
branch_name stringclasses 149 values | text stringlengths 23 89.3M | directory_id stringlengths 40 40 | languages listlengths 1 19 | num_files int64 1 11.8k | repo_language stringclasses 38 values | repo_name stringlengths 6 114 | revision_id stringlengths 40 40 | snapshot_id stringlengths 40 40 |
|---|---|---|---|---|---|---|---|---|
refs/heads/master | <file_sep># <NAME> <<EMAIL>>
#
# Simulate data observed by an interferometer
import numpy
def rot(p, ha, dec):
"""
Rotate x,y,z in earth coordinates to u,v,w relative to direction
defined by ha and dec
p: array of antenna positions
"""
x,y,z=numpy.hsplit(p,3)
t=x*numpy.cos(ha) - y*numpy.sin(ha)
u=x*numpy.sin(ha) + y*numpy.cos(ha)
v=t*numpy.sin(dec)+ z*numpy.cos(dec)
w=t*numpy.cos(dec)+ z*numpy.sin(dec)
return numpy.hstack([u,v,w])
def bls(p):
"""
Compute baseline uvws from station uvw
"""
res=[]
for i in range(p.shape[0]):
for j in range(i+1, p.shape[0]):
res.append(p[i]-p[j])
return numpy.array(res)
def genuv(p, ha, dec):
return(numpy.concatenate([bls(rot(p,hax,dec)) for hax in ha]))
def genvis(p, l, m):
"Simulate visibilities for point source at (l,m)"
s=numpy.array([l, m , numpy.sqrt(1 - l**2 - m**2)])
return numpy.exp(-2j*numpy.pi* numpy.dot(p, s))
| caba8e04590e8edffc98e2d4dccdd01505965e0a | [
"Python"
] | 1 | Python | juandesant/crocodile | 310868ba524b52048b54144368939cd73e3158ed | 1b9d797f21dd9acc17bfed2807e5d0926157d613 |
refs/heads/master | <repo_name>lxh1765492163/studyTest<file_sep>/src/index.js
import './scss/index.scss'
const a = 1
console.log(a)
<file_sep>/README.md
### 为什么打造前端工作流
事实上 , 现在很多的编辑器都有可以做代码检查的插件 , 这个对于开发者个人来说足够了, 但是对于一个开发团队来说略显不足
代码里面的一些坏味道不能得到规范 ,从而降低了代码质量
git hooks的作用就是用来做代码提交时候的一道检查
### eslint
代码质量扫描(未使用变量 , 三等号, 全局变量声明等),一定注意全局安装
### prettier
代码格式校验(单行长度, tab长度, 空格)团队代码风格统一,
prettier目前支持前端大部分的语言处理 ,包括js ts css scss less jsx vue json md等 , 几乎用一个工具搞定所有代码的格式问题
### eslint, prettier结合使用
这简书讲解eslint prettier可以 https://www.jianshu.com/p/dd07cca0a48e
###### 配合使用原因
eslint的规则不如prettier健全, 对于自动修复代码格式推荐使用prettier --write
###### 配合使用存在问题
1. 两者规则出现交集 , 去掉eslint规则 , 使用prettier 规则
eslint-plugin-prettier:将prettier规则作为eslint规则 , 对不符合规则的调用prettier进行提示
eslint-config-prettier: 关闭eslint一些与prettier冲突的规则 ,那样一些错误不会出现两次
官方称eslint-plugin-prettier需要与eslint-config-prettier搭配食用才能获得最佳效果。
### husky
git 钩子插件, 配合npm script的钩子依赖插件husky
本地钩子 precommit prepush
远程仓库钩子prereceive...
为什么添加远程钩子 , git在commit的时候是可以跳过本地的钩子的 --no-verify | -n
### lint-staged
专门做扫描优化 , 只针对git 暂存区的文件进行代码扫描
在package.json 中lint-staged不管是js还是scss在修复代码格式的时候都是用的prettier --write , !!!prettier的参数还没有细看暂时不管
```
"lint-staged": {
"src/**/*.{js,scss}": [
"prettier --write",
"git add"
]
}
```
之前一直以为js的代码格式修复用eslint --fix
```
"lint-staged": {
"src/**/*.{js}": [
"prettier --write",
"eslint --fix",
"git add"
]
}
```
css|scss文件使用stylelint --fix
```
"lint-staged": {
...
"src/**/*.{css|scss}": [
"stylelient",
"git add"
]
}
```
控制台就一直会报错 , 这个错
```
→
× "stylelint" found some errors. Please fix them and try committing again.
Error: No files matching the pattern "F:\studyAndRemote\study_git_hooks\src\scss\index.scss" were found
```
最后发现create-reate-app新版本也加上了eslint prettier lint-staged, 参照了人家的package.js发现代码格式的修复就用了prettier, 上面提到
prettier支持大部分前端语言的规范以及格式修复
### error Parsing error: Unexpected token
解决方法
npm install babel-eslint --save
然后在 .eslintrc.js 中加入代码解析"parser": "babel-eslint"
| b0a13a5df5c5f57f00b5c2625469f9efdf7ba950 | [
"JavaScript",
"Markdown"
] | 2 | JavaScript | lxh1765492163/studyTest | 856fb59bc904a2d8d5dfaedf6299ec409ea38c58 | 4d53c312b2c046ec5e19ae5b3a8dbd5b7e57da02 |
refs/heads/master | <file_sep>/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package principal;
import controller.AlumnoController;
import controller.CursoController;
import controller.FamiliaController;
import controller.ProfesorController;
import controller.MatriculaController;
import java.sql.SQLException;
import model.Familia;
import model.Alumno;
import model.Curso;
import model.Matricula;
import model.Profesor;
public class Principal {
public static void main(String[] args) throws SQLException {
// TODO code application logic here
Familia familia1 = new Familia("Frio");
Familia familia2 = new Familia("Informatica");
FamiliaController familia_controller = new FamiliaController();
//familia_controller.insert(familia1);
//familia_controller.insert(familia2);
//familia_controller.getAllFamilia();
//familia_controller.getFamiliaById(2);
//familia_controller.update_nombre(2, "Informatica");
//familia_controller.getAllFamilia();
//familia_controller.delete(2);
//familia_controller.getAllFamilia();
Profesor profe1 = new Profesor("11111111Z", "Alberto", "Medina", "Faro, 22", "<EMAIL>", "911223344");
Profesor profe2 = new Profesor("22222222Y", "Maria", "Torres", "Acero, 3", "<EMAIL>", "911223311");
ProfesorController profe_controller = new ProfesorController();
//profe_controller.insert(profe1);
//profe_controller.insert(profe2);
//profe_controller.getAllProfesores();
//profe_controller.getProfesorByDni("11111111Z");
//profe_controller.update_email("11111111Z", "<EMAIL>");
//profe_controller.getAllProfesores();
//profe_controller.delete("11111111Y");
//profe_controller.getAllProfesores();
Curso curso1 = new Curso("Sistemas Microinformaticos", 2, "22222222Y");
Curso curso2 = new Curso("Mantenimiento de Inst de frio", 1, "11111111Z");
CursoController curso_controller = new CursoController();
//curso_controller.insert(curso1);
//curso_controller.insert(curso2);
//curso_controller.getAllCursos();
//curso_controller.getAllCursosAvanzado();
//curso_controller.getCursoById(1);
//familia_controller.delete(1);
//curso_controller.getAllCursos();
//familia_controller.getAllFamilia();
//curso_controller.update_nombre(1, "Administracion de redes");
//curso_controller.getAllCursosAvanzado();
//curso_controller.delete(2);
//curso_controller.getAllCursos();
Alumno alumno1 = new Alumno("11111111A", "Alberto", "Medina", "Faro, 22", "<EMAIL>", "911223344");
Alumno alumno2 = new Alumno("11111111B", "Maria", "Torres", "Acero, 3", "<EMAIL>", "911223311");
AlumnoController alumno_controller = new AlumnoController();
//alumno_controller.insert(alumno1);
//alumno_controller.insert(alumno2);
//alumno_controller.getAllAlumnos();
//alumno_controller.getAlumnoByDni("11111111A");
//alumno_controller.update_email("11111111A", "<EMAIL>");
//alumno_controller.getAllAlumnos();
//alumno_controller.delete("11111111B");
//alumno_controller.getAllAlumnos();
Matricula matricula1 = new Matricula("11111111A", 1);
MatriculaController matricula_controller = new MatriculaController();
//matricula_controller.insert(matricula1);
//matricula_controller.getAllMatriculas();
//matricula_controller.cambiar_curso("11111111A", 1, 2);
//matricula_controller.delete("11111111A", 2);
}
}
<file_sep>-- phpMyAdmin SQL Dump
-- version 4.7.4
-- https://www.phpmyadmin.net/
--
-- Servidor: 127.0.0.1
-- Tiempo de generación: 05-05-2018 a las 20:53:22
-- Versión del servidor: 10.1.28-MariaDB
-- Versión de PHP: 7.1.11
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET AUTOCOMMIT = 0;
START TRANSACTION;
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8mb4 */;
--
-- Base de datos: `academia`
--
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `alumno`
--
CREATE TABLE `alumno` (
`dni_alumno` varchar(9) COLLATE utf8_spanish_ci NOT NULL,
`nombre_alumno` varchar(50) COLLATE utf8_spanish_ci NOT NULL,
`apellidos_alumno` varchar(50) COLLATE utf8_spanish_ci NOT NULL,
`direccion_alumno` varchar(50) COLLATE utf8_spanish_ci NOT NULL,
`email_alumno` varchar(50) COLLATE utf8_spanish_ci NOT NULL,
`telefono_alumno` varchar(9) COLLATE utf8_spanish_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_spanish_ci;
--
-- Volcado de datos para la tabla `alumno`
--
INSERT INTO `alumno` (`dni_alumno`, `nombre_alumno`, `apellidos_alumno`, `direccion_alumno`, `email_alumno`, `telefono_alumno`) VALUES
('11111111A', 'Alberto', 'Medina', '<NAME>', '<EMAIL>', '911223344');
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `curso`
--
CREATE TABLE `curso` (
`id_curso` int(4) NOT NULL,
`nombre_curso` varchar(50) COLLATE utf8_spanish_ci NOT NULL,
`id_familia` int(4) NOT NULL,
`id_profesor` varchar(9) COLLATE utf8_spanish_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_spanish_ci;
--
-- Volcado de datos para la tabla `curso`
--
INSERT INTO `curso` (`id_curso`, `nombre_curso`, `id_familia`, `id_profesor`) VALUES
(1, 'Administracion de redes', 2, '11111111Z'),
(2, 'Redes', 2, '11111111Z');
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `familia`
--
CREATE TABLE `familia` (
`id_familia` int(4) NOT NULL,
`nombre_familia` varchar(50) COLLATE utf8_spanish_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_spanish_ci;
--
-- Volcado de datos para la tabla `familia`
--
INSERT INTO `familia` (`id_familia`, `nombre_familia`) VALUES
(2, 'Informatica');
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `matricula`
--
CREATE TABLE `matricula` (
`id_alumno` varchar(9) COLLATE utf8_spanish_ci NOT NULL,
`id_curso` int(4) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_spanish_ci;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `profesor`
--
CREATE TABLE `profesor` (
`dni_profesor` varchar(9) COLLATE utf8_spanish_ci NOT NULL,
`nombre_profesor` varchar(50) COLLATE utf8_spanish_ci NOT NULL,
`apellidos_profesor` varchar(50) COLLATE utf8_spanish_ci NOT NULL,
`direccion_profesor` varchar(50) COLLATE utf8_spanish_ci NOT NULL,
`email_profesor` varchar(50) COLLATE utf8_spanish_ci NOT NULL,
`telefono_profesor` varchar(9) COLLATE utf8_spanish_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_spanish_ci;
--
-- Volcado de datos para la tabla `profesor`
--
INSERT INTO `profesor` (`dni_profesor`, `nombre_profesor`, `apellidos_profesor`, `direccion_profesor`, `email_profesor`, `telefono_profesor`) VALUES
('11111111Z', 'Alberto', 'Medina', 'Faro, 22', '<EMAIL>', '911223344');
--
-- Índices para tablas volcadas
--
--
-- Indices de la tabla `alumno`
--
ALTER TABLE `alumno`
ADD PRIMARY KEY (`dni_alumno`);
--
-- Indices de la tabla `curso`
--
ALTER TABLE `curso`
ADD PRIMARY KEY (`id_curso`),
ADD KEY `FK_curso_familia` (`id_familia`),
ADD KEY `FK_curso profesor` (`id_profesor`),
ADD KEY `id_familia` (`id_familia`);
--
-- Indices de la tabla `familia`
--
ALTER TABLE `familia`
ADD PRIMARY KEY (`id_familia`);
--
-- Indices de la tabla `matricula`
--
ALTER TABLE `matricula`
ADD PRIMARY KEY (`id_alumno`,`id_curso`),
ADD KEY `FK_matricula_curso` (`id_curso`);
--
-- Indices de la tabla `profesor`
--
ALTER TABLE `profesor`
ADD PRIMARY KEY (`dni_profesor`);
--
-- AUTO_INCREMENT de las tablas volcadas
--
--
-- AUTO_INCREMENT de la tabla `curso`
--
ALTER TABLE `curso`
MODIFY `id_curso` int(4) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=5;
--
-- AUTO_INCREMENT de la tabla `familia`
--
ALTER TABLE `familia`
MODIFY `id_familia` int(4) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=3;
--
-- Restricciones para tablas volcadas
--
--
-- Filtros para la tabla `curso`
--
ALTER TABLE `curso`
ADD CONSTRAINT `FK_curso profesor` FOREIGN KEY (`id_profesor`) REFERENCES `profesor` (`dni_profesor`) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT `FK_curso_familia` FOREIGN KEY (`id_familia`) REFERENCES `familia` (`id_familia`) ON DELETE CASCADE ON UPDATE CASCADE;
--
-- Filtros para la tabla `matricula`
--
ALTER TABLE `matricula`
ADD CONSTRAINT `FK_matricula_alumno` FOREIGN KEY (`id_alumno`) REFERENCES `alumno` (`dni_alumno`) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT `FK_matricula_curso` FOREIGN KEY (`id_curso`) REFERENCES `curso` (`id_curso`) ON DELETE CASCADE ON UPDATE CASCADE;
COMMIT;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
<file_sep>/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package controller;
import conexion.Conexion;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import model.Curso;
public class CursoController {
//insertar datos en la tabla curso
public void insert(Curso curso) throws SQLException {
String query = "";
Conexion db = new Conexion();
query = "INSERT INTO curso VALUES (NULL,?,?,?);";
PreparedStatement ps = db.conectar().prepareStatement(query);
//Aquí se asignaran a los interrogantes(?) anteriores el valor oportuno en el orden adecuado
ps.setString(1, curso.getNombre());
ps.setInt(2, curso.getFamilia());
ps.setString(3, curso.getProfesor());
if (ps.executeUpdate() > 0) {
System.out.println("El registro se insertó exitosamente.");
} else {
System.out.println("No se pudo insertar el registro.");
}
ps.close();
db.conexion.close();
}
//obtener el curso con el id específico
public void getCursoById(int id) {
String query = "";
Conexion db = new Conexion();
try {
query = "SELECT * FROM curso WHERE id_curso = ?;";
PreparedStatement ps = db.conectar().prepareStatement(query);
ps.setInt(1, id);
ResultSet rs = ps.executeQuery();
while (rs.next()) {
String nombre = rs.getString("nombre_curso");
int familia = rs.getInt("id_familia");
String profesor = rs.getString("id_profesor");
// Imprimir los resultados.
System.out.format("%s,%d,%s\n", nombre, familia, profesor);
}
ps.close();
db.conexion.close();
} catch (SQLException e) {
System.out.println(e.getMessage());
}
}
//obtener todos los cursos
public void getAllCursos() {
String query = "";
Conexion db = new Conexion();
try {
query = "SELECT * FROM curso;";
Statement stm = db.conectar().createStatement();
ResultSet rs = stm.executeQuery(query);
while (rs.next()) {
int id = rs.getInt("id_curso");
String nombre = rs.getString("nombre_curso");
int familia = rs.getInt("id_familia");
String profesor = rs.getString("id_profesor");
// Imprimir los resultados.
System.out.format("%d,%s,%d,%s\n", id, nombre, familia, profesor);
}
stm.close();
db.conexion.close();
} catch (SQLException e) {
System.out.println(e.getMessage());
}
}
//obtener todos los cursos mostrando el nombre de la familia en lugar de su id.
public void getAllCursosAvanzado() {
String query = "";
Conexion db = new Conexion();
try {
query = "SELECT id_curso, nombre_curso, familia.nombre_familia as familia, id_profesor FROM curso "
+ "INNER JOIN familia ON curso.id_familia = familia.id_familia;";
Statement stm = db.conectar().createStatement();
ResultSet rs = stm.executeQuery(query);
while (rs.next()) {
int id = rs.getInt("id_curso");
String nombre = rs.getString("nombre_curso");
String familia = rs.getString("familia");
String profesor = rs.getString("id_profesor");
// Imprimir los resultados.
System.out.format("%d,%s,%s,%s\n", id, nombre, familia, profesor);
}
stm.close();
db.conexion.close();
} catch (SQLException e) {
System.out.println(e.getMessage());
}
}
//actualizar el nombre del curso
public void update_nombre(int id, String str) {
String query = "";
Conexion bd = new Conexion();
try {
query = "UPDATE curso SET nombre_curso = ? WHERE id_curso = ?;";
PreparedStatement ps = bd.conectar().prepareStatement(query);
ps.setString(1, str);
ps.setInt(2, id);
ps.executeUpdate();
System.out.println("El registro se actualizó exitosamente.");
ps.close();
bd.conexion.close();
} catch (SQLException e) {
System.out.println(e.getMessage());
}
}
//eliminar un curso
public void delete(int id) {
String query = "";
Conexion db = new Conexion();
try {
query = "DELETE FROM curso WHERE id_curso = ?;";
PreparedStatement ps = db.conectar().prepareStatement(query);
ps.setInt(1, id);
ps.execute();
System.out.println("El registro se eliminó exitosamente.");
ps.close();
db.conexion.close();
} catch (SQLException e) {
System.out.println(e.getMessage());
}
}
}
<file_sep>/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package model;
public class Curso {
private int id;
private String nombre;
private int familia;
private String profesor;
public Curso(String nombre, int familia, String profesor) {
this.nombre = nombre;
this.familia = familia;
this.profesor = profesor;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getNombre() {
return nombre;
}
public void setNombre(String nombre) {
this.nombre = nombre;
}
public int getFamilia() {
return familia;
}
public void setFamilia(int familia) {
this.familia = familia;
}
public String getProfesor() {
return profesor;
}
public void setProfesor(String profesor) {
this.profesor = profesor;
}
}
<file_sep>/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package conexion;
import com.mysql.jdbc.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class Conexion {
private final String URL = "jdbc:mysql://localhost:3306/"; // Ubicación de la BD.
private final String BD = "academia"; // Nombre de la BD.
private final String USER = "root";
private final String PASSWORD = "<PASSWORD>";
public Connection conexion = null;
@SuppressWarnings("conectando")
public Connection conectar() throws SQLException {
try {
Class.forName("com.mysql.jdbc.Driver");
conexion = (Connection) DriverManager.getConnection(URL + BD, USER, PASSWORD);
if (conexion != null) {
System.out.println("¡Conexión Exitosa!");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
return conexion;
}
}
}
| b821950062470bb643c77798b621172a8ef54e2b | [
"Java",
"SQL"
] | 5 | Java | SuperK92/CRUD_Academia_JDBC | 549ba54bd279cafcee6df8571d249930caca4a0b | ab03af25d2e5d579ecc1541c0486eaefa8f8abd4 |
refs/heads/master | <file_sep>var diam1 = 0;
var diam2 = 300;
var diam3 = 0;
var diam4 = 500;
function setup() {
// put setup code here
createCanvas(500, 500);
}
function draw() {
// put drawing code here
background("black");
fill("blue");
stroke("green");
strokeWeight(10);
ellipse(diam3, diam4,diam2,diam2);
fill("red");
stroke("red");
ellipse(mouseX,mouseY,diam1,diam1);
fill("red");
stroke("black");
textSize(40);
textFont("chiller");
textStyle(ITALIC);
textAlign(CENTER);
text("CODE RED!", 100, 50);
}
function mousePressed() {
if(diam1>400){
diam3 = 0;
diam4 = 0;
diam2 = 0;
diam1 = 800;
}else{
diam1=diam1+30;
}
} | a368e6314ec8d54b0f06685a1148d100e5b18c84 | [
"JavaScript"
] | 1 | JavaScript | Lufire08/earth | 04cbaa83e330366f5f4980e9d2b959ef36275cf2 | 96e560cc6971250d463660660286595427266036 |
refs/heads/master | <repo_name>SL-RU/osfi-p<file_sep>/core_src/Inc/main.h
/* USER CODE BEGIN Header */
/**
******************************************************************************
* @file : main.h
* @brief : Header for main.c file.
* This file contains the common defines of the application.
******************************************************************************
* @attention
*
* <h2><center>© Copyright (c) 2019 STMicroelectronics.
* All rights reserved.</center></h2>
*
* This software component is licensed by ST under Ultimate Liberty license
* SLA0044, the "License"; You may not use this file except in compliance with
* the License. You may obtain a copy of the License at:
* www.st.com/SLA0044
*
******************************************************************************
*/
/* USER CODE END Header */
/* Define to prevent recursive inclusion -------------------------------------*/
#ifndef __MAIN_H
#define __MAIN_H
#ifdef __cplusplus
extern "C" {
#endif
/* Includes ------------------------------------------------------------------*/
#include "stm32f4xx_hal.h"
#include "stm32f4xx_hal.h"
/* Private includes ----------------------------------------------------------*/
/* USER CODE BEGIN Includes */
/* USER CODE END Includes */
/* Exported types ------------------------------------------------------------*/
/* USER CODE BEGIN ET */
/* USER CODE END ET */
/* Exported constants --------------------------------------------------------*/
/* USER CODE BEGIN EC */
/* USER CODE END EC */
/* Exported macro ------------------------------------------------------------*/
/* USER CODE BEGIN EM */
/* USER CODE END EM */
/* Exported functions prototypes ---------------------------------------------*/
void Error_Handler(void);
/* USER CODE BEGIN EFP */
/* USER CODE END EFP */
/* Private defines -----------------------------------------------------------*/
#define AS_SCK_Pin GPIO_PIN_2
#define AS_SCK_GPIO_Port GPIOE
#define AG_0_Pin GPIO_PIN_3
#define AG_0_GPIO_Port GPIOE
#define AG_1_Pin GPIO_PIN_4
#define AG_1_GPIO_Port GPIOE
#define AS_MISO_Pin GPIO_PIN_5
#define AS_MISO_GPIO_Port GPIOE
#define AS_MOSI_Pin GPIO_PIN_6
#define AS_MOSI_GPIO_Port GPIOE
#define CRYST_2_Pin GPIO_PIN_0
#define CRYST_2_GPIO_Port GPIOC
#define A_SD_Pin GPIO_PIN_3
#define A_SD_GPIO_Port GPIOC
#define CRYST_1_Pin GPIO_PIN_3
#define CRYST_1_GPIO_Port GPIOA
#define C1_Pin GPIO_PIN_6
#define C1_GPIO_Port GPIOA
#define C2_Pin GPIO_PIN_7
#define C2_GPIO_Port GPIOA
#define C3_Pin GPIO_PIN_4
#define C3_GPIO_Port GPIOC
#define C4_Pin GPIO_PIN_5
#define C4_GPIO_Port GPIOC
#define C5_Pin GPIO_PIN_0
#define C5_GPIO_Port GPIOB
#define C6_Pin GPIO_PIN_1
#define C6_GPIO_Port GPIOB
#define BAT_INT_Pin GPIO_PIN_13
#define BAT_INT_GPIO_Port GPIOE
#define BAT_CE_Pin GPIO_PIN_14
#define BAT_CE_GPIO_Port GPIOE
#define BAT_PG_Pin GPIO_PIN_15
#define BAT_PG_GPIO_Port GPIOE
#define BAT_SCL_Pin GPIO_PIN_10
#define BAT_SCL_GPIO_Port GPIOB
#define BAT_SDA_Pin GPIO_PIN_11
#define BAT_SDA_GPIO_Port GPIOB
#define A_WS_Pin GPIO_PIN_12
#define A_WS_GPIO_Port GPIOB
#define A_SCK_Pin GPIO_PIN_13
#define A_SCK_GPIO_Port GPIOB
#define AG_2_Pin GPIO_PIN_3
#define AG_2_GPIO_Port GPIOD
#define AG_3_Pin GPIO_PIN_4
#define AG_3_GPIO_Port GPIOD
#define AG_4_Pin GPIO_PIN_5
#define AG_4_GPIO_Port GPIOD
#define L_MOSI_Pin GPIO_PIN_6
#define L_MOSI_GPIO_Port GPIOD
#define L_SCK_Pin GPIO_PIN_3
#define L_SCK_GPIO_Port GPIOB
#define L_MISO_Pin GPIO_PIN_4
#define L_MISO_GPIO_Port GPIOB
#define AC_SCL_Pin GPIO_PIN_6
#define AC_SCL_GPIO_Port GPIOB
#define AC_SDA_Pin GPIO_PIN_7
#define AC_SDA_GPIO_Port GPIOB
#define L_CS_Pin GPIO_PIN_8
#define L_CS_GPIO_Port GPIOB
#define L_DC_Pin GPIO_PIN_9
#define L_DC_GPIO_Port GPIOB
#define L_RST_Pin GPIO_PIN_0
#define L_RST_GPIO_Port GPIOE
#define L_LED_Pin GPIO_PIN_1
#define L_LED_GPIO_Port GPIOE
/* USER CODE BEGIN Private defines */
/* USER CODE END Private defines */
#ifdef __cplusplus
}
#endif
#endif /* __MAIN_H */
/************************ (C) COPYRIGHT STMicroelectronics *****END OF FILE****/
<file_sep>/core_src/build/Makefile
# CMAKE generated file: DO NOT EDIT!
# Generated by "Unix Makefiles" Generator, CMake Version 3.13
# Default target executed when no arguments are given to make.
default_target: all
.PHONY : default_target
# Allow only one "make -f Makefile2" at a time, but pass parallelism.
.NOTPARALLEL:
#=============================================================================
# Special targets provided by cmake.
# Disable implicit rules so canonical targets will work.
.SUFFIXES:
# Remove some rules from gmake that .SUFFIXES does not remove.
SUFFIXES =
.SUFFIXES: .hpux_make_needs_suffix_list
# Suppress display of executed commands.
$(VERBOSE).SILENT:
# A target that is always out of date.
cmake_force:
.PHONY : cmake_force
#=============================================================================
# Set environment variables for the build.
# The shell in which to execute make rules.
SHELL = /bin/sh
# The CMake executable.
CMAKE_COMMAND = /usr/bin/cmake
# The command to remove a file.
RM = /usr/bin/cmake -E remove -f
# Escaping for special characters.
EQUALS = =
# The top-level source directory on which CMake was run.
CMAKE_SOURCE_DIR = /mnt/doc/prj/osfi-p/core_src
# The top-level build directory on which CMake was run.
CMAKE_BINARY_DIR = /mnt/doc/prj/osfi-p/core_src/build
#=============================================================================
# Targets provided globally by CMake.
# Special rule for the target rebuild_cache
rebuild_cache:
@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --cyan "Running CMake to regenerate build system..."
/usr/bin/cmake -S$(CMAKE_SOURCE_DIR) -B$(CMAKE_BINARY_DIR)
.PHONY : rebuild_cache
# Special rule for the target rebuild_cache
rebuild_cache/fast: rebuild_cache
.PHONY : rebuild_cache/fast
# Special rule for the target edit_cache
edit_cache:
@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --cyan "Running CMake cache editor..."
/usr/bin/ccmake -S$(CMAKE_SOURCE_DIR) -B$(CMAKE_BINARY_DIR)
.PHONY : edit_cache
# Special rule for the target edit_cache
edit_cache/fast: edit_cache
.PHONY : edit_cache/fast
# The main all target
all: cmake_check_build_system
$(CMAKE_COMMAND) -E cmake_progress_start /mnt/doc/prj/osfi-p/core_src/build/CMakeFiles /mnt/doc/prj/osfi-p/core_src/build/CMakeFiles/progress.marks
$(MAKE) -f CMakeFiles/Makefile2 all
$(CMAKE_COMMAND) -E cmake_progress_start /mnt/doc/prj/osfi-p/core_src/build/CMakeFiles 0
.PHONY : all
# The main clean target
clean:
$(MAKE) -f CMakeFiles/Makefile2 clean
.PHONY : clean
# The main clean target
clean/fast: clean
.PHONY : clean/fast
# Prepare targets for installation.
preinstall: all
$(MAKE) -f CMakeFiles/Makefile2 preinstall
.PHONY : preinstall
# Prepare targets for installation.
preinstall/fast:
$(MAKE) -f CMakeFiles/Makefile2 preinstall
.PHONY : preinstall/fast
# clear depends
depend:
$(CMAKE_COMMAND) -S$(CMAKE_SOURCE_DIR) -B$(CMAKE_BINARY_DIR) --check-build-system CMakeFiles/Makefile.cmake 1
.PHONY : depend
#=============================================================================
# Target rules for targets named core_src.bin
# Build rule for target.
core_src.bin: cmake_check_build_system
$(MAKE) -f CMakeFiles/Makefile2 core_src.bin
.PHONY : core_src.bin
# fast build rule for target.
core_src.bin/fast:
$(MAKE) -f CMakeFiles/core_src.bin.dir/build.make CMakeFiles/core_src.bin.dir/build
.PHONY : core_src.bin/fast
#=============================================================================
# Target rules for targets named core_src.elf
# Build rule for target.
core_src.elf: cmake_check_build_system
$(MAKE) -f CMakeFiles/Makefile2 core_src.elf
.PHONY : core_src.elf
# fast build rule for target.
core_src.elf/fast:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/build
.PHONY : core_src.elf/fast
#=============================================================================
# Target rules for targets named core_src.hex
# Build rule for target.
core_src.hex: cmake_check_build_system
$(MAKE) -f CMakeFiles/Makefile2 core_src.hex
.PHONY : core_src.hex
# fast build rule for target.
core_src.hex/fast:
$(MAKE) -f CMakeFiles/core_src.hex.dir/build.make CMakeFiles/core_src.hex.dir/build
.PHONY : core_src.hex/fast
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.s
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.o: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.o
# target to build an object file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.o
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.o
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.i: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.i
# target to preprocess a source file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.i
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.i
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.s: Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.s
# target to generate assembly for a file
Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.s
.PHONY : Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.s
ILI9341/ili9341.o: ILI9341/ili9341.c.o
.PHONY : ILI9341/ili9341.o
# target to build an object file
ILI9341/ili9341.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/ILI9341/ili9341.c.o
.PHONY : ILI9341/ili9341.c.o
ILI9341/ili9341.i: ILI9341/ili9341.c.i
.PHONY : ILI9341/ili9341.i
# target to preprocess a source file
ILI9341/ili9341.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/ILI9341/ili9341.c.i
.PHONY : ILI9341/ili9341.c.i
ILI9341/ili9341.s: ILI9341/ili9341.c.s
.PHONY : ILI9341/ili9341.s
# target to generate assembly for a file
ILI9341/ili9341.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/ILI9341/ili9341.c.s
.PHONY : ILI9341/ili9341.c.s
MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.o: MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.o
.PHONY : MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.o
# target to build an object file
MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.o
.PHONY : MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.o
MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.i: MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.i
.PHONY : MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.i
.PHONY : MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.i
MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.s: MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.s
.PHONY : MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.s
.PHONY : MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.s
MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.o: MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.o
.PHONY : MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.o
# target to build an object file
MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.o
.PHONY : MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.o
MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.i: MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.i
.PHONY : MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.i
.PHONY : MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.i
MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.s: MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.s
.PHONY : MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.s
.PHONY : MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.s
MakiseGUI/MakiseGUI/fonts/Default10x20.o: MakiseGUI/MakiseGUI/fonts/Default10x20.c.o
.PHONY : MakiseGUI/MakiseGUI/fonts/Default10x20.o
# target to build an object file
MakiseGUI/MakiseGUI/fonts/Default10x20.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default10x20.c.o
.PHONY : MakiseGUI/MakiseGUI/fonts/Default10x20.c.o
MakiseGUI/MakiseGUI/fonts/Default10x20.i: MakiseGUI/MakiseGUI/fonts/Default10x20.c.i
.PHONY : MakiseGUI/MakiseGUI/fonts/Default10x20.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/fonts/Default10x20.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default10x20.c.i
.PHONY : MakiseGUI/MakiseGUI/fonts/Default10x20.c.i
MakiseGUI/MakiseGUI/fonts/Default10x20.s: MakiseGUI/MakiseGUI/fonts/Default10x20.c.s
.PHONY : MakiseGUI/MakiseGUI/fonts/Default10x20.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/fonts/Default10x20.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default10x20.c.s
.PHONY : MakiseGUI/MakiseGUI/fonts/Default10x20.c.s
MakiseGUI/MakiseGUI/fonts/Default5x7.o: MakiseGUI/MakiseGUI/fonts/Default5x7.c.o
.PHONY : MakiseGUI/MakiseGUI/fonts/Default5x7.o
# target to build an object file
MakiseGUI/MakiseGUI/fonts/Default5x7.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default5x7.c.o
.PHONY : MakiseGUI/MakiseGUI/fonts/Default5x7.c.o
MakiseGUI/MakiseGUI/fonts/Default5x7.i: MakiseGUI/MakiseGUI/fonts/Default5x7.c.i
.PHONY : MakiseGUI/MakiseGUI/fonts/Default5x7.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/fonts/Default5x7.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default5x7.c.i
.PHONY : MakiseGUI/MakiseGUI/fonts/Default5x7.c.i
MakiseGUI/MakiseGUI/fonts/Default5x7.s: MakiseGUI/MakiseGUI/fonts/Default5x7.c.s
.PHONY : MakiseGUI/MakiseGUI/fonts/Default5x7.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/fonts/Default5x7.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default5x7.c.s
.PHONY : MakiseGUI/MakiseGUI/fonts/Default5x7.c.s
MakiseGUI/MakiseGUI/fonts/Default6x10.o: MakiseGUI/MakiseGUI/fonts/Default6x10.c.o
.PHONY : MakiseGUI/MakiseGUI/fonts/Default6x10.o
# target to build an object file
MakiseGUI/MakiseGUI/fonts/Default6x10.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default6x10.c.o
.PHONY : MakiseGUI/MakiseGUI/fonts/Default6x10.c.o
MakiseGUI/MakiseGUI/fonts/Default6x10.i: MakiseGUI/MakiseGUI/fonts/Default6x10.c.i
.PHONY : MakiseGUI/MakiseGUI/fonts/Default6x10.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/fonts/Default6x10.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default6x10.c.i
.PHONY : MakiseGUI/MakiseGUI/fonts/Default6x10.c.i
MakiseGUI/MakiseGUI/fonts/Default6x10.s: MakiseGUI/MakiseGUI/fonts/Default6x10.c.s
.PHONY : MakiseGUI/MakiseGUI/fonts/Default6x10.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/fonts/Default6x10.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default6x10.c.s
.PHONY : MakiseGUI/MakiseGUI/fonts/Default6x10.c.s
MakiseGUI/MakiseGUI/fonts/Default8x13.o: MakiseGUI/MakiseGUI/fonts/Default8x13.c.o
.PHONY : MakiseGUI/MakiseGUI/fonts/Default8x13.o
# target to build an object file
MakiseGUI/MakiseGUI/fonts/Default8x13.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default8x13.c.o
.PHONY : MakiseGUI/MakiseGUI/fonts/Default8x13.c.o
MakiseGUI/MakiseGUI/fonts/Default8x13.i: MakiseGUI/MakiseGUI/fonts/Default8x13.c.i
.PHONY : MakiseGUI/MakiseGUI/fonts/Default8x13.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/fonts/Default8x13.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default8x13.c.i
.PHONY : MakiseGUI/MakiseGUI/fonts/Default8x13.c.i
MakiseGUI/MakiseGUI/fonts/Default8x13.s: MakiseGUI/MakiseGUI/fonts/Default8x13.c.s
.PHONY : MakiseGUI/MakiseGUI/fonts/Default8x13.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/fonts/Default8x13.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default8x13.c.s
.PHONY : MakiseGUI/MakiseGUI/fonts/Default8x13.c.s
MakiseGUI/MakiseGUI/gui/elements/makise_e.o: MakiseGUI/MakiseGUI/gui/elements/makise_e.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/makise_e.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/makise_e.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/makise_e.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/makise_e.c.o
MakiseGUI/MakiseGUI/gui/elements/makise_e.i: MakiseGUI/MakiseGUI/gui/elements/makise_e.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/makise_e.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/makise_e.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/makise_e.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/makise_e.c.i
MakiseGUI/MakiseGUI/gui/elements/makise_e.s: MakiseGUI/MakiseGUI/gui/elements/makise_e.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/makise_e.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/makise_e.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/makise_e.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/makise_e.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.s
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.o: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.o
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.i: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.i
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.s: MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.s
MakiseGUI/MakiseGUI/gui/makise_gui.o: MakiseGUI/MakiseGUI/gui/makise_gui.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/makise_gui.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui.c.o
MakiseGUI/MakiseGUI/gui/makise_gui.i: MakiseGUI/MakiseGUI/gui/makise_gui.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/makise_gui.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui.c.i
MakiseGUI/MakiseGUI/gui/makise_gui.s: MakiseGUI/MakiseGUI/gui/makise_gui.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/makise_gui.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui.c.s
MakiseGUI/MakiseGUI/gui/makise_gui_container.o: MakiseGUI/MakiseGUI/gui/makise_gui_container.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_container.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/makise_gui_container.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_container.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_container.c.o
MakiseGUI/MakiseGUI/gui/makise_gui_container.i: MakiseGUI/MakiseGUI/gui/makise_gui_container.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_container.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/makise_gui_container.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_container.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_container.c.i
MakiseGUI/MakiseGUI/gui/makise_gui_container.s: MakiseGUI/MakiseGUI/gui/makise_gui_container.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_container.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/makise_gui_container.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_container.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_container.c.s
MakiseGUI/MakiseGUI/gui/makise_gui_elements.o: MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_elements.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.o
MakiseGUI/MakiseGUI/gui/makise_gui_elements.i: MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_elements.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.i
MakiseGUI/MakiseGUI/gui/makise_gui_elements.s: MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_elements.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.s
MakiseGUI/MakiseGUI/gui/makise_gui_input.o: MakiseGUI/MakiseGUI/gui/makise_gui_input.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_input.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/makise_gui_input.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_input.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_input.c.o
MakiseGUI/MakiseGUI/gui/makise_gui_input.i: MakiseGUI/MakiseGUI/gui/makise_gui_input.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_input.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/makise_gui_input.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_input.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_input.c.i
MakiseGUI/MakiseGUI/gui/makise_gui_input.s: MakiseGUI/MakiseGUI/gui/makise_gui_input.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_input.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/makise_gui_input.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_input.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_input.c.s
MakiseGUI/MakiseGUI/gui/makise_gui_interface.o: MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_interface.o
# target to build an object file
MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.o
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.o
MakiseGUI/MakiseGUI/gui/makise_gui_interface.i: MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_interface.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.i
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.i
MakiseGUI/MakiseGUI/gui/makise_gui_interface.s: MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_interface.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.s
.PHONY : MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.s
MakiseGUI/MakiseGUI/makise.o: MakiseGUI/MakiseGUI/makise.c.o
.PHONY : MakiseGUI/MakiseGUI/makise.o
# target to build an object file
MakiseGUI/MakiseGUI/makise.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise.c.o
.PHONY : MakiseGUI/MakiseGUI/makise.c.o
MakiseGUI/MakiseGUI/makise.i: MakiseGUI/MakiseGUI/makise.c.i
.PHONY : MakiseGUI/MakiseGUI/makise.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/makise.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise.c.i
.PHONY : MakiseGUI/MakiseGUI/makise.c.i
MakiseGUI/MakiseGUI/makise.s: MakiseGUI/MakiseGUI/makise.c.s
.PHONY : MakiseGUI/MakiseGUI/makise.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/makise.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise.c.s
.PHONY : MakiseGUI/MakiseGUI/makise.c.s
MakiseGUI/MakiseGUI/makise_bitmap.o: MakiseGUI/MakiseGUI/makise_bitmap.c.o
.PHONY : MakiseGUI/MakiseGUI/makise_bitmap.o
# target to build an object file
MakiseGUI/MakiseGUI/makise_bitmap.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_bitmap.c.o
.PHONY : MakiseGUI/MakiseGUI/makise_bitmap.c.o
MakiseGUI/MakiseGUI/makise_bitmap.i: MakiseGUI/MakiseGUI/makise_bitmap.c.i
.PHONY : MakiseGUI/MakiseGUI/makise_bitmap.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/makise_bitmap.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_bitmap.c.i
.PHONY : MakiseGUI/MakiseGUI/makise_bitmap.c.i
MakiseGUI/MakiseGUI/makise_bitmap.s: MakiseGUI/MakiseGUI/makise_bitmap.c.s
.PHONY : MakiseGUI/MakiseGUI/makise_bitmap.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/makise_bitmap.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_bitmap.c.s
.PHONY : MakiseGUI/MakiseGUI/makise_bitmap.c.s
MakiseGUI/MakiseGUI/makise_colors.o: MakiseGUI/MakiseGUI/makise_colors.c.o
.PHONY : MakiseGUI/MakiseGUI/makise_colors.o
# target to build an object file
MakiseGUI/MakiseGUI/makise_colors.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_colors.c.o
.PHONY : MakiseGUI/MakiseGUI/makise_colors.c.o
MakiseGUI/MakiseGUI/makise_colors.i: MakiseGUI/MakiseGUI/makise_colors.c.i
.PHONY : MakiseGUI/MakiseGUI/makise_colors.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/makise_colors.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_colors.c.i
.PHONY : MakiseGUI/MakiseGUI/makise_colors.c.i
MakiseGUI/MakiseGUI/makise_colors.s: MakiseGUI/MakiseGUI/makise_colors.c.s
.PHONY : MakiseGUI/MakiseGUI/makise_colors.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/makise_colors.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_colors.c.s
.PHONY : MakiseGUI/MakiseGUI/makise_colors.c.s
MakiseGUI/MakiseGUI/makise_primitives.o: MakiseGUI/MakiseGUI/makise_primitives.c.o
.PHONY : MakiseGUI/MakiseGUI/makise_primitives.o
# target to build an object file
MakiseGUI/MakiseGUI/makise_primitives.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_primitives.c.o
.PHONY : MakiseGUI/MakiseGUI/makise_primitives.c.o
MakiseGUI/MakiseGUI/makise_primitives.i: MakiseGUI/MakiseGUI/makise_primitives.c.i
.PHONY : MakiseGUI/MakiseGUI/makise_primitives.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/makise_primitives.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_primitives.c.i
.PHONY : MakiseGUI/MakiseGUI/makise_primitives.c.i
MakiseGUI/MakiseGUI/makise_primitives.s: MakiseGUI/MakiseGUI/makise_primitives.c.s
.PHONY : MakiseGUI/MakiseGUI/makise_primitives.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/makise_primitives.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_primitives.c.s
.PHONY : MakiseGUI/MakiseGUI/makise_primitives.c.s
MakiseGUI/MakiseGUI/makise_primitives_default_drawer.o: MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.o
.PHONY : MakiseGUI/MakiseGUI/makise_primitives_default_drawer.o
# target to build an object file
MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.o
.PHONY : MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.o
MakiseGUI/MakiseGUI/makise_primitives_default_drawer.i: MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.i
.PHONY : MakiseGUI/MakiseGUI/makise_primitives_default_drawer.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.i
.PHONY : MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.i
MakiseGUI/MakiseGUI/makise_primitives_default_drawer.s: MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.s
.PHONY : MakiseGUI/MakiseGUI/makise_primitives_default_drawer.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.s
.PHONY : MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.s
MakiseGUI/MakiseGUI/makise_text.o: MakiseGUI/MakiseGUI/makise_text.c.o
.PHONY : MakiseGUI/MakiseGUI/makise_text.o
# target to build an object file
MakiseGUI/MakiseGUI/makise_text.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_text.c.o
.PHONY : MakiseGUI/MakiseGUI/makise_text.c.o
MakiseGUI/MakiseGUI/makise_text.i: MakiseGUI/MakiseGUI/makise_text.c.i
.PHONY : MakiseGUI/MakiseGUI/makise_text.i
# target to preprocess a source file
MakiseGUI/MakiseGUI/makise_text.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_text.c.i
.PHONY : MakiseGUI/MakiseGUI/makise_text.c.i
MakiseGUI/MakiseGUI/makise_text.s: MakiseGUI/MakiseGUI/makise_text.c.s
.PHONY : MakiseGUI/MakiseGUI/makise_text.s
# target to generate assembly for a file
MakiseGUI/MakiseGUI/makise_text.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_text.c.s
.PHONY : MakiseGUI/MakiseGUI/makise_text.c.s
MakiseGUI/docs/examples/mutex.o: MakiseGUI/docs/examples/mutex.c.o
.PHONY : MakiseGUI/docs/examples/mutex.o
# target to build an object file
MakiseGUI/docs/examples/mutex.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/docs/examples/mutex.c.o
.PHONY : MakiseGUI/docs/examples/mutex.c.o
MakiseGUI/docs/examples/mutex.i: MakiseGUI/docs/examples/mutex.c.i
.PHONY : MakiseGUI/docs/examples/mutex.i
# target to preprocess a source file
MakiseGUI/docs/examples/mutex.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/docs/examples/mutex.c.i
.PHONY : MakiseGUI/docs/examples/mutex.c.i
MakiseGUI/docs/examples/mutex.s: MakiseGUI/docs/examples/mutex.c.s
.PHONY : MakiseGUI/docs/examples/mutex.s
# target to generate assembly for a file
MakiseGUI/docs/examples/mutex.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/MakiseGUI/docs/examples/mutex.c.s
.PHONY : MakiseGUI/docs/examples/mutex.c.s
Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.o: Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.o
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.o
# target to build an object file
Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.o
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.o
Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.i: Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.i
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.i
# target to preprocess a source file
Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.i
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.i
Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.s: Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.s
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.s
# target to generate assembly for a file
Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.s
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.s
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.o: Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.o
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.o
# target to build an object file
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.o
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.o
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.i: Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.i
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.i
# target to preprocess a source file
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.i
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.i
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.s: Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.s
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.s
# target to generate assembly for a file
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.s
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.s
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.o: Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.o
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.o
# target to build an object file
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.o
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.o
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.i: Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.i
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.i
# target to preprocess a source file
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.i
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.i
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.s: Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.s
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.s
# target to generate assembly for a file
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.s
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.s
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.o: Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.o
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.o
# target to build an object file
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.o
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.o
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.i: Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.i
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.i
# target to preprocess a source file
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.i
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.i
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.s: Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.s
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.s
# target to generate assembly for a file
Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.s
.PHONY : Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.s
Middlewares/Third_Party/FatFs/src/diskio.o: Middlewares/Third_Party/FatFs/src/diskio.c.o
.PHONY : Middlewares/Third_Party/FatFs/src/diskio.o
# target to build an object file
Middlewares/Third_Party/FatFs/src/diskio.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/diskio.c.o
.PHONY : Middlewares/Third_Party/FatFs/src/diskio.c.o
Middlewares/Third_Party/FatFs/src/diskio.i: Middlewares/Third_Party/FatFs/src/diskio.c.i
.PHONY : Middlewares/Third_Party/FatFs/src/diskio.i
# target to preprocess a source file
Middlewares/Third_Party/FatFs/src/diskio.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/diskio.c.i
.PHONY : Middlewares/Third_Party/FatFs/src/diskio.c.i
Middlewares/Third_Party/FatFs/src/diskio.s: Middlewares/Third_Party/FatFs/src/diskio.c.s
.PHONY : Middlewares/Third_Party/FatFs/src/diskio.s
# target to generate assembly for a file
Middlewares/Third_Party/FatFs/src/diskio.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/diskio.c.s
.PHONY : Middlewares/Third_Party/FatFs/src/diskio.c.s
Middlewares/Third_Party/FatFs/src/ff.o: Middlewares/Third_Party/FatFs/src/ff.c.o
.PHONY : Middlewares/Third_Party/FatFs/src/ff.o
# target to build an object file
Middlewares/Third_Party/FatFs/src/ff.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/ff.c.o
.PHONY : Middlewares/Third_Party/FatFs/src/ff.c.o
Middlewares/Third_Party/FatFs/src/ff.i: Middlewares/Third_Party/FatFs/src/ff.c.i
.PHONY : Middlewares/Third_Party/FatFs/src/ff.i
# target to preprocess a source file
Middlewares/Third_Party/FatFs/src/ff.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/ff.c.i
.PHONY : Middlewares/Third_Party/FatFs/src/ff.c.i
Middlewares/Third_Party/FatFs/src/ff.s: Middlewares/Third_Party/FatFs/src/ff.c.s
.PHONY : Middlewares/Third_Party/FatFs/src/ff.s
# target to generate assembly for a file
Middlewares/Third_Party/FatFs/src/ff.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/ff.c.s
.PHONY : Middlewares/Third_Party/FatFs/src/ff.c.s
Middlewares/Third_Party/FatFs/src/ff_gen_drv.o: Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.o
.PHONY : Middlewares/Third_Party/FatFs/src/ff_gen_drv.o
# target to build an object file
Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.o
.PHONY : Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.o
Middlewares/Third_Party/FatFs/src/ff_gen_drv.i: Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.i
.PHONY : Middlewares/Third_Party/FatFs/src/ff_gen_drv.i
# target to preprocess a source file
Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.i
.PHONY : Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.i
Middlewares/Third_Party/FatFs/src/ff_gen_drv.s: Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.s
.PHONY : Middlewares/Third_Party/FatFs/src/ff_gen_drv.s
# target to generate assembly for a file
Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.s
.PHONY : Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.s
Middlewares/Third_Party/FatFs/src/option/ccsbcs.o: Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.o
.PHONY : Middlewares/Third_Party/FatFs/src/option/ccsbcs.o
# target to build an object file
Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.o
.PHONY : Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.o
Middlewares/Third_Party/FatFs/src/option/ccsbcs.i: Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.i
.PHONY : Middlewares/Third_Party/FatFs/src/option/ccsbcs.i
# target to preprocess a source file
Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.i
.PHONY : Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.i
Middlewares/Third_Party/FatFs/src/option/ccsbcs.s: Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.s
.PHONY : Middlewares/Third_Party/FatFs/src/option/ccsbcs.s
# target to generate assembly for a file
Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.s
.PHONY : Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.s
Middlewares/Third_Party/FatFs/src/option/syscall.o: Middlewares/Third_Party/FatFs/src/option/syscall.c.o
.PHONY : Middlewares/Third_Party/FatFs/src/option/syscall.o
# target to build an object file
Middlewares/Third_Party/FatFs/src/option/syscall.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/option/syscall.c.o
.PHONY : Middlewares/Third_Party/FatFs/src/option/syscall.c.o
Middlewares/Third_Party/FatFs/src/option/syscall.i: Middlewares/Third_Party/FatFs/src/option/syscall.c.i
.PHONY : Middlewares/Third_Party/FatFs/src/option/syscall.i
# target to preprocess a source file
Middlewares/Third_Party/FatFs/src/option/syscall.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/option/syscall.c.i
.PHONY : Middlewares/Third_Party/FatFs/src/option/syscall.c.i
Middlewares/Third_Party/FatFs/src/option/syscall.s: Middlewares/Third_Party/FatFs/src/option/syscall.c.s
.PHONY : Middlewares/Third_Party/FatFs/src/option/syscall.s
# target to generate assembly for a file
Middlewares/Third_Party/FatFs/src/option/syscall.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/option/syscall.c.s
.PHONY : Middlewares/Third_Party/FatFs/src/option/syscall.c.s
Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.o: Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.o
# target to build an object file
Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.o
Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.i: Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.i
# target to preprocess a source file
Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.i
Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.s: Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.s
# target to generate assembly for a file
Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.s
Middlewares/Third_Party/FreeRTOS/Source/croutine.o: Middlewares/Third_Party/FreeRTOS/Source/croutine.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/croutine.o
# target to build an object file
Middlewares/Third_Party/FreeRTOS/Source/croutine.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/croutine.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/croutine.c.o
Middlewares/Third_Party/FreeRTOS/Source/croutine.i: Middlewares/Third_Party/FreeRTOS/Source/croutine.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/croutine.i
# target to preprocess a source file
Middlewares/Third_Party/FreeRTOS/Source/croutine.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/croutine.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/croutine.c.i
Middlewares/Third_Party/FreeRTOS/Source/croutine.s: Middlewares/Third_Party/FreeRTOS/Source/croutine.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/croutine.s
# target to generate assembly for a file
Middlewares/Third_Party/FreeRTOS/Source/croutine.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/croutine.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/croutine.c.s
Middlewares/Third_Party/FreeRTOS/Source/event_groups.o: Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/event_groups.o
# target to build an object file
Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.o
Middlewares/Third_Party/FreeRTOS/Source/event_groups.i: Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/event_groups.i
# target to preprocess a source file
Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.i
Middlewares/Third_Party/FreeRTOS/Source/event_groups.s: Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/event_groups.s
# target to generate assembly for a file
Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.s
Middlewares/Third_Party/FreeRTOS/Source/list.o: Middlewares/Third_Party/FreeRTOS/Source/list.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/list.o
# target to build an object file
Middlewares/Third_Party/FreeRTOS/Source/list.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/list.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/list.c.o
Middlewares/Third_Party/FreeRTOS/Source/list.i: Middlewares/Third_Party/FreeRTOS/Source/list.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/list.i
# target to preprocess a source file
Middlewares/Third_Party/FreeRTOS/Source/list.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/list.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/list.c.i
Middlewares/Third_Party/FreeRTOS/Source/list.s: Middlewares/Third_Party/FreeRTOS/Source/list.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/list.s
# target to generate assembly for a file
Middlewares/Third_Party/FreeRTOS/Source/list.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/list.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/list.c.s
Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.o: Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.o
# target to build an object file
Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.o
Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.i: Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.i
# target to preprocess a source file
Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.i
Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.s: Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.s
# target to generate assembly for a file
Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.s
Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.o: Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.o
# target to build an object file
Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.o
Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.i: Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.i
# target to preprocess a source file
Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.i
Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.s: Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.s
# target to generate assembly for a file
Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.s
Middlewares/Third_Party/FreeRTOS/Source/queue.o: Middlewares/Third_Party/FreeRTOS/Source/queue.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/queue.o
# target to build an object file
Middlewares/Third_Party/FreeRTOS/Source/queue.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/queue.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/queue.c.o
Middlewares/Third_Party/FreeRTOS/Source/queue.i: Middlewares/Third_Party/FreeRTOS/Source/queue.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/queue.i
# target to preprocess a source file
Middlewares/Third_Party/FreeRTOS/Source/queue.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/queue.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/queue.c.i
Middlewares/Third_Party/FreeRTOS/Source/queue.s: Middlewares/Third_Party/FreeRTOS/Source/queue.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/queue.s
# target to generate assembly for a file
Middlewares/Third_Party/FreeRTOS/Source/queue.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/queue.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/queue.c.s
Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.o: Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.o
# target to build an object file
Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.o
Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.i: Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.i
# target to preprocess a source file
Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.i
Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.s: Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.s
# target to generate assembly for a file
Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.s
Middlewares/Third_Party/FreeRTOS/Source/tasks.o: Middlewares/Third_Party/FreeRTOS/Source/tasks.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/tasks.o
# target to build an object file
Middlewares/Third_Party/FreeRTOS/Source/tasks.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/tasks.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/tasks.c.o
Middlewares/Third_Party/FreeRTOS/Source/tasks.i: Middlewares/Third_Party/FreeRTOS/Source/tasks.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/tasks.i
# target to preprocess a source file
Middlewares/Third_Party/FreeRTOS/Source/tasks.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/tasks.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/tasks.c.i
Middlewares/Third_Party/FreeRTOS/Source/tasks.s: Middlewares/Third_Party/FreeRTOS/Source/tasks.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/tasks.s
# target to generate assembly for a file
Middlewares/Third_Party/FreeRTOS/Source/tasks.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/tasks.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/tasks.c.s
Middlewares/Third_Party/FreeRTOS/Source/timers.o: Middlewares/Third_Party/FreeRTOS/Source/timers.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/timers.o
# target to build an object file
Middlewares/Third_Party/FreeRTOS/Source/timers.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/timers.c.o
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/timers.c.o
Middlewares/Third_Party/FreeRTOS/Source/timers.i: Middlewares/Third_Party/FreeRTOS/Source/timers.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/timers.i
# target to preprocess a source file
Middlewares/Third_Party/FreeRTOS/Source/timers.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/timers.c.i
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/timers.c.i
Middlewares/Third_Party/FreeRTOS/Source/timers.s: Middlewares/Third_Party/FreeRTOS/Source/timers.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/timers.s
# target to generate assembly for a file
Middlewares/Third_Party/FreeRTOS/Source/timers.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/timers.c.s
.PHONY : Middlewares/Third_Party/FreeRTOS/Source/timers.c.s
Src/bsp_driver_sd.o: Src/bsp_driver_sd.c.o
.PHONY : Src/bsp_driver_sd.o
# target to build an object file
Src/bsp_driver_sd.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/bsp_driver_sd.c.o
.PHONY : Src/bsp_driver_sd.c.o
Src/bsp_driver_sd.i: Src/bsp_driver_sd.c.i
.PHONY : Src/bsp_driver_sd.i
# target to preprocess a source file
Src/bsp_driver_sd.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/bsp_driver_sd.c.i
.PHONY : Src/bsp_driver_sd.c.i
Src/bsp_driver_sd.s: Src/bsp_driver_sd.c.s
.PHONY : Src/bsp_driver_sd.s
# target to generate assembly for a file
Src/bsp_driver_sd.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/bsp_driver_sd.c.s
.PHONY : Src/bsp_driver_sd.c.s
Src/dma.o: Src/dma.c.o
.PHONY : Src/dma.o
# target to build an object file
Src/dma.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/dma.c.o
.PHONY : Src/dma.c.o
Src/dma.i: Src/dma.c.i
.PHONY : Src/dma.i
# target to preprocess a source file
Src/dma.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/dma.c.i
.PHONY : Src/dma.c.i
Src/dma.s: Src/dma.c.s
.PHONY : Src/dma.s
# target to generate assembly for a file
Src/dma.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/dma.c.s
.PHONY : Src/dma.c.s
Src/fatfs.o: Src/fatfs.c.o
.PHONY : Src/fatfs.o
# target to build an object file
Src/fatfs.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/fatfs.c.o
.PHONY : Src/fatfs.c.o
Src/fatfs.i: Src/fatfs.c.i
.PHONY : Src/fatfs.i
# target to preprocess a source file
Src/fatfs.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/fatfs.c.i
.PHONY : Src/fatfs.c.i
Src/fatfs.s: Src/fatfs.c.s
.PHONY : Src/fatfs.s
# target to generate assembly for a file
Src/fatfs.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/fatfs.c.s
.PHONY : Src/fatfs.c.s
Src/freertos.o: Src/freertos.c.o
.PHONY : Src/freertos.o
# target to build an object file
Src/freertos.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/freertos.c.o
.PHONY : Src/freertos.c.o
Src/freertos.i: Src/freertos.c.i
.PHONY : Src/freertos.i
# target to preprocess a source file
Src/freertos.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/freertos.c.i
.PHONY : Src/freertos.c.i
Src/freertos.s: Src/freertos.c.s
.PHONY : Src/freertos.s
# target to generate assembly for a file
Src/freertos.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/freertos.c.s
.PHONY : Src/freertos.c.s
Src/gpio.o: Src/gpio.c.o
.PHONY : Src/gpio.o
# target to build an object file
Src/gpio.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/gpio.c.o
.PHONY : Src/gpio.c.o
Src/gpio.i: Src/gpio.c.i
.PHONY : Src/gpio.i
# target to preprocess a source file
Src/gpio.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/gpio.c.i
.PHONY : Src/gpio.c.i
Src/gpio.s: Src/gpio.c.s
.PHONY : Src/gpio.s
# target to generate assembly for a file
Src/gpio.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/gpio.c.s
.PHONY : Src/gpio.c.s
Src/gui.o: Src/gui.c.o
.PHONY : Src/gui.o
# target to build an object file
Src/gui.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/gui.c.o
.PHONY : Src/gui.c.o
Src/gui.i: Src/gui.c.i
.PHONY : Src/gui.i
# target to preprocess a source file
Src/gui.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/gui.c.i
.PHONY : Src/gui.c.i
Src/gui.s: Src/gui.c.s
.PHONY : Src/gui.s
# target to generate assembly for a file
Src/gui.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/gui.c.s
.PHONY : Src/gui.c.s
Src/i2c.o: Src/i2c.c.o
.PHONY : Src/i2c.o
# target to build an object file
Src/i2c.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/i2c.c.o
.PHONY : Src/i2c.c.o
Src/i2c.i: Src/i2c.c.i
.PHONY : Src/i2c.i
# target to preprocess a source file
Src/i2c.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/i2c.c.i
.PHONY : Src/i2c.c.i
Src/i2c.s: Src/i2c.c.s
.PHONY : Src/i2c.s
# target to generate assembly for a file
Src/i2c.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/i2c.c.s
.PHONY : Src/i2c.c.s
Src/i2s.o: Src/i2s.c.o
.PHONY : Src/i2s.o
# target to build an object file
Src/i2s.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/i2s.c.o
.PHONY : Src/i2s.c.o
Src/i2s.i: Src/i2s.c.i
.PHONY : Src/i2s.i
# target to preprocess a source file
Src/i2s.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/i2s.c.i
.PHONY : Src/i2s.c.i
Src/i2s.s: Src/i2s.c.s
.PHONY : Src/i2s.s
# target to generate assembly for a file
Src/i2s.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/i2s.c.s
.PHONY : Src/i2s.c.s
Src/main.o: Src/main.c.o
.PHONY : Src/main.o
# target to build an object file
Src/main.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/main.c.o
.PHONY : Src/main.c.o
Src/main.i: Src/main.c.i
.PHONY : Src/main.i
# target to preprocess a source file
Src/main.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/main.c.i
.PHONY : Src/main.c.i
Src/main.s: Src/main.c.s
.PHONY : Src/main.s
# target to generate assembly for a file
Src/main.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/main.c.s
.PHONY : Src/main.c.s
Src/sd_diskio.o: Src/sd_diskio.c.o
.PHONY : Src/sd_diskio.o
# target to build an object file
Src/sd_diskio.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/sd_diskio.c.o
.PHONY : Src/sd_diskio.c.o
Src/sd_diskio.i: Src/sd_diskio.c.i
.PHONY : Src/sd_diskio.i
# target to preprocess a source file
Src/sd_diskio.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/sd_diskio.c.i
.PHONY : Src/sd_diskio.c.i
Src/sd_diskio.s: Src/sd_diskio.c.s
.PHONY : Src/sd_diskio.s
# target to generate assembly for a file
Src/sd_diskio.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/sd_diskio.c.s
.PHONY : Src/sd_diskio.c.s
Src/sdio.o: Src/sdio.c.o
.PHONY : Src/sdio.o
# target to build an object file
Src/sdio.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/sdio.c.o
.PHONY : Src/sdio.c.o
Src/sdio.i: Src/sdio.c.i
.PHONY : Src/sdio.i
# target to preprocess a source file
Src/sdio.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/sdio.c.i
.PHONY : Src/sdio.c.i
Src/sdio.s: Src/sdio.c.s
.PHONY : Src/sdio.s
# target to generate assembly for a file
Src/sdio.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/sdio.c.s
.PHONY : Src/sdio.c.s
Src/spi.o: Src/spi.c.o
.PHONY : Src/spi.o
# target to build an object file
Src/spi.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/spi.c.o
.PHONY : Src/spi.c.o
Src/spi.i: Src/spi.c.i
.PHONY : Src/spi.i
# target to preprocess a source file
Src/spi.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/spi.c.i
.PHONY : Src/spi.c.i
Src/spi.s: Src/spi.c.s
.PHONY : Src/spi.s
# target to generate assembly for a file
Src/spi.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/spi.c.s
.PHONY : Src/spi.c.s
Src/stm32f4xx_hal_msp.o: Src/stm32f4xx_hal_msp.c.o
.PHONY : Src/stm32f4xx_hal_msp.o
# target to build an object file
Src/stm32f4xx_hal_msp.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/stm32f4xx_hal_msp.c.o
.PHONY : Src/stm32f4xx_hal_msp.c.o
Src/stm32f4xx_hal_msp.i: Src/stm32f4xx_hal_msp.c.i
.PHONY : Src/stm32f4xx_hal_msp.i
# target to preprocess a source file
Src/stm32f4xx_hal_msp.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/stm32f4xx_hal_msp.c.i
.PHONY : Src/stm32f4xx_hal_msp.c.i
Src/stm32f4xx_hal_msp.s: Src/stm32f4xx_hal_msp.c.s
.PHONY : Src/stm32f4xx_hal_msp.s
# target to generate assembly for a file
Src/stm32f4xx_hal_msp.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/stm32f4xx_hal_msp.c.s
.PHONY : Src/stm32f4xx_hal_msp.c.s
Src/stm32f4xx_hal_timebase_tim.o: Src/stm32f4xx_hal_timebase_tim.c.o
.PHONY : Src/stm32f4xx_hal_timebase_tim.o
# target to build an object file
Src/stm32f4xx_hal_timebase_tim.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/stm32f4xx_hal_timebase_tim.c.o
.PHONY : Src/stm32f4xx_hal_timebase_tim.c.o
Src/stm32f4xx_hal_timebase_tim.i: Src/stm32f4xx_hal_timebase_tim.c.i
.PHONY : Src/stm32f4xx_hal_timebase_tim.i
# target to preprocess a source file
Src/stm32f4xx_hal_timebase_tim.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/stm32f4xx_hal_timebase_tim.c.i
.PHONY : Src/stm32f4xx_hal_timebase_tim.c.i
Src/stm32f4xx_hal_timebase_tim.s: Src/stm32f4xx_hal_timebase_tim.c.s
.PHONY : Src/stm32f4xx_hal_timebase_tim.s
# target to generate assembly for a file
Src/stm32f4xx_hal_timebase_tim.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/stm32f4xx_hal_timebase_tim.c.s
.PHONY : Src/stm32f4xx_hal_timebase_tim.c.s
Src/stm32f4xx_it.o: Src/stm32f4xx_it.c.o
.PHONY : Src/stm32f4xx_it.o
# target to build an object file
Src/stm32f4xx_it.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/stm32f4xx_it.c.o
.PHONY : Src/stm32f4xx_it.c.o
Src/stm32f4xx_it.i: Src/stm32f4xx_it.c.i
.PHONY : Src/stm32f4xx_it.i
# target to preprocess a source file
Src/stm32f4xx_it.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/stm32f4xx_it.c.i
.PHONY : Src/stm32f4xx_it.c.i
Src/stm32f4xx_it.s: Src/stm32f4xx_it.c.s
.PHONY : Src/stm32f4xx_it.s
# target to generate assembly for a file
Src/stm32f4xx_it.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/stm32f4xx_it.c.s
.PHONY : Src/stm32f4xx_it.c.s
Src/system_stm32f4xx.o: Src/system_stm32f4xx.c.o
.PHONY : Src/system_stm32f4xx.o
# target to build an object file
Src/system_stm32f4xx.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/system_stm32f4xx.c.o
.PHONY : Src/system_stm32f4xx.c.o
Src/system_stm32f4xx.i: Src/system_stm32f4xx.c.i
.PHONY : Src/system_stm32f4xx.i
# target to preprocess a source file
Src/system_stm32f4xx.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/system_stm32f4xx.c.i
.PHONY : Src/system_stm32f4xx.c.i
Src/system_stm32f4xx.s: Src/system_stm32f4xx.c.s
.PHONY : Src/system_stm32f4xx.s
# target to generate assembly for a file
Src/system_stm32f4xx.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/system_stm32f4xx.c.s
.PHONY : Src/system_stm32f4xx.c.s
Src/tests_hello.o: Src/tests_hello.c.o
.PHONY : Src/tests_hello.o
# target to build an object file
Src/tests_hello.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/tests_hello.c.o
.PHONY : Src/tests_hello.c.o
Src/tests_hello.i: Src/tests_hello.c.i
.PHONY : Src/tests_hello.i
# target to preprocess a source file
Src/tests_hello.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/tests_hello.c.i
.PHONY : Src/tests_hello.c.i
Src/tests_hello.s: Src/tests_hello.c.s
.PHONY : Src/tests_hello.s
# target to generate assembly for a file
Src/tests_hello.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/tests_hello.c.s
.PHONY : Src/tests_hello.c.s
Src/tim.o: Src/tim.c.o
.PHONY : Src/tim.o
# target to build an object file
Src/tim.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/tim.c.o
.PHONY : Src/tim.c.o
Src/tim.i: Src/tim.c.i
.PHONY : Src/tim.i
# target to preprocess a source file
Src/tim.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/tim.c.i
.PHONY : Src/tim.c.i
Src/tim.s: Src/tim.c.s
.PHONY : Src/tim.s
# target to generate assembly for a file
Src/tim.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/tim.c.s
.PHONY : Src/tim.c.s
Src/usart.o: Src/usart.c.o
.PHONY : Src/usart.o
# target to build an object file
Src/usart.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usart.c.o
.PHONY : Src/usart.c.o
Src/usart.i: Src/usart.c.i
.PHONY : Src/usart.i
# target to preprocess a source file
Src/usart.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usart.c.i
.PHONY : Src/usart.c.i
Src/usart.s: Src/usart.c.s
.PHONY : Src/usart.s
# target to generate assembly for a file
Src/usart.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usart.c.s
.PHONY : Src/usart.c.s
Src/usb_device.o: Src/usb_device.c.o
.PHONY : Src/usb_device.o
# target to build an object file
Src/usb_device.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usb_device.c.o
.PHONY : Src/usb_device.c.o
Src/usb_device.i: Src/usb_device.c.i
.PHONY : Src/usb_device.i
# target to preprocess a source file
Src/usb_device.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usb_device.c.i
.PHONY : Src/usb_device.c.i
Src/usb_device.s: Src/usb_device.c.s
.PHONY : Src/usb_device.s
# target to generate assembly for a file
Src/usb_device.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usb_device.c.s
.PHONY : Src/usb_device.c.s
Src/usbd_cdc_if.o: Src/usbd_cdc_if.c.o
.PHONY : Src/usbd_cdc_if.o
# target to build an object file
Src/usbd_cdc_if.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usbd_cdc_if.c.o
.PHONY : Src/usbd_cdc_if.c.o
Src/usbd_cdc_if.i: Src/usbd_cdc_if.c.i
.PHONY : Src/usbd_cdc_if.i
# target to preprocess a source file
Src/usbd_cdc_if.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usbd_cdc_if.c.i
.PHONY : Src/usbd_cdc_if.c.i
Src/usbd_cdc_if.s: Src/usbd_cdc_if.c.s
.PHONY : Src/usbd_cdc_if.s
# target to generate assembly for a file
Src/usbd_cdc_if.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usbd_cdc_if.c.s
.PHONY : Src/usbd_cdc_if.c.s
Src/usbd_conf.o: Src/usbd_conf.c.o
.PHONY : Src/usbd_conf.o
# target to build an object file
Src/usbd_conf.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usbd_conf.c.o
.PHONY : Src/usbd_conf.c.o
Src/usbd_conf.i: Src/usbd_conf.c.i
.PHONY : Src/usbd_conf.i
# target to preprocess a source file
Src/usbd_conf.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usbd_conf.c.i
.PHONY : Src/usbd_conf.c.i
Src/usbd_conf.s: Src/usbd_conf.c.s
.PHONY : Src/usbd_conf.s
# target to generate assembly for a file
Src/usbd_conf.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usbd_conf.c.s
.PHONY : Src/usbd_conf.c.s
Src/usbd_desc.o: Src/usbd_desc.c.o
.PHONY : Src/usbd_desc.o
# target to build an object file
Src/usbd_desc.c.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usbd_desc.c.o
.PHONY : Src/usbd_desc.c.o
Src/usbd_desc.i: Src/usbd_desc.c.i
.PHONY : Src/usbd_desc.i
# target to preprocess a source file
Src/usbd_desc.c.i:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usbd_desc.c.i
.PHONY : Src/usbd_desc.c.i
Src/usbd_desc.s: Src/usbd_desc.c.s
.PHONY : Src/usbd_desc.s
# target to generate assembly for a file
Src/usbd_desc.c.s:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/Src/usbd_desc.c.s
.PHONY : Src/usbd_desc.c.s
startup/startup_stm32f427xx.o: startup/startup_stm32f427xx.s.o
.PHONY : startup/startup_stm32f427xx.o
# target to build an object file
startup/startup_stm32f427xx.s.o:
$(MAKE) -f CMakeFiles/core_src.elf.dir/build.make CMakeFiles/core_src.elf.dir/startup/startup_stm32f427xx.s.o
.PHONY : startup/startup_stm32f427xx.s.o
# Help Target
help:
@echo "The following are some of the valid targets for this Makefile:"
@echo "... all (the default if no target is provided)"
@echo "... clean"
@echo "... depend"
@echo "... rebuild_cache"
@echo "... edit_cache"
@echo "... core_src.bin"
@echo "... core_src.elf"
@echo "... core_src.hex"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.s"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.o"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.i"
@echo "... Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.s"
@echo "... ILI9341/ili9341.o"
@echo "... ILI9341/ili9341.i"
@echo "... ILI9341/ili9341.s"
@echo "... MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.o"
@echo "... MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.i"
@echo "... MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.s"
@echo "... MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.o"
@echo "... MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.i"
@echo "... MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.s"
@echo "... MakiseGUI/MakiseGUI/fonts/Default10x20.o"
@echo "... MakiseGUI/MakiseGUI/fonts/Default10x20.i"
@echo "... MakiseGUI/MakiseGUI/fonts/Default10x20.s"
@echo "... MakiseGUI/MakiseGUI/fonts/Default5x7.o"
@echo "... MakiseGUI/MakiseGUI/fonts/Default5x7.i"
@echo "... MakiseGUI/MakiseGUI/fonts/Default5x7.s"
@echo "... MakiseGUI/MakiseGUI/fonts/Default6x10.o"
@echo "... MakiseGUI/MakiseGUI/fonts/Default6x10.i"
@echo "... MakiseGUI/MakiseGUI/fonts/Default6x10.s"
@echo "... MakiseGUI/MakiseGUI/fonts/Default8x13.o"
@echo "... MakiseGUI/MakiseGUI/fonts/Default8x13.i"
@echo "... MakiseGUI/MakiseGUI/fonts/Default8x13.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/makise_e.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/makise_e.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/makise_e.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.s"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.o"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.i"
@echo "... MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.s"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui.o"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui.i"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui.s"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_container.o"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_container.i"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_container.s"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_elements.o"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_elements.i"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_elements.s"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_input.o"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_input.i"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_input.s"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_interface.o"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_interface.i"
@echo "... MakiseGUI/MakiseGUI/gui/makise_gui_interface.s"
@echo "... MakiseGUI/MakiseGUI/makise.o"
@echo "... MakiseGUI/MakiseGUI/makise.i"
@echo "... MakiseGUI/MakiseGUI/makise.s"
@echo "... MakiseGUI/MakiseGUI/makise_bitmap.o"
@echo "... MakiseGUI/MakiseGUI/makise_bitmap.i"
@echo "... MakiseGUI/MakiseGUI/makise_bitmap.s"
@echo "... MakiseGUI/MakiseGUI/makise_colors.o"
@echo "... MakiseGUI/MakiseGUI/makise_colors.i"
@echo "... MakiseGUI/MakiseGUI/makise_colors.s"
@echo "... MakiseGUI/MakiseGUI/makise_primitives.o"
@echo "... MakiseGUI/MakiseGUI/makise_primitives.i"
@echo "... MakiseGUI/MakiseGUI/makise_primitives.s"
@echo "... MakiseGUI/MakiseGUI/makise_primitives_default_drawer.o"
@echo "... MakiseGUI/MakiseGUI/makise_primitives_default_drawer.i"
@echo "... MakiseGUI/MakiseGUI/makise_primitives_default_drawer.s"
@echo "... MakiseGUI/MakiseGUI/makise_text.o"
@echo "... MakiseGUI/MakiseGUI/makise_text.i"
@echo "... MakiseGUI/MakiseGUI/makise_text.s"
@echo "... MakiseGUI/docs/examples/mutex.o"
@echo "... MakiseGUI/docs/examples/mutex.i"
@echo "... MakiseGUI/docs/examples/mutex.s"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.o"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.i"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.s"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.o"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.i"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.s"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.o"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.i"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.s"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.o"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.i"
@echo "... Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.s"
@echo "... Middlewares/Third_Party/FatFs/src/diskio.o"
@echo "... Middlewares/Third_Party/FatFs/src/diskio.i"
@echo "... Middlewares/Third_Party/FatFs/src/diskio.s"
@echo "... Middlewares/Third_Party/FatFs/src/ff.o"
@echo "... Middlewares/Third_Party/FatFs/src/ff.i"
@echo "... Middlewares/Third_Party/FatFs/src/ff.s"
@echo "... Middlewares/Third_Party/FatFs/src/ff_gen_drv.o"
@echo "... Middlewares/Third_Party/FatFs/src/ff_gen_drv.i"
@echo "... Middlewares/Third_Party/FatFs/src/ff_gen_drv.s"
@echo "... Middlewares/Third_Party/FatFs/src/option/ccsbcs.o"
@echo "... Middlewares/Third_Party/FatFs/src/option/ccsbcs.i"
@echo "... Middlewares/Third_Party/FatFs/src/option/ccsbcs.s"
@echo "... Middlewares/Third_Party/FatFs/src/option/syscall.o"
@echo "... Middlewares/Third_Party/FatFs/src/option/syscall.i"
@echo "... Middlewares/Third_Party/FatFs/src/option/syscall.s"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.o"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.i"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.s"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/croutine.o"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/croutine.i"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/croutine.s"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/event_groups.o"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/event_groups.i"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/event_groups.s"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/list.o"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/list.i"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/list.s"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.o"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.i"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.s"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.o"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.i"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.s"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/queue.o"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/queue.i"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/queue.s"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.o"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.i"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.s"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/tasks.o"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/tasks.i"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/tasks.s"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/timers.o"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/timers.i"
@echo "... Middlewares/Third_Party/FreeRTOS/Source/timers.s"
@echo "... Src/bsp_driver_sd.o"
@echo "... Src/bsp_driver_sd.i"
@echo "... Src/bsp_driver_sd.s"
@echo "... Src/dma.o"
@echo "... Src/dma.i"
@echo "... Src/dma.s"
@echo "... Src/fatfs.o"
@echo "... Src/fatfs.i"
@echo "... Src/fatfs.s"
@echo "... Src/freertos.o"
@echo "... Src/freertos.i"
@echo "... Src/freertos.s"
@echo "... Src/gpio.o"
@echo "... Src/gpio.i"
@echo "... Src/gpio.s"
@echo "... Src/gui.o"
@echo "... Src/gui.i"
@echo "... Src/gui.s"
@echo "... Src/i2c.o"
@echo "... Src/i2c.i"
@echo "... Src/i2c.s"
@echo "... Src/i2s.o"
@echo "... Src/i2s.i"
@echo "... Src/i2s.s"
@echo "... Src/main.o"
@echo "... Src/main.i"
@echo "... Src/main.s"
@echo "... Src/sd_diskio.o"
@echo "... Src/sd_diskio.i"
@echo "... Src/sd_diskio.s"
@echo "... Src/sdio.o"
@echo "... Src/sdio.i"
@echo "... Src/sdio.s"
@echo "... Src/spi.o"
@echo "... Src/spi.i"
@echo "... Src/spi.s"
@echo "... Src/stm32f4xx_hal_msp.o"
@echo "... Src/stm32f4xx_hal_msp.i"
@echo "... Src/stm32f4xx_hal_msp.s"
@echo "... Src/stm32f4xx_hal_timebase_tim.o"
@echo "... Src/stm32f4xx_hal_timebase_tim.i"
@echo "... Src/stm32f4xx_hal_timebase_tim.s"
@echo "... Src/stm32f4xx_it.o"
@echo "... Src/stm32f4xx_it.i"
@echo "... Src/stm32f4xx_it.s"
@echo "... Src/system_stm32f4xx.o"
@echo "... Src/system_stm32f4xx.i"
@echo "... Src/system_stm32f4xx.s"
@echo "... Src/tests_hello.o"
@echo "... Src/tests_hello.i"
@echo "... Src/tests_hello.s"
@echo "... Src/tim.o"
@echo "... Src/tim.i"
@echo "... Src/tim.s"
@echo "... Src/usart.o"
@echo "... Src/usart.i"
@echo "... Src/usart.s"
@echo "... Src/usb_device.o"
@echo "... Src/usb_device.i"
@echo "... Src/usb_device.s"
@echo "... Src/usbd_cdc_if.o"
@echo "... Src/usbd_cdc_if.i"
@echo "... Src/usbd_cdc_if.s"
@echo "... Src/usbd_conf.o"
@echo "... Src/usbd_conf.i"
@echo "... Src/usbd_conf.s"
@echo "... Src/usbd_desc.o"
@echo "... Src/usbd_desc.i"
@echo "... Src/usbd_desc.s"
@echo "... startup/startup_stm32f427xx.o"
.PHONY : help
#=============================================================================
# Special targets to cleanup operation of make.
# Special rule to run CMake to check the build system integrity.
# No rule that depends on this can have commands that come from listfiles
# because they might be regenerated.
cmake_check_build_system:
$(CMAKE_COMMAND) -S$(CMAKE_SOURCE_DIR) -B$(CMAKE_BINARY_DIR) --check-build-system CMakeFiles/Makefile.cmake 0
.PHONY : cmake_check_build_system
<file_sep>/core_src/makise_config.h
#ifndef MAKISE_CONFIG_H
#define MAKISE_CONFIG_H
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#define MAKISE_DEBUG_OUTPUT printf
//comment unused displays
//#define MAKISE_SDL2_USE 0
//#define MAKISE_ILI9340_USE 0
#define MAKISE_PRIMITIVES_DRAWER_DEFAULT
#define MAKISEGUI_DRIVER_DEPTH 16
#define MAKISEGUI_BUFFER_DEPTH 4
#define MAKISEGUI_BUFFER_DEPTHMASK 0b1111
#define MAKISE_BUF_H 80
#define MAKISE_BUF_W 240
//Control section
//len of buffer with input events
#define MAKISE_GUI_INPUT_BUFFER_LEN 10
//use x-y pointing control devices. like mouse or touchscreen
#define MAKISE_GUI_INPUT_POINTER_ENABLE 0
//Select used elements
#define MAKISE_E_SLIST 1
#define MAKISE_E_BUTTONS 1
#define MAKISE_E_CANVAS 1
#define MAKISE_E_LABLE 1
#define MAKISE_E_PROGRESS_BAR 0
#define MAKISE_E_SLIDER 1
#define MAKISE_E_TABS 0
#define MAKISE_E_TEXT_FIELD 0
#define MAKISE_E_TOGGLE 0
#define MAKISE_E_FSVIEWER MAKISE_E_FSVIEWER_FATFS
#define MAKISE_UNICODE 1
#define MAKISE_DISPLAY_INVERTED 0
#define MAKISE_MUTEX 0
#if MAKISE_MUTEX
#include "FreeRTOS.h"
#include "semphr.h"
#define MAKISE_MUTEX_t xSemaphoreHandle //change for your OS
#define MAKISE_MUTEX_TIMEOUT 1000
//implement that functions for your OS
//create mutex object
MAKISE_MUTEX_t m_mutex_create ();
//delete mutex
uint8_t m_mutex_delete (MAKISE_MUTEX_t sobj);
//Request Grant to Access some object
uint8_t m_mutex_request_grant (MAKISE_MUTEX_t sobj);
//Release Grant to Access the Volume
uint8_t m_mutex_release_grant (MAKISE_MUTEX_t sobj);
#endif
// FONTS. Uncomment to use
#define MAKISE_FONTS_DEFAULT10X20
#define MAKISE_FONTS_DEFAULT8X13
#define MAKISE_FONTS_DEFAULT6X10
#define MAKISE_FONTS_DEFAULT5X7
#define MAKISE_COLOR_CUSTOM_TYPE
typedef uint32_t MColor;
#define MC_Transparent UINT32_MAX
#include "ili9341.h"
#endif
<file_sep>/ILI9341/ili9341.h
#ifndef ILI9341_H
#define ILI9341_H
#include "spi.h"
#include "gpio.h"
#include "stm32f4xx_hal.h"
#include "ili9341_registers.h"
#include "makise.h"
#define ILI9341_SPI hspi1
#define ILI9341_CS GPIOA, GPIO_PIN_2
#define ILI9341_DC GPIOA, GPIO_PIN_4
#define ILI9341_LED GPIOC, GPIO_PIN_4
#define ILI9341_RST GPIOA, GPIO_PIN_3
#define ILI9341_LED_PWM &htim3
#define ILI9341_LED_PWM_CHANNEL TIM_CHANNEL_4
#define ILI9341_LED_USE_PWM 0
#if ILI9341_LED_USE_PWM
#include "stm32f4xx_hal_tim.h"
#include "tim.h"
#endif
void ili9341_driver(MakiseDriver*);
uint8_t ili9341_init (MakiseGUI* gui);
uint8_t ili9341_start(MakiseGUI* gui);
uint8_t ili9341_sleep(MakiseGUI* gui);
uint8_t ili9341_awake(MakiseGUI* gui);
uint8_t ili9341_set_backlight(MakiseGUI* gui, uint8_t);
uint8_t ili9341_spi_txhalfcplt(MakiseDriver* driver);
uint8_t ili9341_spi_txcplt(MakiseDriver* driver);
//void ili9341_render(MakiseGUI* gui);
uint8_t ili9341_write_data(uint8_t d);
uint8_t ili9341_write_command(uint8_t c);
#endif
<file_sep>/core_src/ILI9341/ili9341.c
#include "makise_config.h"
#include "ili9341.h"
#include "stm32f4xx_hal_tim.h"
#include "spi.h"
#include "FreeRTOS.h"
#include "cmsis_os.h"
extern inline void _ili9341_delay(uint32_t x) { HAL_Delay(x); }
extern inline void _ili9341_rst(uint8_t st){HAL_GPIO_WritePin(ILI9341_RST, st ? GPIO_PIN_SET : GPIO_PIN_RESET);}
extern inline void _ili9341_cs(uint8_t st){HAL_GPIO_WritePin(ILI9341_CS, st ? GPIO_PIN_SET : GPIO_PIN_RESET);}
extern inline void _ili9341_dc(uint8_t st){HAL_GPIO_WritePin(ILI9341_DC, st ? GPIO_PIN_SET : GPIO_PIN_RESET);}
void _ili9341_setAddrWindow(uint16_t x0, uint16_t y0, uint16_t x1,
uint16_t y1);
void ili9341_driver(MakiseDriver * d, uint32_t* buf, uint32_t size)
{
d->lcd_height = 320;
d->lcd_width = 240;
d->buffer_height = MAKISE_BUF_H;
d->buffer_width = MAKISE_BUF_W;
d->pixeldepth = 16;
d->buffer = buf;
d->size = MAKISE_BUF_H * MAKISE_BUF_W * 2;
d->posx = 0;
d->posy = 321;
}
void transmitCmdData(uint8_t r, uint8_t *data, int l)
{
_ili9341_dc(0);
HAL_SPI_Transmit(&ILI9341_SPI, &r, 1, 10);
_ili9341_dc(1);
HAL_SPI_Transmit(&ILI9341_SPI, data, l, 10);
}
uint8_t ili9341_init(MakiseGUI* gui)
{
_ili9341_rst(1);
_ili9341_delay(5);
_ili9341_rst(0);
_ili9341_delay(20);
_ili9341_rst(1);
_ili9341_delay(150);
uint8_t data[15] = {0};
data[0] = 0x39;
data[1] = 0x2C;
data[2] = 0x00;
data[3] = 0x34;
data[4] = 0x02;
transmitCmdData(0xCB, data, 5);
data[0] = 0x00;
data[1] = 0XC1;
data[2] = 0X30;
transmitCmdData(0xCF, data, 3);
data[0] = 0x85;
data[1] = 0x00;
data[2] = 0x78;
transmitCmdData(0xE8, data, 3);
data[0] = 0x00;
data[1] = 0x00;
transmitCmdData(0xEA, data, 2);
data[0] = 0x64;
data[1] = 0x03;
data[2] = 0X12;
data[3] = 0X81;
transmitCmdData(0xED, data, 4);
data[0] = 0x20;
transmitCmdData(0xF7, data, 1);
data[0] = 0x23; //VRH[5:0]
transmitCmdData(0xC0, data, 1); //Power control
data[0] = 0x10; //SAP[2:0];BT[3:0]
transmitCmdData(0xC1, data, 1); //Power control
data[0] = 0x3e; //Contrast
data[1] = 0x28;
transmitCmdData(0xC5, data, 2); //VCM control
data[0] = 0x86; //--
transmitCmdData(0xC7, data, 1); //VCM control2
data[0] = 0x48; //C8
transmitCmdData(0x36, data, 1); // Memory Access Control
data[0] = 0x55;
transmitCmdData(0x3A, data, 1);
data[0] = 0x00;
data[1] = 0x18;
transmitCmdData(0xB1, data, 2);
data[0] = 0x08;
data[1] = 0x82;
data[2] = 0x27;
transmitCmdData(0xB6, data, 3); // Display Function Control
data[0] = 0x00;
transmitCmdData(0xF2, data, 1); // 3Gamma Function Disable
data[0] = 0x01;
transmitCmdData(0x26, data, 1); //Gamma curve selected
data[0] = 0x0F;
data[1] = 0x31;
data[2] = 0x2B;
data[3] = 0x0C;
data[4] = 0x0E;
data[5] = 0x08;
data[6] = 0x4E;
data[7] = 0xF1;
data[8] = 0x37;
data[9] = 0x07;
data[10] = 0x10;
data[11] = 0x03;
data[12] = 0x0E;
data[13] = 0x09;
data[14] = 0x00;
transmitCmdData(0xE0, data, 15); //Set Gamma
data[0] = 0x00;
data[1] = 0x0E;
data[2] = 0x14;
data[3] = 0x03;
data[4] = 0x11;
data[5] = 0x07;
data[6] = 0x31;
data[7] = 0xC1;
data[8] = 0x48;
data[9] = 0x08;
data[10] = 0x0F;
data[11] = 0x0C;
data[12] = 0x31;
data[13] = 0x36;
data[14] = 0x0F;
transmitCmdData(0xE1, data, 15); //Set Gamma
ili9341_write_command(0x11); //Exit Sleep
_ili9341_delay(120);
ili9341_write_command(0x29); //Display on
ili9341_write_command(0x2c);
HAL_GPIO_WritePin(ILI9341_LED, GPIO_PIN_SET);
_ili9341_setAddrWindow(30, 30, 39, 39);
_ili9341_dc(1);
_ili9341_cs(0);
uint16_t da[100] = { 0xFAAF };
memset(da, 0xFA, 200);
HAL_SPI_Transmit(&ILI9341_SPI, (uint8_t*)da, 200, 100);
return HAL_OK;
}
//set window for drawing buffer
void _ili9341_setAddrWindow(uint16_t x0, uint16_t y0, uint16_t x1,
uint16_t y1)
{
uint8_t _ili9341_addr[4];
_ili9341_cs(0);
ili9341_write_command(ILI9341_CASET); // Column addr set
_ili9341_dc(1);
_ili9341_addr[0] = x0 >> 8;
_ili9341_addr[1] = x0;
_ili9341_addr[2] = x1 >> 8;
_ili9341_addr[3] = x1;
HAL_SPI_Transmit(&ILI9341_SPI, (uint8_t*)_ili9341_addr, 4, 10);
ili9341_write_command(ILI9341_PASET); // Row addr set
_ili9341_dc(1);
_ili9341_addr[0] = y0 >> 8;
_ili9341_addr[1] = y0;
_ili9341_addr[2] = y1 >>8;
_ili9341_addr[3] = y1;
HAL_SPI_Transmit(&ILI9341_SPI, (uint8_t*)_ili9341_addr, 4, 10);
ili9341_write_command(ILI9341_RAMWR); // write to RAM
}
void ili9341_tx(MakiseDriver* d)
{
d->posy = 0;
if(d->gui->draw != 0)
{
d->gui->draw(d->gui);
}
_ili9341_setAddrWindow(0, d->posy, d->lcd_width, d->buffer_height - 1 + d->posy);
makise_render(d->gui, 0);
//_ili9341_cs(1);
_ili9341_dc(1);
_ili9341_cs(0);
HAL_SPI_Transmit_DMA(&ILI9341_SPI, (uint8_t*)d->buffer, d->size);
}
uint8_t ili9341_start(MakiseGUI* gui)
{
/* #if ILI9341_LED_USE_PWM */
/* HAL_TIM_Base_Start(ILI9341_LED_PWM); */
/* HAL_TIM_PWM_Start(ILI9341_LED_PWM, ILI9341_LED_PWM_CHANNEL); */
/* #endif */
// ili9341_set_backlight(1);
//ili9341_set_backlight(gui, 31);
ili9341_tx(gui->driver);
printf("start driver\n");
return M_OK;
}
uint8_t ili9341_set_backlight(MakiseGUI* gui, uint8_t val)
{
#if ILI9341_LED_USE_PWM
__HAL_TIM_SET_COMPARE(ILI9341_LED_PWM, ILI9341_LED_PWM_CHANNEL, val);
#else
HAL_GPIO_WritePin(ILI9341_LED, val ? GPIO_PIN_SET : GPIO_PIN_RESET);
#endif
return M_OK;
}
uint8_t ili9341_spi_txhalfcplt(MakiseDriver* d)
{
if(d->posy < d->lcd_height)
makise_render(d->gui, 1);
return M_OK;
}
uint8_t ili9341_spi_txcplt(MakiseDriver* d)
{
// _ili9341_cs(1);
uint8_t dr = 0;
MakiseBuffer *bu = d->gui->buffer;
if(d->posy >= d->lcd_height)
{
dr = 1;
d->posy = 0;
memset(bu->buffer +
0,//d->lcd_width * (d->lcd_height - d->buffer_height) * bu->pixeldepth / 32,
0,
bu->size);//d->lcd_width * d->buffer_height * bu->pixeldepth / 8);
if(d->gui->draw != 0)
{
d->gui->draw(d->gui);
}
}
//HAL_Delay(100);
_ili9341_setAddrWindow(0, d->posy, d->buffer_width, d->buffer_height - 1 + d->posy);
makise_render(d->gui, dr ? 0 : 2);
_ili9341_dc(1);
_ili9341_cs(0);
HAL_SPI_Transmit_DMA(&ILI9341_SPI, (uint8_t*)d->buffer, d->size);
//HAL_Delay(30);
if(dr)
{
if(d->gui->predraw != 0)
{
d->gui->predraw(d->gui);
}
if(d->gui->update != 0)
{
d->gui->update(d->gui);
}
}
else
{
/* memset(bu->buffer + (d->posy - d->buffer_height * 2) * */
/* d->lcd_width * bu->pixeldepth / 32, */
/* 0, */
/* d->lcd_width * d->buffer_height * bu->pixeldepth / 8); */
}
return M_OK;
}
uint8_t ili9341_write_data(uint8_t d)
{
_ili9341_dc(1);
HAL_SPI_Transmit(&ILI9341_SPI, &d, 1, 10);
return d;
}
uint8_t ili9341_write_command(uint8_t c)
{
_ili9341_dc(0);
HAL_SPI_Transmit(&ILI9341_SPI, &c, 1, 10);
return c;
}
<file_sep>/core_src/Src/gui.h
#ifndef GUI_H
#define GUI_H
#include "ili9341.h"
#include "makise_colors.h"
#include "makise.h"
#include "makise_gui.h"
#include "makise_e.h"
#include "gpio.h"
#include <stdio.h>
#include <string.h>
extern MakiseGUI *mGui;
MakiseGUI* gui_init();
//Define user keys
#define M_KEY_USER_ESC M_KEY_USER_0
#define M_KEY_USER_FOCUS_NEXT M_KEY_USER_0+1
#define M_KEY_USER_FOCUS_PREV M_KEY_USER_0+2
#define M_KEY_USER_TREE M_KEY_USER_0+3
#define M_KEY_USER_EncL M_KEY_USER_0+4
#define M_KEY_USER_EncR M_KEY_USER_0+5
#define M_KEY_USER_Play M_KEY_USER_0+6
#define M_KEY_USER_SD_ERROR M_KEY_USER_0+7
#endif
<file_sep>/core_src/CMakeLists.txt
# BSD 2-Clause License
#
# Copyright (c) 2017, <NAME> <<EMAIL>>
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are met:
#
# * Redistributions of source code must retain the above copyright notice, this
# list of conditions and the following disclaimer.
#
# * Redistributions in binary form must reproduce the above copyright notice,
# this list of conditions and the following disclaimer in the documentation
# and/or other materials provided with the distribution.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# Requirements:
# cmake > 2.6
# arm-none-eabi-gdb
# python3
# HOWTO:
# 1) Create STM32cubeMX SW4STM32 project.
# 2) Copy this CMakeLists.txt & CubeMX2_cmake.py in folder with created project.
# 3) Execute: "mkdir build; cd build"
# 4) Execute: "cmake ../; make"
# 5) DONE
cmake_minimum_required (VERSION 2.6)
#USER CUSTOM SETTINGS
#You can change values here. It's not recommended to change whole script
set(OPT "-O1")
set(USER_LINKER_FLAGS "-u _printf_float")
set(USER_CFLAGS "")
set(USER_COMPILER "Clang") # "Clang" or "GNU"
set(USER_DEBUG TRUE) # Or "False"
#You cam add your own defenitions
add_definitions(-DIS_STM32=1)
#add_definitions(-DYour_defenition=here)
#USER END
#CMAKE
#LOAD CUBE MX CONFIGURATION
#USING PYTHON SCRIPT CubeMX2_cmake.py
set(cubemx_dir ${CMAKE_CURRENT_LIST_DIR})
message("CubeMX dir: " ${cubemx_dir})
string(REPLACE " " "" cubemx_dir ${cubemx_dir})
execute_process(COMMAND bash "-c"
"python3 ${cubemx_dir}/CubeMX2_cmake.py ${cubemx_dir}"
OUTPUT_VARIABLE cubemx_conf
RESULT_VARIABLE cubemx_res
ERROR_VARIABLE cubemx_err)
if(${cubemx_res} EQUAL "0")
message("CubeMX ok")
else()
message(FATAL_ERROR ${cubemx_err})
endif()
foreach(i ${cubemx_conf})
message(${i})
endforeach()
#read IGNORE file and make list from it
file (STRINGS "CMakeIgnore.txt" CMAKE_IGNORE)
STRING(REGEX REPLACE "\n" ";" CMAKE_IGNORE "${CMAKE_IGNORE}")
list(GET cubemx_conf 0 STM32_PRJ_NAME )
list(GET cubemx_conf 1 STM32_PRJ_CFLAGS )
list(GET cubemx_conf 2 STM32_PRJ_DEFS )
list(GET cubemx_conf 3 STM32_PRJ_MCU )
list(GET cubemx_conf 4 STM32_PRJ_LD_SCRIPT)
message("CUBE project name: " ${STM32_PRJ_NAME})
message("CUBE MCU: " ${STM32_PRJ_MCU})
message("CUBE CFLAGS: " ${STM32_PRJ_CFLAGS})
message("CUBE DEFs: " ${STM32_PRJ_DEFS})
message("CUBE LD script " ${STM32_PRJ_LD_SCRIPT})
string(REPLACE " " "" STM32_PRJ_NAME ${STM32_PRJ_NAME})
string(REPLACE "\"" "" STM32_PRJ_DEFS ${STM32_PRJ_DEFS})
string(REPLACE " " ";" STM32_PRJ_DEFS ${STM32_PRJ_DEFS})
string(REPLACE " " "" STM32_PRJ_LD_SCRIPT ${STM32_PRJ_LD_SCRIPT})
string(REPLACE "\n" "" STM32_PRJ_LD_SCRIPT ${STM32_PRJ_LD_SCRIPT})
set(STM32_PRJ_LD_SCRIPT "${cubemx_dir}/${STM32_PRJ_LD_SCRIPT}")
if(POLICY CMP0012)
cmake_policy(SET CMP0012 NEW)
endif()
cmake_policy(SET CMP0057 NEW)
project(${STM32_PRJ_NAME})
set(CMAKE_C_COMPILER_ID ${USER_COMPILER})
if(${USER_DEBUG})
set(CMAKE_BUILD_TYPE "Debug")
else(${USER_DEBUG})
set(CMAKE_BUILD_TYPE "Release")
endif(${USER_DEBUG})
include("CMakeSetCompiler.cmake")
#find and add all headers & sources & asm to target
MACRO(HEADER_DIRECTORIES return_list)
FILE(GLOB_RECURSE new_list *.h)
SET(dir_list "")
FOREACH(file_path ${new_list})
GET_FILENAME_COMPONENT(dir_path ${file_path} PATH)
SET(dir_list ${dir_list} ${dir_path})
ENDFOREACH()
LIST(REMOVE_DUPLICATES dir_list)
SET(${return_list} ${dir_list})
ENDMACRO()
#HEADERS
header_directories(INC)
include_directories(${INC})
#SOURCES
file(GLOB_RECURSE SRC RELATIVE ${CMAKE_CURRENT_SOURCE_DIR} *.c)
string(REGEX REPLACE "[^;]*CMakeFiles/[^;]+;?" "" SRC "${SRC}")
#ASSEMBLER files
file(GLOB_RECURSE asm_SRC "*.s")
set_source_files_properties(${asm_SRC} "-x assembler-with-cpp")
#list all files
message("INCLUDES:")
set(incs "")
foreach(f ${INC})
set(incs "${incs} -I${f}")
message(${f})
endforeach()
message("SOURCES: ")
foreach(f ${SRC})
message(${f})
if (${f} IN_LIST CMAKE_IGNORE)
list(REMOVE_ITEM SRC ${f})
message("Ignored!")
endif()
endforeach()
message("DEFINITIONS: ")
foreach(def ${STM32_PRJ_DEFS})
message(${def})
add_definitions("${def}")
endforeach()
#setup flags
set(CMAKE_C_FLAGS "${EXTERN_C_FLAGS} ${CMAKE_C_FLAGS} ${STM32_PRJ_CFLAGS} ${OPT} ${USER_CFLAGS}")
set(CMAKE_CXX_FLAGS "${EXTERN_C_FLAGS} ${CMAKE_CXX_FLAGS} ${STM32_PRJ_CFLAGS} ${OPT} ${USER_CFLAGS}")
set(CMAKE_ASM_FLAGS "${CMAKE_ASM_FLAGS} ${STM32_PRJ_CFLAGS} ${OPT} ${USER_CFLAGS}")
set(LDSCRIPT "-T${STM32_PRJ_LD_SCRIPT}")
set(LINKER_FLAGS "-specs=nosys.specs ${LDSCRIPT} -lc -lm -lnosys -Wl,--gc-sections ${STM32_PRJ_CFLAGS} ${OPT} ${USER_LINKER_FLAGS} ")
SET(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} ${LINKER_FLAGS}")
SET(TARGET ${CMAKE_PROJECT_NAME})
message(${CMAKE_C_COMPILER})
#setup targets
get_directory_property(C_DEFS COMPILE_DEFINITIONS)
#.elf
add_executable(${TARGET}.elf ${SRC} ${asm_SRC})
#print size
add_custom_command(TARGET ${TARGET}.elf POST_BUILD COMMAND ${CMAKE_SIZE} ${TARGET}.elf)
#other
ADD_CUSTOM_TARGET(${TARGET}.hex DEPENDS ${TARGET}.elf COMMAND ${CMAKE_OBJCOPY} -Oihex ${TARGET}.elf ${TARGET}.hex)
ADD_CUSTOM_TARGET(${TARGET}.bin DEPENDS ${TARGET}.elf COMMAND ${CMAKE_OBJCOPY} -Obinary ${TARGET}.elf ${TARGET}.bin)
<file_sep>/core_src/Src/gui.c
#include "gui.h"
MakiseGUI *mGui;
MHost *host;
static MakiseGUI Gu;
static MakiseDriver Dr;
static MHost hs;
uint32_t
//__attribute__ ((section (".ccmram")))
Makise_Buffer[38400/4] = { 0 };
uint32_t Makise_DBuffer[9600] = { 0 };
void thello();
void HAL_SPI_TxHalfCpltCallback(SPI_HandleTypeDef *hspi)
{
//printf("txHcplt\n");
if(hspi == &ILI9341_SPI)
ili9341_spi_txhalfcplt(mGui->driver);
}
void HAL_SPI_TxCpltCallback(SPI_HandleTypeDef *hspi)
{
//printf("txcplt\n");
thello();
if(hspi == &ILI9341_SPI)
ili9341_spi_txcplt(mGui->driver);
}
void gui_predraw(MakiseGUI * gui)
{
/* if(ldf) */
/* window_play_update(); */
/* ldf = !ldf; */
makise_gui_input_perform(host);
makise_g_host_call(host, gui, M_G_CALL_PREDRAW);
}
void gui_draw(MakiseGUI* gui)
{
makise_g_host_call(host, gui, M_G_CALL_DRAW);
}
MInputData inp_handler(MInputData d, MInputResultEnum res)
{
if(d.event == M_INPUT_CLICK && res == M_INPUT_NOT_HANDLED)
{
//when click wasn't handled in the GUI
//printf("not h %d\n", d.key);
//if(d.key == M_KEY_LEFT) //if left wasn't handled - we'll switch focus
// fm_switch();
//Cmakise_g_host_focus_prev(host);
if(d.key == M_KEY_UP) //the same
makise_g_host_focus_prev(host);
if(d.key == M_KEY_DOWN)
makise_g_host_focus_next(host);
if(d.key == M_KEY_TAB_NEXT)
makise_g_host_focus_next(host);
if(d.key == M_KEY_TAB_BACK)
makise_g_host_focus_prev(host);
if(d.key == M_KEY_USER_FOCUS_NEXT)
makise_g_host_focus_next(host);
if(d.key == M_KEY_USER_FOCUS_PREV)
makise_g_host_focus_prev(host);
}
return (MInputData){0};
}
#if MAKISE_MUTEX
MAKISE_MUTEX_t m_mutex_create ()
{
MAKISE_MUTEX_t sobj = xSemaphoreCreateMutex();
xSemaphoreGive(sobj);
return sobj;
}
//delete mutex
uint8_t m_mutex_delete (MAKISE_MUTEX_t sobj)
{
if(sobj == 0) {
printf("Mutex null\n");
return 0;
}
vSemaphoreDelete(sobj);
return 1;
}
//Request Grant to Access some object
uint8_t m_mutex_request_grant (MAKISE_MUTEX_t sobj)
{
if(sobj == 0 || sobj == 0) {
printf("Mutex null\n");
return 0;
}
int res = (int)(xSemaphoreTake(sobj, MAKISE_MUTEX_TIMEOUT) == pdTRUE);
if(res == 0) {
printf("Mutex err mak\n");
// while(1);
}
return res;
}
//Release Grant to Access the Volume
uint8_t m_mutex_release_grant (MAKISE_MUTEX_t sobj)
{
if(sobj == 0) {
printf("Mutex null\n");
return 0;
}
xSemaphoreGive(sobj);
return 1;
}
#endif
static void* _get_gui_buffer(uint32_t size)
{
printf("ggb %d\n", size);
return Makise_Buffer;
}
void tests_hello_init(MHost *h);
void l_write_reg(uint8_t reg, uint32_t d)
{
HAL_GPIO_WritePin(AG_4_GPIO_Port, AG_4_Pin, GPIO_PIN_RESET);
uint8_t data[4] = { reg, 0, 0, d & 0xFF };
uint8_t dataRx[4] = { 0, 0, 0, 0 };
HAL_SPI_TransmitReceive(&hspi4, data, dataRx, 4, 100);
HAL_GPIO_WritePin(AG_4_GPIO_Port, AG_4_Pin, GPIO_PIN_SET);
}
uint32_t l_read_reg(uint8_t reg)
{
HAL_GPIO_WritePin(AG_4_GPIO_Port, AG_4_Pin, GPIO_PIN_RESET);
uint8_t data[4] = { reg | 0b00100000, 0, 0, 0 };
uint8_t dataRx[4] = { 0, 0, 0, 0 };
HAL_SPI_TransmitReceive(&hspi4, data, dataRx, 4, 100);
HAL_GPIO_WritePin(AG_4_GPIO_Port, AG_4_Pin, GPIO_PIN_SET);
return dataRx[0] | dataRx[0] << 8 | dataRx[0] << 16 | dataRx[3] << 24;
}
MPosition ma_g_hpo;
MakiseGUI* gui_init()
{
//malloc structures
MakiseGUI * gu = &Gu;
MakiseDriver * dr = &Dr;
host = &hs;
ili9341_driver(dr, Makise_DBuffer, sizeof(Makise_DBuffer));
memset((uint8_t*)Makise_Buffer, 0, sizeof(Makise_Buffer));
memset((uint8_t*)Makise_DBuffer, 0, sizeof(Makise_DBuffer));
makise_gui_autoinit(host,
gu, dr,
&_get_gui_buffer,
&inp_handler,
&gui_draw, &gui_predraw, 0, 0, 0);
ili9341_init(gu);
tests_hello_init(host);
mGui = gu;
ili9341_start(gu);
printf("L6470\n");
HAL_GPIO_WritePin(AG_3_GPIO_Port, AG_3_Pin, GPIO_PIN_RESET);
HAL_GPIO_WritePin(AG_4_GPIO_Port, AG_4_Pin, GPIO_PIN_SET);
HAL_Delay(10);
HAL_GPIO_WritePin(AG_3_GPIO_Port, AG_3_Pin, GPIO_PIN_SET);
HAL_Delay(1);
printf("reg %x\n", l_read_reg(0x18));
HAL_Delay(1);
l_write_reg(0b01000001, 100);
return gu;
}
<file_sep>/core_src/Src/spi.c
/**
******************************************************************************
* File Name : SPI.c
* Description : This file provides code for the configuration
* of the SPI instances.
******************************************************************************
* @attention
*
* <h2><center>© Copyright (c) 2019 STMicroelectronics.
* All rights reserved.</center></h2>
*
* This software component is licensed by ST under Ultimate Liberty license
* SLA0044, the "License"; You may not use this file except in compliance with
* the License. You may obtain a copy of the License at:
* www.st.com/SLA0044
*
******************************************************************************
*/
/* Includes ------------------------------------------------------------------*/
#include "spi.h"
/* USER CODE BEGIN 0 */
/* USER CODE END 0 */
SPI_HandleTypeDef hspi3;
SPI_HandleTypeDef hspi4;
DMA_HandleTypeDef hdma_spi3_tx;
/* SPI3 init function */
void MX_SPI3_Init(void)
{
hspi3.Instance = SPI3;
hspi3.Init.Mode = SPI_MODE_MASTER;
hspi3.Init.Direction = SPI_DIRECTION_2LINES;
hspi3.Init.DataSize = SPI_DATASIZE_8BIT;
hspi3.Init.CLKPolarity = SPI_POLARITY_LOW;
hspi3.Init.CLKPhase = SPI_PHASE_1EDGE;
hspi3.Init.NSS = SPI_NSS_SOFT;
hspi3.Init.BaudRatePrescaler = SPI_BAUDRATEPRESCALER_2;
hspi3.Init.FirstBit = SPI_FIRSTBIT_MSB;
hspi3.Init.TIMode = SPI_TIMODE_DISABLE;
hspi3.Init.CRCCalculation = SPI_CRCCALCULATION_DISABLE;
hspi3.Init.CRCPolynomial = 10;
if (HAL_SPI_Init(&hspi3) != HAL_OK)
{
Error_Handler();
}
}
/* SPI4 init function */
void MX_SPI4_Init(void)
{
hspi4.Instance = SPI4;
hspi4.Init.Mode = SPI_MODE_MASTER;
hspi4.Init.Direction = SPI_DIRECTION_2LINES;
hspi4.Init.DataSize = SPI_DATASIZE_8BIT;
hspi4.Init.CLKPolarity = SPI_POLARITY_LOW;
hspi4.Init.CLKPhase = SPI_PHASE_1EDGE;
hspi4.Init.NSS = SPI_NSS_SOFT;
hspi4.Init.BaudRatePrescaler = SPI_BAUDRATEPRESCALER_16;
hspi4.Init.FirstBit = SPI_FIRSTBIT_MSB;
hspi4.Init.TIMode = SPI_TIMODE_DISABLE;
hspi4.Init.CRCCalculation = SPI_CRCCALCULATION_DISABLE;
hspi4.Init.CRCPolynomial = 10;
if (HAL_SPI_Init(&hspi4) != HAL_OK)
{
Error_Handler();
}
}
void HAL_SPI_MspInit(SPI_HandleTypeDef* spiHandle)
{
GPIO_InitTypeDef GPIO_InitStruct = {0};
if(spiHandle->Instance==SPI3)
{
/* USER CODE BEGIN SPI3_MspInit 0 */
/* USER CODE END SPI3_MspInit 0 */
/* SPI3 clock enable */
__HAL_RCC_SPI3_CLK_ENABLE();
__HAL_RCC_GPIOD_CLK_ENABLE();
__HAL_RCC_GPIOB_CLK_ENABLE();
/**SPI3 GPIO Configuration
PD6 ------> SPI3_MOSI
PB3 ------> SPI3_SCK
PB4 ------> SPI3_MISO
*/
GPIO_InitStruct.Pin = L_MOSI_Pin;
GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;
GPIO_InitStruct.Pull = GPIO_NOPULL;
GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_VERY_HIGH;
GPIO_InitStruct.Alternate = GPIO_AF5_SPI1;
HAL_GPIO_Init(L_MOSI_GPIO_Port, &GPIO_InitStruct);
GPIO_InitStruct.Pin = L_SCK_Pin|L_MISO_Pin;
GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;
GPIO_InitStruct.Pull = GPIO_NOPULL;
GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_VERY_HIGH;
GPIO_InitStruct.Alternate = GPIO_AF6_SPI3;
HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);
/* SPI3 DMA Init */
/* SPI3_TX Init */
hdma_spi3_tx.Instance = DMA1_Stream5;
hdma_spi3_tx.Init.Channel = DMA_CHANNEL_0;
hdma_spi3_tx.Init.Direction = DMA_MEMORY_TO_PERIPH;
hdma_spi3_tx.Init.PeriphInc = DMA_PINC_DISABLE;
hdma_spi3_tx.Init.MemInc = DMA_MINC_ENABLE;
hdma_spi3_tx.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;
hdma_spi3_tx.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;
hdma_spi3_tx.Init.Mode = DMA_NORMAL;
hdma_spi3_tx.Init.Priority = DMA_PRIORITY_HIGH;
hdma_spi3_tx.Init.FIFOMode = DMA_FIFOMODE_DISABLE;
if (HAL_DMA_Init(&hdma_spi3_tx) != HAL_OK)
{
Error_Handler();
}
__HAL_LINKDMA(spiHandle,hdmatx,hdma_spi3_tx);
/* SPI3 interrupt Init */
HAL_NVIC_SetPriority(SPI3_IRQn, 5, 0);
HAL_NVIC_EnableIRQ(SPI3_IRQn);
/* USER CODE BEGIN SPI3_MspInit 1 */
/* USER CODE END SPI3_MspInit 1 */
}
else if(spiHandle->Instance==SPI4)
{
/* USER CODE BEGIN SPI4_MspInit 0 */
/* USER CODE END SPI4_MspInit 0 */
/* SPI4 clock enable */
__HAL_RCC_SPI4_CLK_ENABLE();
__HAL_RCC_GPIOE_CLK_ENABLE();
/**SPI4 GPIO Configuration
PE2 ------> SPI4_SCK
PE5 ------> SPI4_MISO
PE6 ------> SPI4_MOSI
*/
GPIO_InitStruct.Pin = AS_SCK_Pin|AS_MISO_Pin|AS_MOSI_Pin;
GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;
GPIO_InitStruct.Pull = GPIO_NOPULL;
GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_VERY_HIGH;
GPIO_InitStruct.Alternate = GPIO_AF5_SPI4;
HAL_GPIO_Init(GPIOE, &GPIO_InitStruct);
/* SPI4 interrupt Init */
HAL_NVIC_SetPriority(SPI4_IRQn, 5, 0);
HAL_NVIC_EnableIRQ(SPI4_IRQn);
/* USER CODE BEGIN SPI4_MspInit 1 */
/* USER CODE END SPI4_MspInit 1 */
}
}
void HAL_SPI_MspDeInit(SPI_HandleTypeDef* spiHandle)
{
if(spiHandle->Instance==SPI3)
{
/* USER CODE BEGIN SPI3_MspDeInit 0 */
/* USER CODE END SPI3_MspDeInit 0 */
/* Peripheral clock disable */
__HAL_RCC_SPI3_CLK_DISABLE();
/**SPI3 GPIO Configuration
PD6 ------> SPI3_MOSI
PB3 ------> SPI3_SCK
PB4 ------> SPI3_MISO
*/
HAL_GPIO_DeInit(L_MOSI_GPIO_Port, L_MOSI_Pin);
HAL_GPIO_DeInit(GPIOB, L_SCK_Pin|L_MISO_Pin);
/* SPI3 DMA DeInit */
HAL_DMA_DeInit(spiHandle->hdmatx);
/* SPI3 interrupt Deinit */
HAL_NVIC_DisableIRQ(SPI3_IRQn);
/* USER CODE BEGIN SPI3_MspDeInit 1 */
/* USER CODE END SPI3_MspDeInit 1 */
}
else if(spiHandle->Instance==SPI4)
{
/* USER CODE BEGIN SPI4_MspDeInit 0 */
/* USER CODE END SPI4_MspDeInit 0 */
/* Peripheral clock disable */
__HAL_RCC_SPI4_CLK_DISABLE();
/**SPI4 GPIO Configuration
PE2 ------> SPI4_SCK
PE5 ------> SPI4_MISO
PE6 ------> SPI4_MOSI
*/
HAL_GPIO_DeInit(GPIOE, AS_SCK_Pin|AS_MISO_Pin|AS_MOSI_Pin);
/* SPI4 interrupt Deinit */
HAL_NVIC_DisableIRQ(SPI4_IRQn);
/* USER CODE BEGIN SPI4_MspDeInit 1 */
/* USER CODE END SPI4_MspDeInit 1 */
}
}
/* USER CODE BEGIN 1 */
/* USER CODE END 1 */
/************************ (C) COPYRIGHT STMicroelectronics *****END OF FILE****/
<file_sep>/core_src/Src/tests_hello.c
#include "gui.h"
MakiseStyle_Button ts_button =
{
.font = &F_Default10x20,
.bitmap_gap = 10,
.active_delay = 5,
// bg font border double_border
.normal = {MC_Red, MC_White, MC_White, 2}, //normal
.focused = {MC_Black, MC_White, MC_White, 6}, //focused
.active = {MC_Green, MC_Gray, MC_White, 2}, //active
};
MakiseStyle_Lable ts_lable =
{
.font = &F_Default10x20,
//font bg border double_border
.font_col = MC_White,
.bg_color = MC_Transparent,
.border_c = MC_Green,
.thickness = 3,
.scroll_speed = 100
};
static const uint8_t B_folder_data[] = {
0x1e, 0xc2, 0x05, 0xcc, 0x5f, 0xb0, 0x60, 0x41, 0x7f,
0x00, };
const MakiseBitmap B_folder = {
.width = 9,
.height = 8,
.data = B_folder_data
};
MakiseStyle_FSViewer ts_fsviewer = {
.font = &F_Default6x10,
.font_line_spacing = 0,
.bitmap_folder = &B_folder,
.left_margin = 0,
.item_margin = 0,
.scroll_width = 3,
.scroll_bg_color = MC_Black,
.scroll_color = MC_White,
.normal = {MC_Black, MC_Black, MC_Black, 0},
.focused = {MC_Black, MC_White, MC_Black, 0},
.active = {MC_Black, MC_White, MC_Black, 0},
};
MakiseStyle_FSViewer_Item ts_fsviewer_item = {
.font = &F_Default6x10,
.font_line_spacing = 0,
.text_scroll_speed = 100,
.normal = {MC_Black, MC_White, MC_Black, MC_White, 0},
.focused = {MC_White, MC_Black, MC_White, MC_Black, 0},
.active = {MC_Black, MC_White, MC_White, MC_Black, 0},
};
static MButton button; //button structure
static MButton button1; //button structure
static MLable lable; //lable structure
static MFSViewer flist;
static void click(MButton* b) //b - button wich was clicked
{
}
//event when button was clicked
static void click1(MButton* b) //b - button wich was clicked
{
//return;
//create lable
m_create_lable(&lable, b->el.parent,
mp_rel(100, 150, 130, 30),
&ts_lable);
m_lable_set_text(&lable, "Hello world!");
//remove button from the container
makise_g_cont_rem(&button1.el);
}
void thello()
{
}
void tests_hello_init(MHost *h)
{
m_create_button(&button, &h->host,
mp_rel(0, 0, 240, 320),
&ts_button);
m_button_set_click(&button, &click);
m_button_set_text(&button, "Sosy !");
m_create_button(&button1, &h->host,
mp_rel(200, 200, 85, 30),
&ts_button);
m_button_set_click(&button1, &click1);
m_button_set_text(&button1, "Click!");
printf("FM initing\n");
//initialize gui elements
/* m_create_fsviewer(&flist, &h->host, */
/* mp_sall(100,100,100,100), //position */
/* MFSViewer_SingleSelect, */
/* &ts_fsviewer, &ts_fsviewer_item); */
/* //m_fsviewer_set_onselection(&flist, &onselection); */
/* fsviewer_open(&flist, "/"); */
//mi_cont_rem(&action_container.el);
/* m_create_lable(&lable, host->host, */
/* mp_rel(20, 20, 80, 30), */
/* str, */
/* &ts_lable); */
/* items[0].text = "lol"; */
/* items[1].text = "kek"; */
/* items[2].text = "Привет"; */
/* m_create_slist(&slist, host->host, */
/* mp_sall(0,0,0,0), */
/* "sdf", */
/* 0, 0, */
/* MSList_List, */
/* &ts_slist, */
/* &ts_slist_item); */
/* makise_g_cont_rem(&slist.el); */
mi_focus(&button.el, M_G_FOCUS_GET);
}
<file_sep>/core_src/ILI9341/ili9341_registers.h
#define ILI9341_TFTWIDTH 240
#define ILI9341_TFTHEIGHT 320
#define ILI9341_NOP 0x00
#define ILI9341_SWRESET 0x01
#define ILI9341_RDDID 0x04
#define ILI9341_RDDST 0x09
#define ILI9341_SLPIN 0x10
#define ILI9341_SLPOUT 0x11
#define ILI9341_PTLON 0x12
#define ILI9341_NORON 0x13
#define ILI9341_RDMODE 0x0A
#define ILI9341_RDMADCTL 0x0B
#define ILI9341_RDPIXFMT 0x0C
#define ILI9341_RDIMGFMT 0x0A
#define ILI9341_RDSELFDIAG 0x0F
#define ILI9341_INVOFF 0x20
#define ILI9341_INVON 0x21
#define ILI9341_GAMMASET 0x26
#define ILI9341_DISPOFF 0x28
#define ILI9341_DISPON 0x29
#define ILI9341_CASET 0x2A
#define ILI9341_PASET 0x2B
#define ILI9341_RAMWR 0x2C
#define ILI9341_RAMRD 0x2E
#define ILI9341_PTLAR 0x30
#define ILI9341_MADCTL 0x36
#define ILI9341_MADCTL_MY 0x80
#define ILI9341_MADCTL_MX 0x40
#define ILI9341_MADCTL_MV 0x20
#define ILI9341_MADCTL_ML 0x10
#define ILI9341_MADCTL_RGB 0x00
#define ILI9341_MADCTL_BGR 0x08
#define ILI9341_MADCTL_MH 0x04
#define ILI9341_PIXFMT 0x3A
#define ILI9341_FRMCTR1 0xB1
#define ILI9341_FRMCTR2 0xB2
#define ILI9341_FRMCTR3 0xB3
#define ILI9341_INVCTR 0xB4
#define ILI9341_DFUNCTR 0xB6
#define ILI9341_PWCTR1 0xC0
#define ILI9341_PWCTR2 0xC1
#define ILI9341_PWCTR3 0xC2
#define ILI9341_PWCTR4 0xC3
#define ILI9341_PWCTR5 0xC4
#define ILI9341_VMCTR1 0xC5
#define ILI9341_VMCTR2 0xC7
#define ILI9341_RDID1 0xDA
#define ILI9341_RDID2 0xDB
#define ILI9341_RDID3 0xDC
#define ILI9341_RDID4 0xDD
#define ILI9341_GMCTRP1 0xE0
#define ILI9341_GMCTRN1 0xE1
/*
#define ILI9341_PWCTR6 0xFC
*/
<file_sep>/core_src/build/CMakeFiles/core_src.elf.dir/cmake_clean.cmake
file(REMOVE_RECURSE
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_cortex.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_dma_ex.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_exti.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ex.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_flash_ramfunc.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_gpio.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2c_ex.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_i2s_ex.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pcd_ex.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_pwr_ex.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_rcc_ex.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_sd.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_spi.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_tim_ex.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_hal_uart.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_sdmmc.c.o"
"CMakeFiles/core_src.elf.dir/Drivers/STM32F4xx_HAL_Driver/Src/stm32f4xx_ll_usb.c.o"
"CMakeFiles/core_src.elf.dir/ILI9341/ili9341.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/drivers/ILI9340C/ili9340.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/drivers/SDL2/makise_sdl2.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default10x20.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default5x7.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default6x10.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/fonts/Default8x13.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/makise_e.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_buttons.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_canvas.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_fatfs.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_fsviewer_stdio.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_lable.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_message_window.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slider.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_slist.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_tabs.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_text_field.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/elements/src/makise_e_toggle.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_container.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_elements.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_input.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/gui/makise_gui_interface.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_bitmap.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_colors.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_primitives.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_primitives_default_drawer.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/MakiseGUI/makise_text.c.o"
"CMakeFiles/core_src.elf.dir/MakiseGUI/docs/examples/mutex.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Class/CDC/Src/usbd_cdc.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_core.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ctlreq.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/ST/STM32_USB_Device_Library/Core/Src/usbd_ioreq.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/diskio.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/ff.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/ff_gen_drv.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/option/ccsbcs.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FatFs/src/option/syscall.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/CMSIS_RTOS/cmsis_os.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/croutine.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/event_groups.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/list.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/portable/GCC/ARM_CM4F/port.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/portable/MemMang/heap_4.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/queue.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/stream_buffer.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/tasks.c.o"
"CMakeFiles/core_src.elf.dir/Middlewares/Third_Party/FreeRTOS/Source/timers.c.o"
"CMakeFiles/core_src.elf.dir/Src/bsp_driver_sd.c.o"
"CMakeFiles/core_src.elf.dir/Src/dma.c.o"
"CMakeFiles/core_src.elf.dir/Src/fatfs.c.o"
"CMakeFiles/core_src.elf.dir/Src/freertos.c.o"
"CMakeFiles/core_src.elf.dir/Src/gpio.c.o"
"CMakeFiles/core_src.elf.dir/Src/gui.c.o"
"CMakeFiles/core_src.elf.dir/Src/i2c.c.o"
"CMakeFiles/core_src.elf.dir/Src/i2s.c.o"
"CMakeFiles/core_src.elf.dir/Src/main.c.o"
"CMakeFiles/core_src.elf.dir/Src/sd_diskio.c.o"
"CMakeFiles/core_src.elf.dir/Src/sdio.c.o"
"CMakeFiles/core_src.elf.dir/Src/spi.c.o"
"CMakeFiles/core_src.elf.dir/Src/stm32f4xx_hal_msp.c.o"
"CMakeFiles/core_src.elf.dir/Src/stm32f4xx_hal_timebase_tim.c.o"
"CMakeFiles/core_src.elf.dir/Src/stm32f4xx_it.c.o"
"CMakeFiles/core_src.elf.dir/Src/system_stm32f4xx.c.o"
"CMakeFiles/core_src.elf.dir/Src/tests_hello.c.o"
"CMakeFiles/core_src.elf.dir/Src/tim.c.o"
"CMakeFiles/core_src.elf.dir/Src/usart.c.o"
"CMakeFiles/core_src.elf.dir/Src/usb_device.c.o"
"CMakeFiles/core_src.elf.dir/Src/usbd_cdc_if.c.o"
"CMakeFiles/core_src.elf.dir/Src/usbd_conf.c.o"
"CMakeFiles/core_src.elf.dir/Src/usbd_desc.c.o"
"CMakeFiles/core_src.elf.dir/startup/startup_stm32f427xx.s.o"
"core_src.elf.pdb"
"core_src.elf"
)
# Per-language clean rules from dependency scanning.
foreach(lang ASM C)
include(CMakeFiles/core_src.elf.dir/cmake_clean_${lang}.cmake OPTIONAL)
endforeach()
| 42d362be8599e4a4d85caae17a13d9dde6ebeac4 | [
"C",
"Makefile",
"CMake"
] | 12 | C | SL-RU/osfi-p | e4f24d82981df83a6a05cd4cbffad08d3645e2e8 | 003e11dc20110085a6542cd54fd1ccbdc6eef83f |
refs/heads/master | <repo_name>WilliamTan2704/Pioneer<file_sep>/backend/sql/seed.js
// This creates initialized items and inserts it to the sql database
const sqlite3 = require("sqlite3");
const db = new sqlite3.Database("./database.sqlite");
<file_sep>/backend/sql/migration.js
// This initializes the table if it hasn't been set. Don't forget to run this!
const sqlite3 = require("sqlite3");
const db = new sqlite3.Database("./database.sqlite");
db.run(`CREATE TABLE IF NOT EXISTS Artist (
id INTEGER PRIMARY KEY NOT NULL,
name TEXT NOT NULL,
date_of_birth DATE NOT NULL,
biography TEXT NOT NULL,
is_currently_employed INTEGER DEFAULT 1
)`);
<file_sep>/backend/sql/sql.js
// This runs sql commands to the database
const sqlite3 = require("sqlite3");
const db = new sqlite3.Database("./database.sqlite");
<file_sep>/README.md
# Pyoneer
A fun project made by a few friends!
<file_sep>/backend/app.js
// This is the main file of the backend server
| 590059a491da5811a68eca2553ccd7f6d9e66a5a | [
"JavaScript",
"Markdown"
] | 5 | JavaScript | WilliamTan2704/Pioneer | 596143022ccce26cda08fb0a23b3c385998501ac | 3c62dc8b53bce3b9b5f7cd2c18e3b30937830456 |
refs/heads/master | <file_sep>package baseobject;
import java.sql.Driver;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.interactions.Actions;
import org.openqa.selenium.support.FindBy;
import org.openqa.selenium.support.PageFactory;
public class dress1 extends basepage123 {
@FindBy(xpath="(//a[@title='Dresses'])[2]")
private WebElement Dresses;
@FindBy(xpath="//a[@href='http://automationpractice.com/index.php?id_category=8&controller=category#size-s']")
private WebElement small;
@FindBy(xpath="//a[@href='http://automationpractice.com/index.php?id_category=8&controller=category#size-m']")
private WebElement medium;
@FindBy(xpath="//a[@href='http://automationpractice.com/index.php?id_category=8&controller=category#size-l']")
private WebElement large;
@FindBy(xpath="(//a[@href='http://automationpractice.com/index.php?id_product=3&controller=product'])[1]")
private WebElement prodect;
@FindBy(xpath="//a[@href='http://automationpractice.com/index.php?controller=cart&add=1&id_product=3&token=e81<PASSWORD>58da<PASSWORD>4c6<PASSWORD>']")
private WebElement cart;
@FindBy(xpath="//a[@href='http://automationpractice.com/index.php?controller=order']")
private WebElement checkout;
@FindBy(xpath="(//input[@value='1'])[2]")
private WebElement value;
public dress1() {
PageFactory.initElements(driver, this);
}
public WebElement getdress() {
return Dresses;
}
public WebElement getsmall() {
return small;
}
public WebElement getmedium() {
return medium;
}
public WebElement getlarge() {
return large;
}
public WebElement getprodect() {
return prodect;
}
public WebElement getcart() {
return cart;
}
public WebElement getchekout() {
return checkout;
}
public WebElement getvalue() {
return getvalue();
}
}
| ed43192d562a06211a002a127e30e9c7768f776b | [
"Java"
] | 1 | Java | monika501/facebook | ae482d858dcec841d73357ad0e7914776c3a9eb7 | 88dbaf3b8fd99fb532a4caa32dc1aa28f552118b |
refs/heads/master | <file_sep>num_list = ['7','5','3','1','9']
target = 12
num_list.sort()
print(num_list)
j = len(num_list) - 1
i = 0
for elem in num_list:
if(int(num_list[i]) + int(num_list[j]) == target):
print(str(i)+','+str(j))
i = i+1
elif(int(num_list[i]) + int(num_list[j]) > target):
j = j-1
else:
i = i+1
<file_sep>import sys
check_list = []
input_str = "[{()}]"
open_list = "[{("
close_list = "]})"
#print(len(input_str))
for i in range(0,len(input_str)):
ind1 = -1
ind = -2
#print(input_str[i])
if(input_str[0] == ']'):
print("unbalanced")
sys.exit()
check_list.append(input_str[i])
check_len = len(check_list)
if(check_len > 1):
if(check_list[check_len-1] in close_list):
ind = close_list.index(check_list[check_len-1])
if(check_list[check_len-2] in open_list):
ind1 = open_list.index(check_list[check_len-2])
if(ind == ind1):
check_list.pop(check_len-1)
check_list.pop(check_len-2)
if(len(check_list) == 0):
print("balanced")
else:
print("unbalanced")
<file_sep>list_1 = [6,7,2,3,3,5,1,9,8,8,8,8]
dict_1 = {}
list_1.sort()
max_1 = max(list_1)
for i in range(1,max_1+1):
dict_1[i] = 0
for elem in list_1:
dict_1[int(elem)] +=1
for key, elem in dict_1.items():
if(elem > 1):
print("duplicate: "+str(key))
if(elem == 0):
print("missing: "+str(key))
| 4a0d85d6b6f73dfa18fe22ad9df94ea5055a0c26 | [
"Python"
] | 3 | Python | 0Sandeep12/My_codes | 226af2f63987f802e7ade0a3df4a7d812a31c5c7 | cd33521c00ab1f1afc089a702a439fa2f048f234 |
refs/heads/main | <file_sep># EECS738 Project3 Says One Neuron To Another
EECS738 Machine Learning course project3. Two deep neural networks have been implemented: a Multilayer Perceptron (MLP) with multiple linear layers and a typical Convolutional Neural Network (CNN). Two image datasets are selected: **MNIST** handwriting characters and **GTSRB** traffic sign recognition. Only third-party packages used in all implementations are **numpy**, **pandas**, **python-mnist** and **Pillow**.
## Function Checklist
These functions are implemented manually in this project in a detailed manner:
* Fully-Connected layers.
* Convolutional layers.
* Batch Normalization 2d & 1d.
* Dropout.
* Maxpooling.
* Activation functions: Sigmoid and ReLU.
* Data loading and data prepossessing (normalization).
* Forwarding and backpropagation using BGD.
* Cross-entropy loss.
## Dataset
* [Modified National Institute of Standards and Technology database (MNIST)](http://yann.lecun.com/exdb/mnist/). This is possibly one of the most commonly-used and simplest dataset in image tasks in machine learning, which combines with different images of hand-written digits. The sizes of training dataset and testing dataset are 60,000 and 10,000 each. Though the attached webpage link seems not to be working, the dataset can be directly accessed by package [python-mnist](https://github.com/sorki/python-mnist). Images and grey-scale with a size of 28\*28 each. Ten labels in total range from 0, 1, 2... to 9.
* [The German Traffic Sign Recognition Benchmark (GTSRB)](https://benchmark.ini.rub.de/gtsrb_dataset.html). This is a more challenging dataset with images of traffic signs captured in real street views. Each image contains exactly one traffic sign, usually located right at the middle. There are 43 labels in total, representing different types of traffic signs, and more than 50,000 samples. Recognition of these signs is much more difficult and practically significant, as many of the signs have similar shapes and colors.
## Ideas and Thinking
* **DNN**: In my opinion, deep neural networks are basically a complex but repetitive variant of weighted function with non-linear operators added. What deep learning does is to tweak the weights gradually by iterating over a large (usually) number of examples. If taking a task as a process of building sand castles, the precise solution will be like building by crafting structures and shapes, and the deep learning will be like flapping and rubbing by frequently looking at samples. Outcome of deep learning are set of parameters to mimic and map certain features, known as saliency, to high confidence scores in exact dimension. This 'learning' process imitates the process of human learning (recognition or understanding), setting up correlations between 'name/meaning' and 'features' through repetitively getting exposed to examples and strengthening neuron connections.
* **Activation Functions**: An important component of deep learning is activation function, which significantly accounts for deep learning's success. The non-linear properties of deep learning are largely contributions of activations. What activations really does is to differentiate neurons to respond to unique features. After activation, some of the neurons will be silent for specific features, while others will not. In this way, the deep neural networks are no longer an inflexible combination of weighted values, but a instead dynamic system where each unit has a 'switch'. This is done mainly by the cut-off (e.g. ReLU) or downgrade (e.g. Sigmoid) in gradients in backpropagation. Once a neuron get silent for certain feature distribution, little changes will be witnessed in its parameters when updating. In forwarding cases, different parts of neurons will 'switch on' for different feature distribution, which greatly increase the fitting ability of the function in limited parameter space.
* **Backpropagation**: Backpropagation is a rather simple but important process. By calculating the partial gradient of the model output over parameters, the parameters are updated from layer to layer to increase highly-activated neurons' contribution to current label, and decrease noises from unrelated neurons.
* **Testing**: After iterations over training samples, the model parameters are tuned to distribution of the task domain, which expects the ability to guide new examples from the same domain into explainable outputs. Different from training, some operators, e.g. dropout and batch normalization, tend to stay static in testing phase to expect stable behaviors, e.g. to eliminate quantity influence and random errors.
## Setup
### Environment
* Python 3.9
* MacOS or Linux
### Package
* Recommend setting up a virtual environment. Different versions of packages may cause unexpected failures.
* Install packages in **requirements.txt**.
```bash
pip install -r requirements.txt
```
* I've updated my environment to python3.9 and there is inconsistency between my previous course projects and this one. Sorry for any possible troubles.
## Usage
### Positional & Optional Parameters
* **data**: Dataset name (task) to choose from 'mnist' and 'gtsrb'.
* **-p**: Whether to load pre-trained model parameters. The parameters for MNIST model is saved in ['./paras'](https://github.com/liuzey/EECS738_Project3/tree/main/paras). The parameters for GTSRB model is saved in ['./paras_save'](https://github.com/liuzey/EECS738_Project3/tree/main/paras_save). (Default: False).
* **-s**: Whether to save the trained model parameters (Default: False).
### Example
```bash
python main.py 'gtsrb' -s 1 -p 1
```
* 'gtsrb': GTSRB recognition task.
* -p: Model parameters are pre-trained and loaded.
* -s: Trained parameters are saved periodically.
## Result Analysis
Training records and results are saved in ['./records'](https://github.com/liuzey/EECS738_Project3/tree/main/records), which shows indeed a decrease in loss. This indicates the training is working in some sense. However, the accuracy doesn't show great improvements. This is a rough implementation of neural networks, which has much space for improvements, especially in gradient calculation. I remain these as my future work.
### MLP
The structure of the MLP model used in MNIST task is
| MLP |
| :-------------: |
| FC1(1\*28\*28, 100) |
| FC2(100, 10) |
All linear layers have biases.
### CNN
For this convolutional neural network in this project, the convolutional kernels is set at (3,3). The structure of the CNN model used in GTSRB task is
| CNN |
| :-------------: |
| Conv1(channels=32, stride=(1, 1), padding=(0, 0)), BatchNorm(32), ReLU |
| Conv2(channels=64, stride=(2, 2), padding=(1, 1)) |
| Conv3(channels=64, stride=(1, 1), padding=(0, 0)), BatchNorm(64), ReLU, Dropout |
| Conv4(channels=128, stride=(2, 2), padding=(1, 1)) |
| Conv5(channels=128, stride=(1, 1), padding=(0, 0)), BatchNorm(128), ReLU |
| FC1(128\*5\*5, 100), ReLU |
| FC2(100, 43) |
## Technical Details
### Activations
[Sigmoid](https://github.com/liuzey/EECS738_Project3/blob/e65024acd5599e13549a8742eb563814eb168b1a/MLP.py#L94):

[ReLU](https://github.com/liuzey/EECS738_Project3/blob/e65024acd5599e13549a8742eb563814eb168b1a/MLP.py#L49) returns the non-negative value of inputs.
### Dropout
[Dropout](https://github.com/liuzey/EECS738_Project3/blob/e65024acd5599e13549a8742eb563814eb168b1a/MLP.py#L80) turns values into 0 at a probability of 50% in training phase, and multiplies value by 0.5 in testing phase.
### Batch Normalization
[BatchNorm](https://github.com/liuzey/EECS738_Project3/blob/e65024acd5599e13549a8742eb563814eb168b1a/CNN.py#L136) follows the similar procedure as normalization over batch, but the final inputs is weighted by gamma and added bias beta. The gamma and beta are adjusted in the training phase. In the testing phase, the outputs are calculated with remembered global values.
### Convolutional Layer
[Forwarding](https://github.com/liuzey/EECS738_Project3/blob/e65024acd5599e13549a8742eb563814eb168b1a/layers.py#L15):
Overview function:

Convolutionalk kernel operation:

[Backwarding](https://github.com/liuzey/EECS738_Project3/blob/e65024acd5599e13549a8742eb563814eb168b1a/layers.py#L34):


### Fully-connected Layer
[Forwarding](https://github.com/liuzey/EECS738_Project3/blob/e65024acd5599e13549a8742eb563814eb168b1a/layers.py#L57):

[Backwarding](https://github.com/liuzey/EECS738_Project3/blob/e65024acd5599e13549a8742eb563814eb168b1a/layers.py#L64):



