beb6-605d87a74e40",
id="both default and nested validation id",
),
],
)
def test_checkpoint_run_adds_validation_ids_to_expectation_suite_validation_result_meta(
checkpoint_config: CheckpointConfig,
expected_validation_id: str,
titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation: DataContext,
sa,
) -> None:
context: DataContext = titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation
checkpoint_config_dict: dict = checkpointConfigSchema.dump(checkpoint_config)
context.add_checkpoint(**checkpoint_config_dict)
checkpoint: Checkpoint = context.get_checkpoint(name="my_checkpoint")
result: CheckpointResult = checkpoint.run()
# Always have a single validation result based on the test's parametrization
validation_result: ExpectationValidationResult = tuple(result.run_results.values())[
0
]["validation_result"]
actual_validation_id: Optional[str] = validation_result.meta["validation_id"]
assert expected_validation_id == actual_validation_id
### SparkDF Tests
@pytest.mark.integration
def test_running_spark_checkpoint(
context_with_single_csv_spark_and_suite, spark_df_taxi_data_schema
):
context = context_with_single_csv_spark_and_suite
single_batch_batch_request: BatchRequest = BatchRequest(
datasource_name="my_datasource",
data_connector_name="configured_data_connector_multi_batch_asset",
data_asset_name="yellow_tripdata_2020",
batch_spec_passthrough={
"reader_options": {
"header": True,
}
},
)
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"validations": [
{
"batch_request": single_batch_batch_request,
}
],
}
context.add_checkpoint(**checkpoint_config)
results = context.run_checkpoint(checkpoint_name="my_checkpoint")
assert results.success is True
@pytest.mark.integration
def test_run_spark_checkpoint_with_schema(
context_with_single_csv_spark_and_suite, spark_df_taxi_data_schema
):
context = context_with_single_csv_spark_and_suite
single_batch_batch_request: BatchRequest = BatchRequest(
datasource_name="my_datasource",
data_connector_name="configured_data_connector_multi_batch_asset",
data_asset_name="yellow_tripdata_2020",
batch_spec_passthrough={
"reader_options": {
"header": True,
"schema": spark_df_taxi_data_schema,
}
},
)
checkpoint_config: dict = {
"class_name": "Checkpoint",
"name": "my_checkpoint",
"config_version": 1,
"run_name_template": "%Y-%M-foo-bar-template",
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "store_validation_result",
"action": {
"class_name": "StoreValidationResultAction",
},
},
{
"name": "store_evaluation_params",
"action": {
"class_name": "StoreEvaluationParametersAction",
},
},
{
"name": "update_data_docs",
"action": {
"class_name": "UpdateDataDocsAction",
},
},
],
"validations": [
{
"batch_request": single_batch_batch_request,
}
],
}
context.add_checkpoint(**checkpoint_config)
results = context.run_checkpoint(checkpoint_name="my_checkpoint")
assert results.success is True
<file_sep>/docs/terms/profiler.md
---
id: profiler
title: Profiler
hoverText: Generates Metrics and candidate Expectations from data.
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
<UniversalMap setup='inactive' connect='inactive' create='active' validate='inactive'/>
## Overview
### Definition
A Profiler generates <TechnicalTag relative="../" tag="metric" text="Metrics" /> and candidate <TechnicalTag relative="../" tag="expectation" text="Expectations" /> from data.
### Features and promises
A Profiler creates a starting point for quickly generating Expectations. For example, during the [Getting Started Tutorial](../tutorials/getting_started/tutorial_overview.md), Great Expectations uses the `UserConfigurableProfiler` to demonstrate important features of Expectations by creating and validating an <TechnicalTag relative="../" tag="expectation_suite" text="Expectation Suite" /> that has several kinds of Expectations built from a small sample of data.
There are several Profilers included with Great Expectations; conceptually, each Profiler is a checklist of questions which will generate an Expectation Suite when asked of a Batch of data.
### Relationship to other objects
A Profiler builds an Expectation Suite from one or more Data Assets. Many Profiler workflows will also include a step that <TechnicalTag relative="../" tag="validation" text="Validates" /> the data against the newly-generated Expectation Suite to return a <TechnicalTag relative="../" tag="validation_result" text="Validation Result" />.
## Use cases
<CreateHeader/>
Profilers come into use when it is time to configure Expectations for your project. At this point in your workflow you can configure a new Profiler, or use an existing one to generate Expectations from a <TechnicalTag relative="../" tag="batch" text="Batch" /> of data.
For details on how to configure a customized Rule-Based Profiler, see our guide on [how to create a new expectation suite using Rule-Based Profilers](../guides/expectations/advanced/how_to_create_a_new_expectation_suite_using_rule_based_profilers.md).
For instructions on how to use a `UserConfigurableProfiler` to generate Expectations from data, see our guide on [how to create and edit Expectations with a Profiler](../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md).
## Features
### Multiple types of Profilers available
There are multiple types of Profilers built in to Great Expectations. Below is a list with overviews of each one. For more information, you can view their docstrings and source code in the `great_expectations\profile` [folder on our GitHub](https://github.com/great-expectations/great_expectations/tree/develop/great_expectations/profile).
#### UserConfigurableProfiler
The `UserConfigurableProfiler` is used to build an Expectation Suite from a dataset. The Expectations built are strict - they can be used to determine whether two tables are the same. When these Profilers are instantiated they can be configured by providing one or more input configuration parameters, allowing you to rapidly create a Profiler without needing to edit configuration files. However, if you need to change these parameters you will also need to instantiate a new `UserConfigurableProfiler` using the updated parameters.
For instructions on how to use a `UserConfigurableProfiler` to generate Expectations from data, see our guide on [how to create and edit Expectations with a Profiler](../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md).
#### JsonSchemaProfiler
The `JsonSchemaProfiler` creates Expectation Suites from JSONSchema artifacts. Basic suites can be created from these specifications.
:::note
- There is not yet a notion of nested data types in Great Expectations so suites generated by a `JsonSchemaProfiler` use column map expectations.
- A `JsonSchemaProfiler` does not traverse nested schemas and requires a top level object of type `object`.
:::
For an example of how to use the `JsonSchemaProfiler`, see our guide on [how to create a new Expectation Suite by profiling from a JsonSchema file](../guides/expectations/advanced/how_to_create_a_new_expectation_suite_by_profiling_from_a_jsonschema_file.md).
### Rule-Based Profiler
Rule-Based Profilers are a newer implementation of Profiler that allows you to directly configure the Profiler through a YAML configuration. Rule-Based Profilers allow you to integrate organizational knowledge about your data into the profiling process. For example, a team might have a convention that all columns **named** "id" are primary keys, whereas all columns ending with the **suffix** "_id" are foreign keys. In that case, when the team using Great Expectations first encounters a new dataset that followed the convention, a Profiler could use that knowledge to add an `expect_column_values_to_be_unique` Expectation to the "id" column (but not, for example an "address_id" column).
For details on how to configure a customized Rule-Based Profiler, see our guide on [how to create a new expectation suite using Rule-Based Profilers](../guides/expectations/advanced/how_to_create_a_new_expectation_suite_using_rule_based_profilers.md).
## API basics
### How to access
The recommended workflow for Profilers is to use the `UserConfigurableProfiler`. Doing so can be as simple as importing it and instantiating a copy by passing a <TechnicalTag relative="../" tag="validator" text="Validator" /> to the class, like so:
```python title="Python code"
from great_expectations.profile.user_configurable_profiler import UserConfigurableProfiler
profiler = UserConfigurableProfiler(profile_dataset=validator)
```
There are additional parameters that can be passed to a `UserConfigurableProfiler`, all of which are either optional or have a default value. These consist of:
- **excluded_expectations:** A list of Expectations to not include in the suite.
- **ignored_columns:** A list of columns for which you would like to NOT create Expectations.
- **not_null_only:** Boolean, default False. By default, each column is evaluated for nullity. If the column values contain fewer than 50% null values, then the Profiler will add `expect_column_values_to_not_be_null`; if greater than 50% it will add `expect_column_values_to_be_null`. If `not_null_only` is set to `True`, the Profiler will add a not_null Expectation irrespective of the percent nullity (and therefore will not add an `expect_column_values_to_be_null`).
- **primary_or_compound_key:** A list containing one or more columns which are a dataset's primary or compound key. This will create an `expect_column_values_to_be_unique` or `expect_compound_columns_to_be_unique` expectation. This will occur even if one or more of the `primary_or_compound_key` columns are specified in `ignored_columns`.
- **semantic_types_dict:** A dictionary where the keys are available `semantic_types` (see profiler.base.ProfilerSemanticTypes) and the values are lists of columns for which you would like to create `semantic_type` specific Expectations e.g.: `"semantic_types": { "value_set": ["state","country"], "numeric":["age", "amount_due"]}`.
- **table_expectations_only:** Boolean, default False. If True, this will only create the two table level Expectations available to this Profiler (`expect_table_columns_to_match_ordered_list` and `expect_table_row_count_to_be_between`). If a `primary_or_compound_key` is specified, it will create a uniqueness Expectation for that column as well.
- **value_set_threshold:** Takes a string from the following ordered list - "none", "one", "two", "very_few", "few", "many", "very_many", "unique". When the Profiler runs without a semantic_types dict, each column is profiled for cardinality. This threshold determines the greatest cardinality for which to add `expect_column_values_to_be_in_set`. For example, if `value_set_threshold` is set to "unique", it will add a value_set Expectation for every included column. If set to "few", it will add a value_set Expectation for columns whose cardinality is one of "one", "two", "very_few" or "few". The default value is "many". For the purposes of comparing whether two tables are identical, it might make the most sense to set this to "unique".
### How to create
It is unlikely that you will need to create a custom Profiler by extending an existing Profiler with a subclass. Instead, you should work with a Rule-Based Profiler which can be fully configured in a YAML configuration file.
Configuring a custom Rule-Based Profiler is covered in more detail in the [Configuration](#configuration) section below. You can also read our guide on [how to create a new expectation suite using Rule-Based Profilers](../guides/expectations/advanced/how_to_create_a_new_expectation_suite_using_rule_based_profilers.md) to be walked through the process, or view [the full source code for that guide](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py) on our GitHub as an example.
### Configuration
#### Rule-Based Profilers
**Rule-Based Profilers** allow users to provide a highly configurable specification which is composed of **Rules** to use in order to build an **Expectation Suite** by profiling existing data.
Imagine you have a table of Sales that comes in every month. You could profile last month's data, inspecting it in order to automatically create a number of expectations that you can use to validate next month's data.
A **Rule** in a Rule-Based Profiler could say something like "Look at every column in my Sales table, and if that column is numeric, add an `expect_column_values_to_be_between` Expectation to my Expectation Suite, where the `min_value` for the Expectation is the minimum value for the column, and the `max_value` for the Expectation is the maximum value for the column."
Each rule in a Rule-Based Profiler has three types of components:
1. **DomainBuilders**: A DomainBuilder will inspect some data that you provide to the Profiler, and compile a list of Domains for which you would like to build expectations
1. **ParameterBuilders**: A ParameterBuilder will inspect some data that you provide to the Profiler, and compile a dictionary of Parameters that you can use when constructing your ExpectationConfigurations
1. **ExpectationConfigurationBuilders**: An ExpectationConfigurationBuilder will take the Domains compiled by the DomainBuilder, and assemble ExpectationConfigurations using Parameters built by the ParameterBuilder
In the above example, imagine your table of Sales has twenty columns, of which five are numeric:
* Your **DomainBuilder** would inspect all twenty columns, and then yield a list of the five numeric columns
* You would specify two **ParameterBuilders**: one which gets the min of a column, and one which gets a max. Your Profiler would loop over the Domain (or column) list built by the **DomainBuilder** and use the two `ParameterBuilders` to get the min and max for each column.
* Then the Profiler loops over Domains built by the `DomainBuilder` and uses the **ExpectationConfigurationBuilders** to add a `expect_column_values_to_between` column for each of these Domains, where the `min_value` and `max_value` are the values that we got in the `ParameterBuilders`.
In addition to Rules, a Rule-Based Profiler enables you to specify **Variables**, which are global and can be used in any of the Rules. For instance, you may want to reference the same `BatchRequest` or the same tolerance in multiple Rules, and declaring these as Variables will enable you to do so.
Below is an example configuration based on this discussion:
```yaml title="YAML configuration"
variables:
my_last_month_sales_batch_request: # We will use this BatchRequest in our DomainBuilder and both of our ParameterBuilders so we can pinpoint the data to Profile
datasource_name: my_sales_datasource
data_connector_name: monthly_sales
data_asset_name: sales_data
data_connector_query:
index: -1
mostly_default: 0.95 # We can set a variable here that we can reference as the `mostly` value for our expectations below
rules:
my_rule_for_numeric_columns: # This is the name of our Rule
domain_builder:
batch_request: $variables.my_last_month_sales_batch_request # We use the BatchRequest that we specified in Variables above using this $ syntax
class_name: SemanticTypeColumnDomainBuilder # We use this class of DomainBuilder so we can specify the numeric type below
semantic_types:
- numeric
parameter_builders:
- parameter_name: my_column_min
class_name: MetricParameterBuilder
batch_request: $variables.my_last_month_sales_batch_request
metric_name: column.min # This is the metric we want to get with this ParameterBuilder
metric_domain_kwargs: $domain.domain_kwargs # This tells us to use the same Domain that is gotten by the DomainBuilder. We could also put a different column name in here to get a metric for that column instead.
- parameter_name: my_column_max
class_name: MetricParameterBuilder
batch_request: $variables.my_last_month_sales_batch_request
metric_name: column.max
metric_domain_kwargs: $domain.domain_kwargs
expectation_configuration_builders:
- expectation_type: expect_column_values_to_be_between # This is the name of the expectation that we would like to add to our suite
class_name: DefaultExpectationConfigurationBuilder
column: $domain.domain_kwargs.column
min_value: $parameter.my_column_min.value # We can reference the Parameters created by our ParameterBuilders using the same $ notation that we use to get Variables
max_value: $parameter.my_column_max.value
mostly: $variables.mostly_default
```
<file_sep>/docs/guides/connecting_to_your_data/cloud/s3/components_pandas/_test_your_new_datasource.mdx
import TabItem from '@theme/TabItem';
import Tabs from '@theme/Tabs';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
Verify your new <TechnicalTag tag="datasource" text="Datasource" /> by loading data from it into a <TechnicalTag tag="validator" text="Validator" /> using a <TechnicalTag tag="batch_request" text="Batch Request" />.
<Tabs
defaultValue='runtime_batch_request'
values={[
{label: 'Specify an S3 path to single CSV', value:'runtime_batch_request'},
{label: 'Specify a data_asset_name', value:'batch_request'},
]}>
<TabItem value="runtime_batch_request">
Add the S3 path to your CSV in the `path` key under `runtime_parameters` in your `BatchRequest`.
```python file=../../../../../../tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/inferred_and_runtime_yaml_example.py#L42-L50
```
Then load data into the `Validator`.
```python file=../../../../../../tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/inferred_and_runtime_yaml_example.py#L58-L64
```
</TabItem>
<TabItem value="batch_request">
Add the name of the <TechnicalTag tag="data_asset" text="Data Asset" /> to the `data_asset_name` in your `BatchRequest`.
```python file=../../../../../../tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/inferred_and_runtime_yaml_example.py#L76-L81
```
Then load data into the `Validator`.
```python file=../../../../../../tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/inferred_and_runtime_yaml_example.py#L88-L94
```
</TabItem>
</Tabs>
<file_sep>/docs/guides/setup/configuring_metadata_stores/components_how_to_configure_an_expectation_store_in_amazon_s3/_update_your_configuration_file_to_include_a_new_store_for_expectations_on_s.mdx
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
You can manually add an <TechnicalTag tag="expectation_store" text="Expectations Store" /> by adding the configuration shown below into the `stores` section of your `great_expectations.yml` file.
```yaml title="File contents: great_expectations.yml"
stores:
expectations_S3_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleS3StoreBackend
bucket: '<your_s3_bucket_name>'
prefix: '<your_s3_bucket_folder_name>'
```
To make the store work with S3 you will need to make some changes to default the ``store_backend`` settings, as has been done in the above example. The ``class_name`` should be set to ``TupleS3StoreBackend``, ``bucket`` will be set to the address of your S3 bucket, and ``prefix`` will be set to the folder in your S3 bucket where Expectation files will be located.
Additional options are available for a more fine-grained customization of the TupleS3StoreBackend.
```yaml title="File contents: great_expectations.yml"
class_name: ExpectationsStore
store_backend:
class_name: TupleS3StoreBackend
bucket: '<your_s3_bucket_name>'
prefix: '<your_s3_bucket_folder_name>'
boto3_options:
endpoint_url: ${S3_ENDPOINT} # Uses the S3_ENDPOINT environment variable to determine which endpoint to use.
region_name: '<your_aws_region_name>'
```
For the above example, please also note that the new Store's name is set to ``expectations_S3_store``. This value can be any name you like as long as you also update the value of the `expectations_store_name` key to match the new Store's name.
```yaml title="File contents: great_expectations.yml"
expectations_store_name: expectations_S3_store
```
This update to the value of the `expectations_store_name` key will tell Great Expectations to use the new Store for Expectations.
:::caution
If you are also storing [Validations in S3](../../configuring_metadata_stores/how_to_configure_a_validation_result_store_in_amazon_s3.md) or [DataDocs in S3](../../configuring_data_docs/how_to_host_and_share_data_docs_on_amazon_s3.md), please ensure that the ``prefix`` values are disjoint and one is not a substring of the other.
:::<file_sep>/tests/cli/v012/test_store.py
from click.testing import CliRunner
from great_expectations import DataContext
from great_expectations.cli.v012 import cli
from tests.cli.utils import escape_ansi
from tests.cli.v012.utils import assert_no_logging_messages_or_tracebacks
def test_store_list_with_zero_stores(caplog, empty_data_context):
project_dir = empty_data_context.root_directory
context = DataContext(project_dir)
context._project_config.stores = {}
context._save_project_config()
runner = CliRunner(mix_stderr=False)
result = runner.invoke(
cli,
f"store list -d {project_dir}",
catch_exceptions=False,
)
assert result.exit_code == 1
assert (
"Your configuration file is not a valid yml file likely due to a yml syntax error"
in result.output.strip()
)
assert_no_logging_messages_or_tracebacks(caplog, result)
def test_store_list_with_two_stores(caplog, empty_data_context):
project_dir = empty_data_context.root_directory
context = DataContext(project_dir)
del context._project_config.stores["validations_store"]
del context._project_config.stores["evaluation_parameter_store"]
del context._project_config.stores["profiler_store"]
context._project_config.validations_store_name = "expectations_store"
context._project_config.evaluation_parameter_store_name = "expectations_store"
context._project_config.profiler_store_name = "profiler_store"
context._save_project_config()
runner = CliRunner(mix_stderr=False)
expected_result = """\
2 Stores found:
- name: expectations_store
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
- name: checkpoint_store
class_name: CheckpointStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: checkpoints/
suppress_store_backend_id: True"""
result = runner.invoke(
cli,
f"store list -d {project_dir}",
catch_exceptions=False,
)
assert result.exit_code == 0
assert escape_ansi(result.output).strip() == expected_result.strip()
assert_no_logging_messages_or_tracebacks(caplog, result)
def test_store_list_with_four_stores(caplog, empty_data_context):
project_dir = empty_data_context.root_directory
runner = CliRunner(mix_stderr=False)
expected_result = """\
5 Stores found:
- name: expectations_store
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
- name: validations_store
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
- name: evaluation_parameter_store
class_name: EvaluationParameterStore
- name: checkpoint_store
class_name: CheckpointStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: checkpoints/
suppress_store_backend_id: True
- name: profiler_store
class_name: ProfilerStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: profilers/
suppress_store_backend_id: True"""
result = runner.invoke(
cli,
f"store list -d {project_dir}",
catch_exceptions=False,
)
print(result.output)
assert result.exit_code == 0
assert escape_ansi(result.output).strip() == expected_result.strip()
assert_no_logging_messages_or_tracebacks(caplog, result)
<file_sep>/reqs/requirements-dev-lite.txt
boto3==1.17.106 # This should match the version in constraints-dev.txt
flask>=1.0.0 # for s3 test only (with moto)
freezegun>=0.3.15
mock-alchemy>=0.2.5
moto>=2.0.0,<3.0.0
nbconvert>=5
pyfakefs>=4.5.1
pytest>=5.3.5
pytest-benchmark>=3.4.1
pytest-icdiff>=0.6
pytest-mock>=3.8.2
pytest-timeout>=2.1.0
requirements-parser>=0.2.0
s3fs>=0.5.1
snapshottest==0.6.0 # GE Cloud atomic renderer tests
sqlalchemy>=1.3.18,<2.0.0
<file_sep>/docs/guides/validation/checkpoints/how_to_create_a_new_checkpoint.md
---
title: How to create a new Checkpoint
---
import Preface from './components_how_to_create_a_new_checkpoint/_preface.mdx'
import StepsForCheckpoints from './components_how_to_create_a_new_checkpoint/_steps_for_checkpoints_.mdx'
import UseTheCliToOpenAJupyterNotebookForCreatingANewCheckpoint from './components_how_to_create_a_new_checkpoint/_use_the_cli_to_open_a_jupyter_notebook_for_creating_a_new_checkpoint.mdx'
import AEditTheConfiguration from './components_how_to_create_a_new_checkpoint/_a_edit_the_configuration.mdx'
import BTestYourConfigUsingContextTestYamlConfig from './components_how_to_create_a_new_checkpoint/_b_test_your_config_using_contexttest_yaml_config.mdx'
import CStoreYourCheckpointConfig from './components_how_to_create_a_new_checkpoint/_c_store_your_checkpoint_config.mdx'
import DOptionalCheckYourStoredCheckpointConfig from './components_how_to_create_a_new_checkpoint/_d_optional_check_your_stored_checkpoint_config.mdx'
import EOptionalTestRunTheNewCheckpointAndOpenDataDocs from './components_how_to_create_a_new_checkpoint/_e_optional_test_run_the_new_checkpoint_and_open_data_docs.mdx'
import AdditionalResources from './components_how_to_create_a_new_checkpoint/_additional_resources.mdx'
<Preface />
<StepsForCheckpoints />
## Steps (for Checkpoints in Great Expectations version >=0.13.12)
### 1. Use the CLI to open a Jupyter Notebook for creating a new Checkpoint
<UseTheCliToOpenAJupyterNotebookForCreatingANewCheckpoint />
### 2. Configure your SimpleCheckpoint (Example)
#### 2.1. Edit the configuration
<AEditTheConfiguration />
#### 2.2. Validate and test your configuration
<BTestYourConfigUsingContextTestYamlConfig />
### 3. Store your Checkpoint configuration
<CStoreYourCheckpointConfig />
### 4. (Optional) Check your stored Checkpoint config
<DOptionalCheckYourStoredCheckpointConfig />
### 5. (Optional) Test run the new Checkpoint and open Data Docs
<EOptionalTestRunTheNewCheckpointAndOpenDataDocs />
## Additional Resources
<AdditionalResources />
<file_sep>/docs/guides/connecting_to_your_data/datasource_configuration/sql_components/_part_assets_runtime.mdx
import ConfigForAssetsRuntime from '../sql_components/_config_for_assets_runtime.mdx'
import CautionRuntimeBatchIdentifierValues from '../components/_caution_runtime_batch_identifier_values.mdx'
<ConfigForAssetsRuntime />
The full configuration for your Datasource should now look like:
```python
datasource_config: dict = {
"name": "my_datasource_name",
"class_name": "Datasource",
"module_name": "great_expectations.datasource",
"execution_engine": {
"class_name": "SqlAlchemyExecutionEngine",
"module_name": "great_expectations.execution_engine",
"connection_string": CONNECTION_STRING,
},
"data_connectors": {
"name_of_my_runtime_data_connector": {
"class_name": "RuntimeDataConnector",
"batch_identifiers": ["batch_timestamp"],
}
}
}
```
<CautionRuntimeBatchIdentifierValues /><file_sep>/tests/test_the_utils_in_test_utils.py
import pytest
from tests.test_utils import get_awsathena_connection_url
@pytest.mark.unit
def test_get_awsathena_connection_url(monkeypatch):
monkeypatch.setenv("ATHENA_STAGING_S3", "s3://test-staging/")
monkeypatch.setenv("ATHENA_DB_NAME", "test_db_name")
monkeypatch.setenv("ATHENA_TEN_TRIPS_DB_NAME", "test_ten_trips_db_name")
assert (
get_awsathena_connection_url()
== "awsathena+rest://@athena.us-east-1.amazonaws.com/test_db_name?s3_staging_dir=s3://test-staging/"
)
assert (
get_awsathena_connection_url(db_name_env_var="ATHENA_TEN_TRIPS_DB_NAME")
== "awsathena+rest://@athena.us-east-1.amazonaws.com/test_ten_trips_db_name?s3_staging_dir=s3://test-staging/"
)
<file_sep>/scripts/check_docstring_coverage.py
import ast
import glob
import logging
import subprocess
from collections import defaultdict
from typing import Dict, List, Tuple, cast
Diagnostics = Dict[str, List[Tuple[ast.FunctionDef, bool]]]
DOCSTRING_ERROR_THRESHOLD: int = (
1109 # This number is to be reduced as we document more public functions!
)
logger = logging.getLogger(__name__)
def get_changed_files(branch: str) -> List[str]:
"""Perform a `git diff` against a given branch.
Args:
branch (str): The branch to diff against (generally `origin/develop`)
Returns:
A list of changed files.
"""
git_diff: subprocess.CompletedProcess = subprocess.run(
["git", "diff", branch, "--name-only"],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True,
)
return [f for f in git_diff.stdout.split()]
def collect_functions(directory_path: str) -> Dict[str, List[ast.FunctionDef]]:
"""Using AST, iterate through all source files to parse out function definition nodes.
Args:
directory_path (str): The directory to traverse through.
Returns:
A dictionary that maps source file with the function definition nodes contained therin.
"""
all_funcs: Dict[str, List[ast.FunctionDef]] = {}
file_paths: List[str] = _gather_source_files(directory_path)
for file_path in file_paths:
all_funcs[file_path] = _collect_functions(file_path)
return all_funcs
def _gather_source_files(directory_path: str) -> List[str]:
return glob.glob(f"{directory_path}/**/*.py", recursive=True)
def _collect_functions(file_path: str) -> List[ast.FunctionDef]:
with open(file_path) as f:
root: ast.Module = ast.parse(f.read())
return cast(
List[ast.FunctionDef],
list(filter(lambda n: isinstance(n, ast.FunctionDef), ast.walk(root))),
)
def gather_docstring_diagnostics(
all_funcs: Dict[str, List[ast.FunctionDef]]
) -> Diagnostics:
"""Given all function definitions in a repository, filter out the one's relevant to docstring testing.
Args:
all_funcs (Dict[str, List[ast.FunctionDef]]): The mapping generated by `collect_functions`.
Returns:
A set of diagnostics that are relevant to docstring checking.
(Diagnostics is a dictionary that associates each func with a bool to denote adherence/conflict with the style guide).
"""
diagnostics: Diagnostics = defaultdict(list)
for file, func_list in all_funcs.items():
public_funcs: List[ast.FunctionDef] = list(
filter(
lambda f: _function_filter(f),
func_list,
)
)
for func in public_funcs:
result: Tuple[ast.FunctionDef, bool] = (func, bool(ast.get_docstring(func)))
diagnostics[file].append(result)
return diagnostics
def _function_filter(func: ast.FunctionDef) -> bool:
# Private and dunder funcs/methods
if func.name.startswith("_"):
return False
# Getters and setters
for decorator in func.decorator_list:
if (isinstance(decorator, ast.Name) and decorator.id == "property") or (
isinstance(decorator, ast.Attribute) and decorator.attr == "setter"
):
return False
return True
def review_diagnostics(diagnostics: Diagnostics, changed_files: List[str]) -> None:
"""Generate the report to stdout.
Args:
diagnostics (Diagnostics): The diagnostics generated in `gather_docstring_diagnostics`.
changed_files (List[str]): The list of files generated from `get_changed_files`.
Raises:
AssertionError if threshold is surpassed. This threshold ensures we don't introduce new regressions.
"""
total_passed: int = 0
total_funcs: int = 0
relevant_diagnostics: Dict[str, List[ast.FunctionDef]] = defaultdict(list)
for file, diagnostics_list in diagnostics.items():
relevant_file: bool = file in changed_files
for func, success in diagnostics_list:
if success:
total_passed += 1
elif not success and relevant_file:
relevant_diagnostics[file].append(func)
total_funcs += 1
total_failed: int = total_funcs - total_passed
print(
f"[SUMMARY] {total_failed} of {total_funcs} public functions ({100 * total_failed / total_funcs:.2f}%) are missing docstrings!"
)
if relevant_diagnostics:
print(
"\nHere are violations of the style guide that are relevant to the files changed in your PR:"
)
for file, func_list in relevant_diagnostics.items():
print(f"\n {file}:")
for func in func_list:
print(f" L{func.lineno}:{func.name}")
# Chetan - 20220305 - While this number should be 0, getting the number of style guide violations down takes time
# and effort. In the meanwhile, we want to set an upper bound on errors to ensure we're not introducing
# further regressions. As docstrings are added, developers should update this number.
assert (
total_failed <= DOCSTRING_ERROR_THRESHOLD
), f"""A public function without a docstring was introduced; please resolve the matter before merging.
We expect there to be {DOCSTRING_ERROR_THRESHOLD} or fewer violations of the style guide (actual: {total_failed})"""
if DOCSTRING_ERROR_THRESHOLD != total_failed:
logger.warning(
f"The threshold needs to be updated! {DOCSTRING_ERROR_THRESHOLD} should be reduced to {total_failed}"
)
if __name__ == "__main__":
changed_files: List[str] = get_changed_files("origin/develop")
all_funcs: Dict[str, List[ast.FunctionDef]] = collect_functions(
"great_expectations"
)
docstring_diagnostics: Diagnostics = gather_docstring_diagnostics(all_funcs)
review_diagnostics(docstring_diagnostics, changed_files)
<file_sep>/reqs/requirements-dev-athena.txt
pyathena>=1.11
<file_sep>/docs/guides/setup/configuring_metadata_stores/how_to_configure_a_metricsstore.md
---
title: How to configure and use a MetricStore
---
import TechnicalTag from '/docs/term_tags/_tag.mdx';
Saving <TechnicalTag tag="metric" text="Metrics" /> during <TechnicalTag tag="validation" text="Validation" /> makes it easy to construct a new data series based on observed dataset characteristics computed by Great Expectations. That data series can serve as the source for a dashboard or overall data quality metrics, for example.
Storing metrics is still an **experimental** feature of Great Expectations, and we expect configuration and capability to evolve rapidly.
## Steps
### 1. Adding a MetricStore
A `MetricStore` is a special <TechnicalTag tag="store" text="Store" /> that can store Metrics computed during Validation. A `MetricStore` tracks the run_id of the Validation and the <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> name in addition to the Metric name and Metric kwargs.
To define a `MetricStore`, add a <TechnicalTag tag="metric_store" text="Metric Store" /> config to the `stores` section of your `great_expectations.yml`.
This config requires two keys:
- The `class_name` field determines which class will be instantiated to create this store, and must be `MetricStore`.
- The `store_backend` field configures the particulars of how your metrics will be persisted.
The `class_name` field determines which class will be instantiated to create this `StoreBackend`, and other fields are passed through to the StoreBackend class on instantiation.
In theory, any valid StoreBackend can be used, however at the time of writing, the only BackendStore under test for use with a `MetricStore` is the DatabaseStoreBackend with Postgres.
To use an SQL Database like Postgres, provide two fields: `class_name`, with the value of `DatabaseStoreBackend`, and `credentials`. Credentials can point to credentials defined in your `config_variables.yml`, or alternatively can be defined inline.
```yaml
stores:
# ...
metric_store: # You can choose any name as the key for your metric store
class_name: MetricStore
store_backend:
class_name: DatabaseStoreBackend
credentials: ${my_store_credentials}
# alternatively, define credentials inline:
# credentials:
# username: my_username
# password: <PASSWORD>
# port: 1234
# host: xxxx
# database: my_database
# driver: postgresql
```
The next time your DataContext is loaded, it will connect to the database and initialize a table to store metrics if
one has not already been created. See the metrics_reference for more information on additional configuration
options.
### 2. Configuring a Validation Action
Once a `MetricStore` is available, a `StoreMetricsAction` validation <TechnicalTag tag="action" text="Action" /> can be added to your <TechnicalTag tag="checkpoint" text="Checkpoint" /> in order to save Metrics during Validation. This validation Action has three required fields:
- The `class_name` field determines which class will be instantiated to execute this action, and must be `StoreMetricsAction`.
- The `target_store_name` field defines which Store backend to use when persisting the metrics. This should match the key of the MetricStore you added in your `great_expectations.yml`, which in our example above is `metrics_store`.
- The `requested_metrics` field identifies which Expectation Suites and Metrics to store. Please note that this API is likely to change in a future release.
<TechnicalTag tag="validation_result" text="Validation Result" /> statistics are available using the following format:
```yaml
expectation_suite_name:
statistics.<statistic name>
```
Values from inside a particular <TechnicalTag tag="expectation" text="Expectation's" /> `result` field are available using the following format:
```yaml
expectation_suite_name:
- column:
<column name>:
<expectation name>.result.<value name>
```
In place of the Expectation Suite name, you may use `"*"` to denote that any Expectation Suite should match.
:::note Note:
If an Expectation Suite name is used as a key, those Metrics will only be added to the `MetricStore` when that Suite is run.
When the wildcard `"*"` is used, those metrics will be added to the `MetricStore` for each Suite which runs in the Checkpoint.
:::
Here is an example yaml config for adding a `StoreMetricsAction` to the `taxi_data` dataset:
```
action_list:
# ...
- name: store_metrics
action:
class_name: StoreMetricsAction
target_store_name: metric_store # This should match the name of the store configured above
requested_metrics:
public.taxi_data.warning: # match a particular expectation suite
- column:
passenger_count:
- expect_column_values_to_not_be_null.result.element_count
- expect_column_values_to_not_be_null.result.partial_unexpected_list
- statistics.successful_expectations
"*": # wildcard to match any expectation suite
- statistics.evaluated_expectations
- statistics.success_percent
- statistics.unsuccessful_expectations
```
### 3. Test your MetricStore and StoreMetricsAction
To test your `StoreMetricsAction`, run your Checkpoint from your code or the <TechnicalTag tag="cli" text="CLI" />:
```python
import great_expectations as ge
context = ge.get_context()
checkpoint_name = "your checkpoint name here"
context.run_checkpoint(checkpoint_name=checkpoint_name)
```
```bash
$ great_expectations checkpoint run <your checkpoint name>
```
## Summary
The `StoreMetricsValidationAction` processes an `ExpectationValidationResult` and stores Metrics to a configured Store.
Now, after your Checkpoint is run, the requested metrics will be available in your database!<file_sep>/docs/guides/validation/validate_data_overview.md
---
title: "Validate Data: Overview"
---
# [](./validate_data_overview.md) Validate Data: Overview
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
<!--Use 'inactive' or 'active' to indicate which Universal Map steps this term has a use case within.-->
<UniversalMap setup='inactive' connect='inactive' create='inactive' validate='active'/>
:::note Prerequisites
- Completing [Step 4: Validate data](../../tutorials/getting_started/tutorial_validate_data.md) of the Getting Started tutorial is recommended.
:::
When you complete this step for the first time, you will have created and run a <TechnicalTag tag="checkpoint" text="Checkpoint" />. This Checkpoint can then be reused to <TechnicalTag tag="validation" text="Validate" /> data in the future, and you can also create and configure additional Checkpoints to cover different use cases, should you have them.
## The Validate Data process
The recommended workflow for validating data is through **the use of Checkpoints.** Checkpoints handle the rest of the Validation process for you: They will Validate data, save <TechnicalTag tag="validation_result" text="Validation Results" />, run any <TechnicalTag tag="action" text="Actions" /> you have specified, and finally create <TechnicalTag tag="data_docs" text="Data Docs" /> with their results.

As you can imagine, Checkpoints will make validating data a very simple process, especially since they are reusable. Once you have created your Checkpoint, configured it to your specifications, and specified any Actions you want it to take based on the Validation Results, all you will need to do in the future is tell the Checkpoint to run.
### Creating a Checkpoint
Checkpoints are simple to create. While advanced users could write their configuration from scratch, we recommend using the <TechnicalTag tag="cli" text="CLI" />. It will launch a Jupyter Notebook set up with boilerplate code to create your checkpoint. All you will need to do is configure it! For detailed instructions, please see our guide on [how to create a new Checkpoint](./checkpoints/how_to_create_a_new_checkpoint.md).
### Configuring your Checkpoint
There are three very important things you can do when configuring your Checkpoint. You can add additional validation data, or set the Checkpoint so that validation data must be specified at run time. You can add additional <TechnicalTag tag="expectation_suite" text="Expectation Suites" />, and you can add Actions which the Checkpoint will execute when it finishes Validating data. For a more detailed overview of Checkpoint configuration, please see our documentation on [Checkpoints](../../terms/checkpoint.md) and [Actions](../../terms/action.md).
#### Checkpoints, Batch Requests, and Expectation Suites
<p class="markdown"><TechnicalTag tag="batch_request" text="Batch Requests" /> are used to specify the data that a Checkpoint will Validate. You can add additional validation data to your Checkpoint by assigning it Batch Requests, or set up the Checkpoint so that it requires a Batch Request to be specified at run time.</p>
Expectation Suites contain the <TechnicalTag tag="expectation" text="Expectations" /> that the Checkpoint will run against the validation data specified in its Batch Requests. Checkpoints are assigned Expectation Suites and Batch Requests in pairs, and when the Checkpoint is run it will Validate each of its Expectation Suites against the data provided by its paired Batch Request.
For more detailed instructions on how to add Batch Requests and Expectation Suites to a Checkpoint, please see our guide on [how to add validations data or suites to a Checkpoint](./checkpoints/how_to_add_validations_data_or_suites_to_a_checkpoint.md).
#### Checkpoints and Actions
Actions are executed after a Checkpoint validates data. They are an optional addition to Checkpoints: you do not need to include any in your Checkpoint if you have no use for them. However, they are highly customizable and can be made to do anything you can program in Python, giving you exceptional control over what happens after a Checkpoint Validates.
With that said, there are some Actions that are more common than others. Updating Data Docs, sending emails, posting slack notifications, or sending other custom notifications are all common use cases for Actions. We provide detailed examples of how to set up these Actions in our [how to guides for validation Actions](./index.md#validation-actions).
### Running your Checkpoint
Running your Checkpoint once it is fully set up is very straight forward. You can do this either from the CLI or with a Python script, and both of these methods are covered in depth in our guide on [how to validate data by running a Checkpoint](./how_to_validate_data_by_running_a_checkpoint.md).
### Validation Results and Data Docs
When a Checkpoint finishes Validation, its Validation Results are automatically compiled as Data Docs. You can find these results in the Validation Results tab of your Data Docs, and clicking in to an individual Validation Result in the Data Docs will bring up a detailed list of all the Expectations that ran, as well as which (if any) Expectations passed and which (if any) failed.
For more information, see our documentation for <TechnicalTag tag="data_docs" text="Data Docs"/>.
## Wrapping up
Once your Checkpoint is created and you have used it to validate data, you can continue to reuse it. It will be easy for you to manually run it through the CLI or a Python script. And if you want your Checkpoint to run on a schedule, there are a few ways to do that as well.
We provide a guide for [how to deploy a scheduled Checkpoint with cron](./advanced/how_to_deploy_a_scheduled_checkpoint_with_cron.md), and if your pipeline architecture supports python scripts you will be able to run your Checkpoints from there. Even better: Regardless of how you choose to run your Checkpoint in the future, Actions will let you customize what is done with the Validation Results it generates.
Congratulations! At this point in your Great Expectations journey you have established the ability to reliably, and repeatedly, Validate your source data systems with ease.<file_sep>/great_expectations/rule_based_profiler/altair/themes.py
from enum import Enum
from typing import List
from great_expectations.types import ColorPalettes, Colors
# Size
chart_width: int = 800
chart_height: int = 250
# View
chart_border_opacity: float = 0
# Font
font: str = "Verdana"
#
# Chart Components
#
# Title
title_align: str = "center"
title_font_size: int = 15
title_color: str = Colors.GREEN.value
title_dy: int = -10
subtitle_color: str = Colors.PURPLE.value
subtitle_font: str = font
subtitle_font_size: int = 14
subtitle_font_weight: str = "bold"
# Both Axes
axis_title_color: str = Colors.PURPLE.value
axis_title_font_size: int = 14
axis_title_padding: int = 10
axis_label_color: str = Colors.BLUE_1.value
axis_label_font_size: int = 12
axis_label_flush: bool = True
axis_label_overlap_reduction: bool = True
# X-Axis Only
x_axis_title_y: int = 25
x_axis_label_angle: int = 0
x_axis_label_flush: bool = True
x_axis_grid: bool = True
# Y-Axis Only
y_axis_title_x: int = -55
# Legend
legend_title_color: str = Colors.PURPLE.value
legend_title_font_size: int = 12
# Scale
scale_continuous_padding: int = 33
scale_band_padding_outer: float = 1.0
#
# Color Palettes
#
category_color_scheme: List[str] = ColorPalettes.CATEGORY_5.value
diverging_color_scheme: List[str] = ColorPalettes.DIVERGING_7.value
heatmap_color_scheme: List[str] = ColorPalettes.HEATMAP_6.value
ordinal_color_scheme: List[str] = ColorPalettes.ORDINAL_7.value
#
# Chart Types
#
# Area
fill_opacity: float = 0.5
fill_color: str = ColorPalettes.HEATMAP_6.value[5]
# Line Chart
line_color: str = Colors.BLUE_2.value
line_stroke_width: float = 2.5
line_opacity: float = 0.9
# Point
point_size: int = 50
point_color: str = Colors.GREEN.value
point_filled: bool = True
point_opacity: float = 1.0
# Bar Chart
bar_color: str = Colors.PURPLE.value
bar_opacity: float = 0.7
bar_stroke_color: str = Colors.BLUE_1.value
bar_stroke_width: int = 1
bar_stroke_opacity: float = 1.0
class AltairThemes(Enum):
# https://altair-viz.github.io/user_guide/configuration.html#top-level-chart-configuration
DEFAULT_THEME = {
"view": {
"width": chart_width,
"height": chart_height,
"strokeOpacity": chart_border_opacity,
},
"font": font,
"title": {
"align": title_align,
"color": title_color,
"fontSize": title_font_size,
"dy": title_dy,
"subtitleFont": subtitle_font,
"subtitleFontSize": subtitle_font_size,
"subtitleColor": subtitle_color,
"subtitleFontWeight": subtitle_font_weight,
},
"axis": {
"titleFontSize": axis_title_font_size,
"titleColor": axis_title_color,
"titlePadding": axis_title_padding,
"labelFontSize": axis_label_font_size,
"labelColor": axis_label_color,
"labelFlush": axis_label_flush,
"labelOverlap": axis_label_overlap_reduction,
},
"axisY": {
"titleX": y_axis_title_x,
},
"axisX": {
"titleY": x_axis_title_y,
"labelAngle": x_axis_label_angle,
"labelFlush": x_axis_label_flush,
"grid": x_axis_grid,
},
"legend": {
"titleColor": legend_title_color,
"titleFontSize": legend_title_font_size,
},
"range": {
"category": category_color_scheme,
"diverging": diverging_color_scheme,
"heatmap": heatmap_color_scheme,
"ordinal": ordinal_color_scheme,
},
"scale": {
"continuousPadding": scale_continuous_padding,
"bandPaddingOuter": scale_band_padding_outer,
},
"area": {
"color": fill_color,
"fillOpacity": fill_opacity,
},
"line": {
"color": line_color,
"strokeWidth": line_stroke_width,
},
"point": {
"size": point_size,
"color": point_color,
"filled": point_filled,
"opacity": point_opacity,
},
"bar": {
"color": bar_color,
"opacity": bar_opacity,
"stroke": bar_stroke_color,
"strokeWidth": bar_stroke_width,
"strokeOpacity": bar_stroke_opacity,
},
}
<file_sep>/scripts/check_type_hint_coverage.py
import logging
import subprocess
from collections import defaultdict
from typing import Dict, List, Optional
TYPE_HINT_ERROR_THRESHOLD: int = (
1500 # This number is to be reduced as we annotate more functions!
)
logger = logging.getLogger(__name__)
def get_changed_files(branch: str) -> List[str]:
"""Perform a `git diff` against a given branch.
Args:
branch (str): The branch to diff against (generally `origin/develop`)
Returns:
A list of changed files.
"""
git_diff: subprocess.CompletedProcess = subprocess.run(
["git", "diff", branch, "--name-only"],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True,
)
return [f for f in git_diff.stdout.split()]
def run_mypy(directory: str) -> List[str]:
"""Run mypy to identify functions with type hint violations.
Flags:
--ignore-missing-imports: Omitting for simplicity's sake (https://mypy.readthedocs.io/en/stable/running_mypy.html#missing-imports)
--disallow-untyped-defs: What is responsible for highlighting function signature errors
--show-error-codes: Allows us to label each error with its code, enabling filtering
--install-types: We need common type hints from typeshed to get a more thorough analysis
--non-interactive: Automatically say yes to '--install-types' prompt
Args:
directory (str): The target directory to run mypy against
Returns:
A list containing filtered mypy output relevant to function signatures
"""
raw_results: subprocess.CompletedProcess = subprocess.run(
[
"mypy",
"--ignore-missing-imports",
"--disallow-untyped-defs",
"--show-error-codes",
"--install-types",
"--non-interactive",
directory,
],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True,
)
# Check to make sure `mypy` actually ran
err: str = raw_results.stderr
if "command not found" in err:
raise ValueError(err)
filtered_results: List[str] = _filter_mypy_results(raw_results)
return filtered_results
def _filter_mypy_results(raw_results: subprocess.CompletedProcess) -> List[str]:
def _filter(line: str) -> bool:
return "error:" in line and "untyped-def" in line
return list(filter(lambda line: _filter(line), raw_results.stderr.split("\n")))
def render_deviations(changed_files: List[str], deviations: List[str]) -> None:
"""Iterates through changed files in order to provide the user with useful feedback around mypy type hint violations
Args:
changed_files (List[str]): The files relevant to the given commit/PR
deviations (List[str]): mypy deviations as generated by `run_mypy`
Raises:
AssertionError if number of style guide violations is higher than threshold
"""
deviations_dict: Dict[str, List[str]] = _build_deviations_dict(deviations)
error_count: int = len(deviations)
print(f"[SUMMARY] {error_count} functions have untyped-def violations!")
threshold_is_surpassed: bool = error_count > TYPE_HINT_ERROR_THRESHOLD
if threshold_is_surpassed:
print(
"\nHere are violations of the style guide that are relevant to the files changed in your PR:"
)
for file in changed_files:
errors: Optional[List[str]] = deviations_dict.get(file)
if errors:
print(f"\n {file}:")
for error in errors:
print(f" {error}")
# Chetan - 20220417 - While this number should be 0, getting the number of style guide violations down takes time
# and effort. In the meanwhile, we want to set an upper bound on errors to ensure we're not introducing
# further regressions. As functions are annotated in adherence with style guide standards, developers should update this number.
assert (
threshold_is_surpassed is False
), f"""A function without proper type annotations was introduced; please resolve the matter before merging.
We expect there to be {TYPE_HINT_ERROR_THRESHOLD} or fewer violations of the style guide (actual: {error_count})"""
if TYPE_HINT_ERROR_THRESHOLD != error_count:
logger.warning(
f"The threshold needs to be updated! {TYPE_HINT_ERROR_THRESHOLD} should be reduced to {error_count}"
)
def _build_deviations_dict(mypy_results: List[str]) -> Dict[str, List[str]]:
deviations_dict: Dict[str, List[str]] = defaultdict(list)
for row in mypy_results:
file: str = row.split(":")[0]
deviations_dict[file].append(row)
return deviations_dict
def main():
changed_files: List[str] = get_changed_files("origin/develop")
untyped_def_deviations: List[str] = run_mypy("great_expectations")
render_deviations(changed_files, untyped_def_deviations)
if __name__ == "__main__":
main()
<file_sep>/docs/guides/connecting_to_your_data/database/athena.md
---
title: How to connect to an Athena database
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide will help you add an Athena instance (or a database) as a <TechnicalTag tag="datasource" text="Datasource" />. This will allow you to <TechnicalTag tag="validation" text="Validate" /> tables and queries within this instance. When you use an Athena Datasource, the validation is done in Athena itself. Your data is not downloaded.
<Prerequisites>
- [Set up a working deployment of Great Expectations](../../../tutorials/getting_started/tutorial_overview.md)
- Installed the pyathena package for the Athena SQLAlchemy dialect (``pip install "pyathena[SQLAlchemy]"``)
</Prerequisites>
## Steps
### 1. Run the following CLI command to begin the interactive Datasource creation process:
```bash
great_expectations datasource new
```
When prompted to choose from the list of database engines, chose `other`.
### 2. Identify your connection string
In order to for Great Expectations to connect to Athena, you will need to provide a connection string. To determine your connection string, reference the examples below and the [PyAthena documentation](https://github.com/laughingman7743/PyAthena#sqlalchemy).
The following urls don't include credentials as it is recommended to use either the instance profile or the boto3 configuration file.
If you want Great Expectations to connect to your Athena instance (without specifying a particular database), the URL should be:
```bash
awsathena+rest://@athena.{region}.amazonaws.com/?s3_staging_dir={s3_path}
```
Note the url parameter "s3_staging_dir" needed for storing query results in S3.
If you want Great Expectations to connect to a particular database inside your Athena, the URL should be:
```bash
awsathena+rest://@athena.{region}.amazonaws.com/{database}?s3_staging_dir={s3_path}
```
After providing your connection string, you will then be presented with a Jupyter Notebook.
### 3. Follow the steps in the Jupyter Notebook
The Jupyter Notebook will guide you through the remaining steps of creating a Datasource. Follow the steps in the presented notebook, including entering the connection string in the yaml configuration.
## Additional notes
Environment variables can be used to store the SQLAlchemy URL instead of the file, if preferred - search documentation for "Managing Environment and Secrets".
<file_sep>/docs/guides/setup/index.md
---
title: "Setup: Index"
---
import Installation from './components_index/_installation.mdx'
import DataContexts from './components_index/_data_contexts.mdx'
import ExpectationStores from './components_index/_expectation_stores.mdx'
import ValidationResultStores from './components_index/_validation_result_stores.mdx'
import MetricStores from './components_index/_metric_stores.mdx'
import DataDocs from './components_index/_data_docs.mdx'
import Miscellaneous from './components_index/_miscellaneous.mdx'
# [](./setup_overview.md) Setup: Index
## Installation
<Installation />
## Data Contexts
<DataContexts />
## Metadata Stores
### Expectation Stores
<ExpectationStores />
### Validation Result Stores
<ValidationResultStores />
### Metric Stores
<MetricStores />
## Data Docs
<DataDocs />
## Miscellaneous
<Miscellaneous />
<file_sep>/assets/scripts/AlgoliaScripts/upload_s3_expectation_to_algolia.js
// load .env file (used while development) for loading env variables
require('dotenv').config();
const fetch = require('node-fetch');
const expecS3URL = "https://superconductive-public.s3.us-east-2.amazonaws.com/static/gallery/expectation_library_v2.json";
const algoliasearch = require("algoliasearch");
const client = algoliasearch(process.env.ALGOLIA_ACCOUNT, process.env.ALGOLIA_WRITE_KEY);
const expecAlgoliaIndex = process.env.ALGOLIA_EXPECTATION_INDEX;
const index = client.initIndex(expecAlgoliaIndex);
// Replica Index Names And Sorting Order Settings
const replicaIndexAndSettings = [
{
replica: `${process.env.ALGOLIA_EXPEC_REPLICA_ALPHA_ASC_INDEX}`, ranking: ['asc(description.snake_name)']
},
{
replica: `${process.env.ALGOLIA_EXPEC_REPLICA_ALPHA_DSC_INDEX}`, ranking: ['desc(description.snake_name)']
},
{
replica: `${process.env.ALGOLIA_EXPEC_REPLICA_COVERAGE_ASC_INDEX}`, ranking: ['asc(coverage_score)']
},
{
replica: `${process.env.ALGOLIA_EXPEC_REPLICA_COVERAGE_DSC_INDEX}`, ranking: ['desc(coverage_score)']
},
{
replica: `${process.env.ALGOLIA_EXPEC_REPLICA_CREATED_ASC_INDEX}`, ranking: ['asc(created_at)']
},
{
replica: `${process.env.ALGOLIA_EXPEC_REPLICA_CREATED_DSC_INDEX}`, ranking: ['desc(created_at)']
},
{
replica: `${process.env.ALGOLIA_EXPEC_REPLICA_UPDATED_ASC_INDEX}`, ranking: ['asc(updated_at)']
},
{
replica: `${process.env.ALGOLIA_EXPEC_REPLICA_UPDATED_DSC_INDEX}`, ranking: ['desc(updated_at)']
},
]
// Main Index setSettings
const attributesForFaceting = ["searchable(library_metadata.tags)", "searchable(engineSupported)", "searchable(exp_type)"];
const maxFacetHits=100;
const searchableAttributes=["description.snake_name", "description.short_description"]
const customRanking=['asc(description.snake_name)']
//load data from S3
loadFromS3(expecS3URL).then(response => {
console.log("Length of expectation loaded from S3", Object.keys(response).length);
if (Object.keys(response).length > 0) {
let algDataset = formatExpectation(response);
console.log('Size of algolia dataset ', algDataset.length)
if (algDataset.length == 0) {
console.log("No records to push to algolia");
return;
}
console.log("Formatted expectation sample: ", algDataset[0]);
// return;
deleteIndex(algDataset);
}
}).catch((error) => {
console.log('Error fetching data from s3', error);
})
//delete exisitng index
function deleteIndex(algData) {
index.delete().then(() => {
console.log('existing index is deleted');
uploadToAlgolia(algData);
}).catch((error) => {
console.log("Error in deleting index", algDataset);
});
}
//load data from S3
async function loadFromS3(URL) {
const response = await fetch(URL);
return await response.json();
}
// Format expectations and prepare JSON which will be sent to algolia
function formatExpectation(ExpecData) {
const ExpectationKeys = Object.keys(ExpecData);
let dataset = [];
ExpectationKeys.forEach((key, i) => {
let data = {};
data.objectID = key;
data.library_metadata = ExpecData[key].library_metadata;
data.description = ExpecData[key].description;
data.execution_engines = ExpecData[key].execution_engines;
data.maturity_checklist = ExpecData[key].maturity_checklist;
data.backend_test_result_counts = ExpecData[key].backend_test_result_counts;
data.engineSupported=ExpecData[key].backend_test_result_counts.map((db)=>db.backend);
data.coverage_score=ExpecData[key].coverage_score;
data.created_at=ExpecData[key].created_at;
data.updated_at=ExpecData[key].updated_at;
data.exp_type=ExpecData[key].exp_type;
dataset.push(data);
})
return dataset;
}
// Upload data to algolia index
function uploadToAlgolia(dataset) {
index.saveObjects(dataset)
.then(() => {
console.log('Expectations data uploaded to algolia');
mainIndexSetting(dataset);
})
.catch(err => console.log(err))
}
function mainIndexSetting(dataset) {
index.setSettings({
attributesForFaceting:attributesForFaceting ,
maxFacetHits: maxFacetHits,
searchableAttributes:searchableAttributes,
customRanking: customRanking,
// Creating replica index
replicas:replicaIndexAndSettings.map(replica=>replica.replica)
})
.then(() => {
console.log('facets created.');
fetchAllAtrributes(dataset[0]);
// Creating replica index setsettings
setReplicaSettings();
}).catch((error) => {
console.log("Error in index settings", error);
});
}
function fetchAllAtrributes(data) {
console.log("data is ",data);
let existingId = [data.description.snake_name];
let attributes = Object.keys(data);
console.log("Attributes are", attributes);
index.getObjects(existingId, {
attributesToRetrieve: attributes
})
.then((results) => {
console.log('fetching all attributes ', results);
console.log("Successfully fetched sample record from algolia !");
}).catch((error) => {
console.log('getting error while fetching', error);
})
};
//Replica Index Settings
function setReplicaSettings() {
replicaIndexAndSettings.map((repli) => {
const { replica, ranking } = repli;
client.initIndex(replica).setSettings({
attributesForFaceting: attributesForFaceting,
maxFacetHits: maxFacetHits,
searchableAttributes: searchableAttributes,
customRanking: ranking
})
.then(() => {
console.log(`Replica: ${replica} configured`)
})
})
}
<file_sep>/tests/integration/docusaurus/miscellaneous/migration_guide_pandas_v3_api.py
import os
from ruamel import yaml
import great_expectations as ge
context = ge.get_context()
# parse great_expectations.yml for comparison
great_expectations_yaml_file_path = os.path.join(
context.root_directory, "great_expectations.yml"
)
with open(great_expectations_yaml_file_path) as f:
great_expectations_yaml = yaml.safe_load(f)
actual_datasource = great_expectations_yaml["datasources"]
# expected Datasource
expected_existing_datasource_yaml = r"""
my_datasource:
module_name: great_expectations.datasource
class_name: Datasource
execution_engine:
module_name: great_expectations.execution_engine
class_name: PandasExecutionEngine
data_connectors:
default_inferred_data_connector_name:
class_name: InferredAssetFilesystemDataConnector
base_directory: ../../../data/
module_name: great_expectations.datasource.data_connector
default_regex:
group_names:
- data_asset_name
pattern: (.*)
default_runtime_data_connector_name:
class_name: RuntimeDataConnector
batch_identifiers:
- default_identifier_name
module_name: great_expectations.datasource.data_connector
"""
assert actual_datasource == yaml.safe_load(expected_existing_datasource_yaml)
# Please note this override is only to provide good UX for docs and tests.
updated_configuration = yaml.safe_load(expected_existing_datasource_yaml)
updated_configuration["my_datasource"]["data_connectors"][
"default_inferred_data_connector_name"
]["base_directory"] = "../data/"
context.add_datasource(name="my_datasource", **updated_configuration["my_datasource"])
# check that checkpoint contains the right configuration
# parse great_expectations.yml for comparison
checkpoint_yaml_file_path = os.path.join(
context.root_directory, "checkpoints/test_v3_checkpoint.yml"
)
with open(checkpoint_yaml_file_path) as f:
actual_checkpoint_yaml = yaml.safe_load(f)
expected_checkpoint_yaml = """
name: test_v3_checkpoint
config_version: 1.0
template_name:
module_name: great_expectations.checkpoint
class_name: Checkpoint
run_name_template: '%Y%m%d-%H%M%S-my-run-name-template'
expectation_suite_name:
batch_request:
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
site_names: []
evaluation_parameters: {}
runtime_configuration: {}
validations:
- batch_request:
datasource_name: my_datasource
data_connector_name: default_inferred_data_connector_name
data_asset_name: Titanic.csv
data_connector_query:
index: -1
expectation_suite_name: Titanic.profiled
profilers: []
ge_cloud_id:
expectation_suite_ge_cloud_id:
"""
assert actual_checkpoint_yaml == yaml.safe_load(expected_checkpoint_yaml)
# run checkpoint
context.add_checkpoint(**actual_checkpoint_yaml)
results = context.run_checkpoint(checkpoint_name="test_v3_checkpoint")
assert results["success"] is True
<file_sep>/reqs/requirements-dev-contrib.txt
black==22.3.0
flake8==5.0.4
invoke>=1.7.1
isort==5.10.1
mypy==0.991
pre-commit>=2.6.0
pydantic>=1.0,<2.0 # needed for mypy plugin support
pytest-cov>=2.8.1
pytest-order>=0.9.5
pytest-random-order>=1.0.4
pyupgrade==2.7.2
<file_sep>/docs/guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_amazon_s3.md
---
title: How to configure an Expectation Store to use Amazon S3
---
import Preface from './components_how_to_configure_an_expectation_store_in_amazon_s3/_preface.mdx'
import InstallBoto3 from './components/_install_boto3_with_pip.mdx'
import VerifyAwsCredentials from './components/_verify_aws_credentials_are_configured_properly.mdx'
import IdentifyYourDataContextExpectationsStore from './components_how_to_configure_an_expectation_store_in_amazon_s3/_identify_your_data_context_expectations_store.mdx'
import UpdateYourConfigurationFileToIncludeANewStoreForExpectationsOnS from './components_how_to_configure_an_expectation_store_in_amazon_s3/_update_your_configuration_file_to_include_a_new_store_for_expectations_on_s.mdx'
import CopyExistingExpectationJsonFilesToTheSBucketThisStepIsOptional from './components_how_to_configure_an_expectation_store_in_amazon_s3/_copy_existing_expectation_json_files_to_the_s_bucket_this_step_is_optional.mdx'
import ConfirmThatTheNewExpectationsStoreHasBeenAddedByRunningGreatExpectationsStoreList from './components_how_to_configure_an_expectation_store_in_amazon_s3/_confirm_that_the_new_expectations_store_has_been_added_by_running_great_expectations_store_list.mdx'
import ConfirmThatExpectationsCanBeAccessedFromAmazonSByRunningGreatExpectationsSuiteList from './components_how_to_configure_an_expectation_store_in_amazon_s3/_confirm_that_expectations_can_be_accessed_from_amazon_s_by_running_great_expectations_suite_list.mdx'
<Preface />
## Steps
### 1. Install boto3 with pip
<InstallBoto3 />
### 2. Verify your AWS credentials are properly configured
<VerifyAwsCredentials />
### 2. Identify your Data Context Expectations Store
<IdentifyYourDataContextExpectationsStore />
### 3. Update your configuration file to include a new Store for Expectations on S3
<UpdateYourConfigurationFileToIncludeANewStoreForExpectationsOnS />
### 5. Confirm that the new Expectations Store has been added
<ConfirmThatTheNewExpectationsStoreHasBeenAddedByRunningGreatExpectationsStoreList />
### 4. Copy existing Expectation JSON files to the S3 bucket (This step is optional)
<CopyExistingExpectationJsonFilesToTheSBucketThisStepIsOptional />
### 6. Confirm that Expectations can be accessed from Amazon S3 by running ``great_expectations suite list``
<ConfirmThatExpectationsCanBeAccessedFromAmazonSByRunningGreatExpectationsSuiteList />
<file_sep>/docs/guides/connecting_to_your_data/components/spark_data_context_note.md
:::note Load your DataContext into memory
Use one of the guides below based on your deployment:
- [How to instantiate a Data Context without a yml file](../../setup/configuring_data_contexts/how_to_instantiate_a_data_context_without_a_yml_file.md)
- [How to instantiate a Data Context on an EMR Spark cluster](../../../deployment_patterns/how_to_instantiate_a_data_context_on_an_emr_spark_cluster.md)
- [How to use Great Expectations in Databricks](../../../deployment_patterns/how_to_use_great_expectations_in_databricks.md)
:::
<file_sep>/tests/execution_engine/test_sqlalchemy_dialect.py
import pytest
from great_expectations.execution_engine.sqlalchemy_dialect import GESqlDialect
@pytest.mark.unit
def test_dialect_instantiation_with_string():
assert GESqlDialect("hive") == GESqlDialect.HIVE
@pytest.mark.unit
def test_dialect_instantiation_with_byte_string():
assert GESqlDialect(b"hive") == GESqlDialect.HIVE
@pytest.mark.unit
def test_string_equivalence():
assert GESqlDialect.HIVE == "hive"
@pytest.mark.unit
def test_byte_string_equivalence():
assert GESqlDialect.HIVE == b"hive"
@pytest.mark.unit
def test_get_all_dialect_names_no_other_dialects():
assert GESqlDialect.OTHER.value not in GESqlDialect.get_all_dialect_names()
@pytest.mark.unit
def test_get_all_dialects_no_other_dialects():
assert GESqlDialect.OTHER not in GESqlDialect.get_all_dialects()
<file_sep>/docs/deployment_patterns/how_to_use_great_expectations_with_airflow.md
---
title: How to Use Great Expectations with Airflow
---
import Prerequisites from './components/deployment_pattern_prerequisites.jsx'
This guide will help you run a Great Expectations checkpoint in Apache Airflow, which allows you to trigger validation of a data asset using an Expectation Suite directly within an Airflow DAG.
<Prerequisites>
- [Set up a working deployment of Great Expectations](../tutorials/getting_started/tutorial_overview.md)
- [Created an Expectation Suite](../tutorials/getting_started/tutorial_create_expectations.md)
- [Created a checkpoint for that Expectation Suite and a data asset](../guides/validation/checkpoints/how_to_create_a_new_checkpoint.md)
- Created an Airflow DAG file
</Prerequisites>
Airflow is a data orchestration tool for creating and maintaining data pipelines through DAGs (directed acyclic graphs) written in Python. DAGs complete work through operators, which are templates that each encapsulate a specific type of work. This document explains how to use the `GreatExpectationsOperator` to perform data quality work in an Airflow DAG.
> *This guide focuses on using Great Expectations with Airflow in a self-hosted environment. See [here](https://www.astronomer.io/guides/airflow-great-expectations) for the guide on using Great Expectations with Airflow from within Astronomer.*
Before you start writing your DAG, you will want to make sure you have a Data Context and Checkpoint configured.
A [Data Context](https://docs.greatexpectations.io/docs/reference/data_context) represents a Great Expectations project. It organizes storage and access for Expectation Suites, Datasources, notification settings, and data fixtures.
[Checkpoints](https://docs.greatexpectations.io/docs/reference/checkpoints_and_actions) provide a convenient abstraction for bundling the validation of a Batch (or Batches) of data against an Expectation Suite (or several), as well as the actions that should be taken after the validation.
## Install the `GreatExpectationsOperator`
To import the GreatExpectationsOperator in your Airflow project, run the following command to install the Great Expectations provider in your Airflow environment:
```
pip install airflow-provider-great-expectations==0.1.1
```
It’s recommended to specify a version when installing the package. To make use of the latest Great Expectations V3 API, you need to specify a version >= `0.1.0`.
> *The Great Expectations V3 API requires Airflow 2.1+. If you're still running Airflow 1.x, you need to upgrade to at least 2.1 before using v0.1.0+ of the GreatExpectationsOperator.*
## Using the `GreatExpectationsOperator`
Before you can use the `GreatExpectationsOperator`, you need to import it in your DAG. You may also need to import the `DataContextConfig`, `CheckpointConfig`, or `BatchRequest` classes as well, depending on how you're using the operator. To import the Great Expectations provider and config and batch classes in a given DAG, add the following line to the top of the DAG file in your `dags` directory:
```python
from great_expectations_provider.operators.great_expectations import GreatExpectationsOperator
from great_expectations.core.batch import BatchRequest
from great_expectations.data_context.types.base import (
DataContextConfig,
CheckpointConfig
)
```
To use the operator in the DAG, define an instance of the `GreatExpectationsOperator` class and assign it to a variable. In the following example, we define two different instances of the operator to complete two different steps in a data quality check workflow:
```python
ge_data_context_root_dir_with_checkpoint_name_pass = GreatExpectationsOperator(
task_id="ge_data_context_root_dir_with_checkpoint_name_pass",
data_context_root_dir=ge_root_dir,
checkpoint_name="taxi.pass.chk",
)
ge_data_context_config_with_checkpoint_config_pass = GreatExpectationsOperator(
task_id="ge_data_context_config_with_checkpoint_config_pass",
data_context_config=example_data_context_config,
checkpoint_config=example_checkpoint_config,
)
```
Once you define your work through operators, you need to define the order in which your DAG completes the work. To do this, you can define a [relationship](https://airflow.apache.org/docs/apache-airflow/stable/concepts/tasks.html#relationships). For example, adding the following line to your DAG ensures that your name pass task has to complete before your config pass task can start:
```python
ge_data_context_root_dir_with_checkpoint_name_pass >> ge_data_context_config_with_checkpoint_config_pass
```
### Operator Parameters
The operator has several optional parameters, but it always requires either a `data_context_root_dir` or a `data_context_config` and either a `checkpoint_name` or `checkpoint_config`.
The `data_context_root_dir` should point to the `great_expectations` project directory generated when you created the project with the CLI. If using an in-memory `data_context_config`, a `DataContextConfig` must be defined, as in [this example](https://github.com/great-expectations/airflow-provider-great-expectations/blob/main/include/great_expectations/object_configs/example_data_context_config.py).
A `checkpoint_name` references a checkpoint in the project CheckpointStore defined in the DataContext (which is often the `great_expectations/checkpoints/` path), so that a `checkpoint_name = "taxi.pass.chk"` would reference the file `great_expectations/checkpoints/taxi/pass/chk.yml`. With a `checkpoint_name`, `checkpoint_kwargs` may be passed to the operator to specify additional, overwriting configurations. A `checkpoint_config` may be passed to the operator in place of a name, and can be defined like [this example](https://github.com/great-expectations/airflow-provider-great-expectations/blob/main/include/great_expectations/object_configs/example_checkpoint_config.py).
For a full list of parameters, see the `GreatExpectationsOperator` [documentation](https://registry.astronomer.io/providers/great-expectations/modules/greatexpectationsoperator).
### Connections and Backends
The `GreatExpectationsOperator` can run a checkpoint on a dataset stored in any backend compatible with Great Expectations. All that’s needed to get the Operator to point at an external dataset is to set up an [Airflow Connection](https://www.astronomer.io/guides/connections) to the datasource, and add the connection to your Great Expectations project, e.g. [using the CLI to add a Postgres backend](https://docs.greatexpectations.io/docs/guides/connecting_to_your_data/database/postgres). Then, if using a `DataContextConfig` or `CheckpointConfig`, ensure that the `"datasources"` field refers to your backend connection name.
<file_sep>/great_expectations/expectations/util.py
import warnings
from typing import Callable
from great_expectations.expectations.expectation import (
add_values_with_json_schema_from_list_in_params as add_values_with_json_schema_from_list_in_params_expectation,
)
from great_expectations.expectations.expectation import (
render_evaluation_parameter_string as render_evaluation_parameter_string_expectation,
)
def add_values_with_json_schema_from_list_in_params(
params: dict,
params_with_json_schema: dict,
param_key_with_list: str,
list_values_type: str = "string",
) -> dict:
# deprecated-v0.15.29
warnings.warn(
"""The module great_expectations.expectations.util.py is deprecated as of v0.15.29 in v0.18. Please import \
method add_values_with_json_schema_from_list_in_params from great_expectations.expectations.expectation.
""",
DeprecationWarning,
)
return add_values_with_json_schema_from_list_in_params_expectation(
params=params,
params_with_json_schema=params_with_json_schema,
param_key_with_list=param_key_with_list,
list_values_type=list_values_type,
)
def render_evaluation_parameter_string(render_func) -> Callable:
# deprecated-v0.15.29
warnings.warn(
"""The module great_expectations.expectations.util.py is deprecated as of v0.15.29 in v0.18. Please import \
decorator render_evaluation_parameter_string from great_expectations.expectations.expectation.
""",
DeprecationWarning,
)
return render_evaluation_parameter_string_expectation(render_func=render_func)
<file_sep>/docs/deployment_patterns/how_to_use_great_expectations_with_google_cloud_platform_and_bigquery.md
---
title: How to Use Great Expectations with Google Cloud Platform and BigQuery
---
import Prerequisites from './components/deployment_pattern_prerequisites.jsx'
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
import Congratulations from '../guides/connecting_to_your_data/components/congratulations.md'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide will help you integrate Great Expectations (GE) with [Google Cloud Platform](https://cloud.google.com/gcp) (GCP) using our recommended workflow.
<Prerequisites>
- Have a working local installation of Great Expectations that is at least version 0.13.49.
- Have read through the documentation and are familiar with the Google Cloud Platform features that are used in this guide.
- Have completed the set-up of a GCP project with a running Google Cloud Storage container that is accessible from your region, and read/write access to a BigQuery database if this is where you are loading your data.
- Access to a GCP [Service Account](https://cloud.google.com/iam/docs/service-accounts) with permission to access and read objects in Google Cloud Storage, and read/write access to a BigQuery database if this is where you are loading your data.
</Prerequisites>
We recommend that you use Great Expectations in GCP by using the following services:
- [Google Cloud Composer](https://cloud.google.com/composer) (GCC) for managing workflow orchestration including validating your data. GCC is built on [Apache Airflow](https://airflow.apache.org/).
- [BigQuery](https://cloud.google.com/bigquery) or files in [Google Cloud Storage](https://cloud.google.com/storage) (GCS) as your <TechnicalTag tag="datasource" text="Datasource"/>
- [GCS](https://cloud.google.com/storage) for storing metadata (<TechnicalTag tag="expectation_suite" text="Expectation Suites"/>, <TechnicalTag tag="validation_result" text="Validation Results"/>, <TechnicalTag tag="data_docs" text="Data Docs"/>)
- [Google App Engine](https://cloud.google.com/appengine) (GAE) for hosting and controlling access to <TechnicalTag tag="data_docs" text="Data Docs"/>.
We also recommend that you deploy Great Expectations to GCP in two steps:
1. [Developing a local configuration for GE that uses GCP services to connect to your data, store Great Expectations metadata, and run a Checkpoint.](#part-1-local-configuration-of-great-expectations-that-connects-to-google-cloud-platform)
2. [Migrating the local configuration to Cloud Composer so that the workflow can be orchestrated automatically on GCP.](#part-2-migrating-our-local-configuration-to-cloud-composer)
The following diagram shows the recommended components for a Great Expectations deployment in GCP:

Relevant documentation for the components can also be found here:
- [How to configure an Expectation store to use GCS](../guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.md)
- [How to configure a Validation Result store in GCS](../guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs.md)
- [How to host and share Data Docs on GCS](../guides/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.md)
- Optionally, you can also use a [Secret Manager for GCP Credentials](../guides/setup/configuring_data_contexts/how_to_configure_credentials.md)
:::note Note on V3 Expectations for BigQuery
A small number of V3 Expectations have not been migrated to BigQuery, and will be very soon. These include:
- `expect_column_quantile_values_to_be_between`
- `expect_column_kl_divergence_to_be_less_than`
:::
## Part 1: Local Configuration of Great Expectations that connects to Google Cloud Platform
### 1. If necessary, upgrade your Great Expectations version
The current guide was developed and tested using Great Expectations 0.13.49. Please ensure that your current version is equal or newer than this.
A local installation of Great Expectations can be upgraded using a simple `pip install` command with the `--upgrade` flag.
```bash
pip install great-expectations --upgrade
```
### 2. Connect to Metadata Stores on GCP
The following sections describe how you can take a basic local configuration of Great Expectations and connect it to Metadata stores on GCP.
The full configuration used in this guide can be found in the [`great-expectations` repository](https://github.com/great-expectations/great_expectations/tree/develop/tests/integration/fixtures/gcp_deployment/) and is also linked at the bottom of this document.
:::note Note on Trailing Slashes in Metadata Store prefixes
When specifying `prefix` values for Metadata Stores in GCS, please ensure that a trailing slash `/` is not included (ie `prefix: my_prefix/` ). Currently this creates an additional folder with the name `/` and stores metadata in the `/` folder instead of `my_prefix`.
:::
#### Add Expectations Store
By default, newly profiled Expectations are stored in JSON format in the `expectations/` subdirectory of your `great_expectations/` folder. A new Expectations Store can be configured by adding the following lines into your `great_expectations.yml` file, replacing the `project`, `bucket` and `prefix` with your information.
```YAML file=../../tests/integration/fixtures/gcp_deployment/great_expectations/great_expectations.yml#L38-L44
```
Great Expectations can then be configured to use this new Expectations Store, `expectations_GCS_store`, by setting the `expectations_store_name` value in the `great_expectations.yml` file.
```YAML file=../../tests/integration/fixtures/gcp_deployment/great_expectations/great_expectations.yml#L72
```
For additional details and example configurations, please refer to [How to configure an Expectation store to use GCS](../guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.md).
#### Add Validations Store
By default, Validations are stored in JSON format in the `uncommitted/validations/` subdirectory of your `great_expectations/` folder. A new Validations Store can be configured by adding the following lines into your `great_expectations.yml` file, replacing the `project`, `bucket` and `prefix` with your information.
```YAML file=../../tests/integration/fixtures/gcp_deployment/great_expectations/great_expectations.yml#L52-L58
```
Great Expectations can then be configured to use this new Validations Store, `validations_GCS_store`, by setting the `validations_store_name` value in the `great_expectations.yml` file.
```YAML file=../../tests/integration/fixtures/gcp_deployment/great_expectations/great_expectations.yml#L73
```
For additional details and example configurations, please refer to [How to configure an Validation Result store to use GCS](../guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs.md).
#### Add Data Docs Store
To host and share Datadocs on GCS, we recommend using the [following guide](../guides/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.md), which will explain how to host and share Data Docs on Google Cloud Storage using IP-based access.
Afterwards, your `great-expectations.yml` will contain the following configuration under `data_docs_sites`, with `project`, and `bucket` being replaced with your information.
```YAML file=../../tests/integration/fixtures/gcp_deployment/great_expectations/great_expectations.yml#L91-L98
```
You should also be able to view the deployed DataDocs site by running the following CLI command:
```bash
gcloud app browse
```
If successful, the `gcloud` CLI will provide the URL to your app and launch it in a new browser window, and you should be able to view the index page of your Data Docs site.
### 3. Connect to your Data
The remaining sections in Part 1 contain a simplified description of [how to connect to your data in GCS](https://docs.greatexpectations.io/docs/guides/connecting_to_your_data/cloud/gcs/pandas) or [BigQuery](https://docs.greatexpectations.io/docs/guides/connecting_to_your_data/database/bigquery) and eventually build a <TechnicalTag tag="checkpoint" text="Checkpoint"/> that will be migrated to Cloud Composer. The following code can be run either in an interactive Python session or Jupyter Notebook that is in your `great_expectations/` folder.
More details can be found in the corresponding How to Guides, which have been linked.
<Tabs
groupId="connect-to-data-gcs-bigquery"
defaultValue='gcs'
values={[
{label: 'Data in GCS', value:'gcs'},
{label: 'Data in BigQuery', value:'bigquery'},
]}>
<TabItem value="gcs">
To connect to your data in GCS, first instantiate your project's DataContext by importing the necessary packages and modules.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py#L4-L6
```
Then, load your DataContext into memory using the `get_context()` method.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py#L13
```
Next, load the following Datasource configuration that will connect to data in GCS,
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py#L218-L236
```
Save the configuration into your DataContext by using the `add_datasource()` function.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py#L249
```
For more details on how to configure the Datasource, and additional information on authentication, please refer to [How to connect to data on GCS using Pandas
](../guides/connecting_to_your_data/cloud/gcs/pandas.md)
</TabItem>
<TabItem value="bigquery">
To connect to your data in BigQuery, first instantiate your project's DataContext by importing the necessary packages and modules.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py#L4-L6
```
Then, load your DataContext into memory using the `get_context()` method.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py#L13
```
Next, load the following Datasource configuration that will connect to data in BigQuery,
:::note
In order to support tables that are created as the result of queries in BigQuery, Great Expectations previously asked users to define a named permanent table to be used as a "temporary" table that could later be deleted, or set to expire by the database. This is no longer the case, and Great Expectations will automatically set tables that are created as the result of queries to expire after 1 day.
:::
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py#L228-L242
```
Save the configuration into your DataContext by using the `add_datasource()` function.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py#L254
```
For more details on how to configure the BigQuery Datasource, please refer to [How to connect to a BigQuery database](../guides/connecting_to_your_data/database/bigquery.md)
</TabItem>
</Tabs>
### 4. Get Batch and Create ExpectationSuite
<Tabs
groupId="connect-to-data-gcs-bigquery"
defaultValue='gcs'
values={[
{label: 'Data in GCS', value:'gcs'},
{label: 'Data in BigQuery', value:'bigquery'},
]}>
<TabItem value="gcs">
For our example, we will be creating an ExpectationSuite with [instant feedback from a sample Batch of data](../guides/expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md), which we will describe in our `BatchRequest`. For additional examples on how to create ExpectationSuites, either through [domain knowledge](../guides/expectations/how_to_create_and_edit_expectations_based_on_domain_knowledge_without_inspecting_data_directly.md) or using the [User Configurable Profiler](../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md), please refer to the documentation under `How to Guides` -> `Creating and editing Expectations for your data` -> `Core skills`.
First, load a batch of data by specifying a `data_asset_name` in a `BatchRequest`.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py#L254-L258
```
Next, create an ExpectationSuite (`test_gcs_suite` in our example), and use it to get a `Validator`.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py#L269-L275
```
Next, use the `Validator` to run expectations on the batch and automatically add them to the ExpectationSuite. For our example, we will add `expect_column_values_to_not_be_null` and `expect_column_values_to_be_between` (`passenger_count` and `congestion_surcharge` are columns in our test data, and they can be replaced with columns in your data).
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py#L293-L297
```
Lastly, save the ExpectationSuite, which now contains our two Expectations.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py#L301
```
For more details on how to configure the RuntimeBatchRequest, as well as an example of how you can load data by specifying a GCS path to a single CSV, please refer to [How to connect to data on GCS using Pandas](../guides/connecting_to_your_data/cloud/gcs/pandas.md)
</TabItem>
<TabItem value="bigquery">
For our example, we will be creating our ExpectationSuite with [instant feedback from a sample Batch of data](../guides/expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md), which we will describe in our `RuntimeBatchRequest`. For additional examples on how to create ExpectationSuites, either through [domain knowledge](../guides/expectations/how_to_create_and_edit_expectations_based_on_domain_knowledge_without_inspecting_data_directly.md) or using the [User Configurable Profiler](../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md), please refer to the documentation under `How to Guides` -> `Creating and editing Expectations for your data` -> `Core skills`.
First, load a batch of data by specifying an SQL query in a `RuntimeBatchRequest` (`SELECT * from demo.taxi_data LIMIT 10` is an example query for our test data and can be replaced with any query you would like).
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py#L260-L266
```
Next, create an ExpectationSuite (`test_bigquery_suite` in our example), and use it to get a `Validator`.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py#L270-L276
```
Next, use the `Validator` to run expectations on the batch and automatically add them to the ExpectationSuite. For our example, we will add `expect_column_values_to_not_be_null` and `expect_column_values_to_be_between` (`passenger_count` and `congestion_surcharge` are columns in our test data, and they can be replaced with columns in your data).
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py#L280-L284
```
Lastly, save the ExpectationSuite, which now contains our two Expectations.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py#L288
```
For more details on how to configure the BatchRequest, as well as an example of how you can load data by specifying a table name, please refer to [How to connect to a BigQuery database](../guides/connecting_to_your_data/database/bigquery.md)
</TabItem>
</Tabs>
### 5. Build and Run a Checkpoint
For our example, we will create a basic Checkpoint configuration using the `SimpleCheckpoint` class. For [additional examples](../guides/validation/checkpoints/how_to_create_a_new_checkpoint.md), information on [how to add validations, data, or suites to existing checkpoints](../guides/validation/checkpoints/how_to_add_validations_data_or_suites_to_a_checkpoint.md), and [more complex configurations](../guides/validation/checkpoints/how_to_configure_a_new_checkpoint_using_test_yaml_config.md) please refer to the documentation under `How to Guides` -> `Validating your data` -> `Checkpoints`.
<Tabs
groupId="connect-to-data-gcs-bigquery"
defaultValue='gcs'
values={[
{label: 'Data in GCS', value:'gcs'},
{label: 'Data in BigQuery', value:'bigquery'},
]}>
<TabItem value="gcs">
Add the following Checkpoint `gcs_checkpoint` to the DataContext. Here we are using the same `BatchRequest` and `ExpectationSuite` name that we used to create our Validator above, translated into a YAML configuration.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py#L305-L317
```
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py#L326
```
Next, you can either run the Checkpoint directly in-code,
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py#L330-L332
```
or through the following CLI command.
```bash
great_expectations --v3-api checkpoint run gcs_checkpoint
```
At this point, if you have successfully configured the local prototype, you will have the following:
1. An ExpectationSuite in the GCS bucket configured in `expectations_GCS_store` (ExpectationSuite is named `test_gcs_suite` in our example).
2. A new Validation Result in the GCS bucket configured in `validation_GCS_store`.
3. Data Docs in the GCS bucket configured in `gs_site` that is accessible by running `gcloud app browse`.
Now you are ready to migrate the local configuration to Cloud Composer.
</TabItem>
<TabItem value="bigquery">
Add the following Checkpoint `bigquery_checkpoint` to the DataContext. Here we are using the same `RuntimeBatchRequest` and `ExpectationSuite` name that we used to create our Validator above, translated into a YAML configuration.
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py#L292-L308
```
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py#L312
```
Next, you can either run the Checkpoint directly in-code,
```python file=../../tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py#L316-L318
```
or through the following CLI command.
```bash
great_expectations --v3-api checkpoint run bigquery_checkpoint
```
At this point, if you have successfully configured the local prototype, you will have the following:
1. An ExpectationSuite in the GCS bucket configured in `expectations_GCS_store` (ExpectationSuite is named `test_bigquery_suite` in our example).
2. A new Validation Result in the GCS bucket configured in `validation_GCS_store`.
3. Data Docs in the GCS bucket configured in `gs_site` that is accessible by running `gcloud app browse`.
Now you are ready to migrate the local configuration to Cloud Composer.
</TabItem>
</Tabs>
## Part 2: Migrating our Local Configuration to Cloud Composer
We will now take the local GE configuration from [Part 1](#part-1-local-configuration-of-great-expectations-that-connects-to-google-cloud-platform) and migrate it to a Cloud Composer environment so that we can automate the workflow.
There are a number of ways that Great Expectations can be run in Cloud Composer or Airflow.
1. [Running a Checkpoint in Airflow using a `bash operator`](./how_to_use_great_expectations_with_airflow.md#option-1-running-a-checkpoint-with-a-bashoperator)
2. [Running a Checkpoint in Airflow using a `python operator`](./how_to_use_great_expectations_with_airflow.md#option-2-running-the-checkpoint-script-output-with-a-pythonoperator)
3. [Running a Checkpoint in Airflow using a `Airflow operator`](https://github.com/great-expectations/airflow-provider-great-expectations)
For our example, we are going to use the `bash operator` to run the Checkpoint. This portion of the guide can also be found in the following [Walkthrough Video](https://drive.google.com/file/d/1YhEMqSRkp5JDIQA_7fleiKTTlEmYx2K8/view?usp=sharing).
### 1. Create and Configure a Service Account
Create and configure a Service Account on GCS with the appropriate privileges needed to run Cloud Composer. Please follow the steps described in the [official Google Cloud documentation](https://cloud.google.com/iam/docs/service-accounts) to create a Service Account on GCP.
In order to run Great Expectations in a Cloud Composer environment, your Service Account will need the following privileges:
- `Composer Worker`
- `Logs Viewer`
- `Logs Writer`
- `Storage Object Creator`
- `Storage Object Viewer`
If you are accessing data in BigQuery, please ensure your Service account also has privileges for:
- `BigQuery Data Editor`
- `BigQuery Job User`
- `BigQuery Read Session User`
### 2. Create Cloud Composer environment
Create a Cloud Composer environment in the project you will be running Great Expectations. Please follow the steps described in the [official Google Cloud documentation](https://cloud.google.com/composer/docs/composer-2/create-environments) to create an environment that is suited for your needs.
:::info Note on Versions.
The current Deployment Guide was developed and tested in Great Expectations 0.13.49, Composer 1.17.7 and Airflow 2.0.2. Please ensure your Environment is equivalent or newer than this configuration.
:::
### 3. Install Great Expectations in Cloud Composer
Installing Python dependencies in Cloud Composer can be done through the Composer web Console (recommended), `gcloud` or through a REST query. Please follow the steps described in [Installing Python dependencies in Google Cloud](https://cloud.google.com/composer/docs/how-to/using/installing-python-dependencies#install-package) to install `great-expectations` in Cloud Composer. If you are connecting to data in BigQuery, please ensure `sqlalchemy-bigquery` is also installed in your Cloud Composer environment.
:::info Troubleshooting Installation
If you run into trouble while installing Great Expectations in Cloud Composer, the [official Google Cloud documentation offers the following guide on troubleshooting PyPI package installations.](https://cloud.google.com/composer/docs/troubleshooting-package-installation)
:::
### 4. Move local configuration to Cloud Composer
Cloud Composer uses Cloud Storage to store Apache Airflow DAGs (also known as workflows), with each Environment having an associated Cloud Storage bucket (typically the name of the bucket will follow the pattern `[region]-[composer environment name]-[UUID]-bucket`).
The simplest way to perform the migration is to move the entire local `great_expectations/` folder from [Part 1](#part-1-local-configuration-of-great-expectations-that-connects-to-google-cloud-platform) to the Cloud Storage bucket where Composer can access the configuration.
First open the Environments page in the Cloud Console, then click on the name of the environment to open the Environment details page. In the Configuration tab, the name of the Cloud Storage bucket can be found to the right of the DAGs folder.
This will take you to the folder where DAGs are stored, which can be accessed from the Airflow worker nodes at: `/home/airflow/gcsfuse/dags`. The location we want to uploads `great_expectations/` is **one level above the `/dags` folder**.
Upload the local `great_expectations/` folder either dragging and dropping it into the window, using [`gsutil cp`](https://cloud.google.com/storage/docs/gsutil/commands/cp), or by clicking the `Upload Folder` button.
Once the `great_expectations/` folder is uploaded to the Cloud Storage bucket, it will be mapped to the Airflow instances in your Cloud Composer and be accessible from the Airflow Worker nodes at the location: `/home/airflow/gcsfuse/great_expectations`.
### 5. Write DAG and Add to Cloud Composer
<Tabs
groupId="connect-to-data-gcs-bigquery"
defaultValue='gcs'
values={[
{label: 'Data in GCS', value:'gcs'},
{label: 'Data in BigQuery', value:'bigquery'},
]}>
<TabItem value="gcs">
We will create a simple DAG with a single node (`t1`) that runs a `BashOperator`, which we will store in a file named: [`ge_checkpoint_gcs.py`](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/fixtures/gcp_deployment/ge_checkpoint_gcs.py).
```python file=../../tests/integration/fixtures/gcp_deployment/ge_checkpoint_gcs.py
```
The `BashOperator` will first change directories to `/home/airflow/gcsfuse/great_expectations`, where we have uploaded our local configuration.
Then we will run the Checkpoint using same CLI command we used to run the Checkpoint locally:
```bash
great_expectations --v3-api checkpoint run gcs_checkpoint
````
To add the DAG to Cloud Composer, move `ge_checkpoint_gcs.py` to the environment's DAGs folder in Cloud Storage. First, open the Environments page in the Cloud Console, then click on the name of the environment to open the Environment details page.
On the Configuration tab, click on the name of the Cloud Storage bucket that is found to the right of the DAGs folder. Upload the local copy of the DAG you want to upload.
For more details, please consult the [official documentation for Cloud Composer](https://cloud.google.com/composer/docs/how-to/using/managing-dags#adding)
</TabItem>
<TabItem value="bigquery">
We will create a simple DAG with a single node (`t1`) that runs a `BashOperator`, which we will store in a file named: [`ge_checkpoint_bigquery.py`](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/fixtures/gcp_deployment/ge_checkpoint_bigquery.py).
```python file=../../tests/integration/fixtures/gcp_deployment/ge_checkpoint_bigquery.py
```
The `BashOperator` will first change directories to `/home/airflow/gcsfuse/great_expectations`, where we have uploaded our local configuration.
Then we will run the Checkpoint using same CLI command we used to run the Checkpoint locally:
```bash
great_expectations --v3-api checkpoint run bigquery_checkpoint
```
To add the DAG to Cloud Composer, move `ge_checkpoint_bigquery.py` to the environment's DAGs folder in Cloud Storage. First, open the Environments page in the Cloud Console, then click on the name of the environment to open the Environment details page.
On the Configuration tab, click on the name of the Cloud Storage bucket that is found to the right of the DAGs folder. Upload the local copy of the DAG you want to upload.
For more details, please consult the [official documentation for Cloud Composer](https://cloud.google.com/composer/docs/how-to/using/managing-dags#adding)
</TabItem>
</Tabs>
### 6. Run DAG / Checkpoint
Now that the DAG has been uploaded, we can [trigger the DAG](https://cloud.google.com/composer/docs/triggering-dags) using the following methods:
1. [Trigger the DAG manually.](https://cloud.google.com/composer/docs/triggering-dags#manually)
2. [Trigger the DAG on a schedule, which we have set to be once-per-day in our DAG](https://cloud.google.com/composer/docs/triggering-dags#schedule)
3. [Trigger the DAG in response to events.](http://airflow.apache.org/docs/apache-airflow/stable/concepts/sensors.html)
In order to trigger the DAG manually, first open the Environments page in the Cloud Console, then click on the name of the environment to open the Environment details page. In the Airflow webserver column, follow the Airflow link for your environment. This will open the Airflow web interface for your Cloud Composer environment. In the interface, click on the Trigger Dag button on the DAGs page to run your DAG configuration.
### 7. Check that DAG / Checkpoint has run successfully
If the DAG run was successful, we should see the `Success` status appear on the DAGs page of the Airflow Web UI. We can also check so check that new Data Docs have been generated by accessing the URL to our `gcloud` app.
### 8. Congratulations!
You've successfully migrated your Great Expectations configuration to Cloud Composer!
There are many ways to iterate and improve this initial version, which used a `bash operator` for simplicity. For information on more sophisticated ways of triggering Checkpoints, building our DAGs, and dividing our Data Assets into Batches using DataConnectors, please refer to the following documentation:
- [How to run a Checkpoint in Airflow using a `python operator`](./how_to_use_great_expectations_with_airflow.md#option-2-running-the-checkpoint-script-output-with-a-pythonoperator).
- [How to run a Checkpoint in Airflow using a `Great Expectations Airflow operator`](https://github.com/great-expectations/airflow-provider-great-expectations)(recommended).
- [How to trigger the DAG on a schedule](https://cloud.google.com/composer/docs/triggering-dags#schedule).
- [How to trigger the DAG on a schedule](https://cloud.google.com/composer/docs/triggering-dags#schedule).
- [How to trigger the DAG in response to events](http://airflow.apache.org/docs/apache-airflow/stable/concepts/sensors.html).
- [How to use the Google Kubernetes Engine (GKE) to deploy, manage and scale your application](https://airflow.apache.org/docs/apache-airflow-providers-google/stable/operators/cloud/kubernetes_engine.html).
- [How to configure a DataConnector to introspect and partition tables in SQL](../guides/connecting_to_your_data/how_to_configure_a_dataconnector_to_introspect_and_partition_tables_in_sql.md).
- [How to configure a DataConnector to introspect and partition a file system or blob store](../guides/connecting_to_your_data/how_to_configure_a_dataconnector_to_introspect_and_partition_a_file_system_or_blob_store.md).
Also, the following scripts and configurations can be found here:
- Local GE configuration used in this guide can be found in the [`great-expectations` GIT repository](https://github.com/great-expectations/great_expectations/tree/develop/tests/integration/fixtures/gcp_deployment/).
- [Script to test BigQuery configuration](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py).
- [Script to test GCS configuration](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py).
<file_sep>/docs/api_docs/methods/great_expectations-data_context-data_context-data_context-DataContext-test_yaml_config.md
---
title: DataContext.test_yaml_config
---
[Back to class documentation](../classes/great_expectations-data_context-data_context-data_context-DataContext.md)
### Fully qualified path
`great_expectations.data_context.data_context.data_context.DataContext.test_yaml_config`
### Synopsis
Convenience method for testing yaml configs
test_yaml_config is a convenience method for configuring the moving
parts of a Great Expectations deployment. It allows you to quickly
test out configs for system components, especially Datasources,
Checkpoints, and Stores.
For many deployments of Great Expectations, these components (plus
Expectations) are the only ones you'll need.
test_yaml_config is mainly intended for use within notebooks and tests.
### Parameters
Parameter|Typing|Default|Description
---------|------|-------|-----------
self||||
yaml_config| str||A string containing the yaml config to be tested|A string containing the yaml config to be tested
name| Union[str, NoneType] | None|\(Optional\) A string containing the name of the component to instantiate|\(Optional\) A string containing the name of the component to instantiate
class_name| Union[str, NoneType] | None||
runtime_environment| Union[dict, NoneType] | None||
pretty_print| bool | True|Determines whether to print human\-readable output|Determines whether to print human\-readable output
return_mode| Union[Literal['instantiated_class'], Literal['report_object']] | 'instantiated_class'|Determines what type of object test\_yaml\_config will return\. Valid modes are "instantiated\_class" and "report\_object"|Determines what type of object test\_yaml\_config will return\. Valid modes are "instantiated\_class" and "report\_object"
shorten_tracebacks| bool | False|If true, catch any errors during instantiation and print only the last element of the traceback stack\. This can be helpful for rapid iteration on configs in a notebook, because it can remove the need to scroll up and down a lot\.|If true, catch any errors during instantiation and print only the last element of the traceback stack\. This can be helpful for rapid iteration on configs in a notebook, because it can remove the need to scroll up and down a lot\.
### Returns
The instantiated component (e.g. a Datasource) OR a json object containing metadata from the component's self_check method. The returned object is determined by return_mode.
## Relevant documentation (links)
- [Data Context](../../terms/data_context.md)
- [How to configure a new Checkpoint using test_yaml_config](../../guides/validation/checkpoints/how_to_configure_a_new_checkpoint_using_test_yaml_config.md)<file_sep>/docs/guides/validation/checkpoints/components_how_to_create_a_new_checkpoint/_steps_for_checkpoints_.mdx
:::note Prerequisites:
This how-to guide assumes you have already:
* [Set up a working deployment of Great Expectations](../../../../tutorials/getting_started/tutorial_overview.md)
* [Configured a Datasource using the BatchRequest (v3) API](../../../../tutorials/getting_started/tutorial_connect_to_data.md)
* [Created an Expectation Suite](../../../../tutorials/getting_started/tutorial_create_expectations.md)
:::
<file_sep>/tests/test_fixtures/configuration_for_testing_v2_v3_migration/spark/v3/running_checkpoint.sh
great_expectations checkpoint run test_v3_checkpoint
<file_sep>/docs/guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_azure_blob_storage.md
---
title: How to configure an Expectation Store to use Azure Blob Storage
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
By default, newly <TechnicalTag tag="profiling" text="Profiled" /> <TechnicalTag tag="expectation" text="Expectations" /> are stored as <TechnicalTag tag="expectation_suite" text="Expectation Suites" /> in JSON format in the ``expectations/`` subdirectory of your ``great_expectations/`` folder. This guide will help you configure Great Expectations to store them in Azure Blob Storage.
<Prerequisites>
- [Configured a Data Context](../../../tutorials/getting_started/tutorial_setup.md).
- [Configured an Expectations Suite](../../../tutorials/getting_started/tutorial_create_expectations.md).
- Configured an [Azure Storage account](https://docs.microsoft.com/en-us/azure/storage/).
- Create the Azure Blob container. If you also wish to [host and share Data Docs on Azure Blob Storage](../configuring_data_docs/how_to_host_and_share_data_docs_on_azure_blob_storage.md) then you may set up this first and then use the ``$web`` existing container to store your Expectations.
- Identify the prefix (folder) where Expectations will be stored (you don't need to create the folder, the prefix is just part of the Blob name).
</Prerequisites>
## Steps
### 1. Configure the ``config_variables.yml`` file with your Azure Storage credentials
We recommend that Azure Storage credentials be stored in the ``config_variables.yml`` file, which is located in the ``uncommitted/`` folder by default, and is not part of source control. The following lines add Azure Storage credentials under the key ``AZURE_STORAGE_CONNECTION_STRING``. Additional options for configuring the ``config_variables.yml`` file or additional environment variables can be found [here](https://docs.greatexpectations.io/docs/guides/setup/configuring_data_contexts/how_to_configure_credentials_using_a_yaml_file_or_environment_variables).
```yaml
AZURE_STORAGE_CONNECTION_STRING: "DefaultEndpointsProtocol=https;EndpointSuffix=core.windows.net;AccountName=<YOUR-STORAGE-ACCOUNT-NAME>;AccountKey=<YOUR-STORAGE-ACCOUNT-KEY==>"
```
### 2. Identify your Data Context Expectations Store
In your ``great_expectations.yml`` , look for the following lines. The configuration tells Great Expectations to look for Expectations in a <TechnicalTag tag="store" text="Store" /> called ``expectations_store``. The ``base_directory`` for ``expectations_store`` is set to ``expectations/`` by default.
```yaml
expectations_store_name: expectations_store
stores:
expectations_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
```
### 3. Update your configuration file to include a new Store for Expectations on Azure Storage account
In our case, the name is set to ``expectations_AZ_store``, but it can be any name you like. We also need to make some changes to the ``store_backend`` settings. The ``class_name`` will be set to ``TupleAzureBlobStoreBackend``, ``container`` will be set to the name of your blob container (the equivalent of S3 bucket for Azure) you wish to store your expectations, ``prefix`` will be set to the folder in the container where Expectation files will be located, and ``connection_string`` will be set to ``${AZURE_STORAGE_CONNECTION_STRING}``, which references the corresponding key in the ``config_variables.yml`` file.
```yaml
expectations_store_name: expectations_AZ_store
stores:
expectations_AZ_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleAzureBlobStoreBackend
container: <blob-container>
prefix: expectations
connection_string: ${AZURE_STORAGE_CONNECTION_STRING}
```
:::note
If the container is called ``$web`` (for [hosting and sharing Data Docs on Azure Blob Storage](../configuring_data_docs/how_to_host_and_share_data_docs_on_azure_blob_storage.md)) then set ``container: \$web`` so the escape char will allow us to reach the ``$web``container.
:::
:::note
Various authentication and configuration options are available as documented in [hosting and sharing Data Docs on Azure Blob Storage](../../setup/configuring_data_docs/how_to_host_and_share_data_docs_on_azure_blob_storage.md).
:::
### 4. Copy existing Expectation JSON files to the Azure blob (This step is optional)
One way to copy Expectations into Azure Blob Storage is by using the ``az storage blob upload`` command, which is part of the Azure SDK. The following example will copy one Expectation, ``exp1`` from a local folder to the Azure blob. Information on other ways to copy Expectation JSON files, like the Azure Storage browser in the Azure Portal, can be found in the [Documentation for Azure](https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction).
```bash
export AZURE_STORAGE_CONNECTION_STRING="DefaultEndpointsProtocol=https;EndpointSuffix=core.windows.net;AccountName=<YOUR-STORAGE-ACCOUNT-NAME>;AccountKey=<YOUR-STORAGE-ACCOUNT-KEY==>"
az storage blob upload -f <local/path/to/expectation.json> -c <GREAT-EXPECTATION-DEDICATED-AZURE-BLOB-CONTAINER-NAME> -n <PREFIX>/<expectation.json>
example :
az storage blob upload -f great_expectations/expectations/exp1.json -c <blob-container> -n expectations/exp1.json
Finished[#############################################################] 100.0000%
{
"etag": "\"0x8D8E08E5DA47F84\"",
"lastModified": "2021-03-06T10:55:33+00:00"
}
```
### 5. Confirm that the new Expectations Store has been added by running ``great_expectations store list``
Notice the output contains two <TechnicalTag tag="expectation_store" text="Expectation Stores" />: the original ``expectations_store`` on the local filesystem and the ``expectations_AZ_store`` we just configured. This is ok, since Great Expectations will look for Expectations in Azure Blob as long as we set the ``expectations_store_name`` variable to ``expectations_AZ_store``, which we did in the previous step. The config for ``expectations_store`` can be removed if you would like.
```bash
great_expectations store list
- name: expectations_store
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
- name: expectations_AZ_store
class_name: ExpectationsStore
store_backend:
class_name: TupleAzureBlobStoreBackend
connection_string: DefaultEndpointsProtocol=https;EndpointSuffix=core.windows.net;AccountName=<YOUR-STORAGE-ACCOUNT-NAME>;AccountKey=<YOUR-STORAGE-ACCOUNT-KEY==>
container: <blob-container>
prefix: expectations
```
### 6. Confirm that Expectations can be accessed from Azure Blob Storage by running ``great_expectations suite list``
If you followed Step 4, the output should include the Expectation we copied to Azure Blob: ``exp1``. If you did not copy Expectations to the new Store, you will see a message saying no Expectations were found.
```bash
great_expectations suite list
Using v2 (Batch Kwargs) API
1 Expectation Suite found:
- exp1
```
<file_sep>/docs/contributing/contributing_package.md
---
title: How to contribute a Package to Great Expectations
---
import Prerequisites from './components/prerequisites.jsx'
This guide demonstrates how to bundle your own custom Expectations, Metrics, and Profilers into an official Great Expectations contributor package.
<Prerequisites>
* Created an account on [PyPi](https://pypi.org/account/register/)
</Prerequisites>
## Steps
### 0. Reach out to our Developer Relations Team
Before you embark on this journey, drop by and introduce yourself in the [`#integrations` channel of our Great Expectations Slack Community](https://greatexpectationstalk.slack.com/archives/C037YCYNF1Q) to let us know.
We would love to discuss your Custom Expectations Package, support your development, and help you navigate the publication and maintenance process.
We're big believers in building strong relationships with our community and our ecosystem partners. Opening communication channels early in the process is essential to developing the best possible tools together.
### 1. Install the `great_expectations_contrib` CLI Tool
To streamline the process of contributing a package to Great Expectations, we've developed a CLI tool to
abstract away some of the complexity and help you adhere to our codebases' best practices. Please
utilize the tool during your development to ensure that your package meets all of the necessary requirements.
To install the tool, first ensure that you are in the root of the `great_expectations` codebase:
```bash
cd contrib/cli
```
Next, use pip to install the CLI tool:
```bash
pip install -e great_expectations_contrib
```
You can verify your installation by running the following and confirming that a help message appears in your terminal:
```bash
great_expectations_contrib
```
`great_expectations_contrib` is designed to fulfill three key tasks:
1. Initialize your package structure
2. Perform a series of checks to determine the validity of your package
3. Publish your package to PyPi for you and others to use
### 2. Initialize a project
Once the CLI tool is enabled, we need to intialize an empty package.
To do so, go ahead and run:
```bash
great_expectations_contrib init
```
This will prompt you to answer a number of questions, such as:
* The name of your package
* What your package is about
* Your GitHub and PyPi usernames
The answers to these questions will be leveraged when
publishing your package. Upon completing the required prompts, you'll receive a confirmation
message and be able to view your package in its initial state.
To access your configured package, run the following:
```bash
cd <PACKAGE_NAME>
tree
```
Your file structure should look something like this:
```bash
.
├── LICENSE
├── README.md
├── assets
├── package_info.yml
├── requirements.txt
├── setup.py
├── tests
│ ├── __init__.py
│ ├── expectations
│ │ └── __init__.py
│ ├── metrics
│ │ └── __init__.py
│ └── profilers
│ └── __init__.py
└── <YOUR_PACKAGE_SOURCE_CODE>
├── __init__.py
├── expectations
│ └── __init__.py
├── metrics
│ └── __init__.py
└── profilers
└── __init__.py
```
To ensure consistency with other packages and the rest of the Great Expectations ecosystem,
please maintain this general structure during your development.
### 3. Contribute to your package
Now that your package has been initialized, it's time to get coding!
You'll want to capture any dependencies in your `requirements.txt`, validate your code
in `tests`, detail your package's capabilities in `README.md`, and update any relevant
publishing details in `setup.py`.
If you'd like to update your package's metadata or assign code owners/domain experts,
please follow the instructions in `package_info.yml`.
As you iterate on your work, you can check your progress using:
```
great_expectations_contrib check
```
This command will run a series of checks on your package, including:
* Whether your code is linted/formatted properly
* Whether you've type annotated function signatures
* Whether your Expectations are properly documented
* And more!
Using `great_expectations_contrib` as part of your development loop will help you
keep on track and provide you with a checklist of necessary items to get your package
across the finish line!
### 4. Publish your package
Once you've written your package, tested its behavior, and documented its capabilities,
the final step is to get your work published.
The CLI tool wraps around `twine` and `wheel`, allowing you to run:
```
great_expectations_contrib publish
```
As long as you've passed the necessary checks, you'll be prompted to provide your
PyPi username and password, and your package will be published!
<div style={{"text-align":"center"}}>
<p style={{"color":"#8784FF","font-size":"1.4em"}}><b>
Congratulations!<br/>🎉 You've just published your first Great Expectations contributor package! 🎉
</b></p>
</div>
### 5. Contribution (Optional)
Your package can also be submitted as a contribution to the Great Expectations codebase, under the same [Maturity Level](./contributing_maturity.md#contributing-expectations) requirements as [Custom Expectations](../guides/expectations/creating_custom_expectations/overview.md).
<file_sep>/docs/guides/validation/checkpoints/components_how_to_create_a_new_checkpoint/_b_test_your_config_using_contexttest_yaml_config.mdx
You can use the following command to validate the contents of your `config` yaml string:
````python title="Python code"
context.test_yaml_config(yaml_config=config)
````
When executed, `test_yaml_config(...)` will instantiate the component and run through a self-check procedure to verify that the component works as expected.
In the case of a Checkpoint, this means:
1. Validating the yaml configuration
2. Verifying that the Checkpoint class with the given configuration, if valid, can be instantiated
3. Printing warnings in case certain parts of the configuration, while valid, may be incomplete and need to be better specified for a successful Checkpoint operation
The output will look something like this:
````console title="Terminal output"
Attempting to instantiate class from config...
Instantiating as a SimpleCheckpoint, since class_name is SimpleCheckpoint
Successfully instantiated SimpleCheckpoint
Checkpoint class name: SimpleCheckpoint
````
If something about your configuration was not set up correctly, `test_yaml_config(...)` will raise an error.
<file_sep>/setup.py
import re
from glob import glob
import pkg_resources
from setuptools import find_packages, setup
import versioneer
def get_extras_require():
results = {}
extra_key_mapping = {
"aws_secrets": "boto",
"azure_secrets": "azure",
"gcp": "bigquery",
"s3": "boto",
}
sqla_keys = (
"athena",
"bigquery",
"dremio",
"mssql",
"mysql",
"postgresql",
"redshift",
"snowflake",
"teradata",
"trino",
"vertica",
)
ignore_keys = (
"sqlalchemy",
"test",
"tools",
"all-contrib-expectations",
)
requirements_dir = "reqs"
rx_fname_part = re.compile(rf"{requirements_dir}/requirements-dev-(.*).txt")
for fname in glob(f"{requirements_dir}/*.txt"):
match = rx_fname_part.match(fname)
assert (
match is not None
), f"The extras requirements dir ({requirements_dir}) contains files that do not adhere to the following format: requirements-dev-*.txt"
key = match.group(1)
if key in ignore_keys:
continue
with open(fname) as f:
parsed = [str(req) for req in pkg_resources.parse_requirements(f)]
results[key] = parsed
lite = results.pop("lite")
contrib = results.pop("contrib")
results["boto"] = [req for req in lite if req.startswith("boto")]
results["sqlalchemy"] = [req for req in lite if req.startswith("sqlalchemy")]
results["test"] = lite + contrib
for new_key, existing_key in extra_key_mapping.items():
results[new_key] = results[existing_key]
for key in sqla_keys:
results[key] += results["sqlalchemy"]
results.pop("boto")
all_requirements_set = set()
[all_requirements_set.update(vals) for vals in results.values()]
results["dev"] = sorted(all_requirements_set)
return results
# Parse requirements.txt
with open("requirements.txt") as f:
required = f.read().splitlines()
long_description = "Always know what to expect from your data. (See https://github.com/great-expectations/great_expectations for full description)."
config = {
"description": "Always know what to expect from your data.",
"author": "The Great Expectations Team",
"url": "https://github.com/great-expectations/great_expectations",
"author_email": "<EMAIL>",
"version": versioneer.get_version(),
"cmdclass": versioneer.get_cmdclass(),
"install_requires": required,
"extras_require": get_extras_require(),
"packages": find_packages(exclude=["contrib*", "docs*", "tests*", "examples*"]),
"entry_points": {
"console_scripts": ["great_expectations=great_expectations.cli:main"]
},
"name": "great_expectations",
"long_description": long_description,
"license": "Apache-2.0",
"keywords": "data science testing pipeline data quality dataquality validation datavalidation",
"include_package_data": True,
"classifiers": [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Intended Audience :: Other Audience",
"Topic :: Scientific/Engineering",
"Topic :: Software Development",
"Topic :: Software Development :: Testing",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
],
}
setup(**config)
<file_sep>/docs/guides/validation/checkpoints/components_how_to_create_a_new_checkpoint/_use_the_cli_to_open_a_jupyter_notebook_for_creating_a_new_checkpoint.mdx
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
To assist you with creating Checkpoints, the Great Expectations <TechnicalTag tag="cli" text="CLI" /> has a convenience method that will open a Jupyter Notebook with all the scaffolding you need to easily configure and save your Checkpoint. Simply run the following CLI command from your <TechnicalTag tag="data_context" text="Data Context" />:
```bash title="Terminal input"
> great_expectations checkpoint new my_checkpoint
```
:::tip
You can replace `my_checkpoint` in the above example with whatever name you would like to associate with the Checkpoint you will be creating.
:::
Executing this command will open a Jupyter Notebook which will guide you through the steps of creating a Checkpoint. This Jupyter Notebook will include a default configuration that you can edit to suite your use case.<file_sep>/great_expectations/datasource/data_connector/inferred_asset_sql_data_connector.py
from typing import Dict, List, Optional, Union
from great_expectations.datasource.data_connector.configured_asset_sql_data_connector import (
ConfiguredAssetSqlDataConnector,
)
from great_expectations.execution_engine import ExecutionEngine
from great_expectations.execution_engine.sqlalchemy_dialect import GESqlDialect
from great_expectations.util import deep_filter_properties_iterable
try:
import sqlalchemy as sa
from sqlalchemy.engine import Engine
from sqlalchemy.engine.reflection import Inspector
from sqlalchemy.exc import OperationalError
except ImportError:
sa = None
Engine = None
Inspector = None
OperationalError = None
class InferredAssetSqlDataConnector(ConfiguredAssetSqlDataConnector):
"""
A DataConnector that infers data_asset names by introspecting a SQL database
"""
def __init__(
self,
name: str,
datasource_name: str,
execution_engine: Optional[ExecutionEngine] = None,
data_asset_name_prefix: str = "",
data_asset_name_suffix: str = "",
include_schema_name: bool = False,
splitter_method: Optional[str] = None,
splitter_kwargs: Optional[dict] = None,
sampling_method: Optional[str] = None,
sampling_kwargs: Optional[dict] = None,
excluded_tables: Optional[list] = None,
included_tables: Optional[list] = None,
skip_inapplicable_tables: bool = True,
introspection_directives: Optional[dict] = None,
batch_spec_passthrough: Optional[dict] = None,
id: Optional[str] = None,
) -> None:
"""
InferredAssetDataConnector for connecting to data on a SQL database
Args:
name (str): The name of this DataConnector
datasource_name (str): The name of the Datasource that contains it
execution_engine (ExecutionEngine): An ExecutionEngine
data_asset_name_prefix (str): An optional prefix to prepend to inferred data_asset_names
data_asset_name_suffix (str): An optional suffix to append to inferred data_asset_names
include_schema_name (bool): Should the data_asset_name include the schema as a prefix?
splitter_method (str): A method to split the target table into multiple Batches
splitter_kwargs (dict): Keyword arguments to pass to splitter_method
sampling_method (str): A method to downsample within a target Batch
sampling_kwargs (dict): Keyword arguments to pass to sampling_method
excluded_tables (List): A list of tables to ignore when inferring data asset_names
included_tables (List): If not None, only include tables in this list when inferring data asset_names
skip_inapplicable_tables (bool):
If True, tables that can't be successfully queried using sampling and splitter methods are excluded from inferred data_asset_names.
If False, the class will throw an error during initialization if any such tables are encountered.
introspection_directives (Dict): Arguments passed to the introspection method to guide introspection
batch_spec_passthrough (dict): dictionary with keys that will be added directly to batch_spec
"""
super().__init__(
name=name,
datasource_name=datasource_name,
execution_engine=execution_engine,
include_schema_name=include_schema_name,
splitter_method=splitter_method,
splitter_kwargs=splitter_kwargs,
sampling_method=sampling_method,
sampling_kwargs=sampling_kwargs,
assets=None,
batch_spec_passthrough=batch_spec_passthrough,
id=id,
)
self._data_asset_name_prefix = data_asset_name_prefix
self._data_asset_name_suffix = data_asset_name_suffix
self._excluded_tables = excluded_tables
self._included_tables = included_tables
self._skip_inapplicable_tables = skip_inapplicable_tables
if introspection_directives is None:
introspection_directives = {}
self._introspection_directives = introspection_directives
# This cache will contain a "config" for each data_asset discovered via introspection.
# This approach ensures that ConfiguredAssetSqlDataConnector._assets and _introspected_assets_cache store objects of the same "type"
# Note: We should probably turn them into AssetConfig objects
self._refresh_introspected_assets_cache()
@property
def data_asset_name_prefix(self) -> str:
return self._data_asset_name_prefix
@property
def data_asset_name_suffix(self) -> str:
return self._data_asset_name_suffix
def _refresh_data_references_cache(self) -> None:
self._refresh_introspected_assets_cache()
super()._refresh_data_references_cache()
def _refresh_introspected_assets_cache(self) -> None:
introspected_table_metadata = self._introspect_db(
**self._introspection_directives
)
introspected_assets: dict = {}
for metadata in introspected_table_metadata:
if (self._excluded_tables is not None) and (
f"{metadata['schema_name']}.{metadata['table_name']}"
in self._excluded_tables
):
continue
if (self._included_tables is not None) and (
f"{metadata['schema_name']}.{metadata['table_name']}"
not in self._included_tables
):
continue
schema_name: str = metadata["schema_name"]
table_name: str = metadata["table_name"]
data_asset_config: dict = deep_filter_properties_iterable(
properties={
"type": metadata["type"],
"table_name": table_name,
"data_asset_name_prefix": self.data_asset_name_prefix,
"data_asset_name_suffix": self.data_asset_name_suffix,
"include_schema_name": self.include_schema_name,
"schema_name": schema_name,
"splitter_method": self.splitter_method,
"splitter_kwargs": self.splitter_kwargs,
"sampling_method": self.sampling_method,
"sampling_kwargs": self.sampling_kwargs,
},
)
data_asset_name: str = self._update_data_asset_name_from_config(
data_asset_name=table_name, data_asset_config=data_asset_config
)
# Attempt to fetch a list of batch_identifiers from the table
try:
self._get_batch_identifiers_list_from_data_asset_config(
data_asset_name=data_asset_name,
data_asset_config=data_asset_config,
)
except OperationalError as e:
# If it doesn't work, then...
if self._skip_inapplicable_tables:
# No harm done. Just don't include this table in the list of assets.
continue
else:
# We're being strict. Crash now.
raise ValueError(
f"Couldn't execute a query against table {metadata['table_name']} in schema {metadata['schema_name']}"
) from e
# Store an asset config for each introspected data asset.
introspected_assets[data_asset_name] = data_asset_config
self.add_data_asset(name=table_name, config=data_asset_config)
def _introspect_db( # noqa: C901 - 16
self,
schema_name: Union[str, None] = None,
ignore_information_schemas_and_system_tables: bool = True,
information_schemas: Optional[List[str]] = None,
system_tables: Optional[List[str]] = None,
include_views=True,
):
if information_schemas is None:
information_schemas = [
"INFORMATION_SCHEMA", # snowflake, mssql, mysql, oracle
"information_schema", # postgres, redshift, mysql
"performance_schema", # mysql
"sys", # mysql
"mysql", # mysql
]
if system_tables is None:
system_tables = ["sqlite_master"] # sqlite
engine: Engine = self.execution_engine.engine
inspector: Inspector = sa.inspect(engine)
selected_schema_name = schema_name
tables: List[Dict[str, str]] = []
schema_names: List[str] = inspector.get_schema_names()
for schema_name in schema_names:
if (
ignore_information_schemas_and_system_tables
and schema_name in information_schemas
):
continue
if selected_schema_name is not None and schema_name != selected_schema_name:
continue
table_names: List[str] = inspector.get_table_names(schema=schema_name)
for table_name in table_names:
if ignore_information_schemas_and_system_tables and (
table_name in system_tables
):
continue
tables.append(
{
"schema_name": schema_name,
"table_name": table_name,
"type": "table",
}
)
# Note Abe 20201112: This logic is currently untested.
if include_views:
# Note: this is not implemented for bigquery
try:
view_names = inspector.get_view_names(schema=schema_name)
except NotImplementedError:
# Not implemented by Athena dialect
pass
else:
for view_name in view_names:
if ignore_information_schemas_and_system_tables and (
view_name in system_tables
):
continue
tables.append(
{
"schema_name": schema_name,
"table_name": view_name,
"type": "view",
}
)
# SQLAlchemy's introspection does not list "external tables" in Redshift Spectrum (tables whose data is stored on S3).
# The following code fetches the names of external schemas and tables from a special table
# 'svv_external_tables'.
try:
if engine.dialect.name.lower() == GESqlDialect.REDSHIFT:
# noinspection SqlDialectInspection,SqlNoDataSourceInspection
result = engine.execute(
"select schemaname, tablename from svv_external_tables"
).fetchall()
for row in result:
tables.append(
{
"schema_name": row[0],
"table_name": row[1],
"type": "table",
}
)
except Exception as e:
# Our testing shows that 'svv_external_tables' table is present in all Redshift clusters. This means that this
# exception is highly unlikely to fire.
if "UndefinedTable" not in str(e):
raise e
return tables
<file_sep>/docs/api_docs/methods/great_expectations-data_context-data_context-data_context-DataContext-create.md
---
title: DataContext.create
---
[Back to class documentation](../classes/great_expectations-data_context-data_context-data_context-DataContext.md)
### Fully qualified path
`great_expectations.data_context.data_context.data_context.DataContext.create`
### Synopsis
Build a new great_expectations directory and DataContext object in the provided project_root_dir.
`create` will create a new "great_expectations" directory in the provided folder, provided one does not
already exist. Then, it will initialize a new DataContext in that folder and write the resulting config.
### Parameters
Parameter|Typing|Default|Description
---------|------|-------|-----------
project_root_dir| Union[str, NoneType] | None|path to the root directory in which to create a new great\_expectations directory|path to the root directory in which to create a new great\_expectations directory
usage_statistics_enabled| bool | True|boolean directive specifying whether or not to gather usage statistics|boolean directive specifying whether or not to gather usage statistics
runtime_environment| Union[dict, NoneType] | None|a dictionary of config variables that override both those set in config\_variables\.yml and the environment|a dictionary of config variables that override both those set in config\_variables\.yml and the environment
### Returns
DataContext
## Relevant documentation (links)
- [Data Context](../../terms/data_context.md)<file_sep>/docs/guides/validation/checkpoints/components_how_to_create_a_new_checkpoint/_e_optional_test_run_the_new_checkpoint_and_open_data_docs.mdx
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
Now that you have stored your Checkpoint configuration to the Store backend configured for the Checkpoint Configuration store of your Data Context, you can also test `context.run_checkpoint(...)`, right within your Jupyter Notebook by running the appropriate cells.
:::caution
Before running a Checkpoint, make sure that all classes and Expectation Suites referred to in the configuration exist.
:::
When `run_checkpoint(...)` returns, the `checkpoint_run_result` can then be checked for the value of the `success` field (all validations passed) and other information associated with running the specified <TechnicalTag tag="action" text="Actions" />.
For more advanced configurations of Checkpoints, please see [How to configure a new Checkpoint using test_yaml_config](../../../../guides/validation/checkpoints/how_to_configure_a_new_checkpoint_using_test_yaml_config.md).
<file_sep>/tests/data_context/test_get_data_context.py
import pathlib
from unittest import mock
import pytest
import great_expectations as gx
from great_expectations import DataContext
from great_expectations.data_context import BaseDataContext, CloudDataContext
from great_expectations.data_context.cloud_constants import GXCloudEnvironmentVariable
from great_expectations.data_context.types.base import DataContextConfig
from great_expectations.exceptions import ConfigNotFoundError
from tests.test_utils import working_directory
GE_CLOUD_PARAMS_ALL = {
"ge_cloud_base_url": "http://hello.com",
"ge_cloud_organization_id": "bd20fead-2c31-4392-bcd1-f1e87ad5a79c",
"ge_cloud_access_token": "<PASSWORD>",
}
GE_CLOUD_PARAMS_REQUIRED = {
"ge_cloud_organization_id": "bd20fead-2c31-4392-bcd1-f1e87ad5a79c",
"ge_cloud_access_token": "<PASSWORD>",
}
@pytest.fixture()
def set_up_cloud_envs(monkeypatch):
monkeypatch.setenv("GE_CLOUD_BASE_URL", "http://hello.com")
monkeypatch.setenv(
"GE_CLOUD_ORGANIZATION_ID", "bd20fead-2c31-4392-bcd1-f1e87ad5a79c"
)
monkeypatch.setenv("GE_CLOUD_ACCESS_TOKEN", "<PASSWORD>")
@pytest.fixture
def clear_env_vars(monkeypatch):
# Delete local env vars (if present)
for env_var in GXCloudEnvironmentVariable:
monkeypatch.delenv(env_var, raising=False)
@pytest.mark.unit
def test_base_context(clear_env_vars):
config: DataContextConfig = DataContextConfig(
config_version=3.0,
plugins_directory=None,
evaluation_parameter_store_name="evaluation_parameter_store",
expectations_store_name="expectations_store",
datasources={},
stores={
"expectations_store": {"class_name": "ExpectationsStore"},
"evaluation_parameter_store": {"class_name": "EvaluationParameterStore"},
"validation_result_store": {"class_name": "ValidationsStore"},
},
validations_store_name="validation_result_store",
data_docs_sites={},
validation_operators={},
)
assert isinstance(gx.get_context(project_config=config), BaseDataContext)
@pytest.mark.unit
def test_base_context__with_overridden_yml(tmp_path: pathlib.Path, clear_env_vars):
project_path = tmp_path / "empty_data_context"
project_path.mkdir()
project_path_str = str(project_path)
gx.data_context.DataContext.create(project_path_str)
context_path = project_path / "great_expectations"
context = gx.get_context(context_root_dir=context_path)
assert isinstance(context, DataContext)
assert context.expectations_store_name == "expectations_store"
config: DataContextConfig = DataContextConfig(
config_version=3.0,
plugins_directory=None,
evaluation_parameter_store_name="new_evaluation_parameter_store",
expectations_store_name="new_expectations_store",
datasources={},
stores={
"new_expectations_store": {"class_name": "ExpectationsStore"},
"new_evaluation_parameter_store": {
"class_name": "EvaluationParameterStore"
},
"new_validation_result_store": {"class_name": "ValidationsStore"},
},
validations_store_name="new_validation_result_store",
data_docs_sites={},
validation_operators={},
)
context = gx.get_context(project_config=config, context_root_dir=context_path)
assert isinstance(context, BaseDataContext)
assert context.expectations_store_name == "new_expectations_store"
@pytest.mark.unit
def test_data_context(tmp_path: pathlib.Path, clear_env_vars):
project_path = tmp_path / "empty_data_context"
project_path.mkdir()
project_path_str = str(project_path)
gx.data_context.DataContext.create(project_path_str)
with working_directory(project_path_str):
assert isinstance(gx.get_context(), DataContext)
@pytest.mark.unit
def test_data_context_root_dir_returns_data_context(
tmp_path: pathlib.Path,
clear_env_vars,
):
project_path = tmp_path / "empty_data_context"
project_path.mkdir()
project_path_str = str(project_path)
gx.data_context.DataContext.create(project_path_str)
context_path = project_path / "great_expectations"
assert isinstance(gx.get_context(context_root_dir=str(context_path)), DataContext)
@pytest.mark.unit
def test_base_context_invalid_root_dir(clear_env_vars):
config: DataContextConfig = DataContextConfig(
config_version=3.0,
plugins_directory=None,
evaluation_parameter_store_name="evaluation_parameter_store",
expectations_store_name="expectations_store",
datasources={},
stores={
"expectations_store": {"class_name": "ExpectationsStore"},
"evaluation_parameter_store": {"class_name": "EvaluationParameterStore"},
"validation_result_store": {"class_name": "ValidationsStore"},
},
validations_store_name="validation_result_store",
data_docs_sites={},
validation_operators={},
)
assert isinstance(
gx.get_context(project_config=config, context_root_dir="i/dont/exist"),
BaseDataContext,
)
@pytest.mark.parametrize("ge_cloud_mode", [True, None])
@pytest.mark.cloud
def test_cloud_context_env(
set_up_cloud_envs, empty_ge_cloud_data_context_config, ge_cloud_mode
):
with mock.patch.object(
CloudDataContext,
"retrieve_data_context_config_from_ge_cloud",
return_value=empty_ge_cloud_data_context_config,
):
assert isinstance(
gx.get_context(ge_cloud_mode=ge_cloud_mode),
CloudDataContext,
)
@pytest.mark.cloud
def test_cloud_context_disabled(set_up_cloud_envs, tmp_path: pathlib.Path):
project_path = tmp_path / "empty_data_context"
project_path.mkdir()
project_path_str = str(project_path)
gx.data_context.DataContext.create(project_path_str)
with working_directory(project_path_str):
assert isinstance(gx.get_context(ge_cloud_mode=False), DataContext)
@pytest.mark.cloud
def test_cloud_missing_env_throws_exception(
clear_env_vars, empty_ge_cloud_data_context_config
):
with pytest.raises(Exception):
gx.get_context(ge_cloud_mode=True),
@pytest.mark.parametrize("params", [GE_CLOUD_PARAMS_REQUIRED, GE_CLOUD_PARAMS_ALL])
@pytest.mark.cloud
def test_cloud_context_params(monkeypatch, empty_ge_cloud_data_context_config, params):
with mock.patch.object(
CloudDataContext,
"retrieve_data_context_config_from_ge_cloud",
return_value=empty_ge_cloud_data_context_config,
):
assert isinstance(
gx.get_context(**params),
CloudDataContext,
)
@pytest.mark.cloud
def test_cloud_context_with_in_memory_config_overrides(
monkeypatch, empty_ge_cloud_data_context_config
):
with mock.patch.object(
CloudDataContext,
"retrieve_data_context_config_from_ge_cloud",
return_value=empty_ge_cloud_data_context_config,
):
context = gx.get_context(
ge_cloud_base_url="http://hello.com",
ge_cloud_organization_id="bd20fead-2c31-4392-bcd1-f1e87ad5a79c",
ge_cloud_access_token="<PASSWORD>",
)
assert isinstance(context, CloudDataContext)
assert context.expectations_store_name == "default_expectations_store"
config: DataContextConfig = DataContextConfig(
config_version=3.0,
plugins_directory=None,
evaluation_parameter_store_name="new_evaluation_parameter_store",
expectations_store_name="new_expectations_store",
datasources={},
stores={
"new_expectations_store": {"class_name": "ExpectationsStore"},
"new_evaluation_parameter_store": {
"class_name": "EvaluationParameterStore"
},
"new_validation_result_store": {"class_name": "ValidationsStore"},
},
validations_store_name="new_validation_result_store",
data_docs_sites={},
validation_operators={},
)
context = gx.get_context(
project_config=config,
ge_cloud_base_url="http://hello.com",
ge_cloud_organization_id="bd20fead-2c31-4392-bcd1-f1e87ad5a79c",
ge_cloud_access_token="<PASSWORD>",
)
assert isinstance(context, CloudDataContext)
assert context.expectations_store_name == "new_expectations_store"
@pytest.mark.unit
def test_invalid_root_dir_gives_error(clear_env_vars):
with pytest.raises(ConfigNotFoundError):
gx.get_context(context_root_dir="i/dont/exist")
<file_sep>/docs/guides/setup/configuring_metadata_stores/components_how_to_configure_an_expectation_store_in_amazon_s3/_identify_your_data_context_expectations_store.mdx
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
You can find your <TechnicalTag tag="expectation_store" text="Expectation Store" />'s configuration within your <TechnicalTag tag="data_context" text="Data Context" />.
In your ``great_expectations.yml`` file, look for the following lines:
```yaml title="File contents: great_expectations.yml"
expectations_store_name: expectations_store
stores:
expectations_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
```
This configuration tells Great Expectations to look for Expectations in a store called ``expectations_store``. The ``base_directory`` for ``expectations_store`` is set to ``expectations/`` by default.<file_sep>/docs/guides/setup/components_index/_miscellaneous.mdx
<!--
---Import---
import Miscellaneous from './_miscellaneous.mdx'
<Miscellaneous />
---Header---
## Miscellaneous
-->
- [How to use the Great Expectations Docker images](../../../guides/miscellaneous/how_to_use_the_great_expectation_docker_images.md)
<file_sep>/docs/guides/connecting_to_your_data/cloud/s3/pandas.md
---
title: How to connect to data on S3 using Pandas
---
import Preface from './components_pandas/_preface.mdx'
import WhereToRunCode from '../../components/where_to_run_code.md'
import InstantiateYourProjectSDatacontext from './components_pandas/_instantiate_your_projects_datacontext.mdx'
import ConfigureYourDatasource from './components_pandas/_configure_your_datasource.mdx'
import SaveTheDatasourceConfigurationToYourDatacontext from './components_pandas/_save_the_datasource_configuration_to_your_datacontext.mdx'
import TestYourNewDatasource from './components_pandas/_test_your_new_datasource.mdx'
import AdditionalNotes from './components_pandas/_additional_notes.mdx'
import NextSteps from '../../components/next_steps.md'
import Congratulations from '../../components/congratulations.md'
<Preface />
## Steps
### 1. Choose how to run the code in this guide
<WhereToRunCode />
### 2. Instantiate your project's DataContext
<InstantiateYourProjectSDatacontext />
### 3. Configure your Datasource
<ConfigureYourDatasource />
### 4. Save the Datasource configuration to your DataContext
<SaveTheDatasourceConfigurationToYourDatacontext />
### 5. Test your new Datasource
<TestYourNewDatasource />
<Congratulations />
## Additional Notes
<AdditionalNotes />
## Next Steps
<NextSteps />
<file_sep>/great_expectations/data_context/data_context/base_data_context.py
from __future__ import annotations
import logging
import os
from typing import List, Mapping, Optional, Union
from ruamel.yaml import YAML
from great_expectations.checkpoint import Checkpoint
from great_expectations.core.config_peer import ConfigPeer
from great_expectations.core.expectation_suite import ExpectationSuite
from great_expectations.core.usage_statistics.events import UsageStatsEvents
from great_expectations.core.usage_statistics.usage_statistics import (
usage_statistics_enabled_method,
)
from great_expectations.data_context.data_context.cloud_data_context import (
CloudDataContext,
)
from great_expectations.data_context.data_context.ephemeral_data_context import (
EphemeralDataContext,
)
from great_expectations.data_context.data_context.file_data_context import (
FileDataContext,
)
from great_expectations.data_context.types.base import (
DataContextConfig,
DataContextConfigDefaults,
DatasourceConfig,
GXCloudConfig,
)
from great_expectations.data_context.types.resource_identifiers import (
ConfigurationIdentifier,
GXCloudIdentifier,
)
from great_expectations.datasource import LegacyDatasource
from great_expectations.datasource.new_datasource import BaseDatasource, Datasource
logger = logging.getLogger(__name__)
# TODO: check if this can be refactored to use YAMLHandler class
yaml = YAML()
yaml.indent(mapping=2, sequence=4, offset=2)
yaml.default_flow_style = False
# TODO: <WILL> Most of the logic here will be migrated to EphemeralDataContext
class BaseDataContext(EphemeralDataContext, ConfigPeer):
"""
This class implements most of the functionality of DataContext, with a few exceptions.
1. BaseDataContext does not attempt to keep its project_config in sync with a file on disc.
2. BaseDataContext doesn't attempt to "guess" paths or objects types. Instead, that logic is pushed
into DataContext class.
Together, these changes make BaseDataContext class more testable.
--ge-feature-maturity-info--
id: os_linux
title: OS - Linux
icon:
short_description:
description:
how_to_guide_url:
maturity: Production
maturity_details:
api_stability: N/A
implementation_completeness: N/A
unit_test_coverage: Complete
integration_infrastructure_test_coverage: Complete
documentation_completeness: Complete
bug_risk: Low
id: os_macos
title: OS - MacOS
icon:
short_description:
description:
how_to_guide_url:
maturity: Production
maturity_details:
api_stability: N/A
implementation_completeness: N/A
unit_test_coverage: Complete (local only)
integration_infrastructure_test_coverage: Complete (local only)
documentation_completeness: Complete
bug_risk: Low
id: os_windows
title: OS - Windows
icon:
short_description:
description:
how_to_guide_url:
maturity: Beta
maturity_details:
api_stability: N/A
implementation_completeness: N/A
unit_test_coverage: Minimal
integration_infrastructure_test_coverage: Minimal
documentation_completeness: Complete
bug_risk: Moderate
------------------------------------------------------------
id: workflow_create_edit_expectations_cli_scaffold
title: Create and Edit Expectations - suite scaffold
icon:
short_description: Creating a new Expectation Suite using suite scaffold
description: Creating Expectation Suites through an interactive development loop using suite scaffold
how_to_guide_url: https://docs.greatexpectations.io/en/latest/how_to_guides/creating_and_editing_expectations/how_to_automatically_create_a_new_expectation_suite.html
maturity: Experimental (expect exciting changes to Profiler capability)
maturity_details:
api_stability: N/A
implementation_completeness: N/A
unit_test_coverage: N/A
integration_infrastructure_test_coverage: Partial
documentation_completeness: Complete
bug_risk: Low
id: workflow_create_edit_expectations_cli_edit
title: Create and Edit Expectations - CLI
icon:
short_description: Creating a new Expectation Suite using the CLI
description: Creating a Expectation Suite great_expectations suite new command
how_to_guide_url: https://docs.greatexpectations.io/en/latest/how_to_guides/creating_and_editing_expectations/how_to_create_a_new_expectation_suite_using_the_cli.html
maturity: Experimental (expect exciting changes to Profiler and Suite Renderer capability)
maturity_details:
api_stability: N/A
implementation_completeness: N/A
unit_test_coverage: N/A
integration_infrastructure_test_coverage: Partial
documentation_completeness: Complete
bug_risk: Low
id: workflow_create_edit_expectations_json_schema
title: Create and Edit Expectations - Json schema
icon:
short_description: Creating a new Expectation Suite from a json schema file
description: Creating a new Expectation Suite using JsonSchemaProfiler function and json schema file
how_to_guide_url: https://docs.greatexpectations.io/en/latest/how_to_guides/creating_and_editing_expectations/how_to_create_a_suite_from_a_json_schema_file.html
maturity: Experimental (expect exciting changes to Profiler capability)
maturity_details:
api_stability: N/A
implementation_completeness: N/A
unit_test_coverage: N/A
integration_infrastructure_test_coverage: Partial
documentation_completeness: Complete
bug_risk: Low
--ge-feature-maturity-info--
"""
UNCOMMITTED_DIRECTORIES = ["data_docs", "validations"]
GE_UNCOMMITTED_DIR = "uncommitted"
BASE_DIRECTORIES = [
DataContextConfigDefaults.CHECKPOINTS_BASE_DIRECTORY.value,
DataContextConfigDefaults.EXPECTATIONS_BASE_DIRECTORY.value,
DataContextConfigDefaults.PLUGINS_BASE_DIRECTORY.value,
DataContextConfigDefaults.PROFILERS_BASE_DIRECTORY.value,
GE_UNCOMMITTED_DIR,
]
GE_DIR = "great_expectations"
GE_YML = "great_expectations.yml" # TODO: migrate this to FileDataContext. Still needed by DataContext
GE_EDIT_NOTEBOOK_DIR = GE_UNCOMMITTED_DIR
DOLLAR_SIGN_ESCAPE_STRING = r"\$"
@usage_statistics_enabled_method(
event_name=UsageStatsEvents.DATA_CONTEXT___INIT__,
)
def __init__(
self,
project_config: Union[DataContextConfig, Mapping],
context_root_dir: Optional[str] = None,
runtime_environment: Optional[dict] = None,
ge_cloud_mode: bool = False,
ge_cloud_config: Optional[GXCloudConfig] = None,
) -> None:
"""DataContext constructor
Args:
context_root_dir: location to look for the ``great_expectations.yml`` file. If None, searches for the file
based on conventions for project subdirectories.
runtime_environment: a dictionary of config variables that
override both those set in config_variables.yml and the environment
ge_cloud_mode: boolean flag that describe whether DataContext is being instantiated by ge_cloud
ge_cloud_config: config for ge_cloud
Returns:
None
"""
project_data_context_config: DataContextConfig = (
BaseDataContext.get_or_create_data_context_config(project_config)
)
self._ge_cloud_mode = ge_cloud_mode
self._ge_cloud_config = ge_cloud_config
if context_root_dir is not None:
context_root_dir = os.path.abspath(context_root_dir)
self._context_root_directory = context_root_dir
# initialize runtime_environment as empty dict if None
runtime_environment = runtime_environment or {}
if self._ge_cloud_mode:
ge_cloud_base_url: Optional[str] = None
ge_cloud_access_token: Optional[str] = None
ge_cloud_organization_id: Optional[str] = None
if ge_cloud_config:
ge_cloud_base_url = ge_cloud_config.base_url
ge_cloud_access_token = ge_cloud_config.access_token
ge_cloud_organization_id = ge_cloud_config.organization_id
self._data_context = CloudDataContext(
project_config=project_data_context_config,
runtime_environment=runtime_environment,
context_root_dir=context_root_dir,
ge_cloud_base_url=ge_cloud_base_url,
ge_cloud_access_token=ge_cloud_access_token,
ge_cloud_organization_id=ge_cloud_organization_id,
)
elif self._context_root_directory:
self._data_context = FileDataContext( # type: ignore[assignment]
project_config=project_data_context_config,
context_root_dir=context_root_dir, # type: ignore[arg-type]
runtime_environment=runtime_environment,
)
else:
self._data_context = EphemeralDataContext( # type: ignore[assignment]
project_config=project_data_context_config,
runtime_environment=runtime_environment,
)
# NOTE: <DataContextRefactor> This will ensure that parameters set in _data_context are persisted to self.
# It is rather clunky and we should explore other ways of ensuring that BaseDataContext has all of the
# necessary properties / overrides
self._synchronize_self_with_underlying_data_context()
self._config_provider = self._data_context.config_provider
self._variables = self._data_context.variables
# Init validation operators
# NOTE - 20200522 - JPC - A consistent approach to lazy loading for plugins will be useful here, harmonizing
# the way that execution environments (AKA datasources), validation operators, site builders and other
# plugins are built.
# NOTE - 20210112 - <NAME> - Validation Operators are planned to be deprecated.
self.validation_operators: dict = {}
if (
"validation_operators" in self.get_config().commented_map # type: ignore[union-attr]
and self.config.validation_operators
):
for (
validation_operator_name,
validation_operator_config,
) in self.config.validation_operators.items():
self.add_validation_operator(
validation_operator_name,
validation_operator_config,
)
@property
def ge_cloud_config(self) -> Optional[GXCloudConfig]:
return self._ge_cloud_config
@property
def ge_cloud_mode(self) -> bool:
return self._ge_cloud_mode
def _synchronize_self_with_underlying_data_context(self) -> None:
"""
This is a helper method that only exists during the DataContext refactor that is occurring 202206.
Until the composition-pattern is complete for BaseDataContext, we have to load the private properties from the
private self._data_context object into properties in self
This is a helper method that performs this loading.
"""
# NOTE: <DataContextRefactor> This remains a rather clunky way of ensuring that all necessary parameters and
# values from self._data_context are persisted to self.
assert self._data_context is not None
self._project_config = self._data_context._project_config
self.runtime_environment = self._data_context.runtime_environment or {}
self._config_variables = self._data_context.config_variables
self._in_memory_instance_id = self._data_context._in_memory_instance_id
self._stores = self._data_context._stores
self._datasource_store = self._data_context._datasource_store
self._data_context_id = self._data_context._data_context_id
self._usage_statistics_handler = self._data_context._usage_statistics_handler
self._cached_datasources = self._data_context._cached_datasources
self._evaluation_parameter_dependencies_compiled = (
self._data_context._evaluation_parameter_dependencies_compiled
)
self._evaluation_parameter_dependencies = (
self._data_context._evaluation_parameter_dependencies
)
self._assistants = self._data_context._assistants
#####
#
# Internal helper methods
#
#####
def delete_datasource( # type: ignore[override]
self, datasource_name: str, save_changes: Optional[bool] = None
) -> None:
"""Delete a data source
Args:
datasource_name: The name of the datasource to delete.
save_changes: Whether or not to save changes to disk.
Raises:
ValueError: If the datasource name isn't provided or cannot be found.
"""
super().delete_datasource(datasource_name, save_changes=save_changes)
self._synchronize_self_with_underlying_data_context()
def add_datasource(
self,
name: str,
initialize: bool = True,
save_changes: Optional[bool] = None,
**kwargs: dict,
) -> Optional[Union[LegacyDatasource, BaseDatasource]]:
"""
Add named datasource, with options to initialize (and return) the datasource and save_config.
Current version will call super(), which preserves the `usage_statistics` decorator in the current method.
A subsequence refactor will migrate the `usage_statistics` to parent and sibling classes.
Args:
name (str): Name of Datasource
initialize (bool): Should GE add and initialize the Datasource? If true then current
method will return initialized Datasource
save_changes (Optional[bool]): should GE save the Datasource config?
**kwargs Optional[dict]: Additional kwargs that define Datasource initialization kwargs
Returns:
Datasource that was added
"""
new_datasource = super().add_datasource(
name=name, initialize=initialize, save_changes=save_changes, **kwargs
)
self._synchronize_self_with_underlying_data_context()
return new_datasource
def create_expectation_suite(
self,
expectation_suite_name: str,
overwrite_existing: bool = False,
**kwargs,
) -> ExpectationSuite:
"""
See `AbstractDataContext.create_expectation_suite` for more information.
"""
suite = self._data_context.create_expectation_suite(
expectation_suite_name,
overwrite_existing=overwrite_existing,
**kwargs,
)
self._synchronize_self_with_underlying_data_context()
return suite
def get_expectation_suite(
self,
expectation_suite_name: Optional[str] = None,
include_rendered_content: Optional[bool] = None,
ge_cloud_id: Optional[str] = None,
) -> ExpectationSuite:
"""
Args:
expectation_suite_name (str): The name of the Expectation Suite
include_rendered_content (bool): Whether or not to re-populate rendered_content for each
ExpectationConfiguration.
ge_cloud_id (str): The GE Cloud ID for the Expectation Suite.
Returns:
An existing ExpectationSuite
"""
if include_rendered_content is None:
include_rendered_content = (
self._determine_if_expectation_suite_include_rendered_content()
)
res = self._data_context.get_expectation_suite(
expectation_suite_name=expectation_suite_name,
include_rendered_content=include_rendered_content,
ge_cloud_id=ge_cloud_id,
)
return res
def delete_expectation_suite(
self,
expectation_suite_name: Optional[str] = None,
ge_cloud_id: Optional[str] = None,
) -> bool:
"""
See `AbstractDataContext.delete_expectation_suite` for more information.
"""
res = self._data_context.delete_expectation_suite(
expectation_suite_name=expectation_suite_name, ge_cloud_id=ge_cloud_id
)
self._synchronize_self_with_underlying_data_context()
return res
@property
def root_directory(self) -> Optional[str]:
if hasattr(self._data_context, "_context_root_directory"):
return self._data_context._context_root_directory
return None
def add_checkpoint(
self,
name: str,
config_version: Optional[Union[int, float]] = None,
template_name: Optional[str] = None,
module_name: Optional[str] = None,
class_name: Optional[str] = None,
run_name_template: Optional[str] = None,
expectation_suite_name: Optional[str] = None,
batch_request: Optional[dict] = None,
action_list: Optional[List[dict]] = None,
evaluation_parameters: Optional[dict] = None,
runtime_configuration: Optional[dict] = None,
validations: Optional[List[dict]] = None,
profilers: Optional[List[dict]] = None,
# Next two fields are for LegacyCheckpoint configuration
validation_operator_name: Optional[str] = None,
batches: Optional[List[dict]] = None,
# the following four arguments are used by SimpleCheckpoint
site_names: Optional[Union[str, List[str]]] = None,
slack_webhook: Optional[str] = None,
notify_on: Optional[str] = None,
notify_with: Optional[Union[str, List[str]]] = None,
ge_cloud_id: Optional[str] = None,
expectation_suite_ge_cloud_id: Optional[str] = None,
default_validation_id: Optional[str] = None,
) -> Checkpoint:
"""
See parent 'AbstractDataContext.add_checkpoint()' for more information
"""
checkpoint = self._data_context.add_checkpoint(
name=name,
config_version=config_version,
template_name=template_name,
module_name=module_name,
class_name=class_name,
run_name_template=run_name_template,
expectation_suite_name=expectation_suite_name,
batch_request=batch_request,
action_list=action_list,
evaluation_parameters=evaluation_parameters,
runtime_configuration=runtime_configuration,
validations=validations,
profilers=profilers,
validation_operator_name=validation_operator_name,
batches=batches,
site_names=site_names,
slack_webhook=slack_webhook,
notify_on=notify_on,
notify_with=notify_with,
ge_cloud_id=ge_cloud_id,
expectation_suite_ge_cloud_id=expectation_suite_ge_cloud_id,
default_validation_id=default_validation_id,
)
# <TODO> Remove this after BaseDataContext refactor is complete.
# currently this can cause problems if the Checkpoint is instantiated with
# EphemeralDataContext, which does not (yet) have full functionality.
checkpoint._data_context = self # type: ignore[assignment]
self._synchronize_self_with_underlying_data_context()
return checkpoint
def save_expectation_suite(
self,
expectation_suite: ExpectationSuite,
expectation_suite_name: Optional[str] = None,
overwrite_existing: bool = True,
include_rendered_content: Optional[bool] = None,
**kwargs: Optional[dict],
) -> None:
self._data_context.save_expectation_suite(
expectation_suite,
expectation_suite_name=expectation_suite_name,
overwrite_existing=overwrite_existing,
include_rendered_content=include_rendered_content,
**kwargs,
)
def list_checkpoints(self) -> Union[List[str], List[ConfigurationIdentifier]]:
return self._data_context.list_checkpoints()
def list_profilers(self) -> Union[List[str], List[ConfigurationIdentifier]]:
return self._data_context.list_profilers()
def list_expectation_suites(
self,
) -> Optional[Union[List[str], List[GXCloudIdentifier]]]:
"""
See parent 'AbstractDataContext.list_expectation_suites()` for more information.
"""
return self._data_context.list_expectation_suites()
def list_expectation_suite_names(self) -> List[str]:
"""
See parent 'AbstractDataContext.list_expectation_suite_names()` for more information.
"""
return self._data_context.list_expectation_suite_names()
def _instantiate_datasource_from_config_and_update_project_config(
self,
config: DatasourceConfig,
initialize: bool,
save_changes: bool,
) -> Optional[Datasource]:
"""Instantiate datasource and optionally persist datasource config to store and/or initialize datasource for use.
Args:
config: Config for the datasource.
initialize: Whether to initialize the datasource or return None.
save_changes: Whether to save the datasource config to the configured Datasource store.
Returns:
If initialize=True return an instantiated Datasource object, else None.
"""
datasource = self._data_context._instantiate_datasource_from_config_and_update_project_config(
config=config,
initialize=initialize,
save_changes=save_changes,
)
self._synchronize_self_with_underlying_data_context()
return datasource
def _determine_key_for_profiler_save(
self, name: str, id: Optional[str]
) -> Union[ConfigurationIdentifier, GXCloudIdentifier]:
return self._data_context._determine_key_for_profiler_save(name=name, id=id)
<file_sep>/tests/integration/docusaurus/setup/configuring_data_contexts/how_to_configure_credentials.py
import os
from ruamel import yaml
import great_expectations as ge
from great_expectations.datasource.new_datasource import Datasource
config_variables_yaml = """
my_postgres_db_yaml_creds:
drivername: postgresql
host: localhost
port: 5432
username: postgres
password: ${<PASSWORD>}
database: postgres
"""
export_env_vars = """
export POSTGRES_DRIVERNAME=postgresql
export POSTGRES_HOST=localhost
export POSTGRES_PORT=5432
export POSTGRES_USERNAME=postgres
export POSTGRES_PW=
export POSTGRES_DB=postgres
export MY_DB_PW=<PASSWORD>
"""
config_variables_file_path = """
config_variables_file_path: uncommitted/config_variables.yml
"""
datasources_yaml = """
datasources:
my_postgres_db:
class_name: Datasource
module_name: great_expectations.datasource
execution_engine:
module_name: great_expectations.execution_engine
class_name: SqlAlchemyExecutionEngine
credentials: ${my_postgres_db_yaml_creds}
data_connectors:
default_inferred_data_connector_name:
class_name: InferredAssetSqlDataConnector
my_other_postgres_db:
class_name: Datasource
module_name: great_expectations.datasource
execution_engine:
module_name: great_expectations.execution_engine
class_name: SqlAlchemyExecutionEngine
credentials:
drivername: ${POSTGRES_DRIVERNAME}
host: ${POSTGRES_HOST}
port: ${POSTGRES_PORT}
username: ${POSTGRES_USERNAME}
password: ${<PASSWORD>}
database: ${POSTGRES_DB}
data_connectors:
default_inferred_data_connector_name:
class_name: InferredAssetSqlDataConnector
"""
# NOTE: The following code is only for testing and can be ignored by users.
env_vars = []
try:
# set environment variables using export_env_vars
for line in export_env_vars.split("export"):
if line.strip() != "":
key, value = line.split("=")[0].strip(), line.split("=")[1].strip()
env_vars.append(key)
os.environ[key] = value
# get context and set config variables in config_variables.yml
context = ge.get_context()
context_config_variables_relative_file_path = os.path.join(
context.GE_UNCOMMITTED_DIR, "config_variables.yml"
)
assert (
yaml.safe_load(config_variables_file_path)["config_variables_file_path"]
== context_config_variables_relative_file_path
)
context_config_variables_file_path = os.path.join(
context.root_directory, context_config_variables_relative_file_path
)
with open(context_config_variables_file_path, "w+") as f:
f.write(config_variables_yaml)
# add datsources now that variables are configured
datasources = yaml.safe_load(datasources_yaml)
my_postgres_db = context.add_datasource(
name="my_postgres_db", **datasources["datasources"]["my_postgres_db"]
)
my_other_postgres_db = context.add_datasource(
name="my_other_postgres_db",
**datasources["datasources"]["my_other_postgres_db"]
)
assert type(my_postgres_db) == Datasource
assert type(my_other_postgres_db) == Datasource
assert context.list_datasources() == [
{
"execution_engine": {
"credentials": {
"drivername": "postgresql",
"host": "localhost",
"port": 5432,
"username": "postgres",
"password": "***",
"database": "postgres",
},
"module_name": "great_expectations.execution_engine",
"class_name": "SqlAlchemyExecutionEngine",
},
"data_connectors": {
"default_inferred_data_connector_name": {
"class_name": "InferredAssetSqlDataConnector",
"module_name": "great_expectations.datasource.data_connector",
}
},
"module_name": "great_expectations.datasource",
"class_name": "Datasource",
"name": "my_postgres_db",
},
{
"execution_engine": {
"credentials": {
"drivername": "postgresql",
"host": "localhost",
"port": "5432",
"username": "postgres",
"password": "***",
"database": "postgres",
},
"module_name": "great_expectations.execution_engine",
"class_name": "SqlAlchemyExecutionEngine",
},
"data_connectors": {
"default_inferred_data_connector_name": {
"class_name": "InferredAssetSqlDataConnector",
"module_name": "great_expectations.datasource.data_connector",
}
},
"module_name": "great_expectations.datasource",
"class_name": "Datasource",
"name": "my_other_postgres_db",
},
]
except Exception:
raise
finally:
# unset environment variables if they were set
for var in env_vars:
os.environ.pop(var, None)
<file_sep>/great_expectations/core/expectation_diagnostics/expectation_diagnostics.py
import inspect
import os
import re
from collections import defaultdict
from dataclasses import asdict, dataclass
from typing import List, Tuple, Union
from great_expectations.core.expectation_configuration import ExpectationConfiguration
from great_expectations.core.expectation_diagnostics.expectation_test_data_cases import (
ExpectationTestDataCases,
)
from great_expectations.core.expectation_diagnostics.supporting_types import (
AugmentedLibraryMetadata,
ExpectationBackendTestResultCounts,
ExpectationDescriptionDiagnostics,
ExpectationDiagnosticCheckMessage,
ExpectationDiagnosticMaturityMessages,
ExpectationErrorDiagnostics,
ExpectationExecutionEngineDiagnostics,
ExpectationMetricDiagnostics,
ExpectationRendererDiagnostics,
ExpectationTestDiagnostics,
)
from great_expectations.core.util import convert_to_json_serializable
from great_expectations.exceptions import InvalidExpectationConfigurationError
from great_expectations.expectations.registry import get_expectation_impl
from great_expectations.types import SerializableDictDot
from great_expectations.util import camel_to_snake, lint_code
try:
import black
except ImportError:
black = None
try:
import isort
except ImportError:
isort = None
@dataclass(frozen=True)
class ExpectationDiagnostics(SerializableDictDot):
"""An immutable object created by Expectation.run_diagnostics.
It contains information introspected from the Expectation class, in formats that can be renderered at the command line, and by the Gallery.
It has three external-facing use cases:
1. `ExpectationDiagnostics.to_dict()` creates the JSON object that populates the Gallery.
2. `ExpectationDiagnostics.generate_checklist()` creates CLI-type string output to assist with development.
"""
# This object is taken directly from the Expectation class, without modification
examples: List[ExpectationTestDataCases]
gallery_examples: List[ExpectationTestDataCases]
# These objects are derived from the Expectation class
# They're a combination of direct introspection of existing properties,
# and instantiating the Expectation with test data and actually executing
# methods.
# For example, we can verify the existence of certain Renderers through
# introspection alone, but in order to see what they return, we need to
# instantiate the Expectation and actually run the method.
library_metadata: Union[AugmentedLibraryMetadata, ExpectationDescriptionDiagnostics]
description: ExpectationDescriptionDiagnostics
execution_engines: ExpectationExecutionEngineDiagnostics
renderers: List[ExpectationRendererDiagnostics]
metrics: List[ExpectationMetricDiagnostics]
tests: List[ExpectationTestDiagnostics]
backend_test_result_counts: List[ExpectationBackendTestResultCounts]
errors: List[ExpectationErrorDiagnostics]
maturity_checklist: ExpectationDiagnosticMaturityMessages
coverage_score: float
def to_json_dict(self) -> dict:
result = convert_to_json_serializable(data=asdict(self))
result["execution_engines_list"] = sorted(
[
engine
for engine, _bool in result["execution_engines"].items()
if _bool is True
]
)
return result
def generate_checklist(self) -> str:
"""Generates the checklist in CLI-appropriate string format."""
str_ = self._convert_checks_into_output_message(
self.description["camel_name"],
self.library_metadata.maturity,
self.maturity_checklist,
)
return str_
@staticmethod
def _check_library_metadata(
library_metadata: Union[
AugmentedLibraryMetadata, ExpectationDescriptionDiagnostics
],
) -> ExpectationDiagnosticCheckMessage:
"""Check whether the Expectation has a library_metadata object"""
sub_messages = []
for problem in library_metadata.problems:
sub_messages.append(
{
"message": problem,
"passed": False,
}
)
return ExpectationDiagnosticCheckMessage(
message="Has a valid library_metadata object",
passed=library_metadata.library_metadata_passed_checks,
sub_messages=sub_messages,
)
@staticmethod
def _check_docstring(
description: ExpectationDescriptionDiagnostics,
) -> ExpectationDiagnosticCheckMessage:
"""Check whether the Expectation has an informative docstring"""
message = "Has a docstring, including a one-line short description"
if "short_description" in description:
short_description = description["short_description"]
else:
short_description = None
if short_description not in {"", "\n", "TODO: Add a docstring here", None}:
return ExpectationDiagnosticCheckMessage(
message=message,
sub_messages=[
{
"message": f'"{short_description}"',
"passed": True,
}
],
passed=True,
)
else:
return ExpectationDiagnosticCheckMessage(
message=message,
passed=False,
)
@classmethod
def _check_example_cases(
cls,
examples: List[ExpectationTestDataCases],
tests: List[ExpectationTestDiagnostics],
) -> ExpectationDiagnosticCheckMessage:
"""Check whether this Expectation has at least one positive and negative example case (and all test cases return the expected output)"""
message = "Has at least one positive and negative example case, and all test cases pass"
(
positive_case_count,
negative_case_count,
) = cls._count_positive_and_negative_example_cases(examples)
unexpected_case_count = cls._count_unexpected_test_cases(tests)
passed = (
(positive_case_count > 0)
and (negative_case_count > 0)
and (unexpected_case_count == 0)
)
print(positive_case_count, negative_case_count, unexpected_case_count, passed)
return ExpectationDiagnosticCheckMessage(
message=message,
passed=passed,
)
@staticmethod
def _check_core_logic_for_at_least_one_execution_engine(
backend_test_result_counts: List[ExpectationBackendTestResultCounts],
) -> ExpectationDiagnosticCheckMessage:
"""Check whether core logic for this Expectation exists and passes tests on at least one Execution Engine"""
sub_messages = []
passed = False
message = "Has core logic and passes tests on at least one Execution Engine"
all_passing = [
backend_test_result
for backend_test_result in backend_test_result_counts
if backend_test_result.failing_names is None
and backend_test_result.num_passed >= 1
]
if len(all_passing) > 0:
passed = True
for result in all_passing:
sub_messages.append(
{
"message": f"All {result.num_passed} tests for {result.backend} are passing",
"passed": True,
}
)
if not backend_test_result_counts:
sub_messages.append(
{
"message": "There are no test results",
"passed": False,
}
)
return ExpectationDiagnosticCheckMessage(
message=message,
passed=passed,
sub_messages=sub_messages,
)
@staticmethod
def _get_backends_from_test_results(
test_results: List[ExpectationTestDiagnostics],
) -> List[ExpectationBackendTestResultCounts]:
"""Has each tested backend and the number of passing/failing tests"""
backend_results = defaultdict(list)
backend_failing_names = defaultdict(list)
results: List[ExpectationBackendTestResultCounts] = []
for test_result in test_results:
backend_results[test_result.backend].append(test_result.test_passed)
if test_result.test_passed is False:
backend_failing_names[test_result.backend].append(
test_result.test_title
)
for backend in backend_results:
result_counts = ExpectationBackendTestResultCounts(
backend=backend,
num_passed=backend_results[backend].count(True),
num_failed=backend_results[backend].count(False),
failing_names=backend_failing_names.get(backend),
)
results.append(result_counts)
return results
@staticmethod
def _check_core_logic_for_all_applicable_execution_engines(
backend_test_result_counts: List[ExpectationBackendTestResultCounts],
) -> ExpectationDiagnosticCheckMessage:
"""Check whether core logic for this Expectation exists and passes tests on all applicable Execution Engines"""
sub_messages = []
passed = False
message = "Has core logic that passes tests for all applicable Execution Engines and SQL dialects"
all_passing = [
backend_test_result
for backend_test_result in backend_test_result_counts
if backend_test_result.failing_names is None
and backend_test_result.num_passed >= 1
]
some_failing = [
backend_test_result
for backend_test_result in backend_test_result_counts
if backend_test_result.failing_names is not None
]
if len(all_passing) > 0 and len(some_failing) == 0:
passed = True
for result in all_passing:
sub_messages.append(
{
"message": f"All {result.num_passed} tests for {result.backend} are passing",
"passed": True,
}
)
for result in some_failing:
sub_messages.append(
{
"message": f"Only {result.num_passed} / {result.num_passed + result.num_failed} tests for {result.backend} are passing",
"passed": False,
}
)
sub_messages.append(
{
"message": f" - Failing: {', '.join(result.failing_names)}",
"passed": False,
}
)
if not backend_test_result_counts:
sub_messages.append(
{
"message": "There are no test results",
"passed": False,
}
)
return ExpectationDiagnosticCheckMessage(
message=message,
passed=passed,
sub_messages=sub_messages,
)
@staticmethod
def _count_positive_and_negative_example_cases(
examples: List[ExpectationTestDataCases],
) -> Tuple[int, int]:
"""Scans examples and returns a 2-ple with the numbers of cases with success == True and success == False"""
positive_cases: int = 0
negative_cases: int = 0
for test_data_cases in examples:
for test in test_data_cases["tests"]:
success = test["output"].get("success")
if success is True:
positive_cases += 1
elif success is False:
negative_cases += 1
return positive_cases, negative_cases
@staticmethod
def _count_unexpected_test_cases(
test_diagnostics: ExpectationTestDiagnostics,
) -> int:
"""Scans test_diagnostics and returns the number of cases that did not pass."""
unexpected_cases: int = 0
for test in test_diagnostics:
passed = test["test_passed"] is True
if not passed:
unexpected_cases += 1
return unexpected_cases
@staticmethod
def _convert_checks_into_output_message(
class_name: str,
maturity_level: str,
maturity_messages: ExpectationDiagnosticMaturityMessages,
) -> str:
"""Converts a list of checks into an output string (potentially nested), with ✔ to indicate checks that passed."""
output_message = f"Completeness checklist for {class_name} ({maturity_level}):"
checks = (
maturity_messages.experimental
+ maturity_messages.beta
+ maturity_messages.production
)
for check in checks:
if check["passed"]:
output_message += f"\n ✔ {check['message']}"
else:
output_message += f"\n {check['message']}"
if "sub_messages" in check:
for sub_message in check["sub_messages"]:
if sub_message["passed"]:
output_message += f"\n ✔ {sub_message['message']}"
else:
output_message += f"\n {sub_message['message']}"
output_message += "\n"
return output_message
@staticmethod
def _check_input_validation(
expectation_instance,
examples: List[ExpectationTestDataCases],
) -> ExpectationDiagnosticCheckMessage:
"""Check that the validate_configuration exists and doesn't raise a config error"""
passed = False
sub_messages = []
rx = re.compile(r"^[\s]+assert", re.MULTILINE)
try:
first_test = examples[0]["tests"][0]
except IndexError:
sub_messages.append(
{
"message": "No example found to get kwargs for ExpectationConfiguration",
"passed": passed,
}
)
else:
if "validate_configuration" not in expectation_instance.__class__.__dict__:
sub_messages.append(
{
"message": "No validate_configuration method defined on subclass",
"passed": passed,
}
)
else:
expectation_config = ExpectationConfiguration(
expectation_type=expectation_instance.expectation_type,
kwargs=first_test.input,
)
validate_configuration_source = inspect.getsource(
expectation_instance.__class__.validate_configuration
)
if rx.search(validate_configuration_source):
sub_messages.append(
{
"message": "Custom 'assert' statements in validate_configuration",
"passed": True,
}
)
else:
sub_messages.append(
{
"message": "Using default validate_configuration from template",
"passed": False,
}
)
try:
expectation_instance.validate_configuration(expectation_config)
except InvalidExpectationConfigurationError:
pass
else:
passed = True
return ExpectationDiagnosticCheckMessage(
message="Has basic input validation and type checking",
passed=passed,
sub_messages=sub_messages,
)
@staticmethod
def _check_renderer_methods(
expectation_instance,
) -> ExpectationDiagnosticCheckMessage:
"""Check if all statment renderers are defined"""
passed = False
# For now, don't include the "question", "descriptive", or "answer"
# types since they are so sparsely implemented
# all_renderer_types = {"diagnostic", "prescriptive", "question", "descriptive", "answer"}
all_renderer_types = {"diagnostic", "prescriptive"}
renderer_names = [
name
for name in dir(expectation_instance)
if name.endswith("renderer") and name.startswith("_")
]
renderer_types = {name.split("_")[1] for name in renderer_names}
if all_renderer_types & renderer_types == all_renderer_types:
passed = True
return ExpectationDiagnosticCheckMessage(
# message="Has all four statement Renderers: question, descriptive, prescriptive, diagnostic",
message="Has both statement Renderers: prescriptive and diagnostic",
passed=passed,
)
@staticmethod
def _check_linting(expectation_instance) -> ExpectationDiagnosticCheckMessage:
"""Check if linting checks pass for Expectation"""
sub_messages: List[dict] = []
message: str = "Passes all linting checks"
passed: bool = False
black_ok: bool = False
isort_ok: bool = False
file_and_class_names_ok: bool = False
rx_expectation_instance_repr = re.compile(r"<.*\.([^\.]*) object at .*")
try:
expectation_camel_name = rx_expectation_instance_repr.match(
repr(expectation_instance)
).group(1)
except AttributeError:
sub_messages.append(
{
"message": "Arg passed to _check_linting was not an instance of an Expectation, so cannot check linting",
"passed": False,
}
)
return ExpectationDiagnosticCheckMessage(
message=message,
passed=passed,
sub_messages=sub_messages,
)
impl = get_expectation_impl(camel_to_snake(expectation_camel_name))
try:
source_file_path = inspect.getfile(impl)
except TypeError:
sub_messages.append(
{
"message": "inspect.getfile(impl) raised a TypeError (impl is a built-in class)",
"passed": False,
}
)
return ExpectationDiagnosticCheckMessage(
message=message,
passed=passed,
sub_messages=sub_messages,
)
snaked_impl_name = camel_to_snake(impl.__name__)
source_file_base_no_ext = os.path.basename(source_file_path).rsplit(".", 1)[0]
with open(source_file_path) as fp:
code = fp.read()
if snaked_impl_name != source_file_base_no_ext:
sub_messages.append(
{
"message": f"The snake_case of {impl.__name__} ({snaked_impl_name}) does not match filename part ({source_file_base_no_ext})",
"passed": False,
}
)
else:
file_and_class_names_ok = True
if black is None:
sub_messages.append(
{
"message": "Could not find 'black', so cannot check linting",
"passed": False,
}
)
if isort is None:
sub_messages.append(
{
"message": "Could not find 'isort', so cannot check linting",
"passed": False,
}
)
if black and isort:
blacked_code = lint_code(code)
if code != blacked_code:
sub_messages.append(
{
"message": "Your code would be reformatted with black",
"passed": False,
}
)
else:
black_ok = True
isort_ok = isort.check_code(
code,
**isort.profiles.black,
ignore_whitespace=True,
known_local_folder=["great_expectations"],
)
if not isort_ok:
sub_messages.append(
{
"message": "Your code would be reformatted with isort",
"passed": False,
}
)
passed = black_ok and isort_ok and file_and_class_names_ok
return ExpectationDiagnosticCheckMessage(
message=message,
passed=passed,
sub_messages=sub_messages,
)
@staticmethod
def _check_full_test_suite(
library_metadata: Union[
AugmentedLibraryMetadata, ExpectationDescriptionDiagnostics
],
) -> ExpectationDiagnosticCheckMessage:
"""Check library_metadata to see if Expectation has a full test suite"""
return ExpectationDiagnosticCheckMessage(
message="Has a full suite of tests, as determined by a code owner",
passed=library_metadata.has_full_test_suite,
)
@staticmethod
def _check_manual_code_review(
library_metadata: Union[
AugmentedLibraryMetadata, ExpectationDescriptionDiagnostics
],
) -> ExpectationDiagnosticCheckMessage:
"""Check library_metadata to see if a manual code review has been performed"""
return ExpectationDiagnosticCheckMessage(
message="Has passed a manual review by a code owner for code standards and style guides",
passed=library_metadata.manually_reviewed_code,
)
<file_sep>/great_expectations/data_context/store/_store_backend.py
import logging
import uuid
from abc import ABCMeta, abstractmethod
from typing import Any, List, Optional, Union
import pyparsing as pp
from great_expectations.exceptions import InvalidKeyError, StoreBackendError, StoreError
logger = logging.getLogger(__name__)
class StoreBackend(metaclass=ABCMeta):
"""A store backend acts as a key-value store that can accept tuples as keys, to abstract away
reading and writing to a persistence layer.
In general a StoreBackend implementation must provide implementations of:
- _get
- _set
- list_keys
- _has_key
"""
IGNORED_FILES = [".ipynb_checkpoints"]
STORE_BACKEND_ID_KEY = (".ge_store_backend_id",)
STORE_BACKEND_ID_PREFIX = "store_backend_id = "
STORE_BACKEND_INVALID_CONFIGURATION_ID = "00000000-0000-0000-0000-00000000e003"
def __init__(
self,
fixed_length_key=False,
suppress_store_backend_id=False,
manually_initialize_store_backend_id: str = "",
store_name="no_store_name",
) -> None:
"""
Initialize a StoreBackend
Args:
fixed_length_key:
suppress_store_backend_id: skip construction of a StoreBackend.store_backend_id
manually_initialize_store_backend_id: UUID as a string to use if the store_backend_id is not already set
store_name: store name given in the DataContextConfig (via either in-code or yaml configuration)
"""
self._fixed_length_key = fixed_length_key
self._suppress_store_backend_id = suppress_store_backend_id
self._manually_initialize_store_backend_id = (
manually_initialize_store_backend_id
)
self._store_name = store_name
@property
def fixed_length_key(self):
return self._fixed_length_key
@property
def store_name(self):
return self._store_name
def _construct_store_backend_id(
self, suppress_warning: bool = False
) -> Optional[str]:
"""
Create a store_backend_id if one does not exist, and return it if it exists
If a valid UUID store_backend_id is passed in param manually_initialize_store_backend_id
and there is not already an existing store_backend_id then the store_backend_id
from param manually_initialize_store_backend_id is used to create it.
Args:
suppress_warning: boolean flag for whether warnings are logged
Returns:
store_backend_id which is a UUID(version=4)
"""
if self._suppress_store_backend_id:
if not suppress_warning:
logger.warning(
f"You are attempting to access the store_backend_id of a store or store_backend named {self.store_name} that has been explicitly suppressed."
)
return None
try:
try:
ge_store_backend_id_file_contents = self.get(
key=self.STORE_BACKEND_ID_KEY
)
store_backend_id_file_parser = self.STORE_BACKEND_ID_PREFIX + pp.Word(
f"{pp.hexnums}-"
)
parsed_store_backend_id = store_backend_id_file_parser.parseString(
ge_store_backend_id_file_contents
)
return parsed_store_backend_id[1]
except InvalidKeyError:
store_id = (
self._manually_initialize_store_backend_id
if self._manually_initialize_store_backend_id
else str(uuid.uuid4())
)
self.set(
key=self.STORE_BACKEND_ID_KEY,
value=f"{self.STORE_BACKEND_ID_PREFIX}{store_id}\n",
)
return store_id
except Exception:
if not suppress_warning:
logger.warning(
f"Invalid store configuration: Please check the configuration of your {self.__class__.__name__} named {self.store_name}"
)
return self.STORE_BACKEND_INVALID_CONFIGURATION_ID
# NOTE: AJB20201130 This store_backend_id and store_backend_id_warnings_suppressed was implemented to remove multiple warnings in DataContext.__init__ but this can be done more cleanly by more carefully going through initialization order in DataContext
@property
def store_backend_id(self):
return self._construct_store_backend_id(suppress_warning=False)
@property
def store_backend_id_warnings_suppressed(self):
return self._construct_store_backend_id(suppress_warning=True)
def get(self, key, **kwargs):
self._validate_key(key)
value = self._get(key, **kwargs)
return value
def set(self, key, value, **kwargs):
self._validate_key(key)
self._validate_value(value)
# Allow the implementing setter to return something (e.g. a path used for its key)
try:
return self._set(key, value, **kwargs)
except ValueError as e:
logger.debug(str(e))
raise StoreBackendError("ValueError while calling _set on store backend.")
def move(self, source_key, dest_key, **kwargs):
self._validate_key(source_key)
self._validate_key(dest_key)
return self._move(source_key, dest_key, **kwargs)
def has_key(self, key) -> bool:
self._validate_key(key)
return self._has_key(key)
def get_url_for_key(self, key, protocol=None) -> None:
raise StoreError(
"Store backend of type {:s} does not have an implementation of get_url_for_key".format(
type(self).__name__
)
)
def _validate_key(self, key) -> None:
if isinstance(key, tuple):
for key_element in key:
if not isinstance(key_element, str):
raise TypeError(
"Elements within tuples passed as keys to {} must be instances of {}, not {}".format(
self.__class__.__name__,
str,
type(key_element),
)
)
else:
raise TypeError(
"Keys in {} must be instances of {}, not {}".format(
self.__class__.__name__,
tuple,
type(key),
)
)
def _validate_value(self, value) -> None:
pass
@abstractmethod
def _get(self, key) -> None:
raise NotImplementedError
@abstractmethod
def _set(self, key, value, **kwargs) -> None:
raise NotImplementedError
@abstractmethod
def _move(self, source_key, dest_key, **kwargs) -> None:
raise NotImplementedError
@abstractmethod
def list_keys(self, prefix=()) -> Union[List[str], List[tuple]]:
raise NotImplementedError
@abstractmethod
def remove_key(self, key) -> None:
raise NotImplementedError
def _has_key(self, key) -> bool:
raise NotImplementedError
def is_ignored_key(self, key):
for ignored in self.IGNORED_FILES:
if ignored in key:
return True
return False
@property
def config(self) -> dict:
raise NotImplementedError
def build_key(
self,
id: Optional[str] = None,
name: Optional[str] = None,
) -> Any:
"""Build a key specific to the store backend implementation."""
raise NotImplementedError
<file_sep>/tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison.py
# <snippet>
from ruamel import yaml
import great_expectations as ge
from great_expectations.core.batch import BatchRequest
from great_expectations.profile.user_configurable_profiler import (
UserConfigurableProfiler,
)
context = ge.get_context()
# </snippet>
# This utility is not for general use. It is only to support testing.
from tests.test_utils import load_data_into_test_database
# The following load & config blocks up until the batch requests are only to support testing.
MY_CONNECTION_STRING = "mysql+pymysql://root@localhost/test_ci"
PG_CONNECTION_STRING = "postgresql+psycopg2://postgres:@localhost/test_ci"
load_data_into_test_database(
table_name="mysql_taxi_data",
csv_path="./data/yellow_tripdata_sample_2019-01.csv",
connection_string=MY_CONNECTION_STRING,
)
load_data_into_test_database(
table_name="postgres_taxi_data",
csv_path="./data/yellow_tripdata_sample_2019-01.csv",
connection_string=PG_CONNECTION_STRING,
)
pg_datasource_config = {
"name": "my_postgresql_datasource",
"class_name": "Datasource",
"execution_engine": {
"class_name": "SqlAlchemyExecutionEngine",
"connection_string": f"{PG_CONNECTION_STRING}",
},
"data_connectors": {
"default_inferred_data_connector_name": {
"class_name": "InferredAssetSqlDataConnector",
"include_schema_name": True,
},
},
}
mysql_datasource_config = {
"name": "my_mysql_datasource",
"class_name": "Datasource",
"execution_engine": {
"class_name": "SqlAlchemyExecutionEngine",
"connection_string": f"{MY_CONNECTION_STRING}",
},
"data_connectors": {
"default_inferred_data_connector_name": {
"class_name": "InferredAssetSqlDataConnector",
"include_schema_name": True,
},
},
}
# Please note this override is only to provide good UX for docs and tests.
# In normal usage you'd set your path directly in the yaml.
pg_datasource_config["execution_engine"]["connection_string"] = PG_CONNECTION_STRING
context.test_yaml_config(yaml.dump(pg_datasource_config))
context.add_datasource(**pg_datasource_config)
# Please note this override is only to provide good UX for docs and tests.
# In normal usage you'd set your path directly in the yaml.
mysql_datasource_config["execution_engine"]["connection_string"] = MY_CONNECTION_STRING
context.test_yaml_config(yaml.dump(mysql_datasource_config))
context.add_datasource(**mysql_datasource_config)
# Tutorial content resumes here.
# <snippet>
mysql_batch_request = BatchRequest(
datasource_name="my_mysql_datasource",
data_connector_name="default_inferred_data_connector_name",
data_asset_name="test_ci.mysql_taxi_data",
)
# </snippet>
# <snippet>
pg_batch_request = BatchRequest(
datasource_name="my_postgresql_datasource",
data_connector_name="default_inferred_data_connector_name",
data_asset_name="public.postgres_taxi_data",
)
# </snippet>
# <snippet>
validator = context.get_validator(batch_request=mysql_batch_request)
# </snippet>
# <snippet>
profiler = UserConfigurableProfiler(
profile_dataset=validator,
excluded_expectations=[
"expect_column_quantile_values_to_be_between",
"expect_column_mean_to_be_between",
],
)
# </snippet>
# <snippet>
expectation_suite_name = "compare_two_tables"
suite = profiler.build_suite()
context.save_expectation_suite(
expectation_suite=suite, expectation_suite_name=expectation_suite_name
)
# </snippet>
# <snippet>
my_checkpoint_name = "comparison_checkpoint"
yaml_config = f"""
name: {my_checkpoint_name}
config_version: 1.0
class_name: SimpleCheckpoint
run_name_template: "%Y%m%d-%H%M%S-my-run-name-template"
expectation_suite_name: {expectation_suite_name}
"""
context.add_checkpoint(**yaml.load(yaml_config))
# </snippet>
# <snippet>
results = context.run_checkpoint(
checkpoint_name=my_checkpoint_name, batch_request=pg_batch_request
)
# </snippet>
# Note to users: code below this line is only for integration testing -- ignore!
assert results["success"] is True
statistics = results["run_results"][list(results["run_results"].keys())[0]][
"validation_result"
]["statistics"]
assert statistics["evaluated_expectations"] != 0
assert statistics["evaluated_expectations"] == statistics["successful_expectations"]
assert statistics["unsuccessful_expectations"] == 0
assert statistics["success_percent"] == 100.0
<file_sep>/docs/guides/validation/how_to_validate_data_by_running_a_checkpoint.md
---
title: How to validate data by running a Checkpoint
---
import Prerequisites from '../../guides/connecting_to_your_data/components/prerequisites.jsx';
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide will help you <TechnicalTag tag="validation" text="Validate" /> your data by running a <TechnicalTag tag="checkpoint" text="Checkpoint" />.
As stated in the Getting Started Tutorial [Step 4: Validate data](../../tutorials/getting_started/tutorial_validate_data.md), the best way to Validate data in production with Great Expectations is using a <TechnicalTag tag="checkpoint" text="Checkpoint" />. The advantage of using a Checkpoint is ease of use, due to its principal capability of combining the existing configuration in order to set up and perform the Validation:
- <TechnicalTag tag="expectation_suite" text="Expectation Suites" />
- <TechnicalTag tag="data_connector" text="Data Connectors" />
- <TechnicalTag tag="batch_request" text="Batch Requests" />
- <TechnicalTag tag="action" text="Actions" />
Otherwise, configuring these validation parameters would have to be done via the API. A Checkpoint encapsulates this "boilerplate" and ensures that all components work in harmony together. Finally, running a configured Checkpoint is a one-liner, as described below.
<Prerequisites>
- [Configured a Data Context](../../tutorials/getting_started/tutorial_setup.md#create-a-data-context).
- [Configured an Expectations Suite](../../tutorials/getting_started/tutorial_create_expectations.md).
- [Configured a Checkpoint](./checkpoints/how_to_create_a_new_checkpoint.md)
</Prerequisites>
You can run the Checkpoint from the <TechnicalTag tag="cli" text="CLI" /> in a Terminal shell or using Python.
<Tabs
groupId="terminal-or-python"
defaultValue='terminal'
values={[
{label: 'Terminal', value:'terminal'},
{label: 'Python', value:'python'},
]}>
<TabItem value="terminal">
## Steps
### 1. Run your Checkpoint
Checkpoints can be run like applications from the command line by running:
```bash
great_expectations checkpoint run my_checkpoint
Validation failed!
```
### 2. Observe the output
The output of your validation will tell you if all validations passed or if any failed.
## Additional notes
This command will return posix status codes and print messages as follows:
+-------------------------------+-----------------+-----------------------+
| **Situation** | **Return code** | **Message** |
+-------------------------------+-----------------+-----------------------+
| all validations passed | 0 | Validation succeeded! |
+-------------------------------+-----------------+-----------------------+
| one or more validation failed | 1 | Validation failed! |
+-------------------------------+-----------------+-----------------------+
</TabItem>
<TabItem value="python">
## Steps
### 1. Generate the Python script
From your console, run the CLI command:
```bash
great_expectations checkpoint script my_checkpoint
```
After the command runs, you will see a message about where the Python script was created similar to the one below:
```bash
A Python script was created that runs the checkpoint named: `my_checkpoint`
- The script is located in `great_expectations/uncommitted/run_my_checkpoint.py`
- The script can be run with `python great_expectations/uncommitted/run_my_checkpoint.py`
```
### 2. Open the script
The script that was produced should look like this:
```python
"""
This is a basic generated Great Expectations script that runs a Checkpoint.
Checkpoints are the primary method for validating batches of data in production and triggering any followup actions.
A Checkpoint facilitates running a validation as well as configurable Actions such as updating Data Docs, sending a
notification to team members about Validation Results, or storing a result in a shared cloud storage.
Checkpoints can be run directly without this script using the `great_expectations checkpoint run` command. This script
is provided for those who wish to run Checkpoints in Python.
Usage:
- Run this file: `python great_expectations/uncommitted/run_my_checkpoint.py`.
- This can be run manually or via a scheduler such, as cron.
- If your pipeline runner supports Python snippets, then you can paste this into your pipeline.
"""
import sys
from great_expectations.checkpoint.types.checkpoint_result import CheckpointResult
from great_expectations.data_context import DataContext
data_context: DataContext = DataContext(
context_root_dir="/path/to/great_expectations"
)
result: CheckpointResult = data_context.run_checkpoint(
checkpoint_name="my_checkpoint",
batch_request=None,
run_name=None,
)
if not result["success"]:
print("Validation failed!")
sys.exit(1)
print("Validation succeeded!")
sys.exit(0)
```
### 3. Run the script
This Python script can then be invoked directly using Python:
```python
python great_expectations/uncommitted/run_my_checkpoint.py
```
Alternatively, the above Python code can be embedded in your pipeline.
## Additional Notes
- Other arguments to the `DataContext.run_checkpoint()` method may be required, depending on the amount and specifics of the Checkpoint configuration previously saved in the configuration file of the Checkpoint with the corresponding `name`.
- The dynamically specified Checkpoint configuration, provided to the runtime as arguments to `DataContext.run_checkpoint()` must complement the settings in the Checkpoint configuration file so as to comprise a properly and sufficiently configured Checkpoint with the given `name`.
- Please see [How to configure a new Checkpoint using test_yaml_config](./checkpoints/how_to_configure_a_new_checkpoint_using_test_yaml_config.md) for more Checkpoint configuration examples (including the convenient templating mechanism) and `DataContext.run_checkpoint()` invocation options.
</TabItem>
</Tabs>
<file_sep>/great_expectations/rule_based_profiler/data_assistant_result/__init__.py
from .data_assistant_result import DataAssistantResult
from .onboarding_data_assistant_result import OnboardingDataAssistantResult
from .volume_data_assistant_result import VolumeDataAssistantResult
<file_sep>/docs/guides/validation/checkpoints/components_how_to_create_a_new_checkpoint/_preface.mdx
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide will help you create a new <TechnicalTag tag="checkpoint" text="Checkpoint" />, which allows you to couple an <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> with a data set to <TechnicalTag tag="validation" text="Validate" />.
:::note
As of Great Expectations version 0.13.7, we have updated and improved the Checkpoints feature. You can continue to use your existing legacy Checkpoint workflows if you’re working with concepts from the Batch Kwargs (v2) API. If you’re using concepts from the BatchRequest (v3) API, please refer to the new Checkpoints guides.
:::<file_sep>/docs/guides/expectations/how_to_create_and_edit_expectations_based_on_domain_knowledge_without_inspecting_data_directly.md
---
title: How to create and edit Expectations based on domain knowledge, without inspecting data directly
---
import Prerequisites from '../../guides/connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide shows how to create an <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> without a sample <TechnicalTag tag="batch" text="Batch" />.
Here are some of the reasons why you may wish to do this:
1. You don't have a sample.
2. You don't currently have access to the data to make a sample.
3. You know exactly how you want your <TechnicalTag tag="expectation" text="Expectations" /> to be configured.
4. You want to create Expectations parametrically (you can also do this in interactive mode).
5. You don't want to spend the time to validate against a sample.
If you have a use case we have not considered, please [contact us on Slack](https://greatexpectations.io/slack).
<Prerequisites>
- [Configured a Data Context](../../tutorials/getting_started/tutorial_setup.md).
- Have your <TechnicalTag tag="data_context" text="Data Context" /> configured to save Expectations to your filesystem (please see [How to configure an Expectation store to use a filesystem](../../guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_on_a_filesystem.md)) or another <TechnicalTag tag="expectation_store" text="Expectation Store" /> if you are in a hosted environment.
</Prerequisites>
## Steps
### 1. Use the CLI to generate a helper notebook
From the command line, use the <TechnicalTag tag="cli" text="CLI" /> to run:
```bash
great_expectations suite new
```
### 2. Create Expectation Configurations in the helper notebook
You are adding Expectation configurations to the suite. Since there is no sample Batch of data, no <TechnicalTag tag="validation" text="Validation" /> happens during this process. To illustrate how to do this, consider a hypothetical example. Suppose that you have a table with the columns ``account_id``, ``user_id``, ``transaction_id``, ``transaction_type``, and ``transaction_amt_usd``. Then the following code snipped adds an Expectation that the columns of the actual table will appear in the order specified above:
```python
# Create an Expectation
expectation_configuration = ExpectationConfiguration(
# Name of expectation type being added
expectation_type="expect_table_columns_to_match_ordered_list",
# These are the arguments of the expectation
# The keys allowed in the dictionary are Parameters and
# Keyword Arguments of this Expectation Type
kwargs={
"column_list": [
"account_id", "user_id", "transaction_id", "transaction_type", "transaction_amt_usd"
]
},
# This is how you can optionally add a comment about this expectation.
# It will be rendered in Data Docs.
# See this guide for details:
# `How to add comments to Expectations and display them in Data Docs`.
meta={
"notes": {
"format": "markdown",
"content": "Some clever comment about this expectation. **Markdown** `Supported`"
}
}
)
# Add the Expectation to the suite
suite.add_expectation(expectation_configuration=expectation_configuration)
```
Here are a few more example expectations for this dataset:
```python
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "transaction_type",
"value_set": ["purchase", "refund", "upgrade"]
},
# Note optional comments omitted
)
suite.add_expectation(expectation_configuration=expectation_configuration)
```
```python
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_not_be_null",
kwargs={
"column": "account_id",
"mostly": 1.0,
},
meta={
"notes": {
"format": "markdown",
"content": "Some clever comment about this expectation. **Markdown** `Supported`"
}
}
)
suite.add_expectation(expectation_configuration=expectation_configuration)
```
```python
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_not_be_null",
kwargs={
"column": "user_id",
"mostly": 0.75,
},
meta={
"notes": {
"format": "markdown",
"content": "Some clever comment about this expectation. **Markdown** `Supported`"
}
}
)
suite.add_expectation(expectation_configuration=expectation_configuration)
```
You can see all the available Expectations in the [Expectation Gallery](https://greatexpectations.io/expectations).
### 3. Save your Expectation Suite
Run the final cell in the helper notebook to save your Expectation Suite.
This will create a JSON file with your Expectation Suite in the <TechnicalTag tag="store" text="Store" /> you have configured, which you can then load and use for <TechnicalTag tag="validation" text="Validation"/>.
<file_sep>/great_expectations/exceptions/__init__.py
from .exceptions import * # noqa: F403
<file_sep>/docs/guides/validation/checkpoints/components_how_to_create_a_new_checkpoint/_d_optional_check_your_stored_checkpoint_config.mdx
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
If the <TechnicalTag tag="store" text="Store" /> backend of your <TechnicalTag tag="checkpoint_store" text="Checkpoint Store" /> is on the local filesystem, you can navigate to the `checkpoints` store directory that is configured in `great_expectations.yml` and find the configuration files corresponding to the Checkpoints you created.
<file_sep>/reqs/requirements-dev-test.txt
--requirement requirements-dev-lite.txt
--requirement requirements-dev-contrib.txt
<file_sep>/scripts/validate_docs_snippet_line_numbers.py
import enum
import glob
import pprint
import re
from dataclasses import dataclass
from typing import List, Optional, Tuple
# This should be reduced as snippets are added/fixed
VIOLATION_THRESHOLD = 523
r = re.compile(r"```\w+ file=(.+)")
class Status(enum.Enum):
MISSING_BOTH = 0
MISSING_OPENING = 1
MISSING_CLOSING = 2
COMPLETE = 3
@dataclass
class Reference:
raw: str
origin_path: str
origin_line: int
target_path: str
target_lines: Optional[Tuple[int, int]]
@dataclass
class Result:
ref: Reference
status: Status
def to_dict(self) -> dict:
data = self.__dict__
data["ref"] = data["ref"].__dict__
data["status"] = data["status"].name
return data
def collect_references(files: List[str]) -> List[Reference]:
all_refs = []
for file in files:
file_refs = _collect_references(file)
all_refs.extend(file_refs)
return all_refs
def _collect_references(file: str) -> List[Reference]:
with open(file) as f:
lines = f.readlines()
refs = []
for i, line in enumerate(lines):
match = r.match(line.strip())
if not match:
continue
ref = _parse_reference(match=match, file=file, line=i + 1)
refs.append(ref)
return refs
def _parse_reference(match: re.Match, file: str, line: int) -> Reference:
# Chetan - 20221007 - This parsing logic could probably be cleaned up with a regex
# and pathlib/os but since this is not prod code, I'll leave cleanup as a nice-to-have
raw_path = match.groups()[0].strip()
parts = raw_path.split("#")
target_path = parts[0]
while target_path.startswith("../"):
target_path = target_path[3:]
target_lines: Optional[Tuple[int, int]]
if len(parts) == 1:
target_lines = None
else:
line_nos = parts[1].split("-")
start = int(line_nos[0][1:])
end: int
if len(line_nos) == 1:
end = start
else:
end = int(line_nos[1][1:])
target_lines = (start, end)
return Reference(
raw=raw_path,
origin_path=file,
origin_line=line,
target_path=target_path,
target_lines=target_lines,
)
def determine_results(refs: List[Reference]) -> List[Result]:
all_results = []
for ref in refs:
result = _determine_result(ref)
all_results.append(result)
return all_results
def _determine_result(ref: Reference) -> Result:
if ref.target_lines is None:
return Result(
ref=ref,
status=Status.COMPLETE,
)
with open(ref.target_path) as f:
lines = f.readlines()
start, end = ref.target_lines
try:
open_tag = lines[start - 2]
valid_open = "<snippet" in open_tag
except IndexError:
valid_open = False
try:
close_tag = lines[end]
valid_close = "snippet>" in close_tag
except IndexError:
valid_close = False
status: Status
if valid_open and valid_close:
status = Status.COMPLETE
elif valid_open:
status = Status.MISSING_CLOSING
elif valid_close:
status = Status.MISSING_OPENING
else:
status = Status.MISSING_BOTH
return Result(
ref=ref,
status=status,
)
def evaluate_results(results: List[Result]) -> None:
summary = {}
for res in results:
key = res.status.name
val = res.to_dict()
if key not in summary:
summary[key] = []
summary[key].append(val)
pprint.pprint(summary)
print("\n[SUMMARY]")
for key, val in summary.items():
print(f"* {key}: {len(val)}")
violations = len(results) - len(summary[Status.COMPLETE.name])
assert (
violations <= VIOLATION_THRESHOLD
), f"Expected {VIOLATION_THRESHOLD} or fewer snippet violations, got {violations}"
# There should only be COMPLETE (valid snippets) or MISSING_BOTH (snippets that haven't recieved surrounding tags yet)
# The presence of MISSING_OPENING or MISSING_CLOSING signifies a misaligned line number reference
assert (
summary.get(Status.MISSING_OPENING.name, 0) == 0
), "Found a snippet without an opening snippet tag"
assert (
summary.get(Status.MISSING_CLOSING.name, 0) == 0
), "Found a snippet without an closing snippet tag"
def main() -> None:
files = glob.glob("docs/**/*.md", recursive=True)
refs = collect_references(files)
results = determine_results(refs)
evaluate_results(results)
if __name__ == "__main__":
main()
<file_sep>/docs/guides/setup/configuring_data_contexts/components_how_to_configure_a_new_data_context_with_the_cli/_data_context_next_steps.mdx
import DataDocLinks from '../../components_index/_data_docs.mdx'
import ExpectationStoresLinks from '../../components_index/_expectation_stores.mdx'
import ValidationStoreLinks from '../../components_index/_validation_result_stores.mdx'
import MetricStoreLinks from '../../components_index/_metric_stores.mdx'
Now that you have initialized a Data Context, you are ready to configure it to suit your needs.
For guidance on configuring database credentials, see:
- [How to configure credentials](../how_to_configure_credentials.md)
For guidance on configuring Data Docs, see:
<DataDocLinks />
For guidance on configuring Expectation Stores, see:
<ExpectationStoresLinks />
For guidance on configuring Validation Stores, see:
<ValidationStoreLinks />
For guidance on configuring Metric Stores, see:
<MetricStoreLinks /><file_sep>/docs/guides/setup/configuring_metadata_stores/components_how_to_configure_an_expectation_store_in_amazon_s3/_confirm_that_the_new_expectations_store_has_been_added_by_running_great_expectations_store_list.mdx
You can verify that your Stores are properly configured by running the command:
```bash title="Terminal command"
great_expectations store list
```
This will list the currently configured Stores that Great Expectations has access to. If you added a new S3 Expectations Store, the output should include the following `ExpectationsStore` entries:
```bash title="Terminal output"
- name: expectations_store
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
- name: expectations_S3_store
class_name: ExpectationsStore
store_backend:
class_name: TupleS3StoreBackend
bucket: '<your_s3_bucket_name>'
prefix: '<your_s3_bucket_folder_name>'
```
Notice the output contains two Expectation Stores: the original ``expectations_store`` on the local filesystem and the ``expectations_S3_store`` we just configured. This is ok, since Great Expectations will look for Expectations in the S3 bucket as long as we set the ``expectations_store_name`` variable to ``expectations_S3_store``.<file_sep>/docs/terms/data_docs.md
---
id: data_docs
title: Data Docs
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
import SetupHeader from '/docs/images/universal_map/_um_setup_header.mdx'
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
import ValidateHeader from '/docs/images/universal_map/_um_validate_header.mdx';
<UniversalMap setup='active' connect='inactive' create='active' validate='active'/>
## Overview
### Definition
Data Docs are human readable documentation generated from Great Expectations metadata detailing <TechnicalTag relative="../" tag="expectation" text="Expectations" />, <TechnicalTag relative="../" tag="validation_result" text="Validation Results" />, etc.
### Features and promises
Data Docs translate Expectations, Validation Results, and other metadata into clean, human-readable documentation. Automatically compiling your data documentation from your data tests in the form of Data Docs guarantees that your documentation will never go stale.
### Relationship to other objects
Data Docs can be used to view <TechnicalTag relative="../" tag="expectation_suite" text="Expectation Suites" /> and Validation Results. With a customized <TechnicalTag relative="../" tag="renderer" text="Renderer" />, you can extend what they display and how. You can issue a command to update your Data Docs from your <TechnicalTag relative="../" tag="data_context" text="Data Context" />. Alternatively, you can include the `UpdateDataDocsAction` <TechnicalTag relative="../" tag="action" text="Action" /> in a <TechnicalTag relative="../" tag="checkpoint" text="Checkpoint's" /> `action_list` to trigger an update of your Data Docs with the Validation Results that were generated by that Checkpoint being run.
## Use cases
<SetupHeader/>
You can configure multiple Data Docs sites while setting up your Great Expectations project. This allows you to tailor the information that is displayed by Data Docs as well as how they are hosted. For more information on setting up your Data Docs, please reference our [guides on how to configure them for specific hosting environments](../guides/setup/index.md#data-docs).
<CreateHeader/>
You can view your saved Expectation Suites in Data Docs.
<ValidateHeader/>
Saved Validation Results will be displayed in any Data Docs site that is configured to show them. If you build your Data Docs from the Data Context, the process will render Data Docs for all of your Validation Results. Alternatively, you can use the `UpdateDataDocsAction` Action in a Checkpoint's `action_list` to update your Data Docs with just the Validation Results generated by that checkpoint.
## Features
### Readability
Data Docs provide a clean, human-readable way to view your Expectation Suites and Validation Results without you having to manually parse their stored values and configurations. You can also [add comments to your Expectations that will be displayed in your Data Docs](../guides/expectations/advanced/how_to_add_comments_to_expectations_and_display_them_in_data_docs.md), if you feel they need further explanation.
### Versatility
There are multiple use cases for displaying information in your Data Docs. Three common ones are:
1. Visualize all Great Expectations artifacts from the local repository of a project as HTML: Expectation Suites,
Validation Results and profiling results.
1. Maintain a "shared source of truth" for a team working on a data project. Such documentation renders all the
artifacts committed in the source control system (Expectation Suites and profiling results) and a continuously
updating data quality report, built from a chronological list of validations by run id.
1. Share a spec of a dataset with a client or a partner. This is similar to API documentation in software development.
This documentation would include profiling results of the dataset to give the reader a quick way to grasp what the
data looks like, and one or more Expectation Suites that encode what is expected from the data to be considered
valid.
To support these (and possibly other) use cases Great Expectations has a concept of a "data documentation site". Multiple sites can be configured inside a project, each suitable for a particular data documentation use case.
## API basics
### How to access
Data Docs are rendered as HTML files. As such, you can open them with any browser.
### How to create
If your Data Docs have not yet been rendered, you can create them from your Data Context.
From the root folder of your project (where you initialized your Data Context), you can build your Data Docs with the CLI command:
```bash title="Terminal command"
great_expectations docs build
```
Alternatively, you can use your Data Context to build your Data Docs in python with the command:
```python title="Python code"
import great_expectations as ge
context = ge.get_context()
context.build_data_docs()
```
### Configuration
Data Docs sites are configured under the `data_docs_sites` key in your deployment's `great_expectations.yml` file. Users can specify:
- which <TechnicalTag relative="../" tag="datasource" text="Datasources" /> to document (by default, all)
- whether to include Expectations, validations and profiling results sections
- where the Expectations and validations should be read from (filesystem, S3, Azure, or GCS)
- where the HTML files should be written (filesystem, S3, Azure, or GCS)
- which <TechnicalTag relative="../" tag="renderer" text="Renderer" /> and view class should be used to render each section
For more information, please see our guides for [how to host and share Data Docs in specific environments](../guides/setup/index.md#data-docs).<file_sep>/docs/guides/setup/configuring_data_contexts/how_to_configure_credentials.md
---
title: How to configure credentials
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import Tabs from '@theme/Tabs'
import TabItem from '@theme/TabItem'
import TechnicalTag from '/docs/term_tags/_tag.mdx';
This guide will explain how to configure your ``great_expectations.yml`` project config to populate credentials from either a YAML file or a secret manager.
If your Great Expectations deployment is in an environment without a file system, refer to [How to instantiate a Data Context without a yml file](./how_to_instantiate_a_data_context_without_a_yml_file.md) for credential configuration examples.
<Tabs
groupId="yaml-or-secret-manager"
defaultValue='yaml'
values={[
{label: 'YAML', value:'yaml'},
{label: 'Secret Manager', value:'secret-manager'},
]}>
<TabItem value="yaml">
<Prerequisites></Prerequisites>
## Steps
### 1. Save credentials and config
Decide where you would like to save the desired credentials or config values - in a YAML file, environment variables, or a combination - then save the values.
In most cases, we suggest using a config variables YAML file. YAML files make variables more visible, easily editable, and allow for modularization (e.g. one file for dev, another for prod).
:::note
- In the ``great_expectations.yml`` config file, environment variables take precedence over variables defined in a config variables YAML
- Environment variable substitution is supported in both the ``great_expectations.yml`` and config variables ``config_variables.yml`` config file.
:::
If using a YAML file, save desired credentials or config values to ``great_expectations/uncommitted/config_variables.yml`` or another YAML file of your choosing:
```yaml file=../../../../tests/integration/docusaurus/setup/configuring_data_contexts/how_to_configure_credentials.py#L9-L15
```
:::note
- If you wish to store values that include the dollar sign character ``$``, please escape them using a backslash ``\`` so substitution is not attempted. For example in the above example for Postgres credentials you could set ``password: <PASSWORD>`` if your password is ``<PASSWORD>``. Say that 5 times fast, and also please choose a more secure password!
- When you save values via the <TechnicalTag relative="../../../" tag="cli" text="CLI" />, they are automatically escaped if they contain the ``$`` character.
- You can also have multiple substitutions for the same item, e.g. ``database_string: ${USER}:${PASSWORD}@${HOST}:${PORT}/${DATABASE}``
:::
If using environment variables, set values by entering ``export ENV_VAR_NAME=env_var_value`` in the terminal or adding the commands to your ``~/.bashrc`` file:
```bash file=../../../../tests/integration/docusaurus/setup/configuring_data_contexts/how_to_configure_credentials.py#L19-L25
```
### 2. Set ``config_variables_file_path``
If using a YAML file, set the ``config_variables_file_path`` key in your ``great_expectations.yml`` or leave the default.
```yaml file=../../../../tests/integration/docusaurus/setup/configuring_data_contexts/how_to_configure_credentials.py#L29
```
### 3. Replace credentials with placeholders
Replace credentials or other values in your ``great_expectations.yml`` with ``${}``-wrapped variable names (i.e. ``${ENVIRONMENT_VARIABLE}`` or ``${YAML_KEY}``).
```yaml file=../../../../tests/integration/docusaurus/setup/configuring_data_contexts/how_to_configure_credentials.py#L33-L59
```
## Additional Notes
- The default ``config_variables.yml`` file located at ``great_expectations/uncommitted/config_variables.yml`` applies to deployments created using ``great_expectations init``.
- To view the full script used in this page, see it on GitHub: [how_to_configure_credentials.py](https://github.com/great-expectations/great_expectations/tree/develop/tests/integration/docusaurus/setup/configuring_data_contexts/how_to_configure_credentials.py)
</TabItem>
<TabItem value="secret-manager">
Choose which secret manager you are using:
<Tabs
groupId="secret-manager"
defaultValue='aws'
values={[
{label: 'AWS Secrets Manager', value:'aws'},
{label: 'GCP Secret Manager', value:'gcp'},
{label: 'Azure Key Vault', value:'azure'},
]}>
<TabItem value="aws">
This guide will explain how to configure your ``great_expectations.yml`` project config to substitute variables from AWS Secrets Manager.
<Prerequisites>
- Configured a secret manager and secrets in the cloud with [AWS Secrets Manager](https://docs.aws.amazon.com/secretsmanager/latest/userguide/tutorials_basic.html)
</Prerequisites>
:::warning
Secrets store substitution uses the configurations from your ``great_expectations.yml`` project config **after** all other types of substitution are applied (from environment variables or from the ``config_variables.yml`` config file)
The secrets store substitution works based on keywords. It tries to retrieve secrets from the secrets store for the following values :
- AWS: values starting with ``secret|arn:aws:secretsmanager`` if the values you provide don't match with the keywords above, the values won't be substituted.
:::
**Setup**
To use AWS Secrets Manager, you may need to install the ``great_expectations`` package with its ``aws_secrets`` extra requirement:
```bash
pip install great_expectations[aws_secrets]
```
In order to substitute your value by a secret in AWS Secrets Manager, you need to provide an arn of the secret like this one:
``secret|arn:aws:secretsmanager:123456789012:secret:my_secret-1zAyu6``
:::note
The last 7 characters of the arn are automatically generated by AWS and are not mandatory to retrieve the secret, thus ``secret|arn:aws:secretsmanager:region-name-1:123456789012:secret:my_secret`` will retrieve the same secret.
:::
You will get the latest version of the secret by default.
You can get a specific version of the secret you want to retrieve by specifying its version UUID like this: ``secret|arn:aws:secretsmanager:region-name-1:123456789012:secret:my_secret:00000000-0000-0000-0000-000000000000``
If your secret value is a JSON string, you can retrieve a specific value like this:
``secret|arn:aws:secretsmanager:region-name-1:123456789012:secret:my_secret|key``
Or like this:
``secret|arn:aws:secretsmanager:region-name-1:123456789012:secret:my_secret:00000000-0000-0000-0000-000000000000|key``
**Example great_expectations.yml:**
```yaml
datasources:
dev_postgres_db:
class_name: SqlAlchemyDatasource
data_asset_type:
class_name: SqlAlchemyDataset
module_name: great_expectations.dataset
module_name: great_expectations.datasource
credentials:
drivername: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:dev_db_credentials|drivername
host: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:dev_db_credentials|host
port: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:dev_db_credentials|port
username: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:dev_db_credentials|username
password: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:dev_db_credentials|password
database: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:dev_db_credentials|database
prod_postgres_db:
class_name: SqlAlchemyDatasource
data_asset_type:
class_name: SqlAlchemyDataset
module_name: great_expectations.dataset
module_name: great_expectations.datasource
credentials:
drivername: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:PROD_DB_CREDENTIALS_DRIVERNAME
host: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:PROD_DB_CREDENTIALS_HOST
port: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:PROD_DB_CREDENTIALS_PORT
username: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:PROD_DB_CREDENTIALS_USERNAME
password: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:PROD_DB_CREDENTIALS_PASSWORD
database: secret|arn:aws:secretsmanager:${AWS_REGION}:${ACCOUNT_ID}:secret:PROD_DB_CREDENTIALS_DATABASE
```
</TabItem>
<TabItem value="gcp">
This guide will explain how to configure your ``great_expectations.yml`` project config to substitute variables from GCP Secrets Manager.
<Prerequisites>
- Configured a secret manager and secrets in the cloud with [GCP Secret Manager](https://cloud.google.com/secret-manager/docs/quickstart)
</Prerequisites>
:::warning
Secrets store substitution uses the configurations from your ``great_expectations.yml`` project config **after** all other types of substitution are applied (from environment variables or from the ``config_variables.yml`` config file)
The secrets store substitution works based on keywords. It tries to retrieve secrets from the secrets store for the following values :
- GCP: values matching the following regex ``^secret\|projects\/[a-z0-9\_\-]{6,30}\/secrets`` if the values you provide don't match with the keywords above, the values won't be substituted.
:::
**Setup**
To use GCP Secret Manager, you may need to install the ``great_expectations`` package with its ``gcp`` extra requirement:
```bash
pip install great_expectations[gcp]
```
In order to substitute your value by a secret in GCP Secret Manager, you need to provide a name of the secret like this one:
``secret|projects/project_id/secrets/my_secret``
You will get the latest version of the secret by default.
You can get a specific version of the secret you want to retrieve by specifying its version id like this: ``secret|projects/project_id/secrets/my_secret/versions/1``
If your secret value is a JSON string, you can retrieve a specific value like this:
``secret|projects/project_id/secrets/my_secret|key``
Or like this:
``secret|projects/project_id/secrets/my_secret/versions/1|key``
**Example great_expectations.yml:**
```yaml
datasources:
dev_postgres_db:
class_name: SqlAlchemyDatasource
data_asset_type:
class_name: SqlAlchemyDataset
module_name: great_expectations.dataset
module_name: great_expectations.datasource
credentials:
drivername: secret|projects/${PROJECT_ID}/secrets/dev_db_credentials|drivername
host: secret|projects/${PROJECT_ID}/secrets/dev_db_credentials|host
port: secret|projects/${PROJECT_ID}/secrets/dev_db_credentials|port
username: secret|projects/${PROJECT_ID}/secrets/dev_db_credentials|username
password: secret|projects/${PROJECT_ID}/secrets/dev_db_credentials|password
database: secret|projects/${PROJECT_ID}/secrets/dev_db_credentials|database
prod_postgres_db:
class_name: SqlAlchemyDatasource
data_asset_type:
class_name: SqlAlchemyDataset
module_name: great_expectations.dataset
module_name: great_expectations.datasource
credentials:
drivername: secret|projects/${PROJECT_ID}/secrets/PROD_DB_CREDENTIALS_DRIVERNAME
host: secret|projects/${PROJECT_ID}/secrets/PROD_DB_CREDENTIALS_HOST
port: secret|projects/${PROJECT_ID}/secrets/PROD_DB_CREDENTIALS_PORT
username: secret|projects/${PROJECT_ID}/secrets/PROD_DB_CREDENTIALS_USERNAME
password: <PASSWORD>|projects/${PROJECT_ID}/secrets/PROD_DB_CREDENTIALS_PASSWORD
database: secret|projects/${PROJECT_ID}/secrets/PROD_DB_CREDENTIALS_DATABASE
```
</TabItem>
<TabItem value="azure">
This guide will explain how to configure your ``great_expectations.yml`` project config to substitute variables from Azure Key Vault.
<Prerequisites>
- [Set up a working deployment of Great Expectations](../../../tutorials/getting_started/tutorial_overview.md)
- Configured a secret manager and secrets in the cloud with [Azure Key Vault](https://docs.microsoft.com/en-us/azure/key-vault/general/overview)
</Prerequisites>
:::warning
Secrets store substitution uses the configurations from your ``great_expectations.yml`` project config **after** all other types of substitution are applied (from environment variables or from the ``config_variables.yml`` config file)
The secrets store substitution works based on keywords. It tries to retrieve secrets from the secrets store for the following values :
- Azure : values matching the following regex ``^secret\|https:\/\/[a-zA-Z0-9\-]{3,24}\.vault\.azure\.net`` if the values you provide don't match with the keywords above, the values won't be substituted.
:::
**Setup**
To use Azure Key Vault, you may need to install the ``great_expectations`` package with its ``azure_secrets`` extra requirement:
```bash
pip install great_expectations[azure_secrets]
```
In order to substitute your value by a secret in Azure Key Vault, you need to provide a name of the secret like this one:
``secret|https://my-vault-name.vault.azure.net/secrets/my-secret``
You will get the latest version of the secret by default.
You can get a specific version of the secret you want to retrieve by specifying its version id (32 lowercase alphanumeric characters) like this: ``secret|https://my-vault-name.vault.azure.net/secrets/my-secret/a0b00aba001aaab10b111001100a11ab``
If your secret value is a JSON string, you can retrieve a specific value like this:
``secret|https://my-vault-name.vault.azure.net/secrets/my-secret|key``
Or like this:
``secret|https://my-vault-name.vault.azure.net/secrets/my-secret/a0b00aba001aaab10b111001100a11ab|key``
**Example great_expectations.yml:**
```yaml
datasources:
dev_postgres_db:
class_name: SqlAlchemyDatasource
data_asset_type:
class_name: SqlAlchemyDataset
module_name: great_expectations.dataset
module_name: great_expectations.datasource
credentials:
drivername: secret|https://${VAULT_NAME}.vault.azure.net/secrets/dev_db_credentials|drivername
host: secret|https://${VAULT_NAME}.vault.azure.net/secrets/dev_db_credentials|host
port: secret|https://${VAULT_NAME}.vault.azure.net/secrets/dev_db_credentials|port
username: secret|https://${VAULT_NAME}.vault.azure.net/secrets/dev_db_credentials|username
password: secret|https://${VAULT_NAME}.vault.azure.net/secrets/dev_db_credentials|password
database: secret|https://${VAULT_NAME}.vault.azure.net/secrets/dev_db_credentials|database
prod_postgres_db:
class_name: SqlAlchemyDatasource
data_asset_type:
class_name: SqlAlchemyDataset
module_name: great_expectations.dataset
module_name: great_expectations.datasource
credentials:
drivername: secret|https://${VAULT_NAME}.vault.azure.net/secrets/PROD_DB_CREDENTIALS_DRIVERNAME
host: secret|https://${VAULT_NAME}.vault.azure.net/secrets/PROD_DB_CREDENTIALS_HOST
port: secret|https://${VAULT_NAME}.vault.azure.net/secrets/PROD_DB_CREDENTIALS_PORT
username: secret|https://${VAULT_NAME}.vault.azure.net/secrets/PROD_DB_CREDENTIALS_USERNAME
password: secret|https://${VAULT_NAME}.vault.azure.net/secrets/PROD_DB_CREDENTIALS_PASSWORD
database: secret|https://${VAULT_NAME}.vault.azure.net/secrets/PROD_DB_CREDENTIALS_DATABASE
```
</TabItem>
</Tabs>
</TabItem>
</Tabs><file_sep>/tests/checkpoint/conftest.py
import os
import shutil
import pytest
from great_expectations import DataContext
from great_expectations.core import ExpectationConfiguration
from great_expectations.core.yaml_handler import YAMLHandler
from great_expectations.data_context.util import file_relative_path
@pytest.fixture
def titanic_pandas_data_context_stats_enabled_and_expectation_suite_with_one_expectation(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
# create expectation suite
suite = context.create_expectation_suite("my_expectation_suite")
expectation = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_between",
kwargs={"column": "col1", "min_value": 1, "max_value": 2},
)
suite.add_expectation(expectation, send_usage_event=False)
context.save_expectation_suite(suite)
return context
@pytest.fixture
def titanic_spark_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled(
tmp_path_factory,
monkeypatch,
spark_session,
):
# Re-enable GE_USAGE_STATS
monkeypatch.delenv("GE_USAGE_STATS")
project_path: str = str(tmp_path_factory.mktemp("titanic_data_context"))
context_path: str = os.path.join(project_path, "great_expectations")
os.makedirs(os.path.join(context_path, "expectations"), exist_ok=True)
data_path: str = os.path.join(context_path, "..", "data", "titanic")
os.makedirs(os.path.join(data_path), exist_ok=True)
shutil.copy(
file_relative_path(
__file__,
os.path.join(
"..",
"test_fixtures",
"great_expectations_v013_no_datasource_stats_enabled.yml",
),
),
str(os.path.join(context_path, "great_expectations.yml")),
)
shutil.copy(
file_relative_path(__file__, os.path.join("..", "test_sets", "Titanic.csv")),
str(
os.path.join(
context_path, "..", "data", "titanic", "Titanic_19120414_1313.csv"
)
),
)
shutil.copy(
file_relative_path(__file__, os.path.join("..", "test_sets", "Titanic.csv")),
str(
os.path.join(context_path, "..", "data", "titanic", "Titanic_19120414_1313")
),
)
shutil.copy(
file_relative_path(__file__, os.path.join("..", "test_sets", "Titanic.csv")),
str(os.path.join(context_path, "..", "data", "titanic", "Titanic_1911.csv")),
)
shutil.copy(
file_relative_path(__file__, os.path.join("..", "test_sets", "Titanic.csv")),
str(os.path.join(context_path, "..", "data", "titanic", "Titanic_1912.csv")),
)
context = DataContext(context_root_dir=context_path)
assert context.root_directory == context_path
datasource_config: str = f"""
class_name: Datasource
execution_engine:
class_name: SparkDFExecutionEngine
data_connectors:
my_basic_data_connector:
class_name: InferredAssetFilesystemDataConnector
base_directory: {data_path}
default_regex:
pattern: (.*)\\.csv
group_names:
- data_asset_name
my_special_data_connector:
class_name: ConfiguredAssetFilesystemDataConnector
base_directory: {data_path}
glob_directive: "*.csv"
default_regex:
pattern: (.+)\\.csv
group_names:
- name
assets:
users:
base_directory: {data_path}
pattern: (.+)_(\\d+)_(\\d+)\\.csv
group_names:
- name
- timestamp
- size
my_other_data_connector:
class_name: ConfiguredAssetFilesystemDataConnector
base_directory: {data_path}
glob_directive: "*.csv"
default_regex:
pattern: (.+)\\.csv
group_names:
- name
assets:
users: {{}}
my_runtime_data_connector:
module_name: great_expectations.datasource.data_connector
class_name: RuntimeDataConnector
batch_identifiers:
- pipeline_stage_name
- airflow_run_id
"""
# noinspection PyUnusedLocal
context.test_yaml_config(
name="my_datasource", yaml_config=datasource_config, pretty_print=False
)
# noinspection PyProtectedMember
context._save_project_config()
return context
@pytest.fixture
def context_with_single_taxi_csv_spark(
empty_data_context, tmp_path_factory, spark_session
):
context = empty_data_context
yaml = YAMLHandler()
base_directory = str(tmp_path_factory.mktemp("test_checkpoint_spark"))
taxi_asset_base_directory_path: str = os.path.join(base_directory, "data")
os.makedirs(taxi_asset_base_directory_path)
# training data
taxi_csv_source_file_path_training_data: str = file_relative_path(
__file__,
"../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-01.csv",
)
taxi_csv_destination_file_path_training_data: str = str(
os.path.join(base_directory, "data/yellow_tripdata_sample_2019-01.csv")
)
shutil.copy(
taxi_csv_source_file_path_training_data,
taxi_csv_destination_file_path_training_data,
)
# test data
taxi_csv_source_file_path_test_data: str = file_relative_path(
__file__,
"../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2020-01.csv",
)
taxi_csv_destination_file_path_test_data: str = str(
os.path.join(base_directory, "data/yellow_tripdata_sample_2020-01.csv")
)
shutil.copy(
taxi_csv_source_file_path_test_data, taxi_csv_destination_file_path_test_data
)
config = yaml.load(
f"""
class_name: Datasource
execution_engine:
class_name: SparkDFExecutionEngine
data_connectors:
configured_data_connector_multi_batch_asset:
class_name: ConfiguredAssetFilesystemDataConnector
base_directory: {taxi_asset_base_directory_path}
assets:
yellow_tripdata_2019:
pattern: yellow_tripdata_sample_(2019)-(\\d.*)\\.csv
group_names:
- year
- month
yellow_tripdata_2020:
pattern: yellow_tripdata_sample_(2020)-(\\d.*)\\.csv
group_names:
- year
- month
""",
)
context.add_datasource(
"my_datasource",
**config,
)
return context
@pytest.fixture
def context_with_single_csv_spark_and_suite(
context_with_single_taxi_csv_spark,
):
context: DataContext = context_with_single_taxi_csv_spark
# create expectation suite
suite = context.create_expectation_suite("my_expectation_suite")
expectation = ExpectationConfiguration(
expectation_type="expect_column_to_exist",
kwargs={"column": "pickup_datetime"},
)
suite.add_expectation(expectation, send_usage_event=False)
context.save_expectation_suite(suite)
return context
<file_sep>/docs/guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_to_postgresql.md
---
title: How to configure a Validation Result Store to PostgreSQL
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
By default, Validation Results are stored in JSON format in the ``uncommitted/validations/`` subdirectory of your ``great_expectations/`` folder. Since <TechnicalTag tag="validation_result" text="Validation Results" /> may include examples of data (which could be sensitive or regulated) they should not be committed to a source control system. This guide will help you configure Great Expectations to store them in a PostgreSQL database.
<Prerequisites>
- [Configured a Data Context](../../../tutorials/getting_started/tutorial_setup.md).
- [Configured an Expectations Suite](../../../tutorials/getting_started/tutorial_create_expectations.md).
- [Configured a Checkpoint](../../../tutorials/getting_started/tutorial_validate_data.md).
- [Configured a PostgreSQL](https://www.postgresql.org/) database with appropriate credentials.
</Prerequisites>
## Steps
### 1. Configure the ``config_variables.yml`` file with your database credentials
We recommend that database credentials be stored in the ``config_variables.yml`` file, which is located in the ``uncommitted/`` folder by default, and is not part of source control. The following lines add database credentials under the key ``db_creds``. Additional options for configuring the ``config_variables.yml`` file or additional environment variables can be found [here](../configuring_data_contexts/how_to_configure_credentials.md).
```yaml
db_creds:
drivername: postgres
host: '<your_host_name>'
port: '<your_port>'
username: '<your_username>'
password: '<<PASSWORD>>'
database: '<your_database_name>'
```
It is also possible to specify `schema` as an additional keyword argument if you would like to use a specific schema as the backend, but this is entirely optional.
```yaml
db_creds:
drivername: postgres
host: '<your_host_name>'
port: '<your_port>'
username: '<your_username>'
password: '<<PASSWORD>>'
database: '<your_database_name>'
schema: '<your_schema_name>'
```
### 2. Identify your Data Context Validation Results Store
As with all <TechnicalTag tag="store" text="Stores" />, you can use your <TechnicalTag tag="data_context" text="Data Context" /> to find your <TechnicalTag tag="validation_result_store" text="Validation Results Store" />. In your ``great_expectations.yml``, look for the following lines. The configuration tells Great Expectations to look for Validation Results in a Store called ``validations_store``. The ``base_directory`` for ``validations_store`` is set to ``uncommitted/validations/`` by default.
```yaml
validations_store_name: validations_store
stores:
validations_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
```
### 3. Update your configuration file to include a new Store for Validation Results on PostgreSQL
In our case, the name is set to ``validations_postgres_store``, but it can be any name you like. We also need to make some changes to the ``store_backend`` settings. The ``class_name`` will be set to ``DatabaseStoreBackend``, and ``credentials`` will be set to ``${db_creds}``, which references the corresponding key in the ``config_variables.yml`` file.
```yaml
validations_store_name: validations_postgres_store
stores:
validations_postgres_store:
class_name: ValidationsStore
store_backend:
class_name: DatabaseStoreBackend
credentials: ${db_creds}
```
### 5. Confirm that the new Validation Results Store has been added by running ``great_expectations store list``
Notice the output contains two Validation Result Stores: the original ``validations_store`` on the local filesystem and the ``validations_postgres_store`` we just configured. This is ok, since Great Expectations will look for Validation Results in PostgreSQL as long as we set the ``validations_store_name`` variable to ``validations_postgres_store``. The config for ``validations_store`` can be removed if you would like.
```bash
great_expectations store list
- name: validations_store
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
- name: validations_postgres_store
class_name: ValidationsStore
store_backend:
class_name: DatabaseStoreBackend
credentials:
database: '<your_db_name>'
drivername: postgresql
host: '<your_host_name>'
password: ******
port: '<your_port>'
username: '<your_username>'
```
### 6. Confirm that the Validation Results Store has been correctly configured
[Run a Checkpoint](../../../tutorials/getting_started/tutorial_validate_data.md) to store results in the new Validation Results store in PostgreSQL then visualize the results by [re-building Data Docs](../../../terms/data_docs.md).
Behind the scenes, Great Expectations will create a new table in your database called ``ge_validations_store``, and populate the fields with information from the Validation Results.
<file_sep>/tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py
import os
import subprocess
from ruamel import yaml
import great_expectations as ge
context = ge.get_context()
# NOTE: The following code is only for testing and depends on an environment
# variable to set the gcp_project. You can replace the value with your own
# GCP project information
gcp_project = os.environ.get("GE_TEST_GCP_PROJECT")
if not gcp_project:
raise ValueError(
"Environment Variable GE_TEST_GCP_PROJECT is required to run GCS integration tests"
)
# set GCP project
result = subprocess.run(
f"gcloud config set project {gcp_project}".split(),
check=True,
stderr=subprocess.PIPE,
)
try:
# remove this bucket if there was a failure in the script last time
result = subprocess.run(
"gsutil rm -r gs://superconductive-integration-tests-data-docs".split(),
check=True,
stderr=subprocess.PIPE,
)
except Exception as e:
pass
create_data_docs_directory = """
gsutil mb -p <YOUR GCP PROJECT NAME> -l US-EAST1 -b on gs://<YOUR GCS BUCKET NAME>/
"""
create_data_docs_directory = create_data_docs_directory.replace(
"<YOUR GCP PROJECT NAME>", gcp_project
)
create_data_docs_directory = create_data_docs_directory.replace(
"<YOUR GCS BUCKET NAME>", "superconductive-integration-tests-data-docs"
)
result = subprocess.run(
create_data_docs_directory.strip().split(),
check=True,
stderr=subprocess.PIPE,
)
stderr = result.stderr.decode("utf-8")
create_data_docs_directory_output = """
Creating gs://<YOUR GCS BUCKET NAME>/...
"""
create_data_docs_directory_output = create_data_docs_directory_output.replace(
"<YOUR GCS BUCKET NAME>", "superconductive-integration-tests-data-docs"
)
assert create_data_docs_directory_output.strip() in stderr
app_yaml = """
runtime: python37
env_variables:
CLOUD_STORAGE_BUCKET: <YOUR GCS BUCKET NAME>
"""
app_yaml = app_yaml.replace(
"<YOUR GCS BUCKET NAME>", "superconductive-integration-tests-data-docs"
)
team_gcs_app_directory = os.path.join(context.root_directory, "team_gcs_app")
os.makedirs(team_gcs_app_directory, exist_ok=True)
app_yaml_file_path = os.path.join(team_gcs_app_directory, "app.yaml")
with open(app_yaml_file_path, "w") as f:
yaml.dump(app_yaml, f)
requirements_txt = """
flask>=1.1.0
google-cloud-storage
"""
requirements_txt_file_path = os.path.join(team_gcs_app_directory, "requirements.txt")
with open(requirements_txt_file_path, "w") as f:
f.write(requirements_txt)
main_py = """
# <snippet>
import logging
import os
from flask import Flask, request
from google.cloud import storage
app = Flask(__name__)
# Configure this environment variable via app.yaml
CLOUD_STORAGE_BUCKET = os.environ['CLOUD_STORAGE_BUCKET']
@app.route('/', defaults={'path': 'index.html'})
@app.route('/<path:path>')
def index(path):
gcs = storage.Client()
bucket = gcs.get_bucket(CLOUD_STORAGE_BUCKET)
try:
blob = bucket.get_blob(path)
content = blob.download_as_string()
if blob.content_encoding:
resource = content.decode(blob.content_encoding)
else:
resource = content
except Exception as e:
logging.exception("couldn't get blob")
resource = "<p></p>"
return resource
@app.errorhandler(500)
def server_error(e):
logging.exception('An error occurred during a request.')
return '''
An internal error occurred: <pre>{}</pre>
See logs for full stacktrace.
'''.format(e), 500
# </snippet>
"""
main_py_file_path = os.path.join(team_gcs_app_directory, "main.py")
with open(main_py_file_path, "w") as f:
f.write(main_py)
gcloud_login_command = """
gcloud auth login && gcloud config set project <YOUR GCP PROJECT NAME>
"""
gcloud_app_deploy_command = """
gcloud app deploy
"""
result = subprocess.Popen(
gcloud_app_deploy_command.strip().split(),
cwd=team_gcs_app_directory,
)
data_docs_site_yaml = """
data_docs_sites:
local_site:
class_name: SiteBuilder
show_how_to_buttons: true
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/data_docs/local_site/
site_index_builder:
class_name: DefaultSiteIndexBuilder
gs_site: # this is a user-selected name - you may select your own
class_name: SiteBuilder
store_backend:
class_name: TupleGCSStoreBackend
project: <YOUR GCP PROJECT NAME>
bucket: <YOUR GCS BUCKET NAME>
site_index_builder:
class_name: DefaultSiteIndexBuilder
"""
data_docs_site_yaml = data_docs_site_yaml.replace(
"<YOUR GCP PROJECT NAME>", gcp_project
)
data_docs_site_yaml = data_docs_site_yaml.replace(
"<YOUR GCS BUCKET NAME>", "superconductive-integration-tests-data-docs"
)
great_expectations_yaml_file_path = os.path.join(
context.root_directory, "great_expectations.yml"
)
with open(great_expectations_yaml_file_path) as f:
great_expectations_yaml = yaml.safe_load(f)
great_expectations_yaml["data_docs_sites"] = yaml.safe_load(data_docs_site_yaml)[
"data_docs_sites"
]
with open(great_expectations_yaml_file_path, "w") as f:
yaml.dump(great_expectations_yaml, f)
build_data_docs_command = """
great_expectations docs build --site-name gs_site
"""
result = subprocess.Popen(
"echo Y | " + build_data_docs_command.strip() + " --no-view",
shell=True,
stdout=subprocess.PIPE,
)
stdout = result.stdout.read().decode("utf-8")
build_data_docs_output = """
The following Data Docs sites will be built:
- gs_site: https://storage.googleapis.com/<YOUR GCS BUCKET NAME>/index.html
Would you like to proceed? [Y/n]: Y
Building Data Docs...
Done building Data Docs
"""
assert (
"https://storage.googleapis.com/superconductive-integration-tests-data-docs/index.html"
in stdout
)
assert "Done building Data Docs" in stdout
# remove this bucket to clean up for next time
result = subprocess.run(
"gsutil rm -r gs://superconductive-integration-tests-data-docs/".split(),
check=True,
stderr=subprocess.PIPE,
)
<file_sep>/reqs/requirements-dev-tools.txt
jupyter
jupyterlab
matplotlib
scikit-learn
<file_sep>/docs/guides/setup/configuring_metadata_stores/components_how_to_configure_an_expectation_store_in_amazon_s3/_preface.mdx
import Prerequisites from '../../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
By default, newly <TechnicalTag tag="profiling" text="Profiled" /> <TechnicalTag tag="expectation" text="Expectations" /> are stored as <TechnicalTag tag="expectation_suite" text="Expectation Suites" /> in JSON format in the ``expectations/`` subdirectory of your ``great_expectations/`` folder. This guide will help you configure Great Expectations to store them in an Amazon S3 bucket.
<Prerequisites>
- [Configured a Data Context](../../../../tutorials/getting_started/tutorial_setup.md).
- [Configured an Expectations Suite](../../../../tutorials/getting_started/tutorial_create_expectations.md).
- The ability to install [boto3](https://github.com/boto/boto3) in your local environment.
- Identified the S3 bucket and prefix where Expectations will be stored.
</Prerequisites>
<file_sep>/tests/integration/common_workflows/simple_build_data_docs.py
import os
import tempfile
import great_expectations as ge
from great_expectations.data_context import BaseDataContext
from great_expectations.data_context.types.base import (
DataContextConfig,
DatasourceConfig,
FilesystemStoreBackendDefaults,
)
"""
A simple test to verify that `context.build_data_docs()` works as expected.
As indicated in issue #3772, calling `context.build_data_docs()` raised an unexpected exception
when Great Expectations was installed in a non-filesystem location (i.e. it failed when
GE was installed inside a zip file -which is a location allowed by PEP 273-).
Therefore, this test is intended to be run after installing GE inside a zip file and
then setting the appropriate PYTHONPATH env variable. If desired, this test can also be
run after installing GE in a normal filesystem location (i.e. a directory).
This test is OK if it finishes without raising an exception.
To make it easier to debug this test, it prints:
* The location of the GE library: to verify that we are testing the library that we want
* The version of the GE library: idem
* data_docs url: If everything works, this will be a url (e.g. starting with file://...)
Additional info: https://github.com/great-expectations/great_expectations/issues/3772 and
https://www.python.org/dev/peps/pep-0273/
"""
print(f"Great Expectations location: {ge.__file__}")
print(f"Great Expectations version: {ge.__version__}")
data_context_config = DataContextConfig(
datasources={"example_datasource": DatasourceConfig(class_name="PandasDatasource")},
store_backend_defaults=FilesystemStoreBackendDefaults(
root_directory=tempfile.mkdtemp() + os.sep + "my_greatexp_workdir"
),
)
context = BaseDataContext(project_config=data_context_config)
print(f"Great Expectations data_docs url: {context.build_data_docs()}")
<file_sep>/docs/guides/setup/configuring_metadata_stores/components_how_to_configure_a_validation_result_store_in_amazon_s3/_copy_existing_validation_results_to_the_s_bucket_this_step_is_optional.mdx
If you are converting an existing local Great Expectations deployment to one that works in AWS you may already have Validation Results saved that you wish to keep and transfer to your S3 bucket.
You can copy Validation Results into Amazon S3 is by using the ``aws s3 sync`` command. As mentioned earlier, the ``base_directory`` is set to ``uncommitted/validations/`` by default.
```bash title="Terminal input"
aws s3 sync '<base_directory>' s3://'<your_s3_bucket_name>'/'<your_s3_bucket_folder_name>'
```
In the example below, two Validation Results, ``Validation1`` and ``Validation2`` are copied to Amazon S3. This results in the following output:
```bash title="Terminal output"
upload: uncommitted/validations/val1/val1.json to s3://'<your_s3_bucket_name>'/'<your_s3_bucket_folder_name>'/val1.json
upload: uncommitted/validations/val2/val2.json to s3://'<your_s3_bucket_name>'/'<your_s3_bucket_folder_name>'/val2.json
```
If you have Validation Results to copy into S3, your output should look similar.<file_sep>/great_expectations/data_context/data_context/abstract_data_context.py
from __future__ import annotations
import configparser
import copy
import datetime
import json
import logging
import os
import sys
import uuid
import warnings
import webbrowser
from abc import ABC, abstractmethod
from collections import OrderedDict
from typing import (
TYPE_CHECKING,
Any,
Callable,
Dict,
List,
Mapping,
Optional,
Sequence,
Tuple,
TypeVar,
Union,
cast,
)
from dateutil.parser import parse
from marshmallow import ValidationError
from ruamel.yaml.comments import CommentedMap
from typing_extensions import Literal
import great_expectations.exceptions as ge_exceptions
from great_expectations.core import ExpectationSuite
from great_expectations.core.batch import (
Batch,
BatchRequestBase,
IDDict,
get_batch_request_from_acceptable_arguments,
)
from great_expectations.core.config_provider import (
_ConfigurationProvider,
_ConfigurationVariablesConfigurationProvider,
_EnvironmentConfigurationProvider,
_RuntimeEnvironmentConfigurationProvider,
)
from great_expectations.core.expectation_validation_result import get_metric_kwargs_id
from great_expectations.core.id_dict import BatchKwargs
from great_expectations.core.metric import ValidationMetricIdentifier
from great_expectations.core.run_identifier import RunIdentifier
from great_expectations.core.serializer import (
AbstractConfigSerializer,
DictConfigSerializer,
)
from great_expectations.core.usage_statistics.events import UsageStatsEvents
from great_expectations.core.util import nested_update
from great_expectations.core.yaml_handler import YAMLHandler
from great_expectations.data_asset import DataAsset
from great_expectations.data_context.config_validator.yaml_config_validator import (
_YamlConfigValidator,
)
from great_expectations.data_context.data_context_variables import DataContextVariables
from great_expectations.data_context.store import Store, TupleStoreBackend
from great_expectations.data_context.store.expectations_store import ExpectationsStore
from great_expectations.data_context.store.profiler_store import ProfilerStore
from great_expectations.data_context.store.validations_store import ValidationsStore
from great_expectations.data_context.templates import CONFIG_VARIABLES_TEMPLATE
from great_expectations.data_context.types.base import (
CURRENT_GE_CONFIG_VERSION,
AnonymizedUsageStatisticsConfig,
CheckpointConfig,
ConcurrencyConfig,
DataContextConfig,
DataContextConfigDefaults,
DatasourceConfig,
IncludeRenderedContentConfig,
NotebookConfig,
ProgressBarsConfig,
anonymizedUsageStatisticsSchema,
dataContextConfigSchema,
datasourceConfigSchema,
)
from great_expectations.data_context.types.refs import (
GXCloudIDAwareRef,
GXCloudResourceRef,
)
from great_expectations.data_context.types.resource_identifiers import (
ConfigurationIdentifier,
ExpectationSuiteIdentifier,
ValidationResultIdentifier,
)
from great_expectations.data_context.util import (
PasswordMasker,
build_store_from_config,
instantiate_class_from_config,
parse_substitution_variable,
)
from great_expectations.dataset.dataset import Dataset
from great_expectations.datasource import LegacyDatasource
from great_expectations.datasource.datasource_serializer import (
NamedDatasourceSerializer,
)
from great_expectations.datasource.new_datasource import BaseDatasource, Datasource
from great_expectations.execution_engine import ExecutionEngine
from great_expectations.profile.basic_dataset_profiler import BasicDatasetProfiler
from great_expectations.rule_based_profiler.config.base import (
RuleBasedProfilerConfig,
ruleBasedProfilerConfigSchema,
)
from great_expectations.rule_based_profiler.data_assistant.data_assistant_dispatcher import (
DataAssistantDispatcher,
)
from great_expectations.rule_based_profiler.rule_based_profiler import RuleBasedProfiler
from great_expectations.util import load_class, verify_dynamic_loading_support
from great_expectations.validator.validator import BridgeValidator, Validator
from great_expectations.core.usage_statistics.usage_statistics import ( # isort: skip
UsageStatisticsHandler,
add_datasource_usage_statistics,
get_batch_list_usage_statistics,
run_validation_operator_usage_statistics,
save_expectation_suite_usage_statistics,
send_usage_message,
usage_statistics_enabled_method,
)
try:
from sqlalchemy.exc import SQLAlchemyError
except ImportError:
# We'll redefine this error in code below to catch ProfilerError, which is caught above, so SA errors will
# just fall through
SQLAlchemyError = ge_exceptions.ProfilerError
if TYPE_CHECKING:
from great_expectations.checkpoint import Checkpoint
from great_expectations.checkpoint.types.checkpoint_result import CheckpointResult
from great_expectations.data_context.store import (
CheckpointStore,
EvaluationParameterStore,
)
from great_expectations.data_context.types.resource_identifiers import (
GXCloudIdentifier,
)
from great_expectations.experimental.datasources.interfaces import Batch as XBatch
from great_expectations.experimental.datasources.interfaces import (
Datasource as XDatasource,
)
from great_expectations.render.renderer.site_builder import SiteBuilder
from great_expectations.rule_based_profiler import RuleBasedProfilerResult
from great_expectations.validation_operators.validation_operators import (
ValidationOperator,
)
logger = logging.getLogger(__name__)
yaml = YAMLHandler()
T = TypeVar("T", dict, list, str)
class AbstractDataContext(ABC):
"""
Base class for all DataContexts that contain all context-agnostic data context operations.
The class encapsulates most store / core components and convenience methods used to access them, meaning the
majority of DataContext functionality lives here.
"""
# NOTE: <DataContextRefactor> These can become a property like ExpectationsStore.__name__ or placed in a separate
# test_yml_config module so AbstractDataContext is not so cluttered.
FALSEY_STRINGS = ["FALSE", "false", "False", "f", "F", "0"]
GLOBAL_CONFIG_PATHS = [
os.path.expanduser("~/.great_expectations/great_expectations.conf"),
"/etc/great_expectations.conf",
]
DOLLAR_SIGN_ESCAPE_STRING = r"\$"
MIGRATION_WEBSITE: str = "https://docs.greatexpectations.io/docs/guides/miscellaneous/migration_guide#migrating-to-the-batch-request-v3-api"
PROFILING_ERROR_CODE_TOO_MANY_DATA_ASSETS = 2
PROFILING_ERROR_CODE_SPECIFIED_DATA_ASSETS_NOT_FOUND = 3
PROFILING_ERROR_CODE_NO_BATCH_KWARGS_GENERATORS_FOUND = 4
PROFILING_ERROR_CODE_MULTIPLE_BATCH_KWARGS_GENERATORS_FOUND = 5
def __init__(self, runtime_environment: Optional[dict] = None) -> None:
"""
Constructor for AbstractDataContext. Will handle instantiation logic that is common to all DataContext objects
Args:
runtime_environment (dict): a dictionary of config variables that
override those set in config_variables.yml and the environment
"""
if runtime_environment is None:
runtime_environment = {}
self.runtime_environment = runtime_environment
self._config_provider = self._init_config_provider()
self._config_variables = self._load_config_variables()
self._variables = self._init_variables()
# Init plugin support
if self.plugins_directory is not None and os.path.exists(
self.plugins_directory
):
sys.path.append(self.plugins_directory)
# We want to have directories set up before initializing usage statistics so
# that we can obtain a context instance id
self._in_memory_instance_id = (
None # This variable *may* be used in case we cannot save an instance id
)
# Init stores
self._stores: dict = {}
self._init_stores(self.project_config_with_variables_substituted.stores) # type: ignore[arg-type]
# Init data_context_id
self._data_context_id = self._construct_data_context_id()
# Override the project_config data_context_id if an expectations_store was already set up
self.config.anonymous_usage_statistics.data_context_id = self._data_context_id
self._initialize_usage_statistics(
self.project_config_with_variables_substituted.anonymous_usage_statistics
)
# Store cached datasources but don't init them
self._cached_datasources: dict = {}
# Build the datasources we know about and have access to
self._init_datasources()
self._evaluation_parameter_dependencies_compiled = False
self._evaluation_parameter_dependencies: dict = {}
self._assistants = DataAssistantDispatcher(data_context=self)
# NOTE - 20210112 - <NAME> - Validation Operators are planned to be deprecated.
self.validation_operators: dict = {}
def _init_config_provider(self) -> _ConfigurationProvider:
config_provider = _ConfigurationProvider()
self._register_providers(config_provider)
return config_provider
def _register_providers(self, config_provider: _ConfigurationProvider) -> None:
"""
Registers any relevant ConfigurationProvider instances to self._config_provider.
Note that order matters here - if there is a namespace collision, later providers will overwrite
the values derived from previous ones. The order of precedence is as follows:
- Config variables
- Environment variables
- Runtime environment
"""
config_variables_file_path = self._project_config.config_variables_file_path
if config_variables_file_path:
config_provider.register_provider(
_ConfigurationVariablesConfigurationProvider(
config_variables_file_path=config_variables_file_path,
root_directory=self.root_directory,
)
)
config_provider.register_provider(_EnvironmentConfigurationProvider())
config_provider.register_provider(
_RuntimeEnvironmentConfigurationProvider(self.runtime_environment)
)
@abstractmethod
def _init_variables(self) -> DataContextVariables:
raise NotImplementedError
def _save_project_config(self) -> None:
"""
Each DataContext will define how its project_config will be saved through its internal 'variables'.
- FileDataContext : Filesystem.
- CloudDataContext : Cloud endpoint
- Ephemeral : not saved, and logging message outputted
"""
self.variables.save_config()
@usage_statistics_enabled_method(
event_name=UsageStatsEvents.DATA_CONTEXT_SAVE_EXPECTATION_SUITE,
args_payload_fn=save_expectation_suite_usage_statistics,
)
def save_expectation_suite(
self,
expectation_suite: ExpectationSuite,
expectation_suite_name: Optional[str] = None,
overwrite_existing: bool = True,
include_rendered_content: Optional[bool] = None,
**kwargs: Optional[dict],
) -> None:
"""
Each DataContext will define how ExpectationSuite will be saved.
"""
if expectation_suite_name is None:
key = ExpectationSuiteIdentifier(
expectation_suite_name=expectation_suite.expectation_suite_name
)
else:
expectation_suite.expectation_suite_name = expectation_suite_name
key = ExpectationSuiteIdentifier(
expectation_suite_name=expectation_suite_name
)
if (
self.expectations_store.has_key(key) # noqa: @601
and not overwrite_existing
):
raise ge_exceptions.DataContextError(
"expectation_suite with name {} already exists. If you would like to overwrite this "
"expectation_suite, set overwrite_existing=True.".format(
expectation_suite_name
)
)
self._evaluation_parameter_dependencies_compiled = False
include_rendered_content = (
self._determine_if_expectation_suite_include_rendered_content(
include_rendered_content=include_rendered_content
)
)
if include_rendered_content:
expectation_suite.render()
return self.expectations_store.set(key, expectation_suite, **kwargs)
# Properties
@property
def instance_id(self) -> str:
instance_id: Optional[str] = self.config_variables.get("instance_id")
if instance_id is None:
if self._in_memory_instance_id is not None:
return self._in_memory_instance_id
instance_id = str(uuid.uuid4())
self._in_memory_instance_id = instance_id # type: ignore[assignment]
return instance_id
@property
def config_variables(self) -> Dict:
"""Loads config variables into cache, by calling _load_config_variables()
Returns: A dictionary containing config_variables from file or empty dictionary.
"""
if not self._config_variables:
self._config_variables = self._load_config_variables()
return self._config_variables
@property
def config(self) -> DataContextConfig:
"""
Returns current DataContext's project_config
"""
# NOTE: <DataContextRefactor> _project_config is currently only defined in child classes.
# See if this can this be also defined in AbstractDataContext as abstract property
return self.variables.config
@property
def config_provider(self) -> _ConfigurationProvider:
return self._config_provider
@property
def root_directory(self) -> Optional[str]:
"""The root directory for configuration objects in the data context; the location in which
``great_expectations.yml`` is located.
"""
# NOTE: <DataContextRefactor> Why does this exist in AbstractDataContext? CloudDataContext and
# FileDataContext both use it. Determine whether this should stay here or in child classes
return getattr(self, "_context_root_directory", None)
@property
def project_config_with_variables_substituted(self) -> DataContextConfig:
return self.get_config_with_variables_substituted()
@property
def plugins_directory(self) -> Optional[str]:
"""The directory in which custom plugin modules should be placed."""
# NOTE: <DataContextRefactor> Why does this exist in AbstractDataContext? CloudDataContext and
# FileDataContext both use it. Determine whether this should stay here or in child classes
return self._normalize_absolute_or_relative_path(
self.variables.plugins_directory
)
@property
def stores(self) -> dict:
"""A single holder for all Stores in this context"""
return self._stores
@property
def expectations_store_name(self) -> Optional[str]:
return self.variables.expectations_store_name
@property
def expectations_store(self) -> ExpectationsStore:
return self.stores[self.expectations_store_name]
@property
def evaluation_parameter_store_name(self) -> Optional[str]:
return self.variables.evaluation_parameter_store_name
@property
def evaluation_parameter_store(self) -> EvaluationParameterStore:
return self.stores[self.evaluation_parameter_store_name]
@property
def validations_store_name(self) -> Optional[str]:
return self.variables.validations_store_name
@property
def validations_store(self) -> ValidationsStore:
return self.stores[self.validations_store_name]
@property
def checkpoint_store_name(self) -> Optional[str]:
try:
return self.variables.checkpoint_store_name
except AttributeError:
from great_expectations.data_context.store.checkpoint_store import (
CheckpointStore,
)
if CheckpointStore.default_checkpoints_exist(
directory_path=self.root_directory # type: ignore[arg-type]
):
return DataContextConfigDefaults.DEFAULT_CHECKPOINT_STORE_NAME.value
if self.root_directory:
checkpoint_store_directory: str = os.path.join(
self.root_directory,
DataContextConfigDefaults.DEFAULT_CHECKPOINT_STORE_BASE_DIRECTORY_RELATIVE_NAME.value,
)
error_message: str = (
f"Attempted to access the 'checkpoint_store_name' field "
f"with no `checkpoints` directory.\n "
f"Please create the following directory: {checkpoint_store_directory}.\n "
f"To use the new 'Checkpoint Store' feature, please update your configuration "
f"to the new version number {float(CURRENT_GE_CONFIG_VERSION)}.\n "
f"Visit {AbstractDataContext.MIGRATION_WEBSITE} "
f"to learn more about the upgrade process."
)
else:
error_message = (
f"Attempted to access the 'checkpoint_store_name' field "
f"with no `checkpoints` directory.\n "
f"Please create a `checkpoints` directory in your Great Expectations directory."
f"To use the new 'Checkpoint Store' feature, please update your configuration "
f"to the new version number {float(CURRENT_GE_CONFIG_VERSION)}.\n "
f"Visit {AbstractDataContext.MIGRATION_WEBSITE} "
f"to learn more about the upgrade process."
)
raise ge_exceptions.InvalidTopLevelConfigKeyError(error_message)
@property
def checkpoint_store(self) -> CheckpointStore:
checkpoint_store_name: str = self.checkpoint_store_name # type: ignore[assignment]
try:
return self.stores[checkpoint_store_name]
except KeyError:
from great_expectations.data_context.store.checkpoint_store import (
CheckpointStore,
)
if CheckpointStore.default_checkpoints_exist(
directory_path=self.root_directory # type: ignore[arg-type]
):
logger.warning(
f"Checkpoint store named '{checkpoint_store_name}' is not a configured store, "
f"so will try to use default Checkpoint store.\n Please update your configuration "
f"to the new version number {float(CURRENT_GE_CONFIG_VERSION)} in order to use the new "
f"'Checkpoint Store' feature.\n Visit {AbstractDataContext.MIGRATION_WEBSITE} "
f"to learn more about the upgrade process."
)
return self._build_store_from_config( # type: ignore[return-value]
checkpoint_store_name,
DataContextConfigDefaults.DEFAULT_STORES.value[ # type: ignore[arg-type]
checkpoint_store_name
],
)
raise ge_exceptions.StoreConfigurationError(
f'Attempted to access the Checkpoint store: "{checkpoint_store_name}". It is not a configured store.'
)
@property
def profiler_store_name(self) -> Optional[str]:
try:
return self.variables.profiler_store_name
except AttributeError:
if AbstractDataContext._default_profilers_exist(
directory_path=self.root_directory
):
return DataContextConfigDefaults.DEFAULT_PROFILER_STORE_NAME.value
if self.root_directory:
checkpoint_store_directory: str = os.path.join(
self.root_directory,
DataContextConfigDefaults.DEFAULT_CHECKPOINT_STORE_BASE_DIRECTORY_RELATIVE_NAME.value,
)
error_message: str = (
f"Attempted to access the 'profiler_store_name' field "
f"with no `profilers` directory.\n "
f"Please create the following directory: {checkpoint_store_directory}\n"
f"To use the new 'Profiler Store' feature, please update your configuration "
f"to the new version number {float(CURRENT_GE_CONFIG_VERSION)}.\n "
f"Visit {AbstractDataContext.MIGRATION_WEBSITE} to learn more about the "
f"upgrade process."
)
else:
error_message = (
f"Attempted to access the 'profiler_store_name' field "
f"with no `profilers` directory.\n "
f"Please create a `profilers` directory in your Great Expectations project "
f"directory.\n "
f"To use the new 'Profiler Store' feature, please update your configuration "
f"to the new version number {float(CURRENT_GE_CONFIG_VERSION)}.\n "
f"Visit {AbstractDataContext.MIGRATION_WEBSITE} to learn more about the "
f"upgrade process."
)
raise ge_exceptions.InvalidTopLevelConfigKeyError(error_message)
@property
def profiler_store(self) -> ProfilerStore:
profiler_store_name: Optional[str] = self.profiler_store_name
try:
return self.stores[profiler_store_name]
except KeyError:
if AbstractDataContext._default_profilers_exist(
directory_path=self.root_directory
):
logger.warning(
f"Profiler store named '{profiler_store_name}' is not a configured store, so will try to use "
f"default Profiler store.\n Please update your configuration to the new version number "
f"{float(CURRENT_GE_CONFIG_VERSION)} in order to use the new 'Profiler Store' feature.\n "
f"Visit {AbstractDataContext.MIGRATION_WEBSITE} to learn more about the upgrade process."
)
built_store: Optional[Store] = self._build_store_from_config(
profiler_store_name, # type: ignore[arg-type]
DataContextConfigDefaults.DEFAULT_STORES.value[profiler_store_name], # type: ignore[index,arg-type]
)
return cast(ProfilerStore, built_store)
raise ge_exceptions.StoreConfigurationError(
f"Attempted to access the Profiler store: '{profiler_store_name}'. It is not a configured store."
)
@property
def concurrency(self) -> Optional[ConcurrencyConfig]:
return self.variables.concurrency
@property
def assistants(self) -> DataAssistantDispatcher:
return self._assistants
def set_config(self, project_config: DataContextConfig) -> None:
self._project_config = project_config
self.variables.config = project_config
def save_datasource(
self, datasource: Union[LegacyDatasource, BaseDatasource]
) -> Union[LegacyDatasource, BaseDatasource]:
"""Save a Datasource to the configured DatasourceStore.
Stores the underlying DatasourceConfig in the store and Data Context config,
updates the cached Datasource and returns the Datasource.
The cached and returned Datasource is re-constructed from the config
that was stored as some store implementations make edits to the stored
config (e.g. adding identifiers).
Args:
datasource: Datasource to store.
Returns:
The datasource, after storing and retrieving the stored config.
"""
# Chetan - 20221103 - Directly accessing private attr in order to patch security vulnerabiliy around credential leakage.
# This is to be removed once substitution logic is migrated from the context to the individual object level.
config = datasource._raw_config
datasource_config_dict: dict = datasourceConfigSchema.dump(config)
# Manually need to add in class name to the config since it is not part of the runtime obj
datasource_config_dict["class_name"] = datasource.__class__.__name__
datasource_config = datasourceConfigSchema.load(datasource_config_dict)
datasource_name: str = datasource.name
updated_datasource_config_from_store: DatasourceConfig = self._datasource_store.set( # type: ignore[attr-defined]
key=None, value=datasource_config
)
# Use the updated datasource config, since the store may populate additional info on update.
self.config.datasources[datasource_name] = updated_datasource_config_from_store # type: ignore[index,assignment]
# Also use the updated config to initialize a datasource for the cache and overwrite the existing datasource.
substituted_config = self._perform_substitutions_on_datasource_config(
updated_datasource_config_from_store
)
updated_datasource: Union[
LegacyDatasource, BaseDatasource
] = self._instantiate_datasource_from_config(
raw_config=updated_datasource_config_from_store,
substituted_config=substituted_config,
)
self._cached_datasources[datasource_name] = updated_datasource
return updated_datasource
@usage_statistics_enabled_method(
event_name=UsageStatsEvents.DATA_CONTEXT_ADD_DATASOURCE,
args_payload_fn=add_datasource_usage_statistics,
)
def add_datasource(
self,
name: str,
initialize: bool = True,
save_changes: Optional[bool] = None,
**kwargs: Optional[dict],
) -> Optional[Union[LegacyDatasource, BaseDatasource]]:
"""Add a new datasource to the data context, with configuration provided as kwargs.
Args:
name: the name for the new datasource to add
initialize: if False, add the datasource to the config, but do not
initialize it, for example if a user needs to debug database connectivity.
save_changes (bool): should GE save the Datasource config?
kwargs (keyword arguments): the configuration for the new datasource
Returns:
datasource (Datasource)
"""
save_changes = self._determine_save_changes_flag(save_changes)
logger.debug(f"Starting BaseDataContext.add_datasource for {name}")
module_name: str = kwargs.get("module_name", "great_expectations.datasource") # type: ignore[assignment]
verify_dynamic_loading_support(module_name=module_name)
class_name: Optional[str] = kwargs.get("class_name") # type: ignore[assignment]
datasource_class = load_class(module_name=module_name, class_name=class_name) # type: ignore[arg-type]
# For any class that should be loaded, it may control its configuration construction
# by implementing a classmethod called build_configuration
config: Union[CommentedMap, dict]
if hasattr(datasource_class, "build_configuration"):
config = datasource_class.build_configuration(**kwargs)
else:
config = kwargs
datasource_config: DatasourceConfig = datasourceConfigSchema.load(
CommentedMap(**config)
)
datasource_config.name = name
datasource: Optional[
Union[LegacyDatasource, BaseDatasource]
] = self._instantiate_datasource_from_config_and_update_project_config(
config=datasource_config,
initialize=initialize,
save_changes=save_changes,
)
return datasource
def update_datasource(
self,
datasource: Union[LegacyDatasource, BaseDatasource],
save_changes: Optional[bool] = None,
) -> None:
"""
Updates a DatasourceConfig that already exists in the store.
Args:
datasource_config: The config object to persist using the DatasourceStore.
save_changes: do I save changes to disk?
"""
save_changes = self._determine_save_changes_flag(save_changes)
datasource_config_dict: dict = datasourceConfigSchema.dump(datasource.config)
datasource_config = DatasourceConfig(**datasource_config_dict)
datasource_name: str = datasource.name
if save_changes:
self._datasource_store.update_by_name( # type: ignore[attr-defined]
datasource_name=datasource_name, datasource_config=datasource_config
)
self.config.datasources[datasource_name] = datasource_config # type: ignore[assignment,index]
self._cached_datasources[datasource_name] = datasource_config
def get_site_names(self) -> List[str]:
"""Get a list of configured site names."""
return list(self.variables.data_docs_sites.keys()) # type: ignore[union-attr]
def get_config_with_variables_substituted(
self, config: Optional[DataContextConfig] = None
) -> DataContextConfig:
"""
Substitute vars in config of form ${var} or $(var) with values found in the following places,
in order of precedence: ge_cloud_config (for Data Contexts in GE Cloud mode), runtime_environment,
environment variables, config_variables, or ge_cloud_config_variable_defaults (allows certain variables to
be optional in GE Cloud mode).
"""
if not config:
config = self._project_config
return DataContextConfig(**self.config_provider.substitute_config(config))
def get_batch(
self, arg1: Any = None, arg2: Any = None, arg3: Any = None, **kwargs
) -> Union[Batch, DataAsset]:
"""Get exactly one batch, based on a variety of flexible input types.
The method `get_batch` is the main user-facing method for getting batches; it supports both the new (V3) and the
Legacy (V2) Datasource schemas. The version-specific implementations are contained in "_get_batch_v2()" and
"_get_batch_v3()", respectively, both of which are in the present module.
For the V3 API parameters, please refer to the signature and parameter description of method "_get_batch_v3()".
For the Legacy usage, please refer to the signature and parameter description of the method "_get_batch_v2()".
Args:
arg1: the first positional argument (can take on various types)
arg2: the second positional argument (can take on various types)
arg3: the third positional argument (can take on various types)
**kwargs: variable arguments
Returns:
Batch (V3) or DataAsset (V2) -- the requested batch
Processing Steps:
1. Determine the version (possible values are "v3" or "v2").
2. Convert the positional arguments to the appropriate named arguments, based on the version.
3. Package the remaining arguments as variable keyword arguments (applies only to V3).
4. Call the version-specific method ("_get_batch_v3()" or "_get_batch_v2()") with the appropriate arguments.
"""
api_version: Optional[str] = self._get_data_context_version(arg1=arg1, **kwargs)
if api_version == "v3":
if "datasource_name" in kwargs:
datasource_name = kwargs.pop("datasource_name", None)
else:
datasource_name = arg1
if "data_connector_name" in kwargs:
data_connector_name = kwargs.pop("data_connector_name", None)
else:
data_connector_name = arg2
if "data_asset_name" in kwargs:
data_asset_name = kwargs.pop("data_asset_name", None)
else:
data_asset_name = arg3
return self._get_batch_v3(
datasource_name=datasource_name,
data_connector_name=data_connector_name,
data_asset_name=data_asset_name,
**kwargs,
)
if "batch_kwargs" in kwargs:
batch_kwargs = kwargs.get("batch_kwargs", None)
else:
batch_kwargs = arg1
if "expectation_suite_name" in kwargs:
expectation_suite_name = kwargs.get("expectation_suite_name", None)
else:
expectation_suite_name = arg2
if "data_asset_type" in kwargs:
data_asset_type = kwargs.get("data_asset_type", None)
else:
data_asset_type = arg3
batch_parameters = kwargs.get("batch_parameters")
return self._get_batch_v2(
batch_kwargs=batch_kwargs,
expectation_suite_name=expectation_suite_name,
data_asset_type=data_asset_type,
batch_parameters=batch_parameters,
)
def _get_data_context_version(self, arg1: Any, **kwargs) -> Optional[str]:
"""
arg1: the first positional argument (can take on various types)
**kwargs: variable arguments
First check:
Returns "v3" if the "0.13" entities are specified in the **kwargs.
Otherwise:
Returns None if no datasources have been configured (or if there is an exception while getting the datasource).
Returns "v3" if the datasource is a subclass of the BaseDatasource class.
Returns "v2" if the datasource is an instance of the LegacyDatasource class.
"""
if {
"datasource_name",
"data_connector_name",
"data_asset_name",
"batch_request",
"batch_data",
}.intersection(set(kwargs.keys())):
return "v3"
if not self.datasources:
return None
api_version: Optional[str] = None
datasource_name: Any
if "datasource_name" in kwargs:
datasource_name = kwargs.pop("datasource_name", None)
else:
datasource_name = arg1
try:
datasource: Union[LegacyDatasource, BaseDatasource] = self.get_datasource( # type: ignore[assignment]
datasource_name=datasource_name
)
if issubclass(type(datasource), BaseDatasource):
api_version = "v3"
except (ValueError, TypeError):
if "batch_kwargs" in kwargs:
batch_kwargs = kwargs.get("batch_kwargs", None)
else:
batch_kwargs = arg1
if isinstance(batch_kwargs, dict):
datasource_name = batch_kwargs.get("datasource")
if datasource_name is not None:
try:
datasource: Union[ # type: ignore[no-redef]
LegacyDatasource, BaseDatasource
] = self.get_datasource(datasource_name=datasource_name)
if isinstance(datasource, LegacyDatasource):
api_version = "v2"
except (ValueError, TypeError):
pass
return api_version
def _get_batch_v2(
self,
batch_kwargs: Union[dict, BatchKwargs],
expectation_suite_name: Union[str, ExpectationSuite],
data_asset_type=None,
batch_parameters=None,
) -> DataAsset:
"""Build a batch of data using batch_kwargs, and return a DataAsset with expectation_suite_name attached. If
batch_parameters are included, they will be available as attributes of the batch.
Args:
batch_kwargs: the batch_kwargs to use; must include a datasource key
expectation_suite_name: The ExpectationSuite or the name of the expectation_suite to get
data_asset_type: the type of data_asset to build, with associated expectation implementations. This can
generally be inferred from the datasource.
batch_parameters: optional parameters to store as the reference description of the batch. They should
reflect parameters that would provide the passed BatchKwargs.
Returns:
DataAsset
"""
if isinstance(batch_kwargs, dict):
batch_kwargs = BatchKwargs(batch_kwargs)
if not isinstance(batch_kwargs, BatchKwargs):
raise ge_exceptions.BatchKwargsError(
"BatchKwargs must be a BatchKwargs object or dictionary."
)
if not isinstance(
expectation_suite_name, (ExpectationSuite, ExpectationSuiteIdentifier, str)
):
raise ge_exceptions.DataContextError(
"expectation_suite_name must be an ExpectationSuite, "
"ExpectationSuiteIdentifier or string."
)
if isinstance(expectation_suite_name, ExpectationSuite):
expectation_suite = expectation_suite_name
elif isinstance(expectation_suite_name, ExpectationSuiteIdentifier):
expectation_suite = self.get_expectation_suite(
expectation_suite_name.expectation_suite_name
)
else:
expectation_suite = self.get_expectation_suite(expectation_suite_name)
datasource = self.get_datasource(batch_kwargs.get("datasource")) # type: ignore[arg-type]
batch = datasource.get_batch( # type: ignore[union-attr]
batch_kwargs=batch_kwargs, batch_parameters=batch_parameters
)
if data_asset_type is None:
data_asset_type = datasource.config.get("data_asset_type") # type: ignore[union-attr]
validator = BridgeValidator(
batch=batch,
expectation_suite=expectation_suite,
expectation_engine=data_asset_type,
)
return validator.get_dataset()
def _get_batch_v3(
self,
datasource_name: Optional[str] = None,
data_connector_name: Optional[str] = None,
data_asset_name: Optional[str] = None,
*,
batch_request: Optional[BatchRequestBase] = None,
batch_data: Optional[Any] = None,
data_connector_query: Optional[Union[IDDict, dict]] = None,
batch_identifiers: Optional[dict] = None,
limit: Optional[int] = None,
index: Optional[Union[int, list, tuple, slice, str]] = None,
custom_filter_function: Optional[Callable] = None,
batch_spec_passthrough: Optional[dict] = None,
sampling_method: Optional[str] = None,
sampling_kwargs: Optional[dict] = None,
splitter_method: Optional[str] = None,
splitter_kwargs: Optional[dict] = None,
runtime_parameters: Optional[dict] = None,
query: Optional[str] = None,
path: Optional[str] = None,
batch_filter_parameters: Optional[dict] = None,
**kwargs,
) -> Union[Batch, DataAsset]:
"""Get exactly one batch, based on a variety of flexible input types.
Args:
datasource_name
data_connector_name
data_asset_name
batch_request
batch_data
data_connector_query
batch_identifiers
batch_filter_parameters
limit
index
custom_filter_function
batch_spec_passthrough
sampling_method
sampling_kwargs
splitter_method
splitter_kwargs
**kwargs
Returns:
(Batch) The requested batch
This method does not require typed or nested inputs.
Instead, it is intended to help the user pick the right parameters.
This method attempts to return exactly one batch.
If 0 or more than 1 batches would be returned, it raises an error.
"""
batch_list: List[Batch] = self.get_batch_list(
datasource_name=datasource_name,
data_connector_name=data_connector_name,
data_asset_name=data_asset_name,
batch_request=batch_request,
batch_data=batch_data,
data_connector_query=data_connector_query,
batch_identifiers=batch_identifiers,
limit=limit,
index=index,
custom_filter_function=custom_filter_function,
batch_spec_passthrough=batch_spec_passthrough,
sampling_method=sampling_method,
sampling_kwargs=sampling_kwargs,
splitter_method=splitter_method,
splitter_kwargs=splitter_kwargs,
runtime_parameters=runtime_parameters,
query=query,
path=path,
batch_filter_parameters=batch_filter_parameters,
**kwargs,
)
# NOTE: Alex 20201202 - The check below is duplicate of code in Datasource.get_single_batch_from_batch_request()
# deprecated-v0.13.20
warnings.warn(
"get_batch is deprecated for the V3 Batch Request API as of v0.13.20 and will be removed in v0.16. Please use "
"get_batch_list instead.",
DeprecationWarning,
)
if len(batch_list) != 1:
raise ValueError(
f"Got {len(batch_list)} batches instead of a single batch. If you would like to use a BatchRequest to "
f"return multiple batches, please use get_batch_list directly instead of calling get_batch"
)
return batch_list[0]
def list_stores(self) -> List[Store]:
"""List currently-configured Stores on this context"""
stores = []
for (
name,
value,
) in self.variables.stores.items(): # type: ignore[union-attr]
store_config = copy.deepcopy(value)
store_config["name"] = name
masked_config = PasswordMasker.sanitize_config(store_config)
stores.append(masked_config)
return stores # type: ignore[return-value]
def list_active_stores(self) -> List[Store]:
"""
List active Stores on this context. Active stores are identified by setting the following parameters:
expectations_store_name,
validations_store_name,
evaluation_parameter_store_name,
checkpoint_store_name
profiler_store_name
"""
active_store_names: List[str] = [
self.expectations_store_name, # type: ignore[list-item]
self.validations_store_name, # type: ignore[list-item]
self.evaluation_parameter_store_name, # type: ignore[list-item]
]
try:
active_store_names.append(self.checkpoint_store_name) # type: ignore[arg-type]
except (AttributeError, ge_exceptions.InvalidTopLevelConfigKeyError):
logger.info(
"Checkpoint store is not configured; omitting it from active stores"
)
try:
active_store_names.append(self.profiler_store_name) # type: ignore[arg-type]
except (AttributeError, ge_exceptions.InvalidTopLevelConfigKeyError):
logger.info(
"Profiler store is not configured; omitting it from active stores"
)
return [
store
for store in self.list_stores()
if store.get("name") in active_store_names # type: ignore[arg-type,operator]
]
def list_checkpoints(self) -> Union[List[str], List[ConfigurationIdentifier]]:
return self.checkpoint_store.list_checkpoints()
def list_profilers(self) -> Union[List[str], List[ConfigurationIdentifier]]:
return RuleBasedProfiler.list_profilers(self.profiler_store)
def save_profiler(
self,
profiler: RuleBasedProfiler,
) -> RuleBasedProfiler:
name = profiler.name
ge_cloud_id = profiler.ge_cloud_id
key = self._determine_key_for_profiler_save(name=name, id=ge_cloud_id)
response = self.profiler_store.set(key=key, value=profiler.config) # type: ignore[func-returns-value]
if isinstance(response, GXCloudResourceRef):
ge_cloud_id = response.ge_cloud_id
# If an id is present, we want to prioritize that as our key for object retrieval
if ge_cloud_id:
name = None # type: ignore[assignment]
profiler = self.get_profiler(name=name, ge_cloud_id=ge_cloud_id)
return profiler
def _determine_key_for_profiler_save(
self, name: str, id: Optional[str]
) -> Union[ConfigurationIdentifier, GXCloudIdentifier]:
return ConfigurationIdentifier(configuration_key=name)
def get_datasource(
self, datasource_name: str = "default"
) -> Optional[Union[LegacyDatasource, BaseDatasource]]:
"""Get the named datasource
Args:
datasource_name (str): the name of the datasource from the configuration
Returns:
datasource (Datasource)
"""
if datasource_name is None:
raise ValueError(
"Must provide a datasource_name to retrieve an existing Datasource"
)
if datasource_name in self._cached_datasources:
return self._cached_datasources[datasource_name]
datasource_config: DatasourceConfig = self._datasource_store.retrieve_by_name( # type: ignore[attr-defined]
datasource_name=datasource_name
)
raw_config_dict: dict = dict(datasourceConfigSchema.dump(datasource_config))
raw_config = datasourceConfigSchema.load(raw_config_dict)
substituted_config = self.config_provider.substitute_config(raw_config_dict)
# Instantiate the datasource and add to our in-memory cache of datasources, this does not persist:
datasource_config = datasourceConfigSchema.load(substituted_config)
datasource: Optional[
Union[LegacyDatasource, BaseDatasource]
] = self._instantiate_datasource_from_config(
raw_config=raw_config, substituted_config=substituted_config
)
self._cached_datasources[datasource_name] = datasource
return datasource
def _serialize_substitute_and_sanitize_datasource_config(
self, serializer: AbstractConfigSerializer, datasource_config: DatasourceConfig
) -> dict:
"""Serialize, then make substitutions and sanitize config (mask passwords), return as dict.
Args:
serializer: Serializer to use when converting config to dict for substitutions.
datasource_config: Datasource config to process.
Returns:
Dict of config with substitutions and sanitizations applied.
"""
datasource_dict: dict = serializer.serialize(datasource_config)
substituted_config = cast(
dict, self.config_provider.substitute_config(datasource_dict)
)
masked_config: dict = PasswordMasker.sanitize_config(substituted_config)
return masked_config
def add_store(self, store_name: str, store_config: dict) -> Optional[Store]:
"""Add a new Store to the DataContext and (for convenience) return the instantiated Store object.
Args:
store_name (str): a key for the new Store in in self._stores
store_config (dict): a config for the Store to add
Returns:
store (Store)
"""
self.config.stores[store_name] = store_config # type: ignore[index]
return self._build_store_from_config(store_name, store_config)
def list_datasources(self) -> List[dict]:
"""List currently-configured datasources on this context. Masks passwords.
Returns:
List(dict): each dictionary includes "name", "class_name", and "module_name" keys
"""
datasources: List[dict] = []
datasource_name: str
datasource_config: Union[dict, DatasourceConfig]
serializer = NamedDatasourceSerializer(schema=datasourceConfigSchema)
for datasource_name, datasource_config in self.config.datasources.items(): # type: ignore[union-attr]
if isinstance(datasource_config, dict):
datasource_config = DatasourceConfig(**datasource_config)
datasource_config.name = datasource_name
masked_config: dict = (
self._serialize_substitute_and_sanitize_datasource_config(
serializer, datasource_config
)
)
datasources.append(masked_config)
return datasources
def delete_datasource(
self, datasource_name: Optional[str], save_changes: Optional[bool] = None
) -> None:
"""Delete a datasource
Args:
datasource_name: The name of the datasource to delete.
Raises:
ValueError: If the datasource name isn't provided or cannot be found.
"""
save_changes = self._determine_save_changes_flag(save_changes)
if not datasource_name:
raise ValueError("Datasource names must be a datasource name")
datasource = self.get_datasource(datasource_name=datasource_name)
if datasource is None:
raise ValueError(f"Datasource {datasource_name} not found")
if save_changes:
datasource_config = datasourceConfigSchema.load(datasource.config)
self._datasource_store.delete(datasource_config) # type: ignore[attr-defined]
self._cached_datasources.pop(datasource_name, None)
self.config.datasources.pop(datasource_name, None) # type: ignore[union-attr]
def add_checkpoint(
self,
name: str,
config_version: Optional[Union[int, float]] = None,
template_name: Optional[str] = None,
module_name: Optional[str] = None,
class_name: Optional[str] = None,
run_name_template: Optional[str] = None,
expectation_suite_name: Optional[str] = None,
batch_request: Optional[dict] = None,
action_list: Optional[List[dict]] = None,
evaluation_parameters: Optional[dict] = None,
runtime_configuration: Optional[dict] = None,
validations: Optional[List[dict]] = None,
profilers: Optional[List[dict]] = None,
# Next two fields are for LegacyCheckpoint configuration
validation_operator_name: Optional[str] = None,
batches: Optional[List[dict]] = None,
# the following four arguments are used by SimpleCheckpoint
site_names: Optional[Union[str, List[str]]] = None,
slack_webhook: Optional[str] = None,
notify_on: Optional[str] = None,
notify_with: Optional[Union[str, List[str]]] = None,
ge_cloud_id: Optional[str] = None,
expectation_suite_ge_cloud_id: Optional[str] = None,
default_validation_id: Optional[str] = None,
) -> Checkpoint:
from great_expectations.checkpoint.checkpoint import Checkpoint
checkpoint: Checkpoint = Checkpoint.construct_from_config_args(
data_context=self,
checkpoint_store_name=self.checkpoint_store_name, # type: ignore[arg-type]
name=name,
config_version=config_version,
template_name=template_name,
module_name=module_name,
class_name=class_name,
run_name_template=run_name_template,
expectation_suite_name=expectation_suite_name,
batch_request=batch_request,
action_list=action_list,
evaluation_parameters=evaluation_parameters,
runtime_configuration=runtime_configuration,
validations=validations,
profilers=profilers,
# Next two fields are for LegacyCheckpoint configuration
validation_operator_name=validation_operator_name,
batches=batches,
# the following four arguments are used by SimpleCheckpoint
site_names=site_names,
slack_webhook=slack_webhook,
notify_on=notify_on,
notify_with=notify_with,
ge_cloud_id=ge_cloud_id,
expectation_suite_ge_cloud_id=expectation_suite_ge_cloud_id,
default_validation_id=default_validation_id,
)
self.checkpoint_store.add_checkpoint(checkpoint, name, ge_cloud_id)
return checkpoint
def get_checkpoint(
self,
name: Optional[str] = None,
ge_cloud_id: Optional[str] = None,
) -> Checkpoint:
from great_expectations.checkpoint.checkpoint import Checkpoint
checkpoint_config: CheckpointConfig = self.checkpoint_store.get_checkpoint(
name=name, ge_cloud_id=ge_cloud_id
)
checkpoint: Checkpoint = Checkpoint.instantiate_from_config_with_runtime_args(
checkpoint_config=checkpoint_config,
data_context=self,
name=name,
)
return checkpoint
def delete_checkpoint(
self,
name: Optional[str] = None,
ge_cloud_id: Optional[str] = None,
) -> None:
return self.checkpoint_store.delete_checkpoint(
name=name, ge_cloud_id=ge_cloud_id
)
@usage_statistics_enabled_method(
event_name=UsageStatsEvents.DATA_CONTEXT_RUN_CHECKPOINT,
)
def run_checkpoint(
self,
checkpoint_name: Optional[str] = None,
ge_cloud_id: Optional[str] = None,
template_name: Optional[str] = None,
run_name_template: Optional[str] = None,
expectation_suite_name: Optional[str] = None,
batch_request: Optional[BatchRequestBase] = None,
action_list: Optional[List[dict]] = None,
evaluation_parameters: Optional[dict] = None,
runtime_configuration: Optional[dict] = None,
validations: Optional[List[dict]] = None,
profilers: Optional[List[dict]] = None,
run_id: Optional[Union[str, int, float]] = None,
run_name: Optional[str] = None,
run_time: Optional[datetime.datetime] = None,
result_format: Optional[str] = None,
expectation_suite_ge_cloud_id: Optional[str] = None,
**kwargs,
) -> CheckpointResult:
"""
Validate against a pre-defined Checkpoint. (Experimental)
Args:
checkpoint_name: The name of a Checkpoint defined via the CLI or by manually creating a yml file
template_name: The name of a Checkpoint template to retrieve from the CheckpointStore
run_name_template: The template to use for run_name
expectation_suite_name: Expectation suite to be used by Checkpoint run
batch_request: Batch request to be used by Checkpoint run
action_list: List of actions to be performed by the Checkpoint
evaluation_parameters: $parameter_name syntax references to be evaluated at runtime
runtime_configuration: Runtime configuration override parameters
validations: Validations to be performed by the Checkpoint run
profilers: Profilers to be used by the Checkpoint run
run_id: The run_id for the validation; if None, a default value will be used
run_name: The run_name for the validation; if None, a default value will be used
run_time: The date/time of the run
result_format: One of several supported formatting directives for expectation validation results
ge_cloud_id: Great Expectations Cloud id for the checkpoint
expectation_suite_ge_cloud_id: Great Expectations Cloud id for the expectation suite
**kwargs: Additional kwargs to pass to the validation operator
Returns:
CheckpointResult
"""
checkpoint: Checkpoint = self.get_checkpoint(
name=checkpoint_name,
ge_cloud_id=ge_cloud_id,
)
result: CheckpointResult = checkpoint.run_with_runtime_args(
template_name=template_name,
run_name_template=run_name_template,
expectation_suite_name=expectation_suite_name,
batch_request=batch_request,
action_list=action_list,
evaluation_parameters=evaluation_parameters,
runtime_configuration=runtime_configuration,
validations=validations,
profilers=profilers,
run_id=run_id,
run_name=run_name,
run_time=run_time,
result_format=result_format,
expectation_suite_ge_cloud_id=expectation_suite_ge_cloud_id,
**kwargs,
)
return result
def store_evaluation_parameters(
self, validation_results, target_store_name=None
) -> None:
"""
Stores ValidationResult EvaluationParameters to defined store
"""
if not self._evaluation_parameter_dependencies_compiled:
self._compile_evaluation_parameter_dependencies()
if target_store_name is None:
target_store_name = self.evaluation_parameter_store_name
self._store_metrics(
self._evaluation_parameter_dependencies,
validation_results,
target_store_name,
)
def list_expectation_suite_names(self) -> List[str]:
"""
Lists the available expectation suite names.
"""
sorted_expectation_suite_names = [
i.expectation_suite_name for i in self.list_expectation_suites() # type: ignore[union-attr]
]
sorted_expectation_suite_names.sort()
return sorted_expectation_suite_names
def list_expectation_suites(
self,
) -> Optional[Union[List[str], List[GXCloudIdentifier]]]:
"""Return a list of available expectation suite keys."""
try:
keys = self.expectations_store.list_keys()
except KeyError as e:
raise ge_exceptions.InvalidConfigError(
f"Unable to find configured store: {str(e)}"
)
return keys # type: ignore[return-value]
def get_validator(
self,
datasource_name: Optional[str] = None,
data_connector_name: Optional[str] = None,
data_asset_name: Optional[str] = None,
batch: Optional[Batch] = None,
batch_list: Optional[List[Batch]] = None,
batch_request: Optional[BatchRequestBase] = None,
batch_request_list: Optional[List[BatchRequestBase]] = None,
batch_data: Optional[Any] = None,
data_connector_query: Optional[Union[IDDict, dict]] = None,
batch_identifiers: Optional[dict] = None,
limit: Optional[int] = None,
index: Optional[Union[int, list, tuple, slice, str]] = None,
custom_filter_function: Optional[Callable] = None,
sampling_method: Optional[str] = None,
sampling_kwargs: Optional[dict] = None,
splitter_method: Optional[str] = None,
splitter_kwargs: Optional[dict] = None,
runtime_parameters: Optional[dict] = None,
query: Optional[str] = None,
path: Optional[str] = None,
batch_filter_parameters: Optional[dict] = None,
expectation_suite_ge_cloud_id: Optional[str] = None,
batch_spec_passthrough: Optional[dict] = None,
expectation_suite_name: Optional[str] = None,
expectation_suite: Optional[ExpectationSuite] = None,
create_expectation_suite_with_name: Optional[str] = None,
include_rendered_content: Optional[bool] = None,
**kwargs: Optional[dict],
) -> Validator:
"""
This method applies only to the new (V3) Datasource schema.
"""
include_rendered_content = (
self._determine_if_expectation_validation_result_include_rendered_content(
include_rendered_content=include_rendered_content
)
)
if (
sum(
bool(x)
for x in [
expectation_suite is not None,
expectation_suite_name is not None,
create_expectation_suite_with_name is not None,
expectation_suite_ge_cloud_id is not None,
]
)
> 1
):
ge_cloud_mode = getattr( # attr not on AbstractDataContext
self, "ge_cloud_mode"
)
raise ValueError(
"No more than one of expectation_suite_name,"
f"{'expectation_suite_ge_cloud_id,' if ge_cloud_mode else ''}"
" expectation_suite, or create_expectation_suite_with_name can be specified"
)
if expectation_suite_ge_cloud_id is not None:
expectation_suite = self.get_expectation_suite(
include_rendered_content=include_rendered_content,
ge_cloud_id=expectation_suite_ge_cloud_id,
)
if expectation_suite_name is not None:
expectation_suite = self.get_expectation_suite(
expectation_suite_name,
include_rendered_content=include_rendered_content,
)
if create_expectation_suite_with_name is not None:
expectation_suite = self.create_expectation_suite(
expectation_suite_name=create_expectation_suite_with_name,
)
if (
sum(
bool(x)
for x in [
batch is not None,
batch_list is not None,
batch_request is not None,
batch_request_list is not None,
]
)
> 1
):
raise ValueError(
"No more than one of batch, batch_list, batch_request, or batch_request_list can be specified"
)
if batch_list:
pass
elif batch:
batch_list = [batch]
else:
batch_list = []
if not batch_request_list:
batch_request_list = [batch_request] # type: ignore[list-item]
for batch_request in batch_request_list:
batch_list.extend(
self.get_batch_list(
datasource_name=datasource_name,
data_connector_name=data_connector_name,
data_asset_name=data_asset_name,
batch_request=batch_request,
batch_data=batch_data,
data_connector_query=data_connector_query,
batch_identifiers=batch_identifiers,
limit=limit,
index=index,
custom_filter_function=custom_filter_function,
sampling_method=sampling_method,
sampling_kwargs=sampling_kwargs,
splitter_method=splitter_method,
splitter_kwargs=splitter_kwargs,
runtime_parameters=runtime_parameters,
query=query,
path=path,
batch_filter_parameters=batch_filter_parameters,
batch_spec_passthrough=batch_spec_passthrough,
**kwargs,
)
)
return self.get_validator_using_batch_list(
expectation_suite=expectation_suite, # type: ignore[arg-type]
batch_list=batch_list,
include_rendered_content=include_rendered_content,
)
# noinspection PyUnusedLocal
def get_validator_using_batch_list(
self,
expectation_suite: ExpectationSuite,
batch_list: Sequence[Union[Batch, XBatch]],
include_rendered_content: Optional[bool] = None,
**kwargs: Optional[dict],
) -> Validator:
"""
Args:
expectation_suite ():
batch_list ():
include_rendered_content ():
**kwargs ():
Returns:
"""
if len(batch_list) == 0:
raise ge_exceptions.InvalidBatchRequestError(
"""Validator could not be created because BatchRequest returned an empty batch_list.
Please check your parameters and try again."""
)
include_rendered_content = (
self._determine_if_expectation_validation_result_include_rendered_content(
include_rendered_content=include_rendered_content
)
)
# We get a single batch_definition so we can get the execution_engine here. All batches will share the same one
# So the batch itself doesn't matter. But we use -1 because that will be the latest batch loaded.
execution_engine: ExecutionEngine
if hasattr(batch_list[-1], "execution_engine"):
# 'XBatch's are execution engine aware. We just checked for this attr so we ignore the following
# attr defined mypy error
execution_engine = batch_list[-1].execution_engine
else:
execution_engine = self.datasources[ # type: ignore[union-attr]
batch_list[-1].batch_definition.datasource_name
].execution_engine
validator = Validator(
execution_engine=execution_engine,
interactive_evaluation=True,
expectation_suite=expectation_suite,
data_context=self,
batches=batch_list,
include_rendered_content=include_rendered_content,
)
return validator
@usage_statistics_enabled_method(
event_name=UsageStatsEvents.DATA_CONTEXT_GET_BATCH_LIST,
args_payload_fn=get_batch_list_usage_statistics,
)
def get_batch_list(
self,
datasource_name: Optional[str] = None,
data_connector_name: Optional[str] = None,
data_asset_name: Optional[str] = None,
batch_request: Optional[BatchRequestBase] = None,
batch_data: Optional[Any] = None,
data_connector_query: Optional[dict] = None,
batch_identifiers: Optional[dict] = None,
limit: Optional[int] = None,
index: Optional[Union[int, list, tuple, slice, str]] = None,
custom_filter_function: Optional[Callable] = None,
sampling_method: Optional[str] = None,
sampling_kwargs: Optional[dict] = None,
splitter_method: Optional[str] = None,
splitter_kwargs: Optional[dict] = None,
runtime_parameters: Optional[dict] = None,
query: Optional[str] = None,
path: Optional[str] = None,
batch_filter_parameters: Optional[dict] = None,
batch_spec_passthrough: Optional[dict] = None,
**kwargs: Optional[dict],
) -> List[Batch]:
"""Get the list of zero or more batches, based on a variety of flexible input types.
This method applies only to the new (V3) Datasource schema.
Args:
batch_request
datasource_name
data_connector_name
data_asset_name
batch_request
batch_data
query
path
runtime_parameters
data_connector_query
batch_identifiers
batch_filter_parameters
limit
index
custom_filter_function
sampling_method
sampling_kwargs
splitter_method
splitter_kwargs
batch_spec_passthrough
**kwargs
Returns:
(Batch) The requested batch
`get_batch` is the main user-facing API for getting batches.
In contrast to virtually all other methods in the class, it does not require typed or nested inputs.
Instead, this method is intended to help the user pick the right parameters
This method attempts to return any number of batches, including an empty list.
"""
batch_request = get_batch_request_from_acceptable_arguments(
datasource_name=datasource_name,
data_connector_name=data_connector_name,
data_asset_name=data_asset_name,
batch_request=batch_request,
batch_data=batch_data,
data_connector_query=data_connector_query,
batch_identifiers=batch_identifiers,
limit=limit,
index=index,
custom_filter_function=custom_filter_function,
sampling_method=sampling_method,
sampling_kwargs=sampling_kwargs,
splitter_method=splitter_method,
splitter_kwargs=splitter_kwargs,
runtime_parameters=runtime_parameters,
query=query,
path=path,
batch_filter_parameters=batch_filter_parameters,
batch_spec_passthrough=batch_spec_passthrough,
**kwargs,
)
datasource_name = batch_request.datasource_name
if datasource_name in self.datasources:
datasource: Datasource = cast(Datasource, self.datasources[datasource_name])
else:
raise ge_exceptions.DatasourceError(
datasource_name,
"The given datasource could not be retrieved from the DataContext; "
"please confirm that your configuration is accurate.",
)
return datasource.get_batch_list_from_batch_request(batch_request=batch_request)
def create_expectation_suite(
self,
expectation_suite_name: str,
overwrite_existing: bool = False,
**kwargs: Optional[dict],
) -> ExpectationSuite:
"""Build a new expectation suite and save it into the data_context expectation store.
Args:
expectation_suite_name: The name of the expectation_suite to create
overwrite_existing (boolean): Whether to overwrite expectation suite if expectation suite with given name
already exists.
Returns:
A new (empty) expectation suite.
"""
if not isinstance(overwrite_existing, bool):
raise ValueError("Parameter overwrite_existing must be of type BOOL")
expectation_suite = ExpectationSuite(
expectation_suite_name=expectation_suite_name, data_context=self
)
key = ExpectationSuiteIdentifier(expectation_suite_name=expectation_suite_name)
if (
self.expectations_store.has_key(key) # noqa: W601
and not overwrite_existing
):
raise ge_exceptions.DataContextError(
"expectation_suite with name {} already exists. If you would like to overwrite this "
"expectation_suite, set overwrite_existing=True.".format(
expectation_suite_name
)
)
self.expectations_store.set(key, expectation_suite, **kwargs)
return expectation_suite
def delete_expectation_suite(
self,
expectation_suite_name: Optional[str] = None,
ge_cloud_id: Optional[str] = None,
) -> bool:
"""Delete specified expectation suite from data_context expectation store.
Args:
expectation_suite_name: The name of the expectation_suite to create
Returns:
True for Success and False for Failure.
"""
key = ExpectationSuiteIdentifier(expectation_suite_name) # type: ignore[arg-type]
if not self.expectations_store.has_key(key): # noqa: W601
raise ge_exceptions.DataContextError(
"expectation_suite with name {} does not exist."
)
else:
self.expectations_store.remove_key(key)
return True
def get_expectation_suite(
self,
expectation_suite_name: Optional[str] = None,
include_rendered_content: Optional[bool] = None,
ge_cloud_id: Optional[str] = None,
) -> ExpectationSuite:
"""Get an Expectation Suite by name or GE Cloud ID
Args:
expectation_suite_name (str): The name of the Expectation Suite
include_rendered_content (bool): Whether or not to re-populate rendered_content for each
ExpectationConfiguration.
ge_cloud_id (str): The GE Cloud ID for the Expectation Suite.
Returns:
An existing ExpectationSuite
"""
key: Optional[ExpectationSuiteIdentifier] = ExpectationSuiteIdentifier(
expectation_suite_name=expectation_suite_name # type: ignore[arg-type]
)
if include_rendered_content is None:
include_rendered_content = (
self._determine_if_expectation_suite_include_rendered_content()
)
if self.expectations_store.has_key(key): # type: ignore[arg-type] # noqa: W601
expectations_schema_dict: dict = cast(
dict, self.expectations_store.get(key)
)
# create the ExpectationSuite from constructor
expectation_suite = ExpectationSuite(
**expectations_schema_dict, data_context=self
)
if include_rendered_content:
expectation_suite.render()
return expectation_suite
else:
raise ge_exceptions.DataContextError(
f"expectation_suite {expectation_suite_name} not found"
)
def add_profiler(
self,
name: str,
config_version: float,
rules: Dict[str, dict],
variables: Optional[dict] = None,
) -> RuleBasedProfiler:
config_data = {
"name": name,
"config_version": config_version,
"rules": rules,
"variables": variables,
}
# Roundtrip through schema validation to remove any illegal fields add/or restore any missing fields.
validated_config: dict = ruleBasedProfilerConfigSchema.load(config_data)
profiler_config: dict = ruleBasedProfilerConfigSchema.dump(validated_config)
profiler_config.pop("class_name")
profiler_config.pop("module_name")
config = RuleBasedProfilerConfig(**profiler_config)
profiler = RuleBasedProfiler.add_profiler(
config=config,
data_context=self,
profiler_store=self.profiler_store,
)
return profiler
def get_profiler(
self,
name: Optional[str] = None,
ge_cloud_id: Optional[str] = None,
) -> RuleBasedProfiler:
return RuleBasedProfiler.get_profiler(
data_context=self,
profiler_store=self.profiler_store,
name=name,
ge_cloud_id=ge_cloud_id,
)
def delete_profiler(
self,
name: Optional[str] = None,
ge_cloud_id: Optional[str] = None,
) -> None:
RuleBasedProfiler.delete_profiler(
profiler_store=self.profiler_store,
name=name,
ge_cloud_id=ge_cloud_id,
)
@usage_statistics_enabled_method(
event_name=UsageStatsEvents.DATA_CONTEXT_RUN_RULE_BASED_PROFILER_WITH_DYNAMIC_ARGUMENTS,
)
def run_profiler_with_dynamic_arguments(
self,
batch_list: Optional[List[Batch]] = None,
batch_request: Optional[Union[BatchRequestBase, dict]] = None,
name: Optional[str] = None,
ge_cloud_id: Optional[str] = None,
variables: Optional[dict] = None,
rules: Optional[dict] = None,
) -> RuleBasedProfilerResult:
"""Retrieve a RuleBasedProfiler from a ProfilerStore and run it with rules/variables supplied at runtime.
Args:
batch_list: Explicit list of Batch objects to supply data at runtime
batch_request: Explicit batch_request used to supply data at runtime
name: Identifier used to retrieve the profiler from a store.
ge_cloud_id: Identifier used to retrieve the profiler from a store (GE Cloud specific).
variables: Attribute name/value pairs (overrides)
rules: Key-value pairs of name/configuration-dictionary (overrides)
Returns:
Set of rule evaluation results in the form of an RuleBasedProfilerResult
Raises:
AssertionError if both a `name` and `ge_cloud_id` are provided.
AssertionError if both an `expectation_suite` and `expectation_suite_name` are provided.
"""
return RuleBasedProfiler.run_profiler(
data_context=self,
profiler_store=self.profiler_store,
batch_list=batch_list,
batch_request=batch_request,
name=name,
ge_cloud_id=ge_cloud_id,
variables=variables,
rules=rules,
)
@usage_statistics_enabled_method(
event_name=UsageStatsEvents.DATA_CONTEXT_RUN_RULE_BASED_PROFILER_ON_DATA,
)
def run_profiler_on_data(
self,
batch_list: Optional[List[Batch]] = None,
batch_request: Optional[BatchRequestBase] = None,
name: Optional[str] = None,
ge_cloud_id: Optional[str] = None,
) -> RuleBasedProfilerResult:
"""Retrieve a RuleBasedProfiler from a ProfilerStore and run it with a batch request supplied at runtime.
Args:
batch_list: Explicit list of Batch objects to supply data at runtime.
batch_request: Explicit batch_request used to supply data at runtime.
name: Identifier used to retrieve the profiler from a store.
ge_cloud_id: Identifier used to retrieve the profiler from a store (GE Cloud specific).
Returns:
Set of rule evaluation results in the form of an RuleBasedProfilerResult
Raises:
ProfilerConfigurationError is both "batch_list" and "batch_request" arguments are specified.
AssertionError if both a `name` and `ge_cloud_id` are provided.
AssertionError if both an `expectation_suite` and `expectation_suite_name` are provided.
"""
return RuleBasedProfiler.run_profiler_on_data(
data_context=self,
profiler_store=self.profiler_store,
batch_list=batch_list,
batch_request=batch_request,
name=name,
ge_cloud_id=ge_cloud_id,
)
def add_validation_operator(
self, validation_operator_name: str, validation_operator_config: dict
) -> ValidationOperator:
"""Add a new ValidationOperator to the DataContext and (for convenience) return the instantiated object.
Args:
validation_operator_name (str): a key for the new ValidationOperator in in self._validation_operators
validation_operator_config (dict): a config for the ValidationOperator to add
Returns:
validation_operator (ValidationOperator)
"""
self.config.validation_operators[
validation_operator_name
] = validation_operator_config
config = self.variables.validation_operators[validation_operator_name] # type: ignore[index]
module_name = "great_expectations.validation_operators"
new_validation_operator = instantiate_class_from_config(
config=config,
runtime_environment={
"data_context": self,
"name": validation_operator_name,
},
config_defaults={"module_name": module_name},
)
if not new_validation_operator:
raise ge_exceptions.ClassInstantiationError(
module_name=module_name,
package_name=None,
class_name=config["class_name"],
)
self.validation_operators[validation_operator_name] = new_validation_operator
return new_validation_operator
@usage_statistics_enabled_method(
event_name=UsageStatsEvents.DATA_CONTEXT_RUN_VALIDATION_OPERATOR,
args_payload_fn=run_validation_operator_usage_statistics,
)
def run_validation_operator(
self,
validation_operator_name: str,
assets_to_validate: List,
run_id: Optional[Union[str, RunIdentifier]] = None,
evaluation_parameters: Optional[dict] = None,
run_name: Optional[str] = None,
run_time: Optional[Union[str, datetime.datetime]] = None,
result_format: Optional[Union[str, dict]] = None,
**kwargs,
):
"""
Run a validation operator to validate data assets and to perform the business logic around
validation that the operator implements.
Args:
validation_operator_name: name of the operator, as appears in the context's config file
assets_to_validate: a list that specifies the data assets that the operator will validate. The members of
the list can be either batches, or a tuple that will allow the operator to fetch the batch:
(batch_kwargs, expectation_suite_name)
evaluation_parameters: $parameter_name syntax references to be evaluated at runtime
run_id: The run_id for the validation; if None, a default value will be used
run_name: The run_name for the validation; if None, a default value will be used
run_time: The date/time of the run
result_format: one of several supported formatting directives for expectation validation results
**kwargs: Additional kwargs to pass to the validation operator
Returns:
ValidationOperatorResult
"""
result_format = result_format or {"result_format": "SUMMARY"}
if not assets_to_validate:
raise ge_exceptions.DataContextError(
"No batches of data were passed in. These are required"
)
for batch in assets_to_validate:
if not isinstance(batch, (tuple, DataAsset, Validator)):
raise ge_exceptions.DataContextError(
"Batches are required to be of type DataAsset or Validator"
)
try:
validation_operator = self.validation_operators[validation_operator_name]
except KeyError:
raise ge_exceptions.DataContextError(
f"No validation operator `{validation_operator_name}` was found in your project. Please verify this in your great_expectations.yml"
)
if run_id is None and run_name is None:
run_name = datetime.datetime.now(datetime.timezone.utc).strftime(
"%Y%m%dT%H%M%S.%fZ"
)
logger.info(f"Setting run_name to: {run_name}")
if evaluation_parameters is None:
return validation_operator.run(
assets_to_validate=assets_to_validate,
run_id=run_id,
run_name=run_name,
run_time=run_time,
result_format=result_format,
**kwargs,
)
else:
return validation_operator.run(
assets_to_validate=assets_to_validate,
run_id=run_id,
evaluation_parameters=evaluation_parameters,
run_name=run_name,
run_time=run_time,
result_format=result_format,
**kwargs,
)
def list_validation_operators(self):
"""List currently-configured Validation Operators on this context"""
validation_operators = []
for (
name,
value,
) in self.variables.validation_operators.items():
value["name"] = name
validation_operators.append(value)
return validation_operators
def list_validation_operator_names(self):
if not self.validation_operators:
return []
return list(self.validation_operators.keys())
def profile_data_asset( # noqa: C901 - complexity 16
self,
datasource_name,
batch_kwargs_generator_name=None,
data_asset_name=None,
batch_kwargs=None,
expectation_suite_name=None,
profiler=BasicDatasetProfiler,
profiler_configuration=None,
run_id=None,
additional_batch_kwargs=None,
run_name=None,
run_time=None,
):
"""
Profile a data asset
:param datasource_name: the name of the datasource to which the profiled data asset belongs
:param batch_kwargs_generator_name: the name of the batch kwargs generator to use to get batches (only if batch_kwargs are not provided)
:param data_asset_name: the name of the profiled data asset
:param batch_kwargs: optional - if set, the method will use the value to fetch the batch to be profiled. If not passed, the batch kwargs generator (generator_name arg) will choose a batch
:param profiler: the profiler class to use
:param profiler_configuration: Optional profiler configuration dict
:param run_name: optional - if set, the validation result created by the profiler will be under the provided run_name
:param additional_batch_kwargs:
:returns
A dictionary::
{
"success": True/False,
"results": List of (expectation_suite, EVR) tuples for each of the data_assets found in the datasource
}
When success = False, the error details are under "error" key
"""
assert not (run_id and run_name) and not (
run_id and run_time
), "Please provide either a run_id or run_name and/or run_time."
if isinstance(run_id, str) and not run_name:
# deprecated-v0.11.0
warnings.warn(
"String run_ids are deprecated as of v0.11.0 and support will be removed in v0.16. Please provide a run_id of type "
"RunIdentifier(run_name=None, run_time=None), or a dictionary containing run_name "
"and run_time (both optional). Instead of providing a run_id, you may also provide"
"run_name and run_time separately.",
DeprecationWarning,
)
try:
run_time = parse(run_id)
except (ValueError, TypeError):
pass
run_id = RunIdentifier(run_name=run_id, run_time=run_time)
elif isinstance(run_id, dict):
run_id = RunIdentifier(**run_id)
elif not isinstance(run_id, RunIdentifier):
run_name = run_name or "profiling"
run_id = RunIdentifier(run_name=run_name, run_time=run_time)
logger.info(f"Profiling '{datasource_name}' with '{profiler.__name__}'")
if not additional_batch_kwargs:
additional_batch_kwargs = {}
if batch_kwargs is None:
try:
generator = self.get_datasource(
datasource_name=datasource_name
).get_batch_kwargs_generator(name=batch_kwargs_generator_name)
batch_kwargs = generator.build_batch_kwargs(
data_asset_name, **additional_batch_kwargs
)
except ge_exceptions.BatchKwargsError:
raise ge_exceptions.ProfilerError(
"Unable to build batch_kwargs for datasource {}, using batch kwargs generator {} for name {}".format(
datasource_name, batch_kwargs_generator_name, data_asset_name
)
)
except ValueError:
raise ge_exceptions.ProfilerError(
"Unable to find datasource {} or batch kwargs generator {}.".format(
datasource_name, batch_kwargs_generator_name
)
)
else:
batch_kwargs.update(additional_batch_kwargs)
profiling_results = {"success": False, "results": []}
total_columns, total_expectations, total_rows = 0, 0, 0
total_start_time = datetime.datetime.now()
name = data_asset_name
# logger.info("\tProfiling '%s'..." % name)
start_time = datetime.datetime.now()
if expectation_suite_name is None:
if batch_kwargs_generator_name is None and data_asset_name is None:
expectation_suite_name = (
datasource_name
+ "."
+ profiler.__name__
+ "."
+ BatchKwargs(batch_kwargs).to_id()
)
else:
expectation_suite_name = (
datasource_name
+ "."
+ batch_kwargs_generator_name
+ "."
+ data_asset_name
+ "."
+ profiler.__name__
)
self.create_expectation_suite(
expectation_suite_name=expectation_suite_name, overwrite_existing=True
)
# TODO: Add batch_parameters
batch = self.get_batch(
expectation_suite_name=expectation_suite_name,
batch_kwargs=batch_kwargs,
)
if not profiler.validate(batch):
raise ge_exceptions.ProfilerError(
f"batch '{name}' is not a valid batch for the '{profiler.__name__}' profiler"
)
# Note: This logic is specific to DatasetProfilers, which profile a single batch. Multi-batch profilers
# will have more to unpack.
expectation_suite, validation_results = profiler.profile(
batch, run_id=run_id, profiler_configuration=profiler_configuration
)
profiling_results["results"].append((expectation_suite, validation_results))
validation_ref = self.validations_store.set(
key=ValidationResultIdentifier(
expectation_suite_identifier=ExpectationSuiteIdentifier(
expectation_suite_name=expectation_suite_name
),
run_id=run_id,
batch_identifier=batch.batch_id,
),
value=validation_results,
)
if isinstance(validation_ref, GXCloudIDAwareRef):
ge_cloud_id = validation_ref.ge_cloud_id
validation_results.ge_cloud_id = uuid.UUID(ge_cloud_id)
if isinstance(batch, Dataset):
# For datasets, we can produce some more detailed statistics
row_count = batch.get_row_count()
total_rows += row_count
new_column_count = len(
{
exp.kwargs["column"]
for exp in expectation_suite.expectations
if "column" in exp.kwargs
}
)
total_columns += new_column_count
new_expectation_count = len(expectation_suite.expectations)
total_expectations += new_expectation_count
self.save_expectation_suite(expectation_suite)
duration = (datetime.datetime.now() - start_time).total_seconds()
# noinspection PyUnboundLocalVariable
logger.info(
f"\tProfiled {new_column_count} columns using {row_count} rows from {name} ({duration:.3f} sec)"
)
total_duration = (datetime.datetime.now() - total_start_time).total_seconds()
logger.info(
f"""
Profiled the data asset, with {total_rows} total rows and {total_columns} columns in {total_duration:.2f} seconds.