## Notes
* Cross entropy loss is only used for printing in a perceptual manner in MLP, but does not participate in actual backpropagation. For CNN records, the loss is the sum of gradient in the last layer.
* Training the CNN for GTSRB can be highly time-consuming, which needs my further improvements.
* I've tried different MLP structures in MNIST task and different learning rates.
* I find it difficult to choose initial parameters, especially for linear layers in adopted rough propagation/gradient strategy. The large dimensions will often make the results big and shrink difference between features, losing expressive ability in sigmoid activations and causing troubles in exponential calculations in softmax.
* In the final version, maxpooling and BatchNormaliztion1d are eliminated for simplification. For maxpooling, the backpropagation requires more work. For batch1d, it makes values deviated largely and result in minus values, which requires more work. Maxpooling should be implemented in a very similar way as Dropout function.
## Schedule
- [x] Set up a new git repository in your GitHub account
- [x] Pick two datasets from https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research
- [x] Choose a programming language (Python, C/C++, Java) **Python**
- [x] Formulate ideas on how neural networks can be used to accomplish the task for the specific dataset
- [x] Build a neural network to model the prediction process programmatically
- [x] Document your process and results
- [x] Commit your source code, documentation and other supporting files to the git repository in GitHub
## Reference
* MNIST - Wikipedia. https://en.wikipedia.org/wiki/MNIST_database
* GTSRB Dataset - Institut für Neuroinformatik. https://benchmark.ini.rub.de/gtsrb_dataset.html
* Python-mnist - Github. https://github.com/sorki/python-mnist
* Simple-Convolutional-Neural-Network - Github. https://github.com/zhangjh915/Simple-Convolutional-Neural-Network
* Numpy.random - Numpy API. https://numpy.org/doc/stable/reference/random/
* A Gentle Introduction to Cross-Entropy for Machine Learning. https://machinelearningmastery.com/cross-entropy-for-machine-learning/
* Softmax Activation Function with Python. https://machinelearningmastery.com/softmax-activation-function-with-python/
* BatchNorm2D - Pytorch Docs. https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html
* Torch.optim - Pytorch Docs. https://pytorch.org/docs/stable/optim.html
* batch-norm - Github. https://github.com/anuvindbhat/batch-norm
* Python PIL | Image.resize() method - GeeksforGeeks. https://www.geeksforgeeks.org/python-pil-image-resize-method/
<file_sep>import os
import numpy as np
import copy
import pandas as pd
from PIL import Image
import pickle
import random
BATCH_SIZE = 128
class GDataLoader:
def __init__(self, data_dir, train, batch_size):
self.data_dir = data_dir
self.batch_size = batch_size
if train:
self.sub_dir, self.csv_name = 'trainingset', 'training.csv'
else:
self.sub_dir, self.csv_name = 'testset', 'test.csv'
csv_path = os.path.join(data_dir, self.sub_dir, self.csv_name)
self.csv_data = pd.read_csv(csv_path)
self.data_num = len(self.csv_data)
def get_item(self, idx):
img_path = os.path.join(self.data_dir, self.sub_dir, self.csv_data.iloc[idx, 0])
_img = Image.open(img_path)
_class = self.csv_data.iloc[idx, 1]
_img = _img.resize((32, 32))
_img = np.array(_img)/255
_img = self.normalize(_img)
return _img, _class
def normalize(self, x):
# (0.3403, 0.3121, 0.3214), (0.2724, 0.2608, 0.2669)
reshape_x = np.zeros((x.shape[2], x.shape[0], x.shape[1]))
for i in range(32):
for j in range(32):
reshape_x[0, i, j] = (x[i, j, 0] - 0) / 1
reshape_x[1, i, j] = (x[i, j, 1] - 0) / 1
reshape_x[2, i, j] = (x[i, j, 2] - 0) / 1
'''
reshape_x[0, i, j] = (x[i, j, 0] - 0.3403)/0.2724
reshape_x[1, i, j] = (x[i, j, 1] - 0.3121)/0.2608
reshape_x[2, i, j] = (x[i, j, 2] - 0.3214)/0.2669
'''
return reshape_x
def stack_in_batch(self):
dataset = []
for batch in range(self.data_num//self.batch_size):
data = np.zeros((self.batch_size, 3, 32, 32))
classes = np.zeros((self.batch_size))
for index in range(self.batch_size):
_img, _class = self.get_item(batch * self.batch_size + index)
data[index] = _img
classes[index] = _class
dataset.append((data, classes))
random.shuffle(dataset)
return dataset<file_sep>numpy==1.20.1
pandas==1.2.3
Pillow==8.1.1
python-mnist==0.7
<file_sep>import os
import numpy as np
import copy
from layers import ConvolutionLayer, FullyConnectLayer
from math import log
class CNN:
def __init__(self, class_num):
self.train = True
self.loss = 0
self.conv1 = ConvolutionLayer(kernel=(3, 3), channels=32, stride=(1, 1), padding=(0, 0))
self.conv2 = ConvolutionLayer(kernel=(3, 3), channels=64, stride=(2, 2), padding=(1, 1))
self.conv3 = ConvolutionLayer(kernel=(3, 3), channels=64, stride=(1, 1), padding=(0, 0))
self.conv4 = ConvolutionLayer(kernel=(3, 3), channels=128, stride=(2, 2), padding=(1, 1))
self.conv5 = ConvolutionLayer(kernel=(3, 3), channels=128, stride=(1, 1), padding=(0, 0))
self.fc1 = FullyConnectLayer(channels=(3200, 100))
self.fc2 = FullyConnectLayer(channels=(100, class_num))
self.bn1 = BatchNormalization2d(32)
self.bn2 = BatchNormalization2d(64)
self.bn3 = BatchNormalization2d(128)
self.dropout1 = DropOut()
def forward(self, x):
batch = x.shape[0]
for bn in [self.bn1, self.bn2, self.bn3, self.dropout1]:
bn.train = self.train
self.block1 = [self.conv1.forward, self.bn1.forward, self.relu]
self.block2 = [self.conv2.forward, self.conv3.forward, self.bn2.forward, self.relu, self.dropout1.forward]
self.block3 = [self.conv4.forward, self.conv5.forward, self.bn3.forward, self.relu]
self.block4 = [self.fc1.forward, self.relu, self.fc2.forward]
for block in [self.block1, self.block2, self.block3]:
for item in block:
x = item(x)
# print(x[0].reshape(-1))
x = x.reshape(batch, -1)
for item in self.block4:
x = item(x)
# print(x[0].reshape(-1))
return x
def backward(self, err):
err = self.fc2.backward(err)
err *= np.where(self.fc2.inputs > 0, 1.0, 0.0)
err = self.fc1.backward(err)
err *= np.where(self.fc1.inputs > 0, 1.0, 0.0)
err = err.reshape(128, 128, 5, 5)
err = self.bn3.backward(err)
err = self.conv5.backward(err)
err = self.conv4.backward(err)
err = self.dropout1.backward(err)
err *= np.where(self.conv4.inputs > 0, 1.0, 0.0)
err = self.bn2.backward(err)
err = self.conv3.backward(err)
err = self.conv2.backward(err)
err *= np.where(self.conv2.inputs > 0, 1.0, 0.0)
err = self.bn1.backward(err)
_ = self.conv1.backward(err)
def save(self, saved_dir):
np.save(saved_dir + 'conv1.npy', self.conv1.weight)
np.save(saved_dir + 'conv2.npy', self.conv2.weight)
np.save(saved_dir + 'conv3.npy', self.conv3.weight)
np.save(saved_dir + 'conv4.npy', self.conv4.weight)
np.save(saved_dir + 'conv5.npy', self.conv5.weight)
np.save(saved_dir + 'fc1.npy', self.fc1.weight)
np.save(saved_dir + 'fc2.npy', self.fc2.weight)
np.save(saved_dir + 'bn.npy', np.array([self.bn1.gamma, self.bn1.beta, self.bn2.gamma, self.bn2.beta, \
self.bn3.gamma, self.bn3.beta]))
def load(self, load_dir):
self.conv1.weight = np.load(load_dir + 'conv1.npy', allow_pickle=True)
self.conv2.weight = np.load(load_dir + 'conv2.npy', allow_pickle=True)
self.conv3.weight = np.load(load_dir + 'conv3.npy', allow_pickle=True)
self.conv4.weight = np.load(load_dir + 'conv4.npy', allow_pickle=True)
self.conv5.weight = np.load(load_dir + 'conv5.npy', allow_pickle=True)
self.fc1.weight = np.load(load_dir + 'fc1.npy', allow_pickle=True)
self.fc2.weight = np.load(load_dir + 'fc2.npy', allow_pickle=True)
bn_paras = np.load(load_dir + 'bn.npy', allow_pickle=True)
self.bn1.gamma = bn_paras[0]
self.bn1.beta = bn_paras[1]
self.bn2.gamma = bn_paras[2]
self.bn2.beta = bn_paras[3]
self.bn3.gamma = bn_paras[4]
self.bn3.beta = bn_paras[5]
@staticmethod
def relu(x):
return np.where(x > 0, x, 0)
@staticmethod
def maxpooling(x):
res = np.zeros((x.shape[0], x.shape[1], x.shape[2]//2, x.shape[3]//2))
for a in range(res.shape[0]):
for b in range(res.shape[1]):
for c in range(res.shape[2]):
for d in range(res.shape[3]):
res[a, b, c, d] = np.max(x[a, b, c*2+2, d*2+2].reshape(-1))
return res
@staticmethod
def loss_(vector, label):
_loss = np.zeros_like(vector)
vector_ = np.zeros_like(vector)
loss_c = np.zeros_like(vector)
for i in range(vector.shape[0]):
for j in range(vector.shape[1]):
vector_[i, j] = np.exp(vector[i, j]) / sum(np.exp(vector[i]))
_loss[i, j] += -(vector_[i, j])
try:
_loss[i, int(label[i])] += (1.0 + 2 * (vector_[i, int(label[i])]))
loss_c[i, int(label[i])] += -log(vector_[i, int(label[i])])
except ValueError:
print(vector[i])
exit()
return _loss, loss_c
class DropOut:
def __init__(self):
self.train = True
def forward(self, x):
if self.train:
self.pos = np.random.binomial(1, 0.5, size=x.shape)
return x * self.pos + np.zeros_like(x)
return x * 0.5
def backward(self, err):
return err * self.pos
class BatchNormalization2d:
def __init__(self, n):
self.n = n
self.train = True
self.gamma = np.ones(self.n)
self.beta = np.zeros(self.n)
self.mean = np.zeros(self.n)
self.var = np.zeros(self.n)
def forward(self, x):
y = np.zeros_like(x)
x_nor = np.zeros_like(x)
if self.train:
self.mu = np.mean(x, axis=(0,2,3))
self.theta = np.var(x, axis=(0,2,3))
self.std_inv = 1.0 / np.sqrt(self.theta + 1e-12)
for i in range(self.n):
x_nor[:, i, :, :] = (x[:, i, :, :] - np.ones_like(x[:, 0, :, :]) * self.mu[i]) * self.std_inv[i]
self.x_nor = x_nor
self.mean = 0.9 * self.mean + 0.1 * self.mu
self.var = 0.9 * self.var + 0.1 * self.theta
for i in range(self.n):
y[:, i, :, :] = self.x_nor[:, i, :, :] * self.gamma[i] + np.ones_like(x[:, 0, :, :]) * self.beta[i]
else:
std_inv = 1.0 / np.sqrt(self.var + 1e-12)
for i in range(self.n):
x_nor[:, i, :, :] = (x[:, i, :, :] - np.ones_like(x[:, 0, :, :]) * self.mu[i]) * std_inv[i]
for i in range(self.n):
y[:, i, :, :] = x_nor[:, i, :, :] * self.gamma[i] + np.ones_like(x[:, 0, :, :]) * self.beta[i]
return y
def backward(self, dy):
dx_nor = np.zeros_like(dy)
for i in range(self.n):
dx_nor[:, i, :, :] = dy[:, i, :, :] * self.gamma[i]
dx = np.zeros_like(dx_nor)
for i in range(self.n):
dx[:, i, :, :] = self.std_inv[i] * (dx_nor - np.mean(dx_nor, axis=0)
- self.x_nor * np.mean(dx_nor * self.x_nor, axis=0))[:, i, :, :]
dgamma = np.sum(dy * self.x_nor, axis=(0, 2, 3))
dbeta = np.sum(dy, axis=(0, 2, 3))
self.gamma += dgamma
self.beta += dbeta
return dx
class BatchNormalization1d:
def __init__(self, n):
self.n = n
self.train = True
self.gamma = np.ones(self.n)
self.beta = np.zeros(self.n)
self.mean = np.zeros(self.n)
self.var = np.zeros(self.n)
def forward(self, x):
y = np.zeros_like(x)
x_1d = copy.deepcopy(x).reshape(x.shape[0], -1)
if self.train:
self.mu = np.mean(x_1d, axis=0)
self.theta = np.var(x_1d, axis=0)
self.std_inv = 1.0 / np.sqrt(self.theta + 1e-12)
self.x_nor = (x - self.mu) * self.std_inv
self.mean = 0.9 * self.mean + 0.1 * self.mu
self.var = 0.9 * self.var + 0.1 * self.theta
for i in range(self.n):
y[:, i] = self.x_nor[:, i] * self.gamma[i] + np.ones_like(x[:, 0]) * self.beta[i]
else:
std_inv = 1.0 / np.sqrt(self.var + 1e-12)
x_nor = (x - self.mean) * std_inv
for i in range(self.n):
y[:, i] = x_nor[:, i] * self.gamma[i] + np.ones_like(x[:, 0]) * self.beta[i]
return y
def backward(self, dy):
dx_nor = dy * self.gamma
dx = self.std_inv * (dx_nor - np.mean(dx_nor, axis=0) - self.x_nor * np.mean(dx_nor * self.x_nor, axis=0))
dgamma = np.sum(dy * self.x_nor, axis=0)
dbeta = np.sum(dy, axis=0)
self.gamma += dgamma
self.beta += dbeta
return dx
<file_sep>import os
import numpy as np
import copy
from layers import ConvolutionLayer, FullyConnectLayer
from math import log
class MLP:
def __init__(self, class_num):
self.train = True
self.loss = 0
self.fc1 = FullyConnectLayer(channels=(28*28, 100))
self.fc2 = FullyConnectLayer(channels=(100, class_num))
self.sigmoid1 = Sigmoid()
self.sigmoid2 = Sigmoid()
self.dropout1 = DropOut()
def forward(self, x):
batch = x.shape[0]
x = x.reshape(batch, -1)
x = x / np.amax(x)
for bn in [self.dropout1, ]:
bn.train = self.train
self.block1 = [self.fc1.forward, self.sigmoid1.forward]
self.block2 = [self.fc2.forward, self.sigmoid2.forward]
for block in [self.block1, self.block2]:
for item in block:
x = item(x)
# print(x[0].reshape(-1))
return x
def backward(self, err):
err = self.sigmoid2.backward(err)
err = self.fc2.backward(err)
err = self.sigmoid1.backward(err)
_ = self.fc1.backward(err)
def save(self, saved_dir):
np.save(saved_dir + 'fc1.npy', self.fc1.weight)
np.save(saved_dir + 'fc2.npy', self.fc2.weight)
def load(self, load_dir):
self.fc1.weight = np.load(load_dir + 'fc1.npy', allow_pickle=True)
self.fc2.weight = np.load(load_dir + 'fc2.npy', allow_pickle=True)
@staticmethod
def relu(x):
return np.where(x > 0, x, 0)
@staticmethod
def maxpooling(x):
res = np.zeros((x.shape[0], x.shape[1], x.shape[2]//2, x.shape[3]//2))
for a in range(res.shape[0]):
for b in range(res.shape[1]):
for c in range(res.shape[2]):
for d in range(res.shape[3]):
res[a, b, c, d] = np.max(x[a, b, c*2+2, d*2+2].reshape(-1))
return res
@staticmethod
def loss_(vector, label):
_loss = np.zeros_like(vector)
vector_ = np.zeros_like(vector)
loss_c = np.zeros_like(vector)
for i in range(vector.shape[0]):
for j in range(vector.shape[1]):
_loss[i, j] += -(vector[i, j])
vector_[i, j] = np.exp(vector[i, j]) / sum(np.exp(vector[i]))
try:
_loss[i, int(label[i])] += 1.0
loss_c[i, int(label[i])] += -log(vector_[i, int(label[i])])
except ValueError:
print(vector[i])
exit()
return _loss, loss_c
class DropOut:
def __init__(self):
self.train = True
def forward(self, x):
if self.train:
self.pos = np.random.binomial(1, 0.5, size=x.shape)
return x * self.pos + np.zeros_like(x)
return x * 0.5
def backward(self, err):
return err * self.pos
class Sigmoid:
def __init__(self):
pass
def forward(self, x):
self.res = 1.0 / (1.0 + np.exp(-x))
return self.res
def backward(self, err):
return err * (self.res * (1.0 - self.res))
<file_sep># This is for Project3 - Save one neuron to another in course EECS738 Machine Learning.
# Written by <NAME> (StudentID: 3001190).
# Run command example:
# {python main.py 'mnist'} for digits classification from scratch without saving.
# {python main.py 'gtsrb' -s 1 -p 1} for traffic sign recognition with parameters pretrained and results saved.
import numpy as np
import os
import time
import sys
import copy
import argparse
from datasets import GDataLoader
from MLP import MLP
from CNN import CNN
from mnist import MNIST
LEARNING_RATE = 1e-3
BATCH_SIZE = 2048
N_EPOCH = 1000
LOG_INTERVAL = 10
CLASS_NUM = {'mnist': 10, 'gtsrb': 43}
parser = argparse.ArgumentParser()
parser.add_argument("data", type=str, help='Dataset. Choose from GTSRB and MNIST')
parser.add_argument("-p", type=bool, default=False, help='Whether to load pre-trained parameters.')
parser.add_argument("-s", type=bool, default=False, help='Whether to save trained parameters.')
args = parser.parse_args()
def load_data(_train=True, dataname='gtsrb'):
if dataname == 'mnist':
mndata = MNIST('./mnist/raw/')
mndata.gz = False
if _train:
images, labels = mndata.load_training()
else:
images, labels = mndata.load_testing()
images = np.array(images)
labels = np.array(labels)
dataloader = [(images[i*BATCH_SIZE:(i+1)*BATCH_SIZE], labels[i*BATCH_SIZE:(i+1)*BATCH_SIZE])
for i in range(images.shape[0]//BATCH_SIZE)]
elif dataname == 'gtsrb':
data = GDataLoader('./GTSRB/', train, BATCH_SIZE)
dataloader = data.stack_in_batch()
else:
print('Dataset not found. Check inputs.')
exit()
print('Data successfully loaded.')
return dataloader
def train(model, dataloader):
model.train = True
for epoch in range(1, N_EPOCH + 1):
len_dataloader = len(dataloader)
for i in range(len_dataloader):
loss_class = 0
pack = dataloader[i]
img, label = pack[0], pack[1]
class_output = model.forward(img)
err, loss_c = model.loss_(class_output, label)
pred = np.argmax(class_output, axis=1)
# print(pred.reshape(-1))
acc = (pred[1] == label).sum()/BATCH_SIZE * 100
# print(class_output[0])
loss_class += np.sum(np.sum(loss_c, axis=0), axis=0)/BATCH_SIZE
model.backward(err)
if i % LOG_INTERVAL == 0:
print('Epoch: [{}/{}], Batch: [{}/{}], Loss: {:.4f}, Acc: {}%'.format(epoch, N_EPOCH, i, len_dataloader, loss_class, acc))
if args.s and i % (1 * LOG_INTERVAL) == 0:
model.save('./paras/')
def test(model, dataloader):
model.train = True
n_correct = 0
len_dataloader = len(dataloader)
for i in range(len_dataloader):
pack = dataloader[i]
img, label = pack[0], pack[1]
class_output = model.forward(img)
pred = np.argmax(class_output, 1)
n_correct += (pred[1] == label).sum()
# print(n_correct)
accu = float(n_correct) / (len(dataloader)*BATCH_SIZE) * 100
print('Accuracy on {} dataset: {:.4f}%'.format(args.data, accu))
return accu
if __name__ == '__main__':
train_data = load_data(_train=True, dataname=args.data)
test_data = load_data(_train=False, dataname=args.data)
if args.data == 'mnist':
model = MLP(CLASS_NUM[args.data])
if args.p:
model.load('./paras/')
elif args.data == 'gtsrb':
model = CNN(CLASS_NUM[args.data])
if args.p:
model.load('./paras_save/')
train(model, train_data)
_ = test(model, test_data)
<file_sep>import os
import numpy as np
import copy
class ConvolutionLayer:
def __init__(self, kernel=(3, 3), channels=32, stride=(1, 1), padding=(0, 0)):
self.kernel = kernel
self.stride = stride
self.padding = padding
self.channels = channels
self.weight = np.ones((self.channels, kernel[0], kernel[1])) * 0.01
self.bias = np.zeros(self.channels)
def forward(self, inputs):
self.inputs = inputs
self.dim = [(inputs.shape[i+2]-self.kernel[i]+2 * self.padding[i])//self.stride[i] + 1 for i in range(2)]
res = np.zeros((inputs.shape[0], self.channels, self.dim[0], self.dim[1]))
padded_inputs = np.zeros((inputs.shape[0], inputs.shape[1], inputs.shape[2]+2*self.padding[0], inputs.shape[3]+2*self.padding[1]))
padded_inputs[:, :, self.padding[0]:padded_inputs.shape[2]-self.padding[0], \
self.padding[1]:padded_inputs.shape[3]-self.padding[1]] = inputs
self.padded_inputs = padded_inputs
for index in range(inputs.shape[0]):
for x in range(self.dim[0]):
for y in range(self.dim[1]):
temp = np.array([np.multiply(self.weight, padded_inputs[index, c, x*self.stride[0]:x*self.stride[0]
+self.kernel[0], y*self.stride[1]:y*self.stride[1]+self.kernel[1]]).reshape(self.channels, -1)
for c in range(inputs.shape[1])])
res[index, :, x, y] = np.sum(np.sum(temp, axis=0), axis=1) + self.bias
self.res = res
return res
def backward(self, err):
inputs = self.padded_inputs
next_error = np.zeros_like(inputs)
for index in range(next_error.shape[0]):
for x in range(self.dim[0]):
for y in range(self.dim[1]):
for c in range(inputs.shape[1]):
next_error[index, c, x*self.stride[0]:x*self.stride[0]+self.kernel[0],
y*self.stride[1]:y*self.stride[1]+self.kernel[1]] += self.weight[c] * err[index,c,x,y]
self.weight[c] += 1e-3 * np.dot(inputs[index, c, x*self.stride[0]:x*self.stride[0]+self.kernel[0],
y*self.stride[1]:y*self.stride[1]+self.kernel[1]].T, err[index,c,x,y]).T
self.bias += 1e-3 * np.sum(err, axis=(0,2,3))
next_error = next_error[:, :, self.padding[0]:next_error.shape[2] - self.padding[0],
self.padding[1]:next_error.shape[3] - self.padding[1]]
return next_error
class FullyConnectLayer:
def __init__(self, channels=(100, 100)):
self.channels = channels
self.weight = np.random.randn(self.channels[0], self.channels[1])
self.bias = np.zeros(self.channels[1])
def forward(self, inputs):
self.inputs = inputs
# res = np.zeros((inputs.shape[0], self.channels[1]))
res = np.dot(inputs, self.weight) + self.bias
self.res = res
return res
def backward(self, err):
next_error = np.dot(err, self.weight.T)
self.weight += 1e-3 * np.dot(self.inputs.T, err)
self.bias += 1e-3 * np.sum(err.T, axis=1)
return next_error | 6a21d87a71332d5eac83ce8abe6519f7fd25aef4 | [
"Markdown",
"Python",
"Text"
] | 7 | Markdown | liuzey/EECS738_Project3 | 87c83c78d69ef0a56fcbcfdb50dfd4feaf860176 | 62de1cb407c294f1914a5c905858c4687a45fdcf |
refs/heads/master | <file_sep>
## Installation
You can install **mobily-api** via composer or by
typing **composer require "wasfapp/mobily-api:dev-master"** in command line using composer.
#### Via Composer:
**mobily-api** is available on Packagist as the
[`wasfapp/mobily-api`](https://packagist.org/packages/wasfapp/mobily-api) package.
## Quickstart
### TO USE Api AFTER DOWNLOAD
In order to use Mobily Api, you must take the following steps:
1. Registration on the site through the following steps:
1. Go to the following link: **[`mobily.ws`](http://www.mobily.ws/sms/index.php)**
2. Go to page (Register now) at the top of the page
3. Enter the information
5. Enable sender name to send messages
2. Download the Mobily Api and install it in your system
3. Insert user information (ApiKEY or mobile and password) ,this information's is provided to you by the site
In the function setInfo defines user information
### Mobily Api Portals
We provide many services that make it easy to use the api, and these are some our of the services:
1. send sms
2. send sms using message template
3. sending sms directly
4. sending status
5. Add mobile number as sender name
6. Activate mobile number as sender name
7. Check that the mobile number is activated as a sender's name
8. Possibility to change password
9. Retrieve password
10. Balance Inquiry
11. Delete sms
12. Add a text sender name
13. Activate the text sender name
## Services Example
### Send SMS message
You can send SMS messages using the transmission gate to ensure the privacy of information and the speed of sending and ensure they arrive, and this portal provid the ability to sending messages to many numbers at once and without any effortless and tired, is the gate to send and receive messages using JSON technology And These an example of how to use the portal:
```php
<?php
require_once('Mobily_sms.inc');
$sms = new MobilySms('user name','password','ApiKEY');
$result=$sms->sendMsg('This is Message','9662222222222,9662222222222,9662222222222','NEW SMS','17:30:00','12/30/2017',1,'deleteKey','curl');
?>
```
### Send SMS using message Template
This portal offers the ability to send SMS messages using a unified message template for different numbers. This portal allows you to add fixed message text and put symbols in it. This portal transmits the information of each number with the symbols in the message to form a message for each number. the operation :
```php
<?php
require_once('Mobily_sms.inc');
$sms = new MobilySms('user name','password','ApiKEY');
$msg = "Welcome (1)، Your subscription date is up to (2)";
$msgKey = "(1),*,William,@,(2),*,12/10/2008***(1),*,jack,@,(2),*,10/10/2008";
$numbers='96622222222222,96622222222222';
$result=$sms->sendMsgWK($msg,$numbers,'aljauoni',$msgKey,'12:00:00','12/27/2017',0,'deleteKey','curl');
?>
```
### Balance Inquiry
You can inquire about mobily account balance through this portal by adding mobile number or Api KEY , this portal sends and returns JSON data and the following example shows how to use this portal :
```php
<?php
require_once('Mobily_sms.inc');
$sms = new MobilySms('user name','password','ApiKEY');
$result=$sms->balance('curl');
?>
```
### Forget Password
You can retrieve the mobily account password through this portal by adding the mobile number or Api KEY to retrieve its password and the way to send the password either on the mobile number or on the email of the account, and this portal sends and returns data from JSON Type The following example shows how to use this portal:
```php
<?php
require_once('Mobily_sms.inc');
// you must insert just user name or ApiKEY
$sms = new MobilySms('user name','password','ApiKEY');
// 1: that means send password to account mobile
$result=$sms->forgetPassword(1,'ar','curl');
// or you can use
// 2: that means send password to account email
$result=$sms->forgetPassword(2,'ar','curl');
?>
```
### Change Password
You can change the password for mobily account through this portal by adding the mobile number or Api KEY to change its password and old and new password, and this portal sends and returns data of type JSON. , And as an example of the required data:
```php
<?php
require_once('Mobily_sms.inc');
$sms = new MobilySms('user name','password','ApiKEY');
$result=$sms->changePassword('111','123','curl');
?>
```
## Documentation
The documentation for the **mobily.ws Api** is located **[`here`](http://www.mobily.ws/)**.
The PHP library documentation can be found **[`here`](http://www.mobily.ws/)**.
## Versions
`Mobily-api`'s versioning strategy can be found **[`here`](http://www.mobily.ws/)**.
## Prerequisites
* PHP >= 5.3
* The PHP JSON extension
# Getting help
If you need help installing or using the library, please contact Mobily.ws Support at **<EMAIL>** first. mobily Support staff are well-versed in all of the mobily.ws Helper Libraries, and usually reply within 24 hours.
If you've instead found a bug in the library or would like new features added, go ahead and open issues or pull requests against this repo!
<file_sep><?php
/**
* Created by PhpStorm.
* User: aljaouni
* Date: 5/11/2017
* Time: 1:01 PM
*/
class MobilySms {
public $userName;
public $password;
public $apiKey;
public $result;
private $method;
private $json = array();
public $error = "";
/**
* Check if user information is it API or mobile and password
* and set curl as default send method
*
* @param string $userName The Account username or mobile in mobily.ws
* @param string $password The password of mobily account
* @param string $apiKey The api key from mobily account
**/
function __construct($userName=NULL, $password=NULL, $apiKey=NULL) {
if (!empty($apiKey)){
$this->apiKey = $apiKey;
}elseif(!empty($userName)&&!empty($userName)){
$this->userName = $userName;
$this->password = $<PASSWORD>;
}
$this->method = 'curl';
}
/**
* Check if user information is it API or mobile and password And if
* this information is not empty set in variables for all api function other return error
*
* @param string $userName The Account username or mobile in mobily.ws
* @param string $password The <PASSWORD> of <PASSWORD>
* @param string $apiKey The api key from mobily account
* @return string $this->error If there is no error, it doesn't return anything
**/
public function setInfo($userName=NULL, $password=NULL, $apiKey=NULL) {
if(empty($userName) && empty($password) && empty($apiKey)) {
$this->error = 'Please Insert Data';
} elseif (!empty($apiKey)) {
$this->apiKey = $apiKey;
} elseif(!empty($userName) & !empty($password)) {
$this->userName = $userName;
$this->password = $password;
}
return $this->error;
}
/**
* Check if user information is not empty and
* prepare information in array to Merge with another message data
* you can call this function just in api function because it's private
*
**/
private function checkUserInfo() {
$this->json = array();
$this->error = "";
if (!empty($this->apiKey)) {
$this->json=array("apiKey"=>$this->apiKey);
} elseif (!empty($this->userName) && !empty($this->password)) {
$this->json=array("mobile"=>$this->userName,"password"=>$this->password);
} else {
$this->error = 'insert APIKEY or Username and Password';
}
}
/**
* Using send method you'r selected in api function and
* if doesn't match with any cases return error
*
* @param string $host The Account username or mobile in mobily.ws (required)
* @param string $path The password of mobily account(required)
* @param string $data Message data
* @return string $this->error If any error found
* @return string $this->result If there is no error , it's json report from mobily.ws
**/
private function run($host,$path,$data='') {
switch ($this->method) {
case 'curl':
// echo "<pre>";
// print_r($data);
// exit();
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $host.$path);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
$this->result = curl_exec($ch);
break;
case 'fsockopen':
$host=str_replace('https://','',$host);
$host=str_replace('http://','',$host);
$length = strlen($data);
$fsockParameter = "POST ".$path." HTTP/1.0 \r\n";
$fsockParameter .= "Host: ".$host." \r\n";
$fsockParameter .= "Content-type: application/x-www-form-urlencoded \r\n";
$fsockParameter .= "Content-length: $length \r\n\r\n";
$fsockParameter .= "$data";
$fsockConn = fsockopen($host, 80, $errno, $errstr, 30);
fputs($fsockConn, $fsockParameter);
$clearResult = false;
while (!feof($fsockConn)) {
$line = fgets($fsockConn, 10240);
if ($line == "\r\n" && !$clearResult)
$clearResult = true;
if ($clearResult)
$this->result = trim($line);
}
break;
case 'fopen':
$contextOptions['http'] = array('method' => 'POST', 'header'=>'Content-type: application/x-www-form-urlencoded', 'content'=> $data, 'max_redirects'=>0, 'protocol_version'=> 1.0, 'timeout'=>10, 'ignore_errors'=>TRUE);
$contextResouce = stream_context_create($contextOptions);
$handle = fopen($host.$path, 'r', false, $contextResouce);
$this->result = stream_get_contents($handle);
break;
case 'file':
$contextOptions['http'] = array('method' => 'POST', 'header'=>'Content-type: application/x-www-form-urlencoded', 'content'=> $data, 'max_redirects'=>0, 'protocol_version'=> 1.0, 'timeout'=>10, 'ignore_errors'=>TRUE);
$contextResouce = stream_context_create($contextOptions);
$arrayResult = file($host.$path, FILE_IGNORE_NEW_LINES, $contextResouce);
$this->result = $arrayResult[0];
break;
case 'file_get_contents':
$contextOptions['http'] = array('method' => 'json', 'header'=>'Content-type: application/x-www-form-urlencoded', 'content'=> $data, 'max_redirects'=>0, 'protocol_version'=> 1.0, 'timeout'=>10, 'ignore_errors'=>TRUE);
$contextResouce = stream_context_create($contextOptions);
$this->result = file_get_contents($host.$path, false, $contextResouce);
break;
default:
$this->error = 'active one of the following portals (curl,fopen,fsockopen,file,file_get_contents) on server';
return $this->error;
}
return $this->result;
}
/**
* Send message directly without separate message data
* you can use to call function (sendMsg Or sendMsgWK).
*
* @param string $functionName Name of the function (required)
* @param string $data Message data (required)
* @return string $this->error If any error found
* @return string $this->result If there is no error , it's json report from mobily.ws
**/
public function callAPI ($functionName, $data,$port=NULL) {
$this->checkUserInfo();
$this->getSendMethod($port);
if(empty($this->error)) {
$this->json=array_merge($this->json,$data);
$this->json['numbers']=explode(',',$this->json['numbers']);
$this->json['lang']='3';
$this->json=json_encode($this->json);
switch ($functionName) {
case 'sendMsg':
return $this->run('http://172.16.17.32', '/~mobilyws/api/msgSend.php', $this->json);
break;
case 'sendMsgWK':
return $this->run('http://172.16.17.32', '/~mobilyws/api/msgSendWK.php', $this->json);
break;
default:
$this->error[] = 'method name not found You can select either (sendMsg,sendMsgWK).';
return $this->error;
}
}else{
return $this->error;
}
}
/**
* Check if send method selected in function and
* test send method if work or if method doesn't selected
* test method and choose which works
*
* @param string $method Send method
* @return string $this->error If not empty method
**/
private function getSendMethod($method=NULL) {
//Change Deafult Method
if(!empty($method)){
$this->method = strtolower($method);
}
//Check CURL
if($this->method == 'curl') {
if(function_exists("curl_init") && function_exists("curl_setopt") && function_exists("curl_exec") && function_exists("curl_close") && function_exists("curl_errno")) {
return 1;
} else {
if(!empty($method)) {
return $this->error = 'CURL is not supported';
} else {
$this->method = 'fsockopen';
}
}
}
//Check fSockOpen
if($this->method == 'fsockopen') {
if(function_exists("fsockopen") && function_exists("fputs") && function_exists("feof") && function_exists("fread") && function_exists("fclose")) {
return 1;
} else {
if(!empty($method)) {
return $this->error = 'fSockOpen is not supported';
} else {
$this->method = 'fopen';
}
}
}
//Check fOpen
if($this->method == 'fopen') {
if(function_exists("fopen") && function_exists("fclose") && function_exists("fread")) {
return 1;
} else {
if(!empty($method)) {
return $this->error = 'fOpen is not supported';
} else {
$this->method = 'file_get_contents';
}
}
}
//Check File
if($this->method == 'file') {
if(function_exists("file") && function_exists("http_build_query") && function_exists("stream_context_create")) {
return 1;
} else {
if(!empty($method)) {
return $this->error = 'File is not supported';
} else {
$this->method = 'file_get_contents';
}
}
}
//Check file_get_contents
if($this->method == 'file_get_contents') {
if(function_exists("file_get_contents") && function_exists("http_build_query") && function_exists("stream_context_create")) {
return 1;
} else {
if(!empty($method)) {
return $this->error = 'file_get_contents is not supported';
} else {
$this->method=NULL;
}
}
}
}
/**
* Send message
*
* @param string $message (required)
* @param string $numbers Numbers to send (between each number comma ",")(required)
* @param string $sender Name of message sender (required)
* @param integer $timeSend Time to send message like this 17:30:00
* @param integer $dateSend Date to send message like this 6/30/2017
* @param integer $notRepeat 1 -> Delete repeated numbers 0 -> Allow repeated numbers
* @param string $deleteKey Key to delete message using deleteKey function
* @param string $method Send method
* @return string $this->error If any error found
*/
public function sendMsg($message, $numbers, $sender,$timeSend='', $dateSend='',$notRepeat=0,$deleteKey='', $method=NULL) {
$this->checkUserInfo();
$this->getSendMethod($method);
if(empty($this->error)) {
$numbers = explode(',',$numbers);
$data = array(
'numbers'=>$numbers,
'sender'=>$sender,
'msg'=>$message,
'timeSend'=>$timeSend,
'dateSend'=>$dateSend,
'notRepeat'=>$notRepeat,
'deleteKey'=>$deleteKey,
'lang'=>'3'
);
$this->json = array_merge($this->json, $data);
$this->json = json_encode($this->json);
return $this->run('http://173.192.165.20','/~mobilyws/api/msgSend.php',$this->json);
}
return $this->error;
}
/**
* Send message with key
* Configuration a message by replacing the symbols and and data in msgKey
* and placing their data in the message ,
* and the number of data must match the count of numbers
*
* @param string $message (required)
* @param string $numbers Numbers to send (between each number comma ",")(required)
* @param string $sender Name of message sender (required)
* @param string $msgKey Template of message (required)
* @param integer $timeSend Time to send message like this 17:30:00
* @param integer $dateSend Date to send message like this 6/30/2017
* @param integer $notRepeat 1 -> Delete repeated numbers 0 -> Allow repeated numbers
* @param string $deleteKey Key to delete message using deleteKey function
* @param string $method Send method
* @return string $this->error If any error found
*/
public function sendMsgWK($message, $numbers, $sender, $msgKey, $timeSend=0, $dateSend=0,$notRepeat=0, $deleteKey='',$method=NULL) {
$this->checkUserInfo();
$this->getSendMethod($method);
if(empty($this->error)) {
$numbers=explode(',',$numbers);
$data=array(
'numbers'=>$numbers,
'sender'=>$sender,
'msgKey'=>$msgKey,
'msg'=>$message,
'timeSend'=>$timeSend,
'notRepeat'=>$notRepeat,
'dateSend'=>$dateSend,
'deleteKey'=>$deleteKey,
'applicationType'=>'68',
'lang'=>'3'
);
$this->json=array_merge($this->json,$data);
$this->json=json_encode($this->json);
return $this->run('http://173.192.165.20','/~mobilyws/api/msgSendWK.php',$this->json);
}
return $this->error;
}
/**
* Get send status
*
* @param string $method Send method
* @return string $this->result
**/
public function sendStatus($method=NULL) {
$this->getSendMethod($method);
$data=array(
'returnJson'=>'1'
);
$this->json=array_merge($this->json,$data);
$this->json=json_encode($this->json);
return $this->run('http://173.192.165.20','/~mobilyws/api/sendStatus.php','returnJson=1');
}
/**
* Change mobily account password
*
* @param string $oldPassword Mobily account password (required)
* @param string $newPassword New mobily account password (required)
* @param string $method Send method
* @return string $this->error If any error found
* @return string $this->result If there is no error
**/
public function changePassword($oldPassword,$newPassword,$method=NULL) {
$this->checkUserInfo();
$this->getSendMethod($method);
if(empty($this->error)) {
if(!empty($this->json['apiKey'])){
$userInfo=array('apiKey'=>$this->json['apiKey']);
}else{
$userInfo=array('mobile'=>$this->json['mobile']);
}
$data=array(
'password'=>$<PASSWORD>,
'newPassword'=>$<PASSWORD>
);
$this->json=array_merge($userInfo,$data);
$this->json=json_encode($this->json);
return $this->run('http://172.16.17.32','/~mobilyws/api/changePassword.php',$this->json);
}
return $this->error;
}
/**
* Send account password to account email or number
*
* @param integer $sendType Send password type 1 -> to number 2 -> email (required)
* @param string $method Send method
* @param string $lang return value language (ar or en)
* @return string $this->error If any error found
* @return string $this->result If there is no error
**/
public function forgetPassword($sendType,$lang,$method=NULL) {
$this->checkUserInfo();
$this->getSendMethod($method);
if(empty($this->error)) {
if(!empty($this->json['apiKey'])){
$userInfo=array('apiKey'=>$this->json['apiKey']);
}else{
$userInfo=array('mobile'=>$this->json['mobile']);
}
$lang=strtolower($lang);
if($lang!='ar'&&$lang!='en'){
$lang='ar';
}
$data=array('type'=>$sendType,'lang'=>$lang);
$this->json=array_merge($userInfo,$data);
$this->json=json_encode($this->json);
return $this->run('http://172.16.17.32','/~mobilyws/api/forgetPassword.php',$this->json);
}
return $this->error;
}
/**
* Get balance of mobily account
*
* @param string $method Send method
* @return string $this->error If any error found
* @return string $this->result If there is no error
**/
public function balance($method=NULL) {
$this->checkUserInfo();
$this->getSendMethod($method);
if(empty($this->error)) {
$this->json=json_encode($this->json);
return $this->run('http://172.16.17.32','/~mobilyws/api/balance.php',$this->json);
}
return $this->error;
}
/**
* Delete message Using message deleteKey
*
* @param string $deleteKey Message deleteKey to delete message (required)
* @param string $method Send method
* @return string $this->error If any error found
* @return string $this->result If there is no error
**/
public function deleteMsg($deleteKey,$method=NULL) {
$this->checkUserInfo();
$this->getSendMethod($method);
if(empty($this->error)) {
$data=array('deleteKey'=>$deleteKey);
$this->json=array_merge($this->json,$data);
$this->json=json_encode($this->json);
return $this->run('http://172.16.17.32','/~mobilyws/api/deleteMsg.php',$this->json);
}
return $this->error;
}
/**
* Request number as sender name From mobily
*
* @param string $sender Sender name(required)
* @param string $lang return value language (ar or en)
* @param string $method Send method
* @return string $this->error If any error found
*/
public function addSender($sender,$lang='',$method=NULL) {
$this->checkUserInfo();
$this->getSendMethod($method);
if(empty($this->error)) {
$lang=strtolower($lang);
if($lang!='ar'&&$lang!='en'){
$lang='ar';
}
$data=array('sender'=>$sender,'lang'=>$lang);
$this->json=array_merge($this->json,$data);
$this->json=json_encode($this->json);
return $this->run('http://173.192.165.20','/~mobilyws/api/addSender.php',$this->json);
}
return $this->error;
}
/**
* Activate the sender name (number) which was requested
*
* @param integer $senderId Id of Sender name was requested(required)
* @param integer $activeKey Key which sent to mobile(required)
* @param string $method Send method
* @return string $this->error If any error found
* @return string $this->result If there is no error
**/
public function activeSender($senderId,$activeKey,$method=NULL) {
$this->checkUserInfo();
$this->getSendMethod($method);
if(empty($this->error)) {
$data=array(
'senderId'=>$senderId,
'activeKey'=>$activeKey,
);
$this->json=array_merge($this->json,$data);
$this->json=json_encode($this->json);
return $this->run('http://173.192.165.20','/~mobilyws/api/activeSender.php',$this->json);
}
return $this->error;
}
/**
* Check if the sender name (number) which was requested is active or not
*
* @param integer $senderId Id of Sender name was requested(required)
* @param string $method Send method
* @return string $this->error If any error found
* @return string $this->result If there is no error
**/
public function checkSender($senderId,$method=NULL) {
$this->checkUserInfo();
$this->getSendMethod($method);
if(empty($this->error)) {
$data=array(
'senderId'=>$senderId,
);
$this->json=array_merge($this->json,$data);
$this->json=json_encode($this->json);
return $this->run('http://173.192.165.20','/~mobilyws/api/checkSender.php',$this->json);
}
return $this->error;
}
/**
* Add sender name as text
*
* @param string $sender Sender name (required)
* @param string $method Send method
* @return string $this->error If any error found
* @return string $this->result If there is no error
**/
public function addAlphaSender($sender,$method=NULL) {
$this->checkUserInfo();
$this->getSendMethod($method);
if(empty($this->error)) {
$data=array(
'sender'=>$sender,
);
$this->json=array_merge($this->json,$data);
$this->json=json_encode($this->json);
return $this->run('http://172.16.17.32','/~mobilyws/api/addAlphaSender.php',$this->json);
}
return $this->error;
}
/**
* Check if the sender name (number) which was requested is active or not
*
* @param string $method Send method
* @return string $this->error If any error found
* @return string $this->result If there is no error
**/
public function checkAlphaSender($method=NULL) {
$this->checkUserInfo();
$this->getSendMethod($method);
if(empty($this->error)) {
$this->json=json_encode($this->json);
return $this->run('http://173.192.165.20','/~mobilyws/api/checkAlphasSender.php',$this->json);
}
return $this->error;
}
} | 23ce7a6fe9abeac0ed38dbb913b2015623618a6f | [
"Markdown",
"PHP"
] | 2 | Markdown | wasfapp/mobily-api | aa58ac32b00077ced2d1ab8d1cdf1383aa9abb04 | b4e9e072ac5fa12a2f26ca74769db9c59d7a7818 |
refs/heads/master | <file_sep>module github.com/goloop/log
go 1.20
require (
github.com/goloop/g v1.10.1
github.com/goloop/trit v1.7.1
)
require github.com/goloop/is v1.4.0
<file_sep>package layout
import (
"errors"
"fmt"
"math/bits"
)
const (
// FullFilePath flag adding in the log message the path to
// the go-file where the logging method was called.
FullFilePath Layout = 1 << iota
// ShortFilePath flag adding in the log message the short path
// to the go-file where the logging method was called.
ShortFilePath
// FuncName flag adding in the log message the function's name
// where the logging method was called.
FuncName
// FuncAddress flag adding in the log message the function's address
// where the logging method was called.
FuncAddress
// LineNumber flag adding in the log message the line number
// of the go-file where the logging method was called.
LineNumber
// The overflowLayoutValue is a exceeding the limit of permissible
// values for the Layout.
overflowLayoutValue Layout = (1 << iota)
// Default is the default format for the log message.
Default = ShortFilePath | FuncName | LineNumber
)
// Layout is the type of single flags of the the Layout.
type Layout uint8
// IsSingle returns true if value contains single of the available flag.
// The custom flags cannot be valid since they should not affect the
// formatting settings. The zero value is an invalid flag too.
func (l *Layout) IsSingle() bool {
return bits.OnesCount(uint(*l)) == 1 &&
*l <= Layout(overflowLayoutValue+1)>>1
}
// Contains method returns true if value contains the specified flag.
// Returns false and an error if the value is invalid or an
// invalid flag is specified.
func (l *Layout) Contains(flag Layout) (bool, error) {
switch {
case !flag.IsValid():
return false, errors.New("incorrect flag value")
case !l.IsValid():
return false, errors.New("the object is damaged")
}
return *l&Layout(flag) == Layout(flag), nil
}
// IsValid returns true if value contains zero, one or an
// unique sum of valid FormatFlag flags. The zero value is a valid value.
func (l *Layout) IsValid() bool {
// Check if object is zero, which is a valid value.
if *l == 0 {
return true
}
copy := *l
// Iterate over all possible values of the constants and
// check whether they are part of object.
for layout := Layout(1); layout < overflowLayoutValue; layout <<= 1 {
// If layout is part of the object, remove it from object.
if copy&layout == layout {
copy ^= layout
}
}
// Check whether all bits of t were "turned off".
// If t is zero, it means that all bits were matched values
// of constants, and therefore t is valid.
return copy == 0
}
// FilePath returns true if value contains the FullPath or ShortPath flags.
// Returns false and an error if the value is invalid.
func (l *Layout) FilePath() bool {
ffp, err := l.Contains(FullFilePath)
if err == nil && ffp {
return true
}
sfp, err := l.Contains(ShortFilePath)
if err == nil && sfp {
return true
}
return false
}
// FullFilePath returns true if value contains the FullPath flag.
func (l *Layout) FullFilePath() bool {
v, _ := l.Contains(FullFilePath)
return v
}
// ShortFilePath returns true if value contains the ShortPath flag.
func (l *Layout) ShortFilePath() bool {
v, _ := l.Contains(ShortFilePath)
return v
}
// FuncName returns true if value contains the FuncName flag.
func (l *Layout) FuncName() bool {
v, _ := l.Contains(FuncName)
return v
}
// FuncAddress returns true if value contains the FuncAddress flag.
func (l *Layout) FuncAddress() bool {
v, _ := l.Contains(FuncAddress)
return v
}
// LineNumber returns true if value contains the LineNumber flag.
func (l *Layout) LineNumber() bool {
v, _ := l.Contains(LineNumber)
return v
}
// Set sets the specified flags ignores duplicates.
// The flags that were set previously will be discarded.
// Returns a new value if all is well or old value and an
// error if one or more invalid flags are specified.
func (l *Layout) Set(flags ...Layout) (Layout, error) {
var r Layout
for _, flag := range flags {
if !flag.IsValid() {
return *l, fmt.Errorf("the %d is invalid flag value", flag)
}
if ok, _ := r.Contains(flag); !ok {
r += Layout(flag)
}
}
*l = r
return *l, nil
}
// Add adds the specified flags ignores duplicates or flags that value
// already contains. Returns a new value if all is well or old value and
// an error if one or more invalid flags are specified.
func (l *Layout) Add(flags ...Layout) (Layout, error) {
r := *l
for _, flag := range flags {
if !flag.IsValid() {
return *l, fmt.Errorf("the %d is invalid flag value", flag)
}
if ok, _ := r.Contains(flag); !ok {
r += Layout(flag)
}
}
*l = r
return *l, nil
}
// Delete deletes the specified flags ignores duplicates or
// flags that were not set. Returns a new value if all is well or
// old value and an error if one or more invalid flags are specified.
func (l *Layout) Delete(flags ...Layout) (Layout, error) {
r := *l
for _, flag := range flags {
if !flag.IsValid() {
return *l, fmt.Errorf("the %d is invalid flag value", flag)
}
if ok, _ := r.Contains(flag); ok {
r -= Layout(flag)
}
}
*l = r
return *l, nil
}
// All returns true if all of the specified flags are set.
func (l *Layout) All(flags ...Layout) bool {
for _, flag := range flags {
if ok, _ := l.Contains(flag); !ok {
return false
}
}
return true
}
// Any returns true if at least one of the specified flags is set.
func (l *Layout) Any(flags ...Layout) bool {
for _, flag := range flags {
if ok, _ := l.Contains(flag); ok {
return true
}
}
return false
}
<file_sep>package level
import (
"errors"
"testing"
)
// TestIsValid tests the IsValid method of the Level type.
func TestIsValid(t *testing.T) {
tests := []struct {
name string
level Level
expect bool
}{
{name: "Panic Level", level: Panic, expect: true},
{name: "Fatal Level", level: Fatal, expect: true},
{name: "Error Level", level: Error, expect: true},
{name: "Overflow Level", level: overflowLevelValue + 1, expect: false},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if got := test.level.IsValid(); got != test.expect {
t.Errorf("IsValid = %v; want %v", got, test.expect)
}
})
}
}
// TestIsSingle tests the IsSingle method of the Level type.
func TestIsSingle(t *testing.T) {
tests := []struct {
name string
level Level
expect bool
}{
{name: "Panic Level", level: Panic, expect: true},
{name: "Combined Level", level: Panic | Fatal, expect: false},
// add more tests as needed
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if got := test.level.IsSingle(); got != test.expect {
t.Errorf("IsSingle = %v; want %v", got, test.expect)
}
})
}
}
// TestContains tests the Contains method of the Level type.
func TestContains(t *testing.T) {
tests := []struct {
name string
level Level
flag Level
expect bool
err error
}{
{
name: "Panic Level contains Panic",
level: Panic,
flag: Panic,
expect: true,
err: nil,
},
{
name: "Panic Level contains Error",
level: Panic,
flag: Error,
expect: false,
err: nil,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
got, err := test.level.Contains(test.flag)
if err != test.err || got != test.expect {
t.Errorf("Contains = %v, error = %v; want %v, error = %v",
got, err, test.expect, test.err)
}
})
}
}
// TestLevelFlags tests the level flags.
func TestLevelFlags(t *testing.T) {
tests := []struct {
name string
level Level
method func(*Level) bool
contain bool
}{
{
name: "Panic Flag in Panic Level",
level: Panic,
method: (*Level).Panic,
contain: true,
},
{
name: "Panic Flag in Error Level",
level: Error,
method: (*Level).Panic,
contain: false,
},
{
name: "Fatal Flag in Fatal Level",
level: Fatal,
method: (*Level).Fatal,
contain: true,
},
{
name: "Fatal Flag in Error Level",
level: Error,
method: (*Level).Fatal,
contain: false,
},
{
name: "Error Flag in Error Level",
level: Error,
method: (*Level).Error,
contain: true,
},
{
name: "Error Flag in Info Level",
level: Info,
method: (*Level).Error,
contain: false,
},
{
name: "Info Flag in Info Level",
level: Info,
method: (*Level).Info,
contain: true,
},
{
name: "Info Flag in Debug Level",
level: Debug,
method: (*Level).Info,
contain: false,
},
{
name: "Debug Flag in Debug Level",
level: Debug,
method: (*Level).Debug,
contain: true,
},
{
name: "Debug Flag in Trace Level",
level: Trace,
method: (*Level).Debug,
contain: false,
},
{
name: "Trace Flag in Trace Level",
level: Trace,
method: (*Level).Trace,
contain: true,
},
{
name: "Trace Flag in Panic Level",
level: Panic,
method: (*Level).Trace,
contain: false,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if got := test.method(&test.level); got != test.contain {
t.Errorf("%s got = %v; want %v", test.name, got, test.contain)
}
})
}
}
// TestSet tests the Set method of Level.
func TestSet(t *testing.T) {
tests := []struct {
name string
level Level
flags []Level
expect Level
err error
}{
{
name: "Set Panic and Error flags",
level: Default,
flags: []Level{Panic, Error},
expect: Panic | Error,
err: nil,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
got, err := test.level.Set(test.flags...)
if err != test.err || got != test.expect {
t.Errorf("Set = %v, error = %v; want %v, error = %v",
got, err, test.expect, test.err)
}
})
}
}
func TestLevelAdd(t *testing.T) {
tests := []struct {
name string
start Level
add []Level
want Level
err error
}{
{
name: "Add Panic to Empty Level",
start: 0,
add: []Level{Panic},
want: Panic,
err: nil,
},
{
name: "Add Panic to Panic Level",
start: Panic,
add: []Level{Panic},
want: Panic,
err: nil,
},
{
name: "Add Error to Panic Level",
start: Panic,
add: []Level{Error},
want: Panic | Error,
err: nil,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
got, err := test.start.Add(test.add...)
if got != test.want || !errors.Is(err, test.err) {
t.Errorf("%s got = %v, err = %v; want %v, %v",
test.name, got, err, test.want, test.err)
}
})
}
}
// TestLevelDelete tests the Delete method of Level.
func TestLevelDelete(t *testing.T) {
tests := []struct {
name string
start Level
delete []Level
want Level
err error
}{
{
name: "Delete Panic from Panic Level",
start: Panic,
delete: []Level{Panic},
want: 0,
err: nil,
},
{
name: "Delete Panic from Error Level",
start: Error,
delete: []Level{Panic},
want: Error,
err: nil,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
got, err := test.start.Delete(test.delete...)
if got != test.want || !errors.Is(err, test.err) {
t.Errorf("%s got = %v, err = %v; want %v, %v",
test.name, got, err, test.want, test.err)
}
})
}
}
// TestLevelAll tests the All method of Level.
func TestLevelAll(t *testing.T) {
tests := []struct {
name string
start Level
all []Level
want bool
}{
{
name: "All Panic and Error in Panic Level",
start: Panic,
all: []Level{Panic, Error},
want: false,
},
{
name: "All Panic and Error in Panic and Error Level",
start: Panic | Error,
all: []Level{Panic, Error},
want: true,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if got := test.start.All(test.all...); got != test.want {
t.Errorf("%s got = %v; want %v", test.name, got, test.want)
}
})
}
}
// TestLevelAny tests the Any method of Level.
func TestLevelAny(t *testing.T) {
tests := []struct {
name string
start Level
any []Level
want bool
}{
{
name: "Any Panic and Error in Panic Level",
start: Panic,
any: []Level{Panic, Error},
want: true,
},
{
name: "Any Panic and Error in Info Level",
start: Info,
any: []Level{Panic, Error},
want: false,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if got := test.start.Any(test.any...); got != test.want {
t.Errorf("%s got = %v; want %v", test.name, got, test.want)
}
})
}
}
<file_sep>package layout
import (
"errors"
"testing"
)
// TestIsValid tests the IsValid method of the Layout type.
func TestIsValid(t *testing.T) {
tests := []struct {
name string
Layout Layout
expect bool
}{
{
name: "FullFilePath Layout",
Layout: FullFilePath,
expect: true,
},
{
name: "ShortFilePath Layout",
Layout: ShortFilePath,
expect: true,
},
{
name: "FuncName Layout",
Layout: FuncName,
expect: true,
},
{
name: "Overflow Layout",
Layout: overflowLayoutValue + 1,
expect: false,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if got := test.Layout.IsValid(); got != test.expect {
t.Errorf("IsValid = %v; want %v", got, test.expect)
}
})
}
}
// TestIsSingle tests the IsSingle method of the Layout type.
func TestIsSingle(t *testing.T) {
tests := []struct {
name string
Layout Layout
expect bool
}{
{
name: "FullFilePath Layout",
Layout: FullFilePath,
expect: true,
},
{
name: "Combined Layout",
Layout: FullFilePath | ShortFilePath,
expect: false,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if got := test.Layout.IsSingle(); got != test.expect {
t.Errorf("IsSingle = %v; want %v", got, test.expect)
}
})
}
}
// TestContains tests the Contains method of the Layout type.
func TestContains(t *testing.T) {
tests := []struct {
name string
Layout Layout
flag Layout
expect bool
err error
}{
{
name: "FullFilePath Layout contains FullFilePath",
Layout: FullFilePath,
flag: FullFilePath,
expect: true,
err: nil,
},
{
name: "FullFilePath Layout contains FuncName",
Layout: FullFilePath,
flag: FuncName,
expect: false,
err: nil,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
got, err := test.Layout.Contains(test.flag)
if err != test.err || got != test.expect {
t.Errorf("Contains = %v, FuncName = %v; "+
"want %v, FuncName = %v", got, err, test.expect, test.err)
}
})
}
}
// TestLayoutFlags tests the methods that check for flags in the Layout type.
func TestLayoutFlags(t *testing.T) {
tests := []struct {
name string
Layout Layout
method func(*Layout) bool
contain bool
}{
{
name: "FullFilePath Flag in FullFilePath Layout",
Layout: FullFilePath,
method: (*Layout).FullFilePath,
contain: true,
},
{
name: "FullFilePath Flag in FuncName Layout",
Layout: FuncName,
method: (*Layout).FullFilePath,
contain: false,
},
{
name: "ShortFilePath Flag in ShortFilePath Layout",
Layout: ShortFilePath,
method: (*Layout).ShortFilePath,
contain: true,
},
{
name: "ShortFilePath Flag in FuncName Layout",
Layout: FuncName,
method: (*Layout).ShortFilePath,
contain: false,
},
{
name: "FuncName Flag in FuncName Layout",
Layout: FuncName,
method: (*Layout).FuncName,
contain: true,
},
{
name: "FuncName Flag in FuncAddress Layout",
Layout: FuncAddress,
method: (*Layout).FuncName,
contain: false,
},
{
name: "FuncAddress Flag in FuncAddress Layout",
Layout: FuncAddress,
method: (*Layout).FuncAddress,
contain: true,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if got := test.method(&test.Layout); got != test.contain {
t.Errorf("%s got = %v; want %v", test.name, got, test.contain)
}
})
}
}
// TestSet tests the Set method of the Layout type.
func TestSet(t *testing.T) {
tests := []struct {
name string
Layout Layout
flags []Layout
expect Layout
err error
}{
{
name: "Set FullFilePath and FuncName flags",
Layout: Default,
flags: []Layout{FullFilePath, FuncName},
expect: FullFilePath | FuncName,
err: nil,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
got, err := test.Layout.Set(test.flags...)
if err != test.err || got != test.expect {
t.Errorf("Set = %v, FuncName = %v; want %v, FuncName = %v",
got, err, test.expect, test.err)
}
})
}
}
// TestLayoutAdd tests the Add method of the Layout type.
func TestLayoutAdd(t *testing.T) {
tests := []struct {
name string
start Layout
add []Layout
want Layout
err error
}{
{
name: "Add FullFilePath to Empty Layout",
start: 0,
add: []Layout{FullFilePath},
want: FullFilePath,
err: nil,
},
{
name: "Add FullFilePath to FullFilePath Layout",
start: FullFilePath,
add: []Layout{FullFilePath},
want: FullFilePath,
err: nil,
},
{
name: "Add FuncName to FullFilePath Layout",
start: FullFilePath,
add: []Layout{FuncName},
want: FullFilePath | FuncName,
err: nil,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
got, err := test.start.Add(test.add...)
if got != test.want || !errors.Is(err, test.err) {
t.Errorf("%s got = %v, err = %v; want %v, %v",
test.name, got, err, test.want, test.err)
}
})
}
}
// TestLayoutDelete tests the Delete method of the Layout type.
func TestLayoutDelete(t *testing.T) {
tests := []struct {
name string
start Layout
delete []Layout
want Layout
err error
}{
{
name: "Delete FullFilePath from FullFilePath Layout",
start: FullFilePath,
delete: []Layout{FullFilePath},
want: 0,
err: nil,
},
{
name: "Delete FullFilePath from FuncName Layout",
start: FuncName,
delete: []Layout{FullFilePath},
want: FuncName,
err: nil,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
got, err := test.start.Delete(test.delete...)
if got != test.want || !errors.Is(err, test.err) {
t.Errorf("%s got = %v, err = %v; want %v, %v",
test.name, got, err, test.want, test.err)
}
})
}
}
// TestLayoutAll tests the All method of the Layout type.
func TestLayoutAll(t *testing.T) {
tests := []struct {
name string
start Layout
all []Layout
want bool
}{
{
name: "All FullFilePath and FuncName in FullFilePath Layout",
start: FullFilePath,
all: []Layout{FullFilePath, FuncName},
want: false,
},
{
name: "All FullFilePath and FuncName in " +
"FullFilePath and FuncName Layout",
start: FullFilePath | FuncName,
all: []Layout{FullFilePath, FuncName},
want: true,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if got := test.start.All(test.all...); got != test.want {
t.Errorf("%s got = %v; want %v", test.name, got, test.want)
}
})
}
}
// TestLayoutAny tests the Any method of the Layout type.
func TestLayoutAny(t *testing.T) {
tests := []struct {
name string
start Layout
any []Layout
want bool
}{
{
name: "Any FullFilePath and FuncName in FullFilePath Layout",
start: FullFilePath,
any: []Layout{FullFilePath, FuncName},
want: true,
},
{
name: "Any FullFilePath and FuncName in FuncAddress Layout",
start: FuncAddress,
any: []Layout{FullFilePath, FuncName},
want: false,
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
if got := test.start.Any(test.any...); got != test.want {
t.Errorf("%s got = %v; want %v", test.name, got, test.want)
}
})
}
}
<file_sep>package log
import (
"os"
"strings"
"testing"
"github.com/goloop/log/level"
"github.com/goloop/trit"
)
// TestEcho tests the echo method of the Logger.
func TestEcho(t *testing.T) {
// Create a new logger.
logger := New("TEST-PREFIX:")
// Classical test.
r, w, _ := os.Pipe()
err := logger.SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
if err != nil {
t.Fatal(err)
}
logger.echo(nil, level.Debug, "test %s", "message")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
if !strings.Contains(out, "test message") {
t.Errorf("echo did not write the correct TEXT message: %s", out)
}
// As JSON.
r, w, _ = os.Pipe()
logger.SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
WithPrefix: trit.False,
})
logger.echo(nil, level.Debug, "test %s", "message")
outC = make(chan string)
go ioCopy(r, outC)
w.Close()
out = <-outC
if strings.Contains(out, "TEST-PREFIX") {
t.Errorf("the prefix should not appear in this test: %s", out)
}
// As JSON.
r, w, _ = os.Pipe()
logger.SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
TextStyle: trit.False,
})
logger.echo(nil, level.Debug, "test %s", "message")
outC = make(chan string)
go ioCopy(r, outC)
w.Close()
out = <-outC
if !strings.Contains(out, "\"level\":\"DEBUG\"") {
t.Errorf("echo did not write the correct JSON message: %s", out)
}
// Disabled.
r, w, _ = os.Pipe()
logger.SetOutputs(Output{
Name: "test",
Writer: w,
Enabled: trit.False,
})
logger.echo(nil, level.Debug, "test %s", "message")
outC = make(chan string)
go ioCopy(r, outC)
w.Close()
out = <-outC
if len(out) != 0 {
t.Errorf("should not write anything: %s", out)
}
}
// TestEchoWithTextFormatting tests the echo method with Text formatting.
func TestEchoWithTextFormatting(t *testing.T) {
tests := []struct {
name string
format string
in []interface{}
want string
}{
{
name: "Empty format",
format: "",
in: []interface{}{"hello", "world"},
want: "helloworld", // used fmt.Print
},
{
name: "System formatStr",
format: formatPrint,
in: []interface{}{"hello", "world"},
want: "helloworld", // used fmt.Print
},
{
name: "System formatStrLn",
format: formatPrintln,
in: []interface{}{"hello", "world"},
want: " hello world\n", // used fmt.Println
},
{
name: "Custom formats",
format: "[%d]-%s is %v",
in: []interface{}{777, "message", true},
want: "[777]-message is true", // used fmt.Printf
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
logger := New()
logger.SetSkipStackFrames(2)
r, w, _ := os.Pipe()
logger.SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
logger.echo(nil, level.Debug, tt.format, tt.in...)
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
if !strings.Contains(out, tt.want) {
t.Errorf("Expression `%v` does not contain `%v`", out, tt.want)
}
})
}
}
// TestEchoWithJSONFormatting tests the echo method with JSON formatting.
func TestEchoWithJSONFormatting(t *testing.T) {
tests := []struct {
name string
format string
in []interface{}
want string
}{
{
name: "Empty format",
format: "",
in: []interface{}{"hello", "world"},
want: "helloworld", // used fmt.Print
},
{
name: "System formatStr",
format: formatPrint,
in: []interface{}{"hello", "world"},
want: "helloworld", // used fmt.Print
},
{
name: "System formatStrLn",
format: formatPrintln,
in: []interface{}{"hello", "world"},
want: "hello world", // used fmt.Println with Trim
},
{
name: "Custom formats",
format: "[%d]-%s is %v",
in: []interface{}{777, "message", true},
want: "[777]-message is true", // used fmt.Printf
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
logger := New()
logger.SetSkipStackFrames(2)
r, w, _ := os.Pipe()
logger.SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
TextStyle: trit.False,
})
logger.echo(nil, level.Debug, tt.format, tt.in...)
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
if !strings.Contains(out, tt.want) {
t.Errorf("Expression `%v` does not contain `%v`", out, tt.want)
}
})
}
}
//
// The others of the method is rolled through global function, see log_test.go
//
<file_sep>package level
import (
"errors"
"fmt"
"math/bits"
)
const (
// Panic is the panic-type logging level.
Panic Level = 1 << iota
// Fatal is the fatal-type logging level.
Fatal
// Error is the error-type logging level.
Error
// Warn is the warning-type logging level.
Warn
// Info is the information-type logging level.
Info
// Debug is the debug-type logging level.
Debug
// Trace is the trace-type logging level.
Trace
// The overflowLevelValue is a exceeding the limit of permissible
// values for the Level.
overflowLevelValue Level = (1 << iota)
// Default is the default logging level.
Default = Panic | Fatal | Error | Warn | Info | Debug | Trace
)
// Labels associates human-readable headings with log levels.
var Labels = map[Level]string{
Panic: "PANIC",
Fatal: "FATAL",
Error: "ERROR",
Warn: "WARNING",
Info: "INFO",
Debug: "DEBUG",
Trace: "TRACE",
}
// ColorLabels associates human-readable headings with log levels.
// See more: https://en.wikipedia.org/wiki/ANSI_escape_code#Colors
var ColorLabels = map[Level]string{
Panic: fmt.Sprintf("\x1b[5m\x1b[1m\x1b[31m%s\x1b[0m", "PANIC"),
Fatal: fmt.Sprintf("\x1b[1m\x1b[31m%s\x1b[0m", "FATAL"),
Error: fmt.Sprintf("\x1b[31m%s\x1b[0m", "ERROR"),
Warn: fmt.Sprintf("\x1b[2m\x1b[1m\x1b[31m%s\x1b[0m", "WARNING"),
Info: fmt.Sprintf("\x1b[2m\x1b[30m%s\x1b[0m", "INFO"),
Debug: fmt.Sprintf("\x1b[1m\x1b[32m%s\x1b[0m", "DEBUG"),
Trace: fmt.Sprintf("\x1b[1m\x1b[33m%s\x1b[0m", "TRACE"),
}
// Level is the type of the level flags.
type Level uint8
// IsSingle returns true if value contains single of the available flag.
func (l *Level) IsSingle() bool {
return bits.OnesCount(uint(*l)) == 1 &&
*l <= Level(overflowLevelValue+1)>>1
}
// Contains method returns true if value contains the specified flag.
// Returns false and an error if the value is invalid or an
// invalid flag is specified.
func (l *Level) Contains(flag Level) (bool, error) {
switch {
case !flag.IsValid():
return false, errors.New("incorrect flag value")
case !l.IsValid():
return false, errors.New("the object is damaged")
}
return *l&flag == flag, nil // *l&flag != 0, nil
}
// IsValid returns true if value contains zero, one or an
// unique sum of valid LevelFlag flags. The zero value is a valid value.
func (l *Level) IsValid() bool {
// Check if object is zero, which is a valid value.
if *l == 0 {
return true
}
copy := *l
// Iterate over all possible values of the constants and
// check whether they are part of object.
for level := Level(1); level < overflowLevelValue; level <<= 1 {
// If layout is part of the object, remove it from object.
if copy&level == level {
copy ^= level
}
}
// Check whether all bits of t were "turned off".
// If t is zero, it means that all bits were matched values
// of constants, and therefore t is valid.
return copy == 0
}
// Panic returns true if value contains the Panic flag.
func (l *Level) Panic() bool {
v, _ := l.Contains(Panic)
return v
}
// Fatal returns true if value contains the Fatal flag.
func (l *Level) Fatal() bool {
v, _ := l.Contains(Fatal)
return v
}
// Error returns true if value contains the Error flag.
func (l *Level) Error() bool {
v, _ := l.Contains(Error)
return v
}
// Info returns true if value contains the Info flag.
func (l *Level) Info() bool {
v, _ := l.Contains(Info)
return v
}
// Debug returns true if value contains the Debug flag.
func (l *Level) Debug() bool {
v, _ := l.Contains(Debug)
return v
}
// Trace returns true if value contains the Trace flag.
func (l *Level) Trace() bool {
v, _ := l.Contains(Trace)
return v
}
// Set sets the specified flags ignores duplicates.
// The flags that were set previously will be discarded.
// Returns a new value if all is well or old value and an
// error if one or more invalid flags are specified.
func (l *Level) Set(flags ...Level) (Level, error) {
var r Level
for _, flag := range flags {
if !flag.IsValid() {
return *l, fmt.Errorf("the %d is invalid flag value", flag)
}
if ok, _ := r.Contains(flag); !ok {
r += Level(flag)
}
}
*l = r
return *l, nil
}
// Add adds the specified flags ignores duplicates or flags that value
// already contains. Returns a new value if all is well or old value and
// an error if one or more invalid flags are specified.
func (l *Level) Add(flags ...Level) (Level, error) {
r := *l
for _, flag := range flags {
if !flag.IsValid() {
return *l, fmt.Errorf("the %d is invalid flag value", flag)
}
if ok, _ := r.Contains(flag); !ok {
r += Level(flag)
}
}
*l = r
return *l, nil
}
// Delete deletes the specified flags ignores duplicates or
// flags that were not set. Returns a new value if all is well or
// old value and an error if one or more invalid flags are specified.
func (l *Level) Delete(flags ...Level) (Level, error) {
r := *l
for _, flag := range flags {
if !flag.IsValid() {
return *l, fmt.Errorf("the %d is invalid flag value", flag)
}
if ok, _ := r.Contains(flag); ok {
r -= Level(flag)
}
}
*l = r
return *l, nil
}
// All returns true if all of the specified flags are set.
func (l *Level) All(flags ...Level) bool {
for _, flag := range flags {
if ok, _ := l.Contains(flag); !ok {
return false
}
}
return true
}
// Any returns true if at least one of the specified flags is set.
func (l *Level) Any(flags ...Level) bool {
for _, flag := range flags {
if ok, _ := l.Contains(flag); ok {
return ok
}
}
return false
}
<file_sep>package log
import (
"os"
"reflect"
"strings"
"testing"
"github.com/goloop/log/level"
)
// TestNew tests the New function.
func TestNew(t *testing.T) {
tests := []struct {
name string
prefixes []string
want string
}{
{
name: "No prefix",
prefixes: []string{},
want: "",
},
{
name: "One prefix",
prefixes: []string{"test"},
want: "test",
},
{
name: "Multiple prefixes",
prefixes: []string{"test", "logger"},
want: "test-logger",
},
{
name: "Empty prefixes",
prefixes: []string{"", " "},
want: "",
},
{
name: "With marker",
prefixes: []string{"myapp", ":"},
want: "myapp:",
},
{
name: "Two words with marker",
prefixes: []string{"my", "app", ":"},
want: "my-app:",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
logger := New(test.prefixes...)
if logger.prefix != test.want {
t.Errorf("%s got = %v; want %v",
test.name, logger.prefix, test.want)
}
if logger.skipStackFrames != skipStackFrames {
t.Errorf("%s skipStackFrames got = %d; want %d",
test.name, logger.skipStackFrames, skipStackFrames)
}
if logger.fatalStatusCode != fatalStatusCode {
t.Errorf("%s fatalStatusCode got = %d; want %d",
test.name, logger.fatalStatusCode, fatalStatusCode)
}
if len(logger.outputs) != 2 ||
logger.outputs["stdout"] == nil ||
logger.outputs["stderr"] == nil {
t.Errorf("%s outputs are not properly set", test.name)
}
})
}
}
// TestCopy tests the Copy function.
func TestCopy(t *testing.T) {
copy := Copy() // copy self logger
// Perform an in-depth comparison of objects.
if !reflect.DeepEqual(copy, self) {
t.Errorf("Copy method doesn't make a complete copy of the object.")
}
}
// TestSetSkipStackFrames tests the SetSkipStackFrames function.
func TestSetSkipStackFrames(t *testing.T) {
skip := SkipStackFrames()
defer SetSkipStackFrames(skip)
tests := []struct {
name string
skip int
want int
}{
{
name: "Seat skip as -1",
skip: -1,
want: SkipStackFrames(), // current value
},
{
name: "Seat skip as 1",
skip: 1,
want: 1,
},
{
name: "Seat skip as 2",
skip: 2,
want: 2,
},
{
name: "Very high value",
skip: 32,
want: -1, // does not have to match
},
}
// Don't use parallel tests here.
for _, tt := range tests {
SetSkipStackFrames(tt.skip)
if tt.want < 0 {
if s := SkipStackFrames(); s == tt.skip {
t.Errorf("%s: skip limit protection did not work", tt.name)
}
} else {
if s := SkipStackFrames(); s != tt.want {
t.Errorf("%s: failed, got %d, want %d",
tt.name, s, tt.want)
}
}
}
}
// TestSetPrefix tests the SetPrefix function.
func TestSetPrefix(t *testing.T) {
prefix := Prefix()
defer SetPrefix(prefix)
tests := []struct {
name string
in string
}{
{
name: "Set: `hello`",
in: "hello",
},
{
name: "Set: `hello-world`",
in: "hello-world",
},
}
// Don't use parallel tests here.
for _, tt := range tests {
SetPrefix(tt.in)
if s := Prefix(); s != tt.in {
t.Errorf("%s: failed, got %s, want %s",
tt.name, s, tt.in)
}
}
}
// TestSetOutputs tests the SetOutputs function.
func TestSetOutputs(t *testing.T) {
outputs := Outputs()
defer SetOutputs(outputs...)
tests := []struct {
name string
in []Output
names []string
hasErr bool
}{
{
name: "Empty outputs",
in: []Output{},
names: []string{},
hasErr: true,
},
{
name: "Wrong output name",
in: []Output{
{
Name: "incorrect name",
Writer: os.Stdout,
},
},
names: []string{},
hasErr: true,
},
{
name: "CSS-style output name",
in: []Output{
{
Name: "file-name",
Writer: os.Stdout,
},
},
names: []string{"file-name"},
hasErr: false,
},
{
name: "Wrong output name, but it is system output",
in: []Output{
{
Name: "*",
Writer: os.Stdout,
isSystem: true,
},
},
names: []string{"*"},
hasErr: false,
},
{
name: "One short output",
in: []Output{
{
Name: "test",
Writer: os.Stdout,
},
},
names: []string{"test"},
hasErr: false,
},
{
name: "One short output with defaults",
in: []Output{
{
Name: "test",
Writer: os.Stdout,
},
Stdout,
Stderr,
},
names: []string{"test", "stdout", "stderr"},
hasErr: false,
},
{
name: "Noname output",
in: []Output{
{
Writer: os.Stdout,
},
},
hasErr: true,
},
{
name: "Nowriter output",
in: []Output{
{
Name: "test",
},
},
hasErr: true,
},
{
name: "Duplicates outputs",
in: []Output{
{
Name: "test",
Writer: os.Stdout,
},
{
Name: "test",
Writer: os.Stdout,
},
},
hasErr: true,
},
}
// Don't use parallel tests here.
for _, tt := range tests {
// Error check.
err := SetOutputs(tt.in...)
if tt.hasErr {
if err == nil {
t.Errorf("%s: an error was expected", tt.name)
}
continue
}
if err != nil {
t.Errorf("%s: an error occurred: %s", tt.name, err.Error())
}
// Len check.
out := Outputs()
if len(out) != len(tt.in) {
t.Errorf("%s: %d items passed but %d items sets",
tt.name, len(out), len(tt.in))
}
// Check names.
for _, n := range tt.names {
if _, ok := self.outputs[n]; !ok {
t.Errorf("%s: %s output not found", tt.name, n)
}
}
}
}
// TestEditOutputs tests the EditOutputs function.
func TestEditOutputs(t *testing.T) {
outputs := Outputs()
defer SetOutputs(outputs...)
tests := []struct {
name string
in []Output
hasErr bool
}{
{
name: "Empty outputs",
in: []Output{},
hasErr: true,
},
{
name: "One short output",
in: []Output{
{
Name: "some-not-real-name",
Writer: os.Stdout,
},
},
hasErr: true,
},
{
name: "Update stdout and stderr",
in: []Output{Stdout, Stderr},
hasErr: false,
},
{
name: "Update stdout levels",
in: []Output{
{
Name: Stdout.Name,
Levels: Stdout.Levels | level.Error,
},
},
hasErr: false,
},
}
// Don't use parallel tests here.
for _, tt := range tests {
// Error check.
SetOutputs(Stdout, Stderr)
err := EditOutputs(tt.in...)
if tt.hasErr {
if err == nil {
t.Errorf("%s: an error was expected", tt.name)
}
continue
}
if err != nil {
t.Errorf("%s: an error occurred: %s", tt.name, err.Error())
}
// Check names.
for _, o := range tt.in {
oo, ok := self.outputs[o.Name]
if !ok {
t.Errorf("%s: %s output not found", tt.name, o.Name)
}
if o.Levels != oo.Levels {
t.Errorf("%s: %s output not updated correctly",
tt.name, o.Name)
}
}
}
}
// TestDeleteOutputs tests the DeleteOutputs function.
func TestDeleteOutputs(t *testing.T) {
outputs := Outputs()
defer SetOutputs(outputs...)
DeleteOutputs(Stdout.Name)
if _, ok := self.outputs[Stdout.Name]; ok {
t.Errorf("DeleteOutputs did not delete the output")
}
}
// TestOutputs tests the Outputs function.
func TestOutputs(t *testing.T) {
outputs := Outputs()
defer SetOutputs(outputs...)
// All outputs.
output := Output{
Name: "test",
Writer: os.Stdout,
}
err := SetOutputs(output)
if err != nil {
t.Fatal(err)
}
out := Outputs()
if len(out) != 1 {
t.Errorf("Outputs did not return the correct number of outputs")
}
if out[0].Name != output.Name {
t.Errorf("Outputs did not return the correct output")
}
// Only std*.
SetOutputs(output, Stdout, Stderr)
out = Outputs(Stdout.Name, Stderr.Name)
if len(out) != 2 {
t.Errorf("Outputs did not return the correct number of outputs")
}
}
// TestFpanic tests the Fpanic function.
func TestFpanic(t *testing.T) {
defer func() {
if r := recover(); r == nil {
t.Errorf("The code did not panic as expected")
}
}()
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Panic,
})
Fpanic(w, "Test fatal")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test fatal"
n := level.Labels[level.Panic]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFpanicf tests the Fpanicf function.
func TestFpanicf(t *testing.T) {
defer func() {
if r := recover(); r == nil {
t.Errorf("The code did not panic as expected")
}
}()
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Panic,
})
Fpanicf(w, "Test fatal %s", "formatted")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test fatal formatted"
n := level.Labels[level.Panic]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFpanicln tests the Fpanicln function.
func TestFpanicln(t *testing.T) {
defer func() {
if r := recover(); r == nil {
t.Errorf("The code did not panic as expected")
}
}()
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Panic,
})
Fpanicln(w, "Test fatalln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test fatalln"
n := level.Labels[level.Panic]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestPanic tests the Panic function.
func TestPanic(t *testing.T) {
defer func() {
if r := recover(); r == nil {
t.Errorf("The code did not panic as expected")
}
}()
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Panic("Test fatal")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test fatal"
n := level.Labels[level.Panic]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestPanicf tests the Panicf function.
func TestPanicf(t *testing.T) {
defer func() {
if r := recover(); r == nil {
t.Errorf("The code did not panic as expected")
}
}()
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Panicf("Test fatal %s", "formatted")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test fatal formatted"
n := level.Labels[level.Panic]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestPanicln tests the Panicln function.
func TestPanicln(t *testing.T) {
defer func() {
if r := recover(); r == nil {
t.Errorf("The code did not panic as expected")
}
}()
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Panicln("Test fatalln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test fatalln"
n := level.Labels[level.Panic]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFfatal tests the Ffatal function.
func TestFfatal(t *testing.T) {
exit = func(i int) {}
defer func() {
exit = os.Exit
}()
r, w, _ := os.Pipe()
Ffatal(w, "Test Ffatal")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Ffatal"
n := level.Labels[level.Fatal]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFfatalf tests the Ffatalf function.
func TestFfatalf(t *testing.T) {
exit = func(i int) {}
defer func() {
exit = os.Exit
}()
r, w, _ := os.Pipe()
Ffatalf(w, "Test fatal %s", "formatted")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test fatal formatted"
n := level.Labels[level.Fatal]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFfatalln tests the Ffatalln function.
func TestFfatalln(t *testing.T) {
exit = func(i int) {}
defer func() {
exit = os.Exit
}()
r, w, _ := os.Pipe()
Ffatalln(w, "Test fatalln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test fatalln"
n := level.Labels[level.Fatal]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFatal tests the Fatal function.
func TestFatal(t *testing.T) {
exit = func(i int) {}
defer func() {
exit = os.Exit
}()
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Fatal("Test fatal")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test fatal"
n := level.Labels[level.Fatal]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFatalf tests the Fatalf function.
func TestFatalf(t *testing.T) {
exit = func(i int) {}
defer func() {
exit = os.Exit
}()
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Fatalf("Test fatal %s", "formatted")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test fatal formatted"
n := level.Labels[level.Fatal]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFatalln tests the Fatalln function.
func TestFatalln(t *testing.T) {
exit = func(i int) {}
defer func() {
exit = os.Exit
}()
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Fatalln("Test fatalln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test fatalln"
n := level.Labels[level.Fatal]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFerror tests the Ferror function.
func TestFerror(t *testing.T) {
r, w, _ := os.Pipe()
Ferror(w, "Test Ferror")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Ferror"
n := level.Labels[level.Error]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFerrorf tests the Ferrorf function.
func TestFerrorf(t *testing.T) {
r, w, _ := os.Pipe()
Ferrorf(w, "Test %s", "Ferrorf")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Ferrorf"
n := level.Labels[level.Error]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFerrorln tests the Ferrorln function.
func TestFerrorln(t *testing.T) {
r, w, _ := os.Pipe()
Ferrorln(w, "Test Ferrorln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Ferrorln"
n := level.Labels[level.Error]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestError tests the Error function.
func TestError(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Error("Test Error")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Error"
n := level.Labels[level.Error]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestErrorf tests the Errorf function.
func TestErrorf(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Errorf("Test %s", "Errorf")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Errorf"
n := level.Labels[level.Error]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestErrorln tests the Errorln function.
func TestErrorln(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Errorln("Test Errorln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Errorln"
n := level.Labels[level.Error]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFwarn tests the Fwarn function.
func TestFwarn(t *testing.T) {
r, w, _ := os.Pipe()
Fwarn(w, "Test Fwarn")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Fwarn"
n := level.Labels[level.Warn]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFwarnf tests the Fwarnf function.
func TestFwarnf(t *testing.T) {
r, w, _ := os.Pipe()
Fwarnf(w, "Test %s", "Fwarnf")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Fwarnf"
n := level.Labels[level.Warn]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFwarnln tests the Fwarnln function.
func TestFwarnln(t *testing.T) {
r, w, _ := os.Pipe()
Fwarnln(w, "Test Fwarnln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Fwarnln"
n := level.Labels[level.Warn]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestWarn tests the Warn function.
func TestWarn(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Warn("Test Warn")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Warn"
n := level.Labels[level.Warn]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestWarnf tests the Warnf function.
func TestWarnf(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Warnf("Test warning %s", "formatted")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test warning formatted"
n := level.Labels[level.Warn]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestWarnln tests the Warnln function.
func TestWarnln(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Warnln("Test warnln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test warnln"
n := level.Labels[level.Warn]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFinfo tests the Finfo function.
func TestFinfo(t *testing.T) {
r, w, _ := os.Pipe()
Finfo(w, "Test finfo")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test finfo"
n := level.Labels[level.Info]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFinfof tests the Finfof function.
func TestFinfof(t *testing.T) {
r, w, _ := os.Pipe()
Finfof(w, "Test %s", "finfof")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test finfof"
n := level.Labels[level.Info]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFinfoln tests the Finfoln function.
func TestFinfoln(t *testing.T) {
r, w, _ := os.Pipe()
Finfoln(w, "Test finfoln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test finfoln"
n := level.Labels[level.Info]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestInfo tests the Info function.
func TestInfo(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Info("Test info")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test info"
n := level.Labels[level.Info]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestInfof tests the Infof function.
func TestInfof(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Infof("Test %s", "infof")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test infof"
n := level.Labels[level.Info]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestInfoln tests the Infoln function.
func TestInfoln(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Infoln("Test infoln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test infoln"
n := level.Labels[level.Info]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFdebug tests the Fdebug function.
func TestFdebug(t *testing.T) {
r, w, _ := os.Pipe()
Fdebug(w, "Test Fdebug")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Fdebug"
n := level.Labels[level.Debug]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFdebugf tests the Fdebugf function.
func TestFdebugf(t *testing.T) {
r, w, _ := os.Pipe()
Fdebugf(w, "Test %s", "Fdebugf")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Fdebugf"
n := level.Labels[level.Debug]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFdebugln tests the Fdebugln function.
func TestFdebugln(t *testing.T) {
r, w, _ := os.Pipe()
Fdebugln(w, "Test Fdebugln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Fdebugln"
n := level.Labels[level.Debug]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestDebug tests the Debug function.
func TestDebug(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Debug("Test Debug")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Debug"
n := level.Labels[level.Debug]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestDebugf tests the Debugf function.
func TestDebugf(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Debugf("Test %s", "Debugf")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Debugf"
n := level.Labels[level.Debug]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestDebugln tests the Debugln function.
func TestDebugln(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Debugln("Test Debugln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Debugln"
n := level.Labels[level.Debug]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFtrace tests the Ftrace function.
func TestFtrace(t *testing.T) {
r, w, _ := os.Pipe()
Ftrace(w, "Test Ftrace")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Ftrace"
n := level.Labels[level.Trace]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFtracef tests the Ftracef function.
func TestFtracef(t *testing.T) {
r, w, _ := os.Pipe()
Ftracef(w, "Test %s", "Ftracef")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Ftracef"
n := level.Labels[level.Trace]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestFtraceln tests the Ftraceln function.
func TestFtraceln(t *testing.T) {
r, w, _ := os.Pipe()
Ftraceln(w, "Test Ftraceln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Ftraceln"
n := level.Labels[level.Trace]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestTrace tests the Trace function.
func TestTrace(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Trace("Test Trace")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Trace"
n := level.Labels[level.Trace]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestTracef tests the Tracef function.
func TestTracef(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Tracef("Test %s", "Tracef")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Tracef"
n := level.Labels[level.Trace]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
// TestTraceln tests the Traceln function.
func TestTraceln(t *testing.T) {
r, w, _ := os.Pipe()
SetOutputs(Output{
Name: "test",
Writer: w,
Levels: level.Default,
})
Traceln("Test Traceln")
outC := make(chan string)
go ioCopy(r, outC)
w.Close()
out := <-outC
expected := "Test Traceln"
n := level.Labels[level.Trace]
if !strings.Contains(out, expected) || !strings.Contains(out, n) {
t.Errorf("Result `%s` doesn't contains `%s` and `%s`",
out, expected, n)
}
}
<file_sep>package log
import (
"fmt"
"io"
"os"
"sync"
"time"
"github.com/goloop/g"
"github.com/goloop/is"
"github.com/goloop/log/layout"
"github.com/goloop/log/level"
"github.com/goloop/trit"
)
const (
// The skipStackFrames specifies the default number of stack frames to
// skip before the program counter stack is collected.
skipStackFrames = 4
// The shortPathSections is the number of sections in the short path
// of the file. I.e. if it is set to display the path to the file as
// short, this value determines how many rightmost sections will be
// displayed, e.g. for full path as /very/long/path/to/project/main.go
// with shortPathSections as 3 will be displayed .../to/project/main.go.
shortPathSections = 3
// The fatalStatusCode is the default status code for the fatal level.
fatalStatusCode = 1
// The outWithPrefix is default values for the output prefix parameters.
outWithPrefix = trit.True
// The outWithColor is default values for the output color parameters.
outWithColor = trit.False
// The outTextStyle is default values for the output text parameters.
outTextStyle = trit.True
// The outEnabled is default values for the output enabled parameters.
outEnabled = trit.True
// The outSpace is the space between the blocks of the
// output prefix.
outSpace = " "
// The outTimestampFormat is the default time format for the output.
outTimestampFormat = "2006/01/02 15:04:05"
// The outLevelFormat is the default level format for the output.
outLevelFormat = "%s"
// There is a difference between text-style message formatting
// and JSON-style formatting.
//
// So, in text style: print simply prints all elements, pasting
// them together without separators; println - adds spaces between
// elements and adds \n at the end of the formed line; and printf -
// outputs according to a special format template.
//
// At the same time, for JSON: print should insert all elements
// without delimiters (as in text style), but all JSON blocks* don't
// contain \n at the end; but println inserts all message elements
// with a space added, and does not add \n to the end of the message,
// instead, each new JSON block* is printed on a new line (\n is appended
// to the JSON block); printf - \n is appended to the JSON block* and the
// message format matches the specified user format.
//
// So, to determine if a custom format pattern is specified, we use
// two constants formatPrint and formatPrintln, which help determine
// the type of function (print, println, or printf) that renders
// the message, and the formatting methods for text or JSON style.
//
// * JSON block is the final text representation of the logger in
// JSON format written as text.
// The formatPrint is the system format string
// for print-type functions.
formatPrint = "{$ string-without-a-newline-character $}"
// The formatPrintln is the system format string
// for println-type functions.
formatPrintln = "{$ string-with-a-newline-character $}"
)
var (
// Stdout standard rules for displaying logger information's
// messages in the console.
Stdout = Output{
Name: "stdout",
Writer: os.Stdout,
Layouts: layout.Default,
Levels: level.Info | level.Debug | level.Trace,
Space: outSpace,
WithPrefix: outWithPrefix,
WithColor: outWithColor,
Enabled: outEnabled,
TextStyle: outTextStyle,
TimestampFormat: outTimestampFormat,
LevelFormat: outLevelFormat,
}
// Stderr standard rules for displaying logger errors
// messages in the console.
Stderr = Output{
Name: "stderr",
Writer: os.Stderr,
Layouts: layout.Default,
Levels: level.Panic | level.Fatal | level.Error | level.Warn,
Space: outSpace,
WithPrefix: outWithPrefix,
WithColor: outWithColor,
Enabled: outEnabled,
TextStyle: outTextStyle,
TimestampFormat: outTimestampFormat,
LevelFormat: outLevelFormat,
}
// Default is output that processes all types of levels
// and outputs the result to stdout.
Default = Output{
Name: "default",
Writer: os.Stdout,
Layouts: layout.Default,
Levels: Stdout.Levels | Stderr.Levels,
Space: outSpace,
WithPrefix: outWithPrefix,
WithColor: outWithColor,
Enabled: outEnabled,
TextStyle: outTextStyle,
TimestampFormat: outTimestampFormat,
LevelFormat: outLevelFormat,
}
// The exit causes the current program to exit with the given status code.
// Redefined this function to be able to test *fatal* methods.
exit = os.Exit
)
// Output is the type of the logging output configuration.
// Specifies the destination where the log and display
// parameters will be output.
type Output struct {
// Name is the name of the output. It is used to identify
// the output in the list of outputs.
//
// Mandatory parameter, cannot be empty.
// The name must sound like a variable name in most programming languages:
// it must have special characters, not start with a number, etc.
// But the name can be a reserved word like return, for, if ... any.
// The name can also be expressed as a selector name in CSS,
// for example "some-log-file" (without the leading . or # symbols).
Name string
// Writer is the point where the login data will be output,
// for example os.Stdout or text file descriptor.
//
// Mandatory parameter, cannot be empty.
Writer io.Writer
// Layouts is the flag-holder where flags responsible for
// formatting the log message prefix.
Layouts layout.Layout
// Levels is the flag-holder where flags responsible for
// levels of the logging: Panic, Fatal, Error, Warn, Info etc.
Levels level.Level
// Space is the space between the blocks of the
// output prefix.
Space string
// WithPrefix is the flag that determines whether to show the prefix
// in the log-message. I.e., if the prefix is set for the logger,
// it will be convenient for os.Stdout to display it, since several
// applications can send messages at the same time, but this is
// not necessary for the log file because each application has
// its own log file.
//
// This only works when the prefix is set to the logger.
// By default, the prefix is enabled.
//
// Values are given by numerical marks, where:
// - values less than zero are considered false;
// - values greater than zero are considered true;
// - the value set to 0 is considered the default value
// (or don't change, for edit mode).
//
// We can also use the github.com/goloop/trit package and
// the trit.True or trit.False value.
WithPrefix trit.Trit
// WithColor is the flag that determines whether to use color for the
// log-message. Each message level has its own color. This is handy for
// the console to visually see the problem or debug information.
//
// By default, the color is disabled.
//
// Values are given by numerical marks, where:
// - values less than zero are considered false;
// - values greater than zero are considered true;
// - the value set to 0 is considered the default value
// (or don't change, for edit mode).
//
// We can also use the github.com/goloop/trit package and
// the trit.True or trit.False value.
//
// The color scheme works only for UNIX-like systems.
// The color scheme works for flat format only (i.e. display of log
// messages in the form of text, not as JSON).
WithColor trit.Trit
// Enabled is the flag that determines whether to enable the output.
//
// By default, the new output is enable.
//
// Values are given by numerical marks, where:
// - values less than zero are considered false;
// - values greater than zero are considered true;
// - the value set to 0 is considered the default value
// (or don't change, for edit mode).
//
// We can also use the github.com/goloop/trit package and
// the trit.True or trit.False value.
Enabled trit.Trit
// TextStyle is the flag that determines whether to use text style for
// the log-message. Otherwise, the result will be displayed in JSON style.
//
// By default, the new output has text style.
//
// Values are given by numerical marks, where:
// - values less than zero are considered false;
// - values greater than zero are considered true;
// - the value set to 0 is considered the default value
// (or don't change, for edit mode).
//
// We can also use the github.com/goloop/trit package and
// the trit.True or trit.False value.
TextStyle trit.Trit
// TimestampFormat is the format of the timestamp in the log-message.
// Must be specified in the format of the time.Format() function.
TimestampFormat string
// LevelFormat is the format of the level in the log-message.
// Allows us to add additional information or a label around
// the ID of the level, for example, to display the level in
// square brackets: [LEVEL_NAME] - we need to specify the
// format as "[%s]".
LevelFormat string
// The isSystem is the flag that determines whether the output is system.
// For example, this can be for all F* functions (Ferror, Finfo etc.) that
// accept a target writer. Package generates a unique Output for them.
isSystem bool
}
// Logger is a structure that encapsulates logging functionality.
// It provides an interface to log messages with varying levels
// of severity, and can be configured to format and output these
// messages in different ways.
type Logger struct {
// The skipStackFrames specifies the number of stack frames to skip before
// the program counter stack is collected. For example, if skip is equal
// to 4, then the top four frames of the stack will be ignored.
skipStackFrames int
// The fatalStatusCode is the status code that will be returned
// to the operating system when the program is terminated
// by the Fatal() method.
fatalStatusCode int
// The prefix (optional) it is a special value that is inserted before
// the log-message. It can be used to identify the application that
// generates the message, if several different applications output
// to one output.
prefix string
// The outputs is the list of the logging outputs.
// The logger can output the log message to several outputs
// at once, for example, to the console and to the log file.
outputs map[string]*Output
// The mu is the mutex for the log object.
mu sync.RWMutex
}
// Copy returns copy of the logger object.
func (logger *Logger) Copy() *Logger {
// Lock the log object for change.
logger.mu.RLock()
defer logger.mu.RUnlock()
// Get outputs.
outputs := make([]Output, 0, len(logger.outputs))
for _, o := range logger.outputs {
outputs = append(outputs, *o)
}
instance := &Logger{
skipStackFrames: logger.skipStackFrames,
fatalStatusCode: logger.fatalStatusCode,
prefix: logger.prefix,
outputs: map[string]*Output{},
}
instance.SetOutputs(outputs...)
return instance
}
// SetSkipStackFrames sets the number of stack frames to skip before
// the program counter stack is collected.
//
// If the specified value is less than zero, the value does not change.
// If too large a value is specified, the maximum allowable value
// will be set.
func (logger *Logger) SetSkipStackFrames(skip int) int {
logger.mu.Lock()
defer logger.mu.Unlock()
// Cannot be a negative value.
if skip < 0 {
return logger.skipStackFrames
}
// Too big a skip can cause panic in the getStackFrame.
// Take the highest possible value.
for {
func() {
// If panic, reduce the skip value by one.
defer func() {
if r := recover(); r != nil {
skip--
}
}()
// If the skip is too large, it can cause panic.
logger.skipStackFrames = skip
getStackFrame(skip + 1) // plus 1 because we in inner func
}()
// If the subtraction is already nowhere or
// the skip didn't cause panic (was not reduced).
if skip <= 0 || logger.skipStackFrames == skip {
break
}
}
return logger.skipStackFrames
}
// SkipStackFrames returns the number of stack frames to skip before
// the program counter stack is collected.
func (logger *Logger) SkipStackFrames() int {
logger.mu.RLock()
defer logger.mu.RUnlock()
return logger.skipStackFrames
}
// SetPrefix sets the prefix to the logger. The prefix is a special value
// that is inserted before the log-message. It can be used to identify
// the application that generates the message, if several different
// applications output to one output.
func (logger *Logger) SetPrefix(prefix string) string {
logger.mu.Lock()
defer logger.mu.Unlock()
logger.prefix = prefix
return logger.prefix
}
// Prefix returns logger prefix.
func (logger *Logger) Prefix() string {
logger.mu.RLock()
defer logger.mu.RUnlock()
return logger.prefix
}
// SetOutputs clears all installed outputs and installs new ones from the list.
// If new outputs are not specified, the logger will not output information
// anywhere. We must explicitly specify at least one output, or use the
// defaults: log.Stdout or/and log.Stderr.
//
// Example usage:
//
// // Show only informational levels.
// logger.SetOutputs(log.Stdout)
//
// // Show only error and fatal levels.
// logger.SetOutputs(log.Stderr)
//
// // Show all levels.
// logger.SetOutputs(log.Stdout, log.Stderr)
//
// // Use custom settings.
// // Output to the console is different from output to a file.
// f, err := os.OpenFile("e.log", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0666)
// if err != nil {
// log.Fatal(err)
// }
// defer f.Close()
//
// logger.SetOutputs(
// log.Output{
// Name: "errors",
// Writer: f,
// Levels: log.PanicLevel|log.FatalLevel|log.ErrorLevel,
// Formats: log.ShortPathFormat|log.LineNumberFormat,
// WithPrefix: log.Yes,
// },
// log.Stdout,
// log.Stderr,
// )
//
// If the specified output has an empty name or writer as nil, the function
// returns an error. An error is returned if two or more outputs have the
// same name. If the function returns an error, it doesn't change or clear
// the previously set values.
//
// Example usage:
//
// // Show only informational levels.
// logger.SetOutputs(log.Stdout)
//
// // Try to update with incorrect data.
// logger.SetOutputs(log.Output{}) // error: the 0 object has empty name
func (logger *Logger) SetOutputs(outputs ...Output) error {
// Lock the logger.
logger.mu.Lock()
defer logger.mu.Unlock()
if len(outputs) == 0 {
return fmt.Errorf("the outputs list is empty")
}
// Check the correctness of the data and create a temporary map.
// If the data is not correct, we cannot change the data already
// set previously.
result := make(map[string]*Output, len(outputs))
for i := range outputs {
o := &outputs[i]
// The name must be specified.
if g.IsEmpty(o.Name) {
return fmt.Errorf("the %d output has empty name", i)
} else if !o.isSystem && !is.SelectorName(o.Name, true) {
return fmt.Errorf("the %d output has incorrect name '%s'",
i, o.Name)
}
// The writer must be specified.
if g.IsEmpty(o.Writer) {
return fmt.Errorf("the %d output has nil writer", i)
}
// If the output is already in the list, then return an error.
if _, ok := result[o.Name]; ok {
return fmt.Errorf("output duplicate name '%s'", o.Name)
}
// Set the new value if it is specified, otherwise set the default one.
//
// Note: g.Value returns the first non-empty value.
o.Layouts = g.Value(o.Layouts, layout.Default)
o.Levels = g.Value(o.Levels, level.Default)
o.Space = g.Value(o.Space, outSpace)
o.WithPrefix = g.Value(o.WithPrefix, outWithPrefix)
o.WithColor = g.Value(o.WithColor, outWithColor)
o.Enabled = g.Value(o.Enabled, outEnabled)
o.TextStyle = g.Value(o.TextStyle, outTextStyle)
o.TimestampFormat = g.Value(o.TimestampFormat, outTimestampFormat)
o.LevelFormat = g.Value(o.LevelFormat, outLevelFormat)
result[o.Name] = o
}
logger.outputs = result
return nil
}
// EditOutputs updates the list of outputs.
// If the output with the specified name is not set,
// the function returns an error.
//
// To edit the output, we must specify its name and only those fields
// that will be edited. Fields that are not specified will not be changed.
//
// Example usage:
//
// // Set default settings.
// logger.SetOutputs(log.Stdout, log.Stderr)
//
// // Change the settings for the "stdout" output.
// logger.EditOutputs(log.Output{
// Name: log.Stdout.Name,
// Levels: log.PanicLevel|log.FatalLevel|log.ErrorLevel,
// })
func (logger *Logger) EditOutputs(outputs ...Output) error {
// Lock the logger.
logger.mu.Lock()
defer logger.mu.Unlock()
if len(outputs) == 0 {
return fmt.Errorf("the outputs list is empty")
}
// Check the correctness of the data and create a temporary map.
// If the data is not correct, we cannot change the data already
// set previously.
result := make(map[string]*Output, len(outputs))
for _, o := range outputs {
out, ok := logger.outputs[o.Name]
if !ok {
return fmt.Errorf("output not found '%s'", o.Name)
}
// Set the new value if it is specified, otherwise leave the old one.
//
// Note: g.Value returns the first non-empty value.
out.Writer = g.Value(o.Writer, out.Writer)
out.Layouts = g.Value(o.Layouts, out.Layouts)
out.Levels = g.Value(o.Levels, out.Levels)
out.Space = g.Value(o.Space, out.Space)
out.WithPrefix = g.Value(o.WithPrefix, out.WithPrefix)
out.WithColor = g.Value(o.WithColor, out.WithColor)
out.Enabled = g.Value(o.Enabled, out.Enabled)
out.TextStyle = g.Value(o.TextStyle, out.TextStyle)
out.TimestampFormat = g.Value(o.TimestampFormat, out.TimestampFormat)
out.LevelFormat = g.Value(o.LevelFormat, out.LevelFormat)
result[o.Name] = out
}
// Update outputs.
for n, o := range result {
logger.outputs[n] = o
}
return nil
}
// DeleteOutputs deletes outputs by name.
//
// Example usage:
//
// // Delete the "stdout" output.
// logger.DeleteOutputs(log.Stdout.Name)
func (logger *Logger) DeleteOutputs(names ...string) {
// Lock the logger.
logger.mu.Lock()
defer logger.mu.Unlock()
for _, name := range names {
delete(logger.outputs, name)
}
}
// Outputs returns a list of outputs.
//
// Example usage:
//
// // Get a list of the current outputs.
// outputs := logger.Outputs()
//
// // Add new output.
// outputs = append(outputs, log.Stdout)
//
// // Set new outputs.
// logger.SetOutputs(outputs...)
func (logger *Logger) Outputs(names ...string) []Output {
logger.mu.RLock()
defer logger.mu.RUnlock()
// If the list of names is not empty, then we return only those outputs
// that are specified in the list of names.
if len(names) > 0 {
result := make([]Output, 0, len(names))
for _, name := range names {
if o, ok := logger.outputs[name]; ok {
result = append(result, *o)
}
}
return result
}
// If the list of names is empty, then we return all outputs.
result := make([]Output, 0, len(logger.outputs))
for _, o := range logger.outputs {
result = append(result, *o)
}
return result
}
// The echo is universal method creates a message of the fmt.Fprint format.
func (logger *Logger) echo(w io.Writer, l level.Level, f string, a ...any) {
// Lock the log object for change.
logger.mu.RLock()
defer logger.mu.RUnlock()
// Get the stack frame.
sf := getStackFrame(logger.skipStackFrames)
// If an additional value is set for the output (writer),
// use it with the default settings.
outputs := logger.outputs
if w != nil {
output := Default
output.Writer = w
output.isSystem = true
outputs["*"] = &output // this name can be used for system names
}
// Output message.
for _, o := range logger.outputs {
var msg string
has, err := o.Levels.Contains(l)
if !has || err != nil || !o.Enabled.IsTrue() {
continue
}
// Hide or show the prefix.
prefix := logger.prefix
if !o.WithPrefix.IsTrue() {
prefix = ""
}
// Text or JSON representation of the message.
if o.TextStyle.IsTrue() {
msg = textMessage(prefix, l, time.Now(), o, sf, f, a...)
} else {
msg = objectMessage(prefix, l, time.Now(), o, sf, f, a...)
}
// Print message.
fmt.Fprint(o.Writer, msg)
}
}
// Fpanic creates message with Panic level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func (logger *Logger) Fpanic(w io.Writer, a ...any) {
logger.echo(w, level.Panic, formatPrint, a...)
panic(fmt.Sprint(a...))
}
// Fpanicf creates message with Panic level, according to a format
// specifier and writes to w.
func (logger *Logger) Fpanicf(w io.Writer, format string, a ...any) {
logger.echo(w, level.Panic, format, a...)
panic(fmt.Sprintf(format, a...))
}
// Fpanicln creates message with Panic level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended.
func (logger *Logger) Fpanicln(w io.Writer, a ...any) {
logger.echo(w, level.Panic, formatPrintln, a...)
panic(fmt.Sprintln(a...))
}
// Panic creates message with Panic level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string.
func (logger *Logger) Panic(a ...any) {
logger.echo(nil, level.Panic, formatPrint, a...)
panic(fmt.Sprint(a...))
}
// Panicf creates message with Panic level, according to a format specifier
// and writes to log.Writer.
func (logger *Logger) Panicf(format string, a ...any) {
logger.echo(nil, level.Panic, format, a...)
panic(fmt.Sprintf(format, a...))
}
// Panicln creates message with Panic, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func (logger *Logger) Panicln(a ...any) (int, error) {
logger.echo(nil, level.Panic, formatPrintln, a...)
panic(fmt.Sprintln(a...))
}
// Ffatal creates message with Fatal level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func (logger *Logger) Ffatal(w io.Writer, a ...any) {
logger.echo(w, level.Fatal, formatPrint, a...)
exit(logger.fatalStatusCode)
}
// Ffatalf creates message with Fatal level, according to a format
// specifier and writes to w.
func (logger *Logger) Ffatalf(w io.Writer, format string, a ...any) {
logger.echo(w, level.Fatal, format, a...)
exit(logger.fatalStatusCode)
}
// Ffatalln creates message with Fatal level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended.
func (logger *Logger) Ffatalln(w io.Writer, a ...any) {
logger.echo(w, level.Fatal, formatPrintln, a...)
exit(logger.fatalStatusCode)
}
// Fatal creates message with Fatal level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string.
func (logger *Logger) Fatal(a ...any) {
logger.echo(nil, level.Fatal, formatPrint, a...)
exit(logger.fatalStatusCode)
}
// Fatalf creates message with Fatal level, according to a format specifier
// and writes to log.Writer.
func (logger *Logger) Fatalf(format string, a ...any) {
logger.echo(nil, level.Fatal, format, a...)
exit(logger.fatalStatusCode)
}
// Fatalln creates message with Fatal, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func (logger *Logger) Fatalln(a ...any) {
logger.echo(nil, level.Fatal, formatPrintln, a...)
exit(logger.fatalStatusCode)
}
// Ferror creates message with Error level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func (logger *Logger) Ferror(w io.Writer, a ...any) {
logger.echo(w, level.Error, formatPrint, a...)
}
// Ferrorf creates message with Error level, according to a format
// specifier and writes to w.
func (logger *Logger) Ferrorf(w io.Writer, f string, a ...any) {
logger.echo(w, level.Error, f, a...)
}
// Ferrorln creates message with Error level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended.
func (logger *Logger) Ferrorln(w io.Writer, a ...any) {
logger.echo(w, level.Error, formatPrintln, a...)
}
// Error creates message with Error level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string.
func (logger *Logger) Error(a ...any) {
logger.echo(nil, level.Error, formatPrint, a...)
}
// Errorf creates message with Error level, according to a format specifier
// and writes to log.Writer.
func (logger *Logger) Errorf(f string, a ...any) {
logger.echo(nil, level.Error, f, a...)
}
// Errorln creates message with Error, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func (logger *Logger) Errorln(a ...any) {
logger.echo(nil, level.Error, formatPrintln, a...)
}
// Fwarn creates message with Warn level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func (logger *Logger) Fwarn(w io.Writer, a ...any) {
logger.echo(w, level.Warn, formatPrint, a...)
}
// Fwarnf creates message with Warn level, according to a format
// specifier and writes to w.
func (logger *Logger) Fwarnf(w io.Writer, format string, a ...any) {
logger.echo(w, level.Warn, format, a...)
}
// Fwarnln creates message with Warn level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended.
func (logger *Logger) Fwarnln(w io.Writer, a ...any) {
logger.echo(w, level.Warn, formatPrintln, a...)
}
// Warn creates message with Warn level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string.
func (logger *Logger) Warn(a ...any) {
logger.echo(nil, level.Warn, formatPrint, a...)
}
// Warnf creates message with Warn level, according to a format specifier
// and writes to log.Writer.
func (logger *Logger) Warnf(format string, a ...any) {
logger.echo(nil, level.Warn, format, a...)
}
// Warnln creates message with Warn, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func (logger *Logger) Warnln(a ...any) {
logger.echo(nil, level.Warn, formatPrintln, a...)
}
// Finfo creates message with Info level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func (logger *Logger) Finfo(w io.Writer, a ...any) {
logger.echo(w, level.Info, formatPrint, a...)
}
// Finfof creates message with Info level, according to a format
// specifier and writes to w.
func (logger *Logger) Finfof(w io.Writer, format string, a ...any) {
logger.echo(w, level.Info, format, a...)
}
// Finfoln creates message with Info level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended.
func (logger *Logger) Finfoln(w io.Writer, a ...any) {
logger.echo(w, level.Info, formatPrintln, a...)
}
// Info creates message with Info level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string.
func (logger *Logger) Info(a ...any) {
logger.echo(nil, level.Info, formatPrint, a...)
}
// Infof creates message with Info level, according to a format specifier
// and writes to log.Writer.
func (logger *Logger) Infof(format string, a ...any) {
logger.echo(nil, level.Info, format, a...)
}
// Infoln creates message with Info, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func (logger *Logger) Infoln(a ...any) {
logger.echo(nil, level.Info, formatPrintln, a...)
}
// Fdebug creates message with Debug level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func (logger *Logger) Fdebug(w io.Writer, a ...any) {
logger.echo(w, level.Debug, formatPrint, a...)
}
// Fdebugf creates message with Debug level, according to a format
// specifier and writes to w.
func (logger *Logger) Fdebugf(w io.Writer, format string, a ...any) {
logger.echo(w, level.Debug, format, a...)
}
// Fdebugln creates message with Debug level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended.
func (logger *Logger) Fdebugln(w io.Writer, a ...any) {
logger.echo(w, level.Debug, formatPrintln, a...)
}
// Debug creates message with Debug level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string.
func (logger *Logger) Debug(a ...any) {
logger.echo(nil, level.Debug, formatPrint, a...)
}
// Debugf creates message with Debug level, according to a format specifier
// and writes to log.Writer. It returns the number of bytes written and any
// write error encountered.
func (logger *Logger) Debugf(format string, a ...any) {
logger.echo(nil, level.Debug, format, a...)
}
// Debugln creates message with Debug, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func (logger *Logger) Debugln(a ...any) {
logger.echo(nil, level.Debug, formatPrintln, a...)
}
// Ftrace creates message with Trace level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func (logger *Logger) Ftrace(w io.Writer, a ...any) {
logger.echo(w, level.Trace, formatPrint, a...)
}
// Ftracef creates message with Trace level, according to a format
// specifier and writes to w.
func (logger *Logger) Ftracef(w io.Writer, format string, a ...any) {
logger.echo(w, level.Trace, format, a...)
}
// Ftraceln creates message with Trace level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended.
func (logger *Logger) Ftraceln(w io.Writer, a ...any) {
logger.echo(w, level.Trace, formatPrintln, a...)
}
// Trace creates message with Trace level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string.
func (logger *Logger) Trace(a ...any) {
logger.echo(nil, level.Trace, formatPrint, a...)
}
// Tracef creates message with Trace level, according to a format specifier
// and writes to log.Writer.
func (logger *Logger) Tracef(format string, a ...any) {
logger.echo(nil, level.Trace, format, a...)
}
// Traceln creates message with Trace, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func (logger *Logger) Traceln(a ...any) {
logger.echo(nil, level.Trace, formatPrintln, a...)
}
<file_sep>// Package log is a custom logging library. It defines a type, Logger,
// with methods for formatting output. Here's an overview of its
// main features:
//
// - Log Levels: This package supports various log levels, including Panic,
// Fatal, Error, Warn, Info, Debug, Trace. Each level has three methods:
// plain (like Info), formatted (like Infof), and line-based (like Infoln).
// This distinction allows for flexible log message creation.
//
// - Flexible Outputs: The logger is designed to output logs to multiple
// destinations (referred to as "Outputs" in the code).
//
// - Prefixing: Each logger can have a prefix, which can be set during
// creation with the New function or later with SetPrefix.
//
// - Skipping Stack Frames: The package also provides a mechanism to skip
// a certain number of stack frames when logging, which can be useful when
// wrapping this logger inside other libraries or utilities.
//
// - Singleton Pattern: The package uses a singleton pattern to instantiate
// a single logger instance that can be used throughout an application.
// It provides global functions that operate on this instance.
//
// - Panic and Fatal: The Fatal functions call os.Exit(1) after writing
// the log message. The Panic functions call panic after writing the
// log message.
package log
/* Default Output Format
MY-APP: 2023/06/26 11:42:08 ERROR .../ground/log/main.go main:13 some text
====== =================== ===== ============================== =========
| | | | |__ message
| | | |_____________________ data
| | |_______________________________________ level
| |_____________________________________________________ date and time
|__________________________________________________________________ prefix (optional) from labels
*/
<file_sep>package log
import (
"bytes"
"encoding/json"
"fmt"
"io"
"runtime"
"strings"
"time"
"github.com/goloop/g"
"github.com/goloop/log/level"
)
// The stackFrame contains the top-level trace information
// where the logging method was called.
type stackFrame struct {
FileLine int // line number
FuncName string // function name
FuncAddress uintptr // address of the function
FilePath string // file path
}
// The ioCopy function is used to copy the output of a reader
// to a channel.
func ioCopy(r io.Reader, c chan string) {
var buf bytes.Buffer
io.Copy(&buf, r)
c <- buf.String()
}
// The getStackFrame returns the stack slice. The skip argument
// is the number of stack frames to skip before taking a slice.
func getStackFrame(skip int) *stackFrame {
sf := &stackFrame{}
// Return program counters of function invocations on
// the calling goroutine's stack and skipping function
// call frames inside *Log.
pc := make([]uintptr, skip+1) // program counters
runtime.Callers(skip, pc)
// Get a function at an address on the stack.
fn := runtime.FuncForPC(pc[0])
// Get name, path and line of the file.
sf.FuncName = fn.Name()
sf.FuncAddress = fn.Entry()
sf.FilePath, sf.FileLine = fn.FileLine(pc[0])
if r := strings.Split(sf.FuncName, "."); len(r) > 0 {
sf.FuncName = r[len(r)-1]
}
return sf
}
// The cutFilePath cuts the path to the file to the
// specified number of sections.
func cutFilePath(n int, path string) string {
sections := strings.Split(path, "/")
// If there are fewer or equal sections than n,
// return the path unmodified.
if len(sections) <= n+1 {
return path
}
return ".../" + strings.Join(sections[len(sections)-n:], "/")
}
// The textMessage creates a text message.
func textMessage(
p string,
l level.Level,
t time.Time,
o *Output,
sf *stackFrame,
f string,
a ...any,
) string {
// Generate log header.
// The text before of the user's message, which includes the
// prefix, the date and time of the event, the message level,
// and additional format data (file, function, line etc.).
sb := strings.Builder{}
// Logger prefix.
if p != "" {
sb.WriteString(p)
sb.WriteString(o.Space)
}
// Timestamp.
sb.WriteString(t.Format(o.TimestampFormat))
sb.WriteString(o.Space)
// Level name.
labels := level.Labels
if o.WithColor.IsTrue() && runtime.GOOS != "windows" {
labels = level.ColorLabels
}
if v, ok := labels[l]; ok {
sb.WriteString(fmt.Sprintf(o.LevelFormat, v))
sb.WriteString(o.Space)
}
// File path.
// The FullPath takes precedence over ShortPath.
if o.Layouts.FilePath() {
if o.Layouts.FullFilePath() {
sb.WriteString(sf.FilePath)
} else {
sb.WriteString(cutFilePath(shortPathSections, sf.FilePath))
}
if o.Layouts.LineNumber() {
sb.WriteString(fmt.Sprintf(":%d", sf.FileLine))
}
sb.WriteString(o.Space)
}
// Line number.
if o.Layouts.LineNumber() && !o.Layouts.FilePath() {
sb.WriteString(fmt.Sprintf("%d%s", sf.FileLine, o.Space))
}
// Function name.
if o.Layouts.FuncName() {
sb.WriteString(sf.FuncName)
if o.Layouts.FuncAddress() {
sb.WriteString(fmt.Sprintf(":%#x", sf.FuncAddress))
}
sb.WriteString(o.Space)
}
// Function address.
if o.Layouts.FuncAddress() && !o.Layouts.FuncName() {
sb.WriteString(fmt.Sprintf("%#x%s", sf.FuncAddress, o.Space))
}
// Add message formatting.
var msg string
switch {
case f == "":
fallthrough
case f == formatPrint:
// For messages that are output on the same line, the task of
// separating the messages falls on the user. We don't need to
// add extra characters to user messages.
// msg = fmt.Sprintf("%s%s%s", sb.String(), fmt.Sprint(a...), o.Space)
msg = fmt.Sprintf("%s%s", sb.String(), fmt.Sprint(a...))
case f == formatPrintln:
msg = fmt.Sprintf("%s%s", sb.String(), fmt.Sprintln(a...))
default:
msg = fmt.Sprintf("%s%s", sb.String(), fmt.Sprintf(f, a...))
}
return msg
}
// The objectMessage creates a JSON message.
func objectMessage(
p string,
l level.Level,
t time.Time,
o *Output,
sf *stackFrame,
f string,
a ...any,
) string {
// Output object.
// A general structure for outputting a logo in JSON format.
obj := struct {
Prefix string `json:"prefix,omitempty"`
Level string `json:"level,omitempty"`
Timestamp string `json:"timestamp,omitempty"`
Message string `json:"message,omitempty"`
FilePath string `json:"filePath,omitempty"`
LineNumber int `json:"lineNumber,omitempty"`
FuncName string `json:"funcName,omitempty"`
FuncAddress string `json:"funcAddress,omitempty"`
}{}
// Logger prefix.
if p != "" {
obj.Prefix = p
}
// Timestamp.
obj.Timestamp = t.Format(o.TimestampFormat)
// Level label.
if v, ok := level.Labels[l]; ok {
obj.Level = v
}
// File path, full path only.
if o.Layouts.FilePath() {
obj.FilePath = sf.FilePath
}
// Function name.
if o.Layouts.FuncName() {
obj.FuncName = sf.FuncName
}
// Function address.
if o.Layouts.FuncAddress() {
obj.FuncName = fmt.Sprintf("%#x", sf.FuncAddress)
}
// Line number.
if o.Layouts.LineNumber() {
obj.LineNumber = sf.FileLine
}
// Clean message for default -ln format.
// Add message formatting.
switch {
case f == "":
fallthrough
case f == formatPrint:
obj.Message = fmt.Sprint(a...)
case f == formatPrintln:
obj.Message = strings.TrimSuffix(fmt.Sprintln(a...), "\n")
default:
obj.Message = fmt.Sprintf(f, a...)
}
// Marshal object to JSON.
data, err := json.Marshal(obj)
data = g.If(err != nil, []byte{}, data)
// Add JSON formatting.
var msg string
switch {
case f == "":
fallthrough
case f == formatPrint:
msg = fmt.Sprintf("%s%s", data, o.Space)
default: // for formatStrLn and others
msg = fmt.Sprintf("%s\n", data)
}
return msg
}
/*
// The getWriterID returns the unique ID of the object
// in the io.Writer interface.
//
// To identify duplicate objects of the os.Writer interface, the actual
// address of the object in memory is used. This does not guarantee 100%
// verification of uniqueness, but there is no need for it.
//
// Usually, these are 2-3 files for logging, which are added almost
// simultaneously, which guarantees a stable address of the object at
// the time of adding it to the list of outputs. And the issue of
// duplicates must be monitored by the developer who uses the logger.
//
// Therefore, checking for duplicates is a useful auxiliary function
// for detecting "stupid" logger creation errors.
func getWriterID(w io.Writer) uintptr {
switch v := w.(type) {
case *os.File:
return reflect.ValueOf(v).Pointer()
case *bytes.Buffer:
return reflect.ValueOf(v).Pointer()
case *strings.Builder:
return reflect.ValueOf(v).Pointer()
case *bufio.Writer:
return reflect.ValueOf(v).Pointer()
case *gzip.Writer:
return reflect.ValueOf(v).Pointer()
case *io.PipeWriter:
return reflect.ValueOf(v).Pointer()
}
// Unknown type.
// Get the address of the interface itself.
return reflect.ValueOf(w).Pointer()
}
*/
<file_sep>package log
import (
"encoding/json"
"fmt"
"runtime"
"strings"
"testing"
"time"
"github.com/goloop/log/layout"
"github.com/goloop/log/level"
"github.com/goloop/trit"
)
// TetsIoCopy tests ioCopy function.
func TestIoCopy(t *testing.T) {
input := "Hello, World!"
r := strings.NewReader(input)
c := make(chan string)
go ioCopy(r, c)
result := <-c
if result != input {
t.Errorf("ioCopy failed, expected %v, got %v", input, result)
}
}
// TestGetStackFrame tests getStackFrame function.
func TestGetStackFrame(t *testing.T) {
frame := getStackFrame(2) // cuerrent function is TestGetStackFrame
if frame == nil {
t.Fatal("Expected frame to not be nil")
}
if frame.FuncName == "" {
t.Errorf("Expected FuncName to not be empty")
}
if frame.FilePath == "" {
t.Errorf("Expected FilePath to not be empty")
}
if frame.FileLine == 0 {
t.Errorf("Expected FileLine to not be zero")
}
if frame.FuncAddress == 0 {
t.Errorf("Expected FuncAddress to not be zero")
}
// Verify the function name
expectedFuncName := "TestGetStackFrame"
if frame.FuncName != expectedFuncName {
t.Errorf("Expected function name to be '%s', got '%s'",
expectedFuncName, frame.FuncName)
}
// Verify the file path
_, fileName, _, _ := runtime.Caller(0)
if !strings.Contains(frame.FilePath, fileName) {
t.Errorf("Expected file path '%s' to contain '%s'",
frame.FilePath, fileName)
}
}
// TestGetStackFramePanicsOnNegativeSkip tests getStackFrame for panic.
func TestGetStackFramePanicsOnLargeSkip(t *testing.T) {
defer func() {
if r := recover(); r == nil {
t.Error("The code did not panic")
}
}()
getStackFrame(1024)
}
// TestCutFilePath tests cutFilePath function.
func TestCutFilePath(t *testing.T) {
tests := []struct {
name string
n int
path string
expected string
}{
{
name: "Test case 1: Three sections, cut to two",
n: 2,
path: "/path/to/file",
expected: ".../to/file",
},
{
name: "Test case 2: Four sections, cut to two",
n: 2,
path: "/path/to/another/file",
expected: ".../another/file",
},
{
name: "Test case 3: One section, cut to two",
n: 2,
path: "/file",
expected: "/file",
},
{
name: "Test case 4: Three sections, cut to three",
n: 3,
path: "/path/to/file",
expected: "/path/to/file",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
result := cutFilePath(test.n, test.path)
if result != test.expected {
t.Errorf("Expected '%s', got '%s'", test.expected, result)
}
})
}
}
// TestTextMessage tests textMessage function.
func TestTextMessage(t *testing.T) {
prefix := "test"
level := level.Info
timestamp := time.Now()
output := &Stdout
output.WithColor = trit.True
output.Layouts = output.Layouts | layout.LineNumber | layout.FuncAddress
stackframe := getStackFrame(2)
tests := []struct {
name string
f string
a []any
e string
}{
{
name: "Text message with formatted string",
f: "formatted string %s",
a: []any{"value"},
e: "formatted string value",
},
{
name: "Text message with multiple formatted values",
f: "formatted string with multiple values %s %d",
a: []any{"value", 1},
e: "formatted string with multiple values value 1",
},
{
name: "Text message with no formatting",
f: "",
a: []any{"value"},
e: "value",
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
result := textMessage(
prefix,
level,
timestamp,
output,
stackframe,
test.f,
test.a...,
)
if !strings.Contains(result, test.e) {
t.Errorf("Message '%s' doesn't contains '%s'", result, test.e)
}
})
}
// Change layouts.
output.Layouts = layout.FullFilePath
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
result := textMessage(
prefix,
level,
timestamp,
output,
stackframe,
test.f,
test.a...,
)
if !strings.Contains(result, test.e) {
t.Errorf("Message '%s' doesn't contains '%s'", result, test.e)
}
})
}
// Change layouts.
output.Layouts = layout.LineNumber | layout.FuncAddress
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
result := textMessage(
prefix,
level,
timestamp,
output,
stackframe,
test.f,
test.a...,
)
if !strings.Contains(result, test.e) {
t.Errorf("Message '%s' doesn't contains '%s'", result, test.e)
}
})
}
}
// TestObjectMessage tests objectMessage function.
func TestObjectMessage(t *testing.T) {
prefix := "test"
level := level.Info
timestamp := time.Now()
output := &Stdout
stackframe := getStackFrame(2)
tests := []struct {
name string
f string
a []any
e map[string]interface{}
}{
{
name: "Object message with formatted string",
f: "formatted string %s",
a: []any{"value"},
e: map[string]interface{}{
"prefix": prefix,
"level": "INFO",
"timestamp": timestamp.Format(output.TimestampFormat),
"message": "formatted string value",
"filePath": stackframe.FilePath,
"funcName": stackframe.FuncName,
"funcAddress": fmt.Sprintf("%#x", stackframe.FuncAddress),
"lineNumber": stackframe.FileLine,
},
},
{
name: "Object message with multiple formatted values",
f: "formatted string with multiple values %s %d",
a: []any{"value", 1},
e: map[string]interface{}{
"prefix": prefix,
"level": "INFO",
"timestamp": timestamp.Format(output.TimestampFormat),
"message": "formatted string with multiple values value 1",
"filePath": stackframe.FilePath,
"funcName": stackframe.FuncName,
"funcAddress": fmt.Sprintf("%#x", stackframe.FuncAddress),
"lineNumber": stackframe.FileLine,
},
},
{
name: "Object message with no formatting",
f: "",
a: []any{"value"},
e: map[string]interface{}{
"prefix": prefix,
"level": "INFO",
"timestamp": timestamp.Format(output.TimestampFormat),
"message": "value",
"filePath": stackframe.FilePath,
"funcName": stackframe.FuncName,
"funcAddress": fmt.Sprintf("%#x", stackframe.FuncAddress),
"lineNumber": stackframe.FileLine,
},
},
}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
result := objectMessage(
prefix,
level,
timestamp,
output,
stackframe,
test.f,
test.a...,
)
// Unmarshal the JSON result into a map
var resultObj map[string]interface{}
err := json.Unmarshal([]byte(result), &resultObj)
if err != nil {
t.Fatalf("Failed to unmarshal JSON: %v", err)
}
if resultObj["level"] != test.e["level"] ||
resultObj["prefix"] != test.e["prefix"] ||
resultObj["message"] != test.e["message"] {
t.Errorf("Expected '%v', got '%v'", test.e, resultObj)
}
})
}
}
/*
// TestGetWriterID tests getWriterID function.
func TestGetWriterID(t *testing.T) {
// Create several types that satisfy the io.Writer interface
file, err := os.Create("test.txt")
if err != nil {
t.Fatalf("Failed to create file: %v", err)
}
defer os.Remove("test.txt")
defer file.Close()
buffer := &bytes.Buffer{}
builder := &strings.Builder{}
writer := bufio.NewWriter(buffer)
gzipWriter := gzip.NewWriter(buffer)
pipeReader, pipeWriter := io.Pipe()
defer pipeReader.Close()
defer pipeWriter.Close()
tests := []struct {
name string
input io.Writer
}{
{"os.File", file},
{"bytes.Buffer", buffer},
{"strings.Builder", builder},
{"bufio.Writer", writer},
{"gzip.Writer", gzipWriter},
{"io.PipeWriter", pipeWriter},
}
// Map to store the IDs of the writers
writerIDs := make(map[uintptr]bool)
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
id := getWriterID(test.input)
if _, exists := writerIDs[id]; exists {
t.Errorf("Non-unique writer ID returned for type: %s",
test.name)
}
writerIDs[id] = true
})
}
}
*/
<file_sep>package log
import (
"io"
"strings"
"github.com/goloop/g"
)
// The self is the default logger instance.
var self *Logger
// New returns a new Logger object. We can optionally provide one or more
// prefixes that will be prepended to each log message. If multiple prefixes
// are provided, they will be joined with hyphens. Additionally, prefixes
// are stripped of leading and trailing whitespace characters.
//
// Example usage:
//
// // The simplest use-case is to create a new logger without any prefixes.
// logger := log.New()
// logger.Info("Hello, World!")
//
// // We can also add a prefix for our logger. Here, 'MYAPP' will be
// // prepended to each log message.
// loggerWithPrefix := log.New("MYAPP")
// loggerWithPrefix.Info("Hello, World!")
//
// // If multiple prefixes are provided, they will be joined with hyphens.
// // Here, 'MYAPP-PREFIX' will be prepended to each log message.
// loggerWithMultiplePrefixes := log.New("MYAPP", "PREFIX")
// loggerWithMultiplePrefixes.Info("Hello, World!")
//
// // Any leading and trailing whitespace characters are removed from
// // prefixes. 'MYAPP-PREFIX' will be prepended to each log message.
// loggerWithWhitespace := log.New(" MYAPP ", " PREFIX ")
// loggerWithWhitespace.Info("Hello, World!")
func New(prefixes ...string) *Logger {
// Generate prefix.
prefix := ""
if len(prefixes) != 0 {
// Concatenate prefixes.
if l := len(prefixes); l == 1 {
// If there is only one prefix, use it as is.
// In this case, no changes are made to the prefix.
prefix = prefixes[0]
} else if l > 1 {
// Several words that characterize the prefix are given.
// In this case, they must be combined as ONE-TWO-THREE in
// upper case, removing all special characters such as spaces,
// colons and \t, \i, \n.
i := 0
sb := strings.Builder{}
for _, p := range prefixes {
v := g.Trim(p, " \t\n\r")
if v == "" {
continue
}
// If one character is installed, it is added without
// the separator '-' and is considered a marker of the
// end of the prefix.
// {"MYAPP:"} => "MYAPP:"
// {"MYAPP", ":"} => "MYAPP:"
// {"MY", "APP", ":"} => "MY-APP:"
if l := len(v); i != 0 && l > 1 {
sb.WriteString("-")
}
i++
sb.WriteString(v)
}
// If the prefix is not empty, add a marker at the end.
if sb.Len() > 0 {
prefix = sb.String()
}
}
}
logger := &Logger{
skipStackFrames: skipStackFrames,
fatalStatusCode: fatalStatusCode,
prefix: prefix,
outputs: map[string]*Output{},
}
logger.SetOutputs(Stdout, Stderr)
return logger
}
// Initializes the logger.
func init() {
self = New()
sik := skipStackFrames + 1 // self works at the imported package level
self.SetSkipStackFrames(sik)
}
// Copy returns copy of the log object.
func Copy() *Logger {
return self.Copy()
}
// SetSkipStackFrames sets skip stack frames level.
func SetSkipStackFrames(skips int) {
self.SetSkipStackFrames(skips)
}
// SkipStackFrames returns skip stack frames level.
func SkipStackFrames() int {
return self.SkipStackFrames()
}
// SetPrefix sets the name of the logger object.
func SetPrefix(prefix string) string {
return self.SetPrefix(prefix)
}
// Prefix returns the name of the log object.
func Prefix() string {
return self.Prefix()
}
// SetOutputs sets the outputs of the log object.
func SetOutputs(outputs ...Output) error {
return self.SetOutputs(outputs...)
}
// EditOutputs edits the outputs of the log object.
func EditOutputs(outputs ...Output) error {
return self.EditOutputs(outputs...)
}
// DeleteOutputs deletes the outputs of the log object.
func DeleteOutputs(names ...string) {
self.DeleteOutputs(names...)
}
// Outputs returns a list of outputs.
func Outputs(names ...string) []Output {
return self.Outputs(names...)
}
// Fpanic creates message with Panic level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func Fpanic(w io.Writer, a ...any) {
self.Fpanic(w, a...)
}
// Fpanicf creates message with Panic level, according to a format
// specifier and writes to w.
func Fpanicf(w io.Writer, format string, a ...any) {
self.Fpanicf(w, format, a...)
}
// Fpanicln creates message with Panic level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended.
func Fpanicln(w io.Writer, a ...any) {
self.Fpanicln(w, a...)
}
// Panic creates message with Panic level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string.
func Panic(a ...any) {
self.Panic(a...)
}
// Panicf creates message with Panic level, according to a format specifier
// and writes to log.Writer.
func Panicf(format string, a ...any) {
self.Panicf(format, a...)
}
// Panicln creates message with Panic, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func Panicln(a ...any) {
self.Panicln(a...)
}
// Ffatal creates message with Fatal level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func Ffatal(w io.Writer, a ...any) {
self.Ffatal(w, a...)
}
// Ffatalf creates message with Fatal level, according to a format
// specifier and writes to w.
func Ffatalf(w io.Writer, format string, a ...any) {
self.Ffatalf(w, format, a...)
}
// Ffatalln creates message with Fatal level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended. It returns the number of bytes
// written and any write error encountered.
func Ffatalln(w io.Writer, a ...any) {
self.Ffatalln(w, a...)
}
// Fatal creates message with Fatal level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string. It returns the number of bytes
// written and any write error encountered.
func Fatal(a ...any) {
self.Fatal(a...)
}
// Fatalf creates message with Fatal level, according to a format specifier
// and writes to log.Writer. It returns the number of bytes written and any
// write error encountered.
func Fatalf(format string, a ...any) {
self.Fatalf(format, a...)
}
// Fatalln creates message with Fatal, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func Fatalln(a ...any) {
self.Fatalln(a...)
}
// Ferror creates message with Error level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func Ferror(w io.Writer, a ...any) {
self.Ferror(w, a...)
}
// Ferrorf creates message with Error level, according to a format
// specifier and writes to w.
func Ferrorf(w io.Writer, format string, a ...any) {
self.Ferrorf(w, format, a...)
}
// Ferrorln creates message with Error level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended. It returns the number of bytes
// written and any write error encountered.
func Ferrorln(w io.Writer, a ...any) {
self.Ferrorln(w, a...)
}
// Error creates message with Error level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string. It returns the number of bytes
// written and any write error encountered.
func Error(a ...any) {
self.Error(a...)
}
// Errorf creates message with Error level, according to a format specifier
// and writes to log.Writer. It returns the number of bytes written and any
// write error encountered.
func Errorf(format string, a ...any) {
self.Errorf(format, a...)
}
// Errorln creates message with Error, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func Errorln(a ...any) {
self.Errorln(a...)
}
// Fwarn creates message with Warn level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func Fwarn(w io.Writer, a ...any) {
self.Fwarn(w, a...)
}
// Fwarnf creates message with Warn level, according to a format
// specifier and writes to w.
func Fwarnf(w io.Writer, format string, a ...any) {
self.Fwarnf(w, format, a...)
}
// Fwarnln creates message with Warn level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended. It returns the number of bytes
// written and any write error encountered.
func Fwarnln(w io.Writer, a ...any) {
self.Fwarnln(w, a...)
}
// Warn creates message with Warn level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string. It returns the number of bytes
// written and any write error encountered.
func Warn(a ...any) {
self.Warn(a...)
}
// Warnf creates message with Warn level, according to a format specifier
// and writes to log.Writer. It returns the number of bytes written and any
// write error encountered.
func Warnf(format string, a ...any) {
self.Warnf(format, a...)
}
// Warnln creates message with Warn, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func Warnln(a ...any) {
self.Warnln(a...)
}
// Finfo creates message with Info level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func Finfo(w io.Writer, a ...any) {
self.Finfo(w, a...)
}
// Finfof creates message with Info level, according to a format
// specifier and writes to w.
func Finfof(w io.Writer, format string, a ...any) {
self.Finfof(w, format, a...)
}
// Finfoln creates message with Info level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended. It returns the number of bytes
// written and any write error encountered.
func Finfoln(w io.Writer, a ...any) {
self.Finfoln(w, a...)
}
// Info creates message with Info level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string. It returns the number of bytes
// written and any write error encountered.
func Info(a ...any) {
self.Info(a...)
}
// Infof creates message with Info level, according to a format specifier
// and writes to log.Writer. It returns the number of bytes written and any
// write error encountered.
func Infof(format string, a ...any) {
self.Infof(format, a...)
}
// Infoln creates message with Info, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func Infoln(a ...any) {
self.Infoln(a...)
}
// Fdebug creates message with Debug level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func Fdebug(w io.Writer, a ...any) {
self.Fdebug(w, a...)
}
// Fdebugf creates message with Debug level, according to a format
// specifier and writes to w.
func Fdebugf(w io.Writer, format string, a ...any) {
self.Fdebugf(w, format, a...)
}
// Fdebugln creates message with Debug level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended. It returns the number of bytes
// written and any write error encountered.
func Fdebugln(w io.Writer, a ...any) {
self.Fdebugln(w, a...)
}
// Debug creates message with Debug level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string. It returns the number of bytes
// written and any write error encountered.
func Debug(a ...any) {
self.Debug(a...)
}
// Debugf creates message with Debug level, according to a format specifier
// and writes to log.Writer. It returns the number of bytes written and any
// write error encountered.
func Debugf(format string, a ...any) {
self.Debugf(format, a...)
}
// Debugln creates message with Debug, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func Debugln(a ...any) {
self.Debugln(a...)
}
// Ftrace creates message with Trace level, using the default formats
// for its operands and writes to w. Spaces are added between operands
// when neither is a string.
func Ftrace(w io.Writer, a ...any) {
self.Ftrace(w, a...)
}
// Ftracef creates message with Trace level, according to a format
// specifier and writes to w.
func Ftracef(w io.Writer, format string, a ...any) {
self.Ftracef(w, format, a...)
}
// Ftraceln creates message with Trace level, using the default formats
// for its operands and writes to w. Spaces are always added between
// operands and a newline is appended. It returns the number of bytes
// written and any write error encountered.
func Ftraceln(w io.Writer, a ...any) {
self.Ftraceln(w, a...)
}
// Trace creates message with Trace level, using the default formats
// for its operands and writes to log.Writer. Spaces are added between
// operands when neither is a string. It returns the number of bytes
// written and any write error encountered.
func Trace(a ...any) {
self.Trace(a...)
}
// Tracef creates message with Trace level, according to a format specifier
// and writes to log.Writer. It returns the number of bytes written and any
// write error encountered.
func Tracef(format string, a ...any) {
self.Tracef(format, a...)
}
// Traceln creates message with Trace, level using the default formats
// for its operands and writes to log.Writer. Spaces are always added
// between operands and a newline is appended.
func Traceln(a ...any) {
self.Traceln(a...)
}
<file_sep>[](https://goreportcard.com/report/github.com/goloop/log) [](https://github.com/goloop/log/blob/master/LICENSE) [](https://godoc.org/github.com/goloop/log) [](https://u24.gov.ua/)
# log
The log module encompasses methods for comprehensive logging, which comprises a variety of logging levels:
- Panic
Panic typically signifies that something has gone unexpectedly awry. It's primarily utilized to swiftly halt on errors that shouldn't surface during regular operation, or those we aren't equipped to handle smoothly.
- Fatal
Fatal corresponds to situations that are immensely disastrous for the application. The application is on the verge of terminating to avert any sort of corruption or severe problem, if feasible. Exit code is 1.
- Error
An error represents a significant issue and depicts the failure of something crucial within an application. Contrary to FATAL, the application itself is not doomed.
- Warn
This log level implies that an application might be experiencing a problem and an unusual situation has been detected. It's an unexpected and unusual issue, but no real damage is done, and it's uncertain whether the problem will persist or happen again.
- Info
The messages at this level relate to standard application behavior and milestones. They offer a framework of the events that took place.
- Debug
This level is meant to provide more detailed, diagnostic information than the INFO level.
- Trace
This level offers incredibly detailed information, even more so than DEBUG. At this level, every possible detail about the application's behavior should be captured.
## Installation
To install this module use `go get` as:
```
$ go get -u github.com/goloop/log
```
## Quick Start
To use this module import it as:
```go
package main
import (
"os"
"github.com/goloop/log"
"github.com/goloop/log/layout"
"github.com/goloop/log/level"
// It is not necessary to import this module, the three-valued logic
// constants can be represented using integers where: -1 is False,
// 0 is Unknown, and 1 is True.
"github.com/goloop/trit"
)
func main() {
// Open the file in append mode. Create the file if it doesn't exist.
// Use appropriate permissions in a production setting.
file, err := os.OpenFile(
"errors.log",
os.O_APPEND|os.O_CREATE|os.O_WRONLY,
0644,
)
if err != nil {
log.Fatal(err)
}
// Defer the closing of the file until the function ends.
defer file.Close()
// Set the outputs of the log to our file.
// We can set many different outputs to record
// individual errors, debug or mixed data.
err = log.SetOutputs(
log.Output{
Name: "stdout",
Writer: os.Stdout,
Levels: level.Debug | level.Info | level.Warn | level.Error,
Layouts: layout.Default,
WithColor: 1, // or trit.True, see github.com/goloop/trit
},
log.Output{
Name: "errorsJSONFile",
Writer: file,
Levels: level.Warn | level.Error, // only errors and warnings
Layouts: layout.Default,
TextStyle: trit.False, // or just -1
},
)
if err != nil {
log.Fatal(err)
}
// A message will be output to a file and to the console.
// * stdout and errorsJSONFile has Error level.
log.Errorln("This is a test log message with ERROR.")
// A message will be output to the console only.
// * stdout has Debug level, but errorsJSONFile has not.
log.Debugln("This is a test log message with DEBUG.")
}
```
| d42a223aa358769dc6532b214c42211bc86f033c | [
"Go",
"Go Module",
"Markdown"
] | 13 | Go Module | goloop/log | 0ddea4d6cec8817878840572f0ce4aea47eef733 | 6c7618feb5844c8c87fd12420b8aefb0de074231 |
refs/heads/master | <file_sep>package threads;
import javafx.application.Platform;
import ui.PacManController;
public class ControlThread extends Thread{
private PacManController pcc;
public ControlThread(PacManController pcc) {
this.pcc = pcc;
}
public void run() {
while (true) {
PacManThread pt = new PacManThread(pcc);
Platform.runLater(pt);
try {
sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
<file_sep>package model;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.PrintWriter;
import java.util.ArrayList;
import java.util.List;
public class Game {
//Attributes
private List<PacMan> pacMans;
private Scores[] scores;
//Constants
public static final String SER_FILE="data/scores.sc";
public static final String SCOR_FILE="data/scores.txt";
//Methods
public Game() throws ClassNotFoundException, IOException {
load();
pacMans= new ArrayList<PacMan>();
}
private void load() throws IOException, ClassNotFoundException {
File archivo= new File(SER_FILE);
if(archivo.exists()) {
ObjectInputStream ois= new ObjectInputStream(new FileInputStream(archivo));
scores=(Scores[]) ois.readObject();
ois.close();
}else {
scores= new Scores[10];
Scores s= new Scores(12);
Scores a= new Scores(20);
scores[0]=s;
scores[1]=a;
}
}
public void save() throws IOException {
ObjectOutputStream oos= new ObjectOutputStream(new FileOutputStream(SER_FILE));
oos.writeObject(scores);
oos.close();
}
public String showBestScores() {
String information="BestScores: \n";
ordenar();
for(int i=0;i<scores.length && scores[i]!=null;i++) {
information+=(i+1)+". "+scores[i].getScore()+"\n";
information+="\n";
}
return information;
}
public void ordenar() {
Scores best=null;
for(int i = 0; i < scores.length; i++){
for(int j=i+1; j < scores.length && scores[j]!=null; j++){
if(scores[i].getScore() > scores[j].getScore()){
best = scores[i];
scores[i]=scores[j];
scores[j]=best;
}
}
}
}
public void importData(String path) throws IOException {
File f= new File(path);
FileReader fr= new FileReader(f);
BufferedReader br= new BufferedReader(fr);
String line=br.readLine();
while(line!=null) {
if(line.startsWith("#")) {
line=br.readLine();
}else {
String[] parts=line.split("\t");
int radio=Integer.parseInt(parts[0]);
int posX=Integer.parseInt(parts[1]);
int posY=Integer.parseInt(parts[2]);
int speed=Integer.parseInt(parts[3]);
int direction=0;
Move move = null;
if(parts[4].equalsIgnoreCase("IZQUIERDA")) {
direction=1;
move=Move.LEFT;
}else if(parts[4].equalsIgnoreCase("DERECHA")) {
move=Move.RIGHT;
direction=2;
}else if(parts[4].equalsIgnoreCase("ARRIBA")) {
move=Move.UP;
direction=3;
}else if(parts[4].equalsIgnoreCase("ABAJO")) {
move=Move.DOWN;
direction=4;
}
boolean state=Boolean.parseBoolean(parts[6]);
int bounces=Integer.parseInt(parts[5]);
PacMan pc= new PacMan(radio, posX, posY,direction, speed , state, move,bounces );
pacMans.add(pc);
line=br.readLine();
}
}
br.close();
fr.close();
}
public void exportCSV(String path) throws FileNotFoundException {
PrintWriter pw= new PrintWriter(new File(path));
String evalu="";
File f=new File(path);
String nameFile=f.getName();
if(nameFile.equals("data/save.txt")) {
}else {
for(int i=0;i<scores.length;i++) {
evalu+=""+(scores[i].getScore())+";";
}
}
pw.println(evalu);
pw.close();
}
public List<PacMan> getPacMans(){
return pacMans;
}
public Scores[] getScores(){
return scores;
}
}
<file_sep>package threads;
import model.Move;
import model.PacMan;
import ui.PacManController;
public class MoveThread extends Thread{
private PacManController pc;
private PacMan pm;
private boolean stop;
public MoveThread(PacManController paco, PacMan pm, boolean stp) {
this.pc = paco;
this.pm = pm;
this.stop=stp;
}
public void run() {
Move m=pm.getMove();
while(stop) {
if(m==Move.UP ||m==Move.DOWN) {
pm.move((int)pc.getHeigth());
}else {
pm.move((int)pc.getWith());
}
try {
sleep(pm.getSpeed());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public void stopsThread() {
stop=!stop;
}
}
<file_sep>package model;
public class PacMan {
public static final int ADVANCE = 5;
//Attributes
private int radio;
private int posX;
private int posY;
private int direction;
private int speed;
private Move ste;
private boolean state;
private double length;
private double angle;
private boolean flag;
private int bounces;
//Methods
public PacMan(int nRadio, int nPosX, int nPosY, int nDirection, int nSpeed, boolean nState, Move st, int nBounces) {
radio=nRadio;
posX=nPosX;
posY=nPosY;
direction=nDirection;
speed=nSpeed;
state=nState;
ste=st;
length=270;
flag=true;
bounces=nBounces;
}
public int getRadio() {
return radio;
}
public void setRadio(int radio) {
this.radio = radio;
}
public int getBounces() {
return bounces;
}
public void setBounces(int bounces) {
this.bounces = bounces;
}
public int getPosX() {
return posX;
}
public void setPosX(int posX) {
this.posX = posX;
}
public int getPosY() {
return posY;
}
public void setPosY(int posY) {
this.posY = posY;
}
public int getDirection() {
return direction;
}
public void setDirection(int direction) {
this.direction = direction;
}
public int getSpeed() {
return speed;
}
public void setSpeed(int speed) {
this.speed = speed;
}
public boolean isState() {
return state;
}
public void setState(boolean state) {
this.state = state;
}
public Move getMove() {
return ste;
}
public double getLength() {
return length;
}
public double getAngle() {
return angle;
}
public void move(int max) {
switch(ste) {
case RIGHT:
angle=0;
movement();
if(posX+ADVANCE+radio>=max) {
ste = Move.LEFT;
posX = max-radio;
bounces++;
}else {
posX = posX+ADVANCE;
}
break;
case LEFT:
angle=180;
movement();
if(posX-ADVANCE-radio<=0) {
ste = Move.RIGHT;
posX = radio;
bounces++;
}else {
posX = posX-ADVANCE;
}
break;
case UP:
angle=270;
movement();
if(posY-ADVANCE-radio<=0) {
ste = Move.DOWN;
posY = radio;
bounces++;
}else {
posY = posY-ADVANCE;
}
break;
case DOWN:
angle=90;
movement();
if(posY+ADVANCE+radio>=max) {
ste = Move.UP;
posY = max-radio;
bounces++;
}else {
posY = posY+ADVANCE;
}
break;
}
}
public void movement() {
if(flag) {
length=length+4;
}
if(length>=360) {
flag=false;
}
if(!flag) {
length=length-4;
}
if(length<=270) {
flag=true;
}
}
}
| c5540b69489eeaf8ed14ef6d8cefefc0ce535413 | [
"Java"
] | 4 | Java | cadav1nci/Bouncing-balls | ad240728b41fdd45b9beca101452ae41e8a3c7e4 | 9bda004e4b7380f7cede376d90c0e7a300e2ef31 |
refs/heads/master | <file_sep># ccng-routes
**An api routes print tool for Cloud Foundry CCng (cloud_controller_ng)**
The Cloud Foundry CCng (cloud_controller_ng) component generates its API routes dynamically. This tool prints the generated routes in Ruby-on-Rails "rake routes" style.
## Example
[Routes for CCng API v2.79.0](https://gist.github.com/nota-ja/d6a29229f21b863ba643ca584ef9e5e3)
## Prerequisites
- git
- ruby
- bundler gem
## Usage
### Simple
- Clone this repository
```
git clone https://github.com/nota-ja/ccng-routes.git
```
- Change directory to the cloned repository and run ccng-routes.sh
```
cd ccng-routes
./ccng-routes.sh
```
### Advanced
You may specify a revision to generate api routes.
```
CCNG_REV=a_git_revision ./ccng-routes.sh
```
Additionally, You may use an exsiting cloud_controller_ng repository.
```
CCNG_REPO=path/to/cloud_controller_ng ./ccng-routes.sh
```
As the details described below, this tool touches the targetted cloud_controller_ng repository.
So it is recommended to use a newly cloned repository.
The script ccng-routes.sh clones the cloud_controller_ng repository to directly under this tool's directory and use it if the environment variable CCNG_REPO is not given.
The routes info is printed to stderr. So if you want to write routes info alone to a file, just do like:
```
CCNG_REPO=path/to/cloud_controller_ng CCNG_REV=a_git_revision ./ccng-routes.sh 2> routes.txt
```
## Details
The ccng-routes.sh script is based on 'routes' task in the Rakefile. You can run the task independently as:
```
BUNDLE_GEMFILE=path/to/cloud_controller_ng/Gemfile bundle exec rake routes
```
Because the task reuses gems used in cloud_controller_ng, BUNDLE_GEMFILE environment variable must be specified properly.
The rake task also accepts CCNG_REPO environment variable described above.
The task actually does following operations:
1. (preparation)
1. Use CCNG_REPO environment variable as cloud_controller_ng repo. If not defined, $PWD/cloud_controller_ng is set.
2. Clone cloud_controller_ng repo if not exist.
2. Apply the patch (routes.rb.patch), that adds printing facility into dynamic route generation process, to lib/cloud_controller/rest_controller/routes.rb in cloud_controller_ng repo.
3. Execute the route-defining code by requiring lib/cloud_controller.rb in cloud_controller_ng repo.
4. Unpatch the patch applied.
When you want to get CCng routes of a specific revision with the rake task, just cd to the cloud_controller_ng repo, checkout the revision, sync / update its submodule, run bundle install to install gems, then back to this tool's directory and run the rake task.
```
pushd path/to/cloud_controller_ng
git checkout a_git_revision
git submodule sync; git submodule update --init --recursive
bundle install --path vendor/bundle
popd
CCNG_REPO=path/to/cloud_controller_ng BUNDLE_GEMFILE=path/to/cloud_controller_ng/Gemfile bundle exec rake routes
```
As a matter of fact, the ccng-routes.sh script executes the process described above.
## Tips
### Post production
A generated route may contain an ID of Proc object and a path to the cloud_controller_ng repo when the action part of the route is defines as a Proc object. It's not convenient to compare two sets of API routes of different revisions and / or in different paths.
I am using the following script to remove those extra information:
```
cat routes.txt | perl -lane 's/Proc:0x[0-9a-f]+@.+\/cloud_controller_ng\//Proc:\@/; print $_' | sort > marshalled.routes.txt
```
(Assume routes.txt is a set of generated routes)
If you make another marshalled set of routes, then you can compare the two route sets.
## Known Issue(s)
Sometimes rake may fail because of version unmatch of nokogiri's dynamically compiled library.
```
rake aborted!
dlopen(cloud_controller_ng/vendor/bundle/ruby/1.9.1/gems/nokogiri-1.6.1/lib/nokogiri/nokogiri.bundle, 9): Library not loaded: cloud_controller_ng/vendor/bundle/ruby/1.9.1/gems/nokogiri-1.6.1/ports/x86_64-apple-darwin13.3.0/libxml2/2.8.0/lib/libxml2.2.dylib
```
A workaround is:
```
pushd $CCNG_REPO
rm vendor/bundle/ruby/1.9.1/specifications/nokogiri-1.6.1.gemspec
rm -rf vendor/bundle/ruby/1.9.1/gems/nokogiri-1.6.1/
bundle install --path vendor/bundle
popd
```
<file_sep>#!/bin/bash
ccng_repo=${CCNG_REPO:-${PWD}/cloud_controller_ng}
if [ ! -d $ccng_repo ]; then
git clone https://github.com/cloudfoundry/cloud_controller_ng.git
fi
if [ -h .ruby-version ]; then
rm -f .ruby-version
fi
ln -s $ccng_repo/.ruby-version .
pushd $ccng_repo
if [ "${CCNG_REV}" != "" ]; then
git checkout ${CCNG_REV} 2>&1
fi
git submodule sync; git submodule update --init --recursive
bundle install --path vendor/bundle
popd
CCNG_REPO=${ccng_repo} BUNDLE_GEMFILE=${ccng_repo}/Gemfile bundle exec rake routes
<file_sep>ccng_repo = File.expand_path(ENV["CCNG_REPO"])
ccng_patch = File.expand_path("../routes.rb.patch", __FILE__)
require "rubygems"
require "bundler/setup"
$:.unshift(File.join(ccng_repo, "lib"))
$:.unshift(File.join(ccng_repo, "app"))
$:.unshift(File.join(ccng_repo, "middleware"))
task :routes do
Dir.chdir(ccng_repo) do
begin
system("git apply #{ccng_patch}")
require "cloud_controller"
ensure
system("git apply --reverse #{ccng_patch}")
end
end
end
| da23ff0d51124fca3b69807b5b47223104d2cc25 | [
"Markdown",
"Ruby",
"Shell"
] | 3 | Markdown | nota-ja/ccng-routes | bdced212a11ea60cd40443ef3a73773f1bc0736a | 2f205de18b412287ee58d83b70396d27707c3781 |
refs/heads/master | <repo_name>kckishan/WaterJugPuzzle<file_sep>/src/waterJugPuzzle/waterJugPuzzle.java
import java.util.*;
/**
*
* @author kishan_kc
*/
public class waterJugPuzzle {
private final int N, target_amount;
private final int size[];
//Define List of list to store nodes
//Define List of list to store visited nodes
private final List<List<Integer>> visited = new ArrayList<>();
private final List<List<Integer>> parent = new ArrayList<>();
private final List<List<Integer>> nodes_list = new ArrayList<>();
//Define constructor to define number of bottles, target amount and size of each bottles
public waterJugPuzzle(int n, int t, int[] s) {
N = n;
target_amount = t;
size = s;
}
//Transfer from one bottle to another bottle
public List<Integer> transfer(List<Integer> node, int from, int to) {
int transfer_amount;
List<Integer> step = new ArrayList(node);
transfer_amount = Math.min(step.get(from), size[to] - step.get(to));
step.set(to, step.get(to) + transfer_amount);
step.set(from, step.get(from) - transfer_amount);
return step;
}
//Fill the first bottle
public List<Integer> fill(List<Integer> node, int jug) {
List<Integer> step = new ArrayList(node);
step.set(jug, size[jug]);
return step;
}
//Empty the last bottle
public List<Integer> empty(List<Integer> node, int jug) {
List<Integer> step = new ArrayList(node);
step.set(jug, 0);
return step;
}
public List<List<Integer>> possible_steps(List<Integer> node) {
List<List<Integer>> next_nodes = new ArrayList<>();
List<Integer> step;
List<Integer> temp = new ArrayList<>(node);
//If first bottle is empty, fill it
for (int i = 0; i < N; i++) {
step = fill(temp, i);
if (!visited.contains(step) & !next_nodes.contains(step) & !step.isEmpty()) {
parent.add(node);
next_nodes.add(step);
}
}
//if first bottle is not empty and last bottle is not full, transfer water
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
if (i != j) {
step = transfer(temp, i, j);
if (!visited.contains(step) & !next_nodes.contains(step) & !step.isEmpty()) {
parent.add(node);
next_nodes.add(step);
}
}
}
}
//if first bottle is not empty but last bottle is full, empty last bottle
for (int i = 0; i < N; i++) {
step = empty(temp, i);
if (!visited.contains(step) & !next_nodes.contains(step) & !step.isEmpty()) {
parent.add(node);
next_nodes.add(step);
}
}
return next_nodes;
}
//Check if target amount is collected
public boolean targetfound(List<List<Integer>> graph) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < graph.size(); i++) {
list = graph.get(i);
}
return list.contains(target_amount);
}
public static void main(String[] args) {
// Define number of bottles
long startTime = System.currentTimeMillis();
//Define size of bottles
int[] s = {3, 5, 7, 13, 19, 29, 31, 37, 39, 41};
//Define size of bottles
//Define target amount to be collected in tank
int num_of_bottles = s.length;
//Define target amount to be collected in tank
int target = 40;
List<List<Integer>> adj = new ArrayList<>();
List<List<Integer>> path = new ArrayList<>();
List<Integer> child_node = new ArrayList<>();
int child_index;
//Create an object for class Graph
waterJugPuzzle states = new waterJugPuzzle(num_of_bottles, target, s);
List<Integer> start = new ArrayList<Integer>(num_of_bottles);
for (int i = 0; i < num_of_bottles; i++) {
start.add(0);
}
states.nodes_list.add(start);
states.parent.add(start);
states.visited.add(start);
//Define Counter to iterate on list
int counter = 0;
//Check if target quantity is collected
while (states.targetfound(adj) == false) {
adj = states.possible_steps(states.nodes_list.get(counter));
System.out.println(adj);
for (int i = 0; i < adj.size(); i++) {
states.nodes_list.add(adj.get(i));
states.visited.add(adj.get(i));
}
counter += 1;
}
// Find the path from start to target point
int solution = states.nodes_list.size() - 1;
child_node = states.nodes_list.get(solution);
path.add(child_node);
while (child_node != start) {
child_index = states.nodes_list.indexOf(child_node);
child_node = states.parent.get(child_index);
path.add(child_node);
// parent_index = ;
}
System.out.println("The solution to water jug puzzle with " + num_of_bottles + " bottles of size " + Arrays.toString(s) + " is:");
for (int i = path.size() - 1; i >= 0; i--) {
System.out.print(path.get(i));
if (i != 0) {
System.out.print("->");
}
}
System.out.print(".");
System.out.println("");
long endTime = System.currentTimeMillis();
long totalTime = endTime - startTime;
System.out.println("Total Sequential time=" + totalTime);
}
}
<file_sep>/README.md
# Water Jug Puzzle (The Die Hard Riddle)
We would like to collect a specific amount of water in a bottle when we have k water bottles with prespecified capacity and only the following operations are allowed:
* Fill up either bottle completely.
* Empty either bottle completely.
* Pour water from one bottle to the other until the poured bottle becomes empty or the other bottle becomes full.
Water Jug Puzzle was solved using Breadth-First Search in
* Sequential and
* Master-worker cluster pattern
Test case: two bottles of size 5, 3 and target amount of 4.
Solution given by Sequential and cluster implementation:
```
The solution to water jug puzzle with 2 bottles of size [5, 3] is: [0, 0]->[5, 0]->[2, 3]->[2, 0]->[0, 2]->[5, 2]->[4, 3].
```
To compare sequential and cluster implementation, 10 bottles of size 3,5,7,13,19,29,31,37,39,41 with target amount 21 was considered.
Solution:
```
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]-> [0, 0, 0, 0, 19, 0, 0, 0, 0, 0]-> [0, 0, 0, 0, 19, 0, 0, 0, 0, 41]-> [0, 0, 0, 0, 0, 0, 0, 0, 19, 41]-> [0, 0, 0, 0, 0, 0, 0, 0, 39, 21].
```
Sequential time | Parallel time| Speedup
---|---|---
7019|4340|7019/4340 = 1.6
### To run Sequential program,
```
# Compile the java file
javac waterJugPuzzle.java
# Execute compiled java class file
java waterJugPuzzle
```
### To run parallel program
```
# Compile the parallel program
javac WaterJugClu.java
# Make jar file from compiled class file
jar cf WaterJugClu.jar *.class
# Execute the jar created
java pj2 jar-WaterJugClu.jar WaterJugClu
```
| 555ec4ad8c8ebc8632aa96daeb5bc000068801b2 | [
"Markdown",
"Java"
] | 2 | Java | kckishan/WaterJugPuzzle | 9eae9196286554e2ce55f850900569de6deb2f32 | f1f7411527a5716ad0864edd93184aa88a18123d |
refs/heads/main | <file_sep>import React from 'react'
// import {Link} from 'react-router-dom'
const Footer = (props) => {
console.log(props)
const footerStyles ={
display: 'flex',
position: 'absolute',
bottom: '0',
justifyContent: 'space-around',
alignItems: 'center'
}
return (
<footer className="App-footer" styles={footerStyles}>
<div>
This is the footer
</div>
</footer>
)
}
export default Footer<file_sep># Planning
## Form Component
1. first half of form contains question
i. <li>Some Question</li>
2. second half of form contains answers
i. Answer = quiz.questions[i].sum
ii. wrongAnswer1 = quiz.questions[i].wrongNum1
iii. wrongAnswer2 = quiz.questions[i].wrongNum2
iv. wrongAnswer3 = quiz.questions[i].wrongNum3
3. form is in <ul>
4. FadeTransition between questions
i. sample code:
<!-- import FadeTransition from "../src/transitions/fadeTransition";
...
{/*Applying to Login Box*/}
<FadeTransition isOpen={this.state.isLoginOpen} duration={500}>
<div className="box-container">
<LoginBox />
</div>
</FadeTransition>
{/*Applying to Register Box*/}
<FadeTransition isOpen={this.state.isRegisterOpen} duration={500}>
<div className="box-container">
<RegisterBox />
</div>
</FadeTransition>
... -->
## Orbit Component
1.
2. <file_sep>import React from 'react'
import {Link} from 'react-router-dom'
import Navbar from 'react-bootstrap/Navbar'
import Nav from 'react-bootstrap/Nav'
import NavDropdown from 'react-bootstrap/NavDropdown'
const NavBar = (props) => {
console.log(props)
const navStyle = {
color: 'rgb(190,255,90)',
textDecoration: 'none',
display: 'inline-block'
}
return (
<Navbar expand="lg" className="App-nav">
<Navbar.Brand href="#home">React-Bootstrap</Navbar.Brand>
<Navbar.Toggle aria-controls="basic-navbar-nav" />
<Navbar.Collapse id="basic-navbar-nav">
<Nav className="mr-auto">
<Link className="nav-item" style={navStyle} to='#'>Wecome</Link>
<Link className="nav-item" style={navStyle} to='#'>Signup/Signin</Link>
<Nav.Link href="#home">Home</Nav.Link>
<Nav.Link href="#link">Link</Nav.Link>
<NavDropdown title="Dropdown" id="basic-nav-dropdown">
<NavDropdown.Item href="#action/3.1">Action</NavDropdown.Item>
<NavDropdown.Item href="#action/3.2">Another action</NavDropdown.Item>
<NavDropdown.Item href="#action/3.3">Something</NavDropdown.Item>
<NavDropdown.Divider />
<NavDropdown.Item href="#action/3.4">Separated link</NavDropdown.Item>
</NavDropdown>
</Nav>
</Navbar.Collapse>
</Navbar>
)
}
export default NavBar<file_sep>import React, { Component } from 'react'
import TabsComponent from '../components/basics/TabsComponent'
// import Container from 'react-bootstrap/Container'
// import Header from '../components/Header'
// import Main from '../components/Main'
// import Footer from '../components/Footer'
class QuizesContainer extends Component {
render() {
return (
<div className="App-quizes-container">
<TabsComponent/>
</div>
)
}
}
export default QuizesContainer<file_sep>import React from 'react'
import { useState } from 'react'
import Tabs from 'react-bootstrap/Tabs'
import Tab from 'react-bootstrap/Tab'
import QuizOrbit from '../quizes/QuizOrbit'
import QuizForm from '../quizes/QuizForm'
const TabsComponent = (props) => {
const [key, setKey] = useState('home');
return (
<Tabs
id="controlled-tab-example"
activeKey={key}
onSelect={(k) => setKey(k)}
>
<Tab eventKey="home" title="Overview" className="App-tabs-overview">
<h2 style={{color: 'white'}} >Click 'Orbit' or 'Form' to start the quiz!</h2>
</Tab>
<Tab eventKey="orbit" title="Orbit" className="App-tabs-orbit">
<QuizOrbit />
</Tab>
<Tab eventKey="form" title="Form" className="App-tabs-form">
<QuizForm />
</Tab>
</Tabs>
);
}
export default TabsComponent<file_sep>import React from 'react'
import Quiz from './Quiz'
import Container from 'react-bootstrap/Container'
const QuizOrbit = (props) => {
const quiz = new Quiz(6)
console.log(quiz)
const orbitStyles = {
backgroundColor: 'white',
color: 'black',
borderRadius: '50%',
minHeight: '50vh',
}
return (
<Container style={orbitStyles}>
<h2>
{quiz.questions[0].correctNum1} + {quiz.questions[0].correctNum2} = {quiz.questions[0].correctSum}
</h2>
<ul>
<li>Wrong Answer 1: {quiz.questions[0].wrongSum1}</li>
<li>Wrong Answer 2: {quiz.questions[0].wrongSum2}</li>
<li>Wrong Answer 3: {quiz.questions[0].wrongSum3}</li>
</ul>
</Container>
)
}
export default QuizOrbit<file_sep>// import React, { Component } from 'react'
class Question {
constructor() {
this.correctNum1 = Math.ceil(Math.random() * 10);
this.correctNum2 = Math.ceil(Math.random() * 10);
this.correctSum = this.correctNum1 + this.correctNum2;
this.wrongSum1 = Math.ceil(Math.random() * 20);
this.wrongSum2 = Math.ceil(Math.random() * 20);
this.wrongSum3 = Math.ceil(Math.random() * 20);
}
}
export default Question<file_sep>import React from 'react'
import NavBar from './NavBar'
const Header = (props) => {
console.log(props)
const headerStyles ={
display: 'flex',
justifyContent: 'space-around',
alignItems: 'center'
}
return (
<header className="App-header" styles={headerStyles}>
<h1>This is the Header</h1>
<NavBar/>
</header>
)
}
export default Header<file_sep>import React from 'react'
// import React, { useState } from 'react'
import Quiz from './Quiz'
import Container from 'react-bootstrap/Container'
import ListGroup from 'react-bootstrap/ListGroup'
import Form from 'react-bootstrap/Form'
import Button from 'react-bootstrap/Button'
// import FadeTransition from '../transitions/FadeTransiton'
class QuizForm extends React.Component {
state = {
count: 1,
correctAnswer: '',
currentAnswer: '',
numOfCorrect: 0,
numOfIncorrect: 0,
isQuestionOpen: false
}
quiz = new Quiz(6)
formStyles = {
backgroundColor: 'white',
color: 'black',
borderRadius: '3%',
padding: '1em',
minHeight: '50vh',
listStyle: 'none'
}
// get formStyles() {
// return this.formStyles
// }
// set formStyles(styles) {
// this.formStyles = styles
// }
questionStyles = {
backgroundColor: 'white',
color: 'black',
borderRadius: '3%',
padding: '2em',
// minHeight: '50vh',
listStyle: 'none'
}
alertClicked = () => {
this.setState(prevState => {
return {count: prevState.count + 1}
})
}
handleChange = (event) => {
event.preventDefault()
this.setState(
(prevState) => {
console.log(this.state)
return {
currentAnswer: parseInt(event.target.innerText),
correctAnswer: this.quiz.questions[this.state.count].correctSum
}
},
() => console.log('Login: ' + JSON.stringify(this.state))
)
}
handleSubmit = (event) => {
event.preventDefault()
console.log(this.props)
// if (this.state.currentAnswer === this.state.correctAnswer) {
// let container = document.querySelector('.container');
// container.setAttribute('style', 'color: green;')
// this.formStyles.backgroundColor = 'green'
// }
this.setState(
(prevState) => {
if (this.state.currentAnswer === this.state.correctAnswer) {
console.log(this.state)
return {count: prevState.count + 1, numOfCorrect: prevState.numOfCorrect + 1}
} else {
console.log(this.state)
return {count: prevState.count + 1, numOfIncorrect: prevState.numOfIncorrect + 1}
}
},
() => console.log('Login: ' + JSON.stringify(this.state))
)
this.shuffleList()
// alert('You clicked the third ListGroupItem');
}
shuffleList = () => {
let listGroup = document.querySelector('.list-group');
for (let i = listGroup.children.length; i >= 0; i--) {
listGroup.appendChild(listGroup.children[Math.random() * i | 0]);
console.log(listGroup.children[1]);
listGroup.children[1].classList.remove('active')
}
}
showQuestion() {
this.setState({isQuestionOpen: true})
}
render() {
console.log(this.quiz)
if (this.state.count < this.quiz.questions.length) {
return (
<Container style={this.formStyles}>
<Form onSubmit={this.handleSubmit}>
<h3>question {this.state.count} of 5</h3>
<h2 style={this.questionStyles}>
What is the sum of {this.quiz.questions[this.state.count].correctNum1} + {this.quiz.questions[this.state.count].correctNum2}
</h2>
<br/><br/>
<ListGroup>
<ListGroup.Item action href="#link1" onClick={this.handleChange}>
{this.quiz.questions[this.state.count].wrongSum1}
</ListGroup.Item>
<ListGroup.Item action href="#link2" onClick={this.handleChange}>
{this.quiz.questions[this.state.count].wrongSum2}
</ListGroup.Item>
<ListGroup.Item action href="#link3" onClick={this.handleChange}>
{this.quiz.questions[this.state.count].wrongSum3}
</ListGroup.Item>
<ListGroup.Item action href="#" onClick={this.handleChange}>
{this.quiz.questions[this.state.count].correctSum}
</ListGroup.Item>
</ListGroup>
<br/>
<Button variant="primary" type="submit">Submit</Button>
</Form>
{this.shuffleList}
</Container>
)
} else {
return (
<div>
<h1>Congradulations for completing the quiz!</h1>
<h3>You scored {this.state.numOfCorrect} out of {this.state.count} correct.</h3>
</div>
)
}
}
}
export default QuizForm<file_sep>import React from 'react'
import QuizesContainer from '../../containers/QuizesContainer'
const Main = (props) => {
console.log(props)
return (
<main className="App-main">
<QuizesContainer/>
</main>
)
}
export default Main | 593db557133d233e0c0895582d4aff6802d854c0 | [
"JavaScript",
"Markdown"
] | 10 | JavaScript | micahabanschick/AweSum | c4a3ed853c5fcbf06b88b18be4e79d0ef80b34c4 | cbea7e4778a7320e24076689a8c446252768a4fe |
refs/heads/master | <repo_name>Mjernstrom/oil_App<file_sep>/src/app/tab1/tab1.page.ts
import { Component } from '@angular/core';
import { Storage } from '@ionic/storage';
import { Router } from '@angular/router';
const isEqual = require('lodash.isequal');
@Component({
selector: "app-tab1",
templateUrl: "tab1.page.html",
styleUrls: ["tab1.page.scss"],
})
export class Tab1Page {
public bailSizes: Array<string>;
public currentBailSize: string;
public tubingOD: Array<string>;
public currentTubingOD: string;
public casingOD: Array<string>;
public currentCasingOD: string;
public gravBailTable: {};
public results = {};
public dropdownInputsTable: Array<string>;
public driftID;
public wellDeviation;
public timeAtSurface;
public bailerLength;
public bht;
public plugSettingDepth;
public wirelineRunSpeed;
public cementHeightDumped;
public plugTestPressure;
public casingODvals;
public tubingTableVals: {};
public displayedResults = [];
constructor(private storage: Storage, private route: Router) {}
// **********************************INPUT CAPTURE AND DATA PREP ***********************************
// Capture values from text-box inputs
fetchTableValues() {
this.driftID = (<HTMLInputElement>document.getElementById("driftID")).value;
this.wellDeviation = (<HTMLInputElement>(document.getElementById("wellDeviation"))).value;
this.wellDeviation = parseInt(this.wellDeviation);
this.timeAtSurface = (<HTMLInputElement>(document.getElementById("timeAtSurface"))).value;
this.timeAtSurface = parseInt(this.timeAtSurface);
this.bailerLength = (<HTMLInputElement>(document.getElementById("bailerLength"))).value;
this.bht = (<HTMLInputElement>document.getElementById("bht")).value;
this.plugSettingDepth = (<HTMLInputElement>(document.getElementById("plugSettingDepth"))).value;
this.wirelineRunSpeed = (<HTMLInputElement>(document.getElementById("wirelineRunSpeed"))).value;
this.cementHeightDumped = (<HTMLInputElement>(document.getElementById("cementHeightDumped"))).value;
this.plugTestPressure = (<HTMLInputElement>(document.getElementById("plugTestPressure"))).value;
this.parameterLogic();
}
// Capture values from dropdown menus
selectChangedGravBail(selectedBailSize) {
this.currentBailSize = selectedBailSize;
this.dropdownInputsTable[0] = this.currentBailSize;
}
selectChangedTubing(selectedTubingOD) {
this.currentTubingOD = selectedTubingOD;
this.dropdownInputsTable[1] = this.currentTubingOD;
}
selectChangedCasing(selectedCasingOD) {
this.currentCasingOD = selectedCasingOD;
this.dropdownInputsTable[2] = this.currentCasingOD;
}
// ********************************** END OF INPUT CAPTURE AND DATA PREP ***********************************
// ************************************** PARAMETER LOGIC **************************************
parameterLogic() {
// Set Total Bailer Volume (this.results[5])
for (let [key, value] of Object.entries(this.gravBailTable)) {
if (parseFloat(this.dropdownInputsTable[0]) === parseFloat(key)) {
this.results[5] = this.gravBailTable[key] * this.bailerLength;
this.displayedResults[5] = Number(this.results[5]).toFixed(2);
break;
}
}
// Match Tubing OD to Tubing ID (this.results[1])
for (let [key, value] of Object.entries(this.tubingTableVals)) {
var check = isEqual(this.dropdownInputsTable[1].trim(), key.trim());
if (check == true) {
this.displayedResults[1] = this.results[1] = this.tubingTableVals[key];
break;
}
}
// Match casing OD to casing ID (this.results[3])
for (let i = 0; i < this.casingOD.length; i++) {
if (this.dropdownInputsTable[2].trim() == this.casingOD[i].trim()) {
this.displayedResults[3] = this.results[3] = this.casingODvals[i];
break;
}
}
// Set Tubing Capacity (this.results[2])
this.results[2] = this.results[1] * this.results[1] * 0.0408;
this.displayedResults[2] = Number(this.results[2]).toFixed(3);
// Set Tubing fill height per bailer run (this.results[0])
this.results[0] = this.results[5] / this.results[2];
this.displayedResults[0] = Number(this.results[0]).toFixed(2);
// Set Casing Capacity (this.results[4])
this.results[4] = this.results[3] * this.results[3] * 0.0408;
this.displayedResults[4] = Number(this.results[4]).toFixed(3);
// Set Casing fill height per bailer run (this.results[6])
this.results[6] = this.results[5] / this.results[4];
this.displayedResults[6] = Number(this.results[6]).toFixed(2);
// Option #1: get cement plug delta psi
if (this.cementHeightDumped !== undefined) {
if (this.wellDeviation > 69) {
this.results[7] = (280 * this.cementHeightDumped * 24) / this.results[3];
} else if (this.wellDeviation > 59) {
this.results[7] = (280 * this.cementHeightDumped * 19.2) / this.results[3];
} else if (this.wellDeviation > 29) {
this.results[7] = (280 * this.cementHeightDumped * 14.4) / this.results[3];
} else if (this.wellDeviation < 30) {
this.results[7] = (280 * this.cementHeightDumped * 12) / this.results[3];
}
this.displayedResults[7] = Number(this.results[7]).toFixed(2);
}
// Option #2: get cement height required
if (this.plugTestPressure !== undefined) {
if (this.wellDeviation > 69) {
this.results[8] = this.plugTestPressure * this.results[3] * 2 / 3360;
} else if (this.wellDeviation > 59) {
this.results[8] = this.plugTestPressure * this.results[3] * 1.6 / 3360;
} else if (this.wellDeviation > 29) {
this.results[8] = this.plugTestPressure * this.results[3] * 1.2 / 3360;
} else if (this.wellDeviation < 30) {
this.results[8] = this.plugTestPressure * this.results[3] / 3360;
}
this.displayedResults[8] = Number(this.results[8]).toFixed(2);
}
this.displayedResults[9] = this.results[9] = this.cementHeightDumped * this.results[4];
this.displayedResults[11] = this.results[11] = Math.ceil(this.cementHeightDumped / this.results[6]);
this.displayedResults[10] = this.results[10] = this.results[11] * this.results[5];
this.displayedResults[12] = this.results[12] = this.results[10] / this.results[4];
var timeOutputMinsTotal = (this.plugSettingDepth / this.wirelineRunSpeed);
var timeOutputHoursTotal = timeOutputMinsTotal / 60;
var timeOutputHours = Math.floor(timeOutputHoursTotal);
var timeOutputMins = (timeOutputHoursTotal - timeOutputHours) * 60;
this.displayedResults[13] = this.results[13] = timeOutputHours;
this.displayedResults[14] = this.results[14] = timeOutputMins;
timeOutputHoursTotal = (timeOutputMinsTotal + this.timeAtSurface) / 60;
timeOutputHours = Math.floor(timeOutputHoursTotal);
timeOutputMins = (timeOutputHoursTotal - timeOutputHours) * 60;
this.displayedResults[15] = this.results[15] = timeOutputHours;
this.displayedResults[16] = this.results[16] = timeOutputMins;
timeOutputHoursTotal = (this.plugSettingDepth / this.wirelineRunSpeed) + this.timeAtSurface;
timeOutputHoursTotal = (this.results[11] * timeOutputHoursTotal) / 60;
timeOutputHours = Math.floor(timeOutputHoursTotal);
timeOutputMins = (timeOutputHoursTotal - timeOutputHours) * 60;
this.displayedResults[17] = this.results[17] = timeOutputHours;
this.displayedResults[18] = this.results[18] = timeOutputMins;
// Set data in storage to be used in Tab 2
this.storage.set('tubingFillHeight', this.displayedResults[0]);
this.storage.set('tubingID', this.displayedResults[1]);
this.storage.set('tubingCapacity', this.displayedResults[2]);
this.storage.set('casingID', this.displayedResults[3]);
this.storage.set('casingCapacity', this.displayedResults[4]);
this.storage.set('totalBailerVol', this.displayedResults[5]);
this.storage.set('casingFillHeight', this.displayedResults[6]);
this.displayedResults[7] = Math.round(this.displayedResults[7]);
this.storage.set('cementPlugDelta', this.displayedResults[7]);
this.storage.set('cementHeightRequired', this.displayedResults[8]);
this.displayedResults[9] = Number(this.displayedResults[9]).toFixed(2);
this.storage.set('cementVolRequired', this.displayedResults[9]);
this.displayedResults[10] = Number(this.displayedResults[10]).toFixed(2);
this.storage.set('cementDumped', this.displayedResults[10]);
this.displayedResults[11] = this.displayedResults[11];
this.storage.set('totalBailerRuns', this.displayedResults[11]);
this.displayedResults[12] = Number(this.displayedResults[12]).toFixed(2);
this.storage.set('cementHeight', this.displayedResults[12]);
this.storage.set('operatingTimeHours', this.displayedResults[13]);
this.displayedResults[14] = Math.round(this.displayedResults[14])
this.storage.set('operatingTimeMins', this.displayedResults[14]);
this.storage.set('perRunTimeHours', this.displayedResults[15]);
this.displayedResults[16] = Math.round(this.displayedResults[16])
this.storage.set('perRunTimeMins', this.displayedResults[16]);
this.displayedResults[18] = Math.round(this.displayedResults[18]);
this.storage.set('bailingRunTimeHours', this.displayedResults[17]);
this.storage.set('bailingRunTimeMins', this.displayedResults[18]);
this.route.navigate(['/dumpBailHeight/tab2']);
}
// ************************************** END PARAMETER LOGIC **************************************
// ***************************** list of paramaters and dictionaries of tables *****************************
ngOnInit() {
// list to store results used in calculations (not rounded, not displayed)
this.results = [
/* 0 Tubing Fill Height per Bailer Run (ft): */ 0,
/* 1 Tubing ID (in): */ 0,
/* 2 Tubing Capacity (US Gal/ft)": */ 0,
/* 3 Casing ID (in)": */ 0,
/* 4 Casing Capacity (US Gal/ft)": */ 0,
/* 5 Total Bailer Volume (US Gal/ft)": */ 0,
/* 6 Casing Fill Height per Bailer Run (ft)": */ 0,
/* 7 Cement Plug ΔP (psi)": */ 0,
/* 8 Cement Height Required (ft)": */ 0,
/* 9 Cement Volume Required (Gals)": */ 0,
/* 10 Cement Dumped (If full Bailer)(Gals)": */ 0,
/* 11 Total Bailer Runs Required": */ 0,
/* 12 Cement Height (If full Bailers used)": */ 0,
/* 13 Inhole Per Run Operating Time Hours": */ 0,
/* 14 Inhole Per Run Operating Time Mins": */ 0,
/* 15 Total Per Run Round Trip Time Hours": */ 0,
/* 16 Total Per Run Round Trip Time Mins": */ 0,
/* 17 Total Bailing Round Trip Time Hours": */ 0,
/* 18 Total Bailing Round Trip Time Mins": */ 0,
];
// list used to store rounded values to be displayed. Same as list above, except its rounded
this.displayedResults = [
/* 0 Tubing Fill Height per Bailer Run (ft): */ 0,
/* 1 Tubing ID (in): */ 0,
/* 2 Tubing Capacity (US Gal/ft)": */ 0,
/* 3 Casing ID (in)": */ 0,
/* 4 Casing Capacity (US Gal/ft)": */ 0,
/* 5 Total Bailer Volume (US Gal/ft)": */ 0,
/* 6 Casing Fill Height per Bailer Run (ft)": */ 0,
/* 7 Cement Plug ΔP (psi)": */ 0,
/* 8 Cement Height Required (ft)": */ 0,
/* 9 Cement Volume Required (Gals)": */ 0,
/* 10 Cement Dumped (If full Bailer)(Gals)": */ 0,
/* 11 Total Bailer Runs Required": */ 0,
/* 12 Cement Height (If full Bailers used)": */ 0,
/* 13 Inhole Per Run Operating Time Hours": */ 0,
/* 14 Inhole Per Run Operating Time Mins": */ 0,
/* 15 Total Per Run Round Trip Time Hours": */ 0,
/* 16 Total Per Run Round Trip Time Mins": */ 0,
/* 17 Total Bailing Round Trip Time Hours": */ 0,
/* 18 Total Bailing Round Trip Time Mins": */ 0,
];
// list for selected values from dropdown inputs
this.dropdownInputsTable = [];
// Set initial values for dropdown inputs
this.dropdownInputsTable[0] = this.currentBailSize = "1.000";
this.dropdownInputsTable[1] = this.currentTubingOD = '2.375" 4.70#';
this.dropdownInputsTable[2] = this.currentCasingOD = '4.500" 9.50#';
this.bailSizes = [
"1.000",
"1.375",
"1.500",
"1.625",
"2.000",
"2.125",
"2.375",
"2.625",
"3.000",
"3.500",
"4.000",
"5.000",
];
this.gravBailTable = {
"1.000": 0.033,
"1.375": 0.067,
"1.500": 0.072,
"1.625": 0.095,
"2.000": 0.137,
"2.125": 0.152,
"2.375": 0.185,
"2.625": 0.206,
"3.000": 0.315,
"3.500": 0.438,
"4.000": 0.587,
"5.000": 0.939,
};
this.tubingOD = [
'2.375" 4.70#',
'2.375" 5.95#',
'2.875" 6.50#',
'2.875" 8.70#',
'3.500" 9.30#',
'3.500" 10.20#',
'3.500" 12.95#',
'4.000" 9.50#',
'4.000" 11.00#',
'4.000" 13.40#',
'4.500" 12.75#',
'4.500" 13.50#',
'4.500" 15.50#',
];
this.tubingTableVals = {
'2.375" 4.70#': 1.995,
'2.375" 5.95#': 1.867,
'2.875" 6.50#': 2.441,
'2.875" 8.70#': 2.259,
'3.500" 9.30#': 2.992,
'3.500" 10.20#': 2.922,
'3.500" 12.95#': 2.750,
'4.000" 9.50#': 3.548,
'4.000" 11.00#': 3.476,
'4.000" 13.40#': 3.340,
'4.500" 12.75#': 3.958,
'4.500" 13.50#': 3.920,
'4.500" 15.50#': 3.826,
};
this.casingOD = [
'4.500" 9.50#',
'4.500" 10.50#',
'4.500" 11.60#',
'4.500" 13.50#',
'4.500" 15.10#',
'5.000" 13.00#',
'5.000" 15.00#',
'5.000" 18.00#',
'5.000" 20.30#',
'5.000" 23.20#',
'5.500" 15.50#',
'5.500" 17.00#',
'5.500" 20.00#',
'5.500" 23.00#',
'5.500" 26.00#',
'6.625" 20.00#',
'6.625" 24.00#',
'6.625" 28.00#',
'6.625" 32.00#',
'7.000" 20.00#',
'7.000" 23.00#',
'7.000" 26.00#',
'7.000" 29.00#',
'7.000" 32.00#',
'7.000" 35.00#',
'7.000" 38.00#',
'7.625" 26.40#',
'7.625" 29.70#',
'7.625" 33.70#',
'7.625" 39.00#',
'7.625" 42.80#',
'7.625" 45.30#',
'8.625" 32.00#',
'8.625" 36.00#',
'8.625" 40.00#',
'8.625" 44.00#',
'8.625" 49.00#',
'9.625" 40.00#',
'9.625" 43.50#',
'9.625" 47.00#',
'9.625" 53.50#',
'9.625" 58.40#',
'10.750" 40.50#',
'10.750" 45.50#',
'10.750" 51.00#',
'10.750" 55.50#',
'10.750" 60.70#',
'10.750" 65.70#',
'10.750" 71.10#',
'10.750" 80.80#',
'11.750" 54.00#',
'11.750" 60.00#',
'11.750" 65.00#',
'11.750" 71.00#',
'11.875" 71.80#',
'12.750" 123.70#',
'13.375" 54.50#',
'13.375" 61.00#',
'13.375" 68.00#',
'13.375" 72.00#',
'13.375" 80.70#',
'13.375" 86.00#',
'13.625" 88.20#',
'16.000" 65.00#',
'16.000" 75.00#',
'16.000" 84.00#',
'16.000" 95.00#',
'16.000" 97.00#',
'16.000" 109.00#',
'16.000" 118.00#',
'16.000" 137.90#',
'18.625" 87.50#',
'18.625" 94.50#',
'18.625" 106.00#',
'18.625" 117.50#',
'20.000" 94.00#',
'20.000" 106.50#',
'20.000" 133.00#',
'20.000" 169.00#',
];
this.casingODvals = [
4.090,
4.052,
4.000,
3.920,
3.826,
4.494,
4.408,
4.276,
4.184,
4.044,
4.950,
4.892,
4.778,
4.670,
4.548,
6.049,
5.921,
5.791,
5.675,
6.456,
6.366,
6.276,
6.184,
6.094,
6.004,
5.920,
6.969,
6.875,
6.765,
6.625,
6.501,
6.435,
7.921,
7.825,
7.725,
7.625,
7.511,
8.835,
8.755,
8.681,
8.535,
8.435,
10.050,
9.950,
9.850,
9.760,
9.660,
9.560,
9.450,
9.250,
10.880,
10.772,
10.682,
10.586,
10.711,
10.782,
12.615,
12.515,
12.415,
12.347,
12.215,
12.125,
12.375,
15.250,
15.124,
15.010,
14.868,
14.850,
14.688,
14.570,
14.323,
17.755,
17.689,
17.563,
17.439,
19.124,
19.000,
18.730,
18.376
];
}
}
<file_sep>/src/app/login/login.page.ts
import { Component, OnInit } from '@angular/core';
import { AngularFireAuth } from '@angular/fire/auth';
import { Router, RouterOutlet } from '@angular/router';
import { ToastController } from '@ionic/angular';
@Component({
selector: 'app-login',
templateUrl: './login.page.html',
styleUrls: ['./login.page.scss'],
})
export class LoginPage implements OnInit {
username: string = "";
password: string = "";
isToastActive = false;
constructor(
private afAuth: AngularFireAuth,
private route: Router,
private toast: ToastController
) {}
ngOnInit() {
}
async createAccount() {
if (this.isToastActive == true) {
this.toast.dismiss();
this.isToastActive = false;
}
this.route.navigate(['signup']);
}
async login(){
const { username, password } = this;
this.afAuth.signInWithEmailAndPassword(username, password)
.then(user => {
this.route.navigate(['directory']);
}).catch(error => {
this.presentLoginError();
})
}
async presentLoginError() {
const toast = await this.toast.create({
cssClass: 'loginError',
message: 'Username/Password Incorrect',
position: 'middle',
color: 'light',
duration: 4000,
});
this.isToastActive = true;
toast.present();
}
}
<file_sep>/src/app/tab2/tab2.page.ts
import { Component } from '@angular/core';
import { Storage } from '@ionic/storage';
@Component({
selector: 'app-tab2',
templateUrl: 'tab2.page.html',
styleUrls: ['tab2.page.scss']
})
export class Tab2Page {
public tubingFillHeight$;
public tubingFillHeight;
public tubingID$;
public tubingID;
public tubingCapacity$;
public tubingCapacity;
public casingID$;
public casingID;
public casingCapacity$;
public casingCapacity;
public totalBailerVol$;
public totalBailerVol;
public casingFillHeight$;
public casingFillHeight;
public cementPlugDelta$;
public cementPlugDelta;
public cementHeightRequired$;
public cementHeightRequired;
public cementVolReq$;
public cementVolReq;
public cementDumped$;
public cementDumped;
public totalBailerRuns$;
public totalBailerRuns;
public cementHeight$;
public cementHeight;
public operatingTimeHours$;
public operatingTimeHours;
public operatingTimeMins$;
public operatingTimeMins;
public perRunTimeHours$;
public perRunTimeHours;
public perRunTimeMins$;
public perRunTimeMins;
public bailingRunTimeHours$;
public bailingRunTimeHours;
public bailingRunTimeMins$;
public bailingRunTimeMins;
constructor(private storage: Storage) {
}
ionViewWillEnter() {
this.tubingFillHeight$ = this.storage.get('tubingFillHeight');
this.tubingFillHeight$.then(val => this.tubingFillHeight = val);
this.tubingID$ = this.storage.get('tubingID');
this.tubingID$.then(val => this.tubingID = val);
this.tubingCapacity$ = this.storage.get('tubingCapacity');
this.tubingCapacity$.then(val => this.tubingCapacity = val);
this.casingID$ = this.storage.get('casingID');
this.casingID$.then(val => this.casingID = val);
this.casingCapacity$ = this.storage.get('casingCapacity');
this.casingCapacity$.then(val => this.casingCapacity = val);
this.totalBailerVol$ = this.storage.get('totalBailerVol');
this.totalBailerVol$.then(val => this.totalBailerVol = val);
this.casingFillHeight$ = this.storage.get('casingFillHeight');
this.casingFillHeight$.then(val => this.casingFillHeight = val);
this.cementPlugDelta$ = this.storage.get('cementPlugDelta');
this.cementPlugDelta$.then(val => this.cementPlugDelta = val);
this.cementHeightRequired$ = this.storage.get('cementHeightRequired');
this.cementHeightRequired$.then(val => this.cementHeightRequired = val);
this.cementVolReq$ = this.storage.get('cementVolRequired');
this.cementVolReq$.then(val => this.cementVolReq = val);
this.cementDumped$ = this.storage.get('cementDumped');
this.cementDumped$.then(val => this.cementDumped = val);
this.totalBailerRuns$ = this.storage.get('totalBailerRuns');
this.totalBailerRuns$.then(val => this.totalBailerRuns = val);
this.cementHeight$ = this.storage.get('cementHeight');
this.cementHeight$.then(val => this.cementHeight = val);
this.operatingTimeHours$ = this.storage.get('operatingTimeHours');
this.operatingTimeHours$.then(val => this.operatingTimeHours = val);
this.operatingTimeMins$ = this.storage.get('operatingTimeMins');
this.operatingTimeMins$.then(val => this.operatingTimeMins = val);
this.perRunTimeHours$ = this.storage.get('perRunTimeHours');
this.perRunTimeHours$.then(val => this.perRunTimeHours = val);
this.perRunTimeMins$ = this.storage.get('perRunTimeMins');
this.perRunTimeMins$.then(val => this.perRunTimeMins = val);
this.bailingRunTimeHours$ = this.storage.get('bailingRunTimeHours');
this.bailingRunTimeHours$.then(val => this.bailingRunTimeHours = val);
this.bailingRunTimeMins$ = this.storage.get('bailingRunTimeMins');
this.bailingRunTimeMins$.then(val => this.bailingRunTimeMins = val);
}
}
<file_sep>/src/app/dumpBailHeight/dumpBailHeight.module.ts
import { IonicModule } from '@ionic/angular';
import { NgModule } from '@angular/core';
import { CommonModule } from '@angular/common';
import { FormsModule } from '@angular/forms';
import { dumpBailHeightPageRoutingModule } from './dumpBailHeight-routing.module';
import { dumpBailHeight } from './dumpBailHeight.page';
@NgModule({
imports: [
IonicModule,
CommonModule,
FormsModule,
dumpBailHeightPageRoutingModule
],
declarations: [dumpBailHeight]
})
export class dumpBailHeightPageModule {}
<file_sep>/src/app/dumpBailHeight/dumpBailHeight.page.ts
import { Component } from '@angular/core';
@Component({
selector: 'app-tabs',
templateUrl: 'dumpBailHeight.page.html',
styleUrls: ['dumpBailHeight.page.scss']
})
export class dumpBailHeight {
constructor() {}
}
| 0fbb986ac65e9a7d0ed4b18ca37e8b839dffbcdb | [
"TypeScript"
] | 5 | TypeScript | Mjernstrom/oil_App | ed95274178f93cfdd8042cfddd5b6c8beb9f165f | e01a23cb5e6a3d2439538953e6cdd8e0737b4c6d |
refs/heads/master | <repo_name>tcnghia/dapr<file_sep>/docs/release_notes/template.md
# Dapr $dapr_version
We're happy to announce the release of Dapr $dapr_version!
We would like to extend our thanks to all the new and existing contributors who helped make this release happen.
**Highlights**
If you're new to Dapr, visit the [getting started](https://docs.dapr.io/getting-started/) page and familiarize yourself with Dapr.
Docs have been updated with all the new features and changes of this release. To get started with new capabilities introduced in this release, go to the [Concepts](https://docs.dapr.io/concepts/) and the [Developing applications](https://docs.dapr.io/developing-applications/).
$warnings
See [this](#upgrading-to-dapr-$dapr_version) section on upgrading Dapr to version $dapr_version.
## New in this release
$dapr_changes
## Upgrading to Dapr $dapr_version
To upgrade to this release of Dapr, follow the steps here to ensure a smooth upgrade. You know, the one where you don't get red errors on the terminal.. we all hate that, right?
### Local Machine / Self-hosted
Uninstall Dapr using the CLI you currently have installed. Note that this will remove the default $HOME/.dapr directory, binaries and all containers dapr_redis, dapr_placement and dapr_zipkin. Linux users need to run sudo if docker command needs sudo:
```bash
dapr uninstall --all
```
Next, follow [these](https://github.com/dapr/cli#installing-dapr-cli) instructions to install the latest CLI version, or alternatively download the latest and greatest release from [here](https://github.com/dapr/cli/releases) and put the `dapr` binary in your PATH.
Once you have installed the CLI, run:
```bash
dapr init
```
Wait for the update to finish, ensure you are using the latest version of Dapr($dapr_version) with:
```bash
$ dapr --version
CLI version: $dapr_version
Runtime version: $dapr_version
```
### Kubernetes
#### Upgrading from previous version
If you previously installed Dapr using Helm, you can upgrade Dapr to a new version.
If you installed Dapr using the CLI, go [here](#starting-fresh-install-on-a-cluster).
##### 1. Get the latest CLI
Get the latest version of the Dapr CLI as outlined above, and put it in your path.
You can also use the helper scripts outlined [here](https://github.com/dapr/cli#installing-dapr-cli) to get the latest version.
##### 2. Upgrade existing cluster
First, add new Dapr helm repository(see [breaking changes](#breaking-changes)) and update your Helm repos:
```bash
helm repo add dapr https://dapr.github.io/helm-charts/ --force-update
helm repo update
```
Run the following commands to upgrade the Dapr control plane system services and data plane services:
* Export certificates
```
dapr mtls export -o ./certs
```
* Updating Dapr control plane pods
* Using the certs exported above, run the following command:
```
helm upgrade dapr dapr/dapr --version $dapr_version --namespace dapr-system --reset-values --set-file dapr_sentry.tls.root.certPEM=./certs/ca.crt --set-file dapr_sentry.tls.issuer.certPEM=./certs/issuer.crt --set-file dapr_sentry.tls.issuer.keyPEM=./certs/issuer.key
```
* Wait until all the pods are in Running state:
```
kubectl get pods -w -n dapr-system
```
* Verify the control plane is updated and healthy:
```
$ dapr status -k
NAME NAMESPACE HEALTHY STATUS REPLICAS VERSION AGE CREATED
dapr-dashboard dapr-system True Running 1 $dapr_dashboard_version 15s $today 13:07.39
dapr-sidecar-injector dapr-system True Running 1 $dapr_version 15s $today 13:07.39
dapr-sentry dapr-system True Running 1 $dapr_version 15s $today 13:07.39
dapr-operator dapr-system True Running 1 $dapr_version 15s $today 13:07.39
dapr-placement dapr-system True Running 1 $dapr_version 15s $today 13:07.39
```
* Updating the data plane (sidecars)
* Next, issue a rolling update to your Dapr enabled deployments. When the pods restart, the new Dapr sidecar version will be picked up.
```
kubectl rollout restart deploy/<DEPLOYMENT-NAME>
```
All done!
#### Starting fresh install on a cluster
If you previously installed Dapr on your Kubernetes cluster using the Dapr CLI, run:
*Note: Make sure you're uninstalling with your existing CLI version*
```bash
dapr uninstall --kubernetes
```
It's fine to ignore any errors that might show up.
If you previously installed Dapr using __Helm 2.X__:
```bash
helm del --purge dapr
```
If you previously installed Dapr using __Helm 3.X__:
```bash
helm uninstall dapr -n dapr-system
```
Update the Dapr repo:
```bash
helm repo update
```
If you installed Dapr with Helm to a namespace other than `dapr-system`, modify the uninstall command above to account for that.
You can now follow [these](https://docs.dapr.io/getting-started/install-dapr/#install-with-helm-advanced) instructions on how to install Dapr using __Helm 3__.
Alternatively, you can use the newer version of CLI:
```
dapr init --kubernetes
```
##### Post installation
Verify the control plane pods are running and are healthy:
```
$ dapr status -k
NAME NAMESPACE HEALTHY STATUS REPLICAS VERSION AGE CREATED
dapr-dashboard dapr-system True Running 1 $dapr_dashboard_version 15s $today 13:07.39
dapr-sidecar-injector dapr-system True Running 1 $dapr_version 15s $today 13:07.39
dapr-sentry dapr-system True Running 1 $dapr_version 15s $today 13:07.39
dapr-operator dapr-system True Running 1 $dapr_version 15s $today 13:07.39
dapr-placement dapr-system True Running 1 $dapr_version 15s $today 13:07.39
```
After Dapr $dapr_version has been installed, perform a rolling restart for your deployments to pick up the new version of the sidecar.
This can be done with:
```
kubectl rollout restart deploy/<deployment-name>
```
## Breaking Changes
$dapr_breaking_changes
## Acknowledgements
Thanks to everyone who made this release possible!
$dapr_contributors<file_sep>/tests/apps/actorfeatures/go.mod
module app
go 1.15
require github.com/gorilla/mux v1.7.3
<file_sep>/pkg/components/state/state_config.go
// ------------------------------------------------------------
// Copyright (c) Microsoft Corporation and Dapr Contributors.
// Licensed under the MIT License.
// ------------------------------------------------------------
package state
import (
"fmt"
"strings"
)
const (
strategyKey = "keyPrefix"
strategyAppid = "appid"
strategyStoreName = "name"
strategyNone = "none"
strategyDefault = strategyAppid
daprSeparator = "||"
)
var statesConfiguration = map[string]*StoreConfiguration{}
type StoreConfiguration struct {
keyPrefixStrategy string
}
func SaveStateConfiguration(storeName string, metadata map[string]string) {
strategy := metadata[strategyKey]
strategy = strings.ToLower(strategy)
if strategy == "" {
strategy = strategyDefault
}
statesConfiguration[storeName] = &StoreConfiguration{keyPrefixStrategy: strategy}
}
func GetModifiedStateKey(key, storeName, appID string) string {
stateConfiguration := getStateConfiguration(storeName)
switch stateConfiguration.keyPrefixStrategy {
case strategyNone:
return key
case strategyStoreName:
return fmt.Sprintf("%s%s%s", storeName, daprSeparator, key)
case strategyAppid:
if appID == "" {
return key
}
return fmt.Sprintf("%s%s%s", appID, daprSeparator, key)
default:
return fmt.Sprintf("%s%s%s", stateConfiguration.keyPrefixStrategy, daprSeparator, key)
}
}
func GetOriginalStateKey(modifiedStateKey string) string {
splits := strings.Split(modifiedStateKey, daprSeparator)
if len(splits) <= 1 {
return modifiedStateKey
}
return splits[1]
}
func getStateConfiguration(storeName string) *StoreConfiguration {
c := statesConfiguration[storeName]
if c == nil {
c = &StoreConfiguration{keyPrefixStrategy: strategyDefault}
statesConfiguration[storeName] = c
}
return c
}
| 51ac798177a6e15edae4329576dea5efdf876e79 | [
"Markdown",
"Go Module",
"Go"
] | 3 | Markdown | tcnghia/dapr | cb1f9a4185c88a449b5bcb9341e5849c9b8fde87 | e919bccaca0835297ec2b0d4d9347b2cb9aa0c45 |
refs/heads/master | <file_sep>#include "LocalSearch.hpp"
LocalSearch::LocalSearch(NeighbourAlgorithm* neighbour_algorithm) {
neighbour_algorithm_ = neighbour_algorithm;
}
Solution LocalSearch::run(Solution& solution) {
return optimal_search(solution);
}
Solution LocalSearch::optimal_search(Solution& solution) {
neighbour_algorithm_->set_solution_to_swap(solution);
return neighbour_algorithm_->execute(solution);
}
Solution LocalSearch::stop_criterion(Solution& current_solution) {
/*int without_improvement = 0;
Solution best_solution = current_solution;
while (without_improvement < 3) {
current_solution = optimal_search(current_solution);
if (current_solution.calculate_objetive_function() >=
best_solution.calculate_objetive_function()) {
without_improvement++;
} else {
best_solution = current_solution;
without_improvement = 0;
}
}
return best_solution;*/
}
<file_sep>#ifndef SOLUCION_H_
#define SOLUCION_H_
#include<vector>
#include <utility>
#include<iostream>
using namespace std;
class Solucion {
public:
Solucion();
virtual ~Solucion();
virtual void resolver();
virtual void mezcla(pair<Solucion*,Solucion*>);
virtual Solucion* getInstance();
};
#endif /* SOLUCION_H_ */
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: April 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 08-MaximumDiversityProblem
|| @Info: http://grafo.etsii.urjc.es/optsicom/mdp/
=======================================================================*/
#include <iostream>
#include "CommandLineArguments.hpp"
#include "Experiment.hpp"
#include "LocalSearch.hpp"
#include "NeighbourAlgorithms/ExchangeExternalPoint.hpp"
#include "Problem.hpp"
int main(int argc, char* argv[]) {
try {
CommandLineArguments cmd_line(argc, argv);
std::string file_name = cmd_line.get_list_arguments()[1];
Problem maximum_diversity(file_name);
// GRASP Experiment
/*std::vector<int> size_solutions = {2, 3, 4, 5};
std::vector<int> size_rcls = {2, 3};
Experiment experiment(maximum_diversity, "grasp");
std::cout << experiment << std::endl;
for (auto&& size_solution : size_solutions) {
for (auto&& rcl_size : size_rcls) {
experiment.grasp(size_solution, new ExchangeExternalPoint(), rcl_size);
experiment.show_table(std::cout);
}
}*/
// Greedy Experiment
/*std::vector<int> size_solutions = {5, 4};
Experiment experiment_greedy(maximum_diversity, "greedy");
std::cout << experiment_greedy << std::endl;
for (auto&& size_solution : size_solutions) {
experiment_greedy.greedy(size_solution);
experiment_greedy.show_table(std::cout);
}*/
// Branch&Bound Experiment
std::vector<int> size_solutions = {4};
Experiment experiment(maximum_diversity, "branch_bound");
Experiment experiment_greedy(maximum_diversity, "greedy");
std::cout << experiment << std::endl;
for (auto&& size_solution : size_solutions) {
experiment_greedy.greedy(size_solution);
experiment.branch_bound(size_solution, experiment_greedy.get_solution(),
1);
experiment.show_table(std::cout);
}
} catch (const std::exception& e) {
std::cerr << e.what() << '\n';
} catch (const char* e) {
std::cerr << e << '\n';
} catch (...) {
}
return 0;
}
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef MEMORY_H
#define MEMORY_H
#include <vector>
#include "Registers.hpp"
/* Memory: Save and Load the Registers
* Register Accumulator: Register 0 of Register Bank */
class Memory {
private:
const int REGISTER_SIZE = 14;
Registers register_bank_;
public:
Memory();
~Memory() {}
int read(int id_register = 0);
void write(int value, int id_register = 0);
void reset();
friend std::ostream& operator<<(std::ostream& os, const Memory& memory);
};
#endif // MEMORY_H<file_sep>#ifndef REINSERTIONOWNMACHINE_H
#define REINSERTIONOWNMACHINE_H
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
class ReinsertionOwnMachine : public NeighbourAlgorithm {
int index_one = 0;
int index_two = 0;
int current_machine_index = 0;
Solution execute(Solution solution) {
Solution best_solution = solution;
// std::cout << "----- Reinsertion ------" << std::endl;
int machine_index = 0;
current_machine_index = machine_index;
for (auto&& machine : solution.get_list_machines()) {
for (size_t i = 0; i < machine.get_processed_tasks().size(); i++) {
for (size_t j = 0; j < machine.get_processed_tasks().size(); j++) {
if (i != j) {
reinsertion(solution, i, j);
}
if (solution.calculate_objetive_function() <
best_solution.calculate_objetive_function()) {
best_solution = solution;
}
}
}
machine_index++;
current_machine_index = machine_index;
}
solution = best_solution;
/*
if (index_one < solution.get_list_machines()[current_machine_index]
.get_processed_tasks()
.size()) {
if (index_two < solution.get_list_machines()[current_machine_index]
.get_processed_tasks()
.size()) {
if (index_one != index_two) {
reinsertion(solution, index_one, index_two);
}
index_two++;
} else {
index_one++;
index_two = 0;
}
} else {
index_one = 0;
index_two = 0;
current_machine_index =
(current_machine_index + 1) % solution.get_list_machines().size();
}*/
return solution;
}
void reinsertion(Solution& solution, int origin, int destination) {
int current_index = origin;
while (current_index + 1 <= destination) {
std::swap(solution.get_list_machines()[current_machine_index]
.get_processed_tasks()[current_index],
solution.get_list_machines()[current_machine_index]
.get_processed_tasks()[current_index + 1]);
current_index++;
}
while (current_index - 1 >= destination) {
std::swap(solution.get_list_machines()[current_machine_index]
.get_processed_tasks()[current_index],
solution.get_list_machines()[current_machine_index]
.get_processed_tasks()[current_index - 1]);
current_index--;
}
}
};
#endif // REINSERTIONOWNMACHINE_H<file_sep>BIN := bin
SRC := src
INCLUDE := include
EXECUTABLE := scheduling_tct
CXX := g++
CXX_FLAGS := -I$(INCLUDE) -g -O2
.PHONY: $(BIN)/$(EXECUTABLE)
all: $(BIN)/$(EXECUTABLE)
debug:
@echo "Mode Debug"
set CXX_FLAGS += -Wall -g
make
run:
clear
@echo "🚀 Executing..."
./$(BIN)/$(EXECUTABLE)
$(BIN)/$(EXECUTABLE): $(SRC)/*.cpp
@echo "🚧 Building..."
mkdir -p $(BIN)
$(CXX) $(CXX_FLAGS) $^ -o $@
clean:
@echo "🧹 Clearing..."
rm -rf $(BIN)<file_sep>// Strategy pattern -- Structural example
#include <iostream>
using namespace std;
enum TYPESTRATEGY{A, B, C, D};
// The 'Strategy' abstract class
class Strategy {
public:
virtual void AlgorithmInterface() = 0;
};
// A 'ConcreteStrategy' class
class ConcreteStrategyA : public Strategy {
void AlgorithmInterface() {
cout << "Called ConcreteStrategyA.AlgorithmInterface()" << endl;
}
};
// A 'ConcreteStrategy' class
class ConcreteStrategyB : public Strategy {
void AlgorithmInterface() {
cout << "Called ConcreteStrategyB.AlgorithmInterface()" << endl;
}
};
// A 'ConcreteStrategy' class
class ConcreteStrategyC : public Strategy {
void AlgorithmInterface() {
cout << "Called ConcreteStrategyC.AlgorithmInterface()" << endl;
}
};
// A new 'ConcreteStrategy' class
class ConcreteStrategyD : public Strategy {
void AlgorithmInterface() {
cout << "Called ConcreteStrategyD.AlgorithmInterface()" << endl;
}
};
// The 'Context' class
class Context {
protected:
Strategy *_strategy;
public:
// Constructor
Context() {
_strategy = NULL;
}
// Constructor
Context(Strategy *strategy) {
_strategy = strategy;
}
void setstrategy(TYPESTRATEGY type ) {
delete _strategy;
if (type == A)
_strategy = new ConcreteStrategyA();
else if (type == B)
_strategy = new ConcreteStrategyB();
else if (type == C)
_strategy = new ConcreteStrategyC();
else {
cout << "ERROR: Stratey not known" << endl;
_strategy = NULL;
}
}
void setstrategy(Strategy *strategy ) {
delete _strategy;
_strategy = strategy;
}
void ContextInterface() {
if (_strategy)
_strategy -> AlgorithmInterface();
else
cout << "ERROR: Strategy not set" << endl;
}
};
// The 'Context' class
class Newcontext: public Context {
public:
void setstrategy(TYPESTRATEGY type ) {
delete _strategy;
if (type == D)
_strategy = new ConcreteStrategyD();
else
Context::setstrategy(type);
}
};
int main() {
Context *pcontext;
Context context;
Newcontext newcontext;
pcontext = new Context(new ConcreteStrategyA());
context.setstrategy(A);
newcontext.setstrategy(A);
pcontext->ContextInterface();
context.ContextInterface();
newcontext.ContextInterface();
pcontext -> setstrategy(new ConcreteStrategyD());
pcontext->ContextInterface();
context.setstrategy(D);
context.ContextInterface();
newcontext.setstrategy(D);
newcontext.ContextInterface();
}
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 04-FrameworkDivideConquer
|| @Info: https://es.wikipedia.org/wiki/Algoritmo_divide_y_vencer%C3%A1s
=======================================================================*/
#ifndef MERGESORTPROBLEM_H
#define MERGESORTPROBLEM_H
#include "Problema.h"
class MergeSortProblem : public Problema {
public:
MergeSortProblem(std::vector<int> array);
~MergeSortProblem() {}
bool isCasoMinimo();
std::pair<Problema*, Problema*> descomponer();
void solver(Solucion* s);
};
#endif // MERGESORTPROBLEM_H<file_sep>#ifndef REINSERTIONEXTERNALMACHINE_H
#define REINSERTIONEXTERNALMACHINE_H
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
class ReinsertionExternalMachine : public NeighbourAlgorithm {
int index_machine_one = 0;
int index_machine_two = 1;
int index_task_one = 0;
int index_task_two = 0;
Solution execute(Solution solution) {
permutationMachine(solution);
return solution;
}
void permutationMachine(Solution& solution) {
Solution best_solution = solution;
// std::cout << "----- Reinsertion ------" << std::endl;
for (size_t i = 0; i < solution.get_list_machines().size(); i++) {
for (size_t j = i + 1; j < solution.get_list_machines().size(); j++) {
permutationTask(solution.get_list_machines()[index_machine_one],
solution.get_list_machines()[index_machine_two],
solution, best_solution);
}
}
solution = best_solution;
/*if (index_machine_one < solution.get_list_machines().size()) {
if (index_machine_two < solution.get_list_machines().size()) {
permutationTask(solution.get_list_machines()[index_machine_one],
solution.get_list_machines()[index_machine_two]);
index_machine_two++;
} else {
index_machine_one++;
index_machine_two = index_machine_one + 1;
}
} else {
index_machine_one = 0;
index_machine_two = 1;
}*/
}
void permutationTask(Machine& machine_one, Machine& machine_two,
Solution& solution, Solution& best_solution) {
for (size_t i = 0; i < machine_one.get_processed_tasks().size(); i++) {
for (size_t i = 0; i < machine_two.get_processed_tasks().size() + 1;
i++) {
/*std::cout << "1 -<< " << solution.calculate_objetive_function()
<< std::endl;*/
if (machine_one.assigned_tasks() >= 1) {
reinsertion(machine_one, machine_two, index_task_one, index_task_two);
}
/*std::cout << "2 -<< " << solution.calculate_objetive_function()
<< std::endl;*/
if (solution.calculate_objetive_function() <
best_solution.calculate_objetive_function()) {
best_solution = solution;
}
}
}
/*if (index_task_one < machine_one.get_processed_tasks().size()) {
if (index_task_two < machine_two.get_processed_tasks().size() + 1) {
reinsertion(machine_one, machine_two, index_task_one, index_task_two);
index_task_two++;
} else {
index_task_one++;
index_task_two = 0;
}
} else {
index_task_one = 0;
index_task_two = 0;
}*/
}
void reinsertion(Machine& machine_origin, Machine& machine_destination,
int origin, int destination) {
Task task_to_insert = machine_origin.get_processed_tasks()[origin];
machine_destination.insert_task(destination, task_to_insert);
machine_origin.erase_task(origin);
}
};
#endif // REINSERTIONEXTERNALMACHINE_H<file_sep>#include "Algorithms/Greedy.hpp"
#include <limits>
Solution Greedy::execute(Graph &graph) {
std::cout << "\nGreedy execute" << std::endl;
Solution solution(graph.get_machines_number());
for (size_t i = 0; i < graph.get_machines_number(); i++) {
solution.add_task(graph.min_values_of_arcs()[i], i);
}
int currentMachine = 0;
do {
Task task = solution.find_task_to_add(graph, currentMachine);
solution.add_task(task, currentMachine);
currentMachine = find_machine_min_tct(solution);
} while (solution.assigned_tasks() < graph.get_tasks_number());
return solution;
}
int Greedy::find_machine_min_tct(Solution solution) {
int index_of_current_machine = 0;
int min_tct = std::numeric_limits<int>::max();
Task machine_min_tct = Task(min_tct, index_of_current_machine);
for (auto &&machine : solution.get_list_machines()) {
int current_tct = machine.calculate_tct();
if (current_tct < machine_min_tct.get_id_task()) {
machine_min_tct.set_id_task(current_tct);
machine_min_tct.set_value_of_arc(index_of_current_machine);
}
index_of_current_machine++;
}
return machine_min_tct.get_value_of_arc();
}
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef ADDRESSINGMODE_H
#define ADDRESSINGMODE_H
#include <iostream>
class AddressingMode {
private:
const unsigned INMEDIATE = 1;
const unsigned INDIRECT = 2;
const unsigned DIRECT = 3;
unsigned mode_;
public:
AddressingMode();
AddressingMode(char symbol);
~AddressingMode() {}
char get_symbol();
unsigned get_mode();
friend std::ostream& operator<<(std::ostream& os,
const AddressingMode& addr_mode);
};
#endif // ADDRESSINGMODE_H<file_sep># Practicas Diseño y Analisis de Algoritmos ULL 2021
#### [01-StrategyDesignPattern](01-StrategyDesignPattern)
#### [02-RamSimulator](02-RamSimulator)<file_sep>#ifndef NEIGHBOURALGORITHM_H
#define NEIGHBOURALGORITHM_H
#include <algorithm>
#include "Solution.hpp"
class NeighbourAlgorithm {
protected:
Solution solution_to_swap;
std::vector<std::vector<Task>> processed_task;
int index_solution_ = 0;
public:
virtual Solution execute(Solution solution) = 0;
void set_solution_to_swap(Solution solution) {
solution_to_swap = solution;
for (auto&& machine : solution.get_list_machines()) {
processed_task.push_back(machine.get_processed_tasks());
}
}
};
class ExchangeOwnMachine : public NeighbourAlgorithm {
Solution execute(Solution solution) {
index_solution_ =
(index_solution_ + 1) % solution.get_list_machines().size();
check_is_permutation(solution, index_solution_);
std::next_permutation(
processed_task[index_solution_].begin(),
processed_task[index_solution_].end(), [](Task first, Task second) {
return first.get_value_of_arc() < second.get_value_of_arc();
});
solution.set_proccessed_tasks(index_solution_,
processed_task[index_solution_]);
return solution;
}
void check_is_permutation(Solution solution, int index_solution) {
std::vector<Task> solution_processed_task =
solution.get_list_machines()[index_solution_].get_processed_tasks();
std::vector<Task> neighbour_processed_task =
solution_to_swap.get_list_machines()[index_solution_]
.get_processed_tasks();
bool is_permutation = std::is_permutation(
solution_processed_task.begin(), solution_processed_task.end(),
neighbour_processed_task.begin(), neighbour_processed_task.end());
if (!is_permutation) {
solution_to_swap = solution;
std::vector<std::vector<Task>> new_processed_task;
for (auto&& machine : solution.get_list_machines()) {
new_processed_task.push_back(machine.get_processed_tasks());
}
processed_task = new_processed_task;
}
}
};
#endif // NEIGHBOURALGORITHM_H<file_sep>#ifndef GVNS_H
#define GVNS_H
#include <vector>
#include "Algorithm.hpp"
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
class GVNS : public Algorithm {
private:
int MAX_ITERATIONS_ = 100;
int VALUE_ENVIRONMENTAL_STRUCTURE = 5;
public:
GVNS(int value_environmental_structure = 5, int max_iterations = 100);
Solution execute(Graph &graph);
Solution generate_boot_solution(Graph &graph);
int calculate_size_min_sequence(Solution &solution);
Solution shaking(Solution &solution, int size_environmental_structure);
Solution vnd(Solution &solution);
std::vector<NeighbourAlgorithm *> generate_environmental_structure(
int size_environmetal_structure);
Solution calculate_min_tct_of_environmental_structure(
std::vector<NeighbourAlgorithm *> environmental_structures,
Solution &solution);
};
#endif // GVNS_H<file_sep>#ifndef STRATEGY_H
#define STRATEGY_H
#include "Algorithms/Algorithm.hpp"
#include "Solution.hpp"
class Strategy {
private:
Algorithm* algorithm_;
public:
Strategy(Algorithm* algorithm) { algorithm_ = algorithm; }
~Strategy() {}
Solution run(Problem problem) { return algorithm_->execute(problem); }
};
#endif // STRATEGY_H<file_sep>#include "Problem.hpp"
#include <algorithm>
#include <cmath>
#include <sstream>
Problem::Problem(std::string file_name) {
file_.open(file_name, std::fstream::in);
file_name_ = file_name;
analize_file();
}
Problem::Problem(const Problem& problem) {
points_size_ = problem.points_size_;
dimension_size_ = problem.dimension_size_;
list_points_ = problem.list_points_;
file_name_ = problem.file_name_;
}
std::string Problem::get_file_name() const { return file_name_; }
int Problem::get_points_size() const { return points_size_; }
int Problem::get_dimension_size() const { return dimension_size_; }
std::vector<Point> Problem::get_list_points() const { return list_points_; }
Point Problem::get_point(int id) {
for (auto&& point : list_points_) {
if (point.get_id() == id) {
return point;
}
}
return Point(-1);
}
void Problem::analize_file() {
parse_points_size();
parse_dimension_size();
parse_points();
}
void Problem::parse_points_size() {
std::string line;
getline(file_ >> std::ws, line);
points_size_ = std::stoi(line);
}
void Problem::parse_dimension_size() {
std::string line;
getline(file_ >> std::ws, line);
dimension_size_ = std::stoi(line);
}
void Problem::parse_points() {
std::string line;
int point_id = 0;
while (getline(file_ >> std::ws, line)) {
std::istringstream iss(line);
std::string coordinate_value;
Point point(point_id);
while (iss >> coordinate_value) {
std::replace(coordinate_value.begin(), coordinate_value.end(), ',', '.');
point.add_coordinate(std::stof(coordinate_value));
}
list_points_.push_back(point);
point_id++;
}
}
std::vector<Point> Problem::unproccessed_points(
std::vector<Point> proccessed_points) {
std::vector<Point> unprocessed_points;
std::copy_if(list_points_.begin(), list_points_.end(),
std::back_inserter(unprocessed_points),
[proccessed_points](Point point) {
for (auto&& proccessed_point : proccessed_points) {
if (proccessed_point.get_id() == point.get_id()) {
return false;
}
}
return true;
});
return unprocessed_points;
}
float Problem::calculate_euclidean_distance(Point first, Point second) const {
float distance = 0;
int dimension_size = first.get_coordinates().size();
for (size_t i = 0; i < dimension_size; i++) {
distance +=
std::pow((first.get_coordinates()[i] - second.get_coordinates()[i]), 2);
}
distance = std::sqrt(distance);
return distance;
}
Point Problem::calculate_center(std::vector<Point> points) const {
Point center;
int dimension_size = points[0].get_coordinates().size();
for (int j = 0; j < dimension_size; j++) {
float sum = 0;
for (int i = 0; i < points.size(); i++) {
sum += points[i].get_coordinates()[j];
}
float coordinate = sum / points.size();
center.add_coordinate(coordinate);
}
return center;
}
Problem& Problem::operator=(const Problem& problem) {
points_size_ = problem.points_size_;
dimension_size_ = problem.dimension_size_;
list_points_ = problem.list_points_;
file_name_ = problem.file_name_;
}
std::ostream& operator<<(std::ostream& os, const Problem& problem) {
os << problem.points_size_ << "\n";
os << problem.dimension_size_ << "\n";
for (auto&& point : problem.list_points_) {
os << point;
}
return os;
}
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 05-PolynomialProduct
|| @Info: https://en.wikipedia.org/wiki/Polynomial_arithmetic
=======================================================================*/
#ifndef PRODUCT_H
#define PRODUCT_H
#include "Algorithm.hpp"
#include "Polynomial.hpp"
class Product {
private:
Algorithm* algorithm_;
public:
Product(Algorithm* algorithm) { algorithm_ = algorithm; }
~Product() {}
Polynomial ProductInterface(Polynomial first, Polynomial second) {
return algorithm_->multiply(first, second);
}
};
#endif // PRODUCT_H<file_sep>#ifndef BRANCHBOUND_H
#define BRANCHBOUND_H
#include "Algorithm.hpp"
#include "Node.hpp"
class BranchBound : public Algorithm {
private:
int size_solution_;
float lower_bound_;
Solution initial_solution_;
std::vector<Node> tree_;
const int DEEP_STRATEGY = 1;
const int MINIMUM_LEVEL_STRATEGY = 0;
int expansion_strategy_;
public:
BranchBound() {}
BranchBound(int size_solution, Solution initial_solution,
int expansion_strategy = 0);
~BranchBound() {}
Solution execute(Problem &problem);
void generate_first_level_tree(Problem &problem, int total_nodes);
void prune(std::vector<int> &active_nodes);
void expand_node(int node_position, std::vector<int> &active_nodes,
Problem &problem);
float calculate_upper_bound(Problem &problem,
std::vector<Point> proccesed_points);
float upper_bound_value(int proccesed_points_size,
std::vector<float> upper_bound,
int number_of_upper_bound);
int minimum_expandend_node();
bool is_greater_equal(float num, float other_num);
};
#endif // BRANCHBOUND_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef PROGRAM_H
#define PROGRAM_H
#include <vector>
#include "FileParser.hpp"
#include "Instruction.hpp"
#include "Labels.hpp"
class Program {
private:
Labels list_labels_;
std::vector<Instruction*> list_instructions_;
public:
Program() {}
Program(std::string program_name);
~Program() {}
Labels get_list_label();
std::vector<Instruction*> get_list_instructions();
// Method: How memory is assign to this program
};
#endif // PROGRAM_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef PROGRAMCOUNTER_H
#define PROGRAMCOUNTER_H
#include <iostream>
class ProgramCounter {
private:
int current_address_;
public:
ProgramCounter();
~ProgramCounter() {}
int get_current_address();
void set_address(int address);
void next_address();
void reset();
};
#endif // PROGRAMCOUNTER_H<file_sep>#include "Menu.hpp"
#include "Memory.hpp"
Menu::Menu(RamMachine ramMachine) {
char option;
while (option != 'x') {
showOptions();
std::cout << "Elige una opcion: ";
std::cin >> option;
system("clear");
switch (option) {
case 'r':
ramMachine.showRegisterOfMemory();
break;
case 't': {
bool mode_trace = true;
ramMachine.execute(mode_trace);
} break;
case 'e':
ramMachine.execute();
break;
case 's':
ramMachine.disassembler();
break;
case 'i':
ramMachine.showInputTape();
break;
case 'o':
ramMachine.showOutputTape();
break;
case 'h':
showHelp();
break;
case 'x': // Salir
break;
default:
break;
}
}
}
void Menu::showOptions() {
std::cout << ">h\n";
std::cout << "r: ver los registros\n";
std::cout << "t: traza\n";
std::cout << "e: ejecutar\n";
std::cout << "s: desensamblador\n";
std::cout << "i: ver cinta de entrada\n";
std::cout << "o: ver cinta de salida\n";
std::cout << "h: ayuda\n";
std::cout << "x: salir\n";
std::cout << ">\n";
}
void Menu::showHelp() {
std::cout << "> Ayuda\n";
std::cout << "Opcion r: Muestra el contenido de los registros.\n";
std::cout << "Opcion t: Hace un pequeño recorrido del codigo.\n";
std::cout << "Opcion e: Ejecuta el programa ram.\n";
std::cout << "Opcion s: Transforma el codigo a codigo maquina.\n";
std::cout << "Opcion i: Nos muestra el contenido de la cinta de entrada.\n";
std::cout << "Opcion o: Nos muestra el contenido de la cinta de salida.\n";
}<file_sep>#include "Algorithms/Greedy.hpp"
#include <algorithm>
Greedy::Greedy(int size_solution) { size_solution_ = size_solution; }
Solution Greedy::execute(Problem &problem) {
std::vector<Point> points = problem.get_list_points();
Solution solution;
Point center = problem.calculate_center(points);
do {
Point point_furthest_of_center = furthest_of_center(center, points);
solution.add_point(point_furthest_of_center);
erase_point(point_furthest_of_center, points);
center = problem.calculate_center(solution.get_list_points());
} while (solution.get_list_points().size() < size_solution_);
return solution;
}
Point Greedy::furthest_of_center(Point center, std::vector<Point> points) {
Point furthest;
float max_distance = 0;
for (auto &&point : points) {
float distance_fursthest_to_point =
center.calculate_euclidean_distance(center, point);
if (distance_fursthest_to_point > max_distance) {
max_distance = distance_fursthest_to_point;
furthest = point;
}
}
return furthest;
}
void Greedy::erase_point(Point point_to_erase, std::vector<Point> &points) {
for (auto &&point : points) {
points.erase(std::remove_if(points.begin(), points.end(),
[point_to_erase](Point point) {
return point.get_id() ==
point_to_erase.get_id();
}),
points.end());
}
}
<file_sep>#ifndef GREEDY_H
#define GREEDY_H
#include <iostream>
#include "Algorithm.hpp"
class Greedy : public Algorithm {
public:
Solution execute(Graph &graph);
int find_machine_min_tct(Solution solution);
};
#endif // GREEDY_H<file_sep>#include "MergeSortSolution.h"
MergeSortSolution::MergeSortSolution() : Solucion::Solucion() {}
void MergeSortSolution::resolver() { std::cout << this << std::endl; }
void MergeSortSolution::mezcla(std::pair<Solucion*, Solucion*> subSolutions) {
std::vector<int> left = subSolutions.first->get_array();
std::vector<int> right = subSolutions.second->get_array();
while (left.size() > 0 && right.size() > 0) {
if (left.front() <= right.front()) {
array_.push_back(left.front());
left.erase(left.begin());
} else {
array_.push_back(right.front());
right.erase(right.begin());
}
}
if (left.size() > 0) {
for (auto&& element : left) {
array_.push_back(element);
}
}
if (right.size() > 0) {
for (auto&& element : right) {
array_.push_back(element);
}
}
}
Solucion* MergeSortSolution::getInstance() { return new MergeSortSolution(); }<file_sep>#ifndef TASK_H
#define TASK_H
#include <iostream>
class Task {
private:
int id_task_;
int value_of_arc_;
public:
Task() {}
Task(int id_task, int value_of_arc);
~Task() {}
int get_id_task() const;
int get_value_of_arc() const;
void set_id_task(int id_task);
void set_value_of_arc(int value_of_arc);
// Task& operator=(const Task& task);
friend bool operator==(const Task& task, const Task& other_task);
};
#endif // TASK_H<file_sep>#include "QuickSortProblem.h"
QuickSortProblem::QuickSortProblem(std::vector<int> array)
: Problema::Problema() {
array_ = array;
}
bool QuickSortProblem::isCasoMinimo() { return array_.size() < 2; }
std::pair<Problema *, Problema *> QuickSortProblem::descomponer() {
std::pair<Problema *, Problema *> subProblems;
std::vector<int> left;
std::vector<int> right;
int pivot = array_.size() / 2;
int low = 0;
int high = array_.size() - 1;
while (low < high) {
if (array_[low] <= array_[pivot]) {
low++;
} else {
swap(array_[low], array_[pivot]);
high--;
}
}
for (size_t i = 0; i < array_.size(); i++) {
if (i < pivot) {
left.push_back(array_[i]);
} else {
right.push_back(array_[i]);
}
}
subProblems.first = new QuickSortProblem(left);
subProblems.second = new QuickSortProblem(right);
return subProblems;
}
void QuickSortProblem::solver(Solucion *s) { s->set_array(array_); }
void QuickSortProblem::swap(int &first, int &second) {
int temporary = first;
first = second;
second = temporary;
}<file_sep>#include "Labels.hpp"
void Labels::push(std::string name, int line_position) {
list_labels_.insert({name, line_position});
}
int Labels::operator[](std::string name) { return list_labels_[name]; }<file_sep>#include "QuickSortSolution.h"
QuickSortSolution::QuickSortSolution() : Solucion::Solucion() {}
void QuickSortSolution::resolver() { std::cout << this << std::endl; }
void QuickSortSolution::mezcla(std::pair<Solucion*, Solucion*> subSolutions) {
std::vector<int> left = subSolutions.first->get_array();
std::vector<int> right = subSolutions.second->get_array();
while (left.size() > 0 && right.size() > 0) {
if (left.front() <= right.front()) {
array_.push_back(left.front());
left.erase(left.begin());
} else {
array_.push_back(right.front());
right.erase(right.begin());
}
}
if (left.size() > 0) {
for (auto&& element : left) {
array_.push_back(element);
}
}
if (right.size() > 0) {
for (auto&& element : right) {
array_.push_back(element);
}
}
}
Solucion* QuickSortSolution::getInstance() { return new QuickSortSolution(); }<file_sep>#include "Experiment.hpp"
#include "Timer/timer.cpp"
Experiment::Experiment(Graph& graph, std::string type_algorithm,
std::string neighbour_algorithm, int max_iterations,
int rcl_size, int value_environmental_structure)
: type_algorithm_(type_algorithm),
neighbour_algorithm_(neighbour_algorithm),
max_iterations_(max_iterations),
rcl_size_(rcl_size),
value_environmental_structure_(value_environmental_structure) {
/*int i = 0;
for (auto&& row : graph.get_values_of_arcs()) {
std::cout << i << ": ";
for (auto&& value : row) {
std::cout << value.get_value_of_arc() << " ";
}
i++;
std::cout << "\n";
}*/
Algorithm* algorithm = choose_algorithm(type_algorithm, neighbour_algorithm);
timer([algorithm, &graph]() {
TaskScheduler taskScheduler(algorithm);
std::cout << taskScheduler.run(graph) << "\n";
});
}
Algorithm* Experiment::choose_algorithm(std::string type_algorithm,
std::string neighbour_algorithm) {
if (type_algorithm == "greedy") {
return new Greedy();
}
if (type_algorithm == "grasp") {
return new GRASP(choose_neighbour_algorithm(neighbour_algorithm),
max_iterations_, rcl_size_);
}
if (type_algorithm == "multiboot") {
return new MultiBoot(choose_neighbour_algorithm(neighbour_algorithm),
max_iterations_);
}
if (type_algorithm == "gvns") {
return new GVNS(value_environmental_structure_, max_iterations_);
}
return new Greedy();
}
NeighbourAlgorithm* Experiment::choose_neighbour_algorithm(
std::string type_algorithm) {
if (type_algorithm == "ExchangeOwnMachine") {
return new ExchangeOwnMachine();
}
if (type_algorithm == "ExchangeExternalMachine") {
return new ExchangeExternalMachine();
}
if (type_algorithm == "ReinsertionOwnMachine") {
return new ReinsertionOwnMachine();
}
if (type_algorithm == "ReinsertionExternalMachine") {
return new ReinsertionExternalMachine();
}
return new ExchangeExternalMachine();
}
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 04-FrameworkDivideConquer
|| @Info: https://es.wikipedia.org/wiki/Algoritmo_divide_y_vencer%C3%A1s
=======================================================================*/
#ifndef MERGESORTSOLUTION_H
#define MERGESORTSOLUTION_H
#include "Solucion.h"
class MergeSortSolution : public Solucion {
public:
MergeSortSolution();
~MergeSortSolution() {}
void resolver();
void mezcla(std::pair<Solucion*, Solucion*> subSolutions);
Solucion* getInstance();
};
#endif // MERGESORTSOLUTION_H<file_sep>// Ejemplo obtenido en http://c.conclase.net
#include <iostream>
using namespace std;
class ClaseA {
public:
void Incrementar() { cout << "Suma 1" << endl; }
void Incrementar(int n) { cout << "Suma " << n << endl; }
};
class ClaseB : public ClaseA {
public:
// void Incrementar() { cout << "Suma 2" << endl; }
};
int main() {
ClaseB objeto;
objeto.Incrementar();
// objeto.Incrementar(10);
objeto.ClaseA::Incrementar();
objeto.ClaseA::Incrementar(10);
return 0;
}
<file_sep>#include "Solution.hpp"
Solution::Solution(int machine_numbers) {
list_machines_.resize(machine_numbers);
}
std::vector<Machine> Solution::get_list_machines() const {
return list_machines_;
}
std::vector<Machine>& Solution::get_list_machines() { return list_machines_; }
void Solution::set_proccessed_tasks(int machine,
std::vector<Task> proccessed_tasks) {
list_machines_[machine].set_processed_task(proccessed_tasks);
}
void Solution::add_task(Task task, int machine) {
list_machines_[machine].add_task(task);
}
int Solution::get_index_last_proccessed_task(int current_machine) {
if (list_machines_[current_machine].get_processed_tasks().size() == 0) {
return 0;
}
return list_machines_[current_machine]
.get_processed_tasks()
[list_machines_[current_machine].get_processed_tasks().size() - 1]
.get_id_task();
}
int Solution::assigned_tasks() {
int assigned_tasks = 0;
for (auto&& machine : list_machines_) {
assigned_tasks += machine.assigned_tasks();
}
return assigned_tasks;
}
int Solution::calculate_objetive_function() const {
int objetive_function = 0;
for (auto&& machine : list_machines_) {
objetive_function += machine.calculate_tct();
}
return objetive_function;
}
Task Solution::find_task_to_add(Graph& graph, int current_machine) {
std::vector<Task> list_all_proccessed_tasks = all_proccessed_tasks();
int index_last_proccessed_task =
get_index_last_proccessed_task(current_machine);
return graph.min_element_of_row(list_all_proccessed_tasks,
index_last_proccessed_task);
}
std::vector<Task> Solution::all_proccessed_tasks() {
std::vector<Task> all_proccessed_tasks;
for (auto&& machine : list_machines_) {
for (auto&& task : machine.get_processed_tasks()) {
all_proccessed_tasks.push_back(task);
}
}
return all_proccessed_tasks;
}
std::ostream& operator<<(std::ostream& os, const Solution& solution) {
int index_machine = 0;
for (auto&& machine : solution.list_machines_) {
os << "M[" << index_machine << "]: " << machine << "\n";
index_machine++;
}
os << "Objetive Function: " << solution.calculate_objetive_function();
return os;
}
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 04-FrameworkDivideConquer
|| @Info: https://es.wikipedia.org/wiki/Algoritmo_divide_y_vencer%C3%A1s
=======================================================================*/
#include <sstream>
#include <vector>
#include "CommandLineArguments.hpp"
#include "Framework.h"
#include "MergeSortProblem.h"
#include "MergeSortSolution.h"
#include "QuickSortProblem.h"
#include "QuickSortSolution.h"
int main(int argc, char* argv[]) {
try {
CommandLineArguments cmd_line(argc, argv);
std::vector<int> array;
std::string array_in_format_string = cmd_line.get_list_arguments()[1];
std::stringstream string_to_parser(array_in_format_string);
// Fill vector with elements pass by arguments
char bracketsAndCommas;
int number;
string_to_parser >> bracketsAndCommas;
while (string_to_parser >> number) {
array.push_back(number);
string_to_parser >> bracketsAndCommas;
}
Framework framework;
Problema* problem = new QuickSortProblem(array);
Solucion* solution = new QuickSortSolution();
framework.divideyVenceras(problem, solution);
solution->resolver();
} catch (const std::exception& e) {
std::cerr << e.what() << '\n';
} catch (const char* e) {
std::cerr << e << '\n';
} catch (...) {
}
return 0;
}<file_sep>#ifndef ALGORITHM_H
#define ALGORITHM_H
#include "Graph.hpp"
#include "Solution.hpp"
class Algorithm {
public:
virtual Solution execute(Graph &graph) = 0;
};
#endif // ALGORITHM_H<file_sep>#include "Polynomial.hpp"
Polynomial::Polynomial() : degree_(0) {}
Polynomial::Polynomial(std::vector<Monomial> monomials) {
degree_ = monomials.size() - 1;
terms_ = monomials;
}
/**
* @brief Construct a new Polynomial:: Polynomial object
*
* @param coefs Array of Coeficients - Ej {3,0,4} = 3X^2 + 4
*/
Polynomial::Polynomial(std::vector<int> coefs) {
degree_ = coefs.size() - 1;
int current_exponent = coefs.size() - 1;
for (auto&& coef : coefs) {
terms_.push_back(Monomial(coef, current_exponent));
current_exponent--;
}
}
int Polynomial::get_degree() const { return degree_; }
std::vector<Monomial> Polynomial::get_terms() const { return terms_; }
int Polynomial::get_terms_size() const { return terms_.size(); }
void Polynomial::add_term(Monomial monomial) {
degree_++;
terms_.push_back(monomial);
}
Polynomial operator+(Polynomial& polynomial_x, Polynomial& polynomial_y) {
// Add polynomials as if they were integers
// and create polynomial of exponent 0
// Ej 2x + 1 = 3
Polynomial add;
int add_coefficient = 0;
for (size_t i = 0; i < polynomial_x.get_terms().size(); i++) {
for (size_t j = 0; j < polynomial_y.get_terms().size(); j++) {
if (polynomial_x.get_terms()[i].get_exponent() ==
polynomial_y.get_terms()[j].get_exponent()) {
add_coefficient += polynomial_x.get_terms()[i].get_coefficient() +
polynomial_y.get_terms()[j].get_coefficient();
i++;
} else if (polynomial_x.get_terms()[i].get_exponent() >
polynomial_y.get_terms()[i].get_exponent()) {
add_coefficient += polynomial_x.get_terms()[i].get_coefficient();
j--;
i++;
} else {
add_coefficient += polynomial_y.get_terms()[i].get_coefficient();
}
}
}
add.add_term(Monomial(add_coefficient, 0));
return add;
}
Polynomial operator-(Polynomial& polynomial_x, Polynomial& polynomial_y) {
Polynomial sub;
int sub_coefficient = 0;
/*for (size_t i = 0; i < polynomial_x.get_terms().size(); i++) {
for (size_t j = 0; j < polynomial_y.get_terms().size(); j++) {
if (polynomial_x.get_terms()[i].get_exponent() ==
polynomial_y.get_terms()[j].get_exponent()) {
sub_coefficient += polynomial_x.get_terms()[i].get_coefficient() -
polynomial_y.get_terms()[j].get_coefficient();
i++;
} else if (polynomial_x.get_terms()[i].get_exponent() >
polynomial_y.get_terms()[i].get_exponent()) {
sub_coefficient += polynomial_x.get_terms()[i].get_coefficient();
j--;
i++;
} else {
sub_coefficient += polynomial_y.get_terms()[i].get_coefficient();
}
}
}*/
for (size_t i = 0; i < polynomial_x.get_terms().size(); i++) {
sub_coefficient += polynomial_x.get_terms()[i].get_coefficient() -
polynomial_y.get_terms()[i].get_coefficient();
}
sub.add_term(Monomial(sub_coefficient, 0));
return sub;
}
Polynomial operator*(Polynomial& polynomial_x, Polynomial& polynomial_y) {}
std::ostream& operator<<(std::ostream& os, const Polynomial& polynomial) {
for (auto&& monomial : polynomial.terms_) {
os << monomial;
if (monomial.get_coefficient() != 0) {
os << " ";
}
}
os << "\n";
}<file_sep>#include "Algorithms/GVNS.hpp"
#include <algorithm>
#include <limits>
#include "LocalSearch.hpp"
#include "NeighbourAlgorithms/ExchangeExternalMachine.hpp"
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
#include "NeighbourAlgorithms/ReinsertionExternalMachine.hpp"
GVNS::GVNS(int value_environmental_structure, int max_iterations) {
VALUE_ENVIRONMENTAL_STRUCTURE = value_environmental_structure;
MAX_ITERATIONS_ = max_iterations;
}
Solution GVNS::execute(Graph &graph) {
Solution best_solution = generate_boot_solution(graph);
for (size_t i = 0; i < MAX_ITERATIONS_; i++) {
int size_environmental_structure = 1;
int size_min_sequence = calculate_size_min_sequence(best_solution);
int max_size_environmental_structure =
std::min(size_min_sequence, VALUE_ENVIRONMENTAL_STRUCTURE);
do {
Solution oneSolution =
shaking(best_solution, size_environmental_structure);
Solution twoSolution = vnd(oneSolution);
if (twoSolution.calculate_objetive_function() <
best_solution.calculate_objetive_function()) {
best_solution = twoSolution;
size_environmental_structure = 1;
} else {
size_environmental_structure++;
}
} while (size_environmental_structure < max_size_environmental_structure);
}
return best_solution;
}
Solution GVNS::generate_boot_solution(Graph &graph) {
Solution solution(graph.get_machines_number());
int task_index = 0;
int number_of_task = graph.get_values_of_arcs().size() - 1;
int number_of_machines = graph.get_machines_number();
int task_by_each_machine = number_of_task / number_of_machines;
for (auto &&list_task : graph.get_values_of_arcs()) {
int machine = (task_index / task_by_each_machine) % number_of_machines;
if (task_index != 0) {
solution.add_task(list_task[task_index], machine);
}
task_index++;
}
return solution;
}
int GVNS::calculate_size_min_sequence(Solution &solution) {
int size_min_sequence = std::numeric_limits<int>::max();
for (auto &&machine : solution.get_list_machines()) {
if (machine.get_processed_tasks().size() < size_min_sequence) {
size_min_sequence = machine.get_processed_tasks().size();
}
}
return size_min_sequence;
}
Solution GVNS::shaking(Solution &solution, int size_environmental_structure) {
Solution oneSolution = solution;
int r = 0;
do {
LocalSearch local_search(new ReinsertionExternalMachine());
oneSolution = local_search.run(oneSolution);
r++;
} while (r < size_environmental_structure);
return oneSolution;
}
Solution GVNS::vnd(Solution &solution) {
Solution best_solution = solution;
do {
solution = best_solution;
int size_environmental_structure = 1;
int size_min_sequence = calculate_size_min_sequence(best_solution);
int max_size_environmental_structure =
std::min(size_min_sequence, VALUE_ENVIRONMENTAL_STRUCTURE);
do {
std::vector<NeighbourAlgorithm *> environmental_structures =
generate_environmental_structure(max_size_environmental_structure);
Solution one_solution = calculate_min_tct_of_environmental_structure(
environmental_structures, best_solution);
if (one_solution.calculate_objetive_function() <
best_solution.calculate_objetive_function()) {
best_solution = one_solution;
size_environmental_structure = 1;
} else {
size_environmental_structure++;
}
} while (size_environmental_structure < max_size_environmental_structure);
} while (solution.calculate_objetive_function() >
best_solution.calculate_objetive_function());
return best_solution;
}
std::vector<NeighbourAlgorithm *> GVNS::generate_environmental_structure(
int size_environmetal_structure) {
std::vector<NeighbourAlgorithm *> environmental_structures;
for (size_t i = 0; i < size_environmetal_structure; i++) {
if (i % 2 == 0) {
environmental_structures.push_back(new ReinsertionExternalMachine());
} else {
environmental_structures.push_back(new ExchangeExternalMachine());
}
}
return environmental_structures;
}
Solution GVNS::calculate_min_tct_of_environmental_structure(
std::vector<NeighbourAlgorithm *> environmental_structures,
Solution &solution) {
Solution best_solution = solution;
for (size_t i = 0; i < environmental_structures.size(); i++) {
LocalSearch local_search(environmental_structures[i]);
Solution oneSolution = local_search.run(best_solution);
if (oneSolution.calculate_objetive_function() <
best_solution.calculate_objetive_function()) {
best_solution = oneSolution;
}
}
return best_solution;
}
<file_sep>#ifndef EXPERIMENT_H
#define EXPERIMENT_H
#include <iostream>
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
#include "Problem.hpp"
#include "Solution.hpp"
class Experiment {
private:
std::string type_algorithm_;
Problem problem_;
Solution solution_;
int size_solution_;
float cpu_time_;
int max_iterations_;
int rcl_size_;
int expansion_strategy_;
public:
Experiment(Problem problem, std::string type_algorithm);
~Experiment() {}
int get_size_solution() const;
float get_cpu_time() const;
Solution get_solution() const;
Solution& get_solution();
std::string get_type_algorithm() const;
Problem get_problem() const;
void greedy(int size_solution);
void grasp(int size_solution, NeighbourAlgorithm* neighbourAlgorithm,
int size_rcl = 3, int max_iterations = 100);
void branch_bound(int size_solution, Solution solution,
int expansion_strategy = 0);
std::ostream& show_table(std::ostream& os);
void algorithm_extra_info(std::ostream& os) const;
void header_extra_info(std::ostream& os) const;
friend std::ostream& operator<<(std::ostream& os,
const Experiment& experiment);
};
#endif // EXPERIMENT_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef MENU_H
#define MENU_H
#include <iostream>
#include "RamMachine.hpp"
class Menu {
private:
/* data */
public:
Menu(RamMachine ramMachine);
~Menu() {}
void showOptions();
void showHelp();
};
#endif // MENU_H<file_sep>#ifndef POINT_H
#define POINT_H
#include <iostream>
#include <vector>
class Point {
private:
int id_;
std::vector<float> coordinates_;
public:
Point() {}
Point(int id);
~Point() {}
void add_coordinate(float coordinate_value);
std::vector<float> get_coordinates() const;
int get_id() const;
void set_id(int id);
float calculate_euclidean_distance(Point first, Point second) const;
friend std::ostream& operator<<(std::ostream& os, const Point& point);
};
#endif // POINT_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 04-FrameworkDivideConquer
|| @Info: https://es.wikipedia.org/wiki/Algoritmo_divide_y_vencer%C3%A1s
=======================================================================*/
#ifndef FRAMEWORK_H_
#define FRAMEWORK_H_
#include <iostream>
#include <utility>
#include <vector>
#include "Problema.h"
#include "Solucion.h"
class Framework {
public:
Framework();
virtual ~Framework();
void divideyVenceras(Problema* p, Solucion* s);
};
#endif /* FRAMEWORK_H_ */
<file_sep>#include "ControlUnit.hpp"
ControlUnit::ControlUnit() {}
Program ControlUnit::get_program() { return program_; }
void ControlUnit::loadProgram(std::string program_name) {
program_ = Program(program_name);
}
void ControlUnit::executeProgram(bool state_machine, Memory &memory,
InTape &inTape, OutTape &outTape,
bool mode_trace) {
program_counter_.reset();
// When program is halt or state_machine is 0 stop the machine
while (state_machine) {
int current_address = program_counter_.get_current_address();
Instruction *current_instruction =
program_.get_list_instructions()[current_address];
state_machine = current_instruction->execute(
memory, program_counter_, inTape, outTape, program_.get_list_label());
std::cout << "CurrentAddress: " << current_address << std::endl;
std::cout << program_.get_list_instructions()[current_address] << std::endl;
if (mode_trace) {
char option;
std::cout << "Show Bank of Register? (y/n)" << std::endl;
std::cin >> option;
if (option == 'y') {
std::cout << memory << std::endl;
}
}
}
}<file_sep>#include "Point.hpp"
#include <cmath>
void Point::add_coordinate(float coordinate_value) {
coordinates_.push_back(coordinate_value);
}
std::vector<float> Point::get_coordinates() const { return coordinates_; }
int Point::get_id() const { return id_; }
void Point::set_id(int id) { id_ = id; }
float Point::calculate_euclidean_distance(Point first, Point second) const {
float distance = 0;
int dimension_size = first.get_coordinates().size();
for (size_t i = 0; i < dimension_size; i++) {
distance +=
std::pow((first.get_coordinates()[i] - second.get_coordinates()[i]), 2);
}
distance = std::sqrt(distance);
return distance;
}
std::ostream& operator<<(std::ostream& os, const Point& point) {
os << "Id:" << point.get_id() << " | ";
for (auto&& coordinate : point.get_coordinates()) {
os << coordinate << " ";
}
os << "\n";
return os;
}
Point::Point(int id) { id_ = id; }
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef JGTZ_H
#define JGTZ_H
#include "InTape.hpp"
#include "Instruction.hpp"
#include "Labels.hpp"
#include "Memory.hpp"
#include "OutTape.hpp"
#include "ProgramCounter.hpp"
class Jgtz : public Instruction {
private:
/* data */
public:
Jgtz(/* args */) {}
Jgtz(std::string name, char mode, std::string value)
: Instruction(name, mode, value) {}
~Jgtz() {}
bool execute(Memory& memory, ProgramCounter& programCounter, InTape& inTape,
OutTape& outTape, Labels listLabel) {
std::cout << "Execute JGTZ" << std::endl;
if ((addressing_mode_.get_mode() == INMEDIATE) ||
(addressing_mode_.get_mode() == INDIRECT)) {
throw "Error Addressing Mode. Addressing Mode for Jzero not Allowed";
}
if (addressing_mode_.get_mode() == DIRECT) {
int value_accumalator = memory.read();
if (value_accumalator > 0) {
// Jump to line of instruction what pointed label
int positionToJump = listLabel[value_];
programCounter.set_address(positionToJump);
} else {
programCounter.next_address();
}
}
}
};
#endif // JGTZ_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 04-FrameworkDivideConquer
|| @Info: https://es.wikipedia.org/wiki/Algoritmo_divide_y_vencer%C3%A1s
=======================================================================*/
#ifndef __COMMANDLINEARGUMENTS_H__
#define __COMMANDLINEARGUMENTS_H__
#include <getopt.h>
#include <fstream>
#include <iostream>
#include <vector>
class CommandLineArguments {
private:
std::vector<std::string> list_arguments_;
public:
CommandLineArguments(int argc, char *argv[]);
~CommandLineArguments() {}
std::vector<std::string> get_list_arguments();
void usage();
};
#endif // __COMMANDLINEARGUMENTS_H__<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: April 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 06-LCS_DynamicProgramming
|| @Info: https://en.wikipedia.org/wiki/Dynamic_programming
=======================================================================*/
#include <iostream>
#include <map>
#include <vector>
class LongestCommonSequence {
private:
std::vector<std::map<int, std::string>> hash_table_;
public:
LongestCommonSequence(std::string sub_chain, std::string chain);
~LongestCommonSequence() {}
void execute(std::string sub_chain, std::string chain, int rows, int cols);
friend std::ostream& operator<<(std::ostream& os,
const LongestCommonSequence& lcs);
};
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: February 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 01-StrategyDesignPattern
|| @Info: https://sourcemaking.com/design_patterns/strategy
=======================================================================*/
#ifndef __STRATEGY_H__
#define __STRATEGY_H__
#include "matrix.hpp"
class Strategy {
public:
virtual Matrix multiply(Matrix firstMatrix, Matrix secondMatrix) = 0;
};
class StrategyColumns : public Strategy {
public:
Matrix multiply(Matrix firstMatrix, Matrix secondMatrix) {
if (firstMatrix.get_cols() == secondMatrix.get_rows()) {
Matrix productMatrix(firstMatrix.get_rows(), secondMatrix.get_cols());
int sumProducts = 0;
for (size_t i = 0; i < firstMatrix.get_rows(); i++) {
for (size_t j = 0; j < secondMatrix.get_cols(); j++) {
for (size_t k = 0; k < firstMatrix.get_cols(); k++) {
sumProducts += firstMatrix.get_value_pos(i, k) *
secondMatrix.get_value_pos(k, j);
}
productMatrix.set_value_pos(i, j, sumProducts);
sumProducts = 0;
}
}
return productMatrix;
}
throw "Error Incorrect Size of Matrix";
}
};
class StrategyRows : public Strategy {
public:
Matrix multiply(Matrix firstMatrix, Matrix secondMatrix) {
if (firstMatrix.get_cols() == secondMatrix.get_rows()) {
Matrix productMatrix(firstMatrix.get_rows(), secondMatrix.get_cols());
Matrix secondMatrixTransposed = secondMatrix.transposed();
int sumProducts = 0;
for (size_t i = 0; i < firstMatrix.get_rows(); i++) {
for (size_t j = 0; j < secondMatrix.get_cols(); j++) {
for (size_t k = 0; k < firstMatrix.get_cols(); k++) {
sumProducts += firstMatrix.get_value_pos(i, k) *
secondMatrixTransposed.get_value_pos(j, k);
}
productMatrix.set_value_pos(i, j, sumProducts);
sumProducts = 0;
}
}
return productMatrix;
}
throw "Error Incorrect Size of Matrix";
}
};
#endif // __STRATEGY_H__<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef CONTROL_UNIT_H
#define CONTROL_UNIT_H
#include <iostream>
#include <vector>
#include "InTape.hpp"
#include "Memory.hpp"
#include "OutTape.hpp"
#include "Program.hpp"
#include "ProgramCounter.hpp"
/* ControlUnit: It is responsible for interpreting and processing the
* instructions received from a program */
class ControlUnit {
private:
Program program_;
ProgramCounter program_counter_;
public:
ControlUnit();
~ControlUnit() {}
Program get_program();
void loadProgram(std::string program_name);
void executeProgram(bool state_machine, Memory& memory, InTape& inTape,
OutTape& outTape, bool mode_trace);
};
#endif // CONTROL_UNIT_H<file_sep>#include "LongestCommonSequence.hpp"
#include <algorithm>
LongestCommonSequence::LongestCommonSequence(std::string sub_chain,
std::string chain) {
int rows = sub_chain.length();
int cols = chain.length();
hash_table_.resize(rows + 1);
execute(sub_chain, chain, rows, cols);
}
void LongestCommonSequence::execute(std::string sub_chain, std::string chain,
int rows, int cols) {
std::string value_memo;
for (size_t i = 0; i <= rows; i++) {
for (size_t j = 0; j <= cols; j++) {
if (i == 0 || j == 0) {
hash_table_[i][j] = "";
} else if (hash_table_[i - 1].count(j - 1) > 0) {
if (sub_chain[i - 1] == chain[j - 1]) {
hash_table_[i][j] = hash_table_[i - 1][j - 1] + sub_chain[i - 1];
} else {
hash_table_[i][j] =
std::max(hash_table_[i - 1][j], hash_table_[i][j - 1]);
}
}
}
}
}
std::ostream& operator<<(std::ostream& os, const LongestCommonSequence& lcs) {
int last_row = lcs.hash_table_[0].size() - 1;
int last_col = lcs.hash_table_.size() - 1;
os << "Longest Common Sequence is "
<< lcs.hash_table_[last_col].rbegin()->second << "\n";
os << "Length of LCS is "
<< lcs.hash_table_[last_col].rbegin()->second.length();
return os;
}<file_sep>#ifndef QUICKSORTSOLUTION_H
#define QUICKSORTSOLUTION_H
#include "Solucion.h"
class QuickSortSolution : public Solucion {
private:
/* data */
public:
QuickSortSolution();
~QuickSortSolution() {}
void resolver();
void mezcla(std::pair<Solucion*, Solucion*> subSolutions);
Solucion* getInstance();
};
#endif // QUICKSORTSOLUTION_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: February 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#include <iostream>
#include "CommandLineArguments.hpp"
#include "Menu.hpp"
#include "RamMachine.hpp"
int main(int argc, char* argv[]) {
try {
CommandLineArguments cmd_line(argc, argv);
std::string program_name = argv[1];
std::string in_tape_name = argv[2];
std::string out_tape_name = argv[3];
int debug_mode = atoi(argv[4]);
RamMachine ramMachine;
ramMachine.startMachine(program_name, in_tape_name, out_tape_name);
if (debug_mode) Menu menu(ramMachine);
} catch (const std::exception& e) {
std::cerr << e.what() << '\n';
} catch (const char* e) {
std::cerr << e << '\n';
} catch (...) {
}
return 0;
}
<file_sep>#ifndef MACHINE_H
#define MACHINE_H
#include <iostream>
#include <vector>
#include "Graph.hpp"
#include "Task.hpp"
class Machine {
private:
std::vector<Task> processed_tasks_;
public:
Machine(/* args */) {}
~Machine() {}
std::vector<Task> get_processed_tasks() const;
std::vector<Task>& get_processed_tasks();
void set_processed_task(std::vector<Task> processed_task);
void add_task(Task task);
void insert_task(int position, Task task);
void erase_task(int position);
int assigned_tasks();
int calculate_tct() const;
friend std::ostream& operator<<(std::ostream& os, const Machine& machine);
};
#endif // MACHINE_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef REGISTERS_H
#define REGISTERS_H
#include <iostream>
#include <map>
class Registers {
private:
std::map<int, int> register_bank_;
public:
Registers(/* args */) {}
~Registers() {}
void assign(int register_size);
void push(int id, int value);
int operator[](int id);
void clear();
friend std::ostream& operator<<(std::ostream& os, const Registers& registers);
};
#endif // REGISTERS_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef HALT_H
#define HALT_H
#include "InTape.hpp"
#include "Instruction.hpp"
#include "Labels.hpp"
#include "Memory.hpp"
#include "OutTape.hpp"
#include "ProgramCounter.hpp"
class Halt : public Instruction {
private:
/* data */
public:
Halt(/* args */) {}
Halt(std::string name) : Instruction(name) {}
~Halt() {}
bool execute(Memory& memory, ProgramCounter& programCounter, InTape& inTape,
OutTape& outTape, Labels listLabel) {
// std::cout << "Execute HALT" << std::endl;
outTape.writeToFile();
bool stateStop = 0;
return stateStop;
}
};
#endif // HALT_H<file_sep>#include "ProgramCounter.hpp"
ProgramCounter::ProgramCounter() { current_address_ = 0; }
int ProgramCounter::get_current_address() { return current_address_; }
void ProgramCounter::set_address(int address) { current_address_ = address; }
void ProgramCounter::next_address() { current_address_++; }
void ProgramCounter::reset() { current_address_ = 0; }<file_sep>#include "Experiment.hpp"
#include <regex>
#include "Algorithms/BranchBound.hpp"
#include "Algorithms/GRASP.hpp"
#include "Algorithms/Greedy.hpp"
#include "Strategy.hpp"
#include "Timer/timer.cpp"
Experiment::Experiment(Problem problem, std::string type_algorithm) {
problem_ = problem;
type_algorithm_ = type_algorithm;
}
int Experiment::get_size_solution() const { return size_solution_; }
float Experiment::get_cpu_time() const { return cpu_time_; }
Solution Experiment::get_solution() const { return solution_; }
Solution& Experiment::get_solution() { return solution_; }
std::string Experiment::get_type_algorithm() const { return type_algorithm_; }
Problem Experiment::get_problem() const { return problem_; }
void Experiment::greedy(int size_solution) {
type_algorithm_ = "greedy";
size_solution_ = size_solution;
cpu_time_ = timer([this, size_solution]() {
Strategy strategy(new Greedy(size_solution));
solution_ = strategy.run(problem_);
});
}
void Experiment::grasp(int size_solution,
NeighbourAlgorithm* neighbourAlgorithm, int size_rcl,
int max_iterations) {
type_algorithm_ = "grasp";
size_solution_ = size_solution;
max_iterations_ = max_iterations;
rcl_size_ = size_rcl;
cpu_time_ = timer(
[this, size_solution, neighbourAlgorithm, size_rcl, max_iterations]() {
Strategy strategy(new GRASP(size_solution, neighbourAlgorithm, size_rcl,
max_iterations));
solution_ = strategy.run(problem_);
});
}
void Experiment::branch_bound(int size_solution, Solution solution,
int expansion_strategy) {
type_algorithm_ = "branch_bound";
size_solution_ = size_solution;
expansion_strategy_ = expansion_strategy;
cpu_time_ = timer([this, size_solution, solution, expansion_strategy]() {
Strategy strategy(
new BranchBound(size_solution, solution, expansion_strategy));
solution_ = strategy.run(problem_);
});
}
std::ostream& Experiment::show_table(std::ostream& os) {
std::string problem_name = get_problem().get_file_name();
problem_name = std::regex_replace(problem_name, std::regex("examples/"), "");
os << "| " << problem_name << " | " << get_problem().get_points_size()
<< " | " << get_problem().get_dimension_size() << " | "
<< get_size_solution() << " |";
algorithm_extra_info(os);
os << get_solution().calculate_objetive_function() << " |";
os << " [";
for (auto&& point : get_solution().get_list_points()) {
os << point.get_id() << " ";
}
os << "] |" << get_cpu_time() << "ms |\n";
return os;
}
void Experiment::header_extra_info(std::ostream& os) const {
if (type_algorithm_ == "grasp") {
os << "| Iter | LRC ";
}
if (type_algorithm_ == "branch_bound") {
os << "| Strategy ";
}
}
void Experiment::algorithm_extra_info(std::ostream& os) const {
if (type_algorithm_ == "grasp") {
os << max_iterations_ << " |" << rcl_size_ << " |";
}
if (type_algorithm_ == "branch_bound") {
std::string name_strategy =
expansion_strategy_ == 0 ? "Minimum Level" : "Deep";
os << name_strategy << " |";
}
}
std::ostream& operator<<(std::ostream& os, const Experiment& experiment) {
os << experiment.get_type_algorithm() << "\n";
os << "| Problema"
<< " ";
os << "| n"
<< " ";
os << "| K"
<< " ";
os << "| m"
<< " ";
experiment.header_extra_info(os);
os << "| z"
<< " ";
os << "| S"
<< " ";
os << "| CPU |\n";
os << "|------------------|-----|-----|-----|--------|------|-------|"
"--|----|---|";
return os;
}
<file_sep>#ifndef PROBLEM_H
#define PROBLEM_H
#include <fstream>
#include <iostream>
#include <vector>
#include "Point.hpp"
class Problem {
private:
int points_size_;
int dimension_size_;
std::vector<Point> list_points_;
std::fstream file_;
std::string file_name_;
public:
Problem() {}
Problem(const Problem& problem);
Problem(std::string file_name);
~Problem() {}
std::string get_file_name() const;
int get_points_size() const;
int get_dimension_size() const;
std::vector<Point> get_list_points() const;
Point get_point(int id);
void analize_file();
void parse_points_size();
void parse_dimension_size();
void parse_points();
std::vector<Point> unproccessed_points(std::vector<Point> proccessed_points);
float calculate_euclidean_distance(Point first, Point second) const;
Point calculate_center(std::vector<Point> points) const;
Problem& operator=(const Problem& problem);
friend std::ostream& operator<<(std::ostream& os, const Problem& problem);
};
#endif // PROBLEM_H<file_sep>#ifndef SOLUTION_H
#define SOLUTION_H
#include <iostream>
#include <vector>
#include "Graph.hpp"
#include "Machine.hpp"
#include "Task.hpp"
class Solution {
private:
std::vector<Machine> list_machines_;
public:
Solution() {}
Solution(int machine_numbers);
~Solution() {}
std::vector<Machine> get_list_machines() const;
std::vector<Machine>& get_list_machines();
void set_proccessed_tasks(int machine, std::vector<Task> proccessed_tasks);
void add_task(Task task, int machine);
int get_index_last_proccessed_task(int current_machine);
int assigned_tasks();
int calculate_objetive_function() const;
Task find_task_to_add(Graph& graph, int currentMachine);
std::vector<Task> all_proccessed_tasks();
friend std::ostream& operator<<(std::ostream& os, const Solution& solution);
};
#endif // SOLUTION_H<file_sep>// Strategy pattern -- Structural example
#include <iostream>
using namespace std;
enum TYPESTRATEGY{A, B, C};
// The 'Strategy' abstract class
class Strategy {
public:
virtual void AlgorithmInterface() = 0;
};
// A 'ConcreteStrategy' class
class ConcreteStrategyA : public Strategy {
void AlgorithmInterface() {
cout << "Called ConcreteStrategyA.AlgorithmInterface()" << endl;
}
};
// A 'ConcreteStrategy' class
class ConcreteStrategyB : public Strategy {
void AlgorithmInterface() {
cout << "Called ConcreteStrategyB.AlgorithmInterface()" << endl;
}
};
// A 'ConcreteStrategy' class
class ConcreteStrategyC : public Strategy {
void AlgorithmInterface() {
cout << "Called ConcreteStrategyC.AlgorithmInterface()" << endl;
}
};
// The 'Context' class
class Context {
private:
Strategy *_strategy;
public:
// Constructor
Context() {
_strategy = NULL;
}
// Constructor
Context(Strategy *strategy) {
_strategy = strategy;
}
void setstrategy(TYPESTRATEGY type ) {
delete _strategy;
if (type == A)
_strategy = new ConcreteStrategyA();
else if (type == B)
_strategy = new ConcreteStrategyB();
else if (type == C)
_strategy = new ConcreteStrategyC();
else
cout << "ERROR: Stratey not known" << endl;
}
void setstrategy(Strategy *strategy ) {
delete _strategy;
_strategy = strategy;
}
void ContextInterface() {
_strategy -> AlgorithmInterface();
}
};
int main() {
Context *pcontext;
Context context;
pcontext = new Context(new ConcreteStrategyA());
context.setstrategy(A);
pcontext->ContextInterface();
context.ContextInterface();
pcontext -> setstrategy(new ConcreteStrategyB());
context.setstrategy(B);
pcontext->ContextInterface();
context.ContextInterface();
}
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 04-FrameworkDivideConquer
|| @Info: https://es.wikipedia.org/wiki/Algoritmo_divide_y_vencer%C3%A1s
=======================================================================*/
#ifndef PROBLEMA_H_
#define PROBLEMA_H_
#include <iostream>
#include <utility>
#include <vector>
#include "Solucion.h"
class Problema {
public:
Problema() {}
virtual ~Problema() {}
virtual bool isCasoMinimo() {}
virtual std::pair<Problema*, Problema*> descomponer() {}
virtual void solver(Solucion* s) = 0;
protected:
std::vector<int> array_;
};
#endif /* PROBLEMA_H_ */
<file_sep>#ifndef GRASP_H
#define GRASP_H
#include <iostream>
#include <vector>
#include "Algorithm.hpp"
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
#include "Task.hpp"
class GRASP : public Algorithm {
private:
int MAX_ITERATIONS_ = 100;
int SIZE_RCL = 3;
NeighbourAlgorithm *neighbour_algorithm_;
public:
GRASP(NeighbourAlgorithm *neighbour_algorithm, int max_iterations = 100,
int size_rcl = 3);
virtual ~GRASP();
Solution execute(Graph &graph);
Solution greedy_randomized_construction(Graph &graph);
std::vector<Task> build_RCL(Graph &graph, Solution &solution,
int current_machine, int size_rcl);
Task select_random_candidate(std::vector<Task> rcl);
int find_machine_min_tct(Solution solution);
};
#endif // GRASP_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: February 2021
|| @University: ULL in Tenerife
|| @Version: 01-StrategyDesignPattern
|| @Info: https://sourcemaking.com/design_patterns/strategy
=======================================================================*/
#ifndef GENERATECASES_H
#define GENERATECASES_H
#include "../Timer/timer.cpp"
#include "matrix.hpp"
#include "strategyTest.cpp"
void generateCases(int sizeRowsOneMatrix, int sizeRowsTwoMatrix,
int sizeColsOneMatrix, int sizeColsTwoMatrix) {
Matrix firstMatrix(sizeRowsOneMatrix, sizeColsOneMatrix, rand());
Matrix secondMatrix(sizeRowsTwoMatrix, sizeColsTwoMatrix, rand());
std::cout << "By Rows - ";
timer([firstMatrix, secondMatrix]() {
strategyRowsTest(firstMatrix, secondMatrix);
});
std::cout << "By Columns - ";
timer([firstMatrix, secondMatrix]() {
strategyColumnsTest(firstMatrix, secondMatrix);
});
std::cout << "\n";
}
#endif // GENERATECASES_H<file_sep>#include "Registers.hpp"
int Registers::operator[](int id) {
std::cout << "ValueRegister[" << id << "]: " << register_bank_[id]
<< std::endl;
return register_bank_[id];
}
void Registers::assign(int register_size) {
for (int id = 0; id < register_size; id++) {
register_bank_.insert({id, -1});
}
}
void Registers::push(int id, int value) { register_bank_[id] = value; }
void Registers::clear() { register_bank_.clear(); }
std::ostream& operator<<(std::ostream& os, const Registers& registers) {
for (auto&& c_register : registers.register_bank_) {
os << "Register [" << c_register.first << "]: " << c_register.second
<< "\n";
}
return os;
}<file_sep>#include "RamMachine.hpp"
void RamMachine::startMachine(std::string ram_program, std::string in_tape,
std::string out_tape) {
std::cout << "StartMachine" << std::endl;
control_unit_.loadProgram(ram_program);
in_tape_ = InTape(in_tape);
out_tape_ = OutTape(out_tape);
state_ = 1;
}
void RamMachine::showRegisterOfMemory() { std::cout << memory_ << std::endl; }
void RamMachine::disassembler() {
for (auto &&instruction :
control_unit_.get_program().get_list_instructions()) {
std::cout << instruction->get_name() << " " << instruction->get_mode()
<< instruction->get_value() << "\n";
}
}
void RamMachine::execute(bool mode_trace) {
reset();
// Execute Instructions
control_unit_.executeProgram(state_, memory_, in_tape_, out_tape_,
mode_trace);
}
void RamMachine::showInputTape() { std::cout << in_tape_ << "\n"; }
void RamMachine::showOutputTape() { std::cout << out_tape_ << "\n"; }
void RamMachine::reset() {
memory_.reset();
in_tape_.reset();
out_tape_.reset();
}<file_sep>#ifndef TIMER_H
#define TIMER_H
#include <chrono>
#include <functional>
#include <iostream>
void timer(std::function<void()> func) {
auto start = std::chrono::system_clock::now();
func();
auto end = std::chrono::system_clock::now();
std::chrono::duration<float, std::milli> duration = end - start;
std::cout << duration.count() << " ms\n";
}
#endif // TIMER_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: February 2021
|| @University: ULL in Tenerife
|| @Version: 01-StrategyDesignPattern
|| @Info: https://sourcemaking.com/design_patterns/strategy
=======================================================================*/
#ifndef STRATEGYTEST_H
#define STRATEGYTEST_H
#include <iostream>
#include "context.hpp"
#include "matrix.hpp"
#include "strategy.hpp"
void strategyColumnsTest(Matrix firstMatrix, Matrix secondMatrix) {
Context *context;
context = new Context(new StrategyColumns());
context->ContextInterface(firstMatrix, secondMatrix);
}
void strategyRowsTest(Matrix firstMatrix, Matrix secondMatrix) {
Context *context;
context = new Context(new StrategyRows());
context->ContextInterface(firstMatrix, secondMatrix);
}
#endif // STRATEGYTEST_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: April 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 06-LCS_DynamicProgramming
|| @Info: https://en.wikipedia.org/wiki/Dynamic_programming
=======================================================================*/
#include <iostream>
#include "LongestCommonSequence.hpp"
int main(int argc, char const *argv[]) {
std::string sub_chain = "AGGTAB";
std::string chain = "GXTXAYB";
LongestCommonSequence lcs(sub_chain, chain);
std::cout << lcs << "\n";
return 0;
}
<file_sep>#include "OutTape.hpp"
OutTape::OutTape(std::string nameFile) {
file_ = new std::fstream(nameFile, std::fstream::out);
}
OutTape::~OutTape() {}
std::vector<int> OutTape::get_data() { return data_; }
void OutTape::add(int value) { data_.push_back(value); }
void OutTape::writeToFile() {
for (auto&& value : data_) {
*file_ << value << " ";
}
file_->close();
}
void OutTape::reset() { data_.clear(); }
std::ostream& operator<<(std::ostream& os, const OutTape* out_tape) {
// Show Data
for (auto&& value : out_tape->data_) {
os << value << " ";
}
return os;
}
std::ostream& operator<<(std::ostream& os, const OutTape& out_tape) {
// Show Data
for (auto&& value : out_tape.data_) {
os << value << " ";
}
return os;
}<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 04-FrameworkDivideConquer
|| @Info: https://es.wikipedia.org/wiki/Algoritmo_divide_y_vencer%C3%A1s
=======================================================================*/
#ifndef SOLUCION_H_
#define SOLUCION_H_
#include <iostream>
#include <utility>
#include <vector>
class Solucion {
public:
Solucion() {}
virtual ~Solucion() {}
virtual void resolver() = 0;
virtual void mezcla(std::pair<Solucion*, Solucion*> subSolutions) {}
virtual Solucion* getInstance() {}
std::vector<int> get_array() { return array_; }
void set_array(std::vector<int> array) { array_ = array; }
friend std::ostream& operator<<(std::ostream& os, const Solucion* solution) {
std::cout << "SizeArray: " << solution->array_.size() << std::endl;
for (auto&& element : solution->array_) {
os << element << " - ";
}
os << "\n";
}
protected:
std::vector<int> array_;
};
#endif /* SOLUCION_H_ */
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef JUMP_H
#define JUMP_H
#include <vector>
#include "InTape.hpp"
#include "Instruction.hpp"
#include "Labels.hpp"
#include "Memory.hpp"
#include "OutTape.hpp"
#include "Program.hpp"
#include "ProgramCounter.hpp"
class Jump : public Instruction {
private:
/* data */
public:
Jump(/* args */) {}
Jump(std::string name, char mode, std::string value)
: Instruction(name, mode, value) {}
~Jump() {}
bool execute(Memory& memory, ProgramCounter& programCounter, InTape& inTape,
OutTape& outTape, Labels listLabel) {
// std::cout << "Execute JUMP" << std::endl;
if ((addressing_mode_.get_mode() == INMEDIATE) ||
(addressing_mode_.get_mode() == INDIRECT)) {
throw "Error Addressing Mode. Addressing Mode for Jump not Allowed";
}
// Indirect mode working only when the register what pointed is valid
if (addressing_mode_.get_mode() == DIRECT) {
// Browse the Label what pointed Instruction in listLabel
int positionToJump = listLabel[value_];
programCounter.set_address(positionToJump);
}
}
};
#endif // JUMP_H<file_sep>#include "InTape.hpp"
InTape::InTape(std::string nameFile) {
std::cout << "Create InTape" << std::endl;
tape_position_ = 0;
file_ = new std::fstream(nameFile, std::fstream::in | std::fstream::out);
analyzeFile();
file_->close();
}
InTape::~InTape() {}
std::vector<int> InTape::get_data() const { return data_; }
void InTape::analyzeFile() {
std::string line;
while (getline(*file_, line)) {
addData(line);
}
}
void InTape::addData(std::string line) {
std::istringstream iss(line);
int num;
while (iss >> num) {
data_.push_back(num);
}
}
int InTape::read() {
int value = 0;
if (tape_position_ < data_.size()) {
value = data_[tape_position_];
tape_position_++;
}
return value;
}
void InTape::reset() { tape_position_ = 0; }
std::ostream& operator<<(std::ostream& os, const InTape* in_tape) {
for (auto&& element : in_tape->get_data()) {
os << element << " - ";
}
os << "\n";
return os;
}
std::ostream& operator<<(std::ostream& os, const InTape& in_tape) {
for (auto&& element : in_tape.get_data()) {
os << element << " - ";
}
os << "\n";
return os;
}<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 05-PolynomialProduct
|| @Info: https://en.wikipedia.org/wiki/Polynomial_arithmetic
=======================================================================*/
#ifndef ALGORITHM_H
#define ALGORITHM_H
#include <algorithm>
#include "Polynomial.hpp"
class Algorithm {
public:
virtual Polynomial multiply(Polynomial &first, Polynomial &second) = 0;
};
class Classic : public Algorithm {
public:
Polynomial multiply(Polynomial &first, Polynomial &second) {
Polynomial product;
int max_terms =
std::max(first.get_terms().size(), second.get_terms().size());
int add;
int terms_of_product = (2 * max_terms) - 2;
for (size_t i = 0; i <= terms_of_product; i++) {
add = 0;
for (size_t j = 0; j <= i; j++) {
if ((i - j) < first.get_terms().size() &&
j < second.get_terms().size()) {
add += first.get_terms()[j].get_coefficient() *
second.get_terms()[i - j].get_coefficient();
}
}
product.add_term(Monomial(add, terms_of_product - i));
}
return product;
}
};
class DivideConquer : public Algorithm {
public:
Polynomial multiply(Polynomial &first, Polynomial &second) {
Polynomial product;
// Min Case
if (first.get_terms().size() == 1 && second.get_terms().size() == 1) {
Monomial multiply_of_monomials(first.get_terms()[0] *
second.get_terms()[0]);
product.add_term(multiply_of_monomials);
} else {
int size_term = first.get_terms()[0].get_exponent() * 2;
std::pair<Polynomial, Polynomial> first_sub_problem = decompose(first);
std::pair<Polynomial, Polynomial> second_sub_problem = decompose(second);
Polynomial low =
multiply(first_sub_problem.first, second_sub_problem.first);
Polynomial high =
multiply(first_sub_problem.second, second_sub_problem.second);
Polynomial add_first = first_sub_problem.first + first_sub_problem.second;
Polynomial add_second =
second_sub_problem.first + second_sub_problem.second;
Polynomial middle = multiply(add_first, add_second);
Polynomial operation_one = middle - low;
Polynomial middle_term = operation_one - high;
Monomial middle_monomial(middle_term.get_terms()[0].get_coefficient(),
size_term - 1);
Monomial low_monomial(low.get_terms()[0].get_coefficient(), size_term);
product.add_term(low_monomial);
product.add_term(middle_monomial);
product.add_term(high.get_terms()[0]);
}
return product;
}
std::pair<Polynomial, Polynomial> decompose(Polynomial polynomial) {
int middle = polynomial.get_terms_size() / 2;
Polynomial low;
Polynomial high;
for (size_t i = 0; i < polynomial.get_terms_size(); i++) {
if (i < middle) {
low.add_term(polynomial.get_terms()[i]);
} else {
high.add_term(polynomial.get_terms()[i]);
}
}
return std::make_pair(low, high);
}
};
#endif // ALGORITHM_H<file_sep>#ifndef SOLUTION_H
#define SOLUTION_H
#include <iostream>
#include <vector>
#include "Point.hpp"
class Solution {
private:
std::vector<Point> list_points_;
public:
Solution() {}
Solution(std::vector<Point> list_points);
~Solution() {}
void add_point(Point point);
std::vector<Point> get_list_points() const;
std::vector<Point>& get_list_points();
float calculate_euclidean_distance(Point first, Point second) const;
float calculate_objetive_function() const;
friend std::ostream& operator<<(std::ostream& os, const Solution& solution);
};
#endif // SOLUTION_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: April 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 07-Scheduling_TCT
|| @Info: https://en.wikipedia.org/wiki/Parallel_task_scheduling_problem
=======================================================================*/
#ifndef GRAPH_H
#define GRAPH_H
#include <fstream>
#include <iostream>
#include <vector>
#include "Task.hpp"
class Graph {
private:
std::vector<int> processing_times_;
std::vector<std::vector<int>> setup_times_;
int tasks_number_;
int machines_number_;
std::fstream file_;
std::vector<std::vector<Task>> values_of_arcs_;
public:
Graph(std::string file_name);
~Graph() {}
int get_tasks_number();
int get_machines_number();
std::vector<std::vector<Task>> get_values_of_arcs();
void analyze_file();
void parse_tasks();
void parse_machines();
void parse_processing_times();
void parse_setup_times();
void calculate_values_of_arcs();
std::vector<Task> min_values_of_arcs();
std::vector<Task> unprocessed_tasks(std::vector<Task> proccessed_task,
int index_last_proccessed_task);
Task min_element_of_row(std::vector<Task> proccessed_task,
int index_last_proccessed_task);
};
#endif // GRAPH_H<file_sep>
#include "Problema.h"
Problema::Problema() {
}
Problema::~Problema() {
}
bool Problema::isCasoMinimo() {
}
pair<Problema*,Problema*> Problema::descomponer() {
}
void Problema::solver(Solucion* s) {
}
<file_sep>#include "Task.hpp"
Task::Task(int id_task, int value_of_arc)
: id_task_(id_task), value_of_arc_(value_of_arc) {}
int Task::get_id_task() const { return id_task_; }
int Task::get_value_of_arc() const { return value_of_arc_; }
void Task::set_id_task(int id_task) { id_task_ = id_task; }
void Task::set_value_of_arc(int value_of_arc) { value_of_arc_ = value_of_arc; }
/*Task& Task::operator=(const Task& task) {
if (this != &task) {
std::copy(&task.id_task_, &task.id_task_, &id_task_);
std::copy(&task.value_of_arc_, &task.value_of_arc_, &value_of_arc_);
}
return *this;
}*/
bool operator==(const Task& task, const Task& other_task) {
return task.get_id_task() == other_task.get_id_task();
}
<file_sep>
#ifndef FIBONACCIP_H_
#define FIBONACCIP_H_
#include "../framework/Problema.h"
#include "FibonacciS.h"
class FibonacciP: public Problema {
public:
FibonacciP(int);
virtual ~FibonacciP();
bool isCasoMinimo();
pair<Problema*,Problema*> descomponer();
void solver(Solucion* s);
private:
int _n;
};
#endif /* FIBONACCIP_H_ */
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: April 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 07-Scheduling_TCT
|| @Info: https://en.wikipedia.org/wiki/Parallel_task_scheduling_problem
=======================================================================*/
#include "CommandLineArguments.hpp"
/**
* @brief Construct a new Command Line Arguments:: Command Line Arguments object
*
* @param argc
* @param argv
*/
CommandLineArguments::CommandLineArguments(int argc, char* argv[]) {
const char* const short_opts = "ha:";
const option long_opts[] = {{"help", no_argument, nullptr, 'h'},
{"algorithm", required_argument, nullptr, 'a'},
{nullptr, no_argument, nullptr, 0}};
bool is_option = false;
int opt;
list_arguments_.push_back(argv[0]);
while ((opt = getopt_long(argc, argv, short_opts, long_opts, nullptr)) !=
-1) {
is_option = true;
switch (opt) {
case 'h':
usage();
throw false;
case 'a': {
std::string name_algorithm = optarg;
set_name_algorithm(name_algorithm);
break;
}
case '?':
std::cerr << "Unknown command line argument\n";
default:
std::cerr << argv[0] << " -h or --help\n";
throw false;
}
}
if (!is_option) {
if (argc < 2) {
std::cerr << argv[0] << " -h or --help\n";
throw false;
} else {
for (int i = 1; i < argc; i++) {
list_arguments_.push_back(argv[i]);
}
}
}
}
/**
* @brief Get list of all arguments
*
* @return std::vector<std::string>
*/
std::vector<std::string> CommandLineArguments::get_list_arguments() {
return list_arguments_;
}
std::string CommandLineArguments::get_name_algorithm() {
return name_algorithm_;
}
void CommandLineArguments::set_name_algorithm(std::string name_algorithm) {
name_algorithm_ = name_algorithm;
}
/**
* @brief Usage Manual
*
*/
void CommandLineArguments::usage() {
std::cerr << "USAGE\n";
std::cerr << "SYNOPSIS\n";
std::cerr << "\t" << list_arguments_[0] << " input_graph.txt\n";
std::cerr << "DESCRIPTION\n";
std::cerr
<< "\tParallel machine scheduling problem with dependent setup times\n ";
std::cerr << "OPTIONS\n";
std::cerr << "\t[-h][--help] Help manual\n";
std::cerr << "\t[-a][--algorithm] Types of Algorithms: Greedy, GRASP, "
"MultiBoot\n";
}<file_sep>// Strategy pattern -- Structural example
#include <iostream>
using namespace std;
// The 'Strategy' abstract class
class Strategy {
public:
virtual void AlgorithmInterface() = 0;
};
// A 'ConcreteStrategy' class
class ConcreteStrategyA : public Strategy {
void AlgorithmInterface() {
cout << "Called ConcreteStrategyA.AlgorithmInterface()" << endl;
}
};
// A 'ConcreteStrategy' class
class ConcreteStrategyB : public Strategy {
void AlgorithmInterface() {
cout << "Called ConcreteStrategyB.AlgorithmInterface()" << endl;
}
};
// A 'ConcreteStrategy' class
class ConcreteStrategyC : public Strategy {
void AlgorithmInterface() {
cout << "Called ConcreteStrategyC.AlgorithmInterface()" << endl;
}
};
// The 'Context' class
class Context {
private:
Strategy *_strategy;
public:
// Constructor
Context(Strategy *strategy) {
_strategy = strategy;
}
void ContextInterface() {
_strategy -> AlgorithmInterface();
}
};
int main() {
Context *context_a, *context_b, *context_c;
// Three contexts following different strategies
context_a = new Context(new ConcreteStrategyA());
context_a->ContextInterface();
context_b = new Context(new ConcreteStrategyB());
context_b->ContextInterface();
context_c = new Context(new ConcreteStrategyC());
context_c->ContextInterface();
}
<file_sep>#ifndef LOCALSEARCH_H
#define LOCALSEARCH_H
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
#include "Solution.hpp"
class LocalSearch {
private:
NeighbourAlgorithm* neighbour_algorithm_;
public:
LocalSearch(NeighbourAlgorithm* neighbour_algorithm);
~LocalSearch() { delete neighbour_algorithm_; }
Solution run(Solution& solution);
Solution optimal_search(Solution& solution);
Solution stop_criterion(Solution& solution);
};
#endif // LOCALSEARCH_H<file_sep>#ifndef EXPERIMENT_H
#define EXPERIMENT_H
#include "Algorithms/GRASP.hpp"
#include "Algorithms/GVNS.hpp"
#include "Algorithms/Greedy.hpp"
#include "Algorithms/MultiBoot.hpp"
#include "Graph.hpp"
#include "NeighbourAlgorithms/ExchangeExternalMachine.hpp"
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
#include "NeighbourAlgorithms/ReinsertionExternalMachine.hpp"
#include "NeighbourAlgorithms/ReinsertionOwnMachine.hpp"
#include "TaskScheduler.hpp"
class Experiment {
private:
std::string type_algorithm_;
std::string neighbour_algorithm_;
int max_iterations_;
int rcl_size_;
int value_environmental_structure_;
public:
Experiment(Graph& graph, std::string type_algorithm = "greedy",
std::string neighbour_algorithm = "ReinsertionOwnMachine",
int max_iterations = 100, int rcl_size = 3,
int value_environmental_structure = 5);
~Experiment() {}
Algorithm* choose_algorithm(std::string type_algorithm,
std::string neighbour_algorithm);
NeighbourAlgorithm* choose_neighbour_algorithm(std::string type_algorithm);
};
#endif // EXPERIMENT_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 05-PolynomialProduct
|| @Info: https://en.wikipedia.org/wiki/Polynomial_arithmetic
=======================================================================*/
#ifndef TIMER_H
#define TIMER_H
#include <chrono>
#include <functional>
#include <iostream>
void timer(std::function<void()> func) {
auto start = std::chrono::system_clock::now();
func();
auto end = std::chrono::system_clock::now();
std::chrono::duration<float, std::milli> duration = end - start;
std::cout << duration.count() << " ms\n";
}
#endif // TIMER_H<file_sep>#include "Program.hpp"
Program::Program(std::string program_name) {
std::cout << "Program Analyze\n";
FileParser fileParser(program_name);
list_labels_ = fileParser.get_list_label();
list_instructions_ = fileParser.get_list_instructions();
}
Labels Program::get_list_label() { return list_labels_; }
std::vector<Instruction *> Program::get_list_instructions() {
return list_instructions_;
}<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef LABELS_H
#define LABELS_H
#include <iostream>
#include <map>
class Labels {
std::map<std::string, int> list_labels_;
private:
/* data */
public:
Labels() {}
~Labels() {}
int operator[](std::string name);
void push(std::string name, int line_position);
};
#endif // LABELS_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef RAMMACHINE_H
#define RAMMACHINE_H
#include <iostream>
#include "ControlUnit.hpp"
#include "InTape.hpp"
#include "Memory.hpp"
#include "OutTape.hpp"
class RamMachine {
private:
Memory memory_;
ControlUnit control_unit_;
InTape in_tape_;
OutTape out_tape_;
bool state_; // State = 0 or Halt -> Stop the Machine | State = 1 Run
public:
RamMachine() {}
~RamMachine() {}
void startMachine(std::string ram_program, std::string in_tape,
std::string out_tape);
void showRegisterOfMemory();
void disassembler(); // Return name de each instruction
void execute(bool mode_trace = 0);
void showInputTape();
void showOutputTape();
void reset();
};
#endif // RAMMACHINE_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: April 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 07-Scheduling_TCT
|| @Info: https://en.wikipedia.org/wiki/Parallel_task_scheduling_problem
=======================================================================*/
#include <iostream>
#include "CommandLineArguments.hpp"
#include "Experiment.hpp"
#include "Graph.hpp"
int main(int argc, char* argv[]) {
try {
CommandLineArguments cmd_line(argc, argv);
std::string file_name = cmd_line.get_list_arguments()[1];
Graph graph(file_name);
// Experiment experiment(graph);
// Experiment experimentOne(graph, "grasp", "ReinsertionExternalMachine",
// 100, 3);
Experiment experimentTwo(graph, "gvns");
} catch (const std::exception& e) {
std::cerr << e.what() << '\n';
} catch (const char* e) {
std::cerr << e << '\n';
} catch (...) {
}
return 0;
}<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef INSTRUCTION_H
#define INSTRUCTION_H
#include <iostream>
#include <vector>
#include "AddressingMode.hpp"
#include "InTape.hpp"
#include "Labels.hpp"
#include "Memory.hpp"
#include "OutTape.hpp"
#include "ProgramCounter.hpp"
class Instruction {
protected:
const unsigned INMEDIATE = 1;
const unsigned INDIRECT = 2;
const unsigned DIRECT = 3;
std::string name_;
std::string value_;
AddressingMode addressing_mode_;
public:
Instruction() {}
Instruction(std::string name, char mode, std::string value);
Instruction(std::string name);
virtual ~Instruction() {}
std::string get_name();
std::string get_value();
char get_mode();
virtual bool execute(Memory& memory, ProgramCounter& programCounter,
InTape& inTape, OutTape& outTape, Labels list_label) {}
friend std::ostream& operator<<(std::ostream& os,
const Instruction& instruction);
friend std::ostream& operator<<(std::ostream& os,
const Instruction* instruction);
};
#endif // INSTRUCTION_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: February 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 01-StrategyDesignPattern
|| @Info: https://sourcemaking.com/design_patterns/strategy
=======================================================================*/
#ifndef __MATRIX_H__
#define __MATRIX_H__
#include <iostream>
#include <vector>
class Matrix {
private:
int rows_;
int cols_;
std::vector<std::vector<int>> matrix_;
public:
Matrix() {}
Matrix(int rows, int cols);
Matrix(int rows, int cols, int randomSeed, int min_range = 0,
int max_range = 10);
~Matrix() {}
int get_rows() const;
int get_cols() const;
Matrix transposed();
void fill_random_matrix(int min_range = 0, int max_range = 10);
int get_value_pos(int row, int col) const;
void set_value_pos(int row, int col, int value);
void operator=(const Matrix& other_matrix);
friend std::ostream& operator<<(std::ostream& os, const Matrix& matrix);
};
#endif // __MATRIX_H__<file_sep>#ifndef NODE_H
#define NODE_H
#include <vector>
#include "Solution.hpp"
class Node {
private:
Solution partial_solution_;
float value_;
float upper_bound_;
bool is_expanded_;
bool is_pruned_;
bool is_solution_;
public:
Node() {}
Node(float value, float upper_bound);
~Node() {}
void add_point(Point point);
void set_solution(Solution solution);
void set_is_expanded(bool expanded);
void set_is_pruned(bool pruned);
void set_is_solution(bool solution);
float get_value();
Solution get_solution();
float get_upper_bound();
bool get_is_pruned();
bool get_is_expanded();
bool get_is_solution();
};
#endif // NODE_H<file_sep># Instructions Table
<file_sep>#include "Solution.hpp"
#include <cmath>
Solution::Solution(std::vector<Point> list_points) {
list_points_ = list_points;
}
std::vector<Point> Solution::get_list_points() const { return list_points_; }
std::vector<Point>& Solution::get_list_points() { return list_points_; }
void Solution::add_point(Point point) { list_points_.push_back(point); }
float Solution::calculate_objetive_function() const {
float objetive_function = 0;
for (size_t i = 0; i < list_points_.size(); i++) {
for (size_t j = i + 1; j < list_points_.size(); j++) {
objetive_function +=
calculate_euclidean_distance(list_points_[i], list_points_[j]);
}
}
return objetive_function;
}
float Solution::calculate_euclidean_distance(Point first, Point second) const {
float distance = 0;
int dimension_size = first.get_coordinates().size();
for (size_t i = 0; i < dimension_size; i++) {
distance +=
std::pow((first.get_coordinates()[i] - second.get_coordinates()[i]), 2);
}
distance = std::sqrt(distance);
return distance;
}
std::ostream& operator<<(std::ostream& os, const Solution& solution) {
os << "ObjetiveFunction: " << solution.calculate_objetive_function() << "\n";
for (auto&& point : solution.get_list_points()) {
os << point;
}
os << "\n";
return os;
}
<file_sep>#ifndef MULTIBOOT_H
#define MULTIBOOT_H
#include "Algorithm.hpp"
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
class MultiBoot : public Algorithm {
private:
int MAX_ITERATIONS_ = 100;
NeighbourAlgorithm *neighbour_algorithm_;
public:
MultiBoot(NeighbourAlgorithm *neighbour_algorithm, int max_iterations = 100);
virtual ~MultiBoot();
Solution execute(Graph &graph);
Solution generate_boot_solution(Graph &graph);
};
#endif // MULTIBOOT_H<file_sep>#include "Algorithms/GRASP.hpp"
#include <algorithm>
#include "LocalSearch.hpp"
GRASP::GRASP(int size_solution, NeighbourAlgorithm *neighbour_algorithm,
int size_rcl, int max_iterations) {
size_solution_ = size_solution;
neighbour_algorithm_ = neighbour_algorithm;
SIZE_RCL = size_rcl;
MAX_ITERATIONS_ = max_iterations;
}
Solution GRASP::execute(Problem &problem) {
Solution solution;
Solution best_solution = greedy_randomized_construction(problem);
LocalSearch local_search(neighbour_algorithm_);
srand(time(NULL));
// Stop criterion
for (size_t i = 0; i < MAX_ITERATIONS_; i++) {
solution = greedy_randomized_construction(problem);
solution = local_search.execute(solution);
if (solution.calculate_objetive_function() >
best_solution.calculate_objetive_function()) {
best_solution = solution;
}
}
return best_solution;
}
Solution GRASP::greedy_randomized_construction(Problem &problem) {
Solution solution;
Point random_point = select_random_candidate(problem.get_list_points());
solution.add_point(random_point);
while (solution.get_list_points().size() < size_solution_) {
std::vector<Point> rcl = build_RCL(problem, solution);
Point candidate = select_random_candidate(rcl);
solution.add_point(candidate);
}
return solution;
}
std::vector<Point> GRASP::build_RCL(Problem &problem, Solution &solution) {
std::vector<Point> candidates =
problem.unproccessed_points(solution.get_list_points());
// Get current rcl in case of that the size of rcl get for user is not valid
int real_size_rcl =
candidates.size() < SIZE_RCL ? candidates.size() : SIZE_RCL;
std::vector<std::pair<float, Point>> list_objetive_function_by_each_point;
for (auto &&point : candidates) {
solution.add_point(point);
float objetive_function_for_this_point =
solution.calculate_objetive_function();
solution.get_list_points().pop_back();
int position_to_insert = 0;
for (auto &&objetive_function : list_objetive_function_by_each_point) {
if (objetive_function_for_this_point < objetive_function.first) {
position_to_insert++;
}
}
list_objetive_function_by_each_point.insert(
list_objetive_function_by_each_point.begin() + position_to_insert,
std::make_pair(objetive_function_for_this_point, point));
}
// Choose the K Best values
std::vector<Point> rclTopElements;
for (int i = 0; i < real_size_rcl; i++) {
rclTopElements.push_back(list_objetive_function_by_each_point[i].second);
}
return rclTopElements;
}
Point GRASP::select_random_candidate(std::vector<Point> rcl) {
int index = 0;
if (rcl.size()) {
index = rand() % rcl.size();
}
return rcl[index];
}
<file_sep>#ifndef NEIGHBOURALGORITHM_H
#define NEIGHBOURALGORITHM_H
#include <vector>
#include "Solution.hpp"
class NeighbourAlgorithm {
public:
virtual std::vector<Solution> generateNeighbour(Solution& solution) = 0;
};
#endif // NEIGHBOURALGORITHM_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef OUTTAPE_H
#define OUTTAPE_H
#include <fstream>
#include <iostream>
#include <vector>
class OutTape {
private:
std::vector<int> data_;
std::fstream* file_;
public:
OutTape() {}
OutTape(std::string nameFile);
~OutTape();
std::vector<int> get_data();
void add(int value);
void writeToFile();
void reset();
friend std::ostream& operator<<(std::ostream& os, const OutTape& out_tape);
friend std::ostream& operator<<(std::ostream& os, const OutTape* out_tape);
};
#endif // OUTTAPE_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 05-PolynomialProduct
|| @Info: https://en.wikipedia.org/wiki/Polynomial_arithmetic
=======================================================================*/
#ifndef MONOMIAL_H
#define MONOMIAL_H
#include <iostream>
class Monomial {
private:
int coefficient_;
int exponent_;
public:
Monomial();
Monomial(int coefficient, int exponent);
~Monomial() {}
int get_coefficient() const;
int get_exponent() const;
void set_coefficient(int value);
void set_exponent(int value);
int evaluate(int value_of_x) const;
friend Monomial operator+(Monomial& monomial_x, Monomial& monomial_y);
friend Monomial operator-(Monomial& monomial_x, Monomial& monomial_y);
friend Monomial operator*(Monomial& monomial_x, Monomial& monomial_y);
friend std::ostream& operator<<(std::ostream& os, const Monomial& monomial);
friend std::istream& operator>>(std::istream& is, const Monomial& monomial);
};
#endif // MONOMIAL_H<file_sep>#include "AddressingMode.hpp"
AddressingMode::AddressingMode() { mode_ = INMEDIATE; }
AddressingMode::AddressingMode(char symbol) {
if (symbol == '=') {
mode_ = INMEDIATE;
} else if (symbol == '*') {
mode_ = INDIRECT;
} else {
mode_ = DIRECT;
}
}
char AddressingMode::get_symbol() {
if (mode_ == INMEDIATE) return '=';
if (mode_ == INDIRECT) return '*';
return '\0';
}
unsigned AddressingMode::get_mode() { return mode_; }
std::ostream& operator<<(std::ostream& os, const AddressingMode& addr_mode) {
if (addr_mode.mode_ == addr_mode.INMEDIATE) {
os << "Inmediate";
} else if (addr_mode.mode_ == addr_mode.INDIRECT) {
os << "Indirect";
} else if (addr_mode.mode_ == addr_mode.DIRECT) {
os << "Direct";
}
return os;
}
<file_sep>#include "Instruction.hpp"
Instruction::Instruction(std::string name, char mode, std::string value)
: name_(name), addressing_mode_(mode), value_(value) {}
Instruction::Instruction(std::string name)
: name_(name), addressing_mode_('\0'), value_("") {}
std::string Instruction::get_name() { return name_; }
std::string Instruction::get_value() { return value_; }
char Instruction::get_mode() { return addressing_mode_.get_symbol(); }
std::ostream& operator<<(std::ostream& os, const Instruction& instruction) {
os << "Name: " << instruction.name_
<< " | AddressingMode: " << instruction.addressing_mode_;
if (instruction.value_ != "") os << " | Value: " << instruction.value_;
return os;
}
std::ostream& operator<<(std::ostream& os, const Instruction* instruction) {
os << "Name: " << instruction->name_
<< " | AddressingMode: " << instruction->addressing_mode_;
if (instruction->value_ != "") os << " | Value: " << instruction->value_;
return os;
}<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 05-PolynomialProduct
|| @Info: https://en.wikipedia.org/wiki/Polynomial_arithmetic
=======================================================================*/
#include <iostream>
#include "Algorithm.hpp"
#include "Polynomial.hpp"
#include "Product.hpp"
#include "RandomPolynomials/random_polynomials.cpp"
#include "Timer/timer.cpp"
int main(int argc, char const *argv[]) {
try {
// Build Two Polynomial
int case_size = 300;
Polynomial first_polynomial(random_polynomials(case_size));
std::cout << "1.Polinomio- " << first_polynomial << std::endl;
Polynomial second_polynomial(random_polynomials(case_size));
std::cout << "2.Polinomio- " << second_polynomial << std::endl;
timer([first_polynomial, second_polynomial]() {
Product *product = new Product(new Classic());
product->ProductInterface(first_polynomial, second_polynomial);
});
timer([first_polynomial, second_polynomial]() {
Product *product2 = new Product(new DivideConquer());
product2->ProductInterface(first_polynomial, second_polynomial);
});
} catch (const std::exception &e) {
std::cerr << e.what() << '\n';
} catch (const char *e) {
std::cerr << e << '\n';
} catch (...) {
}
}
<file_sep>#include "LocalSearch.hpp"
LocalSearch::LocalSearch(NeighbourAlgorithm* neighbour_algorithm) {
neighbour_algorithm_ = neighbour_algorithm;
}
Solution LocalSearch::execute(Solution& solution) {
Solution best_solution = solution;
do {
solution = best_solution;
std::vector<Solution> neighbours =
neighbour_algorithm_->generateNeighbour(solution);
for (auto&& neighbour : neighbours) {
if (neighbour.calculate_objetive_function() >
best_solution.calculate_objetive_function()) {
best_solution = neighbour;
}
}
} while (best_solution.calculate_objetive_function() !=
solution.calculate_objetive_function());
return best_solution;
}
<file_sep>#include "Algorithms/MultiBoot.hpp"
#include "LocalSearch.hpp"
MultiBoot::MultiBoot(NeighbourAlgorithm *neighbour_algorithm,
int max_iterations) {
neighbour_algorithm_ = neighbour_algorithm;
MAX_ITERATIONS_ = max_iterations;
}
MultiBoot::~MultiBoot() { delete neighbour_algorithm_; }
Solution MultiBoot::execute(Graph &graph) {
std::cout << "\nMultiBoot execute" << std::endl;
LocalSearch local_search(neighbour_algorithm_);
Solution solution = generate_boot_solution(graph);
Solution best_solution = solution;
int iteration = 0;
while (iteration < MAX_ITERATIONS_) {
solution = local_search.run(solution);
if (solution.calculate_objetive_function() <
best_solution.calculate_objetive_function()) {
best_solution = solution;
}
iteration++;
}
return best_solution;
}
Solution MultiBoot::generate_boot_solution(Graph &graph) {
Solution solution(graph.get_machines_number());
int task_index = 0;
int number_of_task = graph.get_values_of_arcs().size() - 1;
int number_of_machines = graph.get_machines_number();
int task_by_each_machine = number_of_task / number_of_machines;
for (auto &&list_task : graph.get_values_of_arcs()) {
int machine = (task_index / task_by_each_machine) % number_of_machines;
if (task_index != 0) {
solution.add_task(list_task[task_index], machine);
}
task_index++;
}
return solution;
}
<file_sep>#include "Memory.hpp"
Memory::Memory() { register_bank_.assign(REGISTER_SIZE); }
int Memory::read(int id_register) { return register_bank_[id_register]; }
void Memory::write(int value, int id_register) {
register_bank_.push(id_register, value);
}
void Memory::reset() {
register_bank_.clear();
register_bank_.assign(REGISTER_SIZE);
}
std::ostream& operator<<(std::ostream& os, const Memory& memory) {
os << memory.register_bank_;
return os;
}
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef INTAPE_H
#define INTAPE_H
#include <fstream>
#include <iostream>
#include <sstream>
#include <vector>
class InTape {
private:
std::vector<int> data_;
std::fstream* file_;
unsigned tape_position_;
public:
InTape() {}
InTape(std::string nameFile);
~InTape();
std::vector<int> get_data() const;
void analyzeFile();
void addData(std::string line);
int read();
void reset();
friend std::ostream& operator<<(std::ostream& os, const InTape& in_tape);
friend std::ostream& operator<<(std::ostream& os, const InTape* in_tape);
};
#endif // INTAPE_H<file_sep>#include <iostream>
using namespace std;
class ClaseA {
public:
ClaseA() : datoA(10) {}
int LeerA() const { return datoA; }
void Mostrar() {
cout << "a = " << datoA << endl; // (1)
}
protected:
int datoA;
};
class ClaseB : public ClaseA {
public:
ClaseB() : datoB(20) {}
int LeerB() const { return datoB; }
void Mostrar() {
cout << "a = " << datoA << ", b = "
<< datoB << endl; // (2)
}
protected:
int datoB;
};
int main() {
ClaseB objeto;
objeto.Mostrar();
objeto.ClaseA::Mostrar();
return 0;
}
<file_sep>#ifndef EXCHANGEEXTERNALMACHINE_H
#define EXCHANGEEXTERNALMACHINE_H
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
class ExchangeExternalMachine : public NeighbourAlgorithm {
int index_machine_one = 0;
int index_machine_two = 1;
int index_task_one = 0;
int index_task_two = 0;
Solution execute(Solution solution) {
permutationMachine(solution);
return solution;
}
void permutationMachine(Solution& solution) {
Solution best_solution = solution;
// std::cout << "----- Exchange ------" << std::endl;
for (size_t i = 0; i < solution.get_list_machines().size(); i++) {
for (size_t j = i + 1; j < solution.get_list_machines().size(); j++) {
permutationTask(solution.get_list_machines()[index_machine_one],
solution.get_list_machines()[index_machine_two],
solution, best_solution);
}
}
solution = best_solution;
/*if (index_machine_one < solution.get_list_machines().size()) {
if (index_machine_two < solution.get_list_machines().size()) {
permutationTask(solution.get_list_machines()[index_machine_one],
solution.get_list_machines()[index_machine_two],
solution);
index_machine_two++;
} else {
index_machine_one++;
index_machine_two = index_machine_one + 1;
}
} else {
index_machine_one = 0;
index_machine_two = 1;
}*/
}
void permutationTask(Machine& machine_one, Machine& machine_two,
Solution& solution, Solution& best_solution) {
for (size_t i = 0; i < machine_one.get_processed_tasks().size(); i++) {
for (size_t j = 0; j < machine_two.get_processed_tasks().size(); j++) {
std::swap(machine_one.get_processed_tasks()[i],
machine_two.get_processed_tasks()[j]);
// std::cout << "1 -<< " << solution << std::endl;
if (solution.calculate_objetive_function() <
best_solution.calculate_objetive_function()) {
best_solution = solution;
}
}
}
/*if (index_task_one < machine_one.get_processed_tasks().size()) {
if (index_task_two < machine_two.get_processed_tasks().size()) {
std::swap(machine_one.get_processed_tasks()[index_task_one],
machine_two.get_processed_tasks()[index_task_two]);
index_task_two++;
} else {
index_task_one++;
index_task_two = 0;
}
} else {
index_task_one = 0;
index_task_two = 0;
}*/
}
};
#endif // EXCHANGEEXTERNALMACHINE_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: February 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 01-StrategyDesignPattern
|| @Info: https://sourcemaking.com/design_patterns/strategy
=======================================================================*/
#ifndef __CONTEXT_H__
#define __CONTEXT_H__
#include "matrix.hpp"
#include "strategy.hpp"
class Context {
private:
Strategy *_strategy;
public:
// Constructor
Context(Strategy *strategy) { _strategy = strategy; }
Matrix ContextInterface(Matrix firstMatrix, Matrix secondMatrix) {
return _strategy->multiply(firstMatrix, secondMatrix);
}
};
#endif // __CONTEXT_H__<file_sep>#include "Node.hpp"
Node::Node(float value, float upper_bound) {
value_ = value;
upper_bound_ = upper_bound;
is_pruned_ = false;
is_solution_ = false;
is_expanded_ = false;
}
void Node::add_point(Point point) { partial_solution_.add_point(point); }
void Node::set_solution(Solution solution) { partial_solution_ = solution; }
void Node::set_is_expanded(bool expanded) { is_expanded_ = expanded; }
void Node::set_is_pruned(bool pruned) { is_pruned_ = pruned; }
void Node::set_is_solution(bool solution) { is_solution_ = solution; }
float Node::get_value() { return value_; }
Solution Node::get_solution() { return partial_solution_; }
float Node::get_upper_bound() { return upper_bound_; }
bool Node::get_is_pruned() { return is_pruned_; }
bool Node::get_is_expanded() { return is_expanded_; }
bool Node::get_is_solution() { return is_solution_; }
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 05-PolynomialProduct
|| @Info: https://en.wikipedia.org/wiki/Polynomial_arithmetic
=======================================================================*/
#include <iostream>
#include <vector>
std::vector<int> random_polynomials(int case_size) {
srand(time(NULL));
std::vector<int> random_coefficients;
for (size_t i = 0; i < case_size; i++) {
random_coefficients.push_back(((rand() % 10) + 1));
}
return random_coefficients;
}<file_sep>#include "Machine.hpp"
void Machine::add_task(Task task) { processed_tasks_.push_back(task); }
void Machine::insert_task(int position, Task task) {
processed_tasks_.insert(processed_tasks_.begin() + position, task);
}
void Machine::erase_task(int position) {
processed_tasks_.erase(processed_tasks_.begin() + position);
}
std::vector<Task> Machine::get_processed_tasks() const {
return processed_tasks_;
}
std::vector<Task>& Machine::get_processed_tasks() { return processed_tasks_; }
void Machine::set_processed_task(std::vector<Task> processed_task) {
processed_tasks_ = processed_task;
}
int Machine::assigned_tasks() { return processed_tasks_.size(); }
int Machine::calculate_tct() const {
int tct = 0;
for (size_t i = 1; i <= processed_tasks_.size(); i++) {
int sum = 0;
for (size_t j = 0; j < i; j++) {
sum += processed_tasks_[j].get_value_of_arc();
}
tct += sum;
}
return tct;
}
std::ostream& operator<<(std::ostream& os, const Machine& machine) {
for (auto&& task : machine.processed_tasks_) {
os << task.get_id_task() << " ";
}
os << "TCT: " << machine.calculate_tct();
return os;
}
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: April 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 07-Scheduling_TCT
|| @Info: https://en.wikipedia.org/wiki/Parallel_task_scheduling_problem
=======================================================================*/
#ifndef TASKSCHEDULER_H
#define TASKSCHEDULER_H
#include <iostream>
#include <vector>
#include "Algorithms/Algorithm.hpp"
#include "Solution.hpp"
class TaskScheduler {
private:
Algorithm* algorithm_;
public:
TaskScheduler(Algorithm* algorithm) { algorithm_ = algorithm; }
~TaskScheduler() {}
Solution run(Graph& graph) { return algorithm_->execute(graph); }
};
#endif // TASKSCHEDULER_H<file_sep>#ifndef ALGORITHM_H
#define ALGORITHM_H
#include "Problem.hpp"
#include "Solution.hpp"
class Algorithm {
public:
virtual Solution execute(Problem &problem) = 0;
};
#endif // ALGORITHM_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: February 2021
|| @University: ULL in Tenerife
|| @Version: 01-StrategyDesignPattern
|| @Info: https://sourcemaking.com/design_patterns/strategy
=======================================================================*/
#include <chrono>
#include <iostream>
#include "GenerateCases/generateCases.cpp"
int main(int argc, char const *argv[]) {
try {
generateCases(100, 1000, 1000, 100);
generateCases(500, 500, 500, 500);
generateCases(500, 500, 500, 1000);
generateCases(500, 1000, 1000, 100);
generateCases(500, 100, 100, 1000);
} catch (const std::exception &except) {
std::cerr << except.what() << '\n';
} catch (const char *except) {
std::cerr << except;
}
return 0;
}
<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef FILEPARSER_H
#define FILEPARSER_H
#include <fstream>
#include <iostream>
#include <sstream>
#include <vector>
#include "Instruction.hpp"
#include "Labels.hpp"
class FileParser {
private:
Labels list_label_;
std::vector<Instruction*> list_instruction_;
std::fstream file_;
public:
FileParser(std::string inFileName);
~FileParser() {}
Labels get_list_label();
std::vector<Instruction*> get_list_instructions();
void analyzeFile();
bool isComments(std::string line);
bool isEmptyLine(std::string line);
std::string findLabel(std::string line);
Instruction findInstruction(std::string line);
Instruction* validateOperation(Instruction instruction);
};
#endif // FILEPARSER_H<file_sep>#include "Graph.hpp"
#include <algorithm>
#include <sstream>
Graph::Graph(std::string file_name) {
file_.open(file_name, std::fstream::in);
analyze_file();
values_of_arcs_.resize(tasks_number_ + 1,
std::vector<Task>(tasks_number_ + 1));
calculate_values_of_arcs();
}
int Graph::get_tasks_number() { return tasks_number_; }
int Graph::get_machines_number() { return machines_number_; }
std::vector<std::vector<Task>> Graph::get_values_of_arcs() {
return values_of_arcs_;
}
void Graph::analyze_file() {
parse_tasks();
parse_machines();
parse_processing_times();
parse_setup_times();
}
void Graph::parse_tasks() {
std::string line;
getline(file_ >> std::ws, line);
std::istringstream iss(line);
std::string id, task_number;
iss >> id;
iss >> task_number;
tasks_number_ = std::stoi(task_number);
}
void Graph::parse_machines() {
std::string line;
getline(file_ >> std::ws, line);
std::istringstream iss(line);
std::string id, machine_number;
iss >> id;
iss >> machine_number;
machines_number_ = std::stoi(machine_number);
}
void Graph::parse_processing_times() {
std::string line;
getline(file_ >> std::ws, line);
std::istringstream iss(line);
std::string id, processing_time;
iss >> id;
processing_times_.push_back(0);
while (iss >> processing_time) {
processing_times_.push_back(std::stoi(processing_time));
}
}
void Graph::parse_setup_times() {
std::string line;
getline(file_ >> std::ws, line);
while (getline(file_ >> std::ws, line)) {
std::istringstream iss(line);
std::string setup_time;
std::vector<int> line_setup_time;
while (iss >> setup_time) {
line_setup_time.push_back(std::stoi(setup_time));
}
setup_times_.push_back(line_setup_time);
}
}
void Graph::calculate_values_of_arcs() {
for (size_t i = 0; i < setup_times_.size(); i++) {
for (size_t j = 0; j < processing_times_.size(); j++) {
values_of_arcs_[i][j].set_id_task(j);
values_of_arcs_[i][j].set_value_of_arc(setup_times_[i][j] +
processing_times_[j]);
}
}
}
std::vector<Task> Graph::min_values_of_arcs() {
std::vector<Task> temp_values_of_arcs = values_of_arcs_[0];
std::sort(temp_values_of_arcs.begin(), temp_values_of_arcs.end(),
[](Task before_value, Task after_value) {
if (after_value.get_id_task() != 0) {
return before_value.get_value_of_arc() <
after_value.get_value_of_arc();
} else {
return true;
}
});
std::vector<Task> min_top_values;
for (size_t i = 0; i < machines_number_; i++) {
min_top_values.push_back(temp_values_of_arcs[i]);
}
return min_top_values;
}
std::vector<Task> Graph::unprocessed_tasks(std::vector<Task> proccessed_task,
int index_last_proccessed_task) {
std::vector<Task> unprocessed_tasks;
std::copy_if(values_of_arcs_[index_last_proccessed_task].begin(),
values_of_arcs_[index_last_proccessed_task].end(),
std::back_inserter(unprocessed_tasks),
[proccessed_task](Task task) {
for (auto &&proccess_task : proccessed_task) {
if (proccess_task.get_id_task() == task.get_id_task()) {
return false;
}
}
if (task.get_id_task() == 0) {
return false;
}
return true;
});
return unprocessed_tasks;
}
Task Graph::min_element_of_row(std::vector<Task> proccessed_task,
int index_last_proccessed_task) {
std::vector<Task> list_element_to_search =
unprocessed_tasks(proccessed_task, index_last_proccessed_task);
return *std::min_element(
list_element_to_search.begin(), list_element_to_search.end(),
[](Task before_task, Task after_task) {
return before_task.get_value_of_arc() < after_task.get_value_of_arc();
});
}
<file_sep>#include "MergeSortProblem.h"
MergeSortProblem::MergeSortProblem(std::vector<int> array)
: Problema::Problema() {
array_ = array;
}
bool MergeSortProblem::isCasoMinimo() { return array_.size() < 2; }
std::pair<Problema*, Problema*> MergeSortProblem::descomponer() {
std::pair<Problema*, Problema*> subProblems;
std::vector<int> left;
std::vector<int> right;
int middle = array_.size() / 2;
for (size_t i = 0; i < array_.size(); i++) {
if (i < middle) {
left.push_back(array_[i]);
} else {
right.push_back(array_[i]);
}
}
subProblems.first = new MergeSortProblem(left);
subProblems.second = new MergeSortProblem(right);
return subProblems;
}
void MergeSortProblem::solver(Solucion* s) { s->set_array(array_); }<file_sep>#include <algorithm>
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
class ExchangeExternalPoint : public NeighbourAlgorithm {
public:
std::vector<Solution> generateNeighbour(Solution& solution) {
std::vector<Solution> neighbours;
Solution current_solution = solution;
for (size_t i = 0; i < current_solution.get_list_points().size(); i++) {
for (size_t j = i + 1; j < current_solution.get_list_points().size();
j++) {
std::swap(current_solution.get_list_points()[i],
current_solution.get_list_points()[j]);
neighbours.push_back(current_solution);
}
}
return neighbours;
}
};<file_sep>#include "FileParser.hpp"
#include "Instructions/Add.hpp"
#include "Instructions/Div.hpp"
#include "Instructions/Halt.hpp"
#include "Instructions/Jgtz.hpp"
#include "Instructions/Jump.hpp"
#include "Instructions/Jzero.hpp"
#include "Instructions/Load.hpp"
#include "Instructions/Mult.hpp"
#include "Instructions/Read.hpp"
#include "Instructions/Store.hpp"
#include "Instructions/Sub.hpp"
#include "Instructions/Write.hpp"
/**
* @brief Construct a new FileParser::FileParser object
*
* @param inFileName
* @param outFileName
* @param commentTypes
*/
FileParser::FileParser(std::string inFileName) {
file_.open(inFileName, std::fstream::in | std::fstream::out);
analyzeFile();
}
Labels FileParser::get_list_label() { return list_label_; }
std::vector<Instruction*> FileParser::get_list_instructions() {
return list_instruction_;
}
void FileParser::analyzeFile() {
std::string line;
int line_counter = 0;
// file_ >> std::ws -> Discard the white space
while (getline(file_ >> std::ws, line)) {
// Check Comments & EmptyLine
if (!isComments(line) && !isEmptyLine(line)) {
std::string label_name;
// std::cout << line_counter << ": ";
// std::cout << "Line: " << line << std::endl;
if ((label_name = findLabel(line)) != "") {
// Add Label to List Labels
list_label_.push(label_name, line_counter);
}
Instruction instruction = findInstruction(line);
// Validate Instructions & Set Instructions
list_instruction_.push_back(validateOperation(instruction));
line_counter++;
}
}
// file_.close();
}
bool FileParser::isComments(std::string line) {
if (line.length() < 1) return false;
if (line[0] == '#') {
return true;
}
if (line[0] == ';') {
return true;
}
}
Instruction* FileParser::validateOperation(Instruction instruction) {
std::string name = instruction.get_name();
std::string value = instruction.get_value();
char mode = instruction.get_mode();
if (name == "READ" || name == "read") {
return new Read(name, mode, value);
} else if (name == "LOAD" || name == "load") {
return new Load(name, mode, value);
} else if (name == "JUMP" || name == "jump") {
return new Jump(name, mode, value);
} else if (name == "JZERO" || name == "jzero") {
return new Jzero(name, mode, value);
} else if (name == "JGTZ" || name == "jgtz") {
return new Jgtz(name, mode, value);
} else if (name == "WRITE" || name == "write") {
return new Write(name, mode, value);
} else if (name == "HALT" || name == "halt") {
return new Halt(name);
} else if (name == "STORE" || name == "store") {
return new Store(name, mode, value);
} else if (name == "SUB" || name == "sub") {
return new Sub(name, mode, value);
} else if (name == "ADD" || name == "add") {
return new Add(name, mode, value);
} else if (name == "MULT" || name == "mult") {
return new Mult(name, mode, value);
} else if (name == "DIV" || name == "div") {
return new Div(name, mode, value);
}
throw "Instruction Error. This Instruction Not Valid";
}
bool FileParser::isEmptyLine(std::string line) {
return (line.length() == 0) ? true : false;
}
std::string FileParser::findLabel(std::string line) {
std::istringstream iss(line);
std::string label;
iss >> label;
if (label.back() == ':') {
label.pop_back();
return label;
}
return "";
}
Instruction FileParser::findInstruction(std::string line) {
std::istringstream iss(line);
std::string data;
std::string instructionName;
char instructionMode;
std::string instructionValue;
iss >> data;
// Check if not exist label
if (findLabel(data) == "") {
instructionName = data;
} else {
iss >> instructionName;
}
iss >> instructionValue;
if (instructionValue.front() == '=' || instructionValue.front() == '*') {
instructionMode = instructionValue.front();
instructionValue.erase(instructionValue.begin());
}
return Instruction(instructionName, instructionMode, instructionValue);
}<file_sep>// Ejemplo obtenido en http://c.conclase.net
#include <iostream>
#include <cstring>
using namespace std;
class Persona {
public:
Persona(const char *n) { strcpy(nombre, n); }
virtual void VerNombre() {
cout << "Persona: " << nombre << endl;
}
protected:
char nombre[30];
};
class Empleado : public Persona {
public:
Empleado(const char *n) : Persona(n) {}
void VerNombre() {
cout << "Empleado: " << nombre << endl;
}
};
class Estudiante : public Persona {
public:
Estudiante(const char *n) : Persona(n) {}
void VerNombre() {
cout << "Estudiante: " << nombre << endl;
}
};
int main() {
Estudiante Pepito("Jose");
Empleado Carlos("Carlos");
Persona &rPepito = Pepito; // Referencia como Persona
Persona &rCarlos = Carlos; // Referencia como Persona
rCarlos.VerNombre();
rPepito.VerNombre();
return 0;
}
<file_sep>
#ifndef MAIN_
#define MAIN_
#include<iostream>
#include <stdio.h>
#include <stdlib.h>
#include"framework/Framework.h"
#include"examples/FibonacciP.h"
#include"examples/FibonacciS.h"
using namespace std;
int main(int argc, char* argv[]){
if (argc != 2) {
cout << "\nNúmero de parametros incorrecto. Encontrado " << argc-1 << " requerido 1."<< endl;
exit(-1);
}
Problema* problema = new FibonacciP(atoi(argv[1]));
Solucion* solucion = new FibonacciS();
Framework* framework = new Framework();
framework->divideyVenceras(problema, solucion);
cout << "\nResultado:" << endl;
solucion->resolver();
};
#endif /* MAIN_ */
<file_sep>#include "Algorithms/GRASP.hpp"
#include <algorithm>
#include "LocalSearch.hpp"
GRASP::GRASP(NeighbourAlgorithm *neighbour_algorithm, int max_iterations,
int size_rcl) {
MAX_ITERATIONS_ = max_iterations;
SIZE_RCL = size_rcl;
neighbour_algorithm_ = neighbour_algorithm;
}
GRASP::~GRASP() { delete neighbour_algorithm_; }
Solution GRASP::execute(Graph &graph) {
std::cout << "\nGRASP execute" << std::endl;
Solution solution(graph.get_machines_number());
LocalSearch local_search(neighbour_algorithm_);
Solution best_solution = greedy_randomized_construction(graph);
srand(time(NULL));
for (size_t i = 0; i < MAX_ITERATIONS_; i++) {
solution = greedy_randomized_construction(graph);
solution = local_search.run(solution);
if (solution.calculate_objetive_function() <
best_solution.calculate_objetive_function()) {
best_solution = solution;
}
}
return best_solution;
}
Solution GRASP::greedy_randomized_construction(Graph &graph) {
Solution solution(graph.get_machines_number());
// Evaluate the incremental costs of the candidate elements
int current_machine = 0;
while (solution.assigned_tasks() < graph.get_tasks_number()) {
// Build the restricted candidate list (RCL)
std::vector<Task> rcl =
build_RCL(graph, solution, current_machine, SIZE_RCL);
// Select an element s from the RCL at random
Task candidate = select_random_candidate(rcl);
// Solution ← Solution ∪ {s}
current_machine = find_machine_min_tct(solution);
solution.add_task(candidate, current_machine);
// Reevaluate the incremental costs
}
return solution;
}
std::vector<Task> GRASP::build_RCL(Graph &graph, Solution &solution,
int current_machine, int size_rcl) {
std::vector<Task> rcl = graph.unprocessed_tasks(
solution.all_proccessed_tasks(),
solution.get_index_last_proccessed_task(current_machine));
int real_size_rcl = rcl.size() < size_rcl ? rcl.size() : size_rcl;
std::nth_element(rcl.begin(), rcl.begin() + real_size_rcl, rcl.end(),
[](Task before_task, Task after_task) {
return before_task.get_value_of_arc() <
after_task.get_value_of_arc();
});
std::vector<Task> rclTopThree;
std::copy(rcl.begin(), rcl.begin() + real_size_rcl,
std::back_inserter(rclTopThree));
return rclTopThree;
}
Task GRASP::select_random_candidate(std::vector<Task> rcl) {
int index = 0;
if (rcl.size()) {
index = rand() % rcl.size();
}
return rcl[index];
}
int GRASP::find_machine_min_tct(Solution solution) {
int index_of_current_machine = 0;
int min_tct = std::numeric_limits<int>::max();
Task machine_min_tct = Task(min_tct, index_of_current_machine);
for (auto &&machine : solution.get_list_machines()) {
int current_tct = machine.calculate_tct();
if (current_tct < machine_min_tct.get_id_task()) {
machine_min_tct.set_id_task(current_tct);
machine_min_tct.set_value_of_arc(index_of_current_machine);
}
index_of_current_machine++;
}
return machine_min_tct.get_value_of_arc();
}
<file_sep>#include "Monomial.hpp"
#include <cmath>
Monomial::Monomial() {
coefficient_ = 0;
exponent_ = 0;
}
Monomial::Monomial(int coefficient, int exponent)
: coefficient_(coefficient), exponent_(exponent) {}
int Monomial::get_coefficient() const { return coefficient_; }
int Monomial::get_exponent() const { return exponent_; }
void Monomial::set_coefficient(int value) { coefficient_ = value; }
void Monomial::set_exponent(int value) { exponent_ = value; }
int Monomial::evaluate(int value_of_x) const {
return coefficient_ * pow(value_of_x, exponent_);
}
std::istream& operator>>(std::istream& is, const Monomial& monomial) {}
std::ostream& operator<<(std::ostream& os, const Monomial& monomial) {
if (monomial.get_coefficient() != 0) {
if (monomial.get_coefficient() > 0) {
os << "+";
}
os << monomial.get_coefficient();
if (monomial.get_exponent() != 0) {
os << "x";
}
if (monomial.get_exponent() > 1) {
os << "^" << monomial.get_exponent();
}
}
return os;
}
Monomial operator+(Monomial& monomial_x, Monomial& monomial_y) {
if (monomial_x.exponent_ == monomial_y.exponent_) {
int add_of_coefficients = monomial_x.coefficient_ + monomial_y.coefficient_;
Monomial new_monomial(add_of_coefficients, monomial_x.exponent_);
return new_monomial;
}
}
Monomial operator-(Monomial& monomial_x, Monomial& monomial_y) {
if (monomial_x.exponent_ == monomial_y.exponent_) {
int sub_of_coefficients = monomial_x.coefficient_ - monomial_y.coefficient_;
Monomial new_monomial(sub_of_coefficients, monomial_x.exponent_);
return new_monomial;
}
}
Monomial operator*(Monomial& monomial_x, Monomial& monomial_y) {
int add_of_exponents = monomial_x.exponent_ + monomial_y.exponent_;
int multiply_of_coefficients =
monomial_x.coefficient_ * monomial_y.coefficient_;
Monomial new_monomial(multiply_of_coefficients, add_of_exponents);
return new_monomial;
}<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef LOAD_H
#define LOAD_H
#include "InTape.hpp"
#include "Instruction.hpp"
#include "Labels.hpp"
#include "Memory.hpp"
#include "OutTape.hpp"
#include "ProgramCounter.hpp"
class Load : public Instruction {
private:
/* data */
public:
Load() {}
Load(std::string name, char mode, std::string value)
: Instruction(name, mode, value) {}
~Load() {}
bool execute(Memory& memory, ProgramCounter& programCounter, InTape& inTape,
OutTape& outTape, Labels listLabel) {
// std::cout << "Execute LOAD" << std::endl;
int id_register = std::stoi(value_);
int valueOfRegister = memory.read(id_register);
if (addressing_mode_.get_mode() == INMEDIATE) {
memory.write(id_register);
}
if (addressing_mode_.get_mode() == INDIRECT) {
memory.write(memory.read(valueOfRegister));
}
if (addressing_mode_.get_mode() == DIRECT) {
memory.write(valueOfRegister);
}
programCounter.next_address();
}
};
#endif // LOAD_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 02-RamSimulator
|| @Info: https://www.emustudio.net/documentation/user/ram/ram-cpu
=======================================================================*/
#ifndef JZERO_H
#define JZERO_H
#include <vector>
#include "InTape.hpp"
#include "Instruction.hpp"
#include "Labels.hpp"
#include "Memory.hpp"
#include "OutTape.hpp"
#include "ProgramCounter.hpp"
class Jzero : public Instruction {
private:
/* data */
public:
Jzero(/* args */) {}
Jzero(std::string name, char mode, std::string value)
: Instruction(name, mode, value) {}
~Jzero() {}
bool execute(Memory& memory, ProgramCounter& programCounter, InTape& inTape,
OutTape& outTape, Labels listLabel) {
// std::cout << "Execute JZERO" << std::endl;
if ((addressing_mode_.get_mode() == INMEDIATE) ||
(addressing_mode_.get_mode() == INDIRECT)) {
throw "Error Addressing Mode. Addressing Mode for Jzero not Allowed";
}
if (addressing_mode_.get_mode() == DIRECT) {
int value_accumalator = memory.read();
if (value_accumalator == 0) {
// Jump to line of instruction what pointed label
int positionToJump = listLabel[value_];
programCounter.set_address(positionToJump);
} else {
programCounter.next_address();
}
}
}
};
#endif // JZERO_H<file_sep>#ifndef GREEDY_H
#define GREEDY_H
#include "Algorithm.hpp"
class Greedy : public Algorithm {
int size_solution_;
public:
Greedy(int size_solution);
Solution execute(Problem &problem);
Point furthest_of_center(Point center, std::vector<Point> points);
void erase_point(Point point_to_erase, std::vector<Point> &points);
};
#endif // GREEDY_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: March 2021
|| @University: ULL in Tenerife
|| @Course: DAA
|| @Version: 05-PolynomialProduct
|| @Info: https://en.wikipedia.org/wiki/Polynomial_arithmetic
=======================================================================*/
#ifndef POLYNOMIAL_H
#define POLYNOMIAL_H
#include <vector>
#include "Monomial.hpp"
/**
* @brief Construct a Polynomial
*/
class Polynomial {
private:
int degree_;
std::vector<Monomial> terms_;
public:
Polynomial();
Polynomial(std::vector<int> coefficients);
Polynomial(std::vector<Monomial> monomials);
~Polynomial() {}
int get_degree() const;
std::vector<Monomial> get_terms() const;
int get_terms_size() const;
void add_term(Monomial monomial);
friend Polynomial operator+(Polynomial& polynomial_x,
Polynomial& polynomial_y);
friend Polynomial operator-(Polynomial& polynomial_x,
Polynomial& polynomial_y);
friend Polynomial operator*(Polynomial& polynomial_x,
Polynomial& polynomial_y);
friend std::ostream& operator<<(std::ostream& os,
const Polynomial& polynomial);
};
#endif // POLYNOMIAL_H<file_sep>#ifndef GRASP_H
#define GRASP_H
#include "Algorithm.hpp"
#include "NeighbourAlgorithms/NeighbourAlgorithm.hpp"
class GRASP : public Algorithm {
private:
NeighbourAlgorithm *neighbour_algorithm_;
int size_solution_;
int MAX_ITERATIONS_ = 100;
int SIZE_RCL = 3;
public:
GRASP(int size_solution, NeighbourAlgorithm *neighbour_algorithm,
int size_rcl = 3, int max_iterations = 100);
virtual ~GRASP() {}
Solution execute(Problem &problem);
Solution greedy_randomized_construction(Problem &problem);
std::vector<Point> build_RCL(Problem &problem, Solution &solution);
Point select_random_candidate(std::vector<Point> rcl);
};
#endif // GRASP_H<file_sep>/*=======================================================================
|| @Author: <NAME>
|| @Email: <EMAIL>
|| @Github: https://github.com/AlbertoCruzLuis
|| @Date: February 2021
|| @University: ULL in Tenerife
|| @Version: 01-StrategyDesignPattern
|| @Info: https://sourcemaking.com/design_patterns/strategy
=======================================================================*/
#include "matrix.hpp"
Matrix::Matrix(int rows, int cols) : rows_(rows), cols_(cols) {
// Create Matrix rows * cols
matrix_.resize(rows, std::vector<int>(cols, 0));
}
Matrix::Matrix(int rows, int cols, int randomSeed, int min_range, int max_range)
: rows_(rows), cols_(cols) {
matrix_.resize(rows, std::vector<int>(cols, 0));
srand(randomSeed);
fill_random_matrix(min_range, max_range);
}
int Matrix::get_rows() const { return rows_; }
int Matrix::get_cols() const { return cols_; }
int Matrix::get_value_pos(int row, int col) const { return matrix_[row][col]; }
void Matrix::set_value_pos(int row, int col, int value) {
matrix_[row][col] = value;
}
Matrix Matrix::transposed() {
Matrix matrixTransposed(cols_, rows_);
for (size_t i = 0; i < rows_; i++) {
for (size_t j = 0; j < cols_; j++) {
matrixTransposed.set_value_pos(j, i, matrix_[i][j]);
}
}
return matrixTransposed;
}
void Matrix::fill_random_matrix(int min_range, int max_range) {
for (size_t i = 0; i < rows_; i++) {
for (size_t j = 0; j < cols_; j++) {
int range = max_range - min_range;
matrix_[i][j] = (rand() % range) + min_range;
}
}
}
void Matrix::operator=(const Matrix& other_matrix) {
rows_ = other_matrix.rows_;
cols_ = other_matrix.cols_;
matrix_ = other_matrix.matrix_;
}
std::ostream& operator<<(std::ostream& os, const Matrix& matrix) {
for (auto&& rows : matrix.matrix_) {
for (auto&& cell : rows) {
os << cell << " ";
}
os << "\n";
}
return os;
}<file_sep>#include "Algorithms/BranchBound.hpp"
#include <algorithm>
BranchBound::BranchBound(int size_solution, Solution initial_solution,
int expansion_strategy) {
size_solution_ = size_solution;
initial_solution_ = initial_solution;
lower_bound_ = initial_solution.calculate_objetive_function();
}
Solution BranchBound::execute(Problem &problem) {
Solution best_solution;
generate_first_level_tree(problem, problem.get_points_size());
std::vector<int> active_nodes;
for (size_t i = 0; i < tree_.size(); i++) {
active_nodes.push_back(i);
}
while (active_nodes.size()) {
prune(active_nodes);
int node_position = minimum_expandend_node();
if (node_position != -1) {
expand_node(node_position, active_nodes, problem);
for (auto &&node : tree_) {
if (node.get_solution().get_list_points().size() == size_solution_) {
node.set_is_solution(true);
Solution solution = node.get_solution();
if (is_greater_equal(solution.calculate_objetive_function(),
lower_bound_)) {
lower_bound_ = solution.calculate_objetive_function();
best_solution = solution;
}
}
}
} else {
break;
}
}
return best_solution;
}
void BranchBound::generate_first_level_tree(Problem &problem, int total_nodes) {
for (size_t i = 0; i < (total_nodes - (size_solution_ - 1)); i++) {
std::vector<Point> list_points = {problem.get_point(i)};
Node node(0, calculate_upper_bound(problem, list_points));
node.set_solution(Solution(list_points));
tree_.push_back(node);
}
}
void BranchBound::prune(std::vector<int> &active_nodes) {
int index = 0;
for (auto &&node : tree_) {
if (node.get_value() + node.get_upper_bound() < lower_bound_) {
node.set_is_pruned(true);
if (std::find(active_nodes.begin(), active_nodes.end(), index) !=
active_nodes.end()) {
active_nodes.erase(
std::find(active_nodes.begin(), active_nodes.end(), index));
}
}
index++;
}
}
void BranchBound::expand_node(int node_position, std::vector<int> &active_nodes,
Problem &problem) {
tree_[node_position].set_is_expanded(true);
active_nodes.erase(
std::find(active_nodes.begin(), active_nodes.end(), node_position));
int current_deep_level =
tree_[node_position].get_solution().get_list_points().size();
int last_point =
tree_[node_position].get_solution().get_list_points().back().get_id() + 1;
int number_of_points = problem.get_points_size();
Solution partial_solution = tree_[node_position].get_solution();
for (size_t i = last_point;
i < (number_of_points - (size_solution_ - current_deep_level)); i++) {
Solution solution = partial_solution;
solution.add_point(problem.get_point(i));
float node_value = solution.calculate_objetive_function();
Node node(node_value,
calculate_upper_bound(problem, solution.get_list_points()));
node.set_solution(solution);
tree_.push_back(node);
active_nodes.push_back(tree_.size() - 1);
}
}
float BranchBound::calculate_upper_bound(Problem &problem,
std::vector<Point> proccesed_points) {
std::vector<Point> unprocessed_points =
problem.unproccessed_points(proccesed_points);
std::vector<float> upper_bound_2;
std::vector<float> upper_bound_3;
for (auto &&point : proccesed_points) {
for (auto &&unprocessed_point : unprocessed_points) {
float distance =
problem.calculate_euclidean_distance(point, unprocessed_point);
// Insert distance in upperB2 of orderly fashion
int position = 0;
for (int k = 0; k < upper_bound_2.size(); k++) {
if (distance < upper_bound_2[k]) {
position++;
}
}
upper_bound_2.insert(upper_bound_2.begin() + position, distance);
}
}
float upper_bound_2_value =
upper_bound_value(proccesed_points.size(), upper_bound_2, 2);
for (int i = 0; i < unprocessed_points.size(); i++) {
for (int j = i + 1; j < unprocessed_points.size(); j++) {
float distance = problem.calculate_euclidean_distance(
unprocessed_points[i], unprocessed_points[j]);
int position = 0;
for (int k = 0; k < upper_bound_3.size(); k++) {
if (distance < upper_bound_3[k]) {
position++;
}
}
upper_bound_3.insert(upper_bound_3.begin() + position, distance);
}
}
float upper_bound_3_value =
upper_bound_value(proccesed_points.size(), upper_bound_3, 3);
return upper_bound_2_value + upper_bound_3_value;
}
float BranchBound::upper_bound_value(int proccesed_points_size,
std::vector<float> upper_bound,
int number_of_upper_bound) {
float upper_bound_value = 0;
if (number_of_upper_bound == 2) {
int size = proccesed_points_size * (size_solution_ - proccesed_points_size);
for (int i = 0; i < size; i++) {
upper_bound_value += upper_bound[i];
}
} else if (number_of_upper_bound == 3) {
int size = 0;
for (int i = size_solution_ - proccesed_points_size - 1; i > 0; i--) {
size += i;
}
for (int i = 0; i < size; i++) {
upper_bound_value += upper_bound[i];
}
}
return upper_bound_value;
}
int BranchBound::minimum_expandend_node() {
int node_position = -1;
if (expansion_strategy_ == MINIMUM_LEVEL_STRATEGY) {
float min_distance = std::numeric_limits<float>::max();
int index = 0;
for (auto &&node : tree_) {
if (!node.get_is_pruned() && !node.get_is_expanded() &&
!node.get_is_solution()) {
float distance = node.get_upper_bound();
if (distance < min_distance) {
min_distance = distance;
node_position = index;
}
}
index++;
}
} else if (expansion_strategy_ == DEEP_STRATEGY) {
int max_deep_level = -1;
int index = 0;
for (auto &&node : tree_) {
if (!node.get_is_pruned() && !node.get_is_expanded() &&
!node.get_is_solution()) {
int deep_level = node.get_solution().get_list_points().size();
if (deep_level > max_deep_level) {
max_deep_level = deep_level;
node_position = index;
}
}
index++;
}
}
return node_position;
}
bool BranchBound::is_greater_equal(float num, float other_num) {
return (num - other_num) >= -0.001;
}
| d802f562e217c78708951b2e4e542fd98cd640f4 | [
"Markdown",
"Makefile",
"C++"
] | 127 | C++ | AlbertoCruzLuis/DAA-ULL | abd3f987529071b7344d311942f06495240b8cdd | 65460de14618590ef0c971b5b791ada6b1e86f95 |
refs/heads/master | <file_sep>import pandas as pd
import numpy as np
from lenskit import batch, topn
from lenskit import crossfold as xf
from lenskit.algorithms import item_knn as knn
from lenskit.algorithms import funksvd as funk
from lenskit.algorithms import als
from flask import make_response, abort, jsonify
# read in the movielens 100k ratings with pandas
# https://grouplens.org/datasets/movielens/100k/
ratings = pd.read_csv('ml-100k/u.data', sep='\t',
names=['user', 'item', 'rating', 'timestamp'])
algoKNN = knn.ItemItem(30)
algoFunk = funk.FunkSVD(2)
algoAls = als.BiasedMF(20)
# split the data in a test and a training set
# for each user leave one row out for test purpose
data = ratings
nb_partitions = 1
splits = xf.partition_users(data, nb_partitions, xf.SampleN(1))
for (trainSet, testSet) in splits:
train = trainSet
test = testSet
# train model
modelKNN = algoKNN.fit(train)
modelFunk = algoFunk.fit(train)
modelALS = algoAls.fit(train)
users = test.user.unique()
def get_recommendations_Funk_SVD(user_id, nb_recommendations = 1):
'''
Return a recommendation
:param user: id of user you want a recommendation
:param algorithm: "Funk"
:return:
'''
algo = algoFunk
model = modelFunk
recs = batch.recommend(algo, model, users, nb_recommendations, topn.UnratedCandidates(train))
recs = recs[recs['user'] == user_id]
if not recs.empty:
# select colums
rows = recs[['item', 'score']]
rows_dict = rows.to_dict(orient="records")
recommendations = []
for entry in rows_dict:
recommendations.append({
"item": int(entry['item']),
"score": int(entry["score"])
})
# otherwise, nope, not found
else:
abort(
404, "No ratings for user with user_id {user_id} ".format(user_id=user_id)
)
return recommendations
def get_recommendations_KNN(user_id, nb_recommendations = 1):
'''
Return a recommendation
:param user: id of user you want a recommendation
:param algorithm: "Funk"
:return:
'''
algo = algoKNN
model = modelKNN
recs = batch.recommend(algo, model, users, nb_recommendations, topn.UnratedCandidates(train))
recs = recs[recs['user'] == user_id]
if not recs.empty:
# select colums
rows = recs[['item', 'score']]
rows_dict = rows.to_dict(orient="records")
recommendations = []
for entry in rows_dict:
recommendations.append({
"item": int(entry['item']),
"score": int(entry["score"])
})
# otherwise, nope, not found
else:
abort(
404, "No ratings for user with user_id {user_id} ".format(user_id=user_id)
)
return recommendations
def get_recommendations_als(user_id, nb_recommendations = 1):
'''
Return a recommendation
:param user: id of user you want a recommendation
:param algorithm: "Funk"
:return:
'''
algo = algoFunk
model = modelFunk
recs = batch.recommend(algo, model, users, nb_recommendations, topn.UnratedCandidates(train))
recs = recs[recs['user'] == user_id]
if not recs.empty:
# select colums
rows = recs[['item', 'score']]
rows_dict = rows.to_dict(orient="records")
recommendations = []
for entry in rows_dict:
recommendations.append({
"item": int(entry['item']),
"score": int(entry["score"])
})
# otherwise, nope, not found
else:
abort(
404, "No ratings for user with user_id {user_id} ".format(user_id=user_id)
)
return recommendations<file_sep>#!/bin/bash
docker rm imagerun
docker build -t imagebuild .
docker run -d -p 4000:80 imagebuild
<file_sep>import pandas as pd
from flask import make_response, abort, jsonify
# read in the movielens 100k ratings with pandas
# https://grouplens.org/datasets/movielens/100k/
RATINGS = pd.read_csv('ml-100k/u.data', sep='\t',
names=['user', 'item', 'rating', 'timestamp'])
def ratings_user(user_id):
"""
This function responds to a request for /api/ratings/{user_id}
with complete list of ratings of that person
:param user_id: user_id of persons whose ratings you want
:return: list of ratings matching user_id
"""
df = RATINGS
print(user_id)
# Does the person hava a rating?
rows = df.loc[(df['user'] == user_id)]
if not rows.empty:
# select colums
rows = rows[['item', 'rating']]
rows_dict = rows.to_dict(orient="records")
ratings = []
for entry in rows_dict:
ratings.append({
"item" : int(entry['item']),
"rating": int(entry["rating"])
})
# otherwise, nope, not found
else:
abort(
404, "No ratings for user with user_id {user_id} ".format(user_id=user_id)
)
return ratings
def rating_user_item(user_id, item_id):
"""
This function responds to a request for /api/ratings/{user_id}
with complete list of ratings of that person
:param user_id: user_id of persons whose ratings you want
:return: list of ratings matching user_id
"""
df = RATINGS
print(user_id)
# Does the person hava a rating?
rows = df.loc[(df['user'] == user_id) & (df['item'] == item_id)]
if not rows.empty:
# select colums
rows = rows[['item', 'rating']]
rows_dict = rows.to_dict(orient="records")
ratings = []
for entry in rows_dict:
ratings.append({
"item": int(entry['item']),
"rating": int(entry["rating"])
})
# otherwise, nope, not found
else:
abort(
404, "No ratings for user with user_id {user_id} ".format(user_id=user_id)
)
return ratings<file_sep>import pandas as pd
import numpy as np
from lenskit import batch, topn, util
from lenskit import crossfold as xf
from lenskit.algorithms import als
from lenskit.algorithms import Recommender
# read in the movielens 100k ratings with pandas
# https://grouplens.org/datasets/movielens/100k/
ratings = pd.read_csv('ml-100k/u.data', sep='\t',
names=['user', 'item', 'rating', 'timestamp'])
# define the algorithm we will use
# In this case we use an alternating least square
# implementation of matrix factorization
# We train 6 features
# https://lkpy.lenskit.org/en/stable/mf.html#module-lenskit.algorithms.als
algoAls = als.BiasedMF(6)
# Clone the algoritm as otherwise some
# algorithms can behave strange after they
# fitted multiple times
fittableALS = util.clone(algoAls)
# split the data in a test and a training set
# for each user leave one row out for test purpose
data = ratings
nb_partitions = 1
splits = xf.partition_users(data, nb_partitions, xf.SampleN(1))
for (trainSet, testSet) in splits:
train = trainSet
test = testSet
# Build a model
modelAls = fittableALS.fit(train)
# Inspect the user-feature matrix (numpy array)
print(modelAls.user_features_[0:10])
print(modelAls.user_features_.size)
# Inspect the item-feature matrix (numpy array)
print(modelAls.item_features_[0:10])
print(modelAls.item_features_.size)
# Get all the users in the test set (numpy array)
users = test.user.unique()
print(users.size)
# See that the users are ranked differently in the matrix
print(modelAls.user_index_[0:10])
first = modelAls.user_index_[0]
print(type(first))
firstUser = np.array([first], np.int64)
# Get recommendation for a user
# As als.BiasedMF is not implementing Recommend
# We need to first adapt the model
# https://lkpy.lenskit.org/en/stable/interfaces.html#recommendation
# rec = Recommender.adapt(modelAls)
# recs = rec.recommend(first, 10) #Gives error
# Get 10 recommendations for a user (pandas dataframe)
recs = batch.recommend(modelAls, firstUser,
10, topn.UnratedCandidates(train), test)
print(recs)
# Get the first recommended item
firstRec = recs.iloc[0, 0]
firstRecScore = recs.iloc[0, 1]
print(firstRec)
# Get the explanation of the recommendation
# Get the index of the items
items = modelAls.item_index_
# Find the index of the first item
indexFirstRec = items.get_loc(firstRec)
# Get the feature values of the user
userProfile = modelAls.user_features_[0]
itemProfile = modelAls.item_features_[indexFirstRec]
print(userProfile)
print(itemProfile)
# Get the MF score of item and user
mfScore = np.dot(userProfile, itemProfile)
print(mfScore)
# Get global bias
globalBias = modelAls.global_bias_
print(globalBias)
# Get bias of user
userBias = modelAls.user_bias_[0]
print(userBias)
# Get bias of item
itemBias = modelAls.item_bias_[indexFirstRec]
print(itemBias)
# Get total score
total = globalBias + userBias + itemBias + mfScore
print(total)
# As you can see, this is the same as the calculated score
print(firstRecScore)
<file_sep>**_WebRec_**
**General**
The purpose of this code is to provide
a REST-ful API on top of the Lenskit
package.
**_Local verson_**
**Get started**
To test the API, you can follow next steps:
1) Download this code
2) Install Flask and install connexion
3) Run app.py
4) Go to localhost:5000/ui
5) Test the API
**File Structure**
**App.py** is the controller of this code, it starts the server and connects to the swagger file
**swagger.yml** describes the API and configures the endpoints of the server
For each operation id (e.g. operationId: rating.ratings_user) there needs to be
an according file (rating.py) with corresponding function (ratings_user) that has the same
parameters as described in the parameters section (e.g. user_id)
**recommendation.py** is the file that creates the recommendations. In this case,
it uses the Lenskit package and the Movielens dataset to generate recommendations. In case
you have your own back end, you need to change this file.
**_Deployment_**
We used docker to wrap up the code
and its dependencies into a container.
The reason for this wrapping is to enable
a fast deployment on different servers.
The docker version used for testing is
**18.03.0-ce**
**Get started**
1. Install docker
2. Download the code
3. Go to the folder
```sh
$ cd path/to/Webrec
```
4. Remove the running docker (if needed)
```sh
$ docker rm imagerun
```
5. Build the image
```sh
$ docker build -t imagebuild .
```
6. Run the image
a) interactive (debug)
b) normal
c) background
```sh
$ docker run -it --name imagerun -p 4000:80 imagebuild /bin/bash
$ docker run --name imagerun -p 4000:80 imagebuild
$ docker run -d -p 4000:80 imagebuild
```
7. Test if it is working by checking
`localhost:4000/Home`
<file_sep># Use an official Python runtime as a parent image
FROM continuumio/anaconda3
# Set the working directory to /app
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
RUN conda install flask
RUN conda install -c lenskit lenskit
RUN conda install -c conda-forge flask-restful
# Make port 80 available to the world outside this container
EXPOSE 80
# Define environment variable
ENV NAME World
# Run app.py when the container launches
CMD ["python", "app.py"]
# 1) remove the old dockers
# 2) build the image
# 3) run interactive shell
# 4) run image
# 5) run image in background
# docker rm imagerun
# docker build -t imagebuild .
# docker run -it --name imagerun -p 5000:5000 imagebuild /bin/bash
# docker run --name imagerun -p 5000:5000 imagebuild
# docker run -d -p 4000:80 imagebuild
<file_sep>from datetime import datetime
import pandas as pd
from flask import make_response, abort
def get_timestamp():
return datetime.now().strftime(("%Y-%m-%d %H:%M:%S"))
def invent_zip():
return 12345
PEOPLE = pd.read_csv('ml-100k/u.user', sep='|',
names=['user', 'age', 'sex', 'job', 'zip'])
def set_people(df):
"""
This function set the value of PEOPLE
:param df: the new dataframe
:return: Nothing
"""
global PEOPLE
PEOPLE = df
def get_people():
global PEOPLE
return PEOPLE
def read_all(length=None, offset=0 ):
"""
This function responds to a request for /people
with the complete lists of people
:return: json string of list of people
"""
PEOPLE = get_people()
if length == None:
length = len(PEOPLE)
if not PEOPLE.empty:
# select colums
end = offset + length
rows = PEOPLE.iloc[offset:end]
rows = rows[['user', 'age', 'sex']]
rows_dict = rows.to_dict(orient="records")
users = []
for entry in rows_dict:
users.append({
"user": int(entry['user']),
"age": int(entry["age"]),
"sex": entry["sex"],
})
# otherwise, nope, not found
else:
abort(
404, "No users with ratings"
)
return users
def read_one(user_id):
"""
This function responds to a request for /users/{user_id}
with one matching person from people
:param user_id: id of user
:return: person matching last name
"""
PEOPLE = get_people()
# Does the person exist in people?
person = PEOPLE[PEOPLE['user'] == user_id]
if not person.empty:
# select colums
rows = person[['user', 'age', 'sex']]
rows_dict = rows.to_dict(orient="records")
users = []
for entry in rows_dict:
users.append({
"user": int(entry['user']),
"age": int(entry["age"]),
"sex": entry["sex"],
})
# otherwise, nope, not found
else:
abort(
404, "No user user with user_id {user_id} ".format(user_id=user_id)
)
return users
def create(person):
"""
This function creates a new person in the people structure
based on the passed in person data
:param person: person to create in people structure
:return: 201 on success, 406 on person exists
"""
user_id = int(person.get("user", None))
age = int(person.get("age", None))
sex = person.get("sex", None)
job = person.get("job", None)
zip = invent_zip()
PEOPLE = get_people()
# Does the person exist already?
person = PEOPLE[PEOPLE['user'] == user_id]
if person.empty:
dfNew = pd.DataFrame(columns=['user', 'age', 'sex', 'job', 'zip'])
dfNew.loc[0] = [user_id, age, sex, job, zip]
result = pd.concat([PEOPLE, dfNew])
set_people(result)
return make_response(
"user {user_id} successfully created".format(user_id=user_id), 201
)
# Otherwise, they exist, that's an error
else:
abort(
406,
"Person with user_id {user_id} already exists".format(user_id=user_id),
)
def update(user_id, person):
"""
This function updates an existing person in the people structure
:param lname: last name of person to update in the people structure
:param person: person to update
:return: updated person structure
"""
# Does the person exist in people?
if lname in PEOPLE:
PEOPLE[lname]["fname"] = person.get("fname")
PEOPLE[lname]["timestamp"] = get_timestamp()
return PEOPLE[lname]
# otherwise, nope, that's an error
else:
abort(
404, "Person with last name {lname} not found".format(lname=lname)
)
def delete(user_id):
# todo
"""
This function deletes a person from the people structure
:param lname: last name of person to delete
:return: 200 on successful delete, 404 if not found
"""
# Does the person to delete exist?
if lname in PEOPLE:
del PEOPLE[lname]
return make_response(
"{lname} successfully deleted".format(lname=lname), 200
)
# Otherwise, nope, person to delete not found
else:
abort(
404, "Person with last name {lname} not found".format(lname=lname)
)
# Create a handler for our read (GET) people
def read():
"""
This function responds to a request for /api/people
with the complete lists of people
:return: sorted list of people
"""
# Create the list of people from our data
return [PEOPLE[key] for key in sorted(PEOPLE.keys())]
person_test = {
"user": 955,
"age": 2,
"sex":"M",
"job": "engineer"
}
# create(person_test) | e8eaf4e35c4ea1ed62c4978447598f920b97686b | [
"Markdown",
"Python",
"Dockerfile",
"Shell"
] | 7 | Python | tudousponge/WebRec | 7a5e32a31eff99dcea7d19fbe368aa2eca836dae | 5fef6d00e695b8fad101053a7389d10b25735aab |
refs/heads/master | <file_sep>/**
* Sample React Native App
* https://github.com/facebook/react-native
* @flow
*/
import React, { Component } from 'react';
import {Container,Content} from 'native-base';
import {Footer,FooterTab,Button,Icon,Badge,Text} from 'native-base';
import {AppRegistry,Alert} from 'react-native';
import PushScreen from './components/pushTask';
var PushNotification=require('react-native-push-notification');
import {StackNavigator} from 'react-navigation';
import LinkNavigation from './components/openLink';
export default class INTERN extends Component {
constructor(){
super();
const Localp=new LocalPush();
Localp.configuration();
}
static navigationOptions={
title:'Task Application'
};
render() {
const {navigate}=this.props.navigation;
return (
<Container>
<PushScreen id="1"/>
<Footer>
<FooterTab>
<Button active>
<Icon name="home" />
<Text> Home </Text>
</Button>
<Button verticle onPress={()=>{
navigate('OpenUrl',{url:'http://asifansari.me',title:'Web Resume'})
}}>
<Icon name="paper" />
<Text> Resume</Text>
</Button>
<Button verticle onPress={()=>{
navigate('OpenUrl',{url:'https://github.com/ashifa454',title:'Github Link'})
}}>
<Icon name="flash" />
<Text> Github </Text>
</Button>
</FooterTab>
</Footer>
</Container>
);
}
}
class LocalPush{
configuration=function(){
PushNotification.configure({
onNotification:function(notification){
Alert.alert("HELLO WORLD");
},
permissions:{
alert:true,
badge:true,
sound:true
},
requestPermission:true
});
}
}
const SimpleApp = StackNavigator({
Home: { screen: INTERN }, //Default entry screen
OpenUrl:{screen:LinkNavigation}
});
AppRegistry.registerComponent('INTERN', () => SimpleApp);
<file_sep># TASK-REACT
It is an Experiment Task given by Re-Cash as a part of Internship Selection,
This Application Let you Sechdule Local Push Notification,
and Read The SMS from Notification Tray
# Main Screen

# INSTANT NOTIFICATION

# MESSAGE RENDER

<file_sep>import React,{Component} from 'React';
import {StyleSheet,View,Alert} from 'react-native';
import { Col, Row, Grid } from 'react-native-easy-grid';
import SmsListener from 'react-native-android-sms-listener';
var PushNotification=require('react-native-push-notification');
import {Content,Text,H4,Left,Button,Icon,Card,CardItem,Right,Separator,List,ListItem,Body} from 'native-base';
export default class PushScreen extends Component{
constructor(){
super();
var tempMessage=[];
this.state={messages:[]};
SmsListener.addListener(message=>{
tempMessage.push({
title:message.originatingAddress,
message:message.body
});
this.setState(previous=>{
return {messages:tempMessage}
});
})
}
DoInstantNotication=function(){
PushNotification.localNotification({
autoCancel:true,
largeIcon:"ic_launcher",
smallIcon:"ic_launcer",
bigText:"THIS IS INSTANT NOTIFICATION, DID YOU LIKE THAT",
subText:"HIT IF YOU LIKE IT",
title:"Instant Notification",
message:"IT'S An INSTANT NOTIFICATION",
actions:'["WOW","IT WAS FINE"]'
});
}
SechduleOnDaily=function(){
nextDay=new Date();
if(nextDay.getHours()<18){
nextDay.setHours(18);
nextDay.setMinutes(0);
nextDay.setSeconds(0);
}else{
nextDay.setDate(nextDay.getDate()+1);
nextDay.setHours(18);
nextDay.setMinutes(0);
nextDay.setSeconds(0);
}
PushNotification.localNotificationSchedule({
autoCancel:true,
largeIcon:"ic_launcher",
smallIcon:"ic_launcer",
subText:"HIT IF YOU LIKE IT",
title:"Daily Notification Notification",
message:"Wolla is 6PM, I am Ready to Rock",
actions:'["WOW","IT WAS FINE"]',
date:nextDay,
repeatType:'day',
});
Alert.alert("Status","Notification Sechdule for 6PM "+nextDay);
}
SechduleOnWeekend=function(){
commingSunday=new Date();
commingSunday.setDate(commingSunday.getDate()+(0+(7-commingSunday.getDay()))%7)
commingSunday.setHours(14);
commingSunday.setMinutes(0);
commingSunday.setSeconds(0);
PushNotification.localNotificationSchedule({
autoCancel:true,
largeIcon:"ic_launcher",
smallIcon:"ic_launcer",
subText:"HIT IF YOU LIKE IT",
title:"Weekly Notification",
message:"Its a Lazy Sunday at 2PM, and Here I am",
actions:'["WOW","IT WAS FINE"]',
date:commingSunday,
repeatType:'week',
});
Alert.alert("Status","Notification Sechdule for 2PM "+commingSunday);
}
render(){
return (
<Content>
<Grid>
<Row>
<Card>
<CardItem header>
<Text> Sechdule Notification @</Text>
</CardItem>
<CardItem>
<Icon active name="clock" />
<Text>6 PM Daily</Text>
<Right>
<Button success transparent onPress={()=>{this.SechduleOnDaily()}}>
<Text>See in Action</Text>
</Button>
</Right>
</CardItem>
<CardItem>
<Icon active name="glasses" />
<Text>2 PM Sunday</Text>
<Right>
<Button danger transparent onPress={()=>{this.SechduleOnWeekend()}}>
<Text>See in Action</Text>
</Button>
</Right>
</CardItem>
<CardItem>
<Icon active name="flame" />
<Text>Notify Now</Text>
<Right>
<Button transparent onPress={()=>{this.DoInstantNotication()}}>
<Text>See in Action</Text>
</Button>
</Right>
</CardItem>
</Card>
</Row>
<Row>
<Separator bordered>
<Text>Message Reader</Text>
</Separator>
</Row>
<Row>
<List dataArray={this.state.messages} renderRow={(item)=>
<ListItem>
<Body>
<Text>{item.title}</Text>
<Text note>{item.message}</Text>
</Body>
</ListItem>
}>
</List>
</Row>
</Grid>
</Content>
);
}
}<file_sep>import React,{Component} from 'react';
import {WebView} from 'react-native';
export default class LinkNavigation extends Component{
static navigationOptions=({navigation})=>({
title:navigation.state.params.title
});
render(){
const { params } = this.props.navigation.state;
return(
<WebView
source={{uri:params.url}}
/>
);
}
}<file_sep>rootProject.name = 'INTERN'
include ':react-native-android-sms-listener'
project(':react-native-android-sms-listener').projectDir = new File(rootProject.projectDir, '../node_modules/react-native-android-sms-listener/android')
include ':react-native-push-notification'
project(':react-native-push-notification').projectDir = new File(rootProject.projectDir, '../node_modules/react-native-push-notification/android')
include ':app'
| 8bb0db3dc9a80b9f3550368460107fdadf6b3f99 | [
"JavaScript",
"Markdown",
"Gradle"
] | 5 | JavaScript | ashifa454/TASK-REACT | fa52da70c0979e2ffc37baefd68b81c0638b7fdb | 06bfdd88f90d2ca3b693193024f1de4f2bf2d738 |
refs/heads/master | <file_sep><?php
header('Access-Control-Allow-Origin:*');
$url = $_GET['url'];
$ret = file_get_contents($url);
echo $_GET['callback']."(".json_encode($ret).")";
?>
<file_sep><?php
header('Access-Control-Allow-Origin:*');
$type = $_GET['type'];
$callback = $_GET['callback'];
$url = "http://v.juhe.cn/toutiao/index?type=".$_GET['type']."&key=<KEY>";
$ret = file_get_contents($url);
echo $callback."(".json_encode($ret).")";
?>
| 7ab8c3d5259b047f585bd2d1c979904463d2a3b5 | [
"PHP"
] | 2 | PHP | fangcong27630/newlist | 43a36a7b027b20824fa0cd703648020ec6f4c05c | a9a5932e5ef651c6798649a28546b675ffdfef37 |
refs/heads/master | <repo_name>fazleyKholil/CKOShoppingApi<file_sep>/CHCKOShoppingApi/Models/IShoppingRepository.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace CHCKOShoppingApi.Models
{
interface IShoppingRepository
{
Dictionary<string, List<Item>> GetAll();
IEnumerable<Item> getByType(string itemType);
Item getItem(string type, string itemName);
Item getItem(string type, int id);
List<Item> Add(string itemType, List<Item> items);
void Delete(string type, int id);
bool Update(string type, int id, Item item);
}
}
<file_sep>/CHCKOShoppingApi/Controllers/ShoppingController.cs
using CHCKOShoppingApi.Models;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.Http;
using System.Net.Http;
using System.Web.Mvc;
using System.Net;
namespace CHCKOShoppingApi.Controllers
{
public class ShoppingController : ApiController
{
ShoppingRepository shoppingRepo = ShoppingRepository.getInstance();
public Dictionary<string,List<Item>> GetShoppingItems()
{
return shoppingRepo.GetAll();
}
public HttpResponseMessage GetItems(string type)
{
IEnumerable<Item> items;
try
{
items = shoppingRepo.getByType(type);
return Request.CreateResponse(HttpStatusCode.OK, items);
}
catch (Exception e)
{
return Request.CreateResponse(HttpStatusCode.NotFound);
}
}
public HttpResponseMessage GetItem(string type, string name)
{
Item item;
try
{
item = shoppingRepo.getItem(type, name);
return Request.CreateResponse(HttpStatusCode.OK, item);
}
catch (Exception e)
{
return Request.CreateResponse(HttpStatusCode.NotFound);
}
}
public HttpResponseMessage GetItem(string type, int id)
{
Item item;
try
{
item = shoppingRepo.getItem(type, id);
return Request.CreateResponse(HttpStatusCode.OK, item);
}
catch (Exception e)
{
return Request.CreateResponse(HttpStatusCode.NotFound);
}
}
public HttpResponseMessage PostItem(string type,List<Item> items)
{
if (ModelState.IsValid)
{
items = shoppingRepo.Add(type,items);
var response = Request.CreateResponse(HttpStatusCode.Created, items);
string uri = Url.Link("DefaultApi", items);
response.Headers.Location = new Uri(uri);
return response;
}
else
{
return Request.CreateResponse(HttpStatusCode.BadRequest);
}
}
public HttpResponseMessage Delete(string type,int id)
{
Item item;
try
{
item = shoppingRepo.getItem(type, id);
if (item != null)
{
shoppingRepo.Delete(type, id);
return Request.CreateResponse(HttpStatusCode.OK, item);
}
else
return Request.CreateResponse(HttpStatusCode.NotFound);
}
catch (Exception e)
{
return Request.CreateResponse(HttpStatusCode.BadRequest);
}
}
public HttpResponseMessage Put(string type,int id, Item item)
{
if (ModelState.IsValid && id == item.Id)
{
var result = shoppingRepo.Update(type,id, item);
if (result == false)
{
return Request.CreateResponse(HttpStatusCode.NotFound);
}
return Request.CreateResponse(HttpStatusCode.OK);
}
else
{
return Request.CreateResponse(HttpStatusCode.BadRequest);
}
}
}
}
<file_sep>/CHCKOShoppingApi/Models/Item.cs
using System;
using System.Collections.Generic;
using System.ComponentModel.DataAnnotations;
using System.Linq;
using System.Web;
namespace CHCKOShoppingApi.Models
{
public class Item
{
private DateTime datePurchased;
[Key]
public int Id { get; set; }
public string name { get; set; }
public int quantity { get; set; }
public double price { get; set; }
public DateTime DatePurchased
{
get { return datePurchased; }
set { datePurchased = new DateTime(); }
}
}
}<file_sep>/CHCKOShoppingApi/Models/ShoppingRepository.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
namespace CHCKOShoppingApi.Models
{
class ShoppingRepository : IShoppingRepository
{
public static ShoppingRepository shoppingBasket= null;
public static readonly Dictionary<string, List<Item>> Items = new Dictionary<string, List<Item>>();
static List<Item> items = new List<Item>
{
new Item {Id=1, name = "pepsi", price = 15, quantity = 1 },
new Item {Id=2, name = "fanta", price = 15, quantity = 1 },
new Item {Id=3, name = "sprite", price = 15, quantity = 1 },
};
private ShoppingRepository() {}
public void initRepository()
{
addItems("drinks", items);
}
public static ShoppingRepository getInstance()
{
if (shoppingBasket == null)
{
shoppingBasket = new ShoppingRepository();
Items.Add("drinks", items);
return shoppingBasket;
}
else
return shoppingBasket;
}
public void addItems(string type,List<Item> items)
{
if (!Items.ContainsKey(type))
{
Items.Add(type, items);
}
else
{
foreach (Item item in items)
Items[type].Add(item);
}
}
public Dictionary<string, List<Item>> GetAll()
{
return Items;
}
public IEnumerable<Item> getByType(string itemType)
{
return Items[itemType];
}
public Item getItem(string type, string itemName)
{
return Items[type].Find(i => i.name == itemName);
}
public Item getItem(string type, int itemId)
{
return Items[type].Find(i => i.Id == itemId);
}
public List<Item> Add(string itemType,List<Item> items)
{
ShoppingRepository.getInstance().addItems(itemType, items);
return items;
}
public void Delete(string type,int id)
{
var item = Items[type].FirstOrDefault(i => i.Id == id);
if (item != null)
{
Items[type].Remove(item);
}
}
public bool Update(string type,int id,Item item)
{
Item rItem = Items[type].FirstOrDefault(p => p.Id == id);
if (rItem != null)
{
rItem.name = item.name;
rItem.quantity = item.quantity;
rItem.price = item.price;
return true;
}
return false;
}
}
}<file_sep>/README.md
# checkout-net-shopping-api
### Requirements
.Net Framework 4.5 and later
### How does checkout shopping api operate
This Api enable you to store a list of items that you want to purchase at end of each month.
For example as it has been given in your question that it shall be able to tore a drink.
In addition a shopping list can contain specific type or category of items such as stationary items.
Therefore this Api has cater for that. A sample response can be as follows :
```html
GET : http://localhost:49707/api/Shopping
```
response:
```javascript
{"drinks": [
{"Id":1,"name":"pepsi","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":2,"name":"fanta","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":3,"name":"sprite","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}],
"stationary":[ {"Id":4,"name":"pen","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":5,"name":"eraser","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}]}
```
If you want to retrieve only drinks as per your requirements. Just 'type=drinks as a param':
```html
GET : http://localhost:49707/api/Shopping?type=drinks
```
response:
```javascript
[
{"Id":1,"name":"pepsi","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":2,"name":"fanta","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":3,"name":"sprite","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}
]
```
The shopping api has been design using a repository pattern since the data will be stored
at least for now in an in memory data store thus avoiding duplication of logic to access and store our data.
##### Repository/container for our shopping item
```csharp
namespace CHCKOShoppingApi.Models
{
interface IShoppingRepository
{
Dictionary<string, List<Item>> GetAll();
IEnumerable<Item> getByType(string itemType);
Item getItem(string type, string itemName);
Item getItem(string type, int id);
List<Item> Add(string itemType, List<Item> items);
void Delete(string type, int id);
bool Update(string type, int id, Item item);
}
}
namespace CHCKOShoppingApi.Models
{
class ShoppingRepository : IShoppingRepository
{
public static ShoppingRepository shoppingBasket= null;
public static readonly Dictionary<string, List<Item>> Items = new Dictionary<string, List<Item>>();
static List<Item> items = new List<Item>
{
new Item {Id=1, name = "pepsi", price = 15, quantity = 1 },
new Item {Id=2, name = "fanta", price = 15, quantity = 1 },
new Item {Id=3, name = "sprite", price = 15, quantity = 1 },
};
private ShoppingRepository() {}
public void initRepository()
{
addItems("drinks", items);
}
public static ShoppingRepository getInstance()
{
if (shoppingBasket == null)
{
shoppingBasket = new ShoppingRepository();
Items.Add("drinks", items);
return shoppingBasket;
}
else
return shoppingBasket;
}
public void addItems(string type,List<Item> items)
{
if (!Items.ContainsKey(type))
{
Items.Add(type, items);
}
else
{
foreach (Item item in items)
Items[type].Add(item);
}
}
public Dictionary<string, List<Item>> GetAll()
{
return Items;
}
public IEnumerable<Item> getByType(string itemType)
{
return Items[itemType];
}
public Item getItem(string type, string itemName)
{
return Items[type].Find(i => i.name == itemName);
}
public Item getItem(string type, int itemId)
{
return Items[type].Find(i => i.Id == itemId);
}
public List<Item> Add(string itemType,List<Item> items)
{
ShoppingRepository.getInstance().addItems(itemType, items);
return items;
}
public void Delete(string type,int id)
{
var item = Items[type].FirstOrDefault(i => i.Id == id);
if (item != null)
{
Items[type].Remove(item);
}
}
public bool Update(string type,int id,Item item)
{
Item rItem = Items[type].FirstOrDefault(p => p.Id == id);
if (rItem != null)
{
rItem.name = item.name;
rItem.quantity = item.quantity;
rItem.price = item.price;
return true;
}
return false;
}
}
}
```
##### ShoppingItem model
```csharp
namespace CHCKOShoppingApi.Models
{
public class Item
{
private DateTime datePurchased;
[Key]
public int Id { get; set; }
public string name { get; set; }
public int quantity { get; set; }
public double price { get; set; }
public DateTime DatePurchased
{
get { return datePurchased; }
set { datePurchased = new DateTime(); }
}
}
}
```
##### ShoppingApi controller
```csharp
namespace CHCKOShoppingApi.Controllers
{
public class ShoppingController : ApiController
{
//repo as a singleton
ShoppingRepository shoppingRepo = ShoppingRepository.getInstance();
public Dictionary<string,List<Item>> GetShoppingItems()
{
//(1a) Get all shopping items. Can be of type drinks, stationary and any types that has been stored.
}
public HttpResponseMessage GetItems(string type)
{
//(2a Get shopping items of specific type. For example retrieve all drinks that is to be purchased.
}
public HttpResponseMessage GetItem(string type, string name)
{
//(3a) Get a specific shopping item of specific type given its name. For example retrieve a drink of name pepsi
}
public HttpResponseMessage GetItem(string type, int id)
{
//(4a) Get a specific shopping item of specific type given its id. For example retrieve a drink of id 1
}
public HttpResponseMessage PostItem(string type,List<Item> items)
{
//(5a) Add items to the shopping list. For example add a pepsi of type drinks.
}
public HttpResponseMessage Delete(string type,int id)
{
//(6a) Delete an item of a praticular type by its id.
}
public HttpResponseMessage Put(string type,int id, Item item)
{
//(7a) Update an item of a particular type given its id.
}
}
}
```
### usage and explanation
use case (1a) : Get all shopping items.
url :
```html
GET : http://localhost:49707/api/Shopping
```
code:
```csharp
public Dictionary<string,List<Item>> GetShoppingItems()
{
return shoppingRepo.GetAll();
}
```
Response:
```javascript
{"drinks": [
{"Id":1,"name":"pepsi","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":2,"name":"fanta","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":3,"name":"sprite","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}],
"stationary":[ {"Id":4,"name":"pen","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":5,"name":"eraser","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}]}
```
use case (2a) : Get shopping items of specific type.
url :
```html
GET : http://localhost:49707/api/Shopping?type=drinks
```
code:
```csharp
public HttpResponseMessage GetItems(string type)
{
IEnumerable<Item> items;
try
{
items = shoppingRepo.getByType(type);
return Request.CreateResponse(HttpStatusCode.OK, items);
}
catch (Exception e)
{
return Request.CreateResponse(HttpStatusCode.NotFound);
}
}
```
Response:
```javascript
[
{"Id":1,"name":"pepsi","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":2,"name":"fanta","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":3,"name":"sprite","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}
]
```
use case (3a) : Get a specific shopping item of specific type given its name.
url :
```html
GET : http://localhost:49707/api/Shopping?type=drinks&name=pepsi
```
code:
```csharp
public HttpResponseMessage GetItem(string type, string name)
{
Item item;
try
{
item = shoppingRepo.getItem(type, name);
return Request.CreateResponse(HttpStatusCode.OK, item);
}
catch (Exception e)
{
return Request.CreateResponse(HttpStatusCode.NotFound);
}
}
```
Response:
```javascript
{"Id":1,"name":"pepsi","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}
```
use case (4a) : Get a specific shopping item of specific type given its id.
url :
```html
GET : http://localhost:49707/api/Shopping/3?type=drinks
```
code:
```csharp
public HttpResponseMessage GetItem(string type, int id)
{
Item item;
try
{
item = shoppingRepo.getItem(type, id);
return Request.CreateResponse(HttpStatusCode.OK, item);
}
catch (Exception e)
{
return Request.CreateResponse(HttpStatusCode.NotFound);
}
}
```
Response:
```javascript
{"Id":3,"name":"sprite","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}
```
use case (5a) : Add items to the shopping list.
url :
```html
POST : http://localhost:49707/api/Shopping?type=drinks
```
```javascript
BODY : [{"Id":6,"name":"<NAME>","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}]
```
code:
```csharp
public HttpResponseMessage PostItem(string type,List<Item> items)
{
if (ModelState.IsValid)
{
items = shoppingRepo.Add(type,items);
var response = Request.CreateResponse(HttpStatusCode.Created, items);
string uri = Url.Link("DefaultApi", items);
response.Headers.Location = new Uri(uri);
return response;
}
else
{
return Request.CreateResponse(HttpStatusCode.BadRequest);
}
}
```
Response:
```javascript
//status 201 created
{"Id":6,"name":"<NAME>","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}
```
###Adding a new category of items such as stationary :
url :
```html
POST : http://localhost:49707/api/Shopping?type=stationary
```
```javascript
BODY : [{"Id":6,"name":"<NAME>","quantity":10,"price":1500.0,"DatePurchased":"0001-01-01T00:00:00"}]
```
Response:
```javascript
//status 201 created
[{"Id":6,"name":"<NAME>","quantity":10,"price":1500.0,"DatePurchased":"0001-01-01T00:00:00"}]
```
### Get all shopping items including newly category just added.
url :
```html
GET : http://localhost:49707/api/Shopping
```
Response:
```javascript
{"drinks":
[{"Id":1,"name":"pepsi","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":2,"name":"fanta","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":3,"name":"perona","quantity":10,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"
}],
"stationary":[{"Id":1,"name":"pen","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":2,"name":"eraser","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":6,"name":"<NAME>","quantity":10,"price":1500.0,"DatePurchased":"0001-01-01T00:00:00"}
]}
```
### To get shopping items of just a particular type
url :
```html
GET : http://localhost:49707/api/Shopping?type=stationary
```
Response:
```javascript
[ {"Id":1,"name":"pen","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":2,"name":"eraser","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"},
{"Id":6,"name":"<NAME>","quantity":10,"price":1500.0,"DatePurchased":"0001-01-01T00:00:00"}
]
```
use case (6a) : Delete an item of a praticular type by its id.
url :
```html
DELETE : http://localhost:49707/api/Shopping/6?type=drinks
```
code:
```csharp
public HttpResponseMessage Delete(string type,int id)
{
Item item;
try
{
item = shoppingRepo.getItem(type, id);
if (item != null)
{
shoppingRepo.Delete(type, id);
return Request.CreateResponse(HttpStatusCode.OK, item);
}
else
return Request.CreateResponse(HttpStatusCode.NotFound);
}
catch (Exception e)
{
return Request.CreateResponse(HttpStatusCode.BadRequest);
}
}
```
Response:
```javascript
//status 200 ok
{"Id":6,"name":"<NAME>","quantity":1,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}
```
use case (7a) : Update an item of a particular type given its id.
url :
```html
PUT : http://localhost:49707/api/Shopping/3?type=drinks
```
```javascript
BODY :{"Id":3,"name":"perona","quantity":10,"price":15.0,"DatePurchased":"0001-01-01T00:00:00"}
```
code:
```csharp
public HttpResponseMessage Put(string type,int id, Item item)
{
if (ModelState.IsValid && id == item.Id)
{
var result = shoppingRepo.Update(type,id, item);
if (result == false)
{
return Request.CreateResponse(HttpStatusCode.NotFound);
}
return Request.CreateResponse(HttpStatusCode.OK);
}
else
{
return Request.CreateResponse(HttpStatusCode.BadRequest);
}
}
```
Response:
```javascript
//status 200 ok
```
####Error handling
For any bad request or wrong body,url requested.
The response status will be 404 or others.
| 0554cd50da7d8b3c7a9deb06c9e39a6e51e390ed | [
"Markdown",
"C#"
] | 5 | C# | fazleyKholil/CKOShoppingApi | afc233737e34439037a4a014ea0b6dd394d1dba3 | c7bd5692e404a11c67710765d04260ac2a0cd0ba |
refs/heads/master | <repo_name>KaranKamath/fish-and-chips<file_sep>/test/index.js
var should = require('chai').should(),
fishAndChips = require('../index'),
toAmerican = fishAndChips.toAmerican;
describe('#toAmerican', function() {
it('converts capitalise to capitalize', function() {
toAmerican('text-transform: capitalise;').should.equal(
'text-transform: capitalize;');
});
it('converts centre to center', function() {
toAmerican('float: centre;').should.equal('float: center;');
});
it('converts colour to color', function() {
toAmerican('background-colour: yellow;').should.equal(
'background-color: yellow;');
});
});
<file_sep>/README.md
fish-and-chips
============
A small library providing the conversion of British English words to their American English counterparts for correct usage in HTML and CSS
https://www.npmjs.com/package/fish-and-chips
## Installation
```
npm install fish-and-chips --save
```
## Usage
```js
var fish = require('fish-and-chips')
var css = 'text-align: centre;',
css = fish.toAmerican(css);
```
## Tests
```
npm test
```
## Contributing
General styleguide:
smallcase for filenames
camelCase for methods and variables
PascalCase for Class Names
Add unit tests for any new or changed functionality
Lint and test your code.
| 7a285392805bf8886c9dbe3cb18a4e37babf3bfc | [
"JavaScript",
"Markdown"
] | 2 | JavaScript | KaranKamath/fish-and-chips | e140e1b128fa60fc60bc12893ef43e62b98bc8bf | 525087398ff3a2a05c6020404d6596c70c10e671 |
refs/heads/master | <repo_name>kamalnirajb/SparkProfile<file_sep>/app/src/main/java/com/niraj/sparkprofile/adapters/HomePagerAdapter.java
package com.niraj.sparkprofile.adapters;
import android.os.Parcelable;
import android.support.annotation.NonNull;
import android.support.v4.app.Fragment;
import android.support.v4.app.FragmentManager;
import android.support.v4.app.FragmentStatePagerAdapter;
import android.view.View;
import android.view.ViewGroup;
import com.niraj.sparkprofile.fragments.ProfileFragment;
import com.niraj.sparkprofile.fragments.UsersFragment;
import java.util.ArrayList;
import java.util.List;
public class HomePagerAdapter extends FragmentStatePagerAdapter {
private final String TAG = "HPAdapter";
private List<Fragment> fragments;
public HomePagerAdapter(FragmentManager manager) {
super(manager);
}
public void initFragments(List<Fragment> fragments) {
if (this.fragments != null) {
this.fragments.clear();
}
this.fragments = fragments;
notifyDataSetChanged();
}
@Override
public Fragment getItem(int position) {
return fragments.get(position);
}
@Override
public int getCount() {
return fragments != null ? fragments.size() : 0;
}
@Override
public void startUpdate(ViewGroup container) {
super.startUpdate(container);
}
@Override
public Object instantiateItem(ViewGroup container, int position) {
return super.instantiateItem(container, position);
}
@Override
public void finishUpdate(ViewGroup container) {
super.finishUpdate(container);
}
@Override
public boolean isViewFromObject(View view, Object object) {
return super.isViewFromObject(view, object);
}
@Override
public Parcelable saveState() {
return super.saveState();
}
@Override
public int getItemPosition(@NonNull Object object) {
return POSITION_NONE;
}
}
<file_sep>/app/src/main/java/com/niraj/sparkprofile/SparkProfileApp.java
package com.niraj.sparkprofile;
import android.databinding.DataBindingUtil;
import android.support.multidex.MultiDexApplication;
import com.niraj.sparkprofile.binding.AppDataBindingComponent;
public class SparkProfileApp extends MultiDexApplication {
@Override
public void onCreate() {
super.onCreate();
DataBindingUtil.setDefaultComponent(new AppDataBindingComponent());
}
}
<file_sep>/app/src/main/java/com/niraj/sparkprofile/SparkGlideModule.java
package com.niraj.sparkprofile;
import android.content.Context;
import android.support.annotation.NonNull;
import com.bumptech.glide.GlideBuilder;
import com.bumptech.glide.annotation.GlideModule;
import com.bumptech.glide.module.AppGlideModule;
@GlideModule
public class SparkGlideModule extends AppGlideModule {
public SparkGlideModule() {
super();
}
/**
* Returns {@code true} if Glide should check the AndroidManifest for {@link GlideModule}s.
* <p>
* <p>Implementations should return {@code false} after they and their dependencies have migrated
* to Glide's annotation processor.
* <p>
* <p>Returns {@code true} by default.
*/
@Override
public boolean isManifestParsingEnabled() {
return super.isManifestParsingEnabled();
}
@Override
public void applyOptions(@NonNull Context context, @NonNull GlideBuilder builder) {
super.applyOptions(context, builder);
}
}
<file_sep>/app/src/main/java/com/niraj/sparkprofile/viewmodels/UserItemViewModel.java
package com.niraj.sparkprofile.viewmodels;
import android.databinding.BaseObservable;
import android.databinding.Bindable;
import android.view.View;
import com.niraj.sparkprofile.models.User;
public class UserItemViewModel extends BaseObservable {
private User user;
private View.OnClickListener onClickListener;
public UserItemViewModel(User user) {
this.user = user;
}
public void setUp() {
}
public void tearDown() {
}
@Bindable
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
@Bindable
public View.OnClickListener getOnClickListener() {
return onClickListener;
}
public void setOnClickListener(View.OnClickListener onClickListener) {
this.onClickListener = onClickListener;
}
}
<file_sep>/app/src/main/java/com/niraj/sparkprofile/customui/AppTextViewCFSWithImage.java
package com.niraj.sparkprofile.customui;
import android.content.Context;
import android.content.res.TypedArray;
import android.graphics.Canvas;
import android.graphics.Typeface;
import android.support.v7.widget.AppCompatImageView;
import android.util.AttributeSet;
import android.util.TypedValue;
import android.view.View;
import android.widget.RelativeLayout;
import com.niraj.sparkprofile.R;
import com.niraj.sparkprofile.utils.AppConstants;
/**
* Created by NirajKumar on 19/09/18.
*/
public class AppTextViewCFSWithImage extends RelativeLayout {
private static final String TAG = "AETCRightImage";
private AppCompatImageView imgIcon;
private AppTextViewCFS tvLbl;
private View view;
private String textFontFamily;
public AppTextViewCFSWithImage(Context context) {
super(context);
inflate(context, R.layout.layout_textview_left_icon, this);
}
public AppTextViewCFSWithImage(Context context, AttributeSet attrs) {
super(context, attrs);
setUI(context, attrs);
}
public AppTextViewCFSWithImage(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
setUI(context, attrs);
}
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
}
/**
* Set UI with custom view
*
* @param context
* @param attrs
* @return
*/
private View setUI(Context context, AttributeSet attrs) {
setBackground(context.getDrawable(R.drawable.edittext_bg));
TypedArray a = context.getTheme().obtainStyledAttributes(
attrs,
R.styleable.AppTextViewCFSWithImage,
0, 0);
if (a.getBoolean(R.styleable.AppTextViewCFSWithImage_isLeft, true)) {
view = inflate(context, R.layout.layout_textview_left_icon, this);
} else {
view = inflate(context, R.layout.layout_textview_right_icon, this);
}
tvLbl = (AppTextViewCFS) view.findViewById(R.id.tv_lbl);
imgIcon = (AppCompatImageView) view.findViewById(R.id.img_lbl_icon);
try {
textFontFamily = a.getString(R.styleable.AppTextViewCFSWithImage_textImgButtonFontFamily);
if (textFontFamily != null) {
Typeface iconFont = FontManager.getTypeface(context.getApplicationContext(), textFontFamily);
if (tvLbl.getTypeface() != null) {
tvLbl.setTypeface(iconFont, tvLbl.getTypeface().getStyle());
} else {
tvLbl.setTypeface(iconFont);
}
tvLbl.setTextSize(TypedValue.COMPLEX_UNIT_PX, tvLbl.getTextSize());
}
imgIcon.setImageDrawable(getResources().getDrawable(a.getResourceId(R.styleable.AppTextViewCFSWithImage_textButtonImage, R.drawable.ic_no_image)));
tvLbl.setText(a.getString(R.styleable.AppTextViewCFSWithImage_android_text));
invalidate();
} catch (Exception e) {
AppConstants.logE(TAG, e.getMessage());
} finally {
a.recycle();
}
return view;
}
public AppCompatImageView getImgIcon() {
return imgIcon;
}
public void setImgIcon(AppCompatImageView imgIcon) {
this.imgIcon = imgIcon;
}
public String getText() {
if (tvLbl != null) {
return AppConstants.trim(tvLbl.getText() + "", "");
}
return "";
}
public void setText(String text) {
if (tvLbl != null) {
tvLbl.setText(text);
}
}
}<file_sep>/app/src/main/java/com/niraj/sparkprofile/SplashActivity.java
package com.niraj.sparkprofile;
import android.content.Intent;
import android.os.Handler;
import android.os.Looper;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
public class SplashActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_splash);
new Handler(Looper.getMainLooper()).postDelayed(()->{
Intent profileIntent = new Intent(SplashActivity.this, HomeActivity.class);
startActivity(profileIntent);
},1000);
}
}
<file_sep>/app/src/main/java/com/niraj/sparkprofile/customui/AppButtonCFS.java
package com.niraj.sparkprofile.customui;
import android.content.Context;
import android.content.res.TypedArray;
import android.graphics.Canvas;
import android.graphics.Typeface;
import android.support.v7.widget.AppCompatButton;
import android.util.AttributeSet;
import android.util.TypedValue;
import com.niraj.sparkprofile.R;
import com.niraj.sparkprofile.utils.AppConstants;
/**
* Created by NirajKumar on 10/31/17.
*/
public class AppButtonCFS extends AppCompatButton {
public AppButtonCFS(Context context) {
super(context);
}
public AppButtonCFS(Context context, AttributeSet attrs) {
super(context, attrs);
setCustomFont(context, attrs);
}
public AppButtonCFS(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
setCustomFont(context, attrs);
}
protected void onDraw (Canvas canvas) {
super.onDraw(canvas);
}
private void setCustomFont(Context context, AttributeSet attrs) {
TypedArray a = context.getTheme().obtainStyledAttributes(
attrs,
R.styleable.AppButtonCFS,
0, 0);
String textFontFamily;
try {
textFontFamily = a.getString(R.styleable.AppButtonCFS_buttonFontFamily);
if (!AppConstants.trim(textFontFamily, "").isEmpty()) {
Typeface iconFont = FontManager.getTypeface(context.getApplicationContext(), textFontFamily);
this.setTypeface(iconFont, getTypeface().getStyle());
setTextSize(TypedValue.COMPLEX_UNIT_PX, getTextSize());
}
} finally {
a.recycle();
}
}
}
<file_sep>/app/src/main/java/com/niraj/sparkprofile/viewmodels/UserViewModel.java
package com.niraj.sparkprofile.viewmodels;
import android.databinding.BaseObservable;
import android.databinding.Bindable;
import android.databinding.ObservableArrayList;
import android.databinding.ObservableBoolean;
import android.support.v7.widget.RecyclerView;
import com.niraj.sparkprofile.BR;
import com.niraj.sparkprofile.adapters.UserAdapter;
import com.niraj.sparkprofile.models.User;
import java.util.List;
public class UserViewModel extends BaseObservable {
private static final String TAG = "ScheduleViewModel";
public ObservableBoolean isLoading = new ObservableBoolean();
private UserAdapter adapter;
private ObservableArrayList<User> usersList;
private RecyclerView.OnScrollListener onScrollListener;
public void setUp() {
populateUsers();
}
public void tearDown() {
// perform tear down tasks, such as removing listeners
}
public UserViewModel(ObservableArrayList<User> users) {
this.adapter = new UserAdapter();
this.usersList = users;
}
@Bindable
public UserAdapter getAdapter() {
return adapter;
}
public void setAdapter(UserAdapter adapter) {
this.adapter = adapter;
}
@Bindable
public ObservableArrayList<User> getUsersList() {
return usersList;
}
public void setUsersList(ObservableArrayList<User> usersList) {
this.usersList = usersList;
}
public void populateUsers() {
isLoading.set(false);
notifyPropertyChanged(BR.usersList);
}
public RecyclerView.OnScrollListener getOnScrollListener() {
return onScrollListener;
}
public void setOnScrollListener(RecyclerView.OnScrollListener onScrollListener) {
this.onScrollListener = onScrollListener;
}
public void updateUsers() {
isLoading.set(false);
populateUsers();
}
/* Needs to be public for Databinding */
public void onRefresh() {
isLoading.set(true);
populateUsers();
}
}
<file_sep>/app/src/main/java/com/niraj/sparkprofile/customui/AppEditTextCFSWithRightImage.java
package com.niraj.sparkprofile.customui;
import android.app.Activity;
import android.content.Context;
import android.content.res.TypedArray;
import android.graphics.Canvas;
import android.graphics.Typeface;
import android.support.v7.widget.AppCompatEditText;
import android.text.InputFilter;
import android.text.InputType;
import android.text.TextWatcher;
import android.util.AttributeSet;
import android.util.TypedValue;
import android.view.MotionEvent;
import android.view.View;
import android.view.inputmethod.EditorInfo;
import android.view.inputmethod.InputMethodManager;
import android.widget.RelativeLayout;
import com.niraj.sparkprofile.R;
import com.niraj.sparkprofile.utils.AppConstants;
/**
* Created by NirajKumar on 19/09/18.
*/
public class AppEditTextCFSWithRightImage extends RelativeLayout {
private static final String TAG = "AETCRightImage";
private AppCompatEditText editTextCFS;
private AppTextViewCFS tvRightImage;
private View view;
private String textFontFamily;
private String textRightImage;
private int inputType;
private int maxLength;
private OnRightButtonClickListener onRightButtonClickListener;
private OnEditClickListener onEditClickListener;
public AppEditTextCFSWithRightImage(Context context) {
super(context);
inflate(context, R.layout.layout_edittext_right_image, this);
}
public AppEditTextCFSWithRightImage(Context context, AttributeSet attrs) {
super(context, attrs);
setUI(context, attrs);
}
public AppEditTextCFSWithRightImage(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
setUI(context, attrs);
}
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
}
/**
* Set UI with custom view
*
* @param context
* @param attrs
* @return
*/
private View setUI(Context context, AttributeSet attrs) {
setBackground(context.getDrawable(R.drawable.edittext_bg));
TypedArray a = context.getTheme().obtainStyledAttributes(
attrs,
R.styleable.AppEditTextCFSWithButton,
0, 0);
view = inflate(context, R.layout.layout_edittext_right_image, this);
editTextCFS = (AppCompatEditText) view.findViewById(R.id.et_custom_right_image);
tvRightImage = (AppTextViewCFS) view.findViewById(R.id.tv_right_image);
editTextCFS.setOnFocusChangeListener((view, hasFocus) -> {
if (!hasFocus && getContext() != null) {
InputMethodManager inputMethodManager = (InputMethodManager) getContext().getSystemService(Activity.INPUT_METHOD_SERVICE);
inputMethodManager.hideSoftInputFromWindow(view.getWindowToken(), 0);
}
});
try {
textFontFamily = a.getString(R.styleable.AppEditTextCFSWithButton_textButtonFontFamily);
textRightImage = a.getString(R.styleable.AppEditTextCFSWithButton_textButtonRightImage);
inputType = a.getInteger(R.styleable.AppEditTextCFSWithButton_android_inputType, EditorInfo.TYPE_TEXT_FLAG_MULTI_LINE);
if (textFontFamily != null) {
Typeface iconFont = FontManager.getTypeface(context.getApplicationContext(), textFontFamily);
if (editTextCFS.getTypeface() != null) {
editTextCFS.setTypeface(iconFont, editTextCFS.getTypeface().getStyle());
} else {
editTextCFS.setTypeface(iconFont);
}
editTextCFS.setTextSize(TypedValue.COMPLEX_UNIT_PX, editTextCFS.getTextSize());
}
editTextCFS.setInputType(inputType);
maxLength = a.getInteger(R.styleable.AppEditTextCFSWithButton_android_maxLength, -1);
AppConstants.logI(TAG, "Max Length for edittext:" + maxLength);
if (maxLength != -1) {
editTextCFS.setFilters(new InputFilter[]{new InputFilter.LengthFilter(maxLength)});
}
tvRightImage.setText(textRightImage);
invalidate();
} catch (Exception e) {
AppConstants.logE(TAG, e.getMessage());
} finally {
a.recycle();
}
return view;
}
public CharSequence getTvRightImage() {
if (tvRightImage != null) {
return tvRightImage.getText();
}
return "";
}
/**
* Set right image
*
* @param rightImage
*/
public void setTvRightImage(String rightImage) {
if (tvRightImage != null) {
tvRightImage.setText(rightImage);
}
}
public String getText() {
if (editTextCFS != null) {
return AppConstants.trim(editTextCFS.getText() + "", "");
}
return "";
}
public void setText(String text) {
if (editTextCFS != null) {
editTextCFS.setText(text);
}
}
/**
* set edittext editable
*
* @param isEditable
*/
public void setEditable(boolean isEditable) {
if (!isEditable) {
editTextCFS.setFocusable(false);
editTextCFS.setClickable(false);
editTextCFS.setOnTouchListener((view, motionEvent) -> {
AppEditTextCFSWithRightImage.this.performClick();
return false;
});
}
}
/**
* Set right image
*
* @param inputType
*/
public void setInputType(int inputType) {
if (editTextCFS != null) {
editTextCFS.setInputType(inputType);
}
}
public void setErrorMessage(String errorMessage) {
if (editTextCFS != null) {
editTextCFS.setError(errorMessage);
}
}
public void setEditClickListener(final OnEditClickListener onEditClickListener) {
this.onEditClickListener = onEditClickListener;
if (onEditClickListener != null && editTextCFS != null) {
setOnClickListener(new OnClickListener() {
@Override
public void onClick(View view) {
onEditClickListener.onEditClick(AppEditTextCFSWithRightImage.this, getId());
}
});
}
}
/**
* On Right button click listener
*
* @param onRightButtonClickListener
*/
public void setOnRightButtonClickListener(final OnRightButtonClickListener onRightButtonClickListener) {
this.onRightButtonClickListener = onRightButtonClickListener;
if (tvRightImage != null) {
tvRightImage.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View view) {
CharSequence rightImage = tvRightImage.getText();
if (rightImage != null && getContext().getString(R.string.fa_eye).equals(rightImage)) {
tvRightImage.setText(getContext().getString(R.string.fa_eye_striked));
editTextCFS.setInputType(InputType.TYPE_CLASS_TEXT);
} else if (getContext().getString(R.string.fa_eye_striked).equals(rightImage)) {
editTextCFS.setInputType(InputType.TYPE_CLASS_TEXT | InputType.TYPE_TEXT_VARIATION_PASSWORD);
tvRightImage.setText(getContext().getString(R.string.fa_eye));
}
if (onRightButtonClickListener != null) {
onRightButtonClickListener.onRightButtonClick(AppEditTextCFSWithRightImage.this, getId());
}
}
});
}
}
public void setTextChangeListener(TextWatcher textChangeListener) {
editTextCFS.addTextChangedListener(textChangeListener);
}
public interface OnRightButtonClickListener {
public void onRightButtonClick(View view, int id);
}
public interface OnEditClickListener {
public void onEditClick(View view, int id);
}
}
| fc9a6d431e2153a05c162bfee76bbe1eb961f134 | [
"Java"
] | 9 | Java | kamalnirajb/SparkProfile | 970f40fa7273793239aa8a4654ea5ef6586ab359 | fe29baed75fc5182324910a0f4b3b6da76494ccb |
refs/heads/master | <file_sep># What is the signal-to-noise ratio of phase-contrast imaging? Can it be infinite?
<a href="https://doi.org/10.5281/zenodo.1463273"><img src="https://zenodo.org/badge/DOI/10.5281/zenodo.1463273.svg" alt="DOI"></a>
A scientific publication, describing a puzzle which tackles an apparent paradox in the physics of optical measurement. Read the publication here:
https://calico.github.io/adaptive_interference_inference (hosted via the Calico Labs institutional GitHub account)
or here:
https://andrewgyork.github.io/adaptive_interference_inference (hosted via <NAME>'s personal GitHub account)
This repository holds a self-contained scientific publication. It contains:
* HTML, javascript, CSS, fonts, and images (`index.html`, and the `javascript`, `stylesheets`, `fonts`, and `images` directories)
* A (limited) PDF version of the publication; note that this does not include animated/interactive figures.
* Code which implements part of the puzzle (in the `code` directory). You can run and modify this code to explore the apparent paradox.
<a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/88x31.png" /></a><br />This work is licensed under a <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Creative Commons Attribution 4.0 International License</a>.
<file_sep>#!/usr/bin/python3
# Dependencies from the Scipy stack https://www.scipy.org/stackspec.html :
import numpy as np
class Oracle:
def __init__(self, budget):
assert budget > 0
self.budget = budget
self.total_cost = 0
self.round = 0
self.a_history = []
self.b_history = []
self.r_history = []
self.game_over = False
# Generate some secret numbers.
# Don't peek!
self._magnitude = np.random.random(1)
self._phase = 2*np.pi*np.random.random(1)
self._x = self._magnitude * np.exp(1j*self._phase)
return None
def ask(self, a, b):
if self.game_over:
return None
self.total_cost += np.abs(a)**2
if self.total_cost > self.budget:
self.game_over = True
return None
y = np.abs(a*self._x + b)**2
r = np.random.poisson(y)
self.round += 1
self.a_history.append(a)
self.b_history.append(b)
self.r_history.append(r)
return r
if __name__ == '__main__':
print("An example game")
oracle = Oracle(budget=1000)
print("Budget:", oracle.budget, '\n')
num_phases = 5
for phase_angle in np.arange(0, 2*np.pi, 2*np.pi/num_phases):
print('Round', oracle.round)
a = np.sqrt(oracle.budget / num_phases) * (1 - 1e-12)
b = a * np.exp(1j*phase_angle)
print(' a: %07s (intensity)\n'%('%0.2f'%(np.abs(a)**2)),
' %07s*pi (phase)'%('%0.2f'%(np.angle(a)/np.pi)))
print(' b: %07s (intensity)\n'%('%0.2f'%(np.abs(b)**2)),
' %07s*pi (phase)'%('%0.2f'%(np.angle(b)/np.pi)))
response = oracle.ask(a, b)
print('oracle.ask(a, b):', response)
print('Total cost: %0.2f / %0.2f\n'%(oracle.total_cost,
oracle.budget))
print("Game over.")
print("From these responses, how well can you infer 'x'?")
print("\nIf you'd made smarter choices of 'a' and 'b' on each round,\n",
"could you do a better job inferring 'x'?", sep='')
| 6fc4da5010605c3a8ddeb04d6712cdbb7f5e9830 | [
"Markdown",
"Python"
] | 2 | Markdown | calico/adaptive_interference_inference | 3694f6a3cae916b783c13756f1ef4060cf7d7582 | 2aede0355c4da64233b06b5aac1949f8ff810375 |
refs/heads/master | <file_sep>export class Ride {
departure: string;
arrival: string;
departureTime: Date;
seatsAvailable: number;
pricePerSeat: number;
animalTypeIds: any[] = [];
carTypeId: string;
userId: string;
}<file_sep>
import { HttpClient } from "@angular/common/http";
import { FormGroup } from "@angular/forms";
import { Observable } from "rxjs";
import { environment } from "src/environments/environment";
import { Injectable } from '@angular/core';
import { Ride } from "../models/ride";
@Injectable({
providedIn: 'root'
})
export class RideService {
private apiServerUrl = environment.apiBaseUrl;
public dataForm: FormGroup;
constructor(private http: HttpClient) { }
addRide(ride: Ride): Observable<Object> {
const url = `${this.apiServerUrl}/ride/add-ride`;
return this.http.post(url, ride);
}
getAnimalTypes() {
const url = `${this.apiServerUrl}/ride/animal-types`;
return this.http.get(url);
}
getCarTypes() {
const url = `${this.apiServerUrl}/ride/car-types`;
return this.http.get(url);
}
getAllRides(): Observable<Ride[]> {
const url = `${this.apiServerUrl}/ride/rides`
return this.http.get<Ride[]>(url);
}
getRidesByUserId(userId: string) {
const url = `${this.apiServerUrl}/ride/rides/${userId}`
return this.http.get<Ride[]>(url);
}
}<file_sep>import { User } from './../../models/User';
import { map } from 'rxjs/operators';
import { HttpClient, HttpHeaders } from "@angular/common/http";
import { Injectable } from "@angular/core";
import { Router } from "@angular/router";
import { BehaviorSubject, Observable, of, ReplaySubject } from "rxjs";
import { environment } from "src/environments/environment";
import { FormGroup } from '@angular/forms';
@Injectable({
providedIn: 'root'
})
export class UserService {
private apiServerUrl = environment.apiBaseUrl;
private loginStatus = new BehaviorSubject<boolean>(this.checkLogin());
constructor(private http: HttpClient, private router: Router) { }
loadTokenIntoHeaders(token: string) {
if (token == null || token == "") {
return of(null);
}
let headers = new HttpHeaders();
headers = headers.set('Authorization', `Bearer ${token}`);
return this.http.get(`${this.apiServerUrl}/user/${localStorage.getItem("userEmail")}`, { headers }).pipe(
map(res => {
if (res == true) {
console.log("Trueee!");
// localStorage.setItem("token", user.token);
// localStorage.setItem("userEmail", user.email);
}
}))
}
login(user) {
return this.http.post(`${this.apiServerUrl}/user/login`, user).pipe(
map((user: User) => {
localStorage.setItem("token", user.token);
localStorage.setItem("userEmail", user.email);
this.loginStatus.next(true);
})
)
}
logout() {
localStorage.removeItem('token');
localStorage.removeItem('userEmail');
this.loginStatus.next(false);
}
addUser(values: User): Observable<Object> {
const url = `${this.apiServerUrl}/user/register`;
return this.http.post(url, values);
}
updateUser(values: Object): Observable<Object> {
return this.http.put<Object>(`${this.apiServerUrl}/user/update-user`, values);
}
checkLogin(): boolean {
if (localStorage.getItem('email') != null
&& localStorage.getItem('email') !== ''
&& localStorage.getItem('token') != null
&& localStorage.getItem('token') !== '') {
return true;
} else {
return false;
}
}
get isLoggedIn() {
return this.loginStatus.asObservable();
}
getUserByEmail(email: string) {
return this.http.get(`${this.apiServerUrl}/user/get-user/${email}`);
}
}<file_sep>import { Component, OnInit, ViewChild } from '@angular/core';
import { Router } from '@angular/router';
import { Ride } from 'src/app/models/ride';
import { RideService } from 'src/app/services/ride.service';
import { UserService } from 'src/app/services/user/user.service';
import { MatSelect } from '@angular/material/select';
import { MatOption } from '@angular/material/core';
@Component({
selector: 'app-add-ride',
templateUrl: './add-ride.component.html',
styleUrls: ['./add-ride.component.css']
})
export class AddRideComponent implements OnInit {
newRide: Ride;
animals: any[] = [];
isArray: any[] = [];
cars: any[] = [];
userId: string;
user: any[] = [];
formattedDepartureAddress: string;
formattedArrivalAddress: string;
@ViewChild('select') select: MatSelect;
options = {
strictBounds: false,
bounds: undefined,
types: ['geocode'],
fields: undefined,
origin: undefined,
componentRestrictions: {
country: 'Ro'
}
}
constructor(private rideService: RideService, private userService: UserService, private router: Router) { }
ngOnInit() {
this.newRide = new Ride();
this.rideService.getCarTypes().subscribe((data: []) => {
this.cars.push(data);
})
this.rideService.getAnimalTypes().subscribe((data: []) => {
this.animals.push(data);
for (let animal of this.animals[0]) {
animal.name = animal.name.replace("_", " ");
}
})
this.userService.getUserByEmail(localStorage.getItem("userEmail")).subscribe((data) => {
this.user.push(data);
this.userId = this.user[0].userId;
this.newRide.userId = this.userId;
})
}
allSelected = false;
toggleAllSelection() {
if (this.allSelected) {
this.select.options.forEach((item: MatOption) => item.select());
for (let animal of this.animals[0]) {
let ani = animal.animalId.toString();
if (this.isArray.indexOf(ani) > -1) {
continue;
}
this.isArray.push(animal.animalId.toString());
}
} else {
this.select.options.forEach((item: MatOption) => item.deselect());
this.isArray = [];
}
}
optionClick() {
let newStatus = true;
this.isArray = []
this.select.options.forEach((item: MatOption) => {
if (!item.selected) {
newStatus = false;
}
if (item.selected) {
this.isArray.push(item.value.toString());
}
});
this.allSelected = newStatus;
}
getDeparture(place: any) {
this.formattedDepartureAddress = place.formatted_address;
}
getArrival(place: any) {
this.formattedArrivalAddress = place.formatted_address;
}
addRide() {
this.newRide.departure = this.formattedDepartureAddress;
this.newRide.arrival = this.formattedArrivalAddress;
for (let animal of this.isArray) {
this.newRide.animalTypeIds.push(animal);
}
this.rideService.addRide(this.newRide).subscribe(
data => {
this.newRide = new Ride();
this.router.navigateByUrl("/rides");
}
)
}
}
<file_sep>
import { Ride } from './../../models/ride';
import { Component, OnInit } from '@angular/core';
import { Router } from '@angular/router';
import { RideService } from 'src/app/services/ride.service';
@Component({
selector: 'app-rides',
templateUrl: './rides.component.html',
styleUrls: ['./rides.component.css']
})
export class RidesComponent implements OnInit {
rides: any[];
constructor(private rideService: RideService) { }
ngOnInit() {
this.rideService.getAllRides().subscribe((data: []) => {
this.rides = data;
})
}
getDay(dateTime: string) {
const day = dateTime.split("T");
return day[0];
}
getTime(dateTime: string) {
const time = dateTime.split("T");
return time[1].slice(0, 5);
}
}
<file_sep>import { RideService } from 'src/app/services/ride.service';
import { UserService } from 'src/app/services/user/user.service';
import { Component, OnInit } from '@angular/core';
import { HttpErrorResponse } from '@angular/common/http';
@Component({
selector: 'app-user-profile',
templateUrl: './user-profile.component.html',
styleUrls: ['./user-profile.component.css']
})
export class UserProfileComponent implements OnInit {
user: any;
usersRides: any[] = [];
editedUser: any;
constructor(private userService: UserService, private rideService: RideService) { }
ngOnInit() {
this.getUser();
this.userService.getUserByEmail(localStorage.getItem("userEmail")).subscribe((data) => {
this.user = data;
console.log(this.user);
this.rideService.getRidesByUserId(this.user.userId.toString()).subscribe((data: []) => {
this.usersRides = data;
})
})
}
getUser(): void {
this.userService.getUserByEmail(localStorage.getItem("userEmail")).subscribe((data) => {
this.user = data;
console.log(this.user);
})
}
countRides() {
let counter: number = 0;
if (this.usersRides && this.usersRides.length > 0) {
for (let e of this.usersRides) {
counter++;
}
}
return counter;
}
firstPostedRide() {
let firstDate: string;
if (this.usersRides && this.usersRides.length > 0) {
firstDate = this.usersRides[0].departureTime.split("T");
console.log(firstDate[0]);
}
return firstDate[0];
}
public calculateAge() {
if (this.user.birthDate) {
let birthDate = new Date(this.user.birthDate);
let timeDiff = Math.abs(Date.now() - birthDate.getTime());
return Math.floor((timeDiff / (1000 * 3600 * 24)) / 365);
}
}
updateUser(user: Object): void {
this.userService.updateUser(user).subscribe((response: Object) => {
console.log(response);
this.getUser();
}, (error: HttpErrorResponse) => {
alert(error.message);
}
)
}
onOpenModal(user: Object): void {
const container = document.getElementById("main-container");
const button = document.createElement('button');
button.type = 'button';
button.style.display = "none";
button.setAttribute('data-toggle', 'modal');
this.editedUser = user;
button.setAttribute('data-target', '#updateEmployeeModal');
console.log(this.editedUser);
container.appendChild(button);
button.click();
}
}
<file_sep>import { Router } from '@angular/router';
import { Component, OnInit } from '@angular/core';
import { UserService } from './services/user/user.service';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent implements OnInit {
title = 'woofwoofcarangular';
myLocalStorage;
isLoggedin;
public constructor(private userService: UserService, private router: Router) {
this.myLocalStorage = localStorage;
}
ngOnInit(): void {
this.loadCurrentUser();
}
loadCurrentUser() {
const token = localStorage.getItem('token');
console.log("token from app component : " + token);
this.userService.loadTokenIntoHeaders(token).subscribe(() => {
console.log('loaded user');
}, error => {
console.log(error);
});
}
}
| 2be19da9bf17a8667fc1b3a071294736a47e6cd6 | [
"TypeScript"
] | 7 | TypeScript | KatyIftimie/WoofWoofCarAngular | c439d1776265bcc479864775e904ea5e30e43836 | d84a72912d180654e3fe3d5d1670bdb9dbece372 |
refs/heads/master | <repo_name>dglittle/python-eval<file_sep>/myutil.py
from time import time
import hashlib
import random
from google.appengine.api import memcache
import string
from google.appengine.ext import blobstore
from google.appengine.ext.blobstore import *
from google.appengine.ext.webapp import blobstore_handlers
from google.appengine.ext import db
from google.appengine.ext.db import *
from google.appengine.ext import webapp
from google.appengine.ext.webapp.util import run_wsgi_app
from google.appengine.ext.webapp import template
from google.appengine.api import *
from google.appengine.api.images import *
from google.appengine.api.channel import *
from google.appengine.api import images
from google.appengine.api import taskqueue
def getRaw(o, key):
return eval("o.__class__." + key + ".get_value_for_datastore(o)")
def getKey(x):
if isinstance(x, Key):
return x
if isinstance(x, db.Model):
return x.key()
error("could not get key from: " + str(x))
def myShuffle(a):
random.shuffle(a)
return a
def getJso(o, props):
jso = dict([(p, eval('o.' + p)) for p in props])
jso["key"] = str(o.key())
return jso
def error(msg):
raise BaseException(msg)
def myMemcache(key, func):
val = memcache.get(key)
if val is not None:
return val
else:
val = func()
memcache.set(key, val)
return val
def randomId(n=20):
chars = string.ascii_lowercase + string.digits
return ''.join(random.choice(chars) for r in range(n))
def myIndex(a, v):
try:
return a.index(v)
except ValueError:
return -1
def myRemove(a, v):
try:
a.remove(v)
except ValueError:
pass
def setAppend(a, v):
if myIndex(a, v) < 0:
a.append(v)
def mytime():
return int(time.time() * 1000)
def tsv(data, fields):
return "\n".join([
"\t".join([row[f] for f in fields]) if row != 0 else "0"
for row in data
])
# winner = winner's elo score
# loser = loser's elo score
# p = 0..1 (how sure are we that the winner won?)
# returns two values,
# these are deltas that should be applied
# to the elo scores of the winner and loser
def eloDeltas(winner, loser, p):
Rw = winner
Rl = loser
Qw = 10**(Rw / 400)
Ql = 10**(Rl / 400)
Ew = Qw / (Qw + Ql)
El = Ql / (Qw + Ql)
Sw = 1
Sl = 0
K = 32 * p
return (K * (Sw - Ew)), (K * (Sl - El))
def sha1(s):
return hashlib.sha1(s).hexdigest()
<file_sep>/api.py
import logging
import os
from urlparse import urlparse
import random
import base64
from google.appengine.ext import blobstore
from google.appengine.ext.blobstore import *
from google.appengine.ext.webapp import blobstore_handlers
from google.appengine.ext import db
from google.appengine.ext.db import *
from google.appengine.ext import webapp
from google.appengine.ext.webapp.util import run_wsgi_app
from google.appengine.ext.webapp import template
from google.appengine.api import *
from google.appengine.api.images import *
from google.appengine.api.channel import *
from google.appengine.api import images
from google.appengine.api import taskqueue
from myutil import *
class MyHandler(webapp.RequestHandler):
def get(self):
self.go()
def post(self):
self.go()
def go(self):
ret = []
def output(a):
ret.append(str(a))
exec(self.request.get("code")) in globals(), locals()
self.response.headers['Content-Type'] = 'text/html'
self.response.out.write('\n'.join(ret))
application = webapp.WSGIApplication([
('/.*', MyHandler),
], debug = True)
def main():
run_wsgi_app(application)
if __name__ == "__main__":
main()
| 5b7dfd17a795ba3dc1c7385f0689a556cd55b733 | [
"Python"
] | 2 | Python | dglittle/python-eval | 1b38d8a176858442c6a62559dcbb36499116418e | 0b5a9e69fb376e9d1d59695444af19e68896432e |
refs/heads/master | <repo_name>stuarth/capped-hyper<file_sep>/examples/simple.rs
extern crate capped_hyper;
extern crate futures;
extern crate hyper;
extern crate tokio_core;
// use capped_hyper::Client;
use capped_hyper as ch;
use futures::{future, Future, Stream};
use hyper::{Body, Client, Error, Request};
use std::io::{self, Write};
use tokio_core::reactor::Core;
pub fn main() -> Result<(), Error> {
let mut core = Core::new().unwrap();
let client = Client::new();
let capped = ch::CappedClient::new(client, 2);
let uris = vec![
"http://worldclockapi.com/api/json/utc/now",
"http://worldclockapi.com/api/json/utc/now",
"http://worldclockapi.com/api/json/utc/now",
];
let work = uris.into_iter().map(|uri| {
let uri: hyper::Uri = uri.parse().unwrap();
let req = Request::get(uri).body(Body::empty()).expect("req");
capped.request(req).and_then(move |res| {
println!("Response: {}", &res.status());
res.into_body()
.for_each(|chunk| io::stdout().write_all(&chunk).map_err(|_e| panic!(":(")))
})
});
let _ = core.run(future::join_all(work));
Ok(())
}
<file_sep>/src/lib.rs
extern crate futures;
extern crate hyper;
use futures::{
prelude::*,
task::{self, Task},
};
use std::{
collections::VecDeque,
sync::{Arc, Mutex},
};
pub struct CappedClient<C> {
client: Client<C>,
max: u32,
state: State,
}
pub use hyper::{
body::Body,
client::{connect::Connect, ResponseFuture},
Client, Request, Response,
};
#[derive(Clone)]
struct State(Arc<Mutex<ClientState>>);
impl Default for State {
fn default() -> Self {
State(Arc::new(Mutex::new(ClientState {
in_flight: 0,
queue: VecDeque::new(),
})))
}
}
struct ClientState {
in_flight: u32,
queue: VecDeque<Task>,
}
impl ClientState {
fn queue_task(&mut self, task: Task) {
self.queue.push_back(task);
}
fn notify_next(&mut self) {
if let Some(task) = self.queue.pop_front() {
task.notify();
}
}
}
pub struct CappedFuture {
inner: ResponseFuture,
state: State,
max: u32,
queued: bool,
}
impl Future for CappedFuture {
type Item = Response<Body>;
type Error = hyper::Error;
fn poll(&mut self) -> Poll<Self::Item, Self::Error> {
if self.queued {
let mut s = match self.state.0.try_lock() {
Ok(s) => s,
Err(_) => {
return Ok(Async::NotReady);
}
};
let current = s.in_flight;
if current == self.max {
s.queue_task(task::current());
return Ok(Async::NotReady);
} else {
self.queued = false;
s.in_flight += 1;
}
}
match self.inner.poll() {
Ok(Async::Ready(response)) => {
if let Ok(mut s) = self.state.0.try_lock() {
s.in_flight -= 1;
s.notify_next();
Ok(Async::Ready(response))
} else {
Ok(Async::NotReady)
}
}
other @ _ => other,
}
}
}
impl<C: Connect + 'static> CappedClient<C> {
pub fn new(client: hyper::Client<C>, max: u32) -> Self {
CappedClient {
client,
max,
state: State::default(),
}
}
pub fn request(&self, req: Request<Body>) -> CappedFuture {
let inner = self.client.request(req);
CappedFuture {
inner,
state: self.state.clone(),
max: self.max,
queued: true,
}
}
}
| 03470e93c4a7d32263acc7189528a0162e32695b | [
"Rust"
] | 2 | Rust | stuarth/capped-hyper | c76506ecaf43418e9f623fad6436532351ab4526 | 3c6ca8dd01c4f471dc441c699764c49a26a25f56 |
refs/heads/master | <repo_name>sangramkonde/RetailPro<file_sep>/RetailManager/src/main/java/shop/retail/service/ShopLocatorImpl.java
package shop.retail.service;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import shop.retail.Config;
import shop.retail.RetailMessages;
import shop.retail.dao.RetailShopDao;
import shop.retail.exception.RetailManagerException;
import shop.retail.models.Shop;
import shop.retail.models.ShopAddress;
import com.google.maps.GeoApiContext;
import com.google.maps.GeocodingApi;
import com.google.maps.model.GeocodingResult;
import com.google.maps.model.LatLng;
/**
*
* @author Sangram
*
*/
@Service
public class ShopLocatorImpl implements ShopLocator {
private static final Logger logger = LoggerFactory
.getLogger(ShopLocatorImpl.class);
@Autowired
private RetailShopDao retailShopDao;
@Override
public Shop getShopById(long id) {
return retailShopDao.getShopById(id);
}
@Override
public Shop addShop(Shop shop) {
validate(shop);
Shop oldShop = retailShopDao.shopExists(shop.getShopName());
// Query string for the Geo API
ShopAddress shop_address = shop.getShopAddress();
StringBuilder address = new StringBuilder(shop_address.getNumber())
.append(",").append(shop_address.getPostCode());
// Get the latitude & longitude
LatLng location = geoApiResolver(address.toString());
shop_address.setShopLatitude(location.lat);
shop_address.setShopLongitude(location.lng);
Shop newShop = null;
if (null != oldShop) {
shop.setShopId(oldShop.getShopId());
newShop=retailShopDao.updateShop(shop);
newShop.setOldShopAddress(oldShop.getShopAddress());
} else {
newShop = retailShopDao.addShop(shop);
}
return newShop;
}
@Override
public Shop findNearest(String longitude, String latitude) throws RetailManagerException {
try {
LatLng location = new LatLng(Double.parseDouble(latitude), Double.parseDouble(longitude));
List<Shop> shops = getAll();
if (shops == null || shops.isEmpty()) {
logger.info(RetailMessages.NO_SHOPS_ADDED);
throw new RetailManagerException(RetailMessages.NO_SHOPS_ADDED);
}
double nearest = Double.MAX_VALUE;
double temp = 0;
Shop nearest_shop = shops.get(0);
for (Shop shop : shops) {
temp = calculateDistance(location, new LatLng(shop
.getShopAddress().getShopLatitude(), shop
.getShopAddress().getShopLongitude()));
if (temp < nearest) {
nearest = temp;
nearest_shop = shop;
}
}
if (nearest == 0.0) {
logger.info("Found shop with an exact location match.");
}
return nearest_shop;
} catch (NumberFormatException e) {
logger.error(RetailMessages.INVALID_LOCATION + " - " + longitude+ ", " + latitude, e);
throw new RetailManagerException(RetailMessages.INVALID_LOCATION);
} catch (RetailManagerException rmse) {
throw rmse;
} catch (Exception e) {
logger.error(RetailMessages.ERROR_SHOP + latitude + ", "+ longitude, e);
throw new RetailManagerException(RetailMessages.SERVICE_UNAVAILABLE);
}
}
@Override
public List<Shop> getAll() {
return retailShopDao.getAll();
}
public static LatLng geoApiResolver(String address_in_one_line)
throws RetailManagerException {
Config.loadProperties();
GeoApiContext context = new GeoApiContext()
.setApiKey(Config.GEO_API_KEY);
try {
GeocodingResult result = GeocodingApi.geocode(context,
address_in_one_line).await()[0];
LatLng location = result.geometry.location;
return location;
} catch (Exception e) {
logger.error("Error while fetching data from google geo api.", e);
throw new RetailManagerException(RetailMessages.GEO_LOCATION_ERROR);
}
}
private Double calculateDistance(LatLng l1, LatLng l2)
throws RetailManagerException {
double theta = l1.lng - l2.lng;
double distance = Math.sin(deg2rad(l1.lat)) * Math.sin(deg2rad(l2.lat))
+ Math.cos(deg2rad(l1.lat)) * Math.cos(deg2rad(l2.lat))
* Math.cos(deg2rad(theta));
distance = Math.acos(distance);
distance = rad2deg(distance);
return distance * 60 * 1.1515;
}
private double deg2rad(double deg) {
return (deg * Math.PI / 180.0);
}
private double rad2deg(double rad) {
return (rad * 180 / Math.PI);
}
private void validate(Shop shop) {
if (shop == null || shop.getShopAddress() == null
|| shop.getShopAddress().getNumber() == null
|| shop.getShopAddress().getPostCode() == 0) {
logger.debug("Invalid shop - " + shop);
throw new RetailManagerException(RetailMessages.INVALID_SHOP);
}
}
@Override
public void deleteShop(long shopId) {
retailShopDao.deleteShop(shopId);
}
}
<file_sep>/RetailManager/src/main/java/shop/retail/dao/RetailShopDao.java
package shop.retail.dao;
import java.util.List;
import shop.retail.models.Shop;
/**
* @author Sangram
*
*/
public interface RetailShopDao {
public Shop addShop(Shop shop);
public Shop getShopById(long id);
public Shop shopExists(String shopName);
public Shop updateShop(Shop shop);
public void deleteShop(long shopId);
public Shop findNearest(String longitude, String latitude);
public List<Shop> getAll();
}
<file_sep>/RetailManager/src/main/java/shop/retail/models/ServiceResponse.java
package shop.retail.models;
/**
* This is a class where we returns 'success' as status
* @author Sangram
*
*/
public class ServiceResponse {
private Boolean success;
private String shop_status;
/**
* Gets the 'success' as a status of this service.
* @return 'success'.
*/
public Boolean getSuccess() {
return success;
}
/**
* Initializes status = 'success' for the given service.
*/
public ServiceResponse(Boolean success) {
this.success = success;
}
/**
* Initializes status = 'New shop added' for the given service.
* @param shop_status
* @param success
*/
public ServiceResponse(Boolean success,String shop_status) {
this.success = success;
this.shop_status = shop_status;
}
/**
* Sets the status of this service.
* @param success
*/
public void setSuccess(Boolean success) {
this.success = success;
}
public String getShopStatus() {
return shop_status;
}
public void setShopStatus(String shop_status) {
this.shop_status = shop_status;
}
}
<file_sep>/RetailManager/src/test/java/shop/retail/models/ModelTest.java
package shop.retail.models;
import com.google.maps.model.LatLng;
import shop.retail.BaseTest;
import shop.retail.service.ShopLocator;
import com.fasterxml.jackson.core.JsonProcessingException;
import org.json.JSONException;
import org.json.JSONObject;
import org.junit.Assert;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.skyscreamer.jsonassert.JSONAssert;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
/**
* @author Sangram
*
*/
//@RunWith(SpringJUnit4ClassRunner.class)
public class ModelTest extends BaseTest{
/*@Autowired
private ShopLocator shopLocator;
@Test
public void testShop() throws JsonProcessingException, JSONException {
Shop shop = new Shop();
ShopAddress shopAddress = new ShopAddress();
shop.setShopName("DMART Shop");
shopAddress.setNumber("222891");
shopAddress.setPostCode(411009);
shopAddress.setShopLatitude(18.5793);
shopAddress.setShopLongitude(73.9823);
shop.setShopAddress(shopAddress);
// shop.setShopLongitude(18.5793);
// shop.setShopLatitude(73.9823);
String expected = "{\"shopName\":\"DMART Shop\",\"shopAddress\":{\"number\":\"222891\"," +
"\"postCode\":411009},\"shopLatitude\":73.9823,\"shopLongitude\":18.5793}";
String actual = objectMapper.writeValueAsString(shop);
//JSONObject actuaObject = new JSONObject(actual);
JSONAssert.assertEquals(expected, actual, false);
Shop shop2 = new Shop();
shop2.setShopName("DMART Shop");
shop2.setShopAddress(new Shop.ShopAddress("222891", 411009));
shop2.setShopLongitude(18.5793);
shop2.setShopLatitude(73.9823);
Shop shop2 = new Shop();
ShopAddress shopAddress2 = new ShopAddress();
shop2.setShopName("DMART Shop");
shopAddress2.setNumber("222891");
shopAddress2.setPostCode(411009);
shopAddress2.setShopLatitude(18.5793);
shopAddress2.setShopLongitude(73.9823);
shop2.setShopAddress(shopAddress2);
boolean test = shop.equals(shop2);
assert(shop.equals(shop2));
shop2.setShopName("dmart shop");
assert(!shop.equals(shop2));
}
@Test
public void testShopInMemoryArray() {
// ShopInMemoryArray shopInMemoryArray = new ShopInMemoryArray();
Shop shop = new Shop();
ShopAddress shopAddress = new ShopAddress();
shop.setShopName("DMART Shop");
shop.setShopId(1);
shopAddress.setNumber("222891");
shopAddress.setPostCode(411009);
shopAddress.setShopLatitude(18.5793);
shopAddress.setShopLongitude(73.9823);
shop.setShopAddress(shopAddress);
shopLocator.addShop(shop);
Assert.assertTrue(shop.equals(shopLocator.getShopById(1)));
Shop shop2 = new Shop();
ShopAddress shopAddress2 = new ShopAddress();
shop2.setShopName("DMART Shop");
shop2.setShopId(2);
shopAddress2.setNumber("222891");
shopAddress2.setPostCode(411009);
shopAddress2.setShopLatitude(18.5793);
shopAddress2.setShopLongitude(73.9823);
shop2.setShopAddress(shopAddress2);
shopLocator.addShop(shop);
Assert.assertTrue(shopLocator.getAll().size() == 2);
shopLocator.deleteShop(shop.getShopId());
Assert.assertTrue(shopLocator.getAll().size() == 1);
Assert.assertTrue(shop2.equals(shopLocator.getShopById(shop2.getShopId())));
shopLocator.deleteShop(shop.getShopId());
Assert.assertTrue(shopLocator.getAll().size() == 0);
}*/
}
<file_sep>/RetailManager/src/main/java/shop/retail/models/Shop.java
package shop.retail.models;
import javax.persistence.CascadeType;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.OneToOne;
import javax.persistence.Table;
import javax.persistence.Transient;
import javax.validation.constraints.NotNull;
import com.fasterxml.jackson.annotation.JsonInclude;
/**
*
* Represents a Shop located across the geographical region. A shop can be
* registered on the basis on address, name, number and postcode .
*
* @author Sangram
*
*/
@Entity
@Table(name = "shop")
public class Shop {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "shop_id")
private long shopId;
@Column(name = "shop_name", unique = true)
private String shopName;
@NotNull
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "shop_address_id")
private ShopAddress shopAddress;
@Transient
@JsonInclude(value= JsonInclude.Include.NON_NULL)
private ShopAddress oldShopAddress;
public long getShopId() {
return shopId;
}
public void setShopId(long shopId) {
this.shopId = shopId;
}
/**
* Gets the name of the shop
*
* @return shopName.
*/
public String getShopName() {
return shopName;
}
/**
* Sets the name of the shop.
*
* @param shopName
*/
public void setShopName(String shopName) {
this.shopName = shopName;
}
/**
* Gets the address of the shop
*
* @return shopAddress.
*/
public ShopAddress getShopAddress() {
return shopAddress;
}
/**
* Sets the address of the shop.
*
* @param shopAddress
*/
public void setShopAddress(ShopAddress shopAddress) {
this.shopAddress = shopAddress;
}
public ShopAddress getOldShopAddress() {
return oldShopAddress;
}
public void setOldShopAddress(ShopAddress oldShopAddress) {
this.oldShopAddress = oldShopAddress;
}
@Override
public String toString() {
return "Shop [shopId=" + shopId + ", shopName=" + shopName
+ ", shopAddress=" + shopAddress + "]";
}
}
<file_sep>/README.md
# RetailPro
This is a test repository to improve the retail shop application
<file_sep>/RetailManager/src/test/java/shop/retail/BaseTest.java
package shop.retail;
import shop.retail.service.ShopLocator;
import shop.retail.service.ShopLocatorImpl;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
/**
* @author Sangram
*
*/
@ContextConfiguration({"/test-context.xml"})
public class BaseTest {
@Autowired
protected ObjectMapper objectMapper;
@Autowired
protected ShopLocator shopLocator;
}
<file_sep>/RetailManager/bin/messages.properties
application.running.success = "Retail-manager is running!"<file_sep>/RetailManager/src/main/java/shop/retail/ApplicationLauncher.java
package shop.retail;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* This is the class where we launch the retail manager application
* To run it, here we have used spring boot
* @author Sangram
*
*/
@SpringBootApplication
public class ApplicationLauncher {
public static void main(String[] args) {
SpringApplication.run(ApplicationLauncher.class, args);
System.out.println(RetailMessages.SUCCESS);
}
}
<file_sep>/RetailManager/README.md
# Spring Boot "Retail Manager" Project
This is a simple Java / Gradle / Spring Boot application that can be used to develop a working prototype which satisfies
a Retail Manager that wanting to keep track of their shops.
# About the Service
The service is for retail manager to keep track of their shops, does a RESTful POST to /shops with a JSON of shopName, shopAddress.number and
shopAddress.postCode
to the Shops API (microservice) where shops are stored in memory. Permanent persistence of the data is not required.
The application can be used by multiple users at a time (no login functionality is required). Shops are identified by their unique names.
If user A adds a shop that was already added by user B, the service should replace previous version and REST response to user A should contain
information about the version that was replaced. If two users submit a shop at the same time, exactly one of them should get
information about replacing another version of the shop. Whenever a shop is added the service calls the Google Maps API.
The Google Maps API responds with the longitude and latitude, which allows the shop data to be updates with longitude and latitude.
A customer, using their geolocation on their phone, wants to find the store that is closest to them.
The Shops API will have the customerís longitude and latitude, but also the longitude and latitude of each shop to do the calculation.
The customer does a RESTful GET to the Shops API, providing their current longitude and latitude (e.g. URL request params), and gets back the address,
longitude and latitude of the shop nearest to them.
# How to Run
This application is packaged as a jar. You run it using the ```java -jar``` command.
* Clone this repository
* Make sure you are using JDK 1.8 and Gradle 3.x
* You can build the project and run the tests by running ```gradle build```
* Once successfully built, you can run the service by below commands :
java -jar <path>\retail-manager\build\libs\retail-manager-1.0.jar
OR
gradle run
Once the application runs you should see something like this
````````
2017-06-25 23:18:12.384 INFO 11324 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8080 (http)
2017-06-25 23:18:12.390 INFO 11324 --- [ main] shop.retail.main.ApplicationLauncher : Started ApplicationLauncher in 5.991 seconds (JVM running for 6.919)
````````
Here are some endpoints you can call:
Swagger URL :
http://localhost:8080/swagger-ui.html
================================================
API 1 : Add shop information to in-memory.
================================================
URI : /shop
Method : POST
Request :
{
"shopName": "DMART, Pune",
"shopAddress": {
"number": "Pune-Banglure Hwy, Pune",
"postCode": 411009
}
}
Response : 201 Created
{
"success": true,
"shopStatus": "New shop has been added successfully"
}
================================================
API 2 : To get the nearest shop
================================================
URI : /shop/find
Query Param :
customerLatitude=18.57
customerLongitude=73.76
Method : GET
Response : 200 OK
{
"shopName": "DMART, Pune",
"shopAddress": {
"number": "Pune-Banglure Hwy, Pune",
"postCode": 411009
},
"shopLatitude": 18.4865732,
"shopLongitude": 73.85747620000001
}
# About Spring Boot
Spring Boot is an "opinionated" application bootstrapping framework that makes it easy to create new RESTful services (among other types of applications).
It provides many of the usual Spring facilities that can be configured easily usually without any XML.
In addition to easy set up of Spring Controllers, Spring Data, etc. Spring Boot comes with the Actuator module that gives the application
the following endpoints helpful in monitoring and operating the service: | 0e5bf2afaa790381fbf9f5a944a43a5ecb35a9cc | [
"Markdown",
"Java",
"INI"
] | 10 | Java | sangramkonde/RetailPro | 3c77f2f4fa57b1e21d1e2108726815b1053f43f3 | ae99efef16d6e674e81ec6dd9b1864e74475cbc6 |
refs/heads/master | <repo_name>hoanhnv/Owin<file_sep>/README.md
Owin
====
<file_sep>/Owin.Web/Startup.cs
using Nancy.Owin;
using Owin.Web.App_Start;
namespace Owin.Web
{
public partial class Startup
{
public void Configuration(IAppBuilder app)
{
ConfigureApi(app);
app.UseNancy(new NancyOptions { Bootstrapper = new NancyBootstrapper() });
app.UseHandlerAsync((req, res) =>
{
res.ContentType = "text/plain";
return res.WriteAsync("OWIN Web Application Final step");
});
}
}
}<file_sep>/Owin.Web/Models/Api/Person.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Runtime.Serialization;
using System.Web;
namespace Owin.Web.Models.Api
{
[DataContract]
public class Person
{
[DataMember(Order= 1)]
public int Id { get; set; }
[DataMember(Order = 2)]
public string Name { get; set; }
}
}<file_sep>/Owin.Domain.Tests/LinqToExcelTests.cs
using System;
using System.Linq;
using System.Runtime.InteropServices;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using Should.Fluent;
namespace Owin.Domain.Tests
{
[TestClass]
public class LinqToExcelTests
{
private const string excelFileName = @"files\price.xls";
[TestMethod]
public void InitFactoryTest()
{
var reader = new ExcelReader();
var result = reader.GetProductsFromFile(excelFileName);
var resultArray = result.ToArray();
resultArray.Should().Not.Be.Null()
.Should().Count.AtLeast(1);
}
}
}
<file_sep>/Owin.Domain/ExcelReader.cs
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using LinqToExcel;
using LinqToExcel.Query;
using Owin.Domain.Entities;
using Remotion.Data.Linq.Parsing.Structure.IntermediateModel;
namespace Owin.Domain
{
public class ExcelReader : ISourceReader
{
public IEnumerable<Product> GetProductsFromFile(string filename)
{
var excel = new ExcelQueryFactory(filename);
var worksheetNames = excel.GetWorksheetNames().ToArray();
//
//Mapping
//
for (int i = 0; i < worksheetNames.Length; i++)
{
var columnNames = excel.GetColumnNames(worksheetNames[i]);
var titleRow = FindTitleRow(excel.WorksheetNoHeader(worksheetNames[i]));
var codeIndex = 0;
var priceIndex = GetColumnIndex(titleRow, "Price");
bool skip = true;
foreach (var product in excel.WorksheetNoHeader(worksheetNames[i])
.Where(x => x[codeIndex] != ""))
{
if (skip)
{
skip = product[codeIndex].ToString().Trim() != "No.:";
continue;
}
yield return
new Product
{
Code = product[codeIndex].ToString().Trim(),
Price = product[priceIndex].Cast<decimal>()
};
}
}
}
private int GetColumnIndex(List<Cell> titleRow, string title)
{
return titleRow.FindIndex(c => c.ToString() == title);
}
private RowNoHeader FindTitleRow(IQueryable<RowNoHeader> rows)
{
return rows.FirstOrDefault(row => row[0] == "Item");
}
}
public interface ISourceReader
{
IEnumerable<Product> GetProductsFromFile(string filename);
}
}
<file_sep>/Owin.Web/App_Start/Startup.cs
using System.Web.Http;
using Owin;
namespace Owin.Web
{
public partial class Startup
{
public void ConfigureApi(IAppBuilder app)
{
WebApiConfig.Register(GlobalConfiguration.Configuration);
app.UseWebApi(GlobalConfiguration.Configuration);
}
private void ConfigureMvc(IAppBuilder app)
{
}
}
}<file_sep>/Owin.Web/Controllers/Api/FilesController.cs
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Net;
using System.Net.Http;
using System.Threading.Tasks;
using System.Web.Http;
using Owin.Data;
using Owin.Domain;
using Owin.Domain.Entities;
namespace Owin.Web.Controllers.Api
{
public class FilesController : ApiController
{
private readonly ISourceReader _excelReader;
private HttpClient _httpClient;
public FilesController()
{
_excelReader = new ExcelReader();
}
public async Task<HttpResponseMessage> Post()
{
if (!Request.Content.IsMimeMultipartContent())
{
return Request.CreateErrorResponse(HttpStatusCode.UnsupportedMediaType, "please submit a valid request");
}
var provider = new MultipartMemoryStreamProvider();
try
{
await Request.Content.ReadAsMultipartAsync(provider);
var file = provider.Contents.FirstOrDefault(x => !string.IsNullOrEmpty(x.Headers.ContentDisposition.FileName));
if (file != null)
{
InitHttpClient();
var stream = file.ReadAsStreamAsync().Result;
var filename = SaveFile(stream);
var products = _excelReader.GetProductsFromFile(filename);
var productsWithChangedProperties = FindProductsWithChangedProperties(products);
return Request.CreateResponse(HttpStatusCode.OK, productsWithChangedProperties, "application/json");
}
return Request.CreateErrorResponse(HttpStatusCode.NotFound, "Неверный файл");
}
catch (System.Exception e)
{
return Request.CreateErrorResponse(HttpStatusCode.InternalServerError, e);
}
}
private void InitHttpClient()
{
_httpClient=new HttpClient {BaseAddress = new Uri("http://www.cameronsino.net")};
var content = new FormUrlEncodedContent(new[]
{
new KeyValuePair<string, string>("Username", "slavakis"),
new KeyValuePair<string, string>("Password", "<PASSWORD>"),
new KeyValuePair<string, string>("text", "9384"),
new KeyValuePair<string, string>("checkCode", "9384")
});
var result = _httpClient.PostAsync("/", content).Result;
}
private string SaveFile(Stream stream)
{
var filename = Path.GetTempFileName();
using (var tmpFile = File.OpenWrite(filename))
{
stream.CopyTo(tmpFile);
}
return filename;
}
private IEnumerable<Product> FindProductsWithChangedProperties(IEnumerable<Product> products)
{
IList<Product> productsInDatabase;
using (var context = new DatabaseContext("DatabaseContext"))
{
productsInDatabase = context.Products.AsNoTracking().ToList();
}
var taskList = new List<Task<Product>>();
foreach (var task in products
.Select(product => new Task<Product>(o => ProductTask((Product) o, productsInDatabase)
, product)))
{
task.Start();
taskList.Add(task);
}
var taskArray = taskList.ToArray();
Task.WaitAll(taskArray);
return taskArray.Select(task => task.Result).Where(result => result != null);
}
private Product ProductTask(Product product, IEnumerable<Product> products)
{
var productInDatabase = products.FirstOrDefault(x => x.Code == product.Code);
if (productInDatabase == null) return product;
if (HasDifferences(product, productInDatabase))
{
product.Id = productInDatabase.Id;
product.OldPrice = productInDatabase.Price;
return product;
}
return null;
}
private static bool HasDifferences(Product product, Product productInDatabase)
{
return true; // product.Price != productInDatabase.Price;
}
}
}<file_sep>/Owin.Web/Formatters/ServiceStackJsonFormatter.cs
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Net;
using System.Net.Http.Formatting;
using System.Net.Http.Headers;
using System.Reflection;
using System.Text;
using System.Threading.Tasks;
using Nancy;
using Nancy.ModelBinding;
using ServiceStack.Text;
using JsonSerializer = ServiceStack.Text.JsonSerializer;
namespace Owin.Web.Formatters
{
public class ServiceStackJsonFormatter : MediaTypeFormatter, ISerializer,IBodyDeserializer
{
public ServiceStackJsonFormatter()
{
JsConfig.DateHandler = JsonDateHandler.ISO8601;
SupportedMediaTypes.Add(new MediaTypeHeaderValue("application/json"));
SupportedEncodings.Add(new UTF8Encoding(encoderShouldEmitUTF8Identifier: false, throwOnInvalidBytes: true));
SupportedEncodings.Add(new UnicodeEncoding(bigEndian: false, byteOrderMark: true, throwOnInvalidBytes: true));
}
public override bool CanReadType(Type type)
{
if (type == null) throw new ArgumentNullException("type");
return true;
}
public override bool CanWriteType(Type type)
{
if (type == null) throw new ArgumentNullException("type");
return true;
}
public bool CanSerialize(string contentType)
{
return IsJson(contentType);
}
public bool CanDeserialize(string contentType, BindingContext context)
{
return CanSerialize(contentType);
}
public IEnumerable<string> Extensions
{
get { yield return "json"; }
}
public override Task<object> ReadFromStreamAsync(Type type, Stream readStream, System.Net.Http.HttpContent content, IFormatterLogger formatterLogger)
{
var task = Task<object>.Factory.StartNew(() => JsonSerializer.DeserializeFromStream(type, readStream));
return task;
}
public override Task WriteToStreamAsync(Type type, object value, Stream writeStream, System.Net.Http.HttpContent content, TransportContext transportContext)
{
var task = Task.Factory.StartNew(() => JsonSerializer.SerializeToStream(value, type, writeStream));
return task;
}
public void Serialize<TModel>(string contentType, TModel model, Stream outputStream)
{
JsonSerializer.SerializeToStream(model, outputStream);
}
public object Deserialize(string contentType, Stream bodyStream, BindingContext context)
{
var deserializedObject = JsonSerializer.DeserializeFromStream(context.DestinationType, bodyStream);
if (context.DestinationType.GetProperties(BindingFlags.Public | BindingFlags.Instance).Except(context.ValidModelProperties).Any())
{
return CreateObjectWithBlacklistExcluded(context, deserializedObject);
}
return deserializedObject;
}
private object CreateObjectWithBlacklistExcluded(BindingContext context, object deserializedObject)
{
var returnObject = Activator.CreateInstance(context.DestinationType);
foreach (var property in context.ValidModelProperties)
{
CopyPropertyValue(property, deserializedObject, returnObject);
}
return returnObject;
}
private void CopyPropertyValue(PropertyInfo property, object sourceObject, object destinationObject)
{
property.SetValue(destinationObject, property.GetValue(sourceObject, null), null);
}
private static bool IsJson(string contentType)
{
if (string.IsNullOrEmpty(contentType))
{
return false;
}
var contentMimeType = contentType.Split(';')[0];
return contentMimeType.Equals("application/json", StringComparison.InvariantCultureIgnoreCase) ||
contentMimeType.Equals("text/json", StringComparison.InvariantCultureIgnoreCase) ||
(contentMimeType.StartsWith("application/vnd", StringComparison.InvariantCultureIgnoreCase) &&
contentMimeType.EndsWith("+json", StringComparison.InvariantCultureIgnoreCase));
}
}
}<file_sep>/Owin.Web/IndexModule.cs
using System;
using System.Dynamic;
using Nancy;
using Nancy.Authentication.Forms;
using Nancy.Extensions;
using Nancy.Security;
using Owin.Web.Authentication.Forms;
using Owin.Web.Models;
namespace Owin.Web
{
public class IndexModule : NancyModule
{
public IndexModule()
{
Get["/"] = _ =>
{
//this.RequiresAuthentication();
var indexViewModel = new IndexViewModel
{
UserName = "no",//Context.CurrentUser.UserName,
Title = "База Батареек"
};
return View[indexViewModel];
};
Get["/login"] = x =>
{
dynamic model = new ExpandoObject();
model.Errored = Request.Query.error.HasValue;
return View["login", model];
};
Post["/login"] = x =>
{
var userGuid = UserMapper.ValidateUser((string)Request.Form.Username, (string)Request.Form.Password);
if (userGuid == null)
{
return Context.GetRedirect("~/login?error=true&username=" + (string)Request.Form.Username);
}
DateTime? expiry = null;
if (Request.Form.RememberMe.HasValue)
{
expiry = DateTime.Now.AddDays(7);
}
return this.LoginAndRedirect(userGuid.Value, expiry);
};
Get["/logout"] = x => this.LogoutAndRedirect("~/");
}
}
}<file_sep>/Owin.Web/App_Start/WebApiConfig.cs
using System.Web.Http;
using Owin.Web.Formatters;
namespace Owin.Web
{
public static class WebApiConfig
{
public static void Register(HttpConfiguration config)
{
var index = config.Formatters.IndexOf(config.Formatters.JsonFormatter);
config.Formatters.RemoveAt(index);
config.Formatters.Insert(index, new ServiceStackJsonFormatter()); // //Content-Type: application/json
config.Formatters.Add(new ProtoBufFormatter()); //Content-Type: application/x-protobuf
config.Routes.MapHttpRoute(
name: "DefaultApi",
routeTemplate: "api/{controller}/{id}",
defaults: new { id = RouteParameter.Optional }
);
}
}
}
<file_sep>/Owin.Web.Tests/UnitTest1.cs
using System;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using Should;
namespace Owin.Web.Tests
{
[TestClass]
public class UnitTest1
{
[TestMethod]
public void TestMethod1()
{
new object().ShouldNotBeNull();
}
}
}
<file_sep>/Owin.Data/DatabaseContext.cs
using System.Data.Entity;
using System.Data.Entity.ModelConfiguration;
using Owin.Domain.Entities;
namespace Owin.Data
{
public class DatabaseContext : DbContext
{
public DbSet<Product> Products { get; set; }
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
modelBuilder.Configurations.Add(new ProductConfiguration());
base.OnModelCreating(modelBuilder);
}
public DatabaseContext() { }
public DatabaseContext(string connectionString) : base(connectionString) { }
}
internal class ProductConfiguration : EntityTypeConfiguration<Product>
{
public ProductConfiguration()
{
ToTable("items");
Property(p => p.Id).HasColumnName("ID");
HasKey(p => p.Id);
Property(p => p.Code).HasColumnName("name");
Property(p => p.Price).HasColumnName("price");
Ignore(p => p.OldPrice);
}
}
}
<file_sep>/Owin.Web/App_Start/NancyBootstrapper.cs
using Nancy;
using Nancy.Authentication.Forms;
using Nancy.Bootstrapper;
using Nancy.TinyIoc;
using Owin.Web.Authentication.Forms;
namespace Owin.Web.App_Start
{
public class NancyBootstrapper : DefaultNancyBootstrapper
{
protected override void ConfigureApplicationContainer(TinyIoCContainer container)
{
// We don't call "base" here to prevent auto-discovery of
// types/dependencies
}
protected override void ConfigureRequestContainer(TinyIoCContainer container, NancyContext context)
{
base.ConfigureRequestContainer(container, context);
container.Register<IUserMapper, UserMapper>();
}
protected override void RequestStartup(TinyIoCContainer requestContainer, IPipelines pipelines, NancyContext context)
{
var formsAuthConfiguration =
new FormsAuthenticationConfiguration()
{
RedirectUrl = "~/login",
UserMapper = requestContainer.Resolve<IUserMapper>(),
};
FormsAuthentication.Enable(pipelines, formsAuthConfiguration);
}
//protected override NancyInternalConfiguration InternalConfiguration
//{
// get
// {
// return NancyInternalConfiguration.WithOverrides(c => c.Serializers.Insert(0, typeof(ServiceStackJsonFormatter)));
// }
//}
}
}<file_sep>/Owin.Domain/Entities/Product.cs
namespace Owin.Domain.Entities
{
public class Product
{
public long Id { get; set; }
public string Code { get; set; }
public decimal Price { get; set; }
public decimal OldPrice { get; set; }
}
}
| 3f96443ccd3249b4c45f366c421f974024835f8a | [
"Markdown",
"C#"
] | 14 | Markdown | hoanhnv/Owin | 0694e2fca2c6a02f8432fa9193ab328169293bb4 | 3667bcc6bc1167618d242e8af3643e34b2e200de |
refs/heads/master | <repo_name>work-shop/ln-frontend<file_sep>/templates/partials/about/about-cv.html
{% macro section( item ) %}
{% if item.cv %}
<section class="insight container academic mt4 mb4">
<div class="row">
<div class="col-sm-12 centered mb3">
<h2 class="insight-title page-color">Curriculum Vitae</h2>
</div>
</div>
<div class="row ml1 mr1 mb4">
<div class="col-sm-10 offset-sm-1 wysiwyg italic">
{{ item.cv_introduction|safe }}
</div>
</div>
<ul id="cv" class="mb2">
{% for row in item.cv %}
<li class="row mb1">
<div class="timeline col-xs-10 offset-xs-1 centered-xs col-sm-2"><p class="page-color academic">{{ row.date_range }}</p></div>
<div class="name col-xs-10 offset-xs-1 offset-sm-0 col-sm-4"><p class="bold">{{ row.position }}</p></div>
<div class="location col-xs-10 offset-xs-1 offset-sm-0 col-sm-4"><p>{{ row.location }}</p></div>
{% if row.description %}
<div class="description col-sm-6 offset-sm-3 hidden-xs">
<p class="h5 italic">{{ row.description }}</p>
</div>
{% endif %}
</li>
{% endfor %}
</ul>
</section>
{% endif %}
{% endmacro %}
<file_sep>/dynamic/index.js
"use strict";
var request = require('requestretry');
var generateConfig = require('./config.js');
var routes = require('./routes.js');
var listen = require('./listen.js'); //listen is responsible for actually starting the server
var Logger = require('./logging/index.js');
module.exports = function( express, app, config ) {
require('dnscache')({
"enable": true,
"ttl": 300,
"cachesize": 1000
});
return function() {
var log = new Logger( config );
request({
uri: config.external_api,
json: true,
maxAttempts: 5,
retryDelay: 1000,
retryStrategy: request.RetryStrategies.HTTPOrNetworkError,
fullResponse: false
})
/**
* The initial API request should result in the set of available namespaces
* Installed on WordPress' rest endpoint. We request this schema to instantiate
* the `wp-api` library.
*
* @param schema JSON
*/
.then( function( schema ) {
var globals = generateConfig( express, app, config, schema, log );
routes( express, app, config, globals );
listen( app, config, globals );
})
/**
* If the initial API Request fails, there's not much we can do to recover,
* beyond backing off, and retrying. In this case, it's better for us
* to fail noisily, and wait for the administrator to relaunch the
* application server later.
*
* @param error Error
*/
.catch( function( error ) {
log.error( error, 'initial-api-schema-request' );
process.exit( 1 );
});
};
};
<file_sep>/templates/partials/index/index-thought-groups.html
{% import '../thought/thought-card.html' as card %}
{% macro section( groups ) %}
<section id="index-thought-groups" class="pb6 container">
<ul class="thought-groups">
{% for group in groups %}
<li class="thought-group row">
<div class="col-sm-12 pb2">
<h2 class="thought-group-name academic bold"><span class="academic thoughts-title">{{ group.group_name }}</span></h2>
</div>
<div class="col-sm-3 col-xs-12 pb2">
<p class="thought-group-description pt0">{{ group.group_description|safe }}</p>
</div>
<div class="col-sm-9 col-xs-12 pb2">
<ul class="thoughts">
{% for thought in group.thoughts %}
{{ card.section( thought, 6, 6 ) }}
{% endfor %}
</ul>
</div>
</li>
{% endfor %}
</ul>
</section>
{% endmacro %}
<file_sep>/dynamic/routes.js
"use strict";
/**
* This micro-module installs the desired, application-specific routes on
* the server. This is the file in which to define the route structure
* for the application server.
*
*/
var index = require('./routes/index.js');
var about = require('./routes/about.js');
var thoughts = require('./routes/thoughts.js');
var thought = require('./routes/thought.js');
var error404 = require('./routes/error.js')( 404 );
module.exports = function( express, app, config, globals ) {
/**
* Routes
*/
app.get('/', index( globals.wp, config, globals ) );
app.get('/about', about( globals.wp, config, globals ));
app.get('/thoughts', thoughts( globals.wp, config, globals ));
app.get('/thoughts/:id', thought( globals.wp, config, globals ));
app.get('*', error404( globals.wp, config, globals ) );
/**
* Redirects
*/
};
<file_sep>/dynamic/structures/restructure-thought.js
"use strict";
var log = require('../logging/index.js')({stacktrace:true});
var maybeFeaturedImage = require('../utilities/maybe-with-default.js')({'wp:featuredmedia':[]})
module.exports = function ( thought ) {
try {
return {
title: {
short: thought.title.rendered,
long: thought.acf.longname
},
slug: thought.slug,
link: thought.link,
hero: determineHeroStructure( thought.acf ),
color: thought.acf.color,
summary: thought.acf.summary,
metadata: thought.acf.metadata,
overview: thought.acf.overview,
resources: thought.acf.resources,
format: thought.acf.format,
sections: thought.acf.sections,
featured_image: maybeFeaturedImage( thought._embedded )['wp:featuredmedia'][0]
};
} catch ( err ) {
log.error( err, 'restructure-thought');
return {
title: {
short: thought.title.rendered,
long: thought.acf.longname
},
slug: thought.slug,
link: thought.link,
color: thought.acf.color,
summary: thought.acf.summary,
metadata: thought.acf.metadata,
overview: thought.acf.overview,
format: thought.acf.format,
sections: thought.acf.sections
};
}
};
function determineHeroStructure( acf ) {
if ( acf.hero_type === "image" ) {
return {
type: "image",
image: acf.hero_image
};
} else if ( acf.hero_type === "images" ) {
return {
type: "images",
image: acf.hero_images
};
} else if ( acf.hero_type === "video" ) {
if ( acf.hero_video_type === "youtube" ) {
return {
type: "video",
image: acf.hero_video_file
};
} else if ( acf.hero_video_type === "vimeo" ) {
return {
type: "vimeo",
image: acf.hero_vimeo_video
};
} else if ( acf.hero_video_type === "file" ) {
return {
type: "youtube",
image: acf.hero_youtube_video
};
} else {
throw new Error('determineHeroStructure: Encountered an unrecognized hero video type: \'' + acf.hero_video_type + '\'');
}
} else if ( acf.hero_type === "none" ) {
return {
type: "none"
};
} else {
throw new Error('determineHeroStructure: Encountered an unrecognized hero type: \'' + acf.hero_type + '\'');
}
}
<file_sep>/templates/partials/thoughts/thoughts-grid.html
{% import '../thought/thought-card.html' as card %}
{% macro section( thoughts ) %}
<section id="thoughts-grid" class="container-fluid pb4">
<div class="row">
<div class="col-md-10 offset-md-1 col-sm-12 offset-sm-0">
<ul class="row">
{% for thought in thoughts %}
{{ card.section( thought, 6, 6 ) }}
{% endfor %}
</ul>
</div>
</div>
</section>
{% endmacro %}
<file_sep>/static/javascript/hero-toggle.js
"use strict";
module.exports = function($) {
//open and close the menu
function heroToggle(){
if($('body').hasClass('hero-closed')){
$('body').removeClass('hero-closed').addClass('hero-open');
}
else if($('body').hasClass('hero-open')){
$('body').removeClass('hero-open').addClass('hero-closed');
}
}
//set up the menu and events that interact with it
function initialize() {
$( document ).ready( function() {
$('.hero-toggle').click(function(e) {
e.preventDefault();
heroToggle();
});
});
}
return {
heroToggle: heroToggle,
initialize: initialize
};
};<file_sep>/dynamic/structures/base-structure.js
"use strict";
var extend = require('util-extend');
/**
*
*
*
*/
module.exports = function( compiled, options, globals ) {
return extend({
options: options.acf,
globals: globals,
featured_image: function( item ) {
return item;
},
hero_image_url: function( item ) {
return item.hero.image.sizes.hero;
},
url : function( item ) {
return item.link;
}
}, compiled);
};
<file_sep>/dynamic/structures/restructure-thoughts.js
"use strict";
var baseStructure = require('./base-structure.js');
var restructureThought = require('./restructure-thought.js');
/**
*
*
*
*/
module.exports = function( thoughts, options, globals ) {
return baseStructure({
page: 'thoughts',
thoughts_statement: options.acf.thoughts_description,
items: thoughts.map( function( thought ) {
return restructureThought( thought, options, globals );
})
}, options, globals );
};
<file_sep>/dynamic/routes/thought.js
"use strict";
var util = require('util');
var base = require('./generic/base-route.js')();
var restructureThoughtPage = require('../structures/restructure-thought-page.js');
//var mapResources = require('../utilities/resource-map.js');
/**
*
*
*/
module.exports = function( wp, config, globals ) {
var urlReplace = require('../utilities/resource-map.js')( config );
return base.route(
/**
* Get initial set of resources we need to render the page.
*/
[
wp.namespace( 'acf/v2' ).options().embed(),
resolveRequestedThought
],
/**
* Success Case. All of the needed resources were properly resolved,
* And the data is available for use immediately in the callback, along
* with the request and the response.
*
* @param req the Express Request Object
* @param res the Express Response Object
* @param options JSON, the requested options data
*/
function( req, res, options, thought ) {
globals.log.log( 'Successful request to index.', 'route-thought:success-handler');
res.render('thought.html', urlReplace( restructureThoughtPage( thought, options, globals ) ) );
},
/**
* Error Case. Something went wrong reconciling one or all of the
* requested resources. The error is supplied to the callback
* and *you* handle the problem.
*
* @param req the Express Request Object
* @param res the Express Response Object
* @param err Error the reason for failure.
*/
function( req, res, err ) {
globals.log.error( err, 'route-thought:error-handler');
res.render('error.html', {error_code: err.code, description: err.message });
});
/**
*
*
*
*/
function resolveRequestedThought( callback, req ) {
wp.thoughts().embed().filter('name', req.params.id )
.then( function( thought ) {
if ( thought.length === 0 ) {
var e404 = new Error("404: couldn't find the requested resource");
e404.code = 404;
callback( e404 );
} else if ( thought.length > 1 ) {
var e500 = new Error("500: ConsistencyError: the API returned multiple posts with the same slug.");
e500.code = 500;
callback( e500 );
} else {
callback( null, thought[0] );
}
})
.catch( function( err ) {
callback( err );
});
}
};
<file_sep>/static/javascript/main.js
"use strict";
//configuration
var configuration = require('../../package.json').frontend;
//get third party libraries
var $ = require('jquery');
var slick = require('slick-carousel');
var WebFont = require('webfontloader');
//assign jquery to the window, so it can be accessed in the console
window.$ = $;
WebFont.load({
google: {
families: ['Cabin:n4,i4,n7', 'Playfair+Display']
}
});
//get utilities
// var jumpUtilities = require('./jump-utilities.js')($);
var loading = require('./loading.js')($);
var pageColor = require('./page-color.js')($, configuration);
var sectionShift = require('./section-shift.js')($, configuration);
var gridCardSize = require('./grid-card-size.js')( $, configuration );
// var menuUtilities = require('./menu-utilities.js')($);
var slideshows = require('./slideshows.js')($, slick);
// var modals = require('./modals.js')($);
// var stickyNav = require('./sticky-nav.js')($);
//
//
// //setup utilities
// jumpUtilities.setupJumpEvents('.jump', 75, 567, 50, true);
// jumpUtilities.setupJumpEvents('.spy-link', 134, 567, 50, false);
$( document ).ready( function( ) {
pageColor.setupPageColor();
sectionShift.setupSectionShifts();
loading.setupLoading();
slideshows.setupSlideshows();
gridCardSize.setupSizing( '.thought-card .card-background-image' );
});
$( window ).on('resize', function() {
gridCardSize.setupSizing( '.thought-card .card-background-image' );
});
// menuUtilities.setupMenus();
// modals.setupModals();
//
//
// //site
// var timeline = require('./timeline.js')($);
// timeline.setupTimeline();
// var awardsToggle = require('./awards-toggle.js')($);
// awardsToggle.setupAwardsToggle();
//
//
// //page specific
// if($('body').hasClass('page-about')){
// var scrollSpy = require('./scroll-spy.js')($);
// scrollSpy.initialize('.spy-start', '.spy-target', '.spy-link', 135);
// var aboutNav = require('./about-nav.js')($);
// aboutNav.setupAboutNav();
// }
//
//
// if($('body').hasClass('page-work')){
// var Isotope = require('isotope-layout');
// var iso = require('./iso.js')($, Isotope);
// iso.initialize();
// stickyNav.initialize('.filters', 75, 50);
// }
//
//
if($('body').hasClass('page-thought')){
var heroToggle = require('./hero-toggle.js')($);
heroToggle.initialize();
}
<file_sep>/dynamic/routes/error.js
"use strict";
var base = require('./generic/base-route.js')();
var messages = require('../structures/error-message-structure.js');
var baseStructure = require('../structures/base-structure.js');
/**
*
*
*
*/
module.exports = function( errorNumber ) {
return function( wp, config, globals ) {
var urlReplace = require('../utilities/resource-map.js')( config );
return base.route(
/**
* Get initial set of resources we need to render the page.
*/
[ wp.namespace( 'acf/v2' ).options().embed() ],
/**
* Success Case. All of the needed resources were properly resolved,
* And the data is available for use immediately in the callback, along
* with the request and the response.
*
* @param req the Express Request Object
* @param res the Express Response Object
* @param options JSON, the requested options data
*/
function( req, res, options ) {
globals.log.log( '404 response.', 'route-404:success-handler');
var response = messages["" + errorNumber + ""];
res.status( errorNumber );
if ( typeof response === "function" ) {
res.render('error.html', urlReplace( baseStructure( {error_code: errorNumber, description: response }, options, globals ) ));
} else {
res.render('error.html', urlReplace( baseStructure( {error_code: errorNumber, description: response }, options, globals ) ) );
}
},
/**
* Error Case. Something went wrong reconciling one or all of the
* requested resources. The error is supplied to the callback
* and *you* handle the problem.
*
* @param req the Express Request Object
* @param res the Express Response Object
* @param err Error the reason for failure.
*/
function( req, res, err ) {
globals.log.error( err, 'route-index:error-handler');
res.render('error.html', {error_code: 500, description: err.message });
});
};
};
<file_sep>/dynamic/routes/generic/single.js
"use strict";
var base = require('./base-route.js')();
/**
* Gets a single object from a single wordpress post-type.
*
* {
* type: (string) the wordpress post-type that you'd like to resolve.
* template: (string) the name of the template to be rendered
* restructure: (function) the restructuring function that maps this post-type's API results to usable template contexts.
* resolveArchive: [optional] a (function) that implements custom route resolution logic.
* }
*/
module.exports = function( routeOptions ) {
return function( wp, config, globals ) {
return base.route(
[
wp.namespace( 'acf/v2' ).options().embed(),
routeOptions.resolvePost || resolveRequestedPost
],
/**
* Success Handler
* ===============
* Receives the resolved post object, and calls the appropriate
* success handler, rendering the passed template.
*/
function( req, res, options, post ) {
globals.log.log( 'successful generic request', 'route-generic-single:success-handler');
res.render( routeOptions.template, (routeOptions.restructure || function(x) {return x;})( post, options ) );
},
/**
* Error Handler
* ===============
* Receives the caught error object, and calls the
* error handler, rendering the generic error template.
*/
function( req, res, err ) {
globals.log.error( err, 'route-generic-single:error-handler');
res.render('error.html', {error_code: err.code, description: err.message });
}
);
/**
*
*
*
*/
function resolveRequestedPost( callback, req ) {
wp[ routeOptions.type ]().embed().filter('name', req.params.id )
.then( function( post ) {
if ( post.length === 0 ) {
var e404 = new Error("404: couldn't find the requested resource");
e404.code = 404;
callback( e404 );
} else if ( post.length > 1 ) {
var e500 = new Error("500: ConsistencyError: the API returned multiple posts with the same slug.");
e500.code = 500;
callback( e500 );
} else {
callback( null, post[0] );
}
})
.catch( function( err ) {
callback( err );
});
}
};
};
<file_sep>/dynamic/routes/about.js
"use strict";
var util = require('util');
var base = require('./generic/base-route.js')();
var restructureAbout = require('../structures/restructure-about.js');
/**
*
*
*/
module.exports = function( wp, config, globals ) {
var urlReplace = require('../utilities/resource-map.js')( config );
return base.route(
/**
* Get initial set of resources we need to render the page.
*/
[ wp.namespace( 'acf/v2' ).options().embed() ],
/**
* Success Case. All of the needed resources were properly resolved,
* And the data is available for use immediately in the callback, along
* with the request and the response.
*
* @param req the Express Request Object
* @param res the Express Response Object
* @param options JSON, the requested options data
*/
function( req, res, options ) {
globals.log.log( 'Successful request to about.', 'route-about:success-handler');
res.render('about.html', urlReplace( restructureAbout( options, globals ) ) );
},
/**
* Error Case. Something went wrong reconciling one or all of the
* requested resources. The error is supplied to the callback
* and *you* handle the problem.
*
* @param req the Express Request Object
* @param res the Express Response Object
* @param err Error the reason for failure.
*/
function( req, res, err ) {
globals.log.error( err, 'route-about:error-handler');
res.render('error.html', {error_code: 500, description: err.message });
});
};
<file_sep>/static/javascript/section-shift.js
"use strict";
module.exports = function( $, config ) {
return {
setupSectionShifts: function() {
// var shift = parseInt( $('[data-shift-v]').data('shift') );
$('[data-shift-v]').each( function() {
var shift = parseInt( $(this).data('shift-v') );
$(this).css({
position: "relative",
top: [shift, 'em'].join('')
});
});
$('[data-shift-h]').each( function() {
var shift = parseInt( $(this).data('shift-h') );
$(this).css({
position: "relative",
left: [shift, 'em'].join('')
});
});
}
};
};
<file_sep>/static/javascript/grid-card-size.js
var _ = require('underscore');
module.exports = function( $ ) {
return {
setupSizing: function( selector ) {
var set = $( selector );
if ( set.length ) {
set.height('auto');
var max = $( _.max( set, function( element ) { return $(element).height(); } ) ).height();
set.height( max );
}
}
};
};
| f6acd31f75338fce1e91a948219a6f5e17062594 | [
"JavaScript",
"HTML"
] | 16 | HTML | work-shop/ln-frontend | aaa17bfc3640924bdbbac990e1afaf1d3499cbef | f9917f602d0fe1ac62b83eda435f0256ba9e63ff |
refs/heads/master | <repo_name>lonelyplanet/front-end-candidate-lightbox<file_sep>/lightbox.js
function Lightbox( options )
{
// your code here
}
Lightbox.prototype.open = function()
{
// your code here
};
Lightbox.prototype.close = function()
{
// your code here
};
<file_sep>/readme.md
# Lonely Planet Front End Code Test
Welcome to the Lonely Planet coding test for front end developers wishing to join our team.
All you need to do is fork this repository, make your changes, and then submit a pull request which we will then review.
## Build a lightbox
We want to see your front-end skills and how you approach a problem with a specific set of requirements.
It has been started for you, but implementation details are up to you.
### Technical Requirements
The Lightbox should support the following:
- Be able to create a lightbox instance
- Common ways to close the lightbox (close button and ESC key).
- Fetching remote content.
- Rendering the content in the page.
- When the lightbox is open, the page behind it should not scroll.
#### Optional
- Build the component w/ React
- CSS animations/transitions for opening effects.
- Write in ES6 and transpile to ES5.
- Turn your lightbox into a jQuery plugin.
- Use jshint/jslint to analyze your code.
- Automate your workflow using tools like Webpack, Grunt or Gulp.
- Use Sass and a CSS autoprefixer.
- Add unit tests.
| a108872a516c11ba60d81f0496f1bf9a125aac3a | [
"JavaScript",
"Markdown"
] | 2 | JavaScript | lonelyplanet/front-end-candidate-lightbox | d1fb991170ff42ce62fa9367c4d437b057e972c7 | c288ca452fe0e851e16a32327cf17586b8a283af |
refs/heads/master | <repo_name>elisey20/practica_Tasks_bit<file_sep>/main.cpp
#include <iostream>
#include <stdio.h>
using namespace std;
void task1()
{
unsigned int n;
cout << "TASK__1" << endl << "n = ";
cin >> n;
cout << (1 << n) << endl << endl;
}
void task2()
{
unsigned long x;
cout << "TASK__2" << endl << "x = ";
cin >> x;
cout << "Bit representation = ";
for (int i = 31; i >= 0; i--) {
if (x & (1 << i))
cout << 1;
else
cout << 0;
}
cout << endl << endl;
}
void task3()
{
unsigned long x;
int amount = 0;
cout << "TASK__3" << endl << "x = ";
cin >> x;
for (int i = 31; i >= 0; i--) {
if (x & (1 << i))
amount++;
}
cout << "Number of ones: " << amount << endl << endl;
}
void task4()
{
unsigned long x;
int pos = -1;
cout << "TASK__4" << endl << "x = ";
cin >> x;
for (int i = 31; i >= 0; i--) {
if (x & (1 << i)) {
pos = i;
break;
}
}
if (pos == -1)
cout << "Number is zero\n";
else
cout << "Bit position is " << pos;
cout << endl << endl;
}
void task5()
{
int n, i;
cout << "TASK__5" << endl << "n = ";
cin >> n;
cout << "i = ";
cin >> i;
cout << (n | (1 << i)) << endl << endl;
}
void task6()
{
int n, i;
cout << "TASK__6" << endl << "n = ";
cin >> n;
cout << "i = ";
cin >> i;
cout << (n xor (1 << i)) << endl << endl;
}
void task7()
{
int n, i;
cout << "TASK__7" << endl << "n = ";
cin >> n;
cout << "i = ";
cin >> i;
cout << (n ^ (1 << i)) << endl << endl;
}
void task8()
{
unsigned int n;
cout << "TASK__8" << endl << "n = ";
scanf_s("%d", &n);
n = (unsigned char)((n << 1) | (n >> (8 - 1)));
cout << n << endl << endl;
}
void task9()
{
unsigned long x;
int sum = 0;
short xh = 0;
cout << "TASK__9" << endl << "x = ";
cin >> x;
for (int i = 31; i >= 0; i--)
{
if (x & (1 << i)) {
xh++;
}
else
{
if (xh > 1)
sum += xh - 1;
xh = 0;
}
}
if (xh > 1)
sum += xh - 1;
cout << sum << endl << endl;
}
void task10()
{
int n, i, j;
cout << "TASK__10" << endl << "n = ";
cin >> n;
cout << "i = ";
cin >> i;
cout << "j = ";
cin >> j;
char a = (n >> (i - 1)) & 1;
char b = (n >> (j - 1)) & 1;
if (a == 1)
n = (n | (1 << j));
else
n = (n xor (1 << j));
if (b == 1)
n = (n | (1 << i));
else
n = (n xor (1 << i));
cout << n << endl << endl;
}
void task11()
{
int n, i;
cout << "TASK__11" << endl << "n = ";
cin >> n;
cout << "i = ";
cin >> i;
for (int j = i; j < 32; j++) {
}
}
int main()
{
/*task1();
task2();
task3();
task4();
task5();
task6();
task7();
task8();
task9();
task10();*/
task11();
return 0;
} | f5a2985f7171633d9db932f4c5832234b6ab24b3 | [
"C++"
] | 1 | C++ | elisey20/practica_Tasks_bit | 2ddc1cd6f9fbccd09991315cd10c9c4c10ae0e1b | ec55bd407ad97abba424c34dde045ad806d034ce |
refs/heads/master | <repo_name>pyohannes/shellscript<file_sep>/test/test_design.py
import shellscript
from shellscript.proto import OutString, ErrString, dev
from shellscript.util import to_py_str_list
# Tests that assure that all shellscript commands correctly implement the
# shellscript protocol.
def _get_test_module_for_command(command):
return __import__('test_%s' % command.__name__)
def _get_all_commands_and_input(tmpdir, inputfunc='valid_input'):
for command in shellscript.get_all_commands():
testmod = _get_test_module_for_command(command)
for setup in getattr(testmod, inputfunc)(tmpdir):
yield command, setup
def assert_proper_out(out):
for l in list(out):
assert isinstance(l, str)
assert isinstance(l, OutString) or isinstance(l, ErrString)
def test_call(tmpdir):
# 1. Every command is a Python class.
for command, setup in _get_all_commands_and_input(tmpdir):
command()
def test_valid(tmpdir):
# 2. Every command constructor excepts the arguments *out*, *err* and
# *outerr*.
# 7. Every command instance has a ret attribute.
fname = tmpdir.mkdir('test').join('out.txt').strpath
for command, setup in _get_all_commands_and_input(tmpdir):
l = []
with open(fname, 'w') as f:
for out in (dev.out, dev.err, dev.itr, dev.nul, f, l):
args, kwargs = setup()
c = command(*args, out=out, **kwargs)
if c.ret is None:
list(c)
assert c.ret == 0
args, kwargs = setup()
c = command(*args, err=out, **kwargs)
if c.ret is None:
list(c)
assert c.ret == 0
args, kwargs = setup()
c = command(*args, outerr=out, **kwargs)
if c.ret is None:
list(c)
assert c.ret == 0
def test_invalid(tmpdir):
# 6. A command must not raise an exception
# 7. Every command instance has a ret attribute.
# 8. On error every command generator must yield an ErrString.
for command, setup in _get_all_commands_and_input(tmpdir, 'invalid_input'):
args, kwargs = setup()
c = command(*args, err=dev.itr, **kwargs)
out = list(c)
assert c.ret != 0
assert [ l for l in out if isinstance(l, ErrString) ]
def test_output(tmpdir):
# 4. Every command instance is a generator that yields strings.
# 5. Every string yielded by a command is an instance of OutString or
# ErrString.
for command, setup in _get_all_commands_and_input(tmpdir):
args, kwargs = setup()
c = command(*args, **kwargs)
assert_proper_out(c)
def test_generator(tmpdir):
# 4. Every command instance is a generator that yields strings.
for command, setup in _get_all_commands_and_input(tmpdir, 'invalid_input'):
args, kwargs = setup()
c = command(*args, **kwargs)
out1 = list(c)
assert_proper_out(out1)
args, kwargs = setup()
out2 = list(c)
assert_proper_out(out2)
assert out1 == out2
def test_redirection(tmpdir):
# 2. Every command constructor excepts the arguments *out*, *err* and
# *outerr*.
for num, (command, setup) in enumerate(_get_all_commands_and_input(tmpdir)):
def _read_file(fname):
with open(fname, 'r') as f:
file_content = f.read()
if file_content:
return file_content.split('\n')
else:
return []
# file
fname = tmpdir.join('test_%d_out_fobj.txt' % num).strpath
with open(fname, 'w') as f:
args, kwargs = setup()
c = command(*args, out=f, **kwargs)
fobj_content = _read_file(fname)
# iter
args, kwargs = setup()
c = command(*args, out=dev.itr, **kwargs)
l = list(c)
iter_content = to_py_str_list(l)
# list
list_content = []
args, kwargs = setup()
c = command(*args, out=list_content, **kwargs)
list_content = to_py_str_list(list_content)
# file as string
fname = tmpdir.join('test_%d_out_fname.txt' % num).strpath
args, kwargs = setup()
c = command(*args, out=fname, **kwargs)
fname_content = _read_file(fname)
# default redirection
fname_def = tmpdir.join('test_%d_out_fname_def.txt' % num).strpath
shellscript.settings.default_out = fname_def
args, kwargs = setup()
c = command(*args, **kwargs)
fname_def_content = _read_file(fname_def)
assert fobj_content == iter_content == list_content == fname_content \
== fname_def_content
def test_invalid_output(tmpdir):
# 2. Every command constructor excepts the arguments *out*, *err* and
# *outerr*.
for command, setup in _get_all_commands_and_input(tmpdir):
for arg in ('out', 'err', 'outerr'):
args, kwargs = setup()
kwargs = kwargs.copy()
kwargs[arg] = 3
try:
c = command(*args, **kwargs)
assert False
except:
pass
<file_sep>/test/test_sleep.py
import os
import time
from shellscript import sleep
def valid_input(tmpdir):
yield lambda: ([], dict(secs=0.1))
def invalid_input(tmpdir):
yield lambda: ([], dict(secs=-2))
def test_sleep(tmpdir):
cmd = sleep(2)
start = time.time()
list(cmd)
end = time.time()
assert (end - start) >= 2
<file_sep>/test/test_date.py
import os
import time
from shellscript import date, dev
def valid_input(tmpdir):
yield lambda: ([], dict())
yield lambda: ([], dict(fmt='%m'))
def invalid_input(tmpdir):
yield lambda: ([], dict(fmt=9))
def test_arg_fmt_default(tmpdir):
cmd = date(out=dev.itr)
assert list(cmd) == [ time.strftime('%c') ]
def test_arg_fmt_custom(tmpdir):
cmd = date('%m', out=dev.itr)
assert list(cmd) == [ time.strftime('%m') ]
<file_sep>/test/test_cat.py
import os
from shellscript import cat, dev
from util import file_make_unique_name, file_equals
def valid_input(tmpdir):
f = tmpdir.join('test_cat1')
f.write('ab\ncd\n')
yield lambda: ([], dict(f=f.strpath))
yield lambda: ([], dict(f=__file__))
yield lambda: ([], dict(f=[__file__, f.strpath]))
def invalid_input(tmpdir):
yield lambda: ([], dict(f=tmpdir.strpath))
def test_simple_from_file(tmpdir):
text = [ 'ab', 'cd', 'ef', 'gh' ]
f = tmpdir.join('testfile')
f.write('\n'.join(text))
cmd = cat(f.strpath, out=dev.itr)
assert list(cmd) == text
def test_multiple_files(tmpdir):
text = set([ 'ab', 'cd', 'ef', 'gh' ])
for t in text:
f = tmpdir.join(t)
f.write(t)
cmd = cat(f=[ os.path.join(tmpdir.strpath, n) for n in text], out=dev.itr)
assert set(list(cmd)) == text
def test_glob_from_file(tmpdir):
text = set([ 'ab', 'cd', 'ef', 'gh' ])
for t in text:
f = tmpdir.join(t)
f.write(t)
cmd = cat(f=os.path.join(tmpdir.strpath, '*'), out=dev.itr)
assert set(list(cmd)) == text
def test_simple_from_list(tmpdir):
text = [ 'ab', 'cd', 'ef', 'gh' ]
fs = []
for t in text:
f = tmpdir.join(t)
f.write(t)
fs.append(f.strpath)
cmd = cat(f=fs, out=dev.itr)
assert list(cmd) == text
def test_newline_handling(tmpdir):
text = [ 'ab', '', 'cd', 'ef', 'gh', '' ]
f = tmpdir.join(file_make_unique_name(tmpdir))
f.write('\n'.join(text))
f_out = tmpdir.join(file_make_unique_name(tmpdir))
cmd = cat(f=f.strpath, out=f_out.strpath)
assert file_equals(f.strpath, f_out.strpath)
<file_sep>/doc/commands.rst
.. shellscript documentation master file, created by
sphinx-quickstart on Wed Dec 30 14:51:10 2015.
You can adapt this file completely to your liking, but it should at least
contain the root `toctree` directive.
shellscript commands
====================
Protocol of shellscript commands
--------------------------------
All shellscript commands share properties, receive input and return output and
error codes in the same way. This same way is described in the **protocol** of
shellscript commands - every shellscript command has to conform to this it. The
protocol is designed to integrate other system commands seamless with
*shellscript* commands
1. Every command is a Python class.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
2. Every command constructor excepts the arguments *out*, *err* and *outerr*.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Those arguments must either be commands, file objects, lists or a
*shellscript.dev* enumeration value. If *outerr* is set, this overrides
settings for *out* and *err*.
3. A command constructor can accept further arguments.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
A command can accept further arguments specific to the command.
4. Every command instance is a generator that yields strings.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Per default the command generator exhausts itself once on initialization.
This behaviour can be altered by passing a value of *shellscript.dev.iter* to
*out*, *err* or *outerr*.
One string represents one line. Line breaks are not included in the strings.
5. Every string yielded by a command is an instance of *OutString* or *ErrString*.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
This makes it possible to differentiate between *stdout* and *stderr* output.
6. A command must not raise an exception.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
An error is indicated by the commands return code. Error messages are given via
yielded strings that are of the type *ErrString*.
7. Every command instance has a *ret* attribute.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
This attribute holds the return code of the command instance after its generator
is exhausted.
8. On error, every command generator must yield an *ErrString*.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
This is necessary to diagnose error causes.
Design
------
1. Every command must be importable by the *shellscript* module.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
2. Command names must be as short as possible.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
If possible command names should match names of corresponding POSIX shell
commands.
Protocol API
------------
.. automodule:: shellscript.proto
Commands
--------
.. automodule:: shellscript.cmd.cat
.. automodule:: shellscript.cmd.cd
.. automodule:: shellscript.cmd.grep
.. automodule:: shellscript.cmd.ls
.. automodule:: shellscript.cmd.pwd
Indices and tables
==================
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
<file_sep>/shellscript/cmd/yes.py
import sys
import time
from shellscript.proto import Command, OutString
class yes(Command):
"""Output a string repeatedly until killed.
ret is set to 0 on success and to 1 on failure.
Parameters:
s: The string to output, default 'y'.
Yields:
shellscript.proto.OutString, shellscript.proto.ErrString:
"""
def __init__(self, s='y', *args, **kwargs):
self._s = s
super(yes, self).__init__(*args, **kwargs)
def work(self):
return OutString(self._s)
<file_sep>/shellscript/cmd/cp.py
import os
import shutil
import sys
from shellscript.proto import Command, OutString, ErrString, resolve
class cp(Command):
"""Copy *src* to *dst*.
ret is set to 0 on success and to 1 on failure.
Parameters:
src: The source file or source directory, or a list of those.
dst: The destination file or directory name, or a list of those.
bool recurse: Copy src recursively.
bool verbose: Print verbose output.
str preserve: Preserve the specified attributes (default:
"mode,timestamps").
bool p: The same as preserve="mode,timestamps"
Yields:
shellscript.proto.OutString, shellscript.proto.ErrString:
"""
def __init__(self, src=None, dst=None, recurse=False, verbose=False,
preserve=None, p=False, *args, **kwargs):
self._src = src
self._dst = dst
self._recurse = recurse
self._verbose = verbose
if p:
self._preserve = ('timestamps', 'mode')
elif preserve is not None:
self._preserve = preserve.split(',')
else:
self._preserve = []
super(cp, self).__init__(*args, **kwargs)
def initialize(self):
super(cp, self).initialize()
self._srclist = resolve(self._src)
self._dstlist = resolve(self._dst)
self._get_umask()
if not self._srclist:
self.stop_with_error('No source given.', 1)
if not self._dstlist:
self.stop_with_error('No destination given.', 1)
def _get_umask(self):
self._umask = os.umask(0)
os.umask(self._umask)
self._umask = 0o777 - self._umask # make it compatibel to os.chmod
def _verbose_output(self, src, dst):
self.buffer_return(OutString("`%s' -> `%s'" % (src, dst)))
def _apply_preserve(self, src, dst):
if 'mode' in self._preserve:
shutil.copymode(src, dst)
else:
os.chmod(dst, self._umask)
if 'timestamps' in self._preserve:
if hasattr(os, 'utime'):
st = os.stat(src)
os.utime(dst, (st.st_atime, st.st_mtime))
def _copy_dir(self, src, dst):
if os.path.exists(dst):
dst = os.path.join(dst, os.path.basename(src))
if self._verbose:
self._verbose_output(src, dst)
os.makedirs(dst)
for entry in os.listdir(src):
entry_full = os.path.join(src, entry)
if os.path.isdir(entry_full):
self._copy_dir(entry_full, dst)
else:
self._copy_file(entry_full, os.path.join(dst, entry))
self._apply_preserve(src, dst)
def _copy_file(self, src, dst):
if self._verbose:
self._verbose_output(src, dst)
shutil.copyfile(src, dst)
self._apply_preserve(src, dst)
def work(self):
for src in self._srclist:
for dst in self._dstlist:
try:
if os.path.isdir(src):
if not self._recurse:
self.buffer_return(ErrString(
'%s is a directory' % src))
self.ret = 1
elif os.path.isfile(dst):
self.buffer_return(ErrString(
'%s is a file' % dst))
self.ret = 1
else:
self._copy_dir(src, dst)
elif os.path.isfile(src):
dstfile = dst
if os.path.isdir(dst):
dstfile = os.path.join(dst, os.path.basename(src))
self._copy_file(src, dstfile)
else:
self.buffer_return(ErrString(
'No such file or directory: %s' % src))
self.ret = 1
except:
self.buffer_return(ErrString(sys.exc_info()[1]))
self.ret = 1
self.stop()
<file_sep>/test/test_alias.py
import os
import sys
from shellscript import dev, alias, ls, run
def test_ls_all(tmpdir):
d = os.path.dirname(__file__)
lsall = alias(ls, all=True)
assert list(ls(all=True, out=dev.itr)) == list(lsall(out=dev.itr))
def test_arg_order(tmpdir):
p = alias(run, sys.executable, '-c')
cmd = p('print("ab\\ncd")', out=dev.itr)
assert list(cmd) == [ 'ab', 'cd', '' ] # print adds a newline at the end
<file_sep>/test/test_touch.py
import os
import time
from shellscript import touch, dev
from util import file_make_unique_name, file_make_text
def valid_input(tmpdir):
def _():
f, _ = file_make_text(tmpdir)
return [], dict(f=f)
yield _
def _():
f = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
return [], dict(f=f)
yield _
def invalid_input(tmpdir):
yield lambda: ([], {})
def _():
f = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
return [], dict(f=os.path.join(f, 'f'))
yield _
def test_arg_file_simple(tmpdir):
f = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = touch(f)
assert os.path.exists(f)
def test_arg_file_wildcard(tmpdir):
fs = [
file_make_text(tmpdir, postfix='.txt')[0],
file_make_text(tmpdir, postfix='.py')[0],
file_make_text(tmpdir, postfix='.txt')[0] ]
stats_before = [ os.stat(f) for f in ( fs[0], fs[2] )]
time.sleep(2)
cmd = touch(os.path.join(tmpdir.strpath, '*.txt'))
stats_after = [ os.stat(f) for f in ( fs[0], fs[2] )]
for before, after in zip(stats_before, stats_after):
assert before.st_atime != after.st_atime
assert before.st_mtime != after.st_mtime
def test_arg_no_create(tmpdir):
f, _ = file_make_text(tmpdir)
f2 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = touch([f, f2], nocreate=True)
assert os.path.exists(f)
assert not os.path.exists(f2)
cmd = touch([f, f2])
assert os.path.exists(f)
assert os.path.exists(f2)
def test_arg_time_access(tmpdir):
f, _ = file_make_text(tmpdir)
stat_before = os.stat(f)
time.sleep(2)
cmd = touch(f, time='access')
stat_after = os.stat(f)
assert stat_before.st_atime != stat_after.st_atime
assert stat_before.st_mtime == stat_after.st_mtime
def test_arg_time_modify(tmpdir):
f, _ = file_make_text(tmpdir)
stat_before = os.stat(f)
time.sleep(2)
cmd = touch(f, time='modify')
stat_after = os.stat(f)
assert stat_before.st_atime == stat_after.st_atime
assert stat_before.st_mtime != stat_after.st_mtime
<file_sep>/shellscript/cmd/wc.py
import sys
import time
from shellscript.proto import Command, InputReaderMixin, OutString, ErrString,\
resolve
class wc(Command, InputReaderMixin):
"""Print newline, word and byte counts for each file.
ret is set to 0 on success and to 1 on failure.
Parameters:
f: The files, or a list of those.
bool chars: Print the character counts.
bool lines: Print the line counts.
bool words: Print the word counts.
bool max_line_length: Print the length of the longest line.
Yields:
shellscript.proto.OutString, shellscript.proto.ErrString:
"""
def __init__(self, f=None, chars=None, lines=None, words=None,
max_line_length=None, *args, **kwargs):
self._f = f
if all(v is None for v in [ chars, lines, words, max_line_length ]):
self._chars = self._lines = self._words = True
self._max_line_length = False
else:
self._chars = chars
self._lines = lines
self._words = words
self._max_line_length = max_line_length
super(wc, self).__init__(*args, **kwargs)
def initialize(self):
super(wc, self).initialize()
self.initialize_input(resolve(self._f or []),
file_change_callback=self._count_new_file)
self._counts = []
self._count_filename = None
self._count_chars = self._count_words = self._count_lines \
= self._count_max_line = 0
self._count_total_chars = self._count_total_words \
= self._count_total_lines = self._count_total_max_line = 0
self._count_nr = 0
def _count_new_file(self, fname):
if self._count_nr > 0:
self._count_finish()
self._count_nr += 1
self._count_filename = fname
def _count_finish(self):
self._counts.append([
self._count_chars,
self._count_words,
self._count_lines,
self._count_max_line,
self._count_filename ])
self._count_total_chars += self._count_chars
self._count_total_words += self._count_words
self._count_total_lines += self._count_lines
self._count_total_max_line = max(self._count_total_max_line,
self._count_max_line)
self._count_chars = self._count_words = self._count_lines \
= self._count_max_line = 0
self._count_filename = None
def _make_total(self):
self._counts.append([
self._count_total_chars,
self._count_total_words,
self._count_total_lines,
self._count_total_max_line,
'total'])
def _get_return_line(self):
r = []
l = self._counts[0]
del self._counts[0]
if self._max_line_length:
r.append('%8d' % l[3])
if self._lines:
r.append('%8d' % l[2])
if self._words:
r.append('%8d' % l[1])
if self._chars:
r.append('%8d' % l[0])
if l[4]:
r.append(' %s' % l[4])
return ''.join(r)
def work(self):
try:
l = self.get_input_line()
self._count_lines += 1
linelen = len(l)
self._count_chars += linelen
if l.linebreak:
self._count_chars += 1
self._count_words += len(l.split())
self._count_max_line = max(self._count_max_line, linelen)
if self._counts:
ret = OutString(self._get_return_line(), True)
return ret
except StopIteration:
self._count_finish()
if self.len_input_files > 1:
self._make_total()
while self._counts:
ret = OutString(self._get_return_line(), True)
self.buffer_return(ret)
raise
except IOError:
self.ret = 1
return ErrString(sys.exc_info()[1])
except:
self.stop_with_error(sys.exc_info()[1], 1)
<file_sep>/shellscript/cmd/sleep.py
import sys
import time
from shellscript.proto import Command, OutString
class sleep(Command):
"""Delay for a specified amount of time.
ret is set to 0 on success and to 1 on failure.
Parameters:
secs: Number of seconds to delay.
Yields:
shellscript.proto.OutString, shellscript.proto.ErrString:
"""
def __init__(self, secs=None, *args, **kwargs):
self._secs = secs
super(sleep, self).__init__(*args, **kwargs)
def work(self):
try:
time.sleep(self._secs)
except:
self.stop_with_error(sys.exc_info()[1], 1)
self.stop()
<file_sep>/shellscript/cmd/whoami.py
import getpass
from shellscript.proto import Command, OutString
class whoami(Command):
"""Print the user name associated with the current effective user ID.
ret is set to 0 on success and to 1 on failure.
Yields:
shellscript.proto.OutString: The name of the current user.
"""
def work(self):
self.buffer_return(OutString(getpass.getuser()))
self.stop()
<file_sep>/shellscript/cmd/touch.py
import os
import sys
import time
from shellscript.proto import Command, OutString, ErrString, resolve
class touch(Command):
"""Change file timestamps.
ret is set to 0 on success and to 1 on failure.
Parameters:
f: The files or list of files to be modified.
bool nocreate: Do not create any files.
str time: Which time to change ('access' or 'atime'). Can be a comma
separated list.
Yields:
shellscript.proto.OutString, shellscript.proto.ErrString:
"""
def __init__(self, f=None, nocreate=False, time=None, *args, **kwargs):
self._f = f
self._nocreate = nocreate
if time:
self._time = time.split(',')
else:
self._time = [ 'access', 'modify' ]
super(touch, self).__init__(*args, **kwargs)
def initialize(self):
super(touch, self).initialize()
self._flist = resolve(self._f)
if not self._flist:
self.stop_with_error('No files given.', 1)
def work(self):
t = int(time.time())
for f in self._flist:
try:
if not os.path.exists(f):
if not self._nocreate:
with open(f, 'w'):
pass
else:
continue
times_orig = os.stat(f)
times = (
t if 'access' in self._time else times_orig.st_atime,
t if 'modify' in self._time else times_orig.st_mtime
)
os.utime(f, times)
except:
self.buffer_return(ErrString(sys.exc_info()[1]))
self.ret = 1
self.stop()
<file_sep>/shellscript/cmd/cat.py
import os
import sys
from shellscript.proto import Command, OutString, ErrString, resolve, \
InputReaderMixin
class cat(Command, InputReaderMixin):
"""Concatenate and print files.
ret is set to 0 on success and to 1 on failure.
Parameters:
f: A *str* or a list of *str*. An element is supposed to be a file name
and can contain wild cards.
Yields:
shellscript.proto.OutString: The content of the files.
"""
def __init__(self, f=None, *args, **kwargs):
self._args = dict(
f=f)
super(cat, self).__init__(*args, **kwargs)
def initialize(self):
super(cat, self).initialize()
self.initialize_input(resolve(self._args['f'] or []))
def work(self):
try:
return OutString(self.get_input_line())
except StopIteration:
self.stop()
except:
self.ret = 1
return ErrString(sys.exc_info()[1])
<file_sep>/test/test_cd.py
import os
from shellscript import cd
from util import original_env
def valid_input(tmpdir):
yield lambda: ([], dict(path=os.getcwd()))
yield lambda: ([], dict(path=tmpdir.strpath))
def invalid_input(tmpdir):
def _():
p = os.getcwd()
while os.path.exists(p):
p += 'x'
return [], dict(path=p)
yield _
home = os.environ['HOME']
def _():
try:
del os.environ['HOME']
except KeyError: pass
return [], dict()
yield _
os.environ['HOME'] = home
def test_back_relative(original_env):
curr = os.getcwd()
cmd = cd("..")
assert os.getcwd() == os.path.dirname(curr)
assert cmd.ret == 0
def test_back_absolute(original_env):
curr = os.getcwd()
cmd = cd(os.path.dirname(curr))
assert os.getcwd() == os.path.dirname(curr)
assert cmd.ret == 0
def test_go_home(original_env):
cmd = cd()
assert os.getcwd() == os.environ['HOME']
assert cmd.ret == 0
def test_go_home_via_env(original_env):
cmd = cd('$HOME')
assert os.getcwd() == os.environ['HOME']
assert cmd.ret == 0
def test_no_alteration_on_error(original_env, tmpdir):
curr = os.getcwd()
for setup in invalid_input(tmpdir):
args, kwargs = setup()
cd(*args, **kwargs)
assert os.getcwd() == curr
def test_wildcard(original_env, tmpdir):
d = tmpdir.mkdir('abcdefghijkl')
cd(path=os.path.join(tmpdir.strpath, 'abcd*'))
assert os.getcwd() == d.strpath
<file_sep>/test/test_wc.py
import unittest
import os
from shellscript import wc, cat, dev, astr, pipe
from util import file_make_unique_name, file_make_text, original_env
def valid_input(tmpdir):
yield lambda: ([], dict(f=__file__))
def invalid_input(tmpdir):
yield lambda: ([], dict(f=tmpdir.strpath))
def test_simple(tmpdir):
text = [ 'ab', 'cd', 'ef', 'gh' ]
f = tmpdir.join(file_make_unique_name(tmpdir))
f.write('\n'.join(text))
out1 = astr(wc, f=f.strpath)
out2 = list(cat(f=f.strpath, out=pipe(wc, out=dev.itr)))
out3 = []
cat(f=f.strpath, out=pipe(wc, out=out3))
assert out1.split() == [ '4', '4', '11', f.strpath ]
assert out2[0].split() == [ '4', '4', '11' ]
assert len(out3) == 1
assert out3[0].split() == [ '4', '4', '11' ]
def test_glob(tmpdir, original_env):
text = [ 'ab', 'c de', 'fg hi', 'j klm n' ]
for p in text:
tmpdir.join(p).write(p)
os.chdir(tmpdir.strpath)
out = astr(wc, f='*')
assert sorted([ o.split() for o in out.split('\n') ]) == \
sorted([ [ '1', '1', '2', 'ab' ],
[ '1', '2', '4', 'c', 'de' ],
[ '1', '2', '5', 'fg', 'hi' ],
[ '1', '3', '7', 'j', 'klm', 'n' ],
[ '4', '8', '18', 'total'] ])
def test_args(tmpdir, original_env):
text = [ 'ab', 'c de', 'fg hi', 'j klm n' ]
for p in text:
tmpdir.join(p).write(p)
os.chdir(tmpdir.strpath)
out = astr(wc, f='*', chars=True)
assert sorted([ o.split() for o in out.split('\n') ]) == \
sorted([ [ '2', 'ab' ],
[ '4', 'c', 'de' ],
[ '5', 'fg', 'hi' ],
[ '7', 'j', 'klm', 'n' ],
[ '18', 'total' ] ])
out = astr(wc, f='*', lines=True)
assert sorted([ o.split() for o in out.split('\n') ]) == \
sorted([ [ '1', 'ab' ],
[ '1', 'c', 'de' ],
[ '1', 'fg', 'hi' ],
[ '1', 'j', 'klm', 'n' ],
[ '4', 'total' ] ])
out = astr(wc, f='*', words=True)
assert sorted([ o.split() for o in out.split('\n') ]) == \
sorted([ [ '1', 'ab' ],
[ '2', 'c', 'de' ],
[ '2', 'fg', 'hi' ],
[ '3', 'j', 'klm', 'n' ],
[ '8', 'total', ]])
out = astr(wc, f='*', words=True, chars=True)
assert sorted([ o.split() for o in out.split('\n') ]) == \
sorted([ [ '1', '2', 'ab' ],
[ '2', '4', 'c', 'de' ],
[ '2', '5', 'fg', 'hi' ],
[ '3', '7', 'j', 'klm', 'n' ],
[ '8', '18', 'total' ] ])
def test_max_line_length(tmpdir):
f1 = tmpdir.join(file_make_unique_name(tmpdir))
f1.write('a\nbc\ndefgh\nijklmno\np')
f2 = tmpdir.join(file_make_unique_name(tmpdir))
f2.write('abcdefgh\nijklmno\np\nqrstuv')
out = astr(wc, f=[f1.strpath, f2.strpath], max_line_length=True)
assert sorted([ o.split() for o in out.split('\n') ]) == \
sorted([ [ '7', f1.strpath ],
[ '8', f2.strpath ],
[ '8', 'total' ] ])
def test_files_mixed_existance(tmpdir):
f1 = tmpdir.join(file_make_unique_name(tmpdir))
f1.write('a\nbc\ndefgh\nijklmno\np')
f2 = tmpdir.join(file_make_unique_name(tmpdir))
out = []
err = []
wc(f=[f1.strpath, f2.strpath], lines=True, out=out, err=err)
assert len(err) == 1
assert sorted([ o.split() for o in out ]) == \
sorted([ [ '5', f1.strpath ],
[ '5', 'total' ] ])
<file_sep>/shellscript/cmd/run.py
import os
import subprocess
import sys
from shellscript.proto import Command, OutString, ErrString, resolve, \
InputReaderMixin, dev
class run(Command, InputReaderMixin):
"""Run an executable.
ret is set to the return value of the executable or 1 if none is found.
Parameters:
str cmd: The name or path of the external command.
*args: The arguments for the command.
Yields:
shellscript.proto.OutString: The output of the executable.
"""
def __init__(self, cmd=None, *args, **kwargs):
self._args = dict(
cmd=cmd,
args=args)
super(run, self).__init__(**kwargs)
def initialize(self):
super(run, self).initialize()
self.initialize_input([])
self._terminal_use = (self._out == dev.out and self._err == dev.err)
try:
cmdlist = [ self._args['cmd'] ]
for arg in self._args['args']:
cmdlist.extend(resolve(arg))
if self._terminal_use:
self._initialize_terminal(cmdlist)
else:
self._initialize_redirection(cmdlist)
except:
self.stop_with_error(sys.exc_info()[1], 1)
def _initialize_terminal(self, cmdlist):
self._proc = subprocess.Popen(cmdlist)
def _initialize_redirection(self, cmdlist):
self._proc = subprocess.Popen(
cmdlist,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
stdin=subprocess.PIPE)
self._stdout_buf = []
self._stderr_buf = []
def finalize(self):
super(run, self).finalize()
try:
self._proc.wait()
self.ret = self._proc.returncode
if not self._terminal_use:
self._proc.stdout.close()
self._proc.stderr.close()
self._proc.stdin.close()
except: pass
def _query_stream(self, stream, buf, finished=False):
if not stream.closed:
while True:
r = stream.read(128)
if r:
buf.extend(r.decode('utf-8'))
else:
break
ret = []
while True:
try:
index = buf.index('\n')
ret.append(OutString(''.join(buf[:index]), True))
buf[:] = buf[index+1:]
except:
break
if finished:
ret.append(OutString(''.join(buf), False))
buf.clear()
return ret
def work(self):
if self._terminal_use:
_, __ = self._proc.communicate()
self.ret = self._proc.returncode
self.stop()
stdin_active = True
try:
while True:
finished = self._proc.poll() is not None
# read from stdout and stderr
for l in self._query_stream(
self._proc.stdout, self._stdout_buf, finished):
self.buffer_return(OutString(l))
for l in self._query_stream(
self._proc.stderr, self._stderr_buf, finished):
self.buffer_return(ErrString(l))
# write to stdin
if finished:
self.ret = self._proc.returncode
self.stop()
elif stdin_active:
try:
line = self.get_input_line()
self._proc.stdin.write( ('%s\n' % line).encode('utf-8')
)
except StopIteration:
stdin_active = False
except StopIteration:
raise
except:
self.ret = 1
return ErrString(sys.exc_info()[1])
<file_sep>/test/util.py
import os
import pytest
@pytest.yield_fixture
def original_env():
backup = os.environ.copy()
cwd = os.getcwd()
yield os.environ
os.chdir(cwd)
os.environ.clear()
os.environ.update(backup)
def file_make_unique_name(tmpdir, prefix='', postfix=''):
make_full_name = lambda s: '%s%s%s' % (prefix, s, postfix)
fname = 'testfile'
while os.path.exists(os.path.join(tmpdir.strpath, make_full_name(fname))):
fname += 'f'
return make_full_name(fname)
def file_make_text(tmpdir, prefix='', postfix=''):
txt = None
with open(__file__, 'r') as f:
txt = f.read()
src = tmpdir.join('testfile')
f = tmpdir.join(file_make_unique_name(tmpdir, prefix, postfix))
f.write(txt)
return f.strpath, txt
def file_equals(f1, f2):
if not os.path.isfile(f1) or not os.path.isfile(f2):
return False
with open(f1, 'r') as f1_obj:
with open(f2, 'r') as f2_obj:
return f1_obj.read() == f2_obj.read()
def dir_equals(d1, d2):
if not os.path.exists(d1) or not os.path.exists(d2):
return False
d1_c = os.listdir(d1)
d2_c = os.listdir(d2)
if not sorted(d1_c) == sorted(d2_c):
return False
for entry in d1_c:
e1_name = os.path.join(d1, entry)
e2_name = os.path.join(d2, entry)
if os.path.isfile(e1_name) and os.path.isfile(e2_name):
# file compare
if not file_equals(e1_name, e2_name):
return False
elif os.path.isdir(e1_name) and os.path.isdir(e2_name):
# directory compare
if not dir_equals(e1_name, e2_name):
return False
else:
# type differs
return False
return True
<file_sep>/shellscript/cmd/mv.py
import os
import shutil
import sys
from shellscript.proto import Command, OutString, ErrString, resolve
class mv(Command):
"""Move (rename) files.
ret is set to 0 on success and to 1 on failure.
Parameters:
src: The source file or source directory, or a list of those.
dst: The destination file or directory name.
bool verbose: Print verbose output.
Yields:
shellscript.proto.OutString, shellscript.proto.ErrString:
"""
def __init__(self, src=None, dst=None, verbose=False, *args, **kwargs):
self._src = src
self._dst = dst
self._verbose = verbose
super(mv, self).__init__(*args, **kwargs)
def initialize(self):
super(mv, self).initialize()
self._srclist = resolve(self._src)
self._dstlist = resolve(self._dst)
if not self._srclist:
self.stop_with_error('No source given.', 1)
if not self._dstlist:
self.stop_with_error('No destination given.', 1)
if len(self._dstlist) > 1:
self.stop_with_error('Multiple destinations given.', 1)
if len(self._srclist) > 1 and not os.path.isdir(self._dstlist[0]):
self.stop_with_error("Target '%s' is not a directory" %
self._dstlist[0] , 1)
def _verbose_output(self, src, dst):
self.buffer_return(OutString("`%s' -> `%s'" % (src, dst)))
def work(self):
for src in self._srclist:
dst = self._dstlist[0]
if os.path.isdir(dst):
dst = os.path.join(dst, os.path.basename(src))
try:
shutil.move(src, dst)
if self._verbose:
self._verbose_output(src, dst)
except:
self.buffer_return(ErrString(sys.exc_info()[1]))
self.ret = 1
self.stop()
<file_sep>/shellscript/__init__.py
from .proto import dev, pipe
from .util import alias, astr
from .cmd.cat import cat
from .cmd.cd import cd
from .cmd.cp import cp
from .cmd.date import date
from .cmd.grep import grep
from .cmd.ls import ls
from .cmd.mv import mv
from .cmd.pwd import pwd
from .cmd.rm import rm
from .cmd.run import run
from .cmd.sleep import sleep
from .cmd.tee import tee
from .cmd.touch import touch
from .cmd.wc import wc
from .cmd.whoami import whoami
from .cmd.yes import yes
def get_all_commands():
"""
Returns a list of all shellscript command classes.
"""
return [
cat, cp, cd, date, grep, ls, mv, pwd, rm, run, sleep, tee, touch,
wc, whoami, yes
]
<file_sep>/shellscript/cmd/grep.py
import os
import sys
import re
from shellscript.proto import Command, OutString, ErrString, resolve, \
InputReaderMixin
class grep(Command, InputReaderMixin):
"""Print lines matching a pattern.
*grep* searches given input files for lines matching the given regular
expression.
ret is set to 0 on success and to 1 on failure.
Parameters:
regex: A Python regular expression.
f: A *str* or a list of *str*. An element is supposed to be a file name
and can contain wild cards.
Yields:
shellscript.proto.OutString: Lines matching *regex*.
"""
def __init__(self, regex=None, f=None, *args, **kwargs):
self._args = dict(
regex=regex,
f=f)
super(grep, self).__init__(*args, **kwargs)
def initialize(self):
super(grep, self).initialize()
try:
self._regex = re.compile(self._args['regex'])
except:
self.stop_with_error(sys.exc_info()[1], 1)
self.initialize_input(resolve(self._args['f'] or []))
def work(self):
while True:
try:
line = self.get_input_line()
if self._regex.search(line):
if not self.is_ipipe and self.len_input_files > 1:
return OutString('%s: %s' %
(self.curr_input_file_name, line))
else:
return OutString(line)
except StopIteration:
self.stop()
except:
self.ret = 1
return ErrString(sys.exc_info()[1])
<file_sep>/shellscript/proto.py
import os
import sys
import glob
import string
import shellscript.settings as settings
class ProtocolError(Exception):
pass
class dev(object):
"""
Enumerator that can be used to redirect the output of *Command* objects.
The enumerator values can be passed to the *out*, *err* and *outerr*
arguments.
Attributes:
out: Redirection to *stdout*.
err: Redirection to *stderr*.
itr: Output can be retrieved by iterating over the *Command* object.
nul: The output is discarded.
"""
out = 1
err = 2
itr = 3
nul = 4
class _BaseString(str):
def __new__(cls, s, linebreak=None, *args, **kwargs):
obj = str.__new__(cls, s, *args, **kwargs)
if isinstance(s, _BaseString) and linebreak is None:
obj.linebreak = s.linebreak
elif linebreak is None:
obj.linebreak = True
else:
obj.linebreak = bool(linebreak)
return obj
def to_py_str(self):
return '%s%s' % (self, '\n' if self.linebreak else '')
class OutString(_BaseString):
"""
A line of normal output yielded by a command instance. This corresponds
to a line of stdout.
"""
pass
class ErrString(_BaseString):
"""
A line of error output yielded by a command instance. This corresponds
to a line of stderr.
"""
pass
class InputReaderMixin(object):
"""
"""
def initialize_input(self, files, file_change_callback=None):
self._input_files = files
self._active_input_file = None
self._input_files_pos = -1
self._file_change_cb = file_change_callback or (lambda fname: None)
@property
def curr_input_file_name(self):
if self.is_ipipe:
return '<input>'
else:
return self._input_files[self._input_files_pos]
@property
def len_input_files(self):
return len(self._input_files)
def _is_ready_for_interaction(self):
try:
if self._wait_for_input:
return len(self._input_files) or self.is_ipipe
else:
return True
except AttributeError:
return False
def get_input_line(self):
if self.is_ipipe:
return self._inp.get_line()
if not self.len_input_files and sys.stdin.isatty():
l = sys.stdin.readline()
return OutString(l.strip('\n'), l.endswith('\n'))
if not self._active_input_file:
self._input_files_pos += 1
if self._input_files_pos >= len(self._input_files):
raise StopIteration
else:
fname = self._input_files[self._input_files_pos]
self._active_input_file = open(fname)
self._file_change_cb(fname)
try:
l = self._active_input_file.__next__()
return OutString(l.strip('\n'), l.endswith('\n'))
except StopIteration:
self._active_input_file.close()
self._active_input_file = None
return self.get_input_line()
class OutputWriterMixin(object):
class Writer(object):
def __init__(self, obj):
self._target = obj
def close(self):
pass
def write(self, l):
self._target.write(l.to_py_str())
class StreamWriter(Writer):
@staticmethod
def check(o):
return o in (dev.out, dev.err)
def __init__(self, obj):
if obj == dev.out:
self._target = sys.stdout
elif obj == dev.err:
self._target = sys.stderr
class FileWriter(Writer):
@staticmethod
def check(o):
return hasattr(o, 'write') and hasattr(o, 'tell')
class ListWriter(Writer):
@staticmethod
def check(o):
return hasattr(o, 'append')
def write(self, l):
self._target.append(l)
class FilenameWriter(FileWriter):
@staticmethod
def check(o):
return isinstance(o, str)
def __init__(self, fn):
self._target = open(fn, 'w')
def close(self):
self._target.close()
class NullWriter(Writer):
@staticmethod
def check(o):
return o == dev.nul
def write(self, l):
pass
def make_writer(self, obj, streamname):
for c in (self.StreamWriter, self.FileWriter, self.ListWriter,
self.FilenameWriter, self.NullWriter):
if c.check(obj):
return c(obj)
raise ProtocolError("'%s' is not a valid argument for %s" % (obj,
streamname))
def initialize(self):
self._outwriter = self._errwriter = None
if not self.is_epipe and not self.is_eiter:
self._errwriter = self.make_writer(self._err, 'err')
if not self.is_opipe and not self.is_oiter:
self._outwriter = self.make_writer(self._out, 'out')
def finalize(self):
for w in (self._errwriter, self._outwriter):
if w:
w.close()
def write_error(self, l):
self._errwriter.write(l)
def write_output(self, l):
self._outwriter.write(l)
def pipe(cmd, *args, **kwargs):
if not kwargs:
if len(args) == 1 and isinstance(args[0], dict):
kwargs = args[0]
args = []
elif len(args) == 2 and isinstance(args[0], list) \
and isinstance(args[1], dict):
kwargs = args[1]
args = args[0]
return cmd(*args, _wait_for_input=True, **kwargs)
class Command(OutputWriterMixin):
def __init__(self, out=None, err=None, outerr=None, _wait_for_input=False):
if outerr is not None:
self._out = self._err = outerr
else:
self._out = settings.default_out if out is None else out
self._err = settings.default_err if err is None else err
if isinstance(self._out, tuple):
if self._out == self._err:
self._out = self._err = pipe(*self._out)
else:
self._out = pipe(*self._out)
if isinstance(self._err, tuple):
self._err = pipe(*self._err)
if self.is_opipe and self.is_epipe and self._out != self._err:
raise ProtocolError('Invalid pipe: err pipe cannot differ from ' \
'out pipe.')
for stream in (self._out, self._err):
if isinstance(stream, Command) and not stream._wait_for_input:
raise ProtocolError('Invalid pipe: must not be an ' \
'initialized Command.')
self._wait_for_input = _wait_for_input
if self.is_opipe:
self._out._inp = self
self.ret = None
self._global_initialize()
self.interact_attempt()
def __iter__(self):
self._global_initialize()
return self
def __next__(self):
if self.is_opipe:
return self._out.__next__()
else:
return self.get_line()
def __repr__(self):
r = '<%s return=%s ' % (self.__class__.__name__, str(self.ret))
if self.is_opipe:
r += repr(self._out)
r += '>'
return r
def __str__(self):
return '\n'.join(list(self))
# for derived classes
def initialize(self):
self.ret = 0
self._buffer = []
self._stop = False
super(Command, self).initialize()
def finalize(self):
super(Command, self).finalize()
def work(self):
pass
def stop_with_error(self, msg, ret):
self.ret = ret
self.buffer_return(ErrString(msg))
return self.stop()
def stop(self):
self._stop = True
raise StopIteration
def buffer_return(self, value):
self._buffer.insert(0, value)
def buffer_pop(self):
if self._buffer:
return self._buffer.pop()
else:
return None
# for interaction amongst commands
@property
def is_opipe(self):
"""
Checks if the output of this *Command* is piped into another *Command*.
Return:
bool: True if the output of this *Command* is input for another
*Command*.
"""
return isinstance(self._out, Command)
@property
def is_epipe(self):
"""
Checks if the error output of this *Command* is piped into another
*Command*.
Return:
bool: True if the error output of this *Command* is input for
another *Command*.
"""
return isinstance(self._err, Command)
@property
def is_ipipe(self):
"""
Checks if the input of this *Command* is piped from another *Command*.
Return:
bool: True if the input of this *Command* is piped from another
*Command*.
"""
try:
return isinstance(self._inp, Command)
except:
return False
@property
def is_ready(self):
return all([
cls._is_ready_for_interaction(self) \
for cls in type(self).mro() \
if hasattr(cls, '_is_ready_for_interaction') ])
@property
def is_oiter(self):
if self.is_opipe:
return self._out.is_oiter
else:
return self._out == dev.itr
@property
def is_eiter(self):
return self._err == dev.itr
def get_line(self):
while True:
ret = self.buffer_pop()
if ret is None:
if self._stop:
globals()['ret'] = self.ret
self.finalize()
raise StopIteration
else:
try:
ret = self.work()
#if ret is None:
# ret = OutString('', True)
except StopIteration:
self._stop = True
continue
if ret is None:
continue
elif isinstance(ret, ErrString) and not self.is_epipe \
and not self.is_eiter:
self.write_error(ret)
else:
break
return ret
def interact_attempt(self):
if not self.is_ready:
return
elif self.is_oiter or self.is_eiter:
return
elif self.is_opipe and self._out.is_ready:
self._out.interact_attempt()
else:
self._interact()
# for internal usage
def _global_initialize(self):
try:
self.initialize()
if self.is_opipe:
self._out.initialize()
except StopIteration:
try:
self.stop()
except StopIteration: pass
def _interact(self):
# avoid calling __iter__ - this would cause an call to initialize again
while True:
try:
l = self.__next__()
if isinstance(l, OutString):
self.write_output(l)
elif isinstance(l, ErrString):
self.write_error(l)
else:
raise ProtocolError(
"Not an OutString or ErrString: '%s'" % l)
except StopIteration:
break
def resolve(arg):
if isinstance(arg, str):
arg = string.Template(arg).safe_substitute(os.environ)
if glob.has_magic(arg):
arg = glob.glob(arg)
arg.sort()
else:
arg = [ arg ]
else:
try:
exp = []
for a in arg:
exp.extend(resolve(a))
arg = exp
except TypeError: pass
return arg
<file_sep>/test/test_grep.py
import os
from shellscript import grep, dev
def valid_input(tmpdir):
def _():
f = tmpdir.join('test_grep1')
f.write('ab\ncd\nef\ngh')
return [], dict(regex='.*', f=f.strpath)
yield _
yield lambda: ([], dict(regex='^def', f=__file__))
def invalid_input(tmpdir):
yield lambda: ([], dict(regex='x', f=tmpdir.strpath))
yield lambda: ([], dict(regex=3, f=__file__))
yield lambda: ([], dict(f=__file__))
def test_from_file(tmpdir):
text = [ 'abcdefghij', 'bcdefghijk', 'cdefghijkl', 'defghijklm' ]
f = tmpdir.join('f')
f.write('\n'.join(text))
cmd = grep(regex='cd.*jk', f=f.strpath, out=dev.itr)
assert list(cmd) == text[1:3]
def test_from_multiple_files(tmpdir):
texts = [ [ 'abj', 'kltm', 'a kt', 'bco' ],
[ 'jtl', 'zlm ', 'axew', 'abo' ] ]
files = []
for num, text in enumerate(texts):
f = tmpdir.join('f%d' % num)
f.write('\n'.join(text))
files.append(f.strpath)
cmd1 = grep(regex='^a', f=os.path.join(tmpdir.strpath, '*'), out=dev.itr)
cmd2 = grep(regex='^a', f=files, out=dev.itr)
assert list(cmd1) == list(cmd2) == [
'%s: abj' % files[0],
'%s: a kt' % files[0],
'%s: axew' % files[1],
'%s: abo' % files[1]
]
<file_sep>/test/test_run.py
import os
import sys
from shellscript import run, dev
def valid_input(tmpdir):
yield lambda: ([sys.executable, '-c', 'quit()'], dict())
def invalid_input(tmpdir):
def _():
p = sys.executable
while os.path.exists(p):
p += 'a'
return [p], dict()
yield _
def test_stdout_stderr(tmpdir):
script = [ 'import sys ; ' + \
'sys.stdout.write("ab") ; ' + \
'sys.stderr.write("cd")'
]
out = []
err = []
cmd = run(sys.executable, '-c', script, out=out, err=err)
assert out == [ 'ab' ]
assert err == [ 'cd' ]
def test_stdout_delay(tmpdir):
script = [ 'import sys, time ; ' + \
'sys.stdout.write("ab\\ncd\\nef") ; ' + \
'time.sleep(5)'
]
cmd = run(sys.executable, '-c', script, out=dev.itr)
assert list(cmd) == [ 'ab', 'cd', 'ef' ]
<file_sep>/test/test_tee.py
import os
from shellscript import tee, cat, dev, pipe
from util import file_make_unique_name, file_make_text, file_equals
def valid_input(tmpdir):
return []
def invalid_input(tmpdir):
return []
def test_file(tmpdir):
outf1 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
outf2 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = cat(__file__, out=pipe(tee, outf1, out=outf2))
assert file_equals(outf1, __file__)
assert file_equals(outf2, __file__)
def test_filelist(tmpdir):
outf1 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
outf2 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
outf3 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = cat(__file__, out=pipe(tee, [ outf1, outf2 ], out=outf3))
assert file_equals(__file__, outf1)
assert file_equals(__file__, outf2)
assert file_equals(__file__, outf3)
def test_append(tmpdir):
outf = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
outl = []
cmd = cat(__file__, out=pipe(tee, outf, out=outl))
cmd = cat(__file__, out=pipe(tee, outf, out=outl))
with open(outf, 'r') as f:
assert len(f.readlines()) < len(outl)
outf2 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
outl2 = []
cmd = cat(__file__, out=pipe(tee, outf2, out=outl2))
cmd = cat(__file__, out=pipe(tee, outf2, append=True, out=outl2))
with open(outf2, 'r') as f2:
assert f2.read() == ''.join([ l.to_py_str() for l in outl2 ])
def test_stdout(tmpdir):
outl = []
cmd = cat(__file__, out=pipe(tee, out=outl))
with open(__file__, 'r') as f:
fstr = f.read()
ostr = ''.join([ l.to_py_str() for l in outl ])
assert (len(fstr.split('\n')) * 2 - 1) == len(ostr.split('\n'))
<file_sep>/test/test_pwd.py
import os
from shellscript import pwd, cd, dev
from util import original_env
def valid_input(tmpdir):
yield lambda: ([], {})
def invalid_input(tmpdir):
return []
def test_current():
cmd = pwd(out=dev.itr)
assert list(cmd) == [ os.getcwd() ]
assert cmd.ret == 0
<file_sep>/shellscript/console.py
import code
import sys
from shellscript.settings import prompt_1, prompt_2, load
def readfunc(self, prompt=''):
if prompt == sys.ps2:
return input(prompt_2())
else:
return input(prompt_1())
if __name__ == '__main__':
import shellscript
local = shellscript.__dict__
custom = load()
if custom:
local.update(custom.__dict__)
code.interact(readfunc=readfunc, local=local)
<file_sep>/test/test_yes.py
from shellscript import yes, dev
def valid_input(tmpdir):
return []
def invalid_input(tmpdir):
return []
def test_yes(tmpdir):
cmd = yes(out=dev.itr)
result = []
for step, output in enumerate(cmd):
if step >= 50:
break
result.append(output)
assert result == ([ 'y' ]*50)
def test_yes_custom_string(tmpdir):
s = 'a b c d e f g h'
cmd = yes(s, out=dev.itr)
result = []
for step, output in enumerate(cmd):
if step >= 50:
break
result.append(output)
assert result == ([ s ]*50)
<file_sep>/shellscript/settings.py
"""Global settings.
Attributes:
prompt_1: A callable that returns the root shell prompt.
prompt_2: A callable that returns the nested shell prompt.
"""
import imp
import getpass
import os
import socket
import sys
import tempfile
def load():
rc = os.environ.get('SHELLSCRIPTRC')
if not rc and 'HOME' in os.environ:
rc = os.path.join(os.environ['HOME'], '.shellscriptrc')
if rc:
try:
tmpf = tempfile.mktemp()
with open(tmpf, 'w') as f:
f.write('from shellscript import *\n')
with open(rc, 'r') as frc:
f.write(frc.read())
return imp.load_source('shellscript.custom_settings', tmpf)
except:
sys.stderr.write('%s\n' % sys.exc_info()[1])
finally:
if os.path.exists(tmpf):
os.remove(tmpf)
return None
def _default_prompt(postfix):
def _wrapper():
username = getpass.getuser()
hostname = socket.gethostname().split('.')[0]
cwd = os.getcwd()
return '[%s@%s]%s %s' % (username, hostname, cwd, postfix)
return _wrapper
prompt_1 = _default_prompt('>>> ')
prompt_2 = _default_prompt('... ')
default_out = 1
default_err = 2
<file_sep>/test/test_cp.py
import os
import stat
import time
from shellscript import cp, dev
from util import file_make_unique_name, file_make_text, file_equals, \
dir_equals
def valid_input(tmpdir):
yield lambda: ([], dict(src=__file__, dst=tmpdir.strpath))
yield lambda: ([], dict(src=__file__, dst=os.path.join(tmpdir.strpath,
os.path.basename(__file__))))
def invalid_input(tmpdir):
def _():
f = os.path.join(tmpdir.strpath, 'x')
while os.path.exists(f):
f += 'x'
return [], dict(src=f, dst=tmpdir.strpath)
yield _
f_existing = tmpdir.join('existing')
f_existing.write('xy')
def _():
return [], dict(src=f_existing.strpath)
yield _
yield lambda: ([], dict(dst=f_existing.strpath))
def _():
# dir as src without recurse
d_src = tmpdir.mkdir(file_make_unique_name(tmpdir))
d_tgt = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
return [], dict(src=d_src.strpath, dst=d_tgt)
yield _
def test_arg_srcdst_simple(tmpdir):
src, txt = file_make_text(tmpdir)
tgt = tmpdir.join(file_make_unique_name(tmpdir))
cmd = cp(src, tgt.strpath)
assert file_equals(src, tgt.strpath)
def test_arg_src_dir(tmpdir):
srcdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
srcdir_sub = srcdir.mkdir(file_make_unique_name(srcdir))
file_make_text(srcdir_sub),
file_make_text(srcdir_sub),
file_make_text(srcdir)
tgtdir = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = cp(srcdir.strpath, tgtdir, recurse=True)
assert dir_equals(srcdir.strpath, tgtdir)
def test_arg_src_list(tmpdir):
srcdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
tgtdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
src = [
file_make_text(srcdir)[0],
file_make_text(srcdir)[0] ]
cmd = cp(src, tgtdir.strpath)
assert dir_equals(srcdir.strpath, tgtdir.strpath)
def test_arg_src_wildcard(tmpdir):
f_txt = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir,
postfix='.txt'))
f_rtf = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir,
postfix='.rtf'))
for f in (f_txt, f_rtf):
with open(f, 'w') as fobj:
fobj.write('ab')
tgtdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
cmd = cp(os.path.join(tmpdir.strpath, '*.txt'), tgtdir.strpath)
assert os.listdir(tgtdir.strpath) == [ os.path.basename(f_txt) ]
def test_arg_src_wildcardlist(tmpdir):
f_txt = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir,
postfix='.txt'))
f_rtf = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir,
postfix='.rtf'))
f_py = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir,
postfix='.py'))
for f in (f_txt, f_rtf, f_py):
with open(f, 'w') as fobj:
fobj.write('ab')
tgtdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
src = [ os.path.join(tmpdir.strpath, '*.%s' % ext) \
for ext in ('py', 'txt') ]
cmd = cp(src, tgtdir.strpath)
assert sorted(os.listdir(tgtdir.strpath)) == sorted(
[ os.path.basename(f_txt), os.path.basename(f_py) ])
def test_arg_dst_dir(tmpdir):
src, txt = file_make_text(tmpdir)
tgtdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
cmd = cp(src, tgtdir.strpath)
tgt = os.path.join(tgtdir.strpath, os.path.basename(src))
assert os.path.exists(tgt)
with open(tgt, 'r') as f:
assert f.read() == txt
def test_arg_dst_list(tmpdir):
srcdir1 = tmpdir.mkdir(file_make_unique_name(tmpdir))
src, txt = file_make_text(srcdir1)
tgtdir1 = tmpdir.mkdir(file_make_unique_name(tmpdir))
tgtdir2 = tmpdir.mkdir(file_make_unique_name(tmpdir))
cmd = cp(src, [tgtdir1.strpath, tgtdir2.strpath])
assert dir_equals(tgtdir1.strpath, srcdir1.strpath)
assert dir_equals(tgtdir2.strpath, srcdir1.strpath)
def test_arg_dst_wildcard(tmpdir):
srcdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
src, txt = file_make_text(srcdir)
tgtdir_parent = tmpdir.mkdir(file_make_unique_name(tmpdir))
tgtdir = tgtdir_parent.mkdir(file_make_unique_name(tgtdir_parent))
cmd = cp(src, os.path.join(tgtdir_parent.strpath, '*'))
assert dir_equals(srcdir.strpath, tgtdir.strpath)
def test_arg_dst_wildcardlist(tmpdir):
srcdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
src, txt = file_make_text(srcdir)
tgtdir_parent1 = tmpdir.mkdir(file_make_unique_name(tmpdir))
tgtdir1 = tgtdir_parent1.mkdir(file_make_unique_name(tgtdir_parent1))
tgtdir_parent2 = tmpdir.mkdir(file_make_unique_name(tmpdir))
tgtdir2 = tgtdir_parent2.mkdir(file_make_unique_name(tgtdir_parent2))
cmd = cp(
src,
[ os.path.join(tgtdir_parent1.strpath, '*'),
os.path.join(tgtdir_parent2.strpath, '*') ])
assert dir_equals(srcdir.strpath, tgtdir1.strpath)
assert dir_equals(srcdir.strpath, tgtdir2.strpath)
def test_arg_verbose(tmpdir):
srcdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
file_make_text(srcdir)
file_make_text(srcdir)
file_make_text(srcdir)
out = []
tgtdir = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = cp(srcdir.strpath, tgtdir, recurse=True, out=out)
assert len(out) == 0
tgtdir = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = cp(srcdir.strpath, tgtdir, recurse=True,
verbose=True, out=out)
assert len(out) == 4
def _arg_preserve_template(tmpdir, src, kwargs):
# wait before creating next file
time.sleep(2)
tgt1 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = cp(src, tgt1, **kwargs)
tgt1_stat = os.stat(tgt1)
src_stat = os.stat(src)
assert src_stat.st_mode != tgt1_stat.st_mode
assert src_stat.st_mtime != tgt1_stat.st_mtime
tgt2 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = cp(src, tgt2, preserve="mode", **kwargs)
tgt2_stat = os.stat(tgt2)
src_stat = os.stat(src)
assert src_stat.st_mode == tgt2_stat.st_mode
assert src_stat.st_mtime != tgt2_stat.st_mtime
tgt3 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = cp(src, tgt3, preserve="timestamps", **kwargs)
tgt3_stat = os.stat(tgt3)
src_stat = os.stat(src)
assert src_stat.st_mode != tgt3_stat.st_mode
assert src_stat.st_mtime == tgt3_stat.st_mtime
tgt4 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = cp(src, tgt4, preserve="timestamps,mode", **kwargs)
tgt4_stat = os.stat(tgt4)
src_stat = os.stat(src)
assert src_stat.st_mode == tgt4_stat.st_mode
assert src_stat.st_mtime == tgt4_stat.st_mtime
tgt5 = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = cp(src, tgt5, p=True, **kwargs)
tgt5_stat = os.stat(tgt5)
src_stat = os.stat(src)
assert src_stat.st_mode == tgt5_stat.st_mode
assert src_stat.st_mtime == tgt5_stat.st_mtime
def test_arg_preserve_file(tmpdir):
src, txt = file_make_text(tmpdir)
os.chmod(src, 0o777)
_arg_preserve_template(tmpdir, src, kwargs=dict())
def test_arg_preserve_dir(tmpdir):
d = tmpdir.mkdir(file_make_unique_name(tmpdir))
os.chmod(d.strpath, 0o777)
_arg_preserve_template(tmpdir, d.strpath, kwargs=dict(recurse=True))
<file_sep>/shellscript/cmd/cd.py
import os
import sys
from shellscript.proto import Command, resolve
class cd(Command):
"""Change the current working directory to path. The variable HOME is the
default path.
ret is set to 0 on success and to 1 on failure.
Yields:
shellscript.proto.OutString, shellscript.proto.ErrString:
"""
def __init__(self, path=None, *args, **kwargs):
self._path = resolve(path)
super(cd, self).__init__(*args, **kwargs)
def work(self):
if isinstance(self._path, list) and self._path:
self._path = self._path[0]
if not self._path:
if not 'HOME' in os.environ:
self.stop_with_error('$HOME cannot be determined.', 1)
else:
self._path = os.environ["HOME"]
try:
os.chdir(self._path)
except:
self.stop_with_error(sys.exc_info()[1], 1)
self.stop()
<file_sep>/shellscript/cmd/rm.py
import os
import sys
from shellscript.proto import Command, OutString, ErrString, resolve
class rm(Command):
"""Remove files or directories.
ret is set to 0 on success and to 1 on failure.
Parameters:
f: The file or directory to be removed, or a list of those.
bool recurse: Remove directories and their contents recursively.
bool verbose: Print verbose output.
bool force: Ignore nonexistent files, never prompt.
str interactive: Prompt according to: 'never', 'once', 'always'.
Defaults to 'always' if stdin is a terminal and 'never' otherwise.
Yields:
shellscript.proto.OutString, shellscript.proto.ErrString:
"""
def __init__(self, f=None, recurse=False, verbose=False, force=False,
interactive=None, *args, **kwargs):
self._f = f
self._recurse = recurse
self._verbose = verbose
self._force = force
self._tty = sys.stdin.isatty()
if not interactive:
if sys.stdin.isatty():
self._interactive = 'always'
else:
self._interactive = 'never'
else:
self._interactive = interactive
super(rm, self).__init__(*args, **kwargs)
def initialize(self):
super(rm, self).initialize()
self._flist = resolve(self._f)
if not self._flist:
if self._force:
self.stop()
else:
self.stop_with_error('No files given.', 1)
def _verbose_output(self, fname, isdir=False):
if isdir:
self.buffer_return(OutString("removed directory: `%s'" % fname))
else:
self.buffer_return(OutString("removed `%s'" % fname))
def _ask(self, question):
sys.stdout.write(question)
sys.stdout.flush()
return sys.stdin.readline().strip() in ('y', 'yes')
def _is_interactive_for(self, when):
return self._interactive == when and not self._force
def _remove_dir(self, d):
if self._is_interactive_for('always'):
if not self._ask("descend into directory `%s'? " % d):
return
for entry in os.listdir(d):
entry_full = os.path.join(d, entry)
if os.path.isdir(entry_full):
self._remove_dir(d)
else:
self._remove_file(entry_full)
os.rmdir(d)
if self._verbose:
self._verbose_output(d, True)
def _remove_file(self, f):
if self._is_interactive_for('always'):
if not self._ask("remove regular file `%s'? " % f):
return
os.remove(f)
if self._verbose:
self._verbose_output(f)
def work(self):
if self._is_interactive_for('once'):
if not self._ask("remove all arguments? "):
self.stop()
for f in self._flist:
try:
if os.path.isdir(f):
if not self._recurse:
self.buffer_return(ErrString('%s is a directory' % f))
self.ret = 1
else:
self._remove_dir(f)
elif os.path.isfile(f):
self._remove_file(f)
elif not self._force:
self.buffer_return(ErrString(
'No such file or directory: %s' % f))
self.ret = 1
except:
self.buffer_return(ErrString(sys.exc_info()[1]))
self.ret = 1
self.stop()
<file_sep>/shellscript/cmd/ls.py
import os
import sys
from shellscript.proto import Command, OutString, ErrString, resolve
class ls(Command):
"""List directory contents.
List information about the files (the current directory by default). Sort
entries alphabetically.
ret is set to 0 on success and to 1 on failure.
Parameters:
f: A *str* or a list of *str*. An element is supposed to be a directory
name and can contain wild cards.
bool all: Show hidden files.
bool indicator_slash: Prepend directories with a slash.
Yields:
shellscript.proto.OutString: A file name.
"""
def __init__(self, f='.', all=False, indicator_slash=False, *args, **kwargs):
self._args = dict(
f=f)
self._all = all
self._indicator_slash = indicator_slash
super(ls, self).__init__(*args, **kwargs)
def initialize(self):
super(ls, self).initialize()
self._path = [ p for p in resolve(self._args['f']) \
if os.path.exists(p) ]
self._path_root = None
if not self._path:
self.stop_with_error('Cannot access %s: No such file or directory'\
% self._args['f'], 1)
if len(self._path) == 1 and os.path.isdir(self._path[0]):
self._path_root = self._path[0]
self._path = os.listdir(self._path_root)
if self._all:
self._path.extend([ '.', '..' ])
self._path.sort()
self._path.reverse()
def _get_absolute_path(self, p):
if self._path_root:
return os.path.abspath(os.path.join(self._path_root, p))
else:
return os.path.abspath(p)
def work(self):
while True:
try:
ret = self._path.pop()
except IndexError:
self.stop()
if not self._all:
if os.name == 'nt':
attrs = ctypes.windll.kernel32.GetFileAttributes(ret)
if attrs & (2 | 4):
continue
else:
if ret.startswith('.'):
continue
if self._indicator_slash and \
os.path.isdir(self._get_absolute_path(ret)):
ret += '/'
return OutString(ret)
<file_sep>/test/test_misc.py
import os
from shellscript import *
def test_command_as_input(tmpdir):
files = [ 'a.py', 'b.py', 'c.py', 'd.txt', 'e.py' ]
for t in files:
f = tmpdir.join(t)
f.write(t)
cmd = cat(ls(os.path.join(tmpdir.strpath, '*.py'), out=dev.itr),
out=dev.itr)
cmd_nested = cat(ls(os.path.join(tmpdir.strpath, '*'),
out=pipe(grep, 'py$', out=dev.itr)), out=dev.itr)
assert list(cmd_nested) == list(cmd) == [ t for t in files if t.endswith('.py') ]
<file_sep>/test/test_pipe.py
import os
import pytest
from shellscript import *
from shellscript.proto import ProtocolError
from util import file_make_unique_name
def test_cat_grep(tmpdir):
text = ['def xy():', ' return False']
f = tmpdir.join('input')
f.write('\n'.join(text))
cmd = cat(f.strpath, out=pipe(grep, '^def', out=dev.itr))
assert list(cmd) == [ text[0] ]
def test_cat_grep_multiple_invocation(tmpdir):
text = ['def xy():', ' return False']
f = tmpdir.join('input')
f.write('\n'.join(text))
cmd = cat(f.strpath, out=pipe(grep, '^def', out=dev.itr))
assert list(cmd) == list(cmd) == list(cmd) == [ text[0] ]
def test_cat_grep_out_err(tmpdir):
err = []
cmd = cat(tmpdir.strpath, err=err, out=(grep, '^def'))
assert len(err) != 0
def test_invalid_out_redir():
with pytest.raises(ProtocolError):
cat(__file__, out=3.14)
def test_invalid_err_redir():
with pytest.raises(ProtocolError):
cat(__file__, err=3.14)
def test_invalid_err_pipe():
with pytest.raises(ProtocolError):
cat(__file__, out=(grep, 'ab'), err=(grep, 'cd'))
def test_astr_cat_wc(tmpdir):
text = [ '1', '2', '3', '4' ]
f = tmpdir.join(file_make_unique_name(tmpdir))
f.write('\n'.join(text))
out = astr(cat, f.strpath, out=(wc,))
assert out.split() == [ '4', '4', '7' ]
<file_sep>/shellscript/util.py
from .proto import dev, Command, pipe
def alias(cmd, *alias_args, **alias_kwargs):
"""Define default arguments for *Command*s.
Parameters:
*shellscript.Command* cmd: A command class.
\*alias_args: Default arguments.
\*\*alias_args: Default keyword arguments.
Returns:
*shellscript.Command*: A function that initializes a command.
"""
def _cmd(*args, **kwargs):
args = alias_args + args
kwargs.update(alias_kwargs)
return cmd(*args, **kwargs)
return _cmd
def astr(cmd, *args, **kwargs):
"""Return the *stdout* output of *cmd* as string.
Parameters:
*shellscript.Command* cmd: A command class.
\*args: Arguments.
\*\*args: Keyword arguments.
Returns:
*str*: *stdout* of *cmd* as string.
"""
if 'out' in kwargs:
out = kwargs['out']
if isinstance(out, tuple):
out = pipe(*out)
if isinstance(kwargs['out'], Command):
while out.is_opipe:
out = out._out
out._out = dev.itr
else:
kwargs['out'] = dev.itr
return str(cmd(*args, **kwargs))
def to_py_str_list(l):
"""Convert a list of *shellscript.proto._BaseString* objects into pure
Python *str*s.
The number of elements in both lists may differ, due to the different
treatment of newlines.
Parameters:
[ *shellscript.proto._BaseString* ]: A list of shellscript strings.
returns:
[ *str* ]: A list of Python strings.
"""
ret = [ str(s) for s in l if (s or s.linebreak) ]
try:
if l and l[-1].linebreak:
ret.append('')
except AttributeError:
pass
return ret
<file_sep>/shellscript/cmd/date.py
import sys
import time
from shellscript.proto import Command, OutString, ErrString
class date(Command):
"""Print the system date and time.
ret is set to 0 on success and to 1 on failure.
Parameters:
*str* fmt: A time.strftime format string.
Yields:
shellscript.proto.OutString: The current date time.
"""
def __init__(self, fmt=None, *args, **kwargs):
self._fmt = fmt if fmt is not None else '%c'
super(date, self).__init__(*args, **kwargs)
def work(self):
try:
self.buffer_return(OutString(time.strftime(self._fmt)))
except:
self.buffer_return(ErrString(sys.exc_info()[1]))
self.ret = 1
self.stop()
<file_sep>/test/test_settings.py
import os
from util import original_env
from shellscript.settings import load
def _reset_paths(tmpdir):
os.environ['HOME'] = tmpdir
try:
del os.environ['SHELLSCRIPTRC']
except KeyError: pass
def test_load_nonexistent(tmpdir, original_env):
_reset_paths(tmpdir.strpath)
mod = load()
assert mod is None
def test_load_home(tmpdir, original_env):
_reset_paths(tmpdir.strpath)
tmpdir.join('.shellscriptrc').write('ps = alias(run, "ps")')
mod = load()
assert mod and 'ps' in mod.__dict__
def test_load_envvar(tmpdir, original_env):
_reset_paths(tmpdir.strpath)
f = tmpdir.join('shellscript')
f.write('ps = alias(run, "ps")')
os.environ['SHELLSCRIPTRC'] = f.strpath
mod = load()
assert mod and 'ps' in mod.__dict__
<file_sep>/test/test_rm.py
import os
from shellscript import rm, dev
from util import file_make_unique_name, file_make_text
def valid_input(tmpdir):
def _():
f, _ = file_make_text(tmpdir)
return [], dict(f=f)
yield _
def _():
d = tmpdir.mkdir(file_make_unique_name(tmpdir))
f, _ = file_make_text(d)
return [], dict(f=d.strpath, recurse=True)
yield _
def _():
f = file_make_unique_name(tmpdir)
return [], dict(f=f, force=True)
yield _
def invalid_input(tmpdir):
def _():
d = tmpdir.mkdir(file_make_unique_name(tmpdir))
f, _ = file_make_text(d)
return [], dict(f=d.strpath)
yield _
def _():
f = file_make_unique_name(tmpdir)
return [], dict(f=os.path.join(tmpdir.strpath, f))
yield _
def test_arg_file_simple(tmpdir):
f , _ = file_make_text(tmpdir)
cmd = rm(f)
assert not os.path.exists(f)
def test_arg_file_wildcard(tmpdir):
fs = [
file_make_text(tmpdir, postfix='.txt')[0],
file_make_text(tmpdir, postfix='.py')[0],
file_make_text(tmpdir, postfix='.txt')[0] ]
cmd = rm(os.path.join(tmpdir.strpath, '*.txt'))
assert not os.path.exists(fs[0])
assert os.path.exists(fs[1])
assert not os.path.exists(fs[2])
def test_arg_file_wildcardlist(tmpdir):
fs = [
file_make_text(tmpdir, postfix='.txt')[0],
file_make_text(tmpdir, postfix='.py')[0],
file_make_text(tmpdir, postfix='.rtf')[0] ]
cmd = rm([
os.path.join(tmpdir.strpath, '*.txt'),
os.path.join(tmpdir.strpath, '*.py')])
assert not os.path.exists(fs[0])
assert not os.path.exists(fs[1])
assert os.path.exists(fs[2])
def test_arg_dir(tmpdir):
d = tmpdir.mkdir(file_make_unique_name(tmpdir))
f, _ = file_make_text(d)
cmd = rm(d.strpath, recurse=True)
assert not os.path.exists(d.strpath)
def test_arg_verbose(tmpdir):
d = tmpdir.mkdir(file_make_unique_name(tmpdir))
file_make_text(d)
file_make_text(d)
out = []
cmd = rm(d.strpath, recurse=True, verbose=True, out=out)
assert len(out) == 3
<file_sep>/test/test_astr.py
import os
import sys
from shellscript import dev, astr, ls, whoami
def test_astr_whoami(tmpdir):
assert astr(whoami) == str(whoami(out=dev.itr))
def test_astr_ls(tmpdir):
d = os.path.dirname(os.path.abspath(__file__))
out = []
ls(d, out=out)
assert astr(ls, d) == ('\n'.join(out))
<file_sep>/shellscript/cmd/tee.py
import sys
import time
from shellscript.proto import Command, InputReaderMixin, OutString, ErrString,\
resolve
class tee(Command, InputReaderMixin):
"""Read from standard input and write to standard output and files.
ret is set to 0 on success and to 1 on failure.
Parameters:
f: The destination files, or a list of those.
bool append: Append to given files, do not overwrite.
Yields:
shellscript.proto.OutString, shellscript.proto.ErrString:
"""
def __init__(self, f=None, append=False, *args, **kwargs):
self._f = f
self._append = append
super(tee, self).__init__(*args, **kwargs)
def initialize(self):
super(tee, self).initialize()
flags = 'w' if not self._append else 'a'
fs = resolve(self._f)
if fs:
self._fobjs = [ open(f, flags) for f in resolve(self._f) ]
else:
self._fobjs = None
self.initialize_input([])
def finalize(self):
if self._fobjs:
for f in self._fobjs:
f.close()
def work(self):
try:
l = self.get_input_line()
if self._fobjs:
for f in self._fobjs:
f.write(l.to_py_str())
else:
self.buffer_return(OutString(l))
return OutString(l)
except StopIteration:
raise
except:
self.stop_with_error(sys.exc_info()[1], 1)
<file_sep>/test/test_ls.py
import os
from shellscript import ls, dev
from util import file_make_unique_name
def valid_input(tmpdir):
d = tmpdir.mkdir(file_make_unique_name(tmpdir))
def _():
return [], dict(f=d.strpath)
yield _
def _():
f = d.join('test_ls_1')
f.write('')
return [], dict(f=f.strpath)
yield _
yield lambda: ([], dict(f=os.path.join(d.strpath, '*')))
def invalid_input(tmpdir):
yield lambda: ([], dict(f=os.path.join(tmpdir.strpath, 'invalid')))
def test_empty(tmpdir):
cmd = ls(f=tmpdir.strpath, out=dev.itr)
assert len(list(cmd)) == 0
def test_simple_files(tmpdir):
files = [ 'ab', 'cd', 'ef', 'gh' ]
for t in files:
f = tmpdir.join(t)
f.write(t)
cmd = ls(f=tmpdir.strpath, out=dev.itr)
assert list(cmd) == files
def test_simple_glob(tmpdir):
files = [ 'ab', 'abcd', 'abcdef', 'abcdefgh' ]
for t in files:
f = tmpdir.join(t)
f.write(t)
cmd = ls(os.path.join(tmpdir.strpath, '*ef*'), out=dev.itr)
assert list(cmd) == [ os.path.join(tmpdir.strpath, f) for f in files[2:] ]
def test_hidden_files(tmpdir):
files = [ '.ab', '.abc', 'abcd', 'abcde' ]
for t in files:
f = tmpdir.join(t)
f.write(t)
if os.name == 'nt':
import ctypes
for f in files[:2]:
ctypes.windll.kernel32.SetFileAttributesW(f, 2)
cmd = ls(f=tmpdir.strpath, out=dev.itr)
assert list(cmd) == files[2:]
cmd = ls(f=tmpdir.strpath, all=True, out=dev.itr)
assert list(cmd) == (['.', '..', ] + files)
def test_point(tmpdir):
assert list(ls(out=dev.itr)) == list(ls(f='.', out=dev.itr))
def test_pointpoint(tmpdir):
parent = os.path.dirname(os.getcwd())
assert list(ls(parent, out=dev.itr)) == list(ls(f='..', out=dev.itr))
def test_indicator_slash(tmpdir):
content = [ 'ab/', 'cd.txt', 'ef/', 'gh.txt' ]
tmpdir.join('cd.txt').write('cd.txt')
tmpdir.join('gh.txt').write('gh.txt')
tmpdir.mkdir('ab')
tmpdir.mkdir('ef')
cmd = ls(tmpdir.strpath, indicator_slash=True, out=dev.itr)
assert list(cmd) == content
<file_sep>/doc/roadmap.rst
shellscript commands to implement
=================================
v0.1
~~~~
date
----
-d
-f
-I
-r
-R
--rfc-3339
-s
-u
hostname
--------
-a
-d
-f
-A
-i
-I
-s
-y
-b
-F
sleep
-----
tee
---
-a
uname
-----
-a
-s
-n
-r
-v
-m
-p
-i
-o
wc
--
-c
-m
-l
-L
-w
which
-----
-a
yes
---
v0.2
~~~~
diff
----
--normal
-q
-s
-c
-u
-e
-n
-y
-W
--left-column
--suppress-common-lines
-p
-F
--label
-t
-T
--tabsize
--suppress-blank-empty
-l
-r
-N
--unidirectional-new-file
--ignore-file-name-case
--no-ignore-file-name-case
-x
-X
-S
--from-file
--to-file
-i
-E
-Z
-b
-W
-B
-I
-a
--strip-trailing-cr
-D
-GTYPE
--line-format
--LTYPE
-d
--horizon-lines
--speed-large-files
du
--
-0
-a
--apparent-size
-B
-b
-c
-D
-d
-H
-h
--inodes
-k
-L
-l
-m
-P
-S
-si
-s
-t
--time
-X
--exclude
-x
find
----
-P
-L
-H
-O
-d
--daystart
--depth
-maxdepth
-mindepth
-mount
-noleaf
-warn
-xdef
+n
-n
n
-amin
-anewer
-atime
-cmin
-cnewer
-ctime
-empty
-exectuable
-false
-fstype
-gid
-group
-ilname
-iname
-inum
-ipath
-iregexp
-iwholename
-links
-lname
-mmin
-mtime
-name
-newer
-newerXY
-nogroup
-nouser
-path
-perm
-readable
-regex
-samefile
-size
-true
-type
-uid
-used
-user
-wholename
-writeable
-xtype
-delete
-exec
-execdir
-fls
-fprint
-ls
-ok
-okdir
-print
-print0
-prune
-quit
head
----
-c
-n
-q
-v
kill
----
-0123456789
-s
--signal
-l
-L
less
----
mkdir
-----
-m
-p
-v
-Z
ping
----
-a
-A
-b
-B
-d
-D
-f
-h
-L
-n
-O
-q
-r
-R
-U
-v
-V
-c
-F
-i
-I
-l
-m
-M
-N
-w
-W
-p
-Q
-s
-S
-t
-T
sed
---
-n
-e
-i
-f
-l
--posix
-r
-s
-u
-z
sort
----
-b
-d
-f
-g
-i
-M
-h
-n
-R
--random-source
-r
--sort
-V
-c
-C
-k
-m
-o
-s
-S
-t
-T
--parallel
-u
-z
stat
----
-L
-f
-c
--printf
-t
tail
----
-c
-F
-f
-n
-q
--retry
-s
-v
timeout
-------
-k
-s
time
----
umask
-----
uniq
----
-c
-d
-D
-f
--group
-i
-s
-u
-z
-w
v0.3
~~~~
chgrp
-----
-c
-f
-v
--dereference
--no-preserve-root
--preserve-root
-R
-H
-L
-P
chmod
-----
-c
-f
-v
--no-preserve-root
--preserve-root
-R
chown
-----
-c
-f
-v
--dereference
-h
-from
--no-preserve-root
--preserve-root
--reference
-R
-H
-L
-P
clear
-----
history
-------
man
---
Future versions
~~~~~~~~~~~~~~~
awk
---
cat
---
-n
-E
-s
-T
bzip2
-----
-c
-d
-f
-k
-q
-s
-t
-v
-z
-V
-L
-123456789
cp
--
-a
--attributes-only
--backup
-b
--copy-contents
-d
-f
-i
-H
-l
-L
-n
-P
-p (only timestamp and mode supported)
--preserve (only timestamp and mode supported)
--no-preserve
--parents
-reflink
--remove-destination
--sparse
--strip-trailing-slashes
-s
-S
-t
-T
-u
-x
-z
--context
curl
----
dd
--
bs
cbs
conv
count
ibs
if
iflag
obs
of
oflag
seek
skip
status
df
--
-a
-B
--total
-h
-H
-i
-k
-l
--no-sync
--output
-P
--sync
-t
-T
-x
file
----
-b
-c
-E
-h
-i
-k
-l
-L
-N
-n
-p
-r
-s
-v
-z
-Z
-0
--apple
--extension
--mime-encoding
--mime-type
-e
-F
-f
-m
-P
-C
-m
grep
----
-E
-F
-G
-P
-e
-f
-i
-v
-w
-x
-y
-c
--color
-L
-l
-m
-o
-p
-s
-b
-H
-h
--label
-n
-T
-u
-Z
-A
-B
-C
-a
--binary-files
-D
-d
--exclude
-I
--include
-r
-R
--line-buffered
-U
-z
gzip
----
-a
-c
-d
-f
-h
-k
-l
-L
-n
-N
-r
-t
-v
-V
-1
-9
--rsyncable
-S
gunzip
------
-a
-c
-f
-h
-k
-l
-L
-n
-N
-r
-t
-v
-V
-S
ifconfig
--------
-v
-a
-s
killall
-------
-
--co
-e
-g
-i
-o
-q
-r
-s
-u
-v
-w
-y
-I
-V
ls
--
-a
-A
--author
-b
--block-size
-B
-c
-C
--color
-d
-D
-f
-F
--file-type
--format
--full-time
-g
--group
-G
-h
-si
-H
--hide
--indicator-style
-i
-I
-k
-l
-L
-m
-n
-N
-o
-p
-q
--show-control-chars
-Q
--quoting-style
-r
-R
-s
-S
--sort
--time
--time-style
-t
-T
-u
-U
-v
-w
-X
-x
-Z
-1
lsof
----
-?
-a
-b
-C
-h
-K
-l
-n
-N
-O
-P
-R
-t
-U
-v
-V
-X
-A
-c
-d
-D
-e
-E
-f
-k
-L
-m
-M
-o
-p
-r
-s
-S
-T
-u
-w
-x
-z
-Z
mount
-----
-l
-h
-V
-a
-f
-F
-n
-r
-s
-v
-w
-t
-O
-f
-n
-r
-s
-v
-w
-o
-t
-o
mv
--
--backup
-b
-f
-i
-n
--strip-trailing-slashes
-S
-t
-T
-u
-Z
popd
----
-n
+n
-0-9
ps
--
-A
-a
-d
--deselect
-e
-g
-N
-T
-r
-x
-123
-C
-G
-g
--Group
--group
p
-p
--pid
--ppid
q
-q
--quick-pid
-s
--sid
t
-t
--tty
U
-U
-u
--User
--user
-c
--context
-f
-F
--format
j
-j
l
-l
-M
O
-O
o
-o
s
u
v
x
X
-y
Z
c
--cols
--columns
--cumulative
e
f
--forest
h
-H
--headers
k
--lines
-n
n
N
--no-headers
O
--rows
S
--sort
w
-w
--width
H
-L
m
-m
-T
pushd
-----
-n
+n
-0-9
scp
---
-12346
-B
-C
-p
-q
-r
-v
-c
-f
-F
-i
-l
-o
-S
shutdown
--------
-H
-P
-r
-h
-k
--no-wall
-c
ssh
---
-1246
-A
-a
-C
-f
-G
-g
-K
-k
-M
-N
-n
-q
-s
-T
-t
-V
-v
-X
-x
-Y
-y
-b
-c
-D
-E
-e
-F
-I
-i
-L
-l
-m
-O
-o
-p
-Q
-R
-S
-W
-w
tar
---
top
---
-b
-c
-d
-H
-i
-n
-o
-O
-p
-s
-S
-u
-w
touch
-----
-d
-h
-r
-t
umount
------
-a
-A
-c
-d
--fake
-f
-i
-l
-n
-O
-R
-r
-t
-v
uptime
------
-p
-s
who
---
-a
-b
-d
-H
-l
--lookup
-m
-p
-q
-r
-s
-t
-T
-u
xz
--
-q
-v
-T
--fast
--best
-e
-0123456789
-c
--files
-S
-k
-f
-s
-l
-t
-d
-z
zip
---
-a
-A
-B
-c
-d
-D
-e
-E
-f
-F
-g
-j
-k
-l
-L
-m
-o
-q
-r
-R
-S
-T
-u
-v
-V
-w
-X
-y
-z
-!
-@
-$
Done
~~~~
alias
-----
cd
--
pwd
---
To be provided by Python
~~~~~~~~~~~~~~~~~~~~~~~~
basename
--------
Use os.path.basename.
cut
---
Use Python string operations.
dirname
-------
Use os.path.dirname.
more
----
We only need less.
printf
------
Use the python print statement.
source
------
Use Python means (exec, import ...).
tr
--
Python string operations.
wget
----
Replaced by curl.
xargs
-----
Not needed in Python.
Unknown
~~~~~~~
bg
--
fg
--
ftp
---
link
----
ln
--
locate
------
logout
------
mkisofs
-------
netstat
-------
nice
----
sftp
----
strace
------
su
--
sync
----
wait
----
unrar
-----
Indices and tables
==================
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
<file_sep>/test/test_mv.py
import os
from shellscript import mv, dev
from util import file_make_unique_name, file_make_text, file_equals, \
dir_equals
def valid_input(tmpdir):
def _():
f1, _ = file_make_text(tmpdir)
return [], dict(src=f1, dst=tmpdir.strpath)
yield _
def _():
f2, _ = file_make_text(tmpdir)
return [], dict(src=f2, dst=os.path.join(tmpdir.strpath,
os.path.basename(__file__)))
yield _
def invalid_input(tmpdir):
def _():
f = os.path.join(tmpdir.strpath, 'x')
while os.path.exists(f):
f += 'x'
return [], dict(src=f, dst=tmpdir.strpath)
yield _
def _():
f1, _ = file_make_text(tmpdir)
f2, _ = file_make_text(tmpdir)
f3name = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
return [], dict(src=[f1, f2], dst=f3name)
yield _
def _():
f1, _ = file_make_text(tmpdir)
d1 = tmpdir.mkdir(file_make_unique_name(tmpdir))
d2 = tmpdir.mkdir(file_make_unique_name(tmpdir))
return [], dict(src=f1, dst=[d1.strpath, d2.strpath])
yield _
def test_arg_verbose(tmpdir):
srcdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
file_make_text(srcdir)
file_make_text(srcdir)
file_make_text(srcdir)
tgtdir1 = tmpdir.mkdir(file_make_unique_name(tmpdir))
tgtdir2 = tmpdir.mkdir(file_make_unique_name(tmpdir))
out = []
cmd = mv(os.path.join(srcdir.strpath, '*'), tgtdir1.strpath, out=out)
assert len(out) == 0
cmd = mv(os.path.join(tgtdir1.strpath, '*'), tgtdir2.strpath, verbose=True,
out=out)
assert len(out) == 3
def test_arg_srcdst_simple(tmpdir):
src, txt = file_make_text(tmpdir)
tgt = tmpdir.join(file_make_unique_name(tmpdir))
cmd = mv(src, tgt.strpath)
assert os.path.isfile(tgt.strpath)
with open(tgt.strpath, 'r') as f:
assert f.read() == txt
def test_arg_src_dir(tmpdir):
srcdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
srcdir_sub = srcdir.mkdir(file_make_unique_name(srcdir))
file_make_text(srcdir_sub),
file_make_text(srcdir_sub),
file_make_text(srcdir)
tgtdir = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir))
cmd = mv(srcdir.strpath, tgtdir)
assert len(os.listdir(tgtdir)) == 2
assert not os.path.exists(srcdir.strpath)
def test_arg_src_list(tmpdir):
srcdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
tgtdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
src = [
file_make_text(srcdir)[0],
file_make_text(srcdir)[0] ]
cmd = mv(src, tgtdir.strpath)
assert set(os.listdir(tgtdir.strpath)) == set(
[ os.path.basename(e) for e in src ])
assert len(os.listdir(srcdir.strpath)) == 0
def test_arg_src_wildcard(tmpdir):
f_txt = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir,
postfix='.txt'))
f_rtf = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir,
postfix='.rtf'))
for f in (f_txt, f_rtf):
with open(f, 'w') as fobj:
fobj.write('ab')
tgtdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
cmd = mv(os.path.join(tmpdir.strpath, '*.txt'), tgtdir.strpath)
assert os.listdir(tgtdir.strpath) == [ os.path.basename(f_txt) ]
def test_arg_src_wildcardlist(tmpdir):
f_txt = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir,
postfix='.txt'))
f_rtf = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir,
postfix='.rtf'))
f_py = os.path.join(tmpdir.strpath, file_make_unique_name(tmpdir,
postfix='.py'))
for f in (f_txt, f_rtf, f_py):
with open(f, 'w') as fobj:
fobj.write('ab')
tgtdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
src = [ os.path.join(tmpdir.strpath, '*.%s' % ext) \
for ext in ('py', 'txt') ]
cmd = mv(src, tgtdir.strpath)
assert sorted(os.listdir(tgtdir.strpath)) == sorted(
[ os.path.basename(f_txt), os.path.basename(f_py) ])
def test_arg_dst_dir(tmpdir):
src, txt = file_make_text(tmpdir)
tgtdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
cmd = mv(src, tgtdir.strpath)
tgt = os.path.join(tgtdir.strpath, os.path.basename(src))
assert os.path.exists(tgt)
with open(tgt, 'r') as f:
assert f.read() == txt
def test_arg_dst_wildcard(tmpdir):
srcdir = tmpdir.mkdir(file_make_unique_name(tmpdir))
src, txt = file_make_text(srcdir)
tgtdir_parent = tmpdir.mkdir(file_make_unique_name(tmpdir))
tgtdir = tgtdir_parent.mkdir(file_make_unique_name(tgtdir_parent))
cmd = mv(src, os.path.join(tgtdir_parent.strpath, '*'))
assert os.path.exists(
os.path.join(tgtdir.strpath, os.path.basename(srcdir.strpath)))
<file_sep>/shellscript/cmd/pwd.py
import os
from shellscript.proto import Command, OutString
class pwd(Command):
"""Print the full filename of the current working directory.
ret is set to 0 on success and to 1 on failure.
Yields:
shellscript.proto.OutString: The current working directory.
"""
def work(self):
self.buffer_return(OutString(os.getcwd()))
self.stop()
<file_sep>/test/test_whoami.py
import getpass
import os
from shellscript import whoami, dev
def valid_input(tmpdir):
yield lambda: ([], {})
def invalid_input(tmpdir):
return []
def test_current():
cmd = whoami(out=dev.itr)
assert list(cmd) == [ getpass.getuser() ]
assert cmd.ret == 0
| 5ade64bff3a31c2aa9cef4191e8e831345b56122 | [
"Python",
"reStructuredText"
] | 46 | Python | pyohannes/shellscript | f74b295f6fad35bb4fe32b748453d2ad2d494ada | 64d65e0746618e0d8efcd39d196c71985f7238ee |
refs/heads/master | <repo_name>Yicong-Li/random-process-project<file_sep>/README.md
# random-process-project<file_sep>/seir_with_unscented_kalman_filter/data/convert_mat.py
import pandas as pd
import scipy.io as sio
import numpy as np
# data preprocessing
data = pd.read_csv('owid-covid-data.csv')
country = 'United States'
country_data = data[data.location == country]
country_data = country_data[(country_data['total_cases'] > 0)]
country_data.head()
country_data['date'] = pd.to_datetime(country_data['date'], format='%Y-%m-%d')
I = country_data['new_cases']
date = country_data['date']
I0 = np.zeros(I.size)
d0 = np.zeros([I.size, 3])
for k in np.arange(I.size):
I0[k] = I.iloc[k]
d0[k, :] = [date.iloc[k].month, date.iloc[k].day, date.iloc[k].year]
sio.savemat(country+'.mat', {'I':I0, 'd':d0})
<file_sep>/extract_ukf.py
import pandas as pd
from datetime import datetime, timedelta
from scipy import integrate, optimize
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import r2_score
import warnings
warnings.filterwarnings('ignore')
# data preprocessing
data = pd.read_csv('owid-covid-data.csv')
country = 'Turkey'
country_data = data[data.location == country]
country_data = country_data[(country_data['total_cases'] > 0)]
country_data.head()
# population
pop_dict = {'United Kingdom': 67900000, 'Italy': 60500000, 'China': 1400050000, 'Turkey': 83200000}
pop = pop_dict[country]
# time interval
t_interval = np.arange(len(country_data))
# daily new cases
daily_new_cases = country_data['new_cases'].values
# SEIR model: susceptible, exposed, infected, recovered
# initial values
I0 = daily_new_cases[0]
E0 = 5 * I0
S0 = pop - I0 - E0
R0 = 0
print(I0)
print(E0)
print(S0)
| 52a1e4a04e86d781c893aff94e0525ec17dcc0be | [
"Markdown",
"Python"
] | 3 | Markdown | Yicong-Li/random-process-project | 532c7bfd64219e5e8f16969c568ace69417ae05a | 4ea74a611cf9fb8335c8b3780ca0db918266a748 |
refs/heads/master | <repo_name>alex-hh/motif_projection<file_sep>/core/data.py
import os
import sys
import numpy as np
import h5py
class Data():
"""
Object used to load data. The training data is returned batch by batch
whereas the test and validation data the entire dataset is returned. A
generator can be returned for training using get_training_generator.
get_data for 'valid' or 'train' returns the dataset in full.
The data always returns the 4 DNA channels (A,C,G,T). Other arguments can add more channels
Args:
batch_size - how many samples will be returned per iteration of the training generator
shuffle - Shuffles the order batches are returned in each epoch, should always help convergance
recommended to only set to False for debugging
proportion_train_set_used - Used to subset the training data. For example if set to 0.2 only 20% of
the training data is used per epoch.
"""
def __init__(self, batch_size=256, shuffle=True, proportion_train_set_used=1.0,
proportion_val_set_used=1.0, data_suffix='_full', sequence_length=1000):
self.seqstart_ind = (1000 - sequence_length) // 2
self.seqend_ind = 1000 - self.seqstart_ind
print('Loading data with length ', sequence_length)
print(self.seqstart_ind)
sys.stdout.flush()
self.batch_size = batch_size
self.shuffle = shuffle
self.proportion_train_set_used = proportion_train_set_used
self.proportion_val_set_used = proportion_val_set_used
self.train_index_generator = self.get_train_index_generator()
if data_suffix is not None:
self.suffix = data_suffix
else:
self.suffix = ''
self.dna = h5py.File('data/processed_data/dna{}.h5'.format(self.suffix), 'r')
self.labels = h5py.File('data/processed_data/labels{}.h5'.format(self.suffix), 'r')
self.get_dataset_sizes()
self.max_train_ind = (self.train_n // self.batch_size) * self.batch_size
def get_dataset_sizes(self):
self.train_n = int(self.proportion_train_set_used*self.dna['train'].shape[0])
self.valid_n = int(self.proportion_val_set_used*self.dna['valid'].shape[0])
print('N train {}, N val {}'.format(self.train_n, self.valid_n))
print('Steps per epoch', self.steps_per_epoch())
sys.stdout.flush()
if 'test' in self.dna:
self.test_n = self.dna['test'].shape[0]
def get_training_generator(self, which_set='train'):
while(True):
try:
yield self.get_data(which_set)
except Exception as e:
print(e)
print('Failed to get data')
sys.stdout.flush()
def get_data(self, dataset):
"""
Retrieve the next batch of (inputs, targets), one-hot encoding on the fly
Args:
dataset (str): 'train', 'valid', or 'test'
Returns:
inputs: ndarray (batch_size, SEQUENCE_LENGTH, num_channels)
targets:
"""
try:
indexs = self.get_indexs(dataset) # get indices of next batch
except:
print('Failed to get indexes')
sys.stdout.flush()
self.train_index_generator = self.get_train_index_generator()
indexs = self.get_indexs(dataset)
Y = self.labels[dataset][indexs] # get labels of next batch by slicing? hdF5 file
batch = []
batch.append(self.dna[dataset][indexs])
return np.concatenate(batch, axis=2)[:,self.seqstart_ind:self.seqend_ind,:], Y
@staticmethod
def reversecomp_dnaarr(dnaarr):
"""
This is assuming dnaarr shape is n_samples, n_basepairs, input_dim
"""
arr = np.zeros(dnaarr.shape)
arr[:,:,:4] = np.rot90(dnaarr[:,:,:4], 2, axes=(2,1))
arr[:,:,4:] = dnaarr[:,::-1,4:]
return arr
def get_indexs(self, dataset):
if dataset == 'valid':
indexs = list(range(self.valid_n))
elif dataset == 'test':
indexs = list(range(self.test_n))
else:
indexs = next(self.train_index_generator)
return indexs
def get_train_index_generator(self):
"""
Return indices of datapoints in next batch.
At each epoch, shuffle the order in which the batches are presented,
but preserve the identities of the datapoints in each batch.
i.e. - there are self.train_n // self.batch_size
batches, which are always the same from epoch to epoch, but the order in which the
batches are presented is shuffled
"""
while True:
# starts is calculated once per epoch
self.starts = [x * self.batch_size for x in range(self.train_n//self.batch_size)]
if self.shuffle:
np.random.shuffle(self.starts) # this happens once per epoch
for start in self.starts:
# evaluated for each batch
end = start + self.batch_size
yield(range(start, end))
def steps_per_epoch(self):
"""Number of times generator needs to be called to see entire dataset"""
return self.train_n // self.batch_size
<file_sep>/README.md
Implementation of experiments incorporating projection layer to simplify representation of motifs and improve performance in neural networks for regulatory genomics described in [Projection layers improve deep learning models of regulatory DNA function
(bioRxiv)](https://www.biorxiv.org/content/early/2018/09/10/412734)
## Training Models
python scripts/run_experiments.py <experiment_name>
Experiment names with associated settings are defined in expset_settings:
* expset_settings/500bp_slim.py - experiments with projection layer, dropout in 3 layer cnn with varying number of filters in first layer
* expset_settings/final_crnn_slimpy - experiments with convolutional-recurrent neural networks using projection layer to improve on DanQ performance on DeepSEA dataset.
e.g. to run the convolutional recurrent model with 320 first layer filters
python scripts/run_experiments.py final_crnn_320_300rd20
### License
This project is licensed under the terms of the MIT license
<file_sep>/scripts/calculate_predictions.py
import sys
import os
import argparse
from os.path import join
from core.evaluate_model import make_predictions
from core.data import Data
from core.train_model import get_trained_model, get_data_loader
sys.setrecursionlimit(100000) # Needed for very deep models
RESULT_DIR = os.environ.get('RESULT_DIR', 'results')
def calculate_predictions(experiment_name, dataset):
print('Loading data... ')
sys.stdout.flush()
if experiment_name in ['danq', 'deepsea', 'danqjaspar']:
data = Data(data_suffix='_full')
X, y = data.get_data(dataset)
else:
data = get_data_loader(experiment_name)
X, y = data.get_data(dataset)
print('Loading model... ')
sys.stdout.flush()
model = get_trained_model(experiment_name)
print('Calculating predictions... ')
sys.stdout.flush()
make_predictions(model, X, join(RESULT_DIR, 'predictions-best',
'{}-{}{}.npy'.format(experiment_name, dataset, data.suffix)),
verbose=1)
def make_dirs():
os.makedirs('{}/predictions-best'.format(RESULT_DIR), exist_ok=True)
os.makedirs('{}/predictions-all'.format(RESULT_DIR), exist_ok=True)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('experiment', help='Name of the experiment.')
parser.add_argument('--dataset', help='Which dataset to make predictions on (valid or test)', default="test")
args = parser.parse_args()
print('Calculating predictions for {} on {}'.format(args.experiment, args.dataset))
calculate_predictions(args.experiment, dataset=args.dataset)
<file_sep>/scripts/experiment_settings.py
import os, sys
from importlib import import_module
import pickle
from core.data import Data
def save_experiment_design(model_class, experiment_name, model_args={}, data_args={}, train_settings={},
callback_settings={}, check_model=False, check_data=False):
to_save = {'model_class': model_class,
'model_args': model_args,
'data_args': data_args,
'train_settings': train_settings,
'callback_settings': callback_settings}
if check_model:
model_class(**model_args).get_compiled_model()
if check_data:
Data(**data_args)
os.makedirs('experiment_settings', exist_ok=True)
pickle.dump(to_save, open('experiment_settings/{}.p'.format(experiment_name), 'wb'))
def delete_experiment_design(experiment_name):
os.remove('experiment_settings/{}.p'.format(experiment_name))
def print_experiments(experiments=None):
if experiments is None:
experiments = [x[:-2] for x in os.listdir('experiment_settings')]
for experiment in sorted(experiments):
print('===========', experiment, '===========')
print_experiment(experiment)
print()
def print_experiment(experiment_name):
settings = pickle.load(open('experiment_settings/{}.p'.format(experiment_name), 'rb'))
model_class, model_args, data_args = settings['model_class'], settings['model_args'], settings['data_args']
train_settings, callback_settings = settings['train_settings'], settings['callback_settings']
print('Model type : {}'.format(model_class.__name__))
print('Model args :')
for key in sorted(model_args.keys()):
print('\t', key, model_args[key])
print('Data args :')
for key in sorted(data_args.keys()):
print('\t', key, data_args[key])
print('Train settings :')
for key in sorted(train_settings.keys()):
print('\t', key, train_settings[key])
print('Callback settings :')
for key in sorted(callback_settings.keys()):
print('\t', key, callback_settings[key])
if __name__ == '__main__':
assert len(sys.argv) >= 2
which_exp_set = sys.argv[1]
try:
mod = import_module('expset_settings.' + which_exp_set)
expt_settings = getattr(mod, 'expt_settings')
for settings in expt_settings:
save_experiment_design(**settings)
except:
raise Exception('Experiment name not recognised')
<file_sep>/core/models.py
from keras.optimizers import Adam
from keras.layers import Flatten, Dropout, Dense, Activation, MaxPooling1D,\
Bidirectional, LSTM
from keras.layers.pooling import GlobalAveragePooling1D, GlobalMaxPooling1D
from keras.models import Model, Input, Sequential
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import Conv1D
class CNN():
def __init__(self, l1_filters=300,
sequence_length=1000,
conv_dropout=0.2,
lr=0.0003,
embedding=True):
self.sequence_length = sequence_length
self.l1_filters = l1_filters
self.conv_dropout = conv_dropout
self.embedding = embedding
self.lr = lr
def get_compiled_model(self):
inputs = Input(shape=(self.sequence_length, 4))
x = Conv1D(self.l1_filters, 19, padding='valid')(inputs)
x = LeakyReLU(0.01)(x)
x = MaxPooling1D(6, strides=6)(x)
if self.embedding:
x = Conv1D(64, 1, activation=None, use_bias=False)(x)
x = Dropout(self.conv_dropout)(x)
x = Conv1D(128, 11, padding='valid')(x)
x = LeakyReLU(0.01)(x)
x = MaxPooling1D(2, strides=2)(x)
x = Conv1D(256, 7, padding='valid')(x)
x = LeakyReLU(0.01)(x)
x = MaxPooling1D(2, strides=2)(x)
x = Flatten()(x)
x = Dense(2048, activation=None)(x)
x = LeakyReLU(0.01)(x)
x = Dropout(0.5)(x)
x = Dense(919)(x)
x = Activation('sigmoid')(x)
self.model = Model(inputs, x)
self.model.compile(optimizer=Adam(self.lr), loss='binary_crossentropy')
return self.model
class CRNN():
def __init__(self, filters=[320, 96],
motif_embedding_dim=None,
kernel_size=[30, 11],
conv_dropout=[0., 0.],
pooling_size=[7, 2],
pooling_stride=[7, 2],
sequence_length=1000,
output_dim=919,
recurrent=True,
global_pooltype='mean',
lr=0.0003,
ncell=100,
optimizer='adam',
recurrent_dropout=0.,
dense_dropout=0.,
dense_units=[919]):
self.filters = filters
self.motif_embedding_dim = motif_embedding_dim
self.sequence_length = sequence_length
self.kernel_size = kernel_size
self.conv_dropout = conv_dropout
self.pooling_size = pooling_size
self.output_dim = output_dim
self.lr = lr
self.pooling_stride = pooling_stride
self.recurrent = recurrent
self.global_pooltype = global_pooltype
self.ncell = ncell
self.optimizer = optimizer
self.recurrent_dropout = recurrent_dropout
self.dense_dropout = dense_dropout
self.dense_units = dense_units
self.model = None
def apply_convolutions(self, x):
for idx, params in enumerate(zip(self.filters, self.kernel_size, self.pooling_size, self.pooling_stride, self.conv_dropout)):
f, k, p, p_st, cd = params
x = Conv1D(f, k, padding='valid')(x)
x = LeakyReLU(0.01)(x)
x = MaxPooling1D(p, strides=p_st)(x)
if idx == 0 and self.motif_embedding_dim:
x = Conv1D(self.motif_embedding_dim, 1, activation=None, use_bias=False)(x)
x = Dropout(cd)(x)
return x
def build_model(self):
inputs = Input(shape=(self.sequence_length, 4))
x = self.apply_convolutions(inputs)
if self.recurrent:
lstm_cell = LSTM(self.ncell, return_sequences=True,
recurrent_dropout=self.recurrent_dropout)
x = Bidirectional(lstm_cell, merge_mode='concat')(x)
if self.global_pooltype == 'mean':
x = GlobalAveragePooling1D()(x)
else:
x = Flatten()(x)
for units in self.dense_units:
x = Dense(units)(x)
x = LeakyReLU(0.01)(x)
x = Dropout(self.dense_dropout)(x)
output = Dense(self.output_dim, activation=None)(x)
output = Activation('sigmoid')(output)
self.model = Model(inputs, output)
def get_compiled_model(self):
loss = 'binary_crossentropy'
if self.model == None:
self.build_model()
if self.optimizer == 'adam':
self.model.compile(optimizer=Adam(self.lr), loss=loss)
elif self.optimizer == 'sgd':
self.model.compile(optimizer=SGD(lr=self.lr, momentum=0.9), loss=loss)
else:
raise ValueError('opimizer must be either adam or sgd')
return self.model
<file_sep>/scripts/build_dna_full.py
import h5py
import os
import numpy as np
from scipy.io import loadmat
SEQUENCE_LENGTH = 1000
NO_TASKS = 919
def create_dna(deepsea_path,
dsets=['train', 'valid', 'test']):
trainmat = h5py.File(deepsea_path + 'train.mat')
validmat = loadmat(deepsea_path + 'valid.mat')
testmat = loadmat(deepsea_path + 'test.mat')
# validxdata, testxdata are (n_samples, 4, n_basepairs)
# processed_data/dna['data_name'] are (n_samples, n_basepairs, 4)
if 'train' in dsets:
train_data = np.transpose(np.asarray(
trainmat['trainxdata'], dtype='uint8'), axes=(2, 0, 1))
perm = np.random.permutation(train_data.shape[0])
train_data = train_data[perm]
print('Data with shape {} loaded. Writing to file'.format(train_data.shape), flush=True)
with h5py.File('data/processed_data/dna_full.h5', 'a') as f:
f.create_dataset('train', data=train_data, chunks=(32, SEQUENCE_LENGTH, 4))
f.create_dataset('train_ids', data=perm)
if 'valid' in dsets:
valid_data = np.asarray(np.transpose(
validmat['validxdata'], axes=(0, 2, 1)), dtype='uint8')
with h5py.File('data/processed_data/dna_full.h5', 'a') as f:
f.create_dataset('valid', data=valid_data, chunks=(32, SEQUENCE_LENGTH, 4))
if 'test' in dsets:
test_data = np.asarray(np.transpose(
testmat['testxdata'], axes=(0, 2, 1)), dtype='uint8')
with h5py.File('data/processed_data/dna_full.h5', 'a') as f:
f.create_dataset('test', data=test_data, chunks=(32, SEQUENCE_LENGTH, 4))
def create_labels(deepsea_path,
dsets=['train', 'valid', 'test']):
trainmat = h5py.File(deepsea_path+'train.mat')
validmat = loadmat(deepsea_path+'valid.mat')
testmat = loadmat(deepsea_path+'test.mat')
label_dict = dict()
if 'train' in dsets:
perm = h5py.File('data/processed_data/dna_full.h5', 'r')['train_ids'][:]
label_dict['train'] = np.asarray(trainmat['traindata'], dtype='uint8').T[perm]
print(label_dict['train'].shape, flush=True)
label_dict['valid'] = np.asarray(validmat['validdata'])
label_dict['test'] = np.asarray(testmat['testdata'])
with h5py.File('data/processed_data/labels_full.h5', 'w') as f:
for dset in dsets:
f.create_dataset(dset, data=label_dict[dset], chunks=(32, NO_TASKS))
if __name__ == '__main__':
if not os.path.isfile('data/processed_data/dna_full.h5'):
create_dna()
create_labels()
<file_sep>/scripts/calc_auprc.R
# install.packages("RcppCNPy")
# install.packages("PRROC")
# source("http://bioconductor.org/biocLite.R")
# biocLite("rhdf5")
# library("RcppCNPy")
library("rhdf5")
library("PRROC")
args = commandArgs(trailingOnly=TRUE)
if (length(args)==0) {
stop("At least one argument must be supplied (input file).n", call.=FALSE)
} else if (length(args)==1) {
# default output file
args[2] = "valid"
}
expname <- args[1]
dataset <- args[2]
resdir <- Sys.getenv("RESULT_DIR")
scores <- h5read(file=sprintf("%s/predictions-best/%s-%s_full.h5", resdir, expname, dataset), name="preds")
print(dim(scores))
scores <- t(scores)
labels <- h5read(file="data/processed_data/labels_full.h5", name=dataset)
# matrix with 919 rows and 8000 cols
calcfn <- function(labels, scores, mc_cores = getOption("mc.cores", 2L)) {
calc_col <- function(c) {
PRROC::pr.curve(scores.class0 = scores[, c], weights.class0 = labels[, c])$auc.davis.goadrich
}
parallel::mcmapply(calc_col, 1:ncol(labels), SIMPLIFY = TRUE)
}
labels <- labels[,c(1:(ncol(labels)%/%2))]
labels <- t(labels)
mc_cores <- parallel::detectCores(all.tests = FALSE, logical = TRUE)
print(mc_cores)
print(dim(labels))
print(dim(scores))
aup <- calcfn(labels, scores, mc_cores)
# ma <- matrix(aup)
# da <- as.data.frame(ma)
# colnames(da) <- c("adjlkkl")
write.csv(aup, file=sprintf("%s/auprcs/%s-%s.csv", resdir, expname, dataset))
# now to csv it<file_sep>/expset_settings/500bp_slim.py
import copy
from core.models import CNN
expt_settings = []
base_settings = {'model_class': CNN,
'data_args': {'data_suffix': '_full',
'sequence_length': 500},
'callback_settings': {'es_patience': 5,
'lr_patience': 2,
'lr_factor': 0.2,
'min_lr': 2e-6},
'model_args': {'l1_filters': 300,
'conv_dropout': 0.2,
'embedding': True,
'lr': 0.0003,
'sequence_length': 500},
'train_settings': {'epochs' : 35}}
l1_sizes = [300, 500, 750, 1000]
for l1_size in l1_sizes:
sett = copy.deepcopy(base_settings)
sett['model_args']['l1_filters'] = l1_size
# suff += 'cd{}'.format(100*sett['model_args']['conv_dropout'])
sett['experiment_name'] = 'cnn_slim_{}embedcd20'.format(l1_size)
expt_settings.append(sett)
sett = copy.deepcopy(base_settings)
sett['model_args']['l1_filters'] = l1_size
sett['model_args']['embedding'] = False
sett['experiment_name'] = 'cnn_slim_{}cd20'.format(l1_size)
expt_settings.append(sett)
sett = copy.deepcopy(base_settings)
sett['model_args']['l1_filters'] = l1_size
sett['model_args']['embedding'] = False
sett['model_args']['conv_dropout'] = 0.
sett['experiment_name'] = 'cnn_slim_{}'.format(l1_size)
expt_settings.append(sett)
sett = copy.deepcopy(base_settings)
sett['model_args']['l1_filters'] = l1_size
sett['model_args']['conv_dropout'] = 0.
sett['experiment_name'] = 'cnn_slim_{}embed'.format(l1_size)
expt_settings.append(sett)
<file_sep>/core/deepsea.py
import torch
import torch.nn as nn
import torch.legacy.nn as lnn
import numpy as np
from functools import reduce
from torch.autograd import Variable
class LambdaBase(nn.Sequential):
def __init__(self, fn, *args):
super(LambdaBase, self).__init__(*args)
self.lambda_func = fn
def forward_prepare(self, input):
output = []
for module in self._modules.values():
output.append(module(input))
return output if output else input
class Lambda(LambdaBase):
def forward(self, input):
return self.lambda_func(self.forward_prepare(input))
class LambdaMap(LambdaBase):
def forward(self, input):
return list(map(self.lambda_func,self.forward_prepare(input)))
class LambdaReduce(LambdaBase):
def forward(self, input):
return reduce(self.lambda_func,self.forward_prepare(input))
# extracting intermediate outputs: https://discuss.pytorch.org/t/how-to-extract-features-of-an-image-from-a-trained-model/119/7
# could also use 'register forward hook': http://pytorch.org/docs/master/nn.html
deepsea = nn.Sequential( # Sequential,
nn.Conv2d(4,320,(1, 8)),
nn.Threshold(0,1e-06),
nn.MaxPool2d((1, 4),(1, 4)),
nn.Dropout(0.2),
nn.Conv2d(320,480,(1, 8)),
nn.Threshold(0,1e-06),
nn.MaxPool2d((1, 4),(1, 4)),
nn.Dropout(0.2),
nn.Conv2d(480,960,(1, 8)),
nn.Threshold(0,1e-06),
nn.Dropout(0.5),
Lambda(lambda x: x.view(x.size(0),-1)), # Reshape,
nn.Sequential(Lambda(lambda x: x.view(1,-1) if 1==len(x.size()) else x ),nn.Linear(50880,925)), # Linear,
nn.Threshold(0,1e-06),
nn.Sequential(Lambda(lambda x: x.view(1,-1) if 1==len(x.size()) else x ),nn.Linear(925,919)), # Linear,
nn.Sigmoid(),
)
class DeepSea:
def __init__(self, use_gpu=True):
import torch
if use_gpu:
self.model = deepsea.cuda()
else:
self.model = deepsea
self.use_gpu = use_gpu
self.model.load_state_dict(torch.load('/PATH/TO/deepsea.pth'))
def predict(self, X, batch_size=256):
self.model.eval()
if X.shape[1] == 1000 and X.shape[2] == 4:
X = X.swapaxes(1,2)
preds = np.zeros((X.shape[0],919))
for b in range(X.shape[0] // batch_size):
x = X[b*batch_size:(b+1)*batch_size]
t = torch.from_numpy(x.reshape((x.shape[0],4,1,1000))).float()
inputs = Variable(t, volatile=True)
if self.use_gpu:
inputs = inputs.cuda() # http://pytorch.org/docs/master/notes/autograd.html
output = self.model(inputs)
preds[b*batch_size:(b+1)*batch_size] = output.data.cpu().numpy()
if (b+1) * batch_size < X.shape[0]:
leftover = X[(b+1)*batch_size:]
print(leftover.shape[0])
t = torch.from_numpy(leftover.reshape((leftover.shape[0],4,1,1000))).float()
inputs = Variable(t, volatile=True) # http://pytorch.org/docs/master/notes/autograd.html
if self.use_gpu:
inputs = inputs.cuda()
output = self.model(inputs)
preds[(b+1)*batch_size:] = output.data.cpu().numpy()
return preds
# https://discuss.pytorch.org/t/how-to-extract-features-of-an-image-from-a-trained-model/119/8
class SelectiveSequential(nn.Module):
def __init__(self, to_select, modules_dict):
super(SelectiveSequential, self).__init__()
for key, module in modules_dict.items():
self.add_module(key, module)
self._to_select = to_select
def forward(x):
list = []
for name, module in self._modules.iteritems():
x = module(x)
if name in self._to_select:
list.append(x)
return list
class SelectiveDeepSea(nn.Module):
def __init__(self):
super().__init__()
self.features = SelectiveSequential(
['pred', 'pool1', 'pool2'],
{'conv1': nn.Conv2d(4,320,(1, 8)),
'rel1': nn.Threshold(0,1e-06),
'pool1': nn.MaxPool2d((1, 4),(1, 4)),
'drop1': nn.Dropout(0.2),
'conv2': nn.Conv2d(320,480,(1, 8)),
'rel2': nn.Threshold(0,1e-06),
'pool2': nn.MaxPool2d((1, 4),(1, 4)),
'drop2': nn.Dropout(0.2),
'conv3': nn.Conv2d(480,960,(1, 8)),
'rel3': nn.Threshold(0,1e-06),
'drop3': nn.Dropout(0.5),
'flatten': Lambda(lambda x: x.view(x.size(0),-1)), # Reshape,
'dense1': nn.Sequential(Lambda(lambda x: x.view(1,-1) if 1==len(x.size()) else x ),nn.Linear(50880,925)), # Linear,
'reldense': nn.Threshold(0,1e-06),
'dense2': nn.Sequential(Lambda(lambda x: x.view(1,-1) if 1==len(x.size()) else x ),nn.Linear(925,919)), # Linear,
'pred': nn.Sigmoid()}
)
def forward(self, x):
return self.features(x)<file_sep>/core/evaluate_model.py
import sys
import numpy as np
def make_predictions(model, X, fname, verbose=2):
"""
Makes predictions on data array X using model and saves it to fname
"""
print('Making predictions.')
sys.stdout.flush()
scores = model.predict(X, batch_size = 128, verbose=verbose)
np.save(fname, scores)
return scores <file_sep>/scripts/test_eval.py
import os, sys
from core.data import Data
from core.train_model import get_trained_model
def append_to_losses(expt_name, dataset, loss,
filename='final_losses_{}.csv'.format(sys.argv[2])):
with open(filename, 'a') as f:
f.write('{},{},{}\n'.format(expt_name, dataset, loss))
RESULT_DIR = os.environ.get('RESULT_DIR', 'results')
data = Data(sequence_length=int(sys.argv[2]), data_suffix='_full')
m = get_trained_model(sys.argv[1])
print('evaluating model', flush=True)
l = m.evaluate(*data.get_data('test'))
print('saving results', flush=True)
append_to_losses(sys.argv[1], 'test', l)<file_sep>/scripts/save_avg_pred.py
import argparse, os
import h5py
import numpy as np
def save_avg_preds(experiment_name, dataset):
RESULT_DIR = os.environ.get('RESULT_DIR', 'results')
preds = np.load(RESULT_DIR + '/predictions-best/{}-{}_full.npy'.format(experiment_name, dataset))
nforward = preds.shape[0] // 2
scores = np.stack((preds[:nforward], preds[nforward:]), axis=1)
scores = np.mean(scores, axis=1)
outfilepath = RESULT_DIR + '/predictions-best/{}-{}_full.h5'.format(experiment_name, dataset)
with h5py.File(outfilepath, 'w') as h5f:
h5f['preds'] = scores
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('experiment', help='Name of the experiment.')
parser.add_argument('dataset', nargs='?', default='valid', type=str)
args = parser.parse_args()
save_avg_preds(args.experiment, args.dataset)<file_sep>/scripts/run_experiments.py
import os, sys, re
import pickle
import argparse
from core.train_model import train_model, get_callbacks, get_untrained_model
from core.data import Data
RESULT_DIR = os.environ.get('RESULT_DIR', 'results')
def create_directories():
os.makedirs('results/csv_logs', exist_ok=True)
os.makedirs('results/models', exist_ok=True)
def run_experiment(experiment_name):
train_settings = get_training_settings(experiment_name)
model = get_untrained_model(experiment_name).get_compiled_model()
data = get_data(experiment_name)
print('Model and data loaded')
sys.stdout.flush()
callbacks = get_callbacks(experiment_name, **get_callback_settings(experiment_name))
train_model(model, data, callbacks, **train_settings)
def get_data(experiment_name):
data_args = pickle.load(open('experiment_settings/{}.p'.format(experiment_name), 'rb'))['data_args']
return Data(**data_args)
def get_callback_settings(experiment_name):
return pickle.load(open('experiment_settings/{}.p'.format(experiment_name), 'rb'))['callback_settings']
def get_training_settings(experiment_name):
return pickle.load(open('experiment_settings/{}.p'.format(experiment_name), 'rb'))['train_settings']
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("experiment", help="Name of the experiment.")
args = parser.parse_args()
create_directories()
run_experiment(args.experiment)
<file_sep>/core/train_model.py
import os, sys, pickle
from core.data import Data
from keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau,\
LambdaCallback, CSVLogger
RESULT_DIR = os.environ.get('RESULT_DIR', 'results')
def train_model(model, data, callbacks, steps_per_epoch=None, verbose=2,
epochs=30, class_weight=None, initial_epoch=0):
"""
Trains a model and uses callbacks to save weights.
args:
model - a compiled neural network
data - a Data object which implements get_training_generator
callbacks - A list of callbacks (which can be collected using the get_callbacks method)
epochs - Defaulted to 5000 which will take days/weeks for networks I used i.e. for when I want a network to run
until I cancel it or early stopping kicks in.
class_weight - Weights the loss function, can be used to make some tasks contribute more/loss to the loss function
verbose - 0 is nothing, 1 is full keras pct bar type thing, 2 is epoch end metrics
"""
print('Training model for {} epochs'.format(epochs))
print('model params: {}'.format(model.count_params()))
print(model.summary())
sys.stdout.flush()
if steps_per_epoch is None:
steps_per_epoch = data.steps_per_epoch()
training_generator = data.get_training_generator()
validation_data = data.get_data('valid')
sys.setrecursionlimit(100000) # required for very deep models see https://github.com/fchollet/keras/issues/2931#issuecomment-224504851
model.fit_generator(training_generator, steps_per_epoch=steps_per_epoch, epochs=epochs, callbacks=callbacks,
validation_data=validation_data, verbose=verbose, use_multiprocessing=True,
class_weight = class_weight, initial_epoch=initial_epoch)
def get_callbacks(experiment_name, es_patience=5, lr_patience=5000, lr_factor=0.5,
min_lr=0.0001, save_all_models=False, checkpoint=True):
"""
args:
es_patience - Early stopping patience i.e. how many epochs of not reducing validation loss before stopping
lr_patience/lr_factor - number of epochs where validation loss doesn't decrease until lr reduces by lr_factor.
Defaulted to 5000 to essentially be "off"
min_lr - When using lr_patience and lr_factor the lower limit to the lr
save_all_models - Saves model after every epoch instead of the best one. Models are large in size!
"""
callbacks = []
callbacks.append(CSVLogger('{}/csv_logs/{}.tsv'.format(RESULT_DIR, experiment_name), separator='\t'))
callbacks.append(ModelCheckpoint('{}/models-best/{}.h5'.format(RESULT_DIR, experiment_name), save_best_only=True))
if save_all_models:
callbacks.append(ModelCheckpoint('{}/models-all/{}-{{epoch:02d}}.h5'.format(RESULT_DIR, experiment_name)))
callbacks.append(EarlyStopping(patience=es_patience, verbose=1))
callbacks.append(ReduceLROnPlateau(patience=lr_patience, factor=lr_factor, verbose=1, min_lr=min_lr))
def flush(epoch, logs): return sys.stdout.flush()
callbacks.append(LambdaCallback(on_epoch_begin=flush, on_epoch_end=flush))
return callbacks
def get_untrained_model(experiment_name):
settings = pickle.load(open('experiment_settings/{}.p'.format(experiment_name), 'rb'))
model_class, model_args = settings['model_class'], settings['model_args']
if 'reg_weighting' in model_args:
model_args['reg_weighting'] = get_weighting(**model_args['reg_weighting'])
return model_class(**model_args)
def get_trained_model(experiment_name, epoch=None, use_gpu=True, return_class=False):
if experiment_name == 'deepsea':
from conservation.deepsea import DeepSea
return DeepSea(use_gpu=use_gpu)
else:
model_class = get_untrained_model(experiment_name)
model_class.get_compiled_model()
model_class.model.load_weights('{}/models-best/{}.h5'.format(RESULT_DIR, experiment_name))
if return_class:
return model_class
return model_class.model
def get_data_loader(experiment_name):
data_args = pickle.load(open('experiment_settings/{}.p'.format(experiment_name), 'rb'))['data_args']
return Data(**data_args)
<file_sep>/expset_settings/final_crnn_slim.py
import copy
from core.models import CRNN
expt_settings = []
crnn_base_settings = {'model_class': CRNN,
'model_args': {'kernel_size': [30, 11],
'filters': [700, 96],
'motif_embedding_dim': 64,
'conv_dropout': [0.15, 0],
'pooling_size': [7,2],
'pooling_stride': [7,2],
'lr': 0.0003,
'ncell': 100,
'recurrent': True,
'global_pooltype': 'mean'},
'data_args': {'data_suffix': '_full'},
'callback_settings': {'es_patience': 5,
'lr_patience': 2,
'lr_factor': 0.2,
'min_lr': 2e-6},
'train_settings': {'epochs': 35}}
l1s = [320, 700]
rds = [20]
lstm_sizes = [300]
# lstm_sizes = [200, 300, 500]
for l1 in l1s:
for rd in rds:
for l in lstm_sizes:
# if l1 == 700:
# sett['train_settings']['epochs'] = 1 # this would stop fit_generator...
sett = copy.deepcopy(crnn_base_settings)
sett['model_args']['filters'][0] = l1
sett['model_args']['ncell'] = l
sett['model_args']['recurrent_dropout'] = 0.01*rd
# sett['model_args']['concat_pooled_conv'] = True
sett['experiment_name'] = 'final_crnn_{}_{}rd{}'.format(l1, l, rd)
expt_settings.append(sett)
# if l1 == 700:
# sett['train_settings']['epochs'] = 1
sett = copy.deepcopy(crnn_base_settings)
sett['model_args']['filters'][0] = l1
sett['model_args']['ncell'] = l
sett['model_args']['conv_dropout'] = [0.15, 0]
sett['model_args']['motif_embedding_dim'] = None
sett['model_args']['recurrent_dropout'] = 0.01*rd
# sett['model_args']['concat_pooled_conv'] = True
sett['experiment_name'] = 'final_crnn_{}_{}rd{}-control'.format(l1, l, rd)
expt_settings.append(sett)
<file_sep>/requirements.txt
backcall==0.1.0
biopython==1.72
cycler==0.10.0
decorator==4.3.0
h5py==2.8.0
ipython==6.5.0
ipython-genutils==0.2.0
jedi==0.12.1
Keras==2.0.8
Keras-Applications==1.0.4
Keras-Preprocessing==1.0.2
kiwisolver==1.0.1
matplotlib==2.2.3
numpy==1.15.1
pandas==0.23.4
parso==0.3.1
pexpect==4.6.0
pickleshare==0.7.4
prompt-toolkit==1.0.15
ptyprocess==0.6.0
Pygments==2.2.0
pyparsing==2.2.0
python-dateutil==2.7.3
pytz==2018.5
PyYAML==3.13
scikit-learn==0.19.2
scipy==1.1.0
seaborn==0.9.0
simplegeneric==0.8.1
six==1.11.0
sklearn==0.0
Theano==0.9.0
traitlets==4.3.2
wcwidth==0.1.7
| e4932d0edeb4f798e025737936a6339d3e63f547 | [
"Markdown",
"Python",
"R",
"Text"
] | 16 | Python | alex-hh/motif_projection | 34f6829162959ad896f09a39e1cd13bfc7152b98 | fcc86effd45de0e922c6bbe10da37efdaaffd2f6 |
refs/heads/master | <repo_name>sri-prasanna/WebServiceTestHarness<file_sep>/UI.Core/PortNumberGenerator.cs
using System;
using System.Collections.Generic;
using System.Globalization;
using System.Linq;
using System.Net.NetworkInformation;
namespace TestHarness.UI.Core
{
public delegate void PortNumberAvailable(long nextPortNumber);
public sealed class PortNumberGenerator
{
internal static LinkedList<long> PortList = new LinkedList<long>();
private static object lockObject = new object();
public static event PortNumberAvailable OnPortNumberAvailableEventHandler;
private PortNumberGenerator()
{
}
public static long GetNextAvailablePortNumber()
{
var freePortFound = false;
long portNumber = 5500;
lock (lockObject)
{
if (PortList.Count != 0)
{
portNumber = PortList.Last.Value;
portNumber++;
}
while (freePortFound == false)
{
if (IsPortFree(portNumber))
{
PortList.AddLast(portNumber);
freePortFound = true;
}
}
portNumber = PortList.Last.Value;
Logger.Log(string.Format(CultureInfo.InvariantCulture, "Port number generated is : {0}", portNumber));
}
return portNumber;
}
private static bool IsPortFree(long port)
{
var ipGlobalProperties = IPGlobalProperties.GetIPGlobalProperties();
var tcpConnInfoArray = ipGlobalProperties.GetActiveTcpConnections();
var isPortFree = tcpConnInfoArray.All(tcpi => tcpi.LocalEndPoint.Port != port);
return isPortFree;
}
public static bool IsAllotted(long portNumber)
{
return PortList.Contains(portNumber);
}
public static long GetLastAllocatedPort()
{
return PortList.Last.Value;
}
public static bool AllocatePort(long portNumber)
{
lock (lockObject)
{
if (!IsAllotted(portNumber))
{
PortList.AddLast(portNumber);
return true;
}
Exception portNumberAlreadyAllocatedException = new PortNumberAlreadyAllocatedException(portNumber);
Logger.Log(portNumberAlreadyAllocatedException.Message);
throw portNumberAlreadyAllocatedException;
}
}
public static void ReleasePort(long portNumber)
{
PortList.Remove(portNumber);
}
internal static void Reset()
{
PortList = new LinkedList<long>();
}
}
}
<file_sep>/UI.Service/TestHarnessHostService.cs
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.ServiceModel.Web;
using System.ServiceProcess;
using System.Threading;
using TestHarness.UI.Core;
namespace TestHarness.UI.Service
{
public partial class TestHarnessHostService : ServiceBase
{
private Thread testHarnessHostThread;
private WebServiceHost testHarnessHost;
internal static Dictionary<long, Tuple<string, string, IEndPoint, DateTimeOffset>> PortNumbersInUse = new Dictionary<long, Tuple<string, string, IEndPoint, DateTimeOffset>>();
public TestHarnessHostService()
{
InitializeComponent();
}
protected override void OnStart(string[] args)
{
testHarnessHostThread = new Thread(SetupServiceToListenForRequest);
testHarnessHostThread.Start();
}
protected override void OnPause()
{
if (testHarnessHostThread == null) return;
testHarnessHost.Close();
testHarnessHostThread.Abort();
testHarnessHostThread.Join();
}
protected override void OnContinue()
{
testHarnessHostThread = new Thread(SetupServiceToListenForRequest);
testHarnessHostThread.Start();
}
protected override void OnStop()
{
Logger.OnLoggingAMessageEventHandler -= LoggerOnOnLoggingAMessageEventHandler;
if (testHarnessHostThread == null) return;
testHarnessHost.Close();
testHarnessHostThread.Abort();
testHarnessHostThread.Join();
}
private void SetupServiceToListenForRequest()
{
if (testHarnessHost != null)
{
testHarnessHost.Close();
}
testHarnessHost = new WebServiceHost( typeof(TestHarnessAdmin) );
testHarnessHost.Open();
Logger.OnLoggingAMessageEventHandler += LoggerOnOnLoggingAMessageEventHandler;
}
public void LoggerOnOnLoggingAMessageEventHandler(object sender, LoggingEventArgs e)
{
if (e.LogMessage.ToLower().Contains("exception") || e.LogMessage.ToLower().Contains("error"))
{
EventLog.WriteEntry(e.LogMessage, EventLogEntryType.Error);
}
else
{
Debug.Write(e.LogMessage);
}
}
}
}
<file_sep>/UI.Core/WSHttpBasedSoapEndPoint.cs
using System;
using System.IO;
using System.ServiceModel;
using System.ServiceModel.Channels;
using System.Text;
using System.Threading;
using System.Xml;
namespace Bbc.Ww.Amf.BiztalkTestHarness.UI.Core
{
public class WSHttpBasedSoapEndPoint // : IEndPoint
{
public long DestinationPort { get; set; }
public string DestinationUrl { get; private set; }
public string CurrentStatus { get; private set; }
private IReplyChannel Channel { get; set; }
private IChannelListener<IReplyChannel> Listener { get; set; }
public void Create(object data = null)
{
this.DestinationUrl = string.Format("http://localhost:{0}/", this.DestinationPort);
ThreadPool.QueueUserWorkItem(this.StartListenerAndChannel);
}
private void StartListenerAndChannel(object state)
{
var bindingElements = new BindingElement[2];
bindingElements[0] = new TextMessageEncodingBindingElement();
bindingElements[1] = new HttpTransportBindingElement();
var binding = new CustomBinding(bindingElements);
// var binding= new BasicHttpBinding();
this.Listener = binding.BuildChannelListener<IReplyChannel>(new Uri(this.DestinationUrl), new BindingParameterCollection());
this.Listener.Open();
Log("Listening for incoming channel connections");
this.Channel = this.Listener.AcceptChannel();
Log("Channel accepted. Listening for messages");
this.Channel.Open();
this.CurrentStatus = "Endpoint Generated OK";
WaitForIncomingMessages(binding);
}
private void WaitForIncomingMessages(Binding binding)
{
RequestContext request = this.Channel.ReceiveRequest();
Message incomingMessage = request.RequestMessage;
Log("Message received");
var requestMessage = GetMessage(incomingMessage, false);
Log(requestMessage);
var responseMessage = "this is a dummy response";
Message replyMessage = Message.CreateMessage(binding.MessageVersion, "http://tempuri.org/someotheraction", responseMessage);
request.Reply(replyMessage);
incomingMessage.Close();
request.Close();
WaitForIncomingMessages(binding);
}
private static string GetMessage(Message incomingMessage, bool readFullMessage)
{
var stringBuilderForIncomingMessage = new StringBuilder();
TextWriter textWriterForIncomingMessage = new StringWriter(stringBuilderForIncomingMessage);
using (XmlWriter xmlWriter = new XmlTextWriter(textWriterForIncomingMessage))
{
if (readFullMessage)
{
incomingMessage.WriteMessage(xmlWriter);
}
else
{
incomingMessage.WriteBody(xmlWriter);
}
}
var data = stringBuilderForIncomingMessage.ToString();
return data;
}
public void Terminate()
{
this.Channel.Close();
this.Listener.Close();
}
private void Log(string message)
{
var messageToLog = String.Format("{0}: {1}", Thread.CurrentThread.ManagedThreadId, message);
messageToLog += Environment.NewLine;
File.AppendAllText("c:\\temp\\bts_testharness.log", messageToLog);
}
private void Log(string message, params string [] messageParams)
{
var constructedMessage = string.Format(message, messageParams);
var messageToLog = string.Format("{0}: {1}", Thread.CurrentThread.ManagedThreadId, constructedMessage);
messageToLog += Environment.NewLine;
File.AppendAllText("c:\\temp\\bts_testharness.log", messageToLog);
}
}
}
<file_sep>/UI.Core/Logger.cs
using System;
using System.Globalization;
using System.Threading;
namespace TestHarness.UI.Core
{
public class LoggingEventArgs : EventArgs
{
private readonly string logMessage;
public LoggingEventArgs(string logMessage)
{
this.logMessage = logMessage;
}
public string LogMessage { get { return this.logMessage; } }
}
// public delegate void LogAMessage(string message);
public static class Logger
{
// public static event LogAMessage OnLoggingAMessageEventHandler;
public static event EventHandler<LoggingEventArgs> OnLoggingAMessageEventHandler;
public static void Log(string messageToLog)
{
TriggerLoggingEvent(messageToLog);
}
public static void Log(string messageToLog, params string [] queryParameters)
{
TriggerLoggingEvent(string.Format(CultureInfo.InvariantCulture, messageToLog, queryParameters));
}
private static void TriggerLoggingEvent(string messageToLog)
{
messageToLog = string.Format(CultureInfo.InvariantCulture, "{0}: {1}{2}", DateTime.Now.ToLongTimeString(), messageToLog, Environment.NewLine);
EventHandler<LoggingEventArgs> temp = Interlocked.CompareExchange(ref OnLoggingAMessageEventHandler, null, null);
if (temp != null)
{
temp(null, new LoggingEventArgs(messageToLog));
}
// if (OnLoggingAMessageEventHandler != null)
// {
// OnLoggingAMessageEventHandler(messageToLog);
// }
}
}
}
<file_sep>/ViewModels/DoPostToHttpEndPointViewModel.cs
using System;
using System.Threading;
using System.Windows.Input;
using TestHarness.UI.Core;
namespace TestHarness.ViewModels
{
public class DoPostToHttpEndPointViewModel : BaseViewModel
{
private string _status;
private string _urlToPostTo;
private string _fileToPost;
protected static SynchronizationContext SyncContext = SynchronizationContext.Current;
private delegate void PostMessageToHttpEndPointDelegate();
private EndPointType _endPointType;
private IEndPointPostInterface _endPointPostInterface;
public string Status
{
get
{
return this._status;
}
internal set
{
this._status += value;
RaisePropertyChanged("Status");
}
}
public ICommand PostToEndpoint
{
get
{
return new RelayCommand(PostToEndpointExecute, CanPostToEndpoint);
}
}
public string UrlToPostTo
{
get
{
return this._urlToPostTo;
}
set
{
this._urlToPostTo = value;
RaisePropertyChanged("UrlToPostTo");
}
}
public string FileToPost
{
get
{
return this._fileToPost;
}
set
{
this._fileToPost = value;
RaisePropertyChanged("FileToPost");
}
}
public bool RestEndPoint
{
get { return this._endPointType == EndPointType.Rest; }
set
{
if(value)
{
this._endPointType = EndPointType.Rest;
this._endPointPostInterface = new RestEndPointPostInterface();
}
RaisePropertyChanged("RestEndPoint");
}
}
public bool BasicEndPoint
{
get { return this._endPointType == EndPointType.BasicHttp; }
set
{
if (value)
{
this._endPointType = EndPointType.BasicHttp;
this._endPointPostInterface = new BasicHttpEndPointPostInterface();
}
RaisePropertyChanged("BasicEndPoint");
}
}
public bool WSHttpEndPoint
{
get { return this._endPointType == EndPointType.WsHttp; }
set
{
if (value)
{
this._endPointType = EndPointType.WsHttp;
this._endPointPostInterface = new WsHttpEndPointPostInterface();
}
RaisePropertyChanged("WSHttpEndPoint");
}
}
private static bool CanPostToEndpoint()
{
return true;
}
protected void PostToEndpointExecute()
{
if (!ValidateInput())
{
throw new ArgumentNullException("Mandatory fields do not have values..");
}
this._endPointPostInterface.FileToPost = this._fileToPost;
this._endPointPostInterface.UrlToPostTo = this._urlToPostTo;
PostMessageToHttpEndPointDelegate poster = this._endPointPostInterface.PostToEndPoint;
poster.BeginInvoke(ar => { }, null);
}
private bool ValidateInput()
{
return !(string.IsNullOrWhiteSpace(this.FileToPost) || string.IsNullOrWhiteSpace(this.UrlToPostTo));
}
protected virtual void AddLogMessageToStatusBox(object message)
{
var loggingEventArgs = (LoggingEventArgs)message;
this.Status = loggingEventArgs.LogMessage;
}
public DoPostToHttpEndPointViewModel()
{
// this.RestEndPoint = EndPointType.Rest;
Logger.OnLoggingAMessageEventHandler += (sender, args) => SyncContext.Post(AddLogMessageToStatusBox, args);
}
}
}
<file_sep>/UnitTests/PortNumberGeneratorTests.cs
using System;
using TestHarness.UI.Core;
using NUnit.Framework;
namespace TestHarness.UnitTests
{
[TestFixture]
public class PortNumberGeneratorTests
{
[Test]
public void ShouldReturnNextAvailableFreePort()
{
long portNumber = PortNumberGenerator.GetNextAvailablePortNumber();
Console.WriteLine(portNumber);
Assert.Greater(portNumber, 0);
}
[Test]
public void ShouldReturnNextAvailableFreePortWhichIsNotAlreadyAllocated()
{
long portNumberA = PortNumberGenerator.GetNextAvailablePortNumber();
long portNumberB = PortNumberGenerator.GetNextAvailablePortNumber();
Console.WriteLine(portNumberA);
Console.WriteLine(portNumberB);
Assert.AreNotEqual(portNumberA, portNumberB);
}
[Test]
public void ShouldReturnNextAvailableFreePortWhichIsNotAlreadyAllocated1()
{
long portNumberA = PortNumberGenerator.GetNextAvailablePortNumber();
long portNumberB = PortNumberGenerator.GetNextAvailablePortNumber();
long portNumberC = PortNumberGenerator.GetNextAvailablePortNumber();
Console.WriteLine(portNumberA);
Console.WriteLine(portNumberB);
Console.WriteLine(portNumberC);
Assert.AreNotEqual(portNumberA, portNumberB);
Assert.AreNotEqual(portNumberC, portNumberB);
Assert.AreNotEqual(portNumberC, portNumberA);
}
[Test]
public void ShouldReturnLastAllocatedPort()
{
long portNumberA = PortNumberGenerator.GetNextAvailablePortNumber();
long portNumberB = PortNumberGenerator.GetNextAvailablePortNumber();
long portNumberC = PortNumberGenerator.GetNextAvailablePortNumber();
Console.WriteLine(portNumberA);
Console.WriteLine(portNumberB);
Console.WriteLine(portNumberC);
Assert.AreEqual(portNumberC, PortNumberGenerator.GetLastAllocatedPort());
}
[Test]
public void ShouldIdentifyIfAPortNumberIsAlreadyAllocated()
{
long portNumber = PortNumberGenerator.GetNextAvailablePortNumber();
Assert.IsTrue(PortNumberGenerator.IsAllotted(portNumber));
}
[Test]
public void ShouldIdentifyIfAPortNumberIsNotAlreadyAllocated()
{
var random = new Random();
long portNumber = random.Next(5600, 7000);
Assert.IsFalse(PortNumberGenerator.IsAllotted(portNumber));
}
[Test]
public void ShouldAllocateAGivenPortIfNotAlreadyAllocated()
{
long portNumber = 5678;
Assert.IsTrue(PortNumberGenerator.AllocatePort(portNumber));
}
[Test]
[ExpectedException(typeof(PortNumberAlreadyAllocatedException))]
public void ShouldNotAllocateAGivenPortIfAlreadyAllocated()
{
long portNumber = 5679;
PortNumberGenerator.AllocatePort(portNumber);
PortNumberGenerator.AllocatePort(portNumber);
}
}
}
<file_sep>/UI.Core/IEndPoint.cs
using System;
using System.ServiceModel.Channels;
namespace TestHarness.UI.Core
{
public interface IEndPoint
{
long DestinationPort { get; set; }
string DestinationUrl { get; set; }
string CurrentStatus { get; }
string LogFolder { get; set; }
Binding PortBinding { get; set; }
IReplyChannel Channel { get; set; }
IChannelListener<IReplyChannel> Listener { get; set; }
TimeSpan TimeoutPeriod { get; set; }
ResponseType ResponseType { get; set; }
void Activate();
void Deactivate();
string GetARandomResponseByPortNumber();
string GetARandomResponseByRootNode(string inputMessage);
}
}
<file_sep>/UI.Core/EndPointType.cs
namespace TestHarness.UI.Core
{
public enum EndPointType
{
BasicHttp = 0,
WsHttp = 1,
Rest = 2
}
}
<file_sep>/UI.Core/EndPointBuilder.cs
using System;
using System.Globalization;
using System.ServiceModel;
using System.ServiceModel.Channels;
namespace TestHarness.UI.Core
{
public abstract class EndPointBuilder
{
protected IEndPoint EndPoint;
public abstract void BuildEndPoint(long portNumber = 0, ResponseType responseType = ResponseType.IncomingData);
protected abstract void AssignBinding();
public IEndPoint GetEndPoint()
{
return this.EndPoint;
}
protected virtual void AssignPort(long portNumber = 0)
{
if (portNumber == 0)
{
this.EndPoint.DestinationPort = PortNumberGenerator.GetNextAvailablePortNumber();
}
else
{
PortNumberGenerator.AllocatePort(portNumber);
this.EndPoint.DestinationPort = portNumber;
}
}
protected virtual void AssignUrl()
{
this.EndPoint.DestinationUrl = string.Format(CultureInfo.InvariantCulture, "http://localhost:{0}/", this.EndPoint.DestinationPort);
Logger.Log("Assigning The URL: " + this.EndPoint.DestinationUrl);
}
protected virtual void AssignTimeOut(TimeSpan timeoutPeriod)
{
this.EndPoint.TimeoutPeriod = timeoutPeriod;
Logger.Log("Setting The timeout: " + this.EndPoint.TimeoutPeriod);
}
protected virtual void AssignResponseType(ResponseType responseType)
{
this.EndPoint.ResponseType = responseType;
Logger.Log("Setting The response type: " + this.EndPoint.ResponseType);
}
protected virtual void AssignLogFolder()
{
this.AssignLogFolder("c:\\temp\\");
}
protected virtual void AssignLogFolder(string logFolder)
{
this.EndPoint.LogFolder = logFolder;
}
protected virtual void PrepareListenerAndChannel()
{
this.EndPoint.Listener = this.EndPoint.PortBinding
.BuildChannelListener<IReplyChannel>(new Uri(this.EndPoint.DestinationUrl), new BindingParameterCollection());
}
}
}
<file_sep>/UI.Core/WsHttpEndPointBuilder.cs
using System;
using System.Configuration;
using System.ServiceModel.Channels;
namespace TestHarness.UI.Core
{
public sealed class WSHttpEndPointBuilder : EndPointBuilder
{
public override void BuildEndPoint(long portNumber = 0, ResponseType responseType = ResponseType.IncomingData)
{
var endPointLogFolder = ConfigurationManager.AppSettings["LogFolder"] ?? "c:\\temp";
BuildEndPoint(portNumber, new TimeSpan(8, 0, 0), endPointLogFolder, responseType);
}
public void BuildEndPoint(string logFolder, ResponseType responseType = ResponseType.IncomingData)
{
BuildEndPoint(0, new TimeSpan(8, 0, 0), logFolder, responseType);
}
public void BuildEndPoint(long portNumber, string logFolder, ResponseType responseType = ResponseType.IncomingData)
{
BuildEndPoint(portNumber, new TimeSpan(8, 0, 0), logFolder, responseType);
}
public void BuildEndPoint(long portNumber, TimeSpan timeOut, ResponseType responseType = ResponseType.IncomingData)
{
var endPointLogFolder = ConfigurationManager.AppSettings["LogFolder"] ?? "c:\\temp";
BuildEndPoint(portNumber, timeOut, endPointLogFolder, responseType);
}
public void BuildEndPoint(long portNumber, TimeSpan timeoutPeriod, string logFolder, ResponseType responseType)
{
Logger.Log("Building a WSHttpEndPoint");
this.EndPoint = new EndPoint();
AssignPort(portNumber);
AssignUrl();
AssignTimeOut(timeoutPeriod);
AssignBinding();
AssignLogFolder(logFolder);
AssignResponseType(responseType);
PrepareListenerAndChannel();
}
protected override void AssignBinding()
{
var bindingElements = new BindingElement[2];
bindingElements[0] = new TextMessageEncodingBindingElement();
bindingElements[1] = new HttpTransportBindingElement();
this.EndPoint.PortBinding = new CustomBinding(bindingElements);
}
}
}
<file_sep>/ViewModels/RestEndPointPostInterface.cs
using System.IO;
using TestHarness.UI.Core;
namespace TestHarness.ViewModels
{
class RestEndPointPostInterface : IEndPointPostInterface
{
public string UrlToPostTo { get; set; }
public string FileToPost { get; set; }
public void PostToEndPoint()
{
var httpPoster = new HttpPoster(this.UrlToPostTo);
var httpPosterRespose = httpPoster.SubmitViaPost(new FileInfo(this.FileToPost));
if (httpPosterRespose.StartsWith("ERROR"))
{
Logger.Log(httpPosterRespose);
}
else
{
Logger.Log("Message Posting to {0} succesfull.", this.UrlToPostTo);
}
}
}
}<file_sep>/UI.Service/TestHarnessAdmin.cs
using System;
using System.Configuration;
using System.IO;
using System.Linq;
using System.Reflection;
using System.ServiceModel;
using System.ServiceModel.Web;
using System.Xml.Linq;
using TestHarness.UI.Core;
using TestHarness.UI.Core;
namespace TestHarness.UI.Service
{
[ServiceBehavior]
public class TestHarnessAdmin : ITestHarnessAdmin
{
private static bool AreDataFilesFound(string portNumber, ResponseType responseType)
{
string dataFilesPath;
switch (responseType)
{
case ResponseType.PortSpecificData:
{
dataFilesPath = Path.Combine(ConfigurationManager.AppSettings["DataConfigFolder"], portNumber);
return Directory.Exists(dataFilesPath) && Directory.GetFiles(dataFilesPath).Any();
}
case ResponseType.MsgRootSpecific:
{
dataFilesPath = ConfigurationManager.AppSettings["DataConfigFolder"];
return Directory.Exists(dataFilesPath) && Directory.GetDirectories(dataFilesPath).Any();
}
default:
{
return true;
}
}
}
private static ResponseType GetResponseType(string responseTypeString)
{
ResponseType responseType;
switch (responseTypeString.ToLower())
{
case "msgspecific":
{
responseType = ResponseType.MsgRootSpecific;
break;
}
case "portspecific":
{
responseType = ResponseType.PortSpecificData;
break;
}
default:
{
responseType = ResponseType.IncomingData;
break;
}
}
return responseType;
}
protected void CreateNewEndPoint<T>(long portNumber, ResponseType responseType) where T : EndPointBuilder, new()
{
var t = new T();
t.BuildEndPoint(portNumber, responseType);
var endPoint = t.GetEndPoint();
endPoint.Activate();
DateTimeOffset expiresIn = DateTime.Now.AddHours(8);
TestHarnessHostService.PortNumbersInUse
.Add(portNumber, new Tuple<string, string, IEndPoint, DateTimeOffset>(typeof(T).FullName, responseType.ToString(), endPoint, expiresIn ));
}
private static XElement GetXmlValueForPort(long n)
{
return new XElement("Port",
new XAttribute("Number", n),
new XAttribute("Type", TestHarnessHostService.PortNumbersInUse[n].Item1),
new XAttribute("Returns", TestHarnessHostService.PortNumbersInUse[n].Item2),
new XAttribute("ExpiresAt", TestHarnessHostService.PortNumbersInUse[n].Item4.UtcDateTime));
}
public XElement GetHelp()
{
var contractType = Assembly.GetExecutingAssembly().GetType("TestHarness.UI.Service.ITestHarnessAdmin");
return new XElement("TestHarnessHelp",
contractType.GetMethods(BindingFlags.Instance | BindingFlags.Public)
.SelectMany(o => o.GetCustomAttributes(false))
.Where(o => o is WebInvokeAttribute)
.Select(o =>
{
var oo = o as WebInvokeAttribute;
return new XElement("Method", new XAttribute("Name", oo.Method),
new XAttribute("UriTemplate", oo.UriTemplate));
})
);
}
public XElement ResetSpecificPort(string portNumber)
{
if (!TestHarnessHostService.PortNumbersInUse.ContainsKey(long.Parse(portNumber)))
{
return new XElement("TestHarnessDelete", new XAttribute("port", portNumber), "Port Number not in use!!");
}
var portDetails = TestHarnessHostService.PortNumbersInUse[long.Parse(portNumber)];
var endPoint = portDetails.Item3;
endPoint.Deactivate();
PortNumberGenerator.ReleasePort(long.Parse(portNumber));
TestHarnessHostService.PortNumbersInUse.Remove(long.Parse(portNumber));
return new XElement("TestHarnessDelete");
}
public XElement GetConfig()
{
return new XElement("TestHarnessConfig",
ConfigurationManager.AppSettings.Keys
.OfType<string>()
.Select(k =>
new XElement("ConfigItem", new XAttribute("Key", k),
new XAttribute("Value", ConfigurationManager.AppSettings[k]))
)
);
}
public XElement GetStatus()
{
return new XElement("TestHarnessStatus",
TestHarnessHostService.PortNumbersInUse.Keys.Select( GetXmlValueForPort ));
}
public XElement GetStatusAtPort(string portNumber)
{
return new XElement("TestHarnessStatus",
TestHarnessHostService.PortNumbersInUse.Keys
.Where(n => n == long.Parse(portNumber))
.Select(GetXmlValueForPort));
}
public XElement CreateEndpoint(string portNumber, string responseTypeString, string portType)
{
var responseType = GetResponseType(responseTypeString);
if (TestHarnessHostService.PortNumbersInUse.ContainsKey(long.Parse(portNumber)))
{
return new XElement("TestHarnessCreate", new XAttribute("port", portNumber), "Port Number already in use!!");
}
if (!AreDataFilesFound(portNumber, responseType))
{
return new XElement("TestHarnessCreate", new XAttribute("port", portNumber), "No data files found!!");
}
if (portType.ToLower().Equals("basic"))
{
CreateNewEndPoint<BasicHttpEndPointBuilder>(long.Parse(portNumber), responseType);
return new XElement("TestHarnessCreate", new XAttribute("port", portNumber), "Endpoint Create Is Complete");
}
if (portType.ToLower().Equals("ws"))
{
CreateNewEndPoint<WSHttpEndPointBuilder>(long.Parse(portNumber), responseType);
return new XElement("TestHarnessCreate", new XAttribute("port", portNumber), "Endpoint Create Is Complete");
}
if (portType.ToLower().Equals("rest"))
{
CreateNewEndPoint<RESTEndPointBuilder>(long.Parse(portNumber), responseType);
return new XElement("TestHarnessCreate", new XAttribute("port", portNumber), "Endpoint Create Is Complete");
}
return new XElement("TestHarnessCreate", new XAttribute("port", portNumber), "Dont know what type of port to create!!");
}
}
}
<file_sep>/UI.Core/EndPointAlerter.cs
namespace TestHarness.UI.Core
{
public delegate void AddNewEndPoint(IEndPoint endPoint);
public delegate void RemoveEndPoint(IEndPoint endPoint);
public static class EndPointAlerter
{
public static event AddNewEndPoint OnEndPointAddEventHandler;
public static event RemoveEndPoint OnEndPointRemoveEventHandler;
public static void Add(IEndPoint endPoint)
{
if (OnEndPointAddEventHandler != null)
{
OnEndPointAddEventHandler(endPoint);
}
}
public static void Remove(IEndPoint endPoint)
{
if (OnEndPointRemoveEventHandler != null)
{
OnEndPointRemoveEventHandler(endPoint);
}
}
}
}
<file_sep>/UI.Service/ITestHarnessAdmin.cs
using System.ServiceModel;
using System.ServiceModel.Web;
using System.Xml.Linq;
namespace TestHarness.UI.Service
{
[ServiceContract]
public interface ITestHarnessAdmin
{
[OperationContract]
[WebInvoke(Method = "GET", UriTemplate = "/")]
XElement GetHelp();
[OperationContract]
[WebInvoke(Method = "DELETE", UriTemplate = "/delete/{portNumber}")]
XElement ResetSpecificPort(string portNumber);
[OperationContract]
[WebInvoke(Method = "GET", UriTemplate = "/config")]
XElement GetConfig();
[OperationContract]
[WebInvoke(Method = "GET", UriTemplate = "/status")]
XElement GetStatus();
[OperationContract]
[WebInvoke(Method = "GET", UriTemplate = "/status/at/{portNumber}")]
XElement GetStatusAtPort(string portNumber);
[OperationContract]
[WebInvoke(Method = "POST", UriTemplate = "/start/{portType}/at/{portNumber}/returning/{responseType}")]
XElement CreateEndpoint(string portNumber, string responseType, string portType);
}
}
<file_sep>/UI.Core/HttpPoster.cs
using System;
using System.IO;
using System.Net;
using System.Text;
using System.Xml.Linq;
namespace TestHarness.UI.Core
{
public class HttpPoster
{
private string TargetUrl { get; set; }
public HttpPoster()
{
}
public HttpPoster(string targetUrl)
{
this.TargetUrl = targetUrl;
}
public string SubmitViaPost(string requestString, string contentType = "text/xml; charset=utf-8")
{
var httpWebRequest = (HttpWebRequest)WebRequest.Create(this.TargetUrl);
httpWebRequest.ContentType = contentType;
httpWebRequest.Headers["SOAPAction"] = "http://tempuri.org/someaction";
httpWebRequest.Headers["UserAgent"] = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:14.0) Gecko/20100101 Firefox/14.0.1";
httpWebRequest.Method = "POST";
httpWebRequest.ContentLength = requestString.Length;
var inputBytes = Encoding.ASCII.GetBytes(requestString);
var response = string.Empty;
using (var inputStream = httpWebRequest.GetRequestStream())
{
inputStream.Write(inputBytes, 0, inputBytes.Length);
}
try
{
var webResponse = (HttpWebResponse) httpWebRequest.GetResponse();
byte[] bytes = new byte[1024];
int bytesRead = 1;
using (var responseStream = webResponse.GetResponseStream())
{
while (bytesRead != 0)
{
bytesRead = responseStream.Read(bytes, 0, bytes.Length);
response += Encoding.ASCII.GetString(bytes);
}
}
}
catch(Exception ex)
{
response = "ERROR::" + ex.Message;
}
return response;
}
public string SubmitViaPost(XElement requestXml, string contentType = "text/xml; charset=utf-8")
{
return SubmitViaPost(requestXml.ToString(), contentType);
}
public string SubmitViaPost(FileInfo requestFile, string contentType = "text/xml; charset=utf-8")
{
var streamReader = new StreamReader(requestFile.FullName);
var requestMessage = streamReader.ReadToEnd();
return SubmitViaPost(requestMessage, contentType);
}
}
}
<file_sep>/ViewModels/RelayCommand.cs
using System;
using System.Diagnostics;
using System.Windows.Input;
namespace TestHarness.ViewModels
{
public class RelayCommand : ICommand
{
private Func<bool> canExecute { get; set; }
private Action actionToExecute { get; set; }
public RelayCommand(Action todoAction, Func<bool> canDoAction)
{
if (todoAction == null)
throw new ArgumentNullException("todoAction");
this.actionToExecute = todoAction;
this.canExecute = canDoAction;
}
public void Execute(object parameter)
{
if (this.canExecute())
{
this.actionToExecute();
}
}
[DebuggerStepThrough]
public bool CanExecute(object parameter)
{
return this.canExecute();
}
public event EventHandler CanExecuteChanged
{
add
{
if (this.canExecute != null)
{
CommandManager.RequerySuggested += value;
}
}
remove
{
if (this.canExecute != null)
{
CommandManager.RequerySuggested -= value;
}
}
}
}
}
<file_sep>/ViewModels/BaseViewModel.cs
using System.ComponentModel;
using System.Threading;
namespace TestHarness.ViewModels
{
public class BaseViewModel : INotifyPropertyChanged
{
public event PropertyChangedEventHandler PropertyChanged;
protected void RaisePropertyChanged(string propertyName)
{
PropertyChangedEventHandler handler = null;
Interlocked.CompareExchange(ref handler, PropertyChanged, null);
if (handler != null)
{
handler(this, new PropertyChangedEventArgs(propertyName));
}
}
}
}
<file_sep>/UI.Core/PortNumberAlreadyAllocatedException.cs
using System;
using System.Globalization;
using System.Runtime.Serialization;
namespace TestHarness.UI.Core
{
[Serializable]
public class PortNumberAlreadyAllocatedException : Exception
{
private readonly long portNumber;
public PortNumberAlreadyAllocatedException():this(0)
{
}
protected PortNumberAlreadyAllocatedException(SerializationInfo serializationInfo, StreamingContext streamingContext)
: base(serializationInfo, streamingContext)
{
}
public PortNumberAlreadyAllocatedException(long portNumber)
{
this.portNumber = portNumber;
}
public override string Message
{
get
{
string errorMessage = string.Format(CultureInfo.InvariantCulture, "Exception: The Port Number {0} has already been allocated.", this.portNumber);
return errorMessage;
}
}
public override void GetObjectData(System.Runtime.Serialization.SerializationInfo info, System.Runtime.Serialization.StreamingContext context)
{
base.GetObjectData(info, context);
}
}
[Serializable]
public class PortNumberAlreadyInUseException : Exception
{
private readonly long portNumber;
public PortNumberAlreadyInUseException():this(0)
{
}
protected PortNumberAlreadyInUseException(SerializationInfo serializationInfo, StreamingContext streamingContext)
: base(serializationInfo, streamingContext)
{
}
public PortNumberAlreadyInUseException(long portNumber)
{
this.portNumber = portNumber;
}
public override string Message
{
get
{
string errorMessage = string.Format(CultureInfo.InvariantCulture, "Exception: The Port Number {0} is already in use by another application/service.", this.portNumber);
return errorMessage;
}
}
public override void GetObjectData(System.Runtime.Serialization.SerializationInfo info, System.Runtime.Serialization.StreamingContext context)
{
base.GetObjectData(info, context);
}
}
}
<file_sep>/UnitTests/WsHttpEndPointGeneratorTests.cs
using System;
using TestHarness.UI.Core;
using NUnit.Framework;
namespace TestHarness.UnitTests
{
[TestFixture]
public class WsHttpEndPointGeneratorTests
{
readonly WSHttpEndPointBuilder wsHttpEndPointBuilder = new WSHttpEndPointBuilder();
[Test]
public void ShouldGenerateEndPointsWithDifferentPortNumbers()
{
wsHttpEndPointBuilder.BuildEndPoint();
var endPointA = wsHttpEndPointBuilder.GetEndPoint();
wsHttpEndPointBuilder.BuildEndPoint();
var endPointB = wsHttpEndPointBuilder.GetEndPoint();
Console.WriteLine(endPointA.DestinationPort);
Console.WriteLine(endPointB.DestinationPort);
Assert.AreNotEqual(endPointA.DestinationPort, endPointB.DestinationPort);
}
}
}<file_sep>/UI.Core/ResponseType.cs
namespace TestHarness.UI.Core
{
public enum ResponseType
{
IncomingData = 1,
PortSpecificData = 2,
MsgRootSpecific = 3
}
}<file_sep>/README.md
WebServiceTestHarness
=====================
Web Service Test Harness
This tool serves a very simple purpose of being able to produce web service
endpoints, based on very minimal config.
These endpoints can be used for testing purposes, when the real service may
not be available.
The code is WIP and will be updated as and when I find time.
If you would like to know more about this tool, please do drop the devs a note.
we are more than happy to help.
<file_sep>/UI.Core/EndPoint.cs
using System;
using System.Collections.Generic;
using System.Configuration;
using System.Globalization;
using System.IO;
using System.Linq;
using System.ServiceModel.Channels;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
using System.Xml;
using System.Xml.Linq;
namespace TestHarness.UI.Core
{
public sealed class EndPoint : IEndPoint
{
public long DestinationPort { get; set; }
public string DestinationUrl { get; set; }
public Binding PortBinding { get; set; }
public String LogFolder { get; set; }
public string CurrentStatus { get; internal set; }
public IReplyChannel Channel { get; set; }
public IChannelListener<IReplyChannel> Listener { get; set; }
public TimeSpan TimeoutPeriod { get; set; }
public ResponseType ResponseType { get; set; }
public void Activate()
{
ThreadPool.QueueUserWorkItem(this.StartListenerAndChannel);
while (this.CurrentStatus != "Endpoint Generated OK")
{
Thread.Sleep(1000);
}
}
private void StartListenerAndChannel(object data)
{
Logger.Log("Trying to Activate URL {0}", this.DestinationUrl);
this.Listener.Open();
this.Channel = this.Listener.AcceptChannel();
this.Channel.Open();
this.CurrentStatus = "Endpoint Generated OK";
EndPointAlerter.Add(this);
try
{
Parallel.Invoke(this.AcceptIncomingMessages);
}
catch (AggregateException exception)
{
foreach (Exception innerException in exception.InnerExceptions)
{
if (innerException.Message.LastIndexOf("Receive request timed out", StringComparison.Ordinal) >= 0)
{
Logger.Log("Inner exception occurred as :: {0}", innerException.Message);
}
else
{
throw;
}
}
}
}
public void AcceptIncomingMessages()
{
Logger.Log("Ready to accept connections at {0} (Root log folder: {1})", this.DestinationUrl, this.LogFolder);
var request = this.Channel.ReceiveRequest(this.TimeoutPeriod);
if (request != null)
{
string requestMessage = string.Empty;
string responseMessage = string.Empty;
Message incomingMessage = request.RequestMessage;
MessageProperties requestProperties = incomingMessage.Properties;
var httpRequestMessageProperty = (HttpRequestMessageProperty)requestProperties["httpRequest"];
try
{
if (httpRequestMessageProperty.Method != "GET")
{
requestMessage = GetMessageContent(incomingMessage);
byte[] bytes = Encoding.UTF8.GetBytes(requestMessage);
var tempMessage = RetrieveBase64EncodedMessage(bytes) ?? RetrieveSOAPBodyMessage(bytes);
requestMessage = tempMessage ?? requestMessage;
var logFileName = LogIncomingMessage(requestMessage);
Logger.Log("Incoming message saved @ {0}", logFileName);
}
switch (this.ResponseType)
{
case ResponseType.IncomingData:
responseMessage = requestMessage;
break;
case ResponseType.PortSpecificData:
responseMessage = GetARandomResponseByPortNumber();
break;
case ResponseType.MsgRootSpecific:
responseMessage = GetARandomResponseByRootNode(requestMessage);
break;
}
Message replyMessage = Message.CreateMessage(this.PortBinding.MessageVersion, "http://tempuri.org/replyaction", XmlReader.Create(new MemoryStream(Encoding.UTF8.GetBytes(responseMessage))));
request.Reply(replyMessage);
}
catch (Exception ex)
{
Logger.Log("Exception Occurred :: {0}", ex.Message);
throw;
}
finally
{
incomingMessage.Close();
request.Close();
AcceptIncomingMessages();
}
}
}
public string GetARandomResponseByRootNode(string requestMessage)
{
var inputXElement = XDocument.Parse(requestMessage);
var rootNode = inputXElement.Elements().ElementAt(0).Name;
var messageRepository = Path.Combine(ConfigurationManager.AppSettings["DataConfigFolder"], rootNode.LocalName);
return GetARandomMessage(messageRepository);
}
private static string GetARandomMessage(string messageRepository)
{
Random randomFileSelector = new Random();
var allFiles = Directory.GetFiles(messageRepository);
return allFiles.Length > 0
? File.ReadAllText(allFiles[randomFileSelector.Next(0, allFiles.Length - 1)])
: string.Empty;
}
public string GetARandomResponseByPortNumber()
{
var messageRepository = Path.Combine(ConfigurationManager.AppSettings["DataConfigFolder"],
this.DestinationPort.ToString(CultureInfo.InvariantCulture));
return GetARandomMessage(messageRepository);
}
private static string RetrieveSOAPBodyMessage(byte[] bytes)
{
string requestMessage = null;
Stream stream = new MemoryStream(bytes);
IEnumerable<XElement> qry1;
qry1 = XDocument.Load(stream).Root.Elements().Where(n => n.Name.LocalName == "Body");
if (qry1.FirstOrDefault() != null)
{
requestMessage = qry1.Descendants().First().ToString();
Logger.Log("Identified a SOAP message");
}
return requestMessage;
}
private static string RetrieveBase64EncodedMessage(byte[] bytes)
{
string requestMessage = null;
Stream stream = new MemoryStream(bytes);
var qry = XDocument.Load(stream).Elements("Binary").Select(v => v.Value);
var base64EncodedString = qry.FirstOrDefault();
if (!String.IsNullOrWhiteSpace(base64EncodedString))
{
requestMessage = new string(Encoding.UTF8.GetChars(Convert.FromBase64String(base64EncodedString)));
Logger.Log("Identified a Base64 encoded message");
}
return requestMessage;
}
private string GetMessageContent(Message requestMessage)
{
Stream stream = new MemoryStream();
MessageBuffer messageBuffer = requestMessage.CreateBufferedCopy(int.MaxValue);
XmlWriterSettings settings = new XmlWriterSettings{ Encoding = Encoding.UTF8, ConformanceLevel = ConformanceLevel.Fragment };
XmlWriter writer = XmlWriter.Create(stream, settings);
Message _message = messageBuffer.CreateMessage();
_message.WriteMessage(writer);
writer.Flush();
stream.Flush();
stream.Seek(0, SeekOrigin.Begin);
StreamReader streamReader = new StreamReader(stream);
Logger.Log("Received a message");
return streamReader.ReadToEnd();
}
private string LogIncomingMessage(string requestMessage)
{
var requestMessageBytes = Encoding.UTF8.GetBytes(requestMessage);
var endPointProtocol = this.DestinationUrl.Substring(0,
this.DestinationUrl.IndexOf(":",
StringComparison.OrdinalIgnoreCase));
var endPointSpecificLogFolder = endPointProtocol + "-" + this.DestinationPort + "-" + this.PortBinding.Name;
var logDirInfo = new DirectoryInfo(Path.Combine(this.LogFolder, endPointSpecificLogFolder));
var logFileName = Path.Combine(logDirInfo.FullName, Guid.NewGuid().ToString() + ".xml");
if (!logDirInfo.Exists)
{
logDirInfo.Create();
}
using (var logFile = File.Create(logFileName))
{
logFile.Write(requestMessageBytes, 0, requestMessageBytes.Length);
}
return logFileName;
}
public void Deactivate()
{
Logger.Log("Trying to De-Activate URL {0}", this.DestinationUrl);
this.Listener.Close();
this.Channel.Close();
EndPointAlerter.Remove(this);
}
}
}
<file_sep>/UnitTests/EndPointBuilderTests.cs
using System.Configuration;
using TestHarness.UI.Core;
using NUnit.Framework;
namespace TestHarness.UnitTests
{
[TestFixture]
public class EndPointBuilderTests
{
[Test]
public void BasicHttpEndPointBuilderShouldBuildEndPointWithALogFileLocationFromConfigFile()
{
var dummyLogFolder = ConfigurationManager.AppSettings["LogFolder"];
var endPointBuilder = new BasicHttpEndPointBuilder();
endPointBuilder.BuildEndPoint();
var endPoint = endPointBuilder.GetEndPoint();
Assert.That(endPoint.LogFolder, Is.EqualTo(dummyLogFolder));
}
[Test]
public void BasicHttpEndPointBuilderShouldBuildEndPointWithALogFileLocationFromConfigFileAndGivenPortNumber()
{
var dummyLogFolder = ConfigurationManager.AppSettings["LogFolder"];
var portNumber = 7800;
var endPointBuilder = new BasicHttpEndPointBuilder();
endPointBuilder.BuildEndPoint(portNumber);
var endPoint = endPointBuilder.GetEndPoint();
Assert.That(endPoint.DestinationPort, Is.EqualTo(portNumber));
Assert.That(endPoint.LogFolder, Is.EqualTo(dummyLogFolder));
}
[Test]
public void WSHttpEndPointBuilderShouldBuildEndPointWithALogFileLocationFromConfigFile()
{
var dummyLogFolder = ConfigurationManager.AppSettings["LogFolder"];
var endPointBuilder = new WSHttpEndPointBuilder();
endPointBuilder.BuildEndPoint();
var endPoint = endPointBuilder.GetEndPoint();
Assert.That(endPoint.LogFolder, Is.EqualTo(dummyLogFolder));
}
[Test]
public void WSHttpEndPointBuilderShouldBuildEndPointWithALogFileLocationFromConfigFileAndGivenPortNumber()
{
var dummyLogFolder = ConfigurationManager.AppSettings["LogFolder"];
var portNumber = 7900;
var endPointBuilder = new WSHttpEndPointBuilder();
endPointBuilder.BuildEndPoint(portNumber);
var endPoint = endPointBuilder.GetEndPoint();
Assert.That(endPoint.LogFolder, Is.EqualTo(dummyLogFolder));
Assert.That(endPoint.DestinationPort, Is.EqualTo(portNumber));
}
[Test]
public void RESTEndPointBuilderShouldBuildEndPointWithALogFileLocationFromConfigFile()
{
var dummyLogFolder = ConfigurationManager.AppSettings["LogFolder"];
var endPointBuilder = new RESTEndPointBuilder();
endPointBuilder.BuildEndPoint();
var endPoint = endPointBuilder.GetEndPoint();
Assert.That(endPoint.LogFolder, Is.EqualTo(dummyLogFolder));
}
[Test]
public void RESTEndPointBuilderShouldBuildEndPointWithALogFileLocationFromConfigFileAndGivenPortNumber()
{
var dummyLogFolder = ConfigurationManager.AppSettings["LogFolder"];
var portNumber = 7700;
var endPointBuilder = new RESTEndPointBuilder();
endPointBuilder.BuildEndPoint(portNumber);
var endPoint = endPointBuilder.GetEndPoint();
Assert.That(endPoint.DestinationPort, Is.EqualTo(portNumber));
Assert.That(endPoint.LogFolder, Is.EqualTo(dummyLogFolder));
}
}
}
<file_sep>/UI/CreateEndPointsControl.xaml.cs
using System.Windows.Controls;
namespace TestHarness.UI
{
/// <summary>
/// Interaction logic for CreateEndPointsControl.xaml
/// </summary>
public partial class CreateEndPointsControl : UserControl
{
public CreateEndPointsControl()
{
InitializeComponent();
}
}
}
<file_sep>/UI.Core/RESTEndPointBuilder.cs
using System;
using System.Configuration;
using System.ServiceModel;
using System.ServiceModel.Channels;
namespace TestHarness.UI.Core
{
public sealed class RESTEndPointBuilder : EndPointBuilder
{
public override void BuildEndPoint(long portNumber = 0, ResponseType responseType = ResponseType.IncomingData)
{
var endPointLogFolder = ConfigurationManager.AppSettings["LogFolder"] ?? "c:\\temp";
BuildEndPoint(portNumber, new TimeSpan(8, 0, 0), endPointLogFolder, responseType);
}
public void BuildEndPoint(string logFolder, ResponseType responseType = ResponseType.IncomingData)
{
BuildEndPoint(0, new TimeSpan(8, 0, 0), logFolder, responseType);
}
public void BuildEndPoint(long portNumber, string logFolder, ResponseType responseType = ResponseType.IncomingData)
{
BuildEndPoint(portNumber, new TimeSpan(8, 0, 0), logFolder, responseType);
}
public void BuildEndPoint(long portNumber, TimeSpan timeOut, ResponseType responseType = ResponseType.IncomingData)
{
var endPointLogFolder = ConfigurationManager.AppSettings["LogFolder"] ?? "c:\\temp";
BuildEndPoint(portNumber, timeOut, endPointLogFolder, responseType);
}
public void BuildEndPoint(long portNumber, TimeSpan timeoutPeriod, string logFolder, ResponseType responseType)
{
Logger.Log("Building a RESTEndPoint");
this.EndPoint = new EndPoint();
AssignPort(portNumber);
AssignUrl();
AssignTimeOut(timeoutPeriod);
AssignLogFolder(logFolder);
AssignBinding();
AssignResponseType(responseType);
PrepareListenerAndChannel();
}
protected override void AssignBinding()
{
this.EndPoint.PortBinding = new WebHttpBinding();
}
protected override void PrepareListenerAndChannel()
{
this.EndPoint.Listener = this.EndPoint.PortBinding
.BuildChannelListener<IReplyChannel>(new Uri(this.EndPoint.DestinationUrl), new BindingParameterCollection());
}
}
}
<file_sep>/ViewModels/CreateEndPointsViewModel.cs
using System;
using System.Globalization;
using System.Threading;
using System.Windows.Input;
using TestHarness.UI.Core;
using TestHarness.UI.Core;
namespace TestHarness.ViewModels
{
public class CreateEndPointsViewModel : BaseViewModel
{
private long _portToUse;
private string _status;
private ResponseType _responseType;
private delegate void CreateEndPointDelegate<T>();
protected static SynchronizationContext SyncContext = SynchronizationContext.Current;
public CreateEndPointsViewModel() : this("")
{
}
public CreateEndPointsViewModel(string status)
{
this.Status = status;
this.PortToUse = 5500;
this._responseType = ResponseType.IncomingData;
Logger.OnLoggingAMessageEventHandler += (sender, args) => SyncContext.Post(AddLogMessageToStatusBox, args);
}
public long PortToUse
{
get
{
return this._portToUse;
}
set
{
this._portToUse= value;
RaisePropertyChanged("PortToUse");
}
}
public string Status
{
get
{
return this._status;
}
internal set
{
this._status += value;
RaisePropertyChanged("Status");
}
}
public bool IncomingData
{
get { return this._responseType == ResponseType.IncomingData; }
set
{
if (value)
{
this._responseType = ResponseType.IncomingData;
}
RaisePropertyChanged("IncomingData");
}
}
public bool PortSpecific
{
get { return this._responseType == ResponseType.PortSpecificData; }
set
{
if (value)
{
this._responseType = ResponseType.PortSpecificData;
}
RaisePropertyChanged("PortSpecific");
}
}
public bool MsgRootSpecific
{
get { return this._responseType == ResponseType.MsgRootSpecific; }
set
{
if (value)
{
this._responseType = ResponseType.MsgRootSpecific;
}
RaisePropertyChanged("MsgRootSpecific");
}
}
private ResponseType ResponseType
{
get { return this._responseType; }
}
public ICommand CreateWSHttpSoapEndpoint
{
get
{
return new RelayCommand(CreateWSHttpSoapEndpointExecute, CanCreateWSHttpSoapEndpoint);
}
}
public ICommand CreateBasicSoapEndpoint
{
get
{
return new RelayCommand(CreateBasicSoapEndpointExecute, CanCreateBasicSoapEndpoint);
}
}
public ICommand CreateRESTEndpoint
{
get
{
return new RelayCommand(CreateRESTEndpointExecute, CanCreateRESTEndpoint);
}
}
static bool CanCreateWSHttpSoapEndpoint()
{
return true;
}
static bool CanCreateBasicSoapEndpoint()
{
return true;
}
static bool CanCreateRESTEndpoint()
{
return true;
}
protected void CreateWSHttpSoapEndpointExecute()
{
CreateEndPointDelegate<WSHttpEndPointBuilder> delegateForCreate = CreateNewEndPoint<WSHttpEndPointBuilder>;
delegateForCreate.BeginInvoke(ar => { }, null);
}
protected void CreateBasicSoapEndpointExecute()
{
CreateEndPointDelegate<BasicHttpEndPointBuilder> delegateForCreate = CreateNewEndPoint<BasicHttpEndPointBuilder>;
delegateForCreate.BeginInvoke(ar => { }, null);
}
protected void CreateRESTEndpointExecute()
{
CreateEndPointDelegate<RESTEndPointBuilder> delegateForCreate = CreateNewEndPoint<RESTEndPointBuilder>;
delegateForCreate.BeginInvoke(ar => { }, null);
}
protected void AddLogMessageToStatusBox(object message)
{
var loggingEventArgs = (LoggingEventArgs)message;
this.Status = loggingEventArgs.LogMessage;
}
protected void CreateNewEndPoint<T>() where T : EndPointBuilder, new()
{
var t = new T();
IEndPoint endPoint;
t.BuildEndPoint(this.PortToUse, this.ResponseType);
endPoint = t.GetEndPoint();
endPoint.Activate();
this.PortToUse++;
SyncContext.Post(SetNextPossiblePortNumber, this.PortToUse.ToString(CultureInfo.InvariantCulture));
}
private void SetNextPossiblePortNumber(object nextPossiblePortNumber)
{
this.PortToUse = Convert.ToInt64(nextPossiblePortNumber);
}
}
}
<file_sep>/ViewModels/IEndPointPostInterface.cs
namespace TestHarness.ViewModels
{
interface IEndPointPostInterface
{
string UrlToPostTo { get; set; }
string FileToPost { get; set; }
void PostToEndPoint();
}
} | f32fdd3f1a42c26d86f2781fca4cc04cd4d78aef | [
"Markdown",
"C#"
] | 27 | C# | sri-prasanna/WebServiceTestHarness | 8f39514829343689fc147404f331ee2a08bb46bf | d4eefeaed4e573e504bada13e0b45997bc96fff2 |
refs/heads/main | <repo_name>Martje55555/videos-react<file_sep>/src/components/ButtonMore.js
import React from 'react';
const ButtonMore = () => {
return (
<button className="ui right labeled icon positive button">
<i className="right arrow icon" />
Show More
</button>
)
}
export default ButtonMore;<file_sep>/src/components/ButtonLess.js
import React from 'react';
const ButtonLess = () => {
return (
<button className="ui left labeled icon button ">
<i className="left arrow icon" />
Show Less
</button>
)
}
export default ButtonLess; | 18e3767e9d97a0d25986288b1dfd03f64d095fc5 | [
"JavaScript"
] | 2 | JavaScript | Martje55555/videos-react | f2835c2954b8926c32c703467137cd7132aeb334 | 13799f073a9551a01c9266d0687757179b9266d8 |
refs/heads/main | <file_sep>import { ThrowStmt } from '@angular/compiler';
import { Component, OnInit } from '@angular/core';
@Component({
selector: 'app-input-component',
templateUrl: './input-component.component.html',
styleUrls: ['./input-component.component.css']
})
export class InputComponentComponent implements OnInit {
username: string="";
disabled: boolean = false;
constructor() {
}
ngOnInit(): void {
}
isButtonDisabled(){
console.log("in isButtonDisabled()...");
console.log("this.username: " + this.username);
console.log("this.username.length: " + this.username.length);
if(this.username==='' || this.username.length===0){
return this.disabled = true;
}
return this.disabled = false;
}
}
| fa0825048afbb259e2bf7b579f31946022223b4b | [
"TypeScript"
] | 1 | TypeScript | waqassadiq/basics-assignment-2-start | b6423c31e03319f0ca73da24eb0bb01d7417772e | 204bea4e5b3d502df4b492051b34e253360aaf18 |
refs/heads/main | <file_sep>
$(function(){
$(window).scroll(function(){
var w = window.innerWidth;
if(w<992){
if ($(window).scrollTop() > 30)
{
$("#select-colors").hide('fast');
}
else
{
$("#select-colors").show('fast');
}
}
});
});
window.onresize = function() {
var w = window.innerWidth;
if(w>992){
console.log("window.onresize.. "+w+"px;");
$("#select-colors").show('fast');
}
};
var wow = new WOW({
boxClass: 'wow', // animated element css class (default is wow)
animateClass: 'animate__animated', // animation css class (default is animated)
});
wow.init();
var tag = document.createElement('script');
tag.src = "https://www.youtube.com/iframe_api";
var firstScriptTag = document.getElementsByTagName('script')[0];
firstScriptTag.parentNode.insertBefore(tag, firstScriptTag);
function onYouTubeIframeAPIReady() {
player = new YT.Player('player', {
width: '100%',
videoId: 'b9U3asR7HpM',
events: {
'onReady': onPlayerReady,
'onStateChange': onPlayerStateChange
}
});
}
players = {};
window.onYouTubeIframeAPIReady = function() {
$('.youtube-video').each(function() {
players[$(this).attr('id')] = new YT.Player($(this).attr('id'), {
videoId: $(this).attr('id'),
events: {
'onStateChange': onPlayerStateChange($(this).attr('id'))
}
});
});
};
function onPlayerStateChange(player_id) {
return function(event) {
if (players[player_id].getPlayerState() == 3 || players[player_id].getPlayerState() == 1) {
//stop the auto scrolling
console.log("stop scolling video: " + player_id);
}
if (players[player_id].getPlayerState() == 0 || players[player_id].getPlayerState() == 2) {
//start auto scrolling.
console.log("start scolling video: " + player_id);
$('.ocultar').css('display', 'block');
}
};
}
function reproducir1() {
//document.getElementById("rep").src += "&autoplay=1";
players['b9U3asR7HpM'].playVideo();
$('.ocultar').css('display', 'none');
}<file_sep>import { Component, Input, OnInit } from '@angular/core';
@Component({
selector: 'app-audio',
templateUrl: './audio.component.html',
styleUrls: ['./audio.component.css']
})
export class AudioComponent implements OnInit {
@Input() urlAudio : any;
public audio :any;
public iniciado : boolean = false;
constructor() { }
ngOnInit(): void {
this.audio = new Audio(this.urlAudio);
console.log(this.urlAudio);
}
reproducir() {
this.audio.play();
this.iniciado = true;
}
detener(){
this.audio.pause();
this.iniciado = false;
}
}<file_sep>import { Component, ElementRef, OnInit, ViewChild } from '@angular/core';
// import Swiper core and required modules
import SwiperCore, { SwiperOptions, Pagination, Autoplay } from 'swiper';
import Swal from 'sweetalert2';
import { NavigationEnd, Router } from '@angular/router';
import { SliderModel } from 'src/app/models/slidermodel';
import { AppSettings } from 'src/app/app.settings';
SwiperCore.use([Autoplay,Pagination]);
@Component({
selector: 'app-home',
templateUrl: './home.component.html',
styleUrls: ['./home.component.css']
})
export class HomeComponent implements OnInit {
public Sliders : Array<SliderModel> = [];
config: SwiperOptions = {
slidesPerView: 1,
spaceBetween: 50,
navigation: false,
pagination: { clickable: true },
scrollbar: { draggable: true },
autoplay:{
delay:3000,
disableOnInteraction: false
}
};
public animateBox:any;
constructor(private router: Router) {
this.Sliders = AppSettings.SLIDERS;
this.animateBox = {
reset: true, easing: 'ease-in-out', duration: 300, delay: 500, distance:'0px'
}
}
ngOnInit(): void {
this.router.events.subscribe((evt) => {
if (!(evt instanceof NavigationEnd)) {
return;
}
window.scrollTo(0, 0)
});
if(localStorage.getItem('idEmotion')!=null){
}
let leido = localStorage.getItem("leido");
if (leido == null) {
var boton = document.getElementById("btn-menu");
boton?.classList.add("btn-menu-inactive");
Swal.fire({
position: 'center-left',
customClass: { container: 'inicioHome' },
backdrop: 'rgba(255,255,255,0.8)',
html: '<div class="contenidohoy">'+
'<div class= "tamanohoy">'+
'<div class="imghoy"><img src="assets/img/logo-mide-digital-popup-min.png" alt = "Mide digital"></div>'+
'<div class= "textohoy">'+
'<p>La pandemia nos ha despertado múltiples emociones...</p>' +
'<div class="titulohoy">¿Qué sientes hoy?</div>'+
'<p>Utiliza la barra de colores para expresar tus emociones.</p>' +
'<div class="flechita"><img src="assets/img/menu/arrow-min.png" alt="Mide digital Flechita"></div>' +
'</div>' +
'</div>'+
'</div>',
showConfirmButton: false,
showCloseButton: true,
allowOutsideClick: false,
}).then(() => {
localStorage.setItem("leido", "1");
var boton = document.getElementById("btn-menu");
boton?.classList.remove("btn-menu-inactive");
});
}
}
onSwiper(swiper: any) {
/* console.log(swiper); */
}
onSlideChange() {
}
IraVisita(){
this.router.navigate(['/prepara-tu-visita']);
}
}
<file_sep>export class AppSettings {
//public static API_ENDPOINT='http://localhost/micrositio-arau/data/';
//public static API_ENDPOINT='https://indiga.com.mx/arauservice/data/';
public static API_ENDPOINT='https://arau2020.midedigital.museum/api/data/';
public static SLIDERS = [{
urlDesktop : "assets/img/sliders/santiago-arau-1.jpg",
urlMovil : "assets/img/sliders/movil/expo-santiago-arau1-mobile.jpg",
alt : "Expo Santiago Arau",
orden : 1,
},
{
urlDesktop : "assets/img/sliders/santiago-arau-2.jpg",
urlMovil : "assets/img/sliders/movil/expo-santiago-arau2-mobile.jpg",
alt : "Personal de Sal<NAME>",
orden : 2,
},
{
urlDesktop : "assets/img/sliders/santiago-arau-3.jpg",
urlMovil : "assets/img/sliders/movil/expo-santiago-arau3-mobile.jpg",
alt : "Foto aerea de Bellas Artes",
orden : 3,
},
{
urlDesktop : "assets/img/sliders/santiago-arau-5.jpg",
urlMovil : "assets/img/sliders/movil/santiago-arau-5-mobile.jpg",
alt : "Expo Santiago Arau",
orden : 4,
},
{
urlDesktop : "assets/img/sliders/santiago-arau-4.jpg",
urlMovil : "assets/img/sliders/movil/santiago-arau-4-mobile.jpg",
alt : "Foto aerea de estadio",
orden : 5,
},
{
urlDesktop : "assets/img/sliders/santiago-arau-6.jpg",
urlMovil : "assets/img/sliders/movil/expo-santiago-arau6-mobile.jpeg",
alt : "Foto del angel de la independecia",
orden : 6,
},
{
urlDesktop : "assets/img/sliders/santiago-arau-7.jpg",
urlMovil : "assets/img/sliders/movil/santiago-arau-7-mobile.jpg",
alt : "Torre de antenas",
orden : 7,
}];
}
<file_sep>import { Component, EventEmitter, Input, OnInit, Output } from '@angular/core';
import { EmotionModel } from 'src/app/models/emotion.model';
import { EmotionService } from 'src/app/services/emotions.service';
import Swal from 'sweetalert2';
@Component({
selector: 'app-emotions',
templateUrl: './emotions.component.html',
styleUrls: ['./emotions.component.css']
})
export class EmotionsComponent implements OnInit {
@Input() emociones : Array<any> = [];
@Output() emotions = new EventEmitter<Array<any>>();
public Emocion :EmotionModel;
public viewResult:boolean = false;
constructor(private emotionService:EmotionService) {
this.Emocion = new EmotionModel();
}
ngOnInit(): void {
var boton = document.getElementById("btn-menu");
boton?.classList.add("btn-menu-inactive");
let leido = localStorage.getItem("leido");
if(leido!=null){
this.viewResult = true;
}
this.getData();
}
public changeEmotion(id: number) {
this.viewResult = true;
let contenido:any;
var input=document.getElementById("globalColor");
input?.setAttribute('value',id.toString());
localStorage.setItem('tipo_emocion', id.toString());
contenido = window.document.getElementById("contenido");
if (contenido) {}
this.clearColors(contenido);
this.clieaActive(id);
switch (id) {
case 1:
contenido.classList.add("bc-body-1");
break;
case 2:
contenido.classList.add("bc-body-2");
break;
case 3:
contenido.classList.add("bc-body-3");
break;
case 4:
contenido.classList.add("bc-body-4");
break;
case 5:
contenido.classList.add("bc-body-5");
break;
case 6:
contenido.classList.add("bc-body-6");
break;
case 7:
contenido.classList.add("bc-body-7");
break;
default:
break;
}
this.Emocion.tipo = id;
if(localStorage.getItem('ip')!=null){
let ip = localStorage.getItem('ip');
this.Emocion.ip = String(ip);
}
if(localStorage.getItem('id')!=null){
let id : any = localStorage.getItem('id');
this.Emocion.id = parseInt(id);
}
this.sendData();
}
public clearColors(element:any){
element.classList.remove("bc-body-1");
element.classList.remove("bc-body-2");
element.classList.remove("bc-body-3");
element.classList.remove("bc-body-4");
element.classList.remove("bc-body-5");
element.classList.remove("bc-body-6");
element.classList.remove("bc-body-7");
}
public clieaActive(id:number){
for (let i = 1; i <= 7; i++) {
let option = document.getElementById("numbEmotion"+i);
if(i==id){
option?.classList.add("active");
} else {
option?.classList.remove("active");
}
}
}
public mostrarMenu(){
var menu = document.getElementById("menus");
var contenido = document.getElementById("contenido");
var boton = document.getElementById("btn-menu");
menu?.classList.remove("menu-oculto");
contenido?.classList.remove("contenido-full");
boton?.classList.remove("btn-menu-active");
boton?.classList.add("btn-menu-inactive");
}
public sendData(){
this.emotionService.sendEmotion(this.Emocion).subscribe(
(resp:any)=>{
this.Emocion.id = resp.ID;
localStorage.setItem('id', resp.ID);
this.getData();
},
err=>{
Swal.fire({
icon: 'error',
title: 'Error al guardar emoción',
text: ''
})
}
);
}
public getData(){
this.emotionService.getEmotions().subscribe(
(resp: Array<any>) => {
this.emociones = resp;
this.emotions.emit(this.emociones);
}
);
}
}
<file_sep>export class SliderModel{
urlDesktop: string;
urlMovil: string;
alt: string;
orden: number;
constructor(){
this.urlDesktop = "";
this.urlMovil = "";
this.alt = ""
this.orden = 0;
}
}<file_sep>import { Component, OnInit } from '@angular/core';
import { NavigationEnd, Router } from '@angular/router';
import { AppSettings } from 'src/app/app.settings';
import { SliderModel } from 'src/app/models/slidermodel';
import SwiperCore, { SwiperOptions, Pagination, Autoplay } from 'swiper';
SwiperCore.use([Autoplay,Pagination]);
@Component({
selector: 'app-veinte',
templateUrl: './gratificacion.component.html',
styleUrls: ['./gratificacion.component.css']
})
export class GratificacionComponent implements OnInit {
config: SwiperOptions = {
slidesPerView: 1,
spaceBetween: 50,
navigation: false,
pagination: { clickable: true },
scrollbar: { draggable: true },
autoplay:{
delay:3000,
disableOnInteraction: false
}
};
public Sliders : Array<SliderModel> = [];
constructor(private router:Router) {
this.Sliders = this.cambiarOrden();
}
ngOnInit(): void {
this.router.events.subscribe((evt) => {
if (!(evt instanceof NavigationEnd)) {
return;
}
window.scrollTo(0, 0)
});
}
onSwiper(swiper: any) {
/* console.log(swiper); */
}
onSlideChange() {
}
cambiarOrden(){
let s : Array<SliderModel>=[];
let o = 1;
let d = 7;
AppSettings.SLIDERS.forEach(function(item, indice, array) {
if(indice >= 6){
item.orden = o;
s.push(item);
o++;
} else {
item.orden = d;
s.push(item);
d--;
}
});
return s;
}
}
<file_sep># arau2020
Micrositio para la exposición de <NAME> en el MIDE digital
<file_sep>import { Component, OnInit } from '@angular/core';
import { NavigationEnd, Router } from '@angular/router';
import { AppSettings } from 'src/app/app.settings';
import { SliderModel } from 'src/app/models/slidermodel';
import SwiperCore, { SwiperOptions, Navigation, Pagination, Autoplay } from 'swiper';
SwiperCore.use([Autoplay,Navigation, Pagination]);
@Component({
selector: 'app-visita',
templateUrl: './visita.component.html',
styleUrls: ['./visita.component.css']
})
export class VisitaComponent implements OnInit {
config: SwiperOptions = {
slidesPerView: 1,
spaceBetween: 50,
navigation: true,
pagination: { clickable: true , type: 'fraction'},
scrollbar: { draggable: true },
autoplay:{
delay:3000,
disableOnInteraction: false
},
};
configDos: SwiperOptions = {
navigation: true,
slidesPerView: 1,breakpoints: {
// when window width is >= 320px
768: {
slidesPerView: 2
}
},
watchSlidesProgress:true,
/* autoplay:{
delay:5000,
disableOnInteraction: false
} */
}
public actividades : Array<any> = [{
titulo:'Recorrido Fotografías que nos conectan',
texto:'Recorrido a través de la exposición que invitará a los visitantes a realizar conexiones emocionales, compartir vivencias, hilar narrativas y descubrir en las fotografías un espejo que muestra las diversas realidades que cada persona experimentó desde que se oficializó la pandemia en México.',
dirigido:'Visitantes de la exposición 2020.',
urlImg:'assets/img/visita/recorrido-fotografias.jpg',
tiempo:40,
participantes:10,
fechas:null,
horarios:'13:00 y 16:00 H.',
ubicacion:'Trampantojo, Planta baja.',
logo:'assets/img/visita/recorrido.png',
class:''
},
{
titulo:'Laboratorio de foto creativa',
texto:'Taller que permitirá a los participantes descubrir algunas técnicas para crear diferentes filtros con objetos convencionales para explotar el potencial de la cámara de su celular, particularmente en retratos o autorretratos.',
dirigido:'Jóvenes y adultos.',
urlImg:'assets/img/visita/laboratorio-foto-creativa.jpg',
tiempo:30,
participantes:8,
fechas:null,
horarios:'13:00 y 16:00 H.',
ubicacion:'Zona de talleres, Planta baja.',
logo:'assets/img/visita/laboratorio.png',
class:'logo-lg'
},
{
titulo:'El MIDE desde el cielo: principios básicos de la fotografía aérea',
texto:'Demostración realizada por los especialistas de Drones de México, expertos en la toma de fotografías aéreas, que permitirá a los participantes descubrir los principios de la fotografía aérea mediante una demostración con las cámaras y drones que se utilizan para realizarla.',
dirigido:'Jóvenes y adultos.',
urlImg:'assets/img/visita/mide-desde-el-cielo.jpg',
tiempo:30,
participantes:30,
fechas:'7 de noviembre y 5 de diciembre de 2021, 16 de enero, 20 de febrero, 13 de marzo, 17 de abril y 8 de mayo de 2022.',
horarios:'12:00 y 13:15 H.',
ubicacion:'Patio principal.',
logo:'assets/img/visita/mide-desde-el-cielo.png',
class:''
},
{
titulo:'La fotografía a través del tiempo: taller de fotografía estereoscópica',
texto:'Taller que invita a los participantes a experimentar la fotografía como se realizaba a finales del siglo XIX en el Fotoestudio Vergara y a explorar la fotografía tridimensional a través de un artefacto llamado estereoscopio.',
dirigido:'Jóvenes y adultos.',
urlImg:'assets/img/visita/estereocopia.jpg',
tiempo:45,
participantes:8,
fechas:null,
horarios:'12:00 y 15:00 H.',
ubicacion:'Zona de talleres, Planta baja.',
logo:'assets/img/visita/foto-atraves-del-tiempo.png',
class:''
}
];
public Sliders : Array<SliderModel> = [];
constructor(private router:Router) {
this.Sliders = this.cambiarOrden();
}
ngOnInit(): void {
this.router.events.subscribe((evt) => {
if (!(evt instanceof NavigationEnd)) {
return;
}
window.scrollTo(0, 0)
});
}
onSwiper(swiper: any) {
/* console.log(swiper); */
}
onSlideChange() {
}
comprar(){
window.open("https://wwv.mide.org.mx/MIDE_INTERNET/Operacion/Compras/Compras.aspx", "_blank");
}
cambiarOrden(){
let s : Array<SliderModel>=[];
let o = 1;
let d = 7;
AppSettings.SLIDERS.forEach(function(item, indice, array) {
if(indice >= 4){
item.orden = o;
s.push(item);
o++;
} else {
item.orden = d;
s.push(item);
d--;
}
});
return s;
}
}<file_sep>import { Component, OnInit } from '@angular/core';
@Component({
selector: 'app-menu',
templateUrl: './menu.component.html',
styleUrls: ['./menu.component.css']
})
export class MenuComponent implements OnInit {
constructor() { }
ngOnInit(): void {
}
public cerrarMenu(){
var menu = document.getElementById("menus");
var contenido = document.getElementById("contenido");
var boton = document.getElementById("btn-menu");
menu?.classList.add("menu-oculto");
contenido?.classList.add("contenido-full");
boton?.classList.remove("btn-menu-inactive");
boton?.classList.add("btn-menu-active");
}
}
<file_sep>import { Injectable } from '@angular/core';
import { map } from 'rxjs/operators';
import { HttpClient } from '@angular/common/http';
import { AppSettings } from '../app.settings';
import { EmotionModel } from '../models/emotion.model';
@Injectable({
providedIn: 'root'
})
export class EmotionService {
Headers = new Headers
private configUrl: string = '';
constructor(private http:HttpClient) { }
getEmotions(){
this.configUrl = `${AppSettings.API_ENDPOINT}reactions.php`;
const apod = this.http.get<any>(this.configUrl);
return apod;
}
sendEmotion(emocion:EmotionModel){
this.configUrl = `${AppSettings.API_ENDPOINT}reactions.php`;
return this.http.post<any>(this.configUrl,emocion);
}
}
<file_sep>import { Component, Input, OnInit } from "@angular/core";
import { SliderModel } from "src/app/models/slidermodel";
import SwiperCore, { SwiperOptions, Pagination, Autoplay } from 'swiper';
SwiperCore.use([Autoplay,Pagination]);
@Component({
selector: 'slider-principal',
templateUrl: './slider-principal.component.html',
styleUrls: ['./slider-principal.component.css']
})
export class SliderPrincipalComponent implements OnInit {
@Input() imagenesArr : Array<SliderModel> = [];
config: SwiperOptions = {
slidesPerView: 1,
spaceBetween: 50,
navigation: false,
pagination: { clickable: true },
scrollbar: { draggable: true },
autoplay:{
delay:3000,
disableOnInteraction: false
}
};
ngOnInit(): void {
this.imagenesArr.sort(((a, b) => a.orden - b.orden));
}
onSwiper(swiper: any) {
}
onSlideChange() {
}
}<file_sep>import { NgModule } from '@angular/core';
import { RouterModule, Routes } from '@angular/router';
import { HomeComponent } from './components/pages/home/home.component';
import { ExpoComponent } from './components/pages/expo/expo.component';
import { FotografiaComponent } from './components/pages/fotografia/fotografia.component';
import { VeinteComponent } from './components/pages/veinte/veinte.component';
import { VisitaComponent } from './components/pages/visita/visita.component';
import { AccesibilidadComponent } from './components/pages/accesibilidad/accesibilidad.component';
import { GratificacionComponent } from './components/pages/gratificacion/gratificacion.component';
import { TerminosComponent } from './components/shared/footer/terminos/terminos.component';
import { AvisosComponent } from './components/shared/footer/avisos/avisos.component';
import { AliadosComponent } from './components/shared/footer/aliados/aliados.component';
const routes: Routes = [
{ path: 'home', component: HomeComponent },
{ path: 'expo', component: ExpoComponent },
{ path: 'fotografia', component: FotografiaComponent },
{ path: 'sobre-2020', component: VeinteComponent },
{ path: 'prepara-tu-visita', component: VisitaComponent},
{ path: 'guia-accesibilidad', component: AccesibilidadComponent},
{ path: 'gratificacion', component: GratificacionComponent},
{ path: 'aliados', component:AliadosComponent},
{ path: 'terminos-y-condiciones', component: TerminosComponent},
{ path: 'aviso-de-privacidad', component: AvisosComponent},
{ path: '**', redirectTo: 'home' }
];
@NgModule({
imports: [RouterModule.forRoot(routes)],
exports: [RouterModule]
})
export class AppRoutingModule { }
<file_sep>import { Component, OnInit } from '@angular/core';
import { NavigationEnd, Router } from '@angular/router';
import { AppSettings } from 'src/app/app.settings';
import { SliderModel } from 'src/app/models/slidermodel';
import SwiperCore, { SwiperOptions, Navigation, Pagination, Autoplay } from 'swiper';
SwiperCore.use([Autoplay, Navigation, Pagination]);
@Component({
selector: 'app-fotografia',
templateUrl: './fotografia.component.html',
styleUrls: ['./fotografia.component.css']
})
export class FotografiaComponent implements OnInit {
config: SwiperOptions = {
slidesPerView: 1,
spaceBetween: 50,
navigation: true,
pagination: { clickable: true , type: 'fraction'},
scrollbar: { draggable: true }
};
public Sliders : Array<SliderModel> = [];
public audio1 :string = "";
public bloque :number = 1;
constructor(private router:Router) {
this.audio1 = "assets/audios/file_example_MP3_700KB.mp3";
this.Sliders = this.cambiarOrden();
}
audioList1 = [
{
url: "assets/audios/MIDE_Digital_Joel_Meyerowitz.mp3",
title: "Ver el mundo que nos rodea",
cover: "assets/img/covers/_joel-meyerowitz-min.jpg"
}
];
audioList2 = [
{
url: "assets/audios/MIDE_Digital_Mariana_Yampolsky.mp3",
title: "El color pide color",
cover: "assets/img/covers/mariana-yampolsky-min.jpg"
}
];
audioList3 = [
{
url: "assets/audios/MIDE_Digital_Jose_Kochen.mp3",
title: "La conquista del aire",
cover: "assets/img/covers/juan-jose-koche-min.jpg"
}
];
ngOnInit(): void {
this.router.events.subscribe((evt) => {
if (!(evt instanceof NavigationEnd)) {
return;
}
window.scrollTo(0, 0)
});
}
onSwiper(swiper: any) {
/* console.log(swiper); */
}
onSlideChange() {
}
verBloque(bloque:number){
this.bloque = bloque;
}
link(){
window.open('https://www.mide.org.mx/la-vida-contenida/', '_blank');
}
cambiarOrden(){
let s : Array<SliderModel>=[];
let o = 1;
let d = 7;
AppSettings.SLIDERS.forEach(function(item, indice, array) {
if(indice >= 2){
item.orden = o;
s.push(item);
o++;
} else {
item.orden = d;
s.push(item);
d--;
}
});
return s;
}
}
<file_sep>import { Component, EventEmitter, Input, OnInit, Output } from '@angular/core';
import { Color, Label } from 'ng2-charts';
import { ChartOptions, ChartType, ChartDataSets } from 'chart.js';
import { EmotionService } from 'src/app/services/emotions.service';
@Component({
selector: 'app-modal-resultados',
templateUrl: './modal-resultados.component.html',
styleUrls: ['./modal-resultados.component.css']
})
export class ModalResultadosComponent implements OnInit {
@Input() emociones : Array<any> = [];
constructor(private emotionService:EmotionService) { }
public barChartOptions: ChartOptions = {
responsive: true,
scales : {
yAxes: [{
ticks: {
beginAtZero: true,
max : 100,
}
}]
}
};
public barChartLabels: Label[] = [];
public barChartType: ChartType = 'bar';
public barChartLegend = true;
public barChartPlugins = [];
public barChartData: ChartDataSets[] = [];
ngOnInit(): void {
}
ngOnChanges(){
this.armarGrafico();
}
armarGrafico(){
this.barChartLabels = [];
this.barChartData = [];
let promedios = Array();
let colores = Array();
this.emociones.forEach(emocion => {
this.barChartLabels.push(emocion.nombre);
promedios.push(emocion.promedio);
colores.push(emocion.color);
});
this.barChartData = [ { data: promedios, label: 'Emociones' , backgroundColor:colores } ];
}
}
<file_sep>export class EmotionModel{
id: number;
ip: string;
tipo: number;
constructor(){
this.id = 0;
this.ip = "";
this.tipo = 0;
}
}
<file_sep>import { NgModule } from '@angular/core';
import { BrowserModule } from '@angular/platform-browser';
import { AppRoutingModule } from './app-routing.module';
import { AppComponent } from './app.component';
import { SliderPrincipalComponent } from './components/shared/slider-principal/slider-principal.component';
import { FooterComponent } from './components/shared/footer/footer.component';
import { AvisosComponent } from './components/shared/footer/avisos/avisos.component';
import { TerminosComponent } from './components/shared/footer/terminos/terminos.component';
import { MenuComponent } from './components/shared/menu/menu.component';
import { AudioComponent } from './components/shared/audio/audio.componet';
import { EmotionsComponent } from './components/shared/emotions/emotions.component';
import { HomeComponent } from './components/pages/home/home.component';
import { ExpoComponent } from './components/pages/expo/expo.component';
import { FotografiaComponent } from './components/pages/fotografia/fotografia.component';
import { ModalResultadosComponent } from './components/shared/modal-resultados/modal-resultados.component';
import { VeinteComponent } from './components/pages/veinte/veinte.component';
import { VisitaComponent } from './components/pages/visita/visita.component';
import { GratificacionComponent } from './components/pages/gratificacion/gratificacion.component';
import { SwiperModule } from 'swiper/angular';
import { AngMusicPlayerModule } from 'ang-music-player';
import { SweetAlert2Module } from '@sweetalert2/ngx-sweetalert2';
// Servicios
import { HttpClientModule, HTTP_INTERCEPTORS } from '@angular/common/http';
import { AuthInterceptorService } from './services/auth-interceptor.service';
import { FormsModule, ReactiveFormsModule } from '@angular/forms';
import { ChartsModule } from 'ng2-charts';
import { AccesibilidadComponent } from './components/pages/accesibilidad/accesibilidad.component';
import { AliadosComponent } from './components/shared/footer/aliados/aliados.component';
import { HashLocationStrategy, LocationStrategy } from '@angular/common';
import { YouTubePlayerModule } from '@angular/youtube-player';
@NgModule({
declarations: [
AppComponent,
SliderPrincipalComponent,
FooterComponent,
AliadosComponent,
AvisosComponent,
TerminosComponent,
AudioComponent,
MenuComponent,
EmotionsComponent,
HomeComponent,
ExpoComponent,
FotografiaComponent,
ModalResultadosComponent,
VeinteComponent,
VisitaComponent,
AccesibilidadComponent,
GratificacionComponent
],
imports: [
HttpClientModule,
BrowserModule,
AppRoutingModule,
SwiperModule,
AngMusicPlayerModule,
SweetAlert2Module.forRoot(),
FormsModule,
ReactiveFormsModule,
ChartsModule,
YouTubePlayerModule
],
providers: [
{
provide: HTTP_INTERCEPTORS,
useClass: AuthInterceptorService,
multi: true
},
{
provide: LocationStrategy,
useClass: HashLocationStrategy
}
],
bootstrap: [AppComponent]
})
export class AppModule { }
<file_sep>import { Component, OnInit, SimpleChanges } from '@angular/core';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent implements OnInit{
title = 'mide-arau';
public emotions:Array<any> = [];
public hola:string = "hola";
ngOnInit(): void {
}
setEmotions($event:any){
this.emotions = $event;
}
}
| d09a0e39b626ef4e44b33204ee97979985af4e76 | [
"JavaScript",
"TypeScript",
"Markdown"
] | 18 | JavaScript | birthtecnologia/arau2020 | 644526f9727eb4da016525baca95e5be1df59447 | 56bfc5e8b9516dc7f75ec0db1dc3b5e0c474fb42 |
refs/heads/master | <file_sep>class Solution:
def plusOne(self, digits: List[int]) -> List[int]:
sum = 0
for i in range(len(digits)):
sum += digits[i] * pow(10, len(digits) - 1 -i)
sum_str = str(sum + 1)
return [int(j) for j in sum_str]<file_sep>class Solution:
def singleNumber(self, nums: List[int]) -> int:
no_duplicate_list = []
for num in nums:
if num not in no_duplicate_list:
no_duplicate_list.append(num)
else:
no_duplicate_list.remove(num)
return no_duplicate_list.pop()<file_sep># This one is just used for testing<file_sep>class Solution(object):
def twoSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
hashmap = {}
for index, num in enumerate(nums):
hashmap[num] = index
for index, num in enumerate(nums):
result = target - num
j = hashmap.get(result)
if j is not None and j != index:
return [index,j]<file_sep>class Solution:
def climbStairs(self, n: int) -> int:
f = [1, 2]
for i in range(2, n):
f.append(f[i - 2] + f[i - 1])
return f[n - 1] | 3e9b43191e06f94c08e880e78eefc41ffbae3d5c | [
"Python"
] | 5 | Python | stephenxieber/Leetcode | ca9fb47e4394aeeccd895e2caf6d85bb5207ecd2 | 337edd45fb6847706758f9f92aee33586a58e696 |
refs/heads/main | <repo_name>Dongw1126/algo_team<file_sep>/Project1/robot.h
#pragma once
#include <iostream>
#include <string>
#include <windows.h>
#include "map.h"
using namespace std;
// 아래, 위, 오른쪽, 왼쪽
int dx[4] = { 1,-1,0,0 };
int dy[4] = { 0,0,1,-1 };
class robot
{
private:
int x, y;
public:
robot();
// type 1 : 시간 제한을 두고 알고리즘 수행
// type 2 : 시간제한을 두지않고 coverage 100%를 달성할 때까지 수행
// limit : 시간 제한
void randomMove(Map map, int type,int limit);
void spinMove(Map map, int type,int limit);
void zigzagMove(Map map, int type,int limit);
void printMap(Map& map);
void renderMap(Map& map);
};
robot::robot() {
x = 0; y = 0;
}
void robot::printMap(Map& map)
{
const string a = "■"; //벽
const string b = "□"; //청소하지 않은공간
const string c = "◆"; //로봇청소기
const string d = "▦"; // 청소 완료
for (int i = 0; i < map.width; i++)
{
for (int j = 0; j < map.height; j++)
{
switch (map.map[i][j])
{
case 0:
cout << b;
break;
case 1:
cout << a;
break;
case 2:
cout << c;
break;
case 3:
cout << d;
break;
}
}
cout << endl;
}
}
void robot::renderMap(Map& map) {
system("cls");
this->printMap(map);
Sleep(10);
}
void robot::randomMove(Map map, int type, int limit)
{
srand((unsigned)time(NULL));
int memory_calc = 0;
int move_calc = 0;
int calc_cost = 0;
//연산 종류별로 계산비용 구분
int time_cost = 0; // 소요 시간
int time_limit = limit; // 시간 제한(잔여 배터리)
bool endflag = false;
int coverage = 0; // 청소 면적
int room_size = 0; // 방 면적
for (int i = 0; i < map.width; i++)
for (int j = 0; j < map.height; j++)
if (map.map[i][j] != 1)
room_size++;
// 로봇 시작위치 찾기
for (int i = 0; i < map.width; i++)
{
for (int j = 0; j < map.height; j++)
{
if (map.map[i][j] == 2)
{
this->x = i;
this->y = j;
break;
}
}
}
int map_size = map.width * map.height; //전체 면적
int rotate = -1;//방향전환 비용 계산 변수
int rtcount = 0;
while (!endflag) {
int dir = rand() % 4;
int distance = (rand() % max(map.height, map.width)) + 1; //랜덤 방향,거리 설정
move_calc += 1;
if (dir != rotate)
{
move_calc += 2;
time_cost++;
rtcount++;
}
rotate = dir;
while ((distance-- > 0) && (map.map[this->x + dx[dir]][this->y + dy[dir]] != 1)) {
map.map[this->x][this->y] = 3; // 청소 완료 표시
memory_calc += 1;
this->x += dx[dir];
this->y += dy[dir];
map.map[this->x][this->y] = 2;
move_calc += 1;
time_cost++;
// 청소 과정 출력 (데모 동영상 용)
this->renderMap(map);
// 1번 : 시간제한을 두고 알고리즘을 수행
if (type == 1) {
if (time_limit <= time_cost) {
endflag = true;
break;
}
}
coverage = 1;
// 커버리지 측정
for (int i = 0; i < map.width; i++)
for (int j = 0; j < map.height; j++)
if (map.map[i][j] == 3)
coverage++;
// 2번 : 시간제한을 두지않고 coverage 100%를 달성할 때까지 수행
if (type == 2) {
if (coverage / room_size == 1) {
endflag = true;
break;
}
}
}
}
calc_cost = move_calc + memory_calc;
cout << "맵크기 커버리지 연산횟수 방향전환 소요시간 " << endl;
// 맵 크기 출력
cout << map_size << " ";
// 청소 면적 출력
float coverage_rate = ((float)coverage / (float)room_size) * 100;
cout << fixed;
cout.precision(1);
cout << coverage_rate << " ";
// 연산 횟수 출력
cout << calc_cost << " ";
// 방향전환 횟수 출력
cout << rtcount << " ";
// 소요 시간 출력
cout << time_cost << endl;
}
void robot::spinMove(Map map, int type, int limit)
{
srand((unsigned)time(NULL));
int memory_calc = 0;
int move_calc = 0;
int calc_cost = 0;
//연산 종류별로 계산비용 구분
int time_cost = 0; // 소요 시간
int time_limit = limit; // 시간 제한(잔여 배터리)
int coverage = 0; // 청소 면적
int room_size = 0; // 방 면적
for (int i = 0; i < map.width; i++)
for (int j = 0; j < map.height; j++)
if (map.map[i][j] != 1)
room_size++;
int map_size = map.width * map.height; //전체 면적
enum dirc { DOWN, UP, RIGHT, LEFT }; //방향 가독성
bool traceflag = false;
int dir = UP; //방향성
int rotate = -1;//방향전환 비용 계산 변수
int rtcount = 0;
vector<pair<int, int> > back_path; //백트래킹용 추가 내장 메모리
// 로봇 시작위치 찾기
for (int i = 0; i < map.width; i++)
{
for (int j = 0; j < map.height; j++)
{
if (map.map[i][j] == 2)
{
this->x = i;
this->y = j;
break;
}
}
}
while ((map.map[this->x + dx[LEFT]][this->y + dy[LEFT]] != 1))
{
map.map[this->x][this->y] = 3; // 청소 완료 표시
memory_calc += 1;
this->x += dx[LEFT];
this->y += dy[LEFT];
map.map[this->x][this->y] = 2;
move_calc += 1;
back_path.push_back({ dx[LEFT] * (-1), dy[LEFT] * (-1) });
memory_calc += 1;
// 청소 과정 출력 (데모 동영상 용)
this->renderMap(map);
time_cost++;
}
dir = UP;
// 1칸 이동
while (true)
{
map.map[this->x][this->y] = 3; // 청소 완료 표시
memory_calc += 1;
if (dir != rotate)
{
move_calc += 2;
time_cost++;
rtcount++;
}
rotate = dir;
switch (dir)
{
case 3: //왼쪽방향
if ((map.map[this->x + dx[DOWN]][this->y + dy[DOWN]] != 0))
{
if (map.map[this->x + dx[LEFT]][this->y + dy[LEFT]] == 0) // #1
{
this->x += dx[LEFT];
this->y += dy[LEFT];
map.map[this->x][this->y] = 2;
move_calc += 1;
back_path.push_back({ dx[LEFT] * (-1), dy[LEFT] * (-1) });
memory_calc += 1;
}
else if (map.map[this->x + dx[UP]][this->y + dy[UP]] == 0) // #2
{
this->x += dx[UP];
this->y += dy[UP];
map.map[this->x][this->y] = 2;
move_calc += 1;
dir = UP;
back_path.push_back({ dx[UP] * (-1), dy[UP] * (-1) });
memory_calc += 1;
}
else
{
traceflag = true;
}
}
//벽이 없을때
else if ((map.map[this->x + 1][this->y + 1] != 0 && map.map[this->x + dx[DOWN]][this->y + dy[DOWN]] == 0))
{
this->x += dx[DOWN];
this->y += dy[DOWN];
map.map[this->x][this->y] = 2;
move_calc += 1;
dir = DOWN;
back_path.push_back({ dx[DOWN] * (-1), dy[DOWN] * (-1) });
memory_calc += 1;
}
break;
case 1: // 위쪽방향
if ((map.map[this->x + dx[LEFT]][this->y + dy[LEFT]] != 0))
{
if (map.map[this->x + dx[UP]][this->y + dy[UP]] == 0) // #1
{
this->x += dx[UP];
this->y += dy[UP];
map.map[this->x][this->y] = 2;
move_calc += 1;
back_path.push_back({ dx[UP] * (-1), dy[UP] * (-1) });
memory_calc += 1;
}
else if (map.map[this->x + dx[RIGHT]][this->y + dy[RIGHT]] == 0) // #2
{
this->x += dx[RIGHT];
this->y += dy[RIGHT];
map.map[this->x][this->y] = 2;
move_calc += 1;
dir = RIGHT;
back_path.push_back({ dx[RIGHT] * (-1), dy[RIGHT] * (-1) });
memory_calc += 1;
}
else
traceflag = true;
}
//벽이 없을때
else if ((map.map[this->x + 1][this->y - 1] != 0 && map.map[this->x + dx[LEFT]][this->y + dy[LEFT]] == 0))
{
this->x += dx[LEFT];
this->y += dy[LEFT];
map.map[this->x][this->y] = 2;
move_calc += 1;
dir = LEFT;
back_path.push_back({ dx[LEFT] * (-1), dy[LEFT] * (-1) });
memory_calc += 1;
}
break;
case 2: // 오른쪽
if ((map.map[this->x + dx[UP]][this->y + dy[UP]] != 0))
{
if (map.map[this->x + dx[RIGHT]][this->y + dy[RIGHT]] == 0) // #1
{
this->x += dx[RIGHT];
this->y += dy[RIGHT];
map.map[this->x][this->y] = 2;
move_calc += 1;
back_path.push_back({ dx[RIGHT] * (-1), dy[RIGHT] * (-1) });
memory_calc += 1;
}
else if (map.map[this->x + dx[DOWN]][this->y + dy[DOWN]] == 0) // #2
{
this->x += dx[DOWN];
this->y += dy[DOWN];
map.map[this->x][this->y] = 2;
move_calc += 1;
dir = DOWN;
back_path.push_back({ dx[DOWN] * (-1), dy[DOWN] * (-1) });
memory_calc += 1;
}
else
traceflag = true;
}
//벽이 없을때
else if ((map.map[this->x - 1][this->y - 1] != 0 && map.map[this->x + dx[UP]][this->y + dy[UP]] == 0))
{
this->x += dx[UP];
this->y += dy[UP];
map.map[this->x][this->y] = 2;
move_calc += 1;
dir = UP;
back_path.push_back({ dx[UP] * (-1), dy[UP] * (-1) });
memory_calc += 1;
}
break;
case 0: // 아래
if ((map.map[this->x + dx[RIGHT]][this->y + dy[RIGHT]] != 0))
{
if (map.map[this->x + dx[DOWN]][this->y + dy[DOWN]] == 0) // #1
{
this->x += dx[DOWN];
this->y += dy[DOWN];
map.map[this->x][this->y] = 2;
move_calc += 1;
back_path.push_back({ dx[DOWN] * (-1), dy[DOWN] * (-1) });
memory_calc += 1;
}
else if (map.map[this->x + dx[LEFT]][this->y + dy[LEFT]] == 0) // #2
{
this->x += dx[LEFT];
this->y += dy[LEFT];
map.map[this->x][this->y] = 2;
move_calc += 1;
dir = LEFT;
back_path.push_back({ dx[LEFT] * (-1), dy[LEFT] * (-1) });
memory_calc += 1;
}
else
traceflag = true;
}
//벽이 없을때
else if ((map.map[this->x - 1][this->y + 1] != 0 && map.map[this->x + dx[RIGHT]][this->y + dy[RIGHT]] == 0))
{
this->x += dx[RIGHT];
this->y += dy[RIGHT];
map.map[this->x][this->y] = 2;
move_calc += 1;
dir = RIGHT;
back_path.push_back({ dx[RIGHT] * (-1), dy[RIGHT] * (-1) });
memory_calc += 1;
}
break;
}
if (traceflag == true)
{
if (back_path.size() > 0)
{
int i = back_path.size() - 1;
map.map[this->x][this->y] = 3;
memory_calc += 1;
this->x += back_path[i].first;
this->y += back_path[i].second;
map.map[this->x][this->y] = 2;
move_calc += 1;
switch (back_path[i].first)
{
case 1:
dir = RIGHT;
break;
case -1:
dir = LEFT;
break;
case 0:
if (back_path[i].second == 1)
dir = UP;
else if (back_path[i].second == -1)
dir = DOWN;
break;
}
back_path.pop_back();
memory_calc += 1;
}
traceflag = false;
}
time_cost++;
// 청소 과정 출력 (데모 동영상 용)
this->renderMap(map);
coverage = 1;
// 커버리지 측정
for (int i = 0; i < map.width; i++)
for (int j = 0; j < map.height; j++)
if (map.map[i][j] == 3)
coverage++;
// 1번 : 시간제한을 두고 알고리즘을 수행
if (type == 1) {
if (coverage / room_size == 1) {
break;
}
if (time_limit <= time_cost) {
break;
}
}
// 2번 : 시간제한을 두지않고 coverage 100%를 달성할 때까지 수행
if (type == 2) {
if (coverage / room_size == 1) {
break;
}
}
}
this->renderMap(map);
calc_cost = move_calc + memory_calc;
cout << "맵크기 커버리지 연산횟수 방향전환 소요시간" << endl;
// 맵 크기 출력
cout << map_size << " ";
// 청소 면적 출력
float coverage_rate = ((float)coverage / (float)room_size) * 100;
cout << fixed;
cout.precision(1);
cout << coverage_rate << " ";
// 연산 횟수 출력
cout << calc_cost << " ";
// 방향전환 횟수 출력
cout << rtcount << " ";
// 소요 시간 출력
cout << time_cost << endl;
}
void robot::zigzagMove(Map map, int type, int limit)
{
srand((unsigned)time(NULL));
int memory_calc = 0;
int move_calc = 0;
int calc_cost = 0;
//연산 종류별로 계산비용 구분
int time_cost = 0; // 소요 시간
int time_limit = limit; // 시간 제한(잔여 배터리)
int coverage = 0; // 청소 면적
int room_size = 0; // 방 면적
for (int i = 0; i < map.width; i++)
for (int j = 0; j < map.height; j++)
if (map.map[i][j] != 1)
room_size++;
int map_size = map.width * map.height; //전체 면적
enum dirc { DOWN, UP, RIGHT, LEFT }; //방향 가독성
vector<pair<int, int> > back_path; //백트래킹용 추가 내장 메모리
int rotate = -1; //방향전환 비용 계산 변수
int rtcount = 0;
// 로봇 시작위치 찾기
for (int i = 0; i < map.width; i++)
{
for (int j = 0; j < map.height; j++)
{
if (map.map[i][j] == 2)
{
this->x = i;
this->y = j;
break;
}
}
}
// 1칸 이동
while (true)
{
map.map[this->x][this->y] = 3; // 청소 완료 표시
memory_calc += 1;
if (map.map[this->x + dx[LEFT]][this->y + dy[LEFT]] == 0)
{
this->x += dx[LEFT];
this->y += dy[LEFT];
map.map[this->x][this->y] = 2;
move_calc += 1;
back_path.push_back({ dx[LEFT] * (-1), dy[LEFT] * (-1) });
memory_calc += 1;
if (rotate != LEFT)
{
move_calc += 2;
time_cost++;
rtcount++;
}
rotate = LEFT;
}
else if (map.map[this->x + dx[UP]][this->y + dy[UP]] == 0)
{
this->x += dx[UP];
this->y += dy[UP];
map.map[this->x][this->y] = 2;
move_calc += 1;
back_path.push_back({ dx[UP] * (-1), dy[UP] * (-1) });
memory_calc += 1;
if (rotate != UP)
{
move_calc += 2;
time_cost++;
rtcount++;
}
rotate = UP;
}
else if (map.map[this->x + dx[RIGHT]][this->y + dy[RIGHT]] == 0)
{
this->x += dx[RIGHT];
this->y += dy[RIGHT];
map.map[this->x][this->y] = 2;
move_calc += 1;
back_path.push_back({ dx[RIGHT] * (-1), dy[RIGHT] * (-1) });
memory_calc += 1;
if (rotate != RIGHT)
{
move_calc += 2;
time_cost++;
rtcount++;
}
rotate = RIGHT;
}
else if (map.map[this->x + dx[DOWN]][this->y + dy[DOWN]] == 0 )
{
this->x += dx[DOWN];
this->y += dy[DOWN];
map.map[this->x][this->y] = 2;
move_calc += 1;
back_path.push_back({ dx[DOWN] * (-1), dy[DOWN] * (-1) });
memory_calc += 1;
if (rotate != DOWN)
{
move_calc += 2;
time_cost++;
rtcount++;
}
rotate = DOWN;
}
//사방이 벽 혹은 이미 청소했던 공간일 경우,저장해둔 가장 가까운 빈공간으로 이동
else
{
if (back_path.size() > 0)
{
int i = back_path.size() - 1;
int temp;
this->x += back_path[i].first;
this->y += back_path[i].second;
map.map[this->x][this->y] = 2;
move_calc += 1;
switch (back_path[i].first)
{
case 1:
temp = DOWN;
break;
case -1:
temp = UP;
break;
case 0:
if (back_path[i].second == 1)
temp = RIGHT;
else if (back_path[i].second == -1)
temp = LEFT;
break;
} //방향전환 계산을 위한 가상 설정
back_path.pop_back();
memory_calc += 1;
if (temp != rotate)
{
move_calc += 2;
time_cost++;
rtcount++;
}
rotate = temp;
}
}
time_cost++;
// 청소 과정 출력 (데모 동영상 용)
this->renderMap(map);
// 1번 : 시간제한을 두고 알고리즘을 수행
if (type == 1) {
if (time_limit <= time_cost) {
break;
}
}
coverage = 1;
// 커버리지 측정
for (int i = 0; i < map.width; i++)
for (int j = 0; j < map.height; j++)
if (map.map[i][j] == 3)
coverage++;
// 2번 : 시간제한을 두지않고 coverage 100%를 달성할 때까지 수행
if (type == 2) {
if (coverage / room_size == 1) {
break;
}
}
}
this->renderMap(map);
calc_cost = move_calc + memory_calc;
cout << "맵크기 커버리지 연산횟수 방향전환 소요시간" << endl;
// 맵 크기 출력
cout << map_size << " ";
// 청소 면적 출력
float coverage_rate = ((float)coverage / (float)room_size) * 100;
cout << fixed;
cout.precision(1);
cout << coverage_rate << " ";
// 연산 횟수 출력
cout << calc_cost << " ";
// 방향전환 횟수 출력
cout << rtcount << " ";
// 소요 시간 출력
cout << time_cost << endl;
}<file_sep>/README.md
# algo_team
알골 팀플
<file_sep>/Analysis_result/main.py
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
filepath = "result/"
filename1 = ["randomMove_type1.csv", "spinMove_type1.csv", "zigzagMove_type1.csv"]
filename2 = ["randomMove_type2.csv", "spinMove_type2.csv", "zigzagMove_type2.csv"]
run_type = 2
if __name__ == '__main__':
if run_type == 1:
rm = pd.read_csv(filepath + filename1[0])
sm = pd.read_csv(filepath + filename1[1])
zm = pd.read_csv(filepath + filename1[2])
# 시간 - 커버리지 그래프
'''time_rm = rm.groupby(['제한시간'], as_index=False).mean()
time_sm = sm.groupby(['제한시간'], as_index=False).mean()
time_zm = zm.groupby(['제한시간'], as_index=False).mean()
plt.plot(time_rm['제한시간'], time_rm['커버리지'], label='Random Move')
plt.plot(time_sm['제한시간'], time_sm['커버리지'], label='Spin Move')
plt.plot(time_zm['제한시간'], time_zm['커버리지'], label='Zigzag Move')
plt.legend(loc='best')
plt.xlabel('Time')
plt.ylabel('Coverage')
plt.show()'''
# 시간 - 연산 횟수 그래프
'''time_rm = rm.groupby(['제한시간'], as_index=False).mean()
time_sm = sm.groupby(['제한시간'], as_index=False).mean()
time_zm = zm.groupby(['제한시간'], as_index=False).mean()
plt.plot(time_rm['제한시간'], time_rm['연산횟수'], label='Random Move')
plt.plot(time_sm['제한시간'], time_sm['연산횟수'], label='Spin Move')
plt.plot(time_zm['제한시간'], time_zm['연산횟수'], label='Zigzag Move')
plt.legend(loc='best')
plt.xlabel('Time')
plt.ylabel('Cost')
plt.show()'''
# 시간 - 방향전환
time_rm = rm.groupby(['제한시간'], as_index=False).mean()
time_sm = sm.groupby(['제한시간'], as_index=False).mean()
time_zm = zm.groupby(['제한시간'], as_index=False).mean()
plt.plot(time_rm['제한시간'], time_rm['방향전환'], label='Random Move')
plt.plot(time_sm['제한시간'], time_sm['방향전환'], label='Spin Move')
plt.plot(time_zm['제한시간'], time_zm['방향전환'], label='Zigzag Move')
plt.legend(loc='best')
plt.xlabel('Time')
plt.ylabel('Direction Change')
plt.show()
else:
rm = pd.read_csv(filepath + filename2[0])
sm = pd.read_csv(filepath + filename2[1])
zm = pd.read_csv(filepath + filename2[2])
# 맵크기 - 시간
'''time_rm = rm.groupby(['맵크기'], as_index=False).mean()
time_sm = sm.groupby(['맵크기'], as_index=False).mean()
time_zm = zm.groupby(['맵크기'], as_index=False).mean()
plt.plot(time_rm['맵크기'], time_rm['소요시간'], label='Random Move')
plt.plot(time_sm['맵크기'], time_sm['소요시간'], label='Spin Move')
plt.plot(time_zm['맵크기'], time_zm['소요시간'], label='Zigzag Move')
plt.legend(loc='best')
plt.xlabel('Map Size')
plt.ylabel('Time')
plt.show()'''
# 시간 평균
# fig, ax = plt.subplots()
# ax.boxplot([rm['소요시간'], sm['소요시간'], zm['소요시간']])
# plt.xticks([1, 2, 3], ['Random Move', 'Spin Move', 'Zigzag Move'])
# plt.title('Time')
# plt.show()
# 시간 평균 랜덤 제외
# fig, ax = plt.subplots()
# ax.boxplot([sm['소요시간'], zm['소요시간']])
# plt.title('Time')
# plt.xticks([1, 2], ['Spin Move', 'Zigzag Move'])
# plt.show()
# 연산 평균
# fig, ax = plt.subplots()
# ax.boxplot([rm['연산횟수'], sm['연산횟수'], zm['연산횟수']])
# plt.xticks([1, 2, 3], ['Random Move', 'Spin Move', 'Zigzag Move'])
# plt.title('Compute Cost')
# plt.show()
# 연산 평균 랜덤 제외
fig, ax = plt.subplots()
ax.boxplot([sm['연산횟수'], zm['연산횟수']])
plt.title('Compute Cost')
plt.xticks([1, 2], ['Spin Move', 'Zigzag Move'])
plt.show()
<file_sep>/Project1/map.cpp
#include "map.h"
Map::Map(vector<vector<int> >& _map) {
width = _map.size();
height = _map[0].size();
map = new int* [width];
for (int i = 0; i < width; i++)
map[i] = new int[height];
for (int i = 0; i < width; i++) {
for (int j = 0; j < height; j++) {
map[i][j] = _map[i][j];
}
}
}<file_sep>/Project1/main.cpp
#include "robot.h"
#include "blueprint.h"
#include <vector>
using namespace std;
int main()
{
// map , type , time
Map m(blueprints[0]);
robot a;
a.zigzagMove(m, 1, 50);
}<file_sep>/Project1/map.h
#pragma once
#include <vector>
using namespace std;
class Map
{
public:
int width;
int height;
int** map;
Map(vector<vector<int>>& _map);
}; | 15d9c8a27da8a0be6b9bad0de33806d79c0cb03a | [
"Markdown",
"Python",
"C++"
] | 6 | C++ | Dongw1126/algo_team | cc0e0a0adb7de1646f141699c05a95d27acb831a | 36b7cfbbd1ef0ec81024987f1ed0f22ba59a75c6 |
refs/heads/master | <file_sep>package com.interview.car;
import static com.interview.car.Transmission.*;
public class Car {
private Engine engine;
private Transmission transmission;
private SteeringWheel steeringWheel;
private Brakes brakes;
private Speedometer speedometer;
public void turnRight() {
steeringWheel.turnClockwise();
}
public void turnLeft() {
steeringWheel.turnCounterClockwise();
}
public void driveForward() {
if(!steeringWheel.isStraight()) {
steeringWheel.straighten();
}
transmission.shift(Gear.DRIVE);
engine.setRpm(2000);
}
public void driveBackward() {
if(!steeringWheel.isStraight()) {
steeringWheel.straighten();
}
transmission.shift(Gear.REVERSE);
engine.setRpm(2000);
}
public void stop() {
engine.idle();
brakes.apply();
while(!speedometer.isStopped()) {
waitASecond();
}
}
public void park() {
stop();
transmission.shift(Gear.PARK);
}
public void accelerate() {
int rpms = engine.getRpms();
engine.setRpm(rpms + 500);
}
private void waitASecond() {
// wait for 1 second
}
}
<file_sep>package com.interview.car;
public class Transmission {
public enum Gear {
REVERSE, DRIVE, NEUTRAL, PARK;
}
private Gear gear;
public void shift(Gear gear) {
this.gear = gear;
}
}
<file_sep>package com.interview.car;
public class SteeringWheel {
private int currentDegrees;
public boolean isStraight() {
return currentDegrees == 0;
}
public void straighten() {
setDegrees(0);
}
public void turnClockwise() {
setDegrees(90);
}
public void turnCounterClockwise() {
setDegrees(-90);
}
private void setDegrees(int degrees) {
currentDegrees = degrees;
}
}
| af1e2d153fd1207ad4e7fb25d0bd6df993a77f30 | [
"Java"
] | 3 | Java | ckembel/interview | 1950d504f511ae5983a9c6c725a87ec8d53f88a9 | 65cfe0d27dc96b0e635a87e7955e64200c1d21de |
refs/heads/master | <file_sep>require('dotenv').config();
const server = require('../../server');
const request = require('supertest')(server);
let token;
beforeAll(done => {
request
.post('/api/register')
.send({
first_name: 'Bob',
last_name: 'Robert',
email: '<EMAIL>',
password: '<PASSWORD>'
})
.then(res => {
request
.post('/api/login')
.send({
email: '<EMAIL>',
password: '<PASSWORD>'
})
.end((err, res) => {
token = res.body.token;
done();
});
});
});
describe('Books', () => {
it('Should require authorization', () => {
return request.get('/api/books').expect(401);
});
it('Should return an array of books when header is set with token', () => {
return request
.get('/api/books')
.set('Authorization', token)
.expect(200);
});
it('Should return an object of an individual book when the id is passed in the url', () => {
return request
.get('/api/books/1')
.set('Authorization', token)
.expect(200);
});
it('Should return an error if the book is not available', () => {
return request
.get('/api/books/1000')
.set('Authorization', token)
.expect(404);
});
it('Should delete the book with that id', () => {
return request
.delete('/api/books/8')
.set('Authorization', token)
.expect(200);
});
});
describe('Shelf', () => {
it('Users are add a book to shelf', () => {
return request
.post('/api/books/1/shelf')
.send({
user_id: 1
})
.set('Authorization', token)
.expect(201)
.expect('Content-Type', /json/);
});
});
<file_sep>require('dotenv').config();
const server = require('../../server');
const request = require('supertest')(server);
let token;
beforeAll(done => {
request
.post('/api/login')
.send({
email: '<EMAIL>',
password: '<PASSWORD>'
})
.end((err, res) => {
token = res.body.token;
done();
});
});
describe('Reviews', () => {
it('Should require authorization', () => {
return request.get('/api/user/1/reviews').expect(401);
});
it('Should return an array of user reviews when header is set with token', () => {
return request
.post('/api/books/2/review')
.set('Authorization', token)
.send({
review: 'Awesome read!',
reviewer: 1,
ratings: 5
})
.then(res => {
return request
.get('/api/user/1/reviews')
.set('Authorization', token)
.expect(200);
});
});
it('Should return an object of review when user post a review', () => {
return request
.post('/api/books/2/review')
.set('Authorization', token)
.send({
review: 'Awesome read!',
reviewer: 2,
ratings: 5
})
.expect(201);
});
it('Should return an object of review when user gets a review by ID', () => {
return request
.get('/api/reviews/1')
.set('Authorization', token)
.expect(200);
});
it('Should return an error if the review does not exist', () => {
return request
.get('/api/reviews/1000')
.set('Authorization', token)
.expect(404);
});
it('Should return an object of review when user edits a review', () => {
return request
.put('/api/reviews/1')
.set('Authorization', token)
.send({
review: 'Awesome read! Really understood the subject',
reviewer: 2,
ratings: 5
})
.expect(200);
});
it('Should return an object of deleted review when user deletes a review', () => {
return request
.delete('/api/reviews/1')
.set('Authorization', token)
.expect(200);
});
});
| b2fb6589587a79d4f0e5c87094dfd92d1a658261 | [
"JavaScript"
] | 2 | JavaScript | shahidul56/Back-End | 20ff7cdc0c6f275ddbe8394279b921e904535b3f | e0c90c815d591545c883ca733b392ced2a984cff |
refs/heads/master | <repo_name>mitchneu/BBjGridExWidget<file_sep>/docs/Demo.bbj.md
Demo.bbj
========
A SQL Database Browser with BBjGridExWidget
First of all, add a use statement
```
use ::BBjGridExWidget/BBjGridExWidget.bbj::BBjGridExWidget
```
```
use com.basiscomponents.bc.SqlQueryBC
? 'HIDE'
declare auto BBjTopLevelWindow wnd!
declare auto BBjListButton lb_db!
declare auto BBjListButton lb_tbl!
declare auto BBjToolButton btn_fit!
```
Let's always declare our Grid Widget:
```
declare BBjGridExWidget grid!
```
```
wnd! = BBjAPI().openSysGui("X0").addWindow(10,10,800,600,"BBj Grid Ex Demo")
wnd!.addStaticText(200,5,10,60,25,"Database:")
lb_db! = wnd!.addListButton(201,65,5,160,250,"")
wnd!.addStaticText(202,270,10,60,25,"Table:")
lb_tbl! = wnd!.addListButton(203,310,5,160,250,"")
btn_query! = wnd!.addButton(204,500,5,100,25,"Query")
btn_fit! = wnd!.addToolButton(205,765,5,25,25,"[/]")
grid! = new BBjGridExWidget(wnd!,100,0,35,800,563)
lb_db! .setCallback(BBjAPI.ON_LIST_SELECT,"loadTables")
btn_query! .setCallback(BBjAPI.ON_BUTTON_PUSH,"doQuery")
wnd! .setCallback(BBjAPI.ON_CLOSE,"byebye")
wnd! .setCallback(BBjAPI.ON_RESIZE,"resize")
btn_fit!.setToggleable(1)
btn_fit!.setCallback(BBjAPI.ON_TOOL_BUTTON_PUSH,"toggleFitToGrid")
if (info(3,6)<>"5") then
wnd!.setCallback(BBjAPI.ON_KEYPRESS,"onWinKeypress")
fi
gosub loadDatabases
gosub doQuery
rem disable the selection by default to avoid a backdoor if this demo is installed
rem enable to get the full db browsing functionality
rem lb_db!.setEnabled(0)
process_events
loadData:
return
byebye:
bye
resize:
ev! = BBjAPI().getLastEvent()
grid!.setSize(ev!.getWidth(),ev!.getHeight()-35)
return
loadDatabases:
j=0
i=0
x$ = sqllist(-1)
while x$>""
db$=x$(1,pos($0a$=x$)-1)
x$=x$(pos($0a$=x$)+1)
lb_db!.addItem(db$)
if db$="ChileCompany" then
j=i
fi
i=i+1
wend
lb_db!.selectIndex(j)
gosub loadTables
return
loadTables:
lb_tbl!.removeAllItems()
db$ = lb_db!.getSelectedItem()
sqlopen (1)db$
x$=sqltables(1)
sqlclose(1)
j=0
i=0
while x$>""
tbl$=x$(1,pos($0a$=x$)-1)
x$=x$(pos($0a$=x$)+1)
lb_tbl!.addItem(tbl$)
if tbl$="CUSTOMER" then
j=i
fi
i=i+1
wend
lb_tbl!.selectIndex(j)
return
doQuery:
db$ = lb_db!.getSelectedItem()
tbl$ = lb_tbl!.getSelectedItem()
if (db$>"" and tbl$>"") then
```
note that up to BBj 17, the BBjAPI().getJDBCConnection could not be used with basiscomponents:
```
if rev<"REV 17.10" then
url! = "jdbc:basis:localhost?DATABASE=ChileCompany&SSL=false"
con! = java.sql.DriverManager.getConnection(url!, "admin", "admin123")
else
bc! = new SqlQueryBC(BBjAPI().getJDBCConnection(db$))
fi
```
That's all we need to get a result set that works with the grid:
```
rs! = bc!.retrieve("SELECT * FROM "+tbl$)
```
...and set it as data:
```
grid!.setData(rs!)
```
```
fi
return
```
this is toggling the "fit to grid" functionality in the widget:
```
toggleFitToGrid:
declare auto BBjToolButtonPushEvent toogle_ev!
toggle_ev! = BBjAPI().getLastEvent()
if btn_fit!.isSelected() then
grid!.setFitToGrid(1)
else
grid!.setFitToGrid(0)
fi
return
```
Hidden Easter Egg: get the Console in the Java FX WebView:
```
onWinKeypress:
declare auto BBjKeypressEvent key_ev!
key_ev! = BBjAPI().getLastEvent()
if key_ev!.getKeyCode() = 342 then
grid!.showDeveloperConsole()
fi
return
```<file_sep>/js/src/api/rows.js
/*
* This file is part of the grid project
* (c) <NAME> <<EMAIL>>
*
* For the full copyright and license information, please view the LICENSE
* file that was distributed with this source code.
*/
export function gw_setQuickFilter(filter) {
gw_options.api.setQuickFilter(filter);
}
export function gw_expandAll() {
gw_options.api.expandAll();
}
export function gw_collapseAll() {
gw_options.api.collapseAll();
}
export function gw_setVisibleRow(index, position) {
gw_options.api.ensureIndexVisible(index, position);
}
export function gw_navigateToNextRow(params) {
let previousCell = params.previousCellDef;
let suggestedNextCell = params.nextCellDef;
const KEY_UP = 38;
const KEY_DOWN = 40;
const KEY_LEFT = 37;
const KEY_RIGHT = 39;
switch (params.key) {
case KEY_DOWN:
previousCell = params.previousCellDef;
// set selected cell on current cell + 1
gw_options.api.forEachNode((node) => {
if (previousCell.rowIndex + 1 === node.rowIndex) {
node.setSelected(true);
}
});
return suggestedNextCell;
case KEY_UP:
previousCell = params.previousCellDef;
// set selected cell on current cell - 1
gw_options.api.forEachNode((node) => {
if (previousCell.rowIndex - 1 === node.rowIndex) {
node.setSelected(true);
}
});
return suggestedNextCell;
case KEY_LEFT:
case KEY_RIGHT:
return suggestedNextCell;
default:
throw new Error("You have super strange keyboard");
}
}
export function gw_getRowNodeId(data) {
return data[gw_options.__getRowNodeId];
}
export function gw_getNodeChildDetails(rowItem) {
const key = rowItem[gw_options.__getParentNodeId];
if (rowItem.__node__children) {
return {
group: true,
expanded: false,
// provide ag-Grid with the children of this group
children: rowItem.__node__children,
// the key is used by the default group cellRenderer
key: key ? key : -1
};
} else {
return false;
}
}
export function gw_setRowsData(json) {
gw_options.api.setRowData(json);
gw_options.rowData = json;
gw_options.api.refreshClientSideRowModel('group');
}
export function gw_setRowData(row) {
console.log(row)
gw_options.api.updateRowData({update: [row]});
gw_options.api.refreshClientSideRowModel('group');
}
export function gw_removeRows(indexes) {
let items = [];
indexes.forEach( index => {
items.push(gw_options.api.getRowNode(index).data);
});
gw_options.api.updateRowData({remove: items});
gw_options.api.refreshClientSideRowModel('group');
}
export function gw_addRows(index,rows) {
gw_options.api.updateRowData({add: rows, addIndex: index});
gw_options.api.refreshClientSideRowModel('group');
}
<file_sep>/js/src/index.js
/*
* This file is part of the grid project
* (c) <NAME> <<EMAIL>>
*
* For the full copyright and license information, please view the LICENSE
* file that was distributed with this source code.
*/
import 'expose-loader?jss!../node_modules/jss/jss.js';
import 'expose-loader?Basis.AgGridComponents!../node_modules/ag-grid-components/dist/agc-basic.bundle.js';
require('ag-grid/dist/styles/ag-grid.css');
require('ag-grid/dist/styles/theme-fresh.css');
require('ag-grid/dist/styles/theme-dark.css');
require('ag-grid/dist/styles/theme-blue.css');
require('ag-grid/dist/styles/theme-material.css');
require('ag-grid/dist/styles/theme-bootstrap.css');
require('ag-grid/dist/styles/ag-theme-fresh.css');
require('ag-grid/dist/styles/ag-theme-dark.css');
require('ag-grid/dist/styles/ag-theme-blue.css');
require('ag-grid/dist/styles/ag-theme-material.css');
require('ag-grid/dist/styles/ag-theme-bootstrap.css');
require('ag-grid/dist/styles/ag-theme-balham.css');
require('ag-grid/dist/styles/ag-theme-balham-dark.css');
export * from './utilities.js';
export * from './events.js';
export * from './api.js';
export * from './init.js';
<file_sep>/js/vendor/Datejs/test/partial/index.js
Date.Specification = new Specification({
'Partial Date: No Year': {
setup: function() {
this.today = new Date().clearTime();
this.baseline = [];
this.baseline[0] = this.today.clone().set( { month: 6, day: 1 } )
this.baseline[1] = this.today.clone().set( { month: 6, day: 1, hour: 22 } );
this.baseline[2] = this.today.clone().set( { month: 6, day: 1, hour: 22, minute: 30 } );
this.baseline[3] = this.today.clone().set( { month: 6, day: 15 } )
this.baseline[4] = this.today.clone().set( { month: 6, day: 15, hour: 6 } );
this.baseline[5] = this.today.clone().set( { month: 6, day: 15, hour: 6, minute: 45 } );
},
'7/1 10 PM': {
run: function() { this.date = Date.parse('7/1 10 PM') },
assert: function() { return this.baseline[1].compareTo( this.date ) == 0 }
},
'07/01 10 PM': {
run: function() { this.date = Date.parse('07/01 10 PM') },
assert: function() { return this.baseline[1].compareTo( this.date ) == 0 }
},
'07/01 10 PM': {
run: function() { this.date = Date.parse('07/01 10 PM') },
assert: function() { return this.baseline[1].compareTo( this.date ) == 0 }
},
'7/1 10 PM': {
run: function() { this.date = Date.parse('7/1 10 PM') },
assert: function() { return this.baseline[1].compareTo( this.date ) == 0 }
},
'7/15 6 AM': {
run: function() { this.date = Date.parse('7/15 6 AM') },
assert: function() { return this.baseline[4].compareTo( this.date ) == 0 }
},
'07/15 6 AM': {
run: function() { this.date = Date.parse('07/15 6 AM') },
assert: function() { return this.baseline[4].compareTo( this.date ) == 0 }
},
'07/15 6 AM': {
run: function() { this.date = Date.parse('07/15 6 AM') },
assert: function() { return this.baseline[4].compareTo( this.date ) == 0 }
},
'7/15 6 AM': {
run: function() { this.date = Date.parse('7/15 6 AM') },
assert: function() { return this.baseline[4].compareTo( this.date ) == 0 }
},
'7/1 10pm': {
run: function() { this.date = Date.parse('7/1 10pm') },
assert: function() { return this.baseline[1].compareTo( this.date ) == 0 }
},
'07/01 10pm': {
run: function() { this.date = Date.parse('07/01 10pm') },
assert: function() { return this.baseline[1].compareTo( this.date ) == 0 }
},
'07/01 10pm': {
run: function() { this.date = Date.parse('07/01 10pm') },
assert: function() { return this.baseline[1].compareTo( this.date ) == 0 }
},
'7/1 10pm': {
run: function() { this.date = Date.parse('7/1 10pm') },
assert: function() { return this.baseline[1].compareTo( this.date ) == 0 }
},
'7/15 6am': {
run: function() { this.date = Date.parse('7/15 6am') },
assert: function() { return this.baseline[4].compareTo( this.date ) == 0 }
},
'07/15 6am': {
run: function() { this.date = Date.parse('07/15 6am') },
assert: function() { return this.baseline[4].compareTo( this.date ) == 0 }
},
'07/15 6am': {
run: function() { this.date = Date.parse('07/15 6am') },
assert: function() { return this.baseline[4].compareTo( this.date ) == 0 }
},
'7/15 6am': {
run: function() { this.date = Date.parse('7/15 6am') },
assert: function() { return this.baseline[4].equals( this.date ) }
},
'7/1 10:30 PM': {
run: function() { this.date = Date.parse('7/1 10:30 PM') },
assert: function() { return this.baseline[2].equals( this.date ) }
},
'07/01 10:30 PM': {
run: function() { this.date = Date.parse('07/01 10:30 PM') },
assert: function() { return this.baseline[2].equals( this.date ) }
},
'07/01 10:30 PM': {
run: function() { this.date = Date.parse('07/01 10:30 PM') },
assert: function() { return this.baseline[2].equals( this.date ) }
},
'7/1 10:30 PM': {
run: function() { this.date = Date.parse('7/1 10:30 PM') },
assert: function() { return this.baseline[2].equals( this.date ) }
},
'7/15 6:45 AM': {
run: function() { this.date = Date.parse('7/15 6:45 AM') },
assert: function() { return this.baseline[5].equals( this.date ) }
},
'07/15 6:45 AM': {
run: function() { this.date = Date.parse('07/15 6:45 AM') },
assert: function() { return this.baseline[5].equals( this.date ) }
},
'07/15 6:45 AM': {
run: function() { this.date = Date.parse('07/15 6:45 AM') },
assert: function() { return this.baseline[5].equals( this.date ) }
},
'7/15 6:45 AM': {
run: function() { this.date = Date.parse('7/15 6:45 AM') },
assert: function() { return this.baseline[5].equals( this.date ) }
},
'7/1 10:30p': {
run: function() { this.date = Date.parse('7/1 10:30p') },
assert: function() { return this.baseline[2].equals( this.date ) }
},
'07/01 10:30p': {
run: function() { this.date = Date.parse('07/01 10:30p') },
assert: function() { return this.baseline[2].equals( this.date ) }
},
'07/01 10:30p': {
run: function() { this.date = Date.parse('07/01 10:30p') },
assert: function() { return this.baseline[2].equals( this.date ) }
},
'7/1 10:30p': {
run: function() { this.date = Date.parse('7/1 10:30p') },
assert: function() { return this.baseline[2].equals( this.date ) }
},
'7/15 6:45a': {
run: function() { this.date = Date.parse('7/15 6:45a') },
assert: function() { return this.baseline[5].equals( this.date ) }
},
'07/15 6:45a': {
run: function() { this.date = Date.parse('07/15 6:45a') },
assert: function() { return this.baseline[5].equals( this.date ) }
},
'07/15 6:45a': {
run: function() { this.date = Date.parse('07/15 6:45a') },
assert: function() { return this.baseline[5].equals( this.date ) }
},
'7/15 6:45a': {
run: function() { this.date = Date.parse('7/15 6:45a') },
assert: function() { return this.baseline[5].equals( this.date ) }
},
'1-Jul': {
run: function() { this.date = Date.parse('1-Jul') },
assert: function() { return this.baseline[0].equals( this.date ) }
},
'1-July': {
run: function() { this.date = Date.parse('1-July') },
assert: function() { return this.baseline[0].equals( this.date ) }
},
'01-Jul': {
run: function() { this.date = Date.parse('01-Jul') },
assert: function() { return this.baseline[0].equals( this.date ) }
},
'01-July': {
run: function() { this.date = Date.parse('01-July') },
assert: function() { return this.baseline[0].equals( this.date ) }
},
'15-Jul': {
run: function() { this.date = Date.parse('15-Jul') },
assert: function() { return this.baseline[3].equals( this.date ) }
},
'15-July': {
run: function() { this.date = Date.parse('15-July') },
assert: function() { return this.baseline[3].equals( this.date ) }
},
'July 1': {
run: function() { this.date = Date.parse('July 1') },
assert: function() { return this.baseline[0].equals( this.date ) }
},
'Jul 1': {
run: function() { this.date = Date.parse('Jul 1') },
assert: function() { return this.baseline[0].equals( this.date ) }
},
'July 01': {
run: function() { this.date = Date.parse('July 01') },
assert: function() { return this.baseline[0].equals( this.date ) }
},
'Jul 01': {
run: function() { this.date = Date.parse('Jul 01') },
assert: function() { return this.baseline[0].equals( this.date ) }
},
'July 15': {
run: function() { this.date = Date.parse('July 15') },
assert: function() { return this.baseline[3].equals( this.date ) }
},
'Jul 15': {
run: function() { this.date = Date.parse('Jul 15') },
assert: function() { return this.baseline[3].equals( this.date ) }
},
'July 1st': {
run: function() { this.date = Date.parse('July 1st') },
assert: function() { return this.baseline[0].equals( this.date ) }
},
'July 2nd': {
run: function() { this.date = Date.parse('July 2nd') },
assert: function() { return this.baseline[0].addDays(1).equals( this.date ) }
},
'July 3rd': {
run: function() { this.date = Date.parse('July 3rd') },
assert: function() { return this.baseline[0].addDays(2).equals( this.date ) }
},
'July 4th': {
run: function() { this.date = Date.parse('July 4th') },
assert: function() { return this.baseline[0].addDays(3).equals( this.date ) }
},
'7/1': {
run: function() { this.date = Date.parse('7/1') },
assert: function() { return this.baseline[0].equals( this.date ) }
},
'07/01': {
run: function() { this.date = Date.parse('07/01') },
assert: function() { return this.baseline[0].equals( this.date ) }
},
'7/15': {
run: function() { this.date = Date.parse('7/15') },
assert: function() { return this.baseline[3].equals( this.date ) }
},
'07/15': {
run: function() { this.date = Date.parse('07/15') },
assert: function() { return this.baseline[3].equals( this.date ) }
}
},
'No Day: Default To First Of Month': {
setup: function() {
this.baseline = new Date(2004,6,1);
},
'July 2004': {
run: function() { this.date = Date.parse('July 2004') },
assert: function() { return this.baseline.equals( this.date ) }
},
'Jul 2004': {
run: function() { this.date = Date.parse('Jul 2004') },
assert: function() { return this.baseline.equals( this.date ) }
},
'7/2004': {
run: function() { this.date = Date.parse('7/2004') },
assert: function() { return this.baseline.equals( this.date ) }
},
'7 2004': {
run: function() { this.date = Date.parse('7 2004') },
assert: function() { return this.baseline.equals( this.date ) }
},
'7-2004': {
run: function() { this.date = Date.parse('7-2004') },
assert: function() { return this.baseline.equals( this.date ) }
},
'2004 7': {
run: function() { this.date = Date.parse('2004 7') },
assert: function() { return this.baseline.equals( this.date ) }
},
'2004-7': {
run: function() { this.date = Date.parse('2004-7') },
assert: function() { return this.baseline.equals( this.date ) }
},
'2004/7': {
run: function() { this.date = Date.parse('2004/7') },
assert: function() { return this.baseline.equals( this.date ) }
}
},
'No Year or Month': {
setup: function() {
//default to current Year and Month
this.baseline = new Date(2004,6,1);
this.today = Date.today();
this.now = Date.now();
},
'1': {
run: function() { this.date = Date.parse('1') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 1).equals( this.date ) }
},
'5': {
run: function() { this.date = Date.parse('5') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 5).equals( this.date ) }
},
'12': {
run: function() { this.date = Date.parse('12') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 12).equals( this.date ) }
},
'13': {
run: function() { this.date = Date.parse('13') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 13).equals( this.date ) }
},
'15': {
run: function() { this.date = Date.parse('15') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 15).equals( this.date ) }
},
'28': {
run: function() { this.date = Date.parse('28') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 28).equals( this.date ) }
},
'29 : Returns null if current month does not have 29 days': {
run: function() { },
assert: function() {
this.date = Date.parse('29');
if( this.date != null && Date.today().getDaysInMonth() >= 29 ) {
return true;
}
if( Date.today().getDaysInMonth() < 29 && this.date == null ) {
return true;
}
return false;
}
},
'30 : Returns null if current month does not have 30 days': {
run: function() { },
assert: function() {
this.date = Date.parse('30');
if( this.date != null && Date.today().getDaysInMonth() >= 30 ) {
return true;
}
if( Date.today().getDaysInMonth() < 30 && this.date == null ) {
return true;
}
return false;
}
},
'31 : Returns null if current month does not have 31 days': {
run: function() { },
assert: function() {
this.date = Date.parse('31');
if( this.date != null && Date.today().getDaysInMonth() == 31 ) {
return true;
}
if( Date.today().getDaysInMonth() < 31 && this.date == null ) {
return true;
}
return false;
}
},
'32 : Year 1932': {
run: function() { },
assert: function() {
return Date.today().set( { year: 1932 } ).equals( Date.parse('32') );
}
},
'1st': {
run: function() { this.date = Date.parse('1st') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 1).equals( this.date ) }
},
'2nd': {
run: function() { this.date = Date.parse('2nd') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 2).equals( this.date ) }
},
'3rd': {
run: function() { this.date = Date.parse('3rd') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 3).equals( this.date ) }
},
'5th': {
run: function() { this.date = Date.parse('5th') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 5).equals( this.date ) }
},
'12th': {
run: function() { this.date = Date.parse('12th') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 12).equals( this.date ) }
},
'13th': {
run: function() { this.date = Date.parse('13th') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 13).equals( this.date ) }
},
'15th': {
run: function() { this.date = Date.parse('15th') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 15).equals( this.date ) }
},
'28th': {
run: function() { this.date = Date.parse('28th') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 28).equals( this.date ) }
},
'29th : Returns null if current month does not have 29 days': {
run: function() { },
assert: function() {
this.date = Date.parse('29th');
if( this.date != null && Date.today().getDaysInMonth() >= 29 ) {
return true;
}
if( Date.today().getDaysInMonth() < 29 && this.date == null ) {
return true;
}
return false;
}
},
'30th : Returns null if current month does not have 30 days': {
run: function() { },
assert: function() {
this.date = Date.parse('30th');
if( this.date != null && Date.today().getDaysInMonth() >= 30 ) {
return true;
}
if( Date.today().getDaysInMonth() < 30 && this.date == null ) {
return true;
}
return false;
}
},
'31st : Returns null if current month does not have 31 days': {
run: function() { },
assert: function() {
this.date = Date.parse('31st');
if( this.date != null && Date.today().getDaysInMonth() == 31 ) {
return true;
}
if( Date.today().getDaysInMonth() < 31 && this.date == null ) {
return true;
}
return false;
}
},
'1 st': {
run: function() { this.date = Date.parse('1 st') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 1).equals( this.date ) }
},
' 2 nd': {
run: function() { this.date = Date.parse('2 nd') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 2).equals( this.date ) }
},
'3 rd': {
run: function() { this.date = Date.parse('3 rd') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 3).equals( this.date ) }
},
'5 th': {
run: function() { this.date = Date.parse('5 th') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 5).equals( this.date ) }
},
'12 th': {
run: function() { this.date = Date.parse('12 th') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 12).equals( this.date ) }
},
'13 th': {
run: function() { this.date = Date.parse('13 th') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 13).equals( this.date ) }
},
'15 th': {
run: function() { this.date = Date.parse('15 th') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 15).equals( this.date ) }
},
'28 th': {
run: function() { this.date = Date.parse('28 th') },
assert: function() { return new Date(this.today.getFullYear(), this.today.getMonth(), 28).equals( this.date ) }
},
'29 th : Returns null if current month does not have 29 days': {
run: function() { },
assert: function() {
this.date = Date.parse('29 th');
if( this.date != null && Date.today().getDaysInMonth() >= 29 ) {
return true;
}
if( Date.today().getDaysInMonth() < 29 && this.date == null ) {
return true;
}
return false;
}
},
'30 th : Returns null if current month does not have 30 days': {
run: function() { },
assert: function() {
this.date = Date.parse('30 th');
if( this.date != null && Date.today().getDaysInMonth() >= 30 ) {
return true;
}
if( Date.today().getDaysInMonth() < 30 && this.date == null ) {
return true;
}
return false;
}
},
'31 st : Returns null if current month does not have 31 days': {
run: function() { },
assert: function() {
this.date = Date.parse('31 st');
if( this.date != null && Date.today().getDaysInMonth() == 31 ) {
return true;
}
if( Date.today().getDaysInMonth() < 31 && this.date == null ) {
return true;
}
return false;
}
}
}
});
$(document).ready( function() { Date.Specification.validate().show() } );<file_sep>/js/src/api/state.js
export function gw_setState(state) {
gw_options.columnApi.setColumnState(state);
}
export function gw_getState() {
const state = gw_options.columnApi.getColumnState();
try {
return JSON.stringify(state);
} catch (e) {
console.warn('Failed to parse state', e);
}
}
<file_sep>/README.md
A Grid Widget Plugin for BBj
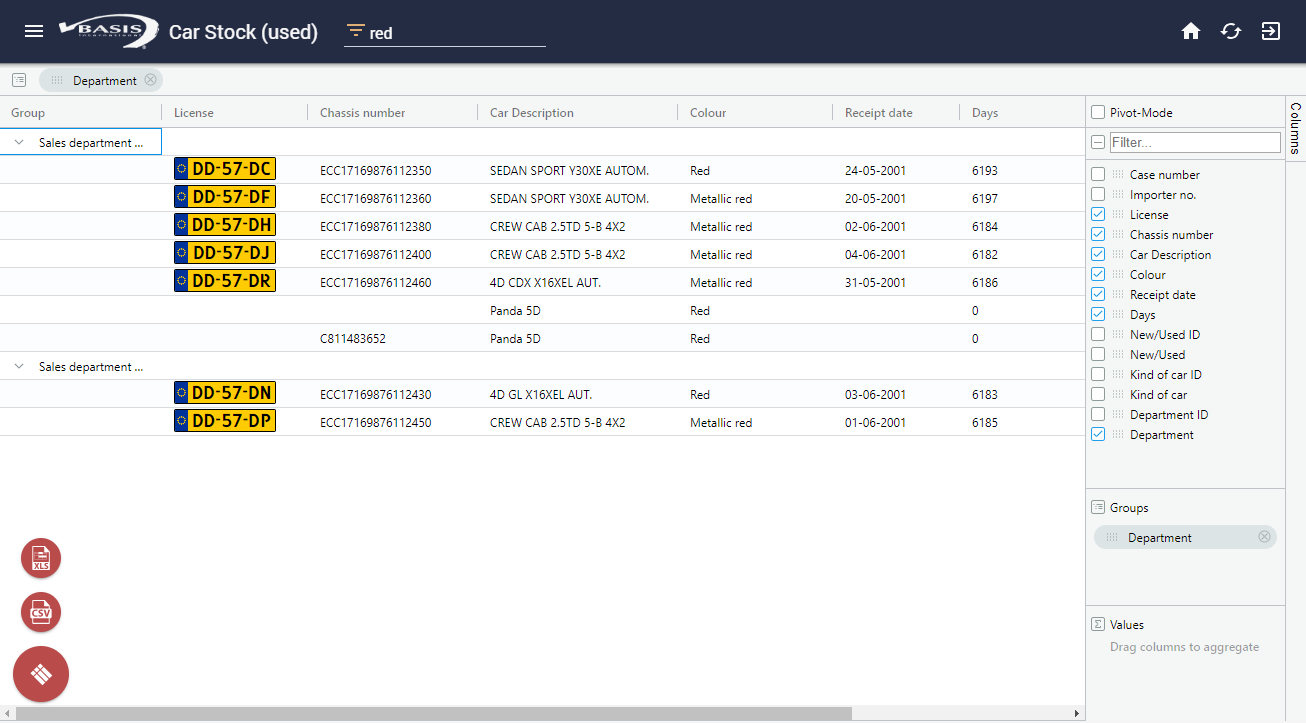
Features:
---------
- Column Ordering, Resizing (Drag & Drop)
- Filtering
- Tree
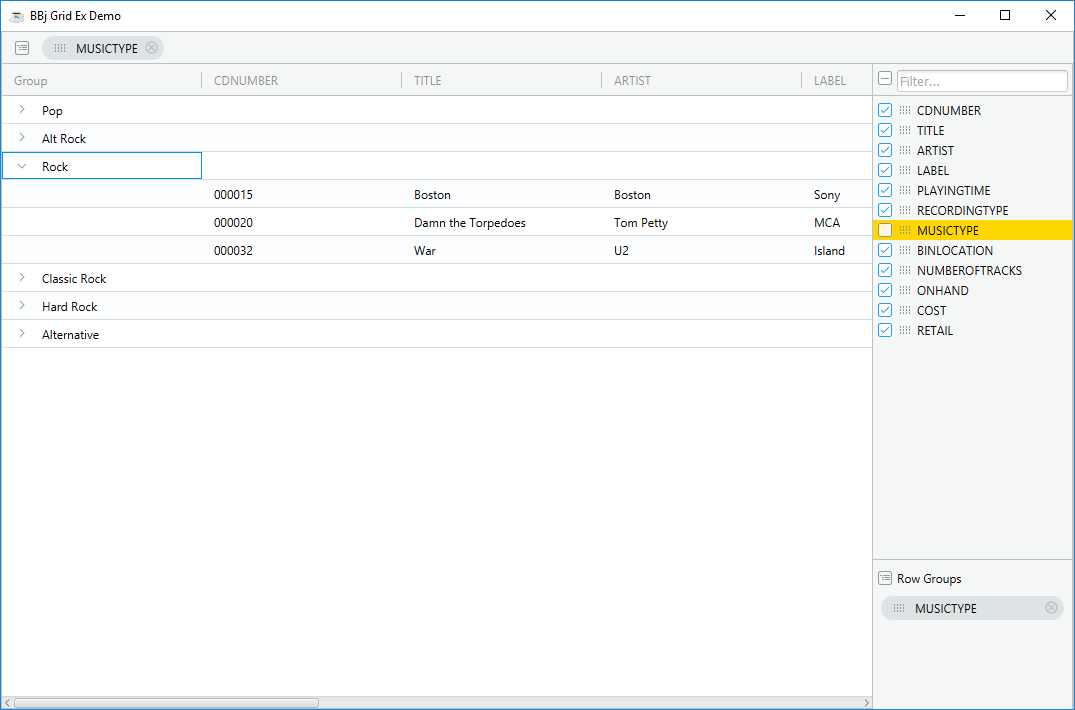
Documentation:
--------------
[Pages](https://bbj-plugins.github.io/BBjGridExWidget/)
[JavaDoc](https://bbj-plugins.github.io/BBjGridExWidget/javadoc)
[Roadmap](https://docs.google.com/spreadsheets/d/14klkzsAGiuStRJulEWxxF1YVrDEa04P26te-jWRnDCc/edit?usp=sharing)
<file_sep>/js/src/api/cells.js
/*
* This file is part of the grid project
* (c) <NAME> <<EMAIL>>
*
* For the full copyright and license information, please view the LICENSE
* file that was distributed with this source code.
*/
export function gw_startEditingCell(row, colKey, key, char) {
gw_options.api.setFocusedCell(Number(row), colKey);
gw_options.api.startEditingCell({
rowIndex: Number(row),
colKey: colKey,
keyPress: Number(key),
charPress: char
});
}
export function gw_stopEditing(cancel) {
gw_options.api.stopEditing(cancel);
}
export function gw_editNextCell(){
gw_options.api.tabToNextCell();
};
export function gw_editPreviousCell() {
gw_options.api.tabToPreviousCell();
}
export function gw_cellStyler(params) {
let cdef = params.column.colDef.cellStyleDefaults || {};
var meta = {};
if (params.data && params.data.meta)
meta = params.data.meta[params.column.colId] || {};
let colStyle = {};
if (meta["FGCOLOR"])
colStyle.color = meta["FGCOLOR"];
else
if (cdef["FGCOLOR"])
colStyle["color"] = cdef["FGCOLOR"];
if (meta["BGCOLOR"])
colStyle["background-color"] = meta["BGCOLOR"];
else
if (cdef["BGCOLOR"])
colStyle["background-color"] = cdef["BGCOLOR"];
if (meta["ALIGN"])
colStyle["text-align"] = meta["ALIGN"];
else
if (cdef["ALIGN"])
colStyle["text-align"] = cdef["ALIGN"];
if (colStyle.color || colStyle["background-color"] || colStyle["text-align"]) {
return colStyle;
}
else {
return null;
}
}
export function gw_getCellClass(params) {
const field = params.colDef.field;
if(params.data && params.data.hasOwnProperty('meta') ) {
return (
params.data.meta.hasOwnProperty(field) &&
params.data.meta[field].hasOwnProperty('CELL_CLASS')
) ? params.data.meta[field].CELL_CLASS : `CELL_CLASS_${field}`
}
}
<file_sep>/js/src/events/selections.js
/*
* This file is part of the grid project
* (c) <NAME> <<EMAIL>>
*
* For the full copyright and license information, please view the LICENSE
* file that was distributed with this source code.
*/
export let gw_selectedRowsStack = [];
export function gw_onRowDoubleClicked(e) {
const node = gw_parseNodeFromEvent(e);
if (node) {
gw_sendEvent({
'type': 'grid-row-doubleclick',
'detail': [[node]]
});
}
}
export function gw_onRowSelected(e) {
gw_selectedRowsStack.push(e);
}
export function gw_onSelectionChanged() {
let details = [];
gw_selectedRowsStack.forEach(function (e) {
const detail = gw_parseNodeFromEvent(e);
if (detail) details.push(detail);
});
if (details.length) {
gw_selectedRowsStack = [];
gw_sendEvent({
'type': 'grid-row-select',
'detail': [details]
});
}
}
export function gw_onCellClickEvent(e) {
const parsed = gw_parseNodeFromEvent(e);
if (parsed) {
gw_sendEvent({
'type': e.type,
'detail': [[
{ row: parsed, value: gw_escape(e.value), column: e.column.colId }
]]
});
}
}
<file_sep>/js/src/events/utilities.js
/*
* This file is part of the grid project
* (c) <NAME> <<EMAIL>>
*
* For the full copyright and license information, please view the LICENSE
* file that was distributed with this source code.
*/
export function gw_postEvent(ev) {
window.basisDispatchCustomEvent(ev, ev.payload);
}
export function gw_sendEvent(payload) {
const div = gw_getDocument().getElementById('eventTransporterDiv');
const event = new CustomEvent('click');
event.payload = payload;
div.dispatchEvent(event);
}
export function gw_parseNodeFromEvent(e) {
if (true === e.node.group) return false; // we do not manage groups
let detail = {
id: !gw_options.__getRowNodeId && e.node.data.__ROW_INDEX ? e.node.data.__ROW_INDEX : e.node.id,
childIndex: e.node.childIndex,
selected: Boolean(e.node.selected),
index: e.node.data.__ROW_INDEX ? e.node.data.__ROW_INDEX : "",
parentKey: e.node.hasOwnProperty('parent') && e.node.parent.hasOwnProperty('key') ? e.node.parent.key : '',
};
return detail;
}
<file_sep>/js/src/api/toolpanel.js
/*
* This file is part of the grid project
* (c) <NAME> <<EMAIL>>
*
* For the full copyright and license information, please view the LICENSE
* file that was distributed with this source code.
*/
export function gw_showToolPanel(show) {
gw_options.api.showToolPanel(Boolean(show));
}
export function gw_setFunctionsReadOnly(readonly) {
gw_options.api.setFunctionsReadOnly(Boolean(readonly));
}
export function gw_getToolPanelClass(params) {
const def = params.colDef;
if (
gw_meta.hasOwnProperty(def.field) &&
gw_meta[def.field].hasOwnProperty('TOOLPANEL_CLASS')
) {
return gw_meta[def.field].TOOLPANEL_CLASS;
}
}
<file_sep>/js/src/api/columns.js
/*
* This file is part of the grid project
* (c) <NAME> <<EMAIL>>
*
* For the full copyright and license information, please view the LICENSE
* file that was distributed with this source code.
*/
export function gw_sizeColumnsToFit() {
gw_options.api.sizeColumnsToFit();
}
export function gw_setSelectedRows(rows) {
gw_options.api.forEachNodeAfterFilterAndSort(function (node) {
if (rows.indexOf(node.rowIndex) > -1) {
node.setSelected(true);
node.expanded = true;
}
}.bind(this));
gw_options.api.onGroupExpandedOrCollapsed();
}
export function gw_selectAll(filtered) {
if (1 === filtered) {
gw_options.api.selectAllFiltered();
} else {
gw_options.api.selectAll();
}
}
export function gw_deselectAll(filtered) {
if (1 === filtered) {
gw_options.api.deselectAllFiltered();
} else {
gw_options.api.deselectAll();
}
}
export function gw_setVisibleColumn(columnId) {
gw_options.api.ensureColumnVisible(columnId);
}
export function gw_setColumnWidth(columnid, width) {
gw_options.columnApi.setColumnWidth(columnid, Number(width));
}
export function gw_pinColumn(columnid, pin) {
gw_options.columnApi.setColumnPinned(columnid, pin);
}
export function gw_moveColumn(columnid, toIndex) {
gw_options.columnApi.moveColumn(columnid, toIndex);
}
export function gw_groupColumns(columns, columnDefs) {
for (const i in columns) {
if (!columns.hasOwnProperty(i)) continue;
const column = JSON.parse(columns[i]);
const children = column.children.split(',');
let newChildren = [];
let newColumnDef = [];
children.forEach(child => {
for (let x = 0; x < columnDefs.length; x++) {
const def = columnDefs[x];
if(def && def.hasOwnProperty("field") && def.field === child) {
newChildren.push(def);
columnDefs.splice(x, 1);
break;
}
}
});
column.children = newChildren;
columnDefs.unshift(column);
}
}
<file_sep>/js/src/api/jss.js
/*
* This file is part of the grid project
* (c) <NAME> <<EMAIL>>
*
* For the full copyright and license information, please view the LICENSE
* file that was distributed with this source code.
*/
export function gw_setStyle(selector, rules) {
jss.forDocument(gw_getDocument()).set(selector, JSON.parse(rules));
}
export function gw_removeStyle(selector) {
jss.forDocument(gw_getDocument()).remove(selector);
}
<file_sep>/js/src/init.js
/*
* This file is part of the grid project
* (c) <NAME> <<EMAIL>>
*
* For the full copyright and license information, please view the LICENSE
* file that was distributed with this source code.
*/
export function gw_getSupportedColumnTypes() {
return {
"basic-string": {
cellEditor: 'agTextCellEditor'
},
"basic-text": {
cellEditor: 'agLargeTextCellEditor'
},
"basic-boolean": {
cellRenderer: 'BasicBooleansRenderer',
cellRendererParams: {
'RENDERER_TRUE': '✔',
'RENDERER_FALSE': '✘'
},
cellEditor: 'BasicBooleansEditor',
filter: 'BasicBooleansFilter'
},
"basic-number": {
valueFormatter: Basis.AgGridComponents.BasicNumbersValueFormatter.format,
cellEditor: 'BasicNumbersEditor',
filter: 'agNumberColumnFilter',
filterParams: {
inRangeInclusive: true,
},
floatingFilter: 'agNumberColumnFilter',
floatingFilterParams: {
inRangeInclusive: true,
},
},
"basic-date": {
valueFormatter: Basis.AgGridComponents.BasicDateTimesValueFormatter.format,
cellEditor: 'BasicDateTimesEditor',
cellEditorParams: {
'EDITOR_MASK': '%Y/%Mz/%Dz',
'EDITOR_ALLOW_INPUT': true,
},
filter: 'BasicDateTimesFilter',
filterParams: {
'FILTER_MASK': '%Y/%Mz/%Dz',
'FILTER_ALLOW_INPUT': true,
},
},
"basic-timestamp": {
valueFormatter: Basis.AgGridComponents.BasicDateTimesValueFormatter.format,
cellEditor: 'BasicDateTimesEditor',
cellEditorParams: {
'EDITOR_MASK': '%Y/%Mz/%Dz %Hz:%mz:%sz',
'EDITOR_ENABLE_TIME': true,
'EDITOR_ALLOW_INPUT': true,
},
filter: 'BasicDateTimesFilter',
filterParams: {
'FILTER_MASK': '%Y/%Mz/%Dz %Hz:%mz:%sz',
'FILTER_ENABLE_TIME': true,
'FILTER_ALLOW_INPUT': true,
}
},
"basic-image": {
cellRenderer: 'BasicImagesRenderer',
suppressMenu: true,
suppressFilter: true,
cellRendererParams: {
'IMAGE_WIDTH': '25px',
'IMAGE_HEIGHT': '25px',
},
},
"basic-image-filterable": {
cellRenderer: 'BasicImagesRenderer',
cellRendererParams: {
'IMAGE_WIDTH': '25px',
'IMAGE_HEIGHT': '25px',
},
}
};
}
export function gw_getDefaultComponents() {
return {
// Booleans
'BasicBooleansRenderer': Basis.AgGridComponents.BasicBooleansRenderer,
'BasicBooleansEditor': Basis.AgGridComponents.BasicBooleansEditor,
'BasicBooleansFilter': Basis.AgGridComponents.BasicBooleansFilter,
// Numbers
// 'BasicNumbersRenderer': Basis.AgGridComponents.BasicNumbersRenderer,
'BasicNumbersEditor': Basis.AgGridComponents.BasicNumbersEditor,
// Dates
'BasicDateTimesEditor': Basis.AgGridComponents.BasicDateTimesEditor,
// 'BasicDateTimesRenderer': Basis.AgGridComponents.BasicDateTimesRenderer,
'BasicDateTimesFilter': Basis.AgGridComponents.BasicDateTimesFilter,
// Images
'BasicImagesRenderer': Basis.AgGridComponents.BasicImagesRenderer,
};
}
export function gw_init(container, license, data, defaultOptions = {}) {
if (agGrid.LicenseManager && license) agGrid.LicenseManager.setLicenseKey(license);
let types = gw_getSupportedColumnTypes();
let options = Object.assign(defaultOptions, {
rowData: data,
getDocument: () => gw_getDocument(),
components: gw_getDefaultComponents(),
columnTypes: types,
onRowDoubleClicked: gw_onRowDoubleClicked,
onRowSelected: gw_onRowSelected,
onSelectionChanged: gw_onSelectionChanged,
onCellEditingStarted: gw_onCellEditingsEvent,
onCellEditingStopped: gw_onCellEditingsEvent,
onCellValueChanged: gw_onCellEditingsEvent,
onRowEditingStarted: gw_onRowEditingsEvent,
onRowEditingStopped: gw_onRowEditingsEvent,
onRowValueChanged: gw_onRowEditingsEvent,
onCellClicked: gw_onCellClickEvent,
onCellDoubleClicked: gw_onCellClickEvent,
getRowNodeId: gw_getRowNodeId,
rememberGroupStateWhenNewData: true,
getContextMenuItems: gw_getContextMenu,
popupParent: gw_getDocument().body,
allowContextMenuWithControlKey:true
});
if (
options.hasOwnProperty('__isTree') &&
true === options.__isTree
) {
options.getNodeChildDetails = gw_getNodeChildDetails;
}
if (
options.hasOwnProperty("__navigateToNextCell") &&
options.__navigateToNextCell
) {
options.navigateToNextCell = gw_navigateToNextRow;
}
for (let i in options.columnDefs) {
const def = options.columnDefs[i];
const field = def.field;
//override numbers group and decimal separators
if (def.hasOwnProperty('type') && 'basic-number' === def.type) {
if (gw_meta && gw_meta.hasOwnProperty(field)) {
if (!gw_meta[field].hasOwnProperty('RENDERER_GROUP_SEPARATOR')){
def['RENDERER_GROUP_SEPARATOR'] = defaultOptions.__numberGroupSep;
}
if (!gw_meta[field].hasOwnProperty('RENDERER_DECIMAL_SEPARATOR'))
def['RENDERER_DECIMAL_SEPARATOR'] = defaultOptions.__numberDecimalSep;
}
}
def.cellStyle = gw_cellStyler;
def.cellClass = gw_getCellClass;
def.toolPanelClass = gw_getToolPanelClass;
def.cellClassRules = gw_getGlobalMeta(field, 'CELL_CLASS_RULES', null, true);
const rowGroup = Number(gw_getGlobalMeta(field, 'ROW_GROUP'));
const enableValue = Number(gw_getGlobalMeta(field, 'ENABLE_VALUE'));
const footerValueGetter = gw_getGlobalMeta(field, 'FOOTER_VALUE_GETTER');
def.rowGroup = rowGroup;
def.enableRowGroup = rowGroup ? true : def.enableRowGroup;
def.rowGroupIndex = rowGroup ? Number(gw_getGlobalMeta(field, 'ROW_GROUP_INDEX')) : null;
def.enableValue = enableValue > 0 ? true : false;
def.showRowGroup = gw_getGlobalMeta(field, 'SHOW_ROW_GROUP', gw_getGlobalMeta(field, "LABEL"));
def.aggFunc = gw_getGlobalMeta(field, 'AGG_FUNC');
def.allowedAggFuncs = gw_getGlobalMeta(field, 'ALLOWED_AGG_FUNCS', 'sum,min,max,count,avg,first,last').split(',');
def.valueGetter = gw_getGlobalMeta(field, 'VALUE_GETTER');
def.valueSetter = gw_getGlobalMeta(field, 'VALUE_SETTER');
def.hide = def.headerName.startsWith('__') || gw_getGlobalMeta(field, 'HIDE', gw_getGlobalMeta(field, 'HIDDEN', false));
def.suppressToolPanel = def.headerName.startsWith('__');
// bbj is handling this part now
// def.editable = param => {
// const global = gw_getGlobalMeta(field, 'EDITABLE', false) === "1" ? true : false;
// if(!param.data.hasOwnProperty('meta')) return global;
// const path = param.data.meta[param.column.colId];
// return path.hasOwnProperty('EDITABLE') ? (path.EDITABLE === "1" ? true : false) : global;
// };
if (footerValueGetter) {
def.cellRenderer = 'agGroupCellRenderer';
def.cellRendererParams = Object.assign({}, def.cellRendererParams, {
footerValueGetter: footerValueGetter
});
}
}
gw_groupColumns(JSON.parse(options.__columnsGroup), options.columnDefs);
return new agGrid.Grid(container, options);
}
export function gw_setData(json, options, license) {
const container = gw_getDocument().getElementById(options['__id']);
container.innerHTML = '';
window.gw_meta = json[0].meta;
window.AGridComponentsMetaConfig = gw_meta;
console.log(options);
window.gw_options = options;
window.gw_instance = gw_init(container, license, json, options);
if (gw_options.hasOwnProperty('__enterKeyBehavior')) {
const behavior = gw_options.__enterKeyBehavior;
switch (behavior) {
case 'next':
container.addEventListener('keydown', gw_onMoveToNextCell);
break;
default:
break;
}
}
}
<file_sep>/js/vendor/Datejs/test/core/index.js
Date.Specification = new Specification({
'Exception Handling': {
setup: function() { },
'Date.parse() : No params': {
run: function() { this.date = Date.parse() },
assert: function() { return null == this.date }
},
'Date.parse("") : string.empty': {
run: function() { this.date = Date.parse('') },
assert: function() { return null == this.date }
},
'Date.parse("asdf") : Random String': {
run: function() { this.date = Date.parse('asdf') },
assert: function() { return null == this.date }
},
'Date.parse(null) : null': {
run: function() { this.date = Date.parse(null) },
assert: function() { return null == this.date }
},
'29-Sep-2008.set( { day: 31 } ) : RangeError': {
run: function() { },
assert: function() {
try {
return new Date(2008,8,29).set( { day: 31 } ).equals( new Date(2008,9,1) );
}
catch(ex) {
return (ex instanceof RangeError);
}
return new Date(2008,8,30).equals( this.date ) }
},
'29-Sep-2008.set( { month: 12 } ) : RangeError': {
run: function() { },
assert: function() {
try {
return new Date(2008,8,29).set( { month: 12 } ).equals( new Date(2009,0,29) );
}
catch(ex) {
return (ex instanceof RangeError);
}
}
},
'new Date("").compareTo( new Date() ) : Error': {
run: function() { },
assert: function() {
try {
return new Date("").compareTo( new Date() ) == 0
}
catch(ex) {
return (ex instanceof Error);
}
}
},
'new Date("").equals( new Date() ) : Error': {
run: function() { },
assert: function() {
try {
return new Date("").equals( new Date() );
}
catch(ex) {
return (ex instanceof Error);
}
}
},
'new Date().compareTo( 0 ) : Error': {
run: function() { },
assert: function() {
try {
return new Date().compareTo( 0 );
}
catch(ex) {
return (ex instanceof TypeError);
}
}
},
'new Date().equals( 0 ) : TypeError': {
run: function() { },
assert: function() {
try {
return new Date().equals( 0 );
}
catch(ex) {
return (ex instanceof TypeError);
}
}
},
'new Date().compareTo( new Date("") ) : TypeError': {
run: function() { },
assert: function() {
try {
return new Date().compareTo( new Date("") );
}
catch(ex) {
return (ex instanceof TypeError);
}
}
},
'new Date().equals( new Date("") ) : TypeError': {
run: function() { },
assert: function() {
try {
return new Date().equals( new Date("") );
}
catch(ex) {
return (ex instanceof TypeError);
}
}
}
},
'.compareTo() and .equals()': {
setup: function() {
},
'.compareTo() : today > yesterday': {
run: function() { },
assert: function() {
return Date.today().compareTo( Date.today().addDays(-1) ) == 1;
}
},
'.compareTo() : today == today': {
run: function() { },
assert: function() {
return Date.today().compareTo( Date.today() ) == 0;
}
},
'.compareTo() : today < tomorrow': {
run: function() { },
assert: function() {
return Date.today().compareTo( Date.today().addDays(1) ) == -1;
}
},
'.equals() : today != yesterday': {
run: function() { },
assert: function() {
return false == Date.today().equals( Date.today().addDays(-1) );
}
},
'.equals() : today == today': {
run: function() { },
assert: function() {
return Date.today().equals( Date.today() );
}
},
'.equals() : today != tomorrow': {
run: function() { },
assert: function() {
return false == Date.today().equals( Date.today().addDays(1) );
}
}
},
'.set() Tests': {
setup: function() {
this.d1 = new Date('');
},
'15-Aug-2008 to 15-Sep-2008': {
run: function() {
this.date = new Date(2008,7,15);
this.date.set( { month: 8 } );
},
assert: function() { return new Date(2008,8,15).equals( this.date ) }
},
'15-Aug-2008 to 15-Jul-2008': {
run: function() {
this.date = new Date(2008,7,15);
this.date.set( { month: 6 } );
},
assert: function() { return new Date(2008,6,15).equals( this.date ) }
},
'29-Feb-2008 to 28-Feb-2009': {
run: function() {
this.date = new Date(2008,1,29);
this.date.set( { year: 2009 } );
},
assert: function() { return new Date(2009,1,28).equals( this.date ) }
},
'29-Feb-2008 to 28-Feb-2007': {
run: function() {
this.date = new Date(2008,1,29);
this.date.set( { year: 2007 } );
},
assert: function() { return new Date(2007,1,28).equals( this.date ) }
},
'31-Jan-2008 to 29-Feb-2008': {
run: function() {
this.date = new Date(2008,0,31);
this.date.set( { month: 1 } );
},
assert: function() { return new Date(2008,1,29).equals( this.date ) }
},
'31-Mar-2008 to 29-Feb-2008': {
run: function() {
this.date = new Date(2008,2,31);
this.date.set( { month: 1 } );
},
assert: function() { return new Date(2008,1,29).equals( this.date ) }
},
'30-Sep-2008 to 30-Oct-2008': {
run: function() {
this.date = new Date(2008,8,30);
this.date.set( { month: 9 } );
},
assert: function() { return new Date(2008,9,30).equals( this.date ) }
},
'30-Sep-2008 to 30-Aug-2008': {
run: function() {
this.date = new Date(2008,8,30);
this.date.set( { month: 7 } );
},
assert: function() { return new Date(2008,7,30).equals( this.date ) }
},
'30-Sep-2008 to 30-Sep-2008': {
run: function() {
this.date = new Date(2008,8,30);
this.date.set( { month: 8 } );
},
assert: function() { return new Date(2008,8,30).equals( this.date ) }
},
'31-Aug-2008 to 30-Sep-2008': {
run: function() {
this.date = new Date(2008,7,31);
this.date.set( { month: 8 } ); },
assert: function() { return new Date(2008,8,30).equals( this.date ) }
},
'31-Oct-2008 to 30-Sep-2008': {
run: function() {
this.date = new Date(2008,9,31);
this.date.set( { month: 8 } ); },
assert: function() { return new Date(2008,8,30).equals( this.date ) }
}
},
'.next() and .previous()': {
setup: function() { },
'next().monday()': {
run: function() {
this.date = new Date().clearTime().next().monday();
},
assert: function() { return Date.parse('next monday').equals( this.date ) }
},
'next().tuesday()': {
run: function() {
this.date = new Date().clearTime().next().tuesday();
},
assert: function() { return Date.parse('next tuesday').equals( this.date ) }
},
'next().wednesday()': {
run: function() {
this.date = new Date().clearTime().next().wednesday();
},
assert: function() { return Date.parse('next wednesday').equals( this.date ) }
},
'next().thursday()': {
run: function() {
this.date = new Date().clearTime().next().thursday();
},
assert: function() { return Date.parse('next thursday').equals( this.date ) }
},
'next().friday()': {
run: function() {
this.date = new Date().clearTime().next().friday();
},
assert: function() { return Date.parse('next friday').equals( this.date ) }
},
'next().saturday()': {
run: function() {
this.date = new Date().clearTime().next().saturday();
},
assert: function() { return Date.parse('next saturday').equals( this.date ) }
},
'next().sunday()': {
run: function() {
this.date = new Date().clearTime().next().sunday();
},
assert: function() { return Date.parse('next sunday').equals( this.date ) }
},
'last().monday()': {
run: function() {
this.date = new Date().clearTime().last().monday();
},
assert: function() { return Date.parse('last monday').equals( this.date ) }
},
'last().tuesday()': {
run: function() {
this.date = new Date().clearTime().last().tuesday();
},
assert: function() { return Date.parse('last tuesday').equals( this.date ) }
},
'last().wednesday()': {
run: function() {
this.date = new Date().clearTime().last().wednesday();
},
assert: function() { return Date.parse('last wednesday').equals( this.date ) }
},
'last().thursday()': {
run: function() {
this.date = new Date().clearTime().last().thursday();
},
assert: function() { return Date.parse('last thursday').equals( this.date ) }
},
'last().friday()': {
run: function() {
this.date = new Date().clearTime().last().friday();
},
assert: function() { return Date.parse('last friday').equals( this.date ) }
},
'last().saturday()': {
run: function() {
this.date = new Date().clearTime().last().saturday();
},
assert: function() { return Date.parse('last saturday').equals( this.date ) }
},
'last().sunday()': {
run: function() {
this.date = new Date().clearTime().last().sunday();
},
assert: function() { return Date.parse('last sunday').equals( this.date ) }
},
'monday()': {
run: function() {
this.date = new Date().clearTime().monday();
},
assert: function() { return Date.parse('next monday').equals( this.date ) }
},
'tuesday()': {
run: function() {
this.date = new Date().clearTime().tuesday();
},
assert: function() { return Date.parse('next tuesday').equals( this.date ) }
},
'wednesday()': {
run: function() {
this.date = new Date().clearTime().wednesday();
},
assert: function() { return Date.parse('next wednesday').equals( this.date ) }
},
'thursday()': {
run: function() {
this.date = new Date().clearTime().thursday();
},
assert: function() { return Date.parse('next thursday').equals( this.date ) }
},
'friday()': {
run: function() {
this.date = new Date().clearTime().friday();
},
assert: function() { return Date.parse('next friday').equals( this.date ) }
},
'saturday()': {
run: function() {
this.date = new Date().clearTime().saturday();
},
assert: function() { return Date.parse('next saturday').equals( this.date ) }
},
'sunday()': {
run: function() {
this.date = Date.today().sunday();
},
assert: function() { return Date.parse('next sunday').equals( this.date ) }
}
},
'.is()': {
setup: function() { },
'.is().monday()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().monday() == true; }
},
'.is().mon()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().mon() == true; }
},
'.is().tuesday()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).is().tuesday() == true; }
},
'.is().tue()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).is().tue() == true; }
},
'.is().wednesday()': {
run: function() { },
assert: function() { return new Date(2001, 0, 3).is().wednesday() == true; }
},
'.is().wed()': {
run: function() { },
assert: function() { return new Date(2001, 0, 3).is().wed() == true; }
},
'.is().thursday()': {
run: function() { },
assert: function() { return new Date(2001, 0, 4).is().thursday() == true; }
},
'.is().thu()': {
run: function() { },
assert: function() { return new Date(2001, 0, 4).is().thu() == true; }
},
'.is().friday()': {
run: function() { },
assert: function() { return new Date(2001, 0, 5).is().friday() == true; }
},
'.is().fri()': {
run: function() { },
assert: function() { return new Date(2001, 0, 5).is().fri() == true; }
},
'.is().saturday()': {
run: function() { },
assert: function() { return new Date(2001, 0, 6).is().saturday() == true; }
},
'.is().sat()': {
run: function() { },
assert: function() { return new Date(2001, 0, 6).is().sat() == true; }
},
'.is().sunday()': {
run: function() { },
assert: function() { return new Date(2001, 0, 7).is().sunday() == true; }
},
'.is().sun()': {
run: function() { },
assert: function() { return new Date(2001, 0, 7).is().sun() == true; }
},
'.is().january()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().january() == true; }
},
'.is().jan()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().jan() == true; }
},
'.is().february()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 1 ).month().is().february() == true; }
},
'.is().feb()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().add( 1 ).month().feb() == true; }
},
'.is().march()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 2 ).months().is().march() == true; }
},
'.is().mar()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().add( 2 ).months().mar() == true; }
},
'.is().april()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 3 ).months().is().april() == true; }
},
'.is().apr()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().add( 3 ).months().april() == true; }
},
'.is().may()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 4 ).months().is().may() == true; }
},
'.is().june()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 5 ).months().is().june() == true; }
},
'.is().jun()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().add( 5 ).months().jun() == true; }
},
'.is().july()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 6 ).months().is().july() == true; }
},
'.is().jul()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().add( 6 ).months().jul() == true; }
},
'.is().august()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 7 ).months().is().august() == true; }
},
'.is().aug()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().add( 7 ).months().aug() == true; }
},
'.is().september()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 8 ).months().is().september() == true; }
},
'.is().sep()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().add( 8 ).months().sep() == true; }
},
'.is().october()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 9 ).months().is().october() == true; }
},
'.is().oct()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().add( 9 ).months().oct() == true; }
},
'.is().november()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 10 ).months().is().november() == true; }
},
'.is().nov()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().add( 10 ).months().nov() == true; }
},
'.is().december()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 11 ).months().is().december() == true; }
},
'.is().dec()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).is().add( 11 ).months().dec() == true; }
}
},
'.add()': {
setup: function() { },
'.add( 1 ).second()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( 1 ).second().equals( new Date(2001, 0, 2, 0, 0, 1) ); }
},
'.add( -1 ).second()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( -1 ).second().equals( new Date(2001, 0, 1, 23, 59, 59) ); }
},
'.add( 10 ).seconds()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( 10 ).seconds().equals( new Date(2001, 0, 2, 0, 0, 10) ); }
},
'.add( -10 ).seconds()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( -10 ).seconds().equals( new Date(2001, 0, 1, 23, 59, 50) ); }
},
'.add( 1 ).minute()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( 1 ).minute().equals( new Date(2001, 0, 2, 0, 1, 0) ); }
},
'.add( -1 ).minute()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( -1 ).minute().equals( new Date(2001, 0, 1, 23, 59, 0) ); }
},
'.add( 10 ).minutes()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( 10 ).minutes().equals( new Date(2001, 0, 2, 0, 10, 0) ); }
},
'.add( -10 ).minutes()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( -10 ).minutes().equals( new Date(2001, 0, 1, 23, 50, 0) ); }
},
'.add( 1 ).hour()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( 1 ).hour().equals( new Date(2001, 0, 2, 1, 0, 0) ); }
},
'.add( -1 ).hour()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( -1 ).hour().equals( new Date(2001, 0, 1, 23, 0, 0) ); }
},
'.add( 10 ).hours()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( 10 ).hours().equals( new Date(2001, 0, 2, 10, 0, 0) ); }
},
'.add( -10 ).hours()': {
run: function() { },
assert: function() { return new Date(2001, 0, 2).add( -10 ).hours().equals( new Date(2001, 0, 1, 14, 0, 0) ); }
},
'.add( 1 ).day()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 1 ).day().equals( new Date(2001, 0, 2) ); }
},
'.add( -1 ).day()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( -1 ).day().equals( new Date(2000, 11, 31) ); }
},
'.add( 31 ).days()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 31 ).days().equals( new Date(2001, 1, 1) ); }
},
'.add( -31 ).days()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( -31 ).days().equals( new Date(2000, 11, 1) ); }
},
'.add( 1 ).month()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 1 ).month().equals( new Date(2001, 1, 1) ); }
},
'.add( -1 ).month()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( -1 ).month().equals( new Date(2000, 11, 1) ); }
},
'.add( 6 ).months()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 6 ).months().equals( new Date(2001, 6, 1) ); }
},
'.add( -6 ).months()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( -6 ).months().equals( new Date(2000, 6, 1) ); }
},
'.add( 1 ).month() : 31-Jan to 28-Feb': {
run: function() { },
assert: function() { return new Date(2001, 0, 31).add( 1 ).month().equals( new Date(2001, 1, 28) ); }
},
'.add( -1 ).month() : 31-Mar to 28-Feb': {
run: function() { },
assert: function() { return new Date(2001, 2, 31).add( -1 ).month().equals( new Date(2001, 1, 28) ); }
},
'.add( 1 ).month() : 31-Jan to 29-Feb [leap year]': {
run: function() { },
assert: function() { return new Date(2008, 0, 31).add( 1 ).month().equals( new Date(2008, 1, 29) ); }
},
'.add( -1 ).month() : 31-Mar to 29-Feb [leap year]': {
run: function() { },
assert: function() { return new Date(2008, 2, 31).add( -1 ).month().equals( new Date(2008, 1, 29) ); }
},
'.add( 1 ).year()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 1 ).year().equals( new Date(2002, 0, 1) ); }
},
'.add( -1 ).year()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( -1 ).year().equals( new Date(2000, 0, 1) ); }
},
'.add( -1 ).year() : 29-Feb-2000 to 28-Feb-2001 [leap year]': {
run: function() { },
assert: function() { return new Date(2000, 1, 29).add( 1 ).year().equals( new Date(2001, 1, 28) ); }
},
'.add( 5 ).years()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( 5 ).years().equals( new Date(2006, 0, 1) ); }
},
'.add( -5 ).years()': {
run: function() { },
assert: function() { return new Date(2001, 0, 1).add( -5 ).years().equals( new Date(1996, 0, 1) ); }
}
}
});
$(document).ready( function() { Date.Specification.validate().show() } );<file_sep>/js/src/events.js
/*
* This file is part of the grid project
* (c) <NAME> <<EMAIL>>
*
* For the full copyright and license information, please view the LICENSE
* file that was distributed with this source code.
*/
export * from './events/pollyfills.js';
export * from './events/utilities.js';
export * from './events/selections.js';
export * from './events/editing.js';
| 22081bb9f39bc8d75120633931c2e4f6839d61c1 | [
"Markdown",
"JavaScript"
] | 15 | Markdown | mitchneu/BBjGridExWidget | 6bb3792fa9523f924316841162f79344ffefa856 | a0feea85fa8f964400e27f91cb5cb80e0126e993 |
refs/heads/master | <file_sep># krsa
krsa <-
function (file ,iterations, numSigSubs, sigSubs) {
withProgress(message = 'KRSA', value = 0, {
#incProgress(1/5, detail = "Reading file")
subKinase <- read.table(file, header = TRUE, sep = "\t", as.is=T, quote = "\"", check.names=FALSE, stringsAsFactors=FALSE)
kinaseSep=" "
subKinaseOnly=toupper(subKinase[,2])
splitKinase=NULL
#incProgress(2/5, detail = "Finding unique kinases")
for(i in 1:length(subKinaseOnly)){
splitKinase=paste0(splitKinase, subKinaseOnly[i], sep=kinaseSep )
}
uniqueKin=unique(unlist(strsplit(splitKinase, split=kinaseSep)))
scores=data.frame(matrix(ncol = iterations, nrow = length(uniqueKin)), row.names=uniqueKin)
for(i in 1:iterations){
incProgress((1/iterations), detail = paste0(i, "/", iterations))
sampleList=sample(subKinaseOnly, numSigSubs)
scores[,i]=iterationScore(sampleList, kinaseSep, uniqueKin)
}
#incProgress(4/5, detail = "Averaging")
scores=cbind(scores, rowMeans(scores)) #get the average kinase amount
yourSubs=subset(subKinase, subKinase$Substrates %in% sigSubs)
yourScores=data.frame(matrix(ncol = 1, nrow = length(uniqueKin)), row.names=uniqueKin)
yourScores[,1]=iterationScore(yourSubs[,2], kinaseSep, uniqueKin)
#section to make overall table
#incProgress(5/5, detail = "Creating results")
overallTable=as.data.frame(cbind(Kinase=uniqueKin, DxAverage=yourScores[,1], ReSamplingAverage=scores[,iterations+1]))
overallTable[,2]=as.numeric(as.character(overallTable[,2]))
overallTable[,3]=as.numeric(as.character(overallTable[,3]))
overallTable=cbind(overallTable, AbsoluteDiference=abs(overallTable[,2]-overallTable[,3]))
overallTable=cbind(overallTable, StandardDeviation=unlist(apply(scores[,1:iterations], 1, sd)))
overallTable=cbind(overallTable, Minus2Sd=overallTable[,3]-2*(overallTable[,5]) , Plus2SD=overallTable[,3]+2*(overallTable[,5]))
overallTable=cbind(overallTable, Down=(ifelse(overallTable[,2]<overallTable[,6], "YES", "x")), Up=(ifelse(overallTable[,2]>overallTable[,7], "YES", "x")))
overallTable=cbind(overallTable, ZScore=abs((overallTable[,2]-overallTable[,3])/overallTable[,5]))
overallTable2=overallTable[order(overallTable$ZScore, decreasing=TRUE),]
#kittyYES<<-overallTable2
print("Done")
})
return(list(overallTable2, scores))
}
# new krsa
samplingPep <- function(x,CovFile,sum_num) {
CovFile %>%
group_by(Kin) %>%
summarise(
counts = sum(Substrates %in% sample(CovFile$Substrates %>% unique(),sum_num))
) %>% mutate(itr = x) -> res
return(res)
}
krsa_2 <- function(x,CovFile,peps) {
# file %>% separate_rows(Kinases) %>%
# rename(Kin = Kinases) -> CovFile
purrr::map_df(1:x,samplingPep,CovFile,length(peps)) -> res
res %>% group_by(Kin) %>% summarise(SamplingAvg = mean(counts), SD= sd(counts)) -> avrages
obs <- CovFile %>%
group_by(Kin) %>%
summarise(
Observed = sum(Substrates %in% peps)
)
left_join(avrages, obs) %>% mutate(Z = (Observed-SamplingAvg)/SD) %>% arrange(desc(abs(Z))) %>%
filter(!Kin %in% c("BARK1", "VRK2")) %>%
select(Kin, Observed, SamplingAvg, SD, Z) %>% rename(Kinase = Kin) -> fin
return(list(
res = res,
krsa_table = fin
))
}
<file_sep>#
# This is a Shiny web application. You can run the application by clicking
# the 'Run App' button above.
#
# Find out more about building applications with Shiny here:
#
# http://shiny.rstudio.com/
#
library(shiny)
# Define UI for application that draws a histogram
ui <- fluidPage(
# Application title
titlePanel("Old Faithful Geyser Data"),
# Sidebar with a slider input for number of bins
sidebarLayout(
sidebarPanel(
fileInput('file0', label = h3("Upload raw data file"),
accept=c('text/csv', 'text/comma-separated-values','text/plain', '.csv'))
),
# Show a plot of the generated distribution
mainPanel(
shiny::dataTableOutput(outputId="contents0")
)
)
)
# Define server logic required to draw a histogram
server <- function(input, output) {
data_set0 <- reactive({
req(input$file0)
inFile <- input$file0
read.csv(inFile$datapath, header=T,
sep="\t", quote='"', stringsAsFactors = F)
})
output$contents0 <- shiny::renderDataTable({
data_set0()
#}, caption = "Preview of raw data file")
}, options=list(scrollX=TRUE, pageLength = 10))
}
# Run the application
shinyApp(ui = ui, server = server)
<file_sep>
library(tidyverse)
reading_data <- function(df) {
meta_rows <- which(df[,1] == "")
epmty_col <- which(df[meta_rows[1],] == "")
meta_info <- df[meta_rows,(epmty_col[length(epmty_col)]+1):ncol(df)]
rows_end <- nrow(df)
rows_start <- meta_rows[(length(meta_rows))]+2
data <- df[rows_start:rows_end,]
data <- data[,c(1,(epmty_col[length(epmty_col)]+2):ncol(data))]
data <- data %>% filter(! V1 %in% c("#REF", "ART_025_CXGLRRWSLGGLRRWSL", "pVASP_150_164", "pTY3H_64_78"))
df2 <- data.frame(t(data[-1]), stringsAsFactors = F)
colnames(df2) <- data[, 1]
colnames(df2) <- make.unique(colnames(df2))
df3 <- data.frame(t(meta_info[-1]), stringsAsFactors = F)
colnames(df3) <- meta_info[, 1]
cbind(df3,df2) -> df4
df4 %>% gather((length(meta_rows)+1):ncol(.), key = "Peptide", value = "Signal") -> tidydata
tidydata$`Exposure time` <- as.numeric(tidydata$`Exposure time`)
tidydata$Cycle <- as.numeric(tidydata$Cycle)
tidydata$Signal <- as.numeric(tidydata$Signal)
return(tidydata)
}
<file_sep>library(shiny)
library(shinydashboard)
library(data.table)
library(DT)
library(ggplot2)
library(dplyr)
library(shinycssloaders)
library(tidyverse)
library(broom)
library(gplots)
library(igraph)
source("scripts/reading_data.R")
source("scripts/dropdown_btn.R")
source("scripts/krsa.R")
source("scripts/heatmap.R")
source("scripts/network.R")
###############################################################################
ui <- shinyUI(fluidPage(
includeCSS("styles.css"),
#Application title
headerPanel("Kinome Random Sampling Analyzer"),
#Layout type
sidebarLayout(
#Sidebar Panel
sidebarPanel(
fileInput('file0', label = h3("Upload raw data file"),
accept=c('text/csv', 'text/comma-separated-values','text/plain', '.csv')),
#Options for file type including header, seperator, and quotes.
h4("File options:"),
checkboxInput('header1', 'Header', TRUE),
radioButtons('sep1', 'Separator', inline=F,
c(Tab='\t',
Comma=',',
Semicolon=';'),
'\t'),
radioButtons('quote1', 'Quote', inline=F,
c(None='',
'Double Quote'='"',
'Single Quote'="'"),
'"'),
tags$hr(),
conditionalPanel(
condition = TRUE,
fileInput('file1', label = h5("Kinase-peptide association file"),
accept=c('text/csv', 'text/comma-separated-values','text/plain', '.csv')),
h4("File options:"),
checkboxInput('header2', 'Header', TRUE),
radioButtons('sep2', 'Separator', inline=F,
c(Tab='\t',
Comma=',',
Semicolon=';'),
'\t'),
radioButtons('quote2', 'Quote', inline=F,
c(None='',
'Double Quote'='"',
'Single Quote'="'"),
'"')
),
tags$hr()
),
#Main Panel
mainPanel(
tags$style(HTML("
.tabbable > .nav > li > a {background-color: #7c7c7c; color:#d6d6d6}
.tabbable > .nav > li[class=active] > a {background-color: #008E94; color:white}
")),
tabsetPanel(
tabPanel("Step 1: Options",
h2("Data Selection:"),
#celltype
fluidRow(
column(4,
dropdownButton(
label = "Step 1: Experiment Barcode", status = "default", width = 80,
actionButton(inputId = "celltypea2z", label = "Sort A to Z", icon = icon("sort-alpha-asc")),
actionButton(inputId = "celltypez2a", label = "Sort Z to A", icon = icon("sort-alpha-desc")),
br(),
actionButton(inputId = "celltypeall", label = "(Un)select all"),
checkboxGroupInput(inputId = "celltype", label = "Choose", choices = c()))),
column(4,
dropdownButton(
label = "Step 2: Control Samples", status = "default", width = 80,
actionButton(inputId = "controlSamplesa2z", label = "Sort A to Z", icon = icon("sort-alpha-asc")),
actionButton(inputId = "controlSamplesz2a", label = "Sort Z to A", icon = icon("sort-alpha-desc")),
br(),
actionButton(inputId = "controlSamplesall", label = "(Un)select all"),
checkboxGroupInput(inputId = "controlSamples", label = "Choose", choices = c()))),
column(4,
dropdownButton(
label = "Step 3: Experimental Samples", status = "default", width = 80,
actionButton(inputId = "experimentalSamplesa2z", label = "Sort A to Z", icon = icon("sort-alpha-asc")),