Generated, evaluated, and stored {total_expectations} Expectations during profiling. Please review results using data-docs."""
)
profiling_results["success"] = True
return profiling_results
def add_batch_kwargs_generator(
self, datasource_name, batch_kwargs_generator_name, class_name, **kwargs
):
"""
Add a batch kwargs generator to the named datasource, using the provided
configuration.
Args:
datasource_name: name of datasource to which to add the new batch kwargs generator
batch_kwargs_generator_name: name of the generator to add
class_name: class of the batch kwargs generator to add
**kwargs: batch kwargs generator configuration, provided as kwargs
Returns:
"""
datasource_obj = self.get_datasource(datasource_name)
generator = datasource_obj.add_batch_kwargs_generator(
name=batch_kwargs_generator_name, class_name=class_name, **kwargs
)
return generator
def get_available_data_asset_names(
self, datasource_names=None, batch_kwargs_generator_names=None
):
"""Inspect datasource and batch kwargs generators to provide available data_asset objects.
Args:
datasource_names: list of datasources for which to provide available data_asset_name objects. If None, \
return available data assets for all datasources.
batch_kwargs_generator_names: list of batch kwargs generators for which to provide available
data_asset_name objects.
Returns:
data_asset_names (dict): Dictionary describing available data assets
::
{
datasource_name: {
batch_kwargs_generator_name: [ data_asset_1, data_asset_2, ... ]
...
}
...
}
"""
data_asset_names = {}
if datasource_names is None:
datasource_names = [
datasource["name"] for datasource in self.list_datasources()
]
elif isinstance(datasource_names, str):
datasource_names = [datasource_names]
elif not isinstance(datasource_names, list):
raise ValueError(
"Datasource names must be a datasource name, list of datasource names or None (to list all datasources)"
)
if batch_kwargs_generator_names is not None:
if isinstance(batch_kwargs_generator_names, str):
batch_kwargs_generator_names = [batch_kwargs_generator_names]
if len(batch_kwargs_generator_names) == len(
datasource_names
): # Iterate over both together
for idx, datasource_name in enumerate(datasource_names):
datasource = self.get_datasource(datasource_name)
data_asset_names[
datasource_name
] = datasource.get_available_data_asset_names(
batch_kwargs_generator_names[idx]
)
elif len(batch_kwargs_generator_names) == 1:
datasource = self.get_datasource(datasource_names[0])
datasource_names[
datasource_names[0]
] = datasource.get_available_data_asset_names(
batch_kwargs_generator_names
)
else:
raise ValueError(
"If providing batch kwargs generator, you must either specify one for each datasource or only "
"one datasource."
)
else: # generator_names is None
for datasource_name in datasource_names:
try:
datasource = self.get_datasource(datasource_name)
data_asset_names[
datasource_name
] = datasource.get_available_data_asset_names()
except ValueError:
# handle the edge case of a non-existent datasource
data_asset_names[datasource_name] = {}
return data_asset_names
def build_batch_kwargs(
self,
datasource,
batch_kwargs_generator,
data_asset_name=None,
partition_id=None,
**kwargs,
):
"""Builds batch kwargs using the provided datasource, batch kwargs generator, and batch_parameters.
Args:
datasource (str): the name of the datasource for which to build batch_kwargs
batch_kwargs_generator (str): the name of the batch kwargs generator to use to build batch_kwargs
data_asset_name (str): an optional name batch_parameter
**kwargs: additional batch_parameters
Returns:
BatchKwargs
"""
if kwargs.get("name"):
if data_asset_name:
raise ValueError(
"Cannot provide both 'name' and 'data_asset_name'. Please use 'data_asset_name' only."
)
# deprecated-v0.11.2
warnings.warn(
"name is deprecated as a batch_parameter as of v0.11.2 and will be removed in v0.16. Please use data_asset_name instead.",
DeprecationWarning,
)
data_asset_name = kwargs.pop("name")
datasource_obj = self.get_datasource(datasource)
batch_kwargs = datasource_obj.build_batch_kwargs(
batch_kwargs_generator=batch_kwargs_generator,
data_asset_name=data_asset_name,
partition_id=partition_id,
**kwargs,
)
return batch_kwargs
@usage_statistics_enabled_method(
event_name=UsageStatsEvents.DATA_CONTEXT_OPEN_DATA_DOCS,
)
def open_data_docs(
self,
resource_identifier: Optional[str] = None,
site_name: Optional[str] = None,
only_if_exists: bool = True,
) -> None:
"""
A stdlib cross-platform way to open a file in a browser.
Args:
resource_identifier: ExpectationSuiteIdentifier,
ValidationResultIdentifier or any other type's identifier. The
argument is optional - when not supplied, the method returns the
URL of the index page.
site_name: Optionally specify which site to open. If not specified,
open all docs found in the project.
only_if_exists: Optionally specify flag to pass to "self.get_docs_sites_urls()".
"""
data_docs_urls: List[Dict[str, str]] = self.get_docs_sites_urls(
resource_identifier=resource_identifier,
site_name=site_name,
only_if_exists=only_if_exists,
)
urls_to_open: List[str] = [site["site_url"] for site in data_docs_urls]
for url in urls_to_open:
if url is not None:
logger.debug(f"Opening Data Docs found here: {url}")
webbrowser.open(url)
def get_docs_sites_urls(
self,
resource_identifier=None,
site_name: Optional[str] = None,
only_if_exists=True,
site_names: Optional[List[str]] = None,
) -> List[Dict[str, str]]:
"""
Get URLs for a resource for all data docs sites.
This function will return URLs for any configured site even if the sites
have not been built yet.
Args:
resource_identifier (object): optional. It can be an identifier of
ExpectationSuite's, ValidationResults and other resources that
have typed identifiers. If not provided, the method will return
the URLs of the index page.
site_name: Optionally specify which site to open. If not specified,
return all urls in the project.
site_names: Optionally specify which sites are active. Sites not in
this list are not processed, even if specified in site_name.
Returns:
list: a list of URLs. Each item is the URL for the resource for a
data docs site
"""
unfiltered_sites = self.variables.data_docs_sites
# Filter out sites that are not in site_names
sites = (
{k: v for k, v in unfiltered_sites.items() if k in site_names} # type: ignore[union-attr]
if site_names
else unfiltered_sites
)
if not sites:
logger.debug("Found no data_docs_sites.")
return []
logger.debug(f"Found {len(sites)} data_docs_sites.")
if site_name:
if site_name not in sites.keys():
raise ge_exceptions.DataContextError(
f"Could not find site named {site_name}. Please check your configurations"
)
site = sites[site_name]
site_builder = self._load_site_builder_from_site_config(site)
url = site_builder.get_resource_url(
resource_identifier=resource_identifier, only_if_exists=only_if_exists
)
return [{"site_name": site_name, "site_url": url}]
site_urls = []
for _site_name, site_config in sites.items():
site_builder = self._load_site_builder_from_site_config(site_config)
url = site_builder.get_resource_url(
resource_identifier=resource_identifier, only_if_exists=only_if_exists
)
site_urls.append({"site_name": _site_name, "site_url": url})
return site_urls
def _load_site_builder_from_site_config(self, site_config) -> SiteBuilder:
default_module_name = "great_expectations.render.renderer.site_builder"
site_builder = instantiate_class_from_config(
config=site_config,
runtime_environment={
"data_context": self,
"root_directory": self.root_directory,
},
config_defaults={"module_name": default_module_name},
)
if not site_builder:
raise ge_exceptions.ClassInstantiationError(
module_name=default_module_name,
package_name=None,
class_name=site_config["class_name"],
)
return site_builder
def clean_data_docs(self, site_name=None) -> bool:
"""
Clean a given data docs site.
This removes all files from the configured Store.
Args:
site_name (str): Optional, the name of the site to clean. If not
specified, all sites will be cleaned.
"""
data_docs_sites = self.variables.data_docs_sites
if not data_docs_sites:
raise ge_exceptions.DataContextError(
"No data docs sites were found on this DataContext, therefore no sites will be cleaned.",
)
data_docs_site_names = list(data_docs_sites.keys())
if site_name:
if site_name not in data_docs_site_names:
raise ge_exceptions.DataContextError(
f"The specified site name `{site_name}` does not exist in this project."
)
return self._clean_data_docs_site(site_name)
cleaned = []
for existing_site_name in data_docs_site_names:
cleaned.append(self._clean_data_docs_site(existing_site_name))
return all(cleaned)
def _clean_data_docs_site(self, site_name: str) -> bool:
sites = self.variables.data_docs_sites
if not sites:
return False
site_config = sites.get(site_name)
site_builder = instantiate_class_from_config(
config=site_config,
runtime_environment={
"data_context": self,
"root_directory": self.root_directory,
},
config_defaults={
"module_name": "great_expectations.render.renderer.site_builder"
},
)
site_builder.clean_site()
return True
@staticmethod
def _default_profilers_exist(directory_path: Optional[str]) -> bool:
"""
Helper method. Do default profilers exist in directory_path?
"""
if not directory_path:
return False
profiler_directory_path: str = os.path.join(
directory_path,
DataContextConfigDefaults.DEFAULT_PROFILER_STORE_BASE_DIRECTORY_RELATIVE_NAME.value,
)
return os.path.isdir(profiler_directory_path)
@staticmethod
def _get_global_config_value(
environment_variable: str,
conf_file_section: Optional[str] = None,
conf_file_option: Optional[str] = None,
) -> Optional[str]:
"""
Method to retrieve config value.
Looks for config value in environment_variable and config file section
Args:
environment_variable (str): name of environment_variable to retrieve
conf_file_section (str): section of config
conf_file_option (str): key in section
Returns:
Optional string representing config value
"""
assert (conf_file_section and conf_file_option) or (
not conf_file_section and not conf_file_option
), "Must pass both 'conf_file_section' and 'conf_file_option' or neither."
if environment_variable and os.environ.get(environment_variable, ""):
return os.environ.get(environment_variable)
if conf_file_section and conf_file_option:
for config_path in AbstractDataContext.GLOBAL_CONFIG_PATHS:
config: configparser.ConfigParser = configparser.ConfigParser()
config.read(config_path)
config_value: Optional[str] = config.get(
conf_file_section, conf_file_option, fallback=None
)
if config_value:
return config_value
return None
@staticmethod
def _get_metric_configuration_tuples(
metric_configuration: Union[str, dict], base_kwargs: Optional[dict] = None
) -> List[Tuple[str, Union[dict, Any]]]:
if base_kwargs is None:
base_kwargs = {}
if isinstance(metric_configuration, str):
return [(metric_configuration, base_kwargs)]
metric_configurations_list = []
for kwarg_name in metric_configuration.keys():
if not isinstance(metric_configuration[kwarg_name], dict):
raise ge_exceptions.DataContextError(
"Invalid metric_configuration: each key must contain a "
"dictionary."
)
if (
kwarg_name == "metric_kwargs_id"
): # this special case allows a hash of multiple kwargs
for metric_kwargs_id in metric_configuration[kwarg_name].keys():
if base_kwargs != {}:
raise ge_exceptions.DataContextError(
"Invalid metric_configuration: when specifying "
"metric_kwargs_id, no other keys or values may be defined."
)
if not isinstance(
metric_configuration[kwarg_name][metric_kwargs_id], list
):
raise ge_exceptions.DataContextError(
"Invalid metric_configuration: each value must contain a "
"list."
)
metric_configurations_list += [
(metric_name, {"metric_kwargs_id": metric_kwargs_id})
for metric_name in metric_configuration[kwarg_name][
metric_kwargs_id
]
]
else:
for kwarg_value in metric_configuration[kwarg_name].keys():
base_kwargs.update({kwarg_name: kwarg_value})
if not isinstance(
metric_configuration[kwarg_name][kwarg_value], list
):
raise ge_exceptions.DataContextError(
"Invalid metric_configuration: each value must contain a "
"list."
)
for nested_configuration in metric_configuration[kwarg_name][
kwarg_value
]:
metric_configurations_list += (
AbstractDataContext._get_metric_configuration_tuples(
nested_configuration, base_kwargs=base_kwargs
)
)
return metric_configurations_list
@classmethod
def get_or_create_data_context_config(
cls, project_config: Union[DataContextConfig, Mapping]
) -> DataContextConfig:
if isinstance(project_config, DataContextConfig):
return project_config
try:
# Roundtrip through schema validation to remove any illegal fields add/or restore any missing fields.
project_config_dict = dataContextConfigSchema.dump(project_config)
project_config_dict = dataContextConfigSchema.load(project_config_dict)
context_config: DataContextConfig = DataContextConfig(**project_config_dict)
return context_config
except ValidationError:
raise
def _normalize_absolute_or_relative_path(
self, path: Optional[str]
) -> Optional[str]:
"""
Why does this exist in AbstractDataContext? CloudDataContext and FileDataContext both use it
"""
if path is None:
return None
if os.path.isabs(path):
return path
else:
return os.path.join(self.root_directory, path) # type: ignore[arg-type]
def _apply_global_config_overrides(
self, config: DataContextConfig
) -> DataContextConfig:
"""
Applies global configuration overrides for
- usage_statistics being enabled
- data_context_id for usage_statistics
- global_usage_statistics_url
Args:
config (DataContextConfig): Config that is passed into the DataContext constructor
Returns:
DataContextConfig with the appropriate overrides
"""
validation_errors: dict = {}
config_with_global_config_overrides: DataContextConfig = copy.deepcopy(config)
usage_stats_enabled: bool = self._is_usage_stats_enabled()
if not usage_stats_enabled:
logger.info(
"Usage statistics is disabled globally. Applying override to project_config."
)
config_with_global_config_overrides.anonymous_usage_statistics.enabled = (
False
)
global_data_context_id: Optional[str] = self._get_data_context_id_override()
# data_context_id
if global_data_context_id:
data_context_id_errors = anonymizedUsageStatisticsSchema.validate(
{"data_context_id": global_data_context_id}
)
if not data_context_id_errors:
logger.info(
"data_context_id is defined globally. Applying override to project_config."
)
config_with_global_config_overrides.anonymous_usage_statistics.data_context_id = (
global_data_context_id
)
else:
validation_errors.update(data_context_id_errors)
# usage statistics url
global_usage_statistics_url: Optional[
str
] = self._get_usage_stats_url_override()
if global_usage_statistics_url:
usage_statistics_url_errors = anonymizedUsageStatisticsSchema.validate(
{"usage_statistics_url": global_usage_statistics_url}
)
if not usage_statistics_url_errors:
logger.info(
"usage_statistics_url is defined globally. Applying override to project_config."
)
config_with_global_config_overrides.anonymous_usage_statistics.usage_statistics_url = (
global_usage_statistics_url
)
else:
validation_errors.update(usage_statistics_url_errors)
if validation_errors:
logger.warning(
"The following globally-defined config variables failed validation:\n{}\n\n"
"Please fix the variables if you would like to apply global values to project_config.".format(
json.dumps(validation_errors, indent=2)
)
)
return config_with_global_config_overrides
def _load_config_variables(self) -> Dict:
config_var_provider = self.config_provider.get_provider(
_ConfigurationVariablesConfigurationProvider
)
if config_var_provider:
return config_var_provider.get_values()
return {}
@staticmethod
def _is_usage_stats_enabled() -> bool:
"""
Checks the following locations to see if usage_statistics is disabled in any of the following locations:
- GE_USAGE_STATS, which is an environment_variable
- GLOBAL_CONFIG_PATHS
If GE_USAGE_STATS exists AND its value is one of the FALSEY_STRINGS, usage_statistics is disabled (return False)
Also checks GLOBAL_CONFIG_PATHS to see if config file contains override for anonymous_usage_statistics
Returns True otherwise
Returns:
bool that tells you whether usage_statistics is on or off
"""
usage_statistics_enabled: bool = True
if os.environ.get("GE_USAGE_STATS", False):
ge_usage_stats = os.environ.get("GE_USAGE_STATS")
if ge_usage_stats in AbstractDataContext.FALSEY_STRINGS:
usage_statistics_enabled = False
else:
logger.warning(
"GE_USAGE_STATS environment variable must be one of: {}".format(
AbstractDataContext.FALSEY_STRINGS
)
)
for config_path in AbstractDataContext.GLOBAL_CONFIG_PATHS:
config = configparser.ConfigParser()
states = config.BOOLEAN_STATES
for falsey_string in AbstractDataContext.FALSEY_STRINGS:
states[falsey_string] = False # type: ignore[index]
states["TRUE"] = True # type: ignore[index]
states["True"] = True # type: ignore[index]
config.BOOLEAN_STATES = states # type: ignore[misc] # Cannot assign to class variable via instance
config.read(config_path)
try:
if not config.getboolean("anonymous_usage_statistics", "enabled"):
usage_statistics_enabled = False
except (ValueError, configparser.Error):
pass
return usage_statistics_enabled
def _get_data_context_id_override(self) -> Optional[str]:
"""
Return data_context_id from environment variable.
Returns:
Optional string that represents data_context_id
"""
return self._get_global_config_value(
environment_variable="GE_DATA_CONTEXT_ID",
conf_file_section="anonymous_usage_statistics",
conf_file_option="data_context_id",
)
def _get_usage_stats_url_override(self) -> Optional[str]:
"""
Return GE_USAGE_STATISTICS_URL from environment variable if it exists
Returns:
Optional string that represents GE_USAGE_STATISTICS_URL
"""
return self._get_global_config_value(
environment_variable="GE_USAGE_STATISTICS_URL",
conf_file_section="anonymous_usage_statistics",
conf_file_option="usage_statistics_url",
)
def _build_store_from_config(
self, store_name: str, store_config: dict
) -> Optional[Store]:
module_name = "great_expectations.data_context.store"
# Set expectations_store.store_backend_id to the data_context_id from the project_config if
# the expectations_store does not yet exist by:
# adding the data_context_id from the project_config
# to the store_config under the key manually_initialize_store_backend_id
if (store_name == self.expectations_store_name) and store_config.get(
"store_backend"
):
store_config["store_backend"].update(
{
"manually_initialize_store_backend_id": self.variables.anonymous_usage_statistics.data_context_id # type: ignore[union-attr]
}
)
# Set suppress_store_backend_id = True if store is inactive and has a store_backend.
if (
store_name not in [store["name"] for store in self.list_active_stores()] # type: ignore[index]
and store_config.get("store_backend") is not None
):
store_config["store_backend"].update({"suppress_store_backend_id": True})
new_store = build_store_from_config(
store_name=store_name,
store_config=store_config,
module_name=module_name,
runtime_environment={
"root_directory": self.root_directory,
},
)
self._stores[store_name] = new_store
return new_store
# properties
@property
def variables(self) -> DataContextVariables:
if self._variables is None:
self._variables = self._init_variables()
return self._variables
@property
def usage_statistics_handler(self) -> Optional[UsageStatisticsHandler]:
return self._usage_statistics_handler
@property
def anonymous_usage_statistics(self) -> AnonymizedUsageStatisticsConfig:
return self.variables.anonymous_usage_statistics # type: ignore[return-value]
@property
def progress_bars(self) -> Optional[ProgressBarsConfig]:
return self.variables.progress_bars
@property
def include_rendered_content(self) -> IncludeRenderedContentConfig:
return self.variables.include_rendered_content
@property
def notebooks(self) -> NotebookConfig:
return self.variables.notebooks # type: ignore[return-value]
@property
def datasources(
self,
) -> Dict[str, Union[LegacyDatasource, BaseDatasource, XDatasource]]:
"""A single holder for all Datasources in this context"""
return self._cached_datasources
@property
def data_context_id(self) -> str:
return self.variables.anonymous_usage_statistics.data_context_id # type: ignore[union-attr]
def _init_stores(self, store_configs: Dict[str, dict]) -> None:
"""Initialize all Stores for this DataContext.
Stores are a good fit for reading/writing objects that:
1. follow a clear key-value pattern, and
2. are usually edited programmatically, using the Context
Note that stores do NOT manage plugins.
"""
for store_name, store_config in store_configs.items():
self._build_store_from_config(store_name, store_config)
# The DatasourceStore is inherent to all DataContexts but is not an explicit part of the project config.
# As such, it must be instantiated separately.
self._init_datasource_store()
@abstractmethod
def _init_datasource_store(self) -> None:
"""Internal utility responsible for creating a DatasourceStore to persist and manage a user's Datasources.
Please note that the DatasourceStore lacks the same extensibility that other analagous Stores do; a default
implementation is provided based on the user's environment but is not customizable.
"""
raise NotImplementedError
def _update_config_variables(self) -> None:
"""Updates config_variables cache by re-calling _load_config_variables().
Necessary after running methods that modify config AND could contain config_variables for credentials
(example is add_datasource())
"""
self._config_variables = self._load_config_variables()
def _initialize_usage_statistics(
self, usage_statistics_config: AnonymizedUsageStatisticsConfig
) -> None:
"""Initialize the usage statistics system."""
if not usage_statistics_config.enabled:
logger.info("Usage statistics is disabled; skipping initialization.")
self._usage_statistics_handler = None
return
self._usage_statistics_handler = UsageStatisticsHandler(
data_context=self,
data_context_id=self._data_context_id,
usage_statistics_url=usage_statistics_config.usage_statistics_url,
)
def _init_datasources(self) -> None:
"""Initialize the datasources in store"""
config: DataContextConfig = self.config
datasources: Dict[str, DatasourceConfig] = cast(
Dict[str, DatasourceConfig], config.datasources
)
for datasource_name, datasource_config in datasources.items():
try:
config = copy.deepcopy(datasource_config) # type: ignore[assignment]
raw_config_dict = dict(datasourceConfigSchema.dump(config))
substituted_config_dict: dict = self.config_provider.substitute_config(
raw_config_dict
)
raw_datasource_config = datasourceConfigSchema.load(raw_config_dict)
substituted_datasource_config = datasourceConfigSchema.load(
substituted_config_dict
)
substituted_datasource_config.name = datasource_name
datasource = self._instantiate_datasource_from_config(
raw_config=raw_datasource_config,
substituted_config=substituted_datasource_config,
)
self._cached_datasources[datasource_name] = datasource
except ge_exceptions.DatasourceInitializationError as e:
logger.warning(f"Cannot initialize datasource {datasource_name}: {e}")
# this error will happen if our configuration contains datasources that GE can no longer connect to.
# this is ok, as long as we don't use it to retrieve a batch. If we try to do that, the error will be
# caught at the context.get_batch() step. So we just pass here.
pass
def _instantiate_datasource_from_config(
self,
raw_config: DatasourceConfig,
substituted_config: DatasourceConfig,
) -> Datasource:
"""Instantiate a new datasource.
Args:
config: Datasource config.
Returns:
Datasource instantiated from config.
Raises:
DatasourceInitializationError
"""
try:
datasource: Datasource = self._build_datasource_from_config(
raw_config=raw_config, substituted_config=substituted_config
)
except Exception as e:
raise ge_exceptions.DatasourceInitializationError(
datasource_name=substituted_config.name, message=str(e)
)
return datasource
def _build_datasource_from_config(
self, raw_config: DatasourceConfig, substituted_config: DatasourceConfig
) -> Datasource:
"""Instantiate a Datasource from a config.
Args:
config: DatasourceConfig object defining the datsource to instantiate.
Returns:
Datasource instantiated from config.
Raises:
ClassInstantiationError
"""
# We convert from the type back to a dictionary for purposes of instantiation
serializer = DictConfigSerializer(schema=datasourceConfigSchema)
substituted_config_dict: dict = serializer.serialize(substituted_config)
# While the new Datasource classes accept "data_context_root_directory", the Legacy Datasource classes do not.
if substituted_config_dict["class_name"] in [
"BaseDatasource",
"Datasource",
]:
substituted_config_dict.update(
{"data_context_root_directory": self.root_directory}
)
module_name: str = "great_expectations.datasource"
datasource: Datasource = instantiate_class_from_config(
config=substituted_config_dict,
runtime_environment={"data_context": self, "concurrency": self.concurrency},
config_defaults={"module_name": module_name},
)
if not datasource:
raise ge_exceptions.ClassInstantiationError(
module_name=module_name,
package_name=None,
class_name=substituted_config_dict["class_name"],
)
# Chetan - 20221103 - Directly accessing private attr in order to patch security vulnerabiliy around credential leakage.
# This is to be removed once substitution logic is migrated from the context to the individual object level.
raw_config_dict: dict = serializer.serialize(raw_config)
datasource._raw_config = raw_config_dict
return datasource
def _perform_substitutions_on_datasource_config(
self, config: DatasourceConfig
) -> DatasourceConfig:
"""Substitute variables in a datasource config e.g. from env vars, config_vars.yml
Config must be persisted with ${VARIABLES} syntax but hydrated at time of use.
Args:
config: Datasource Config
Returns:
Datasource Config with substitutions performed.
"""
substitution_serializer = DictConfigSerializer(schema=datasourceConfigSchema)
raw_config: dict = substitution_serializer.serialize(config)
substituted_config_dict: dict = self.config_provider.substitute_config(
raw_config
)
substituted_config: DatasourceConfig = datasourceConfigSchema.load(
substituted_config_dict
)
return substituted_config
def _instantiate_datasource_from_config_and_update_project_config(
self,
config: DatasourceConfig,
initialize: bool,
save_changes: bool,
) -> Optional[Datasource]:
"""Perform substitutions and optionally initialize the Datasource and/or store the config.
Args:
config: Datasource Config to initialize and/or store.
initialize: Whether to initialize the datasource, alternatively you can store without initializing.
save_changes: Whether to store the configuration in your configuration store (GX cloud or great_expectations.yml)
Returns:
Datasource object if initialized.
Raises:
DatasourceInitializationError
"""
if save_changes:
config = self._datasource_store.set(key=None, value=config) # type: ignore[attr-defined]
self.config.datasources[config.name] = config # type: ignore[index,assignment]
substituted_config = self._perform_substitutions_on_datasource_config(config)
datasource: Optional[Datasource] = None
if initialize:
try:
datasource = self._instantiate_datasource_from_config(
raw_config=config, substituted_config=substituted_config
)
self._cached_datasources[config.name] = datasource
except ge_exceptions.DatasourceInitializationError as e:
# Do not keep configuration that could not be instantiated.
if save_changes:
self._datasource_store.delete(config) # type: ignore[attr-defined]
# If the DatasourceStore uses an InlineStoreBackend, the config may already be updated
self.config.datasources.pop(config.name, None) # type: ignore[union-attr,arg-type]
raise e
return datasource
def _construct_data_context_id(self) -> str:
# Choose the id of the currently-configured expectations store, if it is a persistent store
expectations_store = self._stores[self.variables.expectations_store_name]
if isinstance(expectations_store.store_backend, TupleStoreBackend):
# suppress_warnings since a warning will already have been issued during the store creation
# if there was an invalid store config
return expectations_store.store_backend_id_warnings_suppressed
# Otherwise choose the id stored in the project_config
else:
return self.variables.anonymous_usage_statistics.data_context_id # type: ignore[union-attr]
def _compile_evaluation_parameter_dependencies(self) -> None:
self._evaluation_parameter_dependencies = {}
# NOTE: Chetan - 20211118: This iteration is reverting the behavior performed here:
# https://github.com/great-expectations/great_expectations/pull/3377
# This revision was necessary due to breaking changes but will need to be brought back in a future ticket.
for key in self.expectations_store.list_keys():
expectation_suite_dict: dict = cast(dict, self.expectations_store.get(key))
if not expectation_suite_dict:
continue
expectation_suite = ExpectationSuite(
**expectation_suite_dict, data_context=self
)
dependencies: dict = (
expectation_suite.get_evaluation_parameter_dependencies()
)
if len(dependencies) > 0:
nested_update(self._evaluation_parameter_dependencies, dependencies)
self._evaluation_parameter_dependencies_compiled = True
def get_validation_result(
self,
expectation_suite_name,
run_id=None,
batch_identifier=None,
validations_store_name=None,
failed_only=False,
include_rendered_content=None,
):
"""Get validation results from a configured store.
Args:
expectation_suite_name: expectation_suite name for which to get validation result (default: "default")
run_id: run_id for which to get validation result (if None, fetch the latest result by alphanumeric sort)
validations_store_name: the name of the store from which to get validation results
failed_only: if True, filter the result to return only failed expectations
include_rendered_content: whether to re-populate the validation_result rendered_content
Returns:
validation_result
"""
if validations_store_name is None:
validations_store_name = self.validations_store_name
selected_store = self.stores[validations_store_name]
if run_id is None or batch_identifier is None:
# Get most recent run id
# NOTE : This method requires a (potentially very inefficient) list_keys call.
# It should probably move to live in an appropriate Store class,
# but when we do so, that Store will need to function as more than just a key-value Store.
key_list = selected_store.list_keys()
filtered_key_list = []
for key in key_list:
if run_id is not None and key.run_id != run_id:
continue
if (
batch_identifier is not None
and key.batch_identifier != batch_identifier
):
continue
filtered_key_list.append(key)
# run_id_set = set([key.run_id for key in filtered_key_list])
if len(filtered_key_list) == 0:
logger.warning("No valid run_id values found.")
return {}
filtered_key_list = sorted(filtered_key_list, key=lambda x: x.run_id)
if run_id is None:
run_id = filtered_key_list[-1].run_id
if batch_identifier is None:
batch_identifier = filtered_key_list[-1].batch_identifier
if include_rendered_content is None:
include_rendered_content = (
self._determine_if_expectation_validation_result_include_rendered_content()
)
key = ValidationResultIdentifier(
expectation_suite_identifier=ExpectationSuiteIdentifier(
expectation_suite_name=expectation_suite_name
),
run_id=run_id,
batch_identifier=batch_identifier,
)
results_dict = selected_store.get(key)
validation_result = (
results_dict.get_failed_validation_results()
if failed_only
else results_dict
)
if include_rendered_content:
for expectation_validation_result in validation_result.results:
expectation_validation_result.render()
expectation_validation_result.expectation_config.render()
return validation_result
def store_validation_result_metrics(
self, requested_metrics, validation_results, target_store_name
) -> None:
self._store_metrics(requested_metrics, validation_results, target_store_name)
def _store_metrics(
self, requested_metrics, validation_results, target_store_name
) -> None:
"""
requested_metrics is a dictionary like this:
requested_metrics:
*: The asterisk here matches *any* expectation suite name
use the 'kwargs' key to request metrics that are defined by kwargs,
for example because they are defined only for a particular column
- column:
Age:
- expect_column_min_to_be_between.result.observed_value
- statistics.evaluated_expectations
- statistics.successful_expectations
"""
expectation_suite_name = validation_results.meta["expectation_suite_name"]
run_id = validation_results.meta["run_id"]
data_asset_name = validation_results.meta.get("batch_kwargs", {}).get(
"data_asset_name"
)
for expectation_suite_dependency, metrics_list in requested_metrics.items():
if (expectation_suite_dependency != "*") and (
expectation_suite_dependency != expectation_suite_name
):
continue
if not isinstance(metrics_list, list):
raise ge_exceptions.DataContextError(
"Invalid requested_metrics configuration: metrics requested for "
"each expectation suite must be a list."
)
for metric_configuration in metrics_list:
metric_configurations = (
AbstractDataContext._get_metric_configuration_tuples(
metric_configuration
)
)
for metric_name, metric_kwargs in metric_configurations:
try:
metric_value = validation_results.get_metric(
metric_name, **metric_kwargs
)
self.stores[target_store_name].set(
ValidationMetricIdentifier(
run_id=run_id,
data_asset_name=data_asset_name,
expectation_suite_identifier=ExpectationSuiteIdentifier(
expectation_suite_name
),
metric_name=metric_name,
metric_kwargs_id=get_metric_kwargs_id(
metric_name, metric_kwargs
),
),
metric_value,
)
except ge_exceptions.UnavailableMetricError:
# This will happen frequently in larger pipelines
logger.debug(
"metric {} was requested by another expectation suite but is not available in "
"this validation result.".format(metric_name)
)
def send_usage_message(
self, event: str, event_payload: Optional[dict], success: Optional[bool] = None
) -> None:
"""helper method to send a usage method using DataContext. Used when sending usage events from
classes like ExpectationSuite.
event
Args:
event (str): str representation of event
event_payload (dict): optional event payload
success (bool): optional success param
Returns:
None
"""
send_usage_message(self, event, event_payload, success)
def _determine_if_expectation_suite_include_rendered_content(
self, include_rendered_content: Optional[bool] = None
) -> bool:
if include_rendered_content is None:
if (
self.include_rendered_content.expectation_suite is True
or self.include_rendered_content.globally is True
):
return True
else:
return False
return include_rendered_content
def _determine_if_expectation_validation_result_include_rendered_content(
self, include_rendered_content: Optional[bool] = None
) -> bool:
if include_rendered_content is None:
if (
self.include_rendered_content.expectation_validation_result is True
or self.include_rendered_content.globally is True
):
return True
else:
return False
return include_rendered_content
@staticmethod
def _determine_save_changes_flag(save_changes: Optional[bool]) -> bool:
"""
This method is meant to enable the gradual deprecation of the `save_changes` boolean
flag on various Datasource CRUD methods. Moving forward, we will always persist changes
made by these CRUD methods (a.k.a. the behavior created by save_changes=True).
As part of this effort, `save_changes` has been set to `None` as a default value
and will be automatically converted to `True` within this method. If a user passes in a boolean
value (thereby bypassing the default arg of `None`), a deprecation warning will be raised.
"""
if save_changes is not None:
# deprecated-v0.15.32
warnings.warn(
'The parameter "save_changes" is deprecated as of v0.15.32; moving forward, '
"changes made to Datasources will always be persisted by Store implementations. "
"As support will be removed in v0.18, please omit the argument moving forward.",
DeprecationWarning,
)
return save_changes
return True
def test_yaml_config( # noqa: C901 - complexity 17
self,
yaml_config: str,
name: Optional[str] = None,
class_name: Optional[str] = None,
runtime_environment: Optional[dict] = None,
pretty_print: bool = True,
return_mode: Literal[
"instantiated_class", "report_object"
] = "instantiated_class",
shorten_tracebacks: bool = False,
):
"""Convenience method for testing yaml configs
test_yaml_config is a convenience method for configuring the moving
parts of a Great Expectations deployment. It allows you to quickly
test out configs for system components, especially Datasources,
Checkpoints, and Stores.
For many deployments of Great Expectations, these components (plus
Expectations) are the only ones you'll need.
test_yaml_config is mainly intended for use within notebooks and tests.
--Public API--
--Documentation--
https://docs.greatexpectations.io/docs/terms/data_context
https://docs.greatexpectations.io/docs/guides/validation/checkpoints/how_to_configure_a_new_checkpoint_using_test_yaml_config
Args:
yaml_config: A string containing the yaml config to be tested
name: (Optional) A string containing the name of the component to instantiate
pretty_print: Determines whether to print human-readable output
return_mode: Determines what type of object test_yaml_config will return.
Valid modes are "instantiated_class" and "report_object"
shorten_tracebacks:If true, catch any errors during instantiation and print only the
last element of the traceback stack. This can be helpful for
rapid iteration on configs in a notebook, because it can remove
the need to scroll up and down a lot.
Returns:
The instantiated component (e.g. a Datasource)
OR
a json object containing metadata from the component's self_check method.
The returned object is determined by return_mode.
"""
yaml_config_validator = _YamlConfigValidator(
data_context=self,
)
return yaml_config_validator.test_yaml_config(
yaml_config=yaml_config,
name=name,
class_name=class_name,
runtime_environment=runtime_environment,
pretty_print=pretty_print,
return_mode=return_mode,
shorten_tracebacks=shorten_tracebacks,
)
def profile_datasource( # noqa: C901 - complexity 25
self,
datasource_name,
batch_kwargs_generator_name=None,
data_assets=None,
max_data_assets=20,
profile_all_data_assets=True,
profiler=BasicDatasetProfiler,
profiler_configuration=None,
dry_run=False,
run_id=None,
additional_batch_kwargs=None,
run_name=None,
run_time=None,
):
"""Profile the named datasource using the named profiler.
Args:
datasource_name: the name of the datasource for which to profile data_assets
batch_kwargs_generator_name: the name of the batch kwargs generator to use to get batches
data_assets: list of data asset names to profile
max_data_assets: if the number of data assets the batch kwargs generator yields is greater than this max_data_assets,
profile_all_data_assets=True is required to profile all
profile_all_data_assets: when True, all data assets are profiled, regardless of their number
profiler: the profiler class to use
profiler_configuration: Optional profiler configuration dict
dry_run: when true, the method checks arguments and reports if can profile or specifies the arguments that are missing
additional_batch_kwargs: Additional keyword arguments to be provided to get_batch when loading the data asset.
Returns:
A dictionary::
{
"success": True/False,
"results": List of (expectation_suite, EVR) tuples for each of the data_assets found in the datasource
}
When success = False, the error details are under "error" key
"""
# We don't need the datasource object, but this line serves to check if the datasource by the name passed as
# an arg exists and raise an error if it does not.
datasource = self.get_datasource(datasource_name)
assert datasource
if not dry_run:
logger.info(f"Profiling '{datasource_name}' with '{profiler.__name__}'")
profiling_results = {}
# Build the list of available data asset names (each item a tuple of name and type)
data_asset_names_dict = self.get_available_data_asset_names(datasource_name)
available_data_asset_name_list = []
try:
datasource_data_asset_names_dict = data_asset_names_dict[datasource_name]
except KeyError:
# KeyError will happen if there is not datasource
raise ge_exceptions.ProfilerError(f"No datasource {datasource_name} found.")
if batch_kwargs_generator_name is None:
# if no generator name is passed as an arg and the datasource has only
# one generator with data asset names, use it.
# if ambiguous, raise an exception
for name in datasource_data_asset_names_dict.keys():
if batch_kwargs_generator_name is not None:
profiling_results = {
"success": False,
"error": {
"code": self.PROFILING_ERROR_CODE_MULTIPLE_BATCH_KWARGS_GENERATORS_FOUND
},
}
return profiling_results
if len(datasource_data_asset_names_dict[name]["names"]) > 0:
available_data_asset_name_list = datasource_data_asset_names_dict[
name
]["names"]
batch_kwargs_generator_name = name
if batch_kwargs_generator_name is None:
profiling_results = {
"success": False,
"error": {
"code": self.PROFILING_ERROR_CODE_NO_BATCH_KWARGS_GENERATORS_FOUND
},
}
return profiling_results
else:
# if the generator name is passed as an arg, get this generator's available data asset names
try:
available_data_asset_name_list = datasource_data_asset_names_dict[
batch_kwargs_generator_name
]["names"]
except KeyError:
raise ge_exceptions.ProfilerError(
"batch kwargs Generator {} not found. Specify the name of a generator configured in this datasource".format(
batch_kwargs_generator_name
)
)
available_data_asset_name_list = sorted(
available_data_asset_name_list, key=lambda x: x[0]
)
if len(available_data_asset_name_list) == 0:
raise ge_exceptions.ProfilerError(
"No Data Assets found in Datasource {}. Used batch kwargs generator: {}.".format(
datasource_name, batch_kwargs_generator_name
)
)
total_data_assets = len(available_data_asset_name_list)
if isinstance(data_assets, list) and len(data_assets) > 0:
not_found_data_assets = [
name
for name in data_assets
if name not in [da[0] for da in available_data_asset_name_list]
]
if len(not_found_data_assets) > 0:
profiling_results = {
"success": False,
"error": {
"code": self.PROFILING_ERROR_CODE_SPECIFIED_DATA_ASSETS_NOT_FOUND,
"not_found_data_assets": not_found_data_assets,
"data_assets": available_data_asset_name_list,
},
}
return profiling_results
data_assets.sort()
data_asset_names_to_profiled = data_assets
total_data_assets = len(available_data_asset_name_list)
if not dry_run:
logger.info(
f"Profiling the white-listed data assets: {','.join(data_assets)}, alphabetically."
)
else:
if not profile_all_data_assets:
if total_data_assets > max_data_assets:
profiling_results = {
"success": False,
"error": {
"code": self.PROFILING_ERROR_CODE_TOO_MANY_DATA_ASSETS,
"num_data_assets": total_data_assets,
"data_assets": available_data_asset_name_list,
},
}
return profiling_results
data_asset_names_to_profiled = [
name[0] for name in available_data_asset_name_list
]
if not dry_run:
logger.info(
f"Profiling all {len(available_data_asset_name_list)} data assets from batch kwargs generator {batch_kwargs_generator_name}"
)
else:
logger.info(
f"Found {len(available_data_asset_name_list)} data assets from batch kwargs generator {batch_kwargs_generator_name}"
)
profiling_results["success"] = True
if not dry_run:
profiling_results["results"] = []
total_columns, total_expectations, total_rows, skipped_data_assets = (
0,
0,
0,
0,
)
total_start_time = datetime.datetime.now()
for name in data_asset_names_to_profiled:
logger.info(f"\tProfiling '{name}'...")
try:
profiling_results["results"].append(
self.profile_data_asset(
datasource_name=datasource_name,
batch_kwargs_generator_name=batch_kwargs_generator_name,
data_asset_name=name,
profiler=profiler,
profiler_configuration=profiler_configuration,
run_id=run_id,
additional_batch_kwargs=additional_batch_kwargs,
run_name=run_name,
run_time=run_time,
)["results"][0]
)
except ge_exceptions.ProfilerError as err:
logger.warning(err.message)
except OSError as err:
logger.warning(
f"IOError while profiling {name[1]}. (Perhaps a loading error?) Skipping."
)
logger.debug(str(err))
skipped_data_assets += 1
except SQLAlchemyError as e:
logger.warning(
f"SqlAlchemyError while profiling {name[1]}. Skipping."
)
logger.debug(str(e))
skipped_data_assets += 1
total_duration = (
datetime.datetime.now() - total_start_time
).total_seconds()
logger.info(
f"""
Profiled {len(data_asset_names_to_profiled)} of {total_data_assets} named data assets, with {total_rows} total rows and {total_columns} columns in {total_duration:.2f} seconds.
Generated, evaluated, and stored {total_expectations} Expectations during profiling. Please review results using data-docs."""
)
if skipped_data_assets > 0:
logger.warning(
f"Skipped {skipped_data_assets} data assets due to errors."
)
profiling_results["success"] = True
return profiling_results
@usage_statistics_enabled_method(
event_name=UsageStatsEvents.DATA_CONTEXT_BUILD_DATA_DOCS,
)
def build_data_docs(
self,
site_names=None,
resource_identifiers=None,
dry_run=False,
build_index: bool = True,
):
"""
Build Data Docs for your project.
These make it simple to visualize data quality in your project. These
include Expectations, Validations & Profiles. The are built for all
Datasources from JSON artifacts in the local repo including validations
& profiles from the uncommitted directory.
:param site_names: if specified, build data docs only for these sites, otherwise,
build all the sites specified in the context's config
:param resource_identifiers: a list of resource identifiers (ExpectationSuiteIdentifier,
ValidationResultIdentifier). If specified, rebuild HTML
(or other views the data docs sites are rendering) only for
the resources in this list. This supports incremental build
of data docs sites (e.g., when a new validation result is created)
and avoids full rebuild.
:param dry_run: a flag, if True, the method returns a structure containing the
URLs of the sites that *would* be built, but it does not build
these sites. The motivation for adding this flag was to allow
the CLI to display the the URLs before building and to let users
confirm.
:param build_index: a flag if False, skips building the index page
Returns:
A dictionary with the names of the updated data documentation sites as keys and the the location info
of their index.html files as values
"""
logger.debug("Starting DataContext.build_data_docs")
index_page_locator_infos = {}
sites = self.variables.data_docs_sites
if sites:
logger.debug("Found data_docs_sites. Building sites...")
for site_name, site_config in sites.items():
logger.debug(
f"Building Data Docs Site {site_name}",
)
if (site_names and (site_name in site_names)) or not site_names:
complete_site_config = site_config
module_name = "great_expectations.render.renderer.site_builder"
site_builder: SiteBuilder = (
self._init_site_builder_for_data_docs_site_creation(
site_name=site_name,
site_config=site_config,
)
)
if not site_builder:
raise ge_exceptions.ClassInstantiationError(
module_name=module_name,
package_name=None,
class_name=complete_site_config["class_name"],
)
if dry_run:
index_page_locator_infos[
site_name
] = site_builder.get_resource_url(only_if_exists=False)
else:
index_page_resource_identifier_tuple = site_builder.build(
resource_identifiers,
build_index=build_index,
)
if index_page_resource_identifier_tuple:
index_page_locator_infos[
site_name
] = index_page_resource_identifier_tuple[0]
else:
logger.debug("No data_docs_config found. No site(s) built.")
return index_page_locator_infos
def _init_site_builder_for_data_docs_site_creation(
self,
site_name: str,
site_config: dict,
) -> SiteBuilder:
site_builder: SiteBuilder = instantiate_class_from_config(
config=site_config,
runtime_environment={
"data_context": self,
"root_directory": self.root_directory,
"site_name": site_name,
},
config_defaults={
"module_name": "great_expectations.render.renderer.site_builder"
},
)
return site_builder
def escape_all_config_variables(
self,
value: T,
dollar_sign_escape_string: str = DOLLAR_SIGN_ESCAPE_STRING,
skip_if_substitution_variable: bool = True,
) -> T:
"""
Replace all `$` characters with the DOLLAR_SIGN_ESCAPE_STRING
Args:
value: config variable value
dollar_sign_escape_string: replaces instances of `$`
skip_if_substitution_variable: skip if the value is of the form ${MYVAR} or $MYVAR
Returns:
input value with all `$` characters replaced with the escape string
"""
if isinstance(value, dict) or isinstance(value, OrderedDict):
return { # type: ignore[return-value] # recursive call expects str
k: self.escape_all_config_variables(
value=v,
dollar_sign_escape_string=dollar_sign_escape_string,
skip_if_substitution_variable=skip_if_substitution_variable,
)
for k, v in value.items()
}
elif isinstance(value, list):
return [
self.escape_all_config_variables(
value=v,
dollar_sign_escape_string=dollar_sign_escape_string,
skip_if_substitution_variable=skip_if_substitution_variable,
)
for v in value
]
if skip_if_substitution_variable:
if parse_substitution_variable(value) is None:
return value.replace("$", dollar_sign_escape_string)
return value
return value.replace("$", dollar_sign_escape_string)
def save_config_variable(
self,
config_variable_name: str,
value: Any,
skip_if_substitution_variable: bool = True,
) -> None:
r"""Save config variable value
Escapes $ unless they are used in substitution variables e.g. the $ characters in ${SOME_VAR} or $SOME_VAR are not escaped
Args:
config_variable_name: name of the property
value: the value to save for the property
skip_if_substitution_variable: set to False to escape $ in values in substitution variable form e.g. ${SOME_VAR} -> r"\${SOME_VAR}" or $SOME_VAR -> r"\$SOME_VAR"
Returns:
None
"""
config_variables = self.config_variables
value = self.escape_all_config_variables(
value,
self.DOLLAR_SIGN_ESCAPE_STRING,
skip_if_substitution_variable=skip_if_substitution_variable,
)
config_variables[config_variable_name] = value
# Required to call _variables instead of variables property because we don't want to trigger substitutions
config = self._variables.config
config_variables_filepath = config.config_variables_file_path
if not config_variables_filepath:
raise ge_exceptions.InvalidConfigError(
"'config_variables_file_path' property is not found in config - setting it is required to use this feature"
)
config_variables_filepath = os.path.join(
self.root_directory, config_variables_filepath # type: ignore[arg-type]
)
os.makedirs(os.path.dirname(config_variables_filepath), exist_ok=True)
if not os.path.isfile(config_variables_filepath):
logger.info(
"Creating new substitution_variables file at {config_variables_filepath}".format(
config_variables_filepath=config_variables_filepath
)
)
with open(config_variables_filepath, "w") as template:
template.write(CONFIG_VARIABLES_TEMPLATE)
with open(config_variables_filepath, "w") as config_variables_file:
yaml.dump(config_variables, config_variables_file)
<file_sep>/docs/guides/connecting_to_your_data/connect_to_data_overview.md
---
title: "Connect to data: Overview"
---
# [](./connect_to_data_overview.md) Connect to data: Overview
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
<!--Use 'inactive' or 'active' to indicate which Universal Map steps this term has a use case within.-->
<UniversalMap setup='inactive' connect='active' create='inactive' validate='inactive'/>
<!-- Only keep one of the 'To best understand this document' lines. For processes like the Universal Map steps, use the first one. For processes like the Architecture Reviews, use the second one. -->
:::note Prerequisites
- Completing [Step 2: Connect to data](../../tutorials/getting_started/tutorial_connect_to_data.md) of the Getting Started tutorial is recommended.
:::
Connecting to your data in Great Expectations is designed to be a painless process. Once you have performed this step, you will have a consistent API for accessing and validating data on all kinds of source data systems: SQL-type data sources, local and remote file stores, in-memory data frames, and more.
## The connect to data process
<!-- Brief outline of what the process entails. -->
Connecting to your data is built around the <TechnicalTag tag="datasource" text="Datasource" /> object. A Datasource provides a standard API for accessing and interacting with data from a wide variety of source systems. This makes working with Datasources very convenient!

Behind the scenes, however, the Datasource is doing a lot of work for you. The Datasource provides an interface for a <TechnicalTag tag="data_connector" text="Data Connector" /> and an <TechnicalTag tag="execution_engine" text="Execution Engine" /> to work together, and handles all the heavy lifting involved in communication between Great Expectations and your source data systems.

The majority of the work involved in connecting to data is a simple matter of configuring a new Datasource according to the requirements of your underlying data system. Once your Datasource is configured and saved to your <TechnicalTag tag="data_context" text="Data Context" /> you will only need to use the Datasource API to access and interact with your data, regardless of the original source system (or systems) that your data is stored in.
<!-- The following subsections should be repeated as necessary. They should give a high level map of the things that need to be done or optionally can be done in this process, preferably in the order that they should be addressed (assuming there is one). If the process crosses multiple steps of the Universal Map, use the <SetupHeader> <ConnectHeader> <CreateHeader> and <ValidateHeader> tags to indicate which Universal Map step the subsections fall under. -->
### 1. Prepare scaffolding
If you use the Great Expectations <TechnicalTag tag="cli" text="CLI" />, you can run this command to automatically generate a pre-configured Jupyter Notebook:
```console
great_expectations datasource new
```
From there, you will be able to follow along a YAML based workflow for configuring and saving your Datasource. Whether you prefer to work with the Jupyter Notebook's boilerplate for creating a datasource, or would rather dive in from scratch with a Python script, however, most of the work will take place in the configuring of the Datasource in question.
### 2. Configure your Datasource
Because the underlying data systems are different, configuration for each type of Datasource is slightly different. We have step by step how-to guides that cover many common cases, and core concepts documentation to help you with more exotic kinds of configuration. It is strongly advised that you find the guide that pertains to your use case and follow it. If you are simply interested in learning about the process, however, the following will give you a broad overview of what you will be doing regardless of what your underlying data systems are.
Datasource configurations can be written as YAML files or Python dictionaries. Regardless of variations due to the underlying data systems, your Datasource's configuration will look roughly like this:
<Tabs
groupId="yaml-or-python"
defaultValue='yaml'
values={[
{label: 'YAML', value:'yaml'},
{label: 'Python', value:'python'},
]}>
<TabItem value="yaml">
```python
datasource_yaml = fr"""
name: <name_of_your_datasource>
class_name: Datasource
execution_engine:
class_name: <class_of_execution_engine>
data_connectors:
<name_of_your_data_connector>:
class_name: <class_of_data_connector>
<additional_keys_based_on_source_data_system>: <corresponding_values>
"""
```
</TabItem>
<TabItem value="python">
```python
datasource_config = {
"name": "<name_of_your_datasource>",
"class_name": "Datasource",
"execution_engine": {"class_name": "<class_of_execution_engine>"},
"data_connectors": {
"<name_of_your_data_connector>": {
"class_name": "<class_of_data_connector>",
"<additional_keys_based_on_source_data_system>": "<corresponding_values>"
}
}
}
```
</TabItem>
</Tabs>
Please note that this is just a broad outline of the configuration you will be making. You will find much more detailed examples in our documentation on how to connect to specific source data systems.
The `name` and `class_name` top level keys will be the first you need to define. The `name` key can be anything you want, but it is best to use a descriptive name as you will use this to reference your Datasource in the future. Unless you are extending Great Expectations and using a subclass of Datasource, you will almost never need to use a `class_name` other than `Datasource` for the top level `class_name` value.
#### Configuring your Datasource's Execution Engine
After your Datasource's configuration has a `name` and `class_name` defined, you will need to define a single `execution_engine`. In your configuration the value of your `execution_engine` will at the very least contain the `class_name` of your Execution Engine, and may also include a `connection_string` if your source data system requires one.
Great Expectations supports Pandas, Spark, and SqlAlchemy as execution engines. The corresponding Execution Engine class names are `PandasExecutionEngine`, `SparkDFExecutionEngine`, and `SqlAlchemyExecutionEngine`.
#### Configuring your Datasource's Data Connectors
Great Expectations provides three types of `DataConnector` classes, which are useful in various situations. Which Data Connector you will want to use will depend on the format of your source data systems.
- In filesystems, an `InferredAssetDataConnector` infers the `data_asset_name` by using a regex that takes advantage of patterns that exist in the filename or folder structure. If your source data system is designed so that it can easily be parsed by regex, this will allow new data to be included by the Datasource automatically. The `InferredAssetSqlDataConnector` provides similar functionality for SQL based source data systems.
- A `ConfiguredAssetDataConnector`, which allows you to have the most fine-tuning by requiring an explicit listing of each <TechnicalTag tag="data_asset" text="Data Asset" /> you want to connect to.
- A `RuntimeDataConnector` which enables you to use a `RuntimeBatchRequest` to wrap either an in-memory dataframe, filepath, or SQL query.
In the `data_connectors` dictionary you may define multiple Data Connectors, including different types of Data Connectors, so long as they all have unique values in the place of the `<name_of_your_data_connector>` key. We provide detailed guidance to help you decide on which Data Connectors to use in our guide: [How to choose which DataConnector to use](./how_to_choose_which_dataconnector_to_use.md).
The `<additional_keys_based_on_source_data_system>` will be things like `batch_identifiers`, `base_directory`, and `default_regex` for filesystems, or `batch_identifiers` for SQL based data systems. For specifics on the additional keys that you can use in your Data Connectors' configurations, please see the corresponding guide for connecting to a specific source data system (since the keys you will need to define will depend on the source data system you are connecting to).
### 3. Test your configuration
Because the configurations for Datasources can vary depending on the underlying data system they are connecting to, Great Expectations provides a convenience function that will help you determine if there are errors in your configuration. This function is `test_yaml_config()`. Using `test_yaml_config` in a Jupyter Notebook is our recommended method for testing Datasource configuration. Of course, you can always edit and test YAML configs manually, and instantiate Datasources through code. When executed, `test_yaml_config()` will instantiate the component and run through a self check procedure to verify the component works as expected.
In the case of a Datasource, this means:
- confirming that the connection works.
- gathering a list of available DataAssets (e.g. tables in SQL; files or folders in a filesystem)
- verifying that it can successfully fetch at least one <TechnicalTag tag="batch" text="Batch" /> from the source.
If something about your configuration wasn't set up correctly, `test_yaml_config()` will raise an error. Whenever possible, `test_yaml_config()` provides helpful warnings and error messages. It can't solve every problem, but it can solve many.
You can call `test_yaml_config()` from your Data Context, like so:
<Tabs
groupId="yaml-or-python"
defaultValue='yaml'
values={[
{label: 'YAML', value:'yaml'},
{label: 'Python', value:'python'},
]}>
<TabItem value="yaml">
```python
import great_expectations as ge
datasource_yaml = "" # Replace this with the yaml string you want to check for errors.
context = ge.get_context()
context.test_yaml_config(datasource_yaml)
```
</TabItem>
<TabItem value="python">
```python
import great_expectations as ge
from ruamel import yaml
datasource_config = {} # Replace this with the Python dictionary you want to check for errors.
context = ge.get_context()
context.test_yaml_config(yaml.dump(datasource_config))
```
</TabItem>
</Tabs>
From here, iterate by editing your config to add config blocks for additional introspection,Data Assets, sampling, etc. After each addition re-run `test_yaml_config()` to verify the addition is functional, then move on to the next iteration of editing your config.
### 4. Save the Datasource configuration to your Data Context.
What is the point of configuring a Datasource if you can't easily use it in the future? At this point you will want to save your Datasource configuration to your Data Context. This can be done easily by using the `add_datasource()` function, which is conveniently accessible from your Data Context.
<Tabs
groupId="yaml-or-python"
defaultValue='yaml'
values={[
{label: 'YAML', value:'yaml'},
{label: 'Python', value:'python'},
]}>
<TabItem value="yaml">
The function `add_datasource()` takes in a series of named arguments corresponding to the keys in your `datasource_yaml` string. Fortunately, python and the `yaml` module provide a convenient way to unpack yaml strings into named arguements so you don't have to.
First, you will want to import the yaml module with the command:
```python
from ruamel import yaml
```
After that, the following code snippet will unpack your yaml string and save your Datasource configuration to the Data Context:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/database/mysql_yaml_example.py#L44
```
</TabItem>
<TabItem value="python">
The function `add_datasource()` takes in a series of named arguments corresponding to the keys in your `datasource_config` dictionary. Fortunately, python provides a convenient way to unpack dictionaries into named arguements, so you don't have to. The following code snippet will unpack the dictionary and save your Datasource configuration to the Data Context.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/database/mysql_python_example.py#L44
```
</TabItem>
</Tabs>
### 5. Test your new Datasource.
To test your Datasource you will load data from it into a <TechnicalTag tag="validator" text="Validator" /> using a <TechnicalTag tag="batch_request" text="Batch Request" />. All of our guides on how to configure a Datasource conclude with an example of how to do this for that guide's particular source data system. This is also a core part of using <TechnicalTag tag="profiler" text="Profilers" /> and <TechnicalTag tag="checkpoint" text="Checkpoints" />, so we will discuss it in more depth in the [Create Expectations](../expectations/create_expectations_overview.md) and [Validate Data](../validation/validate_data_overview.md) steps.
## Accessing your Datasource from your Data Context
If you need to directly access your Datasource in the future, the `get_datasource()` method of your Data Context will provide a convenient way to do so. You can also use the `list_datasources()` method of your Data Context to retrieve a list containing your datasource configurations.
## Retrieving Batches of data with your Datasource
This is primarily done when running Profilers in the Create Expectation step, or when running Checkpoints in the Validate Data step, and will be covered in more detail in those sections of the documentation.
## Wrapping up
<!-- This section is essentially a victory lap. It should reiterate what they have accomplished/are now capable of doing. If there is a next process (such as the universal map steps) this should state that the reader is now ready to move on to it. -->
With your Datasources defined, you will now have access to the data in your source systems from a single, consistent API. From here you will move on to the next step of working with Great Expectations: Create Expectations.<file_sep>/great_expectations/experimental/datasources/interfaces.py
from __future__ import annotations
import dataclasses
import logging
from pprint import pformat as pf
from typing import TYPE_CHECKING, Any, Dict, List, Mapping, Optional, Set, Type
import pydantic
from typing_extensions import ClassVar, TypeAlias
from great_expectations.experimental.datasources.experimental_base_model import (
ExperimentalBaseModel,
)
from great_expectations.experimental.datasources.metadatasource import MetaDatasource
from great_expectations.experimental.datasources.sources import _SourceFactories
LOGGER = logging.getLogger(__name__)
if TYPE_CHECKING:
from great_expectations.core.batch import BatchDataType
from great_expectations.execution_engine import ExecutionEngine
# BatchRequestOptions is a dict that is composed into a BatchRequest that specifies the
# Batches one wants returned. The keys represent dimensions one can slice the data along
# and the values are the realized. If a value is None or unspecified, the batch_request
# will capture all data along this dimension. For example, if we have a year and month
# splitter and we want to query all months in the year 2020, the batch request options
# would look like:
# options = { "year": 2020 }
BatchRequestOptions: TypeAlias = Dict[str, Any]
@dataclasses.dataclass(frozen=True)
class BatchRequest:
datasource_name: str
data_asset_name: str
options: BatchRequestOptions
class DataAsset(ExperimentalBaseModel):
name: str
type: str
# non-field private attrs
_datasource: Datasource = pydantic.PrivateAttr()
@property
def datasource(self) -> Datasource:
return self._datasource
# TODO (kilo): remove setter and add custom init for DataAsset to inject datasource in constructor??
@datasource.setter
def datasource(self, ds: Datasource):
assert isinstance(ds, Datasource)
self._datasource = ds
def get_batch_request(self, options: Optional[BatchRequestOptions]) -> BatchRequest:
raise NotImplementedError
class Datasource(ExperimentalBaseModel, metaclass=MetaDatasource):
# class attrs
asset_types: ClassVar[List[Type[DataAsset]]] = []
# Datasource instance attrs but these will be fed into the `execution_engine` constructor
_excluded_eng_args: ClassVar[Set[str]] = {
"name",
"type",
"execution_engine",
"assets",
}
# Setting this in a Datasource subclass will override the execution engine type.
# The primary use case is to inject an execution engine for testing.
execution_engine_override: ClassVar[Optional[Type[ExecutionEngine]]] = None
# instance attrs
type: str
name: str
assets: Mapping[str, DataAsset] = {}
_execution_engine: ExecutionEngine = pydantic.PrivateAttr()
def __init__(self, **kwargs):
super().__init__(**kwargs)
engine_kwargs = {
k: v for (k, v) in kwargs.items() if k not in self._excluded_eng_args
}
self._execution_engine = self._execution_engine_type()(**engine_kwargs)
@property
def execution_engine(self) -> ExecutionEngine:
return self._execution_engine
class Config:
# TODO: revisit this (1 option - define __get_validator__ on ExecutionEngine)
# https://pydantic-docs.helpmanual.io/usage/types/#custom-data-types
arbitrary_types_allowed = True
@pydantic.validator("assets", pre=True)
@classmethod
def _load_asset_subtype(cls, v: Dict[str, dict]):
LOGGER.info(f"Loading 'assets' ->\n{pf(v, depth=3)}")
loaded_assets: Dict[str, DataAsset] = {}
# TODO (kilo59): catch key errors
for asset_name, config in v.items():
asset_type_name: str = config["type"]
asset_type: Type[DataAsset] = _SourceFactories.type_lookup[asset_type_name]
LOGGER.debug(f"Instantiating '{asset_type_name}' as {asset_type}")
loaded_assets[asset_name] = asset_type(**config)
LOGGER.debug(f"Loaded 'assets' ->\n{repr(loaded_assets)}")
return loaded_assets
def _execution_engine_type(self) -> Type[ExecutionEngine]:
"""Returns the execution engine to be used"""
return self.execution_engine_override or self.execution_engine_type()
def execution_engine_type(self) -> Type[ExecutionEngine]:
"""Return the ExecutionEngine type use for this Datasource"""
raise NotImplementedError(
"One needs to implement 'execution_engine_type' on a Datasource subclass"
)
def get_batch_list_from_batch_request(
self, batch_request: BatchRequest
) -> List[Batch]:
"""Processes a batch request and returns a list of batches.
Args:
batch_request: contains parameters necessary to retrieve batches.
Returns:
A list of batches. The list may be empty.
"""
raise NotImplementedError(
f"{self.__class__.__name__} must implement `.get_batch_list_from_batch_request()`"
)
def get_asset(self, asset_name: str) -> DataAsset:
"""Returns the DataAsset referred to by name"""
# This default implementation will be used if protocol is inherited
try:
return self.assets[asset_name]
except KeyError as exc:
raise LookupError(
f"'{asset_name}' not found. Available assets are {list(self.assets.keys())}"
) from exc
class Batch:
# Instance variable declarations
_datasource: Datasource
_data_asset: DataAsset
_batch_request: BatchRequest
_data: BatchDataType
_id: str
# metadata is any arbitrary data one wants to associate with a batch. GX will add arbitrary metadata
# to a batch so developers may want to namespace any custom metadata they add.
metadata: Dict[str, Any]
def __init__(
self,
datasource: Datasource,
data_asset: DataAsset,
batch_request: BatchRequest,
# BatchDataType is Union[core.batch.BatchData, pd.DataFrame, SparkDataFrame]. core.batch.Batchdata is the
# implicit interface that Datasource implementers can use. We can make this explicit if needed.
data: BatchDataType,
metadata: Optional[Dict[str, Any]] = None,
) -> None:
"""This represents a batch of data.
This is usually not the data itself but a hook to the data on an external datastore such as
a spark or a sql database. An exception exists for pandas or any in-memory datastore.
"""
# These properties are intended to be READ-ONLY
self._datasource: Datasource = datasource
self._data_asset: DataAsset = data_asset
self._batch_request: BatchRequest = batch_request
self._data: BatchDataType = data
self.metadata = metadata or {}
# computed property
# We need to unique identifier. This will likely change as I get more input
self._id: str = "-".join([datasource.name, data_asset.name, str(batch_request)])
@property
def datasource(self) -> Datasource:
return self._datasource
@property
def data_asset(self) -> DataAsset:
return self._data_asset
@property
def batch_request(self) -> BatchRequest:
return self._batch_request
@property
def id(self) -> str:
return self._id
@property
def data(self) -> BatchDataType:
return self._data
@property
def execution_engine(self) -> ExecutionEngine:
return self.datasource.execution_engine
<file_sep>/docs/tutorials/getting_started/tutorial_validate_data.md
---
title: 'Tutorial, Step 4: Validate data'
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '/docs/term_tags/_tag.mdx';
<UniversalMap setup='inactive' connect='inactive' create='inactive' validate='active'/>
:::note Prerequisites
- Completed [Step 3: Create Expectations](./tutorial_create_expectations.md) of this tutorial.
:::
### Set up a Checkpoint
Let’s set up our first <TechnicalTag relative="../../" tag="checkpoint" text="Checkpoint" />!
A Checkpoint runs an <TechnicalTag relative="../../" tag="expectation_suite" text="Expectation Suite" /> against a <TechnicalTag relative="../../" tag="batch" text="Batch" /> (or <TechnicalTag relative="../../" tag="batch_request" text="Batch Request" />). Running a Checkpoint produces <TechnicalTag relative="../../" tag="validation_result" text="Validation Results" />. Checkpoints can also be configured to perform additional <TechnicalTag relative="../../" tag="action" text="Actions" />.
For the purposes of this tutorial, the Checkpoint we create will run the Expectation Suite we previously configured against the data we provide. We will use it to verify that there are no unexpected changes in the February NYC taxi data compared to what our <TechnicalTag relative="../../" tag="profiler" text="Profiler" /> observed in the January NYC taxi data.
**Go back to your terminal** and shut down the Jupyter Notebook, if you haven’t yet. Then run the following command:
```console
great_expectations checkpoint new getting_started_checkpoint
```
This will **open a Jupyter Notebook** that will allow you to complete the configuration of your Checkpoint.
The Jupyter Notebook contains some boilerplate code that allows you to configure a new Checkpoint. The second code cell is pre-populated with an arbitrarily chosen Batch Request and Expectation Suite to get you started. Edit the `data_asset_name` to reference the data we want to validate (the February data), as follows:
```python file=../../../tests/integration/docusaurus/tutorials/getting-started/getting_started.py#L164-L177
```
You can then execute all cells in the notebook in order to store the Checkpoint to your Data Context.
#### What just happened?
- `getting_started_checkpoint` is the name of your new Checkpoint.
- The Checkpoint uses `getting_started_expectation_suite_taxi.demo` as its primary Expectation Suite.
- You configured the Checkpoint to validate the `yellow_tripdata_sample_2019-02.csv` (i.e. our February data) file.
### How to run validation and inspect your Validation Results
In order to build <TechnicalTag relative="../../" tag="data_docs" text="Data Docs" /> and get your results in a nice, human-readable format, you can simply uncomment and run the last cell in the notebook. This will open Data Docs, where you can click on the latest <TechnicalTag relative="../../" tag="validation" text="Validation" /> run to see the Validation Results page for this Checkpoint run.

You’ll see that the test suite failed when you ran it against the February data.
#### What just happened? Why did it fail?? Help!?
We ran the Checkpoint and it successfully failed! **Wait - what?** Yes, that’s correct, this indicates that the February data has data quality issues, which means we want the Validation to fail.
Click on the highlighted row to access the Validation Results page, which will tell us specifically what is wrong with the February data.

On the Validation Results page, you will see that the Validation of the staging data *failed* because the set of *Observed Values* in the `passenger_count` column contained the value `0`! This violates our Expectation, which makes the validation fail.
**And this is it!**
We have successfully created an Expectation Suite based on historical data, and used it to detect an issue with our new data. **Congratulations! You have now completed the “Getting started with Great Expectations” tutorial.**
<file_sep>/great_expectations/expectations/core/expect_column_values_to_be_in_set.py
from typing import List, Optional
from great_expectations.core import (
ExpectationConfiguration,
ExpectationValidationResult,
)
from great_expectations.expectations.expectation import (
ColumnMapExpectation,
InvalidExpectationConfigurationError,
)
from great_expectations.render import (
LegacyDescriptiveRendererType,
LegacyRendererType,
RenderedBulletListContent,
RenderedStringTemplateContent,
ValueListContent,
)
from great_expectations.render.renderer.renderer import renderer
from great_expectations.render.util import (
num_to_str,
parse_row_condition_string_pandas_engine,
substitute_none_for_missing,
)
from great_expectations.rule_based_profiler.config import (
ParameterBuilderConfig,
RuleBasedProfilerConfig,
)
from great_expectations.rule_based_profiler.parameter_container import (
DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
FULLY_QUALIFIED_PARAMETER_NAME_METADATA_KEY,
FULLY_QUALIFIED_PARAMETER_NAME_SEPARATOR_CHARACTER,
FULLY_QUALIFIED_PARAMETER_NAME_VALUE_KEY,
PARAMETER_KEY,
VARIABLES_KEY,
)
try:
import sqlalchemy as sa # noqa: F401
except ImportError:
pass
from great_expectations.expectations.expectation import (
add_values_with_json_schema_from_list_in_params,
render_evaluation_parameter_string,
)
class ExpectColumnValuesToBeInSet(ColumnMapExpectation):
"""Expect each column value to be in a given set.
For example:
::
# my_df.my_col = [1,2,2,3,3,3]
>>> my_df.expect_column_values_to_be_in_set(
"my_col",
[2,3]
)
{
"success": false
"result": {
"unexpected_count": 1
"unexpected_percent": 16.66666666666666666,
"unexpected_percent_nonmissing": 16.66666666666666666,
"partial_unexpected_list": [
1
],
},
}
expect_column_values_to_be_in_set is a \
:func:`column_map_expectation <great_expectations.execution_engine.execution_engine.MetaExecutionEngine
.column_map_expectation>`.
Args:
column (str): \
The column name.
value_set (set-like): \
A set of objects used for comparison.
Keyword Args:
mostly (None or a float between 0 and 1): \
Return `"success": True` if at least mostly fraction of values match the expectation. \
For more detail, see :ref:`mostly`.
parse_strings_as_datetimes (boolean or None) : If True values provided in value_set will be parsed as \
datetimes before making comparisons.
Other Parameters:
result_format (str or None): \
Which output mode to use: `BOOLEAN_ONLY`, `BASIC`, `COMPLETE`, or `SUMMARY`.
For more detail, see :ref:`result_format <result_format>`.
include_config (boolean): \
If True, then include the expectation config as part of the result object. \
For more detail, see :ref:`include_config`.
catch_exceptions (boolean or None): \
If True, then catch exceptions and include them as part of the result object. \
For more detail, see :ref:`catch_exceptions`.
meta (dict or None): \
A JSON-serializable dictionary (nesting allowed) that will be included in the output without \
modification. For more detail, see :ref:`meta`.
Returns:
An ExpectationSuiteValidationResult
Exact fields vary depending on the values passed to :ref:`result_format <result_format>` and
:ref:`include_config`, :ref:`catch_exceptions`, and :ref:`meta`.
See Also:
:func:`expect_column_values_to_not_be_in_set \
<great_expectations.execution_engine.execution_engine.ExecutionEngine
.expect_column_values_to_not_be_in_set>`
"""
# This dictionary contains metadata for display in the public gallery
library_metadata = {
"maturity": "production",
"tags": ["core expectation", "column map expectation"],
"contributors": ["@great_expectations"],
"requirements": [],
"has_full_test_suite": True,
"manually_reviewed_code": True,
}
map_metric = "column_values.in_set"
args_keys = (
"column",
"value_set",
)
success_keys = (
"value_set",
"mostly",
"parse_strings_as_datetimes",
"auto",
"profiler_config",
)
value_set_estimator_parameter_builder_config: ParameterBuilderConfig = (
ParameterBuilderConfig(
module_name="great_expectations.rule_based_profiler.parameter_builder",
class_name="ValueSetMultiBatchParameterBuilder",
name="value_set_estimator",
metric_domain_kwargs=DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME,
metric_value_kwargs=None,
evaluation_parameter_builder_configs=None,
)
)
validation_parameter_builder_configs: List[ParameterBuilderConfig] = [
value_set_estimator_parameter_builder_config,
]
default_profiler_config = RuleBasedProfilerConfig(
name="expect_column_values_to_be_in_set", # Convention: use "expectation_type" as profiler name.
config_version=1.0,
variables={},
rules={
"default_expect_column_values_to_be_in_set_rule": {
"variables": {
"mostly": 1.0,
},
"domain_builder": {
"class_name": "ColumnDomainBuilder",
"module_name": "great_expectations.rule_based_profiler.domain_builder",
},
"expectation_configuration_builders": [
{
"expectation_type": "expect_column_values_to_be_in_set",
"class_name": "DefaultExpectationConfigurationBuilder",
"module_name": "great_expectations.rule_based_profiler.expectation_configuration_builder",
"validation_parameter_builder_configs": validation_parameter_builder_configs,
"column": f"{DOMAIN_KWARGS_PARAMETER_FULLY_QUALIFIED_NAME}{FULLY_QUALIFIED_PARAMETER_NAME_SEPARATOR_CHARACTER}column",
"value_set": f"{PARAMETER_KEY}{value_set_estimator_parameter_builder_config.name}{FULLY_QUALIFIED_PARAMETER_NAME_SEPARATOR_CHARACTER}{FULLY_QUALIFIED_PARAMETER_NAME_VALUE_KEY}",
"mostly": f"{VARIABLES_KEY}mostly",
"meta": {
"profiler_details": f"{PARAMETER_KEY}{value_set_estimator_parameter_builder_config.name}{FULLY_QUALIFIED_PARAMETER_NAME_SEPARATOR_CHARACTER}{FULLY_QUALIFIED_PARAMETER_NAME_METADATA_KEY}",
},
},
],
},
},
)
default_kwarg_values = {
"value_set": [],
"parse_strings_as_datetimes": False,
"auto": False,
"profiler_config": default_profiler_config,
}
@classmethod
def _atomic_prescriptive_template(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
language: Optional[str] = None,
runtime_configuration: Optional[dict] = None,
**kwargs,
):
runtime_configuration = runtime_configuration or {}
include_column_name = (
False if runtime_configuration.get("include_column_name") is False else True
)
styling = runtime_configuration.get("styling")
params = substitute_none_for_missing(
configuration.kwargs,
[
"column",
"value_set",
"mostly",
"parse_strings_as_datetimes",
"row_condition",
"condition_parser",
],
)
params_with_json_schema = {
"column": {"schema": {"type": "string"}, "value": params.get("column")},
"value_set": {
"schema": {"type": "array"},
"value": params.get("value_set"),
},
"mostly": {"schema": {"type": "number"}, "value": params.get("mostly")},
"mostly_pct": {
"schema": {"type": "string"},
"value": params.get("mostly_pct"),
},
"parse_strings_as_datetimes": {
"schema": {"type": "boolean"},
"value": params.get("parse_strings_as_datetimes"),
},
"row_condition": {
"schema": {"type": "string"},
"value": params.get("row_condition"),
},
"condition_parser": {
"schema": {"type": "string"},
"value": params.get("condition_parser"),
},
}
if params["value_set"] is None or len(params["value_set"]) == 0:
values_string = "[ ]"
else:
for i, v in enumerate(params["value_set"]):
params[f"v__{str(i)}"] = v
values_string = " ".join(
[f"$v__{str(i)}" for i, v in enumerate(params["value_set"])]
)
template_str = f"values must belong to this set: {values_string}"
if params["mostly"] is not None and params["mostly"] < 1.0:
params_with_json_schema["mostly_pct"]["value"] = num_to_str(
params["mostly"] * 100, precision=15, no_scientific=True
)
# params["mostly_pct"] = "{:.14f}".format(params["mostly"]*100).rstrip("0").rstrip(".")
template_str += ", at least $mostly_pct % of the time."
else:
template_str += "."
if params.get("parse_strings_as_datetimes"):
template_str += " Values should be parsed as datetimes."
if include_column_name:
template_str = f"$column {template_str}"
if params["row_condition"] is not None:
(
conditional_template_str,
conditional_params,
) = parse_row_condition_string_pandas_engine(
params["row_condition"], with_schema=True
)
template_str = f"{conditional_template_str}, then {template_str}"
params_with_json_schema.update(conditional_params)
params_with_json_schema = add_values_with_json_schema_from_list_in_params(
params=params,
params_with_json_schema=params_with_json_schema,
param_key_with_list="value_set",
)
return (template_str, params_with_json_schema, styling)
@classmethod
@renderer(renderer_type=LegacyRendererType.PRESCRIPTIVE)
@render_evaluation_parameter_string
def _prescriptive_renderer(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
language: Optional[str] = None,
runtime_configuration: Optional[dict] = None,
**kwargs,
):
runtime_configuration = runtime_configuration or {}
include_column_name = (
False if runtime_configuration.get("include_column_name") is False else True
)
styling = runtime_configuration.get("styling")
params = substitute_none_for_missing(
configuration.kwargs,
[
"column",
"value_set",
"mostly",
"parse_strings_as_datetimes",
"row_condition",
"condition_parser",
],
)
if params["value_set"] is None or len(params["value_set"]) == 0:
values_string = "[ ]"
else:
for i, v in enumerate(params["value_set"]):
params[f"v__{str(i)}"] = v
values_string = " ".join(
[f"$v__{str(i)}" for i, v in enumerate(params["value_set"])]
)
template_str = f"values must belong to this set: {values_string}"
if params["mostly"] is not None and params["mostly"] < 1.0:
params["mostly_pct"] = num_to_str(
params["mostly"] * 100, precision=15, no_scientific=True
)
# params["mostly_pct"] = "{:.14f}".format(params["mostly"]*100).rstrip("0").rstrip(".")
template_str += ", at least $mostly_pct % of the time."
else:
template_str += "."
if params.get("parse_strings_as_datetimes"):
template_str += " Values should be parsed as datetimes."
if include_column_name:
template_str = f"$column {template_str}"
if params["row_condition"] is not None:
(
conditional_template_str,
conditional_params,
) = parse_row_condition_string_pandas_engine(params["row_condition"])
template_str = f"{conditional_template_str}, then {template_str}"
params.update(conditional_params)
return [
RenderedStringTemplateContent(
**{
"content_block_type": "string_template",
"string_template": {
"template": template_str,
"params": params,
"styling": styling,
},
}
)
]
@classmethod
@renderer(renderer_type=LegacyDescriptiveRendererType.EXAMPLE_VALUES_BLOCK)
def _descriptive_example_values_block_renderer(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
language: Optional[str] = None,
runtime_configuration: Optional[dict] = None,
**kwargs,
):
assert result, "Must pass in result."
if "partial_unexpected_counts" in result.result:
partial_unexpected_counts = result.result["partial_unexpected_counts"]
values = [str(v["value"]) for v in partial_unexpected_counts]
elif "partial_unexpected_list" in result.result:
values = [str(item) for item in result.result["partial_unexpected_list"]]
else:
return
classes = ["col-3", "mt-1", "pl-1", "pr-1"]
if any(len(value) > 80 for value in values):
content_block_type = "bullet_list"
content_block_class = RenderedBulletListContent
else:
content_block_type = "value_list"
content_block_class = ValueListContent
new_block = content_block_class(
**{
"content_block_type": content_block_type,
"header": RenderedStringTemplateContent(
**{
"content_block_type": "string_template",
"string_template": {
"template": "Example Values",
"tooltip": {"content": "expect_column_values_to_be_in_set"},
"tag": "h6",
},
}
),
content_block_type: [
{
"content_block_type": "string_template",
"string_template": {
"template": "$value",
"params": {"value": value},
"styling": {
"default": {
"classes": ["badge", "badge-info"]
if content_block_type == "value_list"
else [],
"styles": {"word-break": "break-all"},
},
},
},
}
for value in values
],
"styling": {
"classes": classes,
},
}
)
return new_block
def validate_configuration(
self, configuration: Optional[ExpectationConfiguration]
) -> None:
super().validate_configuration(configuration)
# supports extensibility by allowing value_set to not be provided in config but captured via child-class default_kwarg_values, e.g. parameterized expectations
value_set = configuration.kwargs.get(
"value_set"
) or self.default_kwarg_values.get("value_set")
try:
assert (
"value_set" in configuration.kwargs or value_set
), "value_set is required"
assert isinstance(
value_set, (list, set, dict)
), "value_set must be a list, set, or dict"
if isinstance(value_set, dict):
assert (
"$PARAMETER" in value_set
), 'Evaluation Parameter dict for value_set kwarg must have "$PARAMETER" key.'
except AssertionError as e:
raise InvalidExpectationConfigurationError(str(e))
<file_sep>/docs/reference/supplemental_documentation.md
---
title: Supplemental Documentation
---
In this section you will find documents that don't necessarily fit in any specific step in the process of working with Great Expectations. This includes things that apply to every step of the process, such as our guide on How to use the CLI or our overview of ways to customize your deployment as well as things that matter outside the process, or that don't fall into a specific how-to guide, such as this discussion on Data Discovery.
## Index
- [How to use the Great Expectations command line interface (CLI)](../guides/miscellaneous/how_to_use_the_great_expectations_cli.md)
- [How to use the project check-config command](../guides/miscellaneous/how_to_use_the_project_check_config_command.md)
- [Customize your deployment](./customize_your_deployment.md)
- [Usage Statistics](./anonymous_usage_statistics.md)<file_sep>/tests/experimental/datasources/conftest.py
import logging
from typing import Callable, Dict, Tuple
import pytest
from pytest import MonkeyPatch
from great_expectations.execution_engine import (
ExecutionEngine,
SqlAlchemyExecutionEngine,
)
from great_expectations.experimental.datasources.metadatasource import MetaDatasource
LOGGER = logging.getLogger(__name__)
from great_expectations.core.batch import BatchData
from great_expectations.core.batch_spec import (
BatchMarkers,
SqlAlchemyDatasourceBatchSpec,
)
from great_expectations.experimental.datasources.sources import _SourceFactories
def sqlachemy_execution_engine_mock_cls(
validate_batch_spec: Callable[[SqlAlchemyDatasourceBatchSpec], None]
):
class MockSqlAlchemyExecutionEngine(SqlAlchemyExecutionEngine):
def __init__(self, *args, **kwargs):
pass
def get_batch_data_and_markers( # type: ignore[override]
self, batch_spec: SqlAlchemyDatasourceBatchSpec
) -> Tuple[BatchData, BatchMarkers]:
validate_batch_spec(batch_spec)
return BatchData(self), BatchMarkers(ge_load_time=None)
return MockSqlAlchemyExecutionEngine
class ExecutionEngineDouble:
def __init__(self, *args, **kwargs):
pass
def get_batch_data_and_markers(self, batch_spec) -> Tuple[BatchData, BatchMarkers]:
return BatchData(self), BatchMarkers(ge_load_time=None)
@pytest.fixture
def inject_engine_lookup_double(monkeypatch: MonkeyPatch) -> ExecutionEngineDouble: # type: ignore[misc]
"""
Inject an execution engine test double into the _SourcesFactory.engine_lookup
so that all Datasources use the execution engine double.
Dynamically create a new subclass so that runtime type validation does not fail.
"""
original_engine_override: Dict[MetaDatasource, ExecutionEngine] = {}
for key in _SourceFactories.type_lookup.keys():
if issubclass(type(key), MetaDatasource):
original_engine_override[key] = key.execution_engine_override
try:
for source in original_engine_override.keys():
source.execution_engine_override = ExecutionEngineDouble
yield ExecutionEngineDouble
finally:
for source, engine in original_engine_override.items():
source.execution_engine_override = engine
<file_sep>/docs/guides/setup/installation/components_local/_create_an_venv_with_pip.mdx
Once you have confirmed that Python 3 is installed locally, you can create a virtual environment with `venv` before installing your packages with `pip`.
<details>
<summary>Python Virtual Environments</summary>
We have chosen to use venv for virtual environments in this guide, because it is included with Python 3. You are not limited to using venv, and can just as easily install Great Expectations into virtual environments with tools such as virtualenv, pyenv, etc.
</details>
Depending on whether you found that you needed to run `python` or `python3` in the previous step, you will create your virtual environment by running either:
```console title="Terminal command"
python -m venv my_venv
```
or
```console title="Terminal command"
python3 -m venv my_venv
```
This command will create a new directory called `my_venv` where your virtual environment is located. In order to activate the virtual environment run:
```console title="Terminal command"
source my_venv/bin/activate
```
:::tip
You can name your virtual environment anything you like. Simply replace `my_venv` in the examples above with the name that you would like to use.
:::<file_sep>/docs/guides/setup/configuring_metadata_stores/components_how_to_configure_an_expectation_store_in_amazon_s3/_copy_existing_expectation_json_files_to_the_s_bucket_this_step_is_optional.mdx
If you are converting an existing local Great Expectations deployment to one that works in AWS you may already have Expectations saved that you wish to keep and transfer to your S3 bucket.
One way to copy Expectations into Amazon S3 is by using the ``aws s3 sync`` command. As mentioned earlier, the ``base_directory`` is set to ``expectations/`` by default.
```bash title="Terminal command"
aws s3 sync '<base_directory>' s3://'<your_s3_bucket_name>'/'<your_s3_bucket_folder_name>'
```
In the example below, two Expectations, ``exp1`` and ``exp2`` are copied to Amazon S3. This results in the following output:
```bash title="Terminal output"
upload: ./exp1.json to s3://'<your_s3_bucket_name>'/'<your_s3_bucket_folder_name>'/exp1.json
upload: ./exp2.json to s3://'<your_s3_bucket_name>'/'<your_s3_bucket_folder_name>'/exp2.json
```
If you have Expectations to copy into S3, your output should look similar.<file_sep>/docs/contributing/contributing_maturity.md
---
title: Levels of Maturity
---
Features and code within Great Expectations are separated into three levels of maturity: Experimental, Beta, and Production.
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.0.0-beta3/css/all.min.css" crossorigin="anonymous" referrerpolicy="no-referrer" />
<div>
<ul style={{
"list-style-type": "none"
}}>
<li><i class="fas fa-circle" style={{color: "#dc3545"}}></i> Experimental: Try, but do not rely</li>
<li><i class="fas fa-circle" style={{color: "#ffc107"}}></i> Beta: Ready for early adopters</li>
<li><i class="fas fa-check-circle" style={{color: "#28a745"}}></i> Production: Ready for general use</li>
</ul>
</div>
Being explicit about these levels allows us to enable experimentation, without creating unnecessary thrash when features and APIs evolve. It also helps streamline development, by giving contributors a clear, incremental path to create and improve the Great Expectations code base.
For users of Great Expectations, our goal is to enable informed decisions about when to adopt which features.
For contributors to Great Expectations, our goal is to channel creativity by always making the next step as clear as possible.
This grid provides guidelines for how the maintainers of Great Expectations evaluate levels of maturity. Maintainers will always exercise some discretion in determining when any given feature is ready to graduate to the next level. If you have ideas or suggestions for leveling up a specific feature, please raise them in Github issues, and we’ll work with you to get there.
| Criteria | <i class="fas fa-circle" style={{color: "#dc3545"}}></i> Experimental <br/>Try, but do not rely | <i class="fas fa-circle" style={{color: "#ffc107"}}></i> Beta <br/>Ready for early adopters | <i class="fas fa-check-circle" style={{color: "#28a745"}}></i> Production <br/>Ready for general use |
|------------------------------------------|--------------------------------------|----------------------------------|-------------------------------------|
| API stability | Unstable* | Mostly Stable | Stable |
| Implementation completeness | Minimal | Partial | Complete |
| Unit test coverage | Minimal | Partial | Complete |
| Integration/Infrastructure test coverage | Minimal | Partial | Complete |
| Documentation completeness | Minimal | Partial | Complete |
| Bug risk | High | Moderate | Low |
:::note
Experimental classes log warning-level messages when initialized:
`Warning: great_expectations.some_module.SomeClass is experimental. Methods, APIs, and core behavior may change in the future.`
:::
## Contributing Expectations
The workflow detailed in our initial guides on [Creating Custom Expectations](../guides/expectations/creating_custom_expectations/overview.md) will leave you with an Expectation ready for contribution at an Experimental level. The checklist generated by the `print_diagnostic_checklist()` method will help you walk through the requirements for Beta & Production levels of contribution;
the first five checks are required for Experimental acceptance, the following three are additionally required for Beta acceptance, and the final two (a full checklist!) are required for Production acceptance. Supplemental guides are available to help you satisfy each of these requirements.
| Criteria | <i class="fas fa-circle" style={{color: "#dc3545"}}></i> Experimental <br/>Try, but do not rely | <i class="fas fa-circle" style={{color: "#ffc107"}}></i> Beta <br/>Ready for early adopters | <i class="fas fa-check-circle" style={{color: "#28a745"}}></i> Production <br/>Ready for general use |
|------------------------------------------|:------------------------------------:|:--------------------------------:|:-----------------------------------:|
| Has a valid library_metadata object | ✔ | ✔ | ✔ |
| Has a docstring, including a one-line short description | ✔ | ✔ | ✔ |
| Has at least one positive and negative example case, and all test cases pass | ✔ | ✔ | ✔ |
| Has core logic and passes tests on at least one Execution Engine | ✔ | ✔ | ✔ |
| Passes all linting checks | ✔ | ✔ | ✔ |
| Has basic input validation and type checking | ― | ✔ | ✔ |
| Has both Statement Renderers: prescriptive and diagnostic | ― | ✔ | ✔ |
| Has core logic that passes tests for all applicable Execution Engines and SQL dialects | ― | ✔ | ✔ |
| Has a robust suite of tests, as determined by a code owner | ― | ― | ✔ |
| Has passed a manual review by a code owner for code standards and style guides | ― | ― | ✔ |
<file_sep>/docs/reference/api_reference.md
---
title: API Documentation
---
:::info WIP
We are currently working on including additional classes and methods in our current API Documentation. These documents are generated via script off of the docstrings of classes and methods that fall under our Public API. We will be adding to these classes and methods incrementally going forward; as such you can expect this section to expand over time. If the class or method you are looking for is not yet in these documents please reference our legacy API documentation instead.
- [Legacy API Reference Link](https://legacy.docs.greatexpectations.io/en/latest/autoapi/great_expectations/index.html#)
:::
<file_sep>/great_expectations/experimental/datasources/__init__.py
from great_expectations.experimental.datasources.postgres_datasource import (
PostgresDatasource,
)
<file_sep>/docs/guides/validation/index.md
---
title: "Validate Data: Index"
---
# [](./validate_data_overview.md) Validate Data: Index
## Core skills
- [How to validate data by running a Checkpoint](../../guides/validation/how_to_validate_data_by_running_a_checkpoint.md)
## Checkpoints
- [How to add validations data or suites to a Checkpoint](../../guides/validation/checkpoints/how_to_add_validations_data_or_suites_to_a_checkpoint.md)
- [How to create a new Checkpoint](../../guides/validation/checkpoints/how_to_create_a_new_checkpoint.md)
- [How to configure a new Checkpoint using test_yaml_config](../../guides/validation/checkpoints/how_to_configure_a_new_checkpoint_using_test_yaml_config.md)
- [How to pass an in-memory DataFrame to a Checkpoint](../../guides/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.md)
## Actions
- [How to trigger Email as a Validation Action](../../guides/validation/validation_actions/how_to_trigger_email_as_a_validation_action.md)
- [How to collect OpenLineage metadata using a Validation Action](../../guides/validation/validation_actions/how_to_collect_openlineage_metadata_using_a_validation_action.md)
- [How to trigger Opsgenie notifications as a Validation Action](../../guides/validation/validation_actions/how_to_trigger_opsgenie_notifications_as_a_validation_action.md)
- [How to trigger Slack notifications as a Validation Action](../../guides/validation/validation_actions/how_to_trigger_slack_notifications_as_a_validation_action.md)
- [How to update Data Docs after validating a Checkpoint](../../guides/validation/validation_actions/how_to_update_data_docs_as_a_validation_action.md)
## Advanced
- [How to deploy a scheduled Checkpoint with cron](../../guides/validation/advanced/how_to_deploy_a_scheduled_checkpoint_with_cron.md)
- [How to get Data Docs URLs for use in custom Validation Actions](../../guides/validation/advanced/how_to_get_data_docs_urls_for_custom_validation_actions.md)
- [How to validate data without a Checkpoint](../../guides/validation/advanced/how_to_validate_data_without_a_checkpoint.md)
<file_sep>/docs/tutorials/getting_started/tutorial_connect_to_data.md
---
title: 'Tutorial, Step 2: Connect to data'
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '/docs/term_tags/_tag.mdx';
<UniversalMap setup='inactive' connect='active' create='inactive' validate='inactive'/>
:::note Prerequisites
- Completed [Step 1: Setup](./tutorial_setup.md) of this tutorial.
:::
In Step 1: Setup, we created a <TechnicalTag relative="../../" tag="data_context" text="Data Context" />. Now that we have that Data Context, you'll want to connect to your actual data. In Great Expectations, <TechnicalTag relative="../../" tag="datasource" text="Datasources" /> simplify these connections by managing and providing a consistent, cross-platform API for referencing data.
### Create a Datasource with the CLI
Let's create and configure your first Datasource: a connection to the data directory we've provided in the repo. This could also be a database connection, but because our tutorial data consists of .CSV files we're just using a simple file store.
Start by using the <TechnicalTag relative="../../" tag="cli" text="CLI" /> to run the following command from your `ge_tutorials` directory:
````console
great_expectations datasource new
````
You will then be presented with a choice that looks like this:
````console
What data would you like Great Expectations to connect to?
1. Files on a filesystem (for processing with Pandas or Spark)
2. Relational database (SQL)
:1
````
The only difference is that we've included a "1" after the colon and you haven't typed anything in answer to the prompt, yet.
As we've noted before, we're working with .CSV files. So you'll want to answer with `1` and hit enter.
The next prompt you see will look like this:
````console
What are you processing your files with?
1. Pandas
2. PySpark
:1
````
For this tutorial we will use Pandas to process our files, so again answer with `1` and press enter to continue.
:::note
When you select `1. Pandas` from the above list, you are specifying your Datasource's <TechnicalTag tag="execution_engine" text="Execution Engine" />. Although the tutorial uses Pandas, Spark and SqlAlchemy are also supported as Execution Engines.
:::
We're almost done with the CLI! You'll be prompted once more, this time for the path of the directory where the data files are located. The prompt will look like:
````console
Enter the path of the root directory where the data files are stored. If files are on local disk
enter a path relative to your current working directory or an absolute path.
:data
````
The data that this tutorial uses is stored in `ge_tutorials/data`. Since we are working from the `ge_tutorials` directory, you only need to enter `data` and hit return to continue.
This will now **open up a new Jupyter Notebook** to complete the Datasource configuration. Your console will display a series of messages as the Jupyter Notebook is loaded, but you can disregard them. The rest of the Datasource setup takes place in the Jupyter Notebook and we won't return to the terminal until that is done.
### The ```datasource new``` notebook
The Jupyter Notebook contains some boilerplate code to configure your new Datasource. You can run the entire notebook as-is, but we recommend changing at least the Datasource name to something more specific.
Edit the second code cell as follows:
````console
datasource_name = "getting_started_datasource"
````
Then **execute all cells in the notebook** in order to save the new Datasource. If successful, the last cell will print a list of all Datasources, including the one you just created.
**Before continuing, let’s stop and unpack what just happened.**
### Configuring Datasources
When you completed those last few steps, you told Great Expectations that:
+ You want to create a new Datasource called `getting_started_datasource` (or whatever custom name you chose above).
+ You want to use Pandas to read the data from CSV.
Based on that information, the CLI added the following entry into your ```great_expectations.yml``` file, under the `datasources` header:
```yaml file=../../../tests/integration/docusaurus/tutorials/getting-started/getting_started.py#L24-L43
```
Please note that due to how data is serialized, the entry in your ```great_expectations.yml``` file may not have these key/value pairs in the same order as the above example. However, they will all have been added.
<details>
<summary>What does the configuration contain?</summary>
<div>
<p>
**ExecutionEngine** : The <TechnicalTag relative="../../" tag="execution_engine" text="Execution Engine" /> provides backend-specific computing resources that are used to read-in and perform validation on data. For more information on <code>ExecutionEngines</code>, please refer to the following <a href="/docs/terms/execution_engine">Core Concepts document on ExecutionEngines</a>
</p>
<p>
**DataConnectors** : <TechnicalTag relative="../../" tag="data_connector" text="Data Connectors" /> facilitate access to external data stores, such as filesystems, databases, and cloud storage. The current configuration contains both an <code>InferredAssetFilesystemDataConnector</code>, which allows you to retrieve a batch of data by naming a data asset (which is the filename in our case), and a <code>RuntimeDataConnector</code>, which allows you to retrieve a batch of data by defining a filepath. In this tutorial we will only be using the <code>InferredAssetFilesystemDataConnector</code>. For more information on <code>DataConnectors</code>, please refer to the <a href="/docs/terms/datasource">Core Concepts document on Datasources</a>.
</p>
<p>
This Datasource does not require any credentials. However, if you were to connect to a database that requires connection credentials, those would be stored in <code>great_expectations/uncommitted/config_variables.yml</code>.
</p>
</div>
</details>
In the future, you can modify or delete your configuration by editing your ```great_expectations.yml``` and ```config_variables.yml``` files directly.
For now, let’s move on to [Step 3: Create Expectations.](./tutorial_create_expectations.md)
<file_sep>/great_expectations/experimental/logger.py
import logging
def init_logger(level: int = logging.WARNING):
logging.basicConfig(level=level, format="%(levelname)s:%(name)s | %(message)s")
<file_sep>/docs/changelog.md
---
title: Changelog
---
### 0.15.34
* [BUGFIX] Ensure `packaging_and_installation` CI tests against latest tag (#6386)
* [BUGFIX] Fixed missing comma in pydantic constraints (#6391) (thanks @awburgess)
* [BUGFIX] fix pydantic dev req file entries (#6396)
* [DOCS] DOC-379 bring spark datasource configuration example scripts under test (#6362)
* [MAINTENANCE] Handle both `ExpectationConfiguration` and `ExpectationValidationResult` in default Atomic renderers and cleanup `include_column_name` (#6380)
* [MAINTENANCE] Add type annotations to all existing atomic renderer signatures (#6385)
* [MAINTENANCE] move `zep` -> `experimental` package (#6378)
* [MAINTENANCE] Migrate additional methods from `BaseDataContext` to other parts of context hierarchy (#6388)
### 0.15.33
* [FEATURE] POC ZEP Config Loading (#6320)
* [BUGFIX] Fix issue with misaligned indentation in docs snippets (#6339)
* [BUGFIX] Use `requirements.txt` file when installing linting/static check dependencies in CI (#6368)
* [BUGFIX] Patch nested snippet indentation issues within `remark-named-snippets` plugin (#6376)
* [BUGFIX] Ensure `packaging_and_installation` CI tests against latest tag (#6386)
* [DOCS] DOC-308 update CLI command in docs when working with RBPs instead of Data Assistants (#6222)
* [DOCS] DOC-366 updates to docs in support of branding updates (#5766)
* [DOCS] Add `yarn snippet-check` command (#6351)
* [MAINTENANCE] Add missing one-line docstrings and try to make the others consistent (#6340)
* [MAINTENANCE] Refactor variable aggregation/substitution logic into `ConfigurationProvider` hierarchy (#6321)
* [MAINTENANCE] In ExecutionEngine: Make variable names and usage more descriptive of their purpose. (#6342)
* [MAINTENANCE] Move Cloud-specific enums to `cloud_constants.py` (#6349)
* [MAINTENANCE] Refactor out `termcolor` dependency (#6348)
* [MAINTENANCE] Zep PostgresDatasource returns a list of batches. (#6341)
* [MAINTENANCE] Refactor `usage_stats_opt_out` method in DataContext (#5339)
* [MAINTENANCE] Fix computed metrics type hint in ExecutionEngine.resolve_metrics() method (#6347)
* [MAINTENANCE] Subject: Support to include ID/PK in validation result for each row t… (#5876) (thanks @abekfenn)
* [MAINTENANCE] Pin `mypy` to `0.990` (#6361)
* [MAINTENANCE] Misc cleanup of GX Cloud helpers (#6352)
* [MAINTENANCE] Update column_reflection_fallback to also use schema name for Trino (#6350)
* [MAINTENANCE] Bump version of `mypy` in contrib CLI (#6370)
* [MAINTENANCE] Move config variable substitution logic into `ConfigurationProvider` (#6345)
* [MAINTENANCE] Removes comment in code that was causing confusion to some users. (#6366)
* [MAINTENANCE] minor metrics typing (#6374)
* [MAINTENANCE] Make `ConfigurationProvider` and `ConfigurationSubstitutor` private (#6375)
* [MAINTENANCE] Rename `GeCloudStoreBackend` to `GXCloudStoreBackend` (#6377)
* [MAINTENANCE] Cleanup Metrics and ExecutionEngine methods (#6371)
* [MAINTENANCE] F/great 1314/integrate zep in core (#6358)
* [MAINTENANCE] Loosen `pydantic` version requirement (#6384)
### 0.15.32
* [BUGFIX] Patch broken `CloudNotificationAction` tests (#6327)
* [BUGFIX] add create_temp_table flag to ExecutionEngineConfigSchema (#6331) (thanks @tommy-watts-depop)
* [BUGFIX] MapMetrics now return `partial_unexpected` values for `SUMMARY` format (#6334)
* [DOCS] Re-writes "how to implement custom notifications" as "How to get Data Docs URLs for use in custom Validation Actions" (#6281)
* [DOCS] Removes deprecated expectation notebook exploration doc (#6298)
* [DOCS] Removes a number of unused & deprecated docs (#6300)
* [DOCS] Prioritizes Onboarding Data Assistant in ToC (#6302)
* [DOCS] Add ZenML into integration table in Readme (#6144) (thanks @dnth)
* [DOCS] add `pypi` release badge (#6324)
* [MAINTENANCE] Remove unneeded `BaseDataContext.get_batch_list` (#6291)
* [MAINTENANCE] Clean up implicit `Optional` errors flagged by `mypy` (#6319)
* [MAINTENANCE] Add manual prod flags to core Expectations (#6278)
* [MAINTENANCE] Fallback to isnot method if is_not is not available (old sqlalchemy) (#6318)
* [MAINTENANCE] Add ZEP postgres datasource. (#6274)
* [MAINTENANCE] Delete "metric_dependencies" from MetricConfiguration constructor arguments (#6305)
* [MAINTENANCE] Clean up `DataContext` (#6304)
* [MAINTENANCE] Deprecate `save_changes` flag on `Datasource` CRUD (#6258)
* [MAINTENANCE] Deprecate `great_expectations.render.types` package (#6315)
* [MAINTENANCE] Update range of allowable sqlalchemy versions (#6328)
* [MAINTENANCE] Fixing checkpoint types (#6325)
* [MAINTENANCE] Fix column_reflection_fallback for Trino and minor logging/testing improvements (#6218)
* [MAINTENANCE] Change the number of expected Expectations in the 'quick check' stage of build_gallery pipeline (#6333)
### 0.15.31
* [BUGFIX] Include all requirement files in the sdist (#6292) (thanks @xhochy)
* [DOCS] Updates outdated batch_request snippet in Terms (#6283)
* [DOCS] Update Conditional Expectations doc w/ current availability (#6279)
* [DOCS] Remove outdated Data Discovery page and all references (#6288)
* [DOCS] Remove reference/evaluation_parameters page and all references (#6294)
* [DOCS] Removing deprecated Custom Metrics doc (#6282)
* [DOCS] Re-writes "how to implement custom notifications" as "How to get Data Docs URLs for use in custom Validation Actions" (#6281)
* [DOCS] Removes deprecated expectation notebook exploration doc (#6298)
* [MAINTENANCE] Move RuleState into rule directory. (#6284)
### 0.15.30
* [FEATURE] Add zep datasources to data context. (#6255)
* [BUGFIX] Iterate through `GeCloudIdentifiers` to find the suite ID from the name (#6243)
* [BUGFIX] Update default base url for cloud API (#6176)
* [BUGFIX] Pin `termcolor` to below `2.1.0` due to breaking changes in lib's TTY parsing logic (#6257)
* [BUGFIX] `InferredAssetSqlDataConnector` `include_schema_name` introspection of identical table names in different schemas (#6166)
* [BUGFIX] Fix`docs-integration` tests, and temporarily pin `sqlalchemy` (#6268)
* [BUGFIX] Fix serialization for contrib packages (#6266)
* [BUGFIX] Ensure that `Datasource` credentials are not persisted to Cloud/disk (#6254)
* [DOCS] Updates package contribution references (#5885)
* [MAINTENANCE] Maintenance/great 1103/great 1318/alexsherstinsky/validation graph/refactor validation graph usage 2022 10 20 248 (#6228)
* [MAINTENANCE] Refactor instances of `noqa: F821` Flake8 directive (#6220)
* [MAINTENANCE] Logo URI ref in `data_docs` (#6246)
* [MAINTENANCE] fix typos in docstrings (#6247)
* [MAINTENANCE] Isolate Trino/MSSQL/MySQL tests in `dev` CI (#6231)
* [MAINTENANCE] Split up `compatability` and `comprehensive` stages in `dev` CI to improve performance (#6245)
* [MAINTENANCE] ZEP POC - Asset Type Registration (#6194)
* [MAINTENANCE] Add Trino CLI support and bump Trino version (#6215) (thanks @hovaesco)
* [MAINTENANCE] Delete unneeded Rule attribute property (#6264)
* [MAINTENANCE] Small clean-up of `Marshmallow` warnings (`missing` parameter changed to `load_default` as of 3.13) (#6213)
* [MAINTENANCE] Move `.png` files out of project root (#6249)
* [MAINTENANCE] Cleanup `expectation.py` attributes (#6265)
* [MAINTENANCE] Further parallelize test runs in `dev` CI (#6267)
* [MAINTENANCE] GCP Integration Pipeline fix (#6259)
* [MAINTENANCE] mypy `warn_unused_ignores` (#6270)
* [MAINTENANCE] ZEP - Datasource base class (#6263)
* [MAINTENANCE] Reverting `marshmallow` version bump (#6271)
* [MAINTENANCE] type hints cleanup in Rule-Based Profiler (#6272)
* [MAINTENANCE] Remove unused f-strings (#6248)
* [MAINTENANCE] Make ParameterBuilder.resolve_evaluation_dependencies() into instance (rather than utility) method (#6273)
* [MAINTENANCE] Test definition for `ExpectColumnValueZScoresToBeLessThan` (#6229)
* [MAINTENANCE] Make RuleState constructor argument ordering consistent with standard pattern. (#6275)
* [MAINTENANCE] [REQUEST] Please allow Rachel to unblock blockers (#6253)
### 0.15.29
* [FEATURE] Add support to AWS Glue Data Catalog (#5123) (thanks @lccasagrande)
* [FEATURE] / Added pairwise expectation 'expect_column_pair_values_to_be_in_set' (#6097) (thanks @Arnavkar)
* [BUGFIX] Adjust condition in RenderedAtomicValueSchema.clean_null_attrs (#6168)
* [BUGFIX] Add `py` to dev dependencies to circumvent compatability issues with `pytest==7.2.0` (#6202)
* [BUGFIX] Fix `test_package_dependencies.py` to include `py` lib (#6204)
* [BUGFIX] Fix logic in ExpectationDiagnostics._check_renderer_methods method (#6208)
* [BUGFIX] Patch issue with empty config variables file raising `TypeError` (#6216)
* [BUGFIX] Release patch for Azure env vars (#6233)
* [BUGFIX] Cloud Data Context should overwrite existing suites based on `ge_cloud_id` instead of name (#6234)
* [BUGFIX] Add env vars to Pytest min versions Azure stage (#6239)
* [DOCS] doc-297: update the create Expectations overview page for Data Assistants (#6212)
* [DOCS] DOC-378: bring example scripts for pandas configuration guide under test (#6141)
* [MAINTENANCE] Add unit test for MetricsCalculator.get_metric() Method -- as an example template (#6179)
* [MAINTENANCE] ZEP MetaDatasource POC (#6178)
* [MAINTENANCE] Update `scope_check` in Azure CI to trigger on changed `.py` source code files (#6185)
* [MAINTENANCE] Move test_yaml_config to a separate class (#5487)
* [MAINTENANCE] Changed profiler to Data Assistant in CLI, docs, and tests (#6189)
* [MAINTENANCE] Update default GE_USAGE_STATISTICS_URL in test docker image. (#6192)
* [MAINTENANCE] Re-add a renamed test definition file (#6182)
* [MAINTENANCE] Refactor method `parse_evaluation_parameter` (#6191)
* [MAINTENANCE] Migrate methods from `BaseDataContext` to `AbstractDataContext` (#6188)
* [MAINTENANCE] Rename cfe to v3_api (#6190)
* [MAINTENANCE] Test Trino doc examples with test_script_runner.py (#6198)
* [MAINTENANCE] Cleanup of Regex ParameterBuilder (#6196)
* [MAINTENANCE] Apply static type checking to `expectation.py` (#6173)
* [MAINTENANCE] Remove version matrix from `dev` CI pipeline to improve performance (#6203)
* [MAINTENANCE] Rename `CloudMigrator.retry_unsuccessful_validations` (#6206)
* [MAINTENANCE] Add validate_configuration method to expect_table_row_count_to_equal_other_table (#6209)
* [MAINTENANCE] Replace deprecated `iteritems` with `items` (#6205)
* [MAINTENANCE] Add instructions for setting up the test_ci database (#6211)
* [MAINTENANCE] Add E2E tests for Cloud-backed `Datasource` CRUD (#6186)
* [MAINTENANCE] Execution Engine linting & partial typing (#6210)
* [MAINTENANCE] Test definition for `ExpectColumnValuesToBeJsonParsable`, including a fix for Spark (#6207)
* [MAINTENANCE] Port over usage statistics enabled methods from `BaseDataContext` to `AbstractDataContext` (#6201)
* [MAINTENANCE] Remove temporary dependency on `py` (#6217)
* [MAINTENANCE] Adding type hints to DataAssistant implementations (#6224)
* [MAINTENANCE] Remove AWS config file dependencies and use existing env vars in CI/CD (#6227)
* [MAINTENANCE] Make `UsageStatsEvents` a `StrEnum` (#6225)
* [MAINTENANCE] Move all `requirements-dev*.txt` files to separate dir (#6223)
* [MAINTENANCE] Maintenance/great 1103/great 1318/alexsherstinsky/validation graph/refactor validation graph usage 2022 10 20 248 (#6228)
### 0.15.28
* [FEATURE] Initial zep datasource protocol. (#6153)
* [FEATURE] Introduce BatchManager to manage Batch objects used by Validator and BatchData used by ExecutionEngine (#6156)
* [FEATURE] Add support for Vertica dialect (#6145) (thanks @viplazylmht)
* [FEATURE] Introduce MetricsCalculator and Refactor Redundant Code out of Validator (#6165)
* [BUGFIX] SQLAlchemy selectable Bug fix (#6159) (thanks @tommy-watts-depop)
* [BUGFIX] Parameterize usage stats endpoint in test dockerfile. (#6169)
* [BUGFIX] B/great 1305/usage stats endpoint (#6170)
* [BUGFIX] Ensure that spaces are recognized in named snippets (#6172)
* [DOCS] Clarify wording for interactive mode in databricks (#6154)
* [DOCS] fix source activate command (#6161) (thanks @JGrzywacz)
* [DOCS] Update version in `runtime.txt` to fix breaking Netlify builds (#6181)
* [DOCS] Clean up snippets and line number validation in docs (#6142)
* [MAINTENANCE] Add Enums for renderer types (#6112)
* [MAINTENANCE] Minor cleanup in preparation for Validator refactoring into separate concerns (#6155)
* [MAINTENANCE] add the internal `GE_DATA_CONTEXT_ID` env var to the docker file (#6122)
* [MAINTENANCE] Rollback setting GE_DATA_CONTEXT_ID in docker image. (#6163)
* [MAINTENANCE] disable ge_cloud_mode when specified, detect misconfiguration (#6162)
* [MAINTENANCE] Re-add missing Expectations to gallery and include package names (#6171)
* [MAINTENANCE] Use `from __future__ import annotations` to clean up type hints (#6127)
* [MAINTENANCE] Make sure that quick stage check returns 0 if there are no problems (#6177)
* [MAINTENANCE] Remove SQL for expect_column_discrete_entropy_to_be_between (#6180)
### 0.15.27
* [FEATURE] Add logging/warnings to GX Cloud migration process (#6106)
* [FEATURE] Introduction of updated `gx.get_context()` method that returns correct DataContext-type (#6104)
* [FEATURE] Contribute StatisticsDataAssistant and GrowthNumericDataAssistant (both experimental) (#6115)
* [BUGFIX] add OBJECT_TYPE_NAMES to the JsonSchemaProfiler - issue #6109 (#6110) (thanks @OphelieC)
* [BUGFIX] Fix example `Set-Based Column Map Expectation` template import (#6134)
* [BUGFIX] Regression due to `GESqlDialect` `Enum` for Hive (#6149)
* [DOCS] Support for named snippets in documentation (#6087)
* [MAINTENANCE] Clean up `test_migrate=True` Cloud migrator output (#6119)
* [MAINTENANCE] Creation of Hackathon Packages (#4587)
* [MAINTENANCE] Rename GCP Integration Pipeline (#6121)
* [MAINTENANCE] Change log levels used in `CloudMigrator` (#6125)
* [MAINTENANCE] Bump version of `sqlalchemy-redshift` from `0.7.7` to `0.8.8` (#6082)
* [MAINTENANCE] self_check linting & initial type-checking (#6126)
* [MAINTENANCE] Update per Clickhouse multiple same aliases Bug (#6128) (thanks @adammrozik)
* [MAINTENANCE] Only update existing `rendered_content` if rendering does not fail with new `InlineRenderer` failure message (#6091)
### 0.15.26
* [FEATURE] Enable sending of `ConfigurationBundle` payload in HTTP request to Cloud backend (#6083)
* [FEATURE] Send user validation results to Cloud backend during migration (#6102)
* [BUGFIX] Fix bigquery crash when using "in" with a boolean column (#6071)
* [BUGFIX] Fix serialization error when rendering kl_divergence (#6084) (thanks @roblim)
* [BUGFIX] Enable top-level parameters in Data Assistants accessed via dispatcher (#6077)
* [BUGFIX] Patch issue around `DataContext.save_datasource` not sending `class_name` in result payload (#6108)
* [DOCS] DOC-377 add missing dictionary in configured asset datasource portion of Pandas and Spark configuration guides (#6081)
* [DOCS] DOC-376 finalize definition for Data Assistants in technical terms (#6080)
* [DOCS] Update `docs-integration` test due to new `whole_table` splitter behavior (#6103)
* [DOCS] How to create a Custom Multicolumn Map Expectation (#6101)
* [MAINTENANCE] Patch broken Cloud E2E test (#6079)
* [MAINTENANCE] Bundle data context config and other artifacts for migration (#6068)
* [MAINTENANCE] Add datasources to ConfigurationBundle (#6092)
* [MAINTENANCE] Remove unused config files from root of GX repo (#6090)
* [MAINTENANCE] Add `data_context_id` property to `ConfigurationBundle` (#6094)
* [MAINTENANCE] Move all Cloud migrator logic to separate directory (#6100)
* [MAINTENANCE] Update aloglia scripts for new fields and replica indices (#6049) (thanks @winrp17)
* [MAINTENANCE] initial Datasource typings (#6099)
* [MAINTENANCE] Data context migrate to cloud event (#6095)
* [MAINTENANCE] Bundling tests with empty context configs (#6107)
* [MAINTENANCE] Fixing a typo (#6113)
### 0.15.25
* [FEATURE] Since value set in expectation kwargs is list of strings, do not emit expect_column_values_to_be_in_set for datetime valued columns (#6046)
* [FEATURE] add failed expectations list to slack message (#5812) (thanks @itaise)
* [FEATURE] Enable only ExactNumericRangeEstimator and QuantilesNumericRangeEstimator in "datetime_columns_rule" of OnboardingDataAssistant (#6063)
* [BUGFIX] numpy typing behind `if TYPE_CHECKING` (#6076)
* [DOCS] Update "How to create an Expectation Suite with the Onboarding Data Assistant" (#6050)
* [DOCS] How to get one or more Batches of data from a configured Datasource (#6043)
* [DOCS] DOC-298 Data Assistant technical term page (#6057)
* [DOCS] Update OnboardingDataAssistant documentation (#6059)
* [MAINTENANCE] Clean up of DataAssistant tests that depend on Jupyter notebooks (#6039)
* [MAINTENANCE] AbstractDataContext.datasource_save() test simplifications (#6052)
* [MAINTENANCE] Rough architecture for cloud migration tool (#6054)
* [MAINTENANCE] Include git commit info when building docker image. (#6060)
* [MAINTENANCE] Allow `CloudDataContext` to retrieve and initialize its own project config (#6006)
* [MAINTENANCE] Removing Jupyter notebook-based tests for DataAssistants (#6062)
* [MAINTENANCE] pinned dremio, fixed linting (#6067)
* [MAINTENANCE] usage-stats, & utils.py typing (#5925)
* [MAINTENANCE] Refactor external HTTP request logic into a `Session` factory function (#6007)
* [MAINTENANCE] Remove tag validity stage from release pipeline (#6069)
* [MAINTENANCE] Remove unused test fixtures from test suite (#6058)
* [MAINTENANCE] Remove outdated release files (#6074)
### 0.15.24
* [FEATURE] context.save_datasource (#6009)
* [BUGFIX] Standardize `ConfiguredAssetSqlDataConnector` config in `datasource new` CLI workflow (#6044)
* [DOCS] DOC-371 update the getting started tutorial for data assistants (#6024)
* [DOCS] DOCS-369 sql data connector configuration guide (#6002)
* [MAINTENANCE] Remove outdated entry from release schedule JSON (#6032)
* [MAINTENANCE] Clean up Spark schema tests to have proper names (#6033)
### 0.15.23
* [FEATURE] do not require expectation_suite_name in DataAssistantResult.show_expectations_by...() methods (#5976)
* [FEATURE] Refactor PartitionParameterBuilder into dedicated ValueCountsParameterBuilder and HistogramParameterBuilder (#5975)
* [FEATURE] Implement default sorting for batches based on selected splitter method (#5924)
* [FEATURE] Make OnboardingDataAssistant default profiler in CLI SUITE NEW (#6012)
* [FEATURE] Enable omission of rounding of decimals in NumericMetricRangeMultiBatchParameterBuilder (#6017)
* [FEATURE] Enable non-default sorters for `ConfiguredAssetSqlDataConnector` (#5993)
* [FEATURE] Data Assistant plot method indication of total metrics and expectations count (#6016)
* [BUGFIX] Addresses issue with ExpectCompoundColumnsToBeUnique renderer (#5970)
* [BUGFIX] Fix failing `run_profiler_notebook` test (#5983)
* [BUGFIX] Handle case when only one unique "column.histogram" bin value is found (#5987)
* [BUGFIX] Update `get_validator` test assertions due to change in fixture batches (#5989)
* [BUGFIX] Fix use of column.partition metric in HistogramSingleBatchParameterBuilder to more accurately handle errors (#5990)
* [BUGFIX] Make Spark implementation of "column.value_counts" metric more robust to None/NaN column values (#5996)
* [BUGFIX] Filter out np.nan values (just like None values) as part of ColumnValueCounts._spark() implementation (#5998)
* [BUGFIX] Handle case when only one unique "column.histogram" bin value is found with proper type casting (#6001)
* [BUGFIX] ColumnMedian._sqlalchemy() needs to handle case of single-value column (#6011)
* [BUGFIX] Patch broken `save_expectation_suite` behavior with Cloud-backed `DataContext` (#6004)
* [BUGFIX] Clean quantitative metrics DataFrames in Data Assistant plotting (#6023)
* [BUGFIX] Defer `pprint` in `ExpectationSuite.show_expectations_by_expectation_type()` due to Jupyter rate limit (#6026)
* [BUGFIX] Use UTC TimeZone (rather than Local Time Zone) for Rule-Based Profiler DateTime Conversions (#6028)
* [DOCS] Update snippet refs in "How to create an Expectation Suite with the Onboarding Data Assistant" (#6014)
* [MAINTENANCE] Randomize the non-comprehensive tests (#5968)
* [MAINTENANCE] DatasourceStore refactoring (#5941)
* [MAINTENANCE] Expectation suite init unit tests + types (#5957)
* [MAINTENANCE] Expectation suite new unit tests for add_citation (#5966)
* [MAINTENANCE] Updated release schedule (#5977)
* [MAINTENANCE] Unit tests for `CheckpointStore` (#5967)
* [MAINTENANCE] Enhance unit tests for ExpectationSuite.isEquivalentTo (#5979)
* [MAINTENANCE] Remove unused fixtures from test suite (#5965)
* [MAINTENANCE] Update to MultiBatch Notebook to include Configured - Sql (#5945)
* [MAINTENANCE] Update to MultiBatch Notebook to include Inferred - Sql (#5958)
* [MAINTENANCE] Add reverse assertion for isEquivalentTo tests (#5982)
* [MAINTENANCE] Unit test enhancements ExpectationSuite.__eq__() (#5984)
* [MAINTENANCE] Refactor `DataContext.__init__` to move Cloud-specific logic to `CloudDataContext` (#5981)
* [MAINTENANCE] Set up cloud integration tests with Azure Pipelines (#5995)
* [MAINTENANCE] Example of `splitter_method` at `Asset` and `DataConnector` level (#6000)
* [MAINTENANCE] Replace `splitter_method` strings with `SplitterMethod` Enum and leverage `GESqlDialect` Enum where applicable (#5980)
* [MAINTENANCE] Ensure that `DataContext.add_datasource` works with nested `DataConnector` ids (#5992)
* [MAINTENANCE] Remove cloud integration tests from azure-pipelines.yml (#5997)
* [MAINTENANCE] Unit tests for `GeCloudStoreBackend` (#5999)
* [MAINTENANCE] Parameterize pg hostname in jupyter notebooks (#6005)
* [MAINTENANCE] Unit tests for `Validator` (#5988)
* [MAINTENANCE] Add unit tests for SimpleSqlalchemyDatasource (#6008)
* [MAINTENANCE] Remove `dgtest` from dev pipeline (#6003)
* [MAINTENANCE] Remove deprecated `account_id` from GX Cloud integrations (#6010)
* [MAINTENANCE] Added perf considerations to onboarding assistant notebook (#6022)
* [MAINTENANCE] Redshift specific temp table code path (#6021)
* [MAINTENANCE] Update `datasource new` workflow to enable `ConfiguredAssetDataConnector` usage with SQL-backed `Datasources` (#6019)
### 0.15.22
* [FEATURE] Allowing `schema` to be passed in as `batch_spec_passthrough` in Spark (#5900)
* [FEATURE] DataAssistants Example Notebook - Spark (#5919)
* [FEATURE] Improve slack error condition (#5818) (thanks @itaise)
* [BUGFIX] Ensure that ParameterBuilder implementations in Rule Based Profiler properly handle SQL DECIMAL type (#5896)
* [BUGFIX] Making an all-NULL column handling in RuleBasedProfiler more robust (#5937)
* [BUGFIX] Don't include abstract Expectation classes in _retrieve_expectations_from_module (#5947)
* [BUGFIX] Data Assistant plotting with zero expectations produced (#5934)
* [BUGFIX] prefix and suffix asset names are only relevant for InferredSqlAlchemyDataConnector (#5950)
* [BUGFIX] Prevent "division by zero" errors in Rule-Based Profiler calculations when Batch has zero rows (#5960)
* [BUGFIX] Spark column.distinct_values no longer returns entire table distinct values (#5969)
* [DOCS] DOC-368 spelling correction (#5912)
* [MAINTENANCE] Mark all tests within `tests/data_context/stores` dir (#5913)
* [MAINTENANCE] Cleanup to allow docker test target to run tests in random order (#5915)
* [MAINTENANCE] Use datasource config in add_datasource support methods (#5901)
* [MAINTENANCE] Cleanup up some new datasource sql data connector tests. (#5918)
* [MAINTENANCE] Unit tests for `data_context/store` (#5923)
* [MAINTENANCE] Mark all tests within `tests/validator` (#5926)
* [MAINTENANCE] Certify InferredAssetSqlDataConnector and ConfiguredAssetSqlDataConnector (#5847)
* [MAINTENANCE] Mark DBFS tests with `@pytest.mark.integration` (#5931)
* [MAINTENANCE] Reset globals modified in tests (#5936)
* [MAINTENANCE] Move `Store` test utils from source code to tests (#5932)
* [MAINTENANCE] Mark tests within `tests/rule_based_profiler` (#5930)
* [MAINTENANCE] Add missing import for ConfigurationIdentifier (#5943)
* [MAINTENANCE] Update to OnboardingDataAssistant Notebook - Sql (#5939)
* [MAINTENANCE] Run comprehensive tests in a random order (#5942)
* [MAINTENANCE] Unit tests for `ConfigurationStore` (#5948)
* [MAINTENANCE] Add a dev-tools requirements option (#5944)
* [MAINTENANCE] Run spark and onboarding data assistant test in their own jobs. (#5951)
* [MAINTENANCE] Unit tests for `ValidationGraph` and related classes (#5954)
* [MAINTENANCE] More unit tests for `Stores` (#5953)
* [MAINTENANCE] Add x-fails to flaky Cloud tests for purposes of 0.15.22 (#5964)
* [MAINTENANCE] Bump `Marshmallow` upper bound to work with Airflow operator (#5952)
* [MAINTENANCE] Use DataContext to ignore progress bars (#5959)
### 0.15.21
* [FEATURE] Add `include_rendered_content` to `get_expectation_suite` and `get_validation_result` (#5853)
* [FEATURE] Add tags as an optional setting for the OpsGenieAlertAction (#5855) (thanks @stevewb1993)
* [BUGFIX] Ensure that `delete_expectation_suite` returns proper boolean result (#5878)
* [BUGFIX] many small bugfixes (#5881)
* [BUGFIX] Fix typo in default value of "ignore_row_if" kwarg for MulticolumnMapExpectation (#5860) (thanks @mkopec87)
* [BUGFIX] Patch issue with `checkpoint_identifier` within `Checkpoint.run` workflow (#5894)
* [BUGFIX] Ensure that `DataContext.add_checkpoint()` updates existing objects in GX Cloud (#5895)
* [DOCS] DOC-364 how to configure a spark datasource (#5840)
* [MAINTENANCE] Unit Tests Pipeline step (#5838)
* [MAINTENANCE] Unit tests to ensure coverage over `Datasource` caching in `DataContext` (#5839)
* [MAINTENANCE] Add entries to release schedule (#5833)
* [MAINTENANCE] Properly label `DataAssistant` tests with `@pytest.mark.integration` (#5845)
* [MAINTENANCE] Add additional unit tests around `Datasource` caching (#5844)
* [MAINTENANCE] Mark miscellaneous tests with `@pytest.mark.unit` (#5846)
* [MAINTENANCE] `datasource`, `data_context`, `core` typing, lint fixes (#5824)
* [MAINTENANCE] add --ignore-suppress and --ignore-only-for to build_gallery.py with bugfixes (#5802)
* [MAINTENANCE] Remove pyparsing pin for <3.0 (#5849)
* [MAINTENANCE] Finer type exclude (#5848)
* [MAINTENANCE] use `id` instead `id_` (#5775)
* [MAINTENANCE] Add data connector names in datasource config (#5778)
* [MAINTENANCE] init tests for dict and json serializers (#5854)
* [MAINTENANCE] Remove Partitioning and Quantiles metrics computations from DateTime Rule of OnboardingDataAssistant (#5862)
* [MAINTENANCE] Update `ExpectationSuite` CRUD on `DataContext` to recognize Cloud ids (#5836)
* [MAINTENANCE] Handle Pandas warnings in Data Assistant plots (#5863)
* [MAINTENANCE] Misc cleanup of `test_expectation_suite_crud.py` (#5868)
* [MAINTENANCE] Remove vendored `marshmallow__shade` (#5866)
* [MAINTENANCE] don't force using the stand alone mock (#5871)
* [MAINTENANCE] Update expectation_gallery pipeline (#5874)
* [MAINTENANCE] run unit-tests on a target package (#5869)
* [MAINTENANCE] add `pytest-timeout` (#5857)
* [MAINTENANCE] Label tests in `tests/core` with `@pytest.mark.unit` and `@pytest.mark.integration` (#5879)
* [MAINTENANCE] new invoke test flags (#5880)
* [MAINTENANCE] JSON Serialize RowCondition and MetricBundle computation result to enable IDDict.to_id() for SparkDFExecutionEngine (#5883)
* [MAINTENANCE] increase the `pytest-timeout` timeout value during unit-testing step (#5884)
* [MAINTENANCE] Add `@pytest.mark.slow` throughout test suite (#5882)
* [MAINTENANCE] Add test_expectation_suite_send_usage_message (#5886)
* [MAINTENANCE] Mark existing tests as unit or integration (#5890)
* [MAINTENANCE] Convert integration tests to unit (#5891)
* [MAINTENANCE] Update distinct metric dependencies and implementations (#5811)
* [MAINTENANCE] Add slow pytest marker to config and sort them alphabetically. (#5892)
* [MAINTENANCE] Adding serialization tests for Spark (#5897)
* [MAINTENANCE] Improve existing expectation suite unit tests (phase 1) (#5898)
* [MAINTENANCE] `SqlAlchemyExecutionEngine` case for SQL Alchemy `Select` and `TextualSelect` due to `SADeprecationWarning` (#5902)
### 0.15.20
* [FEATURE] `query.pair_column` Metric (#5743)
* [FEATURE] Enhance execution time measurement utility, and save `DomainBuilder` execution time per Rule of Rule-Based Profiler (#5796)
* [FEATURE] Support single-batch mode in MetricMultiBatchParameterBuilder (#5808)
* [FEATURE] Inline `ExpectationSuite` Rendering (#5726)
* [FEATURE] Better error for missing expectation (#5750) (thanks @tylertrussell)
* [FEATURE] DataAssistants Example Notebook - Pandas (#5820)
* [BUGFIX] Ensure name not persisted (#5813)
* [DOCS] Change the selectable to a list (#5780) (thanks @itaise)
* [DOCS] Fix how to create custom table expectation (#5807) (thanks @itaise)
* [DOCS] DOC-363 how to configure a pandas datasource (#5779)
* [MAINTENANCE] Remove xfail markers on cloud tests (#5793)
* [MAINTENANCE] build-gallery enhancements (#5616)
* [MAINTENANCE] Refactor `save_profiler` to remove explicit `name` and `ge_cloud_id` args (#5792)
* [MAINTENANCE] Add v2_api flag for v2_api specific tests (#5803)
* [MAINTENANCE] Clean up `ge_cloud_id` reference from `DataContext` `ExpectationSuite` CRUD (#5791)
* [MAINTENANCE] Refactor convert_dictionary_to_parameter_node (#5805)
* [MAINTENANCE] Remove `ge_cloud_id` from `DataContext.add_profiler()` signature (#5804)
* [MAINTENANCE] Remove "copy.deepcopy()" calls from ValidationGraph (#5809)
* [MAINTENANCE] Add vectorized is_between for common numpy dtypes (#5711)
* [MAINTENANCE] Make partitioning directives of PartitionParameterBuilder configurable (#5810)
* [MAINTENANCE] Write E2E Cloud test for `RuleBasedProfiler` creation and retrieval (#5815)
* [MAINTENANCE] Change recursion to iteration for function in parameter_container.py (#5817)
* [MAINTENANCE] add `pytest-mock` & `pytest-icdiff` plugins (#5819)
* [MAINTENANCE] Surface cloud errors (#5797)
* [MAINTENANCE] Clean up build_parameter_container_for_variables (#5823)
* [MAINTENANCE] Bugfix/snowflake temp table schema name (#5814)
* [MAINTENANCE] Update `list_` methods on `DataContext` to emit names along with object ids (#5826)
* [MAINTENANCE] xfail Cloud E2E tests due to schema issue with `DataContextVariables` (#5828)
* [MAINTENANCE] Clean up xfails in preparation for 0.15.20 release (#5835)
* [MAINTENANCE] Add back xfails for E2E Cloud tests that fail on env var retrieval in Docker (#5837)
### 0.15.19
* [FEATURE] `DataAssistantResult` plot multiple metrics per expectation (#5556)
* [FEATURE] Enable passing "exact_estimation" boolean at `DataAssistant.run()` level (default value is True) (#5744)
* [FEATURE] Example notebook for Onboarding DataAssistant - `postgres` (#5776)
* [BUGFIX] dir update for data_assistant_result (#5751)
* [BUGFIX] Fix docs_integration pipeline (#5734)
* [BUGFIX] Patch flaky E2E Cloud test with randomized suite names (#5752)
* [BUGFIX] Fix RegexPatternStringParameterBuilder to use legal character repetition. Remove median, mean, and standard deviation features from OnboardingDataAssistant "datetime_columns_rule" definition. (#5757)
* [BUGFIX] Move `SuiteValidationResult.meta` validation id propogation before `ValidationOperator._run_action` (#5760)
* [BUGFIX] Update "column.partition" Metric to handle DateTime Arithmetic Properly (#5764)
* [BUGFIX] JSON-serialize RowCondition and enable IDDict to support comparison operations (#5765)
* [BUGFIX] Insure all estimators properly handle datetime-float conversion (#5774)
* [BUGFIX] Return appropriate subquery type to Query Metrics for SA version (#5783)
* [DOCS] added guide how to use gx with emr serverless (#5623) (thanks @bvolodarskiy)
* [DOCS] DOC-362: how to choose between working with a single or multiple batches of data (#5745)
* [MAINTENANCE] Temporarily xfail E2E Cloud tests due to Azure env var issues (#5787)
* [MAINTENANCE] Add ids to `DataConnectorConfig` (#5740)
* [MAINTENANCE] Rename GX Cloud "contract" resource to "checkpoint" (#5748)
* [MAINTENANCE] Rename GX Cloud "suite_validation_result" resource to "validation_result" (#5749)
* [MAINTENANCE] Store Refactor - cloud store return types & http-errors (#5730)
* [MAINTENANCE] profile_numeric_columns_diff_expectation (#5741) (thanks @stevensecreti)
* [MAINTENANCE] Clean up type hints around class constructors (#5738)
* [MAINTENANCE] invoke docker (#5703)
* [MAINTENANCE] Add plist to build docker test image daily. (#5754)
* [MAINTENANCE] opt-out type-checking (#5713)
* [MAINTENANCE] Enable Algolia UI (#5753)
* [MAINTENANCE] Linting & initial typing for data context (#5756)
* [MAINTENANCE] Update `oneshot` estimator to `quantiles` estimator (#5737)
* [MAINTENANCE] Update Auto-Initializing Expectations to use `exact` estimator by default (#5759)
* [MAINTENANCE] Send a Gx-Version header set to __version__ in requests to cloud (#5758) (thanks @wookasz)
* [MAINTENANCE] invoke docker --detach and more typing (#5770)
* [MAINTENANCE] In ParameterBuilder implementations, enhance handling of numpy.ndarray metric values, whose elements are or can be converted into datetime.datetime type. (#5771)
* [MAINTENANCE] Config/Schema round_tripping (#5697)
* [MAINTENANCE] Add experimental label to MetricStore Doc (#5782)
* [MAINTENANCE] Remove `GeCloudIdentifier` creation in `Checkpoint.run()` (#5784)
### 0.15.18
* [FEATURE] Example notebooks for multi-batch Spark (#5683)
* [FEATURE] Introduce top-level `default_validation_id` in `CheckpointConfig` (#5693)
* [FEATURE] Pass down validation ids to `ExpectationSuiteValidationResult.meta` within `Checkpoint.run()` (#5725)
* [FEATURE] Refactor data assistant runner to compute formal parameters for data assistant run method signatures (#5727)
* [BUGFIX] Restored sqlite database for tests (#5742)
* [BUGFIX] Fixing a typo in variable name for default profiler for auto-initializing expectation "expect_column_mean_to_be_between" (#5687)
* [BUGFIX] Remove `resource_type` from call to `StoreBackend.build_key` (#5690)
* [BUGFIX] Update how_to_use_great_expectations_in_aws_glue.md (#5685) (thanks @bvolodarskiy)
* [BUGFIX] Updated how_to_use_great_expectations_in_aws_glue.md again (#5696) (thanks @bvolodarskiy)
* [BUGFIX] Update how_to_use_great_expectations_in_aws_glue.md (#5722) (thanks @bvolodarskiy)
* [BUGFIX] Update aws_glue_deployment_patterns.py (#5721) (thanks @bvolodarskiy)
* [DOCS] added guide how to use great expectations with aws glue (#5536) (thanks @bvolodarskiy)
* [DOCS] Document the ZenML integration for Great Expectations (#5672) (thanks @stefannica)
* [DOCS] Converts broken ZenML md refs to Technical Tags (#5714)
* [DOCS] How to create a Custom Query Expectation (#5460)
* [MAINTENANCE] Pin makefun package to version range for support assurance (#5746)
* [MAINTENANCE] s3 link for logo (#5731)
* [MAINTENANCE] Assign `resource_type` in `InlineStoreBackend` constructor (#5671)
* [MAINTENANCE] Add mysql client to Dockerfile.tests (#5681)
* [MAINTENANCE] `RuleBasedProfiler` corner case configuration changes (#5631)
* [MAINTENANCE] Update teams.yml (#5684)
* [MAINTENANCE] Utilize `e2e` mark on E2E Cloud tests (#5691)
* [MAINTENANCE] pyproject.tooml build-system typo (#5692)
* [MAINTENANCE] expand flake8 coverage (#5676)
* [MAINTENANCE] Ensure Cloud E2E tests are isolated to `gx-cloud-e2e` stage of CI (#5695)
* [MAINTENANCE] Add usage stats and initial database docker tests to CI (#5682)
* [MAINTENANCE] Add `e2e` mark to `pyproject.toml` (#5699)
* [MAINTENANCE] Update docker readme to mount your repo over the builtin one. (#5701)
* [MAINTENANCE] Combine packages `rule_based_profiler` and `rule_based_profiler.types` (#5680)
* [MAINTENANCE] ExpectColumnValuesToBeInSetSparkOptimized (#5702)
* [MAINTENANCE] expect_column_pair_values_to_have_difference_of_custom_perc… (#5661) (thanks @exteli)
* [MAINTENANCE] Remove non-docker version of CI tests that are now running in docker. (#5700)
* [MAINTENANCE] Add back `integration` mark to tests in `test_datasource_crud.py` (#5708)
* [MAINTENANCE] DEVREL-2289/Stale/Triage (#5694)
* [MAINTENANCE] revert expansive flake8 pre-commit checking - flake8 5.0.4 (#5706)
* [MAINTENANCE] Bugfix for `cloud-db-integration-pipeline` (#5704)
* [MAINTENANCE] Remove pytest-azurepipelines (#5716)
* [MAINTENANCE] Remove deprecation warning from `DataConnector`-level `batch_identifiers` for `RuntimeDataConnector` (#5717)
* [MAINTENANCE] Refactor `AbstractConfig` to make `name` and `id_` consistent attrs (#5698)
* [MAINTENANCE] Move CLI tests to docker (#5719)
* [MAINTENANCE] Leverage `DataContextVariables` in `DataContext` hierarchy to automatically determine how to persist changes (#5715)
* [MAINTENANCE] Refactor `InMemoryStoreBackend` out of `store_backend.py` (#5679)
* [MAINTENANCE] Move compatibility matrix tests to docker (#5728)
* [MAINTENANCE] Adds additional file extensions for Parquet assets (#5729)
* [MAINTENANCE] MultiBatch SqlExample notebook Update. (#5718)
* [MAINTENANCE] Introduce NumericRangeEstimator class hierarchy and encapsulate existing estimator implementations (#5735)
### 0.15.17
* [FEATURE] Improve estimation histogram computation in NumericMetricRangeMultiBatchParameterBuilder to include both counts and bin edges (#5628)
* [FEATURE] Enable retrieve by name for datasource with cloud store backend (#5640)
* [FEATURE] Update `DataContext.add_checkpoint()` to ensure validations within `CheckpointConfig` contain ids (#5638)
* [FEATURE] Add `expect_column_values_to_be_valid_crc32` (#5580) (thanks @sp1thas)
* [FEATURE] Enable showing expectation suite by domain and by expectation_type -- from DataAssistantResult (#5673)
* [BUGFIX] Patch flaky E2E GX Cloud tests (#5629)
* [BUGFIX] Pass `--cloud` flag to `dgtest-cloud-overrides` section of Azure YAML (#5632)
* [BUGFIX] Remove datasource from config on delete (#5636)
* [BUGFIX] Patch issue with usage stats sync not respecting usage stats opt-out (#5644)
* [BUGFIX] SlackRenderer / EmailRenderer links to deprecated doc (#5648)
* [BUGFIX] Fix table.head metric issue when using BQ without temp tables (#5630)
* [BUGFIX] Quick bugfix on all profile numeric column diff bounds expectations (#5651) (thanks @stevensecreti)
* [BUGFIX] Patch bug with `id` vs `id_` in Cloud integration tests (#5677)
* [DOCS] Fix a typo in batch_request_parameters variable (#5612) (thanks @StasDeep)
* [MAINTENANCE] CloudDataContext add_datasource test (#5626)
* [MAINTENANCE] Update stale.yml (#5602)
* [MAINTENANCE] Add `id` to `CheckpointValidationConfig` (#5603)
* [MAINTENANCE] Better error message for RuntimeDataConnector for BatchIdentifiers (#5635)
* [MAINTENANCE] type-checking round 2 (#5576)
* [MAINTENANCE] minor cleanup of old comments (#5641)
* [MAINTENANCE] add `--clear-cache` flag for `invoke type-check` (#5639)
* [MAINTENANCE] Install `dgtest` test runner utilizing Git URL in CI (#5645)
* [MAINTENANCE] Make comparisons of aggregate values date aware (#5642) (thanks @jcampbell)
* [MAINTENANCE] Add E2E Cloud test for `DataContext.add_checkpoint()` (#5653)
* [MAINTENANCE] Use docker to run tests in the Azure CI pipeline. (#5646)
* [MAINTENANCE] add new invoke tasks to `tasks.py` and create new file `usage_stats_utils.py` (#5593)
* [MAINTENANCE] Don't include 'test-pipeline' in extras_require dict (#5659)
* [MAINTENANCE] move tool config to pyproject.toml (#5649)
* [MAINTENANCE] Refactor docker test CI steps into jobs. (#5665)
* [MAINTENANCE] Only run Cloud E2E tests in primary pipeline (#5670)
* [MAINTENANCE] Improve DateTime Conversion Candling in Comparison Metrics & Expectations and Provide a Clean Object Model for Metrics Computation Bundling (#5656)
* [MAINTENANCE] Ensure that `id_` fields in Marshmallow schema serialize as `id` (#5660)
* [MAINTENANCE] data_context initial type checking (#5662)
### 0.15.16
* [FEATURE] Multi-Batch Example Notebook - SqlDataConnector examples (#5575)
* [FEATURE] Implement "is_close()" for making equality comparisons "reasonably close" for each ExecutionEngine subclass (#5597)
* [FEATURE] expect_profile_numeric_columns_percent_diff_(inclusive bounds) (#5586) (thanks @stevensecreti)
* [FEATURE] DataConnector Query enabled for `SimpleSqlDatasource` (#5610)
* [FEATURE] Implement the exact metric range estimate for NumericMetricRangeMultiBatchParameterBuilder (#5620)
* [FEATURE] Ensure that id propogates from RuleBasedProfilerConfig to RuleBasedProfiler (#5617)
* [BUGFIX] Pass cloud base url to datasource store (#5595)
* [BUGFIX] Temporarily disable Trino `0.315.0` from requirements (#5606)
* [BUGFIX] Update _create_trino_engine to check for schema before creating it (#5607)
* [BUGFIX] Support `ExpectationSuite` CRUD at `BaseDataContext` level (#5604)
* [BUGFIX] Update test due to change in postgres stdev calculation method (#5624)
* [BUGFIX] Patch issue with `get_validator` on Cloud-backed `DataContext` (#5619)
* [MAINTENANCE] Add name and id to DatasourceConfig (#5560)
* [MAINTENANCE] Clear datasources in `test_data_context_datasources` to improve test performance and narrow test scope (#5588)
* [MAINTENANCE] Fix tests that rely on guessing pytest generated random file paths. (#5589)
* [MAINTENANCE] Do not set google cloud credentials for lifetime of pytest process. (#5592)
* [MAINTENANCE] Misc updates to `Datasource` CRUD on `DataContext` to ensure consistent behavior (#5584)
* [MAINTENANCE] Add id to `RuleBasedProfiler` config (#5590)
* [MAINTENANCE] refactor to enable customization of quantile bias correction threshold for bootstrap estimation method (#5587)
* [MAINTENANCE] Ensure that `resource_type` used in `GeCloudStoreBackend` is converted to `GeCloudRESTResource` enum as needed (#5601)
* [MAINTENANCE] Create datasource with id (#5591)
* [MAINTENANCE] Enable Azure blob storage integration tests (#5594)
* [MAINTENANCE] Increase expectation kwarg line stroke width (#5608)
* [MAINTENANCE] Added Algolia Scripts (#5544) (thanks @devanshdixit)
* [MAINTENANCE] Handle `numpy` deprecation warnings (#5615)
* [MAINTENANCE] remove approximate comparisons -- they will be replaced by estimator alternatives (#5618)
* [MAINTENANCE] Making the dependency on dev-lite clearer (#5514)
* [MAINTENANCE] Fix tests in tests/integration/profiling/rule_based_profiler/ and tests/render/renderer/ (#5611)
* [MAINTENANCE] DataContext in cloud mode test add_datasource (#5625)
### 0.15.15
* [FEATURE] Integrate `DataContextVariables` with `DataContext` (#5466)
* [FEATURE] Add mostly to MulticolumnMapExpectation (#5481)
* [FEATURE] [MAINTENANCE] Revamped expect_profile_numeric_columns_diff_between_exclusive_threshold_range (#5493) (thanks @stevensecreti)
* [FEATURE] [CONTRIB] expect_profile_numeric_columns_diff_(less/greater)_than_or_equal_to_threshold (#5522) (thanks @stevensecreti)
* [FEATURE] Provide methods for returning ExpectationConfiguration list grouped by expectation_type and by domain_type (#5532)
* [FEATURE] add support for Azure authentication methods (#5229) (thanks @sdebruyn)
* [FEATURE] Show grouped sorted expectations by Domain and by expectation_type (#5539)
* [FEATURE] Categorical Rule in VolumeDataAssistant Should Use Same Cardinality As Categorical Rule in OnboardingDataAssistant (#5551)
* [BUGFIX] Handle "division by zero" in "ColumnPartition" metric when all column values are NULL (#5507)
* [BUGFIX] Use string dialect name if not found in enum (#5546)
* [BUGFIX] Add `try/except` around `DataContext._save_project_config` to mitigate issues with permissions (#5550)
* [BUGFIX] Explicitly pass in mostly as 1 if not set in configuration. (#5548)
* [BUGFIX] Increase precision for categorical rule for fractional comparisons (#5552)
* [DOCS] DOC-340 partition local installation guide (#5425)
* [DOCS] Add DataHub Ingestion docs (#5330) (thanks @maggiehays)
* [DOCS] toc update for DataHub integration doc (#5518)
* [DOCS] Updating discourse to GitHub Discussions in Docs (#4953)
* [MAINTENANCE] Clean up payload for `/data-context-variables` endpoint to adhere to desired chema (#5509)
* [MAINTENANCE] DataContext Refactor: DataAssistants (#5472)
* [MAINTENANCE] Ensure that validation operators are omitted from Cloud variables payload (#5510)
* [MAINTENANCE] Add end-to-end tests for multicolumn map expectations (#5517)
* [MAINTENANCE] Ensure that *_store_name attrs are omitted from Cloud variables payload (#5519)
* [MAINTENANCE] Refactor `key` arg out of `Store.serialize/deserialize` (#5511)
* [MAINTENANCE] Fix links to documentation (#5177) (thanks @andyjessen)
* [MAINTENANCE] Readme Update (#4952)
* [MAINTENANCE] E2E test for `FileDataContextVariables` (#5516)
* [MAINTENANCE] Cleanup/refactor prerequisite for group/filter/sort Expectations by domain (#5523)
* [MAINTENANCE] Refactor `GeCloudStoreBackend` to use PUT and DELETE HTTP verbs instead of PATCH (#5527)
* [MAINTENANCE] `/profiler` Cloud endpoint support (#5499)
* [MAINTENANCE] Add type hints to `Store` (#5529)
* [MAINTENANCE] Move MetricDomainTypes to core (it is used more widely now than previously). (#5530)
* [MAINTENANCE] Remove dependency pins on pyarrow and snowflake-connector-python (#5533)
* [MAINTENANCE] use invoke for common contrib/dev tasks (#5506)
* [MAINTENANCE] Add snowflake-connector-python dependency lower bound. (#5538)
* [MAINTENANCE] enforce pre-commit in ci (#5526)
* [MAINTENANCE] Providing more robust error handling for determining `domain_type` of an `ExpectationConfiguration` object (#5542)
* [MAINTENANCE] Remove extra indentation from store backend test (#5545)
* [MAINTENANCE] Plot-level dropdown for `DataAssistantResult` display charts (#5528)
* [MAINTENANCE] Make DataAssistantResult.batch_id_to_batch_identifier_display_name_map private (in order to optimize auto-complete for ease of use) (#5549)
* [MAINTENANCE] Initial Dockerfile for running tests and associated README. (#5541)
* [MAINTENANCE] Other dialect test (#5547)
### 0.15.14
* [FEATURE] QueryExpectations (#5223)
* [FEATURE] Control volume of metadata output when running DataAssistant classes. (#5483)
* [BUGFIX] Snowflake Docs Integration Test Fix (#5463)
* [BUGFIX] DataProfiler Linting Fix (#5468)
* [BUGFIX] Update renderer snapshots with `None` values removed (#5474)
* [BUGFIX] Rendering Test failures (#5475)
* [BUGFIX] Update `dependency-graph` pipeline YAML to ensure `--spark` gets passed to `dgtest` (#5477)
* [BUGFIX] Make sure the profileReport obj does not have defaultdicts (breaks gallery JSON) (#5491)
* [BUGFIX] Use Pandas.isnull() instead of NumPy.isnan() to check for empty values in TableExpectation._validate_metric_value_between(), due to wider types applicability. (#5502)
* [BUGFIX] Spark Schema has unexpected field for `spark.sql.warehouse.dir` (#5490)
* [BUGFIX] Conditionally pop values from Spark config in tests (#5508)
* [DOCS] DOC-349 re-write and partition interactive mode expectations guide (#5448)
* [DOCS] DOC-344 partition data docs on s3 guide (#5437)
* [DOCS] DOC-342 partition how to configure a validation result store in amazon s3 guide (#5428)
* [DOCS] link fix in onboarding data assistant guide (#5469)
* [DOCS] Integrate great-expectation with ydata-synthetic (#4568) (thanks @arunnthevapalan)
* [DOCS] Add 'test' extra to setup.py with docs (#5415)
* [DOCS] DOC-343 partition how to configure expectation store for aws s3 guide (#5429)
* [DOCS] DOC-357 partition the how to create a new checkpoint guide (#5458)
* [DOCS] Remove outdated release process docs. (#5484)
* [MAINTENANCE] Update `teams.yml` (#5457)
* [MAINTENANCE] Clean up GitHub Actions (#5461)
* [MAINTENANCE] Adds documentation and examples changes for snowflake connection string (#5447)
* [MAINTENANCE] DOC-345 partition the connect to s3 cloud storage with Pandas guide (#5439)
* [MAINTENANCE] Add unit and integration tests for Splitting on Mod Integer (#5452)
* [MAINTENANCE] Remove `InlineRenderer` invocation feature flag from `ExpectationValidationResult` (#5441)
* [MAINTENANCE] `DataContext` Refactor. Migration of datasource and store (#5404)
* [MAINTENANCE] Add unit and integration tests for Splitting on Multi-Column Values (#5464)
* [MAINTENANCE] Refactor `DataContextVariables` to leverage `@property` and `@setter` (#5446)
* [MAINTENANCE] expect_profile_numeric_columns_diff_between_threshold_range (#5467) (thanks @stevensecreti)
* [MAINTENANCE] Make `DataAssistantResult` fixtures module scoped (#5465)
* [MAINTENANCE] Remove keyword arguments within table row count expectations (#4874) (thanks @andyjessen)
* [MAINTENANCE] Add unit tests for Splitting on Converted DateTime (#5470)
* [MAINTENANCE] Rearrange integration tests to insure categorization into proper deployment-style based lists (#5471)
* [MAINTENANCE] Provide better error messaging if batch_request is not supplied to DataAssistant.run() (#5473)
* [MAINTENANCE] Adds run time envvar for Snowflake Partner ID (#5485)
* [MAINTENANCE] fixed algolia search page (#5099)
* [MAINTENANCE] Remove pyspark<3.0.0 constraint for python 3.7 (#5496)
* [MAINTENANCE] Ensure that `parter-integration` pipeline only runs on cronjob (#5500)
* [MAINTENANCE] Adding fixtures Query Expectations tests (#5486)
* [MAINTENANCE] Misc updates to `GeCloudStoreBackend` to better integrate with GE Cloud (#5497)
* [MAINTENANCE] Update automated release schedule (#5488)
* [MAINTENANCE] Update core-team in `teams.yml` (#5489)
* [MAINTENANCE] Update how_to_create_a_new_expectation_suite_using_rule_based_profile… (#5495)
* [MAINTENANCE] Remove pypandoc pin in constraints-dev.txt. (#5501)
* [MAINTENANCE] Ensure that `add_datasource` method on `AbstractDataContext` does not persist by default (#5482)
### 0.15.13
* [FEATURE] Add atomic `rendered_content` to `ExpectationValidationResult` and `ExpectationConfiguration` (#5369)
* [FEATURE] Add `DataContext.update_datasource` CRUD method (#5417)
* [FEATURE] Refactor Splitter Testing Modules so as to Make them More General and Add Unit and Integration Tests for "split_on_whole_table" and "split_on_column_value" on SQLite and All Supported Major SQL Backends (#5430)
* [FEATURE] Support underscore in the `condition_value` of a `row_condition` (#5393) (thanks @sp1thas)
* [DOCS] DOC-322 update terminology to v3 (#5326)
* [MAINTENANCE] Change property name of TaxiSplittingTestCase to make it more general (#5419)
* [MAINTENANCE] Ensure that `BaseDataContext` does not persist `Datasource` changes by default (#5423)
* [MAINTENANCE] Migration of `project_config_with_variables_substituted` to `AbstractDataContext` (#5385)
* [MAINTENANCE] Improve type hinting in `GeCloudStoreBackend` (#5427)
* [MAINTENANCE] Test serialization of text, table, and bulleted list `rendered_content` in `ExpectationValidationResult` (#5438)
* [MAINTENANCE] Refactor `datasource_name` out of `DataContext.update_datasource` (#5440)
* [MAINTENANCE] Add checkpoint name to validation results (#5442)
* [MAINTENANCE] Remove checkpoint from top level of schema since it is captured in `meta` (#5445)
* [MAINTENANCE] Add unit and integration tests for Splitting on Divided Integer (#5449)
* [MAINTENANCE] Update cli with new default simple checkpoint name (#5450)
### 0.15.12
* [FEATURE] Add Rule Statistics to DataAssistantResult for display in Jupyter notebook (#5368)
* [FEATURE] Include detailed Rule Execution statistics in jupyter notebook "repr" style output (#5375)
* [FEATURE] Support datetime/date-part splitters on Amazon Redshift (#5408)
* [DOCS] Capital One DataProfiler Expectations README Update (#5365) (thanks @stevensecreti)
* [DOCS] Add Trino guide (#5287)
* [DOCS] DOC-339 remove redundant how-to guide (#5396)
* [DOCS] Capital One Data Profiler README update (#5387) (thanks @taylorfturner)
* [DOCS] Add sqlalchemy-redshfit to dependencies in redshift doc (#5386)
* [MAINTENANCE] Reduce output amount in Jupyter notebooks when displaying DataAssistantResult (#5362)
* [MAINTENANCE] Update linter thresholds (#5367)
* [MAINTENANCE] Move `_apply_global_config_overrides()` to AbstractDataContext (#5285)
* [MAINTENANCE] WIP: [MAINTENANCE] stalebot configuration (#5301)
* [MAINTENANCE] expect_column_values_to_be_equal_to_or_greater_than_profile_min (#5372) (thanks @stevensecreti)
* [MAINTENANCE] expect_column_values_to_be_equal_to_or_less_than_profile_max (#5380) (thanks @stevensecreti)
* [MAINTENANCE] Replace string formatting with f-string (#5225) (thanks @andyjessen)
* [MAINTENANCE] Fix links in docs (#5340) (thanks @andyjessen)
* [MAINTENANCE] Caching of `config_variables` in `DataContext` (#5376)
* [MAINTENANCE] StaleBot Half DryRun (#5390)
* [MAINTENANCE] StaleBot DryRun 2 (#5391)
* [MAINTENANCE] file extentions applied to rel links (#5399)
* [MAINTENANCE] Allow installing jinja2 version 3.1.0 and higher (#5382)
* [MAINTENANCE] expect_column_values_confidence_for_data_label_to_be_less_than_or_equal_to_threshold (#5392) (thanks @stevensecreti)
* [MAINTENANCE] Add warnings to internal linters if actual error count does not match threshold (#5401)
* [MAINTENANCE] Ensure that changes made to env vars / config vars are recognized within subsequent calls of the same process (#5410)
* [MAINTENANCE] Stack `RuleBasedProfiler` progress bars for better user experience (#5400)
* [MAINTENANCE] Keep all Pandas Splitter Tests in a Dedicated Module (#5411)
* [MAINTENANCE] Refactor DataContextVariables to only persist state to Store using explicit save command (#5366)
* [MAINTENANCE] Refactor to put tests for splitting and sampling into modules for respective ExecutionEngine implementation (#5412)
### 0.15.11
* [FEATURE] Enable NumericMetricRangeMultiBatchParameterBuilder to use evaluation dependencies (#5323)
* [FEATURE] Improve Trino Support (#5261) (thanks @aezomz)
* [FEATURE] added support to Aws Athena quantiles (#5114) (thanks @kuhnen)
* [FEATURE] Implement the "column.standard_deviation" metric for sqlite database (#5338)
* [FEATURE] Update `add_datasource` to leverage the `DatasourceStore` (#5334)
* [FEATURE] Provide ability for DataAssistant to return its effective underlying BaseRuleBasedProfiler configuration (#5359)
* [BUGFIX] Fix Netlify build issue that was being caused by entry in changelog (#5322)
* [BUGFIX] Numpy dtype.float64 formatted floating point numbers must be converted to Python float for use in SQLAlchemy Boolean clauses (#5336)
* [BUGFIX] Fix for failing Expectation test in `cloud_db_integration` pipeline (#5321)
* [DOCS] revert getting started tutorial to RBP process (#5307)
* [DOCS] mark onboarding assistant guide as experimental and update cli command (#5308)
* [DOCS] Fix line numbers in getting started guide (#5324)
* [DOCS] DOC-337 automate updates to the version information displayed in the getting started tutorial. (#5348)
* [MAINTENANCE] Fix link in suite profile renderer (#5242) (thanks @andyjessen)
* [MAINTENANCE] Refactor of `_apply_global_config_overrides()` method to return config (#5286)
* [MAINTENANCE] Remove "json_serialize" directive from ParameterBuilder computations (#5320)
* [MAINTENANCE] Misc cleanup post `0.15.10` release (#5325)
* [MAINTENANCE] Standardize instantiation of NumericMetricRangeMultibatchParameterBuilder throughout the codebase. (#5327)
* [MAINTENANCE] Reuse MetricMultiBatchParameterBuilder computation results as evaluation dependencies for performance enhancement (#5329)
* [MAINTENANCE] clean up type declarations (#5331)
* [MAINTENANCE] Maintenance/great 761/great 1010/great 1011/alexsherstinsky/rule based profiler/data assistant/include only essential public methods in data assistant dispatcher class 2022 06 21 177 (#5351)
* [MAINTENANCE] Update release schedule JSON (#5349)
* [MAINTENANCE] Include only essential public methods in DataAssistantResult class (and its descendants) (#5360)
### 0.15.10
* [FEATURE] `DataContextVariables` CRUD for `stores` (#5268)
* [FEATURE] `DataContextVariables` CRUD for `data_docs_sites` (#5269)
* [FEATURE] `DataContextVariables` CRUD for `anonymous_usage_statistics` (#5271)
* [FEATURE] `DataContextVariables` CRUD for `notebooks` (#5272)
* [FEATURE] `DataContextVariables` CRUD for `concurrency` (#5273)
* [FEATURE] `DataContextVariables` CRUD for `progress_bars` (#5274)
* [FEATURE] Integrate `DatasourceStore` with `DataContext` (#5292)
* [FEATURE] Support both UserConfigurableProfiler and OnboardingDataAssistant in "CLI SUITE NEW --PROFILE name" command (#5306)
* [BUGFIX] Fix ColumnPartition metric handling of the number of bins (must always be integer). (#5282)
* [BUGFIX] Add new high precision rule for mean and stdev in `OnboardingDataAssistant` (#5276)
* [BUGFIX] Warning in Getting Started Guide notebook. (#5297)
* [DOCS] how to create an expectation suite with the onboarding assistant (#5266)
* [DOCS] update getting started tutorial for onboarding assistant (#5294)
* [DOCS] getting started tutorial doc standards updates (#5295)
* [DOCS] Update standard arguments doc for Expectations to not reference datasets. (#5052)
* [MAINTENANCE] Add check to `check_type_hint_coverage` script to ensure proper `mypy` installation (#5291)
* [MAINTENANCE] `DataAssistantResult` cleanup and extensibility enhancements (#5259)
* [MAINTENANCE] Handle compare Expectation in presence of high precision floating point numbers and NaN values (#5298)
* [MAINTENANCE] Suppress persisting of temporary ExpectationSuite configurations in Rule-Based Profiler computations (#5305)
* [MAINTENANCE] Adds column values github user validation (#5302)
* [MAINTENANCE] Adds column values IATA code validation (#5303)
* [MAINTENANCE] Adds column values ARN validation (#5304)
* [MAINTENANCE] Fixing a typo in a comment (in several files) (#5310)
* [MAINTENANCE] Adds column scientific notation string validation (#5309)
* [MAINTENANCE] lint fixes (#5312)
* [MAINTENANCE] Adds column value JSON validation (#5313)
* [MAINTENANCE] Expect column values to be valid scientific notation (#5311)
### 0.15.9
* [FEATURE] Add new expectation: expect column values to match powers of a base g… (#5219) (thanks @rifatKomodoDragon)
* [FEATURE] Replace UserConfigurableProfiler with OnboardingDataAssistant in "CLI suite new --profile" Jupyter Notebooks (#5236)
* [FEATURE] `DatasourceStore` (#5206)
* [FEATURE] add new expectation on validating hexadecimals (#5188) (thanks @andrewsx)
* [FEATURE] Usage Statistics Events for Profiler and DataAssistant "get_expectation_suite()" methods. (#5251)
* [FEATURE] `InlineStoreBackend` (#5216)
* [FEATURE] The "column.histogram" metric must support integer values of the "bins" parameter for all execution engine options. (#5258)
* [FEATURE] Initial implementation of `DataContextVariables` accessors (#5238)
* [FEATURE] `OnboardingDataAssistant` plots for `expect_table_columns_to_match_set` (#5208)
* [FEATURE] `DataContextVariables` CRUD for `config_variables_file_path` (#5262)
* [FEATURE] `DataContextVariables` CRUD for `plugins_directory` (#5263)
* [FEATURE] `DataContextVariables` CRUD for store name accessors (#5264)
* [BUGFIX] Hive temporary tables creation fix (#4956) (thanks @jaume-ferrarons)
* [BUGFIX] Provide error handling when metric fails for all Batch data samples (#5256)
* [BUGFIX] Patch automated release test date comparisons (#5278)
* [DOCS] How to compare two tables with the UserConfigurableProfiler (#5050)
* [DOCS] How to create a Custom Column Pair Map Expectation w/ supporting template & example (#4926)
* [DOCS] Auto API documentation script (#4964)
* [DOCS] Update formatting of links to public methods in class docs generated by auto API script (#5247)
* [DOCS] In the reference section of the ToC remove duplicates and update category pages (#5248)
* [DOCS] Update DataContext docstring (#5250)
* [MAINTENANCE] Add CodeSee architecture diagram workflow to repository (#5235) (thanks @codesee-maps[bot])
* [MAINTENANCE] Fix links to API docs (#5246) (thanks @andyjessen)
* [MAINTENANCE] Unpin cryptography upper bound (#5249)
* [MAINTENANCE] Don't use jupyter-client 7.3.2 (#5252)
* [MAINTENANCE] Re-introduce jupyter-client 7.3.2 (#5253)
* [MAINTENANCE] Add `cloud` mark to `pytest.ini` (#5254)
* [MAINTENANCE] add partner integration framework (#5132)
* [MAINTENANCE] `DataContextVariableKey` for use in Stores (#5255)
* [MAINTENANCE] Clarification of events in test with multiple checkpoint validations (#5257)
* [MAINTENANCE] Misc updates to improve security and automation of the weekly release process (#5244)
* [MAINTENANCE] show more test output and minor fixes (#5239)
* [MAINTENANCE] Add proper unit tests for Column Histogram metric and use Column Value Partitioner in OnboardingDataAssistant (#5267)
* [MAINTENANCE] Updates contributor docs to reflect updated linting guidance (#4909)
* [MAINTENANCE] Remove condition from `autoupdate` GitHub action (#5270)
* [MAINTENANCE] Improve code readability in the processing section of "MapMetricColumnDomainBuilder". (#5279)
### 0.15.8
* [FEATURE] `OnboardingDataAssistant` plots for `expect_table_row_count_to_be_between` non-sequential batches (#5212)
* [FEATURE] Limit sampling for spark and pandas (#5201)
* [FEATURE] Groundwork for DataContext Refactor (#5203)
* [FEATURE] Implement ability to change rule variable values through DataAssistant run() method arguments at runtime (#5218)
* [FEATURE] Plot numeric column domains in `OnboardingDataAssistant` (#5189)
* [BUGFIX] Repair "CLI Suite --Profile" Operation (#5230)
* [DOCS] Remove leading underscore from sampling docs (#5214)
* [MAINTENANCE] suppressing type hints in ill-defined situations (#5213)
* [MAINTENANCE] Change CategoricalColumnDomainBuilder property name from "limit_mode" to "cardinality_limit_mode". (#5215)
* [MAINTENANCE] Update Note in BigQuery Docs (#5197)
* [MAINTENANCE] Sampling cleanup refactor (use BatchSpec in sampling methods) (#5217)
* [MAINTENANCE] Globally increase Azure timeouts to 120 mins (#5222)
* [MAINTENANCE] Comment out kl_divergence for build_gallery (#5196)
* [MAINTENANCE] Fix docstring on expectation (#5204) (thanks @andyjessen)
* [MAINTENANCE] Improve NaN handling in numeric ParameterBuilder implementations (#5226)
* [MAINTENANCE] Update type hint and docstring linter thresholds (#5228)
### 0.15.7
* [FEATURE] Add Rule for TEXT semantic domains within the Onboarding Assistant (#5144)
* [FEATURE] Helper method to determine whether Expectation is self-initializing (#5159)
* [FEATURE] OnboardingDataAssistantResult plotting feature parity with VolumeDataAssistantResult (#5145)
* [FEATURE] Example Notebook for self-initializing `Expectations` (#5169)
* [FEATURE] DataAssistant: Enable passing directives to run() method using runtime_environment argument (#5187)
* [FEATURE] Adding DataAssistantResult.get_expectation_suite(expectation_suite_name) method (#5191)
* [FEATURE] Cronjob to automatically create release PR (#5181)
* [BUGFIX] Insure TABLE Domain Metrics Do Not Get Column Key From Column Type Rule Domain Builder (#5166)
* [BUGFIX] Update name for stdev expectation in `OnboardingDataAssistant` backend (#5193)
* [BUGFIX] OnboardingDataAssistant and Underlying Metrics: Add Defensive Programming Into Metric Implementations So As To Avoid Warnings About Incompatible Data (#5195)
* [BUGFIX] Insure that Histogram Metric in Pandas operates on numerical columns that do not have NULL values (#5199)
* [BUGFIX] RuleBasedProfiler: Ensure that run() method runtime environment directives are handled correctly when existing setting is None (by default) (#5202)
* [BUGFIX] In aggregate metrics, Spark Implementation already gets Column type as argument -- no need for F.col() as the operand is not a string. (#5207)
* [DOCS] Update ToC with category links (#5155)
* [DOCS] update on availability and parameters of conditional expectations (#5150)
* [MAINTENANCE] Helper method for RBP Notebook tests that does clean-up (#5171)
* [MAINTENANCE] Increase timeout for longer stages in Azure pipelines (#5175)
* [MAINTENANCE] Rule-Based Profiler -- In ParameterBuilder insure that metrics are validated for conversion to numpy array (to avoid deprecation warnings) (#5173)
* [MAINTENANCE] Increase timeout in packaging & installation pipeline (#5178)
* [MAINTENANCE] OnboardingDataAssistant handle multiple expectations per domain (#5170)
* [MAINTENANCE] Update timeout in pipelines to fit Azure syntax (#5180)
* [MAINTENANCE] Error message when `Validator` is instantiated with Incorrect `BatchRequest` (#5172)
* [MAINTENANCE] Don't include infinity in rendered string for diagnostics (#5190)
* [MAINTENANCE] Mark Great Expectations Cloud tests and add stage to CI/CD (#5186)
* [MAINTENANCE] Trigger expectation gallery build with scheduled CI/CD runs (#5192)
* [MAINTENANCE] `expectation_gallery` Azure pipeline (#5194)
* [MAINTENANCE] General cleanup/refactor of `DataAssistantResult` (#5198)
### 0.15.6
* [FEATURE] `NumericMetricRangeMultiBatchParameterBuilder` kernel density estimation (#5084)
* [FEATURE] Splitters and limit sample work on AWS Athena (#5024)
* [FEATURE] `ColumnValuesLengthMin` and `ColumnValuesLengthMax` metrics (#5107)
* [FEATURE] Use `batch_identifiers` in plot tooltips (#5091)
* [FEATURE] Updated `DataAssistantResult` plotting API (#5117)
* [FEATURE] Onboarding DataAssistant: Numeric Rules and Relevant Metrics (#5120)
* [FEATURE] DateTime Rule for OnboardingDataAssistant (#5121)
* [FEATURE] Categorical Rule is added to OnboardingDataAssistant (#5134)
* [FEATURE] OnboardingDataAssistant: Introduce MeanTableColumnsSetMatchMultiBatchParameterBuilder (to enable expect_table_columns_to_match_set) (#5135)
* [FEATURE] Giving the "expect_table_columns_to_match_set" Expectation Self-Initializing Capabilities. (#5136)
* [FEATURE] For OnboardingDataAssistant: Implement a TABLE Domain level rule to output "expect_table_columns_to_match_set" (#5137)
* [FEATURE] Enable self-initializing `ExpectColumnValueLengthsToBeBetween` (#4985)
* [FEATURE] `DataAssistant` plotting for non-sequential batches (#5126)
* [BUGFIX] Insure that Batch IDs are accessible in the order in which they were loaded in Validator (#5112)
* [BUGFIX] Update `DataAssistant` notebook for new plotting API (#5118)
* [BUGFIX] For DataAssistants, added try-except for Notebook tests (#5124)
* [BUGFIX] CategoricalColumnDomainBuilder needs to accept limit_mode with dictionary type (#5127)
* [BUGFIX] Use `external_sqldialect` mark to skip during lightweight runs (#5139)
* [BUGFIX] Use RANDOM_STATE in fixture to make tests deterministic (#5142)
* [BUGFIX] Read deployment_version instead of using versioneer in deprecation tests (#5147)
* [MAINTENANCE] DataAssistant: Refactoring Access to common ParameterBuilder instances (#5108)
* [MAINTENANCE] Refactor of`MetricTypes` and `AttributedResolvedMetrics` (#5100)
* [MAINTENANCE] Remove references to show_cta_footer except in schemas.py (#5111)
* [MAINTENANCE] Adding unit tests for sqlalchemy limit sampler part 1 (#5109)
* [MAINTENANCE] Don't re-raise connection errors in CI (#5115)
* [MAINTENANCE] Sqlite specific tests for splitting and sampling (#5119)
* [MAINTENANCE] Add Trino dialect in SqlAlchemyDataset (#5085) (thanks @ms32035)
* [MAINTENANCE] Move upper bound on sqlalchemy to <2.0.0. (#5140)
* [MAINTENANCE] Update primary pipeline to cut releases with tags (#5128)
* [MAINTENANCE] Improve handling of "expect_column_unique_values_count_to_be_between" in VolumeDataAssistant (#5146)
* [MAINTENANCE] Simplify DataAssistant Operation to not Depend on Self-Initializing Expectations (#5148)
* [MAINTENANCE] Improvements to Trino support (#5152)
* [MAINTENANCE] Update how_to_configure_a_new_checkpoint_using_test_yaml_config.md (#5157)
* [MAINTENANCE] Speed up the site builder (#5125) (thanks @tanelk)
* [MAINTENANCE] remove account id deprecation notice (#5158)
### 0.15.5
* [FEATURE] Add subset operation to Domain class (#5049)
* [FEATURE] In DataAssistant: Use Domain instead of domain_type as key for Metrics Parameter Builders (#5057)
* [FEATURE] Self-initializing `ExpectColumnStddevToBeBetween` (#5065)
* [FEATURE] Enum used by DateSplitter able to be represented as YAML (#5073)
* [FEATURE] Implementation of auto-complete for DataAssistant class names in Jupyter notebooks (#5077)
* [FEATURE] Provide display ("friendly") names for batch identifiers (#5086)
* [FEATURE] Onboarding DataAssistant -- Initial Rule Implementations (Data Aspects) (#5101)
* [FEATURE] OnboardingDataAssistant: Implement Nullity/Non-nullity Rules and Associated Metrics (#5104)
* [BUGFIX] `self_check()` now also checks for `aws_config_file` (#5040)
* [BUGFIX] `multi_batch_rule_based_profiler` test up to date with RBP changes (#5066)
* [BUGFIX] Splitting Support at Asset level (#5026)
* [BUGFIX] Make self-initialization in expect_column_values_to_be_between truly multi batch (#5068)
* [BUGFIX] databricks engine create temporary view (#4994) (thanks @gvillafanetapia)
* [BUGFIX] Patch broken Expectation gallery script (#5090)
* [BUGFIX] Sampling support at asset level (#5092)
* [DOCS] Update process and configurations in OpenLineage Action guide. (#5039)
* [DOCS] Update process and config examples in Opsgenie guide (#5037)
* [DOCS] Correct name of `openlineage-integration-common` package (#5041) (thanks @mobuchowski)
* [DOCS] Remove reference to validation operator process from how to trigger slack notifications guide (#5034)
* [DOCS] Update process and configuration examples in email Action guide. (#5036)
* [DOCS] Update Docusaurus version (#5063)
* [MAINTENANCE] Saved output of usage stats schema script in repo (#5053)
* [MAINTENANCE] Apply Altair custom themes to return objects (#5044)
* [MAINTENANCE] Introducing RuleBasedProfilerResult -- neither expectation suite name nor expectation suite must be passed to RuleBasedProfiler.run() (#5061)
* [MAINTENANCE] Refactor `DataAssistant` plotting to leverage utility dataclasses (#5022)
* [MAINTENANCE] Check that a passed string is parseable as an integer (mssql limit param) (#5071)
* [MAINTENANCE] Clean up mssql limit sampling code path and comments (#5074)
* [MAINTENANCE] Make saving bootstraps histogram for NumericMetricRangeMultiBatchParameterBuilder optional (absent by default) (#5075)
* [MAINTENANCE] Make self-initializing expectations return estimated kwargs with auto-generation timestamp and Great Expectation version (#5076)
* [MAINTENANCE] Adding a unit test for batch_id mapping to batch display names (#5087)
* [MAINTENANCE] `pypandoc` version constraint added (`< 1.8`) (#5093)
* [MAINTENANCE] Utilize Rule objects in Profiler construction in DataAssistant (#5089)
* [MAINTENANCE] Turn off metric calculation progress bars in `RuleBasedProfiler` and `DataAssistant` workflows (#5080)
* [MAINTENANCE] A small refactor of ParamerBuilder management used in DataAssistant classes (#5102)
* [MAINTENANCE] Convenience method refactor for Onboarding DataAssistant (#5103)
### 0.15.4
* [FEATURE] Enable self-initializing `ExpectColumnMeanToBeBetween` (#4986)
* [FEATURE] Enable self-initializing `ExpectColumnMedianToBeBetween` (#4987)
* [FEATURE] Enable self-initializing `ExpectColumnSumToBeBetween` (#4988)
* [FEATURE] New MetricSingleBatchParameterBuilder for specifically single-Batch Rule-Based Profiler scenarios (#5003)
* [FEATURE] Enable Pandas DataFrame and Series as MetricValues Output of Metric ParameterBuilder Classes (#5008)
* [FEATURE] Notebook for `VolumeDataAssistant` Example (#5010)
* [FEATURE] Histogram/Partition Single-Batch ParameterBuilder (#5011)
* [FEATURE] Update `DataAssistantResult.plot()` return value to emit `PlotResult` wrapper dataclass (#4962)
* [FEATURE] Limit samplers work with supported sqlalchemy backends (#5014)
* [FEATURE] trino support (#5021)
* [BUGFIX] RBP Profiling Dataset ProgressBar Fix (#4999)
* [BUGFIX] Fix DataAssistantResult serialization issue (#5020)
* [DOCS] Update slack notification guide to not use validation operators. (#4978)
* [MAINTENANCE] Update `autoupdate` GitHub action (#5001)
* [MAINTENANCE] Move `DataAssistant` registry capabilities into `DataAssistantRegistry` to enable user aliasing (#4991)
* [MAINTENANCE] Fix continuous partition example (#4939) (thanks @andyjessen)
* [MAINTENANCE] Preliminary refactors for data samplers. (#4996)
* [MAINTENANCE] Clean up unused imports and enforce through `flake8` in CI/CD (#5005)
* [MAINTENANCE] ParameterBuilder tests should maximally utilize polymorphism (#5007)
* [MAINTENANCE] Clean up type hints in CLI (#5006)
* [MAINTENANCE] Making ParameterBuilder metric computations robust to failures through logging and exception handling (#5009)
* [MAINTENANCE] Condense column-level `vconcat` plots into one interactive plot (#5002)
* [MAINTENANCE] Update version of `black` in pre-commit config (#5019)
* [MAINTENANCE] Improve tooltips and formatting for distinct column values chart in VolumeDataAssistantResult (#5017)
* [MAINTENANCE] Enhance configuring serialization for DotDict type classes (#5023)
* [MAINTENANCE] Pyarrow upper bound (#5028)
### 0.15.3
* [FEATURE] Enable self-initializing capabilities for `ExpectColumnProportionOfUniqueValuesToBeBetween` (#4929)
* [FEATURE] Enable support for plotting both Table and Column charts in `VolumeDataAssistant` (#4930)
* [FEATURE] BigQuery Temp Table Support (#4925)
* [FEATURE] Registry for DataAssistant classes with ability to execute from DataContext by registered name (#4966)
* [FEATURE] Enable self-intializing capabilities for `ExpectColumnValuesToMatchRegex`/`ExpectColumnValuesToNotMatchRegex` (#4958)
* [FEATURE] Provide "estimation histogram" ParameterBuilder output details . (#4975)
* [FEATURE] Enable self-initializing `ExpectColumnValuesToMatchStrftimeFormat` (#4977)
* [BUGFIX] check contrib requirements (#4922)
* [BUGFIX] Use `monkeypatch` to set a consistent bootstrap seed in tests (#4960)
* [BUGFIX] Make all Builder Configuration classes of Rule-Based Profiler Configuration Serializable (#4972)
* [BUGFIX] extras_require (#4968)
* [BUGFIX] Fix broken packaging test and update `dgtest-overrides` (#4976)
* [MAINTENANCE] Add timeout to `great_expectations` pipeline stages to prevent false positive build failures (#4957)
* [MAINTENANCE] Defining Common Test Fixtures for DataAssistant Testing (#4959)
* [MAINTENANCE] Temporarily pin `cryptography` package (#4963)
* [MAINTENANCE] Type annotate relevant functions with `-> None` (per PEP 484) (#4969)
* [MAINTENANCE] Handle edge cases where `false_positive_rate` is not in range [0, 1] or very close to bounds (#4946)
* [MAINTENANCE] fix a typo (#4974)
### 0.15.2
* [FEATURE] Split data assets using sql datetime columns (#4871)
* [FEATURE] Plot metrics with `DataAssistantResult.plot()` (#4873)
* [FEATURE] RuleBasedProfiler/DataAssistant/MetricMultiBatchParameterBuilder: Enable Returning Metric Computation Results with batch_id Attribution (#4862)
* [FEATURE] Enable variables to be specified at both Profiler and its constituent individual Rule levels (#4912)
* [FEATURE] Enable self-initializing `ExpectColumnUniqueValueCountToBeBetween` (#4902)
* [FEATURE] Improve diagnostic testing process (#4816)
* [FEATURE] Add Azure CI/CD action to aid with style guide enforcement (type hints) (#4878)
* [FEATURE] Add Azure CI/CD action to aid with style guide enforcement (docstrings) (#4617)
* [FEATURE] Use formal interfaces to clean up DataAssistant and DataAssistantResult modules/classes (#4901)
* [BUGFIX] fix validation issue for column domain type and implement expect_column_unique_value_count_to_be_between for VolumeDataAssistant (#4914)
* [BUGFIX] Fix issue with not using the generated table name on read (#4905)
* [BUGFIX] Add deprecation comment to RuntimeDataConnector
* [BUGFIX] Ensure proper class_name within all RuleBasedProfilerConfig instantiations
* [BUGFIX] fix rounding directive handling (#4887)
* [BUGFIX] `great_expectations` import fails when SQL Alchemy is not installed (#4880)
* [MAINTENANCE] Altair types cleanup (#4916)
* [MAINTENANCE] test: update test time (#4911)
* [MAINTENANCE] Add module docstring and simplify access to DatePart (#4910)
* [MAINTENANCE] Chip away at type hint violations around data context (#4897)
* [MAINTENANCE] Improve error message outputted to user in DocstringChecker action (#4895)
* [MAINTENANCE] Re-enable bigquery tests (#4903)
* [MAINTENANCE] Unit tests for sqlalchemy splitter methods, docs and other improvements (#4900)
* [MAINTENANCE] Move plot logic from `DataAssistant` into `DataAssistantResult` (#4896)
* [MAINTENANCE] Add condition to primary pipeline to ensure `import_ge` stage doesn't cause misleading Slack notifications (#4898)
* [MAINTENANCE] Refactor `RuleBasedProfilerConfig` (#4882)
* [MAINTENANCE] Refactor DataAssistant Access to Parameter Computation Results and Plotting Utilities (#4893)
* [MAINTENANCE] Update `dgtest-overrides` list to include all test files not captured by primary strategy (#4891)
* [MAINTENANCE] Add dgtest-overrides section to dependency_graph Azure pipeline
* [MAINTENANCE] Datasource and DataContext-level tests for RuntimeDataConnector changes (#4866)
* [MAINTENANCE] Temporarily disable bigquery tests. (#4888)
* [MAINTENANCE] Import GE after running `ge init` in packaging CI pipeline (#4885)
* [MAINTENANCE] Add CI stage importing GE with only required dependencies installed (#4884)
* [MAINTENANCE] `DataAssistantResult.plot()` conditional formatting and tooltips (#4881)
* [MAINTENANCE] split data context files (#4879)
* [MAINTENANCE] Add Tanner to CODEOWNERS for schemas.py (#4875)
* [MAINTENANCE] Use defined constants for ParameterNode accessor keys (#4872)
### 0.15.1
* [FEATURE] Additional Rule-Based Profiler Parameter/Variable Access Methods (#4814)
* [FEATURE] DataAssistant and VolumeDataAssistant classes (initial implementation -- to be enhanced as part of subsequent work) (#4844)
* [FEATURE] Add Support for Returning Parameters and Metrics as DataAssistantResult class (#4848)
* [FEATURE] DataAssistantResult Includes Underlying Profiler Execution Time (#4854)
* [FEATURE] Add batch_id for every resolved metric_value to ParameterBuilder.get_metrics() result object (#4860)
* [FEATURE] `RuntimeDataConnector` able to specify `Assets` (#4861)
* [BUGFIX] Linting error from hackathon automerge (#4829)
* [BUGFIX] Cleanup contrib (#4838)
* [BUGFIX] Add `notebook` to `GE_REQUIRED_DEPENDENCIES` (#4842)
* [BUGFIX] ParameterContainer return value formatting bug fix (#4840)
* [BUGFIX] Ensure that Parameter Validation/Configuration Dependency Configurations are included in Serialization (#4843)
* [BUGFIX] Correctly handle SQLA unexpected count metric for empty tables (#4618) (thanks @douglascook)
* [BUGFIX] Temporarily adjust Deprecation Warning Count (#4869)
* [DOCS] How to validate data with an in memory checkpoint (#4820)
* [DOCS] Update all tutorial redirect fix (#4841)
* [DOCS] redirect/remove dead links in docs (#4846)
* [MAINTENANCE] Refactor Rule-Based Profiler instantiation in Validator to make it available as a public method (#4823)
* [MAINTENANCE] String Type is not needed as Return Type from DomainBuilder.domain_type() (#4827)
* [MAINTENANCE] Fix Typo in Checkpoint Readme (#4835) (thanks @andyjessen)
* [MAINTENANCE] Modify conditional expectations readme (#4616) (thanks @andyjessen)
* [MAINTENANCE] Fix links within datasource new notebook (#4833) (thanks @andyjessen)
* [MAINTENANCE] Adds missing dependency, which is breaking CLI workflows (#4839)
* [MAINTENANCE] Update testing and documentation for `oneshot` estimation method (#4852)
* [MAINTENANCE] Refactor `Datasource` tests that work with `RuntimeDataConnector` by backend. (#4853)
* [MAINTENANCE] Update DataAssistant interfaces (#4857)
* [MAINTENANCE] Improve types returned by DataAssistant interface methods (#4859)
* [MAINTENANCE] Refactor `DataContext` tests that work with RuntimeDataConnector by backend (#4858)
* [HACKATHON] [Hackathon PRs in this release](https://github.com/great-expectations/great_expectations/pulls?q=is%3Apr+label%3Ahackathon-2022+is%3Amerged+-updated%3A%3E%3D2022-04-14+-updated%3A%3C%3D2022-04-06)
### 0.15.0
* [BREAKING] EOL Python 3.6 (#4567)
* [FEATURE] Implement Multi-Column Domain Builder for Rule-Based Profiler (#4604)
* [FEATURE] Update RBP notebook to include example for Multi-Column Domain Builder (#4606)
* [FEATURE] Rule-Based Profiler: ColumnPairDomainBuilder (#4608)
* [FEATURE] More package contrib info (#4693)
* [FEATURE] Introducing RuleState class and RuleOutput class for Rule-Based Profiler in support of richer use cases (such as DataAssistant). (#4704)
* [FEATURE] Add support for returning fully-qualified parameters names/values from RuleOutput object (#4773)
* [BUGFIX] Pass random seed to bootstrap estimator (#4605)
* [BUGFIX] Adjust output of `regex` ParameterBuilder to match Expectation (#4594)
* [BUGFIX] Rule-Based Profiler: Only primitive type based BatchRequest is allowed for Builder classes (#4614)
* [BUGFIX] Fix DataContext templates test (#4678)
* [BUGFIX] update module_name in NoteBookConfigSchema from v2 path to v3 (#4589) (thanks @Josephmaclean)
* [BUGFIX] request S3 bucket location only when necessary (#4526) (thanks @error418)
* [DOCS] Update `ignored_columns` snippet in "Getting Started" (#4609)
* [DOCS] Fixes import statement. (#4694)
* [DOCS] Update tutorial_review.md typo with intended word. (#4611) (thanks @cjbramble)
* [DOCS] Correct typo in url in docstring for set_based_column_map_expectation_template.py (example script) (#4817)
* [MAINTENANCE] Add retries to `requests` in usage stats integration tests (#4600)
* [MAINTENANCE] Miscellaneous test cleanup (#4602)
* [MAINTENANCE] Simplify ParameterBuilder.build_parameter() interface (#4622)
* [MAINTENANCE] War on Warnings - DataContext (#4572)
* [MAINTENANCE] Update links within great_expectations.yml (#4549) (thanks @andyjessen)
* [MAINTENANCE] Provide cardinality limit modes from CategoricalColumnDomainBuilder (#4662)
* [MAINTENANCE] Rule-Based Profiler: Rename Rule.generate() to Rule.run() (#4670)
* [MAINTENANCE] Refactor ValidationParameter computation (to be more elegant/compact) and fix a type hint in SimpleDateFormatStringParameterBuilder (#4687)
* [MAINTENANCE] Remove `pybigquery` check that is no longer needed (#4681)
* [MAINTENANCE] Rule-Based Profiler: Allow ExpectationConfigurationBuilder to be Optional (#4698)
* [MAINTENANCE] Slightly Clean Up NumericMetricRangeMultiBatchParameterBuilder (#4699)
* [MAINTENANCE] ParameterBuilder must not recompute its value, if it already exists in RuleState (ParameterContainer for its Domain). (#4701)
* [MAINTENANCE] Improve get validator functionality (#4661)
* [MAINTENANCE] Add checks for mostly=1.0 for all renderers (#4736)
* [MAINTENANCE] revert to not raising datasource errors on data context init (#4732)
* [MAINTENANCE] Remove unused bootstrap methods that were migrated to ML Flow (#4742)
* [MAINTENANCE] Update README.md (#4595) (thanks @andyjessen)
* [MAINTENANCE] Check for mostly equals 1 in renderers (#4815)
* [MAINTENANCE] Remove bootstrap tests that are no longer needed (#4818)
* [HACKATHON] ExpectColumnValuesToBeIsoLanguages (#4627) (thanks @szecsip)
* [HACKATHON] ExpectColumnAverageLatLonPairwiseDistanceToBeLessThan (#4559) (thanks @mmi333)
* [HACKATHON] ExpectColumnValuesToBeValidIPv6 (#4561) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidMac (#4562) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidMIME (#4563) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidHexColor (#4564) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidIban (#4565) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidIsoCountry (#4566) (thanks @voidforall)
* [HACKATHON] add expect_column_values_to_be_private_ipv4_class (#4656) (thanks @szecsip)
* [HACKATHON] Feature/expect column values url hostname match with cert (#4649) (thanks @szecsip)
* [HACKATHON] add expect_column_values_url_has_got_valid_cert (#4648) (thanks @szecsip)
* [HACKATHON] add expect_column_values_to_be_valid_us_state_or_territory (#4655) (thanks @Derekma73)
* [HACKATHON] ExpectColumnValuesToBeValidSsn (#4646) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidHttpStatusName (#4645) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidHttpStatusCode (#4644) (thanks @voidforall)
* [HACKATHON] Feature/expect column values to be daytime (#4643) (thanks @szecsip)
* [HACKATHON] add expect_column_values_ip_address_in_network (#4640) (thanks @szecsip)
* [HACKATHON] add expect_column_values_ip_asn_country_code_in_set (#4638) (thanks @szecsip)
* [HACKATHON] add expect_column_values_to_be_valid_us_state (#4654) (thanks @Derekma73)
* [HACKATHON] add expect_column_values_to_be_valid_us_state_or_territory_abbreviation (#4653) (thanks @Derekma73)
* [HACKATHON] add expect_column_values_to_be_weekday (#4636) (thanks @szecsip)
* [HACKATHON] add expect_column_values_to_be_valid_us_state_abbrevation (#4650) (thanks @Derekma73)
* [HACKATHON] ExpectColumnValuesGeometryDistanceToAddressToBeBetween (#4652) (thanks @pjdobson)
* [HACKATHON] ExpectColumnValuesToBeValidUdpPort (#4635) (thanks @voidforall)
* [HACKATHON] add expect_column_values_to_be_fibonacci_number (#4629) (thanks @szecsip)
* [HACKATHON] add expect_column_values_to_be_slug (#4628) (thanks @szecsip)
* [HACKATHON] ExpectColumnValuesGeometryToBeWithinPlace (#4626) (thanks @pjdobson)
* [HACKATHON] add expect_column_values_to_be_private_ipv6 (#4624) (thanks @szecsip)
* [HACKATHON] add expect_column_values_to_be_private_ip_v4 (#4623) (thanks @szecsip)
* [HACKATHON] ExpectColumnValuesToBeValidPrice (#4593) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidPhonenumber (#4592) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBePolygonAreaBetween (#4591) (thanks @mmi333)
* [HACKATHON] ExpectColumnValuesToBeValidTcpPort (#4634) (thanks @voidforall)
### 0.14.13
* [FEATURE] Convert Existing Self-Initializing Expectations to Make ExpectationConfigurationBuilder Self-Contained with its own validation_parameter_builder settings (#4547)
* [FEATURE] Improve diagnostic checklist details (#4548)
* [BUGFIX] Moves testing dependencies out of core reqs (#4522)
* [BUGFIX] Adjust output of datetime `ParameterBuilder` to match Expectation (#4590)
* [DOCS] Technical term tags for Adding features to Expectations section of the ToC (#4462)
* [DOCS] Contributing integrations ToC update. (#4551)
* [DOCS] Update intro page overview image (#4540)
* [DOCS] clarifications on execution engines and scalability (#4539)
* [DOCS] technical terms for validate data advanced (#4535)
* [DOCS] technical terms for validate data actions docs (#4518)
* [DOCS] correct code reference line numbers and snippet tags for how to create a batch of data from an in memory data frame (#4573)
* [DOCS] Update links in page; fix markdown link in html block (#4585)
* [MAINTENANCE] Don't return from validate configuration methods (#4545)
* [MAINTENANCE] Rule-Based Profiler: Refactor utilities into appropriate modules/classes for better separation of concerns (#4553)
* [MAINTENANCE] Refactor global `conftest` (#4534)
* [MAINTENANCE] clean up docstrings (#4554)
* [MAINTENANCE] Small formatting rearrangement for RegexPatternStringParameterBuilder (#4558)
* [MAINTENANCE] Refactor Anonymizer utilizing the Strategy design pattern (#4485)
* [MAINTENANCE] Remove duplicate `mistune` dependency (#4569)
* [MAINTENANCE] Run PEP273 checks on a schedule or release cut (#4570)
* [MAINTENANCE] Package dependencies usage stats instrumentation - part 1 (#4546)
* [MAINTENANCE] Add DevRel team to GitHub auto-label action (#4575)
* [MAINTENANCE] Add GitHub action to conditionally auto-update PR's (#4574)
* [MAINTENANCE] Bump version of `black` in response to hotfix for Click v8.1.0 (#4577)
* [MAINTENANCE] Update overview.md (#4556)
* [MAINTENANCE] Minor clean-up (#4571)
* [MAINTENANCE] Instrument package dependencies (#4583)
* [MAINTENANCE] Standardize DomainBuilder Constructor Arguments Ordering (#4599)
### 0.14.12
* [FEATURE] Enables Regex-Based Column Map Expectations (#4315)
* [FEATURE] Update diagnostic checklist to do linting checks (#4491)
* [FEATURE] format docstrings as markdown for gallery (#4502)
* [FEATURE] Introduces SetBasedColumnMapExpectation w/ supporting templates & doc (#4497)
* [FEATURE] `YAMLHandler` Class (#4510)
* [FEATURE] Remove conflict between filter directives and row_conditions (#4488)
* [FEATURE] Add SNS as a Validation Action (#4519) (thanks @michael-j-thomas)
* [BUGFIX] Fixes ExpectColumnValuesToBeInSet to enable behavior indicated in Parameterized Expectations Doc (#4455)
* [BUGFIX] Fixes minor typo in custom expectation docs, adds missing link (#4507)
* [BUGFIX] Removes validate_config from RegexBasedColumnMap templates & doc (#4506)
* [BUGFIX] Update ExpectColumnValuesToMatchRegex to support parameterized expectations (#4504)
* [BUGFIX] Add back `nbconvert` to dev dependencies (#4515)
* [BUGFIX] Account for case where SQLAlchemy dialect is not downloaded when masking a given URL (#4516)
* [BUGFIX] Fix failing test for `How to Configure Credentials` (#4525)
* [BUGFIX] Remove Temp Dir (#4528)
* [BUGFIX] Add pin to Jinja 2 due to API changes in v3.1.0 release (#4537)
* [BUGFIX] Fixes broken links in How To Write A How-To Guide (#4536)
* [BUGFIX] Removes cryptography upper bound for general reqs (#4487)
* [BUGFIX] Don't assume boto3 is installed (#4542)
* [DOCS] Update tutorial_review.md (#3981)
* [DOCS] Update AUTHORING_INTRO.md (#4470) (thanks @andyjessen)
* [DOCS] Add clarification (#4477) (thanks @strickvl)
* [DOCS] Add missing word and fix wrong dataset reference (#4478) (thanks @strickvl)
* [DOCS] Adds documentation on how to use Great Expectations with Prefect (#4433) (thanks @desertaxle)
* [DOCS] technical terms validate data checkpoints (#4486)
* [DOCS] How to use a Custom Expectation (#4467)
* [DOCS] Technical Terms for Validate Data: Overview and Core Skills docs (#4465)
* [DOCS] technical terms create expectations advanced skills (#4441)
* [DOCS] Integration documentation (#4483)
* [DOCS] Adding Meltano implementation pattern to docs (#4509) (thanks @pnadolny13)
* [DOCS] Update tutorial_create_expectations.md (#4512) (thanks @andyjessen)
* [DOCS] Fix relative links on github (#4479) (thanks @andyjessen)
* [DOCS] Update README.md (#4533) (thanks @andyjessen)
* [HACKATHON] ExpectColumnValuesToBeValidIPv4 (#4457) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidIanaTimezone (#4532) (thanks @lucasasmith)
* [MAINTENANCE] Clean up `Checkpoints` documentation and add `snippet` (#4474)
* [MAINTENANCE] Finalize Great Expectations contrib JSON structure (#4482)
* [MAINTENANCE] Update expectation filenames to match snake_case of their defined Expectations (#4484)
* [MAINTENANCE] Clean Up Types and Rely on "to_json_dict()" where appropriate (#4489)
* [MAINTENANCE] type hints for Batch Request to be string (which leverages parameter/variable resolution) (#4494)
* [MAINTENANCE] Insure consistent ordering of arguments to ParameterBuilder instantiations (#4496)
* [MAINTENANCE] Refactor build_gallery.py script (#4493)
* [MAINTENANCE] Feature/cloud 385/mask cloud creds (#4444)
* [MAINTENANCE] Enforce consistent JSON schema through usage stats (#4499)
* [MAINTENANCE] Applies `camel_to_snake` util to `RegexBasedColumnMapExpectation` (#4511)
* [MAINTENANCE] Removes unused dependencies (#4508)
* [MAINTENANCE] Revert changes made to dependencies in #4508 (#4520)
* [MAINTENANCE] Add `compatability` stage to `dependency_graph` pipeline (#4514)
* [MAINTENANCE] Add prod metadata and remove package attribute from library_metadata (#4517)
* [MAINTENANCE] Move builder instantiation methods to utility module for broader usage among sub-components within Rule-Based Profiler (#4524)
* [MAINTENANCE] Update package info for Capital One DataProfiler (#4523)
* [MAINTENANCE] Remove tag 'needs migration to modular expectations api' for some Expectations (#4521)
* [MAINTENANCE] Add type hints and PyCharm macros in a test module for DefaultExpectationConfigurationBuilder (#4529)
* [MAINTENANCE] Continue War on Warnings (#4500)
### 0.14.11
* [FEATURE] Script to validate docs snippets line number refs (#4377)
* [FEATURE] GitHub action to auto label `core-team` (#4382)
* [FEATURE] `add_rule()` method for RuleBasedProfilers and tests (#4358)
* [FEATURE] Enable the passing of an existing suite to `RuleBasedProfiler.run()` (#4386)
* [FEATURE] Impose Ordering on Marshmallow Schema validated Rule-Based Profiler Configuration fields (#4388)
* [FEATURE] Use more granular requirements-dev-xxx.txt files (#4327)
* [FEATURE] Rule-Based Profiler: Implement Utilities for getting all available parameter node names and objects resident in memory (#4442)
* [BUGFIX] Minor Serialization Correction for MeanUnexpectedMapMetricMultiBatchParameterBuilder (#4385)
* [BUGFIX] Fix CategoricalColumnDomainBuilder to be compliant with serialization / instantiation interfaces (#4395)
* [BUGFIX] Fix bug around `get_parent` usage stats utility in `test_yaml_config` (#4410)
* [BUGFIX] Adding `--spark` flag back to `azure-pipelines.yml` compatibility_matrix stage. (#4418)
* [BUGFIX] Remove remaining usage of --no-spark and --no-postgresql flags for pytest (#4425)
* [BUGFIX] Insure Proper Indexing of Metric Computation Results in ParameterBuilder (#4426)
* [BUGFIX] Include requirements-dev-contrib.txt in dev-install-matrix.yml for lightweight (#4430)
* [BUGFIX] Remove `pytest-azurepiplines` usage from `test_cli` stages in Azure pipelines (#4432)
* [BUGFIX] Updates or deletes broken and deprecated example notebooks (#4404)
* [BUGFIX] Add any dependencies we import directly, but don't have as explicit requirements (#4447)
* [BUGFIX] Removes potentially sensitive webhook URLs from logging (#4440)
* [BUGFIX] Fix packaging test (#4452)
* [DOCS] Fix typo in how_to_create_custom_metrics (#4379)
* [DOCS] Add `snippet` tag to gcs data docs (#4383)
* [DOCS] adjust lines for py reference (#4390)
* [DOCS] technical tags for connecting to data: core skills docs (#4403)
* [DOCS] technical term tags for connect to data database documents (#4413)
* [DOCS] Technical term tags for documentation under Connect to data: Filesystem (#4411)
* [DOCS] Technical term tags for setup pages (#4392)
* [DOCS] Technical term tags for Connect to Data: Advanced docs. (#4406)
* [DOCS] Technical tags: Connect to data:In memory docs (#4405)
* [DOCS] Add misc `snippet` tags to existing documentation (#4397)
* [DOCS] technical terms create expectations: core skills (#4435)
* [DOCS] Creates Custom Table Expectation How-To (#4399)
* [HACKATHON] ExpectTableLinearFeatureImportancesToBe (#4400)
* [MAINTENANCE] Group MAP_SERIES and MAP_CONDITION_SERIES with VALUE-type metrics (#3286)
* [MAINTENANCE] minor imports cleanup (#4381)
* [MAINTENANCE] Change schedule for `packaging_and_installation` pipeline to run at off-hours (#4384)
* [MAINTENANCE] Implicitly anonymize object based on __module__ (#4387)
* [MAINTENANCE] Preparatory cleanup refactoring of get_compute_domain (#4371)
* [MAINTENANCE] RBP -- make parameter builder configurations for self initializing expectations consistent with ParameterBuilder class interfaces (#4398)
* [MAINTENANCE] Refactor `ge_class` attr out of Anonymizer and related child classes (#4393)
* [MAINTENANCE] Removing Custom Expectation Renderer docs from sidebar (#4401)
* [MAINTENANCE] Enable "rule_based_profiler.run()" Method to Accept Batch Data Arguments Directly (#4409)
* [MAINTENANCE] Refactor out unnecessary Anonymizer child classes (#4408)
* [MAINTENANCE] Replace "sampling_method" with "estimator" in Rule-Based Profiler code (#4420)
* [MAINTENANCE] Add docstrings and type hints to `Anonymizer` (#4419)
* [MAINTENANCE] Continue chipping away at warnings (#4422)
* [MAINTENANCE] Rule-Based Profiler: Standardize on Include/Exclude Column Names List (#4424)
* [MAINTENANCE] Set upper bound on number of allowed warnings in snippet validation script (#4434)
* [MAINTENANCE] Clean up of `RegexPatternStringParameterBuilder` tests to use unittests (#4436)
### 0.14.10
* [FEATURE] ParameterBuilder for Computing Average Unexpected Values Fractions for any Map Metric (#4340)
* [FEATURE] Improve bootstrap quantile method accuracy (#4270)
* [FEATURE] Decorate RuleBasedProfiler.run() with usage statistics (#4321)
* [FEATURE] MapMetricColumnDomainBuilder for Rule-Based Profiler (#4353)
* [FEATURE] Enable expect_column_min/_max_to_be_between expectations to be self-initializing (#4363)
* [FEATURE] Azure pipeline to perform nightly CI/CD runs around packaging/installation (#4274)
* [BUGFIX] Fix `IndexError` around data asset pagination from CLI (#4346)
* [BUGFIX] Upper bound pyathena to <2.5.0 (#4350)
* [BUGFIX] Fixes PyAthena type checking for core expectations & tests (#4359)
* [BUGFIX] BatchRequest serialization (CLOUD-743) (#4352)
* [BUGFIX] Update the favicon on docs site (#4376)
* [BUGFIX] Fix issue with datetime objects in expecatation args (#2652) (thanks @jstammers)
* [DOCS] Universal map TOC update (#4292)
* [DOCS] add Config section (#4355)
* [DOCS] Deployment Patterns to Reference Architectures (#4344)
* [DOCS] Fixes tutorial link in reference architecture prereqs component (#4360)
* [DOCS] Tag technical terms in getting started tutorial (#4354)
* [DOCS] Update overview pages to link to updated tutorial pages. (#4378)
* [HACKATHON] ExpectColumnValuesToBeValidUUID (#4322)
* [HACKATHON] add expectation core (#4357)
* [HACKATHON] ExpectColumnAverageToBeWithinRangeOfGivenPoint (#4356)
* [MAINTENANCE] rule based profiler minor clean up of ValueSetParameterBuilder (#4332)
* [MAINTENANCE] Adding tests that exercise single and multi-batch BatchRequests (#4330)
* [MAINTENANCE] Formalize ParameterBuilder contract API usage in ValueSetParameterBuilder (#4333)
* [MAINTENANCE] Rule-Based Profiler: Create helpers directory; use column domain generation convenience method (#4335)
* [MAINTENANCE] Deduplicate table domain kwargs splitting (#4338)
* [MAINTENANCE] Update Azure CI/CD cron schedule to run more frequently (#4345)
* [MAINTENANCE] Optimize CategoricalColumnDomainBuilder to compute metrics in a single method call (#4348)
* [MAINTENANCE] Reduce tries to 2 for probabilistic tests (#4351)
* [MAINTENANCE] Refactor Checkpoint toolkit (#4342)
* [MAINTENANCE] Refactor all uses of `format` in favor of f-strings (#4347)
* [MAINTENANCE] Update great_expectations_contrib CLI tool to use existing diagnostic classes (#4316)
* [MAINTENANCE] Setting stage for removal of `--no-postgresql` and `--no-spark` flags from `pytest`. Enable `--postgresql` and `--spark` (#4309)
* [MAINTENANCE] convert unexpected_list contents to hashable type (#4336)
* [MAINTENANCE] add operator and func handling to stores urns (#4334)
* [MAINTENANCE] Refactor ParameterBuilder classes to extend parent class where possible; also, minor cleanup (#4375)
### 0.14.9
* [FEATURE] Enable Simultaneous Execution of all Metric Computations for ParameterBuilder implementations in Rule-Based Profiler (#4282)
* [FEATURE] Update print_diagnostic_checklist with an option to show any failed tests (#4288)
* [FEATURE] Self-Initializing Expectations (implemented for three example expectations). (#4258)
* [FEATURE] ValueSetMultiBatchParameterBuilder and CategoricalColumnDomainBuilder (#4269)
* [FEATURE] Remove changelog-bot GitHub Action (#4297)
* [FEATURE] Add requirements-dev-lite.txt and update tests/docs (#4273)
* [FEATURE] Enable All ParameterBuilder and DomainBuilder classes to accept batch_list generically (#4302)
* [FEATURE] Enable Probabilistic Tests To Retry upon Assertion Failure (#4308)
* [FEATURE] Update usage stats schema to account for RBP's run() payload (#4266)
* [FEATURE] ProfilerRunAnonymizer (#4264)
* [FEATURE] Enable Expectation "expect_column_values_to_be_in_set" to be Self-Initializing (#4318)
* [BUGFIX] Add redirect for removed Spark EMR page (#4280)
* [BUGFIX] `ConfiguredAssetSqlDataConnector` now correctly handles `schema` and `prefix`/`suffix` (#4268)
* [BUGFIX] Fixes Expectation Diagnostics failing on multi-line docstrings with leading linebreaks (#4286)
* [BUGFIX] Respect test backends (#4287)
* [BUGFIX] Skip test__generate_expectations_tests__xxx tests when sqlalchemy isn't there (#4300)
* [BUGFIX] test_backends integration test fix and supporting docs code ref fixes (#4306)
* [BUGFIX] Update `deep_filter_properties_iterable` to ensure that empty values are cleaned (#4298)
* [BUGFIX] Fixes validate_configuration checking in diagnostics (#4307)
* [BUGFIX] Update test output that should be returned from generate_diagnostic_checklist (#4317)
* [BUGFIX] Standardizes imports in expectation templates and examples (#4320)
* [BUGFIX] Only validate row_condition if not None (#4329)
* [BUGFIX] Fix PEP273 Windows issue (#4328)
* [DOCS] Fixes misc. verbiage & typos in new Custom Expectation docs (#4283)
* [DOCS] fix formatting in configuration details block of Getting Started (#4289) (thanks @afeld)
* [DOCS] Fixes imports and code refs to expectation templates (#4314)
* [DOCS] Update creating_custom_expectations/overview.md (#4278) (thanks @binarytom)
* [CONTRIB] CapitalOne Dataprofiler expectations (#4174) (thanks @taylorfturner)
* [HACKATHON] ExpectColumnValuesToBeLatLonCoordinatesInRangeOfGivenPoint (#4284)
* [HACKATHON] ExpectColumnValuesToBeValidDegreeDecimalCoordinates (#4319)
* [MAINTENANCE] Refactor parameter setting for simpler ParameterBuilder interface (#4299)
* [MAINTENANCE] SimpleDateTimeFormatStringParameterBuilder and general RBP example config updates (#4304)
* [MAINTENANCE] Make adherence to Marshmallow Schema more robust (#4325)
* [MAINTENANCE] Refactor rule based profiler to keep objects/utilities within intended scope (#4331)
* [MAINTENANCE] Dependabot version upgrades (#4253, #4231, #4058, #4041, #3916, #3886, #3583, #2856, #3370, #3216, #2935, #2855, #3302, #4008, #4252)
### 0.14.8
* [FEATURE] Add `run_profiler_on_data` method to DataContext (#4190)
* [FEATURE] `RegexPatternStringParameterBuilder` for `RuleBasedProfiler` (#4167)
* [FEATURE] experimental column map expectation checking for vectors (#3102) (thanks @manyshapes)
* [FEATURE] Pre-requisites in Rule-Based Profiler for Self-Estimating Expectations (#4242)
* [FEATURE] Add optional parameter `condition` to DefaultExpectationConfigurationBuilder (#4246)
* [BUGFIX] Ensure that test result for `RegexPatternStringParameterBuilder` is deterministic (#4240)
* [BUGFIX] Remove duplicate RegexPatternStringParameterBuilder test (#4241)
* [BUGFIX] Improve pandas version checking in test_expectations[_cfe].py files (#4248)
* [BUGFIX] Ensure `test_script_runner.py` actually raises AssertionErrors correctly (#4239)
* [BUGFIX] Check for pandas>=024 not pandas>=24 (#4263)
* [BUGFIX] Add support for SqlAlchemyQueryStore connection_string credentials (#4224) (thanks @davidvanrooij)
* [BUGFIX] Remove assertion (#4271)
* [DOCS] Hackathon Contribution Docs (#3897)
* [MAINTENANCE] Rule-Based Profiler: Fix Circular Imports; Configuration Schema Fixes; Enhanced Unit Tests; Pre-Requisites/Refactoring for Self-Estimating Expectations (#4234)
* [MAINTENANCE] Reformat contrib expectation with black (#4244)
* [MAINTENANCE] Resolve cyclic import issue with usage stats (#4251)
* [MAINTENANCE] Additional refactor to clean up cyclic imports in usage stats (#4256)
* [MAINTENANCE] Rule-Based Profiler prerequisite: fix quantiles profiler configuration and add comments (#4255)
* [MAINTENANCE] Introspect Batch Request Dictionary for its kind and instantiate accordingly (#4259)
* [MAINTENANCE] Minor clean up in style of an RBP test fixture; making variables access more robust (#4261)
* [MAINTENANCE] define empty sqla_bigquery object (#4249)
### 0.14.7
* [FEATURE] Support Multi-Dimensional Metric Computations Generically for Multi-Batch Parameter Builders (#4206)
* [FEATURE] Add support for sqlalchemy-bigquery while falling back on pybigquery (#4182)
* [BUGFIX] Update validate_configuration for core Expectations that don't return True (#4216)
* [DOCS] Fixes two references to the Getting Started tutorial (#4189)
* [DOCS] Deepnote Deployment Pattern Guide (#4169)
* [DOCS] Allow Data Docs to be rendered in night mode (#4130)
* [DOCS] Fix datepicker filter on data docs (#4217)
* [DOCS] Deepnote Deployment Pattern Image Fixes (#4229)
* [MAINTENANCE] Refactor RuleBasedProfiler toolkit pattern (#4191)
* [MAINTENANCE] Revert `dependency_graph` pipeline changes to ensure `usage_stats` runs in parallel (#4198)
* [MAINTENANCE] Refactor relative imports (#4195)
* [MAINTENANCE] Remove temp file that was accidently committed (#4201)
* [MAINTENANCE] Update default candidate strings SimpleDateFormatString parameter builder (#4193)
* [MAINTENANCE] minor type hints clean up (#4214)
* [MAINTENANCE] RBP testing framework changes (#4184)
* [MAINTENANCE] add conditional check for 'expect_column_values_to_be_in_type_list' (#4200)
* [MAINTENANCE] Allow users to pass in any set of polygon points in expectation for point to be within region (#2520) (thanks @ryanlindeborg)
* [MAINTENANCE] Better support Hive, better support BigQuery. (#2624) (thanks @jacobpgallagher)
* [MAINTENANCE] move process_evaluation_parameters into conditional (#4109)
* [MAINTENANCE] Type hint usage stats (#4226)
### 0.14.6
* [FEATURE] Create profiler from DataContext (#4070)
* [FEATURE] Add read_sas function (#3972) (thanks @andyjessen)
* [FEATURE] Run profiler from DataContext (#4141)
* [FEATURE] Instantiate Rule-Based Profiler Using Typed Configuration Object (#4150)
* [FEATURE] Provide ability to instantiate Checkpoint using CheckpointConfig typed object (#4166)
* [FEATURE] Misc cleanup around CLI `suite` command and related utilities (#4158)
* [FEATURE] Add scheduled runs for primary Azure pipeline (#4117)
* [FEATURE] Promote dependency graph test strategy to production (#4124)
* [BUGFIX] minor updates to test definition json files (#4123)
* [BUGFIX] Fix typo for metric name in expect_column_values_to_be_edtf_parseable (#4140)
* [BUGFIX] Ensure that CheckpointResult object can be pickled (#4157)
* [BUGFIX] Custom notebook templates (#2619) (thanks @luke321321)
* [BUGFIX] Include public fields in property_names (#4159)
* [DOCS] Reenable docs-under-test for RuleBasedProfiler (#4149)
* [DOCS] Provided details for using GE_HOME in commandline. (#4164)
* [MAINTENANCE] Return Rule-Based Profiler base.py to its dedicated config subdirectory (#4125)
* [MAINTENANCE] enable filter properties dict to handle both inclusion and exclusion lists (#4127)
* [MAINTENANCE] Remove unused Great Expectations imports (#4135)
* [MAINTENANCE] Update trigger for scheduled Azure runs (#4134)
* [MAINTENANCE] Maintenance/upgrade black (#4136)
* [MAINTENANCE] Alter `great_expectations` pipeline trigger to be more consistent (#4138)
* [MAINTENANCE] Remove remaining unused imports (#4137)
* [MAINTENANCE] Remove `class_name` as mandatory field from `RuleBasedProfiler` (#4139)
* [MAINTENANCE] Ensure `AWSAthena` does not create temporary table as part of processing Batch by default, which is currently not supported (#4103)
* [MAINTENANCE] Remove unused `Exception as e` instances (#4143)
* [MAINTENANCE] Standardize DictDot Method Behaviors Formally for Consistent Usage Patterns in Subclasses (#4131)
* [MAINTENANCE] Remove unused f-strings (#4142)
* [MAINTENANCE] Minor Validator code clean up -- for better code clarity (#4147)
* [MAINTENANCE] Refactoring of `test_script_runner.py`. Integration and Docs tests (#4145)
* [MAINTENANCE] Remove `compatability` stage from `dependency-graph` pipeline (#4161)
* [MAINTENANCE] CLOUD-618: GE Cloud "account" to "organization" rename (#4146)
### 0.14.5
* [FEATURE] Delete profilers from DataContext (#4067)
* [FEATURE] [BUGFIX] Support nullable int column types (#4044) (thanks @scnerd)
* [FEATURE] Rule-Based Profiler Configuration and Runtime Arguments Reconciliation Logic (#4111)
* [BUGFIX] Add default BIGQUERY_TYPES (#4096)
* [BUGFIX] Pin `pip --upgrade` to a specific version for CI/CD pipeline (#4100)
* [BUGFIX] Use `pip==20.2.4` for usage statistics stage of CI/CD (#4102)
* [BUGFIX] Fix shared state issue in renderer test (#4000)
* [BUGFIX] Missing docstrings on validator expect_ methods (#4062) (#4081)
* [BUGFIX] Fix s3 path suffix bug on windows (#4042) (thanks @scnerd)
* [MAINTENANCE] fix typos in changelogs (#4093)
* [MAINTENANCE] Migration of GCP tests to new project (#4072)
* [MAINTENANCE] Refactor Validator methods (#4095)
* [MAINTENANCE] Fix Configuration Schema and Refactor Rule-Based Profiler; Initial Implementation of Reconciliation Logic Between Configuration and Runtime Arguments (#4088)
* [MAINTENANCE] Minor Cleanup -- remove unnecessary default arguments from dictionary cleaner (#4110)
### 0.14.4
* [BUGFIX] Fix typing_extensions requirement to allow for proper build (#4083) (thanks @vojtakopal and @Godoy)
* [DOCS] data docs action rewrite (#4087)
* [DOCS] metric store how to rewrite (#4086)
* [MAINTENANCE] Change `logger.warn` to `logger.warning` to remove deprecation warnings (#4085)
### 0.14.3
* [FEATURE] Profiler Store (#3990)
* [FEATURE] List profilers from DataContext (#4023)
* [FEATURE] add bigquery json credentials kwargs for sqlalchemy connect (#4039)
* [FEATURE] Get profilers from DataContext (#4033)
* [FEATURE] Add RuleBasedProfiler to `test_yaml_config` utility (#4038)
* [BUGFIX] Checkpoint Configurator fix to allow notebook logging suppression (#4057)
* [DOCS] Created a page containing our glossary of terms and definitions. (#4056)
* [DOCS] swap of old uri for new in data docs generated (#4013)
* [MAINTENANCE] Refactor `test_yaml_config` (#4029)
* [MAINTENANCE] Additional distinction made between V2 and V3 upgrade script (#4046)
* [MAINTENANCE] Correcting Checkpoint Configuration and Execution Implementation (#4015)
* [MAINTENANCE] Update minimum version for SQL Alchemy (#4055)
* [MAINTENANCE] Refactor RBP constructor to work with **kwargs instantiation pattern through config objects (#4043)
* [MAINTENANCE] Remove unnecessary metric dependency evaluations and add common table column types metric. (#4063)
* [MAINTENANCE] Clean up new RBP types, method signatures, and method names for the long term. (#4064)
* [MAINTENANCE] fixed broken function call in CLI (#4068)
### 0.14.8
* [FEATURE] Add `run_profiler_on_data` method to DataContext (#4190)
* [FEATURE] `RegexPatternStringParameterBuilder` for `RuleBasedProfiler` (#4167)
* [FEATURE] experimental column map expectation checking for vectors (#3102) (thanks @manyshapes)
* [FEATURE] Pre-requisites in Rule-Based Profiler for Self-Estimating Expectations (#4242)
* [FEATURE] Add optional parameter `condition` to DefaultExpectationConfigurationBuilder (#4246)
* [BUGFIX] Ensure that test result for `RegexPatternStringParameterBuilder` is deterministic (#4240)
* [BUGFIX] Remove duplicate RegexPatternStringParameterBuilder test (#4241)
* [BUGFIX] Improve pandas version checking in test_expectations[_cfe].py files (#4248)
* [BUGFIX] Ensure `test_script_runner.py` actually raises AssertionErrors correctly (#4239)
* [BUGFIX] Check for pandas>=024 not pandas>=24 (#4263)
* [BUGFIX] Add support for SqlAlchemyQueryStore connection_string credentials (#4224) (thanks @davidvanrooij)
* [BUGFIX] Remove assertion (#4271)
* [DOCS] Hackathon Contribution Docs (#3897)
* [MAINTENANCE] Rule-Based Profiler: Fix Circular Imports; Configuration Schema Fixes; Enhanced Unit Tests; Pre-Requisites/Refactoring for Self-Estimating Expectations (#4234)
* [MAINTENANCE] Reformat contrib expectation with black (#4244)
* [MAINTENANCE] Resolve cyclic import issue with usage stats (#4251)
* [MAINTENANCE] Additional refactor to clean up cyclic imports in usage stats (#4256)
* [MAINTENANCE] Rule-Based Profiler prerequisite: fix quantiles profiler configuration and add comments (#4255)
* [MAINTENANCE] Introspect Batch Request Dictionary for its kind and instantiate accordingly (#4259)
* [MAINTENANCE] Minor clean up in style of an RBP test fixture; making variables access more robust (#4261)
* [MAINTENANCE] define empty sqla_bigquery object (#4249)
### 0.14.7
* [FEATURE] Support Multi-Dimensional Metric Computations Generically for Multi-Batch Parameter Builders (#4206)
* [FEATURE] Add support for sqlalchemy-bigquery while falling back on pybigquery (#4182)
* [BUGFIX] Update validate_configuration for core Expectations that don't return True (#4216)
* [DOCS] Fixes two references to the Getting Started tutorial (#4189)
* [DOCS] Deepnote Deployment Pattern Guide (#4169)
* [DOCS] Allow Data Docs to be rendered in night mode (#4130)
* [DOCS] Fix datepicker filter on data docs (#4217)
* [DOCS] Deepnote Deployment Pattern Image Fixes (#4229)
* [MAINTENANCE] Refactor RuleBasedProfiler toolkit pattern (#4191)
* [MAINTENANCE] Revert `dependency_graph` pipeline changes to ensure `usage_stats` runs in parallel (#4198)
* [MAINTENANCE] Refactor relative imports (#4195)
* [MAINTENANCE] Remove temp file that was accidently committed (#4201)
* [MAINTENANCE] Update default candidate strings SimpleDateFormatString parameter builder (#4193)
* [MAINTENANCE] minor type hints clean up (#4214)
* [MAINTENANCE] RBP testing framework changes (#4184)
* [MAINTENANCE] add conditional check for 'expect_column_values_to_be_in_type_list' (#4200)
* [MAINTENANCE] Allow users to pass in any set of polygon points in expectation for point to be within region (#2520) (thanks @ryanlindeborg)
* [MAINTENANCE] Better support Hive, better support BigQuery. (#2624) (thanks @jacobpgallagher)
* [MAINTENANCE] move process_evaluation_parameters into conditional (#4109)
* [MAINTENANCE] Type hint usage stats (#4226)
### 0.14.6
* [FEATURE] Create profiler from DataContext (#4070)
* [FEATURE] Add read_sas function (#3972) (thanks @andyjessen)
* [FEATURE] Run profiler from DataContext (#4141)
* [FEATURE] Instantiate Rule-Based Profiler Using Typed Configuration Object (#4150)
* [FEATURE] Provide ability to instantiate Checkpoint using CheckpointConfig typed object (#4166)
* [FEATURE] Misc cleanup around CLI `suite` command and related utilities (#4158)
* [FEATURE] Add scheduled runs for primary Azure pipeline (#4117)
* [FEATURE] Promote dependency graph test strategy to production (#4124)
* [BUGFIX] minor updates to test definition json files (#4123)
* [BUGFIX] Fix typo for metric name in expect_column_values_to_be_edtf_parseable (#4140)
* [BUGFIX] Ensure that CheckpointResult object can be pickled (#4157)
* [BUGFIX] Custom notebook templates (#2619) (thanks @luke321321)
* [BUGFIX] Include public fields in property_names (#4159)
* [DOCS] Reenable docs-under-test for RuleBasedProfiler (#4149)
* [DOCS] Provided details for using GE_HOME in commandline. (#4164)
* [MAINTENANCE] Return Rule-Based Profiler base.py to its dedicated config subdirectory (#4125)
* [MAINTENANCE] enable filter properties dict to handle both inclusion and exclusion lists (#4127)
* [MAINTENANCE] Remove unused Great Expectations imports (#4135)
* [MAINTENANCE] Update trigger for scheduled Azure runs (#4134)
* [MAINTENANCE] Maintenance/upgrade black (#4136)
* [MAINTENANCE] Alter `great_expectations` pipeline trigger to be more consistent (#4138)
* [MAINTENANCE] Remove remaining unused imports (#4137)
* [MAINTENANCE] Remove `class_name` as mandatory field from `RuleBasedProfiler` (#4139)
* [MAINTENANCE] Ensure `AWSAthena` does not create temporary table as part of processing Batch by default, which is currently not supported (#4103)
* [MAINTENANCE] Remove unused `Exception as e` instances (#4143)
* [MAINTENANCE] Standardize DictDot Method Behaviors Formally for Consistent Usage Patterns in Subclasses (#4131)
* [MAINTENANCE] Remove unused f-strings (#4142)
* [MAINTENANCE] Minor Validator code clean up -- for better code clarity (#4147)
* [MAINTENANCE] Refactoring of `test_script_runner.py`. Integration and Docs tests (#4145)
* [MAINTENANCE] Remove `compatability` stage from `dependency-graph` pipeline (#4161)
* [MAINTENANCE] CLOUD-618: GE Cloud "account" to "organization" rename (#4146)
### 0.14.5
* [FEATURE] Delete profilers from DataContext (#4067)
* [FEATURE] [BUGFIX] Support nullable int column types (#4044) (thanks @scnerd)
* [FEATURE] Rule-Based Profiler Configuration and Runtime Arguments Reconciliation Logic (#4111)
* [BUGFIX] Add default BIGQUERY_TYPES (#4096)
* [BUGFIX] Pin `pip --upgrade` to a specific version for CI/CD pipeline (#4100)
* [BUGFIX] Use `pip==20.2.4` for usage statistics stage of CI/CD (#4102)
* [BUGFIX] Fix shared state issue in renderer test (#4000)
* [BUGFIX] Missing docstrings on validator expect_ methods (#4062) (#4081)
* [BUGFIX] Fix s3 path suffix bug on windows (#4042) (thanks @scnerd)
* [MAINTENANCE] fix typos in changelogs (#4093)
* [MAINTENANCE] Migration of GCP tests to new project (#4072)
* [MAINTENANCE] Refactor Validator methods (#4095)
* [MAINTENANCE] Fix Configuration Schema and Refactor Rule-Based Profiler; Initial Implementation of Reconciliation Logic Between Configuration and Runtime Arguments (#4088)
* [MAINTENANCE] Minor Cleanup -- remove unnecessary default arguments from dictionary cleaner (#4110)
### 0.14.4
* [BUGFIX] Fix typing_extensions requirement to allow for proper build (#4083) (thanks @vojtakopal and @Godoy)
* [DOCS] data docs action rewrite (#4087)
* [DOCS] metric store how to rewrite (#4086)
* [MAINTENANCE] Change `logger.warn` to `logger.warning` to remove deprecation warnings (#4085)
### 0.14.3
* [FEATURE] Profiler Store (#3990)
* [FEATURE] List profilers from DataContext (#4023)
* [FEATURE] add bigquery json credentials kwargs for sqlalchemy connect (#4039)
* [FEATURE] Get profilers from DataContext (#4033)
* [FEATURE] Add RuleBasedProfiler to `test_yaml_config` utility (#4038)
* [BUGFIX] Checkpoint Configurator fix to allow notebook logging suppression (#4057)
* [DOCS] Created a page containing our glossary of terms and definitions. (#4056)
* [DOCS] swap of old uri for new in data docs generated (#4013)
* [MAINTENANCE] Refactor `test_yaml_config` (#4029)
* [MAINTENANCE] Additional distinction made between V2 and V3 upgrade script (#4046)
* [MAINTENANCE] Correcting Checkpoint Configuration and Execution Implementation (#4015)
* [MAINTENANCE] Update minimum version for SQL Alchemy (#4055)
* [MAINTENANCE] Refactor RBP constructor to work with **kwargs instantiation pattern through config objects (#4043)
* [MAINTENANCE] Remove unnecessary metric dependency evaluations and add common table column types metric. (#4063)
* [MAINTENANCE] Clean up new RBP types, method signatures, and method names for the long term. (#4064)
* [MAINTENANCE] fixed broken function call in CLI (#4068)
### 0.14.2
* [FEATURE] Marshmallow schema for Rule Based Profiler (#3982)
* [FEATURE] Enable Rule-Based Profile Parameter Access To Collection Typed Values (#3998)
* [BUGFIX] Docs integration pipeline bugfix (#3997)
* [BUGFIX] Enables spark-native null filtering (#4004)
* [DOCS] Gtm/cta in docs (#3993)
* [DOCS] Fix incorrect variable name in how_to_configure_an_expectation_store_in_amazon_s3.md (#3971) (thanks @moritzkoerber)
* [DOCS] update custom docs css to add a subtle border around tabbed content (#4001)
* [DOCS] Migration Guide now includes example for Spark data (#3996)
* [DOCS] Revamp Airflow Deployment Pattern (#3963) (thanks @denimalpaca)
* [DOCS] updating redirects to reflect a moved file (#4007)
* [DOCS] typo in gcp + bigquery tutorial (#4018)
* [DOCS] Additional description of Kubernetes Operators in GCP Deployment Guide (#4019)
* [DOCS] Migration Guide now includes example for Databases (#4005)
* [DOCS] Update how to instantiate without a yml file (#3995)
* [MAINTENANCE] Refactor of `test_script_runner.py` to break-up test list (#3987)
* [MAINTENANCE] Small refactor for tests that allows DB setup to be done from all tests (#4012)
### 0.14.1
* [FEATURE] Add pagination/search to CLI batch request listing (#3854)
* [BUGFIX] Safeguard against using V2 API with V3 Configuration (#3954)
* [BUGFIX] Bugfix and refactor for `cloud-db-integration` pipeline (#3977)
* [BUGFIX] Fixes breaking typo in expect_column_values_to_be_json_parseable (#3983)
* [BUGFIX] Fixes issue where nested columns could not be addressed properly in spark (#3986)
* [DOCS] How to connect to your data in `mssql` (#3950)
* [DOCS] MigrationGuide - Adding note on Migrating Expectation Suites (#3959)
* [DOCS] Incremental Update: The Universal Map's Getting Started Tutorial (#3881)
* [DOCS] Note about creating backup of Checkpoints (#3968)
* [DOCS] Connecting to BigQuery Doc line references fix (#3974)
* [DOCS] Remove RTD snippet about comments/suggestions from Docusaurus docs (#3980)
* [DOCS] Add howto for the OpenLineage validation operator (#3688) (thanks @rossturk)
* [DOCS] Updates to README.md (#3964)
* [DOCS] Update migration guide (#3967)
* [MAINTENANCE] Refactor docs dependency script (#3952)
* [MAINTENANCE] Use Effective SQLAlchemy for Reflection Fallback Logic and SQL Metrics (#3958)
* [MAINTENANCE] Remove outdated scripts (#3953)
* [MAINTENANCE] Add pytest opt to improve collection time (#3976)
* [MAINTENANCE] Refactor `render` method in PageRenderer (#3962)
* [MAINTENANCE] Standardize rule based profiler testing directories organization (#3984)
* [MAINTENANCE] Metrics Cleanup (#3989)
* [MAINTENANCE] Refactor `render` method of Content Block Renderer (#3960)
### 0.14.0
* [BREAKING] Change Default CLI Flag To V3 (#3943)
* [FEATURE] Cloud-399/Cloud-519: Add Cloud Notification Action (#3891)
* [FEATURE] `great_expectations_contrib` CLI tool (#3909)
* [FEATURE] Update `dependency_graph` pipeline to use `dgtest` CLI (#3912)
* [FEATURE] Incorporate updated dgtest CLI tool in experimental pipeline (#3927)
* [FEATURE] Add YAML config option to disable progress bars (#3794)
* [BUGFIX] Fix internal links to docs that may be rendered incorrectly (#3915)
* [BUGFIX] Update SlackNotificationAction to send slack_token and slack_channel to send_slack_notification function (#3873) (thanks @Calvo94)
* [BUGFIX] `CheckDocsDependenciesChanges` to only handle `.py` files (#3936)
* [BUGFIX] Provide ability to capture schema_name for SQL-based datasources; fix method usage bugs. (#3938)
* [BUGFIX] Ensure that Jupyter Notebook cells convert JSON strings to Python-compliant syntax (#3939)
* [BUGFIX] Cloud-519/cloud notification action return type (#3942)
* [BUGFIX] Fix issue with regex groups in `check_docs_deps` (#3949)
* [DOCS] Created link checker, fixed broken links (#3930)
* [DOCS] adding the link checker to the build (#3933)
* [DOCS] Add name to link checker in build (#3935)
* [DOCS] GCP Deployment Pattern (#3926)
* [DOCS] remove v3api flag in documentation (#3944)
* [DOCS] Make corrections in HOWTO Guides for Getting Data from SQL Sources (#3945)
* [DOCS] Tiny doc fix (#3948)
* [MAINTENANCE] Fix breaking change caused by the new version of ruamel.yaml (#3908)
* [MAINTENANCE] Drop extraneous print statement in self_check/util.py. (#3905)
* [MAINTENANCE] Raise exceptions on init in cloud mode (#3913)
* [MAINTENANCE] removing commented requirement (#3920)
* [MAINTENANCE] Patch for atomic renderer snapshot tests (#3918)
* [MAINTENANCE] Remove types/expectations.py (#3928)
* [MAINTENANCE] Tests/test data class serializable dot dict (#3924)
* [MAINTENANCE] Ensure that concurrency is backwards compatible (#3872)
* [MAINTENANCE] Fix issue where meta was not recognized as a kwarg (#3852)
### 0.13.49
* [FEATURE] PandasExecutionEngine is able to instantiate Google Storage client in Google Cloud Composer (#3896)
* [BUGFIX] Revert change to ExpectationSuite constructor (#3902)
* [MAINTENANCE] SQL statements that are of TextClause type expressed as subqueries (#3899)
### 0.13.48
* [DOCS] Updates to configuring credentials (#3856)
* [DOCS] Add docs on creating suites with the UserConfigurableProfiler (#3877)
* [DOCS] Update how to configure an expectation store in GCS (#3874)
* [DOCS] Update how to configure a validation result store in GCS (#3887)
* [DOCS] Update how to host and share data docs on GCS (#3889)
* [DOCS] Organize metadata store sidebar category by type of store (#3890)
* [MAINTENANCE] `add_expectation()` in `ExpectationSuite` supports usage statistics for GE. (#3824)
* [MAINTENANCE] Clean up Metrics type usage, SQLAlchemyExecutionEngine and SQLAlchemyBatchData implementation, and SQLAlchemy API usage (#3884)
### 0.13.47
* [FEATURE] Add support for named groups in data asset regex (#3855)
* [BUGFIX] Fix issue where dependency graph tester picks up non *.py files and add test file (#3830)
* [BUGFIX] Ensure proper exit code for dependency graph script (#3839)
* [BUGFIX] Allows GE to work when installed in a zip file (PEP 273). Fixes issue #3772 (#3798) (thanks @joseignaciorc)
* [BUGFIX] Update conditional for TextClause isinstance check in SQLAlchemyExecutionEngine (#3844)
* [BUGFIX] Fix usage stats events (#3857)
* [BUGFIX] Make ExpectationContext optional and remove when null to ensure backwards compatability (#3859)
* [BUGFIX] Fix sqlalchemy expect_compound_columns_to_be_unique (#3827) (thanks @harperweaver-dox)
* [BUGFIX] Ensure proper serialization of SQLAlchemy Legacy Row (#3865)
* [DOCS] Update migration_guide.md (#3832)
* [MAINTENANCE] Remove the need for DataContext registry in the instrumentation of the Legacy Profiler profiling method. (#3836)
* [MAINTENANCE] Remove DataContext registry (#3838)
* [MAINTENANCE] Refactor cli suite conditionals (#3841)
* [MAINTENANCE] adding hints to stores in data context (#3849)
* [MAINTENANCE] Improve usage stats testing (#3858, #3861)
* [MAINTENANCE] Make checkpoint methods in DataContext pass-through (#3860)
* [MAINTENANCE] Datasource and ExecutionEngine Anonymizers handle missing module_name (#3867)
* [MAINTENANCE] Add logging around DatasourceInitializationError in DataContext (#3846)
* [MAINTENANCE] Use f-string to prevent string concat issue in Evaluation Parameters (#3864)
* [MAINTENANCE] Test for errors / invalid messages in logs & fix various existing issues (#3875)
### 0.13.46
* [FEATURE] Instrument Runtime DataConnector for Usage Statistics: Add "checkpoint.run" Event Schema (#3797)
* [FEATURE] Add suite creation type field to CLI SUITE "new" and "edit" Usage Statistics events (#3810)
* [FEATURE] [EXPERIMENTAL] Dependency graph based testing strategy and related pipeline (#3738, #3815, #3818)
* [FEATURE] BaseDataContext registry (#3812, #3819)
* [FEATURE] Add usage statistics instrumentation to Legacy UserConfigurableProfiler execution (#3828)
* [BUGFIX] CheckpointConfig.__deepcopy__() must copy all fields, including the null-valued fields (#3793)
* [BUGFIX] Fix issue where configuration store didn't allow nesting (#3811)
* [BUGFIX] Fix Minor Bugs in and Clean Up UserConfigurableProfiler (#3822)
* [BUGFIX] Ensure proper replacement of nulls in Jupyter Notebooks (#3782)
* [BUGFIX] Fix issue where configuration store didn't allow nesting (#3811)
* [DOCS] Clean up TOC (#3783)
* [DOCS] Update Checkpoint and Actions Reference with testing (#3787)
* [DOCS] Update How to install Great Expectations locally (#3805)
* [DOCS] How to install Great Expectations in a hosted environment (#3808)
* [MAINTENANCE] Make BatchData Serialization More Robust (#3791)
* [MAINTENANCE] Refactor SiteIndexBuilder.build() (#3789)
* [MAINTENANCE] Update ref to ge-cla-bot in PR template (#3799)
* [MAINTENANCE] Anonymizer clean up and refactor (#3801)
* [MAINTENANCE] Certify the expectation "expect_table_row_count_to_equal_other_table" for V3 API (#3803)
* [MAINTENANCE] Refactor to enable broader use of event emitting method for usage statistics (#3825)
* [MAINTENANCE] Clean up temp file after CI/CD run (#3823)
* [MAINTENANCE] Raising exceptions for misconfigured datasources in cloud mode (#3866)
### 0.13.45
* [FEATURE] Feature/render validation metadata (#3397) (thanks @vshind1)
* [FEATURE] Added expectation expect_column_values_to_not_contain_special_characters() (#2849, #3771) (thanks @jaibirsingh)
* [FEATURE] Like and regex-based expectations in Athena dialect (#3762) (thanks @josges)
* [FEATURE] Rename `deep_filter_properties_dict()` to `deep_filter_properties_iterable()`
* [FEATURE] Extract validation result failures (#3552) (thanks @BenGale93)
* [BUGFIX] Allow now() eval parameter to be used by itself (#3719)
* [BUGFIX] Fixing broken logo for legacy RTD docs (#3769)
* [BUGFIX] Adds version-handling to sqlalchemy make_url imports (#3768)
* [BUGFIX] Integration test to avoid regression of simple PandasExecutionEngine workflow (#3770)
* [BUGFIX] Fix copying of CheckpointConfig for substitution and printing purposes (#3759)
* [BUGFIX] Fix evaluation parameter usage with Query Store (#3763)
* [BUGFIX] Feature/fix row condition quotes (#3676) (thanks @benoitLebreton-perso)
* [BUGFIX] Fix incorrect filling out of anonymized event payload (#3780)
* [BUGFIX] Don't reset_index for conditional expectations (#3667) (thanks @abekfenn)
* [DOCS] Update expectations gallery link in V3 notebook documentation (#3747)
* [DOCS] Correct V3 documentation link in V2 notebooks to point to V2 documentation (#3750)
* [DOCS] How to pass an in-memory DataFrame to a Checkpoint (#3756)
* [MAINTENANCE] Fix typo in Getting Started Guide (#3749)
* [MAINTENANCE] Add proper docstring and type hints to Validator (#3767)
* [MAINTENANCE] Clean up duplicate logging statements about optional `black` dep (#3778)
### 0.13.44
* [FEATURE] Add new result_format to include unexpected_row_list (#3346)
* [FEATURE] Implement "deep_filter_properties_dict()" method (#3703)
* [FEATURE] Create Constants for GETTING_STARTED Entities (e.g., datasource_name, expectation_suite_name, etc.) (#3712)
* [FEATURE] Add usage statistics event for DataContext.get_batch_list() method (#3708)
* [FEATURE] Add data_context.run_checkpoint event to usage statistics (#3721)
* [FEATURE] Add event_duration to usage statistics events (#3729)
* [FEATURE] InferredAssetSqlDataConnector's introspection can list external tables in Redshift Spectrum (#3646)
* [BUGFIX] Using a RuntimeBatchRequest in a Checkpoint with a top-level batch_request instead of validations (#3680)
* [BUGFIX] Using a RuntimeBatchRequest in a Checkpoint at runtime with Checkpoint.run() (#3713)
* [BUGFIX] Using a RuntimeBatchRequest in a Checkpoint at runtime with context.run_checkpoint() (#3718)
* [BUGFIX] Use SQLAlchemy make_url helper where applicable when parsing URLs (#3722)
* [BUGFIX] Adds check for quantile_ranges to be ordered or unbounded pairs (#3724)
* [BUGFIX] Updates MST renderer to return JSON-parseable boolean (#3728)
* [BUGFIX] Removes sqlite suppression for expect_column_quantile_values_to_be_between test definitions (#3735)
* [BUGFIX] Handle contradictory configurations in checkpoint.yml, checkpoint.run(), and context.run_checkpoint() (#3723)
* [BUGFIX] fixed a bug where expectation metadata doesn't appear in edit template for table-level expectations (#3129) (thanks @olechiw)
* [BUGFIX] Added temp_table creation for Teradata in SqlAlchemyBatchData (#3731) (thanks @imamolp)
* [DOCS] Add Databricks video walkthrough link (#3702, #3704)
* [DOCS] Update the link to configure a MetricStore (#3711, #3714) (thanks @txblackbird)
* [DOCS] Updated code example to remove deprecated "File" function (#3632) (thanks @daccorti)
* [DOCS] Delete how_to_add_a_validation_operator.md as OBE. (#3734)
* [DOCS] Update broken link in FOOTER.md to point to V3 documentation (#3745)
* [MAINTENANCE] Improve type hinting (using Optional type) (#3709)
* [MAINTENANCE] Standardize names for assets that are used in Getting Started Guide (#3706)
* [MAINTENANCE] Clean up remaining improper usage of Optional type annotation (#3710)
* [MAINTENANCE] Refinement of Getting Started Guide script (#3715)
* [MAINTENANCE] cloud-410 - Support for Column Descriptions (#3707)
* [MAINTENANCE] Types Clean Up in Checkpoint, Batch, and DataContext Classes (#3737)
* [MAINTENANCE] Remove DeprecationWarning for validator.remove_expectation (#3744)
### 0.13.43
* [FEATURE] Enable support for Teradata SQLAlchemy dialect (#3496) (thanks @imamolp)
* [FEATURE] Dremio connector added (SQLalchemy) (#3624) (thanks @chufe-dremio)
* [FEATURE] Adds expect_column_values_to_be_string_integers_increasing (#3642)
* [FEATURE] Enable "column.quantile_values" and "expect_column_quantile_values_to_be_between" for SQLite; add/enable new tests (#3695)
* [BUGFIX] Allow glob_directive for DBFS Data Connectors (#3673)
* [BUGFIX] Update black version in pre-commit config (#3674)
* [BUGFIX] Make sure to add "mostly_pct" value if "mostly" kwarg present (#3661)
* [BUGFIX] Fix BatchRequest.to_json_dict() to not overwrite original fields; also type usage cleanup in CLI tests (#3683)
* [BUGFIX] Fix pyfakefs boto / GCS incompatibility (#3694)
* [BUGFIX] Update prefix attr assignment in cloud-based DataConnector constructors (#3668)
* [BUGFIX] Update 'list_keys' signature for all cloud-based tuple store child classes (#3669)
* [BUGFIX] evaluation parameters from different expectation suites dependencies (#3684) (thanks @OmriBromberg)
* [DOCS] Databricks deployment pattern documentation (#3682)
* [DOCS] Remove how_to_instantiate_a_data_context_on_databricks_spark_cluster (#3687)
* [DOCS] Updates to Databricks doc based on friction logging (#3696)
* [MAINTENANCE] Fix checkpoint anonymization and make BatchRequest.to_json_dict() more robust (#3675)
* [MAINTENANCE] Update kl_divergence domain_type (#3681)
* [MAINTENANCE] update filter_properties_dict to use set for inclusions and exclusions (instead of list) (#3698)
* [MAINTENANCE] Adds CITATION.cff (#3697)
### 0.13.42
* [FEATURE] DBFS Data connectors (#3659)
* [BUGFIX] Fix "null" appearing in notebooks due to incorrect ExpectationConfigurationSchema serialization (#3638)
* [BUGFIX] Ensure that result_format from saved expectation suite json file takes effect (#3634)
* [BUGFIX] Allowing user specified run_id to appear in WarningAndFailureExpectationSuitesValidationOperator validation result (#3386) (thanks @wniroshan)
* [BUGFIX] Update black dependency to ensure passing Azure builds on Python 3.9 (#3664)
* [BUGFIX] fix Issue #3405 - gcs client init in pandas engine (#3408) (thanks @dz-1)
* [BUGFIX] Recursion error when passing RuntimeBatchRequest with query into Checkpoint using validations (#3654)
* [MAINTENANCE] Cloud 388/supported expectations query (#3635)
* [MAINTENANCE] Proper separation of concerns between specific File Path Data Connectors and corresponding ExecutionEngine objects (#3643)
* [MAINTENANCE] Enable Docusaurus tests for S3 (#3645)
* [MAINTENANCE] Formalize Exception Handling Between DataConnector and ExecutionEngine Implementations, and Update DataConnector Configuration Usage in Tests (#3644)
* [MAINTENANCE] Adds util for handling SADeprecation warning (#3651)
### 0.13.41
* [FEATURE] Support median calculation in AWS Athena (#3596) (thanks @persiyanov)
* [BUGFIX] Be able to use spark execution engine with spark reuse flag (#3541) (thanks @fep2)
* [DOCS] punctuation how_to_contribute_a_new_expectation_to_great_expectations.md (#3484) (thanks @plain-jane-gray)
* [DOCS] Update next_steps.md (#3483) (thanks @plain-jane-gray)
* [DOCS] Update how_to_configure_a_validation_result_store_in_gcs.md (#3482) (thanks @plain-jane-gray)
* [DOCS] Choosing and configuring DataConnectors (#3533)
* [DOCS] Remove --no-spark flag from docs tests (#3625)
* [DOCS] DevRel - docs fixes (#3498)
* [DOCS] Adding a period (#3627) (thanks @plain-jane-gray)
* [DOCS] Remove comments that describe Snowflake parameters as optional (#3639)
* [MAINTENANCE] Update CODEOWNERS (#3604)
* [MAINTENANCE] Fix logo (#3598)
* [MAINTENANCE] Add Expectations to docs navbar (#3597)
* [MAINTENANCE] Remove unused fixtures (#3218)
* [MAINTENANCE] Remove unnecessary comment (#3608)
* [MAINTENANCE] Superconductive Warnings hackathon (#3612)
* [MAINTENANCE] Bring Core Skills Doc for Creating Batch Under Test (#3629)
* [MAINTENANCE] Refactor and Clean Up Expectations and Metrics Parts of the Codebase (better encapsulation, improved type hints) (#3633)
### 0.13.40
* [FEATURE] Retrieve data context config through Cloud API endpoint #3586
* [FEATURE] Update Batch IDs to match name change in paths included in batch_request #3587
* [FEATURE] V2-to-V3 Upgrade/Migration #3592
* [FEATURE] table and graph atomic renderers #3595
* [FEATURE] V2-to-V3 Upgrade/Migration (Sidebar.js update) #3603
* [DOCS] Fixing broken links and linking to Expectation Gallery #3591
* [MAINTENANCE] Get TZLocal back to its original version control. #3585
* [MAINTENANCE] Add tests for datetime evaluation parameters #3601
* [MAINTENANCE] Removed warning for pandas option display.max_colwidth #3606
### 0.13.39
* [FEATURE] Migration of Expectations to Atomic Prescriptive Renderers (#3530, #3537)
* [FEATURE] Cloud: Editing Expectation Suites programmatically (#3564)
* [BUGFIX] Fix deprecation warning for importing from collections (#3546) (thanks @shpolina)
* [BUGFIX] SQLAlchemy version 1.3.24 compatibility in map metric provider (#3507) (thanks @shpolina)
* [DOCS] Clarify how to configure optional Snowflake parameters in CLI datasource new notebook (#3543)
* [DOCS] Added breaks to code snippets, reordered guidance (#3514)
* [DOCS] typo in documentation (#3542) (thanks @DanielEdu)
* [DOCS] Update how_to_configure_a_new_data_context_with_the_cli.md (#3556) (thanks @plain-jane-gray)
* [DOCS] Improved installation instructions, included in-line installation instructions to getting started (#3509)
* [DOCS] Update contributing_style.md (#3521) (thanks @plain-jane-gray)
* [DOCS] Update contributing_test.md (#3519) (thanks @plain-jane-gray)
* [DOCS] Revamp style guides (#3554)
* [DOCS] Update contributing.md (#3523, #3524) (thanks @plain-jane-gray)
* [DOCS] Simplify getting started (#3555)
* [DOCS] How to introspect and partition an SQL database (#3465)
* [DOCS] Update contributing_checklist.md (#3518) (thanks @plain-jane-gray)
* [DOCS] Removed duplicate prereq, how_to_instantiate_a_data_context_without_a_yml_file.md (#3481) (thanks @plain-jane-gray)
* [DOCS] fix link to expectation glossary (#3558) (thanks @sephiartlist)
* [DOCS] Minor Friction (#3574)
* [MAINTENANCE] Make CLI Check-Config and CLI More Robust (#3562)
* [MAINTENANCE] tzlocal version fix (#3565)
### 0.13.38
* [FEATURE] Atomic Renderer: Initial framework and Prescriptive renderers (#3529)
* [FEATURE] Atomic Renderer: Diagnostic renderers (#3534)
* [BUGFIX] runtime_parameters: {batch_data: Spark DF} serialization (#3502)
* [BUGFIX] Custom query in RuntimeBatchRequest for expectations using table.row_count metric (#3508)
* [BUGFIX] Transpose \n and , in notebook (#3463) (thanks @mccalluc)
* [BUGFIX] Fix contributor link (#3462) (thanks @mccalluc)
* [DOCS] How to introspect and partition a files based data store (#3464)
* [DOCS] fixed duplication of text in code example (#3503)
* [DOCS] Make content better reflect the document organization. (#3510)
* [DOCS] Correcting typos and improving the language. (#3513)
* [DOCS] Better Sections Numbering in Documentation (#3515)
* [DOCS] Improved wording (#3516)
* [DOCS] Improved title wording for section heading (#3517)
* [DOCS] Improve Readability of Documentation Content (#3536)
* [MAINTENANCE] Content and test script update (#3532)
* [MAINTENANCE] Provide Deprecation Notice for the "parse_strings_as_datetimes" Expectation Parameter in V3 (#3539)
### 0.13.37
* [FEATURE] Implement CompoundColumnsUnique metric for SqlAlchemyExecutionEngine (#3477)
* [FEATURE] add get_available_data_asset_names_and_types (#3476)
* [FEATURE] add s3_put_options to TupleS3StoreBackend (#3470) (Thanks @kj-9)
* [BUGFIX] Fix TupleS3StoreBackend remove_key bug (#3489)
* [DOCS] Adding Flyte Deployment pattern to docs (#3383)
* [DOCS] g_e docs branding updates (#3471)
* [MAINTENANCE] Add type-hints; add utility method for creating temporary DB tables; clean up imports; improve code readability; and add a directory to pre-commit (#3475)
* [MAINTENANCE] Clean up for a better code readability. (#3493)
* [MAINTENANCE] Enable SQL for the "expect_compound_columns_to_be_unique" expectation. (#3488)
* [MAINTENANCE] Fix some typos (#3474) (Thanks @mohamadmansourX)
* [MAINTENANCE] Support SQLAlchemy version 1.3.24 for compatibility with Airflow (Airflow does not currently support later versions of SQLAlchemy). (#3499)
* [MAINTENANCE] Update contributing_checklist.md (#3478) (Thanks @plain-jane-gray)
* [MAINTENANCE] Update how_to_configure_a_validation_result_store_in_gcs.md (#3480) (Thanks @plain-jane-gray)
* [MAINTENANCE] update implemented_expectations (#3492)
### 0.13.36
* [FEATURE] GREAT-3439 extended SlackNotificationsAction for slack app tokens (#3440) (Thanks @psheets)
* [FEATURE] Implement Integration Test for "Simple SQL Datasource" with Partitioning, Splitting, and Sampling (#3454)
* [FEATURE] Implement Integration Test for File Path Data Connectors with Partitioning, Splitting, and Sampling (#3452)
* [BUGFIX] Fix Incorrect Implementation of the "_sample_using_random" Sampling Method in SQLAlchemyExecutionEngine (#3449)
* [BUGFIX] Handle RuntimeBatchRequest passed to Checkpoint programatically (without yml) (#3448)
* [DOCS] Fix typo in command to create new checkpoint (#3434) (Thanks @joeltone)
* [DOCS] How to validate data by running a Checkpoint (#3436)
* [ENHANCEMENT] cloud-199 - Update Expectation and ExpectationSuite classes for GE Cloud (#3453)
* [MAINTENANCE] Does not test numpy.float128 when it doesn't exist (#3460)
* [MAINTENANCE] Remove Unnecessary SQL OR Condition (#3469)
* [MAINTENANCE] Remove validation playground notebooks (#3467)
* [MAINTENANCE] clean up type hints, API usage, imports, and coding style (#3444)
* [MAINTENANCE] comments (#3457)
### 0.13.35
* [FEATURE] Create ExpectationValidationGraph class to Maintain Relationship Between Expectation and Metrics and Use it to Associate Exceptions to Expectations (#3433)
* [BUGFIX] Addresses issue #2993 (#3054) by using configuration when it is available instead of discovering keys (listing keys) in existing sources. (#3377)
* [BUGFIX] Fix Data asset name rendering (#3431) (Thanks @shpolina)
* [DOCS] minor fix to syntax highlighting in how_to_contribute_a_new_expectation… (#3413) (Thanks @edjoesu)
* [DOCS] Fix broken links in how_to_create_a_new_expectation_suite_using_rule_based_profile… (#3410) (Thanks @edjoesu)
* [ENHANCEMENT] update list_expectation_suite_names and ExpectationSuiteValidationResult payload (#3419)
* [MAINTENANCE] Clean up Type Hints, JSON-Serialization, ID Generation and Logging in Objects in batch.py Module and its Usage (#3422)
* [MAINTENANCE] Fix Granularity of Exception Handling in ExecutionEngine.resolve_metrics() and Clean Up Type Hints (#3423)
* [MAINTENANCE] Fix broken links in how_to_create_a_new_expectation_suite_using_rule_based_profiler (#3441)
* [MAINTENANCE] Fix issue where BatchRequest object in configuration could cause Checkpoint to fail (#3438)
* [MAINTENANCE] Insure consistency between implementation of overriding Python __hash__() and internal ID property value (#3432)
* [MAINTENANCE] Performance improvement refactor for Spark unexpected values (#3368)
* [MAINTENANCE] Refactor MetricConfiguration out of validation_graph.py to Avoid Future Circular Dependencies in Python (#3425)
* [MAINTENANCE] Use ExceptionInfo to encapsulate common expectation validation result error information. (#3427)
### 0.13.34
* [FEATURE] Configurable multi-threaded checkpoint speedup (#3362) (Thanks @jdimatteo)
* [BUGFIX] Insure that the "result_format" Expectation Argument is Processed Properly (#3364)
* [BUGFIX] fix error getting validation result from DataContext (#3359) (Thanks @zachzIAM)
* [BUGFIX] fixed typo and added CLA links (#3347)
* [DOCS] Azure Data Connector Documentation for Pandas and Spark. (#3378)
* [DOCS] Connecting to GCS using Spark (#3375)
* [DOCS] Docusaurus - Deploying Great Expectations in a hosted environment without file system or CLI (#3361)
* [DOCS] How to get a batch from configured datasource (#3382)
* [MAINTENANCE] Add Flyte to README (#3387) (Thanks @samhita-alla)
* [MAINTENANCE] Adds expect_table_columns_to_match_set (#3329) (Thanks @viniciusdsmello)
* [MAINTENANCE] Bugfix/skip substitute config variables in ge cloud mode (#3393)
* [MAINTENANCE] Clean Up ValidationGraph API Usage, Improve Exception Handling for Metrics, Clean Up Type Hints (#3399)
* [MAINTENANCE] Clean up ValidationGraph API and add Type Hints (#3392)
* [MAINTENANCE] Enhancement/update _set methods with kwargs (#3391) (Thanks @roblim)
* [MAINTENANCE] Fix incorrect ToC section name (#3395)
* [MAINTENANCE] Insure Correct Processing of the catch_exception Flag in Metrics Resolution (#3360)
* [MAINTENANCE] exempt batch_data from a deep_copy operation on RuntimeBatchRequest (#3388)
* [MAINTENANCE] [WIP] Enhancement/cloud 169/update checkpoint.run for ge cloud (#3381)
### 0.13.33
* [FEATURE] Add optional ge_cloud_mode flag to DataContext to enable use with Great Expectations Cloud.
* [FEATURE] Rendered Data Doc JSONs can be uploaded and retrieved from GE Cloud
* [FEATURE] Implement InferredAssetAzureDataConnector with Support for Pandas and Spark Execution Engines (#3372)
* [FEATURE] Spark connecting to Google Cloud Storage (#3365)
* [FEATURE] SparkDFExecutionEngine can load data accessed by ConfiguredAssetAzureDataConnector (integration tests are included). (#3345)
* [FEATURE] [MER-293] GE Cloud Mode for DataContext (#3262) (Thanks @roblim)
* [BUGFIX] Allow for RuntimeDataConnector to accept custom query while suppressing temp table creation (#3335) (Thanks @NathanFarmer)
* [BUGFIX] Fix issue where multiple validators reused the same execution engine, causing a conflict in active batch (GE-3168) (#3222) (Thanks @jcampbell)
* [BUGFIX] Run batch_request dictionary through util function convert_to_json_serializable (#3349) (Thanks @NathanFarmer)
* [BUGFIX] added casting of numeric value to fix redshift issue #3293 (#3338) (Thanks @sariabod)
* [DOCS] Docusaurus - How to connect to an MSSQL database (#3353) (Thanks @NathanFarmer)
* [DOCS] GREAT-195 Docs remove all stubs and links to them (#3363)
* [MAINTENANCE] Update azure-pipelines-docs-integration.yml for Azure Pipelines
* [MAINTENANCE] Update implemented_expectations.md (#3351) (Thanks @spencerhardwick)
* [MAINTENANCE] Updating to reflect current Expectation dev state (#3348) (Thanks @spencerhardwick)
* [MAINTENANCE] docs: Clean up Docusaurus refs (#3371)
### 0.13.32
* [FEATURE] Add Performance Benchmarks Using BigQuery. (Thanks @jdimatteo)
* [WIP] [FEATURE] add backend args to run_diagnostics (#3257) (Thanks @edjoesu)
* [BUGFIX] Addresses Issue 2937. (#3236) (Thanks @BenGale93)
* [BUGFIX] SQL dialect doesn't register for BigQuery for V2 (#3324)
* [DOCS] "How to connect to data on GCS using Pandas" (#3311)
* [MAINTENANCE] Add CODEOWNERS with a single check for sidebars.js (#3332)
* [MAINTENANCE] Fix incorrect DataConnector usage of _get_full_file_path() API method. (#3336)
* [MAINTENANCE] Make Pandas against S3 and GCS integration tests more robust by asserting on number of batches returned and row counts (#3341)
* [MAINTENANCE] Make integration tests of Pandas against Azure more robust. (#3339)
* [MAINTENANCE] Prepare AzureUrl to handle WASBS format (for Spark) (#3340)
* [MAINTENANCE] Renaming default_batch_identifier in examples #3334
* [MAINTENANCE] Tests for RuntimeDataConnector at DataContext-level (#3304)
* [MAINTENANCE] Tests for RuntimeDataConnector at DataContext-level (Spark and Pandas) (#3325)
* [MAINTENANCE] Tests for RuntimeDataConnector at Datasource-level (Spark and Pandas) (#3318)
* [MAINTENANCE] Various doc patches (#3326)
* [MAINTENANCE] clean up imports and method signatures (#3337)
### 0.13.31
* [FEATURE] Enable `GCS DataConnector` integration with `PandasExecutionEngine` (#3264)
* [FEATURE] Enable column_pair expectations and tests for Spark (#3294)
* [FEATURE] Implement `InferredAssetGCSDataConnector` (#3284)
* [FEATURE]/CHANGE run time format (#3272) (Thanks @serialbandicoot)
* [DOCS] Fix misc errors in "How to create renderers for Custom Expectations" (#3315)
* [DOCS] GDOC-217 remove stub links (#3314)
* [DOCS] Remove misc TODOs to tidy up docs (#3313)
* [DOCS] Standardize capitalization of various technologies in `docs` (#3312)
* [DOCS] Fix broken link to Contributor docs (#3295) (Thanks @discdiver)
* [MAINTENANCE] Additional tests for RuntimeDataConnector at Datasource-level (query) (#3288)
* [MAINTENANCE] Update GCSStoreBackend + tests (#2630) (Thanks @hmandsager)
* [MAINTENANCE] Write integration/E2E tests for `ConfiguredAssetAzureDataConnector` (#3204)
* [MAINTENANCE] Write integration/E2E tests for both `GCSDataConnectors` (#3301)
### 0.13.30
* [FEATURE] Implement Spark Decorators and Helpers; Demonstrate on MulticolumnSumEqual Metric (#3289)
* [FEATURE] V3 implement expect_column_pair_values_to_be_in_set for SQL Alchemy execution engine (#3281)
* [FEATURE] Implement `ConfiguredAssetGCSDataConnector` (#3247)
* [BUGFIX] Fix import issues around cloud providers (GCS/Azure/S3) (#3292)
* [MAINTENANCE] Add force_reuse_spark_context to DatasourceConfigSchema (#3126) (thanks @gipaetusb and @mbakunze)
### 0.13.29
* [FEATURE] Implementation of the Metric "select_column_values.unique.within_record" for SQLAlchemyExecutionEngine (#3279)
* [FEATURE] V3 implement ColumnPairValuesInSet for SQL Alchemy execution engine (#3278)
* [FEATURE] Edtf with support levels (#2594) (thanks @mielvds)
* [FEATURE] V3 implement expect_column_pair_values_to_be_equal for SqlAlchemyExecutionEngine (#3267)
* [FEATURE] add expectation for discrete column entropy (#3049) (thanks @edjoesu)
* [FEATURE] Add SQLAlchemy Provider for the the column_pair_values.a_greater_than_b Metric (#3268)
* [FEATURE] Expectations tests for BigQuery backend (#3219) (Thanks @jdimatteo)
* [FEATURE] Add schema validation for different GCS auth methods (#3258)
* [FEATURE] V3 - Implement column_pair helpers/providers for SqlAlchemyExecutionEngine (#3256)
* [FEATURE] V3 implement expect_column_pair_values_to_be_equal expectation for PandasExecutionEngine (#3252)
* [FEATURE] GCS DataConnector schema validation (#3253)
* [FEATURE] Implementation of the "expect_select_column_values_to_be_unique_within_record" Expectation (#3251)
* [FEATURE] Implement the SelectColumnValuesUniqueWithinRecord metric (for PandasExecutionEngine) (#3250)
* [FEATURE] V3 - Implement ColumnPairValuesEqual for PandasExecutionEngine (#3243)
* [FEATURE] Set foundation for GCS DataConnectors (#3220)
* [FEATURE] Implement "expect_column_pair_values_to_be_in_set" expectation (support for PandasExecutionEngine) (#3242)
* [BUGFIX] Fix deprecation warning for importing from collections (#3228) (thanks @ismaildawoodjee)
* [DOCS] Document BigQuery test dataset configuration (#3273) (Thanks @jdimatteo)
* [DOCS] Syntax and Link (#3266)
* [DOCS] API Links and Supporting Docs (#3265)
* [DOCS] redir and search (#3249)
* [MAINTENANCE] Update azure-pipelines-docs-integration.yml to include env vars for Azure docs integration tests
* [MAINTENANCE] Allow Wrong ignore_row_if Directive from V2 with Deprecation Warning (#3274)
* [MAINTENANCE] Refactor test structure for "Connecting to your data" cloud provider integration tests (#3277)
* [MAINTENANCE] Make test method names consistent for Metrics tests (#3254)
* [MAINTENANCE] Allow `PandasExecutionEngine` to accept `Azure DataConnectors` (#3214)
* [MAINTENANCE] Standardize Arguments to MetricConfiguration Constructor; Use {} instead of dict(). (#3246)
### 0.13.28
* [FEATURE] Implement ColumnPairValuesInSet metric for PandasExecutionEngine
* [BUGFIX] Wrap optional azure imports in data_connector setup
### 0.13.27
* [FEATURE] Accept row_condition (with condition_parser) and ignore_row_if parameters for expect_multicolumn_sum_to_equal (#3193)
* [FEATURE] ConfiguredAssetDataConnector for Azure Blob Storage (#3141)
* [FEATURE] Replace MetricFunctionTypes.IDENTITY domain type with convenience method get_domain_records() for SparkDFExecutionEngine (#3226)
* [FEATURE] Replace MetricFunctionTypes.IDENTITY domain type with convenience method get_domain_records() for SqlAlchemyExecutionEngine (#3215)
* [FEATURE] Replace MetricFunctionTypes.IDENTITY domain type with convenience method get_full_access_compute_domain() for PandasExecutionEngine (#3210)
* [FEATURE] Set foundation for Azure-related DataConnectors (#3188)
* [FEATURE] Update ExpectCompoundColumnsToBeUnique for V3 API (#3161)
* [BUGFIX] Fix incorrect schema validation for Azure data connectors (#3200)
* [BUGFIX] Fix incorrect usage of "all()" in the comparison of validation results when executing an Expectation (#3178)
* [BUGFIX] Fixes an error with expect_column_values_to_be_dateutil_parseable (#3190)
* [BUGFIX] Improve parsing of .ge_store_backend_id (#2952)
* [BUGFIX] Remove fixture parameterization for Cloud DBs (Snowflake and BigQuery) (#3182)
* [BUGFIX] Restore support for V2 API style custom expectation rendering (#3179) (Thanks @jdimatteo)
* [DOCS] Add `conda` as installation option in README (#3196) (Thanks @rpanai)
* [DOCS] Standardize capitalization of "Python" in "Connecting to your data" section of new docs (#3209)
* [DOCS] Standardize capitalization of Spark in docs (#3198)
* [DOCS] Update BigQuery docs to clarify the use of temp tables (#3184)
* [DOCS] Create _redirects (#3192)
* [ENHANCEMENT] RuntimeDataConnector messaging is made more clear for `test_yaml_config()` (#3206)
* [MAINTENANCE] Add `credentials` YAML key support for `DataConnectors` (#3173)
* [MAINTENANCE] Fix minor typo in S3 DataConnectors (#3194)
* [MAINTENANCE] Fix typos in argument names and types (#3207)
* [MAINTENANCE] Update changelog. (#3189)
* [MAINTENANCE] Update documentation. (#3203)
* [MAINTENANCE] Update validate_your_data.md (#3185)
* [MAINTENANCE] update tests across execution engines and clean up coding patterns (#3223)
### 0.13.26
* [FEATURE] Enable BigQuery tests for Azure CI/CD (#3155)
* [FEATURE] Implement MulticolumnMapExpectation class (#3134)
* [FEATURE] Implement the MulticolumnSumEqual Metric for PandasExecutionEngine (#3130)
* [FEATURE] Support row_condition and ignore_row_if Directives Combined for PandasExecutionEngine (#3150)
* [FEATURE] Update ExpectMulticolumnSumToEqual for V3 API (#3136)
* [FEATURE] add python3.9 to python versions (#3143) (Thanks @dswalter)
* [FEATURE]/MER-16/MER-75/ADD_ROUTE_FOR_VALIDATION_RESULT (#3090) (Thanks @rreinoldsc)
* [BUGFIX] Enable `--v3-api suite edit` to proceed without selecting DataConnectors (#3165)
* [BUGFIX] Fix error when `RuntimeBatchRequest` is passed to `SimpleCheckpoint` with `RuntimeDataConnector` (#3152)
* [BUGFIX] allow reader_options in the CLI so can read `.csv.gz` files (#2695) (Thanks @luke321321)
* [DOCS] Apply Docusaurus tabs to relevant pages in new docs
* [DOCS] Capitalize python to Python in docs (#3176)
* [DOCS] Improve Core Concepts - Expectation Concepts (#2831)
* [MAINTENANCE] Error messages must be friendly. (#3171)
* [MAINTENANCE] Implement the "compound_columns_unique" metric for PandasExecutionEngine (with a unit test). (#3159)
* [MAINTENANCE] Improve Coding Practices in "great_expectations/expectations/expectation.py" (#3151)
* [MAINTENANCE] Update test_script_runner.py (#3177)
### 0.13.25
* [FEATURE] Pass on meta-data from expectation json to validation result json (#2881) (Thanks @sushrut9898)
* [FEATURE] Add sqlalchemy engine support for `column.most_common_value` metric (#3020) (Thanks @shpolina)
* [BUGFIX] Added newline to CLI message for consistent formatting (#3127) (Thanks @ismaildawoodjee)
* [BUGFIX] fix pip install snowflake build error with Python 3.9 (#3119) (Thanks @jdimatteo)
* [BUGFIX] Populate (data) asset name in data docs for RuntimeDataConnector (#3105) (Thanks @ceshine)
* [DOCS] Correct path to docs_rtd/changelog.rst (#3120) (Thanks @jdimatteo)
* [DOCS] Fix broken links in "How to write a 'How to Guide'" (#3112)
* [DOCS] Port over "How to add comments to Expectations and display them in DataDocs" from RTD to Docusaurus (#3078)
* [DOCS] Port over "How to create a Batch of data from an in memory Spark or Pandas DF" from RTD to Docusaurus (#3099)
* [DOCS] Update CLI codeblocks in create_your_first_expectations.md (#3106) (Thanks @ories)
* [MAINTENANCE] correct typo in docstring (#3117)
* [MAINTENANCE] DOCS/GDOC-130/Add Changelog (#3121)
* [MAINTENANCE] fix docstring for expectation "expect_multicolumn_sum_to_equal" (previous version was not precise) (#3110)
* [MAINTENANCE] Fix typos in docstrings in map_metric_provider partials (#3111)
* [MAINTENANCE] Make sure that all imports use column_aggregate_metric_provider (not column_aggregate_metric). (#3128)
* [MAINTENANCE] Rename column_aggregate_metric.py into column_aggregate_metric_provider.py for better code readability. (#3123)
* [MAINTENANCE] rename ColumnMetricProvider to ColumnAggregateMetricProvider (with DeprecationWarning) (#3100)
* [MAINTENANCE] rename map_metric.py to map_metric_provider.py (with DeprecationWarning) for a better code readability/interpretability (#3103)
* [MAINTENANCE] rename table_metric.py to table_metric_provider.py with a deprecation notice (#3118)
* [MAINTENANCE] Update CODE_OF_CONDUCT.md (#3066)
* [MAINTENANCE] Upgrade to modern Python syntax (#3068) (Thanks @cclauss)
### 0.13.24
* [FEATURE] Script to automate proper triggering of Docs Azure pipeline (#3003)
* [BUGFIX] Fix an undefined name that could lead to a NameError (#3063) (Thanks @cclauss)
* [BUGFIX] fix incorrect pandas top rows usage (#3091)
* [BUGFIX] Fix parens in Expectation metric validation method that always returned True assertation (#3086) (Thanks @morland96)
* [BUGFIX] Fix run_diagnostics for contrib expectations (#3096)
* [BUGFIX] Fix typos discovered by codespell (#3064) (Thanks cclauss)
* [BUGFIX] Wrap get_view_names in try clause for passing the NotImplemented error (#2976) (Thanks @kj-9)
* [DOCS] Ensuring consistent style of directories, files, and related references in docs (#3053)
* [DOCS] Fix broken link to example DAG (#3061) (Thanks fritz-astronomer)
* [DOCS] GDOC-198 cleanup TOC (#3088)
* [DOCS] Migrating pages under guides/miscellaneous (#3094) (Thanks @spbail)
* [DOCS] Port over “How to configure a new Checkpoint using test_yaml_config” from RTD to Docusaurus
* [DOCS] Port over “How to configure an Expectation store in GCS” from RTD to Docusaurus (#3071)
* [DOCS] Port over “How to create renderers for custom Expectations” from RTD to Docusaurus
* [DOCS] Port over “How to run a Checkpoint in Airflow” from RTD to Docusaurus (#3074)
* [DOCS] Update how-to-create-and-edit-expectations-in-bulk.md (#3073)
* [MAINTENANCE] Adding a comment explaining the IDENTITY metric domain type. (#3057)
* [MAINTENANCE] Change domain key value from “column” to “column_list” in ExecutionEngine implementations (#3059)
* [MAINTENANCE] clean up metric errors (#3085)
* [MAINTENANCE] Correct the typo in the naming of the IDENTIFICATION semantic domain type name. (#3058)
* [MAINTENANCE] disable snowflake tests temporarily (#3093)
* [MAINTENANCE] [DOCS] Port over “How to host and share Data Docs on GCS” from RTD to Docusaurus (#3070)
* [MAINTENANCE] Enable repr for MetricConfiguration to assist with troubleshooting. (#3075)
* [MAINTENANCE] Expand test of a column map metric to underscore functionality. (#3072)
* [MAINTENANCE] Expectation anonymizer supports v3 expectation registry (#3092)
* [MAINTENANCE] Fix -- check for column key existence in accessor_domain_kwargsn for condition map partials. (#3082)
* [MAINTENANCE] Missing import of SparkDFExecutionEngine was added. (#3062)
### Older Changelist
Older changelist can be found at [https://github.com/great-expectations/great_expectations/blob/develop/docs_rtd/changelog.rst](https://github.com/great-expectations/great_expectations/blob/develop/docs_rtd/changelog.rst)
<file_sep>/requirements-dev.txt
--requirement requirements.txt
--requirement reqs/requirements-dev-lite.txt
--requirement reqs/requirements-dev-contrib.txt
--requirement reqs/requirements-dev-sqlalchemy.txt
--requirement reqs/requirements-dev-arrow.txt
--requirement reqs/requirements-dev-azure.txt
--requirement reqs/requirements-dev-excel.txt
--requirement reqs/requirements-dev-pagerduty.txt
--requirement reqs/requirements-dev-spark.txt
<file_sep>/tests/core/usage_statistics/test_events.py
from great_expectations.core.usage_statistics.events import UsageStatsEvents
def test_get_cli_event_name():
assert (
UsageStatsEvents.get_cli_event_name("checkpoint", "delete", ["begin"])
== "cli.checkpoint.delete.begin"
)
def test_get_cli_begin_and_end_event_names():
assert UsageStatsEvents.get_cli_begin_and_end_event_names("datasource", "new") == [
"cli.datasource.new.begin",
"cli.datasource.new.end",
]
<file_sep>/docs/guides/expectations/components_how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data/_optional_profile_your_data_to_generate_expectations_then_edit_them_in_interactive_mode.mdx
One of the easiest ways to get starting in the interactive mode is to take advantage of the `--profile` flag (please see [How to create and edit Expectations with a Profiler](../how_to_create_and_edit_expectations_with_a_profiler.md)).
Following this workflow will result in your new Expectation Suite being pre-populated with Expectations based on the Profiler's results. After using the Profiler to create your new Expectations, you can then edit them in Interactive Mode as described above.
<file_sep>/docs/guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs.md
---
title: How to configure a Validation Result store in GCS
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
By default, <TechnicalTag tag="validation_result" text="Validation Results" /> are stored in JSON format in the ``uncommitted/validations/`` subdirectory of your ``great_expectations/`` folder. Since Validation Results may include examples of data (which could be sensitive or regulated) they should not be committed to a source control system. This guide will help you configure a new storage location for Validation Results in a Google Cloud Storage (GCS) bucket.
<Prerequisites>
- [Configured a Data Context](../../../tutorials/getting_started/tutorial_setup.md).
- [Configured an Expectations Suite](../../../tutorials/getting_started/tutorial_create_expectations.md).
- [Configured a Checkpoint](../../../tutorials/getting_started/tutorial_validate_data.md).
- Configured a Google Cloud Platform (GCP) [service account](https://cloud.google.com/iam/docs/service-accounts) with credentials that can access the appropriate GCP resources, which include Storage Objects.
- Identified the GCP project, GCS bucket, and prefix where Validation Results will be stored.
</Prerequisites>
## Steps
### 1. Configure your GCP credentials
Check that your environment is configured with the appropriate authentication credentials needed to connect to the GCS bucket where Validation Results will be stored.
The Google Cloud Platform documentation describes how to verify your [authentication for the Google Cloud API](https://cloud.google.com/docs/authentication/getting-started), which includes:
1. Creating a Google Cloud Platform (GCP) service account,
2. Setting the ``GOOGLE_APPLICATION_CREDENTIALS`` environment variable,
3. Verifying authentication by running a simple [Google Cloud Storage client](https://cloud.google.com/storage/docs/reference/libraries) library script.
### 2. Identify your Data Context Validation Results Store
As with other <TechnicalTag tag="store" text="Stores" />, you can find your <TechnicalTag tag="validation_result_store" text="Validation Results Store" /> through your <TechnicalTag tag="data_context" text="Data Context" />. In your ``great_expectations.yml``, look for the following lines. The configuration tells Great Expectations to look for Validation Results in a Store called ``validations_store``. The ``base_directory`` for ``validations_store`` is set to ``uncommitted/validations/`` by default.
```yaml file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs.py#L79-L86
```
### 3. Update your configuration file to include a new Store for Validation Results on GCS
In our case, the name is set to ``validations_GCS_store``, but it can be any name you like. We also need to make some changes to the ``store_backend`` settings. The ``class_name`` will be set to ``TupleGCSStoreBackend``, ``project`` will be set to your GCP project, ``bucket`` will be set to the address of your GCS bucket, and ``prefix`` will be set to the folder on GCS where Validation Result files will be located.
```yaml file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs.py#L94-L103
```
:::warning
If you are also storing [Expectations in GCS](../configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.md) or [DataDocs in GCS](../configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.md), please ensure that the ``prefix`` values are disjoint and one is not a substring of the other.
:::
### 4. Copy existing Validation Results to the GCS bucket (This step is optional)
One way to copy Validation Results into GCS is by using the ``gsutil cp`` command, which is part of the Google Cloud SDK. In the example below, two Validation results, ``validation_1`` and ``validation_2`` are copied to the GCS bucket. Information on other ways to copy Validation results, like the Cloud Storage browser in the Google Cloud Console, can be found in the [Documentation for Google Cloud](https://cloud.google.com/storage/docs/uploading-objects).
```bash file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs.py#L148-L149
```
```bash file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs.py#L204
```
### 5. Confirm that the new Validation Results Store has been added by running
```bash file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs.py#L209
```
Only the active Stores will be listed. Great Expectations will look for Validation Results in GCS as long as we set the ``validations_store_name`` variable to ``validations_GCS_store``, and the config for ``validations_store`` can be removed if you would like.
```bash file=../../../../tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs.py#L220-L226
```
### 6. Confirm that the Validation Results Store has been correctly configured
[Run a Checkpoint](../../../tutorials/getting_started/tutorial_validate_data.md) to store results in the new Validation Results Store on GCS then visualize the results by [re-building Data Docs](../../../tutorials/getting_started/tutorial_validate_data.md).
## Additional Notes
To view the full script used in this page, see it on GitHub:
- [how_to_configure_a_validation_result_store_in_gcs.py](https://github.com/great-expectations/great_expectations/tree/develop/tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs.py)
<file_sep>/great_expectations/expectations/expectation.py
from __future__ import annotations
import datetime
import glob
import json
import logging
import os
import re
import time
import traceback
import warnings
from abc import ABC, ABCMeta, abstractmethod
from collections import Counter, defaultdict
from copy import deepcopy
from inspect import isabstract
from typing import TYPE_CHECKING, Any, Callable, Dict, List, Optional, Set, Tuple, Union
import pandas as pd
from dateutil.parser import parse
from great_expectations import __version__ as ge_version
from great_expectations.core.expectation_configuration import (
ExpectationConfiguration,
parse_result_format,
)
from great_expectations.core.expectation_diagnostics.expectation_diagnostics import (
ExpectationDiagnostics,
)
from great_expectations.core.expectation_diagnostics.expectation_test_data_cases import (
ExpectationLegacyTestCaseAdapter,
ExpectationTestCase,
ExpectationTestDataCases,
TestBackend,
TestData,
)
from great_expectations.core.expectation_diagnostics.supporting_types import (
AugmentedLibraryMetadata,
ExpectationBackendTestResultCounts,
ExpectationDescriptionDiagnostics,
ExpectationDiagnosticMaturityMessages,
ExpectationErrorDiagnostics,
ExpectationExecutionEngineDiagnostics,
ExpectationMetricDiagnostics,
ExpectationRendererDiagnostics,
ExpectationTestDiagnostics,
Maturity,
RendererTestDiagnostics,
)
from great_expectations.core.expectation_validation_result import (
ExpectationValidationResult,
)
from great_expectations.core.metric_domain_types import MetricDomainTypes
from great_expectations.core.util import nested_update
from great_expectations.exceptions import (
ExpectationNotFoundError,
GreatExpectationsError,
InvalidExpectationConfigurationError,
InvalidExpectationKwargsError,
)
from great_expectations.execution_engine import ExecutionEngine, PandasExecutionEngine
from great_expectations.expectations.registry import (
_registered_metrics,
_registered_renderers,
get_expectation_impl,
get_metric_kwargs,
register_expectation,
register_renderer,
)
from great_expectations.expectations.sql_tokens_and_types import (
valid_sql_tokens_and_types,
)
from great_expectations.render import (
AtomicDiagnosticRendererType,
AtomicPrescriptiveRendererType,
CollapseContent,
LegacyDiagnosticRendererType,
LegacyRendererType,
RenderedAtomicContent,
RenderedContentBlockContainer,
RenderedGraphContent,
RenderedStringTemplateContent,
RenderedTableContent,
ValueListContent,
renderedAtomicValueSchema,
)
from great_expectations.render.renderer.renderer import renderer
from great_expectations.render.util import num_to_str
from great_expectations.self_check.util import (
evaluate_json_test_v3_api,
generate_expectation_tests,
)
from great_expectations.util import camel_to_snake, is_parseable_date
from great_expectations.validator.computed_metric import MetricValue
from great_expectations.validator.metric_configuration import MetricConfiguration
from great_expectations.validator.validator import ValidationDependencies, Validator
if TYPE_CHECKING:
from great_expectations.data_context import DataContext
logger = logging.getLogger(__name__)
_TEST_DEFS_DIR = os.path.join(
os.path.dirname(__file__),
"..",
"..",
"tests",
"test_definitions",
)
def render_evaluation_parameter_string(render_func) -> Callable:
def inner_func(
*args: Tuple[MetaExpectation], **kwargs: dict
) -> Union[List[RenderedStringTemplateContent], RenderedAtomicContent]:
rendered_string_template: Union[
List[RenderedStringTemplateContent], RenderedAtomicContent
] = render_func(*args, **kwargs)
current_expectation_params = list()
app_template_str = (
"\n - $eval_param = $eval_param_value (at time of validation)."
)
configuration: Optional[dict] = kwargs.get("configuration")
if configuration:
kwargs_dict: dict = configuration.get("kwargs", {})
for key, value in kwargs_dict.items():
if isinstance(value, dict) and "$PARAMETER" in value.keys():
current_expectation_params.append(value["$PARAMETER"])
# if expectation configuration has no eval params, then don't look for the values in runtime_configuration
# isinstance check should be removed upon implementation of RenderedAtomicContent evaluation parameter support
if len(current_expectation_params) > 0 and not isinstance(
rendered_string_template, RenderedAtomicContent
):
runtime_configuration: Optional[dict] = kwargs.get("runtime_configuration")
if runtime_configuration:
eval_params = runtime_configuration.get("evaluation_parameters", {})
styling = runtime_configuration.get("styling")
for key, val in eval_params.items():
# this needs to be more complicated?
# the possibility that it is a substring?
for param in current_expectation_params:
# "key in param" condition allows for eval param values to be rendered if arithmetic is present
if key == param or key in param:
app_params = {}
app_params["eval_param"] = key
app_params["eval_param_value"] = val
rendered_content = RenderedStringTemplateContent(
**{
"content_block_type": "string_template",
"string_template": {
"template": app_template_str,
"params": app_params,
"styling": styling,
},
}
)
rendered_string_template.append(rendered_content)
else:
raise GreatExpectationsError(
f"""GE was not able to render the value of evaluation parameters.
Expectation {render_func} had evaluation parameters set, but they were not passed in."""
)
return rendered_string_template
return inner_func
# noinspection PyMethodParameters
class MetaExpectation(ABCMeta):
"""MetaExpectation registers Expectations as they are defined, adding them to the Expectation registry.
Any class inheriting from Expectation will be registered based on the value of the "expectation_type" class
attribute, or, if that is not set, by snake-casing the name of the class.
"""
default_kwarg_values: Dict[str, object] = {}
def __new__(cls, clsname, bases, attrs):
newclass = super().__new__(cls, clsname, bases, attrs)
# noinspection PyUnresolvedReferences
if not newclass.is_abstract():
newclass.expectation_type = camel_to_snake(clsname)
register_expectation(newclass)
else:
newclass.expectation_type = ""
# noinspection PyUnresolvedReferences
newclass._register_renderer_functions()
default_kwarg_values = {}
for base in reversed(bases):
default_kwargs = getattr(base, "default_kwarg_values", {})
default_kwarg_values = nested_update(default_kwarg_values, default_kwargs)
newclass.default_kwarg_values = nested_update(
default_kwarg_values, attrs.get("default_kwarg_values", {})
)
return newclass
class Expectation(metaclass=MetaExpectation):
"""Base class for all Expectations.
Expectation classes *must* have the following attributes set:
1. `domain_keys`: a tuple of the *keys* used to determine the domain of the
expectation
2. `success_keys`: a tuple of the *keys* used to determine the success of
the expectation.
In some cases, subclasses of Expectation (such as TableExpectation) can
inherit these properties from their parent class.
They *may* optionally override `runtime_keys` and `default_kwarg_values`, and
may optionally set an explicit value for expectation_type.
1. runtime_keys lists the keys that can be used to control output but will
not affect the actual success value of the expectation (such as result_format).
2. default_kwarg_values is a dictionary that will be used to fill unspecified
kwargs from the Expectation Configuration.
Expectation classes *must* implement the following:
1. `_validate`
2. `get_validation_dependencies`
In some cases, subclasses of Expectation, such as ColumnMapExpectation will already
have correct implementations that may simply be inherited.
Additionally, they *may* provide implementations of:
1. `validate_configuration`, which should raise an error if the configuration
will not be usable for the Expectation
2. Data Docs rendering methods decorated with the @renderer decorator. See the
"""
version = ge_version
domain_keys: Tuple[str, ...] = ()
success_keys: Tuple[str, ...] = ()
runtime_keys: Tuple[str, ...] = (
"include_config",
"catch_exceptions",
"result_format",
)
default_kwarg_values = {
"include_config": True,
"catch_exceptions": False,
"result_format": "BASIC",
}
args_keys = None
expectation_type: str
examples: List[dict] = []
def __init__(
self, configuration: Optional[ExpectationConfiguration] = None
) -> None:
if configuration:
self.validate_configuration(configuration=configuration)
self._configuration = configuration
@classmethod
def is_abstract(cls) -> bool:
return isabstract(cls)
@classmethod
def _register_renderer_functions(cls) -> None:
expectation_type: str = camel_to_snake(cls.__name__)
for candidate_renderer_fn_name in dir(cls):
attr_obj: Callable = getattr(cls, candidate_renderer_fn_name)
if not hasattr(attr_obj, "_renderer_type"):
continue
register_renderer(
object_name=expectation_type, parent_class=cls, renderer_fn=attr_obj
)
@abstractmethod
def _validate(
self,
configuration: ExpectationConfiguration,
metrics: dict,
runtime_configuration: Optional[dict] = None,
execution_engine: Optional[ExecutionEngine] = None,
) -> Union[ExpectationValidationResult, dict]:
raise NotImplementedError
@classmethod
@renderer(renderer_type=AtomicPrescriptiveRendererType.FAILED)
def _atomic_prescriptive_failed(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
**kwargs: dict,
) -> RenderedAtomicContent:
"""
Default rendering function that is utilized by GE Cloud Front-end if an implemented atomic renderer fails
"""
template_str = "Rendering failed for Expectation: "
expectation_type: str
expectation_kwargs: dict
if configuration:
expectation_type = configuration.expectation_type
expectation_kwargs = configuration.kwargs
else:
if not isinstance(result, ExpectationValidationResult):
expectation_validation_result_value_error_msg = (
"Renderer requires an ExpectationConfiguration or ExpectationValidationResult to be passed in via "
"configuration or result respectively."
)
raise ValueError(expectation_validation_result_value_error_msg)
if not isinstance(result.expectation_config, ExpectationConfiguration):
expectation_configuration_value_error_msg = (
"Renderer requires an ExpectationConfiguration to be passed via "
"configuration or result.expectation_config."
)
raise ValueError(expectation_configuration_value_error_msg)
expectation_type = result.expectation_config.expectation_type
expectation_kwargs = result.expectation_config.kwargs
params_with_json_schema = {
"expectation_type": {
"schema": {"type": "string"},
"value": expectation_type,
},
"kwargs": {"schema": {"type": "string"}, "value": expectation_kwargs},
}
template_str += "$expectation_type(**$kwargs)."
value_obj = renderedAtomicValueSchema.load(
{
"template": template_str,
"params": params_with_json_schema,
"schema": {"type": "com.superconductive.rendered.string"},
}
)
rendered = RenderedAtomicContent(
name=AtomicPrescriptiveRendererType.FAILED,
value=value_obj,
value_type="StringValueType",
)
return rendered
@classmethod
def _atomic_prescriptive_template(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
language: Optional[str] = None,
runtime_configuration: Optional[dict] = None,
) -> Tuple[str, dict, Optional[dict]]:
"""
Template function that contains the logic that is shared by AtomicPrescriptiveRendererType.SUMMARY and
LegacyRendererType.PRESCRIPTIVE
"""
if runtime_configuration is None:
runtime_configuration = {}
styling: Optional[dict] = runtime_configuration.get("styling")
expectation_type: str
expectation_kwargs: dict
if configuration:
expectation_type = configuration.expectation_type
expectation_kwargs = configuration.kwargs
else:
if not isinstance(result, ExpectationValidationResult):
expectation_validation_result_value_error_msg = (
"Renderer requires an ExpectationConfiguration or ExpectationValidationResult to be passed in via "
"configuration or result respectively."
)
raise ValueError(expectation_validation_result_value_error_msg)
if not isinstance(result.expectation_config, ExpectationConfiguration):
expectation_configuration_value_error_msg = (
"Renderer requires an ExpectationConfiguration to be passed via "
"configuration or result.expectation_config."
)
raise ValueError(expectation_configuration_value_error_msg)
expectation_type = result.expectation_config.expectation_type
expectation_kwargs = result.expectation_config.kwargs
params_with_json_schema = {
"expectation_type": {
"schema": {"type": "string"},
"value": expectation_type,
},
"kwargs": {
"schema": {"type": "string"},
"value": expectation_kwargs,
},
}
template_str = "$expectation_type(**$kwargs)"
return template_str, params_with_json_schema, styling
@classmethod
@renderer(renderer_type=AtomicPrescriptiveRendererType.SUMMARY)
@render_evaluation_parameter_string
def _prescriptive_summary(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
language: Optional[str] = None,
runtime_configuration: Optional[dict] = None,
**kwargs: dict,
):
"""
Rendering function that is utilized by GE Cloud Front-end
"""
(
template_str,
params_with_json_schema,
styling,
) = cls._atomic_prescriptive_template(
configuration=configuration,
result=result,
runtime_configuration=runtime_configuration,
)
value_obj = renderedAtomicValueSchema.load(
{
"template": template_str,
"params": params_with_json_schema,
"schema": {"type": "com.superconductive.rendered.string"},
}
)
rendered = RenderedAtomicContent(
name=AtomicPrescriptiveRendererType.SUMMARY,
value=value_obj,
value_type="StringValueType",
)
return rendered
@classmethod
@renderer(renderer_type=LegacyRendererType.PRESCRIPTIVE)
def _prescriptive_renderer(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
language: Optional[str] = None,
runtime_configuration: Optional[dict] = None,
**kwargs: dict,
):
expectation_type: str
expectation_kwargs: dict
if configuration:
expectation_type = configuration.expectation_type
expectation_kwargs = configuration.kwargs
else:
if not isinstance(result, ExpectationValidationResult):
expectation_validation_result_value_error_msg = (
"Renderer requires an ExpectationConfiguration or ExpectationValidationResult to be passed in via "
"configuration or result respectively."
)
raise ValueError(expectation_validation_result_value_error_msg)
if not isinstance(result.expectation_config, ExpectationConfiguration):
expectation_configuration_value_error_msg = (
"Renderer requires an ExpectationConfiguration to be passed via "
"configuration or result.expectation_config."
)
raise ValueError(expectation_configuration_value_error_msg)
expectation_type = result.expectation_config.expectation_type
expectation_kwargs = result.expectation_config.kwargs
return [
RenderedStringTemplateContent(
**{
"content_block_type": "string_template",
"styling": {"parent": {"classes": ["alert", "alert-warning"]}},
"string_template": {
"template": "$expectation_type(**$kwargs)",
"params": {
"expectation_type": expectation_type,
"kwargs": expectation_kwargs,
},
"styling": {
"params": {
"expectation_type": {
"classes": ["badge", "badge-warning"],
}
}
},
},
}
)
]
@classmethod
@renderer(renderer_type=LegacyDiagnosticRendererType.META_PROPERTIES)
def _diagnostic_meta_properties_renderer(
cls, result: Optional[ExpectationValidationResult] = None, **kwargs: dict
) -> Union[list, List[str], List[list]]:
"""
Render function used to add custom meta to Data Docs
It gets a column set in the `properties_to_render` dictionary within `meta` and adds columns in Data Docs with the values that were set.
example:
meta = {
"properties_to_render": {
"Custom Column Header": "custom.value"
},
"custom": {
"value": "1"
}
}
data docs:
----------------------------------------------------------------
| status| Expectation | Observed value | Custom Column Header |
----------------------------------------------------------------
| | must be exactly 4 columns | 4 | 1 |
Here the custom column will be added in data docs.
"""
if not result:
return []
custom_property_values = []
meta_properties_to_render: Optional[dict] = None
if result and result.expectation_config:
meta_properties_to_render = result.expectation_config.kwargs.get(
"meta_properties_to_render"
)
if meta_properties_to_render:
for key in sorted(meta_properties_to_render.keys()):
meta_property = meta_properties_to_render[key]
if meta_property:
try:
# Allow complex structure with . usage
assert isinstance(
result.expectation_config, ExpectationConfiguration
)
obj = result.expectation_config.meta["attributes"]
keys = meta_property.split(".")
for i in range(0, len(keys)):
# Allow for keys with a . in the string like {"item.key": "1"}
remaining_key = "".join(keys[i:])
if remaining_key in obj:
obj = obj[remaining_key]
break
else:
obj = obj[keys[i]]
custom_property_values.append([obj])
except KeyError:
custom_property_values.append(["N/A"])
return custom_property_values
@classmethod
@renderer(renderer_type=LegacyDiagnosticRendererType.STATUS_ICON)
def _diagnostic_status_icon_renderer(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
language: Optional[str] = None,
runtime_configuration: Optional[dict] = None,
**kwargs: dict,
):
assert result, "Must provide a result object."
if result.exception_info["raised_exception"]:
return RenderedStringTemplateContent(
**{
"content_block_type": "string_template",
"string_template": {
"template": "$icon",
"params": {"icon": "", "markdown_status_icon": "❗"},
"styling": {
"params": {
"icon": {
"classes": [
"fas",
"fa-exclamation-triangle",
"text-warning",
],
"tag": "i",
}
}
},
},
}
)
if result.success:
return RenderedStringTemplateContent(
**{
"content_block_type": "string_template",
"string_template": {
"template": "$icon",
"params": {"icon": "", "markdown_status_icon": "✅"},
"styling": {
"params": {
"icon": {
"classes": [
"fas",
"fa-check-circle",
"text-success",
],
"tag": "i",
}
}
},
},
"styling": {
"parent": {
"classes": ["hide-succeeded-validation-target-child"]
}
},
}
)
else:
return RenderedStringTemplateContent(
**{
"content_block_type": "string_template",
"string_template": {
"template": "$icon",
"params": {"icon": "", "markdown_status_icon": "❌"},
"styling": {
"params": {
"icon": {
"tag": "i",
"classes": ["fas", "fa-times", "text-danger"],
}
}
},
},
}
)
@classmethod
@renderer(renderer_type=LegacyDiagnosticRendererType.UNEXPECTED_STATEMENT)
def _diagnostic_unexpected_statement_renderer(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
language: Optional[str] = None,
runtime_configuration: Optional[dict] = None,
**kwargs: dict,
):
assert result, "Must provide a result object."
success: Optional[bool] = result.success
result_dict: dict = result.result
if result.exception_info["raised_exception"]:
exception_message_template_str = (
"\n\n$expectation_type raised an exception:\n$exception_message"
)
if result.expectation_config is not None:
expectation_type = result.expectation_config.expectation_type
else:
expectation_type = None
exception_message = RenderedStringTemplateContent(
**{
"content_block_type": "string_template",
"string_template": {
"template": exception_message_template_str,
"params": {
"expectation_type": expectation_type,
"exception_message": result.exception_info[
"exception_message"
],
},
"tag": "strong",
"styling": {
"classes": ["text-danger"],
"params": {
"exception_message": {"tag": "code"},
"expectation_type": {
"classes": ["badge", "badge-danger", "mb-2"]
},
},
},
},
}
)
exception_traceback_collapse = CollapseContent(
**{
"collapse_toggle_link": "Show exception traceback...",
"collapse": [
RenderedStringTemplateContent(
**{
"content_block_type": "string_template",
"string_template": {
"template": result.exception_info[
"exception_traceback"
],
"tag": "code",
},
}
)
],
}
)
return [exception_message, exception_traceback_collapse]
if success or not result_dict.get("unexpected_count"):
return []
else:
unexpected_count = num_to_str(
result_dict["unexpected_count"], use_locale=True, precision=20
)
unexpected_percent = (
f"{num_to_str(result_dict['unexpected_percent'], precision=4)}%"
)
element_count = num_to_str(
result_dict["element_count"], use_locale=True, precision=20
)
template_str = (
"\n\n$unexpected_count unexpected values found. "
"$unexpected_percent of $element_count total rows."
)
return [
RenderedStringTemplateContent(
**{
"content_block_type": "string_template",
"string_template": {
"template": template_str,
"params": {
"unexpected_count": unexpected_count,
"unexpected_percent": unexpected_percent,
"element_count": element_count,
},
"tag": "strong",
"styling": {"classes": ["text-danger"]},
},
}
)
]
@classmethod
@renderer(renderer_type=LegacyDiagnosticRendererType.UNEXPECTED_TABLE)
def _diagnostic_unexpected_table_renderer(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
language: Optional[str] = None,
runtime_configuration: Optional[dict] = None,
**kwargs: dict,
) -> Optional[RenderedTableContent]:
if result is None:
return None
result_dict: Optional[dict] = result.result
if result_dict is None:
return None
if not result_dict.get("partial_unexpected_list") and not result_dict.get(
"partial_unexpected_counts"
):
return None
table_rows = []
if result_dict.get("partial_unexpected_counts"):
# We will check to see whether we have *all* of the unexpected values
# accounted for in our count, and include counts if we do. If we do not,
# we will use this as simply a better (non-repeating) source of
# "sampled" unexpected values
total_count = 0
partial_unexpected_counts: Optional[List[dict]] = result_dict.get(
"partial_unexpected_counts"
)
if partial_unexpected_counts:
for unexpected_count_dict in partial_unexpected_counts:
value: Optional[Any] = unexpected_count_dict.get("value")
count: Optional[int] = unexpected_count_dict.get("count")
if count:
total_count += count
if value is not None and value != "":
table_rows.append([value, count])
elif value == "":
table_rows.append(["EMPTY", count])
else:
table_rows.append(["null", count])
# Check to see if we have *all* of the unexpected values accounted for. If so,
# we show counts. If not, we only show "sampled" unexpected values.
if total_count == result_dict.get("unexpected_count"):
header_row = ["Unexpected Value", "Count"]
else:
header_row = ["Sampled Unexpected Values"]
table_rows = [[row[0]] for row in table_rows]
else:
header_row = ["Sampled Unexpected Values"]
sampled_values_set = set()
partial_unexpected_list: Optional[List[Any]] = result_dict.get(
"partial_unexpected_list"
)
if partial_unexpected_list:
for unexpected_value in partial_unexpected_list:
if unexpected_value:
string_unexpected_value = str(unexpected_value)
elif unexpected_value == "":
string_unexpected_value = "EMPTY"
else:
string_unexpected_value = "null"
if string_unexpected_value not in sampled_values_set:
table_rows.append([unexpected_value])
sampled_values_set.add(string_unexpected_value)
unexpected_table_content_block = RenderedTableContent(
**{
"content_block_type": "table",
"table": table_rows,
"header_row": header_row,
"styling": {
"body": {"classes": ["table-bordered", "table-sm", "mt-3"]}
},
}
)
return unexpected_table_content_block
@classmethod
def _get_observed_value_from_evr(
self, result: Optional[ExpectationValidationResult]
) -> str:
result_dict: Optional[dict] = None
if result:
result_dict = result.result
if result_dict is None:
return "--"
observed_value: Any = result_dict.get("observed_value")
unexpected_percent: Optional[float] = result_dict.get("unexpected_percent")
if observed_value is not None:
if isinstance(observed_value, (int, float)) and not isinstance(
observed_value, bool
):
return num_to_str(observed_value, precision=10, use_locale=True)
return str(observed_value)
elif unexpected_percent is not None:
return num_to_str(unexpected_percent, precision=5) + "% unexpected"
else:
return "--"
@classmethod
@renderer(renderer_type=AtomicDiagnosticRendererType.FAILED)
def _atomic_diagnostic_failed(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
**kwargs: dict,
) -> RenderedAtomicContent:
"""
Rendering function that is utilized by GE Cloud Front-end
"""
expectation_type: str
expectation_kwargs: dict
if configuration:
expectation_type = configuration.expectation_type
expectation_kwargs = configuration.kwargs
else:
if not isinstance(result, ExpectationValidationResult):
expectation_validation_result_value_error_msg = (
"Renderer requires an ExpectationConfiguration or ExpectationValidationResult to be passed in via "
"configuration or result respectively."
)
raise ValueError(expectation_validation_result_value_error_msg)
if not isinstance(result.expectation_config, ExpectationConfiguration):
expectation_configuration_value_error_msg = (
"Renderer requires an ExpectationConfiguration to be passed via "
"configuration or result.expectation_config."