actionButton(inputId = "experimentalSamplesz2a", label = "Sort Z to A", icon = icon("sort-alpha-desc")),
br(),
actionButton(inputId = "experimentalSamplesall", label = "(Un)select all"),
checkboxGroupInput(inputId = "experimentalSamples", label = "Choose", choices = c())))
),
tags$hr(),
h2("Preview Data:"),
fluidRow(
h3("Preview of all data"),
DT::dataTableOutput(outputId="contents0"),
h3("Preview of control data"),
DT::dataTableOutput(outputId="contents1"),
h3("Preview of experimental data"),
DT::dataTableOutput(outputId="contents2")
)
),
tabPanel("Step 2: Stringency",
sliderInput("FCslider", label = h3("Select Fold Change"), min = 0, max = 2, value = c(0.85,1.15), step=0.05),
h3("Select Stringency Level"),
fluidRow(
column(6,
checkboxGroupInput("StrinRadio",label=NULL, choices = list("Max exposure >= 2" = 1, "R^2 >=0.9" = 2), selected = c(1,2)),
actionButton("calculateData", "Find Significant Substrates")
),
column(6,
textOutput("qc_text"),
textOutput("remain2")
)
),
hr(),
DT::dataTableOutput("fit_table"),
downloadButton('downloadDataFC', 'Download Substrate Results'),
downloadButton('downloadDataFC2', 'Download Substrate Results 2'),
selectInput("pep_sel", "Choose a Substrate:", choices=c()),
plotOutput("pep_plot", width = "100%", height="600px"),
downloadButton('download_pep_plot', 'Download Graph'),
hr()
),
tabPanel("Step 3: Iteration",
sliderInput("itr_num", label = h4("Select the number of iterations"), min = 100,
max = 5000, value = 1000, step=100, width='100%'),
tags$hr(),
h4("Confirm and Run"),
textOutput("subnum"),
textOutput("subnum4"),
textOutput("subnum3"),
htmlOutput("subnum2"),
actionButton("krsa_btn", "Run KRSA")
),
tabPanel("Step 4: Results",
DT::dataTableOutput("overallTable"),
downloadButton('download_krsa_table', 'Download Results')
),
tabPanel("Step 5: Histograms",
selectInput("kin_sel", "Choose a Kinase:", choices=c()),
plotOutput("kin_plot", width = "100%", height="600px"),
downloadButton('download_hist', 'Download Histogram')
),
tabPanel("Step 6: Heatmap",
fluidRow(
column(6,
sliderInput("slider2", label = "Breaks", min = -10,
max = 10, value = c(-4, 4)),
selectInput("clust", "Clustering method:", choices=c("complete", "ward.D", "ward.D2", "single", "average", "mcquitty", "median", "centroid"))
),
column(6,
selectInput("low", "Choose low phosphorylation color:", choices=c("cyan", "orange", "yellow", "green", "darkgreen", "red", "blue", "purple", "magenta")),
selectInput("mid", "Choose middle phosphorylation color:", choices=c("black", "white")),
selectInput("high", "Choose high phosphorylation color:", choices=c("yellow", "orange", "red", "green", "darkgreen", "cyan", "blue", "purple", "magenta")),
downloadButton('download_heatmap', 'Download Heatmap')
)
),
hr(),
plotOutput("heatmap", width = "100%", height="1200px")
),
tabPanel("Step 7: Network",
fluidRow(
column(6,
sliderInput("nodeSize", label = "Node Size", min=1, max=10, value=3, step=1),
sliderInput("nodeTextSize", label = "Node Text Size", min=1, max=10, value=6, step=1)
),
column(6,
selectInput("hitsColor", "Choose color for KRSA kinases:", choices=c("red","cyan", "orange", "yellow", "green", "darkgreen", "blue", "purple", "magenta", "white", "gray")),
selectInput("interColor", "Choose color for interacting proteins:", choices=c("gray","red", "orange", "yellow", "green", "darkgreen", "cyan", "blue", "purple", "magenta", "white")),
selectInput("layout", "Choose layout:", choices=c("Circle", "Fruchterman-Reingold", "Kamada Kawai", "LGL")),
downloadButton('download_net', 'Download Network')
)
),
hr(),
withSpinner(plotOutput("networkPlot", width = "100%", height="1200px"), proxy.height = "10px") #TODO: trying to use proxy height to move the spinner up but no luck
)
)
)
)
))
###############################################################################
server <- function(input, output, session) {
session$onSessionEnded(stopApp)
theme_set(theme_bw())
shared_values <- reactiveValues(
sig_pep = "",
kin_hits = "",
ctl_samples = "",
case_sample = "",
barcodes = "",
sample_ids = ""
)
plots <- reactiveValues()
data_set0 <- reactive({
req(input$file0)
inFile <- input$file0
x<-read.csv(inFile$datapath, header=F,
sep=input$sep1, quote=input$quote1, stringsAsFactors = F)
tidy_data <- reading_data(x)
tidy_data %>% pull(Barcode) %>% unique() %>% as.list() -> barcode_ids
shared_values$barcodes <- barcode_ids
tidy_data %>% pull(`Sample name`) %>% unique() %>% as.list() -> samples_ids
shared_values$sample_ids <- samples_ids
tidy_data
})
observe({
updateCheckboxGroupInput(session, "celltype",
choices = shared_values$barcodes,
selected = shared_values$barcodes)
})
observe({
updateCheckboxGroupInput(session, "controlSamples",
choices = shared_values$sample_ids)
})
observe({
updateCheckboxGroupInput(session, "experimentalSamples",
choices = shared_values$sample_ids)
})
observeEvent(input$calculateData, {
data_set0() %>% filter(`Sample name` %in% c(input$controlSamples, input$experimentalSamples)) -> filtered_samples
filtered_samples %>% filter(`Exposure time` == 200) %>%
select(Peptide, `Sample name`, Signal) %>%
spread(key = `Sample name`, value = Signal) %>%
dplyr::filter(!Peptide %in% c("pVASP_150_164", "pTY3H_64_78", "ART_025_CXGLRRWSLGGLRRWSL")) -> PassDF
pull(PassDF, Peptide) -> ppPassAll
dplyr::filter_at(PassDF, vars(-Peptide) , all_vars(. >= as.numeric(2))) %>%
pull(Peptide) -> ppPass_min
filtered_samples %>% dplyr::filter(Peptide %in% ppPassAll, Cycle == 124) %>%
select(Peptide, `Sample name`, `Exposure time`, Signal) %>%
nest(-`Sample name`, -Peptide) %>%
group_by(`Sample name`, Peptide) %>%
mutate(
fit = map(data,~ lm(Signal ~ `Exposure time`, data = .x)),
coefs = map(fit, tidy),
summary = map(fit, glance),
#.default argument to replace NA/NaN values
slope = map_dbl(coefs,pluck,2,2,.default = 0),
r.seq = map_dbl(summary, "r.squared")
) %>%
select(`Sample name`, Peptide, slope, r.seq) -> Dataset_PW_C1_Fit
Dataset_PW_C1_Fit %>% filter(Peptide %in% ppPassAll) %>%
mutate(Group = ifelse(`Sample name` %in% input$controlSamples, "Control", "Case")) %>%
group_by(Group, Peptide) %>%
summarise(SignalAvg = mean(slope), r.seqAvg = mean(r.seq)) -> grouped_fit
grouped_fit %>%
select(Group, Peptide, r.seqAvg) %>% spread(Group, r.seqAvg) %>%
filter_at( vars(-Peptide) , all_vars(. >= 0.9)) %>% pull(Peptide) -> ppPassR2_avg
pass_both_2 <- intersect(ppPass_min, ppPassR2_avg)
if (identical(input$StrinRadio, c("1", "2"))) {
crit_pep <- pass_both_2
} else if (identical(input$StrinRadio, c("1"))) {
crit_pep <- ppPass_min
} else if (identical(input$StrinRadio, c("2"))) {
crit_pep <- ppPassR2_avg
} else {crit_pep <- ppPassAll}
grouped_fit %>% filter(Peptide %in% crit_pep) %>%
group_by(Peptide) %>%
mutate(FC = SignalAvg[Group == "Control"]/SignalAvg[Group == "Case"]) -> grouped_fit_res
grouped_fit_res %>% filter(FC <= input$FCslider[1] | FC >= input$FCslider[2]) %>%
pull(Peptide) %>% unique() -> sig_pep
shared_values$sig_pep <- sig_pep
output$qc_text <- renderText({
paste0("You have selected ", length(crit_pep), " substrates based on inclusion and exclusion criteria.")
})
output$remain2 <- renderText({
paste0( as.character(length(sig_pep)), " substrates were chosen for KRSA analysis.")
})
updateSelectInput(session, "pep_sel", choices = sig_pep)
output$pep_plot <- renderPlot({
filtered_samples %>% dplyr::filter(Peptide %in% input$pep_sel, Cycle == 124) %>%
mutate(Group = ifelse(`Sample name` %in% input$controlSamples, "Control", "Case")) %>%
ggplot(aes(`Exposure time`, Signal, group = `Sample name`)) +
geom_smooth(method = lm, formula = y~x, se=F, aes(color = factor(Group))) -> pp1
plots$pep <- pp1
output$download_pep_plot <- downloadHandler(
file = function() { paste0(input$pep_sel, ".png") },
content = function(file) {
ggsave(file,plot=plots$pep)
})
pp1
})
output$fit_table <- DT::renderDataTable({
head(Dataset_PW_C1_Fit)
#}, caption = "Preview of raw data file")
}, options=list(scrollX=TRUE, pageLength = 10))
output$heatmap <- renderPlot({
Dataset_PW_C1_Fit %>% filter(Peptide %in% ppPass_min) %>%
select(`Sample name`, Peptide, slope) %>%
pivot_wider(names_from = `Sample name`, values_from = slope) %>%
column_to_rownames("Peptide") %>% as.matrix() %>% log2() -> mm
output$download_heatmap <- downloadHandler( #TODO: download in portrait mode
filename = "heatmap.pdf",
content = function(file) {
pdf(file, height = 10, width = 6, useDingbats = T)
plotInputH(mm, input$slider2[1], input$slider2[2], input$low, input$mid, input$high, input$clust)
dev.off()
})
plotInputH(mm, input$slider2[1], input$slider2[2], input$low, input$mid, input$high, input$clust)
})
grouped_fit %>% filter(Peptide %in% ppPassR2_avg) %>%
group_by(Peptide) %>%
mutate(FC = SignalAvg[Group == "Control"]/SignalAvg[Group == "Case"]) -> grouped_fit_res
grouped_fit_res %>% select(Peptide, FC, Group, SignalAvg) %>%
pivot_wider(names_from = Group, values_from = SignalAvg) -> results_table_download1
output$downloadDataFC <- downloadHandler(
filename = "substrate_results.csv",
content = function(file) {
write.csv(Dataset_PW_C1_Fit, file, row.names = FALSE)
}
)
output$downloadDataFC2 <- downloadHandler(
filename = "substrate_results_2.csv",
content = function(file) {
write.csv(results_table_download1, file, row.names = FALSE)
}
)
})
output$subnum2 <- renderUI({
str1 <- paste0("")
#str2 <- as.character(resultsTable[,1])
HTML(paste(str1, shared_values$sig_pep, sep = '<br/>'))
})
output$subnum3 <- renderText({
paste0("You have selected ", length(shared_values$sig_pep) , " significant substrates from your data set (listed below):")
})
output$subnum4 <- renderText({
paste0("You have selected ", input$itr_num , " iterations.")
})
output$contents0 <- DT::renderDataTable({
data_set0() %>% filter(Barcode %in% input$celltype) %>% head()
#}, caption = "Preview of raw data file")
}, options=list(scrollX=TRUE, pageLength = 10))
output$contents1 <- DT::renderDataTable({
data_set0() %>% filter(`Sample name` %in% input$controlSamples) %>% head()
#}, caption = "Preview of raw data file")
}, options=list(scrollX=TRUE, pageLength = 10))
output$contents2 <- DT::renderDataTable({
data_set0() %>% filter(`Sample name` %in% input$experimentalSamples) %>% head()
#}, caption = "Preview of raw data file")
}, options=list(scrollX=TRUE, pageLength = 10))
observeEvent(input$krsa_btn, {
req(input$file1)
withProgress(message = 'KRSA', value = 0, {
inFile <- input$file1
file <- read.csv(inFile$datapath, header=T,
sep=input$sep1, quote=input$quote1, stringsAsFactors = F)
file %>% separate_rows(Kinases) %>% rename(Kin = Kinases) -> cov_file
incProgress(0.4)
krsa_output <- krsa_2(input$itr_num, cov_file, shared_values$sig_pep)
incProgress(0.8)
output$overallTable <- DT::renderDataTable({
krsa_output$krsa_table
}, options=list(scrollX=TRUE, pageLength = 10))
output$download_krsa_table <- downloadHandler(
filename = "KRSA_results.csv",
content = function(file) {
write.csv(krsa_output$krsa_table, file, row.names = FALSE)
}
)
})
updateSelectInput(session, "kin_sel", choices = krsa_output$krsa_table$Kinase)
output$kin_plot <- renderPlot({
krsa_output$res %>% rename(Kinase = Kin) %>%
filter(Kinase == input$kin_sel) %>%
ggplot() +
geom_histogram(aes(counts),binwidth = 1,fill= "gray30", color = "black") +
geom_rect(data=filter(krsa_output$krsa_table, Kinase == input$kin_sel),aes(xmin=SamplingAvg+(2*SD), xmax=SamplingAvg-(2*SD), ymin=0, ymax=Inf),
fill="gray", alpha=0.5
) +
geom_vline(data=filter(krsa_output$krsa_table, Kinase == input$kin_sel), aes(xintercept = Observed), color = "red", size = 1,show.legend = F) +
labs(x = "Hits", y = "Counts", title = input$kin_sel) +
theme(plot.title = element_text(hjust = 0.5)) -> pp2
plots$hist <- pp2
output$download_hist <- downloadHandler(
file = function() { paste0(input$kin_sel, ".png") },
content = function(file) {
ggsave(file,plot=plots$hist)
#ggsave(filename=file, plot = plotInputG(), device = "pdf")
})
pp2
})
output$networkPlot <- renderPlot({
filter(krsa_output$krsa_table, abs(Z) >= 2) %>% pull(Kinase) -> kin_hits
output$download_net <- downloadHandler(
filename = "network.pdf",
content = function(file) {
pdf(file)
plotInputN(kin_hits, input$hitsColor, input$interColor, input$nodeSize, input$nodeTextSize, input$layout)
dev.off()
})
plotInputN(kin_hits, input$hitsColor, input$interColor, input$nodeSize, input$nodeTextSize, input$layout)
})
})
}
###############################################################################
#Make the app!
shinyApp(ui, server)
<file_sep># Network code
plotInputN <- function(KinHits, hit_col, int_col, n_size, n_text, layout){
HitsColor=hit_col #user input
InterColor=int_col #user input
NodeSize=n_size #user input
NodeTextSize= abs(n_text - 11) #user input
nodes2 <- readRDS("./data/sup/FinNodes_Final_FF.rds")
edges <- readRDS("./data/sup/FinEdges_Final_FF.rds")
nodes2 %>% dplyr::filter(FinName %in% KinHits) %>% pull(FinName) -> sigHITS
edges %>% dplyr::filter(Source %in% sigHITS | Target %in% sigHITS) %>% dplyr::filter(Source != Target) -> modEdges
modsources <- pull(modEdges, Source)
modtargets <- pull(modEdges, Target)
modALL <- unique(c(modsources,modtargets))
nodes2 %>% dplyr::filter(FinName %in% modALL) -> nodesF
listoFkin <- pull(nodesF, FinName)
edges %>% dplyr::filter(Source %in% nodesF$FinName & Target %in% nodesF$FinName) %>% dplyr::filter(Source != Target) -> modEdges
modEdges %>% mutate(line = ifelse(Source %in% sigHITS | Target %in% sigHITS, 2,1 )) -> modEdges
modsources <- pull(modEdges, Source)
modtargets <- pull(modEdges, Target)
modALL <- c(modsources,modtargets)
as.data.frame(table(modALL)) -> concts
concts %>% dplyr::rename(FinName = modALL) -> concts
concts$FinName <- as.character(concts$FinName)
right_join(nodesF,concts) -> nodesF
nodesF %>% mutate(cl = ifelse(FinName %in% sigHITS, HitsColor, InterColor)) -> nodesF
# filter low freqs
nodesF %>% dplyr::filter(Freq>=1|cl==HitsColor) %>%
pull(FinName) -> FinKinases
modEdges %>% dplyr::filter(Source %in% FinKinases & Target %in% FinKinases) -> modEdges
nodesF %>% dplyr::filter(FinName %in% FinKinases) %>% mutate(Freq = ifelse(Freq < 4, 4, Freq)) -> nodesF
net <- graph_from_data_frame(d=modEdges, vertices=nodesF, directed=T)
net <- igraph::simplify(net,remove.loops = F, remove.multiple = F)
V(net)$size = log2(V(net)$Freq)*NodeSize
colrs <- c(HitsColor, InterColor)
V(net)$color <- V(net)$cl
colrs2 <- c("gray", "black")
E(net)$color <- colrs2[E(net)$line]
plot(net, edge.arrow.size=.05,vertex.label=V(net)$FinName,vertex.label.color = "black",
vertex.label.cex=log2(V(net)$Freq)/NodeTextSize, layout = layout_in_circle)
# We can even set the network layout:
if(layout=="Circle"){
plot(net, edge.arrow.size=.05,vertex.label=V(net)$FinName,vertex.label.color = "black",
vertex.label.cex=log2(V(net)$Freq)/NodeTextSize, layout = layout_in_circle)
}else if(layout=="Fruchterman-Reingold"){
plot(net, edge.arrow.size=.05,vertex.label=V(net)$FinName,vertex.label.color = "black",
vertex.label.cex=log2(V(net)$Freq)/NodeTextSize, layout = layout_with_fr)
}else if(layout=="Kamada Kawai"){
plot(net, edge.arrow.size=.05,vertex.label=V(net)$FinName,vertex.label.color = "black",
vertex.label.cex=log2(V(net)$Freq)/NodeTextSize, layout = layout_with_kk)
}else if(layout=="LGL"){
plot(net, edge.arrow.size=.05,vertex.label=V(net)$FinName,vertex.label.color = "black",
vertex.label.cex=log2(V(net)$Freq)/NodeTextSize, layout = layout_with_lgl)
}
}<file_sep># heatmap code
plotInputH <- function(mx, srt, end, low, mid, high, clust){
#For the breaks
breaks=seq(srt, #start point of color key
end, #end point of color key
by=(end-srt)/50) #length of sub-division
#heatmap colors
mycol=colorpanel(n=length(breaks)-1,low=low,mid=mid,high=high)
#Make heatmap
heatmap.2(mx, #the matrix
scale="row",
Colv=F, # No clustering of columns
Rowv = F, #no clustering of rows
hclustfun = function(x) hclust(x,method = clust), #clustering function
col=mycol, #colors used in heatmap
breaks=breaks, #color key details
trace="none", #no trace on map
na.rm=TRUE, #ignore missing values
margins = c(15,10), # size and layout of heatmap window
xlab = "Conditions", #x axis title
ylab = "Substrates",
srtCol=90) # y axis title
}<file_sep>
list_of_rows <- function(fullDataSet) {
sampleNameCol=grep("Sample name", fullDataSet)
sampleNameRow=which(fullDataSet[,sampleNameCol]=="Sample name")
cycleCol=grep("Cycle", fullDataSet)
cycleRow=which(fullDataSet[,cycleCol]=="Cycle")
exposureTimeCol=grep("Exposure time", fullDataSet)
exposureTimeRow=which(fullDataSet[,exposureTimeCol]=="Exposure time")
sequenceCol=grep("Sequence", fullDataSet)
sequenceRow=which(fullDataSet[,sequenceCol]=="Sequence")
substrateCol=unlist(as.numeric(which(apply(fullDataSet, 2, grep, pattern="^ID$", value=FALSE, perl=TRUE)!=0)))
#Clean the data
goodRows=which(fullDataSet[,substrateCol]!="#REF" & fullDataSet[,substrateCol]!="ART_025_CXGLRRWSLGGLRRWSL" &
fullDataSet[,substrateCol]!="pVASP_150_164" & fullDataSet[,substrateCol]!="pTY3H_64_78" &
fullDataSet[,substrateCol]!="" & fullDataSet[,substrateCol]!="ID" & fullDataSet[,substrateCol]!="UniprotAccession")
goodRowsTable=fullDataSet[goodRows,(substrateCol):ncol(fullDataSet)]
goodRowsNames<-goodRowsTable[,1]
return(list(cycleRow = cycleRow,
exposureTimeRow = exposureTimeRow,
sequenceRow = sequenceRow,
goodRows = goodRows,
goodRowsTable = goodRowsTable,
goodRowsNames = goodRowsNames
))
}
make_graphs <- function(controlSamplesTest, experimentalSamplesTest, fullDataSet, opt1, opt2, lower, upper){
#Get list of unique control samples (if the user selected more than one sample type)
controlSamples_u=unique(as.character(controlSamplesTest[sampleNameRow, ]))
experimentalSamples_u=unique(as.character(experimentalSamplesTest[sampleNameRow, ]))
allSamples_u=union(controlSamples_u, experimentalSamples_u)
par(mfrow=c(1,1))
#for ggplot
graphs=list()
for(sub in goodRows){
graphs[[sub-sequenceRow]]=ggplot(as.data.frame(matrix(NA, ncol=2, nrow=5)))
}
barcodeColumns5=as.data.frame(matrix(nrow=nrow(controlSamplesTest), ncol=0))
#For each unique sample (control)
results_table_c=NULL
for(samp in 1:length(controlSamples_u)){
#Pull out the correct samples and reduce this to the post wash phase
barcodeColumns=sapply(controlSamples_u[samp], grep, controlSamplesTest)
barcodeColumns2=controlSamplesTest[,barcodeColumns]
postWashCol=min(which(sapply(1:(length(as.numeric(barcodeColumns2[cycleRow,]))-1), temp_fun, as.numeric(barcodeColumns2[cycleRow,]))==0))
barcodeColumns3=barcodeColumns2[,postWashCol:ncol(barcodeColumns2)]
barcodeColumns5=cbind(barcodeColumns5,barcodeColumns3)
#Some empty vectors to store the results of the linear regression
r2s=NULL
slopes=NULL
#For each substrate
for(sub in goodRows){
#Do and save linear regression results (maybe plot)
temp_graph=graphs[[sub-sequenceRow]] + geom_line(aes(x=V1, y=V2), as.data.frame(cbind(as.numeric(barcodeColumns3[exposureTimeRow,]), as.numeric(barcodeColumns3[sub,])))) + labs( x= "Time", y= "Intensity")
graphs[[sub-sequenceRow]]=temp_graph
df=as.data.frame(cbind(as.numeric(barcodeColumns3[exposureTimeRow,]), as.numeric(barcodeColumns3[sub,])))
linear=lm(V2~V1, df)
#linear=lm(y~0+.,df)
r2s=c(r2s,summary(linear)$r.squared)
slopes=c(slopes, coef(linear)[["V1"]])
}
#If there is more than one sample then average the r2s and slopes
results_table_c=cbind(results_table_c,goodRowsTable[,1], r2s, slopes)
}
kitty<<-cbind(results_table_c[,1], apply(results_table_c[,seq(3,ncol(results_table_c), 3)],2,as.numeric))
for(x in 2:ncol(kitty)){
colnames(kitty)[x]=paste0("control_", (x-1))
}
results_table_c=cbind(results_table_c[,1], apply(apply(results_table_c[,seq(2,ncol(results_table_c), 3)],2,as.numeric), 1, mean),apply(apply(results_table_c[,seq(3,ncol(results_table_c), 3)],2,as.numeric), 1, mean))
#For each unique sample (experimental)
results_table_e=NULL
for(samp in 1:length(experimentalSamples_u)){
#Pull out the correct samples and reduce this to the post wash phase
barcodeColumns=sapply(experimentalSamples_u[samp], grep, experimentalSamplesTest)
barcodeColumns2=experimentalSamplesTest[,barcodeColumns]
postWashCol=min(which(sapply(1:(length(as.numeric(barcodeColumns2[cycleRow,]))-1), temp_fun, as.numeric(barcodeColumns2[cycleRow,]))==0))
barcodeColumns4=barcodeColumns2[,postWashCol:ncol(barcodeColumns2)]
barcodeColumns5=cbind(barcodeColumns5,barcodeColumns4)
#Some empty vectors to store the results of the linear regression
r2s=NULL
slopes=NULL
#For each substrate
for(sub in goodRows){
#Do and save linear regression results (maybe plot)
temp_graph=graphs[[sub-sequenceRow]] + geom_line(color="red", aes(x=V1, y=V2), as.data.frame(cbind(as.numeric(barcodeColumns4[exposureTimeRow,]), as.numeric(barcodeColumns4[sub,])))) + labs( x= "Time", y= "Intensity")
graphs[[sub-sequenceRow]]=temp_graph
df=as.data.frame(cbind(as.numeric(barcodeColumns4[exposureTimeRow,]), as.numeric(barcodeColumns4[sub,])))
linear=lm(V2~V1, df)
r2s=c(r2s,summary(linear)$r.squared)
slopes=c(slopes, coef(linear)[["V1"]])
}
#If there is more than one sample then average the r2s and slopes
# if(samp == 1){
results_table_e=cbind(results_table_e,goodRowsTable[,1], r2s, slopes)
}
kitty2<<-cbind(results_table_e[,1], apply(results_table_e[,seq(3,ncol(results_table_e), 3)],2,as.numeric))
for(x in 2:ncol(kitty2)){
colnames(kitty2)[x]=paste0("experimental_", (x-1))
}
results_table_e=cbind(results_table_e[,1], apply(apply(results_table_e[,seq(2,ncol(results_table_e), 3)],2,as.numeric), 1, mean),apply(apply(results_table_e[,seq(3,ncol(results_table_e), 3)],2,as.numeric), 1, mean))
results_table=inner_join(as.data.frame(results_table_c), as.data.frame(results_table_e), by="V1")
new_kitty=inner_join(as.data.frame(kitty), as.data.frame(kitty2), by="V1")
new_kitty[,ncol(new_kitty)+1]=as.numeric(as.character(results_table[,3]))/as.numeric(as.character(results_table[,5]))
results_table_download2=cbind(new_kitty, results_table[,2:5])
colnames(results_table_download2)=c("Substrate", colnames(new_kitty)[2:(ncol(new_kitty)-1)], "Fold_Change", "R2_Control", "Average_Control", "R2_Experimental", "Average_Experimental")
results_table_download2<<-results_table_download2
print(barcodeColumns5)
if(opt1==T){ #Remove substrates without a max value of above 2 for each sample
print("in opt 1")
temp=matrix(ncol=length(allSamples_u), nrow=length(goodRows))
for(i in 1:(ncol(barcodeColumns5)/5)){
#for(i in 1:length(allSamples_u)){ #this is where i am testing a fix
print(i)
temp[,i]=as.numeric(as.character(apply(barcodeColumns5[goodRows,((1:5)+(i-1)*5)],1,max)))
}
results_table=results_table[which(apply(temp, 1, min)>=2),]
x<<-length(which(apply(temp, 1, min)<2))
}
if(opt2==T){ #Remove substrates without an average R2 of greater than 0.9
print("in opt 2")
y<<-length(which(as.numeric(as.character(results_table[,2]))<0.9 | as.numeric(as.character(results_table[,4]))<0.9))
results_table=results_table[which(as.numeric(as.character(results_table[,2]))>=0.9 & as.numeric(as.character(results_table[,4]))>=0.9),]
}
results_table[,6]=as.numeric(as.character(results_table[,3]))/as.numeric(as.character(results_table[,5]))
results_table_prime=new_kitty
num_good<<-nrow(results_table)
results_table_download1=results_table
colnames(results_table_download1)=c("Substrate", "R2_Control", "Average_Control", "R2_Experimental", "Average_Experimental", "Fold_Change")
results_table_download1<<-results_table_download1
#TODO: save previous results table for heatmap
results_table=results_table[which(results_table[,6]<=lower | results_table[,6]>=upper),]
return(list(results_table, graphs, results_table_prime))
}
#This function is used in the post wash phase identification to find when the cycle is no longer increasing
temp_fun <- function(ind,list){
dist(c(list[ind], list[ind+1]))
}
#To test if a value is non-zero
is.non.zero<-function(x){
if(is.numeric(x)){
return(x>0)
}
}<file_sep>library(shiny)
library(shinydashboard)
library(leaflet)
library(data.table)
library(DT)
library(plyr)
library(ggplot2)
library(dplyr)
library(gplots)
library(igraph)
library(stringr)
library(shinycssloaders)
krsa <-
function (file ,iterations, numSigSubs, sigSubs) {
withProgress(message = 'KRSA', value = 0, {
#incProgress(1/5, detail = "Reading file")
subKinase <- read.table(file, header = TRUE, sep = "\t", as.is=T, quote = "\"", check.names=FALSE, stringsAsFactors=FALSE)
kinaseSep=" "
subKinaseOnly=toupper(subKinase[,2])
splitKinase=NULL
#incProgress(2/5, detail = "Finding unique kinases")
for(i in 1:length(subKinaseOnly)){
splitKinase=paste0(splitKinase, subKinaseOnly[i], sep=kinaseSep )
}
uniqueKin=unique(unlist(strsplit(splitKinase, split=kinaseSep)))
scores=data.frame(matrix(ncol = iterations, nrow = length(uniqueKin)), row.names=uniqueKin)
for(i in 1:iterations){
incProgress((1/iterations), detail = paste0(i, "/", iterations))
sampleList=sample(subKinaseOnly, numSigSubs)
scores[,i]=iterationScore(sampleList, kinaseSep, uniqueKin)
}
#incProgress(4/5, detail = "Averaging")
scores=cbind(scores, rowMeans(scores)) #get the average kinase amount
yourSubs=subset(subKinase, subKinase$Substrates %in% sigSubs)
yourScores=data.frame(matrix(ncol = 1, nrow = length(uniqueKin)), row.names=uniqueKin)
yourScores[,1]=iterationScore(yourSubs[,2], kinaseSep, uniqueKin)
#section to make overall table
#incProgress(5/5, detail = "Creating results")
overallTable=as.data.frame(cbind(Kinase=uniqueKin, DxAverage=yourScores[,1], ReSamplingAverage=scores[,iterations+1]))
overallTable[,2]=as.numeric(as.character(overallTable[,2]))
overallTable[,3]=as.numeric(as.character(overallTable[,3]))
overallTable=cbind(overallTable, AbsoluteDiference=abs(overallTable[,2]-overallTable[,3]))
overallTable=cbind(overallTable, StandardDeviation=unlist(apply(scores[,1:iterations], 1, sd)))
overallTable=cbind(overallTable, Minus2Sd=overallTable[,3]-2*(overallTable[,5]) , Plus2SD=overallTable[,3]+2*(overallTable[,5]))
overallTable=cbind(overallTable, Down=(ifelse(overallTable[,2]<overallTable[,6], "YES", "x")), Up=(ifelse(overallTable[,2]>overallTable[,7], "YES", "x")))
overallTable=cbind(overallTable, ZScore=abs((overallTable[,2]-overallTable[,3])/overallTable[,5]))
overallTable2=overallTable[order(overallTable$ZScore, decreasing=TRUE),]
#kittyYES<<-overallTable2
print("Done")
})
return(list(overallTable2, scores))
}
#Function to get a score for each kinase for each iteration
iterationScore <- function(sampleList, kinaseSep, uniqueKin){
splitKinase=NULL
for(i in 1:length(sampleList)){
splitKinase=paste0(splitKinase, sampleList[i], sep=kinaseSep)
}
splitKinase2=unlist(strsplit(splitKinase, split=kinaseSep))
returnVector=c()
for(i in 1:length(uniqueKin)){
temp=paste("^",uniqueKin[i],"$", sep="")
returnVector[i]=length(grep(temp, splitKinase2))
}
return(returnVector)
}
dropdownButton <- function(label = "", status = c("default", "primary", "success", "info", "warning", "danger"), ..., width = NULL) {
status <- match.arg(status)
# dropdown button content
html_ul <- list(
class = "dropdown-menu",
style = if (!is.null(width))
paste0("width: ", validateCssUnit(width), ";"),
lapply(X = list(...), FUN = tags$li, style = "margin-left: 10px; margin-right: 10px;")
)
# dropdown button apparence
html_button <- list(
class = paste0("btn btn-", status," dropdown-toggle"),
type = "button",
`data-toggle` = "dropdown"
)
html_button <- c(html_button, list(label))
html_button <- c(html_button, list(tags$span(class = "caret")))
# final result
tags$div(
class = "dropdown",
do.call(tags$button, html_button),
do.call(tags$ul, html_ul),
tags$script(
"$('.dropdown-menu').click(function(e) {
e.stopPropagation();
});")
)
}
make_graphs <- function(controlSamplesTest, experimentalSamplesTest, fullDataSet, opt1, opt2, lower, upper){
#Get the correct rows and columns and substrate names
sampleNameCol=grep("Sample name", fullDataSet)
sampleNameRow=which(fullDataSet[,sampleNameCol]=="Sample name")
cycleCol=grep("Cycle", fullDataSet)
cycleRow=which(fullDataSet[,cycleCol]=="Cycle")
exposureTimeCol=grep("Exposure time", fullDataSet)
exposureTimeRow=which(fullDataSet[,exposureTimeCol]=="Exposure time")
sequenceCol=grep("Sequence", fullDataSet)
sequenceRow=which(fullDataSet[,sequenceCol]=="Sequence")
substrateCol=unlist(as.numeric(which(apply(fullDataSet, 2, grep, pattern="^ID$", value=FALSE, perl=TRUE)!=0)))
substrateNames=fullDataSet[(sequenceRow+1):nrow(fullDataSet), substrateCol]
print(substrateNames)
substrateNames2=substrateNames[which(substrateNames!="#REF")]
#Get list of unique control samples (if the user selected more than one sample type)
controlSamples_u=unique(as.character(controlSamplesTest[sampleNameRow, ]))
experimentalSamples_u=unique(as.character(experimentalSamplesTest[sampleNameRow, ]))
allSamples_u=union(controlSamples_u, experimentalSamples_u)
combinedDF=cbind(controlSamplesTest, experimentalSamplesTest)
par(mfrow=c(1,1))
#Clean the data
goodRows=which(fullDataSet[,substrateCol]!="#REF" & fullDataSet[,substrateCol]!="ART_025_CXGLRRWSLGGLRRWSL" &
fullDataSet[,substrateCol]!="pVASP_150_164" & fullDataSet[,substrateCol]!="pTY3H_64_78" &
fullDataSet[,substrateCol]!="" & fullDataSet[,substrateCol]!="ID" & fullDataSet[,substrateCol]!="UniprotAccession")
goodRowsTable=fullDataSet[goodRows,(substrateCol):ncol(fullDataSet)]
goodRowsNames<<-goodRowsTable[,1]
#for ggplot
graphs=list()
for(sub in goodRows){
graphs[[sub-sequenceRow]]=ggplot(as.data.frame(matrix(NA, ncol=2, nrow=5)))
}
barcodeColumns5=as.data.frame(matrix(nrow=nrow(controlSamplesTest), ncol=0))
#For each unique sample (control)
results_table_c=NULL
for(samp in 1:length(controlSamples_u)){
#Pull out the correct samples and reduce this to the post wash phase
barcodeColumns=sapply(controlSamples_u[samp], grep, controlSamplesTest)
barcodeColumns2=controlSamplesTest[,barcodeColumns]
postWashCol=min(which(sapply(1:(length(as.numeric(barcodeColumns2[cycleRow,]))-1), temp_fun, as.numeric(barcodeColumns2[cycleRow,]))==0))
barcodeColumns3=barcodeColumns2[,postWashCol:ncol(barcodeColumns2)]
barcodeColumns5=cbind(barcodeColumns5,barcodeColumns3)
#Some empty vectors to store the results of the linear regression
r2s=NULL
slopes=NULL
#goodRows <- goodRows[goodRows %ni% c("ART_025_CXGLRRWSLGGLRRWSL", "pVASP_150_164","pTY3H_64_78")]
#For each substrate
for(sub in goodRows){
#Do and save linear regression results (maybe plot)
#plot(as.numeric(barcodeColumns3[exposureTimeRow,]), as.numeric(barcodeColumns3[sub,]), xlab="Exposure time", ylab="Values", main=substrateNames[sub-sequenceRow])
#temp_graph=ggplot(as.data.frame(cbind(as.numeric(barcodeColumns3[exposureTimeRow,]), as.numeric(barcodeColumns3[sub,]))), aes(x=V1, y=V2)) +geom_point()
temp_graph=graphs[[sub-sequenceRow]] + geom_line(aes(x=V1, y=V2), as.data.frame(cbind(as.numeric(barcodeColumns3[exposureTimeRow,]), as.numeric(barcodeColumns3[sub,])))) + labs( x= "Time", y= "Intensity")
graphs[[sub-sequenceRow]]=temp_graph
df=as.data.frame(cbind(as.numeric(barcodeColumns3[exposureTimeRow,]), as.numeric(barcodeColumns3[sub,])))
#linear=lm(df)
linear=lm(V2~V1, df)
#linear=lm(y~0+.,df)
r2s=c(r2s,summary(linear)$r.squared)
slopes=c(slopes, coef(linear)[["V1"]])
}
#If there is more than one sample then average the r2s and slopes
# if(samp == 1){
results_table_c=cbind(results_table_c,goodRowsTable[,1], r2s, slopes)
# }else{
# results_table_c[,2]=apply(rbind(r2s, as.numeric(results_table_c[,2])),2, mean)
# results_table_c[,3]=apply(rbind(slopes, as.numeric(results_table_c[,3])),2, mean)
# }
}
kitty<<-cbind(results_table_c[,1], apply(results_table_c[,seq(3,ncol(results_table_c), 3)],2,as.numeric))
for(x in 2:ncol(kitty)){
colnames(kitty)[x]=paste0("control_", (x-1))
}
results_table_c=cbind(results_table_c[,1], apply(apply(results_table_c[,seq(2,ncol(results_table_c), 3)],2,as.numeric), 1, mean),apply(apply(results_table_c[,seq(3,ncol(results_table_c), 3)],2,as.numeric), 1, mean))
#For each unique sample (experimental)
results_table_e=NULL
for(samp in 1:length(experimentalSamples_u)){
#Pull out the correct samples and reduce this to the post wash phase
barcodeColumns=sapply(experimentalSamples_u[samp], grep, experimentalSamplesTest)
barcodeColumns2=experimentalSamplesTest[,barcodeColumns]
postWashCol=min(which(sapply(1:(length(as.numeric(barcodeColumns2[cycleRow,]))-1), temp_fun, as.numeric(barcodeColumns2[cycleRow,]))==0))
barcodeColumns4=barcodeColumns2[,postWashCol:ncol(barcodeColumns2)]
barcodeColumns5=cbind(barcodeColumns5,barcodeColumns4)
#Some empty vectors to store the results of the linear regression
r2s=NULL
slopes=NULL
#For each substrate
for(sub in goodRows){
#Do and save linear regression results (maybe plot)
#plot(as.numeric(barcodeColumns3[exposureTimeRow,]), as.numeric(barcodeColumns3[sub,]), xlab="Exposure time", ylab="Values", main=substrateNames[sub-sequenceRow])
temp_graph=graphs[[sub-sequenceRow]] + geom_line(color="red", aes(x=V1, y=V2), as.data.frame(cbind(as.numeric(barcodeColumns4[exposureTimeRow,]), as.numeric(barcodeColumns4[sub,])))) + labs( x= "Time", y= "Intensity")
graphs[[sub-sequenceRow]]=temp_graph
df=as.data.frame(cbind(as.numeric(barcodeColumns4[exposureTimeRow,]), as.numeric(barcodeColumns4[sub,])))
linear=lm(V2~V1, df)
r2s=c(r2s,summary(linear)$r.squared)
slopes=c(slopes, coef(linear)[["V1"]])
}
#If there is more than one sample then average the r2s and slopes
# if(samp == 1){
results_table_e=cbind(results_table_e,goodRowsTable[,1], r2s, slopes)
# }else{
# results_table_e[,2]=apply(rbind(r2s, as.numeric(results_table_e[,2])),2, mean)
# results_table_e[,3]=apply(rbind(slopes, as.numeric(results_table_e[,3])),2, mean)
# }
}
kitty2<<-cbind(results_table_e[,1], apply(results_table_e[,seq(3,ncol(results_table_e), 3)],2,as.numeric))
for(x in 2:ncol(kitty2)){
colnames(kitty2)[x]=paste0("experimental_", (x-1))
}
results_table_e=cbind(results_table_e[,1], apply(apply(results_table_e[,seq(2,ncol(results_table_e), 3)],2,as.numeric), 1, mean),apply(apply(results_table_e[,seq(3,ncol(results_table_e), 3)],2,as.numeric), 1, mean))
results_table=inner_join(as.data.frame(results_table_c), as.data.frame(results_table_e), by="V1")
new_kitty=inner_join(as.data.frame(kitty), as.data.frame(kitty2), by="V1")
new_kitty[,ncol(new_kitty)+1]=as.numeric(as.character(results_table[,3]))/as.numeric(as.character(results_table[,5]))
results_table_download2=cbind(new_kitty, results_table[,2:5])
colnames(results_table_download2)=c("Substrate", colnames(new_kitty)[2:(ncol(new_kitty)-1)], "Fold_Change", "R2_Control", "Average_Control", "R2_Experimental", "Average_Experimental")
results_table_download2<<-results_table_download2
print(barcodeColumns5)
if(opt1==T){ #Remove substrates without a max value of above 2 for each sample
print("in opt 1")
temp=matrix(ncol=length(allSamples_u), nrow=length(goodRows))
for(i in 1:(ncol(barcodeColumns5)/5)){
#for(i in 1:length(allSamples_u)){ #this is where i am testing a fix
print(i)
temp[,i]=as.numeric(as.character(apply(barcodeColumns5[goodRows,((1:5)+(i-1)*5)],1,max)))
}
results_table=results_table[which(apply(temp, 1, min)>=2),]
x<<-length(which(apply(temp, 1, min)<2))
#results_table=results_table[which(barcodeColumns3[sequenceRow+1:nrow(barcodeColumns3),5]>=2 & barcodeColumns4[sequenceRow+1:nrow(barcodeColumns4),5]>=2, goodRows),]
# results_table_c=results_table_c[intersect(which(barcodeColumns3[,5]>=2), goodRows)-goodRows[1],]
# results_table_e=results_table_e[intersect(which(barcodeColumns4[,5]>=2), goodRows)-goodRows[1],]
}
if(opt2==T){ #Remove substrates without an average R2 of greater than 0.9
print("in opt 2")
#results_table_c=results_table_c[which(results_table_c[,2]>=0.9),] #TODO: variablize this.
#results_table_e=results_table_e[which(results_table_e[,2]>=0.9),]
y<<-length(which(as.numeric(as.character(results_table[,2]))<0.9 | as.numeric(as.character(results_table[,4]))<0.9))
results_table=results_table[which(as.numeric(as.character(results_table[,2]))>=0.9 & as.numeric(as.character(results_table[,4]))>=0.9),]
}
# reduced_peptides=intersect(results_table_c[,1], results_table_e[,1])
# temp_results_table_c=log2(as.numeric(results_table_c[results_table_c[,1] %in% reduced_peptides,3])*100)
# temp_results_table_e=log2(as.numeric(results_table_e[results_table_e[,1] %in% reduced_peptides,3])*100)
# temp_results_table=temp_results_table_c/temp_results_table_e
# results_table_c[,3]=sign(as.numeric(results_table_c[,3]))*log2(abs(as.numeric(results_table_c[,3]))*100)
# results_table_e[,3]=sign(as.numeric(results_table_e[,3]))*log2(abs(as.numeric(results_table_e[,3]))*100)
# goodResults_c=results_table_c[which(sign(as.numeric(results_table_c[,3]))==1),]
# goodResults_e=results_table_e[which(sign(as.numeric(results_table_e[,3]))==1),]
# goodResults=inner_join(as.data.frame(goodResults_c), as.data.frame(goodResults_e), by="V1") #This is what I'm going to return from my function
#goodResults[,6]=as.numeric(as.character(goodResults[,5]))-as.numeric(as.character(goodResults[,3])) #fold change differnce between log slopes
# goodResults[,6]=as.numeric(as.character(goodResults[,5]))/as.numeric(as.character(goodResults[,3])) #fold change differnce between slopes
# goodResults[,7]=2^goodResults[,6]
# goodResults=goodResults[which(goodResults[,7]<=lower | goodResults[,7]>=upper),]
results_table[,6]=as.numeric(as.character(results_table[,3]))/as.numeric(as.character(results_table[,5]))
results_table_prime=new_kitty
num_good<<-nrow(results_table)
results_table_download1=results_table
colnames(results_table_download1)=c("Substrate", "R2_Control", "Average_Control", "R2_Experimental", "Average_Experimental", "Fold_Change")
results_table_download1<<-results_table_download1
#TODO: save previous results table for heatmap
results_table=results_table[which(results_table[,6]<=lower | results_table[,6]>=upper),]
return(list(results_table, graphs, results_table_prime))
}
#This function is used in the post wash phase identification to find when the cycle is no longer increasing
temp_fun <- function(ind,list){
dist(c(list[ind], list[ind+1]))
}
#To test if a value is non-zero
is.non.zero<-function(x){
if(is.numeric(x)){
return(x>0)
}
}
###############################################################################
ui <- shinyUI(fluidPage(
includeCSS("styles.css"),
#Application title
headerPanel("Kinome Random Sampling Analyzer"),
#Layout type
sidebarLayout(
#Sidebar Panel
sidebarPanel(
fileInput('file0', label = h3("Upload raw data file"),
accept=c('text/csv', 'text/comma-separated-values','text/plain', '.csv')),
#Options for file type including header, seperator, and quotes.
h4("File options:"),
checkboxInput('header1', 'Header', TRUE),
radioButtons('sep1', 'Separator', inline=F,
c(Tab='\t',
Comma=',',
Semicolon=';'),
'\t'),
radioButtons('quote1', 'Quote', inline=F,
c(None='',
'Double Quote'='"',
'Single Quote'="'"),
'"'),
tags$hr(),
#TODO: uncomment below for PINET
# radioButtons("radio", label = h3("Chose your kinase-peptide association option"),
# choices = list("PiNET" = 1, "Upload" = 2),
# selected = 2),
#This takes a tab or comma seperated file as input, with the first column "Substrates" and
#the second column "Kinases" being the only two columns and both required.
conditionalPanel(
#TODO: uncomment below for PINET and comment out "condition = TRUE"
#condition = "input.radio==2",
condition = TRUE,
fileInput('file1', label = h5("Kinase-peptide association file"),
accept=c('text/csv', 'text/comma-separated-values','text/plain', '.csv')),
h4("File options:"),
checkboxInput('header2', 'Header', TRUE),
radioButtons('sep2', 'Separator', inline=F,
c(Tab='\t',
Comma=',',
Semicolon=';'),
'\t'),
radioButtons('quote2', 'Quote', inline=F,
c(None='',
'Double Quote'='"',
'Single Quote'="'"),
'"')
),
tags$hr()
),
#Main Panel
mainPanel(
tags$style(HTML("
.tabbable > .nav > li > a {background-color: #7c7c7c; color:#d6d6d6}
.tabbable > .nav > li[class=active] > a {background-color: #008E94; color:white}
")),
tabsetPanel(
tabPanel("Step 1: Options",
h2("Data Selection:"),
#celltype
fluidRow(
column(4,
dropdownButton(
label = "Step 1: Experiment Barcode", status = "default", width = 80,
actionButton(inputId = "celltypea2z", label = "Sort A to Z", icon = icon("sort-alpha-asc")),
actionButton(inputId = "celltypez2a", label = "Sort Z to A", icon = icon("sort-alpha-desc")),
br(),
actionButton(inputId = "celltypeall", label = "(Un)select all"),
checkboxGroupInput(inputId = "celltype", label = "Choose", choices = c()))),
column(4,
dropdownButton(
label = "Step 2: Control Samples", status = "default", width = 80,
actionButton(inputId = "controlSamplesa2z", label = "Sort A to Z", icon = icon("sort-alpha-asc")),
actionButton(inputId = "controlSamplesz2a", label = "Sort Z to A", icon = icon("sort-alpha-desc")),
br(),
actionButton(inputId = "controlSamplesall", label = "(Un)select all"),
checkboxGroupInput(inputId = "controlSamples", label = "Choose", choices = c()))),
column(4,
dropdownButton(
label = "Step 3: Experimental Samples", status = "default", width = 80,
actionButton(inputId = "experimentalSamplesa2z", label = "Sort A to Z", icon = icon("sort-alpha-asc")),
actionButton(inputId = "experimentalSamplesz2a", label = "Sort Z to A", icon = icon("sort-alpha-desc")),
br(),
actionButton(inputId = "experimentalSamplesall", label = "(Un)select all"),
checkboxGroupInput(inputId = "experimentalSamples", label = "Choose", choices = c())))
),
tags$hr(),
h2("Preview Data:"),
fluidRow(
h3("Preview of all data"),
shiny::dataTableOutput(outputId="contents0"),
#DT::dataTableOutput('contents0'),
#column(6,
#DT::dataTableOutput('contents1'),
h3("Preview of control data"),
shiny::dataTableOutput(outputId="contents1"),
#),
#column(6,
h3("Preview of experimental data"),
shiny::dataTableOutput(outputId="contents2")
#)
)
),
tabPanel("Step 2: Stringency",
sliderInput("FCslider", label = h3("Select Fold Change"), min = 0, max = 2, value = c(0.85,1.15), step=0.05),
h3("Select Stringency Level"),
fluidRow(
column(6,
checkboxGroupInput("StrinRadio",label=NULL, choices = list("Max exposure >= 2" = 1, "R^2 >=0.9" = 2), selected = c(1,2)),
actionButton("calculateData", "Find Significant Substrates")
),
column(6,
textOutput("remain1"),
textOutput("remain2")
)
),
hr(),
downloadButton('downloadDataFC', 'Download Substrate Results'),
downloadButton('downloadDataFC2', 'Download Substrate Results 2'),
selectInput("xyplot", "Choose a Substrate:", choices=c()),
plotOutput("xyplot2", width = "100%", height="600px"),
downloadButton('downloadData_LR', 'Download Graph'),
hr()
#dataTableOutput("subTable")
),
tabPanel("Step 3: Iteration",
#This is the slider that allows you to choose the number of iterations of sampling you
#want to do, from 0 to 5000 (1000 default) and jumping in increments of 100.
sliderInput("slider1", label = h4("Select the number of iterations"), min = 0,
max = 5000, value = 1000, step=100, width='100%'),
tags$hr(),
h4("Confirm and Run"),
textOutput("subnum"),
textOutput("subnum4"),
textOutput("subnum3"),
htmlOutput("subnum2"),
actionButton("compute", "Run KRSA")
),
tabPanel("Step 4: Results",
DT::dataTableOutput("overallTable"),
downloadButton('downloadDataR', 'Download Results')
),
tabPanel("Step 5: Histograms",
selectInput("kinase", "Choose a Kinase:", choices=c()),
plotOutput("histo", width = "100%", height="600px"),
downloadButton('downloadData', 'Download Histogram')
),
tabPanel("Step 6: Heatmap",
fluidRow(
column(6,
sliderInput("slider2", label = "Breaks", min = -10,
max = 10, value = c(-4, 4)),
selectInput("clust", "Clustering method:", choices=c("complete", "ward.D", "ward.D2", "single", "average", "mcquitty", "median", "centroid"))
),
column(6,
selectInput("low", "Choose low phosphorylation color:", choices=c("cyan", "orange", "yellow", "green", "darkgreen", "red", "blue", "purple", "magenta")),
selectInput("mid", "Choose middle phosphorylation color:", choices=c("black", "white")),
selectInput("high", "Choose high phosphorylation color:", choices=c("yellow", "orange", "red", "green", "darkgreen", "cyan", "blue", "purple", "magenta")),
downloadButton('downloadDataH', 'Download Heatmap')
)
),
hr(),
plotOutput("heatmap", width = "100%", height="1200px")
),
tabPanel("Step 7: Network",
fluidRow(
column(6,
#sliderInput("sliderExpans", label = "Generations", min = 1, max = 3, value=1),
sliderInput("nodeSize", label = "Node Size", min=1, max=10, value=3, step=1),
sliderInput("nodeTextSize", label = "Node Text Size", min=1, max=10, value=6, step=1)
#checkboxInput("low_conf", "Include Low Confidence Connections", FALSE),
#selectInput("interType", "Interaction Type", choices=c("All Interactions", "Kinase Only"))
),
column(6,
selectInput("hitsColor", "Choose color for KRSA kinases:", choices=c("red","cyan", "orange", "yellow", "green", "darkgreen", "blue", "purple", "magenta", "white", "gray")),
selectInput("interColor", "Choose color for interacting proteins:", choices=c("gray","red", "orange", "yellow", "green", "darkgreen", "cyan", "blue", "purple", "magenta", "white")),
selectInput("layout", "Choose layout:", choices=c("Circle", "Fruchterman-Reingold", "Kamada Kawai", "LGL")),
downloadButton('downloadDataN', 'Download Network')
)
),
hr(),
withSpinner(plotOutput("networkPlot", width = "100%", height="1200px"), proxy.height = "10px") #TODO: trying to use proxy height to move the spinner up but no luck
)
)
)
)
))
###############################################################################
server <- function(input, output, session) {
session$onSessionEnded(stopApp)
overallTable2 <<- reactiveValues()
scores <- reactiveValues()
barcodeOptions2 <<-reactiveValues()
controlOptions2 <<-reactiveValues()
experimentalOptions2 <<-reactiveValues()
graphs<<-reactiveValues()
#Creates an empty object to store the Substrate names in.
dsnames <- c()
#Creates an empty object to store the selected substrates in.
#Not sure the below is correct...
selectedSubnames<-reactive({input$inCheckboxGroup})
#print(selectedSubnames())
#Reactive dataset for the input file 0 (raw data).
data_set0 <- reactive({
req(input$file0)
inFile <- input$file0
data_set0<-read.csv(inFile$datapath, header=input$header1,
sep=input$sep1, quote=input$quote1, stringsAsFactors = F)
fullDataSet<<-data_set0
fullDataSet
})
#Output for rendering the preview table in the main panel.
#output$contents0 <- DT::renderDataTable({
output$contents0 <- shiny::renderDataTable({
if(is.null(input$celltype)){
return(data_set0())
}else{
barcodeColumns=sapply(input$celltype, grep, data_set0())
print(class(barcodeColumns))
#print(barcodeColumns)
if(class(barcodeColumns)=="list"){
barcodeColumns=unlist(barcodeColumns)
}
barcodeColumns2=data_set0()[,barcodeColumns]
return(barcodeColumns2)
}
#}, caption = "Preview of raw data file")
}, options=list(scrollX=TRUE, pageLength = 10))
#Output for rendering the preview table in the main panel.
#output$contents1 <- DT::renderDataTable({
output$contents1 <- shiny::renderDataTable({
if(is.null(input$controlSamples)){
return(data_set0())
}else{
a=paste0("^", input$controlSamples, "$")
b=NULL
for(x in 1:length(a)){
kitty=apply(data_set0()[controlOptions1,], 2, grep, pattern=a[x], value=FALSE, perl=TRUE)
temp=which(unlist(lapply(lapply(kitty, is.non.zero), isTRUE))==TRUE)
#temp=as.numeric(which(unlist(apply(fullDataSet[controlOptions1,], 2, grep, pattern=a[x], value=FALSE, perl=TRUE))!=0))
print(temp)
b=c(b, temp)
}
barcodeColumns=as.numeric(b)
print(barcodeColumns)
#barcodeColumns=sapply(input$controlSamples, grep, data_set0())
barcodeColumns2=data_set0()[,barcodeColumns]
controlSamplesTest<<-barcodeColumns2
return(barcodeColumns2)
}
#}, caption = "Preview of control data", options=list(autoWidth=TRUE))
}, options=list(scrollX=TRUE, pageLength = 10))
#Output for rendering the preview table in the main panel.
#output$contents2 <- DT::renderDataTable({
output$contents2 <- shiny::renderDataTable({
if(is.null(input$experimentalSamples)){
return(data_set0())
}else{
a=paste0("^", input$experimentalSamples, "$")
print(a)
b=NULL
for(x in 1:length(a)){
#b=c(b, as.numeric(which(apply(data_set0(), 2, grep, pattern=a[x], value=FALSE, perl=TRUE)!=0)))
kitty=apply(data_set0()[controlOptions1,], 2, grep, pattern=a[x], value=FALSE, perl=TRUE)
temp=which(unlist(lapply(lapply(kitty, is.non.zero), isTRUE))==TRUE)
#temp=as.numeric(which(unlist(apply(fullDataSet[controlOptions1,], 2, grep, pattern=a[x], value=FALSE, perl=TRUE))!=0))
print(temp)
b=c(b, temp)
}
barcodeColumns=as.numeric(b)
print(barcodeColumns)
#barcodeColumns=sapply(input$experimentalSamples, grep, data_set0())
barcodeColumns2=data_set0()[,barcodeColumns]
experimentalSamplesTest<<-barcodeColumns2
return(barcodeColumns2)
}
#}, caption = "Preview of experimental data", options=list(autoWidth=TRUE))
}, options=list(scrollX=TRUE, pageLength = 10))
#barcode select
observe({
barcodeOptions=grep("Barcode", data_set0())
barcodeOptions1=which(data_set0()[,barcodeOptions]=="Barcode")
barcodeOptions1.5=as.numeric(data_set0()[barcodeOptions1,(barcodeOptions+1):ncol(data_set0())])
barcodeOptions2<<-unique(sort(barcodeOptions1.5))
updateCheckboxGroupInput(session, "celltype",
choices = barcodeOptions2,
selected = NA #This change made it so all of the boxes were selected by default
)
})
# Sorting asc
observeEvent(input$celltypea2z, {
updateCheckboxGroupInput(
session = session, inputId = "celltype",
choices = barcodeOptions2,
selected = input$celltype
)
})
# Sorting desc
observeEvent(input$celltypez2a, {
updateCheckboxGroupInput(
session = session, inputId = "celltype",
choices = sort(barcodeOptions2,decreasing=T),
selected = input$celltype
)
})
# Select all / Unselect all
observeEvent(input$celltypeall, {
if (is.null(input$celltype)) {
updateCheckboxGroupInput(
session = session, inputId = "celltype",
selected = barcodeOptions2
)
} else {
updateCheckboxGroupInput(
session = session,
inputId = "celltype",
selected = ""
)
}
})
#control group select
observeEvent(input$celltype,{
controlOptions=grep("Sample name", data_set0())
controlOptions1<<-which(data_set0()[,controlOptions]=="Sample name")
controlOptions1.1=sapply(input$celltype, grep, data_set0())
if(class(controlOptions1.1)=="list"){
controlOptions1.1=unlist(controlOptions1.1)
}
controlOptions1.5=as.character(data_set0()[controlOptions1,controlOptions1.1])
controlOptions2<<-unique(sort(controlOptions1.5))
#print(controlOptions)
#print(controlOptions1)
#print(controlOptions1.5)
#print(controlOptions2)
updateCheckboxGroupInput(session, "controlSamples",
choices = controlOptions2,
selected = NA #This change made it so all of the boxes were selected by default
)
})
# Sorting asc
observeEvent(input$controlSamplesa2z, {
updateCheckboxGroupInput(
session = session, inputId = "controlSamples",
choices = controlOptions2,
selected = input$controlSamples
)
})
# Sorting desc
observeEvent(input$controlSamplesz2a, {
updateCheckboxGroupInput(
session = session, inputId = "controlSamples",
choices = sort(controlOptions2,decreasing=T),
selected = input$controlSamples
)
})
# Select all / Unselect all
observeEvent(input$controlSamplesall, {
if (is.null(input$controlSamples)) {
updateCheckboxGroupInput(
session = session, inputId = "controlSamples",
selected = controlOptions2
)
} else {
updateCheckboxGroupInput(
session = session,
inputId = "controlSamples",
selected = ""
)
}
})
#experimental group select
observeEvent(input$controlSamples,{
experimentalOptions=grep("Sample name", data_set0())
experimentalOptions1=which(data_set0()[,experimentalOptions]=="Sample name")
experimentalOptions1.1=sapply(input$celltype, grep, data_set0())
if(class(experimentalOptions1.1)=="list"){
experimentalOptions1.1=unlist(experimentalOptions1.1)
}
experimentalOptions1.5=as.character(data_set0()[experimentalOptions1,experimentalOptions1.1])
experimentalOptions2<<-unique(sort(experimentalOptions1.5))
#print(experimentalOptions)
#print(experimentalOptions1)
#print(experimentalOptions1.5)
#print(experimentalOptions2)
updateCheckboxGroupInput(session, "experimentalSamples",
choices = experimentalOptions2,
selected = NA #This change made it so all of the boxes were selected by default
)
})
# Sorting asc
observeEvent(input$experimentalSamplesa2z, {
updateCheckboxGroupInput(
session = session, inputId = "experimentalSamples",
choices = experimentalOptions2,
selected = input$experimentalSamples
)
})
# Sorting desc
observeEvent(input$experimentalSamplesz2a, {
updateCheckboxGroupInput(
session = session, inputId = "experimentalSamples",
choices = sort(experimentalOptions2,decreasing=T),
selected = input$experimentalSamples
)
})
# Select all / Unselect all
observeEvent(input$experimentalSamplesall, {
if (is.null(input$experimentalSamples)) {
updateCheckboxGroupInput(
session = session, inputId = "experimentalSamples",
selected = experimentalOptions2
)
} else {
updateCheckboxGroupInput(
session = session,
inputId = "experimentalSamples",
selected = ""
)
}
})
#Reactive dataset for the input file 1 (kinase peptide associations).
data_set <- reactive({
req(input$file1)
inFile <- input$file1
data_set<-read.csv(inFile$datapath, header=input$header2,
sep=input$sep2, quote=input$quote2)
data_set
})
#Output for rendering the preview table in the main panel.
output$contents <- renderTable({
data_set()
})
#For the stringency tab
output$FCslider <- renderPrint({ input$FCslider })
output$StrinRadio <- renderPrint({ input$StrinRadio })
#Display graph
observeEvent(input$calculateData, {
#print(input$xyplot)
plotInputG <- function(){
plotIndex=which(goodRowsNames==input$xyplot)
print(plotIndex)
graphs[plotIndex]
}
#Display graph
output$xyplot2 <- renderPlot({
plotInputG()
})
#Download graph
output$downloadData_LR <- downloadHandler(
file = function() { paste0(input$xyplot, ".pdf") },
content = function(file) {
pdf(file)
print(plotInputG())
dev.off()
#ggsave(filename=file, plot = plotInputG(), device = "pdf")
})
})
#Run make_graphs
observeEvent(input$calculateData, {
options1=input$StrinRadio
print(options1)
if(1 %in% options1){
opt1=T
}else{
opt1=F
}
if(2 %in% options1){
opt2=T
}else{
opt2=F
}
results<<-make_graphs(controlSamplesTest, experimentalSamplesTest, fullDataSet, opt1, opt2, input$FCslider[1], input$FCslider[2])
#print(class(results))
resultsTable<<-results[[1]]
graphs <<- results[[2]]
resultsTablePrime<<-results[[3]]
print(class(graphs))
updateSelectInput(
session = session, inputId = "xyplot",
choices = resultsTable[,1],
selected = resultsTable[1,1]
)
output$overallTable <- DT::renderDataTable({
datatable(subTable, rownames = TRUE, caption = "Substrates Table")
})
})
#Download table of FC results 1
output$downloadDataFC <- downloadHandler(
filename = "substrate_results.csv",
content = function(file) {
write.csv(results_table_download1, file, row.names = FALSE)
}
)
#Download table of FC results 2
output$downloadDataFC2 <- downloadHandler(
filename = "substrate_results_2.csv",
content = function(file) {
write.csv(results_table_download2, file, row.names = FALSE)
}
)
#Guts for making the dynamic checkboxes work.
observe({
req(input$file1)
dsnames <- data_set()$Substrates
updateCheckboxGroupInput(session, "inCheckboxGroup",
label = "",
choices = dsnames,
selected = "")
})
#You can access the value of the widget with input$slider1, e.g.
#output$value <- renderPrint({ input$slider1 })
#State how many of each element there are.
observeEvent(input$calculateData,{
#Update checkboxes to reflect the number of subs removed by each option
if(1 %in% input$StrinRadio & 2 %in% input$StrinRadio){
kittyx=paste0("Max exposure >= 2 (", x, " substrates removed with Option 1)")
kittyy=paste0("R^2 >=0.9 (", y, " substrates removed with Option 2)")
updateCheckboxGroupInput(session, inputId="StrinRadio", choiceNames = list(kittyx, kittyy), choiceValues=c(1,2), selected = c(1,2))
}else if(1 %in% input$StrinRadio){
kittyx=paste0("Max exposure >= 2 (", x, " substrates removed with Option 1)")
updateCheckboxGroupInput(session, inputId="StrinRadio", choiceNames = list(kittyx, "R^2 >=0.9"), choiceValues=c(1,2), selected = 1)
}else if(2 %in% input$StrinRadio){
kittyy=paste0("R^2 >=0.9 (", y, " substrates removed with Option 2)")
updateCheckboxGroupInput(session, inputId="StrinRadio", choiceNames = list("Max exposure >= 2", kittyy), choiceValues=c(1,2), selected = 2)
}
output$remain1 <- renderText({
paste0("You have selected ", nrow(resultsTable), " substrates based on inclusion and exclusion criteria.")
})
output$remain2 <- renderText({
paste0( nrow(resultsTable), "/", num_good, " (", round((nrow(resultsTable)/num_good)*100, 2), "%) substrates were chosen for KRSA analysis.")
#paste0( nrow(resultsTable), "/", nrow(resultsTablePrime), " (", round((nrow(resultsTable)/nrow(resultsTablePrime))*100, 2), "%) substrates were chosen for KRSA analysis.")
})
output$subnum <- renderText({
paste0("There are ", nrow(data_set()), " substrates in your data set.")
})
output$subnum3 <- renderText({
paste0("You have selected ", nrow(resultsTable) , " significant substrates from your data set (listed below):")
})
output$subnum2 <- renderUI({
str1 <- paste0("")
str2 <- as.character(resultsTable[,1])
HTML(paste(str2, str1, sep = '<br/>'))
})
output$subnum4 <- renderText({
paste0("You have selected ", input$slider1 , " iterations.")
})
})
observeEvent(input$compute, {
functionresults=krsa(input$file1$datapath,iterations=input$slider1, numSigSubs=nrow(resultsTable), sigSubs=as.character(resultsTable[,1]))
showNotification("KRSA Finished")
overallTable2<<-functionresults[[1]]
meow<<-as.data.frame(overallTable2)
scores<<-functionresults[[2]]
output$overallTable <- DT::renderDataTable({
datatable(overallTable2, rownames = TRUE, caption = "Results Table")
})
#Guts for making the histogram drop down work.
updateSelectInput(session, "kinase", choices=rownames(overallTable2))
})
#Download table of KRSA results
output$downloadDataR <- downloadHandler(
filename = "KRSA_results.csv",
content = function(file) {
write.csv(overallTable2, file, row.names = FALSE)
}
)
plotInput <-function(){
OTindex<<-which(rownames(overallTable2)==input$kinase)
Sindex<<-which(rownames(scores)==input$kinase)
kitty<<-as.matrix(scores[Sindex,1:input$slider1])
kitty2=matrix(ncol=2, nrow=(nrow(resultsTable)+1))
kitty2[,1]=0:nrow(resultsTable)
for(i in 0:nrow(resultsTable)){
kitty2[i+1,2]=length(which(kitty==i))
}
theData=as.data.frame(kitty2)
colnames(theData)=c("Hits", "Frequency")
SDrect <- data.frame (xmin=overallTable2[OTindex,6], xmax=overallTable2[OTindex,7], ymin=0, ymax=Inf)
ggplot(theData, aes(Hits,Frequency)) +
geom_bar(stat="identity") +
scale_x_continuous(breaks=seq(0,nrow(resultsTable),ceiling(nrow(resultsTable)/20))) +
geom_rect(data=SDrect, aes(xmin=xmin, xmax=xmax, ymin=ymin, ymax=ymax), fill="gray", alpha=0.5, inherit.aes = FALSE) +
geom_segment(x=overallTable2[OTindex,6], y=0, xend=overallTable2[OTindex,6], yend=Inf, colour="cyan") +
geom_segment(x=overallTable2[OTindex,7], y=0, xend=overallTable2[OTindex,7], yend=Inf, colour="cyan") +
geom_segment(x=overallTable2[OTindex,2], y=0, xend=overallTable2[OTindex,2], yend=Inf, colour="red") +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.background = element_blank(), axis.line = element_line(colour = "black"))
}
output$histo <- renderPlot({
plotInput()
})
#Download Histogram
# output$downloadData <- downloadHandler(
# filename = 'test.pdf', #This is necessary even though it doesn't save it as 'test.pdf', you have to name it 'something.pdf' instead.
# content = function(file) {
# pdf(file,width=7,height=10)
# plotInput()
# dev.off()
# })
output$downloadData <- downloadHandler(
filename = function() { paste0(input$kinase, ".pdf") },
content = function(file) {
ggsave(file, plot = plotInput(), device = "pdf")
}
)
#For Heatmap
plotInputH <- function(){
#For the breaks
breaks=seq(input$slider2[1], #start point of color key
input$slider2[2], #end point of color key
by=(input$slider2[2]-input$slider2[1])/50) #length of sub-division
#Make sure that heatmap doesn't break by trying to cluster all the genes!
# if(nrow(dataForHeatmap)>1000){
# dataForHeatmap=dataForHeatmap[1:1000,]
# }
##TODO: logically reduce samples shown
#Make column 1 rownames
# dataForHeatmap2 <- dataForHeatmap[,-1]
# rownames(dataForHeatmap2) <- dataForHeatmap[,1]
#heatmap colors
mycol=colorpanel(n=length(breaks)-1,low=input$low,mid=input$mid,high=input$high)
resultsTablePrime2=resultsTablePrime[order(-abs(as.numeric(resultsTablePrime[,ncol(resultsTablePrime)]))),]
row.names(resultsTablePrime2)=resultsTablePrime2[,1]
resultsTablePrime2=resultsTablePrime2[,2:(ncol(resultsTablePrime2)-1)]
resultsTablePrime2<<-resultsTablePrime2
#Make heatmap
temp=log2(as.matrix(apply(resultsTablePrime2, 2, as.numeric))+0.1)
row.names(temp)=resultsTablePrime[order(-abs(as.numeric(resultsTablePrime[,ncol(resultsTablePrime)]))),1]
heatmap.2(temp, #the matrix
scale="row",
Colv=F, # No clustering of columns
Rowv = F, #no clustering of rows
hclustfun = function(x) hclust(x,method = input$clust), #clustering function
col=mycol, #colors used in heatmap
# ColSideColors = cc, #column color bar
breaks=breaks, #color key details
trace="none", #no trace on map
na.rm=TRUE, #ignore missing values
margins = c(15,10), # size and layout of heatmap window
xlab = "Conditions", #x axis title
ylab = "Substrates",
srtCol=90) # y axis title
}
#Display Heatmap
output$heatmap <- renderPlot({
plotInputH()
})
#Download Heatmap
output$downloadDataH <- downloadHandler( #TODO: download in portrait mode
filename = "heatmap.pdf",
content = function(file) {
pdf(file)
plotInputH()
dev.off()
})
#For Network
plotInputN <- function(){
meow %>% select(Kinase, Down, Up) %>% dplyr::filter(Down =="YES" | Up == "YES") %>%
pull(Kinase) -> KinHits1
HitsColor=input$hitsColor #user input
InterColor=input$interColor #user input
NodeSize=input$nodeSize #user input
NodeTextSize= abs(input$nodeTextSize - 11) #user input
nodes2 <- readRDS("./data/sup/FinNodes_Final_FF.rds")
edges <- readRDS("./data/sup/FinEdges_Final_FF.rds")
nodes2 %>% dplyr::filter(FinName %in% KinHits1) %>% pull(FinName) -> sigHITS
edges %>% dplyr::filter(Source %in% sigHITS | Target %in% sigHITS) %>% dplyr::filter(Source != Target) -> modEdges
modsources <- pull(modEdges, Source)
modtargets <- pull(modEdges, Target)
modALL <- unique(c(modsources,modtargets))
nodes2 %>% dplyr::filter(FinName %in% modALL) -> nodesF
listoFkin <- pull(nodesF, FinName)
edges %>% dplyr::filter(Source %in% nodesF$FinName & Target %in% nodesF$FinName) %>% dplyr::filter(Source != Target) -> modEdges
modEdges %>% mutate(line = ifelse(Source %in% sigHITS | Target %in% sigHITS, 2,1 )) -> modEdges
modsources <- pull(modEdges, Source)
modtargets <- pull(modEdges, Target)
modALL <- c(modsources,modtargets)
as.data.frame(table(modALL)) -> concts
concts %>% dplyr::rename(FinName = modALL) -> concts
concts$FinName <- as.character(concts$FinName)
right_join(nodesF,concts) -> nodesF
nodesF %>% mutate(cl = ifelse(FinName %in% sigHITS, HitsColor, InterColor)) -> nodesF
# filter low freqs
nodesF %>% dplyr::filter(Freq>=1|cl==HitsColor) %>%
pull(FinName) -> FinKinases
modEdges %>% dplyr::filter(Source %in% FinKinases & Target %in% FinKinases) -> modEdges
nodesF %>% dplyr::filter(FinName %in% FinKinases) %>% mutate(Freq = ifelse(Freq < 4, 4, Freq)) -> nodesF
net <- graph_from_data_frame(d=modEdges, vertices=nodesF, directed=T)
net <- igraph::simplify(net,remove.loops = F, remove.multiple = F)
V(net)$size = log2(V(net)$Freq)*NodeSize
colrs <- c(HitsColor, InterColor)
V(net)$color <- V(net)$cl
colrs2 <- c("gray", "black")
E(net)$color <- colrs2[E(net)$line]
plot(net, edge.arrow.size=.05,vertex.label=V(net)$FinName,vertex.label.color = "black",
vertex.label.cex=log2(V(net)$Freq)/NodeTextSize, layout = layout_in_circle)
# We can even set the network layout:
if(input$layout=="Circle"){
plot(net, edge.arrow.size=.05,vertex.label=V(net)$FinName,vertex.label.color = "black",
vertex.label.cex=log2(V(net)$Freq)/NodeTextSize, layout = layout_in_circle)
}else if(input$layout=="Fruchterman-Reingold"){
plot(net, edge.arrow.size=.05,vertex.label=V(net)$FinName,vertex.label.color = "black",
vertex.label.cex=log2(V(net)$Freq)/NodeTextSize, layout = layout_with_fr)
}else if(input$layout=="Kamada Kawai"){
plot(net, edge.arrow.size=.05,vertex.label=V(net)$FinName,vertex.label.color = "black",
vertex.label.cex=log2(V(net)$Freq)/NodeTextSize, layout = layout_with_kk)
}else if(input$layout=="LGL"){
plot(net, edge.arrow.size=.05,vertex.label=V(net)$FinName,vertex.label.color = "black",
vertex.label.cex=log2(V(net)$Freq)/NodeTextSize, layout = layout_with_lgl)
}
}
#Display Network
output$networkPlot <- renderPlot({
plotInputN()
})
#Download Network
output$downloadDataN <- downloadHandler(
filename = "network.pdf",
content = function(file) {
pdf(file)
plotInputN()
dev.off()
})
}
###############################################################################
#Make the app!
shinyApp(ui, server)
<file_sep>
fulldataset <- read.csv("data/datasets/DPLFC_MvsF_STK.txt", header=T,
sep="\t", quote='"', stringsAsFactors = F)
source("KRSA2/R/main.R")
rows_list <- list_of_rows(fulldataset)
<file_sep>
#Function to get a score for each kinase for each iteration
iterationScore <- function(sampleList, kinaseSep, uniqueKin){
splitKinase=NULL
for(i in 1:length(sampleList)){
splitKinase=paste0(splitKinase, sampleList[i], sep=kinaseSep)
}
splitKinase2=unlist(strsplit(splitKinase, split=kinaseSep))
returnVector=c()
for(i in 1:length(uniqueKin)){
temp=paste("^",uniqueKin[i],"$", sep="")
returnVector[i]=length(grep(temp, splitKinase2))
}
return(returnVector)
} | fc1b9e10cc6ee70a388ba4718f7491500a5ef63e | [
"R"
] | 10 | R | jackylbk/KRSA | a199a11e36bb0579c18f0ec3011b4a31ad2cba17 | 8f4856982412b9866e2e16932bed3378fd2e3ab2 |
refs/heads/master | <repo_name>lmy8848/WeTalkServer<file_sep>/src/com/wt/server/common/User.java
package com.wt.server.common;
public class User {
private String userId;
private String pwd;
private String nickName;
private String sex;
private String email;
private String head;
private long lastModityTime;
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public long getLastModityTime() {
return lastModityTime;
}
public void setLastModityTime(long lastModityTime) {
this.lastModityTime = lastModityTime;
}
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public String getPwd() {
return pwd;
}
public void setPwd(String pwd) {
this.pwd = pwd;
}
public String getNickName() {
return nickName;
}
public void setNickName(String nickName) {
this.nickName = nickName;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getHead() {
return head;
}
public void setHead(String head) {
this.head = head;
}
}
<file_sep>/src/com/wt/server/util/Config.java
package com.wt.server.util;
public interface Config {
public static final int MESSAGE_FROM = -2;
public static final int MESSAGE_TO = -1;
public static final int MESSAGE_TYPE_TXT = 0;
public static final int MESSAGE_TYPE_IMG = 1;
public static final int MESSAGE_TYPE_AUDIO = 2;
public static final int MESSAGE_TYPE_ADD_FRIEND = 3;
public static final int REQUEST_LOGIN = 13;
public static final int REQUEST_REGIST = 14;
public static final int REQUEST_UPDATE_HEAD = 15;
public static final int REQUEST_ADD_FRIEND = 16;
public static final int REQUEST_SEND_TXT = 17;
public static final int REQUEST_SEND_IMG = 18;
public static final int REQUEST_SEND_AUDIO = 19;
public static final int REQUEST_GET_OFFLINE_MSG = 20; // 获取未发送的消息(暂存在服务器端)
public static final int REQUEST_GET_FRIENDS = 21;
public static final int REQUEST_SEARCH_USER = 22;
public static final int REQUEST_EXIT = 23;
public static final int REQUEST_GET_HEAD = 24;
public static final int REQUEST_GET_USER = 25;
public static final int REQUEST_ADD_FRIEND_dialog = 26;
public static final int REQUEST_ADD_FRIEND_request = 27;
public static final int ADD_FRIEND_success = 28;
public static final int REQUEST_ADD_FRIEND_dialog_SUCCESS = 29;
public static final int RESULT_LOGIN = 100;
public static final int RESULT_REGIST = 101;
public static final int RESULT_UPDATE_HEAD = 102;
public static final int RESULT_GET_OFFLINE_MSG = 103;
public static final int RESULT_GET_FRIENDS = 104;
public static final int RESULT_SEARCH_USER = 105;
public static final int RESULT_GET_HEAD = 106;
public static final int RESULT_GET_USER = 107;
public static final int RESULT_ADD_FRIEND_request = 108;
public static final int RECEIVE_TEXT = 500;
public static final int RECEIVE_AUDIO = 501;
public static final int RECEIVE_IMG = 502;
public static final int IMG_NEED_UPDATE = 600;
public static final int IMG_NO_UPDATE = 601;
public static final int LOGIN_SUCCESS = 1000;
public static final int LOGIN_FAILED = 1001;
public static final int RIGEST_SUCCESS = 1002;
public static final int RIGEST_FAILED = 1003;
public static final int SEARCH_USER_SUCCESS = 1004;
public static final int SEARCH_USER_FALSE = 1005;
public static final int USER_HAS_IMG = 1006;
public static final int USER_NOT_IMG = 1007;
public static final int ADD_FRIEND = 1008;
public static final int REGIST_HAS_IMG = 1009;
public static final int ADD_FRIEND_SUCCESS = 1010;
}
<file_sep>/src/com/wt/server/net/ForwardTask.java
package com.wt.server.net;
import com.wt.server.common.Friend;
import com.wt.server.common.Message;
import com.wt.server.common.User;
import com.wt.server.util.Config;
import com.wt.server.util.DbUtil;
import com.wt.server.util.FileUtil;
import com.wt.server.util.LogUtil;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.Socket;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
/**
* 服务器端进行消息转发的Task
*
* @author www
*
*/
public class ForwardTask extends Task {
static HashMap<String, Socket> map = new HashMap<String, Socket>();
Socket socket;
DataInputStream dis;
DataOutputStream dos;
DbUtil dbUtil;
LogUtil log;
private boolean onWork = true;
public ForwardTask(Socket socket) {
this.socket = socket;
log = new LogUtil();
dbUtil = new DbUtil();
try {
dis = new DataInputStream(new BufferedInputStream(
socket.getInputStream()));
dos = new DataOutputStream(new BufferedOutputStream(
socket.getOutputStream()));
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public Task[] taskCore() throws Exception {
return null;
}
@Override
protected boolean useDb() {
return false;
}
@Override
protected boolean needExecuteImmediate() {
return false;
}
@Override
public String info() {
return null;
}
/**
* 设置线程工作状态,true表示运行,false表示将关闭
*
* @param state
*/
private void setWorkState(boolean state) {
onWork = state;
}
/**
* 任务执行入口
*/
public void run() {
while (onWork) {
// 读数据
try {
receiveMsg();
} catch (Exception e) { // 发生异常————通常是连接断开,则跳出循环,一个Task任务执行完毕
e.printStackTrace();
break;
}
}
try {
if (socket != null)
socket.close();
if (dis != null)
dis.close();
if (dos != null)
dos.close();
socket = null;
dis = null;
dos = null;
} catch (IOException e) {
LogUtil.record("在线用户退出时发生异常");
}
}
// 接收消息
public void receiveMsg() throws IOException {
// 读取请求类型,登录,注册,更新头像等等
int requestType = dis.readInt();
switch (requestType) {
case Config.REQUEST_LOGIN: // 处理“登陆”请求
handLogin();
break;
case Config.REQUEST_REGIST: // 处理“注册”请求
handRegist();
break;
case Config.REQUEST_ADD_FRIEND: // 处理“添加好友操作”请求
handAddFriend();
break;
case Config.REQUEST_ADD_FRIEND_request:// 处理“添加好友请求”请求
handRequestAddFriend();
break;
case Config.ADD_FRIEND_success:// 处理“添加好友成功”请求
handAddFriendSuc();
break;
case Config.REQUEST_UPDATE_HEAD: // 处理“更新头像”请求
handUpdateHead();
break;
case Config.REQUEST_GET_HEAD: // 处理“获取头像”请求
handGetHead();
break;
case Config.REQUEST_SEND_TXT: // 处理“发送文本消息”请求
handSendText();
break;
case Config.REQUEST_SEND_IMG: // 处理“发送图片消息”请求
handSendImgOrAudio(Config.RECEIVE_IMG, Config.MESSAGE_TYPE_IMG);
break;
case Config.REQUEST_SEND_AUDIO: // 处理“发送语音消息”请求
handSendImgOrAudio(Config.RECEIVE_AUDIO, Config.MESSAGE_TYPE_AUDIO);
break;
case Config.REQUEST_GET_OFFLINE_MSG: // 处理“获取离线消息”请求
handGetOfflineMsg();
break;
case Config.REQUEST_GET_FRIENDS: // 处理“获取好友列表”请求
handGetFriends();
break;
case Config.REQUEST_SEARCH_USER: // 处理“查询用户信息”请求
handSearchUser();
break;
case Config.REQUEST_GET_USER:
handGetUser();
break;
case Config.RESULT_GET_HEAD:
handGetHead();
break;
case Config.REQUEST_EXIT: // 处理“退出程序”请求
handExit();
break;
}
}
private void handGetUser() {
try {
String userId = dis.readUTF();
User user = dbUtil.searchUser(userId);
dos.writeInt(Config.ADD_FRIEND);
dos.writeUTF(user.getUserId());
dos.writeUTF(user.getNickName());
dos.writeUTF(user.getSex());
dos.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
// 获取指定用户的头像
private void handGetHead() {
try {
String userId = dis.readUTF();
User user = dbUtil.searchUser(userId);
String headPath = user.getHead();
String modifyTime = user.getLastModityTime() + "";
if (headPath.length() != 0) {
dos.writeInt(Config.RESULT_GET_HEAD);
dos.writeUTF(userId);
dos.writeUTF(modifyTime);
dos.flush();
//
readFileSendData(headPath);
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 处理更新头像功能
private void handUpdateHead() {
try {
String userId = dis.readUTF();
long lastModifyTime = dis.readLong();
File file = FileUtil.createHeadFile(Integer.parseInt(userId));
receiveDataWriteFile(file.getAbsolutePath());
String headPath = file.getAbsolutePath().replace("\\", "\\\\");
dbUtil.updateHeadImg(userId, headPath, lastModifyTime);
} catch (IOException e) {
System.out.println("handUpdateHead() exception=" + e.toString());
}
}
private void handRegist() {
try {
System.out.println("handRegist(): 接收到注册用户请求");
String nickName = dis.readUTF();
String pwd = dis.readUTF();
String sex = dis.readUTF();
String email = dis.readUTF();
boolean isHasImg = dis.readBoolean();
System.out.println("handRegist() nickName=" + nickName + ", sex="
+ sex);
// 查看数据库中是否存在这个用户————没必要进行这样的操作。允许存在昵称相同的用户,ID号是由系统提供的,ID号是唯一的辨别标识
// 获得数据库中ID号最大的用户ID
int id = dbUtil.getMaxUserId() + 1;
System.out.println("handRegist(): 新用户ID=" + id);
LogUtil.record("---------------------------------------");
LogUtil.record("接收到注册用户请求:name=" + nickName + " , sex=" + sex
+ " , isHasImg=" + isHasImg);
System.out.println("handRegist(): 用户注册信息 name=" + nickName
+ " , sex=" + sex + " , isHasImg=" + isHasImg);
String headPath = "";
long lastModifyTime = 1l; // 对于没有头像的用户,设置modifyTime字段为1l
if (isHasImg == true) {
File file = FileUtil.createHeadFile(id);
lastModifyTime = file.lastModified();
receiveDataWriteFile(file.getAbsolutePath());
headPath = file.getAbsolutePath().replace("\\", "\\\\");
System.out.println(headPath);
}
boolean registResult = dbUtil.regist(nickName, pwd, email, sex,
headPath, lastModifyTime);
if (registResult == true) {
int id1 = dbUtil.getMaxUserId();
dos.writeInt(Config.RESULT_REGIST);
dos.writeBoolean(true); // 注册成功
dos.writeInt(id1); // 返回其ID
dos.writeLong(lastModifyTime);
LogUtil.record("注册成功!userId=" + id1);
} else {
dos.writeInt(Config.RESULT_REGIST);
dos.writeBoolean(false); // 注册失败
LogUtil.record("注册失败!");
}
dos.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
private void receiveDataWriteFile(String filePath)
throws FileNotFoundException, IOException {
DataOutputStream ddos = new DataOutputStream(new FileOutputStream(
filePath)); // 将语音或图片写入本地SD卡
int length = 0;
int totalNum = 0;
byte[] buffer = new byte[2048];
while ((length = dis.readInt()) != 0) {
length = dis.read(buffer, 0, length);
totalNum += length;
ddos.write(buffer, 0, length);
ddos.flush();
}
if (ddos != null) {
try {
ddos.close();
ddos = null;
} catch (IOException e) {
e.printStackTrace();
}
}
// Log.i(TAG, "handReceiveData() 接收 img.totalNum="+totalNum);
}
private void handExit() {
try {
String userId = dis.readUTF();
LogUtil.record("---------------------------------------");
LogUtil.record("在线用户" + userId + "请求退出登录");
// 结束线程
setWorkState(false);
LogUtil.record("用户" + userId + "退出前,共有" + map.size() + "个用户在线");
// 注意这里不是在转发消息,并不需要查询发送退出请求的用户是否在线。只要是同服务器有Socket连接就是在线的
map.remove(userId);
LogUtil.record("用户" + userId + "退出后,还有" + map.size() + "个用户在线");
dbUtil.close(); // 关闭到数据库的连接
} catch (IOException e) {
e.printStackTrace();
}
}
private void handRequestAddFriend() {
try {
String selfId = dis.readUTF();
String friendId = dis.readUTF();
LogUtil.record("用户" + selfId + "向用户" + friendId + "发出了添加好友的请求");
// 如果用户friendId在线,则向他发出添加好友的消息(在他的手机端存储这对好友关系);若不在线,则将这对好友关系作为离线消息暂存在服务器端
if (map.containsKey(friendId)) {
// 从数据库中获取Id为selfId的用户的详细信息
// A向服务器发出添加B为好友的请求,则服务器应将A的信息回馈给B,B用这个信息插入B的friend表
User user = dbUtil.searchUser(selfId);
if (user != null) { // 存在该用户,其实这种担心是多余的,因为是客户端先查询了该用户的信息,才添加为好友的,所以添加好友请求的Id必定是存在的
Socket socket = map.get(friendId);
DataOutputStream out = new DataOutputStream(
socket.getOutputStream());
out.writeInt(Config.RESULT_ADD_FRIEND_request);
out.writeUTF(user.getUserId());
out.writeUTF(user.getNickName());
out.writeUTF(user.getSex());
out.writeUTF(user.getEmail());
out.flush();
String headPath = user.getHead();
File file = new File(headPath);
if (file.exists() == true) {
out.writeInt(Config.USER_HAS_IMG);
out.writeUTF(file.lastModified() + "");
out.flush();
// 此处的代码同readFileSendData()相似
DataInputStream ddis = new DataInputStream(
new FileInputStream(headPath));
int length = 0;
int totalNum = 0;
byte[] buffer = new byte[1024];
while ((length = ddis.read(buffer)) != -1) {
totalNum += length;
out.writeInt(length);
out.write(buffer, 0, length);
out.flush();
}
out.writeInt(0);
out.flush();
if (ddis != null) {
ddis.close();
ddis = null;
}
} else {
out.writeInt(Config.USER_NOT_IMG);
out.writeUTF(1l + "");
out.flush();
}
}
} else {
// 将这个添加好友请求作为离线消息存储
LogUtil.record("用户" + selfId + "发出添加用户" + friendId + "为好友的请求,"
+ friendId + "不在线,将这个添加好友请求作为离线消息存储");
dbUtil.saveMessage(selfId, friendId,
Config.MESSAGE_TYPE_ADD_FRIEND, "", "");
}
} catch (IOException e) {
e.printStackTrace();
}
}
private void handAddFriendSuc() {
try {
String selfId = dis.readUTF();
String friendId = dis.readUTF();
System.out.println("QQQQQQQQQQ");
if (map.containsKey(friendId)) {
User user = dbUtil.searchUser(selfId);
Socket socket = map.get(friendId);
DataOutputStream out = new DataOutputStream(
socket.getOutputStream());
out.writeInt(Config.ADD_FRIEND_SUCCESS);
out.writeUTF(user.getUserId());
out.writeUTF(user.getNickName());
out.writeUTF(user.getSex());
out.writeUTF(user.getEmail());
out.flush();
String headPath = user.getHead();
File file = new File(headPath);
if (file.exists() == true) {
out.writeInt(Config.USER_HAS_IMG);
out.writeUTF(file.lastModified() + "");
out.flush();
// 此处的代码同readFileSendData()相似
DataInputStream ddis = new DataInputStream(
new FileInputStream(headPath));
int length = 0;
int totalNum = 0;
byte[] buffer = new byte[1024];
while ((length = ddis.read(buffer)) != -1) {
totalNum += length;
out.writeInt(length);
out.write(buffer, 0, length);
out.flush();
}
out.writeInt(0);
out.flush();
if (ddis != null) {
ddis.close();
ddis = null;
}
} else {
out.writeInt(Config.USER_NOT_IMG);
out.writeUTF(1l + "");
out.flush();
System.out.println("WWWWWWWWW");
}
} else {
dbUtil.saveMessage(selfId, friendId,
Config.MESSAGE_TYPE_ADD_FRIEND, "", "");
}
} catch (IOException e) {
e.printStackTrace();
}
}
private void handAddFriend() {
try {
String selfId = dis.readUTF();
String friendId = dis.readUTF();
// 向数据库中添加这对好友关系
boolean result = dbUtil.addFriend(selfId, friendId);
LogUtil.record("用户" + selfId + "发出添加用户" + friendId
+ "为好友的请求,服务器端插入这对好友关系:" + result);
// 如果用户friendId在线,则向他发出添加好友的消息(在他的手机端存储这对好友关系);若不在线,则将这对好友关系作为离线消息暂存在服务器端
if (map.containsKey(friendId)) {
// 从数据库中获取Id为selfId的用户的详细信息
// A向服务器发出添加B为好友的请求,则服务器应将A的信息回馈给B,B用这个信息插入B的friend表
User user = dbUtil.searchUser(selfId);
if (user != null) { // 存在该用户,其实这种担心是多余的,因为是客户端先查询了该用户的信息,才添加为好友的,所以添加好友请求的Id必定是存在的
Socket socket = map.get(friendId);
DataOutputStream out = new DataOutputStream(
socket.getOutputStream());
out.writeInt(Config.ADD_FRIEND);
out.writeUTF(user.getUserId());
out.writeUTF(user.getNickName());
out.writeUTF(user.getSex());
out.writeUTF(user.getEmail());
out.flush();
String headPath = user.getHead();
File file = new File(headPath);
if (file.exists() == true) {
out.writeInt(Config.USER_HAS_IMG);
out.writeUTF(file.lastModified() + "");
out.flush();
// 此处的代码同readFileSendData()相似
DataInputStream ddis = new DataInputStream(
new FileInputStream(headPath));
int length = 0;
int totalNum = 0;
byte[] buffer = new byte[1024];
while ((length = ddis.read(buffer)) != -1) {
totalNum += length;
out.writeInt(length);
out.write(buffer, 0, length);
out.flush();
}
out.writeInt(0);
out.flush();
if (ddis != null) {
ddis.close();
ddis = null;
}
} else {
out.writeInt(Config.USER_NOT_IMG);
out.writeUTF(1l + "");
out.flush();
}
}
} else {
// 将这个添加好友请求作为离线消息存储
LogUtil.record("用户" + selfId + "发出添加用户" + friendId + "为好友的请求,"
+ friendId + "不在线,将这个添加好友请求作为离线消息存储");
dbUtil.saveMessage(selfId, friendId,
Config.MESSAGE_TYPE_ADD_FRIEND, "", "");
}
} catch (IOException e) {
e.printStackTrace();
}
}
private void handSearchUser() {
try {
String userId = dis.readUTF();
// 在服务器上查找该用户 返回用户的各种信息
User user = dbUtil.searchUser(userId);
if (user != null) {
dos.writeInt(Config.RESULT_SEARCH_USER);
dos.writeInt(Config.SEARCH_USER_SUCCESS);
dos.writeUTF(user.getUserId());
dos.writeUTF(user.getNickName());
dos.writeUTF(user.getSex());
dos.writeUTF(user.getEmail());
// 头像的路径
String head = user.getHead();
File file = new File(head);
// 如果存在该头像
if (file.exists() == true) {
dos.writeInt(Config.USER_HAS_IMG);
DataInputStream in = new DataInputStream(
new FileInputStream(file));
// 将字节数组从0开始的size个字节都写到数据输出流
int length = in.available();
byte[] data = new byte[length];
int size = in.read(data);
in.close();
in = null;
dos.writeInt(size);
dos.write(data, 0, size);
}// 不存在头像
else {
dos.writeInt(Config.USER_NOT_IMG);
}
dos.flush();
} else {
dos.writeInt(Config.RESULT_SEARCH_USER);
dos.writeInt(Config.SEARCH_USER_FALSE);
dos.flush();
}
} catch (IOException e) {
e.printStackTrace();
}
}
public void handLogin() {
try {
System.out.println("handLogin() 处理登陆请求");
String userId = dis.readUTF();
System.out.println("handLogin() userId=" + userId);
String pwd = dis.readUTF();
System.out.println("handLogin() pwd=" + pwd);
LogUtil.record("------------------------------------------");
LogUtil.record("使用用户名=" + userId + ", 密码=" + pwd + " 登录");
User user = dbUtil.login(userId, pwd);
if (user != null) {
System.out.println(userId + "登陆, sex=" + user.getSex());
dos.writeInt(Config.RESULT_LOGIN);
dos.writeBoolean(true);
dos.writeUTF(user.getUserId());
dos.writeUTF(user.getNickName());
dos.writeUTF(user.getSex());
dos.writeUTF(user.getEmail());
String head = user.getHead();
System.out.println("handLogin() head=" + head);
if ("".equals(head)) { // 如果为""串,没有头像
dos.writeInt(Config.USER_NOT_IMG);
System.out.println("handLogin() 没有头像");
} else {
DataInputStream in = null;
try {
in = new DataInputStream(new FileInputStream(head));
} catch (FileNotFoundException e) {
LogUtil.record("发生异常:" + e.toString());
e.printStackTrace();
}
if (in != null) { // 指定的文件没有找到,将会发生FileNotFoundException,是不能创建
dos.writeInt(Config.USER_HAS_IMG);
dos.writeLong(user.getLastModityTime());
System.out.println("handLogin() 有头像");
} else {
dos.writeInt(Config.USER_NOT_IMG);
System.out.println("handLogin() 没有找到头像文件");
}
}
dos.flush();
map.put(userId, socket);
LogUtil.record("用户" + userId + "登录成功");
} else {
dos.writeInt(Config.RESULT_LOGIN);
dos.writeBoolean(false);
dos.flush();
LogUtil.record("用户" + userId + "登录失败,userId=" + userId
+ ", pwd=" + pwd);
}
} catch (IOException e) {
LogUtil.record("发生异常:" + e.toString());
e.printStackTrace();
}
}
// 处理文本消息
public void handSendText() {
try {
String sendId = dis.readUTF();
String receiveId = dis.readUTF();
String time = dis.readUTF();
String content = dis.readUTF();
System.out.println("接收到客户端" + sendId + "发来的消息");
log.record("------------------------------------------------------------------------");
log.record("用户" + sendId + " 向用户" + receiveId + "发送文本消息='"
+ content + "'");
// 判断接收者是否在线
if (map.containsKey(receiveId)) {
Socket socket = map.get(receiveId);
log.record("服务器同消息发送者" + sendId + "连接的Socket="
+ map.get(sendId));
log.record("服务器同消息接收者" + receiveId + "连接的Socket=" + socket);
DataOutputStream out = new DataOutputStream(
socket.getOutputStream());
out.writeInt(Config.RECEIVE_TEXT);
out.writeUTF(sendId);
out.writeUTF(receiveId);
out.writeUTF(time);
out.writeUTF(content);
out.flush();
log.record("用户" + receiveId + "在线,可以直接接收到消息,消息已转发给接收者"
+ receiveId);
} else {
// 写入数据库
dbUtil.saveMessage(sendId, receiveId, Config.MESSAGE_TYPE_TXT,
time, content);
log.record("用户" + receiveId + "不在线,先把消息暂存在服务器端");
}
} catch (IOException e) {
e.printStackTrace();
}
}
private void handSendImg() {
try {
String sendId = dis.readUTF();
String receiveId = dis.readUTF();
String time = dis.readUTF();
log.record("用户" + sendId + " 向用户" + receiveId + "发送图片消息'");
// 判断接收者是否在线
if (map.containsKey(receiveId)) {
Socket socket = map.get(receiveId);
log.record("服务器同用户" + receiveId + "连接的Socket=" + socket);
DataOutputStream out = new DataOutputStream(
socket.getOutputStream());
out.writeInt(Config.RECEIVE_IMG);
out.writeUTF(sendId);
out.writeUTF(receiveId);
out.writeUTF(time);
out.flush();
int length = 0;
int totalNum = 0;
byte[] buffer = new byte[2048];
while ((length = dis.readInt()) != 0) {
length = dis.read(buffer, 0, length);
totalNum += length;
out.writeInt(length);
out.write(buffer, 0, length);
out.flush();
}
out.writeInt(0);
out.flush();
System.out.println("img.totalNum=" + totalNum);
log.record("用户" + receiveId + "在线,可以直接接收到消息");
} else {
// 写入数据库
File file = FileUtil
.createFile(sendId, Config.MESSAGE_TYPE_IMG);
FileOutputStream ou = new FileOutputStream(file);
int length = 0;
int totalNum = 0;
byte[] buffer = new byte[2048];
while ((length = dis.readInt()) != 0) {
length = dis.read(buffer, 0, length);
totalNum += length;
ou.write(buffer, 0, length);
ou.flush();
}
ou.close();
ou = null;
System.out.println("img.totalNum=" + totalNum);
dbUtil.saveMessage(sendId, receiveId, Config.MESSAGE_TYPE_IMG,
time, file.getAbsolutePath().replace("\\", "\\\\"));
log.record("用户" + receiveId + "不在线,先把消息暂存在服务器端");
}
} catch (IOException e) {
e.printStackTrace();
}
}
private void handSendImgOrAudio(int requestType, int messageType) {
try {
String sendId = dis.readUTF();
String receiveId = dis.readUTF();
String time = dis.readUTF();
if (messageType == Config.MESSAGE_TYPE_IMG) {
log.record("用户" + sendId + " 向用户" + receiveId + "发送图片消息'");
} else {
log.record("用户" + sendId + " 向用户" + receiveId + "发送语音消息'");
}
// 判断接收者是否在线
if (map.containsKey(receiveId)) {
Socket socket = map.get(receiveId);
log.record("服务器同用户" + receiveId + "连接的Socket=" + socket);
DataOutputStream out = new DataOutputStream(
socket.getOutputStream());
out.writeInt(requestType);
out.writeUTF(sendId);
out.writeUTF(receiveId);
out.writeUTF(time);
out.flush();
int length = 0;
int totalNum = 0;
byte[] buffer = new byte[1024];
while ((length = dis.readInt()) != 0) {
length = dis.read(buffer, 0, length);
totalNum += length;
out.writeInt(length);
out.write(buffer, 0, length);
out.flush();
}
out.writeInt(0);
out.flush();
System.out.println("img.totalNum=" + totalNum);
log.record("用户" + receiveId + "在线,可以直接接收到消息");
} else {
// 写入数据库
File file = FileUtil.createFile(sendId, messageType);
FileOutputStream ou = new FileOutputStream(file);
int length = 0;
int totalNum = 0;
byte[] buffer = new byte[1024];
while ((length = dis.readInt()) != 0) {
length = dis.read(buffer, 0, length);
totalNum += length;
ou.write(buffer, 0, length);
ou.flush();
}
ou.close();
ou = null;
System.out.println("img.totalNum=" + totalNum);
dbUtil.saveMessage(sendId, receiveId, messageType, time, file
.getAbsolutePath().replace("\\", "\\\\"));
log.record("用户" + receiveId + "不在线,先把消息暂存在服务器端");
}
} catch (IOException e) {
e.printStackTrace();
}
}
//
private void handSendAudio() {
try {
String sendId = dis.readUTF();
String receiveId = dis.readUTF();
String time = dis.readUTF();
int length = dis.readInt();
byte[] data = new byte[length];
int realNum = dis.read(data);
log.record("用户" + sendId + " 向用户" + receiveId + "发送语音消息'");
// 判断接收者是否在线
if (map.containsKey(receiveId)) {
Socket socket = map.get(receiveId);
log.record("服务器同用户" + receiveId + "连接的Socket=" + socket);
DataOutputStream out = new DataOutputStream(
socket.getOutputStream());
out.writeInt(Config.RECEIVE_AUDIO);
out.writeUTF(sendId);
out.writeUTF(receiveId);
out.writeUTF(time);
out.writeInt(realNum);
out.write(data, 0, realNum);
out.flush();
log.record("用户" + receiveId + "在线,可以直接接收到消息");
} else {
// 写入数据库
File file = FileUtil.createFile(sendId,
Config.MESSAGE_TYPE_AUDIO);
FileOutputStream ou = new FileOutputStream(file);
ou.write(data, 0, realNum);
ou.flush();
ou.close();
ou = null;
dbUtil.saveMessage(sendId, receiveId,
Config.MESSAGE_TYPE_AUDIO, time, file.getAbsolutePath());
log.record("用户" + receiveId + "不在线,先把消息暂存在服务器端");
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 处理”获取离线消息的请求“
public void handGetOfflineMsg() {
try {
String selfId = dis.readUTF();
ArrayList<Message> list = dbUtil.getMessages(selfId);
int listSize = list.size();
LogUtil.record("----------------------------------------------");
LogUtil.record("用户" + selfId + "发来获取离线消息的请求,共找到与他相关的离线消息"
+ listSize + "条");
if (list != null && listSize > 0) {
LogUtil.record("因服务器已发送离线消息给接收者,所以可以删除相关的消息");
dbUtil.deleteMessages(selfId);
Message msg = null;
dos.writeInt(Config.RESULT_GET_OFFLINE_MSG);
dos.writeInt(listSize);
LogUtil.record("总共有条" + listSize + "离线消息");
for (int i = 0; i < listSize; i++) {
msg = list.get(i);
int type = msg.getType();
if (type == Config.MESSAGE_TYPE_TXT) {
dos.writeUTF(msg.getSendId());
dos.writeUTF(msg.getReceiveId());
dos.writeInt(msg.getType());
dos.writeUTF(msg.getTime());
dos.writeUTF(msg.getContent());
dos.flush();
} else {
dos.writeUTF(msg.getSendId());
dos.writeUTF(msg.getReceiveId());
dos.writeInt(msg.getType());
dos.writeUTF(msg.getTime());
// 获取音频文件的字节数组
File file = new File(msg.getContent());
DataInputStream in = new DataInputStream(
new FileInputStream(file));
int length = in.available();
byte[] data = new byte[length];
int size = in.read(data);
dos.writeInt(size);
dos.write(data, 0, size);
dos.flush();
in.close();
in = null;
// 删除图片或语音文件
file.delete();
}
LogUtil.record("发送第" + (i + 1) + "离线条消息");
}
} else {
System.out.println("服务器端没有有关用户" + selfId + "的未发消息");
}
} catch (IOException e) {
LogUtil.record("handGetOfflineMsg 发生异常:" + e.toString());
e.printStackTrace();
}
}
public void handGetFriends() {
try {
String selfId = dis.readUTF();
int length = dis.readInt();
Map<String, String> map = new HashMap<String, String>();
// 循环读入客户端的好友列表<friendId, modifyTime>
for (int i = 0; i < length; i++) {
String friendId = dis.readUTF();
String modifyTime = dis.readUTF();
map.put(friendId, modifyTime);
}
ArrayList<Friend> list = dbUtil.getFirends(selfId);
dos.writeInt(Config.RESULT_GET_FRIENDS);
int size = list.size();
dos.writeInt(size); // 告诉客户端要接收多少数据
for (int i = 0; i < size; i++) {
Friend friend = list.get(i);
String friendId = friend.getFriendID();
String headPath = friend.getHead();
String modifyTime = friend.getHeadModifyTime();
// 如果包含这个好友,则比较头像时间戳;不包含,则将服务器端的头像发给客户端
if (map.containsKey(friendId)) {
// 时间戳不同,将服务器端的头像发给客户端
if (!map.get(friendId).equals(friend.getHeadModifyTime())) {
dos.writeInt(Config.IMG_NEED_UPDATE);
dos.writeUTF(modifyTime); // 头像的时间戳
dos.flush();
readFileSendData(headPath); // 读取并发送头像
} else {
// 时间戳相同,这样就不需要从服务器端把头像图片发送到客户端
dos.writeInt(Config.IMG_NO_UPDATE);
dos.flush();
}
} else { // 客户端的数据库中还没有包含这个好友,所以将该用户的全部信息发给客户端
dos.writeInt(Config.ADD_FRIEND);
dos.writeUTF(friendId);
dos.writeUTF(friend.getFriendName());
dos.writeUTF(friend.getSex());
if (headPath != null && !headPath.equals("")) {
dos.writeInt(Config.USER_HAS_IMG);
dos.writeUTF(modifyTime);
dos.flush();
// 存在头像
readFileSendData(headPath);
} else {
dos.writeInt(Config.USER_NOT_IMG);
dos.writeUTF(modifyTime);
dos.flush();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 读取文件(图片、语音),发送数据
*
* @param filePath
* @throws FileNotFoundException
* @throws IOException
*/
private void readFileSendData(String filePath)
throws FileNotFoundException, IOException {
DataInputStream ddis = new DataInputStream(
new FileInputStream(filePath));
int length = 0;
int totalNum = 0;
byte[] buffer = new byte[1024];
while ((length = ddis.read(buffer)) != -1) {
totalNum += length;
dos.writeInt(length);
dos.write(buffer, 0, length);
dos.flush();
}
dos.writeInt(0);
dos.flush();
if (ddis != null) {
ddis.close();
ddis = null;
}
}
}
| 60478e3725e946d82c9b405aeef5728a01d0b883 | [
"Java"
] | 3 | Java | lmy8848/WeTalkServer | 4a2489d4393ef7140655200f3b81e4a3942236be | 0b01cc139ec4db3257e4ddf3181526255c46e280 |
refs/heads/master | <file_sep>package com.dai.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import com.dai.dao.ICaseRegisterDao;
import com.dai.daoimpl.CaseRegisterDao;
import com.dai.factory.DaoFactory;
public class CaseRegisterServlet extends HttpServlet {
/**
* Constructor of the object.
*/
public CaseRegisterServlet() {
super();
}
/**
* Destruction of the servlet. <br>
*/
public void destroy() {
super.destroy(); // Just puts "destroy" string in log
// Put your code here
}
/**
* The doGet method of the servlet. <br>
*
* This method is called when a form has its tag value method equals to get.
*
* @param request
* the request send by the client to the server
* @param response
* the response send by the server to the client
* @throws ServletException
* if an error occurred
* @throws IOException
* if an error occurred
*/
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter();
out.println("<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\">");
out.println("<HTML>");
out.println(" <HEAD><TITLE>A Servlet</TITLE></HEAD>");
out.println(" <BODY>");
out.print(" This is ");
out.print(this.getClass());
out.println(", using the GET method");
out.println(" </BODY>");
out.println("</HTML>");
out.flush();
out.close();
}
/**
* The doPost method of the servlet. <br>
*
* This method is called when a form has its tag value method equals to
* post.
*
* @param request
* the request send by the client to the server
* @param response
* the response send by the server to the client
* @throws ServletException
* if an error occurred
* @throws IOException
* if an error occurred
*/
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setCharacterEncoding("utf-8");
// 获取参数
String ajlczl = request.getParameter("ajlczl");
// String zfdw = request.getParameter("zfdw");
// String zfml = request.getParameter("zfml");
// String jgdm = request.getParameter("jgdm");
String wzztlb = request.getParameter("wzztlb");
// String ahz = request.getParameter("ahz");
// String ahhm = request.getParameter("ahhm");
String wzrq = request.getParameter("wzrq");
String wzsj = request.getParameter("wzsj");
String wzdd = request.getParameter("wzdd");
String dsrlxdh = request.getParameter("dsrlxdh");
String dsrzjlx = request.getParameter("dsrzjlx");
String dsrzjhm = request.getParameter("dsrzjhm");
String cphz = request.getParameter("cphz");
String cphm = request.getParameter("cphm");
// String clid = request.getParameter("clid");
// String zkdh = request.getParameter("zkdh");
// String zfdid = request.getParameter("zfdid");
// String zfryid = request.getParameter("zfryid");
// String zfry = request.getParameter("zfry");
// String zfzh = request.getParameter("zfzh");
// String ajzt = request.getParameter("ajzt");
// String cjzbh = request.getParameter("cjzbh");
// String cjrq = request.getParameter("cjrq");
// String cjsj = request.getParameter("cjsj");
// String[] insertInfo = { ajlczl,zfdw, zfml, jgdm, wzztlb, ahz, ahhm,
// wzrq, wzsj,
// wzdd, dsrlxdh, dsrzjlx, dsrzjhm, clid, zkdh, zfdid, zfryid,
// zfry, zfzh, ajzt, cjzbh, cjrq, cjsj };
String[] insertInfo = { ajlczl, wzztlb, wzrq, wzsj, wzdd, dsrlxdh,
dsrzjlx, dsrzjhm };
ICaseRegisterDao dao = DaoFactory.createCaseRegisterDao();
int refluence = dao.CaseRegister(insertInfo, cphz, cphm, request
.getSession().getAttribute("username").toString());
// 应答
response.setContentType("text/html");
PrintWriter out = response.getWriter();
out.print(refluence);
out.flush();
out.close();
}
/**
* Initialization of the servlet. <br>
*
* @throws ServletException
* if an error occurs
*/
public void init() throws ServletException {
// Put your code here
}
}
<file_sep>package com.dai.factory;
import com.dai.dao.IAssistanceDao;
import com.dai.dao.ICarDao;
import com.dai.dao.ICaseManageDao;
import com.dai.dao.ICaseRegisterDao;
import com.dai.dao.ILawsDao;
import com.dai.dao.IUserDao;
public class DaoFactory {
public static IUserDao createUserDao() {
String daoString = "com.dai.daoimpl.UserDao";
try {
IUserDao dao = (IUserDao)Class.forName(daoString).newInstance();
return dao;
} catch (InstantiationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
public static ILawsDao createLawsDao() {
String daoString = "com.dai.daoimpl.LawsDao";
try {
ILawsDao dao = (ILawsDao)Class.forName(daoString).newInstance();
return dao;
} catch (InstantiationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
public static ICarDao createCarDao() {
String daoString = "com.dai.daoimpl.CarDao";
try {
ICarDao dao = (ICarDao)Class.forName(daoString).newInstance();
return dao;
} catch (InstantiationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
public static IAssistanceDao createAssistanceDao() {
String daoString = "com.dai.daoimpl.AssistanceDao";
try {
IAssistanceDao dao = (IAssistanceDao)Class.forName(daoString).newInstance();
return dao;
} catch (InstantiationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
public static ICaseManageDao createCaseManageDao() {
String daoString = "com.dai.daoimpl.CaseManagementDao";
try {
ICaseManageDao dao = (ICaseManageDao)Class.forName(daoString).newInstance();
return dao;
} catch (InstantiationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
public static ICaseRegisterDao createCaseRegisterDao() {
String daoString = "com.dai.daoimpl.CaseRegisterDao";
try {
ICaseRegisterDao dao = (ICaseRegisterDao)Class.forName(daoString).newInstance();
return dao;
} catch (InstantiationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
}
<file_sep>#include <stdio.h>
int main()
{
int a[15],i,j,k,m,temp,p=0,q=14;
for(i=0;i<15;i++)
scanf("%d",&a[i]);
printf("\n");
for(i=0;i<15;i++)
{ k=i;
for(j=i+1;j<15;j++)
if(a[j]>a[k]) k=j;
if(i!=k)
{ temp=a[i]; a[i]=a[k]; a[k]=temp;}
}
for(i=0;i<15;i++)
printf("%5d",a[i]);
printf("\n");
scanf("%d",&m);
for(i=1,j=15;i<5;i++)
{
if(m<a[(p+q)/2])
p=(p+q)/2;
if(m>a[(p+q)/2])
q=(p+q)/2;
if(m==a[(p+q)/2])
{
j=(p+q)/2+1;
break;
}
}
if(j!=15)
printf("%d\n",j);
else printf("ÎÞ´ËÊý\n");
return 0;
}
<file_sep>package com.dai.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import com.dai.dao.ILawsDao;
import com.dai.factory.DaoFactory;
import com.dai.util.ToJson;
public class LawsServlet extends HttpServlet {
/**
* Constructor of the object.
*/
public LawsServlet() {
super();
}
/**
* Destruction of the servlet. <br>
*/
public void destroy() {
super.destroy(); // Just puts "destroy" string in log
// Put your code here
}
/**
* The doGet method of the servlet. <br>
*
* This method is called when a form has its tag value method equals to get.
*
* @param request
* the request send by the client to the server
* @param response
* the response send by the server to the client
* @throws ServletException
* if an error occurred
* @throws IOException
* if an error occurred
*/
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter();
out.println("<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\">");
out.println("<HTML>");
out.println(" <HEAD><TITLE>A Servlet</TITLE></HEAD>");
out.println(" <BODY>");
out.print(" This is ");
out.print(this.getClass());
out.println(", using the GET method");
out.println(" </BODY>");
out.println("</HTML>");
out.flush();
out.close();
}
/**
* The doPost method of the servlet. <br>
*
* This method is called when a form has its tag value method equals to
* post.
*
* @param request
* the request send by the client to the server
* @param response
* the response send by the server to the client
* @throws ServletException
* if an error occurred
* @throws IOException
* if an error occurred
*/
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setCharacterEncoding("utf-8");
// 读取参数
String search = request.getParameter("search");//查询内容
String key = request.getParameter("searchkey");//查询条件
boolean k = false;// 判断查询方式
if (key.equals("issue")) {
k = true;// 按颁发部门查询
} else {
k = false;// 按关键字查询
}
// 访问数据库
//LawsSearch laws = new LawsSearch();
ILawsDao dao = DaoFactory.createLawsDao();
JSONArray json = new JSONArray();
ResultSet rs = dao.searchLaws(search, k);
json = ToJson.resultJSON(rs);
//应答
response.setContentType("text/html");
PrintWriter out = response.getWriter();
out.print(json.toString());
out.flush();
out.close();
}
/**
* Initialization of the servlet. <br>
*
* @throws ServletException
* if an error occurs
*/
public void init() throws ServletException {
// Put your code here
}
}
<file_sep>package com.dai.dao;
public interface ICaseRegisterDao {
public int CaseRegister(String[] strings,String cphz,String cphm,String username);
}
<file_sep>package com.dai.daoimpl;
import java.sql.ResultSet;
import com.dai.dao.ICaseManageDao;
import com.dai.db.DataBase;
public class CaseManagementDao implements ICaseManageDao{
ResultSet rs = null;
String sql = null;
DataBase db = DataBase.getDataBase();
public ResultSet caseList() {
sql = "select * from cp_casinfo where status='0'order by credate desc";
rs = db.executeQueryRS(sql, null);
return rs;
}
public ResultSet xiangxi(String casid) {
sql="select * from cp_casinfo where status='0'and casid=? order by credate desc";
rs = db.executeQueryRS(sql, new String[]{casid});
return rs;
}
}
<file_sep>package com.dai.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import com.dai.dao.ICaseManageDao;
import com.dai.daoimpl.CaseManagementDao;
import com.dai.factory.DaoFactory;
import com.dai.util.ToJson;
public class CaseManagementServlet extends HttpServlet {
/**
* Constructor of the object.
*/
public CaseManagementServlet() {
super();
}
/**
* Destruction of the servlet. <br>
*/
public void destroy() {
super.destroy(); // Just puts "destroy" string in log
// Put your code here
}
/**
* The doGet method of the servlet. <br>
*
* This method is called when a form has its tag value method equals to get.
*
* @param request the request send by the client to the server
* @param response the response send by the server to the client
* @throws ServletException if an error occurred
* @throws IOException if an error occurred
*/
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter();
out.println("<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\">");
out.println("<HTML>");
out.println(" <HEAD><TITLE>A Servlet</TITLE></HEAD>");
out.println(" <BODY>");
out.print(" This is ");
out.print(this.getClass());
out.println(", using the GET method");
out.println(" </BODY>");
out.println("</HTML>");
out.flush();
out.close();
}
/**
* The doPost method of the servlet. <br>
*
* This method is called when a form has its tag value method equals to post.
*
* @param request the request send by the client to the server
* @param response the response send by the server to the client
* @throws ServletException if an error occurred
* @throws IOException if an error occurred
*/
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setCharacterEncoding("utf-8");
//获取参数
String flag = request.getParameter("flag");
int f = Integer.parseInt(flag);
ResultSet rs=null;
JSONArray json = new JSONArray();
//访问数据库
ICaseManageDao dao = DaoFactory.createCaseManageDao();
switch (f) {
case 0:
rs = dao.caseList();
break;
case 1:
String casid = request.getParameter("casid");
rs = dao.xiangxi(casid);
break;
default:
break;
}
json = ToJson.resultJSON(rs);
//System.out.println(rs);
//应答
response.setContentType("text/html");
PrintWriter out = response.getWriter();
//System.out.println(json.toString());
out.print(json.toString());
out.flush();
out.close();
}
/**
* Initialization of the servlet. <br>
*
* @throws ServletException if an error occurs
*/
public void init() throws ServletException {
// Put your code here
}
}
<file_sep>package com.dai.daoimpl;
import java.sql.ResultSet;
import java.sql.SQLException;
import com.dai.dao.IUserDao;
import com.dai.db.DataBase;
import com.dai.entity.UserInfo;
public class UserDao implements IUserDao{
public boolean check(UserInfo user){
String sql="select count(*) from t_pf_user a where a.usercode =? and a.passwrd =?";
DataBase db = DataBase.getDataBase();
ResultSet rs = db.executeQueryRS(sql, new String[]{user.getUsername(),user.getPassword()});
try {
if(rs!=null && rs.next()){
int count=rs.getInt(1);
rs.close();
db.closeAll();
return count>0;
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return false;
}
}
<file_sep>package com.dai.daoimpl;
import java.sql.ResultSet;
import com.dai.dao.IAssistanceDao;
import com.dai.db.DataBase;
public class AssistanceDao implements IAssistanceDao{
//倒序列出有效协查通报
public ResultSet assistanceList() {
String sql = "select * from t_cle_concertaviso a,t_cle_concertreason b where a.xcyy=b.xcyy_id and a.sfla=1 order by a.sxrq desc";
DataBase db = DataBase.getDataBase();
ResultSet rs = db.executeQueryRS(sql, null);
return rs;
}
//关键字匹配查询
public ResultSet assistanceSearchs(String cpzh,String cphm,String cpys,String cllx,String clpp) {
String sql = "select * from t_cle_concertaviso a,t_cle_concertreason b where a.xcyy=b.xcyy_id and a.sfla=1 and a.cphz like ? and a.cphm like ? and a.cpys like ? and a.cllx like ? and a.cltz like ? order by a.sxrq desc";
cpzh="%"+cpzh+"%";
cphm="%"+cphm+"%";
cpys="%"+cpys+"%";
cllx="%"+cllx+"%";
clpp="%"+clpp+"%";
DataBase db =DataBase.getDataBase();
ResultSet rs = db.executeQueryRS(sql, new String[]{cpzh,cphm,cpys,cllx,clpp});
return rs;
}
}
<file_sep>package com.dai.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import java.sql.ResultSet;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.dai.dao.IUserDao;
import com.dai.daoimpl.UserDao;
import com.dai.entity.UserInfo;
import com.dai.factory.DaoFactory;
public class LoginServlet extends HttpServlet {
/**
* Constructor of the object.
*/
public LoginServlet() {
super();
}
/**
* Destruction of the servlet. <br>
*/
public void destroy() {
super.destroy(); // Just puts "destroy" string in log
// Put your code here
}
/**
* The doGet method of the servlet. <br>
*
* This method is called when a form has its tag value method equals to get.
*
* @param request
* the request send by the client to the server
* @param response
* the response send by the server to the client
* @throws ServletException
* if an error occurred
* @throws IOException
* if an error occurred
*/
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setContentType("text/html");
PrintWriter out = response.getWriter();
out.println("<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\">");
out.println("<HTML>");
out.println(" <HEAD><TITLE>A Servlet</TITLE></HEAD>");
out.println(" <BODY>");
out.print(" This is ");
out.print(this.getClass());
out.println(", using the GET method");
out.println(" </BODY>");
out.println("</HTML>");
out.flush();
out.close();
}
/**
* The doPost method of the servlet. <br>
*
* This method is called when a form has its tag value method equals to
* post.
*
* @param request
* the request send by the client to the server
* @param response
* the response send by the server to the client
* @throws ServletException
* if an error occurred
* @throws IOException
* if an error occurred
*/
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 获取参数
String username = request.getParameter("fname");
String password = request.getParameter("<PASSWORD>");
// 访问数据库
IUserDao dao = DaoFactory.createUserDao();
boolean check = dao.check(new UserInfo(username, password));
//System.out.println(check);
// 应答
response.setContentType("text/html");
PrintWriter out = response.getWriter();
if (check) {
out.print("1");
request.getSession().setAttribute("username",username);
request.getSession().setMaxInactiveInterval(1200);
} else {
out.print("0");
}
}
/**
* Initialization of the servlet. <br>
*
* @throws ServletException
* if an error occurs
*/
public void init() throws ServletException {
// Put your code here
}
}
<file_sep>#include <stdio.h>
#define N 100
struct student //学生基本信息
{ int num;
char name[20];
float score[3];
float aver;
};
int main( )
{
void input(struct student *, int ); //声明输入学生信息的函数
float max(struct student *, int ); //声明求最高分学生信息的函数
void aver(struct student *p,int n); //声明求总平均分的函数
struct student stu[N],*p;
p=&stu[0];
int n,i;
float m;
printf("Please enter the number of students: ");
scanf("%d",&n); //输入学生个数
input(stu,n);
aver(stu,n);
m=max(stu,n);
printf("\n平均成绩为:\n");
printf(" 学号 姓名 课程1 课程2 课程3 平均成绩\n"); //输出学生平均成绩
for(i=0;i<n;i++,p++)
printf("%8d%8s%8.1f%8.1f%8.1f%8.1f\n", p->num, p->name, p->score[0], p->score[1], p->score[2] , p->aver);
printf("\n平均成绩最高的学生是: \n");
printf(" 学号 姓名 课程1 课程2 课程3 平均成绩\n"); //输出平均成绩最高的学生信息
p=&stu[0];
for(i=0;i<n;i++,p++)
if(p->aver==m)
printf("%8d%8s%8.1f%8.1f%8.1f%8.1f\n", p->num, p->name, p->score[0], p->score[1], p->score[2] , p->aver);
return 0;
}
void input(struct student *p, int n) //输入学生信息的函数
{
int i;
printf("请输入%d 个学生的信息:学号、姓名、三门课程成绩:\n", n);
for(i=0;i<n;i++,p++)
{
scanf("%d\n", &p->num);
gets(p->name);
scanf("%f%f%f", &p->score[0], &p->score[1], &p->score[2]);
}
}
void aver(struct student *p,int n) //求总平均分的函数
{
int i;
for(i=0;i<n;i++,p++)
p->aver=(p->score[0]+p->score[1]+p->score[2])/3.0;
}
float max(struct student *p, int n) //求最高分学生信息的函数
{
struct student *q;
float max=0;
for(q=p;q<p+n; q++)
if(q->aver>max) max= q->aver;
return max;
}<file_sep>package com.dai.dao;
import java.sql.ResultSet;
public interface ICaseManageDao {
public ResultSet caseList();
public ResultSet xiangxi(String casid);
}
<file_sep>#include<stdio.h>
#include<math.h>
int main()
{
int a,b,c,m,n,k,h=0;
printf("105032013136 杨若楠\n");
printf( "请输入a和b:\n" );
scanf("%d%d",&a,&b);
c=b-a;
if(a<b && b<=1000000000000 && c<=1000000)
{
for(m=a;m<b;m++)
{
if(m/2==1) h++;
else if(m%2==0) continue;
else
{
k = 0;
for(n=2;n<=sqrt(m);n++)
{
if(m%n==0) k++;
if(k!=0) break;
}
if(k==0) h++;
}
}
printf("请输出在a和b之间的素数个数:%d\n",h);
}
return 0;
} | 562b85ebb0c2f81e679a479537e71b313f8437c6 | [
"Java",
"C++"
] | 13 | Java | 210290/experiment | aa42de31b49996fcb8f18c293f89ec33f08ab686 | c3bb6eff3b2a6ddc01e89342b6ff2a344698e2cf |
refs/heads/master | <repo_name>shubhamwattamwar94/Image-Convolution<file_sep>/src/OwnConvolutionCode.java
import com.sun.corba.se.impl.orbutil.ORBUtility;
import java.awt.Color;
import java.awt.image.BufferedImage;
import java.awt.image.ConvolveOp;
import java.awt.image.DataBufferByte;
import java.awt.image.Kernel;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import javax.imageio.ImageIO;
public class OwnConvolutionCode
{
int[][] outputArray;
int[][] outputArrayOfExistingCode;
int[][] redOutputArray;
int[][] blueOutputArray;
int[][] greenOutputArray;
int[][] redArray;
int[][] greenArray;
int[][] blueArray;
float[] kernelArray;
int kernelSize;
BufferedImage imageForIcon=null;
File outputFileForIcon;
void getRGBValues( BufferedImage img){
redArray=new int[img.getWidth()][img.getHeight()];
greenArray=new int[img.getWidth()][img.getHeight()];
blueArray=new int[img.getWidth()][img.getHeight()];
for (int i = 0; i < img.getWidth(); i++) {
for (int j = 0; j < img.getHeight(); j++) {
int c=img.getRGB(i,j);
redArray[i][j]=(c & 0xff0000) >> 16;
greenArray[i][j]=(c & 0xff00) >> 8;
blueArray[i][j]= c & 0xff;
}
}
}
public void initializeOutputArray(BufferedImage img){
outputArray=new int[img.getWidth()][img.getHeight()];
//System.out.println("***Output Array***");
for (int i = 0; i < img.getWidth(); i++) {
for (int j = 0; j < img.getHeight(); j++) {
outputArray[i][j]=0;
}}}
public float[] kernelRead(String Operation) throws Exception
{ String textFilePath="D:\\ImageConvolutionGUI\\Kernels\\"+Operation+".txt";
float[] fileKernelArray=null;
BufferedReader br = new BufferedReader(new FileReader(new File(textFilePath)));
String line="";
String wholeFileInLine="";
int lineCounter=0;
System.out.println("***Kernel File****");
while ((line = br.readLine()) != null) {
lineCounter++;
System.out.println(lineCounter+" "+line);
if(lineCounter>1)
wholeFileInLine=wholeFileInLine+line;
else
kernelSize=Integer.parseInt(line);
}
String[] strArray=null;
strArray = wholeFileInLine.split(",");
fileKernelArray = new float[strArray.length];
for(int i = 0; i < strArray.length; i++) {
fileKernelArray[i] = Float.parseFloat(strArray[i]);
}
return fileKernelArray;
}
public void computOutputArray(BufferedImage img){
redOutputArray=new int[img.getWidth()][img.getHeight()];
greenOutputArray=new int[img.getWidth()][img.getHeight()];
blueOutputArray=new int[img.getWidth()][img.getHeight()];
for(int x=0;x<img.getHeight()-2;x++){
for(int y=0;y<img.getWidth()-2;y++){
int kernelArrayCounter=8;
float resultRed=0;
float resultGreen=0;
float resultBlue=0;
for (int i = x; i < (x+3); i++) {
for (int j = y; j < (y+3); j++) {
resultRed=resultRed+(redArray[i][j]*kernelArray[kernelArrayCounter]);
resultGreen=resultGreen+(greenArray[i][j]*kernelArray[kernelArrayCounter]);
resultBlue=resultBlue+(blueArray[i][j]*kernelArray[kernelArrayCounter]);
kernelArrayCounter--;
}}
if(resultRed<0)
resultRed=0;
else if(resultRed>255)
resultRed=255;
redOutputArray[x+1][y+1]=(int) resultRed;
if(resultBlue<0)
resultBlue=0;
else if(resultBlue>255)
resultBlue=255;
blueOutputArray[x+1][y+1]=(int) resultBlue;
if(resultGreen<0)
resultGreen=0;
else if(resultGreen>255)
resultGreen=255;
greenOutputArray[x+1][y+1]=(int) resultGreen;
}}}
public void writeImage(BufferedImage img,float[] fileKernelArray,String operation,String fileName) throws IOException{
BufferedImage image = new BufferedImage(img.getWidth(), img.getHeight(), BufferedImage.TYPE_INT_RGB);
outputArrayOfExistingCode=new int[img.getWidth()][img.getHeight()];
for (int y = 0; y < img.getHeight(); y++) {
for (int x = 0; x < img.getWidth(); x++) {
int rgb = redOutputArray[y][x];
rgb = (rgb << 8) + greenOutputArray[y][x];
rgb = (rgb << 8) + blueOutputArray[y][x];
outputArray[y][x]=rgb;
image.setRGB(y, x, rgb);
}
}
File outputFile = new File("D:\\ImageConvolutionGUI\\output\\output of "+operation+" for "+fileName+".jpg");
ImageIO.write(image, "jpg", outputFile);
outputFileForIcon=outputFile;
}}<file_sep>/src/ImageConvolution.java
import java.awt.Image;
import java.awt.image.BufferedImage;
import java.awt.image.ConvolveOp;
import java.awt.image.Kernel;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
import java.util.Set;
import java.util.regex.Pattern;
import javax.imageio.ImageIO;
import javax.swing.JFrame;
/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
/**
*
* @author Bhoopal
*/
public class ImageConvolution {
public static void main(String[] args) throws IOException {
String path="C:\\Users\\HP\\Documents\\NetBeansProjects\\convo_gui\\Images\\lenna.jpg";
BufferedImage img = null;
img = ImageIO.read(new File(path));
/* //sharp
float[] SHARPEN3x3 = {
0.f, -1.f, 0.f,
-1.f, 5.0f, -1.f,
0.f, -1.f, 0.f};
//edge Kernel
float[] edgeKernel = {
0.0f, -1.0f, 0.0f,
-1.0f, 4.0f, -1.0f,
0.0f, -1.0f, 0.0f};
//blur kernel
float ninth = 1.0f / 9.0f;
float[] blurKernel = {
ninth, ninth, ninth,
ninth, ninth, ninth,
ninth, ninth, ninth};
//BufferedImage srcimg = new BufferedImage(img.getWidth(),img.getHeight(),BufferedImage.TYP);
BufferedImage dstbimg = new BufferedImage(img.getWidth(),img.getHeight(),BufferedImage.TYPE_INT_RGB);
Kernel kernel = new Kernel(3,3,blurKernel);
ConvolveOp cop = new ConvolveOp(kernel,ConvolveOp.EDGE_NO_OP,null);
BufferedImage output= cop.filter(img, null);
File outputfile = new File("D:\\C or C++ Programs\\ImageConvolution\\src\\images\\savedmapsmall.jpg");
ImageIO.write(output, "jpg", outputfile); // Write the Buffered Image into an output file
int x=10,y=20;
int color =img.getRGB(x,y);
int blue = color & 0xff;
int green = (color & 0xff00) >> 8;
int red = (color & 0xff0000) >> 16;
System.out.println("\nRed="+red+"\nGreen="+green+"\nBlue="+blue);
*/
//file processing
File folder = new File("C:\\Users\\HP\\Documents\\NetBeansProjects\\convo_gui\\Kernels");
File[] listOfFiles = folder.listFiles();
for (int i = 0; i < listOfFiles.length; i++) {
if (listOfFiles[i].isFile()) {
System.out.println("File " + listOfFiles[i].getName());
} else if (listOfFiles[i].isDirectory()) {
System.out.println("Directory " + listOfFiles[i].getName());
}
}
Scanner sc =new Scanner(System.in);
System.out.println("Enter choice \n1.Blur\n2.Sharp=");
int choice=sc.nextInt();
String textFilePath="C:\\Users\\HP\\Documents\\NetBeansProjects\\convo_gui\\Kernels\\"+listOfFiles[choice-1].getName();
String wholeFileInLine="";
int kernelSize=0;
try (BufferedReader br = new BufferedReader(new FileReader(new File(textFilePath)))) {
String line;
int lineCounter=0;
while ((line = br.readLine()) != null) {
lineCounter++;
// System.out.println(lineCounter+" "+line);
if(lineCounter>1)
wholeFileInLine=wholeFileInLine+line;
else
kernelSize=Integer.parseInt(line);
}
}
String[] strArray = wholeFileInLine.split(",");
float[] fileKernelArray = new float[strArray.length];
for(int i = 0; i < strArray.length; i++) {
fileKernelArray[i] = Float.parseFloat(strArray[i]);
}
/*for (int i = 0; i < fileKernelArray.length; i++) {
System.out.println("fileKernelArray["+i+"]"+"="+fileKernelArray[i]);
}*/
Kernel kernel = new Kernel(kernelSize,kernelSize,fileKernelArray);
ConvolveOp cop = new ConvolveOp(kernel,ConvolveOp.EDGE_NO_OP,null);
BufferedImage output= cop.filter(img, null);
File outputfile = new File("C:\\Users\\HP\\Documents\\NetBeansProjects\\convo_gui\\output\\outputOf"+listOfFiles[choice-1].getName().replace(".txt","")+".jpg");
ImageIO.write(output, "jpg", outputfile); // Write the Buffered Image into an output file
int x=10,y=20;
int color =img.getRGB(x,y);
int blue = color & 0xff;
int green = (color & 0xff00) >> 8;
int red = (color & 0xff0000) >> 16;
System.out.println("\nRed="+red+"\nGreen="+green+"\nBlue="+blue);
}
}
| 0756c740165936591f1e183f8e079556a3943fea | [
"Java"
] | 2 | Java | shubhamwattamwar94/Image-Convolution | f274056ab69dd1670852378638e3e715e7538348 | 6f5c99abe12841d3d95aa08410c29ec241c6ea7b |
refs/heads/master | <repo_name>ETagu/midterm<file_sep>/10/prime.js
var primes = [2];
for (i = 3; i <= 300; i += 2) {
for (j = 0; i > primes[j] * primes[j] && i % primes[j] != 0; j++);
if (i < primes[j] * primes[j]) primes.push(i);
}
function prime(aaa){
returnValue = false;
if(Math.floor(aaa)==aaa && aaa>=1){
for(i=0; i<=primes.length; i++){
if(aaa==primes[i]){
returnValue = true;
break;
}
}
}
return returnValue;
}
<file_sep>/03/succ.js
function succ(aaa){
if(aaa == 0) return 1;
if(aaa == -1) return 0;
if(aaa == 9999)return 10000;
}<file_sep>/04/hinge.js
function hinge(aaa){
if(aaa<=10){
return 0;
} else {
return aaa - 10;
}
}<file_sep>/05/fizz.js
function fizz(aaa){
if(!isNaN(aaa)){
if(aaa%3 == 0){
return "fizz";
} else {
return aaa;
}
} else {
return aaa;
}
}
<file_sep>/06/buzz.js
function buzz(aaa){
if(!isNaN(aaa)){
if(aaa%5 == 0){
return "buzz";
} else {
return aaa;
}
} else {
return aaa;
}
}
<file_sep>/02/add.js
function add(aaa, bbb){
return aaa+bbb;
}
| 4b6aaa049ff088f56b8611313f974ffa7eae7fda | [
"JavaScript"
] | 6 | JavaScript | ETagu/midterm | 8e60f01167cbdcbf0785b2175b3b2353a61d2194 | a39ef995eeefe1f8974b7718092f9c4efd7abe8b |
refs/heads/master | <file_sep>//
// PeripheralDiscoverer.swift
// HelloBT4
//
// Created by <NAME> (<EMAIL>) on 06/07/16.
//
import Foundation
import CoreBluetooth
import UIKit
enum kPDNotificationType:String{
case newPeripheralsDiscovered
case peripheralStateChanged
case serviceDiscovered
case characteristicDiscovered
case allServicesAndCharacteristicsDiscovered
case discriptorUpdated
case valueUpdated
}
class PeripheralDiscoverer : NSObject, CBCentralManagerDelegate, CBPeripheralDelegate {
private var D = true
//Singleton pattern, we want only one instance of this class.
static let sharedInstance = PeripheralDiscoverer()
var central:CBCentralManager?
var discovered_devices:[UUID:CBPeripheral] = [:]
private override init()
{
super.init()
self.central = CBCentralManager(delegate: self, queue: DispatchQueue.main)
if(D){print("PeripheralDiscoverer.init()")}
}
// MARK: --- CBCentralManagerDelegate ---
func centralManagerDidUpdateState(_ central: CBCentralManager) {
if(D){print("PeripheralDiscoverer: didUpdateState \(central.state)")}
if (central.state == CBManagerState.poweredOn)
{
if(D){print("PeripheralDiscoverer: didUpdateState ON")}
//Specific service
//let MyServiceUuid = CBUUID.init(string: "7E940010-8030-4261-8523-8953AB03CFC0")
//self.central?.scanForPeripherals(withServices:[MyServiceUuid], options: nil)
//All serivces
self.central?.scanForPeripherals(withServices:nil, options: nil)
}
else
{}
}
func centralManager(_ central: CBCentralManager, didDiscover peripheral: CBPeripheral, advertisementData: [String : Any], rssi RSSI: NSNumber) {
let id = peripheral.identifier //iOS abstraction over hardware address to comply with privacy of the MAC address.
//Add peripheral to dict.
self.discovered_devices[id] = peripheral
if(D){print("PeripheralDiscoverer: didDiscoverPeripheral: \(id.uuidString) \(String(describing: peripheral.name))")}
//Notify via NSNotification
NotificationCenter.default.post(name: NSNotification.Name(rawValue: kPDNotificationType.newPeripheralsDiscovered.rawValue), object: nil)
}
func centralManager(_ central: CBCentralManager, didConnect peripheral: CBPeripheral) {
if(D){print("PeripheralDiscoverer: didConnectPeripheral: \(peripheral.state.rawValue)")}
//Notify that we are connected.
NotificationCenter.default.post(name: NSNotification.Name(rawValue: kPDNotificationType.peripheralStateChanged.rawValue), object: peripheral)
peripheral.delegate = self
peripheral.discoverServices(nil)
}
func centralManager(_ central: CBCentralManager, didDisconnectPeripheral peripheral: CBPeripheral, error: Error?) {
if(D){print("PeripheralDiscoverer: didDisconnectPeripheral: \(peripheral.state.rawValue)")}
//Notify that we are disconnected.
NotificationCenter.default.post(name: NSNotification.Name(rawValue: kPDNotificationType.peripheralStateChanged.rawValue), object: peripheral)
}
//MARK: --- CBPeripheralDelegate ---
func peripheral(_ peripheral: CBPeripheral, didDiscoverServices error: Error?) {
if(D){print("PeripheralDiscoverer: didDiscoverServices")}
for service:CBService in peripheral.services!{
peripheral.discoverCharacteristics(nil, for: service)
}
}
func peripheral(_ peripheral: CBPeripheral, didDiscoverCharacteristicsFor service: CBService, error: Error?) {
if(D){print("PeripheralDiscoverer: didDiscoverCharacteristicsForService")}
for c:CBCharacteristic in service.characteristics!{
if(D){print("\(c.uuid.uuidString)")}
//Notify characteristic discovered.
NotificationCenter.default.post(name: NSNotification.Name(rawValue: kPDNotificationType.characteristicDiscovered.rawValue), object: c)
//Discover descriptors
peripheral.discoverDescriptors(for:c)
}
//Determine if charasteristics for all services has been discovered
var all_characteristics_discovered = true
for s:CBService in peripheral.services!{
if s.characteristics == nil{
all_characteristics_discovered = false
}
}
if all_characteristics_discovered == true {
//Notify when all characteristics for all services has been fund.
NotificationCenter.default.post(name: NSNotification.Name(rawValue: kPDNotificationType.allServicesAndCharacteristicsDiscovered.rawValue), object: peripheral)
}
}
func peripheral(_ peripheral: CBPeripheral, didDiscoverDescriptorsFor characteristic: CBCharacteristic, error: Error?) {
if(D){print("PeripheralDiscoverer: didDiscoverDescriptorsForCharacteristic \(characteristic.uuid.uuidString)")}
//Read values for desctiptors
for d in characteristic.descriptors! {
peripheral.readValue(for:d)
}
}
func peripheral(_ peripheral: CBPeripheral, didUpdateValueFor descriptor: CBDescriptor, error: Error?) {
if(D){print("PeripheralDiscoverer: didUpdateValueForDescriptor")}
//Notify about updated descriptor
NotificationCenter.default.post(name: NSNotification.Name(rawValue: kPDNotificationType.discriptorUpdated.rawValue), object: descriptor)
}
func peripheral(_ peripheral: CBPeripheral, didUpdateValueFor characteristic: CBCharacteristic, error: Error?) {
if(D){print("PeripheralDiscoverer: didUpdateValueForCharacteristic")}
//Notify about updated value
NotificationCenter.default.post(name: NSNotification.Name(rawValue: kPDNotificationType.valueUpdated.rawValue), object: characteristic)
}
func peripheral(_ peripheral: CBPeripheral, didUpdateNotificationStateFor characteristic: CBCharacteristic, error: Error?) {
if(D){print("PeripheralDiscoverer: didUpdateNotificationStateForCharacteristic charac=\(characteristic.uuid.uuidString) isNotifying=\(characteristic.isNotifying)")}
}
}
<file_sep>//
// GameHandler.swift
// JumpIn
//
// Created by <NAME> on 25/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import Foundation
import Firebase
import FirebaseDatabase
class GameHandler {
var score:Int
var highScore: Int
var stars:Int
var savedHighScore:String!
var levelData: NSDictionary!
class var shareInstance:GameHandler {
struct Sigleton {
static let instance = GameHandler()
}
return Sigleton.instance
}
init() {
score = 0
highScore = 0
stars = 0
let userDefaults = UserDefaults.standard
//highScore = userDefaults.integer(forKey: "highScore")
stars = userDefaults.integer(forKey: "stars")
if let path = Bundle.main.path(forResource: "Level01", ofType: "plist") {
if let level = NSDictionary(contentsOfFile: path) {
levelData = level
}
}
}
func saveGameScore() {
highScore = max(score, highScore)
let userDefaults = UserDefaults.standard
userDefaults.set(highScore, forKey: "highScore")
userDefaults.set(stars, forKey: "stars")
userDefaults.synchronize()
}
}
<file_sep>//
// GameObjectNode.swift
// JumpIn
//
// Created by <NAME> on 17/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import SpriteKit
struct CollisionCategoryBitmask {
static let Player: UInt32 = 0x00
static let Star: UInt32 = 0x01
static let Platform: UInt32 = 0x02
}
enum PlateformType:Int {
case normalBrick = 0
case breakableBrick = 1
}
class GameObjectNode: SKNode {
func collisionWithPlayer(player: SKNode) -> Bool {
return false
}
func checkNodeRemoval(playerY: CGFloat) {
if playerY > self.position.y + 300.0 {
self.removeFromParent()
}
}
}
<file_sep>//
// JumpViewController.swift
// JumpIn
//
// Created by <NAME> on 17/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import UIKit
import Firebase
import FirebaseDatabase
import CoreBluetooth
class JumpViewController: UIViewController {
private var pd = PeripheralDiscoverer.sharedInstance //singleton
private var selected_peripheral:CBPeripheral?
var jump = 0
var realjump = 0
var count = 0
var StartPressed = 0
@IBOutlet var jumpText: UILabel!
@IBOutlet var pausestart: UIButton!
@IBOutlet var stop: UIButton!
var pause = false
var sessionNb: String!
var ref:DatabaseReference!
var weight:String!
var timer = Timer()
@IBOutlet var timerLabel: UILabel!
var seconde = 0
var minute = 0
let imageName = "TapToStart.png"
var image: UIImage!
var imageView: UIImageView!
var total: Int = 0
override func viewDidLoad() {
super.viewDidLoad()
stop.isEnabled = false
NotificationCenter.default.addObserver(self, selector: #selector(self.peripheralDiscoveredObs), name:NSNotification.Name(rawValue: kPDNotificationType.newPeripheralsDiscovered.rawValue), object: nil)
NotificationCenter.default.addObserver(
self, selector: #selector(self.peripheralStateChangedObs),
name:NSNotification.Name(rawValue: kPDNotificationType.peripheralStateChanged.rawValue),
object: nil)
NotificationCenter.default.addObserver(
self, selector: #selector(self.servicesAndCharacteristicsDiscoveredObs),
name:NSNotification.Name(rawValue: kPDNotificationType.allServicesAndCharacteristicsDiscovered.rawValue),
object: nil)
NotificationCenter.default.addObserver(
self, selector: #selector(self.descriptorUpdatedObs),
name:NSNotification.Name(rawValue: kPDNotificationType.discriptorUpdated.rawValue),
object: nil)
NotificationCenter.default.addObserver(
self, selector: #selector(self.valueUpdatedObs),
name:NSNotification.Name(rawValue: kPDNotificationType.valueUpdated.rawValue),
object: nil)
pausestart.layer.cornerRadius = 10.0
stop.layer.cornerRadius = 10.0
timerLabel.text = String(format: "%02d:%02d", minute, seconde)
image = UIImage(named: imageName)
imageView = UIImageView(image: image!)
imageView.frame = CGRect(x: view.frame.size.width/8, y: view.frame.size.height-250, width: 150, height: 100)
view.addSubview(imageView)
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
//MARK: Notification Handlers
@objc func peripheralDiscoveredObs(notification: NSNotification){
let devices = PeripheralDiscoverer.sharedInstance.discovered_devices
for key:UUID in devices.keys
{
if let device_name = devices[key]?.name
{
print("Found device:" + device_name)
//If we have found the device we were looking for, then connect..
if device_name=="BandCizer048"
{
self.selected_peripheral = pd.discovered_devices[key]
PeripheralDiscoverer.sharedInstance.central!.connect(self.selected_peripheral!,options: nil)
}
}
}
}
//MARK: Notification Handlers
@objc func peripheralStateChangedObs(notification: NSNotification){
print("peripheralStateChangedObs:")
if let o = notification.object{
let p = o as! CBPeripheral
print("peripheralStateChangedObs:\(p.state.rawValue)")
switch (p.state){
case .connected:
print("peripheralStateChangedObs: .connected")
break
case .disconnected:
print("peripheralStateChangedObs: .disconnected")
break
case .connecting:
print("peripheralStateChangedObs: .connecting")
break
case .disconnecting:
print("peripheralStateChangedObs: .disconnecting")
break
}
}
}
//TODO: Neat feature -let titles be the human readable description of service/characteristic, if available
@objc func servicesAndCharacteristicsDiscoveredObs(notification:NSNotification){
print("servicesAndCharacteristicsDiscoveredObs")
if let o = notification.object{
let p = o as! CBPeripheral
for s:CBService in p.services!{
//Iterate over characteristics in service
for c in s.characteristics!{
print("Found characteristic:" + c.uuid.uuidString)
if c.uuid.uuidString=="A2C70031-8F31-11E3-B148-0002A5D5C51B"
{//enable notification for specific characteristic
p.setNotifyValue(true, for: c)
}
}
}
}
}
//Process descriptors from device: e.g. User Description 0x2901
//Descriptor UUID's:
//https://developer.bluetooth.org/gatt/descriptors/Pages/DescriptorsHomePage.aspx
@objc func descriptorUpdatedObs(notification:NSNotification){
print("descriptorUpdatedObs")
if let o = notification.object{
let d = o as! CBDescriptor
if d.uuid == CBUUID(string: "2901") //User description
{
print("Human readable description for UUID:" +
d.characteristic.uuid.uuidString +
" is" +
(d.value as! String)
)
}
}
}
@objc func valueUpdatedObs(notification:NSNotification){
//print("valueUpdatedObs")
if (StartPressed==1)
{
if let o = notification.object
{
let c = o as! CBCharacteristic
print("length = \((c.value!.count))")
var xvalue: Int = 0
var yvalue: Int = 0
var zvalue: Int = 0
var Avalue: Double = 0
xvalue = c.value!.subdata(in: 2..<4).withUnsafeBytes { $0.pointee }
yvalue = c.value!.subdata(in: 4..<6).withUnsafeBytes { $0.pointee }
zvalue = c.value!.subdata(in: 6..<8).withUnsafeBytes { $0.pointee }
if ( xvalue > 32767)
{
xvalue = xvalue - 65536
}
if ( yvalue > 32767)
{
yvalue = yvalue - 65536
}
if ( zvalue > 32767)
{
zvalue = zvalue - 65536
}
Avalue = sqrt((Double)(xvalue*xvalue + yvalue*yvalue + zvalue*zvalue))
print("X value \(xvalue)")
print("Y value \(yvalue)")
print("Z value \(zvalue)")
print("Average value \(Avalue)")
if ( Avalue > 20000 && count == 0 )
{
jump = jump + 1
count = 1
}
if (Avalue<10000 )
{
count = 0
}
realjump = (Int)(jump/4)
print ("number jump \(realjump)")
self.jumpText.text = (String)(self.realjump)
}
}
}
//User click on pause
@IBAction func pause(_ sender: Any) {
stop.isEnabled = true
if pause == true {
pausestart.setTitle(">",for: .normal)
pause = false
timer.invalidate()
StartPressed=0
} else if pause == false {
//If the user didn't put weight/high, have to alert him
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("users").child(userID).observeSingleEvent(of: .value) { (snapshot) in
if let dictionary = snapshot.value as? [String: AnyObject] {
let high = dictionary["high"] as? String
let weight = dictionary["weight"] as? String
self.startJumping(high: high!, weight: weight!)
self.StartPressed=1
}
}
}
}
func startJumping(high:String, weight:String) {
if (high == "" || weight == "") {
self.alertMissingInfo(title: "Warning", message: "You have to enter weight and high before starting")
} else {
alertBluetooth(title: "Information", message: "Please, before jumping verify that bluetooth is connected")
}
}
@objc func action() {
if seconde == 59 {
seconde = 0
minute = minute+1
} else {
seconde = seconde+1
}
timerLabel.text = String(format: "%02d:%02d", minute, seconde)
}
//User click on stop
@IBAction func stopTouched(_ sender: Any) {
//If the user never use the jump, create the counter (if there is no session)
let databaseRef = Database.database().reference(fromURL: "https://jumpin-c4b57.firebaseio.com/")
let userID = (Auth.auth().currentUser?.uid)!
let usersRef = databaseRef.child("sessions").child(userID)
StartPressed=0
//Check if session 1 exist, else create ot
databaseRef.child("sessions").child(userID).observeSingleEvent(of: .value, with: { (snapshot) in
if snapshot.hasChild("session1"){
self.addSession()
}else{
let counter = ["counter": "0"]
usersRef.updateChildValues(counter, withCompletionBlock: { (err, databaseRef) in
self.addSession()
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
return
}
return
})
}
private func addSession() {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("users").child(userID).observeSingleEvent(of: .value)
{ (snapshot) in
if let dic = snapshot.value as? [String: AnyObject] {
self.weight = dic["weight"] as? String
self.calculeCalories(weight: self.weight)
}
}
}
func calculeCalories(weight: String) {
let jumpValue = jumpText.text
let durationValue = "\(minute).\(seconde)"
//String to double
let durationDouble = Double(durationValue)
let weightDouble = Double(weight)
let calorieDouble = (7.5*3.5*weightDouble!)/200.0
let calorie = round(calorieDouble*durationDouble!)
let calorieValue = String(calorie)
let altitudeValue = "1"
//Retrieve the counter number
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).observeSingleEvent(of: .value) { (snapshot) in
if let dictionary = snapshot.value as? [String: AnyObject] {
self.sessionNb = dictionary["counter"] as? String
//If it is the first time the user is connected
if (self.sessionNb=="0") {
let databaseRef = Database.database().reference(fromURL: "https://jumpin-c4b57.firebaseio.com/")
let userID = (Auth.auth().currentUser?.uid)!
let usersRef = databaseRef.child("sessions").child(userID).child("session1")
let sessionValues = ["jumps":jumpValue, "calories":calorieValue, "duration":durationValue, "altitude":altitudeValue] as [String : Any]
usersRef.updateChildValues(sessionValues, withCompletionBlock: { (err, databaseRef) in
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
//Update the value of the counter
let userID = (Auth.auth().currentUser?.uid)!
self.ref = Database.database().reference()
let newCounter = Int(self.sessionNb)! + 1
let counterString = String(newCounter)
self.ref.child("sessions").child(userID).updateChildValues(["counter": counterString])
self.totalJump(counter: counterString)
})
for i in 2...10 {
let newRef = databaseRef.child("sessions").child(userID).child("session\(i)")
let newsSessions = ["jumps":"0", "calories":"0", "duration":"0", "altitude":"0"]
newRef.updateChildValues(newsSessions, withCompletionBlock: { (err, databaseRef) in
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
}
//Create a tmp session
let refTpmSession = databaseRef.child("sessions").child(userID).child("tmp")
let TpmSessions = ["jumps":"0", "calories":"0", "duration":"0", "altitude":"0"]
refTpmSession.updateChildValues(TpmSessions, withCompletionBlock: { (err, databaseRef) in
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
//Create a new variable to calculte the total number of jumps
let refTotalJump = databaseRef.child("sessions").child(userID)
let totalJump = ["totalJump":"0"]
refTotalJump.updateChildValues(totalJump, withCompletionBlock: { (err, databaseRef) in
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
self.redirectionScreen()
}
//If there are at least 1 session
let counter = Int(self.sessionNb)!
if (counter>0){
//For each records, we decale the session n°
for i in (1...counter).reversed() {
Database.database().reference().child("sessions").child(userID).child("session\(i)").observeSingleEvent(of: .value)
{ (snapshot) in
if let dic = snapshot.value as? [String: AnyObject] {
let newAltitude = dic["altitude"] as? String
let newDuration = dic["duration"] as? String
let newCalories = dic["calories"] as? String
let newJumps = dic["jumps"] as? String
let userID = (Auth.auth().currentUser?.uid)!
self.ref = Database.database().reference()
self.ref.child("sessions").child(userID).child("session\(i+1)").updateChildValues(["altitude": newAltitude,"duration": newDuration, "calories": newCalories, "jumps": newJumps])
}
}
}
//Add the new session
self.addNewSession()
}
}
}
}
func addNewSession() {
let jumpValue = jumpText.text
let durationValue = "\(minute).\(seconde)"
let durationDouble = Double(durationValue)
let weightDouble = Double(weight)
let calorieDouble = (7.5*3.5*weightDouble!)/200.0
let calorie = round(calorieDouble*durationDouble!)
let calorieValue = String(calorie)
let altitudeValue = "1"
//Add the new session to a temporary session
let databaseRef = Database.database().reference(fromURL: "https://jumpin-c4b57.firebaseio.com/")
let userID = (Auth.auth().currentUser?.uid)!
let ref = databaseRef.child("sessions").child(userID).child("tmp")
let tmpSession = ["altitude": altitudeValue,"duration": durationValue, "calories": calorieValue, "jumps": jumpValue]
ref.updateChildValues(tmpSession, withCompletionBlock: { (err, databaseRef) in
self.retrieveSession()
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
}
//Replace the session 1 by the temporary session
func retrieveSession() {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("tmp").observeSingleEvent(of: .value)
{ (snapshot) in
if let dic = snapshot.value as? [String: AnyObject] {
let tmpAltitude = dic["altitude"] as? String
let tmpDuration = dic["duration"] as? String
let tmpJump = dic["jumps"] as? String
let tmpCalories = dic["calories"] as? String
self.replace(altitude: tmpAltitude!, duration: tmpDuration!, jumps: tmpJump!, calories: tmpCalories!)
}
}
}
func replace(altitude: String, duration: String, jumps: String, calories: String) {
let userID = (Auth.auth().currentUser?.uid)!
self.ref = Database.database().reference()
self.ref.child("sessions").child(userID).child("session1").updateChildValues(["altitude": altitude, "duration": duration, "jumps": jumps, "calories": calories])
//Update the counter, incrementation
let newCounter = Int(self.sessionNb)! + 1
let counterString = String(newCounter)
self.ref = Database.database().reference()
self.ref.child("sessions").child(userID).updateChildValues(["counter": counterString])
//Retrieve the counter
Database.database().reference().child("sessions").child(userID).observeSingleEvent(of: .value)
{ (snapshot) in
if let dic = snapshot.value as? [String: AnyObject] {
let counter = dic["counter"] as? String
self.redirectionScreen()
self.totalJump(counter: counter!)
}
}
}
func totalJump(counter: String) {
let counterInt = Int(counter)
for i in 1...counterInt! {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session\(i)").observeSingleEvent(of: .value)
{ (snapshot) in
if let dic = snapshot.value as? [String: AnyObject] {
let jump = dic["jumps"] as? String
let jumpInt = Int(jump!)
self.total = self.total + (jumpInt!)
if i == counterInt! {
self.updateTotalJump(total: self.total)
}
}
}
}
}
func updateTotalJump(total: Int) {
let userID = (Auth.auth().currentUser?.uid)!
ref = Database.database().reference()
ref.child("sessions").child(userID).updateChildValues(["totalJump": total])
}
//Redirections
func redirectionScreen() {
let storyboard: UIStoryboard = UIStoryboard(name: "Main", bundle: nil)
let redirect:StatViewController = storyboard.instantiateViewController(withIdentifier: "StatViewController") as! StatViewController
self.present(redirect, animated: true, completion: nil)
}
func redirectionMenu() {
let storyboard: UIStoryboard = UIStoryboard(name: "Main", bundle: nil)
let redirect:MenuViewController = storyboard.instantiateViewController(withIdentifier: "MenuViewController") as! MenuViewController
self.present(redirect, animated: true, completion: nil)
}
//Alerts
func createAlert(title: String, message:String) {
let alert = UIAlertController (title: title, message: message, preferredStyle: UIAlertControllerStyle.alert)
alert.addAction(UIAlertAction(title:"Ok", style:UIAlertActionStyle.default, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
}))
self.present(alert, animated: true, completion: nil)
}
func alertMissingInfo(title: String, message:String) {
let alert = UIAlertController (title: title, message: message, preferredStyle: UIAlertControllerStyle.alert)
alert.addAction(UIAlertAction(title:"Ok", style:UIAlertActionStyle.default, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
let storyboard = UIStoryboard(name: "Main", bundle: nil)
let viewController = storyboard.instantiateViewController(withIdentifier :"InfoViewController") as! InfoViewController
self.present(viewController, animated: true)
}))
self.present(alert, animated: true, completion: nil)
}
func alertBluetooth(title: String, message:String) {
let alert = UIAlertController (title: title, message: message, preferredStyle: UIAlertControllerStyle.alert)
alert.addAction(UIAlertAction(title:"Cancel", style:UIAlertActionStyle.destructive, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
self.redirectionMenu()
}))
alert.addAction(UIAlertAction(title:"Ok", style:UIAlertActionStyle.default, handler: { (action) in
self.pausestart.setTitle("| |", for: .normal)
self.pause = true
self.imageView.removeFromSuperview()
self.timer = Timer.scheduledTimer(timeInterval: 1, target: self, selector: #selector(JumpViewController.action), userInfo: nil, repeats: true)
}))
self.present(alert, animated: true, completion: nil)
}
}
<file_sep>//
// GameScene.swift
// JumpIn
//
// Created by <NAME> on 17/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import SpriteKit
import CoreMotion
import Firebase
class GameScene: SKScene, SKPhysicsContactDelegate {
//Variables
var backgroundNode: SKNode!
var foregroundNode: SKNode!
var hudNode: SKNode!
var player: SKNode!
var scaleFactor: CGFloat!
let tapToStartNode = SKSpriteNode(imageNamed: "TapToStart")
let motionManager = CMMotionManager()
var xAcceleration:CGFloat = 0.0
var currentMaxY:Int!
var scoreLabel:SKLabelNode!
var starLabel:SKLabelNode!
var playersMaxY:Int!
var gameOver = false
var endLevelY = 0
var counter = 0
var sessionStop = 0
var ref:DatabaseReference!
required init?(coder aDecoder: NSCoder) {
super.init(coder: aDecoder)
}
//Initialization
override init(size: CGSize) {
gameOver = false
super.init(size: size)
scaleFactor = self.size.width / 320.0
let levelData = GameHandler.shareInstance.levelData
backgroundNode = createBackgroundNode()
addChild(backgroundNode)
foregroundNode = SKNode()
addChild(foregroundNode)
player = createPlayer()
foregroundNode.addChild(player)
let platforms = levelData!["Platforms"] as! NSDictionary
let platformPatterns = platforms["Patterns"] as! NSDictionary
let platformPositions = platforms["Positions"] as! [NSDictionary]
for platformPosition in platformPositions {
let x = (platformPosition["x"] as AnyObject).floatValue
let y = (platformPosition["y"] as AnyObject).floatValue
let pattern = platformPosition["pattern"] as! NSString
let platformPattern = platformPatterns[pattern] as! [NSDictionary]
for platformPoint in platformPattern {
let xValue = (platformPoint["x"] as AnyObject).floatValue
let yValue = (platformPoint["y"] as AnyObject).floatValue
let type = PlateformType(rawValue: (platformPoint["type"]! as AnyObject).integerValue)
let xPosition = CGFloat(xValue! + x!)
let yPosition = CGFloat(yValue! + y!)
let platformNode = createPlateformAtPosition(position: CGPoint(x: xPosition, y: yPosition), ofType: type!)
foregroundNode.addChild(platformNode)
}
}
let stars = levelData!["Stars"] as! NSDictionary
let starPatterns = stars["Patterns"] as! NSDictionary
let starPositions = stars["Positions"] as! [NSDictionary]
for starPosition in starPositions {
let x = (starPosition["x"] as AnyObject).floatValue
let y = (starPosition["y"] as AnyObject).floatValue
let pattern = starPosition["pattern"] as! NSString
let starPattern = starPatterns[pattern] as! [NSDictionary]
for starPoint in starPattern {
let xValue = (starPoint["x"] as AnyObject).floatValue
let yValue = (starPoint["y"] as AnyObject).floatValue
let type = StarType(rawValue: (starPoint["type"]! as AnyObject).integerValue)
let xPosition = CGFloat(xValue! + x!)
let yPosition = CGFloat(yValue! + y!)
let starNode = createStarAtPosition(position: CGPoint(x: xPosition, y: yPosition), ofType: type!)
foregroundNode.addChild(starNode)
}
}
let star = createStarAtPosition(position: CGPoint(x:160,y:220), ofType: StarType.NormalStar)
foregroundNode.addChild(star)
physicsWorld.gravity = CGVector(dx: 0.0, dy: -2.0)
physicsWorld.contactDelegate = self
//Tap to start
hudNode = SKNode()
addChild(hudNode)
tapToStartNode.position = CGPoint(x: self.size.width / 2, y: 180.0)
hudNode.addChild(tapToStartNode)
//Motion manager
motionManager.accelerometerUpdateInterval = 0.2
motionManager.startAccelerometerUpdates(to: OperationQueue.current!, withHandler: {(accelData: CMAccelerometerData!, errorOC: Error!) in
let acceleration = accelData.acceleration
self.xAcceleration = (CGFloat(acceleration.x) * 0.75) + (self.xAcceleration * 0.25)
})
//When the game is finish//
currentMaxY = 80
GameHandler.shareInstance.score = 0
gameOver = false
endLevelY = (levelData!["EndY"]! as AnyObject).integerValue
//Scores
let starScore = SKSpriteNode(imageNamed: "Star")
star.position = CGPoint(x: 25, y: self.size.height-30)
hudNode.addChild(starScore)
starLabel = SKLabelNode(fontNamed: "ChalkboardSE-Bold")
starLabel.fontSize = 30
starLabel.fontColor = SKColor.white
starLabel.position = CGPoint(x: 50, y: self.size.height-40)
starLabel.horizontalAlignmentMode = SKLabelHorizontalAlignmentMode.left
//starLabel.text = "\(GameHandler.shareInstance.stars)"
hudNode.addChild(starLabel)
starLabel = SKLabelNode(fontNamed: "ChalkboardSE-Bold")
starLabel.fontSize = 30
starLabel.fontColor = SKColor.white
starLabel.position = CGPoint(x: self.size.width-20, y: self.size.height-40)
starLabel.horizontalAlignmentMode = SKLabelHorizontalAlignmentMode.right
//starLabel.text = "0"
hudNode.addChild(starLabel)
}
//Manage collision
func didBegin(_ contact: SKPhysicsContact) {
var updateHud = false
var otherNode:SKNode!
if contact.bodyA.node != player{
otherNode = contact.bodyA.node
} else {
otherNode = contact.bodyB.node
}
updateHud = (otherNode as! GameObjectNode).collisionWithPlayer(player: player)
if updateHud {
//starLabel.text = "\(GameHandler.shareInstance.stars)"
//scoreLabel.text = "\(GameHandler.shareInstance.score)"
}
}
//Manipulate the velocity of the player
override func didSimulatePhysics() {
player.physicsBody?.velocity = CGVector(dx: xAcceleration * 400.0, dy: player.physicsBody!.velocity.dy)
//If the player is out of the screen by the left or the right, he can appeared by the right or left
if player.position.x < -20.0 {
player.position = CGPoint(x: self.size.width + 20.0, y: player.position.y)
} else if (player.position.x > self.size.width + 20.0) {
player.position = CGPoint(x: -20.0, y: player.position.y)
}
}
//Tap
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
tapToStartNode.removeFromParent()
player.physicsBody?.isDynamic = true
player.physicsBody?.applyImpulse(CGVector(dx: 0.0, dy: 20.0)) //Boost
let userID = (Auth.auth().currentUser?.uid)!
ref = Database.database().reference()
Database.database().reference().child("sessions").child(userID).observeSingleEvent(of: .value)
{ (snapshot) in
if let dic = snapshot.value as? [String: AnyObject] {
let totalJump = dic["totalJump"] as? Int
let total = totalJump! - 1
//Update the new jump counter
self.ref.child("sessions").child(userID).updateChildValues(["totalJump": total])
self.jumpStop(total: total)
}
}
}
//Update the view
override func update(_ currentTime: CFTimeInterval) {
if gameOver {
return
}
foregroundNode.enumerateChildNodes(withName: "PLATEFORMNODE") { (node, stop) in
let platform = node as! PlateformNode
platform.checkNodeRemoval(playerY: self.player.position.y)
}
foregroundNode.enumerateChildNodes(withName: "STARMODE") { (node, stop) in
let star = node as! StarNode
star.checkNodeRemoval(playerY: self.player.position.y)
}
if player.position.y > 200 {
backgroundNode.position = CGPoint(x: 0, y: -((player.position.y - 200)/10))
foregroundNode.position = CGPoint(x: 0, y: -(player.position.y - 200))
}
//Increase the score when the player travels up the screen
if Int(player.position.y) > currentMaxY {
GameHandler.shareInstance.score += Int(player.position.y) - currentMaxY
currentMaxY = Int(player.position.y)
//scoreLabel.text = "\(GameHandler.shareInstance.score)"
}
//Check if we've finished the level
if Int(player.position.y) > endLevelY {
endGame()
}
// Check if we've fallen too far
if Int(player.position.y) < currentMaxY - 300 {
print("loose")
endGame()
}
}
func jumpStop(total: Int) {
print("Test")
print (total)
if total == 0 {
endGame()
}
}
func endGame() {
print ("loose")
gameOver = true
GameHandler.shareInstance.saveGameScore()
let transition = SKTransition.fade(withDuration: 0.5)
let endGameScene = EndGameScene(size: self.size)
self.view!.presentScene(endGameScene, transition: transition)
}
}
<file_sep># JumpIn-iOS
The idea is very simple : motive people to do more exercises.
In order to motivate them, we decide to mixt sport but also fun.
To do this, the user have to make some jumps and then, according to how much jumps the user have done and altitude, the user can have different way of playing our game.
For example: The more he/she did jumps, the more he/she will have jumps to the game.
We decide to mix 2 parts : Game and Sport in order to motivate users as much as possible.
<file_sep>//
// EndGameViewController.swift
// JumpIn
//
// Created by <NAME> on 22/11/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import UIKit
import Firebase
class EndGameViewController: UIViewController {
@IBOutlet var highScoreLabel: UILabel!
@IBOutlet var scoreLabel: UILabel!
@IBOutlet var jumpLabel: UILabel!
override func viewDidLoad() {
super.viewDidLoad()
let score = GameHandler.shareInstance.score
let highscore = GameHandler.shareInstance.highScore
let scoreString = String(score)
let highScoreString = String(highscore)
highScoreLabel.text = highScoreString
scoreLabel.text = scoreString
//Retrieve the number of jumps remaining
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).observeSingleEvent(of: .value) { (snapshot) in
if let dictionary = snapshot.value as? [String: AnyObject] {
let totalJump = dictionary["totalJump"] as? Int
let totalString = String(totalJump!)
self.jumpLabel.text = totalString
}
}
}
@IBAction func shareButton(_ sender: Any) {
let activityController = UIActivityViewController(activityItems: ["Hi! I just finished a game on JumpIn app, I made a score of \(self.scoreLabel.text!). Try to beat me, my highscore is \(self.highScoreLabel.text!)! 😃"], applicationActivities: nil)
present(activityController, animated: true, completion: nil)
}
@IBAction func replayButton(_ sender: Any) {
//Check if the counter is equal to 0
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).observeSingleEvent(of: .value) { (snapshot) in
if let dictionary = snapshot.value as? [String: AnyObject] {
let totalJump = dictionary["totalJump"] as? Int
self.redirection(counter: totalJump!)
}
}
}
func redirection(counter: Int) {
if counter == 0 {
self.createAlert(title: "Error", message: "Sorry, you have to jump again in order to play")
} else {
let storyboard: UIStoryboard = UIStoryboard(name: "Main", bundle: nil)
let redirect:GameViewController = storyboard.instantiateViewController(withIdentifier: "GameViewController") as! GameViewController
self.present(redirect, animated: true, completion: nil)
}
}
func createAlert(title: String, message:String) {
let alert = UIAlertController (title: title, message: message, preferredStyle: UIAlertControllerStyle.alert)
alert.addAction(UIAlertAction(title:"Cancel", style:UIAlertActionStyle.destructive, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
}))
alert.addAction(UIAlertAction(title:"Jump", style:UIAlertActionStyle.default, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
let storyboard = UIStoryboard(name: "Main", bundle: nil)
let viewController = storyboard.instantiateViewController(withIdentifier :"JumpViewController") as! JumpViewController
self.present(viewController, animated: true)
}))
self.present(alert, animated: true, completion: nil)
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
}
<file_sep>//
// PlateformNode.swift
// JumpIn
//
// Created by <NAME> on 17/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import SpriteKit
class PlateformNode: GameObjectNode {
var plateformType:PlateformType!
override func collisionWithPlayer(player: SKNode) -> Bool {
if Int((player.physicsBody?.velocity.dy)!) < 0 {
player.physicsBody?.velocity = CGVector(dx: player.physicsBody!.velocity.dx, dy: 250)
// To go more in deep, we can add a breakable condition
if plateformType == PlateformType.breakableBrick {
self.removeFromParent()
}
}
return false
}
}
<file_sep>//
// SignUpViewController.swift
// JumpIn
//
// Created by <NAME> on 01/11/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import UIKit
import FirebaseAuth
import Firebase
import FirebaseDatabase
class SignUpViewController: UIViewController, UITextFieldDelegate {
@IBOutlet var signUp: UIButton!
@IBOutlet var usernameInput: UITextField!
@IBOutlet var passwordInput: UITextField!
@IBOutlet var weightInput: UITextField!
@IBOutlet var highInput: UITextField!
override func viewDidLoad() {
super.viewDidLoad()
signUp.layer.cornerRadius = 5.0
//Hide keyboard
self.usernameInput.delegate = self
self.passwordInput.delegate = self
self.weightInput.delegate = self
self.highInput.delegate = self
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
@IBAction func createAccount(_ sender: Any) {
//If username and password are filled
let weight = weightInput.text
let high = highInput.text
if let username = usernameInput.text, let password = passwordInput.text {
//Create user
Auth.auth().createUser(withEmail: username, password: <PASSWORD>, completion: { user, error in
//Errors
if let firebaseError = error {
self.createAlert(title: "Error", message: firebaseError.localizedDescription)
return
}
else {
//Add to the firebase DB
let databaseRef = Database.database().reference(fromURL: "https://jumpin-c4b57.firebaseio.com/")
let usersRef = databaseRef.child("users").child((user?.uid)!)
let userValues = ["username" : username, "weight" : weight, "high" : high]
usersRef.updateChildValues(userValues, withCompletionBlock: { (err, databaseRef) in
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
let jumpRef = databaseRef.child("sessions").child((user?.uid)!)
let refValues = ["totalJump" : "0"]
jumpRef.updateChildValues(refValues, withCompletionBlock: { (err, databaseRef) in
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
self.redirectionScreen()
}
})
}
}
//Redirection
func redirectionScreen() {
let storyboard: UIStoryboard = UIStoryboard(name: "Main", bundle: nil)
let redirect:MenuViewController = storyboard.instantiateViewController(withIdentifier: "MenuViewController") as! MenuViewController
self.present(redirect, animated: true, completion: nil)
}
//Create a pop up alert
func createAlert(title: String, message:String) {
let alert = UIAlertController (title: title, message: message, preferredStyle: UIAlertControllerStyle.alert)
alert.addAction(UIAlertAction(title:"Ok", style:UIAlertActionStyle.default, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
}))
self.present(alert, animated: true, completion: nil)
}
//Hide keyboard when user touches outside
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
self.view.endEditing(true)
}
//Hide keyboard when user touches return
func textFieldShouldReturn(_ textField: UITextField) -> Bool {
usernameInput.resignFirstResponder()
passwordInput.resignFirstResponder()
weightInput.resignFirstResponder()
highInput.resignFirstResponder()
return true
}
}
<file_sep>//
// GameElements.swift
// JumpIn
//
// Created by <NAME> on 17/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import SpriteKit
extension GameScene {
//Background
func createBackgroundNode() -> SKNode {
let backgroundNode = SKNode()
let ySpacing = 64.0 * scaleFactor
for index in 0...19 {
let node = SKSpriteNode(imageNamed:String(format: "Background%02d", index + 1))
node.setScale(scaleFactor)
node.anchorPoint = CGPoint(x: 0.5, y: 0.0)
node.position = CGPoint(x: self.size.width / 2, y: ySpacing * CGFloat(index))
backgroundNode.addChild(node)
}
return backgroundNode
}
//Player
func createPlayer() -> SKNode {
let playerNode = SKNode()
playerNode.position = CGPoint(x: self.size.width / 2, y: 80.0)
let sprite = SKSpriteNode(imageNamed: "Player")
playerNode.addChild(sprite)
//Gravity
playerNode.physicsBody = SKPhysicsBody(circleOfRadius: sprite.size.width / 2)
playerNode.physicsBody?.isDynamic = false
playerNode.physicsBody?.allowsRotation = false
playerNode.physicsBody?.restitution = 1.0
playerNode.physicsBody?.friction = 0.0
playerNode.physicsBody?.angularDamping = 0.0
playerNode.physicsBody?.linearDamping = 0.0
//Collision
playerNode.physicsBody?.usesPreciseCollisionDetection = true
playerNode.physicsBody?.categoryBitMask = CollisionCategoryBitmask.Player
playerNode.physicsBody?.collisionBitMask = 0
playerNode.physicsBody?.contactTestBitMask = CollisionCategoryBitmask.Star | CollisionCategoryBitmask.Platform
return playerNode
}
//Plateform
func createPlateformAtPosition(position: CGPoint, ofType type:PlateformType) -> PlateformNode {
let node = PlateformNode()
let position = CGPoint(x:position.x * scaleFactor, y: position.y)
node.position = position
node.name = "PLATEFORMNODE"
node.plateformType = type
var sprite:SKSpriteNode
if type == PlateformType.normalBrick {
sprite = SKSpriteNode(imageNamed: "Platform")
} else {
sprite = SKSpriteNode(imageNamed: "PlatformBreak")
}
node.addChild(sprite)
node.physicsBody = SKPhysicsBody(rectangleOf: sprite.size)
node.physicsBody?.isDynamic = false
node.physicsBody?.categoryBitMask = CollisionCategoryBitmask.Platform
node.physicsBody?.collisionBitMask = 0
return node
}
//Star
func createStarAtPosition(position: CGPoint, ofType type:StarType) -> StarNode {
let node = StarNode()
let position = CGPoint(x: position.x * scaleFactor, y: position.y)
node.position = position
node.name = "STARMODE"
node.starType = type
var sprite: SKSpriteNode
if type == StarType.NormalStar {
sprite = SKSpriteNode(imageNamed: "Star")
} else {
sprite = SKSpriteNode(imageNamed: "StarSpecial")
}
node.addChild(sprite)
node.physicsBody = SKPhysicsBody(circleOfRadius: sprite.size.width / 2)
node.physicsBody?.isDynamic = false
node.physicsBody?.categoryBitMask = CollisionCategoryBitmask.Star
node.physicsBody?.collisionBitMask = 0
return node
}
}
<file_sep>//
// ViewController.swift
// JumpIn
//
// Created by <NAME> on 17/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import UIKit
class ViewController: UIViewController {
@IBOutlet var start: UIButton!
override func viewDidLoad() {
super.viewDidLoad()
start.layer.cornerRadius = 5.0
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
}
<file_sep>//
// DetailViewController.swift
// PNChartSwift
//
// Created by <NAME> on 8/14/17.
//
import UIKit
import Firebase
import FirebaseDatabase
class DetailViewController: UIViewController {
var chartName: String?
var session1: String!
var session2: String!
var session3: String!
var session4: String!
var session5: String!
var session6: String!
var session7: String!
var session8: String!
var session9: String!
var session10: String!
@IBOutlet var warningText: UIButton!
var ref:DatabaseReference!
let loadingTextLabel = UILabel()
var activityIndicator:UIActivityIndicatorView = UIActivityIndicatorView()
@IBOutlet var session1txt: UIButton!
@IBOutlet var session2txt: UIButton!
@IBOutlet var session3txt: UIButton!
@IBOutlet var session4txt: UIButton!
@IBOutlet var session5txt: UIButton!
@IBOutlet var session6txt: UIButton!
@IBOutlet var session7txt: UIButton!
@IBOutlet var session8txt: UIButton!
@IBOutlet var session9txt: UIButton!
@IBOutlet var session10txt: UIButton!
override func viewDidLoad() {
super.viewDidLoad()
guard let _chartName = self.chartName else {
print("Invalid Chart Name")
return
}
self.title = _chartName
switch _chartName {
case "Calories":
printSession1(activity: "calories")
case "Jumps":
printSession1(activity: "jumps")
case "Duration":
printSession1(activity: "duration")
default:
break
}
}
//Display all data
private func printSession1(activity: String) {
let userID = (Auth.auth().currentUser?.uid)!
let databaseRef = Database.database().reference(fromURL: "https://jumpin-c4b57.firebaseio.com/")
databaseRef.child("sessions").child(userID).observeSingleEvent(of: .value, with: { (snapshot) in
if !snapshot.hasChild("session1"){
self.warningText.setTitle("You need to do, at least, one session", for: .normal)
}
})
Database.database().reference().child("sessions").child(userID).child("session1").observeSingleEvent(of: .value) { (snapshot) in
if let userDict = snapshot.value as? [String:Any] {
self.session1txt.setTitle(userDict[activity] as? String, for: .normal)
self.session1 = userDict[activity] as? String
// If the user never did session, we just print a message
if (self.session1 != "0") {
//Waiting message
self.activityIndicator.center = self.view.center
self.activityIndicator.hidesWhenStopped = true
self.activityIndicator.activityIndicatorViewStyle = UIActivityIndicatorViewStyle.gray
self.view.addSubview(self.activityIndicator)
self.activityIndicator.startAnimating()
UIApplication.shared.beginIgnoringInteractionEvents()
self.loadingTextLabel.text = "Wait please, loading..."
self.loadingTextLabel.font = UIFont(name: "Avenir Light", size: 12)
self.loadingTextLabel.sizeToFit()
self.loadingTextLabel.center = CGPoint(x: self.activityIndicator.center.x, y: self.activityIndicator.center.y + 30)
self.view.addSubview(self.loadingTextLabel)
}
self.printSession2(activity: activity, session1: self.session1)
}
}
}
private func printSession2(activity: String, session1: String) {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session2").observeSingleEvent(of: .value) { (snapshot) in
if let userDict = snapshot.value as? [String:Any] {
self.session2txt.setTitle(userDict[activity] as? String, for: .normal)
self.session2 = userDict[activity] as? String
self.printSession3(activity: activity, session1: session1, session2: self.session2)
}
}
}
private func printSession3(activity: String, session1: String, session2: String) {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session3").observeSingleEvent(of: .value) { (snapshot) in
if let userDict = snapshot.value as? [String:Any] {
self.session3txt.setTitle(userDict[activity] as? String, for: .normal)
self.session3 = userDict[activity] as? String
self.printSession4(activity: activity, session1: session1, session2: session2, session3: self.session3)
}
}
}
private func printSession4(activity: String, session1: String, session2: String, session3: String) {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session4").observeSingleEvent(of: .value) { (snapshot) in
if let userDict = snapshot.value as? [String:Any] {
self.session4txt.setTitle(userDict[activity] as? String, for: .normal)
self.session4 = userDict[activity] as? String
self.printSession5(activity: activity, session1: session1, session2: session2, session3: session3, session4: self.session4)
}
}
}
private func printSession5(activity: String, session1: String, session2: String, session3: String, session4: String) {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session5").observeSingleEvent(of: .value) { (snapshot) in
if let userDict = snapshot.value as? [String:Any] {
self.session5txt.setTitle(userDict[activity] as? String, for: .normal)
self.session5 = userDict[activity] as? String
self.printSession6(activity: activity, session1: session1, session2: session2, session3: session3, session4: session4, session5: self.session5)
}
}
}
private func printSession6(activity: String, session1: String, session2: String, session3: String, session4: String, session5: String) {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session6").observeSingleEvent(of: .value) { (snapshot) in
if let userDict = snapshot.value as? [String:Any] {
self.session6txt.setTitle(userDict[activity] as? String, for: .normal)
self.session6 = userDict[activity] as? String
self.printSession7(activity: activity, session1: session1, session2: session2, session3: session3, session4: session4, session5: session5, session6: self.session6)
}
}
}
private func printSession7(activity: String, session1: String, session2: String, session3: String, session4: String, session5: String, session6: String) {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session7").observeSingleEvent(of: .value) { (snapshot) in
if let userDict = snapshot.value as? [String:Any] {
self.session7txt.setTitle(userDict[activity] as? String, for: .normal)
self.session7 = userDict[activity] as? String
self.printSession8(activity: activity, session1: session1, session2: session2, session3: session3, session4: session4, session5: session5, session6: session6, session7: self.session7)
}
}
}
private func printSession8(activity: String, session1: String, session2: String, session3: String, session4: String, session5: String, session6: String, session7: String) {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session8").observeSingleEvent(of: .value) { (snapshot) in
if let userDict = snapshot.value as? [String:Any] {
self.session8txt.setTitle(userDict[activity] as? String, for: .normal)
self.session8 = userDict[activity] as? String
self.printSession9(activity: activity, session1: session1, session2: session2, session3: session3, session4: session4, session5: session5, session6: session6, session7: session7, session8: self.session8)
}
}
}
private func printSession9(activity: String, session1: String, session2: String, session3: String, session4: String, session5: String, session6: String, session7: String, session8: String) {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session9").observeSingleEvent(of: .value) { (snapshot) in
if let userDict = snapshot.value as? [String:Any] {
self.session9txt.setTitle(userDict[activity] as? String, for: .normal)
self.session9 = userDict[activity] as? String
self.printSession10(activity: activity, session1: session1, session2: session2, session3: session3, session4: session4, session5: session5, session6: session6, session7: session7, session8: session8, session9: self.session9)
}
}
}
private func printSession10(activity: String, session1: String, session2: String, session3: String, session4: String, session5: String, session6: String, session7: String, session8: String, session9: String) {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session10").observeSingleEvent(of: .value) { (snapshot) in
if let userDict = snapshot.value as? [String:Any] {
self.session10txt.setTitle(userDict[activity] as? String, for: .normal)
self.session10 = userDict[activity] as? String
self.setChart(activity: activity, session1: session1, session2: session2, session3: session3, session4: session4, session5: session5, session6: session6, session7: session7, session8: session8, session9: session9, session10: self.session10)
}
}
}
//Draw the bar charts
private func setChart(activity: String, session1: String, session2: String, session3: String, session4: String, session5: String, session6: String, session7: String, session8: String, session9: String, session10: String) {
let sess1Double = Double(session1)
let sess2Double = Double(session2)
let sess3Double = Double(session3)
let sess4Double = Double(session4)
let sess5Double = Double(session5)
let sess6Double = Double(session6)
let sess7Double = Double(session7)
let sess8Double = Double(session8)
let sess9Double = Double(session9)
let sess10Double = Double(session10)
if session1 != "0" {
let barChart = PNBarChart(frame: CGRect(x: 0, y: 50, width: 320, height: 200))
barChart.backgroundColor = UIColor.clear
barChart.animationType = .Waterfall
barChart.labelMarginTop = 5.0
barChart.xLabels = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "10" ]
barChart.yValues = [CGFloat(sess1Double!),CGFloat(sess2Double!),CGFloat(sess3Double!),CGFloat(sess4Double!),CGFloat(sess5Double!),CGFloat(sess6Double!),CGFloat(sess7Double!),CGFloat(sess8Double!),CGFloat(sess9Double!), CGFloat(sess10Double!)]
barChart.strokeChart()
barChart.center = self.view.center
self.view.addSubview(barChart)
//Dismiss message
loadingTextLabel.text = ""
activityIndicator.stopAnimating()
UIApplication.shared.endIgnoringInteractionEvents()
} else {
self.warningText.setTitle("You need to do, at least, one jump", for: .normal)
}
}
}
<file_sep>target 'JumpIn' do
project 'JumpIn'
use_frameworks!
pod 'FacebookCore'
pod 'FacebookLogin'
pod 'Firebase'
pod 'Firebase/Core'
pod 'Firebase/Auth'
pod 'Firebase/Database'
pod 'PNChartSwift',:git => 'https://github.com/kevinzhow/PNChart-Swift.git'
end
<file_sep>//
// StatViewController.swift
// JumpIn
//
// Created by <NAME> on 17/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import UIKit
import Firebase
import FirebaseDatabase
class StatViewController: UIViewController {
@IBOutlet var jumpNb: UIButton!
@IBOutlet var calories: UIButton!
@IBOutlet var duration: UIButton!
@IBOutlet var altitude: UIButton!
var newJump: String!
var newCalories: String!
var newDuration: String!
var newAltitude: String!
override func viewDidLoad() {
super.viewDidLoad()
//Print the data of the last session
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session1").observeSingleEvent(of: .value) { (snapshot) in
if let dictionary = snapshot.value as? [String: AnyObject] {
self.newJump = dictionary["jumps"] as? String
self.newCalories = dictionary["calories"] as? String
self.newDuration = dictionary["duration"] as? String
self.newAltitude = dictionary["altitude"] as? String
self.jumpNb.setTitle(self.newJump, for: .normal)
self.calories.setTitle(self.newCalories, for: .normal)
self.duration.setTitle(self.newDuration, for: .normal)
self.altitude.setTitle(self.newAltitude, for: .normal)
}
}
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
//Share the result on social media
@IBAction func shareResult(_ sender: Any) {
let activityController = UIActivityViewController(activityItems: ["Hi! I just finished my session on JumpIn app. I did \(self.newJump!) jumps, I burnt \(self.newCalories!) calories and my average altitude is \(self.newAltitude!) during \(self.newDuration!) minutes. Try this app! 😃"], applicationActivities: nil)
present(activityController, animated: true, completion: nil)
}
}
<file_sep>//
// StarNode.swift
// JumpIn
//
// Created by <NAME> on 17/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import SpriteKit
enum StarType:Int {
case NormalStar = 0
case specialStar = 1
}
class StarNode: GameObjectNode {
var starType:StarType!
override func collisionWithPlayer(player: SKNode) -> Bool {
player.physicsBody?.velocity = CGVector(dx: player.physicsBody!.velocity.dx, dy: 300)
//Normal star = 20 pts to the score
//Special star = 100 pts to the score
GameHandler.shareInstance.score += (starType == StarType.NormalStar ? 20 : 100)
//Normal star = 1 to the nb of stars
//Special star = 5 to the nb of stars
GameHandler.shareInstance.stars += (starType == StarType.NormalStar ? 1 : 5)
self.removeFromParent()
return true
}
}
<file_sep>//
// GameViewController.swift
// JumpIn
//
// Created by <NAME> on 17/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import UIKit
import SpriteKit
import GameplayKit
class GameViewController: UIViewController {
override func viewDidLoad() {
super.viewDidLoad()
let skView = self.view as! SKView
skView.showsFPS = true
skView.showsNodeCount = true
let scene = GameScene(size: skView.bounds.size)
scene.scaleMode = .aspectFit
skView.presentScene(scene)
}
@IBAction func info(_ sender: Any) {
print(GameHandler.shareInstance.stars)
createAlert(title: "Quit the game", message: "You will quit the game")
}
func createAlert(title: String, message:String) {
let alert = UIAlertController (title: title, message: message, preferredStyle: UIAlertControllerStyle.alert)
alert.addAction(UIAlertAction(title:"Cancel", style:UIAlertActionStyle.default, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
}))
alert.addAction(UIAlertAction(title:"Quit", style:UIAlertActionStyle.destructive, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
let storyboard = UIStoryboard(name: "Main", bundle: nil)
let viewController = storyboard.instantiateViewController(withIdentifier :"EndGameViewController") as! EndGameViewController
self.present(viewController, animated: true)
}))
self.present(alert, animated: true, completion: nil)
}
override var shouldAutorotate: Bool {
return true
}
override var supportedInterfaceOrientations: UIInterfaceOrientationMask {
if UIDevice.current.userInterfaceIdiom == .phone {
return .allButUpsideDown
} else {
return .all
}
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
override var prefersStatusBarHidden: Bool {
return true
}
}
<file_sep>//
// AccelerometerViewController.swift
// JumpIn
//
// Created by <NAME> on 20/11/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import UIKit
import Firebase
import FirebaseDatabase
import CoreMotion
class AccelerometerViewController: UIViewController {
@IBOutlet var jumpText: UILabel!
@IBOutlet var pausestart: UIButton!
@IBOutlet var stop: UIButton!
var pause = false
var sessionNb: String!
var ref:DatabaseReference!
var weight:String!
var jump = 0
var realjump = 0
var count = 0
var timer = Timer()
@IBOutlet var countingTime: UILabel!
var seconde = 0
var minute = 0
let imageName = "TapToStart.png"
var image: UIImage!
var imageView: UIImageView!
var total: Int = 0
var TotalJumps: Int = 0
var motionManager = CMMotionManager()
override func viewDidLoad() {
super.viewDidLoad()
pausestart.layer.cornerRadius = 10.0
stop.layer.cornerRadius = 10.0
countingTime.text = String(format: "%02d:%02d", minute, seconde)
image = UIImage(named: imageName)
imageView = UIImageView(image: image!)
imageView.frame = CGRect(x: view.frame.size.width/8, y: view.frame.size.height-250, width: 150, height: 100)
view.addSubview(imageView)
stop.isEnabled = false
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
@IBAction func goHome(_ sender: Any) {
motionManager.stopAccelerometerUpdates()
let storyboard: UIStoryboard = UIStoryboard(name: "Main", bundle: nil)
let redirect:MenuViewController = storyboard.instantiateViewController(withIdentifier: "MenuViewController") as! MenuViewController
self.present(redirect, animated: true, completion: nil)
}
override func viewDidAppear(_ animated: Bool) {}
//User click on pause
@IBAction func pause(_ sender: Any) {
stop.isEnabled = true
if pause == true {
pausestart.setTitle(">",for: .normal)
pause = false
timer.invalidate()
motionManager.stopAccelerometerUpdates()
} else if pause == false {
//If the user didn't put weight/high, have to alert him
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("users").child(userID).observeSingleEvent(of: .value) { (snapshot) in
if let dictionary = snapshot.value as? [String: AnyObject] {
let high = dictionary["high"] as? String
let weight = dictionary["weight"] as? String
self.startJumping(high: high!, weight: weight!)
}
}
}
}
func startJumping(high:String, weight:String) {
if (high == "" || weight == "") {
self.alertMissingInfo(title: "Warning", message: "You have to enter weight and high before starting")
} else {
pausestart.setTitle("| |", for: .normal)
pause = true
imageView.removeFromSuperview()
timer = Timer.scheduledTimer(timeInterval: 1, target: self, selector: #selector(JumpViewController.action), userInfo: nil, repeats: true)
//Accelerometer
motionManager.accelerometerUpdateInterval = 0.1
motionManager.startAccelerometerUpdates(to: OperationQueue.current!) { (data, error) in
if let myData = data {
let xvalue: Double = myData.acceleration.x
let yvalue: Double = myData.acceleration.y
let zvalue: Double = myData.acceleration.z
var Avalue: Double = 0
Avalue = sqrt(xvalue*xvalue + yvalue*yvalue + zvalue*zvalue)
print("X value \(xvalue)")
print("Y value \(yvalue)")
print("Z value \(zvalue)")
print("Average value \(Avalue)")
if ( Avalue > 4.2 && self.count == 0 )
{
self.jump = self.jump + 1
self.count = 1
}
if ( Avalue < 4.2 )
{
self.count = 0
}
self.realjump = (Int)(self.jump)
print ("number jump \(self.realjump)")
//can't make it into the label
self.jumpText.text = (String)(self.realjump)
}
}
}
}
@objc func action() {
if seconde == 59 {
seconde = 0
minute = minute+1
} else {
seconde = seconde+1
}
countingTime.text = String(format: "%02d:%02d", minute, seconde)
}
//User click on stop
@IBAction func stopTouched(_ sender: Any) {
motionManager.stopAccelerometerUpdates()
//If the user never use the jump, create the counter (if there is no session)
let databaseRef = Database.database().reference(fromURL: "https://jumpin-c4b57.firebaseio.com/")
let userID = (Auth.auth().currentUser?.uid)!
let usersRef = databaseRef.child("sessions").child(userID)
//Check if session 1 exist, else create ot
databaseRef.child("sessions").child(userID).observeSingleEvent(of: .value, with: { (snapshot) in
if snapshot.hasChild("session1"){
self.addSession()
}else{
let counter = ["counter": "0"]
usersRef.updateChildValues(counter, withCompletionBlock: { (err, databaseRef) in
self.addSession()
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
return
}
return
})
}
private func addSession() {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("users").child(userID).observeSingleEvent(of: .value)
{ (snapshot) in
if let dic = snapshot.value as? [String: AnyObject] {
self.weight = dic["weight"] as? String
self.calculeCalories(weight: self.weight)
}
}
}
func calculeCalories(weight: String) {
let jumpValue = jumpText.text
let durationValue = "\(minute).\(seconde)"
//String to double
let durationDouble = Double(durationValue)
let weightDouble = Double(weight)
let calorieDouble = (7.5*3.5*weightDouble!)/200.0
let calorie = round(calorieDouble*durationDouble!)
let calorieValue = String(calorie)
let altitudeValue = "1"
//Retrieve the counter number
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).observeSingleEvent(of: .value) { (snapshot) in
if let dictionary = snapshot.value as? [String: AnyObject] {
self.sessionNb = dictionary["counter"] as? String
//If it is the first time the user is connected
if (self.sessionNb=="0") {
let databaseRef = Database.database().reference(fromURL: "https://jumpin-c4b57.firebaseio.com/")
let userID = (Auth.auth().currentUser?.uid)!
let usersRef = databaseRef.child("sessions").child(userID).child("session1")
let sessionValues = ["jumps":jumpValue, "calories":calorieValue, "duration":durationValue, "altitude":altitudeValue] as [String : Any]
usersRef.updateChildValues(sessionValues, withCompletionBlock: { (err, databaseRef) in
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
//Update the value of the counter
let userID = (Auth.auth().currentUser?.uid)!
self.ref = Database.database().reference()
let newCounter = Int(self.sessionNb)! + 1
let counterString = String(newCounter)
self.ref.child("sessions").child(userID).updateChildValues(["counter": counterString])
self.totalJump(counter: counterString)
self.redirectionScreen()
})
for i in 2...10 {
let newRef = databaseRef.child("sessions").child(userID).child("session\(i)")
let newsSessions = ["jumps":"0", "calories":"0", "duration":"0", "altitude":"0"]
newRef.updateChildValues(newsSessions, withCompletionBlock: { (err, databaseRef) in
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
}
//Create a tmp session
let refTpmSession = databaseRef.child("sessions").child(userID).child("tmp")
let TpmSessions = ["jumps":"0", "calories":"0", "duration":"0", "altitude":"0"]
refTpmSession.updateChildValues(TpmSessions, withCompletionBlock: { (err, databaseRef) in
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
//Create a new variable to calculte the total number of jumps
let refTotalJump = databaseRef.child("sessions").child(userID)
let totalJump = ["totalJump":"0"]
refTotalJump.updateChildValues(totalJump, withCompletionBlock: { (err, databaseRef) in
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
}
//If there are at least 1 session
let counter = Int(self.sessionNb)!
if (counter>0){
//For each records, we decale the session n°
for i in (1...counter).reversed() {
print(i)
Database.database().reference().child("sessions").child(userID).child("session\(i)").observeSingleEvent(of: .value)
{ (snapshot) in
if let dic = snapshot.value as? [String: AnyObject] {
let newAltitude = dic["altitude"] as? String
let newDuration = dic["duration"] as? String
let newCalories = dic["calories"] as? String
let newJumps = dic["jumps"] as? String
let userID = (Auth.auth().currentUser?.uid)!
self.ref = Database.database().reference()
self.ref.child("sessions").child(userID).child("session\(i+1)").updateChildValues(["altitude": newAltitude,"duration": newDuration, "calories": newCalories, "jumps": newJumps])
}
}
}
//Add the new session
self.addNewSession()
}
}
}
}
func addNewSession() {
let jumpValue = jumpText.text
let durationValue = "\(minute).\(seconde)"
let durationDouble = Double(durationValue)
let weightDouble = Double(weight)
let calorieDouble = (7.5*3.5*weightDouble!)/200.0
let calorie = round(calorieDouble*durationDouble!)
let calorieValue = String(calorie)
let altitudeValue = "1"
//Add the new session to a temporary session
let databaseRef = Database.database().reference(fromURL: "https://jumpin-c4b57.firebaseio.com/")
let userID = (Auth.auth().currentUser?.uid)!
let ref = databaseRef.child("sessions").child(userID).child("tmp")
let tmpSession = ["altitude": altitudeValue,"duration": durationValue, "calories": calorieValue, "jumps": jumpValue]
ref.updateChildValues(tmpSession, withCompletionBlock: { (err, databaseRef) in
self.retrieveSession()
if err != nil {
self.createAlert(title: "Error", message: (err?.localizedDescription)!)
return
}
})
}
//Replace the session 1 by the temporary session
func retrieveSession() {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("tmp").observeSingleEvent(of: .value)
{ (snapshot) in
if let dic = snapshot.value as? [String: AnyObject] {
let tmpAltitude = dic["altitude"] as? String
let tmpDuration = dic["duration"] as? String
let tmpJump = dic["jumps"] as? String
let tmpCalories = dic["calories"] as? String
self.replace(altitude: tmpAltitude!, duration: tmpDuration!, jumps: tmpJump!, calories: tmpCalories!)
}
}
}
func replace(altitude: String, duration: String, jumps: String, calories: String) {
let userID = (Auth.auth().currentUser?.uid)!
self.ref = Database.database().reference()
self.ref.child("sessions").child(userID).child("session1").updateChildValues(["altitude": altitude, "duration": duration, "jumps": jumps, "calories": calories])
//Update the counter, incrementation
let newCounter = Int(self.sessionNb)! + 1
let counterString = String(newCounter)
self.ref = Database.database().reference()
self.ref.child("sessions").child(userID).updateChildValues(["counter": counterString])
//Retrieve the counter
Database.database().reference().child("sessions").child(userID).observeSingleEvent(of: .value)
{ (snapshot) in
if let dic = snapshot.value as? [String: AnyObject] {
let counter = dic["counter"] as? String
self.redirectionScreen()
self.totalJump(counter: counter!)
}
}
}
func totalJump(counter: String) {
let counterInt = Int(counter)
for i in 1...counterInt! {
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session\(i)").observeSingleEvent(of: .value)
{ (snapshot) in
if let dic = snapshot.value as? [String: AnyObject] {
let jump = dic["jumps"] as? String
let jumpInt = Int(jump!)
self.total = self.total + (jumpInt!)
if i == counterInt! {
self.updateTotalJump(total: self.total)
}
}
}
}
}
func updateTotalJump(total: Int) {
let userID = (Auth.auth().currentUser?.uid)!
ref = Database.database().reference()
ref.child("sessions").child(userID).updateChildValues(["totalJump": total])
}
//Redirection
func redirectionScreen() {
let storyboard: UIStoryboard = UIStoryboard(name: "Main", bundle: nil)
let redirect:StatViewController = storyboard.instantiateViewController(withIdentifier: "StatViewController") as! StatViewController
self.present(redirect, animated: true, completion: nil)
}
//Error alert
func createAlert(title: String, message:String) {
let alert = UIAlertController (title: title, message: message, preferredStyle: UIAlertControllerStyle.alert)
alert.addAction(UIAlertAction(title:"Ok", style:UIAlertActionStyle.default, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
}))
self.present(alert, animated: true, completion: nil)
}
func alertMissingInfo(title: String, message:String) {
let alert = UIAlertController (title: title, message: message, preferredStyle: UIAlertControllerStyle.alert)
alert.addAction(UIAlertAction(title:"Cancel", style:UIAlertActionStyle.destructive, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
}))
alert.addAction(UIAlertAction(title:"Ok", style:UIAlertActionStyle.default, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
let storyboard = UIStoryboard(name: "Main", bundle: nil)
let viewController = storyboard.instantiateViewController(withIdentifier :"InfoViewController") as! InfoViewController
self.present(viewController, animated: true)
}))
self.present(alert, animated: true, completion: nil)
}
}
<file_sep>//
// MainViewController.swift
// PNChartSwift
//
// Created by <NAME> on 8/14/17.
//
import UIKit
class AllStatsViewController: UIViewController {
@IBOutlet weak var tableView: UITableView!
override func viewDidLoad() {
super.viewDidLoad()
self.title = "History - Statistics"
}
}
extension AllStatsViewController: UITableViewDelegate {
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
let indexPath = tableView.indexPathForSelectedRow!
let destinationVC = segue.destination as! DetailViewController
switch indexPath.row {
case 0:
destinationVC.chartName = "Calories"
case 1:
destinationVC.chartName = "Jumps"
case 2:
destinationVC.chartName = "Duration"
default:
break
}
}
}
extension AllStatsViewController: UITableViewDataSource {
func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int) -> Int {
return 3
}
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(withIdentifier: "chartCell", for: indexPath) as! ChartTableViewCell
switch indexPath.row {
case 0:
cell.cellLabel.text = "Calories"
case 1:
cell.cellLabel.text = "Jumps"
case 2:
cell.cellLabel.text = "Duration"
default:
break
}
return cell
}
}
<file_sep>//
// InfoViewController.swift
// JumpIn
//
// Created by <NAME> on 17/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import UIKit
import FacebookLogin
import FBSDKLoginKit
import FirebaseAuth
import FirebaseDatabase
class InfoViewController: UIViewController, UITextFieldDelegate {
@IBOutlet var logOut: UIButton!
@IBOutlet var modify: UIButton!
@IBOutlet var connectButton: UIButton!
@IBOutlet var weightInput: UITextField!
@IBOutlet var highInput: UITextField!
var dict : [String : AnyObject]!
var user = Auth.auth().currentUser
var currentUser = ""
var postData = [String]()
var ref:DatabaseReference!
var refHandle: UInt!
override func viewDidLoad() {
modify.layer.cornerRadius = 5.0
logOut.layer.cornerRadius = 5.0
connectButton.layer.cornerRadius = 5.0
super.viewDidLoad()
//Hide keyboard
self.weightInput.delegate = self
self.highInput.delegate = self
//Facebook connexion
let FBbutton = LoginButton(readPermissions: [ .publicProfile ])
let newCenter = CGPoint(x: UIScreen.main.bounds.size.width*0.5, y: 500)
FBbutton.center = newCenter
//view.addSubview(FBbutton)
if (FBSDKAccessToken.current()) != nil{
getFBUserData()
}
//Print the weight and the high by accessing to firebase DB
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("users").child(userID).observeSingleEvent(of: .value) { (snapshot) in
if let dictionary = snapshot.value as? [String: AnyObject] {
self.highInput.text = dictionary["high"] as? String
self.weightInput.text = dictionary["weight"] as? String
}
}
}
//Update weight and high data
@IBAction func modifyTouched(_ sender: Any) {
let userID = (Auth.auth().currentUser?.uid)!
ref = Database.database().reference()
ref.child("users").child(userID).updateChildValues(["weight": weightInput.text!, "high": highInput.text!])
alertModify(title: "Information", message: "You have modify your data")
}
//Log out
@IBAction func logOutTouch(_ sender: Any) {
do {
try Auth.auth().signOut()
redirectionScreen()
} catch {
print("Problem log")
}
}
//Redirections
func redirectionMenu() {
let storyboard: UIStoryboard = UIStoryboard(name: "Main", bundle: nil)
let redirect:MenuViewController = storyboard.instantiateViewController(withIdentifier: "MenuViewController") as! MenuViewController
self.present(redirect, animated: true, completion: nil)
}
func redirectionScreen() {
let storyboard: UIStoryboard = UIStoryboard(name: "Main", bundle: nil)
let redirect:ViewController = storyboard.instantiateViewController(withIdentifier: "ViewController") as! ViewController
self.present(redirect, animated: true, completion: nil)
}
@IBAction func redirectMerge(_ sender: Any) {
let storyboard: UIStoryboard = UIStoryboard(name: "Main", bundle: nil)
let redirect:UINavigationController = storyboard.instantiateViewController(withIdentifier: "BLEMain") as! UINavigationController
self.present(redirect, animated: true, completion: nil)
}
//Create a pop up alert
func alertModify(title: String, message:String) {
let alert = UIAlertController (title: title, message: message, preferredStyle: UIAlertControllerStyle.alert)
alert.addAction(UIAlertAction(title:"Dismiss", style:UIAlertActionStyle.default, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
self.redirectionMenu()
}))
self.present(alert, animated: true, completion: nil)
}
//function is fetching the user data
func getFBUserData(){
if((FBSDKAccessToken.current()) != nil){
FBSDKGraphRequest(graphPath: "me", parameters: ["fields": "id, name, picture.type(large), email"]).start(completionHandler: { (connection, result, error) -> Void in
if (error == nil){
self.dict = result as! [String : AnyObject]
print(result!)
print(self.dict)
}
})
}
}
//Hide keyboard when user touches outside
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
self.view.endEditing(true)
}
//Hide keyboard when user touches return
func textFieldShouldReturn(_ textField: UITextField) -> Bool {
weightInput.resignFirstResponder()
highInput.resignFirstResponder()
return true
}
}
<file_sep>//
// MenuViewController.swift
// JumpIn
//
// Created by <NAME> on 17/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import UIKit
import FacebookLogin
import FBSDKLoginKit
import Firebase
class MenuViewController: UIViewController {
@IBOutlet var train: UIButton!
@IBOutlet var jumps: UIButton!
@IBOutlet var remainingJump: UILabel!
override func viewDidLoad() {
super.viewDidLoad()
train.layer.cornerRadius = 5.0
//Retrieve values
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).child("session1").observeSingleEvent(of: .value) { (snapshot) in
if let userDict = snapshot.value as? [String:Any] {
self.jumps.setTitle(userDict["jumps"] as? String, for: .normal)
}
}
//Retrieve the number of jumps remaining
Database.database().reference().child("sessions").child(userID).observeSingleEvent(of: .value) { (snapshot) in
if let dictionary = snapshot.value as? [String: AnyObject] {
let totalJump = dictionary["totalJump"] as? Int
if totalJump != nil {
let totalString = String(totalJump!)
self.remainingJump.text = "Jumps remaining: \(totalString)"
}
}
}
}
@IBAction func play(_ sender: Any) {
//Check if the counter is equal to 0
let userID = (Auth.auth().currentUser?.uid)!
Database.database().reference().child("sessions").child(userID).observeSingleEvent(of: .value) { (snapshot) in
if let dictionary = snapshot.value as? [String: AnyObject] {
let totalJump = dictionary["totalJump"] as? Int
if totalJump != nil {
self.redirection(counter: totalJump!)
}
}
}
}
//Redirection
func redirection(counter: Int) {
if counter == 0 {
self.createAlert(title: "Error", message: "Sorry, you have to jump again in order to play")
} else {
let storyboard: UIStoryboard = UIStoryboard(name: "Main", bundle: nil)
let redirect:GameViewController = storyboard.instantiateViewController(withIdentifier: "GameViewController") as! GameViewController
self.present(redirect, animated: true, completion: nil)
}
}
//Alert
func createAlert(title: String, message:String) {
let alert = UIAlertController (title: title, message: message, preferredStyle: UIAlertControllerStyle.alert)
alert.addAction(UIAlertAction(title:"Cancel", style:UIAlertActionStyle.destructive, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
}))
alert.addAction(UIAlertAction(title:"Jump", style:UIAlertActionStyle.default, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
let storyboard = UIStoryboard(name: "Main", bundle: nil)
let viewController = storyboard.instantiateViewController(withIdentifier :"JumpViewController") as! JumpViewController
self.present(viewController, animated: true)
}))
self.present(alert, animated: true, completion: nil)
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
}
<file_sep>//
// EndGameScene.swift
// JumpIn
//
// Created by <NAME> on 25/10/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import SpriteKit
class EndGameScene: SKScene {
required init?(coder aDecoder: NSCoder) {
super.init(coder: aDecoder)
}
override init(size: CGSize) {
super.init(size: size)
// Stars
let star = SKSpriteNode(imageNamed: "Star")
star.position = CGPoint(x: 25, y: self.size.height-70)
addChild(star)
let lblStars = SKLabelNode(fontNamed: "Avenir")
lblStars.fontSize = 30
lblStars.fontColor = SKColor.white
lblStars.position = CGPoint(x: 50, y: self.size.height-80)
lblStars.horizontalAlignmentMode = SKLabelHorizontalAlignmentMode.left
lblStars.text = String(format: "X %d", GameHandler.shareInstance.stars)
addChild(lblStars)
// Score
let lblScore = SKLabelNode(fontNamed: "Avenir")
lblScore.fontSize = 60
lblScore.fontColor = SKColor.white
lblScore.position = CGPoint(x: self.size.width / 2, y: 300)
lblScore.horizontalAlignmentMode = SKLabelHorizontalAlignmentMode.center
lblScore.text = String(format: "%d", GameHandler.shareInstance.score)
addChild(lblScore)
// High Score
let lblHighScore = SKLabelNode(fontNamed: "Avenir")
lblHighScore.fontSize = 30
lblHighScore.fontColor = SKColor.green
lblHighScore.position = CGPoint(x: self.size.width / 2, y: 400)
lblHighScore.horizontalAlignmentMode = SKLabelHorizontalAlignmentMode.center
lblHighScore.text = String(format: "High Score: %d", GameHandler.shareInstance.highScore)
addChild(lblHighScore)
}
}
<file_sep>//
// LoginViewController.swift
// JumpIn
//
// Created by <NAME> on 01/11/2017.
// Copyright © 2017 <NAME>. All rights reserved.
//
import UIKit
import FirebaseAuth
import FacebookLogin
import FBSDKLoginKit
class LoginViewController: UIViewController, UITextFieldDelegate {
@IBOutlet var logIn: UIButton!
@IBOutlet var usernameInput: UITextField!
@IBOutlet var passwordInput: UITextField!
var dict : [String : AnyObject]!
override func viewDidLoad() {
super.viewDidLoad()
logIn.layer.cornerRadius = 5.0
//Facebook connexion
let FBbutton = LoginButton(readPermissions: [ .publicProfile ])
let newCenter = CGPoint(x: UIScreen.main.bounds.size.width*0.5, y: 150)
FBbutton.center = newCenter
//view.addSubview(FBbutton)
//Hide keyboard
self.usernameInput.delegate = self
self.passwordInput.delegate = self
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
}
override func viewWillAppear(_ animated: Bool) {
//if user is already log
if (FBSDKAccessToken.current()) != nil{
getFBUserData()
self.redirectionScreen()
}
}
@IBAction func login(_ sender: Any) {
//If username and password are filled
if let username = usernameInput.text, let password = passwordInput.text {
Auth.auth().signIn(withEmail: username, password: <PASSWORD>, completion: { user, error in
//If there are some errors connection to Firebase
if let firebaseError = error {
self.createAlert(title: "Error", message: firebaseError.localizedDescription)
return
}
else {
self.redirectionScreen()
}
})
}
}
func redirectionScreen() {
let storyboard: UIStoryboard = UIStoryboard(name: "Main", bundle: nil)
let redirect:MenuViewController = storyboard.instantiateViewController(withIdentifier: "MenuViewController") as! MenuViewController
self.present(redirect, animated: true, completion: nil)
}
func createAlert(title: String, message:String) {
let alert = UIAlertController (title: title, message: message, preferredStyle: UIAlertControllerStyle.alert)
alert.addAction(UIAlertAction(title:"Ok", style:UIAlertActionStyle.default, handler: { (action) in
alert.dismiss(animated: true, completion: nil)
}))
self.present(alert, animated: true, completion: nil)
}
//Connexion with Facebook//
func getFBUserData(){
if((FBSDKAccessToken.current()) != nil){
FBSDKGraphRequest(graphPath: "me", parameters: ["fields": "id, name, picture.type(large), email"]).start(completionHandler: { (connection, result, error) -> Void in
if (error == nil){
self.dict = result as! [String : AnyObject]
print(result!)
print(self.dict)
}
})
}
}
//Hide keyboard when user touches outside
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
self.view.endEditing(true)
}
//Hide keyboard when user touches return
func textFieldShouldReturn(_ textField: UITextField) -> Bool {
usernameInput.resignFirstResponder()
passwordInput.resignFirstResponder()
return true
}
}
| db24c335e676dfcc5bf0f46d469684a2bf5568d2 | [
"Swift",
"Ruby",
"Markdown"
] | 22 | Swift | MargauxDang/JumpIn-iOS | 1e74a523d6579f6be4f96f1d6c508003cd98a62f | fdc44b121f75c4c1fdfe6ba126fdfa5ccc86cc1a |
refs/heads/master | <repo_name>LowD/LAMP_2<file_sep>/index.php
<?php
if(isset($_POST['choice'])){
//do stuff pour envoi post
header("Location: index.php");
exit;
}
//stuff pour tout le monde
require('card.php');
//SCENARIO 1
if(empty($_SESSION['game_state'])){
$_SESSION['game_state'] = new GameState();
$deck = new Deck();
$deck->shuffle();
$bank = new Bank();
$player = new Player($hand[]);
}else{
$deck = $_SESSION['game_state']->$deck;
$bank = $_SESSION['game_state']->$bank;
$player = $_SESSION['game_state']->$player;
}
$bank->take($deck->deal(2));
$player->take($deck->deal(2));
//tire 2 cartes du deck, la banque les prends
while( $player->getHandValue() < 21){// || jusqu'à ce que le joueur arrête de tirer
$player->take($deck->deal(1));
}
if($player->getHandValue() > 21){
echo "Le joueur perd ".$player->getHandValue();
echo "La banque gagne";
unset($_SESSION['game_state']);
}elseif($player->getHandValue() > $bank->getHandValue()){
echo "Le joueur gagne";
unset($_SESSION['game_state']);
}else{
echo "Le joueur a ".$player->getHandValue();
echo "Le joueur perd ".$player->getHandValue();
unset($_SESSION['game_state']);
}
while( $bank->getHandValue() < 17){
//tant que la banque a moins de 17, elle tire
$bank->take($deck->deal(1));
}
if($bank->getHandValue() > 21){
echo "La banque perd ".$bank->getHandValue();
echo "Le joueur gagne !";
unset($_SESSION['game_state']);
}elseif($bank->getHandValue() > $player->getHandValue()){
echo "La banque gagne";
unset($_SESSION['game_state']);
}else{
echo "La banque a ".$bank->getHandValue();
echo "La banque perd ".$bank->getHandValue();
unset($_SESSION['game_state']);
}
if($player->getHandValue() == $bank->getHandValue()){
echo "Egalité !";
unset($_SESSION['game_state']);
}
$serialized = serialize($_SESSION['game_state']);
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<form method="POST">
<input type="radio" name="choice" value="yes" checked="checked">
<input type="submit" value="ok">
</form>
</body>
</html>
| 704181fe63b12a06b9371b20b3321a3dbfcc998e | [
"PHP"
] | 1 | PHP | LowD/LAMP_2 | 0c71ce1eae296fd601e5cdc0650a1631dcb6de55 | 9ec34a5a0ec8e2b0a277449c70c600a7ddd72256 |
refs/heads/master | <repo_name>CichoCiemna/java<file_sep>/README.md
# Java calculator
# Running locally
0. Make sure you have openJDK and JRE installed:
- `sudo apt install default-jre`
- `sudo apt install openjdk-8-jdk-headless`
1. Build with `javac -d out src/Main.java`
2. Run with `java -cp out Main`
<file_sep>/src/Main.java
import javax.swing.*;
import java.util.Scanner;
public class Main {
public static void main (String[] args){
double a, b, x;
int w,y;
do{
System.out.print("Podaj liczbe: ");
Scanner l1 = new Scanner(System.in);
a = l1.nextDouble();
System.out.print("Podaj liczbe: ");
Scanner l2 = new Scanner(System.in);
b = l2.nextDouble();
System.out.println("1. Dodawanie");
System.out.println("2. Odejmowanie");
System.out.println("3. Mnożenie");
System.out.println("4. Dzielenie");
do{
Scanner w1 = new Scanner(System.in);
System.out.println("Wybierz liczbe od 1 do 4");
w = w1.nextInt();
}while(w<1 || w>4);
switch (w) {
case 1:
x = a + b;
System.out.println( a +"+"+b + "=" + x);
break;
case 2:
x = a - b;
System.out.println( a +"-"+b + "="+ x);
break;
case 3:
x = a * b;
System.out.println( + a +"*"+b + "=" + x);
break;
case 4:
x = a / b;
System.out.println( + a +"/"+b + "="+ x);
break;
}
System.out.println("Czy chcesz wykonać inne działanie?");
System.out.println("1.Tak");
System.out.println("2.Nie");
do {
Scanner w2 = new Scanner(System.in);
System.out.println("Wybierz 1 lub 2");
y = w2.nextInt();
}while(y<1 || y>2);
}while(y==1);
}
}
| d2a03d737ea5fe9078d6a1894b6eb35fd5d39e6f | [
"Markdown",
"Java"
] | 2 | Markdown | CichoCiemna/java | e6d929be294289563a04688fafae2f49f7b9ba84 | 8536c845d1f42bb54fd52f8a6de6770691de3421 |
refs/heads/master | <repo_name>zuoshangs/sparkApp<file_sep>/src/main/java/com/zuoshangs/spark/config/prop/AppPropertiesConfig.java
package com.zuoshangs.spark.config.prop;
/**
*
* 应用配置类,应用级别的所有配置统一入口<br>
* 不建议将配置进行分散管理,原则上一个项目中仅有一个@ConfigurationProperties注解文件。<br>
* 并且建议应用级别配置均以app.conf开头,用以和框架配置做命名空间区分
*
* @author YuanZhiQiang
*
*/
public class AppPropertiesConfig {
private String hadoopDefaultFs;
private String hbaseZkHost;
private String hbaseZkPort;
private String hbaseZkZnodeParent;
private int hbaseCacheSize;
private boolean enableHbaseCache;
private String hbaseNamespace;
public String getHadoopDefaultFs() {
return hadoopDefaultFs;
}
public void setHadoopDefaultFs(String hadoopDefaultFs) {
this.hadoopDefaultFs = hadoopDefaultFs;
}
public String getHbaseZkHost() {
return hbaseZkHost;
}
public void setHbaseZkHost(String hbaseZkHost) {
this.hbaseZkHost = hbaseZkHost;
}
public String getHbaseZkPort() {
return hbaseZkPort;
}
public void setHbaseZkPort(String hbaseZkPort) {
this.hbaseZkPort = hbaseZkPort;
}
public String getHbaseZkZnodeParent() {
return hbaseZkZnodeParent;
}
public void setHbaseZkZnodeParent(String hbaseZkZnodeParent) {
this.hbaseZkZnodeParent = hbaseZkZnodeParent;
}
public int getHbaseCacheSize() {
return hbaseCacheSize;
}
public void setHbaseCacheSize(int hbaseCacheSize) {
this.hbaseCacheSize = hbaseCacheSize;
}
public boolean isEnableHbaseCache() {
return enableHbaseCache;
}
public void setEnableHbaseCache(boolean enableHbaseCache) {
this.enableHbaseCache = enableHbaseCache;
}
public String getHbaseNamespace() {
return hbaseNamespace;
}
public void setHbaseNamespace(String hbaseNamespace) {
this.hbaseNamespace = hbaseNamespace;
}
}
<file_sep>/pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.zuoshangs</groupId>
<artifactId>spark-app</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<spring.hadoop.version>2.5.0.RELEASE</spring.hadoop.version>
<hadoop.version>2.8.0</hadoop.version>
<hbase.client.version>1.3.1</hbase.client.version>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.31</version>
</dependency>
<!-- hbase -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop</artifactId>
<version>${spring.hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<scope>compile</scope>
<exclusions>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.client.version}</version>
<scope>compile</scope>
<exclusions>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.client.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.zuoshangs.spark.ZhugeIoSparkBatchApplication</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
<file_sep>/src/main/java/com/zuoshangs/spark/UserAttrMakerApplication.java
package com.zuoshangs.spark;
import com.zuoshangs.spark.config.bean.JavaBeanConfig;
import com.zuoshangs.spark.config.prop.AppPropertiesConfig;
import com.zuoshangs.spark.extension.util.HbaseUtil;
import org.apache.commons.lang3.time.DateUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.hbase.protobuf.ProtobufUtil;
import org.apache.hadoop.hbase.protobuf.generated.ClientProtos;
import org.apache.hadoop.hbase.util.Base64;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.text.ParseException;
import java.util.Date;
/**
* Created by weike on 2018/4/12.
*/
public class UserAttrMakerApplication {
public static void main(String[] args) throws ParseException {
if(args.length<3){
System.err.println("Usage: UserAttrMakerApplication <startTime> <endTime> <attrJson> ");
System.err.println("./bin/spark-submit --master spark://10.40.3.236:7077 --class com.zuoshangs.spark.UserAttrMakerApplication /root/code/sparkApp/target/spark-app-1.0-SNAPSHOT-jar-with-dependencies.jar 20180410000000 20180411000000 {\"attrValList\":[{\"id\":1,\"name\":\"男\",\"rule\":\"{\\\"eq\\\":\\\"男\\\"}\"},{\"id\":1,\"name\":\"女\",\"rule\":\"{\\\"eq\\\":\\\"女\\\"}\"}],\"id\":1,\"name\":\"性别\"}");
System.exit(1);
}
String pattern = "yyyyMMddHHmmss";
Date startTime = DateUtils.parseDate(args[0],pattern);
Date endTime = DateUtils.parseDate(args[1],pattern);
System.out.println("start:"+startTime+",end:"+endTime);
SparkConf sparkConf = new SparkConf().setAppName("UserAttrMakerApplication");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
AppPropertiesConfig appPropertiesConfig = new AppPropertiesConfig();
appPropertiesConfig.setEnableHbaseCache(true);
appPropertiesConfig.setHbaseCacheSize(500);
appPropertiesConfig.setHadoopDefaultFs("hdfs://10.40.3.236:9000");
appPropertiesConfig.setHbaseZkHost("10.40.3.236");
appPropertiesConfig.setHbaseZkPort("2181");
appPropertiesConfig.setHbaseZkZnodeParent("/hbase");
JavaBeanConfig javaBeanConfig = new JavaBeanConfig();
org.apache.hadoop.conf.Configuration hadoopConfig = javaBeanConfig.hadoopConfigurationConfigurer(appPropertiesConfig);
String startRow = HbaseUtil.queryStartRowByDate(startTime);
String stopRow = HbaseUtil.queryEndRowByDate(endTime);
System.out.println("-------------------------startRow:"+startRow+",stopRow:"+stopRow);
Scan scan = new Scan(Bytes.toBytes(startRow), Bytes.toBytes(stopRow));
try {
String tableName = "USER_AUTH_BY_DATE";
hadoopConfig.set(TableInputFormat.INPUT_TABLE, tableName);
ClientProtos.Scan proto = ProtobufUtil.toScan(scan);
String ScanToString = Base64.encodeBytes(proto.toByteArray());
hadoopConfig.set(TableInputFormat.SCAN, ScanToString);
JavaPairRDD<ImmutableBytesWritable, Result> myRDD =
sc.newAPIHadoopRDD(hadoopConfig, TableInputFormat.class,
ImmutableBytesWritable.class, Result.class);
System.out.println("----------55555xxxxxxxxxxxxxxxxxxxxxxxxxxx-------"+myRDD.count());
} catch (Exception e) {
e.printStackTrace();
}
}
}
<file_sep>/src/main/java/com/zuoshangs/spark/domain/model/Attr.java
package com.zuoshangs.spark.domain.model;
import java.util.List;
/**
* Created by weike on 2018/4/11.
*/
public class Attr {
private int id;
private String name;
private List<AttrVal> attrValList;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<AttrVal> getAttrValList() {
return attrValList;
}
public void setAttrValList(List<AttrVal> attrValList) {
this.attrValList = attrValList;
}
}
<file_sep>/src/main/java/com/zuoshangs/spark/domain/model/User.java
package com.zuoshangs.spark.domain.model;
/**
* Created by weike on 2018/1/17.
*/
public class User {
private String outerUserId;
private String bizUserId;
public String getOuterUserId() {
return outerUserId;
}
public void setOuterUserId(String outerUserId) {
this.outerUserId = outerUserId;
}
public String getBizUserId() {
return bizUserId;
}
public void setBizUserId(String bizUserId) {
this.bizUserId = bizUserId;
}
}
<file_sep>/src/main/java/com/zuoshangs/spark/domain/MyKafkaProducer.java
package com.zuoshangs.spark.domain;
import java.util.*;
import com.alibaba.fastjson.JSON;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class MyKafkaProducer {
public void send(String broker,String topic,String content) {
Properties props = new Properties();
props.put("bootstrap.servers", broker);
//The "all" setting we have specified will result in blocking on the full commit of the record, the slowest but most durable setting.
//“所有”设置将导致记录的完整提交阻塞,最慢的,但最持久的设置。
props.put("acks", "all");
//如果请求失败,生产者也会自动重试,即使设置成0 the producer can automatically retry.
props.put("retries", 0);
//The producer maintains buffers of unsent records for each partition.
props.put("batch.size", 16384);
//默认立即发送,这里这是延时毫秒数
props.put("linger.ms", 1);
//生产者缓冲大小,当缓冲区耗尽后,额外的发送调用将被阻塞。时间超过max.block.ms将抛出TimeoutException
props.put("buffer.memory", 33554432);
//The key.serializer and value.serializer instruct how to turn the key and value objects the user provides with their ProducerRecord into bytes.
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//创建kafka的生产者类
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
//生产者的主要方法
// close();//Close this producer.
// close(long timeout, TimeUnit timeUnit); //This method waits up to timeout for the producer to complete the sending of all incomplete requests.
// flush() ;所有缓存记录被立刻发送
//这里平均写入4个分区
producer.send(new ProducerRecord<>(topic, content));
producer.close();
}
public void sendBatch(String broker,String topicName, String businessType, List<Map<String, Object>> mapList, Date startDate, int pageNo) {
List<List<Map<String, Object>>> paging = paging(mapList, 1000);// 分页
if (CollectionUtils.isNotEmpty(paging)) {
for (List<Map<String, Object>> list : paging) {
Map<String, Object> sendMap = new HashMap<>();
sendMap.put("businessType", businessType);
sendMap.put("data", list);
sendMap.put("startDate", startDate != null ? DateFormatUtils.format(startDate, "yyyy-MM-dd HH:mm") : "");
sendMap.put("pageNo", pageNo);
String json = JSON.toJSONString(sendMap);
send(broker,topicName, json);
System.out.println("spark send kafka topicName:[{"+topicName+"}], businessType:[{"+businessType+"}], data.size:[{CollectionUtils.size("+list+")}]");
}
}
}
protected List<List<Map<String, Object>>> paging(List<Map<String, Object>> list, int pageSize) {
int totalCount = list.size();
int pageCount;
int m = totalCount % pageSize;
if (m > 0) {
pageCount = totalCount / pageSize + 1;
} else {
pageCount = totalCount / pageSize;
}
List<List<Map<String, Object>>> totalList = new ArrayList<List<Map<String, Object>>>();
for (int i = 1; i <= pageCount; i++) {
if (m == 0) {
List<Map<String, Object>> subList = list.subList((i - 1) * pageSize, pageSize * (i));
totalList.add(subList);
} else {
if (i == pageCount) {
List<Map<String, Object>> subList = list.subList((i - 1) * pageSize, totalCount);
totalList.add(subList);
} else {
List<Map<String, Object>> subList = list.subList((i - 1) * pageSize, pageSize * i);
totalList.add(subList);
}
}
}
return totalList;
}
public static void main(String[] args) {
MyKafkaProducer p = new MyKafkaProducer();
p.send("10.40.3.236:9092,10.40.3.238:9092,10.40.3.239:9092","COLLECT_BATCH","{'businessType':'aaa'}");
}
} | 213f1f896bee91f99bf9e8d66a598c71092a8eb1 | [
"Java",
"Maven POM"
] | 6 | Java | zuoshangs/sparkApp | 849889c07c7514506f831aba30dab161c2844a37 | 746b73974f0c13e6fb487f6d8b082a25f300c957 |
refs/heads/master | <repo_name>tommykishi/dotfiles<file_sep>/.zprezto/runcoms/zshrc
# setting
autoload -Uz colors;colors
fpath=(/usr/local/share/zsh-completions $fpath)
autoload -Uz compinit;compinit -u
setopt auto_cd
export EDITOR=vim
setopt auto_list
setopt auto_menu
setopt list_packed
setopt list_types
zstyle ':completion:*' matcher-list 'm:{a-z}={A-Z}'
zstyle ':completion:*:default' menu select=2
# alias
alias ..='cd ..'
alias ~='cd ~'
alias 'npmgls'='npm -g ls --depth=0'
alias less='less -N'
# peco-history
function peco-history-selection() {
BUFFER=`history -n 1 | tail -r | awk '!a[$0]++' | peco`
CURSOR=$#BUFFER
zle reset-prompt
}
zle -N peco-history-selection
bindkey '^R' peco-history-selection
# zsh-git
autoload -Uz vcs_info
zstyle ':vcs_info:*' formats '[%b]'
zstyle ':vcs_info:*' actionformats '[%a|%b]'
precmd () {
psvar=()
LANG=en_US.UTF-8 vcs_info
[[ -n "$vcs_info_msg_0_" ]] && psvar[1]="$vcs_info_msg_0_"
}
RPROMPT="%1(v|%F{green}%1v%f|)"
# less-coler
export LESS='-R'
export LESSOPEN='| /usr/local/bin/src-hilite-lesspipe.sh %s'
export VISUAL="/usr/bin/vi"
# peco-cd
function peco-cdr () {
local selected_dir=$(cdr -l | awk '{ print $2 }' | peco)
if [ -n "$selected_dir" ]; then
BUFFER="cd ${selected_dir}"
zle accept-line
fi
zle clear-screen
}
zle -N peco-cdr
bindkey '^E' peco-cdr
autoload -Uz zmv
eval "$(rbenv init - zsh)"
eval "$(pyenv init -)"
# 履歴ファイルの保存先
export HISTFILE=${HOME}/.zsh_history
# メモリに保存される履歴の件数
export HISTSIZE=1000
# 履歴ファイルに保存される履歴の件数
export SAVEHIST=100000
# 重複を記録しない
setopt hist_ignore_dups
# 開始と終了を記録
setopt EXTENDED_HISTORY
PROMPT='%% '
<file_sep>/.zprezto/runcoms/zshenv
if [[ "$SHLVL" -eq 1 && ! -o LOGIN && -s "${ZDOTDIR:-$HOME}/.zprofile" ]]; then
source "${ZDOTDIR:-$HOME}/.zprofile"
fi
#nvm
source ~/.nvm/nvm.sh
export NVM_DIR="$HOME/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && . "$NVM_DIR/nvm.sh"
# rbenv
export PATH="$HOME/.rbenv/bin:$PATH"
# pyenv
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
# zprezto
if [[ -s "${ZDOTDIR:-$HOME}/.zprezto/init.zsh" ]]; then
source "${ZDOTDIR:-$HOME}/.zprezto/init.zsh"
fi
# go
export PATH="$HOME/go/bin:$PATH"
# haskell
export PATH="$HOME/Library/Haskell/bin:$PATH"
| 367126f0454dbcd55238f7e51aeee3c6783997e8 | [
"Shell"
] | 2 | Shell | tommykishi/dotfiles | 552d120516844f9883789fca15d2668735e184c0 | ef483c6b487387d243a24bbfa4be4e13e7cd679e |
refs/heads/master | <file_sep>#ifndef PP_HW2_RCCSIM_RCCSIM_H_
#define PP_HW2_RCCSIM_RCCSIM_H_
#include "rcc.hpp"
namespace pp {
namespace hw2 {
namespace rccsim { // Roller Coaster Car Simulation
typedef struct {
int passenger_id;
RollerCoasterCar *car;
} PassengerThreadArgs;
typedef struct {
RollerCoasterCar *car;
int playing_time;
int sim_steps_num;
} CarThreadArgs;
void InitSimluation();
void FinishSimluation();
void *PassengerThread(void *args);
void *CarThread(void *args);
} // namespace rccsim
} // namespace hw2
} // namespace pp
#endif // PP_HW2_RCCSIM_RCCSIM_H_
<file_sep># Declaration of variables
CC = g++
# File names
PTHREAD_EXEC = hw2_NB_pthread
OMP_EXEC = hw2_NB_omp
GH_EXEC = hw2_NB_BHalgo
COMMON_OBJS = nbody.o gui.o bh_tree.o timer.o
# Main target
all: pthread omp gh
pthread: $(COMMON_OBJS)
$(CC) -c -o nbody_pthread.o nbody_pthread.cpp
$(CC) -c main.cpp -o main.o
$(CC) -lpthread -lX11 $(COMMON_OBJS) nbody_pthread.o main.o -o $(PTHREAD_EXEC)
omp: $(COMMON_OBJS)
$(CC) -c -fopenmp nbody_omp.cpp -o nbody_omp.o
$(CC) -c -D OMP main.cpp -o main.o
$(CC) -lpthread -lX11 -fopenmp $(COMMON_OBJS) nbody_omp.o main.o -o $(OMP_EXEC)
gh: $(COMMON_OBJS)
$(CC) -c -D BH_ALGO -o nbody_pthread.o nbody_pthread.cpp
$(CC) -c main.cpp -o main.o
$(CC) -lpthread -lX11 $(COMMON_OBJS) nbody_pthread.o main.o -o $(GH_EXEC)
# To obtain object files
%.o: %.cpp
$(CC) -c $< -o $@
gui.o: ../../gui.cpp
$(CC) -c $< -o $@
timer.o: ../../timer.cpp
$(CC) -c $< -o $@
# To clean all output files
clean:
rm -f *.o $(PTHREAD_EXEC) $(OMP_EXEC) $(GH_EXEC)
<file_sep>#ifndef PP_HW2_NBODY_BHTREE_H_
#define PP_HW2_NBODY_BHTREE_H_
#include <list>
#include <vector>
#include <pthread.h>
#include "nbody.hpp"
#include "../../gui.hpp"
using std::vector;
using std::list;
namespace pp {
namespace hw2 {
namespace nbody {
class BHTreeNode {
friend class BHTree;
public:
BHTreeNode(Vec2 min, Vec2 max);
BHTreeNode(Universe *uni, int body_id, Vec2 min, Vec2 max);
private:
static const int kInternalNode = -1;
Vec2 center_of_mass_;
int body_count_;
Vec2 coord_min_, coord_mid_, coord_max_;
int body_id_; // This is only used when the node is a external node
BHTreeNode *nw_, *ne_, *sw_, *se_;
};
class BHTree {
public:
BHTree(Universe *uni);
~BHTree();
// For multi-threading splitting
void DoASplittingJob();
bool IsThereMoreJobs();
// Calculate force
Vec2 CalculateTotalForce(int source_id, double theta);
Vec2 CalculateTotalForce(int source_id, double theta, BHTreeNode *node);
// Free all resource
void Delete(BHTreeNode *parent);
// For drawing
void DrawRegions(GUI *gui);
void DrawRegions(GUI *gui, BHTreeNode *node);
// For debugging
void PrintInDFS();
void PrintInDFS(BHTreeNode *node);
private:
// For spliting
typedef struct {
BHTreeNode *parent;
vector<int> *bodies;
} SplittingJob;
list<SplittingJob> *job_queue_;
pthread_mutex_t job_queue_mutex_;
pthread_cond_t job_queue_cond_;
size_t job_count_, finish_count_;
void InsertASplittingJob(BHTreeNode *parent, vector<int> *bodies);
void SplitTheNode(BHTreeNode *parent, vector<int> *body_ids);
void CreateRegion(BHTreeNode **region_ptr, vector<int> *bodies, Vec2 min, Vec2 max);
// Properties
BHTreeNode *root_;
Universe *uni_;
Vec2 root_min_, root_max_;
};
} // namespace nbody
} // namespace hw2
} // namespace pp
#endif // PP_HW2_NBODY_BHTREE_H_
<file_sep>#ifndef PP_HW3_MSMPI_H_
#define PP_HW3_MSMPI_H_
#include "mandelbort_set.hpp"
#include "../gui.hpp"
namespace pp {
namespace hw3 {
const int kMPIRoot = 0;
// For the dynamic verion
#ifndef HYBRID
// For normal MPI
// This value has been proved to be an optimal value under all scenario by experiments.
const unsigned kRowCountInJob = 1;
#else
// For hybrid
// This value has been proved to be a good value when there are a lot of procsses by experiments.
const unsigned kRowCountInJob = 10;
#endif
// Tags
const int kTagJobRequest = 1;
const int kTagJobReturnAndRequest = 2;
const int kTagNewJob = 3;
const int kTagTerminate = 4;
void StaticSchedule(int num_threads, ColorHex *colors, int num_rows, int num_colunms, double real_min, double real_max, double imag_min, double imag_max, int proc_count, int rank);
void DynamicScheduleMaster(ColorHex *colors, int num_rows, int num_colunms, int proc_count);
void DynamicScheduleSlave(int num_threads, int num_rows, int num_colunms, double real_min, double real_max, double imag_min, double imag_max, int rank);
} // namespace hw3
} // namespace pp
#endif // PP_HW3_MSMPI_H_
<file_sep>#include "rcc.hpp"
#include <cstdio>
#include <pthread.h>
namespace pp {
namespace hw2 {
namespace rccsim { // Roller Coaster Car Simulation
RollerCoasterCar::RollerCoasterCar(int capacity) {
is_closed_ = false;
car_capacity_ = capacity;
waiting_queue_ = new std::list<int>();
car_seats_ = new std::list<int>();
pthread_mutex_init(&car_mutex_, NULL);
pthread_cond_init(&waiting_cond_, NULL);
pthread_cond_init(&car_full_cond_, NULL);
pthread_cond_init(&playing_cond_, NULL);
}
RollerCoasterCar::~RollerCoasterCar() {
delete waiting_queue_;
delete car_seats_;
pthread_mutex_destroy(&car_mutex_);
pthread_cond_destroy(&waiting_cond_);
pthread_cond_destroy(&car_full_cond_);
pthread_cond_destroy(&playing_cond_);
}
bool RollerCoasterCar::WaifForARide(int id) {
bool is_closed;
pthread_mutex_lock(&car_mutex_);
printf("Passenger no.%d gets in queue for a ride\n", id);
// Check if the car is full
if (car_seats_->size() >= car_capacity_) {
// Add to the waiting queue
waiting_queue_->push_back(id);
// Wait until there is a seat for it and the thread must be the head of the waiting queue
while (!(car_seats_->size() < car_capacity_ &&
waiting_queue_->front() == id))
pthread_cond_wait(&waiting_cond_, &car_mutex_);
// Remove from the queue
waiting_queue_->pop_front();
// Notify other thread to get the seats
pthread_cond_broadcast(&waiting_cond_);
}
is_closed = is_closed_;
if (!is_closed) {
// Get in the car
car_seats_->push_back(id);
if (car_seats_->size() >= car_capacity_) {
// Notify the car thread to start
pthread_cond_signal(&car_full_cond_);
}
// Wait for the ride to departure
pthread_cond_wait(&playing_cond_, &car_mutex_);
}
pthread_mutex_unlock(&car_mutex_);
return is_closed;
}
void RollerCoasterCar::WaitForCarFull(int *passengers) {
pthread_mutex_lock(&car_mutex_);
// Wait for the car full
while (car_seats_->size() < car_capacity_) {
// Wait for the car full
pthread_cond_wait(&car_full_cond_, &car_mutex_);
}
// Return the list
size_t i = 0;
for (std::list<int>::iterator it = car_seats_->begin();
it != car_seats_->end(); it++, i++)
passengers[i] = *it;
pthread_mutex_unlock(&car_mutex_);
}
void RollerCoasterCar::FinishARide(bool close_car) {
pthread_mutex_lock(&car_mutex_);
// Record the car is closed
is_closed_ = close_car;
// Notify the passengers to leave
car_seats_->clear();
pthread_cond_broadcast(&playing_cond_);
// Notify the passengers in the waiting queue waking up
pthread_cond_broadcast(&waiting_cond_);
pthread_mutex_unlock(&car_mutex_);
}
} // namespace rccsim
} // namespace hw2
} // namespace pp
<file_sep>#include <stdlib.h>
#include <stdio.h>
#include <time.h>
double RandFloat(double min, double max)
{
double f = (double) rand() / RAND_MAX;
return min + f * (max - min);
}
int main(int argc, char const *argv[]) {
size_t i;
size_t body_count = (size_t) atoi(argv[1]);
FILE *out = fopen(argv[2], "w");
double min = -1000.0, max = 1000.0;
srand(time(NULL));
fprintf(out, "%u\n", body_count);
for (i = 0; i < body_count; i++)
fprintf(out, "%lf %lf 0.0 0.0\n", RandFloat(min, max), RandFloat(min, max));
return 0;
}
<file_sep>#include <cstdio>
#include <cstdlib>
#include <pthread.h>
#include "rcc_sim.hpp"
#include "rcc.hpp"
using pp::hw2::rccsim::RollerCoasterCar;
using pp::hw2::rccsim::PassengerThreadArgs;
using pp::hw2::rccsim::PassengerThread;
using pp::hw2::rccsim::CarThread;
using pp::hw2::rccsim::CarThreadArgs;
int main(int argc, char const *argv[]) {
// Check arguments
if (argc < 5) {
fprintf(stderr, "Insufficient args\n");
fprintf(stderr, "Usage: %s passengers_num car_capacity playing_time simulation_step_num\nmak", argv[0]);
return 0;
}
// Retrieve the arguments
int passenger_num = (int) strtol(argv[1], NULL, 10);
int car_capacity = (int) strtol(argv[2], NULL, 10);
int playing_time = (int) strtol(argv[3], NULL, 10);
int sim_steps_num = (int) strtol(argv[4], NULL, 10);
// Create a car instance
RollerCoasterCar *car = new RollerCoasterCar(car_capacity);
// Create passenger threads
pthread_t *pass_threads = new pthread_t[passenger_num];
PassengerThreadArgs *pass_thread_args = new PassengerThreadArgs[passenger_num];
for(size_t id = 0; id < passenger_num; id++) {
pass_thread_args[id].passenger_id = id + 1;
pass_thread_args[id].car = car;
pthread_create(pass_threads + id, NULL, PassengerThread, (void *) (pass_thread_args + id));
}
// Create the car thread
pthread_t car_thread;
CarThreadArgs car_thread_args = {car, playing_time, sim_steps_num};
pthread_create(&car_thread, NULL, CarThread, (void *) &car_thread_args);
// Wait for all thread terminates
for(size_t id = 0; id < passenger_num; id++)
pthread_join(pass_threads[id], NULL);
pthread_join(car_thread, NULL);
// Free all resource
delete car;
delete[] pass_threads;
delete[] pass_thread_args;
// Exit by pthread
pthread_exit(NULL);
return 0;
}
<file_sep>// This line must be the front of all other includes
#include <mpi.h>
#include <cstdio>
#include <unistd.h>
#include <omp.h>
#include "mandelbort_set.hpp"
#include "ms_mpi.hpp"
#include "../timer.hpp"
namespace pp {
namespace hw3 {
void MSMain(int num_threads, int num_x_points, int num_y_points, double real_min, double real_max, double imag_min, double imag_max, bool x_enabled) {
// Get MPI Info
int proc_count, rank;
MPI_Comm_size(MPI_COMM_WORLD, &proc_count);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// Allocate the buffer on the first process
ColorHex *colors = NULL;
if (rank == kMPIRoot) {
colors = new ColorHex[num_x_points * num_y_points];
}
// Welcome message
if (rank == kMPIRoot) {
#ifndef HYBRID
#ifndef DYNAMIC
printf("== Mandelbort Set MPI Static Version ==\n");
#else
printf("== Mandelbort Set MPI Dynamic Version ==\n");
#endif
#else
#ifndef DYNAMIC
printf("== Mandelbort Set Hybrid Static Version ==\n");
#else
printf("== Mandelbort Set Hybrid Dynamic Version ==\n");
#endif
#endif
}
// Set the number of threads for OpenMP
#ifdef HYBRID
omp_set_num_threads(num_threads);
#endif
// Record the start time
Time start = GetCurrentTime();
#ifndef DYNAMIC
// Static schedule
StaticSchedule(num_threads, colors, num_x_points, num_y_points, real_min, real_max, imag_min, imag_max, proc_count, rank);
#else
// Dynamic schedule
if (rank == kMPIRoot) {
DynamicScheduleMaster(colors, num_x_points, num_y_points, proc_count);
} else {
DynamicScheduleSlave(num_threads, num_x_points, num_y_points, real_min, real_max, imag_min, imag_max, rank);
}
#endif
// Print the execution time
MPI_Barrier(MPI_COMM_WORLD);
Time end = GetCurrentTime();
if (rank == kMPIRoot) {
printf("It took %ld ms for calculation.\n", TimeDiffInMs(start, end));
}
// Draw on the GUI by the first process
if (x_enabled && rank == kMPIRoot) {
GUI *gui = new GUI(num_x_points, num_y_points);
for (unsigned x = 0; x < num_x_points; x++) {
for (unsigned y = 0; y < num_y_points; y++) {
gui->DrawAPoint(x, y, colors[x * num_y_points + y]);
}
}
gui->Flush();
sleep(20);
delete gui;
}
// Wait for all process reach the barrier
MPI_Barrier(MPI_COMM_WORLD);
}
} // namespace hw3
} // namespace pp
<file_sep>#ifndef PP_HW2_NBODY_NBODYOMP_H_
#define PP_HW2_NBODY_NBODYOMP_H_
#include <cstdio>
#include "nbody.hpp"
#include "../../gui.hpp"
namespace pp {
namespace hw2 {
namespace nbody {
void NBodySim(Universe *uni, size_t num_threads, double delta_time, size_t num_steps, double theta, GUI *gui);
} // namespace nbody
} // namespace hw2
} // namespace pp
#endif // PP_HW2_NBODY_NBODYOMP_H_
<file_sep>// This line must be the front of all other includes
#include <mpi.h>
#include "ms_mpi.hpp"
#include "mandelbort_set.hpp"
#include "../timer.hpp"
namespace pp {
namespace hw3 {
void StaticSchedule(int num_threads, ColorHex *colors, int num_rows, int num_colunms, double real_min, double real_max, double imag_min, double imag_max, int proc_count, int rank) {
// Calculate # of rows for each process
int rows_per_proc = num_rows / proc_count;
int left = num_rows % proc_count;
int *row_counts = new int[proc_count];
int *buffer_counts = new int[proc_count];
int *start_xs = new int[proc_count];
int *offsets = new int[proc_count];
start_xs[0] = 0;
offsets[0] = 0;
for (unsigned r = 0, offset = 0; r < proc_count; r++) {
if (r < left)
row_counts[r] = rows_per_proc + 1;
else
row_counts[r] = rows_per_proc;
buffer_counts[r] = row_counts[r] * num_colunms;
if (r > 0) {
start_xs[r] = start_xs[r - 1] + row_counts[r - 1];
offsets[r] = start_xs[r] * num_colunms;
}
}
// Create a local buffer for each process
ColorHex *results = new ColorHex[buffer_counts[rank]];
// For coordination transform
double x_scale = num_rows / (real_max - real_min);
double y_scale = num_colunms / (imag_max - imag_min);
// Calculate
Time start = GetCurrentTime();
#ifndef HYBRID
SeqMSCalculation(start_xs[rank], row_counts[rank], num_colunms, x_scale, y_scale, real_min, imag_min, results);
#else
Time *th_exe_time = new Time[num_threads];
int *th_row_counts = new int[num_threads];
for (unsigned i = 0; i < num_threads; i++) {
th_exe_time[i] = GetZeroTime();
th_row_counts[i] = 0;
}
OmpMSCalculation(start_xs[rank], row_counts[rank], num_colunms, x_scale, y_scale, real_min, imag_min, results, th_exe_time, th_row_counts);
for (unsigned i = 0; i < num_threads; i++) {
printf("Process %d, thread %d took %ld ms to calculate %d rows (%d points).\n", rank, i, TimeToLongInMs(th_exe_time[i]), th_row_counts[i], th_row_counts[i] * num_colunms);
}
delete[] th_exe_time;
delete[] th_row_counts;
#endif
Time end = GetCurrentTime();
// Print the execution time
printf("Process %d took %ld ms to calculate %d rows (%d points).\n", rank, TimeDiffInMs(start, end), row_counts[rank], row_counts[rank] * num_colunms);
// The first process collect the results
MPI_Gatherv(results, row_counts[rank] * num_colunms, MPI_UNSIGNED_LONG,
colors, buffer_counts, offsets, MPI_UNSIGNED_LONG, kMPIRoot, MPI_COMM_WORLD);
delete[] row_counts;
delete[] buffer_counts;
delete[] start_xs;
delete[] offsets;
delete[] results;
}
} // namespace hw3
} // namespace pp
<file_sep># Declaration of variables
CC = g++
MPI_CC = mpic++
LINK_FLAGS = -lX11 -fopenmp
# File names
OMP_STATIC_EXEC = MS_OpenMP_static
OMP_DYNAMIC_EXEC = MS_OpenMP_dynamic
MPI_STATIC_EXEC = MS_MPI_static
MPI_DYNAMIC_EXEC = MS_MPI_dynamic
HYBRID_STATIC_EXEC = MS_Hybrid_static
HYBRID_DYNAMIC_EXEC = MS_Hybrid_dynamic
COMMON_OBJS = gui.o timer.o
OMP_MAIN_SOURCE = main.cpp main_openmp.cpp mandelbort_set.cpp
MPI_MAIN_SOURCE = main.cpp main_mpi.cpp mandelbort_set.cpp ms_mpi_static.cpp ms_mpi_dynamic.cpp
# Main target
all: omp_static omp_dynamic mpi_static mpi_dynamic hy_static hy_dynamic
omp_static: $(COMMON_OBJS)
$(CC) $(LINK_FLAGS) $(COMMON_OBJS) -D OMP $(OMP_MAIN_SOURCE) -o $(OMP_STATIC_EXEC)
omp_dynamic: $(COMMON_OBJS)
$(CC) $(LINK_FLAGS) $(COMMON_OBJS) -D OMP -D DYNAMIC $(OMP_MAIN_SOURCE) -o $(OMP_DYNAMIC_EXEC)
mpi_static: $(COMMON_OBJS)
$(MPI_CC) $(LINK_FLAGS) $(COMMON_OBJS) $(MPI_MAIN_SOURCE) -o $(MPI_STATIC_EXEC)
mpi_dynamic: $(COMMON_OBJS)
$(MPI_CC) $(LINK_FLAGS) $(COMMON_OBJS) -D DYNAMIC $(MPI_MAIN_SOURCE) -o $(MPI_DYNAMIC_EXEC)
hy_static: $(COMMON_OBJS)
$(MPI_CC) $(LINK_FLAGS) $(COMMON_OBJS) -D HYBRID $(MPI_MAIN_SOURCE) -o $(HYBRID_STATIC_EXEC)
hy_dynamic: $(COMMON_OBJS)
$(MPI_CC) $(LINK_FLAGS) $(COMMON_OBJS) -D HYBRID -D DYNAMIC $(MPI_MAIN_SOURCE) -o $(HYBRID_DYNAMIC_EXEC)
# To obtain object files
%.o: %.cpp
$(CC) -c $< -o $@
gui.o: ../gui.cpp
$(CC) -c $< -o $@
timer.o: ../timer.cpp
$(CC) -c $< -o $@
# To clean all output files
clean:
rm -f *.o $(COMMON_OBJS) $(OMP_STATIC_EXEC) $(OMP_DYNAMIC_EXEC) $(MPI_STATIC_EXEC) $(MPI_DYNAMIC_EXEC) $(HYBRID_STATIC_EXEC) $(HYBRID_DYNAMIC_EXEC)
<file_sep>// This line must be the front of all other includes
#include <mpi.h>
#include <cstring>
#include "ms_mpi.hpp"
#include "mandelbort_set.hpp"
#include "../timer.hpp"
namespace pp {
namespace hw3 {
void DynamicScheduleMaster(ColorHex *colors, int num_rows, int num_colunms, int proc_count) {
// Allocate a receive buffer
unsigned buffer_size = kRowCountInJob * num_colunms;
ColorHex *buffer = new ColorHex[kRowCountInJob * num_colunms];
// Some variables
MPI_Status status;
int next_row_index = 0;
int *index_per_proc = new int[proc_count];
int offset, size;
// Receiving and sending jobs
while (next_row_index < num_rows) {
// Wait for a job request or a more job request
MPI_Recv(buffer, buffer_size, MPI_UNSIGNED_LONG, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status);
// Handle the returned results
if (status.MPI_TAG == kTagJobReturnAndRequest) {
// Calculate the offset and the size
offset = index_per_proc[status.MPI_SOURCE] * num_colunms;
size = (index_per_proc[status.MPI_SOURCE] + kRowCountInJob > num_rows)? num_rows - index_per_proc[status.MPI_SOURCE] : kRowCountInJob;
size = size * num_colunms * sizeof(ColorHex); // in bytes
// Copy the result to the global buffer
memcpy(colors + offset, buffer, size);
}
// Send a new job
MPI_Send(&next_row_index, 1, MPI_INT, status.MPI_SOURCE, kTagNewJob, MPI_COMM_WORLD);
index_per_proc[status.MPI_SOURCE] = next_row_index;
next_row_index += kRowCountInJob;
}
// No more jobs, terminate all slave process
for (int terminated_count = 0; terminated_count < proc_count - 1; terminated_count++) {
// Wait for a request
MPI_Recv(buffer, buffer_size, MPI_UNSIGNED_LONG, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status);
// If it is a job request
if (status.MPI_TAG == kTagJobReturnAndRequest) { // If it is a more job request
// Calculate the offset and the size
offset = index_per_proc[status.MPI_SOURCE] * num_colunms;
size = (index_per_proc[status.MPI_SOURCE] + kRowCountInJob > num_rows)? num_rows - index_per_proc[status.MPI_SOURCE] : kRowCountInJob;
size = size * num_colunms * sizeof(ColorHex); // in bytes
// Copy the result to the global buffer
memcpy(colors + offset, buffer, size);
}
// Send a terminate message
MPI_Send(NULL, 0, MPI_INT, status.MPI_SOURCE, kTagTerminate, MPI_COMM_WORLD);
}
// Free the resource
delete[] buffer;
delete[] index_per_proc;
}
// ColorHex *colors, int num_rows, int num_colunms, double real_min, double real_max, double imag_min, double imag_max, int proc_count, int rank
void DynamicScheduleSlave(int num_threads, int num_rows, int num_colunms, double real_min, double real_max, double imag_min, double imag_max, int rank) {
// Allocate a receive buffer
unsigned buffer_size = kRowCountInJob * num_colunms;
ColorHex *buffer = new ColorHex[kRowCountInJob * num_colunms];
// Local variables
MPI_Status status;
int start, count;
double x_scale = num_rows / (real_max - real_min);
double y_scale = num_colunms / (imag_max - imag_min);
// Record the start time
Time ts = GetCurrentTime();
int total_rows = 0;
#ifdef HYBRID
Time *th_exe_time = new Time[num_threads];
int *th_row_counts = new int[num_threads];
for (unsigned i = 0; i < num_threads; i++) {
th_exe_time[i] = GetZeroTime();
th_row_counts[i] = 0;
}
#endif
// Send a job request
MPI_Send(NULL, 0, MPI_UNSIGNED_LONG, kMPIRoot, kTagJobRequest, MPI_COMM_WORLD);
MPI_Recv(&start, 1, MPI_INT, kMPIRoot, MPI_ANY_TAG, MPI_COMM_WORLD, &status);
while (status.MPI_TAG == kTagNewJob) {
count = (start + kRowCountInJob > num_rows)? num_rows - start : kRowCountInJob;
total_rows += count;
// Calculate
#ifndef HYBRID
SeqMSCalculation(start, count, num_colunms, x_scale, y_scale, real_min, imag_min, buffer);
#else
OmpMSCalculation(start, count, num_colunms, x_scale, y_scale, real_min, imag_min, buffer, th_exe_time, th_row_counts);
#endif
// Request more jobs
MPI_Send(buffer, count * num_colunms, MPI_UNSIGNED_LONG, kMPIRoot, kTagJobReturnAndRequest, MPI_COMM_WORLD);
MPI_Recv(&start, 1, MPI_INT, kMPIRoot, MPI_ANY_TAG, MPI_COMM_WORLD, &status);
}
// Print the execution time
#ifdef HYBRID
for (unsigned i = 0; i < num_threads; i++) {
printf("Process %d, thread %d took %ld ms to calculate %d rows (%d points).\n", rank, i, TimeToLongInMs(th_exe_time[i]), th_row_counts[i], th_row_counts[i] * num_colunms);
}
delete[] th_exe_time;
delete[] th_row_counts;
#endif
Time te = GetCurrentTime();
printf("Process %d took %ld ms to calculate %d rows (%d points).\n", rank, TimeDiffInMs(ts, te), total_rows, total_rows * num_colunms);
// Free the resource
delete[] buffer;
}
} // namespace hw3
} // namespace pp
<file_sep>#ifndef PP_HW2_NBODY_NBODYPTHREAD_H_
#define PP_HW2_NBODY_NBODYPTHREAD_H_
#include <cstdio>
#include "nbody.hpp"
#include "../../gui.hpp"
namespace pp {
namespace hw2 {
namespace nbody {
void NBodySim(Universe *uni, size_t num_threads, double delta_time, size_t num_steps, double theta, GUI *gui);
} // namespace nbody
} // namespace hw2
} // namespace pp
#endif // PP_HW2_NBODY_NBODYPTHREAD_H_
<file_sep>### Declare variables
BIN_DIR = .
### Source path
HW2_SRCC_DIR = src/pp/hw2/rccsim
HW2_NBODY_DIR = src/pp/hw2/nbody
HW3_DIR = src/pp/hw3
## All
all: hw2 hw3
## HW2
hw2: hw2_srcc hw2_nbody
hw2_srcc:
cd $(HW2_SRCC_DIR) && $(MAKE) all
mv $(HW2_SRCC_DIR)/hw2_SRCC $(BIN_DIR)
cd $(HW2_SRCC_DIR) && $(MAKE) clean
hw2_nbody: hw2_nbody_pthread hw2_nbody_omp hw2_nbody_gh
hw2_nbody_pthread:
cd $(HW2_NBODY_DIR) && $(MAKE) pthread
mv $(HW2_NBODY_DIR)/hw2_NB_pthread $(BIN_DIR)
cd $(HW2_NBODY_DIR) && $(MAKE) clean
hw2_nbody_omp:
cd $(HW2_NBODY_DIR) && $(MAKE) omp
mv $(HW2_NBODY_DIR)/hw2_NB_omp $(BIN_DIR)
cd $(HW2_NBODY_DIR) && $(MAKE) clean
hw2_nbody_gh:
cd $(HW2_NBODY_DIR) && $(MAKE) gh
mv $(HW2_NBODY_DIR)/hw2_NB_BHalgo $(BIN_DIR)
cd $(HW2_NBODY_DIR) && $(MAKE) clean
## hw3
hw3: hw3_omp_static hw3_omp_dynamic hw3_mpi_static hw3_mpi_dynamic hw3_hybrid_static hw3_hybrid_dynamic
hw3_omp_static:
cd $(HW3_DIR) && $(MAKE) omp_static
mv $(HW3_DIR)/MS_OpenMP_static $(BIN_DIR)
cd $(HW3_DIR) && $(MAKE) clean
hw3_omp_dynamic:
cd $(HW3_DIR) && $(MAKE) omp_dynamic
mv $(HW3_DIR)/MS_OpenMP_dynamic $(BIN_DIR)
cd $(HW3_DIR) && $(MAKE) clean
hw3_mpi_static:
cd $(HW3_DIR) && $(MAKE) mpi_static
mv $(HW3_DIR)/MS_MPI_static $(BIN_DIR)
cd $(HW3_DIR) && $(MAKE) clean
hw3_mpi_dynamic:
cd $(HW3_DIR) && $(MAKE) mpi_dynamic
mv $(HW3_DIR)/MS_MPI_dynamic $(BIN_DIR)
cd $(HW3_DIR) && $(MAKE) clean
hw3_hybrid_static:
cd $(HW3_DIR) && $(MAKE) hy_static
mv $(HW3_DIR)/MS_Hybrid_static $(BIN_DIR)
cd $(HW3_DIR) && $(MAKE) clean
hw3_hybrid_dynamic:
cd $(HW3_DIR) && $(MAKE) hy_dynamic
mv $(HW3_DIR)/MS_Hybrid_dynamic $(BIN_DIR)
cd $(HW3_DIR) && $(MAKE) clean
<file_sep>#include "mandelbort_set.hpp"
#include <cstdio>
#include <omp.h>
#include "../timer.hpp"
namespace pp {
namespace hw3 {
unsigned MandelbortSetCheck(Comp c) {
double sq_len;
Comp z, next_z;
// Set Z0
z = c;
// Mandelbort Set Check
for (unsigned iter_count = 1; iter_count < kMaxIteration; iter_count++) {
// Check if the length is in the bound
sq_len = z.real * z.real + z.imag * z.imag;
if (sq_len > 4.0)
return iter_count;
// Calculate Zk
next_z.real = z.real * z.real - z.imag * z.imag + c.real;
next_z.imag = 2 * z.real * z.imag + c.imag;
z = next_z;
}
return kMaxIteration;
}
void SeqMSCalculation(unsigned x_start, unsigned num_rows, unsigned num_cols, double x_scale, double y_scale, double x_min, double y_min, ColorHex *results) {
Comp c;
ColorHex color;
for (unsigned rx = x_start, lx = 0; rx < x_start + num_rows; rx++, lx++) {
for (unsigned y = 0; y < num_cols; y++) {
// Map to a complex number
c.real = rx / x_scale + x_min;
c.imag = y / y_scale + y_min;
// Mandelbort Set Check
color = MandelbortSetCheck(c);
// Calculate the color
color = (color % 256) << 20;
results[lx * num_cols + y] = color;
}
}
}
void OmpMSCalculation(unsigned x_start, unsigned num_rows, unsigned num_cols, double x_scale, double y_scale, double x_min, double y_min, ColorHex *results, Time *exe_time, int *cal_rows) {
Comp c;
ColorHex color;
unsigned x, y;
Time tstart, tend;
int count;
#pragma omp parallel default(shared) private(c, color, x, y, tstart, tend, count)
{
count = 0;
tstart = GetCurrentTime();
#ifndef DYNAMIC
#pragma omp for schedule(static, 1)
#else
#pragma omp for schedule(dynamic, 1)
#endif
for (x = 0; x < num_rows; x++) {
for (y = 0; y < num_cols; y++) {
// Map to a complex number
c.real = (x + x_start) / x_scale + x_min;
c.imag = y / y_scale + y_min;
// Mandelbort Set Check
color = MandelbortSetCheck(c);
// Calculate the color
color = (color % 256) << 20;
results[x * num_cols + y] = color;
}
count++;
tend = GetCurrentTime();
}
// For experiments
exe_time[omp_get_thread_num()] = TimeAdd(exe_time[omp_get_thread_num()], TimeDiff(tstart, tend));
cal_rows[omp_get_thread_num()] += count;
}
}
} // namespace hw3
} // namespace pp
<file_sep>#ifndef PP_HW2_RCCSIM_RCC_H_
#define PP_HW2_RCCSIM_RCC_H_
#include <list>
#include <pthread.h>
namespace pp {
namespace hw2 {
namespace rccsim { // Roller Coaster Car Simulation
class RollerCoasterCar {
public:
RollerCoasterCar(int capacity);
~RollerCoasterCar();
inline int GetCarCapacity() {
return car_capacity_;
}
bool WaifForARide(int id);
void WaitForCarFull(int *passengers);
void FinishARide(bool close_car);
private:
bool is_closed_;
int car_capacity_;
std::list<int> *waiting_queue_, *car_seats_;
pthread_mutex_t car_mutex_;
pthread_cond_t waiting_cond_, car_full_cond_, playing_cond_;
};
} // namespace rccsim
} // namespace hw2
} // namespace pp
#endif // PP_HW2_RCCSIM_RCC_H_
<file_sep>#include <cstdio>
#include <cstdlib>
#include <unistd.h>
#include "nbody.hpp"
#include "../../gui.hpp"
#ifndef OMP
#include "nbody_pthread.hpp"
#else
#include "nbody_omp.hpp"
#endif
#include "../../timer.hpp"
using pp::hw2::nbody::Universe;
using pp::hw2::nbody::ReadFromFile;
using pp::hw2::nbody::NBodySim;
using pp::GUI;
using pp::GetCurrentTime;
using pp::TimeDiffInMs;
int main(int argc, char const *argv[]) {
// Check arguments
if (argc < 5) {
fprintf(stderr, "Insufficient args\n");
fprintf(stderr, "Usage: %s #threads m T t FILE theta enable/disable xmin ymin length Length", argv[0]);
return 0;
}
// Retrieve the arguments
size_t num_threads, num_steps;
int mass;
double delta_time, theta, x_min, y_min, coord_len, win_len;
const char *filename;
bool x_enabled;
num_threads = (size_t) strtol(argv[1], NULL, 10);
mass = (int) strtol(argv[2], NULL, 10);
num_steps = (size_t) strtol(argv[3], NULL, 10);
sscanf(argv[4], "%lf", &delta_time);
filename = argv[5];
sscanf(argv[6], "%lf", &theta);
x_enabled = (argv[7][0] == 'e')? true : false;
sscanf(argv[8], "%lf", &x_min);
sscanf(argv[9], "%lf", &y_min);
sscanf(argv[10], "%lf", &coord_len);
win_len = (unsigned) strtol(argv[11], NULL, 10);
// Record the start time
pp::Time start = GetCurrentTime();
// Read the input file
pp::Time io_start = GetCurrentTime();
Universe *uni = ReadFromFile(filename);
uni->body_mass = mass;
pp::Time io_end = GetCurrentTime();
printf("IO took %ld ms.\n", TimeDiffInMs(io_start, io_end));
// Create a GUI for demonstration
GUI *gui = NULL;
if (x_enabled)
gui = new GUI(win_len, coord_len, x_min, y_min);
// Start running
NBodySim(uni, num_threads, delta_time, num_steps, theta, gui);
// Print the execution time
pp::Time end = GetCurrentTime();
printf("The whole program took %ld ms for execution.\n", TimeDiffInMs(start, end));
return 0;
}
<file_sep>#include "nbody.hpp"
#include <cstdio>
namespace pp {
namespace hw2 {
namespace nbody {
Vec2 Add(Vec2 a, Vec2 b) {
Vec2 c;
c.x = a.x + b.x;
c.y = a.y + b.y;
return c;
}
Vec2 CalculateTotalForce(Universe *uni, int target) {
CelestialBody *bodies = uni->bodies;
double mass = uni->body_mass;
Vec2 total_force = {0.0, 0.0}, tmp;
Vec2 dis;
// Force
for (size_t i = 0; i < uni->num_bodies; i++) {
if (i != target) {
// Calculate the distance
dis.x = bodies[i].pos.x - bodies[target].pos.x;
dis.y = bodies[i].pos.y - bodies[target].pos.y;
// Calculate the force
Vec2 force = GravitationFormula(mass, mass, dis);
total_force = Add(force, total_force);
}
}
return total_force;
}
Universe *ReadFromFile(const char *filename) {
// Open the file
FILE *file = fopen(filename, "r");
// Read the first line
size_t num_bodies;
fscanf(file, "%lu", &num_bodies);
// Read the data of bodies
CelestialBody *bodies = new CelestialBody[num_bodies];
for (size_t i = 0; i < num_bodies; i++)
fscanf(file, "%lf %lf %lf %lf", &(bodies[i].pos.x), &(bodies[i].pos.y), &(bodies[i].vel.x), &(bodies[i].vel.y));
// Close the file
fclose(file);
// Return as an universe
Universe *uni = new Universe();
uni->bodies = bodies;
uni->num_bodies = num_bodies;
return uni;
}
} // namespace nbody
} // namespace hw2
} // namespace pp
<file_sep>#include "rcc_sim.hpp"
#include <cstdio>
#include <cstdlib>
#include <ctime>
#include <cstring>
#include <unistd.h>
#include "../../timer.hpp"
namespace pp {
namespace hw2 {
namespace rccsim { // Roller Coaster Car Simulation
pthread_mutex_t random_mutex;
void InitSimluation() {
// Set the seed of random number generator
srand(time(NULL));
// Create a mutex
pthread_mutex_init(&random_mutex, NULL);
}
void FinishSimluation() {
pthread_mutex_destroy(&random_mutex);
}
useconds_t GetRandomTime() {
useconds_t num;
// Protected by mutex
pthread_mutex_lock(&random_mutex);
num = (useconds_t) rand();
pthread_mutex_unlock(&random_mutex);
return num % 1000;
}
void *PassengerThread(void *args) {
PassengerThreadArgs *pta = (PassengerThreadArgs *) args;
bool keep_going = true;
Time start, end, total;
int play_count = 0;
printf("This is passenger thread no.%d\n", pta->passenger_id);
while (keep_going) {
// Wander around
useconds_t walk_time = GetRandomTime();
printf("Passenger no.%d wanders around the park for %ld minisecond\n", pta->passenger_id, walk_time);
usleep(walk_time * 1000);
// Wait for a ride
start = GetCurrentTime();
keep_going = !(pta->car->WaifForARide(pta->passenger_id));
if (keep_going) {
play_count++;
end = GetCurrentTime();
total = TimeAdd(total, TimeDiff(start, end));
}
}
long avg_wait = TimeToLongInMs(total) / play_count;
printf("Passenger no.%d leaves. (The avg. waiting time is %ld ms)\n", pta->passenger_id, avg_wait);
}
void *CarThread(void *args) {
CarThreadArgs *cta = (CarThreadArgs *) args;
int car_capacity = cta->car->GetCarCapacity();
int *passenger_list = new int[car_capacity];
char *tmp_str = new char[10];
char *list_str = new char[car_capacity * 15];
Time start, now;
Time wait_start, wait_end, total_wait;
start = GetCurrentTime();
total_wait = GetZeroTime();
printf("This is the car thread. Playing takes %d ms. It will run %d rounds.\n", cta->playing_time, cta->sim_steps_num);
for (size_t r = 0; r < cta->sim_steps_num; r++) {
// Check queue
wait_start = GetCurrentTime();
cta->car->WaitForCarFull(passenger_list);
wait_end = GetCurrentTime();
total_wait = TimeAdd(total_wait, TimeDiff(wait_start, wait_end));
// Construct string for logging
list_str[0] = 0; // Clear the string
sprintf(list_str, "%d", passenger_list[0]);
for (size_t i = 1; i < car_capacity; i++) {
sprintf(tmp_str, ", %d", passenger_list[i]);
strcat(list_str, tmp_str);
}
// Print departure log
now = GetCurrentTime();
printf("Car departures at %ld millisec. Passengers [%s] are in the car\n", TimeDiffInMs(start, now), list_str);
// Start playing
usleep((useconds_t) (cta->playing_time * 1000));
// Print arrive log
now = GetCurrentTime();
printf("Car arrives at %ld millisec. Passengers [%s] get off\n", TimeDiffInMs(start, now), list_str);
// Release passengers
if (r < cta->sim_steps_num - 1)
cta->car->FinishARide(false);
else {
cta->car->FinishARide(true);
printf("The car thread closes the car.\n");
}
}
// Print the average waitting time
long avg_wait = TimeToLongInMs(total_wait) / cta->sim_steps_num;
printf("The average waitting time is %ld ms.\n", avg_wait);
delete[] passenger_list;
delete[] tmp_str;
delete[] list_str;
}
} // namespace rccsim
} // namespace hw2
} // namespace pp
<file_sep>#include "gui.hpp"
#include <cstdio>
#include <cstdlib>
#include <cmath>
#include <unistd.h>
#include <X11/Xlib.h>
namespace pp {
GUI::GUI(unsigned win_width, unsigned win_height) {
// Set the width and the height
win_width_ = win_width;
win_height_ = win_height;
x_scale_ = 1.0;
y_scale_ = 1.0;
x_min_ = 0;
y_min_ = 0;
InitXWindow();
}
GUI::GUI(unsigned win_len, double coord_len, double x_min, double y_min) {
// Set the width and the height
win_width_ = win_len;
win_height_ = win_len;
x_scale_ = ((double) win_len) / coord_len;
y_scale_ = x_scale_;
x_min_ = x_min;
y_min_ = y_min;
InitXWindow();
}
GUI::~GUI() {
}
void GUI::InitXWindow() {
// Open a connection to the x-window server
display_ = XOpenDisplay(NULL);
if(display_ == NULL) {
fprintf(stderr, "cannot open display\n");
exit(1);
}
// Get the id of the default screen
screen_id_ = DefaultScreen(display_);
// Create a window
window_ = XCreateSimpleWindow(display_, RootWindow(display_, screen_id_), 0, 0, win_width_, win_height_, 0, kColorBlack, kColorWhite);
// Create a graphic context
XGCValues values;
gc_ = XCreateGC(display_, window_, 0, &values);
// map(show) the window
XMapWindow(display_, window_);
XSync(display_, 0);
}
void GUI::CleanAll() {
// Draw a rectangle to clean everything
XSetForeground(display_, gc_, kColorBlack);
XFillRectangle(display_, window_, gc_, 0, 0, win_width_, win_height_);
}
void GUI::DrawAPoint(double x, double y) {
DrawAPoint(x, y, kColorWhite);
}
void GUI::DrawAPoint(double x, double y, unsigned long color) {
XSetForeground(display_, gc_, color);
XDrawPoint(display_, window_, gc_, MapX(x), MapY(y));
}
void GUI::DrawALine(double start_x, double start_y, double end_x, double end_y) {
XSetForeground(display_, gc_, kColorGray);
XDrawLine(display_, window_, gc_, MapX(start_x), MapY(start_y), MapX(end_x), MapY(end_y));
}
void GUI::Flush() {
XFlush(display_);
}
} // namespace pp
<file_sep>#ifndef PP_HW3_MANDELBORTSET_H_
#define PP_HW3_MANDELBORTSET_H_
#include "../gui.hpp"
#include "../timer.hpp"
namespace pp {
namespace hw3 {
typedef struct {
double real, imag;
} Comp;
typedef unsigned long ColorHex;
const unsigned kMaxIteration = 100000;
unsigned MandelbortSetCheck(Comp c);
void SeqMSCalculation(unsigned x_start, unsigned num_rows, unsigned num_cols, double x_scale, double y_scale, double x_min, double y_min, ColorHex *results);
void OmpMSCalculation(unsigned x_start, unsigned num_rows, unsigned num_cols, double x_scale, double y_scale, double x_min, double y_min, ColorHex *results, Time *exe_time, int *cal_rows);
void MSMain(int num_threads, int num_x_points, int num_y_points, double real_min, double real_max, double imag_min, double imag_max, bool x_enabled);
} // namespace hw3
} // namespace pp
#endif // PP_HW3_MANDELBORTSET_H_
<file_sep>#include "nbody_pthread.hpp"
#include <cstdio>
#include <pthread.h>
#include "nbody.hpp"
#include "bh_tree.hpp"
#include "../../gui.hpp"
#include "../../timer.hpp"
namespace pp {
namespace hw2 {
namespace nbody {
typedef struct {
BHTree *tree;
} BHTreePack;
typedef struct {
// Thread info
size_t thread_id;
size_t num_threads;
pthread_barrier_t *barrier;
// N-Body parameters
Universe *uni;
double delta_time;
size_t num_steps;
// BH-Tree
BHTreePack *bh;
double theta;
} PThreadSimArgs;
typedef struct {
pthread_barrier_t *barrier;
size_t num_steps;
GUI *gui;
Universe *uni;
BHTreePack *bh;
} PThreadGUIArgs;
void *PThreadSimTask(void *args) {
PThreadSimArgs *tas = (PThreadSimArgs *) args;
int tid = tas->thread_id;
double dt = tas->delta_time;
CelestialBody *bodies = tas->uni->bodies;
int mass = tas->uni->body_mass;
int thread_count = tas->num_threads;
int body_count = tas->uni->num_bodies;
Time build_start, build_end, build_total = GetZeroTime();
Time com_start, com_end, com_total = GetZeroTime();
// Allocate a buffer
CelestialBody *tmp = new CelestialBody[body_count];
// Loop for a few steps
for (size_t s = 0; s < tas->num_steps; s++) {
#ifdef BH_ALGO
// Create a bh tree
if (tid == 0) {
build_start = GetCurrentTime();
if (tas->bh->tree != NULL)
delete tas->bh->tree;
tas->bh->tree = new BHTree(tas->uni);
}
pthread_barrier_wait(tas->barrier);
// Split the tree
while (tas->bh->tree->IsThereMoreJobs())
tas->bh->tree->DoASplittingJob();
pthread_barrier_wait(tas->barrier);
if (tid == 0) {
build_end = GetCurrentTime();
build_total = TimeAdd(build_total, TimeDiff(build_start, build_end));
com_start = GetCurrentTime();
}
#endif
// Calculate new velocities and positions
for (size_t i = 0; i < body_count; i++) {
if (i % thread_count == tid) {
#ifdef BH_ALGO
Vec2 total_force = tas->bh->tree->CalculateTotalForce(i, tas->theta);
#else
Vec2 total_force = CalculateTotalForce(tas->uni, i);
#endif
// New Velocity
tmp[i].vel.x = bodies[i].vel.x + total_force.x * dt / mass;
tmp[i].vel.y = bodies[i].vel.y + total_force.y * dt / mass;
// New position
tmp[i].pos.x = bodies[i].pos.x + bodies[i].vel.x * dt;
tmp[i].pos.y = bodies[i].pos.y + bodies[i].vel.y * dt;
}
}
pthread_barrier_wait(tas->barrier);
// Update the states
for (size_t i = 0; i < body_count; i++)
if (i % thread_count == tid)
bodies[i] = tmp[i];
pthread_barrier_wait(tas->barrier);
if (tid == 0) {
com_end = GetCurrentTime();
com_total = TimeAdd(com_total, TimeDiff(com_start, com_end));
}
}
// Print time
if (tid == 0) {
printf("Building took %ld ms.\n", TimeToLongInMs(build_total));
printf("Computing took %ld ms.\n", TimeToLongInMs(com_total));
}
// Deallocate the buffer
delete[] tmp;
}
void *PThreadGUITask(void *args) {
PThreadGUIArgs *tgas = (PThreadGUIArgs*) args;
GUI *gui = tgas->gui;
CelestialBody *bodies = tgas->uni->bodies;
// Loop for a few steps
for (size_t s = 0; s < tgas->num_steps; s++) {
#ifdef BH_ALGO
pthread_barrier_wait(tgas->barrier);
pthread_barrier_wait(tgas->barrier);
#endif
// Clean the window
gui->CleanAll();
#ifdef BH_ALGO
// Draw all regions
tgas->bh->tree->DrawRegions(gui);
#endif
// Draw all bodies
for (size_t i = 0; i < tgas->uni->num_bodies; i++) {
gui->DrawAPoint(bodies[i].pos.x, bodies[i].pos.y);
}
// Flush the screen
// XXX: Maybe I can put this after barrier
gui->Flush();
pthread_barrier_wait(tgas->barrier);
pthread_barrier_wait(tgas->barrier);
}
}
void NBodySim(Universe *uni, size_t num_threads, double delta_time, size_t num_steps, double theta, GUI *gui) {
// Initialize pthread barrier
pthread_barrier_t barrier;
if (gui != NULL)
pthread_barrier_init(&barrier, NULL, num_threads + 1);
else
pthread_barrier_init(&barrier, NULL, num_threads);
// Create a bh tree pack
BHTreePack *bh = new BHTreePack();
bh->tree = NULL;
// Create simulation threads
pthread_t *threads = new pthread_t[num_threads];
PThreadSimArgs *thread_args = new PThreadSimArgs[num_threads];
for(size_t id = 0; id < num_threads; id++) {
thread_args[id].thread_id = id;
thread_args[id].num_threads = num_threads;
thread_args[id].barrier = &barrier;
thread_args[id].uni = uni;
thread_args[id].delta_time = delta_time;
thread_args[id].num_steps = num_steps;
thread_args[id].bh = bh;
thread_args[id].theta = theta;
pthread_create(threads + id, NULL, PThreadSimTask, (void *) (thread_args + id));
}
// Create a GUI thread
pthread_t gui_thread;
PThreadGUIArgs gui_args;
if (gui != NULL) {
gui_args.gui = gui;
gui_args.uni = uni;
gui_args.barrier = &barrier;
gui_args.num_steps = num_steps;
gui_args.bh = bh;
pthread_create(&gui_thread, NULL, PThreadGUITask, (void *) &gui_args);
}
// Wait for all thread terminates
for(size_t id = 0; id < num_threads; id++)
pthread_join(threads[id], NULL);
if (gui != NULL)
pthread_join(gui_thread, NULL);
// Free all resource
pthread_barrier_destroy(&barrier);
delete[] threads;
delete[] thread_args;
delete bh;
}
} // namespace nbody
} // namespace hw2
} // namespace pp
<file_sep>#include "timer.hpp"
namespace pp {
Time GetZeroTime() {
Time t;
t.tv_sec = 0;
t.tv_nsec = 0;
return t;
}
Time GetCurrentTime() {
Time t;
clock_gettime(CLOCK_MONOTONIC, &t);
return t;
}
Time TimeAdd(Time base, Time add) {
base.tv_sec += add.tv_sec;
base.tv_nsec += add.tv_nsec;
if (base.tv_nsec >= 1000000000) {
base.tv_sec++;
base.tv_nsec -= 1000000000;
}
return base;
}
Time TimeDiff(Time start, Time end) {
Time tmp;
// Calculate diff
if ((end.tv_nsec - start.tv_nsec) < 0) {
tmp.tv_sec = end.tv_sec - start.tv_sec - 1;
tmp.tv_nsec = end.tv_nsec - start.tv_nsec + 1000000000;
} else {
tmp.tv_sec = end.tv_sec - start.tv_sec;
tmp.tv_nsec = end.tv_nsec - start.tv_nsec;
}
return tmp;
}
long TimeDiffInMs(Time start, Time end) {
Time diff = TimeDiff(start, end);
return TimeToLongInMs(diff);
}
long TimeToLongInMs(Time t) {
long ms;
// Convert it to ms.
ms = t.tv_nsec / 1000000;
ms += t.tv_sec * 1000;
return ms;
}
} // namespace pp
<file_sep>#include "mandelbort_set.hpp"
#include <cstdio>
#include <cstring>
#include <omp.h>
#include <unistd.h>
#include "../timer.hpp"
namespace pp {
namespace hw3 {
void MSMain(int num_threads, int num_x_points, int num_y_points, double real_min, double real_max, double imag_min, double imag_max, bool x_enabled) {
// Welcome message
#ifndef DYNAMIC
printf("== Mandelbort Set OpenMP Static Version ==\n");
#else
printf("== Mandelbort Set OpenMP Dynamic Version ==\n");
#endif
// For coordination transform
double x_scale = num_x_points / (real_max - real_min);
double y_scale = num_y_points / (imag_max - imag_min);
// Allocate a few buffer
ColorHex *colors = new ColorHex[num_x_points * num_y_points];
Time *exe_time = new Time[num_threads];
int *row_counts = new int[num_threads];
for (unsigned i = 0; i < num_threads; i++) {
exe_time[i] = GetZeroTime();
row_counts[i] = 0;
}
// Set the number of threads
omp_set_num_threads(num_threads);
// Calculate the Mandelbort Set
Time start = GetCurrentTime();
OmpMSCalculation(0, num_x_points, num_y_points, x_scale, y_scale, real_min, imag_min, colors, exe_time, row_counts);
Time end = GetCurrentTime();
// Print the execution time
printf("It took %ld ms for calculation.\n", TimeDiffInMs(start, end));
// Draw on the GUI
if (x_enabled) {
GUI *gui = new GUI(num_x_points, num_y_points);
for (unsigned x = 0; x < num_x_points; x++) {
for (unsigned y = 0; y < num_y_points; y++) {
gui->DrawAPoint(x, y, colors[x * num_y_points + y]);
}
}
gui->Flush();
sleep(20);
delete gui;
}
delete[] colors;
delete[] exe_time;
delete[] row_counts;
}
} // namespace hw3
} // namespace pp
<file_sep>#include "nbody_omp.hpp"
#include <cstdio>
#include <omp.h>
#include "nbody.hpp"
#include "../../gui.hpp"
namespace pp {
namespace hw2 {
namespace nbody {
void NBodySim(Universe *uni, size_t num_threads, double delta_time, size_t num_steps, double theta, GUI *gui) {
CelestialBody *bodies = uni->bodies;
size_t body_count = uni->num_bodies;
double mass = uni->body_mass;
double dt = delta_time;
// Set the number of threads
omp_set_num_threads(num_threads);
// Allocate a buffer
CelestialBody *tmp = new CelestialBody[body_count];
// Loop for a few steps
size_t i;
for (size_t s = 0; s < num_steps; s++) {
// Calculate new velocities and positions
#pragma omp parallel for default(shared) private(i)
for (i = 0; i < body_count; i++) {
Vec2 total_force = CalculateTotalForce(uni, i);
// New Velocity
tmp[i].vel.x = bodies[i].vel.x + total_force.x * dt / mass;
tmp[i].vel.y = bodies[i].vel.y + total_force.y * dt / mass;
// New position
tmp[i].pos.x = bodies[i].pos.x + bodies[i].vel.x * dt;
tmp[i].pos.y = bodies[i].pos.y + bodies[i].vel.y * dt;
}
// Update the states
#pragma omp parallel for default(shared) private(i)
for (i = 0; i < body_count; i++)
bodies[i] = tmp[i];
// Draw the results
if (gui != NULL) {
// Draw all points
gui->CleanAll();
for (i = 0; i < body_count; i++) {
gui->DrawAPoint(bodies[i].pos.x, bodies[i].pos.y);
}
// Flush the screen
gui->Flush();
}
}
// Deallocate the buffer
delete[] tmp;
}
} // namespace nbody
} // namespace hw2
} // namespace pp
<file_sep>#ifndef PP_GUI_H_
#define PP_GUI_H_
#include <X11/Xlib.h>
namespace pp {
class GUI {
public:
GUI(unsigned win_width, unsigned win_height);
GUI(unsigned win_len, double coord_len, double x_min, double y_min);
~GUI();
void CleanAll();
void DrawAPoint(double x, double y);
void DrawAPoint(double x, double y, unsigned long color);
void DrawALine(double start_x, double start_y, double end_x, double end_y);
void Flush();
private:
void InitXWindow();
inline unsigned MapX(double coord_x) {
return (unsigned) ((coord_x - x_min_) * x_scale_);
}
inline unsigned MapY(double coord_y) {
return (unsigned) ((coord_y - y_min_) * y_scale_);
}
// Some attributes
unsigned win_width_, win_height_;
double x_scale_, y_scale_;
double x_min_, y_min_;
// X-Window Componenets
Display *display_;
Window window_;
GC gc_;
int screen_id_;
static const unsigned long kColorWhite = 0xFFFFFFL, kColorBlack = 0x000000L, kColorGray = 0x5F5F5FL;
};
} // namespace pp
#endif // PP_GUI_H_
<file_sep>#ifndef PP_TIMER_H_
#define PP_TIMER_H_
#include <ctime>
namespace pp {
typedef struct timespec Time;
Time GetZeroTime();
Time GetCurrentTime();
Time TimeAdd(Time base, Time add);
Time TimeDiff(Time start, Time end);
long TimeDiffInMs(Time start, Time end);
long TimeToLongInMs(Time t);
} // namespace pp
#endif
<file_sep>#ifndef PP_HW2_NBODY_NBODY_H_
#define PP_HW2_NBODY_NBODY_H_
#include <cmath>
namespace pp {
namespace hw2 {
namespace nbody {
// ========================
// N-Body Basic Functions
// ========================
typedef struct {
double x, y;
} Vec2;
Vec2 Add(Vec2 a, Vec2 b);
typedef struct {
Vec2 pos, vel;
} CelestialBody;
typedef struct {
CelestialBody *bodies;
int num_bodies;
double body_mass;
} Universe;
const double kG = 6.674e-011; // Gravitational Constant
const double kMinDis = 1.0e-004;
inline Vec2 GravitationFormula(double m1, double m2, Vec2 dis) {
Vec2 force;
double dis_total = sqrt(dis.x * dis.x + dis.y * dis.y);
/*
double force_value;
if (dis_total < kMinDis) // Give a minimun value to the distance
force_value = (kG * m1 * m2) / (kMinDis * kMinDis);
else
force_value = (kG * m1 * m2) / (dis_total * dis_total);
*/
double force_value = (kG * m1 * m2) / (dis_total * dis_total);
force.x = force_value * dis.x / dis_total;
force.y = force_value * dis.y / dis_total;
return force;
}
Vec2 CalculateTotalForce(Universe *uni, int target);
// ==========================
// Other Untility Functions
// ==========================
Universe *ReadFromFile(const char *filename);
} // namespace nbody
} // namespace hw2
} // namespace pp
#endif // PP_HW2_NBODY_NBODY_H_
<file_sep>#include <cstdio>
#ifndef OMP
#include <mpi.h>
#endif
#include "mandelbort_set.hpp"
using pp::hw3::MSMain;
int main(int argc, char *argv[]) {
// Check arguments
if (argc < 9) {
fprintf(stderr, "Insufficient args\n");
fprintf(stderr, "Usage: %s #threads real-min real-max imag-min imag-max #x-points #y-points enable/disable\n", argv[0]);
return 0;
}
// Retrieve the arguments
int num_threads, num_x_points, num_y_points;
double real_min, real_max, imag_min, imag_max;
bool x_enabled;
sscanf(argv[1], "%d", &num_threads);
sscanf(argv[2], "%lf", &real_min);
sscanf(argv[3], "%lf", &real_max);
sscanf(argv[4], "%lf", &imag_min);
sscanf(argv[5], "%lf", &imag_max);
sscanf(argv[6], "%d", &num_x_points);
sscanf(argv[7], "%d", &num_y_points);
x_enabled = (argv[8][0] == 'e')? true : false;
// Parallel Mandelbort Set Calculation
#ifdef OMP
MSMain(num_threads, num_x_points, num_y_points, real_min, real_max, imag_min, imag_max, x_enabled);
#else
// Init MPI
MPI_Init(&argc, &argv);
MSMain(num_threads, num_x_points, num_y_points, real_min, real_max, imag_min, imag_max, x_enabled);
// Finalize MPI
MPI_Finalize();
#endif
return 0;
}
<file_sep># Parallel Programming Homeworks
This repository has all homeworks I have written in C++ in the parallel programming course of NTHU.
## Dependencies
Some programs require extra dependencies during linking. I concluded the dependencies those programs need in the following table:
| Homework Name | Dependencies |
| :------------- | :------------- |
| HW 2 - Roller Coaster Problem | pthread |
| HW 2 - N-body Problem - Pthread Implementation | pthread, X-Window |
| HW 2 - N-body Problem - OpenMP Implementation | X-Window |
| HW 2 - N-body Problem - BH-Algo Implementation | pthread, X-Window |
| HW 3 - OpenMP Implementation | X-Window |
| HW 3 - MPI, Hybrid Implementation | MPI, X-Window |
## Compile
There is a Makefile in the root directory. You can compile all source code by simply executing `make` or `make all`. All executable files will be generated in the root directory.
If you just want to compile the homeworks you need, please refer to the following table:
| Homework Name | Make Command |
| :------------- | :------------- |
| Entire Homework 2 | `make hw2` |
| HW 2 - Roller Coaster Problem | `make hw2_srcc` |
| HW 2 - N-body Problem - All Implementation | `make hw2_nbody` |
| HW 2 - N-body Problem - Pthread Implementation | `make hw2_nbody_pthread` |
| HW 2 - N-body Problem - OpenMP Implementation | `make hw2_nbody_omp` |
| HW 2 - N-body Problem - BH-Algo Implementation | `make hw2_nbody_gh` |
| Entire Homework 3 | `make hw3` |
| HW 3 - OpenMP - Static Scheduling Implementation | `make hw3_omp_static` |
| HW 3 - OpenMP - Dynamic Scheduling Implementation | `make hw3_omp_dynamic` |
| HW 3 - MPI - Static Scheduling Implementation | `make hw3_mpi_static` |
| HW 3 - MPI - Dynamic Scheduling Implementation | `make hw3_mpi_dynamic` |
| HW 3 - Hybrid - Static Scheduling Implementation | `make hw3_hybrid_static` |
| HW 3 - Hybrid - Dynamic Scheduling Implementation | `make hw3_hybrid_dynamic` |
<file_sep>#include "bh_tree.hpp"
#include <cfloat>
#include <cstdio>
#include <cmath>
#include <vector>
#include "nbody.hpp"
#include "../../gui.hpp"
using std::vector;
namespace pp {
namespace hw2 {
namespace nbody {
BHTreeNode::BHTreeNode(Vec2 min, Vec2 max) {
coord_min_ = min;
coord_mid_.x = (min.x + max.x) / 2;
coord_mid_.y = (min.y + max.y) / 2;
coord_max_ = max;
body_id_ = kInternalNode;
nw_ = NULL;
ne_ = NULL;
sw_ = NULL;
se_ = NULL;
}
BHTreeNode::BHTreeNode(Universe *uni, int body_id, Vec2 min, Vec2 max) {
center_of_mass_.x = uni->bodies[body_id].pos.x;
center_of_mass_.y = uni->bodies[body_id].pos.y;
body_count_ = 1;
coord_min_ = min;
coord_mid_.x = (min.x + max.x) / 2;
coord_mid_.y = (min.y + max.y) / 2;
coord_max_ = max;
body_id_ = body_id;
nw_ = NULL;
ne_ = NULL;
sw_ = NULL;
se_ = NULL;
}
BHTree::BHTree(Universe *uni) {
root_ = NULL;
uni_ = uni;
// Calculate the max and the min
root_min_.x = DBL_MAX;
root_min_.y = DBL_MAX;
root_max_.x = DBL_MIN;
root_max_.y = DBL_MIN;
CelestialBody *bodies = uni->bodies;
for (size_t i = 0; i < uni->num_bodies; i++) {
if (root_min_.x > bodies[i].pos.x)
root_min_.x = bodies[i].pos.x;
if (root_min_.y > bodies[i].pos.y)
root_min_.y = bodies[i].pos.y;
if (root_max_.x < bodies[i].pos.x)
root_max_.x = bodies[i].pos.x;
if (root_max_.y < bodies[i].pos.y)
root_max_.y = bodies[i].pos.y;
}
// Create the job queue
job_queue_ = new std::list<SplittingJob>();
pthread_mutex_init(&job_queue_mutex_, NULL);
pthread_cond_init(&job_queue_cond_, NULL);
job_count_ = 0;
finish_count_ = 0;
// Create a root node
// XXX: Not consider the size = 0
if (uni->num_bodies == 1) {
// Create a external root node
root_ = new BHTreeNode(uni, 0, root_min_, root_max_);
} else {
// Create an internal root node then split it
root_ = new BHTreeNode(root_min_, root_max_);
vector<int> *body_ids = new vector<int>();
for (size_t i = 0; i < uni->num_bodies; i++)
body_ids->push_back(i);
job_count_++;
SplitTheNode(root_, body_ids);
}
}
BHTree::~BHTree() {
// Traverse and free all nodes
Delete(root_);
}
void BHTree::Delete(BHTreeNode *parent) {
// Go deeper
if (parent->nw_ != NULL)
Delete(parent->nw_);
if (parent->ne_ != NULL)
Delete(parent->ne_);
if (parent->sw_ != NULL)
Delete(parent->sw_);
if (parent->se_ != NULL)
Delete(parent->se_);
delete parent;
}
void BHTree::CreateRegion(BHTreeNode **region_ptr, vector<int> *bodies, Vec2 min, Vec2 max) {
size_t size = bodies->size();
if (size == 0)
return;
if (size == 1) {
// Create a external node
*region_ptr = new BHTreeNode(uni_, bodies->front(), min, max);
return;
}
// Create an internal node
*region_ptr = new BHTreeNode(min, max);
InsertASplittingJob(*region_ptr, bodies);
}
void BHTree::SplitTheNode(BHTreeNode *parent, vector<int> *body_ids) {
CelestialBody *bodies = uni_->bodies;
Vec2 tmp = {0.0, 0.0};
// Allocate containers for regions
vector<int> *nw_bodies = new vector<int>();
vector<int> *ne_bodies = new vector<int>();
vector<int> *sw_bodies = new vector<int>();
vector<int> *se_bodies = new vector<int>();
// Traverse all the bodies
Vec2 mid = parent->coord_mid_;
for (vector<int>::iterator it = body_ids->begin(); it != body_ids->end(); ++it) {
int id = *it;
// Calculate the center of the mass
tmp.x += bodies[id].pos.x;
tmp.y += bodies[id].pos.y;
// Put the body to a proper region
int pos = 0;
Vec2 body_pos = (uni_->bodies[id]).pos;
if (body_pos.x <= mid.x && body_pos.y <= mid.y) { // North-West
nw_bodies->push_back(id);
pos = 1;
}else if (body_pos.x >= mid.x && body_pos.y <= mid.y) { // North-East
ne_bodies->push_back(id);
pos = 2;
}else if (body_pos.x <= mid.x && body_pos.y >= mid.y) { // South-West
sw_bodies->push_back(id);
pos = 3;
}else { // South-East
se_bodies->push_back(id);
pos = 4;
}
}
// Record the center of mass and total mass for the node
size_t body_count = body_ids->size();
parent->center_of_mass_.x = tmp.x / body_count;
parent->center_of_mass_.y = tmp.y / body_count;
parent->body_count_ = body_count;
// Free the input container
delete body_ids;
// ====================
// == Create regions ==
// ====================
Vec2 min, max;
// North-West
min = parent->coord_min_;
max = parent->coord_mid_;
CreateRegion(&(parent->nw_), nw_bodies, min, max);
// North-East
min.x = parent->coord_mid_.x;
min.y = parent->coord_min_.y;
max.x = parent->coord_max_.x;
max.y = parent->coord_mid_.y;
CreateRegion(&(parent->ne_), ne_bodies, min, max);
// South-West
min.x = parent->coord_min_.x;
min.y = parent->coord_mid_.y;
max.x = parent->coord_mid_.x;
max.y = parent->coord_max_.y;
CreateRegion(&(parent->sw_), sw_bodies, min, max);
// South-East
min = parent->coord_mid_;
max = parent->coord_max_;
CreateRegion(&(parent->se_), se_bodies, min, max);
// Critical Section
pthread_mutex_lock(&job_queue_mutex_);
// Finish a job, increment the finish job counter
finish_count_++;
// Notify threads to retrieve the pending jobs
pthread_cond_broadcast(&job_queue_cond_);
pthread_mutex_unlock(&job_queue_mutex_);
}
void BHTree::InsertASplittingJob(BHTreeNode *parent, vector<int> *bodies) {
SplittingJob job = {parent, bodies};
pthread_mutex_lock(&job_queue_mutex_);
// Increment the job counter
job_count_++;
// Insert a spliting job
job_queue_->push_back(job);
pthread_mutex_unlock(&job_queue_mutex_);
}
void BHTree::DoASplittingJob() {
SplittingJob job;
// Retrieve a job
pthread_mutex_lock(&job_queue_mutex_);
while (job_queue_->size() == 0) {
// If there is no more job, leave early
if (job_count_ <= finish_count_) {
pthread_mutex_unlock(&job_queue_mutex_);
return;
}
pthread_cond_wait(&job_queue_cond_, &job_queue_mutex_);
}
job = job_queue_->front();
job_queue_->pop_front();
pthread_mutex_unlock(&job_queue_mutex_);
// Do the job
SplitTheNode(job.parent, job.bodies);
}
bool BHTree::IsThereMoreJobs() {
bool result;
pthread_mutex_lock(&job_queue_mutex_);
result = job_count_ > finish_count_;
pthread_mutex_unlock(&job_queue_mutex_);
return result;
}
Vec2 BHTree::CalculateTotalForce(int source_id, double theta) {
return CalculateTotalForce(source_id, theta, root_);
}
Vec2 BHTree::CalculateTotalForce(int source_id, double theta, BHTreeNode *node) {
Vec2 total_force = {0.0, 0.0}, dis;
double target_mass, dis_total;
CelestialBody *bodies = uni_->bodies;
// If this node is the source node
if (node->body_id_ == source_id) {
return total_force;
}
// For an ineternal node
else if (node->body_id_ == BHTreeNode::kInternalNode) {
dis.x = node->center_of_mass_.x - bodies[source_id].pos.x;
dis.y = node->center_of_mass_.y - bodies[source_id].pos.y;
dis_total = sqrt(dis.x * dis.x + dis.y * dis.y);
double region_width = node->coord_max_.x - node->coord_min_.x;
// Check if we need to go deeper
if (region_width / dis_total > theta) {
// Go deeper
if (node->nw_ != NULL)
total_force = Add(CalculateTotalForce(source_id, theta, node->nw_), total_force);
if (node->ne_ != NULL)
total_force = Add(CalculateTotalForce(source_id, theta, node->ne_), total_force);
if (node->sw_ != NULL)
total_force = Add(CalculateTotalForce(source_id, theta, node->sw_), total_force);
if (node->se_ != NULL)
total_force = Add(CalculateTotalForce(source_id, theta, node->se_), total_force);
return total_force;
}
target_mass = uni_->body_mass * node->body_count_;
} else { // For an external node
dis.x = bodies[node->body_id_].pos.x - bodies[source_id].pos.x;
dis.y = bodies[node->body_id_].pos.y - bodies[source_id].pos.y;
target_mass = uni_->body_mass;
}
// Apply the formula
return GravitationFormula(uni_->body_mass, target_mass, dis);
}
void BHTree::DrawRegions(GUI *gui) {
// Draw boundaries
gui->DrawALine(root_min_.x, root_min_.y, root_min_.x, root_max_.y);
gui->DrawALine(root_min_.x, root_max_.y, root_max_.x, root_max_.y);
gui->DrawALine(root_max_.x, root_max_.y, root_max_.x, root_min_.y);
gui->DrawALine(root_max_.x, root_min_.y, root_min_.x, root_min_.y);
DrawRegions(gui, root_);
}
void BHTree::DrawRegions(GUI *gui, BHTreeNode *node) {
// Draw the middle line of the current region
if (node->body_id_ == BHTreeNode::kInternalNode) {
Vec2 min = node->coord_min_;
Vec2 mid = node->coord_mid_;
Vec2 max = node->coord_max_;
gui->DrawALine(mid.x, min.y, mid.x, max.y);
gui->DrawALine(min.x, mid.y, max.x, mid.y);
}
// Go deeper
if (node->nw_ != NULL)
DrawRegions(gui, node->nw_);
if (node->ne_ != NULL)
DrawRegions(gui, node->ne_);
if (node->sw_ != NULL)
DrawRegions(gui, node->sw_);
if (node->se_ != NULL)
DrawRegions(gui, node->se_);
}
void BHTree::PrintInDFS() {
PrintInDFS(root_);
}
void BHTree::PrintInDFS(BHTreeNode *node) {
// Go deeper
if (node->nw_ != NULL)
PrintInDFS(node->nw_);
if (node->ne_ != NULL)
PrintInDFS(node->ne_);
if (node->sw_ != NULL)
PrintInDFS(node->sw_);
if (node->se_ != NULL)
PrintInDFS(node->se_);
// Execute the action
if (node->body_id_ != BHTreeNode::kInternalNode) {
printf("Body Id: %d\n", node->body_id_);
} else {
printf("Center of mass: (%lf, %lf), count: %d\n", node->center_of_mass_.x, node->center_of_mass_.y, node->body_count_);
}
}
} // namespace nbody
} // namespace hw2
} // namespace pp
| 91140cdfb815b7977f8a7cc4891666ec1dde0be8 | [
"Markdown",
"Makefile",
"C++"
] | 31 | C++ | SLMT/course-parallel-programming | b23bdc61cd569a4fa5d3c3c30fc44b7be4cb8ca8 | e414777a2f34956e33f060d79be818a9ed3baaa6 |
refs/heads/master | <repo_name>yulichswift/FastTitleBar<file_sep>/app/src/main/java/com/yulich/fasttitlebar/MainActivity.java
package com.yulich.fasttitlebar;
import android.os.Bundle;
import com.yulich.titlebar.widget.TitleBar;
import androidx.appcompat.app.AppCompatActivity;
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TitleBar bar = findViewById(R.id.title_bar);
bar.addImageBtnToLeft(this, R.drawable.back);
bar.addTextBtnToRight(this, "Edit");
}
}
<file_sep>/library/src/main/java/com/yulich/titlebar/widget/DefaultTitleBar.java
package com.yulich.titlebar.widget;
import android.content.Context;
import android.content.res.TypedArray;
import android.graphics.drawable.Drawable;
import android.util.AttributeSet;
import android.view.View;
import android.widget.ImageView;
import android.widget.TextView;
import com.yulich.titlebar.R;
import androidx.annotation.DrawableRes;
public class DefaultTitleBar extends TitleBar {
public View leftBtn, rightBtn;
public DefaultTitleBar(Context context, AttributeSet attrs) {
super(context, attrs);
int leftId, rightId, leftStrId = 0, rightStrId = 0;
{
TypedArray ta = context.obtainStyledAttributes(attrs, R.styleable.DefaultTitleBar);
leftId = ta.getResourceId(R.styleable.DefaultTitleBar_left_src, 0);
rightId = ta.getResourceId(R.styleable.DefaultTitleBar_right_src, 0);
if (leftId == 0)
leftStrId = ta.getResourceId(R.styleable.DefaultTitleBar_lef_text, 0);
if (rightId == 0)
rightStrId = ta.getResourceId(R.styleable.DefaultTitleBar_right_text, 0);
ta.recycle();
}
if (leftId > 0)
leftBtn = addImageBtnToLeft(context, leftId);
else if (leftStrId > 0)
leftBtn = addTextBtnToLeft(context, context.getString(leftStrId));
if (rightId > 0)
rightBtn = addImageBtnToRight(context, rightId);
else if (rightStrId > 0)
rightBtn = addTextBtnToRight(context, context.getString(rightStrId));
}
public void setLeftBtnSrc(@DrawableRes int res) {
if (leftBtn instanceof ImageView)
((ImageView) leftBtn).setImageResource(res);
}
public void setRightBtnSrc(@DrawableRes int res) {
if (rightBtn instanceof ImageView)
((ImageView) rightBtn).setImageResource(res);
}
public void setLeftBtnSrc(Drawable res) {
if (leftBtn instanceof ImageView)
((ImageView) leftBtn).setImageDrawable(res);
}
public void setRightBtnSrc(Drawable res) {
if (rightBtn instanceof ImageView)
((ImageView) rightBtn).setImageDrawable(res);
}
public void setLeftBtnText(String text) {
if (leftBtn instanceof TextView)
((TextView) leftBtn).setText(text);
}
public void setLeftBtnText(int textId) {
if (leftBtn instanceof TextView)
((TextView) leftBtn).setText(textId);
}
public void setRightBtnText(String text) {
if (rightBtn instanceof TextView)
((TextView) rightBtn).setText(text);
}
public void setRightBtnText(int textId) {
if (leftBtn instanceof TextView)
((TextView) leftBtn).setText(textId);
}
public void setLeftBtnVisibility(int visibility) {
setViewVisibility(leftBtn, visibility);
}
public void setRightBtnVisibility(int visibility) {
setViewVisibility(rightBtn, visibility);
}
} | 94e2948a62f42e81501c8c10573480ecd0bf5b40 | [
"Java"
] | 2 | Java | yulichswift/FastTitleBar | ec0e6fdeb2b59d20028c0011e684d1246595c7e3 | b9371c8645244edc78ffa7823bd695f84f6e5e2d |
refs/heads/main | <repo_name>IamDinni/wpms<file_sep>/complaintreg.php
Your complaint has been Submitted!<file_sep>/README.md
# WPMS
---------------------------------------------------------------------------------------------------------------------------------------
Water Problem Management System
----------------------------------------------------------------------------------------------------------------------------------------
User Side View

Government Side View

# How to contribute
Well you can contribute to this repository by many ways:
- Suggest changes/features you want in future releases.
- Fork the repository, make some additional changes and send me a pull request.
- If there's any issues, please ask them and if you're too good to be good, than you can even rectify those issues on your own.
- Documenting your code is always a good habit. It enhances your code quality and reduces stress of other developers working on your project.
---
# License
This project is licensed under the MIT License - see the [LICENSE](../main/LICENSE) file for details
| d1c2d3cf59877662b38d076b4800d57e890baa3b | [
"Markdown",
"PHP"
] | 2 | PHP | IamDinni/wpms | 47d330bdf8d81b65ede455451fd31ed8965d94eb | b44b0fe3e0a458b60e626544378cea8c774ed4e0 |
refs/heads/master | <file_sep><?php
namespace bkanber\Translator\Parser;
use bkanber\Translator\Translatable;
use bkanber\Translator\Translation;
/**
* Interface ParserInterface
* @package bkanber\Translator\Parser
*/
interface ParserInterface
{
/**
* Returns the parser's input.
* @return mixed
*/
public function getInput();
/**
* Sets the parser's input.
* @param $input
* @return mixed
*/
public function setInput($input);
/**
* Returns the array of Translatable objects that `parse` found.
* @return Translatable[]
*/
public function getTranslatables();
/**
* @param $translatables
* @return mixed
*/
public function setTranslatables($translatables);
/**
* @return Translation[]
*/
public function getTranslations();
/**
* @param Translation[] $translations
* @return mixed
*/
public function setTranslations($translations);
/**
* Returns the unique translation keys found in the input.
* @return array|string[]
*/
public function getTranslatableKeys();
/**
* Parse the input and generate Translatables.
* @return Translatable[]
*/
public function parse();
/**
* Replace the translation keys in the input with the provided Translations
* @param Translation[] $translations
* @return mixed
*/
public function replace($translations);
}
<file_sep><?php
namespace bkanber\Translator\Tests\Parser;
use bkanber\Translator\Parser\StringParser;
use bkanber\Translator\Translation;
/**
* Class StringParserTest
* @package bkanber\Translator\Tests\Parser
*/
class StringParserTest extends \PHPUnit_Framework_TestCase
{
public function testDoesGetAndSetInput()
{
$input = 'hello world!';
$parser = (new StringParser())->setInput($input);
self::assertEquals($input, $parser->getInput());
$parser->setInput('new input');
self::assertEquals('new input', $parser->getInput());
}
public function testParsesTranslatables()
{
$input = '__{{key1}} __{{key2}} __{{keyWithDefault,"default goes here"}}';
$parser = (new StringParser())->setInput($input);
$translatables = $parser->parse();
self::assertCount(3, $translatables);
self::assertEquals('__{{key1}}', $translatables[0]->getReplace());
self::assertEquals('key1', $translatables[0]->getKey());
self::assertEquals('', $translatables[0]->getDefault());
self::assertEquals('__{{key2}}', $translatables[1]->getReplace());
self::assertEquals('key2', $translatables[1]->getKey());
self::assertEquals('', $translatables[1]->getDefault());
self::assertEquals('__{{keyWithDefault,"default goes here"}}', $translatables[2]->getReplace());
self::assertEquals('keyWithDefault', $translatables[2]->getKey());
self::assertEquals('default goes here', $translatables[2]->getDefault());
}
public function testGetTranslatableKeysDoesDedupe()
{
$input = <<<EOSTRING
<p>Hello, __{{person_title, "Friend"}}</p>
<p>The weather is __{{weather}}</p>
<p>And you are __{{person_title}}</p>
EOSTRING;
$parser = (new StringParser())->setInput($input);
$translatables = $parser->parse();
self::assertCount(3, $translatables);
$keys = $parser->getTranslatableKeys();
self::assertCount(2, $keys);
self::assertEquals(['person_title', 'weather'], $keys);
}
public function testMakesReplacements()
{
$input = <<<EOSTRING
<p>Hello, __{{person_title, "Friend"}}</p>
<p>The weather is __{{weather}}</p>
<p>And you are __{{person_title}}</p>
<div><img src="__{{image1,'https://burakkanber.com/image.jpg'}}" /></div>
EOSTRING;
$translations = [
Translation::createFromArray(
['key' =>'person_title', 'content' => 'Burak', 'locale' => 'test']
),
Translation::createFromArray(
['key' =>'weather', 'content' => 'frightful', 'locale' => 'test']
),
];
$parser = (new StringParser())->setInput($input);
$parser->parse();
$replaced = $parser->replace($translations);
self::assertTrue(false !== strpos($replaced, '<p>Hello, Burak</p>'));
self::assertTrue(false !== strpos($replaced, '<p>And you are Burak</p>'));
self::assertTrue(false !== strpos($replaced, '<p>The weather is frightful</p>'));
self::assertTrue(false !== strpos($replaced, '<img src="https://burakkanber.com/image.jpg" />'));
}
}
<file_sep><?php
namespace bkanber\Translator\Handler;
use bkanber\Translator\Translatable;
use bkanber\Translator\Translator;
interface HandlerInterface
{
public function onMissingTranslation(Translatable $translatable, Translator $translator);
}
<file_sep><?php
namespace bkanber\Translator\Exception;
class BadResourceException extends \Exception
{
}
<file_sep><?php
namespace bkanber\Translator\Parser;
use bkanber\Translator\Translatable;
use bkanber\Translator\Translation;
/**
* Class AbstractParser
* @package bkanber\Translator\Parser
*/
abstract class AbstractParser implements ParserInterface
{
/**
* Parse the input and generate Translatables.
* @return Translatable[]
*/
abstract public function parse();
/**
* Replace the translation keys in the input with the provided Translations
* @param Translation[] $translations
* @return mixed
*/
abstract public function replace($translations);
/** @var mixed */
protected $input;
/** @var Translatable[] */
protected $translatables = [];
/** @var Translation[] */
protected $translations = [];
/**
* @return Translation[]
*/
public function getTranslations()
{
return $this->translations;
}
/**
* @param Translation[] $translations
* @return static
*/
public function setTranslations($translations)
{
$this->translations = $translations;
return $this;
}
/**
* @return mixed
*/
public function getInput()
{
return $this->input;
}
/**
* @param mixed $input
* @return static
*/
public function setInput($input)
{
$this->input = $input;
return $this;
}
/**
* @return Translatable[]
*/
public function getTranslatables()
{
return $this->translatables;
}
/**
* @param Translatable[] $translatables
* @return static
*/
public function setTranslatables($translatables)
{
$this->translatables = $translatables;
return $this;
}
/**
* @return array|string[]
*/
public function getTranslatableKeys()
{
return array_values(
array_unique(
array_map(function (Translatable $translatable) {
return $translatable->getKey();
}, $this->getTranslatables())
)
);
}
/**
* @param $key
* @return Translation|null
*/
protected function findTranslation($key)
{
foreach ($this->getTranslations() as $translation) {
if ($translation->getKey() === $key) {
return $translation;
}
}
return null;
}
}
<file_sep><?php
namespace bkanber\Translator\Parser;
use bkanber\Translator\Exception\MalformedInputException;
use bkanber\Translator\Translatable;
use bkanber\Translator\Translation;
/**
* Class ArrayParser
* @package bkanber\Translator\Parser
*/
class ArrayParser extends AbstractParser implements ParserInterface
{
/**
* Parse the input and generate Translatables.
* @return Translatable[]
* @throws MalformedInputException
*/
public function parse()
{
$input = $this->getInput();
if (!is_array($input)) {
throw new MalformedInputException("ArrayParser requires an array as input");
}
$stringParser = new StringParser();
$arrayParser = new self();
$translatables = [];
foreach ($input as $key => $value) {
$theseTranslatables = [];
if (is_string($value)) {
$stringParser->setInput($value);
$theseTranslatables = $stringParser->parse();
} elseif (is_array($value)) {
$arrayParser->setInput($value);
$theseTranslatables = $arrayParser->parse();
}
$translatables = array_merge($translatables, $theseTranslatables);
}
$this->setTranslatables($translatables);
return $this->getTranslatables();
}
/**
* Replace the translation keys in the input with the provided Translations
* @param Translation[] $translations
* @return mixed
* @throws MalformedInputException
*/
public function replace($translations)
{
$output = $this->input;
if (!is_array($output)) {
throw new MalformedInputException("ArrayParser requires an array as input");
}
$stringParser = new StringParser();
$arrayParser = new self();
foreach ($output as $key => $value) {
if (is_string($value)) {
$stringParser->setInput($value);
$stringParser->parse();
$output[$key] = $stringParser->replace($translations);
} elseif (is_array($value)) {
$arrayParser->setInput($value);
$arrayParser->parse();
$output[$key] = $arrayParser->replace($translations);
}
}
return $output;
}
}
<file_sep><?php
namespace bkanber\Translator\Tests;
use bkanber\Translator\Tests\Driver\AbstractPdoDriverTest;
use bkanber\Translator\Translator;
/**
* Class TranslatorTest
* @package bkanber\Translator\Tests
*/
class TranslatorTest extends AbstractPdoDriverTest
{
/** @var Translator */
public static $translator;
public static function setUpBeforeClass()
{
parent::setUpBeforeClass();
$dbFileContents = file_get_contents(realpath(__DIR__ . '/translations.database'));
$dbDefinitions = json_decode($dbFileContents, true);
self::seedFromArray($dbDefinitions);
self::$translator = new Translator(self::$driver);
}
public function setUp()
{
parent::setUp();
self::$translator->setDomain(null)->setLocale(null);
}
public function testTranslatesHtml()
{
$html = file_get_contents(realpath(__DIR__ . '/translatable-html.html'));
$translated = self::$translator->setLocale('en')->translateString($html);
// Translated into english
self::assertTrue(false !== strpos($translated, '<title>English Page Title</title>'));
self::assertTrue(false !== strpos($translated, '<h1 class="title-en">'));
// This tag has a spanish translation but uses default for english:
self::assertTrue(false !== strpos($translated, '<p>Hello, welcome to my webpage.</p>'));
self::assertTrue(false !== strpos($translated, '<img src="https://example.com/image-en.jpg" />'));
self::assertTrue(false !== strpos($translated, '<div class="default-only">Default Only!</div>'));
self::assertTrue(false !== strpos($translated, '<div class="no-default">No Default English</div>'));
// Now translate into spanish
$translated = self::$translator->setLocale('es')->translateString($html);
self::assertTrue(false !== strpos($translated, '<title>Spanish Page Title</title>'));
self::assertTrue(false !== strpos($translated, '<h1 class="title-es">'));
self::assertTrue(false !== strpos($translated, '<p>Intro in Spanish</p>'));
self::assertTrue(false !== strpos($translated, '<img src="https://example.com/image-es.jpg" />'));
self::assertTrue(false !== strpos($translated, '<div class="default-only">Default Only!</div>'));
self::assertTrue(false !== strpos($translated, '<div class="no-default">No Default Spanish</div>'));
// Now do english with a specific domain
$translated = self::$translator->setLocale('en')->setDomain('cust1')->translateString($html);
self::assertTrue(false !== strpos($translated, '<title>English Page Title for Cust1</title>'));
self::assertTrue(false !== strpos($translated, '<h1 class="title-en-cust1">'));
self::assertTrue(false !== strpos($translated, '<p>Hello, welcome to my webpage.</p>'));
self::assertTrue(false !== strpos($translated, '<img src="https://example.com/image-en-cust1.jpg" />'));
self::assertTrue(false !== strpos($translated, '<div class="default-only">Default Only!</div>'));
self::assertTrue(false !== strpos($translated, '<div class="no-default">No Default English For Cust 1</div>'));
// Now do spanish with a specific domain
$translated = self::$translator->setLocale('es')->setDomain('cust1')->translateString($html);
self::assertTrue(false !== strpos($translated, '<title>Spanish Page Title for Cust1</title>'));
self::assertTrue(false !== strpos($translated, '<h1 class="title-es-cust1">'));
self::assertTrue(false !== strpos($translated, '<p>Intro in Spanish For Cust 1</p>'));
self::assertTrue(false !== strpos($translated, '<img src="https://example.com/image-es-cust1.jpg" />'));
self::assertTrue(false !== strpos($translated, '<div class="default-only">Default Only!</div>'));
self::assertTrue(false !== strpos($translated, '<div class="no-default">No Default Spanish For Cust 1</div>'));
}
public function testTranslatesArray()
{
$raw = file_get_contents(realpath(__DIR__ . '/translatable-json.json'));
$json = json_decode($raw, true);
self::$translator->setLocale('en');
$english = self::$translator->translateArray($json);
self::assertEquals('There was an error', $english['meta']['error']);
self::assertEquals('Item description goes here', $english['data']['items'][0]['desc']);
self::assertEquals('Default Child', $english['data']['items'][1]['children'][0]['value']);
self::assertEquals('deep nested in english', $english['data']['items'][1]['children'][0]['subobject']['middle']['end']);
self::$translator->setLocale('es');
$spanish = self::$translator->translateArray($json);
self::assertEquals('Uno error por favor', $spanish['meta']['error']);
self::assertEquals('Item description en espanol', $spanish['data']['items'][0]['desc']);
self::assertEquals('la palapa', $spanish['data']['items'][1]['children'][0]['value']);
self::assertEquals('deep nested in spanish', $spanish['data']['items'][1]['children'][0]['subobject']['middle']['end']);
// Now do everything again with cust1 domain
$english = self::$translator->setLocale('en')->setDomain('cust1')->translateArray($json);
self::assertEquals('There was an error For Cust 1', $english['meta']['error']);
self::assertEquals('Item description goes here For Cust 1', $english['data']['items'][0]['desc']);
self::assertEquals('Default Child', $english['data']['items'][1]['children'][0]['value']);
self::assertEquals('deep nested in english For Cust 1', $english['data']['items'][1]['children'][0]['subobject']['middle']['end']);
$spanish = self::$translator->setLocale('es')->setDomain('cust1')->translateArray($json);
self::assertEquals('Uno error por favor For Cust 1', $spanish['meta']['error']);
self::assertEquals('Item description en espanol For Cust 1', $spanish['data']['items'][0]['desc']);
self::assertEquals('la palapa For Cust 1', $spanish['data']['items'][1]['children'][0]['value']);
self::assertEquals('deep nested in spanish For Cust 1', $spanish['data']['items'][1]['children'][0]['subobject']['middle']['end']);
}
public function testSingletonInstances()
{
$t1 = Translator::instance()->setDriver(self::$driver);
$dupe = Translator::instance();
self::assertEquals($t1, $dupe);
$t2 = Translator::instance('otherdb');
self::assertNotEquals($t2, $t1);
}
/**
* @expectedException \bkanber\Translator\Exception\DriverMissingException
*/
public function testFailsIfNoDriverConfigured()
{
$translator = new Translator();
$translator->translateString('hello world');
}
}
<file_sep><?php
namespace bkanber\Translator;
/**
* Class Translatable
* @package bkanber\Translator
*
* Simple class that represents a "translation key" in a string.
* Translatables are found and created by the Parser classes, in order to keep track of what needs to be replaced.
* At present this class is not much more than a 'struct'.
*/
class Translatable
{
/** @var string */
protected $replace;
/** @var string */
protected $key;
/** @var string */
protected $default;
/**
* Translatable constructor.
* @param string $replace
* @param string $key
* @param string $default
*/
public function __construct($replace, $key, $default)
{
$this->replace = $replace;
$this->key = $key;
$this->default = $default;
}
/**
* @return string
*/
public function getReplace()
{
return $this->replace;
}
/**
* @param string $replace
*/
public function setReplace($replace)
{
$this->replace = $replace;
}
/**
* @return string
*/
public function getKey()
{
return $this->key;
}
/**
* @param string $key
*/
public function setKey($key)
{
$this->key = $key;
}
/**
* @return string
*/
public function getDefault()
{
return $this->default;
}
/**
* @param string $default
*/
public function setDefault($default)
{
$this->default = $default;
}
}
<file_sep># Translations Library
For Splash, by Burak
## Overview
You can translate strings or arrays. String Example:
```php
// Create a driver that provides translations (see also PdoDriver for database functionality)
$driver = ArrayDriver::createFromArray([
['domain' => 'cust1', 'locale' => 'en', 'key' => 'greeting', 'content' => 'Hello'],
['domain' => 'cust1', 'locale' => 'es', 'key' => 'greeting', 'content' => 'Hola']
]);
$enTranslator = new Translator($driver);
$enTranslator->setLocale('en')->setDomain('cust1');
$inEnglish = $enTranslator->translateString("__{{greeting}}, my friend!");
// $inEnglish === 'Hello, my friend!'
$esTranslator = new Translator($driver);
$esTranslator->setLocale('es')->setDomain('cust1');
$inSpanish = $esTranslator->translateString("__{{greeting}}, my friend!");
// $inSpanish === 'Hola, my friend!'
// Translation tags can also have defaults if the key or language isn't found:
$deTranslator = new Translator($db);
$deTranslator->setLocale('de')->setDomain('cust1');
$withDefault = $deTranslator->translateString("__{{greeting, 'Greetings'}}, my friend!");
// $withDefault === 'Greetings, my friend!'
```
You can also recursively translate PHP arrays:
```php
$driver = ArrayDriver::createFromArray([
['locale' => 'en', 'key' => 'greeting', 'content' => 'Hello'],
['locale' => 'es', 'key' => 'greeting', 'content' => 'Hola']
]);
$translator = new Translator($driver);
$translated = $translator->setLocale('en')->translateArray([
"data" => [
"items" => [
[
"content" => [
"tagName" => "h1",
"value" => "__{{greeting, 'Greetings'}}"
]
]
]
]
]);
// $translated['data']['items'][0]['content']['value'] === "Hello"
```
## Translations and Template Tags
Translations (modeled by the `Translation` class) have four properties: a locale, a key, a domain, and content. The locale is a custom string (i.e., it does not need to be an ISO locale code) that represents the language, dialect, or flavor that you wish to translate to. The domain is another custom string that helps you distinguish translation catalogs by (for example) a customer ID or other application domain. For example, in a multi-tentant SaaS application, the domain might represent a customer ID. The key of a translation refers to the template tag that should be used to represent it, and the translation content is what the key will be replaced with.
Template tags are intended to appear in strings with the format `__{{key, "Default text"}}`. The default text is optional and can be wrapped in either single quotes or double quotes. The key is required. Unlike other translation systems, the domain is not part of the key in the template tag. Therefore, a tag like `__{{greeting}}` could have a corresponding translation of "Hello, Splash Customer" or "Hello, Android User", depending on the domain set on the translator.
## Installation
First, `composer require` this library.
If you wish to store translations in your database, you must create the `translations` table with the appropriate columns. If you are already using the `phinx` migration library, you can copy the phinx migration from the `dist/migrations` folder in this repo. If you are using another migration library, create a database table called `translations` with the following columns:
- key; varchar or text, not null
- locale; varchar or text, not null (if you know you're exclusively using ISO locale codes you can make this field varchar(5))
- domain; varchar or text, nullable
- content; text, not null
In your application you will need to at very least instantiate the Translator class and attach a driver to use for translation lookups.
## Connecting to a Database
Instantiate the Translator class with an instance of `PdoDriver` instead of `ArrayDriver`.
You will need a table called 'translations' with the text fields 'key', 'locale', 'domain', and 'content'.
It is a good idea to index on (key,locale,domain). There is an example Phinx migration in the `dist/migrations` folder.
```php
$pdo = new \PDO('mysql::.....', 'user', 'pass');
$driver = new PdoDriver($pdo);
$translator = new Translator($driver);
```
You can manage the translations in the database by interacting with the driver directly:
```php
$pdo = new \PDO('mysql::.....', 'user', 'pass');
$driver = new PdoDriver($pdo);
$driver->upsertTranslation('en', 'greeting', 'customer1', 'Hello');
$driver->deleteTranslation('en', 'greeting', 'customer1');
$driver->createTranslation('en', 'greeting', 'customer1', 'Hello');
$driver->updateTranslation('en', 'greeting', 'customer1', 'Hi');
```
## Singleton Instance
The Translator class provides a singleton/instance manager so that you can use Translator instances globally.
Set up:
```php
Translator::instance()->setDriver(new PdoDriver(new \PDO( ... )));
```
Use elsewhere:
```php
Translator::instance()->setLocale('en')->translateString('__{{name_tag}}');
```
You can also manage multiple, named instances:
```php
Translator::instance()->setDriver(new PdoDriver(new \PDO( ... )));
Translator::instance('temp')->setDriver(ArrayDriver::createFromArray( ... ));
Translator::instance('temp')->setLocale('en')->transArray(...);
```
## Using Custom Drivers
If you need to connect to a translation source that neither ArrayDriver nor PdoDriver can manage, you can create your own.
Simply implement the DriverInterface class in a custom class of your own and use that.
```php
class MyCustomDriver implements DriverInterface {
public function __construct($someCustomResource) { ... }
public function findTranslation($locale, $key, $domain = null) { ... }
public function findTranslations($locale, $keys, $domain = null) { ... }
public function updateTranslation($locale, $key, $domain, $content) { ... }
public function createTranslation($locale, $key, $domain, $content) { ... }
public function upsertTranslation($locale, $key, $domain, $content) { ... }
public function deleteTranslation($locale, $key, $domain = null) { ... }
}
$myCustomResource = new CustomResource(...);
$translator = new Translator(new MyCustomDriver($myCustomResource));
```
## Using Custom Parsers
This library is shipped with a `StringParser` and an `ArrayParser`, with translation methods aliased by `translateString` and `translateArray`. However you can create a custom Parser class to deal with other types of inputs.
Create a class that implements the ParserInterface (and potentially extends AbstractParser) and send an instance of it to `translateCustom`:
```php
class MyCustomParser extends AbstractParser implements ParserInterface {
public function parse() {
// Must return an array of Translatable objects
}
public function replace($translations) {
// Must replace the Translatables in the input with the $translations given, and return the translated output
}
}
```
You can then use it like so:
```php
$translator = new Translator($driver);
$output = $translator->translateCustom($input, new MyCustomParser());
```
## Using a Missing Translation Handler
This library provides a mechanism for alerting you when a translation key with no matching translation is found. This is helpful for putting together a list of translations that still need to be written.
The LogFileHandler accepts a PHP file resource and will write TSV content to it. You should open a file with append mode to append to the log.
```php
$logFile = fopen($filePath, 'a');
$handler = new LogFileHandler($logFile);
$translator->setHandler($handler);
// Missing translation keys will get logged to your $logFile here:
$translator->translateString(...);
```
You can also create a custom handler (to, for instance, log missing translations to a DB, slack, elasticsearch, etc). Simply implement the HandlerInterface.
## Running the tests
```
$ composer install
$ vendor/bin/phpunit tests/
```
<file_sep><?php
namespace bkanber\Translator;
use bkanber\Translator\Driver\DriverInterface;
use bkanber\Translator\Exception\DriverMissingException;
use bkanber\Translator\Handler\HandlerInterface;
use bkanber\Translator\Parser\ParserInterface;
use bkanber\Translator\Parser\StringParser;
/**
* Class Translator
* @package bkanber\Translator
*
* This is the main translations management class.
* In this example, the translator depends on a language and a 'database' object.
* The database object here is a simple in-memory database. In a real implementation,
* the database object might look different but needs to at least have a method that looks up a Translation by language and key.
*
* The two entrypoint methods for this class are `translateString` and `translateArray`.
*
* Example usage:
*
* $database = TranslationsDatabase::createFromArray([['language' => 'en', 'key' => 'some_key', 'content' => 'hello world']]);
* $translator = new Translator('en', $database);
*
* $translatedString = $translator->translateString("In english: __{{some_key, 'default text'}}");
* $translatedArray = $translator->translateArray(['description' => '__{{desc, "default description"}}']);
*/
class Translator
{
/** @var array */
protected static $instances = [];
/** @var string */
protected $domain;
/** @var string */
protected $locale;
/** @var DriverInterface */
protected $driver;
/** @var HandlerInterface */
protected $handler;
/**
* Singleton instance manager.
*
* @param string $name
* @return static
*/
public static function instance($name = 'default')
{
if (isset(self::$instances[$name])) {
return self::$instances[$name];
}
self::$instances[$name] = new self();
return self::$instances[$name];
}
/**
* Translator constructor.
* @param DriverInterface|null $driver
*/
public function __construct(DriverInterface $driver = null)
{
$this->driver = $driver;
}
/**
* @return HandlerInterface
*/
public function getHandler()
{
return $this->handler;
}
/**
* @param HandlerInterface $handler
* @return Translator
*/
public function setHandler($handler)
{
$this->handler = $handler;
return $this;
}
/**
* @return string
*/
public function getDomain()
{
return $this->domain;
}
/**
* @param string $domain
* @return static
*/
public function setDomain($domain)
{
$this->domain = $domain;
return $this;
}
/**
* @return string
*/
public function getLocale()
{
return $this->locale;
}
/**
* @param string $locale
* @return static
*/
public function setLocale($locale)
{
$this->locale = $locale;
return $this;
}
/**
* @return DriverInterface
*/
public function getDriver()
{
return $this->driver;
}
/**
* @param DriverInterface $driver
* @return static
*/
public function setDriver($driver)
{
$this->driver = $driver;
return $this;
}
/**
* @param $input
* @param ParserInterface $parser
* @return mixed
* @throws DriverMissingException
*/
public function translateCustom($input, ParserInterface $parser)
{
if (!$this->getDriver()) {
throw new DriverMissingException("Translator has not yet been configured with a data driver.");
}
$parser->setInput($input);
$translatables = $parser->parse();
// We get all keys at once so we can perform on DB query instead of many.
$translationKeys = $parser->getTranslatableKeys();
$translations = $this->getDriver()->findTranslations($this->getLocale(), $translationKeys, $this->getDomain());
if ($this->getHandler()) {
$this->logMissingTranslationsToHandler($translatables, $translations);
}
return $parser->replace($translations);
}
/**
* @param $input
* @return mixed
* @throws DriverMissingException
*/
public function translateString($input)
{
return $this->translateCustom($input, new StringParser());
}
/**
* @param array $input
* @return mixed
* @throws DriverMissingException
*/
public function translateArray(array $input)
{
foreach ($input as $key => $value) {
if (is_string($value)) {
$input[$key] = $this->translateString($value);
}
elseif (is_array($value)) {
$input[$key] = $this->translateArray($value);
}
}
return $input;
}
/**
* @param array|Translatable[] $translatables
* @param array|Translation[] $translations
*/
protected function logMissingTranslationsToHandler(array $translatables, array $translations)
{
if (!$this->getHandler()) {
return;
}
$translationMap = [];
foreach ($translations as $translation) {
$translationMap[$translation->getKey()] = $translation;
}
foreach ($translatables as $translatable) {
if (!isset($translationMap[$translatable->getKey()])) {
$this->getHandler()->onMissingTranslation($translatable, $this);
}
}
}
}
<file_sep><?php
namespace bkanber\Translator\Tests\Driver;
use bkanber\Translator\Driver\PdoDriver;
use Symfony\Component\Console\Input\StringInput;
use Symfony\Component\Console\Output\NullOutput;
/**
* Class AbstractPdoDriverTest
* @package bkanber\Translator\Tests\Driver
*
* Extend this test class to set up an in-memory sqlite DB with a PdoDriver
*/
abstract class AbstractPdoDriverTest extends \PHPUnit_Framework_TestCase
{
/** @var \PDO */
protected static $pdo;
/** @var PdoDriver */
protected static $driver;
/**
* Creates an in-memory sqlite DB and pdo handle, runs Phinx migrations, and inits a PdoDriver
*/
public static function setUpBeforeClass()
{
self::$pdo = new \PDO('sqlite::memory:', null, null, [
\PDO::ATTR_ERRMODE => \PDO::ERRMODE_EXCEPTION,
\PDO::ATTR_DEFAULT_FETCH_MODE => \PDO::FETCH_ASSOC
]);
$dbConfig = [
'paths' => [
'migrations' => realpath(__DIR__ . '/../../dist/migrations')
],
'environments' => [
'test' => [
'adapter' => 'sqlite',
'connection' => self::$pdo
]
]
];
$config = new \Phinx\Config\Config($dbConfig);
$manager = new \Phinx\Migration\Manager($config, new StringInput(' '), new NullOutput());
$manager->migrate('test');
self::$driver = new PdoDriver(self::$pdo);
}
/**
* @return int
*/
protected function countRows()
{
return (int) self::$pdo->query('select count(*) as count from translations;')->fetchAll()[0]['count'];
}
/**
* @return bool
*/
protected function truncate()
{
return self::$pdo
->query("delete from translations; delete from sqlite_sequence where name = 'translations';")
->execute();
}
/**
* @param $array
* @throws \bkanber\Translator\Exception\MalformedTranslationException
* @throws \bkanber\Translator\Exception\PdoDriverException
*/
protected static function seedFromArray($array)
{
foreach ($array as $row) {
self::$driver->createTranslation(
$row['locale'],
$row['key'],
isset($row['domain']) ? $row['domain'] : null,
$row['content']
);
}
}
public function testDriverIsHealthy()
{
$stmt = self::$driver->getPdo()->query('select 1 as test;');
$stmt->execute();
$rows = $stmt->fetchAll();
self::assertCount(1, $rows);
self::assertEquals(1, $rows[0]['test']);
}
}
<file_sep><?php
namespace bkanber\Translator\Tests\Handler;
use bkanber\Translator\Driver\ArrayDriver;
use bkanber\Translator\Handler\LogFileHandler;
use bkanber\Translator\Translator;
class LogFileHandlerTest extends \PHPUnit_Framework_TestCase
{
public function testHandlesMissingTranslations()
{
$driver = ArrayDriver::createFromArray([
['locale' => 'en', 'key' => 'name', 'content' => 'Burak', 'domain' => 'cust1'],
]);
$file = fopen('php://temp', 'a+');
$handler = new LogFileHandler($file);
$translator = new Translator($driver);
$translator->setHandler($handler);
$output = $translator
->setDomain('cust1')
->setLocale('en')
->translateString('__{{name}} __{{surname}} __{{withDefault, "Hi"}}');
self::assertEquals('Burak Hi', $output);
rewind($file);
$log = stream_get_contents($file);
$logRows = explode("\n", trim($log));
self::assertEquals(2, count($logRows));
$item = explode("\t", $logRows[0]);
self::assertEquals('cust1', $item[1]);
self::assertEquals('en', $item[2]);
self::assertEquals('surname', $item[3]);
self::assertEquals('', $item[4]);
self::assertEquals('__{{surname}}', $item[5]);
$item = explode("\t", $logRows[1]);
self::assertEquals('cust1', $item[1]);
self::assertEquals('en', $item[2]);
self::assertEquals('withDefault', $item[3]);
self::assertEquals('Hi', $item[4]);
self::assertEquals('__{{withDefault, "Hi"}}', $item[5]);
fclose($file);
}
}
<file_sep><?php
namespace bkanber\Translator\Exception;
/**
* Class MalformedTranslationException
* @package bkanber\Translator\Exception
*/
class MalformedTranslationException extends \Exception
{
}
<file_sep><?php
namespace bkanber\Translator\Exception;
class PdoDriverException extends \Exception
{
}
<file_sep><?php
namespace bkanber\Translator;
use bkanber\Translator\Exception\MalformedTranslationException;
/**
* Class Translation
* @package bkanber\Translator
*
* This class represents a database model, a representation of a single key/value translation in a single language.
* The data is accessed by a Driver, and the Driver is responsible for hydrating and returning these Translation objects.
*
* This class itself is not "smart" or connected to an ORM; it is more like a 'struct' and simply provides a structured object shape for Translations.
*/
class Translation
{
/** @var string */
protected $domain;
/** @var string */
protected $locale;
/** @var string */
protected $key;
/** @var string */
protected $content;
/**
* @param array $translation Requires locale, key, and content array keys. 'domain' array key is optional.
*
* @return Translation
* @throws MalformedTranslationException
*/
public static function createFromArray($translation)
{
if (!isset($translation['locale'])) {
throw new MalformedTranslationException("Translation requires a locale");
}
if (!isset($translation['key'])) {
throw new MalformedTranslationException("Translation requires a key");
}
if (!isset($translation['content'])) {
throw new MalformedTranslationException("Translation requires content");
}
return new static(
$translation['locale'],
$translation['key'],
$translation['content'],
isset($translation['domain']) ? $translation['domain'] : null
);
}
/**
* Translation constructor.
* @param string $locale
* @param string $key
* @param string $content
* @param string|null $domain
*/
public function __construct($locale, $key, $content, $domain = null)
{
$this->locale = $locale;
$this->key = $key;
$this->content = $content;
$this->domain = $domain;
}
/**
* @return mixed
*/
public function getLocale()
{
return $this->locale;
}
/**
* @param mixed $locale
*/
public function setLocale($locale)
{
$this->locale = $locale;
}
/**
* @return mixed
*/
public function getKey()
{
return $this->key;
}
/**
* @param mixed $key
*/
public function setKey($key)
{
$this->key = $key;
}
/**
* @return mixed
*/
public function getContent()
{
return $this->content;
}
/**
* @param mixed $content
*/
public function setContent($content)
{
$this->content = $content;
}
/**
* @return string
*/
public function getDomain()
{
return $this->domain;
}
/**
* @param string $domain
*/
public function setDomain($domain)
{
$this->domain = $domain;
}
}
<file_sep><?php
namespace bkanber\Translator\Handler;
use bkanber\Translator\Exception\BadResourceException;
use bkanber\Translator\Translatable;
use bkanber\Translator\Translator;
/**
* Class LogFileHandler
* @package bkanber\Translator\Handler
*/
class LogFileHandler implements HandlerInterface
{
/** @var resource */
private $file;
/**
* LogFileHandler constructor.
* @param resource $file
* @throws BadResourceException
*/
public function __construct($file)
{
if (!is_resource($file)) {
throw new BadResourceException("LogFileHandler must be instantiated with a file handle resource");
}
$this->file = $file;
}
public function __destruct()
{
if (is_resource($this->file)) {
fclose($this->file);
}
}
/**
* @param Translatable $translatable
* @param Translator $translator
* @throws \Exception
*/
public function onMissingTranslation(Translatable $translatable, Translator $translator)
{
$time = new \DateTime();
$line = implode("\t", [
$time->format(\DateTime::ISO8601),
$translator->getDomain(),
$translator->getLocale(),
$translatable->getKey(),
$translatable->getDefault(),
$translatable->getReplace()
]) . "\n";
fwrite($this->file, $line);
}
}
<file_sep><?php
namespace bkanber\Translator\Exception;
class DriverMissingException extends \Exception
{
}
<file_sep><?php
namespace bkanber\Translator\Parser;
use bkanber\Translator\Parser\ParserInterface;
use bkanber\Translator\Translatable;
use bkanber\Translator\Translation;
/**
* Class Parser
* @package bkanber\Translator
*/
class StringParser extends AbstractParser implements ParserInterface
{
/**
* @return Translatable[]
*/
public function parse()
{
/**
* matches[0] is full translation markup
* matches[1] is translation keys
* matches[2] is default stanza
* matches[3] is default content
*/
preg_match_all('/__{{(.*?)(,\s*[\'"](.*?)[\'"])?}}/', $this->getInput(), $matches);
$translatables = [];
foreach ($matches[0] as $index => $match) {
$translatables[] = new Translatable($match, $matches[1][$index], $matches[3][$index]);
}
$this->setTranslatables($translatables);
return $this->getTranslatables();
}
/**
* @param Translation[] $translations
* @return string
*/
public function replace($translations)
{
$output = $this->input;
$this->setTranslations($translations);
foreach ($this->getTranslatables() as $translatable) {
$translation = $this->findTranslation($translatable->getKey());
$replacement = '';
$default = $translatable->getDefault();
$replace = $translatable->getReplace();
// Found a translation entry, so translate it
if ($translation) {
$replacement = $translation->getContent();
}
// No translation entry, but the translation markup had a default
elseif (isset($default) && $default) {
$replacement = $default;
}
$output = str_replace($replace, $replacement, $output);
}
return $output;
}
}
<file_sep><?php
namespace bkanber\Translator\Tests\Parser;
use bkanber\Translator\Parser\ArrayParser;
use bkanber\Translator\Translation;
class ArrayParserTest extends \PHPUnit_Framework_TestCase
{
/** @var ArrayParser */
protected $parser;
public function setUp()
{
$this->parser = new ArrayParser();
$this->parser->setInput([
[
'key' => 'meta',
'content' => [
'error' => '__{{err_msg_generic, "An unknown error occurred."}}',
'status' => '__{{status_code_err}}'
]
],
[
'key' => 'data',
'content' => [
'items' => [
[
'name' => '__{{keyed_name}}'
],
[
'name' => '__{{keyed_name}}',
'meta' => [
'nested' => [
'child' => '__{{nested_child, "Nested child value"}}',
'prepended' => 'This is prepended with: __{{prepended}}'
]
]
]
]
]
]
]);
}
public function testParse()
{
$translatables = $this->parser->parse();
self::assertCount(6, $translatables);
self::assertEquals([
'err_msg_generic',
'status_code_err',
'keyed_name',
'nested_child',
'prepended'
], $this->parser->getTranslatableKeys());
self::assertEquals('An unknown error occurred.', $translatables[0]->getDefault());
self::assertEquals('', $translatables[1]->getDefault());
}
public function testReplace()
{
$translations = [
new Translation('', 'status_code_err', 'STATUS_ERR'),
new Translation('', 'keyed_name', '<NAME>'),
new Translation('', 'nested_child', 'Child of The Sun'),
new Translation('', 'prepended', 'Prependio'),
];
$this->parser->parse();
$translated = $this->parser->replace($translations);
// Untouched
self::assertEquals('meta', $translated[0]['key']);
// Used default
self::assertEquals('An unknown error occurred.', $translated[0]['content']['error']);
// Translated
self::assertEquals('STATUS_ERR', $translated[0]['content']['status']);
// Translated twice
self::assertEquals('<NAME>', $translated[1]['content']['items'][0]['name']);
self::assertEquals('<NAME>', $translated[1]['content']['items'][1]['name']);
// Deeply nested
self::assertEquals('Child of The Sun', $translated[1]['content']['items'][1]['meta']['nested']['child']);
// Translation Mixed with literal string
self::assertEquals('This is prepended with: Prependio', $translated[1]['content']['items'][1]['meta']['nested']['prepended']);
}
/**
* @expectedException \bkanber\Translator\Exception\MalformedInputException
*/
public function testFailsIfMalformedInputGiven()
{
$this->parser->setInput('hello world')->parse();
}
}
<file_sep><?php
namespace bkanber\Translator\Driver;
use bkanber\Translator\Exception\PdoDriverException;
use bkanber\Translator\Translation;
/**
* Class PdoDriver
* @package bkanber\Translator\Driver
*
*
*/
class PdoDriver implements DriverInterface
{
/** @var \PDO */
protected $pdo;
/** @var string */
protected $table = 'translations';
/**
* PdoDriver constructor.
* @param \PDO $pdo
* @param string $table
*/
public function __construct(\PDO $pdo, $table = 'translations')
{
$this->pdo = $pdo;
$this->table = $table;
}
/**
* @return \PDO
*/
public function getPdo()
{
return $this->pdo;
}
/**
* @param \PDO $pdo
* @return PdoDriver
*/
public function setPdo($pdo)
{
$this->pdo = $pdo;
return $this;
}
/**
* @param string $locale
* @param string $key
* @param string|null $domain
* @return Translation|null
* @throws \bkanber\Translator\Exception\MalformedTranslationException
*/
public function findTranslation($locale, $key, $domain = null)
{
$bindings = [':locale' => $locale, ':key' => $key];
$sql = 'SELECT * FROM ' . $this->getPdo()->quote($this->table) . ' WHERE locale = :locale AND key = :key ';
if ($domain) {
$sql .= ' AND domain = :domain ';
$bindings[':domain'] = $domain;
} else {
$sql .= 'AND domain IS NULL ';
}
$sql .= ' LIMIT 1;';
$stmt = $this->pdo->prepare($sql);
$stmt->execute($bindings);
$rows = $stmt->fetchAll(\PDO::FETCH_ASSOC);
if (isset($rows[0])) {
return Translation::createFromArray($rows[0]);
}
return null;
}
/**
* @param string $locale
* @param array|string[] $keys
* @param string|null $domain
* @return array|Translation[]
*/
public function findTranslations($locale, $keys, $domain = null)
{
$bindings = [
$locale
];
$sql = 'SELECT * FROM ' . $this->getPdo()->quote($this->table) . ' WHERE locale = ? ';
if ($domain) {
$sql .= ' AND domain = ? ';
$bindings[] = $domain;
} else {
$sql .= ' AND domain IS NULL ';
}
$sql .= ' AND key IN (' . implode(',', array_fill(0, count($keys), '?')) . ');';
$bindings = array_merge($bindings, $keys);
$stmt = $this->pdo->prepare($sql);
$stmt->execute($bindings);
$rows = $stmt->fetchAll(\PDO::FETCH_ASSOC);
return array_map(function ($row) {
return Translation::createFromArray($row);
}, $rows);
}
/**
* @param $locale
* @param $key
* @param $domain
* @param $content
* @return Translation|null
* @throws \bkanber\Translator\Exception\MalformedTranslationException
*/
public function updateTranslation($locale, $key, $domain, $content)
{
$bindings = [
':locale' => $locale,
':key' => $key,
':content' => $content
];
$sql = 'UPDATE ' . $this->getPdo()->quote($this->table) . ' SET content = :content WHERE locale = :locale AND key = :key ';
if ($domain) {
$sql .= ' AND domain = :domain;';
$bindings[':domain'] = $domain;
} else {
$sql .= ' AND domain IS NULL;';
}
$stmt = $this->pdo->prepare($sql);
$stmt->execute($bindings);
return $this->findTranslation($locale, $key, $domain);
}
/**
* @param $locale
* @param $key
* @param $domain
* @param $content
* @return Translation
* @throws PdoDriverException
* @throws \bkanber\Translator\Exception\MalformedTranslationException
*/
public function createTranslation($locale, $key, $domain, $content)
{
$bindings = [
'locale' => $locale,
'key' => $key,
'domain' => $domain,
'content' => $content
];
$sql = 'INSERT INTO ' . $this->getPdo()->quote($this->table) . ' (locale, key, domain, content) VALUES (:locale, :key, :domain, :content);';
$stmt = $this->pdo->prepare($sql);
$success = $stmt->execute($bindings);
if (!$success) {
throw new PdoDriverException("Could not create translation");
}
return Translation::createFromArray($bindings);
}
/**
* @param string $locale
* @param string $key
* @param string|null $domain
* @param string $content
* @return Translation
* @throws PdoDriverException
* @throws \bkanber\Translator\Exception\MalformedTranslationException
*/
public function upsertTranslation($locale, $key, $domain, $content)
{
$exists = $this->findTranslation($locale, $key, $domain);
if ($exists) {
return $this->updateTranslation($locale, $key, $domain, $content);
} else {
return $this->createTranslation($locale, $key, $domain, $content);
}
}
/**
* @param string $locale
* @param string $key
* @param string|null $domain
* @return bool
*/
public function deleteTranslation($locale, $key, $domain = null)
{
$bindings = [
':locale' => $locale,
':key' => $key
];
$sql = 'DELETE FROM ' . $this->getPdo()->quote($this->table) . ' WHERE locale = :locale AND key = :key ';
if ($domain) {
$sql .= ' AND domain = :domain ;';
$bindings[':domain'] = $domain;
} else {
$sql .= ' AND domain IS NULL ;';
}
$stmt = $this->pdo->prepare($sql);
return $stmt->execute($bindings);
}
}
<file_sep><?php
namespace bkanber\Translator\Driver;
use bkanber\Translator\Translation;
/**
* Interface DriverInterface
* @package bkanber\Translator\Driver
*
* Implement this class in order to create a new translations lookup driver.
* Implemented methods should generally return a Translation instance.
*
* This interface allows any form of constructor in order to give you freedom to deal with implementation details yourself.
*/
interface DriverInterface {
/**
* This method is used to look up a single translation based on locale and key, and optional domain.
* If a domain is not provided, or set null, you should return a translation that also has a null domain.
* That is, do not simply ignore the $domain parameter if it is null -- it should be considered a filter.
*
* Return null if no translation found, otherwise return a Translation instance.
*
* @param string $locale
* @param string $key
* @param string|null $domain
* @return null|Translation
*/
public function findTranslation($locale, $key, $domain = null);
/**
* This method is used to bulk-query multiple translations in a domain and a locale.
* It should return an array in all cases. If no translations for the matching $keys are found, this should return an empty array.
* If translations are found, it should return an array of Translation objects in no particular order.
*
* @param string $locale
* @param array|string[] $keys
* @param string|null $domain
* @return array|Translation[]
*/
public function findTranslations($locale, $keys, $domain = null);
/**
* This method updates a translation in the store. Locale, key, and domain are filters, and only the content should be updated.
* This method should fail or return null if no translation to be updated was found.
*
* @param string $locale
* @param string $key
* @param string|null $domain
* @param string $content
* @return Translation
*/
public function updateTranslation($locale, $key, $domain, $content);
/**
* Creates a translation in the store. This method should fail if the translation already exists. It should return the Translation object on success.
*
* @param string $locale
* @param string $key
* @param string|null $domain
* @param string $content
* @return Translation
*/
public function createTranslation($locale, $key, $domain, $content);
/**
* This method should update an existing translation's content (if found), or create a new translation (if not found). It should therefore never fail (except for errors related to the data store itself). As with updateTranslation, $locale, $key, and $domain are filters, and only $content will be updated if the record already existed.
*
* @param string $locale
* @param string $key
* @param string|null $domain
* @param string $content
* @return Translation
*/
public function upsertTranslation($locale, $key, $domain, $content);
/**
* Deletes a translation.
*
* @param string $locale
* @param string $key
* @param string|null $domain
* @return bool
*/
public function deleteTranslation($locale, $key, $domain = null);
}
<file_sep><?php
namespace bkanber\Translator\Driver;
use bkanber\Translator\Exception\TranslationNotFoundException;
use bkanber\Translator\Translation;
/**
* Class ArrayDriver
* @package bkanber\Translator\Driver
*
* This class allows you to load a translations catalog in-memory, without using a database datastore.
* There are several ways to instantiate this driver, depending on your needs.
*
* Adding translations one at a time:
*
* ```php
* $driver = new ArrayDriver();
*
* $driver->createTranslation($locale, $key, $domain, $content);
* $driver->createTranslation($locale, $key, $domain, $content);
* // etc...
*
* $translator = new Translator($driver);
* ```
*
* You can add translations after the Translator has been instantiated:
*
* ```php
* $translator = new Translator(new ArrayDriver());
*
* $translator->getDriver()->createTranslation( ... );
* ```
*
* You can generate Translation instances and use setTranslations:
*
* ```
* $driver = new ArrayDriver();
*
* $translations = [
* new Translation($locale, $key, $content, $domain),
* new Translation($locale, $key, $content, $domain),
* new Translation($locale, $key, $content, $domain)
* ];
*
* $driver->setTranslations($translations);
* ```
*
* Or you can use the static createFromArray method:
*
* ```php
*
* $translator = new Translator(ArrayDriver::createFromArray([
* ['locale' => 'en', 'key' => 'foo', 'content' => 'bar', 'domain' => 'cust1'],
* ['locale' => 'en', 'key' => 'foo', 'content' => 'bar'],
* ['locale' => 'en', 'key' => 'foo', 'content' => 'bar'],
* // ... etc
* ]));
*
* ```
*
* Locale, key, and content are all required for Translations. Only domain is optional.
*/
class ArrayDriver implements DriverInterface
{
/** @var array|Translation[] */
protected $translations = [];
/**
* @param $translations
* @return ArrayDriver
*/
public static function createFromArray($translations)
{
return (new static())
->setTranslations(
array_map(function ($trans) {
return Translation::createFromArray($trans);
}, $translations)
);
}
/**
* @return array|Translation[]
*/
public function getTranslations()
{
return $this->translations;
}
/**
* @param array|Translation[] $translations
* @return ArrayDriver
*/
public function setTranslations($translations)
{
$this->translations = $translations;
return $this;
}
/**
* @param string $locale
* @param string $key
* @param string|null $domain
* @return Translation|mixed|null
*/
public function findTranslation($locale, $key, $domain = null)
{
foreach ($this->getTranslations() as $translation) {
if (
$translation->getLocale() === $locale
&& $translation->getDomain() === $domain
&& $translation->getKey() === $key
) {
return $translation;
}
}
// Not found.
return null;
}
/**
* @param string $locale
* @param array|string[] $keys
* @param string|null $domain
* @return array|Translation[]
*/
public function findTranslations($locale, $keys, $domain = null)
{
return array_values(
array_filter(
$this->getTranslations(),
function (Translation $translation) use ($locale, $keys, $domain) {
return (
$translation->getDomain() === $domain
&& $translation->getLocale() === $locale
&& in_array($translation->getKey(), $keys, true)
);
}
)
);
}
/**
* @param string $locale
* @param string $key
* @param string|null $domain
* @return bool
*/
public function deleteTranslation($locale, $key, $domain = null)
{
$translations = $this->getTranslations();
$deleted = false;
foreach ($translations as $index => $translation) {
if (
$translation->getKey() === $key
&& $translation->getLocale() === $locale
&& $translation->getDomain() === $domain
) {
unset($translations[$index]);
$deleted = true;
}
}
$this->setTranslations(array_values($translations));
return $deleted;
}
/**
* @param string $locale
* @param string $key
* @param string $domain
* @param string $content
* @return Translation
* @throws TranslationNotFoundException
*/
public function updateTranslation($locale, $key, $domain, $content)
{
$translation = $this->findTranslation($locale, $key, $domain);
if (!$translation) {
throw new TranslationNotFoundException("Translation not found. Try upsertTranslation instead.");
}
$translation->setContent($content);
return $translation;
}
/**
* @param string $locale
* @param string $key
* @param string $domain
* @param string $content
* @return Translation
*/
public function createTranslation($locale, $key, $domain, $content)
{
$translation = new Translation($locale, $key, $content, $domain);
$this->translations[] = $translation;
return $translation;
}
/**
* @param $locale
* @param $key
* @param $domain
* @param $content
* @return Translation|mixed|null
*/
public function upsertTranslation($locale, $key, $domain, $content)
{
$translation = $this->findTranslation($locale, $key, $domain);
if ($translation) {
return $this->updateTranslation($locale, $key, $domain, $content);
} else {
return $this->createTranslation($locale, $key, $domain, $content);
}
}
}
<file_sep><?php
namespace bkanber\Translator\Tests\Driver;
use bkanber\Translator\Driver\ArrayDriver;
use bkanber\Translator\Translation;
/**
* Class ArrayDriverTest
* @package bkanber\Translator\Tests\Driver
*/
class ArrayDriverTest extends \PHPUnit_Framework_TestCase
{
/** @var ArrayDriver */
protected $driver;
public function setUp()
{
$this->driver = ArrayDriver::createFromArray(
[
['domain' => 'cust1', 'locale' => 'en', 'key' => 'title', 'content' => 'Customer One'],
['domain' => 'cust1', 'locale' => 'sp', 'key' => 'title', 'content' => 'Customer Uno'],
['domain' => 'cust2', 'locale' => 'en', 'key' => 'title', 'content' => 'Customer Two'],
['domain' => 'cust2', 'locale' => 'sp', 'key' => 'title', 'content' => 'Customer Dos'],
['domain' => 'cust2', 'locale' => 'sp', 'key' => 'nombre', 'content' => 'Customer Nombre'],
['domain' => 'cust2', 'locale' => 'sp', 'key' => 'preguntas', 'content' => 'Uno Preguntas'],
['domain' => 'test', 'locale' => 'en', 'key' => 'delete_me', 'content' => 'To Be Deleted'],
['domain' => 'test', 'locale' => 'en', 'key' => 'update_me', 'content' => 'To Be Updated'],
['domain' => 'test', 'locale' => 'en', 'key' => 'upsert_me', 'content' => 'To Be Upserted'],
]
);
}
public function tearDown()
{
unset($this->driver);
}
public function testUpdateTranslation()
{
$before = $this->driver->findTranslation('en', 'update_me', 'test');
self::assertNotNull($before);
self::assertInstanceOf(Translation::class, $before);
self::assertEquals('To Be Updated', $before->getContent());
$updated = $this->driver->updateTranslation('en', 'update_me', 'test', 'I was Updated');
self::assertInstanceOf(Translation::class, $updated);
self::assertEquals('I was Updated', $updated->getContent());
$found = $this->driver->findTranslation('en', 'update_me', 'test');
self::assertNotNull($found);
self::assertInstanceOf(Translation::class, $found);
self::assertEquals('I was Updated', $found->getContent());
}
public function testUpsertTranslation()
{
self::assertCount(9, $this->driver->getTranslations());
// Updates existing
$this->driver->upsertTranslation('en', 'upsert_me', 'test', 'I was Updated/Upserted');
$updated = $this->driver->findTranslation('en', 'upsert_me', 'test');
self::assertNotNull($updated);
self::assertEquals('I was Updated/Upserted', $updated->getContent());
// Creates new
$this->driver->upsertTranslation('en', 'new_upsert', 'test', 'I was created by upsert');
$created = $this->driver->findTranslation('en', 'new_upsert', 'test');
self::assertNotNull($created);
self::assertEquals('en', $created->getLocale());
self::assertEquals('test', $created->getDomain());
self::assertEquals('new_upsert', $created->getKey());
self::assertEquals('I was created by upsert', $created->getContent());
}
public function testCreateFromArray()
{
self::assertCount(9, $this->driver->getTranslations());
}
public function testDeleteTranslation()
{
self::assertCount(9, $this->driver->getTranslations());
$found = $this->driver->findTranslation('en', 'delete_me', 'test');
self::assertNotNull($found);
self::assertEquals('To Be Deleted', $found->getContent());
$return = $this->driver->deleteTranslation('en', 'delete_me', 'test');
self::assertTrue($return);
self::assertCount(8, $this->driver->getTranslations());
self::assertNull($this->driver->findTranslation('en', 'delete_me', 'test'));
// Now try deleting something that doesn't exist
$shouldBeFalse = $this->driver->deleteTranslation('en', 'garbage', 'test');
self::assertFalse($shouldBeFalse);
self::assertCount(8, $this->driver->getTranslations());
}
public function testFindTranslation()
{
$notFound = $this->driver->findTranslation('fr', 'title', 'cust1');
self::assertNull($notFound);
$found = $this->driver->findTranslation('sp', 'title', 'cust2');
self::assertNotNull($found);
self::assertInstanceOf(Translation::class, $found);
self::assertEquals('Customer Dos', $found->getContent());
}
public function testFindTranslations()
{
// 'delete_me' should not be found because it is not part of 'cust2' domain or 'sp' locale
$translations = $this->driver->findTranslations('sp', ['title', 'nombre', 'preguntas', 'delete_me'], 'cust2');
self::assertCount(3, $translations);
}
public function testCreateTranslation()
{
$countBefore = count($this->driver->getTranslations());
$translation = $this->driver->createTranslation('en', 'created', 'cust1', 'I was just created');
self::assertInstanceOf(Translation::class, $translation);
self::assertEquals($countBefore + 1, count($this->driver->getTranslations()));
$found = $this->driver->findTranslation('en', 'created', 'cust1');
self::assertInstanceOf(Translation::class, $found);
self::assertEquals('I was just created', $found->getContent());
self::assertEquals('cust1', $found->getDomain());
self::assertEquals('created', $found->getKey());
self::assertEquals('en', $found->getLocale());
}
}
<file_sep><?php
namespace bkanber\Translator\Exception;
class TranslationNotFoundException extends \Exception
{
}
<file_sep><?php
namespace bkanber\Translator\Tests\Driver;
use bkanber\Translator\Driver\PdoDriver;
use bkanber\Translator\Translation;
use bkanber\Translator\Translator;
/**
* Class PdoDriverTest
* @package bkanber\Translator\Tests\Driver
*/
class PdoDriverTest extends AbstractPdoDriverTest
{
public function tearDown()
{
$this->truncate();
}
public function testCreateTranslation()
{
self::assertEquals(0, $this->countRows());
$translation = self::$driver->createTranslation('en', 'test', null, 'some content');
self::assertEquals(1, $this->countRows());
self::assertEquals('some content', $translation->getContent());
$this->truncate();
self::assertEquals(0, $this->countRows());
}
public function testUpdateTranslation()
{
self::seedFromArray([
['domain' => null, 'locale' => 'test', 'key' => 'update', 'content' => 'Needs Update'],
['domain' => 'd1', 'locale' => 'test', 'key' => 'update', 'content' => 'Needs Update'],
['domain' => null, 'locale' => 'untouched', 'key' => 'update', 'content' => 'Needs Update'],
['domain' => 'd1', 'locale' => 'untouched', 'key' => 'update', 'content' => 'Needs Update'],
]);
self::assertEquals(4, $this->countRows());
self::$driver->updateTranslation('test', 'update', null, 'Content for null domain');
$updated = self::$driver->findTranslation('test', 'update', null);
self::assertEquals('Content for null domain', $updated->getContent());
$notUpdated = self::$driver->findTranslation('test', 'update', 'd1');
self::assertEquals('Needs Update', $notUpdated->getContent());
}
public function testUpsertTranslation()
{
self::seedFromArray([
['domain' => null, 'locale' => 'test', 'key' => 'upsert', 'content' => 'Needs Upsert'],
['domain' => 'd1', 'locale' => 'test', 'key' => 'upsert', 'content' => 'Needs Upsert'],
['domain' => null, 'locale' => 'untouched', 'key' => 'update', 'content' => 'Dont touch me'],
['domain' => 'd1', 'locale' => 'untouched', 'key' => 'update', 'content' => 'Dont touch me'],
]);
self::assertEquals(4, $this->countRows());
self::$driver->upsertTranslation('test', 'upsert', null, 'Upserted null domain');
self::$driver->upsertTranslation('test', 'upsert', 'd1', 'Upserted d1 domain');
self::$driver->upsertTranslation('test', 'brand_new', 'd1', 'Brand new d1 domain');
self::$driver->upsertTranslation('test', 'brand_new', null, 'Brand new null domain');
self::assertEquals(6, $this->countRows());
self::assertEquals('Upserted null domain', self::$driver->findTranslation('test', 'upsert', null)->getContent());
self::assertEquals('Upserted d1 domain', self::$driver->findTranslation('test', 'upsert', 'd1')->getContent());
self::assertEquals('Brand new null domain', self::$driver->findTranslation('test', 'brand_new', null)->getContent());
self::assertEquals('Brand new d1 domain', self::$driver->findTranslation('test', 'brand_new', 'd1')->getContent());
}
public function testFindTranslation()
{
$notFound = self::$driver->findTranslation('en', 'missing');
self::assertNull($notFound);
self::$driver->createTranslation('en', 'not_missing', null, 'FooBar');
self::assertEquals(1, $this->countRows());
$found = self::$driver->findTranslation('en', 'not_missing');
self::assertNotNull($found);
self::assertInstanceOf(Translation::class, $found);
self::assertEquals('FooBar', $found->getContent());
self::assertEquals('not_missing', $found->getKey());
self::assertEquals('en', $found->getLocale());
self::assertNull($found->getDomain());
self::$driver->createTranslation('en', 'not_missing', 'cust1', 'Cust1NotMissing');
self::assertEquals(2, $this->countRows());
$found2 = self::$driver->findTranslation('en', 'not_missing', 'cust1');
self::assertNotNull($found2);
self::assertInstanceOf(Translation::class, $found2);
self::assertEquals('Cust1NotMissing', $found2->getContent());
self::assertEquals('not_missing', $found2->getKey());
self::assertEquals('en', $found2->getLocale());
self::assertEquals('cust1', $found2->getDomain());
}
public function testFindTranslations()
{
self::seedFromArray([
['domain' => null, 'key' => 'key1', 'locale' => 'l1', 'content' => 'content1-l1'],
['domain' => null, 'key' => 'key2', 'locale' => 'l1', 'content' => 'content2-l1'],
['domain' => null, 'key' => 'key3', 'locale' => 'l1', 'content' => 'content3-l1'],
['domain' => null, 'key' => 'key1', 'locale' => 'l2', 'content' => 'content1-l2'],
['domain' => null, 'key' => 'key2', 'locale' => 'l2', 'content' => 'content2-l2'],
['domain' => null, 'key' => 'key3', 'locale' => 'l2', 'content' => 'content3-l2'],
['domain' => 'd1', 'key' => 'key1', 'locale' => 'l1', 'content' => 'foo1-l1'],
['domain' => 'd1', 'key' => 'key2', 'locale' => 'l1', 'content' => 'foo2-l1'],
['domain' => 'd1', 'key' => 'key3', 'locale' => 'l1', 'content' => 'foo3-l1'],
['domain' => 'd1', 'key' => 'key1', 'locale' => 'l2', 'content' => 'foo1-l2'],
['domain' => 'd1', 'key' => 'key2', 'locale' => 'l2', 'content' => 'foo2-l2'],
['domain' => 'd1', 'key' => 'key3', 'locale' => 'l2', 'content' => 'foo3-l2'],
]);
self::assertEquals(12, $this->countRows());
// Locale l1, null domain
$translations = self::$driver->findTranslations('l1', ['key1', 'key2', 'key3']);
$contents = array_map(function (Translation $t) { return $t->getContent(); }, $translations);
self::assertCount(3, $translations);
self::assertTrue(in_array('content1-l1', $contents));
self::assertTrue(in_array('content2-l1', $contents));
self::assertTrue(in_array('content3-l1', $contents));
// Locale l2, null domain
$translations = self::$driver->findTranslations('l2', ['key1', 'key2', 'key3']);
$contents = array_map(function (Translation $t) { return $t->getContent(); }, $translations);
self::assertCount(3, $translations);
self::assertTrue(in_array('content1-l2', $contents));
self::assertTrue(in_array('content2-l2', $contents));
self::assertTrue(in_array('content3-l2', $contents));
// Locale l1, d1 domain
$translations = self::$driver->findTranslations('l1', ['key1', 'key2', 'key3'], 'd1');
$contents = array_map(function (Translation $t) { return $t->getContent(); }, $translations);
self::assertCount(3, $translations);
self::assertTrue(in_array('foo1-l1', $contents));
self::assertTrue(in_array('foo2-l1', $contents));
self::assertTrue(in_array('foo3-l1', $contents));
// Locale l2, d2 domain
$translations = self::$driver->findTranslations('l2', ['key1', 'key2', 'key3'], 'd1');
$contents = array_map(function (Translation $t) { return $t->getContent(); }, $translations);
self::assertCount(3, $translations);
self::assertTrue(in_array('foo1-l2', $contents));
self::assertTrue(in_array('foo2-l2', $contents));
self::assertTrue(in_array('foo3-l2', $contents));
}
public function testDeleteTranslation()
{
self::seedFromArray([
['domain' => null, 'locale' => 'test', 'key' => 'preserve', 'content' => 'this is preserved'],
['domain' => null, 'locale' => 'test', 'key' => 'delete', 'content' => 'this is deleted'],
['domain' => 'd1', 'locale' => 'test', 'key' => 'preserve', 'content' => 'd1: this is preserved'],
['domain' => 'd1', 'locale' => 'test', 'key' => 'delete', 'content' => 'd1: this is deleted'],
]);
self::assertEquals(4, $this->countRows());
self::$driver->deleteTranslation('test', 'delete');
self::assertEquals(3, $this->countRows());
self::assertNull(self::$driver->findTranslation('test', 'delete', null));
self::assertNotNull(self::$driver->findTranslation('test', 'delete', 'd1'));
self::$driver->deleteTranslation('test', 'delete', 'd1');
self::assertEquals(2, $this->countRows());
self::assertNull(self::$driver->findTranslation('test', 'delete', null));
self::assertNull(self::$driver->findTranslation('test', 'delete', 'd1'));
}
/**
* @expectedException \PDOException
*/
public function testFailsIfWrongTableName()
{
$driver = new PdoDriver(self::$pdo, 'badtable');
$driver->createTranslation('en', 'hi', 'test', 'test');
}
}
| 633687ae7fb911468523cfaf7ac0e20f4bccec84 | [
"Markdown",
"PHP"
] | 25 | PHP | bkanber/Translator | 5a2426c498bdba41515158f9ab7594af4a831d64 | 44399d677070911ed5d7220628712c40ca67ad40 |
refs/heads/master | <file_sep># Wetty (Web TTY)
Terminal in browser over http/https. (Ajaxterm/Anyterm alternative, but much better)
**[Website](https://www.hivemq.com/docs/hivemq/3.4/web-ui/introduction.html)** | **[Documentation](https://www.hivemq.com/docs/hivemq/3.4/web-ui/introduction.html)** | **[GitHub](https://github.com/hivemq/hivemq-mqtt-web-client)**
## How to enable?
```
platys init --enable-services WETTY
platys gen
```
## How to use?
Navigate to <http://dataplatform:3001>
<file_sep>Place additional Jars here (such as jdbc drivers)<file_sep>Contains the data of opensearch service, if flag OPENSEARCH_volume_map_data is set to true.<file_sep>---
technoglogies: kafka,jikkou
version: 1.14.0
validated-at: 2.2.2022
---
# Automate managment of Kafka topics on the platform
This recipe will show how automate the management of Kafka topics using the jikkou tool, which is part of the platform.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services KAFKA,AKHQ,JIKKOU -s trivadis/platys-modern-data-platform -w 1.14.0
```
Now generate and start the platform
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Automate initial Kafka topic creation
In this recipe we will create to topics
* `topic-1` - with 8 paritions, replication-factor 3 and min.insync.replicas = 2
* `topic-2` - with 1 partition, replication-factor 3 as a log-compacted topic
In the `scripts/jikkou` folder, create a file named `topic-specs.yml` and add the following content
```yml
version: 1
specs:
topics:
- name: '{{ labels.topic.prefix | default('') }}topic-1'
partitions: 8
replication_factor: 3
configs:
min.insync.replicas: 2
- name: '{{ labels.topic.prefix | default('') }}topic-2'
partitions: 1
replication_factor: 3
configs:
cleanup.policy: compact
```
With the file in place, execute once again
```bash
docker-compose up -d
```
To see what Jikkou has done you can visit the log file of the `jikkou` service:
```bash
docker logs -f jikkou
```
you should see an output similar to the one below
```bash
20:34:59.775 [kafka-admin-client-thread | adminclient-1] WARN o.apache.kafka.clients.NetworkClient - [AdminClient clientId=adminclient-1] Connection to node -1 (kafka-1/172.18.0.8:19092) could not be established. Broker may not be available.
Can't read specification from file '/jikkou/topic-specs.yml': /jikkou/topic-specs.yml (No such file or directory)
TASK [CREATE] Create a new topic topic-2 (partitions=1, replicas=3) - CHANGED ***************************
TASK [CREATE] Create a new topic topic-1 (partitions=8, replicas=3) - CHANGED ***************************
EXECUTION in 2s 884ms
ok : 0, created : 2, altered : 0, deleted : 0 failed : 0
```
The first two lines are from the initial startup, where there was not yet a file in the folder. The last 3 lines show that the two new topics have been created.
The topic creation would also work if done initially when first starting the platform.
## Add a new and alter an existing Kafka topic
Edit the file `scripts/jikkou/topic-specs.yml` file and add a new topic `topic-3` and change the data retention of `topic-1` to unlimited (`-1`):
```yml
version: 1
specs:
topics:
- name: '{{ labels.topic.prefix | default('') }}topic-1'
partitions: 8
replication_factor: 3
configs:
min.insync.replicas: 2
retention.ms: -1
- name: '{{ labels.topic.prefix | default('') }}topic-2'
partitions: 1
replication_factor: 3
configs:
cleanup.policy: compact
- name: '{{ labels.topic.prefix | default('') }}topic-3'
partitions: 8
replication_factor: 3
```
Now perform again
```
docker-compose up -d
```
and visit the log. You should see the following additional lines
```bash
TASK [CREATE] Create a new topic topic-3 (partitions=8, replicas=3) - CHANGED ***************************
TASK [ALTER] Alter topic topic-1 - CHANGED *************************************************************
TASK [NONE] Unchanged topic topic-2 - OK ********************************************************
EXECUTION in 2s 371ms
ok : 1, created : 1, altered : 1, deleted : 0 failed : 0
```
## Set the label `topic.prefix`
For the names of the topics in the `topic-specs.yml`, we have used the label `topic.prefix` to specify a prefix for the topic names. So far the prefix is empty, as we have not yet specified it.
We can do that by adding it to the `JIKKOU_set_labels` property.
Edit the `config.yml` and add te follwing line right after `JIKKOU_enable: true`:
```bash
JIKKOU_set_labels: 'topic.prefix=dev-'
```
Regenerate the platform and again run `docker-compose`
```bash
platys gen
docker-compose up -d
```
View the log
```bash
docker logs -f jikkou
```
and see that the old topics have been removed and the new ones with the prefix `dev-` were created.
```bash
TASK [CREATE] Create a new topic dev-topic-3 (partitions=8, replicas=3) - CHANGED ***********************
TASK [DELETE] Delete topic topic-1 - CHANGED ***********************************************************
TASK [CREATE] Create a new topic dev-topic-2 (partitions=1, replicas=3) - CHANGED ***********************
TASK [DELETE] Delete topic topic-2 - CHANGED ***********************************************************
TASK [CREATE] Create a new topic dev-topic-1 (partitions=8, replicas=3) - CHANGED ***********************
TASK [DELETE] Delete topic topic-3 - CHANGED ***********************************************************
EXECUTION in 3s 51ms
ok : 0, created : 3, altered : 0, deleted : 3 failed : 0
```
<file_sep># Markdown Viewer
Easy website using markdown files.
## How to enable?
The Markdown Viewer is automatically enabled. If you need to do it manually, perform
```
platys init --enable-services MARKDOWN_VIEWER
platys gen
```
## How to use?
Navigate to <http://dataplatform:80>
<file_sep>Place group.txt (File Group provider) and rules.json (File-based Access Control) files here ...<file_sep># StreamSets DataOps Platform
StreamSets DataOps Platform is a cloud-native platform for building, running, and monitoring data pipelines.
**[Website](https://streamsets.com/products/dataops-platform/)** | **[Documentation](https://docs.streamsets.com/portal/platform-controlhub/controlhub/UserGuide/GettingStarted/GettingStarted_title.html)**
### How to enable
```
platys init --enable-services STREAMSETS_DATAOPS
platys gen
```
<file_sep>package com.trivadis.kafkaws.kstream.countsession;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.*;
import org.apache.kafka.streams.state.SessionStore;
import org.apache.kafka.streams.state.WindowStore;
import java.time.Duration;
import java.time.Instant;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.Properties;
import java.util.UUID;
import static org.apache.kafka.streams.kstream.Suppressed.BufferConfig.unbounded;
public class KafkaStreamsRunnerCountSessionWindowedSuppressedDSL {
private static final Serde<String> STRING_SERDE = Serdes.String();
private static final Serde<Long> LONG_SERDE = Serdes.Long();
private static DateTimeFormatter formatter = DateTimeFormatter.ofPattern("dd.MM.yyyy HH:mm.ss")
.withZone(ZoneId.of("UTC"));
public static String formatKey (String key, Instant startTime, Instant endTime) {
return key + "@" + formatter.format(startTime) + "->" + formatter.format(endTime);
}
public static void main(String[] args) {
final KafkaStreams streams = new KafkaStreams(getTopology(30,15), getKafkaProperties());
streams.cleanUp();
streams.start();
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
public static Properties getKafkaProperties() {
// set the required properties for running Kafka Streams
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, UUID.randomUUID().toString());
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "dataplatform:9092");
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// disable caching to see session merging
config.put(StreamsConfig.BUFFERED_RECORDS_PER_PARTITION_CONFIG, 1);
config.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0);
config.put(StreamsConfig.POLL_MS_CONFIG, 1);
config.put(StreamsConfig.WINDOW_STORE_CHANGE_LOG_ADDITIONAL_RETENTION_MS_CONFIG, 1);
return config;
}
public static Topology getTopology(int gap, int grace) {
// the builder is used to construct the topology
StreamsBuilder builder = new StreamsBuilder();
Serde<String> stringSerde = Serdes.String();
Serde<Long> longSerde = Serdes.Long();
// read from the source topic, "test-kstream-input-topic"
KStream<String, String> stream = builder.stream("test-kstream-input-topic");
// create a session window with an inactivity gap to <gap> seconds and <grace> seconds grace period
SessionWindows sessionWindow = null;
if (grace > 0) {
sessionWindow =
SessionWindows.ofInactivityGapAndGrace(Duration.ofSeconds(gap), Duration.ofSeconds(grace));
} else {
sessionWindow =
SessionWindows.ofInactivityGapWithNoGrace(Duration.ofSeconds(gap));
}
sessionWindow =
SessionWindows.ofInactivityGapAndGrace(Duration.ofSeconds(gap), Duration.ofSeconds(grace));
KTable<Windowed<String>, Long> counts = stream.groupByKey()
.windowedBy(sessionWindow)
.count(Materialized.<String, Long, SessionStore<Bytes, byte[]>>as("counts")
.withKeySerde(Serdes.String())
.withCachingDisabled());
KStream<Windowed<String>, Long> sessionedStream = counts.suppress(Suppressed.untilWindowCloses(unbounded())).toStream();
KStream<String, String> printableStream = sessionedStream.map((key, value) -> new KeyValue<>(formatKey(key.key(), key.window().startTime(), key.window().endTime())
, String.valueOf(value)));
//printableStream.print(Printed.<String,String>toSysOut().withLabel("count"));
printableStream.to("test-kstream-output-topic", Produced.with(Serdes.String(), Serdes.String()));
// build the topology and start streaming
Topology topology = builder.build();
return topology;
}
}<file_sep># Debezium UI
A web UI for Debezium, which allows users to set up and operate connectors more easily. For instance, a list of all connectors can be viewed along with their status, etc. The Create Connector wizard allows the user to configure connectors, guiding and validating the property entries along the way.
**[Website](https://debezium.io/documentation/reference/operations/debezium-ui.html)** | **[Documentation](https://debezium.io/documentation/reference/operations/debezium-ui.html)** | **[GitHub](https://github.com/debezium/debezium-ui)**
## How to enable?
```
platys init --enable-services DEBEZIUM_UI
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28227><file_sep># Elasticvue
Elasticvue is a free and open-source elasticsearch gui for the browser.
**[Website](https://elasticvue.com/)** | **[Documentation](https://elasticvue.com/usage)** | **[GitHub](https://github.com/cars10/elasticvue)**
## How to enable?
```
platys init --enable-services ELASTICVUE
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28275><file_sep># Redpanda Console
Redpanda Console is a developer-friendly UI for managing your Kafka/Redpanda workloads. Console gives you a simple, interactive approach for gaining visibility into your topics, masking data, managing consumer groups, and exploring real-time data with time-travel debugging.
**[Website](https://redpanda.com/)** | **[Documentation](https://docs.redpanda.com/docs/platform/console/)** | **[GitHub](https://github.com/redpanda-data/console)**
### How to enable?
```
platys init --enable-services KAFKA,REDPANDA_CONSOLE
platys gen
```
### How to use it?
Navigate to <http://dataplatform:28289>
<file_sep>Contains the data of tempo service, if flag TEMPO_volume_map_data is set to true.<file_sep># Elasticsearch
Elasticsearch is a distributed, RESTful search and analytics engine capable of addressing a growing number of use cases. As the heart of the Elastic Stack, it centrally stores your data for lightning fast search, fine‑tuned relevancy, and powerful analytics that scale with ease.
**[Website](https://www.elastic.co/elasticsearch/)** | **[Documentation](https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html)** | **[GitHub](https://github.com/elastic/elasticsearch)**
## How to enable?
```
platys init --enable-services ELASTICSEARCH
platys gen
```
## How to use it?
Navigate to <http://dataplatform:9200><file_sep># Streamsheets
Streamsheets are server-based spreadsheets that consume, process and produce data streams. Data streams can originate from many sources, such as sensors, machines, websites, data bases, applications and many more. How incoming data streams are processed, analysed, visualized and combined as well as which outgoing data streams are produced is modelled entirely with spreadsheet formulas and especially without writing a single line of program code.
**[Website](https://cedalo.com/products/streamsheets/)** | **[Documentation](https://docs.cedalo.com/streamsheets/2.5/installation/)** | **[GitHub](https://github.com/eclipse/streamsheets)**
## How to enable?
```
platys init --enable-services STREAMSHEETS
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28158> and enter `admin` into the **User** and `<PASSWORD>`into the **Password** field.<file_sep># DataStax Studio
Designed to facilitate Cassandra Query Language (CQL), Graph/Gremlin, and Spark SQL language development, DataStax Studio has all the tools needed for ad hoc queries, visualizing and exploring data sets, profiling performance and comes with a notebook interface that fuels collaboration.
**[Website](https://www.datastax.com/dev/datastax-studio)** | **[Documentation](https://docs.datastax.com/en/landing_page/doc/landing_page/docList.html#Studio)**
## How to enable?
```
platys init --enable-services DATASTAX
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28121><file_sep># Pitchfork
Pitchfork converts tracing data between Zipkin and Haystack formats.
**[Website](https://opensource.expediagroup.com/pitchfork/)** | **[Documentation](https://opensource.expediagroup.com/pitchfork/docs/about/introduction.html)** | **[GitHub](https://github.com/ExpediaGroup/pitchfork)**
## How to enable?
```
platys init --enable-services ZIPKIN,PITCHFORK
platys gen
```
## How to use it?
<file_sep># Confluent MQTT Proxy
MQTT Proxy provides a scalable and lightweight interface that allows MQTT clients to produce messages to Apache Kafka® directly, in a Kafka-native way that avoids redundant replication and increased lag.
**[Website](https://docs.confluent.io/platform/current/kafka-mqtt/index.html)** | **[Documentation](https://docs.confluent.io/platform/current/kafka-mqtt/index.html)**
## How to enable?
```
platys init --enable-services KAFKA,KAFKA_MQTTPROXY
platys gen
```
<file_sep>#!/bin/bash
#
# Download connector maven dependencies
#
# Author: <NAME> <https://github.com/gschmutz>
#
set -e
# If there's not maven repository url set externally,
# default to the ones below
MAVEN_REPO_CENTRAL=${MAVEN_REPO_CENTRAL:-"https://repo1.maven.org/maven2"}
MAVEN_REPO_CONFLUENT=${MAVEN_REPO_CONFLUENT:-"https://packages.confluent.io/maven"}
maven_dep() {
local REPO="$1"
local MVN_COORDS="$2"
local MAVEN_DEP_DESTINATION="$3"
for i in $(echo $MVN_COORDS | sed "s/,/ /g")
do
local MVN_COORD=$i
local GROUP_TMP=$(echo $MVN_COORD | cut -d: -f1)
local GROUP=${GROUP_TMP//.//}
local PACKAGE=$(echo $MVN_COORD | cut -d: -f2)
local VERSION=$(echo $MVN_COORD | cut -d: -f3)
local FILE="$PACKAGE-$VERSION.jar"
DOWNLOAD_FILE_TMP_PATH="/tmp/maven_dep/${PACKAGE}"
DOWNLOAD_FILE="$DOWNLOAD_FILE_TMP_PATH/$FILE"
test -d $DOWNLOAD_FILE_TMP_PATH || mkdir -p $DOWNLOAD_FILE_TMP_PATH
DOWNLOAD_URL="$REPO/$GROUP/$PACKAGE/$VERSION/$FILE"
echo "Downloading $DOWNLOAD_URL ...."
curl -sfSL -o "$DOWNLOAD_FILE" "$DOWNLOAD_URL"
mv "$DOWNLOAD_FILE" $MAVEN_DEP_DESTINATION
done
}
maven_central_dep() {
maven_dep $MAVEN_REPO_CENTRAL $1 $2 $3
}
maven_confluent_dep() {
maven_dep $MAVEN_REPO_CONFLUENT $1 $2 $3
}
case $1 in
"central" ) shift
maven_central_dep ${@}
;;
"confluent" ) shift
maven_confluent_dep ${@}
;;
esac
<file_sep># Telegraf
Telegraf is a plugin-driven server agent for collecting & reporting metrics, and is the first piece of the TICK stack. Telegraf has plugins to source a variety of metrics directly from the system it’s running on, pull metrics from third party APIs, or even listen for metrics via a statsd and Kafka consumer services. It also has output plugins to send metrics to a variety of other datastores, services, and message queues, including InfluxDB, Graphite, OpenTSDB, Datadog, Librato, Kafka, MQTT, NSQ, and many others.
**[Website](https://www.influxdata.com/time-series-platform/telegraf/)** | **[Documentation](https://docs.influxdata.com/telegraf/latest/)** | **[GitHub](https://github.com/influxdata/telegraf)**
## How to enable?
```
platys init --enable-services INFLUXDB, INFLUXDB_TELEGRAF
platys gen
```
<file_sep># Spring Cloud Data Flow
A microservices-based Streaming and Batch data processing in Cloud Foundry and Kubernetes.
**[Website](https://spring.io/projects/spring-cloud-dataflow)** | **[Documentation](https://spring.io/projects/spring-cloud-dataflow)** | **[GitHub](https://github.com/spring-cloud/spring-cloud-dataflow)**
## How to enable?
```
platys init --enable-services SPRING_DATAFLOW
platys gen
```
## How to use it?
Navigate to <http://dataplatform:9393><file_sep># Amundsen
Amundsen is a metadata driven application for improving the productivity of data analysts, data scientists and engineers when interacting with data.
**[Website](https://www.amundsen.io/)** | **[Documentation](https://www.amundsen.io/amundsen/)** | **[GitHub](https://github.com/amundsen-io/amundsen)**
## How to enable?
```
platys init --enable-services AMUNDSEN
platys gen
```
## How to use it?
<file_sep># Cedalo Management Center
The Cedalo Management Center allows to easily manage instances of Eclipse Mosquitto, e.g., to manage the new dynamic security feature.
**[Website](https://cedalo.com/)** | **[Documentation](https://docs.cedalo.com/management-center/2.2/mc-overview/)** | **[GitHub](https://github.com/cedalo/management-center)**
## How to enable?
```
platys init --enable-services CEDALO_MANAGEMENT_CENTER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28175> and login as user `cedalo` with password `<PASSWORD>!`.<file_sep>package com.trivadis.kafkaws.springbootkafkastreams.simple;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.Printed;
import org.springframework.boot.autoconfigure.kafka.StreamsBuilderFactoryBeanCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
import java.util.function.Function;
@Component
public class KafkaStreamsRunnerDSL {
@Bean
public Function<KStream<Void, String>, KStream<Void, String>> process() {
return input ->
{
input.foreach(
(key, value) -> {
System.out.println("(From DSL) " + value);
});
// transform the values to upper case
KStream<Void, String> upperStream = input.mapValues(value -> value.toUpperCase());
// you can also print using the `print` operator
upperStream.print(Printed.<Void, String>toSysOut().withLabel("upperValue"));
return upperStream;
};
}
}
<file_sep>---
technologies: spark,delta-lake
version: 1.16.0
validated-at: 20.02.2023
---
# Spark with Delta Lake
This recipe will show how to use a Spark cluster together with the [Delta Lake](http://delta.io) storage framework. We will be using the Python and SQL API.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services SPARK,ZEPPELIN,MINIO,AWSCLI,PROVISIONING_DATA -s trivadis/platys-modern-data-platform -w 1.16.0
```
Before we can generate the platform, we need to extend the `config.yml`:
Specify the table format to use as Delta.
```
SPARK_table_format_type: 'delta'
```
Platys automatically makes sure that the right version according to [the compatibility table in the Delta Lake documentation](https://docs.delta.io/latest/releases.html) is used.
Now set an environment variable to the home folder of the dataplatform and generate and then start the data platform.
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Prepare some data in Object storage
Create the flight bucket:
```bash
docker exec -ti awscli s3cmd mb s3://flight-bucket
```
Now upload the airports to the bucket
```bash
docker exec -ti awscli s3cmd put /data-transfer/flight-data/airports.csv s3://flight-bucket/raw/airports/airports.csv
```
## Working with Delta Lake from Zeppelin
Navigate to Zeppelin <http://dataplatform:28080> and login as user `admin` with password `<PASSWORD>!`.
Create a new notebook and add and execute the following commands:
Import necessary modules
```python
%pyspark
from delta.tables import *
from pyspark.sql.types import *
```
Load the raw Airport data in the CSV format into a data frame
```python
%pyspark
airportsRawDF = spark.read.csv("s3a://flight-bucket/raw/airports",
sep=",", inferSchema="true", header="true")
airportsRawDF.show(5)
```
create a new delta table
```python
%pyspark
deltaTableDest = "s3a://flight-bucket/delta/airports"
airportsRawDF.write.format("delta").save(deltaTableDest)
```
Use the `CREATE TABLE` to register the delta table in SQL
```sql
%sql
CREATE TABLE airports_t
USING DELTA
LOCATION 's3a://flight-bucket/delta/airports'
```
Use the delta table in a SQL statement
```sql
%sql
SELECT * FROM airports_t;
```
<file_sep># DataStax Enterprise (DSE)
Built on Apache Cassandra™, DataStax Enterprise is hardened by the largest internet apps, proven by the Fortune 100, and supports more NoSQL workloads - from Graph to Search and Analytics.
**[Website](https://www.datastax.com/)** | **[Documentation](https://docs.datastax.com/en/landing_page/doc/landing_page/docList.html)**
## How to enable?
```
platys init --enable-services DATASTAX
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28121><file_sep># Gremlin Console
The Gremlin Console serves a variety of use cases that can meet the needs of different types of Gremlin users. This tutorial explores the features of the Gremlin Console through a number of these different use cases to hopefully inspire you to new levels of usage. While a use case may not fit your needs, you may well find it worthwhile to read, as it is possible that a "feature" will be discussed that may be useful to you.
**[Website](https://tinkerpop.apache.org/)** | **[Documentation](https://tinkerpop.apache.org/docs/current/tutorials/the-gremlin-console/)** | **[GitHub](https://github.com/apache/tinkerpop)**
```bash
platys init --enable-services GREMLIN_CONSOLE
platys gen
```
## How to use it?
### Using the Gremlin Console
To start a gremlin console
```bash
docker exec -ti gremlin-console ./bin/gremlin.sh
```
and then connect to
```groovy
:remote connect tinkerpop.server conf/remote.yaml
g = traversal().withRemote('conf/remote-graph.properties')
g.addV('demigod').property('name', 'hercules').iterate()
g.V()
```
### Initialise JanusGraph
When the container is started it will execute files with the extension `.groovy` that are found in `./init/janusgraph/` with the Gremlin Console. These scripts are only executed after the JanusGraph Server instance was started. So, they can connect to it and execute Gremlin traversals.
For example, to add a vertex to the graph, create a file `./init/janusgraph/add-vertex.groovy` with the following content
```groovy
g = traversal().withRemote('conf/remote-graph.properties')
g.addV('demigod').property('name', 'hercules').iterate()
```<file_sep>Contains the postgresql data of kong service<file_sep>package com.trivadis.kafkaws.springbootkafkaproducer;
public class CustomerJson {
public Long id;
public Long customerCode;
public String telephone;
public String email;
public String language;
}
<file_sep># Confluent Replicator
Confluent Replicator allows you to easily and reliably replicate topics from one Kafka cluster to another. In addition to copying the messages, Replicator will create topics as needed preserving the topic configuration in the source cluster.
**[Website](https://docs.confluent.io/platform/current/multi-dc-deployments/replicator/index.html)** | **[Documentation](https://docs.confluent.io/platform/current/multi-dc-deployments/replicator/index.html)**
## How to enable?
```bash
platys init --enable-services KAFKA_REPLICATOR
platys gen
```
## How to use?
<file_sep>package com.trivadis.kafkaws;
import io.streamthoughts.azkarra.api.annotations.Component;
import io.streamthoughts.azkarra.api.config.Conf;
import io.streamthoughts.azkarra.api.config.Configurable;
import io.streamthoughts.azkarra.api.streams.TopologyProvider;
import io.streamthoughts.azkarra.streams.AzkarraApplication;
import io.streamthoughts.azkarra.streams.autoconfigure.annotations.AzkarraStreamsApplication;
import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.*;
import java.time.Duration;
import java.time.ZoneId;
/**
* Azkarra Streams Application
*
* <p>For a tutorial how to write a Azkarra Streams application, check the
* tutorials and examples on the <a href="https://www.azkarrastreams.io/docs/">Azkarra Website</a>.
* </p>
*/
@AzkarraStreamsApplication
public class StreamingApp {
public static void main(final String[] args) {
AzkarraApplication.run(StreamingApp.class, args);
}
@Component
public static class TumbleWindowCountTopologyProvider implements TopologyProvider, Configurable {
private String topicSource;
private String topicSink;
private String stateStoreName;
@Override
public void configure(final Conf conf) {
topicSource = conf.getOptionalString("topic.source").orElse("test-kstream-azkarra-input-topic");
topicSink = conf.getOptionalString("topic.sink").orElse("test-kstream-azkarra-output-topic");
stateStoreName = conf.getOptionalString("state.store.name").orElse("count");
}
@Override
public String version() {
return Version.getVersion();
}
@Override
public Topology topology() {
final StreamsBuilder builder = new StreamsBuilder();
final KStream<String, String> stream = builder.stream(topicSource);
// create a tumbling window of 60 seconds
TimeWindows tumblingWindow = TimeWindows.of(Duration.ofSeconds(60));
KTable<Windowed<String>, Long> counts = stream.groupByKey()
.windowedBy(tumblingWindow)
.count(Materialized.as(stateStoreName));
counts.toStream().print(Printed.<Windowed<String>, Long>toSysOut().withLabel("counts"));
final Serde<String> stringSerde = Serdes.String();
final Serde<Long> longSerde = Serdes.Long();
counts.toStream( (wk,v) -> wk.key() + ":" + wk.window().startTime().atZone(ZoneId.of("Europe/Zurich")) + " to " + wk.window().endTime().atZone(ZoneId.of("Europe/Zurich"))).to(topicSink, Produced.with(stringSerde, longSerde));
return builder.build();
}
}
}<file_sep># Using Kafka from #C (.Net) with Avro & Schema Registry
In this workshop we will learn how to produce and consume messages using the [Kafka .NET API](https://docs.confluent.io/clients-confluent-kafka-dotnet/current/overview.html) using Avro for serialising and deserialising messages.
We assume that .NET Core is installed on your client as well as Visual Code with the C# extension (ms-dotnettools.csharp) enabled. We will use the .NET CLI (`dotnet`) for creating projects and running the code.
## Create the project structure
We will create two projects, one acting as the producer to Kafka and the other one as the consumer from Kafka.
First create the workspace folder, which will hold our projects and navigate into it.
```bash
mkdir kafka-dotnet-avro-workshop
cd kafka-dotnet-avro-workshop
```
Now let's create the producer project
```bash
dotnet new console -o producer
```
Now start Visual Code, on Linux if installed using the [following documentation](https://code.visualstudio.com/docs/setup/linux), then it can be started with `code`.
```bash
code
```
We are now ready to add code to the classes which have been created with the `dotnet new` command.
But before we do that, let's create the topic we will use to produce to and to consume from.
### Creating the necessary Kafka Topic
We will use the topic `test-dotnet-avro-topic` in the Producer and Consumer code below. Because `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
Connect to the `kafka-1` container
```
docker exec -ti kafka-1 bash
```
and execute the necessary kafka-topics command.
```
kafka-topics --create \
--replication-factor 3 \
--partitions 8 \
--topic test-dotnet-avro-topic \
--bootstrap-server kafka-1:19092,kafka-2:19093
```
Cross check that the topic has been created.
```
kafka-topics --list --bootstrap-server kafka-1:19092
```
This finishes the setup steps and our new project is ready to be used. Next we will start implementing a **Kafka Producer**.
## Install the Avro CLI
To use the [Avro CLI](https://www.nuget.org/packages/Apache.Avro.Tools/), you need to have the .NET SDK 5.0 (6.0 is not supported)
To Install it on CentOS, perform
```bash
sudo yum install dotnet-sdk-5.0
```
Now you can install the Avro CLI
```bash
dotnet tool install --global Apache.Avro.Tools --version 1.11.0
```
## Create the Avro Schema
First create a new file `Notification.avsc` and add the following Avro schema
```JSON
{
"type" : "record",
"namespace" : "com.trivadis.kafkaws.avro.v1",
"name" : "Notification",
"description" : "A simple Notification Event message",
"fields" : [
{ "type" : ["long", "null"],
"name" : "id"
},
{ "type" : ["string", "null"],
"name" : "message"
}
]
}
```
## Generate a C# class for the schema
Now you can generate the corresponding C# class using
```bash
avrogen -s Notification.avsc .
```
The following class will be generated
```csharp
// ------------------------------------------------------------------------------
// <auto-generated>
// Generated by avrogen, version 1.11.0.0
// Changes to this file may cause incorrect behavior and will be lost if code
// is regenerated
// </auto-generated>
// ------------------------------------------------------------------------------
namespace com.trivadis.kafkaws.avro.v1
{
using System;
using System.Collections.Generic;
using System.Text;
using Avro;
using Avro.Specific;
public partial class Notification : ISpecificRecord
{
public static Schema _SCHEMA = Avro.Schema.Parse("{\"type\":\"record\",\"name\":\"Notification\",\"namespace\":\"com.trivadis.kafkaws.avro.v1\"" +
",\"fields\":[{\"name\":\"id\",\"type\":[\"long\",\"null\"]},{\"name\":\"message\",\"type\":[\"strin" +
"g\",\"null\"]}],\"description\":\"A simple Notification Event message\"}");
private System.Nullable<System.Int64> _id;
private string _message;
public virtual Schema Schema
{
get
{
return Notification._SCHEMA;
}
}
public System.Nullable<System.Int64> id
{
get
{
return this._id;
}
set
{
this._id = value;
}
}
public string message
{
get
{
return this._message;
}
set
{
this._message = value;
}
}
public virtual object Get(int fieldPos)
{
switch (fieldPos)
{
case 0: return this.id;
case 1: return this.message;
default: throw new AvroRuntimeException("Bad index " + fieldPos + " in Get()");
};
}
public virtual void Put(int fieldPos, object fieldValue)
{
switch (fieldPos)
{
case 0: this.id = (System.Nullable<System.Int64>)fieldValue; break;
case 1: this.message = (System.String)fieldValue; break;
default: throw new AvroRuntimeException("Bad index " + fieldPos + " in Put()");
};
}
}
}
```
## Create a Kafka Producer
To communicate with Kafka, we need to use the [**confluent-kafka-dotnet**](https://docs.confluent.io/clients-confluent-kafka-dotnet/current/overview.html) .NET library].
The reference the library from the .NET Core project, execute the following command from within the `kafka-dotnet-workspace` folder.
```
dotnet add producer package Confluent.Kafka
dotnet add producer package Confluent.SchemaRegistry.Serdes.Avro --version 1.8.2
```
The following reference will be added to project metadata
```
<Project Sdk="Microsoft.NET.Sdk">
...
<ItemGroup>
<PackageReference Include="Confluent.Kafka" Version="1.8.2" />
<PackageReference Include="Confluent.SchemaRegistry.Serdes.Avro" Version="1.8.2" />
</ItemGroup>
</Project>
```
Now let's add the code for producing messages to the Kafka topic. Navigate to the `Program.cs` C# class in the `producer` project and rename it to `KafkaProducer.cs` and then open it in the editor.
Add the following directives on the top with the class and the following two constants for the Broker List and the Topic name:
```csharp
using System.Threading;
using Confluent.Kafka;
class KafkaProducer
{
const string brokerList = "dataplatform:9092,dataplatform:9093";
const string topicName = "test-dotnet-topic";
}
```
Add the following main method to the class:
```csharp
static void Main(string[] args)
{
long startTime = DateTimeOffset.Now.ToUnixTimeMilliseconds();
if (args.Length == 0)
{
runProducerASync(100, 10, 0);
}
else
{
runProducerASync(int.Parse(args[0]), int.Parse(args[1]), int.Parse(args[2]));
}
long endTime = DateTimeOffset.Now.ToUnixTimeMilliseconds();
Console.WriteLine("Producing all records took : " + (endTime - startTime) + " ms = (" + (endTime - startTime) / 1000 + " sec)" );
}
// place the runProducerXXXX methods below
```
The `Main()` method accepts 3 parameters, the number of messages to produce, the time in ms to wait in-between sending each message and the ID of the producer.
Add the following additional method for implementing the Kafka producer. We are using the asynchronous produce option with the `ProduceAsync`
```csharp
static void runProducerASync(int totalMessages, int waitMsInBetween, int id)
{
var config = new ProducerConfig { BootstrapServers = brokerList };
var schemaRegistryConfig = new SchemaRegistryConfig
{
// Note: you can specify more than one schema registry url using the
// schema.registry.url property for redundancy (comma separated list).
// The property name is not plural to follow the convention set by
// the Java implementation.
Url = schemaRegistryUrl
};
var avroSerializerConfig = new AvroSerializerConfig
{
// optional Avro serializer properties:
BufferBytes = 100
};
using (var schemaRegistry = new CachedSchemaRegistryClient(schemaRegistryConfig))
// Create the Kafka Producer
using (var producer = new ProducerBuilder<Null, Notification>(config)
.SetValueSerializer(new AvroSerializer<Notification>(schemaRegistry, avroSerializerConfig))
.Build())
{
for (int index = 0; index < totalMessages; index++)
{
long time = DateTimeOffset.Now.ToUnixTimeMilliseconds();
// Construct the message value
Notification value = new Notification { id = id, message = "[" + index + ":" + id + "] Hello Kafka " + DateTimeOffset.Now };
// send the message to Kafka
var deliveryReport = producer.ProduceAsync(topicName, new Message<Null, Notification> { Value = value });
deliveryReport.ContinueWith(task =>
{
if (task.IsFaulted)
{
}
else
{
Console.WriteLine($"[{id}] sent record (key={task.Result.Key} value={task.Result.Value}) meta (partition={task.Result.TopicPartition.Partition}, offset={task.Result.TopicPartitionOffset.Offset}, time={task.Result.Timestamp.UnixTimestampMs})");
}
});
Thread.Sleep(waitMsInBetween);
}
producer.Flush(TimeSpan.FromSeconds(10));
}
}
```
Before starting the producer, in an additional terminal, let's use `kcat` or `kafka-avro-console-consumer` to consume the messages from the topic `test-dotnet-topic`.
```
kafkacat -b $PUBLIC_IP -t test-java-avro-topic
```
Now run it using the `mvn exec:java` command. It will generate 1000 messages, waiting 10ms in-between sending each message and use 0 for the ID.
```
mvn exec:java@producer -Dexec.args="1000 100 0"
```
You can see that kafkacat shows some special, non-printable characters. This is due to the Avro format. If you want to display the Avro, you can use the `kafka-avro-console-consumer` CLI, which is part of the Schema Registry.
So let's connect to the schema registry container:
```
docker exec -ti schema-registry-1 bash
```
And then invoke the `kafka-avro-console-consumer` similar to the "normal" consumer seen so far.
```
kafka-avro-console-consumer --bootstrap-server kafka-1:19092 --topic test-java-avro-topic
```
You should see an output similar to the one below.
```
...
[2018-07-11 21:32:43,155] INFO [Consumer clientId=consumer-1, groupId=console-consumer-88150] Resetting offset for partition test-java-avro-topic-6 to offset 0. (org.apache.kafka.clients.consumer.internals.Fetcher)
{"id":{"long":0},"message":{"string":"Hello Kafka 0"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 3"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 1"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 2"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 4"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 5"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 6"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 9"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 7"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 10"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 8"}}
...
```
if you want to consume with `kcat` you need to specify the serialisation format `-s` and the address of the schema registry `-r`:
```
kcat -b kafka-1 -t test-java-avro-topic -s value=avro -r http://schema-registry-1:8081
```
**Note**: For Avro support your kafkacat version needs to be `1.6' or later.
## View the Schema in the Registry
The Avro Serializer and Deserializer automatically register the Avro schema, if it is not already in the registry.
The Streamingplatform also contains a tool made by a company called Landoop which allows us to see what's in the registry.
In a browser, navigate to <http://dataplatform:28039> and you should see the home page of the Schema Registry UI.

If you click on the schema to the left, you can view the details of the schema. You can see that version v1 has been assigned automatically.

<file_sep># Kafka Connector Board
Kafka connector management board.
**[Documentation](https://github.com/tranglolab/kafka_connectors_board)** | **[GitHub](https://github.com/tranglolab/kafka_connectors_board)**
## How to enable?
```
platys init --enable-services KAFKA_CONNECTOR_BOARD
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28282>.
<file_sep><?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>kafka-streams-simple</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<confluent.version>7.3.0</confluent.version>
<kafka.version>3.3.1</kafka.version>
<slf4j.version>1.7.32</slf4j.version>
<avro.version>1.11.1</avro.version>
</properties>
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-streams-avro-serde</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>${avro.version}</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
<version>2.14.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!--
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams-test-utils</artifactId>
<version>${kafka.version}</version>
<scope>test</scope>
</dependency>
-->
<dependency>
<groupId>com.bakdata.fluent-kafka-streams-tests</groupId>
<artifactId>fluent-kafka-streams-tests-junit5</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.9.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.assertj</groupId>
<artifactId>assertj-core</artifactId>
<version>3.15.0</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<defaultGoal>install</defaultGoal>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5</version>
<configuration>
<source>${maven.compiler.source}</source>
<target>${maven.compiler.target}</target>
<maxmem>256M</maxmem>
<showDeprecation>true</showDeprecation>
<showWarnings>true</showWarnings>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<id>producer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.kstream.countwindowed.KafkaStreamsRunnerCountWindowedDSL</mainClass>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.9.2</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<excludes>
<exclude>**/mapred/tether/**</exclude>
</excludes>
<sourceDirectory>${project.basedir}/src/main/avro</sourceDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-maven-plugin</artifactId>
<version>4.0.0</version>
<configuration>
<schemaRegistryUrls>
<param>http://dataplatform:8081</param>
</schemaRegistryUrls>
<subjects>
<test-kstream-input-topic-value>src/main/java/com/trivadis/kafkaws/kstream/avro/MyData.avsc</test-kstream-input-topic-value>
</subjects>
</configuration>
<goals>
<goal>register</goal>
</goals>
</plugin>
</plugins>
</build>
</project><file_sep># Data Provisioning
A service to automatically provision sample data to the `data-transfer` folder.
## How to enable?
```
platys init --enable-services PROVISIONING_DATA
platys gen
```
## How to use it?
<file_sep># Tyk Pump
Traffic analytics are captured by the Tyk Gateway nodes and then temporarily stored in Redis. The Tyk Pump is responsible for moving those analytics into a persistent data store, such as MongoDB, where the traffic can be analysed.
**[Website](https://tyk.io/open-source-api-gateway/)** | **[Documentation](https://tyk.io/docs/tyk-pump/)** | **[GitHub](https://github.com/TykTechnologies/tyk-pump)**
## How to enable?
```
platys init --enable-services TYK,TYK_PUMP
platys gen
```
## How to use it?
<file_sep># MLflow
MLflow is an open source platform for managing the end-to-end machine learning lifecycle. It tackles four primary functions
**[Website](https://www.mlflow.org/docs/latest/index.html)** | **[Documentation](https://www.mlflow.org/docs/latest/index.html)** | **[GitHub](https://github.com/mlflow/mlflow)**
## How to enable?
```
platys init --enable-services MLFLOW_SERVER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28229><file_sep>Place grafana plugins here ...<file_sep># JupyterHub
Multi-user server for Jupyter notebooks. JupyterHub is the best way to serve Jupyter notebook for multiple users. It can be used in a class of students, a corporate data science group or scientific research group. It is a multi-user Hub that spawns, manages, and proxies multiple instances of the single-user Jupyter notebook server.
**[Website](https://jupyterhub.readthedocs.io/en/stable/)** | **[Documentation](https://jupyterhub.readthedocs.io/en/stable/)** | **[GitHub](https://github.com/jupyterhub/jupyterhub)**
```bash
platys init --enable-services JUPYTERHUB
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28284>.
By default the user `jupyterhub` with password `<PASSWORD>!` (if not changed in `JUPYTERHUB_global_password`) can be used to log into JupyterHub.
<file_sep># Project Nessie
Transactional Catalog for Data Lakes with Git-like semantics.
**[Website](https://projectnessie.org/)** | **[Documentation](https://projectnessie.org/features/)** | **[GitHub](https://github.com/projectnessie/nessie)**
## How to enable?
```
platys init --enable-services NESSIE
platys gen
```
## How to use it?
Navigate to <http://dataplatform:19120>.<file_sep>Place Redpanda's Enterprise license information into a file here (named redpanda.license).<file_sep>---
technoglogies: apicurio,schema-registry
version: 1.14.0
validated-at: 28.12.2021
---
# Apicurio Registry with SQL Storage (PostgreSQL)
This recipe will show how to use the Apicurio Registry as a Confluent-compliant Schema Registry.
## Initialise data platform
First [initialise a platys-supported data platform](../../../documentation/getting-started) with the following services enabled
```
platys init --enable-services KAFKA,SCHEMA_REGISTRY,POSTGRESQL,KAFKA_UI,ADMINER -s trivadis/platys-modern-data-platform -w 1.14.0
```
edit the `config.yml` and add the followin properties right after `SCHEMA_REGISTRY_enable: true`:
```yaml
SCHEMA_REGISTRY_flavour: apicurio
APICURIO_SCHEMA_REGISTRY_storage: sql
```
By default, Apicurio Registry is configured to use Postgresql with a database of `apicuriodb`, a user of `apicurio` with a password of `<PASSWORD>!`.
Therefore we need to configure PosgreSQL accordingly by adding the following properties after the `POSTGRESQL_enable: true`:
```yaml
POSTGRESQL_multiple_databases: 'apicuriodb'
POSTGRESQL_multiple_users: 'apicurio'
POSTGRESQL_multiple_passwords: '<PASSWORD>!'
```
Now start the platform
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Using Confluent Schema-Registry Compliant URL
The Apicurio Registry is available on port 8081. It offers a confluent-compliant REST interface available under this base URL:
```bash
http://dataplatform:8081/apis/ccompat/v6
```
## Register a schema using Kafka UI
Kafka UI has the option to view and edit a schema registry. It is configured using the confluent-compliant REST API of Apicurio Registry.
In a web browser, navigate to the Kafka UI: <http://192.168.142.129:28179>.
In the menu on the left, click on **Schema Registry**. Click **Create Schema** and add a schema using
* **Subject**: `test-value`
* **Schema**:
```json
{
"type" : "record",
"name" : "MyRecord",
"namespace" : "com.mycompany",
"fields" : [ {
"name" : "id",
"type" : "long"
} ]
}
```
* **Schema Type**: `AVRO`
and click **Submit**. The schema should get registered as shown

## Check the database schema
In a web browser, navigate to the Adminer UI: <http://192.168.142.129:28131>.
Login using the following information
* **System**: `PostgreSQL`
* **Server**: `postgresql`
* **Username**: `apicurio`
* **Password**: `<PASSWORD>!`
* **Database**: `apicuriodb`
and click **Login**.
You should the various tables, such as `apicurio`, `artifacts`, `content` and many others.
<file_sep>Place a jikkou specification file (topics-spec.yml) here.<file_sep># Getting started with Apache Kafka
## Introduction
In this workshop we will learn the basics of working with Apache Kafka. Make sure that you have created the environment as described in [Preparing the Environment](../01-environment/README.md).
The main units of interest in Kafka are topics and messages. A topic is simply what you publish a message to, topics are a stream of messages.
In this workshop you will learn how to create topics, how to produce messages, how to consume messages and how to describe/view metadata in Apache Kafka.
## Working with built-in Command Line Utilities
### Connect to a Kafka Broker
The environment contains of a Kafka cluster with 3 brokers, all running on the Docker host of course. So it's of course not meant to really fault-tolerant but to demonstrate how to work with a Kafka cluster.
To work with Kafka you need the command line utilities. They are available on each broker.
The `kafka-topics` utility is used to create, alter, describe, and delete topics. The `kafka-console-producer` and `kafka-console-consumer` can be used to produce/consume messages to/from a Kafka topic.
So let's connect into one of the broker through a terminal window.
* If you have access through Guacamole, then right click on the dashboard and select **Open Terminal**.
* if you have a user and password, you can also use a browser-based terminal, by navigating to <http://localhost:3001> and then login with username and password.
In the terminal window run a `docker exec` command to start a shell in the `kafka-1` docker container
```bash
docker exec -ti kafka-1 bash
```
if we just execute the `kafka-topics` command without any options, a help page is shown
```bash
root@kafka-1:/# kafka-topics
Create, delete, describe, or change a topic.
Option Description
------ -----------
--alter Alter the number of partitions,
replica assignment, and/or
configuration for the topic.
--at-min-isr-partitions if set when describing topics, only
show partitions whose isr count is
equal to the configured minimum.
--bootstrap-server <String: server to REQUIRED: The Kafka server to connect
connect to> to.
--command-config <String: command Property file containing configs to be
config property file> passed to Admin Client. This is used
only with --bootstrap-server option
for describing and altering broker
configs.
--config <String: name=value> A topic configuration override for the
topic being created or altered. The
following is a list of valid
configurations:
cleanup.policy
compression.type
delete.retention.ms
file.delete.delay.ms
flush.messages
flush.ms
follower.replication.throttled.
replicas
index.interval.bytes
leader.replication.throttled.replicas
local.retention.bytes
local.retention.ms
max.compaction.lag.ms
max.message.bytes
message.downconversion.enable
message.format.version
message.timestamp.difference.max.ms
message.timestamp.type
min.cleanable.dirty.ratio
min.compaction.lag.ms
min.insync.replicas
preallocate
remote.storage.enable
retention.bytes
retention.ms
segment.bytes
segment.index.bytes
segment.jitter.ms
segment.ms
unclean.leader.election.enable
See the Kafka documentation for full
details on the topic configs. It is
supported only in combination with --
create if --bootstrap-server option
is used (the kafka-configs CLI
supports altering topic configs with
a --bootstrap-server option).
--create Create a new topic.
--delete Delete a topic
--delete-config <String: name> A topic configuration override to be
removed for an existing topic (see
the list of configurations under the
--config option). Not supported with
the --bootstrap-server option.
--describe List details for the given topics.
--disable-rack-aware Disable rack aware replica assignment
--exclude-internal exclude internal topics when running
list or describe command. The
internal topics will be listed by
default
--help Print usage information.
--if-exists if set when altering or deleting or
describing topics, the action will
only execute if the topic exists.
--if-not-exists if set when creating topics, the
action will only execute if the
topic does not already exist.
--list List all available topics.
--partitions <Integer: # of partitions> The number of partitions for the topic
being created or altered (WARNING:
If partitions are increased for a
topic that has a key, the partition
logic or ordering of the messages
will be affected). If not supplied
for create, defaults to the cluster
default.
--replica-assignment <String: A list of manual partition-to-broker
broker_id_for_part1_replica1 : assignments for the topic being
broker_id_for_part1_replica2 , created or altered.
broker_id_for_part2_replica1 :
broker_id_for_part2_replica2 , ...>
--replication-factor <Integer: The replication factor for each
replication factor> partition in the topic being
created. If not supplied, defaults
to the cluster default.
--topic <String: topic> The topic to create, alter, describe
or delete. It also accepts a regular
expression, except for --create
option. Put topic name in double
quotes and use the '\' prefix to
escape regular expression symbols; e.
g. "test\.topic".
--topics-with-overrides if set when describing topics, only
show topics that have overridden
configs
--unavailable-partitions if set when describing topics, only
show partitions whose leader is not
available
--under-min-isr-partitions if set when describing topics, only
show partitions whose isr count is
less than the configured minimum.
--under-replicated-partitions if set when describing topics, only
show under replicated partitions
--version Display Kafka version.
```
### List topics in Kafka
First, let's list the topics available on a given Kafka Cluster. For that we use the `kafka-topics` utility with the `--list` option.
```
kafka-topics --list --bootstrap-server kafka-1:19092,kafka-2:19093
```
We can see that there are some technical topics, `_schemas` being the one, where the Confluent Schema Registry stores its schemas.
### Creating a topic in Kafka
Now let's create a new topic. For that we again use the **kafka-topics** utility but this time with the `--create` option. We will create a test topic with 6 partitions and replicated 2 times. The `--if-not-exists` option is handy to avoid errors, if a topic already exists.
```bash
kafka-topics --create \
--if-not-exists \
--bootstrap-server kafka-1:19092,kafka-2:19093 \
--topic test-topic \
--partitions 6 \
--replication-factor 2
```
Re-Run the command to list the topics. You should see the new topic you have just created.
### Describe a Topic
You can use the `--describe` option to
```bash
kafka-topics --describe --bootstrap-server kafka-1:19092,kafka-2:19093 --topic test-topic
```
```bash
Topic:test-topicPartitionCount:6ReplicationFactor:2Configs:
Topic: test-topicPartition: 0Leader: 3Replicas: 3,2Isr: 3,2
Topic: test-topicPartition: 1Leader: 1Replicas: 1,3Isr: 1,3
Topic: test-topicPartition: 2Leader: 2Replicas: 2,1Isr: 2,1
Topic: test-topicPartition: 3Leader: 3Replicas: 3,1Isr: 3,1
Topic: test-topicPartition: 4Leader: 1Replicas: 1,2Isr: 1,2
Topic: test-topicPartition: 5Leader: 2Replicas: 2,3Isr: 2,3
```
### Produce and Consume to Kafka topic with command line utility
Now let's see the topic in use. The most basic way to test it is through the command line. Kafka comes with two handy utilities `kafka-console-consumer` and `kafka-console-producer` to consume and produce messages through the command line.
In a new terminal window, first let's run the consumer on the topic `test-topic` we have created before
```bash
kafka-console-consumer --bootstrap-server kafka-1:19092,kafka-2:19093 \
--topic test-topic
```
After it is started, the consumer just waits for newly produced messages.
In an another terminal, again connect into `kafka-1` using a `docker exec`
```bash
docker exec -ti kafka-1 bash
```
and run the following command to start the producer.
```bash
kafka-console-producer --bootstrap-server kafka-1:19092,kafka-2:19093 --topic test-topic
```
By default, the console producer waits for **1000ms** before sending messages, if they are not larger than 16'384 bytes. The reason for that is as follows:
* the `linger.ms` parameter is set using the `--timeout` option on the command line which if not specified is **1000 ms**.
* the `batch.size` parameter is set using the `--max-partition-memory-bytes` option on the command line which if not specified is **16384**.
* **Note:** even if you specify `linger.ms` and `batch.size` using `--producer-property` or `--producer.config`, they will be always overwritten by the above "specific" options!
The console producer reads from stdin, and takes a bootstrap-server list (you should use it instead of the borker-list, which is deprecated). We specify 2 of the 3 brokers of the Data Platform.
On the `>` prompt enter a few messages, execute each single message by hitting the **Enter** key.<br>
```bash
>aaa
>bbb
>ccc
>ddd
>eee
```
You should see the messages being consumed by the consumer.
```bash
root@kafka-1:/# kafka-console-consumer --bootstrap-server kafka-1:19092,kafka-2:19093 --topic test-topic
aaa
bbb
ccc
ddd
eee
```
Messages arrive in the same order because you are just not able to enter them quick enough.
You can stop the consumer by hitting **Ctrl-C**. If you want to consume from the beginning of the log, use the `--from-beginning` option.
You can also echo a longer message and pipe it into the console producer, as he is reading the next message from the command line:
```bash
echo "This is my first message!" | kafka-console-producer \
--bootstrap-server kafka-1:19092,kafka-2:19093 \
--topic test-topic
```
And of course you can send messages inside a bash for loop:
```bash
for i in 1 2 3 4 5 6 7 8 9 10
do
echo "This is message $i"| kafka-console-producer \
--bootstrap-server kafka-1:19092,kafka-2:19093 \
--topic test-topic \
--batch-size 1 &
done
```
By ending the command in the loop with an & character, we run each command in the background and in parallel.
If you check the consumer, you can see that they are not in the same order as sent, because of the different partitions, and the messages being published in multiple partitions. We can force order by using a key when publishing the messages and always using the same value for the key.
### Working with Keyed Messages
A message produced to Kafka always consists of a key and a value, the value being necessary and representing the message/event payload. If a key is not specified, such as we did so far, then it is passed as a null value and Kafka distributes such messages in a round-robin fashion over the different partitions.
We can check that by re-consuming the messages we have created so far, specifying the option `--from-beginning` together with the option `print.key` and `key.separator` in the console consumer. For that stop the old consumer and restart it again using the following command
```bash
kafka-console-consumer --bootstrap-server kafka-1:19092,kafka-2:19093 \
--topic test-topic \
--property print.key=true \
--property key.separator=, \
--from-beginning
```
We can see that the keys are all `null` because so far we have only created the value part of the messages.
For producing messages also with a key, use the options `parse.key` and `key.separator`.
```bash
kafka-console-producer --bootstrap-server kafka-1:19092,kafka-2:19093 \
--topic test-topic \
--property parse.key=true \
--property key.separator=,
```
Enter your messages so that a key and messages are separated by a comma, i.e. `key1,value1`. Do that for a few messages and check that they are shown in the console consumers as key and value.
### Dropping a Kafka topic
A Kafka topic can be dropped using the `kafka-topics` utility with the `--delete` option.
```bash
kafka-topics --bootstrap-server kafka-1:19092,kafka-2:19093 --delete --topic test-topic
```
## Working with the `kcat` utility
[kcat](https://github.com/edenhill/kcat) is a command line utility that you can use to test and debug Apache Kafka deployments. You can use `kafkacat` to produce, consume, and list topic and partition information for Kafka. Described as “netcat for Kafka”, it is a swiss-army knife of tools for inspecting and creating data in Kafka.
It is similar to the `kafka-console-producer` and `kafka-console-consumer` you have learnt and used above, but much more powerful and also simpler to use.
`kcat` is an open-source utility, available at <hhttps://github.com/edenhill/kcat>. It is not part of the Confluent platform and also not part of the Data Platform we run in docker.
You can run `kcat` as a standalone utility on any **Linux** or **Mac** computer and remotely connect to a running Kafka cluster.
### Installing `kcat`
Officially `kcat` is either supported on **Linux** or **Mac OS-X**. There is no official support for **Windows** yet. There is a Docker image for `kcat` from Confluent as well.
We will show how to install it on **Ubunut** and **Mac OS-X**.
In all the workshops we will assume that `kcat` (used to be named `kafkacat` before version `1.7`) is installed locally on the Docker Host and that `dataplatform` alias has been added to `/etc/hosts`.
#### Ubuntu 20.04 or 22.04
You can install `kcat` directly on the Ubuntu environment. On Ubuntu 20.04 and 22.04 version 1.7 of `kcat` is not available and therefore you still have to install `kafkacat`.
First installhe Confluent public key, which is used to sign the packages in the APT repository:
```bash
wget -qO - https://packages.confluent.io/deb/5.2/archive.key | sudo apt-key add -
```
Add the repository to the `/etc/apt/sources.list`:
```bash
sudo add-apt-repository "deb [arch=amd64] https://packages.confluent.io/deb/5.2 stable main"
```
Run apt-get update and install the 2 dependencies as well as **kafkacat**
```bash
sudo apt-get update
sudo apt-get install librdkafka-dev libyajl-dev
sudo apt-get install kafkacat
```
You can define an alias, so that you can work with `kcat` even though you "only" have `kafkacat`:
```bash
alias kcat=kafkacat
```
let's see the version
```
bfh@casmio-70:~$ kcat -V
kafkacat - Apache Kafka producer and consumer tool
https://github.com/edenhill/kafkacat
Copyright (c) 2014-2019, <NAME>
Version 1.6.0 (JSON, Transactions, librdkafka 1.8.0 builtin.features=gzip,snappy,ssl,sasl,regex,lz4,sasl_gssapi,sasl_plain,sasl_scram,plugins,zstd,sasl_oauthbearer)
```
#### Ubuntu 23.04
```bash
sudo apt-get install kcat
```
let's see the version
```bash
$ kcat -V
kcat - Apache Kafka producer and consumer tool
https://github.com/edenhill/kcat
Copyright (c) 2014-2021, <NAME>
Version 1.7.1 (JSON, Transactions, IncrementalAssign, librdkafka 2.0.2 builtin.features=gzip,snappy,ssl,sasl,regex,lz4,sasl_gssapi,sasl_plain,sasl_scram,plugins,zstd,sasl_oauthbearer)
```
#### Mac OS-X
To install `kcat` on a Macbook, just run the following command:
```bash
brew install kcat
```
let's see the version
```bash
% kcat -V
kcat - Apache Kafka producer and consumer tool
https://github.com/edenhill/kcat
Copyright (c) 2014-2021, <NAME>
Version 1.7.0 (JSON, Avro, Transactions, IncrementalAssign, librdkafka 2.0.2 builtin.features=gzip,snappy,ssl,sasl,regex,lz4,sasl_gssapi,sasl_plain,sasl_scram,plugins,zstd,sasl_oauthbearer,http,oidc)
```
#### Docker Container
There is also a Docker container which can be used to run `kcat`
```bash
docker run --tty --network kafka-workshop edenhill/kcat:1.7.1 kcat
```
By setting an alias, we can work with the dockerized version of `kcat` as it would be a local command. All further examples assume that this is the case.
```bash
alias kcat='docker run --tty --network kafka-workshop edenhill/kcat:1.7.0 kcat'
```
Check the [Running in Docker](https://github.com/edenhill/kcat#running-in-docker) to see more options for using `kcat` with Docker.
#### Windows
There is no official support to run `kcat` on Windows. You might try the following link to run it on Windows: <https://ci.appveyor.com/project/edenhill/kafkacat/builds/23675338/artifacts>.
An other option for Windows is to run it as a Docker container as shown above.
### Display `kcat` options
`kcat` has many options. If you just enter `kcat` without any options, all the options with a short description are shown on the console. Additionally kcat will show the version which is installed. This is currently **1.7.0** if installed on Mac and **1.6.0** if on Ubuntu.
```bash
gus@gusmacbook ~> kcat
Error: -b <broker,..> missing
Usage: kcat <options> [file1 file2 .. | topic1 topic2 ..]]
kcat - Apache Kafka producer and consumer tool
https://github.com/edenhill/kcat
Copyright (c) 2014-2021, <NAME>
Version 1.7.0 (JSON, Avro, Transactions, IncrementalAssign, librdkafka 1.8.2 builtin.features=gzip,snappy,ssl,sasl,regex,lz4,sasl_gssapi,sasl_plain,sasl_scram,plugins,zstd,sasl_oauthbearer)
General options:
-C | -P | -L | -Q Mode: Consume, Produce, Metadata List, Query mode
-G <group-id> Mode: High-level KafkaConsumer (Kafka >=0.9 balanced consumer groups)
Expects a list of topics to subscribe to
-t <topic> Topic to consume from, produce to, or list
-p <partition> Partition
-b <brokers,..> Bootstrap broker(s) (host[:port])
-D <delim> Message delimiter string:
a-z | \r | \n | \t | \xNN ..
Default: \n
-K <delim> Key delimiter (same format as -D)
-c <cnt> Limit message count
-m <seconds> Metadata (et.al.) request timeout.
This limits how long kcat will block
while waiting for initial metadata to be
retrieved from the Kafka cluster.
It also sets the timeout for the producer's
transaction commits, init, aborts, etc.
Default: 5 seconds.
-F <config-file> Read configuration properties from file,
file format is "property=value".
The KCAT_CONFIG=path environment can also be used, but -F takes precedence.
The default configuration file is $HOME/.config/kcat.conf
-X list List available librdkafka configuration properties
-X prop=val Set librdkafka configuration property.
Properties prefixed with "topic." are
applied as topic properties.
-X schema.registry.prop=val Set libserdes configuration property for the Avro/Schema-Registry client.
-X dump Dump configuration and exit.
-d <dbg1,...> Enable librdkafka debugging:
all,generic,broker,topic,metadata,feature,queue,msg,protocol,cgrp,security,fetch,interceptor,plugin,consumer,admin,eos,mock,assignor,conf
-q Be quiet (verbosity set to 0)
-v Increase verbosity
-E Do not exit on non-fatal error
-V Print version
-h Print usage help
Producer options:
-z snappy|gzip|lz4 Message compression. Default: none
-p -1 Use random partitioner
-D <delim> Delimiter to split input into messages
-K <delim> Delimiter to split input key and message
-k <str> Use a fixed key for all messages.
If combined with -K, per-message keys
takes precendence.
-H <header=value> Add Message Headers (may be specified multiple times)
-l Send messages from a file separated by
delimiter, as with stdin.
(only one file allowed)
-T Output sent messages to stdout, acting like tee.
-c <cnt> Exit after producing this number of messages
-Z Send empty messages as NULL messages
file1 file2.. Read messages from files.
With -l, only one file permitted.
Otherwise, the entire file contents will
be sent as one single message.
-X transactional.id=.. Enable transactions and send all
messages in a single transaction which
is committed when stdin is closed or the
input file(s) are fully read.
If kcat is terminated through Ctrl-C
(et.al) the transaction will be aborted.
Consumer options:
-o <offset> Offset to start consuming from:
beginning | end | stored |
<value> (absolute offset) |
-<value> (relative offset from end)
s@<value> (timestamp in ms to start at)
e@<value> (timestamp in ms to stop at (not included))
-e Exit successfully when last message received
-f <fmt..> Output formatting string, see below.
Takes precedence over -D and -K.
-J Output with JSON envelope
-s key=<serdes> Deserialize non-NULL keys using <serdes>.
-s value=<serdes> Deserialize non-NULL values using <serdes>.
-s <serdes> Deserialize non-NULL keys and values using <serdes>.
Available deserializers (<serdes>):
<pack-str> - A combination of:
<: little-endian,
>: big-endian (recommended),
b: signed 8-bit integer
B: unsigned 8-bit integer
h: signed 16-bit integer
H: unsigned 16-bit integer
i: signed 32-bit integer
I: unsigned 32-bit integer
q: signed 64-bit integer
Q: unsigned 64-bit integer
c: ASCII character
s: remaining data is string
$: match end-of-input (no more bytes remaining or a parse error is raised).
Not including this token skips any
remaining data after the pack-str is
exhausted.
avro - Avro-formatted with schema in Schema-Registry (requires -r)
E.g.: -s key=i -s value=avro - key is 32-bit integer, value is Avro.
or: -s avro - both key and value are Avro-serialized
-r <url> Schema registry URL (when avro deserializer is used with -s)
-D <delim> Delimiter to separate messages on output
-K <delim> Print message keys prefixing the message
with specified delimiter.
-O Print message offset using -K delimiter
-c <cnt> Exit after consuming this number of messages
-Z Print NULL values and keys as "NULL" instead of empty.
For JSON (-J) the nullstr is always null.
-u Unbuffered output
Metadata options (-L):
-t <topic> Topic to query (optional)
Query options (-Q):
-t <t>:<p>:<ts> Get offset for topic <t>,
partition <p>, timestamp <ts>.
Timestamp is the number of milliseconds
since epoch UTC.
Requires broker >= 0.10.0.0 and librdkafka >= 0.9.3.
Multiple -t .. are allowed but a partition
must only occur once.
Format string tokens:
%s Message payload
%S Message payload length (or -1 for NULL)
%R Message payload length (or -1 for NULL) serialized
as a binary big endian 32-bit signed integer
%k Message key
%K Message key length (or -1 for NULL)
%T Message timestamp (milliseconds since epoch UTC)
%h Message headers (n=v CSV)
%t Topic
%p Partition
%o Message offset
\n \r \t Newlines, tab
\xXX \xNNN Any ASCII character
Example:
-f 'Topic %t [%p] at offset %o: key %k: %s\n'
JSON message envelope (on one line) when consuming with -J:
{ "topic": str, "partition": int, "offset": int,
"tstype": "create|logappend|unknown", "ts": int, // timestamp in milliseconds since epoch
"broker": int,
"headers": { "<name>": str, .. }, // optional
"key": str|json, "payload": str|json,
"key_error": str, "payload_error": str, //optional
"key_schema_id": int, "value_schema_id": int //optional
}
notes:
- key_error and payload_error are only included if deserialization fails.
- key_schema_id and value_schema_id are included for successfully deserialized Avro messages.
Consumer mode (writes messages to stdout):
kcat -b <broker> -t <topic> -p <partition>
or:
kcat -C -b ...
High-level KafkaConsumer mode:
kcat -b <broker> -G <group-id> topic1 top2 ^aregex\d+
Producer mode (reads messages from stdin):
... | kcat -b <broker> -t <topic> -p <partition>
or:
kcat -P -b ...
Metadata listing:
kcat -L -b <broker> [-t <topic>]
Query offset by timestamp:
kcat -Q -b broker -t <topic>:<partition>:<timestamp>
```
Now let's use it to Produce and Consume messages.
### Consuming messages using `kcat`
All the examples below are shown using `kcat`. If you are still on the older version (before `1.7` replace `kcat` with `kafkacat` or specify an alias as shown above).
**Note:** Replace `dataplatform` by `kafka-1:19092` if you are using the dockerized version of `kcat` in all of the samples below (i.e. `kafka-1:19092`).
The simplest way to consume a topic is just specifying the broker and the topic. By default all messages from the beginning of the topic will be shown.
```bash
kcat -b dataplatform -t test-topic
```
If you want to start at the end of the topic, i.e. only show new messages, add the `-o` option.
```bash
kcat -b dataplatform -t test-topic -o end
```
To show only the last message (one for each partition), set the `-o` option to `-1`. `-2` would show the last 2 messages.
```bash
kcat -b dataplatform -t test-topic -o -1
```
To show only the last message from exactly one partition, add the `-p` option
```bash
kcat -b dataplatform -t test-topic -p1 -o -1
```
You can use the `-f` option to format the output. Here we show the partition (`%p`) as well as key (`%k`) and value (`%s`):
```bash
kcat -b dataplatform -t test-topic -f 'Part-%p => %k:%s\n'
```
If there are keys which are Null, then you can use `-Z` to actually show NULL in the output:
```bash
kcat -b dataplatform -t test-topic -f 'Part-%p => %k:%s\n' -Z
```
There is also the option `-J` to have the output emitted as JSON.
```bash
kcat -b dataplatform -t test-topic -J
```
### Producing messages using `kcat`
Producing messages with `kcat` is as easy as consuming. Just add the `-P` option to switch to Producer mode.
```bash
kcat -b dataplatform -t test-topic -P
```
To produce with key, specify the delimiter to split key and message, using the `-K` option.
```bash
kcat -b dataplatform -t test-topic -P -K , -X topic.partitioner=murmur2_random
```
Find some more example on the [kcat GitHub project](https://github.com/edenhill/kcat) or in the [Confluent Documentation](https://docs.confluent.io/current/app-development/kafkacat-usage.html).
### Send "realistic" test messages to Kafka using Mockaroo and `kcat`
In his [blog article](https://rmoff.net/2018/05/10/quick-n-easy-population-of-realistic-test-data-into-kafka-with-mockaroo-and-kafkacat/) <NAME> shows an interesting and easy approach to send realistic mock data to Kafka. He is using [Mockaroo](https://mockaroo.com/), a free test data generator and API mocking tool, together with [kcat](https://github.com/edenhill/kcat) to produce mock messages.
Taking his example, you can send 10 orders to test-topic (it will not work if you use the dockerized version of `kcat`)
```bash
curl -s "https://api.mockaroo.com/api/d5a195e0?count=20&key=ff7856d0"| kcat -b dataplatform -t test-topic -P
```
## Publishing a "real" data stream to Kafka
Next we will see a more realistic example using the [Streaming Synthetic Sales Data Generator](https://github.com/garystafford/streaming-sales-generator). It is available as a [Docker Image](https://hub.docker.com/repository/docker/trivadis/sales-data-generator).
We can use it to stream simulated sales data into Kafka topics. By no longer manually producing data, we can see unbounded data "in action".
First let's create the necessary 3 topics:
```bash
docker exec -ti kafka-1 kafka-topics --create --bootstrap-server kafka-1:19092 --topic demo.products --replication-factor 3 --partitions 6
docker exec -ti kafka-1 kafka-topics --create --bootstrap-server kafka-1:19092 --topic demo.purchases --replication-factor 3 --partitions 6
docker exec -ti kafka-1 kafka-topics --create --bootstrap-server kafka-1:19092 --topic demo.inventories --replication-factor 3 --partitions 6
```
The default configuration assumes that the container runs in the same network as the Kafka cluster, therefore we have to pass the name of the network when running the container.
```bash
docker network list
```
For the Kafka workshop environment, it should be `kafka-workshop`. If you are using the workshop with another dataplatform, then you have to adapt the `--network` option in following statement:
```bash
docker run -ti --network kafka-workshop trivadis/sales-data-generator:latest
```
Now use `kcat` to see the data streaming into the `demo.purchases` topic.
```bash
kcat -b dataplatform -t demo.purchases
```
You can also use the **Live Tail** option of **AKHQ** (see next section).
## Using AKHQ
[AKHQ](https://akhq.io/) is an open source Kafka GUI for Apache Kafka to manage topics, topics data, consumers group, schema registry, connect and more... It has been started as part of the **dataplatform** and can be reached on <http://dataplatform:28107/>.
By default you will end-up on the topics overview page