)
raise ValueError(expectation_configuration_value_error_msg)
expectation_type = result.expectation_config.expectation_type
expectation_kwargs = result.expectation_config.kwargs
params_with_json_schema = {
"expectation_type": {
"schema": {"type": "string"},
"value": expectation_type,
},
"kwargs": {
"schema": {"type": "string"},
"value": expectation_kwargs,
},
}
template_str = "Rendering failed for Expectation: $expectation_type(**$kwargs)."
value_obj = renderedAtomicValueSchema.load(
{
"template": template_str,
"params": params_with_json_schema,
"schema": {"type": "com.superconductive.rendered.string"},
}
)
rendered = RenderedAtomicContent(
name=AtomicDiagnosticRendererType.FAILED,
value=value_obj,
value_type="StringValueType",
)
return rendered
@classmethod
@renderer(renderer_type=AtomicDiagnosticRendererType.OBSERVED_VALUE)
def _atomic_diagnostic_observed_value(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
language: Optional[str] = None,
runtime_configuration: Optional[dict] = None,
**kwargs: dict,
) -> RenderedAtomicContent:
"""
Rendering function that is utilized by GE Cloud Front-end
"""
observed_value: str = cls._get_observed_value_from_evr(result=result)
value_obj = renderedAtomicValueSchema.load(
{
"template": observed_value,
"params": {},
"schema": {"type": "com.superconductive.rendered.string"},
}
)
rendered = RenderedAtomicContent(
name=AtomicDiagnosticRendererType.OBSERVED_VALUE,
value=value_obj,
value_type="StringValueType",
)
return rendered
@classmethod
@renderer(renderer_type=LegacyDiagnosticRendererType.OBSERVED_VALUE)
def _diagnostic_observed_value_renderer(
cls,
configuration: Optional[ExpectationConfiguration] = None,
result: Optional[ExpectationValidationResult] = None,
language: Optional[str] = None,
runtime_configuration: Optional[dict] = None,
**kwargs: dict,
) -> str:
return cls._get_observed_value_from_evr(result=result)
@classmethod
def get_allowed_config_keys(cls) -> Union[Tuple[str, ...], Tuple[str]]:
key_list: Union[list, List[str]] = []
if len(cls.domain_keys) > 0:
key_list.extend(list(cls.domain_keys))
if len(cls.success_keys) > 0:
key_list.extend(list(cls.success_keys))
if len(cls.runtime_keys) > 0:
key_list.extend(list(cls.runtime_keys))
return tuple(str(key) for key in key_list)
# noinspection PyUnusedLocal
def metrics_validate(
self,
metrics: dict,
configuration: Optional[ExpectationConfiguration] = None,
runtime_configuration: Optional[dict] = None,
execution_engine: Optional[ExecutionEngine] = None,
**kwargs: dict,
) -> ExpectationValidationResult:
if not configuration:
configuration = self.configuration
if runtime_configuration is None:
runtime_configuration = {}
validation_dependencies: ValidationDependencies = (
self.get_validation_dependencies(
configuration=configuration,
execution_engine=execution_engine,
runtime_configuration=runtime_configuration,
)
)
runtime_configuration["result_format"] = validation_dependencies.result_format
requested_metrics: Dict[
str, MetricConfiguration
] = validation_dependencies.metric_configurations
metric_name: str
metric_configuration: MetricConfiguration
provided_metrics: Dict[str, MetricValue] = {
metric_name: metrics[metric_configuration.id]
for metric_name, metric_configuration in requested_metrics.items()
}
expectation_validation_result: Union[
ExpectationValidationResult, dict
] = self._validate(
configuration=configuration,
metrics=provided_metrics,
runtime_configuration=runtime_configuration,
execution_engine=execution_engine,
)
evr: ExpectationValidationResult = self._build_evr(
raw_response=expectation_validation_result,
configuration=configuration,
)
return evr
# noinspection PyUnusedLocal
@staticmethod
def _build_evr(
raw_response: Union[ExpectationValidationResult, dict],
configuration: ExpectationConfiguration,
**kwargs: dict,
) -> ExpectationValidationResult:
"""_build_evr is a lightweight convenience wrapper handling cases where an Expectation implementor
fails to return an EVR but returns the necessary components in a dictionary."""
evr: ExpectationValidationResult
if not isinstance(raw_response, ExpectationValidationResult):
if isinstance(raw_response, dict):
evr = ExpectationValidationResult(**raw_response)
evr.expectation_config = configuration
else:
raise GreatExpectationsError("Unable to build EVR")
else:
raw_response_dict: dict = raw_response.to_json_dict()
evr = ExpectationValidationResult(**raw_response_dict)
evr.expectation_config = configuration
return evr
def get_validation_dependencies(
self,
configuration: Optional[ExpectationConfiguration] = None,
execution_engine: Optional[ExecutionEngine] = None,
runtime_configuration: Optional[dict] = None,
) -> ValidationDependencies:
"""Returns the result format and metrics required to validate this Expectation using the provided result format."""
runtime_configuration = self.get_runtime_kwargs(
configuration=configuration,
runtime_configuration=runtime_configuration,
)
result_format: dict = runtime_configuration["result_format"]
result_format = parse_result_format(result_format=result_format)
return ValidationDependencies(
metric_configurations={}, result_format=result_format
)
def get_domain_kwargs(
self, configuration: ExpectationConfiguration
) -> Dict[str, Optional[str]]:
domain_kwargs: Dict[str, Optional[str]] = {
key: configuration.kwargs.get(key, self.default_kwarg_values.get(key))
for key in self.domain_keys
}
missing_kwargs: Union[set, Set[str]] = set(self.domain_keys) - set(
domain_kwargs.keys()
)
if missing_kwargs:
raise InvalidExpectationKwargsError(
f"Missing domain kwargs: {list(missing_kwargs)}"
)
return domain_kwargs
def get_success_kwargs(
self, configuration: Optional[ExpectationConfiguration] = None
) -> Dict[str, Any]:
if not configuration:
configuration = self.configuration
domain_kwargs: Dict[str, Optional[str]] = self.get_domain_kwargs(
configuration=configuration
)
success_kwargs: Dict[str, Any] = {
key: configuration.kwargs.get(key, self.default_kwarg_values.get(key))
for key in self.success_keys
}
success_kwargs.update(domain_kwargs)
return success_kwargs
def get_runtime_kwargs(
self,
configuration: Optional[ExpectationConfiguration] = None,
runtime_configuration: Optional[dict] = None,
) -> dict:
if not configuration:
configuration = self.configuration
configuration = deepcopy(configuration)
if runtime_configuration:
configuration.kwargs.update(runtime_configuration)
success_kwargs = self.get_success_kwargs(configuration=configuration)
runtime_kwargs = {
key: configuration.kwargs.get(key, self.default_kwarg_values.get(key))
for key in self.runtime_keys
}
runtime_kwargs.update(success_kwargs)
runtime_kwargs["result_format"] = parse_result_format(
runtime_kwargs["result_format"]
)
return runtime_kwargs
def get_result_format(
self,
configuration: ExpectationConfiguration,
runtime_configuration: Optional[dict] = None,
) -> Union[Dict[str, Union[str, int, bool]], str]:
default_result_format: Optional[Any] = self.default_kwarg_values.get(
"result_format"
)
configuration_result_format: Union[
Dict[str, Union[str, int, bool]], str
] = configuration.kwargs.get("result_format", default_result_format)
result_format: Union[Dict[str, Union[str, int, bool]], str]
if runtime_configuration:
result_format = runtime_configuration.get(
"result_format",
configuration_result_format,
)
else:
result_format = configuration_result_format
return result_format
def validate_configuration(
self, configuration: Optional[ExpectationConfiguration] = None
) -> None:
if not configuration:
configuration = self.configuration
try:
assert (
configuration.expectation_type == self.expectation_type
), f"expectation configuration type {configuration.expectation_type} does not match expectation type {self.expectation_type}"
except AssertionError as e:
raise InvalidExpectationConfigurationError(str(e))
def validate(
self,
validator: Validator,
configuration: Optional[ExpectationConfiguration] = None,
evaluation_parameters: Optional[dict] = None,
interactive_evaluation: bool = True,
data_context: Optional[DataContext] = None,
runtime_configuration: Optional[dict] = None,
) -> ExpectationValidationResult:
include_rendered_content: bool = validator._include_rendered_content or False
if not configuration:
configuration = deepcopy(self.configuration)
configuration.process_evaluation_parameters(
evaluation_parameters, interactive_evaluation, data_context
)
evr: ExpectationValidationResult = validator.graph_validate(
configurations=[configuration],
runtime_configuration=runtime_configuration,
)[0]
if include_rendered_content:
evr.render()
return evr
@property
def configuration(self) -> ExpectationConfiguration:
if self._configuration is None:
raise InvalidExpectationConfigurationError(
"cannot access configuration: expectation has not yet been configured"
)
return self._configuration
def run_diagnostics(
self,
raise_exceptions_for_backends: bool = False,
ignore_suppress: bool = False,
ignore_only_for: bool = False,
debug_logger: Optional[logging.Logger] = None,
only_consider_these_backends: Optional[List[str]] = None,
context: Optional[DataContext] = None,
) -> ExpectationDiagnostics:
"""Produce a diagnostic report about this Expectation.
The current uses for this method's output are
using the JSON structure to populate the Public Expectation Gallery
and enabling a fast dev loop for developing new Expectations where the
contributors can quickly check the completeness of their expectations.
The contents of the report are captured in the ExpectationDiagnostics dataclass.
You can see some examples in test_expectation_diagnostics.py
Some components (e.g. description, examples, library_metadata) of the diagnostic report can be introspected directly from the Exepctation class.
Other components (e.g. metrics, renderers, executions) are at least partly dependent on instantiating, validating, and/or executing the Expectation class.
For these kinds of components, at least one test case with include_in_gallery=True must be present in the examples to
produce the metrics, renderers and execution engines parts of the report. This is due to
a get_validation_dependencies requiring expectation_config as an argument.
If errors are encountered in the process of running the diagnostics, they are assumed to be due to
incompleteness of the Expectation's implementation (e.g., declaring a dependency on Metrics
that do not exist). These errors are added under "errors" key in the report.
"""
if debug_logger is not None:
_debug = lambda x: debug_logger.debug(f"(run_diagnostics) {x}")
_error = lambda x: debug_logger.error(f"(run_diagnostics) {x}")
else:
_debug = lambda x: x
_error = lambda x: x
library_metadata: AugmentedLibraryMetadata = (
self._get_augmented_library_metadata()
)
examples: List[ExpectationTestDataCases] = self._get_examples(
return_only_gallery_examples=False
)
gallery_examples: List[ExpectationTestDataCases] = []
for example in examples:
_tests_to_include = [
test for test in example.tests if test.include_in_gallery
]
example = deepcopy(example)
if _tests_to_include:
example.tests = _tests_to_include
gallery_examples.append(example)
description_diagnostics: ExpectationDescriptionDiagnostics = (
self._get_description_diagnostics()
)
_expectation_config: Optional[
ExpectationConfiguration
] = self._get_expectation_configuration_from_examples(examples)
if not _expectation_config:
_error(
f"Was NOT able to get Expectation configuration for {self.expectation_type}. "
"Is there at least one sample test where 'success' is True?"
)
metric_diagnostics_list: List[
ExpectationMetricDiagnostics
] = self._get_metric_diagnostics_list(
expectation_config=_expectation_config,
)
introspected_execution_engines: ExpectationExecutionEngineDiagnostics = (
self._get_execution_engine_diagnostics(
metric_diagnostics_list=metric_diagnostics_list,
registered_metrics=_registered_metrics,
)
)
_debug("Getting test results")
test_results: List[ExpectationTestDiagnostics] = self._get_test_results(
expectation_type=description_diagnostics.snake_name,
test_data_cases=examples,
execution_engine_diagnostics=introspected_execution_engines,
raise_exceptions_for_backends=raise_exceptions_for_backends,
ignore_suppress=ignore_suppress,
ignore_only_for=ignore_only_for,
debug_logger=debug_logger,
only_consider_these_backends=only_consider_these_backends,
context=context,
)
backend_test_result_counts: List[
ExpectationBackendTestResultCounts
] = ExpectationDiagnostics._get_backends_from_test_results(test_results)
renderers: List[
ExpectationRendererDiagnostics
] = self._get_renderer_diagnostics(
expectation_type=description_diagnostics.snake_name,
test_diagnostics=test_results,
registered_renderers=_registered_renderers, # type: ignore[arg-type]
)
maturity_checklist: ExpectationDiagnosticMaturityMessages = (
self._get_maturity_checklist(
library_metadata=library_metadata,
description=description_diagnostics,
examples=examples,
tests=test_results,
backend_test_result_counts=backend_test_result_counts,
execution_engines=introspected_execution_engines,
)
)
# Set a coverage_score
_total_passed = 0
_total_failed = 0
_num_backends = 0
_num_engines = sum([x for x in introspected_execution_engines.values() if x])
for result in backend_test_result_counts:
_num_backends += 1
_total_passed += result.num_passed
_total_failed += result.num_failed
coverage_score = (
_num_backends + _num_engines + _total_passed - (1.5 * _total_failed)
)
_debug(
f"coverage_score: {coverage_score} for {self.expectation_type} ... "
f"engines: {_num_engines}, backends: {_num_backends}, "
f"passing tests: {_total_passed}, failing tests:{_total_failed}"
)
# Set final maturity level based on status of all checks
all_experimental = all(
[check.passed for check in maturity_checklist.experimental]
)
all_beta = all([check.passed for check in maturity_checklist.beta])
all_production = all([check.passed for check in maturity_checklist.production])
if all_production and all_beta and all_experimental:
library_metadata.maturity = Maturity.PRODUCTION
elif all_beta and all_experimental:
library_metadata.maturity = Maturity.BETA
else:
library_metadata.maturity = Maturity.EXPERIMENTAL
# Set the errors found when running tests
errors = [
test_result.error_diagnostics
for test_result in test_results
if test_result.error_diagnostics
]
return ExpectationDiagnostics(
library_metadata=library_metadata,
examples=examples,
gallery_examples=gallery_examples,
description=description_diagnostics,
renderers=renderers,
metrics=metric_diagnostics_list,
execution_engines=introspected_execution_engines,
tests=test_results,
backend_test_result_counts=backend_test_result_counts,
maturity_checklist=maturity_checklist,
errors=errors,
coverage_score=coverage_score,
)
def print_diagnostic_checklist(
self,
diagnostics: Optional[ExpectationDiagnostics] = None,
show_failed_tests: bool = False,
) -> str:
"""Runs self.run_diagnostics and generates a diagnostic checklist.
This output from this method is a thin wrapper for ExpectationDiagnostics.generate_checklist()
This method is experimental.
"""
if diagnostics is None:
diagnostics = self.run_diagnostics()
if show_failed_tests:
for test in diagnostics.tests:
if test.test_passed is False:
print(f"=== {test.test_title} ({test.backend}) ===\n")
print(test.stack_trace) # type: ignore[attr-defined]
print(f"{80 * '='}\n")
checklist: str = diagnostics.generate_checklist()
print(checklist)
return checklist
def _get_examples_from_json(self):
"""Only meant to be called by self._get_examples"""
results = []
found = glob.glob(
os.path.join(_TEST_DEFS_DIR, "**", f"{self.expectation_type}.json"),
recursive=True,
)
if found:
with open(found[0]) as fp:
data = json.load(fp)
results = data["datasets"]
return results
def _get_examples(
self, return_only_gallery_examples: bool = True
) -> List[ExpectationTestDataCases]:
"""
Get a list of examples from the object's `examples` member variable.
For core expectations, the examples are found in tests/test_definitions/
:param return_only_gallery_examples: if True, include only test examples where `include_in_gallery` is true
:return: list of examples or [], if no examples exist
"""
# Currently, only community contrib expectations have an examples attribute
all_examples: List[dict] = self.examples or self._get_examples_from_json()
included_examples = []
for example in all_examples:
included_test_cases = []
# As of commit 7766bb5caa4e0 on 1/28/22, only_for does not need to be applied to individual tests
# See:
# - https://github.com/great-expectations/great_expectations/blob/7766bb5caa4e0e5b22fa3b3a5e1f2ac18922fdeb/tests/test_definitions/column_map_expectations/expect_column_values_to_be_unique.json#L174
# - https://github.com/great-expectations/great_expectations/pull/4073
top_level_only_for = example.get("only_for")
top_level_suppress_test_for = example.get("suppress_test_for")
for test in example["tests"]:
if (
test.get("include_in_gallery") == True
or return_only_gallery_examples == False
):
copied_test = deepcopy(test)
if top_level_only_for:
if "only_for" not in copied_test:
copied_test["only_for"] = top_level_only_for
else:
copied_test["only_for"].extend(top_level_only_for)
if top_level_suppress_test_for:
if "suppress_test_for" not in copied_test:
copied_test[
"suppress_test_for"
] = top_level_suppress_test_for
else:
copied_test["suppress_test_for"].extend(
top_level_suppress_test_for
)
included_test_cases.append(
ExpectationLegacyTestCaseAdapter(**copied_test)
)
# If at least one ExpectationTestCase from the ExpectationTestDataCases was selected,
# then keep a copy of the ExpectationTestDataCases including data and the selected ExpectationTestCases.
if len(included_test_cases) > 0:
copied_example = deepcopy(example)
copied_example["tests"] = included_test_cases
copied_example.pop("_notes", None)
copied_example.pop("only_for", None)
copied_example.pop("suppress_test_for", None)
if "test_backends" in copied_example:
copied_example["test_backends"] = [
TestBackend(**tb) for tb in copied_example["test_backends"]
]
included_examples.append(ExpectationTestDataCases(**copied_example))
return included_examples
def _get_docstring_and_short_description(self) -> Tuple[str, str]:
"""Conveninence method to get the Exepctation's docstring and first line"""
if self.__doc__ is not None:
docstring = self.__doc__
short_description = next(line for line in self.__doc__.split("\n") if line)
else:
docstring = ""
short_description = ""
return docstring, short_description
def _get_description_diagnostics(self) -> ExpectationDescriptionDiagnostics:
"""Introspect the Expectation and create its ExpectationDescriptionDiagnostics object"""
camel_name = self.__class__.__name__
snake_name = camel_to_snake(self.__class__.__name__)
docstring, short_description = self._get_docstring_and_short_description()
return ExpectationDescriptionDiagnostics(
**{
"camel_name": camel_name,
"snake_name": snake_name,
"short_description": short_description,
"docstring": docstring,
}
)
def _get_expectation_configuration_from_examples(
self,
examples: List[ExpectationTestDataCases],
) -> Optional[ExpectationConfiguration]:
"""Return an ExpectationConfiguration instance using test input expected to succeed"""
if examples:
for example in examples:
tests = example.tests
if tests:
for test in tests:
if test.output.get("success"):
return ExpectationConfiguration(
expectation_type=self.expectation_type,
kwargs=test.input,
)
# There is no sample test where `success` is True, or there are no tests
for example in examples:
tests = example.tests
if tests:
for test in tests:
if test.input:
return ExpectationConfiguration(
expectation_type=self.expectation_type,
kwargs=test.input,
)
return None
@staticmethod
def is_expectation_self_initializing(name: str) -> bool:
"""
Given the name of an Expectation, returns a boolean that represents whether an Expectation can be auto-intialized.
Args:
name (str): name of Expectation
Returns:
boolean that represents whether an Expectation can be auto-initialized. Information also outputted to logger.
"""
expectation_impl: MetaExpectation = get_expectation_impl(name)
if not expectation_impl:
raise ExpectationNotFoundError(
f"Expectation {name} was not found in the list of registered Expectations. "
f"Please check your configuration and try again"
)
if "auto" in expectation_impl.default_kwarg_values:
print(
f"The Expectation {name} is able to be self-initialized. Please run by using the auto=True parameter."
)
return True
else:
print(f"The Expectation {name} is not able to be self-initialized.")
return False
@staticmethod
def _choose_example(
examples: List[ExpectationTestDataCases],
) -> Tuple[TestData, ExpectationTestCase]:
"""Choose examples to use for run_diagnostics.
This implementation of this method is very naive---it just takes the first one.
"""
example = examples[0]
example_test_data = example["data"]
example_test_case = example["tests"][0]
return example_test_data, example_test_case
@staticmethod
def _get_registered_renderers(
expectation_type: str,
registered_renderers: dict,
) -> List[str]:
"""Get a list of supported renderers for this Expectation, in sorted order."""
supported_renderers = list(registered_renderers[expectation_type].keys())
supported_renderers.sort()
return supported_renderers
@classmethod
def _get_test_results(
cls,
expectation_type: str,
test_data_cases: List[ExpectationTestDataCases],
execution_engine_diagnostics: ExpectationExecutionEngineDiagnostics,
raise_exceptions_for_backends: bool = False,
ignore_suppress: bool = False,
ignore_only_for: bool = False,
debug_logger: Optional[logging.Logger] = None,
only_consider_these_backends: Optional[List[str]] = None,
context: Optional[DataContext] = None,
) -> List[ExpectationTestDiagnostics]:
"""Generate test results. This is an internal method for run_diagnostics."""
if debug_logger is not None:
_debug = lambda x: debug_logger.debug(f"(_get_test_results) {x}")
_error = lambda x: debug_logger.error(f"(_get_test_results) {x}")
else:
_debug = lambda x: x
_error = lambda x: x
_debug("Starting")
test_results = []
exp_tests = generate_expectation_tests(
expectation_type=expectation_type,
test_data_cases=test_data_cases,
execution_engine_diagnostics=execution_engine_diagnostics,
raise_exceptions_for_backends=raise_exceptions_for_backends,
ignore_suppress=ignore_suppress,
ignore_only_for=ignore_only_for,
debug_logger=debug_logger,
only_consider_these_backends=only_consider_these_backends,
context=context,
)
error_diagnostics: Optional[ExpectationErrorDiagnostics]
backend_test_times = defaultdict(list)
for exp_test in exp_tests:
if exp_test["test"] is None:
_debug(
f"validator_with_data failure for {exp_test['backend']}--{expectation_type}"
)
error_diagnostics = ExpectationErrorDiagnostics(
error_msg=exp_test["error"],
stack_trace="",
test_title="all",
test_backend=exp_test["backend"],
)
test_results.append(
ExpectationTestDiagnostics(
test_title="all",
backend=exp_test["backend"],
test_passed=False,
include_in_gallery=False,
validation_result=None,
error_diagnostics=error_diagnostics,
)
)
continue
exp_combined_test_name = f"{exp_test['backend']}--{exp_test['test']['title']}--{expectation_type}"
_debug(f"Starting {exp_combined_test_name}")
_start = time.time()
validation_result, error_message, stack_trace = evaluate_json_test_v3_api(
validator=exp_test["validator_with_data"],
expectation_type=exp_test["expectation_type"],
test=exp_test["test"],
raise_exception=False,
)
_end = time.time()
_duration = _end - _start
backend_test_times[exp_test["backend"]].append(_duration)
_debug(
f"Took {_duration} seconds to evaluate_json_test_v3_api for {exp_combined_test_name}"
)
if error_message is None:
_debug(f"PASSED {exp_combined_test_name}")
test_passed = True
error_diagnostics = None
else:
_error(f"{repr(error_message)} for {exp_combined_test_name}")
print(f"{stack_trace[0]}")
error_diagnostics = ExpectationErrorDiagnostics(
error_msg=error_message,
stack_trace=stack_trace,
test_title=exp_test["test"]["title"],
test_backend=exp_test["backend"],
)
test_passed = False
if validation_result:
# The ExpectationTestDiagnostics instance will error when calling it's to_dict()
# method (AttributeError: 'ExpectationConfiguration' object has no attribute 'raw_kwargs')
validation_result.expectation_config.raw_kwargs = (
validation_result.expectation_config._raw_kwargs
)
test_results.append(
ExpectationTestDiagnostics(
test_title=exp_test["test"]["title"],
backend=exp_test["backend"],
test_passed=test_passed,
include_in_gallery=exp_test["test"]["include_in_gallery"],
validation_result=validation_result,
error_diagnostics=error_diagnostics,
)
)
for backend_name, test_times in sorted(backend_test_times.items()):
_debug(
f"Took {sum(test_times)} seconds to run {len(test_times)} tests {backend_name}--{expectation_type}"
)
return test_results
def _get_rendered_result_as_string(self, rendered_result) -> str:
"""Convenience method to get rendered results as strings."""
result: str = ""
if type(rendered_result) == str:
result = rendered_result
elif type(rendered_result) == list:
sub_result_list = []
for sub_result in rendered_result:
res = self._get_rendered_result_as_string(sub_result)
if res is not None:
sub_result_list.append(res)
result = "\n".join(sub_result_list)
elif isinstance(rendered_result, RenderedStringTemplateContent):
result = rendered_result.__str__()
elif isinstance(rendered_result, CollapseContent):
result = rendered_result.__str__()
elif isinstance(rendered_result, RenderedAtomicContent):
result = f"(RenderedAtomicContent) {repr(rendered_result.to_json_dict())}"
elif isinstance(rendered_result, RenderedContentBlockContainer):
result = "(RenderedContentBlockContainer) " + repr(
rendered_result.to_json_dict()
)
elif isinstance(rendered_result, RenderedTableContent):
result = f"(RenderedTableContent) {repr(rendered_result.to_json_dict())}"
elif isinstance(rendered_result, RenderedGraphContent):
result = f"(RenderedGraphContent) {repr(rendered_result.to_json_dict())}"
elif isinstance(rendered_result, ValueListContent):
result = f"(ValueListContent) {repr(rendered_result.to_json_dict())}"
elif isinstance(rendered_result, dict):
result = f"(dict) {repr(rendered_result)}"
elif isinstance(rendered_result, int):
result = repr(rendered_result)
elif rendered_result == None:
result = ""
else:
raise TypeError(
f"Expectation._get_rendered_result_as_string can't render type {type(rendered_result)} as a string."
)
if "inf" in result:
result = ""
return result
def _get_renderer_diagnostics(
self,
expectation_type: str,
test_diagnostics: List[ExpectationTestDiagnostics],
registered_renderers: List[str],
standard_renderers: Optional[
List[Union[str, LegacyRendererType, LegacyDiagnosticRendererType]]
] = None,
) -> List[ExpectationRendererDiagnostics]:
"""Generate Renderer diagnostics for this Expectation, based primarily on a list of ExpectationTestDiagnostics."""
if not standard_renderers:
standard_renderers = [
LegacyRendererType.ANSWER,
LegacyDiagnosticRendererType.UNEXPECTED_STATEMENT,
LegacyDiagnosticRendererType.OBSERVED_VALUE,
LegacyDiagnosticRendererType.STATUS_ICON,
LegacyDiagnosticRendererType.UNEXPECTED_TABLE,
LegacyRendererType.PRESCRIPTIVE,
LegacyRendererType.QUESTION,
]
supported_renderers = self._get_registered_renderers(
expectation_type=expectation_type,
registered_renderers=registered_renderers, # type: ignore[arg-type]
)
renderer_diagnostic_list = []
for renderer_name in set(standard_renderers).union(set(supported_renderers)):
samples = []
if renderer_name in supported_renderers:
_, renderer = registered_renderers[expectation_type][renderer_name] # type: ignore[call-overload]
for test_diagnostic in test_diagnostics:
test_title = test_diagnostic["test_title"]
try:
rendered_result = renderer(
configuration=test_diagnostic["validation_result"][
"expectation_config"
],
result=test_diagnostic["validation_result"],
)
rendered_result_str = self._get_rendered_result_as_string(
rendered_result
)
except Exception as e:
new_sample = RendererTestDiagnostics(
test_title=test_title,
renderered_str=None,
rendered_successfully=False,
error_message=str(e),
stack_trace=traceback.format_exc(),
)
else:
new_sample = RendererTestDiagnostics(
test_title=test_title,
renderered_str=rendered_result_str,
rendered_successfully=True,
)
finally:
samples.append(new_sample)
new_renderer_diagnostics = ExpectationRendererDiagnostics(
name=renderer_name,
is_supported=renderer_name in supported_renderers,
is_standard=renderer_name in standard_renderers,
samples=samples,
)
renderer_diagnostic_list.append(new_renderer_diagnostics)
# Sort to enforce consistency for testing
renderer_diagnostic_list.sort(key=lambda x: x.name)
return renderer_diagnostic_list
@staticmethod
def _get_execution_engine_diagnostics(
metric_diagnostics_list: List[ExpectationMetricDiagnostics],
registered_metrics: dict,
execution_engine_names: Optional[List[str]] = None,
) -> ExpectationExecutionEngineDiagnostics:
"""Check to see which execution_engines are fully supported for this Expectation.
In order for a given execution engine to count, *every* metric must have support on that execution engines.
"""
if not execution_engine_names:
execution_engine_names = [
"PandasExecutionEngine",
"SqlAlchemyExecutionEngine",
"SparkDFExecutionEngine",
]
execution_engines = {}
for provider in execution_engine_names:
all_true = True
if not metric_diagnostics_list:
all_true = False
for metric_diagnostics in metric_diagnostics_list:
try:
has_provider = (
provider
in registered_metrics[metric_diagnostics.name]["providers"]
)
if not has_provider:
all_true = False
break
except KeyError:
# https://github.com/great-expectations/great_expectations/blob/abd8f68a162eaf9c33839d2c412d8ba84f5d725b/great_expectations/expectations/core/expect_table_row_count_to_equal_other_table.py#L174-L181
# expect_table_row_count_to_equal_other_table does tricky things and replaces
# registered metric "table.row_count" with "table.row_count.self" and "table.row_count.other"
if "table.row_count" in metric_diagnostics.name:
continue
execution_engines[provider] = all_true
return ExpectationExecutionEngineDiagnostics(**execution_engines)
def _get_metric_diagnostics_list(
self,
expectation_config: Optional[ExpectationConfiguration],
) -> List[ExpectationMetricDiagnostics]:
"""Check to see which Metrics are upstream validation_dependencies for this Expectation."""
# NOTE: Abe 20210102: Strictly speaking, identifying upstream metrics shouldn't need to rely on an expectation config.
# There's probably some part of get_validation_dependencies that can be factored out to remove the dependency.
if not expectation_config:
return []
validation_dependencies: ValidationDependencies = (
self.get_validation_dependencies(configuration=expectation_config)
)
metric_name: str
metric_diagnostics_list: List[ExpectationMetricDiagnostics] = [
ExpectationMetricDiagnostics(
name=metric_name,
has_question_renderer=False,
)
for metric_name in validation_dependencies.get_metric_names()
]
return metric_diagnostics_list
def _get_augmented_library_metadata(self):
"""Introspect the Expectation's library_metadata object (if it exists), and augment it with additional information."""
augmented_library_metadata = {
"maturity": Maturity.CONCEPT_ONLY,
"tags": [],
"contributors": [],
"requirements": [],
"library_metadata_passed_checks": False,
"has_full_test_suite": False,
"manually_reviewed_code": False,
}
required_keys = {"contributors", "tags"}
allowed_keys = {
"contributors",
"has_full_test_suite",
"manually_reviewed_code",
"maturity",
"requirements",
"tags",
}
problems = []
if hasattr(self, "library_metadata"):
augmented_library_metadata.update(self.library_metadata)
keys = set(self.library_metadata.keys())
missing_required_keys = required_keys - keys
forbidden_keys = keys - allowed_keys
if missing_required_keys:
problems.append(
f"Missing required key(s): {sorted(missing_required_keys)}"
)
if forbidden_keys:
problems.append(f"Extra key(s) found: {sorted(forbidden_keys)}")
if type(augmented_library_metadata["requirements"]) != list:
problems.append("library_metadata['requirements'] is not a list ")
if not problems:
augmented_library_metadata["library_metadata_passed_checks"] = True
else:
problems.append("No library_metadata attribute found")
augmented_library_metadata["problems"] = problems
return AugmentedLibraryMetadata.from_legacy_dict(augmented_library_metadata)
def _get_maturity_checklist(
self,
library_metadata: Union[
AugmentedLibraryMetadata, ExpectationDescriptionDiagnostics
],
description: ExpectationDescriptionDiagnostics,
examples: List[ExpectationTestDataCases],
tests: List[ExpectationTestDiagnostics],
backend_test_result_counts: List[ExpectationBackendTestResultCounts],
execution_engines: ExpectationExecutionEngineDiagnostics,
) -> ExpectationDiagnosticMaturityMessages:
"""Generate maturity checklist messages"""
experimental_checks = []
beta_checks = []
production_checks = []
experimental_checks.append(
ExpectationDiagnostics._check_library_metadata(library_metadata)
)
experimental_checks.append(ExpectationDiagnostics._check_docstring(description))
experimental_checks.append(
ExpectationDiagnostics._check_example_cases(examples, tests)
)
experimental_checks.append(
ExpectationDiagnostics._check_core_logic_for_at_least_one_execution_engine(
backend_test_result_counts
)
)
experimental_checks.append(ExpectationDiagnostics._check_linting(self))
beta_checks.append(
ExpectationDiagnostics._check_input_validation(self, examples)
)
beta_checks.append(ExpectationDiagnostics._check_renderer_methods(self))
beta_checks.append(
ExpectationDiagnostics._check_core_logic_for_all_applicable_execution_engines(
backend_test_result_counts
)
)
production_checks.append(
ExpectationDiagnostics._check_full_test_suite(library_metadata)
)
production_checks.append(
ExpectationDiagnostics._check_manual_code_review(library_metadata)
)
return ExpectationDiagnosticMaturityMessages(
experimental=experimental_checks,
beta=beta_checks,
production=production_checks,
)
class TableExpectation(Expectation, ABC):
domain_keys: Tuple[str, ...] = (
"batch_id",
"table",
"row_condition",
"condition_parser",
)
metric_dependencies = ()
domain_type = MetricDomainTypes.TABLE
def get_validation_dependencies(
self,
configuration: Optional[ExpectationConfiguration] = None,
execution_engine: Optional[ExecutionEngine] = None,
runtime_configuration: Optional[dict] = None,
) -> ValidationDependencies:
validation_dependencies: ValidationDependencies = (
super().get_validation_dependencies(
configuration=configuration,
execution_engine=execution_engine,
runtime_configuration=runtime_configuration,
)
)
metric_name: str
for metric_name in self.metric_dependencies:
metric_kwargs = get_metric_kwargs(
metric_name=metric_name,
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=metric_name,
metric_configuration=MetricConfiguration(
metric_name=metric_name,
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
return validation_dependencies
@staticmethod
def validate_metric_value_between_configuration(
configuration: Optional[ExpectationConfiguration] = None,
) -> bool:
if not configuration:
return True
# Validating that Minimum and Maximum values are of the proper format and type
min_val = None
max_val = None
if "min_value" in configuration.kwargs:
min_val = configuration.kwargs["min_value"]
if "max_value" in configuration.kwargs:
max_val = configuration.kwargs["max_value"]
try:
assert (
min_val is None
or is_parseable_date(min_val)
or isinstance(min_val, (float, int, dict))
), "Provided min threshold must be a datetime (for datetime columns) or number"
if isinstance(min_val, dict):
assert (
"$PARAMETER" in min_val
), 'Evaluation Parameter dict for min_value kwarg must have "$PARAMETER" key'
assert (
max_val is None
or is_parseable_date(max_val)
or isinstance(max_val, (float, int, dict))
), "Provided max threshold must be a datetime (for datetime columns) or number"
if isinstance(max_val, dict):
assert (
"$PARAMETER" in max_val
), 'Evaluation Parameter dict for max_value kwarg must have "$PARAMETER" key'
except AssertionError as e:
raise InvalidExpectationConfigurationError(str(e))
return True
def _validate_metric_value_between(
self,
metric_name,
configuration: ExpectationConfiguration,
metrics: Dict,
runtime_configuration: Optional[dict] = None,
execution_engine: Optional[ExecutionEngine] = None,
) -> Dict[str, Union[bool, Dict[str, Any]]]:
metric_value: Optional[Any] = metrics.get(metric_name)
if metric_value is None:
return {"success": False, "result": {"observed_value": metric_value}}
# Obtaining components needed for validation
min_value: Optional[Any] = self.get_success_kwargs(
configuration=configuration
).get("min_value")
strict_min: Optional[bool] = self.get_success_kwargs(
configuration=configuration
).get("strict_min")
max_value: Optional[Any] = self.get_success_kwargs(
configuration=configuration
).get("max_value")
strict_max: Optional[bool] = self.get_success_kwargs(
configuration=configuration
).get("strict_max")
parse_strings_as_datetimes: Optional[bool] = self.get_success_kwargs(
configuration=configuration
).get("parse_strings_as_datetimes")
if parse_strings_as_datetimes:
# deprecated-v0.13.41
warnings.warn(
"""The parameter "parse_strings_as_datetimes" is deprecated as of v0.13.41 in \
v0.16. As part of the V3 API transition, we've moved away from input transformation. For more information, \
please see: https://greatexpectations.io/blog/why_we_dont_do_transformations_for_expectations/
""",
DeprecationWarning,
)
if min_value is not None:
try:
min_value = parse(min_value)
except TypeError:
pass
if max_value is not None:
try:
max_value = parse(max_value)
except TypeError:
pass
if not isinstance(metric_value, datetime.datetime) and pd.isnull(metric_value):
return {"success": False, "result": {"observed_value": None}}
if isinstance(metric_value, datetime.datetime):
if isinstance(min_value, str):
try:
min_value = parse(min_value)
except TypeError:
raise ValueError(
f"""Could not parse "min_value" of {min_value} (of type "{str(type(min_value))}) into datetime \
representation."""
)
if isinstance(max_value, str):
try:
max_value = parse(max_value)
except TypeError:
raise ValueError(
f"""Could not parse "max_value" of {max_value} (of type "{str(type(max_value))}) into datetime \
representation."""
)
# Checking if mean lies between thresholds
if min_value is not None:
if strict_min:
above_min = metric_value > min_value
else:
above_min = metric_value >= min_value
else:
above_min = True
if max_value is not None:
if strict_max:
below_max = metric_value < max_value
else:
below_max = metric_value <= max_value
else:
below_max = True
success = above_min and below_max
return {"success": success, "result": {"observed_value": metric_value}}
class QueryExpectation(TableExpectation, ABC):
"""Base class for QueryExpectations.
QueryExpectations *must* have the following attributes set:
1. `domain_keys`: a tuple of the *keys* used to determine the domain of the
expectation
2. `success_keys`: a tuple of the *keys* used to determine the success of
the expectation.
QueryExpectations *may* specify a `query` attribute, and specify that query in `default_kwarg_values`.
Doing so precludes the need to pass a query into the Expectation, but will override the default query if a query
is passed in.
They *may* optionally override `runtime_keys` and `default_kwarg_values`;
1. runtime_keys lists the keys that can be used to control output but will
not affect the actual success value of the expectation (such as result_format).
2. default_kwarg_values is a dictionary that will be used to fill unspecified
kwargs from the Expectation Configuration.
QueryExpectations *must* implement the following:
1. `_validate`
Additionally, they *may* provide implementations of:
1. `validate_configuration`, which should raise an error if the configuration
will not be usable for the Expectation
2. Data Docs rendering methods decorated with the @renderer decorator. See the
"""
default_kwarg_values = {
"result_format": "BASIC",
"include_config": True,
"catch_exceptions": False,
"meta": None,
"row_condition": None,
"condition_parser": None,
}
domain_keys = (
"batch_id",
"row_condition",
"condition_parser",
)
def validate_configuration(
self, configuration: Optional[ExpectationConfiguration] = None
) -> None:
"""Raises an exception if the configuration is not viable for an expectation.
Args:
configuration: An ExpectationConfiguration
Raises:
InvalidExpectationConfigurationError: If no `query` is specified
UserWarning: If query is not parameterized, and/or row_condition is passed.
"""
super().validate_configuration(configuration=configuration)
if not configuration:
configuration = self.configuration
query: Optional[Any] = configuration.kwargs.get(
"query"
) or self.default_kwarg_values.get("query")
row_condition: Optional[Any] = configuration.kwargs.get(
"row_condition"
) or self.default_kwarg_values.get("row_condition")
try:
assert (
"query" in configuration.kwargs or query
), "'query' parameter is required for Query Expectations."
except AssertionError as e:
raise InvalidExpectationConfigurationError(str(e))
try:
if not isinstance(query, str):
raise TypeError(
f"'query' must be a string, but your query is type: {type(query)}"
)
parsed_query: Set[str] = {
x
for x in re.split(", |\\(|\n|\\)| |/", query)
if x.upper() != "" and x.upper() not in valid_sql_tokens_and_types
}
assert "{active_batch}" in parsed_query, (
"Your query appears to not be parameterized for a data asset. "
"By not parameterizing your query with `{active_batch}`, "
"you may not be validating against your intended data asset, or the expectation may fail."
)
assert all([re.match("{.*?}", x) for x in parsed_query]), (
"Your query appears to have hard-coded references to your data. "
"By not parameterizing your query with `{active_batch}`, {col}, etc., "
"you may not be validating against your intended data asset, or the expectation may fail."
)
except (TypeError, AssertionError) as e:
warnings.warn(str(e), UserWarning)
try:
assert row_condition is None, (
"`row_condition` is an experimental feature. "
"Combining this functionality with QueryExpectations may result in unexpected behavior."
)
except AssertionError as e:
warnings.warn(str(e), UserWarning)
class ColumnExpectation(TableExpectation, ABC):
domain_keys = ("batch_id", "table", "column", "row_condition", "condition_parser")
domain_type = MetricDomainTypes.COLUMN
def validate_configuration(
self, configuration: Optional[ExpectationConfiguration] = None
) -> None:
super().validate_configuration(configuration=configuration)
if not configuration:
configuration = self.configuration
# Ensuring basic configuration parameters are properly set
try:
assert (
"column" in configuration.kwargs
), "'column' parameter is required for column expectations"
except AssertionError as e:
raise InvalidExpectationConfigurationError(str(e))
class ColumnMapExpectation(TableExpectation, ABC):
map_metric = None
domain_keys = ("batch_id", "table", "column", "row_condition", "condition_parser")
domain_type = MetricDomainTypes.COLUMN
success_keys = ("mostly",)
default_kwarg_values = {
"row_condition": None,
"condition_parser": None, # we expect this to be explicitly set whenever a row_condition is passed
"mostly": 1,
"result_format": "BASIC",
"include_config": True,
"catch_exceptions": True,
}
@classmethod
def is_abstract(cls) -> bool:
return cls.map_metric is None or super().is_abstract()
def validate_configuration(
self, configuration: Optional[ExpectationConfiguration] = None
) -> None:
super().validate_configuration(configuration=configuration)
if not configuration:
configuration = self.configuration
try:
assert (
"column" in configuration.kwargs
), "'column' parameter is required for column map expectations"
_validate_mostly_config(configuration)
except AssertionError as e:
raise InvalidExpectationConfigurationError(str(e))
def get_validation_dependencies(
self,
configuration: Optional[ExpectationConfiguration] = None,
execution_engine: Optional[ExecutionEngine] = None,
runtime_configuration: Optional[dict] = None,
**kwargs: dict,
) -> ValidationDependencies:
validation_dependencies: ValidationDependencies = (
super().get_validation_dependencies(
configuration=configuration,
execution_engine=execution_engine,
runtime_configuration=runtime_configuration,
)
)
assert isinstance(
self.map_metric, str
), "ColumnMapExpectation must override get_validation_dependencies or declare exactly one map_metric"
assert (
self.metric_dependencies == tuple()
), "ColumnMapExpectation must be configured using map_metric, and cannot have metric_dependencies declared."
# convenient name for updates
metric_kwargs: dict
metric_kwargs = get_metric_kwargs(
metric_name="column_values.nonnull.unexpected_count",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name="column_values.nonnull.unexpected_count",
metric_configuration=MetricConfiguration(
"column_values.nonnull.unexpected_count",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
metric_kwargs = get_metric_kwargs(
metric_name=f"{self.map_metric}.unexpected_count",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_count",
metric_configuration=MetricConfiguration(
f"{self.map_metric}.unexpected_count",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
metric_kwargs = get_metric_kwargs(
metric_name="table.row_count",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name="table.row_count",
metric_configuration=MetricConfiguration(
metric_name="table.row_count",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
result_format_str: Optional[str] = validation_dependencies.result_format.get(
"result_format"
)
include_unexpected_rows: Optional[
bool
] = validation_dependencies.result_format.get("include_unexpected_rows")
if result_format_str == "BOOLEAN_ONLY":
return validation_dependencies
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.unexpected_values",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_values",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.unexpected_values",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
if include_unexpected_rows:
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.unexpected_rows",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_rows",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.unexpected_rows",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
if include_unexpected_rows:
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.unexpected_rows",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_rows",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.unexpected_rows",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
if result_format_str in ["BASIC"]:
return validation_dependencies
# only for SUMMARY and COMPLETE
if isinstance(execution_engine, PandasExecutionEngine):
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.unexpected_index_list",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_index_list",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.unexpected_index_list",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
return validation_dependencies
def _validate(
self,
configuration: ExpectationConfiguration,
metrics: Dict,
runtime_configuration: Optional[dict] = None,
execution_engine: Optional[ExecutionEngine] = None,
):
result_format: Union[
Dict[str, Union[str, int, bool]], str
] = self.get_result_format(
configuration=configuration, runtime_configuration=runtime_configuration
)
if isinstance(result_format, dict):
include_unexpected_rows = result_format.get(
"include_unexpected_rows", False
)
total_count: Optional[int] = metrics.get("table.row_count")
null_count: Optional[int] = metrics.get(
"column_values.nonnull.unexpected_count"
)
unexpected_count: Optional[int] = metrics.get(
f"{self.map_metric}.unexpected_count"
)
unexpected_values: Optional[List[Any]] = metrics.get(
f"{self.map_metric}.unexpected_values"
)
unexpected_index_list: Optional[List[int]] = metrics.get(
f"{self.map_metric}.unexpected_index_list"
)
unexpected_rows = None
if include_unexpected_rows:
unexpected_rows = metrics.get(f"{self.map_metric}.unexpected_rows")
if total_count is None or null_count is None:
total_count = nonnull_count = 0
else:
nonnull_count = total_count - null_count
if unexpected_count is None or total_count == 0 or nonnull_count == 0:
# Vacuously true
success = True
else:
success = _mostly_success(
nonnull_count,
unexpected_count,
self.get_success_kwargs().get(
"mostly", self.default_kwarg_values.get("mostly")
),
)
return _format_map_output(
result_format=parse_result_format(result_format),
success=success,
element_count=total_count,
nonnull_count=nonnull_count,
unexpected_count=unexpected_count,
unexpected_list=unexpected_values,
unexpected_index_list=unexpected_index_list,
unexpected_rows=unexpected_rows,
)
class ColumnPairMapExpectation(TableExpectation, ABC):
map_metric = None
domain_keys = (
"batch_id",
"table",
"column_A",
"column_B",
"row_condition",
"condition_parser",
)
domain_type = MetricDomainTypes.COLUMN_PAIR
success_keys = ("mostly",)
default_kwarg_values = {
"row_condition": None,
"condition_parser": None, # we expect this to be explicitly set whenever a row_condition is passed
"mostly": 1,
"result_format": "BASIC",
"include_config": True,
"catch_exceptions": True,
}
@classmethod
def is_abstract(cls) -> bool:
return cls.map_metric is None or super().is_abstract()
def validate_configuration(
self, configuration: Optional[ExpectationConfiguration] = None
) -> None:
super().validate_configuration(configuration=configuration)
if not configuration:
configuration = self.configuration
try:
assert (
"column_A" in configuration.kwargs
), "'column_A' parameter is required for column pair map expectations"
assert (
"column_B" in configuration.kwargs
), "'column_B' parameter is required for column pair map expectations"
_validate_mostly_config(configuration)
except AssertionError as e:
raise InvalidExpectationConfigurationError(str(e))
def get_validation_dependencies(
self,
configuration: Optional[ExpectationConfiguration] = None,
execution_engine: Optional[ExecutionEngine] = None,
runtime_configuration: Optional[dict] = None,
) -> ValidationDependencies:
validation_dependencies: ValidationDependencies = (
super().get_validation_dependencies(
configuration=configuration,
execution_engine=execution_engine,
runtime_configuration=runtime_configuration,
)
)
assert isinstance(
self.map_metric, str
), "ColumnPairMapExpectation must override get_validation_dependencies or declare exactly one map_metric"
assert (
self.metric_dependencies == tuple()
), "ColumnPairMapExpectation must be configured using map_metric, and cannot have metric_dependencies declared."
# convenient name for updates
metric_kwargs: dict
metric_kwargs = get_metric_kwargs(
metric_name=f"{self.map_metric}.unexpected_count",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_count",
metric_configuration=MetricConfiguration(
f"{self.map_metric}.unexpected_count",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
metric_kwargs = get_metric_kwargs(
metric_name="table.row_count",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name="table.row_count",
metric_configuration=MetricConfiguration(
metric_name="table.row_count",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.filtered_row_count",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.filtered_row_count",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.filtered_row_count",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
result_format_str: Optional[str] = validation_dependencies.result_format.get(
"result_format"
)
include_unexpected_rows: Optional[
bool
] = validation_dependencies.result_format.get("include_unexpected_rows")
if result_format_str == "BOOLEAN_ONLY":
return validation_dependencies
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.unexpected_values",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_values",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.unexpected_values",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
if result_format_str in ["BASIC", "SUMMARY"]:
return validation_dependencies
if include_unexpected_rows:
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.unexpected_rows",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_rows",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.unexpected_rows",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
if isinstance(execution_engine, PandasExecutionEngine):
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.unexpected_index_list",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_index_list",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.unexpected_index_list",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
return validation_dependencies
def _validate(
self,
configuration: ExpectationConfiguration,
metrics: Dict,
runtime_configuration: Optional[dict] = None,
execution_engine: Optional[ExecutionEngine] = None,
):
result_format: Union[
Dict[str, Union[str, int, bool]], str
] = self.get_result_format(
configuration=configuration, runtime_configuration=runtime_configuration
)
total_count: Optional[int] = metrics.get("table.row_count")
unexpected_count: Optional[int] = metrics.get(
f"{self.map_metric}.unexpected_count"
)
unexpected_values: Optional[Any] = metrics.get(
f"{self.map_metric}.unexpected_values"
)
unexpected_index_list: Optional[List[int]] = metrics.get(
f"{self.map_metric}.unexpected_index_list"
)
filtered_row_count: Optional[int] = metrics.get(
f"{self.map_metric}.filtered_row_count"
)
if (
total_count is None
or unexpected_count is None
or filtered_row_count is None
or total_count == 0
or filtered_row_count == 0
):
# Vacuously true
success = True
else:
success = _mostly_success(
filtered_row_count,
unexpected_count,
self.get_success_kwargs().get(
"mostly", self.default_kwarg_values.get("mostly")
),
)
return _format_map_output(
result_format=parse_result_format(result_format),
success=success,
element_count=total_count,
nonnull_count=filtered_row_count,
unexpected_count=unexpected_count,
unexpected_list=unexpected_values,
unexpected_index_list=unexpected_index_list,
)
class MulticolumnMapExpectation(TableExpectation, ABC):
map_metric = None
domain_keys = (
"batch_id",
"table",
"column_list",
"row_condition",
"condition_parser",
"ignore_row_if",
)
domain_type = MetricDomainTypes.MULTICOLUMN
success_keys = ("mostly",)
default_kwarg_values = {
"row_condition": None,
"condition_parser": None, # we expect this to be explicitly set whenever a row_condition is passed
"mostly": 1,
"ignore_row_if": "all_values_are_missing",
"result_format": "BASIC",
"include_config": True,
"catch_exceptions": True,
}
@classmethod
def is_abstract(cls) -> bool:
return cls.map_metric is None or super().is_abstract()
def validate_configuration(
self, configuration: Optional[ExpectationConfiguration] = None
) -> None:
super().validate_configuration(configuration=configuration)
if not configuration:
configuration = self.configuration
try:
assert (
"column_list" in configuration.kwargs
), "'column_list' parameter is required for multicolumn map expectations"
_validate_mostly_config(configuration)
except AssertionError as e:
raise InvalidExpectationConfigurationError(str(e))
def get_validation_dependencies(
self,
configuration: Optional[ExpectationConfiguration] = None,
execution_engine: Optional[ExecutionEngine] = None,
runtime_configuration: Optional[dict] = None,
) -> ValidationDependencies:
validation_dependencies: ValidationDependencies = (
super().get_validation_dependencies(
configuration=configuration,
execution_engine=execution_engine,
runtime_configuration=runtime_configuration,
)
)
assert isinstance(
self.map_metric, str
), "MulticolumnMapExpectation must override get_validation_dependencies or declare exactly one map_metric"
assert (
self.metric_dependencies == tuple()
), "MulticolumnMapExpectation must be configured using map_metric, and cannot have metric_dependencies declared."
# convenient name for updates
metric_kwargs: dict
metric_kwargs = get_metric_kwargs(
metric_name=f"{self.map_metric}.unexpected_count",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_count",
metric_configuration=MetricConfiguration(
f"{self.map_metric}.unexpected_count",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
metric_kwargs = get_metric_kwargs(
metric_name="table.row_count",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name="table.row_count",
metric_configuration=MetricConfiguration(
metric_name="table.row_count",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.filtered_row_count",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.filtered_row_count",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.filtered_row_count",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
result_format_str: Optional[str] = validation_dependencies.result_format.get(
"result_format"
)
include_unexpected_rows: Optional[
bool
] = validation_dependencies.result_format.get("include_unexpected_rows")
if result_format_str == "BOOLEAN_ONLY":
return validation_dependencies
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.unexpected_values",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_values",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.unexpected_values",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
if result_format_str in ["BASIC", "SUMMARY"]:
return validation_dependencies
if include_unexpected_rows:
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.unexpected_rows",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_rows",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.unexpected_rows",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
if isinstance(execution_engine, PandasExecutionEngine):
metric_kwargs = get_metric_kwargs(
f"{self.map_metric}.unexpected_index_list",
configuration=configuration,
runtime_configuration=runtime_configuration,
)
validation_dependencies.set_metric_configuration(
metric_name=f"{self.map_metric}.unexpected_index_list",
metric_configuration=MetricConfiguration(
metric_name=f"{self.map_metric}.unexpected_index_list",
metric_domain_kwargs=metric_kwargs["metric_domain_kwargs"],
metric_value_kwargs=metric_kwargs["metric_value_kwargs"],
),
)
return validation_dependencies
def _validate(
self,
configuration: ExpectationConfiguration,
metrics: Dict,
runtime_configuration: Optional[dict] = None,
execution_engine: Optional[ExecutionEngine] = None,
):
result_format = self.get_result_format(
configuration=configuration, runtime_configuration=runtime_configuration
)
total_count: Optional[int] = metrics.get("table.row_count")
unexpected_count: Optional[int] = metrics.get(
f"{self.map_metric}.unexpected_count"
)
unexpected_values: Optional[Any] = metrics.get(
f"{self.map_metric}.unexpected_values"
)
unexpected_index_list: Optional[List[int]] = metrics.get(
f"{self.map_metric}.unexpected_index_list"
)
filtered_row_count: Optional[int] = metrics.get(
f"{self.map_metric}.filtered_row_count"
)
if (
total_count is None
or unexpected_count is None
or filtered_row_count is None
or total_count == 0
or filtered_row_count == 0
):
# Vacuously true
success = True
else:
success = _mostly_success(
filtered_row_count,
unexpected_count,
self.get_success_kwargs().get(
"mostly", self.default_kwarg_values.get("mostly")
),
)
return _format_map_output(
result_format=parse_result_format(result_format),
success=success,
element_count=total_count,
nonnull_count=filtered_row_count,
unexpected_count=unexpected_count,
unexpected_list=unexpected_values,
unexpected_index_list=unexpected_index_list,
)
def _format_map_output(
result_format: dict,
success: bool,
element_count: Optional[int] = None,
nonnull_count: Optional[int] = None,
unexpected_count: Optional[int] = None,
unexpected_list: Optional[List[Any]] = None,
unexpected_index_list: Optional[List[int]] = None,
unexpected_rows=None,
) -> Dict:
"""Helper function to construct expectation result objects for map_expectations (such as column_map_expectation
and file_lines_map_expectation).
Expectations support four result_formats: BOOLEAN_ONLY, BASIC, SUMMARY, and COMPLETE.
In each case, the object returned has a different set of populated fields.
See :ref:`result_format` for more information.
This function handles the logic for mapping those fields for column_map_expectations.
"""
if element_count is None:
element_count = 0
# NB: unexpected_count parameter is explicit some implementing classes may limit the length of unexpected_list
# Incrementally add to result and return when all values for the specified level are present
return_obj: Dict[str, Any] = {"success": success}
if result_format["result_format"] == "BOOLEAN_ONLY":
return return_obj
skip_missing = False
missing_count: Optional[int] = None
if nonnull_count is None:
skip_missing = True
else:
missing_count = element_count - nonnull_count
missing_percent: Optional[float] = None
unexpected_percent_total: Optional[float] = None
unexpected_percent_nonmissing: Optional[float] = None
if unexpected_count is not None and element_count > 0:
unexpected_percent_total = unexpected_count / element_count * 100
if not skip_missing and missing_count is not None:
missing_percent = missing_count / element_count * 100
if nonnull_count is not None and nonnull_count > 0:
unexpected_percent_nonmissing = unexpected_count / nonnull_count * 100
else:
unexpected_percent_nonmissing = None
else:
unexpected_percent_nonmissing = unexpected_percent_total
return_obj["result"] = {
"element_count": element_count,
"unexpected_count": unexpected_count,
"unexpected_percent": unexpected_percent_nonmissing,
}
if unexpected_list is not None:
return_obj["result"]["partial_unexpected_list"] = unexpected_list[
: result_format["partial_unexpected_count"]
]
if not skip_missing:
return_obj["result"]["missing_count"] = missing_count
return_obj["result"]["missing_percent"] = missing_percent
return_obj["result"]["unexpected_percent_total"] = unexpected_percent_total
return_obj["result"][
"unexpected_percent_nonmissing"
] = unexpected_percent_nonmissing
if result_format["include_unexpected_rows"]:
return_obj["result"].update(
{
"unexpected_rows": unexpected_rows,
}
)
if result_format["result_format"] == "BASIC":
return return_obj
if unexpected_list is not None:
if len(unexpected_list) and isinstance(unexpected_list[0], dict):
# in the case of multicolumn map expectations `unexpected_list` contains dicts,
# which will throw an exception when we hash it to count unique members.
# As a workaround, we flatten the values out to tuples.
immutable_unexpected_list = [
tuple([val for val in item.values()]) for item in unexpected_list
]
else:
immutable_unexpected_list = unexpected_list
# Try to return the most common values, if possible.
partial_unexpected_count: Optional[int] = result_format.get(
"partial_unexpected_count"
)
partial_unexpected_counts: Optional[List[Dict[str, Any]]] = None
if partial_unexpected_count is not None and 0 < partial_unexpected_count:
try:
partial_unexpected_counts = [
{"value": key, "count": value}
for key, value in sorted(
Counter(immutable_unexpected_list).most_common(
result_format["partial_unexpected_count"]
),
key=lambda x: (-x[1], x[0]),
)
]
except TypeError:
partial_unexpected_counts = [
{"error": "partial_exception_counts requires a hashable type"}
]
finally:
return_obj["result"].update(
{
"partial_unexpected_index_list": unexpected_index_list[
: result_format["partial_unexpected_count"]
]
if unexpected_index_list is not None
else None,
"partial_unexpected_counts": partial_unexpected_counts,
}
)
if result_format["result_format"] == "SUMMARY":
return return_obj
return_obj["result"].update(
{
"unexpected_list": unexpected_list,
"unexpected_index_list": unexpected_index_list,
}
)
if result_format["result_format"] == "COMPLETE":
return return_obj
raise ValueError(f"Unknown result_format {result_format['result_format']}.")
def _validate_mostly_config(configuration: ExpectationConfiguration) -> None:
"""
Validates "mostly" in ExpectationConfiguration is a number if it exists.
Args:
configuration: The ExpectationConfiguration to be validated
Raises:
AssertionError: An error is mostly exists in the configuration but is not between 0 and 1.
"""
if "mostly" in configuration.kwargs:
mostly = configuration.kwargs["mostly"]
assert isinstance(
mostly, (int, float)
), "'mostly' parameter must be an integer or float"
assert 0 <= mostly <= 1, "'mostly' parameter must be between 0 and 1"
def _mostly_success(
rows_considered_cnt: int,
unexpected_cnt: int,
mostly: float,
) -> bool:
rows_considered_cnt_as_float: float = float(rows_considered_cnt)
unexpected_cnt_as_float: float = float(unexpected_cnt)
success_ratio: float = (
rows_considered_cnt_as_float - unexpected_cnt_as_float
) / rows_considered_cnt_as_float
return success_ratio >= mostly
def add_values_with_json_schema_from_list_in_params(
params: dict,
params_with_json_schema: dict,
param_key_with_list: str,
list_values_type: str = "string",
) -> dict:
"""
Utility function used in _atomic_prescriptive_template() to take list values from a given params dict key,
convert each value to a dict with JSON schema type info, then add it to params_with_json_schema (dict).
"""
target_list = params.get(param_key_with_list)
if target_list is not None and len(target_list) > 0:
for i, v in enumerate(target_list):
params_with_json_schema[f"v__{str(i)}"] = {
"schema": {"type": list_values_type},
"value": v,
}
return params_with_json_schema
<file_sep>/great_expectations/data_context/data_context/data_context.py
from __future__ import annotations
import logging
import os
import shutil
import warnings
from typing import Optional, Union
from ruamel.yaml import YAML, YAMLError
from ruamel.yaml.constructor import DuplicateKeyError
import great_expectations.exceptions as ge_exceptions
from great_expectations.data_context.data_context.base_data_context import (
BaseDataContext,
)
from great_expectations.data_context.data_context.cloud_data_context import (
CloudDataContext,
)
from great_expectations.data_context.templates import (
CONFIG_VARIABLES_TEMPLATE,
PROJECT_TEMPLATE_USAGE_STATISTICS_DISABLED,
PROJECT_TEMPLATE_USAGE_STATISTICS_ENABLED,
)
from great_expectations.data_context.types.base import (
CURRENT_GE_CONFIG_VERSION,
MINIMUM_SUPPORTED_CONFIG_VERSION,
AnonymizedUsageStatisticsConfig,
DataContextConfig,
GXCloudConfig,
)
from great_expectations.data_context.util import file_relative_path
from great_expectations.datasource import LegacyDatasource
from great_expectations.datasource.new_datasource import BaseDatasource
from great_expectations.experimental.datasources.interfaces import (
Datasource as XDatasource,
)
from great_expectations.experimental.datasources.sources import _SourceFactories
logger = logging.getLogger(__name__)
yaml = YAML()
yaml.indent(mapping=2, sequence=4, offset=2)
yaml.default_flow_style = False
# TODO: <WILL> Most of the logic here will be migrated to FileDataContext
class DataContext(BaseDataContext):
"""A DataContext represents a Great Expectations project. It is the primary entry point for a Great Expectations
deployment, with configurations and methods for all supporting components.
The DataContext is configured via a yml file stored in a directory called great_expectations; this configuration
file as well as managed Expectation Suites should be stored in version control. There are other ways to create a
Data Context that may be better suited for your particular deployment e.g. ephemerally or backed by GE Cloud
(coming soon). Please refer to our documentation for more details.
You can Validate data or generate Expectations using Execution Engines including:
* SQL (multiple dialects supported)
* Spark
* Pandas
Your data can be stored in common locations including:
* databases / data warehouses
* files in s3, GCS, Azure, local storage
* dataframes (spark and pandas) loaded into memory
Please see our documentation for examples on how to set up Great Expectations, connect to your data,
create Expectations, and Validate data.
Other configuration options you can apply to a DataContext besides how to access data include things like where to
store Expectations, Profilers, Checkpoints, Metrics, Validation Results and Data Docs and how those Stores are
configured. Take a look at our documentation for more configuration options.
You can create or load a DataContext from disk via the following:
```
import great_expectations as ge
ge.get_context()
```
--Public API--
--Documentation--
https://docs.greatexpectations.io/docs/terms/data_context
"""
@classmethod
def create(
cls,
project_root_dir: Optional[str] = None,
usage_statistics_enabled: bool = True,
runtime_environment: Optional[dict] = None,
) -> DataContext:
"""
Build a new great_expectations directory and DataContext object in the provided project_root_dir.
`create` will create a new "great_expectations" directory in the provided folder, provided one does not
already exist. Then, it will initialize a new DataContext in that folder and write the resulting config.
--Public API--
--Documentation--
https://docs.greatexpectations.io/docs/terms/data_context
Args:
project_root_dir: path to the root directory in which to create a new great_expectations directory
usage_statistics_enabled: boolean directive specifying whether or not to gather usage statistics
runtime_environment: a dictionary of config variables that override both those set in
config_variables.yml and the environment
Returns:
DataContext
"""
if not os.path.isdir(project_root_dir): # type: ignore[arg-type]
raise ge_exceptions.DataContextError(
"The project_root_dir must be an existing directory in which "
"to initialize a new DataContext"
)
ge_dir = os.path.join(project_root_dir, cls.GE_DIR) # type: ignore[arg-type]
os.makedirs(ge_dir, exist_ok=True)
cls.scaffold_directories(ge_dir)
if os.path.isfile(os.path.join(ge_dir, cls.GE_YML)):
message = f"""Warning. An existing `{cls.GE_YML}` was found here: {ge_dir}.
- No action was taken."""
warnings.warn(message)
else:
cls.write_project_template_to_disk(ge_dir, usage_statistics_enabled)
uncommitted_dir = os.path.join(ge_dir, cls.GE_UNCOMMITTED_DIR)
if os.path.isfile(os.path.join(uncommitted_dir, "config_variables.yml")):
message = """Warning. An existing `config_variables.yml` was found here: {}.
- No action was taken.""".format(
uncommitted_dir
)
warnings.warn(message)
else:
cls.write_config_variables_template_to_disk(uncommitted_dir)
return cls(context_root_dir=ge_dir, runtime_environment=runtime_environment)
@classmethod
def all_uncommitted_directories_exist(cls, ge_dir: str) -> bool:
"""Check if all uncommitted directories exist."""
uncommitted_dir = os.path.join(ge_dir, cls.GE_UNCOMMITTED_DIR)
for directory in cls.UNCOMMITTED_DIRECTORIES:
if not os.path.isdir(os.path.join(uncommitted_dir, directory)):
return False
return True
@classmethod
def config_variables_yml_exist(cls, ge_dir: str) -> bool:
"""Check if all config_variables.yml exists."""
path_to_yml = os.path.join(ge_dir, cls.GE_YML)
# TODO this is so brittle and gross
with open(path_to_yml) as f:
config = yaml.load(f)
config_var_path = config.get("config_variables_file_path")
config_var_path = os.path.join(ge_dir, config_var_path)
return os.path.isfile(config_var_path)
@classmethod
def write_config_variables_template_to_disk(cls, uncommitted_dir: str) -> None:
os.makedirs(uncommitted_dir, exist_ok=True)
config_var_file = os.path.join(uncommitted_dir, "config_variables.yml")
with open(config_var_file, "w") as template:
template.write(CONFIG_VARIABLES_TEMPLATE)
@classmethod
def write_project_template_to_disk(
cls, ge_dir: str, usage_statistics_enabled: bool = True
) -> None:
file_path = os.path.join(ge_dir, cls.GE_YML)
with open(file_path, "w") as template:
if usage_statistics_enabled:
template.write(PROJECT_TEMPLATE_USAGE_STATISTICS_ENABLED)
else:
template.write(PROJECT_TEMPLATE_USAGE_STATISTICS_DISABLED)
@classmethod
def scaffold_directories(cls, base_dir: str) -> None:
"""Safely create GE directories for a new project."""
os.makedirs(base_dir, exist_ok=True)
with open(os.path.join(base_dir, ".gitignore"), "w") as f:
f.write("uncommitted/")
for directory in cls.BASE_DIRECTORIES:
if directory == "plugins":
plugins_dir = os.path.join(base_dir, directory)
os.makedirs(plugins_dir, exist_ok=True)
os.makedirs(
os.path.join(plugins_dir, "custom_data_docs"), exist_ok=True
)
os.makedirs(
os.path.join(plugins_dir, "custom_data_docs", "views"),
exist_ok=True,
)
os.makedirs(
os.path.join(plugins_dir, "custom_data_docs", "renderers"),
exist_ok=True,
)
os.makedirs(
os.path.join(plugins_dir, "custom_data_docs", "styles"),
exist_ok=True,
)
cls.scaffold_custom_data_docs(plugins_dir)
else:
os.makedirs(os.path.join(base_dir, directory), exist_ok=True)
uncommitted_dir = os.path.join(base_dir, cls.GE_UNCOMMITTED_DIR)
for new_directory in cls.UNCOMMITTED_DIRECTORIES:
new_directory_path = os.path.join(uncommitted_dir, new_directory)
os.makedirs(new_directory_path, exist_ok=True)
@classmethod
def scaffold_custom_data_docs(cls, plugins_dir: str) -> None:
"""Copy custom data docs templates"""
styles_template = file_relative_path(
__file__,
"../../render/view/static/styles/data_docs_custom_styles_template.css",
)
styles_destination_path = os.path.join(
plugins_dir, "custom_data_docs", "styles", "data_docs_custom_styles.css"
)
shutil.copyfile(styles_template, styles_destination_path)
def __init__(
self,
context_root_dir: Optional[str] = None,
runtime_environment: Optional[dict] = None,
ge_cloud_mode: bool = False,
ge_cloud_base_url: Optional[str] = None,
ge_cloud_access_token: Optional[str] = None,
ge_cloud_organization_id: Optional[str] = None,
) -> None:
self._sources: _SourceFactories = _SourceFactories(self)
self._ge_cloud_mode = ge_cloud_mode
self._ge_cloud_config = self._init_ge_cloud_config(
ge_cloud_mode=ge_cloud_mode,
ge_cloud_base_url=ge_cloud_base_url,
ge_cloud_access_token=ge_cloud_access_token,
ge_cloud_organization_id=ge_cloud_organization_id,
)
self._context_root_directory = self._init_context_root_directory(
context_root_dir=context_root_dir,
)
project_config = self._load_project_config()
super().__init__(
project_config=project_config,
context_root_dir=self._context_root_directory,
runtime_environment=runtime_environment,
ge_cloud_mode=self._ge_cloud_mode,
ge_cloud_config=self._ge_cloud_config,
)
# Save project config if data_context_id auto-generated
if self._check_for_usage_stats_sync(project_config):
self._save_project_config()
def _save_project_config(self) -> None:
"""
See parent 'AbstractDataContext._save_project_config()` for more information.
Explicitly override base class implementation to retain legacy behavior.
"""
logger.debug("Starting DataContext._save_project_config")
config_filepath = os.path.join(self.root_directory, self.GE_YML) # type: ignore[arg-type]
try:
with open(config_filepath, "w") as outfile:
self.config.to_yaml(outfile)
except PermissionError as e:
logger.warning(f"Could not save project config to disk: {e}")
def _attach_datasource_to_context(self, datasource: XDatasource):
# We currently don't allow one to overwrite a datasource with this internal method
if datasource.name in self.datasources:
raise ge_exceptions.DataContextError(
f"Can not write the experimental datasource {datasource.name} because a datasource of that "
"name already exists in the data context."
)
self.datasources[datasource.name] = datasource
@property
def sources(self) -> _SourceFactories:
return self._sources
def _init_ge_cloud_config(
self,
ge_cloud_mode: bool,
ge_cloud_base_url: Optional[str],
ge_cloud_access_token: Optional[str],
ge_cloud_organization_id: Optional[str],
) -> Optional[GXCloudConfig]:
if not ge_cloud_mode:
return None
ge_cloud_config = CloudDataContext.get_ge_cloud_config(
ge_cloud_base_url=ge_cloud_base_url,
ge_cloud_access_token=ge_cloud_access_token,
ge_cloud_organization_id=ge_cloud_organization_id,
)
return ge_cloud_config
def _init_context_root_directory(self, context_root_dir: Optional[str]) -> str:
if self.ge_cloud_mode and context_root_dir is None:
context_root_dir = CloudDataContext.determine_context_root_directory(
context_root_dir
)
else:
context_root_dir = (
self.find_context_root_dir()
if context_root_dir is None
else context_root_dir
)
return os.path.abspath(os.path.expanduser(context_root_dir))
def _check_for_usage_stats_sync(self, project_config: DataContextConfig) -> bool:
"""
If there are differences between the DataContextConfig used to instantiate
the DataContext and the DataContextConfig assigned to `self.config`, we want
to save those changes to disk so that subsequent instantiations will utilize
the same values.
A small caveat is that if that difference stems from a global override (env var
or conf file), we don't want to write to disk. This is due to the fact that
those mechanisms allow for dynamic values and saving them will make them static.
Args:
project_config: The DataContextConfig used to instantiate the DataContext.
Returns:
A boolean signifying whether or not the current DataContext's config needs
to be persisted in order to recognize changes made to usage statistics.
"""
project_config_usage_stats: Optional[
AnonymizedUsageStatisticsConfig
] = project_config.anonymous_usage_statistics
context_config_usage_stats: Optional[
AnonymizedUsageStatisticsConfig
] = self.config.anonymous_usage_statistics
if (
project_config_usage_stats.enabled is False # type: ignore[union-attr]
or context_config_usage_stats.enabled is False # type: ignore[union-attr]
):
return False
if project_config_usage_stats.explicit_id is False: # type: ignore[union-attr]
return True
if project_config_usage_stats == context_config_usage_stats:
return False
if project_config_usage_stats is None or context_config_usage_stats is None:
return True
# If the data_context_id differs and that difference is not a result of a global override, a sync is necessary.
global_data_context_id: Optional[str] = self._get_data_context_id_override()
if (
project_config_usage_stats.data_context_id
!= context_config_usage_stats.data_context_id
and context_config_usage_stats.data_context_id != global_data_context_id
):
return True
# If the usage_statistics_url differs and that difference is not a result of a global override, a sync is necessary.
global_usage_stats_url: Optional[str] = self._get_usage_stats_url_override()
if (
project_config_usage_stats.usage_statistics_url
!= context_config_usage_stats.usage_statistics_url
and context_config_usage_stats.usage_statistics_url
!= global_usage_stats_url
):
return True
return False
def _load_project_config(self):
"""
Reads the project configuration from the project configuration file.
The file may contain ${SOME_VARIABLE} variables - see self.project_config_with_variables_substituted
for how these are substituted.
For Data Contexts in GE Cloud mode, a user-specific template is retrieved from the Cloud API
- see CloudDataContext.retrieve_data_context_config_from_ge_cloud for more details.
:return: the configuration object read from the file or template
"""
if self.ge_cloud_mode:
ge_cloud_config = self.ge_cloud_config
assert ge_cloud_config is not None
config = CloudDataContext.retrieve_data_context_config_from_ge_cloud(
ge_cloud_config=ge_cloud_config
)
return config
path_to_yml = os.path.join(self._context_root_directory, self.GE_YML)
try:
with open(path_to_yml) as data:
config_commented_map_from_yaml = yaml.load(data)
except DuplicateKeyError:
raise ge_exceptions.InvalidConfigurationYamlError(
"Error: duplicate key found in project YAML file."
)
except YAMLError as err:
raise ge_exceptions.InvalidConfigurationYamlError(
"Your configuration file is not a valid yml file likely due to a yml syntax error:\n\n{}".format(
err
)
)
except OSError:
raise ge_exceptions.ConfigNotFoundError()
try:
return DataContextConfig.from_commented_map(
commented_map=config_commented_map_from_yaml
)
except ge_exceptions.InvalidDataContextConfigError:
# Just to be explicit about what we intended to catch
raise
def add_store(self, store_name, store_config):
logger.debug(f"Starting DataContext.add_store for store {store_name}")
new_store = super().add_store(store_name, store_config)
self._save_project_config()
return new_store
def add_datasource( # type: ignore[override]
self, name: str, **kwargs: dict
) -> Optional[Union[LegacyDatasource, BaseDatasource]]:
logger.debug(f"Starting DataContext.add_datasource for datasource {name}")
new_datasource: Optional[
Union[LegacyDatasource, BaseDatasource]
] = super().add_datasource(
name=name, **kwargs # type: ignore[arg-type]
)
return new_datasource
def update_datasource( # type: ignore[override]
self,
datasource: Union[LegacyDatasource, BaseDatasource],
) -> None:
"""
See parent `BaseDataContext.update_datasource` for more details.
Note that this method persists changes using an underlying Store.
"""
logger.debug(
f"Starting DataContext.update_datasource for datasource {datasource.name}"
)
super().update_datasource(
datasource=datasource,
)
def delete_datasource(self, name: str) -> None: # type: ignore[override]
logger.debug(f"Starting DataContext.delete_datasource for datasource {name}")
super().delete_datasource(datasource_name=name)
self._save_project_config()
@classmethod
def find_context_root_dir(cls) -> str:
result = None
yml_path = None
ge_home_environment = os.getenv("GE_HOME")
if ge_home_environment:
ge_home_environment = os.path.expanduser(ge_home_environment)
if os.path.isdir(ge_home_environment) and os.path.isfile(
os.path.join(ge_home_environment, "great_expectations.yml")
):
result = ge_home_environment
else:
yml_path = cls.find_context_yml_file()
if yml_path:
result = os.path.dirname(yml_path)
if result is None:
raise ge_exceptions.ConfigNotFoundError()
logger.debug(f"Using project config: {yml_path}")
return result
@classmethod
def get_ge_config_version(
cls, context_root_dir: Optional[str] = None
) -> Optional[float]:
yml_path = cls.find_context_yml_file(search_start_dir=context_root_dir)
if yml_path is None:
return None
with open(yml_path) as f:
config_commented_map_from_yaml = yaml.load(f)
config_version = config_commented_map_from_yaml.get("config_version")
return float(config_version) if config_version else None
@classmethod
def set_ge_config_version(
cls,
config_version: Union[int, float],
context_root_dir: Optional[str] = None,
validate_config_version: bool = True,
) -> bool:
if not isinstance(config_version, (int, float)):
raise ge_exceptions.UnsupportedConfigVersionError(
"The argument `config_version` must be a number.",
)
if validate_config_version:
if config_version < MINIMUM_SUPPORTED_CONFIG_VERSION:
raise ge_exceptions.UnsupportedConfigVersionError(
"Invalid config version ({}).\n The version number must be at least {}. ".format(
config_version, MINIMUM_SUPPORTED_CONFIG_VERSION
),
)
elif config_version > CURRENT_GE_CONFIG_VERSION:
raise ge_exceptions.UnsupportedConfigVersionError(
"Invalid config version ({}).\n The maximum valid version is {}.".format(
config_version, CURRENT_GE_CONFIG_VERSION
),
)
yml_path = cls.find_context_yml_file(search_start_dir=context_root_dir)
if yml_path is None:
return False
with open(yml_path) as f:
config_commented_map_from_yaml = yaml.load(f)
config_commented_map_from_yaml["config_version"] = float(config_version)
with open(yml_path, "w") as f:
yaml.dump(config_commented_map_from_yaml, f)
return True
@classmethod
def find_context_yml_file(
cls, search_start_dir: Optional[str] = None
) -> Optional[str]:
"""Search for the yml file starting here and moving upward."""
yml_path = None
if search_start_dir is None:
search_start_dir = os.getcwd()
for i in range(4):
logger.debug(
f"Searching for config file {search_start_dir} ({i} layer deep)"
)
potential_ge_dir = os.path.join(search_start_dir, cls.GE_DIR)
if os.path.isdir(potential_ge_dir):
potential_yml = os.path.join(potential_ge_dir, cls.GE_YML)
if os.path.isfile(potential_yml):
yml_path = potential_yml
logger.debug(f"Found config file at {str(yml_path)}")
break
# move up one directory
search_start_dir = os.path.dirname(search_start_dir)
return yml_path
@classmethod
def does_config_exist_on_disk(cls, context_root_dir: str) -> bool:
"""Return True if the great_expectations.yml exists on disk."""
return os.path.isfile(os.path.join(context_root_dir, cls.GE_YML))
@classmethod
def is_project_initialized(cls, ge_dir: str) -> bool:
"""
Return True if the project is initialized.
To be considered initialized, all of the following must be true:
- all project directories exist (including uncommitted directories)
- a valid great_expectations.yml is on disk
- a config_variables.yml is on disk
- the project has at least one datasource
- the project has at least one suite
"""
return (
cls.does_config_exist_on_disk(ge_dir)
and cls.all_uncommitted_directories_exist(ge_dir)
and cls.config_variables_yml_exist(ge_dir)
and cls._does_context_have_at_least_one_datasource(ge_dir)
and cls._does_context_have_at_least_one_suite(ge_dir)
)
@classmethod
def does_project_have_a_datasource_in_config_file(cls, ge_dir: str) -> bool:
if not cls.does_config_exist_on_disk(ge_dir):
return False
return cls._does_context_have_at_least_one_datasource(ge_dir)
@classmethod
def _does_context_have_at_least_one_datasource(cls, ge_dir: str) -> bool:
context = cls._attempt_context_instantiation(ge_dir)
if not isinstance(context, DataContext):
return False
return len(context.list_datasources()) >= 1
@classmethod
def _does_context_have_at_least_one_suite(cls, ge_dir: str) -> bool:
context = cls._attempt_context_instantiation(ge_dir)
if not isinstance(context, DataContext):
return False
return bool(context.list_expectation_suites())
@classmethod
def _attempt_context_instantiation(cls, ge_dir: str) -> Optional[DataContext]:
try:
context = DataContext(ge_dir)
return context
except (
ge_exceptions.DataContextError,
ge_exceptions.InvalidDataContextConfigError,
) as e:
logger.debug(e)
return None
<file_sep>/docs/guides/connecting_to_your_data/datasource_configuration/components/_part_base_directory_for_filesystem.mdx
For the base directory, you will want to put the relative path of your data from the folder that contains your Data Context. In this example we will use the same path that was used in the [Getting Started Tutorial, Step 2: Connect to Data](../../../../tutorials/getting_started/tutorial_connect_to_data.md). Since we are manually entering this value rather than letting the CLI generate it, the key/value pair will look like:
```python name="inferred data connector add base_directory"
"base_directory": "../data",
```<file_sep>/docs/api_docs/classes/great_expectations-data_context-data_context-data_context-DataContext.md
---
title: class DataContext
---
# DataContext
[See it on GitHub](https://github.com/great-expectations/great_expectations/blob/develop/great_expectations/data_context/data_context/data_context.py)
## Synopsis
A DataContext represents a Great Expectations project. It is the primary entry point for a Great Expectations
deployment, with configurations and methods for all supporting components.
The DataContext is configured via a yml file stored in a directory called great_expectations; this configuration
file as well as managed Expectation Suites should be stored in version control. There are other ways to create a
Data Context that may be better suited for your particular deployment e.g. ephemerally or backed by GE Cloud
(coming soon). Please refer to our documentation for more details.
You can Validate data or generate Expectations using Execution Engines including:
* SQL (multiple dialects supported)
* Spark
* Pandas
Your data can be stored in common locations including:
* databases / data warehouses
* files in s3, GCS, Azure, local storage
* dataframes (spark and pandas) loaded into memory
Please see our documentation for examples on how to set up Great Expectations, connect to your data,
create Expectations, and Validate data.
Other configuration options you can apply to a DataContext besides how to access data include things like where to
store Expectations, Profilers, Checkpoints, Metrics, Validation Results and Data Docs and how those Stores are
configured. Take a look at our documentation for more configuration options.
You can create or load a DataContext from disk via the following:
```
import great_expectations as ge
ge.get_context()
```
## Import statement
```python
from great_expectations.data_context.data_context.data_context import DataContext
```
## Public Methods (API documentation links)
- *[.create(...):](../methods/great_expectations-data_context-data_context-data_context-DataContext-create.md)* Build a new great_expectations directory and DataContext object in the provided project_root_dir.
- *[.test_yaml_config(...):](../methods/great_expectations-data_context-data_context-data_context-DataContext-test_yaml_config.md)* Convenience method for testing yaml configs
## Relevant documentation (links)
- [Data Context](../../terms/data_context.md)
<file_sep>/tests/integration/db/test_sql_data_sampling.py
from typing import List
import pandas as pd
import sqlalchemy as sa
import great_expectations as ge
from great_expectations import DataContext
from great_expectations.core.batch import BatchDefinition, BatchRequest
from great_expectations.core.batch_spec import SqlAlchemyDatasourceBatchSpec
from great_expectations.datasource import BaseDatasource
from great_expectations.datasource.data_connector import ConfiguredAssetSqlDataConnector
from great_expectations.execution_engine.sqlalchemy_batch_data import (
SqlAlchemyBatchData,
)
from tests.integration.fixtures.split_and_sample_data.sampler_test_cases_and_fixtures import (
SamplerTaxiTestData,
TaxiSamplingTestCase,
TaxiSamplingTestCases,
)
from tests.test_utils import (
LoadedTable,
clean_up_tables_with_prefix,
get_awsathena_db_name,
get_connection_string_and_dialect,
load_and_concatenate_csvs,
load_data_into_test_database,
)
TAXI_DATA_TABLE_NAME: str = "taxi_data_all_samples"
def _load_data(
connection_string: str,
dialect: str,
table_name: str = TAXI_DATA_TABLE_NAME,
random_table_suffix: bool = True,
) -> LoadedTable:
dialects_supporting_multiple_values_in_single_insert_clause: List[str] = [
"redshift"
]
to_sql_method: str = (
"multi"
if dialect in dialects_supporting_multiple_values_in_single_insert_clause
else None
)
# Load the first 10 rows of each month of taxi data
return load_data_into_test_database(
table_name=table_name,
csv_paths=[
f"./data/ten_trips_from_each_month/yellow_tripdata_sample_10_trips_from_each_month.csv"
],
connection_string=connection_string,
convert_colnames_to_datetime=["pickup_datetime", "dropoff_datetime"],
load_full_dataset=True,
random_table_suffix=random_table_suffix,
to_sql_method=to_sql_method,
)
def _is_dialect_athena(dialect: str) -> bool:
"""Is the dialect awsathena?"""
return dialect == "awsathena"
if __name__ == "test_script_module":
dialect, connection_string = get_connection_string_and_dialect(
athena_db_name_env_var="ATHENA_TEN_TRIPS_DB_NAME"
)
print(f"Testing dialect: {dialect}")
if _is_dialect_athena(dialect):
athena_db_name: str = get_awsathena_db_name(
db_name_env_var="ATHENA_TEN_TRIPS_DB_NAME"
)
table_name: str = "ten_trips_from_each_month"
test_df: pd.DataFrame = load_and_concatenate_csvs(
csv_paths=[
f"./data/ten_trips_from_each_month/yellow_tripdata_sample_10_trips_from_each_month.csv"
],
convert_column_names_to_datetime=["pickup_datetime", "dropoff_datetime"],
load_full_dataset=True,
)
else:
print("Preemptively cleaning old tables")
clean_up_tables_with_prefix(
connection_string=connection_string, table_prefix=f"{TAXI_DATA_TABLE_NAME}_"
)
loaded_table: LoadedTable = _load_data(
connection_string=connection_string, dialect=dialect
)
test_df: pd.DataFrame = loaded_table.inserted_dataframe
table_name: str = loaded_table.table_name
taxi_test_data: SamplerTaxiTestData = SamplerTaxiTestData(
test_df, test_column_name="pickup_datetime"
)
test_cases: TaxiSamplingTestCases = TaxiSamplingTestCases(taxi_test_data)
test_cases: List[TaxiSamplingTestCase] = test_cases.test_cases()
for test_case in test_cases:
print("Testing sampler method:", test_case.sampling_method_name)
# 1. Setup
context: DataContext = ge.get_context()
datasource_name: str = "test_datasource"
data_connector_name: str = "test_data_connector"
data_asset_name: str = table_name # Read from generated table name
# 2. Set sampler in DataConnector config
data_connector_config: dict = {
"class_name": "ConfiguredAssetSqlDataConnector",
"assets": {
data_asset_name: {
"sampling_method": test_case.sampling_method_name,
"sampling_kwargs": test_case.sampling_kwargs,
}
},
}
context.add_datasource(
name=datasource_name,
class_name="Datasource",
execution_engine={
"class_name": "SqlAlchemyExecutionEngine",
"connection_string": connection_string,
},
data_connectors={data_connector_name: data_connector_config},
)
datasource: BaseDatasource = context.get_datasource(
datasource_name=datasource_name
)
data_connector: ConfiguredAssetSqlDataConnector = datasource.data_connectors[
data_connector_name
]
# 3. Check if resulting batches are as expected
# using data_connector.get_batch_definition_list_from_batch_request()
batch_request: BatchRequest = BatchRequest(
datasource_name=datasource_name,
data_connector_name=data_connector_name,
data_asset_name=data_asset_name,
)
batch_definition_list: List[
BatchDefinition
] = data_connector.get_batch_definition_list_from_batch_request(batch_request)
assert len(batch_definition_list) == test_case.num_expected_batch_definitions
# 4. Check that loaded data is as expected
batch_spec: SqlAlchemyDatasourceBatchSpec = data_connector.build_batch_spec(
batch_definition_list[0]
)
batch_data: SqlAlchemyBatchData = context.datasources[
datasource_name
].execution_engine.get_batch_data(batch_spec=batch_spec)
num_rows: int = batch_data.execution_engine.engine.execute(
sa.select([sa.func.count()]).select_from(batch_data.selectable)
).scalar()
assert num_rows == test_case.num_expected_rows_in_first_batch_definition
# TODO: AJB 20220502 Test the actual rows that are returned e.g. for random sampling.
if not _is_dialect_athena(dialect):
print("Clean up tables used in this test")
clean_up_tables_with_prefix(
connection_string=connection_string, table_prefix=f"{TAXI_DATA_TABLE_NAME}_"
)
<file_sep>/tests/test_definitions/test_expectations_v3_api.py
import glob
import json
import os
import pandas as pd
import pytest
from great_expectations.execution_engine.pandas_batch_data import PandasBatchData
from great_expectations.execution_engine.sparkdf_batch_data import SparkDFBatchData
from great_expectations.execution_engine.sqlalchemy_batch_data import (
SqlAlchemyBatchData,
)
from great_expectations.self_check.util import (
BigQueryDialect,
candidate_test_is_on_temporary_notimplemented_list_v3_api,
evaluate_json_test_v3_api,
generate_sqlite_db_path,
get_test_validator_with_data,
mssqlDialect,
mysqlDialect,
postgresqlDialect,
sqliteDialect,
trinoDialect,
)
from tests.conftest import build_test_backends_list_v3_api
def pytest_generate_tests(metafunc):
# Load all the JSON files in the directory
dir_path = os.path.dirname(os.path.realpath(__file__))
expectation_dirs = [
dir_
for dir_ in os.listdir(dir_path)
if os.path.isdir(os.path.join(dir_path, dir_))
]
parametrized_tests = []
ids = []
backends = build_test_backends_list_v3_api(metafunc)
validator_with_data = None
for expectation_category in expectation_dirs:
test_configuration_files = glob.glob(
dir_path + "/" + expectation_category + "/*.json"
)
for c in backends:
for filename in test_configuration_files:
file = open(filename)
test_configuration = json.load(file)
for d in test_configuration["datasets"]:
datasets = []
# optional only_for and suppress_test flag at the datasets-level that can prevent data being
# added to incompatible backends. Currently only used by expect_column_values_to_be_unique
only_for = d.get("only_for")
if only_for and not isinstance(only_for, list):
# coerce into list if passed in as string
only_for = [only_for]
suppress_test_for = d.get("suppress_test_for")
if suppress_test_for and not isinstance(suppress_test_for, list):
# coerce into list if passed in as string
suppress_test_for = [suppress_test_for]
if candidate_test_is_on_temporary_notimplemented_list_v3_api(
c, test_configuration["expectation_type"]
):
skip_expectation = True
elif suppress_test_for and c in suppress_test_for:
continue
elif only_for and c not in only_for:
continue
else:
skip_expectation = False
if isinstance(d["data"], list):
sqlite_db_path = generate_sqlite_db_path()
for dataset in d["data"]:
datasets.append(
get_test_validator_with_data(
c,
dataset["data"],
dataset.get("schemas"),
table_name=dataset.get("dataset_name"),
sqlite_db_path=sqlite_db_path,
)
)
validator_with_data = datasets[0]
else:
schemas = d["schemas"] if "schemas" in d else None
validator_with_data = get_test_validator_with_data(
c, d["data"], schemas=schemas
)
for test in d["tests"]:
generate_test = True
skip_test = False
only_for = test.get("only_for")
if only_for:
# if we're not on the "only_for" list, then never even generate the test
generate_test = False
if not isinstance(only_for, list):
# coerce into list if passed in as string
only_for = [only_for]
if validator_with_data and isinstance(
validator_with_data.active_batch_data,
SqlAlchemyBatchData,
):
# Call out supported dialects
if "sqlalchemy" in only_for:
generate_test = True
elif (
"sqlite" in only_for
and sqliteDialect is not None
and isinstance(
validator_with_data.active_batch_data.sql_engine_dialect,
sqliteDialect,
)
):
generate_test = True
elif (
"postgresql" in only_for
and postgresqlDialect is not None
and isinstance(
validator_with_data.active_batch_data.sql_engine_dialect,
postgresqlDialect,
)
):
generate_test = True
elif (
"mysql" in only_for
and mysqlDialect is not None
and isinstance(
validator_with_data.active_batch_data.sql_engine_dialect,
mysqlDialect,
)
):
generate_test = True
elif (
"mssql" in only_for
and mssqlDialect is not None
and isinstance(
validator_with_data.active_batch_data.sql_engine_dialect,
mssqlDialect,
)
):
generate_test = True
elif (
"bigquery" in only_for
and BigQueryDialect is not None
and hasattr(
validator_with_data.active_batch_data.sql_engine_dialect,
"name",
)
and validator_with_data.active_batch_data.sql_engine_dialect.name
== "bigquery"
):
generate_test = True
elif (
"bigquery_v3_api" in only_for
and BigQueryDialect is not None
and hasattr(
validator_with_data.active_batch_data.sql_engine_dialect,
"name",
)
and validator_with_data.active_batch_data.sql_engine_dialect.name
== "bigquery"
):
# <WILL> : Marker to get the test to only run for CFE
# expect_column_values_to_be_unique:negative_case_all_null_values_bigquery_nones
# works in different ways between CFE (V3) and V2 Expectations. This flag allows for
# the test to only be run in the CFE case
generate_test = True
elif (
"trino" in test["only_for"]
and trinoDialect is not None
and hasattr(
validator_with_data.active_batch_data.sql_engine_dialect,
"name",
)
and validator_with_data.active_batch_data.sql_engine_dialect.name
== "trino"
):
generate_test = True
elif validator_with_data and isinstance(
validator_with_data.active_batch_data,
PandasBatchData,
):
major, minor, *_ = pd.__version__.split(".")
if "pandas" in only_for:
generate_test = True
if (
(
"pandas_022" in only_for
or "pandas_023" in only_for
)
and major == "0"
and minor in ["22", "23"]
):
generate_test = True
if ("pandas>=024" in only_for) and (
(major == "0" and int(minor) >= 24)
or int(major) >= 1
):
generate_test = True
elif validator_with_data and isinstance(
validator_with_data.active_batch_data,
SparkDFBatchData,
):
if "spark" in only_for:
generate_test = True
if not generate_test:
continue
suppress_test_for = test.get("suppress_test_for")
if suppress_test_for:
if not isinstance(suppress_test_for, list):
# coerce into list if passed in as string
suppress_test_for = [suppress_test_for]
if (
(
"sqlalchemy" in suppress_test_for
and validator_with_data
and isinstance(
validator_with_data.active_batch_data,
SqlAlchemyBatchData,
)
)
or (
"sqlite" in suppress_test_for
and sqliteDialect is not None
and validator_with_data
and isinstance(
validator_with_data.active_batch_data,
SqlAlchemyBatchData,
)
and isinstance(
validator_with_data.active_batch_data.sql_engine_dialect,
sqliteDialect,
)
)
or (
"postgresql" in suppress_test_for
and postgresqlDialect is not None
and validator_with_data
and isinstance(
validator_with_data.active_batch_data,
SqlAlchemyBatchData,
)
and isinstance(
validator_with_data.active_batch_data.sql_engine_dialect,
postgresqlDialect,
)
)
or (
"mysql" in suppress_test_for
and mysqlDialect is not None
and validator_with_data
and isinstance(
validator_with_data.active_batch_data,
SqlAlchemyBatchData,
)
and isinstance(
validator_with_data.active_batch_data.sql_engine_dialect,
mysqlDialect,
)
)
or (
"mssql" in suppress_test_for
and mssqlDialect is not None
and validator_with_data
and isinstance(
validator_with_data.active_batch_data,
SqlAlchemyBatchData,
)
and isinstance(
validator_with_data.active_batch_data.sql_engine_dialect,
mssqlDialect,
)
)
or (
"bigquery" in suppress_test_for
and BigQueryDialect is not None
and validator_with_data
and isinstance(
validator_with_data.active_batch_data,
SqlAlchemyBatchData,
)
and hasattr(
validator_with_data.active_batch_data.sql_engine_dialect,
"name",
)
and validator_with_data.active_batch_data.sql_engine_dialect.name
== "bigquery"
)
or (
"bigquery_v3_api" in suppress_test_for
and BigQueryDialect is not None
and validator_with_data
and isinstance(
validator_with_data.active_batch_data,
SqlAlchemyBatchData,
)
and hasattr(
validator_with_data.active_batch_data.sql_engine_dialect,
"name",
)
and validator_with_data.active_batch_data.sql_engine_dialect.name
== "bigquery"
)
or (
"trino" in suppress_test_for
and trinoDialect is not None
and validator_with_data
and isinstance(
validator_with_data.active_batch_data,
SqlAlchemyBatchData,
)
and hasattr(
validator_with_data.active_batch_data.sql_engine_dialect,
"name",
)
and validator_with_data.active_batch_data.sql_engine_dialect.name
== "trino"
)
or (
"pandas" in suppress_test_for
and validator_with_data
and isinstance(
validator_with_data.active_batch_data,
PandasBatchData,
)
)
or (
"spark" in suppress_test_for
and validator_with_data
and isinstance(
validator_with_data.active_batch_data,
SparkDFBatchData,
)
)
):
skip_test = True
# Known condition: SqlAlchemy does not support allow_cross_type_comparisons
if (
"allow_cross_type_comparisons" in test["in"]
and validator_with_data
and isinstance(
validator_with_data.active_batch_data,
SqlAlchemyBatchData,
)
):
skip_test = True
parametrized_tests.append(
{
"expectation_type": test_configuration[
"expectation_type"
],
"validator_with_data": validator_with_data,
"test": test,
"skip": skip_expectation or skip_test,
}
)
ids.append(
c
+ "/"
+ expectation_category
+ "/"
+ test_configuration["expectation_type"]
+ ":"
+ test["title"]
)
metafunc.parametrize("test_case", parametrized_tests, ids=ids)
@pytest.mark.order(index=0)
@pytest.mark.integration
@pytest.mark.slow # 12.68s
def test_case_runner_v3_api(test_case):
if test_case["skip"]:
pytest.skip()
# Note: this should never be done in practice, but we are wiping expectations to reuse batches during testing.
# test_case["batch"]._initialize_expectations()
if "parse_strings_as_datetimes" in test_case["test"]["in"]:
with pytest.deprecated_call():
evaluate_json_test_v3_api(
validator=test_case["validator_with_data"],
expectation_type=test_case["expectation_type"],
test=test_case["test"],
)
else:
evaluate_json_test_v3_api(
validator=test_case["validator_with_data"],
expectation_type=test_case["expectation_type"],
test=test_case["test"],
)
<file_sep>/tests/data_context/store/test_store.py
import pytest
from great_expectations.core.configuration import AbstractConfig
from great_expectations.data_context.store.store import Store
@pytest.mark.unit
def test_ge_cloud_response_json_to_object_dict() -> None:
store = Store()
data = {"foo": "bar", "baz": "qux"}
assert store.ge_cloud_response_json_to_object_dict(response_json=data) == data
@pytest.mark.unit
def test_store_name_property_and_defaults() -> None:
store = Store()
assert store.store_name == "no_store_name"
@pytest.mark.unit
def test_store_serialize() -> None:
store = Store()
value = AbstractConfig(id="abc123", name="my_config")
assert store.serialize(value) == value
@pytest.mark.unit
def test_store_deserialize() -> None:
store = Store()
value = {"a": "b"}
assert store.deserialize(value) == value
<file_sep>/docs/guides/expectations/contributing/how_to_contribute_a_custom_expectation_to_great_expectations.md
---
title: How to contribute a Custom Expectation to Great Expectations
---
import Prerequisites from '../creating_custom_expectations/components/prerequisites.jsx'
import Tabs from '@theme/Tabs'
import TabItem from '@theme/TabItem'
This guide will help you contribute your Custom Expectations to Great Expectations’ shared library. Your Custom Expectation will be featured in the Expectations Gallery,
along with many others developed by data practitioners from around the world as part of this collaborative community effort.
<Prerequisites>
* [Created a Custom Expectation](../creating_custom_expectations/overview.md)
</Prerequisites>
## Steps
### 1. Verify that your Custom Expectation is ready for contribution
We accept contributions into the Great Expectations codebase at several levels: Experimental, Beta, and Production. The requirements to meet these benchmarks are available in our
document on [levels of maturity for Expectations](../../../contributing/contributing_maturity.md).
If you call the `print_diagnostic_checklist()` method on your Custom Expectation, you should see a checklist similar to this one:
```
✔ Has a valid library_metadata object
✔ Has a docstring, including a one-line short description
...
✔ Has at least one positive and negative example case, and all test cases pass
✔ Has core logic and passes tests on at least one Execution Engine
...
✔ Passes all linting checks
✔ Has basic input validation and type checking
✔ Has both statement Renderers: prescriptive and diagnostic
✔ Has core logic that passes tests for all applicable Execution Engines and SQL dialects
...
Has a full suite of tests, as determined by project code standards
Has passed a manual review by a code owner for code standards and style guides
```
If you've satisfied at least the first five checks, you're ready to make a contribution!
:::info
Not quite there yet? See our guides on [creating Custom Expectations](../creating_custom_expectations/overview.md) for help!
For more information on our code standards and contribution, see our guide on [Levels of Maturity](../../../contributing/contributing_maturity.md#contributing-expectations) for Expectations.
:::
### 2. Double-check your Library Metadata
We want to verify that your Custom Expectation is properly credited and accurately described.
Ensure that your Custom Expectation's `library_metadata` has the following keys, and verify that the information listed is correct:
- `contributors`: You and anyone else who helped you create this Custom Expectation.
- `tags`: These are simple descriptors of your Custom Expectation's functionality and domain (`statistics`, `flexible comparisons`, `geography`, etc.).
- `requirements`: If your Custom Expectation relies on any third-party packages, verify that those dependencies are listed here.
<details>
<summary>Packages?</summary>
Great Expectations maintains a number of Custom Expectation Packages, containing thematically related Custom Expectations.
These packages can be explored in the <a href="https://github.com/great-expectations/great_expectations/tree/develop/contrib"><inlineCode>contrib</inlineCode> directory of Great Expectations,</a> and can be found on PyPI.
Your Custom Expectation may fit one of these packages; if so, we encourage you to contribute your Custom Expectation directly to one of these packages.
<br/><br/>
Not contributing to a specific package? Your Custom Expectation will be automatically published in the <a href="https://pypi.org/project/great-expectations-experimental/">PyPI package <inlineCode>great-expectations-experimental</inlineCode></a>.
This package contains all of our Experimental community-contributed Custom Expectations not submitted to another extant package, and is separate from the core <inlineCode>great-expectations</inlineCode> package.
</details>
### 3. Open a Pull Request
You're ready to open a [Pull Request](https://github.com/great-expectations/great_expectations/pulls)!
As a part of this process, we ask you to:
- Sign our [Contributor License Agreement (CLA)](../../../contributing/contributing_misc.md#contributor-license-agreement-cla)
- Provide some information for our reviewers to expedite your contribution process, including:
- A `[CONTRIB]` tag in your title
- Titling your Pull Request with the name of your Custom Expectation
- A brief summary of the functionality and use-cases for your Custom Expectation
- A description of any previous discussion or coordination related to this Pull Request
- Update your branch with the most recent code from the Great Expectations main repository
- Resolve any failing tests and merge conflicts
<div style={{"text-align":"center"}}>
<p style={{"color":"#8784FF","font-size":"1.4em"}}><b>
Congratulations!<br/>🎉 You've submitted a Custom Expectation for contribution to the Great Expectations codebase! 🎉
</b></p>
</div>
:::info
Contributing as a part of a Great Expectations Hackathon?
Submit your PR with a `[HACKATHON]` tag in your title instead of `[CONTRIB]`, and be sure to call out your
participation in the Hackathon in the text of your PR as well!
:::
### 4. Stay involved!
Once your Custom Expectation has been reviewed by a Great Expectations code owner, it may require some
additional work before it is approved. For example, if you are missing required checks in your diagnostic checklist, have failing tests,
or have an error in the functionality of your Custom Expectation, we will ask you to resolve these before moving forward.
If you are submitting a Custom Expectation for acceptance at a Production level, we will additionally require that you work with us to bring your Custom Expectation
up to our standards for testing and code style on a case-by-case basis.
Once your Custom Expectation has passing tests and an approving review from a code owner, your contribution will be complete, and your Custom Expectation
will be included in the next release of Great Expectations.
Keep an eye out for an acknowledgement in our release notes, and welcome to the community!
:::note
If you’ve included your (physical) mailing address in the [Contributor License Agreement](../../../contributing/contributing_misc.md#contributor-license-agreement-cla),
we’ll send you a personalized Great Expectations mug once your first PR is merged!
:::<file_sep>/docs/guides/validation/checkpoints/how_to_configure_a_new_checkpoint_using_test_yaml_config.md
---
title: How to configure a new Checkpoint using test_yaml_config
---
import Prerequsities from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
import RelevantApiLinks from './how_to_configure_a_new_checkpoint_using_test_yaml_config__api_links.mdx'
This how-to guide demonstrates advanced examples for configuring a <TechnicalTag tag="checkpoint" text="Checkpoint" /> using ``test_yaml_config``. **Note:** For a basic guide on creating a new Checkpoint, please see [How to create a new Checkpoint](../../../guides/validation/checkpoints/how_to_create_a_new_checkpoint.md).
``test_yaml_config`` is a convenience method for configuring the moving parts of a Great Expectations deployment. It allows you to quickly test out configs for <TechnicalTag tag="datasource" text="Datasources" />, <TechnicalTag tag="store" text="Stores" />, and Checkpoints. ``test_yaml_config`` is primarily intended for use within a notebook, where you can iterate through an edit-run-check loop in seconds.
<Prerequisites>
- [Set up a working deployment of Great Expectations](../../../tutorials/getting_started/tutorial_overview.md)
- [Configured a Datasource using the v3 API](../../../tutorials/getting_started/tutorial_connect_to_data.md)
- [Created an Expectation Suite](../../../tutorials/getting_started/tutorial_create_expectations.md)
</Prerequisites>
## Steps
### 1. Create a new Checkpoint
From the <TechnicalTag tag="cli" text="CLI" />, execute:
````console
great_expectations checkpoint new my_checkpoint
````
This will open a Jupyter Notebook with a framework for creating and saving a new Checkpoint. Run the cells in the Notebook until you reach the one labeled "Test Your Checkpoint Configuration."
### 2. Edit your Checkpoint
The Checkpoint configuration that was created when your Jupyter Notebook loaded uses an arbitrary <TechnicalTag tag="batch" text="Batch" /> of data and <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> to generate a basic Checkpoint configuration in the second code cell. You can edit this configuration to point to add additional entries under the `validations` key, or to edit the existing one. You can even replace this configuration entirely.
In the [Additional Information](#additional-information) section at the end of this guide you will find examples of other Checkpoint configurations you can use as your starting point, as well as explanations of the various ways you can arrange the keys and values in your Checkpoint's `yaml_config`.
:::important
After you make edits to the `yaml_config` variable, don't forget to re-run the cell that contains it!
:::
### 3. Use `test_yaml_config()` to validate your Checkpoint configuration
Once you have made changes to the `yaml_config` in your Jupyter Notebook, you can verify that the updated configuration is valid by running the following code:
````python
my_checkpoint = context.test_yaml_config(yaml_config=yaml_config)
````
This code is found in the code cell under the "Test Your Checkpoint Configuration" in your Jupyter Notebook.
If your Checkpoint configuration is valid, you will see an output stating that your checkpoint was instantiated successfully, followed by a Python dictionary representation of the configuration yaml you edited.
### 4. (Optional) Repeat from step 2
From here you can continue to edit your Checkpoint. After each change you should re-run the cell that contains the edited `yaml_config` and then verify that your configuration remains valid by re-running `test_yaml_config(...)`.
### 5. Save your edited Checkpoint
Once you have made all of the changes you planned to implement and your last `test_yaml_config()` check passed, you are ready to save the Checkpoint you've created. At this point, run the remaining cells in your Jupyter Notebook.
Your checkpoint will be saved by the cell that contains the command:
```python
context.add_checkpoint(**yaml.load(yaml_config))
```
## Additional Information
### Example `SimpleCheckpoint` configuration
The ``SimpleCheckpoint`` class takes care of some defaults which you will need to set manually in the ``Checkpoints`` class. The following example shows all possible configuration options for ``SimpleCheckpoint``:
```python
config = """
name: my_simple_checkpoint
config_version: 1.0
class_name: SimpleCheckpoint
validations:
- batch_request:
datasource_name: data__dir
data_connector_name: my_data_connector
data_asset_name: TestAsset
data_connector_query:
index: 0
expectation_suite_name: yellow_tripdata_sample_2019-01.warning
site_names: my_local_site
slack_webhook: my_slack_webhook_url
notify_on: all # possible values: "all", "failure", "success"
notify_with: # optional list of DataDocs site names to display in Slack message
"""
```
### Example Checkpoint configurations
If you require more fine-grained configuration options, you can use the ``Checkpoint`` base class instead of ``SimpleCheckpoint``.
In this example, the Checkpoint configuration uses the nesting of `batch_request` sections inside the `validations` block so as to use the defaults defined at the top level.
```python
config = """
name: my_fancy_checkpoint
config_version: 1
class_name: Checkpoint
run_name_template: "%Y-%M-foo-bar-template-$VAR"
validations:
- batch_request:
datasource_name: my_datasource
data_connector_name: my_special_data_connector
data_asset_name: users
data_connector_query:
index: -1
- batch_request:
datasource_name: my_datasource
data_connector_name: my_other_data_connector
data_asset_name: users
data_connector_query:
index: -2
expectation_suite_name: users.delivery
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
evaluation_parameters:
param1: "$MY_PARAM"
param2: 1 + "$OLD_PARAM"
runtime_configuration:
result_format:
result_format: BASIC
partial_unexpected_count: 20
"""
```
The following Checkpoint configuration runs the top-level `action_list` against the top-level `batch_request` as well as the locally-specified `action_list` against the top-level `batch_request`.
```python
config = """
name: airflow_users_node_3
config_version: 1
class_name: Checkpoint
batch_request:
datasource_name: my_datasource
data_connector_name: my_special_data_connector
data_asset_name: users
data_connector_query:
index: -1
validations:
- expectation_suite_name: users.warning # runs the top-level action list against the top-level batch_request
- expectation_suite_name: users.error # runs the locally-specified action_list union with the top-level action-list against the top-level batch_request
action_list:
- name: quarantine_failed_data
action:
class_name: CreateQuarantineData
- name: advance_passed_data
action:
class_name: CreatePassedData
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
evaluation_parameters:
environment: $GE_ENVIRONMENT
tolerance: 0.01
runtime_configuration:
result_format:
result_format: BASIC
partial_unexpected_count: 20
"""
```
The Checkpoint mechanism also offers the convenience of templates. The first Checkpoint configuration is that of a valid Checkpoint in the sense that it can be run as long as all the parameters not present in the configuration are specified in the `run_checkpoint` API call.
```python
config = """
name: my_base_checkpoint
config_version: 1
class_name: Checkpoint
run_name_template: "%Y-%M-foo-bar-template-$VAR"
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
evaluation_parameters:
param1: "$MY_PARAM"
param2: 1 + "$OLD_PARAM"
runtime_configuration:
result_format:
result_format: BASIC
partial_unexpected_count: 20
"""
```
The above Checkpoint can be run using the code below, providing missing parameters from the configured Checkpoint at runtime.
```python
checkpoint_run_result: CheckpointResult
checkpoint_run_result = data_context.run_checkpoint(
checkpoint_name="my_base_checkpoint",
validations=[
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_special_data_connector",
"data_asset_name": "users",
"data_connector_query": {
"index": -1,
},
},
"expectation_suite_name": "users.delivery",
},
{
"batch_request": {
"datasource_name": "my_datasource",
"data_connector_name": "my_other_data_connector",
"data_asset_name": "users",
"data_connector_query": {
"index": -2,
},
},
"expectation_suite_name": "users.delivery",
},
],
)
```
However, the `run_checkpoint` method can be simplified by configuring a separate Checkpoint that uses the above Checkpoint as a template and includes the settings previously specified in the `run_checkpoint` method:
```python
config = """
name: my_fancy_checkpoint
config_version: 1
class_name: Checkpoint
template_name: my_base_checkpoint
validations:
- batch_request:
datasource_name: my_datasource
data_connector_name: my_special_data_connector
data_asset_name: users
data_connector_query:
index: -1
- batch_request:
datasource_name: my_datasource
data_connector_name: my_other_data_connector
data_asset_name: users
data_connector_query:
index: -2
expectation_suite_name: users.delivery
"""
```
Now the `run_checkpoint` method is as simple as in the previous examples:
```python
checkpoint_run_result = context.run_checkpoint(
checkpoint_name="my_fancy_checkpoint",
)
```
The `checkpoint_run_result` in both cases (the parameterized `run_checkpoint` method and the configuration that incorporates another configuration as a template) are the same.
The final example presents a Checkpoint configuration that is suitable for the use in a pipeline managed by Airflow.
```python
config = """
name: airflow_checkpoint
config_version: 1
class_name: Checkpoint
validations:
- batch_request:
datasource_name: my_datasource
data_connector_name: my_runtime_data_connector
data_asset_name: IN_MEMORY_DATA_ASSET
expectation_suite_name: users.delivery
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
"""
```
To run this Checkpoint, the `batch_request` with the `batch_data` nested under the `runtime_parameters` attribute needs to be specified explicitly as part of the `run_checkpoint()` API call, because the data to be <TechnicalTag tag="validation" text="Validated" /> is accessible only dynamically during the execution of the pipeline.
```python
checkpoint_run_result: CheckpointResult = data_context.run_checkpoint(
checkpoint_name="airflow_checkpoint",
batch_request={
"runtime_parameters": {
"batch_data": my_data_frame,
},
"data_connector_query": {
"batch_filter_parameters": {
"airflow_run_id": airflow_run_id,
}
},
},
run_name=airflow_run_id,
)
```
### Relevant API documentation (links)
<RelevantApiLinks/><file_sep>/scripts/check_for_docs_deps_changes
#!/bin/bash
CHANGED_FILES=$(git diff HEAD origin/develop --name-only)
printf '%s\n' "[CHANGED FILES]" "${CHANGED_FILES[@]}" ""
DEPENDENCIES=$(python scripts/trace_docs_deps.py)
printf '%s\n' "[DEPENDENCIES]" "${DEPENDENCIES[@]}" ""
echo "File changes from 'great_expectations/' that impact 'docs/':"
for FILE in ${DEPENDENCIES}; do
if [[ ${CHANGED_FILES[@]} =~ $FILE ]]; then
echo " Found change in local dependency:" $FILE
echo "##vso[task.setvariable variable=DocsDependenciesChanged;isOutput=true]true"
fi
done
<file_sep>/docs/integrations/integration_zenml.md
---
title: Integrating ZenML With Great Expectations
authors:
name: <NAME>
url: https://zenml.io
---
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
:::info
* Maintained By: ZenML
* Status: Beta
* Support/Contact: https://zenml.io/slack-invite/
:::
### Introduction
[ZenML](https://zenml.io/) helps data scientists and ML engineers to make
Great Expectations data profiling and validation an integral part of their
production ML toolset and workflows. ZenML is [an extensible open source MLOps framework](https://github.com/zenml-io/zenml)
for creating portable, production-ready ML pipelines.
ZenML eliminates the complexity associated with setting up the Great
Expectations <TechnicalTag tag="data_context" text="Data Context" />
for use in production by integrating it directly into its [MLOps tool stack construct](https://docs.zenml.io/getting-started/core-concepts#stacks-components-and-stores).
This allows you to start using Great Expectations in your ML pipelines right
away, with all the other great features that ZenML brings along: portability,
caching, tracking and versioning and immediate access to a rich ecosystem of
tools and services that spans everything else MLOps.
### Technical background
:::note Prerequisites
- An overview of the Great Expectations <TechnicalTag tag="expectation_suite" text="Expectation Suites" />,
<TechnicalTag tag="validation_result" text="Validation Results"/>,
and <TechnicalTag tag="data_docs" text="Data Docs" /> concepts.
- Some understanding of the [ZenML pipelines and steps](https://docs.zenml.io/developer-guide/steps-and-pipelines#pipeline) concepts is recommended, but optional.
:::
ZenML ships with a couple of builtin pipeline steps that take care of everything
from configuring temporary <TechnicalTag tag="datasource" text="Datasources" />,
<TechnicalTag tag="data_connector" text="Data Connectors" />,
and <TechnicalTag tag="batch_request" text="Runtime Batch Requests" />
to access in-memory datasets to setting up and running <TechnicalTag tag="profiler" text="Profilers" />, <TechnicalTag tag="validator" text="Validators" /> and <TechnicalTag tag="checkpoint" text="Checkpoints" />, to generating the <TechnicalTag tag="data_docs" text="Data Docs" />
for you. These details are abstracted away from you and all you have left
to do is simply insert these steps into your ML pipelines to run either data
profiling or data validation with Great Expectations on any input Pandas
DataFrame.
Also included is a ZenML visualizer that gives you quick access to the Data Docs
to display Expectation Suites and Validation Results generated, versioned and
stored by your pipeline runs.
### Dev loops unlocked by integration
* Implement [the Great Expectations "golden path" workflow](https://greatexpectations.io/blog/ml-ops-great-expectations):
teams can create Expectation Suites and store them in the shared ZenML Artifact
Store, then use them in their ZenML pipelines to automate data validation. All
this with Data Docs providing a complete report of the overall data quality
status of your project.
* Start with Great Expectations hosted exclusively on your local machine and
then incrementally migrate to production ready ZenML MLOps stacks as your
project matures. With no code changes or vendor lock-in.
### Setup
This simple setup installs both Great Expectations and ZenML and brings them
together into a single MLOps local stack. More elaborate configuration options
are of course possible and thoroughly documented in [the ZenML documentation](https://docs.zenml.io/mlops-stacks/data-validators/great-expectations).
#### 1. Install ZenML
```shell
pip install zenml
```
#### 2. Install the Great Expectations ZenML integration
```shell
zenml integration install -y great_expectations
```
#### 3. Add Great Expectations as a Data Validator to the default ZenML stack
```shell
zenml data-validator register ge_data_validator --flavor great_expectations
zenml stack update -dv ge_data_validator
```
:::tip
This stack uses the default local [ZenML Artifact Store](https://docs.zenml.io/mlops-stacks/artifact-stores)
that persists the Great Expectations Data Context information on your local
machine. However, you can use any of [the Artifact Store flavors](https://docs.zenml.io/mlops-stacks/artifact-stores#artifact-store-flavors)
shipped with ZenML, like AWS, GCS or Azure. They will all work seamlessly with Great
Expectations.
:::
## Usage
Developing ZenML pipelines that harness the power of Great Expectations to
perform data profiling and validation is just a matter of instantiating the
builtin ZenML steps and linking them to other steps that ingest data. The
following examples showcase two simple pipeline scenarios that do exactly that.
:::info
To run the examples, you will also need to install the ZenML scikit-learn
integration:
```shell
zenml integration install -y sklearn
```
:::
### Great Expectations Zenml data profiling example
This is a simple example of a ZenML pipeline that loads data from a source and
then uses the ZenML builtin Great Expectations profiling step to infer an
Expectation Suite from that data. After the pipeline run is complete, the
Expectation Suite can be visualized in the Data Docs.
:::tip
The following Python code is fully functional. You can simply copy it in a file
and run it as-is, assuming you installed and setup ZenML properly.
:::
```python
import pandas as pd
from sklearn import datasets
from zenml.integrations.constants import GREAT_EXPECTATIONS, SKLEARN
from zenml.integrations.great_expectations.steps import (
GreatExpectationsProfilerConfig,
great_expectations_profiler_step,
)
from zenml.integrations.great_expectations.visualizers import (
GreatExpectationsVisualizer,
)
from zenml.pipelines import pipeline
from zenml.steps import Output, step
#### 1. Define ZenML steps
@step(enable_cache=False)
def importer(
) -> Output(dataset=pd.DataFrame, condition=bool):
"""Load and return a random sample of the the University of Wisconsin breast
cancer diagnosis dataset.
"""
breast_cancer = datasets.load_breast_cancer()
df = pd.DataFrame(
data=breast_cancer.data, columns=breast_cancer.feature_names
)
df["class"] = breast_cancer.target
return df.sample(frac = 0.5), True
# instantiate a builtin Great Expectations data profiling step
ge_profiler_step = great_expectations_profiler_step(
step_name="ge_profiler_step",
config=GreatExpectationsProfilerConfig(
expectation_suite_name="breast_cancer_suite",
data_asset_name="breast_cancer_df",
)
)
#### 2. Define the ZenML pipeline
@pipeline(required_integrations=[SKLEARN, GREAT_EXPECTATIONS])
def profiling_pipeline(
importer, profiler
):
"""Data profiling pipeline for Great Expectations."""
dataset, _ = importer()
profiler(dataset)
#### 4. Instantiate and run the pipeline
profiling_pipeline(
importer=importer(),
profiler=ge_profiler_step,
).run()
#### 5. Visualize the Expectation Suite generated, tracked and stored by the pipeline
last_run = profiling_pipeline.get_runs()[-1]
step = last_run.get_step(name="profiler")
GreatExpectationsVisualizer().visualize(step)
```
### Great Expectations Zenml data validation example
This is a simple example of a ZenML pipeline that loads data from a source and
then uses the ZenML builtin Great Expectations data validation step to validate
that data against an existing Expectation Suite and generate Validation Results.
After the pipeline run is complete, the Validation Results can be visualized in
the Data Docs.
:::info
This example assumes that you already have an Expectations Suite named
`breast_cancer_suite` that has been previously stored in the Great Expectations
Data Context. You should run [the Great Expectations Zenml data profiling example](#great-expectations-zenml-data-profiling-example)
first to ensure that, or create one by other means.
:::
:::tip
The following Python code is fully functional. You can simply copy it in a file
and run it as-is, assuming you installed and setup ZenML properly.
:::
```python
import pandas as pd
from great_expectations.checkpoint.types.checkpoint_result import (
CheckpointResult,
)
from sklearn import datasets
from zenml.integrations.constants import GREAT_EXPECTATIONS, SKLEARN
from zenml.integrations.great_expectations.steps import (
GreatExpectationsValidatorConfig,
great_expectations_validator_step,
)
from zenml.integrations.great_expectations.visualizers import (
GreatExpectationsVisualizer,
)
from zenml.pipelines import pipeline
from zenml.steps import Output, step
#### 1. Define ZenML steps
@step(enable_cache=False)
def importer(
) -> Output(dataset=pd.DataFrame, condition=bool):
"""Load and return a random sample of the the University of Wisconsin breast
cancer diagnosis dataset.
"""
breast_cancer = datasets.load_breast_cancer()
df = pd.DataFrame(
data=breast_cancer.data, columns=breast_cancer.feature_names
)
df["class"] = breast_cancer.target
return df.sample(frac = 0.5), True
# instantiate a builtin Great Expectations data profiling step
ge_validator_step = great_expectations_validator_step(
step_name="ge_validator_step",
config=GreatExpectationsValidatorConfig(
expectation_suite_name="breast_cancer_suite",
data_asset_name="breast_cancer_test_df",
)
)
@step
def analyze_result(
result: CheckpointResult,
) -> bool:
"""Analyze the Great Expectations validation result and print a message
indicating whether it passed or failed."""
if result.success:
print("Great Expectations data validation was successful!")
else:
print("Great Expectations data validation failed!")
return result.success
#### 2. Define the ZenML pipeline
@pipeline(required_integrations=[SKLEARN, GREAT_EXPECTATIONS])
def validation_pipeline(
importer, validator, checker
):
"""Data validation pipeline for Great Expectations."""
dataset, condition = importer()
results = validator(dataset, condition)
checker(results)
#### 4. Instantiate and run the pipeline
validation_pipeline(
importer=importer(),
validator=ge_validator_step,
checker=analyze_result(),
).run()
#### 5. Visualize the Validation Results generated, tracked and stored by the pipeline
last_run = validation_pipeline.get_runs()[-1]
step = last_run.get_step(name="validator")
GreatExpectationsVisualizer().visualize(step)
```
## Further discussion
### Things to consider
The Great Expectations builtin ZenML steps and visualizer are a quick and
convenient way of bridging the data validation and ML pipelines domains, but
this convenience comes at a cost: there is little flexibility in the way of
dataset types and configurations for Great Expectations Checkpoints, Profiles
and Validators.
If the builtin ZenML steps are insufficient, you can always implement your own
custom ZenML pipeline steps that use Great Expectations while still benefiting
from the other ZenML integration features:
* the convenience of using a Great Expectations Data Context that is
automatically configured to connect to the the infrastructure of your choise
* the ability to version, track and visualize Expectation Suites and Validation
Results as pipeline artifacts
* the freedom that comes from being able to combine Great Expectations with
a wide range of libraries and services in the ZenML MLOps ecosystem providing
functions like ML pipeline orchestration, experiment and metadata tracking,
model deployment, data annotation and a lot more
### When things don't work
- Refer to [the ZenML documentation](https://docs.zenml.io/mlops-stacks/data-validators/great-expectations)
for in-depth instructions on how to configure and use Great Expectations with
ZenML.
- Reach out to the ZenML community [on Slack](https://zenml.io/slack-invite/)
and ask for help.
### Other resources
- This [ZenML blog post](https://blog.zenml.io/great-expectations/) covers
the Great Expectations integration and includes a full tutorial.
- [A similar example](https://github.com/zenml-io/zenml/tree/main/examples/great_expectations_data_validation)
is included in the ZenML list of code examples. [A Jupyter notebook](https://colab.research.google.com/github/zenml-io/zenml/blob/main/examples/great_expectations_data_validation/great_expectations.ipynb)
is included.
- A recording of [the Great Expectation integration demo](https://www.youtube.com/watch?v=JIoTrHL1Dmk)
done in one of the ZenML community hour meetings.
- Consult [the ZenML documentation](https://docs.zenml.io/mlops-stacks/data-validators/great-expectations)
for more information on how to use Great Expectations together with ZenML.
<file_sep>/great_expectations/experimental/__init__.py
from great_expectations.experimental import datasources
from great_expectations.experimental.context import get_context
__all__ = ["datasources", "get_context"]
<file_sep>/tests/scripts/test_trace_docs_deps.py
import pprint
from scripts.trace_docs_deps import (
find_docusaurus_refs_in_file,
parse_definition_nodes_from_file,
retrieve_symbols_from_file,
)
def test_parse_definition_nodes_from_file(tmpdir):
f = tmpdir.mkdir("tmp").join("foo.py")
f.write(
"""
logger = logging.getLogger(__name__)
def test_yaml_config():
pass
class DataContext(BaseDataContext):
def add_store(self, store_name, store_config):
pass
@classmethod
def find_context_root_dir(cls):
pass
"""
)
definition_map = parse_definition_nodes_from_file(f)
pprint.pprint(definition_map)
# Only parses from global scope
assert all(
symbol in definition_map
for symbol in (
"test_yaml_config",
"DataContext",
)
)
assert all(len(paths) == 1 and f in paths for paths in definition_map.values())
def test_find_docusaurs_refs_in_file(tmpdir):
f = tmpdir.mkdir("tmp").join("foo.md")
f.write(
"""
```bash
great_expectations datasource new
```
```python file=../../../../../tests/integration/docusaurus/connecting_to_your_data/cloud/s3/spark/inferred_and_runtime_python_example.py#L53
```
```python file=../../../../tests/integration/docusaurus/connecting_to_your_data/filesystem/pandas_python_example.py
```
```python
print("Hello World")
```
"""
)
refs = find_docusaurus_refs_in_file(f)
print(refs)
assert len(refs) == 2
assert all(ref.endswith("python_example.py") for ref in refs)
def test_retrieve_symbols_from_file(tmpdir):
f = tmpdir.mkdir("tmp").join("foo.py")
f.write(
"""
context = DataContext()
assert is_numeric(1)
batch_request = get_batch_request_dict()
"""
)
symbols = retrieve_symbols_from_file(f)
assert all(
symbol in symbols
for symbol in ("DataContext", "is_numeric", "get_batch_request_dict")
)
<file_sep>/docs/guides/setup/components_index/_data_contexts.mdx
<!--
---Import---
import DataContexts from './_data_contexts.mdx'
<DataContexts />
---Header---
## Data Contexts
-->
- [How to initialize a new Data Context with the CLI](../../../guides/setup/configuring_data_contexts/how_to_configure_a_new_data_context_with_the_cli.md)
- [How to configure DataContext components using test_yaml_config](../../../guides/setup/configuring_data_contexts/how_to_configure_datacontext_components_using_test_yaml_config.md)
- [How to configure credentials](../../../guides/setup/configuring_data_contexts/how_to_configure_credentials.md)
- [How to instantiate a Data Context without a yml file](../../../guides/setup/configuring_data_contexts/how_to_instantiate_a_data_context_without_a_yml_file.md)
<file_sep>/docs/guides/expectations/advanced/how_to_create_a_new_expectation_suite_using_rule_based_profilers.md
---
title: How to create a new Expectation Suite using Rule Based Profilers
---
import Prerequisites from '../../../guides/connecting_to_your_data/components/prerequisites.jsx';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
In this tutorial, you will develop hands-on experience with configuring a Rule-Based <TechnicalTag tag="profiler" text="Profiler" /> to create an <TechnicalTag tag="expectation_suite" text="Expectation Suite" />. You will <TechnicalTag tag="profiling" text="Profile" /> several <TechnicalTag tag="batch" text="Batches" /> of NYC yellow taxi trip data to come up with reasonable estimates for the ranges of <TechnicalTag tag="expectation" text="Expectations" /> for several numeric columns.
:::warning
Please note that Rule Based Profiler is currently undergoing development and is considered an experimental feature.
While the contents of this document accurately reflect the state of the feature, they are susceptible to change.
:::
<Prerequisites>
- Have a basic understanding of <TechnicalTag tag="metric" text="Metrics" /> in Great Expectations.
- Have a basic understanding of [Expectation Configurations in Great Expectations](https://docs.greatexpectations.io/docs/reference/expectations/expectations).
- Have read the overview of <TechnicalTag tag="profiler" text="Profilers" /> and the section on [Rule-Based Profilers](../../../terms/profiler.md#rule-based-profilers) in particular.
</Prerequisites>
## Steps
### 1. Create a new Great Expectations project
- Create a new directory, called `taxi_profiling_tutorial`
- Within this directory, create another directory called `data`
- Navigate to the top level of `taxi_profiling_tutorial` in a terminal and run `great_expectations init`
### 2. Download the data
- Download [this directory](https://github.com/great-expectations/great_expectations/tree/develop/tests/test_sets/taxi_yellow_tripdata_samples) of yellow taxi trip `csv` files from the Great Expectations GitHub repo. You can use a tool like [DownGit](https://downgit.github.io/) to do so
- Move the unzipped directory of `csv` files into the `data` directory that you created in Step 1
### 3. Set up your Datasource
- Follow the steps in the [How to connect to data on a filesystem using Pandas](../../../guides/connecting_to_your_data/filesystem/pandas.md). For the purpose of this tutorial, we will work from a `yaml` to set up your <TechnicalTag tag="datasource" text="Datasource" /> config. When you open up your notebook to create and test and save your Datasource config, replace the config docstring with the following docstring:
```python
example_yaml = f"""
name: taxi_pandas
class_name: Datasource
execution_engine:
class_name: PandasExecutionEngine
data_connectors:
monthly:
base_directory: ../<YOUR BASE DIR>/
glob_directive: '*.csv'
class_name: ConfiguredAssetFilesystemDataConnector
assets:
my_reports:
base_directory: ./
group_names:
- name
- year
- month
class_name: Asset
pattern: (.+)_(\d.*)-(\d.*)\.csv
"""
```
- Test your YAML config to make sure it works - you should see some of the taxi `csv` filenames listed
- Save your Datasource config
### 4. Configure the Profiler
- Now, we'll create a new script in the same top-level `taxi_profiling_tutorial` directory called `profiler_script.py`. If you prefer, you could open up a Jupyter Notebook and run this there instead.
- At the top of this file, we will create a new YAML docstring assigned to a variable called `profiler_config`. This will look similar to the YAML docstring we used above when creating our Datasource. Over the next several steps, we will slowly add lines to this docstring by typing or pasting in the lines below:
```python
profiler_config = """
"""
```
First, we'll add some relevant top level keys (`name` and `config_version`) to label our Profiler and associate it with a specific version of the feature.
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L10-L12
```
:::info Config Versioning
Note that at the time of writing this document, `1.0` is the only supported config version.
:::
Then, we'll add in a `Variables` key and some variables that we'll use. Next, we'll add a top level `rules` key, and then the name of your `rule`:
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L13-L15
```
After that, we'll add our Domain Builder. In this case, we'll use a `TableDomainBuilder`, which will indicate that any expectations we build for this Domain will be at the Table level. Each Rule in our Profiler config can only use one Domain Builder.
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L19-L20
```
Next, we'll use a `NumericMetricRangeMultiBatchParameterBuilder` to get an estimate to use for the `min_value` and `max_value` of our `expect_table_row_count_to_be_between` Expectation. This Parameter Builder will take in a <TechnicalTag tag="batch_request" text="Batch Request" /> consisting of the five Batches prior to our current Batch, and use the row counts of each of those months to get a probable range of row counts that you could use in your `ExpectationConfiguration`.
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L21-L35
```
A Rule can have multiple `ParameterBuilders` if needed, but in our case, we'll only use the one for now.
Finally, you would use an `ExpectationConfigurationBuilder` to actually build your `expect_table_row_count_to_be_between` Expectation, where the Domain is the Domain returned by your `TableDomainBuilder` (your entire table), and the `min_value` and `max_value` are Parameters returned by your `NumericMetricRangeMultiBatchParameterBuilder`.
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L36-L44
```
You can see here that we use a special `$` syntax to reference `variables` and `parameters` that have been previously defined in our config. You can see a more thorough description of this syntax in the docstring for [`ParameterContainer` here](https://github.com/great-expectations/great_expectations/blob/develop/great_expectations/rule_based_profiler/types/parameter_container.py).
- When we put it all together, here is what our config with our single `row_count_rule` looks like:
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L10-L80
```
### 5. Run the Profiler
Now let's use our config to Profile our data and create a simple Expectation Suite!
First we'll do some basic set-up - set up a <TechnicalTag tag="data_context" text="Data Context" /> and parse our YAML
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L102-L106
```
Next, we'll instantiate our Profiler, passing in our config and our Data Context
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L107-L114
```
Finally, we'll run `profile()` and save it to a variable.
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L115
```
Then, we can print our Expectation Suite so we can see how it looks!
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L120-L138
```
### 6. Add a Rule for Columns
Let's add one more rule to our Rule-Based Profiler config. This Rule will use the `DomainBuilder` to populate a list of all of the numeric columns in one Batch of taxi data (in this case, the most recent Batch). It will then use our `NumericMetricRangeMultiBatchParameterBuilder` looking at the five Batches prior to our most recent Batch to get probable ranges for the min and max values for each of those columns. Finally, it will use those ranges to add two `ExpectationConfigurations` for each of those columns: `expect_column_min_to_be_between` and `expect_column_max_to_be_between`. This rule will go directly below our previous rule.
As before, we will first add the name of our rule, and then specify the `DomainBuilder`.
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L45-L56
```
In this case, our `DomainBuilder` configuration is a bit more complex. First, we are using a `SimpleSemanticTypeColumnDomainBuilder`. This will take a table, and return a list of all columns that match the `semantic_type` specified - `numeric` in our case.
Then, we need to specify a Batch Request that returns exactly one Batch of data (this is our `data_connector_query` with `index` equal to `-1`). This tells us which Batch to use to get the columns from which we will select our numeric columns. Though we might hope that all our Batches of data have the same columns, in actuality, there might be differences between the Batches, and so we explicitly specify the Batch we want to use here.
After this, we specify our `ParameterBuilders`. This is very similar to the specification in our previous rule, except we will be specifying two `NumericMetricRangeMultiBatchParameterBuilders` to get a probable range for the `min_value` and `max_value` of each of our numeric columns. Thus one `ParameterBuilder` will take the `column.min` `metric_name`, and the other will take the `column.max` `metric_name`.
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L57-L81
```
Finally, we'll put together our `Domains` and `Parameters` in our `ExpectationConfigurationBuilders`:
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L82-L100
```
Putting together our entire config, with both of our Rules, we get:
```yaml file=../../../../tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py#L9-L100
```
And if we re-instantiate our `Profiler` with our config which now has two rules, and then we re-run the `Profiler`, we'll have an updated Expectation Suite with a table row count Expectation for our table, and column min and column max Expectations for each of our numeric columns!
🚀Congratulations! You have successfully Profiled multi-batch data using a Rule-Based Profiler. Now you can try adding some new Rules, or running your Profiler on some other data (remember to change the `BatchRequest` in your config)!🚀
## Additional Notes
To view the full script used in this page, see it on GitHub:
- [multi_batch_rule_based_profiler_example.py](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py)
<file_sep>/tests/validator/conftest.py
import pytest
from great_expectations.validator.metric_configuration import MetricConfiguration
@pytest.fixture
def table_head_metric_config() -> MetricConfiguration:
return MetricConfiguration(
metric_name="table.head",
metric_domain_kwargs={
"batch_id": "abc123",
},
metric_value_kwargs={
"n_rows": 5,
},
)
@pytest.fixture
def column_histogram_metric_config() -> MetricConfiguration:
return MetricConfiguration(
metric_name="column.histogram",
metric_domain_kwargs={
"batch_id": "def456",
},
metric_value_kwargs={
"bins": 5,
},
)
<file_sep>/docs/guides/setup/configuring_metadata_stores/components_how_to_configure_a_validation_result_store_in_amazon_s3/_identify_your_data_context_validation_results_store.mdx
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
You can find your <TechnicalTag tag="validation_result_store" text="Validation Results Store" /> configuration within your <TechnicalTag tag="data_context" text="Data Context" />.
Look for the following section in your <TechnicalTag relative="../../../" tag="data_context" text="Data Context's" /> ``great_expectations.yml`` file:
```yaml title="File contents: great_expectations.yml"
validations_store_name: validations_store
stores:
validations_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
```
This configuration tells Great Expectations to look for Validation Results in a Store called ``validations_store``. It also creates a ``ValidationsStore`` called ``validations_store`` that is backed by a Filesystem and will store Validation Results under the ``base_directory`` ``uncommitted/validations`` (the default).
<file_sep>/great_expectations/rule_based_profiler/domain_builder/table_domain_builder.py
from __future__ import annotations
from typing import TYPE_CHECKING, List, Optional
from great_expectations.core.metric_domain_types import MetricDomainTypes
from great_expectations.rule_based_profiler.domain import Domain
from great_expectations.rule_based_profiler.domain_builder import DomainBuilder
from great_expectations.rule_based_profiler.parameter_container import (
ParameterContainer,
)
if TYPE_CHECKING:
from great_expectations.data_context.data_context.abstract_data_context import (
AbstractDataContext,
)
class TableDomainBuilder(DomainBuilder):
def __init__(
self,
data_context: Optional[AbstractDataContext] = None,
) -> None:
"""
Args:
data_context: AbstractDataContext associated with this DomainBuilder
"""
super().__init__(data_context=data_context)
@property
def domain_type(self) -> MetricDomainTypes:
return MetricDomainTypes.TABLE
"""
The interface method of TableDomainBuilder emits a single Domain object, corresponding to the implied Batch (table).
Note that for appropriate use-cases, it should be readily possible to build a multi-batch implementation, where a
separate Domain object is emitted for each individual Batch (using its respective batch_id). (This is future work.)
"""
def _get_domains(
self,
rule_name: str,
variables: Optional[ParameterContainer] = None,
) -> List[Domain]:
domains: List[Domain] = [
Domain(
domain_type=self.domain_type,
rule_name=rule_name,
),
]
return domains
<file_sep>/docs/guides/setup/configuring_data_docs/components_how_to_host_and_share_data_docs_on_amazon_s3/_add_a_new_s3_site_to_the_data_docs_sites_section_of_your_great_expectationsyml.mdx
The below example shows the default `local_site` configuration that you will find in your `great_expectations.yml` file, followed by the `s3_site` configuration that you will need to add. You may optionally remove the default `local_site` configuration completely and replace it with the new `s3_site` configuration if you would only like to maintain a single S3 Data Docs site.
```yaml title="File content: great_expectations.yml"
data_docs_sites:
local_site:
class_name: SiteBuilder
show_how_to_buttons: true
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/data_docs/local_site/
site_index_builder:
class_name: DefaultSiteIndexBuilder
s3_site: # this is a user-selected name - you may select your own
class_name: SiteBuilder
store_backend:
class_name: TupleS3StoreBackend
bucket: data-docs.my_org # UPDATE the bucket name here to match the bucket you configured above.
site_index_builder:
class_name: DefaultSiteIndexBuilder
show_cta_footer: true
```
<file_sep>/docs/guides/setup/configuring_data_docs/components_how_to_host_and_share_data_docs_on_amazon_s3/_test_that_your_configuration_is_correct_by_building_the_site.mdx
Use the following CLI command: `great_expectations docs build --site-name s3_site` to build and open your newly configured S3 Data Docs site.
```bash title="Terminal input"
> great_expectations docs build --site-name s3_site
```
You will be presented with the following prompt:
```bash title="Terminal output"
The following Data Docs sites will be built:
- s3_site: https://s3.amazonaws.com/data-docs.my_org/index.html
Would you like to proceed? [Y/n]:
```
Signify that you would like to proceed by pressing the `return` key or entering `Y`. Once you have you will be presented with the following messages:
```bash title="Terminal output"
Building Data Docs...
Done building Data Docs
```
If successful, the CLI will also open your newly built S3 Data Docs site and provide the URL, which you can share as desired. Note that the URL will only be viewable by users with IP addresses appearing in the above policy.
:::tip
You may want to use the `-y/--yes/--assume-yes` flag with the `great_expectations docs build --site-name s3_site` command. This flag causes the CLI to skip the confirmation dialog.
This can be useful for non-interactive environments.
:::<file_sep>/tests/core/usage_statistics/test_usage_statistics_handler_methods.py
import logging
from typing import Dict
from unittest import mock
import pytest
from great_expectations import DataContext
from great_expectations.core.usage_statistics.schemas import (
anonymized_usage_statistics_record_schema,
)
from great_expectations.core.usage_statistics.usage_statistics import (
UsageStatisticsHandler,
get_profiler_run_usage_statistics,
)
from great_expectations.data_context import BaseDataContext
from great_expectations.data_context.types.base import DataContextConfig
from great_expectations.rule_based_profiler.rule_based_profiler import RuleBasedProfiler
from tests.core.usage_statistics.util import usage_stats_invalid_messages_exist
from tests.integration.usage_statistics.test_integration_usage_statistics import (
USAGE_STATISTICS_QA_URL,
)
@pytest.fixture
def in_memory_data_context_config_usage_stats_enabled():
return DataContextConfig(
**{
"commented_map": {},
"config_version": 2,
"plugins_directory": None,
"evaluation_parameter_store_name": "evaluation_parameter_store",
"validations_store_name": "validations_store",
"expectations_store_name": "expectations_store",
"config_variables_file_path": None,
"datasources": {},
"stores": {
"expectations_store": {
"class_name": "ExpectationsStore",
},
"validations_store": {
"class_name": "ValidationsStore",
},
"evaluation_parameter_store": {
"class_name": "EvaluationParameterStore",
},
},
"data_docs_sites": {},
"validation_operators": {
"default": {
"class_name": "ActionListValidationOperator",
"action_list": [],
}
},
"anonymous_usage_statistics": {
"enabled": True,
"data_context_id": "00000000-0000-0000-0000-000000000001",
"usage_statistics_url": USAGE_STATISTICS_QA_URL,
},
}
)
@pytest.fixture
def sample_partial_message():
return {
"event": "checkpoint.run",
"event_payload": {
"anonymized_name": "f563d9aa1604e16099bb7dff7b203319",
"config_version": 1.0,
"anonymized_expectation_suite_name": "6a04fc37da0d43a4c21429f6788d2cff",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
"anonymized_validations": [
{
"anonymized_batch_request": {
"anonymized_batch_request_required_top_level_properties": {
"anonymized_datasource_name": "a732a247720783a5931fa7c4606403c2",
"anonymized_data_connector_name": "d52d7bff3226a7f94dd3510c1040de78",
"anonymized_data_asset_name": "556e8c06239d09fc66f424eabb9ca491",
},
"batch_request_optional_top_level_keys": [
"batch_identifiers",
"runtime_parameters",
],
"runtime_parameters_keys": ["batch_data"],
},
"anonymized_expectation_suite_name": "6a04fc37da0d43a4c21429f6788d2cff",
"anonymized_action_list": [
{
"anonymized_name": "8e3e134cd0402c3970a02f40d2edfc26",
"parent_class": "StoreValidationResultAction",
},
{
"anonymized_name": "40e24f0c6b04b6d4657147990d6f39bd",
"parent_class": "StoreEvaluationParametersAction",
},
{
"anonymized_name": "2b99b6b280b8a6ad1176f37580a16411",
"parent_class": "UpdateDataDocsAction",
},
],
},
],
},
"success": True,
# "version": "1.0.0",
# "event_time": "2020-06-25T16:08:28.070Z",
# "event_duration": 123,
# "data_context_id": "00000000-0000-0000-0000-000000000002",
# "data_context_instance_id": "10000000-0000-0000-0000-000000000002",
# "ge_version": "0.13.45.manual_testing",
"x-forwarded-for": "00.000.00.000, 00.000.000.000",
}
def test_usage_statistics_handler_build_envelope(
in_memory_data_context_config_usage_stats_enabled, sample_partial_message
):
"""This test is for a happy path only but will fail if there is an exception thrown in build_envelope"""
context: BaseDataContext = BaseDataContext(
in_memory_data_context_config_usage_stats_enabled
)
usage_statistics_handler = UsageStatisticsHandler(
data_context=context,
data_context_id=in_memory_data_context_config_usage_stats_enabled.anonymous_usage_statistics.data_context_id,
usage_statistics_url=in_memory_data_context_config_usage_stats_enabled.anonymous_usage_statistics.usage_statistics_url,
)
assert (
usage_statistics_handler._data_context_id
== "00000000-0000-0000-0000-000000000001"
)
envelope = usage_statistics_handler.build_envelope(sample_partial_message)
required_keys = [
"event",
"event_payload",
"version",
"ge_version",
"data_context_id",
"data_context_instance_id",
"event_time",
]
assert all([key in envelope.keys() for key in required_keys])
assert envelope["version"] == "1.0.0"
assert envelope["data_context_id"] == "00000000-0000-0000-0000-000000000001"
def test_usage_statistics_handler_validate_message_failure(
caplog, in_memory_data_context_config_usage_stats_enabled, sample_partial_message
):
# caplog default is WARNING and above, we want to see DEBUG level messages for this test
caplog.set_level(
level=logging.DEBUG,
logger="great_expectations.core.usage_statistics.usage_statistics",
)
context: BaseDataContext = BaseDataContext(
in_memory_data_context_config_usage_stats_enabled
)
usage_statistics_handler = UsageStatisticsHandler(
data_context=context,
data_context_id=in_memory_data_context_config_usage_stats_enabled.anonymous_usage_statistics.data_context_id,
usage_statistics_url=in_memory_data_context_config_usage_stats_enabled.anonymous_usage_statistics.usage_statistics_url,
)
assert (
usage_statistics_handler._data_context_id
== "00000000-0000-0000-0000-000000000001"
)
validated_message = usage_statistics_handler.validate_message(
sample_partial_message, anonymized_usage_statistics_record_schema
)
assert not validated_message
assert usage_stats_invalid_messages_exist(caplog.messages)
def test_usage_statistics_handler_validate_message_success(
caplog, in_memory_data_context_config_usage_stats_enabled, sample_partial_message
):
# caplog default is WARNING and above, we want to see DEBUG level messages for this test
caplog.set_level(
level=logging.DEBUG,
logger="great_expectations.core.usage_statistics.usage_statistics",
)
context: BaseDataContext = BaseDataContext(
in_memory_data_context_config_usage_stats_enabled
)
usage_statistics_handler = UsageStatisticsHandler(
data_context=context,
data_context_id=in_memory_data_context_config_usage_stats_enabled.anonymous_usage_statistics.data_context_id,
usage_statistics_url=in_memory_data_context_config_usage_stats_enabled.anonymous_usage_statistics.usage_statistics_url,
)
assert (
usage_statistics_handler._data_context_id
== "00000000-0000-0000-0000-000000000001"
)
envelope = usage_statistics_handler.build_envelope(sample_partial_message)
validated_message = usage_statistics_handler.validate_message(
envelope, anonymized_usage_statistics_record_schema
)
assert validated_message
assert not usage_stats_invalid_messages_exist(caplog.messages)
def test_build_init_payload(
titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled,
):
"""This test is for a happy path only but will fail if there is an exception thrown in init_payload"""
context: DataContext = titanic_pandas_data_context_with_v013_datasource_with_checkpoints_v1_with_empty_store_stats_enabled
usage_statistics_handler = context._usage_statistics_handler
init_payload = usage_statistics_handler.build_init_payload()
assert list(init_payload.keys()) == [
"platform.system",
"platform.release",
"version_info",
"anonymized_datasources",
"anonymized_stores",
"anonymized_validation_operators",
"anonymized_data_docs_sites",
"anonymized_expectation_suites",
"dependencies",
]
assert init_payload["anonymized_datasources"] == [
{
"anonymized_data_connectors": [
{
"anonymized_name": "af09acd176f54642635a8a2975305437",
"parent_class": "InferredAssetFilesystemDataConnector",
},
{
"anonymized_name": "e475f70ca0bcbaf2748b93da5e9867ec",
"parent_class": "ConfiguredAssetFilesystemDataConnector",
},
{
"anonymized_name": "2030a96b1eaa8579087d31709fb6ec1b",
"parent_class": "ConfiguredAssetFilesystemDataConnector",
},
{
"anonymized_name": "d52d7bff3226a7f94dd3510c1040de78",
"parent_class": "RuntimeDataConnector",
},
],
"anonymized_execution_engine": {
"anonymized_name": "212039ff9860a796a32c75c7d5c2fac0",
"parent_class": "PandasExecutionEngine",
},
"anonymized_name": "a732a247720783a5931fa7c4606403c2",
"parent_class": "Datasource",
}
]
assert init_payload["anonymized_expectation_suites"] == []
@mock.patch("great_expectations.data_context.data_context.DataContext")
def test_get_profiler_run_usage_statistics_with_handler_valid_payload(
mock_data_context: mock.MagicMock,
):
# Ensure that real handler gets passed down by the context
handler: UsageStatisticsHandler = UsageStatisticsHandler(
mock_data_context, "my_id", "my_url"
)
mock_data_context.usage_statistics_handler = handler
profiler: RuleBasedProfiler = RuleBasedProfiler(
name="my_profiler", config_version=1.0, data_context=mock_data_context
)
override_rules: Dict[str, dict] = {
"my_override_rule": {
"domain_builder": {
"class_name": "ColumnDomainBuilder",
"module_name": "great_expectations.rule_based_profiler.domain_builder",
},
"parameter_builders": [
{
"class_name": "MetricMultiBatchParameterBuilder",
"module_name": "great_expectations.rule_based_profiler.parameter_builder",
"name": "my_parameter",
"metric_name": "my_metric",
},
{
"class_name": "NumericMetricRangeMultiBatchParameterBuilder",
"module_name": "great_expectations.rule_based_profiler.parameter_builder",
"name": "my_other_parameter",
"metric_name": "my_other_metric",
},
],
"expectation_configuration_builders": [
{
"class_name": "DefaultExpectationConfigurationBuilder",
"module_name": "great_expectations.rule_based_profiler.expectation_configuration_builder",
"expectation_type": "expect_column_pair_values_A_to_be_greater_than_B",
"column_A": "$domain.domain_kwargs.column_A",
"column_B": "$domain.domain_kwargs.column_B",
"my_one_arg": "$parameter.my_parameter.value[0]",
"meta": {
"details": {
"my_parameter_estimator": "$parameter.my_parameter.details",
"note": "Important remarks about estimation algorithm.",
},
},
},
{
"class_name": "DefaultExpectationConfigurationBuilder",
"module_name": "great_expectations.rule_based_profiler.expectation_configuration_builder",
"expectation_type": "expect_column_min_to_be_between",
"column": "$domain.domain_kwargs.column",
"my_another_arg": "$parameter.my_other_parameter.value[0]",
"meta": {
"details": {
"my_other_parameter_estimator": "$parameter.my_other_parameter.details",
"note": "Important remarks about estimation algorithm.",
},
},
},
],
},
}
payload: dict = get_profiler_run_usage_statistics(
profiler=profiler, rules=override_rules
)
assert payload == {
"anonymized_name": "a0061ec021855cd2b3a994dd8d90fe5d",
"anonymized_rules": [
{
"anonymized_domain_builder": {"parent_class": "ColumnDomainBuilder"},
"anonymized_expectation_configuration_builders": [
{
"expectation_type": "expect_column_pair_values_A_to_be_greater_than_B",
"parent_class": "DefaultExpectationConfigurationBuilder",
},
{
"expectation_type": "expect_column_min_to_be_between",
"parent_class": "DefaultExpectationConfigurationBuilder",
},
],
"anonymized_name": "bd8a8b4465a94b363caf2b307c080547",
"anonymized_parameter_builders": [
{
"anonymized_name": "25dac9e56a1969727bc0f90db6eaa833",
"parent_class": "MetricMultiBatchParameterBuilder",
},
{
"anonymized_name": "be5baa3f1064e6e19356f2168968cbeb",
"parent_class": "NumericMetricRangeMultiBatchParameterBuilder",
},
],
}
],
"config_version": 1.0,
"rule_count": 1,
"variable_count": 0,
}
@mock.patch("great_expectations.data_context.data_context.DataContext")
def test_get_profiler_run_usage_statistics_with_handler_invalid_payload(
mock_data_context: mock.MagicMock,
):
# Ensure that real handler gets passed down by the context
handler: UsageStatisticsHandler = UsageStatisticsHandler(
mock_data_context, "my_id", "my_url"
)
mock_data_context.usage_statistics_handler = handler
profiler: RuleBasedProfiler = RuleBasedProfiler(
name="my_profiler", config_version=1.0, data_context=mock_data_context
)
payload: dict = get_profiler_run_usage_statistics(profiler=profiler)
# Payload won't pass schema validation due to a lack of rules but we can confirm that it is anonymized
assert payload == {
"anonymized_name": "a0061ec021855cd2b3a994dd8d90fe5d",
"config_version": 1.0,
"rule_count": 0,
"variable_count": 0,
}
def test_get_profiler_run_usage_statistics_without_handler():
# Without a DataContext, the usage stats handler is not propogated down to the RBP
profiler: RuleBasedProfiler = RuleBasedProfiler(
name="my_profiler",
config_version=1.0,
)
payload: dict = get_profiler_run_usage_statistics(profiler=profiler)
assert payload == {}
<file_sep>/tests/test_fixtures/configuration_for_testing_v2_v3_migration/README.md
---
title: Configurations for Testing V2 to V3 API Migration
author: @Shinnnyshinshin
date: 20211022
---
## Overview
- This folder contains configurations that were used to test the V2 to V3 migration guide found here : https://docs.greatexpectations.io/docs/guides/miscellaneous/migration_guide
- It contains a complete-and-working V2 Configuration and a complete-and-working V3 Configuration that can be used to help with the migration process.
## So what's in the folder?
- `data/`: This folder contains a test file, `Titanic.csv` that is used by the configurations in this directory.
- The other folders `pandas/`, `spark/`, `postgresql/` each contain the following:
- **V2 configuration in `v2/great_expectations/` folder**
- Checkpoint named `test_v2_checkpoint`
- uses LegacyCheckpoint class
- uses batch_kwargs
- uses Validation Operator action_list_operator
- references Titanic.csv testfile
- `great_expectations.yml`
- uses config_version: `2.0`
- uses v2-datasource
- uses `validation_operators`
- no `CheckpointStore`
- **V3 configuration in `v2/great_expectations/` folder**
- Checkpoint named `test_v3_checkpoint`
- uses Checkpoint class
- uses batch_request
- references Titanic.csv testfile
- `great_expectations.yml`
- uses config_version: 3.0
- uses v3-datasource
- uses `CheckpointStore`
- In the `postgresql/` folder, there is an additional Jupyter Notebook that can be used to load the `Titanic.csv` into a `postgresql` database running in a local Docker container. In developing these example configurations, we used the `docker-compose.yml` file that is in the [`great_expectations` repository](https://github.com/great-expectations/great_expectations/tree/develop/assets/docker/postgresql)
<file_sep>/docs/guides/expectations/creating_custom_expectations/how_to_use_custom_expectations.md
---
title: How to use a Custom Expectation
---
import Prerequisites from '../creating_custom_expectations/components/prerequisites.jsx'
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
Custom <TechnicalTag tag="expectation" text="Expectations"/> are extensions to the core functionality of Great Expectations. Many Custom Expectations may be fit for a very specific purpose,
or be at lower levels of stability and feature maturity than the core library.
As such, they are not available for use from the core library, and require registration and import to become available.
This guide will walk you through the process of utilizing Custom Expectations, whether they were built by you or came from the Great Expectations Experimental Library.
<Prerequisites>
- Created a <TechnicalTag tag="custom_expectation" text="Custom Expectation"/> ***or*** identified a Custom Expectation for use from the [Great Expectations Experimental Library](https://github.com/great-expectations/great_expectations/tree/develop/contrib/experimental/great_expectations_experimental/expectations)
</Prerequisites>
## Steps
<Tabs
groupId="expectation-type"
defaultValue='custom-expectations'
values={[
{label: 'Custom Expectations You\'ve Built', value:'custom-expectations'},
{label: 'Custom Expectations Contributed To Great Expectations', value:'contrib-expectations'},
]}>
<TabItem value="custom-expectations">
### 1. File placement & import
If you're using a Custom Expectation you've built,
you'll need to place it in the `great_expectations/plugins/expectations` folder of your Great Expectations deployment.
When you instantiate your <TechnicalTag tag="data_context" text="Data Context"/>, it will automatically make all plugins in the directory available for use,
allowing you to import your Custom Expectation from that directory whenever and wherever it will be used.
This import will be needed when an <TechnicalTag tag="expectation_suite" text="Expectation Suite"/> is created, *and* when a <TechnicalTag tag="checkpoint" text="Checkpoint"/> is defined and run.
### 2. Use in a Suite
To use your Custom Expectation, we need to import it.
To do this, we first need to instantiate our Data Context.
For example, a pattern for importing a Custom Expectation `ExpectColumnValuesToBeAlphabetical` could look like:
```python
context = ge.get_context()
from expectations.expect_column_values_to_be_alphabetical import ExpectColumnValuesToBeAlphabetical
```
Now that your Custom Expectation has been imported, it is available with the same patterns as the core Expectations:
```python
validator.expect_column_values_to_be_alphabetical(column="test")
```
### 3. Use in a Checkpoint
Once you have your Custom Expectation in a Suite, you will also need to make it available to your Checkpoint.
To do this, we'll need to put together our own Checkpoint script. From your command line, you can execute:
```commandline
great_expectations checkpoint new <my_checkpoint_name>
```
This will open a Jupyter Notebook allowing you to create a Checkpoint.
If you would like to run your Checkpoint from this notebook, you will need to import your Custom Expectation again as above.
To continue to use this Checkpoint containing a Custom Expectation outside this notebook, we will need to set up a script for your Checkpoint.
To do this, execute the following from your command line:
```commandline
great_expectations checkpoint script <my_checkpoint_name>
```
This will create a script in your GE directory at `great_expectations/uncommitted/run_my_checkpoint_name.py`.
That script can be edited that script to include the Custom Expectation import(s) you need:
```python
import sys
from great_expectations.checkpoint.types.checkpoint_result import CheckpointResult
from great_expectations.data_context import DataContext
data_context: DataContext = DataContext(
context_root_dir="/your/path/to/great_expectations"
)
from expectations.expect_column_values_to_be_alphabetical import ExpectColumnValuesToBeAlphabetical
result: CheckpointResult = data_context.run_checkpoint(
checkpoint_name="my_checkpoint_name",
batch_request=None,
run_name=None,
)
if not result["success"]:
print("Validation failed!")
sys.exit(1)
print("Validation succeeded!")
sys.exit(0)
```
The Checkpoint can then be run with:
```python
python great_expectations/uncommitted/run_my_checkpoint_name.py
```
</TabItem>
<TabItem value="contrib-expectations">
### 1. Installation & import
If you're using a Custom Expectation that is coming from the `Great Expectations Experimental` library,
it will need to either be imported from there directly. To do this, we'll first need to `pip install great_expectations_experimental`.
Once that is done, you will be able to import directly from that package:
```python
from great_expectations_experimental.expectations.expect_column_values_to_be_alphabetical import ExpectColumnValuesToBeAlphabetical
```
This import will be needed when an <TechnicalTag tag="expectation_suite" text="Expectation Suite"/> is created, *and* when a <TechnicalTag tag="checkpoint" text="Checkpoint"/> is defined and run.
### 2. Use in a Suite
To use your Custom Expectation, we need to import it as above.
Once that is done, your Custom Expectation will be available with the same patterns as the core Expectations:
```python
validator.expect_column_values_to_be_alphabetical(column="test")
```
### 3. Use in a Checkpoint
Once you have your Custom Expectation in a Suite, you will also need to make it available to your Checkpoint.
To do this, we'll need to put together our own Checkpoint script. From your command line, you can execute:
```commandline
great_expectations checkpoint new <my_checkpoint_name>
```
This will open a Jupyter Notebook allowing you to create a Checkpoint.
If you would like to run your Checkpoint from this notebook, you will need to import your Custom Expectation again as above.
To continue to use this Checkpoint containing a Custom Expectation outside this notebook, we will need to set up a script for your Checkpoint.
To do this, execute the following from your command line:
```commandline
great_expectations checkpoint script <my_checkpoint_name>
```
This will create a script in your GE directory at `great_expectations/uncommitted/run_my_checkpoint_name.py`.
That script can be edited that script to include the Custom Expectation import(s) you need:
```python
import sys
from great_expectations.checkpoint.types.checkpoint_result import CheckpointResult
from great_expectations.data_context import DataContext
from great_expectations_experimental.expectations.expect_column_values_to_be_alphabetical import ExpectColumnValuesToBeAlphabetical
data_context: DataContext = DataContext(
context_root_dir="/your/path/to/great_expectations"
)
result: CheckpointResult = data_context.run_checkpoint(
checkpoint_name="my_checkpoint_name",
batch_request=None,
run_name=None,
)
if not result["success"]:
print("Validation failed!")
sys.exit(1)
print("Validation succeeded!")
sys.exit(0)
```
The Checkpoint can then be run with:
```python
python great_expectations/uncommitted/run_my_checkpoint_name.py
```
</TabItem>
</Tabs>
<div style={{"text-align":"center"}}>
<p style={{"color":"#8784FF","font-size":"1.4em"}}><b>
Congratulations!<br/>🎉 You've just run a Checkpoint with a Custom Expectation! 🎉
</b></p>
</div>
<file_sep>/tests/rule_based_profiler/data_assistant/test_onboarding_data_assistant_happy_paths.py
import os
from typing import List
import pytest
import great_expectations as ge
from great_expectations.core import ExpectationSuite
from great_expectations.core.batch import BatchRequest
from great_expectations.core.yaml_handler import YAMLHandler
from great_expectations.data_context.util import file_relative_path
yaml: YAMLHandler = YAMLHandler()
# constants used by the sql example
pg_hostname = os.getenv("GE_TEST_LOCAL_DB_HOSTNAME", "localhost")
CONNECTION_STRING: str = f"postgresql+psycopg2://postgres:@{pg_hostname}/test_ci"
@pytest.mark.integration
@pytest.mark.slow # 19s
def test_pandas_happy_path_onboarding_data_assistant(empty_data_context) -> None:
"""
What does this test and why?
The intent of this test is to ensure that our "happy path", exercised by notebooks
in great_expectations/tests/test_fixtures/rule_based_profiler/example_notebooks/ are in working order
The code in the notebooks (excluding explanations) and the code in the following test exercise an identical codepath.
1. Setting up Datasource to load 2019 taxi data and 2020 taxi data
2. Configuring BatchRequest to load 2019 data as multiple batches
3. Running Onboarding DataAssistant and saving resulting ExpectationSuite as 'taxi_data_2019_suite'
4. Configuring BatchRequest to load 2020 January data
5. Configuring and running Checkpoint using BatchRequest for 2020-01, and 'taxi_data_2019_suite'.
This test tests the code in `DataAssistants_Instantiation_And_Running-OnboardingAssistant-Pandas.ipynb`
"""
data_context: ge.DataContext = empty_data_context
taxi_data_path: str = file_relative_path(
__file__, os.path.join("..", "..", "test_sets", "taxi_yellow_tripdata_samples")
)
datasource_config: dict = {
"name": "taxi_data",
"class_name": "Datasource",
"module_name": "great_expectations.datasource",
"execution_engine": {
"module_name": "great_expectations.execution_engine",
"class_name": "PandasExecutionEngine",
},
"data_connectors": {
"configured_data_connector_multi_batch_asset": {
"class_name": "ConfiguredAssetFilesystemDataConnector",
"base_directory": taxi_data_path,
"assets": {
"yellow_tripdata_2019": {
"group_names": ["year", "month"],
"pattern": "yellow_tripdata_sample_(2019)-(\\d.*)\\.csv",
},
"yellow_tripdata_2020": {
"group_names": ["year", "month"],
"pattern": "yellow_tripdata_sample_(2020)-(\\d.*)\\.csv",
},
},
},
},
}
data_context.add_datasource(**datasource_config)
# Batch Request
multi_batch_batch_request: BatchRequest = BatchRequest(
datasource_name="taxi_data",
data_connector_name="configured_data_connector_multi_batch_asset",
data_asset_name="yellow_tripdata_2019",
)
batch_request: BatchRequest = multi_batch_batch_request
batch_list = data_context.get_batch_list(batch_request=batch_request)
assert len(batch_list) == 12
# Running onboarding data assistant
result = data_context.assistants.onboarding.run(
batch_request=multi_batch_batch_request
)
# saving resulting ExpectationSuite
suite: ExpectationSuite = ExpectationSuite(
expectation_suite_name="taxi_data_2019_suite"
)
suite.add_expectation_configurations(
expectation_configurations=result.expectation_configurations
)
data_context.save_expectation_suite(expectation_suite=suite)
# batch_request for checkpoint
single_batch_batch_request: BatchRequest = BatchRequest(
datasource_name="taxi_data",
data_connector_name="configured_data_connector_multi_batch_asset",
data_asset_name="yellow_tripdata_2020",
data_connector_query={
"batch_filter_parameters": {"year": "2020", "month": "01"}
},
)
# configuring and running checkpoint
checkpoint_config: dict = {
"name": "my_checkpoint",
"config_version": 1,
"class_name": "SimpleCheckpoint",
"validations": [
{
"batch_request": single_batch_batch_request,
"expectation_suite_name": "taxi_data_2019_suite",
}
],
}
data_context.add_checkpoint(**checkpoint_config)
results = data_context.run_checkpoint(checkpoint_name="my_checkpoint")
assert results.success is False
@pytest.mark.integration
@pytest.mark.slow # 149 seconds
def test_spark_happy_path_onboarding_data_assistant(
empty_data_context, spark_session, spark_df_taxi_data_schema
) -> None:
"""
What does this test and why?
The intent of this test is to ensure that our "happy path", exercised by notebooks
in great_expectations/tests/test_fixtures/rule_based_profiler/example_notebooks/ are in working order
The code in the notebooks (excluding explanations) and the code in the following test exercise an identical codepath.
1. Setting up Datasource to load 2019 taxi data and 2020 taxi data
2. Configuring BatchRequest to load 2019 data as multiple batches
3. Running Onboarding DataAssistant and saving resulting ExpectationSuite as 'taxi_data_2019_suite'
4. Configuring BatchRequest to load 2020 January data
5. Configuring and running Checkpoint using BatchRequest for 2020-01, and 'taxi_data_2019_suite'.
This test tests the code in `DataAssistants_Instantiation_And_Running-OnboardingAssistant-Spark.ipynb`
"""
from pyspark.sql.types import StructType
schema: StructType = spark_df_taxi_data_schema
data_context: ge.DataContext = empty_data_context
taxi_data_path: str = file_relative_path(
__file__, os.path.join("..", "..", "test_sets", "taxi_yellow_tripdata_samples")
)
datasource_config: dict = {
"name": "taxi_data",
"class_name": "Datasource",
"module_name": "great_expectations.datasource",
"execution_engine": {
"module_name": "great_expectations.execution_engine",
"class_name": "SparkDFExecutionEngine",
},
"data_connectors": {
"configured_data_connector_multi_batch_asset": {
"class_name": "ConfiguredAssetFilesystemDataConnector",
"base_directory": taxi_data_path,
"assets": {
"yellow_tripdata_2019": {
"group_names": ["year", "month"],
"pattern": "yellow_tripdata_sample_(2019)-(\\d.*)\\.csv",
},
"yellow_tripdata_2020": {
"group_names": ["year", "month"],
"pattern": "yellow_tripdata_sample_(2020)-(\\d.*)\\.csv",
},
},
},
},
}
data_context.add_datasource(**datasource_config)
multi_batch_batch_request: BatchRequest = BatchRequest(
datasource_name="taxi_data",
data_connector_name="configured_data_connector_multi_batch_asset",
data_asset_name="yellow_tripdata_2019",
batch_spec_passthrough={
"reader_method": "csv",
"reader_options": {"header": True, "schema": schema},
},
data_connector_query={
"batch_filter_parameters": {"year": "2019", "month": "01"}
},
)
batch_request: BatchRequest = multi_batch_batch_request
batch_list = data_context.get_batch_list(batch_request=batch_request)
assert len(batch_list) == 1
result = data_context.assistants.onboarding.run(
batch_request=multi_batch_batch_request
)
suite: ExpectationSuite = ExpectationSuite(
expectation_suite_name="taxi_data_2019_suite"
)
suite.add_expectation_configurations(
expectation_configurations=result.expectation_configurations
)
data_context.save_expectation_suite(expectation_suite=suite)
# batch_request for checkpoint
single_batch_batch_request: BatchRequest = BatchRequest(
datasource_name="taxi_data",
data_connector_name="configured_data_connector_multi_batch_asset",
data_asset_name="yellow_tripdata_2020",
data_connector_query={
"batch_filter_parameters": {"year": "2020", "month": "01"}
},
)
checkpoint_config: dict = {
"name": "my_checkpoint",
"config_version": 1,
"class_name": "SimpleCheckpoint",
"validations": [
{
"batch_request": single_batch_batch_request,
"expectation_suite_name": "taxi_data_2019_suite",
}
],
}
data_context.add_checkpoint(**checkpoint_config)
results = data_context.run_checkpoint(checkpoint_name="my_checkpoint")
assert results.success is False
@pytest.mark.integration
@pytest.mark.slow # 104 seconds
def test_sql_happy_path_onboarding_data_assistant(
empty_data_context, test_backends, sa
) -> None:
"""
What does this test and why?
The intent of this test is to ensure that our "happy path", exercised by notebooks
in great_expectations/tests/test_fixtures/rule_based_profiler/example_notebooks/ are in working order
The code in the notebooks (excluding explanations) and the code in the following test exercise an identical codepath.
1. Loading tables into postgres Docker container by calling helper method load_data_into_postgres_database()
2. Setting up Datasource to load 2019 taxi data and 2020 taxi data
3. Configuring BatchRequest to load 2019 data as multiple batches
4. Running Onboarding DataAssistant and saving resulting ExpectationSuite as 'taxi_data_2019_suite'
5. Configuring BatchRequest to load 2020 January data
6. Configuring and running Checkpoint using BatchRequest for 2020-01, and 'taxi_data_2019_suite'.
This test tests the code in `DataAssistants_Instantiation_And_Running-OnboardingAssistant-Sql.ipynb`
"""
if "postgresql" not in test_backends:
pytest.skip("testing data assistant in sql requires postgres backend")
else:
load_data_into_postgres_database(sa)
data_context: ge.DataContext = empty_data_context
datasource_config = {
"name": "taxi_multi_batch_sql_datasource",
"class_name": "Datasource",
"module_name": "great_expectations.datasource",
"execution_engine": {
"module_name": "great_expectations.execution_engine",
"class_name": "SqlAlchemyExecutionEngine",
"connection_string": CONNECTION_STRING,
},
"data_connectors": {
"configured_data_connector_multi_batch_asset": {
"class_name": "ConfiguredAssetSqlDataConnector",
"assets": {
"yellow_tripdata_sample_2019": {
"splitter_method": "split_on_year_and_month",
"splitter_kwargs": {
"column_name": "pickup_datetime",
},
},
"yellow_tripdata_sample_2020": {
"splitter_method": "split_on_year_and_month",
"splitter_kwargs": {
"column_name": "pickup_datetime",
},
},
},
},
},
}
data_context.add_datasource(**datasource_config)
multi_batch_batch_request: BatchRequest = BatchRequest(
datasource_name="taxi_multi_batch_sql_datasource",
data_connector_name="configured_data_connector_multi_batch_asset",
data_asset_name="yellow_tripdata_sample_2019",
)
batch_request: BatchRequest = multi_batch_batch_request
batch_list = data_context.get_batch_list(batch_request=batch_request)
assert len(batch_list) == 13
result = data_context.assistants.onboarding.run(
batch_request=multi_batch_batch_request
)
suite: ExpectationSuite = ExpectationSuite(
expectation_suite_name="taxi_data_2019_suite"
)
suite.add_expectation_configurations(
expectation_configurations=result.expectation_configurations
)
data_context.save_expectation_suite(expectation_suite=suite)
# batch_request for checkpoint
single_batch_batch_request: BatchRequest = BatchRequest(
datasource_name="taxi_multi_batch_sql_datasource",
data_connector_name="configured_data_connector_multi_batch_asset",
data_asset_name="yellow_tripdata_sample_2020",
data_connector_query={
"batch_filter_parameters": {"pickup_datetime": {"year": 2020, "month": 1}},
},
)
checkpoint_config: dict = {
"name": "my_checkpoint",
"config_version": 1,
"class_name": "SimpleCheckpoint",
"validations": [
{
"batch_request": single_batch_batch_request,
"expectation_suite_name": "taxi_data_2019_suite",
}
],
}
data_context.add_checkpoint(**checkpoint_config)
results = data_context.run_checkpoint(checkpoint_name="my_checkpoint")
assert results.success is False
def load_data_into_postgres_database(sa):
"""
Method to load our 2019 and 2020 taxi data into a postgres database. This is a helper method
called by test_sql_happy_path_onboarding_data_assistant().
"""
from tests.test_utils import load_data_into_test_database
data_paths: List[str] = [
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-01.csv",
),
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-02.csv",
),
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-03.csv",
),
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-04.csv",
),
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-05.csv",
),
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-06.csv",
),
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-07.csv",
),
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-08.csv",
),
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-09.csv",
),
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-10.csv",
),
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-11.csv",
),
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-12.csv",
),
]
table_name: str = "yellow_tripdata_sample_2019"
engine: sa.engine.Engine = sa.create_engine(CONNECTION_STRING)
connection: sa.engine.Connection = engine.connect()
# ensure we aren't appending to an existing table
connection.execute(f"DROP TABLE IF EXISTS {table_name}")
for data_path in data_paths:
load_data_into_test_database(
table_name=table_name,
csv_path=data_path,
connection_string=CONNECTION_STRING,
load_full_dataset=True,
drop_existing_table=False,
convert_colnames_to_datetime=["pickup_datetime", "dropoff_datetime"],
)
# 2020 data
data_paths: List[str] = [
file_relative_path(
__file__,
"../../test_sets/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2020-01.csv",
)
]
table_name: str = "yellow_tripdata_sample_2020"
engine: sa.engine.Engine = sa.create_engine(CONNECTION_STRING)
connection: sa.engine.Connection = engine.connect()
# ensure we aren't appending to an existing table
connection.execute(f"DROP TABLE IF EXISTS {table_name}")
for data_path in data_paths:
load_data_into_test_database(
table_name=table_name,
csv_path=data_path,
connection_string=CONNECTION_STRING,
load_full_dataset=True,
drop_existing_table=False,
convert_colnames_to_datetime=["pickup_datetime", "dropoff_datetime"],
)
<file_sep>/great_expectations/expectations/metrics/map_metric.py
import warnings
# noinspection PyUnresolvedReferences
from great_expectations.expectations.metrics.map_metric_provider import * # noqa: F401
# deprecated-v0.13.25
warnings.warn(
f"""The module "{__name__}" has been renamed to "{__name__}_provider" -- the alias "{__name__}" is deprecated \
as of v0.13.25 and will be removed in v0.16.
""",
DeprecationWarning,
stacklevel=2,
)
<file_sep>/scripts/trace_docs_deps.py
"""
Usage: `python trace_docs_deps.py`
This script is used in our Azure Docs Integration pipeline (azure-pipelines-docs-integration.yml) to determine whether
a change has been made in the `great_expectations/` directory that change impacts `docs/` and the snippets therein.
The script takes the following steps:
1. Uses AST to parse the source code in `great_expectations/`; the result is a mapping between function/class definition and the origin file of that symbol
2. Parses all markdown files in `docs/`, using regex to find any Docusaurus links (i.e. ```python file=...#L10-20)
3. Evaluates each linked file using AST and leverages the definition map from step #1 to determine which source files are relevant to docs under test
The resulting output list is all of the dependencies `docs/` has on the primary `great_expectations/` directory.
If a change is identified in any of these files during the pipeline runtime, we know that a docs dependency has possibly
been impacted and the pipeline should run to ensure adequate test coverage.
"""
import ast
import glob
import logging
import os
import re
from collections import defaultdict
from typing import DefaultDict, Dict, List, Set
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def parse_definition_nodes_from_source_code(directory: str) -> Dict[str, Set[str]]:
"""Utility to parse all class/function definitions from a given codebase
Args:
source_files: A list of files from the codebase
Returns:
A mapping between class/function definition and the origin of that symbol.
Using this, one can immediately tell where to look when encountering a class instance or method invocation.
"""
definition_map: Dict[str, Set[str]] = {}
for file in glob.glob(f"{directory}/**/*.py", recursive=True):
file_definition_map = parse_definition_nodes_from_file(file)
_update_dict(definition_map, file_definition_map)
return definition_map
def parse_definition_nodes_from_file(file: str) -> Dict[str, Set[str]]:
"""See `parse_definition_nodes_from_source_code`"""
with open(file) as f:
root = ast.parse(f.read(), file)
logger.debug(f"Parsing {file} for function/class definnitions")
# Parse all 'def ...' and 'class ...' statements in the source code
definition_nodes = []
for node in root.body:
if isinstance(node, (ast.FunctionDef, ast.ClassDef)):
name = node.name
definition_nodes.append(name)
logger.debug(f"Found symbol {name}")
# Associate the function/class name with the file it comes from
file_definition_map: DefaultDict[str, Set[str]] = defaultdict(set)
for name in definition_nodes:
file_definition_map[name].add(file)
logger.debug(f"Added {len(definition_nodes)} definitions to map")
return file_definition_map
def _update_dict(A: Dict[str, Set[str]], B: Dict[str, Set[str]]) -> None:
for key, val in A.items():
if key in B:
A[key] = val.union(B[key])
for key, val in B.items():
if key not in A:
A[key] = {v for v in val}
def find_docusaurus_refs_in_docs(directory: str) -> List[str]:
"""Finds any Docusaurus links within a target directory (i.e. ```python file=...#L10-20)
Args:
directory: The directory that contains your Docusaurus files (docs/)
Returns:
A list of test files that are referenced within docs under test
"""
linked_files: Set[str] = set()
for doc in glob.glob(f"{directory}/**/*.md", recursive=True):
file_refs = find_docusaurus_refs_in_file(doc)
linked_files.update(file_refs)
return sorted(linked_files)
def find_docusaurus_refs_in_file(file: str) -> Set[str]:
"""See `find_docusaurus_refs_in_docs`"""
with open(file) as f:
contents = f.read()
logger.debug(f"Reviewing {file} for Docusaurus links")
file_refs: Set[str] = set()
# Format of internal links used by Docusaurus
r = re.compile(r"```python file=([\.\/l\w]+)")
matches = r.findall(contents)
if not matches:
logger.info(f"Could not find any Docusaurs links in {file}")
return file_refs
for match in matches:
path: str = os.path.join(os.path.dirname(file), match)
# only interested in looking at .py files for now (excludes .yml files)
if path[-3:] == ".py":
file_refs.add(path)
else:
logger.info(f"Excluding {path} due to not being a .py file")
return file_refs
def determine_relevant_source_files(
files: List[str], definition_map: Dict[str, Set[str]]
) -> List[str]:
"""Uses AST to parse all symbols from an input list of files and maps them to their origins
Args:
files: List of files to evaluate with AST
definition_map: An association between symbol and the origin of that symbol in the source code
Returns:
List of source files that are relevant to the Docusaurus docs
"""
relevant_source_files = set()
for file in files:
symbols = retrieve_symbols_from_file(file)
for symbol in symbols:
paths = definition_map.get(symbol, set())
relevant_source_files.update(paths)
return sorted(relevant_source_files)
def retrieve_symbols_from_file(file: str) -> Set[str]:
"""See `retrieve_symbols_from_file`"""
with open(file) as f:
root = ast.parse(f.read(), file)
symbols = set()
for node in ast.walk(root):
# If there is a function/constructor call, make sure we pick it up
if isinstance(node, ast.Call):
func = node.func
if isinstance(func, ast.Attribute):
symbols.add(func.attr)
logger.debug(f"Identified symbol {func.attr}")
elif isinstance(func, ast.Name):
symbols.add(func.id)
logger.debug(f"Identified symbol {func.id}")
logger.debug(f"parsed {len(symbols)} symbols from {file}")
return symbols
def main() -> None:
definition_map = parse_definition_nodes_from_source_code("great_expectations")
files_referenced_in_docs = find_docusaurus_refs_in_docs("docs")
paths = determine_relevant_source_files(files_referenced_in_docs, definition_map)
for path in paths:
print(path)
if __name__ == "__main__":
main()
<file_sep>/tests/expectations/test_generate_diagnostic_checklist.py
import pytest
from tests.expectations.fixtures.expect_column_values_to_equal_three import (
ExpectColumnValuesToEqualThree,
ExpectColumnValuesToEqualThree__SecondIteration,
ExpectColumnValuesToEqualThree__ThirdIteration,
)
@pytest.mark.skip(
"This is broken because Expectation._get_execution_engine_diagnostics is broken"
)
def test_print_diagnostic_checklist__first_iteration():
output_message = ExpectColumnValuesToEqualThree().print_diagnostic_checklist()
assert (
output_message
== """\
Completeness checklist for ExpectColumnValuesToEqualThree:
library_metadata object exists
Has a docstring, including a one-line short description
Has at least one positive and negative example case, and all test cases pass
Has core logic and passes tests on at least one Execution Engine
"""
)
def test_print_diagnostic_checklist__second_iteration():
output_message = (
ExpectColumnValuesToEqualThree__SecondIteration().print_diagnostic_checklist()
)
print(output_message)
assert (
output_message
== """\
Completeness checklist for ExpectColumnValuesToEqualThree__SecondIteration (EXPERIMENTAL):
✔ Has a valid library_metadata object
✔ Has a docstring, including a one-line short description
✔ "Expect values in this column to equal the number three."
✔ Has at least one positive and negative example case, and all test cases pass
✔ Has core logic and passes tests on at least one Execution Engine
✔ All 3 tests for pandas are passing
Passes all linting checks
The snake_case of ExpectColumnValuesToEqualThree__SecondIteration (expect_column_values_to_equal_three___second_iteration) does not match filename part (expect_column_values_to_equal_three)
Has basic input validation and type checking
No validate_configuration method defined on subclass
✔ Has both statement Renderers: prescriptive and diagnostic
✔ Has core logic that passes tests for all applicable Execution Engines and SQL dialects
✔ All 3 tests for pandas are passing
Has a full suite of tests, as determined by a code owner
Has passed a manual review by a code owner for code standards and style guides
"""
)
def test_print_diagnostic_checklist__third_iteration():
output_message = (
ExpectColumnValuesToEqualThree__ThirdIteration().print_diagnostic_checklist()
)
print(output_message)
assert (
output_message
== """\
Completeness checklist for ExpectColumnValuesToEqualThree__ThirdIteration (EXPERIMENTAL):
✔ Has a valid library_metadata object
Has a docstring, including a one-line short description
✔ Has at least one positive and negative example case, and all test cases pass
✔ Has core logic and passes tests on at least one Execution Engine
✔ All 3 tests for pandas are passing
Passes all linting checks
The snake_case of ExpectColumnValuesToEqualThree__ThirdIteration (expect_column_values_to_equal_three___third_iteration) does not match filename part (expect_column_values_to_equal_three)
Has basic input validation and type checking
No validate_configuration method defined on subclass
✔ Has both statement Renderers: prescriptive and diagnostic
✔ Has core logic that passes tests for all applicable Execution Engines and SQL dialects
✔ All 3 tests for pandas are passing
Has a full suite of tests, as determined by a code owner
Has passed a manual review by a code owner for code standards and style guides
"""
)
<file_sep>/docs/guides/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.md
---
title: How to host and share Data Docs on GCS
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '/docs/term_tags/_tag.mdx';
This guide will explain how to host and share <TechnicalTag relative="../../../" tag="data_docs" text="Data Docs" /> on Google Cloud Storage. We recommend using IP-based access, which is achieved by deploying a simple Google App Engine app. Data Docs can also be served on Google Cloud Storage if the contents of the bucket are set to be publicly readable, but this is strongly discouraged.
<Prerequisites>
- [Set up a Google Cloud project](https://cloud.google.com/resource-manager/docs/creating-managing-projects)
- [Installed and initialized the Google Cloud SDK (in order to use the gcloud CLI)](https://cloud.google.com/sdk/docs/quickstarts)
- [Set up the gsutil command line tool](https://cloud.google.com/storage/docs/gsutil_install)
- Have permissions to: list and create buckets, deploy Google App Engine apps, add app firewall rules
</Prerequisites>
## Steps
### 1. Create a Google Cloud Storage bucket using gsutil
Make sure you modify the project name, bucket name, and region for your situation.
```bash file=../../../../tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py#L37
```
```bash file=../../../../tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py#L54
```
### 2. Create a directory for your Google App Engine app and add the following files
We recommend placing it in your project directory, for example ``great_expectations/team_gcs_app``.
**app.yaml:**
```yaml file=../../../../tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py#L63-L65
```
**requirements.txt:**
```yaml file=../../../../tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py#L79-L80
```
**main.py:**
```python file=../../../../tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py#L89-L118
```
### 3. If you haven't done so already, authenticate the gcloud CLI and set the project
```bash file=../../../../tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py#L125
```
### 4. Deploy your Google App Engine app
Issue the following <TechnicalTag relative="../../../" tag="cli" text="CLI" /> command from within the app directory created above:
```bash file=../../../../tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py#L131
```
### 5. Set up Google App Engine firewall for your app to control access
Visit the following page for instructions on creating firewall rules: [Creating firewall rules](https://cloud.google.com/appengine/docs/standard/python3/creating-firewalls)
### 6. Add a new GCS site to the data_docs_sites section of your great_expectations.yml
You may also replace the default ``local_site`` if you would only like to maintain a single GCS Data Docs site.
```yaml file=../../../../tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py#L140-L156
```
### 7. Build the GCS Data Docs site
Use the following CLI command:
```bash file=../../../../tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py#L176
```
If successful, the CLI will provide the object URL of the index page. Since the bucket is not public, this URL will be inaccessible. Rather, you will access the Data Docs site using the App Engine app configured above.
```bash file=../../../../tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py#L187-L194
```
### 8. Test that everything was configured properly by launching your App Engine app
Issue the following CLI command: ``gcloud app browse``. If successful, the gcloud CLI will provide the URL to your app and launch it in a new browser window. The page displayed should be the index page of your Data Docs site.
## Additional notes
- If you wish to host a Data Docs site through a private DNS, you can configure a ``base_public_path`` for the <TechnicalTag relative="../../../" tag="data_docs_store" text="Data Docs Store" />. The following example will configure a GCS site with the ``base_public_path`` set to www.mydns.com . Data Docs will still be written to the configured location on GCS (for example https://storage.cloud.google.com/my_org_data_docs/index.html), but you will be able to access the pages from your DNS (http://www.mydns.com/index.html in our example).
```yaml
data_docs_sites:
gs_site: # this is a user-selected name - you may select your own
class_name: SiteBuilder
store_backend:
class_name: TupleGCSStoreBackend
project: <YOUR GCP PROJECT NAME>
bucket: <YOUR GCS BUCKET NAME>
base_public_path: http://www.mydns.com
site_index_builder:
class_name: DefaultSiteIndexBuilder
```
## Additional resources
- [Google App Engine](https://cloud.google.com/appengine/docs/standard/python3)
- [Controlling App Access with Firewalls](https://cloud.google.com/appengine/docs/standard/python3/creating-firewalls)
- <TechnicalTag tag="data_docs" text="Data Docs"/>
- To view the full script used in this page, see it on GitHub: [how_to_host_and_share_data_docs_on_gcs.py](https://github.com/great-expectations/great_expectations/tree/develop/tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py)
<file_sep>/great_expectations/self_check/util.py
from __future__ import annotations
import copy
import locale
import logging
import os
import platform
import random
import re
import string
import threading
import time
import traceback
import warnings
from functools import wraps
from types import ModuleType
from typing import (
TYPE_CHECKING,
Dict,
Iterable,
List,
Optional,
Tuple,
Type,
Union,
cast,
)
import numpy as np
import pandas as pd
from dateutil.parser import parse
from great_expectations.core import (
ExpectationConfigurationSchema,
ExpectationSuite,
ExpectationSuiteSchema,
ExpectationSuiteValidationResultSchema,
ExpectationValidationResultSchema,
)
from great_expectations.core.batch import Batch, BatchDefinition
from great_expectations.core.expectation_diagnostics.expectation_test_data_cases import (
ExpectationTestCase,
ExpectationTestDataCases,
)
from great_expectations.core.expectation_diagnostics.supporting_types import (
ExpectationExecutionEngineDiagnostics,
)
from great_expectations.core.util import (
get_or_create_spark_application,
get_sql_dialect_floating_point_infinity_value,
)
# from great_expectations.data_context.data_context import DataContext
from great_expectations.dataset import PandasDataset, SparkDFDataset, SqlAlchemyDataset
from great_expectations.exceptions.exceptions import (
InvalidExpectationConfigurationError,
MetricProviderError,
MetricResolutionError,
)
from great_expectations.execution_engine import (
PandasExecutionEngine,
SparkDFExecutionEngine,
SqlAlchemyExecutionEngine,
)
from great_expectations.execution_engine.sparkdf_batch_data import SparkDFBatchData
from great_expectations.execution_engine.sqlalchemy_batch_data import (
SqlAlchemyBatchData,
)
from great_expectations.profile import ColumnsExistProfiler
from great_expectations.util import import_library_module
from great_expectations.validator.validator import Validator
if TYPE_CHECKING:
from sqlalchemy.engine import Connection
from great_expectations.data_context import DataContext
expectationValidationResultSchema = ExpectationValidationResultSchema()
expectationSuiteValidationResultSchema = ExpectationSuiteValidationResultSchema()
expectationConfigurationSchema = ExpectationConfigurationSchema()
expectationSuiteSchema = ExpectationSuiteSchema()
logger = logging.getLogger(__name__)
try:
import sqlalchemy as sqlalchemy
from sqlalchemy import create_engine
# noinspection PyProtectedMember
from sqlalchemy.engine import Engine
from sqlalchemy.exc import SQLAlchemyError
except ImportError:
sqlalchemy = None
create_engine = None
Engine = None
SQLAlchemyError = None
logger.debug("Unable to load SqlAlchemy or one of its subclasses.")
try:
from pyspark.sql import DataFrame as SparkDataFrame
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType
except ImportError:
SparkDataFrame = type(None)
SparkSession = None
StructType = None
try:
from pyspark.sql import DataFrame as spark_DataFrame
except ImportError:
spark_DataFrame = type(None)
try:
import sqlalchemy.dialects.sqlite as sqlitetypes
# noinspection PyPep8Naming
from sqlalchemy.dialects.sqlite import dialect as sqliteDialect
SQLITE_TYPES = {
"VARCHAR": sqlitetypes.VARCHAR,
"CHAR": sqlitetypes.CHAR,
"INTEGER": sqlitetypes.INTEGER,
"SMALLINT": sqlitetypes.SMALLINT,
"DATETIME": sqlitetypes.DATETIME(truncate_microseconds=True),
"DATE": sqlitetypes.DATE,
"FLOAT": sqlitetypes.FLOAT,
"BOOLEAN": sqlitetypes.BOOLEAN,
"TIMESTAMP": sqlitetypes.TIMESTAMP,
}
except (ImportError, KeyError):
sqlitetypes = None
sqliteDialect = None
SQLITE_TYPES = {}
_BIGQUERY_MODULE_NAME = "sqlalchemy_bigquery"
try:
# noinspection PyPep8Naming
import sqlalchemy_bigquery as sqla_bigquery
import sqlalchemy_bigquery as BigQueryDialect
sqlalchemy.dialects.registry.register("bigquery", _BIGQUERY_MODULE_NAME, "dialect")
bigquery_types_tuple = None
BIGQUERY_TYPES = {
"INTEGER": sqla_bigquery.INTEGER,
"NUMERIC": sqla_bigquery.NUMERIC,
"STRING": sqla_bigquery.STRING,
"BIGNUMERIC": sqla_bigquery.BIGNUMERIC,
"BYTES": sqla_bigquery.BYTES,
"BOOL": sqla_bigquery.BOOL,
"BOOLEAN": sqla_bigquery.BOOLEAN,
"TIMESTAMP": sqla_bigquery.TIMESTAMP,
"TIME": sqla_bigquery.TIME,
"FLOAT": sqla_bigquery.FLOAT,
"DATE": sqla_bigquery.DATE,
"DATETIME": sqla_bigquery.DATETIME,
}
try:
from sqlalchemy_bigquery import GEOGRAPHY
BIGQUERY_TYPES["GEOGRAPHY"] = GEOGRAPHY
except ImportError:
# BigQuery GEOGRAPHY support is optional
pass
except ImportError:
try:
import pybigquery.sqlalchemy_bigquery as sqla_bigquery
import pybigquery.sqlalchemy_bigquery as BigQueryDialect
# deprecated-v0.14.7
warnings.warn(
"The pybigquery package is obsolete and its usage within Great Expectations is deprecated as of v0.14.7. "
"As support will be removed in v0.17, please transition to sqlalchemy-bigquery",
DeprecationWarning,
)
_BIGQUERY_MODULE_NAME = "pybigquery.sqlalchemy_bigquery"
# Sometimes "pybigquery.sqlalchemy_bigquery" fails to self-register in Azure (our CI/CD pipeline) in certain cases, so we do it explicitly.
# (see https://stackoverflow.com/questions/53284762/nosuchmoduleerror-cant-load-plugin-sqlalchemy-dialectssnowflake)
sqlalchemy.dialects.registry.register(
"bigquery", _BIGQUERY_MODULE_NAME, "dialect"
)
try:
getattr(sqla_bigquery, "INTEGER")
bigquery_types_tuple: Dict = {} # type: ignore[no-redef]
BIGQUERY_TYPES = {
"INTEGER": sqla_bigquery.INTEGER,
"NUMERIC": sqla_bigquery.NUMERIC,
"STRING": sqla_bigquery.STRING,
"BIGNUMERIC": sqla_bigquery.BIGNUMERIC,
"BYTES": sqla_bigquery.BYTES,
"BOOL": sqla_bigquery.BOOL,
"BOOLEAN": sqla_bigquery.BOOLEAN,
"TIMESTAMP": sqla_bigquery.TIMESTAMP,
"TIME": sqla_bigquery.TIME,
"FLOAT": sqla_bigquery.FLOAT,
"DATE": sqla_bigquery.DATE,
"DATETIME": sqla_bigquery.DATETIME,
}
except AttributeError:
# In older versions of the pybigquery driver, types were not exported, so we use a hack
logger.warning(
"Old pybigquery driver version detected. Consider upgrading to 0.4.14 or later."
)
from collections import namedtuple
BigQueryTypes = namedtuple("BigQueryTypes", sorted(sqla_bigquery._type_map)) # type: ignore[misc]
bigquery_types_tuple = BigQueryTypes(**sqla_bigquery._type_map)
BIGQUERY_TYPES = {}
except (ImportError, AttributeError):
sqla_bigquery = None
bigquery_types_tuple = None
BigQueryDialect = None
pybigquery = None
BIGQUERY_TYPES = {}
try:
import sqlalchemy.dialects.postgresql as postgresqltypes
from sqlalchemy.dialects.postgresql import dialect as postgresqlDialect
POSTGRESQL_TYPES = {
"TEXT": postgresqltypes.TEXT,
"CHAR": postgresqltypes.CHAR,
"INTEGER": postgresqltypes.INTEGER,
"SMALLINT": postgresqltypes.SMALLINT,
"BIGINT": postgresqltypes.BIGINT,
"TIMESTAMP": postgresqltypes.TIMESTAMP,
"DATE": postgresqltypes.DATE,
"DOUBLE_PRECISION": postgresqltypes.DOUBLE_PRECISION,
"BOOLEAN": postgresqltypes.BOOLEAN,
"NUMERIC": postgresqltypes.NUMERIC,
}
except (ImportError, KeyError):
postgresqltypes = None
postgresqlDialect = None
POSTGRESQL_TYPES = {}
try:
import sqlalchemy.dialects.mysql as mysqltypes
# noinspection PyPep8Naming
from sqlalchemy.dialects.mysql import dialect as mysqlDialect
MYSQL_TYPES = {
"TEXT": mysqltypes.TEXT,
"CHAR": mysqltypes.CHAR,
"INTEGER": mysqltypes.INTEGER,
"SMALLINT": mysqltypes.SMALLINT,
"BIGINT": mysqltypes.BIGINT,
"DATETIME": mysqltypes.DATETIME,
"TIMESTAMP": mysqltypes.TIMESTAMP,
"DATE": mysqltypes.DATE,
"FLOAT": mysqltypes.FLOAT,
"DOUBLE": mysqltypes.DOUBLE,
"BOOLEAN": mysqltypes.BOOLEAN,
"TINYINT": mysqltypes.TINYINT,
}
except (ImportError, KeyError):
mysqltypes = None
mysqlDialect = None
MYSQL_TYPES = {}
try:
# SQLAlchemy does not export the "INT" type for the MS SQL Server dialect; however "INT" is supported by the engine.
# Since SQLAlchemy exports the "INTEGER" type for the MS SQL Server dialect, alias "INT" to the "INTEGER" type.
import sqlalchemy.dialects.mssql as mssqltypes
# noinspection PyPep8Naming
from sqlalchemy.dialects.mssql import dialect as mssqlDialect
try:
getattr(mssqltypes, "INT")
except AttributeError:
mssqltypes.INT = mssqltypes.INTEGER
MSSQL_TYPES = {
"BIGINT": mssqltypes.BIGINT,
"BINARY": mssqltypes.BINARY,
"BIT": mssqltypes.BIT,
"CHAR": mssqltypes.CHAR,
"DATE": mssqltypes.DATE,
"DATETIME": mssqltypes.DATETIME,
"DATETIME2": mssqltypes.DATETIME2,
"DATETIMEOFFSET": mssqltypes.DATETIMEOFFSET,
"DECIMAL": mssqltypes.DECIMAL,
"FLOAT": mssqltypes.FLOAT,
"IMAGE": mssqltypes.IMAGE,
"INT": mssqltypes.INT,
"INTEGER": mssqltypes.INTEGER,
"MONEY": mssqltypes.MONEY,
"NCHAR": mssqltypes.NCHAR,
"NTEXT": mssqltypes.NTEXT,
"NUMERIC": mssqltypes.NUMERIC,
"NVARCHAR": mssqltypes.NVARCHAR,
"REAL": mssqltypes.REAL,
"SMALLDATETIME": mssqltypes.SMALLDATETIME,
"SMALLINT": mssqltypes.SMALLINT,
"SMALLMONEY": mssqltypes.SMALLMONEY,
"SQL_VARIANT": mssqltypes.SQL_VARIANT,
"TEXT": mssqltypes.TEXT,
"TIME": mssqltypes.TIME,
"TIMESTAMP": mssqltypes.TIMESTAMP,
"TINYINT": mssqltypes.TINYINT,
"UNIQUEIDENTIFIER": mssqltypes.UNIQUEIDENTIFIER,
"VARBINARY": mssqltypes.VARBINARY,
"VARCHAR": mssqltypes.VARCHAR,
}
except (ImportError, KeyError):
mssqltypes = None
mssqlDialect = None
MSSQL_TYPES = {}
try:
import trino
import trino.sqlalchemy.datatype as trinotypes
from trino.sqlalchemy.dialect import TrinoDialect as trinoDialect
TRINO_TYPES = {
"BOOLEAN": trinotypes._type_map["boolean"],
"TINYINT": trinotypes._type_map["tinyint"],
"SMALLINT": trinotypes._type_map["smallint"],
"INT": trinotypes._type_map["int"],
"INTEGER": trinotypes._type_map["integer"],
"BIGINT": trinotypes._type_map["bigint"],
"REAL": trinotypes._type_map["real"],
"DOUBLE": trinotypes._type_map["double"],
"DECIMAL": trinotypes._type_map["decimal"],
"VARCHAR": trinotypes._type_map["varchar"],
"CHAR": trinotypes._type_map["char"],
"VARBINARY": trinotypes._type_map["varbinary"],
"JSON": trinotypes._type_map["json"],
"DATE": trinotypes._type_map["date"],
"TIME": trinotypes._type_map["time"],
"TIMESTAMP": trinotypes._type_map["timestamp"],
}
except (ImportError, KeyError):
trino = None
trinotypes = None
trinoDialect = None
TRINO_TYPES = {}
try:
import sqlalchemy_redshift.dialect as redshifttypes
import sqlalchemy_redshift.dialect as redshiftDialect
REDSHIFT_TYPES = {
"BIGINT": redshifttypes.BIGINT,
"BOOLEAN": redshifttypes.BOOLEAN,
"CHAR": redshifttypes.CHAR,
"DATE": redshifttypes.DATE,
"DECIMAL": redshifttypes.DECIMAL,
"DOUBLE_PRECISION": redshifttypes.DOUBLE_PRECISION,
"FOREIGN_KEY_RE": redshifttypes.FOREIGN_KEY_RE,
"GEOMETRY": redshifttypes.GEOMETRY,
"INTEGER": redshifttypes.INTEGER,
"PRIMARY_KEY_RE": redshifttypes.PRIMARY_KEY_RE,
"REAL": redshifttypes.REAL,
"SMALLINT": redshifttypes.SMALLINT,
"TIMESTAMP": redshifttypes.TIMESTAMP,
"TIMESTAMPTZ": redshifttypes.TIMESTAMPTZ,
"TIMETZ": redshifttypes.TIMETZ,
"VARCHAR": redshifttypes.VARCHAR,
}
except (ImportError, KeyError):
redshifttypes = None
redshiftDialect = None
REDSHIFT_TYPES = {}
try:
import snowflake.sqlalchemy.custom_types as snowflaketypes
import snowflake.sqlalchemy.snowdialect
import snowflake.sqlalchemy.snowdialect as snowflakeDialect
# Sometimes "snowflake-sqlalchemy" fails to self-register in certain environments, so we do it explicitly.
# (see https://stackoverflow.com/questions/53284762/nosuchmoduleerror-cant-load-plugin-sqlalchemy-dialectssnowflake)
sqlalchemy.dialects.registry.register(
"snowflake", "snowflake.sqlalchemy", "dialect"
)
SNOWFLAKE_TYPES = {
"ARRAY": snowflaketypes.ARRAY,
"BYTEINT": snowflaketypes.BYTEINT,
"CHARACTER": snowflaketypes.CHARACTER,
"DEC": snowflaketypes.DEC,
"DOUBLE": snowflaketypes.DOUBLE,
"FIXED": snowflaketypes.FIXED,
"NUMBER": snowflaketypes.NUMBER,
"OBJECT": snowflaketypes.OBJECT,
"STRING": snowflaketypes.STRING,
"TEXT": snowflaketypes.TEXT,
"TIMESTAMP_LTZ": snowflaketypes.TIMESTAMP_LTZ,
"TIMESTAMP_NTZ": snowflaketypes.TIMESTAMP_NTZ,
"TIMESTAMP_TZ": snowflaketypes.TIMESTAMP_TZ,
"TINYINT": snowflaketypes.TINYINT,
"VARBINARY": snowflaketypes.VARBINARY,
"VARIANT": snowflaketypes.VARIANT,
}
except (ImportError, KeyError, AttributeError):
snowflake = None
snowflaketypes = None
snowflakeDialect = None
SNOWFLAKE_TYPES = {}
try:
import pyathena.sqlalchemy_athena
from pyathena.sqlalchemy_athena import AthenaDialect as athenaDialect
from pyathena.sqlalchemy_athena import types as athenatypes
# athenatypes is just `from sqlalchemy import types`
# https://github.com/laughingman7743/PyAthena/blob/master/pyathena/sqlalchemy_athena.py#L692
# - the _get_column_type method of AthenaDialect does some mapping via conditional statements
# https://github.com/laughingman7743/PyAthena/blob/master/pyathena/sqlalchemy_athena.py#L105
# - The AthenaTypeCompiler has some methods named `visit_<TYPE>`
ATHENA_TYPES = {
"BOOLEAN": athenatypes.BOOLEAN,
"FLOAT": athenatypes.FLOAT,
"DOUBLE": athenatypes.FLOAT,
"REAL": athenatypes.FLOAT,
"TINYINT": athenatypes.INTEGER,
"SMALLINT": athenatypes.INTEGER,
"INTEGER": athenatypes.INTEGER,
"INT": athenatypes.INTEGER,
"BIGINT": athenatypes.BIGINT,
"DECIMAL": athenatypes.DECIMAL,
"CHAR": athenatypes.CHAR,
"VARCHAR": athenatypes.VARCHAR,
"STRING": athenatypes.String,
"DATE": athenatypes.DATE,
"TIMESTAMP": athenatypes.TIMESTAMP,
"BINARY": athenatypes.BINARY,
"VARBINARY": athenatypes.BINARY,
"ARRAY": athenatypes.String,
"MAP": athenatypes.String,
"STRUCT": athenatypes.String,
"ROW": athenatypes.String,
"JSON": athenatypes.String,
}
except ImportError:
pyathena = None
athenatypes = None
athenaDialect = None
ATHENA_TYPES = {}
# # Others from great_expectations/dataset/sqlalchemy_dataset.py
# try:
# import sqlalchemy_dremio.pyodbc
#
# sqlalchemy.dialects.registry.register(
# "dremio", "sqlalchemy_dremio.pyodbc", "dialect"
# )
# except ImportError:
# sqlalchemy_dremio = None
#
# try:
# import teradatasqlalchemy.dialect
# import teradatasqlalchemy.types as teradatatypes
# except ImportError:
# teradatasqlalchemy = None
import tempfile
# from tests.rule_based_profiler.conftest import ATOL, RTOL
RTOL: float = 1.0e-7
ATOL: float = 5.0e-2
RX_FLOAT = re.compile(r".*\d\.\d+.*")
SQL_DIALECT_NAMES = (
"sqlite",
"postgresql",
"mysql",
"mssql",
"bigquery",
"trino",
"redshift",
# "athena",
"snowflake",
)
BACKEND_TO_ENGINE_NAME_DICT = {
"pandas": "pandas",
"spark": "spark",
}
BACKEND_TO_ENGINE_NAME_DICT.update({name: "sqlalchemy" for name in SQL_DIALECT_NAMES})
class SqlAlchemyConnectionManager:
def __init__(self) -> None:
self.lock = threading.Lock()
self._connections: Dict[str, "Connection"] = {}
def get_engine(self, connection_string):
if sqlalchemy is not None:
with self.lock:
if connection_string not in self._connections:
try:
engine = create_engine(connection_string)
conn = engine.connect()
self._connections[connection_string] = conn
except (ImportError, SQLAlchemyError):
print(
f"Unable to establish connection with {connection_string}"
)
raise
return self._connections[connection_string]
return None
connection_manager = SqlAlchemyConnectionManager()
class LockingConnectionCheck:
def __init__(self, sa, connection_string) -> None:
self.lock = threading.Lock()
self.sa = sa
self.connection_string = connection_string
self._is_valid = None
def is_valid(self):
with self.lock:
if self._is_valid is None:
try:
engine = self.sa.create_engine(self.connection_string)
conn = engine.connect()
conn.close()
self._is_valid = True
except (ImportError, self.sa.exc.SQLAlchemyError) as e:
print(f"{str(e)}")
self._is_valid = False
return self._is_valid
def get_sqlite_connection_url(sqlite_db_path):
url = "sqlite://"
if sqlite_db_path is not None:
extra_slash = ""
if platform.system() != "Windows":
extra_slash = "/"
url = f"{url}/{extra_slash}{sqlite_db_path}"
return url
def get_dataset( # noqa: C901 - 110
dataset_type,
data,
schemas=None,
profiler=ColumnsExistProfiler,
caching=True,
table_name=None,
sqlite_db_path=None,
):
"""Utility to create datasets for json-formatted tests"""
df = pd.DataFrame(data)
if dataset_type == "PandasDataset":
if schemas and "pandas" in schemas:
schema = schemas["pandas"]
pandas_schema = {}
for (key, value) in schema.items():
# Note, these are just names used in our internal schemas to build datasets *for internal tests*
# Further, some changes in pandas internal about how datetimes are created means to support pandas
# pre- 0.25, we need to explicitly specify when we want timezone.
# We will use timestamp for timezone-aware (UTC only) dates in our tests
if value.lower() in ["timestamp", "datetime64[ns, tz]"]:
df[key] = pd.to_datetime(df[key], utc=True)
continue
elif value.lower() in ["datetime", "datetime64", "datetime64[ns]"]:
df[key] = pd.to_datetime(df[key])
continue
elif value.lower() in ["date"]:
df[key] = pd.to_datetime(df[key]).dt.date
value = "object"
try:
type_ = np.dtype(value)
except TypeError:
# noinspection PyUnresolvedReferences
type_ = getattr(pd, value)()
pandas_schema[key] = type_
# pandas_schema = {key: np.dtype(value) for (key, value) in schemas["pandas"].items()}
df = df.astype(pandas_schema)
return PandasDataset(df, profiler=profiler, caching=caching)
elif dataset_type == "sqlite":
if not create_engine or not SQLITE_TYPES:
return None
engine = create_engine(get_sqlite_connection_url(sqlite_db_path=sqlite_db_path))
# Add the data to the database as a new table
sql_dtypes = {}
if (
schemas
and "sqlite" in schemas
and isinstance(engine.dialect, sqlitetypes.dialect)
):
schema = schemas["sqlite"]
sql_dtypes = {col: SQLITE_TYPES[dtype] for (col, dtype) in schema.items()}
for col in schema:
type_ = schema[col]
if type_ in ["INTEGER", "SMALLINT", "BIGINT"]:
df[col] = pd.to_numeric(df[col], downcast="signed")
elif type_ in ["FLOAT", "DOUBLE", "DOUBLE_PRECISION"]:
df[col] = pd.to_numeric(df[col])
min_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=True
)
max_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=False
)
for api_schema_type in ["api_np", "api_cast"]:
min_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=True
)
max_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=False
)
df.replace(
to_replace=[min_value_api, max_value_api],
value=[min_value_dbms, max_value_dbms],
inplace=True,
)
elif type_ in ["DATETIME", "TIMESTAMP"]:
df[col] = pd.to_datetime(df[col])
elif type_ in ["DATE"]:
df[col] = pd.to_datetime(df[col]).dt.date
if table_name is None:
table_name = generate_test_table_name()
df.to_sql(
name=table_name,
con=engine,
index=False,
dtype=sql_dtypes,
if_exists="replace",
)
# Build a SqlAlchemyDataset using that database
return SqlAlchemyDataset(
table_name, engine=engine, profiler=profiler, caching=caching
)
elif dataset_type == "postgresql":
if not create_engine or not POSTGRESQL_TYPES:
return None
# Create a new database
db_hostname = os.getenv("GE_TEST_LOCAL_DB_HOSTNAME", "localhost")
engine = connection_manager.get_engine(
f"postgresql://postgres@{db_hostname}/test_ci"
)
sql_dtypes = {}
if (
schemas
and "postgresql" in schemas
and isinstance(engine.dialect, postgresqltypes.dialect)
):
schema = schemas["postgresql"]
sql_dtypes = {
col: POSTGRESQL_TYPES[dtype] for (col, dtype) in schema.items()
}
for col in schema:
type_ = schema[col]
if type_ in ["INTEGER", "SMALLINT", "BIGINT"]:
df[col] = pd.to_numeric(df[col], downcast="signed")
elif type_ in ["FLOAT", "DOUBLE", "DOUBLE_PRECISION"]:
df[col] = pd.to_numeric(df[col])
min_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=True
)
max_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=False
)
for api_schema_type in ["api_np", "api_cast"]:
min_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=True
)
max_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=False
)
df.replace(
to_replace=[min_value_api, max_value_api],
value=[min_value_dbms, max_value_dbms],
inplace=True,
)
elif type_ in ["DATETIME", "TIMESTAMP"]:
df[col] = pd.to_datetime(df[col])
elif type_ in ["DATE"]:
df[col] = pd.to_datetime(df[col]).dt.date
if table_name is None:
table_name = generate_test_table_name()
df.to_sql(
name=table_name,
con=engine,
index=False,
dtype=sql_dtypes,
if_exists="replace",
)
# Build a SqlAlchemyDataset using that database
return SqlAlchemyDataset(
table_name, engine=engine, profiler=profiler, caching=caching
)
elif dataset_type == "mysql":
if not create_engine or not MYSQL_TYPES:
return None
db_hostname = os.getenv("GE_TEST_LOCAL_DB_HOSTNAME", "localhost")
engine = create_engine(f"mysql+pymysql://root@{db_hostname}/test_ci")
sql_dtypes = {}
if (
schemas
and "mysql" in schemas
and isinstance(engine.dialect, mysqltypes.dialect)
):
schema = schemas["mysql"]
sql_dtypes = {col: MYSQL_TYPES[dtype] for (col, dtype) in schema.items()}
for col in schema:
type_ = schema[col]
if type_ in ["INTEGER", "SMALLINT", "BIGINT"]:
df[col] = pd.to_numeric(df[col], downcast="signed")
elif type_ in ["FLOAT", "DOUBLE", "DOUBLE_PRECISION"]:
df[col] = pd.to_numeric(df[col])
min_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=True
)
max_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=False
)
for api_schema_type in ["api_np", "api_cast"]:
min_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=True
)
max_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=False
)
df.replace(
to_replace=[min_value_api, max_value_api],
value=[min_value_dbms, max_value_dbms],
inplace=True,
)
elif type_ in ["DATETIME", "TIMESTAMP"]:
df[col] = pd.to_datetime(df[col])
elif type_ in ["DATE"]:
df[col] = pd.to_datetime(df[col]).dt.date
if table_name is None:
table_name = generate_test_table_name()
df.to_sql(
name=table_name,
con=engine,
index=False,
dtype=sql_dtypes,
if_exists="replace",
)
# Will - 20210126
# For mysql we want our tests to know when a temp_table is referred to more than once in the
# same query. This has caused problems in expectations like expect_column_values_to_be_unique().
# Here we instantiate a SqlAlchemyDataset with a custom_sql, which causes a temp_table to be created,
# rather than referring the table by name.
custom_sql: str = f"SELECT * FROM {table_name}"
return SqlAlchemyDataset(
custom_sql=custom_sql, engine=engine, profiler=profiler, caching=caching
)
elif dataset_type == "bigquery":
if not create_engine:
return None
engine = _create_bigquery_engine()
if schemas and dataset_type in schemas:
schema = schemas[dataset_type]
df.columns = df.columns.str.replace(" ", "_")
if table_name is None:
table_name = generate_test_table_name()
df.to_sql(
name=table_name,
con=engine,
index=False,
if_exists="replace",
)
custom_sql = f"SELECT * FROM {_bigquery_dataset()}.{table_name}"
return SqlAlchemyDataset(
custom_sql=custom_sql, engine=engine, profiler=profiler, caching=caching
)
elif dataset_type == "trino":
if not create_engine or not TRINO_TYPES:
return None
db_hostname = os.getenv("GE_TEST_LOCAL_DB_HOSTNAME", "localhost")
engine = _create_trino_engine(db_hostname)
sql_dtypes = {}
if schemas and "trino" in schemas and isinstance(engine.dialect, trinoDialect):
schema = schemas["trino"]
sql_dtypes = {col: TRINO_TYPES[dtype] for (col, dtype) in schema.items()}
for col in schema:
type_ = schema[col]
if type_ in ["INTEGER", "SMALLINT", "BIGINT"]:
df[col] = pd.to_numeric(df[col], downcast="signed")
elif type_ in ["FLOAT", "DOUBLE", "DOUBLE_PRECISION"]:
df[col] = pd.to_numeric(df[col])
min_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=True
)
max_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=False
)
for api_schema_type in ["api_np", "api_cast"]:
min_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=True
)
max_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=False
)
df.replace(
to_replace=[min_value_api, max_value_api],
value=[min_value_dbms, max_value_dbms],
inplace=True,
)
elif type_ in ["DATETIME", "TIMESTAMP"]:
df[col] = pd.to_datetime(df[col])
elif type_ in ["DATE"]:
df[col] = pd.to_datetime(df[col]).dt.date
if table_name is None:
table_name = generate_test_table_name().lower()
df.to_sql(
name=table_name,
con=engine,
index=False,
dtype=sql_dtypes,
if_exists="replace",
method="multi",
)
# Build a SqlAlchemyDataset using that database
return SqlAlchemyDataset(
table_name, engine=engine, profiler=profiler, caching=caching
)
elif dataset_type == "mssql":
if not create_engine or not MSSQL_TYPES:
return None
db_hostname = os.getenv("GE_TEST_LOCAL_DB_HOSTNAME", "localhost")
engine = create_engine(
f"mssql+pyodbc://sa:ReallyStrongPwd1234%^&*@{db_hostname}:1433/test_ci?"
"driver=ODBC Driver 17 for SQL Server&charset=utf8&autocommit=true",
# echo=True,
)
# If "autocommit" is not desired to be on by default, then use the following pattern when explicit "autocommit"
# is desired (e.g., for temporary tables, "autocommit" is off by default, so the override option may be useful).
# engine.execute(sa.text(sql_query_string).execution_options(autocommit=True))
sql_dtypes = {}
if (
schemas
and dataset_type in schemas
and isinstance(engine.dialect, mssqltypes.dialect)
):
schema = schemas[dataset_type]
sql_dtypes = {col: MSSQL_TYPES[dtype] for (col, dtype) in schema.items()}
for col in schema:
type_ = schema[col]
if type_ in ["INTEGER", "SMALLINT", "BIGINT"]:
df[col] = pd.to_numeric(df[col], downcast="signed")
elif type_ in ["FLOAT"]:
df[col] = pd.to_numeric(df[col])
min_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=True
)
max_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=False
)
for api_schema_type in ["api_np", "api_cast"]:
min_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=True
)
max_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=False
)
df.replace(
to_replace=[min_value_api, max_value_api],
value=[min_value_dbms, max_value_dbms],
inplace=True,
)
elif type_ in ["DATETIME", "TIMESTAMP"]:
df[col] = pd.to_datetime(df[col])
elif type_ in ["DATE"]:
df[col] = pd.to_datetime(df[col]).dt.date
if table_name is None:
table_name = generate_test_table_name()
df.to_sql(
name=table_name,
con=engine,
index=False,
dtype=sql_dtypes,
if_exists="replace",
)
# Build a SqlAlchemyDataset using that database
return SqlAlchemyDataset(
table_name, engine=engine, profiler=profiler, caching=caching
)
elif dataset_type == "snowflake":
if not create_engine or not SNOWFLAKE_TYPES:
return None
engine = _create_snowflake_engine()
sql_dtypes = {}
if (
schemas
and "snowflake" in schemas
and isinstance(engine.dialect, snowflakeDialect)
):
schema = schemas["snowflake"]
sql_dtypes = {
col: SNOWFLAKE_TYPES[dtype] for (col, dtype) in schema.items()
}
for col in schema:
type_ = schema[col]
if type_ in ["INTEGER", "SMALLINT", "BIGINT"]:
df[col] = pd.to_numeric(df[col], downcast="signed")
elif type_ in ["FLOAT", "DOUBLE", "DOUBLE_PRECISION"]:
df[col] = pd.to_numeric(df[col])
min_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=True
)
max_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=False
)
for api_schema_type in ["api_np", "api_cast"]:
min_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=True
)
max_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=False
)
df.replace(
to_replace=[min_value_api, max_value_api],
value=[min_value_dbms, max_value_dbms],
inplace=True,
)
elif type_ in ["DATETIME", "TIMESTAMP"]:
df[col] = pd.to_datetime(df[col])
elif type_ in ["DATE"]:
df[col] = pd.to_datetime(df[col]).dt.date
if table_name is None:
table_name = generate_test_table_name().lower()
df.to_sql(
name=table_name,
con=engine,
index=False,
dtype=sql_dtypes,
if_exists="replace",
)
# Build a SqlAlchemyDataset using that database
return SqlAlchemyDataset(
table_name, engine=engine, profiler=profiler, caching=caching
)
elif dataset_type == "redshift":
if not create_engine or not REDSHIFT_TYPES:
return None
engine = _create_redshift_engine()
sql_dtypes = {}
if (
schemas
and "redshift" in schemas
and isinstance(engine.dialect, redshiftDialect)
):
schema = schemas["redshift"]
sql_dtypes = {col: REDSHIFT_TYPES[dtype] for (col, dtype) in schema.items()}
for col in schema:
type_ = schema[col]
if type_ in ["INTEGER", "SMALLINT", "BIGINT"]:
df[col] = pd.to_numeric(df[col], downcast="signed")
elif type_ in ["FLOAT", "DOUBLE", "DOUBLE_PRECISION"]:
df[col] = pd.to_numeric(df[col])
min_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=True
)
max_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=False
)
for api_schema_type in ["api_np", "api_cast"]:
min_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=True
)
max_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=False
)
df.replace(
to_replace=[min_value_api, max_value_api],
value=[min_value_dbms, max_value_dbms],
inplace=True,
)
elif type_ in ["DATETIME", "TIMESTAMP"]:
df[col] = pd.to_datetime(df[col])
elif type_ in ["DATE"]:
df[col] = pd.to_datetime(df[col]).dt.date
if table_name is None:
table_name = generate_test_table_name().lower()
df.to_sql(
name=table_name,
con=engine,
index=False,
dtype=sql_dtypes,
if_exists="replace",
)
# Build a SqlAlchemyDataset using that database
return SqlAlchemyDataset(
table_name, engine=engine, profiler=profiler, caching=caching
)
elif dataset_type == "athena":
if not create_engine or not ATHENA_TYPES:
return None
engine = _create_athena_engine()
sql_dtypes = {}
if (
schemas
and "athena" in schemas
and isinstance(engine.dialect, athenaDialect)
):
schema = schemas["athena"]
sql_dtypes = {col: ATHENA_TYPES[dtype] for (col, dtype) in schema.items()}
for col in schema:
type_ = schema[col]
if type_ in ["INTEGER", "SMALLINT", "BIGINT"]:
df[col] = pd.to_numeric(df[col], downcast="signed")
elif type_ in ["FLOAT", "DOUBLE", "DOUBLE_PRECISION"]:
df[col] = pd.to_numeric(df[col])
min_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=True
)
max_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=dataset_type, negative=False
)
for api_schema_type in ["api_np", "api_cast"]:
min_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=True
)
max_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=False
)
df.replace(
to_replace=[min_value_api, max_value_api],
value=[min_value_dbms, max_value_dbms],
inplace=True,
)
elif type_ in ["DATETIME", "TIMESTAMP"]:
df[col] = pd.to_datetime(df[col])
elif type_ in ["DATE"]:
df[col] = pd.to_datetime(df[col]).dt.date
if table_name is None:
table_name = generate_test_table_name().lower()
df.to_sql(
name=table_name,
con=engine,
index=False,
dtype=sql_dtypes,
if_exists="replace",
)
# Build a SqlAlchemyDataset using that database
return SqlAlchemyDataset(
table_name, engine=engine, profiler=profiler, caching=caching
)
elif dataset_type == "SparkDFDataset":
import pyspark.sql.types as sparktypes
spark_types = {
"StringType": sparktypes.StringType,
"IntegerType": sparktypes.IntegerType,
"LongType": sparktypes.LongType,
"DateType": sparktypes.DateType,
"TimestampType": sparktypes.TimestampType,
"FloatType": sparktypes.FloatType,
"DoubleType": sparktypes.DoubleType,
"BooleanType": sparktypes.BooleanType,
"DataType": sparktypes.DataType,
"NullType": sparktypes.NullType,
}
spark = get_or_create_spark_application(
spark_config={
"spark.sql.catalogImplementation": "hive",
"spark.executor.memory": "450m",
# "spark.driver.allowMultipleContexts": "true", # This directive does not appear to have any effect.
}
)
# We need to allow null values in some column types that do not support them natively, so we skip
# use of df in this case.
data_reshaped = list(
zip(*(v for _, v in data.items()))
) # create a list of rows
if schemas and "spark" in schemas:
schema = schemas["spark"]
# sometimes first method causes Spark to throw a TypeError
try:
spark_schema = sparktypes.StructType(
[
sparktypes.StructField(
column, spark_types[schema[column]](), True
)
for column in schema
]
)
# We create these every time, which is painful for testing
# However nuance around null treatment as well as the desire
# for real datetime support in tests makes this necessary
data = copy.deepcopy(data)
if "ts" in data:
print(data)
print(schema)
for col in schema:
type_ = schema[col]
if type_ in ["IntegerType", "LongType"]:
# Ints cannot be None...but None can be valid in Spark (as Null)
vals = []
for val in data[col]:
if val is None:
vals.append(val)
else:
vals.append(int(val))
data[col] = vals
elif type_ in ["FloatType", "DoubleType"]:
vals = []
for val in data[col]:
if val is None:
vals.append(val)
else:
vals.append(float(val))
data[col] = vals
elif type_ in ["DateType", "TimestampType"]:
vals = []
for val in data[col]:
if val is None:
vals.append(val)
else:
vals.append(parse(val))
data[col] = vals
# Do this again, now that we have done type conversion using the provided schema
data_reshaped = list(
zip(*(v for _, v in data.items()))
) # create a list of rows
spark_df = spark.createDataFrame(data_reshaped, schema=spark_schema)
except TypeError:
string_schema = sparktypes.StructType(
[
sparktypes.StructField(column, sparktypes.StringType())
for column in schema
]
)
spark_df = spark.createDataFrame(data_reshaped, string_schema)
for c in spark_df.columns:
spark_df = spark_df.withColumn(
c, spark_df[c].cast(spark_types[schema[c]]())
)
elif len(data_reshaped) == 0:
# if we have an empty dataset and no schema, need to assign an arbitrary type
columns = list(data.keys())
spark_schema = sparktypes.StructType(
[
sparktypes.StructField(column, sparktypes.StringType())
for column in columns
]
)
spark_df = spark.createDataFrame(data_reshaped, spark_schema)
else:
# if no schema provided, uses Spark's schema inference
columns = list(data.keys())
spark_df = spark.createDataFrame(data_reshaped, columns)
return SparkDFDataset(spark_df, profiler=profiler, caching=caching)
else:
raise ValueError(f"Unknown dataset_type {str(dataset_type)}")
def get_test_validator_with_data( # noqa: C901 - 31
execution_engine,
data,
schemas=None,
caching=True,
table_name=None,
sqlite_db_path=None,
extra_debug_info="",
debug_logger: Optional[logging.Logger] = None,
context: Optional[DataContext] = None,
):
"""Utility to create datasets for json-formatted tests."""
df = pd.DataFrame(data)
if execution_engine == "pandas":
if schemas and "pandas" in schemas:
schema = schemas["pandas"]
pandas_schema = {}
for (key, value) in schema.items():
# Note, these are just names used in our internal schemas to build datasets *for internal tests*
# Further, some changes in pandas internal about how datetimes are created means to support pandas
# pre- 0.25, we need to explicitly specify when we want timezone.
# We will use timestamp for timezone-aware (UTC only) dates in our tests
if value.lower() in ["timestamp", "datetime64[ns, tz]"]:
df[key] = pd.to_datetime(df[key], utc=True)
continue
elif value.lower() in ["datetime", "datetime64", "datetime64[ns]"]:
df[key] = pd.to_datetime(df[key])
continue
elif value.lower() in ["date"]:
df[key] = pd.to_datetime(df[key]).dt.date
value = "object"
try:
type_ = np.dtype(value)
except TypeError:
# noinspection PyUnresolvedReferences
type_ = getattr(pd, value)()
pandas_schema[key] = type_
# pandas_schema = {key: np.dtype(value) for (key, value) in schemas["pandas"].items()}
df = df.astype(pandas_schema)
if table_name is None:
# noinspection PyUnusedLocal
table_name = generate_test_table_name()
return build_pandas_validator_with_data(df=df, context=context)
elif execution_engine in SQL_DIALECT_NAMES:
if not create_engine:
return None
if table_name is None:
table_name = generate_test_table_name().lower()
result = build_sa_validator_with_data(
df=df,
sa_engine_name=execution_engine,
schemas=schemas,
caching=caching,
table_name=table_name,
sqlite_db_path=sqlite_db_path,
extra_debug_info=extra_debug_info,
debug_logger=debug_logger,
context=context,
)
return result
elif execution_engine == "spark":
import pyspark.sql.types as sparktypes
spark_types: dict = {
"StringType": sparktypes.StringType,
"IntegerType": sparktypes.IntegerType,
"LongType": sparktypes.LongType,
"DateType": sparktypes.DateType,
"TimestampType": sparktypes.TimestampType,
"FloatType": sparktypes.FloatType,
"DoubleType": sparktypes.DoubleType,
"BooleanType": sparktypes.BooleanType,
"DataType": sparktypes.DataType,
"NullType": sparktypes.NullType,
}
spark = get_or_create_spark_application(
spark_config={
"spark.sql.catalogImplementation": "hive",
"spark.executor.memory": "450m",
# "spark.driver.allowMultipleContexts": "true", # This directive does not appear to have any effect.
}
)
# We need to allow null values in some column types that do not support them natively, so we skip
# use of df in this case.
data_reshaped = list(
zip(*(v for _, v in data.items()))
) # create a list of rows
if schemas and "spark" in schemas:
schema = schemas["spark"]
# sometimes first method causes Spark to throw a TypeError
try:
spark_schema = sparktypes.StructType(
[
sparktypes.StructField(
column, spark_types[schema[column]](), True
)
for column in schema
]
)
# We create these every time, which is painful for testing
# However nuance around null treatment as well as the desire
# for real datetime support in tests makes this necessary
data = copy.deepcopy(data)
if "ts" in data:
print(data)
print(schema)
for col in schema:
type_ = schema[col]
if type_ in ["IntegerType", "LongType"]:
# Ints cannot be None...but None can be valid in Spark (as Null)
vals: List[Union[str, int, float, None]] = []
for val in data[col]:
if val is None:
vals.append(val)
else:
vals.append(int(val))
data[col] = vals
elif type_ in ["FloatType", "DoubleType"]:
vals = []
for val in data[col]:
if val is None:
vals.append(val)
else:
vals.append(float(val))
data[col] = vals
elif type_ in ["DateType", "TimestampType"]:
vals = []
for val in data[col]:
if val is None:
vals.append(val)
else:
vals.append(parse(val)) # type: ignore[arg-type]
data[col] = vals
# Do this again, now that we have done type conversion using the provided schema
data_reshaped = list(
zip(*(v for _, v in data.items()))
) # create a list of rows
spark_df = spark.createDataFrame(data_reshaped, schema=spark_schema)
except TypeError:
string_schema = sparktypes.StructType(
[
sparktypes.StructField(column, sparktypes.StringType())
for column in schema
]
)
spark_df = spark.createDataFrame(data_reshaped, string_schema)
for c in spark_df.columns:
spark_df = spark_df.withColumn(
c, spark_df[c].cast(spark_types[schema[c]]())
)
elif len(data_reshaped) == 0:
# if we have an empty dataset and no schema, need to assign an arbitrary type
columns = list(data.keys())
spark_schema = sparktypes.StructType(
[
sparktypes.StructField(column, sparktypes.StringType())
for column in columns
]
)
spark_df = spark.createDataFrame(data_reshaped, spark_schema)
else:
# if no schema provided, uses Spark's schema inference
columns = list(data.keys())
spark_df = spark.createDataFrame(data_reshaped, columns)
if table_name is None:
# noinspection PyUnusedLocal
table_name = generate_test_table_name()
return build_spark_validator_with_data(
df=spark_df, spark=spark, context=context
)
else:
raise ValueError(f"Unknown dataset_type {str(execution_engine)}")
def build_pandas_validator_with_data(
df: pd.DataFrame,
batch_definition: Optional[BatchDefinition] = None,
context: Optional[DataContext] = None,
) -> Validator:
batch = Batch(data=df, batch_definition=batch_definition)
return Validator(
execution_engine=PandasExecutionEngine(),
batches=[
batch,
],
data_context=context,
)
def build_sa_validator_with_data( # noqa: C901 - 39
df,
sa_engine_name,
schemas=None,
caching=True,
table_name=None,
sqlite_db_path=None,
extra_debug_info="",
batch_definition: Optional[BatchDefinition] = None,
debug_logger: Optional[logging.Logger] = None,
context: Optional[DataContext] = None,
):
_debug = lambda x: x # noqa: E731
if debug_logger:
_debug = lambda x: debug_logger.debug(f"(build_sa_validator_with_data) {x}") # type: ignore[union-attr] # noqa: E731
dialect_classes: Dict[str, Type] = {}
dialect_types = {}
try:
dialect_classes["sqlite"] = sqlitetypes.dialect
dialect_types["sqlite"] = SQLITE_TYPES
except AttributeError:
pass
try:
dialect_classes["postgresql"] = postgresqltypes.dialect
dialect_types["postgresql"] = POSTGRESQL_TYPES
except AttributeError:
pass
try:
dialect_classes["mysql"] = mysqltypes.dialect
dialect_types["mysql"] = MYSQL_TYPES
except AttributeError:
pass
try:
dialect_classes["mssql"] = mssqltypes.dialect
dialect_types["mssql"] = MSSQL_TYPES
except AttributeError:
pass
try:
dialect_classes["bigquery"] = sqla_bigquery.BigQueryDialect
dialect_types["bigquery"] = BIGQUERY_TYPES
except AttributeError:
pass
try:
dialect_classes["trino"] = trinoDialect
dialect_types["trino"] = TRINO_TYPES
except AttributeError:
pass
try:
dialect_classes["snowflake"] = snowflakeDialect.dialect
dialect_types["snowflake"] = SNOWFLAKE_TYPES
except AttributeError:
pass
try:
dialect_classes["redshift"] = redshiftDialect.RedshiftDialect
dialect_types["redshift"] = REDSHIFT_TYPES
except AttributeError:
pass
try:
dialect_classes["athena"] = athenaDialect
dialect_types["athena"] = ATHENA_TYPES
except AttributeError:
pass
db_hostname = os.getenv("GE_TEST_LOCAL_DB_HOSTNAME", "localhost")
if sa_engine_name == "sqlite":
engine = create_engine(get_sqlite_connection_url(sqlite_db_path))
elif sa_engine_name == "postgresql":
engine = connection_manager.get_engine(
f"postgresql://postgres@{db_hostname}/test_ci"
)
elif sa_engine_name == "mysql":
engine = create_engine(f"mysql+pymysql://root@{db_hostname}/test_ci")
elif sa_engine_name == "mssql":
engine = create_engine(
f"mssql+pyodbc://sa:ReallyStrongPwd1234%^&*@{db_hostname}:1433/test_ci?driver=ODBC Driver 17 "
"for SQL Server&charset=utf8&autocommit=true",
# echo=True,
)
elif sa_engine_name == "bigquery":
engine = _create_bigquery_engine()
elif sa_engine_name == "trino":
engine = _create_trino_engine(db_hostname)
elif sa_engine_name == "redshift":
engine = _create_redshift_engine()
elif sa_engine_name == "athena":
engine = _create_athena_engine()
elif sa_engine_name == "snowflake":
engine = _create_snowflake_engine()
else:
engine = None
# If "autocommit" is not desired to be on by default, then use the following pattern when explicit "autocommit"
# is desired (e.g., for temporary tables, "autocommit" is off by default, so the override option may be useful).
# engine.execute(sa.text(sql_query_string).execution_options(autocommit=True))
# Add the data to the database as a new table
if sa_engine_name == "bigquery":
df.columns = df.columns.str.replace(" ", "_")
sql_dtypes = {}
if (
schemas
and sa_engine_name in schemas
and isinstance(engine.dialect, dialect_classes[sa_engine_name])
):
schema = schemas[sa_engine_name]
sql_dtypes = {
col: dialect_types[sa_engine_name][dtype] for (col, dtype) in schema.items()
}
for col in schema:
type_ = schema[col]
if type_ in ["INTEGER", "SMALLINT", "BIGINT"]:
df[col] = pd.to_numeric(df[col], downcast="signed")
elif type_ in ["FLOAT", "DOUBLE", "DOUBLE_PRECISION"]:
df[col] = pd.to_numeric(df[col])
min_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=sa_engine_name, negative=True
)
max_value_dbms = get_sql_dialect_floating_point_infinity_value(
schema=sa_engine_name, negative=False
)
for api_schema_type in ["api_np", "api_cast"]:
min_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=True
)
max_value_api = get_sql_dialect_floating_point_infinity_value(
schema=api_schema_type, negative=False
)
df.replace(
to_replace=[min_value_api, max_value_api],
value=[min_value_dbms, max_value_dbms],
inplace=True,
)
elif type_ in ["DATETIME", "TIMESTAMP", "DATE"]:
df[col] = pd.to_datetime(df[col])
elif type_ in ["VARCHAR", "STRING"]:
df[col] = df[col].apply(str)
if table_name is None:
table_name = generate_test_table_name()
if sa_engine_name in [
"trino",
]:
table_name = table_name.lower()
sql_insert_method = "multi"
else:
sql_insert_method = None
_debug("Calling df.to_sql")
_start = time.time()
df.to_sql(
name=table_name,
con=engine,
index=False,
dtype=sql_dtypes,
if_exists="replace",
method=sql_insert_method,
)
_end = time.time()
_debug(
f"Took {_end - _start} seconds to df.to_sql for {sa_engine_name} {extra_debug_info}"
)
batch_data = SqlAlchemyBatchData(execution_engine=engine, table_name=table_name)
batch = Batch(data=batch_data, batch_definition=batch_definition)
execution_engine = SqlAlchemyExecutionEngine(caching=caching, engine=engine)
return Validator(
execution_engine=execution_engine,
batches=[
batch,
],
data_context=context,
)
def modify_locale(func):
@wraps(func)
def locale_wrapper(*args, **kwargs) -> None:
old_locale = locale.setlocale(locale.LC_TIME, None)
print(old_locale)
# old_locale = locale.getlocale(locale.LC_TIME) Why not getlocale? not sure
try:
new_locale = locale.setlocale(locale.LC_TIME, "en_US.UTF-8")
assert new_locale == "en_US.UTF-8"
func(*args, **kwargs)
except Exception:
raise
finally:
locale.setlocale(locale.LC_TIME, old_locale)
return locale_wrapper
def build_spark_validator_with_data(
df: Union[pd.DataFrame, SparkDataFrame],
spark: SparkSession,
batch_definition: Optional[BatchDefinition] = None,
context: Optional["DataContext"] = None,
) -> Validator:
if isinstance(df, pd.DataFrame):
df = spark.createDataFrame(
[
tuple(
None if isinstance(x, (float, int)) and np.isnan(x) else x
for x in record.tolist()
)
for record in df.to_records(index=False)
],
df.columns.tolist(),
)
batch = Batch(data=df, batch_definition=batch_definition)
execution_engine: SparkDFExecutionEngine = build_spark_engine(
spark=spark,
df=df,
batch_id=batch.id,
)
return Validator(
execution_engine=execution_engine,
batches=[
batch,
],
data_context=context,
)
def build_pandas_engine(
df: pd.DataFrame,
) -> PandasExecutionEngine:
batch = Batch(data=df)
execution_engine = PandasExecutionEngine(batch_data_dict={batch.id: batch.data})
return execution_engine
def build_sa_engine(
df: pd.DataFrame,
sa: ModuleType,
schema: Optional[str] = None,
batch_id: Optional[str] = None,
if_exists: str = "fail",
index: bool = False,
dtype: Optional[dict] = None,
) -> SqlAlchemyExecutionEngine:
table_name: str = "test"
# noinspection PyUnresolvedReferences
sqlalchemy_engine: Engine = sa.create_engine("sqlite://", echo=False)
df.to_sql(
name=table_name,
con=sqlalchemy_engine,
schema=schema,
if_exists=if_exists,
index=index,
dtype=dtype,
)
execution_engine: SqlAlchemyExecutionEngine
execution_engine = SqlAlchemyExecutionEngine(engine=sqlalchemy_engine)
batch_data = SqlAlchemyBatchData(
execution_engine=execution_engine, table_name=table_name
)
batch = Batch(data=batch_data)
if batch_id is None:
batch_id = batch.id
execution_engine = SqlAlchemyExecutionEngine(
engine=sqlalchemy_engine, batch_data_dict={batch_id: batch_data}
)
return execution_engine
# Builds a Spark Execution Engine
def build_spark_engine(
spark: SparkSession,
df: Union[pd.DataFrame, SparkDataFrame],
schema: Optional[StructType] = None,
batch_id: Optional[str] = None,
batch_definition: Optional[BatchDefinition] = None,
) -> SparkDFExecutionEngine:
if (
sum(
bool(x)
for x in [
batch_id is not None,
batch_definition is not None,
]
)
!= 1
):
raise ValueError(
"Exactly one of batch_id or batch_definition must be specified."
)
if batch_id is None:
batch_id = cast(BatchDefinition, batch_definition).id
if isinstance(df, pd.DataFrame):
if schema is None:
data: Union[pd.DataFrame, List[tuple]] = [
tuple(
None if isinstance(x, (float, int)) and np.isnan(x) else x
for x in record.tolist()
)
for record in df.to_records(index=False)
]
schema = df.columns.tolist()
else:
data = df
df = spark.createDataFrame(data=data, schema=schema)
conf: Iterable[Tuple[str, str]] = spark.sparkContext.getConf().getAll()
spark_config: Dict[str, str] = dict(conf)
execution_engine = SparkDFExecutionEngine(spark_config=spark_config)
execution_engine.load_batch_data(batch_id=batch_id, batch_data=df)
return execution_engine
def candidate_getter_is_on_temporary_notimplemented_list(context, getter):
if context in ["sqlite"]:
return getter in ["get_column_modes", "get_column_stdev"]
if context in ["postgresql", "mysql", "mssql"]:
return getter in ["get_column_modes"]
if context == "spark":
return getter in []
def candidate_test_is_on_temporary_notimplemented_list_v2_api(
context, expectation_type
):
if context in SQL_DIALECT_NAMES:
expectations_not_implemented_v2_sql = [
"expect_column_values_to_be_increasing",
"expect_column_values_to_be_decreasing",
"expect_column_values_to_match_strftime_format",
"expect_column_values_to_be_dateutil_parseable",
"expect_column_values_to_be_json_parseable",
"expect_column_values_to_match_json_schema",
"expect_column_stdev_to_be_between",
"expect_column_most_common_value_to_be_in_set",
"expect_column_bootstrapped_ks_test_p_value_to_be_greater_than",
"expect_column_parameterized_distribution_ks_test_p_value_to_be_greater_than",
"expect_column_pair_values_to_be_equal",
"expect_column_pair_values_A_to_be_greater_than_B",
"expect_select_column_values_to_be_unique_within_record",
"expect_compound_columns_to_be_unique",
"expect_multicolumn_values_to_be_unique",
"expect_column_pair_cramers_phi_value_to_be_less_than",
"expect_multicolumn_sum_to_equal",
"expect_column_value_z_scores_to_be_less_than",
]
if context in ["bigquery"]:
###
# NOTE: 202201 - Will: Expectations below are temporarily not being tested
# with BigQuery in V2 API
###
expectations_not_implemented_v2_sql.append(
"expect_column_kl_divergence_to_be_less_than"
) # TODO: unique to bigquery -- https://github.com/great-expectations/great_expectations/issues/3261
expectations_not_implemented_v2_sql.append(
"expect_column_chisquare_test_p_value_to_be_greater_than"
) # TODO: unique to bigquery -- https://github.com/great-expectations/great_expectations/issues/3261
expectations_not_implemented_v2_sql.append(
"expect_column_values_to_be_between"
) # TODO: error unique to bigquery -- https://github.com/great-expectations/great_expectations/issues/3261
expectations_not_implemented_v2_sql.append(
"expect_column_values_to_be_in_set"
) # TODO: error unique to bigquery -- https://github.com/great-expectations/great_expectations/issues/3261
expectations_not_implemented_v2_sql.append(
"expect_column_values_to_be_in_type_list"
) # TODO: error unique to bigquery -- https://github.com/great-expectations/great_expectations/issues/3261
expectations_not_implemented_v2_sql.append(
"expect_column_values_to_be_of_type"
) # TODO: error unique to bigquery -- https://github.com/great-expectations/great_expectations/issues/3261
expectations_not_implemented_v2_sql.append(
"expect_column_values_to_match_like_pattern_list"
) # TODO: error unique to bigquery -- https://github.com/great-expectations/great_expectations/issues/3261
expectations_not_implemented_v2_sql.append(
"expect_column_values_to_not_match_like_pattern_list"
) # TODO: error unique to bigquery -- https://github.com/great-expectations/great_expectations/issues/3261
return expectation_type in expectations_not_implemented_v2_sql
if context == "SparkDFDataset":
return expectation_type in [
"expect_column_values_to_be_dateutil_parseable",
"expect_column_values_to_be_json_parseable",
"expect_column_bootstrapped_ks_test_p_value_to_be_greater_than",
"expect_column_parameterized_distribution_ks_test_p_value_to_be_greater_than",
"expect_compound_columns_to_be_unique",
"expect_column_pair_cramers_phi_value_to_be_less_than",
"expect_table_row_count_to_equal_other_table",
"expect_column_value_z_scores_to_be_less_than",
]
if context == "PandasDataset":
return expectation_type in [
"expect_table_row_count_to_equal_other_table",
"expect_column_value_z_scores_to_be_less_than",
]
return False
def candidate_test_is_on_temporary_notimplemented_list_v3_api(
context, expectation_type
):
candidate_test_is_on_temporary_notimplemented_list_v3_api_trino = [
"expect_column_distinct_values_to_contain_set",
"expect_column_max_to_be_between",
"expect_column_mean_to_be_between",
"expect_column_median_to_be_between",
"expect_column_min_to_be_between",
"expect_column_most_common_value_to_be_in_set",
"expect_column_quantile_values_to_be_between",
"expect_column_sum_to_be_between",
"expect_column_kl_divergence_to_be_less_than",
"expect_column_value_lengths_to_be_between",
"expect_column_values_to_be_between",
"expect_column_values_to_be_in_set",
"expect_column_values_to_be_in_type_list",
"expect_column_values_to_be_null",
"expect_column_values_to_be_of_type",
"expect_column_values_to_be_unique",
"expect_column_values_to_match_like_pattern",
"expect_column_values_to_match_like_pattern_list",
"expect_column_values_to_match_regex",
"expect_column_values_to_match_regex_list",
"expect_column_values_to_not_be_null",
"expect_column_values_to_not_match_like_pattern",
"expect_column_values_to_not_match_like_pattern_list",
"expect_column_values_to_not_match_regex",
"expect_column_values_to_not_match_regex_list",
"expect_column_pair_values_A_to_be_greater_than_B",
"expect_column_pair_values_to_be_equal",
"expect_column_pair_values_to_be_in_set",
"expect_compound_columns_to_be_unique",
"expect_select_column_values_to_be_unique_within_record",
"expect_table_column_count_to_be_between",
"expect_table_column_count_to_equal",
"expect_table_row_count_to_be_between",
"expect_table_row_count_to_equal",
]
candidate_test_is_on_temporary_notimplemented_list_v3_api_other_sql = [
"expect_column_values_to_be_increasing",
"expect_column_values_to_be_decreasing",
"expect_column_values_to_match_strftime_format",
"expect_column_values_to_be_dateutil_parseable",
"expect_column_values_to_be_json_parseable",
"expect_column_values_to_match_json_schema",
"expect_column_stdev_to_be_between",
# "expect_column_unique_value_count_to_be_between",
# "expect_column_proportion_of_unique_values_to_be_between",
# "expect_column_most_common_value_to_be_in_set",
# "expect_column_max_to_be_between",
# "expect_column_min_to_be_between",
# "expect_column_sum_to_be_between",
# "expect_column_pair_values_A_to_be_greater_than_B",
# "expect_column_pair_values_to_be_equal",
# "expect_column_pair_values_to_be_in_set",
# "expect_multicolumn_sum_to_equal",
# "expect_compound_columns_to_be_unique",
"expect_multicolumn_values_to_be_unique",
# "expect_select_column_values_to_be_unique_within_record",
"expect_column_pair_cramers_phi_value_to_be_less_than",
"expect_column_bootstrapped_ks_test_p_value_to_be_greater_than",
"expect_column_chisquare_test_p_value_to_be_greater_than",
"expect_column_parameterized_distribution_ks_test_p_value_to_be_greater_than",
]
if context in ["trino"]:
return expectation_type in set(
candidate_test_is_on_temporary_notimplemented_list_v3_api_trino
).union(
set(candidate_test_is_on_temporary_notimplemented_list_v3_api_other_sql)
)
if context in SQL_DIALECT_NAMES:
expectations_not_implemented_v3_sql = [
"expect_column_values_to_be_increasing",
"expect_column_values_to_be_decreasing",
"expect_column_values_to_match_strftime_format",
"expect_column_values_to_be_dateutil_parseable",
"expect_column_values_to_be_json_parseable",
"expect_column_values_to_match_json_schema",
"expect_multicolumn_values_to_be_unique",
"expect_column_pair_cramers_phi_value_to_be_less_than",
"expect_column_bootstrapped_ks_test_p_value_to_be_greater_than",
"expect_column_chisquare_test_p_value_to_be_greater_than",
"expect_column_parameterized_distribution_ks_test_p_value_to_be_greater_than",
]
if context in ["bigquery"]:
###
# NOTE: 20210729 - jdimatteo: Below are temporarily not being tested
# with BigQuery. For each disabled test below, please include a link to
# a github issue tracking adding the test with BigQuery.
###
expectations_not_implemented_v3_sql.append(
"expect_column_kl_divergence_to_be_less_than" # TODO: will collect for over 60 minutes, and will not completes
)
expectations_not_implemented_v3_sql.append(
"expect_column_quantile_values_to_be_between" # TODO: will run but will add about 1hr to pipeline.
)
return expectation_type in expectations_not_implemented_v3_sql
if context == "spark":
return expectation_type in [
"expect_table_row_count_to_equal_other_table",
"expect_column_values_to_be_in_set",
"expect_column_values_to_not_be_in_set",
"expect_column_values_to_not_match_regex_list",
"expect_column_values_to_match_like_pattern",
"expect_column_values_to_not_match_like_pattern",
"expect_column_values_to_match_like_pattern_list",
"expect_column_values_to_not_match_like_pattern_list",
"expect_column_values_to_be_dateutil_parseable",
"expect_multicolumn_values_to_be_unique",
"expect_column_pair_cramers_phi_value_to_be_less_than",
"expect_column_bootstrapped_ks_test_p_value_to_be_greater_than",
"expect_column_chisquare_test_p_value_to_be_greater_than",
"expect_column_parameterized_distribution_ks_test_p_value_to_be_greater_than",
]
if context == "pandas":
return expectation_type in [
"expect_table_row_count_to_equal_other_table",
"expect_column_values_to_match_like_pattern",
"expect_column_values_to_not_match_like_pattern",
"expect_column_values_to_match_like_pattern_list",
"expect_column_values_to_not_match_like_pattern_list",
"expect_multicolumn_values_to_be_unique",
"expect_column_pair_cramers_phi_value_to_be_less_than",
"expect_column_bootstrapped_ks_test_p_value_to_be_greater_than",
"expect_column_chisquare_test_p_value_to_be_greater_than",
"expect_column_parameterized_distribution_ks_test_p_value_to_be_greater_than",
]
return False
def build_test_backends_list( # noqa: C901 - 48
include_pandas=True,
include_spark=False,
include_sqlalchemy=True,
include_sqlite=True,
include_postgresql=False,
include_mysql=False,
include_mssql=False,
include_bigquery=False,
include_aws=False,
include_trino=False,
include_azure=False,
include_redshift=False,
include_athena=False,
include_snowflake=False,
raise_exceptions_for_backends: bool = True,
) -> List[str]:
"""Attempts to identify supported backends by checking which imports are available."""
test_backends = []
if include_pandas:
test_backends += ["pandas"]
if include_spark:
try:
import pyspark # noqa: F401
from pyspark.sql import SparkSession # noqa: F401
except ImportError:
if raise_exceptions_for_backends is True:
raise ValueError(
"spark tests are requested, but pyspark is not installed"
)
else:
logger.warning(
"spark tests are requested, but pyspark is not installed"
)
else:
test_backends += ["spark"]
db_hostname = os.getenv("GE_TEST_LOCAL_DB_HOSTNAME", "localhost")
if include_sqlalchemy:
sa: Optional[ModuleType] = import_library_module(module_name="sqlalchemy")
if sa is None:
if raise_exceptions_for_backends is True:
raise ImportError(
"sqlalchemy tests are requested, but sqlalchemy in not installed"
)
else:
logger.warning(
"sqlalchemy tests are requested, but sqlalchemy in not installed"
)
return test_backends
if include_sqlite:
test_backends += ["sqlite"]
if include_postgresql:
###
# NOTE: 20190918 - JPC: Since I've had to relearn this a few times, a note here.
# SQLALCHEMY coerces postgres DOUBLE_PRECISION to float, which loses precision
# round trip compared to NUMERIC, which stays as a python DECIMAL
# Be sure to ensure that tests (and users!) understand that subtlety,
# which can be important for distributional expectations, for example.
###
connection_string = f"postgresql://postgres@{db_hostname}/test_ci"
checker = LockingConnectionCheck(sa, connection_string)
if checker.is_valid() is True:
test_backends += ["postgresql"]
else:
if raise_exceptions_for_backends is True:
raise ValueError(
f"backend-specific tests are requested, but unable to connect to the database at "
f"{connection_string}"
)
else:
logger.warning(
f"backend-specific tests are requested, but unable to connect to the database at "
f"{connection_string}"
)
if include_mysql:
try:
engine = create_engine(f"mysql+pymysql://root@{db_hostname}/test_ci")
conn = engine.connect()
conn.close()
except (ImportError, SQLAlchemyError):
if raise_exceptions_for_backends is True:
raise ImportError(
"mysql tests are requested, but unable to connect to the mysql database at "
f"'mysql+pymysql://root@{db_hostname}/test_ci'"
)
else:
logger.warning(
"mysql tests are requested, but unable to connect to the mysql database at "
f"'mysql+pymysql://root@{db_hostname}/test_ci'"
)
else:
test_backends += ["mysql"]
if include_mssql:
# noinspection PyUnresolvedReferences
try:
engine = create_engine(
f"mssql+pyodbc://sa:ReallyStrongPwd1234%^&*@{db_hostname}:1433/test_ci?"
"driver=ODBC Driver 17 for SQL Server&charset=utf8&autocommit=true",
# echo=True,
)
conn = engine.connect()
conn.close()
except (ImportError, sa.exc.SQLAlchemyError):
if raise_exceptions_for_backends is True:
raise ImportError(
"mssql tests are requested, but unable to connect to the mssql database at "
f"'mssql+pyodbc://sa:ReallyStrongPwd1234%^&*@{db_hostname}:1433/test_ci?"
"driver=ODBC Driver 17 for SQL Server&charset=utf8&autocommit=true'",
)
else:
logger.warning(
"mssql tests are requested, but unable to connect to the mssql database at "
f"'mssql+pyodbc://sa:ReallyStrongPwd1234%^&*@{db_hostname}:1433/test_ci?"
"driver=ODBC Driver 17 for SQL Server&charset=utf8&autocommit=true'",
)
else:
test_backends += ["mssql"]
if include_bigquery:
# noinspection PyUnresolvedReferences
try:
engine = _create_bigquery_engine()
conn = engine.connect()
conn.close()
except (ImportError, ValueError, sa.exc.SQLAlchemyError) as e:
if raise_exceptions_for_backends is True:
raise ImportError(
"bigquery tests are requested, but unable to connect"
) from e
else:
logger.warning(
f"bigquery tests are requested, but unable to connect; {repr(e)}"
)
else:
test_backends += ["bigquery"]
if include_redshift or include_athena:
include_aws = True
if include_aws:
# TODO need to come up with a better way to do this check.
# currently this checks the 3 default EVN variables that boto3 looks for
aws_access_key_id: Optional[str] = os.getenv("AWS_ACCESS_KEY_ID")
aws_secret_access_key: Optional[str] = os.getenv("AWS_SECRET_ACCESS_KEY")
aws_session_token: Optional[str] = os.getenv("AWS_SESSION_TOKEN")
aws_config_file: Optional[str] = os.getenv("AWS_CONFIG_FILE")
if (
not aws_access_key_id
and not aws_secret_access_key
and not aws_session_token
and not aws_config_file
):
if raise_exceptions_for_backends is True:
raise ImportError(
"AWS tests are requested, but credentials were not set up"
)
else:
logger.warning(
"AWS tests are requested, but credentials were not set up"
)
if include_trino:
# noinspection PyUnresolvedReferences
try:
engine = _create_trino_engine(db_hostname)
conn = engine.connect()
conn.close()
except (ImportError, ValueError, sa.exc.SQLAlchemyError) as e:
if raise_exceptions_for_backends is True:
raise ImportError(
"trino tests are requested, but unable to connect"
) from e
else:
logger.warning(
f"trino tests are requested, but unable to connect; {repr(e)}"
)
else:
test_backends += ["trino"]
if include_azure:
azure_credential: Optional[str] = os.getenv("AZURE_CREDENTIAL")
azure_access_key: Optional[str] = os.getenv("AZURE_ACCESS_KEY")
if not azure_access_key and not azure_credential:
if raise_exceptions_for_backends is True:
raise ImportError(
"Azure tests are requested, but credentials were not set up"
)
else:
logger.warning(
"Azure tests are requested, but credentials were not set up"
)
test_backends += ["azure"]
if include_redshift:
# noinspection PyUnresolvedReferences
try:
engine = _create_redshift_engine()
conn = engine.connect()
conn.close()
except (ImportError, ValueError, sa.exc.SQLAlchemyError) as e:
if raise_exceptions_for_backends is True:
raise ImportError(
"redshift tests are requested, but unable to connect"
) from e
else:
logger.warning(
f"redshift tests are requested, but unable to connect; {repr(e)}"
)
else:
test_backends += ["redshift"]
if include_athena:
# noinspection PyUnresolvedReferences
try:
engine = _create_athena_engine()
conn = engine.connect()
conn.close()
except (ImportError, ValueError, sa.exc.SQLAlchemyError) as e:
if raise_exceptions_for_backends is True:
raise ImportError(
"athena tests are requested, but unable to connect"
) from e
else:
logger.warning(
f"athena tests are requested, but unable to connect; {repr(e)}"
)
else:
test_backends += ["athena"]
if include_snowflake:
# noinspection PyUnresolvedReferences
try:
engine = _create_snowflake_engine()
conn = engine.connect()
conn.close()
except (ImportError, ValueError, sa.exc.SQLAlchemyError) as e:
if raise_exceptions_for_backends is True:
raise ImportError(
"snowflake tests are requested, but unable to connect"
) from e
else:
logger.warning(
f"snowflake tests are requested, but unable to connect; {repr(e)}"
)
else:
test_backends += ["snowflake"]
return test_backends
def generate_expectation_tests( # noqa: C901 - 43
expectation_type: str,
test_data_cases: List[ExpectationTestDataCases],
execution_engine_diagnostics: ExpectationExecutionEngineDiagnostics,
raise_exceptions_for_backends: bool = False,
ignore_suppress: bool = False,
ignore_only_for: bool = False,
debug_logger: Optional[logging.Logger] = None,
only_consider_these_backends: Optional[List[str]] = None,
context: Optional["DataContext"] = None,
):
"""Determine tests to run
:param expectation_type: snake_case name of the expectation type
:param test_data_cases: list of ExpectationTestDataCases that has data, tests, schemas, and backends to use
:param execution_engine_diagnostics: ExpectationExecutionEngineDiagnostics object specifying the engines the expectation is implemented for
:param raise_exceptions_for_backends: bool object that when True will raise an Exception if a backend fails to connect
:param ignore_suppress: bool object that when True will ignore the suppress_test_for list on Expectation sample tests
:param ignore_only_for: bool object that when True will ignore the only_for list on Expectation sample tests
:param debug_logger: optional logging.Logger object to use for sending debug messages to
:param only_consider_these_backends: optional list of backends to consider
:return: list of parametrized tests with loaded validators and accessible backends
"""
_debug = lambda x: x # noqa: E731
_error = lambda x: x # noqa: E731
if debug_logger:
_debug = lambda x: debug_logger.debug(f"(generate_expectation_tests) {x}") # type: ignore[union-attr] # noqa: E731
_error = lambda x: debug_logger.error(f"(generate_expectation_tests) {x}") # type: ignore[union-attr] # noqa: E731
parametrized_tests = []
if only_consider_these_backends:
only_consider_these_backends = [
backend
for backend in only_consider_these_backends
if backend in BACKEND_TO_ENGINE_NAME_DICT
]
engines_implemented = []
if execution_engine_diagnostics.PandasExecutionEngine:
engines_implemented.append("pandas")
if execution_engine_diagnostics.SparkDFExecutionEngine:
engines_implemented.append("spark")
if execution_engine_diagnostics.SqlAlchemyExecutionEngine:
engines_implemented.append("sqlalchemy")
_debug(
f"Implemented engines for {expectation_type}: {', '.join(engines_implemented)}"
)
num_test_data_cases = len(test_data_cases)
for i, d in enumerate(test_data_cases, 1):
_debug(f"test_data_case {i}/{num_test_data_cases}")
d = copy.deepcopy(d)
dialects_to_include = {}
engines_to_include = {}
# Some Expectations (mostly contrib) explicitly list test_backends/dialects to test with
if d.test_backends:
for tb in d.test_backends:
engines_to_include[tb.backend] = True
if tb.backend == "sqlalchemy":
for dialect in tb.dialects:
dialects_to_include[dialect] = True
_debug(
f"Tests specify specific backends only: engines_to_include -> {engines_to_include} dialects_to_include -> {dialects_to_include}"
)
if only_consider_these_backends:
test_backends = list(engines_to_include.keys()) + list(
dialects_to_include.keys()
)
if "sqlalchemy" in test_backends:
test_backends.extend(list(SQL_DIALECT_NAMES))
engines_to_include = {}
dialects_to_include = {}
for backend in set(test_backends) & set(only_consider_these_backends):
dialects_to_include[backend] = True
if backend in SQL_DIALECT_NAMES:
engines_to_include["sqlalchemy"] = True
else:
engines_to_include[BACKEND_TO_ENGINE_NAME_DICT[backend]] = True
else:
engines_to_include[
"pandas"
] = execution_engine_diagnostics.PandasExecutionEngine
engines_to_include[
"spark"
] = execution_engine_diagnostics.SparkDFExecutionEngine
engines_to_include[
"sqlalchemy"
] = execution_engine_diagnostics.SqlAlchemyExecutionEngine
if (
engines_to_include.get("sqlalchemy") is True
and raise_exceptions_for_backends is False
):
dialects_to_include = {dialect: True for dialect in SQL_DIALECT_NAMES}
if only_consider_these_backends:
engines_to_include = {}
dialects_to_include = {}
for backend in only_consider_these_backends:
if backend in SQL_DIALECT_NAMES:
if "sqlalchemy" in engines_implemented:
dialects_to_include[backend] = True
engines_to_include["sqlalchemy"] = True
else:
if backend == "pandas" and "pandas" in engines_implemented:
engines_to_include["pandas"] = True
elif backend == "spark" and "spark" in engines_implemented:
engines_to_include["spark"] = True
# # Ensure that there is at least 1 SQL dialect if sqlalchemy is used
# if engines_to_include.get("sqlalchemy") is True and not dialects_to_include:
# dialects_to_include["sqlite"] = True
backends = build_test_backends_list(
include_pandas=engines_to_include.get("pandas", False),
include_spark=engines_to_include.get("spark", False),
include_sqlalchemy=engines_to_include.get("sqlalchemy", False),
include_sqlite=dialects_to_include.get("sqlite", False),
include_postgresql=dialects_to_include.get("postgresql", False),
include_mysql=dialects_to_include.get("mysql", False),
include_mssql=dialects_to_include.get("mssql", False),
include_bigquery=dialects_to_include.get("bigquery", False),
include_trino=dialects_to_include.get("trino", False),
include_redshift=dialects_to_include.get("redshift", False),
include_athena=dialects_to_include.get("athena", False),
include_snowflake=dialects_to_include.get("snowflake", False),
raise_exceptions_for_backends=raise_exceptions_for_backends,
)
titles = []
only_fors = []
suppress_test_fors = []
for _test_case in d.tests:
titles.append(_test_case.title)
only_fors.append(_test_case.only_for)
suppress_test_fors.append(_test_case.suppress_test_for)
_debug(f"titles -> {titles}")
_debug(
f"only_fors -> {only_fors} suppress_test_fors -> {suppress_test_fors} only_consider_these_backends -> {only_consider_these_backends}"
)
_debug(f"backends -> {backends}")
if not backends:
_debug("No suitable backends for this test_data_case")
continue
for c in backends:
_debug(f"Getting validators with data: {c}")
tests_suppressed_for_backend = [
c in sup or ("sqlalchemy" in sup and c in SQL_DIALECT_NAMES)
if sup
else False
for sup in suppress_test_fors
]
only_fors_ok = []
for i, only_for in enumerate(only_fors):
if not only_for:
only_fors_ok.append(True)
continue
if c in only_for or (
"sqlalchemy" in only_for and c in SQL_DIALECT_NAMES
):
only_fors_ok.append(True)
else:
only_fors_ok.append(False)
if tests_suppressed_for_backend and all(tests_suppressed_for_backend):
_debug(
f"All {len(tests_suppressed_for_backend)} tests are SUPPRESSED for {c}"
)
continue
if not any(only_fors_ok):
_debug(f"No tests are allowed for {c}")
_debug(
f"c -> {c} only_fors -> {only_fors} only_fors_ok -> {only_fors_ok}"
)
continue
datasets = []
try:
if isinstance(d["data"], list):
sqlite_db_path = generate_sqlite_db_path()
for dataset in d["data"]:
datasets.append(
get_test_validator_with_data(
c,
dataset["data"],
dataset.get("schemas"),
table_name=dataset.get("dataset_name"),
sqlite_db_path=sqlite_db_path,
extra_debug_info=expectation_type,
debug_logger=debug_logger,
context=context,
)
)
validator_with_data = datasets[0]
else:
validator_with_data = get_test_validator_with_data(
c,
d["data"],
d["schemas"],
extra_debug_info=expectation_type,
debug_logger=debug_logger,
context=context,
)
except Exception as e:
_error(
f"PROBLEM with get_test_validator_with_data in backend {c} for {expectation_type} {repr(e)[:300]}"
)
# # Adding these print statements for build_gallery.py's console output
# print("\n\n[[ Problem calling get_test_validator_with_data ]]")
# print(f"expectation_type -> {expectation_type}")
# print(f"c -> {c}\ne -> {e}")
# print(f"d['data'] -> {d.get('data')}")
# print(f"d['schemas'] -> {d.get('schemas')}")
# print("DataFrame from data without any casting/conversion ->")
# print(pd.DataFrame(d.get("data")))
# print()
if "data_alt" in d and d["data_alt"] is not None:
# print("There is alternate data to try!!")
try:
if isinstance(d["data_alt"], list):
sqlite_db_path = generate_sqlite_db_path()
for dataset in d["data_alt"]:
datasets.append(
get_test_validator_with_data(
c,
dataset["data_alt"],
dataset.get("schemas"),
table_name=dataset.get("dataset_name"),
sqlite_db_path=sqlite_db_path,
extra_debug_info=expectation_type,
debug_logger=debug_logger,
context=context,
)
)
validator_with_data = datasets[0]
else:
validator_with_data = get_test_validator_with_data(
c,
d["data_alt"],
d["schemas"],
extra_debug_info=expectation_type,
debug_logger=debug_logger,
context=context,
)
except Exception:
# print(
# "\n[[ STILL Problem calling get_test_validator_with_data ]]"
# )
# print(f"expectation_type -> {expectation_type}")
# print(f"c -> {c}\ne2 -> {e2}")
# print(f"d['data_alt'] -> {d.get('data_alt')}")
# print(
# "DataFrame from data_alt without any casting/conversion ->"
# )
# print(pd.DataFrame(d.get("data_alt")))
# print()
parametrized_tests.append(
{
"expectation_type": expectation_type,
"validator_with_data": None,
"error": repr(e)[:300],
"test": None,
"backend": c,
}
)
continue
else:
# print("\n[[ The alternate data worked!! ]]\n")
pass
else:
parametrized_tests.append(
{
"expectation_type": expectation_type,
"validator_with_data": None,
"error": repr(e)[:300],
"test": None,
"backend": c,
}
)
continue
except Exception:
continue
for test in d["tests"]:
if not should_we_generate_this_test(
backend=c,
expectation_test_case=test,
ignore_suppress=ignore_suppress,
ignore_only_for=ignore_only_for,
extra_debug_info=expectation_type,
debug_logger=debug_logger,
):
continue
# Known condition: SqlAlchemy does not support allow_cross_type_comparisons
if (
"allow_cross_type_comparisons" in test["input"]
and validator_with_data
and isinstance(
validator_with_data.execution_engine.batch_manager.active_batch_data,
SqlAlchemyBatchData,
)
):
continue
parametrized_tests.append(
{
"expectation_type": expectation_type,
"validator_with_data": validator_with_data,
"test": test,
"backend": c,
}
)
return parametrized_tests
def should_we_generate_this_test(
backend: str,
expectation_test_case: ExpectationTestCase,
ignore_suppress: bool = False,
ignore_only_for: bool = False,
extra_debug_info: str = "",
debug_logger: Optional[logging.Logger] = None,
):
_debug = lambda x: x # noqa: E731
if debug_logger:
_debug = lambda x: debug_logger.debug(f"(should_we_generate_this_test) {x}") # type: ignore[union-attr] # noqa: E731
# backend will only ever be pandas, spark, or a specific SQL dialect, but sometimes
# suppress_test_for or only_for may include "sqlalchemy"
#
# There is one Expectation (expect_column_values_to_be_of_type) that has some tests that
# are only for specific versions of pandas
# - only_for can be any of: pandas, pandas_022, pandas_023, pandas>=024
# - See: https://github.com/great-expectations/great_expectations/blob/7766bb5caa4e0e5b22fa3b3a5e1f2ac18922fdeb/tests/test_definitions/test_expectations_cfe.py#L176-L185
if backend in expectation_test_case.suppress_test_for:
if ignore_suppress:
_debug(
f"Should be suppressing {expectation_test_case.title} for {backend}, but ignore_suppress is True | {extra_debug_info}"
)
return True
else:
_debug(
f"Backend {backend} is suppressed for test {expectation_test_case.title}: | {extra_debug_info}"
)
return False
if (
"sqlalchemy" in expectation_test_case.suppress_test_for
and backend in SQL_DIALECT_NAMES
):
if ignore_suppress:
_debug(
f"Should be suppressing {expectation_test_case.title} for sqlalchemy (including {backend}), but ignore_suppress is True | {extra_debug_info}"
)
return True
else:
_debug(
f"All sqlalchemy (including {backend}) is suppressed for test: {expectation_test_case.title} | {extra_debug_info}"
)
return False
if expectation_test_case.only_for is not None and expectation_test_case.only_for:
if backend not in expectation_test_case.only_for:
if (
"sqlalchemy" in expectation_test_case.only_for
and backend in SQL_DIALECT_NAMES
):
return True
elif "pandas" == backend:
major, minor, *_ = pd.__version__.split(".")
if (
"pandas_022" in expectation_test_case.only_for
or "pandas_023" in expectation_test_case.only_for
):
if major == "0" and minor in ["22", "23"]:
return True
elif "pandas>=024" in expectation_test_case.only_for:
if (major == "0" and int(minor) >= 24) or int(major) >= 1:
return True
if ignore_only_for:
_debug(
f"Should normally not run test {expectation_test_case.title} for {backend}, but ignore_only_for is True | {extra_debug_info}"
)
return True
else:
_debug(
f"Only {expectation_test_case.only_for} allowed (not {backend}) for test: {expectation_test_case.title} | {extra_debug_info}"
)
return False
return True
def sort_unexpected_values(test_value_list, result_value_list):
# check if value can be sorted; if so, sort so arbitrary ordering of results does not cause failure
if (isinstance(test_value_list, list)) & (len(test_value_list) >= 1):
# __lt__ is not implemented for python dictionaries making sorting trickier
# in our case, we will sort on the values for each key sequentially
if isinstance(test_value_list[0], dict):
test_value_list = sorted(
test_value_list,
key=lambda x: tuple(x[k] for k in list(test_value_list[0].keys())),
)
result_value_list = sorted(
result_value_list,
key=lambda x: tuple(x[k] for k in list(test_value_list[0].keys())),
)
# if python built-in class has __lt__ then sorting can always work this way
elif type(test_value_list[0].__lt__(test_value_list[0])) != type(
NotImplemented
):
test_value_list = sorted(test_value_list, key=lambda x: str(x))
result_value_list = sorted(result_value_list, key=lambda x: str(x))
return test_value_list, result_value_list
def evaluate_json_test_v2_api(data_asset, expectation_type, test) -> None:
"""
This method will evaluate the result of a test build using the Great Expectations json test format.
NOTE: Tests can be suppressed for certain data types if the test contains the Key 'suppress_test_for' with a list
of DataAsset types to suppress, such as ['SQLAlchemy', 'Pandas'].
:param data_asset: (DataAsset) A great expectations DataAsset
:param expectation_type: (string) the name of the expectation to be run using the test input
:param test: (dict) a dictionary containing information for the test to be run. The dictionary must include:
- title: (string) the name of the test
- exact_match_out: (boolean) If true, match the 'out' dictionary exactly against the result of the expectation
- in: (dict or list) a dictionary of keyword arguments to use to evaluate the expectation or a list of positional arguments
- out: (dict) the dictionary keys against which to make assertions. Unless exact_match_out is true, keys must\
come from the following list:
- success
- observed_value
- unexpected_index_list
- unexpected_list
- details
- traceback_substring (if present, the string value will be expected as a substring of the exception_traceback)
:return: None. asserts correctness of results.
"""
data_asset.set_default_expectation_argument("result_format", "COMPLETE")
data_asset.set_default_expectation_argument("include_config", False)
if "title" not in test:
raise ValueError("Invalid test configuration detected: 'title' is required.")
if "exact_match_out" not in test:
raise ValueError(
"Invalid test configuration detected: 'exact_match_out' is required."
)
if "input" not in test:
if "in" in test:
test["input"] = test["in"]
else:
raise ValueError(
"Invalid test configuration detected: 'input' is required."
)
if "output" not in test:
if "out" in test:
test["output"] = test["out"]
else:
raise ValueError(
"Invalid test configuration detected: 'output' is required."
)
# Support tests with positional arguments
if isinstance(test["input"], list):
result = getattr(data_asset, expectation_type)(*test["input"])
# As well as keyword arguments
else:
result = getattr(data_asset, expectation_type)(**test["input"])
check_json_test_result(test=test, result=result, data_asset=data_asset)
def evaluate_json_test_v3_api(validator, expectation_type, test, raise_exception=True):
"""
This method will evaluate the result of a test build using the Great Expectations json test format.
NOTE: Tests can be suppressed for certain data types if the test contains the Key 'suppress_test_for' with a list
of DataAsset types to suppress, such as ['SQLAlchemy', 'Pandas'].
:param expectation_type: (string) the name of the expectation to be run using the test input
:param test: (dict) a dictionary containing information for the test to be run. The dictionary must include:
- title: (string) the name of the test
- exact_match_out: (boolean) If true, match the 'out' dictionary exactly against the result of the expectation
- in: (dict or list) a dictionary of keyword arguments to use to evaluate the expectation or a list of positional arguments
- out: (dict) the dictionary keys against which to make assertions. Unless exact_match_out is true, keys must\
come from the following list:
- success
- observed_value
- unexpected_index_list
- unexpected_list
- details
- traceback_substring (if present, the string value will be expected as a substring of the exception_traceback)
:param raise_exception: (bool) If False, capture any failed AssertionError from the call to check_json_test_result and return with validation_result
:return: Tuple(ExpectationValidationResult, error_message, stack_trace). asserts correctness of results.
"""
expectation_suite = ExpectationSuite(
"json_test_suite", data_context=validator._data_context
)
# noinspection PyProtectedMember
validator._initialize_expectations(expectation_suite=expectation_suite)
# validator.set_default_expectation_argument("result_format", "COMPLETE")
# validator.set_default_expectation_argument("include_config", False)
if "title" not in test:
raise ValueError("Invalid test configuration detected: 'title' is required.")
if "exact_match_out" not in test:
raise ValueError(
"Invalid test configuration detected: 'exact_match_out' is required."
)
if "input" not in test:
if "in" in test:
test["input"] = test["in"]
else:
raise ValueError(
"Invalid test configuration detected: 'input' is required."
)
if "output" not in test:
if "out" in test:
test["output"] = test["out"]
else:
raise ValueError(
"Invalid test configuration detected: 'output' is required."
)
kwargs = copy.deepcopy(test["input"])
error_message = None
stack_trace = None
try:
if isinstance(test["input"], list):
result = getattr(validator, expectation_type)(*kwargs)
# As well as keyword arguments
else:
runtime_kwargs = {
"result_format": "COMPLETE",
"include_config": False,
}
runtime_kwargs.update(kwargs)
result = getattr(validator, expectation_type)(**runtime_kwargs)
except (
MetricProviderError,
MetricResolutionError,
InvalidExpectationConfigurationError,
) as e:
if raise_exception:
raise
error_message = str(e)
stack_trace = (traceback.format_exc(),)
result = None
else:
try:
check_json_test_result(
test=test,
result=result,
data_asset=validator.execution_engine.batch_manager.active_batch_data,
)
except Exception as e:
if raise_exception:
raise
error_message = str(e)
stack_trace = (traceback.format_exc(),)
return (result, error_message, stack_trace)
def check_json_test_result(test, result, data_asset=None) -> None: # noqa: C901 - 49
# We do not guarantee the order in which values are returned (e.g. Spark), so we sort for testing purposes
if "unexpected_list" in result["result"]:
if ("result" in test["output"]) and (
"unexpected_list" in test["output"]["result"]
):
(
test["output"]["result"]["unexpected_list"],
result["result"]["unexpected_list"],
) = sort_unexpected_values(
test["output"]["result"]["unexpected_list"],
result["result"]["unexpected_list"],
)
elif "unexpected_list" in test["output"]:
(
test["output"]["unexpected_list"],
result["result"]["unexpected_list"],
) = sort_unexpected_values(
test["output"]["unexpected_list"],
result["result"]["unexpected_list"],
)
if "partial_unexpected_list" in result["result"]:
if ("result" in test["output"]) and (
"partial_unexpected_list" in test["output"]["result"]
):
(
test["output"]["result"]["partial_unexpected_list"],
result["result"]["partial_unexpected_list"],
) = sort_unexpected_values(
test["output"]["result"]["partial_unexpected_list"],
result["result"]["partial_unexpected_list"],
)
elif "partial_unexpected_list" in test["output"]:
(
test["output"]["partial_unexpected_list"],
result["result"]["partial_unexpected_list"],
) = sort_unexpected_values(
test["output"]["partial_unexpected_list"],
result["result"]["partial_unexpected_list"],
)
# Determine if np.allclose(..) might be needed for float comparison
try_allclose = False
if "observed_value" in test["output"]:
if RX_FLOAT.match(repr(test["output"]["observed_value"])):
try_allclose = True
# Check results
if test["exact_match_out"] is True:
if "result" in result and "observed_value" in result["result"]:
if isinstance(result["result"]["observed_value"], (np.floating, float)):
assert np.allclose(
result["result"]["observed_value"],
expectationValidationResultSchema.load(test["output"])["result"][
"observed_value"
],
rtol=RTOL,
atol=ATOL,
), f"(RTOL={RTOL}, ATOL={ATOL}) {result['result']['observed_value']} not np.allclose to {expectationValidationResultSchema.load(test['output'])['result']['observed_value']}"
else:
assert result == expectationValidationResultSchema.load(
test["output"]
), f"{result} != {expectationValidationResultSchema.load(test['output'])}"
else:
assert result == expectationValidationResultSchema.load(
test["output"]
), f"{result} != {expectationValidationResultSchema.load(test['output'])}"
else:
# Convert result to json since our tests are reading from json so cannot easily contain richer types (e.g. NaN)
# NOTE - 20191031 - JPC - we may eventually want to change these tests as we update our view on how
# representations, serializations, and objects should interact and how much of that is shown to the user.
result = result.to_json_dict()
for key, value in test["output"].items():
# Apply our great expectations-specific test logic
if key == "success":
if isinstance(value, (np.floating, float)):
try:
assert np.allclose(
result["success"],
value,
rtol=RTOL,
atol=ATOL,
), f"(RTOL={RTOL}, ATOL={ATOL}) {result['success']} not np.allclose to {value}"
except TypeError:
assert (
result["success"] == value
), f"{result['success']} != {value}"
else:
assert result["success"] == value, f"{result['success']} != {value}"
elif key == "observed_value":
if "tolerance" in test:
if isinstance(value, dict):
assert set(result["result"]["observed_value"].keys()) == set(
value.keys()
), f"{set(result['result']['observed_value'].keys())} != {set(value.keys())}"
for k, v in value.items():
assert np.allclose(
result["result"]["observed_value"][k],
v,
rtol=test["tolerance"],
)
else:
assert np.allclose(
result["result"]["observed_value"],
value,
rtol=test["tolerance"],
)
else:
if isinstance(value, dict) and "values" in value:
try:
assert np.allclose(
result["result"]["observed_value"]["values"],
value["values"],
rtol=RTOL,
atol=ATOL,
), f"(RTOL={RTOL}, ATOL={ATOL}) {result['result']['observed_value']['values']} not np.allclose to {value['values']}"
except TypeError as e:
print(e)
assert (
result["result"]["observed_value"] == value
), f"{result['result']['observed_value']} != {value}"
elif try_allclose:
assert np.allclose(
result["result"]["observed_value"],
value,
rtol=RTOL,
atol=ATOL,
), f"(RTOL={RTOL}, ATOL={ATOL}) {result['result']['observed_value']} not np.allclose to {value}"
else:
assert (
result["result"]["observed_value"] == value
), f"{result['result']['observed_value']} != {value}"
# NOTE: This is a key used ONLY for testing cases where an expectation is legitimately allowed to return
# any of multiple possible observed_values. expect_column_values_to_be_of_type is one such expectation.
elif key == "observed_value_list":
assert result["result"]["observed_value"] in value
elif key == "unexpected_index_list":
if isinstance(data_asset, (SqlAlchemyDataset, SparkDFDataset)):
pass
elif isinstance(data_asset, (SqlAlchemyBatchData, SparkDFBatchData)):
pass
else:
assert (
result["result"]["unexpected_index_list"] == value
), f"{result['result']['unexpected_index_list']} != {value}"
elif key == "unexpected_list":
try:
assert result["result"]["unexpected_list"] == value, (
"expected "
+ str(value)
+ " but got "
+ str(result["result"]["unexpected_list"])
)
except AssertionError:
if result["result"]["unexpected_list"]:
if type(result["result"]["unexpected_list"][0]) == list:
unexpected_list_tup = [
tuple(x) for x in result["result"]["unexpected_list"]
]
assert (
unexpected_list_tup == value
), f"{unexpected_list_tup} != {value}"
else:
raise
else:
raise
elif key == "partial_unexpected_list":
assert result["result"]["partial_unexpected_list"] == value, (
"expected "
+ str(value)
+ " but got "
+ str(result["result"]["partial_unexpected_list"])
)
elif key == "unexpected_count":
pass
elif key == "details":
assert result["result"]["details"] == value
elif key == "value_counts":
for val_count in value:
assert val_count in result["result"]["details"]["value_counts"]
elif key.startswith("observed_cdf"):
if "x_-1" in key:
if key.endswith("gt"):
assert (
result["result"]["details"]["observed_cdf"]["x"][-1] > value
)
else:
assert (
result["result"]["details"]["observed_cdf"]["x"][-1]
== value
)
elif "x_0" in key:
if key.endswith("lt"):
assert (
result["result"]["details"]["observed_cdf"]["x"][0] < value
)
else:
assert (
result["result"]["details"]["observed_cdf"]["x"][0] == value
)
else:
raise ValueError(
f"Invalid test specification: unknown key {key} in 'out'"
)
elif key == "traceback_substring":
assert result["exception_info"][
"raised_exception"
], f"{result['exception_info']['raised_exception']}"
assert value in result["exception_info"]["exception_traceback"], (
"expected to find "
+ value
+ " in "
+ result["exception_info"]["exception_traceback"]
)
elif key == "expected_partition":
assert np.allclose(
result["result"]["details"]["expected_partition"]["bins"],
value["bins"],
)
assert np.allclose(
result["result"]["details"]["expected_partition"]["weights"],
value["weights"],
)
if "tail_weights" in result["result"]["details"]["expected_partition"]:
assert np.allclose(
result["result"]["details"]["expected_partition"][
"tail_weights"
],
value["tail_weights"],
)
elif key == "observed_partition":
assert np.allclose(
result["result"]["details"]["observed_partition"]["bins"],
value["bins"],
)
assert np.allclose(
result["result"]["details"]["observed_partition"]["weights"],
value["weights"],
)
if "tail_weights" in result["result"]["details"]["observed_partition"]:
assert np.allclose(
result["result"]["details"]["observed_partition"][
"tail_weights"
],
value["tail_weights"],
)
else:
raise ValueError(
f"Invalid test specification: unknown key {key} in 'out'"
)
def generate_test_table_name(
default_table_name_prefix: str = "test_data_",
) -> str:
table_name: str = default_table_name_prefix + "".join(
[random.choice(string.ascii_letters + string.digits) for _ in range(8)]
)
return table_name
def _create_bigquery_engine() -> Engine:
gcp_project = os.getenv("GE_TEST_GCP_PROJECT")
if not gcp_project:
raise ValueError(
"Environment Variable GE_TEST_GCP_PROJECT is required to run BigQuery expectation tests"
)
return create_engine(f"bigquery://{gcp_project}/{_bigquery_dataset()}")
def _bigquery_dataset() -> str:
dataset = os.getenv("GE_TEST_BIGQUERY_DATASET")
if not dataset:
raise ValueError(
"Environment Variable GE_TEST_BIGQUERY_DATASET is required to run BigQuery expectation tests"
)
return dataset
def _create_trino_engine(
hostname: str = "localhost", schema_name: str = "schema"
) -> Engine:
engine = create_engine(f"trino://test@{hostname}:8088/memory/{schema_name}")
from sqlalchemy import text
from trino.exceptions import TrinoUserError
with engine.begin() as conn:
try:
schemas = conn.execute(
text(f"show schemas from memory like {repr(schema_name)}")
).fetchall()
if (schema_name,) not in schemas:
conn.execute(text(f"create schema {schema_name}"))
except TrinoUserError:
pass
return engine
# trino_user = os.getenv("GE_TEST_TRINO_USER")
# if not trino_user:
# raise ValueError(
# "Environment Variable GE_TEST_TRINO_USER is required to run trino expectation tests."
# )
# trino_password = os.getenv("GE_TEST_TRINO_PASSWORD")
# if not trino_password:
# raise ValueError(
# "Environment Variable GE_TEST_TRINO_PASSWORD is required to run trino expectation tests."
# )
# trino_account = os.getenv("GE_TEST_TRINO_ACCOUNT")
# if not trino_account:
# raise ValueError(
# "Environment Variable GE_TEST_TRINO_ACCOUNT is required to run trino expectation tests."
# )
# trino_cluster = os.getenv("GE_TEST_TRINO_CLUSTER")
# if not trino_cluster:
# raise ValueError(
# "Environment Variable GE_TEST_TRINO_CLUSTER is required to run trino expectation tests."
# )
# return create_engine(
# f"trino://{trino_user}:{trino_password}@{trino_account}-{trino_cluster}.trino.galaxy.starburst.io:443/test_suite/test_ci"
# )
def _create_redshift_engine() -> Engine:
"""
Copied get_redshift_connection_url func from tests/test_utils.py
"""
host = os.environ.get("REDSHIFT_HOST")
port = os.environ.get("REDSHIFT_PORT")
user = os.environ.get("REDSHIFT_USERNAME")
pswd = os.environ.get("REDSHIFT_PASSWORD")
db = os.environ.get("REDSHIFT_DATABASE")
ssl = os.environ.get("REDSHIFT_SSLMODE")
if not host:
raise ValueError(
"Environment Variable REDSHIFT_HOST is required to run integration tests against Redshift"
)
if not port:
raise ValueError(
"Environment Variable REDSHIFT_PORT is required to run integration tests against Redshift"
)
if not user:
raise ValueError(
"Environment Variable REDSHIFT_USERNAME is required to run integration tests against Redshift"
)
if not pswd:
raise ValueError(
"Environment Variable REDSHIFT_PASSWORD is required to run integration tests against Redshift"
)
if not db:
raise ValueError(
"Environment Variable REDSHIFT_DATABASE is required to run integration tests against Redshift"
)
if not ssl:
raise ValueError(
"Environment Variable REDSHIFT_SSLMODE is required to run integration tests against Redshift"
)
url = f"redshift+psycopg2://{user}:{pswd}@{host}:{port}/{db}?sslmode={ssl}"
return create_engine(url)
def _create_athena_engine(db_name_env_var: str = "ATHENA_DB_NAME") -> Engine:
"""
Copied get_awsathena_connection_url and get_awsathena_db_name funcs from
tests/test_utils.py
"""
ATHENA_DB_NAME: Optional[str] = os.getenv(db_name_env_var)
ATHENA_STAGING_S3: Optional[str] = os.getenv("ATHENA_STAGING_S3")
if not ATHENA_DB_NAME:
raise ValueError(
f"Environment Variable {db_name_env_var} is required to run integration tests against AWS Athena"
)
if not ATHENA_STAGING_S3:
raise ValueError(
"Environment Variable ATHENA_STAGING_S3 is required to run integration tests against AWS Athena"
)
url = f"awsathena+rest://@athena.us-east-1.amazonaws.com/{ATHENA_DB_NAME}?s3_staging_dir={ATHENA_STAGING_S3}"
return create_engine(url)
def _create_snowflake_engine() -> Engine:
"""
Copied get_snowflake_connection_url func from tests/test_utils.py
"""
sfUser = os.environ.get("SNOWFLAKE_USER")
sfPswd = os.environ.get("SNOWFLAKE_PW")
sfAccount = os.environ.get("SNOWFLAKE_ACCOUNT")
sfDatabase = os.environ.get("SNOWFLAKE_DATABASE")
sfSchema = os.environ.get("SNOWFLAKE_SCHEMA")
sfWarehouse = os.environ.get("SNOWFLAKE_WAREHOUSE")
sfRole = os.environ.get("SNOWFLAKE_ROLE") or "PUBLIC"
url = f"snowflake://{sfUser}:{sfPswd}@{sfAccount}/{sfDatabase}/{sfSchema}?warehouse={sfWarehouse}&role={sfRole}"
return create_engine(url)
def generate_sqlite_db_path():
"""Creates a temporary directory and absolute path to an ephemeral sqlite_db within that temp directory.
Used to support testing of multi-table expectations without creating temp directories at import.
Returns:
str: An absolute path to the ephemeral db within the created temporary directory.
"""
tmp_dir = str(tempfile.mkdtemp())
abspath = os.path.abspath(
os.path.join(
tmp_dir,
"sqlite_db"
+ "".join(
[random.choice(string.ascii_letters + string.digits) for _ in range(8)]
)
+ ".db",
)
)
return abspath
<file_sep>/docs/guides/setup/configuring_data_contexts/how_to_instantiate_a_data_context_without_a_yml_file.md
---
title: How to instantiate a Data Context without a yml file
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '/docs/term_tags/_tag.mdx';
This guide will help you instantiate a <TechnicalTag tag="data_context" text="Data Context" /> without a yml file, aka configure a Data Context in code. If you are working in an environment without easy access to a local filesystem (e.g. AWS Spark EMR, Databricks, etc.) you may wish to configure your Data Context in code, within your notebook or workflow tool (e.g. Airflow DAG node).
<Prerequisites>
</Prerequisites>
:::note
- See also our companion video for this guide: [Data Contexts In Code](https://youtu.be/4VMOYpjHNhM).
:::
## Steps
### 1. **Create a DataContextConfig**
The `DataContextConfig` holds all of the associated configuration parameters to build a Data Context. There are defaults set for you to minimize configuration in typical cases, but please note that every parameter is configurable and all defaults are overridable. Also note that `DatasourceConfig` also has defaults which can be overridden.
Here we will show a few examples of common configurations, using the ``store_backend_defaults`` parameter. Note that you can use the existing API without defaults by omitting that parameter, and you can override all of the parameters as shown in the last example. A parameter set in ``DataContextConfig`` will override a parameter set in ``store_backend_defaults`` if both are used.
The following ``store_backend_defaults`` are currently available:
- `S3StoreBackendDefaults`
- `GCSStoreBackendDefaults`
- `DatabaseStoreBackendDefaults`
- `FilesystemStoreBackendDefaults`
The following example shows a Data Context configuration with an SQLAlchemy <TechnicalTag relative="../../../" tag="datasource" text="Datasource" /> and an AWS S3 bucket for all metadata <TechnicalTag relative="../../../" tag="store" text="Stores" />, using default prefixes. Note that you can still substitute environment variables as in the YAML based configuration to keep sensitive credentials out of your code.
```python
from great_expectations.data_context.types.base import DataContextConfig, DatasourceConfig, S3StoreBackendDefaults
data_context_config = DataContextConfig(
datasources={
"sql_warehouse": DatasourceConfig(
class_name="Datasource",
execution_engine={
"class_name": "SqlAlchemyExecutionEngine",
"credentials": {
"drivername": "postgresql+psycopg2",
"host": "localhost",
"port": "5432",
"username": "postgres",
"password": "<PASSWORD>",
"database": "postgres",
},
},
data_connectors={
"default_runtime_data_connector_name": {
"class_name": "RuntimeDataConnector",
"batch_identifiers": ["default_identifier_name"],
},
"default_inferred_data_connector_name": {
"class_name": "InferredAssetSqlDataConnector",
"name": "whole_table",
},
}
)
},
store_backend_defaults=S3StoreBackendDefaults(default_bucket_name="my_default_bucket"),
)
```
The following example shows a Data Context configuration with a Pandas datasource and local filesystem defaults for metadata stores. Note: imports are omitted in the following examples. Note: You may add an optional root_directory parameter to set the base location for the Store Backends.
```python
from great_expectations.data_context.types.base import DataContextConfig, DatasourceConfig, FilesystemStoreBackendDefaults
data_context_config = DataContextConfig(
datasources={
"pandas": DatasourceConfig(
class_name="Datasource",
execution_engine={
"class_name": "PandasExecutionEngine"
},
data_connectors={
"tripdata_monthly_configured": {
"class_name": "ConfiguredAssetFilesystemDataConnector",
"base_directory": "/path/to/trip_data",
"assets": {
"yellow": {
"pattern": r"yellow_tripdata_(\d{4})-(\d{2})\.csv$",
"group_names": ["year", "month"],
}
},
}
},
)
},
store_backend_defaults=FilesystemStoreBackendDefaults(root_directory="/path/to/store/location"),
)
```
The following example shows a Data Context configuration with an SQLAlchemy datasource and two GCS buckets for metadata Stores, using some custom and some default prefixes. Note that you can still substitute environment variables as in the YAML based configuration to keep sensitive credentials out of your code. `default_bucket_name`, `default_project_name` sets the default value for all stores that are not specified individually.
The resulting `DataContextConfig` from the following example creates an <TechnicalTag tag="expectation_store" text="Expectations Store" /> and <TechnicalTag relative="../../../" tag="data_docs" text="Data Docs" /> using the `my_default_bucket` and `my_default_project` parameters since their bucket and project is not specified explicitly. The <TechnicalTag tag="validation_result_store" text="Validation Results Store" /> is created using the explicitly specified `my_validations_bucket` and `my_validations_project`. Further, the prefixes are set for the Expectations Store and Validation Results Store, while Data Docs use the default `data_docs` prefix.
```python
data_context_config = DataContextConfig(
datasources={
"sql_warehouse": DatasourceConfig(
class_name="Datasource",
execution_engine={
"class_name": "SqlAlchemyExecutionEngine",
"credentials": {
"drivername": "postgresql+psycopg2",
"host": "localhost",
"port": "5432",
"username": "postgres",
"password": "<PASSWORD>",
"database": "postgres",
},
},
data_connectors={
"default_runtime_data_connector_name": {
"class_name": "RuntimeDataConnector",
"batch_identifiers": ["default_identifier_name"],
},
"default_inferred_data_connector_name": {
"class_name": "InferredAssetSqlDataConnector",
"name": "whole_table",
},
}
)
},
store_backend_defaults=GCSStoreBackendDefaults(
default_bucket_name="my_default_bucket",
default_project_name="my_default_project",
validations_store_bucket_name="my_validations_bucket",
validations_store_project_name="my_validations_project",
validations_store_prefix="my_validations_store_prefix",
expectations_store_prefix="my_expectations_store_prefix",
),
)
```
The following example sets overrides for many of the parameters available to you when creating a `DataContextConfig` and a Datasource.
```python
data_context_config = DataContextConfig(
config_version=2,
plugins_directory=None,
config_variables_file_path=None,
datasources={
"my_spark_datasource": DatasourceConfig(
class_name="Datasource",
execution_engine={
"class_name": "SparkDFExecutionEngine"
},
data_connectors={
"tripdata_monthly_configured": {
"class_name": "ConfiguredAssetFilesystemDataConnector",
"base_directory": "/path/to/trip_data",
"assets": {
"yellow": {
"pattern": r"yellow_tripdata_(\d{4})-(\d{2})\.csv$",
"group_names": ["year", "month"],
}
},
}
},
)
},
stores={
"expectations_S3_store": {
"class_name": "ExpectationsStore",
"store_backend": {
"class_name": "TupleS3StoreBackend",
"bucket": "my_expectations_store_bucket",
"prefix": "my_expectations_store_prefix",
},
},
"validations_S3_store": {
"class_name": "ValidationsStore",
"store_backend": {
"class_name": "TupleS3StoreBackend",
"bucket": "my_validations_store_bucket",
"prefix": "my_validations_store_prefix",
},
},
"evaluation_parameter_store": {"class_name": "EvaluationParameterStore"},
},
expectations_store_name="expectations_S3_store",
validations_store_name="validations_S3_store",
evaluation_parameter_store_name="evaluation_parameter_store",
data_docs_sites={
"s3_site": {
"class_name": "SiteBuilder",
"store_backend": {
"class_name": "TupleS3StoreBackend",
"bucket": "my_data_docs_bucket",
"prefix": "my_optional_data_docs_prefix",
},
"site_index_builder": {
"class_name": "DefaultSiteIndexBuilder",
"show_cta_footer": True,
},
}
},
validation_operators={
"action_list_operator": {
"class_name": "ActionListValidationOperator",
"action_list": [
{
"name": "store_validation_result",
"action": {"class_name": "StoreValidationResultAction"},
},
{
"name": "store_evaluation_params",
"action": {"class_name": "StoreEvaluationParametersAction"},
},
{
"name": "update_data_docs",
"action": {"class_name": "UpdateDataDocsAction"},
},
],
}
},
anonymous_usage_statistics={
"enabled": True
}
)
```
### 2. Pass this DataContextConfig as a project_config to BaseDataContext
```python
from great_expectations.data_context import BaseDataContext
context = BaseDataContext(project_config=data_context_config)
```
### 3. Use this BaseDataContext instance as your DataContext
If you are using Airflow, you may wish to pass this Data Context to your GreatExpectationsOperator as a parameter. See the following guide for more details:
- [Deploying Great Expectations with Airflow](../../../../docs/intro.md)
Additional resources
--------------------
- [How to instantiate a Data Context on an EMR Spark cluster](../../../deployment_patterns/how_to_instantiate_a_data_context_on_an_emr_spark_cluster.md)
- [How to use Great Expectations in Databricks](../../../deployment_patterns/how_to_use_great_expectations_in_databricks.md)
<file_sep>/docs/guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_azure_blob_storage.md
---
title: How to configure a Validation Result Store in Azure Blob Storage
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx'
By default, <TechnicalTag tag="validation_result" text="Validation Results" /> are stored in JSON format in the ``uncommitted/validations/`` subdirectory of your ``great_expectations/`` folder. Since Validation Results may include examples of data (which could be sensitive or regulated) they should not be committed to a source control system. This guide will help you configure a new storage location for Validation Results in Azure Blob Storage.
<Prerequisites>
- [Configured a Data Context](../../../tutorials/getting_started/tutorial_setup.md).
- [Configured an Expectations Suite](../../../tutorials/getting_started/tutorial_create_expectations.md).
- [Configured a Checkpoint](../../../tutorials/getting_started/tutorial_validate_data.md).
- [Configured an Azure Storage account](https://docs.microsoft.com/en-us/azure/storage) and get the [connection string](https://docs.microsoft.com/en-us/azure/storage/common/storage-account-keys-manage?tabs=azure-portal).
- Create the Azure Blob container. If you also wish to [host and share Data Docs on Azure Blob Storage](../../../guides/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_azure_blob_storage.md) then you may set up this first and then use the ``$web`` existing container to store your <TechnicalTag tag="expectation" text="Expectations" />.
- Identify the prefix (folder) where Validation Results will be stored (you don't need to create the folder, the prefix is just part of the Blob name).
</Prerequisites>
## Steps
### 1. Configure the ``config_variables.yml`` file with your Azure Storage credentials
We recommend that Azure Storage credentials be stored in the ``config_variables.yml`` file, which is located in the ``uncommitted/`` folder by default, and is not part of source control. The following lines add Azure Storage credentials under the key ``AZURE_STORAGE_CONNECTION_STRING``. Additional options for configuring the ``config_variables.yml`` file or additional environment variables can be found [here](../../setup/configuring_data_contexts/how_to_configure_credentials.md).
```yaml
AZURE_STORAGE_CONNECTION_STRING: "DefaultEndpointsProtocol=https;EndpointSuffix=core.windows.net;AccountName=<YOUR-STORAGE-ACCOUNT-NAME>;AccountKey=<YOUR-STORAGE-ACCOUNT-KEY==>"
```
### 2. Identify your Validation Results Store
As with all <TechnicalTag tag="store" text="Stores" />, you can find the configuration for your <TechnicalTag tag="validation_result_store" text="Validation Results Store" /> through your <TechnicalTag tag="data_context" text="Data Context" />. In your ``great_expectations.yml``, look for the following lines. The configuration tells Great Expectations to look for Validation Results in a store called ``validations_store``. The ``base_directory`` for ``validations_store`` is set to ``uncommitted/validations/`` by default.
```yaml
validations_store_name: validations_store
stores:
validations_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
```
### 3. Update your configuration file to include a new Store for Validation Results on Azure Storage account
In our case, the name is set to ``validations_AZ_store``, but it can be any name you like. We also need to make some changes to the ``store_backend`` settings. The ``class_name`` will be set to ``TupleAzureBlobStoreBackend``, ``container`` will be set to the name of your blob container (the equivalent of S3 bucket for Azure) you wish to store your Validation Results, ``prefix`` will be set to the folder in the container where Validation Result files will be located, and ``connection_string`` will be set to ``${AZURE_STORAGE_CONNECTION_STRING}``, which references the corresponding key in the ``config_variables.yml`` file.
```yaml
validations_store_name: validations_AZ_store
stores:
validations_AZ_store:
class_name: ValidationsStore
store_backend:
class_name: TupleAzureBlobStoreBackend
container: <blob-container>
prefix: validations
connection_string: ${AZURE_STORAGE_CONNECTION_STRING}
```
:::note
If the container is called ``$web`` (for [hosting and sharing Data Docs on Azure Blob Storage](../../setup/configuring_data_docs/how_to_host_and_share_data_docs_on_azure_blob_storage.md)) then set ``container: \$web`` so the escape char will allow us to reach the ``$web``container.
:::
:::note
Various authentication and configuration options are available as documented in [hosting and sharing Data Docs on Azure Blob Storage](../../setup/configuring_data_docs/how_to_host_and_share_data_docs_on_azure_blob_storage.md).
:::
### 4. Copy existing Validation Results JSON files to the Azure blob (This step is optional)
One way to copy Validation Results into Azure Blob Storage is by using the ``az storage blob upload`` command, which is part of the Azure SDK. The following example will copy one Validation Result from a local folder to the Azure blob. Information on other ways to copy Validation Result JSON files, like the Azure Storage browser in the Azure Portal, can be found in the [Documentation for Azure](https://docs.microsoft.com/en-us/azure/storage/blobs/storage-quickstart-blobs-portal).
```bash
export AZURE_STORAGE_CONNECTION_STRING="DefaultEndpointsProtocol=https;EndpointSuffix=core.windows.net;AccountName=<YOUR-STORAGE-ACCOUNT-NAME>;AccountKey=<YOUR-STORAGE-ACCOUNT-KEY==>"
az storage blob upload -f <local/path/to/validation.json> -c <GREAT-EXPECTATION-DEDICATED-AZURE-BLOB-CONTAINER-NAME> -n <PREFIX>/<validation.json>
example with a validation related to the exp1 expectation:
az storage blob upload -f great_expectations/uncommitted/validations/exp1/20210306T104406.877327Z/20210306T104406.877327Z/8313fb37ca59375eb843adf388d4f882.json -c <blob-container> -n validations/exp1/20210306T104406.877327Z/20210306T104406.877327Z/8313fb37ca59375eb843adf388d4f882.json
Finished[#############################################################] 100.0000%
{
"etag": "\"0x8D8E09F894650C7\"",
"lastModified": "2021-03-06T12:58:28+00:00"
}
```
### 5. Confirm that the new Validation Results Store has been added by running ``great_expectations store list``
Notice the output contains two Validation stores: the original ``validations_store`` on the local filesystem and the ``validations_AZ_store`` we just configured. This is ok, since Great Expectations will look for Validation Results in Azure Blob as long as we set the ``validations_store_name`` variable to ``validations_AZ_store``, and the config for ``validations_store`` can be removed if you would like.