Navigate to **Nodes** in the menu on the left to see the Kafka cluster with its 3 brokers.

To see again the topics, click on **Topics** in the menu.
Currently there is only one topic shown, due to the default setting of hiding internal topics.
You can select **Show all topics** in the drop down to also view the internal topics, such as `__consumer_offsets`.

To view the data stored in a topic, click on the **magnifying glass** icon on the right side

and you should see the first page of messages of the topic

You can also view the live data arriving in a topic by navigating to **Live Tail** in the menu on the left. You might want to re-run the **Streaming Synthetic Sales Data Generator** seen before, if it is no longer running.
Select one or more topics you wish to see the live data streaming in

Click on the **magnifying glass** icon and the data will be shown as it arrives in the topic

If you want to empty a topic, then navigate to **Topics** in the menu, select a topic by clicking on the **magnifying glass** icon on the right side

and click **Empty Topic**.
AKHQ can also be used to
## Using CMAK (Cluster Manager for Apache Apache Kafka)
[CMAK](https://github.com/yahoo/CMAK), previously known as **Kafka Manager** is an open source tool created by Yahoo for managing a Kafka cluster. It has been started as part of the **dataplatform** and can be reached on <http://dataplatform:28104/>.

Navigate to the **Cluster** menu and click on the drop-down and select **Add Cluster**.

The **Add Cluster** details page should be displayed. Enter the following values into the edit fields / drop down windows:
* **Cluster Name**: Streaming Platform
* **Custer Zookeeper Hosts**: zookeeper-1:2181
* **Kafka Version**: 2.0.0
Select the **Enable JMX Polling**, **Poll consumer information**, **Filter out inactive consumers**, **Enable Active OffsetCache** and **Display Broker and Topic Size** and click on **Save** to add the cluster.

You should get a message `Done!` signalling that the cluster has been successfully configured in **Kafka Manager**.

Click on **Go to cluster view**.
<file_sep># Directus
The Modern Data Stack 🐰 — Directus is an instant REST+GraphQL API and intuitive no-code data collaboration app for any SQL database.
**[Website](https://directus.io/)** | **[Documentation](https://docs.directus.io/getting-started/introduction.html)** | **[GitHub](https://github.com/directus/directus)**
## How to enable?
```
platys init --enable-services DIRECTUS, POSTGRESQL
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8055>.<file_sep># Using ksqlDB for Stream Analytics
In this workshop we will learn how to process messages using the [ksqlDB](https://ksqldb.io/).
We will see different processing patterns applied.
## Connect to ksqlDB CLI
In order to use KSQL, we need to connect to the KSQL engine using the ksqlDB CLI. An instance of a ksqlDB server has been started with the Data Platform and can be reached on port `8088`.
```bash
docker exec -it ksqldb-cli ksql http://ksqldb-server-1:8088
```
You should see the KSQL command prompt:
```bash
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
===========================================
= _ _ ____ ____ =
= | | _____ __ _| | _ \| __ ) =
= | |/ / __|/ _` | | | | | _ \ =
= | <\__ \ (_| | | |_| | |_) | =
= |_|\_\___/\__, |_|____/|____/ =
= |_| =
= The Database purpose-built =
= for stream processing apps =
===========================================
Copyright 2017-2022 Confluent Inc.
CLI v0.26.0, Server v0.26.0 located at http://ksqldb-server-1:8088
Server Status: RUNNING
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql>
```
We can use the show command to show topics as well as streams and tables. We have not yet created streams and tables, therefore we won't see anything.
```sql
show streams;
show tables;
show topics;
```
## Create a Stream
Let's create a stream of `transaction`
```sql
CREATE STREAM transaction_s (
email_address VARCHAR KEY,
tx_id VARCHAR,
card_number VARCHAR,
timestamp TIMESTAMP,
amount DECIMAL(12, 2)
) WITH (
kafka_topic = 'transaction',
partitions = 8,
replicas = 3,
value_format = 'avro'
);
```
Now let's view the data in the stream
```sql
SELECT * FROM transaction_s;
```
we have done it as a pull-query (which scans the whole topic behind the stream), and get the following result
```
+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+
|EMAIL_ADDRESS |TX_ID |CARD_NUMBER |TIMESTAMP |AMOUNT |
+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+
Query Completed
Query terminated
```
You can see that the statement ended with no rows. There is no result, as we have not yet send any data to the topic.
Let's change the statement to a push-query by adding `EMIT CHANGES` to the end.
```sql
SELECT * FROM transaction_s EMIT CHANGES;
```
Compared to before, the statement does not end and keeps on running. But there is still now data available.
```
+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+
|EMAIL_ADDRESS |TX_ID |CARD_NUMBER |TIMESTAMP |AMOUNT |
+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+
Press CTRL-C to interrupt
```
Let's change that and add some data to the stream. We could directly produce data to the underlying Kafka topic `transaction` or use the ksqlDB `INSERT` statement, which we will do here. In a new terminal, start again a ksqlDB CLI
```bash
docker exec -it ksqldb-cli ksql http://ksqldb-server-1:8088
```
and add a few transactions
```sql
INSERT INTO transaction_s (email_address, tx_id, card_number, timestamp, amount)
VALUES ('<EMAIL>', '0cf100ca-993c-427f-9ea5-e892ef350363', '352642227248344', FROM_UNIXTIME(UNIX_TIMESTAMP()), 100.00);
INSERT INTO transaction_s (email_address, tx_id, card_number, timestamp, amount)
VALUES ('<EMAIL>', '9fe397e3-990e-449a-afcc-7b652a005c99', '999776673238348', FROM_UNIXTIME(UNIX_TIMESTAMP()), 220.00);
```
you will immediately see them returned as a result of the push-query
```sql
+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+
|EMAIL_ADDRESS |TX_ID |CARD_NUMBER |TIMESTAMP |AMOUNT |
+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+
|<EMAIL> |0cf100ca-993c-427f-9ea5-e892ef350363 |352642227248344 |2022-06-06T20:37:27.973 |100.00 |
|<EMAIL> |9fe397e3-990e-449a-afcc-7b652a005c99 |999776673238348 |2022-06-06T20:38:38.343 |220.00 |
```
Stop the push-query by entering `CTRL-C`.
Let's do the pull-query again (the one without the `EMIT CHANGES` clause).
```sql
SELECT * FROM transaction_s
```
This time you can see the historical data which is stored by the stream (the underlying Kafka topic).
```sql
ksql> SELECT * FROM transaction_s;
+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+
|EMAIL_ADDRESS |TX_ID |CARD_NUMBER |TIMESTAMP |AMOUNT |
+-----------------------------+-----------------------------+-----------------------------+-----------------------------+-----------------------------+
|<EMAIL>.com |9fe397e3-990e-449a-afcc-7b652|999776673238348 |2022-07-03T19:05:37.451 |220.00 |
| |a005c99 | | | |
|<EMAIL> |0cf100ca-993c-427f-9ea5-e892e|352642227248344 |2022-07-03T19:05:37.406 |100.00 |
| |f350363 | | | |
Query Completed
Query terminated
ksql>
```
**Note**: be careful with using a pull-query on a Stream, as it could be very resource intensive.
## Filter on the stream
Let's say we are interested in only the transactions, where the amount is larger than `1000`.
This can easily be done using the `WHERE` clause of the push-query.
```sql
SELECT * FROM transaction_s
WHERE amount > 1000.00
EMIT CHANGES;
```
Now let's add some more transactions, some with smaller values some with larger values:
```sql
INSERT INTO transaction_s (email_address, tx_id, card_number, timestamp, amount)
VALUES ('<EMAIL>', '4c59430a-65a8-4607-bd90-a165a4a9488f', '8878779987897979', FROM_UNIXTIME(UNIX_TIMESTAMP()), 400.20);
INSERT INTO transaction_s (email_address, tx_id, card_number, timestamp, amount)
VALUES ('<EMAIL>', 'c204eb55-d572-4182-80ab-cfcc0f865861', '352642227248344', FROM_UNIXTIME(UNIX_TIMESTAMP()), 1040.20);
INSERT INTO transaction_s (email_address, tx_id, card_number, timestamp, amount)
VALUES ('<EMAIL>', 'c204eb55-d572-4182-80ab-cfcc0f865861', '352642227248344', FROM_UNIXTIME(UNIX_TIMESTAMP()), 300.90);
INSERT INTO transaction_s (email_address, tx_id, card_number, timestamp, amount)
VALUES ('<EMAIL>', '6b69ce08-8506-42c8-900b-079b3f918d97', '9989898989098908', FROM_UNIXTIME(UNIX_TIMESTAMP()), 1090.00);
```
From the total of 4 new transactions, you should only see two in the result, the one which are above 1000.
```
+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+
|EMAIL_ADDRESS |TX_ID |CARD_NUMBER |TIMESTAMP |AMOUNT |
+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+------------------------------------------------------------+
|<EMAIL> |c204eb55-d572-4182-80ab-cfcc0f865861 |352642227248344 |2022-06-06T20:41:27.067 |1040.20 |
|<EMAIL> |6b69ce08-8506-42c8-900b-079b3f918d97 |9989898989098908 |2022-06-06T20:42:13.069 |1090.00 |
```
## Project columns from Stream
Let's see how we can only show the columns we want to see
```ksql
SELECT email_address, amount
FROM transaction_s
EMIT CHANGES;
```
In the 2nd terminal, insert a new transaction
```ksql
INSERT INTO transaction_s (email_address, tx_id, card_number, timestamp, amount)
VALUES ('<EMAIL>', '8227233d-0b66-4e69-b49b-3cd08b21ab7d', '99989898909808', FROM_UNIXTIME(UNIX_TIMESTAMP()), 55.65);
```
And you should see
```
+---------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------+
|EMAIL_ADDRESS |AMOUNT |
+---------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------+
|<EMAIL> |55.65 |
```
## Using Functions
ksqlDB provides with a large set of [useful functions](https://docs.ksqldb.io/en/latest/developer-guide/ksqldb-reference/functions/).
Let's say that we want to mask the credit card number, then we can use either `MASK` to fully mask or `MASK_RIGHT`/`MASK_LEFT` or `MASK_KEEP_LEFT`/`MASK_KEEP_RIGHT` to partially mask a string field.
```ksql
SELECT email_address, MASK(card_number) card_number, MASK_KEEP_RIGHT(card_number, 4, 'X','x','n','-') card_number_masked_keep4, tx_id, amount
FROM transaction_s
EMIT CHANGES;
```
You can also implement your own [User-Defined Functions](https://docs.ksqldb.io/en/latest/reference/user-defined-functions/), by writing Java hooks.
## Counting Values
Now let's see how we can do some stateful processing. Let's start with a simple count of values.
In the first terminal perform
```sql
SELECT email_address, COUNT(*)
FROM transaction_s
GROUP BY email_address
EMIT CHANGES;
```
Now in the 2nd terminal add some new transactions
```sql
INSERT INTO transaction_s (email_address, tx_id, card_number, timestamp, amount)
VALUES ('<EMAIL>', '05ed7709-8a18-4e0d-9608-27894750bd43', '352642227248344', FROM_UNIXTIME(UNIX_TIMESTAMP()), 99.95);
```
We can see that the count starts with 0 and will only increase from now.
How can we make the result a bit more meaningful? By adding a time window to the query!
## Counting Values over a Time Window
### Tumbling Window
Let's see the number of transactions within 30 seconds. We use a **tumbling*** window (Fixed-duration, non-overlapping, gap-less windows) first
```sql
SELECT FROM_UNIXTIME (windowstart) as from_ts
, FROM_UNIXTIME (windowend) as to_ts
, email_address
, COUNT(*) as count
FROM transaction_s
WINDOW TUMBLING (SIZE 30 SECONDS)
GROUP BY email_address
EMIT CHANGES;
```
Now in a second window, `INSERT` some more messages.
```sql
+-----------------------------------------------------------------------+-----------------------------------------------------------------------+-----------------------------------------------------------------------+-----------------------------------------------------------------------+
|FROM_TS |TO_TS |EMAIL_ADDRESS |COUNT |
+-----------------------------------------------------------------------+-----------------------------------------------------------------------+-----------------------------------------------------------------------+-----------------------------------------------------------------------+
|2022-07-04T13:36:00.000 |2022-07-04T13:36:30.000 |<EMAIL> |1 |
|2022-07-04T13:36:00.000 |2022-07-04T13:36:30.000 |<EMAIL> |1 |
|2022-07-04T13:36:00.000 |2022-07-04T13:36:30.000 |<EMAIL> |2 |
|2022-07-04T13:36:00.000 |2022-07-04T13:36:30.000 |<EMAIL> |2 |
```
You can see that a result is displayed before the time window is finished. The EMIT clause lets you control the output refinement of your push query. You can switch from `CHANGES` to `FINAL` to tell ksqlDB to wait for the time window to close before a result is returned.
**Note:** `EMIT FINAL` is data driven, i.e., it emit results only if "stream-time" advanced beyond the window close time. "Stream-time" depends on the observed timestamps of your input record, and thus, if you stop sending input records, "stream-time" does not advance further. If you stop sending data, the last window might never be closed, and thus you never see a result for it.
**Note:** There are some memory considerations with the `FINAL` feature that could cause unbounded growth and eventual an OOM exception. The feature is still in development/beta and we'll definitely document it when it's complete!
### Hopping Window
We can easily switch to a **hopping** window (Fixed-duration, overlapping windows) with 10 seconds overlap
```sql
SELECT FROM_UNIXTIME (WINDOWSTART) as from_ts
, FROM_UNIXTIME (WINDOWEND) as to_ts
, email_address
, COUNT(*) as count
FROM transaction_s
WINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS)
GROUP BY email_address
EMIT CHANGES;
```
## Create a ksqlDB Table holding Customers
A table is a mutable, partitioned collection that models change over time. In contrast with a stream, which represents a historical sequence of events, a table represents what is true as of "now".
Tables work by leveraging the keys of each row. If a sequence of rows shares a key, the last row for a given key represents the most up-to-date information for that key's identity. A background process periodically runs and deletes all but the newest rows for each key.
Let's use a table to model customers.
Create the table `customer_t` and put some data in it
```sql
DROP TABLE customer_t;
CREATE TABLE customer_t (email_address VARCHAR PRIMARY KEY, first_name VARCHAR, last_name VARCHAR, category VARCHAR)
WITH (KAFKA_TOPIC='customer',
VALUE_FORMAT='AVRO',
PARTITIONS=8,
REPLICAS=3);
```
The table is backed by the topic called `customer`. This topic is automatically created using the settings you provide. If it should be a compacted log topic (which could make sense), you have to create it manually first, before creating the table.
Now let's add some data to the KSQL table:
```sql
INSERT INTO customer_t (email_address, first_name, last_name, category) VALUES ('<EMAIL>', 'Peter', 'Muster', 'A');
INSERT INTO customer_t (email_address, first_name, last_name, category) VALUES ('<EMAIL>', 'Barbara', 'Sample', 'B');
```
With that in place, can we use a Pull-Query to retrieve a customer? Let's try that
```sql
SELECT *
FROM customer_t
WHERE email_address = '<EMAIL>';
```
will give an error
```sql
ksql> SELECT *
>FROM customer_t
>WHERE email_address = '<EMAIL>';
The `CUSTOMER_T` table isn't queryable. To derive a queryable table, you can do 'CREATE TABLE QUERYABLE_CUSTOMER_T AS SELECT * FROM CUSTOMER_T'. See https://cnfl.io/queries for more info.
Add EMIT CHANGES if you intended to issue a push query.
```
You can provide the `SOURCE` clause to enable running pull queries on the table. The `SOURCE` clause runs an internal query for the table to create a materialized state that's used by pull queries. When you create a `SOURCE` table, the table is created as read-only. For a read-only table, INSERT, DELETE TOPIC, and DROP TABLE statements aren't permitted.
That's why we reuse the topic `customer` from the table created above, just to see a `SOURCE` table in action. In a real-life situation, usually the data behind the table is created directly either by a connector or a stream processing application.
Let's create a new `SOURCE` table by adding the `SOURCE` keyword:
```sql
DROP TABLE customer_st;
CREATE SOURCE TABLE customer_st (email_address VARCHAR PRIMARY KEY, first_name VARCHAR, last_name VARCHAR, category VARCHAR)
WITH (KAFKA_TOPIC='customer',
VALUE_FORMAT='AVRO',
PARTITIONS=8,
REPLICAS=3);
```
Now on that table a pull-query works:
```sql
SELECT *
FROM customer_st
WHERE email_address = '<EMAIL>';
```
Let's drop that table as we no longer need it
```sql
DROP TABLE customer_st;
```
## Join Stream with a Table
Now let's see how we can enrich the stream of data (transactions) with some static data (customer). We want to do a join between the stream and a table (`customer_t`) holding all the customer data, we just created.
So let's join the table to the transaction stream. We create another push query, which will continuously run.
```sql
SELECT * FROM transaction_s AS tra
LEFT JOIN customer_t AS cus
ON (tra.email_address = cus.email_address)
EMIT CHANGES;
```
In the 2nd terminal, insert a new message into the `transaction_s` stream
```sql
INSERT INTO transaction_s (email_address, tx_id, card_number, timestamp, amount)
VALUES ('<EMAIL>', '05ed7709-8a18-4e0d-9608-27894750bd43', '352642227248344', FROM_UNIXTIME(UNIX_TIMESTAMP()), 99.95);
```
and you should see the result of the join in the 1st terminal window.
```bash
ksql> SELECT * FROM transaction_s AS tra
>LEFT JOIN customer_t AS cus
>ON (tra.email_address = cus.email_address)
>EMIT CHANGES;
+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+
|TRA_EMAIL_ADDRESS |TRA_TX_ID |TRA_CARD_NUMBER |TRA_TIMESTAMP |TRA_AMOUNT |CUS_EMAIL_ADDRESS |CUS_FIRST_NAME |CUS_LAST_NAME |CUS_CATEGORY |
+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+---------------------+
|<EMAIL>|0cf100ca-993c-427f-9e|352642227248344 |2022-07-04T15:44:14.8|100.00 |<EMAIL>|Peter |Muster |A |
| |a5-e892ef350363 | |98 | | | | | |
|<EMAIL>|9fe397e3-990e-449a-af|999776673238348 |2022-07-04T15:44:14.9|220.00 |<EMAIL>|Barbara |Sample |B |
|om |cc-7b652a005c99 | |76 | |om | | | |
Press CTRL-C to interrupt
```
If we are happy with the result, we can materialise it by using a CSAS (CREATE STREAM AS SELECT) statement.
```sql
CREATE STREAM transaction_customer_s
WITH (
KAFKA_TOPIC = 'transaction_customer',
VALUE_FORMAT = 'AVRO',
PARTITIONS = 8,
REPLICAS = 3
)
AS
SELECT *
FROM transaction_s AS tra
LEFT JOIN customer_t AS cus
ON (tra.email_address = cus.email_address)
EMIT CHANGES;
```
If you describe the stream, then you will see that KSQL has derived the column names so that they are unique (using the aliases)
```sql
ksql> describe transaction_customer_s;
Name : TRANSACTION_CUSTOMER_S
Field | Type
--------------------------------------------
TRA_EMAIL_ADDRESS | VARCHAR(STRING) (key)
TRA_TX_ID | VARCHAR(STRING)
TRA_CARD_NUMBER | VARCHAR(STRING)
TRA_TIMESTAMP | TIMESTAMP
TRA_AMOUNT | DECIMAL(12, 2)
CUS_EMAIL_ADDRESS | VARCHAR(STRING)
CUS_FIRST_NAME | VARCHAR(STRING)
CUS_LAST_NAME | VARCHAR(STRING)
CUS_CATEGORY | VARCHAR(STRING)
--------------------------------------------
For runtime statistics and query details run: DESCRIBE <Stream,Table> EXTENDED;
```
You can of course also provide your own column aliases by listing the columns in the `SELECT` list, instead of just using the `*`.
Now you can get the result either by querying the new stream `transaction_customer_s`
```sql
SELECT *
FROM transaction_customer_s
EMIT CHANGES;
```
or by consuming directly from the underlying topic called `transaction_customer`.
```bash
docker run -it --network=host edenhill/kcat:1.7.1 -b dataplatform -t transaction_customer -s value=avro -r http://dataplatform:8081
```
## Total amount of transaction value by category
Now with the enriched stream of transactions and customers, we can get the total amount of transactions by customer category over a tumbling window of 30 seconds.
```ksql
SELECT cus_category AS category
, SUM(tra_amount) AS amount
, FROM_UNIXTIME (WINDOWSTART) AS from_ts
, FROM_UNIXTIME (WINDOWEND) AS to_ts
FROM transaction_customer_s
WINDOW TUMBLING (SIZE 30 SECONDS, RETENTION 120 SECONDS, GRACE PERIOD 60 SECONDS)
GROUP BY cus_category
EMIT CHANGES;
```
We create a **tumbling window** of 30 seconds size, with a **grace period** of 60 seconds (accepting out-of-order events which are older than 1 minute) and a **window retention** of 120 seconds (the number of windows in the past that ksqlDB retains, so that they are available for Pull-Queries).
**Note:** the specified retention period should be larger than the sum of window size and any grace period.
To materialise the result, we can create another table
```sql
CREATE TABLE total_amount_per_category_t
AS
SELECT cus_category AS category
, SUM(tra_amount) AS amount
, FROM_UNIXTIME (WINDOWSTART) AS from_ts
, FROM_UNIXTIME (WINDOWEND) AS to_ts
FROM transaction_customer_s
WINDOW TUMBLING (SIZE 30 SECONDS, RETENTION 120 SECONDS, GRACE PERIOD 60 SECONDS)
GROUP BY cus_category
EMIT CHANGES;
```
We haven't specified an underlying topic, so KSQL will create one with the same name. You can cross-check by doing a DESCRIBE ... EXTENDED
```sql
ksql> describe total_amount_per_category_t extended;
Name : TOTAL_AMOUNT_PER_CATEGORY_T
Type : TABLE
Timestamp field : Not set - using <ROWTIME>
Key format : KAFKA
Value format : AVRO
Kafka topic : TOTAL_AMOUNT_PER_CATEGORY_T (partitions: 8, replication: 3)
Statement : CREATE TABLE TOTAL_AMOUNT_PER_CATEGORY_T WITH (KAFKA_TOPIC='TOTAL_AMOUNT_PER_CATEGORY_T', PARTITIONS=8, REPLICAS=3) AS SELECT
TRANSACTION_CUSTOMER_S.CUS_CATEGORY CATEGORY,
SUM(TRANSACTION_CUSTOMER_S.TRA_AMOUNT) AMOUNT
FROM TRANSACTION_CUSTOMER_S TRANSACTION_CUSTOMER_S
WINDOW TUMBLING ( SIZE 30 SECONDS , RETENTION 120 SECONDS , GRACE PERIOD 60 SECONDS )
GROUP BY TRANSACTION_CUSTOMER_S.CUS_CATEGORY
EMIT CHANGES;
Field | Type
-------------------------------------------------------------------
CATEGORY | VARCHAR(STRING) (primary key) (Window type: TUMBLING)
AMOUNT | DECIMAL(12, 2)
-------------------------------------------------------------------
Queries that write from this TABLE
-----------------------------------
CTAS_TOTAL_AMOUNT_PER_CATEGORY_T_19 (RUNNING) : CREATE TABLE TOTAL_AMOUNT_PER_CATEGORY_T WITH (KAFKA_TOPIC='TOTAL_AMOUNT_PER_CATEGORY_T', PARTITIONS=8, REPLICAS=3) AS SELECT TRANSACTION_CUSTOMER_S.CUS_CATEGORY CATEGORY, SUM(TRANSACTION_CUSTOMER_S.TRA_AMOUNT) AMOUNT FROM TRANSACTION_CUSTOMER_S TRANSACTION_CUSTOMER_S WINDOW TUMBLING ( SIZE 30 SECONDS , RETENTION 120 SECONDS , GRACE PERIOD 60 SECONDS ) GROUP BY TRANSACTION_CUSTOMER_S.CUS_CATEGORY EMIT CHANGES;
For query topology and execution plan please run: EXPLAIN <QueryId>
Local runtime statistics
------------------------
(Statistics of the local KSQL server interaction with the Kafka topic TOTAL_AMOUNT_PER_CATEGORY_T)
Consumer Groups summary:
Consumer Group : _confluent-ksql-ksqldb-clusterquery_CTAS_TOTAL_AMOUNT_PER_CATEGORY_T_19
<no offsets committed by this group yet>
ksql>
```
Push-query on table to get the changes
```sql
SELECT * FROM TOTAL_AMOUNT_PER_CATEGORY_T EMIT CHANGES;
```
Pull-query to get the current state for a category
```sql
SELECT * FROM TOTAL_AMOUNT_PER_CATEGORY_T WHERE category = 'A';
```
Pull-query to get the current state for category with the `windowstart` and `windowend` converted to a readable timestamp
```sql
SELECT category
, amount
, FROM_UNIXTIME (WINDOWSTART) AS from_ts
, FROM_UNIXTIME (WINDOWEND) AS to_ts
FROM TOTAL_AMOUNT_PER_CATEGORY_T
WHERE category = 'A';
```
Insert a transaction with Event Time (`ROWTIME`) 60 seconds ago:
```sql
INSERT INTO transaction_s (ROWTIME, email_address, tx_id, card_number, timestamp, amount)
VALUES (UNIX_TIMESTAMP() - 60000, '<EMAIL>', '0cf100ca-993c-427f-9ea5-e892ef350363', '352642227248344', FROM_UNIXTIME(UNIX_TIMESTAMP()), 100.00);
```
It will be counted in the previous window.
Insert a transaction with Event Time (`ROWTIME`) 3 minutes ago:
```sql
INSERT INTO transaction_s (ROWTIME, email_address, tx_id, card_number, timestamp, amount)
VALUES (UNIX_TIMESTAMP() - 180000, '<EMAIL>', '0cf100ca-993c-427f-9ea5-e892ef350363', '352642227248344', FROM_UNIXTIME(UNIX_TIMESTAMP()), 100.00);
```
it will not be treated as a late arrival, as if falls out of the grace period.
## Anomalies
If a single credit card is transacted many times within a short duration, there's probably something suspicious going on. A table is an ideal choice to model this because you want to aggregate events over time and find activity that spans multiple events.
```sql
CREATE TABLE possible_anomalies WITH (
kafka_topic = 'possible_anomalies',
VALUE_AVRO_SCHEMA_FULL_NAME = 'io.ksqldb.tutorial.PossibleAnomaly'
) AS
SELECT card_number AS `card_number_key`,
as_value(card_number) AS `card_number`,
latest_by_offset(email_address) AS `email_address`,
count(*) AS `n_attempts`,
sum(amount) AS `total_amount`,
collect_list(tx_id) AS `tx_ids`,
WINDOWSTART as `start_boundary`,
WINDOWEND as `end_boundary`
FROM transaction_s
WINDOW TUMBLING (SIZE 30 SECONDS, RETENTION 1000 DAYS)
GROUP BY card_number
HAVING count(*) >= 3
EMIT CHANGES;
```
Now create 3 transactions for the same credit card number within 30 seconds and it show up as a potential anomaly.
## Rest API
You can execute a ksqlDB `SELECT` directly over the [REST API](https://docs.ksqldb.io/en/latest/developer-guide/api/) using a `POST` on `/query-stream` endpoint
```bash
curl -X POST -H 'Content-Type: application/vnd.ksql.v1+json' -i http://dataplatform:8088/query-stream --data '{
"sql": "SELECT card_number, amount, tx_id FROM transaction_s EMIT CHANGES;",
"properties": {
"ksql.streams.auto.offset.reset": "latest"
}
}'
```
This way we can directly get the data into a GUI client.
<file_sep># Mongo Express
Web-based MongoDB admin interface, written with Node.js and express.
**[Documentation](https://github.com/mongo-express/mongo-express)** | **[GitHub](https://github.com/mongo-express/mongo-express)**
## How to enable?
```
platys init --enable-services MONGO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28123><file_sep># Creating a Twitter Application
For the various Twitter consumer of this course, we will connect to twitter through the so-called [Filter Stream API](https://developer.twitter.com/en/docs/tweets/filter-realtime/overview.html). This allows to set some filter options, which defines the Tweets we are interested in. Filters can be set on Terms, Geographic Location, Language and User.
In order to use the Twitter [Filter Stream API](https://developer.twitter.com/en/docs/tweets/filter-realtime/overview.html), we first have to create a Twitter application. If you don't have a Twitter user yet, you also have to create an account, which you can do from the sign in page below. To access the Twitter Application managment, navigate to <http://apps.twitter.com>.
Click on **Sign in** link on the top right corner.

Enter the **Username** and **Password** of your twitter handle into the corresponding fields. If you don’t yet have a twitter handle, then click on the small **Sign up now** link to register at twitter.

Clock on **Create New App** in the upper right corner to create a new Twitter application.

Enter **Name**, **Description**, **Website**
Click on **Create your Twitter application**.

Click on **Keys and Access Tokens** to get the credentials.

Click on **Create my access tokens**

The Acess token pair gets generated and is available to be used.

Note that you will need the **Consumer Key**, the **Consumer Secret** the **Access Token** and the **Access Token Secret** when using the Twitter API and conneting with OAuth protocol.
<file_sep># Azkarra Streams Worker
Explore Data Pipelines in Apache Kafka.
**[Website](https://www.azkarrastreams.io/)** | **[Documentation](https://www.azkarrastreams.io/docs/)** | **[GitHub](https://github.com/streamthoughts/azkarra-streams)**
## How to enable?
```
platys init --enable-services AZKARRA_WORKER
platys gen
```
<file_sep>using System.Threading;
using System;
using Confluent.Kafka;
using Confluent.SchemaRegistry;
using Confluent.SchemaRegistry.Serdes;
using com.trivadis.kafkaws.avro.v1;
class KafkaProducer
{
const string brokerList = "dataplatform:9092,dataplatform:9093";
const string topicName = "test-dotnet-avro-topic";
const string schemaRegistryUrl = "http://dataplatform:8081";
static void Main(string[] args)
{
long startTime = DateTimeOffset.Now.ToUnixTimeMilliseconds();
if (args.Length == 0)
{
runProducerASync(100, 10, 0);
}
else
{
runProducerASync(int.Parse(args[0]), int.Parse(args[1]), int.Parse(args[2]));
}
long endTime = DateTimeOffset.Now.ToUnixTimeMilliseconds();
Console.WriteLine("Producing all records took : " + (endTime - startTime) + " ms = (" + (endTime - startTime) / 1000 + " sec)" );
}
static void runProducerASync(int totalMessages, int waitMsInBetween, int id)
{
var config = new ProducerConfig { BootstrapServers = brokerList };
var schemaRegistryConfig = new SchemaRegistryConfig
{
// Note: you can specify more than one schema registry url using the
// schema.registry.url property for redundancy (comma separated list).
// The property name is not plural to follow the convention set by
// the Java implementation.
Url = schemaRegistryUrl
};
var avroSerializerConfig = new AvroSerializerConfig
{
// optional Avro serializer properties:
BufferBytes = 100
};
using (var schemaRegistry = new CachedSchemaRegistryClient(schemaRegistryConfig))
// Create the Kafka Producer
using (var producer = new ProducerBuilder<Null, Notification>(config)
.SetValueSerializer(new AvroSerializer<Notification>(schemaRegistry, avroSerializerConfig))
.Build())
{
for (int index = 0; index < totalMessages; index++)
{
long time = DateTimeOffset.Now.ToUnixTimeMilliseconds();
// Construct the message value
Notification value = new Notification { id = id, message = "[" + index + ":" + id + "] Hello Kafka " + DateTimeOffset.Now };
// send the message to Kafka
var deliveryReport = producer.ProduceAsync(topicName, new Message<Null, Notification> { Value = value });
deliveryReport.ContinueWith(task =>
{
if (task.IsFaulted)
{
}
else
{
Console.WriteLine($"[{id}] sent record (key={task.Result.Key} value={task.Result.Value}) meta (partition={task.Result.TopicPartition.Partition}, offset={task.Result.TopicPartitionOffset.Offset}, time={task.Result.Timestamp.UnixTimestampMs})");
}
});
Thread.Sleep(waitMsInBetween);
}
producer.Flush(TimeSpan.FromSeconds(10));
}
}
}<file_sep># Using Kafka from Scala
In this workshop we will learn how to use Apache Kafka from Scala.
## Setup
### Creating the necessary Kafka Topic
We will use the topic `test-node-topic` in the Producer and Consumer code below. Due to the fact that `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
Connect to the `kafka-1` container
```
docker exec -ti kafka-1 bash
```
and execute the necessary kafka-topics command.
```
kafka-topics --create \
--replication-factor 3 \
--partitions 12 \
--topic test-scala-topic \
--bootstrap-server kafka-1:19092
```
This finishes the setup steps and our new project is ready to be used. Next we will start implementing the **Kafka Producer** which uses Avro for the serialisation.
## Create a Scala Project
Add the following code to `build.sbt`
```bash
import sbt.fullRunTask
ThisBuild / version := "0.1.0-SNAPSHOT"
ThisBuild / scalaVersion := "2.13.10"
lazy val root = (project in file("."))
.settings(
name := "scala-kafka",
resolvers += "Confluent Repo" at "https://packages.confluent.io/maven",
libraryDependencies ++= (Dependencies.rootDependencies ++ Dependencies.kafkaClientsDeps),
libraryDependencies ++= (Dependencies.testDependencies map(_ % Test)),
fullRunTask(produce, Compile, s"com.trivadis.kafkaws.producer.Producer")
)
lazy val produce: TaskKey[Unit] = taskKey[Unit]("Message Production")
lazy val consume: TaskKey[Unit] = taskKey[Unit]("Message Consumption")
```
Add the following code to `Dependencies.scala`
```
import sbt._
object Dependencies {
lazy val rootDependencies: List[ModuleID] =
"org.typelevel" %% "cats-core" % "2.1.1" ::
"ch.qos.logback" % "logback-classic" % "1.4.5" :: Nil
lazy val kafkaClientsDeps: List[ModuleID] =
"org.apache.kafka" % "kafka-clients" % "3.3.2" :: Nil
lazy val testDependencies: List[ModuleID] =
"org.scalatest" %% "scalatest" % "3.2.3" ::
"org.scalactic" %% "scalactic" % "3.2.3" ::
"org.scalacheck" %% "scalacheck" % "1.15.1" ::
"org.typelevel" %% "cats-core" % "2.3.0" :: Nil
}
```
# Create Kafka Producer
Next we are going to create the producer application by pasting the following Scala code into a file named `Producer.scala`.
```scala
package com.trivadis.kafkaws.producer
import java.util.Properties
import org.apache.kafka.clients.producer._
object KafkaProducerSync {
val bootstrapServers = "dataplatform:9092,dataplatform:9093"
val topic = "test-scala-topic"
val props: Properties = {
val p = new Properties()
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers)
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.LongSerializer")
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
p.put(ProducerConfig.ACKS_CONFIG, "all")
// p.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384)
// p.put(ProducerConfig.LINGER_MS_CONFIG, 1)
// p.put(ProducerConfig.RETRIES_CONFIG, 0)
p
}
def main(args: Array[String]): Unit = {
val sendMessageCount = args(0).toString.toInt
val waitMsInBetween = args(1).toString.toInt
val id = args(2).toString.toLong;
val producer = new KafkaProducer[Long, String](props)
for (i <- 1 to sendMessageCount) {
val metadata = if (id > 0)
producer.send(new ProducerRecord(topic, id, s"[${i}] Hello Kafka ${i}"))
else
producer.send(new ProducerRecord(topic, s"[${i}] Hello Kafka ${i}"))
println(s"[${id}] sent record(topic=${metadata.get().topic()} partition=${metadata.get().partition()}")
// Simulate slow processing
Thread.sleep(waitMsInBetween)
}
producer.close()
}
}
```
# Kafka Consumer
Next let's create the consumer by pasting the following code into a file named `consumer.go`.
```scala
package com.trivadis.kafkaws.consumer
import java.util.{Collections, Properties}
import org.apache.kafka.clients.consumer.{CommitFailedException, ConsumerConfig, KafkaConsumer}
object KafkaConsumerExample {
import scala.collection.JavaConverters._
val bootstrapServers = "dataplatform:9092,dataplatform:9093"
val groupId = "kafka-example"
val topics = "test-scala-topic"
val props: Properties = {
val p = new Properties()
p.put(ConsumerConfig.GROUP_ID_CONFIG, groupId)
p.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers)
p.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.LongDeserializer")
p.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer")
p.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest") // default is latest
p
}
def main(args: Array[String]): Unit = {
val consumer = new KafkaConsumer[Long, String](props)
consumer.subscribe(Collections.singletonList(this.topics))
while (true) {
val records = consumer.poll(1000).asScala
for (record <- records) {
println("Message: (key: " +
record.key() + ", with value: " + record.value() +
") at on partition " + record.partition() + " at offset " + record.offset())
}
try
consumer.commitSync
catch {
case e: CommitFailedException =>
}
}
consumer.close()
}
}
```
<file_sep>connector.name=sqlserver
connection-url=jdbc:sqlserver://sqlserver:1433;database=${ENV:SQLSERVER_DATABASE};encrypt=false
connection-user=${ENV:SQLSERVER_USER}
connection-password=${ENV:SQLSERVER_PASSWORD}
<file_sep># Mendix
Mendix is a low-code platform used by businesses to develop mobile & web apps at scale
**[Website](https://www.mendix.com/)** | **[Documentation](https://docs.mendix.com/)** | **[GitHub](https://github.com/mendix/docker-mendix-buildpack)**
## How to enable?
```
platys init --enable-services MENDIX
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28256><file_sep>Contains the data of cassandra-1 service, if flag CASSANDRA_volume_map_data is set to true.<file_sep>Contains the data of questdb service, if flag QUESTDB_volume_map_data is set to true.<file_sep># Apache Pinot
Realtime distributed OLAP datastore, designed to answer OLAP queries with low latency.
**[Website](https://pinot.apache.org/)** | **[Documentation](https://docs.pinot.apache.org/)** | **[GitHub](https://github.com/apache/pinot)**
## How to enable?
```
platys init --enable-services PINOT
platys gen
```
## How to use it?
## Cookbooks<file_sep>connector.name=druid
connection-url=jdbc:avatica:remote:url=http://druid-broker-1:8082/druid/v2/sql/avatica/
<file_sep># Grafana Tempo
Grafana Tempo is a high volume, minimal dependency distributed tracing backend.
**[Website](https://grafana.com/oss/tempo/)** | **[Documentation](https://grafana.com/docs/tempo/latest/)** | **[GitHub](https://github.com/grafana/tempo)**
## How to enable?
```
platys init --enable-services TEMPO
platys gen
```
## How to use it?
<file_sep># Apache Kafka CLI
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
This is a container for providing the Kafka CLI without a broker running. It's main use is together with an external Kafka cluster.
**[Website](http://kafka.apache.org)** | **[Documentation](https://kafka.apache.org/documentation)** | **[GitHub](https://github.com/apache/kafka)**
## How to enable?
```
platys init --enable-services KAFKA_CLI
platys gen
```
## How to use?
Connecting to the container for using the CLI's
```bash
docker exec -ti kafka-cli bash
```
Using the `kafka-topics` command to list topics
```bash
docker exec -ti kafka-cli kafka-topics --bootstrap-sever kafka-1:29092 --list
```
<file_sep>package com.trivadis.kafkaws.kstream.countsession;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.kstream.Windowed;
import org.apache.kafka.streams.processor.PunctuationType;
import org.apache.kafka.streams.processor.api.*;
import org.apache.kafka.streams.processor.api.Record;
import org.apache.kafka.streams.state.KeyValueIterator;
import org.apache.kafka.streams.state.KeyValueStore;
import org.apache.kafka.streams.state.StoreBuilder;
import java.time.Duration;
import java.time.Instant;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
public class SuppressWindowProcessor implements ProcessorSupplier<Windowed<String>, Long, String, StateValue> {
StoreBuilder<?> storeBuilder;
public SuppressWindowProcessor(StoreBuilder<?> storeBuilder) {
this.storeBuilder = storeBuilder;
}
@Override
public Processor<Windowed<String>, Long, String, StateValue> get() {
return new SupressWindowProcessor();
}
@Override
public Set<StoreBuilder<?>> stores() {
return ProcessorSupplier.super.stores();
}
class SupressWindowProcessor extends ContextualProcessor <Windowed<String>, Long, String, StateValue> {
private KeyValueStore<String, StateValue> kvStore;
@Override
public void init(ProcessorContext<String, StateValue> context) {
super.init(context);
kvStore = (KeyValueStore) context.getStateStore("suppressed_windowed_transformer");
context().schedule(Duration.ofMillis(2000), PunctuationType.WALL_CLOCK_TIME, timestamp -> flushOldWindow(timestamp));
}
@Override
public void process(Record<Windowed<String>, Long> record) {
if (record.value() == null) {
kvStore.delete(record.key().key());
} else {
System.out.println("Handle " + record.value() + ": " + record.key().window().startTime() + "->" + record.key().window().endTime());
kvStore.put(record.key().key(), new StateValue(record.key().window().startTime(), record.key().window().endTime(), record.value())); //buffer (or suppress) the new in coming window
}
}
private void flushOldWindow(long timestamp) {
List<KeyValue<String, StateValue>> toBeClosedItems = new ArrayList<>();
KeyValueIterator<String, StateValue> iterator = kvStore.all();
while (iterator.hasNext() ) {
KeyValue<String, StateValue> item = iterator.next();
System.out.println("FlushOldWindow(): " + item.value.getStartTime() + ":" + item.value.getEndTime());
if (item.value.getEndTime().isBefore(Instant.now().minusSeconds(15))) {
System.out.println (item.value.getEndTime() + " is older than 15secs");
toBeClosedItems.add(item);
}
}
iterator.close();
//your logic to check for old windows in kvStore then
//forward (or unsuppressed) your suppressed records downstream using ProcessorContext.forward(key, value)
for (KeyValue<String, StateValue> item : toBeClosedItems) {
kvStore.delete(item.key);
System.out.println("Close item:" + item.key + ":" + item.value);
context().forward(new Record<String,StateValue>(item.key, item.value, item.value.getEndTime().toEpochMilli()));
}
}
}
}
<file_sep># Working with Kafka from Kotlin
In this workshop we will learn how to produce and consume messages using the [Kafka Java API](https://kafka.apache.org/documentation/#api).
## Create the project in your favourite IDE
Create a new Maven Project (using the functionality of your favourite IDE) and use `com.trivadis.kafkaws` for the **Group Id** and `kotlin-simple-kafka` for the **Artifact Id**.
Navigate to the **pom.xml** and double-click on it. The POM Editor will be displayed.
You can either use the GUI to edit your pom.xml or click on the last tab **pom.xml** to switch to the "code view". Let's do that.
You will see the still rather empty definition.
```xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trivadis.kafkaws</groupId>
<artifactId>kotlin-simple-kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
</project>
```
Let's add some initial dependencies for our project. We will add some more dependencies to the POM throughout this workshop.
Copy the following block right after the <version> tag, before the closing </project> tag.
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trivadis.kafkaws</groupId>
<artifactId>kotlin-simple-kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>Kotlin Kafka application</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<kotlin.code.style>official</kotlin.code.style>
<kotlin.compiler.jvmTarget>1.8</kotlin.compiler.jvmTarget>
<kotlin.version>1.6.21</kotlin.version>
<kafka.version>2.8.0</kafka.version>
</properties>
<repositories>
<repository>
<id>mavenCentral</id>
<url>https://repo1.maven.org/maven2/</url>
</repository>
</repositories>
<build>
<sourceDirectory>src/main/kotlin</sourceDirectory>
<testSourceDirectory>src/test/kotlin</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-plugin</artifactId>
<version>${kotlin.version}</version>
<executions>
<execution>
<id>compile</id>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test-compile</id>
<phase>test-compile</phase>
<goals>
<goal>test-compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.2</version>
</plugin>
<plugin>
<artifactId>maven-failsafe-plugin</artifactId>
<version>2.22.2</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-stdlib</artifactId>
<version>${kotlin.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.6</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.6</version>
</dependency>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-test-junit5</artifactId>
<version>1.6.20</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.6.0</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
```
## Creating the necessary Kafka Topic
We will use the topic `test-kotlin-topic` in the Producer and Consumer code below. Due to the fact that `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
Connect to the `kafka-1` container
```bash
docker exec -ti kafka-1 bash
```
and execute the necessary kafka-topics command.
```bash
kafka-topics --create \
--replication-factor 3 \
--partitions 12 \
--topic test-kotlin-topic \
--bootstrap-server kafka-1:19092
```
Cross check that the topic has been created.
```bash
kafka-topics --list --bootstrap-server kafka-1:19092
```
This finishes the setup steps and our new project is ready to be used. Next we will start implementing a **Kafka Producer**.
## Create a Kafka Producer
Let's first create a producer in synchronous mode.
### Using the Synchronous mode
First create a new Package `com.trivadis.kafkaws.producer` in the folder **src/main/kotlin**.
Create a new Kotlin File `KafkaProducerSync` in the package `com.trivadis.kafkaws.producer` just created.
Add the following code to the empty file to start with the Kafka Producer, specifying the bootstrap server and topic constants
```kotlin
@file:JvmName("KafkaProducerSync")
package com.trivadis.kafkaws.producer
import org.apache.kafka.clients.producer.KafkaProducer
import org.apache.kafka.clients.producer.ProducerConfig.*
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.clients.producer.RecordMetadata
import org.apache.kafka.common.serialization.LongSerializer
import org.apache.kafka.common.serialization.StringSerializer
import java.time.LocalDateTime
import java.util.*
private val TOPIC = "test-kotlin-topic"
private val BOOTSTRAP_SERVERS = "dataplatform:9092,dataplatform:9093"
```
Kafka provides a synchronous send method to send a record to a topic. Let’s use this method to send a number of messages to the Kafka topic we created earlier
```kotlin
fun runProducer(sendMessageCount: Int, waitMsInBetween: Long, id: Long) {
// Define properties.
val props = Properties()
props[BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVERS
props[ACKS_CONFIG] = "all"
props[KEY_SERIALIZER_CLASS_CONFIG] = LongSerializer::class.qualifiedName
props[VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.qualifiedName
KafkaProducer<Long, String>(props).use { producer ->
repeat(sendMessageCount) { index ->
val time = System.currentTimeMillis();
val value = "[" + id + "] Hello Kafka " + index + " => " + LocalDateTime.now()
val m = producer.send(ProducerRecord(TOPIC, value)).get()
val elapsedTime = System.currentTimeMillis() - time;
println("Produced record to topic ${m.topic()} partition [${m.partition()}] @ offset ${m.offset()} time=${elapsedTime}")
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
producer.flush()
}
}
```
Next you define the main method.
```kotlin
fun main(args: Array<String>) {
if (args.size == 0) {
runProducer(100, 10, 0)
} else {
runProducer(args[0].toInt(), args[1].toLong(), args[2].toLong())
}
}
```
The `main()` method accepts 3 parameters, the number of messages to produce, the time in ms to wait in-between sending each message and the ID of the producer.
Add the `exec-maven-plugin` to the maven plugins
```xml
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<id>producer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.producer.KafkaProducerSync</mainClass>
</configuration>
</execution>
</executions>
</plugin>
```
Now run it using the `mvn exec:java` command. It will generate 1000 messages, waiting 100ms in-between sending each message and use 0 for the ID, which will set the key to `null`.
```bash
mvn clean package -Dmaven.test.skip=true
mvn exec:java@producer -Dexec.args="1000 100 0"
```
**Note**: if your maven version does not support profiles, then you have to specify the main class as well: `mvn exec:java -Dexec.mainClass="com.trivadis.kafkaws.producer.KafkaProducerSync" -Dexec.args="1000 100 0"`
Use `kcat` or `kafka-console-consumer` to consume the messages from the topic `test-kotlin-topic`.
```bash
kcat -b dataplatform -t test-kotlin-topic -f 'Part-%p => %k:%s\n' -q
```
```bash
Part-0 => :[0] Hello Kafka 11 => 2022-06-04T09:59:54.746099
Part-0 => :[0] Hello Kafka 19 => 2022-06-04T09:59:55.714062
Part-0 => :[0] Hello Kafka 22 => 2022-06-04T09:59:56.075383
Part-0 => :[0] Hello Kafka 28 => 2022-06-04T09:59:56.796708
Part-0 => :[0] Hello Kafka 30 => 2022-06-04T09:59:57.059571
Part-0 => :[0] Hello Kafka 36 => 2022-06-04T09:59:57.788802
Part-0 => :[0] Hello Kafka 42 => 2022-06-04T09:59:58.505882
Part-0 => :[0] Hello Kafka 44 => 2022-06-04T09:59:58.749233
Part-0 => :[0] Hello Kafka 51 => 2022-06-04T09:59:59.618871
Part-0 => :[0] Hello Kafka 53 => 2022-06-04T09:59:59.861744
Part-0 => :[0] Hello Kafka 58 => 2022-06-04T10:00:00.495284
Part-0 => :[0] Hello Kafka 63 => 2022-06-04T10:00:01.091603
Part-0 => :[0] Hello Kafka 74 => 2022-06-04T10:00:02.458033
Part-0 => :[0] Hello Kafka 86 => 2022-06-04T10:00:03.933116
Part-2 => :[0] Hello Kafka 1 => 2022-06-04T09:59:53.509753
Part-2 => :[0] Hello Kafka 5 => 2022-06-04T09:59:54.025464
Part-2 => :[0] Hello Kafka 12 => 2022-06-04T09:59:54.874822
Part-2 => :[0] Hello Kafka 20 => 2022-06-04T09:59:55.829419
Part-2 => :[0] Hello Kafka 26 => 2022-06-04T09:59:56.559343
Part-2 => :[0] Hello Kafka 31 => 2022-06-04T09:59:57.180112
Part-2 => :[0] Hello Kafka 35 => 2022-06-04T09:59:57.671466
Part-2 => :[0] Hello Kafka 49 => 2022-06-04T09:59:59.372685
Part-2 => :[0] Hello Kafka 61 => 2022-06-04T10:00:00.840579
Part-2 => :[0] Hello Kafka 69 => 2022-06-04T10:00:01.821051
Part-2 => :[0] Hello Kafka 96 => 2022-06-04T10:00:05.141390
Part-1 => :[0] Hello Kafka 2 => 2022-06-04T09:59:53.639559
Part-1 => :[0] Hello Kafka 14 => 2022-06-04T09:59:55.119045
Part-1 => :[0] Hello Kafka 34 => 2022-06-04T09:59:57.553149
Part-1 => :[0] Hello Kafka 41 => 2022-06-04T09:59:58.382445
Part-1 => :[0] Hello Kafka 45 => 2022-06-04T09:59:58.871874
Part-1 => :[0] Hello Kafka 47 => 2022-06-04T09:59:59.121389
Part-1 => :[0] Hello Kafka 57 => 2022-06-04T10:00:00.378376
Part-1 => :[0] Hello Kafka 60 => 2022-06-04T10:00:00.726158
Part-1 => :[0] Hello Kafka 64 => 2022-06-04T10:00:01.211135
Part-1 => :[0] Hello Kafka 77 => 2022-06-04T10:00:02.842668
Part-1 => :[0] Hello Kafka 80 => 2022-06-04T10:00:03.202738
...
```
### Using the Id field as the key
If we specify an id <> `0` when runnning the producer, the id is used as the key
```kotlin
fun runProducer(sendMessageCount: Int, waitMsInBetween: Int, id: Long) {
// Define properties.
val props = Properties()
props[BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVERS
props[ACKS_CONFIG] = "all"
props[KEY_SERIALIZER_CLASS_CONFIG] = LongSerializer::class.qualifiedName
props[VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.qualifiedName
val key = if (id > 0) id else null
KafkaProducer<Long, String>(props).use { producer ->
repeat(sendMessageCount) { index ->
val time = System.currentTimeMillis();
val value = "[" + id + "] Hello Kafka " + index + " => " + LocalDateTime.now()
val m = producer.send(ProducerRecord(TOPIC, key, value)).get()
```
So let's run it for id=`10`
```bash
mvn exec:java@producer -Dexec.args="1000 100 10"
```
you should see that now all messages will be sent to the same partition.
### Changing to Asynchronous mode
The following kotlin file shows the same logic but this time using the asynchronous way for sending records to Kafka. The difference can be seen in the `runProducerAsync` method.
```kotlin
@file:JvmName("KafkaProducerAsync")
package com.trivadis.kafkaws.producer
import org.apache.kafka.clients.producer.KafkaProducer
import org.apache.kafka.clients.producer.ProducerConfig.*
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.clients.producer.RecordMetadata
import org.apache.kafka.common.serialization.LongSerializer
import org.apache.kafka.common.serialization.StringSerializer
import java.time.LocalDateTime
import java.util.*
private val TOPIC = "test-kotlin-topic"
private val BOOTSTRAP_SERVERS = "dataplatform:9092,dataplatform:9093"
fun runProducerAsync(sendMessageCount: Int, waitMsInBetween: Long, id: Long) {
// Define properties.
val props = Properties()
props[BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVERS
props[ACKS_CONFIG] = "all"
props[KEY_SERIALIZER_CLASS_CONFIG] = LongSerializer::class.qualifiedName
props[VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.qualifiedName
val key = if (id > 0) id else null
KafkaProducer<Long, String>(props).use { producer ->
repeat(sendMessageCount) { index ->
val time = System.currentTimeMillis();
val value = "[" + id + "] Hello Kafka " + index + " => " + LocalDateTime.now()
producer.send(ProducerRecord(TOPIC, key, value)) { m: RecordMetadata, e: Exception? ->
when (e) {
// no exception, good to go!
null -> {
val elapsedTime = System.currentTimeMillis() - time;
println("Produced record to topic ${m.topic()} partition [${m.partition()}] @ offset ${m.offset()} time=${elapsedTime}")
}
// print stacktrace in case of exception
else -> e.printStackTrace()
}
}
}
producer.flush()
}
}
fun main(args: Array<String>) {
if (args.size == 0) {
runProducerAsync(100, 10, 0)
} else {
runProducerAsync(args[0].toInt(), args[1].toLong(), args[2].toLong())
}
}
```
add a new profile to the `pom.xml`
```xml
<execution>
<id>producer-async</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.producer.KafkaProducerAsync</mainClass>
</configuration>
</execution>
```
And now build and run it for id=`10`
```bash
mvn clean package
mvn exec:java@producer-async -Dexec.args="1000 100 10"
```
## Create a Kafka Consumer
Just like we did with the producer, you need to specify bootstrap servers. You also need to define a `group.id` that identifies which consumer group this consumer belongs. Then you need to designate a Kafka record key deserializer and a record value deserializer. Then you need to subscribe the consumer to the topic you created in the producer tutorial.
### Kafka Consumer with Automatic Offset Committing
First create a new Package `com.trivadis.kafkaws.consumer` in the folder **src/main/kotlin**.
Create a new Kotlin file `KafkaConsumerAuto` in the package `com.trivadis.kafkaws.consumer` just created.
Add the following code to the empty class.
Now, that we imported the Kafka classes and defined some constants, let’s create a Kafka producer.
First imported the Kafka classes, define some constants and create the Kafka consumer.
```kotlin
@file:JvmName("KafkaConsumerAuto")
package com.trivadis.kafkaws.consumer
import org.apache.kafka.clients.consumer.ConsumerConfig.*
import org.apache.kafka.clients.consumer.KafkaConsumer
import org.apache.kafka.common.serialization.LongDeserializer
import org.apache.kafka.common.serialization.StringDeserializer
import java.time.Duration
import java.util.*
private val TOPIC = "test-kotlin-topic"
private val BOOTSTRAP_SERVERS = "dataplatform:9092,dataplatform:9093"
fun runConsumer(waitMsInBetween: Long) {
// Define properties.
val props = Properties()
props[BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVERS
props[GROUP_ID_CONFIG] = "kotlin-simple-consumer"
props[AUTO_COMMIT_INTERVAL_MS_CONFIG] = 10000
props[KEY_DESERIALIZER_CLASS_CONFIG] = LongDeserializer::class.qualifiedName
props[VALUE_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.qualifiedName
val consumer = KafkaConsumer<Long, String>(props).apply {
subscribe(listOf(TOPIC))
}
consumer.use {
while(true) {
val messages = consumer.poll(Duration.ofMillis(100))
messages.forEach {
println("Consumed record [Key: ${it.key()}, Value: ${it.value()}] @ Partition: ${it.partition()}, Offset: ${it.offset()}")
}
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
fun main(args: Array<String>) {
if (args.size == 0) {
runConsumer(10)
} else {
runConsumer(args[0].toInt())
}
}
```
We configured the consumer to use the `auto.commit` mode (by not setting it, as it is by default set to `true`) and set the commit interval to `10 seconds`.
Next you define the main method. You can pass the amount of time the consumer spends for processing each record consumed.
```kotlin
fun main(args: Array<String>) {
if (args.size == 0) {
runConsumer(10)
} else {
runConsumer(args[0].toInt())
}
}
```
The main method just calls `runConsumer`.
Before we run the consumer, let's add a configuration in `log4j.properties`, by creating that file in `src/main/resources` and add the following lines
```properties
log4j.rootLogger=INFO, out
# CONSOLE appender not used by default
log4j.appender.out=org.apache.log4j.ConsoleAppender
log4j.appender.out.layout=org.apache.log4j.PatternLayout
log4j.appender.out.layout.ConversionPattern=[%30.30t] %-30.30c{1} %-5p %m%n
log4j.logger.org.apache.kafka.clients.consumer.internals.ConsumerCoordinator=DEBUG
```
If will show a DEBUG message whenever the auto commit is executed.
Before we can run it, add the consumer to the `<executions>` section in the `pom.xml`.
```xml
<execution>
<id>consumer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.consumer.KafkaConsumerAuto</mainClass>
</configuration>
</execution>
```
Now run it using the `mvn exec:java` command.
```bash
mvn clean package -Dmaven.test.skip=true
mvn exec:java@consumer -Dexec.args="0"
```
**Note**: if your maven version does not support profiles, then you have to specify the main class as well: `mvn exec:java -Dexec.mainClass="com.trivadis.kafkaws.consumer.KafkaConsumerAuto" -Dexec.args="0"`
on the console you should see an output similar to the one below, with some Debug messages whenever the auto-commit is happening
```bash
Consumed record [Key: 10, Value: [10] Hello Kafka 155 => 2022-06-04T16:17:54.787506] @ Partition: 3, Offset: 12476
Consumed record [Key: 10, Value: [10] Hello Kafka 156 => 2022-06-04T16:17:54.998856] @ Partition: 3, Offset: 12477
Consumed record [Key: 10, Value: [10] Hello Kafka 157 => 2022-06-04T16:17:55.125173] @ Partition: 3, Offset: 12478
Consumed record [Key: 10, Value: [10] Hello Kafka 158 => 2022-06-04T16:17:55.252868] @ Partition: 3, Offset: 12479
Consumed record [Key: 10, Value: [10] Hello Kafka 159 => 2022-06-04T16:17:55.376300] @ Partition: 3, Offset: 12480
Consumed record [Key: 10, Value: [10] Hello Kafka 160 => 2022-06-04T16:17:55.500777] @ Partition: 3, Offset: 12481
Consumed record [Key: 10, Value: [10] Hello Kafka 161 => 2022-06-04T16:17:55.621729] @ Partition: 3, Offset: 12482
Consumed record [Key: 10, Value: [10] Hello Kafka 162 => 2022-06-04T16:17:55.749756] @ Partition: 3, Offset: 12483
Consumed record [Key: 10, Value: [10] Hello Kafka 163 => 2022-06-04T16:17:55.873920] @ Partition: 3, Offset: 12484
Consumed record [Key: 10, Value: [10] Hello Kafka 164 => 2022-06-04T16:17:56.005853] @ Partition: 3, Offset: 12485
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-kotlin-simple-consumer-1, groupId=kotlin-simple-consumer] Sending asynchronous auto-commit of offsets {test-kotlin-topic-1=OffsetAndMetadata{offset=323, leaderEpoch=null, metadata=''}, test-kotlin-topic-0=OffsetAndMetadata{offset=305, leaderEpoch=null, metadata=''}, test-kotlin-topic-3=OffsetAndMetadata{offset=12486, leaderEpoch=10, metadata=''}, test-kotlin-topic-2=OffsetAndMetadata{offset=320, leaderEpoch=null, metadata=''}, test-kotlin-topic-5=OffsetAndMetadata{offset=289, leaderEpoch=null, metadata=''}, test-kotlin-topic-4=OffsetAndMetadata{offset=1324, leaderEpoch=null, metadata=''}, test-kotlin-topic-7=OffsetAndMetadata{offset=307, leaderEpoch=null, metadata=''}, test-kotlin-topic-6=OffsetAndMetadata{offset=323, leaderEpoch=null, metadata=''}}
Consumed record [Key: 10, Value: [10] Hello Kafka 165 => 2022-06-04T16:17:56.122556] @ Partition: 3, Offset: 12486
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-kotlin-simple-consumer-1, groupId=kotlin-simple-consumer] Committed offset 1324 for partition test-kotlin-topic-4
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-kotlin-simple-consumer-1, groupId=kotlin-simple-consumer] Committed offset 305 for partition test-kotlin-topic-0
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-kotlin-simple-consumer-1, groupId=kotlin-simple-consumer] Committed offset 323 for partition test-kotlin-topic-1
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-kotlin-simple-consumer-1, groupId=kotlin-simple-consumer] Committed offset 289 for partition test-kotlin-topic-5
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-kotlin-simple-consumer-1, groupId=kotlin-simple-consumer] Committed offset 323 for partition test-kotlin-topic-6
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-kotlin-simple-consumer-1, groupId=kotlin-simple-consumer] Committed offset 12486 for partition test-kotlin-topic-3
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-kotlin-simple-consumer-1, groupId=kotlin-simple-consumer] Committed offset 320 for partition test-kotlin-topic-2
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-kotlin-simple-consumer-1, groupId=kotlin-simple-consumer] Committed offset 307 for partition test-kotlin-topic-7
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-kotlin-simple-consumer-1, groupId=kotlin-simple-consumer] Completed asynchronous auto-commit of offsets {test-kotlin-topic-1=OffsetAndMetadata{offset=323, leaderEpoch=null, metadata=''}, test-kotlin-topic-0=OffsetAndMetadata{offset=305, leaderEpoch=null, metadata=''}, test-kotlin-topic-3=OffsetAndMetadata{offset=12486, leaderEpoch=10, metadata=''}, test-kotlin-topic-2=OffsetAndMetadata{offset=320, leaderEpoch=null, metadata=''}, test-kotlin-topic-5=OffsetAndMetadata{offset=289, leaderEpoch=null, metadata=''}, test-kotlin-topic-4=OffsetAndMetadata{offset=1324, leaderEpoch=null, metadata=''}, test-kotlin-topic-7=OffsetAndMetadata{offset=307, leaderEpoch=null, metadata=''}, test-kotlin-topic-6=OffsetAndMetadata{offset=323, leaderEpoch=null, metadata=''}}
Consumed record [Key: 10, Value: [10] Hello Kafka 166 => 2022-06-04T16:17:56.247076] @ Partition: 3, Offset: 12487
```
### Kafka Consumer with Manual Offset Control
Create a new Kotlin file `KafkaConsumerManual` in the package `com.trivadis.kafkaws.consumer` just created by copy-pasting from the class `KafkaConsumerAuto`.
Replace the implementation with the code below.
```kotlin
@file:JvmName("KafkaConsumerManual")
package com.trivadis.kafkaws.consumer
import org.apache.kafka.clients.consumer.ConsumerConfig.*
import org.apache.kafka.clients.consumer.KafkaConsumer
import org.apache.kafka.common.serialization.LongDeserializer
import org.apache.kafka.common.serialization.StringDeserializer
import java.time.Duration
import java.util.*
private val TOPIC = "test-kotlin-topic"
private val BOOTSTRAP_SERVERS = "dataplatform:9092,dataplatform:9093"
fun runConsumerManual(waitMsInBetween: Long) {
// Define properties.
val props = Properties()
props[BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVERS
props[GROUP_ID_CONFIG] = "kotlin-simple-consumer"
props[ENABLE_AUTO_COMMIT_CONFIG] = false
props[KEY_DESERIALIZER_CLASS_CONFIG] = LongDeserializer::class.qualifiedName
props[VALUE_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.qualifiedName
val consumer = KafkaConsumer<Long, String>(props).apply {
subscribe(listOf(TOPIC))
}
consumer.use {
while(true) {
val messages = consumer.poll(Duration.ofMillis(100))
messages.forEach {
println("Consumed record [Key: ${it.key()}, Value: ${it.value()}] @ Partition: ${it.partition()}, Offset: ${it.offset()}")
}
consumer.commitSync();
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
fun main(args: Array<String>) {
if (args.size == 0) {
runConsumerManual(10)
} else {
runConsumerManual(args[0].toInt())
}
}
```
Before we can run it, add the consumer to the `<executions>` section in the `pom.xml`.
```xml
<execution>
<id>consumer-manual</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.consumer.KafkaConsumerManual</mainClass>
</configuration>
</execution>
```
Now run it using the `mvn exec:java` command.
```bash
mvn clean package -Dmaven.test.skip=true
mvn exec:java@consumer-manual -Dexec.args="0"
```
## Try running Producer and Consumer
Run the consumer from your IDE or Terminal (Maven). Then run the producer from above from your IDE or Terminal (Maven). You should see the consumer get the records that the producer sent.
### Three Consumers in same group and one Producer sending 25 messages
Start the consumer 3 times by executing the following command in 3 different terminal windows.
```bash
mvn exec:java@consumer -Dexec.args="0"
```
and then start the producer
```bash
mvn exec:java@producer -Dexec.args="25 0 0"
```
#### Producer Output
```bash
[0] sent record(key=null value=[0] Hello Kafka 0) meta(partition=0, offset=284) time=804
[0] sent record(key=null value=[0] Hello Kafka 1) meta(partition=2, offset=283) time=27
[0] sent record(key=null value=[0] Hello Kafka 2) meta(partition=5, offset=284) time=11
[0] sent record(key=null value=[0] Hello Kafka 3) meta(partition=4, offset=1284) time=65
[0] sent record(key=null value=[0] Hello Kafka 4) meta(partition=7, offset=284) time=26
[0] sent record(key=null value=[0] Hello Kafka 5) meta(partition=1, offset=283) time=8
[0] sent record(key=null value=[0] Hello Kafka 6) meta(partition=3, offset=283) time=18
[0] sent record(key=null value=[0] Hello Kafka 7) meta(partition=6, offset=283) time=16
[0] sent record(key=null value=[0] Hello Kafka 8) meta(partition=0, offset=285) time=19
[0] sent record(key=null value=[0] Hello Kafka 9) meta(partition=2, offset=284) time=17
[0] sent record(key=null value=[0] Hello Kafka 10) meta(partition=5, offset=285) time=21
[0] sent record(key=null value=[0] Hello Kafka 11) meta(partition=4, offset=1285) time=11
[0] sent record(key=null value=[0] Hello Kafka 12) meta(partition=7, offset=285) time=7
[0] sent record(key=null value=[0] Hello Kafka 13) meta(partition=1, offset=284) time=15
[0] sent record(key=null value=[0] Hello Kafka 14) meta(partition=3, offset=284) time=21
[0] sent record(key=null value=[0] Hello Kafka 15) meta(partition=6, offset=284) time=18
[0] sent record(key=null value=[0] Hello Kafka 16) meta(partition=0, offset=286) time=12
[0] sent record(key=null value=[0] Hello Kafka 17) meta(partition=2, offset=285) time=18
[0] sent record(key=null value=[0] Hello Kafka 18) meta(partition=5, offset=286) time=9
[0] sent record(key=null value=[0] Hello Kafka 19) meta(partition=4, offset=1286) time=4
[0] sent record(key=null value=[0] Hello Kafka 20) meta(partition=7, offset=286) time=7
[0] sent record(key=null value=[0] Hello Kafka 21) meta(partition=1, offset=285) time=17
[0] sent record(key=null value=[0] Hello Kafka 22) meta(partition=3, offset=285) time=14
[0] sent record(key=null value=[0] Hello Kafka 23) meta(partition=6, offset=285) time=8
[0] sent record(key=null value=[0] Hello Kafka 24) meta(partition=0, offset=287) time=16
```
#### Consumer 1 Output (same consumer group)
```bash
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 0, Partition: 0, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 1, Partition: 2, Offset: 283)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 5, Partition: 1, Offset: 283)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 8, Partition: 0, Offset: 285)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 9, Partition: 2, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 13, Partition: 1, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 16, Partition: 0, Offset: 286)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 17, Partition: 2, Offset: 285)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 21, Partition: 1, Offset: 285)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 24, Partition: 0, Offset: 287)
```
#### Consumer 2 Output (same consumer group)
```bash
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 2, Partition: 5, Offset: 284)
2 - Consumer Record:(Key: null, Value: [0] Hello Kafka 6, Partition: 3, Offset: 283)
2 - Consumer Record:(Key: null, Value: [0] Hello Kafka 3, Partition: 4, Offset: 1284)
2 - Consumer Record:(Key: null, Value: [0] Hello Kafka 10, Partition: 5, Offset: 285)
2 - Consumer Record:(Key: null, Value: [0] Hello Kafka 11, Partition: 4, Offset: 1285)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 14, Partition: 3, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 18, Partition: 5, Offset: 286)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 19, Partition: 4, Offset: 1286)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 22, Partition: 3, Offset: 285)
```
#### Consumer 3 Output (same consumer group)
```bash
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 4, Partition: 7, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 7, Partition: 6, Offset: 283)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 12, Partition: 7, Offset: 285)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 15, Partition: 6, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 20, Partition: 7, Offset: 286)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 23, Partition: 6, Offset: 285)
```
**Questions**
- Which consumer owns partition 10?
- How many ConsumerRecords objects did Consumer 0 get?
- What is the next offset from Partition 11 that Consumer 2 should get?
- Why does each consumer get unique messages?
### Three Consumers in same group and one Producer sending 10 messages using key
Start the consumer 3 times by executing the following command in 3 different terminal windows.
```bash
mvn exec:java@consumer -Dexec.args="0"
```
and then start the producer (using 10 for the ID)
```bash
mvn exec:java@producer -Dexec.args="1000 100 10"
```
#### Producer Output
```bash
[10] sent record(key=10 value=[10] Hello Kafka 0) meta(partition=3, offset=289) time=326
[10] sent record(key=10 value=[10] Hello Kafka 1) meta(partition=3, offset=290) time=7
[10] sent record(key=10 value=[10] Hello Kafka 2) meta(partition=3, offset=291) time=3
[10] sent record(key=10 value=[10] Hello Kafka 3) meta(partition=3, offset=292) time=3
[10] sent record(key=10 value=[10] Hello Kafka 4) meta(partition=3, offset=293) time=3
[10] sent record(key=10 value=[10] Hello Kafka 5) meta(partition=3, offset=294) time=2
[10] sent record(key=10 value=[10] Hello Kafka 6) meta(partition=3, offset=295) time=2
[10] sent record(key=10 value=[10] Hello Kafka 7) meta(partition=3, offset=296) time=2
[10] sent record(key=10 value=[10] Hello Kafka 8) meta(partition=3, offset=297) time=2
[10] sent record(key=10 value=[10] Hello Kafka 9) meta(partition=3, offset=298) time=3
```
#### Consumer 1 Output (same consumer group)
nothing consumed
#### Consumer 2 Output (same consumer group)
```bash
1 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 0, Partition: 3, Offset: 299)
3 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 1, Partition: 3, Offset: 300)
3 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 2, Partition: 3, Offset: 301)
3 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 3, Partition: 3, Offset: 302)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 4, Partition: 3, Offset: 303)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 5, Partition: 3, Offset: 304)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 6, Partition: 3, Offset: 305)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 7, Partition: 3, Offset: 306)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 8, Partition: 3, Offset: 307)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 9, Partition: 3, Offset: 308)
```
#### Consumer 3 Output (same consumer group)
nothing consumed
**Questions**
- Why is consumer 2 the only one getting data?
<file_sep>package com.trivadis.kafkaws.serde;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.common.serialization.Deserializer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
import java.util.Map;
public class JsonDeserializer<T> implements Deserializer<T> {
private Logger logger = LogManager.getLogger(this.getClass());
private Class <T> type;
public JsonDeserializer(Class type) {
this.type = type;
}
@Override
public void configure(Map map, boolean b) {
}
@Override
public T deserialize(String s, byte[] bytes) {
ObjectMapper mapper = new ObjectMapper();
T obj = null;
try {
obj = mapper.readValue(bytes, type);
} catch (Exception e) {
logger.error(e.getMessage());
}
return obj;
}
@Override
public void close() {
}
}<file_sep># Postman
Postman is an API platform for building and using APIs. Postman simplifies each step of the API lifecycle and streamlines collaboration so you can create better APIs—faster.
**[Website](https://www.postman.com/)** | **[Documentation](https://learning.postman.com/docs/getting-started/introduction/)** | **[GitHub](https://github.com/postmanlabs/postman-runtime)**
## How to enable?
```
platys init --enable-services POSTMAN
platys gen
```
## How to use it?
Navigate to <http://dataplatform:3010><file_sep>package com.trivadis.kafkaws.springcloudstreamkafkaproduceravro;
import com.trivadis.kafkaws.avro.v1.Notification;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.stream.messaging.Processor;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Component;
@Component
public class KafkaEventProducer {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaEventProducer.class);
@Autowired
private Processor processor;
@Value("${topic.name}")
String kafkaTopic;
public void produce(Integer id, Long key, Notification notification) {
long time = System.currentTimeMillis();
Message<Notification> message = MessageBuilder.withPayload(notification)
.setHeader(KafkaHeaders.MESSAGE_KEY, key)
.build();
processor.output()
.send(message);
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) time=%d\n",key, notification,elapsedTime);
}
}<file_sep># Memcached
Free & open source, high-performance, distributed memory object caching system, generic in nature, but intended for use in speeding up dynamic web applications by alleviating database load.
**[Website](https://memcached.org/)** | **[Documentation](https://memcached.org/)** | **[GitHub](https://github.com/memcached/memcached)**
## How to enable?
```
platys init --enable-services MEMCACHED
platys gen
```
## How to use it?
<file_sep># Oracle Database Free
Oracle Database 23c Free—Developer Release is the same, powerful Oracle Database that businesses throughout the world rely on. It offers a full-featured experience and is packaged for ease of use and simple download—for free.
**[Website](https://www.oracle.com/database/free/)** | **[Documentation](https://www.oracle.com/database/free/get-started/)** | **[Docker Image](https://github.com/gvenzl/oci-oracle-free)** | **[Docker Image Details](https://github.com/gvenzl/oci-oracle-free/blob/main/ImageDetails)**
## How to enable?
```
platys init --enable-services ORACLE_FREE
platys gen
```
## Initialize database
You can initialize the database automatically by putting the necessary scripts in `./init/oracle-free`:
To create more users, add a bash script, e.g. `01_create-user.sh`
```bash
#!/bin/bash
#
./createAppUser user1 abc123!
./createAppUser user2 abc123!
```
to create schema objects, add an sql script, e.g. `02_create-user1-schema.sql`
```sql
CONNECT user1/abc123!@//localhost/FREEPDB1
DROP TABLE person_t IF EXISTS;
CREATE TABLE person_t (
business_entity_id INTEGER PRIMARY KEY,
person_type VARCHAR2(100),
name_style VARCHAR2(1),
title VARCHAR2(20),
first_name VARCHAR2(100),
middle_name VARCHAR2(100),
last_name VARCHAR2(100),
email_promotion NUMBER(10),
demographics VARCHAR2(2000),
created_date TIMESTAMP,
modified_date TIMESTAMP);
```
## How to use it?
### Connect through SQL Plus
```
docker exec -ti oracledb-free sqlplus "user1/abc123!"@//localhost/FREEPDB1
```
### Connect through JDBC
* **JDBC Url:** `jdbc:oracle:thin:@dataplatform:1523/FREEPDB1`
* **JDBC Driver Class Name:** `oracle.jdbc.driver.OracleDriver`
<file_sep>package com.trivadis.kafkaws.springbootkafkastreams.simple;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.Printed;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.kafka.StreamsBuilderFactoryBeanCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Profile;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.annotation.EnableKafkaStreams;
import org.springframework.kafka.config.KafkaStreamsConfiguration;
import org.springframework.kafka.config.KafkaStreamsCustomizer;
import org.springframework.kafka.config.StreamsBuilderFactoryBean;
import org.springframework.stereotype.Component;
import java.util.Properties;
@Component
//@EnableKafka
//@EnableKafkaStreams
@Configuration
//@SpringBootApplication(scanBasePackages = {"com.trivadis.kafkaws.springbootkafkastreams.simple"})
public class KafkaStreamsRunnerDSL {
private static final Logger LOG = LoggerFactory.getLogger(KafkaStreamsRunnerDSL.class);
@Autowired
private StreamsBuilderFactoryBean factoryBean;
private static final String INPUT_TOPIC_NAME = "test-kstream-spring-input-topic";
private static final String OUTPUT_TOPIC_NAME = "test-kstream-spring-output-topic";
@Bean
@Profile("upper")
public KStream buildPipeline (StreamsBuilder kStreamBuilder) {
KStream<Void, String> stream = kStreamBuilder.stream(INPUT_TOPIC_NAME);
stream.foreach(
(key, value) -> {
System.out.println("(From DSL) " + value);
});
// transform the values to upper case
KStream<Void, String> upperStream = stream.mapValues(value -> value.toUpperCase());
// you can also print using the `print` operator
upperStream.print(Printed.<Void, String>toSysOut().withLabel("upperValue"));
upperStream.to(OUTPUT_TOPIC_NAME);
return upperStream;
}
@Bean
KafkaStreamsCustomizer getKafkaStreamsCustomizer() {
return kafkaStreams -> kafkaStreams.setStateListener((newState, oldState) -> {
if (newState == KafkaStreams.State.RUNNING) {
LOG.info("Streams now in running state");
kafkaStreams.localThreadsMetadata().forEach(tm -> LOG.info("{} assignments {}", tm.threadName(), tm.activeTasks()));
}
});
}
@Bean
StreamsBuilderFactoryBeanCustomizer kafkaStreamsCustomizer() {
return streamsFactoryBean -> streamsFactoryBean.setKafkaStreamsCustomizer(getKafkaStreamsCustomizer());
}
}
<file_sep># Microcks
Microcks is a platform for turning your API and microservices assets - OpenAPI specs, AsyncAPI specs, Postman collections, SoapUI projects - into live mocks in seconds.
**[Website](https://microcks.io/)** | **[Documentation](https://microcks.io/documentation/)** | **[GitHub](https://github.com/microcks/microcks)**
## How to enable?
```
platys init --enable-services MICROCKS
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28203><file_sep># Graphdb
GraphDB is an enterprise ready Semantic Graph Database, compliant with W3C Standards. Semantic graph databases (also called RDF triplestores) provide the core infrastructure for solutions where modelling agility, data integration, relationship exploration and cross-enterprise data publishing and consumption are important.
**[Website](https://graphdb.ontotext.com/)** | **[Documentation](https://graphdb.ontotext.com/documentation/free/)**
## How to enable?
```
platys init --enable-services GRAPHDB
platys gen
```
## How to use it?
Navigate to <http://dataplatform:17200><file_sep># Firefox
Firefox running as a Docker container.
**[Website](https://www.mozilla.org/en-US/firefox/new/)** | **[Documentation](https://www.mozilla.org/en-US/firefox/new/)**
## How to enable?
```
platys init --enable-services FIREFOX
platys gen
```
## How to use it?
Navigate to <http://dataplatform:5801><file_sep>---
technoglogies: trino,minio,adls,azure
version: 1.15.0
validated-at: 14.7.2022
---
# Querying data in Azure Data Lake Storage Gen2 from Trino (formerly PrestoSQL)
This tutorial will show how to query Azure Data Lake Storage Gen2 (ADLS) with Hive and Trino.
## Initialise a platform
First [initialise a platys-supported data platform](../../getting-started) with the following services enabled
```
platys init --enable-services TRINO,HIVE_METASTORE,AZURECLI,PROVISIONING_DATA -s trivadis/platys-modern-data-platform -w 1.15.0
```
add the following property to `config.yml`
```
TRINO_edition: 'oss'
```
Now generate and start the data platform.
```bash
platys gen
docker-compose up -d
```
## Create Data in Azure Data Lake Storage
first login using
```bash
docker exec -ti azurecli az login
```
Navigate to the website as requested and enter the code provided by the login command and authenticate yourself to Azure.
Now create the container
```
docker exec -ti azurecli az storage fs create -n flight-data --account-name gusstorage --auth-mode login
```
create some folders
```bash
docker exec -ti azurecli az storage fs directory create -n /landing/airports/ -f flight-data --account-name gusstorage
docker exec -ti azurecli az storage fs directory create -n /landing/plane/ -f flight-data --account-name gusstorage
```
and upload some data
```bash
docker exec -ti azurecli az storage fs file upload -s "data-transfer/flight-data/airports.json" -p /landing/airports/airports.json -f flight-data --account-name gusstorage
docker exec -ti azurecli az storage fs file upload -s "data-transfer/flight-data/plane-data.json" -p /landing/plane/plane-data.json -f flight-data --account-name gusstorage
```
## Create a table in Hive
On the docker host, start the Hive CLI
```
docker exec -ti hive-metastore hive
```
and create a new database `flight_db` and in that database a table `plane_t`:
```
create database flight_db;
use flight_db;
CREATE EXTERNAL TABLE plane_t (tailnum string
, type string
, manufacturer string , issue_date string
, model string
, status string
, aircraft_type string
, engine_type string
, year string )
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
LOCATION 'abfs://flight-data@gusstorage.dfs.core.windows.net/landing/plane';
```
## Query Table from Trino
Next let's query the data from Trino. Connect to the Trino CLI using
```
docker exec -it trino-cli trino --server trino-1:8080
```
Now on the Trino command prompt, switch to the right database.
```
use adls.flight_db;
```
Let's see that there is one table available:
```
show tables;
```
We can see the `plane_t` table we created in the Hive Metastore before
```
presto:default> show tables;
Table
---------------
plane_t
(1 row)
```
```
SELECT * FROM plane_t;
```
```
SELECT year, count(*)
FROM plane_t
GROUP BY year;
```<file_sep>---
technoglogies: kafka-connect,kafka
version: 1.14.0
validated-at: 27.2.2022
---
# Using a Kafka Connect Connector not in Confluent Hub
This recipe will show how to use a Kafka Connect connector JAR which is not available in [Confluent Hub](https://www.confluent.io/hub). Popular connector not available there are the ones offered as the [Stream Reactor](https://github.com/lensesio/stream-reactor) project.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services KAFKA,KAFKA_CONNECT -s trivadis/platys-modern-data-platform -w 1.13.0
```
start the platform
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Download the Connector
Navigate into the kafka-connect folder
```bash
cd plugins/kafka-connect/connectors
```
and download the a conector JAR from the Landoop Stream-Reactor Project project (here we are using the MQTT connector, but it works in the same way for any other connector)
```bash
wget https://github.com/Landoop/stream-reactor/releases/download/2.1.3/kafka-connect-mqtt-2.1.3-2.5.0-all.tar.gz
```
Once it is successfully downloaded, uncompress it using this tar command and remove the file.
```bash
mkdir kafka-connect-mqtt-2.-2.1.0-all && tar xvf kafka-connect-mqtt-1.2.3-2.1.0-all.tar.gz -C kafka-connect-mqtt-1.2.3-2.1.0-all
rm kafka-connect-mqtt-1.2.3-2.1.0-all.tar.gz
```
Now let's restart Kafka connect in order to pick up the new connector.
```bash
cd ../..
docker-compose restart kafka-connect-1 kafka-connect-2
```
The connector has now been added to the Kafka cluster. You can confirm that by watching the log file of the two containers:
```
docker-compose logs -f kafka-connect-1 kafka-connect-2
```<file_sep># MinIO Console
The MinIO Console is a rich graphical user interface that provides similar functionality to the mc command line tool. You can use the MinIO Console for administration tasks like Identity and Access Management, Metrics and Log Monitoring, or Server Configuration.
**[Website](https://min.io/)** | **[Documentation](https://docs.min.io/minio/baremetal/console/minio-console.html)** | **[GitHub](https://github.com/minio/console)**
## How to enable?
```
platys init --enable-services MINIO_CONSOLE
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28193>
<file_sep># Grafana
The open and composable observability and data visualization platform. Visualize metrics, logs, and traces from multiple sources like Prometheus, Loki, Elasticsearch, InfluxDB, Postgres and many more.
**[Website](https://grafana.com/oss/grafana/)** | **[Documentation](https://grafana.com/grafana/)** | **[GitHub](https://github.com/grafana/grafana)**
### How to enable?
```
platys init --enable-services GRAFANA
platys gen
```
### How to use it?
Navigate to <http://dataplatform:3000> and login with user `admin` and password `<PASSWORD>!`.
<file_sep># Kafka Magic
Kafka Magic is a GUI tool for working with Apache Kafka clusters. It can find and display messages, transform and move messages between topics, review and update schemas, manage topics, and automate complex tasks.
**[Website](https://www.kafkamagic.com/)** | **[Documentation](https://www.kafkamagic.com/)**
## How to enable?
```
platys init --enable-services KAFKA_MAGIC
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28254><file_sep># Lenses Box
Lenses Box is a Docker image which contains Lenses and a full installation of Kafka with all its relevant components. The image packs Lenses’ Stream Reactor Connector collection as well. It is all pre-setup and the only requirement is having Docker installed. It contains Lenses, Kafka Broker, Schema Registry, Kafka Connect, 25+ Kafka Connectors with SQL support and various CLI tools.
**[Website](https://lenses.io/)** | **[Documentation](https://docs.lenses.io/3.0/dev/lenses-box/)** | **[GitHub](https://github.com/lensesio/fast-data-dev)**
## How to enable?
```
platys init --enable-services LENSES_BOX
platys gen
```
Add the `LENSES_BOX_license` property with the license information you have gotten per email from <lenses.io>.
## How to use it?
Navigate to <http://dataplatform:3030> and login with admin/admin.
<file_sep>---
technologies: spark,iceberg
version: 1.16.0
validated-at: 20.02.2023
---
# Spark with Apache Iceberg
This recipe will show how to use a Spark cluster together with the [Apache Iceberg](https://iceberg.apache.org) table format. We will be using the Python and SQL API.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services SPARK,ZEPPELIN,MINIO,AWSCLI,PROVISIONING_DATA -s trivadis/platys-modern-data-platform -w 1.16.0
```
Before we can generate the platform, we need to extend the `config.yml`:
Specify the table format to use as Iceberg.
```
SPARK_table_format_type: 'iceberg'
```
Platys automatically makes sure that the right version according to [Using Iceberg in Spark 3](https://iceberg.apache.org/docs/latest/getting-started/#using-iceberg-in-spark-3) is used.
Now set an environment variable to the home folder of the dataplatform and generate and then start the data platform.
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Prepare some data in Object storage
Create the flight bucket:
```bash
docker exec -ti awscli s3cmd mb s3://flight-bucket
```
Now upload the airports to the bucket
```bash
docker exec -ti awscli s3cmd put /data-transfer/flight-data/airports.csv s3://flight-bucket/raw/airports/airports.csv
```
## Working with Iceberg from Zeppelin
Navigate to Zeppelin <http://dataplatform:28080> and login as user `admin` with password `<PASSWORD>!`.
Create a new notebook and add and execute the following commands:
Import necessary modules
```python
%pyspark
from pyspark.sql.types import DoubleType, FloatType, LongType, StructType,StructField, StringType
```
Load the raw Airport data in the CSV format into a data frame
```python
%pyspark
airportsRawDF = spark.read.csv("s3a://flight-bucket/raw/airports",
sep=",", inferSchema="true", header="true")
airportsRawDF.show(5)
```
add
```python
%pyspark
airportsRawDF.withColumnRenamed('lat','latitude').withColumnRenamed('long','longitude').createOrReplaceTempView("airports_raw")
```
create a new Iceberg table, using the `CREATE TABLE` Spark SQL statement
```sql
%sql
CREATE TABLE iceberg.db.airports_t (iata string
, airport string
, city string
, state string
, country string
, latitude double
, longitude double)
USING ICEBERG;
```
Use the iceberg table in a SQL statement
```sql
%sql
SELECT * FROM iceberg.db.airports_t;
```
Append the raw data loaded before to the Iceberg table.
```python
%pyspark
airportsRawDF.withColumnRenamed('lat','latitude').withColumnRenamed('long','longitude').writeTo("iceberg.db.airports_t").append()
```
We have to rename the columns to fit with the structure of the table.
Now select the data again to check the update
```sql
%sql
SELECT * FROM airports_t;
```
We could have achieved the same using the following SQL INSERT statement
```sql
%sql
INSERT INTO iceberg.db.airports_t
SELECT iata, airport, city, state, country, latitude, longitude FROM airports_raw;
```
Instead of just appending data, we can also use a SQL MERGE to merge data from a source table into the target Iceberg table
```sql
%sql
MERGE INTO iceberg.db.airports_t t USING (SELECT * FROM airports_raw) u ON u.iata = t.iata
WHEN MATCHED THEN
UPDATE SET t.airport = u.airport, t.city = u.city, t.state = u.state, t.country = u.country, t.latitude = u.latitude, t.longitude = u.longitude
WHEN NOT MATCHED
THEN INSERT *
```
<file_sep># Remora
Kafka consumer lag-checking application for monitoring, written in Scala and Akka HTTP; a wrap around the Kafka consumer group command. Integrations with Cloudwatch and Datadog. Authentication recently added
**[Documentation](https://github.com/zalando-incubator/remora)** | **[GitHub](https://github.com/zalando-incubator/remora)**
## How to enable?
```
platys init --enable-services KAFKA,REMORA
platys gen
```
## How to use it?
Show active consumers
```bash
curl http://dataplatform:28256/consumers
```
Show specific consumer group information
```bash
curl http://dataplatform:28256/consumers/<consumer-group-id>
```
Show health
```bash
curl http://dataplatform:28256/health
```
Metrics
```bash
curl http://dataplatform:28256/metrics
```
<file_sep># Adminio UI
This is a Web UI for minio s3 server. Web UI works on top of REST API - adminio-API.
**[Documentation](https://github.com/rzrbld/adminio-ui/)** | **[GitHub](https://github.com/rzrbld/adminio-ui)**
## How to enable?
```
platys init --enable-services ADMINIO_UI
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28190><file_sep>connector.name=hive
hive.metastore.uri=thrift://hive-metastore:9083
hive.s3.path-style-access=${ENV:S3_PATH_STYLE_ACCESS}
hive.s3.endpoint=${ENV:S3_ENDPOINT}
hive.s3.aws-access-key=${ENV:S3_AWS_ACCESS_KEY}
hive.s3.aws-secret-key=${ENV:S3_AWS_SECRET_KEY}
hive.non-managed-table-writes-enabled=true
hive.s3.ssl.enabled=false
hive.s3select-pushdown.enabled=true
hive.storage-format=${ENV:HIVE_STORAGE_FORMAT}
hive.compression-codec=${ENV:HIVE_COMPRESSION_CODEC}
hive.allow-drop-table=true
hive.metastore.thrift.delete-files-on-drop=true
hive.hive-views.enabled=${ENV:HIVE_VIEWS_ENABLED}
hive.hive-views.run-as-invoker=${ENV:HIVE_RUN_AS_INVOKER}
hive.hive-views.legacy-translation=${ENV:HIVE_LEGACY_TRANSLATION}
<file_sep># Anaconda
Anaconda Distribution is a Python/R data science distribution and a collection of over 7,500+ open-source packages, which includes a package and environment manager. Anaconda Distribution is platform-agnostic, so you can use it whether you are on Windows, macOS, or Linux. It’s also is free to install and offers free community support.
**[Website](https://www.anaconda.com/)** | **[Documentation](https://docs.anaconda.com/#)** | **[GitHub](https://github.com/jupyter/notebook)**
## How to enable?
```
platys init --enable-services ANACONDA
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28889>. The token for the login has either be specified in the `config.yml` (`ANACONDA_JUPYTER_token`) or if not set, the generated token can be retrieved from the log (`docker logs -f anaconda`).
<file_sep>connector.name=tpcds
tpcds.split-per-node=4
<file_sep># Apache NiFi Registry
A subproject of Apache NiFi to store and manage shared resources.
**[Website](https://nifi.apache.org/registry.html)** | **[Documentation](https://nifi.apache.org/registry.html)** | **[GitHub](https://github.com/apache/nifi)**
## How to enable?
```bash
platys init --enable-services NIFI,NIFI_REGISTRY
platys gen
```
## How to use it?
Navigate to <http://${PUBLIC_IP}:19090/nifi-registry>
<file_sep># NocoDB
Open Source Airtable Alternative - turns any MySQL, Postgres, SQLite into a Spreadsheet with REST APIs.
**[Website](https://nocodb.com/)** | **[Documentation](https://docs.nocodb.com/)** | **[GitHub](https://github.com/nocodb/nocodb)**
## How to enable?
```
platys init --enable-services NOCODB
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28276><file_sep>Contains the database folder of nidi-registry service, if flag NIFI_REGISTRY_volume_map_data is set to true.<file_sep>Place otel-collector-config.yaml file here to configure otel collector.<file_sep># Stardog
Dgraph is the simplest way to implement a GraphQL backend for your applications. Everything you need to build apps, unite your data, and scale your operations is included, out-of-the-box.
**[Website](https://www.stardog.com/)** | **[Documentation](https://docs.stardog.com/)**
## How to enable?
```
platys init --enable-services STARDOG
platys gen
```
## How to use it?
Navigate to <http://dataplatform:5820><file_sep># Neo4J
Neo4j gives developers and data scientists the most trusted and advanced tools to quickly build today’s intelligent applications and machine learning workflows. Available as a fully managed cloud service or self-hosted.
**[Website](https://neo4j.com/)** | **[Documentation](https://neo4j.com/docs/)** | **[GitHub](https://github.com/neo4j/neo4j)**
## How to enable?
```
platys init --enable-services NEO4J
platys gen
```
## How to use it?
Navigate to <http://dataplatform:7474> to use the Neo4J Browser.
To use the `cypher-shell`, in a terminal window execute
```bash
docker exec -ti neo4j-1 ./bin/cypher-shell -u neo4j -p abc123abc123
```
<file_sep># Azure CLI
Azure Command-Line Interface
**[Website](https://docs.microsoft.com/en-us/cli/azure/)** | **[Documentation](https://docs.microsoft.com/en-us/cli/azure/)** | **[GitHub](https://github.com/Azure/azure-cli)**
## How to enable?
```
platys init --enable-services AZURECLI
platys gen
```
## How to use it?
Within the container, you can either use the `az` command line interface.
<file_sep>---
technoglogies: kafka
version: 1.14.0
validated-at: 31.12.2021
---
# Simulated Multi-DC Setup on one machine
This recipe will show how to setup a 2 datacenter Kafka platform on the same machine using docker compose and platys.
## Initialise data platform
We will create two different platforms, each one in its own directory, and configure them so that the service names are not overlapping.
### Data Center 1
Let's [initialise a platys-supported data platform](../../../documentation/getting-started) with the following services enabled
```bash
platys init --enable-services KAFKA,KAFKA_AKHQ -s trivadis/platys-modern-data-platform -w 1.14.0
```
Rename the `config.yml` file to include the datacenter (`dc1`)
```bash
mv config.yml config-dc1.yml
```
Edit the `config-dc1.yml` file and add the two global properties `data_centers` and `data_center_to_use` and change the header as shown below:
```
# Default values for the generator
# this file can be used as a template for a custom configuration
# or to know about the different variables available for the generator
platys:
platform-name: 'dc1-platform'
platform-stack: 'trivadis/platys-modern-data-platform'
platform-stack-version: '1.14.0'
structure: 'subfolder'
# ========================================================================
# Global configuration, valid for all or a group of services
# ========================================================================
# Timezone, use a Linux string such as Europe/Zurich or America/New_York
use_timezone: ''
# the name of the repository to use for private images, which are not on docker hub (currently only Oracle images)
private_docker_repository_name: 'trivadis'
data_centers: 'dc1,dc2'
data_center_to_use: 1
#
# ===== Apache Kafka ========
#
KAFKA_enable: true
#
# ===== Apache Kafka HQ ========
#
KAFKA_AKHQ_enable: true
```
The `data_center_to_use` property specifies that this configuration is for the first datacenter, which is named `dc1` by the `data_centers` list property.
Using `subfolder` for the `structure` will generate the platform inside a subfolder named according to the `platform-name`.
Generate the stack using the `-c` option to specify the config file to use
```bash
platys gen -c ${PWD}/config-dc1.yml
```
You should now have a subfolder named `dc1-platform`
```bash
docker@ubuntu:~/platys-cookbook$ ls -lsa
total 16
4 drwxrwxr-x 3 docker docker 4096 Dec 31 09:12 .
4 drwxr-xr-x 61 docker docker 4096 Dec 31 03:02 ..
4 -rwxr-xr-x 1 docker docker 1122 Dec 31 09:12 config-dc1.yml
4 drwxrwxr-x 12 docker docker 4096 Dec 31 09:12 dc1-platform
```
Navigate into this folder and start the stack for `dc1`
```bash
docker-compose -f dc1-platform/docker-compose.yml up -d
```
### Data Center 2
For data center 2, we could also go trough the `platys init` as before, but we can also just copy the configuration file and adapt it, like shown here
```bash
cp config-dc1.yml config-dc2.yml
```
now edit `config-dc2.yml` and change the property `platform-name` and `data_center_to_use` to specfiy data center 2:
```yaml
platys:
platform-name: 'dc2-platform'
...
data_center_to_use: 2
```
Generate the stack using the `-c` option to specify the config file to use
```bash
platys gen -c ${PWD}/config-dc2.yml
```
You should now have an additional subfolder named `dc2-platform`
```bash
docker@ubuntu:~/platys-cookbook$ ls -lsa
total 16
4 drwxrwxr-x 3 docker docker 4096 Dec 31 09:12 .
4 drwxr-xr-x 61 docker docker 4096 Dec 31 03:02 ..
4 -rwxr-xr-x 1 docker docker 1122 Dec 31 09:12 config-dc1.yml
4 -rwxr-xr-x 1 docker docker 1122 Dec 31 09:18 config-dc2.yml
4 drwxrwxr-x 12 docker docker 4096 Dec 31 09:12 dc1-platform
4 drwxrwxr-x 12 docker docker 4096 Dec 31 09:20 dc2-platform
```
Navigate into this folder and start the stack for `dc2`
```bash
docker-compose -f dc2-platform/docker-compose.yml up -d
```
We have now 2 different stacks running, each one representing one data center.
### Work with the two data centers and Kafka
Both stack have their own home page generated. You can find them on port `80` and `81`:
* **DC1**
* Homepage: <http://dataplatform:80>
* Service List: <http://dataplatform:80/services>
* **DC2**
* Homepage: <http://dataplatform:81>
* Service List: <http://dataplatform:81/services>
### Restrictions
Currently only [Zookeeper](../../../documentation/services/zookeeper), [Kafka Borker](../../../documentation/services/kafka), [Control Center](../../../documentation/services/confluent-control-center), [CMAK](../../../documentation/services/cmak), [AKHQ](../../../documentation/services/akhq) and [Wetty](../../../documentation/services/wetty) support to run in two different, simulated data centers. All the other services can still be used, but they should only be enabled in one of the two stacks. <file_sep># Apache Atlas
Atlas is a scalable and extensible set of core foundational governance services – enabling enterprises to effectively and efficiently meet their compliance requirements within Hadoop and allows integration with the whole enterprise data ecosystem.
Apache Atlas provides open metadata management and governance capabilities for organizations to build a catalog of their data assets, classify and govern these assets and provide collaboration capabilities around these data assets for data scientists, analysts and the data governance team.
**[Website](https://atlas.apache.org/#/)** | **[Documentation](https://atlas.apache.org/#/)** | **[GitHub](https://github.com/apache/atlas)**
## How to enable?
```
platys init --enable-services ATLAS
platys gen
```
## How to use it?
<file_sep># Apache Zeppelin
Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more.
**[Website](https://zeppelin.apache.org/)** | **[Documentation](https://zeppelin.apache.org/)** | **[GitHub](https://github.com/apache/zeppelin)**
## How to enable?
```
platys init --enable-services ZEPPELIN
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28080>
## Install `s3cmd`
install `s3cmd`
```bash
pip install s3cmd
```
and configure it
```bash
s3cmd --no-ssl --access_key=$AWS_ACCESS_KEY_ID --secret_key=$AWS_SECRET_ACCESS_KEY --host-bucket=$AWS_ENDPOINT --host=$AWS_ENDPOINT --bucket-location=$AWS_DEFAULT_REGION --dump-config 2>&1 | tee .s3cfg
```
<file_sep># MinIO
High Performance, Kubernetes Native Object Storage
**[Website](https://min.io/)** | **[Documentation](https://docs.min.io/minio/baremetal/)** | **[GitHub](https://github.com/minio/minio)**
## How to enable?
```
platys init --enable-services MINIO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:9000>.
Login with username `V42FCGRVMK24JJ8DHUYG` and password `<PASSWORD>` (if left to defaults).
<file_sep># Zipkin
Zipkin is a distributed tracing system. It helps gather timing data needed to troubleshoot latency problems in service architectures. Features include both the collection and lookup of this data.
**[Website](https://zipkin.io/)** | **[Documentation](https://zipkin.io/)** | **[GitHub](https://github.com/openzipkin/zipkin)**
## How to enable?
```
platys init --enable-services ZIPKIN
platys gen
```
## How to use it?
Navigate to <http://dataplatform:9411><file_sep># Using Kafka from Java with Protocol Buffers & Schema Registry
In this workshop we will learn how to produce and consume messages using the [Kafka Java API](https://kafka.apache.org/documentation/#api) using [Google Protocol Buffers](https://developers.google.com/protocol-buffers) for serialising and deserialising messages.
## Create the project in your Java IDE
Create a new Maven Project (using the functionality of your IDE) and in the last step use `com.trivadis.kafkaws` for the **Group Id** and `java-protobuf-kafka` for the **Artifact Id**.
Navigate to the **pom.xml** and double-click on it. The POM Editor will be displayed.
You can either use the GUI to edit your `pom.xml` or navigate to the last tab **pom.xml** to switch to the "code view". Let's do that.
You will see the still rather empty definition.
```xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trivadis.kafkaws</groupId>
<artifactId>java-protobuf-kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
</project>
```
Let's add some initial dependencies for our project. We will add some more dependencies to the POM throughout this workshop.
Copy the following block right after the `<version>` tag, before the closing `</project>` tag.
```xml
<properties>
<kafka.version>2.8.0</kafka.version>
<confluent.version>6.0.0</confluent.version>
<protobuf.version>3.19.4</protobuf.version>
<java.version>1.8</java.version>
<slf4j-version>1.7.5</slf4j-version>
<!-- use utf-8 encoding -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-protobuf-serializer</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>${protobuf.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j-version}</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>github-releases</id>
<url>http://oss.sonatype.org/content/repositories/github-releases/</url>
</repository>
<repository>
<id>clojars.org</id>
<url>http://clojars.org/repo</url>
</repository>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</pluginRepository>
</pluginRepositories>
<build>
<defaultGoal>install</defaultGoal>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<maxmem>256M</maxmem>
<showDeprecation>true</showDeprecation>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<executions>
<execution>
<id>producer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.producer.KafkaProducerProtobuf</mainClass>
</configuration>
</execution>
<execution>
<id>consumer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.consumer.KafkaConsumerProtobuf</mainClass>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
```
## Create log4j settings
Let's also create the necessary log4j configuration.
In the code we are using the [Log4J Logging Framework](https://logging.apache.org/log4j/2.x/), which we have to configure using a property file.
Create a new file `log4j.properties` in the folder **src/main/resources** and add the following configuration properties.
```properties
## ------------------------------------------------------------------------
## Licensed to the Apache Software Foundation (ASF) under one or more
## contributor license agreements. See the NOTICE file distributed with
## this work for additional information regarding copyright ownership.
## The ASF licenses this file to You under the Apache License, Version 2.0
## (the "License"); you may not use this file except in compliance with
## the License. You may obtain a copy of the License at
##
## http://www.apache.org/licenses/LICENSE-2.0
##
## Unless required by applicable law or agreed to in writing, software
## distributed under the License is distributed on an "AS IS" BASIS,
## WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
## See the License for the specific language governing permissions and
## limitations under the License.
## ------------------------------------------------------------------------
#
# The logging properties used for testing, We want to see INFO output on the console.
#
log4j.rootLogger=INFO, out
#log4j.logger.org.apache.kafka=INFO
log4j.logger.org.apache.camel.impl.converter=INFO
log4j.logger.org.apache.camel.util.ResolverUtil=INFO
log4j.logger.org.springframework=WARN
log4j.logger.org.hibernate=WARN
# CONSOLE appender not used by default
log4j.appender.out=org.apache.log4j.ConsoleAppender
log4j.appender.out.layout=org.apache.log4j.PatternLayout
log4j.appender.out.layout.ConversionPattern=[%30.30t] %-30.30c{1} %-5p %m%n
#log4j.appender.out.layout.ConversionPattern=%d [%-15.15t] %-5p %-30.30c{1} - %m%n
log4j.throwableRenderer=org.apache.log4j.EnhancedThrowableRenderer
```
## Creating the necessary Kafka Topic
We will use the topic `test-java-protobuf-topic` in the Producer and Consumer code below. Due to the fact that `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
In a terminal window, connect to the `kafka-1` container
```
docker exec -ti kafka-1 bash
```
and execute the necessary kafka-topics command.
```
kafka-topics --create \
--replication-factor 3 \
--partitions 12 \
--topic test-java-protobuf-topic \
--bootstrap-server kafka-1:19092,kafka-2:19093
```
This finishes the setup steps and our new project is ready to be used. Next we will start implementing the **Kafka Producer** which uses Protocol Buffers for the serialisation.
## Create an Protocol Buffer Schema representing the Notification Message
First create a new Folder `protobuf` under the existing folder **src/main/**.
Create a new File `Notification-v1.proto` in the folder **src/main/protobuf** just created above.
Add the following Protocol Buffer schema to the empty file.
```
syntax = "proto3";
package com.trivadis.kafkaws.protobuf.v1;
option java_outer_classname = "NotificationProtos";
message Notification {
int64 id = 1;
string message = 2;
}
```
In the `pom.xml`, add the `protoc-jar-maven-plugin` plugin to the `<build><plugins>` section, just below the `exec-maven-plugin`.
```xml
<plugin>
<groupId>com.github.os72</groupId>
<artifactId>protoc-jar-maven-plugin</artifactId>
<version>3.11.4</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>run</goal>
</goals>
<configuration>
<inputDirectories>
<include>${project.basedir}/src/main/protobuf</include>
</inputDirectories>
<outputTargets>
<outputTarget>
<type>java</type>
<addSources>main</addSources>
<outputDirectory>${project.basedir}/target/generated-sources/protobuf</outputDirectory>
</outputTarget>
</outputTargets>
</configuration>
</execution>
</executions>
</plugin>
```
This plugin will make sure, that classes are generated based on the Protocol Buffer schema, whenever a `mvn compile` is executed. Execute the following command, to do that:
```
mvn compile
```
After running this command, refresh the project and you should see a new folder named `target/generated-sources/protobuf`. Expand into this folder and you should see one generated Java class named `NotificationProtos`.
Double click on the `NotificationProtos` class to inspect the code.
```java
package com.trivadis.kafkaws.protobuf.v1;
public final class NotificationProtos {
private NotificationProtos() {}
public static void registerAllExtensions(
com.google.protobuf.ExtensionRegistryLite registry) {
}
public static void registerAllExtensions(
com.google.protobuf.ExtensionRegistry registry) {
registerAllExtensions(
(com.google.protobuf.ExtensionRegistryLite) registry);
}
public interface NotificationOrBuilder extends
// @@protoc_insertion_point(interface_extends:com.trivadis.kafkaws.protobuf.v1.Notification)
com.google.protobuf.MessageOrBuilder {
/**
* <code>int64 id = 1;</code>
* @return The id.
*/
long getId();
/**
* <code>string message = 2;</code>
* @return The message.
*/
java.lang.String getMessage();
/**
* <code>string message = 2;</code>
* @return The bytes for message.
*/
com.google.protobuf.ByteString
getMessageBytes();
}
...
```
You can see that the code is based on the information in the Protobuf schema. We will use this class when we produce and consume Protocol Buffer messages to/from Kafka.
## Create a Kafka Producer using Protocol Buffers for serialisation
First create a new Java Package `com.trivadis.kafkaws.producer` in the folder **src/main/java**.
Create a new Java Class `KafkaProducerProtobuf` in the package `com.trivadis.kafakws.producer` just created.
Add the following code to the empty class to create a Kafka Producer. It is similar to the code we have seen in the previous workshop. We have changed both the key and the value serialier to use the Confluent `KafkaProtobufSerializer` class and added the URL to the Confluent Schema Registry API.
```java
package com.trivadis.kafkaws.producer;
import com.trivadis.kafkaws.protobuf.v1.NotificationProtos.Notification;
import io.confluent.kafka.serializers.protobuf.KafkaProtobufSerializer;
import io.confluent.kafka.serializers.protobuf.KafkaProtobufSerializerConfig;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerProtobuf {
private final static String TOPIC = "test-java-protobuf-topic";
private final static String BOOTSTRAP_SERVERS =
"dataplatform:9092, dataplatform:9093, dataplatform:9094";
private final static String SCHEMA_REGISTRY_URL = "http://dataplatform:8081";
private static Producer<Long, Notification> createProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaExampleProducer");
//props.put(KafkaProtobufSerializerConfig.AUTO_REGISTER_SCHEMAS, "false");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, KafkaProtobufSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaProtobufSerializer.class.getName());
props.put(KafkaProtobufSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, SCHEMA_REGISTRY_URL); // use constant for "schema.registry.url"
return new KafkaProducer<>(props);
}
}
```
We will be using the synchronous way for producing messages to the Kafka topic we created above, but the other methods would work as well with Protobuf.
```java
static void runProducer(final int sendMessageCount, final int waitMsInBetween, final long id) throws Exception {
final Producer<Long, Notification> producer = createProducer();
long time = System.currentTimeMillis();
Long key = (id > 0) ? id : null;
try {
for (long index = 0; index < sendMessageCount; index++) {
Notification notification = Notification.newBuilder().setId(id).setMessage("Hello Kafka " + index).build();
final ProducerRecord<Long, Notification> record =
new ProducerRecord<>(TOPIC, key, notification);
RecordMetadata metadata = producer.send(record).get();
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) " +
"meta(partition=%d, offset=%d) time=%d\n",
record.key(), record.value(), metadata.partition(),
metadata.offset(), elapsedTime);
time = System.currentTimeMillis();
Thread.sleep(waitMsInBetween);
}
} finally {
producer.flush();
producer.close();
}
}
```
Next you define the main method.
```
public static void main(String... args) throws Exception {
if (args.length == 0) {
runProducer(100,10,0);
} else {
runProducer(Integer.parseInt(args[0]),Integer.parseInt(args[1]),Long.parseLong(args[2]));
}
}
```
The `main()` method accepts 3 parameters, the number of messages to produce, the time in ms to wait in-between sending each message and the ID of the producer.
Use `kcat` or `kafka-console-consumer` to consume the messages from the topic `test-java-protobuf-topic `.
```
kcat -b kafka-1:19092 -t test-java-protobuf-topic
```
Now run it using the `mvn exec:java` command. It will generate 1000 messages, waiting 10ms in-between sending each message and use 0 for the ID.
```
mvn exec:java@producer -Dexec.args="1000 10 0"
```
You can see that kafkacat shows some special, non-printable characters. This is due to the Protocol Buffer format. If you want to display the Protocol Buffer in a readable way, you can use the `kafka-protobuf-console-consumer` CLI, which is part of the Schema Registry.
So let's connect to the schema registry container:
```
docker exec -ti schema-registry-1 bash
```
And then invoke the `kafka-protobuf-console-consumer` similar to the "normal" consumer seen so far.
```
kafka-protobuf-console-consumer --bootstrap-server kafka-1:19092 --topic test-java-protobuf-topic
```
You should see an output similar to the one below.
```
...
[2018-07-11 21:32:43,155] INFO [Consumer clientId=consumer-1, groupId=console-consumer-88150] Resetting offset for partition test-java-protobuf-topic-6 to offset 0. (org.apache.kafka.clients.consumer.internals.Fetcher)
{"id":"0","message":"Hello Kafka 0"}
{"id":"0","message":"Hello Kafka 3"}
{"id":"0","message":"Hello Kafka 1"}
{"id":"0","message":"Hello Kafka 2"}
{"id":"0","message":"Hello Kafka 6"}
{"id":"0","message":"Hello Kafka 5"}
{"id":"0","message":"Hello Kafka 4"}
{"id":"0","message":"Hello Kafka 7"}
{"id":"0","message":"Hello Kafka 8"}
{"id":"0","message":"Hello Kafka 9"}
{"id":"0","message":"Hello Kafka 10"}
{"id":"0","message":"Hello Kafka 11"}
{"id":"0","message":"Hello Kafka 12"}
{"id":"0","message":"Hello Kafka 13"}
{"id":"0","message":"Hello Kafka 14"}
{"id":"0","message":"Hello Kafka 15"}
{"id":"0","message":"Hello Kafka 16"}
{"id":"0","message":"Hello Kafka 17"}
{"id":"0","message":"Hello Kafka 18"}
{"id":"0","message":"Hello Kafka 19"}
...
```
Consuming with `kcat` and specifying the serialisation format `-s` and the address of the schema registry `-r` does not yet work for Protocol Buffers, it only works for Avro.
**Note:** There is an [open ticket](https://github.com/edenhill/kcat/issues/353) to add Protobuf support to `kcat`.
## View the Schema in the Registry
The Protobuf Serializer and Deserializer automatically register the Protocol Buffer schema, if it is not already in the registry.
The Streamingplatform also contains a tool made by a company called Landoop which allows us to see what's in the registry. But it does not support Protocol Buffer schemas! But we can use [AKHQ](https://akhq.io/) to view the schema registry.
In a browser, navigate to <http://dataplatform:28107> and navigate to the **Schema Registry** menu item on the left.

Click on the hourglass icon on the schema to view the details of the schema

## Create a Kafka Consumer using Protobuf for serialisation
First create a new Java Package `com.trivadis.kafkaws.consumer` in the folder **src/main/java**.
Create a new Java Class `KafkaConsumerProtobuf` in the package `com.trivadis.kafakws.consumer` just created.
Add the following code to the empty class.
```java
package com.trivadis.kafkaws.consumer;
import com.trivadis.kafkaws.protobuf.v1.NotificationProtos.Notification;
import io.confluent.kafka.serializers.protobuf.KafkaProtobufDeserializer;
import io.confluent.kafka.serializers.protobuf.KafkaProtobufDeserializerConfig;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerProtobuf {
private final static String TOPIC = "test-java-protobuf-topic";
private final static String BOOTSTRAP_SERVERS =
"dataplatform:9092, dataplatform:9093, dataplatform:9094";
private final static String SCHEMA_REGISTRY_URL = "http://dataplatform:8081";
private static Consumer<Long, Notification> createConsumer() {
final Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerProtobuf");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 10000);
props.put(KafkaProtobufDeserializerConfig.AUTO_REGISTER_SCHEMAS, "false");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, KafkaProtobufDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaProtobufDeserializer.class.getName());
props.put(KafkaProtobufDeserializerConfig.SCHEMA_REGISTRY_URL_CONFIG, SCHEMA_REGISTRY_URL); // use constant for "schema.registry.url"
// Create the consumer using props.
final Consumer<Long, Notification> consumer =
new KafkaConsumer<>(props);
// Subscribe to the topic.
consumer.subscribe(Collections.singletonList(TOPIC));
return consumer;
}
static void runConsumer(int waitMsInBetween) throws InterruptedException {
final Consumer<Long, Notification> consumer = createConsumer();
final int giveUp = 100;
int noRecordsCount = 0;
while (true) {
final ConsumerRecords<Long, Notification> consumerRecords = consumer.poll(1000);
if (consumerRecords.count()==0) {
noRecordsCount++;
if (noRecordsCount > giveUp)
break;
}
consumerRecords.forEach(record -> {
System.out.printf("%d - Consumer Record:(Key: %d, Value: %s, Partition: %d, Offset: %d)\n",
consumerRecords.count(), record.key(), record.value(),
record.partition(), record.offset());
try {
Thread.sleep(waitMsInBetween);
} catch (InterruptedException e) {
}
});
consumer.commitSync();
}
consumer.close();
System.out.println("DONE");
}
public static void main(String... args) throws Exception {
if (args.length == 0) {
runConsumer(10);
} else {
runConsumer(Integer.parseInt(args[0]));
}
}
}
```
## Register in Schema Registry using Maven
In the test above, the Protocol Buffer schema has been registered in the schema registry when starting the Producer for the first time. To register a Protocol Buffer schema through Maven automatically, you can use the `kafka-schema-registry-maven-plugin` Maven plugin.
Add the following definition to the `pom.xml`.
```xml
<plugin>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-maven-plugin</artifactId>
<version>7.0.0</version>
<configuration>
<schemaRegistryUrls>
<param>http://${DATAPLATFORM_IP}:8081</param>
</schemaRegistryUrls>
<schemaTypes>
<test-java-protobuf-topic-value>PROTOBUF</test-java-protobuf-topic-value>
</schemaTypes>
<subjects>
<test-java-protobuf-topic-value>src/main/protobuf/Notification-v1.proto</test-java-protobuf-topic-value>
</subjects>
</configuration>
<goals>
<goal>register</goal>
<goal>test-compatibility</goal>
</goals>
</plugin>
```
Now you can use the following command to register the schemas with the Schema Registry:
```
mvn schema-registry:register
```
<file_sep># Burrow Dashboard
Kafka Dashboard for Burrow 1.0 API, monitor the topic info and consumer group offsets.
**[Website](https://github.com/joway/burrow-dashboard)** | **[Documentation](https://github.com/joway/burrow-dashboard)** | **[GitHub](https://github.com/joway/burrow-dashboard)**
## How to enable?
```
platys init --enable-services KAFKA,BURROW,BURROW_DASHBOARD
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28259><file_sep>Contains the data of mflow-server service, if flag MLFLOW_SERVER_volume_map_data is set to true.<file_sep># Hazelcast
Open-source distributed computation and storage platform.
**[Website](https://hazelcast.com/)** | **[Documentation](https://docs.hazelcast.com/home/index.html)** | **[GitHub](https://github.com/hazelcast)**
## How to enable?
```
platys init --enable-services HAZELCAST
platys gen
```
## How to use it?
## Cookbooks<file_sep># Miscellaneous
### Creating Kafka Topics upon Docker startup
```
kafka-client:
image: confluentinc/cp-enterprise-kafka:4.1.0
hostname: kafka-client
container_name: kafka-client
depends_on:
- kafka1
volumes:
- $PWD/scripts/security:/etc/kafka/secrets
# We defined a dependency on "kafka", but `depends_on` will NOT wait for the
# dependencies to be "ready" before starting the "kafka-client"
# container; it waits only until the dependencies have started. Hence we
# must control startup order more explicitly.
# See https://docs.docker.com/compose/startup-order/
command: "bash -c -a 'echo Waiting for Kafka to be ready... && \
/etc/confluent/docker/configure && \
cub kafka-ready -b kafka1:9091 1 60 --config /etc/kafka/kafka.properties && \
sleep 5 && \
kafka-topics --zookeeper zookeeper-1:2181 --topic users --create --replication-factor 2 --partitions 2 && \
kafka-topics --zookeeper zookeeper-1:2181 --topic wikipedia.parsed --create --replication-factor 2 --partitions 2 && \
kafka-topics --zookeeper zookeeper-1:2181 --topic wikipedia.failed --create --replication-factor 2 --partitions 2 && \
kafka-topics --zookeeper zookeeper-1:2181 --topic WIKIPEDIABOT --create --replication-factor 2 --partitions 2 && \
kafka-topics --zookeeper zookeeper-1:2181 --topic WIKIPEDIANOBOT --create --replication-factor 2 --partitions 2 && \
kafka-topics --zookeeper zookeeper-1:2181 --topic EN_WIKIPEDIA_GT_1 --create --replication-factor 2 --partitions 2 && \
kafka-topics --zookeeper zookeeper-1:2181 --topic EN_WIKIPEDIA_GT_1_COUNTS --create --replication-factor 2 --partitions 2'"
environment:
# The following settings are listed here only to satisfy the image's requirements.
# We override the image's `command` anyways, hence this container will not start a broker.
KAFKA_BROKER_ID: ignored
KAFKA_ZOOKEEPER_CONNECT: ignored
KAFKA_ADVERTISED_LISTENERS: ignored
KAFKA_SECURITY_PROTOCOL: SASL_SSL
KAFKA_SASL_JAAS_CONFIG: "org.apache.kafka.common.security.plain.PlainLoginModule required \
username=\"client\" \
password=\"<PASSWORD>\";"
KAFKA_SASL_MECHANISM: PLAIN
KAFKA_SSL_TRUSTSTORE_LOCATION: /etc/kafka/secrets/kafka.client.truststore.jks
KAFKA_SSL_TRUSTSTORE_PASSWORD: <PASSWORD>
KAFKA_SSL_KEYSTORE_LOCATION: /etc/kafka/secrets/kafka.client.keystore.jks
KAFKA_SSL_KEYSTORE_PASSWORD: <PASSWORD>
KAFKA_SSL_KEY_PASSWORD: <PASSWORD>
KAFKA_ZOOKEEPER_SET_ACL: "true"
KAFKA_OPTS: -Djava.security.auth.login.config=/etc/kafka/secrets/broker_jaas.conf
ports:
- "7073:7073"
```<file_sep># Cloudbeaver
Light and friendly interface for your datasources
**[Website](https://cloudbeaver.io/)** | **[Documentation](https://cloudbeaver.io/docs/)** | **[GitHub](https://github.com/dbeaver/cloudbeaver)**
## How to enable?
```
platys init --enable-services CLOUDBEAVER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8978><file_sep># Dejavu
The Missing Web UI for Elasticsearch: Import, browse and edit data with rich filters and query views, create search UIs visually.
**[Website](https://opensource.appbase.io/dejavu/)** | **[Documentation](https://opensource.appbase.io/dejavu/)** | **[GitHub](https://github.com/appbaseio/dejavu)**
## How to enable?
```
platys init --enable-services DEJAVU
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28125><file_sep>
# Installing additional software
The Platform contains a fully working and running Kafka installation with the necessary additional tools such as Schema Registry. But an IDE for doing the workshops has to be installed manually.
## For Java-based workshops
### Installing Java 11
Per default Java 8 is installed. However some of the workshops assume Java 11.
To install Java 11 perform
```bash
sudo yum update
sudo yum install java-11-openjdk
sudo yum install java-11-openjdk-devel
```
and then activate the Java 11 environment by executing
```bash
sudo update-alternatives --config 'java'
sudo update-alternatives --config 'javac'
```
select both time the Java 11 environment and then test if Java 11 is used
```bash
java -version
javac -version
```
### Installing Maven 3.6.3
Download and install Maven 3.6.3
```bash
wget https://mirrors.estointernet.in/apache/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
tar -xvf apache-maven-3.6.3-bin.tar.gz
sudo mv apache-maven-3.6.3 /opt/
```
Add the following 3 lines to the end of `.bash_profile`
```bash
M2_HOME=/opt/apache-maven-3.6.3
PATH="$M2_HOME/bin:$PATH"
export PATH
```
No source `.bash_profile` and then test that the new version of Maven is used
```bash
source .bash_profile
mvn -version
```
### Installing IntelliJ IDEA
* Open Firefox by clicking on **Applications** in the top menu and select **Firefox**
* navigate to the IntelliJ Community download: <https://www.jetbrains.com/idea/download/#section=linux> and download the Community Edition as a `tar.gz` file

* Once the download finished, double click on the file and extract it into the home folder

### Starting IntelliJ IDEA
To start IntelliJ
* Open a Terminal window by clicking on **Applications** in the top menu and select **System Tools** | **Terminal**.
* Navigate to the `bin` folder of IntelliJ: `cd idea-IC*/bin`.
* Start the IntelliJ: `./idea.sh`
* confirm the **JETBRAINS COMMUNITY EDITION TERMS** by enabling the checkbox and then click **Continue**.
* on the **DATA SHARING** page click **Don't share**
You now have a working IntelliJ available for the workshops.
## For .NET-based workshops
### Installing .NET core
Install .NET core by performing the following steps
```bash
sudo rpm -Uvh https://packages.microsoft.com/config/centos/7/packages-microsoft-prod.rpm
```
```bash
sudo yum install dotnet-sdk-6.0
```
### Installing Visual Code
Download Visual Studio from <https://code.visualstudio.com/docs/?dv=linux64> as a TAR ball and untar it to `/home/oracle`
Extend the Path by editing `/home/oracle/.bash_profile` and add `/home/oracle/VSCode-linux-x64` to the PATH variable (last line in the file)
```bash
export PATH=$PATH:$LAB_BASE:/u00/app/oracle/local/bdkafkadev/bin:.:/home/oracle/VSCode-linux-x64
```
<file_sep># Apache Cassandra
Apache Cassandra is an open source NoSQL distributed database trusted by thousands of companies for scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data.
**[Website](https://cassandra.apache.org)** | **[Documentation](https://cassandra.apache.org/doc/latest/)** | **[GitHub](https://github.com/apache/cassandra)**
## How to enable?
```
platys init --enable-services CASSANDRA
platys gen
```
## How to use it?
To connect with the Cassandra CLI
```bash
docker exec -ti cassandra-1 cqlsh -u cassandra -p cassandra
```<file_sep># Tyk Dashboard
The Tyk Dashboard is the visual GUI and analytics platform for Tyk. It provides an easy-to-use management interface for managing a Tyk installation as well as clear and granular analytics.
The Dashboard also provides the API Developer Portal, a customisable developer portal for your API documentation, developer auto-enrolment and usage tracking.
Tyk Dashboard is part of the Professional license and not open source.
**[Website](https://tyk.io)** | **[Documentation](https://tyk.io/docs/tyk-dashboard/)**
## How to enable?
```
platys init --enable-services TYK,TYK_DASHBOARD
platys gen
```
Before starting the stack, create an .env file and add an environment variable with the license
```bash
TYK_DB_LICENSEKEY=
```
## How to use it?
Navigate to <http://dataplatform:28281><file_sep># Dataiku
Shiny is an R package that makes it easy to build interactive web apps straight from R. You can host standalone apps on a webpage or embed them in R Markdown documents or build dashboards. You can also extend your Shiny apps with CSS themes, htmlwidgets, and JavaScript actions.
**[Website](https://www.dataiku.com/)** | **[Documentation](https://doc.dataiku.com/dss/latest/)** | **[GitHub](https://github.com/dataiku)**
## How to enable?
```
platys init --enable-services DATAIKU_DSS
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28205><file_sep>Place curity's license file here (named license.json).<file_sep>Contains the flow_storage folder of nidi-registry service, if flag NIFI_REGISTRY_volume_map_data is set to true.<file_sep>---
technologies: nifi,nifi-registry
version: 1.16.0
validated-at: 6.3.2023
---
# NiFi Registry with Git Flow Persistence Provider
This recipe will show how to use [NiFi Registry](https://nifi.apache.org/registry.html) with the [Git Flow Persistence Provider](https://nifi.apache.org/docs/nifi-registry-docs/html/administration-guide.html#gitflowpersistenceprovider) enabled. We will show various configurations and their behaviour.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```bash
export DATAPLATFORM_HOME=${PWD}
platys init --enable-services NIFI,NIFI_REGISTRY -s trivadis/platys-modern-data-platform -w 1.16.0
```
Before we can generate the platform, we need to create a Git Repository and extend the `config.yml` with the necessary configuration.
## Create a Git Repository
Create a new Git repository which will be used as the storage for the Flow Persistence. In this cookbook we will assume that the repository is named `nifi-git-flow-provider`.
## Using Git Flow Persistence Provider without automatic Push
Enable authentication by adding the following settings to the `config.yml`
```yaml
NIFI_REGISTRY_volume_map_flow_storage: true
NIFI_REGISTRY_flow_provider: git
NIFI_REGISTRY_git_user: gschmutz
NIFI_REGISTRY_git_repo: http://github.com/<owner>/nifi-git-flow-provider
NIFI_REGISTRY_flow_storage_folder_on_dockerhost: ./nifi-git-flow-provider
```
The password could also be specified using the `NIFI_REGISTRY_git_password` configuration setting. But to avoid it ending up in the `docker-compose.yml` file, we rather use the option to add it as an environment variable:
Create a `.env` file
```
nano .env
```
and add the following environment variable to specify the password for the Git Repo
```bash
PLATYS_NIFI_REGISTRY_GIT_PASSWORD=<PASSWORD>
```
Save the file and generate and start the data platform.
```bash
platys gen
docker-compose up -d
```
Now let's use NiFi together with the Registry. Here we will only show the most important steps, you can find a more tutorial like documentation [here](https://nifi.apache.org/docs/nifi-registry-docs/index.html).
Navigate to the NiFi Registry: <http://dataplatform:19090/nifi-registry> and create a new bucket and name it `my-bucket`.

Navigate to NiFi <https://dataplatform:18080> and login as user `nifi` with password `<PASSWORD>`.
Click on the Sandwich menu in the top right and open **Controller Settings**. Navigate to the **Registry Clients** tab and add a new Registry Client.

Click **Add** and then edit the client and set the **URL** of the NiFi Registry to `http://nifi-registry:19090` and click on **UPDATE**.

Now with the link to NiFi Registry configured, we can start using it.
Add a new **Process Group** to the NiFi canvas. Right click on the process group and select **Version** | **Start version control** to add it to version control.

Add the information to the **Save Flow Version** screen and hit **SAVE**.

You now have a process group which is under version control, shown by the green checkmark in the top left corner.
If you want the NiFi Registry to automatically push changes to the remote
## Using Git Flow Persistence Provider with automatic Push
Enable authentication by adding the following settings to the `config.yml`
```yaml
NIFI_REGISTRY_flow_provider: git
NIFI_REGISTRY_git_remote: origin
NIFI_REGISTRY_git_user: gschmutz
NIFI_REGISTRY_git_repo: http://github.com/<owner>/nifi-git-flow-provider
NIFI_REGISTRY_flow_storage_folder_on_dockerhost: ./nifi-git-flow-provider
```<file_sep>Contains the data of NocoDB service, if flag NOCODB_volume_map_data is set to true.<file_sep># LakeFS CLI
Git-like capabilities for your object storage.
**[Website](https://lakefs.io/)** | **[Documentation](https://docs.lakefs.io/reference/commands.html#installing-the-lakectl-command-locally)** | **[GitHub](https://github.com/treeverse/lakeFS)**
## How to enable?
```bash
platys init --enable-services LAKEFS, MINIO, POSTGRESQL
platys gen
```
## How to use it?
```bash
docker exec -ti lakectl lakectl
```
```bash
docker exec -ti lakectl lakectl branch list lakefs://example
```<file_sep># Penthao
No-code software to easily integrate, access, and analyze all your enterprise data.
**[Documentation](https://help.hitachivantara.com/Documentation/Pentaho/9.2/)** | **[GitHub](https://github.com/pentaho)**
## How to enable?
```
platys init --enable-services PENTHAO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28154><file_sep># Trino (formerly PrestoSQL)
Trino is a distributed SQL query engine designed to query large data sets distributed over one or more heterogeneous data sources.
**[Website](https://trino.io/)** | **[Documentation](https://trino.io/docs/current/)** | **[GitHub](https://github.com/trinodb/trino)**
## How to enable?
```
platys init --enable-services TRINO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28082>
To connect over the CLI, use:
```
docker exec -it trino-cli trino --server trino-1:8080
```
if authentication is enabled (`TRINO_auth_enabled`), then you have to connect over `https` and specify the user and the keystore:
```
docker exec -it trino-cli trino --server https://trino-1:8443 --user admin --password --insecure --keystore-path /etc/trino/trino.jks --keystore-password <PASSWORD>!
```
### Security
Security for Trino can be enabled with `TRINO_auth_enabled` (to enable authentication) and `TRINO_access_control_enabled` (to enable access control).
#### Authentication
By default the following 3 users and passwords are pre-configured:
1. `admin` : `<PASSWORD>!`
2. `userA` : `<PASSWORD>!`
3. `userB` : `<PASSWORD>!`
You can specify your own password file in `conf/trino/security/password.db` by enabling `TRINO_auth_use_custom_password_file`. See [here](https://trino.io/docs/current/security/password-file.html#creating-a-password-file) for how to add users to the password file.
You can also create groups by enabling `TRINO_auth_with_groups` and specifying them in `custom-conf/trino/security/group.txt`.
#### Access Control
Enable access control with `TRINO_access_control_enabled` and set the access control rules in `custom-conf/trino/security/rules.json`.
<file_sep># Modern Data Platform Cookbooks
Inhere we are documenting cookbooks on how to use the platform:
* **Airflow**
* [Schedule and Run Simple Python Application](./recipes/airflow-schedule-python-app/README.md) - `1.12.0`
* **Trino (Formerly Presto SQL)**
* [Trino, Spark and Delta Lake (Spark 2.4.7 & Delta Lake 0.6.1)](./recipes/delta-lake-and-trino-spark2.4/README.md) - `1.11.0`
* [Trino, Spark and Delta Lake (Spark 3.0.1 & Delta Lake 0.7.0)](./recipes/delta-lake-and-trino-spark3.0/README.md) - `1.11.0`
* [Querying S3 data (MinIO) using MinIO](./recipes/querying-minio-with-trino/README.md) - `1.11.0`
* [Querying PostgreSQL data (MinIO) using MinIO](./recipes/querying-postgresql-with-trino/README.md) - `1.11.0`
* [Querying Kafka data using Trino](./recipes/querying-kafka-with-trino/README.md) - `1.11.0`
* [Querying HDFS data using Trino](./recipes/querying-hdfs-with-presto/README.md) - `1.11.0`
* Joining data between RDBMS and MinIO
* **MQTT**
* [Using Confluent MQTT Proxy](./recipes/using-mqtt-proxy/README.md)
* [Using HiveMQ with Kafka Extensions](./recipes/using-hivemq-with-kafka-extension/README.md) - `1.12.0`
* **Spark**
* [Run Java Spark Application using `spark-submit`](./recipes/run-spark-simple-app-java-submit/README.md)
* [Run Java Spark Application using Docker](./recipes/run-spark-simple-app-java-docker/README.md)
* [Run Scala Spark Application using `spark-submit`](./recipes/run-spark-simple-app-scala-submit/README.md)
* [Run Scala Spark Application using Docker](./recipes/run-spark-simple-app-scala-docker/README.md)
* [Run Python Spark Application using `spark-submit`](./recipes/run-spark-simple-app-python-submit/README.md)
* [Run Python Spark Application using Docker](./recipes/run-spark-simple-app-python-docker/README.md)
* [Spark and Hive Metastore](./recipes/spark-and-hive-metastore/README.md)
* [Spark with internal S3 (using on minIO)](./recipes/spark-with-internal-s3/README.md)
* [Spark with external S3](./recipes/spark-with-external-s3/README.md)
* [Spark with PostgreSQL](./recipes/spark-with-postgresql/README.md) - `1.11.0`
* **Hadoop HDFS**
* [Querying HDFS data using Presto](./recipes/querying-hdfs-with-presto/README.md)
* [Using HDFS data with Spark Data Frame](./recipes/using-hdfs-with-spark/README.md)
* **Livy**
* [Submit Spark Application over Livy](./recipes/run-spark-simple-app-scala-livy/README.md)
* **StreamSets Data Collector**
* [Support StreamSets DataCollector Activation](./recipes/streamsets-oss-activation/README.md) - `1.13.0`
* [Consume a binary file and send it as Kafka message](./recipes/streamsets-binary-file-to-kafka/README.md)
* [Using Dev Simulator Origin to simulate streaming data](./recipes/using-dev-simulator-origin/README.md) - `1.12.0`
* **Confluent Enterprise Platform**
* [Using Confluent Enterprise Tiered Storage](./recipes/confluent-tiered-storage/README.md)
* **ksqlDB**
* [Connecting through ksqlDB CLI](./recipes/connecting-through-ksqldb-cli/README.md)
* [Custom UDF and ksqlDB](./recipes/custom-udf-and-ksqldb/README.md)
* **Kafka Connect**
* [Using additional Kafka Connect Connector](./recipes/using-additional-kafka-connect-connector/README.md)
* **Oracle RDMBS**
* [Using private (Trivadis) Oracle EE image](./recipes/using-private-oracle-ee-image/README.md) - `1.13.0`
* [Using public Oracle XE image](./recipes/using-public-oracle-xe-image/README.md) - `1.13.0`
* **Architecture Decision Records (ADR)**
* [Creating and visualizing ADRs with log4brains](./recipes/creating-adr-with-log4brains/README.md) - `1.12.0`
<file_sep># Portainer
Portainer can be deployed on top of any K8s, Docker or Swarm environment. It works seamlessly in the cloud, on prem and at the edge to give you a consolidated view of all your containers.
**[Website](https://www.portainer.io/)** | **[Documentation](https://docs.portainer.io/)** | **[GitHub](https://github.com/portainer/portainer)**
## How to enable?
```
platys init --enable-services PORTAINER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28137><file_sep># Minio Web
Web server for S3 compatible storage.
**[Documentation](https://github.com/e2fyi/minio-web)** | **[GitHub](https://github.com/e2fyi/minio-web)**
## How to enable?
```bash
platys init --enable-services MINIO, MINIO_WEB
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28306>.<file_sep>connector.name=delta_lake
hive.metastore.uri=thrift://hive-metastore:9083
hive.s3.path-style-access=${ENV:S3_PATH_STYLE_ACCESS}
hive.s3.endpoint=${ENV:S3_ENDPOINT}
hive.s3.aws-access-key=${ENV:S3_AWS_ACCESS_KEY}
hive.s3.aws-secret-key=${ENV:S3_AWS_SECRET_KEY}
delta.enable-non-concurrent-writes=true
<file_sep>Place requirements.txt file here.<file_sep># MongoDB
MongoDB is a document database designed for ease of application development and scaling.
**[Website](https://www.mongodb.com/)** | **[Documentation](https://docs.mongodb.com/manual/?_ga=2.106702979.188924324.1640807635-167415985.1640807632)** | **[GitHub](https://github.com/mongodb/mongo)**
## How to enable?
```
platys init --enable-services MONGO
platys gen
```
## How to use it?
<file_sep># `modern-data-platform` - Port Mappings - 1.17.0
This table reserves the external ports for the various services. Not all services have to be used in the platform at a given time. But by reserving, we can assure that there are no conflicts if a service is added at a later time.
## "Original" Ports
Container Port(s) | Internal Port(s) | Service (alternatives) |
--------------------|------------------|-----------------------|
21 | 21 | ftp |
80 | 80 | markdown-viewer or firefox |
1337 | 1337 | konga |
1433 | 1433 | sqlserver |
1521 | 1521 | oracledb-ee |
1522 | 1521 | oracledb-xe |
1523 | 1521 | oracledb-free |
1095 | 1095 | ksqldb-server-1 (jmx) |
1096 | 1096 | ksqldb-server-2 (jmx) |
1097 | 1097 | ksqldb-server-3 (jmx) |
1113 | 1113 | eventstore |
1880 | 1880 | nodered-1 |
1882 | 1882 | kafka-mqtt-1 |
1883 | 1883 | mosquitto-1 |
1884 | 1883 | mosquitto-2 |
1885 | 1883 | mosquitto-3 |
1886 | 1883 | hivemq3-1 |
1887 | 1883 | hivemq3-2 |
1888 | 1883 | hivemq4-1 |
1889 | 1883 | hivemq4-2 |
1890 | 1883 | activemq |
1891 | 1883 | emqx-1 |
2113 | 2113 | eventstore |
2181 | 2181 | zookeeper-1 |
2182 | 2182 | zookeeper-2 |
2183 | 2183 | zookeeper-3 |
2184 | 2184 | zookeeper-4 |
2185 | 2185 | zookeeper-5 |
2186 | 2186 | zookeeper-6 |
2222 | 22 | sftp |
2424 | 2424 | arcadedb |
2480 | 5432 | arcadedb (postgresql port) |
2481 | 6379 | arcadedb (redis port) |
2482 | 2480 | arcadedb (mongodb port) |
2483 | 27017 | arcadedb |
3000 | 3000 | grafana |
3001 | 3000 | wetty (dc1) |
3002 | 3000 | wetty (dc2 |
3005 | 3000 | marquez-web |
3010 | 3000 | postman |
3006 | 3000 | retool-api |
3030 | 3030 | lenses |
3100 | 3100 | loki |
3200 | 3200 | tempo |
3306 | 3306 | mysql |
3307 | 3306 | datahub-mysql |
3838 | 3838 | shiny-server |
4000 | 4000 | graphql-mesh |
4004 | 4004 | log4brains |
4040 | 4040 | spark-master (ui) |
4041 | 4041 | spark-master (ui) |
4042 | 4042 | spark-master (ui) |
4043 | 4043 | spark-master (ui) |
4044 | 4044 | spark-master (ui) |
4050 | 4050 | zeppelin (spark ui) |
4051 | 4051 | zeppelin (spark ui) |
4052 | 4052 | zeppelin (spark ui) |
4053 | 4053 | zeppelin (spark ui) |
4054 | 4054 | zeppelin (spark ui) |
4195 | 4195 | benthos-1 |
4196 | 4196 | benthos-server |
4317 | 4317 | otel-collector |
4466 | 4466 | curity |
5000 | 5000 | amundsenfrontend |
5001 | 5000 | amundsensearch |
5002 | 5000 | amundsenmetadata |
5010 | 5000 | marquez |
5011 | 5001 | marquez |
5050 | 5050 | zeppelin |
5500 | 5500 | oracledb-ee |
5501 | 5500 | oracledb-xe |
\- | 5432 | hive-metastore-db |
\- | 5432 | hue-db |
5432 | 5432 | postgresql |
5433 | 5432 | timescaledb |
5434 | 5432 | marquez-db |
5555 | 5555 | airflow-flower |
5601 | 5601 | kibana |
5602 | 5601 | datahub-kibana |
5603 | 5601 | opensearch-dashboards |
5672 | 5672 | activemq |
5673 | 5672 | rabbitmq (amqp) |
5701 | 5701 | hazelcast -1 |
5705 | 5701 | zeebe-1 |
5778 | 5778 | jaeger (config) |
5800 | 5800 | filezilla |
5801 | 5800 | firefox |
5820 | 5820 | stardog-1 |
5900 | 5900 | filezilla |
6060 | 6060 | zeppelin |
6066 | 6066 | spark-master |
6080 | 6080 | ranger-admin |
6379 | 6379 | redis-1 |
6380 | 6379 | redis-replica-1 |
6381 | 6379 | redis-replica-1 |
6382 | 6379 | redis-replica-1 |
6385 | 6379 | redash-redis |
6386 | 6379 | tyk-redis |
6831 | 6831 | jaeger (udp) |
6749 | 6749 | curity |
6832 | 6832 | jaeger (udp) |
6875 | 6875 | materialize-1 |
7000 | 7000 | yb-master |
7050 | 7050 | kudu-tserver-1 |
7051 | 7051 | kudo-master-1 |
7077 | 7077 | spark-master |
7199 | 7199 | cassandra-1 |
7200 | 7199 | cassandra-2 |
7201 | 7199 | cassandra-3 |
7202 | 7199 | cassandra-4 |
7203 | 7199 | cassandra-5 |
7444 | 7444 | memgraph-platform |
7474 | 7474 | neo4j-1 |
7475 | 7474 | neo4j-2 |
7476 | 7474 | neo4j-3 |
7577 | 7577 | spring-skipper-server |
7687 | 7687 | neo4j-1 |
7688 | 7687 | neo4j-2 |
7689 | 7687 | neo4j-3 |
7690 | 7687 | memgraph-platform |
8000 | 8000 | kong (proxy) |
8001 | 8001 | kong (admin api) |
8002 | 8002 | kong (admin gui) |
8008 | 80 | markdown-viewer |
8024 | 8024 | axon-server |
8047 | 8047 | drill |
8048 | 8048 | kafka-eagle |
8050 | 8050 | kudu-tserver-1 |
8051 | 8051 | kudo-master-1 |
8055 | 8055 | directus |
8070 | 8070 | nuclio |
8080 | 8080 | spark-master |
8081 | 8081 / 8080 | schema-registry-1 / apicurio-registry-1 |
8082 | 8081 / 8080 | schema-registry-2 / apicurio-registry-2 |
8083 | 8083 | connect-1 |
8084 | 8084 | connect-2 |
8085 | 8085 | connect-3 |
8086 | 8086 | influxdb |
8088 | 8088 | ksqldb-server-1 |
8089 | 8088 | ksqldb-server-2 |
8090 | 8088 | ksqldb-server-3 |
8100 | 8100 | kong-map |
8124 | 8124 | axon-server |
8161 | 8161 | activemq |
8182 | 8182 | janusgraph |
8200 | 8200 | vault |
8443 | 8443 | kong (proxy ssl) |
8444 | 8444 | kong (admin api ssl) |
8446 | 8443 | curity |
8787 | 8787 | r-studio |
8812 | 8812 | questdb |
8888 | 8888 | hue |
8978 | 8978 | cloudbeaver |
8983 | 8983 | solr |
8998 | 8998 | livy |
9000 | 9000 | minio-1 |
9001 | 9000 | minio-2 |
9002 | 9000 | minio-3 |
9003 | 9000 | minio-4 |
9009 | 9009 | questdb |
9010 | 9010 | minio-1 ui |
9011 | 9011 | minio-2 ui |
9012 | 9012 | minio-3 ui |
9013 | 9013 | minio-4 ui |
9042 | 9042 | dse-1 |
9043 | 9042 | dse-2 |
9044 | 9042 | dse-3 |
9047 | 9047 | dremio |
9101 | 9001 | mosquitto-1 |
9102 | 9002 | mosquitto-2 |
9103 | 9003 | mosquitto-3 |
9200 | 9200 | elasticsearch-1 |
9300 | 9300 | elasticsearch-1 |
9160 | 9160 | cassandra-1 |
9161 | 9160 | cassandra-2 |
9162 | 9160 | cassandra-3 |
9163 | 9160 | cassandra-4 |
9164 | 9160 | cassandra-5 |
9083 | 9083 | hive-metastore |
9021 | 9021 | control-center (dc1) |
9022 | 9021 | control-center (dc2) |
9090 | 9090 | prometheus-1 |
9091 | 9091 | prometheus-pushgateway |
9092 | 9092 | kafka-1 |
9093 | 9093 | kafka-2 |
9094 | 9094 | kafka-3 |
9095 | 9095 | kafka-4 |
9096 | 9096 | kafka-5 |
9097 | 9097 | kafka-6 |
9098 | 9098 | kafka-7 |
9099 | 9099 | kafka-8 |
9192 | 9192 | lenses-box |
9393 | 9393 | spring-dataflow-server |
9411 | 9411 | zipkin |
9412 | 9412 | jaeger |
9413 | 9413 | pitchfork |
9600 | 9600 | zeebe-1 |
9851 | 9851 | tile38 |
9870 | 9870 | namenode |
9864 | 9864 | datanode-1 |
9865 | 9864 | datanode-2 |
9866 | 9864 | datanode-3 |
9867 | 9864 | datanode-4 |
9868 | 9864 | datanode-5 |
9869 | 9864 | datanode-6 |
9992 | 9992 | kafka-1 (jmx) |
9993 | 9993 | kafka-2 (jmx) |
9994 | 9994 | kafka-3 (jmx) |
9995 | 9995 | kafka-4 (jmx) |
9996 | 9996 | kafka-5 (jmx) |
9997 | 9997 | kafka-6 (jmx) |
9998 | 9998 | kafka-7 (jmx) |
9999 | 9999 | kafka-8 (jmx) |
10000 | 10000 | hive-server |
10001 | 10001 | hive-server |
10002 | 10002 | hive-server |
10005 | 10000 | nifi-1 |
10006 | 10000 | nifi-2 |
10007 | 10000 | nifi-3 |
11211 | 11211 | memcached |
11212 | 11211 | ignite-1 |
13133 | 13133 | otel-collector |
14250 | 14250 | jaeger (model.proto port)
14271 | 14271 | jaeger (admin port) |
14040 | 4040 | jupyter (spark ui) |
14041 | 4041 | jupyter (spark ui) |
14042 | 4042 | jupyter (spark ui) |
14043 | 4043 | jupyter (spark ui) |
14044 | 4044 | jupyter (spark ui) |
15433 | 5433| yb-tserver-1 |
15672 | 15672 | rabbitmq (ui) |
16379 | 6379| yb-tserver-1 |
16686 | 16686 | jaeger |
17200 | 7200 | graphdb-1 |
17474 | 7474 | amundsen-neo4j |
17687 | 7687 | amundsen-neo4j |
17475 | 7474 | datahub-neo4j |
17688 | 7687 | datahub-neo4j |
18080 | 8080 | nifi-1 |
18081 | 8080 | nifi-2 |
18082 | 8080 | nifi-3 |
18088 | 8088 | resourcemanager |
18042 | 8042 | nodemanager |
18083 | 8083 | replicator-1 |
18086 | 8086 | kafka-rest-1 |
18087 | 8086 | kafka-rest-2 |
18088 | 8086 | kafka-rest-3 |
18188 | 8188 | historyserver |
18620 | 18629 | streamsets-1 |
18621 | 18629 | streamsets-2 |
18622 | 18629 | streamsets-3 |
18630 | 18630 | streamsets-1 |
18631 | 18630 | streamsets-2 |
18632 | 18630 | streamsets-3 |
18633 | 18633 | streamsets-edge-1 |
19000 | 9000 | yb-tserver-1 |
19042 | 9042 | cassandra-atlas |
19043 | 9042 | cassandra-atlas |
19090 | 19090 | nifi-registry |
19160 | 9160 | cassandra-atlas |
19200 | 9200 | elasticsearch-atlas |
19201 | 9200 | amundsen-elasticsearch |
19202 | 9200 | datahub-elasticsearch |
19092 | 19092 | kafka-1 (docker-host) |
19093 | 19093 | kafka-2 (docker-host |
19094 | 19094 | kafka-3 (docker-host) |
19095 | 19095 | kafka-4 (docker-host) |
19096 | 19096 | kafka-5 (docker-host) |
19097 | 19097 | kafka-6 (docker-host) |
19098 | 19098 | kafka-7 (docker-host) |
19099 | 19099 | kafka-8 (docker-host) |
19120 | 19120 | nessie |
19630 | 19630 | streamsets-transformer-1 |
19631 | 19630 | streamsets-transformer-1 |
19632 | 19630 | streamsets-transformer-1 |
19999 | 9999 | influxdb2 |
21000 | 21000 | atlas |
26500 | 26500 | zeebe-1 |
27017 | 27017 | mongodb-1 |
27018 | 27017 | mongodb-2 |
27019 | 27017 | mongodb-3 |
27020 | 27017 | mongodb-3 |
28080 | 8080 | zeppelin |
28081 | 8080 | presto-1 |
28082 | 8080 | trino-1 |
28083 | 8443 | trino-1 (tls) |
28085 | 8080 | azkarra-worker-1 |
28888 | 8888 | jupyter |
28889 | 8888 | anaconda |
29042 | 9042 | cassandra-1 |
29043 | 9042 | cassandra-2 |
29044 | 9042 | cassandra-3 |
29045 | 9042 | cassandra-4 |
29046 | 9042 | cassandra-5 |
29092 | 29092 | kafka-1 (docker-host) |
29093 | 29093 | kafka-2 (docker-host |
29094 | 29094 | kafka-3 (docker-host) |
29095 | 29095 | kafka-4 (docker-host) |
29096 | 29096 | kafka-5 (docker-host) |
29097 | 29097 | kafka-6 (docker-host) |
29098 | 29098 | kafka-7 (docker-host) |
29099 | 29099 | kafka-8 (docker-host) |
29200 | 9200 | opensearch-1 |
29600 | 9600 | opensearch-1 |
31010 | 31010 | dremio |
39092 | 29092 | kafka-1 (localhost) |
39093 | 29093 | kafka-2 (localhost |
39094 | 29094 | kafka-3 (localhost) |
39095 | 29095 | kafka-4 (localhost) |
39096 | 29096 | kafka-5 (localhost) |
39097 | 29097 | kafka-6 (localhost) |
39098 | 29098 | kafka-7 (localhost) |
39099 | 29099 | kafka-8 (localhost) |
78 | 45678 | dremio |
61613 | 61613 | activemq (stomp) |
61614 | 61614 | activemq (ws) |
61616 | 61616 | activemq (jms) |
## Ports > 28100
Container Port(s) | Internal Port(s) | Service (alternatives) |
--------------------|------------------|-----------------------|
28100 | 8010 | zoonavigator-web |
28101 | 9010 | zoonavigator-api |
28102 | 8000 | schema-registry-ui |
28103 | 8000 | kafka-connect-ui |
28104 | 9000 | cmak (dc1) |
28105 | 9000 | cmak (dc2) |
28106 | 8080 | kadmin |
28107 | 8080 | akhq (dc1) |
28107 | 8080 | akhq (dc2) |
28110 | 9020 | kafdrop |
28111 | 28111 | spark-worker-1 |
28112 | 28112 | spark-worker-2 |
28113 | 28113 | spark-worker-3 |
28114 | 28114 | spark-worker-4 |
28115 | 28115 | spark-worker-5 |
28116 | 28116 | spark-worker-6 |
28117 | 18080 | spark-history |
28118 | 10000 | spark-thriftserver |
28119 | 8081 | redis-commander |
28120 | 3000 | cassandra-web |
28121 | 9091 | dse-studio |
28122 | 8888 | dse-opscenter |
28123 | 8081 | mongo-express |
28124 | 1234 | admin-mongo |
28125 | 1358 | dejavu |
28126 | 9000 | cerebro |
28127 | 5000 | elastichq |
28128 | 80 | influxdb-ui |
28129 | 8888 | chronograf |
28130 | 9092 | kapacitor |
28131 | 8080 | adminer |
28132 | 8080 | hivemq3-1 |
28133 | 8000 | hivemq3-1 |
28134 | 8080 | hivemq4-1 |
28135 | 8000 | hivemq4-1 |
28136 | 80 | mqtt-ui |
28137 | 9000 | portainer |
28138 | 8080 | cadvisor |
28139 | 8080 | airflow |
28140 | 8080 | code-server |
28141 | 8000 | kafka-topics-ui |
28142 | 8080 | datahub-gms |
28143 | 9001 | datahub-frontend-ember |
28144 | 9002 | datahub-frontend |
28145 | 9091 | datahub-mae-consumer |
28146 | 9092 | datahub-mce-consumer |
28150 | 8888 | druid-router |
28150 | 8888 | druid-sandbox |
28151 | 8088 | superset |
28152 | 8080 | superset |
28154 | 8080 | penthao |
28155 | 8080 | hawtio |
28156 | 8080 | swagger-editor |
28157 | 8080 | swagger-ui |
28158 | 8081 | streamsheets |
28159 | 8081 | quix-backend |
28160 | 8081 | quix-frontend |
28161 | 5000 | redash-server |
28170 | 80 | stardog-studio |
28171 | 3030 | smashing |
28172 | 3030 | tipboard |
28173 | 3030 | chartboard |
28174 | 8001 | redis-insight |
28175 | 8088 | cedalo-management-center |
28176 | 8080 | s3manager |
28177 | 8080 | hasura |
28178 | 8080 | file-browser |
28179 | 8080 | kafka-ui |
28180 | 8080 | dgraph-1 |
28181 | 9080 | dgraph-1 |
28182 | 8000 | dgraph-1 |
28190 | 80 | adminio_ui |
28191 | 8080 | adminio_api |
28192 | 8334 | filestash |
28193 | 9090 | minio-console |
28194 | 3000 | sqlpad |
28195 | 80 | streams-explorer |
28200 | 9090 | thingsbaord (http) |
28201 | 1883 | thingsbaord (mqtt) |
28202 | 5683 | thingsbaord (coap) |
28203 | 8080 | microcks |
28204 | 8080 | keycloak |
28205 | 10000 | dataiku-dss |
28206 | 3000 | postgrest |
28207 | 8080 | operate |
28208 | 9000 | zeeqs |
28209 | 8080 | hazelcast-mc |
28210 | 9000 | pinot-controller |
28211 | 8099 | pinot-broker-1 |
28212 | 8098 | pinot-server-1 |
28213 | 8098 | pinot-server-2 |
28214 | 8098 | pinot-server-3 |
28220 | 8000 | lakefs |
28221 | 8081 | emqx-1 |
28222 | 8083 | emqx-1 |
28223 | 8084 | emqx-1 |
28224 | 8883 | emqx-1 |
28225 | 18083 | emqx-1 |
28226 | 9000 | questdb |
28227 | 8080 | debezium-ui |
28228 | 9998 | tikka-server |
28229 | 5000 | mlflow-tracking-server |
28230 | 8080 | mlflow-artifacts-server |
28231 | 8080 | optuna-dashboard |
28232 | 8080 | reaper (app UI) |
28233 | 8081 | reaper (admin UI) |
28234 | 8080 | kie-server (drools) |
28235 | 8001 | business-central (drools) |
28236 | 8080 | business-central (drools) |
28237 | 8081 | flink-jobmanager |
28238 | 8083 | flink-sqlgateway |
28239 | 8080 | kowl |
28240 | 8080 | ignite-1 |
28241 | 8080 | ignite-2 |
28242 | 8080 | ignite-3 |
28243 | 8080 | ignite-4 |
28244 | 8080 | ignite-5 |
28245 | 8008 | gridgain-cc-frontend |
28246 | 8080 | debezium-server |
28247 | 80 | pgadmin |
28250 | 8888 | oracle-ee |
28251 | 8888 | oracle-xe |
28252 | 8888 | oracle-rest-1 |
28253 | 8888 | kouncil |
28254 | 80 | kafka-magic |
28255 | 80 | streampipes-ui |
28256 | 80 | remora |
28257 | 80 | metabase |
28258 | 3000 | burrow-ui |
28259 | 80 | burrow-dashboard |
28260 | 8000 | burrow |
28261 | 8888 | otel-collector |
28262 | 8889 | otel-collector |
28263 | 8889 | bpm-platform |
28264 | 8090 | optimize |
28265 | 80 | tempo |
28267 | 16686 | tempo (jaeger ui) |
28268 | 8080 | quine-1 |
28269 | 8080 | conduit |
28270 | 8001 | airbyte-server |
28271 | 80 | airbyte-webapp |
28272 | 7233 | airbyte-temporal |
28273 | 1090 | mockserver |
28274 | 8080 | kafka-webviewer |
28275 | 8080 | elasticvue |
28276 | 8080 | nocodb |
28277 | 8080 | zilla |
28278 | 9090 | zilla |
28279 | 80 | azure-storage-explorer |
28280 | 8080 | tyk-gateway |
28281 | 3000 | tyk-dashboard |
28282 | 80 | kafka-connector-board |
28283 | 3000 | kpow |
28284 | 8000 | jupyterhub |
28285 | 80 | conduktor-platform |
28286 | 80 | kong-admin-ui |
28287 | 8181 | iceberg-rest |
28288 | 3000 | memgraph-platform |
28289 | 8080 | redpanda-console |
28290 | 80 | excalidraw |
28291 | 8200 | invana-engine |
28292 | 8300 | invana-studio |
28293 | 8080 | spring-boot-admin |
28294 | 5000 | ckan |
28295 | 8800 | ckan-datapusher |
28296 | 443 | phpldapadmin |
28297 | 80 | ldap-user-manager |
28298 | 4040 | spark-thriftserver (Spark UI) |
28299 | 80 | baserow |
28300 | 443 | baserow |
28301 | 10001 | querybook |
28302 | 8081 | nussknacker-designer |
28303 | 8080 | kafkistry |
28304 | 8080 | spark-master |
28305 | 3000 | sqlchat |
28306 | 8080 | minio-web |
## Ports > 28500
Container Port(s) | Internal Port(s) | Service (alternatives) |
--------------------|------------------|-----------------------|
28500 - 28510 | 28500 - 28510 | streamsets-1 (additional ports) |
28520 - 28600 | any | reserved for applications |
An overview of the URL for the various web-based UIs can be found [here](./environment/README).
<file_sep>---
technoglogies: jupyter,spark,avro
version: 1.16.0
validated-at: 3.10.2022
---
# Using Jupyter notebook with Spark and Avro
This recipe will show how to use Jupyter with the local Spark engine and working with Avro data. By that we also show how to specify an additional dependency (to Avro).
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services JUPYTER,PROVISIONING_DATA -s trivadis/platys-modern-data-platform -w 1.16.0
```
Edit the `config.yml` and add the following properties after `JUPYTER_enable`
```yaml
JUPYTER_edition: 'all-spark'
JUPYTER_spark_jars_packages: 'org.apache.spark:spark-avro_2.12:3.1.1'
JUPYTER_tokenless: false
JUPYTER_token: '<PASSWORD>!'
```
We specify the `all-spark` edition of Jupyter and specify the dependency on `org.apache.spark:spark-avro_2.12:3.1.1` to be added to the Spark environment. This will automatically be added to `spark-defaults.conf` when starting Jupyter.
Additionally we specify the token to login into Jupyter as `<PASSWORD>!`.
Generate and start the platform
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
The `PROVISIONING_DATA_enable` setting will copy data to the `data-transfer` folder. We will use from `flight-data` folder the `airports.avro` file.
```
docker@ubuntu ~/platys-demo [SIGINT]> ls -lsa data-transfer/flight-data/
total 57056
4 drwxr-xr-x 4 root root 4096 Oct 3 10:26 ./
4 drwxr-xr-x 8 docker docker 4096 Oct 3 10:26 ../
4 -rw-r--r-- 1 root root 1952 Oct 3 10:26 README.md
140 -rw-r--r-- 1 root root 141544 Oct 3 10:26 airports.avro
240 -rwxr-xr-x 1 root root 244438 Oct 3 10:26 airports.csv*
588 -rw-r--r-- 1 root root 598901 Oct 3 10:26 airports.json
44 -rwxr-xr-x 1 root root 43758 Oct 3 10:26 carriers.csv*
76 -rw-r--r-- 1 root root 76537 Oct 3 10:26 carriers.json
4 drwxr-xr-x 2 root root 4096 Oct 3 10:26 flights-medium/
4 drwxr-xr-x 2 root root 4096 Oct 3 10:26 flights-small/
54580 -rw-r--r-- 1 root root 55888790 Oct 3 10:26 pilot_handbook.pdf
420 -rwxr-xr-x 1 root root 428558 Oct 3 10:26 plane-data.csv*
948 -rw-r--r-- 1 root root 968807 Oct 3 10:26 plane-data.json
```
## Using Jupyter to read the Airports.avro file
Navigate to Jupyter on <http://dataplatform:28888>.
Enter `<PASSWORD>!` into the **Password or token** field and click on **Log in**:

On the **Launcher** page, click on **Python 3** Notebook.

Add the following block as the first cell
```python
import os
# make sure pyspark tells workers to use python3 not 2 if both are installed
#os.environ['PYSPARK_PYTHON'] = '/usr/bin/python3'
import pyspark
conf = pyspark.SparkConf()
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('abc').config(conf=conf).getOrCreate()
sc = spark.sparkContext
```
and execute it.
If you check the Jupyter log using `docker log -f jupyter` you can see that the avro jar has been downloaded:
```bash
docker logs -f jupyter
Set username to: jovyan
usermod: no changes
/usr/local/bin/start-notebook.sh: running hooks in /usr/local/bin/before-notebook.d
/usr/local/bin/start-notebook.sh: running /usr/local/bin/before-notebook.d/spark-config.sh
/usr/local/bin/start-notebook.sh: done running hooks in /usr/local/bin/before-notebook.d
...
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
:: loading settings :: url = jar:file:/usr/local/spark-3.1.1-bin-hadoop3.2/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /home/jovyan/.ivy2/cache
The jars for the packages stored in: /home/jovyan/.ivy2/jars
org.apache.spark#spark-avro_2.12 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-3d132608-dd55-4339-acd9-04808d1fd502;1.0
confs: [default]
found org.apache.spark#spark-avro_2.12;3.1.1 in central
found org.spark-project.spark#unused;1.0.0 in central
downloading https://repo1.maven.org/maven2/org/apache/spark/spark-avro_2.12/3.1.1/spark-avro_2.12-3.1.1.jar ...
[SUCCESSFUL ] org.apache.spark#spark-avro_2.12;3.1.1!spark-avro_2.12.jar (78ms)
downloading https://repo1.maven.org/maven2/org/spark-project/spark/unused/1.0.0/unused-1.0.0.jar ...
[SUCCESSFUL ] org.spark-project.spark#unused;1.0.0!unused.jar (38ms)
:: resolution report :: resolve 5160ms :: artifacts dl 120ms
```
Now add the cell to read the `airports.avro` file and show the data
```python
airportDF = spark.read.format("avro").load("/data-transfer/flight-data/airports.avro")
airportDF.show()
```
<file_sep>---
technoglogies: neo4j,jupyter
version: 1.16.0
validated-at: 20.12.2022
---
# Neo4J and yFiles graphs for Jupyter
This recipe will show how to use a Neo4j with the [jFiles Graph for Jupyter](https://www.yworks.com/products/yfiles-graphs-for-jupyter) to visualize graph networks with Python.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services NEO4J,JUPYTER -s trivadis/platys-modern-data-platform -w 1.16.0
```
Before we can generate the platform, we need to extend the `config.yml`:
Add the required python modules to `JUPYTER_python_packages`
```yaml
JUPYTER_python_packages: 'yfiles_jupyter_graphs neo4j ipywidgets'
```
and also add a custom token
```yaml
JUPYTER_token: '<PASSWORD>!'
```
Now set an environment variable to the home folder of the dataplatform and generate and then start the data platform.
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Load a database into Neo4J
Navigate to <http://dataplatform:7474> and login as user `neo4j` and password `<PASSWORD>`.
Now load the movie graph by executing
```
:PLAY movie graph
```
on the resulting cell, navigate to page **2/8** and click on the play icon in the Cypher statement to execute it.

The movie database is loaded into Neo4j.
## Using yFiles Graph from Jupyter
Navigate to <http://dataplatform:28888> and login with the token specified above, i.e. `<PASSWORD>!`.
Create a new notebook and add and execute the following cells:
First let's specify the login config
```cypher
from neo4j import basic_auth
db = "bolt://neo4j-1:7687"
auth = basic_auth("neo4j", "<PASSWORD>")
```
Now connect to the database
```cypher
from neo4j import GraphDatabase
driver = GraphDatabase.driver(db, auth=auth)
session = driver.session()
```
And execute a query against the database and visualize it
```cypher
result = session.run("MATCH (s)-[r]->(t) RETURN s,r,t LIMIT 20")
from yfiles_jupyter_graphs import GraphWidget
w = GraphWidget(graph = result.graph())
w.show()
```
you should see the following output in Jupyter
<file_sep># Zeebe
Distributed Workflow Engine for Microservices Orchestration.
**[Website](https://camunda.com/products/cloud/workflow-engine/)** | **[Documentation](https://docs.camunda.io/docs/components/zeebe/zeebe-overview)** | **[GitHub](https://github.com/camunda-cloud/zeebe)**
## How to enable?
```
platys init --enable-services CAMUNDA_ZEEBE
platys gen
```
## How to use it?
<file_sep>Place StreamSets pipelines to load on start here.<file_sep># RStudio
An integrated development environment for R and Python, with a console, syntax-highlighting editor that supports direct code execution, and tools for plotting, history, debugging and workspace management.
**[Website](https://www.rstudio.com/)** | **[Documentation](https://docs.rstudio.com/)** | **[GitHub](https://github.com/rstudio/rstudio)**
## How to enable?
```
platys init --enable-services RSTUDIO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8787><file_sep># Spark History Server
The Spark history server is a monitoring tool that displays information about completed Spark applications
**[Website](https://spark.apache.org/)** | **[Documentation](https://spark.apache.org/docs/3.2.0/running-on-yarn.html#using-the-spark-history-server-to-replace-the-spark-web-ui)** | **[GitHub](https://github.com/apache/spark/)**
## How to enable?
```
platys init --enable-services SPARK,SPARK_HISTORY
platys gen
```
## How to use it?
<file_sep>Contains the data of arcaded service, if flag ARCADEDB_volume_map_data is set to true.<file_sep>package com.trivadis.kafkaws.consumer;
import java.util.Collections;
import java.util.Properties;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.LongDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import com.trivadis.kafkaws.avro.v1.Notification;
import io.confluent.kafka.serializers.KafkaAvroDeserializer;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializerConfig;
public class KafkaConsumerAvro {
private final static String TOPIC = "test-java-avro-topic";
private final static String BOOTSTRAP_SERVERS =
"dataplatform:9092, dataplatform:9093, dataplatform:9094";
private final static String SCHEMA_REGISTRY_URL = "http://dataplatform:8081";
private static Consumer<Long, Notification> createConsumer() {
final Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerAvro");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 10000);
props.put(KafkaAvroSerializerConfig.AUTO_REGISTER_SCHEMAS, "false");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class.getName());
props.put(KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, SCHEMA_REGISTRY_URL); // use constant for "schema.registry.url"
// Create the consumer using props.
final Consumer<Long, Notification> consumer =
new KafkaConsumer<>(props);
// Subscribe to the topic.
consumer.subscribe(Collections.singletonList(TOPIC));
return consumer;
}
static void runConsumer(int waitMsInBetween) throws InterruptedException {
final Consumer<Long, Notification> consumer = createConsumer();
final int giveUp = 100;
int noRecordsCount = 0;
while (true) {
final ConsumerRecords<Long, Notification> consumerRecords = consumer.poll(1000);
if (consumerRecords.count()==0) {
noRecordsCount++;
if (noRecordsCount > giveUp)
break;
}
consumerRecords.forEach(record -> {
System.out.printf("%d - Consumer Record:(Key: %d, Value: %s, Partition: %d, Offset: %d)\n",
consumerRecords.count(), record.key(), record.value(),
record.partition(), record.offset());
try {
Thread.sleep(waitMsInBetween);
} catch (InterruptedException e) {
}
});
consumer.commitSync();
}
consumer.close();
System.out.println("DONE");
}
public static void main(String... args) throws Exception {
if (args.length == 0) {
runConsumer(10);
} else {
runConsumer(Integer.parseInt(args[0]));
}
}
}<file_sep>---
technologies: spark, hive-metastore
version: 1.16.0
validated-at: 20.02.2023
---
# Spark and Hive Metastore
This recipe will show how to use Hive Metastore with Spark.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```bash
platys init --enable-services SPARK,HIVE_METASTORE,MINIO,PROVISIONING_DATA -s trivadis/platys-modern-data-platform -w 1.15.0
```
Add the following properties to the generated `config.yml` file:
```bash
SPARK_catalog: hive
SPARK_base_version: 3.2
```
Now generate and start the data platform.
```bash
platys gen
docker-compose up -d
```
## Create a table in Hive Metastore
Connect to Hive Metastore Service and create a table:
```bash
docker exec -ti hive-metastore hive
```
on the command line, create the following table
```
CREATE TABLE demo_sales
(id BIGINT, qty BIGINT, name STRING)
COMMENT 'Demo: Connecting Spark SQL to Hive Metastore'
PARTITIONED BY (rx_mth_cd STRING COMMENT 'Prescription Date YYYYMM aggregated')
STORED AS PARQUET;
```
## Connect to Spark Shell to view the table
Connect to the `spark-shell` CLI
```
docker exec -ti spark-master spark-shell
```
Check that the catalog is set to `hive`
```
spark.conf.get("spark.sql.catalogImplementation")
```
List the tables currently in the catalog
```
spark.catalog.listTables.show
```
and you should get the following output
```
scala> spark.catalog.listTables.show
+----------+--------+--------------------+---------+-----------+
| name|database| description|tableType|isTemporary|
+----------+--------+--------------------+---------+-----------+
|demo_sales| default|Demo: Connecting ...| MANAGED| false|
+----------+--------+--------------------+---------+-----------+
```
## Connect to Spark SQL to view the table
Connect to the `spark-sql` CLI
```
docker exec -ti spark-master spark-sql
```
Show the tables currently in the catalog
```
show tables;
```
and you should get the following output
```
spark-sql> show tables;
20/09/14 09:10:07 INFO codegen.CodeGenerator: Code generated in 271.351739 ms
default demo_sales false
Time taken: 2.763 seconds, Fetched 1 row(s)
```
<file_sep># Tile38
Fast Geospatial Database & Geofencing Server.
**[Website](https://tile38.com/)** | **[Documentation](https://tile38.com/topics/installation)** | **[GitHub](https://github.com/tidwall/tile38)**
## How to enable?
```
platys init --enable-services TILE38
platys gen
```
## How to use it?
Navigate to <http://dataplatform:9851><file_sep># Materialize
Materialize simplifies application development with streaming data. Incrementally-updated materialized views - in PostgreSQL and in real time. Materialize is powered by Timely Dataflow.
**[Website](https://materialize.com/)** | **[Documentation](https://materialize.com/docs/)** | **[GitHub](https://github.com/MaterializeInc/materialize)**
## How to enable?
```
platys init --enable-services MATERIALIZE
platys gen
```
## How to use it?
You can connect via `mzcli` (enable it using `MATERIALIZE_CLI_enable`)
```bash
docker exec -ti mzcli mzcli -h materialize-1
```
<file_sep># Redash
Make Your Company Data Driven. Connect to any data source, easily visualize, dashboard and share your data.
**[Website](https://redash.io/)** | **[Documentation](https://redash.io/)** | **[GitHub](https://github.com/getredash/redash)**
## How to enable?
```
platys init --enable-services REDASH
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28161><file_sep>Contains the notebooks of anaconda service, if flag ANACONDA_volume_map_notebooks is set to true.<file_sep># Apache Hive
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
**[Website](https://hive.apache.org/)** | **[Documentation](https://cwiki.apache.org/confluence/display/Hive/GettingStarted)** | **[GitHub](https://github.com/apache/hive)**
## How to enable?
```
platys init --enable-services HIVE
platys gen
```
## How to use it?
<file_sep># Redis
Redis is an in-memory database that persists on disk. The data model is key-value, but many different kind of values are supported: Strings, Lists, Sets, Sorted Sets, Hashes, Streams, HyperLogLogs, Bitmaps.
**[Website](https://redis.io/)** | **[Documentation](https://redis.io/documentation)** | **[GitHub](https://github.com/redis/redis)**
## How to enable?
```
platys init --enable-services REDIS
platys gen
```
## How to use it?
To connect to Redis over the Redis-CLI, use
```
docker exec -ti redis-1 redis-cli
```<file_sep># Marquez
Marquez is an open source metadata service for the collection, aggregation, and visualization of a data ecosystem’s metadata. It maintains the provenance of how datasets are consumed and produced, provides global visibility into job runtime and frequency of dataset access, centralization of dataset lifecycle management, and much more.
**[Website](https://marquezproject.github.io/marquez/)** | **[Documentation](https://marquezproject.github.io/marquez/)** | **[GitHub](https://github.com/MarquezProject/marquez)**
## How to enable?
```
platys init --enable-services MARQUEZ
platys gen
```
## How to use it?
Navigate to <http://dataplatform:3005><file_sep># (Virtual) machine running Ubuntu Linux
This document describes how to install the workshop environment on a Ubuntu Machine, which could be running in a virtual machine, either in the cloud, on a remote server or on your local machine.
The VM should be configured with at least 8 GB and 4 CPUs.
## Setup Software
First let's create some environment variables.
```bash
export GITHUB_PROJECT=kafka-workshop
export GITHUB_OWNER=gschmutz
export DATAPLATFORM_HOME=01-environment/docker
export PLATYS_VERSION=2.4.3
export NETWORK_NAME=<network-name>
```
**Note:** Make sure to replace the `<network-name>` by the value retrieved from `ip addr`, which would be `ens33` in the example below
```
$ ip addr
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:3a:82:45 brd ff:ff:ff:ff:ff:ff
altname enp2s1
```
### Install some helpful utilities
```bash
sudo apt-get install -y curl jq kafkacat openssh-server
```
### Installing Docker
The instructions below are taken from here: <https://docs.docker.com/engine/install/ubuntu/>
**Setup the repository**
Uninstall old versions
```bash
sudo apt-get remove docker docker-engine docker.io containerd runc
```
Update `apt` package index and install packages
```bash
sudo apt-get update
sudo apt-get install \
ca-certificates \
curl \
gnupg \
lsb-release
```
Add Docker's official GPG key
```bash
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
```
Setup the repository
```bash
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
```
**Install Docker Engine**
Update the apt package index, and install the latest version of Docker Engine, containerd, and Docker Compose
```bash
sudo apt-get update
```
**Note:** if you receive a GPG error when running apt-get update
```bash
sudo chmod a+r /etc/apt/keyrings/docker.gpg
sudo apt-get update
```
Now install the latest version of Docker
```bash
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
```
**Add user to `docker` group**
```bash
sudo usermod -aG docker $USER
```
logout and relogin as the user.
**Test if docker is working**
```bash
docker -v
docker ps
```
### Installing Docker Compose Switch
[Compose Switch](https://github.com/docker/compose-switch) is a replacement to the Compose V1 docker-compose (python) executable.
Download compose-switch binary for your architecture:
```bash
sudo curl -fL https://github.com/docker/compose-switch/releases/latest/download/docker-compose-linux-amd64 -o /usr/local/bin/compose-switch
```
Make compose-switch executable:
```bash
sudo chmod +x /usr/local/bin/compose-switch
```
Define an "alternatives" group for docker-compose command
```
sudo update-alternatives --install /usr/local/bin/docker-compose docker-compose /usr/local/bin/compose-switch 99
```
### Installing Platys
Installing `platys` is optional. It is an [open source tool](http://github.com/trivadispf/platys) we have used to generate the docker-compose stack we will use below.
```bash
sudo curl -L "https://github.com/TrivadisPF/platys/releases/download/2.4.3/platys_2.4.3_linux_x86_64.tar.gz" -o /tmp/platys.tar.gz
tar zvxf /tmp/platys.tar.gz
sudo mv platys /usr/local/bin/
sudo chown root:root /usr/local/bin/platys
sudo rm README.md
```
Test that `platys` is working
```bash
platys -v
```
## Prepare Environment
In a terminal terminal window execute the following commands.
### Setup environment variables
If your virtual machine is running in the cloud or on a remote server, set the `PUBLIC_IP` variable to the IP Address you use to reach it
```bash
export PUBLIC_IP=<public-ip>
```
otherwise this command (make sure that `$NETWORK_NAME` has been set correctly)
```bash
export PUBLIC_IP=$(ip addr show $NETWORK_NAME | grep "inet\b" | awk '{print $2}' | cut -d/ -f1)
```
Additionally set the `DOCKER_HOST_IP` to the IP address of the machine (make sure that `$NETWORK_NAME` has been set correctly)
```bash
export DOCKER_HOST_IP=$(ip addr show $NETWORK_NAME | grep "inet\b" | awk '{print $2}' | cut -d/ -f1)
```
### Clone Workshop GitHub project
Now let's clone the Kafka Workshop project from GitHub:
```
cd
git clone https://github.com/${GITHUB_OWNER}/${GITHUB_PROJECT}.git
cd ${GITHUB_PROJECT}/${DATAPLATFORM_HOME}
export DATAPLATFORM_HOME=$PWD
```
### Persist Environment variables
Finally let's persist the 3 environment variables `PUBLIC_IP`, `DOCKER_HOST_IP` and `DATAPLATFORM_HOME`, so that they are available after a logout.
```bash
printf "export PUBLIC_IP=$PUBLIC_IP\n" >> /home/$USER/.bash_profile
printf "export DOCKER_HOST_IP=$DOCKER_HOST_IP\n" >> /home/$USER/.bash_profile
printf "export DATAPLATFORM_HOME=$DATAPLATFORM_HOME\n" >> /home/$USER/.bash_profile
printf "\n" >> /home/$USER/.bash_profile
sudo chown ${USER}:${USER} /home/$USER/.bash_profile
```
### Settings for Elasticsearch
For Elasticsearch to run properly, we have to increase the `vm.max_map_count` parameter like shown below.
```bash
sudo sysctl -w vm.max_map_count=262144
```
## Start Environment
Start the environment by performing a `docker-compose up`
```
docker-compose up -d
```
If started the first time, the necessary docker images will be downloaded from the public docker registry. Therefore you need internet access from your machine.
Depending on the speed of the network, the download takes a few minutes (around 5 minutes).
Once this is done, the docker container will start one by one, and at the end the output should be similar to the one below.

Your instance is now ready to use. Complete the post installation steps documented the [here](README.md).
In a web browser navigate to `http://<public-ip>` to access the markdown page with the relevant information about the docker compose stack.

Click on link **All available services which are part of the platform are listed here** to navigate to the list of services:

## Stop environment
To stop the environment, execute the following command:
```
docker-compose stop
```
after that it can be re-started using `docker-compose start`.
## Remove the environment
To stop and remove all running container, execute the following command:
```
docker-compose down
```
<file_sep>connector.name=kafka
kafka.table-names=${ENV:KAFKA_TABLE_NAMES}
kafka.default-schema=${ENV:KAFKA_DEFAULT_SCHEMA}
kafka.table-description-dir=${ENV:KAFKA_TABLE_DESCRIPTOR_DIR}
kafka.nodes=kafka-1:19092,kafka-2:19093,kafka-3:19094
kafka.hide-internal-columns=false
<file_sep>Place custom keystone and truststore files here to configure NiFi.<file_sep># InfluxDB v2
InfluxDB is an open source time series database. It has everything you need from a time series platform in a single binary – a multi-tenanted time series database, UI and dashboarding tools, background processing and monitoring agent. All this makes deployment and setup a breeze and easier to secure.
**[Website](https://www.influxdata.com/)** | **[Documentation](https://docs.influxdata.com/influxdb/latest/)** | **[GitHub](https://github.com/influxdata/influxdb)**
## How to enable?
```
platys init --enable-services INFLUXDB2
platys gen
```
## How to use it?
Navigate to <http://dataplatform:19999> and login with user `influx` and password `<PASSWORD>!`. <file_sep>Contains the proc of prometheus nodeexporter service, if flag PROMETHEUS_volume_map_data is set to true.<file_sep># adminMongo
adminMongo is a Web based user interface (GUI) to handle all your MongoDB connections/databases needs.
**[Documentation](https://github.com/adicom-systems/adminMongo)** | **[GitHub](https://github.com/adicom-systems/adminMongo)**
## How to enable?
```
platys init --enable-services MONGO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28124><file_sep># Parquet Tools CLI
pache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. Parquet is available in multiple languages including Java, C++, Python, etc...
**[Website](https://parquet.apache.org/)** | **[Documentation](https://parquet.apache.org/docs/)** | **[GitHub](https://github.com/apache/parquet-mr/)**
## How to enable?
```
platys init --enable-services PARQUET_TOOLS
platys gen
```
## How to use it?
To use the parquet tool, once it is generated, just use the `docker exec` command:
```bash
docker compose run --rm parquet-tools <command>
```<file_sep># Zookeeper
ZooKeeper is a high-performance coordination service for distributed applications. It exposes common services - such as naming, configuration management, synchronization, and group services - in a simple interface so you don't have to write them from scratch. You can use it off-the-shelf to implement consensus, group management, leader election, and presence protocols. And you can build on it for your own, specific needs.
**[Website](https://zookeeper.apache.org/)** | **[Documentation](https://zookeeper.apache.org/doc/r3.7.0/index.html)** | **[GitHub](https://github.com/apache/zookeeper)**
### How to enable?
```
platys init --enable-services ZOOKEEPER
platys gen
```
### How to use it?
<file_sep>---
technologies: mlflow,python,jupyter
version: 1.16.0
validated-at: 25.12.2022
---
# Using MLflow from Jupyter
This recipe will show how to use MLflow from Jupyter. We will be using the [Elastic Net example](https://github.com/mlflow/mlflow/tree/master/examples/sklearn_elasticnet_wine) from the MLFlow [Tutorials and Examples](https://mlflow.org/docs/latest/tutorials-and-examples/index.html) page.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```bash
platys init --enable-services MLFLOW_SERVER,MINIO,JUPYTER -s trivadis/platys-modern-data-platform -w 1.16.0
```
add to `config.yml`
```yaml
JUPYTER_edition: 'datascience'
JUPYTER_python_packages: 'mlflow'
JUPYTER_token: 'abc123!'
```
Now generate and start the platform
```bash
platys gen
docker-compose up -d
```
## Working with MLflow
Navigate to Jupyter on <http://dataplatform:28888>.
Create a new notebook and add the following cell
```python
# Wine Quality Sample
def train(in_alpha, in_l1_ratio):
import os
import warnings
import sys
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
import mlflow
import mlflow.sklearn
import logging
logging.basicConfig(level=logging.WARN)
logger = logging.getLogger(__name__)
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
warnings.filterwarnings("ignore")
np.random.seed(40)
# Read the wine-quality csv file from the URL
csv_url = (
"http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
)
try:
data = pd.read_csv(csv_url, sep=";")
except Exception as e:
logger.exception(
"Unable to download training & test CSV, check your internet connection. Error: %s", e
)
# Split the data into training and test sets. (0.75, 0.25) split.
train, test = train_test_split(data)
# The predicted column is "quality" which is a scalar from [3, 9]
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
# Set default values if no alpha is provided
if float(in_alpha) is None:
alpha = 0.5
else:
alpha = float(in_alpha)
# Set default values if no l1_ratio is provided
if float(in_l1_ratio) is None:
l1_ratio = 0.5
else:
l1_ratio = float(in_l1_ratio)
# Useful for multiple runs (only doing one run in this sample notebook)
with mlflow.start_run():
# Execute ElasticNet
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
# Evaluate Metrics
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
# Print out metrics
print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
# Log parameter, metrics, and model to MLflow
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.sklearn.log_model(lr, "model")
```
Now let's invoke it with different parameters
```python
train(0.5, 0.5)
```
```python
train(0.2, 0.2)
```
```python
train(0.1, 0.1)
```
## Check it in MLFlow dashboard
Navigate to <http://dataplatform:28229> to check the results.
<file_sep># ArcadeDB
ArcadeDB Multi-Model Database, one DBMS that supports SQL, Cypher, Gremlin, HTTP/JSON, MongoDB and Redis. ArcadeDB is a conceptual fork of OrientDB, the first Multi-Model DBMS.
**[Website](https://arcadedb.com/)** | **[Documentation](https://docs.arcadedb.com/)** | **[GitHub](https://github.com/ArcadeData/arcadedb)**
```bash
platys init --enable-services ARCADEDB
platys gen
```
## How to use it?
Navigate to <http://dataplatform:2480> and log in as user `root` with default password `<PASSWORD>` (if not changed using `ARCADEDB_root_password` setting).<file_sep># Oracle RDBMS XE
Whether you are a developer, a DBA, a data scientist, an educator, or just curious about databases, Oracle Database Express Edition (XE) is the ideal way to get started. It is the same powerful Oracle Database that enterprises rely on worldwide, packaged for simple download, ease-of-use, and a full-featured experience. You get an Oracle Database to use in any environment, plus the ability to embed and redistribute – all completely free!
**[Website](https://www.oracle.com/database/technologies/appdev/xe.html)** | **[Documentation](https://www.oracle.com/database/technologies/appdev/xe/quickstart.html)**
## How to enable?
```
platys init --enable-services ORACLE_XE
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28152>
<file_sep>#!/usr/bin/env bash
if [ ${FLINK_INSTALL_MAVEN_DEP} ]
then
/platys-scripts/maven-download.sh central ${FLINK_INSTALL_MAVEN_DEP} /opt/flink/lib
fi
if [ ${FLINK_INSTALL_FILE_DEP} ]
then
/platys-scripts/file-download.sh github ${FLINK_INSTALL_FILE_DEP} /opt/flink/lib
fi
if [ -z ${FLINK_DO_NOT_START} ]; then
/docker-entrypoint.sh $@
else
tail -f /dev/null
fi<file_sep>Contains the working directory of kong service<file_sep># Konga
An open source tool that enables you to manage your Kong API Gateway with ease.
**[Website](https://pantsel.github.io/konga/)** | **[Documentation](https://github.com/pantsel/konga/blob/master/README)** | **[GitHub](https://github.com/pantsel/konga)**
## How to enable?
```
platys init --enable-services KONG, KONGA
platys gen
```
## How to use it?
Navigate to <http://dataplatform:1337><file_sep># Working with Kafka Connect and Change Data Capture (CDC)
In this workshop we will see various CDC solutions in action
1. Polling-based CDC using Kafka Connect
2. Log-based CDC using Debezium and Kafka Connect
3. Transactional Outbox Pattern using Debezium and Kafka Connect
## Creating Postgresql Database `cdc_demo `
The `driver` table holds the information of the drivers working for us. Let's connect to the postgresql database running as part of the dataplatform and create the table
```bash
docker exec -ti postgresql psql -d postgres -U postgres
```
If the table is not available, this is the code to run
```sql
CREATE SCHEMA IF NOT EXISTS cdc_demo;
SET search_path TO cdc_demo;
DROP TABLE IF EXISTS address;
DROP TABLE IF EXISTS person;
CREATE TABLE "cdc_demo"."person" (
"id" integer NOT NULL,
"title" character varying(8),
"first_name" character varying(50),
"last_name" character varying(50),
"email" character varying(50),
"modifieddate" timestamp DEFAULT now() NOT NULL,
CONSTRAINT "person_pk" PRIMARY KEY ("id")
);
CREATE TABLE "cdc_demo"."address" (
"id" integer NOT NULL,
"person_id" integer NOT NULL,
"street" character varying(50),
"zip_code" character varying(10),
"city" character varying(50),
"modifieddate" timestamp DEFAULT now() NOT NULL,
CONSTRAINT "address_pk" PRIMARY KEY ("id")
);
ALTER TABLE ONLY "cdc_demo"."address" ADD CONSTRAINT "address_person_fk" FOREIGN KEY (person_id) REFERENCES person(id) NOT DEFERRABLE;
```
## Polling-based CDC using Kafka Connect
In this section we will see how we can use the [JDBC Source Connector](https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc) to perform polling-based CDC on the two tables.

To use the Polling-based CDC with Kafka Connect, we have to install the [JDBC Source Connector](https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc) on our Kafka Connect cluster.
On the workshop environment, this has already been done. You can check the available connectors either from [Kafka Connect UI](http://dataplatform:28103/#/cluster/kafka-connect-1/select-connector) or by using the REST API `curl -XGET http://$DOCKER_HOST_IP:8083/connector-plugins | jq`
#### Create the necessary topics
Let's create a topic for the change records of the two tables 'person` and `address`:
```bash
docker exec -ti kafka-1 kafka-topics --bootstrap-server kafka-1:19092 --create --topic priv.person.cdc.v1 --partitions 8 --replication-factor 3
docker exec -ti kafka-1 kafka-topics --bootstrap-server kafka-1:19092 --create --topic priv.address.cdc.v1 --partitions 8 --replication-factor 3
```
Now let's start two consumers, one on each topic, in separate terminal windows
```bash
kcat -b kafka-1:19092 -t priv.person.cdc.v1 -f '[%p] %k: %s\n' -q
```
```bash
kcat -b kafka-1:19092 -t priv.address.cdc.v1 -f '[%p] %k: %s\n' -q
```
By using the `-f` option we tell `kcat` to also print the partition number and the key for each message.
#### Create some initial data in Postgresql
Let's add a first person and address as a sample. In a terminal connect to Postgresql
```bash
docker exec -ti postgresql psql -d postgres -U postgres
```
execute the following SQL INSERT statements
```sql
INSERT INTO cdc_demo.person (id, title, first_name, last_name, email)
VALUES (1, 'Mr', 'Peter', 'Muster', '<EMAIL>');
INSERT INTO cdc_demo.address (id, person_id, street, zip_code, city)
VALUES (1, 1, 'Somestreet 10', '9999', 'Somewhere');
```
#### Create a JDBC Source connector instance
Now let's create and start the JDBC Source connector
```bash
curl -X "POST" "$DOCKER_HOST_IP:8083/connectors" \
-H "Content-Type: application/json" \
-d $'{
"name": "person.jdbcsrc.cdc",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": "1",
"connection.url":"jdbc:postgresql://postgresql/postgres?user=postgres&password=<PASSWORD>!",
"mode": "timestamp",
"timestamp.column.name":"modifieddate",
"poll.interval.ms":"10000",
"table.whitelist":"cdc_demo.person,cdc_demo.address",
"validate.non.null":"false",
"topic.prefix":"priv.",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"name": "person.jdbcsrc.cdc",
"transforms":"createKey,extractInt,addSuffix",
"transforms.createKey.type":"org.apache.kafka.connect.transforms.ValueToKey",
"transforms.createKey.fields":"id",
"transforms.extractInt.type":"org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractInt.field":"id",
"transforms.addSuffix.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.addSuffix.regex":".*",
"transforms.addSuffix.replacement":"$0.cdc.v1"
}
}'
```
You can find the documentation on the configuration settings [here](https://docs.confluent.io/kafka-connect-jdbc/current/source-connector/source_config_options.html).
After a maximum of 10 seconds (which is the polling interval we set), we should see one message each in the two topic, one for the record in the `person` and one for the record in the `address` table.
You can also monitor the connector in the Kafka Connect UI: <http://dataplatform:28103/>
#### Configuration options
Let's discuss some of the configurations in the connector.
The key get's extracted using two [Single Message Transforms (SMT)](https://docs.confluent.io/platform/current/connect/transforms/overview.html), the `ValueToKey` and the `ExtractField`. They are chained together to set the key for data coming from a JDBC Connector. During the transform, `ValueToKey` copies the message id field into the message key and then `ExtractField` extracts just the integer portion of that field.
```json
"transforms.createKey.type":"org.apache.kafka.connect.transforms.ValueToKey",
"transforms.createKey.fields":"id",
"transforms.extractInt.type":"org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractInt.field":"id",
```
To also add a suffix to the topic (we have added a prefix using the `topic.prefix` configuration) we can use the `RegexRouter` SMT
```json
"transforms.addSuffix.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.addSuffix.regex":".*",
"transforms.addSuffix.replacement":"$0.cdc.v1"
```
#### Add more data
Let's add some more data to the tables and check how quick the data will appear in the topics.
In a new terminal window, again connect to postgresql
```bash
docker exec -ti postgresql psql -d postgres -U postgres
```
Add a new `address` to `person` with `id=1`.
```sql
INSERT INTO cdc_demo.address (id, person_id, street, zip_code, city)
VALUES (2, 1, 'Holiday 10', '1999', 'Ocean Somewhere');
```
Now let's add a new `person`, first without an `address`
```sql
INSERT INTO cdc_demo.person (id, title, first_name, last_name, email)
VALUES (2, 'Ms', 'Karen', 'Muster', '<EMAIL>');
```
and now also add the `address`
```sql
INSERT INTO cdc_demo.address (id, person_id, street, zip_code, city)
VALUES (3, 2, 'Somestreet 10', '9999', 'Somewhere');
```
#### Remove the connector
We have successfully tested the query-based CDC using the JDBC Source connector. So let's remove the connector.
```bash
curl -X "DELETE" "http://$DOCKER_HOST_IP:8083/connectors/person.jdbcsrc.cdc"
```
## Log-based CDC using Debezium and Kafka Connect
In this section we will see how we can use [Debezium](https://debezium.io/) and it's Postgresql connector to perform log-based CDC on the two tables.

The [Debezium connector](https://www.confluent.io/hub/debezium/debezium-connector-postgresql) comes pre-installed with the Dataplatform stack.
#### Create some initial data in Postgresql
Let's add a first person and address as a sample. In a terminal connect to Postgresql
```bash
docker exec -ti postgresql psql -d postgres -U postgres
```
and execute the following SQL TRUNCATE followed by INSERT statements
```sql
TRUNCATE cdc_demo.person CASCADE;
INSERT INTO cdc_demo.person (id, title, first_name, last_name, email)
VALUES (1, 'Mr', 'Peter', 'Muster', '<EMAIL>');
INSERT INTO cdc_demo.address (id, person_id, street, zip_code, city)
VALUES (1, 1, 'Somestreet 10', '9999', 'Somewhere');
```
#### Create the Debezium connector
Now with the connector installed and the Kafka Connect cluster restarted, let's create and start the connector:
```bash
curl -X PUT \
"http://$DOCKER_HOST_IP:8083/connectors/person.dbzsrc.cdc/config" \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-d '{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.server.name": "postgresql",
"database.port": "5432",
"database.user": "postgres",
"database.password": "<PASSWORD>!",
"database.dbname": "postgres",
"schema.include.list": "cdc_demo",
"table.include.list": "cdc_demo.person, cdc_demo.address",
"plugin.name": "pgoutput",
"tombstones.on.delete": "false",
"database.hostname": "postgresql",
"topic.creation.default.replication.factor": 3,
"topic.creation.default.partitions": 8,
"topic.creation.default.cleanup.policy": "compact"
}'
```
#### Check the data in the two Kafka topics
Now let's start two consumers, one on each topic, in separate terminal windows. This time the data is in Avro, as we did not overwrite the serializers. By default the topics are formatted using this naming convention: `<db-host>.<schema>.<table>`
```bash
kcat -b kafka-1:19092 -t postgresql.cdc_demo.person -f '[%p] %k: %s\n' -q -s avro -r http://schema-registry-1:8081
```
and you should get the change record for `person` table
```json
[0] {"id": 1}: {"before": null, "after": {"Value": {"id": 1, "title": {"string": "Mr"}, "first_name": {"string": "Peter"}, "last_name": {"string": "Muster"}, "email": {"string": "<EMAIL>"}, "modifieddate": 1654534797865686}}, "source": {"version": "1.8.1.Final", "connector": "postgresql", "name": "postgresql", "ts_ms": 1654534797866, "snapshot": {"string": "false"}, "db": "postgres", "sequence": {"string": "[\"23426176\",\"23426176\"]"}, "schema": "person", "table": "person", "txId": {"long": 556}, "lsn": {"long": 23426176}, "xmin": null}, "op": "c", "ts_ms": {"long": 1654534798250}, "transaction": null}
```
We can see that the key is also Avro-serialized (`{"id": 1}`).
Now do the same for the `postgresql.cdc_demo.address` topic
```bash
kcat -b kafka-1:19092 -t postgresql.cdc_demo.address -f '[%p] %k: %s\n' -q -s avro -r http://schema-registry-1:8081
```
and you should get the change record for the `address` table.
Let's use `jq` to format the value only (by removing the `-f` parameter).
```
kcat -b kafka-1:19092 -t postgresql.cdc_demo.person -f '%s\n' -q -s avro -r http://schema-registry-1:8081 -u | jq
```
we can see that the change record is wrapped inside the `after` field. The `op` field show the operation, which shows `c` for create/insert.
```json
{
"before": null,
"after": {
"Value": {
"id": 1,
"title": {
"string": "Mr"
},
"first_name": {
"string": "Peter"
},
"last_name": {
"string": "Muster"
},
"email": {
"string": "<EMAIL>"
},
"modifieddate": 1654534797865686
}
},
"source": {
"version": "1.8.1.Final",
"connector": "postgresql",
"name": "postgresql",
"ts_ms": 1654534797866,
"snapshot": {
"string": "false"
},
"db": "postgres",
"sequence": {
"string": "[\"23426176\",\"23426176\"]"
},
"schema": "cdc_demo",
"table": "person",
"txId": {
"long": 556
},
"lsn": {
"long": 23426176
},
"xmin": null
},
"op": "c",
"ts_ms": {
"long": 1654534798250
},
"transaction": null
}
```
Now let's do an update of the `person` table (keep the `kcat` running).
```sql
UPDATE cdc_demo.person SET first_name = UPPER(first_name);
```
and you should get the new change record
```json
{
"before": null,
"after": {
"Value": {
"id": 1,
"title": {
"string": "Mr"
},
"first_name": {
"string": "PETER"
},
"last_name": {
"string": "Muster"
},
"email": {
"string": "<EMAIL>"
},
"modifieddate": 1654534797865686
}
},
"source": {
"version": "1.8.1.Final",
"connector": "postgresql",
"name": "postgresql",
"ts_ms": 1654535300862,
"snapshot": {
"string": "false"
},
"db": "postgres",
"sequence": {
"string": "[\"23426936\",\"23427224\"]"
},
"schema": "cdc_demo",
"table": "person",
"txId": {
"long": 558
},
"lsn": {
"long": 23427224
},
"xmin": null
},
"op": "u",
"ts_ms": {
"long": 1654535301178
},
"transaction": null
}
```
#### Also produce the before image of an Update
You can see that there is `before` field but it is `null`. By default the Postgresql [`REPLICA IDENTITY`](https://www.postgresql.org/docs/9.6/sql-altertable.html#SQL-CREATETABLE-REPLICA-IDENTITY) will not produce the before image.
Let's change it on the `person` table to see the difference
```sql
alter table cdc_demo.person REPLICA IDENTITY FULL;
```
and then once more update the `person` table (keep the `kcat` running).
```sql
UPDATE cdc_demo.person SET first_name = LOWER(first_name);
```
we can now see both the data `before` and `after` the UPDATE:
```json
{
"before": {
"Value": {
"id": 1,
"title": {
"string": "Mr"
},
"first_name": {
"string": "PETER"
},
"last_name": {
"string": "Muster"
},
"email": {
"string": "<EMAIL>"
},
"modifieddate": 1654534797865686
}
},
"after": {
"Value": {
"id": 1,
"title": {
"string": "Mr"
},
"first_name": {
"string": "peter"
},
"last_name": {
"string": "Muster"
},
"email": {
"string": "<EMAIL>"
},
"modifieddate": 1654534797865686
}
},
"source": {
"version": "1.8.1.Final",
"connector": "postgresql",
"name": "postgresql",
"ts_ms": 1654535554791,
"snapshot": {
"string": "false"
},
"db": "postgres",
"sequence": {
"string": "[\"23435472\",\"23435528\"]"
},
"schema": "person",
"table": "person",
"txId": {
"long": 560
},
"lsn": {
"long": 23435528
},
"xmin": null
},
"op": "u",
"ts_ms": {
"long": 1654535555154
},
"transaction": null
}
```
#### Check the latency from the UPDATE until you consume the message from the topic
Let's do an update on the `address` table and make sure that you see the `kcat` in another terminal window
```sql
UPDATE cdc_demo.address SET street = UPPER(street);
```
```bash
kcat -b kafka-1:19092 -t postgresql.cdc_demo.address -f '[%p] %k: %s\n' -q -s avro -r http://schema-registry-1:8081
```
You should see a very minimal latency between doing the update and the message in Kafka.
#### Change the name of the Kafka Topic
The topic name might not fit with your naming conventions. You can change the name using a [Single Message Transforms (SMT)](https://docs.confluent.io/platform/current/connect/transforms/overview.html) as we have already seen in the query-based CDC workshop above.
Let's remove the connector and delete the two topics
```bash
curl -X "DELETE" "http://$DOCKER_HOST_IP:8083/connectors/person.dbzsrc.cdc"
docker exec -ti kafka-1 kafka-topics --delete --bootstrap-server kafka-1:19092 --topic postgresql.person.person
docker exec -ti kafka-1 kafka-topics --delete --bootstrap-server kafka-1:19092 --topic postgresql.person.address
```
Now recreate the connector, this time adding the necessary `RegexRouter` SMT:
```bash
curl -X PUT \
"http://$DOCKER_HOST_IP:8083/connectors/person.dbzsrc.cdc/config" \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-d '{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.server.name": "postgresql",
"database.port": "5432",
"database.user": "postgres",
"database.password": "<PASSWORD>!",
"database.dbname": "postgres",
"schema.include.list": "cdc_demo",
"table.include.list": "cdc_demo.person, cdc_demo.address",
"plugin.name": "pgoutput",
"tombstones.on.delete": "false",
"database.hostname": "postgresql",
"transforms":"dropPrefix",
"transforms.dropPrefix.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.dropPrefix.regex": "postgresql.cdc_demo.(.*)",
"transforms.dropPrefix.replacement": "priv.$1.cdc.v2",
"topic.creation.default.replication.factor": 3,
"topic.creation.default.partitions": 8,
"topic.creation.default.cleanup.policy": "compact"
}'
```
Now let's do an update on `person` table once more
```sql
UPDATE cdc_demo.person SET first_name = UPPER(first_name);
```
to see the new topic `priv.person.cdc.v2` created
```bash
kcat -b kafka-1:19092 -t priv.person.cdc.v2 -f '[%p] %k: %s\n' -q -s avro -r http://schema-registry-1:8081
```
#### Remove the connector
We have successfully tested the log-based CDC connector. So let's remove the connector.
```bash
curl -X "DELETE" "http://$DOCKER_HOST_IP:8083/connectors/person.dbzsrc.cdc"
```
## Transactional Outbox Pattern using Debezium and Kafka Connect
In this section we will see how we can use [Debezium](https://debezium.io/) and it's Postgresql connector to perform log-based CDC on an special `outbox` table, implementing the [Transactional Outbox Pattern](https://microservices.io/patterns/data/transactional-outbox.html).

The [Debezium connector](https://www.confluent.io/hub/debezium/debezium-connector-postgresql), which supports the Outbox Pattern comes pre-installed with the Dataplatform stack.
#### Create the `outbox` table
In a new terminal window, connect to Postgresql
```bash
docker exec -ti postgresql psql -d postgres -U postgres
```
Now create a new table `outbox`
```sql
SET search_path TO cdc_demo;
DROP TABLE IF EXISTS "cdc_demo"."outbox";
CREATE TABLE "cdc_demo"."outbox" (
"id" uuid NOT NULL,
"aggregate_id" bigint,
"created_at" timestamp,
"event_type" character varying(255),
"payload_json" character varying(5000),
CONSTRAINT "outbox_pk" PRIMARY KEY ("id")
);
```
#### Create the Debezium connector
```bash
curl -X PUT \
"http://$DOCKER_HOST_IP:8083/connectors/person.dbzsrc.outbox/config" \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-d '{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.server.name": "postgresql",
"database.port": "5432",
"database.user": "postgres",
"database.password": "<PASSWORD>!",
"database.dbname": "postgres",
"schema.include.list": "cdc_demo",
"table.include.list": "cdc_demo.outbox",
"plugin.name": "pgoutput",
"tombstones.on.delete": "false",
"database.hostname": "postgresql",
"transforms": "outbox",
"transforms.outbox.type": "io.debezium.transforms.outbox.EventRouter",
"transforms.outbox.table.field.event.id": "id",
"transforms.outbox.table.field.event.key": "aggregate_id",
"transforms.outbox.table.field.event.payload": "payload_json",
"transforms.outbox.table.field.event.timestamp": "created_at",
"transforms.outbox.route.by.field": "event_type",
"transforms.outbox.route.topic.replacement": "priv.${routedByValue}.event.v1",
"topic.creation.default.replication.factor": 3,
"topic.creation.default.partitions": 8
}'
```
#### Add data to `outbox` table
Let's first simulate a `CustomerCreated` event:
```sql
INSERT INTO cdc_demo.outbox (id, aggregate_id, created_at, event_type, payload_json)
VALUES (gen_random_uuid(), 13256, current_timestamp, 'CustomerCreated', '{"id":13256,"personType":"IN","nameStyle":"0","firstName":"Carson","middleName":null,"lastName":"Washington","emailPromotion":1,"addresses":[{"addressTypeId":2,"id":22326,"addressLine1":"3809 Lancelot Dr.","addressLine2":null,"city":"Glendale","stateProvinceId":9,"postalCode":"91203","country":{"isoCode2":"US","isoCode3":"USA","numericCode":840,"shortName":"United States of America"},"lastChangeTimestamp":"2022-05-09T20:45:11.798376"}],"phones":[{"phoneNumber":"518-555-0192","phoneNumberTypeId":1,"phoneNumberType":"Cell"}],"emailAddresses":[{"id":12451,"emailAddress":"<EMAIL>"}]}');
```
A new Kafka topic `priv.CustomerCreated.event.v1` will get created with the message.
```bash
kcat -b kafka-1:19092 -t priv.CustomerCreated.event.v1 -f '[%p] %k: %s\n' -q -s avro -r http://schema-registry-1:8081
```
```bash
[4] {"long": 13256}: {"string": "{\"id\":13256,\"personType\":\"IN\",\"nameStyle\":\"0\",\"firstName\":\"Carson\",\"middleName\":null,\"lastName\":\"Washington\",\"emailPromotion\":1,\"addresses\":[{\"addressTypeId\":2,\"id\":22326,\"addressLine1\":\"3809 Lancelot Dr.\",\"addressLine2\":null,\"city\":\"Glendale\",\"stateProvinceId\":9,\"postalCode\":\"91203\",\"country\":{\"isoCode2\":\"US\",\"isoCode3\":\"USA\",\"numericCode\":840,\"shortName\":\"United States of America\"},\"lastChangeTimestamp\":\"2022-05-09T20:45:11.798376\"}],\"phones\":[{\"phoneNumber\":\"518-555-0192\",\"phoneNumberTypeId\":1,\"phoneNumberType\":\"Cell\"}],\"emailAddresses\":[{\"id\":12451,\"emailAddress\":\"<EMAIL>\"}]}"}
```
Now let's also simulate another event, an `CustomerMoved` event
```sql
INSERT INTO cdc_demo.outbox (id, aggregate_id, created_at, event_type, payload_json)
VALUES (gen_random_uuid(), 13256, current_timestamp, 'CustomerMoved', '{"customerId": 13256, "address": {"addressTypeId":2,"id":22326,"addressLine1":"3809 Lancelot Dr.","addressLine2":null,"city":"Glendale","stateProvinceId":9,"postalCode":"91203","country":{"isoCode2":"US","isoCode3":"USA","numericCode":840,"shortName":"United States of America"},"lastChangeTimestamp":"2022-05-09T20:45:11.798376"}}');
```
this will end up in a new topic named `priv.CustomerMoved.event.v1`
```bash
kcat -b kafka-1:19092 -t priv.CustomerMoved.event.v1 -f '[%p] %k: %s\n' -q -s avro -r http://schema-registry-1:8081
```
```bash
[4] {"long": 13256}: {"string": "{\"customerId\": 13256, \"address\": {\"addressTypeId\":2,\"id\":22326,\"addressLine1\":\"3809 Lancelot Dr.\",\"addressLine2\":null,\"city\":\"Glendale\",\"stateProvinceId\":9,\"postalCode\":\"91203\",\"country\":{\"isoCode2\":\"US\",\"isoCode3\":\"USA\",\"numericCode\":840,\"shortName\":\"United States of America\"},\"lastChangeTimestamp\":\"2022-05-09T20:45:11.798376\"}}"}
```
#### Remove the connector
We have successfully tested the transactional outbox using Debezium connector. So let's remove the connector.
```bash
curl -X "DELETE" "http://$DOCKER_HOST_IP:8083/connectors/person.dbzsrc.outbox"
```<file_sep># EFAK (Eagle for Apache Kafka)
A easy and high-performance monitoring system, for comprehensive monitoring and management of kafka cluster.
**[Website](https://www.kafka-eagle.org/)** | **[Documentation](https://www.kafka-eagle.org/articles/docs/documentation.html)** | **[GitHub](https://github.com/smartloli/EFAK)**
## How to enable?
```
platys init --enable-services EFAK
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8048> and login as `admin` with password `<PASSWORD>`.
<file_sep># Excalidraw
Virtual whiteboard for sketching hand-drawn like diagrams.
**[Website](http://excalidraw.com/)** | **[Documentation](https://github.com/excalidraw/excalidraw#documentation)** | **[GitHub](https://github.com/excalidraw/excalidraw)**
### How to enable?
```
platys init --enable-services EXCALIDRAW
platys gen
```
### How to use it?
Navigate to <http://dataplatform:28231><file_sep># kafkactl
CLI for Apache Kafka Management.
**[Website](https://www.jbvm.io/kafkactl/)** | **[Documentation](https://www.jbvm.io/kafkactl/gettingstarted/)** | **[GitHub](https://github.com/jbvmio/kafkactl)**
## How to enable?
```
platys init --enable-services KAFKACTL
platys gen
```
## How to use it?
```
docker exec -ti kafkactl kafkactl
```
<file_sep>package com.trivadis.kafkaws.springbootkafkaconsumer;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.kafka.config.TopicBuilder;
import org.springframework.stereotype.Component;
@Component
public class TopicCreator {
@Value(value = "${topic.out.name}")
private String testTopic;
@Value(value = "${topic.out.partitions}")
private Integer testTopicPartitions;
@Value(value = "${topic.out.replication-factor}")
private short testTopicReplicationFactor;
@Bean
public NewTopic testTopic() {
return TopicBuilder.name(testTopic)
.partitions(testTopicPartitions)
.replicas(testTopicReplicationFactor)
.build();
}
}
<file_sep># Confluent Control Center
Confluent Control Center is a web-based tool for managing and monitoring Apache Kafka®. Control Center provides a user interface that allows developers and operators to get a quick overview of cluster health, observe and control messages, topics, and Schema Registry, and to develop and run ksqlDB queries.
**[Website](https://docs.confluent.io/platform/current/control-center/index.html)** | **[Documentation](https://docs.confluent.io/platform/current/control-center/index.html)**
## How to enable?
```bash
platys init --enable-services KAFKA_CCC
platys gen
```
## How to use?
Navigate to <http://${PUBLIC_IP}:9021><file_sep>package com.trivadis.kafkaws.springbootkotlinkafkaconsumer
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.springframework.kafka.annotation.KafkaListener
import org.springframework.stereotype.Component
@Component
class KafkaEventConsumer {
@KafkaListener(topics = ["\${topic.name}"], groupId = "simple-kotlin-consumer")
fun receive(consumerRecord: ConsumerRecord<Long, String>) {
println("received key = ${consumerRecord.key()} with payload=${consumerRecord.value()}")
}
}<file_sep># HiveMQ 4
HiveMQ CE is a Java-based open source MQTT broker that fully supports MQTT 3.x and MQTT 5. It is the foundation of the HiveMQ Enterprise Connectivity and Messaging Platform
**[Website](https://www.hivemq.com/)** | **[Documentation](https://www.hivemq.com/docs/hivemq/4.7/user-guide/introduction.html)** | **[GitHub](https://github.com/vrana/adminer/)**
## How to enable?
```
platys init --enable-services HIVEMQ4
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28134><file_sep>[default]
accessKey=${PLATYS_AWS_ACCESS_KEY}
secretKey=${PLATYS_AWS_SECRET_ACCESS_KEY}
<file_sep># Grafana
The open and composable observability and data visualization platform. Visualize metrics, logs, and traces from multiple sources like Prometheus, Loki, Elasticsearch, InfluxDB, Postgres and many more.
**[Website](https://grafana.com/oss/grafana/)** | **[Documentation](https://grafana.com/grafana/)** | **[GitHub](https://github.com/grafana/grafana)**
```
platys init --enable-services GRAFANA
platys gen
```
<file_sep># Quine
Quine is a freely available streaming graph that connects to your existing data streams and builds high-volume data into a stateful graph. Quine efficiently analyzes that graph for the “standing queries” you specify and streams results out immediately to trigger real-time event-driven workflows.
**[Website](https://quine.io/)** | **[Documentation](https://quine.io/docs/about-quine/what-is-quine)** | **[GitHub](https://github.com/thatdot/quine)**
## How to enable?
```bash
platys init --enable-services QUINE
platys gen
```
## How to use it?
Navigate to <http:/dataplatform:28268>.<file_sep># Kibana
Kibana is a free and open user interface that lets you visualize your Elasticsearch data and navigate the Elastic Stack. Do anything from tracking query load to understanding the way requests flow through your apps.
**[Website](https://www.elastic.co/kibana/)** | **[Documentation](https://www.elastic.co/guide/en/kibana/current/index.html)** | **[GitHub](https://github.com/elastic/kibana)**
## How to enable?
```
platys init --enable-services ELASTICSEARCH,KIBANA
platys gen
```
## How to use it?
Navigate to <http://dataplatform:5601><file_sep>---
technologies: azure,event-hub,kafka
version: 1.16.0
validated-at: 15.4.2023
---
# Azure Event Hub as external Kafka
This recipe will show how to use Azure Event Hub as an external Kafka cluster.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```bash
export DATAPLATFORM_HOME=${PWD}
platys init --enable-services KAFKA_CONNECT,AKHQ -s trivadis/platys-modern-data-platform -w 1.16.0
```
Edit the `config.yml`
bash
```
external:
KAFKA_enable: true
KAFKA_bootstrap_servers: XXXXXX.servicebus.windows.net:9093
KAFKA_security_protocol: SASL_SSL
KAFKA_sasl_mechanism: PLAIN
KAFKA_sasl_username: $$ConnectionString
```
For the password to not end up in the `docker-compose.yml` file, we have to add it as an environment variable:
Create a `.env` file
```
nano .env
```
and add the following environment variable to specify the password
```bash
PLATYS_KAFKA_PASSWORD=Endpoint=sb://fzageventhub.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=<KEY>
```
Save the file and generate and start the data platform.
```bash
platys gen
docker-compose up -d
```
## Use the Platform
Navigate to AKHQ to manage the Event Hub: <http://dataplatform:28107>
To use the Kafka CLI's
```bash
docker exec -ti kafka-cli kafka-topics --bootstrap-server XXXXXX.servicebus.windows.net:9093 --command-config config.properties --list
```
<file_sep># KIE Server
Drools is a rule engine, DMN engine and complex event processing (CEP) engine for Java.
**[Website](https://drools.org/)** | **[Documentation](https://drools.org/learn/documentation.html)** | **[GitHub](https://github.com/kiegroup/drools)**
## How to enable?
```
platys init --enable-services OPTUNA
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28236/business-central> or <http://dataplatform:28234>.<file_sep>bootstrap.servers=${BOOTSTRAP_SERVERS}
security.protocol=${SECURITY_PROTOCOL}
sasl.mechanism=${SASL_MECHANISM}
sasl.jaas.config=${SASL_JAAS_CONFIG}
<file_sep># Using Spark Structured Streaming for Stream Analytics
In this workshop we will learn how to process messages using Spark Structured Streaming.

With Spark Structured Streaming we assume the data to be available in JSON. Therefore we first transform it using ksqlDB using the ksqlDB stream created in workshop 13b.
```sql
CREATE STREAM truck_position_json_s
WITH (kafka_topic='truck_position_json',
value_format='JSON')
AS
SELECT * FROM truck_position_s
EMIT CHANGES;
```
## Creating Spark environment in Zeppelin
In a web browser navigate to Zeppelin on <http://dataplatform:28080>.
Let's create a local Spark environment by adding a new interpreter. On the right corner, click on **Admin** and select **Interpreter**

Click on **Create** to create a new Interpreter and set **Interpreter Name** to `spark-local` and select `spark` for the **Interpreter Group**.
Scroll down to **Dependencies** and add `org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.3` into the **Artifact** field.

Click **Save** to create the interpreter.
## Creating a new notebook in Zeppelin
Create a new Notebook and select the `spark-local`

## Implement Spark Structured Streaming pipeline in Python
### Define Schema for truck_position events/messages
```python
%pyspark
from pyspark.sql.types import *
truckPositionSchema = StructType().add("TS", StringType()).add("TRUCKID",StringType()).add("DRIVERID", LongType()).add("ROUTEID", LongType()).add("EVENTTYPE", StringType()).add("LATITUDE", DoubleType()).add("LONGITUDE", DoubleType()).add("CORRELATIONID", StringType())
```
### Kafka Consumer
```python
rawDf = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "kafka-1:19092,kafka-2:19093")
.option("subscribe", "truck_position_json")
.load()
```
### Show the schema of the raw Kafka message
```python
rawDf.printSchema
```
### Map to "truck_position" schema and extract event time (trunc to seconds)
```python
%pyspark
from pyspark.sql.functions import from_json
jsonDf = rawDf.selectExpr("CAST(value AS string)")
jsonDf = jsonDf.select(from_json(jsonDf.value, truckPositionSchema).alias("json")).selectExpr("json.*", "cast(cast (json.timestamp as double) / 1000 as timestamp) as eventTime")
```
### Show schema of data frame
```python
%pyspark
jsonDf.printSchema
```
### Run 1st query into in memory "table"
```python
%pyspark
query1 = jsonDf.writeStream.format("memory").queryName("truck_position").start()
```
### Using Spark SQL to read from the in-memory "table"
```python
%pyspark
spark.sql ("select * from truck_position").show()
```
or in Zeppelin using the %sql directive
```sql
%sql
select * from truck_position
```
### Stop the query
```python
%pyspark
query1.stop()
```
### Filter out normal events
```python
%pyspark
jsonDf.printSchema
jsonFilteredDf = jsonDf.where("json.EVENTTYPE !='Normal'")
```
### Run 2nd query on filtered data into in memory "table"
```python
%pyspark
query2 = jsonFilteredDf.writeStream.format("memory").queryName("filtered_truck_position").start()
```
### Use Spark SQL
```python
%pyspark
spark.sql ("select * from filtered_truck_position2").show()
```
### Stop 2nd query
```python
%pyspark
query2.stop
```
### Run 3rd query - Write non-normal events to Kafka topic
Create a new topic
```
docker exec -ti kafka-1 kafka-topics --create --zookeeper zookeeper-1:2181 --topic dangerous_driving_spark --partitions 8 --replication-factor 3
```
```python
%pyspark
query3 = jsonFilteredDf.selectExpr("to_json(struct(*)) AS value").writeStream.format("kafka").option("kafka.bootstrap.servers", "kafka-1:19092").option("topic","dangerous_driving_spark").option("checkpointLocation", "/tmp").start()
```
### Stop 3rd query
```python
query3.stop
```
<file_sep># Cassandra Web
A web interface for Apache Cassandra-
**[Website](http://avalanche123.com/cassandra-web/)** | **[Documentation](http://avalanche123.com/cassandra-web)** | **[GitHub](https://github.com/avalanche123/cassandra-web)**
## How to enable?
```
platys init --enable-services CASSANDRA CASSANDRA_WEB
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28120>.
<file_sep>Place a InfluxDB2 config.yml file here and enable the INFLUXDB2_volume_map_data flag.
<file_sep># OpenSearch Dashboards
Open source visualization dashboards for OpenSearch. OpenSearch is a community-driven, open source fork of Elasticsearch and Kibana following the licence change in early 2021.
**[Website](https://opensearch.org/)** | **[Documentation](https://opensearch.org/docs/latest/dashboards/index/)** | **[GitHub](https://github.com/opensearch-project/OpenSearch-Dashboards)**
## How to enable?
```
platys init --enable-services OPENSEARCH_DASHBOARDS,OPENSEARCH
platys gen
```
## How to use it?
Navigate to <http://dataplatform:5603><file_sep>password-authenticator.name=file
file.password-file=/etc/starburst/password.db
<file_sep># SFTP
Easy to use SFTP (SSH File Transfer Protocol) server with OpenSSH.
**[Website](https://man.openbsd.org/sftp-server)** | **[Documentation](https://man.openbsd.org/sftp-server)** | **[GitHub](https://github.com/atmoz/sftp)**
```bash
platys init --enable-services SFTP
platys gen
```
## How to use it?
<file_sep>connector.name=tpch
tpch.split-per-node=4
<file_sep># awscli
Universal Command Line Interface for Amazon Web Services
**[Website](https://aws.amazon.com/cli/)** | **[Documentation](https://docs.aws.amazon.com/cli/index.html)** | **[GitHub](https://github.com/aws/aws-cli)**
## How to enable?
```
platys init --enable-services AWSCLI
platys gen
```
## How to use it?
Within the container, you can either use the `aws` or `s3cmd` command line interface.
### aws
If using the local `minio` S3 service then you have to specify the endpoint. The rest is configured through the environment variables. I.e. to list all available buckets:
```bash
docker exec -ti awscli aws --endpoint-url http://minio-1:9000 s3 ls
```
### s3cmd
To list all available buckets using s3cmd:
```cmd
docker exec -ti awscli s3cmd ls
```<file_sep>---
technoglogies: spark,postgresql
version: 1.11.0
validated-at: 21.3.2021
---
# Spark with PostgreSQL
This recipe will show how to use a Spark cluster in the platform and connect it to a PostgreSQL relational database.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started.md) with the following services enabled
```
platys init --enable-services SPARK,POSTGRESQL,ZEPPELIN,PROVISIONING_DATA -s trivadis/platys-modern-data-platform -w 1.11.0
```
Before we can generate the platform, we need to extend the `config.yml` with the following SPARK property:
```
SPARK_jars_packages: 'org.postgresql:postgresql:9.4.1212'
```
Now set an environment variable to the home folder of the dataplatform and generate and then start the data platform.
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Create Table in Postgresql
```bash
docker exec -ti postgresql psql -d demodb -U demo
```
```sql
CREATE SCHEMA flight_data;
DROP TABLE flight_data.airport_t;
CREATE TABLE flight_data.airport_t
(
iata character varying(50) NOT NULL,
airport character varying(50),
city character varying(50),
state character varying(50),
country character varying(50),
lat float,
long float,
CONSTRAINT airport_pk PRIMARY KEY (iata)
);
```
```sql
COPY flight_data.airport_t(iata,airport,city,state,country,lat,long)
FROM '/data-transfer/flight-data/airports.csv' DELIMITER ',' CSV HEADER;
```
## Work with data from PostgreSQL
Navigate to Zeppelin <http://dataplatform:28080> and login as user `admin` with password `<PASSWORD>!`.
Create a new notebook and in a cell enter the following Spark code using the Python API. Replace again the `gschmutz` prefix in the bucket name:
```scala
val opts = Map(
"url" -> "jdbc:postgresql://postgresql/demodb?user=demo&password=<PASSWORD>!",
"driver" -> "org.postgresql.Driver",
"dbtable" -> "flight_data.airport_t")
val df = spark
.read
.format("jdbc")
.options(opts)
.load
```
```
df.show
```
<file_sep>package com.trivadis.kafkaws.springbootkafkaproducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.transaction.annotation.Transactional;
import java.time.LocalDateTime;
@SpringBootApplication
public class SpringBootKafkaProducerApplication implements CommandLineRunner {
private static Logger LOG = LoggerFactory.getLogger(SpringBootKafkaProducerApplication.class);
@Autowired
private KafkaEventProducer kafkaEventProducer;
@Value("${force.error.after}")
private Integer forceErrorAfter;
public static void main(String[] args) {
SpringApplication.run(SpringBootKafkaProducerApplication.class, args);
}
@Override
@Transactional
public void run(String... args) throws Exception {
LOG.info("EXECUTING : command line runner");
if (args.length == 0) {
runProducer(100, 10, 0);
} else {
runProducer(Integer.parseInt(args[0]), Integer.parseInt(args[1]), Long.parseLong(args[2]));
}
}
private void runProducer(int sendMessageCount, int waitMsInBetween, long id) throws Exception {
Long key = (id > 0) ? id : null;
for (int index = 0; index < sendMessageCount; index++) {
String value = "[" + id + "] Hello Kafka " + index + " => " + LocalDateTime.now();
if (forceErrorAfter != -1 && index > forceErrorAfter) {
throw new RuntimeException();
}
kafkaEventProducer.produce(index, key, value);
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
<file_sep>Place benthos config files (*.yaml) here.<file_sep># Node-RED
Node-RED is a programming tool for wiring together hardware devices, APIs and online services in new and interesting ways.
It provides a browser-based editor that makes it easy to wire together flows using the wide range of nodes in the palette that can be deployed to its runtime in a single-click.
**[Website](https://nodered.org/)** | **[Documentation](https://nodered.org/docs/)** | **[GitHub](https://github.com/node-red)**
## How to enable?
```
platys init --enable-services NODERED
platys gen
```
## How to use it?
Navigate to <http://dataplatform:1880><file_sep># KongMap
Kongmap is a free visualization tool which allows you to view and edit configurations of your Kong API Gateway Clusters, including Routes, Services, and Plugins/Policies. The tool is being offered for installation via Docker and Kubernetes at this time.
**[Documentation](https://github.com/yesinteractive/kong-map)** | **[GitHub](https://github.com/yesinteractive/kong-map)**
## How to enable?
```
platys init --enable-services KONG, KONG_MAP
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8100><file_sep>Contains the data of redis service, if flag REDIS_volume_map_data is set to true.<file_sep>---
technoglogies: kafka,confluent
version: 1.13.0
validated-at: 8.7.2021
---
# Using Confluent Enterprise Tiered Storage
This recipe will show how to support activation of StreamSets Data Collector in persistent and replayable way.
The problem with the activation of StreamSets is, that an activation code is given for a given `SDC ID` (a.k.a product id). If you restart the StreamSets Data Collector container, everything is fine, but if you stop, remove and recrate the container, a new `SDC ID` is generated and you have to re-activate StreamSets.
This recipe shows, how the `SDC ID` can be fixed to a value, so that recreating a container won't change it.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services KAFKA,PLATYS -s trivadis/platys-modern-data-platform -w 1.13.0
```
Edit the `config.yml` and add the following configuration settings.
```
KAFKA_edition: 'enterprise'
KAFKA_confluent_tier_enable: true
KAFKA_confluent_tier_feature: true
KAFKA_confluent_tier_s3_aws_endpoint_override: http://minio-1:9000
KAFKA_confluent_tier_s3_force_path_style_access: true
KAFKA_confluent_tier_local_hotset_ms: 0
KAFKA_confluent_tier_local_hotset_bytes: -1
KAFKA_confluent_tier_archiver_num_threads: 8
KAFKA_confluent_tier_fetcher_num_threads: 16
KAFKA_confluent_tier_topic_delete_check_interval_ms: 60000
KAFKA_log_segment_bytes: 1048576
```
Now generate data platform
```
platys gen
```
and then start the platform:
```
docker-compose up -d
```
## Creating a Topic with Tiering enabled
```
kafka-topics --bootstrap-server kafka-1:19092 \
--create --topic truck_position \
--partitions 8 \
--replication-factor 3 \
--config confluent.tier.enable=true \
--config confluent.tier.local.hotset.ms=3600000 \
--config retention.ms=604800000
```<file_sep># Retool
Retool enables you to quickly build and deploy internal apps for your team. Connect to your databases and APIs, assemble UIs with drag-and-drop building blocks like tables and forms, and write queries to interact with data using SQL and JavaScript.
**[Website](https://retool.com/)** | **[Documentation](https://docs.retool.com/docs)** | **[GitHub](https://github.com/tryretool/retool-onpremise)**
## How to enable?
```
platys init --enable-services RETOOL
platys gen
```
## How to use it?
Navigate to <http://dataplatform:3006>. <file_sep># Pure FTP
Pure FTP server.
**[Website](https://www.pureftpd.org/project/pure-ftpd/)** | **[Documentation](https://www.pureftpd.org/project/pure-ftpd/doc/)** | **[GitHub](https://github.com/jedisct1/pure-ftpd)**
## How to enable?
```
platys init --enable-services FTP
platys gen
```
## How to use it?
<file_sep># Timescale
An open-source time-series SQL database optimized for fast ingest and complex queries. Packaged as a PostgreSQL extension.
**[Website](https://www.timescale.com/)** | **[Documentation](https://docs.timescale.com/)** | **[GitHub](https://github.com/timescale/timescaledb)**
### How to enable?
```
platys init --enable-services TIMESCALDEB
platys gen
```
### How to use it?
```
docker exec -it timescaledb psql -U timescaledb
```
```
CREATE TABLE IF NOT EXISTS weather_metrics (
time TIMESTAMP WITHOUT TIME ZONE NOT NULL,
timezone_shift int NULL,
city_name text NULL,
temp_c double PRECISION NULL,
feels_like_c double PRECISION NULL,
temp_min_c double PRECISION NULL,
temp_max_c double PRECISION NULL,
pressure_hpa double PRECISION NULL,
humidity_percent double PRECISION NULL,
wind_speed_ms double PRECISION NULL,
wind_deg int NULL,
rain_1h_mm double PRECISION NULL,
rain_3h_mm double PRECISION NULL,
snow_1h_mm double PRECISION NULL,
snow_3h_mm double PRECISION NULL,
clouds_percent int NULL,
weather_type_id int NULL
);
-- Step 2: Turn into hypertable
SELECT create_hypertable('weather_metrics','time');
```
```
wget https://s3.amazonaws.com/assets.timescale.com/docs/downloads/weather_data.zip
unzip wather_data.zip
```
```
\copy weather_metrics (time, timezone_shift, city_name, temp_c, feels_like_c, temp_min_c, temp_max_c, pressure_hpa, humidity_percent, wind_speed_ms, wind_deg, rain_1h_mm, rain_3h_mm, snow_1h_mm, snow_3h_mm, clouds_percent, weather_type_id) from './data-transfer/weather_data.csv' CSV HEADER;
```
```
--------------------------------
-- Total snowfall per city
-- in past 5 years
--------------------------------
SELECT city_name, sum(snow_1h_mm)
FROM weather_metrics
WHERE time > now() - INTERVAL '5 years'
GROUP BY city_name;
```
<file_sep># Presto
Distributed SQL Query Engine for Big Data.
**[Website](https://prestodb.io/)** | **[Documentation](https://prestodb.io/docs/current/)** | **[GitHub](https://github.com/prestodb/presto)**
## How to enable?
```
platys init --enable-services PRESTO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28081><file_sep># Curity Identity Server
The Community Edition is a free version of the Curity Identity Server enabling any organization or individual to secure their APIs and provide a great login experience to users.
**[Website](https://curity.io/)** | **[Documentation](https://curity.io/resources/getting-started/)** | **[GitHub](https://github.com/curityio)**
## How to enable?
```
platys init --enable-services CURITY
platys gen
```
## How to use it?
Navigate to <https://dataplatform:6749> and log-in with user `admin` and the password specified in the `config.yml` file (defaults to `<PASSWORD>!`).
<file_sep>package com.trivadis.kafkaws.springbootkotlinkafkaconsumer
import com.trivadis.kafkaws.avro.v1.Notification
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.springframework.kafka.annotation.KafkaListener
import org.springframework.stereotype.Component
@Component
class KafkaEventConsumer {
@KafkaListener(topics = ["\${topic.name}"], groupId = "simple-kotlin-avro-consumer")
fun receive(consumerRecord: ConsumerRecord<Long, Notification>) {
println("received key = ${consumerRecord.key()} with payload=${consumerRecord.value()}")
}
}<file_sep># Azure Storage Explorer
Manage your Azure Storage blobs, tables, queues and file shares from this simple and intuitive web application.
**[Documentation](https://github.com/sebagomez/azurestorageexplorer)** | **[GitHub](https://github.com/sebagomez/azurestorageexplorer)**
## How to enable?
```
platys init --enable-services AZURE_STORAGE_EXPLORER
platys gen
```
## How to use it?
Navigat to <http://dataplatform:28279>.<file_sep># Adminer
Adminer (formerly phpMinAdmin) is a full-featured database management tool written in PHP. Adminer is available for MySQL, MariaDB, PostgreSQL, SQLite, MS SQL, Oracle, Elasticsearch, MongoDB and others via plugin.
**[Website](https://www.adminer.org/)** | **[Documentation](https://www.adminer.org/en/)** | **[GitHub](https://github.com/vrana/adminer/)**
## How to enable?
```
platys init --enable-services ADMINER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28131><file_sep># Using Kafka from Java with Avro & Schema Registry
In this workshop we will learn how to produce and consume messages using the [Kafka Java API](https://kafka.apache.org/documentation/#api) using Avro for serialising and deserialising messages.
## Create the project in your Java IDE
Create a new Maven Project (using the functionality of your IDE) and in the last step use `com.trivadis.kafkaws` for the **Group Id** and `java-avro-kafka` for the **Artifact Id**.
Navigate to the **pom.xml** and double-click on it. The POM Editor will be displayed.
You can either use the GUI to edit your `pom.xml` or navigate to the last tab **pom.xml** to switch to the "code view". Let's do that.
You will see the still rather empty definition.
```xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trivadis.kafkaws</groupId>
<artifactId>java-avro-kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
</project>
```
Let's add some initial dependencies for our project. We will add some more dependencies to the POM throughout this workshop.
Copy the following block right after the `<version>` tag, before the closing `</project>` tag.
```xml
<properties>
<kafka.version>2.7.0</kafka.version>
<confluent.version>5.1.0</confluent.version>
<avro.version>1.8.2</avro.version>
<java.version>1.8</java.version>
<slf4j-version>1.7.5</slf4j-version>
<!-- use utf-8 encoding -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>${avro.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j-version}</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>confluent</id>
<url>http://packages.confluent.io/maven/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>confluent</id>
<url>http://packages.confluent.io/maven/</url>
</pluginRepository>
</pluginRepositories>
<build>
<defaultGoal>install</defaultGoal>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<maxmem>256M</maxmem>
<showDeprecation>true</showDeprecation>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<executions>
<execution>
<id>producer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.producer.KafkaProducerAvro</mainClass>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
```
## Create log4j settings
Let's also create the necessary log4j configuration.
In the code we are using the [Log4J Logging Framework](https://logging.apache.org/log4j/2.x/), which we have to configure using a property file.
Create a new file `log4j.properties` in the folder **src/main/resources** and add the following configuration properties.
```
## ------------------------------------------------------------------------
## Licensed to the Apache Software Foundation (ASF) under one or more
## contributor license agreements. See the NOTICE file distributed with
## this work for additional information regarding copyright ownership.
## The ASF licenses this file to You under the Apache License, Version 2.0
## (the "License"); you may not use this file except in compliance with
## the License. You may obtain a copy of the License at
##
## http://www.apache.org/licenses/LICENSE-2.0
##
## Unless required by applicable law or agreed to in writing, software
## distributed under the License is distributed on an "AS IS" BASIS,
## WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
## See the License for the specific language governing permissions and
## limitations under the License.
## ------------------------------------------------------------------------
#
# The logging properties used for testing, We want to see INFO output on the console.
#
log4j.rootLogger=INFO, out
#log4j.logger.org.apache.kafka=INFO
log4j.logger.org.apache.camel.impl.converter=INFO
log4j.logger.org.apache.camel.util.ResolverUtil=INFO
log4j.logger.org.springframework=WARN
log4j.logger.org.hibernate=WARN
# CONSOLE appender not used by default
log4j.appender.out=org.apache.log4j.ConsoleAppender
log4j.appender.out.layout=org.apache.log4j.PatternLayout
log4j.appender.out.layout.ConversionPattern=[%30.30t] %-30.30c{1} %-5p %m%n
#log4j.appender.out.layout.ConversionPattern=%d [%-15.15t] %-5p %-30.30c{1} - %m%n
log4j.throwableRenderer=org.apache.log4j.EnhancedThrowableRenderer
```
## Creating the necessary Kafka Topic
We will use the topic `test-java-avro-topic` in the Producer and Consumer code below. Due to the fact that `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
In a terminal window, connect to the `kafka-1` container
```
docker exec -ti kafka-1 bash
```
and execute the necessary kafka-topics command.
```
kafka-topics --create \
--replication-factor 3 \
--partitions 12 \
--topic test-java-avro-topic \
--bootstrap-server kafka-1:19092,kafka-2:19093
```
This finishes the setup steps and our new project is ready to be used. Next we will start implementing the **Kafka Producer** which uses Avro for the serialisation.
## Create an Avro Schema representing the Notification Message
First create a new Folder `avro` under the existing folder **src/main/**.
Create a new File `Notification-v1.avsc` in the folder **src/main/avro** just created above.
Add the following Avro schema to the empty file.
```json
{
"type" : "record",
"namespace" : "com.trivadis.kafkaws.avro.v1",
"name" : "Notification",
"description" : "A simple Notification Event message",
"fields" : [
{ "type" : ["long", "null"],
"name" : "id"
},
{ "type" : ["string", "null"],
"name" : "message"
}
]
}
```
In the `pom.xml`, add the `avro-maven-plugin` plugin to the `<build><plugins>` section, just below the `exec-maven-plugin`.
```xml
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro.version}</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
<configuration>
<fieldVisibility>private</fieldVisibility>
<sourceDirectory>${project.basedir}/src/main/avro</sourceDirectory>
</configuration>
</execution>
</executions>
</plugin>
```
This plugin will make sure, that classes are generated based on the Avro schema, whenever a `mvn compile` is executed. Let's exactly do that on the still rather empty project.
```
mvn compile
```
After running this command, refresh the project and you should see a new folder named `target/generated-sources/avro`. Expand into this folder and you should see one generated Java class named `Notification`.

Double click on the `Notification` class to inspect the code.
```java
package com.trivadis.kafkaws.avro.v1;
import org.apache.avro.specific.SpecificData;
@SuppressWarnings("all")
@org.apache.avro.specific.AvroGenerated
public class Notification extends org.apache.avro.specific.SpecificRecordBase implements org.apache.avro.specific.SpecificRecord {
private static final long serialVersionUID = 799361421243801515L;
public static final org.apache.avro.Schema SCHEMA$ = new org.apache.avro.Schema.Parser().parse("{\"type\":\"record\",\"name\":\"Notification\",\"namespace\":\"com.trivadis.kafkaws.avro.v1\",\"fields\":[{\"name\":\"id\",\"type\":[\"long\",\"null\"]},{\"name\":\"message\",\"type\":[\"string\",\"null\"]}],\"description\":\"A simple Notification Event message\"}");
public static org.apache.avro.Schema getClassSchema() { return SCHEMA$; }
private java.lang.Long id;
private java.lang.CharSequence message;
/**
* Default constructor. Note that this does not initialize fields
* to their default values from the schema. If that is desired then
* one should use <code>newBuilder()</code>.
*/
public Notification() {}
/**
* All-args constructor.
* @param id The new value for id
* @param message The new value for message
*/
public Notification(java.lang.Long id, java.lang.CharSequence message) {
this.id = id;
this.message = message;
}
...
```
You can see that the code is based on the information in the Avro schema. We will use this class when we produce as well as consume Avro messages to/from Kafka.
## Create a Kafka Producer using Avro for serialisation
First create a new Java Package `com.trivadis.kafkaws.producer` in the folder **src/main/java**.
Create a new Java Class `KafkaProducerAvro` in the package `com.trivadis.kafakws.producer` just created.
Add the following code to the empty class to create a Kafka Producer. It is similar to the code we have seen in the previous workshop. We have changed both serialiser to use the Confluent `KafkaAvroSerializer` class and added the URL to the Confluent Schema Registry API.
```java
package com.trivadis.kafkaws.producer;
import com.trivadis.kafkaws.avro.v1.Notification;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializerConfig;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerAvro {
private final static String TOPIC = "test-java-avro-topic";
private final static String BOOTSTRAP_SERVERS =
"dataplatform:9092, dataplatform:9093, dataplatform:9094";
private final static String SCHEMA_REGISTRY_URL = "http://dataplatform:8081";
private static Producer<Long, Notification> createProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaExampleProducer");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class.getName());
props.put(KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, SCHEMA_REGISTRY_URL); // use constant for "schema.registry.url"
return new KafkaProducer<>(props);
}
}
```
We will be using the synchronous way for producing messages to the Kafka topic we created above, but the other methods would work as well with Avro.
```java
static void runProducer(final int sendMessageCount, final int waitMsInBetween, final long id) throws Exception {
final Producer<Long, Notification> producer = createProducer();
long time = System.currentTimeMillis();
Long key = (id > 0) ? id : null;
try {
for (long index = 0; index < sendMessageCount; index++) {
Notification notification = new Notification(id, "Hello Kafka " + index);
final ProducerRecord<Long, Notification> record =
new ProducerRecord<>(TOPIC, key, notification);
RecordMetadata metadata = producer.send(record).get();
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) " +
"meta(partition=%d, offset=%d) time=%d\n",
record.key(), record.value(), metadata.partition(),
metadata.offset(), elapsedTime);
time = System.currentTimeMillis();
Thread.sleep(waitMsInBetween);
}
} finally {
producer.flush();
producer.close();
}
}
```
Next you define the main method.
```
public static void main(String... args) throws Exception {
if (args.length == 0) {
runProducer(100,10,0);
} else {
runProducer(Integer.parseInt(args[0]),Integer.parseInt(args[1]),Long.parseLong(args[2]));
}
}
```
The `main()` method accepts 3 parameters, the number of messages to produce, the time in ms to wait in-between sending each message and the ID of the producer.
Use `kcat` or `kafka-console-consumer` to consume the messages from the topic `test-java-avro-topic `.
```
kcat -b kafka-1:19092 -t test-java-avro-topic
```
Now run it using the `mvn exec:java` command. It will generate 1000 messages, waiting 10ms in-between sending each message and use 0 for the ID.
```
mvn exec:java@producer -Dexec.args="1000 10 0"
```
**Note:** if your maven version does not support profiles, then you have to specify the main class as well: `mvn exec:java -Dexec.mainClass="com.trivadis.kafkaws.producer.KafkaProducerAvro" -Dexec.args="1000 100 0"`
You can see that `kcat` shows some special, non-printable characters. This is due to the Avro format. If you want to display the Avro, you can use the `kafka-avro-console-consumer` CLI, which is part of the Schema Registry.
So let's connect to the schema registry container:
```
docker exec -ti schema-registry-1 bash
```
And then invoke the `kafka-avro-console-consumer` similar to the "normal" consumer seen so far.
```
kafka-avro-console-consumer --bootstrap-server kafka-1:19092 --topic test-java-avro-topic
```
You should see an output similar to the one below.
```
...
[2018-07-11 21:32:43,155] INFO [Consumer clientId=consumer-1, groupId=console-consumer-88150] Resetting offset for partition test-java-avro-topic-6 to offset 0. (org.apache.kafka.clients.consumer.internals.Fetcher)
{"id":{"long":0},"message":{"string":"Hello Kafka 0"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 3"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 1"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 2"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 4"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 5"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 6"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 9"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 7"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 10"}}
{"id":{"long":0},"message":{"string":"Hello Kafka 8"}}
...
```
if you want to consume with `kcat` you need to specify the serialization format `-s` and the address of the schema registry `-r`:
```
kcat -b kafka-1 -t test-java-avro-topic -s value=avro -r http://schema-registry-1:8081
```
**Note**: For Avro support your kafkacat version needs to be `1.6' or later.
## View the Schema in the Registry
The Avro Serialiser and Deserialiser automatically register the Avro schema, if it is not already in the registry.
The Streamingplatform also contains a tool made by a company called Landoop which allows us to see what's in the registry.
In a browser, navigate to <http://dataplatform:28039> and you should see the home page of the Schema Registry UI.

If you click on the schema to the left, you can view the details of the schema. You can see that version v1 has been assigned automatically.

## Create a Kafka Consumer using Avro for serialization
First create a new Java Package `com.trivadis.kafkaws.consumer` in the folder **src/main/java**.
Create a new Java Class `KafkaConsumerAvro` in the package `com.trivadis.kafakws.consumer` just created.
Add the following code to the empty class.
```java
package com.trivadis.kafkaws.consumer;
import java.util.Collections;
import java.util.Properties;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.LongDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import com.trivadis.kafkaws.avro.v1.Notification;
import io.confluent.kafka.serializers.KafkaAvroDeserializer;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializerConfig;
public class KafkaConsumerAvro {
private final static String TOPIC = "test-java-avro-topic";
private final static String BOOTSTRAP_SERVERS =
"dataplatform:9092, dataplatform:9093, dataplatform:9094";
private final static String SCHEMA_REGISTRY_URL = "http://dataplatform:8081";
private static Consumer<Long, Notification> createConsumer() {
final Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerAvro");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 10000);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class.getName());
props.put(KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, SCHEMA_REGISTRY_URL); // use constant for "schema.registry.url"
// Create the consumer using props.
final Consumer<Long, Notification> consumer =
new KafkaConsumer<>(props);
// Subscribe to the topic.
consumer.subscribe(Collections.singletonList(TOPIC));
return consumer;
}
static void runConsumer(int waitMsInBetween) throws InterruptedException {
final Consumer<Long, Notification> consumer = createConsumer();
final int giveUp = 100;
int noRecordsCount = 0;
while (true) {
final ConsumerRecords<Long, Notification> consumerRecords = consumer.poll(1000);
if (consumerRecords.count()==0) {
noRecordsCount++;
if (noRecordsCount > giveUp)
break;
}
consumerRecords.forEach(record -> {
System.out.printf("%d - Consumer Record:(Key: %d, Value: %s, Partition: %d, Offset: %d)\n",
consumerRecords.count(), record.key(), record.value(),
record.partition(), record.offset());
try {
Thread.sleep(waitMsInBetween);
} catch (InterruptedException e) {
}
});
consumer.commitSync();
}
consumer.close();
System.out.println("DONE");
}
public static void main(String... args) throws Exception {
if (args.length == 0) {
runConsumer(10);
} else {
runConsumer(Integer.parseInt(args[0]));
}
}
}
```
## Register in Schema Registry using Maven
In the test above, the Avro schema has been registered in the schema registry when starting the Producer for the first time. To register an Avro schema through Maven automatically, you can use the `kafka-schema-registry-maven-plugin` Maven plugin.
Add the following definition to the `pom.xml`.
```xml
<plugin>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-maven-plugin</artifactId>
<version>7.0.0</version>
<configuration>
<schemaRegistryUrls>
<param>http://dataplatform:8081</param>
</schemaRegistryUrls>
<subjects>
<test-java-avro-topic-value>src/main/avro/Notification-v1.avsc</test-java-avro-topic-value>
</subjects>
</configuration>
<goals>
<goal>register</goal>
<goal>test-compatibility</goal>
</goals>
</plugin>
```
Now you can use the following command to register the schemas with the Schema Registry:
```
mvn schema-registry:register
```
<file_sep># Watchtower
A container-based solution for automating Docker container base image updates.
**[Website](https://containrrr.dev/watchtower/)** | **[Documentation](https://containrrr.dev/watchtower/)** | **[GitHub](https://github.com/containrrr/watchtower)**
## How to enable?
```
platys init --enable-services WATCHTOWER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28137><file_sep># Cerebro
cerebro is an open source(MIT License) elasticsearch web admin tool built using Scala, Play Framework, AngularJS and Bootstrap.
**[Documentation](https://github.com/lmenezes/cerebro)** | **[GitHub](https://github.com/lmenezes/cerebro)**
## How to enable?
```
platys init --enable-services CEREBRO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28126><file_sep># Apicurio Registry
**[Website](https://www.apicur.io/registry/)** | **[Documentation](https://www.apicur.io/registry/docs/apicurio-registry/2.0.1.Final/index.html)** | **[GitHub](https://github.com/Apicurio/apicurio-registry)**
```
platys init --enable-services APICURIO_REGISTRY
platys gen
```
<file_sep># Optuna
An open source hyperparameter optimization framework to automate hyperparameter search.
**[Website](https://optuna.org/)** | **[Documentation](https://optuna.org/)** | **[GitHub](https://github.com/optuna/optuna)**
## How to enable?
```
platys init --enable-services OPTUNA
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28230><file_sep># Camunda BPM Platform
A complete process automation tech stack with powerful execution engines for BPMN workflows and DMN decisions, combined with essential applications for modeling, operations, and analytics.
**[Website](https://camunda.com/products/camunda-platform/)** | **[Documentation](https://docs.camunda.org/manual/latest)**
## How to enable?
```
platys init --enable-services CAMUNDA_BPM_PLATFORM
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28263/camunda-welcome/index.html>.
User: demo, Password: <PASSWORD>
<file_sep>Contains the data of baserow service, if flag BASEROW_volume_map_data is set to true.<file_sep># MySQL
MySQL Server, the world's most popular open source database, and MySQL Cluster, a real-time, open source transactional database.
**[Website](https://www.mysql.com/)** | **[Documentation](https://dev.mysql.com/doc/)** | **[GitHub](https://github.com/mysql)**
### How to enable
```
platys init --enable-services MYSQL
platys gen
```
### Other links
### Backup & Restore
To backup a database perform
```bash
docker exec mysql /usr/bin/mysqldump -u root --password=root DATABASE > backup.sql
```
To restore from a backup, perform
```bash
cat backup.sql | docker exec -i mysql /usr/bin/mysql -u root --password=root DATABASE
```
<file_sep># Markdown Renderer
Renders the Services list page and is automatically activated.
<file_sep>Contains the data of azurecli service, if flag AZURE_CLI_volume_map_data is set to true.<file_sep>#!/bin/sh
apt update
if [ -z "$2" ]
then
echo "No requirements.txt file configured, skipping PIP install phase!"
else
pip3 install --upgrade pip
pip3 install --no-cache-dir -r $2
fi
if [ -z "$1" ]
then
echo "No python script configured, just running python without an application!"
python
else
python $1
fi
<file_sep># Apache Kudu
Apache Kudu is an open source distributed data storage engine that makes fast analytics on fast and changing data easy.
**[Website](https://kudu.apache.org/)** | **[Documentation](https://kudu.apache.org/docs/)** | **[GitHub](https://github.com/projectkudu/kudu)**
## How to enable?
```
platys init --enable-services KUDU
platys gen
```
## How to use it?
<file_sep>package com.trivadis.kafkaws.springbootkotlinkafkaconsumer
import org.junit.jupiter.api.Test
import org.springframework.boot.test.context.SpringBootTest
@SpringBootTest
class SpringBootKotlinKafkaConsumerApplicationTests {
@Test
fun contextLoads() {
}
}
<file_sep># Baserow
Baserow is an open source no-code database and Airtable alternative. Create your own database without technical experience. Our user friendly no-code tool gives you the powers of a developer without leaving your browser.
**[Website](https://baserow.io/)** | **[Documentation](https://baserow.io/docs/index)** | **[GitLab](https://gitlab.com/bramw/baserow)**
## How to enable?
```
platys init --enable-services BASEROW
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28299>. <file_sep># ElasticHQ
Monitoring and Management Web Application for ElasticSearch instances and clusters.
**[Website](http://www.elastichq.org/)** | **[Documentation](http://www.elastichq.org/gettingstarted.html)** | **[GitHub](https://github.com/ElasticHQ/elasticsearch-HQ)**
## How to enable?
```
platys init --enable-services ELASTICHQ
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28127><file_sep>Place a gremlin scripts here to initialise the graph.<file_sep># Using Kafka from Spring Boot using Cloud Stream
In this workshop we will learn how to use the **Spring Cloud Stream** abstraction from within a Spring Boot application. We will implement both a consumer and a producer implementing the same behaviour as in [Workshop 4: Working with Kafka from Java](../04-producing-consuming-kafka-with-java).
We will create two Spring Boot projects, one for the **Producer** and one for the **Consumer**, simulating two independent microservices interacting with eachother via events.
## Create the Spring Boot Producer
First we create an test the Producer microservice.
### Creating the Spring Boot Project
First, let’s navigate to [Spring Initializr](https://start.spring.io/) to generate our project. Our project will need the Spring Cloud Stream support.
Select Generate a **Maven Project** with **Java** and Spring Boot **2.6.5**. Enter `com.trivadis.kafkaws` for the **Group**, `spring-boot-cloud-stream-kafka-producer` for the **Artifact** field and `Kafka Producer with Spring Cloud Stream (Kafka)` for the **Description** field.
Click on **Add Dependencies** and search for the **Cloud Stream** depencency.
Select the dependency and hit the **Enter** key. You should now see the dependency on the right side of the screen.

Click on **Generate Project** and unzip the ZIP file to a convenient location for development.
Once you have unzipped the project, you’ll have a very simple structure.
Import the project as a Maven Project into your favourite IDE for further development.
### Extend the Maven POM with some configurations
In oder to use the Avro serializer and the class generated above, we have to add the following dependencies to the `pom.xml`.
```xml
<dependencies>
...
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>
```
### Implement a Kafka Producer in Spring
Now create a simple Java class `KafkaEventProducer` within the `com.trivadis.kafkaws.springbootkafkaproducer ` package, which we will use to produce messages to Kafka.
```java
package com.trivadis.kafkaws.springbootkafkaproducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.stream.messaging.Processor;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Service;
@Service
public class KafkaEventProducer {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaEventProducer.class);
@Autowired
private Processor processor;
@Value("${topic.name}")
String kafkaTopic;
public void produce(Integer id, Long key, String value) {
long time = System.currentTimeMillis();
Message<String> message = MessageBuilder.withPayload(value)
.setHeader(KafkaHeaders.MESSAGE_KEY, key)
.build();
processor.output()
.send(message);
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) time=%d\n",key, value,elapsedTime);
}
}
```
It uses the `Component` annotation to have it registered as bean in the Spring context. The topic to produce to is specified as a property, which we will specify later in the `applicaiton.yml` file.
We produce the messages synchronously.
### Create the necessary Topics through code
Spring Kafka can automatically add topics to the broker, if they do not yet exists. By that you can replace the `kafka-topics` CLI commands seen so far to create the topics, if you like.
Spring Kafka provides a `TopicBuilder` which makes the creation of the topics very convenient.
```java
package com.trivadis.kafkaws.springbootkafkaproducer;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.kafka.config.TopicBuilder;
import org.springframework.stereotype.Component;
@Component
public class TopicCreator {
@Value(value = "${topic.name}")
private String testTopic;
@Value(value = "${topic.partitions}")
private Integer testTopicPartitions;
@Value(value = "${topic.replication-factor}")
private short testTopicReplicationFactor;
@Bean
public NewTopic testTopic() {
return TopicBuilder.name(testTopic)
.partitions(testTopicPartitions)
.replicas(testTopicReplicationFactor)
.build();
}
}
```
We again refer to properties, which will be defined later in the `application.yml` config file.
### Add Producer logic to the SpringBootKafkaProducerApplication class
We change the generated Spring Boot application to be a console appliation by implementing the `CommandLineRunner` interface. The `run` method holds the same code as the `main()` method in [Workshop 4: Working with Kafka from Java](../04-producing-consuming-kafka-with-java). The `runProducer` method is also similar, we just use the `kafkaEventProducer` instance injected by Spring to produce the messages to Kafka.
```java
package com.trivadis.kafkaws.springbootkafkaproducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Processor;
import java.time.LocalDateTime;
@SpringBootApplication
@EnableBinding(Processor.class)
public class SpringBootKafkaProducerApplication implements CommandLineRunner {
private static Logger LOG = LoggerFactory.getLogger(SpringBootKafkaProducerApplication.class);
@Autowired
private KafkaEventProducer kafkaEventProducer;
public static void main(String[] args) {
SpringApplication.run(SpringBootKafkaProducerApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
LOG.info("EXECUTING : command line runner");
if (args.length == 0) {
runProducer(100, 10, 0);
} else {
runProducer(Integer.parseInt(args[0]), Integer.parseInt(args[1]), Long.parseLong(args[2]));
}
}
private void runProducer(int sendMessageCount, int waitMsInBetween, long id) throws Exception {
Long key = (id > 0) ? id : null;
for (int index = 0; index < sendMessageCount; index++) {
String value = "[" + id + "] Hello Kafka " + index + " => " + LocalDateTime.now();
kafkaEventProducer.produce(index, key, value);
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
```
### Configure Kafka through application.yml configuration file
First let's rename the existing `application.properties` file to `application.yml` to use the `yml` format.
Add the following settings to configure the Kafka cluster and the name of the topic:
```yml
topic:
name: test-spring-cloud-stream-topic
replication-factor: 3
partitions: 12
spring:
cloud:
stream:
default:
producer:
useNativeEncoding: true
kafka:
binder:
producer-properties:
key.serializer: org.apache.kafka.common.serialization.LongSerializer
value.serializer: org.apache.kafka.common.serialization.StringSerializer
bindings:
output:
destination: ${topic.name}
kafka:
bootstrap-servers: ${DATAPLATFORM_IP}:9092
```
For the IP address of the Kafka cluster we refer to an environment variable, which we have to declare before running the application.
```bash
export DATAPLATFORM_IP=nnn.nnn.nnn.nnn
```
### Build the application
First lets build the application:
```bash
mvn package -Dmaven.test.skip=true
```
### Run the application
Now let's run the application
```bash
mvn spring-boot:run
```
Make sure that you see the messages through the console consumer.
To run the producer with custom parameters (for example to specify the key to use), use the `-Dspring-boot.run.arguments`:
```bash
mvn spring-boot:run -Dspring-boot.run.arguments="100 10 10"
```
### Use Console to test the application
In a terminal window start consuming from the output topic:
```bash
kafkacat -b $DATAPLATFORM_IP -t test-spring-topic
```
## Create the Spring Boot Consumer
Now let's create an test the Consumer microservice.
### Creating the Spring Boot Project
Use again the [Spring Initializr](https://start.spring.io/) to generate the project.
Select Generate a **Maven Project** with **Java** and Spring Boot **2.6.5**. Enter `com.trivadis.kafkaws` for the **Group**, `spring-boot-cloud-stram-kafka-consumer` for the **Artifact** field and `Kafka Consumer project for Spring Boot` for the **Description** field.
Click on **Add Dependencies** and search for the **Spring for Apache Kafka** depencency.
Select the dependency and hit the **Enter** key. You should now see the dependency on the right side of the screen.
Click on **Generate Project** and unzip the ZIP file to a convenient location for development.
Once you have unzipped the project, you’ll have a very simple structure.
Import the project as a Maven Project into your favourite IDE for further development.
### Implement a Kafka Consumer in Spring
Start by creating a simple Java class `KafkaEventConsumer` within the `com.trivadis.kafkaws.springbootkafkaconsumer` package, which we will use to consume messages from Kafka.
```java
package com.trivadis.kafkaws.springcloudstreamkafkaconsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Processor;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.stereotype.Component;
@Component
public class KafkaEventConsumer {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaEventConsumer.class);
@StreamListener(Processor.INPUT)
public void receive(Message<String> msg) {
String value = msg.getPayload();
Long key = (Long)msg.getHeaders().get(KafkaHeaders.RECEIVED_MESSAGE_KEY);
LOGGER.info("received key = '{}' with payload='{}'", key, value);
}
}
```
This class uses the `Component` annotation to have it registered as bean in the Spring context and the `StreamListener` annotation to specify a listener method to be called for each record consumed from the Kafka input topic. The name of the topic is specified as a property to be read again from the `application.yml` configuration file.
In the code we only log the key and value received to the console. In real life, we would probably inject another bean into the `KafkaEventConsumer` to perform the message processing.
### Add @EnableBinding to Application class
Add the following annotation to the `SpringCloudStreamKafkaConsumerAvroApplication` class
```yml
@EnableBinding(Processor.class)
public class SpringCloudStreamKafkaConsumerAvroApplication {
...
```
### Configure Kafka through application.yml configuration file
First let's rename the existing `application.properties` file to `application.yml` to use the `yml` format.
Add the following settings to configure the Kafka cluster and the name of the two topics:
```yml
spring:
cloud:
stream:
default:
consumer:
useNativeEncoding: true
bindings:
input:
destination: test-spring-cloud-stream-topic
group: group-1
concurrency: 3
kafka:
binder:
consumer-properties:
key.deserializer: org.apache.kafka.common.serialization.LongDeserializer
value.deserializer: org.apache.kafka.common.serialization.StringDeserializer
kafka:
bootstrap-servers: ${DATAPLATFORM_IP}:9092
```
For the IP address of the Kafka cluster we refer to an environment variable, which we have to declare before running the application.
```bash
export DATAPLATFORM_IP=nnn.nnn.nnn.nnn
```
### Build the application
First lets build the application:
```bash
mvn package -Dmaven.test.skip=true
```
### Run the application
Now let's run the application
```bash
mvn spring-boot:run
```
<file_sep># FileZilla
FileZilla Client is a fast and reliable cross-platform FTP, FTPS and SFTP client with lots of useful features and an intuitive graphical user interface.
**[Website](https://filezilla-project.org/)** | **[Documentation](https://wiki.filezilla-project.org/Documentation)**
```bash
platys init --enable-services FILEZILLA
platys gen
```
## How to use it?
Navigate to <http://dataplatform:5800>.
<file_sep># Working with Kafka from Java
In this workshop we will learn how to produce and consume messages using the [Kafka Java API](https://kafka.apache.org/documentation/#api).
We will fist use just the `StringSerializer` to serialize a `java.lang.String` object for the value of the message. In a second step we will change it to serialize a custom Java bean as a JSON document.
## Create the project in your Java IDE
Create a new Maven Project (using the functionality of your favourite IDE) and use `com.trivadis.kafkaws` for the **Group Id** and `java-kafka` for the **Artifact Id**.
Navigate to the **pom.xml** and double-click on it. The POM Editor will be displayed.
You can either use the GUI to edit your pom.xml or click on the last tab **pom.xml** to switch to the "code view". Let's do that.
You will see the still rather empty definition.
```xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trivadis.kafkaws</groupId>
<artifactId>java-kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
</project>
```
Let's add some initial dependencies for our project. We will add some more dependencies to the POM throughout this workshop.
Copy the following block right after the <version> tag, before the closing </project> tag.
```xml
<properties>
<kafka.version>2.7.0</kafka.version>
<java.version>1.8</java.version>
<slf4j-version>1.7.5</slf4j-version>
<!-- use utf-8 encoding -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j-version}</version>
</dependency>
</dependencies>
<build>
<defaultGoal>install</defaultGoal>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<maxmem>256M</maxmem>
<showDeprecation>true</showDeprecation>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<id>producer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.producer.KafkaProducerSync</mainClass>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
```
## Create log4j settings
Let's also create the necessary log4j configuration.
In the code we are using the [Log4J Logging Framework](https://logging.apache.org/log4j/2.x/), which we have to configure using a property file.
Create a new file `log4j.properties` in the folder **src/main/resources** and add the following configuration properties.
```properties
## ------------------------------------------------------------------------
## Licensed to the Apache Software Foundation (ASF) under one or more
## contributor license agreements. See the NOTICE file distributed with
## this work for additional information regarding copyright ownership.
## The ASF licenses this file to You under the Apache License, Version 2.0
## (the "License"); you may not use this file except in compliance with
## the License. You may obtain a copy of the License at
##
## http://www.apache.org/licenses/LICENSE-2.0
##
## Unless required by applicable law or agreed to in writing, software
## distributed under the License is distributed on an "AS IS" BASIS,
## WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
## See the License for the specific language governing permissions and
## limitations under the License.
## ------------------------------------------------------------------------
log4j.rootLogger=INFO, out
#log4j.logger.org.apache.kafka=INFO
log4j.logger.org.apache.camel.impl.converter=INFO
log4j.logger.org.apache.camel.util.ResolverUtil=INFO
log4j.logger.org.springframework=WARN
log4j.logger.org.hibernate=WARN
# CONSOLE appender not used by default
log4j.appender.out=org.apache.log4j.ConsoleAppender
log4j.appender.out.layout=org.apache.log4j.PatternLayout
log4j.appender.out.layout.ConversionPattern=[%30.30t] %-30.30c{1} %-5p %m%n
#log4j.appender.out.layout.ConversionPattern=%d [%-15.15t] %-5p %-30.30c{1} - %m%n
log4j.throwableRenderer=org.apache.log4j.EnhancedThrowableRenderer
```
## Creating the necessary Kafka Topic
We will use the topic `test-java-topic` in the Producer and Consumer code below. Due to the fact that `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
Connect to the `kafka-1` container
```bash
docker exec -ti kafka-1 bash
```
and execute the necessary `kafka-topics` command.
```bash
kafka-topics --create \
--replication-factor 3 \
--partitions 12 \
--topic test-java-topic \
--bootstrap-server kafka-1:19092
```
Cross check that the topic has been created.
```bash
kafka-topics --list --bootstrap-server kafka-1:19092
```
This finishes the setup steps and our new project is ready to be used. Next we will start implementing a **Kafka Producer**.
## Create a Kafka Producer
Let's first create a producer in synchronous mode.
### Using the Synchronous mode
First create a new Java Package `com.trivadis.kafkaws.producer` in the folder **src/main/java**.
Create a new Java Class `KafkaProducerSync` in the package `com.trivadis.kafkaws.producer` just created.
Add the following code to the empty class to create a Kafka Producer.
```java
package com.trivadis.kafkaws.producer;
import java.time.LocalDateTime;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.LongSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
public class KafkaProducerSync {
private final static String TOPIC = "test-java-topic";
private final static String BOOTSTRAP_SERVERS
= "dataplatform:9092,dataplatform:9093";
private static Producer<Long, String> createProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaExampleProducer");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
return new KafkaProducer<>(props);
}
}
```
Kafka provides a synchronous send method to send a record to a topic. Let’s use this method to send some message ids and messages to the Kafka topic we created earlier.
```java
private static void runProducer(int sendMessageCount, int waitMsInBetween, long id) throws Exception {
try (Producer<Long, String> producer = createProducer()) {
for (int index = 0; index < sendMessageCount; index++) {
long time = System.currentTimeMillis();
ProducerRecord<Long, String> record
= new ProducerRecord<>(TOPIC,
"[" + id + "] Hello Kafka " + index + " => " + LocalDateTime.now());
RecordMetadata metadata = producer.send(record).get();
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) "
+ "meta(partition=%d, offset=%d) time=%d\n",
record.key(), record.value(), metadata.partition(),
metadata.offset(), elapsedTime);
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
```
Next you define the main method.
```java
public static void main(String... args) throws Exception {
if (args.length == 0) {
runProducer(100, 10, 0);
} else {
runProducer(Integer.parseInt(args[0]), Integer.parseInt(args[1]), Long.parseLong(args[2]));
}
}
```
The `main()` method accepts 3 parameters, the number of messages to produce, the time in ms to wait in-between sending each message and the ID of the producer.
Now run it using the `mvn exec:java` command. It will generate 1000 messages, waiting 100ms in-between sending each message and use 0 for the ID, which will set the key to `null`.
```bash
mvn clean package -Dmaven.test.skip=true
mvn exec:java@producer -Dexec.args="1000 100 0"
```
**Note**: if your maven version does not support profiles, then you have to specify the main class as well: `mvn exec:java -Dexec.mainClass="com.trivadis.kafkaws.producer.KafkaProducerSync" -Dexec.args="1000 100 0"`
if you don't have `kafkacat` or `kcat` available, you can use it as a docker container. To simplify using `kcat`, you can use the following alias:
```bash
alias kcat='docker run --tty --network host edenhill/kcat:1.7.0 kcat'
```
Use `kafkacat` or `kafka-console-consumer` to consume the messages from the topic `test-java-topic`.
```bash
kcat -b kafka-1:19092 -t test-java-topic -f 'Part-%p => %k:%s\n'
```
```bash
% Auto-selecting Consumer mode (use -P or -C to override)
Part-5 => :[0] Hello Kafka 0
Part-4 => :[0] Hello Kafka 1
Part-3 => :[0] Hello Kafka 4
Part-2 => :[0] Hello Kafka 7
Part-5 => :[0] Hello Kafka 8
Part-4 => :[0] Hello Kafka 9
Part-7 => :[0] Hello Kafka 2
Part-7 => :[0] Hello Kafka 10
Part-1 => :[0] Hello Kafka 3
Part-1 => :[0] Hello Kafka 11
Part-3 => :[0] Hello Kafka 12
Part-6 => :[0] Hello Kafka 5
Part-6 => :[0] Hello Kafka 13
Part-0 => :[0] Hello Kafka 6
Part-0 => :[0] Hello Kafka 14
Part-2 => :[0] Hello Kafka 15
Part-5 => :[0] Hello Kafka 16
Part-4 => :[0] Hello Kafka 17
Part-7 => :[0] Hello Kafka 18
Part-1 => :[0] Hello Kafka 19
Part-3 => :[0] Hello Kafka 20
Part-6 => :[0] Hello Kafka 21
Part-0 => :[0] Hello Kafka 22
Part-2 => :[0] Hello Kafka 23
Part-2 => :[0] Hello Kafka 31
Part-5 => :[0] Hello Kafka 24
Part-5 => :[0] Hello Kafka 32
Part-4 => :[0] Hello Kafka 25
Part-7 => :[0] Hello Kafka 26
Part-1 => :[0] Hello Kafka 27
Part-4 => :[0] Hello Kafka 33
Part-3 => :[0] Hello Kafka 28
Part-6 => :[0] Hello Kafka 29
Part-0 => :[0] Hello Kafka 30
Part-3 => :[0] Hello Kafka 36
Part-2 => :[0] Hello Kafka 39
Part-5 => :[0] Hello Kafka 40
...
```
### Using the Id field as the key
If we specify an id <> 0 when running the producer, the id is used as the key
```java
private static void runProducer(int sendMessageCount, int waitMsInBetween, long id) throws Exception {
Long key = (id > 0) ? id : null;
try (Producer<Long, String> producer = createProducer()) {
for (int index = 0; index < sendMessageCount; index++) {
long time = System.currentTimeMillis();
ProducerRecord<Long, String> record
= new ProducerRecord<>(TOPIC, key, "[" + id + "] Hello Kafka " + index + " => " + LocalDateTime.now());
RecordMetadata metadata = producer.send(record).get();
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) "
+ "meta(partition=%d, offset=%d) time=%d\n",
record.key(), record.value(), metadata.partition(),
metadata.offset(), elapsedTime);
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
```
So let's run it for id=`10`
```bash
mvn exec:java@producer -Dexec.args="1000 100 10"
```
### Changing to Asynchronous mode
The following class shows the same logic but this time using the asynchronous way for sending records to Kafka. The difference can be seen in the `runProducer` method.
```java
package com.trivadis.kafkaws.producer;
import java.time.LocalDateTime;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.LongSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
public class KafkaProducerASync {
private final static String TOPIC = "test-java-topic";
private final static String BOOTSTRAP_SERVERS
= "dataplatform:9092, dataplatform:9093";
private static Producer<Long, String> createProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
BOOTSTRAP_SERVERS);
props.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaExampleProducer");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
return new KafkaProducer<>(props);
}
private static void runProducer(int sendMessageCount, int waitMsInBetween, long id) throws Exception {
Long key = (id > 0) ? id : null;
final CountDownLatch countDownLatch = new CountDownLatch(sendMessageCount);
try (Producer<Long, String> producer = createProducer()) {
for (int index = 0; index < sendMessageCount; index++) {
long time = System.currentTimeMillis();
ProducerRecord<Long, String> record
= new ProducerRecord<>(TOPIC, key,
"[" + id + "] Hello Kafka " + LocalDateTime.now());
producer.send(record, (metadata, exception) -> {
long elapsedTime = System.currentTimeMillis() - time;
if (metadata != null) {
System.out.printf("[" + id + "] sent record(key=%s value=%s) "
+ "meta(partition=%d, offset=%d) time=%d\n",
record.key(), record.value(), metadata.partition(),
metadata.offset(), elapsedTime);
} else {
exception.printStackTrace();
}
countDownLatch.countDown();
});
}
}
}
public static void main(String... args) throws Exception {
if (args.length == 0) {
runProducer(100, 10, 0);
} else {
runProducer(Integer.parseInt(args[0]), Integer.parseInt(args[1]), Long.parseLong(args[2]));
}
}
}
```
## Create a Kafka Consumer
Just like we did with the producer, you need to specify bootstrap servers. You also need to define a `group.id` that identifies which consumer group this consumer belongs. Then you need to designate a Kafka record key deserializer and a record value deserializer. Then you need to subscribe the consumer to the topic you created in the producer tutorial.
### Kafka Consumer with Automatic Offset Committing
First create a new Java Package `com.trivadis.kafkaws.consumer` in the folder **src/main/java**.
Create a new Java Class `KafkaConsumerAuto` in the package `com.trivadis.kafkaws.consumer` just created.
Add the following code to the empty class.
Now, that we imported the Kafka classes and defined some constants, let’s create a Kafka producer.
First imported the Kafka classes, define some constants and create the Kafka consumer.
```java
package com.trivadis.kafkaws.consumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.LongDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
public class KafkaConsumerAuto {
private final static String TOPIC = "test-java-topic";
private final static String BOOTSTRAP_SERVERS
= "dataplatform:9092,dataplatform:9093,dataplatform:9094";
private final static Duration CONSUMER_TIMEOUT = Duration.ofSeconds(1);
private static Consumer<Long, String> createConsumer() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerAuto");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 10000);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// Create the consumer using props.
Consumer<Long, String> consumer = new KafkaConsumer<>(props);
// Subscribe to the topic.
consumer.subscribe(Collections.singletonList(TOPIC));
return consumer;
}
```
With that in place, let's process the record with the Kafka Consumer.
```java
private static void runConsumer(int waitMsInBetween) throws InterruptedException {
final int giveUp = 100;
try (Consumer<Long, String> consumer = createConsumer()) {
int noRecordsCount = 0;
while (true) {
ConsumerRecords<Long, String> consumerRecords = consumer.poll(CONSUMER_TIMEOUT);
if (consumerRecords.isEmpty()) {
noRecordsCount++;
if (noRecordsCount > giveUp) {
break;
} else {
continue;
}
}
consumerRecords.forEach(record -> {
System.out.printf("%d - Consumer Record:(Key: %d, Value: %s, Partition: %d, Offset: %d)\n",
consumerRecords.count(), record.key(), record.value(),
record.partition(), record.offset());
try {
// Simulate slow processing
Thread.sleep(waitMsInBetween);
} catch (InterruptedException e) {
}
});
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("DONE");
}
```
Notice you use `ConsumerRecords` which is a group of records from a Kafka topic partition. The `ConsumerRecords` class is a container that holds a list of ConsumerRecord(s) per partition for a particular topic. There is one `ConsumerRecord` list for every topic partition returned by the `consumer.poll()`.
Next you define the main method. You can pass the amount of time the consumer spends for processing each record consumed.
```java
public static void main(String... args) throws Exception {
if (args.length == 0) {
runConsumer(10);
} else {
runConsumer(Integer.parseInt(args[0]));
}
}
```
The main method just calls `runConsumer`.
Before we run the consumer, let's add a new line to the `log4j.properties` configuration, just right after the `log4j.logger.org.apache.kafka=INFO` line.
```properties
log4j.logger.org.apache.kafka.clients.consumer.internals.ConsumerCoordinator=DEBUG
```
If will show a DEBUG message whenever the auto commit is executed.
Before we can run it, add the consumer to the `<executions>` section in the `pom.xml`.
```xml
<execution>
<id>consumer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.consumer.KafkaConsumerAuto</mainClass>
</configuration>
</execution>
```
Now run it using the `mvn exec:java` command.
```bash
mvn clean package -Dmaven.test.skip=true
mvn exec:java@consumer -Dexec.args="0"
```
**Note**: if your maven version does not support profiles, then you have to specify the main class as well: `mvn exec:java -Dexec.mainClass="com.trivadis.kafkaws.consumer.KafkaConsumerAuto" -Dexec.args="0"`
on the console you should see an output similar to the one below, with some Debug messages whenever the auto-commit is happening
```bash
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 399 => 2021-08-06T14:33:09.882489, Partition: 2, Offset: 317)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 400 => 2021-08-06T14:33:09.995583, Partition: 7, Offset: 327)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 401 => 2021-08-06T14:33:10.098579, Partition: 1, Offset: 295)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 402 => 2021-08-06T14:33:10.206131, Partition: 7, Offset: 328)
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-KafkaConsumerAuto-1, groupId=KafkaConsumerAuto] Sending asynchronous auto-commit of offsets {test-java-topic-7=OffsetAndMetadata{offset=329, leaderEpoch=0, metadata=''}, test-java-topic-5=OffsetAndMetadata{offset=299, leaderEpoch=0, metadata=''}, test-java-topic-6=OffsetAndMetadata{offset=318, leaderEpoch=0, metadata=''}, test-java-topic-3=OffsetAndMetadata{offset=295, leaderEpoch=0, metadata=''}, test-java-topic-4=OffsetAndMetadata{offset=317, leaderEpoch=0, metadata=''}, test-java-topic-1=OffsetAndMetadata{offset=296, leaderEpoch=0, metadata=''}, test-java-topic-2=OffsetAndMetadata{offset=318, leaderEpoch=0, metadata=''}, test-java-topic-0=OffsetAndMetadata{offset=284, leaderEpoch=0, metadata=''}}
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-KafkaConsumerAuto-1, groupId=KafkaConsumerAuto] Committed offset 318 for partition test-java-topic-6
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-KafkaConsumerAuto-1, groupId=KafkaConsumerAuto] Committed offset 296 for partition test-java-topic-1
[sumer.KafkaConsumerAuto.main()] ConsumerCoordinator DEBUG [Consumer clientId=consumer-KafkaConsumerAuto-1, groupId=KafkaConsumerAuto] Committed offset 329 for partition test-java-topic-7
[
```
### Kafka Consumer with Manual Offset Control
Create a new Java Class `KafkaConsumerManual` in the package `com.trivadis.kafkaws.consumer` just created by copy-pasting from the class `KafkaConsumerAuto`.
Replace the `runConsumer()` method with the code below.
```java
private static void runConsumer(int waitMsInBetween) throws InterruptedException {
final int giveUp = 100;
try (Consumer<Long, String> consumer = createConsumer()) {
int noRecordsCount = 0;
while (true) {
ConsumerRecords<Long, String> consumerRecords = consumer.poll(CONSUMER_TIMEOUT);
if (consumerRecords.isEmpty()) {
noRecordsCount++;
if (noRecordsCount > giveUp) {
break;
}
}
consumerRecords.forEach(record -> {
System.out.printf("%d - Consumer Record:(Key: %d, Value: %s, Partition: %d, Offset: %d)\n",
consumerRecords.count(), record.key(), record.value(),
record.partition(), record.offset());
try {
// Simulate slow processing
Thread.sleep(waitMsInBetween);
} catch (InterruptedException e) {
}
});
consumer.commitAsync();
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("DONE");
}
```
Make sure to change the Consumer Group (`ConsumerConfig.GROUP_ID_CONFIG`) to `KafkaConsumerManual` and set the `ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG` to `false` in the `createConsumer()` method.
```java
props.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerManual");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
```
## Try running Producer and Consumer
Run the consumer from your IDE or Terminal (Maven). Then run the producer from above from your IDE or Terminal (Maven). You should see the consumer get the records that the producer sent.
### Three Consumers in same group and one Producer sending 25 messages
Start the consumer 3 times by executing the following command in 3 different terminal windows.
```bash
mvn exec:java@consumer -Dexec.args="0"
```
and then start the producer
```bash
mvn exec:java@producer -Dexec.args="25 0 0"
```
#### Producer Output
```bash
[0] sent record(key=null value=[0] Hello Kafka 0) meta(partition=0, offset=284) time=804
[0] sent record(key=null value=[0] Hello Kafka 1) meta(partition=2, offset=283) time=27
[0] sent record(key=null value=[0] Hello Kafka 2) meta(partition=5, offset=284) time=11
[0] sent record(key=null value=[0] Hello Kafka 3) meta(partition=4, offset=1284) time=65
[0] sent record(key=null value=[0] Hello Kafka 4) meta(partition=7, offset=284) time=26
[0] sent record(key=null value=[0] Hello Kafka 5) meta(partition=1, offset=283) time=8
[0] sent record(key=null value=[0] Hello Kafka 6) meta(partition=3, offset=283) time=18
[0] sent record(key=null value=[0] Hello Kafka 7) meta(partition=6, offset=283) time=16
[0] sent record(key=null value=[0] Hello Kafka 8) meta(partition=0, offset=285) time=19
[0] sent record(key=null value=[0] Hello Kafka 9) meta(partition=2, offset=284) time=17
[0] sent record(key=null value=[0] Hello Kafka 10) meta(partition=5, offset=285) time=21
[0] sent record(key=null value=[0] Hello Kafka 11) meta(partition=4, offset=1285) time=11
[0] sent record(key=null value=[0] Hello Kafka 12) meta(partition=7, offset=285) time=7
[0] sent record(key=null value=[0] Hello Kafka 13) meta(partition=1, offset=284) time=15
[0] sent record(key=null value=[0] Hello Kafka 14) meta(partition=3, offset=284) time=21
[0] sent record(key=null value=[0] Hello Kafka 15) meta(partition=6, offset=284) time=18
[0] sent record(key=null value=[0] Hello Kafka 16) meta(partition=0, offset=286) time=12
[0] sent record(key=null value=[0] Hello Kafka 17) meta(partition=2, offset=285) time=18
[0] sent record(key=null value=[0] Hello Kafka 18) meta(partition=5, offset=286) time=9
[0] sent record(key=null value=[0] Hello Kafka 19) meta(partition=4, offset=1286) time=4
[0] sent record(key=null value=[0] Hello Kafka 20) meta(partition=7, offset=286) time=7
[0] sent record(key=null value=[0] Hello Kafka 21) meta(partition=1, offset=285) time=17
[0] sent record(key=null value=[0] Hello Kafka 22) meta(partition=3, offset=285) time=14
[0] sent record(key=null value=[0] Hello Kafka 23) meta(partition=6, offset=285) time=8
[0] sent record(key=null value=[0] Hello Kafka 24) meta(partition=0, offset=287) time=16
```
#### Consumer 1 Output (same consumer group)
```bash
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 0, Partition: 0, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 1, Partition: 2, Offset: 283)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 5, Partition: 1, Offset: 283)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 8, Partition: 0, Offset: 285)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 9, Partition: 2, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 13, Partition: 1, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 16, Partition: 0, Offset: 286)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 17, Partition: 2, Offset: 285)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 21, Partition: 1, Offset: 285)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 24, Partition: 0, Offset: 287)
```
#### Consumer 2 Output (same consumer group)
```bash
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 2, Partition: 5, Offset: 284)
2 - Consumer Record:(Key: null, Value: [0] Hello Kafka 6, Partition: 3, Offset: 283)
2 - Consumer Record:(Key: null, Value: [0] Hello Kafka 3, Partition: 4, Offset: 1284)
2 - Consumer Record:(Key: null, Value: [0] Hello Kafka 10, Partition: 5, Offset: 285)
2 - Consumer Record:(Key: null, Value: [0] Hello Kafka 11, Partition: 4, Offset: 1285)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 14, Partition: 3, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 18, Partition: 5, Offset: 286)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 19, Partition: 4, Offset: 1286)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 22, Partition: 3, Offset: 285)
```
#### Consumer 3 Output (same consumer group)
```bash
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 4, Partition: 7, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 7, Partition: 6, Offset: 283)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 12, Partition: 7, Offset: 285)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 15, Partition: 6, Offset: 284)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 20, Partition: 7, Offset: 286)
1 - Consumer Record:(Key: null, Value: [0] Hello Kafka 23, Partition: 6, Offset: 285)
```
**Questions**
- Which consumer owns partition 10?
- How many ConsumerRecords objects did Consumer 0 get?
- What is the next offset from Partition 11 that Consumer 2 should get?
- Why does each consumer get unique messages?
### Three Consumers in same group and one Producer sending 10 messages using key
Start the consumer 3 times by executing the following command in 3 different terminal windows.
```bash
mvn exec:java@consumer -Dexec.args="0"
```
and then start the producer (using 10 for the ID)
```bash
mvn exec:java@producer -Dexec.args="1000 100 10"
```
#### Producer Output
```bash
[10] sent record(key=10 value=[10] Hello Kafka 0) meta(partition=3, offset=289) time=326
[10] sent record(key=10 value=[10] Hello Kafka 1) meta(partition=3, offset=290) time=7
[10] sent record(key=10 value=[10] Hello Kafka 2) meta(partition=3, offset=291) time=3
[10] sent record(key=10 value=[10] Hello Kafka 3) meta(partition=3, offset=292) time=3
[10] sent record(key=10 value=[10] Hello Kafka 4) meta(partition=3, offset=293) time=3
[10] sent record(key=10 value=[10] Hello Kafka 5) meta(partition=3, offset=294) time=2
[10] sent record(key=10 value=[10] Hello Kafka 6) meta(partition=3, offset=295) time=2
[10] sent record(key=10 value=[10] Hello Kafka 7) meta(partition=3, offset=296) time=2
[10] sent record(key=10 value=[10] Hello Kafka 8) meta(partition=3, offset=297) time=2
[10] sent record(key=10 value=[10] Hello Kafka 9) meta(partition=3, offset=298) time=3
```
#### Consumer 1 Output (same consumer group)
nothing consumed
#### Consumer 2 Output (same consumer group)
```bash
1 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 0, Partition: 3, Offset: 299)
3 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 1, Partition: 3, Offset: 300)
3 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 2, Partition: 3, Offset: 301)
3 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 3, Partition: 3, Offset: 302)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 4, Partition: 3, Offset: 303)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 5, Partition: 3, Offset: 304)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 6, Partition: 3, Offset: 305)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 7, Partition: 3, Offset: 306)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 8, Partition: 3, Offset: 307)
6 - Consumer Record:(Key: 10, Value: [10] Hello Kafka 9, Partition: 3, Offset: 308)
```
#### Consumer 3 Output (same consumer group)
nothing consumed
**Questions**
- Why is consumer 2 the only one getting data?
## Producing Kafka Headers
To produce a Kafka message with Kafka Headers, you have to first create a `List<Header>` instance and then headers of type `RecordHeader` as shown below (showing only the enhanced `runProducer` method):
```java
private static void runProducer(int sendMessageCount, int waitMsInBetween, long id) throws Exception {
Long key = (id > 0) ? id : null;
try (Producer<Long, String> producer = createProducer()) {
for (int index = 0; index < sendMessageCount; index++) {
long time = System.currentTimeMillis();
Integer partition = null;
Long timestamp = null;
// creating the Kafka Headers
List<Header> headers = new ArrayList<>();
headers.add(new RecordHeader("messageId", UUID.randomUUID().toString().getBytes(StandardCharsets.UTF_8)));
headers.add(new RecordHeader("source", "java-kafka".getBytes(StandardCharsets.UTF_8)));
ProducerRecord<Long, String> record = new ProducerRecord<>(TOPIC, partition, timestamp, key, "[" + id + "] Hello Kafka " + index + " => " + LocalDateTime.now(), headers);
RecordMetadata metadata = producer.send(record).get();
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) "
+ "meta(partition=%d, offset=%d) time=%d\n",
record.key(), record.value(), metadata.partition(),
metadata.offset(), elapsedTime);
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
```
The `RecordHeader` constructor accepts a key of type `String` and a value of type `byte[]`.
## Changing the Value Serialization/Deserialization to use JSON
So far we have used the `StringSerializer`/`StringDeserializer` to serialize and deserialize a `java.lang.String` for the value of the message. This of course is not really useful in practice, as we want to send complex objects over Kafka. One way to do that is serializing a complex object as JSON on the producer side, send it and doing the opposite on the consumer side. This can be done with or without a schema. In this workshop we show the schema-less version with, in [Workshop Working with Avro and Java](../04a-working-with-avro-and-java) we will see how to work with Schema-based messages together with a schema registry.
### Add Maven dependency
For the JSON serialization we will be using the Jackson library. So let's add that as a dependency to the `pom.xml`
```xml
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.4</version>
</dependency>
```
### Create a Notification class
Create a new Java class which will hold our notification in 3 different fields. We annotate these 3 fields with `@JsonProperty` so that they will be serialized later.
```java
package com.trivadis.kafkaws;
import com.fasterxml.jackson.annotation.JsonProperty;
public class Notification {
@JsonProperty
private long id;
@JsonProperty
private String message;
@JsonProperty
private String createdAt;
public Notification() {};
public Notification(long id, String message, String createdAt) {
this.id = id;
this.message = message;
this.createdAt = createdAt;
}
public long getId() {
return id;
}
public String getMessage() {
return message;
}
public String getCreatedAt() {
return createdAt;
}
@Override
public String toString() {
return "Notification{" +
"id=" + id +
", message='" + message + '\'' +
", createdAt='" + createdAt + '\'' +
'}';
}
}
```
### Create the custom JsonSerializer and JsonDeserializer implemenations
Next we have to create the custom serializer/deseralizer handling the JSON serialization and deserialization.
First create a new package `serde`.
Create a new class for the serializer in the `serde` package
```java
package com.trivadis.kafkaws.serde;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.trivadis.kafkaws.Notification;
import org.apache.kafka.common.errors.SerializationException;
import org.apache.kafka.common.serialization.Serializer;
import java.util.Map;
public class JsonSerializer<T> implements Serializer<T> {
private final ObjectMapper objectMapper = new ObjectMapper();
public JsonSerializer() {
//Nothing to do
}
@Override
public void configure(Map<String, ?> config, boolean isKey) {
//Nothing to Configure
}
@Override
public byte[] serialize(String topic, T data) {
if (data == null) {
return null;
}
try {
return objectMapper.writeValueAsBytes(data);
} catch (JsonProcessingException e) {
throw new SerializationException("Error serializing JSON message", e);
}
}
@Override
public void close() {
}
}
```
And another new class for the deserializer also in the `serde` package
```java
package com.trivadis.kafkaws.serde;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.common.serialization.Deserializer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
import java.util.Map;
public class JsonDeserializer<T> implements Deserializer<T> {
private Logger logger = LogManager.getLogger(this.getClass());
private Class <T> type;
public JsonDeserializer(Class type) {
this.type = type;
}
@Override
public void configure(Map map, boolean b) {
}
@Override
public T deserialize(String s, byte[] bytes) {
ObjectMapper mapper = new ObjectMapper();
T obj = null;
try {
obj = mapper.readValue(bytes, type);
} catch (Exception e) {
logger.error(e.getMessage());
}
return obj;
}
@Override
public void close() {
}
}
```
### Create the new Producer using the JsonSerializer
Create a new class `KafkaProducerJson` next to the exiting producer implementation
```java
package com.trivadis.kafkaws.producer;
import com.trivadis.kafkaws.Notification;
import com.trivadis.kafkaws.serde.JsonSerializer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.LongSerializer;
import java.time.LocalDateTime;
import java.util.Properties;
public class KafkaProducerJson {
private final static String TOPIC = "test-java-json-topic";
private final static String BOOTSTRAP_SERVERS
= "dataplatform:9092,dataplatform:9093";
private static Producer<Long, Notification> createProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaExampleProducer");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class.getName());
return new KafkaProducer<>(props);
}
private static void runProducer(int sendMessageCount, int waitMsInBetween, long id) throws Exception {
Long key = (id > 0) ? id : null;
try (Producer<Long, Notification> producer = createProducer()) {
for (int index = 0; index < sendMessageCount; index++) {
long time = System.currentTimeMillis();
Notification notification = new Notification(id, "[" + id + "] Hello Kafka " + index, LocalDateTime.now().toString());
ProducerRecord<Long, Notification> record
= new ProducerRecord<>(TOPIC, key, notification);
RecordMetadata metadata = producer.send(record).get();
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) "
+ "meta(partition=%d, offset=%d) time=%d\n",
record.key(), record.value(), metadata.partition(),
metadata.offset(), elapsedTime);
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
public static void main(String... args) throws Exception {
if (args.length == 0) {
runProducer(100, 10, 0);
} else {
runProducer(Integer.parseInt(args[0]), Integer.parseInt(args[1]), Long.parseLong(args[2]));
}
}
}
```
Changes to the previous producer implementation are in the configuration were we use the `JsonSerializer`
```java
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class.getName());
```
and with all the generics, where we use `<Long, Notifcation>` instead of `<Long, String>`. Additionally of course for sending the value of the Kafka record, we create a `Notification` object.
We also use another topic `test-java-json-topic`, so we clearly separate the different messages.
### Creating the new Kafka Topic
We show a shortcut version here, instead of first "connecting" to the container and then issuing the `kafka-topics` command, we do it in one
```bash
docker exec -ti kafka-1 kafka-topics --create \
--replication-factor 3 \
--partitions 8 \
--topic test-java-topic \
--zookeeper zookeeper-1:2181
```
### Testing the JsonProducer
To test the producer, let's also add a new section to the `executions` of the `pom.xml`
```xml
<execution>
<id>producer-json</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.producer.KafkaProducerJson</mainClass>
</configuration>
</execution>
```
Now run it using the `mvn exec:java` command. The arguments again tell to create `100` messages, with a delay of `100ms` inbetween and using `null` for the key:
```bash
mvn clean package -Dmaven.test.skip=true
mvn exec:java@producer-json -Dexec.args="100 100 0"
```
Use `kafkacat` to consume the messages from the topic `test-java-json-topic`.
```bash
kafkacat -b dataplatform -t test-java-json-topic -q
```
you can see the messages are all formated as JSON documents
```bash
{"id":0,"message":"[0] Hello Kafka 750","createdAt":"2021-08-06T18:38:10.679026"}
{"id":0,"message":"[0] Hello Kafka 752","createdAt":"2021-08-06T18:38:10.892763"}
{"id":0,"message":"[0] Hello Kafka 755","createdAt":"2021-08-06T18:38:11.207189"}
{"id":0,"message":"[0] Hello Kafka 758","createdAt":"2021-08-06T18:38:11.527921"}
{"id":0,"message":"[0] Hello Kafka 766","createdAt":"2021-08-06T18:38:12.379010"}
{"id":0,"message":"[0] Hello Kafka 776","createdAt":"2021-08-06T18:38:13.442783"}
{"id":0,"message":"[0] Hello Kafka 781","createdAt":"2021-08-06T18:38:13.973201"}
```
This completes the producer, let's now implement the corresponding consumer.
### Create the Consumer
Create a new class `KafkaConsumerJson` next to the exiting consumer implementation. We use the implementation of the non-auto-commit version and adapt it
```java
package com.trivadis.kafkaws.consumer;
import com.trivadis.kafkaws.Notification;
import com.trivadis.kafkaws.serde.JsonDeserializer;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.LongDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerJson {
private final static String TOPIC = "test-java-json-topic";
private final static String BOOTSTRAP_SERVERS
= "dataplatform:9092,dataplatform:9093,dataplatform:9094";
private final static Duration CONSUMER_TIMEOUT = Duration.ofSeconds(1);
private static Consumer<Long, Notification> createConsumer() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerJson");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 10000);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class.getName());
// Create the consumer using props.
Consumer<Long, Notification> consumer = new KafkaConsumer<>(props, new LongDeserializer(), new JsonDeserializer<Notification>(Notification.class));
// Subscribe to the topic.
consumer.subscribe(Collections.singletonList(TOPIC));
return consumer;
}
private static void runConsumer(int waitMsInBetween) throws InterruptedException {
final int giveUp = 100;
try (Consumer<Long, Notification> consumer = createConsumer()) {
int noRecordsCount = 0;
while (true) {
ConsumerRecords<Long, Notification> consumerRecords = consumer.poll(CONSUMER_TIMEOUT);
if (consumerRecords.isEmpty()) {
noRecordsCount++;
if (noRecordsCount > giveUp) {
break;
} else {
continue;
}
}
consumerRecords.forEach(record -> {
System.out.printf("%d - Consumer Record:(Key: %d, Value: %s, Partition: %d, Offset: %d)\n",
consumerRecords.count(), record.key(), record.value(),
record.partition(), record.offset());
try {
// Simulate slow processing
Thread.sleep(waitMsInBetween);
} catch (InterruptedException e) {
}
});
consumer.commitAsync();
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("DONE");
}
public static void main(String... args) throws Exception {
if (args.length == 0) {
runConsumer(10);
} else {
runConsumer(Integer.parseInt(args[0]));
}
}
}
```
Changes to the previous consumer implementation are again in the configuration were we use the `JsonDeserializer`
```java
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class.getName());
```
Additionally when we create the `KafkaConsumer`, we have to initialze an instance of `JsonDeserializer` and pass it as an argument to the constructor
```java
Consumer<Long, Notification> consumer = new KafkaConsumer<>(props, new LongDeserializer(), new JsonDeserializer<Notification>(Notification.class));
```
And again we change all the generics, where we use `<Long, Notifcation>` instead of `<Long, String>`.
### Testing the JsonProducer
To test the consumer, let's also add a new section to the `executions` of the `pom.xml`
```xml
<execution>
<id>consumer-json</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.consumer.KafkaConsumerJson</mainClass>
</configuration>
</execution>
```
Now run it using the `mvn exec:java` command
```bash
mvn clean package -Dmaven.test.skip=true
mvn exec:java@consumer-json -Dexec.args="0"
```
and you should see the `toString()` output of the `Notification` instances, similar to the one shown below
```bash
190 - Consumer Record:(Key: null, Value: Notification{id=0, message='[0] Hello Kafka 742', createdAt='2021-08-06T18:38:09.825359'}, Partition: 1, Offset: 239)
190 - Consumer Record:(Key: null, Value: Notification{id=0, message='[0] Hello Kafka 745', createdAt='2021-08-06T18:38:10.145740'}, Partition: 1, Offset: 240)
190 - Consumer Record:(Key: null, Value: Notification{id=0, message='[0] Hello Kafka 753', createdAt='2021-08-06T18:38:10.999308'}, Partition: 1, Offset: 241)
190 - Consumer Record:(Key: null, Value: Notification{id=0, message='[0] Hello Kafka 761', createdAt='2021-08-06T18:38:11.847942'}, Partition: 1, Offset: 242)
190 - Consumer Record:(Key: null, Value: Notification{id=0, message='[0] Hello Kafka 768', createdAt='2021-08-06T18:38:12.591090'}, Partition: 1, Offset: 243)
190 - Consumer Record:(Key: null, Value: Notification{id=0, message='[0] Hello Kafka 774', createdAt='2021-08-06T18:38:13.233265'}, Partition: 1, Offset: 244)
```
<file_sep># Conduktor Platform
A powerful and flexible UI that lets you search and explore topic data on any Kafka flavor.
**[Website](https://www.conduktor.io/get-started)** | **[Documentation](https://github.com/conduktor/conduktor-platform/tree/main/doc)** | **[GitHub](https://github.com/conduktor/conduktor-platform)**
```
platys init --enable-services KAFKA,CONDUKTOR_PLATFORM
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28285>.
Login with the credentials configured in `config.yml` (defaults to `admin`/`abc123!`).
<file_sep># Modern Data Platform Tutorial - v1.16.0
Inhere we are documenting tutorials on how to use the modern data platform:
* [IoT Vehicle Tracking](./iot-vehicle-tracking/README) - `1.16.0` - this is an end-to-end use case using simulated IoT Vehicle streaming data which is analyzed using Stream Analytics
* `Kafka`, `MQTT`, `StreamSets`, `Kafka Connect`, `ksqlDB`, `Kafka Streams`, `Debezium`, `PostgreSQL` and `MySQL`
<file_sep>#!/bin/bash
echo "removing JDBC Source Connector"
curl -X "DELETE" "http://$DOCKER_HOST_IP:8083/connectors/jdbc-driver-source"
echo "creating JDBC Source Connector"
## Request
curl -X "POST" "$DOCKER_HOST_IP:8083/connectors" \
-H "Content-Type: application/json" \
-d $'{
"name": "jdbc-driver-source",
"config": {
"connector.class": "JdbcSourceConnector",
"tasks.max": "1",
"connection.url":"jdbc:postgresql://db/sample?user=sample&password=<PASSWORD>",
"mode": "timestamp",
"timestamp.column.name":"last_update",
"table.whitelist":"driver",
"validate.non.null":"false",
"topic.prefix":"truck_",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"name": "jdbc-driver-source",
"transforms":"createKey,extractInt",
"transforms.createKey.type":"org.apache.kafka.connect.transforms.ValueToKey",
"transforms.createKey.fields":"id",
"transforms.extractInt.type":"org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractInt.field":"id"
}
}'
<file_sep>#!/bin/bash
#
# Download Files from Internet (currently only Github releases are supported).
#
# - GitHub Release: file-download.sh github "<owner>:<project>:<version>:<artefact-name>"
#
# Author: <NAME> <https://github.com/gschmutz>
#
set -e
# If there's not maven repository url set externally,
# default to the ones below
GITHUB=${GITHUB:-"https://github.com"}
github_download_dep() {
local REPO="$1"
local GIT_COORDS="$2"
local GITHUB_DOWNLOAD_DESTINATION="$3"
for i in $(echo $GIT_COORDS | sed "s/,/ /g")
do
local GIT_COORD=$i
local OWNER=$(echo $GIT_COORDS | cut -d: -f1)
local PROJECT=$(echo $GIT_COORDS | cut -d: -f2)
local VERSION=$(echo $GIT_COORDS | cut -d: -f3)
local ARTEFACT_NAME=$(echo $GIT_COORDS | cut -d: -f4)
local FILE="$ARTEFACT_NAME"
DOWNLOAD_FILE_TMP_PATH="/tmp/git_dep/${OWNER}"
DOWNLOAD_FILE="$DOWNLOAD_FILE_TMP_PATH/$FILE"
test -d $DOWNLOAD_FILE_TMP_PATH || mkdir -p $DOWNLOAD_FILE_TMP_PATH
DOWNLOAD_URL="$REPO/$OWNER/$PROJECT/releases/download/$VERSION/$FILE"
echo "Downloading $DOWNLOAD_URL ...."
curl -sfSL -o "$DOWNLOAD_FILE" "$DOWNLOAD_URL"
mv "$DOWNLOAD_FILE" $GITHUB_DOWNLOAD_DESTINATION
done
}
github_dep() {
github_download_dep $GITHUB $1 $2 $3
}
case $1 in
"github" ) shift
github_dep ${@}
;;
esac
<file_sep># kafka-workshop
| Platform Stack | Platform Stack Version | Public IP | Docker-Host IP
|-------------- |------|------------|------------
| [ trivadis/platys-modern-data-platform ](https://hub.docker.com/repository/docker/trivadis/platys-modern-data-platform) | 1.16.0-preview | 172.26.121.207 | 172.26.121.207
This environment has been generated using the [Platys](http://github.com/trivadispf/platys) toolkit.
All available services which are part of the platform are [listed here](services).
To learn more about `platys`-generated stacks, you can either follow the various [tutorials](./tutorials/README) with detailed instructions and/or one of the more specific [cookbook recipes](./cookbooks/README).
Documentation of the platform stack can be [found here](README).
[Read here](./documentation/configuration) about the various configuration options.
<file_sep># Apache Sqoop
Apache Sqoop(TM) is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
**[Website](https://sqoop.apache.org/)** | **[Documentation](https://sqoop.apache.org/docs/1.4.7/index.html)** | **[GitHub](https://git-wip-us.apache.org/repos/asf?p=sqoop.gits)**
## How to enable?
```
platys init --enable-services SQOOP
platys gen
```
## How to use it?
<file_sep>using Confluent.Kafka;
using Streamiz.Kafka.Net;
using Streamiz.Kafka.Net.SerDes;
using Streamiz.Kafka.Net.Stream;
using Streamiz.Kafka.Net.Table;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Runtime.Intrinsics;
using System.Threading;
using Microsoft.Extensions.Logging;
using Streamiz.Kafka.Net.Crosscutting;
using System.Threading.Tasks;
namespace processor
{
class TruckPosition
{
long timestamp;
int truckId;
int driverId;
int routeId;
String eventType;
Double latitude;
Double longitude;
String correlationId;
public static TruckPosition create(String csvRecord) {
TruckPosition truckPosition = new TruckPosition();
String[] values = csvRecord.Split(',');
truckPosition.timestamp = Convert.ToInt64(values[0]);
truckPosition.truckId = Convert.ToInt32(values[1]);
truckPosition.driverId = Convert.ToInt32(values[2]);
truckPosition.routeId = Convert.ToInt32(values[3]);
truckPosition.eventType = values[4];
truckPosition.latitude = Convert.ToDouble(values[5]);
truckPosition.longitude = Convert.ToDouble(values[6]);
truckPosition.correlationId = values[7];
return truckPosition;
}
public static Boolean filterNonNORMAL(TruckPosition value) {
Boolean result = false;
result = !value.eventType.Equals("Normal");
return result;
}
public String toCSV() {
return timestamp + "," + truckId + "," + driverId + "," + routeId + "," + eventType + "," + latitude + "," + longitude + "," + correlationId;
}
}
class Program
{
static async Task Main(string[] args)
{
var config = new StreamConfig<StringSerDes, StringSerDes>();
config.ApplicationId = "test-app";
config.BootstrapServers = "dataplatform:9092";
StreamBuilder builder = new StreamBuilder();
builder.Stream<string, string>("truck_position")
.MapValues(v => TruckPosition.create(v.Remove(0,6)))
.Filter((k,v) => TruckPosition.filterNonNORMAL(v))
.MapValues(v => v.toCSV())
.To("dangerous_driving_streamiz");
Topology t = builder.Build();
KafkaStream stream = new KafkaStream(t, config);
Console.CancelKeyPress += (o, e) =>
{
stream.Dispose();
};
await stream.StartAsync();
}
}
}
<file_sep># Spring Boot Admin
Spring Boot Admin is a monitoring tool that aims to visualize information provided by Spring Boot Actuators in a nice and accessible way.
This is the deployment of the Spring Boot Admin server that provides a user interface to display and interact with Spring Boot Actuators (using spring boot admin client to allow to access the actuator endpoints).
**[Website](https://codecentric.github.io/spring-boot-admin/3.0.0-M8/)** | **[Documentation](https://codecentric.github.io/spring-boot-admin/3.0.0-M8/getting-started.html)** | **[GitHub](https://github.com/codecentric/spring-boot-admin)**
```bash
platys init --enable-services SPRING_ADMIN_SERVER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28293>.<file_sep>package com.trivadis.kafkaws.springbootkafkaproducer;
import org.junit.jupiter.api.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.kafka.test.context.EmbeddedKafka;
import org.springframework.test.annotation.DirtiesContext;
import org.springframework.test.context.junit4.SpringRunner;
@SpringBootTest
@RunWith(SpringRunner.class)
@DirtiesContext(classMode = DirtiesContext.ClassMode.AFTER_CLASS)
@EmbeddedKafka(partitions = 1, brokerProperties = { "listeners=PLAINTEXT://localhost:9092", "port=9092" })
public class EmbeddedKafkaIntegrationTest {
@Autowired
KafkaEventProducer kafkaEventProducer;
@Test
public void testSend() throws Exception {
String data = "Sending with default template";
kafkaEventProducer.produce(10, 101L, "Hello");
/*
boolean messageConsumed = consumer.getLatch().await(10, TimeUnit.SECONDS);
assertTrue(messageConsumed);
assertThat(consumer.getPayload(), containsString(data));
*/
}
}
<file_sep>package com.trivadis.kafkaws.producer;
import com.trivadis.kafkaws.avro.v1.Notification;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializerConfig;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerAvro {
private final static String TOPIC = "test-java-avro-topic";
private final static String BOOTSTRAP_SERVERS =
"dataplatform:9092, dataplatform:9093, dataplatform:9094";
private final static String SCHEMA_REGISTRY_URL = "http://dataplatform:8081";
private static Producer<Long, Notification> createProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaExampleProducer");
//props.put(KafkaAvroSerializerConfig.AUTO_REGISTER_SCHEMAS, "false");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class.getName());
props.put(KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, SCHEMA_REGISTRY_URL); // use constant for "schema.registry.url"
return new KafkaProducer<>(props);
}
static void runProducer(final int sendMessageCount, final int waitMsInBetween, final long id) throws Exception {
final Producer<Long, Notification> producer = createProducer();
long time = System.currentTimeMillis();
Long key = (id > 0) ? id : null;
try {
for (long index = 0; index < sendMessageCount; index++) {
Notification notification = new Notification(id, "Hello Kafka " + index);
Notification n1 = Notification.newBuilder()
.setId(id)
.setMessage("Hello Kafka " + index)
.build();
final ProducerRecord<Long, Notification> record =
new ProducerRecord<>(TOPIC, key, notification);
RecordMetadata metadata = producer.send(record).get();
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) " +
"meta(partition=%d, offset=%d) time=%d\n",
record.key(), record.value(), metadata.partition(),
metadata.offset(), elapsedTime);
time = System.currentTimeMillis();
Thread.sleep(waitMsInBetween);
}
} finally {
producer.flush();
producer.close();
}
}
public static void main(String... args) throws Exception {
if (args.length == 0) {
runProducer(100,10,0);
} else {
runProducer(Integer.parseInt(args[0]),Integer.parseInt(args[1]),Long.parseLong(args[2]));
}
}
}<file_sep># SQL Server
Apache Kudu is an open source distributed data storage engine that makes fast analytics on fast and changing data easy.
**[Website](https://www.microsoft.com/en-US/sql-server/sql-server-2019?rtc=1)** | **[Documentation](https://docs.microsoft.com/en-us/sql/sql-server/?view=sql-server-ver15)**
## How to enable?
```
platys init --enable-services SQLSERVER
platys gen
```
## How to use it?
<file_sep>connector.name=mysql
connection-url=jdbc:mysql://mysql:3306
connection-user=${ENV:MYSQL_USER}
connection-password=${ENV:MYSQL_PASSWORD}
<file_sep># List of Services
| Service Name | Web UI | Rest API |
|-------------- |------|------------
| akhq|<http://192.168.142.128:28107>
| cmak|<http://192.168.142.128:28104>
| jupyter|<http://192.168.142.128:28888>
| kafka-1|
| kafka-2|
| kafka-3|
| kafka-connect-1|| <http://192.168.142.128:8083>
| kafka-connect-2|| <http://192.168.142.128:8084>
| kafka-connect-ui|<http://192.168.142.128:28103>
| kafka-rest-1|| <http://192.168.142.128:18086>
| kafka-topics-ui|<http://192.168.142.128:28141>
| ksqldb-cli|
| ksqldb-server-1|| <http://192.168.142.128:8088>
| ksqldb-server-2|| <http://192.168.142.128:8089>
| markdown-renderer|
| markdown-viewer|<http://192.168.142.128:80>
| minio|<http://192.168.142.128:9000>
| mosquitto-1|
| mqtt-ui|<http://192.168.142.128:28136>
| schema-registry-1|| <http://192.168.142.128:8081>
| schema-registry-ui|<http://192.168.142.128:28102>
| streamsets-1|<http://192.168.142.128:18630>| <http://192.168.142.128:18630/collector/restapi>
| wetty|<http://192.168.142.128:3001>
| zeppelin|<http://192.168.142.128:28080>
| zookeeper-1|
| zoonavigator|<http://192.168.142.128:28100>
| zoonavigator-api|| <http://192.168.142.128:28101><file_sep># Redis Insight
RedisInsight is a visual tool that provides capabilities to design, develop and optimize your Redis application. Query, analyse and interact with your Redis data.
**[Website](https://redis.com/redis-enterprise/redis-insight/)** | **[Documentation](https://redis.com/redis-enterprise/redis-insight/)** | **[GitHub](https://github.com/RedisInsight/RedisInsight)**
## How to enable?
```
platys init --enable-services REDIS_INSIGHT
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28174><file_sep># Modern Data Platform Cookbooks - v1.16.0
Inhere we are documenting cookbooks on how to use the platform:
* **Airflow**
* [Schedule and Run Simple Python Application with Airflow](./recipes/airflow-schedule-python-app/README) - `1.16.0`
* **Trino (Formerly Presto SQL)**
* [Trino, Spark and Delta Lake (Spark 2.4.7 & Delta Lake 0.6.1)](./recipes/delta-lake-and-trino-spark2.4/README) - `1.11.0`
* [Trino, Spark and Delta Lake (Spark 3.0.1 & Delta Lake 0.7.0)](./recipes/delta-lake-and-trino-spark3.0/README) - `1.11.0`
* [Querying S3 data (MinIO) using MinIO](./recipes/querying-minio-with-trino/README) - `1.11.0`
* [Querying Azure Data Lake Storage Gen2 data (ADLS) from Trino](./recipes/querying-adls-with-trino/README) - `1.15.0`
* [Querying data in Postgresql from Trino](./recipes/querying-postgresql-with-trino/README) - `1.11.0`
* [Querying data in Kafka from Trino (formerly PrestoSQL)](./recipes/querying-kafka-with-trino/README) - `1.14.0`
* [Querying HDFS data using Trino](./recipes/querying-hdfs-with-presto/README) - `1.11.0`
* [Trino Security](./recipes/trino-security/README) - `1.16.0`
* **MQTT**
* [Using Confluent MQTT Proxy](./recipes/using-mqtt-proxy/README)
* [Using HiveMQ with Kafka Extensions](./recipes/using-hivemq-with-kafka-extension/README) - `1.12.0`
* **Spark**
* [Run Java Spark Application using `spark-submit`](./recipes/run-spark-simple-app-java-submit/README)
* [Run Java Spark Application using Docker](./recipes/run-spark-simple-app-java-docker/README)
* [Run Scala Spark Application using `spark-submit`](./recipes/run-spark-simple-app-scala-submit/README)
* [Run Scala Spark Application using Docker](./recipes/run-spark-simple-app-scala-docker/README)
* [Run Python Spark Application using `spark-submit`](./recipes/run-spark-simple-app-python-submit/README)
* [Run Python Spark Application using Docker](./recipes/run-spark-simple-app-python-docker/README)
* [Spark and Hive Metastore](./recipes/spark-and-hive-metastore/README) - `1.15.0`
* [Spark with internal S3 (using on minIO)](./recipes/spark-with-internal-s3/README)
* [Spark with external S3](./recipes/spark-with-external-s3/README)
* [Spark with PostgreSQL](./recipes/spark-with-postgresql/README) - `1.15.0`
* **Delta Lake Table Format**
* [Spark with Delta Lake](./recipes/delta-lake-with-spark/README) - `1.16.0`
* **Iceberg Table Format**
* [Spark with Iceberg](./recipes/iceberg-with-spark/README) - `1.16.0`
* **Hadoop HDFS**
* [Querying HDFS data using Presto](./recipes/querying-hdfs-with-presto/README)
* [Using HDFS data with Spark Data Frame](./recipes/using-hdfs-with-spark/README)
* **Livy**
* [Submit Spark Application over Livy](./recipes/run-spark-simple-app-scala-livy/README)
* **Apache NiFi**
* [NiFi ExecuteScript Processor with Python](./recipes/nifi-execute-processor-with-python/README) - `1.16.0`
* [NiFi Registry with Git Flow Persistence Provider](./recipes/nifi-registry-with-git/README) - `1.16.0`
* **StreamSets Data Collector**
* [Consume a binary file and send it as Kafka message](./recipes/streamsets-binary-file-to-kafka/README)
* [Using Dev Simulator Origin to simulate streaming data](./recipes/using-dev-simulator-origin/README) - `1.12.0`
* [Loading StreamSets Pipeline(s) upon start of container](./recipes/streamsets-loading-pipelines/README) - `1.14.0`
* **StreamSets DataOps Platform**
* [Creating a self-managed StreamSets DataOps Environment using Platys](./recipes/streamsets-dataops-creating-environment/README) - `1.14.0`
* **StreamSets Transformer**
* [Using StreamSets Transformer to transform CSV to Parquet & Delta Lake](./recipes/streamsets-transformer-transform-csv-to-deltalake/README) - `1.16.0`
* **Kafka**
* [Simulated Multi-DC Setup on one machine](./recipes/simulated-multi-dc-setup/README) - `1.14.0`
* [Automate management of Kafka topics on the platform](./recipes/jikkou-automate-kafka-topics-management/README) - `1.14.0`
* [Azure Event Hub as external Kafka](./recipes/azure-event-hub-as-external-kafka/README) - `1.16.0`
* **Confluent Enterprise Platform**
* [Using Confluent Enterprise Tiered Storage](./recipes/confluent-tiered-storage/README) - `1.13.0`
* **ksqlDB**
* [Connecting through ksqlDB CLI](./recipes/connecting-through-ksqldb-cli/README)
* [Custom UDF and ksqlDB](./recipes/custom-udf-and-ksqldb/README)
* [Handle Serialization Errors in ksqlDB](./recipes/ksqldb-handle-deserializaion-error/README)
* **Kafka Connect**
* [Using additional Kafka Connect Connector](./recipes/using-additional-kafka-connect-connector/README)
* [Using a Kafka Connect Connector not in Confluent Hub](./recipes/using-kafka-connector-not-in-confluent-hub/README) - `1.14.0`
* **Apicurio Registry**
* [Apicurio Registry with SQL Storage (PostgreSQL)](./recipes/apicurio-with-database-storage/README) - `1.14.0`
* **Jikkou**
* [Automate management of Kafka topics on the platform](./recipes/jikkou-automate-kafka-topics-management/README)
* **Oracle RDBMS**
* [Using private (Trivadis) Oracle EE image](./recipes/using-private-oracle-ee-image/README) - `1.13.0`
* [Using public Oracle XE image](./recipes/using-public-oracle-xe-image/README) - `1.16.0`
* **Neo4J**
* [Working with Neo4J](./recipes/working-with-neo4j/README) - `1.15.0`
* [Neo4J and yFiles graphs for Jupyter](./recipes/neo4j-jupyter-yfiles/README) - `1.16.0`
* **Tipboard**
* [ Working with Tipboard and Kafka](./recipes/tipboard-and-kafka/README) - `1.14.0`
* **Architecture Decision Records (ADR)**
* [Creating and visualizing ADRs with log4brains](./recipes/creating-adr-with-log4brains/README) - `1.12.0`
* **Jupyter**
* [Using Jupyter notebook with Spark and Avro](./recipes/jupyter-spark/README) - `1.16.0`
* [Using JupyterHub](./recipes/using-jupyter-hub/README) - `1.16.0`
* **MLflow**
* [Using MLflow from Jupyter](./recipes/using-mflow-from-jupyter/README) - `1.16.0`
<file_sep>package main
import (
"fmt"
"strconv"
"github.com/confluentinc/confluent-kafka-go/kafka"
"os"
"time"
)
func main() {
if len(os.Args) < 3 {
fmt.Fprintf(os.Stderr, "Usage: %s <send-message-count> <wait-ms-in-between> <id>\n",
os.Args[0])
os.Exit(1)
}
sendMessageCount, err := strconv.Atoi(os.Args[1])
waitMsInBetween, err := strconv.Atoi(os.Args[2])
id, err := strconv.Atoi(os.Args[3])
p, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": "dataplatform:9092",
"acks": "all"})
if err != nil {
fmt.Printf("Failed to create producer: %s\n", err)
os.Exit(1)
}
fmt.Printf("Created Producer %v\n", p)
// Listen to all the events on the default events channel
go func() {
for e := range p.Events() {
switch ev := e.(type) {
case *kafka.Message:
// The message delivery report, indicating success or
// permanent failure after retries have been exhausted.
// Application level retries won't help since the client
// is already configured to do that.
m := ev
if m.TopicPartition.Error != nil {
fmt.Printf("Delivery failed: %v\n", m.TopicPartition.Error)
} else {
fmt.Printf("Delivered message to topic %s [%d] at offset %v\n",
*m.TopicPartition.Topic, m.TopicPartition.Partition, m.TopicPartition.Offset)
}
case kafka.Error:
// Generic client instance-level errors, such as
// broker connection failures, authentication issues, etc.
//
// These errors should generally be considered informational
// as the underlying client will automatically try to
// recover from any errors encountered, the application
// does not need to take action on them.
fmt.Printf("Error: %v\n", ev)
default:
fmt.Printf("Ignored event: %s\n", ev)
}
}
}()
topic := "test-golang-topic"
for i := 1; i <= sendMessageCount; i++ {
value := fmt.Sprintf("[%d] Hello Kafka #%d => %s", i, i, time.Now().Format(time.RFC3339))
if id == 0 {
err = p.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(value),
Headers: []kafka.Header{{Key: "myTestHeader", Value: []byte("header value")}},
}, nil)
} else {
err = p.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Key: []byte(strconv.Itoa(id)),
Value: []byte(value),
Headers: []kafka.Header{{Key: "myTestHeader", Value: []byte("header value")}},
}, nil)
}
if err != nil {
if err.(kafka.Error).Code() == kafka.ErrQueueFull {
// Producer queue is full, wait 1s for messages
// to be delivered then try again.
time.Sleep(time.Second)
continue
}
fmt.Printf("Failed to produce message: %v\n", err)
}
// Slow down processing
time.Sleep(time.Duration(waitMsInBetween) * time.Millisecond)
}
// Flush and close the producer and the events channel
for p.Flush(10000) > 0 {
fmt.Print("Still waiting to flush outstanding messages\n", err)
}
p.Close()
}
<file_sep>connector.name=hive
hive.metastore.uri=thrift://hive-metastore:9083
hive.azure.abfs-storage-account=${ENV:ADLS_STORAGE_ACCOUNT}
hive.azure.abfs-access-key=${ENV:ADLS_ACCESS_KEY}
<file_sep>connector.name=hive-hadoop2
hive.metastore.uri=thrift://hive-metastore:9083
hive.non-managed-table-writes-enabled=true
<file_sep># Camunda Optimize
Get the insights you need to understand and continuously improve your business processes.
**[Website](https://camunda.com/products/camunda-platform/optimize/)** | **[Documentation](https://docs.camunda.org/optimize/latest/)**
## How to enable?
```
platys init --enable-services CAMUNDA_BPM_PLATFORM,CAMUNDA_OPTIMIZE,ELASTICSEARCH
platys gen
```
```
docker login registry.camunda.cloud
docker-compose up -d
```
## How to use it?
Navigate to <http://dataplatform:28264> and login as user `demo` with password `<PASSWORD>`.
<file_sep># MySQL
MySQL Server, the world's most popular open source database, and MySQL Cluster, a real-time, open source transactional database.
**[Website](https://www.mysql.com/)** | **[Documentation](https://dev.mysql.com/doc/)** | **[GitHub](https://github.com/mysql)**
### How to enable
```
platys init --enable-services MYSQL
platys gen
```
### Other links
<file_sep># OpenLDAP
OpenLDAP Software is an open source implementation of the Lightweight Directory Access Protocol.
**[Website](https://www.openldap.org/)** | **[Documentation](https://www.openldap.org/doc/admin26/quickstart.html)** | **[GitHub](https://github.com/openldap/openldap)**
```bash
platys init --enable-services OPENLDAP
platys gen
```
<file_sep># MQTT UI
A websockets based MQTT Client for your browser.
**[Website](https://www.hivemq.com/docs/hivemq/3.4/web-ui/introduction.html)** | **[Documentation](https://www.hivemq.com/docs/hivemq/3.4/web-ui/introduction.html)** | **[GitHub](https://github.com/hivemq/hivemq-mqtt-web-client)**
## How to enable?
```
platys init --enable-services HIVEMQ_MQTT_WEB_CLIENT
platys gen
```
## How to use?
Navigate to <http://dataplatform:28136>
<file_sep># Using AsyncAPI with Kafka
In this workshop we will learn how to produce and consume messages using the [Kafka Java API](https://kafka.apache.org/documentation/#api) using Avro for serializing and deserializing messages.
```yml
asyncapi: '2.1.0'
info:
title: Notification Service
version: 1.0.0
description: This service is in charge of notifying users
servers:
dataplatform-local:
url: dataplatform:{port}
protocol: kafka
variables:
port:
default: '9092'
enum:
- '9092'
- '9093'
protocolVersion: 2.8.0
description: Kafka borker on local virtual machine
channels:
notify:
description: xxxxx
publish:
bindings:
kafka:
groupId: my-group
message:
schemaFormat: 'application/vnd.apache.avro;version=1.9.0'
payload:
# $ref: 'http://dataplatform:8081/subjects/test-java-avro-topic-value/versions/1/schema'
type: record
doc: User information
fields:
- name: id
type: int
- name: message
type: string
```
```
docker run --rm -it \
-v ${PWD}/kafka.yml:/app/asyncapi.yml \
-v ${PWD}/output:/app/output \
asyncapi/generator -o /app/output /app/asyncapi.yml @asyncapi/java-spring-template --force-write
```
<file_sep># Manipulating Consumer Offsets
In this workshop we will learn how to manipulate the consumer offsets to reset a consumer to a certain place.
We will be using the `kafka-consumer-groups` CLI.
## Create some fresh messages
We will be using the Java client from [Workshop 4 - Working with Kafka from Java](../04-producing-consuming-kafka-with-java/README.md) to produce and consume some messages first. To assure that we start from scratch, lets first remove the data from the topic by recreating it.
You can also use the C# or Python implementation instead of the Java one. Just make sure to adapt the topic and the consumer group.
```bash
docker exec -ti kafka-1 kafka-topics --delete --topic test-java-topic --bootstrap-server kafka-1:19092,kafka-2:19093
docker exec kafka-1 kafka-topics --create \
--replication-factor 3 \
--partitions 8 \
--topic test-java-topic \
--bootstrap-server kafka-1:19092,kafka-2:19093
```
By that we can also make sure, that the offsets will again start at 0.
Start the a producer to produce 1000 messages with a delay of 100ms between sending each message. We deliberately only use one partition by specifying a key (`1`).
Make sure to use the synchronous producer!
```bash
mvn exec:java@producer -Dexec.args="1000 100 1"
```
in the log check the output for a timestamp to use for the reset
```
[1] sent record(key=1 value=[1] Hello Kafka 428 => 2021-09-22T08:19:49.412417) meta(partition=4, offset=428) time=2
[1] sent record(key=1 value=[1] Hello Kafka 429 => 2021-09-22T08:19:49.519555) meta(partition=4, offset=429) time=4
[1] sent record(key=1 value=[1] Hello Kafka 430 => 2021-09-22T08:19:49.625616) meta(partition=4, offset=430) time=5
[1] sent record(key=1 value=[1] Hello Kafka 431 => 2021-09-22T08:19:49.732601) meta(partition=4, offset=431) time=6
[1] sent record(key=1 value=[1] Hello Kafka 432 => 2021-09-22T08:19:49.843735) meta(partition=4, offset=432) time=3
[1] sent record(key=1 value=[1] Hello Kafka 433 => 2021-09-22T08:19:49.951001) meta(partition=4, offset=433) time=3
[1] sent record(key=1 value=[1] Hello Kafka 434 => 2021-09-22T08:19:50.057701) meta(partition=4, offset=434) time=5
[1] sent record(key=1 value=[1] Hello Kafka 435 => 2021-09-22T08:19:50.166302) meta(partition=4, offset=435) time=2
[1] sent record(key=1 value=[1] Hello Kafka 436 => 2021-09-22T08:19:50.273466) meta(partition=4, offset=436) time=3
[1] sent record(key=1 value=[1] Hello Kafka 437 => 2021-09-22T08:19:50.378912) meta(partition=4, offset=437) time=3
```
We will be using `2021-09-22T08:19:50.057701` later to reset to. So we expect the offset after the reset will be `434`.
## Consume Messages
Now let's consume all these messages once:
```bash
mvn exec:java@consumer -Dexec.args="0"
```
By that we are sure to be at the end of topic `test-java-topic`.
## Resetting offsets
To change or reset the offsets of a consumer group, the `kafka-consumer-groups` utility has been created. You need specify the topic, consumer group and use the `--reset-offsets` flag to change the offset.
We can also find it in any of the brokers, similar to the `kafka-topics` CLI. Executing
```bash
docker exec -ti kafka-1 kafka-consumer-groups
```
will display the help page with all the available options
```
$ docker exec -ti kafka-1 kafka-consumer-groups
Missing required argument "[bootstrap-server]"
Option Description
------ -----------
--all-groups Apply to all consumer groups.
--all-topics Consider all topics assigned to a
group in the `reset-offsets` process.
--bootstrap-server <String: server to REQUIRED: The server(s) to connect to.
connect to>
--by-duration <String: duration> Reset offsets to offset by duration
from current timestamp. Format:
'PnDTnHnMnS'
--command-config <String: command Property file containing configs to be
config property file> passed to Admin Client and Consumer.
--delete Pass in groups to delete topic
partition offsets and ownership
information over the entire consumer
group. For instance --group g1 --
group g2
--delete-offsets Delete offsets of consumer group.
Supports one consumer group at the
time, and multiple topics.
--describe Describe consumer group and list
offset lag (number of messages not
yet processed) related to given
group.
--dry-run Only show results without executing
changes on Consumer Groups.
Supported operations: reset-offsets.
--execute Execute operation. Supported
operations: reset-offsets.
--export Export operation execution to a CSV
file. Supported operations: reset-
offsets.
--from-file <String: path to CSV file> Reset offsets to values defined in CSV
file.
--group <String: consumer group> The consumer group we wish to act on.
--help Print usage information.
--list List all consumer groups.
--members Describe members of the group. This
option may be used with '--describe'
and '--bootstrap-server' options
only.
Example: --bootstrap-server localhost:
9092 --describe --group group1 --
members
--offsets Describe the group and list all topic
partitions in the group along with
their offset lag. This is the
default sub-action of and may be
used with '--describe' and '--
bootstrap-server' options only.
Example: --bootstrap-server localhost:
9092 --describe --group group1 --
offsets
--reset-offsets Reset offsets of consumer group.
Supports one consumer group at the
time, and instances should be
inactive
Has 2 execution options: --dry-run
(the default) to plan which offsets
to reset, and --execute to update
the offsets. Additionally, the --
export option is used to export the
results to a CSV format.
You must choose one of the following
reset specifications: --to-datetime,
--by-period, --to-earliest, --to-
latest, --shift-by, --from-file, --
to-current.
To define the scope use --all-topics
or --topic. One scope must be
specified unless you use '--from-
file'.
--shift-by <Long: number-of-offsets> Reset offsets shifting current offset
by 'n', where 'n' can be positive or
negative.
--state [String] When specified with '--describe',
includes the state of the group.
Example: --bootstrap-server localhost:
9092 --describe --group group1 --
state
When specified with '--list', it
displays the state of all groups. It
can also be used to list groups with
specific states.
Example: --bootstrap-server localhost:
9092 --list --state stable,empty
This option may be used with '--
describe', '--list' and '--bootstrap-
server' options only.
--timeout <Long: timeout (ms)> The timeout that can be set for some
use cases. For example, it can be
used when describing the group to
specify the maximum amount of time
in milliseconds to wait before the
group stabilizes (when the group is
just created, or is going through
some changes). (default: 5000)
--to-current Reset offsets to current offset.
--to-datetime <String: datetime> Reset offsets to offset from datetime.
Format: 'YYYY-MM-DDTHH:mm:SS.sss'
--to-earliest Reset offsets to earliest offset.
--to-latest Reset offsets to latest offset.
--to-offset <Long: offset> Reset offsets to a specific offset.
--topic <String: topic> The topic whose consumer group
information should be deleted or
topic whose should be included in
the reset offset process. In `reset-
offsets` case, partitions can be
specified using this format: `topic1:
0,1,2`, where 0,1,2 are the
partition to be included in the
process. Reset-offsets also supports
multiple topic inputs.
--verbose Provide additional information, if
any, when describing the group. This
option may be used with '--
offsets'/'--members'/'--state' and
'--bootstrap-server' options only.
Example: --bootstrap-server localhost:
9092 --describe --group group1 --
members --verbose
--version Display Kafka version.
```
### How to find the current consumer offset?
Use the kafka-consumer-groups along with the consumer group id followed by a describe
```bash
docker exec -ti kafka-1 kafka-consumer-groups --bootstrap-server kafka-2:19093 --group "KafkaConsumerAuto" --verbose --describe
```
You will see 2 entries related to offsets – CURRENT-OFFSET and LOG-END-OFFSET for the partitions in the topic for that consumer group. CURRENT-OFFSET is the current offset for the partition in the consumer group.
```
$ docker exec -ti kafka-1 kafka-consumer-groups --bootstrap-server kafka-1:19093 --group "KafkaConsumerAuto" --verbose --describe
Consumer group 'KafkaConsumerAuto' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
KafkaConsumerAuto test-java-topic 6 0 0 0 consumer-KafkaConsumerAuto-1-e74b46d4-2c43-4278-a006-ae51c779a1e2 /192.168.142.1 consumer-KafkaConsumerAuto-1
KafkaConsumerAuto test-java-topic 1 0 0 0 consumer-KafkaConsumerAuto-1-e74b46d4-2c43-4278-a006-ae51c779a1e2 /192.168.142.1 consumer-KafkaConsumerAuto-1
KafkaConsumerAuto test-java-topic 7 0 0 0 consumer-KafkaConsumerAuto-1-e74b46d4-2c43-4278-a006-ae51c779a1e2 /192.168.142.1 consumer-KafkaConsumerAuto-1
KafkaConsumerAuto test-java-topic 0 0 0 0 consumer-KafkaConsumerAuto-1-e74b46d4-2c43-4278-a006-ae51c779a1e2 /192.168.142.1 consumer-KafkaConsumerAuto-1
KafkaConsumerAuto test-java-topic 4 1000 1000 0 consumer-KafkaConsumerAuto-1-e74b46d4-2c43-4278-a006-ae51c779a1e2 /192.168.142.1 consumer-KafkaConsumerAuto-1
KafkaConsumerAuto test-java-topic 3 0 0 0 consumer-KafkaConsumerAuto-1-e74b46d4-2c43-4278-a006-ae51c779a1e2 /192.168.142.1 consumer-KafkaConsumerAuto-1
KafkaConsumerAuto test-java-topic 5 0 0 0 consumer-KafkaConsumerAuto-1-e74b46d4-2c43-4278-a006-ae51c779a1e2 /192.168.142.1 consumer-KafkaConsumerAuto-1
KafkaConsumerAuto test-java-topic 2 0 0 0 consumer-KafkaConsumerAuto-1-e74b46d4-2c43-4278-a006-ae51c779a1e2 /192.168.142.1 consumer-KafkaConsumerAuto-1
```
We can see that all messages were sent to partition 4.
### Reset offsets to a timestamp
Let's reset the offsets to the timestamp `2021-09-22T08:19:50.057701` we noted above, by rounding it down to the minute. You also have to adapt the timestamp to UTC timestamp (currently -2)
```bash
docker exec -ti kafka-1 kafka-consumer-groups --bootstrap-server kafka-1:19092 --group "KafkaConsumerAuto" --reset-offsets --to-datetime 2021-09-22T06:19:50.00Z --topic test-java-topic --execute
```
You should see the `NEW-OFFST` changed to `434`
```bash
docker exec -ti kafka-1 kafka-consumer-groups --bootstrap-server kafka-1:19092 --group "KafkaConsumerAuto" --reset-offsets --to-datetime 2021-09-22T06:19:50.00Z --topic test-java-topic --execute
GROUP TOPIC PARTITION NEW-OFFSET
KafkaConsumerAuto test-java-topic 6 0
KafkaConsumerAuto test-java-topic 1 0
KafkaConsumerAuto test-java-topic 7 0
KafkaConsumerAuto test-java-topic 0 0
KafkaConsumerAuto test-java-topic 4 434
KafkaConsumerAuto test-java-topic 3 0
KafkaConsumerAuto test-java-topic 5 0
KafkaConsumerAuto test-java-topic 2 0
```
Now lets rerun the consumer and you should see the first message being consumed to be the following one
```
500 - Consumer Record:(Key: 1, Value: [1] Hello Kafka 434 => 2021-09-22T08:19:50.057701, Partition: 4, Offset: 434)
5
```
### Reset offsets to offset to earliest
This command resets the offsets to earliest (oldest) offset available in the topic.
```bash
docker exec -ti kafka-1 kafka-consumer-groups --bootstrap-server kafka-1:19092 --group "KafkaConsumerAuto" --reset-offsets --to-earliest --topic test-java-topic --execute
```
Rerun the consumer to check that again all messages are consumed.
There are many other resetting options, run `kafka-consumer-groups` for details
```
--shift-by
--to-current
--to-latest
--to-offset
--by-duration
```
<file_sep># Apache Ignite
Distributed Database For High-Performance Computing With In-Memory Speed.
**[Website](https://ignite.apache.org/)** | **[Documentation](https://ignite.apache.org/docs/latest/)** | **[GitHub](https://github.com/apache/ignite)**
## How to enable?
```
platys init --enable-services IGNITE
platys gen
```
## How to use it?
## Cookbooks<file_sep>Place additional python scripts here (will be included in PYTHONPATH).<file_sep># HiveMQ Web UI
With the HiveMQ Web UI for advanced analysis and administrative tasks, administrators are able to drill down on specific client information and can perform administrative actions like disconnecting a client.
**[Website](https://www.hivemq.com/docs/hivemq/3.4/web-ui/introduction.html)** | **[Documentation](https://www.hivemq.com/docs/hivemq/3.4/web-ui/introduction.html)**
## How to enable?
```
platys init --enable-services MQTT_UI
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28136><file_sep># Kong API Gateway
Kong Gateway is a lightweight, fast, and flexible cloud-native API gateway. An API gateway is a reverse proxy that lets you manage, configure, and route requests to your APIs.
**[Website](https://konghq.com/products/api-gateway-platform)** | **[Documentation](https://docs.konghq.com/gateway/latest/)** | **[GitHub](https://github.com/Kong/kong)**
## How to enable?
```
platys init --enable-services KONG
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8002><file_sep># Working with Eclipse
Eclipse is a popular IDE (Integrated Development Environment) for working with Java. This guide is based on the latest vesion of Eclipse, [Eclipse OXYGEN](http://www.eclipse.org/downloads/).
## Create a new Maven Project
To create a new Java Project with Maven support, perform the following steps:
In the Menu, select **File** | **New** | **Other...**.
Enter **maven** into the **Wizards** edit field. Select **Maven Project** and click **Next**.

Select the **Create a simple project (skip archetype selection)** and click **Next >**.

Specify the **Group Id** and **Artifact Id** and click **Finsih**.

Eclipse will show the new project in the **Package Explorer** to the right.

You have successfully created an empty Maven Project. Start editing the **pom.xml** as needed.
<file_sep># Apache NiFi Toolkit
The NiFi Toolkit contains several command line utilities to setup and support NiFi in standalone and clustered environments.
**[Website](https://nifi.apache.org)** | **[Documentation](https://nifi.apache.org/docs/nifi-docs/html/toolkit-guide.html)** | **[GitHub](https://github.com/apache/nifi)**
## How to enable?
```bash
platys init --enable-services NIFI,NIFI_TOOLKIT
platys gen
```
## How to use it?
<file_sep># CMAK (Cluster Manager for Apache Kafka, previously known as Kafka Manager)
CMAK is a tool for managing Apache Kafka clusters.
**[Website](https://github.com/yahoo/CMAK)** | **[Documentation](https://github.com/yahoo/CMAK)** | **[GitHub](https://github.com/yahoo/CMAK)**
## How to enable?
```
platys init --enable-services CMAK
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28104>
<file_sep># Apache Livy
Apache Livy is a service that enables easy interaction with a Spark cluster over a REST interface. It enables easy submission of Spark jobs or snippets of Spark code, synchronous or asynchronous result retrieval, as well as Spark Context management, all via a simple REST interface or an RPC client library. Apache Livy also simplifies the interaction between Spark and application servers, thus enabling the use of Spark for interactive web/mobile applications.
**[Website](https://livy.incubator.apache.org/)** | **[Documentation](https://livy.incubator.apache.org/)** | **[GitHub](https://github.com/apache/incubator-livy)**
## How to enable?
```
platys init --enable-services SPARK,LIVY
platys gen
```
## How to use it?
<file_sep>---
technoglogies: log4brains,adr
version: 1.16.0
validated-at: 15.11.2022
---
# Creating and visualising ADRs with log4brains
This recipe will show how to create and visualise Architecture Decision Records (ADR) using [log4brains](https://github.com/thomvaill/log4brains).
If you want to know more on the concept of Architecture Decision Records (ADRs), there is a [Trivadis Platform Factory whitepaper](https://tvdit.sharepoint.com/:b:/r/sites/PlatformFactoryPublic/Shared%20Documents/Architecture%20Blueprints/Modern%20Data%20Architecture/wp-architecture-decision-record-v1.0d.pdf?csf=1&web=1&e=0BP76w) available (currently only in german).
## Initialise a platform
First [initialise a platys-supported data platform](../../getting-started) with the following services enabled
```bash
platys init --enable-services LOG4BRAINS,WETTY,MARKDOWN_VIEWER -s trivadis/platys-modern-data-platform -w 1.16.0
```
add the following property to the `config.yml`
```bash
LOG4BRAINS_adr_source_dir: './adr'
```
Now create the `adr` folder
```
mkdir adr
```
Now generate and start the data platform.
```bash
platys gen
docker-compose up -d
```
For creating the ADR documents, you also may want to install log4brains locally (you need to have Node.js installed)
```
npm install -g log4brains
```
As an alternative you can also use the `log4brains` docker image and use a `docker run` for each of the commands (replace `<cmd>` by the log4brains command to use).
```
docker run -ti -v ${PWD}:/workdir thomvaill/log4brains <cmd>
```
## Create the log4brains ADR project
Navigate to the `adr` folder created above
```
cd adr
log4brains init
```
if you want to use the docker image instead of the local log4brains installation, then perform
```
cd adr
docker run -ti -v ${PWD}:/workdir thomvaill/log4brains init
```
Answer the question asked by the tool as shown below

We can see that the following folder structure has been created.
```
docker@ubuntu:~/platys-cookbook/adr$ tree
.
└── docs
└── adr
├── 20210412-use-log4brains-to-manage-the-adrs.md
├── 20210412-use-markdown-architectural-decision-records.md
├── index.md
├── README.md
└── template.md
2 directories, 5 files
```
With the init 2 sample ADRs were automatically created. They can be removed later.
Now with the ADR project being initialised, can restart the `log4brains` container
```
docker restart log4brains
```
Now navigate to <http://dataplatform:4004> and you should see two ADRs being rendered as a Web application.

## Create a new ADR
Navigate to the `adr` folder created above and run the `adr new` command
```
cd adr
log4brains adr new
```
if you want to use the docker image instead of the local log4brains installation, then perform
```
cd adr
docker run -ti -v ${PWD}:/workdir thomvaill/log4brains adr new
```
Answer the questions asked by the tool, such as the title and if the ADR is a new one or should supersede an existing one.
```
docker@ubuntu:~/platys-cookbook/adr$ docker run -ti -v ${PWD}:/workdir thomvaill/log4brains adr new
? Title of the solved problem and its solution? This is my first ADR
? Does this ADR supersede a previous one? No
✔ New ADR created: docs/adr/20210412-this-is-my-first-adr.md
? How would you like to edit it? Later
```
Because of the preview mode and its hot reload feature, the UI will automatically reflect the newly created ADR.

Edit the file `docs/adr/20210412-this-is-my-first-adr.md` in the Editor of your choice to define the ADR.