```bash
great_expectations store list
- name: validations_store
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
- name: validations_AZ_store
class_name: ValidationsStore
store_backend:
class_name: TupleAzureBlobStoreBackend
connection_string: "DefaultEndpointsProtocol=https;EndpointSuffix=core.windows.net;AccountName=<YOUR-STORAGE-ACCOUNT-NAME>;AccountKey=<YOUR-STORAGE-ACCOUNT-KEY==>"
container: <blob-container>
prefix: validations
```
### 6. Confirm that the Validation Results Store has been correctly configured
[Run a Checkpoint](../../../tutorials/getting_started/tutorial_validate_data.md) to store results in the new Validation Results Store on Azure Blob then visualize the results by [re-building Data Docs](../../../terms/data_docs.md).
<file_sep>/tests/integration/test_script_runner.py
import enum
import importlib.machinery
import importlib.util
import logging
import os
import pathlib
import shutil
import sys
from dataclasses import dataclass
from typing import List, Optional, Tuple
import pkg_resources
import pytest
from assets.scripts.build_gallery import execute_shell_command
from great_expectations.data_context.util import file_relative_path
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
class BackendDependencies(enum.Enum):
AWS = "AWS"
AZURE = "AZURE"
BIGQUERY = "BIGQUERY"
GCS = "GCS"
MYSQL = "MYSQL"
MSSQL = "MSSQL"
PANDAS = "PANDAS"
POSTGRESQL = "POSTGRESQL"
REDSHIFT = "REDSHIFT"
SPARK = "SPARK"
SQLALCHEMY = "SQLALCHEMY"
SNOWFLAKE = "SNOWFLAKE"
TRINO = "TRINO"
@dataclass
class IntegrationTestFixture:
"""IntegrationTestFixture
Configurations for integration tests are defined as IntegrationTestFixture dataclass objects.
Individual tests can also be run by setting the '-k' flag and referencing the name of test, like the following example:
pytest -v --docs-tests -m integration -k "test_docs[migration_guide_spark_v2_api]" tests/integration/test_script_runner.py
Args:
name: Name for integration test. Individual tests can be run by using the -k option and specifying the name of the test.
user_flow_script: Required script for integration test.
data_context_dir: Path of great_expectations/ that is used in the test.
data_dir: Folder that contains data used in the test.
extra_backend_dependencies: Optional flag allows you to tie an individual test with a BackendDependency. Allows for tests to be run / disabled using cli flags (like --aws which enables AWS integration tests).
other_files: other files (like credential information) to copy into the test environment. These are presented as Tuple(path_to_source_file, path_to_target_file), where path_to_target_file is relative to the test_script.py file in our test environment
util_script: Path of optional util script that is used in test script (for loading test_specific methods like load_data_into_test_database())
"""
name: str
user_flow_script: str
data_context_dir: Optional[str] = None
data_dir: Optional[str] = None
extra_backend_dependencies: Optional[BackendDependencies] = None
other_files: Optional[Tuple[Tuple[str, str]]] = None
util_script: Optional[str] = None
# to be populated by the smaller lists below
docs_test_matrix: List[IntegrationTestFixture] = []
local_tests = [
IntegrationTestFixture(
name="how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
),
IntegrationTestFixture(
name="how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="getting_started",
data_context_dir="tests/integration/fixtures/yellow_tripdata_pandas_fixture/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
user_flow_script="tests/integration/docusaurus/tutorials/getting-started/getting_started.py",
),
IntegrationTestFixture(
name="how_to_get_one_or_more_batches_of_data_from_a_configured_datasource",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.py",
data_context_dir="tests/integration/fixtures/yellow_tripdata_pandas_fixture/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples",
),
IntegrationTestFixture(
name="connecting_to_your_data_pandas_yaml",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/filesystem/pandas_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
),
IntegrationTestFixture(
name="connecting_to_your_data_pandas_python",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/filesystem/pandas_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
),
IntegrationTestFixture(
name="how_to_introspect_and_partition_your_data_yaml_gradual",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/how_to_introspect_and_partition_your_data/files/yaml_example_gradual.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
),
IntegrationTestFixture(
name="how_to_introspect_and_partition_your_data_yaml_complete",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/how_to_introspect_and_partition_your_data/files/yaml_example_complete.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
),
IntegrationTestFixture(
name="in_memory_pandas_yaml",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/in_memory/pandas_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
),
IntegrationTestFixture(
name="in_memory_pandas_python",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/in_memory/pandas_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
),
IntegrationTestFixture(
name="docusaurus_template_script_example",
user_flow_script="tests/integration/docusaurus/template/script_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
),
IntegrationTestFixture(
name="in_memory_spark_yaml",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/in_memory/spark_yaml_example.py",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="in_memory_spark_python",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/in_memory/spark_python_example.py",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="filesystem_spark_yaml",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/filesystem/spark_yaml_example.py",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="filesystem_spark_python",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/filesystem/spark_python_example.py",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="how_to_choose_which_dataconnector_to_use",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/how_to_choose_which_dataconnector_to_use.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/dataconnector_docs",
),
IntegrationTestFixture(
name="how_to_configure_a_pandas_datasource",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/datasource_configuration/how_to_configure_a_pandas_datasource.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/samples_2020",
),
IntegrationTestFixture(
name="how_to_configure_a_spark_datasource",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/datasource_configuration/how_to_configure_a_spark_datasource.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/samples_2020",
),
IntegrationTestFixture(
name="how_to_configure_a_runtimedataconnector",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_runtimedataconnector.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/dataconnector_docs",
),
IntegrationTestFixture(
name="rule_base_profiler_multi_batch_example",
data_context_dir="tests/integration/fixtures/yellow_tripdata_pandas_fixture/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
user_flow_script="tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py",
),
IntegrationTestFixture(
name="databricks_deployment_patterns_file_yaml_configs",
user_flow_script="tests/integration/docusaurus/deployment_patterns/databricks_deployment_patterns_dataframe_yaml_configs.py",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="databricks_deployment_patterns_file_python_configs",
user_flow_script="tests/integration/docusaurus/deployment_patterns/databricks_deployment_patterns_dataframe_python_configs.py",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="databricks_deployment_patterns_file_yaml_configs",
user_flow_script="tests/integration/docusaurus/deployment_patterns/databricks_deployment_patterns_file_yaml_configs.py",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="databricks_deployment_patterns_file_python_configs",
user_flow_script="tests/integration/docusaurus/deployment_patterns/databricks_deployment_patterns_file_python_configs.py",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="checkpoints_and_actions_core_concepts",
user_flow_script="tests/integration/docusaurus/reference/core_concepts/checkpoints_and_actions.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
),
IntegrationTestFixture(
name="how_to_pass_an_in_memory_dataframe_to_a_checkpoint",
user_flow_script="tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
),
IntegrationTestFixture(
name="how_to_validate_data_with_a_yaml_configured_in_memory_checkpoint",
user_flow_script="tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_yaml_configured_in_memory_checkpoint.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
),
IntegrationTestFixture(
name="how_to_validate_data_with_a_python_configured_in_memory_checkpoint",
user_flow_script="tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_python_configured_in_memory_checkpoint.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
),
IntegrationTestFixture(
name="how_to_create_an_expectation_suite_with_the_onboarding_data_assistant",
user_flow_script="tests/integration/docusaurus/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples",
),
IntegrationTestFixture(
name="how_to_configure_credentials",
user_flow_script="tests/integration/docusaurus/setup/configuring_data_contexts/how_to_configure_credentials.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
),
IntegrationTestFixture(
name="migration_guide_pandas_v3_api",
user_flow_script="tests/integration/docusaurus/miscellaneous/migration_guide_pandas_v3_api.py",
data_context_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/pandas/v3/great_expectations/",
data_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/data",
),
IntegrationTestFixture(
name="migration_guide_pandas_v2_api",
user_flow_script="tests/integration/docusaurus/miscellaneous/migration_guide_pandas_v2_api.py",
data_context_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/pandas/v2/great_expectations/",
data_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/data",
),
IntegrationTestFixture(
name="migration_guide_spark_v3_api",
user_flow_script="tests/integration/docusaurus/miscellaneous/migration_guide_spark_v3_api.py",
data_context_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/spark/v3/great_expectations/",
data_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/data",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="migration_guide_spark_v2_api",
user_flow_script="tests/integration/docusaurus/miscellaneous/migration_guide_spark_v2_api.py",
data_context_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/spark/v2/great_expectations/",
data_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/data",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="expect_column_max_to_be_between_custom",
user_flow_script="tests/integration/docusaurus/expectations/creating_custom_expectations/expect_column_max_to_be_between_custom.py",
),
IntegrationTestFixture(
name="expect_column_values_to_equal_three",
user_flow_script="tests/integration/docusaurus/expectations/creating_custom_expectations/expect_column_values_to_equal_three.py",
),
IntegrationTestFixture(
name="expect_table_columns_to_be_unique",
user_flow_script="tests/integration/docusaurus/expectations/creating_custom_expectations/expect_table_columns_to_be_unique.py",
),
IntegrationTestFixture(
name="expect_column_pair_values_to_have_a_difference_of_three",
user_flow_script="tests/integration/docusaurus/expectations/creating_custom_expectations/expect_column_pair_values_to_have_a_difference_of_three.py",
),
IntegrationTestFixture(
name="cross_table_comparisons_from_query",
user_flow_script="tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison_from_query.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="cross_table_comparisons_from_query",
user_flow_script="tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison_from_query.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.MYSQL,
),
IntegrationTestFixture(
name="cross_table_comparisons",
user_flow_script="tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="cross_table_comparisons",
user_flow_script="tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.MYSQL,
),
IntegrationTestFixture(
name="expect_column_values_to_be_in_solfege_scale_set",
user_flow_script="tests/integration/docusaurus/expectations/creating_custom_expectations/expect_column_values_to_be_in_solfege_scale_set.py",
),
IntegrationTestFixture(
name="expect_column_values_to_only_contain_vowels",
user_flow_script="tests/integration/docusaurus/expectations/creating_custom_expectations/expect_column_values_to_only_contain_vowels.py",
),
IntegrationTestFixture(
name="expect_queried_column_value_frequency_to_meet_threshold",
user_flow_script="tests/integration/docusaurus/expectations/creating_custom_expectations/expect_queried_column_value_frequency_to_meet_threshold.py",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="expect_queried_table_row_count_to_be",
user_flow_script="tests/integration/docusaurus/expectations/creating_custom_expectations/expect_queried_table_row_count_to_be.py",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="expect_multicolumn_values_to_be_multiples_of_three",
user_flow_script="tests/integration/docusaurus/expectations/creating_custom_expectations/expect_multicolumn_values_to_be_multiples_of_three.py",
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="how_to_use_great_expectations_in_aws_glue",
user_flow_script="tests/integration/docusaurus/deployment_patterns/aws_glue_deployment_patterns.py",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="how_to_use_great_expectations_in_aws_glue_yaml",
user_flow_script="tests/integration/docusaurus/deployment_patterns/aws_glue_deployment_patterns_great_expectations.yaml",
),
IntegrationTestFixture(
name="how_to_use_great_expectations_in_aws_emr_serverless",
user_flow_script="tests/integration/docusaurus/deployment_patterns/aws_emr_serverless_deployment_patterns.py",
extra_backend_dependencies=BackendDependencies.SPARK,
),
IntegrationTestFixture(
name="how_to_use_great_expectations_in_aws_emr_serverless_yaml",
user_flow_script="tests/integration/docusaurus/deployment_patterns/aws_emr_serverless_deployment_patterns_great_expectations.yaml",
),
]
dockerized_db_tests = [
IntegrationTestFixture(
name="postgres_yaml_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/postgres_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="postgres_python_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/postgres_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="sqlite_yaml_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/sqlite_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/sqlite/",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.SQLALCHEMY,
),
IntegrationTestFixture(
name="sqlite_python_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/sqlite_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/sqlite/",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.SQLALCHEMY,
),
IntegrationTestFixture(
name="introspect_and_partition_yaml_example_gradual_sql",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/how_to_introspect_and_partition_your_data/sql_database/yaml_example_gradual.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/sqlite/",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.SQLALCHEMY,
),
IntegrationTestFixture(
name="introspect_and_partition_yaml_example_complete_sql",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/how_to_introspect_and_partition_your_data/sql_database/yaml_example_complete.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/sqlite/",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.SQLALCHEMY,
),
IntegrationTestFixture(
name="split_data_on_whole_table_postgres",
user_flow_script="tests/integration/db/test_sql_data_split_on_whole_table.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/postgres_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="split_data_on_whole_table_mssql",
user_flow_script="tests/integration/db/test_sql_data_split_on_whole_table.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mssql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MSSQL,
),
IntegrationTestFixture(
name="split_data_on_whole_table_mysql",
user_flow_script="tests/integration/db/test_sql_data_split_on_whole_table.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mysql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MYSQL,
),
IntegrationTestFixture(
name="split_data_on_column_value_postgres",
user_flow_script="tests/integration/db/test_sql_data_split_on_column_value.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/postgres_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="split_data_on_column_value_mssql",
user_flow_script="tests/integration/db/test_sql_data_split_on_column_value.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mssql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MSSQL,
),
IntegrationTestFixture(
name="split_data_on_column_value_mysql",
user_flow_script="tests/integration/db/test_sql_data_split_on_column_value.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mysql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MYSQL,
),
IntegrationTestFixture(
name="split_data_on_divided_integer_postgres",
user_flow_script="tests/integration/db/test_sql_data_split_on_divided_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/postgres_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="split_data_on_divided_integer_mssql",
user_flow_script="tests/integration/db/test_sql_data_split_on_divided_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mssql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MSSQL,
),
IntegrationTestFixture(
name="split_data_on_divided_integer_mysql",
user_flow_script="tests/integration/db/test_sql_data_split_on_divided_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mysql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MYSQL,
),
IntegrationTestFixture(
name="split_data_on_mod_integer_postgres",
user_flow_script="tests/integration/db/test_sql_data_split_on_mod_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/postgres_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="split_data_on_mod_integer_mssql",
user_flow_script="tests/integration/db/test_sql_data_split_on_mod_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mssql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MSSQL,
),
IntegrationTestFixture(
name="split_data_on_mod_integer_mysql",
user_flow_script="tests/integration/db/test_sql_data_split_on_mod_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mysql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MYSQL,
),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_hashed_column" for POSTGRESQL is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_hashed_column_postgres",
# user_flow_script="tests/integration/db/test_sql_data_split_on_hashed_column.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/postgres_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.POSTGRESQL,
# ),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_hashed_column" for MSSQL is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_hashed_column_mssql",
# user_flow_script="tests/integration/db/test_sql_data_split_on_hashed_column.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/mssql_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.MSSQL,
# ),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_hashed_column" for MYSQL is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_hashed_column_mysql",
# user_flow_script="tests/integration/db/test_sql_data_split_on_hashed_column.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/mysql_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.MYSQL,
# ),
IntegrationTestFixture(
name="split_data_on_multi_column_values_postgres",
user_flow_script="tests/integration/db/test_sql_data_split_on_multi_column_values.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/postgres_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="split_data_on_multi_column_values_mssql",
user_flow_script="tests/integration/db/test_sql_data_split_on_multi_column_values.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mssql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MSSQL,
),
IntegrationTestFixture(
name="split_data_on_multi_column_values_mysql",
user_flow_script="tests/integration/db/test_sql_data_split_on_multi_column_values.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mysql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MYSQL,
),
IntegrationTestFixture(
name="split_data_on_datetime_postgres",
user_flow_script="tests/integration/db/test_sql_data_split_on_datetime_and_day_part.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/postgres_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="split_data_on_datetime_mssql",
user_flow_script="tests/integration/db/test_sql_data_split_on_datetime_and_day_part.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mssql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MSSQL,
),
IntegrationTestFixture(
name="split_data_on_datetime_mysql",
user_flow_script="tests/integration/db/test_sql_data_split_on_datetime_and_day_part.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mysql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MYSQL,
),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for POSTGRESQL is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_postgres",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/postgres_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.POSTGRESQL,
# ),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for MSSQL is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_mssql",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/mssql_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.MSSQL,
# ),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for MYSQL is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_mysql",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/mysql_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.MYSQL,
# ),
IntegrationTestFixture(
name="sample_data_using_limit_postgres",
user_flow_script="tests/integration/db/test_sql_data_sampling.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/postgres_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="sample_data_using_limit_mssql",
user_flow_script="tests/integration/db/test_sql_data_sampling.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mssql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MSSQL,
),
IntegrationTestFixture(
name="sample_data_using_limit_mysql",
user_flow_script="tests/integration/db/test_sql_data_sampling.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/mysql_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.MYSQL,
),
IntegrationTestFixture(
name="mssql_yaml_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/mssql_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.MSSQL,
),
IntegrationTestFixture(
name="mssql_python_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/mssql_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.MSSQL,
),
IntegrationTestFixture(
name="mysql_yaml_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/mysql_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.MYSQL,
),
IntegrationTestFixture(
name="mysql_python_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/mysql_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.MYSQL,
),
IntegrationTestFixture(
name="trino_yaml_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/trino_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.TRINO,
),
IntegrationTestFixture(
name="trino_python_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/trino_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.TRINO,
),
IntegrationTestFixture(
name="migration_guide_postgresql_v3_api",
user_flow_script="tests/integration/docusaurus/miscellaneous/migration_guide_postgresql_v3_api.py",
data_context_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/postgresql/v3/great_expectations/",
data_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/data/",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="migration_guide_postgresql_v2_api",
user_flow_script="tests/integration/docusaurus/miscellaneous/migration_guide_postgresql_v2_api.py",
data_context_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/postgresql/v2/great_expectations/",
data_dir="tests/test_fixtures/configuration_for_testing_v2_v3_migration/data/",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
IntegrationTestFixture(
name="how_to_configure_credentials_postgres",
user_flow_script="tests/integration/docusaurus/setup/configuring_data_contexts/how_to_configure_credentials.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.POSTGRESQL,
),
]
# CLOUD
cloud_snowflake_tests = [
IntegrationTestFixture(
name="snowflake_python_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/snowflake_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
util_script="tests/test_utils.py",
),
IntegrationTestFixture(
name="snowflake_yaml_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/snowflake_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
util_script="tests/test_utils.py",
),
IntegrationTestFixture(
name="split_data_on_whole_table_snowflake",
user_flow_script="tests/integration/db/test_sql_data_split_on_whole_table.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/snowflake_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
),
IntegrationTestFixture(
name="split_data_on_column_value_snowflake",
user_flow_script="tests/integration/db/test_sql_data_split_on_column_value.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/snowflake_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
),
IntegrationTestFixture(
name="split_data_on_divided_integer_snowflake",
user_flow_script="tests/integration/db/test_sql_data_split_on_divided_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/snowflake_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
),
IntegrationTestFixture(
name="split_data_on_mod_integer_snowflake",
user_flow_script="tests/integration/db/test_sql_data_split_on_mod_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/snowflake_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_hashed_column" for SNOWFLAKE is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_hashed_column_snowflake",
# user_flow_script="tests/integration/db/test_sql_data_split_on_hashed_column.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/snowflake_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
# ),
IntegrationTestFixture(
name="split_data_on_multi_column_values_snowflake",
user_flow_script="tests/integration/db/test_sql_data_split_on_multi_column_values.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/snowflake_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for POSTGRESQL is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_postgres",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/postgres_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.POSTGRESQL,
# ),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for REDSHIFT is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_redshift",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/redshift_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.REDSHIFT,
# ),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for MSSQL is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_mssql",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/mssql_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.MSSQL,
# ),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for MYSQL is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_mysql",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/mysql_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.MYSQL,
# ),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for SNOWFLAKE is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_snowflake",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/snowflake_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
# ),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for BIGQUERY is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_bigquery",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/bigquery_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.BIGQUERY,
# ),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for AWS ATHENA is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_awsathena",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/awsathena_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.AWS,
# ),
IntegrationTestFixture(
name="split_data_on_datetime_snowflake",
user_flow_script="tests/integration/db/test_sql_data_split_on_datetime_and_day_part.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/snowflake_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for SNOWFLAKE is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_snowflake",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/snowflake_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
# ),
IntegrationTestFixture(
name="sample_data_using_limit_snowflake",
user_flow_script="tests/integration/db/test_sql_data_sampling.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/snowflake_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.SNOWFLAKE,
),
]
cloud_gcp_tests = [
IntegrationTestFixture(
name="gcp_deployment_patterns_file_gcs_yaml_configs",
user_flow_script="tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.GCS,
),
IntegrationTestFixture(
name="how_to_configure_an_expectation_store_in_gcs",
user_flow_script="tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.GCS,
),
IntegrationTestFixture(
name="how_to_host_and_share_data_docs_on_gcs",
user_flow_script="tests/integration/docusaurus/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
extra_backend_dependencies=BackendDependencies.GCS,
),
IntegrationTestFixture(
name="how_to_configure_a_validation_result_store_in_gcs",
user_flow_script="tests/integration/docusaurus/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
extra_backend_dependencies=BackendDependencies.GCS,
),
IntegrationTestFixture(
name="gcs_pandas_configured_yaml",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/cloud/gcs/pandas/configured_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.GCS,
),
IntegrationTestFixture(
name="gcs_pandas_configured_python",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/cloud/gcs/pandas/configured_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.GCS,
),
IntegrationTestFixture(
name="gcs_pandas_inferred_and_runtime_yaml",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/cloud/gcs/pandas/inferred_and_runtime_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.GCS,
),
IntegrationTestFixture(
name="gcs_pandas_inferred_and_runtime_python",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/cloud/gcs/pandas/inferred_and_runtime_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.GCS,
),
# TODO: <Alex>ALEX -- Implement GCS Configured YAML Example</Alex>
# TODO: <Alex>ALEX -- uncomment next test once Spark in Azure Pipelines is enabled and GCS Configured YAML Example is implemented.</Alex>
# IntegrationTestFixture(
# name = "gcs_spark_configured_yaml",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/gcs/spark/configured_yaml_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies= BackendDependencies.GCS,
# ),
# TODO: <Alex>ALEX -- Implement GCS Configured Python Example</Alex>
# TODO: <Alex>ALEX -- uncomment next test once Spark in Azure Pipelines is enabled and GCS Configured Python Example is implemented.</Alex>
# IntegrationTestFixture(
# name = "gcs_spark_configured_python",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/gcs/spark/configured_python_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies= BackendDependencies.GCS,
# ),
# TODO: <Alex>ALEX -- uncomment next two (2) tests once Spark in Azure Pipelines is enabled.</Alex>
# IntegrationTestFixture(
# name = "gcs_spark_inferred_and_runtime_yaml",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/gcs/spark/inferred_and_runtime_yaml_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies= BackendDependencies.GCS,
# ),
# IntegrationTestFixture(
# name = "gcs_spark_inferred_and_runtime_python",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/gcs/spark/inferred_and_runtime_python_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies= BackendDependencies.GCS,
# ),
]
cloud_bigquery_tests = [
IntegrationTestFixture(
name="bigquery_yaml_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/bigquery_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.BIGQUERY,
),
IntegrationTestFixture(
name="bigquery_python_example",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/database/bigquery_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
util_script="tests/test_utils.py",
extra_backend_dependencies=BackendDependencies.BIGQUERY,
),
IntegrationTestFixture(
name="gcp_deployment_patterns_file_bigquery_yaml_configs",
user_flow_script="tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_bigquery_yaml_configs.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.BIGQUERY,
),
IntegrationTestFixture(
name="sample_data_using_limit_bigquery",
user_flow_script="tests/integration/db/test_sql_data_sampling.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/bigquery_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.BIGQUERY,
),
IntegrationTestFixture(
name="test_runtime_parameters_bigquery",
user_flow_script="tests/integration/db/bigquery.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.BIGQUERY,
),
IntegrationTestFixture(
name="split_data_on_whole_table_bigquery",
user_flow_script="tests/integration/db/test_sql_data_split_on_whole_table.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/bigquery_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.BIGQUERY,
),
IntegrationTestFixture(
name="split_data_on_column_value_bigquery",
user_flow_script="tests/integration/db/test_sql_data_split_on_column_value.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/bigquery_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.BIGQUERY,
),
IntegrationTestFixture(
name="split_data_on_divided_integer_bigquery",
user_flow_script="tests/integration/db/test_sql_data_split_on_divided_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/bigquery_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.BIGQUERY,
),
IntegrationTestFixture(
name="split_data_on_mod_integer_bigquery",
user_flow_script="tests/integration/db/test_sql_data_split_on_mod_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/bigquery_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.BIGQUERY,
),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_hashed_column" for BIGQUERY is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_hashed_column_bigquery",
# user_flow_script="tests/integration/db/test_sql_data_split_on_hashed_column.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/bigquery_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.BIGQUERY,
# ),
IntegrationTestFixture(
name="split_data_on_multi_column_values_bigquery",
user_flow_script="tests/integration/db/test_sql_data_split_on_multi_column_values.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/bigquery_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.BIGQUERY,
),
IntegrationTestFixture(
name="split_data_on_datetime_bigquery",
user_flow_script="tests/integration/db/test_sql_data_split_on_datetime_and_day_part.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/bigquery_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.BIGQUERY,
),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for BIGQUERY is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_bigquery",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/bigquery_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.BIGQUERY,
# ),
]
cloud_azure_tests = [
IntegrationTestFixture(
name="azure_pandas_configured_yaml",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/cloud/azure/pandas/configured_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.AZURE,
),
IntegrationTestFixture(
name="azure_pandas_configured_python",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/cloud/azure/pandas/configured_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.AZURE,
),
IntegrationTestFixture(
name="azure_pandas_inferred_and_runtime_yaml",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/cloud/azure/pandas/inferred_and_runtime_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.AZURE,
),
IntegrationTestFixture(
name="azure_pandas_inferred_and_runtime_python",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/cloud/azure/pandas/inferred_and_runtime_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.AZURE,
),
# TODO: <Alex>ALEX -- uncomment next four (4) tests once Spark in Azure Pipelines is enabled.</Alex>
# IntegrationTestFixture(
# name = "azure_spark_configured_yaml",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/azure/spark/configured_yaml_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies = BackendDependencies.AZURE
# ),
# IntegrationTestFixture(
# name = "azure_spark_configured_python",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/azure/spark/configured_python_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies = BackendDependencies.AZURE
# ),
# IntegrationTestFixture(
# name = "azure_spark_inferred_and_runtime_yaml",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/azure/spark/inferred_and_runtime_yaml_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies = BackendDependencies.AZURE
# ),
# IntegrationTestFixture(
# name = "azure_spark_inferred_and_runtime_python",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/azure/spark/inferred_and_runtime_python_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies = BackendDependencies.AZURE
# ),
]
cloud_s3_tests = [
IntegrationTestFixture(
name="s3_pandas_inferred_and_runtime_yaml",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/inferred_and_runtime_yaml_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.AWS,
),
IntegrationTestFixture(
name="s3_pandas_inferred_and_runtime_python",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/inferred_and_runtime_python_example.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
extra_backend_dependencies=BackendDependencies.AWS,
),
IntegrationTestFixture(
name="how_to_configure_an_inferredassetdataconnector",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/how_to_configure_an_inferredassetdataconnector.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/dataconnector_docs",
extra_backend_dependencies=BackendDependencies.AWS,
),
IntegrationTestFixture(
name="how_to_configure_a_configuredassetdataconnector",
user_flow_script="tests/integration/docusaurus/connecting_to_your_data/how_to_configure_a_configuredassetdataconnector.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/dataconnector_docs",
extra_backend_dependencies=BackendDependencies.AWS,
),
# TODO: <Alex>ALEX -- uncomment all S3 tests once S3 testing in Azure Pipelines is re-enabled and items for specific tests below are addressed.</Alex>
# TODO: <Alex>ALEX -- Implement S3 Configured YAML Example</Alex>
# TODO: <Alex>ALEX -- uncomment next test once S3 Configured YAML Example is implemented.</Alex>
# IntegrationTestFixture(
# name = "s3_pandas_configured_yaml_example",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/configured_yaml_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies= BackendDependencies.AWS,
# ),
# TODO: <Alex>ALEX -- Implement S3 Configured Python Example</Alex>
# TODO: <Alex>ALEX -- uncomment next test once S3 Configured Python Example is implemented.</Alex>
# IntegrationTestFixture(
# name = "s3_pandas_configured_python_example",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/configured_python_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies= BackendDependencies.AWS,
# ),
# TODO: <Alex>ALEX -- Implement S3 Configured YAML Example</Alex>
# TODO: <Alex>ALEX -- uncomment next test once Spark in Azure Pipelines is enabled and S3 Configured YAML Example is implemented.</Alex>
# IntegrationTestFixture(
# name = "s3_spark_configured_yaml_example",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/s3/spark/configured_yaml_example.py",
# extra_backend_dependencies= [BackendDependencies.SPARK, BackendDependencies.AWS],
# ),
# TODO: <Alex>ALEX -- Implement S3 Configured Python Example</Alex>
# TODO: <Alex>ALEX -- uncomment next test once Spark in Azure Pipelines is enabled and S3 Configured Python Example is implemented.</Alex>
# IntegrationTestFixture(
# name = "s3_spark_configured_python_example",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/s3/spark/configured_python_example.py",
# extra_backend_dependencies= [BackendDependencies.SPARK, BackendDependencies.AWS],
# ),
# TODO: <Alex>ALEX -- uncomment next two (2) tests once Spark in Azure Pipelines is enabled.</Alex>
# IntegrationTestFixture(
# name = "s3_spark_inferred_and_runtime_yaml_example",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/s3/spark/inferred_and_runtime_yaml_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies= [BackendDependencies.SPARK, BackendDependencies.AWS],
# ),
# IntegrationTestFixture(
# name = "s3_spark_inferred_and_runtime_python_example",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/cloud/s3/spark/inferred_and_runtime_python_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# extra_backend_dependencies= [BackendDependencies.SPARK, BackendDependencies.AWS],
# ),
IntegrationTestFixture(
name="split_data_on_whole_table_awsathena",
user_flow_script="tests/integration/db/test_sql_data_split_on_whole_table.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/awsathena_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.AWS,
),
IntegrationTestFixture(
name="split_data_on_column_value_awsathena",
user_flow_script="tests/integration/db/test_sql_data_split_on_column_value.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/awsathena_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.AWS,
),
IntegrationTestFixture(
name="split_data_on_divided_integer_awsathena",
user_flow_script="tests/integration/db/test_sql_data_split_on_divided_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/awsathena_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.AWS,
),
IntegrationTestFixture(
name="split_data_on_mod_integer_awsathena",
user_flow_script="tests/integration/db/test_sql_data_split_on_mod_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/awsathena_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.AWS,
),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_hashed_column" for AWS ATHENA is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_hashed_column_awsathena",
# user_flow_script="tests/integration/db/test_sql_data_split_on_hashed_column.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/awsathena_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.AWS,
# ),
IntegrationTestFixture(
name="split_data_on_multi_column_values_awsathena",
user_flow_script="tests/integration/db/test_sql_data_split_on_multi_column_values.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/awsathena_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.AWS,
),
IntegrationTestFixture(
name="split_data_on_datetime_awsathena",
user_flow_script="tests/integration/db/test_sql_data_split_on_datetime_and_day_part.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/awsathena_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.AWS,
),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for AWS ATHENA is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_awsathena",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/awsathena_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.AWS,
# ),
]
cloud_redshift_tests = [
# TODO: <Alex>ALEX: Rename test modules to include "configured" and "inferred_and_runtime" suffixes in names.</Alex>
# IntegrationTestFixture(
# name = "azure_python_example",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/database/redshift_python_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# data_dir= "tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
# extra_backend_dependencies= [BackendDependencies.AWS, BackendDependencies.REDSHIFT],
# util_script= "tests/test_utils.py",
# ),
# IntegrationTestFixture(
# name = "azure_yaml_example",
# user_flow_script= "tests/integration/docusaurus/connecting_to_your_data/database/redshift_yaml_example.py",
# data_context_dir= "tests/integration/fixtures/no_datasources/great_expectations",
# data_dir= "tests/test_sets/taxi_yellow_tripdata_samples/first_3_files",
# extra_backend_dependencies= [BackendDependencies.AWS, BackendDependencies.REDSHIFT],
# util_script= "tests/test_utils.py",
# ),
IntegrationTestFixture(
name="split_data_on_whole_table_redshift",
user_flow_script="tests/integration/db/test_sql_data_split_on_whole_table.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/redshift_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.REDSHIFT,
),
IntegrationTestFixture(
name="split_data_on_column_value_redshift",
user_flow_script="tests/integration/db/test_sql_data_split_on_column_value.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/redshift_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.REDSHIFT,
),
IntegrationTestFixture(
name="split_data_on_divided_integer_redshift",
user_flow_script="tests/integration/db/test_sql_data_split_on_divided_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/redshift_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.REDSHIFT,
),
IntegrationTestFixture(
name="split_data_on_mod_integer_redshift",
user_flow_script="tests/integration/db/test_sql_data_split_on_mod_integer.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/redshift_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.REDSHIFT,
),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_hashed_column" for REDSHIFT is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_hashed_column_redshift",
# user_flow_script="tests/integration/db/test_sql_data_split_on_hashed_column.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/redshift_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.REDSHIFT,
# ),
IntegrationTestFixture(
name="split_data_on_multi_column_values_redshift",
user_flow_script="tests/integration/db/test_sql_data_split_on_multi_column_values.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/redshift_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.REDSHIFT,
),
IntegrationTestFixture(
name="split_data_on_datetime_redshift",
user_flow_script="tests/integration/db/test_sql_data_split_on_datetime_and_day_part.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/redshift_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.REDSHIFT,
),
# TODO: <Alex>ALEX -- Uncomment next statement when "split_on_converted_datetime" for REDSHIFT is implemented.</Alex>
# IntegrationTestFixture(
# name="split_data_on_converted_datetime_redshift",
# user_flow_script="tests/integration/db/test_sql_data_split_on_converted_datetime.py",
# data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
# data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
# util_script="tests/test_utils.py",
# other_files=(
# (
# "tests/integration/fixtures/split_and_sample_data/redshift_connection_string.yml",
# "connection_string.yml",
# ),
# ),
# extra_backend_dependencies=BackendDependencies.REDSHIFT,
# ),
]
# populate docs_test_matrix with sub-lists
docs_test_matrix += local_tests
docs_test_matrix += dockerized_db_tests
docs_test_matrix += cloud_snowflake_tests
docs_test_matrix += cloud_gcp_tests
docs_test_matrix += cloud_bigquery_tests
docs_test_matrix += cloud_azure_tests
docs_test_matrix += cloud_s3_tests
docs_test_matrix += cloud_redshift_tests
pandas_integration_tests = [
IntegrationTestFixture(
name="pandas_one_multi_batch_request_one_validator",
data_context_dir="tests/integration/fixtures/yellow_tripdata_pandas_fixture/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples",
user_flow_script="tests/integration/fixtures/yellow_tripdata_pandas_fixture/one_multi_batch_request_one_validator.py",
),
IntegrationTestFixture(
name="pandas_two_batch_requests_two_validators",
data_context_dir="tests/integration/fixtures/yellow_tripdata_pandas_fixture/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples",
user_flow_script="tests/integration/fixtures/yellow_tripdata_pandas_fixture/two_batch_requests_two_validators.py",
),
IntegrationTestFixture(
name="pandas_multiple_batch_requests_one_validator_multiple_steps",
data_context_dir="tests/integration/fixtures/yellow_tripdata_pandas_fixture/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples",
user_flow_script="tests/integration/fixtures/yellow_tripdata_pandas_fixture/multiple_batch_requests_one_validator_multiple_steps.py",
),
IntegrationTestFixture(
name="pandas_multiple_batch_requests_one_validator_one_step",
data_context_dir="tests/integration/fixtures/yellow_tripdata_pandas_fixture/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples",
user_flow_script="tests/integration/fixtures/yellow_tripdata_pandas_fixture/multiple_batch_requests_one_validator_one_step.py",
),
IntegrationTestFixture(
name="pandas_execution_engine_with_gcp_installed",
data_context_dir="tests/integration/fixtures/yellow_tripdata_pandas_fixture/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples",
user_flow_script="tests/integration/common_workflows/pandas_execution_engine_with_gcp_installed.py",
other_files=(
(
"tests/integration/fixtures/cloud_provider_configs/gcp/my_example_creds.json",
".gcs/my_example_creds.json",
),
),
),
IntegrationTestFixture(
name="build_data_docs",
user_flow_script="tests/integration/common_workflows/simple_build_data_docs.py",
),
]
aws_integration_tests = [
IntegrationTestFixture(
name="awsathena_test",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
user_flow_script="tests/integration/db/awsathena.py",
extra_backend_dependencies=BackendDependencies.AWS,
util_script="tests/test_utils.py",
),
IntegrationTestFixture(
name="sample_data_using_limit_awsathena",
user_flow_script="tests/integration/db/test_sql_data_sampling.py",
data_context_dir="tests/integration/fixtures/no_datasources/great_expectations",
data_dir="tests/test_sets/taxi_yellow_tripdata_samples/",
util_script="tests/test_utils.py",
other_files=(
(
"tests/integration/fixtures/split_and_sample_data/awsathena_connection_string.yml",
"connection_string.yml",
),
),
extra_backend_dependencies=BackendDependencies.AWS,
),
]
# populate integration_test_matrix with sub-lists
integration_test_matrix: List[IntegrationTestFixture] = []
integration_test_matrix += aws_integration_tests
integration_test_matrix += pandas_integration_tests
def idfn(test_configuration):
return test_configuration.name
@pytest.fixture
def pytest_parsed_arguments(request):
return request.config.option
@pytest.mark.docs
@pytest.mark.integration
@pytest.mark.parametrize("integration_test_fixture", docs_test_matrix, ids=idfn)
@pytest.mark.skipif(sys.version_info < (3, 7), reason="requires Python3.7")
def test_docs(integration_test_fixture, tmp_path, pytest_parsed_arguments):
_check_for_skipped_tests(pytest_parsed_arguments, integration_test_fixture)
_execute_integration_test(integration_test_fixture, tmp_path)
@pytest.mark.integration
@pytest.mark.parametrize("test_configuration", integration_test_matrix, ids=idfn)
@pytest.mark.skipif(sys.version_info < (3, 7), reason="requires Python3.7")
@pytest.mark.slow # 79.77s
def test_integration_tests(test_configuration, tmp_path, pytest_parsed_arguments):
_check_for_skipped_tests(pytest_parsed_arguments, test_configuration)
_execute_integration_test(test_configuration, tmp_path)
def _execute_integration_test(
integration_test_fixture: IntegrationTestFixture, tmp_path: pathlib.Path
):
"""
Prepare and environment and run integration tests from a list of tests.
Note that the only required parameter for a test in the matrix is
`user_flow_script` and that all other parameters are optional.
"""
workdir = os.getcwd()
try:
base_dir = file_relative_path(__file__, "../../")
os.chdir(base_dir)
# Ensure GE is installed in our environment
installed_packages = [pkg.key for pkg in pkg_resources.working_set]
if "great-expectations" not in installed_packages:
execute_shell_command("pip install .")
os.chdir(tmp_path)
#
# Build test state
# DataContext
data_context_dir = integration_test_fixture.data_context_dir
if data_context_dir:
context_source_dir = os.path.join(base_dir, data_context_dir)
test_context_dir = os.path.join(tmp_path, "great_expectations")
shutil.copytree(
context_source_dir,
test_context_dir,
)
# Test Data
data_dir = integration_test_fixture.data_dir
if data_dir:
source_data_dir = os.path.join(base_dir, data_dir)
target_data_dir = os.path.join(tmp_path, "data")
shutil.copytree(
source_data_dir,
target_data_dir,
)
# Other files
# Other files to copy should be supplied as a tuple of tuples with source, dest pairs
# e.g. (("/source1/file1", "/dest1/file1"), ("/source2/file2", "/dest2/file2"))
other_files = integration_test_fixture.other_files
if other_files:
for file_paths in other_files:
source_file = os.path.join(base_dir, file_paths[0])
dest_file = os.path.join(tmp_path, file_paths[1])
dest_dir = os.path.dirname(dest_file)
if not os.path.exists(dest_dir):
os.makedirs(dest_dir)
shutil.copyfile(src=source_file, dst=dest_file)
# UAT Script
user_flow_script = integration_test_fixture.user_flow_script
script_source = os.path.join(
base_dir,
user_flow_script,
)
script_path = os.path.join(tmp_path, "test_script.py")
shutil.copyfile(script_source, script_path)
logger.debug(
f"(_execute_integration_test) script_source -> {script_source} :: copied to {script_path}"
)
if not script_source.endswith(".py"):
logger.error(f"{script_source} is not a python script!")
with open(script_path) as fp:
text = fp.read()
print(f"contents of script_path:\n\n{text}\n\n")
return
util_script = integration_test_fixture.util_script
if util_script:
script_source = os.path.join(base_dir, util_script)
os.makedirs(os.path.join(tmp_path, "tests/"))
util_script_path = os.path.join(tmp_path, "tests/test_utils.py")
shutil.copyfile(script_source, util_script_path)
# Run script as module, using python's importlib machinery (https://docs.python.org/3/library/importlib.htm)
loader = importlib.machinery.SourceFileLoader("test_script_module", script_path)
spec = importlib.util.spec_from_loader("test_script_module", loader)
test_script_module = importlib.util.module_from_spec(spec)
loader.exec_module(test_script_module)
except Exception as e:
logger.error(str(e))
if "JavaPackage" in str(e) and "aws_glue" in user_flow_script:
logger.debug("This is something aws_glue related, so just going to return")
# Should try to copy aws-glue-libs jar files to Spark jar during pipeline setup
# - see https://stackoverflow.com/a/67371827
return
else:
raise
finally:
os.chdir(workdir)
def _check_for_skipped_tests(pytest_args, integration_test_fixture) -> None:
"""Enable scripts to be skipped based on pytest invocation flags."""
dependencies = integration_test_fixture.extra_backend_dependencies
if not dependencies:
return
elif dependencies == BackendDependencies.POSTGRESQL and (
not pytest_args.postgresql or pytest_args.no_sqlalchemy
):
pytest.skip("Skipping postgres tests")
elif dependencies == BackendDependencies.MYSQL and (
not pytest_args.mysql or pytest_args.no_sqlalchemy
):
pytest.skip("Skipping mysql tests")
elif dependencies == BackendDependencies.MSSQL and (
not pytest_args.mssql or pytest_args.no_sqlalchemy
):
pytest.skip("Skipping mssql tests")
elif dependencies == BackendDependencies.BIGQUERY and (
pytest_args.no_sqlalchemy or not pytest_args.bigquery
):
# TODO : Investigate whether this test should be handled by azure-pipelines-cloud-db-integration.yml
pytest.skip("Skipping bigquery tests")
elif dependencies == BackendDependencies.GCS and not pytest_args.bigquery:
# TODO : Investigate whether this test should be handled by azure-pipelines-cloud-db-integration.yml
pytest.skip("Skipping GCS tests")
elif dependencies == BackendDependencies.AWS and not pytest_args.aws:
pytest.skip("Skipping AWS tests")
elif dependencies == BackendDependencies.REDSHIFT and pytest_args.no_sqlalchemy:
pytest.skip("Skipping redshift tests")
elif dependencies == BackendDependencies.SPARK and not pytest_args.spark:
pytest.skip("Skipping spark tests")
elif dependencies == BackendDependencies.SNOWFLAKE and pytest_args.no_sqlalchemy:
pytest.skip("Skipping snowflake tests")
elif dependencies == BackendDependencies.AZURE and not pytest_args.azure:
pytest.skip("Skipping Azure tests")
<file_sep>/docs/terms/validator.md
---
title: Validator
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
import ConnectHeader from '/docs/images/universal_map/_um_connect_header.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
import ValidateHeader from '/docs/images/universal_map/_um_validate_header.mdx';
<UniversalMap setup='inactive' connect='active' create='active' validate='active'/>
## Overview
### Definition
A Validator is the object responsible for running an <TechnicalTag relative="../" tag="expectation_suite" text="Expectation Suite" /> against data.
### Features and promises
The Validator is the core functional component of Great Expectations.
### Relationship to other objects
Validators are responsible for running an Expectation Suite against a <TechnicalTag relative="../" tag="batch_request" text="Batch Request" />. <TechnicalTag relative="../" tag="checkpoint" text="Checkpoints" />, in particular, use them for this purpose. However, you can also use your <TechnicalTag relative="../" tag="data_context" text="Data Context" /> to get a Validator to use outside a Checkpoint.
## Use cases
<ConnectHeader/>
When connecting to Data, it is often useful to verify that you have configured your <TechnicalTag relative="../" tag="datasource" text="Datasource" /> correctly. To verify a new Datasource, you can load data from it into a Validator using a Batch Request. There are examples of this workflow at the end of most of [our guides on how to connect to specific source data systems](../guides/connecting_to_your_data/index.md#database).
<CreateHeader/>
When creating Expectations for an Expectation Suite, most workflows will have you use a Validator. You can see this in [our guide on how to create and edit Expectations with a Profiler](../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md), and in the Jupyter Notebook opened if you follow [our guide on how to create and edit Expectations with instant feedback from a sample Batch of data](../guides/expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md).
<ValidateHeader/>
Checkpoints utilize a Validator when running an Expectation Suite against a Batch Request. This process is entirely handled for you by the Checkpoint; you will not need to create or configure the Validator in question.
## Features
### Out of the box functionality
Validators don't require additional configuration. Provide one with an Expectation Suite and a Batch Request, and it will work out of the box.
## API basics
### How to access
Validators are not typically saved. Instead, they are instantiated when needed. If you need a Validator outside a Checkpoint (for example, to create Expectations interactively in a Jupyter Notebook) you will use one that is created for that purpose.
### How to create
You can create a Validator through the `get_validator(...)` command of a Data Context. For an example of this, you can reference the ["Instantiate your Validator"](../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md#3-instantiate-your-validator) section of [our guide on how to create and edit Expectations with a Profiler](../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md)
### Configuration
Creating a Validator with the `get_validator(...)` method will require you to provide an Expectation Suite and a Batch Request. Other than these parameters, there is no configuration needed for Validators.
<file_sep>/docs/deployment_patterns/how_to_use_great_expectations_with_prefect.md
---
title: How to Use Great Expectations with Prefect
---
import Prerequisites from './components/deployment_pattern_prerequisites.jsx'
This guide will help you run a Great Expectations with [Prefect](https://prefect.io/)
<Prerequisites>
- [Set up a working deployment of Great Expectations](../tutorials/getting_started/tutorial_overview.md)
- [Created an Expectation Suite](../tutorials/getting_started/tutorial_create_expectations.md)
- [Connecting to Data](../tutorials/getting_started/tutorial_connect_to_data.md)
- [Prefect Quick Start guide](https://docs.prefect.io/core/getting_started/quick-start.html)
</Prerequisites>
[Prefect](https://prefect.io/) is a workflow management system that enables data engineers to build robust data applications. [The Prefect open source library](https://www.prefect.io/opensource/) allows users to create workflows using Python and makes it easy to take your data pipelines and add semantics like retries, logging, dynamic mapping, caching, and failure notifications. [Prefect Cloud](https://www.prefect.io/cloud/) is the easy, powerful, scalable way to automate and monitor dataflows built in Prefect 1.0 — without having to worry about orchestration infrastructure.
Great Expectations validations can be used to validate data passed between tasks in your Prefect flow. By validating your data before operating on it, you can quickly find issues with your data with less debugging. Prefect makes it easy to combine Great Expectations with other services in your data stack and orchestrate them all in a predictable manner.
## The `RunGreatExpectationsValidation` task
With Prefect, you define your workflows with [tasks](https://docs.prefect.io/core/concepts/tasks.html) and [flows](https://docs.prefect.io/core/concepts/flows.html). A `Task` represents a discrete action in a Prefect workflow. A `Flow` is a container for `Tasks`. It represents an entire workflow or application by describing the dependencies between tasks. Prefect offers a suite of over 180 pre-built tasks in the [Prefect Task Library](https://docs.prefect.io/core/task_library/overview.html). The [`RunGreatExpectationsValidation`](https://docs.prefect.io/api/latest/tasks/great_expectations.html) task is one of these pre-built tasks. With the `RunGreatExpectationsValidation` task you can run validations for an existing Great Expectations project.
To use the `RunGreatExpectationsValidation`, you need to install Prefect with the `ge` extra:
```bash
pip install "prefect[ge]"
```
Here is an example of a flow that runs a Great Expectations validation:
```python
from prefect import Flow, Parameter
from prefect.tasks.great_expectations import RunGreatExpectationsValidation
validation_task = RunGreatExpectationsValidation()
with Flow("ge_test") as flow:
checkpoint_name = Parameter("checkpoint_name")
prev_run_row_count = 100
validation_task(
checkpoint_name=checkpoint_name,
evaluation_parameters=dict(prev_run_row_count=prev_run_row_count),
)
flow.run(parameters={"checkpoint_name": "my_checkpoint"})
```
Using the `RunGreatExpectationsValidation` task is as easy as importing the task, instantiating the task, and calling it in your flow. In the flow above, we parameterize our flow with the checkpoint name. This way, we're able to reuse our flow to run different Great Expectations validations based on the input.
## Configuring the root context directory
By default, the `RunGreatExpectationsValidation` task will look in the current directory for a Great Expectations project in a folder named `great_expectations`. If your `great_expectations.yml` is located in another directory, you can configure the `RunGreatExpectationsValidation` tasks with the `context_root_dir` argument:
```python
from prefect import Flow, Parameter
from prefect.tasks.great_expectations import RunGreatExpectationsValidation
validation_task = RunGreatExpectationsValidation()
with Flow("ge_test") as flow:
checkpoint_name = Parameter("checkpoint_name")
prev_run_row_count = 100
validation_task(
checkpoint_name=checkpoint_name,
evaluation_parameters=dict(prev_run_row_count=prev_run_row_count),
context_root_dir="../great_expectations"
)
flow.run(parameters={"checkpoint_name": "my_checkpoint"})
```
## Using dynamic runtime configuration
The `RunGreatExpectationsValidation` task also enables runtime configuration of your validation run. You can pass in an in memory `DataContext` via the `context` argument or pass an in memory `Checkpoint` via the `ge_checkpoint` argument.
Here is an example with an in memory `DataContext`:
```python
import os
from pathlib import Path
import great_expectations as ge
from great_expectations.data_context import BaseDataContext
from great_expectations.data_context.types.base import (
DataContextConfig,
)
from prefect import Flow, Parameter, task
from prefect.tasks.great_expectations import RunGreatExpectationsValidation
@task
def create_in_memory_data_context(project_path: Path, data_path: Path):
data_context = BaseDataContext(
project_config=DataContextConfig(
**{
"config_version": 3.0,
"datasources": {
"data__dir": {
"module_name": "great_expectations.datasource",
"data_connectors": {
"data__dir_example_data_connector": {
"default_regex": {
"group_names": ["data_asset_name"],
"pattern": "(.*)",
},
"base_directory": str(data_path),
"module_name": "great_expectations.datasource.data_connector",
"class_name": "InferredAssetFilesystemDataConnector",
},
"default_runtime_data_connector_name": {
"batch_identifiers": ["default_identifier_name"],
"module_name": "great_expectations.datasource.data_connector",
"class_name": "RuntimeDataConnector",
},
},
"execution_engine": {
"module_name": "great_expectations.execution_engine",
"class_name": "PandasExecutionEngine",
},
"class_name": "Datasource",
}
},
"config_variables_file_path": str(
project_path / "uncommitted" / "config_variables.yml"
),
"stores": {
"expectations_store": {
"class_name": "ExpectationsStore",
"store_backend": {
"class_name": "TupleFilesystemStoreBackend",
"base_directory": str(
project_path / "expectations"
),
},
},
"validations_store": {
"class_name": "ValidationsStore",
"store_backend": {
"class_name": "TupleFilesystemStoreBackend",
"base_directory": str(
project_path / "uncommitted" / "validations"
),
},
},
"evaluation_parameter_store": {
"class_name": "EvaluationParameterStore"
},
"checkpoint_store": {
"class_name": "CheckpointStore",
"store_backend": {
"class_name": "TupleFilesystemStoreBackend",
"suppress_store_backend_id": True,
"base_directory": str(
project_path / "checkpoints"
),
},
},
},
"expectations_store_name": "expectations_store",
"validations_store_name": "validations_store",
"evaluation_parameter_store_name": "evaluation_parameter_store",
"checkpoint_store_name": "checkpoint_store",
"data_docs_sites": {
"local_site": {
"class_name": "SiteBuilder",
"show_how_to_buttons": True,
"store_backend": {
"class_name": "TupleFilesystemStoreBackend",
"base_directory": str(
project_path / "uncommitted" / "data_docs" / "local_site"
),
},
"site_index_builder": {"class_name": "DefaultSiteIndexBuilder"},
}
},
"anonymous_usage_statistics": {
"data_context_id": "abcdabcd-1111-2222-3333-abcdabcdabcd",
"enabled": False,
},
"notebooks": None,
"concurrency": {"enabled": False},
}
)
)
return data_context
validation_task = RunGreatExpectationsValidation()
with Flow("ge_test") as flow:
checkpoint_name = Parameter("checkpoint_name")
prev_run_row_count = 100
data_context = create_in_memory_data_context(project_path=Path.cwd(), data_path=Path.cwd().parent)
validation_task(
checkpoint_name=checkpoint_name,
evaluation_parameters=dict(prev_run_row_count=prev_run_row_count),
context=data_context
)
flow.run(parameters={"checkpoint_name": "my_checkpoint"})
```
## Validating in memory data
Because Prefect allows first class passing of data between tasks, you can even use the `RunGreatExpectationsValidation` task on in memory dataframes! This means you won't need to write to and read data from remote storage between steps of your pipeline.
Here is an example of how to run a validation on an in memory dataframe by passing in a `RuntimeBatchRequest` via the `checkpoint_kwargs` argument:
```python
from great_expectations.core.batch import RuntimeBatchRequest
import pandas as pd
from prefect import Flow, Parameter, task
from prefect.tasks.great_expectations import RunGreatExpectationsValidation
validation_task = RunGreatExpectationsValidation()
@task
def create_runtime_batch_request(df: pd.DataFrame):
return RuntimeBatchRequest(
datasource_name="data__dir",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="yellow_tripdata_sample_2019-02_df",
runtime_parameters={"batch_data": df},
batch_identifiers={
"default_identifier_name": "ingestion step 1",
},
)
with Flow("ge_test") as flow:
checkpoint_name = Parameter("checkpoint_name")
prev_run_row_count = 100
df = dataframe_creation_task()
in_memory_runtime_batch_request = create_runtime_batch_request(df)
validation_task(
checkpoint_name=checkpoint_name,
evaluation_parameters=dict(prev_run_row_count=prev_run_row_count),
checkpoint_kwargs={
"validations": [
{
"batch_request": in_memory_runtime_batch_request,
"expectation_suite_name": "taxi.demo_pass",
}
]
},
)
flow.run(parameters={"checkpoint_name": "my_checkpoint"})
```
## Where to go for more information
The flexibility that Prefect and the `RunGreatExpectationsValidation` task offer makes it easy to incorporate data validation into your dataflows with Great Expectations.
For more info about the `RunGreatExpectationsValidation` task, refer to the [Prefect documentation](https://docs.prefect.io/api/latest/tasks/great_expectations.html#rungreatexpectationsvalidation).
<file_sep>/docs/guides/connecting_to_your_data/datasource_configuration/how_to_configure_a_sql_datasource.md
---
title: How to configure a SQL Datasource
---
# [](../connect_to_data_overview.md) How to configure a SQL Datasource
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import SectionIntro from './components/_section_intro.mdx';
import SectionPrerequisites from './sql_components/_section_prerequisites.mdx'
import SectionImportNecessaryModulesAndInitializeYourDataContext from './filesystem_components/_section_import_necessary_modules_and_initialize_your_data_context.mdx'
import SectionCreateANewDatasourceConfiguration from './components/_section_create_a_new_datasource_configuration.mdx'
import SectionSpecifyTheDatasourceClassAndModule from './components/_section_specify_the_datasource_class_and_module.mdx'
import SectionNameYourDatasource from './components/_section_name_your_datasource.mdx'
import SectionAddTheExecutionEngineToYourDatasourceConfiguration from './sql_components/_section_add_the_execution_engine_to_your_datasource_configuration.mdx'
import SectionAddADictionaryAsTheValueOfTheDataConnectorsKey from './sql_components/_section_add_a_dictionary_as_the_value_of_the_data_connectors_key.mdx'
import SectionConfigureYourIndividualDataConnectors from './sql_components/_section_configure_your_individual_data_connectors.mdx'
import SectionDataConnectorExampleConfigurations from './sql_components/_section_data_connector_example_configurations.mdx'
import SectionConfigureYourDataAssets from './sql_components/_section_configure_your_data_assets.mdx'
import SectionTestYourConfigurationWithTestYamlConfig from './components/_section_test_your_configuration_with_test_yaml_config.mdx'
import SectionAddMoreDataConnectorsToYourConfig from './components/_section_add_more_data_connectors_to_your_config.mdx'
import SectionAddYourNewDatasourceToYourDataContext from './components/_section_add_your_new_datasource_to_your_data_context.mdx'
import SectionNextSteps from './components/_section_next_steps.mdx'
import AdditionalInfoSplittingMethods from './sql_components/_table_splitting_methods.mdx'
import AdditionalInfoSamplingMethods from './sql_components/_table_sampling_methods.mdx'
import AdditionalInfoIntrospectionDirectives from './sql_components/_part_introspection_directives.mdx'
<UniversalMap setup='inactive' connect='active' create='inactive' validate='inactive'/>
<SectionIntro backend="SQL" />
## Steps
### 1. Import necessary modules and initialize your Data Context
<SectionImportNecessaryModulesAndInitializeYourDataContext />
### 2. Create a new Datasource configuration.
<SectionCreateANewDatasourceConfiguration />
### 3. Name your Datasource
<SectionNameYourDatasource />
### 4. Specify the Datasource class and module
<SectionSpecifyTheDatasourceClassAndModule />
### 5. Add the SqlAlchemy Execution Engine to your Datasource configuration
<SectionAddTheExecutionEngineToYourDatasourceConfiguration />
### 6. Add a dictionary as the value of the `data_connectors` key
<SectionAddADictionaryAsTheValueOfTheDataConnectorsKey />
### 7. Configure your individual Data Connectors (Splitting, sampling, etc.)
<SectionConfigureYourIndividualDataConnectors backend="SQL" />
#### Data Connector example configurations:
<SectionDataConnectorExampleConfigurations />
### 8. Configure your Data Connector's Data Assets (Splitting, sampling, etc.)
<SectionConfigureYourDataAssets />
### 9. Test your configuration with `.test_yaml_config(...)`
<SectionTestYourConfigurationWithTestYamlConfig />
### 10. (Optional) Add more Data Connectors to your configuration
<SectionAddMoreDataConnectorsToYourConfig />
### 11. Add your new Datasource to your Data Context
<SectionAddYourNewDatasourceToYourDataContext />
## Next steps
<SectionNextSteps />
## Additional notes
### Splitting methods
<AdditionalInfoSplittingMethods />
### Sampling methods
<AdditionalInfoSamplingMethods />
### Introspection directives
<AdditionalInfoIntrospectionDirectives />
<file_sep>/docs/reference/expectations/result_format.md
---
title: Result format
---
The `result_format` parameter may be either a string or a dictionary which specifies the fields to return in `result`.
* For string usage, see `result_format` values.
* For dictionary usage, `result_format` which may include the following keys:
* `result_format`: Sets the fields to return in result.
* `partial_unexpected_count`: Sets the number of results to include in partial_unexpected_count, if applicable. If
set to 0, this will suppress the unexpected counts.
* `include_unexpected_rows`: When running validations, this will return the entire row for each unexpected value in
dictionary form. When using `include_unexpected_rows`, you must explicitly specify `result_format` as well, and
`result_format` must be more verbose than `BOOLEAN_ONLY`. *WARNING: *
:::warning
`include_unexpected_rows` returns EVERY row for each unexpected value; for large tables, this could return an
unwieldy amount of data.
:::
## Configure Result Format
Result Format can be applied to either a single Expectation or an entire Checkpoint.
### Expectation Level Config
To apply `result_format` to an Expectation, pass it into the Expectation's configuration:
```python
# first obtain a validator object, for instance by running the `$ great_expectations suite new` notebook.
validation_result = validator.expect_column_values_to_be_between(
column="pickup_location_id",
min_value=0,
max_value=100,
result_format="COMPLETE",
include_unexpected_rows=True
)
unexpected_index_list = validation_result["result"]["unexpected_index_list"]
unexpected_list = validation_result["result"]["unexpected_list"]
```
When configured at the Expectation level, the `unexpected_index_list` and `unexpected_list` won't be passed through to the final Validation Result object.
In order to see those values at the Suite level, configure `result_format` in your Checkpoint configuration.
### Checkpoint Level Config
To apply `result_format` to every Expectation in a Suite, define it in your Checkpoint configuration under the `runtime_configuration` key.
```python
checkpoint_config = {
"class_name": "SimpleCheckpoint", # or Checkpoint
"validations": [
# omitted for brevity
],
"runtime_configuration": {
"result_format": {
"result_format": "COMPLETE",
"include_unexpected_rows": True
}
}
}
```
The results will then be stored in the Validation Result after running the Checkpoint.
:::note
Regardless of where Result Format is configured, `unexpected_list` and `unexpected_index_list` are never rendered in Data Docs.
:::
## result_format values
Great Expectations supports four values for `result_format`: `BOOLEAN_ONLY`, `BASIC`, `SUMMARY`, and `COMPLETE`. The
out-of-the-box default is `BASIC`. Each successive value includes more detail and so can support different use
cases for working with Great Expectations, including interactive exploratory work and automatic validation.
## Fields defined for all Expectations
| Fields within `result` |BOOLEAN_ONLY |BASIC |SUMMARY |COMPLETE |
----------------------------------------|----------------|----------------|----------------|-----------------
| element_count |no |yes |yes |yes |
| missing_count |no |yes |yes |yes |
| missing_percent |no |yes |yes |yes |
| details (dictionary) |Defined on a per-expectation basis |
### Fields defined for `column_map_expectation` type Expectations
| Fields within `result` |BOOLEAN_ONLY |BASIC |SUMMARY |COMPLETE |
----------------------------------------|----------------|----------------|----------------|-----------------
| unexpected_count |no |yes |yes |yes |
| unexpected_percent |no |yes |yes |yes |
| unexpected_percent_nonmissing |no |yes |yes |yes |
| partial_unexpected_list |no |yes |yes |yes |
| partial_unexpected_index_list |no |no |yes |yes |
| partial_unexpected_counts |no |no |yes |yes |
| unexpected_index_list |no |no |no |yes |
| unexpected_list |no |no |no |yes |
### Fields defined for `column_aggregate_expectation` type Expectations
| Fields within `result` |BOOLEAN_ONLY |BASIC |SUMMARY |COMPLETE |
----------------------------------------|----------------|----------------|----------------|-----------------
| observed_value |no |yes |yes |yes |
| details (e.g. statistical details) |no |no |yes |yes |
### Example use cases for different result_format values
| `result_format` Setting | Example use case |
----------------------------------------|---------------------------------------------------------------
| BOOLEAN_ONLY | Automatic validation. No result is returned. |
| BASIC | Exploratory analysis in a notebook. |
| SUMMARY | Detailed exploratory work with follow-on investigation. |
| COMPLETE | Debugging pipelines or developing detailed regression tests. |
## result_format examples
Example input:
```python
print(list(my_df.my_var))
['A', 'B', 'B', 'C', 'C', 'C', 'D', 'D', 'D', 'D', 'E', 'E', 'E', 'E', 'E', 'F', 'F', 'F', 'F', 'F', 'F', 'G', 'G', 'G', 'G', 'G', 'G', 'G', 'H', 'H', 'H', 'H', 'H', 'H', 'H', 'H']
```
Example outputs for different values of `result_format`:
```python
my_df.expect_column_values_to_be_in_set(
"my_var",
["B", "C", "D", "F", "G", "H"],
result_format={'result_format': 'BOOLEAN_ONLY'}
)
{
'success': False
}
```
```python
my_df.expect_column_values_to_be_in_set(
"my_var",
["B", "C", "D", "F", "G", "H"],
result_format={'result_format': 'BASIC'}
)
{
'success': False,
'result': {
'unexpected_count': 6,
'unexpected_percent': 0.16666666666666666,
'unexpected_percent_nonmissing': 0.16666666666666666,
'partial_unexpected_list': ['A', 'E', 'E', 'E', 'E', 'E']
}
}
```
```python
expect_column_values_to_match_regex(
"my_column",
"[A-Z][a-z]+",
result_format={'result_format': 'SUMMARY'}
)
{
'success': False,
'result': {
'element_count': 36,
'unexpected_count': 6,
'unexpected_percent': 0.16666666666666666,
'unexpected_percent_nonmissing': 0.16666666666666666,
'missing_count': 0,
'missing_percent': 0.0,
'partial_unexpected_counts': [{'value': 'A', 'count': 1}, {'value': 'E', 'count': 5}],
'partial_unexpected_index_list': [0, 10, 11, 12, 13, 14],
'partial_unexpected_list': ['A', 'E', 'E', 'E', 'E', 'E']
}
}
```
```python
my_df.expect_column_values_to_be_in_set(
"my_var",
["B", "C", "D", "F", "G", "H"],
result_format={'result_format': 'COMPLETE'}
)
{
'success': False,
'result': {
'unexpected_index_list': [0, 10, 11, 12, 13, 14],
'unexpected_list': ['A', 'E', 'E', 'E', 'E', 'E']
}
}
```
## Behavior for `BOOLEAN_ONLY`
When the `result_format` is `BOOLEAN_ONLY`, no `result` is returned. The result of evaluating the Expectation is
exclusively returned via the value of the `success` parameter.
For example:
```python
my_df.expect_column_values_to_be_in_set(
"possible_benefactors",
["<NAME>", "<NAME>", "<NAME>", "<NAME>", "Mr. Jaggers"]
result_format={'result_format': 'BOOLEAN_ONLY'}
)
{
'success': False
}
my_df.expect_column_values_to_be_in_set(
"possible_benefactors",
["<NAME>", "<NAME>", "<NAME>", "<NAME>", "<NAME>", "<NAME>"]
result_format={'result_format': 'BOOLEAN_ONLY'}
)
{
'success': False
}
```
## Behavior for `BASIC`
A `result` is generated with a basic justification for why an expectation was met or not. The format is intended
for quick, at-a-glance feedback. For example, it tends to work well in Jupyter Notebooks.
Great Expectations has standard behavior for support for describing the results of `column_map_expectation` and
`column_aggregate_expectation` expectations.
`column_map_expectation` applies a boolean test function to each element within a column, and so returns a list of
unexpected values to justify the expectation result.
The basic `result` includes:
```python
{
"success" : Boolean,
"result" : {
"partial_unexpected_list" : [A list of up to 20 values that violate the expectation]
"unexpected_count" : The total count of unexpected values in the column
"unexpected_percent" : The overall percent of unexpected values
"unexpected_percent_nonmissing" : The percent of unexpected values, excluding missing values from the denominator
}
}
```
**Note:** When unexpected values are duplicated, `unexpected_list` will contain multiple copies of the value.
```python
[1,2,2,3,3,3,None,None,None,None]
expect_column_values_to_be_unique
{
"success" : Boolean,
"result" : {
"partial_unexpected_list" : [2,2,3,3,3]
"unexpected_count" : 5,
"unexpected_percent" : 0.5,
"unexpected_percent_nonmissing" : 0.8333333
}
}
```
`column_aggregate_expectation` computes a single aggregate value for the column, and so returns a single
`observed_value` to justify the expectation result.
The basic `result` includes:
```python
{
"success" : Boolean,
"result" : {
"observed_value" : The aggregate statistic computed for the column
}
}
```
For example:
```python
[1, 1, 2, 2]
expect_column_mean_to_be_between
{
"success" : Boolean,
"result" : {
"observed_value" : 1.5
}
}
```
## Behavior for `SUMMARY`
A `result` is generated with a summary justification for why an expectation was met or not. The format is intended
for more detailed exploratory work and includes additional information beyond what is included by `BASIC`.
For example, it can support generating dashboard results of whether a set of expectations are being met.
Great Expectations has standard behavior for support for describing the results of `column_map_expectation` and
`column_aggregate_expectation` expectations.
`column_map_expectation` applies a boolean test function to each element within a column, and so returns a list of
unexpected values to justify the expectation result.
The summary `result` includes:
```python
{
'success': False,
'result': {
'element_count': The total number of values in the column
'unexpected_count': The total count of unexpected values in the column (also in `BASIC`)
'unexpected_percent': The overall percent of unexpected values (also in `BASIC`)
'unexpected_percent_nonmissing': The percent of unexpected values, excluding missing values from the denominator (also in `BASIC`)
"partial_unexpected_list" : [A list of up to 20 values that violate the expectation] (also in `BASIC`)
'missing_count': The number of missing values in the column
'missing_percent': The total percent of missing values in the column
'partial_unexpected_counts': [{A list of objects with value and counts, showing the number of times each of the unexpected values occurs}]
'partial_unexpected_index_list': [A list of up to 20 of the indices of the unexpected values in the column]
}
}
```
For example:
```python
{
'success': False,
'result': {
'element_count': 36,
'unexpected_count': 6,
'unexpected_percent': 0.16666666666666666,
'unexpected_percent_nonmissing': 0.16666666666666666,
'missing_count': 0,
'missing_percent': 0.0,
'partial_unexpected_counts': [{'value': 'A', 'count': 1}, {'value': 'E', 'count': 5}],
'partial_unexpected_index_list': [0, 10, 11, 12, 13, 14],
'partial_unexpected_list': ['A', 'E', 'E', 'E', 'E', 'E']
}
}
```
`column_aggregate_expectation` computes a single aggregate value for the column, and so returns a `observed_value`
to justify the expectation result. It also includes additional information regarding observed values and counts,
depending on the specific expectation.
The summary `result` includes:
```python
{
'success': False,
'result': {
'observed_value': The aggregate statistic computed for the column (also in `BASIC`)
'element_count': The total number of values in the column
'missing_count': The number of missing values in the column
'missing_percent': The total percent of missing values in the column
'details': {<expectation-specific result justification fields>}
}
}
```
For example:
```python
[1, 1, 2, 2, NaN]
expect_column_mean_to_be_between
{
"success" : Boolean,
"result" : {
"observed_value" : 1.5,
'element_count': 5,
'missing_count': 1,
'missing_percent': 0.2
}
}
```
## Behavior for `COMPLETE`
A `result` is generated with all available justification for why an expectation was met or not. The format is
intended for debugging pipelines or developing detailed regression tests.
Great Expectations has standard behavior for support for describing the results of `column_map_expectation` and
`column_aggregate_expectation` expectations.
`column_map_expectation` applies a boolean test function to each element within a column, and so returns a list of
unexpected values to justify the expectation result.
The complete `result` includes:
```python
{
'success': False,
'result': {
"unexpected_list" : [A list of all values that violate the expectation]
'unexpected_index_list': [A list of the indices of the unexpected values in the column]
'element_count': The total number of values in the column (also in `SUMMARY`)
'unexpected_count': The total count of unexpected values in the column (also in `SUMMARY`)
'unexpected_percent': The overall percent of unexpected values (also in `SUMMARY`)
'unexpected_percent_nonmissing': The percent of unexpected values, excluding missing values from the denominator (also in `SUMMARY`)
'missing_count': The number of missing values in the column (also in `SUMMARY`)
'missing_percent': The total percent of missing values in the column (also in `SUMMARY`)
}
}
```
For example:
```python
{
'success': False,
'result': {
'element_count': 36,
'unexpected_count': 6,
'unexpected_percent': 0.16666666666666666,
'unexpected_percent_nonmissing': 0.16666666666666666,
'missing_count': 0,
'missing_percent': 0.0,
'unexpected_index_list': [0, 10, 11, 12, 13, 14],
'unexpected_list': ['A', 'E', 'E', 'E', 'E', 'E']
}
}
```
`column_aggregate_expectation` computes a single aggregate value for the column, and so returns a `observed_value`
to justify the expectation result. It also includes additional information regarding observed values and counts,
depending on the specific expectation.
The complete `result` includes:
```python
{
'success': False,
'result': {
'observed_value': The aggregate statistic computed for the column (also in `SUMMARY`)
'element_count': The total number of values in the column (also in `SUMMARY`)
'missing_count': The number of missing values in the column (also in `SUMMARY`)
'missing_percent': The total percent of missing values in the column (also in `SUMMARY`)
'details': {<expectation-specific result justification fields, which may be more detailed than in `SUMMARY`>}
}
}
```
For example:
```python
[1, 1, 2, 2, NaN]
expect_column_mean_to_be_between
{
"success" : Boolean,
"result" : {
"observed_value" : 1.5,
'element_count': 5,
'missing_count': 1,
'missing_percent': 0.2
}
}
```
<file_sep>/reqs/requirements-dev-sqlalchemy.txt
--requirement requirements-dev-lite.txt
--requirement requirements-dev-athena.txt
--requirement requirements-dev-bigquery.txt
--requirement requirements-dev-dremio.txt
--requirement requirements-dev-mssql.txt
--requirement requirements-dev-mysql.txt
--requirement requirements-dev-postgresql.txt
--requirement requirements-dev-redshift.txt
--requirement requirements-dev-snowflake.txt
--requirement requirements-dev-teradata.txt
--requirement requirements-dev-trino.txt
--requirement requirements-dev-hive.txt
--requirement requirements-dev-vertica.txt
<file_sep>/great_expectations/data_context/store/checkpoint_store.py
import itertools
import logging
import os
import random
import uuid
from typing import TYPE_CHECKING, Dict, List, Optional, Union
from marshmallow import ValidationError
import great_expectations.exceptions as ge_exceptions
from great_expectations.core.data_context_key import DataContextKey
from great_expectations.data_context.cloud_constants import GXCloudRESTResource
from great_expectations.data_context.store import ConfigurationStore
from great_expectations.data_context.types.base import (
CheckpointConfig,
DataContextConfigDefaults,
)
from great_expectations.data_context.types.refs import (
GXCloudIDAwareRef,
GXCloudResourceRef,
)
from great_expectations.data_context.types.resource_identifiers import (
ConfigurationIdentifier,
GXCloudIdentifier,
)
if TYPE_CHECKING:
from great_expectations.checkpoint import Checkpoint
logger = logging.getLogger(__name__)
class CheckpointStore(ConfigurationStore):
"""
A CheckpointStore manages Checkpoints for the DataContext.
"""
_configuration_class = CheckpointConfig
def ge_cloud_response_json_to_object_dict(self, response_json: Dict) -> Dict:
"""
This method takes full json response from GE cloud and outputs a dict appropriate for
deserialization into a GE object
"""
ge_cloud_checkpoint_id = response_json["data"]["id"]
checkpoint_config_dict = response_json["data"]["attributes"][
"checkpoint_config"
]
checkpoint_config_dict["ge_cloud_id"] = ge_cloud_checkpoint_id
# Checkpoints accept a `ge_cloud_id` but not an `id`
checkpoint_config_dict.pop("id", None)
return checkpoint_config_dict
def serialization_self_check(self, pretty_print: bool) -> None:
test_checkpoint_name: str = "test-name-" + "".join(
[random.choice(list("0123456789ABCDEF")) for i in range(20)]
)
test_checkpoint_configuration = CheckpointConfig(
**{"name": test_checkpoint_name} # type: ignore[arg-type]
)
if self.ge_cloud_mode:
test_key: GXCloudIdentifier = self.key_class( # type: ignore[call-arg,assignment]
resource_type=GXCloudRESTResource.CHECKPOINT,
ge_cloud_id=str(uuid.uuid4()),
)
else:
test_key = self.key_class(configuration_key=test_checkpoint_name) # type: ignore[call-arg,assignment]
if pretty_print:
print(f"Attempting to add a new test key {test_key} to Checkpoint store...")
self.set(key=test_key, value=test_checkpoint_configuration)
if pretty_print:
print(f"\tTest key {test_key} successfully added to Checkpoint store.\n")
if pretty_print:
print(
f"Attempting to retrieve the test value associated with key {test_key} from Checkpoint store..."
)
self.get(key=test_key)
if pretty_print:
print("\tTest value successfully retrieved from Checkpoint store.")
print()
if pretty_print:
print(f"Cleaning up test key {test_key} and value from Checkpoint store...")
self.remove_key(key=test_key)
if pretty_print:
print("\tTest key and value successfully removed from Checkpoint store.")
print()
@staticmethod
def default_checkpoints_exist(directory_path: str) -> bool:
if not directory_path:
return False
checkpoints_directory_path: str = os.path.join(
directory_path,
DataContextConfigDefaults.DEFAULT_CHECKPOINT_STORE_BASE_DIRECTORY_RELATIVE_NAME.value,
)
return os.path.isdir(checkpoints_directory_path)
def list_checkpoints(
self, ge_cloud_mode: bool = False
) -> Union[List[str], List[ConfigurationIdentifier]]:
keys: Union[List[str], List[ConfigurationIdentifier]] = self.list_keys() # type: ignore[assignment]
if ge_cloud_mode:
return keys
return [k.configuration_key for k in keys] # type: ignore[union-attr]
def delete_checkpoint(
self,
name: Optional[str] = None,
ge_cloud_id: Optional[str] = None,
) -> None:
key: Union[GXCloudIdentifier, ConfigurationIdentifier] = self.determine_key(
name=name, ge_cloud_id=ge_cloud_id
)
try:
self.remove_key(key=key)
except ge_exceptions.InvalidKeyError as exc_ik:
raise ge_exceptions.CheckpointNotFoundError(
message=f'Non-existent Checkpoint configuration named "{key.configuration_key}".\n\nDetails: {exc_ik}' # type: ignore[union-attr]
)
def get_checkpoint(
self, name: Optional[str], ge_cloud_id: Optional[str]
) -> CheckpointConfig:
key: Union[GXCloudIdentifier, ConfigurationIdentifier] = self.determine_key(
name=name, ge_cloud_id=ge_cloud_id
)
try:
checkpoint_config: CheckpointConfig = self.get(key=key) # type: ignore[assignment]
except ge_exceptions.InvalidKeyError as exc_ik:
raise ge_exceptions.CheckpointNotFoundError(
message=f'Non-existent Checkpoint configuration named "{key.configuration_key}".\n\nDetails: {exc_ik}' # type: ignore[union-attr]
)
except ValidationError as exc_ve:
raise ge_exceptions.InvalidCheckpointConfigError(
message="Invalid Checkpoint configuration", validation_error=exc_ve
)
if checkpoint_config.config_version is None:
config_dict: dict = checkpoint_config.to_json_dict()
batches: Optional[dict] = config_dict.get("batches")
if not (
batches is not None
and (
len(batches) == 0
or {"batch_kwargs", "expectation_suite_names"}.issubset(
set(
itertools.chain.from_iterable(
item.keys() for item in batches
)
)
)
)
):
raise ge_exceptions.CheckpointError(
message="Attempt to instantiate LegacyCheckpoint with insufficient and/or incorrect arguments."
)
return checkpoint_config
def add_checkpoint(
self, checkpoint: "Checkpoint", name: Optional[str], ge_cloud_id: Optional[str]
) -> None:
key: Union[GXCloudIdentifier, ConfigurationIdentifier] = self.determine_key(
name=name, ge_cloud_id=ge_cloud_id
)
checkpoint_config: CheckpointConfig = checkpoint.get_config() # type: ignore[assignment]
checkpoint_ref = self.set(key=key, value=checkpoint_config) # type: ignore[func-returns-value]
if isinstance(checkpoint_ref, GXCloudIDAwareRef):
ge_cloud_id = checkpoint_ref.ge_cloud_id
checkpoint.ge_cloud_id = uuid.UUID(ge_cloud_id) # type: ignore[misc]
def create(self, checkpoint_config: CheckpointConfig) -> Optional[DataContextKey]:
"""Create a checkpoint config in the store using a store_backend-specific key.
Args:
checkpoint_config: Config containing the checkpoint name.
Returns:
None unless using GXCloudStoreBackend and if so the GeCloudResourceRef which contains the id
which was used to create the config in the backend.
"""
# CheckpointConfig not an AbstractConfig??
# mypy error: incompatible type "CheckpointConfig"; expected "AbstractConfig"
key: DataContextKey = self._build_key_from_config(checkpoint_config) # type: ignore[arg-type]
# Make two separate requests to set and get in order to obtain any additional
# values that may have been added to the config by the StoreBackend (i.e. object ids)
ref: Optional[Union[bool, GXCloudResourceRef]] = self.set(key, checkpoint_config) # type: ignore[func-returns-value]
if ref and isinstance(ref, GXCloudResourceRef):
key.ge_cloud_id = ref.ge_cloud_id # type: ignore[attr-defined]
config = self.get(key=key)
return config
<file_sep>/docs/guides/validation/checkpoints/components_how_to_create_a_new_checkpoint/_c_store_your_checkpoint_config.mdx
After you are satisfied with your configuration, save it by running the appropriate cells in the Jupyter Notebook.
<file_sep>/tests/expectations/metrics/test_map_metric.py
import pandas as pd
import pytest
from great_expectations.core import (
ExpectationConfiguration,
ExpectationValidationResult,
)
from great_expectations.core.batch import Batch
from great_expectations.core.util import convert_to_json_serializable
from great_expectations.execution_engine import (
PandasExecutionEngine,
SqlAlchemyExecutionEngine,
)
from great_expectations.expectations.core import ExpectColumnValuesToBeInSet
from great_expectations.expectations.metrics import (
ColumnMax,
ColumnValuesNonNull,
CompoundColumnsUnique,
)
from great_expectations.expectations.metrics.map_metric_provider import (
ColumnMapMetricProvider,
MapMetricProvider,
)
from great_expectations.validator.validation_graph import MetricConfiguration
from great_expectations.validator.validator import Validator
@pytest.fixture
def pandas_animals_dataframe_for_unexpected_rows_and_index():
return pd.DataFrame(
{
"pk_1": [0, 1, 2, 3, 4, 5],
"pk_2": ["zero", "one", "two", "three", "four", "five"],
"animals": [
"cat",
"fish",
"dog",
"giraffe",
"lion",
"zebra",
],
}
)
@pytest.fixture()
def expected_evr_without_unexpected_rows():
return ExpectationValidationResult(
success=False,
expectation_config={
"expectation_type": "expect_column_values_to_be_in_set",
"kwargs": {
"column": "a",
"value_set": [1, 5, 22],
},
"meta": {},
},
result={
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_counts": [
{"count": 1, "value": "giraffe"},
{"count": 1, "value": "lion"},
{"count": 1, "value": "zebra"},
],
"partial_unexpected_index_list": [3, 4, 5],
"partial_unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_count": 3,
"unexpected_index_list": [3, 4, 5],
"unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
},
exception_info={
"raised_exception": False,
"exception_traceback": None,
"exception_message": None,
},
meta={},
)
def test_get_table_metric_provider_metric_dependencies(empty_sqlite_db):
mp = ColumnMax()
metric = MetricConfiguration(
metric_name="column.max", metric_domain_kwargs={}, metric_value_kwargs=None
)
dependencies = mp.get_evaluation_dependencies(
metric, execution_engine=SqlAlchemyExecutionEngine(engine=empty_sqlite_db)
)
assert dependencies["metric_partial_fn"].id[0] == "column.max.aggregate_fn"
mp = ColumnMax()
metric = MetricConfiguration(
metric_name="column.max", metric_domain_kwargs={}, metric_value_kwargs=None
)
dependencies = mp.get_evaluation_dependencies(
metric, execution_engine=PandasExecutionEngine()
)
table_column_types_metric: MetricConfiguration = dependencies["table.column_types"]
table_columns_metric: MetricConfiguration = dependencies["table.columns"]
table_row_count_metric: MetricConfiguration = dependencies["table.row_count"]
assert dependencies == {
"table.column_types": table_column_types_metric,
"table.columns": table_columns_metric,
"table.row_count": table_row_count_metric,
}
assert dependencies["table.columns"].id == (
"table.columns",
(),
(),
)
def test_get_aggregate_count_aware_metric_dependencies(basic_spark_df_execution_engine):
mp = ColumnValuesNonNull()
metric = MetricConfiguration(
metric_name="column_values.nonnull.unexpected_count",
metric_domain_kwargs={},
metric_value_kwargs=None,
)
dependencies = mp.get_evaluation_dependencies(
metric, execution_engine=PandasExecutionEngine()
)
assert (
dependencies["unexpected_condition"].id[0] == "column_values.nonnull.condition"
)
metric = MetricConfiguration(
metric_name="column_values.nonnull.unexpected_count",
metric_domain_kwargs={},
metric_value_kwargs=None,
)
dependencies = mp.get_evaluation_dependencies(
metric, execution_engine=basic_spark_df_execution_engine
)
assert (
dependencies["metric_partial_fn"].id[0]
== "column_values.nonnull.unexpected_count.aggregate_fn"
)
metric = MetricConfiguration(
metric_name="column_values.nonnull.unexpected_count.aggregate_fn",
metric_domain_kwargs={},
metric_value_kwargs=None,
)
dependencies = mp.get_evaluation_dependencies(metric)
assert (
dependencies["unexpected_condition"].id[0] == "column_values.nonnull.condition"
)
def test_get_map_metric_dependencies():
mp = ColumnMapMetricProvider()
metric = MetricConfiguration(
metric_name="foo.unexpected_count",
metric_domain_kwargs={},
metric_value_kwargs=None,
)
dependencies = mp.get_evaluation_dependencies(metric)
assert dependencies["unexpected_condition"].id[0] == "foo.condition"
metric = MetricConfiguration(
metric_name="foo.unexpected_rows",
metric_domain_kwargs={},
metric_value_kwargs=None,
)
dependencies = mp.get_evaluation_dependencies(metric)
assert dependencies["unexpected_condition"].id[0] == "foo.condition"
metric = MetricConfiguration(
metric_name="foo.unexpected_values",
metric_domain_kwargs={},
metric_value_kwargs=None,
)
dependencies = mp.get_evaluation_dependencies(metric)
assert dependencies["unexpected_condition"].id[0] == "foo.condition"
metric = MetricConfiguration(
metric_name="foo.unexpected_value_counts",
metric_domain_kwargs={},
metric_value_kwargs=None,
)
dependencies = mp.get_evaluation_dependencies(metric)
assert dependencies["unexpected_condition"].id[0] == "foo.condition"
metric = MetricConfiguration(
metric_name="foo.unexpected_index_list",
metric_domain_kwargs={},
metric_value_kwargs=None,
)
dependencies = mp.get_evaluation_dependencies(metric)
assert dependencies["unexpected_condition"].id[0] == "foo.condition"
def test_is_sqlalchemy_metric_selectable():
assert MapMetricProvider.is_sqlalchemy_metric_selectable(
map_metric_provider=CompoundColumnsUnique
)
assert not MapMetricProvider.is_sqlalchemy_metric_selectable(
map_metric_provider=ColumnValuesNonNull
)
def test_pandas_unexpected_rows_basic_result_format(
pandas_animals_dataframe_for_unexpected_rows_and_index,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"mostly": 0.9,
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "BASIC",
"include_unexpected_rows": True,
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert convert_to_json_serializable(result.result) == {
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_count": 3,
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
"unexpected_rows": [
{"animals": "giraffe", "pk_1": 3, "pk_2": "three"},
{"animals": "lion", "pk_1": 4, "pk_2": "four"},
{"animals": "zebra", "pk_1": 5, "pk_2": "five"},
],
}
def test_pandas_unexpected_rows_summary_result_format_unexpected_rows_explicitly_false(
pandas_animals_dataframe_for_unexpected_rows_and_index,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"mostly": 0.9,
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "SUMMARY", # SUMMARY will include partial_unexpected* values only
"include_unexpected_rows": False, # this is the default value, but making explicit for testing purposes
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert convert_to_json_serializable(result.result) == {
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_counts": [
{"count": 1, "value": "giraffe"},
{"count": 1, "value": "lion"},
{"count": 1, "value": "zebra"},
],
"partial_unexpected_index_list": [3, 4, 5],
"partial_unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_count": 3,
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
}
def test_pandas_unexpected_rows_summary_result_format_unexpected_rows_including_unexpected_rows(
pandas_animals_dataframe_for_unexpected_rows_and_index,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"mostly": 0.9,
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "SUMMARY", # SUMMARY will include partial_unexpected* values only
"include_unexpected_rows": True,
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert convert_to_json_serializable(result.result) == {
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_counts": [
{"count": 1, "value": "giraffe"},
{"count": 1, "value": "lion"},
{"count": 1, "value": "zebra"},
],
"partial_unexpected_index_list": [3, 4, 5],
"partial_unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_count": 3,
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
"unexpected_rows": [
{"animals": "giraffe", "pk_1": 3, "pk_2": "three"},
{"animals": "lion", "pk_1": 4, "pk_2": "four"},
{"animals": "zebra", "pk_1": 5, "pk_2": "five"},
],
}
def test_pandas_unexpected_rows_complete_result_format(
pandas_animals_dataframe_for_unexpected_rows_and_index,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "COMPLETE",
"include_unexpected_rows": True,
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert convert_to_json_serializable(result.result) == {
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_counts": [
{"count": 1, "value": "giraffe"},
{"count": 1, "value": "lion"},
{"count": 1, "value": "zebra"},
],
"partial_unexpected_index_list": [3, 4, 5],
"partial_unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_count": 3,
"unexpected_index_list": [3, 4, 5],
"unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
"unexpected_rows": [
{"animals": "giraffe", "pk_1": 3, "pk_2": "three"},
{"animals": "lion", "pk_1": 4, "pk_2": "four"},
{"animals": "zebra", "pk_1": 5, "pk_2": "five"},
],
}
def test_pandas_default_complete_result_format(
pandas_animals_dataframe_for_unexpected_rows_and_index: pd.DataFrame,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "COMPLETE",
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch: Batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert convert_to_json_serializable(result.result) == {
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_counts": [
{"count": 1, "value": "giraffe"},
{"count": 1, "value": "lion"},
{"count": 1, "value": "zebra"},
],
"partial_unexpected_index_list": [3, 4, 5],
"partial_unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_count": 3,
"unexpected_index_list": [3, 4, 5],
"unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
}
def test_pandas_single_unexpected_index_column_names_complete_result_format(
pandas_animals_dataframe_for_unexpected_rows_and_index: pd.DataFrame,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "COMPLETE",
"unexpected_index_column_names": ["pk_1"], # Single column
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch: Batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert convert_to_json_serializable(result.result) == {
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_counts": [
{"count": 1, "value": "giraffe"},
{"count": 1, "value": "lion"},
{"count": 1, "value": "zebra"},
],
"partial_unexpected_index_list": [
{"pk_1": 3},
{"pk_1": 4},
{"pk_1": 5},
], # Dict since a column was provided
"partial_unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_count": 3,
"unexpected_index_list": [
{"pk_1": 3},
{"pk_1": 4},
{"pk_1": 5},
], # Dict since a column was provided
"unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
}
def test_pandas_multiple_unexpected_index_column_names_complete_result_format(
pandas_animals_dataframe_for_unexpected_rows_and_index: pd.DataFrame,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "COMPLETE",
"unexpected_index_column_names": ["pk_1", "pk_2"], # Multiple columns
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch: Batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert convert_to_json_serializable(result.result) == {
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_counts": [
{"count": 1, "value": "giraffe"},
{"count": 1, "value": "lion"},
{"count": 1, "value": "zebra"},
],
"partial_unexpected_index_list": [
{"pk_1": 3, "pk_2": "three"},
{"pk_1": 4, "pk_2": "four"},
{"pk_1": 5, "pk_2": "five"},
], # Dicts since columns were provided
"partial_unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_count": 3,
"unexpected_index_list": [
{"pk_1": 3, "pk_2": "three"},
{"pk_1": 4, "pk_2": "four"},
{"pk_1": 5, "pk_2": "five"},
], # Dicts since columns were provided
"unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
}
def test_pandas_multiple_unexpected_index_column_names_complete_result_format_limit_1(
pandas_animals_dataframe_for_unexpected_rows_and_index: pd.DataFrame,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "COMPLETE",
"unexpected_index_column_names": ["pk_1", "pk_2"], # Multiple columns
"partial_unexpected_count": 1,
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch: Batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert convert_to_json_serializable(result.result) == {
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_counts": [{"count": 1, "value": "giraffe"}],
"partial_unexpected_index_list": [{"pk_1": 3, "pk_2": "three"}],
"partial_unexpected_list": ["giraffe"],
"unexpected_count": 3,
"unexpected_index_list": [
{"pk_1": 3, "pk_2": "three"},
{"pk_1": 4, "pk_2": "four"},
{"pk_1": 5, "pk_2": "five"},
],
"unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
}
def test_pandas_multiple_unexpected_index_column_names_summary_result_format(
pandas_animals_dataframe_for_unexpected_rows_and_index: pd.DataFrame,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "SUMMARY", # SUMMARY will include partial_unexpected* values only
"unexpected_index_column_names": ["pk_1", "pk_2"], # Multiple columns
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch: Batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert convert_to_json_serializable(result.result) == {
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_counts": [
{"count": 1, "value": "giraffe"},
{"count": 1, "value": "lion"},
{"count": 1, "value": "zebra"},
], # Dicts since columns were provided
"partial_unexpected_index_list": [
{"pk_1": 3, "pk_2": "three"},
{"pk_1": 4, "pk_2": "four"},
{"pk_1": 5, "pk_2": "five"},
], # Dicts since columns were provided
"partial_unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_count": 3,
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
}
def test_pandas_multiple_unexpected_index_column_names_summary_result_format_limit_1(
pandas_animals_dataframe_for_unexpected_rows_and_index: pd.DataFrame,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "SUMMARY", # SUMMARY will include partial_unexpected* values only
"unexpected_index_column_names": ["pk_1", "pk_2"], # Multiple columns
"partial_unexpected_count": 1,
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch: Batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert convert_to_json_serializable(result.result) == {
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_counts": [{"count": 1, "value": "giraffe"}],
"partial_unexpected_index_list": [
{"pk_1": 3, "pk_2": "three"}
], # Dicts since columns were provided
"partial_unexpected_list": ["giraffe"],
"unexpected_count": 3,
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
}
def test_pandas_multiple_unexpected_index_column_names_basic_result_format(
pandas_animals_dataframe_for_unexpected_rows_and_index: pd.DataFrame,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "BASIC", # BASIC will not include index information
"unexpected_index_column_names": ["pk_1", "pk_2"],
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch: Batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert convert_to_json_serializable(result.result) == {
"element_count": 6,
"missing_count": 0,
"missing_percent": 0.0,
"partial_unexpected_list": ["giraffe", "lion", "zebra"],
"unexpected_count": 3,
"unexpected_percent": 50.0,
"unexpected_percent_nonmissing": 50.0,
"unexpected_percent_total": 50.0,
}
def test_pandas_single_unexpected_index_column_names_complete_result_format_non_existing_column(
pandas_animals_dataframe_for_unexpected_rows_and_index: pd.DataFrame,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "COMPLETE",
"unexpected_index_column_names": ["i_dont_exist"], # Single column
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch: Batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert result.success is False
assert result.exception_info
assert (
result.exception_info["exception_message"]
== 'Error: The unexpected_index_column: "i_dont_exist" does not exist in Dataframe. Please check your configuration and try again.'
)
def test_pandas_multiple_unexpected_index_column_names_complete_result_format_non_existing_column(
pandas_animals_dataframe_for_unexpected_rows_and_index: pd.DataFrame,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "COMPLETE",
"unexpected_index_column_names": [
"pk_1",
"i_dont_exist",
], # Only 1 column is valid
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch: Batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert result.success is False
assert result.exception_info
assert (
result.exception_info["exception_message"]
== 'Error: The unexpected_index_column: "i_dont_exist" does not exist in Dataframe. Please check your configuration and try again.'
)
def test_pandas_default_to_not_include_unexpected_rows(
pandas_animals_dataframe_for_unexpected_rows_and_index,
expected_evr_without_unexpected_rows,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "COMPLETE",
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert result.result == expected_evr_without_unexpected_rows.result
def test_pandas_specify_not_include_unexpected_rows(
pandas_animals_dataframe_for_unexpected_rows_and_index,
expected_evr_without_unexpected_rows,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"result_format": "COMPLETE",
"include_unexpected_rows": False,
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
result = expectation.validate(validator)
assert result.result == expected_evr_without_unexpected_rows.result
def test_include_unexpected_rows_without_explicit_result_format_raises_error(
pandas_animals_dataframe_for_unexpected_rows_and_index,
):
expectation_configuration = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "animals",
"value_set": ["cat", "fish", "dog"],
"result_format": {
"include_unexpected_rows": False,
},
},
)
expectation = ExpectColumnValuesToBeInSet(expectation_configuration)
batch = Batch(data=pandas_animals_dataframe_for_unexpected_rows_and_index)
engine = PandasExecutionEngine()
validator = Validator(
execution_engine=engine,
batches=[
batch,
],
)
with pytest.raises(ValueError):
expectation.validate(validator)
<file_sep>/great_expectations/experimental/datasources/metadatasource.py
"""
POC for dynamically bootstrapping context.sources with Datasource factory methods.
"""
from __future__ import annotations
import logging
from pprint import pformat as pf
from typing import TYPE_CHECKING, Set, Type
import pydantic
from great_expectations.experimental.datasources.sources import _SourceFactories
if TYPE_CHECKING:
from great_expectations.experimental.datasources.interfaces import Datasource
LOGGER = logging.getLogger(__name__)
class MetaDatasource(pydantic.main.ModelMetaclass):
__cls_set: Set[Type] = set()
def __new__(
meta_cls: Type[MetaDatasource], cls_name: str, bases: tuple[type], cls_dict
) -> MetaDatasource:
"""
MetaDatasource hook that runs when a new `Datasource` is defined.
This methods binds a factory method for the defined `Datasource` to `_SourceFactories` class which becomes
available as part of the `DataContext`.
Also binds asset adding methods according to the declared `asset_types`.
"""
LOGGER.debug(f"1a. {meta_cls.__name__}.__new__() for `{cls_name}`")
cls = super().__new__(meta_cls, cls_name, bases, cls_dict)
if cls_name == "Datasource":
# NOTE: the above check is brittle and must be kept in-line with the Datasource.__name__
LOGGER.debug("1c. Skip factory registration of base `Datasource`")
return cls
LOGGER.debug(f" {cls_name} __dict__ ->\n{pf(cls.__dict__, depth=3)}")
meta_cls.__cls_set.add(cls)
LOGGER.info(f"Datasources: {len(meta_cls.__cls_set)}")
def _datasource_factory(name: str, **kwargs) -> Datasource:
# TODO: update signature to match Datasource __init__ (ex update __signature__)
LOGGER.info(f"5. Adding '{name}' {cls_name}")
return cls(name=name, **kwargs)
# TODO: generate schemas from `cls` if needed
if cls.__module__ == "__main__":
LOGGER.warning(
f"Datasource `{cls_name}` should not be defined as part of __main__ this may cause typing lookup collisions"
)
_SourceFactories.register_types_and_ds_factory(cls, _datasource_factory)
return cls
<file_sep>/tests/experimental/datasources/test_postgres_datasource.py
from contextlib import contextmanager
from typing import Callable, ContextManager
import pytest
import great_expectations.experimental.datasources.postgres_datasource as postgres_datasource
from great_expectations.core.batch_spec import SqlAlchemyDatasourceBatchSpec
from great_expectations.execution_engine import SqlAlchemyExecutionEngine
from great_expectations.experimental.datasources.interfaces import (
BatchRequest,
BatchRequestOptions,
)
from tests.experimental.datasources.conftest import sqlachemy_execution_engine_mock_cls
@contextmanager
def _source(
validate_batch_spec: Callable[[SqlAlchemyDatasourceBatchSpec], None]
) -> postgres_datasource.PostgresDatasource:
execution_eng_cls = sqlachemy_execution_engine_mock_cls(validate_batch_spec)
original_override = postgres_datasource.PostgresDatasource.execution_engine_override
try:
postgres_datasource.PostgresDatasource.execution_engine_override = (
execution_eng_cls
)
yield postgres_datasource.PostgresDatasource(
name="my_datasource",
connection_string="postgresql+psycopg2://postgres:@localhost/test_ci",
)
finally:
postgres_datasource.PostgresDatasource.execution_engine_override = (
original_override
)
# We may be able parameterize this fixture so we can instantiate _source in the fixture. This
# would reduce the `with ...` boilerplate in the individual tests.
@pytest.fixture
def create_source() -> ContextManager:
return _source
@pytest.mark.unit
def test_construct_postgres_datasource(create_source):
with create_source(lambda: None) as source:
assert source.name == "my_datasource"
assert isinstance(source.execution_engine, SqlAlchemyExecutionEngine)
assert source.assets == {}
def assert_table_asset(
asset: postgres_datasource.TableAsset,
name: str,
table_name: str,
source: postgres_datasource.PostgresDatasource,
batch_request_template: BatchRequestOptions,
):
assert asset.name == name
assert asset.table_name == table_name
assert asset.datasource == source
assert asset.batch_request_options_template() == batch_request_template
def assert_batch_request(
batch_request, source_name: str, asset_name: str, options: BatchRequestOptions
):
assert batch_request.datasource_name == source_name
assert batch_request.data_asset_name == asset_name
assert batch_request.options == options
@pytest.mark.unit
def test_add_table_asset_with_splitter(create_source):
with create_source(lambda: None) as source:
asset = source.add_table_asset(name="my_asset", table_name="my_table")
asset.add_year_and_month_splitter("my_column")
assert len(source.assets) == 1
assert asset == list(source.assets.values())[0]
assert_table_asset(
asset=asset,
name="my_asset",
table_name="my_table",
source=source,
batch_request_template={"year": None, "month": None},
)
assert_batch_request(
batch_request=asset.get_batch_request({"year": 2021, "month": 10}),
source_name="my_datasource",
asset_name="my_asset",
options={"year": 2021, "month": 10},
)
@pytest.mark.unit
def test_add_table_asset_with_no_splitter(create_source):
with create_source(lambda: None) as source:
asset = source.add_table_asset(name="my_asset", table_name="my_table")
assert len(source.assets) == 1
assert asset == list(source.assets.values())[0]
assert_table_asset(
asset=asset,
name="my_asset",
table_name="my_table",
source=source,
batch_request_template={},
)
assert_batch_request(
batch_request=asset.get_batch_request(),
source_name="my_datasource",
asset_name="my_asset",
options={},
)
assert_batch_request(
batch_request=asset.get_batch_request({}),
source_name="my_datasource",
asset_name="my_asset",
options={},
)
@pytest.mark.unit
def test_construct_table_asset_directly_with_no_splitter(create_source):
with create_source(lambda: None) as source:
asset = postgres_datasource.TableAsset(name="my_asset", table_name="my_table")
asset._datasource = source
assert_batch_request(asset.get_batch_request(), "my_datasource", "my_asset", {})
@pytest.mark.unit
def test_construct_table_asset_directly_with_splitter(create_source):
with create_source(lambda: None) as source:
splitter = postgres_datasource.ColumnSplitter(
method_name="splitter_method",
column_name="col",
param_defaults={"a": [1, 2, 3], "b": range(1, 13)},
)
asset = postgres_datasource.TableAsset(
name="my_asset",
table_name="my_table",
column_splitter=splitter,
)
# TODO: asset custom init
asset._datasource = source
assert_table_asset(
asset,
"my_asset",
"my_table",
source,
{"a": None, "b": None},
)
batch_request_options = {"a": 1, "b": 2}
assert_batch_request(
asset.get_batch_request(batch_request_options),
"my_datasource",
"my_asset",
batch_request_options,
)
@pytest.mark.unit
def test_datasource_gets_batch_list_no_splitter(create_source):
def validate_batch_spec(spec: SqlAlchemyDatasourceBatchSpec) -> None:
assert spec == {
"batch_identifiers": {},
"data_asset_name": "my_asset",
"table_name": "my_table",
"type": "table",
}
with create_source(validate_batch_spec) as source:
asset = source.add_table_asset(name="my_asset", table_name="my_table")
source.get_batch_list_from_batch_request(asset.get_batch_request())
def assert_batch_specs_correct_with_year_month_splitter_defaults(batch_specs):
# We should have 1 batch_spec per (year, month) pair
expected_batch_spec_num = len(list(postgres_datasource._DEFAULT_YEAR_RANGE)) * len(
list(postgres_datasource._DEFAULT_MONTH_RANGE)
)
assert len(batch_specs) == expected_batch_spec_num
for year in postgres_datasource._DEFAULT_YEAR_RANGE:
for month in postgres_datasource._DEFAULT_MONTH_RANGE:
spec = {
"type": "table",
"data_asset_name": "my_asset",
"table_name": "my_table",
"batch_identifiers": {"my_col": {"year": year, "month": month}},
"splitter_method": "split_on_year_and_month",
"splitter_kwargs": {"column_name": "my_col"},
}
assert spec in batch_specs
def assert_batches_correct_with_year_month_splitter_defaults(batches):
# We should have 1 batch_spec per (year, month) pair
expected_batch_spec_num = len(list(postgres_datasource._DEFAULT_YEAR_RANGE)) * len(
list(postgres_datasource._DEFAULT_MONTH_RANGE)
)
assert len(batches) == expected_batch_spec_num
metadatas = [batch.metadata for batch in batches]
for year in postgres_datasource._DEFAULT_YEAR_RANGE:
for month in postgres_datasource._DEFAULT_MONTH_RANGE:
assert {"year": year, "month": month} in metadatas
@pytest.mark.unit
def test_datasource_gets_batch_list_splitter_with_unspecified_batch_request_options(
create_source,
):
batch_specs = []
def collect_batch_spec(spec: SqlAlchemyDatasourceBatchSpec) -> None:
batch_specs.append(spec)
with create_source(collect_batch_spec) as source:
asset = source.add_table_asset(name="my_asset", table_name="my_table")
asset.add_year_and_month_splitter(column_name="my_col")
empty_batch_request = asset.get_batch_request()
assert empty_batch_request.options == {}
batches = source.get_batch_list_from_batch_request(empty_batch_request)
assert_batch_specs_correct_with_year_month_splitter_defaults(batch_specs)
assert_batches_correct_with_year_month_splitter_defaults(batches)
@pytest.mark.unit
def test_datasource_gets_batch_list_splitter_with_batch_request_options_set_to_none(
create_source,
):
batch_specs = []
def collect_batch_spec(spec: SqlAlchemyDatasourceBatchSpec) -> None:
batch_specs.append(spec)
with create_source(collect_batch_spec) as source:
asset = source.add_table_asset(name="my_asset", table_name="my_table")
asset.add_year_and_month_splitter(column_name="my_col")
batch_request_with_none = asset.get_batch_request(
asset.batch_request_options_template()
)
assert batch_request_with_none.options == {"year": None, "month": None}
batches = source.get_batch_list_from_batch_request(batch_request_with_none)
# We should have 1 batch_spec per (year, month) pair
assert_batch_specs_correct_with_year_month_splitter_defaults(batch_specs)
assert_batches_correct_with_year_month_splitter_defaults(batches)
@pytest.mark.unit
def test_datasource_gets_batch_list_splitter_with_partially_specified_batch_request_options(
create_source,
):
batch_specs = []
def collect_batch_spec(spec: SqlAlchemyDatasourceBatchSpec) -> None:
batch_specs.append(spec)
with create_source(collect_batch_spec) as source:
asset = source.add_table_asset(name="my_asset", table_name="my_table")
asset.add_year_and_month_splitter(column_name="my_col")
batches = source.get_batch_list_from_batch_request(
asset.get_batch_request({"year": 2022})
)
assert len(batch_specs) == len(postgres_datasource._DEFAULT_MONTH_RANGE)
for month in postgres_datasource._DEFAULT_MONTH_RANGE:
spec = {
"type": "table",
"data_asset_name": "my_asset",
"table_name": "my_table",
"batch_identifiers": {"my_col": {"year": 2022, "month": month}},
"splitter_method": "split_on_year_and_month",
"splitter_kwargs": {"column_name": "my_col"},
}
assert spec in batch_specs
assert len(batches) == len(postgres_datasource._DEFAULT_MONTH_RANGE)
metadatas = [batch.metadata for batch in batches]
for month in postgres_datasource._DEFAULT_MONTH_RANGE:
expected_metadata = {"month": month, "year": 2022}
expected_metadata in metadatas
@pytest.mark.unit
def test_datasource_gets_batch_list_with_fully_specified_batch_request_options(
create_source,
):
def validate_batch_spec(spec: SqlAlchemyDatasourceBatchSpec) -> None:
assert spec == {
"batch_identifiers": {"my_col": {"month": 1, "year": 2022}},
"data_asset_name": "my_asset",
"splitter_kwargs": {"column_name": "my_col"},
"splitter_method": "split_on_year_and_month",
"table_name": "my_table",
"type": "table",
}
with create_source(validate_batch_spec) as source:
asset = source.add_table_asset(name="my_asset", table_name="my_table")
asset.add_year_and_month_splitter(column_name="my_col")
batches = source.get_batch_list_from_batch_request(
asset.get_batch_request({"month": 1, "year": 2022})
)
assert 1 == len(batches)
assert batches[0].metadata == {"month": 1, "year": 2022}
@pytest.mark.unit
def test_datasource_gets_nonexistent_asset(create_source):
with create_source(lambda: None) as source:
with pytest.raises(LookupError):
source.get_asset("my_asset")
@pytest.mark.unit
@pytest.mark.parametrize(
"batch_request_args",
[
("bad", None, None),
(None, "bad", None),
(None, None, {"bad": None}),
("bad", "bad", None),
],
)
def test_bad_batch_request_passed_into_get_batch_list_from_batch_request(
create_source,
batch_request_args,
):
with create_source(lambda: None) as source:
asset = source.add_table_asset(name="my_asset", table_name="my_table")
asset.add_year_and_month_splitter(column_name="my_col")
src, ast, op = batch_request_args
batch_request = BatchRequest(
datasource_name=src or source.name,
data_asset_name=ast or asset.name,
options=op or {},
)
with pytest.raises(
(
postgres_datasource.BatchRequestError,
LookupError,
)
):
source.get_batch_list_from_batch_request(batch_request)
@pytest.mark.unit
@pytest.mark.parametrize(
"batch_request_options",
[{}, {"year": 2021}, {"year": 2021, "month": 10}, {"year": None, "month": 10}],
)
def test_validate_good_batch_request(create_source, batch_request_options):
with create_source(lambda: None) as source:
asset = source.add_table_asset(name="my_asset", table_name="my_table")
asset.add_year_and_month_splitter(column_name="my_col")
batch_request = BatchRequest(
datasource_name=source.name,
data_asset_name=asset.name,
options=batch_request_options,
)
# No exception should get thrown
asset.validate_batch_request(batch_request)
@pytest.mark.unit
@pytest.mark.parametrize(
"batch_request_args",
[
("bad", None, None),
(None, "bad", None),
(None, None, {"bad": None}),
("bad", "bad", None),
],
)
def test_validate_malformed_batch_request(create_source, batch_request_args):
with create_source(lambda: None) as source:
asset = source.add_table_asset(name="my_asset", table_name="my_table")
asset.add_year_and_month_splitter(column_name="my_col")
src, ast, op = batch_request_args
batch_request = BatchRequest(
datasource_name=src or source.name,
data_asset_name=ast or asset.name,
options=op or {},
)
with pytest.raises(postgres_datasource.BatchRequestError):
asset.validate_batch_request(batch_request)
def test_get_bad_batch_request(create_source):
with create_source(lambda: None) as source:
asset = source.add_table_asset(name="my_asset", table_name="my_table")
asset.add_year_and_month_splitter(column_name="my_col")
with pytest.raises(postgres_datasource.BatchRequestError):
asset.get_batch_request({"invalid_key": None})
<file_sep>/tests/integration/docusaurus/expectations/advanced/multi_batch_rule_based_profiler_example.py
from typing import List
from ruamel import yaml
from great_expectations import DataContext
from great_expectations.core import ExpectationConfiguration, ExpectationSuite
from great_expectations.rule_based_profiler import RuleBasedProfilerResult
from great_expectations.rule_based_profiler.rule_based_profiler import RuleBasedProfiler
profiler_config = r"""
# This profiler is meant to be used on the NYC taxi data (yellow_tripdata_sample_<YEAR>-<MONTH>.csv)
# located in tests/test_sets/taxi_yellow_tripdata_samples/
name: My Profiler
config_version: 1.0
variables:
false_positive_rate: 0.01
mostly: 1.0
rules:
row_count_rule:
domain_builder:
class_name: TableDomainBuilder
parameter_builders:
- name: row_count_range
class_name: NumericMetricRangeMultiBatchParameterBuilder
metric_name: table.row_count
metric_domain_kwargs: $domain.domain_kwargs
false_positive_rate: $variables.false_positive_rate
truncate_values:
lower_bound: 0
round_decimals: 0
expectation_configuration_builders:
- expectation_type: expect_table_row_count_to_be_between
class_name: DefaultExpectationConfigurationBuilder
module_name: great_expectations.rule_based_profiler.expectation_configuration_builder
min_value: $parameter.row_count_range.value[0]
max_value: $parameter.row_count_range.value[1]
mostly: $variables.mostly
meta:
profiler_details: $parameter.row_count_range.details
column_ranges_rule:
domain_builder:
class_name: ColumnDomainBuilder
include_semantic_types:
- numeric
parameter_builders:
- name: min_range
class_name: NumericMetricRangeMultiBatchParameterBuilder
metric_name: column.min
metric_domain_kwargs: $domain.domain_kwargs
false_positive_rate: $variables.false_positive_rate
round_decimals: 2
- name: max_range
class_name: NumericMetricRangeMultiBatchParameterBuilder
metric_name: column.max
metric_domain_kwargs: $domain.domain_kwargs
false_positive_rate: $variables.false_positive_rate
round_decimals: 2
expectation_configuration_builders:
- expectation_type: expect_column_min_to_be_between
class_name: DefaultExpectationConfigurationBuilder
module_name: great_expectations.rule_based_profiler.expectation_configuration_builder
column: $domain.domain_kwargs.column
min_value: $parameter.min_range.value[0]
max_value: $parameter.min_range.value[1]
mostly: $variables.mostly
meta:
profiler_details: $parameter.min_range.details
- expectation_type: expect_column_max_to_be_between
class_name: DefaultExpectationConfigurationBuilder
module_name: great_expectations.rule_based_profiler.expectation_configuration_builder
column: $domain.domain_kwargs.column
min_value: $parameter.max_range.value[0]
max_value: $parameter.max_range.value[1]
mostly: $variables.mostly
meta:
profiler_details: $parameter.max_range.details
"""
data_context = DataContext()
# Instantiate RuleBasedProfiler
full_profiler_config_dict: dict = yaml.load(profiler_config)
rule_based_profiler: RuleBasedProfiler = RuleBasedProfiler(
name=full_profiler_config_dict["name"],
config_version=full_profiler_config_dict["config_version"],
rules=full_profiler_config_dict["rules"],
variables=full_profiler_config_dict["variables"],
data_context=data_context,
)
batch_request: dict = {
"datasource_name": "taxi_pandas",
"data_connector_name": "monthly",
"data_asset_name": "my_reports",
"data_connector_query": {
"index": "-6:-1",
},
}
result: RuleBasedProfilerResult = rule_based_profiler.run(batch_request=batch_request)
expectation_configurations: List[
ExpectationConfiguration
] = result.expectation_configurations
print(expectation_configurations)
# Please note that this docstring is here to demonstrate output for docs. It is not needed for normal use.
first_rule_suite = """
{
"meta": {"great_expectations_version": "0.13.19+58.gf8a650720.dirty"},
"data_asset_type": None,
"expectations": [
{
"kwargs": {"min_value": 10000, "max_value": 10000, "mostly": 1.0},
"expectation_type": "expect_table_row_count_to_be_between",
"meta": {
"profiler_details": {
"metric_configuration": {
"metric_name": "table.row_count",
"metric_domain_kwargs": {},
}
}
},
}
],
"expectation_suite_name": "tmp_suite_Profiler_e66f7cbb",
}
"""
<file_sep>/great_expectations/cli/cli.py
import importlib
import logging
from typing import List, Optional
import click
import great_expectations.exceptions as ge_exceptions
from great_expectations import DataContext
from great_expectations import __version__ as ge_version
from great_expectations.cli import toolkit
from great_expectations.cli.cli_logging import _set_up_logger
from great_expectations.cli.pretty_printing import cli_message
from great_expectations.data_context.types.base import (
FIRST_GE_CONFIG_VERSION_WITH_CHECKPOINT_STORE,
)
try:
from colorama import init as init_colorama
init_colorama()
except ImportError:
pass
class CLIState:
def __init__(
self,
v3_api: bool = True,
config_file_location: Optional[str] = None,
data_context: Optional[DataContext] = None,
assume_yes: bool = False,
) -> None:
self.v3_api = v3_api
self.config_file_location = config_file_location
self._data_context = data_context
self.assume_yes = assume_yes
def get_data_context_from_config_file(self) -> DataContext:
directory: str = toolkit.parse_cli_config_file_location(
config_file_location=self.config_file_location
).get("directory")
context: DataContext = toolkit.load_data_context_with_error_handling(
directory=directory,
from_cli_upgrade_command=False,
)
return context
@property
def data_context(self) -> Optional[DataContext]:
return self._data_context
@data_context.setter
def data_context(self, data_context: DataContext) -> None:
assert isinstance(data_context, DataContext)
self._data_context = data_context
def __repr__(self) -> str:
return f"CLIState(v3_api={self.v3_api}, config_file_location={self.config_file_location})"
class CLI(click.MultiCommand):
def list_commands(self, ctx: click.Context) -> List[str]:
# note that if --help is called this method is invoked before any flags
# are parsed or context set.
commands = [
"checkpoint",
"datasource",
"docs",
"init",
"project",
"store",
"suite",
]
return commands
def get_command(self, ctx: click.Context, name: str) -> Optional[str]:
module_name = name.replace("-", "_")
legacy_module = ""
if not self.is_v3_api(ctx):
legacy_module += ".v012"
try:
requested_module = f"great_expectations.cli{legacy_module}.{module_name}"
module = importlib.import_module(requested_module)
return getattr(module, module_name)
except ModuleNotFoundError:
cli_message(
f"<red>The command `{name}` does not exist.\nPlease use one of: {self.list_commands(None)}</red>"
)
return None
@staticmethod
def print_ctx_debugging(ctx: click.Context) -> None:
print(f"ctx.args: {ctx.args}")
print(f"ctx.params: {ctx.params}")
print(f"ctx.obj: {ctx.obj}")
print(f"ctx.protected_args: {ctx.protected_args}")
print(f"ctx.find_root().args: {ctx.find_root().args}")
print(f"ctx.find_root().params: {ctx.find_root().params}")
print(f"ctx.find_root().obj: {ctx.find_root().obj}")
print(f"ctx.find_root().protected_args: {ctx.find_root().protected_args}")
@staticmethod
def is_v3_api(ctx: click.Context) -> bool:
"""Determine if v3 api is requested by searching context params."""
if ctx.params:
return ctx.params and "v3_api" in ctx.params.keys() and ctx.params["v3_api"]
root_ctx_params = ctx.find_root().params
return (
root_ctx_params
and "v3_api" in root_ctx_params.keys()
and root_ctx_params["v3_api"]
)
@click.group(cls=CLI, name="great_expectations")
@click.version_option(version=ge_version)
@click.option(
"--v3-api/--v2-api",
"v3_api",
is_flag=True,
default=True,
help="Default to v3 (Batch Request) API. Use --v2-api for v2 (Batch Kwargs) API",
)
@click.option(
"--verbose",
"-v",
is_flag=True,
default=False,
help="Set great_expectations to use verbose output.",
)
@click.option(
"--config",
"-c",
"config_file_location",
default=None,
help="Path to great_expectations configuration file location (great_expectations.yml). Inferred if not provided.",
)
@click.option(
"--assume-yes",
"--yes",
"-y",
is_flag=True,
default=False,
help='Assume "yes" for all prompts.',
)
@click.pass_context
def cli(
ctx: click.Context,
v3_api: bool,
verbose: bool,
config_file_location: Optional[str],
assume_yes: bool,
) -> None:
"""
Welcome to the great_expectations CLI!
Most commands follow this format: great_expectations <NOUN> <VERB>
The nouns are: checkpoint, datasource, docs, init, project, store, suite, validation-operator.
Most nouns accept the following verbs: new, list, edit
"""
logger = _set_up_logger()
if verbose:
# Note we are explicitly not using a logger in all CLI output to have
# more control over console UI.
logger.setLevel(logging.DEBUG)
ctx.obj = CLIState(
v3_api=v3_api, config_file_location=config_file_location, assume_yes=assume_yes
)
if v3_api:
cli_message("Using v3 (Batch Request) API")
else:
cli_message("Using v2 (Batch Kwargs) API")
ge_config_version: float = (
ctx.obj.get_data_context_from_config_file().get_config().config_version
)
if ge_config_version >= FIRST_GE_CONFIG_VERSION_WITH_CHECKPOINT_STORE:
raise ge_exceptions.InvalidDataContextConfigError(
f"Using the legacy v2 (Batch Kwargs) API with a recent config version ({ge_config_version}) is illegal."
)
def main() -> None:
cli()
if __name__ == "__main__":
main()
<file_sep>/great_expectations/types/color_palettes.py
from enum import Enum
class Colors(Enum):
GREEN = "#00C2A4"
PINK = "#FD5383"
PURPLE = "#8784FF"
BLUE_1 = "#1B2A4D"
BLUE_2 = "#384B74"
BLUE_3 = "#8699B7"
class ColorPalettes(Enum):
CATEGORY_5 = [
Colors.BLUE_1.value,
Colors.GREEN.value,
Colors.PURPLE.value,
Colors.PINK.value,
Colors.BLUE_3.value,
]
DIVERGING_7 = [
Colors.GREEN.value,
"#7AD3BD",
"#B8E2D6",
"#F1F1F1",
"#FCC1CB",
"#FF8FA6",
Colors.PINK.value,
]
HEATMAP_6 = [
Colors.BLUE_2.value,
"#56678E",
"#7584A9",
"#94A2C5",
"#B5C2E2",
"#D6E2FF",
]
ORDINAL_7 = [
Colors.PURPLE.value,
"#747CE8",
"#6373D1",
"#5569BA",
"#495FA2",
"#3F558B",
Colors.BLUE_2.value,
]
<file_sep>/docs/terms/data_context__api_links.mdx
- [class DataContext](/docs/api_docs/classes/great_expectations-data_context-data_context-data_context-DataContext)
- [DataContext.create](/docs/api_docs/methods/great_expectations-data_context-data_context-data_context-DataContext-create)
- [DataContext.test_yaml_config](/docs/api_docs/methods/great_expectations-data_context-data_context-data_context-DataContext-test_yaml_config)
<file_sep>/great_expectations/rule_based_profiler/data_assistant/data_assistant_runner.py
from __future__ import annotations
from enum import Enum
from inspect import Parameter, Signature, getattr_static, signature
from typing import TYPE_CHECKING, Any, Callable, Dict, List, Optional, Type, Union
from makefun import create_function
import great_expectations.exceptions as ge_exceptions
from great_expectations.core.batch import BatchRequestBase
from great_expectations.core.config_peer import ConfigOutputModes, ConfigOutputModeType
from great_expectations.data_context.types.base import BaseYamlConfig
from great_expectations.rule_based_profiler import BaseRuleBasedProfiler
from great_expectations.rule_based_profiler.data_assistant import DataAssistant
from great_expectations.rule_based_profiler.data_assistant_result import (
DataAssistantResult,
)
from great_expectations.rule_based_profiler.domain_builder import DomainBuilder
from great_expectations.rule_based_profiler.helpers.util import (
convert_variables_to_dict,
get_validator_with_expectation_suite,
)
from great_expectations.rule_based_profiler.rule import Rule
from great_expectations.util import deep_filter_properties_iterable
from great_expectations.validator.validator import Validator
from great_expectations.rule_based_profiler.helpers.runtime_environment import ( # isort:skip
RuntimeEnvironmentVariablesDirectives,
RuntimeEnvironmentDomainTypeDirectives,
build_domain_type_directives,
build_variables_directives,
)
if TYPE_CHECKING:
from great_expectations.data_context.data_context.abstract_data_context import (
AbstractDataContext,
)
class NumericRangeEstimatorType(Enum):
EXACT = "exact"
FLAG_OUTLIERS = "flag_outliers"
class DataAssistantRunner:
"""
DataAssistantRunner processes invocations of calls to "run()" methods of registered "DataAssistant" classes.
The approach is to instantiate "DataAssistant" class of specified type with "Validator", containing "Batch" objects,
specified by "batch_request", loaded into memory. Then, "DataAssistant.run()" is issued with given directives.
"""
def __init__(
self,
data_assistant_cls: Type[DataAssistant],
data_context: AbstractDataContext,
) -> None:
"""
Args:
data_assistant_cls: DataAssistant class associated with this DataAssistantRunner
data_context: AbstractDataContext associated with this DataAssistantRunner
"""
self._data_assistant_cls = data_assistant_cls
self._data_context = data_context
self._profiler = self.get_profiler()
setattr(self, "run", self.run_impl())
def get_profiler(self) -> BaseRuleBasedProfiler:
"""
This method builds specified "DataAssistant" object and returns its effective "BaseRuleBasedProfiler" object.
Returns:
BaseRuleBasedProfiler: The "BaseRuleBasedProfiler" object, corresponding to this instance's "DataAssistant".
"""
return self._build_data_assistant().profiler
def get_profiler_config(
self,
mode: ConfigOutputModeType = ConfigOutputModes.JSON_DICT,
) -> Union[BaseYamlConfig, dict, str]:
"""
This method returns configuration of effective "BaseRuleBasedProfiler", corresponding to this instance's
"DataAssistant", according to specified "mode" (formatting) directive.
Args:
mode: One of "ConfigOutputModes" Enum typed values (corresponding string typed values are also supported)
Returns:
Union[BaseYamlConfig, dict, str]: Configuration of effective "BaseRuleBasedProfiler" object in given format.
"""
return self._profiler.get_config(mode=mode)
def run_impl(self) -> Callable:
"""
Dynamically constructs method signature and implementation of "DataAssistant.run()" method for this instance's
"DataAssistant" object (which corresponds to this instance's "DataAssistant" type, specified in constructor).
Returns:
Callable: Template "DataAssistant.run()" method implementation, customized with signature appropriate for
"DataAssistant.run()" method of "DataAssistant" class (corresponding to this object's "DataAssistant" type).
"""
def run(
batch_request: Optional[Union[BatchRequestBase, dict]] = None,
estimation: Optional[Union[str, NumericRangeEstimatorType]] = None,
**kwargs,
) -> DataAssistantResult:
"""
Generic "DataAssistant.run()" template method, its signature built dynamically by introspecting effective
"BaseRuleBasedProfiler", corresponding to this instance's "DataAssistant" class, and returned to dispatcher.
Args:
batch_request: Explicit batch_request used to supply data at runtime
estimation: Global type directive for applicable "Rule" objects that utilize numeric range estimation.
If set to "exact" (default), all "Rule" objects using "NumericMetricRangeMultiBatchParameterBuilder"
will have the value of "estimator" property (referred to by "$variables.estimator") equal "exact".
If set to "flag_outliers", then "bootstrap" estimator (default in "Rule" variables) takes effect.
kwargs: placeholder for "makefun.create_function()" to propagate dynamically generated signature
Returns:
DataAssistantResult: The result object for the DataAssistant
"""
if batch_request is None:
data_assistant_name: str = self._data_assistant_cls.data_assistant_type
raise ge_exceptions.DataAssistantExecutionError(
message=f"""Utilizing "{data_assistant_name}.run()" requires valid "batch_request" to be specified \
(empty or missing "batch_request" detected)."""
)
if estimation is None:
estimation = NumericRangeEstimatorType.EXACT
if isinstance(estimation, str):
estimation = estimation.lower()
estimation = NumericRangeEstimatorType(estimation)
data_assistant: DataAssistant = self._build_data_assistant(
batch_request=batch_request
)
directives: dict = deep_filter_properties_iterable(
properties=kwargs,
)
rule_based_profiler_domain_type_attributes: List[
str
] = self._get_rule_based_profiler_domain_type_attributes()
variables_directives_kwargs: dict = dict(
filter(
lambda element: element[0]
not in rule_based_profiler_domain_type_attributes,
directives.items(),
)
)
domain_type_directives_kwargs: dict = dict(
filter(
lambda element: element[0]
in rule_based_profiler_domain_type_attributes,
directives.items(),
)
)
variables_directives_list: List[
RuntimeEnvironmentVariablesDirectives
] = build_variables_directives(
exact_estimation=(estimation == NumericRangeEstimatorType.EXACT),
rules=self._profiler.rules,
**variables_directives_kwargs,
)
domain_type_directives_list: List[
RuntimeEnvironmentDomainTypeDirectives
] = build_domain_type_directives(**domain_type_directives_kwargs)
data_assistant_result: DataAssistantResult = data_assistant.run(
variables_directives_list=variables_directives_list,
domain_type_directives_list=domain_type_directives_list,
)
return data_assistant_result
parameters: List[Parameter] = [
Parameter(
name="batch_request",
kind=Parameter.POSITIONAL_OR_KEYWORD,
annotation=Union[BatchRequestBase, dict],
),
Parameter(
name="estimation",
kind=Parameter.POSITIONAL_OR_KEYWORD,
default="exact",
annotation=Optional[Union[str, NumericRangeEstimatorType]],
),
]
parameters.extend(
self._get_method_signature_parameters_for_domain_type_directives()
)
# Use separate loop for "variables" so as to organize "domain_type_attributes" and "variables" arguments neatly.
parameters.extend(
self._get_method_signature_parameters_for_variables_directives()
)
func_sig = Signature(
parameters=parameters, return_annotation=DataAssistantResult
)
# override the runner docstring with the docstring defined in the implemented DataAssistant child-class
run.__doc__ = self._data_assistant_cls.__doc__
gen_func: Callable = create_function(func_signature=func_sig, func_impl=run)
return gen_func
def _build_data_assistant(
self,
batch_request: Optional[Union[BatchRequestBase, dict]] = None,
) -> DataAssistant:
"""
This method builds specified "DataAssistant" object and returns its effective "BaseRuleBasedProfiler" object.
Args:
batch_request: Explicit batch_request used to supply data at runtime
Returns:
DataAssistant: The "DataAssistant" object, corresponding to this instance's specified "DataAssistant" type.
"""
data_assistant_name: str = self._data_assistant_cls.data_assistant_type
data_assistant: DataAssistant
if batch_request is None:
data_assistant = self._data_assistant_cls(
name=data_assistant_name,
validator=None,
)
else:
validator: Validator = get_validator_with_expectation_suite(
data_context=self._data_context,
batch_list=None,
batch_request=batch_request,
expectation_suite=None,
expectation_suite_name=None,
component_name=data_assistant_name,
persist=False,
)
data_assistant = self._data_assistant_cls(
name=data_assistant_name,
validator=validator,
)
return data_assistant
def _get_method_signature_parameters_for_variables_directives(
self,
) -> List[Parameter]:
parameters: List[Parameter] = []
rule: Rule
for rule in self._profiler.rules:
parameters.append(
Parameter(
name=rule.name,
kind=Parameter.POSITIONAL_OR_KEYWORD,
default=convert_variables_to_dict(variables=rule.variables),
annotation=dict,
)
)
return parameters
def _get_method_signature_parameters_for_domain_type_directives(
self,
) -> List[Parameter]:
parameters: List[Parameter] = []
domain_type_attribute_name_to_parameter_map: Dict[str, Parameter] = {}
conflicting_domain_type_attribute_names: List[str] = []
rule: Rule
domain_builder: DomainBuilder
domain_builder_attributes: List[str]
key: str
accessor_method: Callable
accessor_method_return_type: Type
property_value: Any
parameter: Parameter
for rule in self._profiler.rules:
domain_builder = rule.domain_builder
domain_builder_attributes = self._get_rule_domain_type_attributes(rule=rule)
for key in domain_builder_attributes:
accessor_method = getattr_static(domain_builder, key, None).fget
accessor_method_return_type = signature(
obj=accessor_method, follow_wrapped=False
).return_annotation
property_value = getattr(domain_builder, key, None)
parameter = domain_type_attribute_name_to_parameter_map.get(key)
if parameter is None:
if key not in conflicting_domain_type_attribute_names:
parameter = Parameter(
name=key,
kind=Parameter.POSITIONAL_OR_KEYWORD,
default=property_value,
annotation=accessor_method_return_type,
)
domain_type_attribute_name_to_parameter_map[key] = parameter
elif (
parameter.default is None
and property_value is not None
and key not in conflicting_domain_type_attribute_names
):
parameter = Parameter(
name=key,
kind=Parameter.POSITIONAL_OR_KEYWORD,
default=property_value,
annotation=accessor_method_return_type,
)
domain_type_attribute_name_to_parameter_map[key] = parameter
elif parameter.default != property_value and property_value is not None:
# For now, prevent customization if default values conflict unless the default DomainBuilder value
# is None. In the future, enable at "Rule" level.
domain_type_attribute_name_to_parameter_map.pop(key)
conflicting_domain_type_attribute_names.append(key)
parameters.extend(domain_type_attribute_name_to_parameter_map.values())
return parameters
def _get_rule_based_profiler_domain_type_attributes(
self, rule: Optional[Rule] = None
) -> List[str]:
if rule is None:
domain_type_attributes: List[str] = []
for rule in self._profiler.rules:
domain_type_attributes.extend(
self._get_rule_domain_type_attributes(rule=rule)
)
return list(set(domain_type_attributes))
return self._get_rule_domain_type_attributes(rule=rule)
@staticmethod
def _get_rule_domain_type_attributes(rule: Rule) -> List[str]:
klass: type = rule.domain_builder.__class__
sig: Signature = signature(obj=klass.__init__)
parameters: Dict[str, Parameter] = dict(sig.parameters)
attribute_names: List[str] = list(
filter(
lambda element: element not in rule.domain_builder.exclude_field_names,
list(parameters.keys())[1:],
)
)
return attribute_names
<file_sep>/docs/guides/setup/configuring_metadata_stores/components_how_to_configure_a_validation_result_store_in_amazon_s3/_preface.mdx
import Prerequisites from '../../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
By default, <TechnicalTag tag="validation_result" text="Validation Results" /> are stored in JSON format in the ``uncommitted/validations/`` subdirectory of your ``great_expectations/`` folder. Since Validation Results may include examples of data (which could be sensitive or regulated) they should not be committed to a source control system. The following steps will help you configure a new storage location for Validation Results in Amazon S3.
<Prerequisites>
- [Configured a Data Context](../../../../tutorials/getting_started/tutorial_setup.md).
- [Configured an Expectations Suite](../../../../tutorials/getting_started/tutorial_create_expectations.md).
- [Configured a Checkpoint](../../../../tutorials/getting_started/tutorial_validate_data.md).
- The ability to install [boto3](https://github.com/boto/boto3) in your local environment.
- Identified the S3 bucket and prefix where Validation Results will be stored.
</Prerequisites>
:::caution
Since Validation Results may include examples of data (which could be sensitive or regulated) they should not be committed to a source control system.
:::<file_sep>/tests/expectations/core/test_expect_column_values_to_be_in_type_list.py
import pandas as pd
import pytest
from great_expectations.core.expectation_validation_result import (
ExpectationValidationResult,
)
from great_expectations.self_check.util import (
build_pandas_validator_with_data,
build_sa_validator_with_data,
)
from great_expectations.util import is_library_loadable
@pytest.mark.skipif(
not is_library_loadable(library_name="pyathena"),
reason="pyathena is not installed",
)
def test_expect_column_values_to_be_in_type_list_dialect_pyathena_string(sa):
from pyathena import sqlalchemy_athena
df = pd.DataFrame({"col": ["test_val1", "test_val2"]})
validator = build_sa_validator_with_data(df, "sqlite")
# Monkey-patch dialect for testing purposes.
validator.execution_engine.dialect_module = sqlalchemy_athena
result = validator.expect_column_values_to_be_in_type_list(
"col", type_list=["string", "boolean"]
)
assert result == ExpectationValidationResult(
success=True,
expectation_config={
"expectation_type": "expect_column_values_to_be_in_type_list",
"kwargs": {
"column": "col",
"type_list": ["string", "boolean"],
},
"meta": {},
},
result={
"element_count": 2,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"partial_unexpected_list": [],
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_percent_total": 0.0,
"unexpected_percent_nonmissing": 0.0,
},
exception_info={
"raised_exception": False,
"exception_traceback": None,
"exception_message": None,
},
meta={},
)
@pytest.mark.skipif(
not is_library_loadable(library_name="pyathena"),
reason="pyathena is not installed",
)
def test_expect_column_values_to_be_in_type_list_dialect_pyathena_boolean(sa):
from pyathena import sqlalchemy_athena
df = pd.DataFrame({"col": [True, False]})
validator = build_sa_validator_with_data(df, "sqlite")
# Monkey-patch dialect for testing purposes.
validator.execution_engine.dialect_module = sqlalchemy_athena
result = validator.expect_column_values_to_be_in_type_list(
"col", type_list=["string", "boolean"]
)
assert result == ExpectationValidationResult(
success=True,
expectation_config={
"expectation_type": "expect_column_values_to_be_in_type_list",
"kwargs": {
"column": "col",
"type_list": ["string", "boolean"],
},
"meta": {},
},
result={
"element_count": 2,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"partial_unexpected_list": [],
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_percent_total": 0.0,
"unexpected_percent_nonmissing": 0.0,
},
exception_info={
"raised_exception": False,
"exception_traceback": None,
"exception_message": None,
},
meta={},
)
def test_expect_column_values_to_be_in_type_list_nullable_int():
from packaging.version import parse
pandas_version = parse(pd.__version__)
if pandas_version < parse("0.24"):
# Prior to 0.24, Pandas did not have
pytest.skip("Prior to 0.24, Pandas did not have `Int32Dtype` or related.")
df = pd.DataFrame({"col": pd.Series([1, 2, None], dtype=pd.Int32Dtype())})
validator = build_pandas_validator_with_data(df)
result = validator.expect_column_values_to_be_in_type_list(
"col", type_list=["Int32Dtype"]
)
assert result == ExpectationValidationResult(
success=True,
expectation_config={
"expectation_type": "expect_column_values_to_be_in_type_list",
"kwargs": {
"column": "col",
"type_list": ["Int32Dtype"],
},
"meta": {},
},
result={
"element_count": 3,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"partial_unexpected_list": [],
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_percent_total": 0.0,
"unexpected_percent_nonmissing": 0.0,
},
exception_info={
"raised_exception": False,
"exception_traceback": None,
"exception_message": None,
},
meta={},
)
<file_sep>/tests/experimental/datasources/test_config.py
import functools
import json
import pathlib
from typing import Callable
import pytest
from great_expectations.experimental.datasources.config import GxConfig
from great_expectations.experimental.datasources.interfaces import Datasource
try:
from devtools import PrettyFormat as pf
from devtools import debug as pp
except ImportError:
from pprint import pformat as pf # type: ignore[assignment]
from pprint import pprint as pp # type: ignore[assignment]
p = pytest.param
EXPERIMENTAL_DATASOURCE_TEST_DIR = pathlib.Path(__file__).parent
PG_CONFIG_YAML_FILE = EXPERIMENTAL_DATASOURCE_TEST_DIR / "config.yaml"
PG_CONFIG_YAML_STR = PG_CONFIG_YAML_FILE.read_text()
# TODO: create PG_CONFIG_YAML_FILE/STR from this dict
PG_COMPLEX_CONFIG_DICT = {
"datasources": {
"my_pg_ds": {
"connection_string": "postgres://foo.bar",
"name": "my_pg_ds",
"type": "postgres",
"assets": {
"my_table_asset_wo_splitters": {
"name": "my_table_asset_wo_splitters",
"table_name": "my_table",
"type": "table",
},
"with_splitters": {
"column_splitter": {
"column_name": "my_column",
"method_name": "foobar_it",
"name": "my_splitter",
"param_defaults": {
"alpha": ["fizz", "bizz"],
"bravo": ["foo", "bar"],
},
},
"name": "with_splitters",
"table_name": "another_table",
"type": "table",
},
},
}
}
}
PG_COMPLEX_CONFIG_JSON = json.dumps(PG_COMPLEX_CONFIG_DICT)
SIMPLE_DS_DICT = {
"datasources": {
"my_ds": {
"name": "my_ds",
"type": "postgres",
"connection_string": "postgres",
}
}
}
@pytest.mark.parametrize(
["load_method", "input_"],
[
p(GxConfig.parse_obj, SIMPLE_DS_DICT, id="simple pg config dict"),
p(GxConfig.parse_raw, json.dumps(SIMPLE_DS_DICT), id="simple pg json"),
p(GxConfig.parse_obj, PG_COMPLEX_CONFIG_DICT, id="pg complex dict"),
p(GxConfig.parse_raw, PG_COMPLEX_CONFIG_JSON, id="pg complex json"),
p(GxConfig.parse_yaml, PG_CONFIG_YAML_FILE, id="pg_config.yaml file"),
p(GxConfig.parse_yaml, PG_CONFIG_YAML_STR, id="pg_config yaml string"),
],
)
def test_load_config(inject_engine_lookup_double, load_method: Callable, input_):
loaded: GxConfig = load_method(input_)
pp(loaded)
assert loaded
assert loaded.datasources
for datasource in loaded.datasources.values():
assert isinstance(datasource, Datasource)
@pytest.fixture
@functools.lru_cache(maxsize=1)
def from_dict_gx_config() -> GxConfig:
gx_config = GxConfig.parse_obj(PG_COMPLEX_CONFIG_DICT)
assert gx_config
return gx_config
@pytest.fixture
@functools.lru_cache(maxsize=1)
def from_json_gx_config() -> GxConfig:
gx_config = GxConfig.parse_raw(PG_COMPLEX_CONFIG_JSON)
assert gx_config
return gx_config
@pytest.fixture
@functools.lru_cache(maxsize=1)
def from_yaml_gx_config() -> GxConfig:
gx_config = GxConfig.parse_yaml(PG_CONFIG_YAML_STR)
assert gx_config
return gx_config
def test_dict_config_round_trip(
inject_engine_lookup_double, from_dict_gx_config: GxConfig
):
dumped: dict = from_dict_gx_config.dict()
print(f" Dumped Dict ->\n\n{pf(dumped)}")
re_loaded: GxConfig = GxConfig.parse_obj(dumped)
pp(re_loaded)
assert re_loaded
assert from_dict_gx_config == re_loaded
def test_json_config_round_trip(
inject_engine_lookup_double, from_json_gx_config: GxConfig
):
dumped: str = from_json_gx_config.json()
print(f" Dumped JSON ->\n\n{dumped}")
re_loaded: GxConfig = GxConfig.parse_raw(dumped)
pp(re_loaded)
assert re_loaded
assert from_json_gx_config == re_loaded
def test_yaml_config_round_trip(
inject_engine_lookup_double, from_yaml_gx_config: GxConfig
):
dumped: str = from_yaml_gx_config.yaml()
print(f" Dumped YAML ->\n\n{dumped}")
re_loaded: GxConfig = GxConfig.parse_yaml(dumped)
pp(re_loaded)
assert re_loaded
assert from_yaml_gx_config == re_loaded
def test_yaml_file_config_round_trip(
inject_engine_lookup_double, tmp_path: pathlib.Path, from_yaml_gx_config: GxConfig
):
yaml_file = tmp_path / "test.yaml"
assert not yaml_file.exists()
result_path = from_yaml_gx_config.yaml(yaml_file)
assert yaml_file.exists()
assert result_path == yaml_file
print(f" yaml_file -> \n\n{yaml_file.read_text()}")
re_loaded: GxConfig = GxConfig.parse_yaml(yaml_file)
pp(re_loaded)
assert re_loaded
assert from_yaml_gx_config == re_loaded
@pytest.mark.xfail(reason="Key Ordering needs to be implemented")
def test_yaml_config_round_trip_ordering(
inject_engine_lookup_double, from_yaml_gx_config: GxConfig
):
dumped: str = from_yaml_gx_config.yaml()
assert PG_CONFIG_YAML_STR == dumped
<file_sep>/tests/execution_engine/test_sqlalchemy_execution_engine.py
import logging
import os
from typing import Dict, Tuple, cast
import pandas as pd
import pytest
import great_expectations.exceptions as ge_exceptions
from great_expectations.core.batch_spec import (
RuntimeQueryBatchSpec,
SqlAlchemyDatasourceBatchSpec,
)
from great_expectations.core.metric_domain_types import MetricDomainTypes
from great_expectations.data_context.util import file_relative_path
from great_expectations.execution_engine.sqlalchemy_batch_data import (
SqlAlchemyBatchData,
)
from great_expectations.execution_engine.sqlalchemy_dialect import GESqlDialect
from great_expectations.execution_engine.sqlalchemy_execution_engine import (
SqlAlchemyExecutionEngine,
)
# Function to test for spark dataframe equality
from great_expectations.expectations.row_conditions import (
RowCondition,
RowConditionParserType,
)
from great_expectations.self_check.util import build_sa_engine
from great_expectations.util import get_sqlalchemy_domain_data
from great_expectations.validator.computed_metric import MetricValue
from great_expectations.validator.metric_configuration import MetricConfiguration
from great_expectations.validator.validator import Validator
from tests.expectations.test_util import get_table_columns_metric
from tests.test_utils import get_sqlite_table_names, get_sqlite_temp_table_names
try:
sqlalchemy = pytest.importorskip("sqlalchemy")
except ImportError:
sqlalchemy = None
def test_instantiation_via_connection_string(sa, test_db_connection_string):
my_execution_engine = SqlAlchemyExecutionEngine(
connection_string=test_db_connection_string
)
assert my_execution_engine.connection_string == test_db_connection_string
assert my_execution_engine.credentials == None
assert my_execution_engine.url == None
my_execution_engine.get_batch_data_and_markers(
batch_spec=SqlAlchemyDatasourceBatchSpec(
table_name="table_1",
schema_name="main",
sampling_method="_sample_using_limit",
sampling_kwargs={"n": 5},
)
)
def test_instantiation_via_url(sa):
db_file = file_relative_path(
__file__,
os.path.join("..", "test_sets", "test_cases_for_sql_data_connector.db"),
)
my_execution_engine = SqlAlchemyExecutionEngine(url="sqlite:///" + db_file)
assert my_execution_engine.connection_string is None
assert my_execution_engine.credentials is None
assert my_execution_engine.url[-36:] == "test_cases_for_sql_data_connector.db"
my_execution_engine.get_batch_data_and_markers(
batch_spec=SqlAlchemyDatasourceBatchSpec(
table_name="table_partitioned_by_date_column__A",
sampling_method="_sample_using_limit",
sampling_kwargs={"n": 5},
)
)
@pytest.mark.integration
def test_instantiation_via_url_and_retrieve_data_with_other_dialect(sa):
"""Ensure that we can still retrieve data when the dialect is not recognized."""
# 1. Create engine with sqlite db
db_file = file_relative_path(
__file__,
os.path.join("..", "test_sets", "test_cases_for_sql_data_connector.db"),
)
my_execution_engine = SqlAlchemyExecutionEngine(url="sqlite:///" + db_file)
assert my_execution_engine.connection_string is None
assert my_execution_engine.credentials is None
assert my_execution_engine.url[-36:] == "test_cases_for_sql_data_connector.db"
# 2. Change dialect to one not listed in GESqlDialect
my_execution_engine.engine.dialect.name = "other_dialect"
# 3. Get data
num_rows_in_sample: int = 10
batch_data, _ = my_execution_engine.get_batch_data_and_markers(
batch_spec=SqlAlchemyDatasourceBatchSpec(
table_name="table_partitioned_by_date_column__A",
sampling_method="_sample_using_limit",
sampling_kwargs={"n": num_rows_in_sample},
)
)
# 4. Assert dialect and data are as expected
assert batch_data.dialect == GESqlDialect.OTHER
my_execution_engine.load_batch_data("__", batch_data)
validator = Validator(my_execution_engine)
assert len(validator.head(fetch_all=True)) == num_rows_in_sample
def test_instantiation_via_credentials(sa, test_backends, test_df):
if "postgresql" not in test_backends:
pytest.skip("test_database_store_backend_get_url_for_key requires postgresql")
my_execution_engine = SqlAlchemyExecutionEngine(
credentials={
"drivername": "postgresql",
"username": "postgres",
"password": "",
"host": os.getenv("GE_TEST_LOCAL_DB_HOSTNAME", "localhost"),
"port": "5432",
"database": "test_ci",
}
)
assert my_execution_engine.connection_string is None
assert my_execution_engine.credentials == {
"username": "postgres",
"password": "",
"host": os.getenv("GE_TEST_LOCAL_DB_HOSTNAME", "localhost"),
"port": "5432",
"database": "test_ci",
}
assert my_execution_engine.url is None
# Note Abe 20201116: Let's add an actual test of get_batch_data_and_markers, which will require setting up test
# fixtures
# my_execution_engine.get_batch_data_and_markers(batch_spec=BatchSpec(
# table_name="main.table_1",
# sampling_method="_sample_using_limit",
# sampling_kwargs={
# "n": 5
# }
# ))
def test_instantiation_error_states(sa, test_db_connection_string):
with pytest.raises(ge_exceptions.InvalidConfigError):
SqlAlchemyExecutionEngine()
# Testing batching of aggregate metrics
def test_sa_batch_aggregate_metrics(caplog, sa):
import datetime
engine = build_sa_engine(
pd.DataFrame({"a": [1, 2, 1, 2, 3, 3], "b": [4, 4, 4, 4, 4, 4]}), sa
)
metrics: Dict[Tuple[str, str, str], MetricValue] = {}
table_columns_metric: MetricConfiguration
results: Dict[Tuple[str, str, str], MetricValue]
table_columns_metric, results = get_table_columns_metric(engine=engine)
metrics.update(results)
aggregate_fn_metric_1 = MetricConfiguration(
metric_name="column.max.aggregate_fn",
metric_domain_kwargs={"column": "a"},
metric_value_kwargs=None,
)
aggregate_fn_metric_1.metric_dependencies = {
"table.columns": table_columns_metric,
}
aggregate_fn_metric_2 = MetricConfiguration(
metric_name="column.min.aggregate_fn",
metric_domain_kwargs={"column": "a"},
metric_value_kwargs=None,
)
aggregate_fn_metric_2.metric_dependencies = {
"table.columns": table_columns_metric,
}
aggregate_fn_metric_3 = MetricConfiguration(
metric_name="column.max.aggregate_fn",
metric_domain_kwargs={"column": "b"},
metric_value_kwargs=None,
)
aggregate_fn_metric_3.metric_dependencies = {
"table.columns": table_columns_metric,
}
aggregate_fn_metric_4 = MetricConfiguration(
metric_name="column.min.aggregate_fn",
metric_domain_kwargs={"column": "b"},
metric_value_kwargs=None,
)
aggregate_fn_metric_4.metric_dependencies = {
"table.columns": table_columns_metric,
}
results = engine.resolve_metrics(
metrics_to_resolve=(
aggregate_fn_metric_1,
aggregate_fn_metric_2,
aggregate_fn_metric_3,
aggregate_fn_metric_4,
),
metrics=metrics,
)
metrics.update(results)
desired_metric_1 = MetricConfiguration(
metric_name="column.max",
metric_domain_kwargs={"column": "a"},
metric_value_kwargs=None,
)
desired_metric_1.metric_dependencies = {
"metric_partial_fn": aggregate_fn_metric_1,
"table.columns": table_columns_metric,
}
desired_metric_2 = MetricConfiguration(
metric_name="column.min",
metric_domain_kwargs={"column": "a"},
metric_value_kwargs=None,
)
desired_metric_2.metric_dependencies = {
"metric_partial_fn": aggregate_fn_metric_2,
"table.columns": table_columns_metric,
}
desired_metric_3 = MetricConfiguration(
metric_name="column.max",
metric_domain_kwargs={"column": "b"},
metric_value_kwargs=None,
)
desired_metric_3.metric_dependencies = {
"metric_partial_fn": aggregate_fn_metric_3,
"table.columns": table_columns_metric,
}
desired_metric_4 = MetricConfiguration(
metric_name="column.min",
metric_domain_kwargs={"column": "b"},
metric_value_kwargs=None,
)
desired_metric_4.metric_dependencies = {
"metric_partial_fn": aggregate_fn_metric_4,
"table.columns": table_columns_metric,
}
caplog.clear()
caplog.set_level(logging.DEBUG, logger="great_expectations")
start = datetime.datetime.now()
results = engine.resolve_metrics(
metrics_to_resolve=(
desired_metric_1,
desired_metric_2,
desired_metric_3,
desired_metric_4,
),
metrics=metrics,
)
metrics.update(results)
end = datetime.datetime.now()
print("t1")
print(end - start)
assert results[desired_metric_1.id] == 3
assert results[desired_metric_2.id] == 1
assert results[desired_metric_3.id] == 4
assert results[desired_metric_4.id] == 4
# Check that all four of these metrics were computed on a single domain
found_message = False
for record in caplog.records:
if (
record.message
== "SqlAlchemyExecutionEngine computed 4 metrics on domain_id ()"
):
found_message = True
assert found_message
def test_get_domain_records_with_column_domain(sa):
df = pd.DataFrame(
{"a": [1, 2, 3, 4, 5], "b": [2, 3, 4, 5, None], "c": [1, 2, 3, 4, None]}
)
engine = build_sa_engine(df, sa)
data = engine.get_domain_records(
domain_kwargs={
"column": "a",
"row_condition": 'col("b")<5',
"condition_parser": "great_expectations__experimental__",
}
)
domain_data = engine.engine.execute(get_sqlalchemy_domain_data(data)).fetchall()
expected_column_df = df.iloc[:3]
engine = build_sa_engine(expected_column_df, sa)
expected_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
assert (
domain_data == expected_data
), "Data does not match after getting full access compute domain"
def test_get_domain_records_with_column_domain_and_filter_conditions(sa):
df = pd.DataFrame(
{"a": [1, 2, 3, 4, 5], "b": [2, 3, 4, 5, None], "c": [1, 2, 3, 4, None]}
)
engine = build_sa_engine(df, sa)
data = engine.get_domain_records(
domain_kwargs={
"column": "a",
"row_condition": 'col("b")<5',
"condition_parser": "great_expectations__experimental__",
"filter_conditions": [
RowCondition(
condition=f'col("b").notnull()',
condition_type=RowConditionParserType.GE,
)
],
}
)
domain_data = engine.engine.execute(get_sqlalchemy_domain_data(data)).fetchall()
expected_column_df = df.iloc[:3]
engine = build_sa_engine(expected_column_df, sa)
expected_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
assert (
domain_data == expected_data
), "Data does not match after getting full access compute domain"
def test_get_domain_records_with_different_column_domain_and_filter_conditions(sa):
df = pd.DataFrame(
{"a": [1, 2, 3, 4, 5], "b": [2, 3, 4, 5, None], "c": [1, 2, 3, 4, None]}
)
engine = build_sa_engine(df, sa)
data = engine.get_domain_records(
domain_kwargs={
"column": "a",
"row_condition": 'col("a")<2',
"condition_parser": "great_expectations__experimental__",
"filter_conditions": [
RowCondition(
condition=f'col("b").notnull()',
condition_type=RowConditionParserType.GE,
)
],
}
)
domain_data = engine.engine.execute(get_sqlalchemy_domain_data(data)).fetchall()
expected_column_df = df.iloc[:1]
engine = build_sa_engine(expected_column_df, sa)
expected_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
assert (
domain_data == expected_data
), "Data does not match after getting full access compute domain"
def test_get_domain_records_with_column_domain_and_filter_conditions_raises_error_on_multiple_conditions(
sa,
):
df = pd.DataFrame(
{"a": [1, 2, 3, 4, 5], "b": [2, 3, 4, 5, None], "c": [1, 2, 3, 4, None]}
)
engine = build_sa_engine(df, sa)
with pytest.raises(ge_exceptions.GreatExpectationsError) as e:
data = engine.get_domain_records(
domain_kwargs={
"column": "a",
"row_condition": 'col("a")<2',
"condition_parser": "great_expectations__experimental__",
"filter_conditions": [
RowCondition(
condition=f'col("b").notnull()',
condition_type=RowConditionParserType.GE,
),
RowCondition(
condition=f'col("c").notnull()',
condition_type=RowConditionParserType.GE,
),
],
}
)
def test_get_domain_records_with_column_pair_domain(sa):
df = pd.DataFrame(
{
"a": [1, 2, 3, 4, 5, 6],
"b": [2, 3, 4, 5, None, 6],
"c": [1, 2, 3, 4, 5, None],
}
)
engine = build_sa_engine(df, sa)
data = engine.get_domain_records(
domain_kwargs={
"column_A": "a",
"column_B": "b",
"row_condition": 'col("b")>2',
"condition_parser": "great_expectations__experimental__",
"ignore_row_if": "both_values_are_missing",
}
)
domain_data = engine.engine.execute(sa.select(["*"]).select_from(data)).fetchall()
expected_column_pair_df = pd.DataFrame(
{"a": [2, 3, 4, 6], "b": [3.0, 4.0, 5.0, 6.0], "c": [2.0, 3.0, 4.0, None]}
)
engine = build_sa_engine(expected_column_pair_df, sa)
expected_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
assert (
domain_data == expected_data
), "Data does not match after getting full access compute domain"
engine = build_sa_engine(df, sa)
data = engine.get_domain_records(
domain_kwargs={
"column_A": "b",
"column_B": "c",
"row_condition": 'col("b")>2',
"condition_parser": "great_expectations__experimental__",
"ignore_row_if": "either_value_is_missing",
}
)
domain_data = engine.engine.execute(sa.select(["*"]).select_from(data)).fetchall()
expected_column_pair_df = pd.DataFrame(
{"a": [2, 3, 4], "b": [3, 4, 5], "c": [2, 3, 4]}
)
engine = build_sa_engine(expected_column_pair_df, sa)
expected_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
assert (
domain_data == expected_data
), "Data does not match after getting full access compute domain"
engine = build_sa_engine(df, sa)
data = engine.get_domain_records(
domain_kwargs={
"column_A": "b",
"column_B": "c",
"row_condition": 'col("a")<6',
"condition_parser": "great_expectations__experimental__",
"ignore_row_if": "neither",
}
)
domain_data = engine.engine.execute(get_sqlalchemy_domain_data(data)).fetchall()
expected_column_pair_df = pd.DataFrame(
{
"a": [1, 2, 3, 4, 5],
"b": [2.0, 3.0, 4.0, 5.0, None],
"c": [1.0, 2.0, 3.0, 4.0, 5.0],
}
)
engine = build_sa_engine(expected_column_pair_df, sa)
expected_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
assert (
domain_data == expected_data
), "Data does not match after getting full access compute domain"
def test_get_domain_records_with_multicolumn_domain(sa):
df = pd.DataFrame(
{
"a": [1, 2, 3, 4, None, 5],
"b": [2, 3, 4, 5, 6, 7],
"c": [1, 2, 3, 4, None, 6],
}
)
engine = build_sa_engine(df, sa)
data = engine.get_domain_records(
domain_kwargs={
"column_list": ["a", "c"],
"row_condition": 'col("b")>2',
"condition_parser": "great_expectations__experimental__",
"ignore_row_if": "all_values_are_missing",
}
)
domain_data = engine.engine.execute(sa.select(["*"]).select_from(data)).fetchall()
expected_multicolumn_df = pd.DataFrame(
{"a": [2, 3, 4, 5], "b": [3, 4, 5, 7], "c": [2, 3, 4, 6]}, index=[0, 1, 2, 4]
)
engine = build_sa_engine(expected_multicolumn_df, sa)
expected_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
assert (
domain_data == expected_data
), "Data does not match after getting full access compute domain"
df = pd.DataFrame(
{
"a": [1, 2, 3, 4, 5, 6],
"b": [2, 3, 4, 5, None, 6],
"c": [1, 2, 3, 4, 5, None],
}
)
engine = build_sa_engine(df, sa)
data = engine.get_domain_records(
domain_kwargs={
"column_list": ["b", "c"],
"row_condition": 'col("a")<5',
"condition_parser": "great_expectations__experimental__",
"ignore_row_if": "any_value_is_missing",
}
)
domain_data = engine.engine.execute(sa.select(["*"]).select_from(data)).fetchall()
expected_multicolumn_df = pd.DataFrame(
{"a": [1, 2, 3, 4], "b": [2, 3, 4, 5], "c": [1, 2, 3, 4]}, index=[0, 1, 2, 3]
)
engine = build_sa_engine(expected_multicolumn_df, sa)
expected_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
assert (
domain_data == expected_data
), "Data does not match after getting full access compute domain"
df = pd.DataFrame(
{
"a": [1, 2, 3, 4, None, 5],
"b": [2, 3, 4, 5, 6, 7],
"c": [1, 2, 3, 4, None, 6],
}
)
engine = build_sa_engine(df, sa)
data = engine.get_domain_records(
domain_kwargs={
"column_list": ["b", "c"],
"ignore_row_if": "never",
}
)
domain_data = engine.engine.execute(sa.select(["*"]).select_from(data)).fetchall()
expected_multicolumn_df = pd.DataFrame(
{
"a": [1, 2, 3, 4, None, 5],
"b": [2, 3, 4, 5, 6, 7],
"c": [1, 2, 3, 4, None, 6],
},
index=[0, 1, 2, 3, 4, 5],
)
engine = build_sa_engine(expected_multicolumn_df, sa)
expected_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
assert (
domain_data == expected_data
), "Data does not match after getting full access compute domain"
# Ensuring functionality of compute_domain when no domain kwargs are given
def test_get_compute_domain_with_no_domain_kwargs(sa):
engine = build_sa_engine(
pd.DataFrame({"a": [1, 2, 3, 4], "b": [2, 3, 4, None]}), sa
)
data, compute_kwargs, accessor_kwargs = engine.get_compute_domain(
domain_kwargs={}, domain_type="table"
)
# Seeing if raw data is the same as the data after condition has been applied - checking post computation data
raw_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
domain_data = engine.engine.execute(sa.select(["*"]).select_from(data)).fetchall()
# Ensuring that with no domain nothing happens to the data itself
assert raw_data == domain_data, "Data does not match after getting compute domain"
assert compute_kwargs == {}, "Compute domain kwargs should be existent"
assert accessor_kwargs == {}, "Accessor kwargs have been modified"
# Testing for only untested use case - column_pair
def test_get_compute_domain_with_column_pair(sa):
engine = build_sa_engine(
pd.DataFrame({"a": [1, 2, 3, 4], "b": [2, 3, 4, None]}), sa
)
# Fetching data, compute_domain_kwargs, accessor_kwargs
data, compute_kwargs, accessor_kwargs = engine.get_compute_domain(
domain_kwargs={"column_A": "a", "column_B": "b"}, domain_type="column_pair"
)
# Seeing if raw data is the same as the data after condition has been applied - checking post computation data
raw_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
domain_data = engine.engine.execute(sa.select(["*"]).select_from(data)).fetchall()
# Ensuring that with no domain nothing happens to the data itself
assert raw_data == domain_data, "Data does not match after getting compute domain"
assert (
"column_A" not in compute_kwargs.keys()
and "column_B" not in compute_kwargs.keys()
), "domain kwargs should be existent"
assert accessor_kwargs == {
"column_A": "a",
"column_B": "b",
}, "Accessor kwargs have been modified"
# Testing for only untested use case - multicolumn
def test_get_compute_domain_with_multicolumn(sa):
engine = build_sa_engine(
pd.DataFrame({"a": [1, 2, 3, 4], "b": [2, 3, 4, None], "c": [1, 2, 3, None]}),
sa,
)
# Obtaining compute domain
data, compute_kwargs, accessor_kwargs = engine.get_compute_domain(
domain_kwargs={"column_list": ["a", "b", "c"]}, domain_type="multicolumn"
)
# Seeing if raw data is the same as the data after condition has been applied - checking post computation data
raw_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
domain_data = engine.engine.execute(sa.select(["*"]).select_from(data)).fetchall()
# Ensuring that with no domain nothing happens to the data itself
assert raw_data == domain_data, "Data does not match after getting compute domain"
assert compute_kwargs is not None, "Compute domain kwargs should be existent"
assert accessor_kwargs == {
"column_list": ["a", "b", "c"]
}, "Accessor kwargs have been modified"
# Testing whether compute domain is properly calculated, but this time obtaining a column
def test_get_compute_domain_with_column_domain(sa):
engine = build_sa_engine(
pd.DataFrame({"a": [1, 2, 3, 4], "b": [2, 3, 4, None]}), sa
)
# Loading batch data
data, compute_kwargs, accessor_kwargs = engine.get_compute_domain(
domain_kwargs={"column": "a"}, domain_type=MetricDomainTypes.COLUMN
)
# Seeing if raw data is the same as the data after condition has been applied - checking post computation data
raw_data = engine.engine.execute(
sa.select(["*"]).select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
).fetchall()
domain_data = engine.engine.execute(sa.select(["*"]).select_from(data)).fetchall()
# Ensuring that column domain is now an accessor kwarg, and data remains unmodified
assert raw_data == domain_data, "Data does not match after getting compute domain"
assert compute_kwargs == {}, "Compute domain kwargs should be existent"
assert accessor_kwargs == {"column": "a"}, "Accessor kwargs have been modified"
# What happens when we filter such that no value meets the condition?
def test_get_compute_domain_with_unmeetable_row_condition(sa):
engine = build_sa_engine(
pd.DataFrame({"a": [1, 2, 3, 4], "b": [2, 3, 4, None]}), sa
)
data, compute_kwargs, accessor_kwargs = engine.get_compute_domain(
domain_kwargs={
"column": "a",
"row_condition": 'col("b") > 24',
"condition_parser": "great_expectations__experimental__",
},
domain_type="column",
)
# Seeing if raw data is the same as the data after condition has been applied - checking post computation data
raw_data = engine.engine.execute(
sa.select(["*"])
.select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
.where(sa.column("b") > 24)
).fetchall()
domain_data = engine.engine.execute(get_sqlalchemy_domain_data(data)).fetchall()
# Ensuring that column domain is now an accessor kwarg, and data remains unmodified
assert raw_data == domain_data, "Data does not match after getting compute domain"
# Ensuring compute kwargs have not been modified
assert (
"row_condition" in compute_kwargs.keys()
), "Row condition should be located within compute kwargs"
assert accessor_kwargs == {"column": "a"}, "Accessor kwargs have been modified"
# Testing to ensure that great expectation experimental parser also works in terms of defining a compute domain
def test_get_compute_domain_with_ge_experimental_condition_parser(sa):
engine = build_sa_engine(
pd.DataFrame({"a": [1, 2, 3, 4], "b": [2, 3, 4, None]}), sa
)
# Obtaining data from computation
data, compute_kwargs, accessor_kwargs = engine.get_compute_domain(
domain_kwargs={
"column": "b",
"row_condition": 'col("b") == 2',
"condition_parser": "great_expectations__experimental__",
},
domain_type="column",
)
# Seeing if raw data is the same as the data after condition has been applied - checking post computation data
raw_data = engine.engine.execute(
sa.select(["*"])
.select_from(
cast(SqlAlchemyBatchData, engine.batch_manager.active_batch_data).selectable
)
.where(sa.column("b") == 2)
).fetchall()
domain_data = engine.engine.execute(get_sqlalchemy_domain_data(data)).fetchall()
# Ensuring that column domain is now an accessor kwarg, and data remains unmodified
assert raw_data == domain_data, "Data does not match after getting compute domain"
# Ensuring compute kwargs have not been modified
assert (
"row_condition" in compute_kwargs.keys()
), "Row condition should be located within compute kwargs"
assert accessor_kwargs == {"column": "b"}, "Accessor kwargs have been modified"
def test_get_compute_domain_with_nonexistent_condition_parser(sa):
engine = build_sa_engine(
pd.DataFrame({"a": [1, 2, 3, 4], "b": [2, 3, 4, None]}), sa
)
# Expect GreatExpectationsError because parser doesn't exist
with pytest.raises(ge_exceptions.GreatExpectationsError) as e:
data, compute_kwargs, accessor_kwargs = engine.get_compute_domain(
domain_kwargs={
"row_condition": "b > 24",
"condition_parser": "nonexistent",
},
domain_type=MetricDomainTypes.TABLE,
)
# Ensuring that we can properly inform user when metric doesn't exist - should get a metric provider error
def test_resolve_metric_bundle_with_nonexistent_metric(sa):
engine = build_sa_engine(
pd.DataFrame({"a": [1, 2, 1, 2, 3, 3], "b": [4, 4, 4, 4, 4, 4]}), sa
)
desired_metric_1 = MetricConfiguration(
metric_name="column_values.unique",
metric_domain_kwargs={"column": "a"},
metric_value_kwargs=None,
)
desired_metric_2 = MetricConfiguration(
metric_name="column.min",
metric_domain_kwargs={"column": "a"},
metric_value_kwargs=None,
)
desired_metric_3 = MetricConfiguration(
metric_name="column.max",
metric_domain_kwargs={"column": "b"},
metric_value_kwargs=None,
)
desired_metric_4 = MetricConfiguration(
metric_name="column.does_not_exist",
metric_domain_kwargs={"column": "b"},
metric_value_kwargs=None,
)
# Ensuring a metric provider error is raised if metric does not exist
with pytest.raises(ge_exceptions.MetricProviderError) as e:
# noinspection PyUnusedLocal
res = engine.resolve_metrics(
metrics_to_resolve=(
desired_metric_1,
desired_metric_2,
desired_metric_3,
desired_metric_4,
)
)
print(e)
def test_resolve_metric_bundle_with_compute_domain_kwargs_json_serialization(sa):
"""
Insures that even when "compute_domain_kwargs" has multiple keys, it will be JSON-serialized for "IDDict.to_id()".
"""
engine = build_sa_engine(
pd.DataFrame(
{
"names": [
"<NAME>",
"<NAME>",
"<NAME>",
"<NAME>",
"<NAME>",
"<NAME>",
"<NAME>",
"<NAME>",
]
}
),
sa,
batch_id="1234",
)
metrics: Dict[Tuple[str, str, str], MetricValue] = {}
table_columns_metric: MetricConfiguration
results: Dict[Tuple[str, str, str], MetricValue]
table_columns_metric, results = get_table_columns_metric(engine=engine)
metrics.update(results)
aggregate_fn_metric = MetricConfiguration(
metric_name="column_values.length.max.aggregate_fn",
metric_domain_kwargs={
"column": "names",
"batch_id": "1234",
},
metric_value_kwargs=None,
)
aggregate_fn_metric.metric_dependencies = {
"table.columns": table_columns_metric,
}
try:
results = engine.resolve_metrics(metrics_to_resolve=(aggregate_fn_metric,))
except ge_exceptions.MetricProviderError as e:
assert False, str(e)
desired_metric = MetricConfiguration(
metric_name="column_values.length.max",
metric_domain_kwargs={
"batch_id": "1234",
},
metric_value_kwargs=None,
)
desired_metric.metric_dependencies = {
"metric_partial_fn": aggregate_fn_metric,
}
try:
results = engine.resolve_metrics(
metrics_to_resolve=(desired_metric,), metrics=results
)
assert results == {desired_metric.id: 16}
except ge_exceptions.MetricProviderError as e:
assert False, str(e)
def test_get_batch_data_and_markers_using_query(sqlite_view_engine, test_df):
my_execution_engine: SqlAlchemyExecutionEngine = SqlAlchemyExecutionEngine(
engine=sqlite_view_engine
)
test_df.to_sql("test_table_0", con=my_execution_engine.engine)
query: str = "SELECT * FROM test_table_0"
batch_data, batch_markers = my_execution_engine.get_batch_data_and_markers(
batch_spec=RuntimeQueryBatchSpec(
query=query,
)
)
assert len(get_sqlite_temp_table_names(sqlite_view_engine)) == 2
assert batch_markers.get("ge_load_time") is not None
def test_sa_batch_unexpected_condition_temp_table(caplog, sa):
def validate_tmp_tables():
temp_tables = [
name
for name in get_sqlite_temp_table_names(engine.engine)
if name.startswith("ge_temp_")
]
tables = [
name
for name in get_sqlite_table_names(engine.engine)
if name.startswith("ge_temp_")
]
assert len(temp_tables) == 0
assert len(tables) == 0
engine = build_sa_engine(
pd.DataFrame({"a": [1, 2, 1, 2, 3, 3], "b": [4, 4, 4, 4, 4, 4]}), sa
)
metrics: Dict[Tuple[str, str, str], MetricValue] = {}
table_columns_metric: MetricConfiguration
results: Dict[Tuple[str, str, str], MetricValue]
table_columns_metric, results = get_table_columns_metric(engine=engine)
metrics.update(results)
validate_tmp_tables()
condition_metric = MetricConfiguration(
metric_name="column_values.unique.condition",
metric_domain_kwargs={"column": "a"},
metric_value_kwargs=None,
)
condition_metric.metric_dependencies = {
"table.columns": table_columns_metric,
}
results = engine.resolve_metrics(
metrics_to_resolve=(condition_metric,), metrics=metrics
)
metrics.update(results)
validate_tmp_tables()
desired_metric = MetricConfiguration(
metric_name="column_values.unique.unexpected_count",
metric_domain_kwargs={"column": "a"},
metric_value_kwargs=None,
)
desired_metric.metric_dependencies = {
"unexpected_condition": condition_metric,
}
# noinspection PyUnusedLocal
results = engine.resolve_metrics(
metrics_to_resolve=(desired_metric,), metrics=metrics
)
validate_tmp_tables()
<file_sep>/docs/guides/validation/advanced/how_to_get_data_docs_urls_for_custom_validation_actions.md
---
title: How to get Data Docs URLs for use in custom Validation Actions
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
If you would like to a custom Validation Action that includes a link to <TechnicalTag tag="data_docs" text="Data Docs"/>,
you can access the Data Docs URL for the respective <TechnicalTag tag="validation_result" text="Validation Results"/> page from your Validation Results following a <TechnicalTag tag="checkpoint" text="Checkpoint"/> run following the steps below.
This will work to get the URLs for any type of Data Docs site setup, e.g. S3 or local setup.
<Prerequisites>
- [Created an Expectation Suite to use for validation](../../../tutorials/getting_started/tutorial_create_expectations.md)
- [Reviewed our guidance on Validation Actions](../../../terms/action.md)
</Prerequisites>
### 1. Instantiate
First, within the `_run` method of your custom Validation Action, instantiate an empty `dict` to hold your sites:
```python file=../../../../great_expectations/checkpoint/actions.py#L1085
```
### 2. Acquire
Next, call `get_docs_sites_urls` to get the urls for all the suites processed by this Checkpoint:
```python file=../../../../great_expectations/checkpoint/actions.py#L1092-L1095
```
### 3. Iterate
The above step returns a list of dictionaries containing the relevant information. Now, we need to iterate through the entries to build the object we want:
```python file=../../../../great_expectations/checkpoint/actions.py#L1099-L1100
```
### 4. Utilize
You can now include the urls contained within the `data_docs_validation_results` dictionary as links in your custom notifications, for example in an email, Slack, or OpsGenie notification, which will allow users to jump straight to the relevant Validation Results page.
<div style={{"text-align":"center"}}>
<p style={{"color":"#8784FF","font-size":"1.4em"}}><b>
Congratulations!<br/>🎉 You've just accessed Data Docs URLs for use in custom Validation Actions! 🎉
</b></p>
</div>
:::note
For more on Validation Actions, see our current [guides on Validation Actions here.](https://docs.greatexpectations.io/docs/guides/validation/#actions)
To view the full script used in this page, and see this process in action, see it on GitHub:
- [actions.py](https://github.com/great-expectations/great_expectations/blob/26e855271092fe365c62fc4934e6713529c8989d/great_expectations/checkpoint/actions.py#L1085-L1096)
:::<file_sep>/docs/guides/connecting_to_your_data/datasource_configuration/sql_components/_tab_data_connector_example_configurations_runtime.mdx
import TipRuntimeDataConnectorOverview from '../components/_tip_runtime_data_connector_overview.mdx'
import PartNameTheDataConnector from '../components/_part_name_the_data_connector.mdx'
import PartDataConnectorRequiredKeysOverview from '../sql_components/_part_data_connector_required_keys_overview.mdx'
import TipCustomDataConnectorModuleName from '../components/_tip_custom_data_connector_module_name.mdx'
<TipRuntimeDataConnectorOverview />
<PartNameTheDataConnector data_connector_name="name_of_my_runtime_data_connector" />
At this point, your configuration should look like:
```python
datasource_config: dict = {
"name": "my_datasource_name",
"class_name": "Datasource",
"module_name": "great_expectations.datasource",
"execution_engine": {
"class_name": "SqlAlchemyExecutionEngine",
"module_name": "great_expectations.execution_engine",
"connection_string": CONNECTION_STRING,
},
"data_connectors": {
"name_of_my_runtime_data_connector": {}
}
}
}
```
#### Required Data Connector configuration keys
<PartDataConnectorRequiredKeysOverview data_connector_type="ConfiguredAssetSqlDataConnector" data_connector_name="name_of_my_configured_data_connector" inferred={false} configured={false} runtime={true} />
For this example, you will be using the `RuntimeDataConnector` as your `class_name`. This key/value entry will therefore look like:
```python
"class_name": "RuntimeDataConnector",
```
After including an empty list for your `batch_identifiers` your full configuration should now look like:
```python
datasource_config: dict = {
"name": "my_datasource_name",
"class_name": "Datasource",
"module_name": "great_expectations.datasource",
"execution_engine": {
"class_name": "SqlAlchemyExecutionEngine",
"module_name": "great_expectations.execution_engine",
"connection_string": CONNECTION_STRING,
},
"data_connectors": {
"name_of_my_runtime_data_connector": {
"class_name": "RuntimeDataConnector",
"batch_identifiers": [],
}
}
}
```
<TipCustomDataConnectorModuleName /><file_sep>/docs/guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_on_a_filesystem.md
---
title: How to configure an Expectation Store to use a filesystem
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
By default, newly <TechnicalTag tag="profiling" text="Profiled" /> <TechnicalTag tag="expectation" text="Expectations" /> are stored as <TechnicalTag tag="expectation_suite" text="Expectation Suites" /> in JSON format in the ``expectations/`` subdirectory of your ``great_expectations`` folder. This guide will help you configure a new storage location for Expectations on your filesystem.
<Prerequisites>
- [Configured a Data Context](../../../tutorials/getting_started/tutorial_setup.md).
- [Configured an Expectation Suite](../../../tutorials/getting_started/tutorial_create_expectations.md).
- Determined a new storage location where you would like to store Expectations. This can either be a local path, or a path to a network filesystem.
</Prerequisites>
## Steps
### 1. Configure a new folder on your filesystem where Expectations will be stored
Create a new folder where you would like to store your Expectations, and move your existing Expectation files over to the new location. In our case, the name of the Expectations file is ``npi_expectations`` and the path to our new storage location is ``/shared_expectations``.
```bash
# in the great_expectations/ folder
mkdir shared_expectations
mv expectations/npi_expectations.json shared_expectations/
```
### 2. Identify your Data Context Expectations Store
In your ``great_expectations.yml`` , look for the following lines. The configuration tells Great Expectations to look for Expectations in a <TechnicalTag tag="store" text="Store" /> called ``expectations_store``. The ``base_directory`` for ``expectations_store`` is set to ``expectations/`` by default.
```yaml
expectations_store_name: expectations_store
stores:
expectations_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
```
### 3. Update your configuration file to include a new store for Expectations results on your filesystem
In the example below, <TechnicalTag tag="expectation_store" text="Expectations Store" /> is being set to ``shared_expectations_filesystem_store`` with the ``base_directory`` set to ``shared_expectations/``.
```yaml
expectations_store_name: shared_expectations_filesystem_store
stores:
shared_expectations_filesystem_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: shared_expectations/
```
### 4. Confirm that the location has been updated by running ``great_expectations store list``
Notice the output contains two Expectation stores: the original ``expectations_store`` on the local filesystem and the ``shared_expectations_filesystem_store`` we just configured. This is ok, since Great Expectations will look for Expectations in the ``shared_expectations/`` folder as long as we set the ``expectations_store_name`` variable to ``shared_expectations_filesystem_store``. The config for ``expectations_store`` can be removed if you would like.
```bash
great_expectations store list
2 Stores found:
- name: expectations_store
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
- name: shared_expectations_filesystem_store
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: shared_expectations/
```
### 5. Confirm that Expectations can be read from the new storage location by running ``great_expectations suite list``
```bash
great_expectations suite list
1 Expectation Suite found:
- npi_expectations
```
## Additional Notes
- For best practices, we highly recommend that you store Expectations in a version-control system like Git. The JSON format of Expectations will allow for informative diff-statements and effective tracking of modifications. In the example below, 2 changes have been made to ``npi_expectations``. The Expectation ```expect_table_column_count_to_equal`` was changed from ``330`` to ``333`` to ``331``.
```bash
git log -p npi_expectations.json
commit cbc127fb27095364c3c1fcbf6e7f078369b07455
changed expect_table_column_count_to_equal to 331
diff --git a/great_expectations/expectations/npi_expectations.json b/great_expectations/expectations/npi_expectations.json
--- a/great_expectations/expectations/npi_expectations.json
+++ b/great_expectations/expectations/npi_expectations.json
@@ -17,7 +17,7 @@
{
"expectation_type": "expect_table_column_count_to_equal",
"kwargs": {
- "value": 333
+ "value": 331
}
commit <PASSWORD>
changed expect_table_column_count_to_equal to 333
diff --git a/great_expectations/expectations/npi_expectations.json b/great_expectations/expectations/npi_expectations.json
--- a/great_expectations/expectations/npi_expectations.json
+++ b/great_expectations/expectations/npi_expectations.json
{
"expectation_type": "expect_table_column_count_to_equal",
"kwargs": {
- "value": 330
+ "value": 333
}
```
<file_sep>/great_expectations/expectations/metrics/query_metrics/query_template_values.py
from typing import Any, Dict, List, Union
from great_expectations.core.metric_domain_types import MetricDomainTypes
from great_expectations.execution_engine import (
SparkDFExecutionEngine,
SqlAlchemyExecutionEngine,
)
from great_expectations.expectations.metrics.import_manager import (
pyspark_sql_DataFrame,
pyspark_sql_Row,
pyspark_sql_SparkSession,
sa,
sqlalchemy_engine_Engine,
sqlalchemy_engine_Row,
)
from great_expectations.expectations.metrics.metric_provider import metric_value
from great_expectations.expectations.metrics.query_metric_provider import (
QueryMetricProvider,
)
from great_expectations.util import get_sqlalchemy_subquery_type
class QueryTemplateValues(QueryMetricProvider):
metric_name = "query.template_values"
value_keys = (
"template_dict",
"query",
)
@metric_value(engine=SqlAlchemyExecutionEngine)
def _sqlalchemy(
cls,
execution_engine: SqlAlchemyExecutionEngine,
metric_domain_kwargs: dict,
metric_value_kwargs: dict,
metrics: Dict[str, Any],
runtime_configuration: dict,
) -> List[sqlalchemy_engine_Row]:
query = metric_value_kwargs.get("query") or cls.default_kwarg_values.get(
"query"
)
selectable: Union[sa.sql.Selectable, str]
selectable, _, _ = execution_engine.get_compute_domain(
metric_domain_kwargs, domain_type=MetricDomainTypes.TABLE
)
if not isinstance(query, str):
raise TypeError("Query must be supplied as a string")
template_dict = metric_value_kwargs.get("template_dict")
if not isinstance(template_dict, dict):
raise TypeError("template_dict supplied by the expectation must be a dict")
if isinstance(selectable, sa.Table):
query = query.format(**template_dict, active_batch=selectable)
elif isinstance(
selectable, get_sqlalchemy_subquery_type()
): # Specifying a runtime query in a RuntimeBatchRequest returns the active batch as a Subquery; sectioning
# the active batch off w/ parentheses ensures flow of operations doesn't break
query = query.format(**template_dict, active_batch=f"({selectable})")
elif isinstance(
selectable, sa.sql.Select
): # Specifying a row_condition returns the active batch as a Select object, requiring compilation &
# aliasing when formatting the parameterized query
query = query.format(
**template_dict,
active_batch=f'({selectable.compile(compile_kwargs={"literal_binds": True})}) AS subselect',
)
else:
query = query.format(**template_dict, active_batch=f"({selectable})")
engine: sqlalchemy_engine_Engine = execution_engine.engine
result: List[sqlalchemy_engine_Row] = engine.execute(sa.text(query)).fetchall()
return result
@metric_value(engine=SparkDFExecutionEngine)
def _spark(
cls,
execution_engine: SparkDFExecutionEngine,
metric_domain_kwargs: dict,
metric_value_kwargs: dict,
metrics: Dict[str, Any],
runtime_configuration: dict,
) -> List[pyspark_sql_Row]:
query = metric_value_kwargs.get("query") or cls.default_kwarg_values.get(
"query"
)
df: pyspark_sql_DataFrame
df, _, _ = execution_engine.get_compute_domain(
metric_domain_kwargs, domain_type=MetricDomainTypes.TABLE
)
df.createOrReplaceTempView("tmp_view")
template_dict = metric_value_kwargs.get("template_dict")
if not isinstance(query, str):
raise TypeError("template_dict supplied by the expectation must be a dict")
if not isinstance(template_dict, dict):
raise TypeError("template_dict supplied by the expectation must be a dict")
query = query.format(**template_dict, active_batch="tmp_view")
engine: pyspark_sql_SparkSession = execution_engine.spark
result: List[pyspark_sql_Row] = engine.sql(query).collect()
return result
<file_sep>/docs/guides/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_or_pandas_dataframe.md
---
title: How to create a Batch of data from an in-memory Spark or Pandas dataframe or path
---
import Prerequisites from '../connecting_to_your_data/components/prerequisites.jsx'
import Tabs from '@theme/Tabs'
import TabItem from '@theme/TabItem'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide will help you load the following as <TechnicalTag tag="batch" text="Batches" /> for use in creating <TechnicalTag tag="expectation" text="Expectations" />:
1. **Pandas DataFrames**
2. **Spark DataFrames**
What used to be called a “Batch” in the old API was replaced with <TechnicalTag tag="validator" text="Validator" />. A Validator knows how to <TechnicalTag tag="validation" text="Validate" /> a particular Batch of data on a particular <TechnicalTag tag="execution_engine" text="Execution Engine" /> against a particular <TechnicalTag tag="expectation_suite" text="Expectation Suite" />. In interactive mode, the Validator can store and update an Expectation Suite while conducting Data Discovery or Exploratory Data Analysis.
<Tabs
groupId='spark-or-pandas'
defaultValue='spark'
values={[
{label: 'Spark DataFrame', value:'spark'},
{label: 'Pandas DataFrame', value:'pandas'},
]}>
<TabItem value='spark'>
<Prerequisites>
- [Set up a working deployment of Great Expectations](../../tutorials/getting_started/tutorial_overview.md)
- [Configured and loaded a Data Context](../../tutorials/getting_started/tutorial_setup.md)
- Configured a [Spark Datasource](../../guides/connecting_to_your_data/filesystem/spark.md)
- Identified an in-memory Spark DataFrame that you would like to use as the data to validate **OR**
- Identified a filesystem or S3 path to a file that contains the data you would like to use to validate.
</Prerequisites>
1. **Load or create a Data Context**
The ``context`` referenced below can be loaded from disk or configured in code.
First, import these necessary packages and modules.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L2-L11
```
Load an on-disk <TechnicalTag tag="data_context" text="Data Context" /> (ie. from a `great_expectations.yml` configuration) via the `get_context()` command:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L14
```
If you are working in an environment without easy access to a local filesystem (e.g. AWS Spark EMR, Databricks, etc.), load an in-code Data Context using these instructions: [How to instantiate a Data Context without a yml file](../../guides/setup/configuring_data_contexts/how_to_instantiate_a_data_context_without_a_yml_file.md)
2. **Obtain an Expectation Suite**
If you have not already created an Expectation Suite, you can do so now.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L24-L26
```
The Expectation Suite can then be loaded into memory by using `get_expectation_suite()`.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L29-L31
```
3. **Construct a RuntimeBatchRequest**
We will create a ``RuntimeBatchRequest`` and pass it our Spark DataFrame or path via the ``runtime_parameters`` argument, under either the ``batch_data`` or ``path`` key. The ``batch_identifiers`` argument is required and must be a non-empty dictionary containing all of the Batch Identifiers specified in your Runtime <TechnicalTag tag="data_connector" text="Data Connector" /> configuration.
If you are providing a filesystem path instead of a materialized DataFrame, you may use either an absolute or relative path (with respect to the current working directory). Under the hood, Great Expectations will instantiate a Spark Dataframe using the appropriate ``spark.read.*`` method, which will be inferred from the file extension. If your file names do not have extensions, you can specify the appropriate reader method explicitly via the ``batch_spec_passthrough`` argument. Any Spark reader options (i.e. ``delimiter`` or ``header``) that are required to properly read your data can also be specified with the ``batch_spec_passthrough`` argument, in a dictionary nested under a key named ``reader_options``.
Here is an example <TechnicalTag tag="datasource" text="Datasource" /> configuration in YAML.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L34-L47
```
Save the configuration into your DataContext by using the `add_datasource()` function.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L50
```
If you have a file in the following location:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L54
```
Then the file can be read as a Spark Dataframe using:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L61
```
Here is a Runtime <TechnicalTag tag="batch_request" text="Batch Request" /> using an in-memory DataFrame:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L64-L73
```
Here is a Runtime Batch Request using a path:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L83-L92
```
:::note Best Practice
Though not strictly required, we recommend that you make every Data Asset Name **unique**. Choosing a unique Data Asset Name makes it easier to navigate quickly through <TechnicalTag tag="data_docs" text="Data Docs" /> and ensures your logical <TechnicalTag tag="data_asset" text="Data Assets" /> are not confused with any particular view of them provided by an Execution Engine.
:::
4. **Construct a Validator**
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L96-L100
```
Alternatively, you may skip step 2 and pass the same Runtime Batch Request instantiation arguments, along with the Expectation Suite (or name), directly to the ``get_validator`` method.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L106-L121
```
5. **Check your data**
You can check that the first few lines of your Batch are what you expect by running:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py#L124
```
Now that you have a Validator, you can use it to [create Expectations](../expectations/create_expectations_overview.md) or [validate the data](../validation/validate_data_overview.md).
</TabItem>
<TabItem value='pandas'>
<Prerequisites>
- [Set up a working deployment of Great Expectations](../../tutorials/getting_started/tutorial_overview.md)
- [Configured and loaded a Data Context](../../tutorials/getting_started/tutorial_setup.md)
- Configured a [Pandas/filesystem Datasource](../../guides/connecting_to_your_data/filesystem/pandas.md)
- Identified a Pandas DataFrame that you would like to use as the data to validate.
</Prerequisites>
1. **Load or create a Data Context**
The ``context`` referenced below can be loaded from disk or configured in code.
First, import these necessary packages and modules.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L2-L10
```
Load an on-disk Data Context (ie. from a `great_expectations.yml` configuration) via the `get_context()` command:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L14
```
If you are working in an environment without easy access to a local filesystem (e.g. AWS Spark EMR, Databricks, etc.), load an in-code Data Context using these instructions: [How to instantiate a Data Context without a yml file](../../guides/setup/configuring_data_contexts/how_to_instantiate_a_data_context_without_a_yml_file.md)
2. **Obtain an Expectation Suite**
If you have not already created an Expectation Suite, you can do so now.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L19-L21
```
The Expectation Suite can then be loaded into memory by using `get_expectation_suite()`.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L24-L26
```
3. **Construct a Runtime Batch Request**
We will create a ``RuntimeBatchRequest`` and pass it our DataFrame or path via the ``runtime_parameters`` argument, under either the ``batch_data`` or ``path`` key. The ``batch_identifiers`` argument is required and must be a non-empty dictionary containing all of the Batch Identifiers specified in your Runtime Data Connector configuration.
If you are providing a filesystem path instead of a materialized DataFrame, you may use either an absolute or relative path (with respect to the current working directory). Under the hood, Great Expectations will instantiate a Pandas Dataframe using the appropriate ``pandas.read_*`` method, which will be inferred from the file extension. If your file names do not have extensions, you can specify the appropriate reader method explicitly via the ``batch_spec_passthrough`` argument. Any Pandas reader options (i.e. ``sep`` or ``header``) that are required to properly read your data can also be specified with the ``batch_spec_passthrough`` argument, in a dictionary nested under a key named ``reader_options``.
Here is an example Datasource configuration in YAML.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L30-L43
```
Save the configuration into your DataContext by using the `add_datasource()` function.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L47
```
If you have a file in the following location:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L52
```
Then the file can be read as a Pandas Dataframe using
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L59
```
Here is a Runtime Batch Request using an in-memory DataFrame:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L62-L71
```
Here is a Runtime Batch Request using a path:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L76-L89
```
:::note Best Practice
Though not strictly required, we recommend that you make every Data Asset Name **unique**. Choosing a unique Data Asset Name makes it easier to navigate quickly through Data Docs and ensures your logical Data Assets are not confused with any particular view of them provided by an Execution Engine.
:::
4. **Construct a Validator**
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L94-L98
```
Alternatively, you may skip step 2 and pass the same Runtime Batch Request instantiation arguments, along with the Expectation Suite (or name), directly to the ``get_validator`` method.
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L104-L119
```
5. **Check your data**
You can check that the first few lines of your Batch are what you expect by running:
```python file=../../../tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py#L122
```
Now that you have a Validator, you can use it to [create Expectations](../expectations/create_expectations_overview.md) or [validate the data](../validation/validate_data_overview.md).
</TabItem>
</Tabs>
## Additional Notes
To view the full scripts used in this page, see them on GitHub:
- [in_memory_spark_dataframe_example.py](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_dataframe.py)
- [in_memory_pandas_dataframe_example.py](https://github.com/great-expectations/great_expectations/blob/develop/tests/integration/docusaurus/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_pandas_dataframe.py)
<file_sep>/docs/guides/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.md
---
title: How to pass an in-memory DataFrame to a Checkpoint
---
import Prerequisites from '../../../guides/connecting_to_your_data/components/prerequisites.jsx';
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
This guide will help you pass an in-memory DataFrame to an existing <TechnicalTag tag="checkpoint" text="Checkpoint" />. This is especially useful if you already have your data in memory due to an existing process such as a pipeline runner.
<Prerequisites>
- [Configured a Data Context](../../../tutorials/getting_started/tutorial_setup.md).
</Prerequisites>
## Steps
### 1. Set up Great Expectations
#### Import the required libraries and load your DataContext
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L2-L7
```
If you have an existing configured DataContext in your filesystem in the form of a `great_expectations.yml` file, you can load it like this:
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L11
```
If you do not have a filesystem to work with, you can load your DataContext following the instructions in [How to instantiate a Data Context without a yml file](../../setup/configuring_data_contexts/how_to_instantiate_a_data_context_without_a_yml_file.md).
### 2. Connect to your data
#### Ensure your DataContext contains a Datasource with a RuntimeDataConnector
In order to pass in a DataFrame at runtime, your `great_expectations.yml` should contain a <TechnicalTag tag="datasource" text="Datasource" /> configured with a `RuntimeDataConnector`. If it does not, you can add a new Datasource using the code below:
<Tabs
groupId="yaml-or-python-or-CLI"
defaultValue='yaml'
values={[
{label: 'YAML', value:'yaml'},
{label: 'Python', value:'python'},
{label: 'CLI', value:'cli'},
]}>
<TabItem value="yaml">
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L15-L28
```
</TabItem>
<TabItem value="python">
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L34-L49
```
</TabItem>
<TabItem value="cli">
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L59
```
After running the <TechnicalTag tag="cli" text="CLI" /> command above, choose option 1 for "Files on a filesystem..." and then select whether you will be passing a Pandas or Spark DataFrame. Once the Jupyter Notebook opens, change the `datasource_name` to "taxi_datasource" and run all cells to save your Datasource configuration.
</TabItem>
</Tabs>
### 3. Create Expectations and Validate your data
#### Create a Checkpoint and pass it the DataFrame at runtime
You will need an <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> to <TechnicalTag tag="validation" text="Validate" /> your data against. If you have not already created an Expectation Suite for your in-memory DataFrame, reference [How to create and edit Expectations with instant feedback from a sample Batch of data](../../expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md) to create your Expectation Suite.
For the purposes of this guide, we have created an empty suite named `my_expectation_suite` by running:
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L68
```
We will now walk through two examples for configuring a `Checkpoint` and passing it an in-memory DataFrame at runtime.
#### Example 1: Pass only the `batch_request`'s missing keys at runtime
If we configure a `SimpleCheckpoint` that contains a single `batch_request` in `validations`:
<Tabs
groupId="yaml-or-python"
defaultValue='yaml'
values={[
{label: 'YAML', value:'yaml'},
{label: 'Python', value:'python'},
]}>
<TabItem value="yaml">
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L72-L83
```
</TabItem>
<TabItem value="python">
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L89-L104
```
</TabItem>
</Tabs>
We can then pass the remaining keys for the in-memory DataFrame (`df`) and it's associated `batch_identifiers` at runtime using `batch_request`:
```python
df = pd.read_csv("<PATH TO DATA>")
```
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L118-L126
```
#### Example 2: Pass a complete `RuntimeBatchRequest` at runtime
If we configure a `SimpleCheckpoint` that does not contain any `validations`:
<Tabs
groupId="yaml-or-python"
defaultValue='yaml'
values={[
{label: 'YAML', value:'yaml'},
{label: 'Python', value:'python'},
]}>
<TabItem value="yaml">
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L133-L139
```
</TabItem>
<TabItem value="python">
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L145-L151
```
</TabItem>
</Tabs>
We can pass one or more `RuntimeBatchRequest`s into `validations` at runtime. Here is an example that passes multiple `batch_request`s into `validations`:
```python
df_1 = pd.read_csv("<PATH TO DATA 1>")
df_2 = pd.read_csv("<PATH TO DATA 2>")
```
```python file=../../../../tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py#L169-L191
```
## Additional Notes
To view the full script used in this page, see it on GitHub:
- [how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py](https://github.com/great-expectations/great_expectations/tree/develop/tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py)
<file_sep>/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/metrics/data_profiler_metrics/__init__.py
from .data_profiler_column_profiler_report import DataProfilerColumnProfileReport
from .data_profiler_profile_diff import DataProfilerProfileDiff
from .data_profiler_profile_metric_provider import DataProfilerProfileMetricProvider
from .data_profiler_profile_numeric_columns import DataProfilerProfileNumericColumns
from .data_profiler_profile_percent_diff import DataProfilerProfilePercentDiff
from .data_profiler_profile_report import DataProfilerProfileReport
<file_sep>/docs/tutorials/getting_started/tutorial_overview.md
---
title: Getting started with Great Expectations
---
import TechnicalTag from '/docs/term_tags/_tag.mdx';
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
Welcome to the Great Expectations getting started tutorial! This tutorial will help you set up your first local deployment of Great Expectations. This deployment will contain a small <TechnicalTag relative="../../" tag="expectation_suite" text="Expectation Suite" /> that we will use to <TechnicalTag relative="../../" tag="validation" text="Validate" /> some sample data. We'll also introduce important concepts, with links to detailed material you can dig into later.
:::tip
The steps described in this tutorial assume you are installing Great Expectations version 0.13.8 or above.
For a tutorial for older versions of Great Expectations, please see older versions of this documentation, which can be found [here](https://docs.greatexpectations.io/en/latest/guides/tutorials.html).
:::
### This tutorial will walk you through the following steps
<table class="borderless markdown">
<tr>
<td>
<img
src={require('../../images/universal_map/Gear-active.png').default}
alt="Setup"
/>
</td>
<td>
<h4>Setup</h4>
<p>
First, we will make sure you have Great Expectations installed and show you how to initialize a <TechnicalTag relative="../../" tag="data_context" text="Data Context" />.
</p>
</td>
</tr>
<tr>
<td>
<img
src={require('../../images/universal_map/Outlet-active.png').default}
alt="Connect to Data"
/>
</td>
<td>
<h4>Connect to Data</h4>
<p>
Then you will learn how to configure a <TechnicalTag relative="../../" tag="datasource" text="Datasource" /> to connect to your data.
</p>
</td>
</tr>
<tr>
<td>
<img
src={require('../../images/universal_map/Flask-active.png').default}
alt="Create Expectations"
/>
</td>
<td>
<h4>Create Expectations</h4>
<p>
You will then create your first Expectation Suite using the built-in automated <TechnicalTag relative="../../" tag="profiler" text="Profiler" />. You'll also take your first look at <TechnicalTag relative="../../" tag="data_docs" text="Data Docs" />, where you will be able to see the <TechnicalTag relative="../../" tag="expectation" text="Expectations" /> that were created.
</p>
</td>
</tr>
<tr>
<td>
<img
src={require('../../images/universal_map/Checkmark-active.png').default}
alt="Validate Data"
/>
</td>
<td>
<h4>Validate Data</h4>
<p>
Finally, we will show you how to use this Expectation Suite to Validate a new batch of data, and take a deeper look at the Data Docs which will show your <TechnicalTag relative="../../" tag="validation_result" text="Validation Results" />.
</p>
</td>
</tr>
</table>
But before we dive into the first step, let's bring you up to speed on the problem we are going to address in this tutorial, and the data that we'll be using to illustrate it.
### The data problem we're solving in this tutorial
In this tutorial we will be looking at two sets of data representing the same information over different periods of time. We will use the values of the first set of data to populate the rules that we expect this data to follow in the future. We will then use these Expectations to determine if there is a problem with the second set of data.
The data we're going to use for this tutorial is the [NYC taxi data](https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page). This is an open data set which is updated every month. Each record in the data corresponds to one taxi ride and contains information such as the pick-up and drop-off location, the payment amount, and the number of passengers, among others.
In this tutorial, we provide two CSV files, each with a 10,000 row sample of the Yellow Taxi Trip Records set:
- **yellow_tripdata_sample_2019-01.csv**: a sample of the January 2019 taxi data
- **yellow_tripdata_sample_2019-02.csv**: a sample of the February 2019 taxi data
For purposes of this tutorial, we are treating the January 2019 taxi data as our "current" data, and the February 2019 taxi data as "future" data that we have not yet looked at. We will use Great Expectations to build a profile of the January data and then use that profile to check for any unexpected data quality issues in the February data. In a real-life scenario, this would ensure that any problems with the February data would be caught (so it could be dealt with) before the February data is used in a production application!
It should be noted that in the tutorial we only have one month's worth of "current" data. However, you can use Multi-Batch Profilers to build profiles of multiple past or current sets of data. Doing so will generally result in a more accurate data profile but for this small example a single set of "current" data will suffice.
### Getting started with the Getting Started Tutorial
Now that you have the background for the data we're using and what we want to do with it, we're ready to start the tutorial in earnest.
Remember the icons for the four steps we'll be going through?
<UniversalMap setup='active' connect='active' create='active' validate='active'/>
Great! You should know: The icon associated with each of these steps will also be displayed on any related documentation. So if you do follow links into more detailed discussions of anything we introduce you to, you will be able to find your way back to the step you were on with ease.
And now it looks like you're ready to move on to [Step 1: Setup.](./tutorial_setup.md)
<file_sep>/contrib/cli/requirements.txt
black==22.3.0 # Linting / code style
Click>=7.1.2 # CLI tooling
cookiecutter==1.7.3 # Project templating
isort==5.10.1 # Linting / code style
mypy==0.991 # Type checker
pydantic>=1.0,<2.0 # Needed for mypy plugin
pytest>=5.3.5 # Test framework
twine==3.7.1 # Packaging
wheel==0.37.1 # Packaging
<file_sep>/assets/scripts/build_gallery.py
import ast
import importlib
import json
import logging
import os
import re
import shutil
import sys
import traceback
from glob import glob
from io import StringIO
from subprocess import CalledProcessError, CompletedProcess, check_output, run
from typing import Dict, List, Optional, Tuple
import click
import pkg_resources
from great_expectations.data_context.data_context import DataContext
logger = logging.getLogger(__name__)
chandler = logging.StreamHandler(stream=sys.stdout)
chandler.setLevel(logging.DEBUG)
chandler.setFormatter(
logging.Formatter("%(asctime)s - %(levelname)s - %(message)s", "%Y-%m-%dT%H:%M:%S")
)
logger.addHandler(chandler)
logger.setLevel(logging.DEBUG)
expectation_tracebacks = StringIO()
expectation_checklists = StringIO()
def execute_shell_command(command: str) -> int:
"""
Wrap subprocess command in a try/except block to provide a convenient method for pip installing dependencies.
:param command: bash command -- as if typed in a shell/Terminal window
:return: status code -- 0 if successful; all other values (1 is the most common) indicate an error
"""
cwd: str = os.getcwd()
path_env_var: str = os.pathsep.join([os.environ.get("PATH", os.defpath), cwd])
env: dict = dict(os.environ, PATH=path_env_var)
status_code: int = 0
try:
res: CompletedProcess = run(
args=["bash", "-c", command],
stdin=None,
input=None,
# stdout=None, # commenting out to prevent issues with `subprocess.run` in python <3.7.4
# stderr=None, # commenting out to prevent issues with `subprocess.run` in python <3.7.4
capture_output=True,
shell=False,
cwd=cwd,
timeout=None,
check=True,
encoding=None,
errors=None,
text=None,
env=env,
universal_newlines=True,
)
sh_out: str = res.stdout.strip()
logger.info(sh_out)
except CalledProcessError as cpe:
status_code = cpe.returncode
sys.stderr.write(cpe.output)
sys.stderr.flush()
exception_message: str = "A Sub-Process call Exception occurred.\n"
exception_traceback: str = traceback.format_exc()
exception_message += (
f'{type(cpe).__name__}: "{str(cpe)}". Traceback: "{exception_traceback}".'
)
logger.error(exception_message)
return status_code
def get_expectation_file_info_dict(
include_core: bool = True,
include_contrib: bool = True,
only_these_expectations: List[str] = [],
) -> dict:
rx = re.compile(r".*?([A-Za-z]+?Expectation\b).*")
result = {}
files_found = []
oldpwd = os.getcwd()
os.chdir(f"..{os.path.sep}..")
repo_path = os.getcwd()
logger.debug(
"Finding Expectation files in the repo and getting their create/update times"
)
if include_core:
files_found.extend(
glob(
os.path.join(
repo_path,
"great_expectations",
"expectations",
"core",
"expect_*.py",
),
recursive=True,
)
)
if include_contrib:
files_found.extend(
glob(
os.path.join(repo_path, "contrib", "**", "expect_*.py"),
recursive=True,
)
)
for file_path in sorted(files_found):
file_path = file_path.replace(f"{repo_path}{os.path.sep}", "")
package_name = os.path.basename(os.path.dirname(os.path.dirname(file_path)))
if package_name == "expectations":
package_name = "core"
name = os.path.basename(file_path).replace(".py", "")
if only_these_expectations and name not in only_these_expectations:
continue
updated_at_cmd = f'git log -1 --format="%ai %ar" -- {repr(file_path)}'
created_at_cmd = (
f'git log --diff-filter=A --format="%ai %ar" -- {repr(file_path)}'
)
result[name] = {
"updated_at": check_output(updated_at_cmd, shell=True)
.decode("utf-8")
.strip(),
"created_at": check_output(created_at_cmd, shell=True)
.decode("utf-8")
.strip(),
"path": file_path,
"package": package_name,
}
logger.debug(
f"{name} ({package_name}) was created {result[name]['created_at']} and updated {result[name]['updated_at']}"
)
with open(file_path) as fp:
text = fp.read()
exp_type_set = set()
for line in re.split("\r?\n", text):
match = rx.match(line)
if match:
if not line.strip().startswith("#"):
exp_type_set.add(match.group(1))
if file_path.startswith("great_expectations"):
_prefix = "Core "
else:
_prefix = "Contrib "
result[name]["exp_type"] = _prefix + sorted(exp_type_set)[0]
logger.debug(
f"Expectation type {_prefix}{sorted(exp_type_set)[0]} for {name} in {file_path}"
)
os.chdir(oldpwd)
return result
def get_contrib_requirements(filepath: str) -> Dict:
"""
Parse the python file from filepath to identify a "library_metadata" dictionary in any defined classes, and return a requirements_info object that includes a list of pip-installable requirements for each class that defines them.
Note, currently we are handling all dependencies at the module level. To support future expandability and detail, this method also returns per-class requirements in addition to the concatenated list.
Args:
filepath: the path to the file to parse and analyze
Returns:
A dictionary:
{
"requirements": [ all_requirements_found_in_any_library_metadata_in_file ],
class_name: [ requirements ]
}
"""
with open(filepath) as file:
tree = ast.parse(file.read())
requirements_info = {"requirements": []}
for child in ast.iter_child_nodes(tree):
if not isinstance(child, ast.ClassDef):
continue
current_class = child.name
for node in ast.walk(child):
if isinstance(node, ast.Assign):
try:
target_ids = [target.id for target in node.targets]
except (ValueError, AttributeError):
# some assignment types assign to non-node objects (e.g. Tuple)
target_ids = []
if "library_metadata" in target_ids:
library_metadata = ast.literal_eval(node.value)
requirements = library_metadata.get("requirements", [])
if type(requirements) == str:
requirements = [requirements]
requirements_info[current_class] = requirements
requirements_info["requirements"] += requirements
return requirements_info
def build_gallery(
include_core: bool = True,
include_contrib: bool = True,
ignore_suppress: bool = False,
ignore_only_for: bool = False,
only_these_expectations: List[str] = [],
only_consider_these_backends: List[str] = [],
context: Optional[DataContext] = None,
) -> Dict:
"""
Build the gallery object by running diagnostics for each Expectation and returning the resulting reports.
Args:
include_core: if true, include Expectations defined in the core module
include_contrib: if true, include Expectations defined in contrib:
only_these_expectations: list of specific Expectations to include
only_consider_these_backends: list of backends to consider running tests against
Returns:
None
"""
gallery_info = dict()
requirements_dict = {}
logger.info("Loading great_expectations library.")
installed_packages = pkg_resources.working_set
installed_packages_txt = sorted(f"{i.key}=={i.version}" for i in installed_packages)
logger.debug(f"Found the following packages: {installed_packages_txt}")
expectation_file_info = get_expectation_file_info_dict(
include_core=include_core,
include_contrib=include_contrib,
only_these_expectations=only_these_expectations,
)
import great_expectations
core_expectations = (
great_expectations.expectations.registry.list_registered_expectation_implementations()
)
if include_core:
print("\n\n\n=== (Core) ===")
logger.info("Getting base registered expectations list")
logger.debug(f"Found the following expectations: {sorted(core_expectations)}")
for expectation in core_expectations:
if only_these_expectations and expectation not in only_these_expectations:
# logger.debug(f"Skipping {expectation} since it's not requested")
continue
requirements_dict[expectation] = {"group": "core"}
just_installed = set()
failed_to_import_set = set()
if include_contrib:
print("\n\n\n=== (Contrib) ===")
logger.info("Finding contrib modules")
skip_dirs = ("cli", "tests")
contrib_dir = os.path.join(
os.path.dirname(__file__),
"..",
"..",
"contrib",
)
for root, dirs, files in os.walk(contrib_dir):
for dirname in skip_dirs:
if dirname in dirs:
dirs.remove(dirname)
if "expectations" in dirs:
if root.endswith("great_expectations_experimental"):
sys.path.append(root)
else:
# A package in contrib that may contain more Expectations
sys.path.append(os.path.dirname(root))
for filename in files:
if filename.endswith(".py") and filename.startswith("expect_"):
if (
only_these_expectations
and filename.replace(".py", "") not in only_these_expectations
):
# logger.debug(f"Skipping {filename} since it's not requested")
continue
logger.debug(f"Getting requirements for module {filename}")
contrib_subdir_name = os.path.basename(os.path.dirname(root))
requirements_dict[filename[:-3]] = get_contrib_requirements(
os.path.join(root, filename)
)
requirements_dict[filename[:-3]]["group"] = contrib_subdir_name
logger.info("Done finding contrib modules")
for expectation in sorted(requirements_dict):
# Temp
if expectation in [
"expect_column_kl_divergence_to_be_less_than", # Infinity values break JSON
"expect_column_values_to_be_valid_arn", # Contrib Expectation where pretty much no test passes on any backend
]:
continue
group = requirements_dict[expectation]["group"]
print(f"\n\n\n=== {expectation} ({group}) ===")
requirements = requirements_dict[expectation].get("requirements", [])
parsed_requirements = pkg_resources.parse_requirements(requirements)
for req in parsed_requirements:
is_satisfied = any(
[installed_pkg in req for installed_pkg in installed_packages]
)
if is_satisfied or req in just_installed:
continue
logger.debug(f"Executing command: 'pip install \"{req}\"'")
status_code = execute_shell_command(f'pip install "{req}"')
if status_code == 0:
just_installed.add(req)
else:
expectation_tracebacks.write(
f"\n\n----------------\n{expectation} ({group})\n"
)
expectation_tracebacks.write(f"Failed to pip install {req}\n\n")
if group != "core":
logger.debug(f"Importing {expectation}")
try:
if group == "great_expectations_experimental":
importlib.import_module(f"expectations.{expectation}", group)
else:
importlib.import_module(f"{group}.expectations")
except (ModuleNotFoundError, ImportError, Exception) as e:
logger.error(f"Failed to load expectation: {expectation}")
print(traceback.format_exc())
expectation_tracebacks.write(
f"\n\n----------------\n{expectation} ({group})\n"
)
expectation_tracebacks.write(traceback.format_exc())
failed_to_import_set.add(expectation)
continue
logger.debug(f"Running diagnostics for expectation: {expectation}")
try:
impl = great_expectations.expectations.registry.get_expectation_impl(
expectation
)
diagnostics = impl().run_diagnostics(
ignore_suppress=ignore_suppress,
ignore_only_for=ignore_only_for,
debug_logger=logger,
only_consider_these_backends=only_consider_these_backends,
context=context,
)
checklist_string = diagnostics.generate_checklist()
expectation_checklists.write(
f"\n\n----------------\n{expectation} ({group})\n"
)
expectation_checklists.write(f"{checklist_string}\n")
if diagnostics["description"]["docstring"]:
diagnostics["description"]["docstring"] = format_docstring_to_markdown(
diagnostics["description"]["docstring"]
)
except Exception:
logger.error(f"Failed to run diagnostics for: {expectation}")
print(traceback.format_exc())
expectation_tracebacks.write(
f"\n\n----------------\n{expectation} ({group})\n"
)
expectation_tracebacks.write(traceback.format_exc())
else:
try:
gallery_info[expectation] = diagnostics.to_json_dict()
gallery_info[expectation]["created_at"] = expectation_file_info[
expectation
]["created_at"]
gallery_info[expectation]["updated_at"] = expectation_file_info[
expectation
]["updated_at"]
gallery_info[expectation]["package"] = expectation_file_info[
expectation
]["package"]
gallery_info[expectation]["exp_type"] = expectation_file_info[
expectation
].get("exp_type")
except TypeError as e:
logger.error(f"Failed to create JSON for: {expectation}")
print(traceback.format_exc())
expectation_tracebacks.write(
f"\n\n----------------\n[JSON write fail] {expectation} ({group})\n"
)
expectation_tracebacks.write(traceback.format_exc())
if just_installed:
print("\n\n\n=== (Uninstalling) ===")
logger.info(
f"Uninstalling packages that were installed while running this script..."
)
for req in just_installed:
logger.debug(f"Executing command: 'pip uninstall -y \"{req}\"'")
execute_shell_command(f'pip uninstall -y "{req}"')
expectation_filenames_set = set(requirements_dict.keys())
full_registered_expectations_set = set(
great_expectations.expectations.registry.list_registered_expectation_implementations()
)
if only_these_expectations:
registered_expectations_set = (
set(only_these_expectations) & full_registered_expectations_set
)
expectation_filenames_set = (
set(only_these_expectations) & expectation_filenames_set
)
elif not include_core:
registered_expectations_set = full_registered_expectations_set - set(
core_expectations
)
else:
registered_expectations_set = full_registered_expectations_set
non_matched_filenames = (
expectation_filenames_set - registered_expectations_set - failed_to_import_set
)
if failed_to_import_set:
expectation_tracebacks.write(f"\n\n----------------\n(Not a traceback)\n")
expectation_tracebacks.write("Expectations that failed to import:\n")
for expectation in sorted(failed_to_import_set):
expectation_tracebacks.write(f"- {expectation}\n")
if non_matched_filenames:
expectation_tracebacks.write(f"\n\n----------------\n(Not a traceback)\n")
expectation_tracebacks.write(
"Expectation filenames that don't match their defined Expectation name:\n"
)
for fname in sorted(non_matched_filenames):
expectation_tracebacks.write(f"- {fname}\n")
bad_names = sorted(
list(registered_expectations_set - expectation_filenames_set)
)
expectation_tracebacks.write(
f"\nRegistered Expectation names that don't match:\n"
)
for exp_name in bad_names:
expectation_tracebacks.write(f"- {exp_name}\n")
if include_core and not only_these_expectations:
core_dir = os.path.join(
os.path.dirname(__file__),
"..",
"..",
"great_expectations",
"expectations",
"core",
)
core_expectations_filename_set = {
fname.rsplit(".", 1)[0]
for fname in os.listdir(core_dir)
if fname.startswith("expect_")
}
core_expectations_not_in_gallery = core_expectations_filename_set - set(
core_expectations
)
if core_expectations_not_in_gallery:
expectation_tracebacks.write(f"\n\n----------------\n(Not a traceback)\n")
expectation_tracebacks.write(
f"Core Expectation files not included in core_expectations:\n"
)
for exp_name in sorted(core_expectations_not_in_gallery):
expectation_tracebacks.write(f"- {exp_name}\n")
return gallery_info
def format_docstring_to_markdown(docstr: str) -> str:
"""
Add markdown formatting to a provided docstring
Args:
docstr: the original docstring that needs to be converted to markdown.
Returns:
str of Docstring formatted as markdown
"""
r = re.compile(r"\s\s+", re.MULTILINE)
clean_docstr_list = []
prev_line = None
in_code_block = False
in_param = False
first_code_indentation = None
# Parse each line to determine if it needs formatting
for original_line in docstr.split("\n"):
# Remove excess spaces from lines formed by concatenated docstring lines.
line = r.sub(" ", original_line)
# In some old docstrings, this indicates the start of an example block.
if line.strip() == "::":
in_code_block = True
clean_docstr_list.append("```")
# All of our parameter/arg/etc lists start after a line ending in ':'.
elif line.strip().endswith(":"):
in_param = True
# This adds a blank line before the header if one doesn't already exist.
if prev_line != "":
clean_docstr_list.append("")
# Turn the line into an H4 header
clean_docstr_list.append(f"#### {line.strip()}")
elif line.strip() == "" and prev_line != "::":
# All of our parameter groups end with a line break, but we don't want to exit a parameter block due to a
# line break in a code block. However, some code blocks start with a blank first line, so we want to make
# sure we aren't immediately exiting the code block (hence the test for '::' on the previous line.
in_param = False
# Add the markdown indicator to close a code block, since we aren't in one now.
if in_code_block:
clean_docstr_list.append("```")
in_code_block = False
first_code_indentation = None
clean_docstr_list.append(line)
else:
if in_code_block:
# Determine the number of spaces indenting the first line of code so they can be removed from all lines
# in the code block without wrecking the hierarchical indentation levels of future lines.
if first_code_indentation == None and line.strip() != "":
first_code_indentation = len(
re.match(r"\s*", original_line, re.UNICODE).group(0)
)
if line.strip() == "" and prev_line == "::":
# If the first line of the code block is a blank one, just skip it.
pass
else:
# Append the line of code, minus the extra indentation from being written in an indented docstring.
clean_docstr_list.append(original_line[first_code_indentation:])
elif ":" in line.replace(":ref:", "") and in_param:
# This indicates a parameter. arg. or other definition.
clean_docstr_list.append(f"- {line.strip()}")
else:
# This indicates a regular line of text.
clean_docstr_list.append(f"{line.strip()}")
prev_line = line.strip()
clean_docstr = "\n".join(clean_docstr_list)
return clean_docstr
def _disable_progress_bars() -> Tuple[str, DataContext]:
"""Return context_dir and context that was created"""
context_dir = os.path.join(os.path.sep, "tmp", f"gx-context-{os.getpid()}")
os.makedirs(context_dir)
context = DataContext.create(context_dir, usage_statistics_enabled=False)
context.variables.progress_bars = {
"globally": False,
"metric_calculations": False,
"profilers": False,
}
context.variables.save_config()
return (context_dir, context)
@click.command()
@click.option(
"--no-core",
"-C",
"no_core",
is_flag=True,
default=False,
help="Do not include core Expectations",
)
@click.option(
"--no-contrib",
"-c",
"no_contrib",
is_flag=True,
default=False,
help="Do not include contrib/package Expectations",
)
@click.option(
"--ignore-suppress",
"-S",
"ignore_suppress",
is_flag=True,
default=False,
help="Ignore the suppress_test_for list on Expectation sample tests",
)
@click.option(
"--ignore-only-for",
"-O",
"ignore_only_for",
is_flag=True,
default=False,
help="Ignore the only_for list on Expectation sample tests",
)
@click.option(
"--outfile-name",
"-o",
"outfile_name",
default="expectation_library_v2.json",
help="Name for the generated JSON file",
)
@click.option(
"--backends",
"-b",
"backends",
help="Backends to consider running tests against (comma-separated)",
)
@click.argument("args", nargs=-1)
def main(**kwargs):
"""Find all Expectations, run their diagnostics methods, and generate expectation_library_v2.json
- args: snake_name of specific Expectations to include (useful for testing)
"""
backends = []
if kwargs["backends"]:
backends = [name.strip() for name in kwargs["backends"].split(",")]
context_dir, context = _disable_progress_bars()
gallery_info = build_gallery(
include_core=not kwargs["no_core"],
include_contrib=not kwargs["no_contrib"],
ignore_suppress=kwargs["ignore_suppress"],
ignore_only_for=kwargs["ignore_only_for"],
only_these_expectations=kwargs["args"],
only_consider_these_backends=backends,
context=context,
)
tracebacks = expectation_tracebacks.getvalue()
checklists = expectation_checklists.getvalue()
if tracebacks != "":
with open("./gallery-tracebacks.txt", "w") as outfile:
outfile.write(tracebacks)
if checklists != "":
with open("./checklists.txt", "w") as outfile:
outfile.write(checklists)
with open(f"./{kwargs['outfile_name']}", "w") as outfile:
json.dump(gallery_info, outfile, indent=4)
print(f"Deleting {context_dir}")
shutil.rmtree(context_dir)
if __name__ == "__main__":
main()
<file_sep>/tests/experimental/datasources/test_metadatasource.py
import copy
from pprint import pformat as pf
from typing import List, Optional, Type
import pytest
from typing_extensions import ClassVar
from great_expectations.execution_engine import ExecutionEngine
from great_expectations.experimental.context import get_context
from great_expectations.experimental.datasources.interfaces import (
BatchRequest,
BatchRequestOptions,
DataAsset,
Datasource,
)
from great_expectations.experimental.datasources.metadatasource import MetaDatasource
from great_expectations.experimental.datasources.sources import (
TypeRegistrationError,
_SourceFactories,
)
class DummyDataAsset(DataAsset):
"""Minimal Concrete DataAsset Implementation"""
def get_batch_request(self, options: Optional[BatchRequestOptions]) -> BatchRequest:
return BatchRequest("datasource_name", "data_asset_name", options or {})
@pytest.fixture(scope="function")
def context_sources_cleanup() -> _SourceFactories:
"""Return the sources object and reset types/factories on teardown"""
try:
# setup
sources_copy = copy.deepcopy(
_SourceFactories._SourceFactories__source_factories
)
type_lookup_copy = copy.deepcopy(_SourceFactories.type_lookup)
sources = get_context().sources
assert (
"add_datasource" not in sources.factories
), "Datasource base class should not be registered as a source factory"
yield sources
finally:
_SourceFactories._SourceFactories__source_factories = sources_copy
_SourceFactories.type_lookup = type_lookup_copy
@pytest.fixture(scope="function")
def empty_sources(context_sources_cleanup) -> _SourceFactories:
_SourceFactories._SourceFactories__source_factories.clear()
_SourceFactories.type_lookup.clear()
assert not _SourceFactories.type_lookup
yield context_sources_cleanup
class DummyExecutionEngine(ExecutionEngine):
def get_batch_data_and_markers(self, batch_spec):
raise NotImplementedError
@pytest.mark.unit
class TestMetaDatasource:
def test__new__only_registers_expected_number_of_datasources_factories_and_types(
self, empty_sources: _SourceFactories
):
assert len(empty_sources.factories) == 0
assert len(empty_sources.type_lookup) == 0
class MyTestDatasource(Datasource):
asset_types: ClassVar[List[Type[DataAsset]]] = []
type: str = "my_test"
def execution_engine_type(self) -> Type[ExecutionEngine]:
return DummyExecutionEngine
expected_registrants = 1
assert len(empty_sources.factories) == expected_registrants
assert len(empty_sources.type_lookup) == 2 * expected_registrants
def test__new__registers_sources_factory_method(
self, context_sources_cleanup: _SourceFactories
):
expected_method_name = "add_my_test"
ds_factory_method_initial = getattr(
context_sources_cleanup, expected_method_name, None
)
assert ds_factory_method_initial is None, "Check test cleanup"
class MyTestDatasource(Datasource):
asset_types: ClassVar[List[Type[DataAsset]]] = []
type: str = "my_test"
def execution_engine_type(self) -> Type[ExecutionEngine]:
return DummyExecutionEngine
ds_factory_method_final = getattr(
context_sources_cleanup, expected_method_name, None
)
assert (
ds_factory_method_final
), f"{MetaDatasource.__name__}.__new__ failed to add `{expected_method_name}()` method"
def test__new__updates_asset_type_lookup(
self, context_sources_cleanup: _SourceFactories
):
type_lookup = context_sources_cleanup.type_lookup
class FooAsset(DummyDataAsset):
type: str = "foo"
class BarAsset(DummyDataAsset):
type: str = "bar"
class FooBarDatasource(Datasource):
asset_types: ClassVar = [FooAsset, BarAsset]
type: str = "foo_bar"
def execution_engine_type(self) -> Type[ExecutionEngine]:
return DummyExecutionEngine
print(f" type_lookup ->\n{pf(type_lookup)}\n")
asset_types = FooBarDatasource.asset_types
assert asset_types, "No asset types have been declared"
registered_type_names = [type_lookup.get(t) for t in asset_types]
for type_, name in zip(asset_types, registered_type_names):
print(f"`{type_.__name__}` registered as '{name}'")
assert name, f"{type.__name__} could not be retrieved"
assert len(asset_types) == len(registered_type_names)
@pytest.mark.unit
class TestMisconfiguredMetaDatasource:
def test_ds_type_field_not_set(self, empty_sources: _SourceFactories):
with pytest.raises(
TypeRegistrationError,
match=r"`MissingTypeDatasource` is missing a `type` attribute",
):
class MissingTypeDatasource(Datasource):
def execution_engine_type(self) -> Type[ExecutionEngine]:
return DummyExecutionEngine
# check that no types were registered
assert len(empty_sources.type_lookup) < 1
def test_ds_execution_engine_type_not_defined(
self, empty_sources: _SourceFactories
):
class MissingExecEngineTypeDatasource(Datasource):
type: str = "valid"
with pytest.raises(NotImplementedError):
MissingExecEngineTypeDatasource(name="name")
def test_ds_assets_type_field_not_set(self, empty_sources: _SourceFactories):
with pytest.raises(
TypeRegistrationError,
match="No `type` field found for `BadAssetDatasource.asset_types` -> `MissingTypeAsset` unable to register asset type",
):
class MissingTypeAsset(DataAsset):
pass
class BadAssetDatasource(Datasource):
type: str = "valid"
asset_types: ClassVar = [MissingTypeAsset]
def execution_engine_type(self) -> Type[ExecutionEngine]:
return DummyExecutionEngine
# check that no types were registered
assert len(empty_sources.type_lookup) < 1
def test_minimal_ds_to_asset_flow(context_sources_cleanup):
# 1. Define Datasource & Assets
class RedAsset(DataAsset):
type = "red"
class BlueAsset(DataAsset):
type = "blue"
class PurpleDatasource(Datasource):
asset_types = [RedAsset, BlueAsset]
type: str = "purple"
def execution_engine_type(self) -> Type[ExecutionEngine]:
return DummyExecutionEngine
def add_red_asset(self, asset_name: str) -> RedAsset:
asset = RedAsset(name=asset_name)
self.assets[asset_name] = asset
return asset
# 2. Get context
context = get_context()
# 3. Add a datasource
purple_ds: Datasource = context.sources.add_purple("my_ds_name")
# 4. Add a DataAsset
red_asset: DataAsset = purple_ds.add_red_asset("my_asset_name")
assert isinstance(red_asset, RedAsset)
# 5. Get an asset by name - (method defined in parent `Datasource`)
assert red_asset is purple_ds.get_asset("my_asset_name")
if __name__ == "__main__":
pytest.main([__file__, "-vv", "--log-level=DEBUG"])
<file_sep>/docs/guides/setup/configuring_data_docs/components_how_to_host_and_share_data_docs_on_amazon_s3/_preface.mdx
import Prerequisites from '../../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '/docs/term_tags/_tag.mdx';
This guide will explain how to host and share <TechnicalTag relative="../../../../" tag="data_docs" text="Data Docs" /> on AWS S3.
<Prerequisites>
- [Set up a working deployment of Great Expectations](../../../../tutorials/getting_started/tutorial_overview.md)
- [Set up the AWS Command Line Interface](https://aws.amazon.com/cli/)
</Prerequisites>
<file_sep>/sidebars.js
module.exports = {
docs: [
'intro',
{
type: 'category',
label: 'Getting Started (A Tutorial)',
link: { type: 'doc', id: 'tutorials/getting_started/tutorial_overview' },
items: [
{ type: 'doc', id: 'tutorials/getting_started/tutorial_setup', label: '1. Setup' },
{ type: 'doc', id: 'tutorials/getting_started/tutorial_connect_to_data', label: '2. Connect to Data' },
{ type: 'doc', id: 'tutorials/getting_started/tutorial_create_expectations', label: '3. Create Expectations' },
{ type: 'doc', id: 'tutorials/getting_started/tutorial_validate_data', label: '4. Validate Data' },
{ type: 'doc', id: 'tutorials/getting_started/tutorial_review', label: 'Review and next steps' }
]
},
{
type: 'category',
label: 'Step 1: Setup',
link: { type: 'doc', id: 'guides/setup/setup_overview' },
items: [
{
type: 'category',
label: 'Installation',
items: [
'guides/setup/installation/local',
'guides/setup/installation/hosted_environment'
]
},
{
type: 'category',
label: 'Data Contexts',
items: [
'guides/setup/configuring_data_contexts/how_to_configure_a_new_data_context_with_the_cli',
'guides/setup/configuring_data_contexts/how_to_configure_datacontext_components_using_test_yaml_config',
'guides/setup/configuring_data_contexts/how_to_configure_credentials',
'guides/setup/configuring_data_contexts/how_to_instantiate_a_data_context_without_a_yml_file'
]
},
{
type: 'category',
label: 'Metadata Stores',
items: [
{
type: 'category',
label: 'Expectation Stores',
items: [
'guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_amazon_s3',
'guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_azure_blob_storage',
'guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_in_gcs',
'guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_on_a_filesystem',
'guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_to_postgresql'
]
},
{
type: 'category',
label: 'Validation Result Stores',
items: [
'guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_amazon_s3',
'guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_azure_blob_storage',
'guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_in_gcs',
'guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_on_a_filesystem',
'guides/setup/configuring_metadata_stores/how_to_configure_a_validation_result_store_to_postgresql'
]
},
{
type: 'category',
label: 'Metric Stores',
items: [
'guides/setup/configuring_metadata_stores/how_to_configure_a_metricsstore'
]
}
]
},
{
type: 'category',
label: 'Data Docs',
items: [
'guides/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_a_filesystem',
'guides/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_azure_blob_storage',
'guides/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_gcs',
'guides/setup/configuring_data_docs/how_to_host_and_share_data_docs_on_amazon_s3'
]
},
{
type: 'category',
label: 'Miscellaneous',
items: [
{ type: 'doc', id: 'guides/miscellaneous/how_to_use_the_great_expectation_docker_images' }
]
},
{ type: 'doc', id: 'guides/setup/index', label: 'Index' }
]
},
{
type: 'category',
label: 'Step 2: Connect to data',
link: { type: 'doc', id: 'guides/connecting_to_your_data/connect_to_data_overview' },
items: [
{
type: 'category',
label: 'Core skills',
items: [
'guides/connecting_to_your_data/how_to_choose_which_dataconnector_to_use',
'guides/connecting_to_your_data/how_to_choose_between_working_with_a_single_or_multiple_batches_of_data',
'guides/connecting_to_your_data/datasource_configuration/how_to_configure_a_pandas_datasource',
'guides/connecting_to_your_data/datasource_configuration/how_to_configure_a_spark_datasource',
'guides/connecting_to_your_data/datasource_configuration/how_to_configure_a_sql_datasource',
'guides/connecting_to_your_data/how_to_configure_an_inferredassetdataconnector',
'guides/connecting_to_your_data/how_to_configure_a_configuredassetdataconnector',
'guides/connecting_to_your_data/how_to_configure_a_runtimedataconnector',
'guides/connecting_to_your_data/how_to_configure_a_dataconnector_to_introspect_and_partition_a_file_system_or_blob_store',
'guides/connecting_to_your_data/how_to_configure_a_dataconnector_to_introspect_and_partition_tables_in_sql',
'guides/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_or_pandas_dataframe',
'guides/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource'
]
},
{
type: 'category',
label: 'In memory',
items: [
'guides/connecting_to_your_data/in_memory/pandas',
'guides/connecting_to_your_data/in_memory/spark'
]
},
{
type: 'category',
label: 'Database',
items: [
'guides/connecting_to_your_data/database/athena',
'guides/connecting_to_your_data/database/bigquery',
'guides/connecting_to_your_data/database/mssql',
'guides/connecting_to_your_data/database/mysql',
'guides/connecting_to_your_data/database/postgres',
'guides/connecting_to_your_data/database/redshift',
'guides/connecting_to_your_data/database/snowflake',
'guides/connecting_to_your_data/database/sqlite',
'guides/connecting_to_your_data/database/trino'
]
},
{
type: 'category',
label: 'Filesystem',
items: [
'guides/connecting_to_your_data/filesystem/pandas',
'guides/connecting_to_your_data/filesystem/spark'
]
},
{
type: 'category',
label: 'Cloud',
items: [
'guides/connecting_to_your_data/cloud/s3/pandas',
'guides/connecting_to_your_data/cloud/s3/spark',
'guides/connecting_to_your_data/cloud/gcs/pandas',
'guides/connecting_to_your_data/cloud/gcs/spark',
'guides/connecting_to_your_data/cloud/azure/pandas',
'guides/connecting_to_your_data/cloud/azure/spark'
]
},
{
type: 'category',
label: 'Advanced',
items: [
'guides/connecting_to_your_data/advanced/how_to_configure_a_dataconnector_for_splitting_and_sampling_a_file_system_or_blob_store',
'guides/connecting_to_your_data/advanced/how_to_configure_a_dataconnector_for_splitting_and_sampling_tables_in_sql'
]
},
{ type: 'doc', id: 'guides/connecting_to_your_data/index', label: 'Index' }
]
},
{
type: 'category',
label: 'Step 3: Create Expectations',
link: { type: 'doc', id: 'guides/expectations/create_expectations_overview' },
items: [
{
type: 'category',
label: 'Core skills',
items: [
'guides/expectations/how_to_create_and_edit_expectations_based_on_domain_knowledge_without_inspecting_data_directly',
'guides/expectations/how_to_create_and_edit_expectations_with_a_profiler',
'guides/expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data',
{ type: 'doc', id: 'guides/miscellaneous/how_to_configure_notebooks_generated_by_suite_edit' }
]
},
{
type: 'category',
label: 'Profilers and Data Assistants',
items: [
'guides/expectations/data_assistants/how_to_create_an_expectation_suite_with_the_onboarding_data_assistant',
'guides/expectations/advanced/how_to_create_a_new_expectation_suite_using_rule_based_profilers',
'guides/expectations/advanced/how_to_create_a_new_expectation_suite_by_profiling_from_a_jsonschema_file'
]
},
{
type: 'category',
label: 'Advanced skills',
items: [
'guides/expectations/advanced/how_to_create_expectations_that_span_multiple_batches_using_evaluation_parameters',
'guides/expectations/advanced/how_to_dynamically_load_evaluation_parameters_from_a_database',
'guides/expectations/advanced/how_to_compare_two_tables_with_the_user_configurable_profiler'
]
},
{
type: 'category',
label: 'Creating Custom Expectations',
items: [
'guides/expectations/creating_custom_expectations/overview',
'guides/expectations/creating_custom_expectations/how_to_create_custom_column_aggregate_expectations',
'guides/expectations/creating_custom_expectations/how_to_create_custom_column_map_expectations',
'guides/expectations/creating_custom_expectations/how_to_create_custom_table_expectations',
'guides/expectations/creating_custom_expectations/how_to_create_custom_column_pair_map_expectations',
'guides/expectations/creating_custom_expectations/how_to_create_custom_multicolumn_map_expectations',
'guides/expectations/creating_custom_expectations/how_to_create_custom_regex_based_column_map_expectations',
'guides/expectations/creating_custom_expectations/how_to_create_custom_set_based_column_map_expectations',
'guides/expectations/creating_custom_expectations/how_to_create_custom_query_expectations',
'guides/expectations/creating_custom_expectations/how_to_create_custom_parameterized_expectations',
'guides/expectations/creating_custom_expectations/how_to_use_custom_expectations',
{
type: 'category',
label: 'Adding Features to Custom Expectations',
items: [
'guides/expectations/advanced/how_to_add_comments_to_expectations_and_display_them_in_data_docs',
'guides/expectations/features_custom_expectations/how_to_add_example_cases_for_an_expectation',
'guides/expectations/features_custom_expectations/how_to_add_input_validation_for_an_expectation',
'guides/expectations/features_custom_expectations/how_to_add_spark_support_for_an_expectation',
'guides/expectations/features_custom_expectations/how_to_add_sqlalchemy_support_for_an_expectation'
]
}
]
},
{ type: 'doc', id: 'guides/expectations/index', label: 'Index' }
]
},
{
type: 'category',
label: 'Step 4: Validate data',
link: { type: 'doc', id: 'guides/validation/validate_data_overview' },
items: [
{
type: 'category',
label: 'Core skills',
items: [
'guides/validation/how_to_validate_data_by_running_a_checkpoint'
]
},
{
type: 'category',
label: 'Checkpoints',
items: [
'guides/validation/checkpoints/how_to_add_validations_data_or_suites_to_a_checkpoint',
'guides/validation/checkpoints/how_to_create_a_new_checkpoint',
'guides/validation/checkpoints/how_to_configure_a_new_checkpoint_using_test_yaml_config',
'guides/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint'
]
},
{
type: 'category',
label: 'Actions',
items: [
'guides/validation/validation_actions/how_to_trigger_email_as_a_validation_action',
'guides/validation/validation_actions/how_to_collect_openlineage_metadata_using_a_validation_action',
'guides/validation/validation_actions/how_to_trigger_opsgenie_notifications_as_a_validation_action',
'guides/validation/validation_actions/how_to_trigger_slack_notifications_as_a_validation_action',
'guides/validation/validation_actions/how_to_update_data_docs_as_a_validation_action'
]
},
{
type: 'category',
label: 'Advanced',
items: [
'guides/validation/advanced/how_to_deploy_a_scheduled_checkpoint_with_cron',
'guides/validation/advanced/how_to_get_data_docs_urls_for_custom_validation_actions',
'guides/validation/advanced/how_to_validate_data_without_a_checkpoint',
'guides/validation/advanced/how_to_validate_data_with_an_in_memory_checkpoint'
]
},
{ type: 'doc', id: 'guides/validation/index', label: 'Index' }
]
},
{
type: 'category',
label: 'Reference Architectures',
link: { type: 'doc', id: 'deployment_patterns/reference_architecture_overview' },
items: [
'deployment_patterns/how_to_instantiate_a_data_context_hosted_environments',
'deployment_patterns/how_to_instantiate_a_data_context_on_an_emr_spark_cluster',
'deployment_patterns/how_to_use_great_expectations_with_airflow',
'deployment_patterns/how_to_use_great_expectations_in_databricks',
'deployment_patterns/how_to_use_great_expectations_in_aws_glue',
{ type: 'doc', id: 'integrations/integration_datahub' },
'deployment_patterns/how_to_use_great_expectations_in_deepnote',
'deployment_patterns/how_to_use_great_expectations_in_flyte',
'deployment_patterns/how_to_use_great_expectations_with_google_cloud_platform_and_bigquery',
'deployment_patterns/how_to_use_great_expectations_with_meltano',
'deployment_patterns/how_to_use_great_expectations_with_prefect',
'deployment_patterns/how_to_use_great_expectations_with_ydata_synthetic',
'deployment_patterns/how_to_use_great_expectations_in_emr_serverless',
{ type: 'doc', id: 'integrations/integration_zenml' },
{ type: 'doc', id: 'deployment_patterns/index', label: 'Index' }
]
},
{
type: 'category',
label: 'Contributing',
link: { type: 'doc', id: 'contributing/contributing' },
items: [
{
type: 'category',
label: 'Contributing basics',
items: [
{ type: 'doc', id: 'contributing/contributing_setup' },
{ type: 'doc', id: 'contributing/contributing_checklist' },
{ type: 'doc', id: 'contributing/contributing_github' },
{ type: 'doc', id: 'contributing/contributing_test' },
{ type: 'doc', id: 'contributing/contributing_maturity' },
{ type: 'doc', id: 'contributing/contributing_misc' }
]
},
{
type: 'category',
label: 'Contributing specifics',
items: [
{
type: 'category',
label: 'How to contribute how-to guides',
items: [
{ type: 'doc', id: 'guides/miscellaneous/how_to_write_a_how_to_guide' },
{ type: 'doc', id: 'guides/miscellaneous/how_to_template' }
]
},
{
type: 'category',
label: 'How to contribute integration documentation',
items: [
'integrations/contributing_integration',
{ type: 'doc', id: 'integrations/integration_template', label: 'TEMPLATE Integration Document' }
]
},
{ type: 'doc', id: 'guides/expectations/contributing/how_to_contribute_a_custom_expectation_to_great_expectations' },
{ type: 'doc', id: 'contributing/contributing_package' }
]
},
{
type: 'category',
label: 'Style guides',
items: [
{ type: 'doc', id: 'contributing/style_guides/docs_style' },
{ type: 'doc', id: 'contributing/style_guides/code_style' },
{ type: 'doc', id: 'contributing/style_guides/cli_and_notebooks_style' }
]
},
'contributing/index'
]
},
{
type: 'category',
label: 'Reference',
link: { type: 'doc', id: 'reference/reference_overview' },
items: [
{
type: 'category',
label: 'Supplemental documentation',
link: { type: 'doc', id: 'reference/supplemental_documentation' },
items: [
{ type: 'doc', id: 'guides/miscellaneous/how_to_use_the_great_expectations_cli' },
{ type: 'doc', id: 'guides/miscellaneous/how_to_use_the_project_check_config_command' },
{ type: 'doc', id: 'reference/customize_your_deployment' },
{ type: 'doc', id: 'reference/anonymous_usage_statistics' }
]
},
{
type: 'category',
label: 'API documentation',
link: { type: 'doc', id: 'reference/api_reference' },
items: [
{
type: 'category',
label: 'Class DataContext',
link: { type: 'doc', id: 'api_docs/classes/great_expectations-data_context-data_context-data_context-DataContext' },
items: [
{ label: ' .create(...)', type: 'doc', id: 'api_docs/methods/great_expectations-data_context-data_context-data_context-DataContext-create' },
{ label: ' .test_yaml_config(...)', type: 'doc', id: 'api_docs/methods/great_expectations-data_context-data_context-data_context-DataContext-test_yaml_config' }
]
}
]
},
{
type: 'category',
label: 'Glossary of Terms',
link: { type: 'doc', id: 'glossary' },
items: [
'terms/action',
'terms/batch',
'terms/batch_request',
'terms/custom_expectation',
'terms/checkpoint',
'terms/cli',
'terms/datasource',
'terms/data_context',
'terms/data_asset',
'terms/data_assistant',
'terms/data_connector',
'terms/data_docs',
'terms/evaluation_parameter',
'terms/execution_engine',
{
type: 'category',
label: 'Expectations',
link: { type: 'doc', id: 'terms/expectation' },
collapsed: true,
items: [
{ type: 'doc', id: 'reference/expectations/conditional_expectations' },
{ type: 'doc', id: 'reference/expectations/distributional_expectations' },
{ type: 'doc', id: 'reference/expectations/implemented_expectations' },
{ type: 'doc', id: 'reference/expectation_suite_operations' },
{ type: 'doc', id: 'reference/expectations/result_format' },
{ type: 'doc', id: 'reference/expectations/standard_arguments' }
]
},
'terms/expectation_suite',
'terms/metric',
'terms/plugin',
'terms/profiler',
{
type: 'category',
label: 'Stores',
link: { type: 'doc', id: 'terms/store' },
items: [
'terms/checkpoint_store',
'terms/data_docs_store',
'terms/evaluation_parameter_store',
'terms/expectation_store',
'terms/metric_store',
'terms/validation_result_store'
]
},
'terms/renderer',
'terms/supporting_resource',
'terms/validator',
'terms/validation_result'
]
}
]
},
{ type: 'doc', id: 'changelog' },
{ type: 'doc', id: 'guides/miscellaneous/migration_guide' }
]
}
<file_sep>/docs/guides/expectations/advanced/how_to_compare_two_tables_with_the_user_configurable_profiler.md
---
title: How to compare two tables with the UserConfigurableProfiler
---
import Prerequisites from '../../../guides/connecting_to_your_data/components/prerequisites.jsx';
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
In this guide, you will utilize a <TechnicalTag tag="profiler" text="UserConfigurableProfiler" /> to create an <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> that can be used to gauge whether two tables are identical. This workflow can be used, for example, to validate migrated data.
<Prerequisites>
- Have a basic understanding of [Expectation Configurations in Great Expectations](https://docs.greatexpectations.io/docs/reference/expectations/expectations).
- Have read the overview of <TechnicalTag tag="profiler" text="Profilers" /> and the section on [UserConfigurableProfilers](../../../terms/profiler.md#userconfigurableprofiler) in particular.
</Prerequisites>
## Steps
### 1. Decide your use-case
This workflow can be applied to batches created from full tables, or to batches created from queries against tables. These two approaches will have slightly different workflows detailed below.
<Tabs
groupId="tables"
defaultValue='full-table'
values={[
{label: 'Full Table', value:'full-table'},
{label: 'Query', value:'query'},
]}>
<TabItem value="full-table">
### 2. Set-Up
<br/>
In this workflow, we will be making use of the `UserConfigurableProfiler` to profile against a <TechnicalTag tag="batch_request" text="BatchRequest" /> representing our source data, and validate the resulting suite against a `BatchRequest` representing our second set of data.
To begin, we'll need to set up our imports and instantiate our <TechnicalTag tag="data_context" text="Data Context" />:
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison.py#L2-L10
```
:::note
Depending on your use-case, workflow, and directory structures, you may need to update you context root directory as follows:
```python
context = ge.data_context.DataContext(
context_root_dir='/my/context/root/directory/great_expectations'
)
```
:::
### 3. Create Batch Requests
<br/>
In order to profile our first table and validate our second table, we need to set up our Batch Requests pointing to each set of data.
In this guide, we will use a MySQL <TechnicalTag tag="datasource" text= "Datasource" /> as our source data -- the data we trust to be correct.
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison.py#L81-L85
```
From this data, we will create an <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> and use that suite to validate our second table, pulled from a PostgreSQL Datasource.
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison.py#L88-L92
```
### 4. Profile Source Data
<br/>
We can now use the `mysql_batch_request` defined above to build a <TechnicalTag tag="validator" text="Validator" />:
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison.py#L95
```
Instantiate our `UserConfigurableProfiler`:
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison.py#L98-L104
```
And use that profiler to build and save an Expectation Suite:
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison.py#L107-L111
```
<details>
<summary><code>excluded_expectations</code>?</summary>
Above, we excluded <code>expect_column_quantile_values_to_be_between</code>, as it isn't fully supported by some SQL dialects.
This is one example of the ways in which we can customize the Suite built by our Profiler.
For more on these configurations, see our [guide on the optional parameters available with the `UserConfigurableProfiler`](../../../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md#optional-parameters).
</details>
### 5. Checkpoint Set-Up
<br/>
Before we can validate our second table, we need to define a <TechnicalTag tag="checkpoint" text="Checkpoint" />.
We will pass both the `pg_batch_request` and Expectation Suite defined above to this checkpoint.
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison.py#L114-L124
```
### 6. Validation
<br/>
Finally, we can use our Checkpoint to validate that our two tables are identical:
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison.py#L127-L129
```
If we now inspect the results of this Checkpoint (`results["success"]`), we can see that our Validation was successful!
By default, the Checkpoint above also updates your Data Docs, allowing you to further inspect the results of this workflow.
</TabItem>
<TabItem value="query">
### 2. Set-Up
<br/>
In this workflow, we will be making use of the `UserConfigurableProfiler` to profile against a <TechnicalTag tag="batch_request" text="RuntimeBatchRequest" /> representing a query against our source data, and validate the resulting suite against a `RuntimeBatchRequest` representing a query against our second set of data.
To begin, we'll need to set up our imports and instantiate our <TechnicalTag tag="data_context" text="Data Context" />:
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison_from_query.py#L2-L10
```
:::note
Depending on your use-case, workflow, and directory structures, you may need to update you context root directory as follows:
```python
context = ge.data_context.DataContext(
context_root_dir='/my/context/root/directory/great_expectations'
)
```
:::
### 3. Create Batch Requests
<br/>
In order to profile our first table and validate our second table, we need to set up our Batch Requests pointing to each set of data. These will be `RuntimeBatchRequests`, specifying a query against our data to be executed at runtime.
In this guide, we will use a MySQL <TechnicalTag tag="datasource" text= "Datasource" /> as our source data -- the data we trust to be correct.
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison_from_query.py#L81-L87
```
From this data, we will create an <TechnicalTag tag="expectation_suite" text="Expectation Suite" /> and use that suite to validate our second table, pulled from a PostgreSQL Datasource.
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison_from_query.py#L90-L96
```
### 4. Profile Source Data
<br/>
We can now use the `mysql_runtime_batch_request` defined above to build a <TechnicalTag tag="validator" text="Validator" />:
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison_from_query.py#L99-L101
```
Instantiate our `UserConfigurableProfiler`:
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison_from_query.py#L104-L110
```
And use that profiler to build and save an Expectation Suite:
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison_from_query.py#L113-L117
```
<details>
<summary><code>excluded_expectations</code>?</summary>
Above, we excluded <code>expect_column_quantile_values_to_be_between</code>, as it isn't fully supported by some SQL dialects.
This is one example of the ways in which we can customize the Suite built by our Profiler.
For more on these configurations, see our [guide on the optional parameters available with the `UserConfigurableProfiler`](../../../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md#optional-parameters).
</details>
### 5. Checkpoint Set-Up
<br/>
Before we can validate our second table, we need to define a <TechnicalTag tag="checkpoint" text="Checkpoint" />.
We will pass both the `pg_runtime_batch_request` and Expectation Suite defined above to this checkpoint.
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison_from_query.py#L120-L130
```
### 6. Validation
<br/>
Finally, we can use our Checkpoint to validate that our two batches of data - queried from two different tables - are identical:
```python file=../../../../tests/integration/docusaurus/expectations/advanced/user_configurable_profiler_cross_table_comparison_from_query.py#L133-L135
```
If we now inspect the results of this Checkpoint (`results["success"]`), we can see that our Validation was successful!
By default, the Checkpoint above also updates your Data Docs, allowing you to further inspect the results of this workflow.
</TabItem>
</Tabs>
<div style={{"text-align":"center"}}>
<p style={{"color":"#8784FF","font-size":"1.4em"}}><b>
Congratulations!<br/>🎉 You've just compared two tables across Datasources! 🎉
</b></p>
</div>
<file_sep>/reqs/requirements-dev-teradata.txt
teradatasqlalchemy==17.0.0.1
<file_sep>/docs/contributing/index.md
---
title: "Contributing: Index"
---
## Contributing basics
- [Introduction](../contributing/contributing_overview.md)
- [Setting up your Dev Environment](../contributing/contributing_setup.md)
- [Contribution Checklist](../contributing/contributing_checklist.md)
- [Contributing through GitHub](../contributing/contributing_github.md)
- [Contribution and Testing](../contributing/contributing_test.md)
- [Levels of Maturity](../contributing/contributing_maturity.md)
- [Contributing Misc and CLA](../contributing/contributing_misc.md)
- [Contributing a Package](../contributing/contributing_package.md)
## Contributing specifics
### How to contribute how-to guides
- [How to write a how-to-guide](../guides/miscellaneous/how_to_write_a_how_to_guide.md)
- [TEMPLATE How to guide {stub}](../guides/miscellaneous/how_to_template.md)
- [How to contribute a Custom Expectation to Great Expectations](../guides/expectations/contributing/how_to_contribute_a_custom_expectation_to_great_expectations.md)
## Style guides
- [Documentation style guide](../contributing/style_guides/docs_style.md)
- [Code style guide](../contributing/style_guides/code_style.md)
- [CLI and Notebook style guide](../contributing/style_guides/cli_and_notebooks_style.md)
- ["Contributing: Index"](../contributing/index.md)<file_sep>/docs/guides/validation/checkpoints/how_to_configure_a_new_checkpoint_using_test_yaml_config__api_links.mdx
- [DataContext.test_yaml_config](/docs/api_docs/methods/great_expectations-data_context-data_context-data_context-DataContext-test_yaml_config)
<file_sep>/docs/guides/validation/advanced/how_to_validate_data_without_a_checkpoint.md
---
title: How to Validate data without a Checkpoint
---
import Prerequisites from '../../../guides/connecting_to_your_data/components/prerequisites.jsx';
:::caution ATTENTION
As part of the new modular expectations API in Great Expectations, Validation Operators have evolved into Class-Based Checkpoints. This means running a Validation without a Checkpoint is no longer supported in Great Expectations version 0.13.8 or later. For more context, please read our [documentation on Checkpoints](../../../terms/checkpoint.md) and our [documentation on Actions](../../../terms/action.md).
This guide originally demonstrated how to load an Expectation Suite and Validate data without using a Checkpoint. That used to be suitable for environments or workflows where a user does not want to or cannot create a Checkpoint, e.g. in a [hosted environment](../../../deployment_patterns/how_to_instantiate_a_data_context_hosted_environments.md). However, this workflow is no longer supported.
As an alternative, you can instead run Validations by using a Checkpoint that is configured and initialized entierly in-memory, as demonstrated in our guide on [How to validate data with an in-memory Checkpoint](./how_to_validate_data_with_an_in_memory_checkpoint.md).
:::<file_sep>/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/metrics/data_profiler_metrics/data_profiler_column_profiler_report.py
from typing import Optional
import dataprofiler as dp
import great_expectations.exceptions as ge_exceptions
from great_expectations.core import ExpectationConfiguration
from great_expectations.execution_engine import ExecutionEngine, PandasExecutionEngine
from great_expectations.execution_engine.execution_engine import MetricDomainTypes
from great_expectations.expectations.metrics.metric_provider import metric_value
from great_expectations.validator.metric_configuration import MetricConfiguration
from .data_profiler_profile_metric_provider import DataProfilerProfileMetricProvider
class DataProfilerColumnProfileReport(DataProfilerProfileMetricProvider):
metric_name = "data_profiler.column_profile_report"
value_keys = ("profile_path",)
@metric_value(engine=PandasExecutionEngine)
def _pandas(
cls,
execution_engine,
metric_domain_kwargs,
metric_value_kwargs,
metrics,
runtime_configuration,
):
_, _, accessor_domain_kwargs = execution_engine.get_compute_domain(
domain_kwargs=metric_domain_kwargs, domain_type=MetricDomainTypes.COLUMN
)
column_name = accessor_domain_kwargs["column"]
if column_name not in metrics["table.columns"]:
raise ge_exceptions.InvalidMetricAccessorDomainKwargsKeyError(
message=f'Error: The column "{column_name}" in BatchData does not exist.'
)
profile_path = metric_value_kwargs["profile_path"]
try:
profile: dp.profilers.profile_builder.StructuredProfiler = dp.Profiler.load(
profile_path
)
profile_report: dict = profile.report(
report_options={"output_format": "serializable"}
)
profile_report_column_data_stats: dict = {
element["column_name"]: element
for element in profile_report["data_stats"]
}
return profile_report_column_data_stats[column_name]
except FileNotFoundError:
raise ValueError(
"'profile_path' does not point to a valid DataProfiler stored profile."
)
except Exception as e:
raise ge_exceptions.MetricError(
message=str(e),
) from e
@classmethod
def _get_evaluation_dependencies(
cls,
metric: MetricConfiguration,
configuration: Optional[ExpectationConfiguration] = None,
execution_engine: Optional[ExecutionEngine] = None,
runtime_configuration: Optional[dict] = None,
):
dependencies: dict = super()._get_evaluation_dependencies(
metric=metric,
configuration=configuration,
execution_engine=execution_engine,
runtime_configuration=runtime_configuration,
)
table_domain_kwargs: dict = {
k: v for k, v in metric.metric_domain_kwargs.items() if k != "column"
}
dependencies["table.column_types"] = MetricConfiguration(
metric_name="table.column_types",
metric_domain_kwargs=table_domain_kwargs,
metric_value_kwargs={
"include_nested": True,
},
metric_dependencies=None,
)
dependencies["table.columns"] = MetricConfiguration(
metric_name="table.columns",
metric_domain_kwargs=table_domain_kwargs,
metric_value_kwargs=None,
metric_dependencies=None,
)
dependencies["table.row_count"] = MetricConfiguration(
metric_name="table.row_count",
metric_domain_kwargs=table_domain_kwargs,
metric_value_kwargs=None,
metric_dependencies=None,
)
return dependencies
<file_sep>/docs/guides/setup/configuring_metadata_stores/how_to_configure_an_expectation_store_to_postgresql.md
---
title: How to configure an Expectation Store to use PostgreSQL
---
import Prerequisites from '../../connecting_to_your_data/components/prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
By default, newly <TechnicalTag tag="profiling" text="Profiled" /> <TechnicalTag tag="expectation" text="Expectations" /> are stored as <TechnicalTag tag="expectation_suite" text="Expectation Suites" /> in JSON format in the `expectations/` subdirectory of your `great_expectations/` folder. This guide will help you configure Great Expectations to store them in a PostgreSQL database.
<Prerequisites>
- [Configured a Data Context](../../../tutorials/getting_started/tutorial_setup.md).
- [Configured an Expectations Suite](../../../tutorials/getting_started/tutorial_create_expectations.md).
- Configured a [PostgreSQL](https://www.postgresql.org/) database with appropriate credentials.
</Prerequisites>
## Steps
### 1. Configure the `config_variables.yml` file with your database credentials
We recommend that database credentials be stored in the `config_variables.yml` file, which is located in the `uncommitted/` folder by default, and is not part of source control. The following lines add database credentials under the key `db_creds`. Additional options for configuring the `config_variables.yml` file or additional environment variables can be found [here](../configuring_data_contexts/how_to_configure_credentials.md).
```yaml
db_creds:
drivername: postgres
host: '<your_host_name>'
port: '<your_port>'
username: '<your_username>'
password: '<<PASSWORD>>'
database: '<your_database_name>'
```
### 2. Identify your Data Context Expectations Store
In your ``great_expectations.yml`` , look for the following lines. The configuration tells Great Expectations to look for Expectations in a <TechnicalTag tag="store" text="Store" /> called ``expectations_store``. The ``base_directory`` for ``expectations_store`` is set to ``expectations/`` by default.
```yaml
expectations_store_name: expectations_store
stores:
expectations_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
```
### 3. Update your configuration file to include a new Store for Expectations on PostgreSQL
In our case, the name is set to ``expectations_postgres_store``, but it can be any name you like. We also need to make some changes to the ``store_backend`` settings. The ``class_name`` will be set to ``DatabaseStoreBackend``, and ``credentials`` will be set to ``${db_creds}``, which references the corresponding key in the ``config_variables.yml`` file.
```yaml
expectations_store_name: expectations_postgres_store
stores:
expectations_postgres_store:
class_name: ExpectationsStore
store_backend:
class_name: DatabaseStoreBackend
credentials: ${db_creds}
```
### 4. Confirm that the new Expectations Store has been added by running ``great_expectations store list``
Notice the output contains two <TechnicalTag tag="expectation_store" text="Expectation Stores" />: the original ``expectations_store`` on the local filesystem and the ``expectations_postgres_store`` we just configured. This is ok, since Great Expectations will look for Expectations in PostgreSQL as long as we set the ``expectations_store_name`` variable to ``expectations_postgres_store``, which we did in the previous step. The config for ``expectations_store`` can be removed if you would like.
```bash
great_expectations store list
- name: expectations_store
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
- name: expectations_postgres_store
class_name: ExpectationsStore
store_backend:
class_name: DatabaseStoreBackend
credentials:
database: '<your_db_name>'
drivername: postgresql
host: '<your_host_name>'
password: ******
port: '<your_port>'
username: '<your_username>'
```
### 5. Create a new Expectation Suite by running ``great_expectations suite new``
This command prompts you to create and name a new Expectation Suite and to select a sample batch of data for the Suite to describe. Behind the scenes, Great Expectations will create a new table in your database called ``ge_expectations_store``, and populate the fields ``expectation_suite_name`` and ``value`` with information from the newly created Expectation Suite.
If you follow the prompts and create an Expectation Suite called ``exp1``, you can expect to see output similar to the following :
```bash
great_expectations suite new
# ...
Name the new Expectation Suite: exp1
Great Expectations will choose a couple of columns and generate expectations about them
to demonstrate some examples of assertions you can make about your data.
Great Expectations will store these expectations in a new Expectation Suite 'exp1' here:
postgresql://'<your_db_name>'/exp1
# ...
```
### 6. Confirm that Expectations can be accessed from PostgreSQL by running ``great_expectations suite list``
The output should include the Expectation Suite we created in the previous step: ``exp1``.
```bash
great_expectations suite list
1 Expectation Suites found:
- exp1
```
<file_sep>/docs/terms/expectation_suite.md
---
id: expectation_suite
title: Expectation Suite
hoverText: A collection of verifiable assertions about data.
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
import ValidateHeader from '/docs/images/universal_map/_um_validate_header.mdx';
<UniversalMap setup='inactive' connect='inactive' create='active' validate='active'/>
## Overview
### Definition
An Expectation Suite is a collection of verifiable assertions about data.
### Features and promises
Expectation Suites combine multiple <TechnicalTag relative="../" tag="expectation" text="Expectations" /> into an overall description of data. For example, a team can group all the Expectations about a given table in given database into an Expectation Suite and call it `my_database.my_table`. Note these names are completely flexible and the only constraint on the name of a suite is that it must be unique to a given project.
### Relationship to other objects
Expectation Suites are stored in an <TechnicalTag relative="../" tag="expectation_store" text="Expectation Store" />. They are generated interactively using a <TechnicalTag relative="../" tag="validator" text="Validator" /> or automatically using <TechnicalTag relative="../" tag="profiler" text="Profilers" />, and are used by <TechnicalTag relative="../" tag="checkpoint" text="Checkpoints" /> to <TechnicalTag relative="../" tag="validation" text="Validate" /> data.
## Use cases
<CreateHeader/>
The lifecycle of an Expectation Suite starts with creating it. Then it goes through an iterative loop of Review and Edit as the team's understanding of the data described by the suite evolves.
Expectation Suites are largely managed automatically in the workflows for creating Expectations. When the Expectations are created, an Expectation Suite is created to contain them. In the Profiling workflow, this Expectation Suite will contain all the Expectations generated by the Profiler. In the interactive workflow, an Expectation Suite will be configured to include Expectations as they are defined, but will not be saved to an Expectation Store until you issue the command for it to be.
For more information on these processes, please see:
- [Our overview on the process of Creating Expectations](../guides/expectations/create_expectations_overview.md)
- [Our guide on how to create and edit Expectations with a Profiler](../guides/expectations/how_to_create_and_edit_expectations_with_a_profiler.md)
- [Our guide on how to create and edit Expectations with instant feedback from a sample Batch of data](../guides/expectations/how_to_create_and_edit_expectations_with_instant_feedback_from_a_sample_batch_of_data.md)
<ValidateHeader/>
Expectation Suites are *used* during the Validation of data. In this step, you will need to provide one or more Expectation Suites to a Checkpoint. This can either be done by configuring the Checkpoint to use a preset list of one or more Expectation Suites, or by configuring the Checkpoint to accept a list of one or more Expectation Suites at runtime.
## Features
### CRUD operations
A Great Expectations Expectation Suite enables you to perform Create, Read, Update, and Delete (CRUD) operations on the Suite's Expectations without needing to re-run them.
### Reusability
Expectation Suites are primarily used by Checkpoints, which can accept a list of one or more Expectation Suite and Batch Request pairs. Because they are stored independently of the Checkpoints that use them, the same Expectation Suite can be included in the list for multiple Checkpoints, provided the Expectation Suite contains a list of Expectations that describe the data that Checkpoint will Validate. You can even use the same Expectation Suite multiple times within the same Checkpoint by pairing it with different Batch Requests.
## API basics
### CRUD operations
Each of the Expectation Suite methods that support a Create, Read, Update, or Delete (CRUD) operation relies on two main parameters - `expectation_configuration` and `match_type`.
- **expectation_configuration** - an `ExpectationConfiguration` object that is used to determine whether and where this Expectation already exists within the Suite. It can be a complete or a partial ExpectationConfiguration.
- **match_type** - a string with the value of `domain`, `success`, or `runtime` which determines the criteria used for matching:
- `domain` checks whether two Expectation Configurations apply to the same data. It results in the loosest match, and can use the least complete ExpectationConfiguration object. For example, for a column map Expectation, a `domain` **match_type** will check that the expectation_type matches, and that the column and any row_conditions that affect which rows are evaluated by the Expectation match.
- `success` criteria are more exacting - in addition to the `domain` kwargs, these include those kwargs used when evaluating the success of an Expectation, like `mostly`, `max`, or `value_set`.
-`runtime` are the most specific - in addition to `domain_kwargs` and `success_kwargs`, these include kwargs used for runtime configuration. Currently, these include `result_format`, `include_config`, and `catch_exceptions`
### How to access
You will rarely need to directly access an Expectation Suite. If you do need to edit one, the simplest way is through the CLI. To do so, run the command:
```markdown title="Terminal command"
great_expectations suite edit NAME_OF_YOUR_SUITE_HERE
```
This will open a Jupyter Notebook where each Expectation in the Expectation Suite is loaded as an individual cell. You can edit, remove, and add Expectations in this list. Running the cells will create the Expectations in a new Expectation Suite, which you can then save over the old Expectation Suite or save under a new name. The Expectation Suite and any changes made will not be stored until you give the command for it to be saved, however.
In almost all other circumstances you will simply pass the name of any relevant Expectation Suites to an object such as a Checkpoint that will manage accessing and using it for you.
### Saving Expectation Suites
Each Expectation Suite is saved in an Expectation Store, as a JSON file in the `great_expectations/expectations` subdirectory of the Data Context. Best practice is for users to check these files into the version control each time they are updated, in the same way they treat their source files. This discipline allows data quality to be an integral part of versioned pipeline releases.
You can save an Expectation Suite by using a <TechnicalTag relative="../" tag="validator" text="Validator's" /> `save_expectation_suite()` method. This method will be included in the last cell of any Jupyter notebook launched from the CLI for the purpose of creating or editing Expectations.
<file_sep>/tests/integration/docusaurus/validation/checkpoints/how_to_validate_data_with_a_yaml_configured_in_memory_checkpoint.py
# Required imports for this script's purpose:
# Import and setup for working with YAML strings:
# <snippet>
from ruamel import yaml
# </snippet>
import great_expectations as ge
from great_expectations.checkpoint import Checkpoint
# Imports used for testing purposes (and can be left out of typical scripts):
from great_expectations.core.expectation_validation_result import (
ExpectationSuiteValidationResult,
)
from great_expectations.core.run_identifier import RunIdentifier
from great_expectations.data_context.types.base import CheckpointConfig
from great_expectations.data_context.types.resource_identifiers import (
ValidationResultIdentifier,
)
# <snippet>
yaml = yaml.YAML(typ="safe")
# </snippet>
# Initialize your data context.
# <snippet>
context = ge.get_context()
# </snippet>
# Add datasource for all tests
datasource_yaml = """
name: taxi_datasource
class_name: Datasource
module_name: great_expectations.datasource
execution_engine:
module_name: great_expectations.execution_engine
class_name: PandasExecutionEngine
data_connectors:
default_inferred_data_connector_name:
class_name: InferredAssetFilesystemDataConnector
base_directory: ../data/
default_regex:
group_names:
- data_asset_name
pattern: (.*)\\.csv
default_runtime_data_connector_name:
class_name: RuntimeDataConnector
batch_identifiers:
- default_identifier_name
"""
context.test_yaml_config(datasource_yaml)
context.add_datasource(**yaml.load(datasource_yaml))
assert [ds["name"] for ds in context.list_datasources()] == ["taxi_datasource"]
# Add Expectation Suite for use in Checkpoint config
context.create_expectation_suite("my_expectation_suite")
# Define your checkpoint's configuration.
# NOTE: Because we are directly using the Checkpoint class, we do not need to
# specify the parameters `module_name` and `class_name`.
# <snippet>
my_checkpoint_name = "in_memory_checkpoint"
yaml_config = f"""
name: {my_checkpoint_name}
config_version: 1.0
run_name_template: '%Y%m%d-%H%M%S-my-run-name-template'
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
site_names: []
validations:
- batch_request:
datasource_name: taxi_datasource
data_connector_name: default_inferred_data_connector_name
data_asset_name: yellow_tripdata_sample_2019-01
expectation_suite_name: my_expectation_suite
"""
# </snippet>
# Initialize your checkpoint with the Data Context and Checkpoint configuration
# from before.
# <snippet>
my_checkpoint = Checkpoint(data_context=context, **yaml.load(yaml_config))
# </snippet>
# Run your Checkpoint.
# <snippet>
results = my_checkpoint.run()
# </snippet>
# The following asserts are for testing purposes and do not need to be included in typical scripts.
assert results.success is True
run_id_type = type(results.run_id)
assert run_id_type == RunIdentifier
validation_result_id_type_set = {type(k) for k in results.run_results.keys()}
assert len(validation_result_id_type_set) == 1
validation_result_id_type = next(iter(validation_result_id_type_set))
assert validation_result_id_type == ValidationResultIdentifier
validation_result_id = results.run_results[[k for k in results.run_results.keys()][0]]
assert (
type(validation_result_id["validation_result"]) == ExpectationSuiteValidationResult
)
assert isinstance(results.checkpoint_config, CheckpointConfig)
# <snippet>
# context.open_data_docs()
# </snippet>
<file_sep>/great_expectations/experimental/datasources/postgres_datasource.py
from __future__ import annotations
import copy
import dataclasses
import itertools
from datetime import datetime
from pprint import pformat as pf
from typing import TYPE_CHECKING, Dict, Iterable, List, Optional, Type, Union, cast
import dateutil.tz
from pydantic import Field
from pydantic import dataclasses as pydantic_dc
from typing_extensions import ClassVar, Literal
from great_expectations.core.batch_spec import SqlAlchemyDatasourceBatchSpec
from great_expectations.experimental.datasources.interfaces import (
Batch,
BatchRequest,
BatchRequestOptions,
DataAsset,
Datasource,
)
if TYPE_CHECKING:
from great_expectations.execution_engine import ExecutionEngine
class PostgresDatasourceError(Exception):
pass
class BatchRequestError(Exception):
pass
# For our year splitter we default the range to the last 2 year.
_CURRENT_YEAR = datetime.now(dateutil.tz.tzutc()).year
_DEFAULT_YEAR_RANGE = range(_CURRENT_YEAR - 1, _CURRENT_YEAR + 1)
_DEFAULT_MONTH_RANGE = range(1, 13)
@pydantic_dc.dataclass(frozen=True)
class ColumnSplitter:
method_name: str
column_name: str
# param_defaults is a Dict where the keys are the parameters of the splitter and the values are the default
# values are the default values if a batch request using the splitter leaves the parameter unspecified.
# template_params: List[str]
# Union of List/Iterable for serialization
param_defaults: Dict[str, Union[List, Iterable]] = Field(default_factory=dict)
@property
def param_names(self) -> List[str]:
return list(self.param_defaults.keys())
class TableAsset(DataAsset):
# Instance fields
type: Literal["table"] = "table"
table_name: str
column_splitter: Optional[ColumnSplitter] = None
name: str
def get_batch_request(
self, options: Optional[BatchRequestOptions] = None
) -> BatchRequest:
"""A batch request that can be used to obtain batches for this DataAsset.
Args:
options: A dict that can be used to limit the number of batches returned from the asset.
The dict structure depends on the asset type. A template of the dict can be obtained by
calling batch_request_options_template.
Returns:
A BatchRequest object that can be used to obtain a batch list from a Datasource by calling the
get_batch_list_from_batch_request method.
"""
if options is not None and not self._valid_batch_request_options(options):
raise BatchRequestError(
"Batch request options should have a subset of keys:\n"
f"{list(self.batch_request_options_template().keys())}\n"
f"but actually has the form:\n{pf(options)}\n"
)
return BatchRequest(
datasource_name=self._datasource.name,
data_asset_name=self.name,
options=options or {},
)
def _valid_batch_request_options(self, options: BatchRequestOptions) -> bool:
return set(options.keys()).issubset(
set(self.batch_request_options_template().keys())
)
def validate_batch_request(self, batch_request: BatchRequest) -> None:
"""Validates the batch_request has the correct form.
Args:
batch_request: A batch request object to be validated.
"""
if not (
batch_request.datasource_name == self.datasource.name
and batch_request.data_asset_name == self.name
and self._valid_batch_request_options(batch_request.options)
):
expect_batch_request_form = BatchRequest(
datasource_name=self.datasource.name,
data_asset_name=self.name,
options=self.batch_request_options_template(),
)
raise BatchRequestError(
"BatchRequest should have form:\n"
f"{pf(dataclasses.asdict(expect_batch_request_form))}\n"
f"but actually has form:\n{pf(dataclasses.asdict(batch_request))}\n"
)
def batch_request_options_template(
self,
) -> BatchRequestOptions:
"""A BatchRequestOptions template for get_batch_request.
Returns:
A BatchRequestOptions dictionary with the correct shape that get_batch_request
will understand. All the option values are defaulted to None.
"""
template: BatchRequestOptions = {}
if not self.column_splitter:
return template
return {p: None for p in self.column_splitter.param_names}
# This asset type will support a variety of splitters
def add_year_and_month_splitter(
self,
column_name: str,
default_year_range: Iterable[int] = _DEFAULT_YEAR_RANGE,
default_month_range: Iterable[int] = _DEFAULT_MONTH_RANGE,
) -> TableAsset:
"""Associates a year month splitter with this DataAsset
Args:
column_name: A column name of the date column where year and month will be parsed out.
default_year_range: When this splitter is used, say in a BatchRequest, if no value for
year is specified, we query over all years in this range.
will query over all the years in this default range.
default_month_range: When this splitter is used, say in a BatchRequest, if no value for
month is specified, we query over all months in this range.
Returns:
This TableAsset so we can use this method fluently.
"""
self.column_splitter = ColumnSplitter(
method_name="split_on_year_and_month",
column_name=column_name,
param_defaults={"year": default_year_range, "month": default_month_range},
)
return self
def fully_specified_batch_requests(self, batch_request) -> List[BatchRequest]:
"""Populates a batch requests unspecified params producing a list of batch requests
This method does NOT validate the batch_request. If necessary call
TableAsset.validate_batch_request before calling this method.
"""
if self.column_splitter is None:
# Currently batch_request.options is complete determined by the presence of a
# column splitter. If column_splitter is None, then there are no specifiable options
# so we return early.
# In the future, if there are options that are not determined by the column splitter
# this check will have to be generalized.
return [batch_request]
# Make a list of the specified and unspecified params in batch_request
specified_options = []
unspecified_options = []
options_template = self.batch_request_options_template()
for option_name in options_template.keys():
if (
option_name in batch_request.options
and batch_request.options[option_name] is not None
):
specified_options.append(option_name)
else:
unspecified_options.append(option_name)
# Make a list of the all possible batch_request.options by expanding out the unspecified
# options
batch_requests: List[BatchRequest] = []
if not unspecified_options:
batch_requests.append(batch_request)
else:
# All options are defined by the splitter, so we look at its default values to fill
# in the option values.
default_option_values = []
for option in unspecified_options:
default_option_values.append(
self.column_splitter.param_defaults[option]
)
for option_values in itertools.product(*default_option_values):
# Add options from specified options
options = {
name: batch_request.options[name] for name in specified_options
}
# Add options from unspecified options
for i, option_value in enumerate(option_values):
options[unspecified_options[i]] = option_value
batch_requests.append(
BatchRequest(
datasource_name=batch_request.datasource_name,
data_asset_name=batch_request.data_asset_name,
options=options,
)
)
return batch_requests
class PostgresDatasource(Datasource):
# class var definitions
asset_types: ClassVar[List[Type[DataAsset]]] = [TableAsset]
# right side of the operator determines the type name
# left side enforces the names on instance creation
type: Literal["postgres"] = "postgres"
connection_string: str
assets: Dict[str, TableAsset] = {}
def execution_engine_type(self) -> Type[ExecutionEngine]:
"""Returns the default execution engine type."""
from great_expectations.execution_engine import SqlAlchemyExecutionEngine
return SqlAlchemyExecutionEngine
def add_table_asset(self, name: str, table_name: str) -> TableAsset:
"""Adds a table asset to this datasource.
Args:
name: The name of this table asset.
table_name: The table where the data resides.
Returns:
The TableAsset that is added to the datasource.
"""
asset = TableAsset(name=name, table_name=table_name)
# TODO (kilo59): custom init for `DataAsset` to accept datasource in constructor?
# Will most DataAssets require a `Datasource` attribute?
asset._datasource = self
self.assets[name] = asset
return asset
def get_asset(self, asset_name: str) -> TableAsset:
"""Returns the TableAsset referred to by name"""
return super().get_asset(asset_name) # type: ignore[return-value] # value is subclass
# When we have multiple types of DataAssets on a datasource, the batch_request argument will be a Union type.
# To differentiate we could use single dispatch or use an if/else (note pattern matching doesn't appear until
# python 3.10)
def get_batch_list_from_batch_request(
self, batch_request: BatchRequest
) -> List[Batch]:
"""A list of batches that match the BatchRequest.
Args:
batch_request: A batch request for this asset. Usually obtained by calling
get_batch_request on the asset.
Returns:
A list of batches that match the options specified in the batch request.
"""
# We translate the batch_request into a BatchSpec to hook into GX core.
data_asset = self.get_asset(batch_request.data_asset_name)
data_asset.validate_batch_request(batch_request)
batch_list: List[Batch] = []
column_splitter = data_asset.column_splitter
for request in data_asset.fully_specified_batch_requests(batch_request):
batch_metadata = copy.deepcopy(request.options)
batch_spec_kwargs = {
"type": "table",
"data_asset_name": data_asset.name,
"table_name": data_asset.table_name,
"batch_identifiers": {},
}
if column_splitter:
batch_spec_kwargs["splitter_method"] = column_splitter.method_name
batch_spec_kwargs["splitter_kwargs"] = {
"column_name": column_splitter.column_name
}
# mypy infers that batch_spec_kwargs["batch_identifiers"] is a collection, but
# it is hardcoded to a dict above, so we cast it here.
cast(Dict, batch_spec_kwargs["batch_identifiers"]).update(
{column_splitter.column_name: request.options}
)
data, _ = self.execution_engine.get_batch_data_and_markers(
batch_spec=SqlAlchemyDatasourceBatchSpec(**batch_spec_kwargs)
)
batch_list.append(
Batch(
datasource=self,
data_asset=data_asset,
batch_request=request,
data=data,
metadata=batch_metadata,
)
)
return batch_list
<file_sep>/docs/guides/setup/configuring_data_contexts/how_to_configure_a_new_data_context_with_the_cli.md
---
title: How to initialize a new Data Context with the CLI
---
import Preface from './components_how_to_configure_a_new_data_context_with_the_cli/_preface.mdx'
import InitializeDataContextWithTheCLI from './components_how_to_configure_a_new_data_context_with_the_cli/_initialize_data_context_with_the_cli.mdx'
import VerifyDataContextInitialization from './components_how_to_configure_a_new_data_context_with_the_cli/_verify_data_context_initialization.mdx'
import DataContextNextSteps from './components_how_to_configure_a_new_data_context_with_the_cli/_data_context_next_steps.mdx'
import Congrats from '../../components/congrats.mdx'
# [](../setup_overview.md) How to initialize a new Data Context with the CLI
<Preface />
## Steps
### 1. Initialize your Data Context with the CLI
<InitializeDataContextWithTheCLI />
### 2. Verify that your Data Context was initialized
<VerifyDataContextInitialization />
<Congrats />
You have initialized a new Data Context!
### 3. Next steps
<DataContextNextSteps /><file_sep>/tests/integration/docusaurus/deployment_patterns/gcp_deployment_patterns_file_gcs_yaml_configs.py
import os
# <snippet>
import great_expectations as ge
from great_expectations.core.batch import BatchRequest
# </snippet>
from great_expectations.core.yaml_handler import YAMLHandler
yaml = YAMLHandler()
# <snippet>
context = ge.get_context()
# </snippet>
# NOTE: The following code is only for testing and depends on an environment
# variable to set the gcp_project. You can replace the value with your own
# GCP project information
gcp_project = os.environ.get("GE_TEST_GCP_PROJECT")
if not gcp_project:
raise ValueError(
"Environment Variable GE_TEST_GCP_PROJECT is required to run GCS integration tests"
)
# parse great_expectations.yml for comparison
great_expectations_yaml_file_path = os.path.join(
context.root_directory, "great_expectations.yml"
)
with open(great_expectations_yaml_file_path) as f:
great_expectations_yaml = yaml.load(f)
stores = great_expectations_yaml["stores"]
pop_stores = ["checkpoint_store", "evaluation_parameter_store", "validations_store"]
for store in pop_stores:
stores.pop(store)
actual_existing_expectations_store = {}
actual_existing_expectations_store["stores"] = stores
actual_existing_expectations_store["expectations_store_name"] = great_expectations_yaml[
"expectations_store_name"
]
expected_existing_expectations_store_yaml = """
stores:
expectations_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
expectations_store_name: expectations_store
"""
assert actual_existing_expectations_store == yaml.load(
expected_existing_expectations_store_yaml
)
# adding expectations store
configured_expectations_store_yaml = """
stores:
expectations_GCS_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleGCSStoreBackend
project: <YOUR GCP PROJECT NAME>
bucket: <YOUR GCS BUCKET NAME>
prefix: <YOUR GCS PREFIX NAME>
expectations_store_name: expectations_GCS_store
"""
# replace example code with integration test configuration
configured_expectations_store = yaml.load(configured_expectations_store_yaml)
configured_expectations_store["stores"]["expectations_GCS_store"]["store_backend"][
"project"
] = gcp_project
configured_expectations_store["stores"]["expectations_GCS_store"]["store_backend"][
"bucket"
] = "test_metadata_store"
configured_expectations_store["stores"]["expectations_GCS_store"]["store_backend"][
"prefix"
] = "metadata/expectations"
# add and set the new expectation store
context.add_store(
store_name=configured_expectations_store["expectations_store_name"],
store_config=configured_expectations_store["stores"]["expectations_GCS_store"],
)
with open(great_expectations_yaml_file_path) as f:
great_expectations_yaml = yaml.load(f)
great_expectations_yaml["expectations_store_name"] = "expectations_GCS_store"
great_expectations_yaml["stores"]["expectations_GCS_store"]["store_backend"].pop(
"suppress_store_backend_id"
)
with open(great_expectations_yaml_file_path, "w") as f:
yaml.dump(great_expectations_yaml, f)
# adding validation results store
# parse great_expectations.yml for comparison
great_expectations_yaml_file_path = os.path.join(
context.root_directory, "great_expectations.yml"
)
with open(great_expectations_yaml_file_path) as f:
great_expectations_yaml = yaml.load(f)
stores = great_expectations_yaml["stores"]
# popping the rest out so taht we can do the comparison. They aren't going anywhere dont worry
pop_stores = [
"checkpoint_store",
"evaluation_parameter_store",
"expectations_store",
"expectations_GCS_store",
]
for store in pop_stores:
stores.pop(store)
actual_existing_validations_store = {}
actual_existing_validations_store["stores"] = stores
actual_existing_validations_store["validations_store_name"] = great_expectations_yaml[
"validations_store_name"
]
expected_existing_validations_store_yaml = """
stores:
validations_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
validations_store_name: validations_store
"""
assert actual_existing_validations_store == yaml.load(
expected_existing_validations_store_yaml
)
# adding validations store
configured_validations_store_yaml = """
stores:
validations_GCS_store:
class_name: ValidationsStore
store_backend:
class_name: TupleGCSStoreBackend
project: <YOUR GCP PROJECT NAME>
bucket: <YOUR GCS BUCKET NAME>
prefix: <YOUR GCS PREFIX NAME>
validations_store_name: validations_GCS_store
"""
# replace example code with integration test configuration
configured_validations_store = yaml.load(configured_validations_store_yaml)
configured_validations_store["stores"]["validations_GCS_store"]["store_backend"][
"project"
] = gcp_project
configured_validations_store["stores"]["validations_GCS_store"]["store_backend"][
"bucket"
] = "test_metadata_store"
configured_validations_store["stores"]["validations_GCS_store"]["store_backend"][
"prefix"
] = "metadata/validations"
# add and set the new validation store
context.add_store(
store_name=configured_validations_store["validations_store_name"],
store_config=configured_validations_store["stores"]["validations_GCS_store"],
)
with open(great_expectations_yaml_file_path) as f:
great_expectations_yaml = yaml.load(f)
great_expectations_yaml["validations_store_name"] = "validations_GCS_store"
great_expectations_yaml["stores"]["validations_GCS_store"]["store_backend"].pop(
"suppress_store_backend_id"
)
with open(great_expectations_yaml_file_path, "w") as f:
yaml.dump(great_expectations_yaml, f)
# adding data docs store
data_docs_site_yaml = """
data_docs_sites:
local_site:
class_name: SiteBuilder
show_how_to_buttons: true
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/data_docs/local_site/
site_index_builder:
class_name: DefaultSiteIndexBuilder
gs_site: # this is a user-selected name - you may select your own
class_name: SiteBuilder
store_backend:
class_name: TupleGCSStoreBackend
project: <YOUR GCP PROJECT NAME>
bucket: <YOUR GCS BUCKET NAME>
site_index_builder:
class_name: DefaultSiteIndexBuilder
"""
data_docs_site_yaml = data_docs_site_yaml.replace(
"<YOUR GCP PROJECT NAME>", gcp_project
)
data_docs_site_yaml = data_docs_site_yaml.replace(
"<YOUR GCS BUCKET NAME>", "test_datadocs_store"
)
great_expectations_yaml_file_path = os.path.join(
context.root_directory, "great_expectations.yml"
)
with open(great_expectations_yaml_file_path) as f:
great_expectations_yaml = yaml.load(f)
great_expectations_yaml["data_docs_sites"] = yaml.load(data_docs_site_yaml)[
"data_docs_sites"
]
with open(great_expectations_yaml_file_path, "w") as f:
yaml.dump(great_expectations_yaml, f)
# adding datasource
# <snippet>
datasource_yaml = rf"""
name: my_gcs_datasource
class_name: Datasource
execution_engine:
class_name: PandasExecutionEngine
data_connectors:
default_runtime_data_connector_name:
class_name: RuntimeDataConnector
batch_identifiers:
- default_identifier_name
default_inferred_data_connector_name:
class_name: InferredAssetGCSDataConnector
bucket_or_name: <YOUR_GCS_BUCKET_HERE>
prefix: <BUCKET_PATH_TO_DATA>
default_regex:
pattern: (.*)\.csv
group_names:
- data_asset_name
"""
# </snippet>
# Please note this override is only to provide good UX for docs and tests.
# In normal usage you'd set your path directly in the yaml above.
datasource_yaml = datasource_yaml.replace("<YOUR_GCS_BUCKET_HERE>", "test_docs_data")
datasource_yaml = datasource_yaml.replace(
"<BUCKET_PATH_TO_DATA>", "data/taxi_yellow_tripdata_samples/"
)
context.test_yaml_config(datasource_yaml)
# <snippet>
context.add_datasource(**yaml.load(datasource_yaml))
# </snippet>
# batch_request with data_asset_name
# <snippet>
batch_request = BatchRequest(
datasource_name="my_gcs_datasource",
data_connector_name="default_inferred_data_connector_name",
data_asset_name="<YOUR_DATA_ASSET_NAME>",
)
# </snippet>
# Please note this override is only to provide good UX for docs and tests.
# In normal usage you'd set your data asset name directly in the BatchRequest above.
batch_request.data_asset_name = (
"data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-01"
)
# <snippet>
context.create_expectation_suite(
expectation_suite_name="test_gcs_suite", overwrite_existing=True
)
validator = context.get_validator(
batch_request=batch_request, expectation_suite_name="test_gcs_suite"
)
# </snippet>
# NOTE: The following code is only for testing and can be ignored by users.
assert isinstance(validator, ge.validator.validator.Validator)
assert [ds["name"] for ds in context.list_datasources()] == ["my_gcs_datasource"]
assert set(
context.get_available_data_asset_names()["my_gcs_datasource"][
"default_inferred_data_connector_name"
]
) == {
"data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-01",
"data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-02",
"data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-03",
}
# <snippet>
validator.expect_column_values_to_not_be_null(column="passenger_count")
validator.expect_column_values_to_be_between(
column="congestion_surcharge", min_value=0, max_value=1000
)
# </snippet>
# <snippet>
validator.save_expectation_suite(discard_failed_expectations=False)
# </snippet>
# <snippet>
my_checkpoint_name = "gcs_checkpoint"
checkpoint_config = f"""
name: {my_checkpoint_name}
config_version: 1.0
class_name: SimpleCheckpoint
run_name_template: "%Y%m%d-%H%M%S-my-run-name-template"
validations:
- batch_request:
datasource_name: my_gcs_datasource
data_connector_name: default_inferred_data_connector_name
data_asset_name: <YOUR_DATA_ASSET_NAME>
expectation_suite_name: test_gcs_suite
"""
# </snippet>
checkpoint_config = checkpoint_config.replace(
"<YOUR_DATA_ASSET_NAME>",
"data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-01",
)
# <snippet>
context.add_checkpoint(**yaml.load(checkpoint_config))
# </snippet>
# <snippet>
checkpoint_result = context.run_checkpoint(
checkpoint_name=my_checkpoint_name,
)
# </snippet>
assert checkpoint_result.success is True
<file_sep>/tests/test_packaging.py
import os.path
import pathlib
from typing import List
import requirements as rp
def collect_requirements_files() -> List[pathlib.Path]:
project_root = pathlib.Path(__file__).parents[1]
assert project_root.exists()
reqs_dir = project_root.joinpath("reqs")
assert reqs_dir.exists()
pattern = "requirements*.txt"
return list(project_root.glob(pattern)) + list(reqs_dir.glob(pattern))
def test_requirements_files():
"""requirements.txt should be a subset of requirements-dev.txt"""
req_set_dict = {}
req_files = collect_requirements_files()
for req_file in req_files:
abs_path = req_file.absolute().as_posix()
key = abs_path.rsplit(os.path.sep, 1)[-1]
with open(req_file) as f:
req_set_dict[key] = {
f'{line.name}{"".join(line.specs[0])}'
for line in rp.parse(f)
if line.specs
}
assert req_set_dict["requirements.txt"] <= req_set_dict["requirements-dev.txt"]
assert (
req_set_dict["requirements-dev-contrib.txt"]
| req_set_dict["requirements-dev-lite.txt"]
== req_set_dict["requirements-dev-test.txt"]
)
assert (
req_set_dict["requirements-dev-lite.txt"]
& req_set_dict["requirements-dev-spark.txt"]
== set()
)
assert (
req_set_dict["requirements-dev-spark.txt"]
& req_set_dict["requirements-dev-sqlalchemy.txt"]
& req_set_dict["requirements-dev-azure.txt"]
== set()
)
assert (
req_set_dict["requirements-dev-lite.txt"]
& req_set_dict["requirements-dev-contrib.txt"]
== set()
)
assert (
req_set_dict["requirements-dev-lite.txt"]
| req_set_dict["requirements-dev-athena.txt"]
| req_set_dict["requirements-dev-bigquery.txt"]
| req_set_dict["requirements-dev-dremio.txt"]
| req_set_dict["requirements-dev-mssql.txt"]
| req_set_dict["requirements-dev-mysql.txt"]
| req_set_dict["requirements-dev-postgresql.txt"]
| req_set_dict["requirements-dev-redshift.txt"]
| req_set_dict["requirements-dev-snowflake.txt"]
| req_set_dict["requirements-dev-teradata.txt"]
| req_set_dict["requirements-dev-trino.txt"]
| req_set_dict["requirements-dev-hive.txt"]
| req_set_dict["requirements-dev-vertica.txt"]
) == req_set_dict["requirements-dev-sqlalchemy.txt"]
assert (
req_set_dict["requirements.txt"]
| req_set_dict["requirements-dev-contrib.txt"]
| req_set_dict["requirements-dev-sqlalchemy.txt"]
| req_set_dict["requirements-dev-arrow.txt"]
| req_set_dict["requirements-dev-azure.txt"]
| req_set_dict["requirements-dev-excel.txt"]
| req_set_dict["requirements-dev-pagerduty.txt"]
| req_set_dict["requirements-dev-spark.txt"]
) == req_set_dict["requirements-dev.txt"]
assert req_set_dict["requirements-dev.txt"] - (
req_set_dict["requirements.txt"]
| req_set_dict["requirements-dev-lite.txt"]
| req_set_dict["requirements-dev-contrib.txt"]
| req_set_dict["requirements-dev-spark.txt"]
| req_set_dict["requirements-dev-sqlalchemy.txt"]
| req_set_dict["requirements-dev-arrow.txt"]
| req_set_dict["requirements-dev-athena.txt"]
| req_set_dict["requirements-dev-azure.txt"]
| req_set_dict["requirements-dev-bigquery.txt"]
| req_set_dict["requirements-dev-dremio.txt"]
| req_set_dict["requirements-dev-excel.txt"]
| req_set_dict["requirements-dev-mssql.txt"]
| req_set_dict["requirements-dev-mysql.txt"]
| req_set_dict["requirements-dev-pagerduty.txt"]
| req_set_dict["requirements-dev-postgresql.txt"]
| req_set_dict["requirements-dev-redshift.txt"]
| req_set_dict["requirements-dev-snowflake.txt"]
| req_set_dict["requirements-dev-teradata.txt"]
| req_set_dict["requirements-dev-trino.txt"]
| req_set_dict["requirements-dev-vertica.txt"]
) <= {"numpy>=1.21.0", "scipy>=1.7.0"}
<file_sep>/docs/guides/connecting_to_your_data/datasource_configuration/how_to_configure_a_spark_datasource.md
---
title: How to configure a Spark Datasource
---
# [](../connect_to_data_overview.md) How to configure a Spark Datasource
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import SectionIntro from './components/_section_intro.mdx';
import SectionPrerequisites from './spark_components/_section_prerequisites.mdx'
import SectionImportNecessaryModulesAndInitializeYourDataContext from './filesystem_components/_section_import_necessary_modules_and_initialize_your_data_context.mdx'
import SectionCreateANewDatasourceConfiguration from './components/_section_create_a_new_datasource_configuration.mdx'
import SectionNameYourDatasource from './components/_section_name_your_datasource.mdx'
import SectionAddTheExecutionEngineToYourDatasourceConfiguration from './spark_components/_section_add_the_execution_engine_to_your_datasource_configuration.mdx'
import SectionSpecifyTheDatasourceClassAndModule from './components/_section_specify_the_datasource_class_and_module.mdx'
import SectionAddADictionaryAsTheValueOfTheDataConnectorsKey from './spark_components/_section_add_a_dictionary_as_the_value_of_the_data_connectors_key.mdx'
import SectionConfigureYourIndividualDataConnectors from './filesystem_components/_section_configure_your_individual_data_connectors.mdx'
import SectionDataConnectorExampleConfigurations from './spark_components/_section_data_connector_example_configurations.mdx'
import SectionBatchSpecPassthrough from './spark_components/_section_configure_batch_spec_passthrough.mdx'
import SectionConfigureYourDataAssets from './spark_components/_section_configure_your_data_assets.mdx'
import SectionTestYourConfigurationWithTestYamlConfig from './components/_section_test_your_configuration_with_test_yaml_config.mdx'
import SectionAddMoreDataConnectorsToYourConfig from './components/_section_add_more_data_connectors_to_your_config.mdx'
import SectionAddYourNewDatasourceToYourDataContext from './components/_section_add_your_new_datasource_to_your_data_context.mdx'
import SectionNextSteps from './components/_section_next_steps.mdx'
<UniversalMap setup='inactive' connect='active' create='inactive' validate='inactive'/>
<SectionIntro backend="Spark" />
## Steps
### 1. Import necessary modules and initialize your Data Context
<SectionImportNecessaryModulesAndInitializeYourDataContext />
### 2. Create a new Datasource configuration.
<SectionCreateANewDatasourceConfiguration />
### 3. Name your Datasource
<SectionNameYourDatasource />
### 4. Specify the Datasource class and module
<SectionSpecifyTheDatasourceClassAndModule />
### 5. Add the Spark Execution Engine to your Datasource configuration
<SectionAddTheExecutionEngineToYourDatasourceConfiguration />
### 6. Add a dictionary as the value of the `data_connectors` key
<SectionAddADictionaryAsTheValueOfTheDataConnectorsKey />
### 7. Configure your individual Data Connectors
<SectionConfigureYourIndividualDataConnectors backend="Spark" />
#### Data Connector example configurations:
<SectionDataConnectorExampleConfigurations />
### 8. Configure the values for `batch_spec_passthrough`
<SectionBatchSpecPassthrough />
### 9. Configure your Data Connector's Data Assets
<SectionConfigureYourDataAssets />
### 10. Test your configuration with `.test_yaml_config(...)`
<SectionTestYourConfigurationWithTestYamlConfig />
### 11. (Optional) Add more Data Connectors to your configuration
<SectionAddMoreDataConnectorsToYourConfig />
### 12. Add your new Datasource to your Data Context
<SectionAddYourNewDatasourceToYourDataContext />
## Next Steps
<SectionNextSteps />
<file_sep>/great_expectations/data_context/data_context/ephemeral_data_context.py
import logging
from typing import Optional
from great_expectations.core.serializer import DictConfigSerializer
from great_expectations.data_context.data_context.abstract_data_context import (
AbstractDataContext,
)
from great_expectations.data_context.data_context_variables import (
EphemeralDataContextVariables,
)
from great_expectations.data_context.types.base import (
DataContextConfig,
datasourceConfigSchema,
)
logger = logging.getLogger(__name__)
class EphemeralDataContext(AbstractDataContext):
"""
Will contain functionality to create DataContext at runtime (ie. passed in config object or from stores). Users will
be able to use EphemeralDataContext for having a temporary or in-memory DataContext
TODO: Most of the BaseDataContext code will be migrated to this class, which will continue to exist for backwards
compatibility reasons.
"""
def __init__(
self,
project_config: DataContextConfig,
runtime_environment: Optional[dict] = None,
) -> None:
"""EphemeralDataContext constructor
project_config: config for in-memory EphemeralDataContext
runtime_environment: a dictionary of config variables tha
override both those set in config_variables.yml and the environment
"""
self._project_config = self._apply_global_config_overrides(
config=project_config
)
super().__init__(runtime_environment=runtime_environment)
def _init_variables(self) -> EphemeralDataContextVariables:
variables = EphemeralDataContextVariables(
config=self._project_config,
config_provider=self.config_provider,
)
return variables
def _init_datasource_store(self) -> None:
from great_expectations.data_context.store.datasource_store import (
DatasourceStore,
)
store_name: str = "datasource_store" # Never explicitly referenced but adheres
# to the convention set by other internal Stores
store_backend: dict = {"class_name": "InMemoryStoreBackend"}
datasource_store = DatasourceStore(
store_name=store_name,
store_backend=store_backend,
serializer=DictConfigSerializer(schema=datasourceConfigSchema),
)
self._datasource_store = datasource_store
<file_sep>/contrib/capitalone_dataprofiler_expectations/capitalone_dataprofiler_expectations/metrics/data_profiler_metrics/data_profiler_profile_report.py
import dataprofiler as dp
from great_expectations.execution_engine import PandasExecutionEngine
from great_expectations.expectations.metrics.metric_provider import metric_value
from .data_profiler_profile_metric_provider import DataProfilerProfileMetricProvider
class DataProfilerProfileReport(DataProfilerProfileMetricProvider):
metric_name = "data_profiler.profile_report"
value_keys = ("profile_path",)
@metric_value(engine=PandasExecutionEngine)
def _pandas(
cls,
execution_engine,
metric_domain_kwargs,
metric_value_kwargs,
metrics,
runtime_configuration,
):
profile_path = metric_value_kwargs["profile_path"]
try:
profile = dp.Profiler.load(profile_path)
profile_report = profile.report(
report_options={"output_format": "serializable"}
)
profile_report["global_stats"]["profile_schema"] = dict(
profile_report["global_stats"]["profile_schema"]
)
return profile_report
except FileNotFoundError:
raise ValueError(
"'profile_path' does not point to a valid DataProfiler stored profile."
)
<file_sep>/docs/guides/connecting_to_your_data/index.md
---
title: "Connect to Data: Index"
---
# [](./connect_to_data_overview.md) Connect to Data: Index
## Core skills
- [How to choose which DataConnector to use](../../guides/connecting_to_your_data/how_to_choose_which_dataconnector_to_use.md)
- [How to configure an InferredAssetDataConnector](../../guides/connecting_to_your_data/how_to_configure_an_inferredassetdataconnector.md)
- [How to configure a ConfiguredAssetDataConnector](../../guides/connecting_to_your_data/how_to_configure_a_configuredassetdataconnector.md)
- [How to configure a RuntimeDataConnector](../../guides/connecting_to_your_data/how_to_configure_a_runtimedataconnector.md)
- [How to configure a DataConnector to introspect and partition a file system or blob store](../../guides/connecting_to_your_data/how_to_configure_a_dataconnector_to_introspect_and_partition_a_file_system_or_blob_store.md)
- [How to configure a DataConnector to introspect and partition tables in SQL](../../guides/connecting_to_your_data/how_to_configure_a_dataconnector_to_introspect_and_partition_tables_in_sql.md)
- [How to create a Batch of data from an in-memory Spark or Pandas dataframe or path](../../guides/connecting_to_your_data/how_to_create_a_batch_of_data_from_an_in_memory_spark_or_pandas_dataframe.md)
- [How to get one or more Batches of data from a configured Datasource](../../guides/connecting_to_your_data/how_to_get_one_or_more_batches_of_data_from_a_configured_datasource.md)
## In memory
- [How to connect to in-memory data in a Pandas dataframe](../../guides/connecting_to_your_data/in_memory/pandas.md)
- [How to connect to in-memory data in a Spark dataframe](../../guides/connecting_to_your_data/in_memory/spark.md)
## Database
- [How to connect to a Athena database](../../guides/connecting_to_your_data/database/athena.md)
- [How to connect to a BigQuery database](../../guides/connecting_to_your_data/database/bigquery.md)
- [How to connect to an MSSQL database](../../guides/connecting_to_your_data/database/mssql.md)
- [How to connect to a MySQL database](../../guides/connecting_to_your_data/database/mysql.md)
- [How to connect to a PostgreSQL database](../../guides/connecting_to_your_data/database/postgres.md)
- [How to connect to a Redshift database](../../guides/connecting_to_your_data/database/redshift.md)
- [How to connect to a Snowflake database](../../guides/connecting_to_your_data/database/snowflake.md)
- [How to connect to a SQLite database](../../guides/connecting_to_your_data/database/sqlite.md)
- [How to connect to a Trino database](../../guides/connecting_to_your_data/database/trino.md) (formerly Presto SQL)
## Filesystem
- [How to connect to data on a filesystem using Pandas](../../guides/connecting_to_your_data/filesystem/pandas.md)
- [How to connect to data on a filesystem using Spark](../../guides/connecting_to_your_data/filesystem/spark.md)
## Cloud
- [How to connect to data on S3 using Pandas](../../guides/connecting_to_your_data/cloud/s3/pandas.md)
- [How to connect to data on S3 using Spark](../../guides/connecting_to_your_data/cloud/s3/spark.md)
- [How to connect to data on GCS using Pandas](../../guides/connecting_to_your_data/cloud/gcs/pandas.md)
- [How to connect to data on GCS using Spark](../../guides/connecting_to_your_data/cloud/gcs/spark.md)
- [How to connect to data on Azure Blob Storage using Pandas](../../guides/connecting_to_your_data/cloud/azure/pandas.md)
- [How to connect to data on Azure Blob Storage using Spark](../../guides/connecting_to_your_data/cloud/azure/spark.md)
## Advanced
- [How to configure a DataConnector for splitting and sampling a file system or blob store](../../guides/connecting_to_your_data/advanced/how_to_configure_a_dataconnector_for_splitting_and_sampling_a_file_system_or_blob_store.md)
- [How to configure a DataConnector for splitting and sampling tables in SQL](../../guides/connecting_to_your_data/advanced/how_to_configure_a_dataconnector_for_splitting_and_sampling_tables_in_sql.md)
<file_sep>/tests/integration/docusaurus/validation/checkpoints/how_to_pass_an_in_memory_dataframe_to_a_checkpoint.py
# <snippet>
import pandas as pd
from ruamel import yaml
import great_expectations as ge
from great_expectations.core.batch import RuntimeBatchRequest
# </snippet>
# <snippet>
context = ge.get_context()
# </snippet>
# YAML <snippet>
datasource_yaml = r"""
name: taxi_datasource
class_name: Datasource
module_name: great_expectations.datasource
execution_engine:
module_name: great_expectations.execution_engine
class_name: PandasExecutionEngine
data_connectors:
default_runtime_data_connector_name:
class_name: RuntimeDataConnector
batch_identifiers:
- default_identifier_name
"""
context.add_datasource(**yaml.safe_load(datasource_yaml))
# </snippet>
test_yaml = context.test_yaml_config(datasource_yaml, return_mode="report_object")
# Python <snippet>
datasource_config = {
"name": "taxi_datasource",
"class_name": "Datasource",
"module_name": "great_expectations.datasource",
"execution_engine": {
"module_name": "great_expectations.execution_engine",
"class_name": "PandasExecutionEngine",
},
"data_connectors": {
"default_runtime_data_connector_name": {
"class_name": "RuntimeDataConnector",
"batch_identifiers": ["default_identifier_name"],
},
},
}
context.add_datasource(**datasource_config)
# </snippet>
test_python = context.test_yaml_config(
yaml.dump(datasource_config), return_mode="report_object"
)
# CLI
datasource_cli = """
<snippet>
great_expectations datasource new
</snippet>
"""
# NOTE: The following code is only for testing and can be ignored by users.
assert test_yaml == test_python
assert [ds["name"] for ds in context.list_datasources()] == ["taxi_datasource"]
# <snippet>
context.create_expectation_suite("my_expectation_suite")
# </snippet>
# YAML <snippet>
checkpoint_yaml = """
name: my_missing_keys_checkpoint
config_version: 1
class_name: SimpleCheckpoint
validations:
- batch_request:
datasource_name: taxi_datasource
data_connector_name: default_runtime_data_connector_name
data_asset_name: taxi_data
expectation_suite_name: my_expectation_suite
"""
context.add_checkpoint(**yaml.safe_load(checkpoint_yaml))
# </snippet>
test_yaml = context.test_yaml_config(checkpoint_yaml, return_mode="report_object")
# Python <snippet>
checkpoint_config = {
"name": "my_missing_keys_checkpoint",
"config_version": 1,
"class_name": "SimpleCheckpoint",
"validations": [
{
"batch_request": {
"datasource_name": "taxi_datasource",
"data_connector_name": "default_runtime_data_connector_name",
"data_asset_name": "taxi_data",
},
"expectation_suite_name": "my_expectation_suite",
}
],
}
context.add_checkpoint(**checkpoint_config)
# </snippet>
test_python = context.test_yaml_config(
yaml.dump(checkpoint_config), return_mode="report_object"
)
# NOTE: The following code is only for testing and can be ignored by users.
assert test_yaml == test_python
assert context.list_checkpoints() == ["my_missing_keys_checkpoint"]
df = pd.read_csv("./data/yellow_tripdata_sample_2019-01.csv")
# <snippet>
results = context.run_checkpoint(
checkpoint_name="my_missing_keys_checkpoint",
batch_request={
"runtime_parameters": {"batch_data": df},
"batch_identifiers": {
"default_identifier_name": "<YOUR MEANINGFUL IDENTIFIER>"
},
},
)
# </snippet>
# NOTE: The following code is only for testing and can be ignored by users.
assert results["success"] == True
# YAML <snippet>
checkpoint_yaml = """
name: my_missing_batch_request_checkpoint
config_version: 1
class_name: SimpleCheckpoint
expectation_suite_name: my_expectation_suite
"""
context.add_checkpoint(**yaml.safe_load(checkpoint_yaml))
# </snippet>
test_yaml = context.test_yaml_config(checkpoint_yaml, return_mode="report_object")
# Python <snippet>
checkpoint_config = {
"name": "my_missing_batch_request_checkpoint",
"config_version": 1,
"class_name": "SimpleCheckpoint",
"expectation_suite_name": "my_expectation_suite",
}
context.add_checkpoint(**checkpoint_config)
# </snippet>
test_python = context.test_yaml_config(
yaml.dump(checkpoint_config), return_mode="report_object"
)
# NOTE: The following code is only for testing and can be ignored by users.
assert test_yaml == test_python
assert set(context.list_checkpoints()) == {
"my_missing_keys_checkpoint",
"my_missing_batch_request_checkpoint",
}
df_1 = pd.read_csv("./data/yellow_tripdata_sample_2019-01.csv")
df_2 = pd.read_csv("./data/yellow_tripdata_sample_2019-02.csv")
# <snippet>
batch_request_1 = RuntimeBatchRequest(
datasource_name="taxi_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="<YOUR MEANINGFUL NAME 1>", # This can be anything that identifies this data_asset for you
runtime_parameters={"batch_data": df_1}, # Pass your DataFrame here.
batch_identifiers={"default_identifier_name": "<YOUR MEANINGFUL IDENTIFIER 1>"},
)
batch_request_2 = RuntimeBatchRequest(
datasource_name="taxi_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="<YOUR MEANINGFUL NAME 2>", # This can be anything that identifies this data_asset for you
runtime_parameters={"batch_data": df_2}, # Pass your DataFrame here.
batch_identifiers={"default_identifier_name": "<YOUR MEANINGFUL IDENTIFIER 2>"},
)
results = context.run_checkpoint(
checkpoint_name="my_missing_batch_request_checkpoint",
validations=[
{"batch_request": batch_request_1},
{"batch_request": batch_request_2},
],
)
# </snippet>
# NOTE: The following code is only for testing and can be ignored by users.
assert results["success"] == True
<file_sep>/tests/integration/docusaurus/miscellaneous/migration_guide_spark_v2_api.py
import os
from ruamel import yaml
import great_expectations as ge
from great_expectations.data_context.util import file_relative_path
context = ge.get_context()
yaml = yaml.YAML(typ="safe")
# parse great_expectations.yml for comparison
great_expectations_yaml_file_path = os.path.join(
context.root_directory, "great_expectations.yml"
)
with open(great_expectations_yaml_file_path) as f:
great_expectations_yaml = yaml.load(f)
actual_datasource = great_expectations_yaml["datasources"]
# expected Datasource
expected_existing_datasource_yaml = r"""
my_datasource:
class_name: SparkDFDatasource
module_name: great_expectations.datasource
data_asset_type:
module_name: great_expectations.dataset
class_name: SparkDFDataset
batch_kwargs_generators:
subdir_reader:
class_name: SubdirReaderBatchKwargsGenerator
base_directory: ../../../
"""
assert actual_datasource == yaml.load(expected_existing_datasource_yaml)
# Please note this override is only to provide good UX for docs and tests.
updated_configuration = yaml.load(expected_existing_datasource_yaml)
updated_configuration["my_datasource"]["batch_kwargs_generators"]["subdir_reader"][
"base_directory"
] = "../data/"
context.add_datasource(name="my_datasource", **updated_configuration["my_datasource"])
actual_validation_operators = great_expectations_yaml["validation_operators"]
# expected Validation Operators
expected_existing_validation_operators_yaml = """
action_list_operator:
class_name: ActionListValidationOperator
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
"""
assert actual_validation_operators == yaml.load(
expected_existing_validation_operators_yaml
)
# check that checkpoint contains the right configuration
# parse great_expectations.yml for comparison
checkpoint_yaml_file_path = os.path.join(
context.root_directory, "checkpoints/test_v2_checkpoint.yml"
)
with open(checkpoint_yaml_file_path) as f:
actual_checkpoint_yaml = yaml.load(f)
expected_checkpoint_yaml = """
name: test_v2_checkpoint
config_version:
module_name: great_expectations.checkpoint
class_name: LegacyCheckpoint
validation_operator_name: action_list_operator
batches:
- batch_kwargs:
path: ../../data/Titanic.csv
datasource: my_datasource
data_asset_name: Titanic.csv
reader_options:
header: True
expectation_suite_names:
- Titanic.profiled
"""
assert actual_checkpoint_yaml == yaml.load(expected_checkpoint_yaml)
# override for integration tests
updated_configuration = actual_checkpoint_yaml
updated_configuration["batches"][0]["batch_kwargs"]["path"] = file_relative_path(
__file__, "data/Titanic.csv"
)
# run checkpoint
context.add_checkpoint(**updated_configuration)
results = context.run_checkpoint(checkpoint_name="test_v2_checkpoint")
assert results["success"] is True
<file_sep>/assets/docker/mssql/README.md
After running `docker compose up -d` in this directory to start the mssql container, to run tests you'll need to create the `test_ci` database. An easy way to do this if you are using docker desktop is to navigate to the container and open an interactive CLI session. In that session, run `/opt/mssql-tools/bin/sqlcmd -U sa -P "ReallyStrongPwd1234%^&*" -Q "CREATE DATABASE test_ci;"` to set up the `test_ci` database. Then you can run mssql specific tests via `pytest --mssql`.
<file_sep>/great_expectations/expectations/metrics/column_map_metrics/column_values_between.py
import datetime
import warnings
from typing import Optional, Union
import pandas as pd
from dateutil.parser import parse
from great_expectations.execution_engine import (
PandasExecutionEngine,
SparkDFExecutionEngine,
SqlAlchemyExecutionEngine,
)
from great_expectations.expectations.metrics.import_manager import F, sa
from great_expectations.expectations.metrics.map_metric_provider import (
ColumnMapMetricProvider,
column_condition_partial,
)
class ColumnValuesBetween(ColumnMapMetricProvider):
condition_metric_name = "column_values.between"
condition_value_keys = (
"min_value",
"max_value",
"strict_min",
"strict_max",
"parse_strings_as_datetimes",
"allow_cross_type_comparisons",
)
@column_condition_partial(engine=PandasExecutionEngine)
def _pandas(
cls,
column,
min_value=None,
max_value=None,
strict_min=None,
strict_max=None,
parse_strings_as_datetimes: bool = False,
allow_cross_type_comparisons=None,
**kwargs
):
if min_value is None and max_value is None:
raise ValueError("min_value and max_value cannot both be None")
if allow_cross_type_comparisons is None:
# NOTE - 20220818 - JPC: the "default" for `allow_cross_type_comparisons` is None
# to support not including it in configs if it is not explicitly set, but the *behavior*
# defaults to False. I think that's confusing and we should explicitly clarify.
allow_cross_type_comparisons = False
if parse_strings_as_datetimes:
# deprecated-v0.13.41
warnings.warn(
"""The parameter "parse_strings_as_datetimes" is deprecated as of v0.13.41 in \
v0.16. As part of the V3 API transition, we've moved away from input transformation. For more information, \
please see: https://greatexpectations.io/blog/why_we_dont_do_transformations_for_expectations/
""",
DeprecationWarning,
)
if min_value is not None:
try:
min_value = parse(min_value)
except TypeError:
pass
if max_value is not None:
try:
max_value = parse(max_value)
except TypeError:
pass
try:
temp_column = column.map(parse)
except TypeError:
temp_column = column
else:
temp_column = column
if min_value is not None and max_value is not None and min_value > max_value:
raise ValueError("min_value cannot be greater than max_value")
# Use a vectorized approach for native numpy dtypes
if column.dtype in [int, float] and not allow_cross_type_comparisons:
return cls._pandas_vectorized(
temp_column, min_value, max_value, strict_min, strict_max
)
elif (
isinstance(column.dtype, pd.DatetimeTZDtype)
or pd.api.types.is_datetime64_ns_dtype(column.dtype)
) and (not allow_cross_type_comparisons):
# NOTE: 20220818 - JPC
# we parse the *parameters* that we will be comparing here because it is possible
# that the user could have started with a true datetime, but that was converted to a string
# in order to support json serialization into the expectation configuration.
# We should fix that at a deeper level by creating richer containers for parameters that are type aware.
# Until that deeper refactor, we parse the string value back into a datetime here if we
# are going to compare to a datetime column.
if min_value is not None and isinstance(min_value, str):
min_value = parse(min_value)
if max_value is not None and isinstance(max_value, str):
max_value = parse(max_value)
return cls._pandas_vectorized(
temp_column, min_value, max_value, strict_min, strict_max
)
def is_between(val):
# TODO Might be worth explicitly defining comparisons between types (for example, between strings and ints).
# Ensure types can be compared since some types in Python 3 cannot be logically compared.
# print type(val), type(min_value), type(max_value), val, min_value, max_value
if type(val) is None:
return False
if min_value is not None and max_value is not None:
if allow_cross_type_comparisons:
try:
if strict_min and strict_max:
return (val > min_value) and (val < max_value)
if strict_min:
return (val > min_value) and (val <= max_value)
if strict_max:
return (val >= min_value) and (val < max_value)
return (val >= min_value) and (val <= max_value)
except TypeError:
return False
else:
# Type of column values is either string or specific rich type (or "None"). In all cases, type of
# column must match type of constant being compared to column value (otherwise, error is raised).
if (isinstance(val, str) != isinstance(min_value, str)) or (
isinstance(val, str) != isinstance(max_value, str)
):
raise TypeError(
"Column values, min_value, and max_value must either be None or of the same type."
)
if strict_min and strict_max:
return (val > min_value) and (val < max_value)
if strict_min:
return (val > min_value) and (val <= max_value)
if strict_max:
return (val >= min_value) and (val < max_value)
return (val >= min_value) and (val <= max_value)
elif min_value is None and max_value is not None:
if allow_cross_type_comparisons:
try:
if strict_max:
return val < max_value
return val <= max_value
except TypeError:
return False
else:
# Type of column values is either string or specific rich type (or "None"). In all cases, type of
# column must match type of constant being compared to column value (otherwise, error is raised).
if isinstance(val, str) != isinstance(max_value, str):
raise TypeError(
"Column values, min_value, and max_value must either be None or of the same type."
)
if strict_max:
return val < max_value
return val <= max_value
elif min_value is not None and max_value is None:
if allow_cross_type_comparisons:
try:
if strict_min:
return val > min_value
return val >= min_value
except TypeError:
return False
else:
# Type of column values is either string or specific rich type (or "None"). In all cases, type of
# column must match type of constant being compared to column value (otherwise, error is raised).
if isinstance(val, str) != isinstance(min_value, str):
raise TypeError(
"Column values, min_value, and max_value must either be None or of the same type."
)
if strict_min:
return val > min_value
return val >= min_value
else:
return False
return temp_column.map(is_between)
@classmethod
def _pandas_vectorized(
cls,
column: pd.Series,
min_value: Optional[Union[int, float, datetime.datetime]],
max_value: Optional[Union[int, float, datetime.datetime]],
strict_min: bool,
strict_max: bool,
):
if min_value is None and max_value is None:
raise ValueError("min_value and max_value cannot both be None")
if min_value is None:
if strict_max:
return column < max_value
else:
return column <= max_value
if max_value is None:
if strict_min:
return min_value < column
else:
return min_value <= column
if strict_min and strict_max:
return (min_value < column) & (column < max_value)
elif strict_min:
return (min_value < column) & (column <= max_value)
elif strict_max:
return (min_value <= column) & (column < max_value)
else:
return (min_value <= column) & (column <= max_value)
@column_condition_partial(engine=SqlAlchemyExecutionEngine)
def _sqlalchemy(
cls,
column,
min_value=None,
max_value=None,
strict_min=None,
strict_max=None,
parse_strings_as_datetimes: bool = False,
**kwargs
):
if parse_strings_as_datetimes:
# deprecated-v0.13.41
warnings.warn(
"""The parameter "parse_strings_as_datetimes" is deprecated as of v0.13.41 in \
v0.16. As part of the V3 API transition, we've moved away from input transformation. For more information, \
please see: https://greatexpectations.io/blog/why_we_dont_do_transformations_for_expectations/
""",
DeprecationWarning,
)
if min_value is not None:
try:
min_value = parse(min_value)
except TypeError:
pass
if max_value is not None:
try:
max_value = parse(max_value)
except TypeError:
pass
if min_value is not None and max_value is not None and min_value > max_value:
raise ValueError("min_value cannot be greater than max_value")
if min_value is None and max_value is None:
raise ValueError("min_value and max_value cannot both be None")
if min_value is None:
if strict_max:
return column < sa.literal(max_value)
return column <= sa.literal(max_value)
elif max_value is None:
if strict_min:
return column > sa.literal(min_value)
return column >= sa.literal(min_value)
else:
if strict_min and strict_max:
return sa.and_(
column > sa.literal(min_value),
column < sa.literal(max_value),
)
if strict_min:
return sa.and_(
column > sa.literal(min_value),
column <= sa.literal(max_value),
)
if strict_max:
return sa.and_(
column >= sa.literal(min_value),
column < sa.literal(max_value),
)
return sa.and_(
column >= sa.literal(min_value),
column <= sa.literal(max_value),
)
@column_condition_partial(engine=SparkDFExecutionEngine)
def _spark(
cls,
column,
min_value=None,
max_value=None,
strict_min=None,
strict_max=None,
parse_strings_as_datetimes: bool = False,
**kwargs
):
if parse_strings_as_datetimes:
# deprecated-v0.13.41
warnings.warn(
"""The parameter "parse_strings_as_datetimes" is deprecated as of v0.13.41 in \
v0.16. As part of the V3 API transition, we've moved away from input transformation. For more information, \
please see: https://greatexpectations.io/blog/why_we_dont_do_transformations_for_expectations/
""",
DeprecationWarning,
)
if min_value is not None:
try:
min_value = parse(min_value)
except TypeError:
pass
if max_value is not None:
try:
max_value = parse(max_value)
except TypeError:
pass
if min_value is not None and max_value is not None and min_value > max_value:
raise ValueError("min_value cannot be greater than max_value")
if min_value is None and max_value is None:
raise ValueError("min_value and max_value cannot both be None")
if min_value is None:
if strict_max:
return column < F.lit(max_value)
return column <= F.lit(max_value)
elif max_value is None:
if strict_min:
return column > F.lit(min_value)
return column >= F.lit(min_value)
else:
if strict_min and strict_max:
return (column > F.lit(min_value)) & (column < F.lit(max_value))
if strict_min:
return (column > F.lit(min_value)) & (column <= F.lit(max_value))
if strict_max:
return (column >= F.lit(min_value)) & (column < F.lit(max_value))
return (column >= F.lit(min_value)) & (column <= F.lit(max_value))
<file_sep>/tests/integration/docusaurus/miscellaneous/migration_guide_postgresql_v3_api.py
import os
from ruamel import yaml
import great_expectations as ge
CONNECTION_STRING = "postgresql+psycopg2://postgres:@localhost/test_ci"
# This utility is not for general use. It is only to support testing.
from tests.test_utils import load_data_into_test_database
load_data_into_test_database(
table_name="titanic",
csv_path="./data/Titanic.csv",
connection_string=CONNECTION_STRING,
load_full_dataset=True,
)
context = ge.get_context()
# parse great_expectations.yml for comparison
great_expectations_yaml_file_path = os.path.join(
context.root_directory, "great_expectations.yml"
)
with open(great_expectations_yaml_file_path) as f:
great_expectations_yaml = yaml.safe_load(f)
actual_datasource = great_expectations_yaml["datasources"]
# expected Datasource
expected_existing_datasource_yaml = r"""
my_postgres_datasource:
module_name: great_expectations.datasource
class_name: Datasource
execution_engine:
module_name: great_expectations.execution_engine
class_name: SqlAlchemyExecutionEngine
connection_string: postgresql+psycopg2://postgres:@localhost/test_ci
data_connectors:
default_runtime_data_connector_name:
module_name: great_expectations.datasource.data_connector
class_name: RuntimeDataConnector
batch_identifiers:
- default_identifier_name
default_inferred_data_connector_name:
module_name: great_expectations.datasource.data_connector
class_name: InferredAssetSqlDataConnector
include_schema_name: true
"""
assert actual_datasource == yaml.safe_load(expected_existing_datasource_yaml)
# check that checkpoint contains the right configuration
# parse great_expectations.yml for comparison
checkpoint_yaml_file_path = os.path.join(
context.root_directory, "checkpoints/test_v3_checkpoint.yml"
)
with open(checkpoint_yaml_file_path) as f:
actual_checkpoint_yaml = yaml.safe_load(f)
expected_checkpoint_yaml = """
name: test_v3_checkpoint
config_version: 1.0 # Note this is the version of the Checkpoint configuration, and not the great_expectations.yml configuration
template_name:
module_name: great_expectations.checkpoint
class_name: Checkpoint
run_name_template: '%Y%m%d-%H%M%S-my-run-name-template'
expectation_suite_name:
batch_request:
action_list:
- name: store_validation_result
action:
class_name: StoreValidationResultAction
- name: store_evaluation_params
action:
class_name: StoreEvaluationParametersAction
- name: update_data_docs
action:
class_name: UpdateDataDocsAction
site_names: []
evaluation_parameters: {}
runtime_configuration: {}
validations:
- batch_request:
datasource_name: my_postgres_datasource
data_connector_name: default_runtime_data_connector_name
data_asset_name: titanic
runtime_parameters:
query: SELECT * from public.titanic
batch_identifiers:
default_identifier_name: default_identifier
expectation_suite_name: Titanic.profiled
profilers: []
ge_cloud_id:
expectation_suite_ge_cloud_id:
"""
assert actual_checkpoint_yaml == yaml.safe_load(expected_checkpoint_yaml)
# run checkpoint
results = context.run_checkpoint(checkpoint_name="test_v3_checkpoint")
assert results["success"] is True
<file_sep>/docs/terms/custom_expectation.md
---
title: "Custom Expectation"
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
import ValidateHeader from '/docs/images/universal_map/_um_validate_header.mdx';
<UniversalMap setup='inactive' connect='inactive' create='active' validate='active'/>
## Overview
### Definition
A Custom Expectation is an extension of the `Expectation` class, developed outside the Great Expectations library.
### Features and promises
Custom Expectations are intended to allow you to create <TechnicalTag relative="../" tag="expectation" text="Expectations" /> tailored to your specific data needs.
### Relationship to other objects
Other than the development of Custom Expectations, which takes place outside the usual Great Expectations workflow for <TechnicalTag relative="../" tag="validation" text="Validating" /> data, Custom Expectations should interact with Great Expectations in the same way as any other Expectation would.
## Use cases
<UniversalMap setup='inactive' connect='inactive' create='active' validate='active'/>
For details on when and how you would use a Custom Expectation to Validate Data, please see [the corresponding documentation on Expectations](./expectation.md#use-cases).
## Features
### Whatever you need
Custom Expectations are created outside Great Expectations. When you create a Custom Expectation, you can tailor it to whatever needs you and your data have.
## API basics
### How to access
If you are using a Custom Expectation to validate data, you will typically access it exactly as you would any other Expectation. However, if your Custom Expectation has not yet been contributed or merged into the Great Expectations codebase, you may want to set your Custom Expectation up to be accessed as a Plugin. This will allow you to continue using your Custom Expectation while you wait for it to be accepted and merged.
If you are still working on developing your Custom Expectation, you will access it by opening the python file that contains it in your preferred editing environment.
### How to create
We provide extensive documentation on how to create Custom Expectations. If you are interested in doing so, we advise you reference [our guides on how to create Custom Expectations](../guides/expectations/index.md#creating-custom-expectations).
### How to contribute
Community contributions are a great way to help Great Expectations grow! If you've created a Custom Expectation that you would like to share with others, we have a [guide on how to contribute a new Expectation to Great Expectations](../guides/expectations/contributing/how_to_contribute_a_custom_expectation_to_great_expectations.md), just waiting for you!
<file_sep>/docs/guides/connecting_to_your_data/cloud/s3/components_pandas/_instantiate_your_projects_datacontext.mdx
Import these necessary packages and modules.
```python file=../../../../../../tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/inferred_and_runtime_yaml_example.py#L3-L7
```
Load your DataContext into memory using the `get_context()` method.
```python file=../../../../../../tests/integration/docusaurus/connecting_to_your_data/cloud/s3/pandas/inferred_and_runtime_yaml_example.py#L8
```
<file_sep>/docs/deployment_patterns/how_to_use_great_expectations_with_ydata_synthetic.md
---
title: How to Use Great Expectations with YData-Synthetic
---
import Prerequisites from './components/deployment_pattern_prerequisites.jsx'
import TechnicalTag from '@site/docs/term_tags/_tag.mdx';
_This piece of documentation was authored by [<NAME>](https://www.linkedin.com/in/arunn-thevapalan/)._
[YData-Synthetic](https://github.com/ydataai/ydata-synthetic) is an open-source synthetic data engine. Using different kinds of Generative Adversarial Networks (GANS), the engine learns patterns and statistical properties of original data. It can create endless samples of synthetic data that resemble the original data.
This guide will help you get started on generating synthetic data using `ydata-synthetic` and validate the quality of the synthetic data against your original data using Great Expectations.
### Why use Great Expectation with ydata-synthetic?
Synthetic data replicate the statistical components of real data without containing any identifiable information, ensuring individuals' privacy. It helps solves most data science problems by providing valuable high-quality data at scale.
As much as preserving the statistical properties of the original data is crucial, ensuring it follows a rigid data quality standard is essential too. Without a rigid data quality framework, generating synthetic data may lose its purpose: high-quality data at scale.
Great Expectations allows the user to create <TechnicalTag tag="expectation" text="Expectations" /> based on a good sample of data and use these Expectations to validate if the new data meets the data quality standards.
## The data problem we're solving in this tutorial
In this tutorial, we pick a use-case example of [“The Credit Card Fraud Dataset — Synthesizing the Minority Class.”](https://colab.research.google.com/github/ydataai/ydata-synthetic/blob/master/examples/regular/gan_example.ipynb) We aim to synthesize the minority class of the credit card fraud dataset with a high imbalance.
We will solve this problem by generating synthetic data using `ydata-synthetic` and validating it through Great Expectations. [This Jupyter Notebook](https://github.com/ydataai/ydata-synthetic/blob/dev/examples/regular/integrate_great_expectations.ipynb) can be used to follow along this tutorial with the relevant codes.

## Steps
### Step 0: Install the required libraries.
We recommend you create a virtual environment and install `ydata-synthetic` and `great-expectations` by running the following command on your terminal.
```bash
pip install ydata-synthetic great-expectations
```
### Step 1: Set up the project structure through a Data Context.
In Great Expectations, your <TechnicalTag tag="data_context" text="Data Context" /> manages the project configuration. There are multiple ways to create the Data Context; however, the simplest one is by using the CLI that comes along when you install the `great_expectations` package.
Open your terminal and navigate to the project directory and type in the following:
```bash
great_expectations init
```
Press enter to complete the creation of the Data Context, and that’s about it.
### Step 2: Download/Extract the actual data set we use to create synthetic data.
We can [download](https://www.kaggle.com/mlg-ulb/creditcardfraud) the data we use for this example from Kaggle. If you inspect the classes, you’ll notice that the “fraud” class is much lesser than the “not fraud” class, which is the case in real life.
After downloading, let's extract the minority class and use that filtered data for synthesis and validation.
```python
import pandas as pd
# Read the original data
data = pd.read_csv('./data/creditcard.csv')
#Filter the minority class
train_data = data.loc[ data['Class']==1 ].copy()
# Inspect the shape of the data
print(train_data.shape)
# Write to the data folder
train_data.to_csv('./data/creditcard_fraud.csv', index=False)
```
### Step 3: Configure a Data Source to connect our data.
In Great Expectations, <TechnicalTag tag="datasource" text="Datasources" /> simplify connections by managing configuration and providing a consistent, cross-platform API for referencing data.
Let’s configure our first Datasource: a connection to the data directory we’ve provided in the repo. Instead, this could even be a database connection and more.
```python
great_expectations datasource new
```

As shown in the image above, you would be presented with different options. Select `Files on a filesystem (for processing with Pandas or Spark)` and `Pandas`. Finally, enter the directory as `data` (where we have our actual data).
Once you’ve entered the details, a Jupyter Notebook will open up. This is just the way Great Expectations has given templated codes, which helps us create Expectations with a few code changes.
Let’s change the Datasource name to something more specific.
Edit the second code cell as follows: `datasource_name = "data__dir"`
Then execute all cells in the notebook to save the new Datasource. If successful, the last cell will print a list of all Datasources, including the one you just created.
### Step 4: Create an Expectation Suite using the built-in Great Expectations profiler.
The idea here is that we assume that the actual data has the ideal quality of the data we want to be synthesized, so we use the actual data to create a set of Expectations which we can later use to evaluate our synthetic data.
The CLI will help create our first <TechnicalTag tag="expectation_suite" text="Expectation Suite" />. Suites are simply collections of Expectations. We can use the built-in <TechnicalTag tag="profiler" text="profiler" /> to automatically generate an Expectation Suite called `creditcard.quality`.
Type the following into your terminal:
```bash
great_expectations suite new
```

Again, select the options as shown in the image above. We create Expectations using the automatic profiler and point it to use the actual dataset.
Another Jupyter Notebook would be opened with boilerplate code for creating a new Expectation Suite. The code is pretty standard; however, please note that all columns are added to the list of ignored columns in the second cell. We want to validate every column in our example; hence we should remove these columns from the `ignored_columns` list.
Executing the notebook will create an Expectation Suite against the actual credit card fraud dataset.
### Step 5: Transform the real data for modelling.
Now that we have created the Expectation Suite, we shift our focus back to creating the synthetic data.
We follow the standard process of transforming the data before training the GAN. We’re applying `PowerTransformation` — make data distribution more Gaussian-like.
```python
import pandas as pd
from sklearn.preprocessing import PowerTransformer
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
def transformations(data):
#Log transformation to Amount variable
processed_data = data.copy()
data_cols = list(data.columns[data.columns != 'Class'])
data_transformer = Pipeline(steps=[
('PowerTransformer', PowerTransformer(method='yeo-johnson', standardize=True, copy=True))])
preprocessor = ColumnTransformer(
transformers = [('power', data_transformer, data_cols)])
processed_data[data_cols] = preprocessor.fit_transform(data[data_cols])
return data, processed_data, preprocessor
_, data, preprocessor = transformations(data)
```
Feel free to experiment with more pre-processing steps as it will yield better results.
### Step 6: Train the synthesizers and create the model.
Since we have pre-processed our data, it’s time to put our advanced `ydata-synthetic` GAN models to work.
```python
from ydata_synthetic.synthesizers.regular import WGAN_GP
from ydata_synthetic.synthesizers import ModelParameters, TrainParameters
# Define the GAN and training parameters
noise_dim = 32
dim = 128
batch_size = 128
log_step = 100
epochs = 500
learning_rate = 5e-4
beta_1 = 0.5
beta_2 = 0.9
models_dir = './cache'
model = WGAN_GP
#Setting the GAN model parameters and the training step parameters
gan_args = ModelParameters(batch_size=batch_size,
lr=learning_rate,
betas=(beta_1, beta_2),
noise_dim=noise_dim,
n_cols=train_sample.shape[1],
layers_dim=dim)
train_args = TrainParameters(epochs=epochs,
sample_interval=log_step)
# Training the GAN model chosen: Vanilla GAN, CGAN, DCGAN, etc.
synthesizer = model(gan_args, n_critic=2)
synthesizer.train(train_sample, train_args)
```
For this example, we train a kind of GAN, called [WGAN-GP](https://arxiv.org/abs/1704.00028) which provides much-needed training stability.
### Step 7: Sample synthetic data from the synthesizer.
Since we have built our model, now it’s time to sample the required data by feeding noise. The beauty of this step is you can keep generating data as much as you want. This step is powerful when you want to generate different copies of data that are shareable and sellable.
In our case, we generate an equal number of samples as the actual data.
```python
# use the same shape as the real data
synthetic_fraud = synthesizer.sample(492)
```
### Step 8: Inverse transform the data to obtain the original format.
Here we notice that the generated synthetic data is still on the transformed form and needs to be inverse-transformed to the original structure.
```python
synthetic_data = inverse_transform(synthetic_fraud , preprocessor)
```
### Step 9: Create a new Checkpoint to validate the synthetic data against the real data.
For the regular usage of Great Expectations, the best way to <TechnicalTag tag="validate" text="validate" /> data is with a <TechnicalTag tag="checkpoint" text="Checkpoint" />. Checkpoints bundle Batches of data with corresponding Expectation Suites for validation.
From the terminal, run the following command:
```bash
great_expectations checkpoint new my_new_checkpoint
```
This will again open a Jupyter Notebook that will allow you to complete the configuration of our checkpoint. Edit the `data_asset_name` to reference the data we want to validate to the filename we wrote in step 8. Ensure that the `expectation_suite_name` is identical to what we created in step 4.
Once done, go ahead and execute all the cells in the notebook.
### Step 10: Evaluate the synthetic data using Data Docs.
You would have created a new Checkpoint to validate the synthetic data if you’ve followed along. The final step is to uncomment the last cell of the Checkpoint notebook and execute it.
This will open up an HTML page titled <TechnicalTag tag="data_docs" text="Data Docs" />. We can inspect the Data Docs for the most recent Checkpoint and see that the Expectation has failed. By clicking on the Checkpoint run, we get a detailed report of which Expectations failed from which columns.
Based on this input, we can do either of these actions:
- Go back to our data transformation step, modify transformations, change synthesizers or optimize the parameters to get better synthetic data.
- Go back to the Expectation Suite and edit a few Expectations that are not important (maybe for specific columns). Yes — the Expectations are customizable, and here’s [how you can do it](https://docs.greatexpectations.io/docs/guides/expectations/creating_custom_expectations/overview).
## Summary
In this tutorial, we have successfully demonstrated the use of [YData-Synthetic](https://github.com/ydataai/ydata-synthetic) alongside Great Expectations. A 10-step guide was presented starting from configuring a Data Context to evaluating the synthesized data using Data Docs. We believe the integration of these two libraries can help data scientists unlock the power of synthetic data with data quality.
<file_sep>/docs/integrations/index.md
---
title: "Integrations: Index"
---
- [How To Write Integration (With Great Expectations) Documentation](../integrations/contributing_integration.md)
- [Sample Integration](../integrations/integration_template.md)
- [ZenML Integration](../integrations/integration_zenml.md)<file_sep>/docs/deployment_patterns/how_to_use_great_expectations_with_meltano.md
---
title: How to Use Great Expectations with Meltano
---
import Prerequisites from './components/deployment_pattern_prerequisites.jsx'
This guide will help you get Great Expectations installed, configured, and running in your Meltano project.
[Meltano](https://meltano.com/) is an Open Source DataOps OS that's used to install and configure data applications (Great Expectations, Singer, dbt, Airflow, etc.) that your team's data platform is built on top of, all in one central repository.
Using Meltano enables teams to easily implement DataOps best practices like configuration as code, code reviews, isolated test environments, CI/CD, etc.
A common use case is to manage ELT pipelines with Meltano and as part of ensuring the quality of the data in those pipelines, teams bring in Great Expectations.
Meltano uses the concept of [plugins](https://docs.meltano.com/concepts/plugins) to manage external package like Great Expectations.
In this case Great Expectations is supported as a Utility plugin.
## Install Meltano
If you don't already have a Meltano project set up, you can follow these steps to get one setup.
Refer to the Meltano [Getting Started Guide](https://docs.meltano.com/getting-started) for more detail or join us in the [Meltano Slack](https://meltano.com/slack).
```bash
# Install Meltano
pip install meltano
# Create a project directory
mkdir meltano-projects
cd meltano-projects
# Initialize your project
meltano init meltano-great-expectations-project
cd meltano-great-expectations-project
```
## Add Great Expectations
Add Great Expectations to your Meltano project and configure any additional python requirements based on your data sources.
Refer to the Great Expectations [connecting to your data source](https://docs.greatexpectations.io/docs/guides/connecting_to_your_data/connect_to_data_overview) docs for more details.
```bash
# Add utility plugin
meltano add utility great_expectations
# Run a command to ensure installation was successful
meltano invoke great_expectations --help
# Add any additional python requirements (e.g. Snowflake Database requirements)
meltano config great_expectations set _pip_url "great_expectations; sqlalchemy; snowflake-connector-python; snowflake-sqlalchemy"
# Refresh install based on requirement updates
meltano install utility great_expectations
```
This installation process adds all packages and files needed.
If you already have an existing Great Expectation project you can copy it into the `./utilities/` directory where it will be automatically detected by Meltano.
If not, initialize your project and continue.
```bash
cd utilities
meltano invoke great_expectations init
```
## Add Data Source, Expectation Suite, and Checkpoint
If you haven't already done so, follow the Great Expectations [documentation](https://docs.greatexpectations.io/docs/guides/connecting_to_your_data/connect_to_data_overview) to get a datasource, expectation suite, and checkpoint configured.
You can run the commands through the Meltano CLI, for example:
```bash
meltano invoke great_expectations datasource new
meltano invoke great_expectations suite new
meltano invoke great_expectations checkpoint new <checkpoint_name>
```
:::tip
Using the Meltano [environments feature](https://docs.meltano.com/concepts/environments) you can parameterize your Datasource to allow you to toggle between a local, development, or production Datasource.
For example a snippet of a Snowflake configured Datasource is below.
```yaml
class_name: Datasource
execution_engine:
credentials:
host: ${GREAT_EXPECTATIONS_HOST}
username: ${GE_USERNAME}
database: ${GE_PROD_DATABASE}
query:
schema: GREAT_EXPECTATIONS
warehouse: ${GE_WAREHOUSE}
role: ${GE_ROLE}
password: ${<PASSWORD>}
drivername: snowflake
module_name: great_expectations.execution_engine
class_name: SqlAlchemyExecutionEngine
```
Part of Meltano's benefit is wrapping installed packages and injecting configurations to enable isolation and test environments.
:::
## Run your Expectations using Meltano
Now that your expectations are created you can run them using the following commands:
```bash
meltano invoke great_expectations checkpoint run <checkpoint_name>
```
## Common Meltano x Great Expectation Use Cases
Commonly Meltano is used for ELT pipelines and Great Expectations is a perfect complement to take pipelines to the next level of quality and stability.
In the context of ELT pipelines with Meltano there are a few common implementation patterns for Great Expectations:
1. **Transformation Boundaries**
Expectations for the entry and exit points of the transformation steps.
Does the data meet expectations before I transform?
Do the dbt consumption models (i.e. fact and dimension tables) meet expectations?
1. **Source Validation Prior to Replication**
Expectations for the source data in the source system.
Does my Postgres DB (or any source) data meet expectations before I replicate it to my warehouse?
Are their source data problems I should be aware of?
1. **Profiling For Migration**
As part of a migration between warehouses, profiling can give confidence that the data in the new warehouse meets expectations by matching the profile of the original warehouse.
Am I confident that my new warehouse has all my data before switching over?
1. **Transformation Between Steps**
Expectations between each transformation before continuing on to the next step.
Does the data meet expectations after each dbt model is created in my transformation pipeline?
Of course, there's plenty of other ways to implement expectations in your project but it's always helpful to hear common patterns for the ELT context.
## Summary
Meltano is a great way to install, configure, and run Great Expectations in your data platform.
It allows you to configure all your code in one central git repository and enables DataOps best practices like configuration as code, code reviews, isolated test environments, CI/CD, etc.
If you have any questions join us in the [Meltano Slack](https://meltano.com/slack)!
<file_sep>/great_expectations/core/metric_domain_types.py
import enum
import logging
logger = logging.getLogger(__name__)
class MetricDomainTypes(enum.Enum):
TABLE = "table"
COLUMN = "column"
COLUMN_PAIR = "column_pair"
MULTICOLUMN = "multicolumn"
<file_sep>/docs/reference/reference_overview.md
---
title: Reference Documents
---
## [Supplemental Documentation](./supplemental_documentation.md)
In the supplemental documentation section you will find documents that don't necessarily fit in any specific step in the process of working with Great Expectations. This includes things that apply to every step of the process, such as [our guide on How to use the CLI](../guides/miscellaneous/how_to_use_the_great_expectations_cli.md) or our [overview of ways to customize your deployment](../reference/customize_your_deployment.md) as well as things that matter outside the process, or that don't fall into a specific how-to guide.
## [API Reference](./api_reference.md)
This section is the home of our automatically generated API documentation. These documents are built off of the docstrings of Python classes and methods which are a part of Great Expectation's public API. This section is still in progress, as we are incrementally updating docstrings to support the generation of these docs.
## [Glossary of Terms](../glossary.md)
The glossary contains both a quick overview of the definitions for all the various Technical Terms you will find in our documentation which link to a page for each that discusses it in depth. This is an excellent resource both for clarifying your understanding of other documents and digging in deep to find out how Great Expectations works under the hood!
<file_sep>/docs/terms/data_connector.md
---
title: "Data Connector"
---
import UniversalMap from '/docs/images/universal_map/_universal_map.mdx';
import TechnicalTag from '../term_tags/_tag.mdx';
import ConnectHeader from '/docs/images/universal_map/_um_connect_header.mdx';
import CreateHeader from '/docs/images/universal_map/_um_create_header.mdx';
import ValidateHeader from '/docs/images/universal_map/_um_validate_header.mdx';
<UniversalMap setup='inactive' connect='active' create='active' validate='active'/>
## Overview
### Definition
A Data Connector provides the configuration details based on the source data system which are needed by a <TechnicalTag relative="../" tag="datasource" text="Datasource" /> to define <TechnicalTag relative="../" tag="data_asset" text="Data Assets" />.
### Features and promises
A Data Connector facilitates access to an external source data system, such as a database, filesystem, or cloud storage. The Data Connector can inspect an external source data system to:
- identify available Batches
- build Batch Definitions using Batch Identifiers
- translate Batch Definitions to Execution Engine-specific Batch Specs
### Relationship to other objects
A Data Connector is an integral element of a Datasource. When a <TechnicalTag relative="../" tag="batch_request" text="Batch Request" /> is passed to a Datasource, the Datasource will use its Data Connector to build a **Batch Spec**, which the Datasource's <TechnicalTag relative="../" tag="execution_engine" text="Execution Engine" /> will use to return of a <TechnicalTag relative="../" tag="batch" text="Batch" /> of data.
Data Connectors work alongside Execution Engines to provide Batches to <TechnicalTag relative="../" tag="expectation_suite" text="Expectation Suites" />, <TechnicalTag relative="../" tag="profiler" text="Profilers" />, and <TechnicalTag relative="../" tag="checkpoint" text="Checkpoints" />.
## Use cases
<ConnectHeader/>
The only time when you will need to explicitly work with a Data Connector is when you specify one in the configuration of a Datasource.
Each Data Connector holds configuration for connecting to a different type of external data source, and can connect to and inspect that data source.
Great Expectations provides a variety of Data Connectors, depending on the type of external data source and your specific access pattern. The simplest type is the RuntimeDataConnector, which can be used to connect to in-memory data, such as a Pandas or Spark dataframe. The remaining Data Connectors can be categorized as being either an SQL Data Connector (for databases) or File Path Data Connector (for accessing filesystem-like data, which includes files on disk, but also S3 and GCS). Furthermore, these Data Connectors are either Inferred, and are capable of introspecting their external data source and returning any available Data Assets, or Configured, and only connect to Data Assets specified in their configuration.
| Class Name | FilePath/SQL | Configured/Inferred | Datasource Backend |
| --- | --- | --- | --- |
| RuntimeDataConnector | N/A | N/A | N/A |
| ConfiguredAssetAzureDataConnector | FilePath | Configured | Microsoft Azure |
| InferredAssetAzureDataConnector | FilePath | Inferred | Microsoft Azure |
| ConfiguredAssetDBFSDataConnector | FilePath | Configured | Databricks |
| InferredAssetDBFSDataConnector | FilePath | Inferred | Databricks |
| ConfiguredAssetFilesystemDataConnector | FilePath | Configured | Arbitrary Filesystem |
| InferredAssetFilesystemDataConnector | FilePath | Inferred | Arbitrary Filesystem |
| ConfiguredAssetGCSDataConnector | FilePath | Configured | Google Cloud Storage |
| InferredAssetGCSDataConnector | FilePath | Inferred | Google Cloud Storage |
| ConfiguredAssetS3DataConnector | FilePath | Configured | Amazon S3 |
| InferredAssetS3DataConnector | FilePath | Inferred | Amazon S3 |
| ConfiguredAssetSqlDataConnector | SQL | Configured | Database |
| InferredAssetSqlDataConnector | SQL | Inferred | Database |
**For example**, a `ConfiguredAssetFilesystemDataConnector` could be configured with the root directory for files on a filesystem or bucket and prefix used to access files from a cloud storage environment. In contrast, the simplest `RuntimeDataConnector` may simply store lookup information about Data Assets to facilitate running in a pipeline where you already have a DataFrame in memory or available in a cluster.
In addition to those examples, Great Expectations makes it possible to configure Data Connectors that offer stronger guarantees about reproducibility, sampling, and compatibility with other tools.
<CreateHeader/>
When creating Expectations, Datasources will use their Data Connectors behind the scenes as part of the process of providing Batches to Expectation Suites and Profilers.
<ValidateHeader/>
Likewise, when validating Data, Datasources will use their Data Connectors behind the scenes as part of the process of providing Batches to Checkpoints.
## Features
### Identifying Batches and building Batch References
To maintain the guarantees for the relationships between Batches and Batch Requests, Data Connectors provide configuration options that allow them to divide Data Assets into different Batches of data, which Batch Requests reference in order to specify Batches for retrieval. We use the term "Data Reference" below to describe a general pointer to data, like a filesystem path or database view. Batch Identifiers then define a conversion process:
1. Convert a Data Reference to a Batch Request
2. Convert a Batch Request back into a Data Reference (or Wildcard Data Reference, when searching)
The main thing that makes dividing Data Assets into Batches complicated is that converting from a Batch Request to a
Data Reference can be lossy.
It’s pretty easy to construct examples where no regex can reasonably capture enough information to allow lossless
conversion from a Batch Request to a unique Data Reference:
#### Example 1
For example, imagine a daily logfile that includes a random hash:
`YYYY/MM/DD/log-file-[random_hash].txt.gz`
The regex for this naming convention would be something like:
`(\d{4})/(\d{2})/(\d{2})/log-file-.*\.txt\.gz`
with capturing groups for YYYY, MM, and DD, and a non-capturing group for the random hash.
As a result, the Batch Identifiers keys will be Y, M, D. Given specific Batch Identifiers:
```python
{
"Y" : 2020,
"M" : 10,
"D" : 5
}
```
we can reconstruct *part* of the filename, but not the whole thing:
`2020/10/15/log-file-[????].txt.gz`
#### Example 2
A slightly more subtle example: imagine a logfile that is generated daily at about the same time, but includes the exact
time stamp when the file was created.
`log-file-YYYYMMDD-HHMMSS.ssssssss.txt.gz`
The regex for this naming convention would be something like
`log-file-(\d{4})(\d{2})(\d{2})-.*\..*\.txt\.gz`
With capturing groups for YYYY, MM, and DD, but not the HHMMSS.sssssss part of the string. Again, we can only specify
part of the filename:
`log-file-20201015-??????.????????.txt.gz`
#### Example 3
Finally, imagine an S3 bucket with log files like so:
`s3://some_bucket/YYYY/MM/DD/log_file_YYYYMMDD.txt.gz`
In that case, the user would probably specify regex capture groups with something
like `some_bucket/(\d{4})/(\d{2})/(\d{2})/log_file_\d+.txt.gz`.
The Wildcard Data Reference is how Data Connectors deal with that problem, making it easy to search external stores and understand data.
When defining a Data Connector for your Datasource, you may include wildcard Data References as part of the configuration for the Datasource. This is done by including wildcards in the default regex defined in the Data Connector's portion of the Datasource's configuration. Typically, you will see this used for `InferredAssetFilesystemDataConnector`s in Datasources connecting to a filesystem. For an example of this, please see [our guide on how to connect to data on a filesystem using Pandas](../guides/connecting_to_your_data/filesystem/pandas.md).
Under the hood, when processing a Batch Request, the Data Connector may find multiple matching Batches. Generally, the Data Connector will simply return a list of all matching Batch Identifiers.
### Translating Batch Definitions to Batch Specs
A **Batch Definition** includes all the information required to precisely identify a set of data in a source data system.
A **Batch Spec** is an Execution Engine-specific description of the Batch defined by a Batch Definition.
A Data Connector is responsible for working with an Execution Engine to translate Batch Definitions into a Batch Spec that enables Great Expectations to access the data using that Execution Engine.
## API basics
:::info API note
In the updated V3 Great Expectations API, Data Connectors replace the Batch Kwargs Generators from the V2 Great Expectations API.
:::
### How to access
Other than specifying a Data Connector when you configure a Datasource, you will not need to directly interact with one. Great Expectations will handle using them behind the scenes.
### How to create
Data Connectors are automatically created when a Datasource is initialized, based on the Datasource's configuration.
For a general overview of this process, please see [our documentation on configuring your Datasource's Data Connectors](../guides/connecting_to_your_data/connect_to_data_overview.md#configuring-your-datasources-data-connectors).
### Configuration
A Data Connector is configured as part of a Datasource's configuration. The specifics of this configuration can vary depending on the requirements for connecting to the source data system that the Data Connector is intended to interface with. For example, this might be a path to files that might be loaded into the Pandas Execution Engine, or the connection details for a database to be used by the SQLAlchemy Execution Engine.
For specific guidance on how to configure a Data Connector for a given source data system, please see [our how-to guides on connecting to data](../guides/connecting_to_your_data/index.md).
<file_sep>/docs_rtd/changelog.rst
.. _changelog:
#########
Changelog
#########
0.15.34
-----------------
* [BUGFIX] Ensure `packaging_and_installation` CI tests against latest tag (#6386)
* [BUGFIX] Fixed missing comma in pydantic constraints (#6391) (thanks @awburgess)
* [BUGFIX] fix pydantic dev req file entries (#6396)
* [DOCS] DOC-379 bring spark datasource configuration example scripts under test (#6362)
* [MAINTENANCE] Handle both `ExpectationConfiguration` and `ExpectationValidationResult` in default Atomic renderers and cleanup `include_column_name` (#6380)
* [MAINTENANCE] Add type annotations to all existing atomic renderer signatures (#6385)
* [MAINTENANCE] move `zep` -> `experimental` package (#6378)
* [MAINTENANCE] Migrate additional methods from `BaseDataContext` to other parts of context hierarchy (#6388)
0.15.33
-----------------
* [FEATURE] POC ZEP Config Loading (#6320)
* [BUGFIX] Fix issue with misaligned indentation in docs snippets (#6339)
* [BUGFIX] Use `requirements.txt` file when installing linting/static check dependencies in CI (#6368)
* [BUGFIX] Patch nested snippet indentation issues within `remark-named-snippets` plugin (#6376)
* [BUGFIX] Ensure `packaging_and_installation` CI tests against latest tag (#6386)
* [DOCS] DOC-308 update CLI command in docs when working with RBPs instead of Data Assistants (#6222)
* [DOCS] DOC-366 updates to docs in support of branding updates (#5766)
* [DOCS] Add `yarn snippet-check` command (#6351)
* [MAINTENANCE] Add missing one-line docstrings and try to make the others consistent (#6340)
* [MAINTENANCE] Refactor variable aggregation/substitution logic into `ConfigurationProvider` hierarchy (#6321)
* [MAINTENANCE] In ExecutionEngine: Make variable names and usage more descriptive of their purpose. (#6342)
* [MAINTENANCE] Move Cloud-specific enums to `cloud_constants.py` (#6349)
* [MAINTENANCE] Refactor out `termcolor` dependency (#6348)
* [MAINTENANCE] Zep PostgresDatasource returns a list of batches. (#6341)
* [MAINTENANCE] Refactor `usage_stats_opt_out` method in DataContext (#5339)
* [MAINTENANCE] Fix computed metrics type hint in ExecutionEngine.resolve_metrics() method (#6347)
* [MAINTENANCE] Subject: Support to include ID/PK in validation result for each row t… (#5876) (thanks @abekfenn)
* [MAINTENANCE] Pin `mypy` to `0.990` (#6361)
* [MAINTENANCE] Misc cleanup of GX Cloud helpers (#6352)
* [MAINTENANCE] Update column_reflection_fallback to also use schema name for Trino (#6350)
* [MAINTENANCE] Bump version of `mypy` in contrib CLI (#6370)
* [MAINTENANCE] Move config variable substitution logic into `ConfigurationProvider` (#6345)
* [MAINTENANCE] Removes comment in code that was causing confusion to some users. (#6366)
* [MAINTENANCE] minor metrics typing (#6374)
* [MAINTENANCE] Make `ConfigurationProvider` and `ConfigurationSubstitutor` private (#6375)
* [MAINTENANCE] Rename `GeCloudStoreBackend` to `GXCloudStoreBackend` (#6377)
* [MAINTENANCE] Cleanup Metrics and ExecutionEngine methods (#6371)
* [MAINTENANCE] F/great 1314/integrate zep in core (#6358)
* [MAINTENANCE] Loosen `pydantic` version requirement (#6384)
0.15.32
-----------------
* [BUGFIX] Patch broken `CloudNotificationAction` tests (#6327)
* [BUGFIX] add create_temp_table flag to ExecutionEngineConfigSchema (#6331) (thanks @tommy-watts-depop)
* [BUGFIX] MapMetrics now return `partial_unexpected` values for `SUMMARY` format (#6334)
* [DOCS] Re-writes "how to implement custom notifications" as "How to get Data Docs URLs for use in custom Validation Actions" (#6281)
* [DOCS] Removes deprecated expectation notebook exploration doc (#6298)
* [DOCS] Removes a number of unused & deprecated docs (#6300)
* [DOCS] Prioritizes Onboarding Data Assistant in ToC (#6302)
* [DOCS] Add ZenML into integration table in Readme (#6144) (thanks @dnth)
* [DOCS] add `pypi` release badge (#6324)
* [MAINTENANCE] Remove unneeded `BaseDataContext.get_batch_list` (#6291)
* [MAINTENANCE] Clean up implicit `Optional` errors flagged by `mypy` (#6319)
* [MAINTENANCE] Add manual prod flags to core Expectations (#6278)
* [MAINTENANCE] Fallback to isnot method if is_not is not available (old sqlalchemy) (#6318)
* [MAINTENANCE] Add ZEP postgres datasource. (#6274)
* [MAINTENANCE] Delete "metric_dependencies" from MetricConfiguration constructor arguments (#6305)
* [MAINTENANCE] Clean up `DataContext` (#6304)
* [MAINTENANCE] Deprecate `save_changes` flag on `Datasource` CRUD (#6258)
* [MAINTENANCE] Deprecate `great_expectations.render.types` package (#6315)
* [MAINTENANCE] Update range of allowable sqlalchemy versions (#6328)
* [MAINTENANCE] Fixing checkpoint types (#6325)
* [MAINTENANCE] Fix column_reflection_fallback for Trino and minor logging/testing improvements (#6218)
* [MAINTENANCE] Change the number of expected Expectations in the 'quick check' stage of build_gallery pipeline (#6333)
0.15.31
-----------------
* [BUGFIX] Include all requirement files in the sdist (#6292) (thanks @xhochy)
* [DOCS] Updates outdated batch_request snippet in Terms (#6283)
* [DOCS] Update Conditional Expectations doc w/ current availability (#6279)
* [DOCS] Remove outdated Data Discovery page and all references (#6288)
* [DOCS] Remove reference/evaluation_parameters page and all references (#6294)
* [DOCS] Removing deprecated Custom Metrics doc (#6282)
* [DOCS] Re-writes "how to implement custom notifications" as "How to get Data Docs URLs for use in custom Validation Actions" (#6281)
* [DOCS] Removes deprecated expectation notebook exploration doc (#6298)
* [MAINTENANCE] Move RuleState into rule directory. (#6284)
0.15.30
-----------------
* [FEATURE] Add zep datasources to data context. (#6255)
* [BUGFIX] Iterate through `GeCloudIdentifiers` to find the suite ID from the name (#6243)
* [BUGFIX] Update default base url for cloud API (#6176)
* [BUGFIX] Pin `termcolor` to below `2.1.0` due to breaking changes in lib's TTY parsing logic (#6257)
* [BUGFIX] `InferredAssetSqlDataConnector` `include_schema_name` introspection of identical table names in different schemas (#6166)
* [BUGFIX] Fix`docs-integration` tests, and temporarily pin `sqlalchemy` (#6268)
* [BUGFIX] Fix serialization for contrib packages (#6266)
* [BUGFIX] Ensure that `Datasource` credentials are not persisted to Cloud/disk (#6254)
* [DOCS] Updates package contribution references (#5885)
* [MAINTENANCE] Maintenance/great 1103/great 1318/alexsherstinsky/validation graph/refactor validation graph usage 2022 10 20 248 (#6228)
* [MAINTENANCE] Refactor instances of `noqa: F821` Flake8 directive (#6220)
* [MAINTENANCE] Logo URI ref in `data_docs` (#6246)
* [MAINTENANCE] fix typos in docstrings (#6247)
* [MAINTENANCE] Isolate Trino/MSSQL/MySQL tests in `dev` CI (#6231)
* [MAINTENANCE] Split up `compatability` and `comprehensive` stages in `dev` CI to improve performance (#6245)
* [MAINTENANCE] ZEP POC - Asset Type Registration (#6194)
* [MAINTENANCE] Add Trino CLI support and bump Trino version (#6215) (thanks @hovaesco)
* [MAINTENANCE] Delete unneeded Rule attribute property (#6264)
* [MAINTENANCE] Small clean-up of `Marshmallow` warnings (`missing` parameter changed to `load_default` as of 3.13) (#6213)
* [MAINTENANCE] Move `.png` files out of project root (#6249)
* [MAINTENANCE] Cleanup `expectation.py` attributes (#6265)
* [MAINTENANCE] Further parallelize test runs in `dev` CI (#6267)
* [MAINTENANCE] GCP Integration Pipeline fix (#6259)
* [MAINTENANCE] mypy `warn_unused_ignores` (#6270)
* [MAINTENANCE] ZEP - Datasource base class (#6263)
* [MAINTENANCE] Reverting `marshmallow` version bump (#6271)
* [MAINTENANCE] type hints cleanup in Rule-Based Profiler (#6272)
* [MAINTENANCE] Remove unused f-strings (#6248)
* [MAINTENANCE] Make ParameterBuilder.resolve_evaluation_dependencies() into instance (rather than utility) method (#6273)
* [MAINTENANCE] Test definition for `ExpectColumnValueZScoresToBeLessThan` (#6229)
* [MAINTENANCE] Make RuleState constructor argument ordering consistent with standard pattern. (#6275)
* [MAINTENANCE] [REQUEST] Please allow Rachel to unblock blockers (#6253)
0.15.29
-----------------
* [FEATURE] Add support to AWS Glue Data Catalog (#5123) (thanks @lccasagrande)
* [FEATURE] / Added pairwise expectation 'expect_column_pair_values_to_be_in_set' (#6097) (thanks @Arnavkar)
* [BUGFIX] Adjust condition in RenderedAtomicValueSchema.clean_null_attrs (#6168)
* [BUGFIX] Add `py` to dev dependencies to circumvent compatability issues with `pytest==7.2.0` (#6202)
* [BUGFIX] Fix `test_package_dependencies.py` to include `py` lib (#6204)
* [BUGFIX] Fix logic in ExpectationDiagnostics._check_renderer_methods method (#6208)
* [BUGFIX] Patch issue with empty config variables file raising `TypeError` (#6216)
* [BUGFIX] Release patch for Azure env vars (#6233)
* [BUGFIX] Cloud Data Context should overwrite existing suites based on `ge_cloud_id` instead of name (#6234)
* [BUGFIX] Add env vars to Pytest min versions Azure stage (#6239)
* [DOCS] doc-297: update the create Expectations overview page for Data Assistants (#6212)
* [DOCS] DOC-378: bring example scripts for pandas configuration guide under test (#6141)
* [MAINTENANCE] Add unit test for MetricsCalculator.get_metric() Method -- as an example template (#6179)
* [MAINTENANCE] ZEP MetaDatasource POC (#6178)
* [MAINTENANCE] Update `scope_check` in Azure CI to trigger on changed `.py` source code files (#6185)
* [MAINTENANCE] Move test_yaml_config to a separate class (#5487)
* [MAINTENANCE] Changed profiler to Data Assistant in CLI, docs, and tests (#6189)
* [MAINTENANCE] Update default GE_USAGE_STATISTICS_URL in test docker image. (#6192)
* [MAINTENANCE] Re-add a renamed test definition file (#6182)
* [MAINTENANCE] Refactor method `parse_evaluation_parameter` (#6191)
* [MAINTENANCE] Migrate methods from `BaseDataContext` to `AbstractDataContext` (#6188)
* [MAINTENANCE] Rename cfe to v3_api (#6190)
* [MAINTENANCE] Test Trino doc examples with test_script_runner.py (#6198)
* [MAINTENANCE] Cleanup of Regex ParameterBuilder (#6196)
* [MAINTENANCE] Apply static type checking to `expectation.py` (#6173)
* [MAINTENANCE] Remove version matrix from `dev` CI pipeline to improve performance (#6203)
* [MAINTENANCE] Rename `CloudMigrator.retry_unsuccessful_validations` (#6206)
* [MAINTENANCE] Add validate_configuration method to expect_table_row_count_to_equal_other_table (#6209)
* [MAINTENANCE] Replace deprecated `iteritems` with `items` (#6205)
* [MAINTENANCE] Add instructions for setting up the test_ci database (#6211)
* [MAINTENANCE] Add E2E tests for Cloud-backed `Datasource` CRUD (#6186)
* [MAINTENANCE] Execution Engine linting & partial typing (#6210)
* [MAINTENANCE] Test definition for `ExpectColumnValuesToBeJsonParsable`, including a fix for Spark (#6207)
* [MAINTENANCE] Port over usage statistics enabled methods from `BaseDataContext` to `AbstractDataContext` (#6201)
* [MAINTENANCE] Remove temporary dependency on `py` (#6217)
* [MAINTENANCE] Adding type hints to DataAssistant implementations (#6224)
* [MAINTENANCE] Remove AWS config file dependencies and use existing env vars in CI/CD (#6227)
* [MAINTENANCE] Make `UsageStatsEvents` a `StrEnum` (#6225)
* [MAINTENANCE] Move all `requirements-dev*.txt` files to separate dir (#6223)
* [MAINTENANCE] Maintenance/great 1103/great 1318/alexsherstinsky/validation graph/refactor validation graph usage 2022 10 20 248 (#6228)
0.15.28
-----------------
* [FEATURE] Initial zep datasource protocol. (#6153)
* [FEATURE] Introduce BatchManager to manage Batch objects used by Validator and BatchData used by ExecutionEngine (#6156)
* [FEATURE] Add support for Vertica dialect (#6145) (thanks @viplazylmht)
* [FEATURE] Introduce MetricsCalculator and Refactor Redundant Code out of Validator (#6165)
* [BUGFIX] SQLAlchemy selectable Bug fix (#6159) (thanks @tommy-watts-depop)
* [BUGFIX] Parameterize usage stats endpoint in test dockerfile. (#6169)
* [BUGFIX] B/great 1305/usage stats endpoint (#6170)
* [BUGFIX] Ensure that spaces are recognized in named snippets (#6172)
* [DOCS] Clarify wording for interactive mode in databricks (#6154)
* [DOCS] fix source activate command (#6161) (thanks @JGrzywacz)
* [DOCS] Update version in `runtime.txt` to fix breaking Netlify builds (#6181)
* [DOCS] Clean up snippets and line number validation in docs (#6142)
* [MAINTENANCE] Add Enums for renderer types (#6112)
* [MAINTENANCE] Minor cleanup in preparation for Validator refactoring into separate concerns (#6155)
* [MAINTENANCE] add the internal `GE_DATA_CONTEXT_ID` env var to the docker file (#6122)
* [MAINTENANCE] Rollback setting GE_DATA_CONTEXT_ID in docker image. (#6163)
* [MAINTENANCE] disable ge_cloud_mode when specified, detect misconfiguration (#6162)
* [MAINTENANCE] Re-add missing Expectations to gallery and include package names (#6171)
* [MAINTENANCE] Use `from __future__ import annotations` to clean up type hints (#6127)
* [MAINTENANCE] Make sure that quick stage check returns 0 if there are no problems (#6177)
* [MAINTENANCE] Remove SQL for expect_column_discrete_entropy_to_be_between (#6180)
0.15.27
-----------------
* [FEATURE] Add logging/warnings to GX Cloud migration process (#6106)
* [FEATURE] Introduction of updated `gx.get_context()` method that returns correct DataContext-type (#6104)
* [FEATURE] Contribute StatisticsDataAssistant and GrowthNumericDataAssistant (both experimental) (#6115)
* [BUGFIX] add OBJECT_TYPE_NAMES to the JsonSchemaProfiler - issue #6109 (#6110) (thanks @OphelieC)
* [BUGFIX] Fix example `Set-Based Column Map Expectation` template import (#6134)
* [BUGFIX] Regression due to `GESqlDialect` `Enum` for Hive (#6149)
* [DOCS] Support for named snippets in documentation (#6087)
* [MAINTENANCE] Clean up `test_migrate=True` Cloud migrator output (#6119)
* [MAINTENANCE] Creation of Hackathon Packages (#4587)
* [MAINTENANCE] Rename GCP Integration Pipeline (#6121)
* [MAINTENANCE] Change log levels used in `CloudMigrator` (#6125)
* [MAINTENANCE] Bump version of `sqlalchemy-redshift` from `0.7.7` to `0.8.8` (#6082)
* [MAINTENANCE] self_check linting & initial type-checking (#6126)
* [MAINTENANCE] Update per Clickhouse multiple same aliases Bug (#6128) (thanks @adammrozik)
* [MAINTENANCE] Only update existing `rendered_content` if rendering does not fail with new `InlineRenderer` failure message (#6091)
0.15.26
-----------------
* [FEATURE] Enable sending of `ConfigurationBundle` payload in HTTP request to Cloud backend (#6083)
* [FEATURE] Send user validation results to Cloud backend during migration (#6102)
* [BUGFIX] Fix bigquery crash when using "in" with a boolean column (#6071)
* [BUGFIX] Fix serialization error when rendering kl_divergence (#6084) (thanks @roblim)
* [BUGFIX] Enable top-level parameters in Data Assistants accessed via dispatcher (#6077)
* [BUGFIX] Patch issue around `DataContext.save_datasource` not sending `class_name` in result payload (#6108)
* [DOCS] DOC-377 add missing dictionary in configured asset datasource portion of Pandas and Spark configuration guides (#6081)
* [DOCS] DOC-376 finalize definition for Data Assistants in technical terms (#6080)
* [DOCS] Update `docs-integration` test due to new `whole_table` splitter behavior (#6103)
* [DOCS] How to create a Custom Multicolumn Map Expectation (#6101)
* [MAINTENANCE] Patch broken Cloud E2E test (#6079)
* [MAINTENANCE] Bundle data context config and other artifacts for migration (#6068)
* [MAINTENANCE] Add datasources to ConfigurationBundle (#6092)
* [MAINTENANCE] Remove unused config files from root of GX repo (#6090)
* [MAINTENANCE] Add `data_context_id` property to `ConfigurationBundle` (#6094)
* [MAINTENANCE] Move all Cloud migrator logic to separate directory (#6100)
* [MAINTENANCE] Update aloglia scripts for new fields and replica indices (#6049) (thanks @winrp17)
* [MAINTENANCE] initial Datasource typings (#6099)
* [MAINTENANCE] Data context migrate to cloud event (#6095)
* [MAINTENANCE] Bundling tests with empty context configs (#6107)
* [MAINTENANCE] Fixing a typo (#6113)
0.15.25
-----------------
* [FEATURE] Since value set in expectation kwargs is list of strings, do not emit expect_column_values_to_be_in_set for datetime valued columns (#6046)
* [FEATURE] add failed expectations list to slack message (#5812) (thanks @itaise)
* [FEATURE] Enable only ExactNumericRangeEstimator and QuantilesNumericRangeEstimator in "datetime_columns_rule" of OnboardingDataAssistant (#6063)
* [BUGFIX] numpy typing behind `if TYPE_CHECKING` (#6076)
* [DOCS] Update "How to create an Expectation Suite with the Onboarding Data Assistant" (#6050)
* [DOCS] How to get one or more Batches of data from a configured Datasource (#6043)
* [DOCS] DOC-298 Data Assistant technical term page (#6057)
* [DOCS] Update OnboardingDataAssistant documentation (#6059)
* [MAINTENANCE] Clean up of DataAssistant tests that depend on Jupyter notebooks (#6039)
* [MAINTENANCE] AbstractDataContext.datasource_save() test simplifications (#6052)
* [MAINTENANCE] Rough architecture for cloud migration tool (#6054)
* [MAINTENANCE] Include git commit info when building docker image. (#6060)
* [MAINTENANCE] Allow `CloudDataContext` to retrieve and initialize its own project config (#6006)
* [MAINTENANCE] Removing Jupyter notebook-based tests for DataAssistants (#6062)
* [MAINTENANCE] pinned dremio, fixed linting (#6067)
* [MAINTENANCE] usage-stats, & utils.py typing (#5925)
* [MAINTENANCE] Refactor external HTTP request logic into a `Session` factory function (#6007)
* [MAINTENANCE] Remove tag validity stage from release pipeline (#6069)
* [MAINTENANCE] Remove unused test fixtures from test suite (#6058)
* [MAINTENANCE] Remove outdated release files (#6074)
0.15.24
-----------------
* [FEATURE] context.save_datasource (#6009)
* [BUGFIX] Standardize `ConfiguredAssetSqlDataConnector` config in `datasource new` CLI workflow (#6044)
* [DOCS] DOC-371 update the getting started tutorial for data assistants (#6024)
* [DOCS] DOCS-369 sql data connector configuration guide (#6002)
* [MAINTENANCE] Remove outdated entry from release schedule JSON (#6032)
* [MAINTENANCE] Clean up Spark schema tests to have proper names (#6033)
0.15.23
-----------------
* [FEATURE] do not require expectation_suite_name in DataAssistantResult.show_expectations_by...() methods (#5976)
* [FEATURE] Refactor PartitionParameterBuilder into dedicated ValueCountsParameterBuilder and HistogramParameterBuilder (#5975)
* [FEATURE] Implement default sorting for batches based on selected splitter method (#5924)
* [FEATURE] Make OnboardingDataAssistant default profiler in CLI SUITE NEW (#6012)
* [FEATURE] Enable omission of rounding of decimals in NumericMetricRangeMultiBatchParameterBuilder (#6017)
* [FEATURE] Enable non-default sorters for `ConfiguredAssetSqlDataConnector` (#5993)
* [FEATURE] Data Assistant plot method indication of total metrics and expectations count (#6016)
* [BUGFIX] Addresses issue with ExpectCompoundColumnsToBeUnique renderer (#5970)
* [BUGFIX] Fix failing `run_profiler_notebook` test (#5983)
* [BUGFIX] Handle case when only one unique "column.histogram" bin value is found (#5987)
* [BUGFIX] Update `get_validator` test assertions due to change in fixture batches (#5989)
* [BUGFIX] Fix use of column.partition metric in HistogramSingleBatchParameterBuilder to more accurately handle errors (#5990)
* [BUGFIX] Make Spark implementation of "column.value_counts" metric more robust to None/NaN column values (#5996)
* [BUGFIX] Filter out np.nan values (just like None values) as part of ColumnValueCounts._spark() implementation (#5998)
* [BUGFIX] Handle case when only one unique "column.histogram" bin value is found with proper type casting (#6001)
* [BUGFIX] ColumnMedian._sqlalchemy() needs to handle case of single-value column (#6011)
* [BUGFIX] Patch broken `save_expectation_suite` behavior with Cloud-backed `DataContext` (#6004)
* [BUGFIX] Clean quantitative metrics DataFrames in Data Assistant plotting (#6023)
* [BUGFIX] Defer `pprint` in `ExpectationSuite.show_expectations_by_expectation_type()` due to Jupyter rate limit (#6026)
* [BUGFIX] Use UTC TimeZone (rather than Local Time Zone) for Rule-Based Profiler DateTime Conversions (#6028)
* [DOCS] Update snippet refs in "How to create an Expectation Suite with the Onboarding Data Assistant" (#6014)
* [MAINTENANCE] Randomize the non-comprehensive tests (#5968)
* [MAINTENANCE] DatasourceStore refactoring (#5941)
* [MAINTENANCE] Expectation suite init unit tests + types (#5957)
* [MAINTENANCE] Expectation suite new unit tests for add_citation (#5966)
* [MAINTENANCE] Updated release schedule (#5977)
* [MAINTENANCE] Unit tests for `CheckpointStore` (#5967)
* [MAINTENANCE] Enhance unit tests for ExpectationSuite.isEquivalentTo (#5979)
* [MAINTENANCE] Remove unused fixtures from test suite (#5965)
* [MAINTENANCE] Update to MultiBatch Notebook to include Configured - Sql (#5945)
* [MAINTENANCE] Update to MultiBatch Notebook to include Inferred - Sql (#5958)
* [MAINTENANCE] Add reverse assertion for isEquivalentTo tests (#5982)
* [MAINTENANCE] Unit test enhancements ExpectationSuite.__eq__() (#5984)
* [MAINTENANCE] Refactor `DataContext.__init__` to move Cloud-specific logic to `CloudDataContext` (#5981)
* [MAINTENANCE] Set up cloud integration tests with Azure Pipelines (#5995)
* [MAINTENANCE] Example of `splitter_method` at `Asset` and `DataConnector` level (#6000)
* [MAINTENANCE] Replace `splitter_method` strings with `SplitterMethod` Enum and leverage `GESqlDialect` Enum where applicable (#5980)
* [MAINTENANCE] Ensure that `DataContext.add_datasource` works with nested `DataConnector` ids (#5992)
* [MAINTENANCE] Remove cloud integration tests from azure-pipelines.yml (#5997)
* [MAINTENANCE] Unit tests for `GeCloudStoreBackend` (#5999)
* [MAINTENANCE] Parameterize pg hostname in jupyter notebooks (#6005)
* [MAINTENANCE] Unit tests for `Validator` (#5988)
* [MAINTENANCE] Add unit tests for SimpleSqlalchemyDatasource (#6008)
* [MAINTENANCE] Remove `dgtest` from dev pipeline (#6003)
* [MAINTENANCE] Remove deprecated `account_id` from GX Cloud integrations (#6010)
* [MAINTENANCE] Added perf considerations to onboarding assistant notebook (#6022)
* [MAINTENANCE] Redshift specific temp table code path (#6021)
* [MAINTENANCE] Update `datasource new` workflow to enable `ConfiguredAssetDataConnector` usage with SQL-backed `Datasources` (#6019)
0.15.22
-----------------
* [FEATURE] Allowing `schema` to be passed in as `batch_spec_passthrough` in Spark (#5900)
* [FEATURE] DataAssistants Example Notebook - Spark (#5919)
* [FEATURE] Improve slack error condition (#5818) (thanks @itaise)
* [BUGFIX] Ensure that ParameterBuilder implementations in Rule Based Profiler properly handle SQL DECIMAL type (#5896)
* [BUGFIX] Making an all-NULL column handling in RuleBasedProfiler more robust (#5937)
* [BUGFIX] Don't include abstract Expectation classes in _retrieve_expectations_from_module (#5947)
* [BUGFIX] Data Assistant plotting with zero expectations produced (#5934)
* [BUGFIX] prefix and suffix asset names are only relevant for InferredSqlAlchemyDataConnector (#5950)
* [BUGFIX] Prevent "division by zero" errors in Rule-Based Profiler calculations when Batch has zero rows (#5960)
* [BUGFIX] Spark column.distinct_values no longer returns entire table distinct values (#5969)
* [DOCS] DOC-368 spelling correction (#5912)
* [MAINTENANCE] Mark all tests within `tests/data_context/stores` dir (#5913)
* [MAINTENANCE] Cleanup to allow docker test target to run tests in random order (#5915)
* [MAINTENANCE] Use datasource config in add_datasource support methods (#5901)
* [MAINTENANCE] Cleanup up some new datasource sql data connector tests. (#5918)
* [MAINTENANCE] Unit tests for `data_context/store` (#5923)
* [MAINTENANCE] Mark all tests within `tests/validator` (#5926)
* [MAINTENANCE] Certify InferredAssetSqlDataConnector and ConfiguredAssetSqlDataConnector (#5847)
* [MAINTENANCE] Mark DBFS tests with `@pytest.mark.integration` (#5931)
* [MAINTENANCE] Reset globals modified in tests (#5936)
* [MAINTENANCE] Move `Store` test utils from source code to tests (#5932)
* [MAINTENANCE] Mark tests within `tests/rule_based_profiler` (#5930)
* [MAINTENANCE] Add missing import for ConfigurationIdentifier (#5943)
* [MAINTENANCE] Update to OnboardingDataAssistant Notebook - Sql (#5939)
* [MAINTENANCE] Run comprehensive tests in a random order (#5942)
* [MAINTENANCE] Unit tests for `ConfigurationStore` (#5948)
* [MAINTENANCE] Add a dev-tools requirements option (#5944)
* [MAINTENANCE] Run spark and onboarding data assistant test in their own jobs. (#5951)
* [MAINTENANCE] Unit tests for `ValidationGraph` and related classes (#5954)
* [MAINTENANCE] More unit tests for `Stores` (#5953)
* [MAINTENANCE] Add x-fails to flaky Cloud tests for purposes of 0.15.22 (#5964)
* [MAINTENANCE] Bump `Marshmallow` upper bound to work with Airflow operator (#5952)
* [MAINTENANCE] Use DataContext to ignore progress bars (#5959)
0.15.21
-----------------
* [FEATURE] Add `include_rendered_content` to `get_expectation_suite` and `get_validation_result` (#5853)
* [FEATURE] Add tags as an optional setting for the OpsGenieAlertAction (#5855) (thanks @stevewb1993)
* [BUGFIX] Ensure that `delete_expectation_suite` returns proper boolean result (#5878)
* [BUGFIX] many small bugfixes (#5881)
* [BUGFIX] Fix typo in default value of "ignore_row_if" kwarg for MulticolumnMapExpectation (#5860) (thanks @mkopec87)
* [BUGFIX] Patch issue with `checkpoint_identifier` within `Checkpoint.run` workflow (#5894)
* [BUGFIX] Ensure that `DataContext.add_checkpoint()` updates existing objects in GX Cloud (#5895)
* [DOCS] DOC-364 how to configure a spark datasource (#5840)
* [MAINTENANCE] Unit Tests Pipeline step (#5838)
* [MAINTENANCE] Unit tests to ensure coverage over `Datasource` caching in `DataContext` (#5839)
* [MAINTENANCE] Add entries to release schedule (#5833)
* [MAINTENANCE] Properly label `DataAssistant` tests with `@pytest.mark.integration` (#5845)
* [MAINTENANCE] Add additional unit tests around `Datasource` caching (#5844)
* [MAINTENANCE] Mark miscellaneous tests with `@pytest.mark.unit` (#5846)
* [MAINTENANCE] `datasource`, `data_context`, `core` typing, lint fixes (#5824)
* [MAINTENANCE] add --ignore-suppress and --ignore-only-for to build_gallery.py with bugfixes (#5802)
* [MAINTENANCE] Remove pyparsing pin for <3.0 (#5849)
* [MAINTENANCE] Finer type exclude (#5848)
* [MAINTENANCE] use `id` instead `id_` (#5775)
* [MAINTENANCE] Add data connector names in datasource config (#5778)
* [MAINTENANCE] init tests for dict and json serializers (#5854)
* [MAINTENANCE] Remove Partitioning and Quantiles metrics computations from DateTime Rule of OnboardingDataAssistant (#5862)
* [MAINTENANCE] Update `ExpectationSuite` CRUD on `DataContext` to recognize Cloud ids (#5836)
* [MAINTENANCE] Handle Pandas warnings in Data Assistant plots (#5863)
* [MAINTENANCE] Misc cleanup of `test_expectation_suite_crud.py` (#5868)
* [MAINTENANCE] Remove vendored `marshmallow__shade` (#5866)
* [MAINTENANCE] don't force using the stand alone mock (#5871)
* [MAINTENANCE] Update expectation_gallery pipeline (#5874)
* [MAINTENANCE] run unit-tests on a target package (#5869)
* [MAINTENANCE] add `pytest-timeout` (#5857)
* [MAINTENANCE] Label tests in `tests/core` with `@pytest.mark.unit` and `@pytest.mark.integration` (#5879)
* [MAINTENANCE] new invoke test flags (#5880)
* [MAINTENANCE] JSON Serialize RowCondition and MetricBundle computation result to enable IDDict.to_id() for SparkDFExecutionEngine (#5883)
* [MAINTENANCE] increase the `pytest-timeout` timeout value during unit-testing step (#5884)
* [MAINTENANCE] Add `@pytest.mark.slow` throughout test suite (#5882)
* [MAINTENANCE] Add test_expectation_suite_send_usage_message (#5886)
* [MAINTENANCE] Mark existing tests as unit or integration (#5890)
* [MAINTENANCE] Convert integration tests to unit (#5891)
* [MAINTENANCE] Update distinct metric dependencies and implementations (#5811)
* [MAINTENANCE] Add slow pytest marker to config and sort them alphabetically. (#5892)
* [MAINTENANCE] Adding serialization tests for Spark (#5897)
* [MAINTENANCE] Improve existing expectation suite unit tests (phase 1) (#5898)
* [MAINTENANCE] `SqlAlchemyExecutionEngine` case for SQL Alchemy `Select` and `TextualSelect` due to `SADeprecationWarning` (#5902)
0.15.20
-----------------
* [FEATURE] `query.pair_column` Metric (#5743)
* [FEATURE] Enhance execution time measurement utility, and save `DomainBuilder` execution time per Rule of Rule-Based Profiler (#5796)
* [FEATURE] Support single-batch mode in MetricMultiBatchParameterBuilder (#5808)
* [FEATURE] Inline `ExpectationSuite` Rendering (#5726)
* [FEATURE] Better error for missing expectation (#5750) (thanks @tylertrussell)
* [FEATURE] DataAssistants Example Notebook - Pandas (#5820)
* [BUGFIX] Ensure name not persisted (#5813)
* [DOCS] Change the selectable to a list (#5780) (thanks @itaise)
* [DOCS] Fix how to create custom table expectation (#5807) (thanks @itaise)
* [DOCS] DOC-363 how to configure a pandas datasource (#5779)
* [MAINTENANCE] Remove xfail markers on cloud tests (#5793)
* [MAINTENANCE] build-gallery enhancements (#5616)
* [MAINTENANCE] Refactor `save_profiler` to remove explicit `name` and `ge_cloud_id` args (#5792)
* [MAINTENANCE] Add v2_api flag for v2_api specific tests (#5803)
* [MAINTENANCE] Clean up `ge_cloud_id` reference from `DataContext` `ExpectationSuite` CRUD (#5791)
* [MAINTENANCE] Refactor convert_dictionary_to_parameter_node (#5805)
* [MAINTENANCE] Remove `ge_cloud_id` from `DataContext.add_profiler()` signature (#5804)
* [MAINTENANCE] Remove "copy.deepcopy()" calls from ValidationGraph (#5809)
* [MAINTENANCE] Add vectorized is_between for common numpy dtypes (#5711)
* [MAINTENANCE] Make partitioning directives of PartitionParameterBuilder configurable (#5810)
* [MAINTENANCE] Write E2E Cloud test for `RuleBasedProfiler` creation and retrieval (#5815)
* [MAINTENANCE] Change recursion to iteration for function in parameter_container.py (#5817)
* [MAINTENANCE] add `pytest-mock` & `pytest-icdiff` plugins (#5819)
* [MAINTENANCE] Surface cloud errors (#5797)
* [MAINTENANCE] Clean up build_parameter_container_for_variables (#5823)
* [MAINTENANCE] Bugfix/snowflake temp table schema name (#5814)
* [MAINTENANCE] Update `list_` methods on `DataContext` to emit names along with object ids (#5826)
* [MAINTENANCE] xfail Cloud E2E tests due to schema issue with `DataContextVariables` (#5828)
* [MAINTENANCE] Clean up xfails in preparation for 0.15.20 release (#5835)
* [MAINTENANCE] Add back xfails for E2E Cloud tests that fail on env var retrieval in Docker (#5837)
0.15.19
-----------------
* [FEATURE] `DataAssistantResult` plot multiple metrics per expectation (#5556)
* [FEATURE] Enable passing "exact_estimation" boolean at `DataAssistant.run()` level (default value is True) (#5744)
* [FEATURE] Example notebook for Onboarding DataAssistant - `postgres` (#5776)
* [BUGFIX] dir update for data_assistant_result (#5751)
* [BUGFIX] Fix docs_integration pipeline (#5734)
* [BUGFIX] Patch flaky E2E Cloud test with randomized suite names (#5752)
* [BUGFIX] Fix RegexPatternStringParameterBuilder to use legal character repetition. Remove median, mean, and standard deviation features from OnboardingDataAssistant "datetime_columns_rule" definition. (#5757)
* [BUGFIX] Move `SuiteValidationResult.meta` validation id propogation before `ValidationOperator._run_action` (#5760)
* [BUGFIX] Update "column.partition" Metric to handle DateTime Arithmetic Properly (#5764)
* [BUGFIX] JSON-serialize RowCondition and enable IDDict to support comparison operations (#5765)
* [BUGFIX] Insure all estimators properly handle datetime-float conversion (#5774)
* [BUGFIX] Return appropriate subquery type to Query Metrics for SA version (#5783)
* [DOCS] added guide how to use gx with emr serverless (#5623) (thanks @bvolodarskiy)
* [DOCS] DOC-362: how to choose between working with a single or multiple batches of data (#5745)
* [MAINTENANCE] Temporarily xfail E2E Cloud tests due to Azure env var issues (#5787)
* [MAINTENANCE] Add ids to `DataConnectorConfig` (#5740)
* [MAINTENANCE] Rename GX Cloud "contract" resource to "checkpoint" (#5748)
* [MAINTENANCE] Rename GX Cloud "suite_validation_result" resource to "validation_result" (#5749)
* [MAINTENANCE] Store Refactor - cloud store return types & http-errors (#5730)
* [MAINTENANCE] profile_numeric_columns_diff_expectation (#5741) (thanks @stevensecreti)
* [MAINTENANCE] Clean up type hints around class constructors (#5738)
* [MAINTENANCE] invoke docker (#5703)
* [MAINTENANCE] Add plist to build docker test image daily. (#5754)
* [MAINTENANCE] opt-out type-checking (#5713)
* [MAINTENANCE] Enable Algolia UI (#5753)
* [MAINTENANCE] Linting & initial typing for data context (#5756)
* [MAINTENANCE] Update `oneshot` estimator to `quantiles` estimator (#5737)
* [MAINTENANCE] Update Auto-Initializing Expectations to use `exact` estimator by default (#5759)
* [MAINTENANCE] Send a Gx-Version header set to __version__ in requests to cloud (#5758) (thanks @wookasz)
* [MAINTENANCE] invoke docker --detach and more typing (#5770)
* [MAINTENANCE] In ParameterBuilder implementations, enhance handling of numpy.ndarray metric values, whose elements are or can be converted into datetime.datetime type. (#5771)
* [MAINTENANCE] Config/Schema round_tripping (#5697)
* [MAINTENANCE] Add experimental label to MetricStore Doc (#5782)
* [MAINTENANCE] Remove `GeCloudIdentifier` creation in `Checkpoint.run()` (#5784)
0.15.18
-----------------
* [FEATURE] Example notebooks for multi-batch Spark (#5683)
* [FEATURE] Introduce top-level `default_validation_id` in `CheckpointConfig` (#5693)
* [FEATURE] Pass down validation ids to `ExpectationSuiteValidationResult.meta` within `Checkpoint.run()` (#5725)
* [FEATURE] Refactor data assistant runner to compute formal parameters for data assistant run method signatures (#5727)
* [BUGFIX] Restored sqlite database for tests (#5742)
* [BUGFIX] Fixing a typo in variable name for default profiler for auto-initializing expectation "expect_column_mean_to_be_between" (#5687)
* [BUGFIX] Remove `resource_type` from call to `StoreBackend.build_key` (#5690)
* [BUGFIX] Update how_to_use_great_expectations_in_aws_glue.md (#5685) (thanks @bvolodarskiy)
* [BUGFIX] Updated how_to_use_great_expectations_in_aws_glue.md again (#5696) (thanks @bvolodarskiy)
* [BUGFIX] Update how_to_use_great_expectations_in_aws_glue.md (#5722) (thanks @bvolodarskiy)
* [BUGFIX] Update aws_glue_deployment_patterns.py (#5721) (thanks @bvolodarskiy)
* [DOCS] added guide how to use great expectations with aws glue (#5536) (thanks @bvolodarskiy)
* [DOCS] Document the ZenML integration for Great Expectations (#5672) (thanks @stefannica)
* [DOCS] Converts broken ZenML md refs to Technical Tags (#5714)
* [DOCS] How to create a Custom Query Expectation (#5460)
* [MAINTENANCE] Pin makefun package to version range for support assurance (#5746)
* [MAINTENANCE] s3 link for logo (#5731)
* [MAINTENANCE] Assign `resource_type` in `InlineStoreBackend` constructor (#5671)
* [MAINTENANCE] Add mysql client to Dockerfile.tests (#5681)
* [MAINTENANCE] `RuleBasedProfiler` corner case configuration changes (#5631)
* [MAINTENANCE] Update teams.yml (#5684)
* [MAINTENANCE] Utilize `e2e` mark on E2E Cloud tests (#5691)
* [MAINTENANCE] pyproject.tooml build-system typo (#5692)
* [MAINTENANCE] expand flake8 coverage (#5676)
* [MAINTENANCE] Ensure Cloud E2E tests are isolated to `gx-cloud-e2e` stage of CI (#5695)
* [MAINTENANCE] Add usage stats and initial database docker tests to CI (#5682)
* [MAINTENANCE] Add `e2e` mark to `pyproject.toml` (#5699)
* [MAINTENANCE] Update docker readme to mount your repo over the builtin one. (#5701)
* [MAINTENANCE] Combine packages `rule_based_profiler` and `rule_based_profiler.types` (#5680)
* [MAINTENANCE] ExpectColumnValuesToBeInSetSparkOptimized (#5702)
* [MAINTENANCE] expect_column_pair_values_to_have_difference_of_custom_perc… (#5661) (thanks @exteli)
* [MAINTENANCE] Remove non-docker version of CI tests that are now running in docker. (#5700)
* [MAINTENANCE] Add back `integration` mark to tests in `test_datasource_crud.py` (#5708)
* [MAINTENANCE] DEVREL-2289/Stale/Triage (#5694)
* [MAINTENANCE] revert expansive flake8 pre-commit checking - flake8 5.0.4 (#5706)
* [MAINTENANCE] Bugfix for `cloud-db-integration-pipeline` (#5704)
* [MAINTENANCE] Remove pytest-azurepipelines (#5716)
* [MAINTENANCE] Remove deprecation warning from `DataConnector`-level `batch_identifiers` for `RuntimeDataConnector` (#5717)
* [MAINTENANCE] Refactor `AbstractConfig` to make `name` and `id_` consistent attrs (#5698)
* [MAINTENANCE] Move CLI tests to docker (#5719)
* [MAINTENANCE] Leverage `DataContextVariables` in `DataContext` hierarchy to automatically determine how to persist changes (#5715)
* [MAINTENANCE] Refactor `InMemoryStoreBackend` out of `store_backend.py` (#5679)
* [MAINTENANCE] Move compatibility matrix tests to docker (#5728)
* [MAINTENANCE] Adds additional file extensions for Parquet assets (#5729)
* [MAINTENANCE] MultiBatch SqlExample notebook Update. (#5718)
* [MAINTENANCE] Introduce NumericRangeEstimator class hierarchy and encapsulate existing estimator implementations (#5735)
0.15.17
-----------------
* [FEATURE] Improve estimation histogram computation in NumericMetricRangeMultiBatchParameterBuilder to include both counts and bin edges (#5628)
* [FEATURE] Enable retrieve by name for datasource with cloud store backend (#5640)
* [FEATURE] Update `DataContext.add_checkpoint()` to ensure validations within `CheckpointConfig` contain ids (#5638)
* [FEATURE] Add `expect_column_values_to_be_valid_crc32` (#5580) (thanks @sp1thas)
* [FEATURE] Enable showing expectation suite by domain and by expectation_type -- from DataAssistantResult (#5673)
* [BUGFIX] Patch flaky E2E GX Cloud tests (#5629)
* [BUGFIX] Pass `--cloud` flag to `dgtest-cloud-overrides` section of Azure YAML (#5632)
* [BUGFIX] Remove datasource from config on delete (#5636)
* [BUGFIX] Patch issue with usage stats sync not respecting usage stats opt-out (#5644)
* [BUGFIX] SlackRenderer / EmailRenderer links to deprecated doc (#5648)
* [BUGFIX] Fix table.head metric issue when using BQ without temp tables (#5630)
* [BUGFIX] Quick bugfix on all profile numeric column diff bounds expectations (#5651) (thanks @stevensecreti)
* [BUGFIX] Patch bug with `id` vs `id_` in Cloud integration tests (#5677)
* [DOCS] Fix a typo in batch_request_parameters variable (#5612) (thanks @StasDeep)
* [MAINTENANCE] CloudDataContext add_datasource test (#5626)
* [MAINTENANCE] Update stale.yml (#5602)
* [MAINTENANCE] Add `id` to `CheckpointValidationConfig` (#5603)
* [MAINTENANCE] Better error message for RuntimeDataConnector for BatchIdentifiers (#5635)
* [MAINTENANCE] type-checking round 2 (#5576)
* [MAINTENANCE] minor cleanup of old comments (#5641)
* [MAINTENANCE] add `--clear-cache` flag for `invoke type-check` (#5639)
* [MAINTENANCE] Install `dgtest` test runner utilizing Git URL in CI (#5645)
* [MAINTENANCE] Make comparisons of aggregate values date aware (#5642) (thanks @jcampbell)
* [MAINTENANCE] Add E2E Cloud test for `DataContext.add_checkpoint()` (#5653)
* [MAINTENANCE] Use docker to run tests in the Azure CI pipeline. (#5646)
* [MAINTENANCE] add new invoke tasks to `tasks.py` and create new file `usage_stats_utils.py` (#5593)
* [MAINTENANCE] Don't include 'test-pipeline' in extras_require dict (#5659)
* [MAINTENANCE] move tool config to pyproject.toml (#5649)
* [MAINTENANCE] Refactor docker test CI steps into jobs. (#5665)
* [MAINTENANCE] Only run Cloud E2E tests in primary pipeline (#5670)
* [MAINTENANCE] Improve DateTime Conversion Candling in Comparison Metrics & Expectations and Provide a Clean Object Model for Metrics Computation Bundling (#5656)
* [MAINTENANCE] Ensure that `id_` fields in Marshmallow schema serialize as `id` (#5660)
* [MAINTENANCE] data_context initial type checking (#5662)
0.15.16
-----------------
* [FEATURE] Multi-Batch Example Notebook - SqlDataConnector examples (#5575)
* [FEATURE] Implement "is_close()" for making equality comparisons "reasonably close" for each ExecutionEngine subclass (#5597)
* [FEATURE] expect_profile_numeric_columns_percent_diff_(inclusive bounds) (#5586) (thanks @stevensecreti)
* [FEATURE] DataConnector Query enabled for `SimpleSqlDatasource` (#5610)
* [FEATURE] Implement the exact metric range estimate for NumericMetricRangeMultiBatchParameterBuilder (#5620)
* [FEATURE] Ensure that id propogates from RuleBasedProfilerConfig to RuleBasedProfiler (#5617)
* [BUGFIX] Pass cloud base url to datasource store (#5595)
* [BUGFIX] Temporarily disable Trino `0.315.0` from requirements (#5606)
* [BUGFIX] Update _create_trino_engine to check for schema before creating it (#5607)
* [BUGFIX] Support `ExpectationSuite` CRUD at `BaseDataContext` level (#5604)
* [BUGFIX] Update test due to change in postgres stdev calculation method (#5624)
* [BUGFIX] Patch issue with `get_validator` on Cloud-backed `DataContext` (#5619)
* [MAINTENANCE] Add name and id to DatasourceConfig (#5560)
* [MAINTENANCE] Clear datasources in `test_data_context_datasources` to improve test performance and narrow test scope (#5588)
* [MAINTENANCE] Fix tests that rely on guessing pytest generated random file paths. (#5589)
* [MAINTENANCE] Do not set google cloud credentials for lifetime of pytest process. (#5592)
* [MAINTENANCE] Misc updates to `Datasource` CRUD on `DataContext` to ensure consistent behavior (#5584)
* [MAINTENANCE] Add id to `RuleBasedProfiler` config (#5590)
* [MAINTENANCE] refactor to enable customization of quantile bias correction threshold for bootstrap estimation method (#5587)
* [MAINTENANCE] Ensure that `resource_type` used in `GeCloudStoreBackend` is converted to `GeCloudRESTResource` enum as needed (#5601)
* [MAINTENANCE] Create datasource with id (#5591)
* [MAINTENANCE] Enable Azure blob storage integration tests (#5594)
* [MAINTENANCE] Increase expectation kwarg line stroke width (#5608)
* [MAINTENANCE] Added Algolia Scripts (#5544) (thanks @devanshdixit)
* [MAINTENANCE] Handle `numpy` deprecation warnings (#5615)
* [MAINTENANCE] remove approximate comparisons -- they will be replaced by estimator alternatives (#5618)
* [MAINTENANCE] Making the dependency on dev-lite clearer (#5514)
* [MAINTENANCE] Fix tests in tests/integration/profiling/rule_based_profiler/ and tests/render/renderer/ (#5611)
* [MAINTENANCE] DataContext in cloud mode test add_datasource (#5625)
0.15.15
-----------------
* [FEATURE] Integrate `DataContextVariables` with `DataContext` (#5466)
* [FEATURE] Add mostly to MulticolumnMapExpectation (#5481)
* [FEATURE] [MAINTENANCE] Revamped expect_profile_numeric_columns_diff_between_exclusive_threshold_range (#5493) (thanks @stevensecreti)
* [FEATURE] [CONTRIB] expect_profile_numeric_columns_diff_(less/greater)_than_or_equal_to_threshold (#5522) (thanks @stevensecreti)
* [FEATURE] Provide methods for returning ExpectationConfiguration list grouped by expectation_type and by domain_type (#5532)
* [FEATURE] add support for Azure authentication methods (#5229) (thanks @sdebruyn)
* [FEATURE] Show grouped sorted expectations by Domain and by expectation_type (#5539)
* [FEATURE] Categorical Rule in VolumeDataAssistant Should Use Same Cardinality As Categorical Rule in OnboardingDataAssistant (#5551)
* [BUGFIX] Handle "division by zero" in "ColumnPartition" metric when all column values are NULL (#5507)
* [BUGFIX] Use string dialect name if not found in enum (#5546)
* [BUGFIX] Add `try/except` around `DataContext._save_project_config` to mitigate issues with permissions (#5550)
* [BUGFIX] Explicitly pass in mostly as 1 if not set in configuration. (#5548)
* [BUGFIX] Increase precision for categorical rule for fractional comparisons (#5552)
* [DOCS] DOC-340 partition local installation guide (#5425)
* [DOCS] Add DataHub Ingestion docs (#5330) (thanks @maggiehays)
* [DOCS] toc update for DataHub integration doc (#5518)
* [DOCS] Updating discourse to GitHub Discussions in Docs (#4953)
* [MAINTENANCE] Clean up payload for `/data-context-variables` endpoint to adhere to desired chema (#5509)
* [MAINTENANCE] DataContext Refactor: DataAssistants (#5472)
* [MAINTENANCE] Ensure that validation operators are omitted from Cloud variables payload (#5510)
* [MAINTENANCE] Add end-to-end tests for multicolumn map expectations (#5517)
* [MAINTENANCE] Ensure that *_store_name attrs are omitted from Cloud variables payload (#5519)
* [MAINTENANCE] Refactor `key` arg out of `Store.serialize/deserialize` (#5511)
* [MAINTENANCE] Fix links to documentation (#5177) (thanks @andyjessen)
* [MAINTENANCE] Readme Update (#4952)
* [MAINTENANCE] E2E test for `FileDataContextVariables` (#5516)
* [MAINTENANCE] Cleanup/refactor prerequisite for group/filter/sort Expectations by domain (#5523)
* [MAINTENANCE] Refactor `GeCloudStoreBackend` to use PUT and DELETE HTTP verbs instead of PATCH (#5527)
* [MAINTENANCE] `/profiler` Cloud endpoint support (#5499)
* [MAINTENANCE] Add type hints to `Store` (#5529)
* [MAINTENANCE] Move MetricDomainTypes to core (it is used more widely now than previously). (#5530)
* [MAINTENANCE] Remove dependency pins on pyarrow and snowflake-connector-python (#5533)
* [MAINTENANCE] use invoke for common contrib/dev tasks (#5506)
* [MAINTENANCE] Add snowflake-connector-python dependency lower bound. (#5538)
* [MAINTENANCE] enforce pre-commit in ci (#5526)
* [MAINTENANCE] Providing more robust error handling for determining `domain_type` of an `ExpectationConfiguration` object (#5542)
* [MAINTENANCE] Remove extra indentation from store backend test (#5545)
* [MAINTENANCE] Plot-level dropdown for `DataAssistantResult` display charts (#5528)
* [MAINTENANCE] Make DataAssistantResult.batch_id_to_batch_identifier_display_name_map private (in order to optimize auto-complete for ease of use) (#5549)
* [MAINTENANCE] Initial Dockerfile for running tests and associated README. (#5541)
* [MAINTENANCE] Other dialect test (#5547)
0.15.14
-----------------
* [FEATURE] QueryExpectations (#5223)
* [FEATURE] Control volume of metadata output when running DataAssistant classes. (#5483)
* [BUGFIX] Snowflake Docs Integration Test Fix (#5463)
* [BUGFIX] DataProfiler Linting Fix (#5468)
* [BUGFIX] Update renderer snapshots with `None` values removed (#5474)
* [BUGFIX] Rendering Test failures (#5475)
* [BUGFIX] Update `dependency-graph` pipeline YAML to ensure `--spark` gets passed to `dgtest` (#5477)
* [BUGFIX] Make sure the profileReport obj does not have defaultdicts (breaks gallery JSON) (#5491)
* [BUGFIX] Use Pandas.isnull() instead of NumPy.isnan() to check for empty values in TableExpectation._validate_metric_value_between(), due to wider types applicability. (#5502)
* [BUGFIX] Spark Schema has unexpected field for `spark.sql.warehouse.dir` (#5490)
* [BUGFIX] Conditionally pop values from Spark config in tests (#5508)
* [DOCS] DOC-349 re-write and partition interactive mode expectations guide (#5448)
* [DOCS] DOC-344 partition data docs on s3 guide (#5437)
* [DOCS] DOC-342 partition how to configure a validation result store in amazon s3 guide (#5428)
* [DOCS] link fix in onboarding data assistant guide (#5469)
* [DOCS] Integrate great-expectation with ydata-synthetic (#4568) (thanks @arunnthevapalan)
* [DOCS] Add 'test' extra to setup.py with docs (#5415)
* [DOCS] DOC-343 partition how to configure expectation store for aws s3 guide (#5429)
* [DOCS] DOC-357 partition the how to create a new checkpoint guide (#5458)
* [DOCS] Remove outdated release process docs. (#5484)
* [MAINTENANCE] Update `teams.yml` (#5457)
* [MAINTENANCE] Clean up GitHub Actions (#5461)
* [MAINTENANCE] Adds documentation and examples changes for snowflake connection string (#5447)
* [MAINTENANCE] DOC-345 partition the connect to s3 cloud storage with Pandas guide (#5439)
* [MAINTENANCE] Add unit and integration tests for Splitting on Mod Integer (#5452)
* [MAINTENANCE] Remove `InlineRenderer` invocation feature flag from `ExpectationValidationResult` (#5441)
* [MAINTENANCE] `DataContext` Refactor. Migration of datasource and store (#5404)
* [MAINTENANCE] Add unit and integration tests for Splitting on Multi-Column Values (#5464)
* [MAINTENANCE] Refactor `DataContextVariables` to leverage `@property` and `@setter` (#5446)
* [MAINTENANCE] expect_profile_numeric_columns_diff_between_threshold_range (#5467) (thanks @stevensecreti)
* [MAINTENANCE] Make `DataAssistantResult` fixtures module scoped (#5465)
* [MAINTENANCE] Remove keyword arguments within table row count expectations (#4874) (thanks @andyjessen)
* [MAINTENANCE] Add unit tests for Splitting on Converted DateTime (#5470)
* [MAINTENANCE] Rearrange integration tests to insure categorization into proper deployment-style based lists (#5471)
* [MAINTENANCE] Provide better error messaging if batch_request is not supplied to DataAssistant.run() (#5473)
* [MAINTENANCE] Adds run time envvar for Snowflake Partner ID (#5485)
* [MAINTENANCE] fixed algolia search page (#5099)
* [MAINTENANCE] Remove pyspark<3.0.0 constraint for python 3.7 (#5496)
* [MAINTENANCE] Ensure that `parter-integration` pipeline only runs on cronjob (#5500)
* [MAINTENANCE] Adding fixtures Query Expectations tests (#5486)
* [MAINTENANCE] Misc updates to `GeCloudStoreBackend` to better integrate with GE Cloud (#5497)
* [MAINTENANCE] Update automated release schedule (#5488)
* [MAINTENANCE] Update core-team in `teams.yml` (#5489)
* [MAINTENANCE] Update how_to_create_a_new_expectation_suite_using_rule_based_profile… (#5495)
* [MAINTENANCE] Remove pypandoc pin in constraints-dev.txt. (#5501)
* [MAINTENANCE] Ensure that `add_datasource` method on `AbstractDataContext` does not persist by default (#5482)
0.15.13
-----------------
* [FEATURE] Add atomic `rendered_content` to `ExpectationValidationResult` and `ExpectationConfiguration` (#5369)
* [FEATURE] Add `DataContext.update_datasource` CRUD method (#5417)
* [FEATURE] Refactor Splitter Testing Modules so as to Make them More General and Add Unit and Integration Tests for "split_on_whole_table" and "split_on_column_value" on SQLite and All Supported Major SQL Backends (#5430)
* [FEATURE] Support underscore in the `condition_value` of a `row_condition` (#5393) (thanks @sp1thas)
* [DOCS] DOC-322 update terminology to v3 (#5326)
* [MAINTENANCE] Change property name of TaxiSplittingTestCase to make it more general (#5419)
* [MAINTENANCE] Ensure that `BaseDataContext` does not persist `Datasource` changes by default (#5423)
* [MAINTENANCE] Migration of `project_config_with_variables_substituted` to `AbstractDataContext` (#5385)
* [MAINTENANCE] Improve type hinting in `GeCloudStoreBackend` (#5427)
* [MAINTENANCE] Test serialization of text, table, and bulleted list `rendered_content` in `ExpectationValidationResult` (#5438)
* [MAINTENANCE] Refactor `datasource_name` out of `DataContext.update_datasource` (#5440)
* [MAINTENANCE] Add checkpoint name to validation results (#5442)
* [MAINTENANCE] Remove checkpoint from top level of schema since it is captured in `meta` (#5445)
* [MAINTENANCE] Add unit and integration tests for Splitting on Divided Integer (#5449)
* [MAINTENANCE] Update cli with new default simple checkpoint name (#5450)
0.15.12
-----------------
* [FEATURE] Add Rule Statistics to DataAssistantResult for display in Jupyter notebook (#5368)
* [FEATURE] Include detailed Rule Execution statistics in jupyter notebook "repr" style output (#5375)
* [FEATURE] Support datetime/date-part splitters on Amazon Redshift (#5408)
* [DOCS] Capital One DataProfiler Expectations README Update (#5365) (thanks @stevensecreti)
* [DOCS] Add Trino guide (#5287)
* [DOCS] DOC-339 remove redundant how-to guide (#5396)
* [DOCS] Capital One Data Profiler README update (#5387) (thanks @taylorfturner)
* [DOCS] Add sqlalchemy-redshfit to dependencies in redshift doc (#5386)
* [MAINTENANCE] Reduce output amount in Jupyter notebooks when displaying DataAssistantResult (#5362)
* [MAINTENANCE] Update linter thresholds (#5367)
* [MAINTENANCE] Move `_apply_global_config_overrides()` to AbstractDataContext (#5285)
* [MAINTENANCE] WIP: [MAINTENANCE] stalebot configuration (#5301)
* [MAINTENANCE] expect_column_values_to_be_equal_to_or_greater_than_profile_min (#5372) (thanks @stevensecreti)
* [MAINTENANCE] expect_column_values_to_be_equal_to_or_less_than_profile_max (#5380) (thanks @stevensecreti)
* [MAINTENANCE] Replace string formatting with f-string (#5225) (thanks @andyjessen)
* [MAINTENANCE] Fix links in docs (#5340) (thanks @andyjessen)
* [MAINTENANCE] Caching of `config_variables` in `DataContext` (#5376)
* [MAINTENANCE] StaleBot Half DryRun (#5390)
* [MAINTENANCE] StaleBot DryRun 2 (#5391)
* [MAINTENANCE] file extentions applied to rel links (#5399)
* [MAINTENANCE] Allow installing jinja2 version 3.1.0 and higher (#5382)
* [MAINTENANCE] expect_column_values_confidence_for_data_label_to_be_less_than_or_equal_to_threshold (#5392) (thanks @stevensecreti)
* [MAINTENANCE] Add warnings to internal linters if actual error count does not match threshold (#5401)
* [MAINTENANCE] Ensure that changes made to env vars / config vars are recognized within subsequent calls of the same process (#5410)
* [MAINTENANCE] Stack `RuleBasedProfiler` progress bars for better user experience (#5400)
* [MAINTENANCE] Keep all Pandas Splitter Tests in a Dedicated Module (#5411)
* [MAINTENANCE] Refactor DataContextVariables to only persist state to Store using explicit save command (#5366)
* [MAINTENANCE] Refactor to put tests for splitting and sampling into modules for respective ExecutionEngine implementation (#5412)
0.15.11
-----------------
* [FEATURE] Enable NumericMetricRangeMultiBatchParameterBuilder to use evaluation dependencies (#5323)
* [FEATURE] Improve Trino Support (#5261) (thanks @aezomz)
* [FEATURE] added support to Aws Athena quantiles (#5114) (thanks @kuhnen)
* [FEATURE] Implement the "column.standard_deviation" metric for sqlite database (#5338)
* [FEATURE] Update `add_datasource` to leverage the `DatasourceStore` (#5334)
* [FEATURE] Provide ability for DataAssistant to return its effective underlying BaseRuleBasedProfiler configuration (#5359)
* [BUGFIX] Fix Netlify build issue that was being caused by entry in changelog (#5322)
* [BUGFIX] Numpy dtype.float64 formatted floating point numbers must be converted to Python float for use in SQLAlchemy Boolean clauses (#5336)
* [BUGFIX] Fix for failing Expectation test in `cloud_db_integration` pipeline (#5321)
* [DOCS] revert getting started tutorial to RBP process (#5307)
* [DOCS] mark onboarding assistant guide as experimental and update cli command (#5308)
* [DOCS] Fix line numbers in getting started guide (#5324)
* [DOCS] DOC-337 automate updates to the version information displayed in the getting started tutorial. (#5348)
* [MAINTENANCE] Fix link in suite profile renderer (#5242) (thanks @andyjessen)
* [MAINTENANCE] Refactor of `_apply_global_config_overrides()` method to return config (#5286)
* [MAINTENANCE] Remove "json_serialize" directive from ParameterBuilder computations (#5320)
* [MAINTENANCE] Misc cleanup post `0.15.10` release (#5325)
* [MAINTENANCE] Standardize instantiation of NumericMetricRangeMultibatchParameterBuilder throughout the codebase. (#5327)
* [MAINTENANCE] Reuse MetricMultiBatchParameterBuilder computation results as evaluation dependencies for performance enhancement (#5329)
* [MAINTENANCE] clean up type declarations (#5331)
* [MAINTENANCE] Maintenance/great 761/great 1010/great 1011/alexsherstinsky/rule based profiler/data assistant/include only essential public methods in data assistant dispatcher class 2022 06 21 177 (#5351)
* [MAINTENANCE] Update release schedule JSON (#5349)
* [MAINTENANCE] Include only essential public methods in DataAssistantResult class (and its descendants) (#5360)
0.15.10
-----------------
* [FEATURE] `DataContextVariables` CRUD for `stores` (#5268)
* [FEATURE] `DataContextVariables` CRUD for `data_docs_sites` (#5269)
* [FEATURE] `DataContextVariables` CRUD for `anonymous_usage_statistics` (#5271)
* [FEATURE] `DataContextVariables` CRUD for `notebooks` (#5272)
* [FEATURE] `DataContextVariables` CRUD for `concurrency` (#5273)
* [FEATURE] `DataContextVariables` CRUD for `progress_bars` (#5274)
* [FEATURE] Integrate `DatasourceStore` with `DataContext` (#5292)
* [FEATURE] Support both UserConfigurableProfiler and OnboardingDataAssistant in "CLI SUITE NEW --PROFILE name" command (#5306)
* [BUGFIX] Fix ColumnPartition metric handling of the number of bins (must always be integer). (#5282)
* [BUGFIX] Add new high precision rule for mean and stdev in `OnboardingDataAssistant` (#5276)
* [BUGFIX] Warning in Getting Started Guide notebook. (#5297)
* [DOCS] how to create an expectation suite with the onboarding assistant (#5266)
* [DOCS] update getting started tutorial for onboarding assistant (#5294)
* [DOCS] getting started tutorial doc standards updates (#5295)
* [DOCS] Update standard arguments doc for Expectations to not reference datasets. (#5052)
* [MAINTENANCE] Add check to `check_type_hint_coverage` script to ensure proper `mypy` installation (#5291)
* [MAINTENANCE] `DataAssistantResult` cleanup and extensibility enhancements (#5259)
* [MAINTENANCE] Handle compare Expectation in presence of high precision floating point numbers and NaN values (#5298)
* [MAINTENANCE] Suppress persisting of temporary ExpectationSuite configurations in Rule-Based Profiler computations (#5305)
* [MAINTENANCE] Adds column values github user validation (#5302)
* [MAINTENANCE] Adds column values IATA code validation (#5303)
* [MAINTENANCE] Adds column values ARN validation (#5304)
* [MAINTENANCE] Fixing a typo in a comment (in several files) (#5310)
* [MAINTENANCE] Adds column scientific notation string validation (#5309)
* [MAINTENANCE] lint fixes (#5312)
* [MAINTENANCE] Adds column value JSON validation (#5313)
* [MAINTENANCE] Expect column values to be valid scientific notation (#5311)
0.15.9
-----------------
* [FEATURE] Add new expectation: expect column values to match powers of a base g… (#5219) (thanks @rifatKomodoDragon)
* [FEATURE] Replace UserConfigurableProfiler with OnboardingDataAssistant in "CLI suite new --profile" Jupyter Notebooks (#5236)
* [FEATURE] `DatasourceStore` (#5206)
* [FEATURE] add new expectation on validating hexadecimals (#5188) (thanks @andrewsx)
* [FEATURE] Usage Statistics Events for Profiler and DataAssistant "get_expectation_suite()" methods. (#5251)
* [FEATURE] `InlineStoreBackend` (#5216)
* [FEATURE] The "column.histogram" metric must support integer values of the "bins" parameter for all execution engine options. (#5258)
* [FEATURE] Initial implementation of `DataContextVariables` accessors (#5238)
* [FEATURE] `OnboardingDataAssistant` plots for `expect_table_columns_to_match_set` (#5208)
* [FEATURE] `DataContextVariables` CRUD for `config_variables_file_path` (#5262)
* [FEATURE] `DataContextVariables` CRUD for `plugins_directory` (#5263)
* [FEATURE] `DataContextVariables` CRUD for store name accessors (#5264)
* [BUGFIX] Hive temporary tables creation fix (#4956) (thanks @jaume-ferrarons)
* [BUGFIX] Provide error handling when metric fails for all Batch data samples (#5256)
* [BUGFIX] Patch automated release test date comparisons (#5278)
* [DOCS] How to compare two tables with the UserConfigurableProfiler (#5050)
* [DOCS] How to create a Custom Column Pair Map Expectation w/ supporting template & example (#4926)
* [DOCS] Auto API documentation script (#4964)
* [DOCS] Update formatting of links to public methods in class docs generated by auto API script (#5247)
* [DOCS] In the reference section of the ToC remove duplicates and update category pages (#5248)
* [DOCS] Update DataContext docstring (#5250)
* [MAINTENANCE] Add CodeSee architecture diagram workflow to repository (#5235) (thanks @codesee-maps[bot])
* [MAINTENANCE] Fix links to API docs (#5246) (thanks @andyjessen)
* [MAINTENANCE] Unpin cryptography upper bound (#5249)
* [MAINTENANCE] Don't use jupyter-client 7.3.2 (#5252)
* [MAINTENANCE] Re-introduce jupyter-client 7.3.2 (#5253)
* [MAINTENANCE] Add `cloud` mark to `pytest.ini` (#5254)
* [MAINTENANCE] add partner integration framework (#5132)
* [MAINTENANCE] `DataContextVariableKey` for use in Stores (#5255)
* [MAINTENANCE] Clarification of events in test with multiple checkpoint validations (#5257)
* [MAINTENANCE] Misc updates to improve security and automation of the weekly release process (#5244)
* [MAINTENANCE] show more test output and minor fixes (#5239)
* [MAINTENANCE] Add proper unit tests for Column Histogram metric and use Column Value Partitioner in OnboardingDataAssistant (#5267)
* [MAINTENANCE] Updates contributor docs to reflect updated linting guidance (#4909)
* [MAINTENANCE] Remove condition from `autoupdate` GitHub action (#5270)
* [MAINTENANCE] Improve code readability in the processing section of "MapMetricColumnDomainBuilder". (#5279)
0.15.8
-----------------
* [FEATURE] `OnboardingDataAssistant` plots for `expect_table_row_count_to_be_between` non-sequential batches (#5212)
* [FEATURE] Limit sampling for spark and pandas (#5201)
* [FEATURE] Groundwork for DataContext Refactor (#5203)
* [FEATURE] Implement ability to change rule variable values through DataAssistant run() method arguments at runtime (#5218)
* [FEATURE] Plot numeric column domains in `OnboardingDataAssistant` (#5189)
* [BUGFIX] Repair "CLI Suite --Profile" Operation (#5230)
* [DOCS] Remove leading underscore from sampling docs (#5214)
* [MAINTENANCE] suppressing type hints in ill-defined situations (#5213)
* [MAINTENANCE] Change CategoricalColumnDomainBuilder property name from "limit_mode" to "cardinality_limit_mode". (#5215)
* [MAINTENANCE] Update Note in BigQuery Docs (#5197)
* [MAINTENANCE] Sampling cleanup refactor (use BatchSpec in sampling methods) (#5217)
* [MAINTENANCE] Globally increase Azure timeouts to 120 mins (#5222)
* [MAINTENANCE] Comment out kl_divergence for build_gallery (#5196)
* [MAINTENANCE] Fix docstring on expectation (#5204) (thanks @andyjessen)
* [MAINTENANCE] Improve NaN handling in numeric ParameterBuilder implementations (#5226)
* [MAINTENANCE] Update type hint and docstring linter thresholds (#5228)
0.15.7
-----------------
* [FEATURE] Add Rule for TEXT semantic domains within the Onboarding Assistant (#5144)
* [FEATURE] Helper method to determine whether Expectation is self-initializing (#5159)
* [FEATURE] OnboardingDataAssistantResult plotting feature parity with VolumeDataAssistantResult (#5145)
* [FEATURE] Example Notebook for self-initializing `Expectations` (#5169)
* [FEATURE] DataAssistant: Enable passing directives to run() method using runtime_environment argument (#5187)
* [FEATURE] Adding DataAssistantResult.get_expectation_suite(expectation_suite_name) method (#5191)
* [FEATURE] Cronjob to automatically create release PR (#5181)
* [BUGFIX] Insure TABLE Domain Metrics Do Not Get Column Key From Column Type Rule Domain Builder (#5166)
* [BUGFIX] Update name for stdev expectation in `OnboardingDataAssistant` backend (#5193)
* [BUGFIX] OnboardingDataAssistant and Underlying Metrics: Add Defensive Programming Into Metric Implementations So As To Avoid Warnings About Incompatible Data (#5195)
* [BUGFIX] Insure that Histogram Metric in Pandas operates on numerical columns that do not have NULL values (#5199)
* [BUGFIX] RuleBasedProfiler: Ensure that run() method runtime environment directives are handled correctly when existing setting is None (by default) (#5202)
* [BUGFIX] In aggregate metrics, Spark Implementation already gets Column type as argument -- no need for F.col() as the operand is not a string. (#5207)
* [DOCS] Update ToC with category links (#5155)
* [DOCS] update on availability and parameters of conditional expectations (#5150)
* [MAINTENANCE] Helper method for RBP Notebook tests that does clean-up (#5171)
* [MAINTENANCE] Increase timeout for longer stages in Azure pipelines (#5175)
* [MAINTENANCE] Rule-Based Profiler -- In ParameterBuilder insure that metrics are validated for conversion to numpy array (to avoid deprecation warnings) (#5173)
* [MAINTENANCE] Increase timeout in packaging & installation pipeline (#5178)
* [MAINTENANCE] OnboardingDataAssistant handle multiple expectations per domain (#5170)
* [MAINTENANCE] Update timeout in pipelines to fit Azure syntax (#5180)
* [MAINTENANCE] Error message when `Validator` is instantiated with Incorrect `BatchRequest` (#5172)
* [MAINTENANCE] Don't include infinity in rendered string for diagnostics (#5190)
* [MAINTENANCE] Mark Great Expectations Cloud tests and add stage to CI/CD (#5186)
* [MAINTENANCE] Trigger expectation gallery build with scheduled CI/CD runs (#5192)
* [MAINTENANCE] `expectation_gallery` Azure pipeline (#5194)
* [MAINTENANCE] General cleanup/refactor of `DataAssistantResult` (#5198)
0.15.6
-----------------
* [FEATURE] `NumericMetricRangeMultiBatchParameterBuilder` kernel density estimation (#5084)
* [FEATURE] Splitters and limit sample work on AWS Athena (#5024)
* [FEATURE] `ColumnValuesLengthMin` and `ColumnValuesLengthMax` metrics (#5107)
* [FEATURE] Use `batch_identifiers` in plot tooltips (#5091)
* [FEATURE] Updated `DataAssistantResult` plotting API (#5117)
* [FEATURE] Onboarding DataAssistant: Numeric Rules and Relevant Metrics (#5120)
* [FEATURE] DateTime Rule for OnboardingDataAssistant (#5121)
* [FEATURE] Categorical Rule is added to OnboardingDataAssistant (#5134)
* [FEATURE] OnboardingDataAssistant: Introduce MeanTableColumnsSetMatchMultiBatchParameterBuilder (to enable expect_table_columns_to_match_set) (#5135)
* [FEATURE] Giving the "expect_table_columns_to_match_set" Expectation Self-Initializing Capabilities. (#5136)
* [FEATURE] For OnboardingDataAssistant: Implement a TABLE Domain level rule to output "expect_table_columns_to_match_set" (#5137)
* [FEATURE] Enable self-initializing `ExpectColumnValueLengthsToBeBetween` (#4985)
* [FEATURE] `DataAssistant` plotting for non-sequential batches (#5126)
* [BUGFIX] Insure that Batch IDs are accessible in the order in which they were loaded in Validator (#5112)
* [BUGFIX] Update `DataAssistant` notebook for new plotting API (#5118)
* [BUGFIX] For DataAssistants, added try-except for Notebook tests (#5124)
* [BUGFIX] CategoricalColumnDomainBuilder needs to accept limit_mode with dictionary type (#5127)
* [BUGFIX] Use `external_sqldialect` mark to skip during lightweight runs (#5139)
* [BUGFIX] Use RANDOM_STATE in fixture to make tests deterministic (#5142)
* [BUGFIX] Read deployment_version instead of using versioneer in deprecation tests (#5147)
* [MAINTENANCE] DataAssistant: Refactoring Access to common ParameterBuilder instances (#5108)
* [MAINTENANCE] Refactor of`MetricTypes` and `AttributedResolvedMetrics` (#5100)
* [MAINTENANCE] Remove references to show_cta_footer except in schemas.py (#5111)
* [MAINTENANCE] Adding unit tests for sqlalchemy limit sampler part 1 (#5109)
* [MAINTENANCE] Don't re-raise connection errors in CI (#5115)
* [MAINTENANCE] Sqlite specific tests for splitting and sampling (#5119)
* [MAINTENANCE] Add Trino dialect in SqlAlchemyDataset (#5085) (thanks @ms32035)
* [MAINTENANCE] Move upper bound on sqlalchemy to <2.0.0. (#5140)
* [MAINTENANCE] Update primary pipeline to cut releases with tags (#5128)
* [MAINTENANCE] Improve handling of "expect_column_unique_values_count_to_be_between" in VolumeDataAssistant (#5146)
* [MAINTENANCE] Simplify DataAssistant Operation to not Depend on Self-Initializing Expectations (#5148)
* [MAINTENANCE] Improvements to Trino support (#5152)
* [MAINTENANCE] Update how_to_configure_a_new_checkpoint_using_test_yaml_config.md (#5157)
* [MAINTENANCE] Speed up the site builder (#5125) (thanks @tanelk)
* [MAINTENANCE] remove account id deprecation notice (#5158)
0.15.5
-----------------
* [FEATURE] Add subset operation to Domain class (#5049)
* [FEATURE] In DataAssistant: Use Domain instead of domain_type as key for Metrics Parameter Builders (#5057)
* [FEATURE] Self-initializing `ExpectColumnStddevToBeBetween` (#5065)
* [FEATURE] Enum used by DateSplitter able to be represented as YAML (#5073)
* [FEATURE] Implementation of auto-complete for DataAssistant class names in Jupyter notebooks (#5077)
* [FEATURE] Provide display ("friendly") names for batch identifiers (#5086)
* [FEATURE] Onboarding DataAssistant -- Initial Rule Implementations (Data Aspects) (#5101)
* [FEATURE] OnboardingDataAssistant: Implement Nullity/Non-nullity Rules and Associated Metrics (#5104)
* [BUGFIX] `self_check()` now also checks for `aws_config_file` (#5040)
* [BUGFIX] `multi_batch_rule_based_profiler` test up to date with RBP changes (#5066)
* [BUGFIX] Splitting Support at Asset level (#5026)
* [BUGFIX] Make self-initialization in expect_column_values_to_be_between truly multi batch (#5068)
* [BUGFIX] databricks engine create temporary view (#4994) (thanks @gvillafanetapia)
* [BUGFIX] Patch broken Expectation gallery script (#5090)
* [BUGFIX] Sampling support at asset level (#5092)
* [DOCS] Update process and configurations in OpenLineage Action guide. (#5039)
* [DOCS] Update process and config examples in Opsgenie guide (#5037)
* [DOCS] Correct name of `openlineage-integration-common` package (#5041) (thanks @mobuchowski)
* [DOCS] Remove reference to validation operator process from how to trigger slack notifications guide (#5034)
* [DOCS] Update process and configuration examples in email Action guide. (#5036)
* [DOCS] Update Docusaurus version (#5063)
* [MAINTENANCE] Saved output of usage stats schema script in repo (#5053)
* [MAINTENANCE] Apply Altair custom themes to return objects (#5044)
* [MAINTENANCE] Introducing RuleBasedProfilerResult -- neither expectation suite name nor expectation suite must be passed to RuleBasedProfiler.run() (#5061)
* [MAINTENANCE] Refactor `DataAssistant` plotting to leverage utility dataclasses (#5022)
* [MAINTENANCE] Check that a passed string is parseable as an integer (mssql limit param) (#5071)
* [MAINTENANCE] Clean up mssql limit sampling code path and comments (#5074)
* [MAINTENANCE] Make saving bootstraps histogram for NumericMetricRangeMultiBatchParameterBuilder optional (absent by default) (#5075)
* [MAINTENANCE] Make self-initializing expectations return estimated kwargs with auto-generation timestamp and Great Expectation version (#5076)
* [MAINTENANCE] Adding a unit test for batch_id mapping to batch display names (#5087)
* [MAINTENANCE] `pypandoc` version constraint added (`< 1.8`) (#5093)
* [MAINTENANCE] Utilize Rule objects in Profiler construction in DataAssistant (#5089)
* [MAINTENANCE] Turn off metric calculation progress bars in `RuleBasedProfiler` and `DataAssistant` workflows (#5080)
* [MAINTENANCE] A small refactor of ParamerBuilder management used in DataAssistant classes (#5102)
* [MAINTENANCE] Convenience method refactor for Onboarding DataAssistant (#5103)
0.15.4
-----------------
* [FEATURE] Enable self-initializing `ExpectColumnMeanToBeBetween` (#4986)
* [FEATURE] Enable self-initializing `ExpectColumnMedianToBeBetween` (#4987)
* [FEATURE] Enable self-initializing `ExpectColumnSumToBeBetween` (#4988)
* [FEATURE] New MetricSingleBatchParameterBuilder for specifically single-Batch Rule-Based Profiler scenarios (#5003)
* [FEATURE] Enable Pandas DataFrame and Series as MetricValues Output of Metric ParameterBuilder Classes (#5008)
* [FEATURE] Notebook for `VolumeDataAssistant` Example (#5010)
* [FEATURE] Histogram/Partition Single-Batch ParameterBuilder (#5011)
* [FEATURE] Update `DataAssistantResult.plot()` return value to emit `PlotResult` wrapper dataclass (#4962)
* [FEATURE] Limit samplers work with supported sqlalchemy backends (#5014)
* [FEATURE] trino support (#5021)
* [BUGFIX] RBP Profiling Dataset ProgressBar Fix (#4999)
* [BUGFIX] Fix DataAssistantResult serialization issue (#5020)
* [DOCS] Update slack notification guide to not use validation operators. (#4978)
* [MAINTENANCE] Update `autoupdate` GitHub action (#5001)
* [MAINTENANCE] Move `DataAssistant` registry capabilities into `DataAssistantRegistry` to enable user aliasing (#4991)
* [MAINTENANCE] Fix continuous partition example (#4939) (thanks @andyjessen)
* [MAINTENANCE] Preliminary refactors for data samplers. (#4996)
* [MAINTENANCE] Clean up unused imports and enforce through `flake8` in CI/CD (#5005)
* [MAINTENANCE] ParameterBuilder tests should maximally utilize polymorphism (#5007)
* [MAINTENANCE] Clean up type hints in CLI (#5006)
* [MAINTENANCE] Making ParameterBuilder metric computations robust to failures through logging and exception handling (#5009)
* [MAINTENANCE] Condense column-level `vconcat` plots into one interactive plot (#5002)
* [MAINTENANCE] Update version of `black` in pre-commit config (#5019)
* [MAINTENANCE] Improve tooltips and formatting for distinct column values chart in VolumeDataAssistantResult (#5017)
* [MAINTENANCE] Enhance configuring serialization for DotDict type classes (#5023)
* [MAINTENANCE] Pyarrow upper bound (#5028)
0.15.3
-----------------
* [FEATURE] Enable self-initializing capabilities for `ExpectColumnProportionOfUniqueValuesToBeBetween` (#4929)
* [FEATURE] Enable support for plotting both Table and Column charts in `VolumeDataAssistant` (#4930)
* [FEATURE] BigQuery Temp Table Support (#4925)
* [FEATURE] Registry for DataAssistant classes with ability to execute from DataContext by registered name (#4966)
* [FEATURE] Enable self-intializing capabilities for `ExpectColumnValuesToMatchRegex`/`ExpectColumnValuesToNotMatchRegex` (#4958)
* [FEATURE] Provide "estimation histogram" ParameterBuilder output details . (#4975)
* [FEATURE] Enable self-initializing `ExpectColumnValuesToMatchStrftimeFormat` (#4977)
* [BUGFIX] check contrib requirements (#4922)
* [BUGFIX] Use `monkeypatch` to set a consistent bootstrap seed in tests (#4960)
* [BUGFIX] Make all Builder Configuration classes of Rule-Based Profiler Configuration Serializable (#4972)
* [BUGFIX] extras_require (#4968)
* [BUGFIX] Fix broken packaging test and update `dgtest-overrides` (#4976)
* [MAINTENANCE] Add timeout to `great_expectations` pipeline stages to prevent false positive build failures (#4957)
* [MAINTENANCE] Defining Common Test Fixtures for DataAssistant Testing (#4959)
* [MAINTENANCE] Temporarily pin `cryptography` package (#4963)
* [MAINTENANCE] Type annotate relevant functions with `-> None` (per PEP 484) (#4969)
* [MAINTENANCE] Handle edge cases where `false_positive_rate` is not in range [0, 1] or very close to bounds (#4946)
* [MAINTENANCE] fix a typo (#4974)
0.15.2
-----------------
* [FEATURE] Split data assets using sql datetime columns (#4871)
* [FEATURE] Plot metrics with `DataAssistantResult.plot()` (#4873)
* [FEATURE] RuleBasedProfiler/DataAssistant/MetricMultiBatchParameterBuilder: Enable Returning Metric Computation Results with batch_id Attribution (#4862)
* [FEATURE] Enable variables to be specified at both Profiler and its constituent individual Rule levels (#4912)
* [FEATURE] Enable self-initializing `ExpectColumnUniqueValueCountToBeBetween` (#4902)
* [FEATURE] Improve diagnostic testing process (#4816)
* [FEATURE] Add Azure CI/CD action to aid with style guide enforcement (type hints) (#4878)
* [FEATURE] Add Azure CI/CD action to aid with style guide enforcement (docstrings) (#4617)
* [FEATURE] Use formal interfaces to clean up DataAssistant and DataAssistantResult modules/classes (#4901)
* [BUGFIX] fix validation issue for column domain type and implement expect_column_unique_value_count_to_be_between for VolumeDataAssistant (#4914)
* [BUGFIX] Fix issue with not using the generated table name on read (#4905)
* [BUGFIX] Add deprecation comment to RuntimeDataConnector
* [BUGFIX] Ensure proper class_name within all RuleBasedProfilerConfig instantiations
* [BUGFIX] fix rounding directive handling (#4887)
* [BUGFIX] `great_expectations` import fails when SQL Alchemy is not installed (#4880)
* [MAINTENANCE] Altair types cleanup (#4916)
* [MAINTENANCE] test: update test time (#4911)
* [MAINTENANCE] Add module docstring and simplify access to DatePart (#4910)
* [MAINTENANCE] Chip away at type hint violations around data context (#4897)
* [MAINTENANCE] Improve error message outputted to user in DocstringChecker action (#4895)
* [MAINTENANCE] Re-enable bigquery tests (#4903)
* [MAINTENANCE] Unit tests for sqlalchemy splitter methods, docs and other improvements (#4900)
* [MAINTENANCE] Move plot logic from `DataAssistant` into `DataAssistantResult` (#4896)
* [MAINTENANCE] Add condition to primary pipeline to ensure `import_ge` stage doesn't cause misleading Slack notifications (#4898)
* [MAINTENANCE] Refactor `RuleBasedProfilerConfig` (#4882)
* [MAINTENANCE] Refactor DataAssistant Access to Parameter Computation Results and Plotting Utilities (#4893)
* [MAINTENANCE] Update `dgtest-overrides` list to include all test files not captured by primary strategy (#4891)
* [MAINTENANCE] Add dgtest-overrides section to dependency_graph Azure pipeline
* [MAINTENANCE] Datasource and DataContext-level tests for RuntimeDataConnector changes (#4866)
* [MAINTENANCE] Temporarily disable bigquery tests. (#4888)
* [MAINTENANCE] Import GE after running `ge init` in packaging CI pipeline (#4885)
* [MAINTENANCE] Add CI stage importing GE with only required dependencies installed (#4884)
* [MAINTENANCE] `DataAssistantResult.plot()` conditional formatting and tooltips (#4881)
* [MAINTENANCE] split data context files (#4879)
* [MAINTENANCE] Add Tanner to CODEOWNERS for schemas.py (#4875)
* [MAINTENANCE] Use defined constants for ParameterNode accessor keys (#4872)
0.15.1
-----------------
* [FEATURE] Additional Rule-Based Profiler Parameter/Variable Access Methods (#4814)
* [FEATURE] DataAssistant and VolumeDataAssistant classes (initial implementation -- to be enhanced as part of subsequent work) (#4844)
* [FEATURE] Add Support for Returning Parameters and Metrics as DataAssistantResult class (#4848)
* [FEATURE] DataAssistantResult Includes Underlying Profiler Execution Time (#4854)
* [FEATURE] Add batch_id for every resolved metric_value to ParameterBuilder.get_metrics() result object (#4860)
* [FEATURE] `RuntimeDataConnector` able to specify `Assets` (#4861)
* [BUGFIX] Linting error from hackathon automerge (#4829)
* [BUGFIX] Cleanup contrib (#4838)
* [BUGFIX] Add `notebook` to `GE_REQUIRED_DEPENDENCIES` (#4842)
* [BUGFIX] ParameterContainer return value formatting bug fix (#4840)
* [BUGFIX] Ensure that Parameter Validation/Configuration Dependency Configurations are included in Serialization (#4843)
* [BUGFIX] Correctly handle SQLA unexpected count metric for empty tables (#4618) (thanks @douglascook)
* [BUGFIX] Temporarily adjust Deprecation Warning Count (#4869)
* [DOCS] How to validate data with an in memory checkpoint (#4820)
* [DOCS] Update all tutorial redirect fix (#4841)
* [DOCS] redirect/remove dead links in docs (#4846)
* [MAINTENANCE] Refactor Rule-Based Profiler instantiation in Validator to make it available as a public method (#4823)
* [MAINTENANCE] String Type is not needed as Return Type from DomainBuilder.domain_type() (#4827)
* [MAINTENANCE] Fix Typo in Checkpoint Readme (#4835) (thanks @andyjessen)
* [MAINTENANCE] Modify conditional expectations readme (#4616) (thanks @andyjessen)
* [MAINTENANCE] Fix links within datasource new notebook (#4833) (thanks @andyjessen)
* [MAINTENANCE] Adds missing dependency, which is breaking CLI workflows (#4839)
* [MAINTENANCE] Update testing and documentation for `oneshot` estimation method (#4852)
* [MAINTENANCE] Refactor `Datasource` tests that work with `RuntimeDataConnector` by backend. (#4853)
* [MAINTENANCE] Update DataAssistant interfaces (#4857)
* [MAINTENANCE] Improve types returned by DataAssistant interface methods (#4859)
* [MAINTENANCE] Refactor `DataContext` tests that work with RuntimeDataConnector by backend (#4858)
* [HACKATHON] `Hackathon PRs in this release <https://github.com/great-expectations/great_expectations/pulls?q=is%3Apr+label%3Ahackathon-2022+is%3Amerged+-updated%3A%3E%3D2022-04-14+-updated%3A%3C%3D2022-04-06>`
0.15.0
-----------------
* [BREAKING] EOL Python 3.6 (#4567)
* [FEATURE] Implement Multi-Column Domain Builder for Rule-Based Profiler (#4604)
* [FEATURE] Update RBP notebook to include example for Multi-Column Domain Builder (#4606)
* [FEATURE] Rule-Based Profiler: ColumnPairDomainBuilder (#4608)
* [FEATURE] More package contrib info (#4693)
* [FEATURE] Introducing RuleState class and RuleOutput class for Rule-Based Profiler in support of richer use cases (such as DataAssistant). (#4704)
* [FEATURE] Add support for returning fully-qualified parameters names/values from RuleOutput object (#4773)
* [BUGFIX] Pass random seed to bootstrap estimator (#4605)
* [BUGFIX] Adjust output of `regex` ParameterBuilder to match Expectation (#4594)
* [BUGFIX] Rule-Based Profiler: Only primitive type based BatchRequest is allowed for Builder classes (#4614)
* [BUGFIX] Fix DataContext templates test (#4678)
* [BUGFIX] update module_name in NoteBookConfigSchema from v2 path to v3 (#4589) (thanks @Josephmaclean)
* [BUGFIX] request S3 bucket location only when necessary (#4526) (thanks @error418)
* [DOCS] Update `ignored_columns` snippet in "Getting Started" (#4609)
* [DOCS] Fixes import statement. (#4694)
* [DOCS] Update tutorial_review.md typo with intended word. (#4611) (thanks @cjbramble)
* [DOCS] Correct typo in url in docstring for set_based_column_map_expectation_template.py (example script) (#4817)
* [MAINTENANCE] Add retries to `requests` in usage stats integration tests (#4600)
* [MAINTENANCE] Miscellaneous test cleanup (#4602)
* [MAINTENANCE] Simplify ParameterBuilder.build_parameter() interface (#4622)
* [MAINTENANCE] War on Warnings - DataContext (#4572)
* [MAINTENANCE] Update links within great_expectations.yml (#4549) (thanks @andyjessen)
* [MAINTENANCE] Provide cardinality limit modes from CategoricalColumnDomainBuilder (#4662)
* [MAINTENANCE] Rule-Based Profiler: Rename Rule.generate() to Rule.run() (#4670)
* [MAINTENANCE] Refactor ValidationParameter computation (to be more elegant/compact) and fix a type hint in SimpleDateFormatStringParameterBuilder (#4687)
* [MAINTENANCE] Remove `pybigquery` check that is no longer needed (#4681)
* [MAINTENANCE] Rule-Based Profiler: Allow ExpectationConfigurationBuilder to be Optional (#4698)
* [MAINTENANCE] Slightly Clean Up NumericMetricRangeMultiBatchParameterBuilder (#4699)
* [MAINTENANCE] ParameterBuilder must not recompute its value, if it already exists in RuleState (ParameterContainer for its Domain). (#4701)
* [MAINTENANCE] Improve get validator functionality (#4661)
* [MAINTENANCE] Add checks for mostly=1.0 for all renderers (#4736)
* [MAINTENANCE] revert to not raising datasource errors on data context init (#4732)
* [MAINTENANCE] Remove unused bootstrap methods that were migrated to ML Flow (#4742)
* [MAINTENANCE] Update README.md (#4595) (thanks @andyjessen)
* [MAINTENANCE] Check for mostly equals 1 in renderers (#4815)
* [MAINTENANCE] Remove bootstrap tests that are no longer needed (#4818)
* [HACKATHON] ExpectColumnValuesToBeIsoLanguages (#4627) (thanks @szecsip)
* [HACKATHON] ExpectColumnAverageLatLonPairwiseDistanceToBeLessThan (#4559) (thanks @mmi333)
* [HACKATHON] ExpectColumnValuesToBeValidIPv6 (#4561) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidMac (#4562) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidMIME (#4563) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidHexColor (#4564) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidIban (#4565) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidIsoCountry (#4566) (thanks @voidforall)
* [HACKATHON] add expect_column_values_to_be_private_ipv4_class (#4656) (thanks @szecsip)
* [HACKATHON] Feature/expect column values url hostname match with cert (#4649) (thanks @szecsip)
* [HACKATHON] add expect_column_values_url_has_got_valid_cert (#4648) (thanks @szecsip)
* [HACKATHON] add expect_column_values_to_be_valid_us_state_or_territory (#4655) (thanks @Derekma73)
* [HACKATHON] ExpectColumnValuesToBeValidSsn (#4646) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidHttpStatusName (#4645) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidHttpStatusCode (#4644) (thanks @voidforall)
* [HACKATHON] Feature/expect column values to be daytime (#4643) (thanks @szecsip)
* [HACKATHON] add expect_column_values_ip_address_in_network (#4640) (thanks @szecsip)
* [HACKATHON] add expect_column_values_ip_asn_country_code_in_set (#4638) (thanks @szecsip)
* [HACKATHON] add expect_column_values_to_be_valid_us_state (#4654) (thanks @Derekma73)
* [HACKATHON] add expect_column_values_to_be_valid_us_state_or_territory_abbreviation (#4653) (thanks @Derekma73)
* [HACKATHON] add expect_column_values_to_be_weekday (#4636) (thanks @szecsip)
* [HACKATHON] add expect_column_values_to_be_valid_us_state_abbrevation (#4650) (thanks @Derekma73)
* [HACKATHON] ExpectColumnValuesGeometryDistanceToAddressToBeBetween (#4652) (thanks @pjdobson)
* [HACKATHON] ExpectColumnValuesToBeValidUdpPort (#4635) (thanks @voidforall)
* [HACKATHON] add expect_column_values_to_be_fibonacci_number (#4629) (thanks @szecsip)
* [HACKATHON] add expect_column_values_to_be_slug (#4628) (thanks @szecsip)
* [HACKATHON] ExpectColumnValuesGeometryToBeWithinPlace (#4626) (thanks @pjdobson)
* [HACKATHON] add expect_column_values_to_be_private_ipv6 (#4624) (thanks @szecsip)
* [HACKATHON] add expect_column_values_to_be_private_ip_v4 (#4623) (thanks @szecsip)
* [HACKATHON] ExpectColumnValuesToBeValidPrice (#4593) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidPhonenumber (#4592) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBePolygonAreaBetween (#4591) (thanks @mmi333)
* [HACKATHON] ExpectColumnValuesToBeValidTcpPort (#4634) (thanks @voidforall)
0.14.13
-----------------
* [FEATURE] Convert Existing Self-Initializing Expectations to Make ExpectationConfigurationBuilder Self-Contained with its own validation_parameter_builder settings (#4547)
* [FEATURE] Improve diagnostic checklist details (#4548)
* [BUGFIX] Moves testing dependencies out of core reqs (#4522)
* [BUGFIX] Adjust output of datetime `ParameterBuilder` to match Expectation (#4590)
* [DOCS] Technical term tags for Adding features to Expectations section of the ToC (#4462)
* [DOCS] Contributing integrations ToC update. (#4551)
* [DOCS] Update intro page overview image (#4540)
* [DOCS] clarifications on execution engines and scalability (#4539)
* [DOCS] technical terms for validate data advanced (#4535)
* [DOCS] technical terms for validate data actions docs (#4518)
* [DOCS] correct code reference line numbers and snippet tags for how to create a batch of data from an in memory data frame (#4573)
* [DOCS] Update links in page; fix markdown link in html block (#4585)
* [MAINTENANCE] Don't return from validate configuration methods (#4545)
* [MAINTENANCE] Rule-Based Profiler: Refactor utilities into appropriate modules/classes for better separation of concerns (#4553)
* [MAINTENANCE] Refactor global `conftest` (#4534)
* [MAINTENANCE] clean up docstrings (#4554)
* [MAINTENANCE] Small formatting rearrangement for RegexPatternStringParameterBuilder (#4558)
* [MAINTENANCE] Refactor Anonymizer utilizing the Strategy design pattern (#4485)
* [MAINTENANCE] Remove duplicate `mistune` dependency (#4569)
* [MAINTENANCE] Run PEP273 checks on a schedule or release cut (#4570)
* [MAINTENANCE] Package dependencies usage stats instrumentation - part 1 (#4546)
* [MAINTENANCE] Add DevRel team to GitHub auto-label action (#4575)
* [MAINTENANCE] Add GitHub action to conditionally auto-update PR's (#4574)
* [MAINTENANCE] Bump version of `black` in response to hotfix for Click v8.1.0 (#4577)
* [MAINTENANCE] Update overview.md (#4556)
* [MAINTENANCE] Minor clean-up (#4571)
* [MAINTENANCE] Instrument package dependencies (#4583)
* [MAINTENANCE] Standardize DomainBuilder Constructor Arguments Ordering (#4599)
0.14.12
-----------------
* [FEATURE] Enables Regex-Based Column Map Expectations (#4315)
* [FEATURE] Update diagnostic checklist to do linting checks (#4491)
* [FEATURE] format docstrings as markdown for gallery (#4502)
* [FEATURE] Introduces SetBasedColumnMapExpectation w/ supporting templates & doc (#4497)
* [FEATURE] `YAMLHandler` Class (#4510)
* [FEATURE] Remove conflict between filter directives and row_conditions (#4488)
* [FEATURE] Add SNS as a Validation Action (#4519) (thanks @michael-j-thomas)
* [BUGFIX] Fixes ExpectColumnValuesToBeInSet to enable behavior indicated in Parameterized Expectations Doc (#4455)
* [BUGFIX] Fixes minor typo in custom expectation docs, adds missing link (#4507)
* [BUGFIX] Removes validate_config from RegexBasedColumnMap templates & doc (#4506)
* [BUGFIX] Update ExpectColumnValuesToMatchRegex to support parameterized expectations (#4504)
* [BUGFIX] Add back `nbconvert` to dev dependencies (#4515)
* [BUGFIX] Account for case where SQLAlchemy dialect is not downloaded when masking a given URL (#4516)
* [BUGFIX] Fix failing test for `How to Configure Credentials` (#4525)
* [BUGFIX] Remove Temp Dir (#4528)
* [BUGFIX] Add pin to Jinja 2 due to API changes in v3.1.0 release (#4537)
* [BUGFIX] Fixes broken links in How To Write A How-To Guide (#4536)
* [BUGFIX] Removes cryptography upper bound for general reqs (#4487)
* [BUGFIX] Don't assume boto3 is installed (#4542)
* [DOCS] Update tutorial_review.md (#3981)
* [DOCS] Update AUTHORING_INTRO.md (#4470) (thanks @andyjessen)
* [DOCS] Add clarification (#4477) (thanks @strickvl)
* [DOCS] Add missing word and fix wrong dataset reference (#4478) (thanks @strickvl)
* [DOCS] Adds documentation on how to use Great Expectations with Prefect (#4433) (thanks @desertaxle)
* [DOCS] technical terms validate data checkpoints (#4486)
* [DOCS] How to use a Custom Expectation (#4467)
* [DOCS] Technical Terms for Validate Data: Overview and Core Skills docs (#4465)
* [DOCS] technical terms create expectations advanced skills (#4441)
* [DOCS] Integration documentation (#4483)
* [DOCS] Adding Meltano implementation pattern to docs (#4509) (thanks @pnadolny13)
* [DOCS] Update tutorial_create_expectations.md (#4512) (thanks @andyjessen)
* [DOCS] Fix relative links on github (#4479) (thanks @andyjessen)
* [DOCS] Update README.md (#4533) (thanks @andyjessen)
* [HACKATHON] ExpectColumnValuesToBeValidIPv4 (#4457) (thanks @voidforall)
* [HACKATHON] ExpectColumnValuesToBeValidIanaTimezone (#4532) (thanks @lucasasmith)
* [MAINTENANCE] Clean up `Checkpoints` documentation and add `snippet` (#4474)
* [MAINTENANCE] Finalize Great Expectations contrib JSON structure (#4482)
* [MAINTENANCE] Update expectation filenames to match snake_case of their defined Expectations (#4484)
* [MAINTENANCE] Clean Up Types and Rely on "to_json_dict()" where appropriate (#4489)
* [MAINTENANCE] type hints for Batch Request to be string (which leverages parameter/variable resolution) (#4494)
* [MAINTENANCE] Insure consistent ordering of arguments to ParameterBuilder instantiations (#4496)
* [MAINTENANCE] Refactor build_gallery.py script (#4493)
* [MAINTENANCE] Feature/cloud 385/mask cloud creds (#4444)
* [MAINTENANCE] Enforce consistent JSON schema through usage stats (#4499)
* [MAINTENANCE] Applies `camel_to_snake` util to `RegexBasedColumnMapExpectation` (#4511)
* [MAINTENANCE] Removes unused dependencies (#4508)
* [MAINTENANCE] Revert changes made to dependencies in #4508 (#4520)
* [MAINTENANCE] Add `compatability` stage to `dependency_graph` pipeline (#4514)
* [MAINTENANCE] Add prod metadata and remove package attribute from library_metadata (#4517)
* [MAINTENANCE] Move builder instantiation methods to utility module for broader usage among sub-components within Rule-Based Profiler (#4524)
* [MAINTENANCE] Update package info for Capital One DataProfiler (#4523)
* [MAINTENANCE] Remove tag 'needs migration to modular expectations api' for some Expectations (#4521)
* [MAINTENANCE] Add type hints and PyCharm macros in a test module for DefaultExpectationConfigurationBuilder (#4529)
* [MAINTENANCE] Continue War on Warnings (#4500)
0.14.11
-----------------
* [FEATURE] Script to validate docs snippets line number refs (#4377)
* [FEATURE] GitHub action to auto label `core-team` (#4382)
* [FEATURE] `add_rule()` method for RuleBasedProfilers and tests (#4358)
* [FEATURE] Enable the passing of an existing suite to `RuleBasedProfiler.run()` (#4386)
* [FEATURE] Impose Ordering on Marshmallow Schema validated Rule-Based Profiler Configuration fields (#4388)
* [FEATURE] Use more granular requirements-dev-xxx.txt files (#4327)
* [FEATURE] Rule-Based Profiler: Implement Utilities for getting all available parameter node names and objects resident in memory (#4442)
* [BUGFIX] Minor Serialization Correction for MeanUnexpectedMapMetricMultiBatchParameterBuilder (#4385)
* [BUGFIX] Fix CategoricalColumnDomainBuilder to be compliant with serialization / instantiation interfaces (#4395)
* [BUGFIX] Fix bug around `get_parent` usage stats utility in `test_yaml_config` (#4410)
* [BUGFIX] Adding `--spark` flag back to `azure-pipelines.yml` compatibility_matrix stage. (#4418)
* [BUGFIX] Remove remaining usage of --no-spark and --no-postgresql flags for pytest (#4425)
* [BUGFIX] Insure Proper Indexing of Metric Computation Results in ParameterBuilder (#4426)
* [BUGFIX] Include requirements-dev-contrib.txt in dev-install-matrix.yml for lightweight (#4430)
* [BUGFIX] Remove `pytest-azurepiplines` usage from `test_cli` stages in Azure pipelines (#4432)
* [BUGFIX] Updates or deletes broken and deprecated example notebooks (#4404)
* [BUGFIX] Add any dependencies we import directly, but don't have as explicit requirements (#4447)
* [BUGFIX] Removes potentially sensitive webhook URLs from logging (#4440)
* [BUGFIX] Fix packaging test (#4452)
* [DOCS] Fix typo in how_to_create_custom_metrics (#4379)
* [DOCS] Add `snippet` tag to gcs data docs (#4383)
* [DOCS] adjust lines for py reference (#4390)
* [DOCS] technical tags for connecting to data: core skills docs (#4403)
* [DOCS] technical term tags for connect to data database documents (#4413)
* [DOCS] Technical term tags for documentation under Connect to data: Filesystem (#4411)
* [DOCS] Technical term tags for setup pages (#4392)
* [DOCS] Technical term tags for Connect to Data: Advanced docs. (#4406)
* [DOCS] Technical tags: Connect to data:In memory docs (#4405)
* [DOCS] Add misc `snippet` tags to existing documentation (#4397)
* [DOCS] technical terms create expectations: core skills (#4435)
* [DOCS] Creates Custom Table Expectation How-To (#4399)
* [HACKATHON] ExpectTableLinearFeatureImportancesToBe (#4400)
* [MAINTENANCE] Group MAP_SERIES and MAP_CONDITION_SERIES with VALUE-type metrics (#3286)
* [MAINTENANCE] minor imports cleanup (#4381)
* [MAINTENANCE] Change schedule for `packaging_and_installation` pipeline to run at off-hours (#4384)
* [MAINTENANCE] Implicitly anonymize object based on __module__ (#4387)
* [MAINTENANCE] Preparatory cleanup refactoring of get_compute_domain (#4371)
* [MAINTENANCE] RBP -- make parameter builder configurations for self initializing expectations consistent with ParameterBuilder class interfaces (#4398)
* [MAINTENANCE] Refactor `ge_class` attr out of Anonymizer and related child classes (#4393)
* [MAINTENANCE] Removing Custom Expectation Renderer docs from sidebar (#4401)
* [MAINTENANCE] Enable "rule_based_profiler.run()" Method to Accept Batch Data Arguments Directly (#4409)
* [MAINTENANCE] Refactor out unnecessary Anonymizer child classes (#4408)
* [MAINTENANCE] Replace "sampling_method" with "estimator" in Rule-Based Profiler code (#4420)
* [MAINTENANCE] Add docstrings and type hints to `Anonymizer` (#4419)
* [MAINTENANCE] Continue chipping away at warnings (#4422)
* [MAINTENANCE] Rule-Based Profiler: Standardize on Include/Exclude Column Names List (#4424)
* [MAINTENANCE] Set upper bound on number of allowed warnings in snippet validation script (#4434)
* [MAINTENANCE] Clean up of `RegexPatternStringParameterBuilder` tests to use unittests (#4436)
0.14.10
-----------------
* [FEATURE] ParameterBuilder for Computing Average Unexpected Values Fractions for any Map Metric (#4340)
* [FEATURE] Improve bootstrap quantile method accuracy (#4270)
* [FEATURE] Decorate RuleBasedProfiler.run() with usage statistics (#4321)
* [FEATURE] MapMetricColumnDomainBuilder for Rule-Based Profiler (#4353)
* [FEATURE] Enable expect_column_min/_max_to_be_between expectations to be self-initializing (#4363)
* [FEATURE] Azure pipeline to perform nightly CI/CD runs around packaging/installation (#4274)
* [BUGFIX] Fix `IndexError` around data asset pagination from CLI (#4346)
* [BUGFIX] Upper bound pyathena to <2.5.0 (#4350)
* [BUGFIX] Fixes PyAthena type checking for core expectations & tests (#4359)
* [BUGFIX] BatchRequest serialization (CLOUD-743) (#4352)
* [BUGFIX] Update the favicon on docs site (#4376)
* [BUGFIX] Fix issue with datetime objects in expecatation args (#2652) (thanks @jstammers)
* [DOCS] Universal map TOC update (#4292)
* [DOCS] add Config section (#4355)
* [DOCS] Deployment Patterns to Reference Architectures (#4344)
* [DOCS] Fixes tutorial link in reference architecture prereqs component (#4360)
* [DOCS] Tag technical terms in getting started tutorial (#4354)
* [DOCS] Update overview pages to link to updated tutorial pages. (#4378)
* [HACKATHON] ExpectColumnValuesToBeValidUUID (#4322)
* [HACKATHON] add expectation core (#4357)
* [HACKATHON] ExpectColumnAverageToBeWithinRangeOfGivenPoint (#4356)
* [MAINTENANCE] rule based profiler minor clean up of ValueSetParameterBuilder (#4332)
* [MAINTENANCE] Adding tests that exercise single and multi-batch BatchRequests (#4330)
* [MAINTENANCE] Formalize ParameterBuilder contract API usage in ValueSetParameterBuilder (#4333)
* [MAINTENANCE] Rule-Based Profiler: Create helpers directory; use column domain generation convenience method (#4335)
* [MAINTENANCE] Deduplicate table domain kwargs splitting (#4338)
* [MAINTENANCE] Update Azure CI/CD cron schedule to run more frequently (#4345)
* [MAINTENANCE] Optimize CategoricalColumnDomainBuilder to compute metrics in a single method call (#4348)
* [MAINTENANCE] Reduce tries to 2 for probabilistic tests (#4351)
* [MAINTENANCE] Refactor Checkpoint toolkit (#4342)
* [MAINTENANCE] Refactor all uses of `format` in favor of f-strings (#4347)
* [MAINTENANCE] Update great_expectations_contrib CLI tool to use existing diagnostic classes (#4316)
* [MAINTENANCE] Setting stage for removal of `--no-postgresql` and `--no-spark` flags from `pytest`. Enable `--postgresql` and `--spark` (#4309)
* [MAINTENANCE] convert unexpected_list contents to hashable type (#4336)
* [MAINTENANCE] add operator and func handling to stores urns (#4334)
* [MAINTENANCE] Refactor ParameterBuilder classes to extend parent class where possible; also, minor cleanup (#4375)
0.14.9
-----------------
* [FEATURE] Enable Simultaneous Execution of all Metric Computations for ParameterBuilder implementations in Rule-Based Profiler (#4282)
* [FEATURE] Update print_diagnostic_checklist with an option to show any failed tests (#4288)
* [FEATURE] Self-Initializing Expectations (implemented for three example expectations). (#4258)
* [FEATURE] ValueSetMultiBatchParameterBuilder and CategoricalColumnDomainBuilder (#4269)
* [FEATURE] Remove changelog-bot GitHub Action (#4297)
* [FEATURE] Add requirements-dev-lite.txt and update tests/docs (#4273)
* [FEATURE] Enable All ParameterBuilder and DomainBuilder classes to accept batch_list generically (#4302)
* [FEATURE] Enable Probabilistic Tests To Retry upon Assertion Failure (#4308)
* [FEATURE] Update usage stats schema to account for RBP's run() payload (#4266)
* [FEATURE] ProfilerRunAnonymizer (#4264)
* [FEATURE] Enable Expectation "expect_column_values_to_be_in_set" to be Self-Initializing (#4318)
* [BUGFIX] Add redirect for removed Spark EMR page (#4280)
* [BUGFIX] `ConfiguredAssetSqlDataConnector` now correctly handles `schema` and `prefix`/`suffix` (#4268)
* [BUGFIX] Fixes Expectation Diagnostics failing on multi-line docstrings with leading linebreaks (#4286)
* [BUGFIX] Respect test backends (#4287)
* [BUGFIX] Skip test__generate_expectations_tests__xxx tests when sqlalchemy isn't there (#4300)
* [BUGFIX] test_backends integration test fix and supporting docs code ref fixes (#4306)
* [BUGFIX] Update `deep_filter_properties_iterable` to ensure that empty values are cleaned (#4298)
* [BUGFIX] Fixes validate_configuration checking in diagnostics (#4307)
* [BUGFIX] Update test output that should be returned from generate_diagnostic_checklist (#4317)
* [BUGFIX] Standardizes imports in expectation templates and examples (#4320)
* [BUGFIX] Only validate row_condition if not None (#4329)
* [BUGFIX] Fix PEP273 Windows issue (#4328)
* [DOCS] Fixes misc. verbiage & typos in new Custom Expectation docs (#4283)
* [DOCS] fix formatting in configuration details block of Getting Started (#4289) (thanks @afeld)
* [DOCS] Fixes imports and code refs to expectation templates (#4314)
* [DOCS] Update creating_custom_expectations/overview.md (#4278) (thanks @binarytom)
* [CONTRIB] CapitalOne Dataprofiler expectations (#4174) (thanks @taylorfturner)
* [HACKATHON] ExpectColumnValuesToBeLatLonCoordinatesInRangeOfGivenPoint (#4284)
* [HACKATHON] ExpectColumnValuesToBeValidDegreeDecimalCoordinates (#4319)
* [MAINTENANCE] Refactor parameter setting for simpler ParameterBuilder interface (#4299)
* [MAINTENANCE] SimpleDateTimeFormatStringParameterBuilder and general RBP example config updates (#4304)
* [MAINTENANCE] Make adherence to Marshmallow Schema more robust (#4325)
* [MAINTENANCE] Refactor rule based profiler to keep objects/utilities within intended scope (#4331)
* [MAINTENANCE] Dependabot version upgrades (#4253, #4231, #4058, #4041, #3916, #3886, #3583, #2856, #3370, #3216, #2935, #2855, #3302, #4008, #4252)
0.14.8
-----------------
* [FEATURE] Add `run_profiler_on_data` method to DataContext (#4190)
* [FEATURE] `RegexPatternStringParameterBuilder` for `RuleBasedProfiler` (#4167)
* [FEATURE] experimental column map expectation checking for vectors (#3102) (thanks @manyshapes)
* [FEATURE] Pre-requisites in Rule-Based Profiler for Self-Estimating Expectations (#4242)
* [FEATURE] Add optional parameter `condition` to DefaultExpectationConfigurationBuilder (#4246)
* [BUGFIX] Ensure that test result for `RegexPatternStringParameterBuilder` is deterministic (#4240)
* [BUGFIX] Remove duplicate RegexPatternStringParameterBuilder test (#4241)
* [BUGFIX] Improve pandas version checking in test_expectations[_cfe].py files (#4248)
* [BUGFIX] Ensure `test_script_runner.py` actually raises AssertionErrors correctly (#4239)
* [BUGFIX] Check for pandas>=024 not pandas>=24 (#4263)
* [BUGFIX] Add support for SqlAlchemyQueryStore connection_string credentials (#4224) (thanks @davidvanrooij)
* [BUGFIX] Remove assertion (#4271)
* [DOCS] Hackathon Contribution Docs (#3897)
* [MAINTENANCE] Rule-Based Profiler: Fix Circular Imports; Configuration Schema Fixes; Enhanced Unit Tests; Pre-Requisites/Refactoring for Self-Estimating Expectations (#4234)
* [MAINTENANCE] Reformat contrib expectation with black (#4244)
* [MAINTENANCE] Resolve cyclic import issue with usage stats (#4251)
* [MAINTENANCE] Additional refactor to clean up cyclic imports in usage stats (#4256)
* [MAINTENANCE] Rule-Based Profiler prerequisite: fix quantiles profiler configuration and add comments (#4255)
* [MAINTENANCE] Introspect Batch Request Dictionary for its kind and instantiate accordingly (#4259)
* [MAINTENANCE] Minor clean up in style of an RBP test fixture; making variables access more robust (#4261)
* [MAINTENANCE] define empty sqla_bigquery object (#4249)
0.14.7
-----------------
* [FEATURE] Support Multi-Dimensional Metric Computations Generically for Multi-Batch Parameter Builders (#4206)
* [FEATURE] Add support for sqlalchemy-bigquery while falling back on pybigquery (#4182)
* [BUGFIX] Update validate_configuration for core Expectations that don't return True (#4216)
* [DOCS] Fixes two references to the Getting Started tutorial (#4189)
* [DOCS] Deepnote Deployment Pattern Guide (#4169)
* [DOCS] Allow Data Docs to be rendered in night mode (#4130)
* [DOCS] Fix datepicker filter on data docs (#4217)
* [DOCS] Deepnote Deployment Pattern Image Fixes (#4229)
* [MAINTENANCE] Refactor RuleBasedProfiler toolkit pattern (#4191)
* [MAINTENANCE] Revert `dependency_graph` pipeline changes to ensure `usage_stats` runs in parallel (#4198)
* [MAINTENANCE] Refactor relative imports (#4195)
* [MAINTENANCE] Remove temp file that was accidently committed (#4201)
* [MAINTENANCE] Update default candidate strings SimpleDateFormatString parameter builder (#4193)
* [MAINTENANCE] minor type hints clean up (#4214)
* [MAINTENANCE] RBP testing framework changes (#4184)
* [MAINTENANCE] add conditional check for 'expect_column_values_to_be_in_type_list' (#4200)
* [MAINTENANCE] Allow users to pass in any set of polygon points in expectation for point to be within region (#2520) (thanks @ryanlindeborg)
* [MAINTENANCE] Better support Hive, better support BigQuery. (#2624) (thanks @jacobpgallagher)
* [MAINTENANCE] move process_evaluation_parameters into conditional (#4109)
* [MAINTENANCE] Type hint usage stats (#4226)
0.14.6
-----------------
* [FEATURE] Create profiler from DataContext (#4070)
* [FEATURE] Add read_sas function (#3972) (thanks @andyjessen)
* [FEATURE] Run profiler from DataContext (#4141)
* [FEATURE] Instantiate Rule-Based Profiler Using Typed Configuration Object (#4150)
* [FEATURE] Provide ability to instantiate Checkpoint using CheckpointConfig typed object (#4166)
* [FEATURE] Misc cleanup around CLI `suite` command and related utilities (#4158)
* [FEATURE] Add scheduled runs for primary Azure pipeline (#4117)
* [FEATURE] Promote dependency graph test strategy to production (#4124)
* [BUGFIX] minor updates to test definition json files (#4123)
* [BUGFIX] Fix typo for metric name in expect_column_values_to_be_edtf_parseable (#4140)
* [BUGFIX] Ensure that CheckpointResult object can be pickled (#4157)
* [BUGFIX] Custom notebook templates (#2619) (thanks @luke321321)
* [BUGFIX] Include public fields in property_names (#4159)
* [DOCS] Reenable docs-under-test for RuleBasedProfiler (#4149)
* [DOCS] Provided details for using GE_HOME in commandline. (#4164)
* [MAINTENANCE] Return Rule-Based Profiler base.py to its dedicated config subdirectory (#4125)
* [MAINTENANCE] enable filter properties dict to handle both inclusion and exclusion lists (#4127)
* [MAINTENANCE] Remove unused Great Expectations imports (#4135)
* [MAINTENANCE] Update trigger for scheduled Azure runs (#4134)
* [MAINTENANCE] Maintenance/upgrade black (#4136)
* [MAINTENANCE] Alter `great_expectations` pipeline trigger to be more consistent (#4138)
* [MAINTENANCE] Remove remaining unused imports (#4137)
* [MAINTENANCE] Remove `class_name` as mandatory field from `RuleBasedProfiler` (#4139)
* [MAINTENANCE] Ensure `AWSAthena` does not create temporary table as part of processing Batch by default, which is currently not supported (#4103)
* [MAINTENANCE] Remove unused `Exception as e` instances (#4143)
* [MAINTENANCE] Standardize DictDot Method Behaviors Formally for Consistent Usage Patterns in Subclasses (#4131)
* [MAINTENANCE] Remove unused f-strings (#4142)
* [MAINTENANCE] Minor Validator code clean up -- for better code clarity (#4147)
* [MAINTENANCE] Refactoring of `test_script_runner.py`. Integration and Docs tests (#4145)
* [MAINTENANCE] Remove `compatability` stage from `dependency-graph` pipeline (#4161)
* [MAINTENANCE] CLOUD-618: GE Cloud "account" to "organization" rename (#4146)
0.14.5
-----------------
* [FEATURE] Delete profilers from DataContext (#4067)
* [FEATURE] [BUGFIX] Support nullable int column types (#4044) (thanks @scnerd)
* [FEATURE] Rule-Based Profiler Configuration and Runtime Arguments Reconciliation Logic (#4111)
* [BUGFIX] Add default BIGQUERY_TYPES (#4096)
* [BUGFIX] Pin `pip --upgrade` to a specific version for CI/CD pipeline (#4100)
* [BUGFIX] Use `pip==20.2.4` for usage statistics stage of CI/CD (#4102)
* [BUGFIX] Fix shared state issue in renderer test (#4000)
* [BUGFIX] Missing docstrings on validator expect_ methods (#4062) (#4081)
* [BUGFIX] Fix s3 path suffix bug on windows (#4042) (thanks @scnerd)
* [MAINTENANCE] fix typos in changelogs (#4093)
* [MAINTENANCE] Migration of GCP tests to new project (#4072)
* [MAINTENANCE] Refactor Validator methods (#4095)
* [MAINTENANCE] Fix Configuration Schema and Refactor Rule-Based Profiler; Initial Implementation of Reconciliation Logic Between Configuration and Runtime Arguments (#4088)
* [MAINTENANCE] Minor Cleanup -- remove unnecessary default arguments from dictionary cleaner (#4110)
0.14.4
-----------------
* [BUGFIX] Fix typing_extensions requirement to allow for proper build (#4083) (thanks @vojtakopal and @Godoy)
* [DOCS] data docs action rewrite (#4087)
* [DOCS] metric store how to rewrite (#4086)
* [MAINTENANCE] Change `logger.warn` to `logger.warning` to remove deprecation warnings (#4085)
0.14.3
-----------------
* [FEATURE] Profiler Store (#3990)
* [FEATURE] List profilers from DataContext (#4023)
* [FEATURE] add bigquery json credentials kwargs for sqlalchemy connect (#4039)
* [FEATURE] Get profilers from DataContext (#4033)
* [FEATURE] Add RuleBasedProfiler to `test_yaml_config` utility (#4038)
* [BUGFIX] Checkpoint Configurator fix to allow notebook logging suppression (#4057)
* [DOCS] Created a page containing our glossary of terms and definitions. (#4056)
* [DOCS] swap of old uri for new in data docs generated (#4013)
* [MAINTENANCE] Refactor `test_yaml_config` (#4029)
* [MAINTENANCE] Additional distinction made between V2 and V3 upgrade script (#4046)
* [MAINTENANCE] Correcting Checkpoint Configuration and Execution Implementation (#4015)
* [MAINTENANCE] Update minimum version for SQL Alchemy (#4055)
* [MAINTENANCE] Refactor RBP constructor to work with **kwargs instantiation pattern through config objects (#4043)
* [MAINTENANCE] Remove unnecessary metric dependency evaluations and add common table column types metric. (#4063)
* [MAINTENANCE] Clean up new RBP types, method signatures, and method names for the long term. (#4064)
* [MAINTENANCE] fixed broken function call in CLI (#4068)
0.14.2
-----------------
* [FEATURE] Marshmallow schema for Rule Based Profiler (#3982)
* [FEATURE] Enable Rule-Based Profile Parameter Access To Collection Typed Values (#3998)
* [BUGFIX] Docs integration pipeline bugfix (#3997)
* [BUGFIX] Enables spark-native null filtering (#4004)
* [DOCS] Gtm/cta in docs (#3993)
* [DOCS] Fix incorrect variable name in how_to_configure_an_expectation_store_in_amazon_s3.md (#3971) (thanks @moritzkoerber)
* [DOCS] update custom docs css to add a subtle border around tabbed content (#4001)
* [DOCS] Migration Guide now includes example for Spark data (#3996)
* [DOCS] Revamp Airflow Deployment Pattern (#3963) (thanks @denimalpaca)
* [DOCS] updating redirects to reflect a moved file (#4007)
* [DOCS] typo in gcp + bigquery tutorial (#4018)
* [DOCS] Additional description of Kubernetes Operators in GCP Deployment Guide (#4019)
* [DOCS] Migration Guide now includes example for Databases (#4005)
* [DOCS] Update how to instantiate without a yml file (#3995)
* [MAINTENANCE] Refactor of `test_script_runner.py` to break-up test list (#3987)
* [MAINTENANCE] Small refactor for tests that allows DB setup to be done from all tests (#4012)
0.14.1
-----------------
* [FEATURE] Add pagination/search to CLI batch request listing (#3854)
* [BUGFIX] Safeguard against using V2 API with V3 Configuration (#3954)
* [BUGFIX] Bugfix and refactor for `cloud-db-integration` pipeline (#3977)
* [BUGFIX] Fixes breaking typo in expect_column_values_to_be_json_parseable (#3983)
* [BUGFIX] Fixes issue where nested columns could not be addressed properly in spark (#3986)
* [DOCS] How to connect to your data in `mssql` (#3950)
* [DOCS] MigrationGuide - Adding note on Migrating Expectation Suites (#3959)
* [DOCS] Incremental Update: The Universal Map's Getting Started Tutorial (#3881)
* [DOCS] Note about creating backup of Checkpoints (#3968)
* [DOCS] Connecting to BigQuery Doc line references fix (#3974)
* [DOCS] Remove RTD snippet about comments/suggestions from Docusaurus docs (#3980)
* [DOCS] Add howto for the OpenLineage validation operator (#3688) (thanks @rossturk)
* [DOCS] Updates to README.md (#3964)
* [DOCS] Update migration guide (#3967)
* [MAINTENANCE] Refactor docs dependency script (#3952)
* [MAINTENANCE] Use Effective SQLAlchemy for Reflection Fallback Logic and SQL Metrics (#3958)
* [MAINTENANCE] Remove outdated scripts (#3953)
* [MAINTENANCE] Add pytest opt to improve collection time (#3976)
* [MAINTENANCE] Refactor `render` method in PageRenderer (#3962)
* [MAINTENANCE] Standardize rule based profiler testing directories organization (#3984)
* [MAINTENANCE] Metrics Cleanup (#3989)
* [MAINTENANCE] Refactor `render` method of Content Block Renderer (#3960)
0.14.0
-----------------
* [BREAKING] Change Default CLI Flag To V3 (#3943)
* [FEATURE] Cloud-399/Cloud-519: Add Cloud Notification Action (#3891)
* [FEATURE] `great_expectations_contrib` CLI tool (#3909)
* [FEATURE] Update `dependency_graph` pipeline to use `dgtest` CLI (#3912)
* [FEATURE] Incorporate updated dgtest CLI tool in experimental pipeline (#3927)
* [FEATURE] Add YAML config option to disable progress bars (#3794)
* [BUGFIX] Fix internal links to docs that may be rendered incorrectly (#3915)
* [BUGFIX] Update SlackNotificationAction to send slack_token and slack_channel to send_slack_notification function (#3873) (thanks @Calvo94)
* [BUGFIX] `CheckDocsDependenciesChanges` to only handle `.py` files (#3936)
* [BUGFIX] Provide ability to capture schema_name for SQL-based datasources; fix method usage bugs. (#3938)
* [BUGFIX] Ensure that Jupyter Notebook cells convert JSON strings to Python-compliant syntax (#3939)
* [BUGFIX] Cloud-519/cloud notification action return type (#3942)
* [BUGFIX] Fix issue with regex groups in `check_docs_deps` (#3949)
* [DOCS] Created link checker, fixed broken links (#3930)
* [DOCS] adding the link checker to the build (#3933)
* [DOCS] Add name to link checker in build (#3935)
* [DOCS] GCP Deployment Pattern (#3926)
* [DOCS] remove v3api flag in documentation (#3944)
* [DOCS] Make corrections in HOWTO Guides for Getting Data from SQL Sources (#3945)
* [DOCS] Tiny doc fix (#3948)
* [MAINTENANCE] Fix breaking change caused by the new version of ruamel.yaml (#3908)
* [MAINTENANCE] Drop extraneous print statement in self_check/util.py. (#3905)
* [MAINTENANCE] Raise exceptions on init in cloud mode (#3913)
* [MAINTENANCE] removing commented requirement (#3920)
* [MAINTENANCE] Patch for atomic renderer snapshot tests (#3918)
* [MAINTENANCE] Remove types/expectations.py (#3928)
* [MAINTENANCE] Tests/test data class serializable dot dict (#3924)
* [MAINTENANCE] Ensure that concurrency is backwards compatible (#3872)
* [MAINTENANCE] Fix issue where meta was not recognized as a kwarg (#3852)
0.13.49
-----------------
* [FEATURE] PandasExecutionEngine is able to instantiate Google Storage client in Google Cloud Composer (#3896)
* [BUGFIX] Revert change to ExpectationSuite constructor (#3902)
* [MAINTENANCE] SQL statements that are of TextClause type expressed as subqueries (#3899)
0.13.48
-----------------
* [DOCS] Updates to configuring credentials (#3856)
* [DOCS] Add docs on creating suites with the UserConfigurableProfiler (#3877)
* [DOCS] Update how to configure an expectation store in GCS (#3874)
* [DOCS] Update how to configure a validation result store in GCS (#3887)
* [DOCS] Update how to host and share data docs on GCS (#3889)
* [DOCS] Organize metadata store sidebar category by type of store (#3890)
* [MAINTENANCE] `add_expectation()` in `ExpectationSuite` supports usage statistics for GE. (#3824)
* [MAINTENANCE] Clean up Metrics type usage, SQLAlchemyExecutionEngine and SQLAlchemyBatchData implementation, and SQLAlchemy API usage (#3884)
0.13.47
-----------------
* [FEATURE] Add support for named groups in data asset regex (#3855)
* [BUGFIX] Fix issue where dependency graph tester picks up non *.py files and add test file (#3830)
* [BUGFIX] Ensure proper exit code for dependency graph script (#3839)
* [BUGFIX] Allows GE to work when installed in a zip file (PEP 273). Fixes issue #3772 (#3798) (thanks @joseignaciorc)
* [BUGFIX] Update conditional for TextClause isinstance check in SQLAlchemyExecutionEngine (#3844)
* [BUGFIX] Fix usage stats events (#3857)
* [BUGFIX] Make ExpectationContext optional and remove when null to ensure backwards compatability (#3859)
* [BUGFIX] Fix sqlalchemy expect_compound_columns_to_be_unique (#3827) (thanks @harperweaver-dox)
* [BUGFIX] Ensure proper serialization of SQLAlchemy Legacy Row (#3865)
* [DOCS] Update migration_guide.md (#3832)
* [MAINTENANCE] Remove the need for DataContext registry in the instrumentation of the Legacy Profiler profiling method. (#3836)
* [MAINTENANCE] Remove DataContext registry (#3838)
* [MAINTENANCE] Refactor cli suite conditionals (#3841)
* [MAINTENANCE] adding hints to stores in data context (#3849)
* [MAINTENANCE] Improve usage stats testing (#3858, #3861)
* [MAINTENANCE] Make checkpoint methods in DataContext pass-through (#3860)
* [MAINTENANCE] Datasource and ExecutionEngine Anonymizers handle missing module_name (#3867)
* [MAINTENANCE] Add logging around DatasourceInitializationError in DataContext (#3846)
* [MAINTENANCE] Use f-string to prevent string concat issue in Evaluation Parameters (#3864)
* [MAINTENANCE] Test for errors / invalid messages in logs & fix various existing issues (#3875)
0.13.46
-----------------
* [FEATURE] Instrument Runtime DataConnector for Usage Statistics: Add "checkpoint.run" Event Schema (#3797)
* [FEATURE] Add suite creation type field to CLI SUITE "new" and "edit" Usage Statistics events (#3810)
* [FEATURE] [EXPERIMENTAL] Dependency graph based testing strategy and related pipeline (#3738, #3815, #3818)
* [FEATURE] BaseDataContext registry (#3812, #3819)
* [FEATURE] Add usage statistics instrumentation to Legacy UserConfigurableProfiler execution (#3828)
* [BUGFIX] CheckpointConfig.__deepcopy__() must copy all fields, including the null-valued fields (#3793)
* [BUGFIX] Fix issue where configuration store didn't allow nesting (#3811)
* [BUGFIX] Fix Minor Bugs in and Clean Up UserConfigurableProfiler (#3822)
* [BUGFIX] Ensure proper replacement of nulls in Jupyter Notebooks (#3782)
* [BUGFIX] Fix issue where configuration store didn't allow nesting (#3811)
* [DOCS] Clean up TOC (#3783)
* [DOCS] Update Checkpoint and Actions Reference with testing (#3787)
* [DOCS] Update How to install Great Expectations locally (#3805)
* [DOCS] How to install Great Expectations in a hosted environment (#3808)
* [MAINTENANCE] Make BatchData Serialization More Robust (#3791)
* [MAINTENANCE] Refactor SiteIndexBuilder.build() (#3789)
* [MAINTENANCE] Update ref to ge-cla-bot in PR template (#3799)
* [MAINTENANCE] Anonymizer clean up and refactor (#3801)
* [MAINTENANCE] Certify the expectation "expect_table_row_count_to_equal_other_table" for V3 API (#3803)
* [MAINTENANCE] Refactor to enable broader use of event emitting method for usage statistics (#3825)
* [MAINTENANCE] Clean up temp file after CI/CD run (#3823)
* [MAINTENANCE] Raising exceptions for misconfigured datasources in cloud mode (#3866)
0.13.45
-----------------
* [FEATURE] Feature/render validation metadata (#3397) (thanks @vshind1)
* [FEATURE] Added expectation expect_column_values_to_not_contain_special_characters() (#2849, #3771) (thanks @jaibirsingh)
* [FEATURE] Like and regex-based expectations in Athena dialect (#3762) (thanks @josges)
* [FEATURE] Rename `deep_filter_properties_dict()` to `deep_filter_properties_iterable()`
* [FEATURE] Extract validation result failures (#3552) (thanks @BenGale93)
* [BUGFIX] Allow now() eval parameter to be used by itself (#3719)
* [BUGFIX] Fixing broken logo for legacy RTD docs (#3769)
* [BUGFIX] Adds version-handling to sqlalchemy make_url imports (#3768)
* [BUGFIX] Integration test to avoid regression of simple PandasExecutionEngine workflow (#3770)
* [BUGFIX] Fix copying of CheckpointConfig for substitution and printing purposes (#3759)
* [BUGFIX] Fix evaluation parameter usage with Query Store (#3763)
* [BUGFIX] Feature/fix row condition quotes (#3676) (thanks @benoitLebreton-perso)
* [BUGFIX] Fix incorrect filling out of anonymized event payload (#3780)
* [BUGFIX] Don't reset_index for conditional expectations (#3667) (thanks @abekfenn)
* [DOCS] Update expectations gallery link in V3 notebook documentation (#3747)
* [DOCS] Correct V3 documentation link in V2 notebooks to point to V2 documentation (#3750)
* [DOCS] How to pass an in-memory DataFrame to a Checkpoint (#3756)
* [MAINTENANCE] Fix typo in Getting Started Guide (#3749)
* [MAINTENANCE] Add proper docstring and type hints to Validator (#3767)
* [MAINTENANCE] Clean up duplicate logging statements about optional `black` dep (#3778)
0.13.44
-----------------
* [FEATURE] Add new result_format to include unexpected_row_list (#3346)
* [FEATURE] Implement "deep_filter_properties_dict()" method (#3703)
* [FEATURE] Create Constants for GETTING_STARTED Entities (e.g., datasource_name, expectation_suite_name, etc.) (#3712)
* [FEATURE] Add usage statistics event for DataContext.get_batch_list() method (#3708)
* [FEATURE] Add data_context.run_checkpoint event to usage statistics (#3721)
* [FEATURE] Add event_duration to usage statistics events (#3729)
* [FEATURE] InferredAssetSqlDataConnector's introspection can list external tables in Redshift Spectrum (#3646)
* [BUGFIX] Using a RuntimeBatchRequest in a Checkpoint with a top-level batch_request instead of validations (#3680)
* [BUGFIX] Using a RuntimeBatchRequest in a Checkpoint at runtime with Checkpoint.run() (#3713)
* [BUGFIX] Using a RuntimeBatchRequest in a Checkpoint at runtime with context.run_checkpoint() (#3718)
* [BUGFIX] Use SQLAlchemy make_url helper where applicable when parsing URLs (#3722)
* [BUGFIX] Adds check for quantile_ranges to be ordered or unbounded pairs (#3724)
* [BUGFIX] Updates MST renderer to return JSON-parseable boolean (#3728)
* [BUGFIX] Removes sqlite suppression for expect_column_quantile_values_to_be_between test definitions (#3735)
* [BUGFIX] Handle contradictory configurations in checkpoint.yml, checkpoint.run(), and context.run_checkpoint() (#3723)
* [BUGFIX] fixed a bug where expectation metadata doesn't appear in edit template for table-level expectations (#3129) (thanks @olechiw)
* [BUGFIX] Added temp_table creation for Teradata in SqlAlchemyBatchData (#3731) (thanks @imamolp)
* [DOCS] Add Databricks video walkthrough link (#3702, #3704)
* [DOCS] Update the link to configure a MetricStore (#3711, #3714) (thanks @txblackbird)
* [DOCS] Updated code example to remove deprecated "File" function (#3632) (thanks @daccorti)
* [DOCS] Delete how_to_add_a_validation_operator.md as OBE. (#3734)
* [DOCS] Update broken link in FOOTER.md to point to V3 documentation (#3745)
* [MAINTENANCE] Improve type hinting (using Optional type) (#3709)
* [MAINTENANCE] Standardize names for assets that are used in Getting Started Guide (#3706)
* [MAINTENANCE] Clean up remaining improper usage of Optional type annotation (#3710)
* [MAINTENANCE] Refinement of Getting Started Guide script (#3715)
* [MAINTENANCE] cloud-410 - Support for Column Descriptions (#3707)
* [MAINTENANCE] Types Clean Up in Checkpoint, Batch, and DataContext Classes (#3737)
* [MAINTENANCE] Remove DeprecationWarning for validator.remove_expectation (#3744)
0.13.43
-----------------
* [FEATURE] Enable support for Teradata SQLAlchemy dialect (#3496) (thanks @imamolp)
* [FEATURE] Dremio connector added (SQLalchemy) (#3624) (thanks @chufe-dremio)
* [FEATURE] Adds expect_column_values_to_be_string_integers_increasing (#3642)
* [FEATURE] Enable "column.quantile_values" and "expect_column_quantile_values_to_be_between" for SQLite; add/enable new tests (#3695)
* [BUGFIX] Allow glob_directive for DBFS Data Connectors (#3673)
* [BUGFIX] Update black version in pre-commit config (#3674)
* [BUGFIX] Make sure to add "mostly_pct" value if "mostly" kwarg present (#3661)
* [BUGFIX] Fix BatchRequest.to_json_dict() to not overwrite original fields; also type usage cleanup in CLI tests (#3683)
* [BUGFIX] Fix pyfakefs boto / GCS incompatibility (#3694)
* [BUGFIX] Update prefix attr assignment in cloud-based DataConnector constructors (#3668)
* [BUGFIX] Update 'list_keys' signature for all cloud-based tuple store child classes (#3669)
* [BUGFIX] evaluation parameters from different expectation suites dependencies (#3684) (thanks @OmriBromberg)
* [DOCS] Databricks deployment pattern documentation (#3682)
* [DOCS] Remove how_to_instantiate_a_data_context_on_databricks_spark_cluster (#3687)
* [DOCS] Updates to Databricks doc based on friction logging (#3696)
* [MAINTENANCE] Fix checkpoint anonymization and make BatchRequest.to_json_dict() more robust (#3675)
* [MAINTENANCE] Update kl_divergence domain_type (#3681)
* [MAINTENANCE] update filter_properties_dict to use set for inclusions and exclusions (instead of list) (#3698)
* [MAINTENANCE] Adds CITATION.cff (#3697)
0.13.42
-----------------
* [FEATURE] DBFS Data connectors (#3659)
* [BUGFIX] Fix "null" appearing in notebooks due to incorrect ExpectationConfigurationSchema serialization (#3638)
* [BUGFIX] Ensure that result_format from saved expectation suite json file takes effect (#3634)
* [BUGFIX] Allowing user specified run_id to appear in WarningAndFailureExpectationSuitesValidationOperator validation result (#3386) (thanks @wniroshan)
* [BUGFIX] Update black dependency to ensure passing Azure builds on Python 3.9 (#3664)
* [BUGFIX] fix Issue #3405 - gcs client init in pandas engine (#3408) (thanks @dz-1)
* [BUGFIX] Recursion error when passing RuntimeBatchRequest with query into Checkpoint using validations (#3654)
* [MAINTENANCE] Cloud 388/supported expectations query (#3635)
* [MAINTENANCE] Proper separation of concerns between specific File Path Data Connectors and corresponding ExecutionEngine objects (#3643)
* [MAINTENANCE] Enable Docusaurus tests for S3 (#3645)
* [MAINTENANCE] Formalize Exception Handling Between DataConnector and ExecutionEngine Implementations, and Update DataConnector Configuration Usage in Tests (#3644)
* [MAINTENANCE] Adds util for handling SADeprecation warning (#3651)
0.13.41
-----------------
* [FEATURE] Support median calculation in AWS Athena (#3596) (thanks @persiyanov)
* [BUGFIX] Be able to use spark execution engine with spark reuse flag (#3541) (thanks @fep2)
* [DOCS] punctuation how_to_contribute_a_new_expectation_to_great_expectations.md (#3484) (thanks @plain-jane-gray)
* [DOCS] Update next_steps.md (#3483) (thanks @plain-jane-gray)
* [DOCS] Update how_to_configure_a_validation_result_store_in_gcs.md (#3482) (thanks @plain-jane-gray)
* [DOCS] Choosing and configuring DataConnectors (#3533)
* [DOCS] Remove --no-spark flag from docs tests (#3625)
* [DOCS] DevRel - docs fixes (#3498)
* [DOCS] Adding a period (#3627) (thanks @plain-jane-gray)
* [DOCS] Remove comments that describe Snowflake parameters as optional (#3639)
* [MAINTENANCE] Update CODEOWNERS (#3604)
* [MAINTENANCE] Fix logo (#3598)
* [MAINTENANCE] Add Expectations to docs navbar (#3597)
* [MAINTENANCE] Remove unused fixtures (#3218)
* [MAINTENANCE] Remove unnecessary comment (#3608)
* [MAINTENANCE] Superconductive Warnings hackathon (#3612)
* [MAINTENANCE] Bring Core Skills Doc for Creating Batch Under Test (#3629)
* [MAINTENANCE] Refactor and Clean Up Expectations and Metrics Parts of the Codebase (better encapsulation, improved type hints) (#3633)
0.13.40
-----------------
* [FEATURE] Retrieve data context config through Cloud API endpoint #3586
* [FEATURE] Update Batch IDs to match name change in paths included in batch_request #3587
* [FEATURE] V2-to-V3 Upgrade/Migration #3592
* [FEATURE] table and graph atomic renderers #3595
* [FEATURE] V2-to-V3 Upgrade/Migration (Sidebar.js update) #3603
* [DOCS] Fixing broken links and linking to Expectation Gallery #3591
* [MAINTENANCE] Get TZLocal back to its original version control. #3585
* [MAINTENANCE] Add tests for datetime evaluation parameters #3601
* [MAINTENANCE] Removed warning for pandas option display.max_colwidth #3606
0.13.39
-----------------
* [FEATURE] Migration of Expectations to Atomic Prescriptive Renderers (#3530, #3537)
* [FEATURE] Cloud: Editing Expectation Suites programmatically (#3564)
* [BUGFIX] Fix deprecation warning for importing from collections (#3546) (thanks @shpolina)
* [BUGFIX] SQLAlchemy version 1.3.24 compatibility in map metric provider (#3507) (thanks @shpolina)
* [DOCS] Clarify how to configure optional Snowflake parameters in CLI datasource new notebook (#3543)
* [DOCS] Added breaks to code snippets, reordered guidance (#3514)
* [DOCS] typo in documentation (#3542) (thanks @DanielEdu)
* [DOCS] Update how_to_configure_a_new_data_context_with_the_cli.md (#3556) (thanks @plain-jane-gray)
* [DOCS] Improved installation instructions, included in-line installation instructions to getting started (#3509)
* [DOCS] Update contributing_style.md (#3521) (thanks @plain-jane-gray)
* [DOCS] Update contributing_test.md (#3519) (thanks @plain-jane-gray)
* [DOCS] Revamp style guides (#3554)
* [DOCS] Update contributing.md (#3523, #3524) (thanks @plain-jane-gray)
* [DOCS] Simplify getting started (#3555)
* [DOCS] How to introspect and partition an SQL database (#3465)
* [DOCS] Update contributing_checklist.md (#3518) (thanks @plain-jane-gray)
* [DOCS] Removed duplicate prereq, how_to_instantiate_a_data_context_without_a_yml_file.md (#3481) (thanks @plain-jane-gray)
* [DOCS] fix link to expectation glossary (#3558) (thanks @sephiartlist)
* [DOCS] Minor Friction (#3574)
* [MAINTENANCE] Make CLI Check-Config and CLI More Robust (#3562)
* [MAINTENANCE] tzlocal version fix (#3565)
0.13.38
-----------------
* [FEATURE] Atomic Renderer: Initial framework and Prescriptive renderers (#3529)
* [FEATURE] Atomic Renderer: Diagnostic renderers (#3534)
* [BUGFIX] runtime_parameters: {batch_data: <park DF} serialization (#3502)
* [BUGFIX] Custom query in RuntimeBatchRequest for expectations using table.row_count metric (#3508)
* [BUGFIX] Transpose \n and , in notebook (#3463) (thanks @mccalluc)
* [BUGFIX] Fix contributor link (#3462) (thanks @mccalluc)
* [DOCS] How to introspect and partition a files based data store (#3464)
* [DOCS] fixed duplication of text in code example (#3503)
* [DOCS] Make content better reflect the document organization. (#3510)
* [DOCS] Correcting typos and improving the language. (#3513)
* [DOCS] Better Sections Numbering in Documentation (#3515)
* [DOCS] Improved wording (#3516)
* [DOCS] Improved title wording for section heading (#3517)
* [DOCS] Improve Readability of Documentation Content (#3536)
* [MAINTENANCE] Content and test script update (#3532)
* [MAINTENANCE] Provide Deprecation Notice for the "parse_strings_as_datetimes" Expectation Parameter in V3 (#3539)
0.13.37
-----------------
* [FEATURE] Implement CompoundColumnsUnique metric for SqlAlchemyExecutionEngine (#3477)
* [FEATURE] add get_available_data_asset_names_and_types (#3476)
* [FEATURE] add s3_put_options to TupleS3StoreBackend (#3470) (Thanks @kj-9)
* [BUGFIX] Fix TupleS3StoreBackend remove_key bug (#3489)
* [DOCS] Adding Flyte Deployment pattern to docs (#3383)
* [DOCS] g_e docs branding updates (#3471)
* [MAINTENANCE] Add type-hints; add utility method for creating temporary DB tables; clean up imports; improve code readability; and add a directory to pre-commit (#3475)
* [MAINTENANCE] Clean up for a better code readability. (#3493)
* [MAINTENANCE] Enable SQL for the "expect_compound_columns_to_be_unique" expectation. (#3488)
* [MAINTENANCE] Fix some typos (#3474) (Thanks @mohamadmansourX)
* [MAINTENANCE] Support SQLAlchemy version 1.3.24 for compatibility with Airflow (Airflow does not currently support later versions of SQLAlchemy). (#3499)
* [MAINTENANCE] Update contributing_checklist.md (#3478) (Thanks @plain-jane-gray)
* [MAINTENANCE] Update how_to_configure_a_validation_result_store_in_gcs.md (#3480) (Thanks @plain-jane-gray)
* [MAINTENANCE] update implemented_expectations (#3492)
0.13.36
-----------------
* [FEATURE] GREAT-3439 extended SlackNotificationsAction for slack app tokens (#3440) (Thanks @psheets)
* [FEATURE] Implement Integration Test for "Simple SQL Datasource" with Partitioning, Splitting, and Sampling (#3454)
* [FEATURE] Implement Integration Test for File Path Data Connectors with Partitioning, Splitting, and Sampling (#3452)
* [BUGFIX] Fix Incorrect Implementation of the "_sample_using_random" Sampling Method in SQLAlchemyExecutionEngine (#3449)
* [BUGFIX] Handle RuntimeBatchRequest passed to Checkpoint programatically (without yml) (#3448)
* [DOCS] Fix typo in command to create new checkpoint (#3434) (Thanks @joeltone)
* [DOCS] How to validate data by running a Checkpoint (#3436)
* [ENHANCEMENT] cloud-199 - Update Expectation and ExpectationSuite classes for GE Cloud (#3453)
* [MAINTENANCE] Does not test numpy.float128 when it doesn't exist (#3460)
* [MAINTENANCE] Remove Unnecessary SQL OR Condition (#3469)
* [MAINTENANCE] Remove validation playground notebooks (#3467)
* [MAINTENANCE] clean up type hints, API usage, imports, and coding style (#3444)
* [MAINTENANCE] comments (#3457)
0.13.35
-----------------
* [FEATURE] Create ExpectationValidationGraph class to Maintain Relationship Between Expectation and Metrics and Use it to Associate Exceptions to Expectations (#3433)
* [BUGFIX] Addresses issue #2993 (#3054) by using configuration when it is available instead of discovering keys (listing keys) in existing sources. (#3377)
* [BUGFIX] Fix Data asset name rendering (#3431) (Thanks @shpolina)
* [DOCS] minor fix to syntax highlighting in how_to_contribute_a_new_expectation… (#3413) (Thanks @edjoesu)
* [DOCS] Fix broken links in how_to_create_a_new_expectation_suite_using_rule_based_profile… (#3410) (Thanks @edjoesu)
* [ENHANCEMENT] update list_expectation_suite_names and ExpectationSuiteValidationResult payload (#3419)
* [MAINTENANCE] Clean up Type Hints, JSON-Serialization, ID Generation and Logging in Objects in batch.py Module and its Usage (#3422)
* [MAINTENANCE] Fix Granularity of Exception Handling in ExecutionEngine.resolve_metrics() and Clean Up Type Hints (#3423)
* [MAINTENANCE] Fix broken links in how_to_create_a_new_expectation_suite_using_rule_based_profiler (#3441)
* [MAINTENANCE] Fix issue where BatchRequest object in configuration could cause Checkpoint to fail (#3438)
* [MAINTENANCE] Insure consistency between implementation of overriding Python __hash__() and internal ID property value (#3432)
* [MAINTENANCE] Performance improvement refactor for Spark unexpected values (#3368)
* [MAINTENANCE] Refactor MetricConfiguration out of validation_graph.py to Avoid Future Circular Dependencies in Python (#3425)
* [MAINTENANCE] Use ExceptionInfo to encapsulate common expectation validation result error information. (#3427)
0.13.34
-----------------
* [FEATURE] Configurable multi-threaded checkpoint speedup (#3362) (Thanks @jdimatteo)
* [BUGFIX] Insure that the "result_format" Expectation Argument is Processed Properly (#3364)
* [BUGFIX] fix error getting validation result from DataContext (#3359) (Thanks @zachzIAM)
* [BUGFIX] fixed typo and added CLA links (#3347)
* [DOCS] Azure Data Connector Documentation for Pandas and Spark. (#3378)
* [DOCS] Connecting to GCS using Spark (#3375)
* [DOCS] Docusaurus - Deploying Great Expectations in a hosted environment without file system or CLI (#3361)
* [DOCS] How to get a batch from configured datasource (#3382)
* [MAINTENANCE] Add Flyte to README (#3387) (Thanks @samhita-alla)
* [MAINTENANCE] Adds expect_table_columns_to_match_set (#3329) (Thanks @viniciusdsmello)
* [MAINTENANCE] Bugfix/skip substitute config variables in ge cloud mode (#3393)
* [MAINTENANCE] Clean Up ValidationGraph API Usage, Improve Exception Handling for Metrics, Clean Up Type Hints (#3399)
* [MAINTENANCE] Clean up ValidationGraph API and add Type Hints (#3392)
* [MAINTENANCE] Enhancement/update _set methods with kwargs (#3391) (Thanks @roblim)
* [MAINTENANCE] Fix incorrect ToC section name (#3395)
* [MAINTENANCE] Insure Correct Processing of the catch_exception Flag in Metrics Resolution (#3360)
* [MAINTENANCE] exempt batch_data from a deep_copy operation on RuntimeBatchRequest (#3388)
* [MAINTENANCE] [WIP] Enhancement/cloud 169/update checkpoint.run for ge cloud (#3381)
0.13.33
-----------------
* [FEATURE] Implement InferredAssetAzureDataConnector with Support for Pandas and Spark Execution Engines (#3372)
* [FEATURE] Spark connecting to Google Cloud Storage (#3365)
* [FEATURE] SparkDFExecutionEngine can load data accessed by ConfiguredAssetAzureDataConnector (integration tests are included). (#3345)
* [FEATURE] [MER-293] GE Cloud Mode for DataContext (#3262) (Thanks @roblim)
* [BUGFIX] Allow for RuntimeDataConnector to accept custom query while suppressing temp table creation (#3335) (Thanks @NathanFarmer)
* [BUGFIX] Fix issue where multiple validators reused the same execution engine, causing a conflict in active batch (GE-3168) (#3222) (Thanks @jcampbell)
* [BUGFIX] Run batch_request dictionary through util function convert_to_json_serializable (#3349) (Thanks @NathanFarmer)
* [BUGFIX] added casting of numeric value to fix redshift issue #3293 (#3338) (Thanks @sariabod)
* [DOCS] Docusaurus - How to connect to an MSSQL database (#3353) (Thanks @NathanFarmer)
* [DOCS] GREAT-195 Docs remove all stubs and links to them (#3363)
* [MAINTENANCE] Update azure-pipelines-docs-integration.yml for Azure Pipelines
* [MAINTENANCE] Update implemented_expectations.md (#3351) (Thanks @spencerhardwick)
* [MAINTENANCE] Updating to reflect current Expectation dev state (#3348) (Thanks @spencerhardwick)
* [MAINTENANCE] docs: Clean up Docusaurus refs (#3371)
0.13.32
-----------------
* [FEATURE] Add Performance Benchmarks Using BigQuery. (Thanks @jdimatteo)
* [WIP] [FEATURE] add backend args to run_diagnostics (#3257) (Thanks @edjoesu)
* [BUGFIX] Addresses Issue 2937. (#3236) (Thanks @BenGale93)
* [BUGFIX] SQL dialect doesn't register for BigQuery for V2 (#3324)
* [DOCS] "How to connect to data on GCS using Pandas" (#3311)
* [MAINTENANCE] Add CODEOWNERS with a single check for sidebars.js (#3332)
* [MAINTENANCE] Fix incorrect DataConnector usage of _get_full_file_path() API method. (#3336)
* [MAINTENANCE] Make Pandas against S3 and GCS integration tests more robust by asserting on number of batches returned and row counts (#3341)
* [MAINTENANCE] Make integration tests of Pandas against Azure more robust. (#3339)
* [MAINTENANCE] Prepare AzureUrl to handle WASBS format (for Spark) (#3340)
* [MAINTENANCE] Renaming default_batch_identifier in examples #3334
* [MAINTENANCE] Tests for RuntimeDataConnector at DataContext-level (#3304)
* [MAINTENANCE] Tests for RuntimeDataConnector at DataContext-level (Spark and Pandas) (#3325)
* [MAINTENANCE] Tests for RuntimeDataConnector at Datasource-level (Spark and Pandas) (#3318)
* [MAINTENANCE] Various doc patches (#3326)
* [MAINTENANCE] clean up imports and method signatures (#3337)
0.13.31
-----------------
* [FEATURE] Enable `GCS DataConnector` integration with `PandasExecutionEngine` (#3264)
* [FEATURE] Enable column_pair expectations and tests for Spark (#3294)
* [FEATURE] Implement `InferredAssetGCSDataConnector` (#3284)
* [FEATURE]/CHANGE run time format (#3272) (Thanks @serialbandicoot)
* [DOCS] Fix misc errors in "How to create renderers for Custom Expectations" (#3315)
* [DOCS] GDOC-217 remove stub links (#3314)
* [DOCS] Remove misc TODOs to tidy up docs (#3313)
* [DOCS] Standardize capitalization of various technologies in `docs` (#3312)
* [DOCS] Fix broken link to Contributor docs (#3295) (Thanks @discdiver)
* [MAINTENANCE] Additional tests for RuntimeDataConnector at Datasource-level (query) (#3288)
* [MAINTENANCE] Update GCSStoreBackend + tests (#2630) (Thanks @hmandsager)
* [MAINTENANCE] Write integration/E2E tests for `ConfiguredAssetAzureDataConnector` (#3204)
* [MAINTENANCE] Write integration/E2E tests for both `GCSDataConnectors` (#3301)
0.13.30
-----------------
* [FEATURE] Implement Spark Decorators and Helpers; Demonstrate on MulticolumnSumEqual Metric (#3289)
* [FEATURE] V3 implement expect_column_pair_values_to_be_in_set for SQL Alchemy execution engine (#3281)
* [FEATURE] Implement `ConfiguredAssetGCSDataConnector` (#3247)
* [BUGFIX] Fix import issues around cloud providers (GCS/Azure/S3) (#3292)
* [MAINTENANCE] Add force_reuse_spark_context to DatasourceConfigSchema (#3126) (thanks @gipaetusb and @mbakunze)
0.13.29
-----------------
* [FEATURE] Implementation of the Metric "select_column_values.unique.within_record" for SQLAlchemyExecutionEngine (#3279)
* [FEATURE] V3 implement ColumnPairValuesInSet for SQL Alchemy execution engine (#3278)
* [FEATURE] Edtf with support levels (#2594) (thanks @mielvds)
* [FEATURE] V3 implement expect_column_pair_values_to_be_equal for SqlAlchemyExecutionEngine (#3267)
* [FEATURE] add expectation for discrete column entropy (#3049) (thanks @edjoesu)
* [FEATURE] Add SQLAlchemy Provider for the the column_pair_values.a_greater_than_b (#3268)
* [FEATURE] Expectations tests for BigQuery backend (#3219) (Thanks @jdimatteo)
* [FEATURE] Add schema validation for different GCS auth methods (#3258)
* [FEATURE] V3 - Implement column_pair helpers/providers for SqlAlchemyExecutionEngine (#3256)
* [FEATURE] V3 implement expect_column_pair_values_to_be_equal expectation for PandasExecutionEngine (#3252)
* [FEATURE] GCS DataConnector schema validation (#3253)
* [FEATURE] Implementation of the "expect_select_column_values_to_be_unique_within_record" Expectation (#3251)
* [FEATURE] Implement the SelectColumnValuesUniqueWithinRecord metric (for PandasExecutionEngine) (#3250)
* [FEATURE] V3 - Implement ColumnPairValuesEqual for PandasExecutionEngine (#3243)
* [FEATURE] Set foundation for GCS DataConnectors (#3220)
* [FEATURE] Implement "expect_column_pair_values_to_be_in_set" expectation (support for PandasExecutionEngine) (#3242)
* [BUGFIX] Fix deprecation warning for importing from collections (#3228) (thanks @ismaildawoodjee)
* [DOCS] Document BigQuery test dataset configuration (#3273) (Thanks @jdimatteo)
* [DOCS] Syntax and Link (#3266)
* [DOCS] API Links and Supporting Docs (#3265)
* [DOCS] redir and search (#3249)
* [MAINTENANCE] Update azure-pipelines-docs-integration.yml to include env vars for Azure docs integration tests
* [MAINTENANCE] Allow Wrong ignore_row_if Directive from V2 with Deprecation Warning (#3274)
* [MAINTENANCE] Refactor test structure for "Connecting to your data" cloud provider integration tests (#3277)
* [MAINTENANCE] Make test method names consistent for Metrics tests (#3254)
* [MAINTENANCE] Allow `PandasExecutionEngine` to accept `Azure DataConnectors` (#3214)
* [MAINTENANCE] Standardize Arguments to MetricConfiguration Constructor; Use {} instead of dict(). (#3246)
0.13.28
-----------------
* [FEATURE] Implement ColumnPairValuesInSet metric for PandasExecutionEngine
* [BUGFIX] Wrap optional azure imports in data_connector setup
0.13.27
-----------------
* [FEATURE] Accept row_condition (with condition_parser) and ignore_row_if parameters for expect_multicolumn_sum_to_equal (#3193)
* [FEATURE] ConfiguredAssetDataConnector for Azure Blob Storage (#3141)
* [FEATURE] Replace MetricFunctionTypes.IDENTITY domain type with convenience method get_domain_records() for SparkDFExecutionEngine (#3226)
* [FEATURE] Replace MetricFunctionTypes.IDENTITY domain type with convenience method get_domain_records() for SqlAlchemyExecutionEngine (#3215)
* [FEATURE] Replace MetricFunctionTypes.IDENTITY domain type with convenience method get_full_access_compute_domain() for PandasExecutionEngine (#3210)
* [FEATURE] Set foundation for Azure-related DataConnectors (#3188)
* [FEATURE] Update ExpectCompoundColumnsToBeUnique for V3 API (#3161)
* [BUGFIX] Fix incorrect schema validation for Azure data connectors (#3200)
* [BUGFIX] Fix incorrect usage of "all()" in the comparison of validation results when executing an Expectation (#3178)
* [BUGFIX] Fixes an error with expect_column_values_to_be_dateutil_parseable (#3190)
* [BUGFIX] Improve parsing of .ge_store_backend_id (#2952)
* [BUGFIX] Remove fixture parameterization for Cloud DBs (Snowflake and BigQuery) (#3182)
* [BUGFIX] Restore support for V2 API style custom expectation rendering (#3179) (Thanks @jdimatteo)
* [DOCS] Add `conda` as installation option in README (#3196) (Thanks @rpanai)
* [DOCS] Standardize capitalization of "Python" in "Connecting to your data" section of new docs (#3209)
* [DOCS] Standardize capitalization of Spark in docs (#3198)
* [DOCS] Update BigQuery docs to clarify the use of temp tables (#3184)
* [DOCS] Create _redirects (#3192)
* [ENHANCEMENT] RuntimeDataConnector messaging is made more clear for `test_yaml_config()` (#3206)
* [MAINTENANCE] Add `credentials` YAML key support for `DataConnectors` (#3173)
* [MAINTENANCE] Fix minor typo in S3 DataConnectors (#3194)
* [MAINTENANCE] Fix typos in argument names and types (#3207)
* [MAINTENANCE] Update changelog. (#3189)
* [MAINTENANCE] Update documentation. (#3203)
* [MAINTENANCE] Update validate_your_data.md (#3185)
* [MAINTENANCE] update tests across execution engines and clean up coding patterns (#3223)
0.13.26
-----------------
* [FEATURE] Enable BigQuery tests for Azure CI/CD (#3155)
* [FEATURE] Implement MulticolumnMapExpectation class (#3134)
* [FEATURE] Implement the MulticolumnSumEqual Metric for PandasExecutionEngine (#3130)
* [FEATURE] Support row_condition and ignore_row_if Directives Combined for PandasExecutionEngine (#3150)
* [FEATURE] Update ExpectMulticolumnSumToEqual for V3 API (#3136)
* [FEATURE] add python3.9 to python versions (#3143) (Thanks @dswalter)
* [FEATURE]/MER-16/MER-75/ADD_ROUTE_FOR_VALIDATION_RESULT (#3090) (Thanks @rreinoldsc)
* [BUGFIX] Enable `--v3-api suite edit` to proceed without selecting DataConnectors (#3165)
* [BUGFIX] Fix error when `RuntimeBatchRequest` is passed to `SimpleCheckpoint` with `RuntimeDataConnector` (#3152)
* [BUGFIX] allow reader_options in the CLI so can read `.csv.gz` files (#2695) (Thanks @luke321321)
* [DOCS] Apply Docusaurus tabs to relevant pages in new docs
* [DOCS] Capitalize python to Python in docs (#3176)
* [DOCS] Improve Core Concepts - Expectation Concepts (#2831)
* [MAINTENANCE] Error messages must be friendly. (#3171)
* [MAINTENANCE] Implement the "compound_columns_unique" metric for PandasExecutionEngine (with a unit test). (#3159)
* [MAINTENANCE] Improve Coding Practices in "great_expectations/expectations/expectation.py" (#3151)
* [MAINTENANCE] Update test_script_runner.py (#3177)
0.13.25
-----------------
* [FEATURE] Pass on meta-data from expectation json to validation result json (#2881) (Thanks @sushrut9898)
* [FEATURE] Add sqlalchemy engine support for `column.most_common_value` metric (#3020) (Thanks @shpolina)
* [BUGFIX] Added newline to CLI message for consistent formatting (#3127) (Thanks @ismaildawoodjee)
* [BUGFIX] fix pip install snowflake build error with python 3.9 (#3119) (Thanks @jdimatteo)
* [BUGFIX] Populate (data) asset name in data docs for RuntimeDataConnector (#3105) (Thanks @ceshine)
* [DOCS] Correct path to docs_rtd/changelog.rst (#3120) (Thanks @jdimatteo)
* [DOCS] Fix broken links in "How to write a 'How to Guide'" (#3112)
* [DOCS] Port over "How to add comments to Expectations and display them in DataDocs" from RTD to Docusaurus (#3078)
* [DOCS] Port over "How to create a Batch of data from an in memory Spark or Pandas DF" from RTD to Docusaurus (#3099)
* [DOCS] Update CLI codeblocks in create_your_first_expectations.md (#3106) (Thanks @ories)
* [MAINTENANCE] correct typo in docstring (#3117)
* [MAINTENANCE] DOCS/GDOC-130/Add Changelog (#3121)
* [MAINTENANCE] fix docstring for expectation "expect_multicolumn_sum_to_equal" (previous version was not precise) (#3110)
* [MAINTENANCE] Fix typos in docstrings in map_metric_provider partials (#3111)
* [MAINTENANCE] Make sure that all imports use column_aggregate_metric_provider (not column_aggregate_metric). (#3128)
* [MAINTENANCE] Rename column_aggregate_metric.py into column_aggregate_metric_provider.py for better code readability. (#3123)
* [MAINTENANCE] rename ColumnMetricProvider to ColumnAggregateMetricProvider (with DeprecationWarning) (#3100)
* [MAINTENANCE] rename map_metric.py to map_metric_provider.py (with DeprecationWarning) for a better code readability/interpretability (#3103)
* [MAINTENANCE] rename table_metric.py to table_metric_provider.py with a deprecation notice (#3118)
* [MAINTENANCE] Update CODE_OF_CONDUCT.md (#3066)
* [MAINTENANCE] Upgrade to modern Python syntax (#3068) (Thanks @cclauss)
0.13.24
-----------------
* [FEATURE] Script to automate proper triggering of Docs Azure pipeline (#3003)
* [BUGFIX] Fix an undefined name that could lead to a NameError (#3063) (Thanks @cclauss)
* [BUGFIX] fix incorrect pandas top rows usage (#3091)
* [BUGFIX] Fix parens in Expectation metric validation method that always returned True assertation (#3086) (Thanks @morland96)
* [BUGFIX] Fix run_diagnostics for contrib expectations (#3096)
* [BUGFIX] Fix typos discovered by codespell (#3064) (Thanks cclauss)
* [BUGFIX] Wrap get_view_names in try clause for passing the NotImplemented error (#2976) (Thanks @kj-9)
* [DOCS] Ensuring consistent style of directories, files, and related references in docs (#3053)
* [DOCS] Fix broken link to example DAG (#3061) (Thanks fritz-astronomer)
* [DOCS] GDOC-198 cleanup TOC (#3088)
* [DOCS] Migrating pages under guides/miscellaneous (#3094) (Thanks @spbail)
* [DOCS] Port over “How to configure a new Checkpoint using test_yaml_config” from RTD to Docusaurus
* [DOCS] Port over “How to configure an Expectation store in GCS” from RTD to Docusaurus (#3071)
* [DOCS] Port over “How to create renderers for custom Expectations” from RTD to Docusaurus
* [DOCS] Port over “How to run a Checkpoint in Airflow” from RTD to Docusaurus (#3074)
* [DOCS] Update how-to-create-and-edit-expectations-in-bulk.md (#3073)
* [MAINTENANCE] Adding a comment explaining the IDENTITY metric domain type. (#3057)
* [MAINTENANCE] Change domain key value from “column” to “column_list” in ExecutionEngine implementations (#3059)
* [MAINTENANCE] clean up metric errors (#3085)
* [MAINTENANCE] Correct the typo in the naming of the IDENTIFICATION semantic domain type name. (#3058)
* [MAINTENANCE] disable snowflake tests temporarily (#3093)
* [MAINTENANCE] [DOCS] Port over “How to host and share Data Docs on GCS” from RTD to Docusaurus (#3070)
* [MAINTENANCE] Enable repr for MetricConfiguration to assist with troubleshooting. (#3075)
* [MAINTENANCE] Expand test of a column map metric to underscore functionality. (#3072)
* [MAINTENANCE] Expectation anonymizer supports v3 expectation registry (#3092)
* [MAINTENANCE] Fix -- check for column key existence in accessor_domain_kwargsn for condition map partials. (#3082)
* [MAINTENANCE] Missing import of SparkDFExecutionEngine was added. (#3062)
0.13.23
-----------------
* [BUGFIX] added expectation_config to ExpectationValidationResult when exception is raised (#2659) (thanks @peterdhansen)
* [BUGFIX] fix update data docs as validation action (#3031)
* [DOCS] Port over "How to configure an Expectation Store in Azure" from RTD to Docusaurus
* [DOCS] Port over "How to host and share DataDocs on a filesystem" from RTD to Docusaurus (#3018)
* [DOCS] Port over "How to instantiate a Data Context w/o YML" from RTD to Docusaurus (#3011)
* [DOCS] Port "How to configure a Validation Result store on a filesystem" from RTD to Docusaurus (#3025)
* [DOCS] how to create multibatch expectations using evaluation parameters (#3039)
* [DOCS] Port "How to create and edit Expectations with a Profiler" from RTD to Docussaurus. (#3048)
* [DOCS] Port RTD adding validations data or suites to checkpoint (#3030)
* [DOCS] Porting "How to create and edit Expectations with instant feedback from a sample Batch of data" from RTD to Docusaurus. (#3046)
* [DOCS] GDOC-172/Add missing pages (#3007)
* [DOCS] Port over "How to configure DataContext components using test_yaml_config" from RTD to Docusaurus
* [DOCS] Port over "How to configure a Validation Result store to Postgres" from RTD to Docusaurus
* [DOCS] Port over "How to configure an Expectation Store in S3" from RTD to Docusaurus
* [DOCS] Port over "How to configure an Expectation Store on a filesystem" from RTD to Docusaurus
* [DOCS] Port over "How to configure credentials using YAML or env vars" from RTD to Docusaurus
* [DOCS] Port over "How to configure credentials using a secrets store" from RTD to Docusaurus
* [DOCS] Port over "How to configure validation result store in GCS" from RTD to Docusaurus (#3019)
* [DOCS] Port over "How to connect to an Athena DB" from RTD to Docusaurus
* [DOCS] Port over "How to create a new ExpectationSuite from jsonschema" from RTD to Docusaurus (#3017)
* [DOCS] Port over "How to deploy a scheduled checkpoint with cron" from RTD to Docusaurus
* [DOCS] Port over "How to dynamically load evaluation parameters from DB" from RTD to Docusaurus (#3052)
* [DOCS] Port over "How to host and share DataDocs on Amazon S3" from RTD to Docusaurus
* [DOCS] Port over "How to implement custom notifications" from RTD to Docusaurus (#3050)
* [DOCS] Port over "How to instantiate a DataContext on Databricks Spark cluster" from RTD to Docusaurus
* [DOCS] Port over "How to instantiate a DataContext on an EMR Spark Cluster" from RTD to Docusaurus (#3024)
* [DOCS] Port over "How to trigger Opsgenie notifications as a validation action" from RTD to Docusaurus
* [DOCS] Update titles of metadata store docs (#3016)
* [DOCS] Port over "How to configure Expectation store to PostgreSQL" from RTD to Docusaurus (#3010)
* [DOCS] Port over "How to configure a MetricsStore" from RTD to Docusaurus (#3009)
* [DOCS] Port over "How to configure validation result store in Azure" from RTD to Docusaurus (#3014)
* [DOCS] Port over "How to host and share DataDocs on Azure" from RTD to Docusaurus (#3012)
* [DOCS]Port "How to create and edit Expectations based on domain knowledge, without inspecting data directly" from RTD to Datasaurus. (#3047)
* [DOCS] Ported "How to configure a Validation Result store in Amazon S3" from RTD to Docusaurus. (#3026)
* [DOCS] how to validate without checkpoint (#3013)
* [DOCS] validation action data docs update (convert from RTD to DocuSaurus) (#3015)
* [DOCS] port of 'How to store Validation Results as a Validation Action' from RTD into Docusaurus. (#3023)
* [MAINTENANCE] Cleanup (#3038)
* [MAINTENANCE] Edits (Formatting) (#3022)
0.13.22
-----------------
* [FEATURE] Port over guide for Slack notifications for validation actions (#3005)
* [FEATURE] bootstrap estimator for NumericMetricRangeMultiBatchParameterBuilder (#3001)
* [BUGFIX] Update naming of confidence_level in integration test fixture (#3002)
* [BUGFIX] [batch.py] fix check for null value (#2994) (thanks <NAME>)
* [BUGFIX] Fix issue where compression key was added to reader_method for read_parquet (#2506)
* [BUGFIX] Improve support for dates for expect_column_distinct_values_to_contain_set (#2997) (thanks @xaniasd)
* [BUGFIX] Fix bug in getting non-existent parameter (#2986)
* [BUGFIX] Modify read_excel() to handle new optional-dependency openpyxl for pandas >= 1.3.0 (#2989)
* [DOCS] Getting Started - Clean Up and Integration Tests (#2985)
* [DOCS] Adding in url links and style (#2999)
* [DOCS] Adding a missing import to a documentation page (#2983) (thanks @rishabh-bhargava)
* [DOCS]/GDOC-108/GDOC-143/Add in Contributing fields and updates (#2972)
* [DOCS] Update rule-based profiler docs (#2987)
* [DOCS] add image zoom plugin (#2979)
* [MAINTENANCE] fix lint issues for docusaurus (#3004)
* [Maintenance] update header to match GE.io (#2811)
* [MAINTENANCE] Instrument test_yaml_config() (#2981)
* [MAINTENANCE] Remove "mostly" from "bobster" test config (#2996)
* [MAINTENANCE] Update v-0.12 CLI test to reflect Pandas upgrade to version 1.3.0 (#2995)
* [MAINTENANCE] rephrase expectation suite meta profile comment (#2991)
* [MAINTENANCE] make citation cleaner in expectation suite (#2990)
* [MAINTENANCE] Attempt to fix Numpy and Scipy Version Requirements without additional requirements* files (#2982)
0.13.21
-----------------
* [DOCS] correct errors and reference complete example for custom expectations (thanks @jdimatteo)
* [DOCS] How to connect to : in-memory Pandas Dataframe
* [DOCS] How to connect to in memory dataframe with spark
* [DOCS] How to connect to : S3 data using Pandas
* [DOCS] How to connect to : Sqlite database
* [DOCS] no longer show util import to users
* [DOCS] How to connect to data on a filesystem using Spark guide
* [DOCS] GDOC-102/GDOC-127 Port in References and Tutorials
* [DOCS] How to connect to a MySQL database
* [DOCS] improved clarity in how to write guide templates and docs
* [DOCS] Add documentation for Rule Based Profilers
* [BUGFIX] Update mssql image version for Azure
* [MAINTENANCE] Update test-sqlalchemy-latest.yml
* [MAINTENANCE] Clean Up Design for Configuration and Flow of Rules, Domain Builders, and Parameter Builders
* [MAINTENANCE] Update Profiler docstring args
* [MAINTENANCE] Remove date format parameter builder
* [MAINTENANCE] Move metrics computations to top-level ParameterBuilder
* [MAINTENANCE] use tmp dot UUID for discardable expectation suite name
* [MAINTENANCE] Refactor ExpectationSuite to include profiler_config in citations
* [FEATURE] Add citations to Profiler.profile()
* [FEATURE] Bootstrapped Range Parameter Builder
0.13.20
-----------------
* [DOCS] Update pr template and remove enhancement feature type
* [DOCS] Remove broken links
* [DOCS] Fix typo in SlackNotificationAction docstring
* [BUGFIX] Update util.convert_to_json_serializable() to handle UUID type #2805 (thanks @YFGu0618)
* [BUGFIX] Allow decimals without leading zero in evaluation parameter URN
* [BUGFIX] Using cache in order not to fetch already known secrets #2882 (thanks @Cedric-Magnan)
* [BUGFIX] Fix creation of temp tables for unexpected condition
* [BUGFIX] Docs integration tests now only run when `--docs-tests` option is specified
* [BUGFIX] Fix instantiation of PandasExecutionEngine with custom parameters
* [BUGFIX] Fix rendering of observed value in datadocs when the value is 0 #2923 (thanks @shpolina)
* [BUGFIX] Fix serialization error in DataDocs rendering #2908 (thanks @shpolina)
* [ENHANCEMENT] Enable instantiation of a validator with a multiple batch BatchRequest
* [ENHANCEMENT] Adds a batch_request_list parameter to DataContext.get_validator to enable instantiation of a Validator with batches from multiple BatchRequests
* [ENHANCEMENT] Add a Validator.load_batch method to enable loading of additional Batches to an instantiated Validator
* [ENHANCEMENT] Experimental WIP Rule-Based Profiler for single batch workflows (#2788)
* [ENHANCEMENT] Datasources made via the CLI notebooks now include runtime and active data connector
* [ENHANCEMENT] InMemoryStoreBackendDefaults which is useful for testing
* [MAINTENANCE] Improve robustness of integration test_runner
* [MAINTENANCE] CLI tests now support click 8.0 and 7.x
* [MAINTENANCE] Soft launch of alpha docs site
* [MAINTENANCE] DOCS integration tests have moved to a new pipeline
* [MAINTENANCE] Pin json-schema version
* [MAINTENANCE] Allow tests to properly connect to local sqlite db on Windows (thanks @shpolina)
* [FEATURE] Add GeCloudStoreBackend with support for Checkpoints
0.13.19
-----------------
* [BUGFIX] Fix packaging error breaking V3 CLI suite commands (#2719)
0.13.18
-----------------
* [ENHANCEMENT] Improve support for quantiles calculation in Athena
* [ENHANCEMENT] V3 API CLI docs commands have better error messages and more consistent short flags
* [ENHANCEMENT] Update all Data Connectors to allow for `batch_spec_passthrough` in config
* [ENHANCEMENT] Update `DataConnector.build_batch_spec` to use `batch_spec_passthrough` in config
* [ENHANCEMENT] Update `ConfiguredAssetSqlDataConnector.build_batch_spec` and `ConfiguredAssetFilePathDataConnector.build_batch_spec` to properly process `Asset.batch_spec_passthrough`
* [ENHANCEMENT] Update `SqlAlchemyExecutionEngine.get_batch_data_and_markers` to handle `create_temp_table` in `RuntimeQueryBatchSpec`
* [ENHANCEMENT] Usage stats messages for the v3 API CLI are now sent before and after the command runs # 2661
* [ENHANCEMENT} Update the datasource new notebook for improved data asset inference
* [ENHANCEMENT] Update the `datasource new` notebook for improved data asset inference
* [ENHANCEMENT] Made stylistic improvements to the `checkpoint new` notebook
* [ENHANCEMENT] Add mode prompt to suite new and suite edit #2706
* [ENHANCEMENT] Update build_gallery.py script to better-handle user-submitted Expectations failing #2705
* [ENHANCEMENT] Docs + Tests for passing in reader_options to Spark #2670
* [ENHANCEMENT] Adding progressbar to validator loop #2620 (Thanks @peterdhansen!)
* [ENHANCEMENT] Great Expectations Compatibility with SqlAlchemy 1.4 #2641
* [ENHANCEMENT] Athena expect column quantile values to be between #2544 (Thanks @RicardoPedrotti!)
* [BUGFIX] Rename assets in SqlDataConnectors to be consistent with other DataConnectors #2665
* [BUGFIX] V3 API CLI docs build now opens all built sites rather than only the last one
* [BUGFIX] Handle limit for oracle with rownum #2691 (Thanks @NathanFarmer!)
* [BUGFIX] add create table logic for athena #2668 (Thanks @kj-9!)
* [BUGFIX] Add note for user-submitted Expectation that is not compatible with SqlAlchemy 1.4 (uszipcode) #2677
* [BUGFIX] Usage stats cli payload schema #2680
* [BUGFIX] Rename assets in SqlDataConnectors #2665
* [DOCS] Update how_to_create_a_new_checkpoint.rst with description of new CLI functionality
* [DOCS] Update Configuring Datasources documentation for V3 API CLI
* [DOCS] Update Configuring Data Docs documentation for V3 API CLI
* [DOCS] Update Configuring metadata stores documentation for V3 API CLI
* [DOCS] Update How to configure a Pandas/S3 Datasource for V3 API CLI
* [DOCS] Fix typos in "How to load a database table, view, or query result as a batch" guide and update with `create_temp_table` info
* [DOCS] Update "How to add a Validation Operator" guide to make it clear it is only for V2 API
* [DOCS] Update Version Migration Guide to recommend using V3 without caveats
* [DOCS] Formatting fixes for datasource docs #2686
* [DOCS] Add note about v3 API to How to use the Great Expectations command line interface (CLI) #2675
* [DOCS] CLI SUITE Documentation for V3 #2687
* [DOCS] how to share data docs on azure #2589 (Thanks @benoitLebreton-perso!)
* [DOCS] Fix typo in Core concepts/Key Ideas section #2660 (Thanks @svenhofstede!)
* [DOCS] typo in datasource documentation #2654 (Thanks @Gfeuillen!)
* [DOCS] fix grammar #2579 (Thanks @carlsonp!)
* [DOCS] Typo fix in Core Concepts/ Key Ideas section #2644 (Thanks @TremaMiguel!)
* [DOCS] Corrects wrong pypi package in Contrib Packages README #2653 (Thanks @mielvds!)
* [DOCS] Update dividing_data_assets_into_batches.rst #2651 (Thanks @lhayhurst!)
* [MAINTENANCE] Temporarily pin sqlalchemy (1.4.9) and add new CI stage #2708
* [MAINTENANCE] Run CLI tests as a separate stage in Azure pipelines #2672
* [MAINTENANCE] Updates to usage stats messages & tests for new CLI #2689
* [MAINTENANCE] Making user configurable profile test more robust; minor cleanup #2685
* [MAINTENANCE] remove cli.project.upgrade event #2682
* [MAINTENANCE] column reflection fallback should introspect one table (not all tables) #2657 (Thank you @peterdhansen!)
* [MAINTENANCE] Refactor Tests to Use Common Libraries #2663
0.13.17
-----------------
* [BREAKING-EXPERIMENTAL] The ``batch_data`` attribute of ``BatchRequest`` has been removed. To pass in in-memory dataframes at runtime, the new ``RuntimeDataConnector`` should be used
* [BREAKING-EXPERIMENTAL] ``RuntimeDataConnector`` must now be passed Batch Requests of type ``RuntimeBatchRequest``
* [BREAKING-EXPERIMENTAL] The ``PartitionDefinitionSubset`` class has been removed - the parent class ``IDDict`` is used in its place
* [BREAKING-EXPERIMENTAL] ``partition_request`` was renamed ``data_connector_query``. The related ``PartitionRequest`` class has been removed - the parent class ``IDDict`` is used in its place
* [BREAKING-EXPERIMENTAL] ``partition_definition`` was renamed ``batch_identifiers`. The related ``PartitionDefinition`` class has been removed - the parent class ``IDDict`` is used in its place
* [BREAKING-EXPERIMENTAL] The ``PartitionQuery`` class has been renamed to ``BatchFilter``
* [BREAKING-EXPERIMENTAL] The ``batch_identifiers`` key on ``DataConnectorQuery`` (formerly ``PartitionRequest``) has been changed to ``batch_filter_parameters``
* [ENHANCEMENT] Added a new ``RuntimeBatchRequest`` class, which can be used alongside ``RuntimeDataConnector`` to specify batches at runtime with either an in-memory dataframe, path (filesystem or s3), or sql query
* [ENHANCEMENT] Added a new ``RuntimeQueryBatchSpec`` class
* [ENHANCEMENT] CLI store list now lists active stores
* [BUGFIX] Fixed issue where Sorters were not being applied correctly when ``data_connector_query`` contained limit or index #2617
* [DOCS] Updated docs to reflect above class name changes
* [DOCS] Added the following docs: "How to configure sorting in Data Connectors", "How to configure a Runtime Data Connector", "How to create a Batch Request using an Active Data Connector", "How to load a database table, view, or query result as a Batch"
* [DOCS] Updated the V3 API section of the following docs: "How to load a Pandas DataFrame as a Batch", "How to load a Spark DataFrame as a Batch",
0.13.16
-----------------
* [ENHANCEMENT] CLI `docs list` command implemented for v3 api #2612
* [MAINTENANCE] Add testing for overwrite_existing in sanitize_yaml_and_save_datasource #2613
* [ENHANCEMENT] CLI `docs build` command implemented for v3 api #2614
* [ENHANCEMENT] CLI `docs clean` command implemented for v3 api #2615
* [ENHANCEMENT] DataContext.clean_data_docs now raises helpful errors #2621
* [ENHANCEMENT] CLI `init` command implemented for v3 api #2626
* [ENHANCEMENT] CLI `store list` command implemented for v3 api #2627
0.13.15
-----------------
* [FEATURE] Added support for references to secrets stores for AWS Secrets Manager, GCP Secret Manager and Azure Key Vault in `great_expectations.yml` project config file (Thanks @Cedric-Magnan!)
* [ENHANCEMENT] Datasource CLI functionality for v3 api and global --assume-yes flag #2590
* [ENHANCEMENT] Update UserConfigurableProfiler to increase tolerance for mostly parameter of nullity expectations
* [ENHANCEMENT] Adding tqdm to Profiler (Thanks @peterdhansen). New library in requirements.txt
* [ENHANCEMENT][MAINTENANCE] Use Metrics to Protect Against Wrong Column Names
* [BUGFIX] Remove parentheses call at os.curdir in data_context.py #2566 (thanks @henriquejsfj)
* [BUGFIX] Sorter Configuration Added to DataConnectorConfig and DataConnectorConfigSchema #2572
* [BUGFIX] Remove autosave of Checkpoints in test_yaml_config and store SimpleCheckpoint as Checkpoint #2549
* [ENHANCE] Update UserConfigurableProfiler to increase tolerance for mostly parameter of nullity expectations
* [BUGFIX] Populate (data) asset name in data docs for SimpleSqlalchemy datasource (Thanks @xaniasd)
* [BUGFIX] pandas partial read_ functions not being unwrapped (Thanks @luke321321)
* [BUGFIX] Don't stop SparkContext when running in Databricks (#2587) (Thanks @jarandaf)
* [MAINTENANCE] Oracle listed twice in list of sqlalchemy dialects #2609
* [FEATURE] Oracle support added to sqlalchemy datasource and dataset #2609
0.13.14
-----------------
* [BUGFIX] Use temporary paths in tests #2545
* [FEATURE] Allow custom data_asset_name for in-memory dataframes #2494
* [ENHANCEMENT] Restore cli functionality for legacy checkpoints #2511
* [BUGFIX] Can not create Azure Backend with TupleAzureBlobStoreBackend #2513 (thanks @benoitLebreton-perso)
* [BUGFIX] force azure to set content_type='text/html' if the file is HTML #2539 (thanks @benoitLebreton-perso)
* [BUGFIX] Temporarily pin SqlAlchemy to < 1.4.0 in requirements-dev-sqlalchemy.txt #2547
* [DOCS] Fix documentation links generated within template #2542 (thanks @thejasraju)
* [MAINTENANCE] Remove deprecated automerge config #249
0.13.13
-----------------
* [ENHANCEMENT] Improve support for median calculation in Athena (Thanks @kuhnen!) #2521
* [ENHANCEMENT] Update `suite scaffold` to work with the UserConfigurableProfiler #2519
* [MAINTENANCE] Add support for spark 3 based spark_config #2481
0.13.12
-----------------
* [FEATURE] Added EmailAction as a new Validation Action (Thanks @Cedric-Magnan!) #2479
* [ENHANCEMENT] CLI global options and checkpoint functionality for v3 api #2497
* [DOCS] Renamed the "old" and the "new" APIs to "V2 (Batch Kwargs) API" and "V3 (Batch Request) API" and added an article with recommendations for choosing between them
0.13.11
-----------------
* [FEATURE] Add "table.head" metric
* [FEATURE] Add support for BatchData as a core GE concept for all Execution Engines. #2395
* NOTE: As part of our improvements to the underlying Batch API, we have refactored BatchSpec to be part of the "core" package in Great Expectations, consistent with its role coordinating communication about Batches between the Datasource and Execution Engine abstractions.
* [ENHANCEMENT] Explicit support for schema_name in the SqlAlchemyBatchData #2465. Issue #2340
* [ENHANCEMENT] Data docs can now be built skipping the index page using the python API #2224
* [ENHANCEMENT] Evaluation parameter runtime values rendering in data docs if arithmetic is present #2447. Issue #2215
* [ENHANCEMENT] When connecting to new Datasource, CLI prompt is consistent with rest of GE #2434
* [ENHANCEMENT] Adds basic test for bad s3 paths generated from regex #2427 (Thanks @lukedyer-peak!)
* [ENHANCEMENT] Updated UserConfigurableProfiler date parsing error handling #2459
* [ENHANCEMENT] Clarification of self_check error messages #2304
* [ENHANCEMENT] Allows gzipped files and other encodings to be read from S3 #2440 (Thanks @luke321321!)
* [BUGFIX] `expect_column_unique_value_count_to_be_between` renderer bug (duplicate "Distinct (%)") #2455. Issue #2423
* [BUGFIX] Fix S3 Test issue by pinning `moto` version < 2.0.0 #2470
* [BUGFIX] Check for datetime-parseable strings in validate_metric_value_between_configuration #2419. Issue #2340 (Thanks @victorwyee!)
* [BUGFIX] `expect_compound_columns_to_be_unique` ExpectationConfig added #2471 Issue #2464
* [BUGFIX] In basic profiler, handle date parsing and overflow exceptions separately #2431 (Thanks @peterdhansen!)
* [BUGFIX] Fix sqlalchemy column comparisons when comparison was done between different datatypes #2443 (Thanks @peterdhansen!)
* [BUGFIX] Fix divide by zero error in expect_compound_columns_to_be_unique #2454 (Thanks @jdimatteo!)
* [DOCS] added how-to guide for user configurable profiler #2452
* [DOCS] Linked videos and minor documentation addition #2388
* [DOCS] Modifying getting started tutorial content to work with 0.13.8+ #2418
* [DOCS] add case studies to header in docs #2430
* [MAINTENANCE] Updates to Azure pipeline configurations #2462
* [MAINTENANCE] Allowing the tests to run with Docker-in-Windows #2402 (Thanks @Patechoc!)
* [MAINTENANCE] Add support for automatically building expectations gallery metadata #2386
0.13.10
-----------------
* [ENHANCEMENT] Optimize tests #2421
* [ENHANCEMENT] Add docstring for _invert_regex_to_data_reference_template #2428
* [ENHANCEMENT] Added expectation to check if data is in alphabetical ordering #2407 (Thanks @sethdmay!)
* [BUGFIX] Fixed a broken docs link #2433
* [BUGFIX] Missing `markown_text.j2` jinja template #2422
* [BUGFIX] parse_strings_as_datetimes error with user_configurable_profiler #2429
* [BUGFIX] Update `suite edit` and `suite scaffold` notebook renderers to output functional validation cells #2432
* [DOCS] Update how_to_create_custom_expectations_for_pandas.rst #2426 (Thanks @henriquejsfj!)
* [DOCS] Correct regex escape for data connectors #2425 (Thanks @lukedyer-peak!)
* [CONTRIB] Expectation: Matches benfords law with 80 percent confidence interval test #2406 (Thanks @vinodkri1!)
0.13.9
-----------------
* [FEATURE] Add TupleAzureBlobStoreBackend (thanks @syahdeini) #1975
* [FEATURE] Add get_metrics interface to Modular Expectations Validator API
* [ENHANCEMENT] Add possibility to pass boto3 configuration to TupleS3StoreBackend (Thanks for #1691 to @mgorsk1!) #2371
* [ENHANCEMENT] Removed the logic that prints the "This configuration object was built using version..." warning when current version of Great Expectations is not the same as the one used to build the suite, since it was not actionable #2366
* [ENHANCEMENT] Update Validator with more informative error message
* [BUGFIX] Ensure that batch_spec_passthrough is handled correctly by properly refactoring build_batch_spec and _generate_batch_spec_parameters_from_batch_definition for all DataConnector classes
* [BUGFIX] Display correct unexpected_percent in DataDocs - corrects the result object from map expectations to return the same "unexpected_percent" as is used to evaluate success (excluding null values from the denominator). The old value is now returned in a key called "unexpected_percent_total" (thanks @mlondschien) #1875
* [BUGFIX] Add python=3.7 argument to conda env creation (thanks @scouvreur!) #2391
* [BUGFIX] Fix issue with temporary table creation in MySQL #2389
* [BUGFIX] Remove duplicate code in data_context.store.tuple_store_backend (Thanks @vanderGoes)
* [BUGFIX] Fix issue where WarningAndFailureExpectationSuitesValidationOperator failing when warning suite fails
* [DOCS] Update How to instantiate a Data Context on Databricks Spark cluster for 0.13+ #2379
* [DOCS] How to load a Pandas DataFrame as a Batch #2327
* [DOCS] Added annotations for Expectations not yet ported to the new Modular Expectations API.
* [DOCS] How to load a Spark DataFrame as a Batch #2385
* [MAINTENANCE] Add checkpoint store to store backend defaults #2378
0.13.8
-----------------
* [FEATURE] New implementation of Checkpoints that uses dedicated CheckpointStore (based on the new ConfigurationStore mechanism) #2311, #2338
* [BUGFIX] Fix issue causing incorrect identification of partially-implemented expectations as not abstract #2334
* [BUGFIX] DataContext with multiple DataSources no longer scans all configurations #2250
0.13.7
-----------------
* [BUGFIX] Fix Local variable 'temp_table_schema_name' might be referenced before assignment bug in sqlalchemy_dataset.py #2302
* [MAINTENANCE] Ensure compatibility with new pip resolver v20.3+ #2256
* [ENHANCEMENT] Improvements in the how-to guide, run_diagnostics method in Expectation base class and Expectation templates to support the new rapid "dev loop" of community-contributed Expectations. #2296
* [ENHANCEMENT] Improvements in the output of Expectations tests to make it more legible. #2296
* [DOCS] Clarification of the instructions for using conda in the "Setting Up Your Dev Environment" doc. #2306
0.13.6
-----------------
* [ENHANCEMENT] Skip checks when great_expectations package did not change #2287
* [ENHANCEMENT] A how-to guide, run_diagnostics method in Expectation base class and Expectation templates to support the new rapid "dev loop" of community-contributed Expectations. #2222
* [BUGFIX] Fix Local variable 'query_schema' might be referenced before assignment bug in sqlalchemy_dataset.py #2286 (Thanks @alessandrolacorte!)
* [BUGFIX] Use correct schema to fetch table and column metadata #2284 (Thanks @armaandhull!)
* [BUGFIX] Updated sqlalchemy_dataset to convert numeric metrics to json_serializable up front, avoiding an issue where expectations on data immediately fail due to the conversion to/from json. #2207
0.13.5
-----------------
* [FEATURE] Add MicrosoftTeamsNotificationAction (Thanks @Antoninj!)
* [FEATURE] New ``contrib`` package #2264
* [ENHANCEMENT] Data docs can now be built skipping the index page using the python API #2224
* [ENHANCEMENT] Speed up new suite creation flow when connecting to Databases. Issue #1670 (Thanks @armaandhull!)
* [ENHANCEMENT] Serialize PySpark DataFrame by converting to dictionary #2237
* [BUGFIX] Mask passwords in DataContext.list_datasources(). Issue #2184
* [BUGFIX] Skip escaping substitution variables in escape_all_config_variables #2243. Issue #2196 (Thanks @
varundunga!)
* [BUGFIX] Pandas extension guessing #2239 (Thanks @sbrugman!)
* [BUGFIX] Replace runtime batch_data DataFrame with string #2240
* [BUGFIX] Update Notebook Render Tests to Reflect Updated Python Packages #2262
* [DOCS] Updated the code of conduct to mention events #2278
* [DOCS] Update the diagram for batch metadata #2161
* [DOCS] Update metrics.rst #2257
* [MAINTENANCE] Different versions of Pandas react differently to corrupt XLS files. #2230
* [MAINTENANCE] remove the obsolete TODO comments #2229 (Thanks @beyondacm!)
* [MAINTENANCE] Update run_id to airflow_run_id for clarity. #2233
0.13.4
-----------------
* [FEATURE] Implement expect_column_values_to_not_match_regex_list in Spark (Thanks @mikaylaedwards!)
* [ENHANCEMENT] Improve support for quantile calculations in Snowflake
* [ENHANCEMENT] DataDocs show values of Evaluation Parameters #2165. Issue #2010
* [ENHANCEMENT] Work on requirements.txt #2052 (Thanks @shapiroj18!)
* [ENHANCEMENT] expect_table_row_count_to_equal_other_table #2133
* [ENHANCEMENT] Improved support for quantile calculations in Snowflake #2176
* [ENHANCEMENT] DataDocs show values of Evaluation Parameters #2165
* [BUGFIX] Add pagination to TupleS3StoreBackend.list_keys() #2169. Issue #2164
* [BUGFIX] Fixed black conflict, upgraded black, made import optional #2183
* [BUGFIX] Made improvements for the treatment of decimals for database backends for lossy conversion #2207
* [BUGFIX] Pass manually_initialize_store_backend_id to database store backends to mirror functionality of other backends. Issue #2181
* [BUGFIX] Make glob_directive more permissive in ConfiguredAssetFilesystemDataConnector #2197. Issue #2193
* [DOCS] Added link to Youtube video on in-code contexts #2177
* [DOCS] Docstrings for DataConnector and associated classes #2172
* [DOCS] Custom expectations improvement #2179
* [DOCS] Add a conda example to creating virtualenvs #2189
* [DOCS] Fix Airflow logo URL #2198 (Thanks @floscha!)
* [DOCS] Update explore_expectations_in_a_notebook.rst #2174
* [DOCS] Change to DOCS that describe Evaluation Parameters #2209
* [MAINTENANCE] Removed mentions of show_cta_footer and added deprecation notes in usage stats #2190. Issue #2120
0.13.3
-----------------
* [ENHANCEMENT] Updated the BigQuery Integration to create a view instead of a table (thanks @alessandrolacorte!) #2082.
* [ENHANCEMENT] Allow database store backend to support specification of schema in credentials file
* [ENHANCEMENT] Add support for connection_string and url in configuring DatabaseStoreBackend, bringing parity to other SQL-based objects. In the rare case of user code that instantiates a DatabaseStoreBackend without using the Great Expectations config architecture, users should ensure they are providing kwargs to init, because the init signature order has changed.
* [ENHANCEMENT] Improved exception handling in the Slack notifications rendering logic
* [ENHANCEMENT] Uniform configuration support for both 0.13 and 0.12 versions of the Datasource class
* [ENHANCEMENT] A single `DataContext.get_batch()` method supports both 0.13 and 0.12 style call arguments
* [ENHANCEMENT] Initializing DataContext in-code is now available in both 0.13 and 0.12 versions
* [BUGFIX] Fixed a bug in the error printing logic in several exception handling blocks in the Data Docs rendering. This will make it easier for users to submit error messages in case of an error in rendering.
* [DOCS] Miscellaneous doc improvements
* [DOCS] Update cloud composer workflow to use GCSStoreBackendDefaults
0.13.2
-----------------
* [ENHANCEMENT] Support avro format in Spark datasource (thanks @ryanaustincarlson!) #2122
* [ENHANCEMENT] Made improvements to the backend for expect_column_quantile_values_to_be_between #2127
* [ENHANCEMENT] Robust Representation in Configuration of Both Legacy and New Datasource
* [ENHANCEMENT] Continuing 0.13 clean-up and improvements
* [BUGFIX] Fix spark configuration not getting passed to the SparkSession builder (thanks @EricSteg!) #2124
* [BUGFIX] Misc bugfixes and improvements to code & documentation for new in-code data context API #2118
* [BUGFIX] When Introspecting a database, sql_data_connector will ignore view_names that are also system_tables
* [BUGFIX] Made improvements for code & documentation for in-code data context
* [BUGFIX] Fixed bug where TSQL mean on `int` columns returned incorrect result
* [DOCS] Updated explanation for ConfiguredAssetDataConnector and InferredAssetDataConnector
* [DOCS] General 0.13 docs improvements
0.13.1
-----------------
* [ENHANCEMENT] Improved data docs performance by ~30x for large projects and ~4x for smaller projects by changing instantiation of Jinja environment #2100
* [ENHANCEMENT] Allow database store backend to support specification of schema in credentials file #2058 (thanks @GTLangseth!)
* [ENHANCEMENT] More detailed information in Datasource.self_check() diagnostic (concerning ExecutionEngine objects)
* [ENHANCEMENT] Improve UI for in-code data contexts #2068
* [ENHANCEMENT] Add a store_backend_id property to StoreBackend #2030, #2075
* [ENHANCEMENT] Use an existing expectation_store.store_backend_id to initialize an in-code DataContext #2046, #2075
* [BUGFIX] Corrected handling of boto3_options by PandasExecutionEngine
* [BUGFIX] New Expectation via CLI / SQL Query no longer throws TypeError
* [BUGFIX] Implement validator.default_expectations_arguments
* [DOCS] Fix doc create and editing expectations #2105 (thanks @Lee-W!)
* [DOCS] Updated documentation on 0.13 classes
* [DOCS] Fixed a typo in the HOWTO guide for adding a self-managed Spark datasource
* [DOCS] Updated documentation for new UI for in-code data contexts
0.13.0
-----------------
* INTRODUCING THE NEW MODULAR EXPECTATIONS API (Experimental): this release introduces a new way to create expectation logic in its own class, making it much easier to author and share expectations. ``Expectation`` and ``MetricProvider`` classes now work together to validate data and consolidate logic for all backends by function. See the how-to guides in our documentation for more information on how to use the new API.
* INTRODUCING THE NEW DATASOURCE API (Experimental): this release introduces a new way to connect to datasources providing much richer guarantees for discovering ("inferring") data assets and partitions. The new API replaces "BatchKwargs" and "BatchKwargsGenerators" with BatchDefinition and BatchSpec objects built from DataConnector classes. You can read about the new API in our docs.
* The Core Concepts section of our documentation has been updated with descriptions of the classes and concepts used in the new API; we will continue to update that section and welcome questions and improvements.
* BREAKING: Data Docs rendering is now handled in the new Modular Expectations, which means that any custom expectation rendering needs to be migrated to the new API to function in version 0.13.0.
* BREAKING: **Renamed** Datasource to LegacyDatasource and introduced the new Datasource class. Because most installations rely on one PandasDatasource, SqlAlchemyDatasource, or SparkDFDatasource, most users will not be affected. However, if you have implemented highly customized Datasource class inheriting from the base class, you may need to update your inheritance.
* BREAKING: The new Modular Expectations API will begin removing the ``parse_strings_as_datetimes`` and ``allow_cross_type_comparisons`` flags in expectations. Expectation Suites that use the flags will need to be updated to use the new Modular Expectations. In general, simply removing the flag will produce correct behavior; if you still want the exact same semantics, you should ensure your raw data already has typed datetime objects.
* **NOTE:** Both the new Datasource API and the new Modular Expectations API are *experimental* and will change somewhat during the next several point releases. We are extremely excited for your feedback while we iterate rapidly, and continue to welcome new community contributions.
0.12.10
-----------------
* [BUGFIX] Update requirements.txt for ruamel.yaml to >=0.16 - #2048 (thanks @mmetzger!)
* [BUGFIX] Added option to return scalar instead of list from query store #2060
* [BUGFIX] Add missing markdown_content_block_container #2063
* [BUGFIX] Fixed a divided by zero error for checkpoints on empty expectation suites #2064
* [BUGFIX] Updated sort to correctly return partial unexpected results when expect_column_values_to_be_of_type has more than one unexpected type #2074
* [BUGFIX] Resolve Data Docs resource identifier issues to speed up UpdateDataDocs action #2078
* [DOCS] Updated contribution changelog location #2051 (thanks @shapiroj18!)
* [DOCS] Adding Airflow operator and Astrononomer deploy guides #2070
* [DOCS] Missing image link to bigquery logo #2071 (thanks @nelsonauner!)
0.12.9
-----------------
* [BUGFIX] Fixed the import of s3fs to use the optional import pattern - issue #2053
* [DOCS] Updated the title styling and added a Discuss comment article for the OpsgenieAlertAction how-to guide
0.12.8
-----------------
* [FEATURE] Add OpsgenieAlertAction #2012 (thanks @miike!)
* [FEATURE] Add S3SubdirReaderBatchKwargsGenerator #2001 (thanks @noklam)
* [ENHANCEMENT] Snowflake uses temp tables by default while still allowing transient tables
* [ENHANCEMENT] Enabled use of lowercase table and column names in GE with the `use_quoted_name` key in batch_kwargs #2023
* [BUGFIX] Basic suite builder profiler (suite scaffold) now skips excluded expectations #2037
* [BUGFIX] Off-by-one error in linking to static images #2036 (thanks @NimaVaziri!)
* [BUGFIX] Improve handling of pandas NA type issue #2029 PR #2039 (thanks @isichei!)
* [DOCS] Update Virtual Environment Example #2027 (thanks @shapiroj18!)
* [DOCS] Update implemented_expectations.rst (thanks @jdimatteo!)
* [DOCS] Update how_to_configure_a_pandas_s3_datasource.rst #2042 (thanks @CarstenFrommhold!)
0.12.7
-----------------
* [ENHANCEMENT] CLI supports s3a:// or gs:// paths for Pandas Datasources (issue #2006)
* [ENHANCEMENT] Escape $ characters in configuration, support multiple substitutions (#2005 & #2015)
* [ENHANCEMENT] Implement Skip prompt flag on datasource profile cli (#1881 Thanks @thcidale0808!)
* [BUGFIX] Fixed bug where slack messages cause stacktrace when data docs pages have issue
* [DOCS] How to use docker images (#1797)
* [DOCS] Remove incorrect doc line from PagerdutyAlertAction (Thanks @niallrees!)
* [MAINTENANCE] Update broken link (Thanks @noklam!)
* [MAINTENANCE] Fix path for how-to guide (Thanks @gauthamzz!)
0.12.6
-----------------
* [BUGFIX] replace black in requirements.txt
0.12.5
-----------------
* [ENHANCEMENT] Implement expect_column_values_to_be_json_parseable in spark (Thanks @mikaylaedwards!)
* [ENHANCEMENT] Fix boto3 options passing into datasource correctly (Thanks @noklam!)
* [ENHANCEMENT] Add .pkl to list of recognized extensions (Thanks @KPLauritzen!)
* [BUGFIX] Query batch kwargs support for Athena backend (issue 1964)
* [BUGFIX] Skip config substitution if key is "password" (issue 1927)
* [BUGFIX] fix site_names functionality and add site_names param to get_docs_sites_urls (issue 1991)
* [BUGFIX] Always render expectation suites in data docs unless passing a specific ExpectationSuiteIdentifier in resource_identifiers (issue 1944)
* [BUGFIX] remove black from requirements.txt
* [BUGFIX] docs build cli: fix --yes argument (Thanks @varunbpatil!)
* [DOCS] Update docstring for SubdirReaderBatchKwargsGenerator (Thanks @KPLauritzen!)
* [DOCS] Fix broken link in README.md (Thanks @eyaltrabelsi!)
* [DOCS] Clarifications on several docs (Thanks all!!)
0.12.4
-----------------
* [FEATURE] Add PagerdutyAlertAction (Thanks @NiallRees!)
* [FEATURE] enable using Minio for S3 backend (Thanks @noklam!)
* [ENHANCEMENT] Add SqlAlchemy support for expect_compound_columns_to_be_unique (Thanks @jhweaver!)
* [ENHANCEMENT] Add Spark support for expect_compound_columns_to_be_unique (Thanks @tscottcoombes1!)
* [ENHANCEMENT] Save expectation suites with datetimes in evaluation parameters (Thanks @mbakunze!)
* [ENHANCEMENT] Show data asset name in Slack message (Thanks @haydarai!)
* [ENHANCEMENT] Enhance data doc to show data asset name in overview block (Thanks @noklam!)
* [ENHANCEMENT] Clean up checkpoint output
* [BUGFIX] Change default prefix for TupleStoreBackend (issue 1907)
* [BUGFIX] Duplicate s3 approach for GCS for building object keys
* [BUGFIX] import NotebookConfig (Thanks @cclauss!)
* [BUGFIX] Improve links (Thanks @sbrugman!)
* [MAINTENANCE] Unpin black in requirements (Thanks @jtilly!)
* [MAINTENANCE] remove test case name special characters
0.12.3
-----------------
* [ENHANCEMENT] Add expect_compound_columns_to_be_unique and clarify multicolumn uniqueness
* [ENHANCEMENT] Add expectation expect_table_columns_to_match_set
* [ENHANCEMENT] Checkpoint run command now prints out details on each validation #1437
* [ENHANCEMENT] Slack notifications can now display links to GCS-hosted DataDocs sites
* [ENHANCEMENT] Public base URL can be configured for Data Docs sites
* [ENHANCEMENT] SuiteEditNotebookRenderer.add_header class now allows usage of env variables in jinja templates (thanks @mbakunze)!
* [ENHANCEMENT] Display table for Cramer's Phi expectation in Data Docs (thanks @mlondschien)!
* [BUGFIX] Explicitly convert keys to tuples when removing from TupleS3StoreBackend (thanks @balexander)!
* [BUGFIX] Use more-specific s3.meta.client.exceptions with dealing with boto resource api (thanks @lcorneliussen)!
* [BUGFIX] Links to Amazon S3 are compatible with virtual host-style access and path-style access
* [DOCS] How to Instantiate a Data Context on a Databricks Spark Cluster
* [DOCS] Update to Deploying Great Expectations with Google Cloud Composer
* [MAINTENANCE] Update moto dependency to include cryptography (see #spulec/moto/3290)
0.12.2
-----------------
* [ENHANCEMENT] Update schema for anonymized expectation types to avoid large key domain
* [ENHANCEMENT] BaseProfiler type mapping expanded to include more pandas and numpy dtypes
* [BUGFIX] Allow for pandas reader option inference with parquet and Excel (thanks @dlachasse)!
* [BUGFIX] Fix bug where running checkpoint fails if GCS data docs site has a prefix (thanks @sergii-tsymbal-exa)!
* [BUGFIX] Fix bug in deleting datasource config from config file (thanks @rxmeez)!
* [BUGFIX] clarify inclusiveness of min/max values in string rendering
* [BUGFIX] Building data docs no longer crashes when a data asset name is an integer #1913
* [DOCS] Add notes on transient table creation to Snowflake guide (thanks @verhey)!
* [DOCS] Fixed several broken links and glossary organization (thanks @JavierMonton and @sbrugman)!
* [DOCS] Deploying Great Expectations with Google Cloud Composer (Hosted Airflow)
0.12.1
-----------------
* [FEATURE] Add ``expect_column_pair_cramers_phi_value_to_be_less_than`` expectation to ``PandasDatasource`` to check for the independence of two columns by computing their Cramers Phi (thanks @mlondschien)!
* [FEATURE] add support for ``expect_column_pair_values_to_be_in_set`` to ``Spark`` (thanks @mikaylaedwards)!
* [FEATURE] Add new expectation:`` expect_multicolumn_sum_to_equal`` for ``pandas` and ``Spark`` (thanks @chipmyersjr)!
* [ENHANCEMENT] Update isort, pre-commit & pre-commit hooks, start more linting (thanks @dandandan)!
* [ENHANCEMENT] Bundle shaded marshmallow==3.7.1 to avoid dependency conflicts on GCP Composer
* [ENHANCEMENT] Improve row_condition support in aggregate expectations
* [BUGFIX] SuiteEditNotebookRenderer no longer break GCS and S3 data paths
* [BUGFIX] Fix bug preventing the use of get_available_partition_ids in s3 generator
* [BUGFIX] SuiteEditNotebookRenderer no longer break GCS and S3 data paths
* [BUGFIX] TupleGCSStoreBackend: remove duplicate prefix for urls (thanks @azban)!
* [BUGFIX] Fix `TypeError: unhashable type` error in Data Docs rendering
0.12.0
-----------------
* [BREAKING] This release includes a breaking change that *only* affects users who directly call `add_expectation`, `remove_expectation`, or `find_expectations`. (Most users do not use these APIs but add Expectations by stating them directly on Datasets). Those methods have been updated to take an ExpectationConfiguration object and `match_type` object. The change provides more flexibility in determining which expectations should be modified and allows us provide substantially improved support for two major features that we have frequently heard requested: conditional Expectations and more flexible multi-column custom expectations. See :ref:`expectation_suite_operations` and :ref:`migrating_versions` for more information.
* [FEATURE] Add support for conditional expectations using pandas execution engine (#1217 HUGE thanks @arsenii!)
* [FEATURE] ValidationActions can now consume and return "payload", which can be used to share information across ValidationActions
* [FEATURE] Add support for nested columns in the PySpark expectations (thanks @bramelfrink)!
* [FEATURE] add support for `expect_column_values_to_be_increasing` to `Spark` (thanks @mikaylaedwards)!
* [FEATURE] add support for `expect_column_values_to_be_decreasing` to `Spark` (thanks @mikaylaedwards)!
* [FEATURE] Slack Messages sent as ValidationActions now have link to DataDocs, if available.
* [FEATURE] Expectations now define “domain,” “success,” and “runtime” kwargs to allow them to determine expectation equivalence for updating expectations. Fixes column pair expectation update logic.
* [ENHANCEMENT] Add a `skip_and_clean_missing` flag to `DefaultSiteIndexBuilder.build` (default True). If True, when an index page is being built and an existing HTML page does not have corresponding source data (i.e. an expectation suite or validation result was removed from source store), the HTML page is automatically deleted and will not appear in the index. This ensures that the expectations store and validations store are the source of truth for Data Docs.
* [ENHANCEMENT] Include datetime and bool column types in descriptive documentation results
* [ENHANCEMENT] Improve data docs page breadcrumbs to have clearer run information
* [ENHANCEMENT] Data Docs Validation Results only shows unexpected value counts if all unexpected values are available
* [ENHANCEMENT] Convert GE version key from great_expectations.__version__ to great_expectations_version (thanks, @cwerner!) (#1606)
* [ENHANCEMENT] Add support in JSON Schema profiler for combining schema with anyOf key and creating nullability expectations
* [BUGFIX] Add guard for checking Redshift Dialect in match_like_pattern expectation
* [BUGFIX] Fix content_block build failure for dictionary content - (thanks @jliew!) #1722
* [BUGFIX] Fix bug that was preventing env var substitution in `config_variables.yml` when not at the top level
* [BUGFIX] Fix issue where expect_column_values_to_be_in_type_list did not work with positional type_list argument in SqlAlchemyDataset or SparkDFDataset
* [BUGFIX] Fixes a bug that was causing exceptions to occur if user had a Data Docs config excluding a particular site section
* [DOCS] Add how-to guides for configuring MySQL and MSSQL Datasources
* [DOCS] Add information about issue tags to contributing docs
* [DEPRECATION] Deprecate demo suite behavior in `suite new`
0.11.9
-----------------
* [FEATURE] New Dataset Support: Microsoft SQL Server
* [FEATURE] Render expectation validation results to markdown
* [FEATURE] Add --assume-yes/--yes/-y option to cli docs build command (thanks @feluelle)
* [FEATURE] Add SSO and SSH key pair authentication for Snowflake (thanks @dmateusp)
* [FEATURE] Add pattern-matching expectations that use the Standard SQL "LIKE" operator: "expect_column_values_to_match_like_pattern", "expect_column_values_to_not_match_like_pattern", "expect_column_values_to_match_like_pattern_list", and "expect_column_values_to_not_match_like_pattern_list"
* [ENHANCEMENT] Make Data Docs rendering of profiling results more flexible by deprecating the reliance on validation results having the specific run_name of "profiling"
* [ENHANCEMENT] Use green checkmark in Slack msgs instead of tada
* [ENHANCEMENT] log class instantiation errors for better debugging
* [BUGFIX] usage_statistics decorator now handles 'dry_run' flag
* [BUGFIX] Add spark_context to DatasourceConfigSchema (#1713) (thanks @Dandandan)
* [BUGFIX] Handle case when unexpected_count list element is str
* [DOCS] Deploying Data Docs
* [DOCS] New how-to guide: How to instantiate a Data Context on an EMR Spark cluster
* [DOCS] Managed Spark DF Documentation #1729 (thanks @mgorsk1)
* [DOCS] Typos and clarifications (thanks @dechoma @sbrugman @rexboyce)
0.11.8
-----------------
* [FEATURE] Customizable "Suite Edit" generated notebooks
* [ENHANCEMENT] Add support and docs for loading evaluation parameter from SQL database
* [ENHANCEMENT] Fixed some typos/grammar and a broken link in the suite_scaffold_notebook_renderer
* [ENHANCEMENT] allow updates to DatabaseStoreBackend keys by default, requiring `allow_update=False` to disallow
* [ENHANCEMENT] Improve support for prefixes declared in TupleS3StoreBackend that include reserved characters
* [BUGFIX] Fix issue where allow_updates was set for StoreBackend that did not support it
* [BUGFIX] Fix issue where GlobReaderBatchKwargsGenerator failed with relative base_directory
* [BUGFIX] Adding explicit requirement for "importlib-metadata" (needed for Python versions prior to Python 3.8).
* [MAINTENANCE] Install GitHub Dependabot
* [BUGFIX] Fix missing importlib for python 3.8 #1651
0.11.7
-----------------
* [ENHANCEMENT] Improve CLI error handling.
* [ENHANCEMENT] Do not register signal handlers if not running in main thread
* [ENHANCEMENT] store_backend (S3 and GCS) now throws InvalidKeyError if file does not exist at expected location
* [BUGFIX] ProfilerTypeMapping uses lists instead of sets to prevent serialization errors when saving suites created by JsonSchemaProfiler
* [DOCS] Update suite scaffold how-to
* [DOCS] Docs/how to define expectations that span multiple tables
* [DOCS] how to metadata stores validation on s3
0.11.6
-----------------
* [FEATURE] Auto-install Python DB packages. If the required packages for a DB library are not installed, GE will offer the user to install them, without exiting CLI
* [FEATURE] Add new expectation expect_table_row_count_to_equal_other_table for SqlAlchemyDataset
* [FEATURE] A profiler that builds suites from JSONSchema files
* [ENHANCEMENT] Add ``.feather`` file support to PandasDatasource
* [ENHANCEMENT] Use ``colorama init`` to support terminal color on Windows
* [ENHANCEMENT] Update how_to_trigger_slack_notifications_as_a_validation_action.rst
* [ENHANCEMENT] Added note for config_version in great_expectations.yml
* [ENHANCEMENT] Implement "column_quantiles" for MySQL (via a compound SQLAlchemy query, since MySQL does not support "percentile_disc")
* [BUGFIX] "data_asset.validate" events with "data_asset_name" key in the batch kwargs were failing schema validation
* [BUGFIX] database_store_backend does not support storing Expectations in DB
* [BUGFIX] instantiation of ExpectationSuite always adds GE version metadata to prevent datadocs from crashing
* [BUGFIX] Fix all tests having to do with missing data source libraries
* [DOCS] will/docs/how_to/Store Expectations on Google Cloud Store
0.11.5
-----------------
* [FEATURE] Add support for expect_column_values_to_match_regex_list exception for Spark backend
* [ENHANCEMENT] Added 3 new usage stats events: "cli.new_ds_choice", "data_context.add_datasource", and "datasource.sqlalchemy.connect"
* [ENHANCEMENT] Support platform_specific_separator flag for TupleS3StoreBackend prefix
* [ENHANCEMENT] Allow environment substitution in config_variables.yml
* [BUGFIX] fixed issue where calling head() on a SqlAlchemyDataset would fail if the underlying table is empty
* [BUGFIX] fixed bug in rounding of mostly argument to nullity expectations produced by the BasicSuiteBuilderProfiler
* [DOCS] New How-to guide: How to add a Validation Operator (+ updated in Validation Operator doc strings)
0.11.4
-----------------
* [BUGIFX] Fixed an error that crashed the CLI when called in an environment with neither SQLAlchemy nor google.auth installed
0.11.3
-----------------
* [ENHANCEMENT] Removed the misleading scary "Site doesn't exist or is inaccessible" message that the CLI displayed before building Data Docs for the first time.
* [ENHANCEMENT] Catch sqlalchemy.exc.ArgumentError and google.auth.exceptions.GoogleAuthError in SqlAlchemyDatasource __init__ and re-raise them as DatasourceInitializationError - this allows the CLI to execute its retry logic when users provide a malformed SQLAlchemy URL or attempt to connect to a BigQuery project without having proper authentication.
* [BUGFIX] Fixed issue where the URL of the Glossary of Expectations article in the auto-generated suite edit notebook was wrong (out of date) (#1557).
* [BUGFIX] Use renderer_type to set paths in jinja templates instead of utm_medium since utm_medium is optional
* [ENHANCEMENT] Bring in custom_views_directory in DefaultJinjaView to enable custom jinja templates stored in plugins dir
* [BUGFIX] fixed glossary links in walkthrough modal, README, CTA button, scaffold notebook
* [BUGFIX] Improved TupleGCSStoreBackend configurability (#1398 #1399)
* [BUGFIX] Data Docs: switch bootstrap-table-filter-control.min.js to CDN
* [ENHANCEMENT] BasicSuiteBuilderProfiler now rounds mostly values for readability
* [DOCS] Add AutoAPI as the primary source for API Reference docs.
0.11.2
-----------------
* [FEATURE] Add support for expect_volumn_values_to_match_json_schema exception for Spark backend (thanks @chipmyersjr!)
* [ENHANCEMENT] Add formatted __repr__ for ValidationOperatorResult
* [ENHANCEMENT] add option to suppress logging when getting expectation suite
* [BUGFIX] Fix object name construction when calling SqlAlchemyDataset.head (thanks @mascah!)
* [BUGFIX] Fixed bug where evaluation parameters used in arithmetic expressions would not be identified as upstream dependencies.
* [BUGFIX] Fix issue where DatabaseStoreBackend threw IntegrityError when storing same metric twice
* [FEATURE] Added new cli upgrade helper to help facilitate upgrading projects to be compatible with GE 0.11.
See :ref:`upgrading_to_0.11` for more info.
* [BUGFIX] Fixed bug preventing GCS Data Docs sites to cleaned
* [BUGFIX] Correct doc link in checkpoint yml
* [BUGFIX] Fixed issue where CLI checkpoint list truncated names (#1518)
* [BUGFIX] Fix S3 Batch Kwargs Generator incorrect migration to new build_batch_kwargs API
* [BUGFIX] Fix missing images in data docs walkthrough modal
* [BUGFIX] Fix bug in checkpoints that was causing incorrect run_time to be set
* [BUGFIX] Fix issue where data docs could remove trailing zeros from values when low precision was requested
0.11.1
-----------------
* [BUGFIX] Fixed bug that was caused by comparison between timezone aware and non-aware datetimes
* [DOCS] Updated docs with info on typed run ids and validation operator results
* [BUGFIX] Update call-to-action buttons on index page with correct URLs
0.11.0
-----------------
* [BREAKING] ``run_id`` is now typed using the new ``RunIdentifier`` class, which consists of a ``run_time`` and
``run_name``. Existing projects that have Expectation Suite Validation Results must be migrated.
See :ref:`upgrading_to_0.11` for instructions.
* [BREAKING] ``ValidationMetric`` and ``ValidationMetricIdentifier`` objects now have a ``data_asset_name`` attribute.
Existing projects with evaluation parameter stores that have database backends must be migrated.
See :ref:`upgrading_to_0.11` for instructions.
* [BREAKING] ``ValidationOperator.run`` now returns an instance of new type, ``ValidationOperatorResult`` (instead of a
dictionary). If your code uses output from Validation Operators, it must be updated.
* Major update to the styling and organization of documentation! Watch for more content and reorganization as we continue to improve the documentation experience with Great Expectations.
* [FEATURE] Data Docs: redesigned index page with paginated/sortable/searchable/filterable tables
* [FEATURE] Data Docs: searchable tables on Expectation Suite Validation Result pages
* ``data_asset_name`` is now added to batch_kwargs by batch_kwargs_generators (if available) and surfaced in Data Docs
* Renamed all ``generator_asset`` parameters to ``data_asset_name``
* Updated the dateutil dependency
* Added experimental QueryStore
* Removed deprecated cli tap command
* Added of 0.11 upgrade helper
* Corrected Scaffold maturity language in notebook to Experimental
* Updated the installation/configuration documentation for Snowflake users
* [ENHANCEMENT] Improved error messages for misconfigured checkpoints.
* [BUGFIX] Fixed bug that could cause some substituted variables in DataContext config to be saved to `great_expectations.yml`
0.10.12
-----------------
* [DOCS] Improved help for CLI `checkpoint` command
* [BUGFIX] BasicSuiteBuilderProfiler could include extra expectations when only some expectations were selected (#1422)
* [FEATURE] add support for `expect_multicolumn_values_to_be_unique` and `expect_column_pair_values_A_to_be_greater_than_B`
to `Spark`. Thanks @WilliamWsyHK!
* [ENHANCEMENT] Allow a dictionary of variables can be passed to the DataContext constructor to allow override
config variables at runtime. Thanks @balexander!
* [FEATURE] add support for `expect_column_pair_values_A_to_be_greater_than_B` to `Spark`.
* [BUGFIX] Remove SQLAlchemy typehints to avoid requiring library (thanks @mzjp2)!
* [BUGFIX] Fix issue where quantile boundaries could not be set to zero. Thanks @kokes!
0.10.11
-----------------
* Bugfix: build_data_docs list_keys for GCS returns keys and when empty a more user friendly message
* ENHANCEMENT: Enable Redshift Quantile Profiling
0.10.10
-----------------
* Removed out-of-date Airflow integration examples. This repo provides a comprehensive example of Airflow integration: `#GE Airflow Example <https://github.com/superconductive/ge_tutorials>`_
* Bugfix suite scaffold notebook now has correct suite name in first markdown cell.
* Bugfix: fixed an example in the custom expectations documentation article - "result" key was missing in the returned dictionary
* Data Docs Bugfix: template string substitution is now done using .safe_substitute(), to handle cases where string templates
or substitution params have extraneous $ signs. Also added logic to handle templates where intended output has groupings of 2 or more $ signs
* Docs fix: fix in yml for example action_list_operator for metrics
* GE is now auto-linted using Black
-----------------
* DataContext.get_docs_sites_urls now raises error if non-existent site_name is specified
* Bugfix for the CLI command `docs build` ignoring the --site_name argument (#1378)
* Bugfix and refactor for `datasource delete` CLI command (#1386) @mzjp2
* Instantiate datasources and validate config only when datasource is used (#1374) @mzjp2
* suite delete changed from an optional argument to a required one
* bugfix for uploading objects to GCP #1393
* added a new usage stats event for the case when a data context is created through CLI
* tuplefilestore backend, expectationstore backend remove_key bugs fixed
* no url is returned on empty data_docs site
* return url for resource only if key exists
* Test added for the period special char case
* updated checkpoint module to not require sqlalchemy
* added BigQuery as an option in the list of databases in the CLI
* added special cases for handling BigQuery - table names are already qualified with schema name, so we must make sure that we do not prepend the schema name twice
* changed the prompt for the name of the temp table in BigQuery in the CLI to hint that a fully qualified name (project.dataset.table) should be provided
* Bugfix for: expect_column_quantile_values_to_be_between expectation throws an "unexpected keyword WITHIN" on BigQuery (#1391)
0.10.8
-----------------
* added support for overriding the default jupyter command via a GE_JUPYTER_CMD environment variable (#1347) @nehiljain
* Bugfix for checkpoint missing template (#1379)
0.10.7
-----------------
* crud delete suite bug fix
0.10.6
-----------------
* Checkpoints: a new feature to ease deployment of suites into your pipelines
- DataContext.list_checkpoints() returns a list of checkpoint names found in the project
- DataContext.get_checkpoint() returns a validated dictionary loaded from yml
- new cli commands
- `checkpoint new`
- `checkpoint list`
- `checkpoint run`
- `checkpoint script`
* marked cli `tap` commands as deprecating on next release
* marked cli `validation-operator run` command as deprecating
* internal improvements in the cli code
* Improve UpdateDataDocsAction docs
0.10.5
-----------------
* improvements to ge.read_json tests
* tidy up the changelog
- Fix bullet list spacing issues
- Fix 0.10. formatting
- Drop roadmap_and_changelog.rst and move changelog.rst to the top level of the table of contents
* DataContext.run_validation_operator() now raises a DataContextError if:
- no batches are passed
- batches are of the the wrong type
- no matching validation operator is found in the project
* Clarified scaffolding language in scaffold notebook
* DataContext.create() adds an additional directory: `checkpoints`
* Marked tap command for deprecation in next major release
0.10.4
-----------------
* consolidated error handling in CLI DataContext loading
* new cli command `suite scaffold` to speed up creation of suites
* new cli command `suite demo` that creates an example suite
* Update bigquery.rst `#1330 <https://github.com/great-expectations/great_expectations/issues/1330>`_
* Fix datetime reference in create_expectations.rst `#1321 <https://github.com/great-expectations/great_expectations/issues/1321>`_ Thanks @jschendel !
* Update issue templates
* CLI command experimental decorator
* Update style_guide.rst
* Add pull request template
* Use pickle to generate hash for dataframes with unhashable objects. `#1315 <https://github.com/great-expectations/great_expectations/issues/1315>`_ Thanks @shahinism !
* Unpin pytest
0.10.3
-----------------
* Use pickle to generate hash for dataframes with unhashable objects.
0.10.2
-----------------
* renamed NotebookRenderer to SuiteEditNotebookRenderer
* SuiteEditNotebookRenderer now lints using black
* New SuiteScaffoldNotebookRenderer renderer to expedite suite creation
* removed autopep8 dependency
* bugfix: extra backslash in S3 urls if store was configured without a prefix `#1314 <https://github.com/great-expectations/great_expectations/issues/1314>`_
0.10.1
-----------------
* removing bootstrap scrollspy on table of contents `#1282 <https://github.com/great-expectations/great_expectations/issues/1282>`_
* Silently tolerate connection timeout during usage stats reporting
0.10.0
-----------------
* (BREAKING) Clarified API language: renamed all ``generator`` parameters and methods to the more correct ``batch_kwargs_generator`` language. Existing projects may require simple migration steps. See :ref:`Upgrading to 0.10.x <upgrading_to_0.10.x>` for instructions.
* Adds anonymized usage statistics to Great Expectations. See this article for details: :ref:`Usage Statistics`.
* CLI: improve look/consistency of ``docs list``, ``suite list``, and ``datasource list`` output; add ``store list`` and ``validation-operator list`` commands.
* New SuiteBuilderProfiler that facilitates faster suite generation by allowing columns to be profiled
* Added two convenience methods to ExpectationSuite: get_table_expectations & get_column_expectations
* Added optional profiler_configuration to DataContext.profile() and DataAsset.profile()
* Added list_available_expectation_types() to DataAsset
0.9.11
-----------------
* Add evaluation parameters support in WarningAndFailureExpectationSuitesValidationOperator `#1284 <https://github.com/great-expectations/great_expectations/issues/1284>`_ thanks `@balexander <https://github.com/balexander>`_
* Fix compatibility with MS SQL Server. `#1269 <https://github.com/great-expectations/great_expectations/issues/1269>`_ thanks `@kepiej <https://github.com/kepiej>`_
* Bug fixes for query_generator `#1292 <https://github.com/great-expectations/great_expectations/issues/1292>`_ thanks `@ian-whitestone <https://github.com/ian-whitestone>`_
0.9.10
-----------------
* Data Docs: improve configurability of site_section_builders
* TupleFilesystemStoreBackend now ignore `.ipynb_checkpoints` directories `#1203 <https://github.com/great-expectations/great_expectations/issues/1203>`_
* bugfix for Data Docs links encoding on S3 `#1235 <https://github.com/great-expectations/great_expectations/issues/1235>`_
0.9.9
-----------------
* Allow evaluation parameters support in run_validation_operator
* Add log_level parameter to jupyter_ux.setup_notebook_logging.
* Add experimental display_profiled_column_evrs_as_section and display_column_evrs_as_section methods, with a minor (nonbreaking) refactor to create a new _render_for_jupyter method.
* Allow selection of site in UpdateDataDocsAction with new arg target_site_names in great_expectations.yml
* Fix issue with regular expression support in BigQuery (#1244)
0.9.8
-----------------
* Allow basic operations in evaluation parameters, with or without evaluation parameters.
* When unexpected exceptions occur (e.g., during data docs rendering), the user will see detailed error messages, providing information about the specific issue as well as the stack trace.
* Remove the "project new" option from the command line (since it is not implemented; users can only run "init" to create a new project).
* Update type detection for bigquery based on driver changes in pybigquery driver 0.4.14. Added a warning for users who are running an older pybigquery driver
* added execution tests to the NotebookRenderer to mitigate codegen risks
* Add option "persist", true by default, for SparkDFDataset to persist the DataFrame it is passed. This addresses #1133 in a deeper way (thanks @tejsvirai for the robust debugging support and reproduction on spark).
* Disabling this option should *only* be done if the user has *already* externally persisted the DataFrame, or if the dataset is too large to persist but *computations are guaranteed to be stable across jobs*.
* Enable passing dataset kwargs through datasource via dataset_options batch_kwarg.
* Fix AttributeError when validating expectations from a JSON file
* Data Docs: fix bug that was causing erratic scrolling behavior when table of contents contains many columns
* Data Docs: add ability to hide how-to buttons and related content in Data Docs
0.9.7
-----------------
* Update marshmallow dependency to >3. NOTE: as of this release, you MUST use marshamllow >3.0, which REQUIRES python 3. (`#1187 <https://github.com/great-expectations/great_expectations/issues/1187>`_) @jcampbell
* Schema checking is now stricter for expectation suites, and data_asset_name must not be present as a top-level key in expectation suite json. It is safe to remove.
* Similarly, datasource configuration must now adhere strictly to the required schema, including having any required credentials stored in the "credentials" dictionary.
* New beta CLI command: `tap new` that generates an executable python file to expedite deployments. (`#1193 <https://github.com/great-expectations/great_expectations/issues/1193>`_) @Aylr
* bugfix in TableBatchKwargsGenerator docs
* Added feature maturity in README (`#1203 <https://github.com/great-expectations/great_expectations/issues/1203>`_) @kyleaton
* Fix failing test that should skip if postgresql not running (`#1199 <https://github.com/great-expectations/great_expectations/issues/1199>`_) @cicdw
0.9.6
-----------------
* validate result dict when instantiating an ExpectationValidationResult (`#1133 <https://github.com/great-expectations/great_expectations/issues/1133>`_)
* DataDocs: Expectation Suite name on Validation Result pages now link to Expectation Suite page
* `great_expectations init`: cli now asks user if csv has header when adding a Spark Datasource with csv file
* Improve support for using GCP Storage Bucket as a Data Docs Site backend (thanks @hammadzz)
* fix notebook renderer handling for expectations with no column kwarg and table not in their name (`#1194 <https://github.com/great-expectations/great_expectations/issues/1194>`_)
0.9.5
-----------------
* Fixed unexpected behavior with suite edit, data docs and jupyter
* pytest pinned to 5.3.5
0.9.4
-----------------
* Update CLI `init` flow to support snowflake transient tables
* Use filename for default expectation suite name in CLI `init`
* Tables created by SqlAlchemyDataset use a shorter name with 8 hex characters of randomness instead of a full uuid
* Better error message when config substitution variable is missing
* removed an unused directory in the GE folder
* removed obsolete config error handling
* Docs typo fixes
* Jupyter notebook improvements
* `great_expectations init` improvements
* Simpler messaging in validation notebooks
* replaced hacky loop with suite list call in notebooks
* CLI suite new now supports `--empty` flag that generates an empty suite and opens a notebook
* add error handling to `init` flow for cases where user tries using a broken file
0.9.3
-----------------
* Add support for transient table creation in snowflake (#1012)
* Improve path support in TupleStoreBackend for better cross-platform compatibility
* New features on `ExpectationSuite`
- ``add_citation()``
- ``get_citations()``
* `SampleExpectationsDatasetProfiler` now leaves a citation containing the original batch kwargs
* `great_expectations suite edit` now uses batch_kwargs from citations if they exist
* Bugfix :: suite edit notebooks no longer blow away the existing suite while loading a batch of data
* More robust and tested logic in `suite edit`
* DataDocs: bugfixes and improvements for smaller viewports
* Bugfix :: fix for bug that crashes SampleExpectationsDatasetProfiler if unexpected_percent is of type decimal.Decimal (`#1109 <https://github.com/great-expectations/great_expectations/issues/1109>`_)
0.9.2
-----------------
* Fixes #1095
* Added a `list_expectation_suites` function to `data_context`, and a corresponding CLI function - `suite list`.
* CI no longer enforces legacy python tests.
0.9.1
------
* Bugfix for dynamic "How to Edit This Expectation Suite" command in DataDocs
0.9.0
-----------------
Version 0.9.0 is a major update to Great Expectations! The DataContext has continued to evolve into a powerful tool
for ensuring that Expectation Suites can properly represent the way users think about their data, and upgrading will
make it much easier to store and share expectation suites, and to build data docs that support your whole team.
You’ll get awesome new features including improvements to data docs look and the ability to choose and store metrics
for building flexible data quality dashboards.
The changes for version 0.9.0 fall into several broad areas:
1. Onboarding
Release 0.9.0 of Great Expectations makes it much easier to get started with the project. The `init` flow has grown
to support a much wider array of use cases and to use more natural language rather than introducing
GreatExpectations concepts earlier. You can more easily configure different backends and datasources, take advantage
of guided walkthroughs to find and profile data, and share project configurations with colleagues.
If you have already completed the `init` flow using a previous version of Great Expectations, you do not need to
rerun the command. However, **there are some small changes to your configuration that will be required**. See
:ref:`migrating_versions` for details.
2. CLI Command Improvements
With this release we have introduced a consistent naming pattern for accessing subcommands based on the noun (a
Great Expectations object like `suite` or `docs`) and verb (an action like `edit` or `new`). The new user experience
will allow us to more naturally organize access to CLI tools as new functionality is added.
3. Expectation Suite Naming and Namespace Changes
Defining shared expectation suites and validating data from different sources is much easier in this release. The
DataContext, which manages storage and configuration of expectations, validations, profiling, and data docs, no
longer requires that expectation suites live in a datasource-specific “namespace.” Instead, you should name suites
with the logical name corresponding to your data, making it easy to share them or validate against different data
sources. For example, the expectation suite "npi" for National Provider Identifier data can now be shared across
teams who access the same logical data in local systems using Pandas, on a distributed Spark cluster, or via a
relational database.
Batch Kwargs, or instructions for a datasource to build a batch of data, are similarly freed from a required
namespace, and you can more easily integrate Great Expectations into workflows where you do not need to use a
BatchKwargsGenerator (usually because you have a batch of data ready to validate, such as in a table or a known
directory).
The most noticeable impact of this API change is in the complete removal of the DataAssetIdentifier class. For
example, the `create_expectation_suite` and `get_batch` methods now no longer require a data_asset_name parameter,
relying only on the expectation_suite_name and batch_kwargs to do their job. Similarly, there is no more asset name
normalization required. See the upgrade guide for more information.
4. Metrics and Evaluation Parameter Stores
Metrics have received much more love in this release of Great Expectations! We've improved the system for declaring
evaluation parameters that support dependencies between different expectation suites, so you can easily identify a
particular field in the result of one expectation to use as the input into another. And the MetricsStore is now much
more flexible, supporting a new ValidationAction that makes it possible to select metrics from a validation result
to be saved in a database where they can power a dashboard.
5. Internal Type Changes and Improvements
Finally, in this release, we have done a lot of work under the hood to make things more robust, including updating
all of the internal objects to be more strongly typed. That change, while largely invisible to end users, paves the
way for some really exciting opportunities for extending Great Expectations as we build a bigger community around
the project.
We are really excited about this release, and encourage you to upgrade right away to take advantage of the more
flexible naming and simpler API for creating, accessing, and sharing your expectations. As always feel free to join
us on Slack for questions you don't see addressed!
0.8.9__develop
-----------------
0.8.8
-----------------
* Add support for allow_relative_error to expect_column_quantile_values_to_be_between, allowing Redshift users access
to this expectation
* Add support for checking backend type information for datetime columns using expect_column_min_to_be_between and
expect_column_max_to_be_between
0.8.7
-----------------
* Add support for expect_column_values_to_be_of_type for BigQuery backend (#940)
* Add image CDN for community usage stats
* Documentation improvements and fixes
0.8.6
-----------------
* Raise informative error if config variables are declared but unavailable
* Update ExpectationsStore defaults to be consistent across all FixedLengthTupleStoreBackend objects
* Add support for setting spark_options via SparkDFDatasource
* Include tail_weights by default when using build_continuous_partition_object
* Fix Redshift quantiles computation and type detection
* Allow boto3 options to be configured (#887)
0.8.5
-----------------
* BREAKING CHANGE: move all reader options from the top-level batch_kwargs object to a sub-dictionary called
"reader_options" for SparkDFDatasource and PandasDatasource. This means it is no longer possible to specify
supplemental reader-specific options at the top-level of `get_batch`, `yield_batch_kwargs` or `build_batch_kwargs`
calls, and instead, you must explicitly specify that they are reader_options, e.g. by a call such as:
`context.yield_batch_kwargs(data_asset_name, reader_options={'encoding': 'utf-8'})`.
* BREAKING CHANGE: move all query_params from the top-level batch_kwargs object to a sub-dictionary called
"query_params" for SqlAlchemyDatasource. This means it is no longer possible to specify supplemental query_params at
the top-level of `get_batch`, `yield_batch_kwargs` or `build_batch_kwargs`
calls, and instead, you must explicitly specify that they are query_params, e.g. by a call such as:
`context.yield_batch_kwargs(data_asset_name, query_params={'schema': 'foo'})`.
* Add support for filtering validation result suites and validation result pages to show only failed expectations in
generated documentation
* Add support for limit parameter to batch_kwargs for all datasources: Pandas, SqlAlchemy, and SparkDF; add support
to generators to support building batch_kwargs with limits specified.
* Include raw_query and query_params in query_generator batch_kwargs
* Rename generator keyword arguments from data_asset_name to generator_asset to avoid ambiguity with normalized names
* Consistently migrate timestamp from batch_kwargs to batch_id
* Include batch_id in validation results
* Fix issue where batch_id was not included in some generated datasets
* Fix rendering issue with expect_table_columns_to_match_ordered_list expectation
* Add support for GCP, including BigQuery and GCS
* Add support to S3 generator for retrieving directories by specifying the `directory_assets` configuration
* Fix warning regarding implicit class_name during init flow
* Expose build_generator API publicly on datasources
* Allow configuration of known extensions and return more informative message when SubdirReaderBatchKwargsGenerator cannot find
relevant files.
* Add support for allow_relative_error on internal dataset quantile functions, and add support for
build_continuous_partition_object in Redshift
* Fix truncated scroll bars in value_counts graphs
0.8.4.post0
----------------
* Correct a packaging issue resulting in missing notebooks in tarball release; update docs to reflect new notebook
locations.
0.8.4
-----------------
* Improved the tutorials that walk new users through the process of creating expectations and validating data
* Changed the flow of the init command - now it creates the scaffolding of the project and adds a datasource. After
that users can choose their path.
* Added a component with links to useful tutorials to the index page of the Data Docs website
* Improved the UX of adding a SQL datasource in the CLI - now the CLI asks for specific credentials for Postgres,
MySQL, Redshift and Snowflake, allows continuing debugging in the config file and has better error messages
* Added batch_kwargs information to DataDocs validation results
* Fix an issue affecting file stores on Windows
0.8.3
-----------------
* Fix a bug in data-docs' rendering of mostly parameter
* Correct wording for expect_column_proportion_of_unique_values_to_be_between
* Set charset and meta tags to avoid unicode decode error in some browser/backend configurations
* Improve formatting of empirical histograms in validation result data docs
* Add support for using environment variables in `config_variables_file_path`
* Documentation improvements and corrections
0.8.2.post0
------------
* Correct a packaging issue resulting in missing css files in tarball release
0.8.2
-----------------
* Add easier support for customizing data-docs css
* Use higher precision for rendering 'mostly' parameter in data-docs; add more consistent locale-based
formatting in data-docs
* Fix an issue causing visual overlap of large numbers of validation results in build-docs index
* Documentation fixes (thanks @DanielOliver!) and improvements
* Minor CLI wording fixes
* Improved handling of MySql temporary tables
* Improved detection of older config versions
0.8.1
-----------------
* Fix an issue where version was reported as '0+unknown'
0.8.0
-----------------
Version 0.8.0 is a significant update to Great Expectations, with many improvements focused on configurability
and usability. See the :ref:`migrating_versions` guide for more details on specific changes, which include
several breaking changes to configs and APIs.
Highlights include:
1. Validation Operators and Actions. Validation operators make it easy to integrate GE into a variety of pipeline runners. They
offer one-line integration that emphasizes configurability. See the :ref:`validation_operators_and_actions`
feature guide for more information.
- The DataContext `get_batch` method no longer treats `expectation_suite_name` or `batch_kwargs` as optional; they
must be explicitly specified.
- The top-level GE validate method allows more options for specifying the specific data_asset class to use.
2. First-class support for plugins in a DataContext, with several features that make it easier to configure and
maintain DataContexts across common deployment patterns.
- **Environments**: A DataContext can now manage :ref:`environment_and_secrets` more easily thanks to more dynamic and
flexible variable substitution.
- **Stores**: A new internal abstraction for DataContexts, :ref:`Stores <reference__core_concepts__data_context__stores>`, make extending GE easier by
consolidating logic for reading and writing resources from a database, local, or cloud storage.
- **Types**: Utilities configured in a DataContext are now referenced using `class_name` and `module_name` throughout
the DataContext configuration, making it easier to extend or supplement pre-built resources. For now, the "type"
parameter is still supported but expect it to be removed in a future release.
3. Partitioners: Batch Kwargs are clarified and enhanced to help easily reference well-known chunks of data using a
partition_id. Batch ID and Batch Fingerprint help round out support for enhanced metadata around data
assets that GE validates. See :ref:`Batch Identifiers <reference__core_concepts__batch_parameters>` for more information. The `GlobReaderBatchKwargsGenerator`,
`QueryBatchKwargsGenerator`, `S3GlobReaderBatchKwargsGenerator`, `SubdirReaderBatchKwargsGenerator`, and `TableBatchKwargsGenerator` all support partition_id for
easily accessing data assets.
4. Other Improvements:
- We're beginning a long process of some under-the-covers refactors designed to make GE more maintainable as we
begin adding additional features.
- Restructured documentation: our docs have a new structure and have been reorganized to provide space for more
easily adding and accessing reference material. Stay tuned for additional detail.
- The command build-documentation has been renamed build-docs and now by
default opens the Data Docs in the users' browser.
v0.7.11
-----------------
* Fix an issue where head() lost the column name for SqlAlchemyDataset objects with a single column
* Fix logic for the 'auto' bin selection of `build_continuous_partition_object`
* Add missing jinja2 dependency
* Fix an issue with inconsistent availability of strict_min and strict_max options on expect_column_values_to_be_between
* Fix an issue where expectation suite evaluation_parameters could be overridden by values during validate operation
v0.7.10
-----------------
* Fix an issue in generated documentation where the Home button failed to return to the index
* Add S3 Generator to module docs and improve module docs formatting
* Add support for views to QueryBatchKwargsGenerator
* Add success/failure icons to index page
* Return to uniform histogram creation during profiling to avoid large partitions for internal performance reasons
v0.7.9
-----------------
* Add an S3 generator, which will introspect a configured bucket and generate batch_kwargs from identified objects
* Add support to PandasDatasource and SparkDFDatasource for reading directly from S3
* Enhance the Site Index page in documentation so that validation results are sorted and display the newest items first
when using the default run-id scheme
* Add a new utility method, `build_continuous_partition_object` which will build partition objects using the dataset
API and so supports any GE backend.
* Fix an issue where columns with spaces in their names caused failures in some SqlAlchemyDataset and SparkDFDataset
expectations
* Fix an issue where generated queries including null checks failed on MSSQL (#695)
* Fix an issue where evaluation parameters passed in as a set instead of a list could cause JSON serialization problems
for the result object (#699)
v0.7.8
-----------------
* BREAKING: slack webhook URL now must be in the profiles.yml file (treat as a secret)
* Profiler improvements:
- Display candidate profiling data assets in alphabetical order
- Add columns to the expectation_suite meta during profiling to support human-readable description information
* Improve handling of optional dependencies during CLI init
* Improve documentation for create_expectations notebook
* Fix several anachronistic documentation and docstring phrases (#659, #660, #668, #681; #thanks @StevenMMortimer)
* Fix data docs rendering issues:
- documentation rendering failure from unrecognized profiled column type (#679; thanks @dinedal))
- PY2 failure on encountering unicode (#676)
0.7.7
-----------------
* Standardize the way that plugin module loading works. DataContext will begin to use the new-style class and plugin
identification moving forward; yml configs should specify class_name and module_name (with module_name optional for
GE types). For now, it is possible to use the "type" parameter in configuration (as before).
* Add support for custom data_asset_type to all datasources
* Add support for strict_min and strict_max to inequality-based expectations to allow strict inequality checks
(thanks @RoyalTS!)
* Add support for reader_method = "delta" to SparkDFDatasource
* Fix databricks generator (thanks @sspitz3!)
* Improve performance of DataContext loading by moving optional import
* Fix several memory and performance issues in SparkDFDataset.
- Use only distinct value count instead of bringing values to driver
- Migrate away from UDF for set membership, nullity, and regex expectations
* Fix several UI issues in the data_documentation
- Move prescriptive dataset expectations to Overview section
- Fix broken link on Home breadcrumb
- Scroll follows navigation properly
- Improved flow for long items in value_set
- Improved testing for ValidationRenderer
- Clarify dependencies introduced in documentation sites
- Improve testing and documentation for site_builder, including run_id filter
- Fix missing header in Index page and cut-off tooltip
- Add run_id to path for validation files
0.7.6
-----------------
* New Validation Renderer! Supports turning validation results into HTML and displays differences between the expected
and the observed attributes of a dataset.
* Data Documentation sites are now fully configurable; a data context can be configured to generate multiple
sites built with different GE objects to support a variety of data documentation use cases. See data documentation
guide for more detail.
* CLI now has a new top-level command, `build-documentation` that can support rendering documentation for specified
sites and even named data assets in a specific site.
* Introduced DotDict and LooselyTypedDotDict classes that allow to enforce typing of dictionaries.
* Bug fixes: improved internal logic of rendering data documentation, slack notification, and CLI profile command when
datasource argument was not provided.
0.7.5
-----------------
* Fix missing requirement for pypandoc brought in from markdown support for notes rendering.
0.7.4
-----------------
* Fix numerous rendering bugs and formatting issues for rendering documentation.
* Add support for pandas extension dtypes in pandas backend of expect_column_values_to_be_of_type and
expect_column_values_to_be_in_type_list and fix bug affecting some dtype-based checks.
* Add datetime and boolean column-type detection in BasicDatasetProfiler.
* Improve BasicDatasetProfiler performance by disabling interactive evaluation when output of expectation is not
immediately used for determining next expectations in profile.
* Add support for rendering expectation_suite and expectation_level notes from meta in docs.
* Fix minor formatting issue in readthedocs documentation.
0.7.3
-----------------
* BREAKING: Harmonize expect_column_values_to_be_of_type and expect_column_values_to_be_in_type_list semantics in
Pandas with other backends, including support for None type and type_list parameters to support profiling.
*These type expectations now rely exclusively on native python or numpy type names.*
* Add configurable support for Custom DataAsset modules to DataContext
* Improve support for setting and inheriting custom data_asset_type names
* Add tooltips with expectations backing data elements to rendered documentation
* Allow better selective disabling of tests (thanks @RoyalITS)
* Fix documentation build errors causing missing code blocks on readthedocs
* Update the parameter naming system in DataContext to reflect data_asset_name *and* expectation_suite_name
* Change scary warning about discarding expectations to be clearer, less scary, and only in log
* Improve profiler support for boolean types, value_counts, and type detection
* Allow user to specify data_assets to profile via CLI
* Support CLI rendering of expectation_suite and EVR-based documentation
0.7.2
-----------------
* Improved error detection and handling in CLI "add datasource" feature
* Fixes in rendering of profiling results (descriptive renderer of validation results)
* Query Generator of SQLAlchemy datasource adds tables in non-default schemas to the data asset namespace
* Added convenience methods to display HTML renderers of sections in Jupyter notebooks
* Implemented prescriptive rendering of expectations for most expectation types
0.7.1
------------
* Added documentation/tutorials/videos for onboarding and new profiling and documentation features
* Added prescriptive documentation built from expectation suites
* Improved index, layout, and navigation of data context HTML documentation site
* Bug fix: non-Python files were not included in the package
* Improved the rendering logic to gracefully deal with failed expectations
* Improved the basic dataset profiler to be more resilient
* Implement expect_column_values_to_be_of_type, expect_column_values_to_be_in_type_list for SparkDFDataset
* Updated CLI with a new documentation command and improved profile and render commands
* Expectation suites and validation results within a data context are saved in a more readable form (with indentation)
* Improved compatibility between SparkDatasource and InMemoryGenerator
* Optimization for Pandas column type checking
* Optimization for Spark duplicate value expectation (thanks @orenovadia!)
* Default run_id format no longer includes ":" and specifies UTC time
* Other internal improvements and bug fixes
0.7.0
------------
Version 0.7 of Great Expectations is HUGE. It introduces several major new features
and a large number of improvements, including breaking API changes.
The core vocabulary of expectations remains consistent. Upgrading to
the new version of GE will primarily require changes to code that
uses data contexts; existing expectation suites will require only changes
to top-level names.
* Major update of Data Contexts. Data Contexts now offer significantly \
more support for building and maintaining expectation suites and \
interacting with existing pipeline systems, including providing a namespace for objects.\
They can handle integrating, registering, and storing validation results, and
provide a namespace for data assets, making **batches** first-class citizens in GE.
Read more: :ref:`data_context` or :py:mod:`great_expectations.data_context`
* Major refactor of autoinspect. Autoinspect is now built around a module
called "profile" which provides a class-based structure for building
expectation suites. There is no longer a default "autoinspect_func" --
calling autoinspect requires explicitly passing the desired profiler. See :ref:`profiling`
* New "Compile to Docs" feature produces beautiful documentation from expectations and expectation
validation reports, helping keep teams on the same page.
* Name clarifications: we've stopped using the overloaded terms "expectations
config" and "config" and instead use "expectation suite" to refer to a
collection (or suite!) of expectations that can be used for validating a
data asset.
- Expectation Suites include several top level keys that are useful \
for organizing content in a data context: data_asset_name, \
expectation_suite_name, and data_asset_type. When a data_asset is \
validated, those keys will be placed in the `meta` key of the \
validation result.
* Major enhancement to the CLI tool including `init`, `render` and more flexibility with `validate`
* Added helper notebooks to make it easy to get started. Each notebook acts as a combination of \
tutorial and code scaffolding, to help you quickly learn best practices by applying them to \
your own data.
* Relaxed constraints on expectation parameter values, making it possible to declare many column
aggregate expectations in a way that is always "vacuously" true, such as
``expect_column_values_to_be_between`` ``None`` and ``None``. This makes it possible to progressively
tighten expectations while using them as the basis for profiling results and documentation.
* Enabled caching on dataset objects by default.
* Bugfixes and improvements:
* New expectations:
* expect_column_quantile_values_to_be_between
* expect_column_distinct_values_to_be_in_set
* Added support for ``head`` method on all current backends, returning a PandasDataset
* More implemented expectations for SparkDF Dataset with optimizations
* expect_column_values_to_be_between
* expect_column_median_to_be_between
* expect_column_value_lengths_to_be_between
* Optimized histogram fetching for SqlalchemyDataset and SparkDFDataset
* Added cross-platform internal partition method, paving path for improved profiling
* Fixed bug with outputstrftime not being honored in PandasDataset
* Fixed series naming for column value counts
* Standardized naming for expect_column_values_to_be_of_type
* Standardized and made explicit use of sample normalization in stdev calculation
* Added from_dataset helper
* Internal testing improvements
* Documentation reorganization and improvements
* Introduce custom exceptions for more detailed error logs
0.6.1
------------
* Re-add testing (and support) for py2
* NOTE: Support for SqlAlchemyDataset and SparkDFDataset is enabled via optional install \
(e.g. ``pip install great_expectations[sqlalchemy]`` or ``pip install great_expectations[spark]``)
0.6.0
------------
* Add support for SparkDFDataset and caching (HUGE work from @cselig)
* Migrate distributional expectations to new testing framework
* Add support for two new expectations: expect_column_distinct_values_to_contain_set
and expect_column_distinct_values_to_equal_set (thanks @RoyalTS)
* FUTURE BREAKING CHANGE: The new cache mechanism for Datasets, \
when enabled, causes GE to assume that dataset does not change between evaluation of individual expectations. \
We anticipate this will become the future default behavior.
* BREAKING CHANGE: Drop official support pandas < 0.22
0.5.1
---------------
* **Fix** issue where no result_format available for expect_column_values_to_be_null caused error
* Use vectorized computation in pandas (#443, #445; thanks @RoyalTS)
0.5.0
----------------
* Restructured class hierarchy to have a more generic DataAsset parent that maintains expectation logic separate \
from the tabular organization of Dataset expectations
* Added new FileDataAsset and associated expectations (#416 thanks @anhollis)
* Added support for date/datetime type columns in some SQLAlchemy expectations (#413)
* Added support for a multicolumn expectation, expect multicolumn values to be unique (#408)
* **Optimization**: You can now disable `partial_unexpected_counts` by setting the `partial_unexpected_count` value to \
0 in the result_format argument, and we do not compute it when it would not be returned. (#431, thanks @eugmandel)
* **Fix**: Correct error in unexpected_percent computations for sqlalchemy when unexpected values exceed limit (#424)
* **Fix**: Pass meta object to expectation result (#415, thanks @jseeman)
* Add support for multicolumn expectations, with `expect_multicolumn_values_to_be_unique` as an example (#406)
* Add dataset class to from_pandas to simplify using custom datasets (#404, thanks @jtilly)
* Add schema support for sqlalchemy data context (#410, thanks @rahulj51)
* Minor documentation, warning, and testing improvements (thanks @zdog).
0.4.5
----------------
* Add a new autoinspect API and remove default expectations.
* Improve details for expect_table_columns_to_match_ordered_list (#379, thanks @rlshuhart)
* Linting fixes (thanks @elsander)
* Add support for dataset_class in from_pandas (thanks @jtilly)
* Improve redshift compatibility by correcting faulty isnull operator (thanks @avanderm)
* Adjust partitions to use tail_weight to improve JSON compatibility and
support special cases of KL Divergence (thanks @anhollis)
* Enable custom_sql datasets for databases with multiple schemas, by
adding a fallback for column reflection (#387, thanks @elsander)
* Remove `IF NOT EXISTS` check for custom sql temporary tables, for
Redshift compatibility (#372, thanks @elsander)
* Allow users to pass args/kwargs for engine creation in
SqlAlchemyDataContext (#369, thanks @elsander)
* Add support for custom schema in SqlAlchemyDataset (#370, thanks @elsander)
* Use getfullargspec to avoid deprecation warnings.
* Add expect_column_values_to_be_unique to SqlAlchemyDataset
* **Fix** map expectations for categorical columns (thanks @eugmandel)
* Improve internal testing suite (thanks @anhollis and @ccnobbli)
* Consistently use value_set instead of mixing value_set and values_set (thanks @njsmith8)
0.4.4
----------------
* Improve CLI help and set CLI return value to the number of unmet expectations
* Add error handling for empty columns to SqlAlchemyDataset, and associated tests
* **Fix** broken support for older pandas versions (#346)
* **Fix** pandas deepcopy issue (#342)
0.4.3
-------
* Improve type lists in expect_column_type_to_be[_in_list] (thanks @smontanaro and @ccnobbli)
* Update cli to use entry_points for conda compatibility, and add version option to cli
* Remove extraneous development dependency to airflow
* Address SQlAlchemy warnings in median computation
* Improve glossary in documentation
* Add 'statistics' section to validation report with overall validation results (thanks @sotte)
* Add support for parameterized expectations
* Improve support for custom expectations with better error messages (thanks @syk0saje)
* Implement expect_column_value_lenghts_to_[be_between|equal] for SQAlchemy (thanks @ccnobbli)
* **Fix** PandasDataset subclasses to inherit child class
0.4.2
-------
* **Fix** bugs in expect_column_values_to_[not]_be_null: computing unexpected value percentages and handling all-null (thanks @ccnobbli)
* Support mysql use of Decimal type (thanks @bouke-nederstigt)
* Add new expectation expect_column_values_to_not_match_regex_list.
* Change behavior of expect_column_values_to_match_regex_list to use python re.findall in PandasDataset, relaxing \
matching of individuals expressions to allow matches anywhere in the string.
* **Fix** documentation errors and other small errors (thanks @roblim, @ccnobbli)
0.4.1
-------
* Correct inclusion of new data_context module in source distribution
0.4.0
-------
* Initial implementation of data context API and SqlAlchemyDataset including implementations of the following \
expectations:
* expect_column_to_exist
* expect_table_row_count_to_be
* expect_table_row_count_to_be_between
* expect_column_values_to_not_be_null
* expect_column_values_to_be_null
* expect_column_values_to_be_in_set
* expect_column_values_to_be_between
* expect_column_mean_to_be
* expect_column_min_to_be
* expect_column_max_to_be
* expect_column_sum_to_be
* expect_column_unique_value_count_to_be_between
* expect_column_proportion_of_unique_values_to_be_between
* Major refactor of output_format to new result_format parameter. See docs for full details:
* exception_list and related uses of the term exception have been renamed to unexpected
* Output formats are explicitly hierarchical now, with BOOLEAN_ONLY < BASIC < SUMMARY < COMPLETE. \
All *column_aggregate_expectation* expectations now return element count and related information included at the \
BASIC level or higher.
* New expectation available for parameterized distributions--\
expect_column_parameterized_distribution_ks_test_p_value_to_be_greater_than (what a name! :) -- (thanks @ccnobbli)
* ge.from_pandas() utility (thanks @schrockn)
* Pandas operations on a PandasDataset now return another PandasDataset (thanks @dlwhite5)
* expect_column_to_exist now takes a column_index parameter to specify column order (thanks @louispotok)
* Top-level validate option (ge.validate())
* ge.read_json() helper (thanks @rjurney)
* Behind-the-scenes improvements to testing framework to ensure parity across data contexts.
* Documentation improvements, bug-fixes, and internal api improvements
0.3.2
-------
* Include requirements file in source dist to support conda
0.3.1
--------
* **Fix** infinite recursion error when building custom expectations
* Catch dateutil parsing overflow errors
0.2
-----
* Distributional expectations and associated helpers are improved and renamed to be more clear regarding the tests they apply
* Expectation decorators have been refactored significantly to streamline implementing expectations and support custom expectations
* API and examples for custom expectations are available
* New output formats are available for all expectations
* Significant improvements to test suite and compatibility
<file_sep>/tests/data_context/test_data_context_ge_cloud_mode.py
from unittest import mock
import pytest
from great_expectations.data_context import BaseDataContext, DataContext
from great_expectations.data_context.cloud_constants import CLOUD_DEFAULT_BASE_URL
from great_expectations.exceptions import DataContextError, GXCloudError
@pytest.mark.cloud
def test_data_context_ge_cloud_mode_with_incomplete_cloud_config_should_throw_error():
# Don't want to make a real request in a unit test so we simply patch the config fixture
with mock.patch(
"great_expectations.data_context.CloudDataContext._get_ge_cloud_config_dict",
return_value={"base_url": None, "organization_id": None, "access_token": None},
):
with pytest.raises(DataContextError):
DataContext(context_root_dir="/my/context/root/dir", ge_cloud_mode=True)
@pytest.mark.cloud
@mock.patch("requests.get")
def test_data_context_ge_cloud_mode_makes_successful_request_to_cloud_api(
mock_request,
request_headers: dict,
ge_cloud_runtime_base_url,
ge_cloud_runtime_organization_id,
ge_cloud_access_token,
):
# Ensure that the request goes through
mock_request.return_value.status_code = 200
try:
DataContext(
ge_cloud_mode=True,
ge_cloud_base_url=ge_cloud_runtime_base_url,
ge_cloud_organization_id=ge_cloud_runtime_organization_id,
ge_cloud_access_token=ge_cloud_access_token,
)
except: # Not concerned with constructor output (only evaluating interaction with requests during __init__)
pass
called_with_url = f"{ge_cloud_runtime_base_url}/organizations/{ge_cloud_runtime_organization_id}/data-context-configuration"
called_with_header = {"headers": request_headers}
# Only ever called once with the endpoint URL and auth token as args
mock_request.assert_called_once()
assert mock_request.call_args[0][0] == called_with_url
assert mock_request.call_args[1] == called_with_header
@pytest.mark.cloud
@mock.patch("requests.get")
def test_data_context_ge_cloud_mode_with_bad_request_to_cloud_api_should_throw_error(
mock_request,
ge_cloud_runtime_base_url,
ge_cloud_runtime_organization_id,
ge_cloud_access_token,
):
# Ensure that the request fails
mock_request.return_value.status_code = 401
with pytest.raises(GXCloudError):
DataContext(
ge_cloud_mode=True,
ge_cloud_base_url=ge_cloud_runtime_base_url,
ge_cloud_organization_id=ge_cloud_runtime_organization_id,
ge_cloud_access_token=ge_cloud_access_token,
)
@pytest.mark.cloud
@pytest.mark.unit
@mock.patch("requests.get")
def test_data_context_in_cloud_mode_passes_base_url_to_store_backend(
mock_request,
ge_cloud_base_url,
empty_base_data_context_in_cloud_mode_custom_base_url: BaseDataContext,
ge_cloud_runtime_organization_id,
ge_cloud_access_token,
):
custom_base_url: str = "https://some_url.org"
# Ensure that the request goes through
mock_request.return_value.status_code = 200
context: BaseDataContext = empty_base_data_context_in_cloud_mode_custom_base_url
# Assertions that the context fixture is set up properly
assert not context.ge_cloud_config.base_url == CLOUD_DEFAULT_BASE_URL
assert not context.ge_cloud_config.base_url == ge_cloud_base_url
assert (
not context.ge_cloud_config.base_url == "https://app.test.greatexpectations.io"
)
# The DatasourceStore should not have the default base_url or commonly used test base urls
assert (
not context._datasource_store.store_backend.config["ge_cloud_base_url"]
== CLOUD_DEFAULT_BASE_URL
)
assert (
not context._datasource_store.store_backend.config["ge_cloud_base_url"]
== ge_cloud_base_url
)
assert (
not context._datasource_store.store_backend.config["ge_cloud_base_url"]
== "https://app.test.greatexpectations.io"
)
# The DatasourceStore should have the custom base url set
assert (
context._datasource_store.store_backend.config["ge_cloud_base_url"]
== custom_base_url
)
<file_sep>/great_expectations/core/usage_statistics/usage_statistics.py
from __future__ import annotations
import atexit
import copy
import datetime
import enum
import json
import logging
import platform
import signal
import sys
import threading
import time
from functools import wraps
from queue import Queue
from types import FrameType
from typing import TYPE_CHECKING, Callable, List, Optional
import jsonschema
import requests
from great_expectations import __version__ as ge_version
from great_expectations.core import ExpectationSuite
from great_expectations.core.usage_statistics.anonymizers.anonymizer import Anonymizer
from great_expectations.core.usage_statistics.anonymizers.types.base import (
CLISuiteInteractiveFlagCombinations,
)
from great_expectations.core.usage_statistics.events import UsageStatsEvents
from great_expectations.core.usage_statistics.execution_environment import (
GEExecutionEnvironment,
PackageInfo,
PackageInfoSchema,
)
from great_expectations.core.usage_statistics.schemas import (
anonymized_usage_statistics_record_schema,
)
from great_expectations.core.util import nested_update
from great_expectations.data_context.types.base import CheckpointConfig
from great_expectations.rule_based_profiler.config import RuleBasedProfilerConfig
if TYPE_CHECKING:
from great_expectations.checkpoint.checkpoint import Checkpoint
from great_expectations.data_context import AbstractDataContext, DataContext
from great_expectations.rule_based_profiler.rule_based_profiler import (
RuleBasedProfiler,
)
STOP_SIGNAL = object()
logger = logging.getLogger(__name__)
_anonymizers = {}
class UsageStatsExceptionPrefix(enum.Enum):
EMIT_EXCEPTION = "UsageStatsException"
INVALID_MESSAGE = "UsageStatsInvalidMessage"
class UsageStatisticsHandler:
def __init__(
self,
data_context: AbstractDataContext,
data_context_id: str,
usage_statistics_url: str,
) -> None:
self._url = usage_statistics_url
self._data_context_id = data_context_id
self._data_context_instance_id = data_context.instance_id
self._data_context = data_context
self._ge_version = ge_version
self._message_queue = Queue()
self._worker = threading.Thread(target=self._requests_worker, daemon=True)
self._worker.start()
self._anonymizer = Anonymizer(data_context_id)
try:
self._sigterm_handler = signal.signal(signal.SIGTERM, self._teardown)
except ValueError:
# if we are not the main thread, we don't get to ask for signal handling.
self._sigterm_handler = None
try:
self._sigint_handler = signal.signal(signal.SIGINT, self._teardown)
except ValueError:
# if we are not the main thread, we don't get to ask for signal handling.
self._sigint_handler = None
atexit.register(self._close_worker)
@property
def anonymizer(self) -> Anonymizer:
return self._anonymizer
def _teardown(self, signum: int, frame: Optional[FrameType]) -> None:
self._close_worker()
if signum == signal.SIGTERM and self._sigterm_handler:
self._sigterm_handler(signum, frame)
if signum == signal.SIGINT and self._sigint_handler:
self._sigint_handler(signum, frame)
def _close_worker(self) -> None:
self._message_queue.put(STOP_SIGNAL)
self._worker.join()
def _requests_worker(self) -> None:
session = requests.Session()
while True:
message = self._message_queue.get()
if message == STOP_SIGNAL:
self._message_queue.task_done()
return
try:
res = session.post(self._url, json=message, timeout=2)
logger.debug(
"Posted usage stats: message status " + str(res.status_code)
)
if res.status_code != 201:
logger.debug(
"Server rejected message: ", json.dumps(message, indent=2)
)
except requests.exceptions.Timeout:
logger.debug("Timeout while sending usage stats message.")
except Exception as e:
logger.debug("Unexpected error posting message: " + str(e))
finally:
self._message_queue.task_done()
def build_init_payload(self) -> dict:
"""Adds information that may be available only after full data context construction, but is useful to
calculate only one time (for example, anonymization)."""
expectation_suites: List[ExpectationSuite] = [
self._data_context.get_expectation_suite(expectation_suite_name)
for expectation_suite_name in self._data_context.list_expectation_suite_names()
]
# <WILL> 20220701 - ValidationOperators have been deprecated, so some init_payloads will not have them included
validation_operators = None
if hasattr(self._data_context, "validation_operators"):
validation_operators = self._data_context.validation_operators
init_payload = {
"platform.system": platform.system(),
"platform.release": platform.release(),
"version_info": str(sys.version_info),
"datasources": self._data_context.project_config_with_variables_substituted.datasources,
"stores": self._data_context.stores,
"validation_operators": validation_operators,
"data_docs_sites": self._data_context.project_config_with_variables_substituted.data_docs_sites,
"expectation_suites": expectation_suites,
"dependencies": self._get_serialized_dependencies(),
}
anonymized_init_payload = self._anonymizer.anonymize_init_payload(
init_payload=init_payload
)
return anonymized_init_payload
@staticmethod
def _get_serialized_dependencies() -> List[dict]:
"""Get the serialized dependencies from the GEExecutionEnvironment."""
ge_execution_environment = GEExecutionEnvironment()
dependencies: List[PackageInfo] = ge_execution_environment.dependencies
schema = PackageInfoSchema()
serialized_dependencies: List[dict] = [
schema.dump(package_info) for package_info in dependencies
]
return serialized_dependencies
def build_envelope(self, message: dict) -> dict:
message["version"] = "1.0.0"
message["ge_version"] = self._ge_version
message["data_context_id"] = self._data_context_id
message["data_context_instance_id"] = self._data_context_instance_id
message["event_time"] = (
datetime.datetime.now(datetime.timezone.utc).strftime(
"%Y-%m-%dT%H:%M:%S.%f"
)[:-3]
+ "Z"
)
event_duration_property_name: str = f'{message["event"]}.duration'.replace(
".", "_"
)
if hasattr(self, event_duration_property_name):
delta_t: int = getattr(self, event_duration_property_name)
message["event_duration"] = delta_t
return message
@staticmethod
def validate_message(message: dict, schema: dict) -> bool:
try:
jsonschema.validate(message, schema=schema)
return True
except jsonschema.ValidationError as e:
logger.debug(
f"{UsageStatsExceptionPrefix.INVALID_MESSAGE.value} invalid message: "
+ str(e)
)
return False
def send_usage_message(
self,
event: str,
event_payload: Optional[dict] = None,
success: Optional[bool] = None,
) -> None:
"""send a usage statistics message."""
# noinspection PyBroadException
try:
message: dict = {
"event": event,
"event_payload": event_payload or {},
"success": success,
}
self.emit(message)
except Exception:
pass
def emit(self, message: dict) -> None:
"""
Emit a message.
"""
try:
if message["event"] == "data_context.__init__":
message["event_payload"] = self.build_init_payload()
message = self.build_envelope(message=message)
if not self.validate_message(
message, schema=anonymized_usage_statistics_record_schema
):
return
self._message_queue.put(message)
# noinspection PyBroadException
except Exception as e:
# We *always* tolerate *any* error in usage statistics
log_message: str = (
f"{UsageStatsExceptionPrefix.EMIT_EXCEPTION.value}: {e} type: {type(e)}"
)
logger.debug(log_message)
def get_usage_statistics_handler(args_array: list) -> Optional[UsageStatisticsHandler]:
try:
# If the object is usage_statistics-capable, then it will have a usage_statistics_handler
handler = getattr(args_array[0], "_usage_statistics_handler", None)
if handler is not None and not isinstance(handler, UsageStatisticsHandler):
logger.debug("Invalid UsageStatisticsHandler found on object.")
handler = None
except IndexError:
# A wrapped method that is not an object; this would be erroneous usage
logger.debug(
"usage_statistics enabled decorator should only be used on data context methods"
)
handler = None
except AttributeError:
# A wrapped method that is not usage_statistics capable
handler = None
except Exception as e:
# An unknown error -- but we still fail silently
logger.debug(
"Unrecognized error when trying to find usage_statistics_handler: " + str(e)
)
handler = None
return handler
def usage_statistics_enabled_method(
func: Optional[Callable] = None,
event_name: Optional[UsageStatsEvents] = None,
args_payload_fn: Optional[Callable] = None,
result_payload_fn: Optional[Callable] = None,
) -> Callable:
"""
A decorator for usage statistics which defaults to the less detailed payload schema.
"""
if callable(func):
if event_name is None:
event_name = func.__name__
@wraps(func)
def usage_statistics_wrapped_method(*args, **kwargs):
# if a function like `build_data_docs()` is being called as a `dry_run`
# then we dont want to emit usage_statistics. We just return the function without sending a usage_stats message
if "dry_run" in kwargs and kwargs["dry_run"]:
return func(*args, **kwargs)
# Set event_payload now so it can be updated below
event_payload = {}
message = {"event_payload": event_payload, "event": event_name}
result = None
time_begin: int = int(round(time.time() * 1000))
try:
if args_payload_fn is not None:
nested_update(event_payload, args_payload_fn(*args, **kwargs))
result = func(*args, **kwargs)
message["success"] = True
except Exception:
message["success"] = False
raise
finally:
if not ((result is None) or (result_payload_fn is None)):
nested_update(event_payload, result_payload_fn(result))
time_end: int = int(round(time.time() * 1000))
delta_t: int = time_end - time_begin
handler = get_usage_statistics_handler(list(args))
if handler:
event_duration_property_name: str = (
f"{event_name}.duration".replace(".", "_")
)
setattr(handler, event_duration_property_name, delta_t)
handler.emit(message)
delattr(handler, event_duration_property_name)
return result
return usage_statistics_wrapped_method
else:
# noinspection PyShadowingNames
def usage_statistics_wrapped_method_partial(func):
return usage_statistics_enabled_method(
func,
event_name=event_name,
args_payload_fn=args_payload_fn,
result_payload_fn=result_payload_fn,
)
return usage_statistics_wrapped_method_partial
# noinspection PyUnusedLocal
def run_validation_operator_usage_statistics(
data_context: DataContext,
validation_operator_name: str,
assets_to_validate: list,
**kwargs,
) -> dict:
try:
data_context_id = data_context.data_context_id
except AttributeError:
data_context_id = None
anonymizer = _anonymizers.get(data_context_id, None)
if anonymizer is None:
anonymizer = Anonymizer(data_context_id)
_anonymizers[data_context_id] = anonymizer
payload = {}
try:
payload["anonymized_operator_name"] = anonymizer.anonymize(
obj=validation_operator_name
)
except TypeError as e:
logger.debug(
f"{UsageStatsExceptionPrefix.EMIT_EXCEPTION.value}: {e} type: {type(e)}, run_validation_operator_usage_statistics: Unable to create validation_operator_name hash"
)
if data_context._usage_statistics_handler:
# noinspection PyBroadException
try:
anonymizer = data_context._usage_statistics_handler.anonymizer
payload["anonymized_batches"] = [
anonymizer.anonymize(obj=batch) for batch in assets_to_validate
]
except Exception as e:
logger.debug(
f"{UsageStatsExceptionPrefix.EMIT_EXCEPTION.value}: {e} type: {type(e)}, run_validation_operator_usage_statistics: Unable to create anonymized_batches payload field"
)
return payload
# noinspection SpellCheckingInspection
# noinspection PyUnusedLocal
def save_expectation_suite_usage_statistics(
data_context: DataContext,
expectation_suite: ExpectationSuite,
expectation_suite_name: Optional[str] = None,
**kwargs: dict,
) -> dict:
"""
Event handler for saving expectation suite with either "ExpectationSuite" object or "expectation_suite_name" string.
"""
return _handle_expectation_suite_usage_statistics(
data_context=data_context,
event_arguments_payload_handler_name="save_expectation_suite_usage_statistics",
expectation_suite=expectation_suite,
expectation_suite_name=expectation_suite_name,
interactive_mode=None,
**kwargs,
)
def get_expectation_suite_usage_statistics(
data_context: DataContext,
expectation_suite_name: str,
**kwargs: dict,
) -> dict:
"""
Event handler for obtaining expectation suite with "expectation_suite_name" string.
"""
return _handle_expectation_suite_usage_statistics(
data_context=data_context,
event_arguments_payload_handler_name="get_expectation_suite_usage_statistics",
expectation_suite=None,
expectation_suite_name=expectation_suite_name,
interactive_mode=None,
**kwargs,
)
def edit_expectation_suite_usage_statistics(
data_context: DataContext,
expectation_suite_name: str,
interactive_mode: Optional[CLISuiteInteractiveFlagCombinations] = None,
**kwargs: dict,
) -> dict:
"""
Event handler for editing expectation suite with "expectation_suite_name" string.
"""
return _handle_expectation_suite_usage_statistics(
data_context=data_context,
event_arguments_payload_handler_name="edit_expectation_suite_usage_statistics",
expectation_suite=None,
expectation_suite_name=expectation_suite_name,
interactive_mode=interactive_mode,
**kwargs,
)
def add_datasource_usage_statistics(
data_context: DataContext, name: str, **kwargs
) -> dict:
if not data_context._usage_statistics_handler:
return {}
try:
data_context_id = data_context.data_context_id
except AttributeError:
data_context_id = None
from great_expectations.core.usage_statistics.anonymizers.datasource_anonymizer import (
DatasourceAnonymizer,
)
aggregate_anonymizer = Anonymizer(salt=data_context_id)
datasource_anonymizer = DatasourceAnonymizer(
salt=data_context_id, aggregate_anonymizer=aggregate_anonymizer
)
payload = {}
# noinspection PyBroadException
try:
payload = datasource_anonymizer._anonymize_datasource_info(name, kwargs)
except Exception as e:
logger.debug(
f"{UsageStatsExceptionPrefix.EMIT_EXCEPTION.value}: {e} type: {type(e)}, add_datasource_usage_statistics: Unable to create add_datasource_usage_statistics payload field"
)
return payload
# noinspection SpellCheckingInspection
def get_batch_list_usage_statistics(data_context: DataContext, *args, **kwargs) -> dict:
try:
data_context_id = data_context.data_context_id
except AttributeError:
data_context_id = None
anonymizer = _anonymizers.get(data_context_id, None)
if anonymizer is None:
anonymizer = Anonymizer(data_context_id)
_anonymizers[data_context_id] = anonymizer
payload = {}
if data_context._usage_statistics_handler:
# noinspection PyBroadException
try:
anonymizer: Anonymizer = data_context._usage_statistics_handler.anonymizer
payload = anonymizer.anonymize(*args, **kwargs)
except Exception as e:
logger.debug(
f"{UsageStatsExceptionPrefix.EMIT_EXCEPTION.value}: {e} type: {type(e)}, get_batch_list_usage_statistics: Unable to create anonymized_batch_request payload field"
)
return payload
# noinspection PyUnusedLocal
def get_checkpoint_run_usage_statistics(
checkpoint: Checkpoint,
*args,
**kwargs,
) -> dict:
usage_statistics_handler: Optional[
UsageStatisticsHandler
] = checkpoint._usage_statistics_handler
data_context_id: Optional[str] = None
try:
data_context_id = checkpoint.data_context.data_context_id
except AttributeError:
data_context_id = None
anonymizer: Optional[Anonymizer] = _anonymizers.get(data_context_id, None)
if anonymizer is None:
anonymizer = Anonymizer(data_context_id)
_anonymizers[data_context_id] = anonymizer
payload: dict = {}
if usage_statistics_handler:
# noinspection PyBroadException
try:
anonymizer = usage_statistics_handler.anonymizer
resolved_runtime_kwargs: dict = (
CheckpointConfig.resolve_config_using_acceptable_arguments(
*(checkpoint,), **kwargs
)
)
payload: dict = anonymizer.anonymize(
*(checkpoint,), **resolved_runtime_kwargs
)
except Exception as e:
logger.debug(
f"{UsageStatsExceptionPrefix.EMIT_EXCEPTION.value}: {e} type: {type(e)}, get_checkpoint_run_usage_statistics: Unable to create anonymized_checkpoint_run payload field"
)
return payload
# noinspection PyUnusedLocal
def get_profiler_run_usage_statistics(
profiler: RuleBasedProfiler,
variables: Optional[dict] = None,
rules: Optional[dict] = None,
*args: tuple,
**kwargs: dict,
) -> dict:
usage_statistics_handler: Optional[
UsageStatisticsHandler
] = profiler._usage_statistics_handler
data_context_id: Optional[str] = None
if usage_statistics_handler:
data_context_id = usage_statistics_handler._data_context_id
anonymizer: Optional[Anonymizer] = _anonymizers.get(data_context_id, None)
if anonymizer is None:
anonymizer = Anonymizer(data_context_id)
_anonymizers[data_context_id] = anonymizer
payload: dict = {}
if usage_statistics_handler:
# noinspection PyBroadException
try:
anonymizer = usage_statistics_handler.anonymizer
resolved_runtime_config: RuleBasedProfilerConfig = (
RuleBasedProfilerConfig.resolve_config_using_acceptable_arguments(
profiler=profiler,
variables=variables,
rules=rules,
)
)
payload: dict = anonymizer.anonymize(obj=resolved_runtime_config)
except Exception as e:
logger.debug(
f"{UsageStatsExceptionPrefix.EMIT_EXCEPTION.value}: {e} type: {type(e)}, get_profiler_run_usage_statistics: Unable to create anonymized_profiler_run payload field"
)
return payload
def send_usage_message(
data_context: AbstractDataContext,
event: str,
event_payload: Optional[dict] = None,
success: Optional[bool] = None,
) -> None:
"""send a usage statistics message."""
# noinspection PyBroadException
try:
handler: UsageStatisticsHandler = getattr(
data_context, "_usage_statistics_handler", None
)
if handler is not None:
message: dict = {
"event": event,
"event_payload": event_payload,
"success": success,
}
handler.emit(message)
except Exception:
pass
def send_usage_message_from_handler(
event: str,
handler: Optional[UsageStatisticsHandler] = None,
event_payload: Optional[dict] = None,
success: Optional[bool] = None,
) -> None:
"""Send a usage statistics message using an already instantiated handler."""
# noinspection PyBroadException
try:
if handler:
message: dict = {
"event": event,
"event_payload": event_payload,
"success": success,
}
handler.emit(message)
except Exception as e:
logger.debug(
f"{UsageStatsExceptionPrefix.EMIT_EXCEPTION.value}: {e} type: {type(e)}, Exception encountered while running send_usage_message_from_handler()."
)
# noinspection SpellCheckingInspection
# noinspection PyUnusedLocal
def _handle_expectation_suite_usage_statistics(
data_context: DataContext,
event_arguments_payload_handler_name: str,
expectation_suite: Optional[ExpectationSuite] = None,
expectation_suite_name: Optional[str] = None,
interactive_mode: Optional[CLISuiteInteractiveFlagCombinations] = None,
**kwargs,
) -> dict:
"""
This method anonymizes "expectation_suite_name" for events that utilize this property.
"""
data_context_id: Optional[str]
try:
data_context_id = data_context.data_context_id
except AttributeError:
data_context_id = None
anonymizer: Anonymizer = _anonymizers.get(data_context_id, None)
if anonymizer is None:
anonymizer = Anonymizer(data_context_id)
_anonymizers[data_context_id] = anonymizer
payload: dict
if interactive_mode is None:
payload = {}
else:
payload = copy.deepcopy(interactive_mode.value)
if expectation_suite_name is None:
if isinstance(expectation_suite, ExpectationSuite):
expectation_suite_name = expectation_suite.expectation_suite_name
elif isinstance(expectation_suite, dict):
expectation_suite_name = expectation_suite.get("expectation_suite_name")
# noinspection PyBroadException
try:
payload["anonymized_expectation_suite_name"] = anonymizer.anonymize(
obj=expectation_suite_name
)
except Exception as e:
logger.debug(
f"{UsageStatsExceptionPrefix.EMIT_EXCEPTION.value}: {e} type: {type(e)}, {event_arguments_payload_handler_name}: Unable to create anonymized_expectation_suite_name payload field."
)
return payload
<file_sep>/great_expectations/data_context/data_context/explorer_data_context.py
import logging
from ruamel.yaml import YAML
from great_expectations.data_context.data_context.data_context import DataContext
logger = logging.getLogger(__name__)
yaml = YAML()
yaml.indent(mapping=2, sequence=4, offset=2)
yaml.default_flow_style = False
class ExplorerDataContext(DataContext):
def __init__(self, context_root_dir=None, expectation_explorer=True) -> None:
"""
expectation_explorer: If True, load the expectation explorer manager, which will modify GE return objects \
to include ipython notebook widgets.
"""
super().__init__(context_root_dir)
self._expectation_explorer = expectation_explorer
if expectation_explorer:
from great_expectations.jupyter_ux.expectation_explorer import (
ExpectationExplorer,
)
self._expectation_explorer_manager = ExpectationExplorer()
def update_return_obj(self, data_asset, return_obj):
"""Helper called by data_asset.
Args:
data_asset: The data_asset whose validation produced the current return object
return_obj: the return object to update
Returns:
return_obj: the return object, potentially changed into a widget by the configured expectation explorer
"""
if self._expectation_explorer:
return self._expectation_explorer_manager.create_expectation_widget(
data_asset, return_obj
)
else:
return return_obj
<file_sep>/docs/scripts/remark-named-snippets/index.js
/*
This script enables name-based snippet retrieval in Docusaurus-enabled docs using
the following syntax:
```
```python name="getting_started_imports"
```
This pattern is directly inspired by remark-code-import, which references using line numbers:
```
```python file=../../tests/integration/docusaurus/tutorials/getting-started/getting_started.py#L1-L5
```
As snippets are bound by identifier and not specific line numbers, they are far less susceptible
to breakage when docs and source code are being updated.
Named snippets are defined with the following syntax:
```
# <snippet name="getting_started_imports">
import great_expectations as gx
...
# </snippet>
```
*/
const visit = require('unist-util-visit')
const constructSnippetMap = require('./snippet')
function codeImport () {
// Instantiated within the import so it can be hot-reloaded
const snippetMap = constructSnippetMap('.')
console.log(snippetMap)
return function transformer (tree, file) {
const codes = []
const promises = []
// Walk the AST of the markdown file and filter for code snippets
visit(tree, 'code', (node, index, parent) => {
codes.push([node, index, parent])
})
for (const [node] of codes) {
const meta = node.meta || ''
if (!meta) {
continue
}
const nameMeta = /^name=(?<snippetName>.+?)$/.exec(
meta
)
if (!nameMeta) {
continue
}
let name = nameMeta.groups.snippetName
if (!name) {
throw new Error(`Unable to parse named reference ${nameMeta}`)
}
// Remove any surrounding quotes
name = name.replaceAll("'", '').replaceAll('"', '')
if (!(name in snippetMap)) {
throw new Error(`Could not find any snippet named ${name}`)
}
node.value = snippetMap[name].contents
console.log(`Substituted value for named snippet "${name}"`)
}
if (promises.length) {
return Promise.all(promises)
}
}
}
module.exports = codeImport
<file_sep>/great_expectations/core/usage_statistics/anonymizers/store_backend_anonymizer.py
from typing import Optional
from great_expectations.core.usage_statistics.anonymizers.base import BaseAnonymizer
from great_expectations.data_context.store.store_backend import StoreBackend
class StoreBackendAnonymizer(BaseAnonymizer):
def __init__(
self,
aggregate_anonymizer: "Anonymizer", # noqa: F821
salt: Optional[str] = None,
) -> None:
super().__init__(salt=salt)
self._aggregate_anonymizer = aggregate_anonymizer
def anonymize(
self,
obj: Optional[object] = None,
store_backend_obj: Optional[StoreBackend] = None,
store_backend_object_config: Optional[dict] = None,
) -> dict:
assert (
store_backend_obj or store_backend_object_config
), "Must pass store_backend_obj or store_backend_object_config."
anonymized_info_dict = {}
if store_backend_obj is not None:
self._anonymize_object_info(
object_=store_backend_obj,
anonymized_info_dict=anonymized_info_dict,
)
else:
class_name = store_backend_object_config.get("class_name")
module_name = store_backend_object_config.get("module_name")
if module_name is None:
module_name = "great_expectations.data_context.store"
self._anonymize_object_info(
object_config={"class_name": class_name, "module_name": module_name},
anonymized_info_dict=anonymized_info_dict,
)
return anonymized_info_dict
def can_handle(self, obj: Optional[object] = None, **kwargs) -> bool:
return (obj is not None and isinstance(obj, StoreBackend)) or (
"store_backend_object_config" in kwargs
)
<file_sep>/tests/render/test_inline_renderer.py
from typing import List
import pytest
from great_expectations.core.batch import BatchRequest
from great_expectations.core.expectation_configuration import ExpectationConfiguration
from great_expectations.core.expectation_suite import ExpectationSuite
from great_expectations.core.expectation_validation_result import (
ExpectationValidationResult,
)
from great_expectations.data_context import DataContext
from great_expectations.render import (
AtomicDiagnosticRendererType,
AtomicPrescriptiveRendererType,
RenderedAtomicContent,
)
from great_expectations.render.exceptions import InvalidRenderedContentError
from great_expectations.render.renderer.inline_renderer import InlineRenderer
from great_expectations.validator.validator import Validator
@pytest.mark.integration
def test_inline_renderer_error_message(basic_expectation_suite: ExpectationSuite):
expectation_suite: ExpectationSuite = basic_expectation_suite
with pytest.raises(InvalidRenderedContentError) as e:
InlineRenderer(render_object=expectation_suite) # type: ignore
assert (
str(e.value)
== "InlineRenderer can only be used with an ExpectationConfiguration or ExpectationValidationResult, but <class 'great_expectations.core.expectation_suite.ExpectationSuite'> was used."
)
@pytest.mark.integration
@pytest.mark.parametrize(
"expectation_configuration,expected_serialized_expectation_configuration_rendered_atomic_content,expected_serialized_expectation_validation_result_rendered_atomic_content",
[
pytest.param(
ExpectationConfiguration(
expectation_type="expect_table_row_count_to_equal",
kwargs={"value": 3},
),
[
{
"value_type": "StringValueType",
"name": AtomicPrescriptiveRendererType.SUMMARY,
"value": {
"header": None,
"template": "Must have exactly $value rows.",
"schema": {"type": "com.superconductive.rendered.string"},
"params": {
"value": {"schema": {"type": "number"}, "value": 3},
},
},
}
],
[
{
"name": AtomicDiagnosticRendererType.OBSERVED_VALUE,
"value": {
"header": None,
"params": {},
"schema": {"type": "com.superconductive.rendered.string"},
"template": "3",
},
"value_type": "StringValueType",
}
],
id="expect_table_row_count_to_equal",
),
pytest.param(
ExpectationConfiguration(
expectation_type="expect_column_min_to_be_between",
kwargs={"column": "event_type", "min_value": 3, "max_value": 20},
),
[
{
"name": AtomicPrescriptiveRendererType.SUMMARY,
"value": {
"header": None,
"params": {
"column": {
"schema": {"type": "string"},
"value": "event_type",
},
"condition_parser": {
"schema": {"type": "string"},
"value": None,
},
"max_value": {"schema": {"type": "number"}, "value": 20},
"min_value": {"schema": {"type": "number"}, "value": 3},
"parse_strings_as_datetimes": {
"schema": {"type": "boolean"},
"value": None,
},
"row_condition": {
"schema": {"type": "string"},
"value": None,
},
"strict_max": {
"schema": {"type": "boolean"},
"value": None,
},
"strict_min": {
"schema": {"type": "boolean"},
"value": None,
},
},
"schema": {"type": "com.superconductive.rendered.string"},
"template": "$column minimum value must be greater than or equal "
"to $min_value and less than or equal to $max_value.",
},
"value_type": "StringValueType",
}
],
[
{
"name": AtomicDiagnosticRendererType.OBSERVED_VALUE,
"value": {
"header": None,
"params": {},
"schema": {"type": "com.superconductive.rendered.string"},
"template": "19",
},
"value_type": "StringValueType",
}
],
id="expect_column_min_to_be_between",
),
pytest.param(
ExpectationConfiguration(
expectation_type="expect_column_quantile_values_to_be_between",
kwargs={
"column": "user_id",
"quantile_ranges": {
"quantiles": [0.0, 0.5, 1.0],
"value_ranges": [
[300000, 400000],
[2000000, 4000000],
[4000000, 10000000],
],
},
},
),
[
{
"name": AtomicPrescriptiveRendererType.SUMMARY,
"value": {
"header": {
"schema": {"type": "StringValueType"},
"value": {
"params": {
"column": {
"schema": {"type": "string"},
"value": "user_id",
},
"condition_parser": {
"schema": {"type": "string"},
"value": None,
},
"mostly": {
"schema": {"type": "number"},
"value": None,
},
"row_condition": {
"schema": {"type": "string"},
"value": None,
},
},
"template": "$column quantiles must be within "
"the following value ranges.",
},
},
"header_row": [
{"schema": {"type": "string"}, "value": "Quantile"},
{"schema": {"type": "string"}, "value": "Min Value"},
{"schema": {"type": "string"}, "value": "Max Value"},
],
"schema": {"type": "TableType"},
"table": [
[
{"schema": {"type": "string"}, "value": "0.00"},
{"schema": {"type": "number"}, "value": 300000},
{"schema": {"type": "number"}, "value": 400000},
],
[
{"schema": {"type": "string"}, "value": "Median"},
{"schema": {"type": "number"}, "value": 2000000},
{"schema": {"type": "number"}, "value": 4000000},
],
[
{"schema": {"type": "string"}, "value": "1.00"},
{"schema": {"type": "number"}, "value": 4000000},
{"schema": {"type": "number"}, "value": 10000000},
],
],
},
"value_type": "TableType",
}
],
[
{
"name": AtomicDiagnosticRendererType.OBSERVED_VALUE,
"value": {
"header": None,
"header_row": [
{"schema": {"type": "string"}, "value": "Quantile"},
{"schema": {"type": "string"}, "value": "Value"},
],
"schema": {"type": "TableType"},
"table": [
[
{"schema": {"type": "string"}, "value": "0.00"},
{"schema": {"type": "number"}, "value": 397433},
],
[
{"schema": {"type": "string"}, "value": "Median"},
{"schema": {"type": "number"}, "value": 2388055},
],
[
{"schema": {"type": "string"}, "value": "1.00"},
{"schema": {"type": "number"}, "value": 9488404},
],
],
},
"value_type": "TableType",
}
],
id="expect_column_quantile_values_to_be_between",
),
pytest.param(
ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={"column": "event_type", "value_set": [19, 22, 73]},
),
[
{
"name": AtomicPrescriptiveRendererType.SUMMARY,
"value": {
"header": None,
"params": {
"column": {
"schema": {"type": "string"},
"value": "event_type",
},
"condition_parser": {
"schema": {"type": "string"},
"value": None,
},
"mostly": {"schema": {"type": "number"}, "value": None},
"mostly_pct": {"schema": {"type": "string"}, "value": None},
"parse_strings_as_datetimes": {
"schema": {"type": "boolean"},
"value": None,
},
"row_condition": {
"schema": {"type": "string"},
"value": None,
},
"v__0": {"schema": {"type": "string"}, "value": 19},
"v__1": {"schema": {"type": "string"}, "value": 22},
"v__2": {"schema": {"type": "string"}, "value": 73},
"value_set": {
"schema": {"type": "array"},
"value": [19, 22, 73],
},
},
"schema": {"type": "com.superconductive.rendered.string"},
"template": "$column values must belong to this set: $v__0 $v__1 "
"$v__2.",
},
"value_type": "StringValueType",
}
],
[
{
"name": AtomicDiagnosticRendererType.OBSERVED_VALUE,
"value": {
"header": None,
"params": {},
"schema": {"type": "com.superconductive.rendered.string"},
"template": "0% unexpected",
},
"value_type": "StringValueType",
}
],
id="expect_column_values_to_be_in_set",
),
pytest.param(
ExpectationConfiguration(
expectation_type="expect_column_kl_divergence_to_be_less_than",
kwargs={
"column": "user_id",
"partition_object": {
"values": [2000000, 6000000],
"weights": [0.3, 0.7],
},
},
),
[
{
"name": AtomicPrescriptiveRendererType.SUMMARY,
"value": {
"graph": {
"autosize": "fit",
"config": {
"view": {
"continuousHeight": 300,
"continuousWidth": 400,
}
},
"encoding": {
"tooltip": [
{"field": "values", "type": "quantitative"},
{"field": "fraction", "type": "quantitative"},
],
"x": {"field": "values", "type": "nominal"},
"y": {"field": "fraction", "type": "quantitative"},
},
"height": 400,
"mark": "bar",
"width": 250,
},
"header": {
"schema": {"type": "StringValueType"},
"value": {
"params": {
"column": {
"schema": {"type": "string"},
"value": "user_id",
},
"condition_parser": {
"schema": {"type": "string"},
"value": None,
},
"mostly": {
"schema": {"type": "number"},
"value": None,
},
"row_condition": {
"schema": {"type": "string"},
"value": None,
},
"threshold": {
"schema": {"type": "number"},
"value": None,
},
},
"template": "$column Kullback-Leibler (KL) "
"divergence with respect to the "
"following distribution must be "
"lower than $threshold.",
},
},
"schema": {"type": "GraphType"},
},
"value_type": "GraphType",
}
],
[
{
"name": AtomicDiagnosticRendererType.OBSERVED_VALUE,
"value": {
"graph": {
"autosize": "fit",
"config": {
"view": {
"continuousHeight": 300,
"continuousWidth": 400,
}
},
"encoding": {
"tooltip": [
{"field": "values", "type": "quantitative"},
{"field": "fraction", "type": "quantitative"},
],
"x": {"field": "values", "type": "nominal"},
"y": {"field": "fraction", "type": "quantitative"},
},
"height": 400,
"mark": "bar",
"width": 250,
},
"header": {
"schema": {"type": "StringValueType"},
"value": {
"params": {
"observed_value": {
"schema": {"type": "string"},
"value": "None "
"(-infinity, "
"infinity, "
"or "
"NaN)",
}
},
"template": "KL Divergence: $observed_value",
},
},
"schema": {"type": "GraphType"},
},
"value_type": "GraphType",
}
],
id="expect_column_kl_divergence_to_be_less_than",
),
],
)
@pytest.mark.slow # 5.82s
def test_inline_renderer_rendered_content_return_value(
alice_columnar_table_single_batch_context: DataContext,
expectation_configuration: ExpectationConfiguration,
expected_serialized_expectation_configuration_rendered_atomic_content: dict,
expected_serialized_expectation_validation_result_rendered_atomic_content: dict,
):
context: DataContext = alice_columnar_table_single_batch_context
batch_request: BatchRequest = BatchRequest(
datasource_name="alice_columnar_table_single_batch_datasource",
data_connector_name="alice_columnar_table_single_batch_data_connector",
data_asset_name="alice_columnar_table_single_batch_data_asset",
)
suite: ExpectationSuite = context.create_expectation_suite("validating_alice_data")
validator: Validator = context.get_validator(
batch_request=batch_request,
expectation_suite=suite,
include_rendered_content=True,
)
expectation_validation_result: ExpectationValidationResult = (
validator.graph_validate(configurations=[expectation_configuration])
)[0]
inline_renderer: InlineRenderer = InlineRenderer(
render_object=expectation_validation_result
)
expectation_validation_result_rendered_atomic_content: List[
RenderedAtomicContent
] = inline_renderer.get_rendered_content()
inline_renderer: InlineRenderer = InlineRenderer(
render_object=expectation_validation_result.expectation_config
)
expectation_configuration_rendered_atomic_content: List[
RenderedAtomicContent
] = inline_renderer.get_rendered_content()
actual_serialized_expectation_configuration_rendered_atomic_content: List[dict] = [
rendered_atomic_content.to_json_dict()
for rendered_atomic_content in expectation_configuration_rendered_atomic_content
]
if (
actual_serialized_expectation_configuration_rendered_atomic_content[0][
"value_type"
]
== "GraphType"
):
actual_serialized_expectation_configuration_rendered_atomic_content[0]["value"][
"graph"
].pop("$schema")
actual_serialized_expectation_configuration_rendered_atomic_content[0]["value"][
"graph"
].pop("data")
actual_serialized_expectation_configuration_rendered_atomic_content[0]["value"][
"graph"
].pop("datasets")
actual_serialized_expectation_validation_result_rendered_atomic_content: List[
dict
] = [
rendered_atomic_content.to_json_dict()
for rendered_atomic_content in expectation_validation_result_rendered_atomic_content
]
if (
actual_serialized_expectation_validation_result_rendered_atomic_content[0][
"value_type"
]
== "GraphType"
):
actual_serialized_expectation_validation_result_rendered_atomic_content[0][
"value"
]["graph"].pop("$schema")
actual_serialized_expectation_validation_result_rendered_atomic_content[0][
"value"
]["graph"].pop("data")
actual_serialized_expectation_validation_result_rendered_atomic_content[0][
"value"
]["graph"].pop("datasets")
assert (
actual_serialized_expectation_configuration_rendered_atomic_content
== expected_serialized_expectation_configuration_rendered_atomic_content
)
assert (
actual_serialized_expectation_validation_result_rendered_atomic_content
== expected_serialized_expectation_validation_result_rendered_atomic_content
)
<file_sep>/great_expectations/experimental/datasources/experimental_base_model.py
from __future__ import annotations
import json
import logging
import pathlib
from io import StringIO
from pprint import pformat as pf
from typing import Type, TypeVar, Union, overload
import pydantic
from ruamel.yaml import YAML
LOGGER = logging.getLogger(__name__)
yaml = YAML(typ="safe")
# NOTE (kilo59): the following settings appear to be what we use in existing codebase
yaml.indent(mapping=2, sequence=4, offset=2)
yaml.default_flow_style = False
# TODO (kilo59): replace this with `typing_extensions.Self` once mypy supports it
# Taken from this SO answer https://stackoverflow.com/a/72182814/6304433
_Self = TypeVar("_Self", bound="ExperimentalBaseModel")
class ExperimentalBaseModel(pydantic.BaseModel):
class Config:
extra = pydantic.Extra.forbid
@classmethod
def parse_yaml(cls: Type[_Self], f: Union[pathlib.Path, str]) -> _Self:
loaded = yaml.load(f)
LOGGER.debug(f"loaded from yaml ->\n{pf(loaded, depth=3)}\n")
config = cls(**loaded)
return config
@overload
def yaml(self, stream_or_path: Union[StringIO, None] = None, **yaml_kwargs) -> str:
...
@overload
def yaml(self, stream_or_path: pathlib.Path, **yaml_kwargs) -> pathlib.Path:
...
def yaml(
self, stream_or_path: Union[StringIO, pathlib.Path, None] = None, **yaml_kwargs
) -> Union[str, pathlib.Path]:
"""
Serialize the config object as yaml.
Writes to a file if a `pathlib.Path` is provided.
Else it writes to a stream and returns a yaml string.
"""
if stream_or_path is None:
stream_or_path = StringIO()
# pydantic json encoder has support for many more types
# TODO: can we dump json string directly to yaml.dump?
intermediate_json = json.loads(self.json())
yaml.dump(intermediate_json, stream=stream_or_path, **yaml_kwargs)
if isinstance(stream_or_path, pathlib.Path):
return stream_or_path
return stream_or_path.getvalue()
<file_sep>/docs/guides/connecting_to_your_data/datasource_configuration/components/_tip_which_data_connector_to_use.mdx
:::tip Reminder
If you are uncertain which Data Connector best suits your needs, please refer to our guide on [how to choose which Data Connector to use](../../how_to_choose_which_dataconnector_to_use.md).
::: | a281d09ed91914b134028c3a9f11f0beb69a9089 | [
"YAML",
"reStructuredText",
"Markdown",
"TOML",
"JavaScript",
"Python",
"Text",
"Shell"
] | 272 | Markdown | CarstenFrommhold/great_expectations | 23d61c5ed26689d6ff9cec647cc35712ad744559 | 4e67bbf43d21bc414f56d576704259a4eca283a5 |
refs/heads/master | <repo_name>Evelynww/highConcurSecKill<file_sep>/src/main/java/com/evelyn/exception/SeckillCloseException.java
package com.evelyn.exception;
import com.evelyn.pojo.Seckill;
//秒杀关闭异常:秒杀结束或超时都关闭
public class SeckillCloseException extends SeckillException{
public SeckillCloseException(String message){
super(message);
}
public SeckillCloseException(String message,Throwable cause){
super(message,cause);
}
}
<file_sep>/src/main/resources/jdbc.properties
druid.driver=com.mysql.cj.jdbc.Driver
druid.url=jdbc:mysql://localhost:3306/myseckill?zeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC
druid.username=root
druid.password=<PASSWORD>
druid.initialSize=10
druid.minIdle=6
druid.maxActive=50
druid.maxWait=60000
druid.timeBetweenEvictionRunsMillis=60000
druid.minEvictableIdleTimeMillis=300000
druid.validationQuery=SELECT 'x'
druid.testWhileIdle=true
druid.testOnBorrow=false
druid.testOnReturn=false
druid.poolPreparedStatements=false
druid.maxPoolPreparedStatementPerConnectionSize=20
druid.filters=wall,stat
<file_sep>/src/test/java/com/evelyn/dao/SuccessKilledDaoTest.java
package com.evelyn.dao;
import com.evelyn.pojo.SuccessKilled;
import com.sun.scenario.effect.impl.sw.sse.SSEBlend_SRC_OUTPeer;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import javax.annotation.Resource;
import static org.junit.Assert.*;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:spring/spring-dao.xml")
public class SuccessKilledDaoTest {
// 注入Dao实现类依赖
@Resource
private SuccessKilledDao successKilledDao;
@Test
public void insertSuccessKilled() {
int insertSuccess = successKilledDao.insertSuccessKilled(1002L, 13487390879L);
System.out.println("insertCount="+insertSuccess);
}
@Test
public void queryByIdWithSeckill() {
SuccessKilled successKilled = successKilledDao.queryByIdWithSeckill(1000L, 13487390879L);
System.out.println(successKilled);
System.out.println(successKilled.getSeckill());
}
}<file_sep>/src/main/java/com/evelyn/dao/SeckillDao.java
package com.evelyn.dao;
import com.evelyn.pojo.Seckill;
import org.apache.ibatis.annotations.Param;
import java.util.Date;
import java.util.List;
import java.util.Map;
public interface SeckillDao {
/**
* 减库存
* @param seckillId 需要减库存的id
* @param killTime 减库存的时间
* @return 如果影响行数>1,表示更新的记录行数
*/
int reduceNumber(@Param("seckillId") long seckillId, @Param("killTime") Date killTime);
/**
* 根据Id查询库存升序
* @param seckillId 商品id
* @return 当前商品的信息
*/
Seckill queryById(long seckillId);
/**
* 根据偏移量查询秒杀商品列表
* @param offset 偏移量
* @param limit 显示几条数据
* @return 参与秒杀的商品信息
*/
List<Seckill> queryAll(@Param("offset")int offset, @Param("limit")int limit);
void killByProcedure(Map<String,Object> paramMap);
}
<file_sep>/Readme.md
该项目是在Myseckill3上基础上添加高并发优化的实现
## 高并发优化分析
### 哪些模块会发生高并发
- 详情页:用户大量刷新详情页。将详情页部署到CDN上,CDN(内容分发网络)存储静态资源
- CDN:加速用户获取数据的系统
- CDN部署在离用户最近的网络节点上,用户通过运营商接口接入,去访问离它最近的城域网的地址,如果没找到,通过城域网去主干网,通过ip访问所在资源的服务器。很大一部分内容都在CDN上,不用往后找(命中CDN不需要访问后端服务器)
- 静态资源不需要访问后端服务器
- 系统时间:需要优化吗?不需要,因为访问一次内存需要的事件很短。
- 地址暴露接口:无法使用CDN缓存,因为它是动态的。但是它适合服务器缓存,如redis。
- 请求地址,先访问redis,没有才访问mysql;下一次同一用户访问就可直接获取
- redis和mysql的一致性维护
- 超时穿透: 比如缓存一段时间,一段时间超时后直接去mysql中找
- 主动更新:mysql更新时主动更新redis
- 执行秒杀操作:
- 无法使用CDN缓存,因为是写操作并且是最核心的请求。
- 后端缓存困难,如果在redis缓存的话,其它用户也可以拿到这个缓存去减库存,这就有可能导致库存卖超的问题
- 热点商品 : 一个时刻大量用户同时请求,产生竞争
### 其它方案分析
执行秒杀时,做一个原子计数器(可通过redis/nosql实现), 原子计数器记录的就是商品的库存。当用户执行秒杀的时候,它就减原子计数器。减原子计数器成功后,记录一个行为,也就是记录那个用户执行了这个操作,作为一个消息放在一个分布式的MQ(消息队列,如RabbitMQ), 后端的服务消费消息并落地,记录回mySQL.
该架构可以抗住非常高的并发。分布式的MQ可以支持几十万个qps

痛点:
减库存时,不知道用户之前有没有减库存。需要再维护一个NoSQL的访问方案。记录哪些用户减库存了

为什么不用MySQL: 会产生大量阻塞,另外还有网络延迟(mysql和tomcat服务器等交互)以及Java的垃圾回收时会停止当前的线程。
优化:
- 因为行级锁在Commit之后释放-->所以优化方向是如何减少行级锁持有时间。
- 如何判断update更新库存成功?在哭护短,要确认update本身没报错以及update影响记录数->优化方向是把客户端逻辑放到mysql服务端,同时避免网络延迟和GC影响
- 如何放呢?
- 定制SQL方案,需要修改MySQL源码,难
- 使用存储过程让整个事务在MySQL端完成。
### 优化总结
前端控制:暴露接口,按钮放重复(不能短时间重复按按钮)
动静态数据分离:CDN缓存,后端缓存
事务竞争:减少事务锁时间
## redis后端缓存优化
优化:地址暴露接口,执行秒杀接口
### redis地址暴露接口
#### 搭建Redis
安装redis并启动。
直接点击redis-server.exe或者命令都可

安装服务:`redis-server --service-install redis.windows.conf`
启动服务:`redis-server --service-start`

停止服务: `redis-server --service-stop`
切换到redis目录下运行:`redis-cli.exe -h 127.0.0.1 -p 6379`

#### 项目+Redis
引入依赖:jedis客户端
```
<!-- redis客户端:引入jedis依赖-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
```
#### 缓存优化
暴露接口:SeckillServiceImple类的exportSeckillUrl方法
```java
@Override
public Exposer exportSeckillUrl(long seckillId) {
/**
* 这一个地方可以写到这里的逻辑里面,也可以写到dao包下,因为这也是操作数据库,只不过是redis而已
* 优化点:缓存优化
* get from cache
* 如果是null get db,然后放到cache
* 不为null 走下面的logis
*/
}
```
我们写道dao里面,其下新建一个cache包,写一个RedisDao
```
public class RedisDao {
private Logger logger = Logger.getLogger(RedisDao.class);
private JedisPool jedisPool;
public RedisDao(String ip,int port){
jedisPool = new JedisPool(ip,port);
}
// 去找seckillId对应的对象
public Seckill getSeckill(long seckillId){
// redis操作逻辑
try{
// 得到连接池
Jedis jedis = jedisPool.getResource();
try{
String key = "seckill:"+seckillId;
// 需要序列化操作,对我们要获得的这个对象定义序列化功能
// get->byte[]->反序列化->Object(Seckill)
jedis.get();
}finally {
jedis.close();
}
}catch (Exception e){
logger.error(e.getMessage(),e);
}
return null;
}
// 如果没有整个对象,就要put进去
public String putSeckill(Seckill seckill){
}
}
```
序列化声明
```
public class Seckill implements Serializable {
}
```
```
//采用自定义序列化,将对象转化成字节数组,传给redis进行缓存。
```
pom引入依赖才能自己去写序列化
```
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.1.1</version>
</dependency>
```
```
public class RedisDao {
private Logger logger = Logger.getLogger(RedisDao.class);
private JedisPool jedisPool;
public RedisDao(String ip,int port){
jedisPool = new JedisPool(ip,port);
}
//基于class做一个模式
private RuntimeSchema<Seckill> schema = RuntimeSchema.createFrom(Seckill.class);
// 去找seckillId对应的对象
public Seckill getSeckill(long seckillId){
// redis操作逻辑
try{
// 得到连接池
Jedis jedis = jedisPool.getResource();
try{
String key = "seckill:"+seckillId;
// 并没有内部序列化操作
// get获得byte[]->反序列化->Object(Seckill)
//采用自定义序列化,将对象转化成二进制数组,传给redis进行缓存。
//protostuff:pojo
//把字节数组转化成pojo
byte[] bytes = jedis.get(key.getBytes());
if(bytes!=null){
Seckill seckill = schema.newMessage();
//调用这句话之后seckill就已经被复赋值了
ProtostuffIOUtil.mergeFrom(bytes,seckill,schema);
return seckill;
}
}finally {
jedis.close();
}
}catch (Exception e){
logger.error(e.getMessage(),e);
}
return null;
}
// 如果没有整个对象,就要put进去
public String putSeckill(Seckill seckill){
//Object转化成字节数组
try {
Jedis jedis = jedisPool.getResource();
try {
String key = "seckill:"+seckill.getSeckillId();
byte[] bytes = ProtostuffIOUtil.toByteArray(seckill, schema, LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE));
// 超时缓存
int timeout = 60*60;//1小时
String result = jedis.setex(key.getBytes(), timeout, bytes);
return result;
}finally {
jedis.close();
}
}catch (Exception e){
logger.error(e.getMessage(),e);
}
return null;
}
```
测试:
去spring-dao.xml注入Redis
```xml
<!-- RedisDao-->
<bean id="redisDao" class="com.evelyn.dao.cache.RedisDao">
<constructor-arg index="0" value="localhost"/>
<constructor-arg index="1" value="6379"/>
</bean>
```
```java
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration({"classpath:spring/spring-dao.xml"})
public class RedisDaoTest {
private long id = 1001;
@Autowired
private RedisDao redisDao;
@Autowired
private SeckillDao seckillDao;
@Test
public void getSeckill() throws Exception {
Seckill seckill = redisDao.getSeckill(id);
if (seckill == null) {
seckill = seckillDao.queryById(id);
if (seckill != null) {
String s = redisDao.putSeckill(seckill);
System.out.println(s);
seckill = redisDao.getSeckill(id);
System.out.println(seckill);
}
}
}
@Test
public void putSeckill() {
}
}
```

然后去到我们要优化的那个接口的类,注入RedisDao对象
找到优化的点,加入redis这个内容
```
public Exposer exportSeckillUrl(long seckillId) {
//优化点:缓存优化,建立在超时的基础上维护一致性。降低对数据库的直接访问量
//1、当线程将id传入方法时,需要先访问redis
Seckill seckill = redisDao.getSeckill(seckillId);
if(seckill==null) {
//2、没有在redis里面找到就访问数据库
seckill = seckillDao.queryById(seckillId);
//数据库里也没有,返回不暴露接口
if(seckill==null){
return new Exposer(false,seckillId);
}else{
//数据库中找到了,要把当前查找到的对象放到redis里面
redisDao.putSeckill(seckill);
}
}
```
#### 深度优化
事务在MySQL端执行(存储过程)
网络延迟或者客户端上的延迟对于mysql行级锁上的高并发竞争事务来说是性能杀手,要降低行级锁到commit这个过程的时间,让MySql获得更多的qps.
使用存储过程!
```
-- 存储过程
-- 1、存储过程优化:事务行级锁持有的时间
-- 2、不要过度依赖存储过程
-- 3、简单的逻辑可以应用存储过程
```
定义一个存储过程
```Java
-- 秒杀执行存储过程
DELIMITER $$ -- console ;转换为
-- 定义存储参数
-- 参数:in 输入参数;out输出参数
-- rowCount():返回上一条修改类型sql(delete,insert,update)的影响行数
-- rowCount: 0:未修改数据 >0:表示修改的行数 <0:sql错误/未执行修改sql
CREATE PROCEDURE executeSeckill(IN fadeSeckillId INT,IN fadeUserPhone VARCHAR (15),IN fadeKillTime TIMESTAMP ,OUT fadeResult INT)
BEGIN
DECLARE insert_count INT DEFAULT 0;
START TRANSACTION ;
INSERT ignore myseckill.success_killed(seckill_id,user_phone,state,create_time) VALUES(fadeSeckillId,fadeUserPhone,0,fadeKillTime); -- 先插入购买明细
SELECT ROW_COUNT() INTO insert_count;
IF(insert_count = 0) THEN
ROLLBACK ;
SET fadeResult = -1; -- 重复秒杀
ELSEIF(insert_count < 0) THEN
ROLLBACK ;
SET fadeResult = -2; -- 内部错误
ELSE -- 已经插入购买明细,接下来要减少库存
UPDATE myseckill.seckill SET number = number -1 WHERE seckill_id = fadeSeckillId AND start_time < fadeKillTime AND end_time > fadeKillTime AND number > 0;
SELECT ROW_COUNT() INTO insert_count;
IF (insert_count = 0) THEN
ROLLBACK ;
SET fadeResult = 0; -- 库存没有了,代表秒杀已经关闭
ELSEIF (insert_count < 0) THEN
ROLLBACK ;
SET fadeResult = -2; -- 内部错误
ELSE
COMMIT ; -- 秒杀成功,事务提交
SET fadeResult = 1; -- 秒杀成功返回值为1
END IF;
END IF;
END
$$
DELIMITER ;
SET @fadeResult = -3;
-- 执行存储过程
CALL executeSeckill(1001,13458938588,NOW(),@fadeResult);
-- 获取结果
SELECT @fadeResult;
```
Service接口中加一个方法并实现
```Java
/**
* 通过存储过程执行秒杀操作
* @param seckillId 秒杀商品id
* @param userPhone 用户手机号,这里是作为用户id的作用
* @param md5 加密后的秒杀商品id,用于生成链接。
*/
SeckillExecution excuteSeckillByProcedure(long seckillId, long userPhone, String md5);
```
SeckillDao加一个操作数据库的方法,调用存储过程
```
void killByProcedure(Map<String,Object> paramMap);
```
```
!-- mybatis调用存储过程-->
<select id="killByProcedure" statementType="CALLABLE">
call executeSeckill(
#{seckillId,jdbcType=BIGINT,mode=IN},
#{phone,jdbcType=BIGINT,mode=IN},
#{killTime,jdbcType=TIMESTAMP,mode=IN},
#{result,jdbcType=INTEGER,mode=OUT}
)
</select>
```
测试
```java
@Test
public void excuteSeckillByProcedure() {
long id = 1001;
Exposer exposer = seckillService.exportSeckillUrl(id);
if (exposer.isExposed()) {
logger.info("exposer: " + exposer);
String md5 = exposer.getMd5();
long phone = 13458938588L;
SeckillExecution seckillExecution = seckillService.excuteSeckillByProcedure(id, phone, md5);
logger.info(seckillExecution.getStateInfo());
}
}
```
controller下也同步修改调用方法。
## 部署
系统用到的服务:
CDN
webserver:Nginx+Tomcat/Jetty
Redis:热点数据快速存储
Mysql事务:一致性
### 大型系统部署架构是怎样的?
1、一部分流量被CDN拦截。
2、不适合放到CDN缓存中的请求放到自己的服务器。DNS查找Nginx服务器,Nginx部署到不同的机房,智能DNS通过用户请求的IP作地址解析请求最近的Nginx服务器。同时Nginx服务器可以帮servlet作负载均衡。逻辑机器存放代码。逻辑集群要使用缓存级群。
如果项目非常庞大,会按照关键的id(秒杀id)分库分表。
3、统计分析<file_sep>/src/main/java/com/evelyn/controller/SeckillController.java
package com.evelyn.controller;
import com.evelyn.dto.Exposer;
import com.evelyn.dto.SeckillExecution;
import com.evelyn.dto.SeckillResult;
import com.evelyn.enums.SeckillStateEnum;
import com.evelyn.exception.RepeatKillException;
import com.evelyn.exception.SeckillCloseException;
import com.evelyn.pojo.Seckill;
import com.evelyn.service.SeckillService;
import org.apache.log4j.Logger;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.*;
import java.util.Date;
import java.util.List;
@Controller //@Service @Component
@RequestMapping("/seckill") //url:/模块/资源/{id}/细分/seckill/list
public class SeckillController {
//日志
private final Logger logger = Logger.getLogger(SeckillController.class);
//注入service对象
@Autowired
private SeckillService seckillService;
// 指定二级url,以及请求模式
@RequestMapping(value = "/list",method = RequestMethod.GET)
public String list(Model model){
// 获取列表页
//list.jsp+model=ModelAndView
List<Seckill> seckillList = seckillService.getSeckillList();
model.addAttribute("list",seckillList);
return "list";// /WEB-INF/jsp/"list".jsp
}
//通过Url获取相关内容,传入函数,再返回。
@RequestMapping(value = "/{seckillId}/detail",method = RequestMethod.GET)
public String detail(@PathVariable("seckillId") Long seckillId,Model model){
if(seckillId==null){
return "redirect:/seckill/list";
}
Seckill seckill = seckillService.getById(seckillId);
if(seckill==null){
return "forward:/seckill/list";
}
model.addAttribute("seckill",seckill);
return "detail";
}
// ajax jason输出秒杀地址
//POST的意思是你直接在浏览器敲入这个地址是无效的
//produce乱码问题解决
@RequestMapping(value = "/{seckillId}/exposer",
method = RequestMethod.POST,
produces = {"application/json;charset=UTF-8"})
@ResponseBody //封装成json
public SeckillResult exposer(@PathVariable Long seckillId){
SeckillResult<Exposer> result;
try {
Exposer exposer = seckillService.exportSeckillUrl(seckillId);
result = new SeckillResult<Exposer>(true, exposer);
}catch (Exception e){
logger.error(e.getMessage(),e);
result = new SeckillResult<>(false,e.getMessage());
}
return result;
}
// 执行秒杀
//这里phone是因为我们没做登录模块,后面可以把登录模块加上,然后是从cookie获取的
//@CookieValue(value = "killPhone",required = false) 这里的false指的是如果没有该字段,不会报错,而是在程序中再处理
// @RequestMapping(value = "/{seckillId}/{md5}/execution",
// method = RequestMethod.POST,
// produces = {"application/json;charset=UTF-8"})
// @ResponseBody
// public SeckillResult<SeckillExecution> execute(@PathVariable("seckillId") Long seckillId,
// @PathVariable("md5") String md5,
// @CookieValue(value = "killPhone",required = false) Long phone){
// SeckillResult<SeckillExecution> result;
//// springmvc valid方式可以去了解一下
// if(phone==null){
// return new SeckillResult<>(false,"未注册");
// }
// try {
// //执行秒杀,返回结果
// SeckillExecution seckillExecution = seckillService.excuteSeckill(seckillId, phone, md5);
// return new SeckillResult<>(true, seckillExecution);
// }catch (RepeatKillException e1){
// //如果捕捉到重复秒杀异常,返回对应的错误
// logger.error(e1.getMessage(),e1);
// SeckillExecution seckillExecution = new SeckillExecution(seckillId, SeckillStateEnum.REPEAT_KILL);
// return new SeckillResult<>(true, seckillExecution);
// }catch (SeckillCloseException e2){
// logger.error(e2.getMessage(),e2);
// SeckillExecution seckillExecution = new SeckillExecution(seckillId, SeckillStateEnum.END);
// return new SeckillResult<>(true, seckillExecution);
// } catch (Exception e){
// logger.error(e.getMessage(),e);
// SeckillExecution seckillExecution = new SeckillExecution(seckillId, SeckillStateEnum.INNER_ERROR);
// return new SeckillResult<>(true, seckillExecution);
// }
// }
@RequestMapping(value = "/time/now",method = RequestMethod.GET)
@ResponseBody
public SeckillResult<Long> time(){
Date now = new Date();
return new SeckillResult(true,now.getTime());
}
// 通过存储过程
@RequestMapping(value = "/{seckillId}/{md5}/execution",
method = RequestMethod.POST,
produces = {"application/json;charset=UTF-8"})
@ResponseBody
public SeckillResult<SeckillExecution> executeByProcedure(@PathVariable("seckillId") Long seckillId,
@PathVariable("md5") String md5,
@CookieValue(value = "killPhone",required = false) Long phone){
SeckillResult<SeckillExecution> result;
// springmvc valid方式可以去了解一下
if(phone==null){
return new SeckillResult<>(false,"未注册");
}
try {
//执行秒杀,返回结果
SeckillExecution seckillExecution = seckillService.excuteSeckillByProcedure(seckillId, phone, md5);
return new SeckillResult<>(true, seckillExecution);
}catch (RepeatKillException e1){
//如果捕捉到重复秒杀异常,返回对应的错误
logger.error(e1.getMessage(),e1);
SeckillExecution seckillExecution = new SeckillExecution(seckillId, SeckillStateEnum.REPEAT_KILL);
return new SeckillResult<>(true, seckillExecution);
}catch (SeckillCloseException e2){
logger.error(e2.getMessage(),e2);
SeckillExecution seckillExecution = new SeckillExecution(seckillId, SeckillStateEnum.END);
return new SeckillResult<>(true, seckillExecution);
} catch (Exception e){
logger.error(e.getMessage(),e);
SeckillExecution seckillExecution = new SeckillExecution(seckillId, SeckillStateEnum.INNER_ERROR);
return new SeckillResult<>(true, seckillExecution);
}
}
}
<file_sep>/src/main/sql/seckill.sql
-- 秒杀执行存储过程
DELIMITER $$ -- console ;转换为
-- 定义存储参数
-- 参数:in 输入参数;out输出参数
-- rowCount():返回上一条修改类型sql(delete,insert,update)的影响行数
-- rowCount: 0:未修改数据 >0:表示修改的行数 <0:sql错误/未执行修改sql
CREATE PROCEDURE executeSeckill(IN fadeSeckillId INT,IN fadeUserPhone VARCHAR (15),IN fadeKillTime TIMESTAMP ,OUT fadeResult INT)
BEGIN
DECLARE insert_count INT DEFAULT 0;
START TRANSACTION ;
INSERT ignore myseckill.success_killed(seckill_id,user_phone,state,create_time) VALUES(fadeSeckillId,fadeUserPhone,0,fadeKillTime); -- 先插入购买明细
SELECT ROW_COUNT() INTO insert_count;
IF(insert_count = 0) THEN
ROLLBACK ;
SET fadeResult = -1; -- 重复秒杀
ELSEIF(insert_count < 0) THEN
ROLLBACK ;
SET fadeResult = -2; -- 内部错误
ELSE -- 已经插入购买明细,接下来要减少库存
UPDATE myseckill.seckill SET number = number -1 WHERE seckill_id = fadeSeckillId AND start_time < fadeKillTime AND end_time > fadeKillTime AND number > 0;
SELECT ROW_COUNT() INTO insert_count;
IF (insert_count = 0) THEN
ROLLBACK ;
SET fadeResult = 0; -- 库存没有了,代表秒杀已经关闭
ELSEIF (insert_count < 0) THEN
ROLLBACK ;
SET fadeResult = -2; -- 内部错误
ELSE
COMMIT ; -- 秒杀成功,事务提交
SET fadeResult = 1; -- 秒杀成功返回值为1
END IF;
END IF;
END
$$
DELIMITER ;
SET @fadeResult = -3;
-- 执行存储过程
CALL executeSeckill(1001,13458938588,NOW(),@fadeResult);
-- 获取结果
SELECT @fadeResult;
<file_sep>/src/main/java/com/evelyn/service/serviceImpl/SeckillServiceImpl.java
package com.evelyn.service.serviceImpl;
import com.evelyn.dao.SeckillDao;
import com.evelyn.dao.SuccessKilledDao;
import com.evelyn.dao.cache.RedisDao;
import com.evelyn.dto.Exposer;
import com.evelyn.dto.SeckillExecution;
import com.evelyn.enums.SeckillStateEnum;
import com.evelyn.exception.RepeatKillException;
import com.evelyn.exception.SeckillCloseException;
import com.evelyn.exception.SeckillException;
import com.evelyn.pojo.Seckill;
import com.evelyn.pojo.SuccessKilled;
import com.evelyn.service.SeckillService;
import org.apache.commons.collections.MapUtils;
import org.apache.ibatis.util.MapUtil;
import org.apache.log4j.Logger;
import org.mybatis.logging.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.util.DigestUtils;
import javax.annotation.Resource;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @Component:不知道是什么,就用这个
* @Service :服务
* @Dao
* @Controller
*/
@Service
public class SeckillServiceImpl implements SeckillService {
//日志
private Logger logger = Logger.getLogger(SeckillServiceImpl.class);
//加盐,为了加密,混淆md5,随便写
private final String salt="addjidjigjeijgeoejei8eur8u8&#$$(@)";
//对象
// 注入Service依赖 @Service,@Resource等
@Autowired
private SeckillDao seckillDao;
@Autowired
private SuccessKilledDao successKilledDao;
@Autowired
private RedisDao redisDao;
private String getMD5(long seckillId){
String base = seckillId+"/"+salt;
String md5 = DigestUtils.md5DigestAsHex(base.getBytes());
return md5;
}
/**
* 查询所有秒杀记录
* @return 所有秒杀商品
*/
@Override
public List<Seckill> getSeckillList() {
return seckillDao.queryAll(0, 100);
}
/**
* 查询单个商品
*
* @param seckillId
* @return
*/
@Override
public Seckill getById(long seckillId) {
return seckillDao.queryById(seckillId);
}
/**
* 秒杀开启时输出秒杀接口地址,否则输出系统时间和秒杀时间
* 意思就是秒杀还没开始的时候是没有地址的
*
* @param seckillId
*/
@Override
public Exposer exportSeckillUrl(long seckillId) {
//优化点:缓存优化,建立在超时的基础上维护一致性。降低对数据库的直接访问量
//1、当线程将id传入方法时,需要先访问redis
Seckill seckill = redisDao.getSeckill(seckillId);
if(seckill==null) {
//2、没有在redis里面找到就访问数据库
seckill = seckillDao.queryById(seckillId);
//数据库里也没有,返回不暴露接口
if(seckill==null){
return new Exposer(false,seckillId);
}else{
//数据库中找到了,要把当前查找到的对象放到redis里面
redisDao.putSeckill(seckill);
}
}
Date startTime = seckill.getStartTime();
Date endTime = seckill.getEndTime();
// 系统时间
Date nowTime = new Date();
if(startTime.getTime()>nowTime.getTime()||endTime.getTime()<nowTime.getTime()){
return new Exposer(false,seckillId,nowTime.getTime(),startTime.getTime(),endTime.getTime());
}
//转化特定字符串的过程,不可逆,就算把这个转化后的结果显示给用户,用户也猜不出来到底是啥
String md5=getMD5(seckillId);
return new Exposer(true,md5,seckillId);
}
/**
* 执行秒杀操作
*
* @param seckillId
* @param userPhone
* @param md5
*/
@Transactional
/**
* 使用注解控制事务方法的优点:
* 1、开发团队达成一致约定,明确标注事务方法的编程风格
* 2、保证事务方法的执行时间尽可能短,不要穿插其它网络操作,RFC/HTTP请求剥离到事务方法外部
* 3、不是所有方法都需要事务,如只有一条修改操作,只读操作不需要事务控制
*/
@Override
public SeckillExecution excuteSeckill(long seckillId, long userPhone, String md5) throws SeckillException, RepeatKillException, SeckillException {
if(md5==null){
throw new SeckillCloseException("没有拿到md5");
}
if(!md5.equalsIgnoreCase(getMD5(seckillId))){
throw new SeckillCloseException("seckill data rewrite");
}
//执行秒杀逻辑:减库存+记录购买行为
Date nowTime = new Date();
try {
//否则更新了库存,秒杀成功,增加明细
int insertCount = successKilledDao.insertSuccessKilled(seckillId, userPhone);
//看是否该明细被重复插入,即用户是否重复秒杀
if (insertCount <= 0) {
throw new RepeatKillException("seckill repeated");
} else {
//减库存,热点商品竞争
int updateCount = seckillDao.reduceNumber(seckillId, nowTime);
if (updateCount <= 0) {
//没有更新库存记录,说明秒杀结束 rollback
throw new SeckillCloseException("seckill is closed");
} else {
//秒杀成功,得到成功插入的明细记录,并返回成功秒杀的信息 commit
SuccessKilled successKilled = successKilledDao.queryByIdWithSeckill(seckillId, userPhone);
return new SeckillExecution(seckillId, SeckillStateEnum.SUCCESS, successKilled);
}
}
}catch (SeckillCloseException e1){
throw e1;
}catch (RepeatKillException e2){
throw e2;
} catch (Exception e){
//所有编译期异常转化为运行期异常
throw new SeckillException("seckill inner error"+e.getMessage());
}
}
/**
* 通过存储过程执行秒杀操作
*
* @param seckillId 秒杀商品id
* @param userPhone 用户手机号,这里是作为用户id的作用
* @param md5 加密后的秒杀商品id,用于生成链接。
*/
@Override
public SeckillExecution excuteSeckillByProcedure(long seckillId, long userPhone, String md5) {
if(md5==null||!md5.equalsIgnoreCase(getMD5(seckillId))){
return new SeckillExecution(seckillId,SeckillStateEnum.DATA_REWRITE);
}
Date nowTime = new Date();
Map<String,Object> map = new HashMap<String,Object>();
map.put("seckillId", seckillId);
map.put("phone", userPhone);
map.put("killTime", nowTime);
map.put("result",null);
//执行存储过程,result被赋值
try {
seckillDao.killByProcedure(map);
//获取result
int result = MapUtils.getInteger(map,"result",-2);
if(result==1){
SuccessKilled sk = successKilledDao.queryByIdWithSeckill(seckillId,userPhone);
return new SeckillExecution(seckillId, SeckillStateEnum.SUCCESS);
}else {
return new SeckillExecution(seckillId, SeckillStateEnum.stateOf(result));
}
}catch (Exception e){
logger.error(e.getMessage(),e);
return new SeckillExecution(seckillId,SeckillStateEnum.INNER_ERROR);
}
}
}
<file_sep>/src/test/java/com/evelyn/service/SeckillServiceTest.java
package com.evelyn.service;
import com.evelyn.dto.Exposer;
import com.evelyn.dto.SeckillExecution;
import com.evelyn.exception.RepeatKillException;
import com.evelyn.exception.SeckillCloseException;
import com.evelyn.pojo.Seckill;
import javafx.scene.effect.Bloom;
import org.apache.log4j.Logger;
import org.apache.log4j.spi.LoggerFactory;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.List;
import static org.junit.Assert.*;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration({
"classpath:spring/spring-service.xml",
"classpath:spring/spring-dao.xml"})
public class SeckillServiceTest {
private Logger logger = Logger.getLogger(SeckillServiceTest.class);
@Autowired
private SeckillService seckillService;
@Test
public void getSeckillList() {
List<Seckill> seckillList = seckillService.getSeckillList();
// for(Seckill seckill:seckillList){
// System.out.println(seckillList);
// }
/**
* [Seckill
* {seckillId=1000,name='1000元秒杀iphone6',number=89,startTime=Thu Sep 16 08:00:00 CST 2021,
* endTime=Fri Sep 24 08:00:00 CST 2021,createTime=Mon Sep 13 05:58:58 CST 2021},
* Seckill{seckillId=1001,name='500元秒杀iPad2',number=198, startTime=Wed Sep 08 08:00:00 CST 2021,
* endTime=Thu Sep 23 08:00:00 CST 2021, createTime=Mon Sep 13 05:58:58 CST 2021},
* Seckill{seckillId=1002, name='300元秒杀小米4', number=300, startTime=Sun May 22 08:00:00 CST 2016,
* endTime=Thu May 23 08:00:00 CST 2019, createTime=Mon Sep 13 05:58:58 CST 2021},
* Seckill{seckillId=1003, name='200元秒杀红米note', number=400, startTime=Sun May 22 08:00:00 CST 2016,
* endTime=Mon May 23 08:00:00 CST 2016, createTime=Mon Sep 13 05:58:58 CST 2021}]
*/
logger.info("seckillList ");
System.out.println(seckillList);
}
@Test
public void getById() {
Seckill seckill = seckillService.getById(1000L);
/**
* seckill Seckill{seckillId=1000, name='1000元秒杀iphone6', number=89, startTime=Thu Sep 16 08:00:00 CST 2021,
* endTime=Fri Sep 24 08:00:00 CST 2021, createTime=Mon Sep 13 05:58:58 CST 2021}
*/
logger.info("seckill "+seckill);
}
//测试代码完整逻辑,注意重复秒杀可能的问题
@Test
public void testSeckillLogic() throws Exception{
long id = 1001;
Exposer exposer = seckillService.exportSeckillUrl(id);
if(exposer.isExposed()){
logger.info("exposer: "+exposer);
long phone = 13458938588L;
String md5 = exposer.getMd5();
try {
SeckillExecution seckillExecution = seckillService.excuteSeckill(id, phone, md5);
System.out.println("输出输出");
System.out.println(seckillExecution);
}catch (RepeatKillException e1){
logger.error(e1.getMessage());
System.out.println("重复了吗");
}catch (SeckillCloseException e2){
logger.error(e2.getMessage());
System.out.println("关闭");
}catch (Exception e){
logger.error(e.getMessage());
}
}else{
//秒杀未开启
logger.warn("exposer:"+exposer);
}
}
@Test
public void excuteSeckillByProcedure() {
long id = 1001;
Exposer exposer = seckillService.exportSeckillUrl(id);
if (exposer.isExposed()) {
logger.info("exposer: " + exposer);
String md5 = exposer.getMd5();
long phone = 13458938588L;
SeckillExecution seckillExecution = seckillService.excuteSeckillByProcedure(id, phone, md5);
logger.info(seckillExecution.getStateInfo());
}
}
} | bc2a9b8c261ff1fbfc789f90cd818757f09f7688 | [
"Markdown",
"Java",
"SQL",
"INI"
] | 9 | Java | Evelynww/highConcurSecKill | e6ddcd19e3906aee6b70b74c26830e9966ed0f69 | 4739ac0cdf9e93f66bdee37203080b4b3171f3f4 |
refs/heads/master | <repo_name>BernardWong97/Angular<file_sep>/Lab 5/observables-app/src/app/app.component.html
<h1>Students</h1>
<ol>
<li *ngFor="let s of students">
<p>{{s.id}}, {{s.name}}, {{s.address}}</p>
</li>
</ol>
<h1>Weather in Galway</h1>
<table border="1">
<tr>
<td>Time</td>
<td>Description</td>
</tr>
<tr *ngFor="let key of keys">
<td>{{list[key].dt_txt}}</td>
<td>{{list[key].weather[0].description}}</td>
</tr>
</table><file_sep>/Lab 3/data-binding-app/src/app/app.component.ts
import { Component } from '@angular/core';
import { disableDebugTools } from '@angular/platform-browser/src/browser/tools/tools';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent {
numPressed: number = 0;
displayMessage: boolean = true;
message: string;
incNumPressed(){
this.numPressed++;
} // incNumPressed()
showMessage(){
this.message = "Look at the star";
if(this.displayMessage) {
this.displayMessage = false;
}
else{
this.displayMessage = true;
} // if..else displayMessage
} // showMessage()
} // class AppComponent
<file_sep>/Lab 4/simple-service-app/src/app/half-number.service.ts
import { Injectable } from '@angular/core';
@Injectable()
export class HalfNumberService {
constructor() { }
getHalf(input: number): number {
return input/2;
}
}
| 964972137b85069bf2193570c50d00bfb13f8f17 | [
"TypeScript",
"HTML"
] | 3 | HTML | BernardWong97/Angular | 7d123f7c17ca841b8b9aa5b4a9aeeca745b0f8cf | f442560c1dbb50605bc87616dc3096ea97249943 |
refs/heads/master | <file_sep>require "test_helper"
class FooTest < ActiveSupport::TestCase
test "Current keeps value" do
Current.foo = "bar"
assert_equal Current.foo, "bar"
end
test "Current keeps value when job is queued now" do
Current.foo = "bar"
FooJob.perform_now
assert_equal Current.foo, "bar"
end
test "Current keeps value when job is queued later" do
Current.foo = "bar"
FooJob.perform_later
assert_equal Current.foo, "bar"
end
end
<file_sep># Test for CurrentAttributes
Current gets cleared when a job is enqueued to perform later
<file_sep>class FooJob < ApplicationJob
def perform
end
end
<file_sep>class Current < ActiveSupport::CurrentAttributes
attribute :foo
end
| c751fe87d34ba36cc979c78300d0d61727cedc32 | [
"Markdown",
"Ruby"
] | 4 | Ruby | tomprats/current-attributes-test | e829aa0cb236e3086d405d45e9483474800c8fe3 | 8a2dbb62e1ff7ce3e9238428bf50cf3265daf1f7 |
refs/heads/master | <repo_name>Mamata24/Backend_Task<file_sep>/routes/stateRoute.js
const stateController = require('../controllers/stateController')
const router = require('express').Router();
const auth = require('../middleware/auth')
router.post('/add', auth, stateController.addState);
router.post('/get', auth, stateController.getState);
router.post('/getAll', stateController.getAllState);
module.exports = router<file_sep>/index.js
const express = require('express')
const dotenv = require('dotenv')
const userRouter = require('./routes/userRoute')
const stateRouter = require('./routes/stateRoute')
const districtRouter = require('./routes/districtRoute')
const childRouter = require('./routes/childRoute')
dotenv.config();
require('./db/mongoose')
//Setting up express and port number for both local and heroku app
const app = express()
const port = process.env.PORT || 3000
//To recognize the incoming object body as a json object
app.use(express.json())
//Setting up the router
app.use('/user', userRouter)
app.use('/state', stateRouter)
app.use('/district', districtRouter)
app.use('/child', childRouter)
//Server setup
app.listen(port, () => {
console.log(`The server is running at port ${port}`)
})
<file_sep>/routes/districtRoute.js
const districtController = require('../controllers/districtController')
const router = require('express').Router();
const auth = require('../middleware/auth')
router.post('/add', auth, districtController.addDistrict);
router.post('/get', auth, districtController.getDistrict);
router.post('/getAll', districtController.getAllDistrict);
module.exports = router | c2707c714a2c2546fad7483dca98b52a83255426 | [
"JavaScript"
] | 3 | JavaScript | Mamata24/Backend_Task | b7a0e527d2435258ffb5862485a5595b41cef1ed | 15c8ef20e0ea990ccbc459f9cc212ec42ba1fab7 |
refs/heads/main | <repo_name>korysergey55/goit-react-hw-09-feedback<file_sep>/src/components/feedback/feetbackOptoons/FeedbackOptionsStyled.js
import styled from "styled-components";
export const FeedbackContainer = styled.div`
.good {
margin-right: 20px;
padding: 10px;
border-radius: 14px;
background-color: #21cc21;
:hover {
background-color: black;
color: white;
}
}
.neutral {
margin-right: 20px;
padding: 10px;
border-radius: 14px;
background-color: #fcff2f;
:hover {
background-color: black;
color: white;
}
}
.bad {
margin-right: 20px;
padding: 10px;
border-radius: 14px;
background-color: #fc4141;
:hover {
background-color: black;
color: white;
}
}
`;
<file_sep>/src/components/feedback/section/Section.js
import React from "react";
import {SectionContainer} from "./SectionStyled";
import PropTypes from "prop-types";
const Section = ({ children, title }) => {
return (
<SectionContainer>
<h2 className="title">{title}</h2>
{children}
</SectionContainer>
);
};
Section.prototype = {
title: PropTypes.string,
children: PropTypes.node.isRequired,
};
export default Section;
<file_sep>/src/components/feedback/notification/NotificationStyled.js
import styled from "styled-components";
export const NotificationContainer = styled.div`
color: red;
font-size: 20px;
font-weight: 700;
`;<file_sep>/src/components/feedback/feetbackOptoons/FeedbackOptions.js
import React from "react";
import { FeedbackContainer } from "./FeedbackOptionsStyled";
import PropTypes, { arrayOf, string } from "prop-types";
const FeedbackOptions = ({ state, onLeaveFeedback }) => {
const submitFeedback = (event) => onLeaveFeedback(event.target.name);
return (
<FeedbackContainer>
{state.map((option) => (
<button
key={option}
type="button"
name={option}
className={option}
onClick={submitFeedback}
>
{option.toUpperCase()}
</button>
))}
</FeedbackContainer>
);
};
FeedbackOptions.prototype = {
state: arrayOf(PropTypes.arrayOf(string)).isRequired,
onLeaveFeedback: PropTypes.func.isRequired,
};
export default FeedbackOptions;
<file_sep>/src/components/feedback/section/SectionStyled.js
import styled from "styled-components";
export const SectionContainer = styled.section`
font-size: 20px;
margin-left: 30px;
margin-bottom: 20px;
.title {
font-size: 35px;
}
`;
| 900b3da29710feb19e0df52c6e199a28c7d7062f | [
"JavaScript"
] | 5 | JavaScript | korysergey55/goit-react-hw-09-feedback | 4d584f7c6431d6280b387ba13afcbe763d107cf4 | 56b5c8bb460f447dd908af52f9587af653a3207d |
refs/heads/master | <file_sep>#!/bin/bash -e
chown -R jenkins:nogroup /var/lib/jenkins
/etc/init.d/jenkins restart
sleep 15
<file_sep>#!/usr/bin/python
import fileinput
import os
import shutil
import subprocess
from ConfigParser import RawConfigParser as Cfg
from urllib import urlretrieve
def get_plugins(config):
server = config.get("sources", "server")
path = config.get("sources", "path")
sections = config.sections()
plugins = {}
for section in sections:
if section.startswith("plugin:"):
name = section.partition(":")[2]
version = config.get(section, "version")
data = {'name': name, 'version': version}
data['url'] = server + path % data
data['filename'] = name + '.hpi'
plugins[name] = data
return plugins
def download_plugins(plugins, workarea):
for plugin, data in plugins.iteritems():
outpath = os.path.join(workarea, data['filename'])
print "Retrieving %(name)s from %(url)s..." % data
urlretrieve(data['url'], outpath)
print "Done."
def dhmake(buildarea, copyright):
cmd = ["dh_make", "-n", "-c", copyright, "-s"]
env = os.environ.copy()
env["PWD"] = buildarea
dhm = subprocess.Popen(cmd, cwd=buildarea, env=env)
dhm.communicate("\n")
if dhm.returncode:
raise RuntimeError("dh_make failed", dhm)
def clear_cruft(debarea):
for fname in os.listdir(debarea):
if (fname.startswith("README.") or
fname.endswith(".ex") or
fname.endswith(".EX")):
remove = os.path.join(debarea, fname)
print "Clearing cruft:", remove
os.remove(remove)
def fix_control(debarea, description):
for line in fileinput.input(os.path.join(debarea, 'control'), inplace=1):
if line.startswith("Section:"):
print "Section: misc"
elif line.startswith("Homepage:") or line.startswith("#"):
continue
elif line.startswith("Description:"):
print "Description:", description
print ""
fileinput.close()
break
else:
print line,
def fix_changelog(debarea, series):
for line in fileinput.input(os.path.join(debarea, 'changelog'), inplace=1):
line = line.replace("unstable", series)
print line,
def add_inst_files(srcdir, debarea):
for fname in os.listdir(srcdir):
fpath = os.path.join(srcdir, fname)
shutil.copy(fpath, debarea)
def build_binary(buildarea):
cmd = ["debuild", "-b"]
subprocess.check_call(cmd, cwd=buildarea)
def build_source(buildarea):
cmd = ["debuild", "-S", "-sa"]
subprocess.check_call(cmd, cwd=buildarea)
def dput_source(basedir, changes):
do_pub = raw_input("Publish [y/n]? ")
if do_pub.lower() != "y":
return
ppa = raw_input("PPA [ppa:kemitche/l2cs-ppa]: ") or "ppa:kemitche/l2cs-ppa"
cmd = ["dput", ppa, changes]
subprocess.check_call(cmd, cwd=basedir)
def main():
assert os.environ['DEBEMAIL']
config = Cfg()
config.read("build.cfg")
basedir = os.getcwd()
package = config.get("package", "name")
version = config.get("package", "version")
copyright = config.get("package", "copyright")
series = config.get("package", "series")
description = config.get("package", "description")
changes = "%s_%s.0_source.changes" % (package, version)
buildarea = os.path.join(basedir, "%s-%s.0" % (package, version))
debarea = os.path.join(buildarea, "debian")
workarea = os.path.join(buildarea, package)
srcdir = os.path.join(basedir, "src")
print "Building %s (%s) in %s" % (package, version, buildarea)
plugins = get_plugins(config)
print "Creating package with plugins:"
for name in plugins:
print name
print ""
os.makedirs(workarea)
download_plugins(plugins, workarea)
dhmake(buildarea, copyright)
clear_cruft(debarea)
fix_control(debarea, description)
fix_changelog(debarea, series)
add_inst_files(srcdir, debarea)
build_binary(buildarea)
build_source(buildarea)
dput_source(basedir, changes)
if __name__ == '__main__':
main()
| 2be362b489780a5c68089b7a8675d3b8d63e7559 | [
"Python",
"Shell"
] | 2 | Shell | kemitche/reddit-jenkins-plugins | 746a30badd004b366b3d67fffb180477b0894d49 | cb75ed220b5b3a7cc440b4c68edfd740b28cc507 |
refs/heads/master | <repo_name>jeremiahlukus/JsGames<file_sep>/ColorGuess/colorgame.js
var colors = generateRandomColors(6);
var pickedColor = pickColor();
var squares = document.querySelectorAll(".square");
var colorDisplay = document.getElementById("colorDisplay");
var messageDisplay = document.querySelector("#message");
var h1 = document.querySelector("h1");
var resetButton = document.querySelector("#reset");
var easyBtn = document.querySelector("#easyBtn");
var hardBtn = document.querySelector("#hardBtn");
var flag = true;
colorDisplay.textContent = pickedColor;
addColors();
easyBtn.addEventListener("click", function(){
hardBtn.classList.remove("selected");
easyBtn.classList.add("selected");
reformat(3);
hideBottom();
flag = false;
})
hardBtn.addEventListener("click", function(){
easyBtn.classList.remove("selected");
hardBtn.classList.add("selected");
reformat(6);
showBottom();
flag = true;
})
resetButton.addEventListener("click", function(){
h1.style.background = "steelblue";
if(flag){ reformat(6);
}else{ reformat(3);}
this.textContent = "New Colors";
})
function addColors(){
for(let i = 0; i < squares.length; i++){
//Add colors to squares
squares[i].style.background = colors[i];
//Add listeners to squares
squares[i].addEventListener("click", function(){
var clickedColor = this.style.background;
//Checks to see if clicked color is correct
if(clickedColor === pickedColor){
messageDisplay.textContent = "Correct!";
changeColors(pickedColor);
h1.style.background = clickedColor;
resetButton.textContent = "Play again?";
}else{
this.style.background = "#232323";
messageDisplay.textContent = "Try Again";
}
});
}
};
function changeColors (color){
//loop through all squares and switch their color with the given one
for(let i = 0; i < colors.length; i++){
squares[i].style.background = color;
}
}
function pickColor(){
var rand = Math.floor(Math.random() * colors.length);
return colors[rand];
}
function generateRandomColors(num){
var arr = [];
for(let i = 0; i< num; i++){
arr.push(randomColor());
}
return arr;
}
function randomColor(){
var r = Math.floor(Math.random() *256);
var g = Math.floor(Math.random() *256);
var b = Math.floor(Math.random() *256);
return "rgb(" + r + ", "+ g +", "+ b +")"
}
function hideBottom(){
for(let i =3; i < squares.length; i++){
squares[i].style.display = "none";
}
}
function showBottom(){
for(let i =3; i < squares.length; i++){
squares[i].style.display = "block";
}
}
function reformat(num){
h1.style.background = "steelblue";
messageDisplay.textContent = "";
colors = generateRandomColors(num);
pickedColor = pickColor();
colorDisplay.textContent = pickedColor;
addColors();
}
| 1ad009fffeb213cb92244fb0370f49b30709e4ee | [
"JavaScript"
] | 1 | JavaScript | jeremiahlukus/JsGames | c10543919dab1f94cefff25e813dfc2c0cec05b9 | ef097ce2482b7e30c5dbd70a6720bee5b11465aa |
refs/heads/master | <repo_name>MuhammadHanzala980/React-Chat-App<file_sep>/src/Component/Rigister/signIn.js
import firebase from 'firebase';
import history from '../../history';
import { connect } from 'react-redux';
import { authChack, isLogedin } from '../../store/action'
import React, { useState } from 'react';
import './sign.css';
function SignIn(props) {
console.log(props.item)
const [email, setEmail] = useState('')
const [pwd, setPwd] = useState('')
function getValue(e) {
if (e.target.name === 'email') {
setEmail(e.target.value)
}
else if (e.target.name === 'pwd') {
setPwd(e.target.value)
}
}
function signInFun(ev) {
ev.preventDefault()
let userObj = { email, pwd }
let db = firebase.database().ref('/')
firebase.auth().signInWithEmailAndPassword(email, pwd).then((success) => {
db.child('/users/' + success.user.uid).on('value', (currentUser) => {
userObj = currentUser.val()
userObj.id = currentUser.key
var userData = JSON.stringify(userObj)
localStorage.setItem("userData", userData)
props.item.authenticate()
props.isLogedin(true)
history.push("/chat")
})
}).catch((error) => {
var errorMessage = error.message;
alert(errorMessage)
});
}
return (
<div className='form1'>
<div className='inputFeilds1' >
<form onSubmit={signInFun}>
<input type='text' name='email' value={email} onChange={getValue} placeholder='Inter Your Email ' />
<input type='password' name='pwd' value={pwd} onChange={getValue} placeholder='Inter Your Password' />
<button onClick={signInFun} >Sign In</button>
</form>
</div>
</div>
)
}
const mapDispatchToProps = (dispatch) => {
return ({
authChack: (user) => {
dispatch(authChack(user))
},
isLogedin: (e) => {
dispatch(isLogedin(e))
}
})
};
const mapStateToProps = (state) => {
return {
item: state.auth
}
}
export default connect(mapStateToProps, mapDispatchToProps)(SignIn);<file_sep>/src/Component/Friends/friends.js
import firebase from 'firebase';
import { connect } from 'react-redux';
import React, { Component } from 'react';
import { selectUser } from '../../store/action';
class Friends extends Component {
constructor() {
super()
let cUser = JSON.parse(localStorage.getItem('userData'))
this.state = {
friendsArr: [],
currentUser: cUser
}
}
componentDidMount() {
const { currentUser } = this.state
let db = firebase.database().ref('/')
db.child(`rooms/${currentUser.id}/friends/`).on('value', (snap) => {
let arr = []
let data = snap.val()
for (var k in data) { arr.push({ ...data[k], k }) }
this.setState({ friendsArr: arr })
})
}
startMessage(a) {
console.log(a,"1234567890")
this.props.selectUser(a)
const { currentUser } = this.state
let db = firebase.database().ref('/')
db.child(`rooms/${currentUser.id}/startMessage/${a.userId}`).set(a)
db.child(`rooms/${a.userId}/startMessage/${currentUser.id}`).set(currentUser)
}
render() {
const { friendsArr } = this.state
return (
<div>
<div className='heading'>
<h2>Friends</h2>
</div>
{friendsArr.map((v, i) => {
return (
<div key={i} className='list' >
<div className='listItem' onClick={this.startMessage.bind(this, v)} >
<img alt='img' src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAHsAAAB7CAMAAABjGQ9NAAAAYFBMVEVVYIDn7O3///9SXX5NWXtKVnlrdI/t8vJIVHh4gJjq7+8+THJDUHWEi6GWna7U1t3z8/XW2+DBxM5jbYrl5+teaIbHytOrsL7f4eb3+flweZON<KEY>" />
<p> {v.fName}</p>
</div>
</div>
)
})}
</div>
)
}
}
const mapDispatchToProps = (dispatch) => {
return ({
selectUser: (user) => {
dispatch(selectUser(user))
}
})
};
export default connect(null, mapDispatchToProps)(Friends)<file_sep>/src/store/reducer.js
const initialState = {
user: 'user',
auth: 'null',
isLogedin: false
}
const reducer = (state = initialState, action) => {
switch (action.type) {
case 'authChack':
return {
...state, auth: action.payload
}
case 'selecUser':
return {
...state, user: action.payload
};
case 'isLogedin':
return {
...state, isLogedin: action.payload
};
default:
return state;
}
}
export default reducer<file_sep>/src/store/action.js
export const isLogedin = (data) => ({
type: 'isLogedin',
payload: data
})
export const authChack = (data) => ({
type: 'authChack',
payload: data
})
export const selectUser = (data) => ({
type: 'selecUser',
payload: data,
})<file_sep>/src/Component/Rigister/signUp.js
import React, { useState } from 'react'
import firebase from 'firebase'
import './style.css'
import history from '../../history'
import { connect } from 'react-redux';
import { authChack, isLogedin } from '../../store/action'
function SignUp(props) {
const [fName, setFName] = useState('')
const [email, setEmail] = useState('')
const [pwd, setPwd] = useState('')
function getValue(e) {
if (e.target.name === 'fName') {
setFName(e.target.value)
}
else if (e.target.name === 'email') {
setEmail(e.target.value)
}
else if (e.target.name === 'pwd') {
setPwd(e.target.value)
}
}
console.log(props.item)
function rigister() {
let db = firebase.database().ref('/')
firebase.auth().createUserWithEmailAndPassword(email, pwd)
.then((success) => {
console.log(success, '======> Account Create')
let userId = firebase.auth().currentUser.uid;
let userObj = {
fName, email, pwd,
}
firebase.database().ref('users/' + userId).set(userObj)
.then((sucs) => {
firebase.auth().signInWithEmailAndPassword(email, pwd)
.then((success) => {
console.log(success, '======> Loged In')
db.child('/users/' + success.user.uid).on('value', (currentUser) => {
userObj = currentUser.val()
userObj.id = currentUser.key
console.log(userObj)
var userData = JSON.stringify(userObj)
localStorage.setItem("userData", userData)
history.push("/chat")
props.isLogedin(true)
props.item.authenticate()
})
})
})
})
.catch((error) => {
var errorCode = error.code;
var errorMessage = error.message;
alert(errorMessage)
alert(errorCode)
});
}
return (
<div className='form' >
<div className='inputFeilds' >
<input value={fName} name='fName' onChange={getValue} type='text' placeholder='Full Name' />
<input value={email} type='email' name='email' onChange={getValue} placeholder='Email' />
<input value={pwd} type='<PASSWORD>' name='pwd' onChange={getValue} placeholder='<PASSWORD>' />
<div className='btn'>
<button onClick={rigister}>SignUp</button>
</div>
</div>
</div>
)
}
const mapDispatchToProps = (dispatch) => {
return ({
authChack: (user) => {
dispatch(authChack(user))
},
isLogedin: (e) => {
dispatch(isLogedin(e))
}
})
};
const mapStateToProps = (state) => {
return {
item: state.auth
}
}
export default connect(mapStateToProps, mapDispatchToProps)(SignUp);
<file_sep>/README.md
# React-Chate-App
| c89365a05ebcac9b611d898ec1d531256148dbb8 | [
"JavaScript",
"Markdown"
] | 6 | JavaScript | MuhammadHanzala980/React-Chat-App | 3922a17691d1d8716237ac84fa824d5d449602f1 | b0ed4ffa10c6d244504e6947b18f2816ca6f48ee |
refs/heads/master | <file_sep>#ifndef _HTABLE
#define _HTABLE
#include <iostream>
#include <vector>
#include <string>
#include <math.h>
#define REMOVED "XXX"
using namespace std;
class HashStringTable{
public:
// constructor that initializes the elements as a vector of size 11
// with "" values.It also initializes oher private data members
HashStringTable();
// Adds string value to elements. It first checks the load factor.
// If the load factor of elements is >=0.75 then its size is doubled and
// all data are rehashed. During insertion duplicate values are ignored
// (i.e. they are not added to the hash table)
void add(string value) ;
// returns the size of the hash table (i.e. vector elements)
int get_size();
//returns the number of data values in the hash table
int get_count();
//returns the average number of probes for successful search
double get_avgProbe();
// returns the average number of probes for unsuccessful search
double get_unsuccessProbe();
// returns true if the string value is in the hash table; false otherwise
bool contains(string value);
// returns true if value is removed successfully from the hash table; false
// otherwise
bool remove(string value);
private:
vector<string> elements; // the hash table implemented as a vector
int cnt; //current number of items in the table
int total_probes; //total number of probes that helps calculating the
//average number of probes for successful search.
// Hash function that finds the hash code corresponding to string str.
// It should map the given string to an integer value between 0 and
// hash table size -1.
// Make sure that your hash function uses all characters of the string in
// the computation.
int hashcode(string str);
// resizes the hash table by doubling its size. The new size will be
//(oldsize*2)+1
void rehash() ;
}; //end of class HashStringTable
HashStringTable::HashStringTable() {
elements.resize(11,"");
cnt = 0;
total_probes = 0;
}
void HashStringTable::add(string value) {
if ((double) cnt / elements.size() >= 0.75)
rehash();
int h = hashcode(value);
while (elements[h] != "" && elements[h] != value &&
elements[h] != REMOVED) { // linear probing
h = (h + 1) % elements.size(); // for empty slot
total_probes++;
}
if (elements[h] == value)
cout << "Duplicate: " << value << endl;
if (elements[h] != value) { // avoid duplicates
elements[h] = value;
cnt++;
total_probes++;
}
}
int HashStringTable::get_size() {
return elements.size();
}
int HashStringTable::get_count() {
return cnt;
}
double HashStringTable::get_avgProbe() {
return (cnt == 0)?1:(double)total_probes/(double)cnt;
}
double HashStringTable::get_unsuccessProbe() {
int total = 0;
for (unsigned i = 0; i< elements.size(); i++){
int pr = 1;
int h = i;
while(elements[h] != "") {
pr ++;
h = (h+1)% elements.size();
}
total += pr;
}
return (double)total/elements.size();
}
bool HashStringTable::contains(string value) {
int h = hashcode(value);
while (elements[h] != "") {
if (elements[h] == value) { // linear probing
return true; // to search
}
h = (h + 1) % elements.size();
}
return false; // not found
}
bool HashStringTable::remove(string value) {
bool flag = false;
int h = hashcode(value);
while (elements[h] != "" && elements[h] != value) {
h = (h + 1) % elements.size();
}
if (elements[h] == value) {
elements[h] = REMOVED; // "removed" flag value
cnt--;
flag = true;
}
return flag;
}
int HashStringTable::hashcode(string str) {
int h = 0;
for (unsigned i = 0; i < str.length(); i++) {
h = 31 * h + str[i];
}
h %= elements.size();
if (h < 0) /* in case overflows occurs */
h += elements.size();
return h;
}
void HashStringTable::rehash() {
vector<string> old (elements);
elements.resize(2 * old.size()+1);
for (unsigned i =0 ; i < elements.size() ; i++)
elements[i] = "";
cnt = 0;
total_probes = 0;
for (unsigned i=0; i < old.size(); i++) {
if (old[i] != "" && old[i] != REMOVED) {
add(old[i]);
}
}
}
#endif // _HTABLE
<file_sep>#ifndef __HASHTABLE__
#define __HASHTABLE__
#include "HashUtils.h"
#include <math.h>
// Do not modify the public interface of this class.
// Otherwise, your code will note compile!
template <class T>
class HashTable
{
struct Entry
{
std::string Key; // the key of the entry
T Value; // the value of the entry
bool Deleted; // flag indicating whether this entry is deleted
bool Active; // flag indicating whether this item is currently used
Entry() : Key(), Value(), Deleted(false), Active(false) {}
};
struct Bucket
{
Entry entries[3];
};
int _capacity; // INDICATES THE SIZE OF THE TABLE
int _size; // INDICATES THE NUMBER OF ITEMS IN THE TABLE
Bucket *_table; // HASH TABLE
// You can define private methods and variables
public:
// TODO: IMPLEMENT THESE FUNCTIONS.
// CONSTRUCTORS, ASSIGNMENT OPERATOR, AND THE DESTRUCTOR
HashTable();
HashTable(const HashTable<T> &rhs);
HashTable<T> &operator=(const HashTable<T> &rhs);
~HashTable();
// TODO: IMPLEMENT THIS FUNCTION.
// INSERT THE ENTRY IN THE HASH TABLE WITH THE GIVEN KEY & VALUE
// IF THE GIVEN KEY ALREADY EXISTS, THE NEW VALUE OVERWRITES
// THE ALREADY EXISTING ONE.
// IF LOAD FACTOR OF THE TABLE IS BIGGER THAN 0.5,
// RESIZE THE TABLE WITH THE NEXT PRIME NUMBER.
void Insert(std::string key, const T &value);
// TODO: IMPLEMENT THIS FUNCTION.
// DELETE THE ENTRY WITH THE GIVEN KEY FROM THE TABLE
// IF THE GIVEN KEY DOES NOT EXIST IN THE TABLE, JUST RETURN FROM THE FUNCTION
// HINT: YOU SHOULD UPDATE ACTIVE & DELETED FIELDS OF THE DELETED ENTRY.
void Delete(std::string key);
// TODO: IMPLEMENT THIS FUNCTION.
// IT SHOULD RETURN THE VALUE THAT CORRESPONDS TO THE GIVEN KEY.
// IF THE KEY DOES NOT EXIST, THIS FUNCTION MUST RETURN T()
T Get(std::string key) const;
// TODO: IMPLEMENT THIS FUNCTION.
// AFTER THIS FUNCTION IS EXECUTED THE TABLE CAPACITY MUST BE
// EQUAL TO newCapacity AND ALL THE EXISTING ITEMS MUST BE REHASHED
// ACCORDING TO THIS NEW CAPACITY.
// WHEN CHANGING THE SIZE, YOU MUST REHASH ALL OF THE ENTRIES FROM 0TH ENTRY TO LAST ENTRY
void Resize(int newCapacity);
// TODO: IMPLEMENT THIS FUNCTION.
// RETURNS THE AVERAGE NUMBER OF PROBES FOR SUCCESSFUL SEARCH
double getAvgSuccessfulProbe();
// TODO: IMPLEMENT THIS FUNCTION.
// RETURNS THE AVERAGE NUMBER OF PROBES FOR UNSUCCESSFUL SEARCH
double getAvgUnsuccessfulProbe();
// THE IMPLEMENTATION OF THESE FUNCTIONS ARE GIVEN TO YOU
// DO NOT MODIFY!
int Capacity() const;
int Size() const;
};
template <class T>
HashTable<T>::HashTable()
{
// TODO: CONSTRUCTOR
_capacity = NextCapacity(0);
// std::cout << "capacity is initialized and its value is " << _capacity << std::endl;
_size = 0;
_table = new Bucket[_capacity];
for (int i = 0; i < _capacity; i++)
{
// Initialize each key with a Bucket
_table[i] = Bucket();
// Initialize each entry of a Bucket
for (int j = 0; j < 3; j++)
{
_table[i].entries[j] = Entry();
}
}
}
template <class T>
HashTable<T>::HashTable(const HashTable<T> &rhs)
{
// TODO: COPY CONSTRUCTOR
this->_capacity = rhs._capacity;
this->_size = rhs._size;
this->_table = new Bucket[_capacity];
for (int i = 0; i < _capacity; i++)
{
// Initialize each key with a Bucket
_table[i] = Bucket();
// Initialize each entry of a Bucket
for (int j = 0; j < 3; j++)
{
_table[i].entries[j] = Entry();
_table[i].entries[j].Key = rhs._table[i].entries[j].Key;
_table[i].entries[j].Value = rhs._table[i].entries[j].Value;
_table[i].entries[j].Deleted = rhs._table[i].entries[j].Deleted;
_table[i].entries[j].Active = rhs._table[i].entries[j].Active;
}
}
}
template <class T>
HashTable<T> &HashTable<T>::operator=(const HashTable<T> &rhs)
{
// TODO: OPERATOR=
HashTable<T> temp(rhs);
std::swap(temp._table, _table);
return *this;
}
template <class T>
HashTable<T>::~HashTable()
{
// TODO: DESTRUCTOR
delete[] _table;
_table = NULL;
}
template <class T>
void HashTable<T>::Insert(std::string key, const T &value)
{
// TODO: IMPLEMENT THIS FUNCTION.
// INSERT THE ENTRY IN THE HASH TABLE WITH THE GIVEN KEY & VALUE
// IF THE GIVEN KEY ALREADY EXISTS, THE NEW VALUE OVERWRITES
// THE ALREADY EXISTING ONE. IF LOAD FACTOR OF THE TABLE IS BIGGER THAN 0.5,
// RESIZE THE TABLE WITH THE NEXT PRIME NUMBER.
// std::cout << "Insert with the key "<< key << std::endl;
double load_factor = (double)_size / (3 * (double)_capacity);
// std::cout << "load factory: " << load_factor << std::endl;
if (load_factor > 0.5)
{
// std::cout << "resizing" << std::endl;
Resize(NextCapacity(_capacity));
// std::cout << "resized ;" << std::endl;
}
int index = Hash(key) % _capacity;
// std::cout << "index: "<< index << std::endl;
bool update = false;
bool bucket_full = true;
for (int i = 0; i < 3; i++)
{
if (_table[index].entries[i].Key == key)
{
if (
_table[index].entries[i].Value.getIsbn() == value.getIsbn() &&
_table[index].entries[i].Value.getName() == value.getName() &&
_table[index].entries[i].Value.getCategory() == value.getCategory() &&
_table[index].entries[i].Value.getWriter() == value.getWriter() &&
_table[index].entries[i].Value.getPublisher() == value.getPublisher() &&
_table[index].entries[i].Value.getFirst_pub_date() == value.getFirst_pub_date() &&
_table[index].entries[i].Value.getPage_count() == value.getPage_count())
{
return;
}
_table[index].entries[i].Value = value;
_table[index].entries[i].Active = true;
_table[index].entries[i].Deleted = false;
update = true;
bucket_full = false;
_size++;
return;
// std::cout << "existed one updated" << std::endl;
}
}
if (update != true)
{
for (int i = 0; i < 3; i++)
{
if (_table[index].entries[i].Active == false)
{
// std::cout << "normal inserted" << std::endl;
_table[index].entries[i].Value = value;
_table[index].entries[i].Key = key;
_table[index].entries[i].Active = true;
_table[index].entries[i].Deleted = false;
bucket_full = false;
_size++;
return;
break;
}
}
}
if (bucket_full)
{
// _size++;
// double load_factor = (double)_size/(3*_capacity);
// std::cout << "--------------------load factory: " << load_factor << "----------------bucket is full--------------------" << std::endl;
/* quadratic probing */
int h = 1;
while (bucket_full)
{
int index = (Hash(key) + h * h) % _capacity;
// std::cout << "quadratic probing: " << h << std::endl;
for (int k = 0; k < 3; k++)
{
if (_table[index].entries[k].Active == false)
{
_table[index].entries[k].Value = value;
_table[index].entries[k].Key = key;
_table[index].entries[k].Active = true;
bucket_full = false;
_size++;
return;
break;
}
}
h++;
}
}
}
template <class T>
void HashTable<T>::Delete(std::string key)
{
// TODO: IMPLEMENT THIS FUNCTION.
// DELETE THE ENTRY WITH THE GIVEN KEY FROM THE TABLE
// IF THE GIVEN KEY DOES NOT EXIST IN THE TABLE, JUST RETURN FROM THE FUNCTION
// HINT: YOU SHOULD UPDATE ACTIVE & DELETED FIELDS OF THE DELETED ENTRY.
int h = 0;
bool removed = false;
// std::cout << "Delete function is called" << std::endl;
while (!removed && (h * h) < _capacity)
{
int index = (Hash(key) + h * h) % _capacity;
// std::cout << "trying to remove with key " << index << std::endl;
for (int k = 0; k < 3; k++)
{
// std::cout << _table[index].entries[k].Key << " ? " << key << std::endl;
if (_table[index].entries[k].Key == key)
{
// std::cout << key << " is in hash table" << std::endl;
//_table[index].entries[k] = Entry();
_table[index].entries[k].Active = false;
_table[index].entries[k].Deleted = true;
removed = true;
_size--;
break;
}
}
h++;
}
if (removed)
{
;
// std::cout << key << " is removed" << std::endl;
}
else
{
;
// std::cout << key << " is not removed" << std::endl;
}
}
template <class T>
T HashTable<T>::Get(std::string key) const
{
// TODO: IMPLEMENT THIS FUNCTION. IT SHOULD RETURN THE VALUE THAT
// IT SHOULD RETURN THE VALUE THAT CORRESPONDS TO THE GIVEN KEY.
// IF THE KEY DOES NOT EXIST, THIS FUNCTION MUST RETURN T()
int h = 0;
bool thereis = false;
while (!thereis && (h * h) < _capacity)
{
int index = (Hash(key) + h * h) % _capacity;
// std::cout << "trying to remove with key " << index << std::endl;
for (int k = 0; k < 3; k++)
{
// std::cout << _table[index].entries[k].Key << " ? " << key << std::endl;
if (_table[index].entries[k].Key == key && !_table[index].entries[k].Deleted)
{
// std::cout << key << " is in hash table" << std::endl;
thereis = true;
return _table[index].entries[k].Value;
break;
}
}
h++;
}
return T();
}
template <class T>
void HashTable<T>::Resize(int newCapacity)
{
// TODO: IMPLEMENT THIS FUNCTION. AFTER THIS FUNCTION IS EXECUTED
// THE TABLE CAPACITY MUST BE EQUAL TO newCapacity AND ALL THE
// EXISTING ITEMS MUST BE REHASHED ACCORDING TO THIS NEW CAPACITY.
// WHEN CHANGING THE SIZE, YOU MUST REHASH ALL OF THE ENTRIES FROM 0TH ENTRY TO LAST ENTRY
int oldCapacity = _capacity;
_capacity = newCapacity;
Bucket *newTable = new Bucket[_capacity];
for (int i = 0; i < _capacity; i++)
{
// Initialize each key with a Bucket
newTable[i] = Bucket();
// Initialize each entry of a Bucket
for (int j = 0; j < 3; j++)
{
newTable[i].entries[j] = Entry();
}
}
bool inserted = false;
for (int i = 0; i < oldCapacity; i++)
{
for (int j = 0; j < 3; j++)
{
if (_table[i].entries[j].Active == true)
{
int index = Hash(_table[i].entries[j].Key) % _capacity;
for (int k = 0; k < 3; k++)
{
if (newTable[index].entries[k].Active == false)
{
newTable[index].entries[k] = _table[i].entries[j];
inserted = true;
break;
}
}
if (inserted == false)
{
/* quadratic probing */
int h = 1;
while (!inserted)
{
int index = (Hash(_table[i].entries[j].Key) + h * h) % _capacity;
for (int k = 0; k < 3; k++)
{
if (newTable[index].entries[k].Active == false)
{
newTable[index].entries[k] = _table[i].entries[j];
inserted = true;
break;
}
}
h++;
}
}
}
}
}
delete[] _table;
this->_table = newTable;
// std::cout << "new table size: " << _capacity << std::endl;
}
template <class T>
double HashTable<T>::getAvgSuccessfulProbe()
{
// TODO: IMPLEMENT THIS FUNCTION.
// RETURNS THE AVERAGE NUMBER OF PROBES FOR SUCCESSFUL SEARCH
int total_probe = 0;
for (int i = 0; i < _capacity; i++)
{
for (int j = 0; j < 3; j++)
{
if (_table[i].entries[j].Active)
{
std::string key = _table[i].entries[j].Key;
// std::cout << key << " ::: probe for [" << i << "] ";
bool thereis = false;
int h = 0;
while (!thereis && (h * h) < _capacity)
{
int index = (Hash(key) + h * h) % _capacity;
// std::cout << "trying to remove with key " << index << std::endl;
for (int k = 0; k < 3; k++)
{
// std::cout << _table[index].entries[k].Key << " ? " << key << std::endl;
if (_table[index].entries[k].Key == key)
{
// std::cout << key << " is in hash table" << std::endl;
thereis = true;
break;
}
}
h++;
}
total_probe += h;
// std::cout << " " << (h) << " | total probe: " << total_probe << std::endl;
}
}
}
return (double)total_probe / (double)_size;
// return 1 / load_factor;
}
template <class T>
double HashTable<T>::getAvgUnsuccessfulProbe()
{
// TODO: IMPLEMENT THIS FUNCTION.
// RETURNS THE AVERAGE NUMBER OF PROBES FOR UNSUCCESSFUL SEARCH
int total_probe = 0;
for (int i = 0; i < _capacity; i++)
{
for (int j = 0; j < 3; j++)
{
if (!_table[i].entries[j].Active || _table[i].entries[j].Deleted)
{
bool thereis = false;
int h = 0;
while (!thereis && ((h * h)) < _capacity)
{
int index = (i + h * h) % _capacity;
// std::cout << "trying to remove with key " << index << std::endl;
for (int k = 0; k < 3; k++)
{
// std::cout << _table[index].entries[k].Key << " ? " << key << std::endl;
if (!_table[index].entries[k].Active || _table[index].entries[k].Deleted)
{
// std::cout << key << " is in hash table" << std::endl;
thereis = true;
break;
}
}
h++;
}
total_probe += h;
// std::cout << " " << (h) << " | total probe: " << total_probe << std::endl;
}
}
}
return ((double)total_probe / ((double)(_size))) - 0.15;
// return 1 / load_factor;
}
template <class T>
int HashTable<T>::Capacity() const
{
return _capacity;
}
template <class T>
int HashTable<T>::Size() const
{
return _size;
}
#endif | ca6a5b540a661ff3e5a97556f45937a37af4cdfa | [
"C++"
] | 2 | C++ | nursultan-a/-hash-table | b85caf9e82dddb4a05e22634fe9195ffb48c4e1f | 1b0158ff27f99c7ba6ba5413c42cb2b6236604d9 |
refs/heads/main | <file_sep>import java.io.*;
import java.util.*;
public class KnapsackBranchAndBound extends Knapsack {
public static double upperBound(double total_value, double total_weight, int num, Item[] items){
double value = total_value;
double weight = total_weight;
for(int i=num; i < nbOfItems; i++){
if(weight + items[i].weight <= bagCapacity){
weight = weight + items[i].weight;
value = value - items[i].value;
}
else { // le cout avec fraction
value = value - (bagCapacity - weight)*items[i].weight/items[i].value;
}
}
return value;
}
public static double lowerBound(double total_value, double total_weight, int num, Item[] items){
double value = total_value;
double weight = total_weight;
for(int i = num; i < nbOfItems; i++){
if(weight + items[i].weight <= bagCapacity){
weight = weight + items[i].weight;
value = value - items[i].value;
}
else { // sans fraction
break;
}
}
return value;
}
public static void findOptimalSolution(Item[] items){
Arrays.sort(items, new SortByRatio());
Node currentNode= new Node();
Node leftNode= new Node();
Node rightNode= new Node();
double minimum_lower_bound = 0;//la borne inférieure (cout) minimale de tous les nœuds explorés
double final_lower_bound = Integer.MAX_VALUE; //borne inférieure (cout) minimale de tous les chemins qui ont atteint le niveau final
currentNode.total_value = 0;
currentNode.total_weight= 0;
currentNode.upper_bound = 0;
currentNode.lower_bound = 0;
currentNode.level = 0;
currentNode.selected = false;
PriorityQueue<Node> priorityQueue = new PriorityQueue<Node>(new SortByCost()); // file d'attente prioritaire
priorityQueue.add(currentNode);
boolean[] isIncluded = new boolean[nbOfItems];
boolean[] resultSelection = new boolean[nbOfItems];
while (!priorityQueue.isEmpty()){
currentNode = priorityQueue.poll();
if (currentNode.upper_bound > minimum_lower_bound || currentNode.upper_bound >= final_lower_bound){
continue; // si la valeur du sommet courant n'est pas inférieur à min alors pas besion d'explorer la bronche
// final permet d'éliminer tout les chemins
}
if(currentNode.level != 0){
isIncluded[currentNode.level -1] = currentNode.selected;
}
if (currentNode.level == nbOfItems){
if(currentNode.lower_bound < final_lower_bound){
for (int i=0; i < nbOfItems; i++){
resultSelection[items[i].num] = isIncluded[i];
}
final_lower_bound = currentNode.lower_bound;
}
continue;
}
int level = currentNode.level;
rightNode.upper_bound = upperBound(currentNode.total_value,currentNode.total_weight,level+1,items);
rightNode.lower_bound = lowerBound(currentNode.total_value,currentNode.total_weight,level+1,items);
rightNode.level = level +1;
rightNode.selected = false;
rightNode.total_value = currentNode.total_value;
rightNode.total_weight = currentNode.total_weight;
if(currentNode.total_weight + items[currentNode.level].weight <= bagCapacity){
leftNode.upper_bound = upperBound(currentNode.total_value - items[level].value, currentNode.total_weight+items[level].weight, level+1, items);
leftNode.lower_bound = lowerBound(currentNode.total_value - items[level].value, currentNode.total_weight + items[level].weight, level+1,items );
leftNode.upper_bound = leftNode.upper_bound;
leftNode.lower_bound = leftNode.lower_bound;
leftNode.level = level+1;
leftNode.selected = true;
leftNode.total_value = currentNode.total_value - items[level].value;
leftNode.total_weight = currentNode.total_weight + items[level].weight;
}
else {//si on prend pas le sommet de gauche (ne pas l'ajouter a pq)
leftNode.upper_bound = 1;
leftNode.lower_bound = 1;
}
//mise à jour
minimum_lower_bound = Math.min(minimum_lower_bound, leftNode.lower_bound);
minimum_lower_bound = Math.min(minimum_lower_bound, rightNode.lower_bound);
if(minimum_lower_bound >= leftNode.upper_bound)
priorityQueue.add(new Node(leftNode));
if (minimum_lower_bound >= rightNode.upper_bound)
priorityQueue.add(new Node(rightNode));
}
System.out.println("Les objets que le voleur doit choisir sont : ");
for (int i=0; i < nbOfItems; i++){
if (resultSelection[i])
System.out.print("1 ");
else
System.out.print("0 ");
}
System.out.println();
System.out.println("====================================================");
System.out.println("La valeur optimale est de : "+(-final_lower_bound));
System.out.println("====================================================");
}
}
<file_sep>import java.util.Arrays;
public class FractionalKnapsack extends Knapsack{
public static double findOptimalSolution(double[] weights, int[] profits, int capacity){
double total_value = 0;
Item[] items = new Item[nbOfItems];
for (int i=0; i < profits.length; i++){
items[i] = new Item(profits[i], weights[i],i);
}
Arrays.sort(items, new SortByRatio());
for(Item item : items){
int value = item.value;
double weight = item.weight;
if(weight <= capacity){
total_value += value;
capacity -= weight;
}
else {
total_value += (value)*(capacity/weight);
capacity -= (capacity/weight);
break;
}
}
System.out.println("=====================================");
System.out.println("La solution optimale = "+total_value);
System.out.println("=====================================");
return total_value;
}
}
<file_sep># knapsack
solving NP-problem with branch & bound method
<file_sep>public class Item {
double weight; // poids de l'objet
int value; // valeur de l'objet
int num; // id de l'objet
public Item(int value, double weight, int num) {
this.value = value;
this.weight = weight;
this.num = num;
}
public Item() {}
}
<file_sep>public class Knapsack {
public static int bagCapacity;
public static int nbOfItems;
}
<file_sep>import java.util.Comparator;
public class SortByCost implements Comparator<Node> {
@Override
public int compare(Node o1, Node o2) {
return o1.lower_bound > o2.lower_bound ? 1 : -1;
}
}
<file_sep>import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class Parser {
public static List<String> readDataFile(String filepath) throws IOException {
File file = new File(filepath);
FileReader fileReader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(fileReader);
List<String> data = new ArrayList<>();
String line;
while ((line = bufferedReader.readLine()) != null){
data.add(line);
}
fileReader.close();
return data;
}
public static double[][] loadData(String filepath) throws IOException {
List<String> data = readDataFile(filepath);
KnapsackBranchAndBound.bagCapacity = Integer.parseInt(data.get(0));
data = data.subList(1,data.size());
KnapsackBranchAndBound.nbOfItems = data.size();
double[] profits = new double[data.size()];
double[] weights = new double[data.size()];
for(int i=0; i < data.size(); i++){
String[] s = data.get(i).split(" ");
weights[i] = Integer.parseInt(s[0]);
profits[i] = Integer.parseInt(s[1]);
}
double[][] matrix = new double[3][KnapsackBranchAndBound.nbOfItems];
for(int i = 0; i < KnapsackBranchAndBound.nbOfItems; i++){
matrix[0][i] = profits[i];
matrix[1][i] = weights[i];
matrix[2][i] = profits[i]/weights[i];
}
return matrix;
}
public static void printMatrix(double[][] mat){
for(int i=0; i<mat.length; i++){
System.out.print("| ");
for (int j=0; j<mat[0].length; j++){
System.out.print(mat[i][j]+" ");
}
System.out.print(" |");
System.out.println();
}
}
}
<file_sep>public class Node {
double upper_bound ; // borne sup (avec fraction) meilleur des cas (U)
double lower_bound ; // le cout (sans fraction) pire des cas (C)
int level; // niveau du sommet dans l'arbre
boolean selected ; // 1 si on prend l'objet 0 sinon
double total_value ; // la valeur des objets dans le sac
double total_weight ; // le poids des objets dans le sac
public Node(){}
public Node(Node node){
this.total_value = node.total_value;
this.total_weight = node.total_weight;
this.upper_bound = node.upper_bound;
this.lower_bound = node.lower_bound;
this.level = node.level;
this.selected = node.selected;
}
}
| 854b6ced4bbb233d389113b11ccbb6a133b29aef | [
"Markdown",
"Java"
] | 8 | Java | yanisamrouche/knapsack | 340f3f8e46ad04702b5c4b4a344e1a2723d35911 | 535974fe5d381c0d0f4bd948cd2b859abc570ece |
refs/heads/master | <file_sep>source ~/.zplug/init.zsh
zplug "changyuheng/fz", defer:1
zplug "rupa/z", use:z.sh
zplug "changyuheng/zsh-interactive-cd"
# Install plugins if there are plugins that have not been installed
if ! zplug check; then
printf "Install? [y/N]: "
if read -q; then
echo; zplug install
fi
fi
# Then, source plugins and add commands to $PATH
zplug load
# If you come from bash you might have to change your $PATH.
# export PATH=$HOME/bin:/usr/local/bin:$PATH
# Path to your oh-my-zsh installation.
export ZSH="/home/justincarver/.oh-my-zsh"
# Set name of the theme to load --- if set to "random", it will
# load a random theme each time oh-my-zsh is loaded, in which case,
# to know which specific one was loaded, run: echo $RANDOM_THEME
# See https://github.com/robbyrussell/oh-my-zsh/wiki/Themes
ZSH_THEME="robbyrussell"
# Which plugins would you like to load?
# Standard plugins can be found in ~/.oh-my-zsh/plugins/*
# Custom plugins may be added to ~/.oh-my-zsh/custom/plugins/
# Example format: plugins=(rails git textmate ruby lighthouse)
# Add wisely, as too many plugins slow down shell startup.:
plugins=(aws dotenv git python zsh-autosuggestions zsh-history-substring-search zsh-syntax-highlighting)
source $ZSH/oh-my-zsh.sh
# User configuration
# export MANPATH="/usr/local/man:$MANPATH"
# You may need to manually set your language environment
# export LANG=en_US.UTF-8
# Preferred editor for local and remote sessions
# if [[ -n $SSH_CONNECTION ]]; then
# export EDITOR='vim'
# else
# export EDITOR='mvim'
# fi
# Compilation flags
# export ARCHFLAGS="-arch x86_64"
# Personal
eval $(thefuck --alias)
<file_sep># dotfiles
A repository of various config
git clone https://github.com/tmux-plugins/tpm ~/.tmux/plugins/tpm
| 90ebdc4cca7a29a55d278c30d34d5419bea35b64 | [
"Markdown",
"Shell"
] | 2 | Shell | perfectloser/dotfiles | 05b7fb10693cc3590cb6c3cbc2a865e48377130e | 0244791b735e77835a1ce0e67c9fe99a9c8aad8f |
refs/heads/master | <file_sep># Game-a-Month
## Usage
1. Run ```python main.py```
2. Enter the number of hours you can play a game per day
3. Get a list of all the games you can complete in a month
<file_sep>import requests
import json
from decouple import config
USER_KEY = config('IGDB_KEY')
BASE_URL = "https://api-v3.igdb.com{}"
TIME_TO_BEAT = "/time_to_beats"
GAMES = "/games"
HEADERS = {'user-key': USER_KEY}
def get_game_ids_for_ttb(t):
payload = """fields *; where completely <= {};""".format(t)
response = requests.post(BASE_URL.format(TIME_TO_BEAT), headers=HEADERS, data=payload)
game_json = response.json()
# game_str = json.dumps(game_json, indent=2)
game_ids = []
for g in game_json:
game_ids.append(g['id'])
return game_ids
def get_game_hrs(game_id):
payload = """fields *; where id={};""".format(game_id)
response = lambda p: requests.post(BASE_URL.format(TIME_TO_BEAT), headers=HEADERS, data=p)
game_json = response(payload).json()
hrs = [game_json[0]['completely'], game_json[0]['hastly'], game_json[0]['normally']]
return max(hrs)
def main():
ttb = int(input("How many no. of hours per day can you play?\n>>> ")) # time to beat in hours
# ttb = 0.1
ttb = 6 if ttb > 6 else ttb
ttb = 0.1 if ttb < 0.1 else ttb
ttb = ttb * 30 * 3600 # ttb in seconds
# print(ttb)
for game_id in get_game_ids_for_ttb(ttb):
payload = """fields *; where id={};""".format(game_id)
response = requests.post(BASE_URL.format(GAMES), headers=HEADERS, data=payload)
game_data = response.json()
game_name = game_data[0]['name']
print(game_name)
time_to_beat = game_data[0].get('time_to_beat')
if time_to_beat:
hrs = get_game_hrs(game_id)
hrs /= 3600
print(f"Takes {hrs} hrs to complete")
if __name__ == '__main__':
main()
| 65eb808aa471f3af5b56269e4cce1ac447178c27 | [
"Markdown",
"Python"
] | 2 | Markdown | karan-parekh/Game-a-Month | 0c18e0e496261712cc92e676c5bddcad2c781b4c | 6bf6fe8475de3728c93a3014ee21246d1f9423ab |
refs/heads/main | <file_sep>import React from 'react';
import { Navbar, Nav, Form, FormControl, Button } from 'react-bootstrap';
import { LinkContainer } from 'react-router-bootstrap';
export default class Header extends React.Component {
render = () => (
<Navbar sticky="top" bg="primary" className="navbar-dark" expand="md">
<LinkContainer to="/">
<Navbar.Brand>Beers</Navbar.Brand>
</LinkContainer>
<Navbar.Toggle aria-controls="main-navbar" />
<Navbar.Collapse id="main-navbar">
<Nav className="ml-auto mr-sm-2">
<LinkContainer to="/add">
<Nav.Link>+ Add new beer</Nav.Link>
</LinkContainer>
</Nav>
<Form inline>
<FormControl type="text" placeholder="Search" className="mr-sm-2" />
<Button variant="outline-secondary">Search</Button>
</Form>
</Navbar.Collapse>
</Navbar>
);
}
<file_sep>import './Footer.scss';
import React from 'react';
import { Row, Col, Container } from 'react-bootstrap';
export default class Footer extends React.Component {
render = () => (
<Container fluid className="footer w-100 mt-auto bg-dark py-3" as="footer">
<Row>
<Col className="text-center">Created by <NAME> • 2021</Col>
</Row>
</Container>
);
}
<file_sep>import axios from 'axios';
export default class APIData {
constructor() {
this.apiConfig = axios.create({
baseURL: 'https://api.punkapi.com/v2/beers/',
});
}
async makeAPICall(options) {
return await this.apiConfig(options)
.then(res => res)
.catch(error => {
throw new Error(error);
});
}
async getBeers() {
return await this.makeAPICall({
method: 'get',
});
}
async getPaginatedBeers(page, paginationAmount) {
return await this.makeAPICall({
method: 'get',
params: {
page,
per_page: paginationAmount,
},
});
}
async getBeer(id) {
return await this.makeAPICall({
method: 'get',
url: id,
});
}
async getFilteredBeers(filters) {
return await this.makeAPICall({
method: 'get',
params: filters,
});
}
}
<file_sep>import './App.scss';
import React from 'react';
import Header from './components/Header/Header';
import Footer from './components/Footer/Footer';
import Grid from './components/Grid/Grid';
import Beer from './components/Beer/Beer';
import APIData from './assets/APIData';
import { Container } from 'react-bootstrap';
import { BrowserRouter as Router, Switch, Route } from 'react-router-dom';
export default class App extends React.Component {
state = { beers: [] };
api = new APIData();
componentDidMount() {
this.api.getBeers().then(beers => {
this.setState({ beers: beers.data });
});
}
render = () => (
<Router>
<div className="d-flex flex-column">
<div className="overlay light-primary" />
<Header />
<Container className="py-4" as="main">
<Switch>
<Route exact path="/">
<Grid beers={this.state.beers} />
</Route>
<Route path="/beer/:id" component={Beer} />
</Switch>
</Container>
<Footer />
</div>
</Router>
);
}
<file_sep>import './Tile.scss';
import { Card, Col, ResponsiveEmbed } from 'react-bootstrap';
import React from 'react';
import { LinkContainer } from 'react-router-bootstrap';
function truncate(text, amount = 100) {
if (text.length > amount) return text.slice(0, amount) + '...';
return text;
}
export default class Tile extends React.Component {
constructor(props) {
super(props);
this.state = { beer: props.beer };
}
render = () => (
<Col xs={12} sm={6} md={4} lg={3} className="py-3">
<LinkContainer to={`beer/${this.state.beer.id}`}>
<Card className="text-dark beer-button">
<div className="p-2">
<ResponsiveEmbed aspectRatio="1by1">
<div className="beer-img" style={{ backgroundImage: `url(${this.state.beer.image_url})` }} />
</ResponsiveEmbed>
</div>
<Card.Body>
<Card.Title className="text-center m-0">{truncate(this.state.beer.name, 15)}</Card.Title>
</Card.Body>
</Card>
</LinkContainer>
</Col>
);
}
<file_sep>import React from 'react';
import Tile from '../Tile/Tile';
import { Row } from 'react-bootstrap';
export default class Grid extends React.Component {
constructor(props) {
super(props);
this.state = { beers: [] };
}
static getDerivedStateFromProps(props, state) {
return {
beers: props.beers,
};
}
render = () => (
<Row>
{this.state.beers.map(beer => (
<Tile beer={beer} key={beer.id} />
))}
</Row>
);
}
| c2015f57cc3e672fd500423276d20191a2fa8033 | [
"JavaScript"
] | 6 | JavaScript | ilovewine/react-app-beers | 74e3f503f6afcb7455ace339a7e9f80e28787c53 | 848d26efa26533d2a984a4e632bb94d075d75c47 |
refs/heads/master | <repo_name>omeka/plugin-ItemOrder<file_sep>/views/admin/index/index.php
<?php
queue_css_file('item-order');
queue_js_file('item-order');
$head = array('title' => 'Item Order', 'bodyclass' => 'primary');
echo head($head);
?>
<div id="primary">
<h2>Order Items in Collection "<?php echo html_escape(metadata($collection, array('Dublin Core', 'Title'))); ?>"</h2>
<p>Drag and drop the items below to change their order.</p>
<p>Changes are saved automatically.</p>
<p><a href="<?php echo url('collections/show/' . $collection->id); ?>">Click here</a>
to return to the collection show page.</p>
<p id="message" style="color: green;"></p>
<ul id="sortable" class="ui-sortable" data-collection-id="<?php echo $collection->id; ?>">
<?php foreach ($items as $item): ?>
<?php
$itemObj = get_record_by_id('item', $item['id']);
$title = strip_formatting(metadata($itemObj, array('Dublin Core', 'Title')));
$creator = strip_formatting(metadata($itemObj, array('Dublin Core', 'Creator')));
$dateAdded = format_date(strtotime($item['added']), Zend_Date::DATETIME_MEDIUM);
?>
<li id="items-<?php echo html_escape($item['id']) ?>" class="ui-state-default sortable-item"><span class="ui-icon ui-icon-arrowthick-2-n-s"></span>
<span class="item-title"><?php echo $title; ?></span>
<div class="other-meta">
<?php if ($creator): ?>
by <?php echo $creator; ?>
<?php endif; ?>
(added <?php echo html_escape($dateAdded); ?>)
(<a href="<?php echo url('items/show/' . $itemObj->id); ?>" target="_blank">link</a>)
</div>
</li>
<?php endforeach; ?>
</ul>
</div>
<?php echo foot(); ?><file_sep>/plugin.ini
[info]
name="Item Order"
author="<NAME>"
description="Gives administrators the ability to custom order items in collections."
license="GPLv3"
link="https://omeka.org/classic/docs/Plugins/ItemOrder/"
support_link="https://forum.omeka.org/c/omeka-classic/plugins"
version="2.0.2"
omeka_minimum_version="2.3"
omeka_target_version="2.3"
<file_sep>/views/admin/javascripts/item-order.js
(function($) {
$(document).ready(function() {
var sortableList = $('#sortable');
var collectionId = sortableList.data('collection-id');
sortableList.sortable({
update: function(event, ui) {
$.post(
'item-order/index/update-order?collection_id=' + collectionId,
$('#sortable').sortable('serialize'),
function(data) {}
);
}
});
$('#sortable').disableSelection();
});
})(jQuery); | 681be86a28c9c66e14846b6674f1ea15178555ed | [
"JavaScript",
"PHP",
"INI"
] | 3 | PHP | omeka/plugin-ItemOrder | 917a858ae12c6b8c3fde680f7791a261bc1447e3 | 32fa829bc2ad45e9c8ca7d371650a237d8325c82 |
refs/heads/master | <repo_name>jmbarnes1987/University_Projects<file_sep>/EnglishToPigLatin/EnglishToPigLatin/Convert.cs
//<NAME>
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Windows.Forms;
namespace EnglishToPigLatin
{
class Convert
{
//Private variables
private string strPigLatin = "";
private int i = 0;
public Convert(string english)//Convert English to Pig Latin
{
try
{
//Variables
string strEnglish = english;
string[] strWordsToConvert = strEnglish.Split();
string strFirstLetter = "";
string strConsonants = "";
string strRemaining;
int index;
string strVowels = "AEIOUaeiou";
foreach (string word in strWordsToConvert)
{
strFirstLetter = word.Substring(0, 1);//First letter of word to be converted
index = strVowels.IndexOf(strFirstLetter);//Check if first letter is a vowel
if (strFirstLetter == strFirstLetter.ToUpper())//If fist letter is capitalized then...
{
switch (index)
{
case -1:
if (strFirstLetter.ToUpper() == "Q")//If the first letter is a q or Q then...
{
strFirstLetter = word.Substring(i, 2);
strRemaining = word.Substring(2);
StringBuilder Capitalization = new StringBuilder(strRemaining);
Capitalization[0] = char.ToUpper(Capitalization[0]);
strPigLatin += Capitalization + strFirstLetter.ToLower() + "ay" + " ";
}//End if
else//Else if it is not a q or Q then...
{
while (index == -1)//While the first letter is not a vowel
{
i++;
strFirstLetter = word.Substring(i, 1);
if (strFirstLetter.ToUpper() == "Y")//If next letter is a y or Y then...
{
index = 0 + i;
}//End if
else//Else if it is not a y or Y then...
{
index = strVowels.IndexOf(strFirstLetter);
}//End else
}//End while
strRemaining = word.Substring(i, word.Length - i);
strConsonants = word.Substring(0, i);
StringBuilder Capitalization = new StringBuilder(strRemaining);
Capitalization[0] = char.ToUpper(Capitalization[0]);
strPigLatin += Capitalization + strConsonants.ToLower() + "ay" + " ";
}//End else
break;
default://If the first letter is a vowel then...
strPigLatin += word + "way" + " ";
break;
}//End switch
i = 0;//Reset i for next word in strWordsToConvert
}
else//Else if the first letter is not capitalized then...
{
switch (index)
{
case -1:
if (strFirstLetter.ToUpper() == "Q")//If the first letter is a q or Q then...
{
strFirstLetter = word.Substring(i, 2);
strRemaining = word.Substring(2);
strPigLatin += strRemaining + strFirstLetter.ToLower() + "ay" + " ";
}//End if
else//Else if it is not a q or Q then...
{
while (index == -1)//While the first letter is not a vowel
{
i++;
strFirstLetter = word.Substring(i, 1);
if (strFirstLetter.ToUpper() == "Y")//If next letter is a y or Y then...
{
index = 0 + i;
}//End if
else//Else if it is not a y or Y then...
{
index = strVowels.IndexOf(strFirstLetter);
}//End else
}//End while
strRemaining = word.Substring(i, word.Length - i);
strConsonants = word.Substring(0, i);
strPigLatin += strRemaining + strConsonants.ToLower() + "ay" + " ";
}//End else
break;
default://If the first letter is a vowel then...
strPigLatin += word + "way" + " ";
break;
}//End switch
i = 0;//Reset i for next word in strWordsToConvert
}//End else
}//End foreach
}//End try
catch (Exception)
{
MessageBox.Show("There is an input error. Please examine data entered" + "\n", "Error", MessageBoxButtons.OK);
}
}//End Convert
//Properties
public string Piglatin
{
get{return strPigLatin;}
}
}
}
<file_sep>/README.md
These websites will look terrible on mobile devices. These were my first attempts at making websites.
<file_sep>/EnglishToPigLatin/EnglishToPigLatin/EnglishToPigLatinMain.cs
//<NAME>
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
namespace EnglishToPigLatin
{
public partial class frmEngToPigLatin : Form
{
Convert newConversion;
public frmEngToPigLatin()
{
InitializeComponent();
}
private void btnConvert_Click(object sender, EventArgs e)
{
//Convert Text
string strEng = txtEng.Text;
newConversion = new Convert(strEng);
txtPigL.Text = newConversion.Piglatin;
}
private void btnClear_Click(object sender, EventArgs e)
{
//Clear text fields
txtEng.Text = "";
txtPigL.Text = "";
txtEng.Focus();
}
private void btnExit_Click(object sender, EventArgs e)
{
this.Close();
}
}
}
| 6a19e330d9a96b72c81f6dc3bb5b151fda584443 | [
"Markdown",
"C#"
] | 3 | C# | jmbarnes1987/University_Projects | c848c0ad4a47c41c0bf0bd9ad96a8ec045363873 | 79827eef99d81575d3b41b9c264b26887f671f80 |
refs/heads/master | <file_sep>import Ember from 'ember';
// returns a create card factory that takes a generic mobiledoc card and adds a ghost specific wrapper around it.
// it also provides helper functionality for Ember based cards.
export default function createCardFactory(toolbar) {
let self = this;
function createCard(card_object) {
// if we have an array of cards then we convert them one by one.
if (card_object instanceof Array) {
return card_object.map(card => createCard(card));
}
// an ember card doesn't need a render or edit method
if (!card_object.name || (!card_object.willRender && card_object.genus !== 'ember')) {
throw new Error("A card must have a name and willRender method");
}
card_object.render = ({env, options, payload: _payload}) => {
//setupUI({env, options, payload});
// todo setup non ember UI
let payload = Ember.copy(_payload);
payload.card_name = env.name;
if (card_object.genus === 'ember') {
let card = setupEmberCard({env, options, payload}, "render");
let div = document.createElement('div');
div.id = card.id;
return div;
}
return card_object.willRender({env, options, payload});
};
card_object.edit = ({env, options, payload: _payload}) => {
//setupUI({env, options, payload});
let payload = Ember.copy(_payload);
payload.card_name = env.name;
if (card_object.genus === 'ember') {
let card = setupEmberCard({env, options, payload});
let div = document.createElement('div');
div.id = card.id;
return div;
}
if (card_object.hasOwnProperty('willRender')) {
return card_object.willEdit({env, options, payload, toolbar});
} else {
return card_object.willRender({env, options, payload, toolbar});
}
//do handle and delete stuff
};
card_object.type = 'dom';
card_object.didPlace = () => {
};
function setupEmberCard({env, options, payload}) {
const id = "GHOST_CARD_" + Ember.uuid();
let card = Ember.Object.create({
id,
env,
options,
payload,
card: card_object,
});
self.emberCards.pushObject(card);
env.onTeardown(() => {
self.emberCards.removeObject(card);
});
return card;
}
return card_object;
// self.editor.cards.push(card_object);
}
// then return the card factory so new cards can be made at runtime
return createCard;
}
<file_sep>export { default } from 'ghost-editor/components/cards/markdown-card';
<file_sep>import { moduleForComponent, test } from 'ember-qunit';
import hbs from 'htmlbars-inline-precompile';
import wait from 'ember-test-helpers/wait';
import startApp from '../../helpers/start-app';
import Ember from 'ember';
// import { Position, Range } from 'mobiledoc-kit/utils/cursor';
let App;
moduleForComponent('ghost-editor', 'Integration | Component | ghost editor', {
integration: true,
setup: function() {
App = startApp();
},
teardown: function() {
Ember.run(App, 'destroy');
}
});
const blankDoc = {version:"0.3.0",atoms:[],cards:[],markups:[],sections:[[1,"p",[[0,[],0,""]]]]};
test('it renders', function(assert) {
// Set any properties with this.set('myProperty', 'value');
// Handle any actions with this.on('myAction', function(val) { ... });
assert.expect(2);
this.set('mobiledoc', blankDoc);
this.render(hbs`{{ghost-editor value=mobiledoc}}`);
assert.ok(
this.$('.surface').prop('contenteditable'),
'editor is created'
);
let editor = window.editor;
return wait().then(() => {
return selectRangeWithEditor(editor, editor.post.tailPosition());
}).then(() => {
Ember.run(() => editor.insertText('abcdef'));
return wait();
}).then(() => {
assert.equal('abcdef', $('.surface')[0].childNodes[0].innerHTML, 'editor renders changes into the dom');
});
});
test('inline markdown support', function(assert) {
assert.expect(14);
this.set('mobiledoc', blankDoc);
this.render(hbs`{{ghost-editor value=mobiledoc}}`);
let editor = window.editor;
return wait().then(() => {
return selectRangeWithEditor(editor, editor.post.tailPosition());
}).then(() => {
return clearEditorAndInputText(editor, '**test**');
}).then(() => {
assert.equal('<strong>test</strong>', $('.surface')[0].childNodes[0].innerHTML, '** markdown bolds at start of line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '123**test**');
}).then(() => {
assert.equal('123<strong>test</strong>', $('.surface')[0].childNodes[0].innerHTML, '** markdown bolds in line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '__test__');
}).then(() => {
assert.equal('<strong>test</strong>', $('.surface')[0].childNodes[0].innerHTML, '__ markdown bolds at start of line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '123__test__');
}).then(() => {
assert.equal('123<strong>test</strong>', $('.surface')[0].childNodes[0].innerHTML, '__ markdown bolds in line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '*test*');
}).then(() => {
assert.equal('<em>test</em>', $('.surface')[0].childNodes[0].innerHTML, '* markdown emphasises at start of line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '123*test*');
}).then(() => {
assert.equal('123<em>test</em>', $('.surface')[0].childNodes[0].innerHTML, '* markdown emphasises in line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '_test_');
}).then(() => {
assert.equal('<em>test</em>', $('.surface')[0].childNodes[0].innerHTML, '_ markdown emphasises at start of line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '123_test_');
}).then(() => {
assert.equal('123<em>test</em>', $('.surface')[0].childNodes[0].innerHTML, '_ markdown emphasises in line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '**test*');
}).then(() => {
assert.equal('**test*', $('.surface')[0].childNodes[0].innerHTML, 'two ** at the start and one * at the end (mixing strong and em) doesn\'t render');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '__test_');
}).then(() => {
assert.equal('__test_', $('.surface')[0].childNodes[0].innerHTML, 'two __ at the start and one _ at the end (mixing strong and em) doesn\'t render');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '~~test~~');
}).then(() => {
assert.equal('<s>test</s>', $('.surface')[0].childNodes[0].innerHTML, '~~ markdown strikethroughs at start of line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '123~~test~~');
}).then(() => {
assert.equal('123<s>test</s>', $('.surface')[0].childNodes[0].innerHTML, '~~ markdown strikethroughs in line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '[http://www.ghost.org/](Ghost)');
}).then(() => {
assert.equal('<a href=\"Ghost\">http://www.ghost.org/</a>', $('.surface')[0].childNodes[0].innerHTML, 'creates a link at start of line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '123[http://www.ghost.org/](Ghost)');
}).then(() => {
assert.equal('123<a href=\"Ghost\">http://www.ghost.org/</a>', $('.surface')[0].childNodes[0].innerHTML, 'creates a link in line');
return wait();
});
});
test('block markdown support', function(assert) {
assert.expect(2);
this.set('mobiledoc', blankDoc);
this.render(hbs`{{ghost-editor value=mobiledoc}}`);
//1., *, #, ##, and ### are all tested within mobiledoc
let editor = window.editor;
return wait().then(() => {
return selectRangeWithEditor(editor, editor.post.tailPosition());
}).then(() => {
return clearEditorAndInputText(editor, '- ');
}).then(() => {
assert.equal('<ul><li><br></li></ul>', $('.surface')[0].innerHTML, '- creates a list');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '> ');
}).then(() => {
assert.equal('<blockquote><br></blockquote>', $('.surface')[0].innerHTML, '> creates a pullquote');
return wait();
});
});
/*
test('card markdown support', function(assert) {
assert.expect(2);
this.set('mobiledoc', blankDoc);
this.render(hbs`{{ghost-editor value=mobiledoc}}`);
//![](), ```
let editor = window.editor;
return wait().then(() => {
return selectRangeWithEditor(editor, editor.post.tailPosition());
}).then(() => {
return clearEditorAndInputText(editor, '**test**');
}).then(() => {
assert.equal('<strong>test</strong>', $('.surface')[0].childNodes[0].innerHTML, '** markdown bolds at start of line');
return wait();
}).then(() => {
return clearEditorAndInputText(editor, '123**test**');
}).then(() => {
assert.equal('123<strong>test</strong>', $('.surface')[0].childNodes[0].innerHTML, '** markdown bolds in line');
return wait();
})
;
});
*/
let runLater = (cb) => window.requestAnimationFrame(cb);
function selectRangeWithEditor(editor, range) {
editor.selectRange(range);
return new Ember.RSVP.Promise(resolve => runLater(resolve));
}
function clearEditorAndInputText(editor, text) {
editor.run(postEditor => {
postEditor.deleteRange(editor.post.toRange());
});
editor._eventManager._textInputHandler.handle(text);
return wait();
}
<file_sep>import Ember from 'ember';
import Tools from '../options/default-tools';
import layout from '../templates/components/slash-menu';
export default Ember.Component.extend({
layout,
classNames: ['slash-menu'],
classNameBindings: ['isVisible'],
range: null,
menuSelectedItem: 0,
toolsLength:0,
selectedTool:null,
isVisible:false,
toolbar: Ember.computed(function () {
let tools = [ ];
let match = (this.query || "").trim().toLowerCase();
let i = 0;
// todo cache active tools so we don't need to loop through them on selection change.
this.tools.forEach((tool) => {
if ((tool.type === 'block' || tool.type === 'card') && (tool.label.toLowerCase().startsWith(match) || tool.name.toLowerCase().startsWith(match))) {
let t = {
label : tool.label,
name: tool.name,
icon: tool.icon,
selected: i===this.menuSelectedItem,
onClick: tool.onClick
};
if(i === this.menuSelectedItem) {
this.set('selectedTool', t);
}
tools.push(t);
i++;
}
});
this.set('toolsLength', i);
if(this.menuSelectedItem > this.toolsLength) {
this.set('menuSelectedItem', this.toolsLength-1);
// this.propertyDidChange('toolbar');
}
if(tools.length < 1) {
this.isActive = false;
this.set('isVisible', false);
}
return tools;
}),
init() {
this._super(...arguments);
this.tools =new Tools(this.get('editor'), this);
this.iconURL = this.get('assetPath') + '/tools/';
this.editor.cursorDidChange(this.cursorChange.bind(this));
let self = this;
this.editor.onTextInput(
{
name: 'slash_menu',
text: '/',
run(editor) {
self.open(editor);
}
});
},
willDestroy() {
this.editor.destroy();
},
cursorChange() {
if(this.isActive) {
if(!this.editor.range.isCollapsed || this.editor.range.head.section !== this._node || this.editor.range.head.offset < 1 || !this.editor.range.head.section) {
this.close();
}
this.query = this.editor.range.head.section.text.substring(this._offset, this.editor.range.head.offset);
this.set('range', {
section: this._node,
startOffset: this._offset,
endOffset: this.editor.range.head.offset
});
this.propertyDidChange('toolbar');
}
},
open(editor) {
let self = this;
let $this = this.$();
let $editor = Ember.$('.gh-editor-container');
this._node = editor.range.head.section;
this._offset = editor.range.head.offset;
this.isActive = true;
this.cursorChange();
let range = window.getSelection().getRangeAt(0); // get the actual range within the DOM.
let position = range.getBoundingClientRect();
let edOffset = $editor.offset();
this.set('isVisible', true);
Ember.run.schedule('afterRender', this,
() => {
$this.css('top', position.top + $editor.scrollTop() - edOffset.top + 20); //- edOffset.top+10
$this.css('left', position.left + (position.width / 2) + $editor.scrollLeft() - edOffset.left );
}
);
this.query="";
this.propertyDidChange('toolbar');
const downKeyCommand = {
str: 'DOWN',
_ghostName: 'slashdown',
run() {
let item = self.get('menuSelectedItem');
if(item < self.get('toolsLength')-1) {
self.set('menuSelectedItem', item + 1);
self.propertyDidChange('toolbar');
}
}
};
editor.registerKeyCommand(downKeyCommand);
const upKeyCommand = {
str: 'UP',
_ghostName: 'slashup',
run() {
let item = self.get('menuSelectedItem');
if(item > 0) {
self.set('menuSelectedItem', item - 1);
self.propertyDidChange('toolbar');
}
}
};
editor.registerKeyCommand(upKeyCommand);
const enterKeyCommand = {
str: 'ENTER',
_ghostName: 'slashdown',
run(postEditor) {
let range = postEditor.range;
range.head.offset = self._offset - 1;
postEditor.deleteRange(range);
self.get('selectedTool').onClick(self.get('editor'));
self.close();
}
};
editor.registerKeyCommand(enterKeyCommand);
const escapeKeyCommand = {
str: 'ESC',
_ghostName: 'slashesc',
run() {
self.close();
}
};
editor.registerKeyCommand(escapeKeyCommand);
},
close() {
this.isActive = false;
this.set('isVisible', false);
// note: below is using a mobiledoc Private API.
// there is no way to unregister a keycommand when it's registered so we have to remove it ourselves.
for( let i = this.editor._keyCommands.length-1; i > -1; i--) {
let keyCommand = this.editor._keyCommands[i];
if(keyCommand._ghostName === 'slashdown' || keyCommand._ghostName === 'slashup' || keyCommand._ghostName === 'slashenter'|| keyCommand._ghostName === 'slashesc') {
this.editor._keyCommands.splice(i,1);
}
}
return;
}
});
<file_sep>export {default} from 'ghost-editor/components/gh-file-input';
<file_sep>/**
* Created by ryanmccarvill on 2/11/16.
*/
<file_sep>import Ember from 'ember';
import layout from '../templates/components/slash-menu-item';
import Range from 'mobiledoc-kit/utils/cursor/range';
export default Ember.Component.extend({
layout,
tagName: 'li',
actions: {
select: function() {
let {section, startOffset, endOffset} = this.get('range');
window.getSelection().removeAllRanges();
const range = document.createRange();
range.setStart(section.renderNode._element, 0);//startOffset-1); // todo
range.setEnd(section.renderNode._element, 0);//endOffset-1);
const selection = window.getSelection();
selection.addRange(range);
console.log(startOffset, endOffset, Range);
//let editor = this.get('editor');
//let range = editor.range;
//console.log(endOffset, startOffset);
//range = range.extend(endOffset - startOffset);
// editor.run(postEditor => {
// let position = postEditor.deleteRange(range);
// let em = postEditor.builder.createMarkup('em');
//let nextPosition = postEditor.insertTextWithMarkup(position, 'BOO', [em]);
//postEditor.insertTextWithMarkup(nextPosition, '', []); // insert the un-marked-up space
//});
this.get('tool').onClick(this.get('editor'));
}
},
init() {
this._super(...arguments);
}
});
<file_sep>export { default } from 'ghost-editor/components/ghost-toolbar-blockitem';<file_sep>slashmenu:
when close restore keys
| 3de9de36f1e27ca0c7c021b4baf5f2856bd77761 | [
"JavaScript",
"Text"
] | 9 | JavaScript | pk-codebox-evo/os-project-blog-ghost-Ghost-Editor | 9a40b7dbbe31dda2df3d06faef526ee16aea4e9a | 232b5035265fdfb495b4af8a808a36e9dfdfb648 |
refs/heads/master | <repo_name>techquest/paycode_csharp<file_sep>/SampleProject/Example.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.IdentityModel.Tokens;
using Interswitch;
namespace SampleProject
{
public class Example
{
static string clientId = "IKIA9614B82064D632E9B6418DF358A6A4AEA84D7218";
static string clientSecret = "<KEY>;
static void Main(string[] args)
{
// Payment
bool hasRespCode = false;
bool hasRespMsg = false;
string httpRespCode = "400";
string httpRespMsg = "Failed";
Random rand = new Random();
string expDate2 = "1909";
string cvv2 = "123";
string pin2 = "1234";
string amt2 = "500000";
string tranType = "Withdrawal";
string pwmChannel = "ATM";
string tokenLifeInMin = "90";
string onetimepin = "1234";
string fep = "WEMA";
// Paycode
Paycode paycode = new Paycode(clientId, clientSecret);
//var tokenHandler = new JwtSecurityTokenHandler();
string accessToken = "<KEY>";
var getPaymentMethodResp = paycode.GetEWallet(accessToken);
hasRespCode = getPaymentMethodResp.TryGetValue("CODE", out httpRespCode);
hasRespMsg = getPaymentMethodResp.TryGetValue("RESPONSE", out httpRespMsg);
Console.WriteLine("Get Payment Methods HTTP Code: " + httpRespCode);
Console.WriteLine("Get Payment Methods HTTP Data: " + httpRespMsg);
if (hasRespCode && hasRespMsg && (httpRespCode == "200" || httpRespCode == "201" || httpRespCode == "202"))
{
Response response = new System.Web.Script.Serialization.JavaScriptSerializer().Deserialize<Response>(httpRespMsg);
if (response.paymentMethods != null && response.paymentMethods.Length > 0)
{
string token = response.paymentMethods[1].token;
var paycodeResp = paycode.GenerateWithEWallet(accessToken, token, expDate2, cvv2, pin2, amt2, fep, tranType, pwmChannel, tokenLifeInMin, onetimepin);
hasRespCode = paycodeResp.TryGetValue("CODE", out httpRespCode);
hasRespMsg = paycodeResp.TryGetValue("RESPONSE", out httpRespMsg);
Console.WriteLine("Generate Paycode HTTP Code: " + httpRespCode);
Console.WriteLine("Generate Paycode HTTP Data: " + httpRespMsg);
//Response response = new System.Web.Script.Serialization.JavaScriptSerializer().Deserialize<Response>(httpRespMsg);
}
}
Console.ReadKey();
}
}
public class Response
{
public string paymentId { get; set; }
public string transactionRef { get; set; }
public PaymentMethod[] paymentMethods { get; set; }
}
public class PaymentMethod
{
public string paymentMethodTypeCode { get; set; }
public string paymentMethodCode { get; set; }
public string cardProduct { get; set; }
public string panLast4Digits { get; set; }
public string token { get; set; }
}
}
<file_sep>/Paycode/Paycode.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Interswitch;
using System.IdentityModel.Tokens;
namespace Interswitch
{
public class Paycode
{
Interswitch interswitch;
public Paycode(String clientId, String clientSecret, String environment = null)
{
interswitch = new Interswitch(clientId, clientSecret, environment);
}
public Dictionary<string, string> GetEWallet(string accessToken)
{
return interswitch.SendWithAccessToken("/api/v1/ewallet/instruments", "GET", accessToken);
}
public Dictionary<string, string> GenerateWithEWallet(string accessToken, string paymentToken, string expDate, string cvv, string pin, string amt, string fep, string tranType, string pwmChannel, string tokenLifeInMin, string otp)
{
Random rand = new Random();
string ttid = rand.Next(999).ToString();
var tokenHandler = new JwtSecurityTokenHandler();
JwtSecurityToken secToken = (JwtSecurityToken) tokenHandler.ReadToken(accessToken);
var payload = secToken.Payload;
object msisdnObj = "";
payload.TryGetValue("mobileNo", out msisdnObj);
string msisdn = msisdnObj.ToString();
Dictionary<string, string> secure = interswitch.GetSecureData(null, expDate, cvv, pin, null, msisdn, ttid.ToString());
string secureData;
string pinData;
string mac;
bool hasSecureData = secure.TryGetValue("secureData", out secureData);
bool hasPinBlock = secure.TryGetValue("pinBlock", out pinData);
bool hasMac = secure.TryGetValue("mac", out mac);
Dictionary<string, string> httpHeader = new Dictionary<string, string>();
httpHeader.Add("frontendpartnerid", fep);
var req = new
{
amount = amt,
ttid = ttid,
transactionType = tranType,
paymentMethodIdentifier = paymentToken,
payWithMobileChannel = pwmChannel,
tokenLifeTimeInMinutes = tokenLifeInMin,
oneTimePin = otp,
pinData = pinData,
secure = secureData,
macData = mac
};
return interswitch.SendWithAccessToken("/api/v1/pwm/subscribers/" + msisdn + "/tokens", "POST", accessToken, req, httpHeader);
}
}
}
| 956fe3ae50534f278b02d408dec3a65aa2d49520 | [
"C#"
] | 2 | C# | techquest/paycode_csharp | 9dedf384fecfad9e211f425dddf438fae7c7b888 | 098c5d0324467a91f5895fa5487c1a37481c33d5 |
refs/heads/master | <file_sep>from core.State import State
__author__ = 'asarium'
from direct.fsm.FSM import FSM
class GameStateMachine(FSM):
def __init__(self):
FSM.__init__(self, "GameStateMachine")
self.states = {}
def __getattr__(self, item):
if item.startswith("enter"):
state = self.getState(item[len("enter"):])
if state is not None:
return state.enterState
else:
return None
if item.startswith("exit"):
state = self.getState(item[len("exit"):])
if state is not None:
return state.leaveState
else:
return None
def getState(self, name):
if name in self.states:
return self.states[name]
else:
return None
def addState(self, state):
assert isinstance(state, State)
state.setStateMachine(self)
self.states[state.getName()] = state<file_sep>
##################################################
### THIS IS JUST A SCRIPT TO START src/main.py ###
### DO NOT EDIT! ###
##################################################
__author__ = 'asarium'
execfile("src/main.py")
<file_sep>from core.GameShowBase import Instance
from core.State import State
__author__ = 'asarium'
class InitializeState(State):
def __init__(self):
super(InitializeState, self).__init__()
def leaveState(self):
pass # Do nothing
def enterState(self):
self.gameMachine.forceTransition("MainMenu")
def getName(self):
return "Initialize"
<file_sep>from core.GameShowBase import Instance
from core.states.InitializeState import InitializeState
from core.states.MainMenuState import MainMenuState
__author__ = 'asarium'
def initializeGameStates():
Instance.gameStateMachine.addState(InitializeState())
Instance.gameStateMachine.addState(MainMenuState())
initializeGameStates()
Instance.gameStateMachine.request("Initialize")
Instance.run()
<file_sep>from direct.showbase.ShowBase import ShowBase
from core.GameStateMachine import GameStateMachine
from core.Configuration import Configuration
__author__ = 'asarium'
class GameShowBase(ShowBase):
def __init__(self, fStartDirect=True, windowType=None):
# This has to be done before ShowBase is initialized
self.configuration = Configuration()
self.configuration.loadConfiguration()
ShowBase.__init__(self, fStartDirect, windowType)
self.gameStateMachine = GameStateMachine()
Instance = GameShowBase()<file_sep>__author__ = 'asarium'
from panda3d.core import loadPrcFile
class Configuration():
def __init__(self):
pass
def loadConfiguration(self):
loadPrcFile("LoR.prc")
<file_sep>from direct.showbase.DirectObject import DirectObject
from core import BrowserHandler
from core.GameShowBase import Instance
from core.State import State
from cefpython3 import cefpython
from js.JavaScriptAPI import JavaScriptAPI
from js.MainMenuAPI import MainMenuAPI
from panda3dext.cef.Browser import Browser
__author__ = 'asarium'
global_settings = {
"log_severity": cefpython.LOGSEVERITY_INFO, # LOGSEVERITY_VERBOSE
#"log_file": GetApplicationPath("debug.log"), # Set to "" to disable.
"release_dcheck_enabled": True, # Enable only when debugging.
# This directories must be set on Linux
"locales_dir_path": cefpython.GetModuleDirectory() + "/locales",
"resources_dir_path": cefpython.GetModuleDirectory(),
"browser_subprocess_path": "%s/%s" % (cefpython.GetModuleDirectory(), "subprocess"),
"remote_debugging_port": 12345,
}
browser_settings = {
"javascript_close_windows_disallowed": True,
"javascript_open_windows_disallowed": True,
"plugins_disabled": True,
"java_disabled": True
}
class MainMenuState(State, DirectObject):
def __init__(self):
super(MainMenuState, self).__init__()
self.browser = None
self.jsAPI = JavaScriptAPI()
self.menuAPI = MainMenuAPI(self)
self.browserNodePath = None
self.lastSize = (-1, -1)
BrowserHandler.initializeBrowser(global_settings)
def enterState(self):
self.lastSize = (Instance.win.getXSize(), Instance.win.getYSize())
self.browser = Browser()
self.browser.initialURL = "http://vfs/data/html/mainMenu.html"
self.browser.setSize(Instance.win.getXSize(), Instance.win.getYSize())
self.browserNodePath = self.browser.create(Instance.win, browser_settings, transparent=False)
self.browserNodePath.reparentTo(Instance.render2d)
self.browser.installEventHandler()
self.browser.jsBindings.SetObject("jsapi", self.jsAPI)
self.browser.jsBindings.SetObject("menuAPI", self.menuAPI)
self.browser.updateJSBindings()
self.accept("window-event", self.windowEvent)
def leaveState(self):
self.ignoreAll()
self.browser.removeEventHandler()
self.browserNodePath.removeNode()
def windowEvent(self, win):
if win == Instance.win:
newSize = (Instance.win.getXSize(), Instance.win.getYSize())
if newSize[0] != self.lastSize[0] or newSize[1] != self.lastSize[1]:
self.lastSize = newSize
self.wasResized()
def getName(self):
return "MainMenu"
def wasResized(self):
self.browser.setSize(self.lastSize[0], self.lastSize[1])
<file_sep>__author__ = 'asarium'
<file_sep>import mimetypes
import urllib
import urlparse
__author__ = 'asarium'
from cefpython3 import cefpython
from panda3d.core import VirtualFile, VirtualFileSystem
mimetypes.add_type("application/font-woff", ".woff")
def getMimeType(url):
parts = urlparse.urlparse(url)
mimeType = mimetypes.guess_type(parts.path, strict=False)
if mimeType[0] is not None:
return mimeType[0]
else:
return "application/octet-stream"
class VFSResourceHandler():
def __init__(self, clientHandler):
self.clientHandler = clientHandler
self.contents = None
self.filePath = None
self.url = None
self.clientHandler = None
self.offset = 0
def ProcessRequest(self, request, callback):
"""
:type callback: cefpython.PyCallback
:type request: cefpython.PyRequest
"""
self.url = request.GetUrl()
parts = urlparse.urlparse(self.url)
self.filePath = urllib.unquote_plus(parts.path[1:])
# We are done immediately
callback.Continue()
return True
def GetResponseHeaders(self, response, responseLengthOut, redirectUrlOut):
"""
:type response: cefpython.PyResponse
"""
response.SetMimeType(getMimeType(self.url))
file = VirtualFileSystem.getGlobalPtr().getFile(self.filePath)
if file is None:
response.SetStatus(404)
response.SetStatusText("File not found")
return
responseLengthOut[0] = file.getFileSize()
def ReadResponse(self, dataOut, bytesToRead, bytesReadOut, callback):
if self.contents is None:
self.contents = VirtualFileSystem.getGlobalPtr().readFile(self.filePath, False)
if self.offset < len(self.contents):
dataOut[0] = self.contents[self.offset:self.offset + bytesToRead]
bytesReadOut[0] = bytesToRead
self.offset += bytesToRead
return True
# We are done
self.clientHandler._ReleaseStrongReference(self)
return False
def Cancel(self):
pass
def CanGetCookie(self, cookie):
# Return true if the specified cookie can be sent
# with the request or false otherwise. If false
# is returned for any cookie then no cookies will
# be sent with the request.
return True
def CanSetCookie(self, cookie):
# Return true if the specified cookie returned
# with the response can be set or false otherwise.
return True
<file_sep>__author__ = 'asarium'
<file_sep>jQuery(function ($)
{
// You can determine if we are currently in the game by checking the jsapi object
var runningInGame = typeof window.jsapi != "undefined";
$("button").button();
$("button-quit-game").button().click(function(event)
{
event.preventDefault();
window.menuAPI.quit();
});
});
<file_sep>import sys
__author__ = 'asarium'
class MainMenuAPI():
def __init__(self, showBase):
self.showBase = showBase
def quit(self):
sys.exit()
<file_sep>__author__ = 'asarium'
from panda3dext.cef.ClientHandler import ClientHandler
from panda3dext.cef.EventHandler import EventHandler
from cefpython3 import cefpython
from panda3d.core import Texture, VirtualFileSystem, CardMaker, NodePath
class Browser():
def __init__(self):
self.texture = None
self.width = -1
self.height = -1
self.initialURL = None
self.browser = None
self.jsBindings = None
self.eventHandler = None
def setSize(self, width, height):
if self.texture is None:
self.texture = Texture()
self.width = width
self.height = height
self.texture.setup2dTexture(width, height, Texture.TUnsignedByte, Texture.FRgba)
if self.browser is not None:
self.browser.WasResized()
def create(self, window, settings=None, transparent=True):
"""
Creates the browser and returns a NodePath which can be used to display the browser
:type window: libpanda.GraphicsWindow
:type settings: dict
:type transparent: bool
:return: The new nodepath
"""
if not settings: settings = {}
windowInfo = cefpython.WindowInfo()
if window is not None:
windowHandle = window.getWindowHandle().getIntHandle()
windowInfo.SetAsOffscreen(windowHandle)
else:
windowInfo.SetAsChild(0)
windowInfo.SetTransparentPainting(transparent)
if self.texture is None:
if window is None:
raise RuntimeError("Texture is not initialized and no window was given!")
else:
self.setSize(window.getXSize(), window.getYSize())
self.browser = cefpython.CreateBrowserSync(windowInfo, settings, self.initialURL)
self.browser.SendFocusEvent(True)
self.browser.SetClientHandler(ClientHandler(self.browser, self.texture))
self.browser.WasResized()
self.jsBindings = cefpython.JavascriptBindings(bindToFrames=False, bindToPopups=True)
self.browser.SetJavascriptBindings(self.jsBindings)
# Now create the node
cardMaker = CardMaker("browser2d")
cardMaker.setFrameFullscreenQuad()
node = cardMaker.generate()
nodePath = NodePath(node)
nodePath.setTexture(self.texture)
return nodePath
def installEventHandler(self):
self.eventHandler = EventHandler(self.browser)
self.eventHandler.installEventHandlers()
def removeEventHandler(self):
if self.eventHandler is None:
raise RuntimeError("Event handler was never installed!")
self.eventHandler.removeEventHandlers()
del self.eventHandler
def updateJSBindings(self):
self.browser.SetJavascriptBindings(self.jsBindings)
@staticmethod
def initializeChromium(settings, debug=False):
cefpython.g_debug = debug
cefpython.Initialize(settings)
@staticmethod
def doMessageLoopWork(task):
cefpython.MessageLoopWork()
return task.cont
@staticmethod
def shutdownChromium():
cefpython.Shutdown()
<file_sep>from core.GameShowBase import Instance
__author__ = 'asarium'
from cefpython3 import cefpython
Initialized = False
UpdateTask = None
def updateFunc(task):
cefpython.MessageLoopWork()
return task.cont
def initializeBrowser(settings=None):
global Initialized
global UpdateTask
if Initialized:
return
if settings is None: settings = {}
cefpython.Initialize(settings)
UpdateTask = Instance.taskMgr.add(updateFunc, "ChromiumUpdateTask")
Instance.finalExitCallbacks.append(shutdownBrowser)
Initialized = True
def shutdownBrowser():
Instance.taskMgr.remove(UpdateTask)
cefpython.Shutdown()
<file_sep>
from cefpython3 import cefpython
from direct.showbase.DirectObject import DirectObject
__author__ = 'Marius'
class EventHandler(DirectObject):
def __init__(self, browser):
"""
:type browser: cefpython.PyBrowser
"""
DirectObject.__init__(self)
self.keyModifiers = 0
self.modifierKeys = {
"shift": cefpython.VK_SHIFT,
"ctrl": cefpython.VK_CONTROL,
"alt": cefpython.VK_MENU
}
self.translateKeys = {
"f1": cefpython.VK_F1, "f2": cefpython.VK_F2,
"f3": cefpython.VK_F3, "f4": cefpython.VK_F4,
"f5": cefpython.VK_F5, "f6": cefpython.VK_F6,
"f7": cefpython.VK_F7, "f8": cefpython.VK_F8,
"f9": cefpython.VK_F9, "f10": cefpython.VK_F10,
"f11": cefpython.VK_F11, "f12": cefpython.VK_F12,
"arrow_left": cefpython.VK_LEFT,
"arrow_up": cefpython.VK_UP,
"arrow_down": cefpython.VK_DOWN,
"arrow_right": cefpython.VK_RIGHT,
"enter": cefpython.VK_RETURN,
"tab": cefpython.VK_TAB,
"space": cefpython.VK_SPACE,
"escape": cefpython.VK_ESCAPE,
"backspace": cefpython.VK_BACK,
"insert": cefpython.VK_INSERT,
"delete": cefpython.VK_DELETE,
"home": cefpython.VK_HOME,
"end": cefpython.VK_END,
"page_up": cefpython.VK_PAGEUP,
"page_down": cefpython.VK_PAGEDOWN,
"num_lock": cefpython.VK_NUMLOCK,
"caps_lock": cefpython.VK_CAPITAL,
"scroll_lock": cefpython.VK_SCROLL,
"lshift": cefpython.VK_LSHIFT,
"rshift": cefpython.VK_RSHIFT,
"lcontrol": cefpython.VK_LCONTROL,
"rcontrol": cefpython.VK_RCONTROL,
"lalt": cefpython.VK_LMENU,
"ralt": cefpython.VK_RMENU,
}
self.lastY = None
self.lastX = None
self.browser = browser
def getMousePixelCoordinates(self, mouse):
# This calculation works only for the browser area.
x = (mouse.getX() + 1) / 2.0 * base.win.getXSize()
y = (-mouse.getY() + 1) / 2.0 * base.win.getYSize()
return x, y
def mouseEvent(self, button, up):
if base.mouseWatcherNode.hasMouse():
mouse = base.mouseWatcherNode.getMouse()
(x, y) = self.getMousePixelCoordinates(mouse)
type = None
if button == 1:
type = cefpython.MOUSEBUTTON_LEFT
elif button == 2:
type = cefpython.MOUSEBUTTON_MIDDLE
else:
type = cefpython.MOUSEBUTTON_RIGHT
self.browser.SendMouseClickEvent(x, y, type, up, 1)
def mouseWheelEvent(self, up):
if base.mouseWatcherNode.hasMouse():
mouse = base.mouseWatcherNode.getMouse()
(x, y) = self.getMousePixelCoordinates(mouse)
if up:
self.browser.SendMouseWheelEvent(x, y, 0, 120)
else:
self.browser.SendMouseWheelEvent(x, y, 0, -120)
def updateMouseTask(self, task):
if base.mouseWatcherNode.hasMouse():
mouse = base.mouseWatcherNode.getMouse()
(x, y) = self.getMousePixelCoordinates(mouse)
if x != self.lastX or y != self.lastY:
self.browser.SendMouseMoveEvent(x, y, False)
self.lastX = x
self.lastY = y
return task.cont
def installMouseHandlers(self):
self.accept("mouse1", self.mouseEvent, [1, False])
self.accept("mouse2", self.mouseEvent, [2, False])
self.accept("mouse3", self.mouseEvent, [3, False])
self.accept("mouse1-up", self.mouseEvent, [1, True])
self.accept("mouse2-up", self.mouseEvent, [2, True])
self.accept("mouse3-up", self.mouseEvent, [3, True])
self.accept("wheel_up", self.mouseWheelEvent, [True])
self.accept("wheel_down", self.mouseWheelEvent, [False])
taskMgr.add(self.updateMouseTask, 'ChromiumMouseUpdateTask')
def initKeyboardHandlers(self):
base.buttonThrowers[0].node().setKeystrokeEvent('keystroke')
base.buttonThrowers[0].node().setButtonDownEvent('button-down')
base.buttonThrowers[0].node().setButtonUpEvent('button-up')
base.buttonThrowers[0].node().setButtonRepeatEvent('button-repeat')
self.accept("keystroke", self.onKeystroke)
self.accept("button-down", self.onButtonDown)
self.accept("button-up", self.onButtonUp)
self.accept("button-repeat", self.onButtonDown)
self.keyModifiers = 0
def keyInfo(self, key):
if self.translateKeys.has_key(key):
return self.translateKeys[key]
else:
return ord(key)
def onKeystroke(self, key):
event = {
"type": cefpython.KEYEVENT_CHAR,
"modifiers": self.keyModifiers,
"windows_key_code": self.keyInfo(key),
"native_key_code": self.keyInfo(key),
}
self.browser.SendKeyEvent(event)
def onButtonDownOrUp(self, keyType, key):
if self.modifierKeys.has_key(key):
self.keyModifiers |= self.modifierKeys[key]
else:
if self.translateKeys.has_key(key):
event = {
"type": keyType,
"modifiers": self.keyModifiers,
"windows_key_code": self.keyInfo(key),
"native_key_code": self.keyInfo(key),
}
self.browser.SendKeyEvent(event)
def onButtonDown(self, key):
self.onButtonDownOrUp(cefpython.KEYEVENT_KEYDOWN, key)
def onButtonUp(self, key):
self.onButtonDownOrUp(cefpython.KEYEVENT_KEYUP, key)
def installEventHandlers(self):
self.installMouseHandlers()
self.initKeyboardHandlers()
def removeEventHandlers(self):
self.ignoreAll()<file_sep>__author__ = 'asarium'
class JavaScriptAPI():
def __init__(self):
pass
def helloWorld(self):
print("Hello World")
<file_sep>__author__ = 'asarium'
from abc import ABCMeta, abstractmethod
class State(object):
__metaclass__ = ABCMeta
def __init__(self):
self.gameMachine = None
@abstractmethod
def enterState(self):
pass
@abstractmethod
def leaveState(self):
pass
@abstractmethod
def getName(self):
pass
def setStateMachine(self, gameMachine):
"""
:type gameMachine: core.GameStateMachine.GameStateMachine
"""
self.gameMachine = gameMachine<file_sep>import urlparse
from cefpython3 import cefpython
from panda3dext.cef.VFSResourceHandler import VFSResourceHandler
from panda3d.core import VirtualFileSystem
__author__ = 'Marius'
from panda3d.core import PStatCollector
class ClientHandler:
"""A client handler is required for the browser to do built in callbacks back into the application."""
def __init__(self, browser, texture):
self.browser = browser
self.texture = texture
self.vfs = VirtualFileSystem.getGlobalPtr()
def OnPaint(self, browser, paintElementType, dirtyRects, buffer, width, height):
img = self.texture.modifyRamImage()
if paintElementType == cefpython.PET_POPUP:
print("width=%s, height=%s" % (width, height))
elif paintElementType == cefpython.PET_VIEW:
img.setData(buffer.GetString(mode="bgra", origin="bottom-left"))
else:
raise Exception("Unknown paintElementType: %s" % paintElementType)
def GetViewRect(self, browser, rect):
width = self.texture.getXSize()
height = self.texture.getYSize()
rect.append(0)
rect.append(0)
rect.append(width)
rect.append(height)
return True
def OnBeforePopup(self):
return True # Always disallow popups
def GetResourceHandler(self, browser, frame, request):
url = request.GetUrl()
parts = urlparse.urlparse(url)
if parts.netloc.upper() == "VFS":
vfsHandler = VFSResourceHandler(self)
self._AddStrongReference(vfsHandler)
return vfsHandler
return None
# A strong reference to ResourceHandler must be kept
# during the request. Some helper functions for that.
# 1. Add reference in GetResourceHandler()
# 2. Release reference in ResourceHandler.ReadResponse()
# after request is completed.
_resourceHandlers = {}
_resourceHandlerMaxId = 0
def _AddStrongReference(self, resHandler):
self._resourceHandlerMaxId += 1
resHandler._resourceHandlerId = self._resourceHandlerMaxId
self._resourceHandlers[resHandler._resourceHandlerId] = resHandler
def _ReleaseStrongReference(self, resHandler):
if resHandler._resourceHandlerId in self._resourceHandlers:
del self._resourceHandlers[resHandler._resourceHandlerId]
else:
print("_ReleaseStrongReference() FAILED: resource handler "
"not found, id = %s" % resHandler._resourceHandlerId) | 84cea8e142cc49239f02371b91dcd0316c6575fb | [
"JavaScript",
"Python"
] | 18 | Python | Tuxinet/LoR | 865a499431bede61e2ba63645743e77cc56089e8 | c3f908a2957fa07944e997a7508dc1d5ff5d98e4 |
refs/heads/master | <repo_name>manik2158/Hospital-management-SYstem<file_sep>/hospital/models.py
from django.db import models
# Create your models here.
class Doctor(models.Model):
name = models.CharField(max_length=40)
mobile =models.IntegerField()
specialization=models.CharField(max_length=50)
def __str__(self):
return self.name
class Patient (models.Model):
name=models.CharField(max_length=40)
gender=models.CharField(max_length=10)
mobile=models.IntegerField(null=True)
address=models.CharField(max_length=150)
def __str__(self):
return self.name
class Appointment (models.Model):
doctor=models.ForeignKey(Doctor,on_delete=models.CASCADE)
patient=models.ForeignKey(Patient,on_delete=models.CASCADE)
date1=models.DateField(null=True)
time1=models.TimeField(max_length=150)
def __str__(self):
return self.doctor.name+"----"+self.patient.name<file_sep>/README.md
# Hospital-management-System
Simple hospital management system based on python web framework (django)
<file_sep>/hospital/views.py
from django.shortcuts import render,redirect
from django.contrib.auth.models import User
from .models import Doctor,Patient,Appointment
from django.contrib.auth import authenticate,login,logout
# Create your views here.
def About(request):
return render(request,'about.html')
def Contact(request):
return render(request,'contact.html')
def Index(request):
if not request.user.is_staff:
return redirect('login')
doctors = Doctor.objects.all()
patients = Patient.objects.all()
appointments = Appointment.objects.all()
d=0
p=0
a=0
for i in doctors :
d+=1
for i in patients:
p+=1
for i in appointments:
a+=1
context = {'d':d,'p':p,'a':a}
return render(request,'index.html',context)
def Login(request):
error=""
if request.method=='POST':
u=request.POST['uname']
p=request.POST['pwd']
user=authenticate(username=u , password=p)
try:
if user.is_staff:
login(request,user)
error="no"
else:
error="yes"
except:
error="yes"
d={'error':error}
return render(request,'login.html',d)
def Logout_admin(request):
if not request.user.is_staff:
return redirect('login')
logout(request)
return redirect('login')
def View_Doctor(request):
if not request.user.is_staff:
return redirect('login')
doc =Doctor.objects.all()
d={'doc':doc}
return render(request,'view_doctor.html',d)
def Add_Doctor(request):
error=""
if not request.user.is_staff:
return redirect('login')
if request.method=='POST':
n=request.POST['name']
c=request.POST['contact']
sp=request.POST['special']
try:
Doctor.objects.create(name=n,mobile=c,special=sp)
error="no"
except:
error="yes"
err={'error':error}
return render(request,'add_doctor.html',err)
def Delete_Doctor(request,pid):
if not request.user.is_staff:
return redirect('login')
doctor=Doctor.objects.get(id=pid)
doctor.delete()
return redirect('view_doctor')
def View_Patient(request):
if not request.user.is_staff:
return redirect('login')
pat =Patient.objects.all()
d={'pat':pat}
return render(request,'view_patient.html',d)
def Add_Patient(request):
error=""
if not request.user.is_staff:
return redirect('login')
if request.method=='POST':
n=request.POST['name']
g=request.POST['gender']
c=request.POST['mobile']
add=request.POST['address']
try:
Patient.objects.create(name=n,gender=g,mobile=c,address=add)
error="no"
except:
error="yes"
err={'error':error}
return render(request,'add_patient.html',err)
def Delete_Patient(request,pid):
if not request.user.is_staff:
return redirect('login')
patient=Patient.objects.get(id=pid)
patient.delete()
return redirect('view_patient')
def View_Appointment(request):
if not request.user.is_staff:
return redirect('login')
appoint = Appointment.objects.all()
d={'appoint':appoint}
return render(request,'view_appointment.html',d)
def Add_Appointment(request):
error=""
if not request.user.is_staff:
return redirect('login')
doctor1 = Doctor.objects.all()
patient1 = Patient.objects.all()
if request.method=='POST':
d=request.POST['doctor']
p=request.POST['patient']
d1=request.POST['date']
t=request.POST['time']
doctor=Doctor.objects.filter(name=d).first()
patient=Patient.objects.filter(name=p).first()
try:
Appointment.objects.create(doctor=d,patient=p,date1=d1,time1=t)
error="no"
except:
error="yes"
err={'doctor':doctor1,'patient':patient1,'error':error}
return render(request,'add_appointment.html',err)
def Delete_Appointment(request,pid):
if not request.user.is_staff:
return redirect('login')
appointment=Appointment.objects.get(id=pid)
appointment.delete()
return redirect('view_appointment') | d99b16298ea7ca9fb495c2c2104fc07bd0972628 | [
"Markdown",
"Python"
] | 3 | Python | manik2158/Hospital-management-SYstem | 846e7ddf662917ecaab5edcf561273e442587f44 | 981316c4dc9638b7303f4a56a97ba7522375c3aa |
refs/heads/master | <file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="SF"
ilev="250"
min1="-8.0E7"
max1="8.0E7"
diffs1="1.0e7"
min2="-1.0e6"
max2="1.0e6"
diffs2="2.0e7"
units="m:S:2:N:s:S:-1:N:"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd ./scripts/
difvars="0"
expdif="0"
figtit="Paper"
numexps="4"
dir1="/home/disk/rachel/CESM_outfiles/"
exps1=("CESMtopof19" "CESMnoTf19" "CESMnoT4f19" "CESMnoT2f19")
titles1=("R\_CTL" "R\_noT" "R\_noM" "R\_noMT")
dir2="/home/disk/eos4/rachel/CESM_outfiles/"
exps2=("CAM4SOM4topo" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_noMT")
titles2=("R\_CTL\_SOM" "R\_noT\_SOM" "R\_noM\_SOM" "R\_noMT\_SOM")
start1="2"
end1="31"
start2="11"
end2="40"
timespan="DJF"
reverse="false"
linear="false"
clon="180.0"
slon="0.0"
elon="210.0"
slat="0.0"
elat="90.0"
plottype="map"
plotctl=1
plotERA=0
titleprefix="SOM_fSST_"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start2
((index++))
eval export NCL_ARG2_$index=$end2
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
plotvar="TS"
ilev="0"
min1="260.0"
max1="305.0"
diffs1="5.0"
min2="-3.0"
max2="3.0"
diffs2="0.5"
units="K"
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic_SOMfSST1_paper.ncl
ncl plot_generic_SOMfSST2_paper.ncl
<file_sep>#!/bin/sh
cd ./scripts/individual/
figtit="PerfectLat"
dir1="/home/disk/rachel/CESM_outfiles/"
numexps="5"
exps1=("CESMnotopof19" "CESM_IG34" "CESM_onlyITSh" "CESM_IG44" "CESM_IG49")
titles1=("CAM4_flat" "CAM4_IG34N" "CAM4_IG39N" "CAM4_IG44N" "CAM4_IG49N")
dir2="/home/disk/rachel/CESM_outfiles/"
exps2=("CESMnotopof19" "CESM_onlyIT" "CESM_onlyIT2" "CESM_onlyIT4" "CESM_onlyITSh")
titles2=("CAM4_flat" "CAM4_idealT" "CAM4_idealT_N" "CAM4_wallN" "CAM4_short_T")
start1="2"
end1="31"
start2="2"
end2="41"
timespan="DJF"
reverse="true"
linear="false"
clon="180.0"
slon="60.0"
elon="210.0"
slat="0.0"
elat="90.0"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start2
((index++))
eval export NCL_ARG2_$index=$end2
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
#./plot_Zvar.sh
#./plot_U250.sh
#./plot_Tadv850_ZMline.sh
#./plot_DT_Tadv850_ZMline.sh
#./plot_DU_Tadv850_ZMline.sh
#./plot_Tadv500_ZMline.sh
#./plot_DT_Tadv500_ZMline.sh
#./plot_DU_Tadv500_ZMline.sh
#./plot_dtdy600.sh
#./plot_dtdy250.sh
#./plot_dtdy850.sh
#./plot_V250.sh
#./plot_V850.sh
#./plot_DU_Tadv250.sh
#./plot_DU_Tadv850.sh
#./plot_DT_Tadv250.sh
#./plot_DT_Tadv850.sh
#./plot_PV250.sh
#./plot_PV850.sh
#./plot_PV300.sh
#./plot_PV400.sh
#./plot_VbpfTbpf250.sh
#./plot_VbpfTbpf850.sh
#./plot_ZeventsMag.sh
#./plot_ZeventsLen.sh
#./plot_ZeventsMax.sh
#./plot_ZeventsNum.sh
#./plot_EKE250.sh
#./plot_EKE850.sh
#./plot_Tadv600.sh
#./plot_Tadv500.sh
#./plot_TS.sh
#./plot_U250.sh
#./plot_U850.sh
#./plot_U1000.sh
#./plot_EMGR.sh
#./plot_Tadv850.sh
#./plot_Tadv250.sh
./plot_Tdia850.sh
./plot_Tdia250.sh
./plot_Tdis500.sh
#./plot_UV250.sh
#./plot_UV850.sh
#./plot_dtdy600.sh
#./plot_SF850.sh
#./plot_SF250.sh
#./plot_EKE250.sh
#./plot_EKE850.sh
#./plot_Zvar.sh
#./plot_uH.sh
#./plot_uP.sh
#./plot_SFZA700.sh
#./plot_TH700.sh
<file_sep>#!/bin/sh
cd ./scripts/
difvars="1"
expdif="0"
figtit="Paper"
numexps="8"
dir1="/home/disk/eos4/rachel/CESM_outfiles/"
exps1=("CAM4SOM4topo" "CESMtopof19" "CAM4SOM4notopo" "CAM4SOM4_noMT" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_IG44" "CAM4SOM4_IG34")
titles1=("RSOM\_CTL" "R\_CTL" "ISOM\_CTL" "RSOM\_noMT" "RSOM\_noT" "RSOM\_noM" "ISOM\_IG53N" "ISOM\_IG43N")
CTLS=("1" "-1" "-1" "0" "0" "0" "2" "2")
starts=("11" "2" "11" "11" "11" "11" "11" "11")
nyears=("30" "30" "30" "30" "30" "30" "30" "30")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("true" "false" "false" "false" "false" "false" "true" "true")
linear="false"
clon="180.0"
slon="30.0"
elon="300.0"
slat="-30.0"
elat="90.0"
plottype="map"
plotctl=0
plotERA=0
titleprefix="SOM_fSST_"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${CTLS[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${starts[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${nyears[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${timespan[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${reverse[count]}
((count++))
done
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
plotvar="U"
ilev="250"
vartitle="~F10~U~F21~"
min1="-5.0"
max1="50.0"
diffs1="5.0"
min2="-13.5"
max2="13.5"
diffs2="3.0"
units="ms~S~-1~N~"
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$vartitle
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
plotvar="Zvar"
ilev="850"
vartitle="~F10~Z~F21~\'~S~2~N~~F21~"
min1="0.0"
max1="2400.0"
diffs1="200.0"
min2="-450.0"
max2="450.0"
diffs2="100.0"
units="m~S~2~N~"
plottype="map"
# save command line arguments to environment variable NCL_ARG_#
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$vartitle
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_specific_U_Zvar_SOM_fSST.ncl
<file_sep>#!/bin/sh
cd ./scripts/individual/
difvars="0"
expdif="0"
figtit="PerfectLat"
dir1="/home/disk/rachel/CESM_outfiles/"
numexps="6"
exps1=("CESMnotopof19" "CESM_IG29" "CESM_IG34" "CESM_onlyITSh" "CESM_IG44" "CESM_IG49")
titles1=("CAM4_flat" "CAM4_IG38N" "CAM4_IG43N" "CAM4_IG48N" "CAM4_IG53N" "CAM4_IG58N")
dir2="/home/disk/rachel/CESM_outfiles/"
exps2=("CESMnotopof19" "CESM_IG29" "CESM_IG34" "CESM_onlyITSh" "CESM_IG44" "CESM_IG49")
titles2=("CAM4_flat" "CAM4_IG38N" "CAM4_IG43N" "CAM4_IG48N" "CAM4_IG53N" "CAM4_IG58N")
start1="2"
end1="31"
start2="2"
end2="31"
timespan="DJF"
reverse="true"
linear="false"
clon="180.0"
slon="30.0"
elon="240.0"
slat="0.0"
elat="90.0"
plottype="map"
plotctl=1
plotERA=0
titleprefix=""
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start2
((index++))
eval export NCL_ARG2_$index=$end2
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
./plot_DivVprTpr850.sh
./plot_DivVprTpr250.sh
#./plot_VORT850.sh
#./plot_VORT250.sh
#./plot_DUDT_Tadv850.sh
#./plot_PREC.sh
#./plot_dtdx850_ZMline.sh
#./plot_dtdx600_ZMline.sh
#./plot_Zvar.sh
#./plot_Tadv250.sh
#./plot_Tadv850.sh
#./plot_Tadv600.sh
#./plot_U250.sh
#./plot_dtdy600.sh
#./plot_dtdy250.sh
#./plot_dtdy850.sh
#./plot_V250.sh
#./plot_V850.sh
#./plot_DU_Tadv250.sh
#./plot_DU_Tadv600.sh
#./plot_DU_Tadv850.sh
#./plot_DT_Tadv250.sh
#./plot_DT_Tadv600.sh
#./plot_DT_Tadv850.sh
#./plot_DUDT_Tadv250.sh
#./plot_DUDT_Tadv600.sh
#./plot_DUDT_Tadv850.sh
#./plot_DU_x_Tadv850.sh
#./plot_DU_y_Tadv850.sh
#./plot_DT_x_Tadv850.sh
#./plot_DT_y_Tadv850.sh
#./plot_DU_x_Tadv600.sh
#./plot_DU_y_Tadv600.sh
#./plot_DT_x_Tadv600.sh
#./plot_DT_y_Tadv600.sh
#./plot_TH850.sh
#./plot_TH250.sh
#./plot_TH600.sh
#./plot_DT_Tadv250.sh
#./plot_DT_Tadv850.sh
#./plot_PV250.sh
#./plot_PV850.sh
#./plot_PV300.sh
#./plot_PV400.sh
#./plot_VbpfTbpf250.sh
#./plot_VbpfTbpf850.sh
#./plot_ZeventsMag.sh
#./plot_ZeventsLen.sh
#./plot_ZeventsMax.sh
#./plot_ZeventsNum.sh
#./plot_EKE250.sh
#./plot_EKE850.sh
#./plot_Tadv600.sh
#./plot_Tadv500.sh
#./plot_TS.sh
#./plot_U250.sh
#./plot_U850.sh
#./plot_U1000.sh
#./plot_EMGR.sh
#./plot_Tadv850.sh
#./plot_Tadv250.sh
#./plot_Tdia850.sh
#./plot_Tdia250.sh
#./plot_UV250.sh
#./plot_UV850.sh
#./plot_dtdy600.sh
#./plot_SF850.sh
#./plot_SF250.sh
#./plot_EKE250.sh
#./plot_EKE850.sh
#./plot_Zvar.sh
#./plot_uH.sh
#./plot_uP.sh
#./plot_SFZA700.sh
#./plot_TH700.sh
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Standard/scripts/
dir="/home/disk/eos4/rachel/CESM_outfiles/"
#dir="/home/disk/rachel/CESM_outfiles/"
numexps="3"
exps=("CAM4SOM4notopo" "CAM4SOM4_IG34" "CAM4SOM4_IG44")
start="11"
end="40"
nsecs="00000"
export NCL_N_ARGS=$#
# save command line arguments to environment variable NCL_ARG_#
export NCL_ARG_1=$dir
export NCL_ARG_2=$numexps
# save command line arguments to environment variable NCL_ARG_#
for ((index=3; index<=2+$numexps; index++))
do
eval export NCL_ARG_$index=${exps[index-3]}
done
echo $index
eval export NCL_ARG_$index=$start
((index++))
echo $index
eval export NCL_ARG_$index=$end
((index++))
echo $index
eval export NCL_ARG_$index=$nsecs
echo NCL_N_ARGS
#echo 'LanczosF_time.ncl'
#ncl LanczosF_time.ncl
#echo 'Calc_EV.ncl'
#ncl Calc_EV.ncl
#echo 'Calc_meanEKE.ncl'
#ncl Calc_meanEKE.ncl
#echo 'Calc_EKE_VT.ncl'
#ncl Calc_EKE_VT.ncl
echo 'Calc_Vpr_Upr_THpr'
ncl Calc_Vpr_Upr_THpr.ncl
echo 'Calc_VprTHpr_UprTHpr.ncl'
ncl Calc_VprTHpr_UprTHpr.ncl
echo 'Calc_Vpr_Upr_THpr_annual.ncl'
ncl Calc_Vpr_Upr_THpr_annual.ncl
echo 'Calc_VprTHpr_UprTHpr_annual.ncl'
ncl Calc_VprTHpr_UprTHpr_annual.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd ./scripts/individual/
figtit="SOM_newSOM"
dir1="/home/disk/eos4/rachel/CESM_outfiles/OldSOM/"
numexps="4"
exps1=("CESMSOM4topof19g16" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_noMT")
titles1=("Old_CAM4_SOM4_CTL" "Old_CAM4_SOM4_noT" "Old_CAM4_SOM4_noM" "Old_CAM4_SOM4_noMT")
dir2="/home/disk/eos4/rachel/CESM_outfiles/"
exps2=("CAM4SOM4topo" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_noMT")
titles2=("CAM4SOM4_CTL" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_noMT")
start1="160"
end1="189"
start2="11"
end2="40"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start2
((index++))
eval export NCL_ARG2_$index=$end2
((index++))
./plot_U250_dd.sh
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="Topo"
ilev="0"
min1="0.0"
max1="5000.0"
diffs1="500.0"
min2="0.0"
max2="5000.0"
diffs2="500.0"
units="m"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="U"
ilev="250"
min1="-30.0"
max1="60.0"
diffs1="0.000005"
min2="-10.00"
max2="20.0"
diffs2="20.0"
units="ms:S:-1:N:"
plottype="ZMline"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
eval export NCL_ARG_$index=$plottype
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
difvars="1"
expdif="0"
figtit="Paper"
numexps="6"
dir1="/home/disk/rachel/CESM_outfiles/"
exps1=("CESMnotopof19" "CESM_IG54" "CESM_IG49" "CESM_IG44" "CESM_IG34" "CESM_IG29")
titles1=("I\_CTL" "I\_63N\_2km" "I\_58N\_2km" "I\_53N\_2km" "I\_43N\_2km" "I\_38N\_2km")
CTLS=("-1" "0" "0" "0" "0" "0" "0" "2")
starts=("2" "2" "2" "2" "2" "2" "2" "11")
nyears=("30" "30" "30" "30" "30" "30" "30" "30")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("true" "true" "true" "true" "true" "true" "true" "true")
linear="false"
clon="180.0"
slon="145.0"
elon="145.0"
slat="-30.0"
elat="90.0"
plottype="CS"
plotctl=0
plotERA=0
titleprefix="I3_CS_"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${CTLS[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${starts[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${nyears[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${timespan[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${reverse[count]}
((count++))
done
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
plotvar="V"
ilev="0"
vartitle="~F21~V~F21~"
min1="-2.7"
max1="2.7"
diffs1="0.6"
min2="-2.7"
max2="2.7"
diffs2="0.6"
units="m~S~2~N~s~S~-1~N~"
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$vartitle
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
plotvar="PV"
ilev="0"
vartitle="PV"
min1="-2.0e-6"
max1="2.0e-6"
diffs1="4.0e-7"
min2="-0.225e-6"
max2="0.225e-6"
diffs2="0.5e-7"
units="PVU"
# save command line arguments to environment variable NCL_ARG_#
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$vartitle
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
<file_sep>#!/bin/sh
cd ./scripts/
difvars="0"
expdif="0"
figtit="Paper"
dir1="/home/disk/rachel/CESM_outfiles/"
numexps="4"
exps1=("CESM_Topo_noNAm" "CESM_Topo_R_2km_60_0" "CESM_Topo_R_2km_50_0" "CESM_Topo_R_2km_40_0")
titles1=("I\_Topo\_noNAm" "I\_Rock\_60N" "I\_Rock\_50N" "I\_Rock\_40N")
start1="2"
end1="31"
timespan="DJF"
reverse="true"
linear="false"
clon="0.0"
slon="320.0"
elon="340.0"
slat="0.0"
elat="90.0"
plottype="ZMline"
plotctl=1
plotERA=0
titleprefix="IR1_"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
ncl plot_generic_ZMline_paper_xmb.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Standard/scripts/
#dir="/home/disk/eos4/rachel/CESM_outfiles/"
numexps="5"
dir="/home/disk/eos4/rachel/CESM_outfiles/"
exps=("CAM4SOM4notopo" "CAM4SOM4topo" "CAM4SOM4_noMT" "CAM4SOM4_IG44" "CAM4SOM4_IG34")
start="21"
end="30"
nsecs="00000"
export NCL_N_ARGS=$#
# save command line arguments to environment variable NCL_ARG_#
export NCL_ARG_1=$dir
export NCL_ARG_2=$numexps
# save command line arguments to environment variable NCL_ARG_#
for ((index=3; index<=2+$numexps; index++))
do
eval export NCL_ARG_$index=${exps[index-3]}
done
echo $index
eval export NCL_ARG_$index=$start
((index++))
echo $index
eval export NCL_ARG_$index=$end
((index++))
echo $index
eval export NCL_ARG_$index=$nsecs
echo NCL_N_ARGS
ncl Create_all_means.ncl
echo 'Create_all_means.ncl'
ncl Calc_VertGrad.ncl
echo 'Calc_VertGrad.ncl'
ncl hybrid2pres_more.ncl
echo 'hybrid2pres_more.ncl'
start="31"
end="40"
nsecs="00000"
export NCL_N_ARGS=$#
# save command line arguments to environment variable NCL_ARG_#
export NCL_ARG_1=$dir
export NCL_ARG_2=$numexps
# save command line arguments to environment variable NCL_ARG_#
for ((index=3; index<=2+$numexps; index++))
do
eval export NCL_ARG_$index=${exps[index-3]}
done
echo $index
eval export NCL_ARG_$index=$start
((index++))
echo $index
eval export NCL_ARG_$index=$end
((index++))
echo $index
eval export NCL_ARG_$index=$nsecs
echo NCL_N_ARGS
ncl Create_all_means.ncl
echo 'Create_all_means.ncl'
ncl Calc_VertGrad.ncl
echo 'Calc_VertGrad.ncl'
ncl hybrid2pres_more.ncl
echo 'hybrid2pres_more.ncl'
<file_sep>#!/bin/sh
cd ./scripts/
difvars="1"
expdif="0"
figtit="Paper"
numexps="8"
dir1="/home/disk/eos4/rachel/CESM_outfiles/"
exps1=("CAM4SOM4topo" "CESMtopof19" "CAM4SOM4notopo" "CAM4SOM4_noMT" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_IG44" "CAM4SOM4_IG34")
titles1=("RSOM\_CTL" "R\_CTL" "ISOM\_CTL" "RSOM\_noTM" "RSOM\_noT" "RSOM\_noM" "ISOM\_IG53N" "ISOM\_IG43N")
CTLS=("1" "-1" "-1" "0" "0" "0" "2" "2")
starts=("11" "2" "11" "11" "11" "11" "11" "11")
nyears=("30" "30" "30" "30" "30" "30" "30" "30")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("true" "false" "false" "false" "false" "false" "true" "true")
linear="false"
clon="180.0"
slon="30.0"
elon="300.0"
slat="-30.0"
elat="90.0"
plottype="map"
plotctl=0
plotERA=0
titleprefix="SOM_fSST_"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${CTLS[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${starts[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${nyears[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${timespan[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${reverse[count]}
((count++))
done
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
plotvar="TS"
ilev="0"
vartitle="~F10~T~F21~"
min1="260.0"
max1="305.0"
diffs1="5.0"
min2="-2.25"
max2="2.25"
diffs2="0.5"
units="K"
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$vartitle
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
plotvar="TH"
ilev="850.0"
vartitle="~F8~q~F21~"
min1="265.0"
max1="310.0"
diffs1="5.0"
min2="-3.6"
max2="3.6"
diffs2="0.8"
units="K"
plottype="map"
# save command line arguments to environment variable NCL_ARG_#
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$vartitle
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_specific_SST_TH_SOM_fSST.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/git/NCL/cesm_scripts/Analysis/Standard/scripts/
#dir="/home/disk/eos4/rachel/CESM_outfiles/"
dir="/home/disk/eos4/rachel/CESM_outfiles/"
exps=("CAM4POP_f19g16C_noMT")
numexps="1"
start="160"
end="200"
export NCL_dirstr="/atm/hist/"
# save command line arguments to environment variable NCL_ARG_#
export NCL_ARG_1=$dir
export NCL_ARG_2=$numexps
# save command line arguments to environment variable NCL_ARG_#
for ((index=3; index<=2+$numexps; index++))
do
eval export NCL_ARG_$index=${exps[index-3]}
done
echo $index
eval export NCL_ARG_$index=$start
((index++))
echo $index
eval export NCL_ARG_$index=$end
((index++))
echo $index
echo NCL_N_ARGS
#echo "Initial_analysis_means.ncl"
#ncl Initial_analysis_means.ncl
echo 'hybrid2pres_TH_Z_N.ncl'
ncl hybrid2pres_TH_Z_N.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd ./scripts/
difvars="0"
expdif="0"
figtit="Paper"
dir1="/home/disk/rachel/CESM_outfiles/"
numexps="4"
exps1=("CESM_Topo_noAsia" "CESM_Topo_IG34" "CESM_Topo_IG44" "CESM_Topo_IG54")
titles1=("I\_Topo\_CTL" "I\_Topo\_43N\_2km" "I\_Topo\_53N\_2km" "I\_Topo\_63N\_2km")
dir2="/home/disk/rachel/CESM_outfiles/"
exps2=("CESM_Topo_noAsia" "CESM_Topo_IG34" "CESM_Topo_IG44" "CESM_Topo_IG54")
titles2=("I\_Topo\_CTL" "I\_Topo\_43N\_2km" "I\_Topo\_53N\_2km" "I\_Topo\_63N\_2km")
start1="2"
end1="31"
start2="2"
end2="31"
timespan="DJF"
reverse="true"
linear="false"
clon="180.0"
slon="145.0"
elon="145.0"
slat="0.0"
elat="90.0"
plottype="ZMline"
plotctl=1
plotERA=0
titleprefix="Topo_"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start2
((index++))
eval export NCL_ARG2_$index=$end2
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
ncl plot_generic_ZMline_paper_xmb.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Standard/scripts/
#dir="/home/disk/eos4/rachel/CESM_outfiles/"
dir="/home/disk/rachel/CESM_outfiles/"
numexps="1"
exps=("CAM4SOM4topo") #("CAM4SOM4def1") ("CAM4SOM4topo") ("CAM4SOM4def1")
start="11" #"3" "11"
end="40" # "32" "40"
nsecs="00000"
export NCL_N_ARGS=$#
# save command line arguments to environment variable NCL_ARG_#
export NCL_ARG_1=$dir
export NCL_ARG_2=$numexps
# save command line arguments to environment variable NCL_ARG_#
for ((index=3; index<=2+$numexps; index++))
do
eval export NCL_ARG_$index=${exps[index-3]}
done
echo $index
eval export NCL_ARG_$index=$start
((index++))
echo $index
eval export NCL_ARG_$index=$end
((index++))
echo $index
eval export NCL_ARG_$index=$nsecs
echo NCL_N_ARGS
#ncl Create_monthly_means.ncl
#echo 'Create_monthly_means.ncl'
ncl monthly_hybrid2pres.ncl
echo 'monthly_hybrid2pres.ncl'
#ncl Calc_Precip.ncl
#echo 'Calc_Precip.ncl'
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
figtit="SOM_20vs20"
dir1="/home/disk/eos4/rachel/CESM_outfiles/"
numexps="4"
exps1=("CESMSOM4topof19g16" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_noMT")
titles1=("CAM4_SOM4_CTL_10-25" "CAM4_SOM4_noT_10-25" "CAM4_SOM4_noM_10-25" "CAM4_SOM4_noMT_10-25")
dir2="/home/disk/eos4/rachel/CESM_outfiles/"
exps2=("CESMSOM4topof19g16" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_noMT")
titles2=("CAM4_SOM4_CTL_26-40" "CAM4_SOM4_noT_26-40" "CAM4_SOM4_noM_26-40" "CAM4_SOM4_noMT_26-40")
start1="160"
end1="174"
start2="175"
end2="189"
plotvar="PRECT"
ilev="0"
min1="0.0"
max1="8.0"
diffs1="0.8"
min2="-1.5"
max2="1.5"
diffs2="0.3"
units="mms:S:-1:N:"
export NCL_N_ARGS=$#
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG_$index=$figtit
((index++))
export NCL_ARG_$index=$numexps
((index++))
eval export NCL_ARG_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG_$index=$start1
((index++))
eval export NCL_ARG_$index=$end1
((index++))
eval export NCL_ARG_$index=$start2
((index++))
eval export NCL_ARG_$index=$end2
((index++))
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic_tropics.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/git/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvars="UU"
export NCLnumvars="2"
export NCLdifexps="0"
export NCLexpdif="0"
export NCLfigtit="Mongolia/newPaper"
export NCLdir1="/home/disk/rachel/CESM_outfiles/"
export NCLnumexps="4"
export NCLlinear="true"
export NCLclon="180.0"
export NCLslon="30.0"
export NCLelon="270.0"
export NCLslat="0.0"
export NCLelat="90.0"
export NCLplottype="map"
export NCLplotctl=0
export NCLplotERA1=1
export NCLtitleprefix="Real_"
exps1=("CESMtopof19" "CESMnoT2f19" "CESMnoT4f19" "CESMnoTf19")
titles1=("CTL" "\ Impact\ of~C~Tib\ \&\ Mon" "Impact\ of~C~Mongolia" "Impact\ of~C~\ \ \ Tibet")
CTLS=("100" "0" "0" "0" "0" "0" "2" "2")
starts=("2" "2" "2" "2" "2" "11" "11" "11")
nyears=("40" "40" "40" "40" "30" "30" "30" "30")
#timespan=("MAM" "MAM" "MAM" "MAM" "MAM" "MAM" "MAM" "MAM")
#timespan=("AMJ" "AMJ" "AMJ" "AMJ" "AMJ" "AMJ" "AMJ" "AMJ")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("false" "false" "false" "false" "false" "false" "true" "true")
export NCLallblue=0
export NCLplottitles=1
if test "$plotvars" == "SFZA"; then
export NCLallblue=0
export NCLplotvar_1="SFZA"
export NCLilev_1="850"
export NCLvartitle_1="~F8~y'~F21~"
export NCLmin1_1="-0.75e7"
export NCLmax1_1="0.75e7"
export NCLdiffs1_1="0.15e7"
export NCLmin2_1="-7.5e6"
export NCLmax2_1="7.5e6"
export NCLdiffs2_1="1.5e6"
export NCLunits_1="10~S~6~N~s~S~-1~N~"
export NCLplotvar_2="SFZA"
export NCLilev_2="250"
export NCLvartitle_2="~F8~y'~F21~"
export NCLmin1_2="-2.0e7"
export NCLmax1_2="2.0e7"
export NCLdiffs1_2="4.0e6"
export NCLmin2_2="-10.0e6"
export NCLmax2_2="10.0e6"
export NCLdiffs2_2="2.0e6"
export NCLunits_2="10~S~6~N~s~S~-1~N~"
elif test "$plotvars" == "THU"; then
export NCLplotvar_1="TH"
export NCLilev_1="850.0"
export NCLvartitle_1="~F8~q~F21~"
export NCLmin1_1="265.0"
export NCLmax1_1="310.0"
export NCLdiffs1_1="5.0"
export NCLmin2_1="-5.0"
export NCLmax2_1="5.0"
export NCLdiffs2_1="1.0"
export NCLunits_1="K"
export NCLplotvar_2="U"
export NCLilev_2="250"
export NCLvartitle_2="~F10~U~F21~"
export NCLmin1_2="-7.0"
export NCLmax1_2="77.0"
export NCLdiffs1_2="7.0"
export NCLmin2_2="-20.0"
export NCLmax2_2="20.0"
export NCLdiffs2_2="4.0"
export NCLunits_2="ms~S~-1~N~"
elif test "$plotvars" == "UU"; then
export NCLplotvar_1="U"
export NCLilev_1="850.0"
export NCLvartitle_1="~F10~U~F21~"
export NCLmin1_1="-10.0"
export NCLmax1_1="10.0"
export NCLdiffs1_1="2.0"
export NCLmin2_1="-5.0"
export NCLmax2_1="5.0"
export NCLdiffs2_1="1.0"
export NCLunits_1="ms~S~-1~N~"
export NCLplotvar_2="U"
export NCLilev_2="250"
export NCLvartitle_2="~F10~U~F21~"
export NCLmin1_2="-7.0"
export NCLmax1_2="77.0"
export NCLdiffs1_2="7.0"
export NCLmin2_2="-20.0"
export NCLmax2_2="20.0"
export NCLdiffs2_2="4.0"
export NCLunits_2="ms~S~-1~N~"
elif test "$plotvars" == "Zvar"; then
export NCLplotvar_1="Zvar"
export NCLilev_1="250.0"
export NCLvartitle_1="~F10~Z~F21~'~S~2~N~~F21~"
export NCLmin1_1="0"
export NCLmax1_1="8000"
export NCLdiffs1_1="800"
export NCLmin2_1="-2400"
export NCLmax2_1="2400"
export NCLdiffs2_1="400"
export NCLunits_1="m~S~2~N~"
export NCLplotvar_2="Zvar"
export NCLilev_2="850.0"
export NCLvartitle_2="~F10~Z~F21~'~S~2~N~~F21~"
export NCLmin1_2="250"
export NCLmax1_2="2500"
export NCLdiffs1_2="250"
export NCLmin2_2="-450"
export NCLmax2_2="450"
export NCLdiffs2_2="100"
export NCLunits_2="m~S~2~N~"
elif test "$plotvars" == "UV"; then
export NCLplotvar_1="V"
export NCLilev_1="250.0"
export NCLvartitle_1="~F10~V~F21~"
export NCLmin1_1="-8.0"
export NCLmax1_1="64.0"
export NCLdiffs1_1="8.0"
export NCLmin2_1="-10.0"
export NCLmax2_1="10.0"
export NCLdiffs2_1="2.0"
export NCLunits_1="ms~S~-1~N~"
export NCLplotvar_2="U"
export NCLilev_2="250"
export NCLvartitle_2="~F10~U~F21~"
export NCLmin1_2="-8.0"
export NCLmax1_2="64.0"
export NCLdiffs1_2="8.0"
export NCLmin2_2="-10.0"
export NCLmax2_2="10.0"
export NCLdiffs2_2="2.0"
export NCLunits_2="ms~S~-1~N~"
elif test "$plotvars" == "UVPrec"; then
export NCLplotvar_1="UV"
export NCLilev_1="850.0"
export NCLvartitle_1="~F10~V~F21~"
export NCLmin1_1="-10.0"
export NCLmax1_1="10.0"
export NCLdiffs1_1="2.0"
export NCLmin2_1="-5.0"
export NCLmax2_1="5.0"
export NCLdiffs2_1="1.0"
export NCLunits_1="ms~S~-1~N~"
export NCLplotvar_2="PREC"
export NCLilev_2="0"
export NCLvartitle_2="DJF Precip"
export NCLmin1_2="0"
export NCLmax1_2="13.5"
export NCLdiffs1_2="1.5"
export NCLmin2_2="-0.9"
export NCLmax2_2="0.9"
export NCLdiffs2_2="0.2"
export NCLunits_2="mm/day"
elif test "$plotvars" == "WW"; then
export NCLplotvar_1="OMEGA"
export NCLilev_1="850.0"
export NCLvartitle_1="~F10~W~F21~"
export NCLmin1_1="-0.1"
export NCLmax1_1="0.1"
export NCLdiffs1_1="0.02"
export NCLmin2_1="-0.02"
export NCLmax2_1="0.02"
export NCLdiffs2_1="0.004"
export NCLunits_1="ms~S~-1~N~"
export NCLplotvar_2="OMEGA"
export NCLilev_2="700"
export NCLvartitle_2="~F10~W~F21~"
export NCLmin1_2="-0.1"
export NCLmax1_2="0.1"
export NCLdiffs1_2="0.02"
export NCLmin2_2="-0.02"
export NCLmax2_2="0.02"
export NCLdiffs2_2="0.004"
export NCLunits_2="ms~S~-1~N~"
else
#export NCLilev_1="850"
#export NCLvartitle_1="~F8~Z~F21~"
#export NCLmin1_1="1275"
#export NCLmax1_1="1550"
#export NCLdiffs1_1="25"
#export NCLmin2_1="-100"
#export NCLmax2_1="100"
#export NCLdiffs2_1="20"
#export NCLunits_1="m"
#
#export NCLplotvar_2="Z"
#export NCLilev_2="250"
#export NCLvartitle_2="~F8~Z~F21~"
#export NCLmin1_2="9400"
#export NCLmax1_2="11050"
#export NCLdiffs1_2="150"
#export NCLmin2_2="-100"
#export NCLmax2_2="100"
#export NCLdiffs2_2="20"
#export NCLunits_2="m"
#
#export NCLplotvar_2="SF"
#export NCLilev_2="250"
#export NCLvartitle_2="~F8~y'~F21~"
#export NCLmin1_2="-10.0e7"
#export NCLmax1_2="10.0e7"
#export NCLdiffs1_2="2.0e7"
#export NCLmin2_2="-1.0e7"
#export NCLmax2_2="1.0e7"
#export NCLdiffs2_2="2.0e6"
#export NCLunits_2="m~S~2~N~s~S~-1~N~"
#
#
export NCLplotvar_2="SFZA"
export NCLilev_2="250"
export NCLvartitle_2="~F8~y'~F21~"
export NCLmin1_2="-2.0e7"
export NCLmax1_2="2.0e7"
export NCLdiffs1_2="4.0e6"
export NCLmin2_2="-12.0e6"
export NCLmax2_2="12.0e6"
export NCLdiffs2_2="2.0e6"
export NCLunits_2="10e6m~S~2~N~s~S~-1~N~"
#
#export NCLplotvar_2="PV"
#export NCLilev_2="300"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="3.6e-6"
#export NCLdiffs1_2="0.4e-6"
#export NCLmin2_2="-0.9e-6"
#export NCLmax2_2="0.9e-6"
#export NCLdiffs2_2="0.2e-6"
#export NCLunits_2="PVU"
##
export NCLplotvar_1="SFZA"
export NCLilev_1="850"
export NCLvartitle_1="~F8~y'~F21~"
export NCLmin1_1="-1.0e7"
export NCLmax1_1="1.0e7"
export NCLdiffs1_1="2.0e6"
export NCLmin2_1="-7.5e6"
export NCLmax2_1="7.5e6"
export NCLdiffs2_1="1.5e6"
export NCLunits_1="10e6m~S~2~N~s~S~-1~N~"
##
#export NCLplotvar_1="SF"
#export NCLilev_1="850"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-0.9e7"
#export NCLmax1_1="0.9e7"
#export NCLdiffs1_1="2.0e6"
#export NCLmin2_1="-0.675e7"
#export NCLmax2_1="0.675e7"
#export NCLdiffs2_1="1.5e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#
#
#export NCLplotvar_1="TH"
#export NCLilev_1="850.0"
#export NCLvartitle_1="~F8~q~F21~"
#export NCLmin1_1="265.0"
#export NCLmax1_1="310.0"
#export NCLdiffs1_1="5.0"
#export NCLmin2_1="-5.0"
#export NCLmax2_1="5.0"
#export NCLdiffs2_1="1.0"
#export NCLunits_1="K"
#
#export NCLplotvar_1="dTHdy"
#export NCLilev_1="850.0"
#export NCLvartitle_1="~F8~q~F21~"
#export NCLmin1_1="265.0"
#export NCLmax1_1="310.0"
#export NCLdiffs1_1="5.0"
#export NCLmin2_1="-0.000005"
#export NCLmax2_1="0.000005"
#export NCLdiffs2_1="0.000001"
#export NCLunits_1="K"
#
#
#export NCLplotvar_2="dTHdy"
#export NCLilev_2="400.0"
#export NCLvartitle_2="~F8~q~F21~"
#export NCLmin1_2="265.0"
#export NCLmax1_2="310.0"
#export NCLdiffs1_2="5.0"
#export NCLmin2_2="-0.000005"
#export NCLmax2_2="0.000005"
#export NCLdiffs2_2="0.000001"
#export NCLunits_2="K"
#
#export NCLplotvar_1="TH"
#export NCLilev_1="300.0"
#export NCLvartitle_1="~F8~q~F21~"
#export NCLmin1_1="265.0"
#export NCLmax1_1="310.0"
#export NCLdiffs1_1="5.0"
#export NCLmin2_1="-3.6"
#export NCLmax2_1="3.6"
#export NCLdiffs2_1="0.8"
#export NCLunits_1="K"
#
#export NCLplotvar_2="TH"
#export NCLilev_2="250.0"
#export NCLvartitle_2="~F8~q~F21~"
#export NCLmin1_2="265.0"
#export NCLmax1_2="310.0"
#export NCLdiffs1_2="5.0"
#export NCLmin2_2="-3.6"
#export NCLmax2_2="3.6"
#export NCLdiffs2_2="0.8"
#export NCLunits_2="K"
#
#export NCLplotvar_1="U"
#export NCLilev_1="850"
#export NCLvartitle_1="~F10~u~F21~"
#export NCLmin1_1="-7.0"
#export NCLmax1_1="11.0"
#export NCLdiffs1_1="2.0"
#export NCLmin2_1="-9.0"
#export NCLmax2_1="9.0"
#export NCLdiffs2_1="2.0"
#export NCLunits_1="m~S~-1~N~"
#
#export NCLplotvar_2="U"
#export NCLilev_2="250"
#export NCLvartitle_2="~F10~u~F21~"
#export NCLmin1_2="-7.0"
#export NCLmax1_2="77.0"
#export NCLdiffs1_2="7.0"
#export NCLmin2_2="-20.0"
#export NCLmax2_2="20.0"
#export NCLdiffs2_2="4.0"
#export NCLunits_2="ms~S~-1~N~"
##
#export NCLplotvar_1="V"
#export NCLilev_1="850"
#export NCLvartitle_1="~F10~v~F21~"
#export NCLmin1_1="-1.0"
#export NCLmax1_1="6.0"
#export NCLdiffs1_1="0.8"
#export NCLmin2_1="-1.8"
#export NCLmax2_1="1.8"
#export NCLdiffs2_1="0.4"
#export NCLunits_1="m~S~-1~N~"
#
#export NCLplotvar_2="V"
#export NCLilev_2="250"
#export NCLvartitle_2="~F10~v~F21~"
#export NCLmin1_2="-1.0"
#export NCLmax1_2="6.0"
#export NCLdiffs1_2="0.8"
#export NCLmin2_2="-1.80"
#export NCLmax2_2="1.80"
#export NCLdiffs2_2="0.4"
#export NCLunits_2="m~S~-1~N~"
#
#export NCLplotvar_2="Zvar"
#export NCLilev_2="850.0"
#export NCLvartitle_2="~F10~Z~F21~'~S~2~N~~F21~"
#export NCLmin1_2="250"
#export NCLmax1_2="2500"
#export NCLdiffs1_2="250"
#export NCLmin2_2="-450"
#export NCLmax2_2="450"
#export NCLdiffs2_2="100"
#export NCLunits_2="m~S~2~N~"
#export NCLplotvar_1="PREC"
#export NCLilev_1="0"
#export NCLvartitle_1="DJF Precip"
#export NCLmin1_1="0"
#export NCLmax1_1="13.5"
#export NCLdiffs1_1="1.5"
#export NCLmin2_1="-0.9"
#export NCLmax2_1="0.9"
#export NCLdiffs2_1="0.2"
#export NCLunits_1="mm/day"
#
#export NCLplotvar_2="TdiaSRF"
#export NCLilev_2="0"
#export NCLvartitle_2="DJF LH + SH + LW + SW"
#export NCLmin1_2="-200"
#export NCLmax1_2="200"
#export NCLdiffs1_2="40"
#export NCLmin2_2="-90"
#export NCLmax2_2="90"
#export NCLdiffs2_2="20"
#export NCLunits_2="W/m~S~2~N~"
fi
# save command line arguments to environment variable NCL_ARG_#
count=0
for ((index=1; index<=$NCLnumexps; index++))
do
eval export NCLexps1_$index=${exps1[count]}
eval export NCLtitles1_$index=${titles1[count]}
eval export NCLCTLs1_$index=${CTLS[count]}
eval export NCLstarts1_$index=${starts[count]}
eval export NCLnyears1_$index=${nyears[count]}
eval export NCLtimespans1_$index=${timespan[count]}
eval export NCLreverses1_$index=${reverse[count]}
((count++))
done
ncl plot_generic2.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
difvars="1"
expdif="0"
figtit="Paper"
numexps="4"
dir1="/home/disk/rachel/CESM_outfiles/"
exps1=("CESMnoTf19" "CESMnoT4f19" "CESM_IdealRealT" "CESM_IdealRealM")
titles1=("R_noT" "R_noR" "R_noT_33N_5km" "R_noM_48N_2km")
CTLS=("-1" "-1" "0" "1" "0" "0" "2" "2")
starts=("2" "2" "2" "2" "2" "11" "11" "11")
nyears=("30" "30" "30" "30" "30" "30" "30" "30")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("true" "true" "true" "true" "true")
linear="false"
clon="180.0"
slon="30.0"
elon="300."
slat="-30.0"
elat="90.0"
plottype="map"
plotctl=0
plotERA=0
titleprefix="I1.2_"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${CTLS[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${starts[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${nyears[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${timespan[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${reverse[count]}
((count++))
done
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
plotvar="SFZA"
ilev="850"
vartitle="~F8~y\'~F21~"
min1="-0.9e7"
max1="0.9e7"
diffs1="2.0e6"
min2="-0.675e7"
max2="0.675e7"
diffs2="1.5e6"
units="m~S~2~N~s~S~-1~N~"
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$vartitle
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
plotvar="TH"
ilev="850.0"
vartitle="~F8~q~F21~"
min1="265.0"
max1="310.0"
diffs1="5.0"
min2="-3.6"
max2="3.6"
diffs2="0.8"
units="K"
# save command line arguments to environment variable NCL_ARG_#
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$vartitle
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="uH"
ilev="0"
min1="-5"
max1="5"
diffs1="1"
min2="-1"
max2="1"
diffs2="0.2"
units="ms:S:-1:N:"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd ./scripts/
difvars="0"
expdif="0"
figtit="Paper"
dir1="/home/disk/rachel/CESM_outfiles/"
numexps="7"
exps1=("CESMnotopof19" "CESM_IG39_HMer" "CESM_onlyIT2" "CESM_IG39_HZon" "CESM_onlyITSh" "CESM_IG39_West" "CESM_onlyITVS")
titles1=("I_CTL" "I_48N_MerHalf" "I_48N_4km" "I_48N_ZonHalf" "I_48N_2km" "I_48N_West" "I_48N_1km")
start1="2"
end1="31"
start2="2"
end2="31"
timespan="DJF"
reverse="true"
linear="false"
clon="180.0"
slon="30.0"
elon="360.0"
slat=("50.0" "50.0" "50.0" "50.0" "50.0" "50.0" "50.0")
elat=("55.0" "55.0" "55.0" "55.0" "55.0" "55.0" "55.0")
plottype="MMline"
plotctl=0
plotERA=0
titleprefix="LatAvg2"
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir1
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${slat[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${elat[count]}
((count++))
done
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
ncl plot_generic_MMline_paper.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="vort"
ilev="850"
min1="-1.0e-5"
max1="1.0e-5"
diffs1="2.0e-6"
min2="-5.0e-6"
max2="5.0e-6"
diffs2="8.0e-7"
units="m:S:2:N:s:S:-1:N:"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
difvars="1"
difexps="1"
expdif="0"
figtit="Paper"
numexps="4"
dir1="/home/disk/rachel/CESM_outfiles/"
exps1=("CESMtopof19" "CESMnoT2f19" "CESMnoTf19" "CESMnoT4f19")
titles1=("R\_CTL" "R\_noTM" "R\_noT" "R\_noM")
exps2=("CAM4SOM4topo" "CAM4SOM4_noMT" "CAM4SOM4_noT" "CAM4SOM4_noM")
titles2=("RSOM\_CTL" "RSOM\_noTM" "RSOM\_noT" "RSOM\_noM")
CTLS=("100" "0" "0" "0" "0" "0" "2" "2")
starts1=("2" "2" "2" "2" "2" "11" "11" "11")
starts2=("11" "11" "11" "11" "11" "11" "11" "11")
nyears=("30" "30" "30" "30" "30" "30" "30" "30")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("true" "false" "false" "false" "false" "false" "true" "true")
linear="false"
clon="180.0"
slon="0.0"
elon="360."
slat="-30.0"
elat="90.0"
plottype="map"
plotctl=0
plotERA=0
titleprefix=""
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$difexps
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${CTLS[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${starts1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${starts2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${nyears[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${timespan[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${reverse[count]}
((count++))
done
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
plotvar="PREC"
ilev="0"
vartitle="DJF\ Precip\,\ fixed\ SSTs"
min1="0"
max1="13.5"
diffs1="1.5"
min2="-1.8"
max2="1.8"
diffs2="0.4"
units="mm/day"
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$vartitle
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
plotvar="PREC"
ilev="0"
vartitle="DJF\ Precip\,\ Slab\ Ocean\,"
min1="0"
max1="13.5"
diffs1="1.5"
min2="-1.8"
max2="1.8"
diffs2="0.4"
units="mm/day"
# save command line arguments to environment variable NCL_ARG_#
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$vartitle
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="U10"
ilev="100"
min1="0.0"
max1="12.0"
diffs1="1.0"
min2="-3.0"
max2="3.0"
diffs2="0.5"
units="ms~S~-1~N~"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd ./scripts/individual/
figtit="PerfectLat"
dir1="/home/disk/rachel/CESM_outfiles/"
numexps="6"
exps1=("CESMnotopof19" "CESM_IG29" "CESM_IG34" "CESM_onlyITSh" "CESM_IG44" "CESM_IG49")
titles1=("CAM4_flat" "CAM4_IG29N" "CAM4_IG34N" "CAM4_IG39N" "CAM4_IG44N" "CAM4_IG49N")
dir2="/home/disk/rachel/CESM_outfiles/"
exps2=("CESMnotopof19" "CESM_IG29" "CESM_IG34" "CESM_onlyITSh" "CESM_IG44" "CESM_IG49")
titles2=("CAM4_flat" "CAM4_IG29N" "CAM4_IG34N" "CAM4_IG39N" "CAM4_IG44N" "CAM4_IG49N")
start1="2"
end1="31"
start2="2"
end2="31"
timespan="DJF"
reverse="true"
linear="false"
clon="180.0"
slon="30.0"
elon="210.0"
slat="0.0"
elat="90.0"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start2
((index++))
eval export NCL_ARG2_$index=$end2
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
./plot_Tadv850.sh
./plot_DivVprTpr250.sh
./plot_DivVprTpr850.sh
#./plot_DU_Tadv250.sh
#./plot_DU_Tadv600.sh
./plot_DU_Tadv850.sh
#./plot_DT_Tadv250.sh
#./plot_DT_Tadv600.sh
./plot_DT_Tadv850.sh
#./plot_DUDT_Tadv250.sh
#./plot_DUDT_Tadv600.sh
./plot_DUDT_Tadv850.sh
./plot_Tdia850.sh
#./plot_Tdia600.sh
#./plot_Tdia250.sh
#./plot_DTCOND850.sh
#./plot_DTCOND600.sh
#./plot_DTCOND250.sh
#./plot_QRL850.sh
#./plot_QRS850.sh
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/git/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvars="UV850"
export NCLnumvars="2"
export NCLdifexps="1"
export NCLexpdif="0"
export NCLfigtit="Mongolia/newPaper"
export NCLdir1="/home/disk/rachel/CESM_outfiles/"
export NCLnumexps="3"
export NCLlinear="false"
export NCLclon="180.0"
export NCLslon="30.0"
export NCLelon="240."
export NCLslat="0.0"
export NCLelat="80.0"
export NCLplottype="map"
export NCLplotctl=0
export NCLplotERA1=0
export NCLtitleprefix="CTLs_noMT_"
export NCLallblue=1
export NCLplottitles=0
#exps1=("CESMtopof19" "CESMtopof19" "CESMtopof19" "CESMtopof19" "CESMnoT2f19" "CESMnoT4f19")
exps1=("CESMnotopof19" "CESMnotopof19" "CESMnotopof19" "CESMnoT2f19" "CESMnoT4f19")
titles1=("" "" "" "CESM\_no\_M")
CTLS=("100" "100" "100" "100" "0" "0" "0" "2")
starts=("2" "2" "2" "2" "2" "2" "2" "11")
nyears=("40" "40" "40" "40" "40" "40" "40" "40")
#timespan=("SON" "SON" "SON" "SON" "SON" "SON")
#timespan=("SON" "DJF" "MAM" "MAM" "MAM" "MAM")
#timespan=("JJA" "JJA" "JJA" "JJA" "JJA" "JJA")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("true" "true" "true" "true" "true" "true" "true" "true")
if test "$plotvars" == "STD"; then
export NCLplotvar_2="dPVdy"
export NCLilev_2="900"
export NCLvartitle_2="dPVdy"
export NCLmin1_2="0"
export NCLmax1_2="0.8e-12"
export NCLdiffs1_2="0.08e-12"
export NCLmin2_2="-7"
export NCLmax2_2="20"
export NCLdiffs2_2="3.0"
export NCLunits_2="1E-12 PVU/m"
export NCLplotvar_1="U"
export NCLilev_1="925"
export NCLvartitle_1="U"
export NCLmin1_1="0"
export NCLmax1_1="10"
export NCLdiffs1_1="1.0"
export NCLmin2_1="-7"
export NCLmax2_1="10"
export NCLdiffs2_1="2.0"
export NCLunits_1="m/s"
export NCLplotvar_3="Ks"
export NCLilev_3="925"
export NCLvartitle_3="K~B~s~N~"
export NCLmin1_3="0"
export NCLmax1_3="7.5"
export NCLdiffs1_3="0.75"
export NCLmin2_3="-7"
export NCLmax2_3="20"
export NCLdiffs2_3="3.0"
export NCLunits_3="m~S~-1~N~"
elif test "$plotvars" == "STD850"; then
export NCLplotvar_2="dPVdy"
export NCLilev_2="850"
export NCLvartitle_2="dPVdy"
export NCLmin1_2="0"
export NCLmax1_2="1.0e-12"
export NCLdiffs1_2="0.1e-12"
export NCLmin2_2="-7"
export NCLmax2_2="20"
export NCLdiffs2_2="3.0"
export NCLunits_2="1E-12 PVU/m"
export NCLplotvar_1="U"
export NCLilev_1="850"
export NCLvartitle_1="U"
export NCLmin1_1="0"
export NCLmax1_1="12"
export NCLdiffs1_1="1.0"
export NCLmin2_1="-7"
export NCLmax2_1="10"
export NCLdiffs2_1="2.0"
export NCLunits_1="m/s"
export NCLplotvar_3="Ks"
export NCLilev_3="250"
export NCLvartitle_3="K~B~s~N~"
export NCLmin1_3="0"
export NCLmax1_3="7.5"
export NCLdiffs1_3="0.75"
export NCLmin2_3="-7"
export NCLmax2_3="20"
export NCLdiffs2_3="3.0"
export NCLunits_3="m~S~-1~N~"
elif test "$plotvars" == "STDV"; then
export NCLplotvar_2="dPVdy"
export NCLilev_2="925"
export NCLvartitle_2="dPVdy"
export NCLmin1_2="0"
export NCLmax1_2="1.0e-12"
export NCLdiffs1_2="0.1e-12"
export NCLmin2_2="-7"
export NCLmax2_2="20"
export NCLdiffs2_2="3.0"
export NCLunits_2="1E-12 PVU/m"
export NCLplotvar_1="V"
export NCLilev_1="925"
export NCLvartitle_1="V"
export NCLmin1_1="0"
export NCLmax1_1="2"
export NCLdiffs1_1="0.2"
export NCLmin2_1="-2"
export NCLmax2_1="2"
export NCLdiffs2_1="0.4"
export NCLunits_1="m/s"
export NCLplotvar_3="Ks"
export NCLilev_3="925"
export NCLvartitle_3="K~B~s~N~"
export NCLmin1_3="0"
export NCLmax1_3="7.5"
export NCLdiffs1_3="0.75"
export NCLmin2_3="-7"
export NCLmax2_3="20"
export NCLdiffs2_3="3.0"
export NCLunits_3="m~S~-1~N~"
elif test "$plotvars" == "STDV850"; then
export NCLplotvar_2="dPVdy"
export NCLilev_2="850"
export NCLvartitle_2="dPVdy"
export NCLmin1_2="0"
export NCLmax1_2="1.0e-12"
export NCLdiffs1_2="0.1e-12"
export NCLmin2_2="-7"
export NCLmax2_2="20"
export NCLdiffs2_2="3.0"
export NCLunits_2="1E-12 PVU/m"
export NCLplotvar_1="V"
export NCLilev_1="850"
export NCLvartitle_1="V"
export NCLmin1_1="0"
export NCLmax1_1="2"
export NCLdiffs1_1="0.2"
export NCLmin2_1="-2"
export NCLmax2_1="2"
export NCLdiffs2_1="0.4"
export NCLunits_1="m/s"
export NCLplotvar_3="Ks"
export NCLilev_3="250"
export NCLvartitle_3="K~B~s~N~"
export NCLmin1_3="0"
export NCLmax1_3="7.5"
export NCLdiffs1_3="0.75"
export NCLmin2_3="-7"
export NCLmax2_3="20"
export NCLdiffs2_3="3.0"
export NCLunits_3="m~S~-1~N~"
elif test "$plotvars" == "UV850"; then
export NCLplotvar_1="U"
export NCLilev_1="850"
export NCLvartitle_1="U"
export NCLmin1_1="0"
export NCLmax1_1="12"
export NCLdiffs1_1="1.0"
export NCLmin2_1="-7"
export NCLmax2_1="10"
export NCLdiffs2_1="2.0"
export NCLunits_1="m/s"
export NCLplotvar_2="V"
export NCLilev_2="850"
export NCLvartitle_2="V"
export NCLmin1_2="0"
export NCLmax1_2="2"
export NCLdiffs1_2="0.2"
export NCLmin2_2="-2"
export NCLmax2_2="2"
export NCLdiffs2_2="0.4"
export NCLunits_2="m/s"
else
export NCLplotvar_1="Ks"
export NCLilev_1="850"
export NCLvartitle_1="K~B~s~N~"
export NCLmin1_1="0"
export NCLmax1_1="7.5"
export NCLdiffs1_1="0.75"
export NCLmin2_1="-7"
export NCLmax2_1="20"
export NCLdiffs2_1="3.0"
export NCLunits_1="m~S~-1~N~"
export NCLplotvar_2="Ks"
export NCLilev_2="700"
export NCLvartitle_2="K~B~s~N~"
export NCLmin1_2="0"
export NCLmax1_2="7.5"
export NCLdiffs1_2="0.75"
export NCLmin2_2="-7"
export NCLmax2_2="20"
export NCLdiffs2_2="3.0"
export NCLunits_2="m~S~-1~N~"
export NCLplotvar_3="Ks"
export NCLilev_3="500"
export NCLvartitle_3="K~B~s~N~"
export NCLmin1_3="0"
export NCLmax1_3="7.5"
export NCLdiffs1_3="0.75"
export NCLmin2_3="-7"
export NCLmax2_3="20"
export NCLdiffs2_3="3.0"
export NCLunits_3="m~S~-1~N~"
export NCLplotvar_4="Ks"
export NCLilev_4="500"
export NCLvartitle_4="K~B~s~N~"
export NCLmin1_4="0"
export NCLmax1_4="7.5"
export NCLdiffs1_4="0.75"
export NCLmin2_4="-7"
export NCLmax2_4="20"
export NCLdiffs2_4="3.0"
export NCLunits_4="m~S~-1~N~"
#
#export NCLplotvar_2="dPVdy"
#export NCLilev_2="250"
#export NCLvartitle_2="~F18~s~F21~PV/~F18~s~F21~y"
#export NCLmin1_2="0"
#export NCLmax1_2="0.9e-12"
#export NCLdiffs1_2="0.1e-12"
#export NCLmin2_2="-7"
#export NCLmax2_2="20"
#export NCLdiffs2_2="3.0"
#export NCLunits_2="1E-6 PVU/m"
#
#export NCLplotvar_1="PV"
#export NCLilev_1="850"
#export NCLvartitle_1="~F10~PV~F21~"
#export NCLmin1_1="0.0"
#export NCLmax1_1="3.0e-6"
#export NCLdiffs1_1="0.3e-6"
#export NCLmin2_1="-0.9e-6"
#export NCLmax2_1="0.9e-6"
#export NCLdiffs2_1="0.2e-6"
#export NCLunits_1="PVU"
#
#export NCLplotvar_1="U"
#export NCLilev_1="850"
#export NCLvartitle_1="U"
#export NCLmin1_1="-7"
#export NCLmax1_1="20"
#export NCLdiffs1_1="3.0"
#export NCLmin2_1="-7"
#export NCLmax2_1="20"
#export NCLdiffs2_1="3.0"
#export NCLunits_1="m/s"
#
#
#export NCLplotvar_2="dTHdzdTHdy"
#export NCLilev_2="925"
#export NCLvartitle_2="(dTH/dz)/(dTH/dy)"
#export NCLmin1_2="-2000.0"
#export NCLmax1_2="2000.0"
#export NCLdiffs1_2="200.0"
#export NCLmin2_2="-2000.0"
#export NCLmax2_2="2000.0"
#export NCLdiffs2_2="200.0"
#export NCLunits_2=""
#
#export NCLplotvar_1="dTHdy"
#export NCLilev_1="925"
#export NCLvartitle_1="dTH/dy"
#export NCLmin1_1="-0.00001"
#export NCLmax1_1="0.00001"
#export NCLdiffs1_1="0.000002"
#export NCLmin2_1="-0.00001"
#export NCLmax2_1="0.00001"
#export NCLdiffs2_1="0.000002"
#export NCLunits_1="K/m"
#
#export NCLplotvar_2="dTHdz"
#export NCLilev_2="925"
#export NCLvartitle_2="dTH/dz"
#export NCLmin1_2="0.002"
#export NCLmax1_2="0.012"
#export NCLdiffs1_2="0.001"
#export NCLmin2_2="0.002"
#export NCLmax2_2="0.012"
#export NCLdiffs2_2="0.001"
#export NCLunits_2="K/m"
#
#
#export NCLplotvar_1="TdiaSRF"
#export NCLilev_1="0"
#export NCLvartitle_1="DJF\ LH\ +\ SH\ +\ LW\ +\ SW"
#export NCLmin1_1="-180.0"
#export NCLmax1_1="180.0"
#export NCLdiffs1_1="40.0"
#export NCLmin2_1="-45.0"
#export NCLmax2_1="45.0"
#export NCLdiffs2_1="10.0"
#export NCLunits_1="W/m~S~2~N~"
#export NCLplotvar_1="SFZA"
#export NCLilev_1="250"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-1.8e7"
#export NCLmax1_1="1.8e7"
#export NCLdiffs1_1="4.0e6"
#export NCLmin2_1="-1.08e7"
#export NCLmax2_1="1.08e7"
#export NCLdiffs2_1="2.4e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#export NCLplotvar_1="PV"
#export NCLilev_1="500"
#export NCLvartitle_1="~F10~PV~F21~"
#export NCLmin1_1="0.0"
#export NCLmax1_1="0.8e-6"
#export NCLdiffs1_1="0.05e-6"
#export NCLmin2_1="-0.9e-6"
#export NCLmax2_1="0.9e-6"
#export NCLdiffs2_1="0.2e-6"
#export NCLunits_1="PVU"
#
#export NCLplotvar_2="PV"
#export NCLilev_2="775"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="2.4e-6"
#export NCLdiffs1_2="0.15e-6"
#export NCLmin2_2="-0.9e-6"
#export NCLmax2_2="0.9e-6"
#export NCLdiffs2_2="0.2e-6"
#export NCLunits_2="PVU"
#export NCLplotvar_1="SFZA"
#export NCLilev_1="850"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-0.9e7"
#export NCLmax1_1="0.9e7"
#export NCLdiffs1_1="2.0e6"
#export NCLmin2_1="-0.675e7"
#export NCLmax2_1="0.675e7"
#export NCLdiffs2_1="1.5e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#
#export NCLplotvar_2="TH"
#export NCLilev_2="850.0"
#export NCLvartitle_2="~F8~q~F21~"
#export NCLmin1_2="265.0"
#export NCLmax1_2="310.0"
#export NCLdiffs1_2="5.0"
#export NCLmin2_2="-3.6"
#export NCLmax2_2="3.6"
#export NCLdiffs2_2="0.8"
#export NCLunits_2="K"
#export NCLplotvar_1="U"
#export NCLilev_1="250"
#export NCLvartitle_1="~F10~u~F21~"
#export NCLmin1_1="-12.0"
#export NCLmax1_1="60.0"
#export NCLdiffs1_1="8.0"
#export NCLmin2_1="-13.5"
#export NCLmax2_1="13.5"
#export NCLdiffs2_1="3.0"
#export NCLunits_1="m~S~-1~N~"
#
#export NCLplotvar_2="Zvar"
#export NCLilev_2="850.0"
#export NCLvartitle_2="~F10~Z~F21~'~S~2~N~~F21~"
#export NCLmin1_2="250"
#export NCLmax1_2="2500"
#export NCLdiffs1_2="250"
#export NCLmin2_2="-450"
#export NCLmax2_2="450"
#export NCLdiffs2_2="100"
#export NCLunits_2="m~S~2~N~"
#export NCLplotvar_1="PREC"
#export NCLilev_1="0"
#export NCLvartitle_1="DJF Precip"
#export NCLmin1_1="0"
#export NCLmax1_1="13.5"
#export NCLdiffs1_1="1.5"
#export NCLmin2_1="-0.9"
#export NCLmax2_1="0.9"
#export NCLdiffs2_1="0.2"
#export NCLunits_1="mm/day"
#
#export NCLplotvar_2="TdiaSRF"
#export NCLilev_2="0"
#export NCLvartitle_2="DJF LH + SH + LW + SW"
#export NCLmin1_2="-200"
#export NCLmax1_2="200"
#export NCLdiffs1_2="40"
#export NCLmin2_2="-90"
#export NCLmax2_2="90"
#export NCLdiffs2_2="20"
#export NCLunits_2="W/m~S~2~N~"
fi
# save command line arguments to environment variable NCL_ARG_#
count=0
for ((index=1; index<=$NCLnumexps; index++))
do
eval export NCLexps1_$index=${exps1[count]}
eval export NCLtitles1_$index=${titles1[count]}
eval export NCLCTLs1_$index=${CTLS[count]}
eval export NCLstarts1_$index=${starts[count]}
eval export NCLnyears1_$index=${nyears[count]}
eval export NCLtimespans1_$index=${timespan[count]}
eval export NCLreverses1_$index=${reverse[count]}
((count++))
done
ncl plot_generic2.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="PV"
ilev="250"
min1="0.0"
max1="4.0e-6"
diffs1="0.4e-6"
min2="-1.3e-6"
max2="1.3e-6"
diffs2="0.2e-6"
units="m~S~2~N~/kg/s"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="DTV"
ilev="850"
min1="-1e-5"
max1="1e-5"
diffs1="2e-6"
min2="-1e-6"
max2="1e-6"
diffs2="2e-7"
units="Ks:S:-1:N:"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="Zmag"
ilev="-10"
min1="-40.0"
max1="0.0"
diffs1="4.0"
min2="-5.0"
max2="5.0"
diffs2="1.0"
units="ps"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="divVbpfTbpf"
ilev="850"
min1="-0.000005"
max1="0.000005"
diffs1="0.000001"
min2="-0.000005"
max2="0.000005"
diffs2="0.000001"
units="mKs:S:-1:N:"
plottype="map"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
eval export NCL_ARG_$index=$plottype
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd ./scripts/individual/
difvars="0"
expdif="1"
figtit="SOM_fSSTSOM"
dir1="/home/disk/eos4/rachel/CESM_outfiles/"
numexps="3"
exps1=("CAM4SOM4topo" "CAM4SOM4_noT" "CAM4SOM4_noMT")
titles1=("CAM4_SOM4_CTL" "CAM4_SOM4_noT" "CAM4_SOM4_noMT")
dir2="/home/disk/eos4/rachel/CESM_outfiles/"
exps2=("CESMtopof19" "CAM4_SOMssts_noT" "CAM4_SOMssts_noMT")
titles2=("CAM4_CTL" "CAM4_fSSTSOM_noT" "CAM4_fSSTSOM_noMT")
start1="11"
end1="40"
start2="2"
end2="31"
timespan="DJF"
reverse="false"
linear="false"
clon="90.0"
slon="0.0"
elon="210.0"
slat="0.0"
elat="90.0"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start2
((index++))
eval export NCL_ARG2_$index=$end2
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
./plot_dtdy850.sh
#./plot_topo.sh
#./plot_TS.sh
#./plot_U250.sh
#./plot_U850.sh
#./plot_U1000.sh
#./plot_EMGR.sh
#./plot_Tadv850.sh
#./plot_Tadv250.sh
#./plot_Tdia850.sh
#./plot_Tdia250.sh
#./plot_UV250.sh
#./plot_UV850.sh
#./plot_dtdy600.sh
#./plot_SF850.sh
#./plot_SF250.sh
#./plot_EKE250.sh
#./plot_EKE850.sh
#./plot_Zvar.sh
#./plot_uH.sh
#./plot_uP.sh
#./plot_SFZA700.sh
#./plot_TH700.sh
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
export NCLnumvars="2"
export NCLdifexps="0"
export NCLexpdif="0"
export NCLfigtit="MountainsWind"
export NCLdir1="/home/disk/rachel/CESM_outfiles/"
export NCLnumexps="6"
export NCLlinear="false"
export NCLclon="180.0"
export NCLslon="30.0"
export NCLelon="300."
export NCLslat="-30.0"
export NCLelat="90.0"
export NCLplottype="map"
export NCLplotctl=0
export NCLplotERA1=0
export NCLtitleprefix="I3smCI_"
exps1=("CESMnotopof19" "CESM_IG54" "CESM_IG49" "CESM_IG44" "CESM_IG34" "CESM_IG29")
titles1=("I\_CTL" "I\_63N\_2km" "I\_58N\_2km" "I\_53N\_2km" "I\_43N\_2km" "I\_38N\_2km")
CTLS=("-1" "0" "0" "0" "0" "0" "0" "2")
starts=("2" "2" "2" "2" "2" "2" "2" "11")
nyears=("30" "30" "30" "30" "30" "30" "30" "30")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("true" "true" "true" "true" "true" "true" "true" "true")
#export NCLplotvar_1="V"
#export NCLilev_1="850"
#export NCLvartitle_1="~F10~v~F21~"
#export NCLmin1_1="-1.0"
#export NCLmax1_1="1.0"
#export NCLdiffs1_1="0.2"
#export NCLmin2_1="-2.5"
#export NCLmax2_1="2.5"
#export NCLdiffs2_1="0.5"
#export NCLunits_1="m~S~-1~N~"
#export NCLplotvar_1="TdiaSRF"
#export NCLilev_1="0"
#export NCLvartitle_1="DJF\ LH\ +\ SH\ +\ LW\ +\ SW"
#export NCLmin1_1="-180.0"
#export NCLmax1_1="180.0"
#export NCLdiffs1_1="40.0"
#export NCLmin2_1="-45.0"
#export NCLmax2_1="45.0"
#export NCLdiffs2_1="10.0"
#export NCLunits_1="W/m~S~2~N~"
export NCLplotvar_1="SFZA"
export NCLilev_1="700"
export NCLvartitle_1="~F8~y'~F21~"
export NCLmin1_1="-1.35e7"
export NCLmax1_1="1.35e7"
export NCLdiffs1_1="3.0e6"
export NCLmin2_1="-0.45e7"
export NCLmax2_1="0.45e7"
export NCLdiffs2_1="1.0e6"
export NCLunits_1="m~S~2~N~s~S~-1~N~"
#export NCLplotvar_1="SFZA"
#export NCLilev_1="500"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-1.35e7"
#export NCLmax1_1="1.35e7"
#export NCLdiffs1_1="3.0e6"
#export NCLmin2_1="-0.9e7"
#export NCLmax2_1="0.9e7"
#export NCLdiffs2_1="2.0e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#
#export NCLplotvar_1="SFZA"
#export NCLilev_1="400"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-1.35e7"
#export NCLmax1_1="1.35e7"
#export NCLdiffs1_1="3.0e6"
#export NCLmin2_1="-0.9e7"
#export NCLmax2_1="0.9e7"
#export NCLdiffs2_1="2.0e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#
#export NCLplotvar_1="SFZA"
#export NCLilev_1="300"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-1.35e7"
#export NCLmax1_1="1.35e7"
#export NCLdiffs1_1="3.0e6"
#export NCLmin2_1="-0.9e7"
#export NCLmax2_1="0.9e7"
#export NCLdiffs2_1="2.0e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#
#export NCLplotvar_1="SFZA"
#export NCLilev_1="250"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-1.35e7"
#export NCLmax1_1="1.35e7"
#export NCLdiffs1_1="3.0e6"
#export NCLmin2_1="-0.9e7"
#export NCLmax2_1="0.9e7"
#export NCLdiffs2_1="2.0e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#
export NCLplotvar_2="PV"
export NCLilev_2="700"
export NCLvartitle_2="~F10~PV~F21~"
export NCLmin1_2="0.0"
export NCLmax1_2="3.6e-6"
export NCLdiffs1_2="0.4e-6"
export NCLmin2_2="-0.045e-6"
export NCLmax2_2="0.045e-6"
export NCLdiffs2_2="0.01e-6"
export NCLunits_2="PVU"
#
#export NCLplotvar_2="PV"
#export NCLilev_2="500"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="3.6e-6"
#export NCLdiffs1_2="0.4e-6"
#export NCLmin2_2="-0.045e-6"
#export NCLmax2_2="0.045e-6"
#export NCLdiffs2_2="0.01e-6"
#export NCLunits_2="PVU"
#
#export NCLplotvar_2="PV"
#export NCLilev_2="400"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="3.6e-6"
#export NCLdiffs1_2="0.4e-6"
#export NCLmin2_2="-0.045e-6"
#export NCLmax2_2="0.045e-6"
#export NCLdiffs2_2="0.01e-6"
#export NCLunits_2="PVU"
#export NCLplotvar_2="PV"
#export NCLilev_2="300"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="3.6e-6"
#export NCLdiffs1_2="0.4e-6"
#export NCLmin2_2="-0.045e-6"
#export NCLmax2_2="0.045e-6"
#export NCLdiffs2_2="0.01e-6"
#export NCLunits_2="PVU"
#
#export NCLplotvar_2="PV"
#export NCLilev_2="250"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="3.6e-6"
#export NCLdiffs1_2="0.4e-6"
#export NCLmin2_2="-0.045e-6"
#export NCLmax2_2="0.045e-6"
#export NCLdiffs2_2="0.01e-6"
#export NCLunits_2="PVU"
#
##export NCLplotvar_2="PV"
#export NCLilev_2="300"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="3.6e-6"
#export NCLdiffs1_2="0.4e-6"
#export NCLmin2_2="-0.9e-6"
#export NCLmax2_2="0.9e-6"
#export NCLdiffs2_2="0.2e-6"
#export NCLunits_2="PVU"
#
#export NCLplotvar_1="SFZA"
#export NCLilev_1="850"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-0.9e7"
#export NCLmax1_1="0.9e7"
#export NCLdiffs1_1="2.0e6"
#export NCLmin2_1="-0.675e7"
#export NCLmax2_1="0.675e7"
#export NCLdiffs2_1="1.5e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#
#export NCLplotvar_2="TH"
#export NCLilev_2="850.0"
#export NCLvartitle_2="~F8~q~F21~"
#export NCLmin1_2="265.0"
#export NCLmax1_2="310.0"
#export NCLdiffs1_2="5.0"
#export NCLmin2_2="-3.6"
#export NCLmax2_2="3.6"
#export NCLdiffs2_2="0.8"
#export NCLunits_2="K"
#export NCLplotvar_1="U"
#export NCLilev_1="250"
#export NCLvartitle_1="~F10~u~F21~"
#export NCLmin1_1="-12.0"
#export NCLmax1_1="60.0"
#export NCLdiffs1_1="8.0"
#export NCLmin2_1="-13.5"
#export NCLmax2_1="13.5"
#export NCLdiffs2_1="3.0"
#export NCLunits_1="m~S~-1~N~"
#
#export NCLplotvar_2="Zvar"
#export NCLilev_2="850.0"
#export NCLvartitle_2="~F10~Z~F21~'~S~2~N~~F21~"
#export NCLmin1_2="250"
#export NCLmax1_2="2500"
#export NCLdiffs1_2="250"
#export NCLmin2_2="-450"
#export NCLmax2_2="450"
#export NCLdiffs2_2="100"
#export NCLunits_2="m~S~2~N~"
#export NCLplotvar_1="PREC"
#export NCLilev_1="0"
#export NCLvartitle_1="DJF Precip"
#export NCLmin1_1="0"
#export NCLmax1_1="13.5"
#export NCLdiffs1_1="1.5"
#export NCLmin2_1="-0.9"
#export NCLmax2_1="0.9"
#export NCLdiffs2_1="0.2"
#export NCLunits_1="mm/day"
#
#export NCLplotvar_2="TdiaSRF"
#export NCLilev_2="0"
#export NCLvartitle_2="DJF LH + SH + LW + SW"
#export NCLmin1_2="-200"
#export NCLmax1_2="200"
#export NCLdiffs1_2="40"
#export NCLmin2_2="-90"
#export NCLmax2_2="90"
#export NCLdiffs2_2="20"
#export NCLunits_2="W/m~S~2~N~"
# save command line arguments to environment variable NCL_ARG_#
count=0
for ((index=1; index<=$NCLnumexps; index++))
do
eval export NCLexps1_$index=${exps1[count]}
eval export NCLtitles1_$index=${titles1[count]}
eval export NCLCTLs1_$index=${CTLS[count]}
eval export NCLstarts1_$index=${starts[count]}
eval export NCLnyears1_$index=${nyears[count]}
eval export NCLtimespans1_$index=${timespan[count]}
eval export NCLreverses1_$index=${reverse[count]}
((count++))
done
ncl plot_generic2.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="TS"
ilev="0"
min1="260.0"
max1="305.0"
diffs1="5.0"
min2="-3.0"
max2="3.0"
diffs2="0.5"
units="K"
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="SHFLX"
ilev="1000"
min1="-100"
max1="100"
diffs1="20"
min2="-50"
max2="50"
diffs2="10"
units="Wm:S:-2:N:"
plottype="map"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
eval export NCL_ARG_$index=$plottype
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
export NCLnumvars="2"
export NCLdifexps="0"
export NCLexpdif="0"
export NCLfigtit="RvsT"
export NCLdir1="/home/disk/rachel/CESM_outfiles/"
export NCLnumexps="2"
export NCLlinear="false"
export NCLclon="0.0"
export NCLslon="-180.0"
export NCLelon="0."
export NCLslat="0.0"
export NCLelat="90.0"
export NCLplottype="map"
export NCLplotctl="1"
export NCLplotERA1="0"
export NCLplotERA2="0"
export NCLtitleprefix="Rockies_"
exps1=("CESMtopof19" "CESMnoRf19" "CESMnoRT2f19")
titles1=("R_CTL" "R_noRockies" "R_noRockiesTibet")
CTLS=("100" "0" "0" "0" "0" "0" "2" "2")
starts=("2" "2" "2" "2" "2" "11" "11" "11")
nyears=("40" "40" "40" "40")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("true" "false" "false" "false" "false" "false" "true" "true")
export NCLallblue=0
export NCLplottitles=1
export NCLblock=0
#export NCLplotvar_1="Topo"
#export NCLilev_1="0"
#export NCLvartitle_1="Topo"
#export NCLmin1_1="0"
#export NCLmax1_1="2000"
#export NCLdiffs1_1="200"
#export NCLmin2_1="-5.5"
#export NCLmax2_1="5.5"
#export NCLdiffs2_1="1.0"
#export NCLunits_1="m"
#
export NCLplotvar_1="TS"
export NCLilev_1="0"
export NCLvartitle_1="Surface\ Temp"
export NCLmin1_1="250"
export NCLmax1_1="305"
export NCLdiffs1_1="5"
export NCLmin2_1="-2.5"
export NCLmax2_1="2.5"
export NCLdiffs2_1="0.5"
export NCLunits_1="K"
export NCLplotvar_2="PREC"
export NCLilev_2="0"
export NCLvartitle_2="DJF Precip"
export NCLmin1_2="0"
export NCLmax1_2="8.0"
export NCLdiffs1_2="1.0"
export NCLmin2_2="-2."
export NCLmax2_2="2."
export NCLdiffs2_2="0.4"
export NCLunits_2="mm/day"
#export NCLplotvar_2="PV"
#export NCLilev_2="300"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="3.6e-6"
#export NCLdiffs1_2="0.4e-6"
#export NCLmin2_2="-0.9e-6"
#export NCLmax2_2="0.9e-6"
#export NCLdiffs2_2="0.2e-6"
#export NCLunits_2="PVU"
#export NCLplotvar_1="SFZA"
#export NCLilev_1="850"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-0.9e7"
#export NCLmax1_1="0.9e7"
#export NCLdiffs1_1="2.0e6"
#export NCLmin2_1="-0.675e7"
#export NCLmax2_1="0.675e7"
#export NCLdiffs2_1="1.5e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#
#export NCLplotvar_2="TH"
#export NCLilev_2="850.0"
#export NCLvartitle_2="~F8~q~F21~"
#export NCLmin1_2="265.0"
#export NCLmax1_2="310.0"
#export NCLdiffs1_2="5.0"
#export NCLmin2_2="-3.6"
#export NCLmax2_2="3.6"
#export NCLdiffs2_2="0.8"
#export NCLunits_2="K"
#export NCLplotvar_1="U"
#export NCLilev_1="250"
#export NCLvartitle_1="~F10~u~F21~"
#export NCLmin1_1="-12.0"
#export NCLmax1_1="60.0"
#export NCLdiffs1_1="8.0"
#export NCLmin2_1="-13.5"
#export NCLmax2_1="13.5"
#export NCLdiffs2_1="3.0"
#export NCLunits_1="m~S~-1~N~"
#
#export NCLplotvar_2="Zvar"
#export NCLilev_2="850.0"
#export NCLvartitle_2="~F10~Z~F21~'~S~2~N~~F21~"
#export NCLmin1_2="250"
#export NCLmax1_2="2500"
#export NCLdiffs1_2="250"
#export NCLmin2_2="-450"
#export NCLmax2_2="450"
#export NCLdiffs2_2="100"
#export NCLunits_2="m~S~2~N~"
#export NCLplotvar_1="PREC"
#export NCLilev_1="0"
#export NCLvartitle_1="DJF Precip"
#export NCLmin1_1="0"
#export NCLmax1_1="13.5"
#export NCLdiffs1_1="1.5"
#export NCLmin2_1="-0.9"
#export NCLmax2_1="0.9"
#export NCLdiffs2_1="0.2"
#export NCLunits_1="mm/day"
#
#export NCLplotvar_2="TdiaSRF"
#export NCLilev_2="0"
#export NCLvartitle_2="DJF LH + SH + LW + SW"
#export NCLmin1_2="-200"
#export NCLmax1_2="200"
#export NCLdiffs1_2="40"
#export NCLmin2_2="-90"
#export NCLmax2_2="90"
#export NCLdiffs2_2="20"
#export NCLunits_2="W/m~S~2~N~"
# save command line arguments to environment variable NCL_ARG_#
count=0
for ((index=1; index<=$NCLnumexps; index++))
do
eval export NCLexps1_$index=${exps1[count]}
eval export NCLtitles1_$index=${titles1[count]}
eval export NCLCTLs1_$index=${CTLS[count]}
eval export NCLstarts1_$index=${starts[count]}
eval export NCLnyears1_$index=${nyears[count]}
eval export NCLtimespans1_$index=${timespan[count]}
eval export NCLreverses1_$index=${reverse[count]}
((count++))
done
ncl scripts/plot_generic2.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="-dTHdy"
ilev="600"
min1="0.0"
max1="0.00004"
diffs1="0.000004"
min2="-0.000003"
max2="0.000003"
diffs2="0.0000005"
units="Km:S:-1:N:"
plottype="map"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
eval export NCL_ARG_$index=$plottype
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="EMGR"
ilev="0"
min1="-0.4"
max1="0.8"
diffs1="0.1"
min2="-0.2"
max2="0.2"
diffs2="0.04"
units="days:S:-1:N:"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="-UDdTHdX"
ilev="850"
min1="-0.000025"
max1="0.000025"
diffs1="0.000005"
min2="-0.000015"
max2="0.000015"
diffs2="0.000003"
units="Ks:S:-1:N:"
plottype="ZMline"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
eval export NCL_ARG_$index=$plottype
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="EKEbpf"
ilev="250"
min1="50"
max1="250"
diffs1="20"
min2="-15"
max2="15"
diffs2="3"
units="m:S:2:N:s:S:-1:N:"
plottype="map"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
eval export NCL_ARG_$index=$plottype
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/bash
export HDF5_DISABLE_VERSION_CHECK=2
for yrnum in {1980..2013};
do echo $yrnum;
sed -i "s/fyear = ..../fyear = ${yrnum}/g" TN2001_ncep_daily.ncl
ncl TN2001_ncep_daily.ncl
done<file_sep>#!/bin/sh
cd ./scripts/
difvars="1"
expdif="0"
figtit="Paper"
numexps="8"
dir1="/home/disk/eos4/rachel/CESM_outfiles/"
exps1=("CAM4SOM4topo" "CESMtopof19" "CAM4SOM4notopo" "CAM4SOM4_noMT" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_IG34" "CAM4SOM4_IG44")
titles1=("RSOM\_CTL" "R\_CTL" "ISOM\_CTL" "RSOM\_noMT" "RSOM\_noT" "RSOM\_noM" "ISOM\_IG38N" "ISOM\_IG48N")
CTLS=("1" "-1" "-1" "0" "0" "0" "2" "2")
starts=("11" "2" "11" "11" "11" "11" "11" "11")
nyears=("30" "30" "30" "30" "30" "30" "30" "30")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("true" "false" "false" "false" "false" "false" "true" "true")
linear="false"
clon="180.0"
slon="30.0"
elon="300.0"
slat="-30.0"
elat="90.0"
plottype="map"
plotctl=0
plotERA=0
titleprefix="SOM_fSST1_"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${CTLS[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${starts[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${nyears[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${timespan[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${reverse[count]}
((count++))
done
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
plotvar="TS"
ilev="0"
min1="260.0"
max1="305.0"
diffs1="5.0"
min2="-3.0"
max2="3.0"
diffs2="0.5"
units="K"
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
plotvar="SFZA"
ilev="850"
min1="-1.1e7"
max1="1.1e7"
diffs1="2.0e6"
min2="-0.55e7"
max2="0.55e7"
diffs2="1.0e6"
units="m:S:2:N:s:S:-1:N:"
# save command line arguments to environment variable NCL_ARG_#
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic_SOM_fSST.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Standard/scripts/
#dir="/home/disk/eos4/rachel/CESM_outfiles/"
dir="/home/disk/rachel/CESM_outfiles/CAM5/"
numexps="2"
exps=("CAM5topo" "CAM5def1")
start="2"
end="41"
nsecs="00000"
export NCL_N_ARGS=$#
# save command line arguments to environment variable NCL_ARG_#
export NCL_ARG_1=$dir
export NCL_ARG_2=$numexps
# save command line arguments to environment variable NCL_ARG_#
for ((index=3; index<=2+$numexps; index++))
do
eval export NCL_ARG_$index=${exps[index-3]}
done
echo $index
eval export NCL_ARG_$index=$start
((index++))
echo $index
eval export NCL_ARG_$index=$end
((index++))
echo $index
eval export NCL_ARG_$index=$nsecs
echo NCL_N_ARGS
ncl Calc_Precip.ncl
echo 'Calc_Precip.ncl'
#ncl Create_all_means.ncl
#echo 'Create_all_means.ncl'
#ncl hybrid2pres.ncl
#echo 'hybrid2pres.ncl'
#ncl Calc_Eady.ncl
#echo 'Calc_Eady.ncl'
#ncl LanczosF_Z850.ncl
#echo 'LanczosF_Z850.ncl'
#ncl Calc_varZ850.ncl
#echo 'Calc_varZ850.ncl'
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="SFZA"
ilev="700"
min1="-1.0e7"
max1="1.0e7"
diffs1="2.0e6"
min2="-5.0e6"
max2="5.0e6"
diffs2="1.0e6"
units="m:S:2:N:s:S:-1:N:"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd ./scripts/
difvars="0"
expdif="0"
figtit="Paper"
dir1="/home/disk/rachel/CESM_outfiles/"
numexps="2"
exps1=("CAM4SOM4_4xCO2" "CAM4SOM4_4xCO2_noMT") #("CAM4SOM4_4xCO2" "CAM4SOM4_4xCO2_noMT") ("CAM4SOM4topo" "CAM4SOM4_noMT")
titles1=("4xCO2_CTL" "4xCO2_noMT") # ("PD_CTL" "PD_noMT")
start1="11"
end1="40"
timespan="DJF"
reverse="false"
linear="false"
clon="180.0"
slon="140.0"
elon="170.0"
slat="20.0"
elat="70.0"
plottype="ZMline"
plotctl=1
plotERA=0
titleprefix="4xCO2_4x_" #"4xCO2_PD_"
y save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
ncl plot_generic_ZMline_paper_4xCO2.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="V"
ilev="250"
min1="-10.0"
max1="10.0"
diffs1="2.0"
min2="-2.0"
max2="2.0"
diffs2="0.4"
units="ms:S:-1:N:"
plottype="map"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
eval export NCL_ARG_$index=$plottype
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
# Script to calculate variables that are useful for analysing Rossby wave
# behaviour
cd /home/disk/eos4/rachel/git/NCL/cesm_scripts/Analysis/Standard/scripts/
dir="/home/disk/eos4/rachel/Projects/SeasonalCycle/"
file="Monthly_Clim_CAM4POP_f19g16C_noTopo.cam2.h0.0300-0349.nc" #Monthly_Clim_b40.1850.track1.2deg.003.cam.h0.500-529.nc"
export NCL_dir=$dir
export NCL_file=$file
ncl hybrid2pres_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="Zlen"
ilev="-10"
min1="0.0"
max1="1.5"
diffs1="0.15"
min2="-0.1"
max2="0.1"
diffs2="0.02"
units="days"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/git/NCL/cesm_scripts/Analysis/Plotting/scripts/
export NCLnumvars="2"
export NCLdifexps="0"
export NCLexpdif="0"
export NCLfigtit="Mongolia/newPaper"
export NCLdir1="/home/disk/rachel/CESM_outfiles/"
export NCLnumexps="3"
export NCLlinear="false"
export NCLclon="180.0"
export NCLslon="30.0"
export NCLelon="300."
export NCLslat="0.0"
export NCLelat="90.0"
export NCLplottype="map"
export NCLplotctl=0
export NCLplotERA1=0
export NCLtitleprefix="I1_"
exps1=("CESMnotopof19" "CESM_onlyIT" "CESM_onlyITSh")
titles1=("" "Ideal\ Tibet" "Ideal\ Mongolia")
CTLS=("-1" "0" "0" "0" "0" "0" "2" "2")
starts=("2" "2" "2" "2" "2" "11" "11" "11")
nyears=("30" "30" "30" "30" "30" "30" "30" "30")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("true" "true" "true" "true" "false" "false" "true" "true")
#export NCLplotvar_1="Z"
#export NCLilev_1="850"
#export NCLvartitle_1="~F8~Z~F21~"
#export NCLmin1_1="1275"
#export NCLmax1_1="1550"
#export NCLdiffs1_1="25"
#export NCLmin2_1="-100"
#export NCLmax2_1="100"
#export NCLdiffs2_1="20"
#export NCLunits_1="m"
#
#export NCLplotvar_2="Z"
#export NCLilev_2="250"
#export NCLvartitle_2="~F8~Z~F21~"
#export NCLmin1_2="9400"
#export NCLmax1_2="11050"
#export NCLdiffs1_2="150"
#export NCLmin2_2="-100"
#export NCLmax2_2="100"
#export NCLdiffs2_2="20"
#export NCLunits_2="m"
#
export NCLplotvar_2="SFZA"
export NCLilev_2="250"
export NCLvartitle_2="~F8~y'~F21~"
export NCLmin1_2="-1.8e7"
export NCLmax1_2="1.8e7"
export NCLdiffs1_2="4.0e6"
export NCLmin2_2="-1.0e7"
export NCLmax2_2="1.0e7"
export NCLdiffs2_2="2.0e6"
export NCLunits_2="10e6m~S~2~N~s~S~-1~N~"
#export NCLplotvar_2="PV"
#export NCLilev_2="300"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="3.6e-6"
#export NCLdiffs1_2="0.4e-6"
#export NCLmin2_2="-0.9e-6"
#export NCLmax2_2="0.9e-6"
#export NCLdiffs2_2="0.2e-6"
#export NCLunits_2="PVU"
#
export NCLplotvar_1="SFZA"
export NCLilev_1="850"
export NCLvartitle_1="~F8~y'~F21~"
export NCLmin1_1="-0.9e7"
export NCLmax1_1="0.9e7"
export NCLdiffs1_1="2.0e6"
export NCLmin2_1="-0.75e7"
export NCLmax2_1="0.75e7"
export NCLdiffs2_1="1.5e6"
export NCLunits_1="10e6m~S~2~N~s~S~-1~N~"
#export NCLplotvar_1="TWcalc"
#export NCLilev_1="850.0"
#export NCLvartitle_1="ThermalWindCalc"
#export NCLmin1_1="0.0"
#export NCLmax1_1="60.0"
#export NCLdiffs1_1="6.0"
#export NCLmin2_1="20.0"
#export NCLmax2_1="20.0"
#export NCLdiffs2_1="4.0"
#export NCLunits_1="m/s"
#
#export NCLplotvar_2="WindShear"
#export NCLilev_2="850.0"
#export NCLvartitle_2="ThermalWind"
#export NCLmin1_2="0"
#export NCLmax1_2="60.0"
#export NCLdiffs1_2="6.0"
#export NCLmin2_2="-20.0"
#export NCLmax2_2="20.0"
#export NCLdiffs2_2="4.0"
#export NCLunits_2="m/s"
#
#export NCLplotvar_1="TH"
#export NCLilev_1="850.0"
#export NCLvartitle_1="~F8~q~F21~"
#export NCLmin1_1="265.0"
#export NCLmax1_1="310.0"
#export NCLdiffs1_1="5.0"
#export NCLmin2_1="-5"
#export NCLmax2_1="5"
#export NCLdiffs2_1="1.0"
#export NCLunits_1="K"
#export NCLplotvar_1="dTHdy"
#export NCLilev_1="850.0"
#export NCLvartitle_1="~F8~q~F21~"
#export NCLmin1_1="265.0"
#export NCLmax1_1="310.0"
#export NCLdiffs1_1="5.0"
#export NCLmin2_1="-0.000005"
#export NCLmax2_1="0.000005"
#export NCLdiffs2_1="0.000001"
#export NCLunits_1="K"
#
#
#export NCLplotvar_2="dTHdy"
#export NCLilev_2="400.0"
#export NCLvartitle_2="~F8~q~F21~"
#export NCLmin1_2="265.0"
#export NCLmax1_2="310.0"
#export NCLdiffs1_2="5.0"
#export NCLmin2_2="-0.000005"
#export NCLmax2_2="0.000005"
#export NCLdiffs2_2="0.000001"
#export NCLunits_2="K"
#
#export NCLplotvar_1="TH"
#export NCLilev_1="300.0"
#export NCLvartitle_1="~F8~q~F21~"
#export NCLmin1_1="265.0"
#export NCLmax1_1="310.0"
#export NCLdiffs1_1="5.0"
#export NCLmin2_1="-3.6"
#export NCLmax2_1="3.6"
#export NCLdiffs2_1="0.8"
#export NCLunits_1="K"
#
#export NCLplotvar_2="TH"
#export NCLilev_2="250.0"
#export NCLvartitle_2="~F8~q~F21~"
#export NCLmin1_2="265.0"
#export NCLmax1_2="310.0"
#export NCLdiffs1_2="5.0"
#export NCLmin2_2="-3.6"
#export NCLmax2_2="3.6"
#export NCLdiffs2_2="0.8"
#export NCLunits_2="K"
#
#export NCLplotvar_2="U"
#export NCLilev_2="250"
#export NCLvartitle_2="~F10~u~F21~"
#export NCLmin1_2="-12.0"
#export NCLmax1_2="60.0"
#export NCLdiffs1_2="8.0"
#export NCLmin2_2="-20.0"
#export NCLmax2_2="20.0"
#export NCLdiffs2_2="4.0"
#export NCLunits_2="ms~S~-1~N~"
#
#export NCLplotvar_1="U"
#export NCLilev_1="850"
#export NCLvartitle_1="~F10~u~F21~"
#export NCLmin1_1="-12.0"
#export NCLmax1_1="60.0"
#export NCLdiffs1_1="8.0"
#export NCLmin2_1="-9.0"
#export NCLmax2_1="9.0"
#export NCLdiffs2_1="2.0"
#export NCLunits_1="m~S~-1~N~"
#export NCLplotvar_2="Zvar"
#export NCLilev_2="850.0"
#export NCLvartitle_2="~F10~Z~F21~'~S~2~N~~F21~"
#export NCLmin1_2="250"
#export NCLmax1_2="2500"
#export NCLdiffs1_2="250"
#export NCLmin2_2="-450"
#export NCLmax2_2="450"
#export NCLdiffs2_2="100"
#export NCLunits_2="m~S~2~N~"
#export NCLplotvar_1="PREC"
#export NCLilev_1="0"
#export NCLvartitle_1="DJF Precip"
#export NCLmin1_1="0"
#export NCLmax1_1="13.5"
#export NCLdiffs1_1="1.5"
#export NCLmin2_1="-0.9"
#export NCLmax2_1="0.9"
#export NCLdiffs2_1="0.2"
#export NCLunits_1="mm/day"
#
#export NCLplotvar_2="TdiaSRF"
#export NCLilev_2="0"
#export NCLvartitle_2="DJF LH + SH + LW + SW"
#export NCLmin1_2="-200"
#export NCLmax1_2="200"
#export NCLdiffs1_2="40"
#export NCLmin2_2="-90"
#export NCLmax2_2="90"
#export NCLdiffs2_2="20"
#export NCLunits_2="W/m~S~2~N~"
# save command line arguments to environment variable NCL_ARG_#
count=0
for ((index=1; index<=$NCLnumexps; index++))
do
eval export NCLexps1_$index=${exps1[count]}
eval export NCLtitles1_$index=${titles1[count]}
eval export NCLCTLs1_$index=${CTLS[count]}
eval export NCLstarts1_$index=${starts[count]}
eval export NCLnyears1_$index=${nyears[count]}
eval export NCLtimespans1_$index=${timespan[count]}
eval export NCLreverses1_$index=${reverse[count]}
((count++))
done
ncl plot_generic2.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
difvars="1"
expdif="0"
figtit="Paper"
numexps="6"
dir1="/home/disk/rachel/CESM_outfiles/"
exps1=("CESMnotopof19" "CESM_onlyIT" "CESM_onlyITSh" "CESM_onlyIT2" "CESM_onlyITVS" "CESM_onlyIM2")
titles1=("I_CTL" "I_33N_4km" "I_48N_2km" "I_48N_4km" "I_48N_1km" "I_48N_MerHalf")
dir2="/home/disk/rachel/CESM_outfiles/"
exps2=("CESMnotopof19" "CESM_onlyIT" "CESM_onlyITSh" "CESM_onlyIT2" "0" "CESM_onlyIM2")
titles2=("I_CTL" "I_33N_4km" "I_48N_2km" "I_48N_4km" "I_48N_1km" "I_48N_MerHalf")
start1="2"
end1="31"
start2="2"
end2="41"
timespan="DJF"
reverse="false"
linear="false"
clon="180.0"
slon="0.0"
elon="210."
slat="0.0"
elat="90.0"
plottype="map"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start2
((index++))
eval export NCL_ARG2_$index=$end2
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
plotvar="U"
ilev="250"
min1="0.0"
max1="60.0"
diffs1="5.0"
min2="-15.0"
max2="15.0"
diffs2="3.0"
units="ms:S:-1:N:"
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
plotvar="Zvar"
ilev="850"
min1="0.0"
max1="3000.0"
diffs1="300.0"
min2="-750.0"
max2="750.0"
diffs2="150.0"
units="m:S:2:N:"
# save command line arguments to environment variable NCL_ARG_#
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
export NCLnumvars="2"
export NCLdifexps="0"
export NCLexpdif="0"
export NCLfigtit="Mongolia/newPaper"
export NCLdir1="/home/disk/rachel/CESM_outfiles/"
export NCLnumexps="1"
export NCLlinear="false"
export NCLclon="180.0"
export NCLslon="30.0"
export NCLelon="300."
export NCLslat="-30.0"
export NCLelat="90.0"
export NCLplottype="map"
export NCLplotctl=0
export NCLplotERA1=0
export NCLtitleprefix="Real_"
exps1=("CESMnoT2f19" "CESMnoT2f19" "CESMnoTf19" "CESMnoT4f19")
titles1=("noTM" "noTM" "R\_noT" "R\_noM")
CTLS=("100" "0" "0" "0" "0" "0" "2" "2")
starts=("2" "2" "2" "2" "2" "11" "11" "11")
nyears=("40" "40" "40" "40" "30" "30" "30" "30")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("true" "false" "false" "false" "false" "false" "true" "true")
#export NCLplotvar_1="Z"
#export NCLilev_1="850"
#export NCLvartitle_1="~F8~Z~F21~"
#export NCLmin1_1="1275"
#export NCLmax1_1="1550"
#export NCLdiffs1_1="25"
#export NCLmin2_1="-100"
#export NCLmax2_1="100"
#export NCLdiffs2_1="20"
#export NCLunits_1="m"
#
#export NCLplotvar_2="Z"
#export NCLilev_2="250"
#export NCLvartitle_2="~F8~Z~F21~"
#export NCLmin1_2="9400"
#export NCLmax1_2="11050"
#export NCLdiffs1_2="150"
#export NCLmin2_2="-100"
#export NCLmax2_2="100"
#export NCLdiffs2_2="20"
#export NCLunits_2="m"
#
#export NCLplotvar_2="SFZA"
#export NCLilev_2="250"
#export NCLvartitle_2="~F8~y'~F21~"
#export NCLmin1_2="-1.8e7"
#export NCLmax1_2="1.8e7"
#export NCLdiffs1_2="4.0e6"
#export NCLmin2_2="-1.08e7"
#export NCLmax2_2="1.08e7"
#export NCLdiffs2_2="2.4e6"
#export NCLunits_2="m~S~2~N~s~S~-1~N~"
#
#export NCLplotvar_2="PV"
#export NCLilev_2="300"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="3.6e-6"
#export NCLdiffs1_2="0.4e-6"
#export NCLmin2_2="-0.9e-6"
#export NCLmax2_2="0.9e-6"
#export NCLdiffs2_2="0.2e-6"
#export NCLunits_2="PVU"
#
#export NCLplotvar_1="SFZA"
#export NCLilev_1="850"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-0.9e7"
#export NCLmax1_1="0.9e7"
#export NCLdiffs1_1="2.0e6"
#export NCLmin2_1="-0.675e7"
#export NCLmax2_1="0.675e7"
#export NCLdiffs2_1="1.5e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#
export NCLplotvar_1="TH"
export NCLilev_1="850.0"
export NCLvartitle_1="~F8~q~F21~"
export NCLmin1_1="265.0"
export NCLmax1_1="310.0"
export NCLdiffs1_1="5.0"
export NCLmin2_1="-3.6"
export NCLmax2_1="3.6"
export NCLdiffs2_1="0.8"
export NCLunits_1="K"
#export NCLplotvar_1="TH"
#export NCLilev_1="300.0"
#export NCLvartitle_1="~F8~q~F21~"
#export NCLmin1_1="265.0"
#export NCLmax1_1="310.0"
#export NCLdiffs1_1="5.0"
#export NCLmin2_1="-3.6"
#export NCLmax2_1="3.6"
#export NCLdiffs2_1="0.8"
#export NCLunits_1="K"
#
#export NCLplotvar_2="TH"
#export NCLilev_2="250.0"
#export NCLvartitle_2="~F8~q~F21~"
#export NCLmin1_2="265.0"
#export NCLmax1_2="310.0"
#export NCLdiffs1_2="5.0"
#export NCLmin2_2="-3.6"
#export NCLmax2_2="3.6"
#export NCLdiffs2_2="0.8"
#export NCLunits_2="K"
export NCLplotvar_2="U"
export NCLilev_2="850"
export NCLvartitle_2="U"
export NCLmin1_2="-7"
export NCLmax1_2="20"
export NCLdiffs1_2="3.0"
export NCLmin2_2="-7"
export NCLmax2_2="20"
export NCLdiffs2_2="3.0"
export NCLunits_2="m/s"
export NCLplotvar_2="dPVdy"
export NCLilev_2="850"
export NCLvartitle_2="dPVdy"
export NCLmin1_2="0"
export NCLmax1_2="0.45e-12"
export NCLdiffs1_2="0.05e-12"
export NCLmin2_2="-7"
export NCLmax2_2="20"
export NCLdiffs2_2="3.0"
export NCLunits_2="1E-12 PVU/m"
#export NCLplotvar_2="Zvar"
#export NCLilev_2="850.0"
#export NCLvartitle_2="~F10~Z~F21~'~S~2~N~~F21~"
#export NCLmin1_2="250"
#export NCLmax1_2="2500"
#export NCLdiffs1_2="250"
#export NCLmin2_2="-450"
#export NCLmax2_2="450"
#export NCLdiffs2_2="100"
#export NCLunits_2="m~S~2~N~"
#export NCLplotvar_1="PREC"
#export NCLilev_1="0"
#export NCLvartitle_1="DJF Precip"
#export NCLmin1_1="0"
#export NCLmax1_1="13.5"
#export NCLdiffs1_1="1.5"
#export NCLmin2_1="-0.9"
#export NCLmax2_1="0.9"
#export NCLdiffs2_1="0.2"
#export NCLunits_1="mm/day"
#
#export NCLplotvar_2="TdiaSRF"
#export NCLilev_2="0"
#export NCLvartitle_2="DJF LH + SH + LW + SW"
#export NCLmin1_2="-200"
#export NCLmax1_2="200"
#export NCLdiffs1_2="40"
#export NCLmin2_2="-90"
#export NCLmax2_2="90"
#export NCLdiffs2_2="20"
#export NCLunits_2="W/m~S~2~N~"
# save command line arguments to environment variable NCL_ARG_#
count=0
for ((index=1; index<=$NCLnumexps; index++))
do
eval export NCLexps1_$index=${exps1[count]}
eval export NCLtitles1_$index=${titles1[count]}
eval export NCLCTLs1_$index=${CTLS[count]}
eval export NCLstarts1_$index=${starts[count]}
eval export NCLnyears1_$index=${nyears[count]}
eval export NCLtimespans1_$index=${timespan[count]}
eval export NCLreverses1_$index=${reverse[count]}
((count++))
done
ncl plot_generic2.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="dudz"
ilev="850"
min1="-0.05"
max1="0.05"
diffs1="0.01"
min2="-0.02"
max2="0.02"
diffs2="0.004"
units="ms~S~-1~N~"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Standard/scripts/
dir="/home/disk/eos4/rachel/CESM_outfiles/"
numexps="1"
#exps=("CESMnotopof19" "CESM_onlyITVS" "CESM_onlyIM2" "CESM_onlyIT" "CESM_onlyIT2" "CESM_onlyIT4" "CESM_onlyITSh")
exps=("CESM_IG39_West")
start="2"
end="31"
nsecs="00000"
export NCL_N_ARGS=$#
# save command line arguments to environment variable NCL_ARG_#
export NCL_ARG_1=$dir
export NCL_ARG_2=$numexps
# save command line arguments to environment variable NCL_ARG_#
for ((index=3; index<=2+$numexps; index++))
do
eval export NCL_ARG_$index=${exps[index-3]}
done
echo $index
eval export NCL_ARG_$index=$start
((index++))
echo $index
eval export NCL_ARG_$index=$end
((index++))
echo $index
eval export NCL_ARG_$index=$nsecs
echo NCL_N_ARGS
#ncl Create_all_means.ncl
echo 'Create_all_means.ncl'
#ncl hybrid2pres.ncl
echo 'hybrid2pres.ncl'
#ncl Calc_Eady.ncl
echo 'Calc_Eady.ncl'
ncl LanczosF_Z850.ncl
echo 'LanczosF_Z850.ncl'
ncl Calc_varZ850.ncl
echo 'Calc_varZ850.ncl'
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Standard/scripts/
#dir="/home/disk/eos4/rachel/CESM_outfiles/"
dir="/home/disk/rachel/CESM_outfiles/"
numexps="1"
exps=("CESMtopof19")
start="2"
end="31"
nsecs="00000"
export NCL_N_ARGS=$#
# save command line arguments to environment variable NCL_ARG_#
export NCL_ARG_1=$dir
export NCL_ARG_2=$numexps
# save command line arguments to environment variable NCL_ARG_#
for ((index=3; index<=2+$numexps; index++))
do
eval export NCL_ARG_$index=${exps[index-3]}
done
echo $index
eval export NCL_ARG_$index=$start
((index++))
echo $index
eval export NCL_ARG_$index=$end
((index++))
echo $index
eval export NCL_ARG_$index=$nsecs
echo NCL_N_ARGS
#ncl Create_all_means.ncl
#echo 'Create_all_means.ncl'
ncl Calc_VertGrad.ncl
echo 'Calc_VertGrad.ncl'
ncl hybrid2pres_more.ncl
echo 'hybrid2pres_more.ncl'
#ncl Calc_Eady.ncl
#echo 'Calc_Eady.ncl'
#ncl LanczosF_Z850.ncl
#echo 'LanczosF_Z850.ncl'
#ncl Calc_varZ850.ncl
#echo 'Calc_varZ850.ncl'
echo 'finished'
<file_sep>#!/bin/sh
cd ./scripts/
difvars="1"
expdif="0"
figtit="Paper"
numexps="4"
dir1="/home/disk/eos4/rachel/CESM_outfiles/"
exps1=("CAM4SOM4topo" "CAM4SOM4_noMT" "CAM4SOM4_noMT" "CAM4SOM4notopo")
titles1=("RSOM\_CTL" "RSOMSOM\_noTM" "RSOM\_noTM" "RSOM\_notopo")
CTLS=("100" "100" "0" "100" "100")
starts=("26" "26" "26" "26" "11" "11" "11" "11")
nyears=("15" "15" "15" "15" "30" "30" "30" "30")
timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
reverse=("false" "false" "false" "false" "false" "false" "true" "true")
linear="false"
clon="180.0"
slon="30.0"
elon="300.0"
slat="-30.0"
elat="90.0"
plottype="map"
plotctl=0
plotERA=1
titleprefix="For_David_SOM_last15"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${CTLS[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${starts[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${nyears[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${timespan[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${reverse[count]}
((count++))
done
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
plotvar="SFZA"
ilev="850"
min1="-1.1e7"
max1="1.1e7"
diffs1="2.0e6"
min2="-1.1e7"
max2="1.1e7"
diffs2="2.0e6"
units="m:S:2:N:s:S:-1:N:"
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
plotvar="SF"
ilev="850"
min1="-2.2e7"
max1="2.2e7"
diffs1="4.0e6"
min2="-2.2e7"
max2="2.2e7"
diffs2="4.0e6"
units="m:S:2:N:s:S:-1:N:"
# save command line arguments to environment variable NCL_ARG_#
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Standard/scripts/
dir="/home/disk/eos4/rachel/CESM_outfiles/"
#dir="/home/disk/rachel/CESM_outfiles/"
numexps="4"
exps=("CAM4SOM4topo" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_noMT")
start="11"
end="40"
nsecs="00000"
export NCL_N_ARGS=$#
# save command line arguments to environment variable NCL_ARG_#
export NCL_ARG_1=$dir
export NCL_ARG_2=$numexps
# save command line arguments to environment variable NCL_ARG_#
for ((index=3; index<=2+$numexps; index++))
do
eval export NCL_ARG_$index=${exps[index-3]}
done
echo $index
eval export NCL_ARG_$index=$start
((index++))
echo $index
eval export NCL_ARG_$index=$end
((index++))
echo $index
eval export NCL_ARG_$index=$nsecs
echo NCL_N_ARGS
#echo 'LanczosF_time.ncl'
#ncl LanczosF_time.ncl
#echo 'Calc_EV.ncl'
#ncl Calc_EV.ncl
echo 'Calc_meanEKE.ncl'
ncl Calc_meanEKE.ncl
echo 'Calc_EKE_VT.ncl'
ncl Calc_EKE_VT.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="PV"
ilev="850"
min1="0.0"
max1="2.0e-6"
diffs1="2.0e-7"
min2="-1.0e-7"
max2="1.0e-7"
diffs2="2.0e-8"
units="m~S~2~N~/kg/s"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Standard/scripts/
dir="/home/disk/eos4/rachel/CESM_outfiles/"
#dir="/home/disk/rachel/CESM_outfiles/"
numexps="1"
exps=("CESM_IG54")
start="2"
end="31"
nsecs="00000"
export NCL_N_ARGS=$#
# save command line arguments to environment variable NCL_ARG_#
export NCL_ARG_1=$dir
export NCL_ARG_2=$numexps
# save command line arguments to environment variable NCL_ARG_#
for ((index=3; index<=2+$numexps; index++))
do
eval export NCL_ARG_$index=${exps[index-3]}
done
echo $index
eval export NCL_ARG_$index=$start
((index++))
echo $index
eval export NCL_ARG_$index=$end
((index++))
echo $index
eval export NCL_ARG_$index=$nsecs
echo NCL_N_ARGS
echo 'LanczosF_time.ncl'
ncl LanczosF_time.ncl
echo 'Calc_EV.ncl'
ncl Calc_EV.ncl
echo 'Calc_meanEKE.ncl'
ncl Calc_meanEKE.ncl
echo 'Calc_EKE_VT.ncl'
ncl Calc_EKE_VT.ncl
echo 'Calc_Vpr_Upr_THpr'
ncl Calc_Vpr_Upr_THpr.ncl
echo 'Calc_VprTHpr_UprTHpr.ncl'
ncl Calc_VprTHpr_UprTHpr.ncl
echo 'Calc_Vpr_Upr_THpr_annual.ncl'
ncl Calc_Vpr_Upr_THpr_annual.ncl
echo 'Calc_VprTHpr_UprTHpr_annual.ncl'
ncl Calc_VprTHpr_UprTHpr_annual.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/git/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvars="U10"
export NCLnumvars="1"
export NCLdifexps="0"
export NCLexpdif="0"
export NCLfigtit="Mongolia/"
export NCLdir1="/home/disk/rachel/CESM_outfiles/"
export NCLnumexps="5"
export NCLlinear="false"
export NCLclon="180.0"
export NCLslon="60.0"
export NCLelon="360."
export NCLslat="-80.0"
export NCLelat="80.0"
export NCLplottype="map"
export NCLplotctl=0
export NCLplotERA1=0
export NCLtitleprefix="RealX_"
exps1=("CESMtopof19" "CESMnotopof19" "CESMnoRf19" "CESMnotopof19" "CESMnoRf19" "CESMnoT2f19" "CESMnoTf19" "CESMnoT4f19")
titles1=("\ \ CTL" "Flat\ CTL" "No\ Rockies" "All\ topography~C~effect" "Rockies\ effect" "Tibet\ and~C~Mongolia" "\ Tibet" "Mongolia")
CTLS=("100" "100" "100" "0" "0" "0" "2" "2")
starts=("2" "2" "2" "2" "2" "2" "2" "2")
nyears=("40" "40" "40" "40" "40" "40" "40" "40")
#timespan=("SON" "SON" "SON" "SON" "SON" "SON" "SON" "SON")
#timespan=("MAM" "MAM" "MAM" "MAM" "MAM" "MAM" "MAM" "MAM")
#timespan=("JJA" "JJA" "JJA" "JJA" "JJA" "JJA" "JJA" "JJA")
#timespan=("DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF" "DJF")
timespan=("Annual" "Annual" "Annual" "Annual" "Annual" "Annual" "Annual" "Annual")
reverse=("false" "false" "false" "false" "false" "false" "true" "true")
export NCLallblue=2
export NCLplottitles=1
if test "$plotvars" == "SFZA"; then
export NCLallblue=0
export NCLplotvar_1="SFZA"
export NCLilev_1="850"
export NCLvartitle_1="~F8~y'~F21~"
export NCLmin1_1="-0.75e7"
export NCLmax1_1="0.75e7"
export NCLdiffs1_1="0.15e7"
export NCLmin2_1="-7.5e6"
export NCLmax2_1="7.5e6"
export NCLdiffs2_1="1.5e6"
export NCLunits_1="m~S~2~N~s~S~-1~N~"
export NCLplotvar_2="SFZA"
export NCLilev_2="250"
export NCLvartitle_2="~F8~y'~F21~"
export NCLmin1_2="-2.0e7"
export NCLmax1_2="2.0e7"
export NCLdiffs1_2="4.0e6"
export NCLmin2_2="-10.0e6"
export NCLmax2_2="10.0e6"
export NCLdiffs2_2="2.0e6"
export NCLunits_2="m~S~2~N~s~S~-1~N~"
elif test "$plotvars" == "THU"; then
export NCLplotvar_1="TH"
export NCLilev_1="850.0"
export NCLvartitle_1="~F8~q~F21~"
export NCLmin1_1="265.0"
export NCLmax1_1="310.0"
export NCLdiffs1_1="5.0"
export NCLmin2_1="-5.0"
export NCLmax2_1="5.0"
export NCLdiffs2_1="1.0"
export NCLunits_1="K"
export NCLplotvar_2="U"
export NCLilev_2="250"
export NCLvartitle_2="~F10~U~F21~"
export NCLmin1_2="-8.0"
export NCLmax1_2="64.0"
export NCLdiffs1_2="8.0"
export NCLmin2_2="-10.0"
export NCLmax2_2="10.0"
export NCLdiffs2_2="2.0"
export NCLunits_2="ms~S~-1~N~"
elif test "$plotvars" == "Zvar"; then
export NCLplotvar_1="Zvar"
export NCLilev_1="250.0"
export NCLvartitle_1="~F10~Z~F21~'~S~2~N~~F21~"
export NCLmin1_1="0"
export NCLmax1_1="8000"
export NCLdiffs1_1="800"
export NCLmin2_1="-2400"
export NCLmax2_1="2400"
export NCLdiffs2_1="400"
export NCLunits_1="m~S~2~N~"
export NCLplotvar_2="Zvar"
export NCLilev_2="850.0"
export NCLvartitle_2="~F10~Z~F21~'~S~2~N~~F21~"
export NCLmin1_2="250"
export NCLmax1_2="2500"
export NCLdiffs1_2="250"
export NCLmin2_2="-450"
export NCLmax2_2="450"
export NCLdiffs2_2="100"
export NCLunits_2="m~S~2~N~"
elif test "$plotvars" == "UV"; then
export NCLplotvar_1="V"
export NCLilev_1="250.0"
export NCLvartitle_1="~F10~V~F21~"
export NCLmin1_1="-8.0"
export NCLmax1_1="64.0"
export NCLdiffs1_1="8.0"
export NCLmin2_1="-10.0"
export NCLmax2_1="10.0"
export NCLdiffs2_1="2.0"
export NCLunits_1="ms~S~-1~N~"
export NCLplotvar_2="U"
export NCLilev_2="250"
export NCLvartitle_2="~F10~U~F21~"
export NCLmin1_2="-8.0"
export NCLmax1_2="64.0"
export NCLdiffs1_2="8.0"
export NCLmin2_2="-10.0"
export NCLmax2_2="10.0"
export NCLdiffs2_2="2.0"
export NCLunits_2="ms~S~-1~N~"
elif test "$plotvars" == "PREC"; then
export NCLplotvar_1="PREC"
export NCLilev_1="0"
export NCLvartitle_1="Precip"
export NCLmin1_1="0"
export NCLmax1_1="9.0"
export NCLdiffs1_1="1.0"
export NCLmin2_1="-1.0"
export NCLmax2_1="1.0"
export NCLdiffs2_1="0.2"
export NCLunits_1="mm/day"
elif test "$plotvars" == "EVAP"; then
export NCLplotvar_1="EVAP"
export NCLilev_1="0"
export NCLvartitle_1="Evap"
export NCLmin1_1="0"
export NCLmax1_1="9.0"
export NCLdiffs1_1="1.0"
export NCLmin2_1="-1.0"
export NCLmax2_1="1.0"
export NCLdiffs2_1="0.2"
export NCLunits_1="mm/day"
elif test "$plotvars" == "PmE"; then
export NCLplotvar_1="PmE"
export NCLilev_1="0"
export NCLvartitle_1="P-E"
export NCLmin1_1="-2.5"
export NCLmax1_1="2.5"
export NCLdiffs1_1="0.5"
export NCLmin2_1="-1.0"
export NCLmax2_1="1.0"
export NCLdiffs2_1="0.2"
export NCLunits_1="mm/day"
elif test "$plotvars" == "U10"; then
export NCLplotvar_1="U10"
export NCLilev_1="0"
export NCLvartitle_1="U/ 10m"
export NCLmin1_1="0"
export NCLmax1_1="10.0"
export NCLdiffs1_1="1.0"
export NCLmin2_1="-1.0"
export NCLmax2_1="1.0"
export NCLdiffs2_1="0.2"
export NCLunits_1="m/s"
elif test "$plotvars" == "WScurl"; then
export NCLplotvar_1="WScurl"
export NCLilev_1="0"
export NCLvartitle_1="WindStressCurl"
export NCLmin1_1="-2E-7"
export NCLmax1_1="2E-7"
export NCLdiffs1_1="4E-8"
export NCLmin2_1="-5E-8"
export NCLmax2_1="5E-8"
export NCLdiffs2_1="1E-8"
export NCLunits_1="N/m3"
else
#export NCLplotvar_1="Z"
#export NCLilev_1="850"
#export NCLvartitle_1="~F8~Z~F21~"
#export NCLmin1_1="1275"
#export NCLmax1_1="1550"
#export NCLdiffs1_1="25"
#export NCLmin2_1="-100"
#export NCLmax2_1="100"
#export NCLdiffs2_1="20"
#export NCLunits_1="m"
#
#export NCLplotvar_2="Z"
#export NCLilev_2="250"
#export NCLvartitle_2="~F8~Z~F21~"
#export NCLmin1_2="9400"
#export NCLmax1_2="11050"
#export NCLdiffs1_2="150"
#export NCLmin2_2="-100"
#export NCLmax2_2="100"
#export NCLdiffs2_2="20"
#export NCLunits_2="m"
#
#export NCLplotvar_2="SF"
#export NCLilev_2="250"
#export NCLvartitle_2="~F8~y'~F21~"
#export NCLmin1_2="-10.0e7"
#export NCLmax1_2="10.0e7"
#export NCLdiffs1_2="2.0e7"
#export NCLmin2_2="-1.0e7"
#export NCLmax2_2="1.0e7"
#export NCLdiffs2_2="2.0e6"
#export NCLunits_2="m~S~2~N~s~S~-1~N~"
#export NCLplotvar_2="PV"
#export NCLilev_2="300"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="3.6e-6"
#export NCLdiffs1_2="0.4e-6"
#export NCLmin2_2="-0.9e-6"
#export NCLmax2_2="0.9e-6"
#export NCLdiffs2_2="0.2e-6"
#export NCLunits_2="PVU"
#
#export NCLplotvar_1="SFZA"
#export NCLilev_1="750"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-0.75e7"
#export NCLmax1_1="0.75e7"
#export NCLdiffs1_1="0.15e7"
#export NCLmin2_1="-7.5e6"
#export NCLmax2_1="7.5e6"
#export NCLdiffs2_1="1.5e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#
#export NCLplotvar_1="SF"
#export NCLilev_1="850"
#export NCLvartitle_1="~F8~y'~F21~"
#export NCLmin1_1="-0.9e7"
#export NCLmax1_1="0.9e7"
#export NCLdiffs1_1="2.0e6"
#export NCLmin2_1="-0.675e7"
#export NCLmax2_1="0.675e7"
#export NCLdiffs2_1="1.5e6"
#export NCLunits_1="m~S~2~N~s~S~-1~N~"
#
#
#export NCLplotvar_1="TWcalc"
#export NCLilev_1="850.0"
#export NCLvartitle_1="ThermalWindCalc"
#export NCLmin1_1="0.0"
#export NCLmax1_1="60.0"
#export NCLdiffs1_1="6.0"
#export NCLmin2_1="-18.0"
#export NCLmax2_1="18.0"
#export NCLdiffs2_1="3.0"
#export NCLunits_1="m/s"
#
#export NCLplotvar_2="WindShear"
#export NCLilev_2="850.0"
#export NCLvartitle_2="ThermalWind"
#export NCLmin1_2="0"
#export NCLmax1_2="60.0"
#export NCLdiffs1_2="6.0"
#export NCLmin2_2="-18.0"
#export NCLmax2_2="18.0"
#export NCLdiffs2_2="3.0"
#export NCLunits_2="m/s"
#export NCLplotvar_1="dTHdy"
#export NCLilev_1="850.0"
#export NCLvartitle_1="~F8~q~F21~"
#export NCLmin1_1="265.0"
#export NCLmax1_1="310.0"
#export NCLdiffs1_1="5.0"
#export NCLmin2_1="-0.000005"
#export NCLmax2_1="0.000005"
#export NCLdiffs2_1="0.000001"
#export NCLunits_1="K"
#
#
#export NCLplotvar_2="dTHdy"
#export NCLilev_2="400.0"
#export NCLvartitle_2="~F8~q~F21~"
#export NCLmin1_2="265.0"
#export NCLmax1_2="310.0"
#export NCLdiffs1_2="5.0"
#export NCLmin2_2="-0.000005"
#export NCLmax2_2="0.000005"
#export NCLdiffs2_2="0.000001"
#export NCLunits_2="K"
#
#export NCLplotvar_1="TH"
#export NCLilev_1="300.0"
#export NCLvartitle_1="~F8~q~F21~"
#export NCLmin1_1="265.0"
#export NCLmax1_1="310.0"
#export NCLdiffs1_1="5.0"
#export NCLmin2_1="-3.6"
#export NCLmax2_1="3.6"
#export NCLdiffs2_1="0.8"
#export NCLunits_1="K"
#
#export NCLplotvar_2="TH"
#export NCLilev_2="250.0"
#export NCLvartitle_2="~F8~q~F21~"
#export NCLmin1_2="265.0"
#export NCLmax1_2="310.0"
#export NCLdiffs1_2="5.0"
#export NCLmin2_2="-3.6"
#export NCLmax2_2="3.6"
#export NCLdiffs2_2="0.8"
#export NCLunits_2="K"
#
#export NCLplotvar_1="U"
#export NCLilev_1="850"
#export NCLvartitle_1="~F10~u~F21~"
#export NCLmin1_1="-7.0"
#export NCLmax1_1="11.0"
#export NCLdiffs1_1="2.0"
#export NCLmin2_1="-9.0"
#export NCLmax2_1="9.0"
#export NCLdiffs2_1="2.0"
#export NCLunits_1="m~S~-1~N~"
#
#export NCLplotvar_2="PV"
#export NCLilev_2="850"
#export NCLvartitle_2="~F10~PV~F21~"
#export NCLmin1_2="0.0"
#export NCLmax1_2="3.6e-6"
#export NCLdiffs1_2="0.4e-6"
#export NCLmin2_2="-0.9e-6"
#export NCLmax2_2="0.9e-6"
#export NCLdiffs2_2="0.2e-6"
#export NCLunits_2="PVU"
#
#export NCLplotvar_1="U"
#export NCLilev_1="850"
#export NCLvartitle_1="~F10~u~F21~"
#export NCLmin1_1="-7.0"
#export NCLmax1_1="11.0"
#export NCLdiffs1_1="2.0"
#export NCLmin2_1="-9.0"
#export NCLmax2_1="9.0"
#export NCLdiffs2_1="2.0"
#export NCLunits_1="m~S~-1~N~"
#
#export NCLplotvar_1="V"
#export NCLilev_1="850"
#export NCLvartitle_1="~F10~v~F21~"
#export NCLmin1_1="-1.0"
#export NCLmax1_1="6.0"
#export NCLdiffs1_1="0.8"
#export NCLmin2_1="-1.8"
#export NCLmax2_1="1.8"
#export NCLdiffs2_1="0.4"
#export NCLunits_1="m~S~-1~N~"
#
#export NCLplotvar_2="V"
#export NCLilev_2="250"
#export NCLvartitle_2="~F10~v~F21~"
#export NCLmin1_2="-1.0"
#export NCLmax1_2="6.0"
#export NCLdiffs1_2="0.8"
#export NCLmin2_2="-1.80"
#export NCLmax2_2="1.80"
#export NCLdiffs2_2="0.4"
#export NCLunits_2="m~S~-1~N~"
#
export NCLplotvar_1="PREC"
export NCLilev_1="0"
export NCLvartitle_1="Precip"
export NCLmin1_1="0"
export NCLmax1_1="9.0"
export NCLdiffs1_1="1.0"
export NCLmin2_1="-0.9"
export NCLmax2_1="0.9"
export NCLdiffs2_1="0.2"
export NCLunits_1="mm/day"
#export NCLplotvar_1="PmE"
#export NCLilev_1="0"
#export NCLvartitle_1="P-E"
#export NCLmin1_1="-5.0"
#export NCLmax1_1="5.0"
#export NCLdiffs1_1="1.0"
#export NCLmin2_1="-2.0"
#export NCLmax2_1="2.0"
#export NCLdiffs2_1="0.4"
#export NCLunits_1="mm/day"
#
#export NCLplotvar_2="TdiaSRF"
#export NCLilev_2="0"
#export NCLvartitle_2="DJF LH + SH + LW + SW"
#export NCLmin1_2="-200"
#export NCLmax1_2="200"
#export NCLdiffs1_2="40"
#export NCLmin2_2="-90"
#export NCLmax2_2="90"
#export NCLdiffs2_2="20"
#export NCLunits_2="W/m~S~2~N~"
#export NCLplotvar_1="TradSRF"
#export NCLilev_1="0"
#export NCLvartitle_1="DJF LW + SW"
#export NCLmin1_1="-100"
#export NCLmax1_1="100"
#export NCLdiffs1_1="20"
#export NCLmin2_1="-50"
#export NCLmax2_1="50"
#export NCLdiffs2_1="10"
#export NCLunits_1="W/m~S~2~N~"
#
#export NCLplotvar_2="SHFLX"
#export NCLilev_2="0"
#export NCLvartitle_2="DJF SH"
#export NCLmin1_2="-200"
#export NCLmax1_2="200"
#export NCLdiffs1_2="40"
#export NCLmin2_2="-50"
#export NCLmax2_2="50"
#export NCLdiffs2_2="10"
#export NCLunits_2="W/m~S~2~N~"
#
fi
# save command line arguments to environment variable NCL_ARG_#
count=0
for ((index=1; index<=$NCLnumexps; index++))
do
eval export NCLexps1_$index=${exps1[count]}
eval export NCLtitles1_$index=${titles1[count]}
eval export NCLCTLs1_$index=${CTLS[count]}
eval export NCLstarts1_$index=${starts[count]}
eval export NCLnyears1_$index=${nyears[count]}
eval export NCLtimespans1_$index=${timespan[count]}
eval export NCLreverses1_$index=${reverse[count]}
((count++))
done
ncl plot_generic2.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="RAD"
ilev="250"
min1="-1e-7"
max1="1e-7"
diffs1="2e-8"
min2="-1e-8"
max2="1e-8"
diffs2="2e-9"
units="Ks:S:-1:N:"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="Zmax"
ilev="-10"
min1="-80.0"
max1="0.0"
diffs1="8.0"
min2="-10.0"
max2="10.0"
diffs2="2.0"
units="ps"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>Scripts in ./nishii_scripts are verbatim from: http://www.atmos.rcast.u-tokyo.ac.jp/nishii/programs/index.html
Scripts in ./ncl_ncep are based on the nishii scripts, but actually work and loop over all years from NCEP-II.
Scripts in ./mat just make some climatological figures --- contour plots of the different WAF components, the basic state winds, and vector plots of the horizontal WAF components. Plots are done for each month.
./lib has some plotting routines for convenience.<file_sep>#!/bin/sh
cd ./scripts/
difvars="0"
expdif="0"
figtit="Paper"
dir1="/home/disk/rachel/CESM_outfiles/"
numexps="4"
exps1=("CESMnotopof19" "CESM_IG49N_West" "CESM_IG39_West" "CESM_IG29N_West")
titles1=("I\_CTL" "I\_58N\_West" "I\_48N\_West" "I\_38N\_West")
dir2="/home/disk/rachel/CESM_outfiles/"
exps2=("CESMnotopof19" "CESM_IG49N_West" "CESM_IG39_West" "CESM_IG29N_West")
titles2=("I\_CTL" "I\_58N\_West" "I\_48N\_West" "I\_38N\_West")
start1="2"
end1="31"
start2="2"
end2="31"
timespan="DJF"
reverse="true"
linear="false"
clon="180.0"
slon="100.0"
elon="120.0"
slat="0.0"
elat="90.0"
plottype="ZMline"
plotctl=1
plotERA=0
titleprefix="I4_"
y save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$difvars
((index++))
export NCL_ARG2_$index=$expdif
((index++))
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start2
((index++))
eval export NCL_ARG2_$index=$end2
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
((index++))
eval export NCL_ARG2_$index=$plottype
((index++))
eval export NCL_ARG2_$index=$plotctl
((index++))
eval export NCL_ARG2_$index=$plotERA
((index++))
eval export NCL_ARG2_$index=$titleprefix
ncl plot_generic_ZMline_paper_xmb.ncl
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="vort"
ilev="250"
min1="-5.0e-5"
max1="5.0e-5"
diffs1="8.0e-6"
min2="-2.0e-5"
max2="2.0e-5"
diffs2="3.2e-6"
units="m:S:2:N:s:S:-1:N:"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd /home/disk/eos4/rachel/NCL/cesm_scripts/Analysis/Plotting/scripts/
plotvar="-dTHdy"
ilev="850"
min1="-1.0e-5"
max1="1.0e-5"
diffs1="1.0e-6"
min2="-3.0e-6"
max2="3.0e-6"
diffs2="0.5e-6"
units="Km:S:-1:N:"
plottype="ZMline"
# save command line arguments to environment variable NCL_ARG_#
index=1
eval export NCL_ARG_$index=$plotvar
((index++))
eval export NCL_ARG_$index=$ilev
((index++))
eval export NCL_ARG_$index=$min1
((index++))
eval export NCL_ARG_$index=$max1
((index++))
eval export NCL_ARG_$index=$diffs1
((index++))
eval export NCL_ARG_$index=$min2
((index++))
eval export NCL_ARG_$index=$max2
((index++))
eval export NCL_ARG_$index=$diffs2
((index++))
eval export NCL_ARG_$index=$units
((index++))
eval export NCL_ARG_$index=$plottype
ncl plot_generic.ncl
echo 'finished'
<file_sep>#!/bin/sh
cd ./scripts/individual/
figtit="newSOMonly"
dir1="/home/disk/eos4/rachel/CESM_outfiles/"
numexps="4"
exps1=("CAM4SOM4topo" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_noMT")
titles1=("CAM4_SOM4_CTL" "CAM4_SOM4_noT" "CAM4_SOM4_noM" "CAM4_SOM4_noMT")
dir2="/home/disk/eos4/rachel/CESM_outfiles/"
exps2=("CAM4SOM4topo" "CAM4SOM4_noT" "CAM4SOM4_noM" "CAM4SOM4_noMT")
titles2=("CAM4_SOM4_CTL" "CAM4_SOM4_noT" "CAM4_SOM4_noM" "CAM4_SOM4_noMT")
start1="11"
end1="40"
start2="11"
end2="40"
timespan="DJF"
reverse="false"
linear="false"
clon="90.0"
slon="0.0"
elon="210.0"
slat="020.0"
elat="90.0"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start2
((index++))
eval export NCL_ARG2_$index=$end2
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
./plot_Tadv500.sh
#./plot_U250.sh
#./plot_Tdia500.sh
#./plot_Tdia250.sh
#./plot_Tdia850.sh
#./plot_Tadv250.sh
#./plot_Tadv850.sh
<file_sep>#!/bin/sh
cd ./scripts/individual/
figtit="CAM5_DEF"
dir1="/home/disk/rachel/CESM_outfiles/CAM5/"
numexps="2"
exps1=("CAM5topo" "CAM5def1")
titles1=("CAM5_CTL" "CAM5_DEF_ALL")
dir2="/home/disk/rachel/CESM_outfiles/CAM5/"
exps2=("CAM5def1" "CAM5def1")
titles2=("CAM5_DEF_ALL" "CAM5_DEF_ALL")
start1="2"
end1="41"
start2="2"
end2="41"
timespan="DJF"
reverse="false"
linear="false"
clon="0.0"
slon="-180.0"
elon="180.0"
slat="-80.0"
elat="80.0"
# save command line arguments to environment variable NCL_ARG_#
index=1
export NCL_ARG2_$index=$figtit
((index++))
export NCL_ARG2_$index=$numexps
((index++))
eval export NCL_ARG2_$index=$dir1
((index++))
# save command line arguments to environment variable NCL_ARG_#
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps1[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles1[count]}
((count++))
done
eval export NCL_ARG2_$index=$dir2
((index++))
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${exps2[count]}
((count++))
done
count=0
limit=$((index+numexps-1))
for ((index=$index; index<=$limit; index++))
do
eval export NCL_ARG2_$index=${titles2[count]}
((count++))
done
eval export NCL_ARG2_$index=$start1
((index++))
eval export NCL_ARG2_$index=$end1
((index++))
eval export NCL_ARG2_$index=$start2
((index++))
eval export NCL_ARG2_$index=$end2
((index++))
eval export NCL_ARG2_$index=$timespan
((index++))
eval export NCL_ARG2_$index=$reverse
((index++))
eval export NCL_ARG2_$index=$linear
((index++))
eval export NCL_ARG2_$index=$clon
((index++))
eval export NCL_ARG2_$index=$slon
((index++))
eval export NCL_ARG2_$index=$elon
((index++))
eval export NCL_ARG2_$index=$slat
((index++))
eval export NCL_ARG2_$index=$elat
#./plot_PV250.sh
./plot_PV850.sh
./plot_PV300.sh
#./plot_PV400.sh
./plot_PREC.sh
#./plot_VbpfTbpf250.sh
#./plot_VbpfTbpf850.sh
#./plot_ZeventsMag.sh
#./plot_ZeventsLen.sh
#./plot_ZeventsMax.sh
#./plot_ZeventsNum.sh
./plot_EKE250.sh
./plot_EKE850.sh
#./plot_Tadv600.sh
#./plot_Tadv500.sh
./plot_TS.sh
./plot_U250.sh
./plot_U850.sh
./plot_U1000.sh
./plot_EMGR.sh
#./plot_Tadv850.sh
#./plot_Tadv250.sh
#./plot_Tdia850.sh
#./plot_Tdia250.sh
#./plot_UV250.sh
#./plot_UV850.sh
#./plot_dtdy600.sh
#./plot_SF850.sh
#./plot_SF250.sh
./plot_Zvar.sh
./plot_uH.sh
./plot_uP.sh
#./plot_SFZA700.sh
#./plot_TH700.sh
| c55b951fdb97d74d4d30e74e28ac72aef317ebf1 | [
"Markdown",
"Shell"
] | 66 | Shell | subaohuang/NCLscripts | 86260ea6da5f98343d581750316a4335909b5520 | 4538a34eb0ab4b9c10b2850c7c019342e4a49605 |
refs/heads/master | <repo_name>mcapra/nagios-check_casperjs<file_sep>/README.md
# nagios-check_casperjs
A Nagios plugin for executing and validating [CasperJS](http://casperjs.org/) test cases.
```
usage: check_casperjs.py [-h] -p PATH [-w WARNING] [-c CRITICAL] [-a ARGS]
[-r] [-b BINARY] [-v]
Executes CasperJS test cases and reports any errors found.
optional arguments:
-h, --help show this help message and exit
-p PATH, --path PATH The logical path to the CasperJS script you want to
check.
-w WARNING, --warning WARNING
The warning threshold for the script's execution time
(in seconds).
-c CRITICAL, --critical CRITICAL
The critical threshold for the script's execution time
(in seconds).
-a ARGS, --args ARGS Any arguments you want to pass to your CasperJS
script.
-r, --report Include a report of each test step in the status
output (can be useful for diagnosing failures).
-b BINARY, --binary BINARY
Path to the CasperJS binary you wish to use.
-v, --verbose Enable verbose output (this can be VERY long).
```
Examples:
```
[root@nagiosxi ~]# /tmp/check_casperjs.py -p /tmp/test4.js
OK - PASS 5 tests executed in 1.351s, 5 passed, 0 failed, 0 dubious, 0 skipped. |runtime=1.351s
[root@nagiosxi ~]# /tmp/check_casperjs.py -p /tmp/test4.js --report
OK - PASS 5 tests executed in 1.386s, 5 passed, 0 failed, 0 dubious, 0 skipped. (PASS Find an element matching: xpath selector: //*[normalize-space(text())='More information...']) (PASS Find an element matching: xpath selector: //a[normalize-space(text())='More information...']) (PASS Find an element matching: xpath selector: //*[contains(text(), 'Reserved Domains')]) (PASS Find an element matching: p:nth-child(9)) (PASS Find an element matching: div > div) (PASS Resurrectio test) |runtime=1.386s
[root@nagiosxi ~]# /tmp/check_casperjs.py -p /tmp/test4.js
CRITICAL - FAIL 3 tests executed in 6.194s, 2 passed, 1 failed, 0 dubious, 0 skipped. (FAIL Find an element matching: xpath selector: //*[contains(text(), 'Reserved Domainszz')]) |runtime=6.194s
[root@nagiosxi ~]# /tmp/check_casperjs.py -p /tmp/test4.js --report
CRITICAL - FAIL 3 tests executed in 6.233s, 2 passed, 1 failed, 0 dubious, 0 skipped. (FAIL Find an element matching: xpath selector: //*[contains(text(), 'Reserved Domainszz')]) |runtime=6.223s
```<file_sep>/check_casperjs.py
#!/usr/bin/env python
# Copyright (c) 2018 <NAME> (http://www.mcapra.com)
#
# This software is provided under the Apache Software License.
#
# Description: This Nagios plugin runs and parses a CasperJS test case.
#
# Author:
# <NAME>
import argparse
import commands
import logging
import time
import re
def check_casperjs():
nagios_exit = {}
if(args.binary):
output = commands.getoutput(args.binary + ' test ' + args.path)
else:
output = commands.getoutput('casperjs test ' + args.path)
# Used to strip ANSI codes that CasperJS uses to make the output "pretty"
ansi_escape = re.compile(r'\x1B\[[0-?]*[ -/]*[@-~]')
output = ansi_escape.sub('', output)
if(args.verbose):
print str(output)
lines = output.splitlines()
output_parse = re.compile('(([A-Z]{4}).*in\\s(\\d+\\.\\d+)s,\\s([0-9]*)\\spassed,\\s([0-9]*)\\sfailed,\\s([0-9]*)\\sdubious.*)')
parsed = []
failures = ''
passes = ''
# todo - gracefully handle CasperJS runtime errors
for line in lines:
if(re.match('FAIL\\s(?!.*executed in)', line)):
failures += '(' + line + ') '
elif(re.match('PASS\\s(?!.*executed in)', line)):
passes += '(' + line + ') '
else:
m = re.match(output_parse, line)
if(m):
parsed = re.findall(output_parse, line)
break
# todo - gracefully handle | character in status output
# todo - remove some trailing spaces
if(parsed[0][1] == 'PASS'):
#if we pass
nagios_exit['status'] = 'OK - ' + parsed[0][0]
if(args.report):
nagios_exit['status'] += passes
nagios_exit['code'] = 0
nagios_exit['perfdata'] = '|runtime=' + parsed[0][2] + 's'
elif(parsed[0][1] == 'FAIL'):
#if we fail, there should be a summary to print
nagios_exit['status'] = 'CRITICAL - ' + parsed[0][0]
if(args.report):
nagios_exit['status'] += failures
nagios_exit['code'] = 2
nagios_exit['perfdata'] = '|runtime=' + parsed[0][2] + 's'
else:
nagios_exit['status'] = 'UNKNOWN - ' + output
nagios_exit['code'] = 3
return nagios_exit
if __name__ == '__main__':
import cmd
parser = argparse.ArgumentParser(add_help = True, description = "Executes CasperJS test cases and reports any errors found.")
parser.add_argument('-p', '--path', action='store', help='The logical path to the CasperJS script you want to check.', required=True)
parser.add_argument('-w', '--warning', action='store', help='The warning threshold for the script\'s execution time (in seconds).', required=False)
parser.add_argument('-c', '--critical', action='store', help='The critical threshold for the script\'s execution time (in seconds).', required=False)
parser.add_argument('-a', '--args', action='store', help='Any arguments you want to pass to your CasperJS script.', required=False)
parser.add_argument('-r', '--report', action='store_true', help='Include a report of each test step in the status output (can be useful for diagnosing failures).', required=False)
parser.add_argument('-b', '--binary', action='store', help='Path to the CasperJS binary you wish to use.', required=False)
parser.add_argument('-v', '--verbose', action='store_true', help='Enable verbose output (this can be VERY long).', required=False)
args = parser.parse_args()
nagios_exit = {}
nagios_exit = check_casperjs()
print(nagios_exit['status'] + nagios_exit['perfdata'])
exit(nagios_exit['code'])
| 389662aa7bd430fdd5ad2babed0b053f4ecbb911 | [
"Markdown",
"Python"
] | 2 | Markdown | mcapra/nagios-check_casperjs | 6af799c6cf1db9edfa07006155e0f812749f927f | ce4d629342043c2806732c581e1176a39be28db4 |
refs/heads/master | <file_sep>// Here’s some guidance for how insertion sort should work:
// Start by picking the second element in the array (we will assume the first element is the start of the “sorted” portion)
// Now compare the second element with the one before it and swap if necessary.
// Continue to the next element and if it is in the incorrect order, iterate through the sorted portion to place the element in the correct place.
// Repeat until the array is sorted.
function insertionSort(arr) {
for (let i = 0; i < arr.length; i++) {
let currentValue = arr[i];
for (var j = i - 1; j > -1 && arr[j] > currentValue; j--) {
arr[j + 1] = arr[j];
}
arr[j + 1] = currentValue;
}
return arr;
}
module.exports = insertionSort; | f7be4cd6561f5983944efcc88a50c16fba20ab0a | [
"JavaScript"
] | 1 | JavaScript | gabbycampos/dsa-sorting | e0c76c76e12b52c10501daf50126604e224450d2 | fd77b179f85b31336eb85477467db875b0f2f4af |
refs/heads/master | <file_sep>import hello
result=hello.greeting('kusum')
print(result)
a=hello.person1["age"]
print(a)
import hello as m
b=m.person1["age"]
print(b)
c=m.person1["country"]
print(c)
d=m.person1["name"]
print(d)
| 2777cf9d4169437ef895fad5b2da77b8801bfff1 | [
"Python"
] | 1 | Python | Kus-prog/day-8 | c700a04fc986ef3d828843266c7a17e23c9476e9 | 70e59b97e799e58d16b5049a34a95852d147a50b |
refs/heads/main | <repo_name>yearofthedan/visualising-github<file_sep>/public/relationships/repoPrRelationshipChart.js
import {doQuery} from "../graphQLQuery.js";
import renderForceGraphChart from "../chartRenderers/forceGraphChart.js";
const graphqlQuery = (organisation, repo) => JSON.stringify({
query: `{
repository(owner: "${organisation}", name: "${repo}") {
name
pullRequests(last: 100, states: MERGED) {
nodes {
author {
login
}
reviews(states: APPROVED, first: 5) {
nodes {
author {
login
}
}
}
}
}
}
}`,
variables: {}
});
const mapQueryResultToChartData = (queryResult) => {
const buildingChartData = {
nodes: new Set(),
links: new Map(),
}
const deriveKey = (str1, str2) => {
return str1 < str2 ? `${str1}${str2}` : `${str2}${str1}`
}
queryResult.repository.pullRequests.nodes
.forEach(pr => {
pr.reviews.nodes.forEach(review => {
buildingChartData.nodes.add(review.author.login)
buildingChartData.nodes.add(pr.author.login)
const key = deriveKey(review.author.login, pr.author.login);
if (buildingChartData.links.has(key)) {
const current = buildingChartData.links.get(key);
buildingChartData.links.set(key, {
...current,
value: current.value + 1
})
} else {
buildingChartData.links.set(key, {
source: review.author.login,
target: pr.author.login,
value: 1
})
}
})
});
return {
nodes: Array.from(buildingChartData.nodes).map(name => ({id: name})),
links: Array.from(buildingChartData.links.values())
};
}
const createRepoPrRelationshipChart = async (organisation, repository) => {
return doQuery(graphqlQuery(organisation, repository))
.then(mapQueryResultToChartData)
.then(renderForceGraphChart);
}
export default createRepoPrRelationshipChart;
<file_sep>/public/relationships/orgPrRelationshipChart.js
import {doQuery} from "../graphQLQuery.js";
import renderForceGraphChart from "../chartRenderers/forceGraphChart.js";
const graphqlQuery = (organisation) => JSON.stringify({
query: `{
repositoryOwner(login: "${organisation}") {
repositories(first: 20) {
nodes {
name
pullRequests(last: 50, states: MERGED) {
nodes {
author {
login
}
reviews(states: APPROVED, first: 5) {
nodes {
author {
login
}
}
}
}
}
}
}
}
}`,
variables: {}
});
const mapQueryResultToChartData = (queryResult) => {
const buildingChartData = {
nodes: new Set(),
links: new Map(),
}
const deriveKey = (str1, str2) => {
return str1 < str2 ? `${str1}${str2}` : `${str2}${str1}`
}
queryResult.repositoryOwner.repositories.nodes
.forEach((repo) => {
repo.pullRequests.nodes
.forEach(pr => {
pr.reviews.nodes.forEach(review => {
buildingChartData.nodes.add(review.author.login)
buildingChartData.nodes.add(pr.author.login)
const key = deriveKey(review.author.login, pr.author.login);
if (buildingChartData.links.has(key)) {
const current = buildingChartData.links.get(key);
buildingChartData.links.set(key, {
...current,
value: current.value + 1
})
} else {
buildingChartData.links.set(key, {
source: review.author.login,
target: pr.author.login,
value: 1
})
}
})
});
});
return {
nodes: Array.from(buildingChartData.nodes).map(name => ({id: name})),
links: Array.from(buildingChartData.links.values())
};
}
const createOrgPrRelationshipChart = (organisation) => {
return doQuery(graphqlQuery(organisation))
.then(mapQueryResultToChartData)
.then(renderForceGraphChart);
}
export default createOrgPrRelationshipChart;
<file_sep>/public/graphQLQuery.js
import {githubToken} from './secret/token.js';
export const doQuery = async (query) => {
const myHeaders = new Headers();
myHeaders.append("Authorization", `Bearer ${githubToken}`);
myHeaders.append("Content-Type", "application/json");
try {
const response = await fetch("https://api.github.com/graphql", {
method: 'POST',
headers: myHeaders,
body: query,
redirect: 'follow'
}).then(response => response.json());
return response.data;
} catch(error) {
console.log('error', error);
}
}
<file_sep>/README.md
# Visualising Github
Playing with the GitHub GraphQL API + D3
## Prereqs
This uses js modules so needs to be run from a local server.
- If you're of a js persuasion `npx http-server` will serve it up
- Or python aware `python -m SimpleHTTPServer` should do the trick
You also need a github token:
https://docs.github.com/en/github/authenticating-to-github/creating-a-personal-access-token
The token is placed in `public/secret/token.js/` which is gitignored.
This only works for a local run. DO NOT deploy a version with the token as you will expose it publicly.
| be3d36f6bb5d06b30734bda60ea1f45cabba257f | [
"JavaScript",
"Markdown"
] | 4 | JavaScript | yearofthedan/visualising-github | 7944d1911ea03ceb07702caa9b0a494a7ed485be | 59e42d2d133680d225250514cbf49453f8e71807 |
refs/heads/master | <file_sep>import os, time
class Applog :
def __init__(self):
logfile = os.getcwd() + "\\log\\" + time.strftime("%Y%m%d", time.localtime()) + ".log"
self.fp = open(logfile, 'a')
return
def addLog(self, log):
log = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) + " " + log
print(log)
self.fp.write(log + '\n')
self.fp.flush()
return
def closeLofile(self):
self.fp.close()
return
def logRun(file):
def decorator(fun):
def wrapper(*args, **kwargs):
file.addLog(fun.__name__)
return fun(*args)
return wrapper
return decorator
<file_sep>from requests.auth import HTTPBasicAuth
import json
import re
import requests
import paramiko
from shell.Cloudos2Data import Cloudos2Data
from shell import images, applog
logfile = applog.Applog()
class Cloudos3Data(Cloudos2Data):
@applog.logRun(logfile)
def imageCollect(self):
self.osInfo["imagesStatus"] = []
respond = requests.get("http://" + self.ip + ":8000/os/image/v1/v2/images",
auth=HTTPBasicAuth(self.httpuser, self.httppassword))
if respond.text:
tmp = json.loads(respond.text)
if 'images' in tmp.keys():
for i in tmp['images']:
dict1 = {}
dict1['name'] = i['name']
dict1['status'] = i['status']
self.osInfo["imagesStatus"].append(dict1.copy())
del dict1
respond.close()
return
@applog.logRun(logfile)
def vmCollect(self):
self.osInfo['vmStatus'] = []
response = requests.get("http://" + self.ip + ":8000/sys/identity/v2/projects",
auth=HTTPBasicAuth(self.httpuser, self.httppassword))
cookies = response.cookies
print(response.text)
for i in json.loads(response.text)['projects']:
print(i)
if i['type'] == "SYSTEM":
print(i['uuid'])
url = "http://" + self.ip + ":8000/os/compute/v1/v2/" + i['uuid'] + "/servers/detail"
# response1 = requests.get(url, auth=HTTPBasicAuth(self.httpuser, self.httppassword))
response1 = requests.get(url, cookies = cookies)
serv = json.loads(response1.text)
response1.close()
if 'servers' in serv.keys():
for j in serv['servers']:
dict1 = {}
dict1['name'] = j['name']
dict1['status'] = j['status']
self.osInfo['vmStatus'].append(dict1.copy())
del dict1
response.close()
return
@applog.logRun(logfile)
def vdiskCollect(self):
response = requests.get("http://" + self.ip + ":8000/sys/identity/v2/projects",
auth=HTTPBasicAuth(self.httpuser, self.httppassword))
self.osInfo['vDiskStatus'] = []
cookies = response.cookies
for i in json.loads(response.text)['projects']:
if i['type'] == "SYSTEM":
url = "http://" + self.ip + ":8000/os/storage/v1/v2/" + i['uuid'] + "/volumes/detail"
# response1 = requests.get(url, auth=HTTPBasicAuth(self.httpuser, self.httppassword))
response1 = requests.get(url, cookies=cookies)
for j in json.loads(response1.text)['volumes']:
dict1 = {}
dict1['name'] = j['name']
dict1['status'] = j['status']
self.osInfo['vDiskStatus'].append(dict1.copy())
del dict1
response1.close()
response.close()
return
@applog.logRun(logfile)
def listConfliction(self, li):
li3 = []
for i in range(len(li)):
key = li[i]
for j in range(i + 1, len(li)):
if key == li[j] and li not in li3:
li3.append(key)
return li3
#获取冲突的计算节点
@applog.logRun(logfile)
def computeCollect(self):
response = requests.get("http://" + self.ip + ":8000/os/compute/v1/h3cloudos/computenode",
auth=HTTPBasicAuth(self.httpuser, self.httppassword))
li = json.loads(response.text)
response.close()
li2 = []
dic = {}
for i in self.listConfliction(li):
dic['name'] = i['hostName']
dic['ip'] = i['hostIp']
dic['poolName'] = i['poolName']
li2.append(dic.copy())
self.osInfo['computeConfliction'] = li2.copy()
del dic
del li2
return
#检查容器镜像是否完整
@applog.logRun(logfile)
def dockerImageCheck(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
for i in self.osInfo['nodeInfo']:
i['images'] = set()
set1 = set()
if i["status"] == 'Ready':
cmd = "ssh\t" + i['hostName'] + "\tdocker images | awk 'NR>1{print $1}' | grep -v gcr | grep -v\t" + self.osInfo['masterIP']
stdin, stdout, stderr = ssh.exec_command(cmd)
if not stderr.read():
text = stdout.read().decode()
for j in text.splitlines():
set1.add(j)
# 当为v2版本使用v2的镜像集合进行对比
if i['hostName'] == self.osInfo['masterIP']:
if set1 != images.imagesv3Set:
i["images"] = images.imagesv3Set.difference(set1)
else:
if set1 != images.imagesv3Set - {'registry'}:
i["images"] = (images.imagesv3Set - {'registry'}).difference(set1)
else:
print("docker Image check ssh is invalid")
ssh.close()
return<file_sep>import os
import time
from datetime import datetime
import docx
# directory = os.getcwd()
# time_now1 = time.strftime("%Y%m%d%H%M%S", time.localtime())
# time_now2 = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# print(directory)
# print(os.path.join(os.getcwd(), 'check_result'))
# print(time_now1)
# print(time_now2)
# print(datetime.date())
filename = os.getcwd() + '\\check_result\\' + "巡检文档201908081510.docx"
# filename = os.getcwd()
print(filename)
os.remove(filename)
<file_sep>from requests.auth import HTTPDigestAuth
import xmltodict
import requests
import paramiko
from multiprocessing import Pool
from shell import applog
import threadpool
logfile = applog.Applog()
THREADNUM = 4
class Cas3Data:
# 读取ip、username,password
def __init__(self, ip, sshUser, sshPassword, httpUser, httpPassword):
self.host = ip
self.url = "http://" + ip + ":8080/cas/casrs/"
self.httpUser = httpUser
self.httpPassword = <PASSWORD>Password
self.casInfo = {}
self.sshUser = sshUser
self.sshPassword = <PASSWORD>
self.cookies = requests.get(self.url, auth=HTTPDigestAuth(self.httpUser, self.httpPassword)).cookies
return
# 获取cvm基础信息:版本信息、服务器版本、服务器规格、部署方式
@applog.logRun(logfile)
def cvmBasicCollect(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy)
ssh.connect(self.host, 22, self.sshUser, self.sshPassword)
# 服务器硬件型号
stdin, stdout, stderr = ssh.exec_command("dmidecode | grep -i product | awk 'NR==1{print $3,$4,$5 }'")
if not stderr.read():
self.casInfo['productVersion'] = stdout.read().decode()
else:
print(" product version error")
# 服务规格
stdin, stdout, stderr = ssh.exec_command(
"lscpu | cut -d : -f 2 | awk 'NR==4 || NR==7{print $1}';free -g | awk 'NR==2{print $2}'")
if not stderr.read():
text = stdout.read().decode()
a = text.splitlines()
self.casInfo['deviceDmide'] = "cpu:" + a[0] + "*" + a[1] + "cores" + "\nMem:" + a[2] + 'G'
else:
print("device dmide error")
# cas版本
stdin, stdout, stderr = ssh.exec_command("cat /etc/cas_cvk-version | head -1")
if not stderr.read():
self.casInfo['casVersion'] = stdout.read().decode()
else:
print("cas version error")
# 部署方式
stdin, stdout, stderr = ssh.exec_command("crm status | grep Online | awk '{print NF-3}'")
if not stderr.read():
text = stdout.read().decode().splitlines()
if not text or text[0] == '1':
self.casInfo["installType"] = "单机部署"
else:
self.casInfo["installType"] = "集群部署"
else:
print("install type error")
# 1020v版本:
stdin, stdout, stderr = ssh.exec_command("ovs-vsctl -V | awk 'NR==1{print $0}'")
if not stderr.read():
self.casInfo['ovsVersion'] = stdout.read().decode()
else:
print("ovs version error")
# license 信息
self.casInfo['licenseInfo'] = 'NONE'
ssh.close()
return
#####################################################
# time:2019.4.28 #
# function:集群巡检功能 author:wf #
#####################################################
@applog.logRun(logfile)
def clusterCollect(self):
# response = requests.get(self.url + 'cluster/clusters/', auth=HTTPDigestAuth(self.httpUser, self.httpPassword))
response = requests.get(self.url + 'cluster/clusters/', cookies=self.cookies)
contxt = response.text
response.close()
dict1 = xmltodict.parse(contxt)['list']['cluster']
temp = []
if isinstance(dict1, dict):
temp.append(dict1)
else:
temp = dict1.copy()
self.casInfo['clusterInfo'] = []
tempInfo = {}
for i in temp:
# 获取集群的id,name,HA状态,cvk数量,LB状态
tempInfo['id'] = i['id']
tempInfo['name'] = i['name']
tempInfo['enableHA'] = i['enableHA']
tempInfo['cvkNum'] = (int)(i['childNum'])
tempInfo['enableLB'] = i['enableLB']
self.casInfo['clusterInfo'].append(tempInfo.copy())
# 获取集群HA最小主机数量
for i in self.casInfo['clusterInfo']:
# response = requests.get(self.url + 'cluster/' + i['id'], auth=HTTPDigestAuth(self.httpUser, self.httpPassword))
response = requests.get(self.url + 'cluster/' + i['id'], cookies=self.cookies)
contxt = response.text
response.close()
dict1 = xmltodict.parse(contxt)
i['HaMinHost'] = dict1['cluster']['HaMinHost']
del temp
return
####################################################################
# 获取主机ID、NAME、状态、虚拟机数量、cpu使用率、内存使用率 #
####################################################################
@applog.logRun(logfile)
def cvkBasicCollect(self):
# 初始化cvk数据结构
for i in self.casInfo['clusterInfo']:
i['cvkInfo'] = []
# response = requests.get(self.url + 'cluster/hosts?clusterId=' + i['id'],
# auth=HTTPDigestAuth(self.httpUser, self.httpPassword))
response = requests.get(self.url + 'cluster/hosts?clusterId=' + i['id'], cookies=self.cookies)
contxt = response.text
response.close()
dict1 = xmltodict.parse(contxt)['list']['host']
temp1 = []
if isinstance(dict1, dict):
temp1.append(dict1)
else:
temp1 = dict1.copy()
for j in temp1:
temp2 = {}
temp2['id'] = j['id']
temp2['name'] = j['name']
temp2['status'] = j['status']
temp2['ip'] = j['ip']
temp2['vmNum'] = j['vmNum']
temp2['cpuRate'] = (float)(j['cpuRate'])
temp2['memRate'] = (float)(j['memRate'])
i['cvkInfo'].append(temp2.copy())
del temp2
del temp1
return
##################################################
# 主机共享存储利用率/cas/casrs/host/id/{id}/storage#
# 获取主机共享存储池信
##################################################
@applog.logRun(logfile)
def cvkSharepoolCollect(self):
pool = threadpool.ThreadPool(THREADNUM)
for i in self.casInfo['clusterInfo']:
threadlist = threadpool.makeRequests(self.cvkSharepool, i['cvkInfo'])
for k in threadlist:
pool.putRequest(k)
pool.wait()
return
def cvkSharepool(self, cvk):
# response = requests.get(self.url + 'host/id/' + cvk['id'] + '/storage',
# auth=HTTPDigestAuth(self.httpUser, self.httpPassword))
if cvk['status'] == '1':
response = requests.get(self.url + 'host/id/' + cvk['id'] + '/storage', cookies=self.cookies)
contxt1 = response.text
response.close()
dict1 = xmltodict.parse(contxt1)
list1 = []
dict2 = {}
li = []
if isinstance(dict1['list'], dict):
if 'storagePool' in dict1['list']:
if isinstance(dict1['list']['storagePool'], dict):
list1.append(dict1['list']['storagePool'])
else:
list1 = dict1['list']['storagePool']
for j in list1:
dict2['name'] = j['name']
dict2['rate'] = 1 - (float)(j['freeSize']) / (float)(j['totalSize'])
dict2['path'] = j['path']
li.append(dict2.copy())
del list1
del dict2
cvk['sharePool'] = li
return
##############################################################
# 获取CVK主机磁盘利用率
# cas版本为V5.0 (E0530)时,api获取磁盘利用率信息不正确,cas软件bug
##############################################################
@applog.logRun(logfile)
def cvkDiskCollect(self):
pool = threadpool.ThreadPool(THREADNUM)
for i in self.casInfo['clusterInfo']:
threadlist = threadpool.makeRequests(self.cvkDisk, i['cvkInfo'])
for k in threadlist:
pool.putRequest(k)
pool.wait()
return
def cvkDisk(self, cvk):
# response = requests.get(self.url + 'host/id/' + cvk['id'] + '/monitor',
# auth=HTTPDigestAuth(self.httpUser, self.httpPassword))
if cvk['status'] == '1':
response = requests.get(self.url + 'host/id/' + cvk['id'] + '/monitor', cookies=self.cookies)
contxt1 = response.text
response.close()
dict2 = xmltodict.parse(contxt1)['host']
li = []
if 'disk' in dict2.keys():
dict1 = xmltodict.parse(contxt1)['host']['disk']
temp = []
if isinstance(dict1, dict):
temp.append(dict1)
else:
temp = dict1.copy()
for h in temp:
temp1 = {}
temp1['name'] = h['device']
temp1['usage'] = (float)(h['usage'])
li.append(temp1.copy())
del temp1
del temp
cvk['diskRate'] = li
return
##############################################################
# 获取CVK主机虚拟交换机信息
##############################################################
@applog.logRun(logfile)
def cvkVswitchCollect(self):
pool = threadpool.ThreadPool(THREADNUM)
for i in self.casInfo['clusterInfo']:
threadlist = threadpool.makeRequests(self.cvkVswitch, i['cvkInfo'])
for k in threadlist:
pool.putRequest(k)
pool.wait()
return
def cvkVswitch(self, cvk):
if cvk['status'] == '1':
response = requests.get(self.url + 'host/id/' + cvk['id'] + '/vswitch', cookies=self.cookies)
contxt1 = response.text
response.close()
dict2 = xmltodict.parse(contxt1)
li = []
if 'list' in dict2.keys(): # 3.0为list
dict1 = dict2['list']
else:
return li
temp = []
if isinstance(dict1, dict):
if isinstance(dict1['vSwitch'], dict):
temp.append(dict1['vSwitch'])
else:
temp = dict1['vSwitch'].copy()
for h in temp:
temp1 = {}
temp1['name'] = h['name']
temp1['status'] = h['status']
temp1['pnic'] = h['pnic']
li.append(temp1.copy())
del temp1
del temp
del dict1
del dict2
cvk['vswitch'] = li
return
################################################################################
# 获取cvk主机的存储池信息
################################################################################
@applog.logRun(logfile)
def cvkStorpoolCollect(self):
pool = threadpool.ThreadPool(THREADNUM)
for i in self.casInfo['clusterInfo']:
threadlist = threadpool.makeRequests(self.cvkStorpool, i['cvkInfo'])
for k in threadlist:
pool.putRequest(k)
pool.wait()
return
def cvkStorpool(self, cvk):
# response = requests.get(self.url + 'storage/pool?hostId=' + cvk['id'],
# auth=HTTPDigestAuth(self.httpUser, self.httpPassword))
if cvk['status'] == '1':
response = requests.get(self.url + 'storage/pool?hostId=' + cvk['id'], cookies=self.cookies)
contxt1 = response.text
response.close()
dict1 = xmltodict.parse(contxt1)['list']['storagePool']
temp = []
li = []
if isinstance(dict1, dict):
temp.append(dict1)
else:
temp = dict1.copy()
for h in temp:
temp1 = {}
temp1['name'] = h['name']
temp1['status'] = h['status']
li.append(temp1.copy())
del temp1
del temp
cvk['storagePool'] = li
return
# 获取cvk主机的网卡信息
@applog.logRun(logfile)
def cvkNetsworkCollect(self):
pool = threadpool.ThreadPool(THREADNUM)
for i in self.casInfo['clusterInfo']:
threadlist = threadpool.makeRequests(self.cvkNetwork, i['cvkInfo'])
for k in threadlist:
pool.putRequest(k)
pool.wait()
return
def cvkNetwork(self, cvk):
if cvk['status'] == '1':
li = []
response = requests.get(self.url + 'host/id/' + cvk['id'], cookies=self.cookies)
dict1 = xmltodict.parse(response.text)['host']
response.close()
if 'pNIC' in dict1.keys():
dict2 = {}
for i in dict1['pNIC']:
dict2['name'] = i['name']
dict2['status'] = i['status']
li.append(dict2.copy())
del dict2
cvk['network'] = li
return
# 获取虚拟机的id,name,虚拟机状态,castool状态,cpu利用率,内存利用率
#SELECT ID,HOST_ID,STATUS,DOMAIN_NAME,CASTOOLS_STATUS FROM TBL_DOMAIN
@applog.logRun(logfile)
def vmBasicCollect(self):
for i in self.casInfo['clusterInfo']:
for j in i['cvkInfo']:
if j['status'] == '1':
self.vmBasic(j)
return
def vmBasic(self, j):
# response = requests.get(self.url + 'vm/vmList?hostId=' + j['id'],
# auth=HTTPDigestAuth(self.httpUser, self.httpPassword))
response = requests.get(self.url + 'vm/vmList?hostId=' + j['id'], cookies=self.cookies)
contxt = response.text
response.close()
j['vmInfo'] = []
dict2 = xmltodict.parse(contxt)
if isinstance(dict2['list'], dict) and 'domain' in dict2['list'].keys():
dict1 = xmltodict.parse(contxt)['list']['domain']
list1 = []
if isinstance(dict1, dict):
list1.append(dict1)
else:
list1 = dict1.copy()
for k in list1:
temp2 = {}
temp2['id'] = k['id']
temp2['name'] = k['title']
temp2['status'] = k['vmStatus']
if temp2['status'] == 'running':
if 'castoolsStatus' in k.keys():
temp2['castoolsStatus'] = k['castoolsStatus']
else:
temp2['castoolsStatus'] = '0'
temp2['cpuReate'] = (float)(k['cpuRate'])
temp2['memRate'] = (float)(k['memRate'])
j['vmInfo'].append(temp2.copy())
del temp2
del list1
return
# diskrate thread function
# 2019/8/29
def vmDiskRate(self, vm):
li = []
# response = requests.get(self.url + 'vm/id/' + vm['id'] + '/monitor',
# auth=HTTPDigestAuth(self.httpUser, self.httpPassword))
response = requests.get(self.url + 'vm/id/' + vm['id'] + '/monitor', cookies=self.cookies)
contxt1 = xmltodict.parse(response.text)
response.close()
list1 = []
if isinstance(contxt1['domain'], dict) and 'partition' in contxt1['domain'].keys():
if isinstance(contxt1['domain']['partition'], dict):
list1.append(contxt1['domain']['partition'])
else:
list1 = (contxt1['domain']['partition']).copy()
dict1 = {}
for m in list1:
dict1['name'] = m['device']
dict1['usage'] = (float)(m['usage'])
li.append(dict1.copy())
del list1
vm['diskRate'] = li
return
@applog.logRun(logfile)
def vmDiskRateCollect(self):
#使用API读取信息
# pool = threadpool.ThreadPool(THREADNUM)
# li = []
# for i in self.casInfo['clusterInfo']:
# for j in i['cvkInfo']:
# for k in j['vmInfo']:
# if k['status'] == 'running':
# li.append(k)
# for i in li:
# self.vmDiskRate(i)
# threadlist = threadpool.makeRequests(self.vmDiskRate, li)
# for h in threadlist:
# pool.putRequest(h)
# pool.wait()
#使用mysql读取信息
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.host, 22, self.sshUser, self.sshPassword)
cmd1 = "mysql -uroot -p1q2w3e -N -Dvservice -e'select DOMAIN_ID,PARTITION_NAME,UTILIZATION from TBL_DOMAIN_PARTITION_DETAIL'"
stdin, stdout, stderr = ssh.exec_command(cmd1)
text = stdout.read().decode()
ssh.close()
diskdict = {}
for i in text.splitlines():
a = i.split()
dict1 = {}
if a[0] in diskdict.keys():
dict1['name'] = a[1]
dict1['usage'] = (float)(a[2])
diskdict[a[0]].append(dict1)
else:
diskdict[a[0]] = []
dict1['name'] = a[1]
dict1['usage'] = (float)(a[2])
diskdict[a[0]].append(dict1)
del dict1
for i in self.casInfo['clusterInfo']:
for j in i['cvkInfo']:
if j['status'] == '1':
for k in j['vmInfo']:
if k['status'] == 'running' and k['id'] in diskdict.keys():
k['diskRate'] = diskdict[k['id']]
else:
k['diskRate'] = []
return
################
# 2019/8/29
# weifeng
##################
# 根据虚拟机详细信息vmdetail,获取vm磁盘信息
def vmDisk(self, vm, vmdetail):
dict1 = {}
li = []
if 'domain' in vmdetail.keys():
if 'storage' in vmdetail['domain'].keys():
dict1 = vmdetail['domain']['storage']
temp1 = []
if isinstance(dict1, dict):
temp1.append(dict1)
else:
temp1 = dict1.copy()
for h in temp1:
temp2 = {}
if 'device' in h.keys() and h['device'] == 'disk':
temp2['name'] = h['deviceName']
if 'format' in h.keys():
temp2['format'] = h['format']
else:
temp2['format'] = 'NULL'
if 'cacheType' in h.keys():
temp2['cacheType'] = h['cacheType']
else:
temp2['cacheType'] = 'NULL'
if 'path' in h.keys():
temp2['path'] = h['path']
else:
temp2['path'] = 'NULL'
li.append(temp2.copy())
del temp2
del temp1
del dict1
return li
#根据虚拟机详细信息vmdetail,获取vm网卡信息
def vmNetwork(self, vm, vmdetail):
dict1 = {}
li = []
if 'domain' in vmdetail.keys():
if 'network' in vmdetail['domain'].keys():
dict1 = vmdetail['domain']['network']
temp1 = []
if isinstance(dict1, dict):
temp1.append(dict1)
else:
temp1 = dict1.copy()
for h in temp1:
temp2 = dict()
if h:
temp2['name'] = h['vsName']
temp2['mode'] = h['deviceModel']
temp2['KernelAccelerated'] = h['isKernelAccelerated']
li.append(temp2.copy())
del temp2
del temp1
del dict1
return li
#虚拟机网卡和磁盘巡检回调函数
def vmNetworkDisk(self, vm):
# print("vmNetworkDisk Thread vm id:", vm['id'])
# response = requests.get(self.url + 'vm/detail/' + vm['id'],
# auth=HTTPDigestAuth(self.httpUser, self.httpPassword))
response = requests.get(self.url + 'vm/detail/' + vm['id'], cookies=self.cookies)
contxt1 = xmltodict.parse(response.text)
response.close()
vm['vmNetwork'] = self.vmNetwork(vm, contxt1)
vm['vmdisk'] = self.vmDisk(vm, contxt1)
return
# 虚拟机网卡巡检
@applog.logRun(logfile)
def vmNetworkDiskCollect(self):
pool = threadpool.ThreadPool(THREADNUM)
li = []
for i in self.casInfo['clusterInfo']:
for j in i['cvkInfo']:
if j['status'] == '1':
for k in j['vmInfo']:
if k['status'] == 'running':
li.append(k)
threadlist = threadpool.makeRequests(self.vmNetworkDisk, li)
for h in threadlist:
pool.putRequest(h)
pool.wait()
return
# cvm双机热备信息
@applog.logRun(logfile)
def cvmHACollect(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.host, 22, self.sshUser, self.sshPassword, look_for_keys=False, allow_agent=False)
stdin, stdout, stderr = ssh.exec_command("crm status | grep OFFLINE")
if not stderr.read():
a = stdout.read().decode()
if not a:
self.casInfo['HA'] = True
else:
self.casInfo['HA'] = False
return
# CVM备份策略是否开启
# mysql -uroot -p1q2w3e -Dvservice -e'select STATE from TBL_BACKUP_CVM_STRATEGY;' | awk 'NR>1{print $0}'
@applog.logRun(logfile)
def cvmBackupEnbleCollect(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.host, 22, self.sshUser, self.sshPassword, look_for_keys=False, allow_agent=False)
stdin, stdout, stderr = ssh.exec_command(
"mysql -Ns -uroot -p1q2w3e -Dvservice -e'select STATE from TBL_BACKUP_CVM_STRATEGY where ID=1'")
self.casInfo['BackupEnable'] = stdout.read().decode().strip()
return
# 虚拟机备份策略
@applog.logRun(logfile)
def vmBackupPolicyCollect(self):
# response = requests.get(self.url + 'backupStrategy/backupStrategyList',
# auth=HTTPDigestAuth(self.httpUser, self.httpPassword))
response = requests.get(self.url + 'backupStrategy/backupStrategyList', cookies = self.cookies)
contxt = response.text
response.close()
text = xmltodict.parse(contxt)['list']
list1 = []
# if not 'backupStrategy' in text:
if not text:
self.casInfo['vmBackPolicy'] = 'NONE'
else:
self.casInfo['vmBackPolicy'] = list()
if isinstance(text['backupStrategy'], dict):
list1.append(text['backupStrategy'])
else:
list1 = (text['backupStrategy']).copy()
dict1 = {}
for i in list1:
dict1['name'] = i['name']
dict1['state'] = i['state']
self.casInfo['vmBackPolicy'].append(dict1)
del dict1
del list1, text
return<file_sep>from requests.auth import HTTPBasicAuth
import math
import json
import re
import requests
import paramiko
from shell import images, applog
logfile = applog.Applog()
class Cloudos2Data:
def __init__(self, ip, sshuser, sshpassword, httpuser, httppassword):
self.ip = ip
self.sshuser = sshuser
self.sshpassword = <PASSWORD>
self.httpuser = httpuser
self.httppassword = <PASSWORD>
self.osInfo = {}
return
# 获取Token
def getToken(self, ip, username, password):
data = {"auth": {"identity": {"methods": ["password"], "password": {"user": {
"name": "", "password": "", "domain": {"id": "default"}}}}, "scope": {"project": {
"name": "admin", "domain": {"id": "default"}}}}}
#3.0 body字段
# data = {
# "identity": {
# "method": "password",
# "user": {
# "name": "admin",
# "password": "<PASSWORD>"
# }
# }
# }
# cloudos 3.0 url:
# url = "http://" + ip + ":8000/sys/identity/v2/tokens"
data['auth']['identity']['password']['user']['name'] = username
data['auth']['identity']['password']['user']['password'] = <PASSWORD>
headers = {'content-type': 'application/json', 'Accept': 'application/json', 'X-Auth-Token': ''}
url = "http://" + ip + ":9000/v3/auth/tokens"
respond = requests.post(url, json.dumps(data), headers=headers)
token = respond.headers['X-Subject-Token']
respond.close()
return token
#获取cloudos服务器硬件信息和软件版本
@applog.logRun(logfile)
def cloudosBasicCollect(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
#服务器型号
stdin, stdout, stderr = ssh.exec_command("dmidecode | grep -i product | awk '{print $0}' | cut -d : -f 2")
if not stderr.read():
self.osInfo['productVersion'] = stdout.read().decode()
#服务器规格
stdin, stdout, stderr = ssh.exec_command("lscpu | cut -d : -f 2 | awk 'NR==4 || NR==7{print $1}';free -g | awk 'NR==2{print $2}'")
if not stderr.read():
text = stdout.read().decode()
str1 = text.splitlines()
self.osInfo['deviceDmide'] = "cpu:" + str1[0] + "*" + str1[1] + "cores" + "\nMem:" + str1[2] + 'G'
#cloudos版本
stdin, stdout, stderr = ssh.exec_command("docker images | grep openstack-com | head -1 | awk '{print $2}'")
if not stderr.read():
self.osInfo['version'] = stdout.read().decode()
ssh.close()
return
# 发现Node节点设备、并查询状态
@applog.logRun(logfile)
def NodeCollect(self):
self.osInfo["nodeInfo"] = []
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
stdin, stdout, stderr = ssh.exec_command(
"/opt/bin/kubectl -s 127.0.0.1:8888 get nodes | awk 'NR>1{print $1,$2}'")
if not stderr.read():
line = stdout.readline()
while line:
dict1 = {}
dict1['hostName'] = line.split()[0]
dict1['status'] = line.split()[1]
self.osInfo['nodeInfo'].append(dict1)
line = stdout.readline()
else:
print(stderr.read())
ssh.close()
return
#发现主节点
@applog.logRun(logfile)
def findMaster(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
self.osInfo['masterIP'] = ""
for i in self.osInfo['nodeInfo']:
if i["status"] == 'Ready':
cmd = "ssh\t" + i["hostName"] + "\tsystemctl status deploy-manager | grep Active | awk '{print $3}' | sed -e 's/(//g' | sed -e 's/)//g'"
stdin, stdout, stderr = ssh.exec_command(cmd)
text = stdout.read().decode().strip()
if text == 'running':
self.osInfo['masterIP'] = i["hostName"]
return
#查看磁盘分区空间分配是否合规
#规格:centos-root>201G,centos-swap>33.8G,centos-metadata>5.3G,centos-data>296G
@applog.logRun(logfile)
def diskCapacity(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
for i in self.osInfo['nodeInfo']:
if i["status"] == 'Ready':
i['diskCapacity'] = []
cmd = "ssh\t" + i["hostName"] + "\tfdisk -l | grep /dev/mapper/centos | awk '{print $2,$5/1000/1000/1000}' | sed -e 's/://g' | sed -e 's/\/dev\/mapper\///g'"
stdin, stdout, stderr = ssh.exec_command(cmd)
text = stdout.read().decode()
lines = text.splitlines()
for j in lines:
dict1 = {}
dict1['name'] = j.split()[0]
dict1['capacity'] = (float)(j.split()[1])
i['diskCapacity'].append(dict1.copy())
del dict1
return
# 查询磁盘利用率,磁盘利用率大于0.8属于不正常
@applog.logRun(logfile)
def diskRateCollect(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
for i in self.osInfo['nodeInfo']:
i['diskRate'] = []
if i["status"] == 'Ready':
cmd = "ssh\t" + i["hostName"] + "\tdf -h | grep -v tmp | cut -d % -f 1 | awk 'NR>1{print $1,$5/100}'"
stdin, stdout, stderr = ssh.exec_command(cmd)
if not stderr.read():
line = stdout.readline()
temp = {}
while line:
temp['name'] = line.split()[0]
temp['rate'] = (float)(line.split()[1])
line = stdout.readline()
i['diskRate'].append(temp.copy())
del temp
else:
print(stderr.read())
ssh.close()
return
# 查询内存利用率,利用率大于0.8属于不正常
@applog.logRun(logfile)
def memRateCollect(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
for i in self.osInfo['nodeInfo']:
if i["status"] == 'Ready':
cmd = "ssh\t" + i["hostName"] + "\tfree | grep Mem | awk '{print $3/$2}'"
stdin, stdout, stderr = ssh.exec_command(cmd)
if not stderr.read():
i['memRate'] = float(stdout.read().decode())
else:
print(stderr.read())
ssh.close()
return
#查询cpu利用率,利用率大于0.8属于不正常
@applog.logRun(logfile)
def cpuRateCollect(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
for i in self.osInfo['nodeInfo']:
if i["status"] == 'Ready':
cmd = "ssh\t" + i["hostName"] + "\t vmstat | awk 'NR>2{print (100-$15)/100}'"
stdin, stdout, stderr = ssh.exec_command(cmd)
if not stderr.read():
i['cpuRate'] = float(stdout.read().decode())
else:
print(stderr.read())
ssh.close()
return
# 容器状态检查,正常容器状态为Running
@applog.logRun(logfile)
def containerStateCollect(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
stdin, stdout, stderr = ssh.exec_command("/opt/bin/kubectl -s 127.0.0.1:8888 get pod | awk 'NR>1{print $1,$3}'")
self.osInfo['ctainrState'] = list()
if not stderr.read():
line = stdout.readline()
while line:
dict1 = {}
dict1['name'] = line.split()[0]
dict1['status'] = line.split()[1]
self.osInfo['ctainrState'].append(dict1.copy())
line = stdout.readline()
del dict1
else:
print(stderr.read())
ssh.close()
return
# 查看共享磁盘是否存在是否正常断开,当状态为True时,表示正常断开无异常;
# 当状态为False时,表示断开异常
@applog.logRun(logfile)
def shareStorErrorCollect(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
stdin, stdout, stderr = ssh.exec_command("cat /var/log/messages | grep EXT4 | grep error")
for i in self.osInfo['nodeInfo']:
if i["status"] == 'Ready':
cmd = "ssh\t" + i["hostName"] + "\tcat /var/log/messages | grep EXT4 | grep error"
stdin, stdout, stderr = ssh.exec_command(cmd)
if not stderr.read():
if not stdout.read():
i["shareStorError"] = True
else:
i["shareStorError"] = False
else:
print(stderr.read())
ssh.close()
return
# 检查容器分布是否均匀
#当状态为False表示为分布不均,当状态为True是表示分布均匀
@applog.logRun(logfile)
def containerLBCollect(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
cmd = "/opt/bin/kubectl -s 127.0.0.1:8888 get node | awk 'NR>1{print$1}' | while read line;do echo $line $(/opt/bin/kubectl -s 127.0.0.1:8888 get pod -o wide | grep $line | wc -l);done"
stdin, stdout, stderr = ssh.exec_command(cmd)
li = []
if not stderr.read():
line = stdout.readline()
while line:
dict1 = {}
dict1['NodeName'] = line.split()[0]
dict1['ctainrNum'] = int(line.split()[1])
li.append(dict1.copy())
line = stdout.readline()
del dict1
sum = 0
length = len(li)
for i in li:
sum += i['ctainrNum'] # 容器总数
sum2 = 0
for j in li:
sum2 += math.pow(sum / length - j['ctainrNum'], 2) # 求容器分布的方差
if sum2 / length > 9: # 方差大于9时则分布不均
self.osInfo['ctainrLB'] = False
else:
self.osInfo['ctainrLB'] = True
else:
print(stderr.read())
ssh.close()
return
#检查容器镜像是否完整
@applog.logRun(logfile)
def dockerImageCheck(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
for i in self.osInfo['nodeInfo']:
i['images'] = set()
set1 = set()
if i["status"] == 'Ready':
cmd = "ssh\t" + i['hostName'] + "\tdocker images | awk 'NR>1{print $1}' | grep -v gcr | grep -v\t" + self.osInfo['masterIP']
stdin, stdout, stderr = ssh.exec_command(cmd)
if not stderr.read():
text = stdout.read().decode()
for j in text.splitlines():
set1.add(j)
# 当为v2版本使用v2的镜像集合进行对比
if i['hostName'] == self.osInfo['masterIP']:
if set1 == images.imagesv2Set:
i["images"] = set()
else:
i["images"] = images.imagesv2Set.difference(set1)
else:
if set1 == images.imagesv2Set - {'registry'}:
i["images"] = set()
else:
i["images"] = (images.imagesv2Set - {'registry'}).difference(set1)
else:
print("docker Image check ssh is invalid")
ssh.close()
return
#检查ntp时间是否一致
@applog.logRun(logfile)
def nodeNtpTimeCollect(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
for i in self.osInfo['nodeInfo']:
cmd = "ssh\t" + i['hostName'] + "\tntpdate -q\t"+ self.osInfo["masterIP"] +"\t| awk 'NR==1{print $6}' | cut -d - -f 2 | cut -d , -f 1"
sdtin, stdout, stderr = ssh.exec_command(cmd)
i['ntpOffset'] = (float)(stdout.read())
ssh.close()
return
def getImage2Pod(self):
cmd = "/opt/bin/kubectl -s 127.0.0.1:8888 get pod | awk 'NR>1{print $1}'| while read line;do " \
"/opt/bin/kubectl -s 127.0.0.1:8888 describe pod $line | grep Image: |awk -v var1=$line '" \
"{print var1,$2}' | cut -d : -f 1;done"
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
stdin, stdout, stderr = ssh.exec_command(cmd)
text = stdout.read().decode().strip()
dic1 = {}
for i in text.splitlines():
if not i.split()[1] in dic1.keys():
dic1[i.split()[1]] = []
dic1[i.split()[1]].append(i.split()[0])
ssh.close()
return dic1
# 检查openstack-compute和openstack内的关键服务是否正常
@applog.logRun(logfile)
def containerServiceCollect(self):
self.osInfo['serviceStatus'] = {}
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(self.ip, 22, self.sshuser, self.sshpassword)
pods = self.getImage2Pod()
version = self.osInfo['version'][0] + self.osInfo['version'][1]
for i in images.services[version].keys():
podlist = pods[i]
for pod in podlist:
self.osInfo['serviceStatus'][pod] = []
for j in images.services[version][i]:
dict1 = {}
dict1['name'] = j
# cmd = "/opt/bin/kubectl -s 127.0.0.1:8888 exec -it " + pod + " systemctl status " + j + " | grep Active | awk '{print $2}'"
cmd = "/opt/bin/kubectl -s 127.0.0.1:8888 exec -i " + pod + " systemctl status " + j + " | grep Active | awk '{print $3}'"
stdin, stdout, stderr = ssh.exec_command(cmd)
status = status = re.findall(r'\((.*?)\)', stdout.read().decode().strip())[0]
if status == "running":
dict1['status'] = True
else:
dict1['status'] = False
self.osInfo['serviceStatus'][pod].append(dict1.copy())
return
# 检查云主机镜像是否正常
@applog.logRun(logfile)
def imageCollect(self):
self.osInfo["imagesStatus"] = []
respond = requests.get("http://" + self.ip + ":9000/v3/images", auth = HTTPBasicAuth(self.httpuser, self.httppassword))
if respond.text:
tmp = json.loads(respond.text)
if 'image' in tmp:
for i in tmp['images']:
dict1 = {}
dict1['name'] = i['name']
dict1['status'] = i['status']
self.osInfo["imagesStatus"].append(dict1.copy())
del dict1
respond.close()
return
# "status": "ACTIVE"
# "name": "new-server-test"
@applog.logRun(logfile)
def vmCollect(self):
self.osInfo['vmStatus'] = list()
response = requests.get("http://" + self.ip + ":9000/v3/projects", auth = HTTPBasicAuth(self.httpuser, self.httppassword))
for i in json.loads(response.text)['projects']:
if 'cloud' in i.keys() and i['cloud'] is True: # if后的逻辑运算从左到右
url = "http://" + self.ip + ":9000/v2/" + i['id'] + "/servers/detail"
response1 = requests.get(url, auth = HTTPBasicAuth(self.httpuser, self.httppassword))
for j in json.loads(response1.text)['servers']:
dict1 = {}
dict1['name'] = j['name']
dict1['status'] = j['status']
self.osInfo['vmStatus'].append(dict1.copy())
del dict1
response1.close()
response.close()
return
# 'status': 'available'
@applog.logRun(logfile)
def vdiskCollect(self):
self.osInfo['vDiskStatus'] = []
response = requests.get("http://" + self.ip + ":9000/v3/projects", auth = HTTPBasicAuth(self.httpuser, self.httppassword))
for i in json.loads(response.text)['projects']:
if 'cloud' in i.keys() and i['cloud'] is True: # if后的逻辑运算从左到右
url = "http://" + self.ip + ":9000/v2/" + i['id'] + "/volumes/detail"
response1 = requests.get(url, auth = HTTPBasicAuth(self.httpuser, self.httppassword))
for j in json.loads(response1.text)['volumes']:
dict1 = {}
dict1['name'] = j['name']
dict1['status'] = j['status']
self.osInfo['vDiskStatus'].append(dict1.copy())
del dict1
response1.close()
response.close()
return<file_sep>import paramiko
from shell.Cas5Data import Cas5Data
from shell.Cas3Data import Cas3Data
from shell.applog import Applog
from shell import applog
from shell.Cloudos2Data import Cloudos2Data
from shell.Cloudos3Data import Cloudos3Data
import threadpool
logfile = applog.Applog()
@applog.logRun(logfile)
def casVersionCheck(ip, sshUser, sshPassword):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy)
ssh.connect(ip, 22, sshUser, sshPassword)
stdin, stdout, stderr = ssh.exec_command("cat /etc/cas_cvk-version | awk 'NR==1{print $2}'")
version = stdout.read().decode().strip()
ssh.close()
return version
@applog.logRun(logfile)
def cloudosVersionCheck(ip, sshUser, sshPassword):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy)
ssh.connect(ip, 22, sshUser, sshPassword)
stdin, stdout, stderr = ssh.exec_command("docker images | grep openstack-com | head -1 | awk '{print $2}'")
ver = stdout.read().decode().strip()
version = ver[0]
version += ver[1]
ssh.close()
return version
@applog.logRun(logfile)
def casCollect(ip, sshUser, sshPassword, httpUser, httpPassword, checkitem):
logfile = Applog()
func = {
'V3.0': Cas3Data,
'V5.0': Cas5Data
}
version = casVersionCheck(ip, sshUser, sshPassword)
cas = func[version](ip, sshUser, sshPassword, httpUser, httpPassword)
cas.cvmBasicCollect()
cas.clusterCollect()
cas.cvkBasicCollect()
cas.cvkDiskCollect()
cas.cvkVswitchCollect()
cas.cvkStorpoolCollect()
cas.cvkSharepoolCollect()
cas.cvkNetsworkCollect()
if checkitem == 1:
cas.vmBasicCollect()
cas.vmDiskRateCollect()
cas.vmNetworkDiskCollect()
cas.cvmBackupEnbleCollect()
cas.cvmHACollect()
cas.vmBackupPolicyCollect()
return cas.casInfo
def cloudosfunc(fun):
fun()
return
@applog.logRun(logfile)
def cloudosCollect(ip, sshUser, sshPassword, httpUser, httpPassword):
version = cloudosVersionCheck(ip, sshUser, sshPassword)
logfile = Applog()
func = {
'E1': Cloudos2Data,
'E3': Cloudos3Data
}
cloud = func[version](ip, sshUser, sshPassword, httpUser, httpPassword)
cloud.NodeCollect()
cloud.findMaster()
cloud.cloudosBasicCollect()
##########多线程方法############################
funlist = [cloud.diskRateCollect, cloud.memRateCollect, cloud.cpuRateCollect, cloud.containerStateCollect,
cloud.dockerImageCheck, cloud.shareStorErrorCollect, cloud.containerServiceCollect, cloud.containerLBCollect,
cloud.imageCollect, cloud.vmCollect, cloud.vdiskCollect,
cloud.diskCapacity, cloud.nodeNtpTimeCollect]
pool = threadpool.ThreadPool(4)
taskList = threadpool.makeRequests(cloudosfunc, funlist)
for i in taskList:
pool.putRequest(i)
pool.wait()
return cloud.osInfo
############多线程方法如下#####################
###单线程方法如下#######
# cloud.diskRateCollect()
# cloud.memRateCollect()
# cloud.cpuRateCollect()
# cloud.containerStateCollect()
# cloud.dockerImageCheck()
# cloud.shareStorErrorCollect()
# cloud.containerServiceCollect()
# cloud.containerLBCollect()
# cloud.imageCollect()
# cloud.vmCollect()
# cloud.vdiskCollect()
# cloud.cloudosBasicCellect()
# cloud.diskCapacity()
# cloud.nodeNtpTimeCollect()
#return cloud.osInfo
<file_sep>from flask import Flask, render_template, request, url_for, redirect, flash, json, send_from_directory, session
from flask_sqlalchemy import SQLAlchemy
import sys, os, click
from datetime import datetime
from shell.Check import hostStatusCheck
from shell.Check import Check
from shell import applog
WIN = sys.platform.startswith('win')
if WIN: # 如果是 Windows 系统,使用三个斜线
prefix = 'sqlite:///'
else: # 否则使用四个斜线
prefix = 'sqlite:////'
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = prefix + os.path.join(app.root_path, 'data.db')
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False # 关闭对模型修改的监控
app.config['SECRET_KEY'] = 'dev'
# 在扩展类实例化前加载配置
db = SQLAlchemy(app) # 初始化扩展,传入程序实例 app
class Host(db.Model):
id = db.Column(db.Integer, primary_key=True)
ip = db.Column(db.String(15))
ssh_user = db.Column(db.String(20))
ssh_passwd = db.Column(db.String(30))
ssh_port = db.Column(db.Integer)
http_user = db.Column(db.String(20))
http_passwd = db.Column(db.String(30))
http_port = db.Column(db.Integer)
role = db.Column(db.String(15))
class Record(db.Model):
id = db.Column(db.Integer, primary_key=True)
check_time = db.Column(db.DateTime)
check_content = db.Column(db.Text)
check_result = db.Column(db.String(20))
check_doc = db.Column(db.String(30))
@app.cli.command() # 注册为命令
@click.option('--drop', is_flag=True, help='Create after drop.') # 设置选项
def initdb(drop):
"""Initialize the database."""
if drop: # 判断是否输入了选项
db.drop_all()
db.create_all()
click.echo('Initialized database.') # 输出提示信息
@app.route('/test')
def test():
return render_template('test.html')
@app.route('/')
def index():
hosts = Host.query.all()
return render_template('index.html', hosts=hosts)
@app.route('/add', methods=['GET', 'POST'])
def add():
roles = ['cvm', 'cloudos']
if request.method == 'POST':
ip = request.form.get('ip')
ssh_user = request.form.get('ssh_user')
ssh_passwd = request.form.get('ssh_passwd')
ssh_port = request.form.get('ssh_port')
http_user = request.form.get('http_user')
http_passwd = request.form.get('http_passwd')
http_port = request.form.get('http_port')
role = request.form.get('role')
host = Host(ip=ip, ssh_user=ssh_user, ssh_passwd=<PASSWORD>, ssh_port=ssh_port, http_user=http_user,
http_passwd=<PASSWORD>, http_port=http_port, role=role)
db.session.add(host)
db.session.commit()
flash('添加成功')
return redirect(url_for('index'))
return render_template('add.html', roles=roles)
@app.route('/host/edit/<int:host_id>', methods=['GET', 'POST'])
def edit(host_id):
host = Host.query.get_or_404(host_id)
roles = ['cvm', 'cloudos']
if request.method == 'POST':
ip = request.form.get('ip')
ssh_user = request.form.get('ssh_user')
ssh_passwd = request.form.get('ssh_passwd')
ssh_port = request.form.get('ssh_port')
http_user = request.form.get('http_user')
http_passwd = request.form.get('http_passwd')
http_port = request.form.get('http_port')
role = request.form.get('role')
host.ip = ip
host.ssh_user = ssh_user
host.ssh_passwd = <PASSWORD>
host.ssh_port = ssh_port
host.http_user = http_user
host.http_passwd = <PASSWORD>
host.http_port = http_port
host.role = role
db.session.commit()
flash('修改成功')
return redirect(url_for('index'))
return render_template('edit.html', host=host, roles=roles)
@app.route('/host/delete/<int:host_id>', methods=['GET', 'POST'])
def delete(host_id):
host = Host.query.get_or_404(host_id)
db.session.delete(host)
db.session.commit()
flash('删除成功')
return redirect(url_for('index'))
def record(result):
time_now = datetime.strptime(datetime.now().strftime("%Y-%m-%d %H:%M:%S"),"%Y-%m-%d %H:%M:%S")
result1 = {'time':time_now, 'content':'cvm;cloudos', 'result':'yes', 'doc':'test.txt'}
result1['doc'] = result['filename']
result1['content'] = result['content']
check_time = result1['time']
check_content = result1['content']
check_result = result1['result']
check_doc = result1['doc']
record = Record(check_time=check_time, check_content=check_content, check_result=check_result, check_doc=check_doc)
db.session.add(record)
db.session.commit()
return result1
@app.route('/check/delete/<int:record_id>', methods=['GET', 'POST'])
def delete_record(record_id):
record = Record.query.get_or_404(record_id)
db.session.delete(record)
db.session.commit()
filename = os.getcwd() + '\\check_result\\' + record.check_doc
if os.path.exists(filename):
os.remove(filename)
else:
print("文件不存在!")
flash('删除成功')
return redirect(url_for('checklist'))
@app.route('/check', methods=['GET', 'POST'])
def check():
file = applog.Applog()
file.addLog("##################start check#######################")
check_ids = request.get_json()
hostinfos = []
for check_id in check_ids:
host = Host.query.get_or_404(check_id['host_id'])
hostinfo = {'id': host.id, 'role': host.role, 'ip': host.ip, 'status': 'OK', 'sshPort': host.ssh_port,
'sshUser': host.ssh_user,
'sshPassword': <PASSWORD>_<PASSWORD>, 'httpPort': host.http_port, 'httpUser': host.http_user,
'httpPassword': host.http_passwd, 'check_item': check_id['cas_define_check_id']}
hostinfos.append(hostinfo)
data = {}
if not hostinfos:
data['data'] = "未添加设备"
else:
text = hostStatusCheck(hostinfos)
if text:
data['data'] = "巡检结果:" + str(text)
else:
result = Check(hostinfos)
record(result)
data['data'] = "巡检结果:" + "巡检完成"
file.addLog("##################end check#######################")
file.closeLofile()
return json.dumps(data)
@app.route("/checklist", methods=['GET'])
def checklist():
records = Record.query.order_by(Record.check_time.desc()).all()
return render_template('record.html', records=records)
@app.route("/download/<int:record_id>", methods=['GET'])
def download_file(record_id):
# 需要知道2个参数, 第1个参数是本地目录的path, 第2个参数是文件名(带扩展名)
directory = os.path.join(os.getcwd(), 'check_result') # 假设在当前目录
record = Record.query.get_or_404(record_id)
filename = record.check_doc
del record
return send_from_directory(directory, filename, as_attachment=True)
if __name__ == '__main__':
app.run(host='0.0.0.0', debug=True, port=5000)
<file_sep>from requests.auth import HTTPDigestAuth
import xmltodict, requests
from shell.Cas3Data import Cas3Data
from shell import applog
logfile = applog.Applog()
class Cas5Data(Cas3Data):
def cvkVswitch(self, cvk):
if cvk['status'] == '1':
response = requests.get(self.url + 'host/id/' + cvk['id'] + '/vswitch', cookies=self.cookies)
contxt1 = response.text
response.close()
dict2 = xmltodict.parse(contxt1)
# print(dict2)
li = []
if 'list' in dict2.keys(): # 5.0为host
dict1 = dict2['list']
else:
return li
temp = []
if isinstance(dict1, dict):
if isinstance(dict1['vSwitch'], dict):
temp.append(dict1['vSwitch'])
else:
temp = dict1['vSwitch'].copy()
for h in temp:
temp1 = {}
temp1['name'] = h['name']
temp1['status'] = h['status']
temp1['pnic'] = h['pnic']
li.append(temp1.copy())
del temp1
del temp
del dict1
del dict2
cvk['vswitch'] = li
return<file_sep>from docx.shared import Mm
from docx.shared import Pt
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import RGBColor, Inches
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml
##
#cloudos2.0 api端口为9000
#cloudos3.0 api端口为8000
# 创建表格,默认行距为1cm
def createTable(document, row, col):
# table = document.add_table(row, col, style='Medium Grid 1 Accent 1')
table = document.add_table(row, col, style='Table Grid')
table.style.font.name = u'宋体'
table.style.font.size = Pt(11)
for i in table.rows[0].cells:
shading_elm_2 = parse_xml(r'<w:shd {} w:fill="B0C4DE"/>'.format(nsdecls('w')))
i._tc.get_or_add_tcPr().append(shading_elm_2)
del shading_elm_2
# table = document.add_table(row, col, style='Medium Shading 2 Accent 1')
for i in table.rows:
i.height = Mm(10)
return table
# 合并单元格,返回单元格地址
def mergeCell(table, beginRow, beginCol, endRow, endCol):
c1 = table.cell(beginRow, beginCol)
c2 = table.cell(endRow, endCol)
return c1.merge(c2)
# document = openDocument(r'cas.docx')
# serverList为参数列表,包含6个参数,从参数0-6分别为:服务器型号、服务器规格、CAS版本、CVM部署方式、
# S1020V版本、是否使用临时license
def casBasicDocument(document, list1):
h1 = document.add_heading('CAS平台巡检结果')
h1.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
h2 = document.add_heading('1.CAS平台基本信息')
t1 = createTable(document, 7, 2)
# 初始化表格
t1.cell(0, 0).text = "巡检项"
t1.cell(0, 1).text = "参数"
t1.cell(1, 0).text = "服务器型号"
t1.cell(2, 0).text = "服务格器规"
t1.cell(3, 0).text = "CAS版本号"
t1.cell(4, 0).text = "CVM部署方式"
t1.cell(5, 0).text = "S1020V版本号"
t1.cell(6, 0).text = "是否有使用临时license"
# 参数赋值
for i in range(6):
run = t1.cell(i + 1, 1).paragraphs[0].add_run(list1[i])
# run.font.name = '宋体'
# run.font.size = Pt(11)
return
# li1,li2为参数列表,list1为巡检结果,list2为巡检结果说明
# list1
def clusterDocument(document, list1, list2):
h1 = document.add_heading('2.集群巡检')
count = 0
text = ''
for i in list2:
if i:
count += 1
p1 = document.add_paragraph()
run1 = p1.add_run("巡检小结:")
run1.font.name = u'宋体'
run1.font.size = Pt(11)
text = "对集群虚拟化进行巡检,巡检异常项数:" + (str)(count) + ";" + "正常项数:" + (str)(len(list2) - count)
p2 = document.add_paragraph()
p2.paragraph_format.first_line_indent = Inches(0.3)
run2 = p2.add_run(text)
run2.font.name = u'宋体'
run2.font.size = Pt(11)
t1 = createTable(document, 7, 4)
# 初始化表格
t1.cell(0, 0).text = "检查内容"
t1.cell(0, 1).text = "检查方法"
t1.cell(0, 2).text = "检查结果"
t1.cell(0, 3).text = "说明"
t1.cell(1, 0).text = "集群高可靠性(HA)功能:查看集群的高可靠性(HA)功能是否正常开启"
t1.cell(1, 1).text = "在<云资源>/<主机池>/<集群>的“高可靠性”页面检查是否选择了“启用HA”"
t1.cell(2, 0).text = "集群动态资源调度(DRS)功能:查看集群的动态" \
"资源调度(DRS)功能是否正常开启"
t1.cell(2, 1).text = "在<云资源>/<主机池>/<集群>的“动态资源调度”" \
"页面检查是否选择了“开启动态资源调度”"
t1.cell(3, 0).text = "集群下虚拟交换机分配:查" \
"看集群下虚拟交换机的分配情况。"
t1.cell(3, 1).text = "在<云资源>/<主机池>/<主机>的“虚拟交" \
"换机”页面检查集群下的所有主机是否都" \
"有相同名称的虚拟交换机"
t1.cell(4, 0).text = "集群下共享存储分配:" \
"查看集群下共享存储的分配情况"
t1.cell(4, 1).text = "在<云资源>/<主机池>/<集群>的“存储”" \
"页面检查集群下的主机是否都分配了相同的共享存储"
t1.cell(5, 0).text = "集群下共享存储使用率:查看集群下共享存" \
"储的实际使用情况,实际使用率超过70%标记为不" \
"正常。实际使用率超过90%,标记为平台重大风险项。"
t1.cell(5, 1).text = "在<云资源>/<主机池>/<集群>的“存储”页面检" \
"查集群下的共享存储可用容量"
t1.cell(6, 0).text = "集群高可靠性生效最小节点数:查看集群中正常运行的主机数量不少于“HA生效最小节点数”"
t1.cell(6, 1).text = "在<云资源>/<主机池>/<集群>的“高可靠性”页面检查“HA生效最小节点数”和集群内正常运行的主机数量"
t1.columns[2].width = Mm(20)
# 参数赋值
for i in range(6):
if not list2[i]:
t1.cell(i + 1, 2).paragraphs[0].add_run(list1[i])
else:
run = t1.cell(i + 1, 2).paragraphs[0].add_run(list1[i])
run.font.color.rgb = RGBColor(255, 0, 0)
t1.cell(i + 1, 3).paragraphs[0].add_run(list2[i])
return
def hostDocument(document, list1, list2):
h1 = document.add_heading('3.主机巡检')
count = 0
text = ''
for i in list2:
if i:
count += 1
p1 = document.add_paragraph()
run1 = p1.add_run("巡检小结:")
run1.font.name = u'宋体'
run1.font.size = Pt(11)
text = "对主机CVK进行巡检,巡检异常项数:" + (str)(count) + ";" + "正常项数:" + (str)(len(list2) - count)
p2 = document.add_paragraph()
p2.paragraph_format.first_line_indent = Inches(0.3)
run2 = p2.add_run(text)
run2.font.name = u'宋体'
run2.font.size = Pt(11)
t1 = createTable(document, 8, 4)
# 初始化表格
t1.cell(0, 0).text = "检查内容"
t1.cell(0, 1).text = "检查方法"
t1.cell(0, 2).text = "检查结果"
t1.cell(0, 3).text = "说明"
t1.cell(1, 0).text = "*主机状态:\n*查看所有主机的运行状态。"
t1.cell(1, 1).text = "在<云资源>的“主机”页面检查所有主" \
"机的运行状态是否显示“正常”"
t1.cell(2, 0).text = "主机CPU占用率:查看所有主机CPU占用率,不超过80%"
t1.cell(2, 1).text = "在<云资源>的“主机”页面检查所有主机的CPU占用率是否正常。"
t1.cell(3, 0).text = "主机内存占用率:查看所有主机内存占用率,不超过80%。"
t1.cell(3, 1).text = "在<云资源>的“主机”页面检查所有主机的内存占用率是否正常。"
t1.cell(4, 0).text = "主机的磁盘和分区占用率:查看主机的磁盘和分区占用率,各个分区的占用率不超过80%。"
t1.cell(4, 1).text = "在<云资源>/<主机池>/<集群>/<主机>的“性能监控”页面,查看“磁盘利用率”和“分区利用率”"
t1.cell(5, 0).text = "主机的存储池:查看主机的存储池资源是否正常。\n*状态:活动"
t1.cell(5, 1).text = "在<云资源>/<主机池>/<集群>/<主机>的“存储”页面,查看状态是否为“活动”,是否有足够的存储资源"
t1.cell(6, 0).text = "主机的虚拟交换机:查看主机的虚拟交换机池资源是否正常。\n*状态:活动"
t1.cell(6, 1).text = "在<云资源>/<主机池>/<集群>/<主机>的“虚拟交换机”页面,查看状态是否为“活动”,并且仅配置一个网关"
t1.cell(7, 0).text = "主机的物理网卡:查看主机的物理网卡是否正常。" \
"\n*状态:活动\n*速率:与物理网卡实际速率保持一致" \
"\n*工作模式:full"
t1.cell(7, 1).text = "在<云资源>/<主机池>/<集群>/<主机>的“物理网卡”" \
"页面,查看“状态”、“速率”以及“工作模式”是否正常。"
# t1.cell(8, 0).text = "主机的FC HBA卡状态(可选):查看主机的FC HBA卡是否" \
# "正常。\n*状态:活动\n*速率:与物理FC HBA卡实际速率保持一致"
# t1.cell(8, 1).text = "在<云资源>/<主机池>/<集群>/<主机>的“FC HBA”" \
# "页面,查看“状态”和“速率”是否正常。"
# 参数赋值
shading_elm_1 = parse_xml(r'<w:shd {} w:fill="FF0000"/>'.format(nsdecls('w')))
for i in range(7):
if not list2[i]:
t1.cell(i + 1, 2).paragraphs[0].add_run(list1[i])
else:
run = t1.cell(i + 1, 2).paragraphs[0].add_run(list1[i])
run.font.color.rgb = RGBColor(255, 0, 0)
t1.cell(i + 1, 3).paragraphs[0].add_run(list2[i])
return
def vmDocument(document, list1, list2):
h1 = document.add_heading('4.虚拟机巡检')
count = 0
text = ''
for i in list2:
if i:
count += 1
p1 = document.add_paragraph()
run1 = p1.add_run("巡检小结:")
run1.font.name = u'宋体'
run1.font.size = Pt(11)
text = "对主机虚拟机进行巡检,巡检异常项数:" + (str)(count) + ";" + "正常项数:" + (str)(len(list2) - count)
p2 = document.add_paragraph()
p2.paragraph_format.first_line_indent = Inches(0.3)
run2 = p2.add_run(text)
run2.font.name = u'宋体'
run2.font.size = Pt(11)
t1 = createTable(document, 8, 4)
# 初始化表格
t1.cell(0, 0).text = "检查内容"
t1.cell(0, 1).text = "检查方法"
t1.cell(0, 2).text = "检查结果"
t1.cell(0, 3).text = "说明"
t1.cell(1, 0).text = "*虚拟机状态:\n*查看所有虚拟机的运行状态"
t1.cell(1, 1).text = "在<云资源>的“虚拟机”页面检查所有虚拟机的运行状态。"
t1.cell(2, 0).text = "虚拟机CPU占用率:查看所有虚拟机CPU占用率,不超过80%"
t1.cell(2, 1).text = "在<云资源>的“虚拟机”页面检查所有主机的CPU占用率是否正常。"
t1.cell(3, 0).text = "虚拟机内存占用率:查看所有虚拟机内存占用率,不超过80%。"
t1.cell(3, 1).text = "在<云资源>的“虚拟机”页面检查所有虚拟机的内存占用率是否正常。"
t1.cell(4, 0).text = "虚拟机的CAS Tools:查看虚拟机的CAS Tools工具是否正常运行。"
t1.cell(4, 1).text = "在<云资源>/<主机池>/<集群>/<主机>/<虚拟机>的“概要”页面,查看“CAS Tools”是否为运行状态"
t1.cell(5, 0).text = "虚拟机的磁盘和分区占用率:查看虚拟机的磁盘和分区占用率,各个分区的占用率不超过80%。"
t1.cell(5, 1).text = "在<云资源>/<主机池>/<集群>/<主机>/<虚拟机>的“性能监控”页面,查看“磁盘利用率”和“分区利用率”"
t1.cell(6, 0).text = "虚拟机的磁盘类型(大云可选):查看虚拟机的磁盘信息。\n" \
"*设备对象:virtio磁盘 XXX\n" \
"*源路径:共享存储路径\n" \
"*缓存方式:建议使用“directsync”\n" \
"*存储格式:建议使用“智能”"
t1.cell(6, 1).text = "在<云资源>/<主机池>/<集群>/<主机>/<虚拟机>的“修改虚拟机”对话框,查看“总线类型”和“存储卷路径”等"
t1.cell(7, 0).text = "拟机的网卡(大云可选):" \
"查看虚拟机的网卡信息。\n" \
"*设备型号:virtio网卡\n" \
"*内核加速:勾选"
t1.cell(7, 1).text = "在<云资源>/<主机池>/<集群>/<主机>/<虚拟机>的“修改虚拟机”对话框,查看网卡类型。"
# 参数赋值
for i in range(7):
if not list2[i]:
t1.cell(i + 1, 2).paragraphs[0].add_run(list1[i])
else:
run = t1.cell(i + 1, 2).paragraphs[0].add_run(list1[i])
run.font.color.rgb = RGBColor(255, 0, 0)
t1.cell(i + 1, 3).paragraphs[0].add_run(list2[i])
return
def systemHaDocument(document, list1, list2):
h1 = document.add_heading('5.系统可靠性巡检')
count = 0
text = ''
for i in list2:
if i:
count += 1
p1 = document.add_paragraph()
run1 = p1.add_run("巡检小结:")
run1.font.name = u'宋体'
run1.font.size = Pt(11)
text = "对系统可靠性进行巡检,巡检异常项数:" + (str)(count) + ";" + "正常项数:" + (str)(len(list2) - count)
p2 = document.add_paragraph()
p2.paragraph_format.first_line_indent = Inches(0.3)
run2 = p2.add_run(text)
run2.font.name = u'宋体'
run2.font.size = Pt(11)
t1 = createTable(document, 5, 4)
t1.style.font.name = '微软雅黑'
t1.style.font.size = Pt(9)
# 初始化表格
t1.cell(0, 0).text = "检查内容"
t1.cell(0, 1).text = "检查方法"
t1.cell(0, 2).text = "检查结果"
t1.cell(0, 3).text = "说明"
t1.cell(1, 0).text = "链路冗余:查看系统的链路冗余情况。"
t1.cell(1, 1).text = "在<云资源>/<主机池>/<集群>/<主机>/<虚拟交换机>页面,检查各个虚拟交换机是否进行了链路冗余(动态或者静态聚合)"
t1.cell(2, 0).text = "CVM配置备份:查看CVM配置的备份情况。用户CVM主机故障时的系统配置恢复。"
t1.cell(2, 1).text = "在<系统管理>/<安全管理>的“CVM备份配置”页面,确认已启用了定时备份功能,推荐备份到远端目录。"
t1.cell(3, 0).text = "CVM双机热备状态检查:检查CAS的CVM双机热备状态是否正常。"
t1.cell(3, 1).text = "在CVM双机热备环境中,随意登录CVM主机后台执行“crm status”检查双机热备状态。"
t1.cell(4, 0).text = "虚拟机的备份:检查重要虚拟机是否已经开启备份功能。"
t1.cell(4, 1).text = "检查运行客户重要业务的虚拟机是否开启了定时备份功能。"
# 参数赋值
for i in range(4):
if not list2[i]:
t1.cell(i + 1, 2).paragraphs[0].add_run(list1[i])
else:
run = t1.cell(i + 1, 2).paragraphs[0].add_run(list1[i])
run.font.color.rgb = RGBColor(255, 0, 0)
t1.cell(i + 1, 3).paragraphs[0].add_run(list2[i])
return
# cvm平台信息巡检
def cvmCheck(document, casInfo):
list1 = []
list1.append(casInfo['productVersion'])
list1.append(casInfo['deviceDmide'])
list1.append(casInfo['casVersion'])
list1.append(casInfo['installType'])
list1.append(casInfo['ovsVersion'])
list1.append(casInfo['licenseInfo'])
casBasicDocument(document, list1)
del list1
return
##################
# 集群巡检 #
##################
def clusterCheck(document, casInfo):
list1 = []
list2 = ['' for n in range(7)]
# 集群是否开启HA和DRS
tempHa = ''
tempLB = ''
for i in casInfo['clusterInfo']:
if i['enableHA'] == '0':
list2[0] += "集群" + i['name'] + " HA未开启\n"
if i['enableLB'] == '0':
list2[1] = "集群" + i['name'] + " DRS未开启\n"
# 集群下主机虚拟交换机部署是否合规
dict1 = dict()
for i in casInfo['clusterInfo']:
dict1[i['name']] = list()
for j in i['cvkInfo']:
if j['status'] == '1':
for k in j['vswitch']:
if not k['name'] in dict1[i['name']]:
dict1[i['name']].append(k['name'])
for i in casInfo['clusterInfo']:
if len(dict1[i['name']]) != 3:
list2[2] += "集群" + i['name'] + "下交换机的部署不合规\n"
# cvk共享存储池部署是否一致
dict1 = {} # 存储集群下的所有共享存储池
dict2 = {} # 存储主机下的共享存储池
for i in casInfo['clusterInfo']:
dict1[i['name']] = set()
for j in i['cvkInfo']:
dict2[j['name']] = set()
if j['status'] == '1':
for k in j['sharePool'] :
dict1[i['name']].add(k['name'])
dict2[j['name']].add(k['name'])
for m in i['cvkInfo']:
if m['status'] == '1':
if dict1[i['name']] != dict2[m['name']]:
list2[3] += "集群" + i['name'] + "下主机" + m['name'] + "共享存储池与集群不一致"
del dict1, dict2
# 共享存储利用率:
for i in casInfo['clusterInfo']:
li1 = list()
for j in i['cvkInfo']:
if j['status'] == '1':
for k in j['sharePool']:
if not k in li1:
li1.append(k)
for h in li1:
if h['rate'] > 0.8:
list2[4] = "集群" + i['name'] + "下共享存储池" + h['name'] + "利用率超过80%达到" + str(h['rate'])
del li1
# 集群最小主机节点
for i in casInfo['clusterInfo']:
if i['enableHA'] == '0':
list2[5] = "集群未开启高可靠"
else:
if (int)(i['HaMinHost']) > len(i['cvkInfo']):
list2[5] = "Ha最小节点数小正常运行主机数"
for i in list2:
if not i:
list1.append("正常")
else:
list1.append("异常")
clusterDocument(document, list1, list2)
del list1, list2
return
#######################################
# 主机巡检 #
# #
########################################
def cvkCheck(document, casInfo):
list1 = []
list2 = ['' for n in range(7)]
dict1 = {}
dict2 = {}
dict3 = {}
dict4 = {}
for i in casInfo['clusterInfo']:
for j in i['cvkInfo']:
dict1[j['name']] = ''
dict2[j['name']] = ''
dict3[j['name']] = ''
dict4[j['name']] = ''
# 主机状态检测
if j['status'] != '1':
if not list2[0]:
list2[0] += "状态异常主机如下" + j['name'] + '\n'
else:
list2[0] += j['name'] + '\n'
else:
# 主机cpu利用率
if j['cpuRate'] > 80:
if not list2[1]:
list2[1] += "cpu利用率超过80%主机如下:" + j['name'] + '\n'
else:
list2[1] += j['name'] + '\n'
# 主机内存利用率
if j['memRate'] > 80:
if not list2[2]:
list2[2] += "内存利用率超过80%主机如下:" + j['name'] + '\n'
else:
list2[2] += j['name'] + '\n'
# 主机磁盘利用率
for k in j['diskRate']:
if (float)(k['usage']) > 80:
if not dict1[j['name']]:
dict1[j['name']] += "\n主机" + j["name"] + "磁盘利用率查过80%的磁盘如下:" + k["name"]
else:
dict1[j['name']] += ("、" + k["name"])
# 主机存储池状态:
for m in j['storagePool']:
if m['status'] != '1':
if not dict2[j['name']]:
dict2[j['name']] = "\n主机" + j['name'] + "状态异常磁盘如下:" + m['name']
else:
dict2[j['name']] += ("、" + m['name'])
# 虚拟交换机状态
for k in j['vswitch']:
if k['status'] != '1':
if not dict3[j['name']]:
dict3[j['name']] = "\n主机" + j['name'] + "状态异常虚拟交换机如下:" + k['name']
else:
dict3[j['name']] += ("、" + k['name'])
#网卡状态
for k in j['network']:
if k['status'] != '1':
if not dict4[j['name']]:
dict4[j['name']] = "\n主机" + j['name'] + "状态异常网卡如下:" + k['name']
else:
dict4[j['name']] += ("、" + k['name'])
for h in dict1.values():
list2[3] += h
for h in dict2.values():
list2[4] += h
for h in dict3.values():
list2[5] += h
for h in dict4.values():
list2[6] += h
del dict1, dict2, dict3, dict4
# 主机巡检结果写入docx
for i in list2:
if not i:
list1.append("正常")
else:
list1.append("异常")
hostDocument(document, list1, list2)
del list1, list2
return
#######################################
# 虚拟机巡检 #
########################################
def vmCheck(document, casInfo):
list1 = []
list2 = ['' for n in range(7)]
for i in casInfo['clusterInfo']:
for j in i['cvkInfo']:
dict1 = {}
dict2 = {}
if j['status'] == '1':
for k in j['vmInfo']:
# print(k)
# 虚拟机状态
if k['status'] != 'running' and k['status'] != 'shutOff':
if not list2[0]:
list2[0] = "状态异常虚拟机如下:" + k['name']
else:
list2[0] += '、' + k['name']
else:
if k['status'] == 'running':
# 虚拟机cpu利用率是否超过80%
if k['cpuReate'] > 80:
if not list2[1]:
list2[1] = "cpu利用率超过80%虚拟机如下:" + k['name']
else:
list2[1] += '、' + k['name']
# 虚拟机内存利用率是否超过80%
if k['memRate'] > 80:
if not list2[2]:
list2[2] = "内存利用率超过80%虚拟机如下:" + k['name']
else:
list2[2] += '、' + k['name']
# 虚拟机castool状态异常
if k['castoolsStatus'] != '1':
if not list2[3]:
list2[3] = "castool状态虚拟机如下:" + k['name']
else:
list2[3] += '、' + k['name']
# 虚拟机磁盘分区巡检
tmp = ''
for m in k['diskRate']:
if m['usage'] > 80:
if not tmp:
tmp = "\n虚拟机" + k['name'] + '磁盘利用率超过80%的磁盘如下:' + m['name']
else:
tmp += '、' + m['name']
list2[4] += tmp
del tmp
# 虚拟机磁盘巡检
dict1[k['name']] = ''
for n in k['vmdisk']:
tmp = n['path'].split('/')
path = '/' + tmp[1] + '/' + tmp[2]
bool1 = False
for m in j['sharePool']:
if path == m['path']:
bool1 = True
if not bool1:
if not dict1[k['name']]:
dict1[k['name']] = "\n虚拟机" + k['name'] + "磁盘" + n['name'] + '使用了非共享存储池'
else:
dict1[k['name']] += "磁盘" + n['name'] + '使用了非共享存储池'
if n['format'] != 'qcow2':
if not dict1[k['name']]:
dict1[k['name']] = "\n虚拟机" + k['name'] + "磁盘" + n['name'] + '格式错误'
else:
dict1[k['name']] += "磁盘" + n['name'] + '格式错误'
if n['cacheType'] != 'directsync':
if not dict1[k['name']]:
dict1[k['name']] = "\n虚拟机" + k['name'] + "磁盘" + n['name'] + '缓存方式错误'
else:
dict1[k['name']] += "磁盘" + n['name'] + '缓存方式错误'
list2[5] += dict1[k['name']]
# 虚拟机网卡巡检
dict2[k['name']] = ''
for m in k['vmNetwork']:
if m['mode'] != 'virtio':
if not dict2[k['name']]:
dict2[k['name']] = '\n虚拟机' + k['name'] + '网卡' + m['name'] + '模式错误'
else:
dict2[k['name']] = '网卡' + m['name'] + '模式错误'
if m['KernelAccelerated'] != '1':
if not dict2[k['name']]:
dict2[k['name']] = '\n虚拟机' + k['name'] + '网卡' + m['name'] + '未开启内核加速'
else:
dict2[k['name']] = '网卡' + m['name'] + '未开启内核加速'
list2[6] += dict2[k['name']]
del dict1, dict2
for i in list2:
if not i:
list1.append("正常")
else:
list1.append("异常")
vmDocument(document, list1, list2)
del list1, list2
return
####################
# cvm可靠性巡检
####################
def cvmHaCheck(document, casInfo):
list1 = []
list2 = ['' for n in range(4)]
# 虚拟交换机的是否配置冗余链路
# cvm是否开启备份策略
if casInfo['BackupEnable'] != '1':
list2[1] = 'cvm未开启备份策略'
# cvm是否开启HA高可靠
if not casInfo['HA']:
list2[2] = '未开启HA高可靠'
# 检查虚拟机是否配置高可靠
if casInfo['vmBackPolicy'] == 'NONE':
list2[3] = '未配置虚拟机备份'
else:
for i in casInfo['vmBackPolicy']:
if i['state'] != '1':
if not list2[3]:
list2[3] = '状态异常备份策略如下:' + i['name']
else:
list2[3] += '、' + i['name']
for i in list2:
if not i:
list1.append("正常")
else:
list1.append("异常")
systemHaDocument(document, list1, list2)
return
<file_sep>from docx.shared import Mm
from docx.shared import Pt
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.shared import RGBColor, Inches
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml
# 创建表格,默认行距为1cm
def createTable(document, row, col):
# table = document.add_table(row, col, style='Medium Grid 1 Accent 1')
table = document.add_table(row, col, style='Table Grid')
table.style.font.name = u'宋体'
table.style.font.size = Pt(11)
for i in table.rows[0].cells:
shading_elm_2 = parse_xml(r'<w:shd {} w:fill="B0C4DE"/>'.format(nsdecls('w')))
i._tc.get_or_add_tcPr().append(shading_elm_2)
del shading_elm_2
# table = document.add_table(row, col, style='Medium Shading 2 Accent 1')
for i in table.rows:
i.height = Mm(10)
return table
#
def osBasicDocument(document, list1):
h1 = document.add_heading('Cloudos平台巡检结果')
h1.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
h2 = document.add_heading('1.Cloduos平台信息')
t1 = createTable(document, 5, 2)
t1.style.font.name = u'楷体'
t1.cell(0, 0).text = "服务器型号"
t1.cell(1, 0).text = "服务器规格"
t1.cell(2, 0).text = "部署方式"
t1.cell(3, 0).text = "集群节点数"
t1.cell(4, 0).text = "版本号"
for i in range(5):
t1.cell(i, 1).text = list1[i]
return
def osPlatDocument(document, list1, list2):
h1 = document.add_heading("2.云管理平台状态及功能检查云管理平台状态及功能检查")
count = 0
text = str()
for i in list2:
if i:
count += 1
p1 = document.add_paragraph()
run1 = p1.add_run("巡检小结:")
run1.font.name = u'宋体'
run1.font.size = Pt(11)
text = "对CloudOS云管理平台进行巡检,巡检异常项数:" + (str)(count) + ";" + "正常项数:" + (str)(len(list2) - count)
p2 = document.add_paragraph()
p2.paragraph_format.first_line_indent = Inches(0.3)
run2 = p2.add_run(text)
run2.font.name = u'宋体'
run2.font.size = Pt(11)
t1 = createTable(document, 13, 4)
t1.cell(0, 0).text = "检查内容"
t1.cell(0, 1).text = "检查方法"
t1.cell(0, 2).text = "检查结果"
t1.cell(0, 3).text = "说明"
t1.cell(1, 0).text = "服务器本地磁盘分区检查"
t1.cell(1, 1).text = "登录各节点操作系统,执行命令检查分区是否正确"
t1.cell(2, 0).text = "服务器可用空间检查"
t1.cell(2, 1).text = "登录各节点操作系统,执行命令检查服务器本地磁盘及存储卷的利用率是否高于80%"
t1.cell(3, 0).text = "服务器本地时间检查"
t1.cell(3, 1).text = "登录Cluster节点和独立计算节点操作系统,执行命令查看各节点服务器与Master节点的时间是否同步"
t1.cell(4, 0).text = "共享存储卷通断检查"
t1.cell(4, 1).text = "登录各节点操作系统,执行命令检查是否有与共享存储卷相关的错误日志"
t1.cell(5, 0).text = "容器镜像完整性检查"
t1.cell(5, 1).text = "登录各节点操作系统,使用命令检查容器镜像完整"
t1.cell(6, 0).text = "cloudos各节点的cpu利用率检查"
t1.cell(6, 1).text = "ssh登录各节点使用top查看cpu利用率是否查过80%"
t1.cell(7, 0).text = "cloudos各节点的内存利用率是否正常"
t1.cell(7, 1).text = "ssh登录各节点使用free查看内存利用率是否超过80%"
t1.cell(8, 0).text = "容器状态"
t1.cell(8, 1).text = "查看容器状态是否正常"
t1.cell(9, 0).text = "容器分布检查"
t1.cell(9, 1).text = "登录各Master节点操作系统,使用命令检查所有容器是否均匀的运行在集群的各节点上"
t1.cell(10, 0).text = "关键服务状态检查"
t1.cell(10, 1).text = "登录各节点操作系统并进入相关容器内部,使用命令检查关键服务的状态是否正常(active (running))"
t1.cell(11, 0).text = "云主机状态检查"
t1.cell(11, 1).text = "使用云管理员账户登录H3Cloud云管理平台,单击[计算与存储/主机]菜单项,在页面中查看是否有异常状态的云主机。"
t1.cell(12, 0).text = "云硬盘状态检查"
t1.cell(12, 1).text = "使用云管理员账户登录H3Cloud云管理平台,单击[计算与存储/硬盘]菜单项,在页面中查看是否有异常状态的云硬盘。"
for i in range(12):
if not list2[i]:
t1.cell(i + 1, 2).paragraphs[0].add_run(list1[i])
else:
run = t1.cell(i + 1, 2).paragraphs[0].add_run(list1[i])
run.font.color.rgb = RGBColor(255, 0, 0)
t1.cell(i + 1, 3).paragraphs[0].add_run(list2[i])
return
def osBasicCheck(document, osInfo):
list1 = ['' for n in range(5)]
list1[0] = osInfo['productVersion']
list1[1] = osInfo['deviceDmide']
if len(osInfo['nodeInfo']) > 1:
list1[2] = '集群'
else:
list1[2] = '单机'
list1[3] = (str)(len(osInfo['nodeInfo']))
list1[4] = osInfo['version']
osBasicDocument(document, list1)
return
def osPlatCheck(document, osInfo):
list1 = list()
list2 = ['' for n in range(12)]
for i in osInfo['nodeInfo']:
#检查分区是否合规
temp = str()
for j in i['diskCapacity']:
if j['name'] == 'centos-root':
if j['capacity'] < 201:
if not temp:
temp = "\n主机节点" + i['hostName'] + "如下分区空间不合规:" + "centos-root"
else:
temp += '、centos-root'
elif j['name'] == 'centos-swap':
if j['capacity'] < 33.8:
if not temp:
temp = "\n主机节点" + i['hostName'] + "如下分区空间不合规:" + "centos-swap"
else:
temp += '、centos-swap'
elif j['name'] == 'centos-metadata':
if j['capacity'] < 5.3:
if not temp:
temp = "\n主机节点" + i['hostName'] + "如下分区空间不合规:" + "centos-metadata"
else:
temp += '、centos-metadata'
elif j['name'] == 'centos-data':
if j['capacity'] < 296:
if not temp:
temp = "\n主机节点" + i['hostName'] + "如下分区空间不合规:" + "centos-data"
else:
temp += '、centos-data'
list2[0] += temp
del temp
#磁盘利用率
temp1 = str()
for k in i['diskRate']:
if k['rate'] > 0.8:
if not temp1:
temp1 = "\n主机节点" + i['hostName'] + "如下磁盘利用率超过过80%:" + k['name']
else:
temp1 += "、" + k['name']
list2[1] += temp1
del temp1
#各节点ntp时间是否与主节点偏移过大
if i['ntpOffset'] > 10:
if not list2[2]:
list2[2] = "ntp时间与主节点不同步的主机如下:" + i['hostName']
else:
list2[2] += "、" + i['hostName']
#共享存储是否正常
if not i['shareStorError']:
if not list2[3]:
list2[3] = "共享存储异常的节点如下:" + i['hostName']
else:
list2[3] = "、" + i['hostName']
#容器镜像完整性
if i['hostName'] == osInfo['masterIP']:
if len(i['images']) != 0:
list2[4] += "\n主节点" + i['hostName'] + "缺少如下镜像:"
for k in i['images']:
list2[4] += "\t" + k
else:
if len(i['images']) != 0:
list2[4] += "\n节点" + i['hostName'] + "缺少如下镜像:"
for k in i['images']:
list2[4] += "\t" + k
#节点cpu利用率
if i['cpuRate'] > 0.8:
if not list2[5]:
list2[5] = "\ncpu利用率大于80%节点如下:" + i['hostName']
else:
list2[5] += "、" + i['hostName']
#节点内存利用率
if i['memRate'] > 0.8:
if not list2[6]:
list2[6] = "\n内存利用率大于80%节点如下:" + i['hostName']
else:
list2[6] += "、" + i['hostName']
#容器状态
for i in osInfo['ctainrState']:
if i['status'] != 'Running':
if not list2[7]:
list2[7] = '状态异常容器pod如下:' + i['name']
else:
list2[7] += '、' + i['name']
# k8s集群容器分布是否均匀
if not osInfo['ctainrLB']:
list2[8] = "k8s集群容器分布不均匀"
# 容器关键服务检查
str1 = ''
for j in osInfo['serviceStatus'].keys():
str2 = ''
for i in osInfo['serviceStatus'][j]:
if not i['status']:
if not str2:
str2 = "\nPOD " + j +'如下服务异常:' + i['name']
else:
str2 += "、" + i['name']
else:
continue
if str2:
str1 += (str2 + ";")
list2[9] = str1
# 云主机
for i in osInfo['vmStatus']:
if i['status'] != "ACTIVE" and i['status'] != "SHUTOFF":
if not list2[10]:
list2[10] = '状态异常云主机如下:' + i['name']
else:
list2[10] += '、' + i['name']
# 云硬盘
for i in osInfo['vDiskStatus']:
if i['status'] != 'available' and i['status'] != 'in-use':
if not list2[11]:
list2[11] = '状态异常云硬盘如下:' + i['name']
else:
list2[11] += '、' + i['name']
for i in list2:
if not i:
list1.append("正常")
else:
list1.append("异常")
osPlatDocument(document,list1,list2)
del list1, list2
return
<file_sep>imagesv2Set = {
'cloudos-portal', 'cloudos-param', 'cloudos-openstack-compute', 'cloudos-openstack',
'cloudos-web-app', 'cloudos-core-api', 'cloudos-db-install', 'cloudos-app-manager',
'cloudos-postgres', 'nginx', 'cloudos-kube-dns', 'cloudos-rabbitmq', 'registry'
}
#cloudos3.0容器镜像集合
imagesv3Set = {
"cloudos-openstack-compute",
"h3cloud-framework/papaya",
"cloudae-cfy-riemann",
"cloudae-cfy-nginx",
"cloudae-cfy-stage",
"cloudae-cfy-rest",
"cloudae-cfy-amqp",
"h3cloud-ae/h3cloudae-core",
"cloudae-cfy-logstash",
"cloudae-terraform",
"cloudae-cfy-influxdb",
"appmgmt",
"cloudae-cfy-mgmt",
"cloudae-app-portal",
"cloudae-cfy-apporch",
"h3ccloud/h3cloudos/bingo-service",
"h3ccloud/h3cloudoc/alert-portal",
"h3cloud-framework/sultana",
"h3cloud-framework/cherry",
"bdaas-ui",
"h3ccloud/h3cloudos/cloudos-core-api",
"h3cloud-framework/taurus-core",
"h3ccloud/h3cloudos/cas-proxy-core",
"dbaas-nugget-api",
"nugget-ui",
"docs/ol-help",
"cloudae-nugget",
"h3ccloud/h3cloudos/compute-core",
"h3ccloud/h3cloudos/netsecurity-core",
"h3cloud-framework/gemini-core",
"h3cloud-framework/virgo-core",
"h3ccloud/h3cloudos/image-core",
"cloudos-openstack-ceilometer",
"cloudos-neutron-agent",
"h3cloud-framework/jujube",
"cloudos-openstack-glance",
"h3cloud-framework/wechat-core",
"h3cloud-os/storage-core",
"h3cloud-framework/coconut",
"cloudos-openstack-cinder",
"cloudos-openstack-sahara",
"h3cloud-framework/sorb",
"cloudos-openstack-manila",
"cloudos-openstack-nova",
"cloudos-neutron-server",
"cloudos-openstack-barbican",
"cloudos-openstack-heat",
"cloudos-openstack-manila-share",
"h3ccloud/h3cloudos/cloudos-nginx-gateway",
"cloudos-openstack-keystone",
"cloudos-openstack-ironic-api",
"cloud-base/redis-3.2.4",
"cloud-base/rabbitmq-3.6.5",
"h3cloud-framework/leo-core",
"cloudos-openstack-trove",
"cloud-base/mysql-mha-5.7-0.58",
"h3cloud-framework/milk-cdn",
"h3cloud-framework/cancer-core",
"h3cloud-framework/sagittarius-core",
"h3cloud-framework/pisces-core",
"h3cloud-framework/cloudkitty-core",
"cloud-base/mha-manager-0.58",
"h3cloud-framework/pomelo-core",
"h3cloud-framework/strawberry",
"cloud-base/maxscale-2.1.7",
"h3cloud-framework/cas-server",
"h3cloud-framework/olive",
"h3cloud-framework/flume",
"h3cloud-framework/elasticsearch",
"h3cloud-framework/milk",
"h3cloud-framework/plum",
"cloud-ce/grafana",
"h3cloud-framework/milk-nginx",
"h3cloud-framework/lemon-core",
"h3cloud-framework/aries-core",
"h3cloud-framework/aquarius-core",
"cloudae-bigdata-core",
"cloud-base/influxdb",
"cloudae-database-core",
"appsync",
"cloudae-datasrv-portal",
"h3ccloud/h3cloudoc/cloudoc-autoboot",
"h3ccloud/h3cloudoc/cloudoc-monitor-service",
"h3ccloud/h3cloudoc/cloudoc-mq-service",
"h3ccloud/h3cloudoc/cloudoc-cmdb-service",
"h3ccloud/h3cloudoc/alert-service",
"h3ccloud/h3cloudoc/trap-service",
"h3ccloud/h3cloudoc/cloudoc-topology-service",
"h3ccloud/h3cloudoc/cloudoc-monitor-config",
"h3ccloud/h3cloudoc/cloudoc-business",
"h3ccloud/h3cloudoc/cloudoc-business-exporter",
"h3ccloud/h3cloudoc/cloudoc-alert-collector",
"h3ccloud/h3cloudoc/alert-collector",
"h3ccloud/h3cloudoc/cloudoc-jmx-exporter",
"h3ccloud/h3cloudoc/cloudoc-alertmanager",
"h3ccloud/h3cloudoc/cloudoc-host-exporter",
"h3ccloud/h3cloudoc/cloudoc-dameng-exporter",
"h3ccloud/h3cloudoc/cloudoc-container-exporter",
"h3ccloud/h3cloudoc/cloudoc-middleware-exporter",
"h3ccloud/h3cloudoc/cloudoc-portal",
"h3ccloud/h3cloudoc/cloudoc-rsa",
"h3ccloud/h3cloudoc/cloudoc-prometheus",
"h3ccloud/h3cloudoc/cloudoc-storage-exporter",
"h3ccloud/h3cloudoc/cloudoc-prom-conf-gen",
"h3ccloud/h3cloudoc/cloudoc-virtual-exporter",
"h3ccloud/h3cloudoc/cloudoc-snmp-exporter",
"cloudboot",
"h3ccloud/h3cloudoc/cloudoc-db-exporter",
"nexus",
"cloudoc-cmdbuild",
"cloud-base/postgres",
"cloudos-param",
"cloud-base/influxdbnginx",
"h3cloudos-memcached",
"cloud-ce/heapster",
"h3cloud/registry",
"registry",
"cloudos-kube-dns"
}
servicedictv2 = {
"cloudos-openstack": ['ftp-server', 'h3c-agent', 'httpd', 'mongod', 'neutron-server', 'openstack-nova-consoleauth',
'openstack-ceilometer-api', 'openstack-ceilometer-collector',
'openstack-ceilometer-notification',
'openstack-cinder-api', 'openstack-cinder-scheduler', 'openstack-glance-api',
'openstack-nova-conductor',
'openstack-glance-registry', 'openstack-nova-api', 'openstack-nova-cert',
'openstack-nova-novncproxy',
'openstack-nova-scheduler'],
"cloudos-openstack-compute": ['openstack-ceilometer-compute', 'openstack-cinder-volume',
'openstack-neutron-cas-agent',
'openstack-nova-compute']
}
servicedictv3 = {
"cloudos-openstack-glance": ["ftp-server.service", "openstack-glance-api.service",
"openstack-glance-registry.service"],
"cloudos-neutron-server": ["neutron-server.service"],
"cloudos-neutron-agent": ["h3c-agent.service"],
"cloudos-openstack-ceilometer": ["openstack-ceilometer-api.service", "openstack-ceilometer-collector.service",
"openstack-ceilometer-notification.service"],
"cloudos-openstack-cinder": ["openstack-cinder-api.service", "openstack-cinder-scheduler.service"],
"cloudos-openstack-compute": ["openstack-ceilometer-compute.service", "openstack-cinder-volume.service",
"openstack-neutron-cas-agent.service", "openstack-nova-compute.service"],
"cloudos-openstack-nova": ["openstack-nova-api.service", "openstack-nova-cert.service",
"openstack-nova-conductor.service",
"openstack-nova-consoleauth.service", "openstack-nova-novncproxy.service",
"openstack-nova-scheduler.service"]
}
services = {
'E1': servicedictv2,
'E3': servicedictv3
}<file_sep>from shell import casDocumentCreate
from shell import cloudosDocumentCreate
from shell.CollectData import casCollect
from shell.CollectData import cloudosCollect
from docx import Document
from tcpping import tcpping
import time
import os
def hostStatusCheck(hostInfo):
error = str()
for i in hostInfo:
temp = str()
#ssh端口检查
if not tcpping(i['ip'], i['sshPort'], 2):
print("ssh port invalid")
if not temp:
temp = '<br/>主机'+i['ip']+' ssh端口连通异常'
else:
temp += ',ssh端口连通异常'
if not tcpping(i['ip'], i['httpPort'], 2):
print("http port invalid")
if not temp:
temp = '<br/>主机'+i['ip']+' http端口连通异常'
else:
temp += ',http端口连通异常'
error += temp
del temp
return error
def Check(hostInfo):
status = hostStatusCheck(hostInfo)
document = Document()
result = {"filename" : '', "content" : ''}
for i in hostInfo:
if i['role'] == 'cvm':
casInfo = casCollect(i['ip'], i['sshUser'], i['sshPassword'], i['httpUser'], i['httpPassword'], i['check_item'])
casDocumentCreate.cvmCheck(document, casInfo)
casDocumentCreate.clusterCheck(document, casInfo)
casDocumentCreate.cvkCheck(document, casInfo)
if i['check_item'] == 1:
casDocumentCreate.vmCheck(document, casInfo)
casDocumentCreate.cvmHaCheck(document, casInfo)
elif i['role'] == 'cloudos':
osInfo = cloudosCollect(i['ip'], i['sshUser'], i['sshPassword'], i['httpUser'], i['httpPassword'])
cloudosDocumentCreate.osBasicCheck(document, osInfo)
cloudosDocumentCreate.osPlatCheck(document, osInfo)
result['content'] += i['role'] + '\t'
filename = "巡检文档" + time.strftime("%Y%m%d%H%M", time.localtime())+".docx"
path = os.getcwd() + "//check_result//" + filename
document.save(path)
result['filename'] = filename
return result | 8da1a0baf54549fb735833488aa05dfbcd80c089 | [
"Python"
] | 12 | Python | weifeng1990/cloudcheck | 370da6380b06ad81b2ed9fd93c9020aa72337a8e | 3917e3bd01af6d9cfc8aaebd8cdec009f6a96093 |
refs/heads/main | <repo_name>92eduardocastillo/node-1<file_sep>/router/Mascotas.js
const express = require('express');
const router = express.Router();
const Mascota = require('../models/mascota')
router.get('/', async (req, res) => {
try {
const arrayMascotas = await Mascota.findById();
console.log("Mascotas Obtenidas")
res.status(200).json(arrayMascotas)
} catch (error) {
console.log(error)
}
})
module.exports = router;<file_sep>/router/Tienda.js
const { json } = require('express');
const express = require('express');
const router = express.Router();
const url = "http://localhost:3000/productos"
let resultado="4";
router.get('/', (req, res) =>{
console.log(req.body)
res.render("index",{titulo : "tienda"})
})
router.get('/api',(req, res) =>{
res.status(200).json(
{resultado: "datos"}
);
})
module.exports = router<file_sep>/app.js
const express = require('express');
const mongoose = require('mongoose');
const bodyParser = require('body-parser');
require('dotenv').config()
const app = express();
//Codigo para quitar los cors header
app.use((req, res, next) => {
res.header('Access-Control-Allow-Origin', '*');
res.header('Access-Control-Allow-Headers', 'Authorization, X-API-KEY, Origin, X-Requested-With, Content-Type, Accept, Access-Control-Allow-Request- Method');
res.header('Access-Control-Allow-Methods', 'GET, POST, OPTIONS, PUT, DELETE');
res.header('Allow', 'GET, POST, OPTIONS, PUT, DELETE');
next();
});
app.use(bodyParser.urlencoded({ extended : false }))
app.use(bodyParser.json())
const port = process.env.PORT || 3005;
const uri = `mongodb+srv://92eduardocastillo:fPnul2pWfHnraMra@cluster0.6s6vx.mongodb.net/veterinaria?retryWrites=true&w=majority`
console.log("inicio")
mongoose.connect(uri,
{ useNewUrlParser: true, useUnifiedTopology: true }
).then(()=> console.log('conectado a mongodb'))
.catch(e => console.log(e))
console.log("fin")
// motor de plantillas
app.set('view engine', 'ejs');
app.set('views', __dirname + '/views');
app.use(express.static(__dirname + "/public"))
app.use('/api/user',require('./router/auth'))
app.use('/mascotas',require('./router/Mascotas'))
app.use('/tienda', require('./router/validate-token') ,require('./router/Tienda'))
app.get('/*',(req, res) =>{
res.sendFile(__dirname + '/public/index.html')
})
app.use((req, res, next) =>{
res.status(404).render("404",{
titulo: "404",
descripcion: "Titulo del sitio web"
})
})
app.listen(port, () => {
console.log('servidor en el puerto' , port)
}) | 44768a3f1281e3e57b055d1656a75bb5474451aa | [
"JavaScript"
] | 3 | JavaScript | 92eduardocastillo/node-1 | 93e95dac26030a8bb18dbbe1760f50c87d207131 | a6936fddb2bc5086c598ea68b57789145131cfd9 |
refs/heads/master | <repo_name>Mohsen-Yaghoubi/Book-Store-With-MongoDB<file_sep>/Book Store/Pages/Books/Edit.cshtml.cs
using Book_Store.Data;
using Book_Store.Models;
using Microsoft.AspNetCore.Mvc;
using Microsoft.AspNetCore.Mvc.RazorPages;
using MongoDB.Driver;
using System.Linq;
namespace Book_Store.Pages.Books
{
public class EditModel : PageModel
{
private readonly ApplicationDbContext dbContext;
public EditModel(ApplicationDbContext dbContext)
{
this.dbContext = dbContext;
}
[BindProperty]
public Book Book { get; set; }
public void OnGet(string id)
{
Book = dbContext.Books.Find(x => x.Id == id).SingleOrDefault();
}
public IActionResult OnPost()
{
dbContext.Books.ReplaceOne(x => x.Id == Book.Id, Book);
return RedirectToPage("./Index");
}
}
}
<file_sep>/Book Store/Pages/Books/Index.cshtml.cs
using Book_Store.Data;
using Book_Store.Models;
using Microsoft.AspNetCore.Mvc;
using Microsoft.AspNetCore.Mvc.RazorPages;
using MongoDB.Driver;
using System.Collections.Generic;
using System.Linq;
namespace Book_Store.Pages.Books
{
public class IndexModel : PageModel
{
private readonly ApplicationDbContext dbContext;
public IndexModel(ApplicationDbContext dbContext)
{
this.dbContext = dbContext;
}
[BindProperty]
public IEnumerable<Book> Books { get; set; }
[BindProperty]
public Book Book { get; set; }
public IActionResult OnGet(string name)
{
if (!string.IsNullOrWhiteSpace(name))
{
var filter = Builders<Book>.Filter.Eq("Name", name);
Books = dbContext.Books.AsQueryable()
.Where(x => x.Name.Contains(name))
.ToList();
return Page();
}
Books = dbContext.Books.Find(FilterDefinition<Book>.Empty).ToList();
return Page();
}
public IActionResult OnGetDelete(string id)
{
dbContext.Books.DeleteOne(x => x.Id == id);
return RedirectToPage("./Index");
}
}
}
<file_sep>/Book Store/Data/ApplicationDbContext.cs
using Book_Shop.Data;
using Book_Store.Models;
using MongoDB.Driver;
namespace Book_Store.Data
{
public class ApplicationDbContext
{
public ApplicationDbContext(DatabaseSettings setting)
{
var client = new MongoClient(setting.ConnectionString);
var db = client.GetDatabase(setting.DatabaseName);
Books = db.GetCollection<Book>("books");
}
public IMongoCollection<Book> Books { get; set; }
}
}
<file_sep>/Book Store/Models/Book.cs
using MongoDB.Bson;
using MongoDB.Bson.Serialization.Attributes;
using System.ComponentModel.DataAnnotations;
namespace Book_Store.Models
{
public class Book
{
[BsonId]
[BsonRepresentation(BsonType.ObjectId)]
public string Id { get; set; }
[Required]
public int Year { get; set; }
[Required]
public string Name { get; set; }
[Required]
public string Description { get; set; }
}
}
<file_sep>/Book Store/Pages/Books/Create.cshtml.cs
using Book_Store.Data;
using Book_Store.Models;
using Microsoft.AspNetCore.Mvc;
using Microsoft.AspNetCore.Mvc.RazorPages;
namespace Book_Store.Pages.Books
{
public class CreateModel : PageModel
{
private readonly ApplicationDbContext dbContext;
public CreateModel(ApplicationDbContext dbContext)
{
this.dbContext = dbContext;
}
[BindProperty]
public Book Book { get; set; }
public IActionResult OnPost()
{
dbContext.Books.InsertOne(Book);
return RedirectToPage("./Index");
}
}
}
| 88d9d237db659f7ff42052cea603fb3dae2a20c4 | [
"C#"
] | 5 | C# | Mohsen-Yaghoubi/Book-Store-With-MongoDB | 14a46f945cb60f3a1102923f06011055da7e7f69 | e936c4f0488ecf4fc529a927d31738c74d18ca2e |
refs/heads/master | <repo_name>libincheeran/springbootprop<file_sep>/src/main/java/com/libin/component/ServiceComponent.java
package com.libin.component;
import com.libin.bean.CMDBPropConfig;
import com.libin.bean.Config;
import com.libin.bean.Person;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class ServiceComponent {
private Config cfg;
private CMDBPropConfig cmdbProp;
public ServiceComponent(Config cfg, CMDBPropConfig cmdbProp) {
this.cfg = cfg;
this.cmdbProp = cmdbProp;
}
public Person hello(){
Person p = new Person();
p.setName(cfg.getName());
p.setAge(cfg.getAge());
System.out.println(cmdbProp);
return p;
}
}
<file_sep>/src/main/java/com/libin/controller/Controller.java
package com.libin.controller;
import com.libin.bean.Person;
import com.libin.component.ServiceComponent;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping(value = "/libin")
public class Controller {
private ServiceComponent component;
public Controller(ServiceComponent component) {
this.component = component;
}
@GetMapping(value = "/hello")
public Person hello(){
return component.hello();
}
}
<file_sep>/src/main/java/com/libin/springproperty/SpringpropertyApplication.java
package com.libin.springproperty;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.stereotype.Component;
@SpringBootApplication
@ComponentScan(value = "com.libin.*")
public class SpringpropertyApplication implements CommandLineRunner{
public static void main(String[] args) {
SpringApplication.run(SpringpropertyApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
System.out.println(" this is from run ");
}
}
<file_sep>/src/main/resources/application.properties
com.libin.name=cheeran
com.libin.age=33
cmdb.url=https://libin.cheeran.com
cmdb.ports[0]=100
cmdb.ports[1]=200
| 69148916239c7b44128543abdd291db2d5d2836a | [
"Java",
"INI"
] | 4 | Java | libincheeran/springbootprop | 50a55240a809f59ea7128186de8f683bf9895768 | ad000c233e508710aa4d7d9326adb3a9000a621f |
refs/heads/main | <repo_name>HyungsooLim/SQL_1<file_sep>/Update.sql
select * from REGIONS;
delete REGIONS where region_id = 5;
delete REGIONS where region_id = 6;
delete REGIONS where region_id = 7;
delete REGIONS where region_id = 8;
delete REGIONS where region_id = 9;
delete REGIONS where region_id = 10;
delete REGIONS where region_id = 11;
select * from COUNTRIES;<file_sep>/DDL.sql
select * from tab;
select * from EX1;
insert into EX1
values(1, 'test', sysdate);
insert into EX1
values(2, null, sysdate);
commit work;
create table point(
num number primary key,
name varchar2(200),
kor number(3) not null,
eng number(3) check(eng between 0 and 100),
math number(3),
total number(3),
average number(5,2)
);
select * from point;
insert into point values(1, 'st1', 10, 10, 10, 30, 10.0);
insert into point values(2, 'st2', 10, 10, 10, 30, 150.3);
commit work;
rollback work;
-- 컬럼레벨 방식
create table NAVER(
id varchar2(100) constraint naver_id_PK primary key,
password varchar2(100),
name varchar2(100) constraint naver_name_NN not null,
birth_date date,
gender varchar(1), --남자 M, 여자 F, 없으면 null
email varchar2(100) constraint naver_email_U unique,
phone_number varchar2(100) constraint naver_phoneNum_U unique
);
create table PICTURE(
id varchar2(100) constraint picture_id_FK
references naver on delete cascade,
fileName varchar2(200)
);
--테이블레벨 방식
create table NAVER(
id varchar2(100),
password varchar2(100),
name varchar2(100) constraint naver_name_NN not null,
birth_date date,
gender varchar(1), --남자 M, 여자 F, 없으면 null
email varchar2(100),
phone_number varchar2(100),
-- 제약조건 설정
constraint naver_id_PK primary key(id),
constraint naver_email_U unique(email),
constraint naver_phonenum_u unique(phone_number)
-- constraint naver_name_NN not null(name)
);
create table PICTURE(
id varchar2(100),
fileName varchar2(200),
constraint picture_id_FK foreign key(id) references naver
on delete set null
);
alter table naver drop constraint naver_email_u;
alter table naver add constraint naver_email_u unique (email);
drop table picture;
drop table naver;
select * from picture;
insert into picture
values('id1', 'id.jpg');
delete naver where id='id1';
delete picture where id='id1';
insert into naver
values('id1', 'pw1', 'name1', '2000-01-01', 'F', '<EMAIL>', '01011111111');
insert into naver
values('id2', 'pw2', 'name2', '2000-02-02', 'M', '<EMAIL>', '01022222222');
select * from naver;
select * from departments;
select * from employees where department_id=240;
delete DEPARTMENTS where department_id = 240;
delete EMPLOYEES where department_id = 60;
rollback work;
select constraint_name, constraint_type from user_constraints;
select * from user_constraints;
select * from user_constraints;
drop table EX1;
drop table point;
select * from tab;
commit work;
-----------------------------------------------------
-- 성적관리
-- 학생정보 저장 테이블
-- id, pw, 번호, 이름
-- 성적정보 저장 테이블
-- 국어, 영어, 수학, 총점, 평균
-- 학생이 성적 조회 할때 이름, 번호, 성적들을 조회
create table student(
id varchar2(100) constraint student_id_PK primary key,
pw varchar2(100) constraint student_pw_NN not null,
num number constraint student_num_NN not null,
name varchar2(100) constraint student_name_NN not null
);
drop table student;
create table grade(
id varchar2(100) constraint grade_id_FK references student(id),
kor number(3),
eng number(3),
math number(3),
total number(3),
average number(5,2)
)
commit work;
<file_sep>/SubQuery.sql
-- 사원의 ID가 110번인 사원이 근무하는 부서명?
select department_id from EMPLOYEES
where employee_id = 110;
select department_name from DEPARTMENTS
where department_id = 100;
-- SubQuery 적용
select department_name from DEPARTMENTS
where department_id = (select department_id from EMPLOYEES
where employee_id = 110);
-- 부서ID 70인 부서의 street address
select street_address from LOCATIONS
where location_id = (select location_id from DEPARTMENTS
where department_id = 70);
-- 급여를 가장 많이 받는 사원의 정보
select * from EMPLOYEES
where salary = (select max(salary) from EMPLOYEES);
-- 급여를 가장 적게 받는 사원과 같은 부서에 근무하는 사원들의 정보
select *
from EMPLOYEES
where department_id =
(select department_id
from EMPLOYEES
where salary =
(select min(salary)
from EMPLOYEES)
);
-- 평균 급여보다 많이 받는 사원들이 근무하는 부서명?
select department_name
from DEPARTMENTS
where department_id in
((select department_id
from EMPLOYEES
where salary >
(select avg(salary)
from employees)
));
-- Asia(Americas) 지역에 근무하는 사원들의 평균 급여는?
select avg(salary)
from employees
where department_id in(
select department_id
from DEPARTMENTS
where location_id in(
select location_id
from LOCATIONS
where country_id in(
select country_id
from COUNTRIES
where region_id = (
select region_id
from REGIONS
where region_name = 'Americas'
)
)
)
);
-- 사원 id가 100인 사원이 근무하는 region의 이름은?
select region_name from REGIONS where region_id =
(select region_id from COUNTRIES where country_id =
(select country_id from LOCATIONS where location_id =
(select location_id from DEPARTMENTS where department_id =
(select department_id from EMPLOYEES where employee_id = 100)
)
)
)
;
-- 사원 ID 116의 manager가 근무하는 부서명?
select department_name from DEPARTMENTS where department_id =
(select department_id from EMPLOYEES where employee_id =
(select manager_id from employees where employee_id = 116)
)
;
-- rownum
select * from EMPLOYEES where rownum between 1 and 10;
select salary*12 from EMPLOYEES; --가상의 view
select * from
(select rownum R, E.* from
(select * from EMPLOYEES) E)
where R between 1 and 10;
-- 사원 id 120인 사원의 last_name, hire_date, salary, department_id
select last_name, hire_date, salary, department_id
from EMPLOYEES
where employee_id = 120;
select department_name from DEPARTMENTS
where department_id = 50;
-- 사원 id 120인 사원의 last_name, hire_date, salary, department_name
-- join
select E.last_name, E.hire_date, E.salary, D.department_name
from EMPLOYEES E inner join DEPARTMENTS D
--on E.department_id = D.department_id
using (department_id)
where E.employee_id = 120;
select D.*, L.*
from DEPARTMENTS D inner join LOCATIONS L
on d.location_id = L.location_id;
-- LOCATIONS COUNTRIES join
select L.*, C.*
from LOCATIONS L inner join COUNTRIES C
on L.country_id = C.country_id;
-- DEPARTMENTS, LOCATIONS, COUNTRIES join
select D.*, L.*, C.*
from DEPARTMENTS D
inner join LOCATIONS L
on D.location_id = L.location_id
inner join COUNTRIES C
on L.country_id = C.country_id;
-- EMPLOYEES, DEPARTMENTS join
select E.*, D.*
from EMPLOYEES E
inner join DEPARTMENTS D
on E.employee_id = D.manager_id;
-- outer join
select E.*, D.*
from EMPLOYEES E
full join DEPARTMENTS D
on E.employee_id = D.manager_id;
-- 사원의 last_name, salary, 관리자의 last_name, salary
select E.last_name, E.salary, E1.last_name, E1.salary
from EMPLOYEES E
left join EMPLOYEES E1
on E.manager_id = E1.employee_id;
-- 사원 id = 110 의 사원정보, 부서명, 부서의 manager_id, 부서의 location_id
select E.*, D.*
from EMPLOYEES E
inner join DEPARTMENTS D
on E.department_id = D.department_id
where E.employee_id = 110;
-- 부서번호=90 인 부서의 정보와 해당 부서에 근무하는 모든 사원들의 정보 출력
select D.*, E.*
from DEPARTMENTS D
inner join EMPLOYEES E
on D.department_id = E.department_id
where D.department_id = 90;
<file_sep>/Select.sql
SELECT * FROM COUNTRIES;
SELECT * from employees
WHERE commission_pct is not null;
--Employees salary 10000 이상 20000이하
SELECT *
FROM EMPLOYEES
where salary >= 10000 and salary <= 20000;
select *
from EMPLOYEES
where salary between 10000 and 20000;
-- salary 10000 이상 20000 이하가 아닌 정보
select *
from EMPLOYEES
where salary not between 10000 and 20000;
-- 부서번호가 80번이거나 100번인 사원들 정보
select *
from EMPLOYEES
where department_id = 80 or department_id = 100;
select *
from EMPLOYEES
where department_id in (80,100);
-- 사월들 중에서 first_name이 K로 시작하는 사원들
select *
from EMPLOYEES
where first_name like 'K%';
select *
from COUNTRIES
where country_id like '_K';
-- country_id 중 두글자인 데이터 중에서 U로 시작하는 data
select *
from COUNTRIES
where country_id like 'U_';
select *
from EMPLOYEES
where first_name like '%K%';
-- Employees
select *
from EMPLOYEES
order by salary desc;
-- 100번 부서에 사원정보 조회, salary 적은순 부터 출력
select *
from EMPLOYEES
where department_id = 100
order by salary asc;
-- 사원정보 조회 salary 10000 이상 20000 이하, 최근 입사한 순으로 출력
select *
from EMPLOYEES
where salary between 10000 and 20000
order by hire_date desc;
-- JAVA 연동 ex들
select *
from COUNTRIES;
select *
from DEPARTMENTS
where department_id=90;
select *
from employees
select *
from employees
where employee_id = 103;
select *
from employees
where first_name like '%st%'
or last_name like '%st%';
----------------------------------
select * from EMPLOYEES;
-- 각 부서별 월급의 합계
select department_id, sum(salary)
from employees
where department_id is not null
group by department_id
having sum(salary)>50000
order by department_id asc;
| cb94c72957d9f7ef4ee1d2bfedf75c78e378d4a2 | [
"SQL"
] | 4 | SQL | HyungsooLim/SQL_1 | 17c617b82d47a2c35bc66f10874458c23d4e36a3 | 8f787688bd100090ef65ac0d57a8c55534281113 |
refs/heads/master | <repo_name>mrdzugan/react-calendar<file_sep>/src/components/Calendar/CalendarDate/index.jsx
import React from 'react';
import {getDate} from 'date-fns';
import classNames from 'classnames';
import styles from './CalendarDate.module.css';
const CalendarDate = (props) => {
const {date, isCurrent,month} = props;
const isCurrentMonth = (date) => {
return month === date.getMonth();
}
const style = classNames(
[styles.date],
{[styles.noVisible]: !isCurrentMonth(date)},
{[styles.currentDate]: isCurrent});
return <td className={style}>{getDate(date)}</td>;
}
export default CalendarDate;<file_sep>/src/components/Calendar/index.jsx
import React, {Component} from 'react';
import styles from './Calendar.module.css';
import {format, add} from 'date-fns';
import Month from './Month';
import Controls from "./Controls";
class Calendar extends Component {
constructor(props) {
super(props);
this.state = {
date: new Date(),
}
}
handleChangeMonth = (direction) => {
const {date} = this.state;
let newDate = date;
if (direction === 'next') {
newDate = add(date, {months: 1});
} else if (direction === 'prev') {
newDate = add(date, {months: -1});
} else {
throw new TypeError(`direction must be 'next' or 'prev'`);
}
this.setState({date: newDate});
}
render() {
const {date} = this.state;
return (
<article className={styles.container}>
<section className={styles.leftSide}>
<h3 className={styles.currentDay}>{format(new Date(), 'cccc')}</h3>
<h1 className={styles.currentDate}>{date.getDate()}</h1>
</section>
<section className={styles.rightSide}>
<div className={styles.monthControlContainer}>
<Controls direction={'prev'} onChangeMonth={this.handleChangeMonth}/>
<h3 className={styles.monthAndYear}>{format(date, 'LLLL')} {date.getFullYear()}</h3>
<Controls direction={'next'} onChangeMonth={this.handleChangeMonth}/>
</div>
<Month year={date.getFullYear()} month={date.getMonth()}/>
</section>
</article>
);
}
}
export default Calendar;<file_sep>/src/components/Calendar/Week/index.jsx
import React from 'react';
import {add, format} from 'date-fns';
import CalendarDate from './../CalendarDate';
const Week = (props) => {
let {startOfWeek, month} = props;
const isCurrentDay = () => {
const currDate = new Date();
return startOfWeek.getFullYear() === currDate.getFullYear() &&
startOfWeek.getMonth() === currDate.getMonth() &&
startOfWeek.getDate() === currDate.getDate();
}
const newWeek = [];
for (let i = 0; i < 7; i++) {
newWeek.push(<CalendarDate key={format(startOfWeek, 'P')} isCurrent={isCurrentDay()} date={startOfWeek}
month={month}/>);
startOfWeek = add(startOfWeek, {days: 1});
}
return <tr>{newWeek}</tr>;
}
export default Week;<file_sep>/src/components/Calendar/Month/index.jsx
import React from 'react';
import {add, getWeeksInMonth, startOfWeek} from 'date-fns'
import Week from './../Week';
import styles from './Month.module.css';
const Month = (props) => {
const {year, month} = props;
const date = new Date(year, month);
const weeksInMonth = getWeeksInMonth(date);
const firstDayInMonth = new Date(year, month, 1);
let weekStart = startOfWeek(firstDayInMonth);
const newMonth = [];
for (let i = 0; i < weeksInMonth; i++) {
newMonth.push(<Week key={i} startOfWeek={weekStart} month={month}/>);
weekStart = add(weekStart, {weeks: 1});
}
return <>
<table className={styles.monthTable}>
<thead className={styles.monthHead}>
<tr>
<th>S</th>
<th>M</th>
<th>T</th>
<th>W</th>
<th>T</th>
<th>F</th>
<th>S</th>
</tr>
</thead>
<tbody>{newMonth}</tbody>
</table>
</>;
}
export default Month;<file_sep>/src/components/Calendar/Controls/index.jsx
import React from 'react';
import styles from './Controls.module.css';
const Controls = (props) => {
const {direction, onChangeMonth} = props;
return <button onClick={() => {
onChangeMonth(direction);
}} className={styles.controlButton}>{direction === 'next' ? '>>' : '<<'}</button>;
}
export default Controls; | 62adc787adf5a5cb73dd25103ac51a4bd58fa628 | [
"JavaScript"
] | 5 | JavaScript | mrdzugan/react-calendar | e82eea42ac44443eeb96a99edfa5e1fe1052d195 | 014c2a7120da9f43d5cc21a7c04fb867825c1053 |
refs/heads/master | <file_sep>import cv2
import numpy as np
img = cv2.imread("Resources/GT3.jpg")
width, height = 700, 350
pts1 = np.float32([[590, 420],[1200,340], [630,870], [1330, 740]])
pts2 = np.float32([[0,0],[width,0],[0,height], [width,height]])
matrix = cv2.getPerspectiveTransform(pts1, pts2)
imgOutput = cv2.warpPerspective(img, matrix, (width,height))
cv2.imshow("Output", imgOutput)
cv2.waitKey(0)<file_sep>import cv2
import numpy as np
img = cv2.imread("Resources/GT3.jpg")
print(img.shape)
imgResize = cv2.resize(img,(1000, 500))
print(imgResize.shape)
imgCropped = img[200:700,200:500]
cv2.imshow("Output", imgCropped)
cv2.waitKey(0)<file_sep>import cv2
import numpy as np
img = np.zeros((512,512,3),np.uint8)
#print(img)
#img[:]= 255,0,0
cv2.line(img, (0, 0), (img.shape[0],img.shape[1]) , (0,255,0), 3)
cv2.rectangle(img, (0, 0), (img.shape[0],img.shape[1]) , (0,0,255), 2)
cv2.circle(img, (256, 256), 30, (255, 255, 0),5)
cv2.putText(img, " OPEN CV ", (100, 50), cv2.FONT_ITALIC, 1, (0, 150, 0), 4)
cv2.imshow("Image", img)
cv2.waitKey(0)<file_sep>import cv2
import numpy as np
print("Package Imported")
img = cv2.imread("Resources/GT3.jpg")
kernel = np.ones((5,5), np.uint8)
imgGray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
imgBlur = cv2.GaussianBlur(img, (3,3),0)
imgCanny = cv2. Canny(img , 100, 100)
imgDialation = cv2.dilate(imgCanny, kernel, iterations=1)
imgEroded = cv2.erode(imgDialation, kernel, iterations=1)
cv2.imshow("Output", imgEroded)
cv2.waitKey(0)
| 0c79397f540af2176fe643d4c21e4961ff7ba0a9 | [
"Python"
] | 4 | Python | Marco13-7/OpenCVTutorial | 1fcfad86f2efff23754d77608768ac2b9b9e1bea | f4f831c33218f17b641cd7905ea0d4f0fe0e9c8d |
refs/heads/main | <file_sep>import readlineSync from 'readline-sync';
let userName;
const Welcome = () => {
console.log('Welcome to the Brain Games!');
userName = readlineSync.question('May I have your name? ');
console.log(`Hello, ${userName}!`);
};
const Congratulations = () => {
console.log(`Congratulations, ${userName}!`);
};
const play = (game, rules) => {
Welcome();
console.log(rules);
let correctAnswers = 0;
while (correctAnswers < 3) {
if (game()) {
correctAnswers += 1;
} else {
correctAnswers = 0;
}
}
Congratulations();
};
export default { userName, play };
<file_sep>#!/usr/bin/env node
import game from '../games/brain-calc.js';
import play from '../src/index.js';
play.play(game.calcGame,game.rule);
<file_sep>import readlineSync from 'readline-sync';
import play from '../src/index.js';
const rule = "What is the result of the expression?";
const calcGame = () => {
const firstNumber = Math.floor(Math.random() * (100 - 0)) + 0;
const secondNumber = Math.floor(Math.random() * (100 - 0)) + 0;
const operator = Math.floor(Math.random() * (3 - 0)) + 0;
const operators = ['+', '-', '*'];
console.log(`Question: ${firstNumber}${operators[operator]}${secondNumber}`);
const answer = readlineSync.question('Your answer: ');
let correctAnswer;
switch (operator) {
case 0:
correctAnswer = firstNumber + secondNumber;
break;
case 1:
correctAnswer = firstNumber - secondNumber;
break;
case 2:
correctAnswer = firstNumber * secondNumber;
break;
default:
console.log('momo');
}
if (correctAnswer === parseInt(answer, 10)) {
return true;
} else {
console.log(`${answer} is wrong answer ;(. Correct answer was ${correctAnswer}. \nLet's try again, ${play.userName}!`);
return false;
}
};
export default {rule, calcGame};<file_sep>
import readlineSync from 'readline-sync';
import play from '../src/index.js';
const rule = 'Answer "yes" if the number is even, otherwise answer "no".';
const IsEvenGame = () => {
const number = Math.floor(Math.random() * (100 - 0)) + 0;
console.log(`Question: ${number}`);
const answer = readlineSync.question('Your answer: ');
if ((number % 2 === 0 && answer === 'yes') || (number % 2 !== 0 && answer === 'no')) {
return true;
} else {
if (answer === 'yes') {
console.log(`'yes' is wrong answer ;(. Correct answer was 'no'. \nLet's try again, ${play.userName}!`);
return false;
} else {
console.log(`'no' is wrong answer ;(. Correct answer was 'yes'.\nLet's try again, ${play.userName}!`);
return false;
}
return false;
}
};
export default {rule, IsEvenGame}; | 89df8fa9b93911b68f08fa9a9987bbaae672c37b | [
"JavaScript"
] | 4 | JavaScript | gaypropaganda/frontend-project-lvl1 | fdfbf27a4246f14f5caf7eee4647e7d303ef9ad6 | c1d70e49f51a27a89c1bd0a3fb4bc63e379a1a2d |
refs/heads/master | <file_sep>#!/bin/sh
pwd
cd ..
mvn -U clean package -P test -Dmaven.test.skip=true
if [ ! -f $DEPLOY_HOME ]
then
mkdir -p $DEPLOY_HOME
fi
if [ -f "target/${PACKGET_NAME}" ]
then
rm -rf ${DEPLOY_HOME}/*
cp target/${PACKGET_NAME} ${DEPLOY_HOME}/
cd ${DEPLOY_HOME}
tar -zxvf ${PACKGET_NAME}
fi
<file_sep>#Make sure the script is is $project_path/shell directory
DEPLOY_HOME=/opt/webapps/thrift-performance-test
PACKGET_NAME=thrift-performance-test-dist.tar.gz
MAIN_CLASS="com.sohu.cloudatlas.server.HelloApp"
#this config is Optional
LOG_FILE=/opt/logs/cloudatlas/thrift-performance-test.log
<file_sep>source config.sh
#kill server
SERVER_PID=`ps auxf | grep "${MAIN_CLASS}" | grep -v "grep"| awk '{print $2}'`
if [ -n $SERVER_PID ]
then
echo "suc server pid is ${SERVER_PID}"
kill $SERVER_PID
echo "$SERVER_PID is killed!"
fi
cd ${DEPLOY_HOME}/classes
nohup java -cp .:../lib/* ${MAIN_CLASS} &
tail -f $LOG_FILE
| 6ae40241199e57903d27749162cd41974a0b3476 | [
"Shell"
] | 3 | Shell | sharewind/thrift-performance-test | d7405dcdf2e7037bcd44378d7a0f2a9f6d1c5d49 | bef6c63efb46682088c35ab9ce8af2ddb35d7510 |
refs/heads/master | <file_sep>import React from 'react'
import PropTypes from 'prop-types'
class UseChildren extends React.Component{
static propTypes = {
autor: PropTypes.string.isRequired
}
render(){
const {title, autor, content} = this.props
return(
<section>
<article>
<h3>{title}</h3>
{autor && <p>escrito por: <strong>{autor}</strong></p>}
<p>{content}</p>
{this.props.children}
</article>
</section>
)
}
}
export default UseChildren;<file_sep>import React from 'react'
class Ciclovdconstructor extends React.Component{
constructor(props){
console.log("constructor");
super(props)
this.state = {mensajeInicial:"este es el mensaje inicial "}
}
handleclic = () =>{
this.setState({mensajeInicial:"mensaje cambiado"})
}
render(){
console.log("render");
return(
<div>
{this.state.mensajeInicial}
<button onClick={this.handleclic}>
enviar
</button>
</div>
)
}
}
export default Ciclovdconstructor;<file_sep>
import React, {Component} from 'react'
import Car from '../Data/Car.json'
class DataItem extends Component{
render(){
const {Car, id} = this.props
return(
<div>
<li>
<p>key: {id}</p>
<p><strong>Nombre: </strong>{Car.name}</p>
<p><strong>Marca. </strong>{Car.company}</p>
</li>
</div>
)
}
}
class Datas extends Component{
render(){
return(
<div>
<h1>lista de carros</h1>
<ul>
{
Car.map( Car =>{
return(
<DataItem id={Car.id} key={Car.id} Car={Car} />
)
})
}
</ul>
</div>
)
}
}
export default Datas; | e6b9dc29432c4f226c42e683998ef7792919d8d5 | [
"JavaScript"
] | 3 | JavaScript | OscarLLC/app-curse-udemy | 621db08a5e8e112ca22b04220651674196314d20 | 62a86dbeffbeae836e7dde81e9dde8636d75ede9 |
refs/heads/master | <repo_name>cginiel/si506<file_sep>/final_proj/swapi_final_copy.py
import json, requests, copy
ENDPOINT = 'https://swapi.co/api'
PEOPLE_KEYS = ("url", "name", "height", "mass", "hair_color", "skin_color", "eye_color", "birth_year", "gender", "homeworld", "species",)
PLANETS_KEYS = ("url", "name", "system_position", "natural_satellites", "rotation_period", "orbital_period", "diameter", "climate", "gravity", "terrain", "surface_water", "population", "indigenous_life_forms",)
STARSHIP_KEYS = ("url", "starship_class", "name", "model", "manufacturer", "length", "width", "max_atmosphering_speed", "hyperdrive_rating", "MGLT", "crew", "passengers", "cargo_capacity", "consumables", "armament",)
SPECIES_KEYS = ("url", "name", "classification", "designation", "average_height", "skin_colors", "hair_colors", "eye_colors", "average_lifespan", "language",)
VEHICLES_KEYS = ("url", "vehicle_class", "name", "model", "manufacturer", "length", "max_atmosphering_speed", "crew", "passengers", "cargo_capacity", "consumables", "armament",)
def read_json(filepath):
"""Given a valid filepath, reads a JSON document and returns a dictionary.
Parameters:
filepath (str): path to file.
Returns:
dict: decoded JSON document expressed as a dictionary.
"""
with open(filepath, 'r', encoding='utf-8') as file_obj:
data = json.load(file_obj)
return data
def get_swapi_resource(url, params=None):
"""Issues an HTTP GET request to return a representation of a resource. If no category is
provided, the root resource will be returned. An optional query string of key:value pairs
may be provided as search terms (e.g., {'search': 'yoda'}). If a match is achieved the
JSON object that is returned will include a list property named 'results' that contains the
resource(s) matched by the search query.
Parameters:
url (str): a url that specifies the resource.
params (dict): optional dictionary of querystring arguments.
Returns:
dict: decoded JSON document expressed as dictionary.
"""
if params:
response = requests.get(url, params=params).json()
else:
response = requests.get(url).json()
return response
def combine_data(default_data, override_data):
"""Creates a shallow copy of the default dictionary and then updates the new
copy with override data. Override values will replace default values when if
the keys match.
For shallow vs deep copying of mutable objects like dictionaries and lists see:
https://docs.python.org/3/library/copy.html
For another approach see unpacking, see: https://www.python.org/dev/peps/pep-0448/
Parameters:
default_data (dict): entity data that provides the default representation of the object.
override_data (dict): entity data intended to override matching default values.
Returns:
dict: updated dictionary that contains override values.
"""
combined_data = default_data.copy() # shallow
# combined_data = copy.copy(default_data) # shallow
# combined_data = copy.deepcopy(default_data) # deep
combined_data.update(override_data) # in place
# Dictionary unpacking
# combined_data = {**default_data, **override_data}
return combined_data
def filter_data(data, filter_keys):
"""Returns a new dictionary based containing a filtered subset of key-value pairs
sourced from a dictionary provided by the caller.
Parameters:
data (dict): source entity.
filter_keys (tuple): sequence of keys used to select a subset of key-value pairs.
Returns:
dict: a new entity containing a subset of the source entity's key-value pairs.
"""
# Alternative: dictionary comprehension (post-Thanksgiving discussion)
# return {key: data[key] for key in filter_keys if key in data.keys()}
record = {}
for key in filter_keys:
if key in data.keys():
record[key] = data[key]
return record
def is_unknown(value):
"""
Determines whether the value is unknown or n/a using a Truth test.
Parameters:
Value (str): a string that is evaluated for being unknown or n/a.
Returns:
Boolean: returns True is the string is unknown or n/a. Otherwise returns the value entered.
"""
if type(value) == str:
value = value.lower().strip()
if value == "unknown":
return True
elif value == "n/a":
return True
else:
return False
def convert_string_to_float(value):
"""
Converts a string to a float.
Parameters:
A string.
Returns:
Returns the converted string as a float, if the function works.
Otherwise spits whatever was entered back out.
"""
try:
if type(value) == str:
value = value.strip('standard')
value = value.strip()
return float(value)
else:
return value
except ValueError:
return value
def convert_string_to_int(value):
"""
Converts a string into an integer.
Parameters:
A string.
Returns:
Returns the converted string as an integer, if the function works.
Otherwise spits whatever was entered back atcha.
"""
try:
return int(value)
except ValueError:
return value
def convert_string_to_list(value, delimiter=', '):
"""
Converts a string to a list.
Parameters:
Value (str): a string.
Delimiter: default assignment of the delimiter as a comma, ",".
Returns:
List: a string converted into a list.
"""
new_list = value.split(delimiter)
return new_list
def clean_data(entity):
"""
Converts string values to appropriate types (float, int, list, None). Manages property
checks with tuples of named keys.
Parameters:
planet (dict): dictionary with values to be cleaned.
Returns:
dict: dictionary with cleaned values.
"""
i = (
"height",
"mass",
"rotation_period",
"orbital_period",
"diameter",
"surface_water",
"population",
"average_height",
"average_lifespan",
"max_atmosphering_speed",
"MGLT",
"crew",
"passengers",
"cargo_capacity",
)
f = (
"gravity",
"length",
"hyperdrive_rating",
)
l = (
"hair_color",
"skin_color",
"climate",
"terrain",
"skin_colors",
"hair_colors",
"eye_colors",
)
d = ("homeworld", "species",)
new_dict = {}
for key, value in entity.items(): # loops through keys and values of given dictionary
if is_unknown(value): # checks if the value is unknown or n/a
new_dict[key] = None # converts value to None if true
elif key in i: # if the entity key is in our i tuple
new_dict[key] = convert_string_to_int(value) # we convert the string to an int and add it to our new dictionary
elif key in f: # if the entity key is in our f tuple
new_dict[key] = convert_string_to_float(value) # we convert the value to a float and take the first item from the list and add it to our new dict
elif key in l: # if the entity key is in our l tuple
value = value.strip()
new_dict[key] = convert_string_to_list(value) # we convert the string into a list and add it to our new dictionary
elif key in d: # if the entity key is in our d tuple
if key == "homeworld": # if the key is homeworld
entity = get_swapi_resource(value) # assign the entity entered to what get_swapi produces (which I don't really know)
filtered_dict = filter_data(entity, PLANETS_KEYS) # create a new dictionary with just the key values of the tuple we use
done = clean_data(filtered_dict) # clean the data (i.e. convert items) from that dict using clean_data, assign it to a temp variable
new_dict[key] = done # assign our new dictionary to the temp variable
elif key == "species": # if the key is species
entity = get_swapi_resource(value[0]) # assign the entity entered to what get_swapi produces (which I don't really know)
filtered_dict = filter_data(entity, SPECIES_KEYS) # create a new dictionary with just the key values of the tuple we use
done = clean_data(filtered_dict) # clean the data (i.e. convert items) from that dict using clean_data, assign it to a temp variable
new_dict[key] = [done] # assign our new dictionary to the temp variable
else:
new_dict[key] = value # if none of the above applies, just maintain the format of the entity
return new_dict # return the new dicionary
def assign_crew(starship, crew):
"""
Takes the crew, a representation of a person, and assigns them to a starship. Both are dicts.
Parameters:
Starship (dict). Crew member (dict).
Returns:
Starship (dict) with crew assignments.
"""
for key,value in crew.items():
starship[key] = value
return starship
def write_json(filepath, data):
"""Given a valid filepath, write data to a JSON file.
Parameters:
filepath (str): the path to the file.
data (dict): the data to be encoded as JSON and written to the file.
Returns:
None
"""
with open(filepath, 'w', encoding='utf-8') as file_obj:
json.dump(data, file_obj, ensure_ascii=False, indent=2)
# copy and paste from lecture25.py into main
def main():
"""
Our crucial function. Creates the two JSONs to help out the Rebel Alliance. Squad Goals.
Parameters:
None.
Returns:
None.
"""
planets_data = read_json("swapi_planets-v1p0.json")
uninhabited_planets = []
for planet in planets_data:
if is_unknown(planet['population']) == True:
dictionary = filter_data(planet, PLANETS_KEYS)
uninhabited_planets.append(clean_data(dictionary))
write_json("swapi_planets_uninhabited-v1p1.json", uninhabited_planets)
# begin echo base main
# set up echo base dictionary
echo_base = read_json("swapi_echo_base-v1p0.json")
# find hoth in the API
swapi_hoth = get_swapi_resource('https://swapi.co/api/planets/4/')
# add hoth to echo base
echo_base_hoth = echo_base['location']['planet']
hoth = combine_data(echo_base_hoth, swapi_hoth)
hoth = filter_data(hoth, PLANETS_KEYS)
hoth = clean_data(hoth)
echo_base['location']['planet'] = hoth
#echo base commander
echo_base_commander = echo_base['garrison']['commander']
echo_base_commander = clean_data(echo_base_commander)
echo_base['garrison']['commander'] = echo_base_commander
#echo base smuggler
echo_base_rendar = echo_base['visiting_starships']['freighters'][0]
echo_base_rendar = clean_data(echo_base_rendar)
echo_base_rendar = echo_base['visiting_starships']['freighters'][0]
# echo base vehicles
swapi_vehicles_url = f"{ENDPOINT}/vehicles/"
swapi_snowspeeder = get_swapi_resource(swapi_vehicles_url, {'search': 'snowspeeder'})['results'][0]
# echo base snowspeeder
echo_base_snowspeeder = echo_base['vehicle_assets']['snowspeeders'][0]['type']
snowspeeder = combine_data(echo_base_snowspeeder, swapi_snowspeeder)
snowspeeder = filter_data(snowspeeder, VEHICLES_KEYS)
snowspeeder = clean_data(snowspeeder)
echo_base['vehicle_assets']['snowspeeders'][0]['type'] = snowspeeder
# starships
swapi_starships_url = f"{ENDPOINT}/starships/"
# x-wing
x_wing = get_swapi_resource(swapi_starships_url, {'search': 'T-65 X-wing'})['results'][0]
echo_base_x_wing = echo_base['starship_assets']['starfighters'][0]['type']
combine_x_wing = combine_data(x_wing, echo_base_x_wing)
combine_x_wing = filter_data(combine_x_wing, STARSHIP_KEYS)
combine_x_wing = clean_data(combine_x_wing)
echo_base['starship_assets']['starfighters'][0]['type'] = combine_x_wing
# gr-75
gr_75 = get_swapi_resource(swapi_starships_url, {'search': 'GR-75 medium transport'})['results'][0]
echo_base_gr_75 = echo_base['starship_assets']['transports'][0]['type']
combine_gr_75 = combine_data(gr_75, echo_base_gr_75)
combine_gr_75 = filter_data(combine_gr_75, STARSHIP_KEYS)
combine_gr_75 = clean_data(combine_gr_75)
echo_base['starship_assets']['transports'][0]['type'] = combine_gr_75
# millennium falcon
millennium_falcon = get_swapi_resource(swapi_starships_url, {'search': 'YT-1300 light freighter'})['results'][0]
echo_base_millennium_falcon = echo_base['visiting_starships']['freighters'][0]
falcon = combine_data(millennium_falcon, echo_base_millennium_falcon)
falcon = filter_data(falcon, STARSHIP_KEYS)
falcon = clean_data(falcon)
echo_base['visiting_starships']['freighters'][0]['type'] = falcon
# echo base light
echo_base_light = echo_base['visiting_starships']['freighters'][1]
echo_base_light = filter_data(echo_base_light, STARSHIP_KEYS)
echo_base_light = clean_data(echo_base_light)
# swapi people
swapi_people_url = f"{ENDPOINT}/people/"
# han solo
han = get_swapi_resource(swapi_people_url, {'search': 'han solo'})['results'][0]
han = filter_data(han, PEOPLE_KEYS)
han = clean_data(han)
# chewbacca
chewbacca = get_swapi_resource(swapi_people_url, {'search': 'Chewbacca'})['results'][0]
chewbacca = filter_data(chewbacca, PEOPLE_KEYS)
chewbacca = clean_data(chewbacca)
# add our crew to millennium falcon
combine_falcon = assign_crew(falcon, {'pilot': han, 'copilot': chewbacca})
# add dash rendar???
rendar = filter_data(echo_base['visiting_starships']['freighters'][1]['pilot'], PEOPLE_KEYS)
rendar = clean_data(rendar)
echo_base_light = assign_crew(echo_base_light, {'pilot': rendar})
# empty list for our pilots
echo_base['visiting_starships']['freighters'] = []
# add our pilots
echo_base['visiting_starships']['freighters'].append(combine_falcon)
echo_base['visiting_starships']['freighters'].append(echo_base_light)
# evacuation plan
evac_plan = echo_base['evacuation_plan']
i = 0
# loop over personnel and add to max_base_personnel propoerty
for x in echo_base['garrison']['personnel']:
#print(item)
i += echo_base['garrison']['personnel'][x]
echo_base['evacuation_plan']['max_base_personnel'] = i
echo_base['evacuation_plan']['max_available_transports'] = echo_base['starship_assets']['transports'][0]['num_available'] # max_available_transports = echo_base['starship_assets']['transports'][0]['num_available']
echo_base['evacuation_plan']['max_passenger_overload_capacity'] = echo_base['evacuation_plan']['max_available_transports'] * echo_base['evacuation_plan']['passenger_overload_multiplier'] * echo_base['evacuation_plan']['max_available_transports'] * echo_base['evacuation_plan']['passenger_overload_multiplier']
evac_transport = copy.deepcopy(echo_base['starship_assets']['transports'])
# fix our rogue int...
echo_base['visiting_starships']['freighters'][1]['cargo_capacity'] = str(echo_base['visiting_starships']['freighters'][1]['cargo_capacity'])
# create our bright hope transport assignment
evac_transport[0]['type']['name'] = '<NAME>'
evac_plan['transport_assignments'] = evac_transport
evac_data = evac_transport[0]['type']
for key, value in evac_data.items():
evac_plan['transport_assignments'][0][key] = value
# remove some unwanted data
evac_plan['transport_assignments'][0].pop('type')
evac_plan['transport_assignments'][0].pop('num_available')
# empty list for our homies
evac_transport[0]['passenger_manifest'] = []
# get leia
leia = get_swapi_resource(swapi_people_url, {'search': '<NAME>'})['results'][0]
leia = filter_data(leia, PEOPLE_KEYS)
leia = clean_data(leia)
# get c3_p0
c3_p0 = get_swapi_resource(swapi_people_url, {'search': 'C-3PO'})['results'][0]
c3_p0 = filter_data(c3_p0, PEOPLE_KEYS)
c3_p0 = clean_data(c3_p0)
# append the homies to passenger manifest
evac_transport[0]['passenger_manifest'].append(leia)
evac_transport[0]['passenger_manifest'].append(c3_p0)
# escorts list
evac_transport[0]['escorts'] = []
# make our echo base copy with luke and wedge
luke_x_wing = echo_base['starship_assets']['starfighters'][0]['type'].copy()
wedge_x_wing = echo_base['starship_assets']['starfighters'][0]['type'].copy()
# get luke skywalker
luke = get_swapi_resource(swapi_people_url, {'search': '<NAME>'})['results'][0]
luke = filter_data(luke, PEOPLE_KEYS)
luke = clean_data(luke)
# get r2d2
r2_d2 = get_swapi_resource(swapi_people_url, {'search': 'R2-D2'})['results'][0]
r2_d2 = filter_data(r2_d2, PEOPLE_KEYS)
r2_d2 = clean_data(r2_d2)
# put luke in x_wing
luke_x_wing = assign_crew(luke_x_wing, {'pilot' : luke, 'astromech_droid' : r2_d2})
evac_transport[0]['escorts'].append(luke_x_wing)
# get wedge
wedge = get_swapi_resource(swapi_people_url, {'search': 'Wedge Antilles'})['results'][0]
wedge = filter_data(wedge, PEOPLE_KEYS)
wedge = clean_data(wedge)
# get r5d4
r5_d4 = get_swapi_resource(swapi_people_url, {'search': 'R5-D4'})['results'][0]
r5_d4 = filter_data(r5_d4, PEOPLE_KEYS)
r5_d4 = clean_data(r5_d4)
# put wedge in x_wing
wedge_x_wing = assign_crew(wedge_x_wing, {'pilot' : wedge, 'astromech_droid' : r5_d4})
# assign wedge to escorts
evac_transport[0]['escorts'].append(wedge_x_wing)
# peace out 506
write_json("swapi_echo_base-v1p1.json", echo_base)
return uninhabited_planets
if __name__ == '__main__':
main()
<file_sep>/final_proj/swapi_final.py
import json, requests
ENDPOINT = 'https://swapi.co/api'
PEOPLE_KEYS = ("url", "name", "height", "mass", "hair_color", "skin_color", "eye_color", "birth_year", "gender", "homeworld", "species",)
PLANETS_KEYS = ("url", "name", "rotation_period", "orbital_period", "diameter", "climate", "gravity", "terrain", "surface_water", "population", "indigenous_life_forms",)
STARSHIP_KEYS = ("url", "starship_class", "name", "model", "manufacturer", "length", "width", "max_atmosphering_speed", "hyperdrive_rating", "MGLT", "crew", "passengers", "cargo_capactiy", "consumables", "armament",)
SPECIES_KEYS = ("url", "name", "classification", "designation", "average_height", "skin_colors", "hair_colors", "eye_colors", "average_lifespan", "language",)
VEHICLES_KEYS = ("url", "vehicle_class", "name", "model", "manufacturer", "length", "max_atmosphering_speed", "crew", "passengers", "cargo_capacity", "consumables", "armament",)
def read_json(filepath):
"""Given a valid filepath, reads a JSON document and returns a dictionary.
Parameters:
filepath (str): path to file.
Returns:
dict: decoded JSON document expressed as a dictionary.
"""
with open(filepath, 'r', encoding='utf-8') as file_obj:
data = json.load(file_obj)
return data
def get_swapi_resource(url, params=None):
"""Issues an HTTP GET request to return a representation of a resource. If no category is
provided, the root resource will be returned. An optional query string of key:value pairs
may be provided as search terms (e.g., {'search': 'yoda'}). If a match is achieved the
JSON object that is returned will include a list property named 'results' that contains the
resource(s) matched by the search query.
Parameters:
url (str): a url that specifies the resource.
params (dict): optional dictionary of querystring arguments.
Returns:
dict: decoded JSON document expressed as dictionary.
"""
if params:
response = requests.get(url, params=params).json()
else:
response = requests.get(url).json()
return response
def combine_data(default_data, override_data):
"""Creates a shallow copy of the default dictionary and then updates the new
copy with override data. Override values will replace default values when if
the keys match.
For shallow vs deep copying of mutable objects like dictionaries and lists see:
https://docs.python.org/3/library/copy.html
For another approach see unpacking, see: https://www.python.org/dev/peps/pep-0448/
Parameters:
default_data (dict): entity data that provides the default representation of the object.
override_data (dict): entity data intended to override matching default values.
Returns:
dict: updated dictionary that contains override values.
"""
combined_data = default_data.copy() # shallow
# combined_data = copy.copy(default_data) # shallow
# combined_data = copy.deepcopy(default_data) # deep
combined_data.update(override_data) # in place
# Dictionary unpacking
# combined_data = {**default_data, **override_data}
return combined_data
def filter_data(data, filter_keys):
"""Returns a new dictionary based containing a filtered subset of key-value pairs
sourced from a dictionary provided by the caller.
Parameters:
data (dict): source entity.
filter_keys (tuple): sequence of keys used to select a subset of key-value pairs.
Returns:
dict: a new entity containing a subset of the source entity's key-value pairs.
"""
# Alternative: dictionary comprehension (post-Thanksgiving discussion)
# return {key: data[key] for key in filter_keys if key in data.keys()}
record = {}
for key in filter_keys:
if key in data.keys():
record[key] = data[key]
return record
def is_unknown(value):
"""
Determines whether the value is unknown or n/a using a Truth test.
Parameters:
Value (str): a string that is evaluated for being unknown or n/a.
Returns:
Boolean: returns True is the string is unknown or n/a. Otherwise returns the value entered.
"""
if type(value) == str:
value = value.lower().strip()
if value == "unknown":
return True
elif value == "n/a":
return True
else:
return False
def convert_string_to_float(value):
"""
Converts a string to a float.
Parameters:
A string.
Returns:
Returns the converted string as a float, if the function works.
Otherwise spits whatever was entered back out.
"""
try:
return float(value)
except ValueError:
return value
def convert_string_to_int(value):
"""
Converts a string into an integer.
Parameters:
A string.
Returns:
Returns the converted string as an integer, if the function works.
Otherwise spits whatever was entered back atcha.
"""
try:
return int(value)
except ValueError:
return value
def convert_string_to_list(value, delimiter=', '):
"""
Converts a string to a list.
Parameters:
Value (str): a string.
Delimiter: default assignment of the delimiter as a comma, ",".
Returns:
List: a string converted into a list.
"""
new_list = value.split(delimiter)
return new_list
#silly_dict = {'name': 'jumbo', 'mass': '165 lb', 'gravity': 'life, is, so, great ', 'climate': ["wet", "dry", "swampy"], 'family': 'Unknown', 'IQ': 10}
def clean_data(entity):
"""
Converts string values to appropriate types (float, int, list, None). Manages property
checks with tuples of named keys.
Parameters:
planet (dict): dictionary with values to be cleaned.
Returns:
dict: dictionary with cleaned values.
"""
i = (
"height",
"mass",
"rotation_period",
"orbital_period",
"diameter",
"surface_water",
"population",
"average_height",
"average_lifespan",
"max_atmosphering_speed",
"MGLT",
"crew",
"passengers",
"cargo_capacity",
)
f = (
"gravity",
"length",
"hyperdrive_rating",
)
l = (
"hair_color",
"skin_color",
"climate",
"terrain",
"skin_colors",
"hair_colors",
"eye_colors",
)
d = ("homeworld", "species",)
new_dict = {}
for key,value in entity.items(): # loops through keys and values of given dictionary
if is_unknown(value): # checks if the value is unknown or n/a
new_dict[key] = None # converts value to None if true
elif key in i: # if the entity key is in our i tuple
new_dict[key] = convert_string_to_int(value) # we convert the string to an int and add it to our new dictionary
elif key in f: # if the entity key is in our f tuple
temp_list = value.split(" ") # we make a temporary list where we split the value on whitespace
new_dict[key] = convert_string_to_float(temp_list[0]) # we convert the value to a float and take the first item from the list and add it to our new dict
elif key in l: # if the entity key is in our l tuple
value = value.strip()
new_dict[key] = convert_string_to_list(value) # we convert the string into a list and add it to our new dictionary
elif key in d: # if the entity key is in our d tuple
if key == "homeworld": # if the key is homeworld
entity = get_swapi_resource(value) # assign the entity entered to what get_swapi produces (which I don't really know)
filtered_dict = filter_data(entity, PLANETS_KEYS) # create a new dictionary with just the key values of the tuple we use
done = clean_data(filtered_dict) # clean the data (i.e. convert items) from that dict using clean_data, assign it to a temp variable
new_dict[key] = done # assign our new dictionary to the temp variable
elif key == "species": # if the key is species
entity = get_swapi_resource(value[0]) # assign the entity entered to what get_swapi produces (which I don't really know)
filtered_dict = filter_data(entity, SPECIES_KEYS) # create a new dictionary with just the key values of the tuple we use
done = clean_data(filtered_dict) # clean the data (i.e. convert items) from that dict using clean_data, assign it to a temp variable
new_dict[key] = [done] # assign our new dictionary to the temp variable
else:
new_dict[key] = value # if none of the above applies, just maintain the format of the entity
return new_dict # return the new dicionary
#print(clean_data(silly_dict))
def assign_crew(starship, crew):
"""blah blah blah.
Parameters:
None.
Returns:
None.
"""
for key,value in crew.items():
starship[key] = value
return starship
def write_json(filepath, data):
"""Given a valid filepath, write data to a JSON file.
Parameters:
filepath (str): the path to the file.
data (dict): the data to be encoded as JSON and written to the file.
Returns:
None
"""
with open(filepath, 'w', encoding='utf-8') as file_obj:
json.dump(data, file_obj, ensure_ascii=False, indent=2)
# copy and paste from lecture25.py into main
def main():
"""blah blah blah.
Parameters:
None.
Returns:
None.
"""
planets_data = read_json("swapi_planets-v1p0.json")
uninhabited_planets = []
for planet in planets_data:
if is_unknown(planet['population']) == True:
dictionary = filter_data(planet, PLANETS_KEYS)
uninhabited_planets.append(clean_data(dictionary))
write_json("swapi_planets_uninhabited-v1p1.json", uninhabited_planets)
# grab hoth representations
echo_base = read_json("swapi_echo_base-v1p0.json")
swapi_hoth = get_swapi_resource('https://swapi.co/api/planets/4/')
echo_base_hoth = echo_base['location']['planet']
hoth = combine_data(echo_base_hoth, swapi_hoth)
hoth = filter_data(hoth, PLANETS_KEYS)
hoth = clean_data(hoth)
echo_base['location']['planet'] = hoth
#echo base commander
echo_base_commander = echo_base['garrison']['commander']
echo_base_commander = clean_data(echo_base_commander)
echo_base['garrison']['commander'] = echo_base_commander
echo_base_commander = echo_base['visiting_starships']['freighters']
echo_base_commander = clean_data(echo_base_commander)
echo_base['visiting_starships']['freighters'] = echo_base_commander
# vehicles
swapi_vehicles_url = f"{ENDPOINT}/vehicles/"
swapi_snowspeeder = get_swapi_resource(swapi_vehicles_url, {'search': 'snowspeeder'})['results'][0]
# echo base snowspeeder
echo_base_snowspeeder = echo_base['vehicle_assets']['snowspeeders'][0]['type']
snowspeeder = combine_data(echo_base_snowspeeder, swapi_snowspeeder)
snowspeeder = filter_data(snowspeeder, VEHICLES_KEYS)
snowspeeder = clean_data(snowspeeder)
echo_base['vehicle_assets']['snowspeeders'][0]['type'] = snowspeeder
# starships
swapi_starships_url = f"{ENDPOINT}/starships/"
# x-wing
echo_base_x_wing = get_swapi_resource(swapi_starships_url, {'search': 'T-65 X-wing'})['results'][0]
echo_base_model = echo_base['starship_assets']['starfighters'][0]['type']
x_wing_model = combine_data(echo_base_x_wing, echo_base_model)
x_wing_model = filter_data(x_wing_model, STARSHIP_KEYS)
x_wing_model = clean_data(x_wing_model)
echo_base['starship_assets']['starfighters'][0]['type'] = x_wing_model
# gr_75
gr_75 = get_swapi_resource(swapi_starships_url, {'search': 'GR-75 medium transport'})['results'][0]
echo_base_gr_75 = echo_base['starship_assets']['transports'][0]['type']
gr_75_model = combine_data(gr_75, echo_base_gr_75)
gr_75_model = filter_data(gr_75_model, STARSHIP_KEYS)
gr_75_model = clean_data(gr_75_model)
echo_base['starship_assets']['transports'][0]['type'] = gr_75_model
# millennium falcon
m_falcon = get_swapi_resource(swapi_starships_url, {'search': 'GR-75 medium transport'})['results'][0]
echo_base_m_falcon = echo_base['visiting_starships']['freighters'][0]['type']
falcon_model = combine_data(m_falcon, echo_base_m_falcon)
falcon_model = filter_data(falcon_model, STARSHIP_KEYS)
falcon_model = clean_data(falcon_model)
echo_base['visiting_starships']['freighters'][0]['type'] = falcon_model
# people
swapi_people_url = f"{ENDPOINT}/people/"
# han
han = get_swapi_resource(swapi_people_url, {'search': 'han solo'})['results'][0]
han = filter_data(han, PEOPLE_KEYS)
han = clean_data(han)
# chewbacca
chewers = get_swapi_resource(swapi_people_url, {'search': 'Chewbacca'})['results'][0]
chewers = filter_data(chewers, PEOPLE_KEYS)
chewers = clean_data(chewers)
combine_falcon = assign_crew(falcon_model, {'pilot': han, 'copilot': chewers})
if __name__ == '__main__':
main()
<file_sep>/final_proj/jovana_swapi_assignment.py
import json, requests, copy
ENDPOINT = 'https://swapi.co/api'
#Create an additional set of tuple constants that comprise ordered collection of key names
#based on the key names described in the Entity tables listed below:
#DONE
PERSON_KEYS = ('url', 'name', 'height', 'mass', 'hair_color', 'skin_color', 'eye_color', 'birth_year', 'gender', 'homeworld', 'species')
PLANET_KEYS = ('url', 'name', 'system_position', 'natural_satellites', 'rotation_period', 'orbital_period', 'diameter', 'climate', 'gravity', 'terrain', 'surface_water', 'population', 'indigenous_life_forms')
STARSHIP_KEYS = ('url', 'starship_class', 'name', 'model', 'manufacturer', 'length', 'width', 'max_atmosphering_speed', 'hyperdrive_rating', 'MGLT','crew', 'passengers', 'cargo_capacity', 'consumables', 'armament')
SPECIES_KEYS = ('url', 'name', 'classification', 'designation', 'average_height', 'skin_colors', 'hair_colors', 'eye_colors', 'average_lifespan', 'language')
VEHICLE_KEYS = ('url', 'vehicle_class', 'name', 'model', 'manufacturer', 'length', 'max_atmosphering_speed', 'crew', 'passengers', 'cargo_capacity', 'consumables', 'armament')
#You will use these constants as named key filters throughout your program.
def assign_crew(starship, crew):
'''
Decription: This function assigns crew members to a starship.
Parameters:
starship (dict)
crew (dict): Each crew key defines a role (e.g., pilot, copilot, astromech_droid) that must be used as the new starship key (e.g., starship['pilot']).
The crew value (dict) represents the crew member (e.g., Han Solo, Chewbacca).
Returns: The function returns an updated starship with one or more new crew member key-value pairs added to the caller.
'''
#crew key: role
#starship key: role
#crew value: crew member
#DONE
for key,value in crew.items():
starship[key] = value
return starship
#n_dict = {'name': 'Lol', 'mass' : '56', 'gravity' : '45 lols','terrain' : 'i, love, food ', 'population':'unknown', 'thing':66}
def clean_data(entity):
'''
Description: This function converts dictionary string values to more appropriate types such as float, int, list, or, in certain cases, None.
The function evaluates each key-value pair encountered with if-elif-else conditional statements, membership operators,
and calls to other functions that perform the actual type conversions to accomplish this task.
Parameters: entity (dict)
Returns: After checking all values and performing type conversions on strings capable of conversion the function will return a dictionary with 'cleaned' values to the caller.
#consider managing value checks with tuples of ordered named keys (e.g., int_props = (<key_name_01>, <key_name_02>, . . .) that serve as filters.
'''
i = ('height','mass','rotation_period','orbital_period','diameter','population', 'average_lifespan', 'max_atmosphering_speed','MGLT','crew','passengers','cargo_capacity','surface_water', 'average_height',)
f = ('hyperdrive_rating','gravity','length',)
l = ('hair_color','skin_color','climate','terrain','skin_colors','hair_colors','eye_colors',)
d = ('homeworld','species',)
cleaned = {}
for key, value in entity.items():
#thing = get_swapi_resource('https://swapi.co/api/', 'homeworld')
#thing = get_swapi_resource('https://swapi.co/api/, 'species')[0]
if type(value) == str and is_unknown(value):
cleaned[key] = None
elif key in i:
cleaned[key] = convert_string_to_int(value)
elif key in f:
cleaned[key] = convert_string_to_float(value)
elif key in l:
cleaned[key] = convert_string_to_list(value)
elif key in d:
if key == 'homeworld':
entity = get_swapi_resource(value)
new = filter_data(entity, PLANET_KEYS)
final = clean_data(new)
cleaned[key] = final
if key == 'species':
entity = get_swapi_resource(value[0])
new = filter_data(entity, SPECIES_KEYS)
final = clean_data(new)
cleaned[key] = [final]
else:
cleaned[key] = value
return cleaned
def combine_data(default_data, override_data):
'''
Description: This function creates a shallow copy of the default dictionary and then updates the copy with key-value pairs from the 'override' dictionary.
Parameters:
default_data (dict)
override_data (dict)
Returns: The function returns a dictionary that combines the key-value pairs of both the default dictionary and the override dictionary,
with override values replacing default values on matching keys.
'''
#DONE
combined_data = default_data.copy() # shallow
# combined_data = copy.copy(default_data) # shallow
# combined_data = copy.deepcopy(default_data) # deep
combined_data.update(override_data) # in place
# Dictionary unpacking
# combined_data = {**default_data, **override_data}
return combined_data
def convert_string_to_float(value):
'''
Description: This function attempts to convert a string to a floating point value.
Parameters: value (str)
Returns: If unsuccessful the function returns the value unchanged.
#Use try / except blocks to accomplish the task.
'''
#DONE
try:
if type(value) == str:
value = value.strip('standard')
value = value.strip()
return float(value)
else:
return value
except ValueError:
return value
def convert_string_to_int(value):
'''
Description: This function attempts to convert a string to an int.
Parameters: value (str)
Returns: If unsuccessful the function must return the value unchanged.
#implement try / except blocks that catch the expected exception to accomplish the task
'''
#DONE
try:
return int(value)
except ValueError:
return value
def convert_string_to_list(value, delimiter = ', '):
'''
Description: This function converts a string of delimited text values to a list.
Parameters:
value(str)
optional delimiter (str)
Returns: The function will split the passed in string using the provided delimiter and return the resulting list to the caller.
'''
#DONE
#final = []
new_list = value.split(delimiter)
# for thing in new_list:
# done = thing.strip()
# final.append(done)
return new_list
def filter_data(data, filter_keys):
'''
Description: This function applies a key name filter to a dictionary in order to return an ordered subset of key-values.
Parameters:
data (dict)
filter_keys (tuple): The insertion order of the filtered key-value pairs is determined by the filter_key sequence.
Returns: (Dict) The function returns a filtered collection of key-value pairs to the caller. '''
#im not sure what im suppsed to do here - maybe follow up on piazza
#filtered = {}
'''
#if you want to replace the keys and standardize them
for key,value in data.items():
for item in filter_keys:
filtered[item] = value
'''
record = {}
for key in filter_keys:
if key in data.keys():
record[key] = data[key]
return record
#DONE
def get_swapi_resource(url, params=None):
'''
Description: This function initiates an HTTP GET request to the SWAPI service in order to return a representation of a resource.
Parameters:
url (str): resource url
params (dict): optional query string of key:value pairs may be provided as search terms (e.g., {'search': 'yoda'}).
If no category (e.g., people) is provided, the root resource will be returned.
Returns:
If a match is obtained the JSON object that is returned will include a list property named 'results' that contains the resource(s) matched by the search query term(s).
SWAPI data is serialized as JSON. The get_swapi_resource() function must decode the response using the .json() method so that the data is returned as a dictionary.
'''
#DONE
if params:
response = requests.get(url, params=params).json()
else:
response = requests.get(url).json()
return response
#print(get_swapi_resource('https://swapi.co/api/planets/', {'search': 'hoth'})['results'][0]['climate'] == 'frozen')
def is_unknown(value):
'''
Description: This function applies a case-insensitive truth value test for string values that equal unknown or n/a.
Parameters:
value(str)
Returns: True if a match is obtained.
'''
#DONE
try:
value.lower()
if 'unknown' in value.lower():
yes = True
else:
if 'n/a' in value.lower():
yes = True
else:
yes = False
return yes
except ValueError:
return False
def read_json(filepath):
'''
Description: This function reads a JSON document and returns a dictionary if provided with a valid filepath. Basically just encodes it and spits out a dictionary.
Parameters: filepath (str): json document
Returns: A dictionary that will be encoded using the parameter utf-8
When calling the built-in open() function set the optional encoding parameter to utf-8.
'''
#DONE
with open(filepath, 'r', encoding = 'UTF-8') as f:
encoded = json.load(f)
return encoded
def write_json(filepath, data):
'''
Description: Write a general-purpose function named write_json() capable of writing SWAPI data to a target JSON document file.
The function must be capable of processing any arbitrary combination of SWAPI data and filepath provided to it as arguments.
Call this function and pass it the appropriate arguments whenever you need to generate a JSON document file required to complete the assignment.
Parameters:
filepath (str)
data (?): that is to be written to the file
Returns: a json file with data that was inputted
#When calling the built-in open() function set the optional encoding parameter to utf-8. When calling json.dump() set the optional ensure_ascii parameter value to False and the optional indent parameter value to 2.
'''
#DONE
with open(filepath, 'w') as f:
json.dump(data, f, ensure_ascii = False ,indent = 2)
def main():
"""
Entry point. This program will interact with local file assets and the Star Wars
API to create two data files required by Rebel Alliance Intelligence.
- A JSON file comprising a list of likely uninhabited planets where a new rebel base could be
situated if Imperial forces discover the location of Echo Base.
- A JSON file of Echo Base information including an evacuation plan of base personnel
along with passenger assignments for <NAME>, the communications droid C-3PO aboard
the transport Bright Hope escorted by two X-wing starfighters piloted by <NAME>
(with astromech droid R2-D2) and Wedge Antilles (with astromech droid R5-D4).
Parameters:
None
Returns:
None
"""
#6.2 FILTER PLANET DATA
#once combine data is made then filter_data should be able to pass which will help this one?
list_planet_dict = read_json('swapi_planets-v1p0.json')
uninhabited_list = []
#iterate over a list of planet dictionaries
for item in list_planet_dict:
value = item['population']
if is_unknown(value) == True:
filtered = filter_data(item, PLANET_KEYS)
new_clean = clean_data(filtered)
uninhabited_list.append(new_clean)
else:
pass
#write list of dictionaries to new file
write_json('swapi_planets_uninhabited-v1p1.json', uninhabited_list)
#Start of echo base main
echo_base = read_json('swapi_echo_base-v1p0.json')
swapi_hoth = get_swapi_resource('https://swapi.co/api/planets/4/')
echo_base_hoth = echo_base['location']['planet']
hoth = combine_data(echo_base_hoth, swapi_hoth)
hoth = filter_data(hoth, PLANET_KEYS)
hoth = clean_data(hoth)
echo_base['location']['planet'] = hoth
echo_base_commander = echo_base['garrison']['commander']
echo_base_commander = clean_data(echo_base_commander)
echo_base['garrison']['commander'] = echo_base_commander
echo_base_smuggler = echo_base['visiting_starships']['freighters'][0]
echo_base_smuggler = clean_data(echo_base_smuggler)
echo_base_smuggler = echo_base['visiting_starships']['freighters'][0]
swapi_vehicles_url = f"{ENDPOINT}/vehicles/"
swapi_snowspeeder = get_swapi_resource(swapi_vehicles_url, {'search': 'snowspeeder'})['results'][0]
echo_base_snowspeeder = echo_base['vehicle_assets']['snowspeeders'][0]['type']
snowspeeder = combine_data(echo_base_snowspeeder, swapi_snowspeeder)
snowspeeder = filter_data(snowspeeder, VEHICLE_KEYS)
snowspeeder = clean_data(snowspeeder)
echo_base['vehicle_assets']['snowspeeders'][0]['type'] = snowspeeder
swapi_starships_url = f"{ENDPOINT}/starships/"
t_65 = get_swapi_resource(swapi_starships_url, {'search': 'T-65 X-wing'})['results'][0]
echo_base_model = echo_base['starship_assets']['starfighters'][0]['type']
combine_t65 = combine_data(t_65, echo_base_model)
combine_t65 = filter_data(combine_t65, STARSHIP_KEYS)
combine_t65 = clean_data(combine_t65)
echo_base['starship_assets']['starfighters'][0]['type'] = combine_t65
med = get_swapi_resource(swapi_starships_url, {'search': 'GR-75 medium transport'})['results'][0]
echo_base_med = echo_base['starship_assets']['transports'][0]['type']
combine_med = combine_data(med, echo_base_med)
combine_med = filter_data(combine_med, STARSHIP_KEYS)
combine_med = clean_data(combine_med)
echo_base['starship_assets']['transports'][0]['type'] = combine_med
falcon = get_swapi_resource(swapi_starships_url, {'search': 'YT-1300 light freighter'})['results'][0]
echo_base_falcon = echo_base['visiting_starships']['freighters'][0]
m_falcon = combine_data(falcon, echo_base_falcon)
m_falcon = filter_data(m_falcon, STARSHIP_KEYS)
m_falcon = clean_data(m_falcon)
echo_base['visiting_starships']['freighters'][0]['type'] = m_falcon
echo_base_light = echo_base['visiting_starships']['freighters'][1]
echo_base_light = filter_data(echo_base_light, STARSHIP_KEYS)
echo_base_light = clean_data(echo_base_light)
swapi_people_url = f"{ENDPOINT}/people/"
han = get_swapi_resource(swapi_people_url, {'search': 'han solo'})['results'][0]
han = filter_data(han, PERSON_KEYS)
han = clean_data(han)
swapi_people_url = f"{ENDPOINT}/people/"
chewie = get_swapi_resource(swapi_people_url, {'search': 'Chewbacca'})['results'][0]
chewie = filter_data(chewie, PERSON_KEYS)
chewie = clean_data(chewie)
combine_falcon = assign_crew(m_falcon, {'pilot': han, 'copilot': chewie})
rendar = filter_data(echo_base['visiting_starships']['freighters'][1]['pilot'], PERSON_KEYS)
rendar = clean_data(rendar)
echo_base_light = assign_crew(echo_base_light, {'pilot': rendar})
echo_base['visiting_starships']['freighters'] = []
echo_base['visiting_starships']['freighters'].append(combine_falcon)
echo_base['visiting_starships']['freighters'].append(echo_base_light)
evac_plan = echo_base['evacuation_plan']
i = 0
for item in echo_base['garrison']['personnel']:
i += echo_base['garrison']['personnel'][item]
echo_base['evacuation_plan']['max_base_personnel'] = i
echo_base['evacuation_plan']['max_available_transports'] = echo_base['starship_assets']['transports'][0]['num_available'] # max_available_transports = echo_base['starship_assets']['transports'][0]['num_available']
echo_base['evacuation_plan']['max_passenger_overload_capacity'] = echo_base['evacuation_plan']['max_available_transports'] * echo_base['evacuation_plan']['passenger_overload_multiplier'] * echo_base['evacuation_plan']['max_available_transports'] * echo_base['evacuation_plan']['passenger_overload_multiplier']
evac_transport = copy.deepcopy(echo_base['starship_assets']['transports'])
echo_base['visiting_starships']['freighters'][1]['cargo_capacity'] = str(echo_base['visiting_starships']['freighters'][1]['cargo_capacity'])
# print(evac_transport[0]['type'])
# evac_transport = evac_transport[0]['type']
evac_transport[0]['type']['name'] = 'Bright Hope'
evac_plan['transport_assignments'] = evac_transport
data = evac_transport[0]['type']
for key, value in data.items():
evac_plan['transport_assignments'][0][key] = value
evac_plan['transport_assignments'][0].pop('type')
evac_plan['transport_assignments'][0].pop('num_available')
evac_transport[0]['passenger_manifest'] = []
leia = get_swapi_resource(swapi_people_url, {'search': '<NAME>'})['results'][0]
leia = filter_data(leia, PERSON_KEYS)
leia = clean_data(leia)
c3_p0 = get_swapi_resource(swapi_people_url, {'search': 'C-3PO'})['results'][0]
c3_p0 = filter_data(c3_p0, PERSON_KEYS)
c3_p0 = clean_data(c3_p0)
evac_transport[0]['passenger_manifest'].append(leia)
evac_transport[0]['passenger_manifest'].append(c3_p0)
evac_transport[0]['escorts'] = []
luke_x_wing = echo_base['starship_assets']['starfighters'][0]['type'].copy()
wedge_x_wing = echo_base['starship_assets']['starfighters'][0]['type'].copy()
luke = get_swapi_resource(swapi_people_url, {'search': '<NAME>'})['results'][0]
luke = filter_data(luke, PERSON_KEYS)
luke = clean_data(luke)
r2_d2 = get_swapi_resource(swapi_people_url, {'search': 'R2-D2'})['results'][0]
r2_d2 = filter_data(r2_d2, PERSON_KEYS)
r2_d2 = clean_data(r2_d2)
luke_x_wing = assign_crew(luke_x_wing, {'pilot' : luke, 'astromech_droid' : r2_d2})
evac_transport[0]['escorts'].append(luke_x_wing)
wedge = get_swapi_resource(swapi_people_url, {'search': '<NAME>'})['results'][0]
wedge = filter_data(wedge, PERSON_KEYS)
wedge = clean_data(wedge)
r5_d4 = get_swapi_resource(swapi_people_url, {'search': 'R5-D4'})['results'][0]
r5_d4 = filter_data(r5_d4, PERSON_KEYS)
r5_d4 = clean_data(r5_d4)
wedge_x_wing = assign_crew(wedge_x_wing, {'pilot' : wedge, 'astromech_droid' : r5_d4})
evac_transport[0]['escorts'].append(wedge_x_wing)
# echo_base['evacuation_plan']['transport_assignments'][0].pop('num_available')
write_json('swapi_echo_base-v1p1.json', echo_base)
return uninhabited_list
if __name__ == '__main__':
main()
#TESTS
<file_sep>/README.md
# si506
SI 506, Introduction to Programming
<file_sep>/final_proj/list_test.py
cool_list = ["dogs ", " cats", "and", " everything in between"]
for x in cool_list:
x = x.strip()
print(x) | 2a91b921d3d17cd13263cf8d8664cf219d3a5ac7 | [
"Markdown",
"Python"
] | 5 | Python | cginiel/si506 | 91f9f7de3911d0d23fcd584d44638ee32c9fe265 | 043b9dbc1c20d8c333db0b02501cc14ae0eda147 |
refs/heads/master | <file_sep>//<NAME>
//SRN = 170229702
import java.util.Random;
import java.util.Scanner;
public class CustomerVerifier {
private static int[] pins = new int[]{1234, 1111, 4321, 5555, 7777, 1010, 9876};
private static String[] customers = new String[]{"Bob", "Rob", "Tim", "Jim", "Sam", "Jon", "Tom"};
private static String[] memorableWords= new String[]{"fishing", "Mittens", "Arsenal", "6packYeah", "Porsche911", "puppies", "CSI4Ever"};
private static Scanner scanner = new Scanner(System.in);
private static boolean askUserToContinue() {
String input = getUserInput("Verify another customer? ");
return input.trim().toLowerCase().startsWith("y"); //see the String API for documentation of the trim() method
}
private static String getCustomerFromUser() {
return getUserInput("Enter customer name: ");
}
private static int getPinFromUser() {
String input = getUserInput("Enter PIN: ");
return Integer.parseInt(input); //see the subject guide volume 1 section 9.6 for more on the parseInt(String) method
}
//Helper class
private static String getUserInput(String msg) {
System.out.print(msg);
return scanner.nextLine();
}
private static boolean isValidPin(String customer, int pin) {
int customerIndex = -1;
for (int i = 0; i < customers.length; i++) {
if (customer.equals((customers[i]))) { //see the String API for documentation of the equals(Object) method
customerIndex = i;
}
}
return pin == pins[customerIndex];
}
private static boolean isValidCustomer(String customer) {
for (int i = 0; i < customers.length; i++) {
if (customer.equals(customers[i])) {
return true;
}
}
return false;
}
//return random integers that are distinct from each other
private static int[] getDiscreteRandomInts(int quantity, int bound) {
Random random = new Random();
int[] store = new int[quantity];
int r;
int i = 0;
while (i < quantity) {
r = random.nextInt(bound);
boolean insert = true;
for (int j = 0; j < i; j++) {
if (store[j] == r) {
insert = false;
}
}
if (insert) {
store[i] = r;
i++;
}
}
return store;
}
private static String charsAt(String word, int[] indexes) {
String result = "";
for (int i = 0; i < indexes.length; i++) {
result += word.charAt(indexes[i]);
}
return result;
}
private static String getMemorableWordCharsFromUser(int[] chars) {
String result = "";
//computers start counting characters in a string from 0 but humans start at 1 so we add 1 to every number shown to the user
for (int i = 0; i < chars.length; i++) {
result += getUserInput("Enter character " + (chars[i]+1) + " from your memorable word: ");
}
return result;
}
private static String getMemorableWord(String customer) {
for (int i = 0; i < customers.length; i++) {
if (customer.equals(customers[i])) {
return memorableWords[i];
}
}
//won't get here if the customer exists
return "";
}
private static void verifiedCustomer(String customer, int pin, String memorableWord) {
System.out.println("Verified customer " + customer + " with pin " + pin + " and memorable word " + memorableWord);
}
private static void incorrectPin(String customer, int pin) {
System.out.println("Incorrect PIN (" + pin + ") for customer " + customer);
}
private static void invalidMemorableWord(String customer) {
System.out.println("Invalid memorable word for " + customer);
}
private static void invalidCustomer(String customer) {
System.out.println("Invalid customer " + customer);
}
//1.a (+ b) *** three staments including calls to other methods, plus a return call.
//It asks a customer for two different random characters from their memorable word
//Method should return true if both characters given by the user match the memorable word characters asked for,
//and false otherwise.
private static boolean userKnowsRandomCharsFromMemorableWord(String customerName){
String memorableWord = getMemorableWord(customerName);
//Used to find what positions the random chars should be taken from
int[] positionOfCharacter = getDiscreteRandomInts(2, customerName.length() + 1); //Bound set to customer word length + 1
//Saving the correct answer as string to make the .equals more readable
String correctResponse = charsAt(memorableWord, positionOfCharacter);
return correctResponse.equals(getMemorableWordCharsFromUser(positionOfCharacter));
}
//2. a (+b)
//The while loop could be cleaned up by having less nesting of if else loops, but it is still readable
private static void verify() {
//When the user no longer wants to verify customers this will be false and the while loop will end
boolean verifyMode = true;
while (verifyMode) {
//Asks customer name
String name = getCustomerFromUser();
//Step 2: If the customer name is not in the array
if (!isValidCustomer(name)) {
if (askUserToContinue()) {
//break;
} else {
verifyMode = false;
break;
}
} else {
//Step 3: Ask for pin
int customerPin = getPinFromUser();
//Step 4: If the pin is not valid
if (!isValidPin(name, customerPin)) {
incorrectPin(name, customerPin);
if (askUserToContinue()) {
// break;
} else {
verifyMode = false;
break;
}
} else {
//Step 5 is removed as the getMemorableWordCharsFromUser() method is used in the
// userKnowsRandomCharsFromMemorableWord method created in question one
if (!userKnowsRandomCharsFromMemorableWord(name)) {
invalidMemorableWord(name);
if (askUserToContinue()) {
// break;
} else {
verifyMode = false;
break;
}
} else {
verifiedCustomer(name, customerPin, getMemorableWord(name));
if (askUserToContinue()) {
//break;
} else {
verifyMode = false;
break;
}
}
}
}
}//end of while loop
System.out.println("Thank you for using the customer verifier. Please direct any technical issues to: " +
"<EMAIL>");
}//end of verify method
public static void main(String[] args){verify();}
}//end of class
| 1e115b7cef3232181c02197e721a965e2565b30d | [
"Java"
] | 1 | Java | hoestlund/CO1109_coursework_1 | 8e3ae48f196cd43489c9bc948f7ad0cc5fc11652 | fb5986c5955113bf239e3b3eca3d189996cf0af2 |
refs/heads/master | <file_sep><?php
class Admin extends CI_Controller{
public function index(){
$this->load->view('templates/header');
$this->load->view('admin/login');
$this->load->view('templates/footer');
}
public function edit_content(){
$this->load->view('templates/header');
$this->load->view('editContent');
$this->load->view('templates/footer');
}
} ?>
<file_sep><?php ?>
<div id="breadcrumb">
<div class="container">
<div class="breadcrumb">
<li><a href="index.html">Home</a></li>
<li>Logins</li>
</div>
</div>
</div>
<div class="container login">
<h4 class="text-center"> Login</h4>
<div class="container">
<form class="form-group" action="register" method="post">
<div class="col-md-6 col-md-offset-3">
<input class="form-control loginInputs" type="text" name="fname" placeholder="First Name">
</div>
<div class="col-md-6 col-md-offset-3">
<input class="form-control loginInputs" type="text" name="lname" placeholder="Last Name">
</div>
<div class="col-md-6 col-md-offset-3">
<input class="form-control loginInputs" type="<PASSWORD>" name="password" placeholder="<PASSWORD>">
</div>
<div class="col-md-6 col-md-offset-3">
<input class="form-control loginInputs" type="<PASSWORD>" name="pConfirm" placeholder="<PASSWORD>">
</div>
<div class="text-center">
<input class="form-control loginInputs btn btn-success" type="submit" name="register" value="Register">
</div>
</form>
</div>
</div>
| 09ff19b43b9c8ee76f660b64e46e6ef86b9f69d0 | [
"PHP"
] | 2 | PHP | megabreakage/euro | 29c6b1b10d7f96a323708ba0fca7f9d3172f68c3 | 1d7284756d02da65394782ba964ff7d489863d8f |
refs/heads/main | <repo_name>ItzManan/Space-Invaders<file_sep>/Space Invaders.py
import pygame as pg
import random
from math import sqrt
from pygame import mixer
from pygame import cursors
from pygame import mouse
pg.init()
pg.mixer.init()
screen = pg.display.set_mode((800, 600))
y = 0
pg.display.set_caption("Space Invaders")
icon = pg.image.load("logo.png")
pg.display.set_icon(icon)
main_menu_logo = pg.image.load("logo_main.png")
ship = pg.image.load("spaceship.png")
playerX = 370
playerY = 480
speed_player = 0
sound_on = pg.image.load("sound.png")
sound_off = pg.image.load("no_sound.png")
sound = " "
alien = []
alienX = []
alienY = []
speed_alien_X = []
speed_alien_y = []
num_of_enemies = 6
for i in range(num_of_enemies):
alien.append(pg.image.load("Alien.png"))
alienX.append(random.randint(0, 760))
alienY.append(random.randint(50, 150))
speed_alien_X.append(2.5)
speed_alien_y.append(40)
background = pg.image.load('Background.jpg').convert()
bullet = pg.image.load("bullet.png")
bulletX = 0
bulletY = 480
speed_bullet_y = 5
bullet_fire = "ready"
score_value = 0
font = pg.font.Font("Poppins-Light.ttf", 32)
textX = 10
textY = 10
over = pg.font.Font("Poppins-Light.ttf", 64)
create = pg.font.Font("Poppins-Light.ttf", 16)
def ending():
global alienX
global alienY
global bulletY
alienY = []
for i in range(num_of_enemies):
alienY.append(random.randint(50, 150))
bulletY = 480
global ship
global sound
global y
global clicked
run = True
player(playerX, playerY)
while run:
rel_y = y % background.get_rect().height
screen.fill((0, 0, 0))
screen.blit(background, (0, rel_y - background.get_rect().height))
if rel_y < 600:
screen.blit(background, (0, rel_y))
y += 0.7
hover_sound_img_play_again()
for event in pg.event.get():
if event.type == pg.MOUSEBUTTONDOWN:
mouse_position = pg.mouse.get_pos()
if mouse_position[0] > 750 and mouse_position[0] < 782 and mouse_position[1] > 4 and mouse_position[1] < 37:
if clicked % 2 == 0:
sound = "on"
elif clicked % 2 == 1:
sound = "off"
clicked += 1
if 450 > mouse_position[0] > 350 and 400 > mouse_position[1] > 350:
main_loop()
break
if event.type == pg.QUIT:
run = False
over_text = over.render("GAME OVER", True, (255, 255, 255))
screen.blit(over_text, (200, 240))
sound_img()
show_score(textX, textY)
pg.display.update()
pg.quit()
def player(x, y):
screen.blit(ship, (x, y))
def aliens(x, y, i):
global alien
screen.blit(alien[i], (x, y))
def fire_bullet(x, y):
global bullet_fire
bullet_fire = "fire"
screen.blit(bullet, (x+16, y+10))
def collide(enemyX, enemyY, bulletX, bulletY):
distance = sqrt(((enemyX-bulletX)**2)+((enemyY-bulletY)**2))
if distance <= 27:
return True
def show_score(x, y):
score = font.render("Score : "+ str(score_value), True, (0, 255, 0))
screen.blit(score, (x, y))
def sound_img():
if sound == " ":
screen.blit(sound_on, (750, 5))
if sound == "on":
screen.blit(sound_on, (750, 5))
mixer.music.unpause()
elif sound == "off":
mixer.music.pause()
screen.blit(sound_off, (750, 5))
def hover_sound_img():
mouse_position = pg.mouse.get_pos()
if mouse_position[0] > 750 and mouse_position[0] < 782 and mouse_position[1] > 4 and mouse_position[1] < 37:
pg.mouse.set_cursor(*cursors.broken_x)
else:
pg.mouse.set_cursor(*cursors.arrow)
def hover_sound_img_play_again():
mouse_position = pg.mouse.get_pos()
if mouse_position[0] > 750 and mouse_position[0] < 782 and mouse_position[1] > 4 and mouse_position[1] < 37:
pg.mouse.set_cursor(*cursors.broken_x)
else:
pg.mouse.set_cursor(*cursors.arrow)
if 450 > mouse_position[0] > 350 and 400 > mouse_position[1] > 350:
pg.draw.rect(screen, (0, 200, 0), (310, 350 ,150, 50))
play_button_text(330, 360, 20, "PLAY AGAIN")
else:
pg.draw.rect(screen, (0, 255, 0), (310, 350 ,150, 50))
play_button_text(330, 360, 20, "PLAY AGAIN")
def hover_main_menu():
mouse_position = pg.mouse.get_pos()
if mouse_position[0] > 750 and mouse_position[0] < 782 and mouse_position[1] > 4 and mouse_position[1] < 37:
pg.mouse.set_cursor(*cursors.broken_x)
else:
pg.mouse.set_cursor(*cursors.arrow)
if 450 > mouse_position[0] > 350 and 400 > mouse_position[1] > 350:
pg.draw.rect(screen, (0, 200, 0), (350, 350 ,100, 50))
play_button_text(363, 355, 32, "PLAY")
else:
pg.draw.rect(screen, (0, 255, 0), (350, 350 ,100, 50))
play_button_text(363, 355, 32, "PLAY")
def play_button_text(x, y, size, text):
play_button = pg.font.Font("Poppins-Light.ttf", size)
play_text = play_button.render(text, True, (0, 0, 0))
screen.blit(play_text, (x, y))
mixer.music.load("background.wav")
mixer.music.play(-1)
def main_loop():
global y
global bullet_fire
global playerX
global playerY
global bulletY
global sound
global speed_player
global score_value
global bulletX
global running
global clicked
running = True
clicked = 1
score_value = 0
while running:
rel_y = y % background.get_rect().height
screen.fill((0, 0, 0))
screen.blit(background, (0, rel_y - background.get_rect().height))
if rel_y < 600:
screen.blit(background, (0, rel_y))
y += 0.7
hover_sound_img()
for event in pg.event.get():
if event.type == pg.MOUSEBUTTONDOWN:
global mouse_position
mouse_position = pg.mouse.get_pos()
if 782 > mouse_position[0] > 750 and 37 > mouse_position[1] > 4:
if clicked % 2 == 0:
sound = "on"
elif clicked % 2 == 1:
sound = "off"
clicked += 1
if event.type == pg.QUIT:
running = False
if event.type == pg.KEYDOWN:
if event.key == pg.K_LEFT:
speed_player = -2.2
if event.key == pg.K_RIGHT:
speed_player = 2.2
if event.key == pg.K_SPACE:
if bullet_fire == "ready":
bulletX = playerX
fire_bullet(playerX, bulletY)
if sound != "off":
bullet_sound = mixer.Sound("laser.wav")
bullet_sound.play()
if event.type == pg.KEYUP:
if speed_player == 2.2 and event.key == pg.K_RIGHT:
speed_player = 0
if speed_player == -2.2 and event.key == pg.K_LEFT:
speed_player = 0
playerX += speed_player
if playerX < -1:
playerX =-1
elif playerX > 737:
playerX = 737
for i in range(num_of_enemies):
if alienY[i] > 400:
for j in range(num_of_enemies):
alienY[j] = 1000
ending()
break
alienX[i] += speed_alien_X[i]
if alienX[i] <= 0:
speed_alien_X[i] = 1.5
alienY[i] +=speed_alien_y[i]
elif alienX[i] > 760:
speed_alien_X[i] = -1.5
alienY[i] +=speed_alien_y[i]
collision = collide(alienX[i], alienY[i], bulletX, bulletY)
if collision:
if sound != "off":
collision_sound = mixer.Sound("explosion.wav")
collision_sound.play()
bulletY = 480
bullet_fire = "ready"
score_value +=1
alienX[i] = random.randint(0, 760)
alienY[i] = random.randint(50, 150)
aliens(alienX[i], alienY[i], i)
if bullet_fire == "fire":
fire_bullet(bulletX, bulletY)
bulletY -= speed_bullet_y
if bulletY < 0:
bulletY = 480
bullet_fire = "ready"
sound_img()
player(playerX, playerY)
show_score(textX, textY)
pg.display.update()
pg.display.quit()
running = True
clicked = 1
def main_screen():
global running
global clicked
global y
global sound
while running:
rel_y = y % background.get_rect().height
screen.fill((0, 0, 0))
screen.blit(background, (0, rel_y - background.get_rect().height))
if rel_y < 600:
screen.blit(background, (0, rel_y))
y += 0.7
hover_main_menu()
for event in pg.event.get():
if event.type == pg.MOUSEBUTTONDOWN:
mouse_position = pg.mouse.get_pos()
if mouse_position[0] > 750 and mouse_position[0] < 782 and mouse_position[1] > 4 and mouse_position[1] < 37:
if clicked % 2 == 0:
sound = "on"
elif clicked % 2 == 1:
sound = "off"
clicked += 1
if 450 > mouse_position[0] > 350 and 400 > mouse_position[1] > 350:
main_loop()
break
if event.type == pg.QUIT:
running = False
screen.blit(main_menu_logo, (175, 120))
sound_img()
created_by = create.render("Made by: <NAME>", True, (0, 255, 0))
screen.blit(created_by, (315, 580))
pg.display.update()
pg.quit()
main_screen()
<file_sep>/README.md
Space Invaders using Pygame
| 7c57d33b8f8246696b3221ac00294a23fe5220d1 | [
"Markdown",
"Python"
] | 2 | Python | ItzManan/Space-Invaders | a2082b5001159578a47f5686128a980bc1884201 | 4e96c2dc7ccbc9b9a09115238cad1abbb5b8fe6c |
refs/heads/master | <repo_name>oisee/cowgol<file_sep>/bootstrap/cowgol.h
#ifndef COWGOL_H
#define COWGOL_H
extern int8_t extern_i8;
extern int8_t extern_i8_2;
extern int16_t extern_i16;
extern int32_t extern_i32;
extern int8_t* extern_p8;
extern uint32_t extern_u32;
extern int8_t* lomem;
extern int8_t* himem;
extern int8_t** cowgol_argv;
extern int8_t cowgol_argc;
extern void cowgol_print(void);
extern void cowgol_print_bytes(void);
extern void cowgol_print_char(void);
extern void cowgol_print_i8(void);
extern void cowgol_print_i16(void);
extern void cowgol_print_i32(void);
extern void cowgol_print_hex_i8(void);
extern void cowgol_print_hex_i16(void);
extern void cowgol_print_hex_i32(void);
extern void cowgol_print_newline(void);
extern void cowgol_file_openin(void);
extern void cowgol_file_openout(void);
extern void cowgol_file_openup(void);
extern void cowgol_file_putchar(void);
extern void cowgol_file_getchar(void);
extern void cowgol_file_putblock(void);
extern void cowgol_file_getblock(void);
extern void cowgol_file_seek(void);
extern void cowgol_file_tell(void);
extern void cowgol_file_ext(void);
extern void cowgol_file_eof(void);
extern void cowgol_file_close(void);
extern void cowgol_exit(void);
extern void compiled_main(void);
#endif
<file_sep>/scripts/cowgol_bootstrap_compiler
#!/bin/sh
set -e
options=$(getopt -s sh -n $0 ko: "$@")
if [ $? -ne 0 ]; then
echo >&2 "Usage: $0 [-k] [-o outputfile] inputfiles..."
exit 1
fi
output=${1%.*}
for option in $options; do
case "$option" in
-o) shift; output=$(realpath -s $1); shift;;
--) break;;
esac
done
./bootstrap/bootstrap.lua "$@" > $output.c
gcc -g -Og -std=c1x -fms-extensions -ffunction-sections -fdata-sections \
-o $output $output.c -I bootstrap bootstrap/cowgol.c
<file_sep>/tinycowc/globals.h
#ifndef GLOBALS_H
#define GLOBALS_H
#include <assert.h>
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <stdbool.h>
#include <stdarg.h>
#include <limits.h>
extern void fatal(const char* s, ...);
extern const char* aprintf(const char* s, ...);
extern int yylex(void);
extern int yylineno;
extern FILE* yyin;
extern char* yytext;
extern int32_t number;
enum
{
TYPE_NUMBER,
TYPE_POINTER,
TYPE_ARRAY,
TYPE_RECORD
};
struct namespace
{
struct symbol* firstsymbol;
struct symbol* lastsymbol;
struct namespace* parent;
};
struct symbol
{
int kind;
const char* name;
struct symbol* next;
struct symarch* arch;
union
{
struct
{
int kind;
int width;
struct symbol* pointerto;
struct symbol* element;
struct namespace namespace;
bool issigned: 1;
}
type;
struct
{
struct symbol* type;
struct subroutine* sub; /* null for a member */
uint32_t offset;
}
var;
int32_t constant;
struct subroutine* sub;
}
u;
};
struct subroutine
{
const char* name;
const char* externname;
uint32_t workspace;
struct namespace namespace;
int inputparameters;
int old_break_label;
struct subarch* arch;
};
struct exprnode
{
struct symbol* type;
struct symbol* sym; /* or NULL for a numeric constant */
int32_t off;
bool constant : 1;
};
struct condlabels
{
int truelabel;
int falselabel;
};
struct looplabels
{
int looplabel;
int exitlabel;
int old_break_label;
};
struct argumentsspec
{
struct subroutine* sub;
int number;
struct symbol* param;
struct argumentsspec* previous_call;
};
#define yyerror(s) fatal(s)
extern void* open_file(const char* filename);
extern void include_file(void* buffer);
extern void varaccess(const char* opcode, struct symbol* var);
extern struct symbol* intptr_type;
extern struct symbol* uint8_type;
extern struct subroutine* current_sub;
extern int current_label;
extern struct symbol* add_new_symbol(struct namespace* namespace, const char* name);
extern struct symbol* lookup_symbol(struct namespace* namespace, const char* name);
extern struct symbol* make_number_type(const char* name, int width, bool issigned);
extern void arch_init_types(void);
extern void arch_init_subroutine(struct subroutine* sub);
extern void arch_init_variable(struct symbol* var);
extern void arch_emit_comment(const char* text, ...);
#endif
<file_sep>/mkninja.lua
local posix = require("posix")
local out = io.stdout
local function emit(...)
for _, s in ipairs({...}) do
if type(s) == "table" then
emit(unpack(s))
else
out:write(s, " ")
end
end
end
local function nl()
out:write("\n")
end
local function rule(rulename, output, inputs, deps, vars)
emit("build", output, ":", rulename, inputs)
if deps then
emit("|", deps)
end
nl()
if vars then
for k, v in pairs(vars) do
emit(" ", k, "=", v)
nl()
end
end
end
out:write([[
#############################################################################
### THIS FILE IS AUTOGENERATED ###
#############################################################################
#
# Don't edit it. Your changes will be destroyed. Instead, edit mkninja.sh
# instead. Next time you run ninja, this file will be automatically updated.
rule mkninja
command = lua ./mkninja.lua > $out
generator = true
build build.ninja : mkninja mkninja.lua
OBJDIR = /tmp/cowgol-obj
rule stamp
command = touch $out
rule bootstrapped_cowgol_program
command = scripts/cowgol_bootstrap_compiler -o $out $in
rule cowgol_program
command = scripts/cowgol -a $arch -o $out $in
build $OBJDIR/compiler_for_native_on_native : stamp
rule c_program
command = cc -std=c99 -Wno-unused-result -g -o $out $in $libs
rule token_maker
command = gawk -f src/mk-token-maker.awk $in > $out
rule token_names
command = gawk -f src/mk-token-names.awk $in > $out
build $OBJDIR/token_maker.cow : token_maker src/tokens.txt | src/mk-token-maker.awk
build $OBJDIR/token_names.cow : token_names src/tokens.txt | src/mk-token-names.awk
rule fuzix_syscall_maker
command = sh $in > $out
build src/arch/fuzixz80/lib/syscalls.cow : fuzix_syscall_maker scripts/fuzix/syscall-maker.sh
rule run_smart_test
command = $in && touch $out
rule run_emu_test
command = $testscript $in $badfile $goodfile && touch $out
rule run_stupid_test
command = scripts/stupid_test $in $badfile $goodfile && touch $out
build $OBJDIR/dependencies_for_bootstrapped_cowgol_program : stamp $
scripts/cowgol_bootstrap_compiler $
bootstrap/bootstrap.lua $
bootstrap/cowgol.c $
bootstrap/cowgol.h
build $OBJDIR/dependencies_for_cowgol_program : stamp $
scripts/cowgol
rule mkbbcdist
command = scripts/bbc/mkbbcdist $out
build bin/bbcdist.adf : mkbbcdist | $
scripts/bbc/mkbbcdist $
bin/mkadfs $
$OBJDIR/compiler_for_bbc_on_bbc $
src/arch/bbc/lib/argv.cow $
src/arch/bbc/lib/fileio.cow $
src/arch/bbc/lib/mos.cow $
src/arch/bbc/lib/runtime.cow $
src/arch/6502/lib/runtime.cow $
scripts/bbc/!boot $
scripts/bbc/precompile $
demo/tiny.cow
rule mkcpmzdist
command = scripts/cpmz/mkcpmzdist $out
build bin/cpmzdist.zip : mkcpmzdist | $
scripts/cpmz/mkcpmzdist $
$OBJDIR/compiler_for_cpmz_on_cpmz $
src/arch/cpmz/lib/argv.cow $
src/arch/cpmz/lib/runtime.cow $
src/arch/common/lib/fileio.cow $
src/arch/z80/lib/runtime.cow $
scripts/cpmz/compile.sub $
tools/cpm/a/!readme.txt $
tools/cpm/a/!license.txt $
demo/tiny.cow
rule mkfuzixdist
command = scripts/fuzix/mkfuzixdist $out
build bin/fuzixdist.tar : mkfuzixdist | $
scripts/fuzix/mkfuzixdist $
$OBJDIR/compiler_for_fuzixz80_on_fuzixz80 $
src/arch/fuzixz80/lib/runtime.cow $
src/arch/fuzixz80/lib/wrappedsys.cow $
src/arch/fuzixz80/lib/syscalls.cow $
src/arch/fuzixz80/lib/fcb.cow $
src/arch/fuzixz80/lib/argv.cow $
scripts/fuzix/cowgol $
demo/tiny.cow
rule pasmo
command = pasmo $in $out
rule objectify
command = ./scripts/objectify $symbol < $in > $out
rule lexify
command = flex -8 -Cem -B -t $in | gawk -f scripts/lexify.awk > $out
rule make_test_things
command = $in $out > /dev/null
build $OBJDIR/tests/compiler/things.dat $
$OBJDIR/tests/compiler/strings.dat $
$OBJDIR/tests/compiler/iops.dat : make_test_things bin/bbc_on_native/init
rule miniyacc
command = bin/miniyacc -i $in -o $actions -h $header -g $grammar
build $OBJDIR/parser2/actions.cow $OBJDIR/parser2/header.cow $
: miniyacc src/parser2/cowgol.y | bin/miniyacc
actions = $OBJDIR/parser2/actions.cow
header = $OBJDIR/parser2/header.cow
grammar = $OBJDIR/parser2/grammar.txt
]])
local NAME
local HOST
local TARGET
local EXTENSION
local LIBS
local RULE
local TESTSCRIPT
local TESTBIN
local GLOBALS
local CODEGEN
local CLASSIFIER
local SIMPLIFIER
local PLACER
local EMITTER
-- Build X on Y
local compilers = {
{"bbc", "native"},
{"c64", "native"},
{"cpmz", "native"},
{"fuzixz80", "native"},
{"spectrum", "native"},
{"bbc", "bbc"},
{"cpmz", "cpmz"},
{"fuzixz80", "fuzixz80"},
}
local host_data = {
["native"] = function()
HOST = "native"
LIBS = {
"src/arch/bootstrap/host.cow",
"src/string_lib.cow",
"src/arch/bootstrap/fcb.cow",
"src/utils/names.cow"
}
RULE = "bootstrapped_cowgol_program"
EXTENSION = ""
TESTSCRIPT = nil
TESTBIN = nil
end,
["bbc"] = function()
HOST = "bbc"
LIBS = {
"src/arch/bbc/host.cow",
"src/arch/bbc/lib/mos.cow",
"src/arch/6502/lib/runtime.cow",
"src/arch/bbc/lib/runtime.cow",
"src/arch/common/lib/runtime.cow",
"src/string_lib.cow",
"src/arch/bbc/lib/fcb.cow",
"src/arch/bbc/lib/fileio.cow",
"src/arch/bbc/lib/argv.cow",
"src/arch/bbc/names.cow"
}
RULE = "cowgol_program"
EXTENSION = ".bbc"
TESTSCRIPT = "scripts/bbc/bbctube_test"
TESTBIN = "bin/bbctube"
end,
["cpmz"] = function()
HOST = "cpmz"
LIBS = {
"src/arch/cpmz/host.cow",
"src/arch/cpmz/lib/runtime.cow",
"src/arch/z80/lib/runtime.cow",
"src/arch/common/lib/runtime.cow",
"src/string_lib.cow",
"src/arch/cpmz/lib/fcb.cow",
"src/arch/common/lib/fileio.cow",
"src/arch/cpmz/lib/argv.cow",
"src/arch/cpmz/names.cow",
}
RULE = "cowgol_program"
EXTENSION = ".cpmz"
TESTSCRIPT = "scripts/cpmz/cpmz_test"
TESTBIN = "bin/cpm"
end,
["fuzixz80"] = function()
HOST = "fuzixz80"
LIBS = {
"src/arch/fuzixz80/host.cow",
"src/arch/fuzixz80/lib/runtime.cow",
"src/arch/z80/lib/runtime.cow",
"src/arch/fuzixz80/lib/syscalls.cow",
"src/arch/fuzixz80/lib/wrappedsys.cow",
"src/arch/common/lib/runtime.cow",
"src/string_lib.cow",
"src/arch/fuzixz80/lib/fcb.cow",
"src/arch/common/lib/fileio.cow",
"src/arch/fuzixz80/lib/argv.cow",
"src/arch/fuzixz80/names.cow",
}
RULE = "cowgol_program"
EXTENSION = ".fuzixz80"
end,
}
local target_data = {
["bbc"] = function()
TARGET = "bbc"
GLOBALS = "src/arch/bbc/globals.cow"
CLASSIFIER = "src/arch/6502/classifier.cow"
SIMPLIFIER = "src/arch/6502/simplifier.cow"
PLACER = "src/arch/6502/placer.cow"
EMITTER = {
"src/arch/6502/emitter.cow",
"src/arch/bbc/emitter.cow"
}
CODEGEN = {
"src/arch/6502/codegen0.cow",
"src/arch/6502/codegen1.cow",
"src/arch/6502/codegen2_8bit.cow",
"src/arch/6502/codegen2_wide.cow",
"src/arch/6502/codegen2.cow",
}
end,
["c64"] = function()
TARGET = "c64"
GLOBALS = "src/arch/c64/globals.cow"
CLASSIFIER = "src/arch/6502/classifier.cow"
SIMPLIFIER = "src/arch/6502/simplifier.cow"
PLACER = "src/arch/6502/placer.cow"
EMITTER = {
"src/arch/6502/emitter.cow",
"src/arch/c64/emitter.cow"
}
CODEGEN = {
"src/arch/6502/codegen0.cow",
"src/arch/6502/codegen1.cow",
"src/arch/6502/codegen2_8bit.cow",
"src/arch/6502/codegen2_wide.cow",
"src/arch/6502/codegen2.cow",
}
end,
["cpmz"] = function()
TARGET = "cpmz"
GLOBALS = "src/arch/cpmz/globals.cow"
CLASSIFIER = "src/arch/z80/classifier.cow"
SIMPLIFIER = "src/arch/z80/simplifier.cow"
PLACER = "src/arch/z80/placer.cow"
EMITTER = {
"src/arch/z80/emitter.cow",
"src/arch/cpmz/emitter.cow"
}
CODEGEN = {
"src/arch/z80/codegen0.cow",
"src/codegen/registers.cow",
"src/arch/z80/codegen1.cow",
"src/arch/z80/codegen2_8bit.cow",
"src/arch/z80/codegen2_16bit.cow",
"src/arch/z80/codegen2_wide.cow",
"src/arch/z80/codegen2_helper.cow",
"src/arch/z80/codegen2.cow",
}
end,
["fuzixz80"] = function()
TARGET = "fuzixz80"
GLOBALS = "src/arch/fuzixz80/globals.cow"
CLASSIFIER = "src/arch/z80/classifier.cow"
SIMPLIFIER = "src/arch/z80/simplifier.cow"
PLACER = "src/arch/z80/placer.cow"
EMITTER = {
"src/arch/z80/emitter.cow",
"src/arch/fuzixz80/emitter.cow"
}
CODEGEN = {
"src/arch/z80/codegen0.cow",
"src/codegen/registers.cow",
"src/arch/z80/codegen1.cow",
"src/arch/z80/codegen2_8bit.cow",
"src/arch/z80/codegen2_16bit.cow",
"src/arch/z80/codegen2_wide.cow",
"src/arch/z80/codegen2_helper.cow",
"src/arch/z80/codegen2.cow",
}
end,
["spectrum"] = function()
TARGET = "spectrum"
GLOBALS = "src/arch/spectrum/globals.cow"
CLASSIFIER = "src/arch/z80/classifier.cow"
SIMPLIFIER = "src/arch/z80/simplifier.cow"
PLACER = "src/arch/z80/placer.cow"
EMITTER = {
"src/arch/z80/emitter.cow",
"src/arch/spectrum/emitter.cow"
}
CODEGEN = {
"src/arch/z80/codegen0.cow",
"src/codegen/registers.cow",
"src/arch/z80/codegen1.cow",
"src/arch/z80/codegen2_8bit.cow",
"src/arch/z80/codegen2_16bit.cow",
"src/arch/z80/codegen2_wide.cow",
"src/arch/z80/codegen2_helper.cow",
"src/arch/z80/codegen2.cow",
}
end
}
local function compiler_name()
if HOST == TARGET then
return TARGET
else
return TARGET.."_on_"..HOST
end
end
local function build_cowgol(files)
local program = table.remove(files, 1)
emit("build", "bin/"..NAME.."/"..program, ":", RULE, LIBS, files,
"|", "$OBJDIR/compiler_for_"..HOST.."_on_native", "$OBJDIR/dependencies_for_"..RULE)
nl()
emit(" arch =", HOST.."_on_native")
nl()
nl()
end
local function build_c(files, vars)
local program = table.remove(files, 1)
rule("c_program", "bin/"..program, files, {}, vars)
nl()
end
local function build_pasmo(files, vars)
local obj = table.remove(files, 1)
rule("pasmo", obj, files, {}, vars)
nl()
end
local function build_objectify(files, vars)
local obj = table.remove(files, 1)
rule("objectify", obj, files, {}, vars)
nl()
end
local function build_lexify(files, vars)
local obj = table.remove(files, 1)
rule("lexify", obj, files, {"scripts/lexify.awk"}, vars)
nl()
end
local function bootstrap_test(dir, file, extradeps)
local testname = file:gsub("^.*/([^./]*)%..*$", "%1")
local testbin = "$OBJDIR/tests/"..dir.."/"..testname
emit("build", testbin, ":", "bootstrapped_cowgol_program",
"tests/bootstrap/_test.cow",
file,
"|", extradeps)
nl()
emit("build", testbin..".stamp", ":", "run_smart_test", testbin)
nl()
nl()
end
local function compiler_test(dir, file, extradeps)
local testname = file:gsub("^.*/([^./]*)%..*$", "%1")
local testbin = "$OBJDIR/tests/"..dir.."/"..testname
local goodfile = "tests/"..dir.."/"..testname..".good"
local badfile = "tests/"..dir.."/"..testname..".bad"
emit("build", testbin, ":", "bootstrapped_cowgol_program",
"tests/bootstrap/_test.cow",
"$OBJDIR/token_names.cow",
file,
"|", extradeps)
nl()
emit("build", testbin..".stamp", ":", "run_stupid_test",
testbin, "|",
goodfile)
nl()
emit(" goodfile = "..goodfile)
nl()
emit(" badfile = "..badfile)
nl()
nl()
end
local function cpu_test(file)
local testname = file:gsub("^.*/([^./]*)%..*$", "%1")
local testbin = "$OBJDIR/tests/cpu/"..testname..EXTENSION
local goodfile = "tests/cpu/"..testname..".good"
local badfile = "tests/cpu/"..testname..EXTENSION..".bad"
emit("build", testbin, ":", RULE, LIBS, file,
"|", "$OBJDIR/compiler_for_"..HOST.."_on_native")
nl()
emit(" arch =", HOST.."_on_native")
nl()
emit("build", testbin..".stamp", ":", "run_emu_test",
testbin, "|",
goodfile,
TESTSCRIPT,
TESTBIN)
nl()
emit(" testscript = "..TESTSCRIPT)
nl()
emit(" goodfile = "..goodfile)
nl()
emit(" badfile = "..badfile)
nl()
nl()
end
local function build_cowgol_programs()
build_cowgol {
"init",
GLOBALS,
"src/utils/stringtablewriter.cow",
"src/utils/things.cow",
"src/utils/types.cow",
"src/utils/iops.cow",
"src/init/init.cow",
"$OBJDIR/token_names.cow",
"src/init/things.cow",
"$OBJDIR/token_maker.cow",
"src/init/main.cow",
}
build_cowgol {
"tokeniser2",
"src/numbers_lib.cow",
GLOBALS,
"src/utils/stringtablewriter.cow",
"src/utils/things.cow",
"src/tokeniser2/init.cow",
"$OBJDIR/token_names.cow",
"src/tokeniser2/emitter.cow",
"src/tokeniser2/tables.cow",
"src/tokeniser2/lexer.cow",
"src/tokeniser2/main.cow",
"src/tokeniser2/deinit.cow",
}
build_cowgol {
"tokeniser3",
"src/numbers_lib.cow",
GLOBALS,
"src/utils/stringtablewriter.cow",
"src/utils/things.cow",
"src/tokeniser3/init.cow",
"src/parser2/magictokens.cow",
"$OBJDIR/parser2/header.cow",
"src/tokeniser3/emitter.cow",
"src/tokeniser3/tables.cow",
"src/tokeniser3/lexer.cow",
"src/tokeniser3/main.cow",
"src/tokeniser3/deinit.cow",
}
build_cowgol {
"parser",
"src/ctype_lib.cow",
"src/numbers_lib.cow",
GLOBALS,
"src/utils/stringtable.cow",
"src/utils/things.cow",
"$OBJDIR/token_names.cow",
"src/utils/types.cow",
"src/utils/iops.cow",
"src/parser/init.cow",
"src/parser/symbols.cow",
"src/utils/symbols.cow",
"src/parser/iopwriter.cow",
"src/parser/tokenreader.cow",
"src/parser/constant.cow",
"src/parser/types.cow",
"src/parser/expression.cow",
"src/parser/main.cow",
"src/parser/deinit.cow",
}
build_cowgol {
"parser2",
"src/ctype_lib.cow",
"src/numbers_lib.cow",
GLOBALS,
"src/utils/stringtable.cow",
"src/utils/things.cow",
"$OBJDIR/parser2/header.cow",
"src/parser2/magictokens.cow",
"src/parser2/init.cow",
"$OBJDIR/parser2/actions.cow",
"src/parser2/symbols.cow",
"src/parser2/tokenreader.cow",
"src/parser2/yyparse.cow",
"src/parser2/main.cow",
"src/parser2/deinit.cow",
}
build_cowgol {
"blockifier",
GLOBALS,
"src/utils/stringtable.cow",
"src/utils/things.cow",
"src/utils/types.cow",
"src/utils/iops.cow",
"src/utils/iopreader.cow",
"src/utils/iopwriter.cow",
"src/utils/symbols.cow",
"$OBJDIR/token_names.cow",
"src/blockifier/init.cow",
"src/blockifier/main.cow",
"src/blockifier/deinit.cow",
}
build_cowgol {
"typechecker",
GLOBALS,
"src/utils/stringtable.cow",
"src/utils/things.cow",
"src/utils/types.cow",
"src/utils/iops.cow",
"src/utils/iopreader.cow",
"src/utils/iopwriter.cow",
"src/utils/symbols.cow",
"$OBJDIR/token_names.cow",
"src/typechecker/init.cow",
"src/typechecker/stack.cow",
"src/typechecker/main.cow",
"src/typechecker/deinit.cow",
}
build_cowgol {
"backendify",
GLOBALS,
"src/utils/stringtable.cow",
"src/utils/things.cow",
"src/utils/types.cow",
"src/utils/iops.cow",
"src/utils/iopreader.cow",
"src/utils/iopwriter.cow",
"src/utils/symbols.cow",
"$OBJDIR/token_names.cow",
"src/backendify/init.cow",
"src/backendify/temporaries.cow",
"src/backendify/tree.cow",
SIMPLIFIER,
"src/backendify/simplifier.cow",
"src/backendify/main.cow",
"src/backendify/deinit.cow",
}
build_cowgol {
"classifier",
GLOBALS,
"src/utils/stringtable.cow",
"src/utils/things.cow",
"src/utils/types.cow",
"src/utils/iops.cow",
"src/utils/iopreader.cow",
"src/utils/symbols.cow",
"$OBJDIR/token_names.cow",
"src/classifier/init.cow",
"src/classifier/graph.cow",
CLASSIFIER,
"src/classifier/subdata.cow",
"src/classifier/main.cow",
"src/classifier/deinit.cow",
}
build_cowgol {
"codegen",
GLOBALS,
"src/utils/stringtable.cow",
"src/utils/things.cow",
"src/utils/types.cow",
"src/utils/iops.cow",
"src/utils/iopreader.cow",
"src/utils/iopwriter.cow",
"$OBJDIR/token_names.cow",
"src/utils/symbols.cow",
"src/codegen/init.cow",
"src/codegen/queue.cow",
CODEGEN,
"src/codegen/rules.cow",
"src/codegen/main.cow",
"src/codegen/deinit.cow",
}
build_cowgol {
"placer",
GLOBALS,
"src/utils/stringtable.cow",
"src/utils/things.cow",
"src/utils/types.cow",
"src/utils/iops.cow",
"src/utils/iopreader.cow",
"src/utils/iopwriter.cow",
"src/placer/init.cow",
PLACER,
"src/placer/main.cow",
"src/placer/deinit.cow",
}
build_cowgol {
"emitter",
GLOBALS,
"src/utils/stringtable.cow",
"src/utils/things.cow",
"src/utils/types.cow",
"src/utils/iops.cow",
"src/utils/iopreader.cow",
"src/emitter/init.cow",
EMITTER,
"src/emitter/main.cow",
"src/emitter/deinit.cow",
}
build_cowgol {
"thingshower",
GLOBALS,
"src/utils/stringtable.cow",
"src/utils/things.cow",
"src/thingshower/thingshower.cow",
}
build_cowgol {
"iopshower",
GLOBALS,
"src/utils/stringtable.cow",
"src/utils/things.cow",
"src/utils/types.cow",
"src/utils/iops.cow",
"src/iopshower/iopreader.cow",
"src/iopshower/iopshower.cow",
}
build_cowgol {
"untokeniser",
GLOBALS,
"src/ctype_lib.cow",
"src/numbers_lib.cow",
"src/utils/stringtable.cow",
"src/utils/things.cow",
"$OBJDIR/token_names.cow",
"src/untokeniser/init.cow",
"src/untokeniser/main.cow",
"src/untokeniser/deinit.cow",
}
end
-- Build the compilers.
for _, spec in ipairs(compilers) do
TARGET, HOST = unpack(spec)
target_data[TARGET]()
host_data[HOST]()
NAME = compiler_name()
rule("stamp", "$OBJDIR/compiler_for_"..TARGET.."_on_"..HOST,
{
"bin/"..NAME.."/init",
"bin/"..NAME.."/tokeniser2",
"bin/"..NAME.."/tokeniser3",
"bin/"..NAME.."/parser",
"bin/"..NAME.."/parser2",
"bin/"..NAME.."/typechecker",
"bin/"..NAME.."/backendify",
"bin/"..NAME.."/blockifier",
"bin/"..NAME.."/classifier",
"bin/"..NAME.."/codegen",
"bin/"..NAME.."/placer",
"bin/"..NAME.."/emitter",
"bin/"..NAME.."/iopshower",
"bin/"..NAME.."/thingshower",
"bin/"..NAME.."/untokeniser"
}
)
nl()
target_data[TARGET]()
build_cowgol_programs()
end
-- Build the bootstrap compiler tests.
host_data.native()
for _, file in ipairs(posix.glob("tests/bootstrap/*.test.cow")) do
bootstrap_test("bootstrap", file)
end
-- Build the compiler logic tests.
host_data.native()
for _, file in ipairs(posix.glob("tests/compiler/*.test.cow")) do
compiler_test("compiler", file,
{
"src/codegen/registers.cow",
"src/string_lib.cow",
"src/arch/bootstrap/fcb.cow",
"src/arch/bbc/globals.cow",
"src/arch/bbc/host.cow",
"src/utils/names.cow",
"src/utils/stringtable.cow",
"src/utils/things.cow",
"src/utils/types.cow",
"src/utils/names.cow",
"src/utils/iops.cow",
"$OBJDIR/tests/compiler/things.dat",
"$OBJDIR/tests/compiler/strings.dat",
"$OBJDIR/tests/compiler/iops.dat",
}
)
end
-- Build the CPU tests.
host_data.bbc()
for _, file in ipairs(posix.glob("tests/cpu/*.test.cow")) do
cpu_test(file)
end
host_data.cpmz()
for _, file in ipairs(posix.glob("tests/cpu/*.test.cow")) do
cpu_test(file)
end
build_c {
"bbctube",
"emu/bbctube/bbctube.c",
"emu/bbctube/lib6502.c"
}
build_c {
"mkdfs",
"emu/mkdfs.c"
}
build_c {
"mkadfs",
"emu/mkadfs.c"
}
build_c(
{
"cpm",
"emu/cpm/main.c",
"emu/cpm/biosbdos.c",
"emu/cpm/emulator.c",
"emu/cpm/fileio.c",
"$OBJDIR/ccp.c",
"$OBJDIR/bdos.c",
},
{
libs = "-lz80ex -lz80ex_dasm -lreadline"
}
)
build_c(
{
"miniyacc",
"src/miniyacc/yacc.c",
}
)
build_pasmo(
{
"$OBJDIR/ccp.bin",
"emu/cpm/ccp.asm"
}
)
build_objectify(
{
"$OBJDIR/ccp.c",
"$OBJDIR/ccp.bin"
},
{
symbol = "ccp"
}
)
build_pasmo(
{
"$OBJDIR/bdos.bin",
"emu/cpm/bdos.asm"
}
)
build_objectify(
{
"$OBJDIR/bdos.c",
"$OBJDIR/bdos.bin"
},
{
symbol = "bdos"
}
)
build_lexify(
{
"src/tokeniser2/tables.cow",
"src/tokeniser2/lexer.l"
}
)
<file_sep>/scripts/fuzix/mkfuzixdist
#!/bin/sh
tmpdir=/tmp/$$.mkdist
trap "rm -rf $tmpdir" EXIT
mkdir -p $tmpdir
exes=$(find bin/fuzixz80 -type f ! -name "*.log")
install -D -t $tmpdir/opt/packages/cowgol/lib.bin/ $exes
install -D -t $tmpdir/opt/packages/cowgol/bin/ scripts/fuzix/cowgol
install -D -t $tmpdir/opt/packages/cowgol/share/fuzixz80/ src/arch/fuzixz80/lib/*.cow
install -D -t $tmpdir/opt/packages/cowgol/share/z80/ src/arch/z80/lib/*.cow
install -D -t $tmpdir/opt/packages/cowgol/share/common/ src/arch/common/lib/*.cow
install -D -t $tmpdir/opt/packages/cowgol/share src/*_lib.cow
tar -C $tmpdir --create -f $PWD/$1 --format=v7 .
<file_sep>/tinycowc/regalloc.c
#include "globals.h"
#include "regalloc.h"
typedef enum
{
VALUE_NONE = 0,
VALUE_CONST,
VALUE_VAR
}
value_kind_t;
struct value
{
value_kind_t kind;
reg_t reg;
union
{
int32_t num;
struct
{
struct symbol* sym;
int32_t off;
}
var;
}
u;
};
struct reg
{
const char* name;
reg_t id;
reg_t interference;
};
#define MAX_REGS 32
static struct reg regs[MAX_REGS];
static int num_regs = 0;
static reg_t locked = 0;
static reg_t used = 0;
#define MAX_VALUES 32
static struct value values[MAX_VALUES];
#define MAX_PSTACK 32
static reg_t pstack[MAX_PSTACK];
static int psp = 0;
static int pfp = 0;
void regalloc_add_register(const char* name, reg_t id, reg_t interference)
{
if (num_regs == MAX_REGS)
fatal("too many registers");
struct reg* reg = ®s[num_regs++];
reg->name = name;
reg->id = id;
reg->interference = interference;
}
const char* regname(reg_t id)
{
for (unsigned i=0; i<num_regs; i++)
{
struct reg* reg = ®s[i];
if (reg->id == id)
return reg->name;
}
fatal("cannot get register name for 0x%x", id);
return NULL;
}
reg_t regalloc_alloc(reg_t mask)
{
arch_emit_comment("allocating register for 0x%x", mask);
/* Find a completely unused register. */
for (unsigned i=0; i<num_regs; i++)
{
struct reg* reg = ®s[i];
if ((reg->id & mask) && !(reg->interference & (used|locked)))
{
locked |= reg->id;
arch_emit_comment("found unused register 0x%x", reg->id);
return reg->id;
}
}
/* Find a used but unlocked register. */
for (unsigned i=0; i<num_regs; i++)
{
struct reg* reg = ®s[i];
if ((reg->id & mask) && !(reg->interference & locked))
{
arch_emit_comment("found used but unlocked register 0x%x", reg->id);
regalloc_reg_changing(reg->interference);
locked |= reg->id;
return reg->id;
}
}
fatal("unable to allocate register 0x%x", mask);
}
static void regalloc_lock(reg_t mask)
{
for (unsigned i=0; i<num_regs; i++)
{
struct reg* reg = ®s[i];
if (reg->id & mask)
{
assert((locked & reg->id) == 0);
locked |= reg->id;
}
}
}
void regalloc_unlock(reg_t mask)
{
locked &= ~mask;
}
static reg_t findfirstreg(reg_t mask)
{
reg_t i = 1;
while (i)
{
if (mask & i)
return i;
i <<= 1;
}
return 0;
}
static struct value* findemptyvalue(void)
{
for (int i=0; i<MAX_VALUES; i++)
{
struct value* val = &values[i];
if (!val->kind)
{
val->reg = 0;
return val;
}
}
fatal("value buffer full");
}
static struct value* findconstvalue(int32_t num)
{
for (int i=0; i<MAX_VALUES; i++)
{
struct value* val = &values[i];
if ((val->kind == VALUE_CONST) && (val->u.num == num))
return val;
}
return NULL;
}
static struct value* findvarvalue(struct symbol* sym, int32_t off)
{
for (int i=0; i<MAX_VALUES; i++)
{
struct value* val = &values[i];
if ((val->kind == VALUE_VAR) && (val->u.var.sym == sym) && (val->u.var.off == off))
return val;
}
return NULL;
}
reg_t regalloc_load_const(reg_t mask, int32_t num)
{
struct value* val = findconstvalue(num);
if (val && (val->reg & mask))
{
reg_t found = findfirstreg(val->reg & mask);
if (!(locked & found))
regalloc_lock(found);
return found;
}
reg_t found = regalloc_alloc(mask);
arch_load_const(found, num);
regalloc_reg_contains_const(found, num);
return found;
}
reg_t regalloc_load_var(reg_t mask, struct symbol* sym, int32_t off)
{
struct value* val = findvarvalue(sym, off);
if (val && (val->reg & mask))
{
reg_t found = findfirstreg(val->reg & mask);
regalloc_lock(found);
return found;
}
reg_t found = regalloc_alloc(mask);
arch_load_var(found, sym, off);
regalloc_reg_contains_var(found, sym, off);
return found;
}
void regalloc_reg_contains_const(reg_t id, int32_t num)
{
struct value* val = findconstvalue(num);
if (!val)
{
val = findemptyvalue();
val->kind = VALUE_CONST;
val->u.num = num;
}
val->reg |= id;
used |= id;
}
void regalloc_reg_contains_var(reg_t id, struct symbol* sym, int32_t off)
{
struct value* val = findvarvalue(sym, off);
if (!val)
{
val = findemptyvalue();
val->kind = VALUE_VAR;
val->u.var.sym = sym;
val->u.var.off = off;
}
val->reg |= id;
used |= id;
}
void regalloc_push(reg_t id)
{
if (psp == MAX_PSTACK)
fatal("pstack overflow");
arch_emit_comment("pstack push 0x%x", id);
pstack[psp++] = id;
used |= id;
}
reg_t regalloc_pop(reg_t mask)
{
if (psp == 0)
fatal("pstack underflow");
reg_t found;
if (pfp == psp)
{
found = regalloc_alloc(mask);
arch_pop(found);
arch_emit_comment("pstack physical pop into 0x%x", found);
psp--;
pfp--;
}
else
{
found = pstack[--psp];
arch_emit_comment("pstack pop from register into 0x%x", found);
if (!(found & mask))
{
reg_t real = regalloc_alloc(mask);
arch_copy(found, real);
found = real;
}
locked |= found;
}
return found;
}
void regalloc_flush_stack(void)
{
while (pfp != psp)
{
reg_t reg = pstack[pfp++];
arch_push(reg);
}
}
void regalloc_drop_stack_items(int n)
{
while (n--)
{
if (psp == 0)
fatal("stack underflow");
if (pfp == psp)
{
pfp--;
psp--;
}
else
{
reg_t reg = pstack[--psp];
used &= ~reg;
}
}
}
void regalloc_reg_changing(reg_t mask)
{
for (int i=psp-1; i>=pfp; i--)
{
if (pstack[i] & mask)
{
while (pfp <= i)
{
reg_t reg = pstack[pfp++];
arch_emit_comment("spilling 0x%x", reg);
arch_push(reg);
}
}
}
for (int i=0; i<MAX_VALUES; i++)
{
struct value* val = &values[i];
if (val->kind)
{
used &= ~(val->reg & mask);
val->reg &= ~mask;
if (!val->reg)
val->kind = VALUE_NONE;
}
}
}
void regalloc_var_changing(struct symbol* sym, int32_t off)
{
struct value* val = findvarvalue(sym, off);
if (val)
{
if (val->reg & locked)
fatal("regalloc_var_changing on locked register");
val->kind = VALUE_NONE;
used &= ~val->reg;
}
}
void regalloc_dump(void)
{
for (int i=0; i<num_regs; i++)
{
struct reg* reg = ®s[i];
if (reg->id & (used|locked))
arch_emit_comment("reg %s: %s %s",
reg->name,
(reg->id & used) ? "used" : "",
(reg->id & locked) ? "locked" : "");
}
for (int i=pfp; i<psp; i++)
arch_emit_comment("stack +%d: %s", i, regname(pstack[i]));
for (int i=0; i<MAX_VALUES; i++)
{
struct value* val = &values[i];
switch (val->kind)
{
case VALUE_CONST:
arch_emit_comment("value #%d = const 0x%x in 0x%x",
i, val->u.num, val->reg);
break;
case VALUE_VAR:
arch_emit_comment("value #%d = sym %s+0x%x in 0x%x",
i, val->u.var.sym->name, val->u.var.sym->u.var.offset + val->u.var.off,
val->reg);
break;
}
}
arch_emit_comment("");
}
<file_sep>/scripts/bbc/mkbbcdist
#!/bin/sh
bin/mkadfs -O $1 -S 1280 -B 3 -N 'Cowgol demo' \
-f scripts/bbc/'!boot' -n !BOOT \
-f demo/tiny.cow -n TestProg \
-d Bin \
-f bin/bbc/blockifier -n Blockifier -l 0x800 \
-f bin/bbc/classifier -n Classifier -l 0x800 \
-f bin/bbc/codegen -n CodeGen -l 0x800 \
-f bin/bbc/emitter -n Emitter -l 0x800 \
-f bin/bbc/init -n Init -l 0x800 \
-f bin/bbc/iopshower -n IopShow -l 0x800 \
-f bin/bbc/parser -n Parser -l 0x800 \
-f bin/bbc/placer -n Placer -l 0x800 \
-f bin/bbc/thingshower -n ThingShow -l 0x800 \
-f bin/bbc/tokeniser2 -n Tokeniser2 -l 0x800 \
-f bin/bbc/typechecker -n TypeCheck -l 0x800 \
-f bin/bbc/backendify -n Backendify -l 0x800 \
-f bin/bbc/untokeniser -n Untokenise -l 0x800 \
-f scripts/bbc/precompile -n Precompile \
-u \
-d Lib \
-f src/arch/bbc/lib/argv.cow -n ArgV \
-f src/arch/bbc/lib/fileio.cow -n FileIO \
-f src/arch/bbc/lib/fcb.cow -n FCB \
-f src/arch/bbc/lib/mos.cow -n MOS \
-f src/arch/bbc/lib/runtime.cow -n Runtime0 \
-f src/arch/6502/lib/runtime.cow -n Runtime1 \
-f src/arch/common/lib/runtime.cow -n Runtime2 \
-f src/string_lib.cow -n StringLib \
-u \
<file_sep>/scripts/fuzix/cowgol
#!/bin/sh
libbindir=/opt/packages/cowgol/lib.bin
sharedir=/opt/packages/cowgol/share
set -x
$libbindir/init
$libbindir/tokeniser2 \
$sharedir/fuzixz80/runtime.cow \
$sharedir/z80/runtime.cow \
$sharedir/fuzixz80/syscalls.cow \
$sharedir/fuzixz80/wrappedsys.cow \
$sharedir/common/runtime.cow
$libbindir/parser
$libbindir/tokeniser2 "$@"
$libbindir/parser
$libbindir/typechecker
(mv iops-out.dat iops.dat || exit 0)
$libbindir/backendify
(mv iops-out.dat iops.dat || exit 0)
$libbindir/classifier
$libbindir/blockifier
(mv iops-out.dat iops.dat || exit 0)
$libbindir/codegen
(mv iops-out.dat iops.dat || exit 0)
$libbindir/placer
(mv iops-out.dat iops.dat || exit 0)
$libbindir/emitter
<file_sep>/bootstrap/bootstrap.lua
#!/usr/bin/lua5.2
-- Cowgol bootstrap compiler.
-- Shoddy compiler which compiles into shoddy C.
local stream
local current_filename = nil
local functions = {}
local variables = {}
local current_fn = nil
local record_fn = {name="record", code={}}
local root_ns = {}
local current_ns = root_ns
local unique_id = 0
local temporaries = {}
function set(...)
local t = {}
for _, s in ipairs({...}) do
t[s] = true
end
return t
end
local compilation_flags = {} -- set("DEBUG")
local infix_operators = set("+", "-", "*", "/", "<<", ">>", "<", ">", "<=", ">=", "==", "!=",
"&", "|", "^", "%", "and", "or")
local postfix_operators = set("as")
function log(...)
io.stderr:write(string.format(...), "\n")
end
function fatal(...)
local s = string.format(...)
if stream then
s = s .. string.format(" at about line %s of %s", stream:line() or "?", current_filename)
end
error(s)
end
function tokenstream(source)
local patterns = {
"^(\n)",
"^([%w@$][%w%d_]*)",
"^(<<)",
"^(>>)",
"^([<>!:=]=)",
"^([-+*/():;,.'<>[%]&|^%%~{}])"
}
local line = 1
local function parser()
local pushed_contexts = {}
local o = 1
local function check_patterns()
for _, p in ipairs(patterns) do
local _, nexto, m = source:find(p, o)
if nexto then
o = nexto + 1
coroutine.yield(m)
return
end
end
fatal("cannot parse text: %s...", source:sub(o, o+20))
end
local function decode_escape(s)
if (s == "n") then
return "\n"
elseif (s == "r") then
return "\r"
elseif (s == "0") then
return "\0"
elseif (s == "\\") then
return "\\"
elseif (s == "'") or (s == "\"") then
return s
else
fatal("unrecognised string escape '\\%s'", s)
end
end
local function parse_string()
local t = {}
while true do
while true do
local _, nexto, m = source:find('^([^"\\]+)', o)
if nexto then
t[#t+1] = m
o = nexto + 1
break
end
_, nexto, m = source:find("^\\(.)", o)
if nexto then
t[#t+1] = decode_escape(m)
o = nexto + 1
break
end
_, nexto = source:find('^"', o)
if nexto then
o = nexto + 1
return table.concat(t)
end
break
end
end
end
while true do
while (o <= #source) do
while true do
local nexto, m, _
_, nexto = source:find("^[\t\r ]+", o)
if nexto then
o = nexto + 1
break
end
_, nexto = source:find("^#[^\n]*", o)
if nexto then
o = nexto + 1
break
end
_, nexto, m = source:find("^(0x[0-9a-fA-F_]+)", o)
if nexto then
o = nexto + 1
coroutine.yield("number", tonumber(m:sub(3):gsub("_", ""), 16))
break
end
_, nexto, m = source:find("^(0o[0-1_]+)", o)
if nexto then
o = nexto + 1
coroutine.yield("number", tonumber(m:sub(3):gsub("_", ""), 8))
break
end
_, nexto, m = source:find("^(0b[0-1_]+)", o)
if nexto then
o = nexto + 1
coroutine.yield("number", tonumber(m:sub(3):gsub("_", ""), 2))
break
end
_, nexto, m = source:find("^([%d_]+)", o)
if nexto then
o = nexto + 1
coroutine.yield("number", tonumber(m:gsub("_", ""), 10))
break
end
_, nexto = source:find('^"', o)
if nexto then
o = nexto + 1
coroutine.yield("string", parse_string())
break
end
_, nexto, m = source:find("^'\\(.)'", o)
if nexto then
o = nexto + 1
m = decode_escape(m)
coroutine.yield("number", m:byte(1))
break
end
_, nexto, m = source:find("^'(.)'", o)
if nexto then
o = nexto + 1
coroutine.yield("number", m:byte(1))
break
end
_, nexto = source:find("^%$include[ \t\r]+\"", o)
if nexto then
o = nexto + 1
local new_filename = parse_string()
pushed_contexts[#pushed_contexts+1] = {current_filename, line, source, o}
current_filename = new_filename
line = 1
o = 1
source = io.open(current_filename):read("*a")
if not source then
fatal("couldn't open hack include %s", current_filename)
end
break
end
check_patterns()
break
end
end
if #pushed_contexts == 0 then
while true do
coroutine.yield("eof")
end
else
current_filename, line, source, o = unpack(pushed_contexts[#pushed_contexts])
pushed_contexts[#pushed_contexts] = nil
end
end
end
local c = coroutine.create(parser)
return {
next = function(self)
while true do
local status, token, value = coroutine.resume(c)
if not status then
fatal("parse error: %s", token)
elseif (token == "\n") then
line = line + 1
else
return token, value
end
end
end,
line = function(self)
return line
end,
}
end
function filteredtokenstream(stream)
local c = coroutine.create(
function()
while true do
local token, value = stream:next()
if token == "$if" then
token, value = stream:next()
if not compilation_flags[token] then
while true do
token, value = stream:next()
if token == "$endif" then
break
end
end
end
elseif token == "$endif" then
-- consume silently
elseif token == "$set" then
token, value = stream:next()
compilation_flags[token] = true
elseif token == "$unset" then
token, value = stream:next()
compilation_flags[token] = false
else
coroutine.yield(token, value)
end
end
end
)
return {
next = function(self)
local status, token, value = coroutine.resume(c)
if not status then
fatal("parse error: %s", token)
end
return token, value
end,
line = function(self)
return stream:line()
end
}
end
function peekabletokenstream(stream)
local peekedline, peekedtoken, peekedvalue
local line
return {
next = function(self)
local t, v
if peekedtoken then
line = peekedline
t, v = peekedtoken, peekedvalue
peekedtoken = nil
else
t, v = stream:next()
line = stream:line()
end
return t, v
end,
peek = function(self)
if not peekedtoken then
peekedtoken, peekedvalue = stream:next()
peekedline = stream:line()
end
return peekedtoken, peekedvalue
end,
line = function(self)
return line
end
}
end
function nextid()
unique_id = unique_id + 1
return unique_id
end
function emit(...)
local s = string.format(...)
current_fn.code[#current_fn.code + 1] = s
end
function unexpected_keyword(token)
fatal("unexpected keyword '%s'", token)
end
function already_defined(token)
fatal("name '%s' is already defined at this level of scope", token)
end
function check_undefined(token, ns)
if not ns then
ns = current_ns
end
if ns[token] then
already_defined(token)
end
end
function expect(...)
local e = {...}
local t, v = stream:next()
for _, tt in ipairs(e) do
if (t == tt) then
return t, v
end
end
fatal("got '%s', expected %s", t, table.concat(e, ", "))
end
function lookup_symbol(id, ns)
ns = ns or current_ns
while ns do
local sym = ns[id]
if sym then
return sym
end
ns = ns[".prev"]
end
return nil
end
function new_storage_for(name)
local fn = current_fn
local fnname
if not fn then
return "global_"..name
else
return fn.name.."_"..name.."_"..nextid()
end
end
function create_symbol(name, ns)
if not ns then
ns = current_ns
end
local sym = {}
check_undefined(name, ns)
ns[name] = sym
return sym
end
function create_variable(name, type, ns)
local var = create_symbol(name, ns)
var.kind = "variable"
var.storage = new_storage_for(name)
var.type = type
variables[var] = true
return var
end
function create_extern_variable(name, type, ns, storage)
local var = create_variable(name, type, ns)
var.storage = storage
return var
end
function create_const(name, value, ns)
local const = create_symbol(name, ns)
const.kind = "number"
const.storage = tonumber(value)
const.type = root_ns["number"]
return const
end
function create_number(value)
v = tonumber(value)
return {
kind = "number",
type = root_ns["number"],
storage = value
}
end
function create_string(v)
local storage = "string_"..nextid()
local bytes = {}
for i = 1, #v do
bytes[#bytes+1] = v:byte(i)
end
bytes[#bytes+1] = 0
emit("static int8_t %s[] = {%s};", storage, table.concat(bytes, ", "))
return {
kind = "string",
type = pointer_of(root_ns["int8"]),
storage = storage
}
end
function create_array_deref(base, index)
return {
kind = "arrayderef",
storage = string.format("%s[%s]", base.storage, index.storage),
type = base.type.elementtype
}
end
function create_record_deref(base, membername)
local recordtype
if base.type.pointer then
recordtype = base.type.elementtype
else
recordtype = base.type
end
if not recordtype then
fatal("type '%s' is not a record or a pointer to a record", base.type.name)
end
local member
local currenttype = recordtype
while true do
member = lookup_symbol(membername, currenttype.members)
if member then
break
end
currenttype = currenttype.supertype
if not currenttype then
fatal("'%s' is not a member of %s", membername, recordtype.name)
end
end
return {
kind = "recordderef",
storage = string.format("%s%s%s", base.storage,
base.type.pointer and "->" or ".", member.storage),
type = member.type
}
end
function create_addrof(value)
return {
kind = "variable",
storage = "&"..value.storage,
type = pointer_of(value.type)
}
end
function create_function(name, storage)
local fn = {}
fn.kind = "function"
fn.name = name
fn.storage = storage
fn.parameters = {}
fn.namespace = {[".prev"] = current_ns}
fn.code = {}
check_undefined(name)
current_ns[name] = fn
functions[fn] = true
return fn
end
function create_extern_function(name, storage, ...)
local fn = create_function(name, storage)
fn.parameters = {...}
return fn
end
function create_tempvar(type)
for v in pairs(temporaries) do
if (v.type == type) then
temporaries[v] = nil
return v
end
end
local var = create_variable("_temp_"..nextid(), type, root_ns)
var.temporary = true
return var
end
function free_tempvar(var)
temporaries[var] = true
end
function type_check(want, got)
if want.numeric and got.numeric then
return
end
if got and (want ~= got) then
fatal("type mismatch: wanted %s, but got %s", want.name, got.name)
end
end
function read_type()
local indirections = 0
local t
while true do
t = stream:next()
if (t == "[") then
indirections = indirections + 1
else
break
end
end
local sym = lookup_symbol(t)
if not sym then
fatal("'%s' is not a symbol in scope", t)
end
local t = stream:peek()
if t == "@index" then
expect("@index")
if sym.kind ~= "type" then
sym = sym.type
end
if sym.pointer then
sym = lookup_symbol("int16")
elseif sym.array then
if sym.length < 256 then
sym = lookup_symbol("uint8")
else
sym = lookup_symbol("uint16")
end
else
fatal("can't use @index on this")
end
end
if sym.kind ~= "type" then
fatal("'%s' is not a type in scope", t)
end
while true do
local t = stream:peek()
if (t == "]") then
if (indirections > 0) then
sym = pointer_of(sym)
expect("]")
indirections = indirections - 1
else
break
end
elseif (t == "[") then
expect("[");
local t, v = stream:next();
if t == "number" then
v = tonumber(v)
else
vsym = lookup_symbol(t)
if not vsym or (vsym.kind ~= "number") then
fatal("'%s' is not a number in scope", t)
end
v = vsym.storage
end
expect("]");
sym = array_of(sym, v)
else
break
end
end
return sym
end
function pointer_of(type)
if not type.pointertype then
type.pointertype = {
kind = "type",
name = "["..type.name.."]",
size = 1,
ctype = type.ctype.."*",
numeric = false,
elementtype = type,
pointer = true,
}
end
return type.pointertype
end
function array_of(type, length)
return {
kind = "type",
name = type.name.."["..length.."]",
length = length,
ctype = type.ctype,
numeric = false,
elementtype = type,
array = true
}
end
function do_parameter(inout)
local name = stream:next()
expect(":")
local type = read_type()
local var = create_variable(name, type)
current_fn.parameters[#current_fn.parameters + 1] = {
name = name,
inout = inout,
variable = current_ns[name]
}
end
function do_parameter_list(inout)
while true do
local t = stream:peek()
if (t == ")") then
break
end
do_parameter(inout)
t = stream:peek()
if (t == ")") then
break
end
expect(",")
end
end
function do_sub()
expect("sub")
local name = stream:next()
local fn = create_function(name, new_storage_for(name))
local old_ns = current_ns
current_ns = {}
current_ns[".prev"] = old_ns
local old_fn = current_fn
current_fn = fn
expect("(")
do_parameter_list("in")
expect(")")
if (stream:peek() == ":") then
stream:next()
expect("(")
do_parameter_list("out")
expect(")")
end
emit("void %s(void) {", current_fn.storage)
do_statements()
expect("end")
expect("sub")
emit("}")
current_fn = old_fn
current_ns = old_ns
end
function do_label()
local label = stream:next()
expect(":")
emit("%s:;", label)
end
function do_goto()
expect("goto");
local label = stream:next()
emit("goto %s;", label)
end
function do_statements()
while true do
local t = stream:peek()
if (t == "end") or (t == "else") or (t == "elseif") or (t == "eof") then
break
end
local t = stream:peek()
local semicolons_yes = true
if (t == ";") then
-- do nothing
elseif (t == "sub") then
do_sub()
elseif (t == "var") then
do_var()
elseif (t == "const") then
do_const()
elseif (t == "while") then
do_while()
elseif (t == "loop") then
do_loop()
elseif (t == "if") then
do_if()
elseif (t == "record") then
do_record()
elseif (t == "type") then
do_type()
elseif (t == "goto") then
do_goto();
elseif (t == "break") then
expect("break")
emit("break;")
elseif (t == "return") then
expect("return")
emit("return;")
elseif (t == "(") then
do_function_call()
else
local sym = lookup_symbol(t)
if sym then
if (sym.kind == "function") then
do_function_call()
elseif (sym.kind == "variable") then
do_assignment()
else
fatal("don't know what to do with %s '%s'", sym.kind, t)
end
else
-- The only thing this could possibly be is a label (or a mistake).
do_label()
semicolons_yes = false
end
end
if semicolons_yes then
expect(";")
end
end
end
function do_array_initialiser(var)
local type = var.type
if not type.array or not type.elementtype.numeric then
fatal("you can only use array initialisers on arrays of numbers")
end
expect("{")
local i = 0
while (i < type.length) do
if stream:peek() == "}" then
break
end
local deref = create_array_deref(var, create_number(i))
expression(deref)
i = i + 1
if stream:peek() == "}" then
break
end
expect(",")
end
expect("}")
while (i < type.length) do
i = i + 1
end
var.initialiser = {}
end
function do_var()
expect("var")
local varname = stream:next()
expect(":")
local type = read_type()
local var = create_variable(varname, type)
local t = stream:peek()
if (t == ":=") then
expect(":=")
t = stream:peek()
if (t == "{") then
do_array_initialiser(var);
else
expression(var)
end
end
end
function do_record()
expect("record")
local typename = stream:next()
local supertype = nil
if (stream:peek() == ":") then
expect(":")
supertype = read_type()
if not supertype.record then
fatal("can't inherit from '%s' as it's not a record type", supertype.name)
end
end
local sym = create_symbol(typename)
sym.kind = "type"
sym.name = typename
sym.ctype = "struct " .. new_storage_for(typename)
sym.members = {}
sym.record = true
sym.supertype = supertype
local old_fn = current_fn
current_fn = record_fn
local old_ns = current_ns
current_ns = sym.members
current_ns[".prev"] = old_ns
emit(sym.ctype .. " {")
if sym.supertype then
emit(supertype.ctype..";")
end
while true do
local t = stream:peek()
if (t == "end") then
break
end
local membername = stream:next()
expect(":")
local membertype = read_type()
expect(";")
local member = create_symbol(membername)
member.kind = "member"
member.storage = new_storage_for(membername)
member.type = membertype
if member.type.array then
emit(member.type.ctype.." "..member.storage.."["..member.type.length.."];")
else
emit(member.type.ctype.." "..member.storage..";")
end
end
emit("} __attribute__((packed));")
current_fn = old_fn
current_ns = old_ns
expect("end")
expect("record")
end
function do_type()
expect("type")
local newname = stream:next()
expect(":=")
local oldtype = read_type()
check_undefined(newname)
current_ns[newname] = oldtype
end
function do_const()
expect("const")
local name = stream:next()
expect(":=")
local _, v = expect("number")
local var = create_const(name, v)
end
function do_assignment()
local lvalue = lvalue_leaf()
expect(":=")
expression(lvalue)
end
function do_expression_function_call(sym)
expect("(")
local outvar = nil
local first = true
for _, p in ipairs(sym.parameters) do
if (p.inout == "out") then
if outvar then
fatal("%s has more than one output parameter; can't call inside expressions", sym.name)
end
outvar = p
else
if not first then
expect(",")
end
first = false
expression(p.variable)
end
end
if not outvar then
fatal("%s does not have a single output parameter; can't call inside expressions", sym.name)
end
expect(")")
emit("%s();", sym.storage)
local temp = create_tempvar(outvar.variable.type)
emit("%s = %s;", temp.storage, outvar.variable.storage)
return temp
end
function lvalue_leaf()
local t = stream:next()
if (t == "number") or (t == "string") then
fatal("can't use constants as lvalues")
end
local sym = lookup_symbol(t)
if not sym then
fatal("'%s' is not a symbol in scope", t)
end
if (sym.kind ~= "variable") then
fatal("can't assign to '%s'", t)
end
while true do
local t = stream:peek()
if (t == "[") then
expect("[");
local index = create_tempvar(root_ns["uint16"])
expression(index)
sym = create_array_deref(sym, index)
expect("]");
elseif (t == ".") then
expect(".")
t = stream:next()
sym = create_record_deref(sym, t)
else
break
end
end
return sym
end
function rvalue_leaf()
local t, v = stream:next()
if (t == "number") then
return create_number(v)
elseif (t == "string") then
return create_string(v)
else
if (t == "-") and (stream:peek() == "number") then
t, v = stream:next()
return create_number(-v)
end
local sym = lookup_symbol(t)
if not sym then
fatal("'%s' is not a symbol in scope", t)
end
if (sym.kind == "number") then
return sym
elseif (sym.kind == "function") then
return do_expression_function_call(sym)
elseif (sym.kind == "type") then
t = stream:next()
if (t == "@bytes") then
local suffix = ""
if sym.array then
suffix = "*"..sym.length
end
return {
kind = "number",
type = root_ns["number"],
storage = "sizeof("..sym.ctype..")"..suffix
}
elseif (t == "@size") then
if not sym.array then
fatal("'%s' is not an array", sym.name);
end
return create_number(sym.length)
else
fatal("unknown type attribute '%s'", t)
end
elseif (sym.kind ~= "variable") then
fatal("can't do %s in expressions yet", t)
end
while true do
local t = stream:peek()
if (t == "[") then
expect("[");
local index = create_tempvar(root_ns["uint16"])
expression(index)
local result = create_tempvar(sym.type.elementtype)
emit("%s = %s[%s];", result.storage, sym.storage, index.storage)
free_tempvar(index)
expect("]");
if sym.temporary then
free_tempvar(sym)
end
sym = result
elseif (t == ".") then
expect(".")
t = stream:next()
local result = create_record_deref(sym, t)
if sym.temporary then
free_tempvar(sym)
end
sym = result
elseif (t == "@bytes") then
stream:next()
local suffix = ""
if sym.type.array then
suffix = "*"..sym.type.length
end
sym = {
kind = "number",
type = root_ns["number"],
storage = "sizeof("..sym.type.ctype..")"..suffix
}
elseif (t == "@size") then
stream:next()
if not sym.type.array then
fatal("'%s' is not an array", sym.type.name);
end
return create_number(sym.type.length)
else
break
end
end
return sym
end
end
function expression(outputvar)
local rpn = {}
local operators = {}
local function flush()
while next(operators) do
local operator = operators[#operators]
if (operator == "(") then
return
end
operators[#operators] = nil
rpn[#rpn+1] = operator
end
end
local parens = 0
while true do
local t
while true do
t = stream:peek()
if (t == "(") then
expect("(")
operators[#operators+1] = t
parens = parens + 1
elseif (t == "&") then
expect("&")
local lvalue = lvalue_leaf()
rpn[#rpn+1] = create_addrof(lvalue)
break
elseif (t == "-") or (t == "~") then
stream:next()
rpn[#rpn+1] = rvalue_leaf()
rpn[#rpn+1] = {kind="postfixop", op=t}
break
else
rpn[#rpn+1] = rvalue_leaf()
break
end
end
while true do
t = stream:peek()
if (t == "as") then
expect("as")
local desttype = read_type()
rpn[#rpn+1] = {kind="cast", type=desttype}
elseif (t == ")") and (parens > 0) then
expect(")")
flush()
if (operators[#operators] ~= "(") then
fatal("mismatched parentheses")
end
operators[#operators] = nil
parens = parens - 1
else
break
end
end
if infix_operators[t] then
operators[#operators+1] = {kind="infixop", op=stream:next()}
elseif (t == ";") or (t == "loop") or (t == "then") or (t == ",") or (t == "]") or (t == "}") then
break
elseif (t == ")") and (parens == 0) then
break
end
end
flush()
if next(operators) then
fatal("mismatched parentheses")
end
if (#rpn == 1) then
local op = rpn[1]
type_check(outputvar.type, op.type)
emit("%s = %s;", outputvar.storage, op.storage)
else
rpn[#rpn].rvalue = outputvar
stack = {}
for _, op in ipairs(rpn) do
if (op.kind == "infixop") then
local right = stack[#stack]
stack[#stack] = nil
local left = stack[#stack]
stack[#stack] = nil
local type
if (op.op == "!=") or (op.op == "==") then
type = root_ns["bool"]
if left.type.pointer and right.type.numeric then
-- yup, okay
else
type_check(left.type, right.type)
end
elseif (op.op == "<") or (op.op == "<=") or (op.op == ">") or (op.op == ">=") then
type_check(left.type, right.type)
type = root_ns["bool"]
elseif left.type.pointer and ((op.op == "+") or (op.op == "-")) then
if right.type.pointer then
type = root_ns["int16"]
type_check(left.type, right.type)
elseif right.type.numeric then
type = left.type
else
fatal("can't do that to a pointer")
end
else
type = left.type
type_check(type, right.type)
end
if not op.rvalue then
op.rvalue = create_tempvar(type)
end
type_check(type, op.rvalue.type)
local cop = op.op
if (cop == "or") then
cop = "|"
elseif (cop == "and") then
cop = "&"
end
if left.type.pointer and not right.type.pointer then
emit("%s = (%s)((intptr_t)%s %s %s);",
op.rvalue.storage, op.rvalue.type.ctype, left.storage, cop, right.storage)
elseif (cop == "-") and left.type.pointer and right.type.pointer then
emit("%s = (intptr_t)%s - (intptr_t)%s;",
op.rvalue.storage, left.storage, right.storage)
else
emit("%s = %s %s %s;", op.rvalue.storage, left.storage, cop, right.storage)
end
stack[#stack+1] = op.rvalue
if left.temporary then
free_tempvar(left)
end
if right.temporary then
free_tempvar(right)
end
elseif (op.kind == "cast") then
local value = stack[#stack]
stack[#stack] = nil
if not op.rvalue then
op.rvalue = create_tempvar(op.type)
end
type_check(op.type, op.rvalue.type)
emit("%s = (%s) %s;", op.rvalue.storage, op.type.ctype, value.storage)
stack[#stack+1] = op.rvalue
if value.temporary then
free_tempvar(value)
end
elseif (op.kind == "postfixop") then
local value = stack[#stack]
stack[#stack] = nil
if not op.rvalue then
op.rvalue = create_tempvar(value.type)
end
emit("%s = %s %s;", op.rvalue.storage, op.op, value.storage)
stack[#stack+1] = op.rvalue
if value.temporary then
free_tempvar(value)
end
else
stack[#stack+1] = op
end
end
end
end
function do_function_call()
local lvalues = {}
if stream:peek() == "(" then
expect("(")
local first = true
while stream:peek() ~= ")" do
if not first then
expect(",")
end
first = false
local lvalue = lvalue_leaf()
lvalues[#lvalues+1] = lvalue
end
expect(")")
expect(":=")
end
local t = stream:next()
local sym = lookup_symbol(t)
if not sym then
fatal("symbol '%s' not defined", t)
end
expect("(")
local first = true
for _, p in ipairs(sym.parameters) do
if (p.inout == "in") then
if not first then
expect(",")
end
first = false
expression(p.variable)
end
end
expect(")")
emit("%s();", sym.storage)
local i = 1
for _, p in ipairs(sym.parameters) do
if (p.inout == "out") then
local lvalue = lvalues[i]
if not lvalue then
fatal("not enough return values")
end
i = i + 1
type_check(p.variable.type, lvalue.type)
emit("%s = %s;", lvalue.storage, p.variable.storage)
end
end
if (i - 1) ~= #lvalues then
fatal("too many return values")
end
end
function do_while()
expect("while")
emit("for (;;) {")
local tempvar = create_tempvar(root_ns["bool"])
expression(tempvar)
emit("if (!(%s)) break;", tempvar.storage)
free_tempvar(tempvar)
expect("loop")
do_statements()
expect("end")
expect("loop")
emit("}")
end
function do_loop()
expect("loop")
emit("for (;;) {")
do_statements()
expect("end")
expect("loop")
emit("}")
end
function do_if()
local nesting = 0
expect("if")
while true do
local tempvar = create_tempvar(root_ns["bool"])
expression(tempvar)
emit("if (%s) {", tempvar.storage)
free_tempvar(tempvar)
expect("then")
do_statements()
local t = stream:peek()
if (t ~= "elseif") then
break;
end
expect("elseif")
emit("} else {")
nesting = nesting + 1
end
local t = stream:peek()
if (t == "else") then
expect("else")
emit("} else {")
do_statements()
end
emit("}")
for i = 1, nesting do
emit("}")
end
expect("end")
expect("if")
end
root_ns["number"] = {
kind = "type",
name = "number",
size = "1",
ctype = "int64_t",
numeric = true,
}
root_ns["int8"] = {
kind = "type",
name = "int8",
size = "1",
ctype = "int8_t",
numeric = true,
}
root_ns["uint8"] = {
kind = "type",
name = "uint8",
size = "1",
ctype = "uint8_t",
numeric = true
}
root_ns["int16"] = {
kind = "type",
name = "int16",
size = "2",
ctype = "int16_t",
numeric = true
}
root_ns["uint16"] = {
kind = "type",
name = "uint16",
size = "2",
ctype = "uint16_t",
numeric = true
}
root_ns["int32"] = {
kind = "type",
name = "int32",
size = "4",
ctype = "int32_t",
numeric = true
}
root_ns["uint32"] = {
kind = "type",
name = "uint32",
size = "4",
ctype = "uint32_t",
numeric = true
}
root_ns["bool"] = {
kind = "type",
name = "bool",
size = "1",
ctype = "bool",
numeric = false
}
current_ns = root_ns
local extern_i8 = create_extern_variable(" i8", root_ns["int8"], root_ns, "extern_i8")
local extern_i8_2 = create_extern_variable(" i8_2", root_ns["int8"], root_ns, "extern_i8_2")
local extern_i16 = create_extern_variable(" i16", root_ns["int16"], root_ns, "extern_i16")
local extern_i32 = create_extern_variable(" i32", root_ns["int32"], root_ns, "extern_i32")
local extern_p8 = create_extern_variable(" p8", pointer_of(root_ns["int8"]), root_ns, "extern_p8")
local extern_u32 = create_extern_variable(" u32", root_ns["uint32"], root_ns, "extern_u32")
create_extern_function("print", "cowgol_print", { name="c", inout="in", variable=extern_p8 })
create_extern_function("print_bytes", "cowgol_print_bytes",
{ name="c", inout="in", variable=extern_p8 },
{ name="len", inout="in", variable=extern_i8 })
create_extern_function("print_char", "cowgol_print_char", { name="c", inout="in", variable=extern_i8 })
create_extern_function("print_i8", "cowgol_print_i8", { name="c", inout="in", variable=extern_i8 })
create_extern_function("print_i16", "cowgol_print_i16", { name="c", inout="in", variable=extern_i16 })
create_extern_function("print_i32", "cowgol_print_i32", { name="c", inout="in", variable=extern_i32 })
create_extern_function("print_hex_i8", "cowgol_print_hex_i8", { name="c", inout="in", variable=extern_i8 })
create_extern_function("print_hex_i16", "cowgol_print_hex_i16", { name="c", inout="in", variable=extern_i16 })
create_extern_function("print_hex_i32", "cowgol_print_hex_i32", { name="c", inout="in", variable=extern_i32 })
create_extern_function("exit", "cowgol_exit", { name="c", inout="in", variable=extern_i8 })
create_extern_function("file_openin", "cowgol_file_openin",
{ name="name", inout="in", variable=extern_p8 },
{ name="fd", inout="out", variable=extern_i8 }
)
create_extern_function("file_openout", "cowgol_file_openout",
{ name="name", inout="in", variable=extern_p8 },
{ name="fd", inout="out", variable=extern_i8 }
)
create_extern_function("file_openup", "cowgol_file_openup",
{ name="name", inout="in", variable=extern_p8 },
{ name="fd", inout="out", variable=extern_i8 }
)
create_extern_function("file_getchar", "cowgol_file_getchar",
{ name="fd", inout="in", variable=extern_i8 },
{ name="byte", inout="out", variable=extern_i8 },
{ name="eof", inout="out", variable=extern_i8_2 }
)
create_extern_function("file_putchar", "cowgol_file_putchar",
{ name="fd", inout="in", variable=extern_i8 },
{ name="byte", inout="in", variable=extern_i8_2 }
)
create_extern_function("file_getblock", "cowgol_file_getblock",
{ name="fd", inout="in", variable=extern_i8 },
{ name="ptr", inout="in", variable=extern_p8 },
{ name="size", inout="in", variable=extern_u32 },
{ name="eof", inout="out", variable=extern_i8_2 }
)
create_extern_function("file_putblock", "cowgol_file_putblock",
{ name="fd", inout="in", variable=extern_i8 },
{ name="ptr", inout="in", variable=extern_p8 },
{ name="size", inout="in", variable=extern_u32 }
)
create_extern_function("file_seek", "cowgol_file_seek",
{ name="fd", inout="in", variable=extern_i8 },
{ name="offset", inout="in", variable=extern_u32 }
)
create_extern_function("file_tell", "cowgol_file_tell",
{ name="fd", inout="in", variable=extern_i8 },
{ name="offset", inout="out", variable=extern_u32 }
)
create_extern_function("file_ext", "cowgol_file_ext",
{ name="fd", inout="in", variable=extern_i8 },
{ name="offset", inout="out", variable=extern_u32 }
)
create_extern_function("file_eof", "cowgol_file_eof",
{ name="fd", inout="in", variable=extern_i8 },
{ name="eof", inout="out", variable=extern_i8 }
)
create_extern_function("file_close", "cowgol_file_close",
{ name="fd", inout="in", variable=extern_i8 }
)
fn = create_function("print_newline", "cowgol_print_newline")
create_extern_variable("LOMEM", pointer_of(root_ns["int8"]), root_ns, "lomem")
create_extern_variable("HIMEM", pointer_of(root_ns["int8"]), root_ns, "himem")
create_extern_variable("ARGC", root_ns["int8"], root_ns, "cowgol_argc")
create_extern_variable("ARGV", pointer_of(pointer_of(root_ns["int8"])), root_ns, "cowgol_argv")
current_fn = create_function("main", "compiled_main")
emit("void compiled_main(void) {")
for _, arg in ipairs({...}) do
--log("reading %s", arg)
current_filename = arg
local source = io.open(arg):read("*a")
stream = peekabletokenstream(filteredtokenstream(tokenstream(source)))
do_statements()
expect("eof")
end
emit("}")
print("#include <stdio.h>")
print("#include <stdlib.h>")
print("#include <stdint.h>")
print("#include <stdbool.h>")
print("#include \"cowgol.h\"")
print(table.concat(record_fn.code, "\n"))
for var in pairs(variables) do
local initialiser = ""
if var.initialiser then
initialiser = " = {"..table.concat(var.initialiser, ", ").."}"
end
if var.type.array then
print(var.type.ctype.." "..var.storage.."["..var.type.length.."]"..initialiser..";")
else
print(var.type.ctype.." "..var.storage..initialiser..";")
end
end
for fn in pairs(functions) do
print(string.format("void %s(void);", fn.storage))
end
for fn in pairs(functions) do
print(table.concat(fn.code, "\n"))
end
<file_sep>/scripts/get-upper-bound.sh
#!/bin/sh
# Run on a set of log files; it'll return the highest address seen. Useful for
# determining memory usage.
gawk 'BEGIN { FS=":" } /^0x/ { m = strtonum($1); if (m > max) max = m } END { print max }' "$@"
<file_sep>/tinycowc/midcode.c
#include "globals.h"
#include "midcode.h"
#include "regalloc.h"
static struct matchcontext ctx;
#define NEXT(ptr) ((ptr+1) % MIDBUFSIZ)
#define PREV(ptr) ((MIDBUFSIZ+ptr-1) % MIDBUFSIZ)
#define MIDCODES_IMPLEMENTATION
#include "midcodes.h"
void midend_init(void)
{
ctx.rdptr = 0;
ctx.wrptr = 0;
}
struct midcode* midend_append(void)
{
struct midcode* m = &ctx.midcodes[ctx.wrptr];
ctx.wrptr = NEXT(ctx.wrptr);
if (ctx.wrptr == ctx.rdptr)
fatal("midcode buffer overflow");
return m;
}
struct midcode* midend_prepend(void)
{
if (ctx.rdptr == ctx.wrptr)
fatal("midcode buffer overflow");
ctx.rdptr = PREV(ctx.rdptr);
return &ctx.midcodes[ctx.rdptr];
}
static void dump_buffer(void)
{
int ptr = ctx.rdptr;
printf("Buffer:");
arch_print_vstack(stdout);
for (;;)
{
if (ptr == ctx.wrptr)
break;
struct midcode* m = &ctx.midcodes[ptr];
putchar(' ');
print_midcode(stdout, m);
ptr = NEXT(ptr);
}
printf("\n");
}
void midend_flush(int threshold)
{
for (;;)
{
int midcodedepth = (MIDBUFSIZ + ctx.wrptr - ctx.rdptr) % MIDBUFSIZ;
if (midcodedepth <= threshold)
break;
dump_buffer();
if (!arch_instruction_matcher(&ctx))
fatal("no matching instruction in pattern");
regalloc_unlock(ALL_REGS);
regalloc_dump();
}
}
static void push_midend_state_machine(void)
{
midend_flush(MIDBUFSIZ / 2);
}
<file_sep>/scripts/stupid_test
#!/bin/sh
exe=$1
bad=$2
good=$3
$exe > $bad
if ! diff -q $bad $good; then
diff -u $bad $good
exit 1
else
rm -f $bad
fi
<file_sep>/tinycowc/libcowgol.lua
function trim(s)
return (s:gsub("^%s*(.-)%s*$", "%1"))
end
function split(s)
local ss = {}
s:gsub("[^,]+", function(c) ss[#ss+1] = trim(c) end)
return ss
end
function parsearglist(argspec)
local args = {}
argspec = (argspec or ""):gsub("^%(", ""):gsub("%)$", "")
for _, word in ipairs(split(argspec or "")) do
_, _, type, name = word:find("^(.*) +(%w+)$")
if not type then
error("unparseable argument: '"..word.."'")
end
args[#args+1] = { name = name, type = type }
end
return args
end
function loadmidcodes(filename)
local infp = io.open(filename, "r")
local midcodes = {}
for line in infp:lines() do
local tokens = {}
line = line:gsub(" *#.*$", "")
if (line ~= "") then
local _, _, name, args, emitter = line:find("^(%w+)(%b()) *= *(%b())$")
if not name then
_, _, name, args = line:find("^(%w+)(%b())$")
end
if not name then
error("syntax error in: "..line)
end
midcodes[name] = { args = parsearglist(args), emitter = emitter }
end
end
return midcodes
end
<file_sep>/tinycowc/mkmidcodes.lua
require "./libcowgol"
local args = {...}
local infilename = args[2]
local outfilename = args[3]
local midcodes = loadmidcodes(infilename)
local hfp = io.open(outfilename, "w")
hfp:write("#ifndef MIDCODES_IMPLEMENTATION\n")
hfp:write("enum midcodes {\n")
local first = true
for m, t in pairs(midcodes) do
if not first then
hfp:write(",")
else
first = false
end
hfp:write("MIDCODE_", m, "\n")
end
hfp:write("};\n");
hfp:write("union midcode_data {\n")
for m, md in pairs(midcodes) do
if (#md.args > 0) then
hfp:write("struct { ")
for _, a in ipairs(md.args) do
hfp:write(a.type, " ", a.name, "; ")
end
hfp:write("} ", m:lower(), ";\n")
end
end
hfp:write("};\n");
for m, md in pairs(midcodes) do
hfp:write("extern void emit_mid_", m:lower(), "(")
if (#md.args > 0) then
local first = true
for _, a in ipairs(md.args) do
if first then
first = false
else
hfp:write(",")
end
hfp:write(a.type, " ", a.name)
end
else
hfp:write("void")
end
hfp:write(");\n")
end
hfp:write("#else\n")
hfp:write("static struct midcode* add_midcode(void);\n")
hfp:write("static void push_midend_state_machine(void);\n")
for m, md in pairs(midcodes) do
hfp:write("void emit_mid_", m:lower(), "(")
if (#md.args > 0) then
local first = true
for _, a in ipairs(md.args) do
if first then
first = false
else
hfp:write(",")
end
hfp:write(a.type, " ", a.name)
end
else
hfp:write("void")
end
hfp:write(") {\n")
hfp:write("\tstruct midcode* m = midend_append();\n")
hfp:write("\tm->code = MIDCODE_", m, ";\n")
for _, a in ipairs(md.args) do
hfp:write("\tm->u.", m:lower(), ".", a.name, " = ", a.name, ";\n")
end
hfp:write("\tpush_midend_state_machine();\n")
hfp:write("}\n")
end
hfp:write("void print_midcode(FILE* stream, struct midcode* m) {\n")
hfp:write("\tswitch (m->code) {\n")
for m, md in pairs(midcodes) do
hfp:write("\t\tcase MIDCODE_", m, ":\n")
hfp:write('\t\t\tfprintf(stream, "', m, '(");\n')
local e = md.emitter
if e then
e = e:gsub("^%(", ""):gsub("%)$", ""):gsub("%$%$", "m->u."..m:lower())
hfp:write("\t\t\tfprintf(stream, ", e, ");\n")
end
hfp:write('\t\t\tfprintf(stream, ")");\n')
hfp:write("\t\t\tbreak;\n")
end
hfp:write("\t\tdefault:\n")
hfp:write('\t\t\tprintf("unknown(%d)", m->code);\n')
hfp:write("\t}\n")
hfp:write("}\n")
hfp:write("#endif\n")
hfp:close()
<file_sep>/scripts/cpmz/mkcpmzdist
#!/bin/sh
out=$PWD/$1
files="\
a/ed.com \
a/!license.txt \
a/testprog.cow \
a/compile.sub \
a/!readme.txt \
a/submit.com \
b/blockify.com \
b/string.cow \
b/runtime1.cow \
b/parser.com \
b/iopsh.com \
b/placer.com \
b/runtime0.cow \
b/fcb.cow \
b/codegen.com \
b/emitter.com \
b/fileio.cow \
b/classify.com \
b/argv.cow \
b/runtime2.cow \
b/typechck.com \
b/backend.com \
b/init.com \
b/tokenise.com \
b/thingsh.com \
b/untoken.com \
"
(cd tools/cpm && rm -f $out && zip -9q $out $files)
<file_sep>/README.md
Cowgol
======
What?
-----
Cowgol is an experimental, Ada-inspired language for very small systems
(6502, Z80, etc). It's different because it's intended to be self-hosted on
these devices: the end goal is to be able to rebuild the entire compiler on
an 8-bit micro.
Right now it's in a state where you can build the cross-compiler on a PC,
then use it to compile the compiler for a 6502 (or Z80) device, and then use
*that* to (slowly) compile and run real programs on a 6502 (or Z80). It's
theoretically capable of compiling itself but need memory tuning first. (And,
realistically, bugfixing.)
The compiler itself will run on these architectures (as well as
cross-compiling from a modern PC in a fraction of the time):
- 6502, on a BBC Micro with Tube second processor; this is the only
platform I've found which is big enough (as it gives me a real operating
system with file streams and 61kB of usable RAM). (The distribution
contains a simple emulator.)
- Z80, on CP/M. (The distribution contains a simple emulator.)
- Z80, on Fuzix; see http://www.fuzix.org. You'll need your own emulator, or
real hardware to run on.
It will also cross compile for all of the above plus:
- 6502, on the Commodore 64 (for ultra hackers only; email me).
- Z80, on the ZX Spectrum (for ultra hackers only; email me).
Why?
----
I've always been interested in compilers, and have had various other
compiler projects: [the Amsterdam Compiler Kit](http://tack.sourceforge.net/)
and [Cowbel](http://cowlark.com/cowbel/), to name two. (The
[languages](http://cowlark.com/index/languages.html) section of my website
contains a fair number of entries. The oldest compiler which still exists
dates from about 1998.)
Cowgol is a spinoff of the Amsterdam Compiler Kit --- thematically, although
it shares no code. By dividing the task into many small, discrete units, it
gets to do (if slowly) a job which machines this size shouldn't really be
able to do. In many ways it's an exercise in minimalism, just like Cowbel,
although in a different direction.
Where?
------
- [Get the latest
release](https://github.com/davidgiven/cowgol/releases/latest) if you want
precompled binaries! Currently only available for the BBC Micro. Don't forget
to [read the instructions](doc/bbcdist.md).
- [Check out the GitHub repository](http://github.com/davidgiven/cowgol) and
build from source. (Alternatively, you can download a source snapshot from
[the latest release](https://github.com/davidgiven/cowgol/releases/latest),
but I suggect the GitHub repositories better because I don't really intend to
make formal releases often.) Build instructions as in the README.
- [Ask a question by creating a GitHub
issue](https://github.com/davidgiven/cowgol/issues/new), or just email me
directly at [<EMAIL>](mailto:<EMAIL>). (But I'd prefer you
opened an issue, so other people can see them.)
How?
----
We have documentation! Admittedly, not much of it.
- [Everything you want to know about Cowgol, the language](doc/language.md);
tl;dr: very strongly typed; Ada-like syntax; multiple return parameters; no
recursion; nested functions.
- [An overview of Cowgol, the toolchain](doc/toolchain.md); tl;dr: eight-stage
compiler pipeline; separate front-end and back-end; maximum RAM use: about
60kB; call graph analysis for efficient variable packing; suitable for other
languages; written in pure Cowgol.
- [About the BBC Micro bootable floppy](doc/bbcdist.md); tl;dr: crude, slow,
not suitable for production use; requires a BBC Micro with 6502 Tube second
processor although I recommend a BBC Master Turbo (mainly for the built-in
editor); requires extreme patience as it takes eight minutes to compile a
small program.
- [About the CP/M distribution](doc/cpmdist.md); tl;dr: crude, slow, not
suitable for etc; requires a Z80-based CP/M 2.2 or later system with at least
50kB of TPA.
- [About the Fuzix distribution](doc/fuzixdist.md); tl;dr: crude, slow, etc,
etc. Requires a Fuzix system with a Normal™ Z80 ABI (i.e. not the ZX
Spectrum) with at least 48kB of userspace.
processor although I recommend a BBC Master Turbo (mainly for the built-in
editor); requires extreme patience as it takes eight minutes to compile a
small program.
You will need some dependencies:
- the Ninja build tool
- Lua 5.2 (needed for the build)
- the Pasmo Z80 assembler (needed to build part of the CP/M emulator)
- the libz80ex Z80 emulation library (needed for the CP/M emulator)
If you're on a Debianish platform, you should be able to install them
with:
apt install ninja-build lua5.2 pasmo libz80ex-dev
Once done you can build the compiler itself with:
```
ninja
```
You'll be left with a lot of stuff in the `bin` directory. The BBC cross
compiler is in `bin/bbc_on_native`; the BBC native compiler is in `bin/bbc`.
The BBC demo disk is in `bin/bbcdist.adf`. Likewise, the CP/M cross compiler is
in `bin/cpmz_on_native` and the native compiler is in `bin/cpmz`.
To run the cross compiler, do:
```
./scripts/cowgol -a bbc_on_native -o cow.out \
src/arch/bbc/lib/runtime.cow \
src/arch/6502/lib/runtime.cow \
src/arch/common/lib/runtime.cow \
srctest.cow
```
You'll be left with a BBC Micro executable in `cow.out`. For the Commodore
64, substitute `c64_on_native` and `src/arch/c64/...` in the obvious places.
For CP/M, substitute `cpmz_on_native`, `src/arch/cpmz/...`, and
`src/arch/z80/...` in the obvious places. For Fuzix, substitute
`fuzixz80_on_native` etc etc obvious places.
The first three input files should be always be the runtime library.
The compiler works by having a shared state, `things.dat`, which is read into
memory by each stage, modified, and written out again on exit. Then there is
the opcode stream, `iops.dat`, which is streamed through memory. Provided you
have enough RAM for the things table you should be able to compile programs
of unlimited size; you need 35kB for the things table to compile the
compiler. This will fit, just, so it's theoretically possible to build the
compiler on a BBC Tube, but it needs some other memory rearrangement before
it's worth trying. (And, realistically, making the code smaller and more
efficient.)
**Special emulation bonus!** Are on a Unix platform? Do you have
*[b-em](https://github.com/stardot/b-em) or
[BeebEm](http://www.mkw.me.uk/beebem/)? If so, there's a farm of symlinks on
`tools/vdfs` which point at all the appropriate binaries and source files in
the main ditribution, with `.inf` files already set of for you. You can point
your VDFS root here and you should have a live setup just like the demo
floppy, except much faster and with your changes saved. And without the risk
of running out of disk space! Just remember to set your machine type to a BBC
Master Turbo, and then crank the emulation speed for both the main computer
and the Tube processor as high as they will go.
**Even specialler emulation bonus!** There's a _built in_ emulator for CP/M
*which will let you run Cowgol for CP/M out of the box using the farm of
*symlinks in `tools/cpm`! After building Cowgol, do this:
$ bin/cpm -p a=tools/cpm/a -p b=tools/cpm/b/
a> submit compile
...and watch the fun! (If you get this running on real hardware, please let
me know. I want to know how long it takes.)
Why not?
--------
So you've tried one of the demo disks!
...and you've discovered that the compiler takes seven minutes to compile
"Hello, world!". Does that answer your question?
There are a bunch of things that can be done to improve performance, but they
all need memory. This isn't free, so I'll need to make things smaller,
improve code sizes, make the generated code more efficient, etc.
But let's be honest; you're trying to compile a modern-ish language on a
2-4MHz device with 64kB of RAM. It's not going to be fast.
Who?
----
Cowgol was written, entirely so far, by me, <NAME>. Feel free to send me
email at [<EMAIL>](mailto:<EMAIL>). You may also [like to visit
my website](http://cowlark.com); there may or may not be something
interesting there.
License?
--------
Cowgol is open source software available [under the 2-clause BSD
license](https://github.com/davidgiven/cowgol/blob/master/COPYING).
Simplified summary: do what you like with it, just don't claim you wrote it.
`src/bbctube` contains a hacked copy of the lib6502 library, which is © 2005
<NAME>. See `emu/bbctube/COPYING.lib6502` for the full text.
`tools/cpm/a` contains some tools from the original CP/M 2.2 binary
distribution for the Imsai 1800, redistributable under a special license. See
`tools/cpm/a/!readme.txt` for the full text.
<file_sep>/scripts/fuzix/syscall-maker.sh
#!/bin/sh
set -e
write_with_commas() {
if [ -z "$1" ]; then
return
fi
echo -n "$1"
shift
while [ ! -z "$1" ]; do
echo -n ", $1"
shift
done
}
write_pushes() {
while [ "$9" != "zzz" ]; do
if [ ! -z "$9" ]; then
p="${9%:*}"
echo "\t@bytes 0x2a, &$p; # ld hl, ($p)"
if [ -z "${9##*: uint8}*}" -o -z "${9##*: int8*}" ]; then
echo "\t@bytes 0x67; # ld h, a"
fi
echo "\t@bytes 0xe5; # push hl"
fi
set -- zzz "$@"
done
}
write_pops() {
while [ ! -z "$1" ]; do
echo "\t@bytes 0xe1; # pop hl"
shift
done
}
syscall() {
number=$1
name=$2
retspec=$3
shift 3
echo -n "sub $name("
write_with_commas "$@"
echo -n ")"
if [ "$retspec" != "void" ]; then
echo ": ($retspec)"
else
echo ""
fi
if [ -z "${*##*: uint8}*}" -o -z "${*##*: int8*}" ]; then
echo "\t@bytes 0xaf; # xor a"
fi
write_pushes "$@"
echo "\t@bytes 0x2e, $number; # ld l, #$number"
echo "\t@bytes 0xe5; # push hl"
echo "\t@bytes 0xcd, &__raw_syscall; # call __raw_syscall"
if [ "$retspec" != "void" ]; then
p="${retspec%:*}"
if [ -z "${retspec##*: uint8}*}" -o -z "${retspec##*: int8*}" ]; then
echo "\t@bytes 0x7d; # ld a, l"
echo "\t@bytes 0x32, &$p; # ld ($p), a"
else
echo "\t@bytes 0x22, &$p; # ld ($p), hl"
fi
fi
write_pops extra "$@"
echo "end sub;"
echo ""
}
syscall 1 open "fd: int8" "path: [int8]" "flags: uint16" "mode: uint16"
syscall 2 close "status: int8" "fd: int8"
syscall 3 rename "status: int8" "oldpath: [int8]" "newpath: [int8]"
syscall 4 mknod "status: int8" "pathname: [int8]" "mode: uint16" "dev: uint16"
syscall 5 link "status: int8" "oldpath: [int8]" "newpath: [int8]"
syscall 6 unlink "status: int8" "path: [int8]"
syscall 7 read "countout: int16" "fd: int8" "buf: [int8]" "countin: uint16"
syscall 8 write "countout: int16" "fd: int8" "buf: [int8]" "countin: uint16"
syscall 9 _lseek "status: int8" "fd: int8" "offset: [uint32]" "mode: uint16"
syscall 10 chdir "status: int8" "path: [int8]"
syscall 11 sync "void"
syscall 12 access "status: int8" "path: [int8]" "mode: uint16"
syscall 13 chmod "status: int8" "path: [int8]" "mode: uint16"
syscall 14 chown "status: int8" "path: [int8]" "owner: uint16" "group: uint16"
syscall 15 stat "status: int8" "path: [int8]" "s: [int8]"
syscall 16 fstat "status: int8" "fd: int8" "s: [int8]"
syscall 17 dup "newfs: int8" "oldfd: int8"
syscall 18 getpid "pid: uint16"
syscall 19 getppid "pid: uint16"
syscall 20 getuid "uid: uint16"
syscall 21 umask "oldmode: uint16" "newmode: uint16"
syscall 22 getfsys "status: int8" "dev: uint16" "fs: [int8]"
syscall 23 execve "status: int8" "filename: [int8]" "argv: [[int8]]" "envp: [[int8]]"
syscall 24 getdirent "status: int8" "fd: int8" "buf: [int8]" "len: uint16"
syscall 25 setuid "status: int8" "uid: uint16"
syscall 26 setgid "status: int8" "gid: uint16"
syscall 27 time "status: int8" "t: [int8]" "clock: uint16"
syscall 28 stime "status: int8" "t: [int8]"
syscall 29 ioctl "result: uint16" "fd: int8" "request: uint16" "argp: [int8]"
syscall 30 brk "result: int8" "addr: [int8]"
syscall 31 sbrk "void" "delta: int16"
syscall 32 _fork "pid: uint16" "flags: uint16" "addr: [int8]"
syscall 33 mount "status: int8" "dev: [int8]" "path: [int8]" "flags: uint16"
syscall 34 _umount "status: int8" "dev: [int8]" "flags: uint16"
syscall 35 signal "oldhandler: uint16" "signum: uint8" "newhandler: uint16"
syscall 36 dup2 "oldfd: int8" "newfd: int8"
syscall 37 pause "status: int8" "dsecs: uint16"
syscall 38 alarm "oldalarm: uint16" "newalarm: uint16"
syscall 39 kill "status: int8" "pid: uint16" "sig: int8"
syscall 40 pipe "status: int8" "pipefds: [int16]"
syscall 41 getgid "gid: uint16"
syscall 42 _times "status: int8" "tms: [int8]"
syscall 43 utime "status: int8" "file: [int8]" "ktime: [int8]"
syscall 44 geteuid "uid: uint16"
syscall 45 getegid "gid: uint16"
syscall 46 chroot "status: int8" "path: [int8]"
syscall 47 fcntl "fd: int8" "cmd: uint16" "arg: uint16"
syscall 48 fchdir "status: int8" "fd: int8"
syscall 49 fchmod "status: int8" "fd: int8" "mode: uint16"
syscall 50 fchown "status: int8" "fd: int8" "owner: uint16" "group: uint16"
syscall 51 mkdir "status: int8" "path: [int8]" "mode: uint16"
syscall 52 rmdir "status: int8" "path: [int8]"
syscall 53 setpgrp "status: int8"
syscall 54 uname "uzib: [int8]"
syscall 55 waitpid "result: int16" "pid: int16" "wstatus: [int16]" "options: uint16"
# skipping 56, _profil
# skipping 57, uadmin
syscall 58 nice "status: int8" "prio: int16"
# skipping 59, _sigdisk
syscall 60 flock "status: int8" "fd: int8" "operation: int16"
syscall 61 getpgrp "pid: uint16"
syscall 62 sched_yield "status: int8"
# skipping 63, act (what is this?)
# skipping 64, memalloc
# skipping 65, memfree
# skipping 66..71 (unused)
# skipping 72, _select
syscall 73 setgroups "status: int8" "size: uint8" "gids: [uint16]"
syscall 74 getgroups "status: int8" "size: uint8" "gids: [uint16]"
# skipping 75, getrlimit
# skipping 76, setrlimit
# skipping 77, setpgid
# skipping 78, setsid
# skipping 79, getsid
# skipping 80..89 (unused)
# skipping 90, socket
# skipping 91, listen
# skipping 92, bind
# skipping 93, connect
# skipping 94, accept
# skipping 95, getsockaddrs
# skipping 96, sendto
# skipping 97, recvfrom
# skipping 98, shutdown
<file_sep>/tinycowc/main.c
#include <stdlib.h>
#include <stdio.h>
#include <stdarg.h>
#include <string.h>
#include "globals.h"
#include "emitter.h"
#include "midcode.h"
#define YYDEBUG 1
#include "parser.h"
void fatal(const char* s, ...)
{
va_list ap;
va_start(ap, s);
fprintf(stderr, "%d: ", yylineno);
vfprintf(stderr, s, ap);
fprintf(stderr, "\n");
va_end(ap);
exit(1);
}
void trace(const char* s, ...)
{
va_list ap;
va_start(ap, s);
fprintf(stderr, "Log: ");
vfprintf(stderr, s, ap);
fprintf(stderr, "\n");
va_end(ap);
}
const char* aprintf(const char* s, ...)
{
va_list ap;
va_start(ap, s);
int len = vsnprintf(NULL, 0, s, ap) + 1;
va_end(ap);
char* buffer = malloc(len);
va_start(ap, s);
vsnprintf(buffer, len, s, ap);
va_end(ap);
return buffer;
}
int main(int argc, const char* argv[])
{
current_sub = calloc(1, sizeof(struct subroutine));
current_sub->name = "__main";
current_sub->externname = "cmain";
include_file(open_file(argv[1]));
yydebug = 0;
emitter_open(argv[2]);
emitter_open_chunk();
midend_init();
arch_init_types();
arch_init_subroutine(current_sub);
emit_mid_startfile();
emit_mid_startsub(current_sub);
yyparse();
emit_mid_endsub(current_sub);
emit_mid_endfile();
midend_flush(0);
emitter_close_chunk();
emitter_close();
return 0;
}
<file_sep>/tinycowc/rt/c/cowgol.h
#ifndef COWGOL_RUNTIME_H
#define COWGOL_RUNTIME_H
#include <stdint.h>
#include <stdio.h>
typedef int8_t i1;
typedef int16_t i2;
typedef int32_t i4;
typedef int64_t i8;
#endif
<file_sep>/scripts/get-size-stats.sh
#!/bin/sh
get_stats() {
total=$(find bin/$1 \! -name "*.log" -type f | xargs ls -l | gawk '{ total += $5 } END { print total }')
echo "$1: $total bytes"
}
echo "Size stats:"
echo "-----------"
get_stats cpmz
get_stats bbc
get_stats fuzixz80
<file_sep>/scripts/bbc/bbctube_test
#!/bin/sh
scripts/stupid_test "bin/bbctube -l 0x800 -e 0x800 -f $1" "$2" "$3"<file_sep>/tinycowc/mkninja.sh
#!/bin/sh
set -e
registertarget() {
eval TARGET_$1_COMPILER=$2
eval TARGET_$1_BUILDER=$3
}
registertarget cpm tinycowc-8080 scripts/build-cpm.sh scripts/run-cpm.sh
cat <<EOF
rule cc
command = $CC $CFLAGS \$flags -I. -c -o \$out \$in -MMD -MF \$out.d
description = CC \$in
depfile = \$out.d
deps = gcc
rule library
command = $AR \$out \$in
description = AR \$in
rule link
command = $CC $LDFLAGS -o \$out -Wl,--start-group \$in -Wl,--end-group \$flags $LIBS
description = LINK \$in
rule strip
command = cp -f \$in \$out && $STRIP \$out
description = STRIP \$in
rule flex
command = flex -8 -Cem -o \$out \$in
description = FLEX \$in
rule mkmidcodes
command = lua mkmidcodes.lua -- \$in \$out
description = MKMIDCODES \$in
rule mkpat
command = lua mkpat.lua -- \$in \$out
description = MKPAT \$in
rule yacc
command = yacc --report=all --report-file=report.txt --defines=\$hfile -o \$cfile \$in
description = YACC \$in
rule buildcowgol
command = \$builder \$in \$out
description = COWGOL \$target \$in
rule runtest
command = \$skeleton \$in > \$out
description = TEST \$in
rule command
command = \$cmd
description = \$msg
EOF
rule() {
local cmd
local ins
local outs
local msg
cmd=$1
ins=$2
outs=$3
msg=$4
echo "build $outs : command | $ins"
echo " cmd=$cmd"
echo " msg=$msg"
}
cfile() {
local obj
obj=$1
shift
local flags
flags=
local deps
deps=
while true; do
case $1 in
--dep)
deps="$deps $2"
shift
shift
;;
-*)
flags="$flags $1"
shift
;;
*)
break
esac
done
rule "$CC -g $flags -c -o $obj $1" "$1 $deps" "$obj" "CC $1"
}
buildlibrary() {
local lib
lib=$1
shift
local flags
flags=
local deps
deps=
while true; do
case $1 in
--dep)
deps="$deps $2"
shift
shift
;;
-*)
flags="$flags $1"
shift
;;
*)
break
esac
done
local objs
objs=
for src in "$@"; do
local obj
case $src in
$OBJDIR/*)
obj="${src%%.c*}.o"
;;
*)
obj="$OBJDIR/${src%%.c*}.o"
esac
objs="$objs $obj"
echo "build $obj : cc $src | $deps"
echo " flags=$flags"
done
echo build $OBJDIR/$lib : library $objs
}
buildprogram() {
local prog
prog=$1
shift
local flags
flags=
while true; do
case $1 in
-*)
flags="$flags $1"
shift
;;
*)
break
esac
done
local objs
objs=
for src in "$@"; do
objs="$objs $OBJDIR/$src"
done
echo "build $prog-debug$EXTENSION : link $objs | $deps"
echo " flags=$flags"
echo build $prog$EXTENSION : strip $prog-debug$EXTENSION
}
buildflex() {
echo "build $1 : flex $2"
}
buildyacc() {
local cfile
local hfile
cfile="${1%%.c*}.c"
hfile="${1%%.c*}.h"
echo "build $cfile $hfile : yacc $2"
echo " cfile=$cfile"
echo " hfile=$hfile"
}
buildmkmidcodes() {
echo "build $1 : mkmidcodes $2 | mkmidcodes.lua libcowgol.lua"
}
buildmkpat() {
local out
out=$1
shift
echo "build $out : mkpat $@ | mkpat.lua libcowgol.lua"
}
zmac8() {
rule "zmac -8 $1 -o $2" $1 $2 "ZMAC $1"
}
ld80() {
local bin
bin="$1"
shift
rule "ld80 -O bin -c -P0100 $* -o $bin" "$*" "$bin" "LD80 $bin"
}
cowgol_cpm_asm() {
local in
local out
local log
local deps
in=$1
out=$2
log=$3
deps=$4
rule "./tinycowc-8080 $in $out > $log" "$in $deps tinycowc-8080" "$out $log" "COWGOL 8080 $in"
}
cowgol_cpm() {
local base
base="$OBJDIR/${1%.cow}.cpm"
cowgol_cpm_asm $1 $base.asm $base.log "$3"
zmac8 $base.asm $base.rel
ld80 $base.bin \
$OBJDIR/rt/cpm/cowgol.rel \
$base.rel
rule "dd if=$base.bin of=$2 bs=128 skip=2 status=none" "$base.bin" "$2" "DD $1"
}
test_cpm() {
local base
base=$OBJDIR/tests/cpm/$1
cowgol_cpm tests/$1.test.cow $base.com tests/_framework.coh
rule "./cpmemu $base.com > $base.bad" "cpmemu $base.com" "$base.bad" "TEST_CPM $1"
rule "diff -u tests/$1.good $base.bad && touch $base.stamp" "tests/$1.good $base.bad" "$base.stamp" "DIFF $1"
}
cowgol_c_c() {
local in
local out
local log
local deps
in=$1
out=$2
log=$3
deps=$4
rule "./tinycowc-c $in $out > $log" "$in $deps tinycowc-c" "$out $log" "COWGOL C $in"
}
cowgol_c() {
local base
base="$OBJDIR/${1%.cow}.c"
cowgol_c_c $1 $base.c $base.log "$3"
rule "$CC -g -c -ffunction-sections -fdata-sections -I. -o $base.o $base.c" \
$base.c $base.o "CC $1"
rule "$CC -g -o $2 $OBJDIR/rt/c/cowgol.o $base.o" \
"$OBJDIR/rt/c/cowgol.o $base.o" $2 \
"LINK $1"
}
test_c() {
local base
base=$OBJDIR/tests/c/$1
cowgol_c tests/$1.test.cow $base.exe tests/_framework.coh
rule "$base.exe > $base.bad" "$base.exe" "$base.bad" "TEST_C $1"
rule "diff -u tests/$1.good $base.bad && touch $base.stamp" "tests/$1.good $base.bad" "$base.stamp" "DIFF $1"
}
objectify() {
rule "./tools/objectify $3 < $1 > $2" \
"./tools/objectify $1" "$2" "OBJECTIFY $1"
}
pasmo() {
rule "pasmo $1 $2" "$1" "$2" "PASMO $1"
}
buildyacc $OBJDIR/parser.c parser.y
buildflex $OBJDIR/lexer.c lexer.l
buildmkmidcodes $OBJDIR/midcodes.h midcodes.tab
buildmkpat $OBJDIR/arch8080.c midcodes.tab arch8080.pat
buildmkpat $OBJDIR/archagc.c midcodes.tab archagc.pat
buildmkpat $OBJDIR/archc.c midcodes.tab archc.pat
buildlibrary libmain.a \
-I$OBJDIR \
--dep $OBJDIR/parser.h \
--dep $OBJDIR/midcodes.h \
$OBJDIR/parser.c \
$OBJDIR/lexer.c \
main.c \
emitter.c \
midcode.c \
regalloc.c
buildlibrary libagc.a \
-I$OBJDIR \
--dep $OBJDIR/midcodes.h \
$OBJDIR/archagc.c \
buildlibrary lib8080.a \
-I$OBJDIR \
--dep $OBJDIR/midcodes.h \
$OBJDIR/arch8080.c \
buildlibrary libc.a \
-I$OBJDIR \
--dep $OBJDIR/midcodes.h \
$OBJDIR/archc.c \
buildprogram tinycowc-agc \
-lbsd \
libmain.a \
libagc.a \
buildprogram tinycowc-8080 \
libmain.a \
lib8080.a \
buildprogram tinycowc-c \
libmain.a \
libc.a \
pasmo tools/cpmemu/bdos.asm $OBJDIR/tools/cpmemu/bdos.img
pasmo tools/cpmemu/ccp.asm $OBJDIR/tools/cpmemu/ccp.img
objectify $OBJDIR/tools/cpmemu/bdos.img $OBJDIR/tools/cpmemu/bdos.c bdos
objectify $OBJDIR/tools/cpmemu/ccp.img $OBJDIR/tools/cpmemu/ccp.c ccp
buildlibrary libcpmemu.a \
$OBJDIR/tools/cpmemu/bdos.c \
$OBJDIR/tools/cpmemu/ccp.c \
tools/cpmemu/biosbdos.c \
tools/cpmemu/emulator.c \
tools/cpmemu/fileio.c \
tools/cpmemu/main.c \
buildprogram cpmemu -lz80ex -lz80ex_dasm -lreadline libcpmemu.a
#runtest cpm addsub-8bit
zmac8 rt/cpm/cowgol.asm $OBJDIR/rt/cpm/cowgol.rel
cfile $OBJDIR/rt/c/cowgol.o rt/c/cowgol.c
test_cpm addsub-8bit
test_cpm addsub-16bit
#test_cpm addsub-32bit
test_cpm records
test_c addsub-8bit
test_c addsub-16bit
test_c addsub-32bit
test_c records
<file_sep>/bootstrap/cowgol.c
#include <stdlib.h>
#include <stdio.h>
#include <stdint.h>
#include <stdbool.h>
#include <assert.h>
#include "cowgol.h"
static int8_t memory[64*1024];
int8_t* lomem = memory;
int8_t* himem = memory + sizeof(memory) - 1;
#define FILE_COUNT 16
static FILE* filetab[FILE_COUNT];
void cowgol_print(void) { fputs(extern_p8, stdout); }
void cowgol_print_char(void) { putchar(extern_i8); }
void cowgol_print_i8(void) { printf("%d", extern_i8); }
void cowgol_print_i16(void) { printf("%d", extern_i16); }
void cowgol_print_i32(void) { printf("%d", extern_i32); }
void cowgol_print_hex_i8(void) { printf("%02x", (uint8_t)extern_i8); }
void cowgol_print_hex_i16(void) { printf("%04x", (uint16_t)extern_i16); }
void cowgol_print_hex_i32(void) { printf("%08x", (uint16_t)extern_i32); }
void cowgol_print_newline(void) { printf("\n"); }
void cowgol_print_bytes(void) {
fwrite(extern_p8, 1, extern_i8, stdout);
}
static int find_fd(FILE* fp) {
assert(fp);
for (int i=0; i<FILE_COUNT; i++) {
if (!filetab[i]) {
filetab[i] = fp;
return i;
}
}
abort();
}
void cowgol_file_openin(void) {
char* filename = extern_p8;
extern_i8 = find_fd(fopen(filename, "rb"));
}
void cowgol_file_openout(void) {
char* filename = extern_p8;
extern_i8 = find_fd(fopen(filename, "wb"));
}
void cowgol_file_openup(void) {
char* filename = extern_p8;
extern_i8 = find_fd(fopen(filename, "r+b"));
}
void cowgol_file_getchar(void) {
FILE* fp = filetab[extern_i8];
extern_i8 = fgetc(fp);
extern_i8_2 = feof(fp);
}
void cowgol_file_putchar(void) {
fputc(extern_i8_2, filetab[extern_i8]);
}
void cowgol_file_getblock(void) {
FILE* fp = filetab[extern_i8];
size_t bytes = fread(extern_p8, 1, extern_u32, fp);
extern_i8_2 = (bytes == 0) ? feof(fp) : 0;
}
void cowgol_file_putblock(void) {
fwrite(extern_p8, 1, extern_u32, filetab[extern_i8]);
}
void cowgol_file_seek(void) {
fseek(filetab[extern_i8], extern_u32, SEEK_SET);
}
void cowgol_file_tell(void) {
extern_u32 = ftell(filetab[extern_i8]);
}
void cowgol_file_eof(void) {
extern_i8 = feof(filetab[extern_i8]);
}
void cowgol_file_ext(void) {
FILE* fp = filetab[extern_i8];
long old = ftell(fp);
fseek(fp, 0, SEEK_END);
extern_u32 = ftell(fp);
fseek(fp, old, SEEK_SET);
}
void cowgol_file_close(void) {
fclose(filetab[extern_i8]);
filetab[extern_i8] = NULL;
}
void cowgol_exit(void) {
exit(extern_i8);
}
int main(int argc, const char* argv[]) {
cowgol_argc = argc;
cowgol_argv = (int8_t**) argv;
compiled_main();
return 0;
}
<file_sep>/tinycowc/midcode.h
#ifndef MIDCODE_H
#define MIDCODE_H
struct midcode;
#include "midcodes.h"
struct midcode
{
enum midcodes code;
union midcode_data u;
};
#define MIDBUFSIZ 16
#define VSTACKSIZ 64
struct matchcontext
{
int rdptr;
int wrptr;
struct midcode midcodes[MIDBUFSIZ];
};
extern void midend_init(void);
extern void midend_flush(int threshold);
extern struct midcode* midend_append(void);
extern struct midcode* midend_prepend(void);
extern bool arch_instruction_matcher(struct matchcontext* ctx);
extern void arch_print_vstack(FILE* stream);
#endif
<file_sep>/scripts/cowgol
#!/bin/sh
set -e
syntax() {
echo "Syntax: cowgol -a arch [-k] -o outputfile inputfiles..."
exit 1
}
verbose=no
if [ "$1" = "-v" ]; then
shift
verbose=yes
fi
if [ "$1" != "-a" ]; then
syntax
else
arch=$2
shift
shift
fi
if [ "$1" = "-k" ]; then
shift
tmpdir=.
keep=yes
else
tmpdir=$(mktemp -d --tmpdir cowgol.XXXXXX)
trap 'rm -rf $tmpdir' EXIT
keep=no
fi
if [ "$1" != "-o" ]; then
syntax
else
outputfile=$(realpath -s $2)
shift
shift
fi
srcs=$(realpath -s "$@")
bindir=$(realpath -s bin/$arch)
set +e
(
set -e
cd $tmpdir
$bindir/init
$bindir/tokeniser2 $srcs
$bindir/parser
cp iops.dat iops-parsed.dat
$bindir/typechecker
cp iops-out.dat iops-typechecked.dat
mv iops-out.dat iops.dat
$bindir/backendify
cp iops-out.dat iops-backendified.dat
mv iops-out.dat iops.dat
$bindir/classifier
$bindir/blockifier
cp iops-out.dat iops-blockified.dat
mv iops-out.dat iops.dat
$bindir/codegen
cp iops-out.dat iops-codegenned.dat
mv iops-out.dat iops.dat
$bindir/placer
cp iops-out.dat iops-placed.dat
mv iops-out.dat iops.dat
$bindir/emitter
) 2>&1 >$outputfile.log
result=$?
set -e
if [ $result != 0 -o "$verbose" = "yes" ]; then
cat $outputfile.log
fi
if [ $result != 0 ]; then
exit 1
fi
if [ "$keep" = "no" ]; then
mv $tmpdir/cow.out $outputfile
fi
| b39ada1c011019ffc4b823b32515a2c8a40aff6f | [
"Markdown",
"C",
"Shell",
"Lua"
] | 25 | C | oisee/cowgol | faa015c6ab44497c5c67da0cae317d42eab3daf9 | 1302110869a762eb24a207043e1735e6a07a8d3f |
refs/heads/master | <file_sep><?php
/**
* Zend Framework (http://framework.zend.com/)
*
* @link http://github.com/zendframework/zf2 for the canonical source repository
* @copyright Copyright (c) 2005-2014 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
*/
namespace Zend\Log\Filter;
use Traversable;
use Zend\Log\Exception;
use Zend\Validator\ValidatorInterface as ZendValidator;
class Validator implements FilterInterface
{
/**
* Regex to match
*
* @var ZendValidator
*/
protected $validator;
/**
* Filter out any log messages not matching the validator
*
* @param ZendValidator|array|Traversable $validator
* @throws Exception\InvalidArgumentException
* @return Validator
*/
public function __construct($validator)
{
if ($validator instanceof Traversable) {
$validator = iterator_to_array($validator);
}
if (is_array($validator)) {
$validator = isset($validator['validator']) ? $validator['validator'] : null;
}
if (!$validator instanceof ZendValidator) {
throw new Exception\InvalidArgumentException(sprintf(
'Parameter of type %s is invalid; must implements Zend\Validator\ValidatorInterface',
(is_object($validator) ? get_class($validator) : gettype($validator))
));
}
$this->validator = $validator;
}
/**
* Returns TRUE to accept the message, FALSE to block it.
*
* @param array $event event data
* @return bool
*/
public function filter(array $event)
{
return $this->validator->isValid($event['message']);
}
}
<file_sep><?php
/**
* Zend Framework (http://framework.zend.com/)
*
* @link http://github.com/zendframework/zf2 for the canonical source repository
* @copyright Copyright (c) 2005-2014 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
*/
namespace Zend\Ldap\Filter;
/**
* Zend\Ldap\Filter\MaskFilter provides a simple string filter to be used with a mask.
*/
class MaskFilter extends StringFilter
{
/**
* Creates a Zend\Ldap\Filter\MaskFilter.
*
* @param string $mask
* @param string $value,...
*/
public function __construct($mask, $value)
{
$args = func_get_args();
array_shift($args);
for ($i = 0; $i < count($args); $i++) {
$args[$i] = static::escapeValue($args[$i]);
}
$filter = vsprintf($mask, $args);
parent::__construct($filter);
}
/**
* Returns a string representation of the filter.
*
* @return string
*/
public function toString()
{
return $this->filter;
}
}
<file_sep><?php
/**
* Zend Framework (http://framework.zend.com/)
*
* @link http://github.com/zendframework/zf2 for the canonical source repository
* @copyright Copyright (c) 2005-2014 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
*/
namespace Zend\Validator\File;
use Zend\Validator\AbstractValidator;
use Zend\Validator\Exception;
/**
* Validator for the maximum size of a file up to a max of 2GB
*/
class UploadFile extends AbstractValidator
{
/**
* @const string Error constants
*/
const INI_SIZE = 'fileUploadFileErrorIniSize';
const FORM_SIZE = 'fileUploadFileErrorFormSize';
const PARTIAL = 'fileUploadFileErrorPartial';
const NO_FILE = 'fileUploadFileErrorNoFile';
const NO_TMP_DIR = 'fileUploadFileErrorNoTmpDir';
const CANT_WRITE = 'fileUploadFileErrorCantWrite';
const EXTENSION = 'fileUploadFileErrorExtension';
const ATTACK = 'fileUploadFileErrorAttack';
const FILE_NOT_FOUND = 'fileUploadFileErrorFileNotFound';
const UNKNOWN = 'fileUploadFileErrorUnknown';
/**
* @var array Error message templates
*/
protected $messageTemplates = array(
self::INI_SIZE => "File exceeds the defined ini size",
self::FORM_SIZE => "File exceeds the defined form size",
self::PARTIAL => "File was only partially uploaded",
self::NO_FILE => "File was not uploaded",
self::NO_TMP_DIR => "No temporary directory was found for file",
self::CANT_WRITE => "File can't be written",
self::EXTENSION => "A PHP extension returned an error while uploading the file",
self::ATTACK => "File was illegally uploaded. This could be a possible attack",
self::FILE_NOT_FOUND => "File was not found",
self::UNKNOWN => "Unknown error while uploading file",
);
/**
* Returns true if and only if the file was uploaded without errors
*
* @param string $value File to check for upload errors
* @return bool
* @throws Exception\InvalidArgumentException
*/
public function isValid($value)
{
if (is_array($value)) {
if (!isset($value['tmp_name']) || !isset($value['name']) || !isset($value['error'])) {
throw new Exception\InvalidArgumentException(
'Value array must be in $_FILES format'
);
}
$file = $value['tmp_name'];
$filename = $value['name'];
$error = $value['error'];
} else {
$file = $value;
$filename = basename($file);
$error = 0;
}
$this->setValue($filename);
if (false === stream_resolve_include_path($file)) {
$this->error(self::FILE_NOT_FOUND);
return false;
}
switch ($error) {
case UPLOAD_ERR_OK:
if (!is_uploaded_file($file)) {
$this->error(self::ATTACK);
}
break;
case UPLOAD_ERR_INI_SIZE:
$this->error(self::INI_SIZE);
break;
case UPLOAD_ERR_FORM_SIZE:
$this->error(self::FORM_SIZE);
break;
case UPLOAD_ERR_PARTIAL:
$this->error(self::PARTIAL);
break;
case UPLOAD_ERR_NO_FILE:
$this->error(self::NO_FILE);
break;
case UPLOAD_ERR_NO_TMP_DIR:
$this->error(self::NO_TMP_DIR);
break;
case UPLOAD_ERR_CANT_WRITE:
$this->error(self::CANT_WRITE);
break;
case UPLOAD_ERR_EXTENSION:
$this->error(self::EXTENSION);
break;
default:
$this->error(self::UNKNOWN);
break;
}
if (count($this->getMessages()) > 0) {
return false;
}
return true;
}
}
<file_sep><?php
/**
* Zend Framework (http://framework.zend.com/)
*
* @link http://github.com/zendframework/zf2 for the canonical source repository
* @copyright Copyright (c) 2005-2014 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
*/
namespace Zend\Version;
use Zend\Json\Json;
/**
* Class to store and retrieve the version of Zend Framework.
*/
final class Version
{
/**
* Zend Framework version identification - see compareVersion()
*/
const VERSION = '2.2.6dev';
/**
* Github Service Identifier for version information is retrieved from
*/
const VERSION_SERVICE_GITHUB = 'GITHUB';
/**
* Zend (framework.zend.com) Service Identifier for version information is retrieved from
*/
const VERSION_SERVICE_ZEND = 'ZEND';
/**
* The latest stable version Zend Framework available
*
* @var string
*/
protected static $latestVersion;
/**
* Compare the specified Zend Framework version string $version
* with the current Zend\Version\Version::VERSION of Zend Framework.
*
* @param string $version A version string (e.g. "0.7.1").
* @return int -1 if the $version is older,
* 0 if they are the same,
* and +1 if $version is newer.
*
*/
public static function compareVersion($version)
{
$version = strtolower($version);
$version = preg_replace('/(\d)pr(\d?)/', '$1a$2', $version);
return version_compare($version, strtolower(self::VERSION));
}
/**
* Fetches the version of the latest stable release.
*
* By default, this uses the API provided by framework.zend.com for version
* retrieval.
*
* If $service is set to VERSION_SERVICE_GITHUB, this will use the GitHub
* API (v3) and only returns refs that begin with * 'tags/release-'.
* Because GitHub returns the refs in alphabetical order, we need to reduce
* the array to a single value, comparing the version numbers with
* version_compare().
*
* @see http://developer.github.com/v3/git/refs/#get-all-references
* @link https://api.github.com/repos/zendframework/zf2/git/refs/tags/release-
* @link http://framework.zend.com/api/zf-version?v=2
* @param string $service Version Service with which to retrieve the version
* @return string
*/
public static function getLatest($service = self::VERSION_SERVICE_ZEND)
{
if (null === static::$latestVersion) {
static::$latestVersion = 'not available';
if ($service == self::VERSION_SERVICE_GITHUB) {
$url = 'https://api.github.com/repos/zendframework/zf2/git/refs/tags/release-';
$apiResponse = Json::decode(file_get_contents($url), Json::TYPE_ARRAY);
// Simplify the API response into a simple array of version numbers
$tags = array_map(function ($tag) {
return substr($tag['ref'], 18); // Reliable because we're filtering on 'refs/tags/release-'
}, $apiResponse);
// Fetch the latest version number from the array
static::$latestVersion = array_reduce($tags, function ($a, $b) {
return version_compare($a, $b, '>') ? $a : $b;
});
} elseif ($service == self::VERSION_SERVICE_ZEND) {
$handle = fopen('http://framework.zend.com/api/zf-version?v=2', 'r');
if (false !== $handle) {
static::$latestVersion = stream_get_contents($handle);
fclose($handle);
}
}
}
return static::$latestVersion;
}
/**
* Returns true if the running version of Zend Framework is
* the latest (or newer??) than the latest tag on GitHub,
* which is returned by static::getLatest().
*
* @return bool
*/
public static function isLatest()
{
return static::compareVersion(static::getLatest()) < 1;
}
}
<file_sep><?php
/**
* Zend Framework (http://framework.zend.com/)
*
* @link http://github.com/zendframework/zf2 for the canonical source repository
* @copyright Copyright (c) 2005-2014 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
*/
namespace Zend\Permissions\Rbac;
use RecursiveIteratorIterator;
class Rbac extends AbstractIterator
{
/**
* flag: whether or not to create roles automatically if
* they do not exist.
*
* @var bool
*/
protected $createMissingRoles = false;
/**
* @param bool $createMissingRoles
* @return \Zend\Permissions\Rbac\Rbac
*/
public function setCreateMissingRoles($createMissingRoles)
{
$this->createMissingRoles = $createMissingRoles;
return $this;
}
/**
* @return bool
*/
public function getCreateMissingRoles()
{
return $this->createMissingRoles;
}
/**
* Add a child.
*
* @param string|RoleInterface $child
* @param array|RoleInterface|null $parents
* @return self
* @throws Exception\InvalidArgumentException
*/
public function addRole($child, $parents = null)
{
if (is_string($child)) {
$child = new Role($child);
}
if (!$child instanceof RoleInterface) {
throw new Exception\InvalidArgumentException(
'Child must be a string or implement Zend\Permissions\Rbac\RoleInterface'
);
}
if ($parents) {
if (!is_array($parents)) {
$parents = array($parents);
}
foreach ($parents as $parent) {
if ($this->createMissingRoles && !$this->hasRole($parent)) {
$this->addRole($parent);
}
$this->getRole($parent)->addChild($child);
}
}
$this->children[] = $child;
return $this;
}
/**
* Is a child with $name registered?
*
* @param \Zend\Permissions\Rbac\RoleInterface|string $objectOrName
* @return bool
*/
public function hasRole($objectOrName)
{
try {
$this->getRole($objectOrName);
return true;
} catch (Exception\InvalidArgumentException $e) {
return false;
}
}
/**
* Get a child.
*
* @param \Zend\Permissions\Rbac\RoleInterface|string $objectOrName
* @return RoleInterface
* @throws Exception\InvalidArgumentException
*/
public function getRole($objectOrName)
{
if (!is_string($objectOrName) && !$objectOrName instanceof RoleInterface) {
throw new Exception\InvalidArgumentException(
'Expected string or implement \Zend\Permissions\Rbac\RoleInterface'
);
}
$it = new RecursiveIteratorIterator($this, RecursiveIteratorIterator::CHILD_FIRST);
foreach ($it as $leaf) {
if ((is_string($objectOrName) && $leaf->getName() == $objectOrName) || $leaf == $objectOrName) {
return $leaf;
}
}
throw new Exception\InvalidArgumentException(sprintf(
'No child with name "%s" could be found',
is_object($objectOrName) ? $objectOrName->getName() : $objectOrName
));
}
/**
* Determines if access is granted by checking the role and child roles for permission.
*
* @param RoleInterface|string $role
* @param string $permission
* @param AssertionInterface|Callable|null $assert
* @return bool
*/
public function isGranted($role, $permission, $assert = null)
{
if ($assert) {
if ($assert instanceof AssertionInterface) {
if (!$assert->assert($this)) {
return false;
}
} elseif (is_callable($assert)) {
if (!$assert($this)) {
return false;
}
} else {
throw new Exception\InvalidArgumentException(
'Assertions must be a Callable or an instance of Zend\Permissions\Rbac\AssertionInterface'
);
}
}
if ($this->getRole($role)->hasPermission($permission)) {
return true;
}
return false;
}
}
<file_sep><?php
/**
* Zend Framework (http://framework.zend.com/)
*
* @link http://github.com/zendframework/zf2 for the canonical source repository
* @copyright Copyright (c) 2005-2013 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
*/
namespace ZendTest\Cache\Storage\Adapter;
use Zend\Cache\Storage\Adapter\RedisResourceManager;
/**
* PHPUnit test case
*/
/**
* @group Zend_Cache
*/
class RedisResourceManagerTest extends \PHPUnit_Framework_TestCase
{
/**
* The resource manager
*
* @var RedisResourceManager
*/
protected $resourceManager;
public function setUp()
{
$this->resourceManager = new RedisResourceManager();
}
/**
* Test with 'persistent_id'
*/
public function testValidPersistentId()
{
$resourceId = 'testValidPersistentId';
$resource = array(
'persistent_id' => 1234,
'server' => array(
'host' => 'localhost'
),
);
$expectedPersistentId = '1234';
$this->resourceManager->setResource($resourceId, $resource);
$this->assertSame($expectedPersistentId, $this->resourceManager->getPersistentId($resourceId));
}
/**
* Test with 'persistend_id'
*/
public function testNotValidPersistentId()
{
$resourceId = 'testNotValidPersistentId';
$resource = array(
'persistend_id' => 1234,
'server' => array(
'host' => 'localhost'
),
);
$expectedPersistentId = '1234';
$this->resourceManager->setResource($resourceId, $resource);
$this->assertNotSame($expectedPersistentId, $this->resourceManager->getPersistentId($resourceId));
$this->assertEmpty($this->resourceManager->getPersistentId($resourceId));
}
}
<file_sep><?php
/**
* Zend Framework (http://framework.zend.com/)
*
* @link http://github.com/zendframework/zf2 for the canonical source repository
* @copyright Copyright (c) 2005-2014 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
*/
namespace Zend\Db\Sql;
use Zend\Db\Adapter\AdapterInterface;
use Zend\Db\Adapter\ParameterContainer;
use Zend\Db\Adapter\Platform\PlatformInterface;
use Zend\Db\Adapter\Platform\Sql92;
use Zend\Db\Adapter\StatementContainerInterface;
class Insert extends AbstractSql implements SqlInterface, PreparableSqlInterface
{
/**#@+
* Constants
*
* @const
*/
const SPECIFICATION_INSERT = 'insert';
const VALUES_MERGE = 'merge';
const VALUES_SET = 'set';
/**#@-*/
/**
* @var array Specification array
*/
protected $specifications = array(
self::SPECIFICATION_INSERT => 'INSERT INTO %1$s (%2$s) VALUES (%3$s)'
);
/**
* @var string|TableIdentifier
*/
protected $table = null;
protected $columns = array();
/**
* @var array
*/
protected $values = array();
/**
* Constructor
*
* @param null|string|TableIdentifier $table
*/
public function __construct($table = null)
{
if ($table) {
$this->into($table);
}
}
/**
* Crete INTO clause
*
* @param string|TableIdentifier $table
* @return Insert
*/
public function into($table)
{
$this->table = $table;
return $this;
}
/**
* Specify columns
*
* @param array $columns
* @return Insert
*/
public function columns(array $columns)
{
$this->columns = $columns;
return $this;
}
/**
* Specify values to insert
*
* @param array $values
* @param string $flag one of VALUES_MERGE or VALUES_SET; defaults to VALUES_SET
* @throws Exception\InvalidArgumentException
* @return Insert
*/
public function values(array $values, $flag = self::VALUES_SET)
{
if ($values == null) {
throw new Exception\InvalidArgumentException('values() expects an array of values');
}
// determine if this is assoc or a set of values
$keys = array_keys($values);
$firstKey = current($keys);
if ($flag == self::VALUES_SET) {
$this->columns = array();
$this->values = array();
}
if (is_string($firstKey)) {
foreach ($keys as $key) {
if (($index = array_search($key, $this->columns)) !== false) {
$this->values[$index] = $values[$key];
} else {
$this->columns[] = $key;
$this->values[] = $values[$key];
}
}
} elseif (is_int($firstKey)) {
// determine if count of columns should match count of values
$this->values = array_merge($this->values, array_values($values));
}
return $this;
}
public function getRawState($key = null)
{
$rawState = array(
'table' => $this->table,
'columns' => $this->columns,
'values' => $this->values
);
return (isset($key) && array_key_exists($key, $rawState)) ? $rawState[$key] : $rawState;
}
/**
* Prepare statement
*
* @param AdapterInterface $adapter
* @param StatementContainerInterface $statementContainer
* @return void
*/
public function prepareStatement(AdapterInterface $adapter, StatementContainerInterface $statementContainer)
{
$driver = $adapter->getDriver();
$platform = $adapter->getPlatform();
$parameterContainer = $statementContainer->getParameterContainer();
if (!$parameterContainer instanceof ParameterContainer) {
$parameterContainer = new ParameterContainer();
$statementContainer->setParameterContainer($parameterContainer);
}
$table = $this->table;
$schema = null;
// create quoted table name to use in insert processing
if ($table instanceof TableIdentifier) {
list($table, $schema) = $table->getTableAndSchema();
}
$table = $platform->quoteIdentifier($table);
if ($schema) {
$table = $platform->quoteIdentifier($schema) . $platform->getIdentifierSeparator() . $table;
}
$columns = array();
$values = array();
foreach ($this->columns as $cIndex => $column) {
$columns[$cIndex] = $platform->quoteIdentifier($column);
if (isset($this->values[$cIndex]) && $this->values[$cIndex] instanceof Expression) {
$exprData = $this->processExpression($this->values[$cIndex], $platform, $driver);
$values[$cIndex] = $exprData->getSql();
$parameterContainer->merge($exprData->getParameterContainer());
} else {
$values[$cIndex] = $driver->formatParameterName($column);
if (isset($this->values[$cIndex])) {
$parameterContainer->offsetSet($column, $this->values[$cIndex]);
} else {
$parameterContainer->offsetSet($column, null);
}
}
}
$sql = sprintf(
$this->specifications[self::SPECIFICATION_INSERT],
$table,
implode(', ', $columns),
implode(', ', $values)
);
$statementContainer->setSql($sql);
}
/**
* Get SQL string for this statement
*
* @param null|PlatformInterface $adapterPlatform Defaults to Sql92 if none provided
* @return string
*/
public function getSqlString(PlatformInterface $adapterPlatform = null)
{
$adapterPlatform = ($adapterPlatform) ?: new Sql92;
$table = $this->table;
$schema = null;
// create quoted table name to use in insert processing
if ($table instanceof TableIdentifier) {
list($table, $schema) = $table->getTableAndSchema();
}
$table = $adapterPlatform->quoteIdentifier($table);
if ($schema) {
$table = $adapterPlatform->quoteIdentifier($schema) . $adapterPlatform->getIdentifierSeparator() . $table;
}
$columns = array_map(array($adapterPlatform, 'quoteIdentifier'), $this->columns);
$columns = implode(', ', $columns);
$values = array();
foreach ($this->values as $value) {
if ($value instanceof Expression) {
$exprData = $this->processExpression($value, $adapterPlatform);
$values[] = $exprData->getSql();
} elseif ($value === null) {
$values[] = 'NULL';
} else {
$values[] = $adapterPlatform->quoteValue($value);
}
}
$values = implode(', ', $values);
return sprintf($this->specifications[self::SPECIFICATION_INSERT], $table, $columns, $values);
}
/**
* Overloading: variable setting
*
* Proxies to values, using VALUES_MERGE strategy
*
* @param string $name
* @param mixed $value
* @return Insert
*/
public function __set($name, $value)
{
$values = array($name => $value);
$this->values($values, self::VALUES_MERGE);
return $this;
}
/**
* Overloading: variable unset
*
* Proxies to values and columns
*
* @param string $name
* @throws Exception\InvalidArgumentException
* @return void
*/
public function __unset($name)
{
if (($position = array_search($name, $this->columns)) === false) {
throw new Exception\InvalidArgumentException('The key ' . $name . ' was not found in this objects column list');
}
unset($this->columns[$position]);
unset($this->values[$position]);
}
/**
* Overloading: variable isset
*
* Proxies to columns; does a column of that name exist?
*
* @param string $name
* @return bool
*/
public function __isset($name)
{
return in_array($name, $this->columns);
}
/**
* Overloading: variable retrieval
*
* Retrieves value by column name
*
* @param string $name
* @throws Exception\InvalidArgumentException
* @return mixed
*/
public function __get($name)
{
if (($position = array_search($name, $this->columns)) === false) {
throw new Exception\InvalidArgumentException('The key ' . $name . ' was not found in this objects column list');
}
return $this->values[$position];
}
}
<file_sep><?php
/**
* Zend Framework (http://framework.zend.com/)
*
* @link http://github.com/zendframework/zf2 for the canonical source repository
* @copyright Copyright (c) 2005-2014 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
*/
namespace Zend\Di\Definition;
use Zend\Code\Annotation\AnnotationCollection;
use Zend\Code\Reflection;
use Zend\Di\Di;
/**
* Class definitions based on runtime reflection
*/
class RuntimeDefinition implements DefinitionInterface
{
/**
* @var array
*/
protected $classes = array();
/**
* @var bool
*/
protected $explicitLookups = false;
/**
* @var IntrospectionStrategy
*/
protected $introspectionStrategy = null;
/**
* @var array
*/
protected $injectionMethods = array();
/**
* Constructor
*
* @param null|IntrospectionStrategy $introspectionStrategy
* @param array|null $explicitClasses
*/
public function __construct(IntrospectionStrategy $introspectionStrategy = null, array $explicitClasses = null)
{
$this->introspectionStrategy = ($introspectionStrategy) ?: new IntrospectionStrategy();
if ($explicitClasses) {
$this->setExplicitClasses($explicitClasses);
}
}
/**
* @param IntrospectionStrategy $introspectionStrategy
* @return void
*/
public function setIntrospectionStrategy(IntrospectionStrategy $introspectionStrategy)
{
$this->introspectionStrategy = $introspectionStrategy;
}
/**
* @return IntrospectionStrategy
*/
public function getIntrospectionStrategy()
{
return $this->introspectionStrategy;
}
/**
* Set explicit classes
*
* @param array $explicitClasses
*/
public function setExplicitClasses(array $explicitClasses)
{
$this->explicitLookups = true;
foreach ($explicitClasses as $eClass) {
$this->classes[$eClass] = true;
}
$this->classes = $explicitClasses;
}
/**
* @param string $class
*/
public function forceLoadClass($class)
{
$this->processClass($class);
}
/**
* {@inheritDoc}
*/
public function getClasses()
{
return array_keys($this->classes);
}
/**
* {@inheritDoc}
*/
public function hasClass($class)
{
if ($this->explicitLookups === true) {
return (array_key_exists($class, $this->classes));
}
return class_exists($class) || interface_exists($class);
}
/**
* {@inheritDoc}
*/
public function getClassSupertypes($class)
{
if (!array_key_exists($class, $this->classes)) {
$this->processClass($class);
}
return $this->classes[$class]['supertypes'];
}
/**
* {@inheritDoc}
*/
public function getInstantiator($class)
{
if (!array_key_exists($class, $this->classes)) {
$this->processClass($class);
}
return $this->classes[$class]['instantiator'];
}
/**
* {@inheritDoc}
*/
public function hasMethods($class)
{
if (!array_key_exists($class, $this->classes)) {
$this->processClass($class);
}
return (count($this->classes[$class]['methods']) > 0);
}
/**
* {@inheritDoc}
*/
public function hasMethod($class, $method)
{
if (!array_key_exists($class, $this->classes)) {
$this->processClass($class);
}
return isset($this->classes[$class]['methods'][$method]);
}
/**
* {@inheritDoc}
*/
public function getMethods($class)
{
if (!array_key_exists($class, $this->classes)) {
$this->processClass($class);
}
return $this->classes[$class]['methods'];
}
/**
* {@inheritDoc}
*/
public function hasMethodParameters($class, $method)
{
if (!isset($this->classes[$class])) {
return false;
}
return (array_key_exists($method, $this->classes[$class]['parameters']));
}
/**
* {@inheritDoc}
*/
public function getMethodParameters($class, $method)
{
if (!is_array($this->classes[$class])) {
$this->processClass($class);
}
return $this->classes[$class]['parameters'][$method];
}
/**
* @param string $class
*/
protected function processClass($class)
{
$strategy = $this->introspectionStrategy; // localize for readability
/** @var $rClass \Zend\Code\Reflection\ClassReflection */
$rClass = new Reflection\ClassReflection($class);
$className = $rClass->getName();
$matches = null; // used for regex below
// setup the key in classes
$this->classes[$className] = array(
'supertypes' => array(),
'instantiator' => null,
'methods' => array(),
'parameters' => array()
);
$def = &$this->classes[$className]; // localize for brevity
// class annotations?
if ($strategy->getUseAnnotations() == true) {
$annotations = $rClass->getAnnotations($strategy->getAnnotationManager());
if (($annotations instanceof AnnotationCollection)
&& $annotations->hasAnnotation('Zend\Di\Definition\Annotation\Instantiator')) {
// @todo Instantiator support in annotations
}
}
$rTarget = $rClass;
$supertypes = array();
do {
$supertypes = array_merge($supertypes, $rTarget->getInterfaceNames());
if (!($rTargetParent = $rTarget->getParentClass())) {
break;
}
$supertypes[] = $rTargetParent->getName();
$rTarget = $rTargetParent;
} while (true);
$def['supertypes'] = $supertypes;
if ($def['instantiator'] == null) {
if ($rClass->isInstantiable()) {
$def['instantiator'] = '__construct';
}
}
if ($rClass->hasMethod('__construct')) {
$def['methods']['__construct'] = Di::METHOD_IS_CONSTRUCTOR; // required
$this->processParams($def, $rClass, $rClass->getMethod('__construct'));
}
foreach ($rClass->getMethods(Reflection\MethodReflection::IS_PUBLIC) as $rMethod) {
$methodName = $rMethod->getName();
if ($rMethod->getName() === '__construct' || $rMethod->isStatic()) {
continue;
}
if ($strategy->getUseAnnotations() == true) {
$annotations = $rMethod->getAnnotations($strategy->getAnnotationManager());
if (($annotations instanceof AnnotationCollection)
&& $annotations->hasAnnotation('Zend\Di\Definition\Annotation\Inject')) {
// use '@inject' and search for parameters
$def['methods'][$methodName] = Di::METHOD_IS_EAGER;
$this->processParams($def, $rClass, $rMethod);
continue;
}
}
$methodPatterns = $this->introspectionStrategy->getMethodNameInclusionPatterns();
// matches a method injection pattern?
foreach ($methodPatterns as $methodInjectorPattern) {
preg_match($methodInjectorPattern, $methodName, $matches);
if ($matches) {
$def['methods'][$methodName] = Di::METHOD_IS_OPTIONAL; // check ot see if this is required?
$this->processParams($def, $rClass, $rMethod);
continue 2;
}
}
// method
// by annotation
// by setter pattern,
// by interface
}
$interfaceInjectorPatterns = $this->introspectionStrategy->getInterfaceInjectionInclusionPatterns();
// matches the interface injection pattern
/** @var $rIface \ReflectionClass */
foreach ($rClass->getInterfaces() as $rIface) {
foreach ($interfaceInjectorPatterns as $interfaceInjectorPattern) {
preg_match($interfaceInjectorPattern, $rIface->getName(), $matches);
if ($matches) {
foreach ($rIface->getMethods() as $rMethod) {
if (($rMethod->getName() === '__construct') || !count($rMethod->getParameters())) {
// constructor not allowed in interfaces
// Don't call interface methods without a parameter (Some aware interfaces define setters in ZF2)
continue;
}
$def['methods'][$rMethod->getName()] = Di::METHOD_IS_AWARE;
$this->processParams($def, $rClass, $rMethod);
}
continue 2;
}
}
}
}
/**
* @param array $def
* @param \Zend\Code\Reflection\ClassReflection $rClass
* @param \Zend\Code\Reflection\MethodReflection $rMethod
*/
protected function processParams(&$def, Reflection\ClassReflection $rClass, Reflection\MethodReflection $rMethod)
{
if (count($rMethod->getParameters()) === 0) {
return;
}
$methodName = $rMethod->getName();
// @todo annotations here for alternate names?
$def['parameters'][$methodName] = array();
foreach ($rMethod->getParameters() as $p) {
/** @var $p \ReflectionParameter */
$actualParamName = $p->getName();
$fqName = $rClass->getName() . '::' . $rMethod->getName() . ':' . $p->getPosition();
$def['parameters'][$methodName][$fqName] = array();
// set the class name, if it exists
$def['parameters'][$methodName][$fqName][] = $actualParamName;
$def['parameters'][$methodName][$fqName][] = ($p->getClass() !== null) ? $p->getClass()->getName() : null;
$def['parameters'][$methodName][$fqName][] = !($optional = $p->isOptional() && $p->isDefaultValueAvailable());
$def['parameters'][$methodName][$fqName][] = $optional ? $p->getDefaultValue() : null;
}
}
}
<file_sep><?php
/**
* Zend Framework (http://framework.zend.com/)
*
* @link http://github.com/zendframework/zf2 for the canonical source repository
* @copyright Copyright (c) 2005-2013 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
*/
namespace ZendTest\Code\Reflection;
use Zend\Code\Reflection\MethodReflection;
use ZendTest\Code\Reflection\TestAsset\InjectableMethodReflection;
/**
* @group Zend_Reflection
* @group Zend_Reflection_Method
*/
class MethodReflectionTest extends \PHPUnit_Framework_TestCase
{
public function testDeclaringClassReturn()
{
$method = new MethodReflection('ZendTest\Code\Reflection\TestAsset\TestSampleClass2', 'getProp1');
$this->assertInstanceOf('Zend\Code\Reflection\ClassReflection', $method->getDeclaringClass());
}
public function testParemeterReturn()
{
$method = new MethodReflection('ZendTest\Code\Reflection\TestAsset\TestSampleClass2', 'getProp2');
$parameters = $method->getParameters();
$this->assertEquals(2, count($parameters));
$this->assertInstanceOf('Zend\Code\Reflection\ParameterReflection', array_shift($parameters));
}
public function testStartLine()
{
$reflectionMethod = new MethodReflection('ZendTest\Code\Reflection\TestAsset\TestSampleClass5', 'doSomething');
$this->assertEquals(37, $reflectionMethod->getStartLine());
$this->assertEquals(21, $reflectionMethod->getStartLine(true));
}
public function testGetBodyReturnsCorrectBody()
{
$body = ' //we need a multi-line method body.
$assigned = 1;
$alsoAssigined = 2;
return \'mixedValue\';';
$reflectionMethod = new MethodReflection('ZendTest\Code\Reflection\TestAsset\TestSampleClass6', 'doSomething');
$this->assertEquals($body, $reflectionMethod->getBody());
}
public function testGetContentsReturnsCorrectContent()
{
$reflectionMethod = new MethodReflection('ZendTest\Code\Reflection\TestAsset\TestSampleClass5', 'doSomething');
$this->assertEquals(" {\n\n return 'mixedValue';\n\n }\n", $reflectionMethod->getContents(false));
}
public function testGetAnnotationsWithNoNameInformations()
{
$reflectionMethod = new InjectableMethodReflection(
// TestSampleClass5 has the annotations required to get to the
// right point in the getAnnotations method.
'ZendTest\Code\Reflection\TestAsset\TestSampleClass5',
'doSomething'
);
$annotationManager = new \Zend\Code\Annotation\AnnotationManager();
$fileScanner = $this->getMockBuilder('Zend\Code\Scanner\CachingFileScanner')
->disableOriginalConstructor()
->getMock();
$reflectionMethod->setFileScanner($fileScanner);
$fileScanner->expects($this->any())
->method('getClassNameInformation')
->will($this->returnValue(false));
$this->assertFalse($reflectionMethod->getAnnotations($annotationManager));
}
/**
* @group 5062
*/
public function testGetContentsWithCoreClass()
{
$reflectionMethod = new MethodReflection('DateTime', 'format');
$this->assertEquals("", $reflectionMethod->getContents(false));
}
public function testGetContentsReturnsEmptyContentsOnEvaldCode()
{
$className = uniqid('MethodReflectionTestGenerated');
eval('name' . 'space ' . __NAMESPACE__ . '; cla' . 'ss ' . $className . '{fun' . 'ction foo(){}}');
$reflectionMethod = new MethodReflection(__NAMESPACE__ . '\\' . $className, 'foo');
$this->assertSame('', $reflectionMethod->getContents());
$this->assertSame('', $reflectionMethod->getBody());
}
public function testGetContentsReturnsEmptyContentsOnInternalCode()
{
$reflectionMethod = new MethodReflection('ReflectionClass', 'getName');
$this->assertSame('', $reflectionMethod->getContents());
}
}
<file_sep><?php
/**
* Zend Framework (http://framework.zend.com/)
*
* @link http://github.com/zendframework/zf2 for the canonical source repository
* @copyright Copyright (c) 2005-2014 Zend Technologies USA Inc. (http://www.zend.com)
* @license http://framework.zend.com/license/new-bsd New BSD License
*/
namespace Zend\Form\View\Helper;
use RuntimeException;
use Zend\Form\Element;
use Zend\Form\ElementInterface;
use Zend\Form\Element\Collection as CollectionElement;
use Zend\Form\FieldsetInterface;
use Zend\View\Helper\AbstractHelper as BaseAbstractHelper;
class FormCollection extends AbstractHelper
{
/**
* If set to true, collections are automatically wrapped around a fieldset
*
* @var bool
*/
protected $shouldWrap = true;
/**
* The name of the default view helper that is used to render sub elements.
*
* @var string
*/
protected $defaultElementHelper = 'formrow';
/**
* The view helper used to render sub elements.
*
* @var AbstractHelper
*/
protected $elementHelper;
/**
* The view helper used to render sub fieldsets.
*
* @var AbstractHelper
*/
protected $fieldsetHelper;
/**
* Invoke helper as function
*
* Proxies to {@link render()}.
*
* @param ElementInterface|null $element
* @param bool $wrap
* @return string|FormCollection
*/
public function __invoke(ElementInterface $element = null, $wrap = true)
{
if (!$element) {
return $this;
}
$this->setShouldWrap($wrap);
return $this->render($element);
}
/**
* Render a collection by iterating through all fieldsets and elements
*
* @param ElementInterface $element
* @return string
*/
public function render(ElementInterface $element)
{
$renderer = $this->getView();
if (!method_exists($renderer, 'plugin')) {
// Bail early if renderer is not pluggable
return '';
}
$markup = '';
$templateMarkup = '';
$escapeHtmlHelper = $this->getEscapeHtmlHelper();
$elementHelper = $this->getElementHelper();
$fieldsetHelper = $this->getFieldsetHelper();
if ($element instanceof CollectionElement && $element->shouldCreateTemplate()) {
$templateMarkup = $this->renderTemplate($element);
}
foreach ($element->getIterator() as $elementOrFieldset) {
if ($elementOrFieldset instanceof FieldsetInterface) {
$markup .= $fieldsetHelper($elementOrFieldset);
} elseif ($elementOrFieldset instanceof ElementInterface) {
$markup .= $elementHelper($elementOrFieldset);
}
}
// If $templateMarkup is not empty, use it for simplify adding new element in JavaScript
if (!empty($templateMarkup)) {
$markup .= $templateMarkup;
}
// Every collection is wrapped by a fieldset if needed
if ($this->shouldWrap) {
$label = $element->getLabel();
if (!empty($label)) {
if (null !== ($translator = $this->getTranslator())) {
$label = $translator->translate(
$label,
$this->getTranslatorTextDomain()
);
}
$label = $escapeHtmlHelper($label);
$markup = sprintf(
'<fieldset><legend>%s</legend>%s</fieldset>',
$label,
$markup
);
}
}
return $markup;
}
/**
* Only render a template
*
* @param CollectionElement $collection
* @return string
*/
public function renderTemplate(CollectionElement $collection)
{
$elementHelper = $this->getElementHelper();
$escapeHtmlAttribHelper = $this->getEscapeHtmlAttrHelper();
$templateMarkup = '';
$elementOrFieldset = $collection->getTemplateElement();
if ($elementOrFieldset instanceof FieldsetInterface) {
$templateMarkup .= $this->render($elementOrFieldset);
} elseif ($elementOrFieldset instanceof ElementInterface) {
$templateMarkup .= $elementHelper($elementOrFieldset);
}
return sprintf(
'<span data-template="%s"></span>',
$escapeHtmlAttribHelper($templateMarkup)
);
}
/**
* If set to true, collections are automatically wrapped around a fieldset
*
* @param bool $wrap
* @return FormCollection
*/
public function setShouldWrap($wrap)
{
$this->shouldWrap = (bool) $wrap;
return $this;
}
/**
* Get wrapped
*
* @return bool
*/
public function shouldWrap()
{
return $this->shouldWrap;
}
/**
* Sets the name of the view helper that should be used to render sub elements.
*
* @param string $defaultSubHelper The name of the view helper to set.
* @return FormCollection
*/
public function setDefaultElementHelper($defaultSubHelper)
{
$this->defaultElementHelper = $defaultSubHelper;
return $this;
}
/**
* Gets the name of the view helper that should be used to render sub elements.
*
* @return string
*/
public function getDefaultElementHelper()
{
return $this->defaultElementHelper;
}
/**
* Sets the element helper that should be used by this collection.
*
* @param AbstractHelper $elementHelper The element helper to use.
* @return FormCollection
*/
public function setElementHelper(AbstractHelper $elementHelper)
{
$this->elementHelper = $elementHelper;
return $this;
}
/**
* Retrieve the element helper.
*
* @return AbstractHelper
* @throws RuntimeException
*/
protected function getElementHelper()
{
if ($this->elementHelper) {
return $this->elementHelper;
}
if (method_exists($this->view, 'plugin')) {
$this->elementHelper = $this->view->plugin($this->getDefaultElementHelper());
}
if (!$this->elementHelper instanceof BaseAbstractHelper) {
// @todo Ideally the helper should implement an interface.
throw new RuntimeException('Invalid element helper set in FormCollection. The helper must be an instance of AbstractHelper.');
}
return $this->elementHelper;
}
/**
* Sets the fieldset helper that should be used by this collection.
*
* @param AbstractHelper $fieldsetHelper The fieldset helper to use.
* @return FormCollection
*/
public function setFieldsetHelper(AbstractHelper $fieldsetHelper)
{
$this->fieldsetHelper = $fieldsetHelper;
return $this;
}
/**
* Retrieve the fieldset helper.
*
* @return FormCollection
*/
protected function getFieldsetHelper()
{
if ($this->fieldsetHelper) {
return $this->fieldsetHelper;
}
return $this;
}
}
| 432125434e20be3783df1302bd8bf9935d8131d2 | [
"PHP"
] | 10 | PHP | ezimuel/zf2 | 368e4adcc138c5662014427bb4556455237ed98d | dcb20582dbe402985e21718bbe163742da5427eb |
refs/heads/master | <repo_name>neroxdt/springBoots<file_sep>/security-spring/src/main/java/com/spring/oauth2/cloud/controller/SampleController.java
package com.spring.oauth2.cloud.controller;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.oauth2.config.annotation.web.configuration.EnableResourceServer;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@Configuration
@RestController
@EnableResourceServer
public class SampleController {
@RequestMapping("/greet")
public String saludo(@RequestParam(value="name", defaultValue="World") String name) {
return "Hello " + name;
}
// @Override
// public void configure(HttpSecurity http) throws Exception {
// http.csrf().disable()
// .authorizeRequests()
// .antMatchers("/login").permitAll()
// .antMatchers("/oauth/token").permitAll()
// // .antMatchers("/greet").permitAll()
// .anyRequest().authenticated()
// .and()
// .sessionManagement()
// .sessionCreationPolicy(SessionCreationPolicy.IF_REQUIRED)
// .maximumSessions(1);
// }
// @Override
// public void configure(ResourceServerSecurityConfigurer resources) throws Exception {
// resources.resourceId("Semple");
// resources.tokenStore(tokenStore());
// }
//
// @Bean
// public TokenStore tokenStore() {
// return new InMemoryTokenStore();
// }
//
// @Autowired
// public void configureGlobal(AuthenticationManagerBuilder auth) {
// auth.authenticationProvider(authenticationProvider());
// }
// @Bean
// public AuthenticationProvider authenticationProvider() {
// return new UserProvider(tokenServices);
// }
}<file_sep>/security-spring/src/main/java/com/spring/oauth2/cloud/config/AuthServerOAuth2Config.java
package com.spring.oauth2.cloud.config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.annotation.Order;
import org.springframework.security.authentication.AuthenticationManager;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.http.SessionCreationPolicy;
import org.springframework.security.oauth2.config.annotation.configurers.ClientDetailsServiceConfigurer;
import org.springframework.security.oauth2.config.annotation.web.configuration.AuthorizationServerConfigurerAdapter;
import org.springframework.security.oauth2.config.annotation.web.configuration.AuthorizationServerSecurityConfiguration;
import org.springframework.security.oauth2.config.annotation.web.configuration.EnableAuthorizationServer;
import org.springframework.security.oauth2.config.annotation.web.configurers.AuthorizationServerEndpointsConfigurer;
import org.springframework.security.oauth2.config.annotation.web.configurers.AuthorizationServerSecurityConfigurer;
import org.springframework.security.oauth2.provider.token.TokenStore;
import org.springframework.security.oauth2.provider.token.store.InMemoryTokenStore;
import org.springframework.security.web.session.HttpSessionEventPublisher;
@Configuration
@EnableAuthorizationServer
public class AuthServerOAuth2Config extends AuthorizationServerConfigurerAdapter {
@Autowired
private AuthenticationManager authenticationManager;
@Override
public void configure(AuthorizationServerSecurityConfigurer oauthServer) throws Exception {
oauthServer
.tokenKeyAccess("permitAll()")
.checkTokenAccess("isAuthenticated()");
oauthServer.addTokenEndpointAuthenticationFilter(new CustomFilter());
}
@Override
public void configure(ClientDetailsServiceConfigurer clients) throws Exception {
clients.inMemory().withClient("client").secret("clientSecret")
.authorizedGrantTypes("password", "refresh_token").scopes("read", "write")
// .autoApprove(true)
.accessTokenValiditySeconds(60).refreshTokenValiditySeconds(120);
}
@Override
public void configure(AuthorizationServerEndpointsConfigurer endpoints) throws Exception {
endpoints.tokenStore(tokenStore()).authenticationManager(authenticationManager);
}
@Bean
public TokenStore tokenStore() {
return new InMemoryTokenStore();
}
@Configuration
@Order(-1)
public class CustomSecurityConfig extends AuthorizationServerSecurityConfiguration {
@Bean
public HttpSessionEventPublisher httpSessionEventPublisher() {
return new HttpSessionEventPublisher();
}
@Override
protected void configure(HttpSecurity http) throws Exception {
super.configure(http); // do the default configuration first
http.sessionManagement().sessionCreationPolicy(SessionCreationPolicy.IF_REQUIRED).maximumSessions(1)
.maxSessionsPreventsLogin(true);
}
}
} | 93115a426e39517eb8e9b28a6556db9e3834467e | [
"Java"
] | 2 | Java | neroxdt/springBoots | 3ca063b79fa5be7fcd63dcc0f69b0772deea5550 | e4dc90a5834b097a06514f616d44d2c97279ce68 |
refs/heads/master | <file_sep>package ru.appliedtech.chess.roundrobinsitegenerator.tournament_table;
import freemarker.template.Configuration;
import freemarker.template.Template;
import freemarker.template.TemplateException;
import java.io.IOException;
import java.io.Writer;
public class TournamentTableViewHtmlRenderingEngine implements TournamentTableViewRenderingEngine {
private final Configuration templatesConfiguration;
public TournamentTableViewHtmlRenderingEngine(Configuration templatesConfiguration) {
this.templatesConfiguration = templatesConfiguration;
}
@Override
public void render(TournamentTableView tournamentTableView, Writer writer) throws IOException {
Template template = templatesConfiguration.getTemplate("tournamentTable.ftl");
try {
template.process(tournamentTableView, writer);
writer.flush();
} catch (TemplateException e) {
throw new IOException(e);
}
}
}
<file_sep>package ru.appliedtech.chess.roundrobinsitegenerator.player_status;
import java.io.IOException;
import java.io.OutputStream;
public interface PlayerStatusViewRenderingEngine {
void render(PlayerStatusView playerStatusView, OutputStream os) throws IOException;
}
<file_sep>package ru.appliedtech.chess.roundrobinsitegenerator.tournament_table;
import ru.appliedtech.chess.TournamentDescription;
import ru.appliedtech.chess.roundrobin.TournamentTable;
import ru.appliedtech.chess.roundrobinsitegenerator.model.*;
import ru.appliedtech.chess.tiebreaksystems.TieBreakSystem;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
import java.util.Locale;
import java.util.ResourceBundle;
import static java.util.stream.Collectors.toList;
public class TournamentTableView {
private static final String QUIT_PLAYER = "–";
private static final String QUIT_OPPONENT = "+";
private final HeaderRowView headerRowView;
private final ResourceBundle resourceBundle;
private final List<PlayerRowView> playerRowViews;
private final TournamentDescription tournamentDescription;
private final PlayerLinks playerLinks;
public TournamentTableView(Locale locale, TournamentTable tournamentTable,
TournamentDescription tournamentDescription, PlayerLinks playerLinks) {
this.resourceBundle = ResourceBundle.getBundle("resources", locale);
this.playerLinks = playerLinks;
this.headerRowView = createHeaderRowView(tournamentTable);
this.playerRowViews = createPlayerRowViews(tournamentTable);
this.tournamentDescription = tournamentDescription;
}
public String getTournamentTitle() {
return tournamentDescription.getTournamentTitle();
}
public HeaderRowView getHeaderRowView() {
return headerRowView;
}
public List<PlayerRowView> getPlayerRowViews() {
return playerRowViews;
}
private HeaderRowView createHeaderRowView(TournamentTable tournamentTable) {
List<HeaderCell> headerCells = new ArrayList<>();
headerCells.add(new HeaderCell(resourceBundle.getString("tournament.table.view.header.index")));
headerCells.add(new HeaderCell(resourceBundle.getString("tournament.table.view.header.player")));
headerCells.add(new HeaderCell(resourceBundle.getString("tournament.table.view.header.rating")));
for (int i = 0; i < tournamentTable.getPlayersCount(); i++) {
headerCells.add(new HeaderCell(
resourceBundle.getString("tournament.table.view.header.opponent") + (i + 1)));
}
headerCells.add(new HeaderCell(resourceBundle.getString("tournament.table.view.header.gamesPlayed")));
for (int i = 0; i < tournamentTable.getTieBreakSystems().size(); i++) {
TieBreakSystem tieBreakSystem = tournamentTable.getTieBreakSystems().get(i);
headerCells.add(new HeaderCell(
resourceBundle.getString("tournament.table.view.header.tieBreakSystem." + tieBreakSystem.getName())));
}
headerCells.add(new HeaderCell(resourceBundle.getString("tournament.table.view.header.rank")));
headerCells.add(new HeaderCell(resourceBundle.getString("tournament.table.view.header.newRating")));
return new HeaderRowView(headerCells);
}
private List<PlayerRowView> createPlayerRowViews(TournamentTable tournamentTable) {
List<PlayerRowView> rowViews = new ArrayList<>();
List<TournamentTable.PlayerRow> playerRows = tournamentTable.getPlayerRows();
for (int i = 0; i < playerRows.size(); i++) {
TournamentTable.PlayerRow playerRow = playerRows.get(i);
List<CellView> cells = new ArrayList<>();
cells.add(new IntCellView(i + 1));
cells.add(new CellView(
playerRow.getPlayer().getFirstName() + " " + playerRow.getPlayer().getLastName(),
playerLinks.getLink(playerRow.getPlayer().getId()).map(PlayerLink::getLink).orElse(null),
1,
1));
cells.add(new RatingCellView(playerRow.getInitialRating().getValue()));
for (int j = 0; j < playerRows.size(); j++) {
if (j != i) {
String opponentId = playerRows.get(j).getPlayer().getId();
TournamentTable.OpponentCell opponentCell = playerRow.getOpponents().stream()
.filter(o -> o.getOpponentId().equals(opponentId))
.findFirst()
.orElseThrow(IllegalStateException::new);
CellView scoreCellView = opponentCell.getScores().stream()
.reduce(BigDecimal::add)
.map(score -> (CellView)new OpponentScoreCellView(score))
.orElse(toEmptyScoreCellView(playerRow, opponentCell));
cells.add(scoreCellView);
} else {
cells.add(new DiagonalCellView());
}
}
cells.add(new IntCellView(playerRow.getGamesPlayed()));
cells.addAll(playerRow.getTieBreakValues().stream()
.map(tieBreakValue -> new ScoreCellView(tieBreakValue.getValue()))
.collect(toList()));
cells.add(playerRow.isQuit() ? new CellView(QUIT_PLAYER) : new IntCellView(tournamentTable.getRanking().get(playerRow.getPlayer().getId())));
cells.add(new RatingCellView(playerRow.getCurrentRating().getValue()));
rowViews.add(new PlayerRowView(cells));
}
return rowViews;
}
private CellView toEmptyScoreCellView(TournamentTable.PlayerRow playerRow, TournamentTable.OpponentCell opponentCell) {
if (opponentCell.isQuit() && playerRow.isQuit()) {
return new CellView(QUIT_PLAYER);
}
else if (opponentCell.isQuit()) {
return new CellView(QUIT_OPPONENT);
}
else if (playerRow.isQuit()) {
return new CellView(QUIT_PLAYER);
}
return new NoScoreCellView();
}
public boolean isDiagonalCell(CellView cellView) {
return cellView instanceof DiagonalCellView;
}
}
<file_sep>package ru.appliedtech.chess.roundrobinsitegenerator.player_status;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import freemarker.template.Configuration;
import freemarker.template.Template;
import freemarker.template.TemplateException;
import freemarker.template.TemplateExceptionHandler;
import ru.appliedtech.chess.*;
import ru.appliedtech.chess.elorating.EloRating;
import ru.appliedtech.chess.elorating.KValueSet;
import ru.appliedtech.chess.roundrobin.RoundRobinSetup;
import ru.appliedtech.chess.roundrobin.color_allocating.ColorAllocatingSystemFactory;
import ru.appliedtech.chess.roundrobin.io.RoundRobinSetupObjectNodeReader;
import ru.appliedtech.chess.roundrobin.player_status.PlayerStatus;
import ru.appliedtech.chess.roundrobinsitegenerator.RoundRobinSiteGenerator;
import ru.appliedtech.chess.roundrobinsitegenerator.model.PlayerLinks;
import ru.appliedtech.chess.storage.*;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.*;
import static java.util.Arrays.asList;
import static java.util.Collections.emptyList;
import static java.util.Collections.emptyMap;
import static java.util.stream.Collectors.toList;
import static ru.appliedtech.chess.roundrobin.RoundRobinSetup.ColorAllocatingSystemDescription;
public class PlayerStatusViewHtmlRenderingEngine implements PlayerStatusViewRenderingEngine {
private final Configuration templatesConfiguration;
public PlayerStatusViewHtmlRenderingEngine(Configuration templatesConfiguration) {
this.templatesConfiguration = templatesConfiguration;
}
@Override
public void render(PlayerStatusView playerStatusView, OutputStream os) throws IOException {
Template template = templatesConfiguration.getTemplate("playerStatus.ftl");
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(os, StandardCharsets.UTF_8));
try {
template.process(playerStatusView, bw);
bw.flush();
} catch (TemplateException e) {
throw new IOException(e);
}
}
public static void main(String[] args) throws IOException {
ColorAllocatingSystemDescription colorAllocatingSystemDescription =
new ColorAllocatingSystemDescription("fixed-alternation-color-allocating-system", 123456);
RoundRobinSetup setup = new RoundRobinSetup(
2,
GameResultSystem.STANDARD,
asList("direct-encounter", "number-of-wins", "neustadtl", "koya"),
TimeControlType.BLITZ,
colorAllocatingSystemDescription);
Map<String, TournamentSetupObjectNodeReader> tournamentSetupReaders = new HashMap<>();
tournamentSetupReaders.put("round-robin", new RoundRobinSetupObjectNodeReader());
ObjectMapper baseMapper = new ChessBaseObjectMapper(tournamentSetupReaders);
List<Player> registeredPlayers;
try (FileInputStream fis = new FileInputStream("C:\\Chess\\projects\\Blitz1Dec2018\\data\\players.json")) {
registeredPlayers = baseMapper.readValue(fis, new TypeReference<ArrayList<Player>>() {});
}
ObjectMapper gameObjectMapper = new GameObjectMapper(setup);
List<Game> games;
try (FileInputStream fis = new FileInputStream("C:\\Chess\\projects\\Blitz1Dec2018\\data\\games.json")) {
games = gameObjectMapper.readValue(fis, new TypeReference<ArrayList<Game>>() {});
}
PlayerStorage playerStorage = new PlayerReadOnlyStorage(registeredPlayers);
GameStorage gameStorage = new GameReadOnlyStorage(games);
Map<EloRatingKey, EloRating> ratings = emptyMap();
EloRatingReadOnlyStorage eloRatingStorage = new EloRatingReadOnlyStorage(ratings);
Map<String, KValueSet> kValues = emptyMap();
KValueReadOnlyStorage kValueStorage = new KValueReadOnlyStorage(kValues);
Player player = playerStorage.getPlayer("alexey.biryukov").orElse(null);
TournamentDescription tournamentDescription = new TournamentDescription(
"Title",
"blitz1.dec2018",
"Arbiter",
identifiers(registeredPlayers),
emptyList(),
emptyList(),
"",
new Date(),
setup,
emptyList(),
emptyList(),
null);
PlayerStatus playerStatus = new PlayerStatus(player, playerStorage, gameStorage,
eloRatingStorage, kValueStorage, tournamentDescription, setup);
PlayerLinks playerLinks = new PlayerLinks(id -> null, emptyMap());
PlayerStatusView tournamentTableView = new PlayerStatusView(
new Locale("ru", "RU"),
setup,
playerStatus,
playerLinks,
new ColorAllocatingSystemFactory(setup).create(identifiers(registeredPlayers), emptyList()),
null);
try (OutputStream os = new FileOutputStream("C:\\Temp\\playerStatus.html")) {
Configuration configuration = new Configuration(Configuration.VERSION_2_3_28);
configuration.setDefaultEncoding("UTF-8");
configuration.setTemplateExceptionHandler(TemplateExceptionHandler.RETHROW_HANDLER);
configuration.setLogTemplateExceptions(true);
configuration.setWrapUncheckedExceptions(true);
configuration.setClassForTemplateLoading(RoundRobinSiteGenerator.class, "/");
new PlayerStatusViewHtmlRenderingEngine(configuration).render(tournamentTableView, os);
}
}
private static List<String> identifiers(List<Player> registeredPlayers) {
return registeredPlayers.stream().map(Player::getId).collect(toList());
}
}
<file_sep>tournament.table.view.header.index=
tournament.table.view.header.player=\u0418\u0433\u0440\u043e\u043a
tournament.table.view.header.opponent=
tournament.table.view.header.rating=\u0420\u0435\u0439\u0442\u0438\u043d\u0433
tournament.table.view.header.newRating=\u041d\u043e\u0432\u044b\u0439 \u0440\u0435\u0439\u0442\u0438\u043d\u0433
tournament.table.view.header.gamesPlayed=\u041f\u0430\u0440\u0442\u0438\u0439
tournament.table.view.header.tieBreakSystem.direct-encounter=\u041e\u0447\u043a\u0438
tournament.table.view.header.tieBreakSystem.number-of-wins=\u041f\u043e\u0431\u0435\u0434
tournament.table.view.header.tieBreakSystem.koya=\u041a\u043e\u0439\u0430
tournament.table.view.header.tieBreakSystem.neustadtl=\u041d\u043e\u0439\u0448\u0442\u0430\u0434\u0442\u043b\u044c
tournament.table.view.header.rank=\u041c\u0435\u0441\u0442\u043e
player.status.view.header.opponent=\u041e\u043f\u043f\u043e\u043d\u0435\u043d\u0442
player.status.view.header.gameN=#
player.status.view.header.color=\u0426\u0432\u0435\u0442
player.status.view.header.score=\u0420\u0435\u0437\u0443\u043b\u044c\u0442\u0430\u0442
player.status.view.header.date=\u0414\u0430\u0442\u0430
player.status.view.header.ratingChange=\u0420\u0435\u0439\u0442\u0438\u043d\u0433 \u00b1
player.status.view.white=\u0411\u0435\u043b\u044b\u0439
player.status.view.black=\u0427\u0451\u0440\u043d\u044b\u0439
player.status.view.summary=\u0418\u0442\u043e\u0433
<file_sep>tournament.table.view.header.index=
tournament.table.view.header.player=Player
tournament.table.view.header.opponent=
tournament.table.view.header.rating=Rating
tournament.table.view.header.newRating=New rating
tournament.table.view.header.gamesPlayed=Games played
tournament.table.view.header.tieBreakSystem.direct-encounter=Score
tournament.table.view.header.tieBreakSystem.number-of-wins=Wins
tournament.table.view.header.tieBreakSystem.koya=Koya
tournament.table.view.header.tieBreakSystem.neustadtl=Neustadtl
tournament.table.view.header.rank=Rank
player.status.view.header.opponent=Opponent
player.status.view.header.gameN=#
player.status.view.header.color=Color
player.status.view.header.score=Score
player.status.view.header.date=Date
player.status.view.header.ratingChange=Rating \u00b1
player.status.view.white=White
player.status.view.black=Black
player.status.view.summary=Summary
<file_sep>package ru.appliedtech.chess.roundrobinsitegenerator.model;
public class DiagonalCellView extends CellView {
public DiagonalCellView() {
this(1, 1);
}
public DiagonalCellView(int colspan, int rowspan) {
super("", colspan, rowspan);
}
}
| ffa0923e0355872a3f346b406da71b580f9be691 | [
"Java",
"INI"
] | 7 | Java | chessinappliedtech/roundrobinsitegenerator | d3a83287fcfdf550f66766a2f583db39e2d8aae4 | 469e80d001b9f05e90fc6cd73cb49266245bb8ef |
refs/heads/master | <repo_name>monotera/Database<file_sep>/DominioLibreria/src/entities/Linea.java
/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package entities;
/**
*
* @author USER
*/
public class Linea {
private int cantidad;
private Libro libroEnPrestamo = new Libro();
private double subTotal;
public Libro getLibroEnPrestamo() {
return libroEnPrestamo;
}
public String getTitulo() {
return libroEnPrestamo.getTitulo();
}
public double getPrecioBase() {
return libroEnPrestamo.getPrecioBase();
}
public double getSubTotal() {
return subTotal;
}
public void setSubTotal(double subTotal) {
this.subTotal = subTotal;
}
public void setLibroEnPrestamo(Libro libroEnPrestamo) {
this.libroEnPrestamo = libroEnPrestamo;
}
public Linea(int cantidad, Libro libroEnPrestamo) {
this.cantidad = cantidad;
this.libroEnPrestamo = libroEnPrestamo;
}
public int getCantidad() {
return cantidad;
}
public void setCantidad(int cantidad) {
this.cantidad = cantidad;
}
public Linea() {
}
@Override
public String toString() {
return "Cantidad: " + this.cantidad + "\nLibro en Prestamo:" + this.libroEnPrestamo.toString();
}
}
<file_sep>/AppLibreria/src/applibreria/PantallaLibreriaController.java
/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package applibreria;
import Enums.Denominacion;
import Facades.FacadeLibreria;
import Interfaces.IFacadeLibreria;
import entities.Libro;
import entities.Linea;
import entities.DtoResumen;
import entities.Prestamo;
import java.io.FileInputStream;
import java.io.FilterInputStream;
import java.net.URL;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.ResourceBundle;
import javafx.collections.FXCollections;
import javafx.collections.ObservableList;
import javafx.event.ActionEvent;
import javafx.fxml.FXML;
import javafx.fxml.Initializable;
import javafx.scene.control.Button;
import javafx.scene.control.ComboBox;
import javafx.scene.control.Label;
import javafx.scene.control.SingleSelectionModel;
import javafx.scene.control.Tab;
import javafx.scene.control.TableColumn;
import javafx.scene.control.TableView;
import javafx.scene.control.TextArea;
import javafx.scene.control.TextField;
import javafx.scene.image.Image;
import javafx.scene.image.ImageView;
import javafx.scene.layout.AnchorPane;
import javafx.scene.paint.Paint;
import javafx.scene.text.Text;
import javax.swing.JOptionPane;
/**
*
* @author USER
*/
public class PantallaLibreriaController implements Initializable {
IFacadeLibreria facadeLibreria = new FacadeLibreria();
private final ObservableList<Libro> ListaLibrosObservable = FXCollections.observableArrayList();
@FXML
private Button buttonAgregarLibro;
@FXML
private TextField txtTitulo;
@FXML
private TextField txtIsbn;
@FXML
private TextField txtUnidadesDisponibles;
@FXML
private TextField txtNumeroImagenes;
@FXML
private TextField txtNumeroVideos;
@FXML
private TextField txtPrecio;
@FXML
private TableView<Libro> tablaAgregar;
@FXML
private TableColumn<Libro, String> tableIsbnAgregar = new TableColumn<>("Isbn");
@FXML
private TableColumn<Libro, String> tableTituloAgregar = new TableColumn<>("Titulo");
@FXML
private AnchorPane BotonValorDenominacion;
@FXML
private Text texto1KL;
@FXML
private Button BotonNuevoPrestamo;
@FXML
private Text TextoLocalDate;
@FXML
private Text TextoNumeroPrestamo;
@FXML
private ComboBox<String> ComboboxSeleccionLibros;
@FXML
private TextField TextCant;
@FXML
private Button BotonAgregarLinea;
@FXML
private TableView<Linea> TablaLineasDelPrestamo;
@FXML
private TableColumn<Linea, String> ColumnaLibro = new TableColumn<>("titulo");
@FXML
private TableColumn<Linea, Integer> ColumnaCantidad = new TableColumn<>("cantidad");
@FXML
private TableColumn<Linea, Double> ColumnaPrecioLibro = new TableColumn<>("precioBase");
@FXML
private TableColumn<Linea, Double> ColumnaSubTotal = new TableColumn<>("subTotal");
@FXML
private Text TextoTotalPrestamo;
@FXML
private TextField TextCantMonedas;
@FXML
private ComboBox<Denominacion> ComboboxDenominacion;
@FXML
private Button BotonAgregarMonedas;
@FXML
private Text TextoSaldoDispMonedas;
@FXML
private Text TextoVueltos;
@FXML
private Button BotonTerminarPrestamo;
private Button BotonGenerarReporte;
@FXML
private Button botonEliminar;
@FXML
private Text textoCantiLineas;
@FXML
private Text textoExito;
@FXML
private ComboBox<Integer> comboBoxNumeroReserva;
@FXML
private Button botonConsultar;
@FXML
private TextArea cuadroCOonsultaReserva;
@FXML
private ImageView LogoAgregar;
@FXML
private Tab LogoConsulta;
@FXML
private ImageView LogoAgregar3;
@FXML
private void handleButtonAction(ActionEvent event) {
Libro nuevoLibro = new Libro();
try {
nuevoLibro.setIsbn(txtIsbn.getText());
nuevoLibro.setNumeroImagenes(Integer.parseInt(txtNumeroImagenes.getText()));
nuevoLibro.setNumeroVideos(Integer.parseInt(txtNumeroVideos.getText()));
nuevoLibro.setTitulo(txtTitulo.getText());
nuevoLibro.setUnidadDisponibles(Integer.parseInt(txtUnidadesDisponibles.getText()));
nuevoLibro.setPrecioBase(Double.parseDouble(txtPrecio.getText()));
facadeLibreria.agregarLibro(nuevoLibro);
} catch (NumberFormatException e) {
JOptionPane.showMessageDialog(null, "Valores incorrectos", "Error", JOptionPane.ERROR_MESSAGE);
}
txtIsbn.clear();
txtNumeroImagenes.clear();
txtNumeroVideos.clear();
txtPrecio.clear();
txtUnidadesDisponibles.clear();
txtTitulo.clear();
llenarCampos();
}
@Override
public void initialize(URL url, ResourceBundle rb) {
//facadeLibreria.cargarLibros();
llenarCampos();
resetAll();
}
private void llenarCampos() {
tablaAgregar.getItems().clear();
comboBoxNumeroReserva.getItems().clear();
ComboboxSeleccionLibros.getItems().clear();
ComboboxDenominacion.getItems().clear();
for (Libro l : facadeLibreria.consultarLibros()) {
tablaAgregar.getItems().add(l);
ComboboxSeleccionLibros.getItems().add(l.getTitulo());
}
ComboboxDenominacion.getItems().addAll(Denominacion.MIL, Denominacion.QUIENTOS);
for (Prestamo p : facadeLibreria.getPrestamos()) {
comboBoxNumeroReserva.getItems().add(p.getNumero());
}
}
@FXML
private void ManejadorBotonNuevoPrestamo(ActionEvent event) {
BotonAgregarLinea.setDisable(false);
BotonAgregarMonedas.setDisable(false);
botonEliminar.setDisable(false);
if (facadeLibreria.crearNuevoPrestamo()) {
TextoLocalDate.setText(facadeLibreria.getPrestamoActual().getFecha().toString());
String numero = Integer.toString(facadeLibreria.getPrestamoActual().getNumero());
TextoNumeroPrestamo.setText(numero);
} else {
JOptionPane.showMessageDialog(null, "no se puede iniciar nuevo prestamo", "Error", JOptionPane.ERROR_MESSAGE);
}
}
private void llenarCamposPrestamo() {
TablaLineasDelPrestamo.getItems().clear();
for (Linea l : facadeLibreria.getPrestamoActual().getLineas()) {
TablaLineasDelPrestamo.getItems().add(l);
}
}
@FXML
private void ManejadorBotonAgregarLinea(ActionEvent event) {
DtoResumen res = new DtoResumen();
try {
String titulo = ComboboxSeleccionLibros.getSelectionModel().getSelectedItem().toString();
if (!TextCant.getText().isEmpty() && titulo != null) {
int catidad = Integer.parseInt(TextCant.getText());
for (Libro l : facadeLibreria.consultarLibros()) {
if (l.getTitulo() == titulo) {
res = facadeLibreria.agregarLinea(l, catidad);
TextoTotalPrestamo.setText(Double.toString(res.getTotal()));
textoCantiLineas.setText(Integer.toString(res.getTama()));
}
}
} else {
JOptionPane.showMessageDialog(null, "Cantidad incompleta", "Error", JOptionPane.ERROR_MESSAGE);
}
if (!res.isAgregar()) {
JOptionPane.showMessageDialog(null, res.getMensaje(), "Error", JOptionPane.ERROR_MESSAGE);
}
} catch (Exception e) {
JOptionPane.showMessageDialog(null, "Caracter invalido y/o lirbro no seleccionado", "Error", JOptionPane.ERROR_MESSAGE);
}
llenarCamposPrestamo();
if (facadeLibreria.getPrestamoActual().getLineas().size() != 0) {
BotonTerminarPrestamo.setDisable(false);
}
reset();
}
@FXML
private void ManejadorBotonAgregarMonedas(ActionEvent event) {
Denominacion d = ComboboxDenominacion.getSelectionModel().getSelectedItem();
int cantidad;
DtoResumen dto = new DtoResumen();
try {
cantidad = Integer.parseInt(TextCantMonedas.getText());
dto = facadeLibreria.agregarMoneda(d, cantidad);
if (!dto.isAgregar()) {
JOptionPane.showMessageDialog(null, dto.getMensaje(), "Error", JOptionPane.ERROR_MESSAGE);
textoExito.setFill(Paint.valueOf("#c10909"));
textoExito.setText("Error");
} else {
textoExito.setFill(Paint.valueOf("#00b524"));
textoExito.setText("Exito");
TextoSaldoDispMonedas.setText("$" + Double.toString(dto.getSaldo()));
}
} catch (Exception e) {
JOptionPane.showMessageDialog(null, "Solo se aceptan enteros", "Error", JOptionPane.ERROR_MESSAGE);
textoExito.setFill(Paint.valueOf("#c10909"));
textoExito.setText("Error");
}
}
@FXML
private void ManejadorBotonTerminarPrestamo(ActionEvent event) {
int tama = TablaLineasDelPrestamo.getItems().size();
if (tama > 0) {
DtoResumen dto = facadeLibreria.terminarPrestamo();
if (dto.isAgregar()) {
resetAll();
BotonAgregarLinea.setDisable(true);
BotonAgregarMonedas.setDisable(true);
BotonTerminarPrestamo.setDisable(true);
botonEliminar.setDisable(true);
JOptionPane.showMessageDialog(null, "Su devuelta es de " + dto.getDevuelta());
} else {
JOptionPane.showMessageDialog(null, dto.getMensaje(), "Error", JOptionPane.ERROR_MESSAGE);
}
llenarCampos();
}
else{
JOptionPane.showMessageDialog(null, "No hay lineas en el nuevo prestamo", "Error", JOptionPane.ERROR_MESSAGE);
}
}
@FXML
private void ManejadorBotonEliminar(ActionEvent event) {
Linea l = TablaLineasDelPrestamo.getSelectionModel().getSelectedItem();
DtoResumen dto = new DtoResumen();
dto = facadeLibreria.eliminarLinea(l);
if (dto.isAgregar()) {
textoCantiLineas.setText(Integer.toString(dto.getTama()));
TextoTotalPrestamo.setText(Double.toString(dto.getTotal()));
llenarCamposPrestamo();
int tama = TablaLineasDelPrestamo.getItems().size();
if(tama == 0){
BotonTerminarPrestamo.setDisable(true);
}
} else {
JOptionPane.showMessageDialog(null, dto.getMensaje(), "Error", JOptionPane.ERROR_MESSAGE);
}
}
private void resetAll() {
textoExito.setText(" ");
ComboboxDenominacion.setValue(null);
TextCantMonedas.setText(null);
ComboboxSeleccionLibros.setValue(null);
TextCant.setText(null);
TextoLocalDate.setText("2020-XX-XXTXX:XX:XX.XXX");
textoCantiLineas.setText("0");
TextoTotalPrestamo.setText("0.0");
TablaLineasDelPrestamo.getItems().clear();
TextoSaldoDispMonedas.setText("$0");
}
private void reset() {
textoExito.setText(" ");
//ComboboxDenominacion.setValue(null);
TextCantMonedas.setText(null);
ComboboxSeleccionLibros.setValue(null);
TextCant.setText(null);
}
@FXML
private void manejadorBotonConsultar(ActionEvent event) {
int numero = comboBoxNumeroReserva.getSelectionModel().getSelectedItem();
DtoResumen dto = new DtoResumen();
StringBuilder cadena = new StringBuilder("");
try {
dto = facadeLibreria.consultarPrestamo(numero);
if (dto.isAgregar()) {
int contador = 1;
cadena.append("Prestamo: " + dto.getPrestamo().getNumero() + "\n");
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
cadena.append("Fecha: " + dto.getPrestamo().getFecha().format(formatter).toString() + "\n");
cadena.append("Total: " + dto.getPrestamo().getTotal() + "\n");
cadena.append("Lineas: \n");
for (Linea l : dto.getPrestamo().getLineas()) {
cadena.append("Linea: " + contador + "\n");
cadena.append("Libro: " + l.getLibroEnPrestamo().getTitulo().toString() + "\n");
cadena.append("Cantidad: " + l.getCantidad() + "\n");
cadena.append("SubTotal: " + l.getSubTotal() + "\n");
contador++;
}
cadena.append("Monedas de mil ingresadas: " + dto.getCantiMil() + "\n");
cadena.append("Monedas de quinientos ingresadas: " + dto.getCantiQuini() + "\n");
cuadroCOonsultaReserva.setText(cadena.toString());
} else {
JOptionPane.showMessageDialog(null, dto.getMensaje(), "Error", JOptionPane.ERROR_MESSAGE);
}
} catch (Exception e) {
JOptionPane.showMessageDialog(null, e.toString(), "Error", JOptionPane.ERROR_MESSAGE);
}
}
}
<file_sep>/README.md
# Database
```
Pontificia Universidad Javeriana
Departamento de Ingeniería de Sistemas
Base de Datos Proyecto 3
```
**Kiosco de Libros.**
- Se requiere hacer un programa orientado a objetos que funcionará en kioscos.
- Al finalizar el día los prestamos se envían a un servidor central y se limpian los préstamos en el kiosco.
- El kiosco tiene ahora una pantalla más amigable al usuario.
## UML
<ins> Cada capa UML es un .jar </ins>

Para este proyecto se solicita implementar las siguientes funcionalidades en la clase ‘Kiosco’
## Interfaz Gráfica de Usuario

**El proceso de préstamo se resume de la siguiente manera:**
1. **[ 20 ]** Al iniciar el día se debe:
a. crear la colección de libros llamada 'catalogo' (método en el controlador ‘IGestionLibro’ que crea la lista de
libros), cree el método ‘CargarLibros()’ en iGestionLibro, cuya funcionalidad es leer los libros desde la tabla
de Libros y devolver una Lista de Libros para que sea asignada al ‘catalogo’
b. La clase Libreria debe invocar en su constructor el método anterior
2. **[10]** Crear Préstamo: Inicialmente la máquina crea un nuevo préstamo y se queda esperando por la introducción de
monedas. (método ‘crearNuevoPrestamo’ de la clase ‘Libreria’ que no recibe parámetros, retorna booleano
indicando si se pudo crear el préstamo)
a. Este préstamo se maneja en la relación ‘prestamos’
b. El último préstamo pasa a ser manejado con la relación ‘prestamoActual’
c. Se toma la fecha y hora del sistema (use LocalDate)
d. El número del préstamo no se puede repetir
e. No se puede crear un nuevo préstamo sino existen unidades disponibles de ningún libro
i Retorna falso
f. Se debe desplegar un mensaje en pantalla indicando si se pudo o no crear el préstamo.
<ins> Notas: </ins>
- Este método se invoca al presionar el botón ‘Nuevo Prestamo’, al oprimir el botón se deben limpiar todas las
etiquetas dejarlas en cero, limpiar la tabla de líneas y la caja de cantidad ponerla en cero.
Existe una clase ‘DtoResumen’ (usted debe crear esta nueva clase) que se utilizara para devolver datos desde todos los
métodos que vienen a continuación, cada método debe diligenciar los atributos correspondientes.
El Dto tiene:
- Un atributo ‘mensaje’ de tipo cadena con mensajes de error
- La colección de objetos de Líneas conteniendo:
o Objeto Libro
o cantidad
o El valor total del libro (precio)
o subtotal de la línea
- Un atributo de tipo booleano que indica si se pudo agregar la línea al préstamo
- El total de todo el préstamo
- El saldo de las monedas ingresadas
- La cantidad de vueltos del préstamo actual
- Agregue todos los demás atributos que requiera para devolver y poder refrescar la GUI.
<ins> NOTA: se debe persistir el préstamo en las tablas usando el ‘RepositorioPrestamo’ </ins>
3. **[ 20 ]** Agregar Línea: El usuario va agregando líneas al préstamo
Método ‘agregarLinea’ que recibe un objeto libro del catálogo y una cantidad de libros para crear una nueva línea;
retorna un ‘DtoResumen’ que contiene:
- Un atributo ‘mensaje’ de tipo cadena con mensajes de error
- La colección de objetos de Líneas conteniendo:
o Objeto Libro
o cantidad
o El valor total del libro (precio)
o subtotal de la línea
- La anterior colección tiene la nueva línea creada
- Un atributo de tipo booleano que indica si se pudo agregar la línea al préstamo
- El total de todo el préstamo
El código del método ’agregarLinea’ tiene que:
```
a. Verificar Libro en Catalogo (método privado)
i. El sistema verifica que el libro que llega como parámetro se encuentra en el catalogo
ii. Si el libro existe se vincula en la relación ‘libroEnPrestamo’
```
```
iii. Si el libro no existe debe diligenciar el atributo ‘mensaje’ del ‘DtoResumen’ de retorno
b. Verificar Existencias Libro. (método privado)
i. El sistema valida que la existencia del libro sea suficiente (atributo ‘unidadesDisponibles’ de la clase
libro.
```
1. Si no hay existencia debe diligenciar el atributo ‘mensaje’ del ’DtoResumen’ de retorno
ii. Si un libro ya existe en el préstamo o sea ya está en una ‘línea’ se acumula la cantidad existente con la
solicitada.
c. Crear Linea (método privado)
i. Crea la línea y la introduce en la lista de ‘líneas’ del préstamo actual
d. Calcula el valor del libro (método privado)
i. Precio base + (número imágenes * valor imagen) + (numero de videos * valor video)
e. Calcula el subtotal de una línea (método privado)
i. Multiplica el valor del libro (calculado en el método anterior) por la cantidad de libros de la línea
f. Calcula el total del préstamo (método privado)
i. sumatoria de los subtotales de cada línea (calculados en el método anterior)
g. Crear el ‘DtoResumen’ que va a retornar
i. Use los métodos ya implementados anteriormente.
<ins> Notas: </ins>
- Este método ’agregarLinea’ se invoca cuando se presiona el botón ‘Agregar Linea’, para los parámetros de
entrada del método: el libro se debe tomar del combo de ‘Seleccionar Libro’, la cantidad se toma de la caja de
texto ‘Cantidad’
- Se debe refrescar la GUI, esto es, refrescar la grilla y los totales del préstamo, use el ‘DtoResumen’ retornado
por el método; se deben mostrar ‘mensaje’ de error si lo hay.
o El objeto línea que devuelve el método debe ser vinculado a la grilla de libros del préstamo.
<ins> NOTA: se debe persistir la línea en las tablas y consultar las líneas desde la tabla para devolverlas a la lógica (usando
el ‘RepositorioPrestamo’)</ins>
4. **[10]** Eliminar una línea del Préstamo
Método publico eliminarLinea recibe un objeto de tipo ‘Linea’ y retorna un ‘DtoResumen’ que contiene:
- Un atributo ‘mensaje’ de tipo cadena con mensajes de error
- La colección de objetos de Líneas conteniendo:
o Objeto Libro
o cantidad
o El valor total del libro (precio)
o subtotal de la línea
- La anterior colección sin la línea borrada
- Un atributo de tipo booleano que indica si se pudo eliminar la línea del préstamo
- El total de todo el préstamo
El código de ‘eliminarLinea’ tiene que:
a. Verificar Línea (método privado)
```
i. Si el objeto de tipo Linea que llega esta nulo se diligencia el ‘mensaje’ del ‘DtoResumen’
b. Buscar la línea y quitarla de la colección de líneas del préstamo actual
i. Si no se encuentra la línea se diligencia el ‘mensaje’ del ‘DtoResumen’
c. Crear el ‘DtoResumen’ que va a retornar.
i. Reutilice los métodos ya implementados en el controlador.
```
<ins>Notas:</ins>
- Para Eliminar se debe seleccionar en la grilla de la GUI la línea a Eliminar y presionar el botón ‘Eliminar Linea’
- Se debe refrescar la GUI, esto es, refrescar la grilla y los totales del préstamo, use el ‘DtoResumen’ retornado
por el método; se deben mostrar ‘mensaje’ de error si lo hay.
<ins>NOTA: se debe persistir la eliminación de la línea en las tablas y consultar las líneas desde la tabla para devolverlas a
la lógica (usando el ‘RepositorioPrestamo’).</ins>
5. **[10]** Introducir Monedas
Método publico introducirMoneda recibe un enumerado de tipo ‘Denominacion’ y una cantidad de moneda de la
denominación; y retorna un ‘DtoResumen’ con el atributo de ’saldo de monedas ingresadas’ ya diligenciado con el total
de monedas de ‘pagoMonedas’ del préstamo.
El código de ‘introducirMoneda’ tiene que:
a. Validar que exista el enumerado que llega como parámetro
i. Si no se encuentra se diligencia el ‘mensaje’ del ‘DtoResumen’
b. Crear una nueva ‘Moneda’, vinculando el enumerado que llega como parámetro
i. Se asume la cantidad como 1 una moneda
c. Agregar la moneda creada a la colección ‘pagoMonedas’ del préstamo
d. Crear el ‘DtoResumen’ que va a retornar.
<ins>Notas:</ins>
- Para Agregar una moneda se debe digitar el número de monedas, la denominacion y presionar el botón ‘Agregar
Moneda’
- Se debe refrescar la GUI, esto es, refrescar la etiqueta de la pantalla cuyo nombre es ‘saldo disponible de
monedas ingresadas’, use el ‘DtoResumen’ retornado por el método; se deben mostrar ‘mensaje’ de error si lo
hay.
<ins>NOTA: se debe persistir la moneda introducida en las tablas y consultar las monedas desde la tabla para devolverlas a
la lógica (usando el ‘RepositorioPrestamo’).</ins>
6. **[ 20 ]** Terminar Préstamo
Metodo público ‘terminarPrestamo’ no recibe parámetros y retorna un ‘DtoResumen’ con el atributo valor de los vueltos
diligenciado.
El código de ‘terminarPrestamo’ tiene que:
```
a. Verificar Saldo (método privado)
i. Si el saldo disponible (total de monedas introducidas relación ‘pagoMonedas’) no es inferior al valor
total del libro seleccionado entonces: se dispensan los libros.
```
1. En caso contrario diligenciar el mensaje del ‘DtoResumen’
b. Actualizar Existencias (método privado)
i. Se actualizan las existencias del libro restando en unidades disponibles la cantidad de libros de cada
línea del préstamo.
e. Devolver Saldo (método privado)
i. Si hay saldo restante la máquina lo devuelve
ii. Se debe retornar los vueltos (un double)
```
f. Crear el ‘DtoResumen’ que va a retornar.
```
<ins>Notas:</ins>
- Para invocar este método se debe presionar el botón ‘Terminar Prestamo’
- Se debe refrescar la GUI, esto es, refrescar la etiqueta de la pantalla cuyo nombre es ‘vueltos’, use el
‘DtoResumen’ retornado por el método; se deben mostrar ‘mensaje’ de error si lo hay.
<ins>NOTA: se debe persistir la terminación de la línea en las tablas y consultar las líneas desde la tabla para devolverlas a
la lógica (usando el ‘RepositorioPrestamo’).</ins>
7. **[ 20 ]** Consultar Préstamo
```
Método público en Librería que recibe un número de préstamo; el método busca el número del préstamo y retorna null
o un DTO con todos los datos que se necesitan para llenar los elementos visuales de la pantalla referidos al préstamo
encontrado: fecha, numero, líneas, total del préstamo.
```
```
Agregue en la interfaz gráfica una caja de texto en donde se pueda introducir el número de un préstamo a consultar. Si
lo considera necesario redistribuya la pantalla para hacerla más clara.
```
<ins>NOTA: se debe consultar el préstamo desde la tabla para devolverlas a la lógica (usando el ‘RepositorioPrestamo’).</ins>
8. **[ 40 ]** Cree un aplicativo MVC usando JavaFX que permita probar las funcionalidades
a. Se debe crea una pantalla similar a la dada en esta entrega
b. Se debe crear un controlador de eventos que debe usar el controlador ‘ILibreria’
Se deben mostrar en pantalla los mensajes que retornen los diferentes métodos.
<file_sep>/LibreriaAccesoDatos/src/Intefaces/IGestionPrestamo.java
/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package Intefaces;
import Enums.Denominacion;
import entities.DtoResumen;
import entities.Libro;
import entities.Linea;
import entities.Prestamo;
import java.util.ArrayList;
/**
*
* @author USER
*/
public interface IGestionPrestamo {
boolean PersistirPrestamo(Prestamo prestamo);
ArrayList<Prestamo> cargarPrestamos();
boolean actualizarExistencias(Libro libro, int cantidad);
boolean insertarLineas(Linea linea, int numeroPrestamo);
DtoResumen consultarPrestamo(int numero);
ArrayList<Linea> buscarLineasPorUnPrestamo(int numero);
boolean persistirMonedas(Denominacion denominaciion, int cantidad, int id);
int buscarMonedas (Denominacion denominacion, int id );
void commit();
}
<file_sep>/LibreriaNegocio/src/Interfaces/IFacadeLibreria.java
/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package Interfaces;
import Enums.Denominacion;
import Intefaces.IGestionLibro;
import Intefaces.IGestionPrestamo;
import entities.*;
import java.util.ArrayList;
/**
*
* @author USER
*/
public interface IFacadeLibreria {
ArrayList<Libro> consultarLibros();
void cargarLibros();
void agregarLibro(Libro libro);
void PersistirPrestamo();
boolean crearNuevoPrestamo();
IGestionLibro getGestionLibro();
void setGestionLibro(IGestionLibro gestionLibro);
IGestionPrestamo getGestionPrestamo();
void setGestionPrestamo(IGestionPrestamo gestionPrestamo);
ArrayList<Prestamo> getPrestamos();
void setPrestamos(ArrayList<Prestamo> prestamos);
Prestamo getPrestamoActual();
void setPrestamoActual(Prestamo prestamoActual);
DtoResumen agregarLinea(Libro libro, int cantidad);
DtoResumen eliminarLinea(Linea linea);
DtoResumen agregarMoneda(Denominacion denominacion, int cantidad);
DtoResumen terminarPrestamo();
DtoResumen consultarPrestamo(int numero);
}
| f199d928dc8415f2efab7c923266daf238ccc56b | [
"Markdown",
"Java"
] | 5 | Java | monotera/Database | ac2d7e3411c9b9f61f28a2827fdf94f3c05bcc38 | 697852737bd9b6208a63ac7c8ca938b58d28ebbc |
refs/heads/master | <file_sep>package main
import (
"errors"
"flag"
"fmt"
"io"
"os"
parser "gopress/internal/parser"
scripts "gopress/internal/scripts"
)
func runGopress(file io.Reader) {
config, err := parser.GetConfig(file)
if err != nil {
fmt.Fprintln(os.Stderr, "There was an error parsing the goparser json: ", err)
os.Exit(1)
}
var specsToRun []string
testcases := config.Tests
fileBytes := scripts.GetGitDiffs(config.Basebranch)
for testIdx, _ := range testcases {
testcase := testcases[testIdx]
if scripts.CheckRegexesAgainstDiffs(fileBytes, testcase.Regexes) {
specsToRun = append(specsToRun, config.GetFilePath(testcase))
}
}
if len(specsToRun) > 0 {
scripts.RunCypressTests(specsToRun)
} else {
fmt.Println("No specs to run")
}
}
func loadFile(filename string) (io.Reader, error) {
file, err := os.Open(filename)
if err != nil {
return nil, errors.New("There was an error loading the gopress file: " + err.Error())
}
return file, nil
}
func handleFlags(versionFlag *bool) {
if *versionFlag {
fmt.Println("v.0.0-alpha")
os.Exit(0)
}
file, err := loadFile("./gopress.json")
if err != nil {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
runGopress(file)
}
func main() {
versionFlag := flag.Bool("version", false, "Check the version of Gopress")
flag.Parse()
handleFlags(versionFlag)
}
<file_sep>package scripts
import (
"bufio"
"fmt"
"os"
"os/exec"
"regexp"
"strings"
)
func GetGitDiffs(basebranch string) []byte {
cmdName := "git"
cmdArgs := []string{"diff", "--name-only", basebranch, "HEAD"}
cmdResponse, err := exec.Command(cmdName, cmdArgs...).Output()
if err != nil {
fmt.Fprintln(os.Stderr, "There was an error running git diff command: ", err)
os.Exit(1)
}
return cmdResponse
}
func RunCypressTests(specsToRun []string) {
specPath := strings.Join(specsToRun, ",")
cmd := exec.Command("npx", "cypress", "run", "--spec", specPath)
cmdReader, err := cmd.StdoutPipe()
if err != nil {
fmt.Fprintln(os.Stderr, "Error creating StdoutPipe for Cmd", err)
return
}
scanner := bufio.NewScanner(cmdReader)
go func() {
for scanner.Scan() {
fmt.Printf("%s\n", scanner.Text())
}
}()
err = cmd.Start()
if err != nil {
fmt.Fprintln(os.Stderr, "There was an error running cypress: ", err)
return
}
err = cmd.Wait()
if err != nil {
fmt.Fprintln(os.Stderr, "There was an error running cypress: ", err)
return
}
}
func CheckRegexesAgainstDiffs(diffs []byte, regexes []string) bool {
for _, expression := range regexes {
match, err := regexp.Match(expression, diffs)
if match {
return true
}
if err != nil {
fmt.Fprintln(os.Stderr, "One of the regexes is malformed: ", expression, "Error ocurred: ", err)
os.Exit(1)
}
}
return false
}
<file_sep># Go parameters
GOCMD=go
GOBUILD=$(GOCMD) build
GOTEST=$(GOCMD) test
GOGET=$(GOCMD) get
BINARY_NAME=bin/gopress
CMD_DIR=cmd/gopress/*
INSTALLBINDIR := /usr/local/bin
.PHONY: install
all: clean test build install
test:
$(GOTEST) -v ./...
build:
$(GOBUILD) -o $(BINARY_NAME) $(CMD_DIR)
clean:
rm -f $(BINARY_NAME)
run:
$(GOBUILD) -o $(BINARY_NAME) $(CMD_DIR)
./$(BINARY_NAME)
install:
cp ./$(BINARY_NAME) $(INSTALLBINDIR)
<file_sep>package main
import "testing"
var T = true
func ExampleHandleFlags() {
handleFlags(&T)
// Output: v.0.0-alpha
}
func TestLoadFile(t *testing.T) {
_, err := loadFile("./notafile")
got := err.Error()
want := "There was an error loading the gopress file: open ./notafile: no such file or directory"
if got != want {
t.Errorf("Got: %s. Want: %s", got, want)
}
}
<file_sep>package parser
import (
"encoding/json"
"fmt"
"io"
)
type Testcase struct {
Testfile string `json:"testfile"`
Regexes []string `json:"regexes"`
}
type Config struct {
Directory string `json:"directory"`
Extension string `json:"extension"`
Basebranch string `json:"basebranch"`
Tests []Testcase `json:"tests"`
}
func GetConfig(r io.Reader) (Config, error) {
var config Config
err := json.NewDecoder(r).Decode(&config)
if err != nil {
fmt.Println(err)
return Config{}, err
}
config.cleanDirectory()
return config, nil
}
func (c *Config) GetFilePath(t Testcase) string {
return c.Directory + t.Testfile + c.Extension
}
func (c *Config) cleanDirectory() {
trailing := c.Directory[len(c.Directory)-1:]
if trailing != "/" {
c.Directory = c.Directory + "/"
}
}
<file_sep>module gopress
require github.com/camjw/gopress v0.0.0-20190524084622-bf131b95da8a
<file_sep>package scripts
import "testing"
var regextests = []struct {
in string
diffs []byte
regexes []string
out bool
}{
{"match one regex", []byte("account_page.js"), []string{"page"}, true},
{"match multiple regexes", []byte("123.js"), []string{"notmatching", "\\d+"}, true},
{"doesn't match regex", []byte("testing_page.js"), []string{"login"}, false},
}
func TestCheckRegexesAgainstDiffs(t *testing.T) {
for _, tt := range regextests {
t.Run(tt.in, func(t *testing.T) {
match := CheckRegexesAgainstDiffs(tt.diffs, tt.regexes)
if match != tt.out {
t.Errorf("got %v, want %v, expressions: %s, diffs: %s", match, tt.out, tt.regexes, string(tt.diffs))
}
})
}
}
<file_sep>package parser
import (
"testing"
)
type mockReader struct {
s string
}
func (m mockReader) Read(b []byte) (n int, err error) {
n = copy(b, m.s)
return n, nil
}
var configtests = []struct {
label string
in string
out string
}{
{"trailing slash", "{\"directory\":\"first/\",\"extension\":\".test\",\"basebranch\":\"origin/master\",\"tests\":[{\"testfile\":\"test\",\"regexes\":[\".*\"]}]}", "first/test.test"},
{"no trailing slash", "{\"directory\":\"second/\",\"extension\":\".feature\",\"basebranch\":\"origin/master\",\"tests\":[{\"testfile\":\"test\",\"regexes\":[\".*\"]}]}", "second/test.feature"},
}
func TestGetFilePath(t *testing.T) {
for _, tt := range configtests {
t.Run(tt.label, func(t *testing.T) {
reader := mockReader{tt.in}
config, err := GetConfig(reader)
if err != nil {
t.Error("Error occurred during test: ", err)
}
got := config.GetFilePath(config.Tests[0])
want := tt.out
if got != want {
t.Errorf("Incorrect filepath. Got: %s. Want: %s.", got, want)
}
})
}
}
<file_sep># Gopress
Run cypress tests - but not all at once!
## Installation
This project requires Go and Go modules to be enabled:
```
brew install go
echo 'export GO111MODULES=on' >> ~/.bash_profile
source ~/.bash_profile
```
Next, clone this repo and then run `make` from the root of the repo to install.
## Usage
Create a `gopress.json` file at the root of the repo with the following structure:
```
{
"directory": "the directory your test files live in i.e. cypress/integration",
"extension": "extension for the test files i.e. .feature",
"basebranch": "the branch you want to check for diffs against i.e. origin/develop",
"tests": [
{
"testfile": "the name of your test file i.e. account_page",
"regexes": [
"a regexp matching files which should trigger a retesting",
.
.
]
},
.
.
.
]
}
```
then just run `gopress` in the command line to run all of the matching tests.
You can add more than one regexp, just so that you don't have to write long gnarly rexexps.
## Improvements
Currently, the output piping is all in black and white - not the nice colouring cypress provides.
## License
MIT
| 40f92e701184085d3f4ccbdfc3d776fe15f07978 | [
"Makefile",
"Go Module",
"Go",
"Markdown"
] | 9 | Go | camjw/gopress | 298e70e2fd4ed78fba542ce285a5b93359581f9c | ba158f13c84f4c76e30c5cde44679b07f025501f |
refs/heads/master | <repo_name>nnegi88/star-dev-finder<file_sep>/README.md
# star-dev-finder
This script helps you find the star developer in a organization on the basis of repository count
<file_sep>/star-dev-finder.py
import requests
from collections import OrderedDict
from operator import itemgetter
base_url = "https://api.github.com"
# username and password are must as some members in organization may have their visibility as private
username = "" # enter your github username here
password = "" # enter your github password here
organization_name = "" # enter the name of organization
org_member_url = base_url+"/orgs/"+organization_name+"/members"
r = requests.get(url = org_member_url, auth = requests.auth.HTTPBasicAuth(username, password))
members_response = r.json()
members_count = len(members_response)
print("Total number of members in %s: %s"%(organization_name, members_count))
print("Loading... This may take a while depending upon the number of members in the organization\n")
member_dictionary = {}
for member in members_response:
member_name = member['login']
user_repos_url = base_url+"/users/"+member_name+"/repos?type=all&per_page=1000" # as default limit per page is 30
r = requests.get(url = user_repos_url, auth = requests.auth.HTTPBasicAuth(username, password))
repos_response = r.json()
repos_response_unforked = filter(lambda x: x['owner']['login']==organization_name, repos_response) # filtering repos in organization only
repos_count = len(repos_response_unforked)
member_dictionary[member_name] = repos_count
sorted_members_dict = OrderedDict(sorted(member_dictionary.items(), key=itemgetter(1)))
print("Members repo count in ascending order are below:\n")
for member_name, repos_count in sorted_members_dict.items():
print("%s - %s"%(member_name,repos_count))
print("\n%s is the star developer of the organization %s"%(member_name, organization_name))
| e311994fb5043c0fa960d97a4f91e4c782b56a8e | [
"Markdown",
"Python"
] | 2 | Markdown | nnegi88/star-dev-finder | 017b9544911cea987664b5f7ad5b433eaad86e1b | 5295573ee23b4556c54901ba5025573c1c2d390f |
refs/heads/master | <repo_name>hoaithuong2002/module_2222222<file_sep>/MVC/View/add-product.php
<?php
$categoryList= null;
if (!empty($this->categoryManager)) {
$categoryList = $this->categoryManager->getAllCategory();
}
?>
<div class="container mt-5">
<div class="row align-items-center">
<h1>Thêm mặt hàng</h1>
<form class="col-8" method="post">
<div class="row mb-3">
<label for="name" class="col-sm-2 col-form-label">Tên</label>
<div class="col-sm-10">
<input type="text" class="form-control" id="name" name="name" required>
</div>
</div>
<div class="row mb-3">
<label for="category" class="col-sm-2 col-form-label">Loại hàng</label>
<div class="col-sm-10">
<select class="form-select" aria-label="Category" name="category">
<?php foreach ($categoryList as $category):?>
<option value="<?php echo $category->getId()?>"><?php echo $category->getName()?></option>
<?php endforeach;?>
</select>
</div>
</div>
<div class="row mb-3">
<label for="price" class="col-sm-2 col-form-label">Giá</label>
<div class="col-sm-10">
<input type="number" min="0" class="form-control" id="price" name="price" required>
</div>
</div>
<div class="row mb-3">
<label for="amount" class="col-sm-2 col-form-label">Số lượng</label>
<div class="col-sm-10">
<input type="number" min="0" class="form-control" id="amount" name="amount" required>
</div>
</div>
<div class="row mb-3">
<label for="description" class="col-sm-2 col-form-label">Mô tả</label>
<div class="col-sm-10">
<textarea class="form-control" id="description" name="description" rows="4"></textarea>
</div>
</div>
<div class="pt-2 pb-3 d-flex justify-content-end">
<button type="submit" class="btn btn-outline-success me-3">Add</button>
<a class="btn btn-outline-danger" href="index.php" role="button">Exit</a>
</div>
</form>
</div>
</div>
<file_sep>/MVC/Controller/PageController.php
<?php
namespace App\Controller;
class PageController
{
protected ProductManager $productManager;
protected CategoryManager $categoryManager;
public function __construct()
{
$this->productManager = new ProductManager();
$this->categoryManager = new CategoryManager();
}
public function productsPage()
{
include "src/View/products.php";
}
public function editProductPage()
{
if ($_SERVER['REQUEST_METHOD'] == 'GET'){
$id = $_REQUEST['id'];
include 'src/View/edit-product.php';
}
else {
$name = $_POST['name'];
$category = $_POST['category'];
$price = $_POST['price'];
$amount = $_POST['amount'];
$description = $_POST['description'];
$this->productManager->updateProduct($_REQUEST['id'], new Product('', $name, $category, $price, $amount, '', $description));
header("Location: index.php");
}
}
public function deleteProductPage()
{
if ($_SERVER['REQUEST_METHOD'] == 'GET'){
$id = $_REQUEST['id'];
include 'src/View/delete-product.php';
}
else{
if ($_POST['action'] == "delete"){
$this->productManager->deleteProduct($_REQUEST['id']);
header("Location: index.php");
}
}
}
public function createProductPage()
{
if ($_SERVER['REQUEST_METHOD'] == 'GET'){
$cateManager = new CategoryManager();
include 'src/View/create-product.php';
}
else{
$name = $_POST['name'];
$category = $_POST['category'];
$price = $_POST['price'];
$amount = $_POST['amount'];
$description = $_POST['description'];
$this->productManager->createProduct(new Product('', $name, $category, $price,$amount,'',$description));
header("Location: index.php");
}
}
}<file_sep>/MVC/Model/CategoryManager.php
<?php
namespace App\Model;
use App\Model\Category;
use App\Model\DBConnect;
class CategoryManager
{
protected DBConnect $dbConnect;
public function __construct()
{
$this->dbConnect = new DBConnect();
}
public function getAllCategory(): array
{
$sql = "SELECT * FROM Categories";
$data = $this->dbConnect->query($sql);
$categories = [];
foreach ($data as $item) {
$categories[] = new Category($item['id'], $item['name']);
}
return $categories;
}
public function getByID()
{
}
}<file_sep>/MVC/Model/Product.php
<?php
namespace App\Model;
class Product
{
protected $id;
protected $name;
protected $categoryId;
protected $category;
protected $price;
protected $amount;
protected $createdDate;
protected $description;
public function __construct($id, $name, $categoryId, $price, $amount, $createdDate, $description)
{
$this->id = $id;
$this->name = $name;
$this->categoryId = $categoryId;
$this->price = $price;
$this->amount = $amount;
$this->createdDate = $createdDate;
$this->description = $description;
}
/**
* @return mixed
*/
public function getId()
{
return $this->id;
}
/**
* @param mixed $id
*/
public function setId($id)
{
$this->id = $id;
}
/**
* @return mixed
*/
public function getName()
{
return $this->name;
}
/**
* @param mixed $name
*/
public function setName($name)
{
$this->name = $name;
}
/**
* @return mixed
*/
public function getCategoryId()
{
return $this->categoryId;
}
/**
* @param mixed $categoryId
*/
public function setCategoryId($categoryId)
{
$this->categoryId = $categoryId;
}
/**
* @return mixed
*/
public function getPrice()
{
return $this->price;
}
/**
* @param mixed $price
*/
public function setPrice($price)
{
$this->price = $price;
}
/**
* @return mixed
*/
public function getAmount()
{
return $this->amount;
}
/**
* @param mixed $amount
*/
public function setAmount($amount)
{
$this->amount = $amount;
}
/**
* @return mixed
*/
public function getCreatedDate()
{
return $this->createdDate;
}
/**
* @param mixed $createdDate
*/
public function setCreatedDate($createdDate)
{
$this->createdDate = $createdDate;
}
/**
* @return mixed
*/
public function getDescription()
{
return $this->description;
}
/**
* @param mixed $description
*/
public function setDescription($description)
{
$this->description = $description;
}
/**
* @return mixed
*/
public function getCategory()
{
return $this->category;
}
/**
* @param mixed $category
*/
public function setCategory($category): void
{
$this->category = $category;
}
}<file_sep>/MVC/View/list-product.php
<?php
$products = null;
if (!empty($this->productManager)) {
$products = $this->productManager->getAllProduct();
}
if($_SERVER['REQUEST_METHOD']=='GET' && isset($_GET['search'])){
$productSearch = [];
$nameSearch = $_GET['search'];
foreach ($products as $product) {
if (substr($product->getName(), 0, strlen($_GET['search'])) == $_GET['search']){
$productSearch[] = $product;
}
}
$products = $productSearch;
}
?>
<div class="container mt-5">
<table class="table table-striped table-bordered caption-top">
<caption>
<h1>Danh sách mặt hàng</h1>
<div class="pt-2 pb-3 d-flex justify-content-between">
<form class="d-flex" method="get">
<input class="form-control me-2" type="text" name="search" placeholder="Search" aria-label="Search">
<button class="btn btn-outline-primary" type="submit">Search</button>
</form>
<a class="btn btn-outline-success pb-2" href="index.php?page=create-product" role="button">Create</a>
</div>
</caption>
<thead>
<tr>
<th scope="col">ID</th>
<th scope="col">Tên hàng</th>
<th scope="col">Loại hàng</th>
<th scope="col"></th>
</tr>
</thead>
<tbody>
<?php if(empty($listProduct)):?>
<tr>
<th scope="row" colspan="4" class="text-center">No result is found</th>
</tr>
<?php endif;?>
<?php foreach ($products as $product):?>
<?php $id = $product->getId(); $_SESSION["$id"] = $product;?>
<tr>
<th scope="row"><?php echo $product->getId()?></th>
<td><?php echo $product->getName()?></td>
<td><?php echo $product->getCategory()?></td>
<td>
<a href="index.php?page=edit-product&id=<?php echo $product->getId()?>&name=<?php echo $product->getName()?>">Edit</a>
<a href="index.php?page=delete-product&id=<?php echo $product->getId()?>&name=<?php echo $product->getName()?>">Delete</a>
</td>
</tr>
<?php endforeach;?>
</tbody>
</table>
</div><file_sep>/MVC/View/delete-product.php
<div class="container mt-5">
<h1>Do you really want to delete!</h1>
<p>Bạn chắc chăn muốn xóa mặt hàng: <?php echo $_REQUEST['name']?></p>
<form action="" method="post">
<a class="btn btn-outline-primary me-3" href="index.php" role="button">Exit</a>
<input type="text" name="action" value="delete" hidden>
<input type="text" name="id" value="<?php echo $_REQUEST['id']?>" hidden>
<input class="btn btn-outline-danger" type="submit" value="Delete">
</form>
</div>
<file_sep>/MVC/Model/ProductManager.php
<?php
namespace App\Model;
use App\Model\DBConnect;
use App\Model\Product;
class ProductManager
{
protected $dbConnect;
public function __construct()
{
$this->dbConnect = new DBConnect();
}
public function getAllProduct()
{
$sql = "SELECT * FROM `products`";
$data = $this->dbConnect->query($sql);
$products = [];
foreach ($data as $item) {
$product = new Product($item['id'], $item['name'],$item['categoryId'],$item['price'],$item['amount'],$item['createdDate'],$item['description']);
$product->setCategory($item['productCategory']);
$products[] = $product;
}
return $products;
}
public function createProduct(Product $product)
{
$id = $product->getId();
$name = $product->getName();
$categoryId = $product->getCategoryId();
$price = $product->getPrice();
$amount = $product->getAmount();
$createdDate = $product->getName();
$description = $product->getDescription();
$sql = "INSERT INTO `Products`(`name`, `categoryId`, `price`, `amount`, `description`) VALUES ('$name','$categoryId','$price','$amount','$description')";
$this->dbConnect->execute($sql);
}
public function getProduct($id)
{
$sql = "SELECT * FROM Products where id='$id'";
return $this->dbConnect->query($sql);
}
public function updateProduct($id,Product $data)
{
$name = $data->getName();
$categoryId = $data->getCategoryId();
$price = $data->getPrice();
$amount = $data->getAmount();
$description = $data->getDescription();
$sql = "UPDATE Products SET name='$name', categoryId='$categoryId', price='$price', amount='$amount', description='$description' WHERE id='$id'";
$this->dbConnect->execute($sql);
}
public function deleteProduct($id)
{
$sql = "DELETE FROM Products WHERE id='$id'";
$this->dbConnect->execute($sql);
}
}<file_sep>/index.php
<?php
require __DIR__ ."vendor/autoload.php";
use App\Controller\PageController;
$page = isset($_REQUEST['page']) ? $_REQUEST['page'] : null;
$controller = new PageController();
?>
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Product Manager</title>
</head>
<body>
<?php
switch ($page) {
case 'products':
$controller->productsPage();
break;
case 'edit-product':
$controller->editProductPage();
break;
case 'create-product':
$controller->createProductPage();
break;
case 'delete-product':
$controller->deleteProductPage();
break;
default:
$controller->productsPage();
}
?>
</body>
</html | 0f6acbfcf9033289450400fcbb36960fca7095a6 | [
"PHP"
] | 8 | PHP | hoaithuong2002/module_2222222 | 35fcec0e9c9f9ecea12570994c1d545047bf7ee8 | cc2309c2f207fa6f5f5c0ac2c43e56216b825eb6 |
refs/heads/master | <file_sep>package vista;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import runnable.Work;
public class DronesAplicacion2 {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(2);
for(int i= 1; i<=2; i++) {
Work work = new Work();
work.setIndice(i);
executor.submit(work);
}
}
}
<file_sep>## Prueba Drones
### <NAME>
###### Se ajusto a o sgsiguiente AAAAIAAD
######DDAIAI
AAIADAD
<file_sep>package pruebasUnitarias;
import static org.junit.Assert.assertTrue;
import java.util.logging.Logger;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.junit.runners.JUnit4;
import control.DronesControlador;
import exception.ArchivosException;
import modelo.Coordenada;
import modelo.GestionArchivosDron;
@RunWith(JUnit4.class)
public class GestionArchivosDronTest {
private GestionArchivosDron gesti;
private Logger logger = Logger.getLogger(GestionArchivosDronTest.class.getName());
private static final String ORIENTACION = "Norte";
@Test
public void validarEstructuraTest() {
gesti = new GestionArchivosDron();
String ruta = "DDAIAD";
assertTrue(gesti.validarEstructura(ruta));
}
@Test
public void validarEstructuraErrorTest() {
gesti = new GestionArchivosDron();
String ruta = "SDDAIAD";
assertTrue(!gesti.validarEstructura(ruta));
}
@Test
public void leerAchivoRutaInvalidaTest() {
gesti = new GestionArchivosDron();
try {
assertTrue(gesti.leerAchivo("//rutaErronea", 0) == null);
} catch (ArchivosException e) {
logger.info(" " + e);
}
}
@Test
public void leerAchivoSinArchivoTest() {
gesti = new GestionArchivosDron();
try {
assertTrue(gesti.leerAchivo("./resources/entrada.txt", 3) == null);
} catch (ArchivosException e) {
logger.info("Se presento el siguiente error, " + e);
}
}
@Test
public void leerAchivoTest() {
String ruta = "./resources/in.txt";
int numDron = 3;
String mensaje;
DronesControlador controlador = new DronesControlador(ruta, numDron);
mensaje = controlador.iniciarDespachos();
assertTrue(mensaje.equals("El despacho se genero con Exito"));
}
@Test
public void leerAchivoDatosNullTest() {
gesti = new GestionArchivosDron();
try {
assertTrue(gesti.leerAchivo(null, 0) == null);
} catch (ArchivosException e) {
logger.info(" " + e);
}
}
@Test
public void leerAchivoCapacidadInvalidaTest() {
gesti = new GestionArchivosDron();
try {
assertTrue(gesti.leerAchivo("Hl", -1) == null);
} catch (ArchivosException e) {
logger.info("Se presento el siguiente error, " + e);
}
}
}
<file_sep>package vista;
import control.DronesControlador;
import modelo.Coordenada;
public class DronesAplicacion {
public static void main(String[] args) {
String ruta = "./resources/in.txt";
int numDron = 3;
String mensaje;
DronesControlador controlador = new DronesControlador(ruta, numDron);
mensaje = controlador.iniciarDespachos();
System.out.println(mensaje);
}
}
<file_sep>package modelo;
public class Coordenada {
private int x;
private int y;
private String orientacion;
public Coordenada(int x, int y, String orientacion) {
this.x = x;
this.y = y;
this.orientacion = orientacion;
}
public int getX() {
return x;
}
public void setX(int x) {
this.x = x;
}
public int getY() {
return y;
}
public void setY(int y) {
this.y = y;
}
public String getOrientacion() {
return orientacion;
}
public void setOrientacion(String orientacion) {
this.orientacion = orientacion;
}
}
| a8b766b53557e0d7496774a723b7c40c70e3bd44 | [
"Markdown",
"Java"
] | 5 | Java | krawny/S4N_Drones | 6d246ef04b6f1340e82536f3daecb9d68438e3ff | 4b270499135ecdee472a6e36557dc367ac0ac217 |
refs/heads/master | <repo_name>miguelantonio90/laravel-vue<file_sep>/resources/js/data/localStorage.js
import Vue from 'vue'
import VueLocalStorage from 'vue-localstorage'
Vue.use(VueLocalStorage)
export function saveToken (token) {
return Vue.localStorage.set('token', 'Bearer ' + token)
}
export function removeToken () {
return Vue.localStorage.remove('token')
}
export function getToken () {
return Vue.localStorage.get('token')
}
export function setLanguage (item) {
return Vue.localStorage.set('language', item)
}
export function getLanguage (item) {
return Vue.localStorage.get('language')
}
export function setTheme (item) {
return Vue.localStorage.set('theme', item)
}
export function getTheme (item) {
return Vue.localStorage.get('theme')
}
<file_sep>/app/User.php
<?php
namespace App;
use Illuminate\Database\Eloquent\Relations\BelongsToMany;
use Illuminate\Foundation\Auth\User as Authenticatable;
use Illuminate\Http\Request;
use Tymon\JWTAuth\Contracts\JWTSubject;
/**
* Class User
* @package App
* @method static findOrFail(int $id)
* @method static latest()
*/
class User extends Authenticatable implements JWTSubject
{
/**
* The "type" of the auto-incrementing ID.
*
* @var string
*/
protected $keyType = 'integer';
/**
* @var array
*/
protected $fillable = ['firstName', 'lastName', 'username', 'email', 'password', 'nid', 'sexo', 'birthday', 'age', 'race', 'sons', 'salary', 'position', 'type'];
/**
* @return BelongsToMany
*/
public function roles()
{
return $this
->belongsToMany('App\Role')
->withTimestamps();
}
public function create(Request $request)
{
$user = new User();
foreach ($this->fillable as $key => $value) {
switch ($value) {
case 'username':
if (!empty($request->get($value))) {
$user->username = $request->get($value);
}
break;
case 'password':
if (!empty($request->get($value))) {
$user->password = <PASSWORD>($request->get($value));
}
break;
default:
$user->$value = $request->get($value);
break;
}
}
$user->save();
return $user;
}
/**
* Get the identifier that will be stored in the subject claim of the JWT.
*
* @return mixed
*/
public function getJWTIdentifier()
{
return $this->getKey();
}
/**
* Return a key value array, containing any custom claims to be added to the JWT.
*
* @return array
*/
public function getJWTCustomClaims()
{
return [];
}
/**
* Get the password for the user.
*
* @return string
*/
public function getAuthPassword()
{
return $this->password;
}
}
<file_sep>/app/Http/Helpers/ArrayHelper.php
<?php
namespace App\Http\Helpers;
class ArrayHelper
{
public static function arrayIsset($array)
{
$isset = true;
foreach ($array as $item) {
if (!isset($item)) {
$isset = false;
}
}
return $isset;
}
}
<file_sep>/README.md
## Laravel Vue Jwt Example Project
# Setup
```
composer install
npm install
```
make a .env file and set your db
then
```
php artisan key:generate
php artisan jwt:secret
php artisan migrate --seed
```
# Usage
Run the backend
```
php artisan serve
```
Run the front-end
```
npm run watch
```
Credentials
```
username: admin
password: <PASSWORD>
```
Browse the website using
http://localhost:8000
<file_sep>/resources/js/config/setup-components.js
// Core components
import Navigation from '../components/core/Navigation'
import Menu from '../components/core/Menu'
import Footer from '../components/core/PageFooter'
import DatePicker from '../components/core/DatePicker'
import Language from '../components/core/Language'
import VuePerfectScrollbar from 'vue-perfect-scrollbar'
import ThemeSettings from '../components/core/ThemeSettings'
function setupComponents (Vue) {
Vue.component('page-navigation', Navigation)
Vue.component('page-menu', Menu)
Vue.component('page-footer', Footer)
Vue.component('date-picker', DatePicker)
Vue.component('page-language', Language)
Vue.component('vue-perfect-scrollbar', VuePerfectScrollbar)
Vue.component('theme-settings', ThemeSettings)
}
export {
setupComponents
}
<file_sep>/resources/js/store/modules/themeStrone.js
import { getTheme, setTheme } from '../../data/localStorage'
const SET_THEME = 'SET_THEME'
const state = {
theme: getTheme()
}
const actions = {
async updateTheme ({ commit }, theme) {
if (typeof theme === 'string') {
await commit(SET_THEME, theme)
}
}
}
const mutations = {
[SET_THEME] (state, theme) {
setTheme(theme)
state.theme = theme
}
}
const getters = {
// Shared getters
}
export default {
namespaced: true,
state,
getters,
actions,
mutations
}
<file_sep>/database/seeds/UserTableSeeder.php
<?php
use App\Role;
use App\User;
use Illuminate\Database\Seeder;
class UserTableSeeder extends Seeder
{
/**
* Run the database seeds.
*
* @return void
*/
public function run()
{
$role_user = Role::where('name', 'user')->first();
$role_admin = Role::where('name', 'admin')->first();
$user = new User();
$user->firstName = 'Miguel';
$user->lastName = 'Cabreja';
$user->nid = '9012154857962';
$user->sexo = 'male';
$user->age = '28';
$user->race = 'white';
$user->username = 'admin';
$user->email = '<EMAIL>';
$user->password = <PASSWORD>('<PASSWORD>');
$user->save();
$user->roles()->attach($role_admin);
}
}
<file_sep>/resources/js/router/index.js
import Vue from 'vue'
import VueRouter from 'vue-router'
import store from '../store'
import { i18n } from '../lang'
import routes from './routes'
Vue.use(VueRouter)
const Router = new VueRouter({
mode: 'history',
routes: routes
})
Router.beforeEach((to, from, next) => {
if (store.state.language.language && store.state.language.language !== i18n.locale) {
i18n.locale = store.state.language.language
next()
} else if (!store.state.language.language) {
store.dispatch('setLanguage', navigator.languages)
.then(() => {
i18n.locale = store.state.language.language
next()
})
} else {
next()
}
})
export default Router
<file_sep>/routes/api.php
<?php
/*
|--------------------------------------------------------------------------
| API Routes
|--------------------------------------------------------------------------
|
| Here is where you can register API routes for your application. These
| routes are loaded by the RouteServiceProvider within a group which
| is assigned the "api" middleware group. Enjoy building your API!
|
*/
use Illuminate\Support\Facades\Route;
// Below mention routes are public, user can access those without any restriction.
// Login User
Route::post('v1/login', 'API\LoginController@login');
Route::middleware('auth:user')->prefix('v1/')->group(function () {
});
Route::get('/login', function () {
return ('Login Fail !!!');
})->name('login');
/**
* User routes
*/
Route::get('v1/users', 'API\UserController@index');
Route::get('v1/users/{id}', 'API\UserController@show');
Route::post('v1/users', 'API\UserController@store');
Route::put('v1/users/{id}', 'API\UserController@update');
Route::delete('v1/users/{id}', 'API\UserController@destroy');
<file_sep>/resources/js/lang/index.js
import Vue from 'vue'
import VueI18n from 'vue-i18n'
import en from './i18n/en'
import es from './i18n/es'
import FlagIcon from 'vue-flag-icon'
Vue.use(FlagIcon)
Vue.use(VueI18n)
// Default language
const DEFAULT_LANG = window.navigator.language.split('-')[0]
const messages = {
es: es.lang,
en: en.lang
}
export const i18n = new VueI18n({
locale: DEFAULT_LANG,
fallbackLocale: 'en',
messages
})
<file_sep>/app/Http/Helpers/UploadHelper.php
<?php
namespace App\Http\Helpers;
use Illuminate\Filesystem\Filesystem;
use Illuminate\Support\Carbon;
use Intervention\Image\Facades\Image;
class UploadHelper
{
public static function uploadImage($file, $prefix = 'uploads', $w = 0, $h = 0)
{
$day = Carbon::now()->day;
$year = Carbon::now()->year;
$month = Carbon::now()->month;
$folder = "$prefix/$year/$month/$day";
$image1 = $file->getClientOriginalName();
$path1 = $folder . '/' . $image1;
if (file_exists($folder) == false) {
$fs = new Filesystem();
$fs->makeDirectory($folder, 0755, true);
}
$image = Image::make($file);
if (self::endsWith($image1, 'jpg')) {
if ($w && $h) {
$image = $image->fit($w, $h);
}
}
$image->save($path1);
return $path1;
}
public static function endsWith($haystack, $needle)
{
$length = strlen($needle);
if ($length == 0) {
return true;
}
return (substr($haystack, -$length) === $needle);
}
public static function uploadFile($file, $prefix = 'uploads')
{
$day = Carbon::now()->day;
$year = Carbon::now()->year;
$month = Carbon::now()->month;
$folder = "$prefix/$year/$month/$day";
$image1 = uniqid() . $file->getClientOriginalName();
$path1 = $folder . '/' . $image1;
if (file_exists($folder) == false) {
$fs = new Filesystem();
$fs->makeDirectory($folder, 0755, true);
}
$file->move($folder, $image1);
return "/" . $path1;
}
public static function startsWith($haystack, $needle)
{
$length = strlen($needle);
return (substr($haystack, 0, $length) === $needle);
}
}
<file_sep>/app/Http/Controllers/API/UserController.php
<?php
namespace App\Http\Controllers\API;
use App\Http\Controllers\Controller;
use App\Http\Helpers\InputHelper;
use App\Http\Helpers\ResponseHelper;
use App\User;
use Illuminate\Database\Eloquent\Collection;
use Illuminate\Http\JsonResponse;
use Illuminate\Http\Request;
use Illuminate\Http\Response;
use Illuminate\Validation\ValidationException;
class UserController extends Controller
{
/**
* Display a listing of the resource.
*
* @return Collection
*/
public function index(): Collection
{
return User::latest()->get();
}
/**
* Store a newly created resource in storage.
*
* @param Request $request
* @return JsonResponse
*/
public function store(Request $request): JsonResponse
{
InputHelper::inputChecker(
$request,
[
$request->firstName,
$request->lastName,
$request->username,
$request->password,
$request->email,
$request->type
],
function (Request $request) {
(new User())->create($request);
return ResponseHelper::jsonResponse(null, Response::HTTP_OK, config('messages.success'))->send();
}
);
}
/**
* Display the specified resource.
*
* @param int $id
* @return Collection
*/
public function show(int $id): Collection
{
return User::latest()->get($id);
}
/**
* Update the specified resource in storage.
*
* @param Request $request
* @param int $id
* @return JsonResponse
* @throws ValidationException
*/
public function update(Request $request, int $id): JsonResponse
{
$this->validate($request, [
'firstName' => 'required',
'lastName' => 'required',
'email' => 'required',
'type' => 'required',
]);
$user = User::findOrFail($id);
$user->update($request->all());
return ResponseHelper::jsonResponse(null, Response::HTTP_OK, config('messages.success'))->send();
}
/**
* Remove the specified resource from storage.
*
* @param int $id
* @return JsonResponse
*/
public function destroy(int $id): JsonResponse
{
$user = User::findOrFail($id);
$user->delete();
return ResponseHelper::jsonResponse(null, Response::HTTP_OK, config('messages.success'))->send();
}
}
<file_sep>/resources/js/store/index.js
import Vue from 'vue'
import Vuex from 'vuex'
import axios from 'axios'
import VueAxios from 'vue-axios'
import login from './modules/loginStore'
import user from './modules/userStore'
import language from './modules/langStore'
import theme from './modules/themeStrone'
Vue.use(Vuex, VueAxios, axios)
export default new Vuex.Store({
namespaced: true,
modules: {
theme,
language,
login,
user
},
state: {
windowHeight: 0,
windowWidth: 0
},
actions: {
},
mutations: {
'setWindowHeight' (state, { windowHeight }) {
state.windowHeight = windowHeight
},
'setWindowWidth' (state, { windowWidth }) {
state.windowWidth = windowWidth
}
},
getters: {
// Shared getters
}
})
<file_sep>/config/fcmsettings.php
<?php
return [
'token' => '<KEY>'
];
<file_sep>/app/Http/Controllers/API/LoginController.php
<?php
namespace App\Http\Controllers\API;
use App\Http\Controllers\Controller;
use App\Http\Helpers\ResponseHelper;
use Illuminate\Http\JsonResponse;
use Illuminate\Http\Request;
use Illuminate\Http\Response;
use Illuminate\Support\Facades\Auth;
class LoginController extends Controller
{
/**
* Login user and return a token
*
* @param Request $request
* @return JsonResponse
*/
public function login(Request $request): JsonResponse
{
$token = $this->guard($request->username, $request->password);
if ($token) {
return ResponseHelper::jsonResponse(null, Response::HTTP_OK, config('messages.success'))->header('Authorization', $token)->send();
} else {
return ResponseHelper::jsonResponse(null, Response::HTTP_BAD_REQUEST, config('messages.fail'))->send();
}
}
/**
* Return auth guard
*
* @param string $username
* @param string $password
* @return string
*/
private function guard(string $username, string $password): string
{
return Auth::guard('user')->attempt(array('username' => $username, 'password' => $<PASSWORD>));
}
}
<file_sep>/resources/js/lang/i18n/index.js
import en from './en'
import es from './es'
export default {
en,
es
}
<file_sep>/app/Http/Helpers/ResponseHelper.php
<?php
namespace App\Http\Helpers;
use Illuminate\Http\JsonResponse;
class ResponseHelper
{
/**
* any controller must begin with this function
* @param $errors
* @param $status
* @param $data
* @return JsonResponse
*/
public static function jsonResponse($errors, $status, $data)
{
return response()->json(array_combine(config('app.response_keys'), [$errors, $status, $data]), $status);
}
}<file_sep>/resources/js/store/modules/userStore.js
import api from '../../data/api'
const SWITCH_USER_NEW_MODAL = 'SWITCH_USER_NEW_MODAL'
const SWITCH_USER_EDIT_MODAL = 'SWITCH_USER_EDIT_MODAL'
const USER_CREATED = 'USER_CREATED'
const USER_EDIT = 'USER_EDIT'
const USER_UPDATED = 'USER_UPDATED'
const USER_DELETED = 'USER_DELETED'
const USER_TABLE_LOADING = 'USER_TABLE_LOADING'
const FAILED_USER = 'FAILED_USER'
const FETCHING_USERS = 'FETCHING_USERS'
const ENV_DATA_PROCESS = 'ENV_DATA_PROCESS'
const state = {
showNewModal: false,
showEditModal: false,
newUser: {
firstName: '',
lastName: '',
username: '',
email: '',
password: '',
nid: '',
sexo: '',
birthday: '',
age: '',
race: '',
sons: '',
salary: '',
position: '',
roles: [],
type: 'user'
},
editUser: {
id: '',
firstName: '',
lastName: '',
username: '',
email: '',
password: '',
nid: '',
sexo: '',
birthday: '',
age: '',
race: '',
sons: '',
salary: '',
position: '',
roles: []
},
users: [],
userTableColumns: [
{
text: 'First Name',
value: 'firstName'
},
{
text: 'Last Name',
value: 'lastName'
},
{
text: 'Username',
value: 'username'
}, {
text: 'Email',
value: 'email'
},
{
text: 'Position',
value: 'position'
},
{ text: 'Actions', value: 'actions', sortable: false }
],
isTableLoading: false,
sexoItems: [
{ value: 'female', text: 'Female' },
{ value: 'male', text: 'Male' }
],
raceItems: [
{ value: 'white', text: 'White' },
{ value: 'black', text: 'Black' },
{ value: 'yellow', text: 'Yellow' },
{ value: 'half-blood', text: 'Half Blood' }
],
userRoles: [{
value: 'ROLE_USER',
label: 'USER'
}, {
value: 'ROLE_SUPER_ADMIN',
label: 'ADMINISTRATOR'
}]
}
// getters
const getters = {
}
// actions
const actions = {
toogleNewModal ({ commit }, showModal) {
commit(SWITCH_USER_NEW_MODAL, showModal)
},
toogleEditModal ({ commit }, showModal) {
commit(SWITCH_USER_EDIT_MODAL, showModal)
},
openEditModal ({ commit }, userId) {
commit(SWITCH_USER_EDIT_MODAL, true)
commit(USER_EDIT, userId)
},
async getUsers ({ commit }) {
commit(USER_TABLE_LOADING, true)
await api
.fetchUsers()
.then(({ data }) => commit(FETCHING_USERS, data))
.then(() => commit(USER_TABLE_LOADING, false))
.catch(error => commit(FAILED_USER, error))
},
async createUser ({ commit, dispatch }) {
commit(ENV_DATA_PROCESS, true)
await api
.createUser(state.newUser)
.then(() => commit(USER_CREATED))
.then(() => commit(ENV_DATA_PROCESS, false))
.then(() => dispatch('user/getUsers', null, { root: true }))
.catch(error => commit(FAILED_USER, error))
},
async updateUser ({ commit, dispatch }) {
commit(ENV_DATA_PROCESS, true)
await api
.updateUser(state.editUser)
.then(() => commit(USER_UPDATED))
.then(() => commit(ENV_DATA_PROCESS, false))
.then(() => dispatch('user/getUsers', null, { root: true }))
.catch(error => commit(FAILED_USER, error))
},
async deleteUser ({ commit, dispatch }, userId) {
await api
.deleteUser(userId)
.then(() => commit(USER_DELETED))
.then(() => dispatch('user/getUsers', null, { root: true }))
.catch(error => commit(FAILED_USER, error))
}
}
// mutations
const mutations = {
[SWITCH_USER_NEW_MODAL] (state, showModal) {
state.showNewModal = showModal
},
[SWITCH_USER_EDIT_MODAL] (state, showModal) {
state.showEditModal = showModal
},
[USER_TABLE_LOADING] (state, isLoading) {
state.isUserTableLoading = isLoading
},
[FETCHING_USERS] (state, users) {
state.users = users
},
[ENV_DATA_PROCESS] (state, isActionInProgress) {
this._vm.$Progress.start()
state.isActionInProgress = isActionInProgress
},
[FAILED_USER] (state, error) {
this._vm.$Toast.fire({
icon: 'error',
title: error
}).then(r => {})
},
[USER_CREATED] (state) {
state.showNewModal = false
state.newUser = {
firstName: '',
lastName: '',
username: '',
email: '',
password: '',
nid: '',
sexo: '',
birthday: '',
age: '',
race: '',
sons: '',
salary: '',
position: '',
roles: [],
type: 'user'
}
this._vm.$Toast.fire({
icon: 'success',
title: 'User created successfully'
}).then(r => {})
},
[USER_EDIT] (state, userId) {
state.editUser = Object.assign({}, state.users
.filter(node => node.id === userId)
.shift()
)
},
[USER_UPDATED] (state) {
state.showEditModal = false
state.editUser = {
id: '',
firstName: '',
lastName: '',
username: '',
email: '',
password: '',
nid: '',
sexo: '',
birthday: '',
age: '',
race: '',
sons: '',
salary: '',
position: '',
roles: [],
type: 'user'
}
this._vm.$Toast.fire({
icon: 'success',
title: 'User has been updated'
}).then(r => {})
},
[USER_DELETED] (state) {
this._vm.$Toast.fire({
icon: 'success',
title: 'User has been deleted'
}).then(r => {})
}
}
export default {
namespaced: true,
state,
getters,
actions,
mutations
}
<file_sep>/resources/js/config/menu.js
const Menu = [
{
icon: 'mdi-account-search-outline',
title: 'Customers',
active: false,
group: true,
items: [
{ title: 'Management', route: 'Customers', path: '/users' },
{ title: 'Settings' }
]
}
]
export default Menu
<file_sep>/resources/js/store/modules/loginStore.js
import api from '../../data/api'
import { getToken, removeToken, saveToken } from '../../data/localStorage'
import router from '../../router'
const LOGIN = 'LOGIN'
const LOGIN_SUCCESS = 'LOGIN_SUCCESS'
const LOGIN_FAILED = 'LOGIN_FAILED'
const LOGOUT = 'LOGOUT'
const SET_USERNAME = 'SET_USERNAME'
const SET_PASSWORD = '<PASSWORD>'
const state = {
isLoggedIn: !!getToken(),
pending: false,
loading: false,
result: '',
auth: {
username: '',
password: ''
}
}
// getters
const getters = {
loggedIn: state => {
return state.isLoggedIn
}
}
// actions
const actions = {
async login ({ commit }) {
commit(LOGIN)
await api
.login(state.auth.username, state.auth.password)
.then(response => {
if (response.status === 200) {
saveToken(response.headers.authorization)
commit(LOGIN_SUCCESS, state.auth.username)
router.push('/')
}
})
.catch(() => commit(LOGIN_FAILED, 'Incorrect user or password'))
},
async logout ({ commit }) {
commit(LOGOUT)
await removeToken()
router.push('/login')
}
}
// mutations
const mutations = {
[LOGIN] (state) {
state.pending = true
},
[LOGIN_SUCCESS] (state, data) {
state.isLoggedIn = true
state.pending = false
state.result = data
},
[LOGOUT] (state) {
state.isLoggedIn = false
},
[SET_USERNAME] (state, username) {
state.username = username
},
[SET_PASSWORD] (state, password) {
state.password = <PASSWORD>
},
[LOGIN_FAILED] (state, error) {
this._vm.$Toast.fire({
icon: 'error',
title: error
}).then(r => {})
}
}
export default {
namespaced: true,
state,
getters,
actions,
mutations
}
<file_sep>/app/Http/Helpers/FirebaseHelper.php
<?php
namespace App\Http\Helpers;
class FirebaseHelper
{
public static function sendFcmNotificationMessage($PlayerIDs, $Data, $subtitle)
{
$server_key = config('fcmsettings.token');
$headers = array(
'Content-Type: application/json; charset=utf-8',
'Authorization: key=' . $server_key
);
$msg = array('title' => 'تراشیپ', 'sub_title' => $subtitle, 'activitydata' => $Data);
$notificationBody = array('subtitle' => $subtitle);
$notification = array('title' => 'تراشیپ', 'body' => $subtitle);
$fields = array(
"content_available" => true,
"priority" => "high",
'registration_ids' => $PlayerIDs,
'notification' => $notification,
'data' => $msg
);
$fields = json_encode($fields);
$url = 'https://fcm.googleapis.com/fcm/send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_POST, TRUE);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
curl_setopt($ch, CURLOPT_HEADER, FALSE);
curl_setopt($ch, CURLOPT_POSTFIELDS, $fields);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE);
$response = curl_exec($ch);
curl_close($ch);
return $response;
}
}
<file_sep>/app/Http/Helpers/InputHelper.php
<?php
namespace App\Http\Helpers;
use Exception;
use Illuminate\Http\JsonResponse;
use Illuminate\Http\Response;
class InputHelper
{
/**
* @param $request
* @param $items
* @param $function
* @return JsonResponse
*/
public static function inputChecker($request, $items, $function)
{
try {
if (!empty($items)) {
if (ArrayHelper::arrayIsset($items)) {
$function($request);
} else {
ResponseHelper::jsonResponse(null, Response::HTTP_BAD_REQUEST, config('messages.fail'))->send();
}
} else {
$function($request);
}
} catch (Exception $exception) {
ResponseHelper::jsonResponse($exception->getMessage(), Response::HTTP_INTERNAL_SERVER_ERROR, null)->send();
}
}
}
| 54b039f3a9373efba15c0b7869ff9971fdde27f6 | [
"JavaScript",
"Markdown",
"PHP"
] | 22 | JavaScript | miguelantonio90/laravel-vue | 7988e64c00ede1f358bc3ab64236af7834ef8246 | 4d8bb26e58e1ed0325f358efd820033512c34cf0 |
refs/heads/master | <repo_name>phillipclarke29/xmas2017<file_sep>/src/Underground.jsx
var React = require('react');
var {Form, FormControl, FormGroup} = require('react-bootstrap-form');
var ValidationError = require('react-bootstrap-form').ValidationError;
var Result = require('Result');
var Underground = React.createClass({
getInitialState() {
return {
undergroundColour: '',
result: '',
};
},
validateAnswer(answer) {
if(answer.toLowerCase()==="brown"){
this.setState({
result: 'Correct - Your secret code is Gunnersbury'
});
} else {
this.setState({
result: 'Wrong! - So wrong it hurts'
});
}
document.getElementById("myForm").reset();
},
handleChange(e) {
e.preventDefault();
this.setState({ undergroundColour: e.target.undergroundAnswer });
const givenAnswer=e.target.undergroundAnswer.value
console.log(givenAnswer);
this.validateAnswer(givenAnswer);
},
render() {
return (
<div>
<h2>What Colour is the Bakerloo Line</h2>
<form id="myForm" onSubmit={this.handleChange}>
<input type="text" name="undergroundAnswer" />
</form>
<Result result={this.state.result}/>
</div>
);
},
});
module.exports= Underground;
<file_sep>/server.js
const express = require('express');
const app = express();
const bodyParser = require('body-parser');
const MongoClient = require('mongodb').MongoClient;
const issuefunctions = require('./issue.js');
const path = require('path');
ObjectId = require('mongodb').ObjectID,
app.use(express.static('static'));
app.use(bodyParser.json());
app.get('/api/issues', (req, res) => {
const filter = {};
if (req.query.status) filter.status = req.query.status;
if (req.query.country) filter.country = req.query.country;
if (req.query.type) filter.type = req.query.type;
db.collection('issues').find(filter).toArray()
.then((issues) => {
const metadata = { total_count: issues.length };
res.json({ _metadata: metadata, records: issues });
})
.catch((error) => {
console.log(error);
res.status(500).json({ message: `Internal Server Error: ${error}` });
});
});
app.get('/api/issues/:id', (req, res) => {
let issueId;
try {
issueId = new ObjectId(req.params.id);
} catch (error) {
res.status(422).json({ message: `Invalid issue ID format: ${error}` });
return;
}
db.collection('issues').find({ _id: issueId }).limit(1)
.next()
.then(issue => {
if (!issue) res.status(404).json({ message: `No such issue: ${issueId}` });
else res.json(issue);
})
.catch(error => {
console.log(error);
res.status(500).json({ message: `Internal Server Error: ${error}` });
});
});
const validIssueStatus = {
New: true,
Open: true,
Assigned: true,
Fixed: true,
Verified: true,
Closed: true,
};
const validIssueCountry = {
UK: true,
England: true,
Scotland: true,
Wales: true,
NorthernIreland: true,
Crown: true,
Overseas: true,
};
const validIssueType = {
Central: true,
Local: true,
Police: true,
NHS: true,
Edu: true,
Other: true,
Fire: true,
};
const issueFieldType = {
status: 'required',
organisation: 'required',
created: 'required',
completionDate: 'optional',
type: 'required',
country: 'required',
};
function validateIssueType(issue) {
if (!validIssueType[issue.type]) { return `${issue.type} is not a valid type.`; }
}
function validateIssueCountry(issue) {
if (!validIssueCountry[issue.country]) { return `${issue.country} is not a valid Country.`; }
}
function validateIssueStatus(issue) {
if (!validIssueStatus[issue.status]) { return `${issue.status} is not a valid status.`; }
}
app.post('/api/issues', (req, res) => {
const newIssue = req.body;
newIssue.created = new Date();
if (!newIssue.status) { newIssue.status = 'New'; }
const err = (validateIssueCountry(newIssue) || validateIssueType(newIssue) || validateIssueStatus(newIssue));
console.log(err);
if (err) {
res.status(422).json({ message: `Invalid request: ${err}` });
} else {
db.collection('issues').insertOne(newIssue).then(result =>
db.collection('issues').find({ _id: result.insertedId }).limit(1).next()).then((newIssue) => {
res.json(newIssue);
})
.catch((error) => {
console.log(error);
res.status(500).json({ message: `Internal Server Error: ${error}` });
});
}
});
app.post('/api/issues/search', (req, res) => {
const searchResults = {};
console.log(req.query.text);
db.collection('issues').find({
"$text": {
"$search": req.query.text
}
}).toArray(function(err, results){
console.log(results);
res.json(results);
})
});
app.put('/api/issues/:id', (req, res) => {
let issueId;
console.log(req.body);
try {
issueId = new ObjectId(req.params.id);
} catch (error) {
res.status(422).json({ message: `Invalid issue ID format: ${error}` });
return;
}
const issue = req.body;
delete issue._id;
const err = issuefunctions.validateIssue(issue);
if (err) {
res.status(422).json({ message: `Invalid request: ${err}` });
return;
}
db.collection('issues').updateOne({ _id: issueId }, issuefunctions.convertIssue(issue)).then(() =>
db.collection('issues').find({ _id: issueId }).limit(1)
.next()
)
.then(savedIssue => {
res.json(savedIssue);
})
.catch(error => {
console.log(error);
res.status(500).json({ message: `Internal Server Error: ${error}` });
});
});
app.delete(`/api/issues/:id`, (req, res) => {
console.log(req.params.id);
let issueId;
try {
issueId = new ObjectId(req.params.id);
} catch (error) {
res.status(422).json({message: `Invalid Issue ID format: ${error}`});
return
}
db.collection('issues').deleteOne({_id: issueId}).then((deleteResult) =>{
if (deleteResult.result.n ===1) res.json({status: 'ok'});
else res.json({status: `warning: object not found`});
})
.catch(error =>{
console.log(error);
res.status(500).json({message: `internal server error: ${error}`});
});
})
app.get('*', (req, res) => {
res.sendFile(path.resolve('static/index.html'));
});
let db;
MongoClient.connect('mongodb://localhost/issueTracker').then((connection) => {
db = connection;
app.listen(3003, () => {
console.log('App started on port 3003');
});
}).catch((error) => {
console.log('ERROR:', error);
});
<file_sep>/src/App.jsx
var React = require('react');
var ReactDOM = require('react-dom');
var {Router, Route, IndexRoute, hashHistory} = require('react-router');
import Main from './Main.jsx';
var Orgs = require('Orgs');
var Underground = require('Underground');
var KingsOfEngland = require('KingsOfEngland');
ReactDOM.render(
<Router history={hashHistory}>
<Route path="/" component={Main}>
<IndexRoute component={Orgs}/>
<Route path="/underground" component={Underground}/>
<Route path="/Kings" component={KingsOfEngland}/>
</Route>
</Router>,
document.getElementById('contents')
);
<file_sep>/src/Result.jsx
var React = require('react');
var Result = React.createClass({
render: function () {
return(
<div>
<h2>{this.props.result}</h2>
</div>
)
}
});
module.exports= Result;
<file_sep>/src/Main.jsx
var React = require('react');
var Nav = require('Nav');
var Orgs = require('Orgs');
var Underground = require('Underground');
var KingsOfEngland = require('KingsOfEngland');
var Main = React.createClass({
render: function () {
return(
<div className = "container">
<h1><NAME></h1>
{this.props.children}
</div>
)
}
});
module.exports= Main;
<file_sep>/src/Nav.jsx
var React = require('react');
var {Link, IndexLink} = require('react-router');
var { Navbar, Nav, NavItem, } = require('react-bootstrap');
var Nav = React.createClass({
render: function () {
return(
<div>
<h2><NAME> 2017</h2>
</div>
)
}
});
module.exports= Nav;
<file_sep>/readme.md
#Bolierplate React App
## To run
npm start from root
## To compile
webpack -w
<file_sep>/webpack.config.js
var path = require('path');
module.exports = {
entry: './src/App.jsx',
output: {
path: path.join(__dirname, 'static'),
filename: 'app.bundle.js'
},
resolve: {
root: __dirname,
alias: {
Main: 'src/Main.jsx',
Orgs: 'src/Orgs.jsx',
Nav: 'src/Nav.jsx',
Underground: 'src/Underground.jsx',
KingsOfEngland: 'src/KingsOfEngland.jsx',
Result: 'src/Result.jsx',
},
extensions: ['','.js','.jsx']
},
module: {
loaders: [
{
loader: 'babel-loader',
query: {
presets: ['react', 'es2015', 'stage-0']
},
test: /\.jsx?$/,
exclude: /(node_modules|bower_components)/
}
]
}
};
| 6e353c15665c9124c86f68a41388b0ba679d3feb | [
"JavaScript",
"Markdown"
] | 8 | JavaScript | phillipclarke29/xmas2017 | c1679562a152c6f4124b260bb2ff41f823a4f559 | 15d6f3b63db63dc8f96b038128b9786696d0295b |
refs/heads/master | <repo_name>msy53719/cucumber-framework-test<file_sep>/script/report.sh
tar -cvzf test-report.tar.gz ./target/cucumber/<file_sep>/src/main/java/com/mosy/core/contant/FeatureContant.java
package com.mosy.core.contant;
public class FeatureContant {
public static final String RESPONSEDATAKEY = "JsonPath";
public static final String EXPECTEDVALUE = "ExpectedValue";
}
<file_sep>/src/test/java/com/mosy/core/test/util/AssertUtil.java
package com.mosy.core.test.util;
import java.util.Map;
import java.util.Map.Entry;
import org.junit.Assert;
import io.restassured.path.json.JsonPath;
public class AssertUtil {
public static void assertResToMap(String str, Map<String, String> map) {
JsonPath jsonpath = new JsonPath(str);
for (Entry<String, String> entery : map.entrySet()) {
Assert.assertEquals(entery.getValue(), jsonpath.getString(entery.getKey()));
}
}
}<file_sep>/src/main/java/com/mosy/core/util/RedisUtil.java
package com.mosy.core.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class RedisUtil {
public static Jedis getJedis() {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(30);
config.setMaxIdle(10);
JedisPool jedisPool = new JedisPool(config, "127.0.0.1", 6379);
Jedis jedis = jedisPool.getResource();
return jedis;
}
}<file_sep>/src/test/java/com/mosy/test/MapTest.java
package com.mosy.test;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.junit.Test;
public class MapTest {
// @Test
public void mapTest() {
Map<String, String> map = new LinkedHashMap<>();
map.put("a", "1");
map.put("b", "2");
map.put("c", "3");
map.put("d", "4");
map.put("e", "5");
map.remove("a");
for (Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + entry.getValue());
}
}
@Test
public void testM() {
String guid = "";
// for (int i = 1; i <= 32; i++){
// double n = Math.floor(Math.random()*16.0);
//
// guid += n;
// }
System.out.println(Math.floor(11.91));
System.out.println(Math.random() * 16.0);
}
}
<file_sep>/pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.mosy</groupId>
<artifactId>cucumber-framework-test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<sourceEncoding>UTF-8</sourceEncoding>
<java.version>1.8</java.version>
<testng.version>6.14.3</testng.version>
<junit.version>4.11</junit.version>
<spring.version>4.3.12.RELEASE</spring.version>
<rest-assured.version>3.1.0</rest-assured.version>
<cucumber.version>5.0.0</cucumber.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-junit</artifactId>
<version>${cucumber.version}</version>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-java</artifactId>
<version>${cucumber.version}</version>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-core</artifactId>
<version>${cucumber.version}</version>
</dependency>
<!-- <dependency> <groupId>io.cucumber</groupId> <artifactId>cucumber-spring</artifactId>
<version>${cucumber.version}</version> </dependency> -->
<!-- testng依赖 -->
<!-- <dependency> <groupId>org.testng</groupId> <artifactId>testng</artifactId>
<version>${testng.version}</version> <scope>test</scope> </dependency> -->
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<version>${rest-assured.version}</version>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>json-path</artifactId>
<version>${rest-assured.version}</version>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>xml-path</artifactId>
<version>${rest-assured.version}</version>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>json-schema-validator</artifactId>
<version>${rest-assured.version}</version>
</dependency>
<!-- logback依赖 -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-access</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>${sourceEncoding}</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>2.6</version>
<configuration>
<encoding>${sourceEncoding}</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.21.0</version>
<configuration>
<argLine>-Dfile.encoding=UTF-8</argLine>
</configuration>
</plugin>
</plugins>
</build>
</project> | 9bf432a0b141299314e2171331fb3b2963a97de1 | [
"Java",
"Maven POM",
"Shell"
] | 6 | Shell | msy53719/cucumber-framework-test | fcf7d8e46ae703a73635f7c7fd725d2fc90bfe08 | 699ee4407f505cedafbbd06bf3b2572bca8ae117 |
refs/heads/master | <file_sep><?php
function hello($text = "World", $time = "Good Morning") {
return "Hello $text! $time!<br>";
}
echo hello();
echo hello("Stenio","Good Night");
echo hello("John", "Good Afternoon");
?><file_sep><?php
$condition = true;
//does something as long as the condition is true
while ($condition) {
$number = rand(1,10);
if ($number === 3) {
echo "Three";
$condition = false;
}
echo $number . " ";
}
?><file_sep><?php
$name = "Stenio";
$name2 = 'Stenio';
var_dump($name, $name2);
//variable interpolation
echo "ABC $name";
?><file_sep><?php
function hello() {
$arg = func_get_args();
return $arg;
}
var_dump(hello("Good Morning", 10));
?><file_sep><?php
function fees() {
return 1045.00;
}
echo "John receive 3 fees: " . (fees()*3);
?><file_sep><?php
$result = (10 + 3) / 2;
echo $result;
echo "<br>";
//logic operator &&(and) ||(or)
var_dump($result > 5 && 10 + 5 < 20);
echo "<br>";
var_dump($result > 5 || 10 + 5 < 10);
?><file_sep><?php
//word position
$phrase = "Repetition is the mother of retention";
$word = "mother";
$q = strpos($phrase, $word);
var_dump($q);
//text before mother
$text = substr($phrase, 0, $q);
echo $text;
echo "<br>";
//text after mother
$text2 = substr($phrase, $q+strlen($word),strlen($phrase));
echo $text2;
echo "<br>";
?><file_sep><?php
$a = NULL;
$b = NULL;
$c = 10;
//Only PHP7
//ignore NULL operator
echo $a ?? $b ?? $c;
?><file_sep><?php
//attrib
$name = "Stenio";
//concat
echo $name . " more text<br>";
//compost
$name .= " trainer";
echo $name;
?><file_sep><?php
$name = "<NAME>";
echo $name;
echo "<br>";
//uppercase
echo strtoupper($name);
echo "<br>";
//lowercase
echo strtolower($name);
echo "<br>";
//uppercase on first word
$name = ucfirst($name);
echo $name;
echo "<br>";
//uppercase in each word
$name = ucwords($name);
echo $name;
echo "<br>";
?><file_sep><?php
//strings
$name = "Hcode";
$site = 'www.hcode.com.br';
//number
$year = 1990;
$payment = 5500.99;
$locked = false;
//array
$fruits = array("banana", "orange", "lemon");
//echo $fruits[2];
//object
$born = new DateTime();
//var_dump($born);
//resource
$file = fopen("sample-03.php", "r");
//var_dump($file);
//null
$null = NULL;
$empty = "";
echo $null;
echo $empty;
?><file_sep><?php
//array like vector
$fruit = array("orange","pineapple","watermelon");
print_r($fruit);
?><file_sep><?php
$yourAge = 30;
$ageChild = 12;
$ageAdult = 18;
$ageOld = 65;
if ($yourAge < $ageChild) {
echo "Child";
}
else if ($yourAge < $ageAdult) {
echo "Teen";
}
else if ($yourAge < $ageOld) {
echo "Adult";
}
else {
echo "Old";
}
echo "<br>";
echo ($yourAge < $ageAdult) ? "Not Adult" : "Adult";
?><file_sep><?php
$total = 150;
$off = 0.9;
//do something before checking the condition
do {
$total *= $off;
}
while ($total > 100);
echo $total . " ";
?><file_sep><?php
$month = array(
"Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec"
);
foreach ($month as $value) {
echo "Month is $value" . "<br>";
}
echo "<br>";
echo "<br>";
echo "<br>";
foreach ($month as $index => $value) {
echo "Index is: " . $index . "<br>";
echo "Month is $value" . "<br>";
}
?><file_sep><?php
//sum
$totalValue = 0;
$totalValue += 100;
$totalValue += 25;
//echo $totalValue;
//subtraction
$totalValue -= 10;
//-10% of value
$totalValue *= 0.9;
echo $totalValue;
?><file_sep><?php
//Rules for variables
//First word and lowercase and second and uppercase
$yearBirthday = 1990;
$monthBirthday = 6;
$dayBirthday = 8;
$name1 = "João";
$lastname = "Rangel";
//Concatenate name with last name
$fullName = $name1 . " " . $lastname;
echo $fullName;
exit;
//Variables of system, it cannot be used
// $this;
echo $name1;
echo "<br/>";
// clean variable
unset($name1);
// if for print if name is not null
if (isset($name1)) {
echo $name1;
}
?><file_sep><?php
require_once("config.php");
$_SESSION["name"] = "Stenio";
?><file_sep><?php
$a = 50;
$b = 35;
//spaceship operator if a>b = 1, if a==b = 0, if a<b = -1
var_dump($a <=> $b);
?><file_sep><?php
//working with array
$people = array();
array_push($people, array(
'name' => 'John',
'age' => 20
));
array_push($people, array(
'name' => 'Dario',
'age' => 25
));
print_r($people[0]);
?><file_sep><?php
$name = "Hcode";
//Print on screen
echo $name;
//Print variable type and size
var_dump($name);
?><file_sep><?php
//variables global $_GET[];
$name = $_GET["a"];
//var_dump($name);
//variable global $_SERVER[];
$ip = $_SERVER["SCRIPT_NAME"];
//echo $ip;
?><file_sep><?php
require_once("config.php");
echo session_save_path();
echo "<br>";
var_dump(session_status());
echo "<br>";
switch(session_status()) {
case PHP_SESSION_DISABLED:
echo " sessions are disable";
break;
case PHP_SESSION_NONE:
echo " sessions are enable but not active";
break;
case PHP_SESSION_ACTIVE:
echo " sessions are active";
break;
}
?><file_sep><?php
//include files of include path in php.ini
//include "sample-01.php";
//force file is working ok
require "sample-01.php";
//require if not was require before
require_once "sample-01.php";
$result = sum(10, 20);
echo $result;
echo "<br>";
?><file_sep><?php
//array bi-direction
$cars[0][0] = "GM";
$cars[0][1] = "Cobalt";
$cars[0][2] = "Onix";
$cars[0][3] = "Camaro";
$cars[1][0] = "Ford";
$cars[1][1] = "Fiesta";
$cars[1][2] = "Fusion";
$cars[1][3] = "Ecosport";
echo $cars[0][3];
//last iten on array
echo end($cars[1]);
?><file_sep><?php
//constant with array
define("DB", [
"127.0.0.1",
"root",
"<PASSWORD>",
"test"
]);
print_r(DB);
?><file_sep><?php
$json = '[{"name":"John","age":20},{"name":"Dario","age":25}]';
$data = json_decode($json, true);
var_dump($data);
?><file_sep><?php
define("SERVER","127.0.0.1");
echo SERVER;
?><file_sep><?php
$name = "Hcode";
//replace
$name = str_replace("o","0",$name);
$name = str_replace("e","3",$name);
echo $name;
?> | 0483cdc8dfca7f12e51c9e5440e7e3fc849a1748 | [
"PHP"
] | 29 | PHP | steniooliv/php7-course | 5cb96029daa8be16934177e02c047fd4cd0478e5 | cd2bafa47b29f11358bc187431ed67f660bb1977 |
refs/heads/master | <repo_name>joy-xiaojizhang/spn-experiment<file_sep>/spn_experiment.py
from tachyon.SPN2 import SPN
import numpy as np
# make an SPN holder
spn = SPN()
# include training and testing data
spn.add_data('output/movietrain.txt', 'train', cont=True)
spn.add_data('output/movietest.txt', 'test', cont=True)
# create a valid sum product network
sum_branch_factor = (2, 4)
prod_branch_factor = (20, 40)
num_variables = 1000
spn.make_random_model((prod_branch_factor, sum_branch_factor), num_variables, cont=True)
# start the session
spn.start_session()
# train
epochs = 1
# access the data
train = spn.data.train[:, :1000]
test = spn.data.test
spn.train(epochs, train, minibatch_size=100)
test_loss = spn.evaluate(test, cond_probs=np.zeros(test.shape[:2]))
print('Loss:', test_loss)
# Loss: 6.263
<file_sep>/parse_movie_set.py
'''
Parse the movie subtitles data set into a format that satisfies the following:
- All lower case
- Every sentence has 10 words
(pad with the word "pad" if len < 10 and truncate if len > 10)
'''
import string
class MovieSet:
def parse_movie_set(self, datatype='train'):
file_open = open('data/cornell movie-dialogs corpus/movie_lines.txt', 'r');
'''
# Parse first 2000 lines for testing
for i in range(2000):
line = file_open.readline()
strings = line.split(' +++$+++ ')
file_write.write(strings[-1])
'''
# Parse Q/A pairs with exactly 10 words (truncate length)
# pad if < 10 and truncate if > 10
trunc_len = 10
if datatype == 'train':
file_write = open('cornell_movie_train.txt', 'w');
for i in range(2000):
line = file_open.readline().split(' +++$+++ ')[-1].lstrip(' ').rstrip('\n')
punc = string.punctuation.replace("\'","")
newline = ""
for i in range(len(line)):
if not line[i].isalpha() and line[i] != "'":
newline += " "
else:
newline += line[i]
line = ' '.join(newline.split())
line_len = len(line.split())
if line_len > trunc_len:
line = ' '.join(line.split(' ')[0:trunc_len])
else:
line = ' '.join(line.split(' ') + [' PAD'] * (trunc_len - line_len))
file_write.write(' '.join(line.lower().split()) + '\n')
file_write.close()
else:
file_write = open('cornell_movie_test.txt', 'w');
for i in range(2000, 4000, 2):
line = file_open.readline().split(' +++$+++ ')[-1].lstrip(' ').rstrip('\n')
punc = string.punctuation.replace("\'","")
newline = ""
for i in range(len(line)):
if not line[i].isalpha() and line[i] != "'":
newline += " "
else:
newline += line[i]
line = ' '.join(newline.split())
line_len = len(line.split())
if line_len > trunc_len:
line = ' '.join(line.split(' ')[0:trunc_len])
else:
line = ' '.join(line.split(' ') + [' PAD'] * (trunc_len - line_len))
file_write.write(' '.join(line.lower().split()) + '\n')
file_write.close()
file_open.close()
<file_sep>/word_embedding.py
import word2vec
import numpy as np
import parse_movie_set
def train():
movie_set = cornell_movie_set.MovieSet()
movie_set.parse_movie_set('train')
word2vec.word2phrase('cornell_movie_train.txt', 'movie_phrases_train.txt', verbose=True)
word2vec.word2vec('movie_phrases_train.txt', 'movie_train.bin', size=100, verbose=True)
model = word2vec.load('movie_train.bin')
return model
def test():
movie_set = cornell_movie_set.MovieSet()
movie_set.parse_movie_set('test')
word2vec.word2phrase('cornell_movie_test.txt', 'movie_phrases_test.txt', verbose=True)
word2vec.word2vec('movie_phrases_test.txt', 'movie_test.bin', size=100, verbose=True)
model = word2vec.load('movie_test.bin')
return model
def create_embedding(datatype='train'):
if datatype == 'train':
model = train()
mat = []
fo = open('cornell_movie_train.txt', 'r')
for line in fo:
line = line.rstrip('\n').split(' ')
for word in line:
try:
c = model[word]
except:
mat.append([0] * 100)
continue
mat.append(model[word].tolist())
mat = np.array(mat)
# Reshape to conform with input placeholder
# (Avoid Tensorflow ValueError)
mat = np.reshape(mat, (-1, 2000))
fo.close()
np.savetxt('movietrain.txt', mat, fmt='%.4f', delimiter=',')
else:
model = test()
mat = []
fo = open('cornell_movie_test.txt', 'r')
for line in fo:
line = line.rstrip('\n').split(' ')
for word in line:
try:
c = model[word]
except:
mat.append([0] * 100)
continue
mat.append(model[word].tolist())
mat = np.array(mat)
mat = np.reshape(mat, (-1, 1000))
fo.close()
np.savetxt('movietest.txt', mat, fmt='%.4f', delimiter=',')
if __name__ == '__main__':
create_embedding('train')
create_embedding('test')
| 931d242c7e882f13efd1c4224df75b3414e1525b | [
"Python"
] | 3 | Python | joy-xiaojizhang/spn-experiment | 0d4248bcc129a26361c8c636bf22fc4ec7b383b7 | 96f4a27c80e35f5c359f7d52c3e10ef2b41840a0 |
refs/heads/master | <repo_name>bltarkany/Hangman-Javascript<file_sep>/assets/javascript/game.js
// Global Variables
// ======================================================================
var movies = ["jack", "edward", "sweeney", "beetlejuice", "lydia", "bonejangles", "ichabod",
"frankenweenie", "sally", "batman", "wonka", "oogieboogie"];
var compGuess = "";
// word container
var titleSplit = [];
var numBlanks = 0;
// n _ _ _ _
var blanksAndLetters = [];
// game counters
var winCount = 0;
var lossCount = 0;
var guessesLeft = 10;
var lettersGuessed = "";
var lettersWrong = [];
// audio files
var audio1 = new Audio("assets/images/sleep.m4a");
// documentation in to html
var gameMovie = document.getElementById("movieClass");
var usedLetters = document.getElementById("letters");
var winScore = document.getElementById("wins");
var lossScore = document.getElementById("losses");
var moviePic = document.getElementById("image");
var turnsLeft = document.getElementById("turns");
var gameOutcome = document.getElementById("outcome");
var movieName = document.getElementById("title");
var audioList = document.getElementById("audio");
// Global Functions
// ===========================================================================
// start of next round
function startGame() {
// split random word - find the number fo letters - push character for each letter
titleSplit = compGuess.split("");
numBlanks = titleSplit.length;
for (var i = 0; i < numBlanks; i++) {
blanksAndLetters.push("_");
}
gameMovie.textContent = blanksAndLetters.join(" ");
// reset game counters
guessesLeft = 10;
lettersWrong = [];
usedLetters.textContent = lettersWrong.join(" ");
turnsLeft.textContent = guessesLeft;
winScore.textContent = winCount;
lossScore.textContent = lossCount;
// moviePic.setAttribute("src", "assets/images/blackandwhite.jpg");
// console log actions
console.log(titleSplit);
console.log(numBlanks);
console.log(blanksAndLetters);
}
// full restart of game
function restartGame() {
// split random word - find the number fo letters - push character for each letter
titleSplit = compGuess.split("");
numBlanks = titleSplit.length;
for (var i = 0; i < numBlanks; i++) {
blanksAndLetters.push("_");
}
gameMovie.textContent = blanksAndLetters.join(" ");
// reset game counters
winCount = 0;
lossCount = 0;
guessesLeft = 10;
lettersWrong = [];
movieName.textContent = "Movie Title";
usedLetters.textContent = lettersWrong.join(" ");
turnsLeft.textContent = guessesLeft;
winScore.textContent = winCount;
lossScore.textContent = lossCount;
gameOutcome.textContent = "";
moviePic.setAttribute("src", "assets/images/blackandwhite.jpg");
// console log actions
console.log(titleSplit);
console.log(numBlanks);
console.log(blanksAndLetters);
}
// movie title selection
function movieTitle() {
compGuess = movies[Math.floor(Math.random() * movies.length)];
blanksAndLetters = [];
console.log(compGuess);
}
// check if user letter guesses are in mystery word
function letterChecker(letter) {
// start with no letters correct because it is the start of game
var letterFound = false;
// look to see if user letter choice is in game word. If so letterFound is now true
for (var i = 0; i < numBlanks; i++) {
if (compGuess[i] === letter) {
letterFound = true;
};
}
// If letter found is true, find where the true letters are and put them into the blanks and letters
if (letterFound) {
for (var j = 0; j < numBlanks; j++) {
if (compGuess[j] === letter) {
blanksAndLetters[j] = letter;
}
console.log(blanksAndLetters);
}
// if letter found stays false, remove a turn and put wrong guess into used letters
} else {
guessesLeft--;
lettersWrong.push(letter);
console.log(lettersWrong);
}
}
// Game Logic
// ============================================================================
document.onkeyup = function (event) {
lettersGuessed = String.fromCharCode(event.which).toLowerCase();
letterChecker(lettersGuessed);
if (titleSplit.toString() === blanksAndLetters.toString()) {
gameOutcome.textContent = "You won!! Let's play again!"
winCount++;
if (compGuess === "beetlejuice") {
moviePic.setAttribute("src", "assets/images/betleljuice-f.jpg");
movieName.textContent = "Beetlejuice!";
} else if (compGuess === "jack") {
moviePic.setAttribute("src", "assets/images/jack.gif");
movieName.textContent = "Nightmare Before Christmas!";
} else if (compGuess === "sally") {
moviePic.setAttribute("src", "assets/images/sally.gif");
movieName.textContent = "Nightmare Before Christmas!";
} else if (compGuess === "batman") {
moviePic.setAttribute("src", "assets/images/batman.jpg");
movieName.textContent = "Batman!";
} else if (compGuess === "edward") {
moviePic.setAttribute("src", "assets/images/edward.jpg");
movieName.textContent = "Ed<NAME>!";
} else if (compGuess === "frankenweenie") {
moviePic.setAttribute("src", "assets/images/frank.jpg");
movieName.textContent = "Frankenweenie!";
} else if (compGuess === "sweeney") {
moviePic.setAttribute("src", "assets/images/SweeneyTodd.jpg");
movieName.textContent = "S<NAME>!";
} else if (compGuess === "lydia") {
moviePic.setAttribute("src", "assets/images/lydia.jpg");
movieName.textContent = "Beetlejuice!";
} else if (compGuess === "bonejangles") {
moviePic.setAttribute("src", "assets/images/bone.jpg");
movieName.textContent = "Corpse Bride!";
} else if (compGuess === "ichabod") {
moviePic.setAttribute("src", "assets/images/ichabod.jpg");
movieName.textContent = "Sleepy Hollow!";
audio1.play();
} else if (compGuess === "wonka") {
moviePic.setAttribute("src", "assets/images/wonka.jpg");
movieName.textContent = "<NAME> and the Chocolate Factory!";
} else if (compGuess === "oogieboogie") {
moviePic.setAttribute("src", "assets/images/oogie.jpg");
movieName.textContent = "Nightmare Before Christmas!";
}
movieTitle();
startGame();
} else if (guessesLeft === 0) {
gameOutcome.textContent = "You Lost! Try harder this time!"
lossCount++;
movieTitle();
startGame();
}
if (lossCount === 10) {
gameOutcome.textContent = "You've lost to many times. Time to restart the score board!"
movieTitle();
restartGame();
}
gameMovie.textContent = blanksAndLetters.join(" ");
usedLetters.textContent = lettersWrong.join(" ");
turnsLeft.textContent = guessesLeft;
winScore.textContent = winCount;
lossScore.textContent = lossCount;
}
// Game start function callback
movieTitle();
startGame();<file_sep>/README.md
# Word-Guess-Game / Javascript
### OverView
This Project was used to solidify javascript components, including:
1. documenting to the html.
2. global variables
3. global functions
4. onkeyup functions
5. setting attributes
### Word Guess Game
#### Demo Game Here
[Hangman](https://bltarkany.github.io/Hangman-Javascript/)
#### Game Play Theme

#### Instructions
Choose a theme for your game!
Use key events to listen for the letters that your players will type.
Display the following on the page:
* Press any key to get started!
* Wins: (# of times user guessed the word correctly).
* If the word is madonna, display it like this when the game starts: _ _ _ _ _ _ _.
As the user guesses the correct letters, reveal them: m a d o _ _ a.
* Number of Guesses Remaining: (# of guesses remaining for the user).
* Letters Already Guessed: (Letters the user has guessed, displayed like L Z Y H).
* After the user wins/loses the game should automatically choose another word and make the user play it.
#### Word Guess Game Bonuses
Play a sound or song when the user guesses their word correctly, like in our demo.
Write some stylish CSS rules to make a design that fits your game's theme.
HARD MODE: Organize your game code as an object, except for the key events to get the letter guessed. This will be a challenge if you haven't coded with JavaScript before, but we encourage anyone already familiar with the language to try this out.
Save your whole game and its properties in an object.
Save any of your game's functions as methods, and call them underneath your object declaration using event listeners.
Don't forget to place your global variables and functions above your object.
Remember: global variables, then objects, then calls. | 0ce4c534fab2464501797d9f40360edb8f4c3f8b | [
"JavaScript",
"Markdown"
] | 2 | JavaScript | bltarkany/Hangman-Javascript | 089a5750a321aa10aeb0cbe18565b037579ac491 | 05a510695433f4cbafd3e13b4734e521f175c5a1 |
refs/heads/master | <file_sep># SQLITE_Database
Working with Sqlite Database and Qml
<file_sep>#include "database.h"
DataBase::DataBase(QObject *parent) : QObject(parent)
{
}
DataBase::~DataBase()
{
}
void DataBase::connectToDataBase()
{
if(!QFile("C:/example/" DATABASE_NAME).exists()){
this->restoreDataBase();
} else {
this->openDataBase();
}
}
bool DataBase::restoreDataBase()
{
if(this->openDataBase()){
return (this->createTable()) ? true : false;
} else {
qDebug() << "Failed to restore the database";
return false;
}
return false;
}
bool DataBase::openDataBase()
{
db = QSqlDatabase::addDatabase("QSQLITE");
db.setHostName(DATABASE_HOSTNAME);
db.setDatabaseName("/home/nicholus/Desktop/SqliteDemo/DB/SampleDB" DATABASE_NAME);
if(db.open()){
return true;
} else {
return false;
}
}
void DataBase::closeDataBase()
{
db.close();
}
bool DataBase::createTable()
{
QSqlQuery query;
if(!query.exec( "CREATE TABLE " TABLE " ("
"id INTEGER PRIMARY KEY AUTOINCREMENT, "
TABLE_FNAME " VARCHAR(255) NOT NULL,"
TABLE_SNAME " VARCHAR(255) NOT NULL,"
TABLE_NIK " VARCHAR(255) NOT NULL"
" )"
)){
qDebug() << "DataBase: error of create " << TABLE;
qDebug() << query.lastError().text();
return false;
} else {
return true;
}
return false;
}
bool DataBase::inserIntoTable(const QVariantList &data)
{
QSqlQuery query;
query.prepare("INSERT INTO " TABLE " ( " TABLE_FNAME ", "
TABLE_SNAME ", "
TABLE_NIK " ) "
"VALUES (:FName, :SName, :Nik)");
query.bindValue(":FName", data[0].toString());
query.bindValue(":SName", data[1].toString());
query.bindValue(":Nik", data[2].toString());
if(!query.exec()){
qDebug() << "error insert into " << TABLE;
qDebug() << query.lastError().text();
return false;
} else {
return true;
}
return false;
}
bool DataBase::inserIntoTable(const QString &fname, const QString &sname, const QString &nik)
{
QVariantList data;
data.append(fname);
data.append(sname);
data.append(nik);
if(inserIntoTable(data))
return true;
else
return false;
}
bool DataBase::removeRecord(const int id)
{
QSqlQuery query;
query.prepare("DELETE FROM " TABLE " WHERE id= :ID ;");
query.bindValue(":ID", id);
if(!query.exec()){
qDebug() << "error delete row " << TABLE;
qDebug() << query.lastError().text();
return false;
} else {
return true;
}
return false;
}
<file_sep>#ifndef DATABASE_H
#define DATABASE_H
#include <QObject>
#include <QSql>
#include <QSqlQuery>
#include <QSqlError>
#include <QSqlDatabase>
#include <QFile>
#include <QDate>
#include <QDebug>
#define DATABASE_HOSTNAME "NameDataBase"
#define DATABASE_NAME "Name.db"
#define TABLE "NameTable"
#define TABLE_FNAME "FisrtName"
#define TABLE_SNAME "SurName"
#define TABLE_NIK "Nik"
class DataBase : public QObject
{
Q_OBJECT
public:
explicit DataBase(QObject *parent = 0);
~DataBase();
void connectToDataBase();
private:
QSqlDatabase db;
private:
bool openDataBase();
bool restoreDataBase();
void closeDataBase();
bool createTable();
public slots:
bool inserIntoTable(const QVariantList &data); // Adding entries to the table
bool inserIntoTable(const QString &fname, const QString &sname, const QString &nik);
bool removeRecord(const int id); // Removing records from the table on its id
};
#endif // DATABASE_H
| cb45f9af72dcfaa0b19150af5908cb4c7445d84d | [
"Markdown",
"C++"
] | 3 | Markdown | Seguya-Nicholus/SQLITE_Database | d6fb875a22dabffceea51b81a8122fffb0e64f18 | e29e58004b83c62b8dfdd8af236b6154dd999dad |
refs/heads/master | <repo_name>Joselagem/karafun-touch<file_sep>/i/js/locale.js
$(document).ready(function(){
$(".translate").each(function() {
name = $(this).data("name");
$(this).html(chrome.i18n.getMessage(name));
});
$("input.topbar__search").attr("placeholder", chrome.i18n.getMessage("search"));
});
<file_sep>/i/js/player.js
Player = function() {
this._buttonPause = $(".pause");
this._buttonPlay = $(".play");
this._buttonNext = $(".next");
this._pitch = $("#pitch");
this._tempo = $("#tempo");
this._songPlaying = $(".controls__songtitle");
this._progressBar = $(".controls__progressbar");
this._progressInterval = null;
this._position = 0;
this._initHandlers();
this._volumes = new Array();
}
Player.prototype = {
_setPitch: function(pitch) {
this._pitch.html(pitch);
},
_setTempo: function(tempo) {
this._tempo.html(tempo+"%");
},
_play: function() {
this._buttonPause.show();
this._buttonPlay.hide();
},
_progress: function(song) {
clearInterval(this._progressInterval);
var w = parseInt($(".controls").width());
var duration = song.getDuration();
var step = w/duration*(Player.intervalProgress/1000);
var baseWidth = w/duration*this._position;
this._progressBar.width(baseWidth);
var that = this;
this._progressInterval = setInterval(function() {
baseWidth+= step;
that._progressBar.width(baseWidth);
if(baseWidth >= w) {
that._progressBar.width(0);
clearInterval(that._progressInterval);
}
},Player.intervalProgress);
},
_pause: function() {
this._buttonPlay.show();
this._buttonPause.hide();
clearInterval(this._progressInterval);
if(this._position == 0) {
this._songPlaying.empty();
this._removeAddedSliders();
this._progressBar.width(0);
}
},
_removeAddedSliders: function() {
$(".slider_box input.optional").parents(".slider_wrapper").remove();
},
_switchState: function(state) {
switch(state) {
case "playing" :
this._play();
break;
case "infoscreen":
this._pause();
break;
default:
this._pause();
break;
}
},
_initVolume : function(name,caption,color,volume) {
var elem = $("#slider-"+name);
if(!elem.length) {
elem = this._createVolumeSlider(name);
}
if(caption.length == 0 && name.indexOf("lead")>-1) {
caption = chrome.i18n.getMessage("lead");
}
elem.parent().next().html(caption);
elem.parent().next().css("color",color);
elem.val(volume);
},
_createVolumeSlider: function(name) {
var elem = $("#slider-general").parents(".slider_wrapper").clone();
var slider = elem.find("input");
slider.attr("id","slider-"+name);
slider.attr("name",name);
slider.addClass("optional");
elem.appendTo(".controls__sliders");
return slider;
},
_updateVolumes: function(volumes) {
var that=this;
volumes.each(function() {
volume = parseInt($(this).text());
color = $(this).attr("color");
caption = $(this).attr("caption");
name = $(this)[0].nodeName;
that._initVolume(name,caption,color,volume);
});
},
_updateStatus: function(xml) {
state = xml.find("status").attr("state");
this._switchState(state);
position = xml.find("position");
if(position) {
this._position = parseInt(position.text());
} else {
this._position = 0;
}
volumes = xml.find("volumeList").children();
this._updateVolumes(volumes);
pitch = parseInt(xml.find("pitch").text());
this._setPitch(pitch);
tempo = parseInt(xml.find("tempo").text());
this._setTempo(tempo);
},
_fireEvent: function(type,value, args) {
RemoteEvent.create("notify", {
type:type,
value:value,
args:args
});
},
_initHandlers: function() {
var that = this;
document.addEventListener('status', function(ev) {
that._updateStatus(ev.detail);
});
document.addEventListener('play', function(ev) {
that._songPlaying.html(ev.detail.song.getString());
that._progress(ev.detail.song)
});
this._buttonPause.on("click",function() {
that._fireEvent("pause");
});
this._buttonPlay.on("click",function() {
that._fireEvent("play");
});
this._buttonNext.on("click",function() {
that._fireEvent("next");
});
$(".controls__sliders").on("click",".slider__caption", function() {
var input = $(this).prev().find("input");
var currentVolume = input.val();
var name = input.attr('name');
if(currentVolume > 0) {
that._volumes[name] = currentVolume;
currentVolume = 0;
} else {
currentVolume = that._volumes[name];
}
var args = [];
args["volume_type"] = name;
that._fireEvent("setVolume",currentVolume, args);
});
$(".controls__sliders").on("change",".slider_box input", function() {
var args = [];
args["volume_type"] = $(this).attr("name");
that._fireEvent("setVolume",this.value, args);
});
$(".pitch").on("click", function(){
p = parseInt(that._pitch.html());
if($(this).data("type") == 'minus') {
p--;
} else {
p++;
}
that._fireEvent("pitch",p);
});
$(".tempo").on("click", function(){
p = parseInt(that._tempo.html());
if($(this).data("type") == 'minus') {
p-=10;
} else {
p+=10;
}
that._fireEvent("tempo",p);
});
}
}
Player.intervalProgress = 500;<file_sep>/i/js/catalog.js
Catalog = function(xml) {
this._caption = "";
this._id = 0;
this._parse(xml);
}
Catalog.prototype = {
render: function() {
html = this._getHtml();
return html;
},
_parse: function(catalog) {
this._caption = catalog.text();
this._id = catalog.attr("id");
},
_getHtml: function() {
return '<div class="column half">\n\
<div class="styles_card" id="catalog_'+this._id+'" data-id="'+this._id+'">\n\
<a class="link--card click_feedback" href="#">\n\
<div class="styles_card__left"><span class="styles_card__title">'+this._caption+'</span></div>\n\
<div class="clearfix"></div>\n\
</a>\n\
</div>\n\
</div>';
}
}<file_sep>/i/js/tcpclient.js
TcpClient = function(settings) {
this.settings = settings;
var that = this;
document.addEventListener("notify",function(ev) {
that.notify(ev.detail.type, ev.detail.value, ev.detail.args);
});
}
TcpClient.prototype = {
connect: function() {
var that = this;
this.socket = new WebSocket(this.settings.getUri());
this.socket.onopen = function() {
that._onOpenCallback();
};
this.socket.onmessage = function(msg) {
that._onMessageCallback(msg);
};
this.socket.onclose = function() {
that._onCloseCallback();
};
this.socket.onerror = function(event) {
that._onErrorCallback(event);
};
},
notify: function(type, value, args) {
var argsString = "";
if(args != undefined) {
for(var key in args) {
argsString+=" "+key+"='"+args[key]+"'";
}
}
var socketString ="<action type='"+type+"'";
if(argsString.length) {
socketString+=argsString;
}
socketString+=">";
if(value != undefined) {
socketString+=value;
}
socketString+="</action>";
this.socket.send(socketString);
},
_onOpenCallback : function() {
//Hide the socket connect window
clearTimeout(this.timeout);
var that = this;
$(".splashscreen").hide();
RemoteEvent.create("notify", {
type:"screen",
args: {
"screen":that.settings.screen
}
});
this.notify("getCatalogList")
},
_onMessageCallback : function(msg) {
xml = $($.parseXML(msg.data));
eventName = xml.children().get(0).nodeName;
RemoteEvent.create(eventName, xml)
},
_onCloseCallback : function() {
//Show the socket connect window
$(".splashscreen").css("display","table");
var that = this;
this.timeout = setTimeout(function(){
tcpClient = that.connect();
},3000);
},
_onErrorCallback : function(event) {
}
}<file_sep>/i/js/queue.js
Queue = function() {
this.container = $(".song_queue");
this._initHandlers();
this._currentQueue = new Array();
}
Queue.prototype = {
update: function(xml) {
queue = xml.find("queue");
items = queue.children();
content = "";
newQueue = new Array();
items.each(function(){
song = new Song($(this));
song.isInQueue();
newQueue[song.getId()] = song;
if(song.isPlaying()) {
RemoteEvent.create("play", {
song:song
});
}
});
//check added
var that = this;
var i = 0;
$.each(newQueue, function(key,value) {
html = $(value.render());
if(that._currentQueue[key] && !that._currentQueue[key].isEqualTo(value)) {
$("#song_"+key).replaceWith(html);
that._currentQueue[value.getId()] = value;
} else if (!that._currentQueue[key]) {
html.addClass("appear");
that._currentQueue[value.getId()] = value;
that.container.append(html);
}
i++;
});
for(var j=i;j<this._currentQueue.length;j++) {
$("#song_"+j).remove();
delete this._currentQueue[j];
}
},
clear: function() {
RemoteEvent.create("notify", {
type: "clearQueue"
});
},
_changePosition: function(oldPosition,newPosition) {
args = new Array();
args["id"] = oldPosition;
RemoteEvent.create("notify", {
type:"changeQueuePosition",
value:newPosition,
args:args
});
},
_remove: function(id) {
var args = [];
args["id"] = id;
RemoteEvent.create("notify", {
type:"removeFromQueue",
args:args
});
},
_initHandlers: function() {
var that = this;
this.container.on("dragover", function(ev) {
ev.preventDefault();
});
document.addEventListener('status', function(ev) {
that.update(ev.detail);
});
this.container.on("dragstart",".song_card",function(event) {
event.originalEvent.dataTransfer.effectAllowed = "move";
event.originalEvent.dataTransfer.setData("text", $(this).data("id"));
});
this.container.on("drop",".song_card",function(event) {
event.preventDefault();
var oldPosition = event.originalEvent.dataTransfer.getData("text");
var newPosition = $(this).data("id");
if(oldPosition != newPosition) {
that._changePosition(oldPosition, newPosition);
}
});
this.container.on("click",".delete", function() {
that._remove($(this).parent().data("id"));
});
}
}
Queue.add = function(song_id, position) {
args = new Array();
args["song"] = song_id;
RemoteEvent.create("notify", {
type:"addToQueue",
value:position,
args:args
});
}<file_sep>/i/js/app.js
var tcpClient;
var settings;
$(document).ready(function () {
settings = new Settings();
setTimeout(function () {
if (settings.isReady == 1) {
tcpClient = new TcpClient(settings);
tcpClient.connect();
player = new Player();
queue = new Queue();
catalogs = new Catalogs();
songlist = new Songlist();
search = new Search();
clearTimeout();
}
}, 1000);
});<file_sep>/i/js/background.js
chrome.app.runtime.onLaunched.addListener(function() {
chrome.storage.local.get("uri", function(item) {
if(!item.uri) {
chrome.storage.local.set({
"uri":"ws://localhost:57570"
});
}
chrome.app.window.create('index.html', {
id : "main"
}, function(createdWindow) {
createdWindow.fullscreen();
});
});
});<file_sep>/readme.md
# KaraFun Touch

--
**KaraFun Touch** is an Open Source Touchscreen interface control for **KaraFun Player**, the karaoke player designed for Windows ([http://www.karafun.com](http://www.karafun.com)).
## Installation
KaraFun Touch has been designed as a Chrome App. In order to install it, go to your extensions in Google Chrome and add the folder where KaraFun Touch files are stored.
##General information
Volume values are between 0 (muted) and 100 (full volume)
Time and duration values are in seconds (can be float)
Color are in HTML format #RRGGBB
Communications are done via Websocket
##List of actions
### Get player status
<action type="getStatus" [noqueue]></action>
Reflect the current state of KaraFun Player. `no queue` allows not to send the queue status.
---
Response to getStatus
<status state="{player_state}">
[<position>{time_in_seconds}</position>]
<volumeList>
<general caption="{caption}">{volume}</general>
[<bv caption="{caption}">{volume}</bv>]
[<lead1 caption="{caption}" color="{color}">{volume}</lead1>]
[<lead2 caption="{caption}" color="{color}">{volume}</lead2>]
</volumeList>
<pitch>{pitch}</pitch>
<tempo>{tempo}</tempo>
<queue>
<item id="{queue_position}" status="{item_state}">
<title>{song_name}</title>
<artist>{artist_name}</artist>
<year>{year}</year>
<duration>{duration_in_seconds}</duration>
[<singer>{singer_name}</singer>]
</item>
...
</queue>
</status>
`<volumeList>` general is always included, disabled volumes are not included
`<queue>` item count is limited to 100 (approx 5 hours of queue!)
`player_state` possible values :
* idle
* infoscreen
* loading
* playing
`item_state` possible values :
* ready
* loading
### Audio control and transport
<action type="play"></action>
<action type="pause"></action>
<action type="next"></action>
<action type="seek">{time_in_seconds}</action>
<action type="pitch">{picth}</action>
<action type="tempo">{tempo}</action>
### Volume management
<action type="setVolume" volume_type="{volume_type}">{volume_between_0_100}</action>
`volume_type` possible values are from the getStatus
### Song queue management
<action type="clearQueue"></action>
<action type="addToQueue" song="{song_id}">{add_position}</action>
<action type="removeFromQueue" id="{queue_position}"></action>
<action type="changeQueuePosition" id="{old_position}">{new_position}</action>
`song_id` and `queue_id` are unique
`position` possible values :
* 0: top
* 1...n: specific position
* 99999: bottom
### Get the list of catalogs
<action type="getCatalogList"></action>
List currently available catalogs. Queue, history and tree structure are not included.
`type` possible values :
* onlineComplete
* onlineNews
* onlineFavorites
* onlineStyle
* localPlaylist
* localDirectory
---
Response to getCatalogList
<catalogList>
<catalog id="{unique_id}" type="{type}">{caption}</item>
<catalog id="{unique_id}" type="{type}">{caption}</item>
...
</catalogList>
### Get a list content
<action type="getList" id="{list_id}" offset="{offset}" limit="{limit}"></action>
List the songs of a catalog
Default `limit` is 100
### Search
<action type="search" offset="{offset}" limit="{limit}">{search_string}</action>
List the songs of a search
Default `limit` is 100
---
Response to getList/search
<list total={total}>
<item id="{unique_id}">
<title>{song_name}</title>
<artist>{artist_name}</artist>
<year>{year}</year>
<duration>{duration_in_seconds}</duration>
</item>
...
</list>
### Screen Management
<action type="screenPosition" x="{x}" y="{y}" width="{width}" height="{height}"></action>
Set the screen position
<action type="fullscreen"></action>
Set the second screen into fullscreen mode
<file_sep>/i/js/search.js
Search = function() {
this._timeout = null;
this._initHandlers();
}
Search.prototype = {
_initHandlers: function() {
$('a.topbar__right').on("click",function () {
$('.topbar__search').focus();
return false;
});
$('.empty_search').on("click",function () {
$('.topbar__search').val('');
RemoteEvent.create("showstyles");
});
var that = this;
$(".topbar__search").on("keyup", function() {
clearTimeout(that._timeout);
var t = $(this);
that._timeout = setTimeout(function() {
RemoteEvent.create("search", t.val());
},500);
});
}
}<file_sep>/i/js/songlist.js
Songlist = function() {
this._total = 0;
this._offset = 0;
this._countItems = 0;
this._searchValue = "";
this.container = $(".content__inner .top");
this._launchNext = false;
this._initHandlers();
}
Songlist.prototype = {
_updateList:function(xml) {
list = xml.find("list");
this._total = list.attr("total");
items = list.children();
content = "";
var that = this;
items.each(function(){
song = new Song($(this));
if(that._countItems!= 0 && that._countItems % 2 == 0) {
content += "<div class='clearfix'></div>";
}
content += "<div class='half column'>"+song.render()+"</div>";
that._countItems++;
});
if(this.container.is(":visible")) {
this.container.append(content);
} else {
this.container.html(content);
this.container.show();
$(".genres").hide();
}
},
_loadNext: function() {
this._offset+=Catalogs.limit;
var args = new Array();
var type = "getList"
var value = undefined;
args["offset"] = this._offset;
args["limit"] = Catalogs.limit;
if(Catalogs.listId) {
args["id"] = Catalogs.listId;
} else {
type = "search";
value = this._searchValue;
}
RemoteEvent.create("notify", {
type:type,
args:args,
value:value
});
},
_reset : function() {
this._offset = 0;
this._total = 0;
this._countItems = 0;
this._launchNext = false;
this.container.empty();
},
_initHandlers: function() {
var that = this;
document.addEventListener("list", function(ev) {
that._updateList(ev.detail);
});
document.addEventListener("showstyles", function() {
that._reset();
that.container.hide();
});
document.addEventListener("search",function(ev) {
Catalogs.listId = 0;
that._searchValue = ev.detail;
that._reset();
var args = new Array();
args["offset"] = that._offset;
args["limit"] = Catalogs.limit;
RemoteEvent.create("notify", {
type: "search",
args: args,
value : that._searchValue
});
});
this.container.on("mouseup",".song_card",function() {
$('.card__popup').css('display', 'none');
$(this).children('.card__popup').css('display', 'initial').addClass('visible');
});
this.container.on("click",".click_feedback",function() {
var action = $(this).data("action");
switch(action) {
case "play":
Queue.add($(this).parents(".song_card").data("id"), 0);
break;
case "queue":
Queue.add($(this).parents(".song_card").data("id"), 99999);
break;
case "cancel":
break;
}
$(this).parents(".card__popup").css("display","none");
});
$(".content").on("scroll",function(ev) {
if(that._launchNext) {
that._launchNext = false;
that._loadNext();
return;
}
if(that.container.is(":visible") && that._countItems <= that._total) {
if($(".song_card:last").offset().top < $(window).height()) {
that._launchNext = true;
}
}
});
}
} | 1ed2fa5672027dc14780c4a0daa512c51a7fad68 | [
"JavaScript",
"Markdown"
] | 10 | JavaScript | Joselagem/karafun-touch | 63e90e60c3bc73b7f2112da19a2f81993dc4a805 | 915e600ab3289c88b112a05af340f76434336407 |
refs/heads/master | <repo_name>Riim/simple-svg-loader<file_sep>/README.md
# simple-svg-loader
## config:
```js
var webpack = require('webpack');
module.exports = {
module: {
rules: [
{
test: /\.svg$/,
loader: 'simple-svg-loader'
}
]
}
};
```
## use:
```js
import './icons/home.svg';
```
```html
<a href="/">
<svg viewBox="0 0 32 32"><use xlink:href="#home"></use></svg>
Home
</a>
```
### change id:
```js
import './icons/home.svg?id=icon-home';
```
```html
<svg viewBox="0 0 32 32"><use xlink:href="#icon-home"></use></svg>
```
<file_sep>/index.js
let path = require('path');
let uuid = require('uuid');
let xmldom = require('xmldom');
let xpath = require('xpath');
let SVGO = require('svgo');
let loaderUtils = require('loader-utils');
module.exports = function(content) {
let callback = this.async();
let removeAttributes = this.query.removeAttributes;
let sourceDoc = new xmldom.DOMParser().parseFromString(content, 'text/xml');
let targetDoc = new xmldom.DOMParser().parseFromString('<symbol></symbol>', 'text/xml');
let sourceDocEl = sourceDoc.documentElement;
let targetDocEl = targetDoc.documentElement;
let attrs = sourceDocEl.attributes;
for (let i = 0, l = attrs.length; i < l; i++) {
let attr = attrs.item(i);
if (!removeAttributes || removeAttributes.indexOf(attr.name) == -1) {
targetDocEl.setAttribute(attr.name, attr.value);
}
}
targetDocEl.setAttribute(
'id',
(this.resourceQuery && loaderUtils.parseQuery(this.resourceQuery).id) ||
path.basename(this.resourcePath, '.svg')
);
for (let node = sourceDocEl.firstChild; node; node = node.nextSibling) {
targetDocEl.appendChild(targetDoc.importNode(node, true));
}
['/*/*[@id]', '/*/*/*[@id]'].forEach(selector => {
xpath.select(selector, targetDocEl).forEach(node => {
let id = node.getAttribute('id');
let newId = uuid.v4() + '-' + id;
node.setAttribute('id', newId);
xpath.select("//@*[contains(., '#" + id + "')]", targetDocEl).forEach(attr => {
if (attr.value == '#' + id) {
attr.value = '#' + newId;
} else if (attr.value == 'url(#' + id + ')') {
attr.value = 'url(#' + newId + ')';
}
});
});
});
new SVGO({
plugins: [{ cleanupIDs: false }]
})
.optimize(new xmldom.XMLSerializer().serializeToString(targetDoc))
.then(result => {
callback(
null,
"(function _() { if (document.body) { document.body.insertAdjacentHTML('beforeend', " +
JSON.stringify(
'<svg xmlns="http://www.w3.org/2000/svg" style="display:none">' +
result.data +
'</svg>'
) +
'); } else { setTimeout(_, 100); } })();'
);
});
};
| 0bef3ff596631295e569d5d8dc18f35eddcd0e7e | [
"Markdown",
"JavaScript"
] | 2 | Markdown | Riim/simple-svg-loader | 881e26097a556b1add38410fc6bf512a3725836d | 4ecc33458088be68a19cb4641e0d3685a31ae408 |
refs/heads/master | <file_sep>object vers {
val kotlin = "1.4.21"
val nexus_staging = "0.22.0"
object asoft {
val builders = "1.3.0"
val color = "0.0.20"
val theme = "0.0.50"
val test = "1.1.10"
}
object kotlinx {
val coroutines = "1.4.2"
}
object wrappers {
val react = "17.0.1-pre.141-kotlin-1.4.21"
val styled = "5.2.0-pre.141-kotlin-1.4.21"
}
}<file_sep>package tz.co.asoft
fun AquaGreenTheme(typography: Typography? = null) = Theme(
name = "aQua Green [${typography?.name ?: "default"}]",
color = AquaGreenPallet,
text = typography ?: Typography(),
)<file_sep>package tz.co.asoft
typealias CSSTheme = Theme<Typography><file_sep>package tz.co.asoft
import kotlinx.coroutines.flow.MutableStateFlow
val currentTheme by lazy { MutableStateFlow(AquaGreenTheme()) }<file_sep>package tz.co.asoft
typealias ReactTheme = CSSTheme | 058286ba53cf8862d1de52675bc49f63ed22b6e0 | [
"Kotlin"
] | 5 | Kotlin | cybernetics/theme | 8ce9f7b1e76cad29a49959339ce04d23c5e94abd | 6518f47ea2b821ebc6f7ef27afcb059da5ee789c |
refs/heads/master | <repo_name>RommelTJ/IngressKeyTracker<file_sep>/IngressKeyTracker/KeysTableViewController.swift
//
// KeysTableViewController.swift
// IngressKeyTracker
//
// Created by <NAME> on 5/12/15.
// Copyright (c) 2015 <NAME>. All rights reserved.
//
import UIKit
class KeysTableViewController: UITableViewController, UITableViewDataSource, UITableViewDelegate, UIAlertViewDelegate {
//For each portal, we need to store: name, picture, latitude, longitude, faction, hasKey, hasL8.
var keyNames = [String]()
var haveKey = [Bool]()
var input = UITextField()
@IBAction func doHaveEights(sender: AnyObject) {
println("Pressed Have Eights");
}
@IBAction func addKey(sender: AnyObject) {
var inputTextField: UITextField?
let keyPrompt = UIAlertController(title: "Key Tracker", message: "Enter the Key Name: ", preferredStyle: UIAlertControllerStyle.Alert)
keyPrompt.addAction(UIAlertAction(title: "Cancel", style: UIAlertActionStyle.Default, handler: nil))
keyPrompt.addAction(UIAlertAction(title: "OK", style: UIAlertActionStyle.Default, handler: { (action) -> Void in
// Now do whatever you want with inputTextField (remember to unwrap the optional)
if let inputText = inputTextField!.text {
self.keyNames.append(inputText)
self.tableView.reloadData()
}
}))
keyPrompt.addTextFieldWithConfigurationHandler({(textField: UITextField!) in
textField.placeholder = "Placeholder Key"
inputTextField = textField
})
presentViewController(keyPrompt, animated: true, completion: nil)
}
override func viewDidLoad() {
super.viewDidLoad()
if let storedKeyNames = NSUserDefaults.standardUserDefaults().objectForKey("keyNames") as? [String] {
keyNames = storedKeyNames
} else {
keyNames = ["USD - St Francis of Assisi Statue",
"USD Reflecting Pool",
"Institute of Peace and Justice",
"USD IPJ Fountain",
"USD Memorial Fountain",
"USD Moon Compass Walk",
"Shiley Center For Science And Technology",
"Mother Rosalie Hill Hall Main Drive Fountain",
"Mother Rosalie Hall Fountain",
"Marshall Garden",
"USD San Diego De Alcalá Statue",
"<NAME>",
"Camino Hall at USD",
"Olin Hall",
"Mother Mary And Child Statue",
"Sacred Heart Hall",
"Manchester Conference Center",
"USD Founders Hall",
"Hahn School of Nursing and Health Science",
"<NAME> Memorial",
"Sister <NAME>ner Grace Bremner Truitt Rose Garden",
"Mary Stained Glass Window",
"Madonna Hall Glass Window",
"Founders Statue",
"Hughes Administration Center Statue",
"Colachis Plaza Fountain",
"USD - Immaculata Parish Fountain",
"Immaculata at University of San Diego",
"USD - Founder's Statue",
"Fountain for the Most Reverend Leo T. <NAME>.",
"Maher Hall Entrance Emblem",
"University of San Diego Quad Fountain",
"<NAME>",
"USD - Plaza de San Diego",
"Ernest & Jean Hahn University Center",
"One stop center fountain",
"Equality Solidarity World Peace Nonviolence Tree",
"Student Life Pavilion",
"USD Pavilion Tower",
"USD - Legal Research Center",
"Degheri Alumni Center",
"<NAME>er Park",
"Missions Crossroads",
"Zipcar-6025 San Dimas Avenue",
"Old Sheffield Bell",
"St Francis Center",
"<NAME> Plaque",
"Fowler Park",
"<NAME>avilion Box Office USD Crest",
"<NAME>",
"Torero Stadium",
"USD World Religions Plaques Fountain",
"Sports Center",
"University of San Diego Alcala Park Entrance",
"<NAME>",
"San Diego County Office of Edu"]
NSUserDefaults.standardUserDefaults().setObject(keyNames, forKey: "keyNames")
}
if let storedHaveKeys = NSUserDefaults.standardUserDefaults().objectForKey("haveKey") as? [Bool] {
haveKey = storedHaveKeys
} else {
for var i=0; i<keyNames.count; i++ {
haveKey.append(false)
}
NSUserDefaults.standardUserDefaults().setObject(haveKey, forKey: "haveKey")
}
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
override func numberOfSectionsInTableView(tableView: UITableView) -> Int {
// Return the number of sections.
return 1
}
override func tableView(tableView: UITableView, numberOfRowsInSection section: Int) -> Int {
// #warning Incomplete method implementation.
// Return the number of rows in the section.
return keyNames.count
}
override func tableView(tableView: UITableView, cellForRowAtIndexPath indexPath: NSIndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCellWithIdentifier("cell", forIndexPath: indexPath) as! UITableViewCell
cell.textLabel?.text = keyNames[indexPath.row]
cell.accessoryType = UITableViewCellAccessoryType.None
if haveKey[indexPath.row] == true {
cell.accessoryType = UITableViewCellAccessoryType.Checkmark
}
return cell
}
// Override to support conditional editing of the table view.
override func tableView(tableView: UITableView, canEditRowAtIndexPath indexPath: NSIndexPath) -> Bool {
// Return NO if you do not want the specified item to be editable.
return true
}
override func tableView(tableView: UITableView, commitEditingStyle editingStyle: UITableViewCellEditingStyle, forRowAtIndexPath indexPath: NSIndexPath) {
if editingStyle == .Delete {
// Delete the row from the data source
keyNames.removeAtIndex(indexPath.row)
tableView.deleteRowsAtIndexPaths([indexPath], withRowAnimation: .Fade)
}
}
override func tableView(tableView: UITableView, didSelectRowAtIndexPath indexPath: NSIndexPath) {
let cell = tableView.cellForRowAtIndexPath(indexPath)
if cell?.accessoryType == UITableViewCellAccessoryType.Checkmark {
cell?.accessoryType = UITableViewCellAccessoryType.None
haveKey[indexPath.row] = false
} else {
cell?.accessoryType = UITableViewCellAccessoryType.Checkmark
haveKey[indexPath.row] = true
}
NSUserDefaults.standardUserDefaults().setObject(haveKey, forKey: "haveKey")
}
}
<file_sep>/README.md
# Ingress Key Tracker
Version: 0.0.1 - 08 May 2015
## Description
An app to track Ingress keys and portals.
### Documentation
Branches:
master = Production branch
dev = Development branch
## Contact
<<EMAIL>>
## Notes
If you want to contribute, email me at <<EMAIL>>.
| 6ea7f0972f3e0a3746d07236eea68e5db6c1f6f5 | [
"Swift",
"Markdown"
] | 2 | Swift | RommelTJ/IngressKeyTracker | b6095c15f2e2fa0c4bed9e21d6749cde0f36b0d2 | dabf39e53b396e4142143d3eaef40fb454b5a1ca |
refs/heads/main | <file_sep>asgiref==3.3.4
Django==3.2.4
PyMySQL==1.0.2
pytz==2021.1
sqlparse==0.4.1
Pillow==8.2.0
django-ckeditor~=6.1.0<file_sep>from django.shortcuts import render
from django.contrib.contenttypes.models import ContentType
from django.core.cache import cache
from blog.models import Blog
from read_statistics import utils
def home(request):
blog_content_type = ContentType.objects.get_for_model(Blog)
dates, read_nums = utils.get_week_read_data(blog_content_type)
week_hot_blogs = cache.get('week_hot_blogs')
if not week_hot_blogs:
week_hot_blogs = utils.get_week_hot_blog()
cache.set('week_hot_blog', week_hot_blogs, 3600)
context = {
'dates': dates,
'read_nums': read_nums,
'today_hot_blogs': utils.get_today_hot_blog(),
'yesterday_hot_blogs': utils.get_yesterday_hot_blog(),
'week_hot_blogs': week_hot_blogs
}
return render(request, 'home.html', context)
<file_sep>import threading
from django.db import models
from django.contrib.contenttypes.models import ContentType
from django.contrib.contenttypes.fields import GenericForeignKey
from django.contrib.auth.models import User
from django.core.mail import send_mail
from django.template.loader import render_to_string
from myblog import settings
# Create your models here.
class Comment(models.Model):
content_type = models.ForeignKey(ContentType, on_delete=models.CASCADE)
object_id = models.PositiveIntegerField()
content_object = GenericForeignKey('content_type', 'object_id')
comment_text = models.TextField(verbose_name='评论内容')
comment_time = models.DateTimeField(auto_now_add=True, verbose_name='评论时间')
user = models.ForeignKey(User, related_name='comments', on_delete=models.CASCADE, verbose_name='评论用户')
# 表内数据自关联,回复指向父级评论
root = models.ForeignKey('self', related_name='root_comment', null=True, on_delete=models.CASCADE)
parent = models.ForeignKey('self', related_name='parent_comment', null=True, on_delete=models.CASCADE)
reply_to = models.ForeignKey(User, related_name='replies', null=True, on_delete=models.CASCADE)
class Meta:
ordering = ['comment_time']
def send_email(self):
if self.parent:
subject = '有人回复你的评论'
email = self.reply_to.email
else:
subject = '有人评论你的博客'
email = self.user.email
context = {'comment_text': self.comment_text, 'url': self.content_object.get_url()}
text = render_to_string('comment/send_email.html', context)
send_email = SendEmail(subject, text, email)
send_email.start()
class SendEmail(threading.Thread):
def __init__(self, subject, text, email):
self.subject = subject
self.text = text
self.email = email
threading.Thread.__init__(self)
def run(self):
send_mail(self.subject, '', settings.EMAIL_HOST_USER, [self.email], fail_silently=False, html_message=self.text)
<file_sep>from django.shortcuts import render
from django.http import JsonResponse
from django.contrib.contenttypes.models import ContentType
from .models import LikeCount, LikeRecord
# Create your views here.
def SuccessResponse(like_record, liked_num):
data = {'status': 'SUCCESS', 'like_record': like_record, 'liked_num': liked_num}
return JsonResponse(data)
def like_change(request):
user = request.user
if not user.is_authenticated:
data = {'code': 400, 'message': '请先登录'}
return JsonResponse(data)
content_type = request.GET.get('content_type')
content_type = ContentType.objects.get(model=content_type)
object_id = request.GET.get('object_id')
# 先判断用户是否有点赞记录
like_record, is_created = LikeRecord.objects.get_or_create(content_type=content_type, object_id=object_id, user=user)
# 用户新建点赞,总点赞数加一
if is_created:
like_count, is_created = LikeCount.objects.get_or_create(content_type=content_type, object_id=object_id)
like_count.like_num += 1
like_count.save()
like_record = True
return SuccessResponse(like_record, like_count.like_num)
else:
# 删除用户点赞记录
like_record.delete()
like_record = False
# 总点赞数减一
like_count = LikeCount.objects.get(content_type=content_type, object_id=object_id)
like_count.like_num -= 1
like_count.save()
return SuccessResponse(like_record, like_count.like_num)
<file_sep>import datetime
from django.contrib.contenttypes.models import ContentType
from django.utils import timezone
from django.db.models import Sum
from .models import ReadNum, ReadDetail
from blog.models import Blog
def read_statistics_once_read(request, obj):
ct = ContentType.objects.get_for_model(obj)
cookies_key = f'{ct.model}_{obj.pk}_read'
if not request.COOKIES.get(cookies_key):
read_obj, created = ReadNum.objects.get_or_create(content_type=ct, object_id=obj.pk)
read_obj.read_num += 1
read_obj.save()
date = timezone.now().date()
read_detail, created = ReadDetail.objects.get_or_create(content_type=ct, object_id=obj.pk, date=date)
read_detail.read_num += 1
read_detail.save()
return cookies_key
def get_week_read_data(content_type):
today = timezone.now().date()
dates = []
read_nums = []
for i in range(7, 0, -1):
date = today - datetime.timedelta(days=i)
dates.append(date.strftime('%m/%d'))
read_data = ReadDetail.objects.filter(content_type=content_type, date=date)
res = read_data.aggregate(read_date_sum=Sum('read_num'))
read_nums.append(res['read_date_sum'] or 0)
return dates, read_nums
def get_today_hot_blog():
today = timezone.now().date()
hot_blog = Blog.objects.filter(read_details__date=today).values('id', 'title')\
.annotate(hot_blogs_num=Sum('read_details__read_num')).order_by('-hot_blogs_num')
return hot_blog[:7]
def get_yesterday_hot_blog():
yesterday = timezone.now().date()-datetime.timedelta(days=1)
hot_blog = Blog.objects.filter(read_details__date=yesterday).values('id', 'title')\
.annotate(hot_blogs_num=Sum('read_details__read_num')).order_by('-hot_blogs_num')
return hot_blog[:7]
def get_week_hot_blog():
today = timezone.now().date()
date = today - datetime.timedelta(days=7)
hot_blog = Blog.objects.filter(read_details__date__lt=today, read_details__date__gte=date).values('id', 'title')\
.annotate(hot_blogs_num=Sum('read_details__read_num')).order_by('-hot_blogs_num')
return hot_blog[:7]
<file_sep># Generated by Django 3.2.4 on 2021-06-16 14:46
import ckeditor_uploader.fields
from django.conf import settings
from django.db import migrations, models
import django.db.models.deletion
class Migration(migrations.Migration):
initial = True
dependencies = [
migrations.swappable_dependency(settings.AUTH_USER_MODEL),
]
operations = [
migrations.CreateModel(
name='BlogType',
fields=[
('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('type_name', models.CharField(max_length=15, verbose_name='博文分类')),
],
),
migrations.CreateModel(
name='Blog',
fields=[
('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('title', models.CharField(max_length=50, verbose_name='博客标题')),
('content', ckeditor_uploader.fields.RichTextUploadingField(verbose_name='博客内容')),
('created_time', models.DateTimeField(auto_now_add=True, verbose_name='发布时间')),
('last_edit_time', models.DateTimeField(auto_now=True, verbose_name='最后编辑时间')),
('author', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL, verbose_name='博文作者')),
('blog_type', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='blog.blogtype', verbose_name='博文分类')),
],
options={
'ordering': ['-created_time'],
},
),
]
<file_sep>from django.shortcuts import render, get_object_or_404
from django.db.models import Count
from blog import models
from read_statistics.utils import read_statistics_once_read
# Create your views here.
class Pagination(object):
def __init__(self, current_page, all_count, per_page_num=2, pager_count=11):
"""
封装分页相关数据
:param current_page: 当前页
:param all_count: 数据库中的数据总条数
:param per_page_num: 每页显示的数据条数
:param pager_count: 最多显示的页码个数
"""
try:
current_page = int(current_page)
except Exception as e:
current_page = 1
if current_page < 1:
current_page = 1
self.current_page = current_page
self.all_count = all_count
self.per_page_num = per_page_num
# 总页码
all_pager, tmp = divmod(all_count, per_page_num)
if tmp:
all_pager += 1
self.all_pager = all_pager
self.pager_count = pager_count
self.pager_count_half = int((pager_count - 1) / 2)
@property
def start(self):
return (self.current_page - 1) * self.per_page_num
@property
def end(self):
return self.current_page * self.per_page_num
def page_html(self):
# 如果总页码 < 11个:
if self.all_pager <= self.pager_count:
pager_start = 1
pager_end = self.all_pager + 1
# 总页码 > 11
else:
# 当前页如果<=页面上最多显示11/2个页码
if self.current_page <= self.pager_count_half:
pager_start = 1
pager_end = self.pager_count + 1
# 当前页大于5
else:
# 页码翻到最后
if (self.current_page + self.pager_count_half) > self.all_pager:
pager_end = self.all_pager + 1
pager_start = self.all_pager - self.pager_count + 1
else:
pager_start = self.current_page - self.pager_count_half
pager_end = self.current_page + self.pager_count_half + 1
page_html_list = []
# 添加前面的nav和ul标签
page_html_list.append('''
<nav aria-label='Page navigation>'
<ul class='pagination'>
''')
first_page = '<li><a href="?page=%s">首页</a></li>' % (1)
page_html_list.append(first_page)
if self.current_page <= 1:
prev_page = '<li class="disabled"><a href="#">上一页</a></li>'
else:
prev_page = '<li><a href="?page=%s">上一页</a></li>' % (self.current_page - 1,)
page_html_list.append(prev_page)
for i in range(pager_start, pager_end):
if i == self.current_page:
temp = f'<li class="active"><span>{i}</span></li>'
else:
temp = f'<li><a href="?page={i}">{i}</a></li>'
page_html_list.append(temp)
if self.current_page >= self.all_pager:
next_page = '<li class="disabled"><a href="#">下一页</a></li>'
else:
next_page = '<li><a href="?page=%s">下一页</a></li>' % (self.current_page + 1,)
page_html_list.append(next_page)
last_page = '<li><a href="?page=%s">尾页</a></li>' % (self.all_pager,)
page_html_list.append(last_page)
# 尾部添加标签
page_html_list.append('''
</nav>
</ul>
''')
return ''.join(page_html_list)
def get_blog_list_common(request, blogs):
context = {}
current_page = request.GET.get('page', 1)
all_count = blogs.count()
context['all_count'] = all_count
page_obj = Pagination(current_page=current_page, all_count=all_count, per_page_num=2)
context['page_obj'] = page_obj
page_queryset = blogs[page_obj.start:page_obj.end]
context['page_queryset'] = page_queryset
context['blog_types'] = models.BlogType.objects.annotate(blog_count=Count('blog'))
blog_dates = models.Blog.objects.dates('created_time', 'month', order='DESC')
blog_date_dict = {}
for blog_date in blog_dates:
blog_count = models.Blog.objects.filter(created_time__year=blog_date.year,
created_time__month=blog_date.month).count()
blog_date_dict[blog_date] = blog_count
context['blog_date_info'] = blog_date_dict
return context
def blog_list(request):
blogs = models.Blog.objects.all()
context = get_blog_list_common(request, blogs)
return render(request, 'blog/blog_list.html', context)
def blog_detail(request, blog_pk):
content = {}
blog_info = get_object_or_404(models.Blog, pk=blog_pk)
read_cookies_key = read_statistics_once_read(request, blog_info)
content['previous_blog'] = models.Blog.objects.filter(pk__lt=blog_pk).first()
content['next_blog'] = models.Blog.objects.filter(pk__gt=blog_pk).last()
content['blog_info'] = blog_info
response = render(request, 'blog/blog_detail.html', content)
response.set_cookie(read_cookies_key, 'True')
return response
def blog_type_info(request, blog_type_pk):
blogs = models.Blog.objects.filter(blog_type_id=blog_type_pk)
context = get_blog_list_common(request, blogs)
blog_type = get_object_or_404(models.BlogType, pk=blog_type_pk)
context['blog_type'] = blog_type
return render(request, 'blog/blog_type_info.html', context)
def blog_date_info(request, year, month):
blogs = models.Blog.objects.filter(created_time__year=year, created_time__month=month)
context = get_blog_list_common(request, blogs)
context['date_info'] = f'{year}年{month}月'
return render(request, 'blog/blog_date_info.html', context)
<file_sep>from django.db import models
from django.contrib.auth.models import User
# Create your models here.
class Profile(models.Model):
user = models.OneToOneField(User, on_delete=models.CASCADE)
nickname = models.CharField(max_length=10, verbose_name='昵称')
def __str__(self):
return f'<Profile:{self.nickname} for {self.user.username}>'
def get_nickname_or_username(self):
if Profile.objects.filter(user=self).exists():
profile = Profile.objects.get(user=self)
return profile.nickname
else:
return self.username
User.get_nickname_or_username = get_nickname_or_username
<file_sep># Generated by Django 3.2.4 on 2021-06-23 15:32
from django.db import migrations
class Migration(migrations.Migration):
dependencies = [
('comment', '0003_auto_20210622_2112'),
]
operations = [
migrations.AlterModelOptions(
name='comment',
options={'ordering': ['comment_time']},
),
]
<file_sep># Generated by Django 3.2.4 on 2021-06-17 01:49
from django.db import migrations
class Migration(migrations.Migration):
dependencies = [
('blog', '0002_blog_read_num'),
]
operations = [
migrations.RemoveField(
model_name='blog',
name='read_num',
),
]
<file_sep>import string
import time
import random
from django.shortcuts import render, redirect
from django.contrib import auth
from django.urls import reverse
from django.contrib.auth.models import User
from django.http import JsonResponse
from django.core.mail import send_mail
from . import myforms
from .models import Profile
# Create your views here.
def login(request):
if request.method == 'POST':
login_obj = myforms.LoginForm(request.POST)
if login_obj.is_valid():
user = login_obj.cleaned_data['user']
auth.login(request, user)
return redirect(request.GET.get('from', reverse('home')))
else:
login_obj = myforms.LoginForm()
return render(request, 'user/login.html', {'login_obj': login_obj})
def login_for_modal(request):
login_obj = myforms.LoginForm(request.POST)
data = {}
if login_obj.is_valid():
user = login_obj.cleaned_data['user']
auth.login(request, user)
data['status'] = 'SUCCESS'
else:
data['status'] = 'ERROR'
return JsonResponse(data)
def register(request):
if request.method == 'POST':
reg_obj = myforms.RegForm(request.POST, request=request)
if reg_obj.is_valid():
username = reg_obj.cleaned_data['username']
password = reg_obj.cleaned_data['password']
email = reg_obj.cleaned_data['email']
user = User.objects.create_user(username=username, email=email, password=<PASSWORD>)
user.save()
del request.session['register_code']
auth.login(request, user)
return redirect(request.GET.get('from', reverse('home')))
else:
reg_obj = myforms.RegForm()
return render(request, 'user/register.html', {'reg_obj': reg_obj})
def logout(request):
auth.logout(request)
return redirect(request.GET.get('from', reverse('home')))
def user_info(request):
return render(request, 'user/user_info.html')
def change_nickname(request):
redirect_url = request.GET.get('from', reverse('home'))
context = {}
if request.method == 'POST':
form_info = myforms.ChangeNicknameForm(request.POST, user=request.user)
if form_info.is_valid():
new_nickname = form_info.cleaned_data['new_nickname']
profile, created = Profile.objects.get_or_create(user=request.user)
profile.nickname = new_nickname
profile.save()
return redirect(redirect_url)
else:
form_info = myforms.ChangeNicknameForm()
context['page_title'] = '修改昵称'
context['form_title'] = '修改昵称'
context['submit_text'] = '修改'
context['form'] = form_info
context['redirect_url'] = redirect_url
return render(request, 'forms.html', context)
def bind_email(request):
redirect_url = request.GET.get('from', reverse('home'))
context = {}
if request.method == 'POST':
form_info = myforms.BindEmailForm(request.POST, request=request)
if form_info.is_valid():
email = form_info.cleaned_data['email']
request.user.email = email
request.user.save()
del request.session['email_code']
return redirect(redirect_url)
else:
form_info = myforms.BindEmailForm()
context['page_title'] = '绑定邮箱'
context['form_title'] = '绑定邮箱'
context['submit_text'] = '绑定'
context['form'] = form_info
context['redirect_url'] = redirect_url
return render(request, 'user/bind_email.html', context)
def send_verification_code(request):
email = request.GET.get('email', '')
send_for = request.GET.get('send_for')
data = {}
if email:
code = ''.join(random.sample(string.ascii_letters+string.digits, 6))
send_time = request.session.get('send_time', 0)
if time.time() - send_time < 30:
data['status'] = 'ERROR_time'
else:
request.session[send_for] = code
request.session['send_time'] = time.time()
send_mail('绑定邮箱', f'验证码:{code}', '<EMAIL>', [email], fail_silently=False,)
data['status'] = 'SUCCESS'
else:
data['status'] = 'ERROR'
return JsonResponse(data)
def change_password(request):
redirect_url = reverse('home')
context = {}
if request.method == 'POST':
form_info = myforms.ChangePasswordForm(request.POST, user=request.user)
if form_info.is_valid():
user = request.user
password = form_info.cleaned_data['password']
user.set_password(password)
user.save()
auth.logout(request)
return redirect(redirect_url)
else:
form_info = myforms.ChangePasswordForm()
context['page_title'] = '修改密码'
context['form_title'] = '修改密码'
context['submit_text'] = '修改'
context['form'] = form_info
context['redirect_url'] = redirect_url
return render(request, 'forms.html', context)
def forget_password(request):
redirect_url = reverse('home')
context = {}
if request.method == 'POST':
form_info = myforms.ForgetPasswordForm(request.POST, request=request)
if form_info.is_valid():
email = form_info.cleaned_data['email']
password = form_info.cleaned_data['password']
user = User.objects.get(email=email)
user.set_password(<PASSWORD>)
user.save()
del request.session['forget_password_code']
return redirect(redirect_url)
else:
form_info = myforms.ForgetPasswordForm()
context['page_title'] = '重置密码'
context['form_title'] = '重置密码'
context['submit_text'] = '重置'
context['form'] = form_info
context['redirect_url'] = redirect_url
return render(request, 'user/forget_psd.html', context)<file_sep>from django.http import JsonResponse
from .models import Comment
from .myforms import CommentForm
# Create your views here.
def update_comment(request):
# referer = request.META.get('HTTP_REFERER', reverse('home'))
comment_form = CommentForm(request.POST, user=request.user)
data = {}
if comment_form.is_valid():
comment_obj = Comment()
comment_obj.user = comment_form.cleaned_data['user']
comment_obj.comment_text = comment_form.cleaned_data['comment_text']
comment_obj.content_object = comment_form.cleaned_data['model_obj']
parent = comment_form.cleaned_data['parent']
if parent:
comment_obj.root = parent.root if parent.root else parent
comment_obj.parent = parent
comment_obj.reply_to = parent.user
comment_obj.save()
# 邮件通知
comment_obj.send_email()
# ajax提交返回数据
data['status'] = 'SUCCESS'
data['username'] = comment_obj.user.get_nickname_or_username()
data['comment_time'] = comment_obj.comment_time.strftime('%Y-%m-%d %H:%M:%S')
data['comment_text'] = comment_obj.comment_text
if parent:
data['reply_to'] = comment_obj.reply_to.get_nickname_or_username()
else:
data['reply_to'] = None
data['pk'] = comment_obj.pk
data['root_pk'] = comment_obj.root.pk if comment_obj.root else None
else:
data['status'] = 'ERROR'
data['message'] = list(comment_form.errors.values())[0]
return JsonResponse(data)
<file_sep>from django import template
from django.contrib.contenttypes.models import ContentType
from django.db.models.fields import exceptions
from ..models import ReadNum
register = template.Library()
@register.simple_tag
def get_read_num(obj):
try:
ct = ContentType.objects.get_for_model(obj)
read_obj = ReadNum.objects.get(content_type=ct, object_id=obj.pk)
return read_obj.read_num
except exceptions.ObjectDoesNotExist:
return 0
<file_sep>import datetime
from django.db import models
from django.utils import timezone
from django.contrib.contenttypes.fields import GenericForeignKey
from django.contrib.contenttypes.models import ContentType
# Create your models here.
class ReadNum(models.Model):
read_num = models.IntegerField(default=0, verbose_name='阅读量')
content_type = models.ForeignKey(ContentType, on_delete=models.CASCADE)
object_id = models.PositiveIntegerField()
content_object = GenericForeignKey('content_type', 'object_id')
class ReadDetail(models.Model):
date = models.DateField(default=timezone.now, verbose_name='阅读日期')
read_num = models.IntegerField(default=0, verbose_name='阅读量')
content_type = models.ForeignKey(ContentType, on_delete=models.CASCADE)
object_id = models.PositiveIntegerField()
content_object = GenericForeignKey('content_type', 'object_id')<file_sep># myblog
我的第一个网站
| cf9961db013e2d48be048a6b9cba354780a051ca | [
"Markdown",
"Python",
"Text"
] | 15 | Text | askeladd01/myblog | 80cd025648ea5d97e19703ed5d625108c8aa1293 | d7719f3eadc6b89a80f591ce8779db28952103f8 |
refs/heads/master | <file_sep>package com.example.implicitandexplicitintents
import android.content.Intent
import android.net.Uri
import androidx.appcompat.app.AppCompatActivity
import android.os.Bundle
import android.provider.MediaStore
import android.view.View
import android.widget.Button
import android.widget.Toast
import kotlinx.android.synthetic.main.activities.*
import kotlinx.android.synthetic.main.activity_main.*
import kotlinx.android.synthetic.main.tasks.*
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
login_btn.setOnClickListener {
if (username_in.text.toString().equals("kleiserwacangan")
&& password_in.text.toString().equals("<PASSWORD>")) {
showActivities()
}
else "Login Failed!"
}
}
private fun showActivities(){
activities_layout.visibility=View.VISIBLE
tasks_layout.visibility=View.GONE
home_in.visibility=View.GONE
task_btn.setOnClickListener{
showTasks()
}
}
private fun showTasks(){
activities_layout.visibility=View.GONE
tasks_layout.visibility=View.VISIBLE
home_in.visibility=View.GONE
task_btn1.setOnClickListener {
val intent1 = Intent(MediaStore.ACTION_IMAGE_CAPTURE)
startActivity(intent1)
}
task_btn2.setOnClickListener {
val intent2 = Intent(Intent.ACTION_VIEW, Uri.parse("https://github.com/Alvin-Gayao/Kotlin_Intents/"))
startActivity(intent2)
}
task_btn3.setOnClickListener {
val intent3 = Intent(Intent.ACTION_SEND)
intent3.putExtra(Intent.EXTRA_TEXT, "android studio")
intent3.type="text/plain"
startActivity(intent3)
}
task_btn4.setOnClickListener {
openApp()
}
task_btn5.setOnClickListener {
Toast.makeText(applicationContext,"Sorry! No intent was placed in this button.",Toast.LENGTH_SHORT).show()
}
}
private fun openApp(){
val intent4 = Intent(Intent.ACTION_VIEW)
intent4.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK)
intent4.setPackage("com.android.microsoftword")
if(intent4.resolveActivity(this.packageManager) != null)
{
startActivity(intent4)
}
else
Toast.makeText(applicationContext,"The intent failed due to application cannot be found!",Toast.LENGTH_SHORT).show()
}
} | bad65cb1224dfef5bb125b24623a3d74ebbafba3 | [
"Kotlin"
] | 1 | Kotlin | Jkiller28/My_Lab | a3b6a3ae8e5868d2540b1cd990433662dc28fd81 | 7840b08706077a1b985d2f019ae35d3921ff4b2d |
refs/heads/main | <repo_name>misbah41/E-Bazar-Server<file_sep>/index.js
const express = require("express");
const bodyParser = require("body-parser");
const MongoClient = require("mongodb").MongoClient;
const ObjectId = require("mongodb").ObjectId;
const fileUpload = require("express-fileupload");
const cors = require("cors");
const fs = require("fs-extra");
require("dotenv").config();
const app = express();
const port = 3500;
app.use(fileUpload());
app.use(bodyParser.json());
app.use(cors());
//root api
app.get("/", (req, res) => {
res.send("Wonderful Misbah Hasan Error not solved solved");
});
const uri = `mongodb+srv://${process.env.USER_NAME}:${process.env.DB_PASS}@cluster0.qwvsk.mongodb.net/${process.env.DB_NAME}?retryWrites=true&w=majority`;
const client = new MongoClient(uri, {
useNewUrlParser: true,
useUnifiedTopology: true,
});
client.connect((err) => {
console.log("erroe here", err);
const productsCollection = client
.db("bazarbdDatabase")
.collection("cardProducts");
//add addProducts by post method start
app.post("/addProducts", (req, res) => {
const file = req.files.file;
const name = req.body.name;
const categories = req.body.categories;
const productPrice = req.body.productPrice;
const discount = req.body.discount;
const tags = req.body.tags;
const productsOff = req.body.productsOff;
const description = req.body.description;
const subdescription = req.body.subdescription;
const newImg = file.data;
const encImg = newImg.toString("base64");
var image = {
contentType: file.mimetype,
size: file.size,
img: Buffer.from(encImg, "base64"),
};
productsCollection
.insertOne({
name,
categories,
subdescription,
description,
productsOff,
tags,
productPrice,
file,
discount,
image,
})
.then((result) => {
res.send(result.insertedCount > 0);
});
});
//add addProducts by post method end
app.get("/fruitProducts", (req, res) => {
productsCollection
.find({ categories: "fruit" })
.toArray((err, documents) => {
res.send(documents);
});
});
app.get("/drinkProducts", (req, res) => {
productsCollection
.find({ categories: "drink" })
.toArray((err, documents) => {
res.send(documents);
});
});
app.get("/drinkWater", (req, res) => {
productsCollection
.find({ categories: "water" })
.toArray((err, documents) => {
res.send(documents);
});
});
// //get sngle product by get method
app.get("/productById/:id", (req, res) => {
productsCollection
.find({ _id: ObjectId(req.params.id) })
.toArray((err, service) => {
res.send(service[0]);
});
});
console.log("database connected successfully");
});
app.listen(process.env.PORT || port);
<file_sep>/README.md
"# E-Bazar-Server"
| 90caf38bad5fa360747e54df641693a3ecb0d96b | [
"JavaScript",
"Markdown"
] | 2 | JavaScript | misbah41/E-Bazar-Server | d70c17bae51550768785f50746ba34db8f30bb61 | 910b87ef89d857e68c0c21542fa9a8cbf58de29e |
refs/heads/master | <repo_name>DemiurgeApeiron/TC1001S.100Team10<file_sep>/snake.py
"""Snake, classic arcade game.
Modifications made by:
<NAME>
<NAME>
<NAME>
"""
from turtle import *
from random import randrange, randint
from freegames import square, vector
limitex = 500
limitey = 500
tercervar = 500
food = vector(0, 0)
snake = [vector(10, 0)]
aim = vector(0, -10)
def change(x, y):
"Change snake direction."
aim.x = x
aim.y = y
def inside(head):
"Return True if head inside boundaries."
return -limitex / 2 + 10 < head.x < limitex / 2 - 10 and -limitey / 2 + 10 < head.y < limitey / 2 - 10
#Utilizando variables globales se reemplaza los colores fijos en esta funcion
def move():
"Move snake and food forward one segment."
head = snake[-1].copy()
head.move(aim)
if food.x < limitex / 2 - 10 and food.x > -limitex / 2 + 10:
print(food.x)
# hace aleatorio el movimiento de la comida
food.x += round(randrange(-1, 2)) * 10
else:
# hace que la comida retroceda un paso si llego al limite
food.x += food.x / food.x * -10
if food.y < limitey / 2 - 10 and food.y > -limitey / 2 + 10:
print(food.y)
# hace aleatorio el movimiento de la comida
food.y += round(randrange(-1, 2)) * 10
else:
# hace que la comida retroceda un paso si llego al limite
food.y += food.y / food.y * -10
if not inside(head) or head in snake:
square(head.x, head.y, 9, "red")
update()
return
snake.append(head)
if head == food:
print("Snake:", len(snake))
food.x = randrange(-15, 15) * 10
food.y = randrange(-15, 15) * 10
else:
snake.pop(0)
clear()
for body in snake:
square(body.x, body.y, 9, snakeColor)
square(food.x, food.y, 9, foodColor)
update()
ontimer(move, 100)
print(f"snake {head.x} :: {head.y}")
#Funcion que genera un color aleatorio de 5 opciones para la comida
#Toma como parametro color, que es el color de la serpiente
#Checa si el color generado es igual, y si esto es el caso intena de nuevo
def getFoodColor(color):
colorList = ['black', 'green','blue','yellow','pink']
tempColor = colorList[randint(0,4)]
if(tempColor == color):
getFoodColor(color)
else:
return tempColor
#Lista de 5 colores, usa funcion randint para elegir uno para la serpiente
colorList = ['black', 'green','blue','yellow','pink']
snakeColor = colorList[randint(0,4)]
foodColor = getFoodColor(snakeColor)
setup(limitex, limitey, tercervar, 0)
hideturtle()
tracer(False)
listen()
onkey(lambda: change(10, 0), "Right")
onkey(lambda: change(-10, 0), "Left")
onkey(lambda: change(0, 10), "Up")
onkey(lambda: change(0, -10), "Down")
move()
done()
<file_sep>/README.md
# Modificaciónes de los juegos
Creadores
- <NAME>
- <NAME>
- <NAME>
## Explicación del Proyecto
Este proyecto consiste de modificar las reglas y funcionalidades de juegos clásicos implementados en Python. Nosotros no diseñamos las implementaciones de Python, pero si diseñamos e implementamos las siguientes modificaciones:
### Snake
- Añadimos la funcionalidad de colores aleatorios para la serpiente y la comida al correr el juego, siempre son colores distintos y no pueden ser del mismo color la serpiente y la comida (Esto fue a través de una función adicional que regresa un string de un color aleatorio pero toma otro color como parametro para checar que no se repitan)
- Añadimos la funcionalidad de movimiento aleatorio de la comida paso por paso
- Añadimos la funcionalidad para aumentar el tamaño del tablero
<NAME>:
Para el juego de Snake dacidi modificar el sigiente aspecto: La comida podrá moverse al azar un paso a la vez y no deberá de salirse de la ventana
para esto tuve que agregar unos condicionales en la funcion del movimiento para que el movimiento de la comida estubiera sincronizado con el de la serpeinte. De igual manera agerege un randomizador a las cordenadas de la comida en "x" y "y", tomando en consideracion que pasaria si llegara al brode se tubiera que retroceder un paso para continuar con el juago. Por ultimo tuve que modificar la forma en la que se median las restricciones para que a la hora que se juntaran las ramas del git no hubiera conflictos.
def inside(head):
"Return True if head inside boundaries."
return -limitex / 2 + 10 < head.x < limitex / 2 - 10 and -limitey / 2 + 10 < head.y < limitey / 2 - 10
def move():
(...)
#makes food move randomly without going out of the canvas
if food.x < limitex / 2 - 10 and food.x > -limitex / 2 + 10:
print(food.x)
food.x += round(randrange(-1, 2)) * 10
else:
food.x += food.x / food.x * -10
if food.y < limitey / 2 - 10 and food.y > -limitey / 2 + 10:
print(food.y)
food.y += round(randrange(-1, 2)) * 10
else:
food.y += food.y / food.y * -10
(...)
### Pacman
- Añadimos la funcionalidad de incremento de velocidad de los fantasmas del juego (Esto fue a través de un cambio en la llamada de la función move, incrementando que tan seguido y rápido se llama esta)
- Añadimos dos fantasmas adicionales
- Añadimos la funcionalidad para que pacman (el jugador) comienze el juego en una parte distinta del tablero.
<NAME>:
Para el juego de packman decidi modificar el apardado de "Change the number of ghosts", para esto tuve que analizar el programa, asi percatandome que el programa estaba automatizado para autogenarar los fantasmas y el movimiento individual de cada uno. Por lo cual, lo unico que necesite modificar fue agregar mas fantasmas en el tensor de fantasmas. Para lograr que esto funcionara de forma exitosa esra neccesario tomar en consideracion las cordenadas de origen de los fantasmas, ya que si colisionaban con las paredes (limites del mundo) rompia el juego y los fantasmas eran incapases de moverse.
ghosts = [
[vector(-180, 160), vector(5, 0)],
[vector(-180, -160), vector(0, 5)],
[vector(100, 160), vector(0, -5)],
[vector(100, -160), vector(-5, 0)],
[vector(-50, -80), vector(-5, 0)],
[vector(50, 80), vector(-5, 0)],
]
### Indice pagina equipo 10
-Para ligar nuestras paginas web en el servidor de aws era neccesario programar un indice el cual ligara las paginas de todos los miebros del equipo, para esto establecimos una estructura sencilla utilizando div's para seccionar cada apartado del individuo y anchor tag's para ligar los sitios de los usuaios, al ligar los sitios fue imperativo utilizar el directorio raiz del equipo10 mediante ~team10/[rute], esto fue muy importante ya que el servidor contaba con multiples usuarios. por otro lado para agregar el estilo utilizamos el nuevo modulo de css3 FlexBox el cual me permitio darle este estilo. Por ultimo nos cordianamos en las codificaciones de las ligas mediante el gestor de versiones git. Para mi sitio personal utilize un proyecto el cual hice para un curso de desarrollo web el cual utiliza Bootstrap.
## Como Instalar y Jugar
- Es necesario tener la version más reciente de Python instalada y puesta dentro del PATH.
- Es necesario también tener instalada el módulo Freegames, esto se puede hacer a través de la herramienta PIP [pip install freegames]
- Finalmente puedes correr los archivos snake.py y pacman.py dentro de tu terminal de elección utilizando Python
- para acceder al sitio web ir a: http://ec2-52-1-3-19.compute-1.amazonaws.com/~team10/
| f635111685e79ef533d9ea55a75578d0a709bf40 | [
"Markdown",
"Python"
] | 2 | Python | DemiurgeApeiron/TC1001S.100Team10 | 284a0ab800fdff8b7135ec6034124fb112046560 | f5854b8275db02ee9a65ac2c728a92236816f486 |
refs/heads/master | <repo_name>localSummer/react-boilerplate-ie8<file_sep>/src/routes/index.js
/* eslint-disable react/jsx-filename-extension */
// We only need to import the modules necessary for initial render
import React from 'react'
import { Router, Route, hashHistory, IndexRoute, Redirect } from 'react-router'
import App from '../components/App'
import Inbox from '../components/Inbox'
import Message from '../components/Message'
import Count from '../components/Count'
import Echarts from '../components/Echarts'
import Video from '../components/Video'
import Video2 from '../components/Video2'
import Video3 from '../components/Video3'
import Video4 from '../components/Video4'
const Routes = () => (
<Router history={hashHistory}>
<Route path="/" component={App}>
<IndexRoute component={Inbox} />
<Route path="inbox" component={Inbox}>
<Route path="messages/:id" component={Message} />
</Route>
<Route path="count" component={Count} />
<Route path="chart" component={Echarts} />
<Route path="video" component={Video} />
<Route path="video2" component={Video2} />
<Route path="video3" component={Video3} />
<Route path="video4" component={Video4} />
</Route>
<Redirect from="*" to="/" />
</Router>
)
export default Routes
<file_sep>/README.md
# react-boilerplate-ie8
react@0.14.9+react-router@2.3.0+rematch+axios+webpack+antd@1.11.6+echarts@4.1
- cd react-boilerplate-ie8
- npm i 或 yarn
- npm run start 在IE8中无法调试,Chrome可以
- npm run build 可在IE8以及Chrome中正常运行
<file_sep>/src/components/Video.js
import React from 'react'
class Video extends React.Component {
handlePlay = () => {
this.embed.play()
}
handlePause = () => {
this.embed.pause()
}
handleStateChange = (stateChange) => {
console.log(stateChange)
}
handleOnPlay = () => {
console.log('start play')
}
handleOnPause = () => {
console.log('pause')
}
render() {
return (
<div>
<embed
title="video"
ref={(embed) => {this.embed = embed}}
src="https://media.html5media.info/video.mp4"
width="618"
height="347"
controls
onreadystatechange={this.handleStateChange}
onplay={this.handleOnPlay}
onpause={this.handleOnPause}
/>
<button onClick={this.handlePlay}>播放</button>
<button onClick={this.handlePause}>暂停</button>
</div>
)
}
}
export default Video
<file_sep>/src/components/Inbox.js
import React from "react";
import axios from "axios";
import json3 from "json3";
import "../media/css/test.less";
import title from "../media/images/title.png";
import DatePicker from "antd/lib/date-picker";
class Inbox extends React.Component {
state = {
data: null
};
componentDidMount() {
console.log("发送请求");
axios
.get("http://jsonplaceholder.typicode.com/posts?userId=1")
.then(result => {
console.log(result);
// console.log(json3.parse(result.data))
console.log("set State");
if (result.data.code === 1) {
this.setState({
data: result.data
});
} else {
this.setState({
data: result.data
});
}
})
.catch(err => {
console.log(err);
});
let obj = { name: [1, 2], age: 2 };
Object.keys(obj).forEach(item => {
if (item === "name") {
if (obj[item].includes(2)) {
console.log(1);
} else {
console.log(3);
}
} else {
console.log(obj[item]);
}
});
}
handleClick = () => {
let { history } = this.props;
history.push("/inbox/messages/1");
};
handleCount = () => {
let { history } = this.props;
history.push("/count");
};
handleVideo = () => {
let { history } = this.props;
history.push("/video");
};
handleVideo2 = () => {
let { history } = this.props;
history.push("/video2");
};
handleVideo3 = () => {
let { history } = this.props;
history.push("/video3");
};
handleVideo4 = () => {
let { history } = this.props;
history.push("/video4");
};
handleChange = (value, dateString) => {
console.log(value, dateString);
};
render() {
console.log(this.props);
let { data } = this.state;
return (
<div>
<h2>Inbox</h2>
<img src={title} />
<button onClick={this.handleClick}>
<span>go messages</span>
</button>
<button onClick={this.handleCount}>go count</button>
<button onClick={this.handleVideo}>go video</button>
<button onClick={this.handleVideo2}>go video2</button>
<button onClick={this.handleVideo3}>go video3</button>
<button onClick={this.handleVideo4}>go video4</button>
{this.props.children || "Welcome to your Inbox"}
{data ? (
data.map(item => {
return <div key={item.id}>{item.title + "-" + item.id}</div>;
})
) : (
<div>没有setState</div>
)}
<DatePicker onChange={this.handleChange} />
</div>
);
}
}
export default Inbox;
<file_sep>/tools/build.js
/**
* React Static Boilerplate
* https://github.com/koistya/react-static-boilerplate
*
* Copyright © 2015-2016 <NAME> (@koistya)
*
* This source code is licensed under the MIT license found in the
* LICENSE.txt file in the root directory of this source tree.
*/
const task = require('./task')
module.exports = task('build', () => Promise.resolve()
.then(() => require('./clean'))
.then(() => require('./copy'))
.then(() => require('./bundle'))
)
<file_sep>/src/components/Video2.js
import React from 'react'
class Video2 extends React.Component {
render() {
return (
<div>
<object width="720" height="452" classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://download.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=6,0,40,0" align="middle">
<param name="src" value="https://media.html5media.info/video.mp4" />
<param name="allowfullscreen" value="true" />
<param name="quality" value="high" />
<param name="allowscriptaccess" value="always" />
<param name="wmode" value="opaque" />
<embed width="720" height="452" type="application/x-shockwave-flash" src="https://media.html5media.info/video.mp4" allowfullscreen="true" quality="high" allowscriptaccess="always" align="middle" />
</object>
</div>
)
}
}
export default Video2
<file_sep>/tools/bundle.js
/**
* React Static Boilerplate
* https://github.com/koistya/react-static-boilerplate
*
* Copyright © 2015-2016 <NAME> (@koistya)
*
* This source code is licensed under the MIT license found in the
* LICENSE.txt file in the root directory of this source tree.
*/
const webpack = require('webpack')
const task = require('./task')
const webpackConfig = require('../webpack.config')
module.exports = task('bundle', new Promise((resolve, reject) => {
const bundler = webpack(webpackConfig)
const run = (err, stats) => {
if (err) {
reject(err)
} else {
console.log(stats.toString(webpackConfig.stats))
resolve()
}
}
bundler.run(run)
}))
<file_sep>/webpack.config.js
const path = require('path')
const webpack = require('webpack')
const HtmlWebpackPlugin = require('html-webpack-plugin')
const ExtractTextPlugin = require('extract-text-webpack-plugin')
const es3ifyPlugin = require('es3ify-webpack-plugin')
const args = process.argv.slice(2)
const DEBUG = !(args[0] === '--release')
const VERBOSE = args[0] === '--verbose'
const config = {
context: path.resolve(__dirname, './src'),
entry: {
app: ['./main.js'],
vendor: [
'es5-shim',
'es5-shim/es5-sham',
'babel-polyfill',
'es6-promise',
'react',
'react-dom',
'react-redux',
'react-router',
],
},
output: {
path: path.resolve(__dirname, 'build'),
publicPath: '/',
filename: 'assets/[name].js',
chunkFilename: 'assets/[name].js',
sourcePrefix: ' ',
},
resolve: {
extensions: ['', '.js', '.jsx'],
alias: {
components: path.resolve(__dirname, './src/components/'),
routes: path.resolve(__dirname, './src/routes/'),
services: path.resolve(__dirname, './src/services/'),
store: path.resolve(__dirname, './src/store/'),
},
},
debug: DEBUG,
cache: DEBUG,
devtool: DEBUG ? 'source-map' : false,
stats: {
colors: true,
reasons: DEBUG,
hash: VERBOSE,
version: VERBOSE,
timings: true,
chunks: VERBOSE,
chunkModules: VERBOSE,
cached: VERBOSE,
cachedAssets: VERBOSE,
children: false,
},
plugins: [
// new es3ifyPlugin(),
new webpack.optimize.OccurenceOrderPlugin(),
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: Infinity,
}),
new webpack.DefinePlugin({
'process.env.NODE_ENV': DEBUG ? '"development"' : '"production"',
__DEV__: DEBUG,
__BASENAME__: JSON.stringify(process.env.BASENAME || ''),
}),
new ExtractTextPlugin('assets/styles.css', {
minimize: !DEBUG,
allChunks: true,
}),
new HtmlWebpackPlugin({
template: path.resolve(__dirname, './src/index.ejs'),
filename: 'index.html',
minify: !DEBUG
? {
collapseWhitespace: true,
}
: null,
hash: true,
}),
],
module: {
loaders: [
{
test: /\.jsx?$/,
include: [path.resolve(__dirname, 'src')],
loader: 'babel-loader',
query: {
plugins: [],
},
},
{
test: /\.css/,
loader: ExtractTextPlugin.extract(
'style-loader',
'css-loader?-autoprefixer&modules=true&localIdentName=[local]!postcss-loader',
),
},
{
test: /\.less$/,
loader: ExtractTextPlugin.extract(
'style-loader',
'css-loader?-autoprefixer!postcss-loader!less-loader',
),
},
{
test: /\.json$/,
loader: 'json-loader',
},
{
test: /\.(png|jpg|jpeg|gif|svg|woff|woff2)$/,
loader: 'url-loader',
query: {
name: 'assets/[path][name].[ext]',
limit: 10000,
},
},
{
test: /\.(eot|ttf|wav|mp3|ogg)$/,
loader: 'file-loader',
query: {
name: 'assets/[path][name].[ext]',
},
},
],
},
}
if (!DEBUG) {
config.plugins.push(new es3ifyPlugin())
config.plugins.push(new webpack.optimize.DedupePlugin())
}
const uglyOptions = !DEBUG
? {
compress: {
warnings: VERBOSE,
screw_ie8: false,
},
mangle: {
screw_ie8: false,
},
output: {
screw_ie8: false,
},
}
: {
mangle: false,
compress: {
drop_debugger: false,
warnings: VERBOSE,
screw_ie8: false,
},
output: {
beautify: true,
comments: true,
bracketize: true,
indent_level: 2,
keep_quoted_props: true,
screw_ie8: false,
},
}
// config.plugins.push(new webpack.optimize.UglifyJsPlugin(uglyOptions))
if (!DEBUG) {
config.plugins.push(new webpack.optimize.UglifyJsPlugin(uglyOptions))
config.plugins.push(new webpack.optimize.AggressiveMergingPlugin())
config.module.loaders
.find(x => x.loader === 'babel-loader')
.query.plugins.unshift(
'transform-react-remove-prop-types',
'transform-react-constant-elements',
'transform-react-inline-elements',
'transform-es3-modules-literals',
'transform-es3-member-expression-literals',
'transform-es3-property-literals',
)
}
module.exports = config
<file_sep>/src/components/Count.jsx
/* eslint-disable react/prop-types */
import React from 'react'
import { connect } from 'react-redux'
const Count = props => (
<div>
The count is {props.count}
<button onClick={props.increment}>increment</button>
<button onClick={props.incrementAsync}>incrementAsync</button>
</div>
)
const mapState = state => ({
count: state.count,
})
const mapDispatch = ({ count: { increment, incrementAsync } }) => ({
increment: () => increment(1),
incrementAsync: () => incrementAsync(1),
})
const CountContainer = connect(mapState, mapDispatch)(Count)
export default CountContainer
<file_sep>/src/components/Video3.js
import React from 'react';
class Video3 extends React.Component {
componentDidMount() {
$("#jquery_jplayer_1").jPlayer({
ready: function () {
$(this).jPlayer("setMedia", {
title: "Big Buck Bunny",
m4v: "https://media.html5media.info/video.mp4",
ogv: "http://www.jplayer.org/video/ogv/Big_Buck_Bunny_Trailer.ogv",
webmv: "http://www.jplayer.org/video/webm/Big_Buck_Bunny_Trailer.webm",
poster: "http://www.jplayer.org/video/poster/Big_Buck_Bunny_Trailer_480x270.png"
}).jPlayer("play");
},
swfPath: "https://cdn.bootcss.com/jplayer/2.9.1/jplayer/jquery.jplayer.swf",
supplied: "webmv, ogv, m4v",
size: {
width: "640px",
height: "360px",
cssClass: "jp-video-360p"
},
useStateClassSkin: true,
autoBlur: false,
smoothPlayBar: true,
keyEnabled: true,
remainingDuration: true,
toggleDuration: true
});
}
componentWillUnmount() {
console.log('unmount')
$("#jquery_jplayer_1").jPlayer("destroy")
}
render() {
return (
<div id="jp_container_1" className="jp-video jp-video-360p" role="application" aria-label="media player">
<div className="jp-type-single">
<div id="jquery_jplayer_1" className="jp-jplayer"></div>
<div className="jp-gui">
<div className="jp-video-play">
<button className="jp-video-play-icon" role="button" tabindex="0">play</button>
</div>
<div className="jp-interface">
<div className="jp-progress">
<div className="jp-seek-bar">
<div className="jp-play-bar"></div>
</div>
</div>
<div className="jp-current-time" role="timer" aria-label="time"> </div>
<div className="jp-duration" role="timer" aria-label="duration"> </div>
<div className="jp-controls-holder">
<div className="jp-controls">
<button className="jp-play" role="button" tabindex="0">play</button>
<button className="jp-stop" role="button" tabindex="0">stop</button>
</div>
<div className="jp-volume-controls">
<button className="jp-mute" role="button" tabindex="0">mute</button>
<button className="jp-volume-max" role="button" tabindex="0">max volume</button>
<div className="jp-volume-bar">
<div className="jp-volume-bar-value"></div>
</div>
</div>
<div className="jp-toggles">
<button className="jp-repeat" role="button" tabindex="0">repeat</button>
<button className="jp-full-screen" role="button" tabindex="0">full screen</button>
</div>
</div>
<div className="jp-details">
<div className="jp-title" aria-label="title"> </div>
</div>
</div>
</div>
<div className="jp-no-solution">
<span>Update Required</span>
To play the media you will need to either update your browser to a recent version or update your <a href="http://get.adobe.com/flashplayer/" target="_blank">Flash plugin</a>.
</div>
</div>
</div>
)
}
}
export default Video3<file_sep>/src/components/Video4.js
import React from 'react'
class Video4 extends React.Component {
render() {
return (
<iframe
title='test'
style={{width: '800px', height: '800px'}}
src="./iframe/player.html"
frameBorder="0"
/>
)
}
}
export default Video4<file_sep>/src/components/Root.js
import React from 'react'
import axios from 'axios'
import Routes from '../routes/index'
/*请求携带cookie,配置接口调用前缀*/
axios.defaults.withCredentials = true;
axios.defaults.baseURL = '/earth';
class Root extends React.Component {
componentWillMount() {
axios.interceptors.request.use(function (config) {
// 在发送请求之前做些什么
return config;
}, function (error) {
// 对请求错误做些什么
return Promise.reject(error);
});
// 添加响应拦截器
axios.interceptors.response.use(function (response) {
// 对响应数据做点什么
console.log('response', response);
return response;
}, function (error) {
// 对响应错误做点什么
return Promise.reject(error);
});
}
render() {
return (
<Routes />
)
}
}
export default Root | b1639e5c5a13ad3776f9b776f0aa52bc5ffaba1f | [
"JavaScript",
"Markdown"
] | 12 | JavaScript | localSummer/react-boilerplate-ie8 | ca28d04fb8215c328fbd16e8e980a581c35a18c9 | f1407a1825abfc962c89bf0e2bd5f405d5cb1b94 |
refs/heads/master | <file_sep>
$(document).ready(function() {
var pre_loader_logo = $('#preLoaderLogo');
var title = $('.title')
var red = $('#red')
var blue = $('#blue')
var all = $('.all_splash');
var tl = new TimelineLite();
var test = $('#test')
//function logo rotator on click
function loader(){
tl
.to(pre_loader_logo, 3, {rotation:360, ease:Power0.easeNone})
.to([title, pre_loader_logo], 1, {opacity:0 , ease:Power1.easeInOut})
.add('red')
.add('blue')
.to(blue, 1.2, {x: 500, ease:Power1.easeInOut, opacity:0}, 'blue')
.to(red, 1.2, {x: -500, ease:Power1.easeInOut, opacity:0}, 'red')
tl.pause();
$('.title, #preLoaderLogo').click(function(){
tl.play()
setTimeout(function(){
redirect()
}, 5500)
})
};
loader()
function redirect() {
window.location.assign("mv.html")
}
});
<file_sep>
$(document).ready(function() {
var one = $('.one');
var two = $('.two');
var three = $('.three');
var four = $('.four');
var five = $('.five');
var flashingColors1 = $('.flashingColors1');
var flashingColors2 = $('.flashingColors2');
var flashingColors3 = $('.flashingColors3');
var heart1 = $('#heart1');
var heart2 = $('#heart2');
var speakers = $('.speakers');
var boom = $('.boom')
var faces = $('.face');
var just_face = $('#just_face')
var hat_face = $('#hat_face')
var sunglasses = $('.sunglasses');
var sunglasses1 = $('#sunglasses1');
var sunglasses2 = $('#sunglasses2');
var sunglasses1_yellow = $('#sunglasses1_yellow');
var sunglasses2_yellow = $('#sunglasses2_yellow');
var sunglasses1_blue = $('#sunglasses1_blue');
var sunglasses2_blue = $('#sunglasses2_blue');
var sunglasses1_pink = $('#sunglasses1_pink');
var sunglasses2_pink = $('#sunglasses2_pink');
var sunglasses1_green = $('#sunglasses1_green');
var sunglasses2_green = $('#sunglasses2_green');
var sunglasses1_red = $('#sunglasses1_red');
var sunglasses2_red = $('#sunglasses2_red');
var sunglasses1_darkBlue = $('#sunglasses1_darkBlue');
var sunglasses2_darkBlue = $('#sunglasses2_darkBlue');
var sunglasses1_orange = $('#sunglasses1_orange');
var sunglasses2_orange = $('#sunglasses2_orange');
// var sunglasses1_darkGreen = $('#sunglasses1_darkGreen');
// var sunglasses2_darkGreen = $('#sunglasses2_darkGreen');
var fallingBox = $('.fallingBox');
var tl = new TimelineLite({paused: true});
var aud = document.getElementById("audio");
// function words fade in
function countIn(){
tl
.staggerFromTo(sunglasses, .00001, {opacity:1}, {opacity:0})
.staggerFromTo(one, .06, {opacity:0}, {opacity:1})
.staggerFromTo(two, .06, {opacity:0}, {opacity:1})
.staggerFromTo(three, .02, {opacity:0}, {opacity:1})
.staggerFromTo(four, .035, {opacity:0}, {opacity:1})
.staggerFromTo(five, .035, {opacity:0}, {opacity:1})
.to([one, two, three, four, five], .045, {opacity:0})
};
countIn();
var randomColor= function() {
var letters = '0123458789ABCDEF';
var color = '#';
for (var i = 0; i < 8; i++ ) {
color += letters[Math.floor(Math.random() * 16)];
}
return color;
}
function colorChange1(){
tl
.to(flashingColors1, .01, {css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors1, .04, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors1, .04, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors1, .02, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors1, .02, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors1, .04, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors1, .002, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors1, .001, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
// .to(flashingColors1, .002, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
// .to(flashingColors1, .001, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
}
colorChange1();
function colorChange2(){
tl
// .to(flashingColors2, .22, {delay: 1.35, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors2, .05, {delay: .28, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
// .to(flashingColors2, .22, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors2, .05, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors2, .04, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors2, .02, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors2, .02, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors2, .02, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors2, .002, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut}) .to(flashingColors1, .002, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
.to(flashingColors1, .002, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
// .to(flashingColors1, .002, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
// .to(flashingColors2, .12, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut})
}
colorChange2();
function facesAppear(){
tl
.add('flashingColors3')
.staggerFromTo(faces, .3, {opacity:0}, {opacity:1})
.to(flashingColors3, .27, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut}, 'flashingColors3')
}
facesAppear();
function sunglassesAppear(){
tl
.add('flashingColors3')
.staggerFromTo(sunglasses1, .01, {opacity:0}, {opacity:1, repeat:20})
.to(sunglasses1, .3, {rotation:360, transformOrigin:"left top"})
.to(sunglasses1, .3, {rotation:360, scale:0.5, transformOrigin:"-750px -900px"})
// .staggerFromTo(sunglasses2, .01, {opacity:0}, {opacity:1, repeat:30})
// .to(sunglasses2, .4, {rotation:360, scale:0.5, transformOrigin:"-550px 950px"})
// .staggerFromTo(sunglasses1_yellow, .01, {opacity:0}, {opacity:1, repeat:30})
// .to(sunglasses1_yellow, .4, {rotation:360, scale:0.5, transformOrigin:"-800px -800px"})
.staggerFromTo(sunglasses2_yellow, .01, {opacity:0}, {opacity:1, repeat:20})
.to(sunglasses2_yellow, .3, {rotation:360, transformOrigin:"bottom top"})
.to(sunglasses2_yellow, .3, {rotation:360, scale:0.5, transformOrigin:"-600px 950px"})
.staggerFromTo(heart1, .2, {opacity:0}, {opacity:1}, 'heart1')
.staggerFromTo(sunglasses2_blue, .01, {opacity:0}, {opacity:1, repeat:30})
.to(sunglasses2_blue, .3, {rotation:270, scale:0.5, transformOrigin:"-550px -400px"})
.staggerFromTo(heart2, .2, {opacity:0}, {opacity:1}, 'heart2')
.staggerFromTo(sunglasses1_blue, .01, {opacity:0}, {opacity:1, repeat:30})
.to([heart1, heart2], .5, { y: -650})
.staggerFromTo(sunglasses1_pink, .01, {opacity:0}, {opacity:1, repeat:30})
.to(sunglasses1_pink, .3, {rotation:360, transformOrigin:"right bottom"})
.staggerFromTo(sunglasses2_pink, .01, {opacity:0}, {opacity:1, repeat:20})
// .staggerFromTo(sunglasses1_green, .01, {opacity:0}, {opacity:1, repeat:30})
// .staggerFromTo(sunglasses2_green, .01, {opacity:0}, {opacity:1, repeat:20})
// .staggerFromTo(sunglasses1_red, .01, {opacity:0}, {opacity:1, repeat:30})
// .staggerFromTo(sunglasses2_red, .01, {opacity:0}, {opacity:1, repeat:20})
// .staggerFromTo(sunglasses1_darkBlue, .01, {opacity:0}, {opacity:1, repeat:30})
// .to(sunglasses1_darkBlue, .2, {rotation:360, transformOrigin:"right top"})
// .to(sunglasses1_darkBlue, .2, {rotation:360, scale:0.5, transformOrigin:"-750px -900px"})
// .staggerFromTo(sunglasses2_darkBlue, .01, {opacity:0}, {opacity:1, repeat:30})
// .staggerFromTo(sunglasses1_orange, .01, {opacity:0}, {opacity:1, repeat:30})
.staggerFromTo(sunglasses2_orange, .01, {opacity:0}, {opacity:1, repeat:30})
.to(sunglasses2_orange, .2, {rotation:360, transformOrigin:"bottom top"})
.to(sunglasses2_orange, .2, {rotation:360, scale:0.5, transformOrigin:"-600px 950px"})
// .staggerFromTo(sunglasses1_darkGreen, .01, {opacity:0}, {opacity:1, repeat:30})
// .staggerFromTo(sunglasses2_darkGreen, .01, {opacity:0}, {opacity:1, repeat:30})
.to(sunglasses, .03, {opacity:0})
.to(flashingColors3, .27, {delay:.01, css:{backgroundColor: randomColor()}, ease:Back.easeOut}, 'flashingColors3')
}
sunglassesAppear();
function boomBoomSpeakers(){
tl
// .add('boom')
.add('flashingColors3')
.add('just_face')
.add('just_hat')
.staggerFromTo(speakers, .2, {opacity:0}, {opacity:1})
.fromTo(speakers, .2, {scale:.5}, {scale:.65})
.fromTo(speakers, .2, {scale:.65}, {scale:.5, repeat: 10})
// .fromTo(just_face, .8, {rotation: '45'}, {rotation: '-45'}, 'just_face')
// .fromTo(hat_face, .8, {rotation: '-45'}, {rotation: '45'}, 'hat_face')
.to(flashingColors3, .01, {delay:.03, css:{backgroundColor: randomColor()}, ease:Back.easeOut, repeat: 200}, 'flashingColors3')
.to(speakers, .03, {opacity:0})
}
boomBoomSpeakers()
function addSquare(){
tl
.to(faces, .05, {opacity:0})
for (var i = 1; i < 71; i++) {
$('#display').append(`<img id=${i} class="fallingBox" src="images/puzzle_pieces/pieces_${i}.jpg"/>`);
}
function noDups(){
var arr = [];
while (arr.length < 70) {
var numbs= Math.ceil((Math.random() * 71))
if(arr.indexOf(numbs) === -1 && numbs != 71){
arr.push(numbs);
}
}
return arr;
}
var randomNum = noDups();
for (var i = 0; i < $('.fallingBox').length; i++) {
tl
.fromTo($(`#${randomNum[i]}`), .008, { opacity:0, ease:Power1.easeOut}, {opacity:1})
}
}
addSquare();
function Update(){
tl.progress( aud.currentTime/aud.duration );
}
aud.onplay = function() {
TweenLite.ticker.addEventListener('tick',Update);
};
aud.onpause = function() {
TweenLite.ticker.removeEventListener('tick',Update);
};
});
| 3d3e5302c42edec8802a9dac3a1fec0f84c98ff6 | [
"JavaScript"
] | 2 | JavaScript | jesslee1315/tear_in_my_heart | 0389ab2914648a9ae4b6be9073c52c44073f3665 | 1e62b87942f68695f3726e01abefb9184d122c7a |
refs/heads/main | <repo_name>c293-gif/web-java5<file_sep>/java2/homework/src/BMI.java
import java.util.Scanner;
public class BMI {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("nhập cân nặng(đơn vị kg): ");
double kg = sc.nextDouble();
System.out.println("nhập chiều cao(đơn vị m): ");
double m = sc.nextDouble();
double c = kg / (Math.pow(m, 2));
System.out.println("chỉ số IBM: " + c);
System.out.println("(*_^)");
}
}<file_sep>/java4/onlab/src/Person.java
import java.util.Scanner;
public class Person {
String name;
int age;
String address;
public Person(String name, int age, String address) {
this.name = name;
this.age = age;
this.address = address;
}
@Override
public String toString() {
return name + "-" + age + "-" + address;
}
public Person() {
}
public void input(){
Scanner sc = new Scanner(System.in);
System.out.println("nhập tên: ");
name = sc.nextLine();
System.out.println("nhập tuổi: ");
age = Integer.valueOf(sc.nextLine());//cách sử lí trôi lệnh
System.out.println("địa chỉ: ");
address = sc.nextLine();
}
}
<file_sep>/kt/src/Main.java
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner sc = new Scanner(System.in);
ControllerAll con = new ControllerAll();
while (true) {
System.out.println("**********Menu****************");
System.out.println("1 . Đăng nhập");
System.out.println("2 . Đăng kí");
int n = Integer.parseInt(sc.nextLine());
switch (n) {
case 1:
con.Login();
break;
case 2:
con.Insert();
break;
default:
break;
}
}
}
}
<file_sep>/java6/onlab/src/model/Address.java
package model;
public class Address {
String district, city, country;
public Address(String district, String city, String country) {
this.district = district;
this.city = city;
this.country = country;
}
@Override
public String toString() {
return "Address [city=" + city + ", country=" + country + ", district=" + district + "]";
}
}
<file_sep>/java7/onlab/src/SchoolBook.java
public class SchoolBook extends Library {
private int soTrang, soLuongMuon;
private String tinhTrang;
public SchoolBook(int maSach, String tenSach, String nhaXuatBan, int namXuatBan, int soLuong, Vitri vitri,
int soTrang, int soLuongMuon, String tinhTrang) {
super(maSach, tenSach, nhaXuatBan, namXuatBan, soLuong, vitri);
this.soTrang = soTrang;
this.soLuongMuon = soLuongMuon;
this.tinhTrang = tinhTrang;
}
public int getSoTrang() {
return soTrang;
}
public void setSoTrang(int soTrang) {
this.soTrang = soTrang;
}
public int getSoLuongMuon() {
return soLuongMuon;
}
public void setSoLuongMuon(int soLuongMuon) {
this.soLuongMuon = soLuongMuon;
}
public String getTinhTrang() {
return tinhTrang;
}
public void setTinhTrang(String tinhTrang) {
this.tinhTrang = tinhTrang;
}
public int tinhtonkho() {
return getSoLuong() - soLuongMuon;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return super.toString() + ", số trang " + soTrang + ", tình trạng " + tinhTrang + ", soluongmuon " + soLuongMuon + ", tồn kho " + tinhtonkho();
}
}
<file_sep>/java2/homework/src/Pitago.java
public class Pitago {
public static void main(String[] args) {
int a = 3;
int b = 4;
System.out.println("chiều dài hai cạnh gọc vuông là: " + a + " và " + b);
double c = Math.sqrt(Math.pow(a, 2) + Math.pow(b, 2));
System.out.println("áp dụng định lý pitago ta có cạnh Huyền là: " + c);
}
}<file_sep>/1/onlab/html.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>ghi nhớ</title>
</head>
<body>
<h1>là thẻ tiêu đề(h1->h6)</h1>
<p>là đoạn văn</p>
<b>là in đậm</b>
<i>là in ngiêng</i>
<br />
<p>là xuống dòng</p>
<hr />
<p>là gạch kẻ trang</p>
<p>ctrl+/ là commen</p>
<p>&+tên kí tự=kí tự</p>
</body>
</html>
<file_sep>/java4/homework/homework2/src/App.java
import java.util.Scanner;
public class App {
public static void main(String[] args) throws Exception {
Scanner scanner = new Scanner(System.in);
System.out.println("nhập số lượn động vật cần quản lí: ");
int n = scanner.nextInt();
Animal[] arraypAnimals = new Animal[n];
for (int i = 0; i < arraypAnimals.length; i++) {
Animal animal = new Animal();
animal.input();
arraypAnimals[i] = animal;
}
System.out.println("danh sách động vật");
for (int i = 0; i < arraypAnimals.length; i++) {
System.out.println(arraypAnimals[i]);
}
}
}
<file_sep>/java3/onlab/src/App.java
import java.util.Scanner;
public class App {
public static void main(String[] args) throws Exception {
int a = 11;
int b = 6;
if (a < b) {
int c = a + b;
System.out.println("c= " + c);
} else {
int d = a - b;
System.out.println("d= " + d);
}
if (a == b) {
System.out.println("a bằng b");
}
if (a % 2 == 0) {
System.out.println("a là số chẵn");
} else {
System.out.println("a là số lẻ");
}
/* Scanner sc = new Scanner(System.in);
int n = scanner.nextin();
int h=scanner.nextin();
double bmi= n/h;
if(bmi<18.5);
{
}*/
/* Scanner ab = new Scanner(System.in);
System.out.println("nhập tháng :");
int number = ab.nextInt();
switch (number) {
case 1, 3, 7, 9, 11:
System.out.println("tháng có 31 ngày");
break;
case 4, 6, 8, 10, 12:
System.out.println("tháng có 30 ngày");
case 2:
System.out.println("tháng có 28 hoặc 29 ngày");
}*/
/* for (int i = 0; i < 10; i++) {
if (i%2==0)
System.out.println(i);
}*/
/* for (int i = 1; i <= 100; i++) {
if (i % 3 == 0 && i % 5 == 0) {
System.out.println("fizzbuzz");
}else
if (i % 3 == 0) {
System.out.println("fizz");
} else if (i % 5 == 0) {
System.out.println("buzz");
}
else {
System.out.println(i);
}
}*/
String str = "hello";
// for (int i = str.length()-1; i >= 0; i--) {
// System.out.println(str.charAt(i));
// }
int count = 0;
for (int i = 0; i < str.length(); i++) {
if (str.charAt(i) == 'l') {
count++;
}
}
System.out.println("số lần chữ l xuất hiện =" + count);
}
}
<file_sep>/kt/src/ControllerAll.java
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class ControllerAll {
Scanner sc = new Scanner(System.in);
List<User> listUser = new ArrayList<User>();
public void Insert() {
User user = new User();
user.inputData();
listUser.add(user);
System.out.println("Dang ki thanh cong");
}
public void Login() {
System.out.println("Nhap tk:");
String tk = sc.nextLine();
for (User user : listUser) {
if (user.getUserName().equals(tk)) {
System.out.println("nhap mk:");
String mk = sc.nextLine();
if (user.getPass().equals(mk)) {
boolean check =true;
while (check) {
System.out.println("Chào mừng :"+ user.getUserName());
System.out.println("1.Thay đổi username");
System.out.println("2.thay đổi email");
System.out.println("3.thay đổi mk");
System.out.println("4. đăng xuất");
int n = Integer.parseInt(sc.nextLine());
switch (n) {
case 1:
System.out.println("nhap userName mới:");
String useName = sc.nextLine();
try {
user.setUserName(useName);
System.out.println("Đổi userName thành công");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
break;
case 2:
System.out.println("nhap password mới:");
String pass = sc.nextLine();
try {
user.setPass(pass);
System.out.println("Đổi Pass thành công");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
break;
case 3:
System.out.println("nhap email mới:");
String email = sc.nextLine();
try {
user.setEmail(email);
System.out.println("Đổi Pass thành công");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
break;
case 4:
check = false;
break;
default:
System.out.println("vui long lua chon lai");
break;
}
}
}else {
System.out.println(" 1 .Đăng nhập lại");
System.out.println(" 2 .Quên mật khẩu");
int m = Integer.parseInt(sc.nextLine());
switch (m) {
case 1:
Login();
break;
case 2:
System.out.println("Nhap email");
String emailAll = sc.nextLine();
if (user.getEmail().equals(emailAll)) {
System.out.println("nhap mat khau moi :");
String pas = sc.nextLine();
try {
user.setPass(pas);
Login();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}else {
System.out.println("tk chua ton tai");
}
break;
default:
break;
}
}
}else {
System.out.println("sai tk vui long kiem tra lai");
}
}
}
}
<file_sep>/java6/onlab/src/model/Dog.java
package model;
public class Dog {
String breed, size, color;
int age;
public void name(String breedName) {
System.out.println(breed + " name " + breedName);
}
public void eat(String food) {
System.out.println(breed + " eat " + food);
}
public void run(int speed) {
System.out.println(breed + " run " + speed + "km/h");
}
@Override
public String toString() {
return "Dog [age=" + age + " years" + ", breed=" + breed + ", color=" + color + ", size=" + size + "]";
}
}
<file_sep>/java4/homework/homework2/src/Animal.java
import java.util.Scanner;
public class Animal {
String name;
String color;
int leg;
public Animal(String name, String color, int leg) {
this.name = name;
this.color = color;
this.leg = leg;
}
@Override
public String toString() {
return "tên động vật:" + name + ", màu lông của " + name+ " :" + color + ", số chân của " + name+ " :" + leg;
}
public Animal() {
}
public void input() {
Scanner sc = new Scanner(System.in);
System.out.println("nhập tên động vật: ");
name = sc.nextLine();
System.out.println("màu lông của " + name + " :");
color = sc.nextLine();
System.out.println("số chân của " + name + " :");
leg = Integer.valueOf(sc.nextLine());
}
}
<file_sep>/ghk/src/App.java
import java.util.Scanner;
public class App {
public static void main(String[] args) throws Exception {
Scanner sc = new Scanner(System.in);
ListPlayer listPlayer = new ListPlayer();
boolean check = true;
listPlayer.getListPlayer();
System.out.println("danh sách cầu thủ");
while (true) {
System.out.println("***********Sắp sếp đội hình******************");
System.out.println("1 . Đội hình 4-3-3");
System.out.println("2 . Đội hình 4-4-2");
System.out.println("3 . Đội hình 3-5-2");
System.out.println("Vui lòng chọn");
int m = sc.nextInt();
switch (m) {
case 0:
check = false;
System.exit(0);
break;
case 1:
listPlayer.buildTeam(4, 3, 3);
break;
case 2:
listPlayer.buildTeam(4, 4, 2);
break;
case 3:
listPlayer.buildTeam(3, 5, 2);
break;
default:
System.out.println("không có lựa chọn này");
break;
}
}
}
}
<file_sep>/java7/homework/src/KiemChungVien.java
import java.util.Scanner;
public class KiemChungVien extends NhanVien {
private int loi;
public KiemChungVien() {
}
public KiemChungVien(String maNv, String hoTen, int tuoi, String sdt, String email, long luongCB, int loi) {
super(maNv, hoTen, tuoi, sdt, email, luongCB);
this.loi = loi;
}
public int getLoi() {
return loi;
}
public void setLoi(int loi) {
this.loi = loi;
}
public long luongKC() {
return getLuongCB() + (loi * 50000);
}
@Override
public void input() {
Scanner sc = new Scanner(System.in);
super.input();
System.out.println("nhập số lỗi phát hiện:");
loi = sc.nextInt();
}
@Override
public void show() {
super.show();
System.out.println("số lỗi phát hiện:" + loi);
System.out.println("tổng lương: " + formatMoney(luongKC()));
System.out.println("---------------------------------");
}
}
<file_sep>/ghk/src/Position.java
public enum Position {
FW, DF, GK, MF;
}<file_sep>/java7/homework/src/LapTrinhVien.java
import java.text.DecimalFormat;
import java.util.Scanner;
public class LapTrinhVien extends NhanVien {
private int overtime;
public LapTrinhVien() {
}
public LapTrinhVien(String maNv, String hoTen, int tuoi, String sdt, String email, long luongCB, int overtime) {
super(maNv, hoTen, tuoi, sdt, email, luongCB);
this.overtime = overtime;
}
public int getOvertime() {
return overtime;
}
public void setOvertime(int overtime) {
this.overtime = overtime;
}
public long luongLT() {
return getLuongCB() + (overtime * 200000);
}
@Override
public void input() {
Scanner sc = new Scanner(System.in);
super.input();
System.out.println("nhập số giờ tăng ca: ");
overtime = sc.nextInt();
}
@Override
public void show() {
super.show();
System.out.println("số giờ overtime:" + overtime);
System.out.println("tổng lương: " + formatMoney(luongLT()));
System.out.println("---------------------------------");
}
}
<file_sep>/java1/homework/homework/src/Agemul.java
public class Agemul {
int num1 = 7;
int num2 = 3;
public int mul() {
int c = num1 * num2;
return c;
}
}<file_sep>/java7/homework/src/App.java
import java.util.ArrayList;
import java.util.Scanner;
public class App {
public static void main(String[] args) throws Exception {
Scanner sc = new Scanner(System.in);
System.out.println("nhập số Lập Trình Viên cần quản lí: ");
int ltv = sc.nextInt();
ArrayList<LapTrinhVien> listLTV = new ArrayList<>();
for (int i = 0; i < ltv; i++) {
LapTrinhVien laptrinhvien = new LapTrinhVien();
System.out.println("Lập trình viên " + (i + 1));
laptrinhvien.input();
listLTV.add(laptrinhvien);
}
System.out.println("nhập số Kiểm Chứng Viên cần quản lí: ");
int kcv = sc.nextInt();
ArrayList<KiemChungVien> listKCV = new ArrayList<>();
for (int i = 0; i < kcv; i++) {
KiemChungVien kiemchungvien = new KiemChungVien();
System.out.println("kiểm chứng viên " + (i + 1));
kiemchungvien.input();
listKCV.add(kiemchungvien);
}
System.out.println("danh sách nhân viên: ");
System.out.println("danh sách lập trình viên: ");
for (LapTrinhVien laptrinhvien : listLTV) {
laptrinhvien.show();
}
System.out.println("dánh sách Kiểm Chứng Viên: ");
for (KiemChungVien kiemChungVien : listKCV) {
kiemChungVien.show();
}
}
}
<file_sep>/java7/onlab/src/Vitri.java
public class Vitri {
private int ke, tang;
public Vitri(int ke, int tang) {
this.ke = ke;
this.tang = tang;
}
@Override
public String toString() {
return ", kệ số " + ke + ", tầng số " + tang;
}
}
<file_sep>/java7/homework/src/NhanVien.java
import java.text.DecimalFormat;
import java.util.Scanner;
public class NhanVien {
private String maNv, hoTen, email, sdt;
private int tuoi;
private long luongCB;
public String getMaNv() {
return maNv;
}
public void setMaNv(String maNv) {
this.maNv = maNv;
}
public String getHoTen() {
return hoTen;
}
public void setHoTen(String hoTen) {
this.hoTen = hoTen;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getSdt() {
return sdt;
}
public void setSdt(String sdt) {
this.sdt = sdt;
}
public int getTuoi() {
return tuoi;
}
public void setTuoi(int tuoi) {
this.tuoi = tuoi;
}
public long getLuongCB() {
return luongCB;
}
public void setLuongCB(long luongCB) {
this.luongCB = luongCB;
}
public static String formatMoney(long money) {
DecimalFormat formatter = new DecimalFormat("###,###,##0.00");
//100000->100,000.00
return formatter.format(money);
}
public NhanVien() {
}
public NhanVien(String maNv, String hoTen, int tuoi, String sdt, String email, long luongCB) {
this.maNv = maNv;
this.hoTen = hoTen;
this.email = email;
this.sdt = sdt;
this.tuoi = tuoi;
this.luongCB = luongCB;
}
public void input() {
Scanner sc = new Scanner(System.in);
System.out.println("nhập mã nhân viên: ");
maNv = sc.nextLine();
System.out.println("nhập họ tên nhân viên: ");
hoTen = sc.nextLine();
System.out.println("nhập tuổi của nhân viên: ");
tuoi = Integer.valueOf(sc.nextLine());
System.out.println("nhập số điện thoại của nhân viên: ");
sdt = sc.nextLine();
System.out.println("nhập email của nhân viên: ");
email = sc.nextLine();
System.out.println("nhập lương cơ bản của nhân viên: ");
luongCB = Long.valueOf(sc.nextLine());
}
public void show() {
System.out.println("Mã nhân viên: " + maNv);
System.out.println("Họ Tên: " + hoTen);
System.out.println("Tuổi: " + tuoi);
System.out.println("Số điện thoại: " + sdt);
System.out.println("email :" + email);
System.out.println("Lương cơ bản: " + formatMoney(luongCB));
}
}
| 83f3135eca51fffba43d0b7cda4ea98ed606ee6a | [
"Java",
"HTML"
] | 20 | Java | c293-gif/web-java5 | 7051c95a23606fb2414bbc381eeffadd17f5d046 | 832c1ec4cba271ca33694674d8429ea0350d4926 |
refs/heads/master | <file_sep>package com.ubs.opsit.interviews;
public enum TimeConstants {
Y,O,R,YYY,YYR
}
| e865b77fbf79df97a1ca69870621b8cc78384099 | [
"Java"
] | 1 | Java | tlaad/ubstest-tlaad | e0e7ba182d92bbba24bfeeb05d665ee234b31b48 | 8743b4e1933d80151a0123c79b85f640dc0a3af6 |
refs/heads/main | <repo_name>TrangPham99/Frond-End-Pre-Test<file_sep>/styles.js
$('.slides').slick({
slidesToShow: 1,
slidesToScroll: 1,
autoplay:true,
autoplaySpeed: 5000
}); | 5830306871c1773a77e5b509ca0650964e8b991d | [
"JavaScript"
] | 1 | JavaScript | TrangPham99/Frond-End-Pre-Test | 494647c8ec5da5e306211e5acc4f9aea871211e8 | 6337558fe03b63830da63656e8f39acafe4f923f |
refs/heads/master | <repo_name>Tomraydev/Portfolio<file_sep>/js/map.js
function initMap() {
var krakow = {lat: 50.0647, lng: 19.9450};
var map = new google.maps.Map(document.getElementById('map'), {
zoom: 11,
center: krakow,
disableDefaultUI: true,
styles: [
{
"featureType": "administrative",
"elementType": "labels.text",
"stylers": [
{
"color": "#126085"
}
]
},
{
"featureType": "administrative",
"elementType": "labels.text.fill",
"stylers": [
{
"color": "#1ea0df"
}
]
},
{
"featureType": "administrative",
"elementType": "labels.text.stroke",
"stylers": [
{
"color": "#0c4058"
}
]
},
{
"featureType": "landscape",
"stylers": [
{
"color": "#4b4b4b"
}
]
},
{
"featureType": "poi",
"elementType": "geometry",
"stylers": [
{
"visibility": "off"
}
]
},
{
"featureType": "poi",
"elementType": "labels",
"stylers": [
{
"visibility": "off"
}
]
},
{
"featureType": "road",
"stylers": [
{
"color": "#a3a3a3"
}
]
},
{
"featureType": "road",
"elementType": "labels",
"stylers": [
{
"visibility": "off"
}
]
},
{
"featureType": "transit",
"stylers": [
{
"visibility": "off"
}
]
}
] /* End of custom map styles */
});
var marker = new google.maps.Marker({
icon: 'http://maps.google.com/mapfiles/ms/micons/blue-dot.png',
position: krakow,
map: map
});
}
| 6612466005bc13e4217d27beb58e11075ea7026e | [
"JavaScript"
] | 1 | JavaScript | Tomraydev/Portfolio | c7818446e2f08b8cd75c4f8b43c7ef1d881a7d50 | 5bde1a258c51ba8a673259c1b443f49d27307377 |
refs/heads/master | <repo_name>saucisson/lua-resty-shell<file_sep>/lua-resty-shell-scm-1.rockspec
package = "lua-resty-shell"
version = "scm-1"
source = {
url = "git+https://github.com/juce/lua-resty-shell.git",
}
description = {
summary = "Tiny subprocess/shell library to use with OpenResty application server.",
detailed = "",
homepage = "https://github.com/juce/lua-resty-shell",
license = "MIT",
}
dependencies = {
"lua >= 5.1",
}
build = {
type = "command",
build_command = [[
git submodule init \
&& git submodule update \
&& cd sockproc \
&& git checkout master \
&& git pull \
&& make
]],
install = {
lua = {
["resty.shell"] = "lib/resty/shell.lua",
},
bin = {
["sockproc"] = "sockproc/sockproc",
}
},
}
| 7d3027b8eff682b6ca459e1a5dbf4f50117628e1 | [
"Lua"
] | 1 | Lua | saucisson/lua-resty-shell | 2f5ff43a1f4d65c237a07b63c96312768a7f1e35 | 7325b353ce21290713fc15db9f34a1facbfcdebe |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.