## Building a static website
Navigate to the `adr` folder created above and run the `build` command
```
cd adr
docker run -ti -v ${PWD}:/workdir thomvaill/log4brains build
```
After a while you should see the following output
```
docker@ubuntu:~/platys-cookbook/adr$ docker run -ti -v "${PWD}":/workdir thomvaill/log4brains build
Building Log4brains...
info - Creating an optimized production build
info - Collecting page data
info - Finalizing page optimization
[====] Generating search index... Done
✔ Your Log4brains static site was successfully generated to .log4brains/out with a total of 3 ADRs
```
The static website is available in `.log4brains/out`. Consult the [Log4brains GitHub](https://github.com/thomvaill/log4brains#-cicd-configuration-examples) to see examples on how deploy it to various static hosting services.
<file_sep>#!/bin/bash
echo "removing MQTT Source Connector"
curl -X "DELETE" "$DOCKER_HOST_IP:8083/connectors/mqtt-truck-position-source"
echo "creating MQTT Source Connector"
curl -X "POST" "$DOCKER_HOST_IP:8083/connectors" \
-H "Content-Type: application/json" \
-d '{
"name": "mqtt-truck-position-source",
"config": {
"connector.class": "com.datamountaineer.streamreactor.connect.mqtt.source.MqttSourceConnector",
"connect.mqtt.connection.timeout": "1000",
"tasks.max": "1",
"connect.mqtt.kcql": "INSERT INTO truck_position SELECT * FROM truck/+/position",
"connect.mqtt.connection.clean": "true",
"connect.mqtt.service.quality": "0",
"connect.mqtt.connection.keep.alive": "1000",
"connect.mqtt.client.id": "tm-mqtt-connect-01",
"connect.mqtt.converter.throw.on.error": "true",
"connect.mqtt.hosts": "tcp://mosquitto-1:1883"
}
}'<file_sep>Put the following files here:
- sdc-security.policy for overriding the default file inside the container
- configuration.properties for defining runtime properties external to the sdc.properties file <file_sep># Apache Hive Metastore
Hive Metastore (HMS) is a service that stores metadata related to Apache Hive and other services, in a backend RDBMS, such as MySQL or PostgreSQL. Impala, Spark, Hive, and other services share the metastore. The connections to and from HMS include HiveServer, Ranger, and the NameNode that represents HDFS.
**[Website](https://hive.apache.org/)** | **[Documentation](https://cwiki.apache.org/confluence/display/Hive/GettingStarted)** | **[GitHub](https://github.com/apache/hive)**
## How to enable?
```
platys init --enable-services HIVE_METASTORE
platys gen
```
## How to use it?
To connect to the Hive Metastore servcice CLI
```bash
docker exec -ti hive-metastore hive
```
<file_sep># Apache ActiveMQ
Apache ActiveMQ® is the most popular open source, multi-protocol, Java-based message broker. It supports industry standard protocols so users get the benefits of client choices across a broad range of languages and platforms. Connect from clients written in JavaScript, C, C++, Python, .Net, and more. Integrate your multi-platform applications using the ubiquitous AMQP protocol. Exchange messages between your web applications using STOMP over websockets. Manage your IoT devices using MQTT. Support your existing JMS infrastructure and beyond. ActiveMQ offers the power and flexibility to support any messaging use-case.
**[Website](https://activemq.apache.org/)** | **[Documentation](https://activemq.apache.org/components/classic/documentation)** | **[GitHub](https://github.com/apache/activemq)**
## How to enable?
```
platys init --enable-services ACTIVEMQ
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8161> for the ActiveMQ dashboard.
To manage the ActiveMQ server, navigate to <http://dataplatform:8161/admin/> and use `admin` for the user and `admin` for the password when asked for.<file_sep># Python
Python is a programming language that lets you work quickly and integrate systems more effectively.
**[Homepage](https://www.python.org/)** | **[Documentation](https://www.python.org/doc/)** | **[GitHub](https://github.com/python/cpython)**
## How to enable?
```
platys init --enable-services PYTHON
platys gen
```
## How to use it?
<file_sep># Using Confluent REST APIs (REST Proxy)
These APIs are available both on Confluent Server (as a part of Confluent Enterprise) and REST Proxy. When using the API in Confluent Server, all paths should be prefixed with `/kafka`. For example, the path to list clusters is:
* **Confluent Server:** `/kafka/v3/clusters`
* **REST Proxy:** `/v3/clusters`
All the folloing exampe
## List and desribe cluster
```bash
curl --silent -X GET http://dataplatform:18086/v3/clusters/ | jq
```
Result:
```
{
"kind": "KafkaClusterList",
"metadata": {
"self": "http://kafka-rest-1:8086/v3/clusters",
"next": null
},
"data": [
{
"kind": "KafkaCluster",
"metadata": {
"self": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg",
"resource_name": "crn:///kafka=fE05MX_MQLWvruHKXUQeRg"
},
"cluster_id": "fE05MX_MQLWvruHKXUQeRg",
"controller": {
"related": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg/brokers/2"
},
"acls": {
"related": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg/acls"
},
"brokers": {
"related": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg/brokers"
},
"broker_configs": {
"related": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg/broker-configs"
},
"consumer_groups": {
"related": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg/consumer-groups"
},
"topics": {
"related": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg/topics"
},
"partition_reassignments": {
"related": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg/topics/-/partitions/-/reassignment"
}
}
]
}
```
Extract the cluster id from the response and set it as environment variable `CLUSTER_ID`:
```bash
export CLUSTER_ID=$(curl -X GET "http://dataplatform:18086/v3/clusters/" | jq -r ".data[0].cluster_id")
```
## Create a topic
To create a topic, use the topics endpoint POST `/clusters/{cluster_id}/topics` as shown below.
```bash
curl --silent -X POST -H "Content-Type: application/json" \
--data '{"topic_name": "rest-proxy-topic", "replication_factor":"3", "partitions_count": "8"}' \
http://dataplatform:18086/v3/clusters/${CLUSTER_ID}/topics | jq
```
Result:
```bash
{
"kind": "KafkaTopic",
"metadata": {
"self": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg/topics/rest-proxy-topic",
"resource_name": "crn:///kafka=fE05MX_MQLWvruHKXUQeRg/topic=rest-proxy-topic"
},
"cluster_id": "fE05MX_MQLWvruHKXUQeRg",
"topic_name": "rest-proxy-topic",
"is_internal": false,
"replication_factor": 3,
"partitions_count": 0,
"partitions": {
"related": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg/topics/rest-proxy-topic/partitions"
},
"configs": {
"related": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg/topics/rest-proxy-topic/configs"
},
"partition_reassignments": {
"related": "http://kafka-rest-1:8086/v3/clusters/fE05MX_MQLWvruHKXUQeRg/topics/rest-proxy-topic/partitions/-/reassignment"
}
}
```
## List topics
To list detailed descriptions of all topics (internal and user created topics), use the topics endpoint GET `/clusters/{cluster_id}/topics/`
```bash
curl --silent -X GET http://dataplatform:18086/v3/clusters/${CLUSTER_ID}/topics | jq
```
to show only the topic names, use a grep on the output of `jq`
```bash
curl --silent -X GET http://dataplatform:18086/v3/clusters/${CLUSTER_ID}/topics | jq | grep '.topic_name'
```
## Describe a topic
To get a full description of a specified topic, use the topics endpoint GET `/clusters/{cluster_id}/topics/{topic_name}`
```bash
curl --silent -X GET http://dataplatform:18086/v3/clusters/${CLUSTER_ID}/topics/rest-proxy-topic | jq
```
## Working with JSON data
### Produce JSON
```bash
curl --silent -X POST 'http://dataplatform:18086/topics/rest-proxy-topic' \
--header 'Content-Type: application/vnd.kafka.json.v2+json' \
--data-raw '{
"records": [
{
"key": "1",
"value": {
"id": 1,
"customerCode": 1,
"telephone": "888582158",
"email": "<EMAIL>",
"language": "EN"
}
}
]
}'
```
### Consume JSON
1. create a consumer `ci1` belonging to consumer group `cg1`.
Specify `auto.offset.reset` to be `earliest` so it starts at the beginning of the topic.
```bash
curl --silent -X POST \
-H "Content-Type: application/vnd.kafka.v2+json" \
--data '{"name": "ci1", "format": "json", "auto.offset.reset": "earliest"}' \
http://dataplatform:18086/consumers/cg1 | jq .
```
Result:
```
{
"instance_id": "ci1",
"base_uri": "http://kafka-rest-1:8086/consumers/cg1/instances/ci1"
}
```
2. Subscribe the consumer to topic `rest-proxy-topic`
```bash
curl --silent -X POST \
-H "Content-Type: application/vnd.kafka.v2+json" \
--data '{"topics":["rest-proxy-topic"]}' \
http://dataplatform:18086/consumers/cg1/instances/ci1/subscription | jq .
```
3. Consume data using the base URL in the first reponse.
```bash
curl --silent -X GET \
-H "Accept: application/vnd.kafka.json.v2+json" \
http://dataplatform:18086/consumers/cg1/instances/ci1/records | jq .
```
4. Close the consumer with a DELETE to make it leave the group and clean up its resources
```bash
curl --silent -X DELETE \
-H "Content-Type: application/vnd.kafka.v2+json" \
http://dataplatform:18086/consumers/cg1/instances/ci1 | jq .
```
## Working with Avro data
### Create a new topic
To create a topic, use the topics endpoint POST `/clusters/{cluster_id}/topics` as shown below.
```bash
curl --silent -X POST -H "Content-Type: application/json" \
--data '{"topic_name": "rest-proxy-avro-topic", "replication_factor":"3", "partitions_count": "8"}' \
http://dataplatform:18086/v3/clusters/${CLUSTER_ID}/topics | jq
```
### Register the Avro Schema
Navigate to http://dataplatform:28102 and register the following Avro schema under subject `rest-proxy-avro-topic-value`:
```json
{
"type": "record",
"name": "Customer",
"namespace": "com.trivadis.kafkaws.sample",
"doc": "This is a sample Avro schema to get you started. Please edit",
"fields": [
{
"name": "id",
"type": "long"
},
{
"name": "customerCode",
"type": "long"
},
{
"name": "telephone",
"type": "string"
},
{
"name": "email",
"type": "string"
},
{
"name": "language",
"type": "string"
}
]
}
```
Set the variable `SCHEMA_ID` to the value of the schema ID of the schema registry
```bash
export SCHEMA_ID=$(curl -X GET "http://dataplatform:8081/subjects/rest-proxy-avro-topic-value/versions/latest" | jq '.id')
```
### Produce Avro
Produce three Avro messages to the topic `rest-proxy-avro-topic`
```bash
curl --silent -X POST \
-H "Content-Type: application/vnd.kafka.avro.v2+json" \
-H "Accept: application/vnd.kafka.v2+json" \
--data '{"value_schema_id": '"$SCHEMA_ID"', "records": [{"value": {
"id": 1,
"customerCode": 1,
"telephone": "888582158",
"email": "<EMAIL>",
"language": "EN"
} }]}' \
"http://dataplatform:18086/topics/rest-proxy-avro-topic" | jq .
```
Result:
```
{
"offsets": [
{
"partition": 1,
"offset": 0,
"error_code": null,
"error": null
}
],
"key_schema_id": null,
"value_schema_id": 3
}
```
### Consume Avro
1. Create a consumer `ci2` belonging to consumer group `cg2`. Specify `auto.offset.reset` to be earliest so it starts at the beginning of the topic.
```bash
curl --silent -X POST \
-H "Content-Type: application/vnd.kafka.v2+json" \
--data '{"name": "ci2", "format": "avro", "auto.offset.reset": "earliest"}' \
http://dataplatform:18086/consumers/cg2 | jq .
```
Result:
```
{
"instance_id": "ci2",
"base_uri": "http://kafka-rest-1:8086/consumers/cg2/instances/ci2"
}
```
2. Subscribe the consumer to topic `rest-proxy-avro-topic`
```bash
curl --silent -X POST \
-H "Content-Type: application/vnd.kafka.v2+json" \
--data '{"topics":["rest-proxy-avro-topic"]}' \
http://dataplatform:18086/consumers/cg2/instances/ci2/subscription | jq .
```
3. Consume data using the base URL in the first reponse.
```bash
curl --silent -X GET \
-H "Accept: application/vnd.kafka.avro.v2+json" \
http://dataplatform:18086/consumers/cg2/instances/ci2/records | jq .
```
4. Close the consumer with a DELETE to make it leave the group and clean up its resources
```bash
curl --silent -X DELETE \
-H "Content-Type: application/vnd.kafka.v2+json" \
http://dataplatform:18086/consumers/cg2/instances/ci2 | jq .
```
<file_sep># Schema Registry UI
Web tool for Avro Schema Registry
**[Website](https://github.com/lensesio/schema-registry-ui)** | **[Documentation](https://github.com/lensesio/schema-registry-ui)** | **[GitHub](https://github.com/lensesio/schema-registry-ui)**
## How to enable?
```
platys init --enable-services KAFKA,SCHEMA_REGISTRY,SCHEMA_REGISTRY_UI
platys gen
```
## How to use it?
<file_sep>Contains the data of filebrowser service, if flag FILEBROWSER_volume_map_data is set to true.<file_sep># Hazelcast Management Center
Hazelcast Management Center enables monitoring and management of nodes running Hazelcast IMDG or Jet. This includes monitoring the overall state of clusters, as well as detailed analysis and browsing of data structures in real time, updating map configurations, and taking thread dumps from nodes.
**[Website](https://hazelcast.com/product-features/management-center/)** | **[Documentation](https://docs.hazelcast.com/management-center/latest/)** | **[GitHub](https://github.com/hazelcast)**
## How to enable?
```
platys init --enable-services HAZELCAST HAZELCAST_MC
platys gen
```
## How to use it?
## Cookbooks<file_sep># Jupyter
Open-source software, open standards, and services for interactive computing across dozens of programming languages.
**[Website](https://jupyter.org/)** | **[Documentation](https://jupyter.org/documentation)** | **[GitHub](https://github.com/jupyter/notebook)**
## How to enable?
```
platys init --enable-services JUPYTER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28888>. The token for the login has either be specified in the `config.yml` (`JUPYTER_token`) or if not set, the generated token can be retrieved from the log (`docker logs -f jupyter`).
If you enable the `all-spark` edition and run spark, then the Spark UI will be available at <http://dataplatform:14040>.<file_sep># Code Server
VS Code in the browser.
**[Website](https://code.visualstudio.com/)** | **[Documentation](https://code.visualstudio.com/docs)** | **[GitHub](https://github.com/coder/code-server)**
## How to enable?
```
platys init --enable-services CODE_SERVER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28140><file_sep># Apache Hadoop
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
**[Website](https://hadoop.apache.org/)** | **[Documentation](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html)** | **[GitHub](https://github.com/apache/hadoop)**
## How to enable?
```
platys init --enable-services HADOOP
platys gen
```
## How to use it?
<file_sep>package com.trivadis.kafkaws.springbootkafkaconsumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.DltHandler;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.RetryableTopic;
import org.springframework.kafka.retrytopic.TopicSuffixingStrategy;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.retry.annotation.Backoff;
import org.springframework.stereotype.Component;
@Component
public class RetryableKafkaEventConsumer {
private static final Logger LOGGER = LoggerFactory.getLogger(RetryableKafkaEventConsumer.class);
@RetryableTopic(attempts = "4",
backoff = @Backoff(delay = 1000, multiplier = 2.0),
autoCreateTopics = "true",
topicSuffixingStrategy = TopicSuffixingStrategy.SUFFIX_WITH_INDEX_VALUE)
@KafkaListener(topics = "${topic.retryable-topic-name}", groupId = "simple-consumer-group")
public void listen(ConsumerRecord<String, String> consumerRecord, @Header(KafkaHeaders.RECEIVED_TOPIC) String topicName) {
String value = consumerRecord.value();
String key = consumerRecord.key();
LOGGER.info("received key = '{}' with payload='{}' from topic='{}'", key, value, topicName);
// message is invalid, if value starts with @
if (value.startsWith("@")) {
throw new RuntimeException("Error in consumer");
}
LOGGER.info("message with key = '{}' with payload='{}' from topic='{}' processed successfully!", key, value, topicName);
}
@DltHandler
public void dlt(String in, @Header(KafkaHeaders.RECEIVED_TOPIC) String topicName) {
LOGGER.info(in + " from " + topicName);
}
}<file_sep># Working with Kafka from .NET
In this workshop we will learn how to produce and consume messages using the [Kafka .NET API](https://docs.confluent.io/clients-confluent-kafka-dotnet/current/overview.html).
We will show how to build the .NET application using the Visual Code IDE, but any other IDE or just a simple Editor would be fine as well.
We assume that .NET Core is installed on your client as well as Visual Code with the C# extension (ms-dotnettools.csharp) enabled. We will use the .NET CLI (`dotnet`) for creating projects and running the code.
## Create the project structure
We will create two projects, one acting as the producer to Kafka and the other one as the consumer from Kafka.
First create the workspace folder, which will hold our projects and navigate into it.
```bash
mkdir kafka-dotnet-workshop
cd kafka-dotnet-workshop
```
Now let's create the producer project
```bash
dotnet new console -o producer
```
Now start Visual Code, on Linux if installed using the [following documentation](https://code.visualstudio.com/docs/setup/linux), then it can be started with `code`.
```bash
code
```
On the **Getting Started** page, click on **Open...** and select the `kafka-dotnet-workspace` folder created above. Confirm the **Required assets to build and debug are missing from ... Add them?** message pop-up with **Yes**. Open a Terminal in Visual Code over the menu **Terminal** | **New Terminal**.

We are now ready to add code to the classes which have been created with the `dotnet new` command.
But before we do that, let's create the topic we will use to produce to and to consume from.
### Creating the necessary Kafka Topic
We will use the topic `test-dotnet-topic` in the Producer and Consumer code below. Because `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
Connect to the `kafka-1` container
```
docker exec -ti kafka-1 bash
```
and execute the necessary kafka-topics command.
```
kafka-topics --create \
--replication-factor 3 \
--partitions 12 \
--topic test-dotnet-topic \
--bootstrap-server kafka-1:19092,kafka-2:19093
```
Cross check that the topic has been created.
```
kafka-topics --list --bootstrap-server kafka-1:19092
```
This finishes the setup steps and our new project is ready to be used. Next we will start implementing a **Kafka Producer**.
## Create a Kafka Producer
To communicate with Kafka, we need to use the [**confluent-kafka-dotnet**](https://docs.confluent.io/clients-confluent-kafka-dotnet/current/overview.html) .NET library].
The reference the library from the .NET Core project, execute the following command from within the `kafka-dotnet-workspace` folder.
```
dotnet add producer package Confluent.Kafka
```
The following reference will be added to project metadata
```
<Project Sdk="Microsoft.NET.Sdk">
...
<ItemGroup>
<PackageReference Include="Confluent.Kafka" Version="1.8.2" />
</ItemGroup>
</Project>
```
Now let's add the code for producing messages to the Kafka topic. Navigate to the `Program.cs` C# class in the `producer` project and rename it to `KafkaProducer.cs` and then open it in the editor.
Add the following directives on the top with the class and the following two constants for the Broker List and the Topic name:
```csharp
using System;
using System.Threading;
using Confluent.Kafka;
namespace producer
{
class Program
{
const string brokerList = "dataplatform:9092,dataplatform:9093";
const string topicName = "test-dotnet-topic";
}
}
```
Add the following main method to the class:
```csharp
private static async Task Main(string[] args)
{
long startTime = DateTimeOffset.Now.ToUnixTimeMilliseconds();
if (args.Length == 0)
{
runProducerSync(100, 10, 0);
}
else
{
runProducerSync(int.Parse(args[0]), int.Parse(args[1]), int.Parse(args[2]));
}
long endTime = DateTimeOffset.Now.ToUnixTimeMilliseconds();
Console.WriteLine("Producing all records took : " + (endTime - startTime) + " ms = (" + (endTime - startTime) / 1000 + " sec)");
}
// place the runProducerXXXX methods below
```
The `Main()` method accepts 3 parameters, the number of messages to produce, the time in ms to wait in-between sending each message and the ID of the producer.
Add the following additional method for implementing the Kafka producer. To write messages to Kafka, we can either use the `ProduceAsync` or `Produce` method.
### Produce Synchronously with a `Null` key
We will first use the `ProducerAsync` method in a synchronous way using the `await` operator. We are producing just a value and leave the key empty (`Null`).
```csharp
static async Task runProducerSync(int totalMessages, int waitMsInBetween, int id)
{
var config = new ProducerConfig { BootstrapServers = brokerList };
// Create the Kafka Producer
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
for (int index = 0; index < totalMessages; index++)
{
// Construct the message value
string value = "[" + index + ":" + id + "] Hello Kafka " + DateTimeOffset.Now;
// send the message to Kafka
var deliveryReport = await producer.ProduceAsync(topicName, new Message<Null, string> { Value = value });
Console.WriteLine($"[{id}] sent record (key={deliveryReport.Key} value={deliveryReport.Value}) meta (partition={deliveryReport.TopicPartition.Partition}, offset={deliveryReport.TopicPartitionOffset.Offset}, time={deliveryReport.Timestamp.UnixTimestampMs})");
Thread.Sleep(waitMsInBetween);
}
}
}
```
Before starting the producer, in an additional terminal, let's use `kcat` or `kafka-console-consumer` to consume the messages from the topic `test-dotnet-topic`.
```bash
kcat -b kafka-1 -t test-dotnet-topic -f 'Part-%p => %k:%s\n' -q
```
Now run it using the `dotnet run` command. It will generate 1000 messages, waiting 10ms in-between sending each message and use 0 for the `id`.
```bash
dotnet run -p ./producer/producer.csproj 1000 10 0
```
The log will show each messages metadata after it has been sent and at the end you can see that it took **20 seconds** to send the 1000 records
```bash
[0] sent record (key= value=[0:0] Hello Kafka 04/03/2022 12:33:21 +02:00) meta (partition=[2], offset=652, time=1648982001348)
[0] sent record (key= value=[1:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[5], offset=649, time=1648982002348)
[0] sent record (key= value=[2:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[5], offset=650, time=1648982002357)
[0] sent record (key= value=[3:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[2], offset=653, time=1648982002368)
[0] sent record (key= value=[4:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[2], offset=654, time=1648982002377)
[0] sent record (key= value=[5:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[4], offset=1566, time=1648982002386)
[0] sent record (key= value=[6:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[4], offset=1567, time=1648982002396)
[0] sent record (key= value=[7:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[7], offset=2244, time=1648982002405)
[0] sent record (key= value=[8:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[7], offset=2245, time=1648982002415)
[0] sent record (key= value=[9:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[1], offset=974, time=1648982002425)
[0] sent record (key= value=[10:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[4], offset=1568, time=1648982002436)
[0] sent record (key= value=[11:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[3], offset=1619, time=1648982002447)
[0] sent record (key= value=[12:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[0], offset=1479, time=1648982002457)
[0] sent record (key= value=[13:0] Hello Kafka 04/03/2022 12:33:22 +02:00) meta (partition=[7], offset=2246, time=1648982002469)
...
Producing all records took : 20589 ms = (20 sec)
```
On the console consumer window, we can see in the output that the data is distributed over all 8 partitions using the round robin partition strategy. This is caused by the key being `Null`.
```bash
Part-6 => :[0:0] Hello Kafka 04/03/2022 13:07:53 +02:00
Part-2 => :[1:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-4 => :[2:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-7 => :[3:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-6 => :[4:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-1 => :[5:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-2 => :[6:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-6 => :[7:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-1 => :[8:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-2 => :[9:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-6 => :[10:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-2 => :[11:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-3 => :[12:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-7 => :[13:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-3 => :[14:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-5 => :[15:0] Hello Kafka 04/03/2022 13:07:54 +02:00
Part-5 => :[16:0] Hello Kafka 04/03/2022 13:07:54 +02:00
...
```
### Produce Synchronously using the `id` field as the key
Instead of producing a `Null` key as before, let's use the `id` argument as the key. You can either change the current method or copy/paste it to a new one as we do here:
```csharp
static async Task runProducerSyncWithKey(int totalMessages, int waitMsInBetween, int id)
{
var config = new ProducerConfig { BootstrapServers = brokerList };
// Create the Kafka Producer
using (var producer = new ProducerBuilder<int, string>(config).Build())
{
for (int index = 0; index < totalMessages; index++)
{
long time = DateTimeOffset.Now.ToUnixTimeMilliseconds();
// Construct the message value
string value = "[" + index + ":" + id + "] Hello Kafka " + DateTimeOffset.Now;
// send the message to Kafka
var deliveryReport = await producer.ProduceAsync(topicName, new Message<int, string> { Key = id, Value = value });
Console.WriteLine($"[{id}] sent record (key={deliveryReport.Key} value={deliveryReport.Value}) meta (partition={deliveryReport.TopicPartition.Partition}, offset={deliveryReport.TopicPartitionOffset.Offset}, time={deliveryReport.Timestamp.UnixTimestampMs})");
Thread.Sleep(waitMsInBetween);
}
}
}
```
Change the `Main()` method to run the new method
```csharp
...
{
if (args.Length == 0) {
runProducerSyncWithKey(100, 10, 0);
} else {
runProducerSyncWithKey(int.Parse(args[0]), int.Parse(args[1]), int.Parse(args[2]));
}
}
...
```
Again use `kcat` or `kafka-console-consumer` to consume the messages from the topic `test-dotnet-topic` before starting the producer.
```bash
kcat -b kafka-1 -t test-dotnet-topic -f 'Part-%p => %k:%s\n' -q
```
Now run the producer and check the output in kafka console consumer
```bash
dotnet run --project ./producer/producer.csproj 1000 10 0
```
you can see from the log that all the message have been sent to the same partitions
```bash
[0] sent record (key=0 value=[0:0] Hello Kafka 04/03/2022 12:36:15 +02:00) meta (partition=[4], offset=1587, time=1648982175963)
[0] sent record (key=0 value=[1:0] Hello Kafka 04/03/2022 12:36:16 +02:00) meta (partition=[4], offset=1588, time=1648982176961)
[0] sent record (key=0 value=[2:0] Hello Kafka 04/03/2022 12:36:16 +02:00) meta (partition=[4], offset=1589, time=1648982176971)
[0] sent record (key=0 value=[3:0] Hello Kafka 04/03/2022 12:36:16 +02:00) meta (partition=[4], offset=1590, time=1648982176981)
[0] sent record (key=0 value=[4:0] Hello Kafka 04/03/2022 12:36:16 +02:00) meta (partition=[4], offset=1591, time=1648982176991)
[0] sent record (key=0 value=[5:0] Hello Kafka 04/03/2022 12:36:17 +02:00) meta (partition=[4], offset=1592, time=1648982177001)
[0] sent record (key=0 value=[6:0] Hello Kafka 04/03/2022 12:36:17 +02:00) meta (partition=[4], offset=1593, time=1648982177012)
[0] sent record (key=0 value=[7:0] Hello Kafka 04/03/2022 12:36:17 +02:00) meta (partition=[4], offset=1594, time=1648982177023)
[0] sent record (key=0 value=[8:0] Hello Kafka 04/03/2022 12:36:17 +02:00) meta (partition=[4], offset=1595, time=1648982177033)
[0] sent record (key=0 value=[9:0] Hello Kafka 04/03/2022 12:36:17 +02:00) meta (partition=[4], offset=1596, time=1648982177043)
[0] sent record (key=0 value=[10:0] Hello Kafka 04/03/2022 12:36:17 +02:00) meta (partition=[4], offset=1597, time=1648982177052)
...
Producing all records took : 20643 ms = (20 sec)
```
On the console consumer, we can see in the output that the data is distributed over all 8 partitions using the round robin partition strategy. This is caused by the key being `Null`.
```bash
Part-4 => :[0:0] Hello Kafka 04/03/2022 12:36:15 +02:00
Part-4 => :[1:0] Hello Kafka 04/03/2022 12:36:16 +02:00
Part-4 => :[2:0] Hello Kafka 04/03/2022 12:36:16 +02:00
Part-4 => :[3:0] Hello Kafka 04/03/2022 12:36:16 +02:00
Part-4 => :[4:0] Hello Kafka 04/03/2022 12:36:16 +02:00
Part-4 => :[5:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[6:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[7:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[8:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[9:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[10:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[11:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[12:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[13:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[14:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[15:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[16:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[17:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[18:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[19:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[20:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[21:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[22:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[23:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[24:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[25:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[26:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[27:0] Hello Kafka 04/03/2022 12:36:17 +02:00
Part-4 => :[28:0] Hello Kafka 04/03/2022 12:36:17 +02:00
...
```
### Produce Asynchronously
To produce asynchronously, we can either use the `ProduceAsync` or the `Produce` method. We first show the `ProduceAsync` method and basically adapt the version used for the synchronous produce.
To asynchronously handle delivery result notifications, we can use `Task.ContinueWith` as shown by the `runProducerASync` method:
```csharp
static void runProducerASync(int totalMessages, int waitMsInBetween, int id)
{
var config = new ProducerConfig { BootstrapServers = brokerList };
// Create the Kafka Producer
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
for (int index = 0; index < totalMessages; index++)
{
long time = DateTimeOffset.Now.ToUnixTimeMilliseconds();
// Construct the message value
string value = "[" + index + ":" + id + "] Hello Kafka " + DateTimeOffset.Now;
// send the message to Kafka
var deliveryReport = producer.ProduceAsync(topicName, new Message<Null, string> { Value = value });
deliveryReport.ContinueWith(task =>
{
if (task.IsFaulted)
{
}
else
{
Console.WriteLine($"[{id}] sent record (key={task.Result.Key} value={task.Result.Value}) meta (partition={task.Result.TopicPartition.Partition}, offset={task.Result.TopicPartitionOffset.Offset}, time={task.Result.Timestamp.UnixTimestampMs})");
}
});
Thread.Sleep(waitMsInBetween);
}
producer.Flush(TimeSpan.FromSeconds(10));
}
}
```
Change the `Main()` method to use the new method
```csharp
...
{
if (args.Length == 0) {
runProducerASync(100, 10, 0);
} else {
runProducerASync(int.Parse(args[0]), int.Parse(args[1]), int.Parse(args[2]));
}
}
...
```
Once again use `kcat` or `kafka-console-consumer` to consume the messages from the topic `test-dotnet-topic` before starting the producer.
```bash
kcat -b kafka-1 -t test-dotnet-topic -f 'Part-%p => %k:%s\n' -q
```
Now run the producer and check the output in kafka console consumer.
```bash
dotnet run --project ./producer/producer.csproj 1000 10 0
```
We can see that asynchronously the processing went down to **12 seconds** compared to the **20 seconds** it took for the synchronous way. The speed up is only because we no longer wait for the metadata before sending the next message.
```bash
[0] sent record (key= value=[16:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[7], offset=3776, time=1648984330895)
[0] sent record (key= value=[67:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[7], offset=3783, time=1648984331533)
[0] sent record (key= value=[51:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[7], offset=3780, time=1648984331340)
[0] sent record (key= value=[14:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[5], offset=1995, time=1648984330870)
[0] sent record (key= value=[28:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[5], offset=1997, time=1648984331036)
[0] sent record (key= value=[26:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[5], offset=1996, time=1648984331015)
[0] sent record (key= value=[34:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[5], offset=1998, time=1648984331116)
[0] sent record (key= value=[18:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[7], offset=3777, time=1648984330921)
[0] sent record (key= value=[35:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[7], offset=3779, time=1648984331128)
[0] sent record (key= value=[60:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[5], offset=2001, time=1648984331452)
[0] sent record (key= value=[13:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[6], offset=2977, time=1648984330857)
[0] sent record (key= value=[79:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[5], offset=2002, time=1648984331682)
[0] sent record (key= value=[70:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[7], offset=3784, time=1648984331574)
[0] sent record (key= value=[21:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[6], offset=2979, time=1648984330959)
[0] sent record (key= value=[25:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2980, time=1648984331004)
[0] sent record (key= value=[36:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2982, time=1648984331139)
[0] sent record (key= value=[30:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2981, time=1648984331062)
[0] sent record (key= value=[39:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2983, time=1648984331178)
[0] sent record (key= value=[42:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2984, time=1648984331220)
[0] sent record (key= value=[11:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[7], offset=3775, time=1648984330832)
[0] sent record (key= value=[47:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2985, time=1648984331284)
...
Producing all records took : 12978 ms = (12 sec)
```
**Note:** We will later see (after seeing how to consume) how we can increase the producer rate by enabling batching on the producer side.
As we said before, there is a second was to produce asynchronously using the `Produce` method, which takes a delivery handler delegate as a parameter. Let's add it as another method called `runProducerAsync2`
```csharp
static void runProducerASync2(int totalMessages, int waitMsInBetween, int id)
{
var config = new ProducerConfig { BootstrapServers = brokerList };
// Create the Kafka Producer
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
for (int index = 0; index < totalMessages; index++)
{
long time = DateTimeOffset.Now.ToUnixTimeMilliseconds();
// Construct the message value
string value = "[" + index + ":" + id + "] Hello Kafka " + DateTimeOffset.Now;
try
{
// send the message to Kafka
producer.Produce(topicName, new Message<Null, string> { Value = value },
(deliveryReport) =>
{
if (deliveryReport.Error.Code != ErrorCode.NoError)
{
Console.WriteLine($"Failed to deliver message: {deliveryReport.Error.Reason}");
}
else
{
Console.WriteLine($"[{id}] sent record (key={deliveryReport.Key} value={deliveryReport.Value}) meta (partition={deliveryReport.TopicPartition.Partition}, offset={deliveryReport.TopicPartitionOffset.Offset}, time={deliveryReport.Timestamp.UnixTimestampMs})");
}
});
}
catch (ProduceException<Null, string> e)
{
Console.WriteLine($"failed to deliver message: {e.Message} [{e.Error.Code}]");
}
Thread.Sleep(waitMsInBetween);
}
producer.Flush(TimeSpan.FromSeconds(10));
}
}
```
Change the `Main()` method to use the new method `runProducerAsync2`
```csharp
...
{
if (args.Length == 0) {
runProducerASync2(100, 10, 0);
} else {
runProducerASync2(int.Parse(args[0]), int.Parse(args[1]), int.Parse(args[2]));
}
}
...
```
Once again use `kcat` or `kafka-console-consumer` to consume the messages from the topic `test-dotnet-topic` before starting the producer.
```bash
kcat -b kafka-1 -t test-dotnet-topic -f 'Part-%p => %k:%s\n' -q
```
Now run the producer and check the output in kafka console consumer.
```bash
dotnet run --project ./producer/producer.csproj 1000 10 0
```
We can see that asynchronously the processing took the same **12 seconds** as with the `AsyncProduce` method.
```bash
[0] sent record (key= value=[16:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[7], offset=3776, time=1648984330895)
[0] sent record (key= value=[67:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[7], offset=3783, time=1648984331533)
[0] sent record (key= value=[51:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[7], offset=3780, time=1648984331340)
[0] sent record (key= value=[14:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[5], offset=1995, time=1648984330870)
[0] sent record (key= value=[28:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[5], offset=1997, time=1648984331036)
[0] sent record (key= value=[26:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[5], offset=1996, time=1648984331015)
[0] sent record (key= value=[34:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[5], offset=1998, time=1648984331116)
[0] sent record (key= value=[18:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[7], offset=3777, time=1648984330921)
[0] sent record (key= value=[35:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[7], offset=3779, time=1648984331128)
[0] sent record (key= value=[60:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[5], offset=2001, time=1648984331452)
[0] sent record (key= value=[13:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[6], offset=2977, time=1648984330857)
[0] sent record (key= value=[79:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[5], offset=2002, time=1648984331682)
[0] sent record (key= value=[70:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[7], offset=3784, time=1648984331574)
[0] sent record (key= value=[21:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[6], offset=2979, time=1648984330959)
[0] sent record (key= value=[25:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2980, time=1648984331004)
[0] sent record (key= value=[36:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2982, time=1648984331139)
[0] sent record (key= value=[30:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2981, time=1648984331062)
[0] sent record (key= value=[39:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2983, time=1648984331178)
[0] sent record (key= value=[42:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2984, time=1648984331220)
[0] sent record (key= value=[11:0] Hello Kafka 04/03/2022 13:12:10 +02:00) meta (partition=[7], offset=3775, time=1648984330832)
[0] sent record (key= value=[47:0] Hello Kafka 04/03/2022 13:12:11 +02:00) meta (partition=[6], offset=2985, time=1648984331284)
...
Producing all records took : 12959 ms = (12 sec)
```
As noted before, we will later see how we can increase the throughput by adding batching. But first let's see how to write a consumer in C#.
## Create a Kafka Consumer
Now let's create the consumer, which consumes the messages from the Kafka topic.
First let's create a new project
```bash
dotnet new console -o consumer
```
Again add a reference to library from the .NET Core project, by executing the following command from within the `kafka-dotnet-workspace` folder.
```bash
dotnet add consumer package Confluent.Kafka
```
Now let's add the code for consuming the messages from the Kafka topic. Navigate to the `Program.cs` C# class in the consumer project and rename it to `KafkaConsumer.cs` and then open it in the editor.
Add the following directives on the top with the class and the following two constants for the Broker List, the Topic name and the consumer group to use
```csharp
using System.Threading;
using Confluent.Kafka;
class KafkaConsumer
{
const string brokerList = "dataplatform:9092,dataplatform:9093";
const string topicName = "test-dotnet-topic";
const string groupId = "KafkaConsumerAuto";
}
```
Add the following main method to the class:
```csharp
static void Main(string[] args)
{
if (args.Length == 0)
{
runConsumerAuto(10);
}
else
{
runConsumerAuto(int.Parse(args[0]));
}
}
```
Add the following additional method for implementing the Kafka consumer. First we implement a consumer with using Auto Commit mode.
```csharp
static void runConsumerAuto(int waitMsInBetween)
{
var config = new ConsumerConfig
{
BootstrapServers = brokerList,
GroupId = groupId,
AutoOffsetReset = AutoOffsetReset.Earliest,
EnableAutoCommit = true,
AutoCommitIntervalMs = 2000
};
bool cancelled = false;
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
consumer.Subscribe(topicName);
var cancelToken = new CancellationTokenSource();
while (!cancelled)
{
var consumeResult = consumer.Consume(cancelToken.Token);
// handle message
Console.WriteLine($"Consumer Record:(Key: {consumeResult.Message.Key}, Value: {consumeResult.Message.Value} Partition: {consumeResult.TopicPartition.Partition} Offset: {consumeResult.TopicPartitionOffset.Offset}");
Thread.Sleep(waitMsInBetween);
}
consumer.Close();
}
}
```
Now run it using the `dotnet run` command. It will print the consumed messages to the console.
```
dotnet run -p ./consumer/consumer.csproj
```
Rerun one of the producers, if you need additional messages.
You can check the commits by consuming from the internal `__consumer_offsets` topic. For that we have to specify a special formatter for deserialising the commit messages.
```
docker exec -ti kafka-1 kafka-console-consumer --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --bootstrap-server kafka-1:19092 --topic __consumer_offsets
```
In the output of the consumer you can see that a commit message is issued every **5 seconds**, due to the `AutoCommitIntervalMs = 5000` setting.
```bash
[KafkaConsumerAuto,test-dotnet-topic,1]::OffsetAndMetadata(offset=9253, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648988661678, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,2]::OffsetAndMetadata(offset=6160, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648988661678, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,3]::OffsetAndMetadata(offset=3731, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648988661678, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,7]::OffsetAndMetadata(offset=4185, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648988666697, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,0]::OffsetAndMetadata(offset=4834, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648988666697, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,4]::OffsetAndMetadata(offset=5563, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648988666697, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,3]::OffsetAndMetadata(offset=3748, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648988666697, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,5]::OffsetAndMetadata(offset=2479, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648988666697, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,6]::OffsetAndMetadata(offset=3455, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648988671713, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,7]::OffsetAndMetadata(offset=4279, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648988671713, expireTimestamp=None)
```
Now let's switch from auto commit mode to manual commit.
### Kafka Consumer with Manual Commit
Create a new method `runConsumerManual` which uses the manual method to commit offsets.
We use a hardcoded value (`50`) for the commit block size, so that a commit will happen every 50 messages.
```csharp
static void runConsumerManual(int waitMsInBetween)
{
var config = new ConsumerConfig
{
BootstrapServers = brokerList,
GroupId = groupId,
EnableAutoCommit = false
};
bool cancelled = false;
int noRecordsCount = 0;
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
consumer.Subscribe(topicName);
var cancelToken = new CancellationTokenSource();
ConsumeResult<Ignore, string> consumeResult = null;
while (!cancelled)
{
consumeResult = consumer.Consume(cancelToken.Token);
noRecordsCount++;
// handle message
Console.WriteLine($"Consumer Record:(Key: {consumeResult.Message.Key}, Value: {consumeResult.Message.Value} Partition: {consumeResult.TopicPartition.Partition} Offset: {consumeResult.TopicPartitionOffset.Offset}");
Thread.Sleep(waitMsInBetween);
if (consumeResult.Offset % 50 == 0)
{
consumer.Commit(consumeResult);
}
}
// commit the rest
consumer.Commit(consumeResult);
consumer.Close();
}
}
```
Change the `Main` method to use the new `runConsumerManual` method.
```csharp
...
{
if (args.Length == 0)
{
runConsumerManual(10);
}
else
{
runConsumerManual(int.Parse(args[0]));
}
}
```
Run the program again (produce some new messages before, if you have consumed all messages in the previous run)
```bash
dotnet run -p ./consumer/consumer.csproj
```
and check the commits by consuming again from the internal `__consumer_offsets` topic.
```
docker exec -ti kafka-1 kafka-console-consumer --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --bootstrap-server kafka-1:19092 --topic __consumer_offsets
```
We can see that we clearly commit every 50 records
```bash
[KafkaConsumerAuto,test-dotnet-topic,1]::OffsetAndMetadata(offset=9301, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648989071728, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,1]::OffsetAndMetadata(offset=9351, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648989072383, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,1]::OffsetAndMetadata(offset=9401, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648989073024, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,0]::OffsetAndMetadata(offset=4901, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648989073987, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,0]::OffsetAndMetadata(offset=4951, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648989074610, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,5]::OffsetAndMetadata(offset=2551, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648989075843, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,5]::OffsetAndMetadata(offset=2601, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648989076468, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,4]::OffsetAndMetadata(offset=5601, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648989077335, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,4]::OffsetAndMetadata(offset=5651, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648989077976, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,4]::OffsetAndMetadata(offset=5701, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648989078622, expireTimestamp=None)
[KafkaConsumerAuto,test-dotnet-topic,3]::OffsetAndMetadata(offset=3801, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1648989079600, expireTimestamp=None)
```
## Using Batching with ProducerAsync
Let's see how we can add the throughput by enabling batching on producer side.
For that we have to add either one or both of `LingerMs` and `BatchSize` to the `ProducerConfig`.
Before we add it, let's see how fast we can produce by running the producer with 5x more records (`5000`) and no wait in between each produce (`waitMsInBetween = 0`).
First using the `runProducerSync` method, producing the 5000 records with no delay takes 43 seconds:
```bash
Producing all records took : 43324 ms = (43 sec)
```
Now lets run the `runProducerASync` method, first with `LingerMs` set to `0`, no batching.
```bash
var config = new ProducerConfig { BootstrapServers = brokerList, LingerMs = 0 };
```
we can see that in this case, producing is down to 1 second:
```bash
Producing all records took : 1068 ms = (1 sec)
```
Lets increase `linger.ms` to 1 second:
```bash
var config = new ProducerConfig { BootstrapServers = brokerList, LingerMs = 1000 };
```
Running it reveals the better throughput with batching, we are down to **377ms** for producing the 5000 records.
```bash
Producing all records took : 377 ms = (0 sec)
```
## Try running Producer and Consumer together
To see how scalability on the consumer side works, let's start multiple consumers consuming the records sent by the producer. Run the various consumers from a terminal window each and the producer from another one.
You should see that the consumers get the records that the producer sent.
### Three Consumers in same group and one Producer sending 25 messages
Make sure that you switch back to the first version of the producer where no key is produced (method `runProducer`). Start the consumer 3 times by executing the following command in 3 different terminal windows.
```bash
dotnet run -p ./consumer/consumer.csproj
```
and then start one of the producer which distributes the messages over all partitions:
```bash
dotnet run -p ./producer/producer.csproj 25 0 0
```
#### Producer Output
you see the 25 records being created to different partitions.
```bash
[0] sent record (key= value=[0:0] Hello Kafka 05/19/2021 21:54:44 +02:00) meta (partition=[3], offset=555, time=61)
[0] sent record (key= value=[1:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[5], offset=544, time=0)
[0] sent record (key= value=[2:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[5], offset=545, time=0)
[0] sent record (key= value=[3:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[6], offset=526, time=0)
[0] sent record (key= value=[4:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[6], offset=527, time=0)
[0] sent record (key= value=[5:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[5], offset=546, time=0)
[0] sent record (key= value=[6:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[5], offset=547, time=0)
[0] sent record (key= value=[7:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[5], offset=548, time=0)
[0] sent record (key= value=[8:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[5], offset=549, time=0)
[0] sent record (key= value=[9:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[4], offset=617, time=0)
[0] sent record (key= value=[10:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[4], offset=618, time=0)
[0] sent record (key= value=[11:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[4], offset=619, time=1)
[0] sent record (key= value=[12:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[4], offset=620, time=0)
[0] sent record (key= value=[13:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[0], offset=582, time=0)
[0] sent record (key= value=[14:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[0], offset=583, time=0)
[0] sent record (key= value=[15:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[0], offset=584, time=0)
[0] sent record (key= value=[16:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[0], offset=585, time=0)
[0] sent record (key= value=[17:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[2], offset=540, time=0)
[0] sent record (key= value=[18:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[2], offset=541, time=0)
[0] sent record (key= value=[19:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[1], offset=9765, time=0)
[0] sent record (key= value=[20:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[1], offset=9766, time=0)
[0] sent record (key= value=[21:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[0], offset=586, time=0)
[0] sent record (key= value=[22:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[0], offset=587, time=0)
[0] sent record (key= value=[23:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[7], offset=709, time=0)
[0] sent record (key= value=[24:0] Hello Kafka 05/19/2021 21:54:45 +02:00) meta (partition=[7], offset=710, time=0)
```
#### Consumer 1 Output (same consumer group)
The first consumer only consumes part of the messages, in this case from Partition 4 and 5:
```bash
Consumer Record:(Key: , Value: [5:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [4] Offset: 613
Consumer Record:(Key: , Value: [6:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [4] Offset: 614
Consumer Record:(Key: , Value: [19:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [4] Offset: 615
Consumer Record:(Key: , Value: [20:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [4] Offset: 616
Consumer Record:(Key: , Value: [13:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [5] Offset: 542
Consumer Record:(Key: , Value: [14:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [5] Offset: 543
Consumer Record:(Key: , Value: [1:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [5] Offset: 544
Consumer Record:(Key: , Value: [2:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [5] Offset: 545
Consumer Record:(Key: , Value: [5:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [5] Offset: 546
Consumer Record:(Key: , Value: [6:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [5] Offset: 547
Consumer Record:(Key: , Value: [7:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [5] Offset: 548
Consumer Record:(Key: , Value: [8:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [5] Offset: 549
Consumer Record:(Key: , Value: [9:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [4] Offset: 617
Consumer Record:(Key: , Value: [10:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [4] Offset: 618
Consumer Record:(Key: , Value: [11:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [4] Offset: 619
Consumer Record:(Key: , Value: [12:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [4] Offset: 620
```
#### Consumer 2 Output (same consumer group)
The second consumer consumes the messages from Partition 6 and 7:
```bash
Consumer Record:(Key: , Value: [7:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [7] Offset: 705
Consumer Record:(Key: , Value: [8:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [7] Offset: 706
Consumer Record:(Key: , Value: [9:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [7] Offset: 707
Consumer Record:(Key: , Value: [10:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [7] Offset: 708
Consumer Record:(Key: , Value: [11:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [6] Offset: 522
Consumer Record:(Key: , Value: [12:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [6] Offset: 523
Consumer Record:(Key: , Value: [23:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [6] Offset: 524
Consumer Record:(Key: , Value: [24:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [6] Offset: 525
Consumer Record:(Key: , Value: [3:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [6] Offset: 526
Consumer Record:(Key: , Value: [4:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [6] Offset: 527
Consumer Record:(Key: , Value: [23:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [7] Offset: 709
Consumer Record:(Key: , Value: [24:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [7] Offset: 710
```
#### Consumer 3 Output (same consumer group)
And the third consumer consumes the message from Partition 0 and 1
```bash
Consumer Record:(Key: , Value: [3:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [1] Offset: 9763
Consumer Record:(Key: , Value: [4:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [1] Offset: 9764
Consumer Record:(Key: , Value: [1:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [0] Offset: 578
Consumer Record:(Key: , Value: [2:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [0] Offset: 579
Consumer Record:(Key: , Value: [15:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [0] Offset: 580
Consumer Record:(Key: , Value: [16:0] Hello Kafka 05/19/2021 21:54:00 +02:00 Partition: [0] Offset: 581
Consumer Record:(Key: , Value: [13:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [0] Offset: 582
Consumer Record:(Key: , Value: [14:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [0] Offset: 583
Consumer Record:(Key: , Value: [15:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [0] Offset: 584
Consumer Record:(Key: , Value: [16:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [0] Offset: 585
Consumer Record:(Key: , Value: [19:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [1] Offset: 9765
Consumer Record:(Key: , Value: [20:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [1] Offset: 9766
Consumer Record:(Key: , Value: [21:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [0] Offset: 586
Consumer Record:(Key: , Value: [22:0] Hello Kafka 05/19/2021 21:54:45 +02:00 Partition: [0] Offset: 587
```
### Three Consumers in same group and one Producer sending 10 messages using key
Switch the producer to use the method with key (`runProducerSyncWithKey`). Start the consumer 3 times by executing the following command in 3 different terminal windows.
```bash
dotnet run -p ./consumer/consumer.csproj
```
and then start the producer (using 10 for the ID)
```
dotnet run -p ./producer/producer.csproj 25 0 10
```
#### Producer Output
```
[0] sent record (key=0 value=[0:0] Hello Kafka 05/19/2021 22:25:51 +02:00) meta (partition=[1], offset=12532, time=51)
[0] sent record (key=0 value=[1:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12533, time=0)
[0] sent record (key=0 value=[2:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12534, time=0)
[0] sent record (key=0 value=[3:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12535, time=0)
[0] sent record (key=0 value=[4:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12536, time=0)
[0] sent record (key=0 value=[5:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12537, time=0)
[0] sent record (key=0 value=[6:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12538, time=0)
[0] sent record (key=0 value=[7:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12539, time=1)
[0] sent record (key=0 value=[8:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12540, time=0)
[0] sent record (key=0 value=[9:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12541, time=0)
[0] sent record (key=0 value=[10:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12542, time=0)
[0] sent record (key=0 value=[11:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12543, time=0)
[0] sent record (key=0 value=[12:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12544, time=0)
[0] sent record (key=0 value=[13:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12545, time=0)
[0] sent record (key=0 value=[14:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12546, time=0)
[0] sent record (key=0 value=[15:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12547, time=0)
[0] sent record (key=0 value=[16:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12548, time=0)
[0] sent record (key=0 value=[17:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12549, time=0)
[0] sent record (key=0 value=[18:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12550, time=0)
[0] sent record (key=0 value=[19:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12551, time=0)
[0] sent record (key=0 value=[20:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12552, time=0)
[0] sent record (key=0 value=[21:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12553, time=0)
[0] sent record (key=0 value=[22:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12554, time=0)
[0] sent record (key=0 value=[23:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12555, time=0)
[0] sent record (key=0 value=[24:0] Hello Kafka 05/19/2021 22:25:52 +02:00) meta (partition=[1], offset=12556, time=0)
```
#### Consumer 1 Output (same consumer group)
```
Consumer Record:(Key: , Value: [0:0] Hello Kafka 05/19/2021 22:25:51 +02:00 Partition: [1] Offset: 12532
Consumer Record:(Key: , Value: [1:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12533
Consumer Record:(Key: , Value: [2:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12534
Consumer Record:(Key: , Value: [3:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12535
Consumer Record:(Key: , Value: [4:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12536
Consumer Record:(Key: , Value: [5:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12537
Consumer Record:(Key: , Value: [6:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12538
Consumer Record:(Key: , Value: [7:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12539
Consumer Record:(Key: , Value: [8:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12540
Consumer Record:(Key: , Value: [9:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12541
Consumer Record:(Key: , Value: [10:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12542
Consumer Record:(Key: , Value: [11:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12543
Consumer Record:(Key: , Value: [12:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12544
Consumer Record:(Key: , Value: [13:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12545
Consumer Record:(Key: , Value: [14:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12546
Consumer Record:(Key: , Value: [15:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12547
Consumer Record:(Key: , Value: [16:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12548
Consumer Record:(Key: , Value: [17:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12549
Consumer Record:(Key: , Value: [18:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12550
Consumer Record:(Key: , Value: [19:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12551
Consumer Record:(Key: , Value: [20:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12552
Consumer Record:(Key: , Value: [21:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12553
Consumer Record:(Key: , Value: [22:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12554
Consumer Record:(Key: , Value: [23:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12555
Consumer Record:(Key: , Value: [24:0] Hello Kafka 05/19/2021 22:25:52 +02:00 Partition: [1] Offset: 12556
```
#### Consumer 2 Output (same consumer group)
nothing consumed
#### Consumer 3 Output (same consumer group)
nothing consumed
<file_sep># Kong decK
decK helps manage Kong’s configuration in a declarative fashion. This means that a developer can define the desired state of Kong Gateway or Konnect – services, routes, plugins, and more – and let decK handle implementation without needing to execute each step manually, as you would with the Kong Admin API.
**[Website](https://konghq.com/products/api-gateway-platform)** | **[Documentation](https://docs.konghq.com/deck/latest/)** | **[GitHub](https://github.com/kong/deck/)**
## How to enable?
```
platys init --enable-services KONG KONG_DECK
platys gen
```
## How to use it?
```bash
docker exec -ti kong-deck deck
```<file_sep># Kafka Connect
Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka® and other data systems. It makes it simple to quickly define connectors that move large data sets into and out of Kafka.
**[Website](http://kafka.apache.org)** | **[Documentation](https://kafka.apache.org/documentation/#connectapi)** | **[GitHub](https://github.com/apache/kafka)**
## How to enable?
```
platys init --enable-services KAFKA,KAFKA_CONNECT
platys gen
```
## How to use it?<file_sep># LakeFS
Git-like capabilities for your object storage.
**[Website](https://lakefs.io/)** | **[Documentation](https://docs.lakefs.io/)** | **[GitHub](https://github.com/treeverse/lakeFS)**
## How to enable?
```
platys init --enable-services LAKEFS, MINIO, POSTGRESQL
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28220>
Login with username `V42FCGRVMK24JJ8DHUYG` and password `<PASSWORD>` (if left to defaults).
<file_sep>Place the kafka topic description files here.<file_sep>---
technoglogies: streamsets
version: 1.13.0
validated-at: 6.7.2021
---
# Support StreamSets Data Collector Activation
This recipe will show how to support activation of StreamSets Data Collector in persistent and replayable way.
The problem with the activation of StreamSets is, that an activation code is given for a given `SDC ID` (a.k.a product id). If you restart the StreamSets Data Collector container, everything is fine, but if you stop, remove and recrate the container, a new `SDC ID` is generated and you have to re-activate StreamSets.
This recipe shows, how the `SDC ID` can be fixed to a value, so that recreating a container won't change it.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services STREAMSETS -s trivadis/platys-modern-data-platform -w 1.13.0
```
Edit the `config.yml` and add the following configuration settings.
```
STREAMSETS_http_authentication: 'form'
STREAMSETS_sdc_id: ''
```
Now generate data platform
```
platys gen
```
and then start the platform:
```
docker-compose up -d
```
## Activate StreamSets
Navigate to <http://172.26.121.207:18630> and login with **user** set to `admin` and **password** set to `<PASSWORD>`.
Click on **Enter a Code** and on the **Activation** page click on **Back**. The **Register** page should be shown.

Fill out all the fields and click on **Agree to Terms and Register**.
Check your email inbox, after a short while you should get and email with an Activation Code.
Copy the section within `--------SDC ACTIVATION CODE--------` (example below has been tampered, so it is no longer usable)
```
--------SDC ACTIVATION CODE--------
xcv<KEY>
--------SDC ACTIVATION CODE--------
```
and paste it into the **Activation Code** field on the **Activation** screen. Take note of the product id shown above the **Activation Code** (will use that in the next section).

Make sure that you replace both `SDC ACTIVATION CODE` with `SDC ACTIVATION KEY` and click on **Activate**. The window should close and on another pop-up dialog you should be able to click on **Reload** to finish activation of StreamSets.
## Fix SDC ID to the value used for the Activation
Now we will enter the `SDC ID` (product id) into the `config.yml` so that it "surrive" a container stop and remove.
To get the right value, you can check the log or use the value from the Activation page before.
To retrieve it from the log, perform
```
docker-compose logs -f streamsets-1 | grep "SDC ID"
```
you should see an output similar to the one below
```
docker@ubuntu:~/platys-cookbook$ docker-compose logs -f streamsets-1 | grep "SDC ID"
streamsets-1 | 2021-07-06 19:49:59,955 [user:] [pipeline:] [runner:] [thread:main] [stage:]
INFO Main - SDC ID : 577164ca-de93-11eb-818c-892d3b5f064a
```
Copy the SDC ID info `577164ca-de93-11eb-818c-892d3b5f064a` and paste it into the `STREAMSETS_sdc_id` of the `config.yml`.
```
STREAMSETS_sdc_id: '577164ca-de93-11eb-818c-892d3b5f064a'
```
Regenerate the stack
```
platys gen
```
restart docker-compose
```
docker-compose up -d
```
and the follwing output should be shown on the console
```
Recreating streamsets-1 ...
wetty is up-to-date
Recreating streamsets-1 ... done
Starting markdown-renderer ... done
```
As you can see, the `streamsets-1` container will be re-created, using the same `SDC ID` as before.
When reloading the StreamSets UI, you will have to re-activate, but you can now use the exact same Activation Code as before.
<file_sep># OpenTelemetry Collector
The OpenTelemetry Collector offers a vendor-agnostic implementation on how to receive, process and export telemetry data. In addition, it removes the need to run, operate and maintain multiple agents/collectors in order to support open-source telemetry data formats (e.g. Jaeger, Prometheus, etc.) sending to multiple open-source or commercial back-ends.
**[Website](https://opentelemetry.io/)** | **[Documentation](https://opentelemetry.io/docs/collector/)** | **[GitHub](https://github.com/open-telemetry/opentelemetry-collector)**
## How to enable?
```
platys init --enable-services OTEL_COLLECTOR
platys gen
```
## How to use it?
OLTP receiver is listening on Port `4317` and recives data via gRPC or HTTP using [OTLP](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/protocol/otlp) format.
```
"-javaagent:/tmp/opentelemetry-javaagent.jar -Dotel.exporter.otlp.endpoint=otel-collector:4317"
```
<file_sep># DataHub
Data ecosystems are diverse — too diverse. DataHub's extensible metadata platform enables data discovery, data observability and federated governance that helps you tame this complexity.
**[Website](https://datahubproject.io/)** | **[Documentation](https://datahubproject.io/docs/)** | **[GitHub](https://github.com/linkedin/datahub)**
## How to enable?
```
platys init --enable-services DATAHUB
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28144> and log in with user `datahub` and password `<PASSWORD>`.
### How to change the password of the `datahub`user?
Create a file `user.props` in `./security/datahub` and add a line with `datahub:<password>`
```
datahub:abc123!
```
Enable the mapping of `user.props` into the docker container
```yaml
DATAHUB_map_user_props: true
```
and re-run `platys gen`.
<file_sep>---
technoglogies: tipboard,kafka
version: 1.14.0
validated-at: 28.11.2021
---
# Working with Tipboard and Kafka
This recipe will show how to use Tipboard with Kafka to stream data to the dashboard.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services TIPBOARD,KAFKA,KSQLDB,AKHQ,KCAT -n cookbook-platform -s trivadis/platys-modern-data-platform -w 1.14.0
```
edit the `config.yml` and add the connector to the following property
```
TIPBOARD_volume_map_dashboards: true
TIPBOARD_redis_password: '<PASSWORD>!'
```
start the platform
```
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Create the Tipboard Layout
Create a file `layout_config.yaml` in the `scripts/tipboard` folder
```
details:
page_title: Sample Dashboard
layout:
- row_1_of_2:
- col_1_of_2:
- tile_template: text
tile_id: Status
title: Status
classes:
- col_1_of_2:
- tile_template: empty
tile_id: empty
title: Empty Tile
classes:
- row_1_of_2:
- col_1_of_4:
- tile_template: empty
tile_id: empty
title: Empty Tile
classes:
- col_1_of_4:
- tile_template: empty
tile_id: empty
title: Empty Tile
classes:
- col_1_of_4:
- tile_template: empty
tile_id: empty
title: Empty Tile
classes:
- col_1_of_4:
- tile_template: empty
tile_id: empty
title: Empty Tile
classes:
```
## Create a Kafka topic and simulate values
Create a Kafka topic
```bash
docker exec -ti kafka-1 kafka-topics --bootstrap-server kafka-1:19092 --create --topic sensor-readings --replication-factor 3 --partitions 3
```
Create the simulator definition
```bash
mkdir simulator-conf
nano simulator-conf/devices-def.json
```
```json
[
{
"type":"simple",
"uuid":"",
"topic":"sensor-readings",
"sampling":{"type":"fixed", "interval":1000},
"copy":10,
"sensors":[
{"type":"dev.timestamp", "name":"ts", "format":"yyyy-MM-dd'T'HH:mm:ss.SSSZ"},
{"type":"dev.uuid", "name":"uuid"},
{"type":"double_walk", "name":"temp", "min":-15, "max":3},
{"type":"double_cycle", "name":"level", "values": [1.1,3.2,8.3,9.4]},
{"type":"string", "name":"level", "random": ["a","b","c","d","e","f","g","h","i","j","k","l","m","n","o"]}
]
}
]
```
Run the simulator
```bash
docker run --network cookbook-platform -v $PWD/simulator-conf/devices-def.json:/conf/devices-def.json trivadis/iot-simulator -dt KAFKA -u kafka-1:19092 -t iot/ -cf /conf/devices-def.json
```
<file_sep># Burrow UI
A frontend UI for Kafka cluster monitoring with Burrow.
**[Website](https://github.com/GeneralMills/BurrowUI)** | **[Documentation](https://github.com/GeneralMills/BurrowUI)** | **[GitHub](https://github.com/GeneralMills/BurrowUI)**
## How to enable?
```
platys init --enable-services KAFKA,BURROW,BURROW_UI
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28258><file_sep>[client-profile.platys]
kafka-version="2.8.0"
client-id="burrow-client"
[cluster.local]
client-profile="platys"
class-name="kafka"
servers=[ "kafka-1:19092","kafka-2:19093" ]
topic-refresh=60
offset-refresh=30
groups-reaper-refresh=30
[zookeeper]
servers=[ "zookeeper-1:2181" ]
timeout=6
root-path="/burrow"
[consumer.local]
class-name="kafka"
client-profile="platys"
cluster="local"
servers=[ "kafka-1:19092" ]
group-denylist="^(console-consumer-|python-kafka-consumer-).*$"
group-allowlist=".*"
[consumer.local_zk]
class-name="kafka_zk"
cluster="local"
servers=[ "zookeeper-1:2181" ]
zookeeper-path=""
zookeeper-timeout=30
group-denylist="^(console-consumer-|python-kafka-consumer-).*$"
group-allowlist=""
[httpserver.default]
address=":8000"
[storage.default]
class-name="inmemory"
workers=20
intervals=15
expire-group=604800
min-distance=1<file_sep>package com.trivadis.kafkaws.springbootkafkastreams.simple;
import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.test.TestUtils;
import org.junit.jupiter.api.*;
import java.util.Properties;
import java.util.UUID;
import java.util.function.Function;
import static org.assertj.core.api.Assertions.assertThat;
public class KafkaStreamsRunnerDSLTest {
private TopologyTestDriver testDriver;
private static final String INPUT_TOPIC = "input-topic";
private static final String OUTPUT_TOPIC = "output-topic";;
private TestInputTopic inputTopic;
private TestOutputTopic outputTopic;
final Serde<String> stringSerde = Serdes.String();
final Serde<Void> voidSerde = Serdes.Void();
public static Properties getStreamsConfig(final String applicationId,
final String bootstrapServers,
final String keySerdeClassName,
final String valueSerdeClassName,
final Properties additional) {
final Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, applicationId);
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, keySerdeClassName);
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, valueSerdeClassName);
props.put(StreamsConfig.STATE_DIR_CONFIG, TestUtils.tempDirectory().getPath());
// props.put(StreamsConfig.METRICS_RECORDING_LEVEL_CONFIG, "DEBUG");
props.putAll(additional);
return props;
}
public static Properties getStreamsConfig(final Serde<?> keyDeserializer,
final Serde<?> valueDeserializer) {
return getStreamsConfig(
UUID.randomUUID().toString(),
"localhost:9091",
keyDeserializer.getClass().getName(),
valueDeserializer.getClass().getName(),
new Properties());
}
/**
* Setup Stream topology
* Add KStream based on @StreamListener annotation
* Add to(topic) based @SendTo annotation
*/
@BeforeEach
public void setup() {
final StreamsBuilder builder = new StreamsBuilder();
buildStreamProcessingPipeline(builder);
final Properties props = getStreamsConfig(Serdes.Void(), Serdes.String());
testDriver = new TopologyTestDriver(builder.build(), props);
inputTopic = testDriver.createInputTopic(INPUT_TOPIC, voidSerde.serializer(), stringSerde.serializer());
outputTopic = testDriver.createOutputTopic(OUTPUT_TOPIC, voidSerde.deserializer(), stringSerde.deserializer());
}
private void buildStreamProcessingPipeline(StreamsBuilder builder) {
KStream<Void, String> input = builder.stream(INPUT_TOPIC, Consumed.with(voidSerde, stringSerde));
KafkaStreamsRunnerDSL app = new KafkaStreamsRunnerDSL();
final Function<KStream<Void, String>, KStream<Void, String>> process = app.process();
final KStream<Void, String> output = process.apply(input);
output.to(OUTPUT_TOPIC, Produced.with(voidSerde, stringSerde));
}
@AfterEach
public void tearDown() {
try {
testDriver.close();
} catch (RuntimeException e) {
// https://issues.apache.org/jira/browse/KAFKA-6647 causes exception when executed in Windows, ignoring it
// Logged stacktrace cannot be avoided
System.out.println("Ignoring exception, test failing in Windows due this exception:" + e.getLocalizedMessage());
}
}
@Test
void shouldUpperCase() {
final Void voidKey = null;
String KEY = null;
inputTopic.pipeInput(voidKey, "Hello", 1L);
final Object output = outputTopic.readValue();
// assert that the output has a value
assertThat(output).isNotNull();
assertThat(output).isEqualTo("HELLO");
// no more data in topic
assertThat(outputTopic.isEmpty()).isTrue();
}
@Test
void shouldUpperCase2() {
final Void voidKey = null;
String KEY = null;
inputTopic.pipeInput(voidKey, "Hello", 1L);
final Object output = outputTopic.readValue();
// assert that the output has a value
assertThat(output).isNotNull();
assertThat(output).isEqualTo("HELLO");
// no more data in topic
assertThat(outputTopic.isEmpty()).isTrue();
}
}
<file_sep>#!/bin/bash
# Pre-runner for Data Collector.
# Restores registration
# Installs any missing stage libraries
echo
echo "$(date -Iseconds) Entering: $0"
echo
set -e
# Install dockerize
DOCKERIZE_VERSION=v0.6.1
wget https://github.com/jwilder/dockerize/releases/download/$DOCKERIZE_VERSION/dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \
&& sudo tar -C /usr/local/bin -xzvf dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz \
&& sudo rm dockerize-linux-amd64-$DOCKERIZE_VERSION.tar.gz
# Install SDC sample pipelines
if [ -z "${SDC_INSTALL_PIPELINES_FROM}" ]
then
echo "INFO: No sample pipelines to install. SDC_INSTALL_PIPELINES_FROM not configured."
elif [ ! -d "${SDC_INSTALL_PIPELINES_FROM}" ]
then
echo "ERROR: SDC_INSTALL_PIPELINES_FROM did not specify a folder. SDC_INSTALL_PIPELINES_FROM=${SDC_INSTALL_PIPELINES_FROM}"
else
echo "Installing sample pipelines ${SDC_INSTALL_PIPELINES_FROM}/*"
# Recurse. And do not copy if the file is older.
cp -r -u "${SDC_INSTALL_PIPELINES_FROM}"/* "${SDC_DIST}/samplePipelines/"
fi
# Prepare the working folder
rm -fr /tmp/libraries-extracted
mkdir -p /tmp/libraries-extracted # Temporary path to extract files into
BASE_URL=https://archives.streamsets.com/datacollector
SDC_VERSION=${SDC_VERSION:=${SDC_DIST##*-}} # If SDC_VERSION is not specified then extract it from the path
echo
if [ -z "${SDC_INSTALL_STAGES}" ]
then
echo "INFO: No stages to install. SDC_INSTALL_STAGES not configured."
else
echo "Installing stages specified by environment variable SDC_INSTALL_STAGES"
echo ---------------------------
for stage in ${SDC_INSTALL_STAGES//[,;]/ }
do
if [ ! -d "${SDC_DIST}/streamsets-libs/${stage}" ]
then
echo "Installing stage library ${stage}"
if [ -d /tmp/sdc_stagecache -a ! -f /tmp/sdc_stagecache/${stage}-${SDC_VERSION}.tgz ]
then
# Cache directory exists and this stage isn't there. Download it.
echo "...Downloading to cache and then installing"
wget -q -T 30 -O /tmp/sdc_stagecache/${stage}-${SDC_VERSION}.tgz ${BASE_URL}/${SDC_VERSION}/tarball/${stage}-${SDC_VERSION}.tgz
fi
if [ -d /tmp/sdc_stagecache -a -f /tmp/sdc_stagecache/${stage}-${SDC_VERSION}.tgz ]
then
# Cache directory exists and this stage is there. Use the cache.
tar -xzf /tmp/sdc_stagecache/${stage}-${SDC_VERSION}.tgz -C /tmp/libraries-extracted
else
# Download and extract at the same time
wget -q -T 30 -O - ${BASE_URL}/${SDC_VERSION}/tarball/${stage}-${SDC_VERSION}.tgz | tar -xz -C /tmp/libraries-extracted
fi
mv /tmp/libraries-extracted/streamsets-datacollector-*/streamsets-libs/* "${SDC_DIST}/streamsets-libs/" || true # Will not overwrite and will ignore errors
else
echo "Stage already installed ${stage}"
fi
done
echo
fi
echo
if [ -z "${SDC_INSTALL_ENTERPRISE_STAGES}" ]
then
echo "INFO: No enterprise stages to install. SDC_INSTALL_ENTERPRISE_STAGES not configured."
else
echo "Installing enterprise stages specified by environment variable SDC_INSTALL_ENTERPRISE_STAGES"
echo ---------------------------
for stage in ${SDC_INSTALL_ENTERPRISE_STAGES//[,;]/ }
do
stage_without_version=${stage%-*}
if [ ! -d "${SDC_DIST}/streamsets-libs/${stage_without_version}" ]
then
echo "Installing enterprise stage library ${stage}"
if [ -d /tmp/sdc_stagecache -a ! -f /tmp/sdc_stagecache/${stage}.tgz ]
then
# Cache directory exists and this stage isn't there. Download it.
echo "...Downloading to cache and then installing"
wget -q -T 30 -O /tmp/sdc_stagecache/${stage}.tgz ${BASE_URL}/latest/tarball/enterprise/${stage}.tgz
fi
if [ -d /tmp/sdc_stagecache -a -f /tmp/sdc_stagecache/${stage}.tgz ]
then
# Cache directory exists and this stage is there. Use the cache.
tar -xzf /tmp/sdc_stagecache/${stage}.tgz -C /tmp/libraries-extracted
else
# Download and extract at the same time
wget -q -T 30 -O - ${BASE_URL}/latest/tarball/enterprise/${stage}.tgz | tar -xz -C /tmp/libraries-extracted
fi
mv /tmp/libraries-extracted/streamsets-libs/* "${SDC_DIST}/streamsets-libs/" || true # Will not overwrite and will ignore errors
else
echo "Stage already installed ${stage}"
fi
done
fi
echo
echo 'List of stages installed in ${SDC_DIST}/streamsets-libs'
ls -l "${SDC_DIST}/streamsets-libs"
echo
# We translate environment variables to sdc.properties and rewrite them.
set_dpm_conf() {
if [ $# -ne 2 ]; then
echo "set_conf requires two arguments: <key> <value>"
exit 1
fi
if [ -z "$SDC_CONF" ]; then
echo "SDC_CONF is not set."
exit 1
fi
grep -q "^$1" ${SDC_CONF}/dpm.properties && sed 's|^#\?\('"$1"'=\).*|\1'"$2"'|' -i ${SDC_CONF}/dpm.properties || echo -e "\n$1=$2" >> ${SDC_CONF}/dpm.properties
}
for e in $(env); do
key=${e%=*}
value=${e#*=}
if [[ $key == DPM_CONF_* ]]; then
lowercase=$(echo $key | tr '[:upper:]' '[:lower:]')
key=$(echo ${lowercase#*dpm_conf_} | sed 's|_|.|g')
set_dpm_conf $key $value
fi
done
#if [ ! -z "${SCH_REGISTRATION_URL}" ]
#then
# SCH_REGISTRATION_URL
# SCH_AUTHENTICATION_TOKEN
# SCH_SDC_INSTANCE_ID
#fi
if [ -n "${PLATYS_SDC_ID}" ]
then
echo 'write the configured SDC_ID (${PLATYS_SDC_ID}) to the sdc.id file'
echo "${PLATYS_SDC_ID}" > $SDC_DATA/sdc.id
fi
echo "$(date -Iseconds) Exiting: $0"
exec /docker-entrypoint.sh "$@"
<file_sep># Kafka WebView
Full-featured web-based Apache Kafka consumer UI.
**[Documentation](https://github.com/SourceLabOrg/kafka-webview)** | **[GitHub](https://github.com/SourceLabOrg/kafka-webview)**
## How to enable?
```
platys init --enable-services KAFKA_WEBVIEW
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28274>.
<file_sep>---
technoglogies: streamsets
version: 1.16.0
validated-at: 26.11.2022
---
# Using Dev Simulator Origin to simulate streaming data
This recipe shows how to use the StreamSets Dev Simulator Origin to simulate event data taken from one or more CSV files. Each CSV row must contain a timestamp which tells the simulator when to publish the data.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services STREAMSETS,KAFKA,KAFKA_AKHQ,KCAT -s trivadis/platys-modern-data-platform -w 1.16.0
```
Edit the `config.yml` and add the following configuration settings.
```
STREAMSETS_stage_libs: 'streamsets-datacollector-apache-kafka_2_7-lib'
```
Now generate data platform and download the Streamsets Custom origin to the right folder.
```
platys gen
```
Download and unpack the Dev Simulator custom origin
```
cd plugins/streamsets/user-libs
wget https://github.com/TrivadisPF/streamsets-dev-simulator/releases/download/0.8.2/dev-simulator-0.8.2.tar.gz
tar -xvzf dev-simulator-0.8.2.tar.gz
rm dev-simulator-0.8.2.tar.gz
cd ../../..
```
Download the data and unpack into `data-transfer` folder
```
cd data-transfer
wget https://github.com/TrivadisPF/platys-modern-data-platform/raw/master/cookbooks/recipes/using-dev-simulator-origin/cookbook-data.tar.gz
tar -xvzf cookbook-data.tar.gz
rm cookbook-data.tar.gz
```
Start the platform:
```
docker-compose up -d
```
You can find the StreamSets pipelines of this cookbook recipe in the folder `streamsets`.
All samples write the data to a Kafka topic called `streamsets-simulator`. You need to create that first, either through the graphical UI **AKHQ** or using the command line:
```bash
docker exec -ti kafka-1 kafka-topics --create --bootstrap-server kafka-1:19092 --topic streamsets-simulator
```
To consume from it, use `kcat` as shown here:
```bash
docker exec -ti kcat kcat -b kafka-1:19092 -t streamsets-simulator -q -o end
```
The data written to Kafka also include the `EventTimestamp` field as a string as well as the start timestamp formatted as string.
## Using Relative from Anchor Time
When using the **Relative from Anchor Time** mode, the anchor is representing the start of the simulation and all the timestamp of the rows of the input file(s) are relative to that anchor. The following diagram represents the data of the input files shown below.

### File without header row (01)
The following examples shows the simulator used for a file without a header row and with the timestamp resolution of second.
`relative-anchor-without-header.csv`
```
1,10,1
5,10,2
10,10,3
15,10,4
20,10,5
```
Streamsets Pipeline: `01 - RelativeAnchorTimeWithoutHeader`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `relative-anchor-without-header.csv`
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Relative from Anchor Timestamp`
* **Timestamp Field:** `/0`
* **Relative Time Resolution:** `seconds`
* **Anchor Time is Now?:** `true`
* **Data Format**
* **Header Line:** `No Header Line`
The output on `kcat` should show these events
```bash
{"0":"1","1":"10","2":"1","EventTimestamp":1669533859458,"EventTimestampString":"07:24:19","StartEventTimestampString":"07:24:18"}
{"0":"5","1":"10","2":"2","EventTimestamp":1669533863458,"EventTimestampString":"07:24:23","StartEventTimestampString":"07:24:18"}
{"0":"10","1":"10","2":"3","EventTimestamp":1669533868458,"EventTimestampString":"07:24:28","StartEventTimestampString":"07:24:18"}
{"0":"15","1":"10","2":"4","EventTimestamp":1669533873458,"EventTimestampString":"07:24:33","StartEventTimestampString":"07:24:18"}
{"0":"20","1":"10","2":"5","EventTimestamp":1669533878458,"EventTimestampString":"07:24:38","StartEventTimestampString":"07:24:18"}
```
### File without header and milliseconds (02)
The following examples shows the simulator used for a file without a header row and with the timestamp resolution of milli-seconds.
`relative-anchor-without-header-millisec.csv`
```
1000,10,1
5000,10,2
10000,10,3
15000,10,4
20000,10,5
```
Streamsets: `02 - RelativeAnchorTimeWithoutHeaderMillisec`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `relative-anchor-without-header-millisec.csv`
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Relative from Anchor Timestamp`
* **Timestamp Field:** `/0`
* **Relative Time Resolution:** `milliseconds`
* **Anchor Time is Now?:** `true`
* **Data Format**
* **Header Line:** `No Header Line`
The output on `kcat` should show these events
```bash
{"0":"1000","1":"10","2":"1","EventTimestamp":1669533981035,"EventTimestampString":"07:26:21","StartEventTimestampString":"07:26:20"}
{"0":"5000","1":"10","2":"2","EventTimestamp":1669533985035,"EventTimestampString":"07:26:25","StartEventTimestampString":"07:26:20"}
{"0":"10000","1":"10","2":"3","EventTimestamp":1669533990035,"EventTimestampString":"07:26:30","StartEventTimestampString":"07:26:20"}
{"0":"15000","1":"10","2":"4","EventTimestamp":1669533995035,"EventTimestampString":"07:26:35","StartEventTimestampString":"07:26:20"}
{"0":"20000","1":"10","2":"5","EventTimestamp":1669534000035,"EventTimestampString":"07:26:40","StartEventTimestampString":"07:26:20"}
```
### File without header and milliseconds with decimals (03)
The following examples shows the simulator used for a file without a header row and with the timestamp resolution of milli-seconds with decimals.
`relative-anchor-without-header-millisec-decimals.csv`
```
1000.10,10,1
5000.11,10,2
10000.12,10,3
15000.00,10,4
20000.50,10,5
```
Streamsets: `03 - RelativeAnchorTimeWithoutHeaderMillisecDecimals`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `relative-anchor-without-header-millisec.csv`
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Relative from Anchor Timestamp`
* **Timestamp Field:** `/0`
* **Relative Time Resolution:** `milliseconds`
* **Anchor Time is Now?:** `true`
* **Data Format**
* **Header Line:** `No Header Line`
The output on `kcat` should show these events
```bash
{"0":"1000.10","1":"10","2":"1","EventTimestamp":1669534946098,"EventTimestampString":"07:42:26","StartEventTimestampString":"07:42:25"}
{"0":"5000.11","1":"10","2":"2","EventTimestamp":1669534950098,"EventTimestampString":"07:42:30","StartEventTimestampString":"07:42:25"}
{"0":"10000.12","1":"10","2":"3","EventTimestamp":1669534955098,"EventTimestampString":"07:42:35","StartEventTimestampString":"07:42:25"}
{"0":"15000.00","1":"10","2":"4","EventTimestamp":1669534960098,"EventTimestampString":"07:42:40","StartEventTimestampString":"07:42:25"}
{"0":"20000.50","1":"10","2":"5","EventTimestamp":1669534965099,"EventTimestampString":"07:42:45","StartEventTimestampString":"07:42:25"}
```
### File with header (04)
The following examples shows the simulator used for a file with a header row and with the timestamp resolution of second.
Input File: `relative-anchor-with-header.csv`
```
time,id,value
1,10,1
5,10,2
10,10,3
15,10,4
20,10,5
```
Streamsets: `04 - RelativeAnchorTimeWithHeader`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `relative-anchor-with-header.csv`
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Relative from Anchor Timestamp`
* **Timestamp Field:** `/time`
* **Relative Time Resolution:** `seconds`
* **Anchor Time is Now?:** `true`
* **Data Format**
* **Header Line:** `With Header Line`
The output on `kcat` should show these events
```bash
{"time":"1","id":"10","value":"1","EventTimestamp":1669535057050,"EventTimestampString":"07:44:17","StartEventTimestampString":"07:44:16"}
{"time":"5","id":"10","value":"2","EventTimestamp":1669535061050,"EventTimestampString":"07:44:21","StartEventTimestampString":"07:44:16"}
{"time":"10","id":"10","value":"3","EventTimestamp":1669535066050,"EventTimestampString":"07:44:26","StartEventTimestampString":"07:44:16"}
{"time":"15","id":"10","value":"4","EventTimestamp":1669535071050,"EventTimestampString":"07:44:31","StartEventTimestampString":"07:44:16"}
{"time":"20","id":"10","value":"5","EventTimestamp":1669535076050,"EventTimestampString":"07:44:36","StartEventTimestampString":"07:44:16"}
```
### with header and empty values to remove (05)
The following examples shows the simulator used for a file with a header row and with some empty values.
Input File: `relative-anchor-with-header-and-empty-values.csv` `
```
time,id,value,emptyval1,emptyval2
1,10,1,,
5,10,2,A,
10,10,3,,
15,10,4,A,
20,10,5,,
```
Streamsets: `05 - RelativeAnchorTimeWithHeaderAndEmptyValues`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `relative-anchor-with-header-and-empty-values.csv`
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Relative from Anchor Timestamp`
* **Timestamp Field:** `/time`
* **Relative Time Resolution:** `seconds`
* **Anchor Time is Now?:** `true`
* **Data Format**
* **Header Line:** `With Header Line`
* **Remove Empty Fields**: `true`
The output on `kcat` should show these events
```bash
{"time":"1","id":"10","value":"1","EventTimestamp":1669535156643,"EventTimestampString":"07:45:56","StartEventTimestampString":"07:45:55"}
{"time":"5","id":"10","value":"2","emptyval1":"A","EventTimestamp":1669535160643,"EventTimestampString":"07:46:00","StartEventTimestampString":"07:45:55"}
{"time":"10","id":"10","value":"3","EventTimestamp":1669535165643,"EventTimestampString":"07:46:05","StartEventTimestampString":"07:45:55"}
{"time":"15","id":"10","value":"4","emptyval1":"A","EventTimestamp":1669535170643,"EventTimestampString":"07:46:10","StartEventTimestampString":"07:45:55"}
{"time":"20","id":"10","value":"5","EventTimestamp":1669535175643,"EventTimestampString":"07:46:15","StartEventTimestampString":"07:45:55"}
```
## Using Relative from Anchor Time with Fast Forward
When using the **Relative from Anchor Time with Fast Forward** mode, the anchor is representing the start of the simulation and all the timestamp of the rows of the input file(s) are relative to that anchor. The fast forward parameter represents the time-span to move the start-time from the anchor.
The following diagram represents the data of the input files shown below and a fast forward by a time span of 10 seconds.

### File without header row (06)
The following examples shows the simulator used for a file without a header row and with the timestamp resolution of second.
`relative-anchor-without-header.csv`
```
1,10,1
5,10,2
10,10,3
15,10,4
20,10,5
```
Streamsets: `06 - RelativeAnchorTimeWithoutHeaderAndFastForward`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `relative-anchor-without-header.csv`
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Relative from Anchor Timestamp`
* **Timestamp Field:** `/0`
* **Relative Time Resolution:** `seconds`
* **Anchor Time is Now?:** `true`
* **Fast forward in data:** `true`
* **Fast forward by time span:** `10`
* **Skip initial time span:** `false`
* **Data Format**
* **Header Line:** `No Header Line`
The output on `kcat` should show these events
```bash
{"0":"1","1":"10","2":"1","EventTimestamp":1669535420759,"EventTimestampString":"07:50:20","StartEventTimestampString":"07:50:29"}
{"0":"5","1":"10","2":"2","EventTimestamp":1669535424759,"EventTimestampString":"07:50:24","StartEventTimestampString":"07:50:29"}
{"0":"10","1":"10","2":"3","EventTimestamp":1669535429759,"EventTimestampString":"07:50:29","StartEventTimestampString":"07:50:29"}
{"0":"15","1":"10","2":"4","EventTimestamp":1669535434759,"EventTimestampString":"07:50:34","StartEventTimestampString":"07:50:29"}
{"0":"20","1":"10","2":"5","EventTimestamp":1669535439759,"EventTimestampString":"07:50:39","StartEventTimestampString":"07:50:29"}
```
## Using Relative from Anchor Time with Fast Forward and skip
When using the **Relative from Anchor Time with Fast Forward** mode, the anchor is representing the start of the simulation and all the timestamp of the rows of the input file(s) are relative to that anchor. The fast forward parameter represents the time-span to move the start-time from the anchor.
The following diagram represents the data of the input files shown below and a fast forward by a time span of 10 seconds.

### File without header row (07)
The following examples shows the simulator used for a file without a header row and with the timestamp resolution of second.
`relative-anchor-without-header.csv`
```
1,10,1
5,10,2
10,10,3
15,10,4
20,10,5
```
Streamsets: `07 - RelativeAnchorTimeWithoutHeaderAndFastForwardWithSkip`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `relative-anchor-without-header.csv`
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Relative from Anchor Timestamp`
* **Timestamp Field:** `/0`
* **Relative Time Resolution:** `seconds`
* **Anchor Time is Now?:** `true`
* **Fast forward in data:** `true`
* **Fast forward by time span:** `10`
* **Skip initial time span:** `true`
* **Data Format**
* **Header Line:** `No Header Line`
The output on `kcat` should show these events
```bash
{"0":"10","1":"10","2":"3","EventTimestamp":1669535597195,"EventTimestampString":"07:53:17","StartEventTimestampString":"07:53:17"}
{"0":"15","1":"10","2":"4","EventTimestamp":1669535602195,"EventTimestampString":"07:53:22","StartEventTimestampString":"07:53:17"}
{"0":"20","1":"10","2":"5","EventTimestamp":1669535607195,"EventTimestampString":"07:53:27","StartEventTimestampString":"07:53:17"}
```
## Using Relative from Previous Event
When using the **Relative from Previous event** mode, the the timestamp of the row is relative to the timestamp of the previous row.
The following diagram represents the data of the input files shown.

### File with header (08)
The following examples shows the simulator used for a file with a header row and where the timestamps are relative to the timestamp of the previous row.
Input File: `relative-previous-event-with-header.csv`
```
time,id,value
1,10,1
4,10,2
5,10,3
5,10,4
5,10,5
```
Streamsets: `08 - RelativePrevEventTimeWithHeader`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `relative-previous-event-with-header.csv `
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Relative from Previous Event`
* **Timestamp Field:** `/time`
* **Relative Time Resolution:** `seconds`
* **Anchor Time is Now?:** `true`
* **Data Format**
* **Header Line:** `With Header Line`
The output on `kcat` should show these events
```bash
{"time":"1","id":"10","value":"1","EventTimestamp":1669535653884,"EventTimestampString":"07:54:13","StartEventTimestampString":"07:54:12"}
{"time":"4","id":"10","value":"2","EventTimestamp":1669535657884,"EventTimestampString":"07:54:17","StartEventTimestampString":"07:54:12"}
{"time":"5","id":"10","value":"3","EventTimestamp":1669535662884,"EventTimestampString":"07:54:22","StartEventTimestampString":"07:54:12"}
{"time":"5","id":"10","value":"4","EventTimestamp":1669535667884,"EventTimestampString":"07:54:27","StartEventTimestampString":"07:54:12"}
{"time":"5","id":"10","value":"5","EventTimestamp":1669535672884,"EventTimestampString":"07:54:32","StartEventTimestampString":"07:54:12"}
```
## Using Relative from Anchor - with multiple record types in same file
When using the **Relative from Anchor with multiple record types** mode, then the rows with the data do not contain uniform record but different record types.
### File without header (09)
The following examples shows the simulator used for a file without a header row and with multiple records types in the same file.
`relative-anchor-without-header-with-muliple-types-one-file.csv`
```
0,A,10,1
5,A,10,2
10,A,10,3
11,B,10,4
15,B,10,5
17,A,10,3
```
Streamsets: `09 - RelativeAnchorTimeWithoutHeaderMultiTypeOneFile`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `relative-anchor-without-header-with-muliple-types-one-file.csv`
* **Different Record Types?:** `true`
* **Event Time**
* **Timestamp Mode:** `Relative from Anchor Timestamp`
* **Timestamp Field:** `/0`
* **Relative Time Resolution:** `seconds`
* **Anchor Time is Now?:** `true`
* **Multi Record Types**
* **Data Types:**
* **Descriminator value 1:** `A`
* **Descriminator value 2:** `B`
* **Descriminator field:** `/1`
* **Data Format**
* **Header Line:** `No Header Line`
The output on `kcat` should show these events
```bash
{"time":"1","id":"10","value":"1","EventTimestamp":1669535653884,"EventTimestampString":"07:54:13","StartEventTimestampString":"07:54:12"}
{"time":"4","id":"10","value":"2","EventTimestamp":1669535657884,"EventTimestampString":"07:54:17","StartEventTimestampString":"07:54:12"}
{"time":"5","id":"10","value":"3","EventTimestamp":1669535662884,"EventTimestampString":"07:54:22","StartEventTimestampString":"07:54:12"}
{"time":"5","id":"10","value":"4","EventTimestamp":1669535667884,"EventTimestampString":"07:54:27","StartEventTimestampString":"07:54:12"}
{"time":"5","id":"10","value":"5","EventTimestamp":1669535672884,"EventTimestampString":"07:54:32","StartEventTimestampString":"07:54:12"}
```
### File with header (10)
The following examples shows the simulator used for a file with a header row .
`relative-anchor-with-header-with-muliple-types-one-file.csv`
```csv
time,descriminator,id,value
0,A,10,1
5,A,10,2
10,A,10,3
11,B,10,4
15,B,10,5
17,A,10,3
```
Streamsets: `10 - RelativeAnchorTimeWithHeaderMultiTypeOneFile `
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `relative-anchor-with-header-with-muliple-types-one-file.csv`
* **Different Record Types?:** `true`
* **Event Time**
* **Timestamp Mode:** `Relative from Anchor Timestamp`
* **Timestamp Field:** `/time`
* **Relative Time Resolution:** `seconds`
* **Anchor Time is Now?:** `true`
* **Multi Record Types**
* **Data Types:**
* **Descriminator value 1:** `A`
* **Descriminator value 2:** `B`
* **Descriminator field:** `/descriminator`
* **Data Format**
* **Header Line:** `With Header Line`
The output on `kcat` should show these events
```bash
{"time":"0","descriminator":"A","id":"10","value":"1","EventTimestamp":1669535921514,"EventTimestampString":"07:58:41","StartEventTimestampString":"07:58:41","type":"A"}
{"time":"5","descriminator":"A","id":"10","value":"2","EventTimestamp":1669535926514,"EventTimestampString":"07:58:46","StartEventTimestampString":"07:58:41","type":"A"}
{"time":"10","descriminator":"A","id":"10","value":"3","EventTimestamp":1669535931514,"EventTimestampString":"07:58:51","StartEventTimestampString":"07:58:41","type":"A"}
{"time":"11","descriminator":"B","id":"10","value":"4","EventTimestamp":1669535932514,"EventTimestampString":"07:58:52","StartEventTimestampString":"07:58:41","type":"B"}
{"time":"15","descriminator":"B","id":"10","value":"5","EventTimestamp":1669535936514,"EventTimestampString":"07:58:56","StartEventTimestampString":"07:58:41","type":"B"}
{"time":"17","descriminator":"A","id":"10","value":"3","EventTimestamp":1669535938514,"EventTimestampString":"07:58:58","StartEventTimestampString":"07:58:41","type":"A"}
```
## Using Relative from Anchor - with multiple record types in file per type
When using the **Relative from Anchor with multiple record types in file per type** mode, then the rows with the data do not contain uniform record but different record types, but they are in different files, one file per record type.
### File with header (11)
The following examples shows the simulator used for a file with a header row and with multiple records types, one file for each type.
`relative-anchor-with-header-with-muliple-types-fileA.csv`
```csv
time,descriminator,id,value
11,B,10,4
15,B,10,5
```
`relative-anchor-with-header-with-muliple-types-fileB.csv`
```csv
time,descriminator,id,value
0,A,10,1
5,A,10,2
10,A,10,3
17,A,10,3
```
Streamsets: `11 - RelativeAnchorTimeWithHeaderMultiTypeMultiFile`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `relative-anchor-with-header-with-muliple-types-file*.csv`
* **Different Record Types?:** `true`
* **Event Time**
* **Timestamp Mode:** `Relative from Anchor Timestamp`
* **Timestamp Field:** `/time`
* **Relative Time Resolution:** `seconds`
* **Anchor Time is Now?:** `true`
* **Multi Record Types**
* **Data Types:**
* **Descriminator value 1:** `A`
* **Descriminator value 2:** `B`
* **Descriminator field:** `/descriminator`
* **Data Format**
* **Header Line:** `With Header Line`
The output on `kcat` should show these events
```bash
{"time":"0","descriminator":"A","id":"10","value":"1","EventTimestamp":1669536246778,"EventTimestampString":"08:04:06","StartEventTimestampString":"08:04:06","type":"A"}
{"time":"5","descriminator":"A","id":"10","value":"2","EventTimestamp":1669536251778,"EventTimestampString":"08:04:11","StartEventTimestampString":"08:04:06","type":"A"}
{"time":"10","descriminator":"A","id":"10","value":"3","EventTimestamp":1669536256778,"EventTimestampString":"08:04:16","StartEventTimestampString":"08:04:06","type":"A"}
{"time":"11","descriminator":"B","id":"10","value":"4","EventTimestamp":1669536257778,"EventTimestampString":"08:04:17","StartEventTimestampString":"08:04:06","type":"B"}
{"time":"15","descriminator":"B","id":"10","value":"5","EventTimestamp":1669536261778,"EventTimestampString":"08:04:21","StartEventTimestampString":"08:04:06","type":"B"}
{"time":"17","descriminator":"A","id":"10","value":"3","EventTimestamp":1669536263778,"EventTimestampString":"08:04:23","StartEventTimestampString":"08:04:06","type":"A"}
```
## Using Absolute
When using the **Absolute** mode, a file with absolute timestamp is used and the earliest timestamp is used for the start timestamp.
The following diagram represents the data of the input files shown.

### File without header (12)
The following examples shows the simulator used for a file without a header row and with absolute timestamps.
`absolute-without-header.csv`
```
2021-11-16T09:00:01+0100,10,1
2021-11-16T09:00:05+0100,10,2
2021-11-16T09:00:10+0100,10,3
2021-11-16T09:00:15+0100,10,3
2021-11-16T09:00:20+0100,10,3
```
`2021-11-16T09:00:01` will be used for the start timestamp.
Streamsets: `12 - AbsoluteTimeWithoutHeader`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `absolute-without-header.csv`
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Absolute`
* **Timestamp Field:** `/0`
* **Timestamp Format:** `yyyy-MM-dd'T'HH:mm:ssZ`
* **Data Format**
* **Header Line:** `No Header Line`
The output on `kcat` should show these events
```bash
{"0":"2021-11-16T09:00:01+0100","1":"10","2":"1","EventTimestamp":1637049601000,"EventTimestampString":"2021-11-16 08:00:01","StartEventTimestampString":"08:00:01"}
{"0":"2021-11-16T09:00:05+0100","1":"10","2":"2","EventTimestamp":1637049605000,"EventTimestampString":"2021-11-16 08:00:05","StartEventTimestampString":"08:00:01"}
{"0":"2021-11-16T09:00:10+0100","1":"10","2":"3","EventTimestamp":1637049610000,"EventTimestampString":"2021-11-16 08:00:10","StartEventTimestampString":"08:00:01"}
{"0":"2021-11-16T09:00:15+0100","1":"10","2":"3","EventTimestamp":1637049615000,"EventTimestampString":"2021-11-16 08:00:15","StartEventTimestampString":"08:00:01"}
{"0":"2021-11-16T09:00:20+0100","1":"10","2":"3","EventTimestamp":1637049620000,"EventTimestampString":"2021-11-16 08:00:20","StartEventTimestampString":"08:00:01"}
```
### File without header and millisecond timestamps (13)
The following examples shows the simulator used for a file without a header row and with absolute timestamps in milliseconds.
`absolute-millisecond-without-header.csv`
```
2021-11-16T09:00:01.001+0100,10,1
2021-11-16T09:00:01.011+0100,10,1
2021-11-16T09:00:01.021+0100,10,1
2021-11-16T09:00:01.031+0100,10,1
2021-11-16T09:00:01.041+0100,10,1
2021-11-16T09:00:01.061+0100,10,1
2021-11-16T09:00:01.081+0100,10,1
2021-11-16T09:00:02.001+0100,10,1
2021-11-16T09:00:02.011+0100,10,1
2021-11-16T09:00:02.021+0100,10,1
2021-11-16T09:00:02.031+0100,10,1
2021-11-16T09:00:02.041+0100,10,1
2021-11-16T09:00:02.061+0100,10,1
2021-11-16T09:00:02.081+0100,10,1
```
Streamsets: `13 - AbsoluteTimeWithoutHeaderMillisec`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `absolute-millisecond-without-header.csv`
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Absolute`
* **Timestamp Field:** `/0`
* **Other Date Format:** `yyyy-MM-dd'T'HH:mm:ss.SSSZ`
* **Data Format**
* **Header Line:** `No Header Line`
The output on `kcat` should show these events
```bash
{"0":"2021-11-16T09:00:01.001+0100","1":"10","2":"1","EventTimestamp":1637049601001,"EventTimestampString":"2021-11-16 08:00:01.001","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:01.011+0100","1":"10","2":"1","EventTimestamp":1637049601011,"EventTimestampString":"2021-11-16 08:00:01.011","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:01.021+0100","1":"10","2":"1","EventTimestamp":1637049601021,"EventTimestampString":"2021-11-16 08:00:01.021","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:01.031+0100","1":"10","2":"1","EventTimestamp":1637049601031,"EventTimestampString":"2021-11-16 08:00:01.031","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:01.041+0100","1":"10","2":"1","EventTimestamp":1637049601041,"EventTimestampString":"2021-11-16 08:00:01.041","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:01.061+0100","1":"10","2":"1","EventTimestamp":1637049601061,"EventTimestampString":"2021-11-16 08:00:01.061","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:01.081+0100","1":"10","2":"1","EventTimestamp":1637049601081,"EventTimestampString":"2021-11-16 08:00:01.081","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:02.001+0100","1":"10","2":"1","EventTimestamp":1637049602001,"EventTimestampString":"2021-11-16 08:00:02.001","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:02.011+0100","1":"10","2":"1","EventTimestamp":1637049602011,"EventTimestampString":"2021-11-16 08:00:02.011","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:02.021+0100","1":"10","2":"1","EventTimestamp":1637049602021,"EventTimestampString":"2021-11-16 08:00:02.021","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:02.031+0100","1":"10","2":"1","EventTimestamp":1637049602031,"EventTimestampString":"2021-11-16 08:00:02.031","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:02.041+0100","1":"10","2":"1","EventTimestamp":1637049602041,"EventTimestampString":"2021-11-16 08:00:02.041","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:02.061+0100","1":"10","2":"1","EventTimestamp":1637049602061,"EventTimestampString":"2021-11-16 08:00:02.061","StartEventTimestampString":"08:00:01.001"}
{"0":"2021-11-16T09:00:02.081+0100","1":"10","2":"1","EventTimestamp":1637049602081,"EventTimestampString":"2021-11-16 08:00:02.081","StartEventTimestampString":"08:00:01.001"}
```
## Using Absolute with Start Timestamp earlier than first Event
When using the **Absolute with Start Timestamp earlier than first Event** mode, a start timestamp is specified which is before for equal to the first timestamp in the data. The start timestamp specified is used as the start time for the simulation
The following diagram represents the data of the input files shown.

### File without header (14)
The following examples shows the simulator used for a file without a header row and with absolute timestamps.
`absolute-without-header.csv`
```
2021-11-16T09:00:01+0100,10,1
2021-11-16T09:00:05+0100,10,2
2021-11-16T09:00:10+0100,10,3
2021-11-16T09:00:15+0100,10,3
2021-11-16T09:00:20+0100,10,3
```
Streamsets: `14 - AbsoluteTimeWithoutHeaderAndStartTimeEarlierFirstEvent`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `absolute-without-header.csv`
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Absolute with Start Timestamp`
* **Timestamp Field:** `/0`
* **Timestamp Format:** `yyyy-MM-dd'T'HH:mm:ssZ`
* **Simulation Start Timestamp:** `2021-11-16T08:59:50+0100`
* **Simulation Start Timestamp Format** `yyyy-MM-dd'T'HH:mm:ssZ`
* **Data Format**
* **Header Line:** `No Header Line`
The output on `kcat` should show these events
```bash
{"0":"2021-11-16T09:00:01+0100","1":"10","2":"1","EventTimestamp":1637049601000,"EventTimestampString":"2021-11-16 08:00:01","StartEventTimestampString":"07:59:50"}
{"0":"2021-11-16T09:00:05+0100","1":"10","2":"2","EventTimestamp":1637049605000,"EventTimestampString":"2021-11-16 08:00:05","StartEventTimestampString":"07:59:50"}
{"0":"2021-11-16T09:00:10+0100","1":"10","2":"3","EventTimestamp":1637049610000,"EventTimestampString":"2021-11-16 08:00:10","StartEventTimestampString":"07:59:50"}
{"0":"2021-11-16T09:00:15+0100","1":"10","2":"3","EventTimestamp":1637049615000,"EventTimestampString":"2021-11-16 08:00:15","StartEventTimestampString":"07:59:50"}
{"0":"2021-11-16T09:00:20+0100","1":"10","2":"3","EventTimestamp":1637049620000,"EventTimestampString":"2021-11-16 08:00:20","StartEventTimestampString":"07:59:50"}
```
## Using Absolute with Start Timestamp later than first event
When using the **Absolute with Start Timestamp** mode with a timestamp which is later than the first event, then all the rows with a timestamp lower/earlier than this timestamp **will be skipped**.
The following diagram represents the data of the input files shown.

### File without header (15)
The following examples shows the simulator used for a file without a header row and with absolute timestamps.
`absolute-without-header.csv`
```
2021-11-16T09:00:01+0100,10,1
2021-11-16T09:00:05+0100,10,2
2021-11-16T09:00:10+0100,10,3
2021-11-16T09:00:15+0100,10,3
2021-11-16T09:00:20+0100,10,3
```
Streamsets: `15 - AbsoluteTimeWithoutHeaderAndStartTimeLaterFirstEvent`
Dev Simulator Properties (only the ones which have to change from the defaults):
* **Files**
* **Files Directory:** `/data-transfer/cookbook-data`
* **File Name Pattern:** `absolute-without-header.csv`
* **Different Record Types?:** `false`
* **Event Time**
* **Timestamp Mode:** `Absolute with Start Timestamp`
* **Timestamp Field:** `/0`
* **Timestamp Format:** `yyyy-MM-dd'T'HH:mm:ssZ`
* **Simulation Start Timestamp:** `2021-11-16T09:00:07+0100`
* **Simulation Start Timestamp Format** `yyyy-MM-dd'T'HH:mm:ssZ`
* **Data Format**
* **Header Line:** `No Header Line`
The output on `kcat` should show 3 events
```bash
{"0":"2021-11-16T09:00:10+0100","1":"10","2":"3","EventTimestamp":1637049610000,"EventTimestampString":"2021-11-16 08:00:10","StartEventTimestampString":"08:00:07"}
{"0":"2021-11-16T09:00:15+0100","1":"10","2":"3","EventTimestamp":1637049615000,"EventTimestampString":"2021-11-16 08:00:15","StartEventTimestampString":"08:00:07"}
{"0":"2021-11-16T09:00:20+0100","1":"10","2":"3","EventTimestamp":1637049620000,"EventTimestampString":"2021-11-16 08:00:20","StartEventTimestampString":"08:00:07"}
```<file_sep># Log4brains
Log and publish your architecture decisions (ADR)
**[Documentation](https://github.com/thomvaill/log4brains)** | **[GitHub](https://github.com/thomvaill/log4brains)**
## How to enable?
```
platys init --enable-services LOG4BRAINS
platys gen
```
## How to use it?
Navigate to <http://dataplatform:4004>.
<file_sep>---
technoglogies: trino,postgresql
version: 1.11.0
validated-at: 20.3.2021
---
# Querying data in Postgresql from Trino (formerly PrestoSQL)
This tutorial will show how to query Postgresql table from Trino.
## Initialise a platform
First [initialise a platys-supported data platform](../../getting-started.md) with the following services enabled
```
platys init --enable-services TRINO,POSTGRESQL,ADMINER,PROVISIONING_DATA -s trivadis/platys-modern-data-platform -w 1.11.0
```
add the follwing property to `config.yml`
```
TRINO_edition: 'oss'
```
Now set an environment variable to the home folder of the dataplatform and generate and then start the data platform.
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Create Table in Postgresql
```
docker exec -ti postgresql psql -d demodb -U demo
```
```
CREATE SCHEMA flight_data;
DROP TABLE flight_data.airport_t;
CREATE TABLE flight_data.airport_t
(
iata character varying(50) NOT NULL,
airport character varying(50),
city character varying(50),
state character varying(50),
country character varying(50),
lat float,
long float,
CONSTRAINT airport_pk PRIMARY KEY (iata)
);
```
```
COPY flight_data.airport_t(iata,airport,city,state,country,lat,long)
FROM '/data-transfer/flight-data/airports.csv' DELIMITER ',' CSV HEADER;
```
```
SELECT * FROM flight_data.airport_t LIMIT 20;
```
## Query Table from Trino
Next let's query the data from Trino. Connect to the Trino CLI using
```
docker exec -it trino-cli trino --server trino-1:8080
```
Now on the Presto command prompt, switch to the right database.
```
use postgresql.flight_data;
```
Let's see that there is one table available:
```
show tables;
```
We can see the `airport_t` table we created in the Hive Metastore before
```
presto:default> show tables;
Table
---------------
airport_t
(1 row)
```
```
SELECT * FROM airport_t;
```
```
SELECT country, count(*)
FROM airport_t
GROUP BY country;
```
<file_sep>Contains the sys of prometheus node exporter service, if flag PROMETHEUS_volume_map_data is set to true.<file_sep># Custom UDF and ksqlDB
This recipe will show how to use a custom UDF with ksqlDB. We will see a "normal" UDF in action, which is a stateless function working on scalar value. Besides the UDFs, you can also create stateful aggregate functions (UDAFs) and table functions (UDTFs). Find more information on these 3 types of user-defined functions in the [ksqlDB documentation](https://docs.ksqldb.io/en/latest/concepts/functions/).
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started.md) with the following services enabled
```bash
platys init --enable-services KAFKA,KAFKA_KSQLDB -s trivadis/platys-modern-data-platform -w 1.9.1
```
Now set an environment variable to the home folder of the dataplatform and generate and then start the data platform.
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Create the UDF
You can find the complete Java project in the subfolder [ksql-udf-string](./ksql-udf-string).
Add the following to the `~/.m2/settings.xml`:
```xml
<settings>
<profiles>
<profile>
<id>myprofile</id>
<repositories>
<!-- Confluent releases -->
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
<!-- further repository entries here -->
</repositories>
</profile>
</profiles>
<activeProfiles>
<activeProfile>myprofile</activeProfile>
</activeProfiles>
</settings>
```
Run the following command to create a new Maven project:
```bash
mvn archetype:generate -X \
-DarchetypeGroupId=io.confluent.ksql \
-DarchetypeArtifactId=ksqldb-udf-quickstart \
-DarchetypeVersion=6.0.0
```
Fill out the arguments being prompted for.
Add the following dependency to the POM:
```xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.11</version>
</dependency>
```
Create a Java package `com.trivadis.ksql.demo` and in it create the following Java class:
```java
package com.trivadis.ksql.demo;
import io.confluent.ksql.function.udf.Udf;
import io.confluent.ksql.function.udf.UdfDescription;
import io.confluent.ksql.function.udf.UdfParameter;
import org.apache.commons.lang3.StringUtils;
@UdfDescription(name = "del_whitespace", description = "Deletes all whitespaces from a String")
public class StringUDF {
@Udf(description = "Deletes all whitespaces from a String")
public String adjacentHash(@UdfParameter(value="string", description = "the string to apply the function on") String value) {
return StringUtils.deleteWhitespace(value);
}
}
```
Build the Java project using
```
mvn clean package
```
Inside the `target` folder, a jar named `ksql-udf-string-1.0-jar-with-dependencies.jar` should be created.
## Copy the JAR to the ksqlDB engine folder
When working with Platys, the `target/ksql-udf-string-1.0-jar-with-dependencies.jar` JAR file has to be copied into the folder `$DATAPLATFORM_HOME/plugins/ksql`, from where it will be picked-up by the kqlDB engine.
Restart the ksqldb servers using
```
docker restart ksqldb-server-1
docker restart ksqldb-server-2
```
If you have more than 2 servers running, do it for the other ones as well.
## Test the UDF
Now let's see our UDF in action. For that let's connect to ksqlDB CLI
```bash
docker exec -it ksqldb-cli ksql http://ksqldb-server-1:8088
```
And show all functions
```
show functions;
```
Besides the built-in functions, our new UDF called `del_whitespace` should show up as well.
Let's create a new Stream backed by a topic, just for doing a `SELECT ...` to test the UDF
```
CREATE STREAM test_s (v1 VARCHAR)
WITH (kafka_topic='test',
value_format='JSON',
partitions=8,
replicas=3);
```
Let's call the UDF inside a `SELECT ... EMIT CHANGES`
```
SELECT del_whitespace(v1)
FROM test_s
EMIT CHANGES;
```
To see it working, we have to publish some data into the topic. The simplest way to do that is using an `INSERT INTO ...` from an other ksqlDB CLI.
```
INSERT INTO test_s VALUES ('<NAME>');
```
You should see the result in the previous ksqlDB CLI
```
ksql> select del_whitespace(v1) from test_s emit changes;
+-----------------------------------------------------------------------------------------------------------------+
|KSQL_COL_0 |
+-----------------------------------------------------------------------------------------------------------------+
|GuidoSchmutz |
Press CTRL-C to interrupt
```
<file_sep># Keycloak
Open Source Identity and Access Management For Modern Applications and Services.
**[Website](https://www.keycloak.org/)** | **[Documentation](https://www.keycloak.org/documentation)** | **[GitHub](https://github.com/keycloak/keycloak)**
## How to enable?
```
platys init --enable-services KEYCLOAK
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28204>
## How to export data from a realm
Replace `<realm-name>` by the name of the realm to export:
```bash
docker exec -it keycloak /opt/jboss/keycloak/bin/keycloak-export.sh <realm-name>
```
<file_sep><project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trivadis.kafkaws</groupId>
<artifactId>java-kafka-jsonschema</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<kafka.version>3.3.0</kafka.version>
<confluent.version>7.3.1</confluent.version>
<java.version>11</java.version>
<slf4j-version>1.7.5</slf4j-version>
<!-- use utf-8 encoding -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-json-schema-serializer</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j-version}</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>github-releases</id>
<url>http://oss.sonatype.org/content/repositories/github-releases/</url>
</repository>
<repository>
<id>clojars.org</id>
<url>http://clojars.org/repo</url>
</repository>
<repository>
<id>local-maven-repo</id>
<url>file:///${project.parent.basedir}/local-maven-repo</url>
</repository>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</pluginRepository>
</pluginRepositories>
<build>
<defaultGoal>install</defaultGoal>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5</version>
<configuration>
<source>11</source>
<target>11</target>
<maxmem>256M</maxmem>
<showDeprecation>true</showDeprecation>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<id>producer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.producer.KafkaProducerJson</mainClass>
</configuration>
</execution>
<execution>
<id>consumer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.consumer.KafkaConsumerJson</mainClass>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.jsonschema2pojo</groupId>
<artifactId>jsonschema2pojo-maven-plugin</artifactId>
<version>1.2.1</version>
<configuration>
<sourceDirectory>${basedir}/src/main/jsonschema/</sourceDirectory>
<targetPackage>com.trivadis.types</targetPackage>
<generateBuilders>true</generateBuilders>
<includeRequiredPropertiesConstructor>true</includeRequiredPropertiesConstructor>
</configuration>
<executions>
<execution>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-maven-plugin</artifactId>
<version>${confluent.version}</version>
<configuration>
<schemaRegistryUrls>
<param>http://${DATAPLATFORM_IP}:8081</param>
</schemaRegistryUrls>
<schemaTypes>
<test-java-json-topic-value>JSON</test-java-json-topic-value>
</schemaTypes>
<subjects>
<test-java-json-topic-value>src/main/jsonschema/Notification-v1.json</test-java-json-topic-value>
</subjects>
</configuration>
<goals>
<goal>register</goal>
<goal>test-compatibility</goal>
</goals>
</plugin>
</plugins>
</build>
</project><file_sep># Hue
Open source SQL Query Assistant service for Databases/Warehouses.
**[Website](https://gethue.com//)** | **[Documentation](https://gethue.com/)** | **[GitHub](https://github.com/cloudera/hue)**
## How to enable?
```
platys init --enable-services HUE
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8888><file_sep>module TestGo
go 1.20
require github.com/confluentinc/confluent-kafka-go v1.9.2
<file_sep># Spark Thriftserver
Thrift JDBC/ODBC Server (aka Spark Thrift Server or STS) is Spark SQL’s port of Apache Hive’s HiveServer2 that allows JDBC/ODBC clients to execute SQL queries over JDBC and ODBC protocols on Apache Spark.
**[Website](https://spark.apache.org/)** | **[Documentation](https://spark.apache.org/docs/latest/sql-distributed-sql-engine.html#running-the-thrift-jdbcodbc-server)** | **[GitHub](https://github.com/apache/spark/tree/master/sql/hive-thriftserver)**
## How to enable?
```
platys init --enable-services SPARK,SPARK_THRIFTSERVER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28298> to view the Thriftserver UI.
### Connect with Beeline
Start beeline
```bash
docker exec -ti spark-thriftserver /spark/bin/beeline
```
and connect to Spark Thrift Server (enter blank for username and password)
```bash
!connect jdbc:hive2://spark-thriftserver:10000
```
### Connect with JDBC
Download Hive JDBC Driver 3.1.2 (standalone) from [here](https://repo.maven.apache.org/maven2/org/apache/hive/hive-jdbc/3.1.2/hive-jdbc-3.1.2-standalone.jar).
Use `jdbc:hive2://dataplatform:28118` (external) or `jdbc:hive2://spark-thriftserver:10000` (internal) for the JDBC URL and use `org.apache.hive.jdbc.HiveDriver` for the class name.
<file_sep>---
technologies: nifi,python
version: 1.16.0
validated-at: 6.3.2023
---
# NiFi ExecuteScript Processor with Python
This recipe will show how to use NiFi with Python.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```bash
export DATAPLATFORM_HOME=${PWD}
platys init --enable-services NIFI -s trivadis/platys-modern-data-platform -w 1.16.0
```
Before we can generate the platform, we need to extend the `config.yml`:
```
NIFI_python_enabled: true
NIFI_python_provide_requirements_file: true
NIFI_python_version: 3.10
```
We set enable the python environment (will switch to a custom Docker image extending the official NiFi image with python) and specify to provide additional Python modules with a `requirements.txt` file.
Save the file and generate and start the data platform.
```bash
platys gen
```
## Create the `requirements.txt` file
The `requirements.txt` file has to be created in `./custom-conf/nifi` folder of the platform.
Edit the file
```bash
nano ./custom-conf/nifi/requirments.txt`
```
and add the following module
```bash
XXXX
```
Now start the platform
```bash
docker-compose up -d
```
and once it is running navigate to the NiFi UI: <https://dataplatform:18080/nifi>.<file_sep># IoT Vehicle Tracking Workshop
In this workshop we will be ingesting data not directly into Kafka but rather through MQTT first. We will be using a fictitious Trucking company with a fleet of trucks constantly providing some data about the moving vehicles.
The following diagram shows the setup of the data flow we will be implementing.

We will show the implementation step-by-step. For the streaming analytics step we will see different solutions:
* [IoT Data Ingestion through MQTT into Kafka](../13a-iot-data-ingestion-over-mqtt)
* Stream Analytics
* [Stream Analytics using ksqlDB](../13b-stream-analytics-using-ksql)
* [Stream Analytcis with Java using Kafka Streams](../13c-stream-analytics-using-java-kstreams)
* [Stream Analytics using Streamiz](../13d-stream-analytics-using-dotnet-streamiz)
* [Stream Analytics using Spark Structured Streaming](../13e-stream-analytics-using-spark-structured-streaming)
* [Static Data Ingestion into Kafka](../13f-static-data-ingestion)
<file_sep>Contains the data of dataverse service, if flag DATAVERSE_volume_map_data is set to true.<file_sep># Kafka Data Platform on Docker
The environment for this course is completely based on docker containers.
In order to simplify the provisioning, a single docker-compose configuration is used. All the necessary software will be provisioned using Docker.
For Kafka we will be using the Docker images provided by Confluent and available under the following GitHub project: <https://github.com/confluentinc/cp-docker-images>. In this project, there is an example folder with a few different docker compose configuration for various Confluent Platform configurations.
You have the following options to start the environment:
* [**Local Virtual Machine Environment**](./LocalVirtualMachine.md) - a Virtual Machine with Docker and Docker Compose pre-installed will be distributed at by the course infrastructure. You will need 50 GB free disk space.
* [**Local Docker Environment**](./LocalDocker.md) - you have a local Docker and Docker Compose setup in place which you want to use
* [**AWS Lightsail Environment**](./Lightsail.md) - AWS Lightsail is a service in Amazon Web Services (AWS) with which we can easily startup an environment and provide all the necessary bootstrapping as a script.
## Post Provisioning
These steps are necessary after the starting the docker environment.
### Add entry to local `/etc/hosts` File
To simplify working with the Data Platform and for the links below to work, add the following entry to your local `/etc/hosts` file.
```
192.168.127.12 dataplatform
```
Replace the IP address by the public IP address of the docker host.
<file_sep># cAdvisor
Analyzes resource usage and performance characteristics of running containers.
**[Documentation](https://github.com/google/cadvisor)** | **[GitHub](https://github.com/google/cadvisor)**
## How to enable?
```
platys init --enable-services CADVISOR
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28138><file_sep># Quix
An easy-to-use notebook manager.
**[Website](https://wix.github.io/quix/)** | **[Documentation](https://wix.github.io/quix/docs/installation)** | **[GitHub](https://github.com/wix/quix)**
## How to enable?
```
platys init --enable-services QUIX
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28160><file_sep># Local Virtual Machine Environment
Create and start virtual machine with Linux (i.e. Ubuntu) either by using **VMWare Workstation** on Windows or **VMWare Fusion** on Mac or **Virtual Box**.
Configure the VM to use at 12 GB of Memory.
Install the following software
* [Docker](https://docs.docker.com/engine/install/ubuntu/)
* [Docker Compose](https://docs.docker.com/compose/install/)
* [Platys](https://github.com/TrivadisPF/platys/blob/master/documentation/install.md) (optional)
## Prepare Environment
In the Virtual Machine, start a terminal window and execute the following commands.
First let's add the environment variables. Make sure to adapt the network interface (**ens33** according to your environment. You can retrieve the interface name by using **ipconfig** on windows or **ifconfig** on Mac/Linux.
```
# Prepare Environment Variables
export PUBLIC_IP=$(curl ipinfo.io/ip)
export DOCKER_HOST_IP=$(ip addr show ens33 | grep "inet\b" | awk '{print $2}' | cut -d/ -f1)
```
Now for Elasticsearch to run properly, we have to increase the `vm.max_map_count` parameter like shown below.
```
# needed for elasticsearch
sudo sysctl -w vm.max_map_count=262144
```
Now let's checkout the NoSQL Workshop project from GitHub:
```
# Get the project
cd /home/bigdata
git clone https://github.com/gschmutz/kafka-workshop.git
cd kafka-workshop/01-environment/docker
```
## Start Environment
And finally let's start the environment:
```
# Make sure that the environment is not running
docker-compose down
# Startup Environment
docker-compose up -d
```
The environment should start immediately, as all the necessary images should already be available in the local docker image registry.
The output should be similar to the one below.

Your instance is now ready to use. Complete the post installation steps documented the [here](README.md).
## Stop environment
To stop the environment, execute the following command:
```
docker-compose stop
```
after that it can be re-started using `docker-compose start`.
To stop and remove all running container, execute the following command:
```
docker-compose down
```
<file_sep>package com.trivadis.kafkaws.kstream.countsession;
import com.bakdata.fluent_kafka_streams_tests.junit5.TestTopologyExtension;
import org.apache.kafka.common.serialization.Serdes;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.RegisterExtension;
import java.time.Instant;
public class KafkaStreamsRunnerCountSessionWindowedDSLTest {
private final KafkaStreamsRunnerCountSessionWindowedDSL app = new KafkaStreamsRunnerCountSessionWindowedDSL();
@RegisterExtension
final TestTopologyExtension<Object, String> testTopology =
new TestTopologyExtension<>(KafkaStreamsRunnerCountSessionWindowedDSL::getTopology, KafkaStreamsRunnerCountSessionWindowedDSL.getKafkaProperties());
@BeforeEach
void start() {
this.testTopology.start();
}
@AfterEach
void stop() {
//this.testTopology.stop();
}
@Test
void shouldAggregateSameWordStream() {
String KEY = "A";
Instant TIME1 = Instant.now();
System.out.println(TIME1);
System.out.println(KafkaStreamsRunnerCountSessionWindowedDSL.formatKey(KEY,TIME1, TIME1));
this.testTopology.input()
.add(KEY, "cat", TIME1.toEpochMilli());
this.testTopology.streamOutput().withSerde(Serdes.String(), Serdes.Long())
.expectNextRecord().hasKey(KafkaStreamsRunnerCountSessionWindowedDSL.formatKey(KEY,TIME1, TIME1)).hasValue(1L)
.expectNoMoreRecord();
}
}
<file_sep>---
technologies: airflow,python
version: 1.16.0
validated-at: 24.12.2022
---
# Schedule and Run Simple Python Application with Airflow
This recipe will show how to use the [Apache Airflow](https://airflow.apache.org/) job orchestration engine with the [Bash Operator](https://airflow.apache.org/docs/apache-airflow/stable/_api/airflow/operators/bash/index.html#airflow.operators.bash.BashOperator) and [Python Operator](https://airflow.apache.org/docs/apache-airflow/stable/howto/operator/python.html).
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```bash
platys init --enable-services AIRFLOW -s trivadis/platys-modern-data-platform -w 1.16.0
```
add to `config.yml`
```yaml
AIRFLOW_executor: celery
AIRFLOW_dag_dir_list_interval: 30
```
Now generate and start the platform
```bash
platys gen
docker-compose up -d
```
Check the log of `airflow` to be up and running by running `docker logs -f airflow`. Airflow is ready if you see the **Listing at:...** in the log
```
...
[2022-12-23 13:20:59,065] {providers_manager.py:235} INFO - Optional provider feature disabled when importing 'airflow.providers.google.leveldb.hooks.leveldb.LevelDBHook' from 'apache-airflow-providers-google' package
[2022-12-23 13:20:59 +0000] [54] [INFO] Listening at: http://0.0.0.0:8080 (54)
[2022-12-23 13:20:59 +0000] [54] [INFO] Using worker: sync
[2022-12-23 13:20:59 +0000] [62] [INFO] Booting worker with pid: 62
[2022-12-23 13:20:59 +0000] [63] [INFO] Booting worker with pid: 63
[2022-12-23 13:20:59 +0000] [64] [INFO] Booting worker with pid: 64
[2022-12-23 13:20:59 +0000] [65] [INFO] Booting worker with pid: 65
```
## Open Airflow Dashboard
Navigate to <http://dataplatform:28139> and login with user `airflow` and password `<PASSWORD>!`. You should see the empty Airflow dashboard.

## Create an Airflow DAG
Now let's create a first example DAG.
In the `./scripts/airflow/dags` create a new file with the following DAG logic (we start the DAG every 5 minutes with a start date of today minus 2 hours.
`example-python.py`
```python
from datetime import datetime, timedelta
from textwrap import dedent
from airflow import DAG
# Operators; we need this to operate!
from airflow.operators.bash import BashOperator
from airflow.operators.dummy import DummyOperator
from airflow.operators.python import BranchPythonOperator
from airflow.operators.python_operator import PythonOperator
from airflow.utils.trigger_rule import TriggerRule
default_args = {
'owner': 'owner-name',
'depends_on_past': False,
'email': ['<EMAIL>'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=15),
}
dag_args = dict(
dag_id="tutorial-python-op",
default_args=default_args,
description='tutorial DAG python',
schedule_interval=timedelta(minutes=5),
start_date=datetime.today() - timedelta(hours=2, minutes=0),
tags=['example-sj'],
)
def random_branch_path():
# 필요 라이브러리는 여기서 import
# https://airflow.apache.org/docs/apache-airflow/stable/best-practices.html#writing-a-dag 참고
from random import randint
return "cal_a_id" if randint(1, 2) == 1 else "cal_m_id"
def calc_add(x, y, **kwargs):
result = x + y
print("x + y : ", result)
kwargs['task_instance'].xcom_push(key='calc_result', value=result)
return "calc add"
def calc_mul(x, y, **kwargs):
result = x * y
print("x * y : ", result)
kwargs['task_instance'].xcom_push(key='calc_result', value=result)
return "calc mul"
def print_result(**kwargs):
r = kwargs["task_instance"].xcom_pull(key='calc_result')
print("message : ", r)
print("*"*100)
print(kwargs)
def end_seq():
print("end")
with DAG( **dag_args ) as dag:
start = BashOperator(
task_id='start',
bash_command='echo "start!"',
)
branch = BranchPythonOperator(
task_id='branch',
python_callable=random_branch_path,
)
calc_add = PythonOperator(
task_id='cal_a_id',
python_callable=calc_add,
op_kwargs={'x': 10, 'y':4}
)
calc_mul = PythonOperator(
task_id='cal_m_id',
python_callable=calc_mul,
op_kwargs={'x': 10, 'y':4}
)
msg = PythonOperator(
task_id='msg',
python_callable=print_result,
trigger_rule=TriggerRule.NONE_FAILED
)
complete_py = PythonOperator(
task_id='complete_py',
python_callable=end_seq,
trigger_rule=TriggerRule.NONE_FAILED
)
complete = BashOperator(
task_id='complete_bash',
depends_on_past=False,
bash_command='echo "complete~!"',
trigger_rule=TriggerRule.NONE_FAILED
)
start >> branch >> calc_add >> msg >> complete_py >> complete
start >> branch >> calc_mul >> msg >> complete
```
After > 30 seconds (the `AIRFLOW_dag_dir_list_interval` configured in `config.yml`), the Airflow dashboard should refresh and show the newly created DAG.

By default the DAG will be initially in paused mode. Click on the button to the left of the DAG to unpause it.
Jobs will be immediately started for the last 2 hours, with an interval of 5 minutes between them.

If you click on the job you can see the details of the job with a graphic of each run.

Click on one of the successful tasks to see the details of this task

Clock on the **Log** tab to see the log output of this task's run
<file_sep># kcat (formerly known as Kafkacat)
Generic command line non-JVM Apache Kafka producer and consumer.
**[Website](https://github.com/edenhill/kcat)** | **[Documentation](https://github.com/edenhill/kcat)** | **[GitHub](https://github.com/edenhill/kcat)**
## How to enable?
```
platys init --enable-services KCAT
platys gen
```
## How to use it?
```
docker exec -ti kcat kcat
```<file_sep>-- SELECT pe.p.firstname, hr.e.jobtitle
<file_sep>Contains the data of oracle db service, if flag ORACLE_volume_map_data is set to true.<file_sep>connector.name=oracle
connection-url=jdbc:oracle:thin:@oracledb-xe:1521/XEPDB1
connection-user=${ENV:ORACLE_USER}
connection-password=${ENV:ORACLE_PASSWORD}
<file_sep># Burrow
Burrow is a monitoring companion for Apache Kafka that provides consumer lag checking as a service without the need for specifying thresholds. It monitors committed offsets for all consumers and calculates the status of those consumers on demand. An HTTP endpoint is provided to request status on demand, as well as provide other Kafka cluster information. There are also configurable notifiers that can send status out via email or HTTP calls to another service.
**[Website](https://github.com/linkedin/Burrow)** | **[Documentation](https://github.com/linkedin/Burrow)** | **[GitHub](https://github.com/linkedin/Burrow)**
## How to enable?
```
platys init --enable-services KAFKA,BURROW
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28260><file_sep># Apache Flink
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments perform computations at in-memory speed and at any scale.
**[Website](https://flink.apache.org/)** | **[Documentation](https://nightlies.apache.org/flink/flink-docs-master/)** | **[GitHub](https://github.com/apache/flink)**
## How to enable?
```bash
platys init --enable-services FLINK
platys gen
```
## How to use it?
Navigate to <http://${PUBLIC_IP}:28237><file_sep># ZeeQS - Zeebe Query Service
A Zeebe community extension that provides a GraphQL query API over Zeebe's data. The data is imported from the broker using an exporter (e.g. Hazelcast, Elasticsearch) and aggregated in the service.
**[Documentation](https://github.com/camunda-community-hub/zeeqs)** | **[GitHub](https://github.com/camunda-community-hub/zeeqs)**
## How to enable?
```
platys init --enable-services CAMUNDA_ZEEQS
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28208/graphiql>.
<file_sep># Kafka Topics UI
Web tool for Kafka Connect
**[Website](https://lenses.io/product/features/)** | **[Documentation](https://github.com/lensesio/kafka-topics-ui)** | **[GitHub](https://github.com/lensesio/kafka-topics-ui)**
## How to enable?
```bash
platys init --enable-services KAFKA,KAFKA_TOPICS_UI
platys gen
```
## How to use it?
Navigate to <http://${PUBLIC_IP}:28141>
<file_sep># Redis Commander
Redis-Commander is a node.js web application used to view, edit, and manage a Redis Database
**[Website](http://joeferner.github.io/redis-commander/)** | **[Documentation](http://joeferner.github.io/redis-commander/)** | **[GitHub](https://github.com/joeferner/redis-commander)**
## How to enable?
```
platys init --enable-services REDIS_COMMANDER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28119><file_sep>Place custom Starburst connectors here and register them using TRINO_additional_connectors ...<file_sep>---
technoglogies: oracle,rdbms
version: 1.16.0
validated-at: 14.04.2023
---
# Using Public Oracle XE Docker image
This recipe will show how to use a public docker image for Oracle XE. This is instead of the "normal" way of referring to a private repository for the Oracle database docker images, due to licensing requirements by Oracle.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```bash
platys init --enable-services ORACLE_XE -s trivadis/platys-modern-data-platform -w 1.16.0
```
We are using the following docker image [gvenzl/oracle-xe](https://hub.docker.com/r/gvenzl/oracle-xe).
Now generate and start the data platform.
```bash
platys gen
docker-compose up -d
```
## Connect to Oracle
First connect to the docker instance
```bash
docker exec -ti oracledb-xe bash
```
and run SQL Plus to connect as user `sys` to the PDB.
```bash
sqlplus sys/EAo4KsTfRR@oracledb-xe:1521/XEPDB1 as sysdba
```
<file_sep># kpow
Kpow is the toolkit that empowers your team to deliver with Kafka.
Once installed, Kpow gathers information about your Kafka resources every minute, stores the results locally in internal topics, then provides custom telemetry and insights to you in a rich data-oriented UI.
**[Website](https://kpow.io/)** | **[Documentation](https://docs.kpow.io/)** | **[GitHub](https://github.com/factorhouse/kpow)**
```
platys init --enable-services KAFKA,KPOW
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28283>.
You have to get a license from [kpow](https://kpow.io/) here: <https://kpow.io/pricing/>.
Either add the license details to `config.yml` (if `KPOW_use_external_license_info` is set to `false`)
```yaml
KPOW_use_external_license_info: false
KPOW_license_id:
KPOW_license_code:
KPOW_licensee:
KPOW_license_expiry:
KPOW_license_signature:
```
or add it to `./licenses/kpow/kpow-license.env` if `KPOW_use_external_license_info` is set to `true`
```
## Your license details.
LICENSE_ID=xxxxxxx
LICENSE_CODE=TRIAL_30D
LICENSEE=yyyyy
LICENSE_EXPIRY=yyyy-mm-dd
LICENSE_SIGNATURE=zzzzzzzzzzzzzzzzzzz
```<file_sep># Apache Tika (Server)
The Apache Tika toolkit detects and extracts metadata and text from over a thousand different file types (such as PPT, XLS, and PDF).
**[Website](https://tika.apache.org/)** | **[Documentation](https://tika.apache.org/2.2.1/index.html)** | **[GitHub](https://github.com/apache/tika)**
## How to enable?
```
platys init --enable-services TIKA
platys gen
```
## How to use it?
<file_sep>Place Flink applications here and set FLINK_deployment_mode to 'application'<file_sep>Contains the /data folder of airbyte service.<file_sep># SQLPad
Web-based SQL editor run in your own private cloud. Supports MySQL, Postgres, SQL Server, Vertica, Crate, ClickHouse, Trino, Presto, SAP HANA, Cassandra, Snowflake, BigQuery, SQLite, and more with ODBC
**[Website](https://getsqlpad.com/#/)** | **[Documentation](https://getsqlpad.com/#/)** | **[GitHub](https://github.com/sqlpad/sqlpad)**
## How to enable?
```
platys init --enable-services SQLPAD
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28194><file_sep># Tyk Gateway
Tyk is an open source Enterprise API Gateway, supporting REST, GraphQL, TCP and gRPC protocols.
**[Website](https://tyk.io/open-source-api-gateway/)** | **[Documentation](https://tyk.io/docs/tyk-oss-gateway/)** | **[GitHub](https://github.com/TykTechnologies/tyk)**
## How to enable?
```
platys init --enable-services TYK
platys gen
```
## How to use it?
<file_sep># Stream Analytics using Streamiz
Let's redo the simple message filtering process of the previous workshop, using the [Streamiz.Kafka.Net](https://lgouellec.github.io/kafka-streams-dotnet) instead of KSQL. Streamiz.Kafka.Net is a .NET stream processing library for Apache Kafka (TM).

## Create the project structure
First create the workspace folder, which will hold our projects and navigate into it.
```bash
mkdir kafka-dotnet-streamiz
cd kafka-dotnet-streamiz
```
Now let's create the processor project
```bash
dotnet new console -o processor
```
Now start Visual Code, on Linux if installed using the [following documentation](https://code.visualstudio.com/docs/setup/linux), then it can be started with `code`.
```bash
code .
```
## Create the processor
To reference the library from the .NET Core project, execute the following command from within the `kafka-dotnet-streamiz` folder.
```
dotnet add processor package Streamiz.Kafka.Net
```
## Create the necessary Kafka Topic
We will use the topic `dangerous_driving_kstreams` for the output stream in the Kafka Streams code below. Due to the fact that `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
Connect to the `broker-1` container
```bash
docker exec -ti broker-1 bash
```
and execute the necessary `kafka-topics` command.
```bash
kafka-topics --bootstrap-server kafka-1:19092,kafka-2:19093 --create --topic dangerous_driving_streamiz --partitions 8 --replication-factor 2
```
## Create a Streamiz Topology
Open `Program.cs` in the editor and add a `TruckPosition` class, which is handling the transformation from/to CSV and then add the Streamiz topology after.
```csharp
using Confluent.Kafka;
using Streamiz.Kafka.Net;
using Streamiz.Kafka.Net.SerDes;
using Streamiz.Kafka.Net.Stream;
using Streamiz.Kafka.Net.Table;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Runtime.Intrinsics;
using System.Threading;
using Microsoft.Extensions.Logging;
using Streamiz.Kafka.Net.Crosscutting;
using System.Threading.Tasks;
namespace processor
{
class TruckPosition
{
long timestamp;
int truckId;
int driverId;
int routeId;
String eventType;
Double latitude;
Double longitude;
String correlationId;
public static TruckPosition create(String csvRecord) {
TruckPosition truckPosition = new TruckPosition();
String[] values = csvRecord.Split(',');
truckPosition.timestamp = Convert.ToInt64(values[0]);
truckPosition.truckId = Convert.ToInt32(values[1]);
truckPosition.driverId = Convert.ToInt32(values[2]);
truckPosition.routeId = Convert.ToInt32(values[3]);
truckPosition.eventType = values[4];
truckPosition.latitude = Convert.ToDouble(values[5]);
truckPosition.longitude = Convert.ToDouble(values[6]);
truckPosition.correlationId = values[7];
return truckPosition;
}
public static Boolean filterNonNORMAL(TruckPosition value) {
Boolean result = false;
result = !value.eventType.Equals("Normal");
return result;
}
public String toCSV() {
return timestamp + "," + truckId + "," + driverId + "," + routeId + "," + eventType + "," + latitude + "," + longitude + "," + correlationId;
}
}
class Program
{
static async Task Main(string[] args)
{
var config = new StreamConfig<StringSerDes, StringSerDes>();
config.ApplicationId = "test-app";
config.BootstrapServers = "dataplatform:9092";
StreamBuilder builder = new StreamBuilder();
builder.Stream<string, string>("truck_position")
.MapValues(v => TruckPosition.create(v.Remove(0,6)))
.Filter((k,v) => TruckPosition.filterNonNORMAL(v))
.MapValues(v => v.toCSV())
.To("dangerous_driving_streamiz");
Topology t = builder.Build();
KafkaStream stream = new KafkaStream(t, config);
Console.CancelKeyPress += (o, e) =>
{
stream.Dispose();
};
await stream.StartAsync();
}
}
}
```
With this in place, we can run the Topology from the terminal.
```bash
dotnet run -p ./processor/processor.csproj
```
Now let's see that we actually produce data on that new topic by running a `kafka-console-consumer` or alternatively a `kafkacat`.
```bash
kcat -b kafka-1:19092 -t dangerous_driving_streamiz
```
<file_sep># Apache Spark
Apache Spark - A unified analytics engine for large-scale data processing.
**[Website](http://https://spark.apache.org/)** | **[Documentation](https://spark.apache.org/docs/latest/)** | **[GitHub](https://github.com/apache/spark)**
## How to enable?
```bash
platys init --enable-services SPARK
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28304> to see the Spark Master UI.<file_sep># Apache Drill
Schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage.
**[Website](https://drill.apache.org/)** | **[Documentation](https://drill.apache.org/docs/)** | **[GitHub](https://github.com/apache/drill)**
## How to enable?
```
platys init --enable-services DRILL
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8047s><file_sep># StreamSets Transformer Engine
StreamSets TransformerTM is an execution engine that runs data processing pipelines on Apache Spark, an open-source cluster-computing framework. Because Transformer pipelines run on Spark deployed on a cluster, the pipelines can perform transformations that require heavy processing on the entire data set in batch or streaming mode.
**[Website](https://streamsets.com/products/dataops-platform/transformer-etl-engine/)** | **[Documentation](https://docs.streamsets.com/portal/transformer/latest/help/index.html)**
### How to enable
```
platys init --enable-services STREAMSETS_TRANSFORMER
platys gen
```
### How to use it?
Navigate to <http://dataplatform:19630>
<file_sep>Place additional NARs for NiFi here ...<file_sep>Place nifi.properties file here to configure NiFi.<file_sep># Trino (formerly PrestoSQL)
Trino is a distributed SQL query engine designed to query large data sets distributed over one or more heterogeneous data sources.
**[Website](https://trino.io/)** | **[Documentation](https://trino.io/docs/current/)** | **[GitHub](https://github.com/trinodb/trino)**
## How to enable?
```
platys init --enable-services TRINO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28082>
<file_sep># Kong Admin UI
A Web UI for the Kong(The Cloud-Native API Gateway & Service Mesh) admin api.
**[Documentation](https://github.com/pocketdigi/kong-admin-ui)** | **[GitHub](https://github.com/pocketdigi/kong-admin-ui)**
## How to enable?
```
platys init --enable-services KONG, KONG_ADMIN_UI
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28286><file_sep># Kafka UI
Open-Source Web GUI for Apache Kafka Management
**[Website](https://github.com/provectus/kafka-ui)** | **[Documentation](https://github.com/provectus/kafka-ui)** | **[GitHub](https://github.com/provectus/kafka-ui)**
```
platys init --enable-services KAFKA,KAFKA_UI
platys gen
```
<file_sep># JanusGraph
JanusGraph is a scalable graph database optimized for storing and querying graphs containing hundreds of billions of vertices and edges distributed across a multi-machine cluster.
**[Website](https://janusgraph.org/)** | **[Documentation](https://docs.janusgraph.org/)** | **[GitHub](https://github.com/janusgraph/janusgraph/)**
```bash
platys init --enable-services JANUSGRAPH
platys gen
```
## How to use it?
### Using the Gremlin Console
To start a gremlin console
```bash
docker-compose -f docker-compose.yml run --rm \
-e GREMLIN_REMOTE_HOSTS=janusgraph-1 janusgraph-1 ./bin/gremlin.sh
```
```groovy
:remote connect tinkerpop.server conf/remote.yaml
g = traversal().withRemote('conf/remote-graph.properties')
g.addV('demigod').property('name', 'hercules').iterate()
g.V()
```
### Initialise JanusGraph
When the container is started it will execute files with the extension `.groovy` that are found in `./init/janusgraph/` with the Gremlin Console. These scripts are only executed after the JanusGraph Server instance was started. So, they can connect to it and execute Gremlin traversals.
For example, to add a vertex to the graph, create a file `./init/janusgraph/add-vertex.groovy` with the following content
```groovy
g = traversal().withRemote('conf/remote-graph.properties')
g.addV('demigod').property('name', 'hercules').iterate()
```<file_sep>package com.trivadis.kafkaws.springbootkotlinkafkaproducer
import com.trivadis.kafkaws.avro.v1.Notification
import org.springframework.beans.factory.annotation.Value
import org.springframework.kafka.core.KafkaTemplate
import org.springframework.kafka.support.SendResult
import org.springframework.stereotype.Component
@Component
class KafkaEventProducer (private val kafkaTemplate: KafkaTemplate<Long, Notification>) {
@Value("\${topic.name}")
private lateinit var kafkaTopic: String
fun produce(key: Long, value: Notification) {
val time = System.currentTimeMillis()
var result: SendResult<Long, Notification>
if (key > 0) {
result = kafkaTemplate.send(kafkaTopic, key, value).get()
} else {
result = kafkaTemplate.send(kafkaTopic, value).get()
}
val elapsedTime = System.currentTimeMillis() - time
println("[$key] sent record(key=$key value=$value) meta(partition=${result.recordMetadata.partition()}, offset=${result.recordMetadata.offset()}) time=$elapsedTime")
}
}<file_sep># PostgREST
PostgREST is a standalone web server that turns your PostgreSQL database directly into a RESTful API. The structural constraints and permissions in the database determine the API endpoints and operations.
**[Website](https://postgrest.org/en/stable/)** | **[Documentation](https://postgrest.org/en/stable/)** | **[GitHub](https://github.com/PostgREST/postgrest)**
## How to enable?
```
platys init --enable-services POSTGREST
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28206><file_sep>---
technoglogies: trino,kafka
version: 1.14.0
validated-at: 18.11.2021
---
# Querying data in Kafka from Trino (formerly PrestoSQL)
This recipe will show how to query data from a Kakfa topic using Trino. It is an adapted version of the tutorial in the [Trino documentation](https://trino.io/docs/current/connector/kafka-tutorial.html).
## Initialise a platform
First [initialise a platys-supported data platform](../../getting-started) with the following services enabled
```bash
platys init --enable-services TRINO,KAFKA,SCHEMA_REGISTRY,KAFKA_AKHQ,KAFKACAT,PROVISIONING_DATA -s trivadis/platys-modern-data-platform -w 1.13.0
```
add the follwing property to `config.yml`
```bash
KAFKA_auto_create_topics_enable: true
TRINO_edition: 'oss'
TRINO_kafka_table_names: 'tpch.customer,tpch.orders,tpch.lineitem,tpch.part,tpch.partsupp,tpch.supplier,tpch.nation,tpch.region'
```
Now generate and start the data platform.
```bash
platys gen
docker-compose up -d
```
## Create Data in Kafka
Download the tpch-kafka loader from Maven central
```bash
curl -o kafka-tpch https://repo1.maven.org/maven2/de/softwareforge/kafka_tpch_0811/1.0/kafka_tpch_0811-1.0.sh
```
```bash
chmod 755 kafka-tpch
```
Now run the kafka-tpch program to preload a number of topics with tpch data
```bash
./kafka-tpch load --brokers localhost:29092 --prefix tpch. --tpch-type tiny
```
## Query Customer Table from Trino
Next let's query the data from Trino. Connect to the Trino CLI using
```bash
docker exec -it trino-cli trino --server trino-1:8080 --catalog kafka --schema tpch
```
List the tables to verify that things are working
```sql
show tables;
```
Kafka data is unstructured, and it has no metadata to describe the format of the messages.
```sql
DESCRIBE customer;
```
Without further configuration, the Kafka connector can access the data, and map it in raw form. However there are no actual columns besides the built-in ones:
```sql
trino:tpch> describe customer
-> ;
Column | Type | Extra | Comment
-------------------+--------------------------------+-------+---------------------------------------------
_partition_id | bigint | | Partition Id
_partition_offset | bigint | | Offset for the message within the partition
_message_corrupt | boolean | | Message data is corrupt
_message | varchar | | Message text
_headers | map(varchar, array(varbinary)) | | Headers of the message as map
_message_length | bigint | | Total number of message bytes
_key_corrupt | boolean | | Key data is corrupt
_key | varchar | | Key text
_key_length | bigint | | Total number of key bytes
_timestamp | timestamp(3) | | Message timestamp
(10 rows)
```
```sql
SELECT * FROM customer;
```
```sql
trino:tpch> select * from customer;
_partition_id | _partition_offset | _message_corrupt | _message >
---------------+-------------------+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------->
0 | 0 | false | {"rowNumber":1,"customerKey":1,"name":"Customer#000000001","address":"IVhzIApeRb ot,c,E","nationKey":15,"phone":"25-989-741-2988","accountBalance":711.56,"marketSegment":"BUILDING","comment":"to the even, >
0 | 1 | false | {"rowNumber":2,"customerKey":2,"name":"Customer#000000002","address":"XSTf4,NCwDVaWNe6tEgvwfmRchLXak","nationKey":13,"phone":"23-768-687-3665","accountBalance":121.65,"marketSegment":"AUTOMOBILE","comment">
0 | 2 | false | {"rowNumber":3,"customerKey":3,"name":"Customer#000000003","address":"MG9kdTD2WBHm","nationKey":1,"phone":"11-719-748-3364","accountBalance":7498.12,"marketSegment":"AUTOMOBILE","comment":" deposits eat sl>
0 | 3 | false | {"rowNumber":4,"customerKey":4,"name":"Customer#000000004","address":"XxVSJsLAGtn","nationKey":4,"phone":"14-128-190-5944","accountBalance":2866.83,"marketSegment":"MACHINERY","comment":" requests. final, >
```
The data from Kafka can be queried using Trino, but it is not yet in actual table shape. The raw data is available through the _message and _key columns, but it is not decoded into columns. As the sample data is in JSON format, the [JSON functions and operators](https://trino.io/docs/current/functions/json.html) built into Trino can be used to slice the data.
We can use the `json_extract_scalar` function to extract the values from the `_message` column:
```sql
SELECT sum(cast(json_extract_scalar(_message, '$.accountBalance') AS double)) FROM customer LIMIT 10;
```
### Add a topic description file
The Kafka connector supports topic description files to turn raw data into table format. These files are located in the `etc/kafka` folder in the Trino installation and must end with .json. It is recommended that the file name matches the table name, but this is not necessary.
Create a file `tpch.customer.json` in the folder `conf/trino/kafka` (this is the folder which is mapped to `etc/kafka` inside the container)
```json
{
"tableName": "customer",
"schemaName": "tpch",
"topicName": "tpch.customer",
"key": {
"dataFormat": "raw",
"fields": [
{
"name": "kafka_key",
"dataFormat": "LONG",
"type": "BIGINT",
"hidden": "false"
}
]
},
"message": {
"dataFormat": "json",
"fields": [
{
"name": "row_number",
"mapping": "rowNumber",
"type": "BIGINT"
},
{
"name": "customer_key",
"mapping": "customerKey",
"type": "BIGINT"
},
{
"name": "name",
"mapping": "name",
"type": "VARCHAR"
},
{
"name": "address",
"mapping": "address",
"type": "VARCHAR"
},
{
"name": "nation_key",
"mapping": "nationKey",
"type": "BIGINT"
},
{
"name": "phone",
"mapping": "phone",
"type": "VARCHAR"
},
{
"name": "account_balance",
"mapping": "accountBalance",
"type": "DOUBLE"
},
{
"name": "market_segment",
"mapping": "marketSegment",
"type": "VARCHAR"
},
{
"name": "comment",
"mapping": "comment",
"type": "VARCHAR"
}
]
}
}
```
Restart trino
```bash
docker restart trino-1
```
```bash
docker exec -it trino-cli trino --server trino-1:8080 --catalog kafka --schema tpch
```
Now for all the fields in the JSON of the message, columns are defined and the sum query from earlier can operate on the `account_balance` column directly:
```sql
DESCRIBE customer;
```
```sql
trino:tpch> describe customer
-> ;
Column | Type | Extra | Comment
-------------------+--------------------------------+-------+---------------------------------------------
kafka_key | bigint | |
row_number | bigint | |
customer_key | bigint | |
name | varchar | |
address | varchar | |
nation_key | bigint | |
phone | varchar | |
account_balance | double | |
market_segment | varchar | |
comment | varchar | |
_partition_id | bigint | | Partition Id
_partition_offset | bigint | | Offset for the message within the partition
_message_corrupt | boolean | | Message data is corrupt
_message | varchar | | Message text
_headers | map(varchar, array(varbinary)) | | Headers of the message as map
_message_length | bigint | | Total number of message bytes
_key_corrupt | boolean | | Key data is corrupt
_key | varchar | | Key text
_key_length | bigint | | Total number of key bytes
_timestamp | timestamp(3) | | Message timestamp
(20 rows)
```
```sql
SELECT * FROM customer LIMIT 5;
```
```sql
SELECT sum(account_balance) FROM customer LIMIT 10;
```
Now all the fields from the customer topic messages are available as Trino table columns.
<file_sep># Setup necessary environment variables
Now the Platform is ready to be started. Before doing that, you have to create some environment variables, depending on the services you use. In minimum you should create
* `DOCKER_HOST_IP` - the IP address of the network interface of the Docker Host
* `PUBLIC_IP` - the IP address of the public network interface of the Docker Host (different to `DOCKER_HOST_IP` if in a public cloud environment
## Linux or Mac
First let's get the network interface name
```
$ ip addr
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:3a:82:45 brd ff:ff:ff:ff:ff:ff
altname enp2s1
```
and set it as a variable
```
export NETWORK_NAME=ens33
```
If the Docker host is running in the cloud (as a VM), where a specific public IP address is needed to reach it, perform this command
```bash
export PUBLIC_IP=$(curl ipinfo.io/ip)
```
otherwise this command
```bash
export PUBLIC_IP=$(ip addr show $NETWORK_NAME | grep "inet\b" | awk '{print $2}' | cut -d/ -f1)
```
Additionally set the `DOCKER_HOST_IP` to the IP address of the machine (make sure that `$NETWORK_NAME` has been set correctly)
```bash
export DOCKER_HOST_IP=$(ip addr show $NETWORK_NAME | grep "inet\b" | awk '{print $2}' | cut -d/ -f1)
```
Now persist these two environment variables, so that they are available after a logout.
You can set these environment variables persistently on the machine (`/etc/environment`) or user (`~/.pam_environment` or `~/.bash_profile`) level. The following script sets the `.bash_profile` in the user home.
```bash
# Prepare Environment Variables into .bash_profile file
printf "export PUBLIC_IP=$PUBLIC_IP\n" >> /home/$USER/.bash_profile
printf "export DOCKER_HOST_IP=$DOCKER_HOST_IP\n" >> /home/$USER/.bash_profile
printf "\n" >> /home/$USER/.bash_profile
sudo chown ${USER}:${USER} /home/$USER/.bash_profile
```
Another option is to use the `.env` file in the folder where the `docker-compose.yml` file is located. All environment variables set in there are used when the docker compose environment is started.
## Windows
t.b.d.
<file_sep># Debezium Server
Debezium can be deployed either as connector instances in a Kafka Connect cluster, or as a standalone application - Debezium Server. Debezium Server is a Quarkus-based high-performance application that streams data from database to a one of supported sinks or a user developed sink.
**[Website](https://debezium.io/documentation/reference/operations/debezium-ui.html)** | **[Documentation](https://debezium.io/documentation/reference/operations/debezium-server.html)** | **[GitHub](https://github.com/debezium/debezium/tree/master/debezium-server)**
## How to enable?
```
platys init --enable-services DEBEZIUM_SERVER
platys gen
```
## How to use it?
<file_sep># Confluent Schema Registry
Confluent Schema Registry for Kafka
**[Website](https://docs.confluent.io/1.0/schema-registry/docs/intro.html)** | **[Documentation](https://docs.confluent.io/1.0/schema-registry/docs/intro.html)** | **[GitHub](https://github.com/confluentinc/schema-registry)**
## How to enable?
```
platys init --enable-services SCHEMA_REGISTRY
platys gen
```
## How to use it?
### Uploading a Schema via script
using `curl`
```bash
export TOPIC=topicName
export SCHEMA=$(jq tostring $TOPIC-value.avsc)
echo "{\"schema\":$SCHEMA}"
curl -XPOST -H "Content-Type:application/json" -d"{\"schema\":$SCHEMA}" http://dataplatform:8081/subjects/$TOPIC-value/versions
```
using `httpie`
```bash
export TOPIC=topicName
http -v POST :8081/subjects/example.with-schema.user-value/versions \
Accept:application/vnd.schemaregistry.v1+json \
schema=@avro/src/main/avro/user.avsc
```
### Downloading a schema (for a subject) from schema registry
using `curl`
```bash
export TOPIC=topicName
curl http://dataplatfor:8081/subjects/$TOPIC-value/versions/latest | jq -r '.schema|fromjson' > $TOPIC-value.avsc
```
using `httpie`
```bash
export TOPIC=topicName
http http://dataplatform:8081/subjects/$TOPIC-value/versions/latest \
| jq -r '.schema|fromjson' \
> $TOPIC-value.avsc
```
<file_sep># DGraph
Dgraph is the simplest way to implement a GraphQL backend for your applications. Everything you need to build apps, unite your data, and scale your operations is included, out-of-the-box.
**[Website](https://dgraph.io/)** | **[Documentation](https://dgraph.io/docs)** | **[GitHub](https://github.com/dgraph-io/dgraph)**
## How to enable?
```
platys init --enable-services DGRAPH
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28182><file_sep># Mosquitto
Eclipse Mosquitto - An open source MQTT broker
**[Website](https://mosquitto.org/)** | **[Documentation](https://mosquitto.org/documentation/)** | **[GitHub](https://github.com/eclipse/mosquitto)**
## How to enable?
```
platys init --enable-services MOSQUITTO
platys gen
```
## How to use it?
<file_sep>package com.trivadis.kafkaws.kstream.aggregate;
import com.trivadis.kafkaws.kstream.avro.AggregatedItem;
import io.confluent.kafka.serializers.AbstractKafkaSchemaSerDeConfig;
import io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde;
import org.apache.avro.specific.SpecificRecord;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.*;
import org.apache.kafka.streams.state.SessionStore;
import org.apache.kafka.streams.state.WindowStore;
import java.time.Duration;
import java.time.ZoneId;
import java.util.Collections;
import java.util.Map;
import java.util.Properties;
public class KafkaStreamsRunnerAggregateWithAvroDSL {
private static <VT extends SpecificRecord> SpecificAvroSerde<VT> createSerde(String schemaRegistryUrl) {
SpecificAvroSerde<VT> serde = new SpecificAvroSerde<>();
Map<String, String> serdeConfig = Collections
.singletonMap(AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG, schemaRegistryUrl);
serde.configure(serdeConfig, false);
return serde;
}
public static void main(String[] args) {
// the builder is used to construct the topology
StreamsBuilder builder = new StreamsBuilder();
final String schemaRegistryUrl = "http://dataplatform:8081";
final SpecificAvroSerde<AggregatedItem> valueSerde = createSerde(schemaRegistryUrl);
// read from the source topic, "test-kstream-input-topic"
KStream<String, String> stream = builder.stream("test-kstream-input-topic");
// transform the value from String to Long (this is necessary as from the console you can only produce String)
KStream<String, Long> transformed = stream.mapValues(v -> Long.valueOf(v));
// group by key
KGroupedStream<String, Long> grouped = transformed.groupByKey();
// create a tumbling window of 60 seconds
TimeWindows tumblingWindow =
TimeWindows.of(Duration.ofSeconds(60));
SessionWindows sessionWindow =
SessionWindows.with(Duration.ofSeconds(30)).grace(Duration.ofSeconds(10));
Aggregator<String, Long, AggregatedItem> aggregator = (k, v, aggV) -> {
aggV.setValueMin(Math.min(aggV.getValueMin(), v));
aggV.setValueMax(Math.max(aggV.getValueMax(), v));
return aggV;
};
Merger<String, AggregatedItem> merger = (k, v1,v2) -> {
return AggregatedItem.newBuilder()
.setValueMin(Math.min(v1.getValueMin(), v2.getValueMin()))
.setValueMax(Math.max(v1.getValueMax(), v2.getValueMax()))
.build();
};
// sum the values over the tumbling window of 60 seconds
KTable<Windowed<String>, AggregatedItem> sumOfValues = grouped
//.windowedBy(tumblingWindow)
.windowedBy(sessionWindow)
.aggregate(
() -> AggregatedItem.newBuilder().setValueMax(Long.MIN_VALUE).setValueMin(Long.MAX_VALUE).build() , /* initializer */
aggregator,
merger, /* merger */
Materialized.<String, AggregatedItem, SessionStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store") /* state store name */
.withKeySerde(Serdes.String())
.withValueSerde(valueSerde)
)
.suppress(Suppressed.untilWindowCloses(Suppressed.BufferConfig.unbounded()));
// print the sumOfValues stream
sumOfValues.toStream().print(Printed.<Windowed<String>,AggregatedItem>toSysOut().withLabel("sumOfValues"));
// publish the sumOfValues stream
final Serde<String> stringSerde = Serdes.String();
KStream<Windowed<String>, AggregatedItem> sumOfValuesStream = sumOfValues.toStream();
KStream<String,String> sumStream = sumOfValuesStream.filter((k,v) -> k.key() == null).map((wk,v) -> new KeyValue<String,String>(wk.key() + " : " + wk.window().startTime().atZone(ZoneId.of("Europe/Zurich")) + " to " + wk.window().endTime().atZone(ZoneId.of("Europe/Zurich")), v.toString()));
sumStream.to("test-kstream-output-topic", Produced.with(stringSerde, stringSerde));
// set the required properties for running Kafka Streams
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, "count");
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "dataplatform:9092");
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0);
config.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 0);
// build the topology and start streaming
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
// close Kafka Streams when the JVM shuts down (e.g. SIGTERM)
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
}<file_sep>---
technoglogies: spark,postgresql
version: 1.15.0
validated-at: 23.4.2022
---
# Spark with PostgreSQL
This recipe will show how to use a Spark cluster in the platform and connect it to a PostgreSQL relational database.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services SPARK,POSTGRESQL,ZEPPELIN,PROVISIONING_DATA -s trivadis/platys-modern-data-platform -w 1.15.0
```
Before we can generate the platform, we need to extend the `config.yml`. There are two options
**1. use the `SPARK_jars_packages` property to specify a maven coordinate**
add the following property to `config.yml`
```
SPARK_jars_packages: 'org.postgresql:postgresql:42.3.4'
```
**2. use the `SPARK_jars` property to point to jar provided in `./plugins/spark/jars`**
download the Jar file from the maven repository to `./plugins/spark/jars`
```bash
cd $DATAPLATFORM_HOME
cd ./plugins/spark/jars
wget https://repo1.maven.org/maven2/org/postgresql/postgresql/42.3.4/postgresql-42.3.4.jar -O postgresql-42.3.4.jar
```
now add the following property to `config.yml`
```
SPARK_jars: '/extra-jars/postgresql:42.3.4.jar'
```
Now set an environment variable to the home folder of the dataplatform and generate and then start the data platform.
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Create Table in Postgresql
```bash
docker exec -ti postgresql psql -d demodb -U demo
```
```sql
CREATE SCHEMA flight_data;
DROP TABLE flight_data.airport_t;
CREATE TABLE flight_data.airport_t
(
iata character varying(50) NOT NULL,
airport character varying(50),
city character varying(50),
state character varying(50),
country character varying(50),
lat float,
long float,
CONSTRAINT airport_pk PRIMARY KEY (iata)
);
```
```sql
COPY flight_data.airport_t(iata,airport,city,state,country,lat,long)
FROM '/data-transfer/flight-data/airports.csv' DELIMITER ',' CSV HEADER;
```
## Work with data from PostgreSQL
Navigate to Zeppelin <http://dataplatform:28080> and login as user `admin` with password `<PASSWORD>!`.
Create a new notebook and in a cell enter the following Spark code using the Python API.
```scala
val opts = Map(
"url" -> "jdbc:postgresql://postgresql/demodb?user=demo&password=<PASSWORD>!",
"driver" -> "org.postgresql.Driver",
"dbtable" -> "flight_data.airport_t")
val df = spark
.read
.format("jdbc")
.options(opts)
.load
```
```
df.show
```
<file_sep># pgAdmin
pgAdmin is the most popular and feature rich Open Source administration and development platform for PostgreSQL.
**[Website](https://www.pgadmin.org/)** | **[Documentation](https://www.pgadmin.org/docs/pgadmin4/latest/index.html)** | **[GitHub](https://github.com/postgres/pgadmin4)**
## How to enable?
```
platys init --enable-services POSTRESQL PGADMIN
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28247>
<file_sep># StreamSets Data Collector Edge
StreamSets Data Collector Edge (SDC Edge) enables at-scale data ingestion and analytics for edge systems. An ultralight, small-footprint agent, it is an ideal solution for use cases like Internet of Things (IoT) or cybersecurity applications that collect data from resource-constrained sensors and personal devices.
**[Website](https://streamsets.com/products/dataops-platform/data-collector-engine//)** | **[Documentation](https://docs.streamsets.com/portal/datacollector/latest/help/datacollector/UserGuide/Edge_Mode/GettingStartedSamples.html?hl=edge)** | **[GitHub](https://github.com/streamsets/datacollector-edge-oss)**
### How to enable
```
platys init --enable-services STREAMSETS_EDGE
platys gen
```
### How to use it?
Navigate to <http://dataplatform:18633>
<file_sep># Kafdrop
Kafdrop is a web UI for viewing Kafka topics and browsing consumer groups. The tool displays information such as brokers, topics, partitions, consumers, and lets you view messages.
**[Documentation](https://github.com/obsidiandynamics/kafdrop)** | **[GitHub](https://github.com/obsidiandynamics/kafdrop)**
### How to enable?
```
platys init --enable-services KAFDROP
platys gen
```
### How to use it?
Navigate to <http://dataplatform:28110>
<file_sep># Eventstore
The stream database built for Event Sourcing.
**[Website](https://www.eventstore.com/)** | **[Documentation](https://developers.eventstore.com/)** | **[GitHub](https://github.com/EventStore/EventStore)**
## How to enable?
```
platys init --enable-services EVENTSTORE
platys gen
```
## How to use it?
Navigate to <http://dataplatform:2113><file_sep>Contains the data of timescale db service, if flag STREAMSETS_volume_map_data is set to true.<file_sep>Contains the server data folder of pinot service, if flag PINOT_volume_map_data is set to true.<file_sep>group-provider.name=file
file.group-file=/etc/trino/security/group.txt
<file_sep># Solr
Solr is the popular, blazing-fast, open source enterprise search platform built on Apache Lucene.
**[Website](https://solr.apache.org/)** | **[Documentation](https://solr.apache.org/)** | **[GitHub](https://github.com/apache/solr)**
## How to enable?
```
platys init --enable-services SOLR
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8983><file_sep>package com.trivadis.kafkaws.springbootkafkastreams.simple;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Profile;
import org.springframework.kafka.config.StreamsBuilderFactoryBean;
import org.springframework.stereotype.Component;
import java.time.Duration;
import java.time.Instant;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
@Component
@Configuration
public class SessionKafkaStreamsRunnerDSL {
private static final Logger LOG = LoggerFactory.getLogger(SessionKafkaStreamsRunnerDSL.class);
private static DateTimeFormatter formatter = DateTimeFormatter.ofPattern("dd.MM.yyyy hh:mm.ss")
.withZone(ZoneId.systemDefault());
public static String formatKey (String key, Instant startTime, Instant endTime) {
return key + "@" + formatter.format(startTime) + "->" + formatter.format(endTime);
}
@Autowired
private StreamsBuilderFactoryBean factoryBean;
private static final String INPUT_TOPIC_NAME = "test-kstream-spring-input-topic";
private static final String OUTPUT_TOPIC_NAME = "test-kstream-spring-output-topic";
@Bean
@Profile("session-suppressed")
public KStream buildPipeline (StreamsBuilder kStreamBuilder) {
KStream<String, String> stream = kStreamBuilder.stream(INPUT_TOPIC_NAME, Consumed.with(Serdes.String(), Serdes.String()));
// create a session window with an inactivity gap to 30 seconds and a Grace period of 10 seconds
SessionWindows sessionWindow =
SessionWindows.ofInactivityGapAndGrace(Duration.ofSeconds(30), Duration.ofSeconds(0));
KTable<Windowed<String>, Long> counts = stream.groupByKey()
.windowedBy(sessionWindow)
.count(Materialized.as("countSessionWindowed"));
KStream<Windowed<String>, Long> sessionedStream = counts.toStream();
KStream<String, Long> printableStream = sessionedStream.map((key, value) -> new KeyValue<>(SessionKafkaStreamsRunnerDSL.formatKey(key.key(), key.window().startTime(), key.window().endTime()), value));
// you can also print using the `print` operator
printableStream.print(Printed.<String, Long>toSysOut().withLabel("session"));
printableStream.to(OUTPUT_TOPIC_NAME, Produced.with(Serdes.String(), Serdes.Long()));
return printableStream;
}
}
<file_sep># Using Kafka from Spring Boot with Kotlin using Kafka Spring
In this workshop we will learn how to use the **Spring Kafka** abstraction from within a Spring Boot application using the **Kotlin** language.
We will implement both a consumer and a producer implementing the same behaviour as in [Workshop 6: Working with Kafka from Kotlin](../06-producing-consuming-kafka-with-kotlin).
We will create two Spring Boot projects, one for the **Producer** and one for the **Consumer**, simulating two independent microservices interacting with eachother via events.
## Create the Spring Boot Producer
First we create an test the Producer microservice.
### Creating the Spring Boot Project
First, let’s navigate to [Spring Initializr](https://start.spring.io/) to generate our project. Our project will need the Apache Kafka support.
Select Generate a **Maven Project** with **Kotlin** and Spring Boot **2.7.0**. Enter `com.trivadis.kafkaws` for the **Group**, `spring-boot-kotlin-kafka-producer` for the **Artifact** field and `Kafka Producer project for Spring Boot` for the **Description** field.

Click on **Add Dependencies** and search for the **Spring for Apache Kafka** depencency.

Select the dependency and hit the **Enter** key. You should now see the dependency on the right side of the screen.

Click on **Generate Project** and unzip the ZIP file to a convenient location for development.
Once you have unzipped the project, you’ll have a very simple structure.
Import the project as a Maven Project into your favourite IDE for further development.
### Implement a Kafka Producer in Spring
Now create a simple Kotlin class `KafkaEventProducer` within the `com.trivadis.kafkaws.springbootkotlinkafkaproducer ` package, which we will use to produce messages to Kafka.
```kotlin
package com.trivadis.kafkaws.springbootkotlinkafkaproducer
import org.springframework.beans.factory.annotation.Value
import org.springframework.kafka.core.KafkaTemplate
import org.springframework.kafka.support.SendResult
import org.springframework.stereotype.Component
@Component
class KafkaEventProducer (private val kafkaTemplate: KafkaTemplate<Long, String>) {
@Value("\${topic.name}")
private lateinit var kafkaTopic: String
fun produce(key: Long, value: String) {
val time = System.currentTimeMillis()
var result: SendResult<Long, String>
if (key > 0) {
result = kafkaTemplate.send(kafkaTopic, key, value).get()
} else {
result = kafkaTemplate.send(kafkaTopic, value).get()
}
val elapsedTime = System.currentTimeMillis() - time
println("[$key] sent record(key=$key value=$value) meta(partition=${result.recordMetadata.partition()}, offset=${result.recordMetadata.offset()}) time=$elapsedTime")
}
}
```
It uses the `Component` annotation to have it registered as bean in the Spring context. The topic to produce to is specified as a property, which we will specify later in the `applicaiton.yml` file.
We produce the messages synchronously. You can see that because we are using `get()` on the `send` method: `result = kafkaTemplate.send(kafkaTopic, key, value).get()`.
### Create the necessary Topics through code
Spring Kafka can automatically add topics to the broker, if they do not yet exists. By that you can replace the `kafka-topics` CLI commands seen so far to create the topics, if you like.
Spring Kafka provides a `TopicBuilder` which makes the creation of the topics very convenient.
```kotlin
package com.trivadis.kafkaws.springbootkotlinkafkaproducer
import org.apache.kafka.clients.admin.NewTopic
import org.springframework.beans.factory.annotation.Value
import org.springframework.context.annotation.Bean
import org.springframework.kafka.config.TopicBuilder
import org.springframework.stereotype.Component
@Component
class TopicCreator {
@Value("\${topic.name}")
private lateinit var kafkaTopic: String
@Value("\${topic.partitions}")
private var partitions: Int = 0
@Value("\${topic.replication-factor}")
private var replicationFactor: Int = 0
@Bean
fun topic(): NewTopic? {
return TopicBuilder.name(kafkaTopic)
.partitions(partitions)
.replicas(replicationFactor)
.build()
}
}
```
We again refer to properties, which will be defined later in the `application.yml` config file.
### Add Producer logic to the SpringBootKafkaProducerApplication class
We change the generated Spring Boot application to be a console appliation by implementing the `CommandLineRunner` interface.
```kotlin
package com.trivadis.kafkaws.springbootkotlinkafkaproducer
import org.springframework.boot.CommandLineRunner
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
import org.springframework.context.annotation.Bean
import java.time.LocalDateTime
@SpringBootApplication
class SpringBootKotlinKafkaProducerApplication{
@Bean
fun init(kafkaEventProducer: KafkaEventProducer) = CommandLineRunner { args ->
val sendMessageCount = if (args.size==0) 100 else args[0].toInt()
val waitMsInBetween = if (args.size==0) 10 else args[1].toLong()
val id = if (args.size==0) 0 else args[2].toLong()
for (index in 1 .. sendMessageCount) {
val value = "[$id" + "] Hello Kafka " + index + " => " + LocalDateTime.now()
kafkaEventProducer.produce(id, value);
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
fun main(args: Array<String>) {
runApplication<SpringBootKotlinKafkaProducerApplication>(*args)
}
```
### Configure Kafka through application.yml configuration file
First let's rename the existing `application.properties` file to `application.yml` to use the `yml` format.
Add the following settings to configure the Kafka cluster and the name of the topic:
```yml
topic:
name: test-kotlin-spring-topic
replication-factor: 3
partitions: 12
spring:
kafka:
bootstrap-servers: ${DATAPLATFORM_IP}:9092
producer:
key-serializer: org.apache.kafka.common.serialization.LongSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
logging:
level:
root: info
```
For the IP address of the Kafka cluster we refer to an environment variable, which we have to declare before running the application.
```bash
export DATAPLATFORM_IP=nnn.nnn.nnn.nnn
```
### Build the application
First lets build the application:
```bash
mvn package -Dmaven.test.skip=true
```
### Run the application
Now let's run the application
```bash
mvn spring-boot:run
```
Make sure that you see the messages through the console consumer.
To run the producer with custom parameters (for example to specify the key to use), use the `-Dspring-boot.run.arguments`:
```bash
mvn spring-boot:run -Dspring-boot.run.arguments="100 10 10"
```
### Use Console to test the application
In a terminal window start consuming from the output topic:
```bash
kcat -b kafka-1:19092 -t test-kotlin-spring-topic
```
## Create the Spring Boot Consumer
Now let's create an test the Consumer microservice.
### Creating the Spring Boot Project
Use again the [Spring Initializr](https://start.spring.io/) to generate the project.
Select Generate a **Maven Project** with **Kotlin** and Spring Boot **2.7.0**. Enter `com.trivadis.kafkaws` for the **Group**, `spring-boot-kotlin-kafka-consumer` for the **Artifact** field and `Kafka Consumer project for Spring Boot` for the **Description** field.
Click on **Add Dependencies** and search for the **Spring for Apache Kafka** depencency.
Select the dependency and hit the **Enter** key. You should now see the dependency on the right side of the screen.
Click on **Generate Project** and unzip the ZIP file to a convenient location for development.
Once you have unzipped the project, you’ll have a very simple structure.
Import the project as a Maven Project into your favourite IDE for further development.
### Implement a Kafka Consumer in Spring
Start by creating a simple Kotlin class `KafkaEventConsumer` within the `com.trivadis.kafkaws.springbootkafkaconsumer` package, which we will use to consume messages from Kafka.
```kotlin
package com.trivadis.kafkaws.springbootkotlinkafkaconsumer
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.springframework.kafka.annotation.KafkaListener
import org.springframework.stereotype.Component
@Component
class KafkaEventConsumer {
@KafkaListener(topics = ["\${topic.name}"], groupId = "simple-kotlin-consumer")
fun receive(consumerRecord: ConsumerRecord<Long, String>) {
println("received key = ${consumerRecord.key()} with payload=${consumerRecord.value()}")
}
}
```
This class uses the `Component` annotation to have it registered as bean in the Spring context and the `KafkaListener` annotation to specify a listener method to be called for each record consumed from the Kafka input topic. The name of the topic is specified as a property to be read again from the `application.yml` configuration file.
In the code we only log the key and value received to the console. In real life, we would probably inject another bean into the `KafkaEventConsumer` to perform the message processing.
### Configure Kafka through application.yml configuration file
First let's rename the existing `application.properties` file to `application.yml` to use the `yml` format.
Add the following settings to configure the Kafka cluster and the name of the two topics:
```yml
topic:
name: test-kotlin-spring-topic
spring:
kafka:
bootstrap-servers: ${DATAPLATFORM_IP}:9092
consumer:
key-deserializer: org.apache.kafka.common.serialization.LongDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
logging:
level:
root: info
```
For the IP address of the Kafka cluster we refer to an environment variable, which we have to declare before running the application.
```bash
export DATAPLATFORM_IP=nnn.nnn.nnn.nnn
```
### Build the application
First lets build the application:
```bash
mvn package -Dmaven.test.skip=true
```
### Run the application
Now let's run the application
```bash
mvn spring-boot:run
```
## Various Options for Producer & Consumer
### Produce asynchronously
You can also produce asynchronously using Spring Kafka. Let's implement the `KafkaEventProducer` class in an asynchronous way:
```kotlin
package com.trivadis.kafkaws.springbootkotlinkafkaproducer
import org.springframework.beans.factory.annotation.Value
import org.springframework.kafka.core.KafkaTemplate
import org.springframework.kafka.support.SendResult
import org.springframework.stereotype.Component
import org.springframework.util.concurrent.ListenableFuture
@Component
class KafkaEventProducerAsync(private val kafkaTemplate: KafkaTemplate<Long, String>) {
@Value("\${topic.name}")
private lateinit var kafkaTopic: String
fun produce(key: Long, value: String) {
val time = System.currentTimeMillis()
var future: ListenableFuture<SendResult<Long, String>>
if (key > 0) {
future = kafkaTemplate.send(kafkaTopic, key, value)
} else {
future = kafkaTemplate.send(kafkaTopic, value)
}
future.addCallback({
val elapsedTime = System.currentTimeMillis() - time
println("[$key] sent record(key=$key value=$value) meta(partition=${it?.recordMetadata?.partition()}, offset=${it?.recordMetadata?.offset()}) time=$elapsedTime")
}, {
it.printStackTrace()
})
}
}
```
To test it, switch the injection in the `SpringBootKotlinKafkaProducerApplication` class to use the `KafkaEventProducerAsync` class:
```kotlin
fun init(kafkaEventProducer: KafkaEventProducerAsync) = CommandLineRunner { args ->
```
### Adding Message Filters for Listeners
Configuring message filtering is actually very simple. You only need to configure a `RecordFilterStrategy` (message filtering strategy) for the listening container factory. When it returns `true`, the message will be discarded. When it returns `false`, the message can normally reach the listening container.
Add the following additional configuration to the `SpringBootKafkaConsumerApplication` class. Here we just discard all messages which do not contain `Kafka 5' in its value:
```kotlin
package com.trivadis.kafkaws.springbootkotlinkafkaconsumer
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Configuration
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory
import org.springframework.kafka.core.ConsumerFactory
@Configuration
class FilterConfiguration {
@Autowired
private lateinit var consumerFactory: ConsumerFactory<Long, String>
@Bean
fun filterContainerFactory(): ConcurrentKafkaListenerContainerFactory<Long, String> {
val factory = ConcurrentKafkaListenerContainerFactory<Long, String>()
factory.setConsumerFactory(consumerFactory)
factory.setRecordFilterStrategy { record: ConsumerRecord<Long, String> ->
!record.value().contains("Kafka 5")
}
return factory
}
}
```
To use this factory instead of the default one created by the Spring Boot framework, you have to specify the `containerFactory` parameter in the `@KafakListener` annotation.
```kotlin
@KafkaListener(topics = ["\${topic.name}"], groupId = "simple-kotlin-consumer", containerFactory = "filterContainerFactory")
fun receive(consumerRecord: ConsumerRecord<Long, String>) {
```
Message filtering can be used for example to filter duplicate messages.
### Commit after given number of records
Starting with version 2.3, Spring Kafka sets `enable.auto.commit` to `false` unless explicitly set in the configuration. Previously, the Kafka default (true) was used if the property was not set.
If `enable.auto.commit` is false, the containers support several `AckMode` settings ([see documentation](https://docs.spring.io/spring-kafka/reference/html/#committing-offsets)). The default AckMode is `BATCH`, which commit the offset when all the records returned by the `poll()` have been processed. Other options allow to commit manually, after a given time has passed or after a given number of records have been consumed.
To commit offsets after a given number of records have been processed, switch the `AckMode` from `batch` to `count` and add the `ackCount` configuration to the `application.yml` file:
```yml
spring:
kafka:
bootstrap-servers: ${DATAPLATFORM_IP}:9092
consumer:
key-deserializer: org.apache.kafka.common.serialization.LongDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
ack-mode: count
ack-count: 40
```
To check that commits are done after 40 records, you can consume from the `__consumer_offsets` topic using the following enhanced version of the `kafka-console-consumer`:
```bash
docker exec -ti kafka-1 kafka-console-consumer --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --bootstrap-server kafka-1:19092 --topic __consumer_offsets
```
An alternative way to check for the commits is to set the logging of the `ConsumerCoordinator` to debug
```yml
logging:
level:
root: info
org:
apache:
kafka:
clients:
consumer:
internals:
ConsumerCoordinator: debug
```
### Manual Commit when consuming records
In the `@KafkaListener` method, add an additional parameter to get the `acknowledgment` bean on which you can invoke the `acknowledge()` method.
```kontlin
class KafkaEventConsumer {
@KafkaListener(topics = ["\${topic.name}"], groupId = "simple-kotlin-consumer", containerFactory = "filterContainerFactory")
fun receive(consumerRecord: ConsumerRecord<Long, String>, acknowledgment: Acknowledgment) {
println("received key = ${consumerRecord.key()} with payload=${consumerRecord.value()}")
acknowledgment.acknowledge();
}
}
```
Set the `ack-mode` to `manual` in the `application.yml`.
<file_sep># Invana Engine
GraphQL API for creating and managing graph data
**[Website](https://invana.io/)** | **[Documentation](https://docs.invana.io/products/invana-engine)** | **[GitHub](https://github.com/invana/invana-engine)**
```bash
platys init --enable-services INVANA_ENGINE
platys gen
```
## How to use it?
The GraphQL Endpoint can be reached here:
```
http://dataplatform:28291/graphql
```<file_sep># Oracle REST Data Services (ORDS)
Oracle REST Data Services (ORDS) bridges HTTPS and your Oracle Database. A mid-tier Java application, ORDS provides a Database Management REST API, SQL Developer Web, a PL/SQL Gateway, SODA for REST, and the ability to publish RESTful Web Services for interacting with the data and stored procedures in your Oracle Database.
**[Website](https://www.oracle.com/database/technologies/appdev/rest.html)** | **[Documentation](https://docs.oracle.com/en/database/oracle/oracle-rest-data-services/)**
## How to enable?
```
platys init --enable-services ORACLE_REST_DATA_SERVICE
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28252>
<file_sep># Swagger Editor
Design, describe, and document your API on the first open source editor fully dedicated to OpenAPI-based APIs. The Swagger Editor is an easy way to get started with the OpenAPI Specification (formerly known as Swagger), with support for Swagger 2.0 and OpenAPI 3.0.
**[Website](https://swagger.io/tools/swagger-editor/)** | **[Documentation](https://swagger.io/docs/open-source-tools/swagger-editor/)** | **[GitHub](https://github.com/swagger-api/swagger-editor)**
## How to enable?
```
platys init --enable-services SWAGGER_EDITOR
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28156><file_sep># Nuclio
Nuclio is an open source and managed serverless platform used to minimize development and maintenance overhead and automate the deployment of data-science based applications.
**[Website](https://nuclio.io/)** | **[Documentation](https://nuclio.io/docs/latest)** | **[GitHub](https://github.com/nuclio/nuclio)**
## How to enable?
```
platys init --enable-services NUCLIO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28131><file_sep>Contains the data of dataiku-dss service, if flag DATAIKU_DSS_volume_map_data is set to true.<file_sep>Contains the data of Oracle Database Free service, if flag ORACLE_FREE_volume_map_data is set to true.<file_sep># Docker Commands
## Docker Core
### Show Log
```
docker logs -f <container-name>
```
### Stopping a container
To stop a container, run the following command
```
docker stop <container-name>
```
The container is only stopped, but will still be around and could be started again. You can use `docker ps -a` to view also containers, which are stopped.
### Running a command inside a running container
To run a command in a running container
```
docker exec -ti <container-name> bash
```
### Remove all unused local volumes
```
docker volume prune
```
## Docker Compose
To get the logs for all of the services running inside the docker compose environment, perform
```
docker-compose logs -f
```
if you only want to see the logs for one of the services, say of `connect-1`, perform
```
docker-compose logs -f connect-1
```
To see the log of multiple services, just list them as shown below
```
docker-compose logs -f connect-1 connect-2
```
<file_sep># Kaskade
Kafka text user interface in style!
**[Documentation](https://https://github.com/sauljabin/kaskade)** | **[GitHub](https://github.com/sauljabin/kaskade)**
## How to enable?
```
platys init --enable-services KASKADE
platys gen
```
## How to use it?
```
docker exec -ti kaskade kaskade
```
<file_sep># Oracle RDBMS XE
Whether you are a developer, a DBA, a data scientist, an educator, or just curious about databases, Oracle Database Express Edition (XE) is the ideal way to get started. It is the same powerful Oracle Database that enterprises rely on worldwide, packaged for simple download, ease-of-use, and a full-featured experience. You get an Oracle Database to use in any environment, plus the ability to embed and redistribute – all completely free!
**[Website](https://www.oracle.com/database/technologies/appdev/xe.html)** | **[Documentation](https://www.oracle.com/database/technologies/appdev/xe/quickstart.html)** | **[Docker Image](https://github.com/gvenzl/oci-oracle-xe)** | **[Docker Image Details](https://github.com/gvenzl/oci-oracle-xe/blob/main/ImageDetails)**
## How to enable?
```
platys init --enable-services ORACLE_XE
platys gen
```
## Initialize database
You can initialize the database automatically by putting the necessary scripts in `./init/oracle-xe`:
To create more users, add a bash script, e.g. `01_create-user.sh`
```bash
#!/bin/bash
#
./createAppUser user1 abc123!
./createAppUser user2 abc123!
```
to create schema objects, add an sql script, e.g. `02_create-user1-schema.sql`
```sql
CONNECT user1/abc123!@//localhost/XEPDB1
DROP TABLE person_t IF EXISTS;
CREATE TABLE person_t (
business_entity_id INTEGER PRIMARY KEY,
person_type VARCHAR2(100),
name_style VARCHAR2(1),
title VARCHAR2(20),
first_name VARCHAR2(100),
middle_name VARCHAR2(100),
last_name VARCHAR2(100),
email_promotion NUMBER(10),
demographics VARCHAR2(2000),
created_date TIMESTAMP,
modified_date TIMESTAMP);
```
## How to use it?
### Connect through SQL Plus
```
docker exec -ti oracledb-xe sqlplus "user1/abc123!"@//localhost/XEPDB1
```
### Connect through JDBC
* **JDBC Url:** `jdbc:oracle:thin:@dataplatform:1522/XEPDB1`
* **JDBC Driver Class Name:** `oracle.jdbc.driver.OracleDriver`
<file_sep>---
technoglogies: ksqldb,kafka
version: 1.16.0
validated-at: 1.10.2022
---
# Handle Serialization Errors in ksqlDB
This recipe will show how to find serialization errors that cause some events from a Kafka topic to not be written into a ksqlDB stream or table.
The example code shown in this cookbook recipe is taken from the Confluent tutorial ["How to handle deserialization errors"](https://developer.confluent.io/tutorials/handling-deserialization-errors/ksql.html).
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services KAFKA,KAFKA_KSQLDB -s trivadis/platys-modern-data-platform -w 1.16.0
```
start the platform
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Create the input topic with a stream
To start off the implementation of this scenario, you need to create a stream that represent sensors. This stream will contain a field called ENABLED to indicate the status of the sensor. While this stream acts upon data stored in a topic called `SENSORS_RAW`, we will create derived stream called `SENSORS` to actually handle the sensors. This stream simply copies the data from the previous stream, ensuring that the ID field is used as the key.
Connect to ksqldb cli
```bash
docker exec -it ksqldb-cli ksql http://ksqldb-server-1:8088
```
and create the two streams
```sql
CREATE STREAM SENSORS_RAW (id VARCHAR, timestamp VARCHAR, enabled BOOLEAN)
WITH (KAFKA_TOPIC = 'SENSORS_RAW',
VALUE_FORMAT = 'JSON',
TIMESTAMP = 'TIMESTAMP',
TIMESTAMP_FORMAT = 'yyyy-MM-dd HH:mm:ss',
PARTITIONS = 1);
CREATE STREAM SENSORS AS
SELECT
ID, TIMESTAMP, ENABLED
FROM SENSORS_RAW
PARTITION BY ID;
```
## Produce events to the input topic
Before we move forward with the implementation, we need to produce records to the `SENSORS_RAW` topic, that as explained earlier, is the underlying topic behind the `SENSORS` stream. Let’s use the console producer to create some records.
```bash
docker exec -i kafka-1 /usr/bin/kafka-console-producer --bootstrap-server kafka-1:19092 --topic SENSORS_RAW
```
Type in one line at a time and press enter to send it. Each line represents a sensor with the required data. Note that for testing purposes, we are providing two records with data in the right format (notably the first two records) and one record with an error. The record with the error contains the field `ENABLED` specified as string instead of a boolean.
```json
{"id": "e7f45046-ad13-404c-995e-1eca16742801", "timestamp": "2020-01-15 02:20:30", "enabled": true}
{"id": "835226cf-caf6-4c91-a046-359f1d3a6e2e", "timestamp": "2020-01-15 02:25:30", "enabled": true}
{"id": "1a076a64-4a84-40cb-a2e8-2190f3b37465", "timestamp": "2020-01-15 02:30:30", "enabled": "true"}
```
## Checking for deserialization errors
Create a new client session for KSQL using the following command:
```bash
docker exec -it ksqldb-cli ksql http://ksqldb-server-1:8088
```
We know that we produced three records to the stream but only two of them were actually correct. In order to check if these two records were properly written into the stream, run the pull query (without the `EMIT CHANGES` clause) below
```sql
SELECT
ID,
TIMESTAMP,
ENABLED
FROM SENSORS;
```
and the output should look similar to:
```
+--------------------------------------------------------+--------------------------------------------------------+--------------------------------------------------------+
|ID |TIMESTAMP |ENABLED |
+--------------------------------------------------------+--------------------------------------------------------+--------------------------------------------------------+
|e7f45046-ad13-404c-995e-1eca16742801 |2020-01-15 02:20:30 |true |
|e7f45046-ad13-404c-995e-1eca16742801 |2020-01-15 02:20:30 |true |
|e7f45046-ad13-404c-995e-1eca16742801 |2020-01-15 02:20:30 |true |
Query Completed
Query terminated
```
We know that at least one of the records produced had an error, because we specified the field ENABLED as a string instead of a boolean.
With the [KSQL Processing Log](https://docs.ksqldb.io/en/latest/reference/processing-log) feature enabled, you can query a stream called KSQL_PROCESSING_LOG to check for deserialization errors.
The query below is extracting some of the data available in the processing log. As the ksqldb-server is configured so that the processing log includes the payload of the message, we can also use the encode method to convert the record from `base64` encoded into a human readable `utf8` encoding:
```sql
SELECT
message->deserializationError->errorMessage,
message->deserializationError->`topic`,
encode(message->deserializationError->RECORDB64, 'base64', 'utf8') AS MSG,
message->deserializationError->cause
FROM KSQL_PROCESSING_LOG;
```
this query should produce the following output
```
+-----------------------------------------+-----------------------------------------+-----------------------------------------+-----------------------------------------+
|ERRORMESSAGE |topic |MSG |CAUSE |
+-----------------------------------------+-----------------------------------------+-----------------------------------------+-----------------------------------------+
|Failed to deserialize value from topic: S|SENSORS_RAW |{"id": "1a076a64-4a84-40cb-a2e8-2190f3b37|[Can't convert type. sourceType: TextNode|
|ENSORS_RAW. Can't convert type. sourceTyp| |465", "timestamp": "2020-01-15 02:30:30",|, requiredType: BOOLEAN, path: $.ENABLED,|
|e: TextNode, requiredType: BOOLEAN, path:| | "enabled": "true"} | Can't convert type. sourceType: TextNode|
| $.ENABLED | | |, requiredType: BOOLEAN, path: .ENABLED, |
Query Completed
Query terminated
```
<file_sep>---
technologies: trino
version: 1.16.0
validated-at: 25.02.2023
---
# Trino Security
This recipe will show how to use [Trino](http://trino.io) with [security enabled](https://trino.io/docs/current/security/overview.html). We will first enable [TLS and HTTPS](https://trino.io/docs/current/security/tls.html) with [Password File Authentication](https://trino.io/docs/current/security/password-file.html) and then in a second step we will also enable [File-based access control](https://trino.io/docs/current/security/file-system-access-control.html).
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services TRINO,PROVISIONING_DATA -s trivadis/platys-modern-data-platform -w 1.16.0
```
Before we can generate the platform, we need to extend the `config.yml`:
## Add Authentication
Enable authentication by adding the following settings to the `config.yml`
```
TRINO_auth_enabled: true
TRINO_auth_use_custom_password_file: false
TRINO_auth_with_groups: false
```
Now set an environment variable to the home folder of the dataplatform and generate the data platform.
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
```
Platys uses a self-signed certificate for TLS, you can create you own certificate.
It also uses the [Password File Authentication](https://trino.io/docs/current/security/password-file.html) type of Trino and for that a password file is needed. By default a password file with 3 users (`admin`, `userA` and `userB`) with password `<PASSWORD>!` is used.
### Create a custom Password file (optional)
You can use your own password file and add your own users. For that you need to enable `TRINO_auth_use_custom_password_file` and then create the password file using
```bash
cd $DATAPLATFORM_HOME
touch custom-conf/trino/security/password.db
```
Now add or update the password for a user (replace `<new-user>` by the username).
```bash
htpasswd -B -C 10 custom-conf/trino/security/password.db <new-user>
```
### Create Custom Certificates (optional)
You can create your own certificate and add it to a keystore. For that you need to enable `TRINO_auth_use_custom_certs` and then create the self-signed certificate and add it to the keystore using these commands
```bash
cd $DATAPLATFORM/custom-conf/trino
keytool -genkeypair -alias trino -keyalg RSA -keystore certs/keystore.jks \
-dname "CN=coordinator, OU=datalake, O=dataco, L=Sydney, ST=NSW, C=AU" \
-ext san=dns:coordinator,dns:coordinator.presto,dns:coordinator.presto.svc,dns:coordinator.presto.svc.cluster.local,dns:coordinator-headless,dns:coordinator-headless.presto,dns:coordinator-headless.presto.svc,dns:coordinator-headless.presto.svc.cluster.local,dns:localhost,dns:trino-proxy,ip:127.0.0.1,ip:192.168.64.5,ip:192.168.64.6 \
-storepass <PASSWORD>!
keytool -exportcert -file certs/trino.cer -alias trino -keystore certs/keystore.jks -storepass <PASSWORD>!
keytool -import -v -trustcacerts -alias trino_trust -file certs/trino.cer -keystore certs/truststore.jks -storepass password -keypass <PASSWORD>! -noprompt
keytool -keystore certs/keystore.jks -exportcert -alias trino -storepass abc123! | openssl x509 -inform der -text
keytool -importkeystore -srckeystore certs/keystore.jks -destkeystore certs/trino.p12 -srcstoretype jks -deststoretype pkcs12 -storepass <PASSWORD>!
openssl pkcs12 -in certs/trino.p12 -out certs/trino.pem
openssl x509 -in certs/trino.cer -inform DER -out certs/trino.crt
```
### Start the platform
Now start the data platform.
```bash
docker-compose up -d
```
## Test Authentication
First let's see what happens if we use the Trino CLI without specifying a user and still over HTTP port:
```bash
docker exec -it trino-cli trino --server trino-1:8080
```
if we execute the SQL statement `SELECT * FROM system.runtime.nodes` we can see a HTTP `403` error.
```bash
trino> SELECT * FROM system.runtime.nodes;
Error running command: Error starting query at http://trino-1:8080/v1/statement returned an invalid response: JsonResponse{statusCode=403, headers={cache-control=[must-revalidate,no-cache,no-store], content-length=[422], content-type=[text/html;charset=iso-8859-1]}, hasValue=false} [Error: <html>
<head>
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1"/>
<title>Error 403 Forbidden</title>
</head>
<body><h2>HTTP ERROR 403 Forbidden</h2>
<table>
<tr><th>URI:</th><td>/v1/statement</td></tr>
<tr><th>STATUS:</th><td>403</td></tr>
<tr><th>MESSAGE:</th><td>Forbidden</td></tr>
<tr><th>SERVLET:</th><td>org.glassfish.jersey.servlet.ServletContainer-5810772a</td></tr>
</table>
</body>
</html>
]
```
we have to specify the `8443` port for using HTTPs, the username and the keystore to use:
```bash
docker exec -it trino-cli trino --server https://trino-1:8443 --user admin --password --insecure --keystore-path /etc/trino/trino.jks --keystore-password <PASSWORD>!
```
Use `<PASSWORD>!` for the password.
if we now execute the SQL statement `SELECT * FROM system.runtime.nodes` we can see that it works
```bash
trino> SELECT * FROM system.runtime.nodes;
node_id | http_uri | node_version | coordinator | state
---------+------------------------+--------------+-------------+--------
trino-1 | http://172.19.0.4:8080 | 407 | true | active
(1 row)
Query 20230225_215138_00001_fd6cc, FINISHED, 1 node
Splits: 1 total, 1 done (100.00%)
0.20 [1 rows, 39B] [4 rows/s, 194B/s]
```
## Add Authorization
Enable authorization by adding the following settings to the `config.yml`
```
TRINO_access_control_enabled: true
```
Regenerate the platform.
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
```
### Configure the access control rules file
Create a file `rules.json` in `custom-conf/trino/security/` and add the following configuration
```json
{
"catalogs": [
{
"catalog": "system",
"allow": "none"
}
]
}
```
With this configuration, we disallow access to the system catalog for all users.
Now update the platform using
```bash
docker-compose up -d
```
## Test Authorization
Let's test if the authorization works by using the Trino CLI
```bash
docker exec -it trino-cli trino --server https://trino-1:8443 --user admin --password --insecure --keystore-path /etc/trino/trino.jks --keystore-password <PASSWORD>!
```
Use `<PASSWORD>!` for the password.
if we now execute the SQL statement `SELECT * FROM system.runtime.nodes` we can see that we get an access denied error!
```bash
trino> SELECT * FROM system.runtime.nodes
-> ;
Query 20230225_221051_00000_guu2i failed: Access Denied: Cannot access catalog system
```
<file_sep># LDAP User Manager
A PHP web-based interface for LDAP user account management and self-service password change.
**[Documentation](https://github.com/wheelybird/ldap-user-manager)** | **[GitHub](https://github.com/wheelybird/ldap-user-manager)**
```bash
platys init --enable-services OPENLDAP, LDAP_USER_MANAGER
platys gen
```
## How to use it?
Navigate to <https://dataplatform:28297>.
<file_sep>Place kpow's license information into a file here (named kpow-license.env).<file_sep># StreamSets Data Collector Engine
StreamSets Data Collector is a lightweight, powerful design and execution engine that streams data in real time. Use Data Collector to route and process data in your data streams.
**[Website](https://streamsets.com/products/dataops-platform/data-collector-engine/)** | **[Documentation](https://docs.streamsets.com/portal/#datacollector/latest/help/index.html)** | **[GitHub](https://github.com/streamsets/datacollector-oss)**
### How to enable
```
platys init --enable-services STREAMSETS
platys gen
```
### How to use it?
Navigate to <http://dataplatform:18630>
<file_sep>package com.trivadis.kafkaws.springbootkotlinkafkaproducer
import org.springframework.beans.factory.annotation.Value
import org.springframework.kafka.core.KafkaTemplate
import org.springframework.kafka.support.SendResult
import org.springframework.stereotype.Component
import org.springframework.util.concurrent.ListenableFuture
@Component
class KafkaEventProducerAsync(private val kafkaTemplate: KafkaTemplate<Long, String>) {
@Value("\${topic.name}")
private lateinit var kafkaTopic: String
fun produce(key: Long, value: String) {
val time = System.currentTimeMillis()
var future: ListenableFuture<SendResult<Long, String>>
if (key > 0) {
future = kafkaTemplate.send(kafkaTopic, key, value)
} else {
future = kafkaTemplate.send(kafkaTopic, value)
}
future.addCallback({
val elapsedTime = System.currentTimeMillis() - time
println("[$key] sent record(key=$key value=$value) meta(partition=${it?.recordMetadata?.partition()}, offset=${it?.recordMetadata?.offset()}) time=$elapsedTime")
}, {
it.printStackTrace()
})
}
}<file_sep># Memgraph
Open-source graph database, built for real-time streaming data, compatible with Neo4j.
**[Website](https://memgraph.com/)** | **[Documentation](https://memgraph.com/docs)** | **[GitHub](https://github.com/memgraph/memgraph)**
```
platys init --enable-services MEMGRAPH
```
Use the `MEMGRAPH_edition` setting to choose if you want to use the Memgraph database (with or without Mage) or the Memgraph-Platform including the Memgraph Labe environment.
```
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28288> if you have the Memgraph-Platform enabled.
You can also download and install [Memgraph Lab](https://memgraph.com/lab) and [mgconsole](https://memgraph.com/docs/memgraph/connect-to-memgraph/mgconsole) ([download here](https://memgraph.com/download#memgraph-lab)) to your local machine and connect to the Memgraph instance running on the Platys stack.<file_sep># Working with Maven
### Compile a Java project
```
mvn package
```
### Clean all the build code
```
mvn clean
```
### Build metadata for Eclipse IDE
```
mvn eclipse:eclipse
```
<file_sep># Various Kafka Tricks
## Consuming from __consumer_offsets topic
```
kafka-console-consumer --consumer.config /tmp/consumer.config \
--formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" \
--bootstrap-server kafka-1:19092 --topic __consumer_offsets
```
<file_sep># Kafka Workshop
Kafka Workshops with hands-on tutorials for working with Kafka, Java, Spring Boot, KafkaStreams and ksqlDB ...
This workshop is part of the Trivadis course [Apache Kafka for Developer](https://www.trivadis-training.com/en/training/apache-kafka-fuer-entwickler-bd-kafka-dev).
All the workshops can be done on a container-based infrastructure using Docker Compose for the container orchestration. It can be run on a local machine or in a cloud environment. Check [01-environment](https://github.com/gschmutz/kafka-workshop/tree/master/01-environment) for instructions on how to setup the infrastructure.
## List of Workshops
ID | Title | Description
------------- | ------------- | -------------
2 | [Getting started with Apache Kafka](./02-working-with-kafka-broker) | Create topics from the command line, use the Console Producer and Console Consumer to publish and consume messages and show how to use `kcat` (used to be `kafakcat`).
3 | [Testing Consumer Scalability and Kafka Failover](./03-understanding-failover) | demonstrates consumer failover and broker failover and load balancing over various consumers within a consumer group
4 | [Simple Kafka Consumer & Producer from Java](./04-producing-consuming-kafka-with-java) | learn how to produce and consume simple messages using the **Kafka Java API**. Secondly we will see how to produce/consume complex objects using JSON serialization.
4a | [Simple Kafka Consumer & Producer from Java with Avro (JSON language) & Schema Registry](./04a-working-with-avro-and-java) | learn how to produce and consume messages using the **Kafka Java API** using Avro for serialization with the Confluent Schema Registry.
4b | [Using Kafka from Java with Avro (IDL language) & Schema Registry](./04b-working-with-avro-idl-and-java) | learn how to produce and consume messages using the **Kafka Java API** using Avro for serialization with the Confluent Schema Registry.
4c | [Simple Kafka Consumer & Producer from Java with Protocol Buffers & Schema Registry](./04c-working-with-protobuf-and-java) | learn how to produce and consume messages using the **Kafka Java API** using Protocol Buffers for serialisation with the Confluent Schema Registry.
4d | [Simple Kafka Consumer & Producer from Java with JSON Schema & Schema Registry](./04d-working-with-jsonschema-and-java) | learn how to produce and consume messages using the **Kafka Java API** using JSON Schema for serialisation with the Confluent Schema Registry.
4e | [Using CloudEvents with Kafka from Java](./04e-working-with-cloudenvent-and-java) | learn how to produce and consume messages using the **Kafka Java API** using CloudEvents for serialisation.
5 | [Kafka from Spring Boot using Kafka Spring](./05-producing-consuming-kafka-with-springboot) | learn how to use **Spring Boot** to consume and produce from/to Kafka
5a | [Kafka from Spring Boot with Avro & Schema Registry](./05a-working-with-avro-and-springboot) | learn how to use **Spring Boot** to consume and produce from/to Kafka using Avro for serialization with the Confluent Schema Registry.
5b | [Kafka from Spring Boot with Avro IDL & Schema Registry](./05b-working-with-avro-idl-and-springboot) | learn how to use **Spring Boot** to consume and produce from/to Kafka using Avro (using IDL for schema definition) for serialization with the Confluent Schema Registry.
5c | [Kafka Heterogenous Topic from Spring Boot with Avro IDL & Schema Registry](./05c-working-with-heterogenous-topic-avro-idl-and-springboot) | learn how to use **Spring Boot** to consume and produce from/to Kafka using a heterogenous topic (to transport different Avro objects) using Avro IDL.
5d | [Kafka from Spring Boot using Cloud Stream](./05d-producing-consuming-kafka-with-springboot-cloud-stream) | learn how to use **Spring Cloud Streams** to consume and produce from/to Kafka
5e | [Kafka from Spring Boot using Cloud Stream with Avro & Schema Registry](./05e-working-with-avro-and-springboot-cloud-stream) | learn how to use **Spring Cloud Streams** to consume and produce from/to Kafka using Avro for serialization with the Confluent Schema Registry.
5f | [Using Kafka Transactions from Spring Boot with Kafka Spring](./05f-kafka-transactions-with-springboot) | learn how to use **Spring Boot** to consume and produce from/to Kafka using exactly-once semantics through Kafka transactions.
6 | [Simple Kafka Consumer & Producer from Kotlin](./06-producing-consuming-kafka-with-kotlin) | learn how to produce and consume messages using the **Kotlin** with the Java API.
6a | [Using Kafka from Kotlin with Avro & Schema Registry](./06a-working-with-avro-and-kotlin) | learn how to produce and consume messages with **Kotlin** and the Kafka Java API using Avro for serialization with the Confluent Schema Registry.
6b | [Using Kafka from Spring Boot with Kotlin using Kafka Spring](./06b-producing-consuming-kafka-with-kotlin-springboot) | learn how to use **Kotlin** with **Spring Boot** to consume and produce from/to Kafka
6c | [Using Kafka from Spring Boot with Kotlin and Avro & Schema Registry](./06c-working-with-avro-and-kotlin-springboot) | learn how to use **Kotlin** with **Spring Boot** to consume and produce from/to Kafka using Avro for serialization with the Confluent Schema Registry.
7 | [Kafka with Confluent's .NET client](./07-producing-consuming-kafka-with-dotnet) | learn how to use **.NET** to consume and produce from/to Kafka
7b | [Using Kafka from #C (.Net) with Avro & Schema Registry](./07b-working-with-avro-and-dotnet) | learn how to use **.NET** to consume and produce messages from/to Kafka using Avro for serialization with the Confluent Schema Registry
8 |[Kafka with Confluent's Python client](./08-producing-consuming-kafka-with-python) | learn how to use **Python** to consume and produce from/to Kafka
9a |[Using Kafka from Go](./09a-working-with-go) | learn how to use **Go** to consume and produce from/to Kafka
9b |[Kafka from Node.js](./09b-working-with-nodejs) | learn how to use **Node.js** to consume and produce from/to Kafka
10 | [Function as a Service (FaaS) with Kafka and Nuclio](./10-faas-and-kafka-with-nuclio) | uses **Nuclio** to demonstrate implementing serverless functions (Faas = Function-as-a-Service) triggered by Kafka.
11 | [Using ksqlDB for Stream Analytics](./11-using-ksqldb-simple) | uses **Confluent ksqlDB** to demonstrate analytics on data-in-motion.
12 | [Using Kafka Streams for Stream Analytics](./12-using-kafka-streams-simple) | uses **Kafka Streams** to demonstrate analytics on data-in-motion.
12a | [Using Kafka Streams from Spring Boot for Stream Analytics](./12a-using-kafka-streams-from-springboot) | uses **Kafka Streams** from **Spring Boot** to demonstrate analytics on data-in-motion.
12b | [Using Kafka Streams from Spring Cloud Stream & Spring Boot for Stream Analytics](./12b-using-kafka-streams-from-springcloud-springboot) | uses **Kafka Streams** from **Spring Boot** with ** Kafka Streams Binder of Spring Cloud Stream** to demonstrate analytics on data-in-motion.
12c | [Using Kafka Streams with Azkarra Streams for Stream Analytics](./12c-using-kafka-streams-with-azkarra) | uses **Kafka Streams** with **Azkarra Streams** to demonstrate analytics on data-in-motion.
13 | [IoT Vehicle Tracking Workshop](./13-iot-vehicle-tracking-workshop) | a multi-step end-to-end workshop around IoT Vehicle Tracking
13a | [IoT Data Ingestion through MQTT into Kafka](./13a-iot-data-ingestion-over-mqtt) | learn how to use Kafka Connect to ingest data from MQTT into Kafka
13b | [Stream Analytics using ksqlDB](./13b-stream-analytics-using-ksql) | learn how to use ksqlDB to execute processing and analytics directly on a stream of data
13c | [Stream Analytics with using Kafka Streams](./13c-stream-analytics-using-java-kstreams) | learn how to use Kafka Streams from Java to execute processing and analytics directly on a stream of data
13d | [Stream Analytics with .Net using Streamiz](./13d-stream-analytics-using-dotnet-streamiz) | learn how to use Streamiz from .NET to execute processing and analytics directly on a stream of data
13e | [Stream Analytics using Spark Structured Streaming](./13e-stream-analytics-using-spark-structured-streaming) | learn how to use Spark Structured Streaming to execute processing and analytics directly on a stream of data
13f | [Static Data Ingestion into Kafka](./13f-static-data-ingestion) | use Kafka Connect to ingest data from relational database (static data) and then join it with a data stream using ksqlDB
14 | [Working with Kafka Connect and Change Data Capture (CDC)](./14-working-with-kafka-connect-and-cdc) | uses **Kafka Connect** to demonstrate various way for doing CDC on a set of PostgreSQL tables.
16 |[Manipulating Consumer Offsets](./16-manipulating-consumer-offsets) | learn how to use the `kafka-consumer-groups` CLI for manipulating consumer offsets
20 | [Using Confluent REST APIs (REST Proxy)](./20-using-rest-proxy) | use Confluent REST Proxy
<file_sep># Vault
A tool for secrets management, encryption as a service, and privileged access management.
**[Website](https://www.vaultproject.io/)** | **[Documentation](https://www.vaultproject.io/docs)** | **[GitHub](https://github.com/hashicorp/vault)**
## How to enable?
```
platys init --enable-services VAULT
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8200><file_sep>package com.trivadis.kafkaws.springcloudstreamkafkaproducer;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class nmSpringBootKafkaProducerApplicationTests {
@Test
void contextLoads() {
}
}
<file_sep># Reaper
Automated Repair Awesomeness for Apache Cassandra.
**[Website](http://cassandra-reaper.io/)** | **[Documentation](http://cassandra-reaper.io/docs/)** | **[GitHub](https://github.com/thelastpickle/cassandra-reaper)**
## How to enable?
```
platys init --enable-services CASSANDRA REAPER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28232>.
<file_sep>Place application.properties file here for configuring debezium-server.
https://hub.docker.com/r/debezium/server<file_sep># Jikkou
A command-line tool to help you automate the management of the configurations that live on your Apache Kafka clusters.
**[Website](https://streamthoughts.github.io/jikkou/)** | **[Documentation](https://streamthoughts.github.io/jikkou/docs/)** | **[GitHub](https://github.com/streamthoughts/jikkou)**
## How to enable?
```
platys init --enable-services JIKKOU
platys gen
```
## How to use it?
Place desired state of Kafka Topics, ACLs, or Quotas into the `./scripts/jikkou/topic-specs.yml` file.
Here a sample of a `topic-specs.yml` file
```yaml
version: 1
specs:
topics:
- name: 'my-first-topic-with-jikkou'
partitions: 12
replication_factor: 3
configs:
min.insync.replicas: 2
```
The file is applied the first time you start the stack using `docker-compose up -d` as well as anytime you apply the `docker-compose up -d` on an already running stack, where it will apply the necessary changes to get from the current to the desired state (if you have changed the topic-specs.yml file).<file_sep>Place a certificate file here.<file_sep>Contains the storage of clan service, if flag CKAN_volume_map_storage is set to true.<file_sep>Place a Neo4J extension script here.<file_sep># Tipboard
Tipboard - in-house, tasty, local dashboarding system
**[Website](https://github.com/allegro/tipboard)** | **[Documentation](https://tipboard.readthedocs.io/en/latest/)** | **[GitHub](https://github.com/allegro/tipboard)**
## How to enable?
```bash
platys init --enable-services TIPBOARD
platys gen
```
## How to use it?
Navigate to <http://${PUBLIC_IP}:28172>
<file_sep># kafka-workshop - List of Services
| Service Name | Web UI | Rest API |
|-------------- |------|------------
|[adminer](./documentation/services/adminer )|<http://172.26.121.207:28131>
|[akhq](./documentation/services/akhq )|<http://172.26.121.207:28107>
|[cmak](./documentation/services/cmak )|<http://172.26.121.207:28104>
|[conduktor-platform](./documentation/services/conduktor-platform )|<http://172.26.121.207:28285>
|[jupyter](./documentation/services/jupyter )|<http://172.26.121.207:28888>
|[kafka-1](./documentation/services/kafka )|
|[kafka-2](./documentation/services/kafka )|
|[kafka-3](./documentation/services/kafka )|
|[kafka-connect-1](./documentation/services/kafka-connect )|| <http://172.26.121.207:8083>
|[kafka-connect-2](./documentation/services/kafka-connect )|| <http://172.26.121.207:8084>
|[kafka-connect-ui](./documentation/services/kafka-connect-ui )|<http://172.26.121.207:28103>
|[kafka-rest-1](./documentation/services/kafka-rest )|| <http://172.26.121.207:18086>
|[kcat](./documentation/services/kcat )|
|[ksqldb-cli](./documentation/services/ksqldb-cli )|
|[ksqldb-server-1](./documentation/services/ksqldb )|| <http://172.26.121.207:8088>
|[ksqldb-server-2](./documentation/services/ksqldb )|| <http://172.26.121.207:8089>
|[markdown-renderer](./documentation/services/markdown-renderer )|
|[markdown-viewer](./documentation/services/markdown-viewer )|<http://172.26.121.207:80>
|[minio-1](./documentation/services/minio )|<http://172.26.121.207:9000>
|[minio-mc](./documentation/services/minio )|
|[mosquitto-1](./documentation/services/mosquitto )|
|[mqtt-ui](./documentation/services/hivemq-ui )|<http://172.26.121.207:28136>
|[nifi-1](./documentation/services/nifi )|<https://172.26.121.207:18080/nifi>
|[postgresql](./documentation/services/postgresql )|
|[schema-registry-1](./documentation/services/schema-registry )|| <http://172.26.121.207:8081>
|[schema-registry-ui](./documentation/services/schema-registry-ui )|<http://172.26.121.207:28102>
|[streamsets-1](./documentation/services/streamsets )|<http://172.26.121.207:18630>| <http://172.26.121.207:18630/collector/restapi>
|[wetty](./documentation/services/wetty )|<http://172.26.121.207:3001>
|[zeppelin](./documentation/services/zeppelin )|<http://172.26.121.207:28080>
|[zookeeper-1](./documentation/services/zookeeper )|<file_sep># Apache NiFi
Apache NiFi supports powerful and scalable directed graphs of data routing, transformation, and system mediation logic.
**[Website](https://nifi.apache.org/)** | **[Documentation](https://nifi.apache.org/docs.html)** | **[GitHub](https://github.com/apache/nifi)**
## How to enable?
```bash
platys init --enable-services NIFI
platys gen
```
## How to use it?
Navigate to <http://dataplatform:18080/nifi>
Login with User `nifi` and password `<PASSWORD>`.
### Installing JDBC Driver
If you want to use one of the Database Processors, you need to install a JDBC Driver for the database. Download it into `./plugins/nifi/jars` of your Platys stack and specify the folder `/extra-jars` folder when creating the Controller service in Apache NiFi.
### AWS (S3) Credentials
Platys automatically creates the file `/opt/nifi/nifi-current/s3-credentials.properties` in the `nifi-1` container with the AWS credentials configured for either Minio or External S3. It is meant to be used as the **Credentials File** in either one of the AWS/S3 related processors or the [AWSCredentialsProviderControllerService](https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-aws-nar/latest/org.apache.nifi.processors.aws.credentials.provider.service.AWSCredentialsProviderControllerService/index.html).
Platys also injects the following environment variables into the `nifi-1` container.
* `S3_ENDPOINT` - the S3 endpoint to use
* `S3_PATH_STYLE_ACCESS` - if path style access should be used
* `S3_REGION` - the AWS region to use
<file_sep># InfluxDB
InfluxDB is a time series database designed to handle high write and query loads. It is an integral component of the TICK stack. InfluxDB is meant to be used as a backing store for any use case involving large amounts of timestamped data, including DevOps monitoring, application metrics, IoT sensor data, and real-time analytics.
**[Website](https://www.influxdata.com/)** | **[Documentation](https://docs.influxdata.com/influxdb/v1.8/)** | **[GitHub](https://github.com/influxdata/influxdb)**
## How to enable?
```
platys init --enable-services INFLUXDB
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8086><file_sep># File Browser
A Web-based File Browser.
**[Documentation](https://filebrowser.org/)** | **[GitHub](https://github.com/filebrowser/filebrowser)**
## How to enable?
```
platys init --enable-services FILE_BROWSER
platys gen
```
## How to use it?
Navigate to <http://172.26.121.207:28178> and login as user `admin` and password `<PASSWORD>`. <file_sep># Camunda Operate
Operate is a tool for monitoring and troubleshooting process instances running in Zeebe.
**[Website](https://camunda.com/de/products/cloud/operate/)** | **[Documentation](https://docs.camunda.io/docs/components/operate/index/)** | **[GitHub](https://github.com/camunda-cloud/zeebe)**
## How to enable?
```
platys init --enable-services CAMUNDA_OPERATE
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28207>.
<file_sep>Place additional JARs for NiFi here ...<file_sep>connector.name=postgresql
connection-url=jdbc:postgresql://postgresql:5432/${ENV:POSTGRESQL_DATABASE}
connection-user=${ENV:POSTGRESQL_USER}
connection-password=${ENV:POSTGRESQL_PASSWORD}
<file_sep># Airbyte
Airbyte is an open-source EL(T) platform that helps you replicate your data in your warehouses, lakes and databases.
**[Website](https://airbyte.com/)** | **[Documentation](https://docs.airbyte.com/)** | **[GitHub](https://github.com/airbytehq/airbyte)**
## How to enable?
```
platys init --enable-services AIRBYTE
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28271>.
<file_sep>Contains the data of thingsboard service, if flag THINGSBOARD_volume_map_data is set to true.<file_sep># Nussknacker
A visual tool to define and run real-time decision algorithms. Brings agility to business teams, liberates developers to focus on technology.
**[Website](https://nussknacker.io/)** | **[Documentation](https://nussknacker.io/documentation/)** | **[GitHub](https://github.com/touk/nussknacker)**
## How to enable?
```
platys init --enable-services FLINK,NUSSKNACKER
platys gen
```
## How to use it?
<file_sep>package com.trivadis.kafkaws.springbootkafkaproducer;
import com.fasterxml.jackson.databind.JsonNode;
public class Record {
public String key;
public Object value;
}
<file_sep>Add configurations of repositorieswhich should be executed upon initialisation of the graphdb database. This will only be done once, in the init phase of the database.
dbpedia/
├── config.ttl
├── fts-m2-index.sparql
└── toLoad
Check: https://github.com/khaller93/graphdb-free<file_sep># Apache Iceberg REST Catalog API
The Iceberg REST Catalog
**[Website](https://iceberg.apache.org/)** | **[Documentation](https://tabular.io/blog/rest-catalog-docker/)** | **[GitHub](https://github.com/apache/iceberg)**
## How to enable?
```
platys init --enable-services SPARK,ICEBERG_REST
platys gen
```
## How to use it?
Navigate to <http://172.26.121.207:28287><file_sep>Place a OpenLDAP ldif files here.<file_sep>using System.Threading;
using Confluent.Kafka;
class KafkaProducer
{
const string brokerList = "dataplatform:9092,dataplatform:9093";
const string topicName = "test-dotnet-topic";
static void Main(string[] args)
{
long startTime = DateTimeOffset.Now.ToUnixTimeMilliseconds();
if (args.Length == 0)
{
runProducerSync(100, 10, 0);
}
else
{
runProducerSync(int.Parse(args[0]), int.Parse(args[1]), int.Parse(args[2]));
}
long endTime = DateTimeOffset.Now.ToUnixTimeMilliseconds();
Console.WriteLine("Producing all records took : " + (endTime - startTime) + " ms = (" + (endTime - startTime) / 1000 + " sec)");
}
static void runProducerSync(int totalMessages, int waitMsInBetween, int id)
{
var config = new ProducerConfig { BootstrapServers = brokerList };
Func<Task> mthd = async () =>
{
// Create the Kafka Producer
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
for (int index = 0; index < totalMessages; index++)
{
// Construct the message value
string value = "[" + index + ":" + id + "] Hello Kafka " + DateTimeOffset.Now;
// send the message to Kafka
var deliveryReport = await producer.ProduceAsync(topicName, new Message<Null, string> { Value = value });
Console.WriteLine($"[{id}] sent record (key={deliveryReport.Key} value={deliveryReport.Value}) meta (partition={deliveryReport.TopicPartition.Partition}, offset={deliveryReport.TopicPartitionOffset.Offset}, time={deliveryReport.Timestamp.UnixTimestampMs})");
Thread.Sleep(waitMsInBetween);
}
}
};
mthd().Wait();
}
static void runProducerSyncWithKey(int totalMessages, int waitMsInBetween, int id)
{
var config = new ProducerConfig { BootstrapServers = brokerList };
Func<Task> mthd = async () =>
{
// Create the Kafka Producer
using (var producer = new ProducerBuilder<int, string>(config).Build())
{
for (int index = 0; index < totalMessages; index++)
{
long time = DateTimeOffset.Now.ToUnixTimeMilliseconds();
// Construct the message value
string value = "[" + index + ":" + id + "] Hello Kafka " + DateTimeOffset.Now;
// send the message to Kafka
var deliveryReport = await producer.ProduceAsync(topicName, new Message<int, string> { Key = id, Value = value });
Console.WriteLine($"[{id}] sent record (key={deliveryReport.Key} value={deliveryReport.Value}) meta (partition={deliveryReport.TopicPartition.Partition}, offset={deliveryReport.TopicPartitionOffset.Offset}, time={deliveryReport.Timestamp.UnixTimestampMs})");
Thread.Sleep(waitMsInBetween);
}
}
};
mthd().Wait();
}
static void runProducerASync(int totalMessages, int waitMsInBetween, int id)
{
var config = new ProducerConfig { BootstrapServers = brokerList };
// Create the Kafka Producer
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
for (int index = 0; index < totalMessages; index++)
{
long time = DateTimeOffset.Now.ToUnixTimeMilliseconds();
// Construct the message value
string value = "[" + index + ":" + id + "] Hello Kafka " + DateTimeOffset.Now;
// send the message to Kafka
var deliveryReport = producer.ProduceAsync(topicName, new Message<Null, string> { Value = value });
deliveryReport.ContinueWith(task =>
{
if (task.IsFaulted)
{
}
else
{
Console.WriteLine($"[{id}] sent record (key={task.Result.Key} value={task.Result.Value}) meta (partition={task.Result.TopicPartition.Partition}, offset={task.Result.TopicPartitionOffset.Offset}, time={task.Result.Timestamp.UnixTimestampMs})");
}
});
Thread.Sleep(waitMsInBetween);
}
producer.Flush(TimeSpan.FromSeconds(10));
}
}
static void runProducerASync2(int totalMessages, int waitMsInBetween, int id)
{
var config = new ProducerConfig { BootstrapServers = brokerList };
// Create the Kafka Producer
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
for (int index = 0; index < totalMessages; index++)
{
long time = DateTimeOffset.Now.ToUnixTimeMilliseconds();
// Construct the message value
string value = "[" + index + ":" + id + "] Hello Kafka " + DateTimeOffset.Now;
try
{
// send the message to Kafka
producer.Produce(topicName, new Message<Null, string> { Value = value },
(deliveryReport) =>
{
if (deliveryReport.Error.Code != ErrorCode.NoError)
{
Console.WriteLine($"Failed to deliver message: {deliveryReport.Error.Reason}");
}
else
{
Console.WriteLine($"[{id}] sent record (key={deliveryReport.Key} value={deliveryReport.Value}) meta (partition={deliveryReport.TopicPartition.Partition}, offset={deliveryReport.TopicPartitionOffset.Offset}, time={deliveryReport.Timestamp.UnixTimestampMs})");
}
});
}
catch (ProduceException<Null, string> e)
{
Console.WriteLine($"failed to deliver message: {e.Message} [{e.Error.Code}]");
}
Thread.Sleep(waitMsInBetween);
}
producer.Flush(TimeSpan.FromSeconds(10));
}
}
}<file_sep>Contains the controller data folder of pinot service, if flag PINOT_volume_map_data is set to true.<file_sep># Shiny
Shiny is an R package that makes it easy to build interactive web apps straight from R. You can host standalone apps on a webpage or embed them in R Markdown documents or build dashboards. You can also extend your Shiny apps with CSS themes, htmlwidgets, and JavaScript actions.
**[Website](https://shiny.rstudio.com/)** | **[Documentation](https://shiny.rstudio.com/)** | **[GitHub](https://github.com/rstudio/shiny)**
## How to enable?
```
platys init --enable-services SHINY_SERVER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:3838><file_sep># Apache Kafka
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
**[Website](http://kafka.apache.org)** | **[Documentation](https://kafka.apache.org/documentation)** | **[GitHub](https://github.com/apache/kafka)**
## How to enable?
```
platys init --enable-services KAFKA
platys gen
```
## How to use?
Connecting to one of the borkers (i.e. `kafka-1`)
```
docker exec -ti kafka-1 bash
```
Show all the topics
```
docker exec -ti kafka-1 kafka-topics --bootstrap-sever kafka-1:29092 --list
```
<file_sep>package com.trivadis.kafkaws.springbootkafkaproducer;
import com.trivadis.kafkaws.avro.v1.Notification;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Component;
import java.time.Instant;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
@Component
public class KafkaEventProducer {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaEventProducer.class);
@Autowired
private KafkaTemplate<Long, Notification> kafkaTemplate;
@Value("${topic.name}")
String kafkaTopic;
public void produce(Integer id, Long key, Notification notification) {
long time = System.currentTimeMillis();
SendResult<Long, Notification> result = null;
try {
result = kafkaTemplate.send(kafkaTopic, key, notification).get(10, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) "
+ "meta(partition=%d, offset=%d) time=%d\n",
key, notification, result.getRecordMetadata().partition(),
result.getRecordMetadata().offset(), elapsedTime);
}
}<file_sep># Prometheus
The Prometheus monitoring system and time series database.
**[Website](https://prometheus.io/)** | **[Documentation](https://prometheus.io/docs/introduction/overview/)** | **[GitHub](https://github.com/prometheus/prometheus)**
## How to enable?
```
platys init --enable-services PROMETHEUS
platys gen
```
## How to use it?
Navigate to <http://dataplatform:9090/graph><file_sep># Avro Tools CLI
Apache Avro™ is a data serialization system and Avro Tools help workin with Avro instances and schmeas.
**[Website](https://avro.apache.org/)** | **[Documentation](https://avro.apache.org/)** | **[GitHub](https://github.com/apache/avro)**
## How to enable?
```
platys init --enable-services AVRO_TOOLS
platys gen
```
## How to use it?
To use the avro tool, once it is generated, just use the `docker exec` command:
```bash
docker compose run --rm avro-tools <command>
```<file_sep># Chronograf
Chronograf is InfluxData’s open source web application. Use Chronograf with the other components of the TICK stack to visualize your monitoring data and easily create alerting and automation rules.
**[Website](https://www.influxdata.com/time-series-platform/chronograf/)** | **[Documentation](https://docs.influxdata.com/chronograf/v1.7)** | **[GitHub](https://github.com/influxdata/chronograf)**
## How to enable?
```
platys init --enable-services INFLUXDB, INFLUXDB_CHRONOGRAF
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28129><file_sep># QuestDB
QuestDB is a relational column-oriented database designed for time series and event data. It uses SQL with extensions for time series to assist with real-time analytics. These pages cover core concepts of QuestDB, including setup steps, usage guides, and reference documentation for syntax, APIs and configuration.
**[Website](https://questdb.io/)** | **[Documentation](https://questdb.io/docs/introduction/)** | **[GitHub](https://github.com/questdb/questdb)**
## How to enable?
```
platys init --enable-services QUESTDB
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28226><file_sep># MockServer
MockServer enables easy mocking of any system you integrate with via HTTP or HTTPS with clients written in Java, JavaScript and Ruby. MockServer also includes a proxy that introspects all proxied traffic including encrypted SSL traffic and supports Port Forwarding, Web Proxying (i.e. HTTP proxy), HTTPS Tunneling Proxying (using HTTP CONNECT) and…
**[Website](https://mock-server.com/)** | **[Documentation](https://mock-server.com/)** | **[GitHub](https://github.com/mock-server/mockserver)**
## How to enable?
```
platys init --enable-services MOCK_SERVER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28273/mockserver/dashboard>.
### Setting expectations using Json Config File
```json
[ {
"httpRequest" : {
"path" : "/some/path"
},
"httpResponse" : {
"statusCode": 200,
"body": {
"value": "one"
}
}
} ]
```
### Setting expectations using Curl
```bash
curl -X PUT 'localhost:28273/mockserver/expectation' \
-d '[
{
"httpRequest": {
"path": "/some/path"
},
"httpResponse": {
"statusCode": 200,
"body": {
"value": "one"
}
}
}
]'
```<file_sep># Thingsboard
ThingsBoard is an open-source IoT platform that enables rapid development, management, and scaling of IoT projects. Our goal is to provide the out-of-the-box IoT cloud or on-premises solution that will enable server-side infrastructure for your IoT applications.
**[Website](https://thingsboard.io/)** | **[Documentation](https://thingsboard.io/docs/)** | **[GitHub](https://github.com/thingsboard/thingsboard)**
## How to enable?
```
platys init --enable-services THINGSBOARD
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28200><file_sep># dbt CLI (Data Build Tool)
dbt enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications.
**[Website](https://www.getdbt.com/)** | **[Documentation](https://www.getdbt.com/docs/)** | **[GitHub](https://github.com/dbt-labs/dbt-core)**
## How to enable?
```bash
platys init --enable-services DBT
platys gen
```
## How to use it?
To work with the dbt CLI, use:
```bash
docker exec -it dbt-cli dbt --version
```
<file_sep># GraphQL Mesh
GraphQL Mesh — Query anything, run anywhere.
**[Website](https://www.graphql-mesh.com/)** | **[Documentation](https://www.graphql-mesh.com/docs/getting-started/introduction)** | **[GitHub](https://github.com/urigo/graphql-mesh)**
## How to enable?
```
platys init --enable-services GRAPHQL_MESH
platys gen
```
## How to use it?
Navigate to <http://dataplatform:4000><file_sep># Filestash
A modern web client for SFTP, S3, FTP, WebDAV, Git, Minio, LDAP, CalDAV, CardDAV, Mysql, Backblaze, ...
**[Documentation](https://github.com/mickael-kerjean/filestash)** | **[GitHub](https://github.com/mickael-kerjean/filestash)**
## How to enable?
```
platys init --enable-services FILESTASH
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28193><file_sep>---
technologies: streamsets
version: 1.14.0
validated-at: 19.2.2022
---
# Creating a self-managed StreamSets DataOps Environment using Platys
This recipe will show how to create a self-managed environment for the [StreamSets DataOps Platform](https://streamsets.com/products/dataops-platform/).
## Signup for StreamSets DataPlatform
Navigate to <https://cloud.login.streamsets.com/signup> and create an account as shown in the diagram.

Click on **Create Account**. Verify the account using the link in the email you should have received on the emial provided.
Now login to the newly created account and fill in the account details and click on **Agree & Continue**

and you will get to the StreamSets DataOps homepage

## Create a StreamSets Data Collector deployment
In the navigator to the left, click on **Set Up** and navigate to the **Environments** item. You should see a default Self-Managed environment **Default Self-Managed Environment**. We will use this and next create a deployment.
Navigate to **Deployments** and click on the **Create deployment** link in the main canvas.

Scroll down and click on **Save & Next**.
On the next step, click on the link **3 stage libraries selected**

to configure additional libraries to be installed. On the rigtht side, the installed stage libraries are shown, on the left side, the available stage libraries can be found. Install a library by clicking on the **+** icon.

Once you are finished, click on **OK** to go back the configuration of the deployment.
Now click once again on **Save & Next**. Chose `Docker Image` for the **Install Type**.

Click on **Save & Next** and again **Save & Next** and the **Start & Generate Install Script** and you should see the script to start the docker container.

Leave the screen open, we will need the environment variables when configuring the service in `platys`.
```
docker run -d -e STREAMSETS_DEPLOYMENT_SCH_URL=https://eu01.hub.streamsets.com -e STREAMSETS_DEPLOYMENT_ID=68f53dc7-1aa7-44b8-a8e5-f73ac9da041c:14e83b51-91b3-11ec-a4ba-f369fd3f0937 -e STREAMSETS_DEPLOYMENT_TOKEN=XXXXXX streamsets/datacollector:4.4.0
```
The deployment-token has been replaced, the real value will be much larger.
## Initialise data platform
Now let's [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services STREAMSETS_DATAOPS -s trivadis/platys-modern-data-platform -w 1.14.0
```
Either add the value of `STREAMSETS_DEPLOYMENT_ID` and `STREAMSETS_DEPLOYMENT_TOKEN` to the `config.yml`
```
STREAMSETS_DATAOPS_deployment_id: '68f53dc7-1aa7-44b8-a8e5-f73ac9da041c:14e83b51-91b3-11ec-a4ba-f369fd3f0937'
STREAMSETS_DATAOPS_deployment_token: 'XXXXXX'
```
or add the environment variables to the environment, for example by using the `.env` file
```
STREAMSETS_DATAOPS_DEPLOYMENT_ID=68f53dc7-1aa7-44b8-a8e5-f73ac9da041c:14e83b51-91b3-11ec-a4ba-f369fd3f0937
STREAMSETS_DATAOPS_DEPLOYMENT_TOKEN=<PASSWORD>XX
```
The URL by default is set to `https://eu01.hub.streamsets.com`. If you need another value, then specify it in the `config.yml` file using the property `STREAMSETS_DATAOPS_deployment_sch_url`.
## Check the status in Streamsets DataOps Platform
In StreamSets DataOps Platform screen, click on **Check Engine Status after runing the script**, if you have not done it yet.

Now generate and start the platform
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
In StreamSets DataOps Platform after a while you should get the following confirmation message.

The engine running in docker has successfully connected to the StreamSets DataOps Platform. Click on **Close**.
The environment is ready to be used.
<file_sep># EMQ X
An Open-Source, Cloud-Native, Distributed MQTT Broker for IoT.
**[Website](https://www.emqx.io/)** | **[Documentation](https://docs.emqx.io/en/broker/v4.3/index.html)** | **[GitHub](https://github.com/emqx/emqx)**
## How to enable?
```
platys init --enable-services EMQX
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28225><file_sep># Invana Studio
Open source graph visualiser.
**[Website](https://invana.io/)** | **[Documentation](https://docs.invana.io/products/invana-studio)** | **[GitHub](https://github.com/invana/invana-studio)**
```bash
platys init --enable-services INVANA_STUDIO, INVANA_ENGINE
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28292> and enter `http://dataplatform:28291/graphql` into the connection string to connect to the Invana GraphQL Engine. <file_sep># Oracle SQLcl
Oracle SQL Developer Command Line (SQLcl) is a free command line interface for Oracle Database. It allows you to interactively or batch execute SQL and PL/SQL. SQLcl provides in-line editing, statement completion, and command recall for a feature-rich experience, all while also supporting your previously written SQL*Plus scripts.
**[Website](https://www.oracle.com/database/technologies/appdev/sqlcl.html)** | **[Documentation](https://docs.oracle.com/en/database/oracle/sql-developer-command-line/)**
## How to enable?
```
platys init --enable-services ORACLE_SQLCL
platys gen
```
## How to use it?
<file_sep>Contains the data of metabase service, if flag METABASE_volume_map_data is set to true.<file_sep># CKAN - The Open Source Data Portal Software
CKAN is an open-source DMS (data management system) for powering data hubs and data portals. CKAN makes it easy to publish, share and use data. It powers catalog.data.gov, open.canada.ca/data, data.humdata.org among many other sites.
**[Website](https://ckan.org/)** | **[Documentation](https://docs.ckan.org/en/2.9/)** | **[GitHub](https://github.com/ckan/ckan)**
```bash
platys init --enable-services CKAN
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28294>.
### Using CLI
```bash
docker exec -ti ckan ckan -c /srv/app/production.ini
```<file_sep>Place custom Trino plugins here and register them using TRINO_ ...<file_sep># Using Kafka from Kotlin with Avro & Schema Registry
In this workshop we will learn how to produce and consume messages from **Kotlin** using the [Kafka Java API](https://kafka.apache.org/documentation/#api) with Avro for serialising and deserialising messages.
## Create the project in your favourite IDE
Create a new Maven Project (using the functionality of your IDE) and in the last step use `com.trivadis.kafkaws` for the **Group Id** and `kotlin-simple-kafka-avro` for the **Artifact Id**.
Navigate to the **pom.xml** and double-click on it. The POM Editor will be displayed.
You can either use the GUI to edit your `pom.xml` or navigate to the last tab **pom.xml** to switch to the "code view". Let's do that.
You will see the still rather empty definition.
```xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trivadis.kafkaws</groupId>
<artifactId>kotlin-simple-kafka-avro</artifactId>
<version>0.0.1-SNAPSHOT</version>
</project>
```
Let's add some initial dependencies for our project. We will add some more dependencies to the POM throughout this workshop.
Copy the following block right after the `<version>` tag, before the closing `</project>` tag.
```xml
<properties>
<kafka.version>2.8.0</kafka.version>
<confluent.version>7.0.0</confluent.version>
<avro.version>1.11.0</avro.version>
<java.version>11</java.version>
<kotlin.version>1.6.21</kotlin.version>
<slf4j-version>1.7.5</slf4j-version>
<!-- use utf-8 encoding -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>${avro.version}</version>
</dependency>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-stdlib</artifactId>
<version>${kotlin.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j-version}</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>github-releases</id>
<url>http://oss.sonatype.org/content/repositories/github-releases/</url>
</repository>
<repository>
<id>clojars.org</id>
<url>http://clojars.org/repo</url>
</repository>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</pluginRepository>
</pluginRepositories>
<build>
<defaultGoal>install</defaultGoal>
<plugins>
<plugin>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-plugin</artifactId>
<version>${kotlin.version}</version>
<executions>
<execution>
<id>compile</id>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
<configuration>
<sourceDirs>
<sourceDir>${project.basedir}/src/main/kotlin</sourceDir>
<sourceDir>${project.basedir}/src/main/java</sourceDir>
</sourceDirs>
</configuration>
</execution>
<execution>
<id>test-compile</id>
<phase>test-compile</phase>
<goals>
<goal>test-compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<maxmem>256M</maxmem>
<showDeprecation>true</showDeprecation>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<executions>
<execution>
<id>producer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.producer.KafkaProducerAvro</mainClass>
</configuration>
</execution>
<execution>
<id>consumer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.consumer.KafkaConsumerAvro</mainClass>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
```
## Creating the necessary Kafka Topic
We will use the topic `test-kotlin-avro-topic` in the Producer and Consumer code below. Due to the fact that `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
In a terminal window, connect to the `kafka-1` container
```
docker exec -ti kafka-1 bash
```
and execute the necessary kafka-topics command.
```
kafka-topics --create \
--replication-factor 3 \
--partitions 12 \
--topic test-kotlin-avro-topic \
--bootstrap-server kafka-1:19092,kafka-2:19093
```
This finishes the setup steps and our new project is ready to be used. Next we will start implementing the **Kafka Producer** which uses Avro for the serialisation.
## Create an Avro Schema representing the Notification Message
First create a new Folder `avro` under the existing folder **src/main/**.
Create a new File `Notification-v1.avsc` in the folder **src/main/avro** just created above.
Add the following Avro schema to the empty file.
```json
{
"type" : "record",
"namespace" : "com.trivadis.kafkaws.avro.v1",
"name" : "Notification",
"description" : "A simple Notification Event message",
"fields" : [
{ "type" : ["long", "null"],
"name" : "id"
},
{ "type" : ["string", "null"],
"name" : "message"
}
]
}
```
In the `pom.xml`, add the `avro-maven-plugin` plugin to the `<build><plugins>` section, just below the `exec-maven-plugin`.
```xml
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro.version}</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
<configuration>
<fieldVisibility>private</fieldVisibility>
<sourceDirectory>${project.basedir}/src/main/avro</sourceDirectory>
</configuration>
</execution>
</executions>
</plugin>
```
This plugin will make sure, that classes are generated based on the Avro schema, whenever a `mvn compile` is executed. Let's exactly do that on the still rather empty project.
```
mvn compile
```
After running this command, refresh the project and you should see a new folder named `target/generated-sources/avro`. Expand into this folder and you should see one generated Java class named `Notification`.

Double click on the `Notification` class to inspect the code.
```kotlin
package com.trivadis.kafkaws.avro.v1;
import org.apache.avro.specific.SpecificData;
@SuppressWarnings("all")
@org.apache.avro.specific.AvroGenerated
public class Notification extends org.apache.avro.specific.SpecificRecordBase implements org.apache.avro.specific.SpecificRecord {
private static final long serialVersionUID = 799361421243801515L;
public static final org.apache.avro.Schema SCHEMA$ = new org.apache.avro.Schema.Parser().parse("{\"type\":\"record\",\"name\":\"Notification\",\"namespace\":\"com.trivadis.kafkaws.avro.v1\",\"fields\":[{\"name\":\"id\",\"type\":[\"long\",\"null\"]},{\"name\":\"message\",\"type\":[\"string\",\"null\"]}],\"description\":\"A simple Notification Event message\"}");
public static org.apache.avro.Schema getClassSchema() { return SCHEMA$; }
private java.lang.Long id;
private java.lang.CharSequence message;
/**
* Default constructor. Note that this does not initialize fields
* to their default values from the schema. If that is desired then
* one should use <code>newBuilder()</code>.
*/
public Notification() {}
/**
* All-args constructor.
* @param id The new value for id
* @param message The new value for message
*/
public Notification(java.lang.Long id, java.lang.CharSequence message) {
this.id = id;
this.message = message;
}
...
```
You can see that the code is based on the information in the Avro schema. We will use this class when we produce as well as consume Avro messages to/from Kafka.
Add an addtional source folder to the `kotlin-maven-plugin` so that Maven can find the generated classes
```xml
<plugin>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-plugin</artifactId>
<version>${kotlin.version}</version>
<executions>
<execution>
<id>compile</id>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
<configuration>
<sourceDirs>
<sourceDir>${project.basedir}/src/main/kotlin</sourceDir>
<sourceDir>${project.basedir}/src/main/java</sourceDir>
<sourceDir>${project.basedir}/target/generated-sources/avro</sourceDir>
</sourceDirs>
</configuration>
```
## Create a Kafka Producer using Avro for serialisation
First create a new Package `com.trivadis.kafkaws.producer` in the folder **src/main/kotlin**.
Create a new Kotlin File `KafkaProducerAvro` in the package `com.trivadis.kafakws.producer` just created.
Add the following code to the empty class to create a Kafka Producer. It is similar to the code we have seen in the previous workshop. We have changed both serialiser to use the Confluent `KafkaAvroSerializer` class and added the URL to the Confluent Schema Registry API.
We will be using the synchronous way for producing messages to the Kafka topic we created above, but the other methods would work as well with Avro.
```kotlin
@file:JvmName("KafkaProducerAvro")
package com.trivadis.kafkaws.producer
import com.trivadis.kafkaws.avro.v1.Notification
import io.confluent.kafka.serializers.KafkaAvroSerializer
import io.confluent.kafka.serializers.KafkaAvroSerializerConfig
import org.apache.kafka.clients.producer.KafkaProducer
import org.apache.kafka.clients.producer.ProducerConfig.*
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.common.serialization.LongSerializer
import java.time.LocalDateTime
import java.util.*
private val TOPIC = "test-kotlin-avro-topic"
private val BOOTSTRAP_SERVERS = "dataplatform:9092,dataplatform:9093"
private val SCHEMA_REGISTRY_URL = "http://dataplatform:8081"
fun runProducer(sendMessageCount: Int, waitMsInBetween: Long, id: Long) {
// Define properties.
val props = Properties()
props[BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVERS
props[ACKS_CONFIG] = "all"
props[KEY_SERIALIZER_CLASS_CONFIG] = KafkaAvroSerializer::class.qualifiedName
props[VALUE_SERIALIZER_CLASS_CONFIG] = KafkaAvroSerializer::class.qualifiedName
props[KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG] = SCHEMA_REGISTRY_URL
val key = if (id > 0) id else null
KafkaProducer<Long, Notification>(props).use { producer ->
repeat(sendMessageCount) { index ->
val time = System.currentTimeMillis();
//val notification = Notification(id, "test")
val notification = Notification.newBuilder().setId(id)
.setMessage("[" + id + "] Hello Kafka " + index + " => " + LocalDateTime.now()).build()
val m = producer.send(ProducerRecord(TOPIC, key, notification)).get()
val elapsedTime = System.currentTimeMillis() - time;
println("Produced record to topic ${m.topic()} partition [${m.partition()}] @ offset ${m.offset()} time=${elapsedTime}")
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
producer.flush()
}
}
```
Next you define the main method.
```kotlin
fun main(args: Array<String>) {
if (args.size == 0) {
runProducer(100, 10, 0)
} else {
runProducer(args[0].toInt(), args[1].toLong(), args[2].toLong())
}
}
```
The `main()` method accepts 3 parameters, the number of messages to produce, the time in ms to wait in-between sending each message and the ID of the producer.
Use `kcat` or `kafka-console-consumer` to consume the messages from the topic `test-java-avro-topic `.
```
kcat -b kafka-1:19092 -t test-kotlin-avro-topic
```
Now run it using the `mvn exec:java` command. It will generate 1000 messages, waiting 10ms in-between sending each message and use 0 for the ID.
```
mvn exec:java@producer -Dexec.args="1000 10 0"
```
You can see that `kcat` shows some special, non-printable characters. This is due to the Avro format. If you want to display the Avro, you can use the `kafka-avro-console-consumer` CLI, which is part of the Schema Registry.
So let's connect to the schema registry container:
```
docker exec -ti schema-registry-1 bash
```
And then invoke the `kafka-avro-console-consumer` similar to the "normal" consumer seen so far.
```
kafka-avro-console-consumer --bootstrap-server kafka-1:19092 --topic test-kotlin-avro-topic
```
You should see an output similar to the one below.
```
...
[2018-07-11 21:32:43,155] INFO [Consumer clientId=consumer-1, groupId=console-consumer-88150] Resetting offset for partition test-java-avro-topic-6 to offset 0. (org.apache.kafka.clients.consumer.internals.Fetcher)
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 0 => 2022-06-04T20:45:07.482566"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 1 => 2022-06-04T20:45:07.835552"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 3 => 2022-06-04T20:45:07.954605"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 5 => 2022-06-04T20:45:08.033523"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 2 => 2022-06-04T20:45:07.924455"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 4 => 2022-06-04T20:45:07.992334"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 6 => 2022-06-04T20:45:08.077028"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 7 => 2022-06-04T20:45:08.123285"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 8 => 2022-06-04T20:45:08.166146"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 9 => 2022-06-04T20:45:08.248690"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 10 => 2022-06-04T20:45:08.400525"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 11 => 2022-06-04T20:45:08.441321"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 12 => 2022-06-04T20:45:08.476113"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 13 => 2022-06-04T20:45:08.515611"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 14 => 2022-06-04T20:45:08.564089"}}
{"id":{"long":0},"message":{"string":"[0] Hello Kafka 15 => 2022-06-04T20:45:08.604500"}}
...
```
if you want to consume with `kcat` you need to specify the serialization format `-s` and the address of the schema registry `-r`:
```
kcat -b kafka-1 -t test-kotlin-avro-topic -s value=avro -r http://schema-registry-1:8081
```
**Note**: For Avro support your kafkacat/kcat version needs to be `1.6' or later.
## View the Schema in the Registry
The Avro Serialiser and Deserialiser automatically register the Avro schema, if it is not already in the registry.
The Streamingplatform also contains a tool made by a company called Landoop which allows us to see what's in the registry.
In a browser, navigate to <http://dataplatform:28039> and you should see the home page of the Schema Registry UI.

If you click on the schema to the left, you can view the details of the schema. You can see that version v1 has been assigned automatically.

## Create a Kafka Consumer using Avro for serialization
First create a new Package `com.trivadis.kafkaws.consumer` in the folder **src/main/kotlin**.
Create a new Java Class `KafkaConsumerAvro` in the package `com.trivadis.kafakws.consumer` just created.
Add the following code to the empty class.
```kotlin
@file:JvmName("KafkaConsumerAvro")
package com.trivadis.kafkaws.consumer
import com.trivadis.kafkaws.avro.v1.Notification
import io.confluent.kafka.serializers.KafkaAvroDeserializer
import io.confluent.kafka.serializers.KafkaAvroSerializerConfig
import org.apache.kafka.clients.consumer.ConsumerConfig.*
import org.apache.kafka.clients.consumer.KafkaConsumer
import org.apache.kafka.common.serialization.LongDeserializer
import org.apache.kafka.common.serialization.StringDeserializer
import java.time.Duration
import java.util.*
private val TOPIC = "test-kotlin-avro-topic"
private val BOOTSTRAP_SERVERS = "dataplatform:9092,dataplatform:9093"
private val SCHEMA_REGISTRY_URL = "http://dataplatform:8081"
fun runConsumerManual(waitMsInBetween: Long) {
// Define properties.
val props = Properties()
props[BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVERS
props[GROUP_ID_CONFIG] = "kotlin-simple-avro-consumer"
props[ENABLE_AUTO_COMMIT_CONFIG] = false
props[KEY_DESERIALIZER_CLASS_CONFIG] = KafkaAvroDeserializer::class.qualifiedName
props[VALUE_DESERIALIZER_CLASS_CONFIG] = KafkaAvroDeserializer::class.qualifiedName
props[KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG] = SCHEMA_REGISTRY_URL
val consumer = KafkaConsumer<Long, Notification>(props).apply {
subscribe(listOf(TOPIC))
}
consumer.use {
while(true) {
val messages = consumer.poll(Duration.ofMillis(100))
messages.forEach {
println("Consumed record [Key: ${it.key()}, Value: ${it.value()}] @ Partition: ${it.partition()}, Offset: ${it.offset()}")
}
consumer.commitSync();
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
fun main(args: Array<String>) {
if (args.size == 0) {
runConsumerManual(10)
} else {
runConsumerManual(args[0].toLong())
}
}
```
Now compile and start the consumer
```bash
mvn clean package
mvn exec:java@consumer
```
## Register in Schema Registry using Maven
In the test above, the Avro schema has been registered in the schema registry when starting the Producer for the first time. To register an Avro schema through Maven automatically, you can use the following Maven plugin.
Add the following definition to the `pom.xml`.
```xml
<plugin>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-maven-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<schemaRegistryUrls>
<param>http://dataplatform:8081</param>
</schemaRegistryUrls>
<subjects>
<test-java-avro-topic-value>src/main/avro/Notification-v1.avsc</test-java-avro-topic-value>
</subjects>
</configuration>
<goals>
<goal>register</goal>
<goal>test-compatibility</goal>
</goals>
</plugin>
```
Now you can use the following command to register the schemas with the Schema Registry:
```
mvn schema-registry:register
```
<file_sep>---
technoglogies: jupyter,jupyterhub
version: 1.16.0
validated-at: 27.11.2022
---
# Using JupyterHub
This recipe will show how to use JupyterHub with Platys.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services JUPYTER,POSTGRESQL -s trivadis/platys-modern-data-platform -w 1.16.0
```
Edit the `config.yml` and add the following properties after `JUPYTERHUB_enable`
```yaml
JUPYTERHUB_python_packages: ''
JUPYTERHUB_authenticator_class: 'jupyterhub.auth.DummyAuthenticator'
JUPYTERHUB_global_password: <PASSWORD>!
JUPYTERHUB_use_postgres: true
JUPYTERHUB_postgres_host: postgresql
JUPYTERHUB_postgres_db: postgres
JUPYTERHUB_postgres_username: postgres
JUPYTERHUB_postgres_password: <PASSWORD>!
```
Configure users for JupyterHub by creating the file `userlist` in `custom-conf/jupyterhub`.
```bash
jhadmin admin
jhuser
```
Generate and start the platform
```bash
export DATAPLATFORM_HOME=${PWD}
platys gen
docker-compose up -d
```
## Using JupyterHub
Navigate to JupyterHub on <http://dataplatform:28284>.
<file_sep># Apache Ranger
Apache Ranger™ is a framework to enable, monitor and manage comprehensive data security across the Hadoop platform.
The vision with Ranger is to provide comprehensive security across the Apache Hadoop ecosystem. With the advent of Apache YARN, the Hadoop platform can now support a true data lake architecture. Enterprises can potentially run multiple workloads, in a multi tenant environment. Data security within Hadoop needs to evolve to support multiple use cases for data access, while also providing a framework for central administration of security policies and monitoring of user access.
**[Website](https://ranger.apache.org/)** | **[Documentation](https://ranger.apache.org/)** | **[GitHub](https://github.com/apache/ranger)**
## How to enable?
```
platys init --enable-services RANGER
platys gen
```
## How to use it?
<file_sep># Metabase
Metabase is a simple and powerful analytics tool which lets anyone learn and make decisions from their company’s data—no technical knowledge required.
**[Website](https://www.metabase.com/)** | **[Documentation](https://www.metabase.com/docs/latest/)** | **[GitHub](https://github.com/metabase/metabase)**
## How to enable?
```
platys init --enable-services METABASE
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28257><file_sep># Hasura
Hasura is a fast, instant realtime GraphQL APIs on your DB with fine grained access control, also trigger webhooks on database events.
**[Website](https://hasura.io/)** | **[Documentation](https://hasura.io/docs/latest/graphql/core/index.html)** | **[GitHub](https://github.com/hasura/graphql-engine)**
## How to enable?
```
platys init --enable-services HASURA
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28177><file_sep>---
technoglogies: trino,minio
version: 1.11.0
validated-at: 20.3.2021
---
# Querying data in Minio (S3) from Trino (formerly PrestoSQL)
This tutorial will show how to query Minio with Hive and Trino.
## Initialise a platform
First [initialise a platys-supported data platform](../../getting-started) with the following services enabled
```
platys init --enable-services TRINO,HIVE_METASTORE,MINIO,AWSCLI,PROVISIONING_DATA -s trivadis/platys-modern-data-platform -w 1.11.0
```
add the following property to `config.yml`
```
TRINO_edition: 'oss'
```
Now generate and start the data platform.
```bash
platys gen
docker-compose up -d
```
## Create Data in Minio
create the bucket
```
docker exec -ti awscli s3cmd mb s3://flight-bucket
```
and upload some data
```
docker exec -ti awscli s3cmd put /data-transfer/flight-data/airports.json s3://flight-bucket/landing/airports/airports.json
docker exec -ti awscli s3cmd put /data-transfer/flight-data/plane-data.json s3://flight-bucket/landing/plane/plane-data.json
```
## Create a table in Hive
On the docker host, start the Hive CLI
```
docker exec -ti hive-metastore hive
```
and create a new database `flight_db` and in that database a table `plane_t`:
```
create database flight_db;
use flight_db;
CREATE EXTERNAL TABLE plane_t (tailnum string
, type string
, manufacturer string , issue_date string
, model string
, status string
, aircraft_type string
, engine_type string
, year string )
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
LOCATION 's3a://flight-bucket/landing/plane';
```
## Query Table from Trino
Next let's query the data from Trino. Connect to the Trino CLI using
```
docker exec -it trino-cli trino --server trino-1:8080
```
Now on the Trino command prompt, switch to the right database.
```
use minio.flight_db;
```
Let's see that there is one table available:
```
show tables;
```
We can see the `plane_t` table we created in the Hive Metastore before
```
presto:default> show tables;
Table
---------------
plane_t
(1 row)
```
```
SELECT * FROM plane_t;
```
```
SELECT year, count(*)
FROM plane_t
GROUP BY year;
```<file_sep>connector.name=mongodb
mongodb.seeds=mongo-1:27017
<file_sep>@file:JvmName("KafkaConsumerManual")
package com.trivadis.kafkaws.consumer
import org.apache.kafka.clients.consumer.ConsumerConfig.*
import org.apache.kafka.clients.consumer.KafkaConsumer
import org.apache.kafka.common.serialization.LongDeserializer
import org.apache.kafka.common.serialization.StringDeserializer
import java.time.Duration
import java.util.*
private val TOPIC = "test-kotlin-topic"
private val BOOTSTRAP_SERVERS = "dataplatform:9092,dataplatform:9093"
fun runConsumerManual(waitMsInBetween: Long) {
// Define properties.
val props = Properties()
props[BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVERS
props[GROUP_ID_CONFIG] = "kotlin-simple-consumer"
props[ENABLE_AUTO_COMMIT_CONFIG] = false
props[KEY_DESERIALIZER_CLASS_CONFIG] = LongDeserializer::class.qualifiedName
props[VALUE_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.qualifiedName
val consumer = KafkaConsumer<Long, String>(props).apply {
subscribe(listOf(TOPIC))
}
consumer.use {
while(true) {
val messages = consumer.poll(Duration.ofMillis(100))
messages.forEach {
println("Consumed record [Key: ${it.key()}, Value: ${it.value()}] @ Partition: ${it.partition()}, Offset: ${it.offset()}")
}
consumer.commitSync();
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
fun main(args: Array<String>) {
if (args.size == 0) {
runConsumerManual(10)
} else {
runConsumerManual(args[0].toLong())
}
}
<file_sep>#!/usr/bin/env sh
jinja2 /templates/services.md.j2 /variables/docker-compose.yml --format=yaml --outfile /output/services.md
jinja2 /templates/index.md.j2 /variables/docker-compose.yml --format=yaml --outfile /output/index.md
# in all .md files, replace dataplatform: by the environment variable
cd /output
if [ ${USE_PUBLIC_IP:-True} == "True" ]
then
find . -name "*.md" -exec sed -i 's/dataplatform:/'"$PUBLIC_IP"':/g' {} \;
else
find . -name "*.md" -exec sed -i 's/dataplatform:/'"$DOCKER_HOST_IP"':/g' {} \;
fi
# move data folders from cookbooks
if [ ${PLATYS_COPY_COOKBOOK_DATA:-True} == "True" ]
then
find cookbooks/recipes -type d -name "data" -exec cp -r -i {} /data-transfer/cookbook-data \;
fi <file_sep>Contains the data of graphed service, if flag GRAPHDB_volume_map_data is set to true.<file_sep>@file:JvmName("KafkaProducerSync")
package com.trivadis.kafkaws.producer
import org.apache.kafka.clients.producer.KafkaProducer
import org.apache.kafka.clients.producer.ProducerConfig.*
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.common.serialization.LongSerializer
import org.apache.kafka.common.serialization.StringSerializer
import java.time.LocalDateTime
import java.util.*
private val TOPIC = "test-kotlin-topic"
private val BOOTSTRAP_SERVERS = "dataplatform:9092,dataplatform:9093"
fun runProducer(sendMessageCount: Int, waitMsInBetween: Long, id: Long) {
// Define properties.
val props = Properties()
props[BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVERS
props[ACKS_CONFIG] = "all"
props[KEY_SERIALIZER_CLASS_CONFIG] = LongSerializer::class.qualifiedName
props[VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.qualifiedName
val key = if (id > 0) id else null
KafkaProducer<Long, String>(props).use { producer ->
repeat(sendMessageCount) { index ->
val time = System.currentTimeMillis();
val value = "[" + id + "] Hello Kafka " + index + " => " + LocalDateTime.now()
val m = producer.send(ProducerRecord(TOPIC, key, value)).get()
val elapsedTime = System.currentTimeMillis() - time;
println("Produced record to topic ${m.topic()} partition [${m.partition()}] @ offset ${m.offset()} time=${elapsedTime}")
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
producer.flush()
}
}
fun main(args: Array<String>) {
if (args.size == 0) {
runProducer(100, 10, 0)
} else {
runProducer(args[0].toInt(), args[1].toLong(), args[2].toLong())
}
}
<file_sep># Hawtio
Hawtio web console helps you manage your JVM stuff and stay cool!
**[Homepage](https://hawt.io/)** | **[Documentation](https://hawt.io/docs/)** | **[GitHub](https://github.com/hawtio/hawtio)**
## How to enable?
```
platys init --enable-services HAWTIO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28155><file_sep># Function as a Service (FaaS) with Kafka and Nuclio
In this workshop we will learn how to use [Nuclio](https://nuclio.io/) to implement serverless functions to consume from Kafka. We will be using Python to implement the function.
You can find many examples of using Nuclio with various languages [here](https://nuclio.io/docs/latest/examples/).
This guide assumes that you already have a dataplatform with Kafka and Nuclio available.
We will be using the [Streaming Synthetic Sales Data Generator](https://github.com/garystafford/streaming-sales-generator) we have used in [Getting started with Apache Kafka](./02-working-with-kafka-broker) to produce sales orders to a Kafka topic. Nuclio will then be used to consume the messages and process them with a serverless functions.
For the creation of the serverless function, we will use the [Nuclio GUI](http://dataplatform:8070).
## Setup
### Creating the necessary Kafka Topics
Let's create the necessary 3 topics, if they no longer exist:
```bash
docker exec -ti kafka-1 kafka-topics --create --bootstrap-server kafka-1:19092 --topic demo.products --replication-factor 3 --partitions 8
docker exec -ti kafka-1 kafka-topics --create --bootstrap-server kafka-1:19092 --topic demo.purchases --replication-factor 3 --partitions 8
docker exec -ti kafka-1 kafka-topics --create --bootstrap-server kafka-1:19092 --topic demo.inventories --replication-factor 3 --partitions 8
```
## Working with Nuclio
Let's navigate to the [Nuclio GUI](http://dataplatform:8070). You should see the projects, with the **default** project being the only one available.

Let's create a new project by clicking **NEW PROJECT**. In the pop-up window, enter `kafka-workshop` for **Project name** and `Kafka Workshop` for the **Description** and click **CREATE**. The new project should appear in the list of projects.
Navigate into the newly created project and you will see the 3 different options to **Start a new function**:

Let's start from scratch by clicking on **Start from scratch**. Enter `consume-purchases` into **Name**, select `Python 3.9` for the **Runtime** and click **CREATE**.

A new page will appear, with the function code to the left.

Let's implement the handler
```python
def handler(context, event):
body = event.body.decode('utf-8')
context.logger.info('New message received from Kafka:' + body)
return ""
```
Navigate to **TRIGGERS**

and click on **Create a new trigger**
Enter `kafka-purchases` into the **Name** field and select `Kafka` from the **Class** drop-down.
Now enter `kafka-1:19092` into the **Brokers** field, `demo.purchases` into the **Topics** field and `nuclio-purchases-cg` into the **Consumer group name**. Select `3` for the **Max workers** drop-down. We don't need to change any of the **Advanced** options.

Navigate back to **CODE**. As we have used the container name of Kafka to connect to the Kafka broker, we have to make sure, that the Docker container, Nuclio will create for the function is started in the same network as the Kafka cluster.
We can not control that over the Nuclio GUI, but it is available as an [inline configuration snippet](https://github.com/nuclio/nuclio/blob/master/docs/tasks/deploying-functions.md#providing-configuration-via-inline-configuration) in your functions source code
```
# @nuclio.configure
# function.yaml:
# spec:
# platform:
# attributes:
# network: kafka-workshop
def handler(context, event):
context.logger.info('message received from Kafka')
return ""
```
Click on **DEPLOY** to deploy the serverless function for the first time. You should see a **Successfully deployed** message.
Let's do a `docker ps | grep nuclio` to see the docker container started by
```bash
$ docker ps | grep nuclio
bbdfd35cb484 nuclio/processor-consume-purchases:latest "processor" 32 second ago Up Less than 31 second 0.0.0.0:32770->8080/tcp nuclio-nuclio-consume-purchases
b519d987df2d gcr.io/iguazio/alpine:3.17 "/bin/sh -c '/bin/sl…" 5 hours ago Up 5 hours nuclio-local-storage-reader
82f8a1f8707a quay.io/nuclio/dashboard:stable-amd64 "/docker-entrypoint.…" 7 hours ago Up 7 hours (healthy) 80/tcp, 0.0.0.0:8070->8070/tcp nuclio
```
We can see that a new container named `nuclio-nuclio-consume-purchases` has been started a few seconds ago. This is the container running the Nuclio serverless function.

Now let's quickly test that the serverless function is invoked. We are not yet using the simulator but only send one single example message using `kcat`.
Before we send to Kafka, let's see the log of the container where the function is running in
```bash
docker logs -f nuclio-nuclio-consume-purchases
```
And in another terminal, now let's send a sample message.
Add the following sample purchase to a file named `purchase-1.json`
```json
{
"transaction_time": "2023-08-12 18:53:00.114048",
"transaction_id": "6951846465568416216",
"product_id": "SF07",
"price": 5.99,
"quantity": 1,
"is_member": true,
"member_discount": 0.1,
"add_supplements": false,
"supplement_price": 0.0,
"total_purchase": 5.39
}
```
Now use `kcat` to send the message to the Kafka topic
```bash
kcat -b dataplatform -t demo.purchases -P purchase-1.json
```
and you should see the output of the log message from the serverless function in the log of the container
```bash
$ docker logs -f nuclio-nuclio-consume-purchases
...
23.08.13 17:13:00.537 er.kafka-purchases.sarama (D) Sarama: client/metadata fetching metadata for all topics from broker kafka-1:19092
23.08.13 17:23:00.537 er.kafka-purchases.sarama (D) Sarama: client/metadata fetching metadata for all topics from broker kafka-1:19092
23.08.13 17:33:00.537 er.kafka-purchases.sarama (D) Sarama: client/metadata fetching metadata for all topics from broker kafka-1:19092
23.08.13 17:43:00.537 er.kafka-purchases.sarama (D) Sarama: client/metadata fetching metadata for all topics from broker kafka-1:19092
23.08.13 17:52:40.359 -cluster.w0.python.logger (I) New message received from Kafka:{
"transaction_time": "2023-08-12 18:53:00.114048",
"transaction_id": "6951846465568416216",
"product_id": "SF07",
"price": 5.99,
"quantity": 1,
"is_member": true,
"member_discount": 0.1,
"add_supplements": false,
"supplement_price": 0.0,
"total_purchase": 5.39
}
{"worker_id": "0"}
23.08.13 17:53:00.536 er.kafka-purchases.sarama (D) Sarama: client/metadata fetching metadata for all topics from broker kafka-1:19092
```
So the basic functionality of retrieving a message from Kafka works. Now let's add some functionality to process the message. We will simply write each message to a Redis Key/Value store.
For Redis will use the [`redis-py`](https://github.com/redis/redis-py#advanced-topics) Python Redis client. We can install it into the container by adding it to the Configuration of the image.
In the Nuclio GUI, navigate back to the `consume-purchases` function and select the **CONFIGURATION** tab. Scroll down to the **Build** canvas and add `pip install redis` to the **Build commands** edit field.

Again click on **DEPLOY** to redeploy the container. You can also click on **STATUS** to see the log of the deployment

Again the deployment should be successful.
Now let's add the necessary code to the function.
The `body` we get into the function is of type String. So we are using the built-in `json` package to parse the JSON string into a Python dictionary.
Next we connect to Redis using the `redis` package and then use the `set` command to add the purchase document as a value to Redis, using the `transaction_id` as the key. We will add it to Redis with a time to live of 120 seconds.
```python
# @nuclio.configure
# function.yaml:
# spec:
# platform:
# attributes:
# network: kafka-workshop
import redis
import json
def handler(context, event):
body = event.body.decode('utf-8')
body_json = json.loads(body)
context.logger.info('New message received from Kafka:' + body)
r = redis.Redis(host='redis-1', port=6379, password='<PASSWORD>!', db=0)
r.set(body_json["transaction_id"], body, ex=120)
return ""
```
Let's test it once again with our sample purchase message:
```bash
kcat -b dataplatform -t demo.purchases -P purchase-1.json
```
Navigate to Redis Commander on <http://dataplatform:28119> to see the new entry:

It will automatically "disappear" once the 120 seconds have expired.
Now let's see the solution in action using the Sales Data Generator to generate messages.
```bash
docker run -ti --network kafka-workshop trivadis/sales-data-generator:latest
```
Refresh the Redis Commander window to see new key/value pairs constantly be added and after 120 seconds being automatically removed.

<file_sep>Place starburstdata's license file here (named starburstdata.license).<file_sep># Jaeger
Jaeger, inspired by Dapper and OpenZipkin, is a distributed tracing system released as open source by Uber Technologies. It is used for monitoring and troubleshooting microservices-based distributed systems.
**[Website](https://www.jaegertracing.io/)** | **[Documentation](https://www.jaegertracing.io/docs/1.29/)** | **[GitHub](https://github.com/jaegertracing/jaeger)**
## How to enable?
```
platys init --enable-services JAEGER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:16686><file_sep>Contains the logs of airflow service, if flag AIRFLOW_volume_map_logs is set to true.<file_sep># Using Kafka from Spring Boot with Kotlin and Avro & Schema Registry
In this workshop we will learn how to use the **Spring Kafka** abstraction with **Avro message serialization** from within a Spring Boot application using the **Kotlin** language.
We will create two Spring Boot projects, one for the **Producer** and one for the **Consumer**, simulating two independent Microservices interacting with each other via events.
Additionally we will create another Maven project called `meta` which holds the Avro Schema(s). A dependency to that project will be added to both Spring Boot projects.
## Create the Avro Metadata Project
First we will define the Avro schema and generate the classes. As both Microservices will need the generated class to work, we do that in a separate project, and then use it as a dependency in the two Microservices.
### Create a new Maven project
From your IDE (screenshot taken from IntelliJ), create a new Maven project and use `meta` for the **Name**, `com.trivadis.kafkaws.meta` for the **GroupId** and leave the **Version** as is.

Click on **Finish**.
### Add some configuration to Maven pom
Edit the `pom.xml` and . First add an additional property to the `<properties>`
```xml
<properties>
...
<avro.version>1.11.0</avro.version>
</properties>
```
and now add the dependency to [Avro](https://mvnrepository.com/artifact/org.apache.avro/avro) right after the `</properties>` element
```xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.avro/avro -->
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>${avro.version}</version>
</dependency>
</dependencies>
```
Now add the following section at the end before the `</project>` element.
```xml
<build>
<plugins>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro.version}</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
<configuration>
<stringType>String</stringType>
<fieldVisibility>private</fieldVisibility>
<sourceDirectory>${project.basedir}/src/main/avro</sourceDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-maven-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<schemaRegistryUrls>
<param>http://${env.DATAPLATFORM_IP}:8081</param>
</schemaRegistryUrls>
<subjects>
<test-java-avro-topic-value>src/main/avro/Notification-v1.avsc</test-java-avro-topic-value>
</subjects>
</configuration>
<goals>
<goal>register</goal>
<goal>test-compatibility</goal>
</goals>
</plugin>
</plugins>
</build>
```
The first plugin will make sure, that classes are generated based on the Avro schema, whenever a `mvn compile` is executed.
To second plugin will help to register the Avro schema(s) via Maven into the Confluent Schema Registry.
We also have to specify the additional Maven repository, where the plugins can be found. Add the following XML fragement at the end right before the `project` element.
```xml
<pluginRepositories>
<pluginRepository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</pluginRepository>
</pluginRepositories>
```
### Create an Avro Schema representing the Avro Message to send
First create a new Folder `avro` under the existing folder **src/main/**.
Create a new File `Notification-v1.avsc` in the folder **src/main/avro** just created above.
Add the following Avro schema to the empty file.
```json
{
"type" : "record",
"namespace" : "com.trivadis.kafkaws.avro.v1",
"name" : "Notification",
"description" : "A simple Notification Event message",
"fields" : [
{ "name" : "id",
"type" : ["long", "null"]
},
{ "name" : "message",
"type" : ["string", "null"]
},
{ "name" : "createdAt",
"type" : {
"type" : "long",
"logicalType" : "timestamp-millis"
}
}
]
}
```
The Maven plugin added above will make sure, that classes are generated based on the Avro schema, whenever a `mvn compile` is executed. Let's exactly do that on the still rather empty project.
```bash
mvn compile
```
After running this command, refresh the project in your IDE and you should see a new folder named `target/generated-sources/avro`. Navigate into this folder and you should see one generated Java class named `Notification`.
### Register the Avro Schema with the registry
Register the schema with the Schema Registry:
For the IP address of the platform the Schema Registry is running on, we refer to an environment variable, which we have to declare.
```bash
export DATAPLATFORM_IP=nnn.nnn.nnn.nnn
```
Now use the maven command
```bash
mvn schema-registry:register
```
### Publish the artefact to the local Maven repo
Now let's make sure that the project is available as a Maven dependency:
```bash
mvn install
```
## Create the Spring Boot Producer
First we create an test the Producer microservice.
### Creating the Spring Boot Project
First, let’s navigate to [Spring Initializr](https://start.spring.io/) to generate our project. Our project will need the Apache Kafka support.
Select Generate a **Maven Project** with **Kotlin** and Spring Boot **2.7.0**. Enter `com.trivadis.kafkaws` for the **Group**, `spring-boot-kotlin-kafka-producer-avro` for the **Artifact** field and `Kafka Producer with Avro project for Spring Boot` for the **Description** field.
Click on **Add Dependencies** and search for the **Spring for Apache Kafka** depencency.
Select the dependency and hit the **Enter** key. You should now see the dependency on the right side of the screen.
Click on **Generate Project** and unzip the ZIP file to a convenient location for development.
Once you have unzipped the project, you’ll have a very simple structure.
Import the project as a Maven Project into your favourite IDE for further development.
### Extend the Maven POM with some configurations
In oder to use the Avro serializer and the class generated above, we have to add the following dependencies to the `pom.xml`.
```xml
<dependencies>
...
<dependency>
<groupId>com.trivadis.kafkaws.meta</groupId>
<artifactId>meta</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${confluent.version}</version>
</dependency>
```
Add the version of the Confluent Platform to use as an additional property
```xml
<properties>
...
<confluent.version>7.0.0</confluent.version>
</properties>
```
We also have to specify the additional Maven repository
```xml
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
```
### Implement a Kafka Producer in Spring
Now create a simple Kotlin class `KafkaEventProducer` within the `com.trivadis.kafkaws.springbootkotlinkafkaproducer ` package, which we will use to produce messages to Kafka.
```kotlin
package com.trivadis.kafkaws.springbootkotlinkafkaproducer
import com.trivadis.kafkaws.avro.v1.Notification
import org.springframework.beans.factory.annotation.Value
import org.springframework.kafka.core.KafkaTemplate
import org.springframework.kafka.support.SendResult
import org.springframework.stereotype.Component
@Component
class KafkaEventProducer (private val kafkaTemplate: KafkaTemplate<Long, Notification>) {
@Value("\${topic.name}")
private lateinit var kafkaTopic: String
fun produce(key: Long, value: Notification) {
val time = System.currentTimeMillis()
var result: SendResult<Long, Notification>
if (key > 0) {
result = kafkaTemplate.send(kafkaTopic, key, value).get()
} else {
result = kafkaTemplate.send(kafkaTopic, value).get()
}
val elapsedTime = System.currentTimeMillis() - time
println("[$key] sent record(key=$key value=$value) meta(partition=${result.recordMetadata.partition()}, offset=${result.recordMetadata.offset()}) time=$elapsedTime")
}
}
```
We no longer use `String` as type for the value but the `Nofification` class, which has been generated based on the Avro schema above.
### Create the necessary Topics through code
Spring Kafka can automatically add topics to the broker, if they do not yet exists. By that you can replace the `kafka-topics` CLI commands seen so far to create the topics, if you like.
Spring Kafka provides a `TopicBuilder` which makes the creation of the topics very convenient.
```kotlin
package com.trivadis.kafkaws.springbootkotlinkafkaproducer
import org.apache.kafka.clients.admin.NewTopic
import org.springframework.beans.factory.annotation.Value
import org.springframework.context.annotation.Bean
import org.springframework.kafka.config.TopicBuilder
import org.springframework.stereotype.Component
@Component
class TopicCreator {
@Value("\${topic.name}")
private lateinit var kafkaTopic: String
@Value("\${topic.partitions}")
private var partitions: Int = 0
@Value("\${topic.replication-factor}")
private var replicationFactor: Int = 0
@Bean
fun topic(): NewTopic? {
return TopicBuilder.name(kafkaTopic)
.partitions(partitions)
.replicas(replicationFactor)
.build()
}
}
```
We again refer to properties, which will be defined later in the `application.yml` config file.
### Add Producer logic to the SpringBootKotlinKafkaProducerApplication class
We change the generated Spring Boot application to be a console appliation by implementing the `CommandLineRunner` interface.
```kotlin
package com.trivadis.kafkaws.springbootkotlinkafkaproducer
import com.trivadis.kafkaws.avro.v1.Notification
import org.springframework.boot.CommandLineRunner
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
import org.springframework.context.annotation.Bean
import java.time.Instant
import java.time.LocalDateTime
@SpringBootApplication
class SpringBootKotlinKafkaProducerApplication{
@Bean
fun init(kafkaEventProducer: KafkaEventProducer) = CommandLineRunner { args ->
val sendMessageCount = if (args.size==0) 100 else args[0].toInt()
val waitMsInBetween = if (args.size==0) 10 else args[1].toLong()
val id = if (args.size==0) 0 else args[2].toLong()
for (index in 1 .. sendMessageCount) {
val value = Notification.newBuilder()
.setId(id)
.setMessage("[$id" + "] Hello Kafka " + index + " => " + LocalDateTime.now())
.setCreatedAt(Instant.now())
.build()
kafkaEventProducer.produce(id, value);
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
fun main(args: Array<String>) {
runApplication<SpringBootKotlinKafkaProducerApplication>(*args)
}
```
The difference here to the non-avro version is, that we are using the builder of the generated `Nofification` class to create an instance of a notification, which we then pass as the value to the `produce()` method.
### Configure Kafka through application.yml configuration file
First let's rename the existing `application.properties` file to `application.yml` to use the `yml` format.
Add the following settings to configure the Kafka cluster and the name of the topic:
```yml
topic:
name: test-kotlin-spring-avro-topic
replication-factor: 3
partitions: 12
spring:
kafka:
bootstrap-servers:
- ${DATAPLATFORM_IP}:9092
- ${DATAPLATFORM_IP}:9093
producer:
key-serializer: org.apache.kafka.common.serialization.LongSerializer
value-serializer: io.confluent.kafka.serializers.KafkaAvroSerializer
properties:
auto.register.schemas: false
use.latest.version: true
properties:
schema.registry.url: http://${DATAPLATFORM_IP}:8081
logging:
level:
root: info
```
Here again we swith the value-serializer from `StringSerializer` to the `KafkaAvroSerializer` and add the property `schema.registry.url` to configure the location of the Confluent Schema Registry REST API.
For the IP address of the Kafka cluster we refer to an environment variable, which we have to declare before running the application.
```bash
export DATAPLATFORM_IP=nnn.nnn.nnn.nnn
```
### Build the application
First lets build the application:
```bash
mvn package -Dmaven.test.skip=true
```
### Run the application
Now let's run the application
```bash
mvn spring-boot:run
```
Make sure that you see the messages through the console consumer.
To run the producer with custom parameters (for example to specify the key to use), use the `-Dspring-boot.run.arguments`:
```bash
mvn spring-boot:run -Dspring-boot.run.arguments="100 10 10"
```
### Use Console to test the application
In a terminal window start consuming from the output topic:
```bash
kcat -b kafka-1:19092 -t test-kotlin-spring-avro-topic -s value=avro -r http://schema-registry-1:8081
```
## Create the Spring Boot Consumer
Now let's create an test the Consumer microservice.
### Creating the Spring Boot Project
Use again the [Spring Initializr](https://start.spring.io/) to generate the project.
Select Generate a **Maven Project** with **Kotlin** and Spring Boot **2.7.0**. Enter `com.trivadis.kafkaws` for the **Group**, `spring-boot-kotlin-kafka-consumer-avro` for the **Artifact** field and `Kafka Consumer with Avro project for Spring Boot` for the **Description** field.
Click on **Add Dependencies** and search for the **Spring for Apache Kafka** depencency.
Select the dependency and hit the **Enter** key. You should now see the dependency on the right side of the screen.
Click on **Generate Project** and unzip the ZIP file to a convenient location for development.
Once you have unzipped the project, you’ll have a very simple structure.
Import the project as a Maven Project into your favourite IDE for further development.
### Extend the Maven POM with some configurations
In oder to use the Avro deserializer and the Avro generated classes, we have to add the following dependencies to the `pom.xml`.
```xml
<dependencies>
...
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>com.trivadis.kafkaws.meta</groupId>
<artifactId>meta</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
```
Add the version of the Confluent Platform to use as an additional property
```xml
<properties>
...
<confluent.version>7.0.0</confluent.version>
</properties>
```
We also have to specify the additional Maven repository
```xml
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
```
### Implement a Kafka Consumer in Spring
Start by creating a simple Kotlin class `KafkaEventConsumer` within the `com.trivadis.kafkaws.springbootkafkaconsumer` package, which we will use to consume messages from Kafka.
```kotlin
package com.trivadis.kafkaws.springbootkotlinkafkaconsumer
import com.trivadis.kafkaws.avro.v1.Notification
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.springframework.kafka.annotation.KafkaListener
import org.springframework.stereotype.Component
@Component
class KafkaEventConsumer {
@KafkaListener(topics = ["\${topic.name}"], groupId = "simple-kotlin-avro-consumer")
fun receive(consumerRecord: ConsumerRecord<Long, Notification>) {
println("received key = ${consumerRecord.key()} with payload=${consumerRecord.value()}")
}
}
```
This class uses the `Component` annotation to have it registered as bean in the Spring context and the `KafkaListener` annotation to specify a listener method to be called for each record consumed from the Kafka input topic. The name of the topic is specified as a property to be read again from the `application.yml` configuration file.
In the code we only log the key and value received to the console. In real life, we would probably inject another bean into the `KafkaEventConsumer` to perform the message processing.
### Configure Kafka through application.yml configuration file
First let's rename the existing `application.properties` file to `application.yml` to use the `yml` format.
Add the following settings to configure the Kafka cluster and the name of the two topics:
```yml
topic:
name: test-kotlin-spring-avro-topic
spring:
kafka:
bootstrap-servers:
- ${DATAPLATFORM_IP}:9092
- ${DATAPLATFORM_IP}:9093
consumer:
key-deserializer: org.apache.kafka.common.serialization.LongDeserializer
value-deserializer: io.confluent.kafka.serializers.KafkaAvroDeserializer
properties:
auto.register.schemas: false
specific.avro.reader: true
properties:
schema.registry.url: http://${DATAPLATFORM_IP}:8081
logging:
level:
root: info
```
For the IP address of the Kafka cluster we refer to an environment variable, which we have to declare before running the application.
```bash
export DATAPLATFORM_IP=nnn.nnn.nnn.nnn
```
### Build the application
First lets build the application:
```bash
mvn package -Dmaven.test.skip=true
```
### Run the application
Now let's run the application
```bash
mvn spring-boot:run
```
<file_sep># Apache Superset
Apache Superset is a modern data exploration and visualization platform.
**[Website](https://superset.apache.org/)** | **[Documentation](https://superset.apache.org/docs/intro)** | **[GitHub](https://github.com/apache/superset)**
### How to enable?
```bash
platys init --enable-services SUPERSET
platys gen
```
### How to use it?
Navigate to <http://${PUBLIC_IP}:28151>
<file_sep>@file:JvmName("KafkaConsumerAvro")
package com.trivadis.kafkaws.consumer
import com.trivadis.kafkaws.avro.v1.Notification
import io.confluent.kafka.serializers.KafkaAvroDeserializer
import io.confluent.kafka.serializers.KafkaAvroSerializerConfig
import org.apache.kafka.clients.consumer.ConsumerConfig.*
import org.apache.kafka.clients.consumer.KafkaConsumer
import org.apache.kafka.common.serialization.LongDeserializer
import org.apache.kafka.common.serialization.StringDeserializer
import java.time.Duration
import java.util.*
private val TOPIC = "test-kotlin-avro-topic"
private val BOOTSTRAP_SERVERS = "dataplatform:9092,dataplatform:9093"
private val SCHEMA_REGISTRY_URL = "http://dataplatform:8081"
fun runConsumerManual(waitMsInBetween: Long) {
// Define properties.
val props = Properties()
props[BOOTSTRAP_SERVERS_CONFIG] = BOOTSTRAP_SERVERS
props[GROUP_ID_CONFIG] = "kotlin-simple-avro-consumer"
props[ENABLE_AUTO_COMMIT_CONFIG] = false
props[KEY_DESERIALIZER_CLASS_CONFIG] = KafkaAvroDeserializer::class.qualifiedName
props[VALUE_DESERIALIZER_CLASS_CONFIG] = KafkaAvroDeserializer::class.qualifiedName
props[KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG] = SCHEMA_REGISTRY_URL
val consumer = KafkaConsumer<Long, Notification>(props).apply {
subscribe(listOf(TOPIC))
}
consumer.use {
while(true) {
val messages = consumer.poll(Duration.ofMillis(100))
messages.forEach {
println("Consumed record [Key: ${it.key()}, Value: ${it.value()}] @ Partition: ${it.partition()}, Offset: ${it.offset()}")
}
consumer.commitSync();
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
fun main(args: Array<String>) {
if (args.size == 0) {
runConsumerManual(10)
} else {
runConsumerManual(args[0].toLong())
}
}
<file_sep>connector.name=elasticsearch
elasticsearch.host=elasticsearch-1
elasticsearch.port=9200
<file_sep>Contains the flow_storage folder of nifi-registry service, if flag NIFI_REGISTRY_volume_map_flow_storage is set to true.<file_sep>Contains the data of spark logs<file_sep># Grafana Loki
Like Prometheus, but for logs. Grafana Loki is a set of components that can be composed into a fully featured logging stack.
**[Website](https://grafana.com/oss/loki/)** | **[Documentation](https://grafana.com/docs/loki/latest/)** | **[GitHub](https://github.com/grafana/loki)**
## How to enable?
```
platys init --enable-services LOKI
platys gen
```
## How to use it?
<file_sep>Contains the log of thingsboard service, if flag THINGSBOARD_volume_map_log is set to true.<file_sep># Streams Explorer
Explore Data Pipelines in Apache Kafka.
**[Website](https://github.com/bakdata/streams-explorer#streams-explorer)** | **[Documentation](https://github.com/bakdata/streams-explorer#streams-explorer)** | **[GitHub](https://github.com/bakdata/streams-explorer)**
## How to enable?
```
platys init --enable-services STREAMS_EXPLORER
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28195><file_sep>Place license file here OptimizeLicense.txt<file_sep>connector.name=postgresql
connection-url=jdbc:postgresql://postgresql:5432/truckdb
connection-user=truck
connection-password=<PASSWORD>
<file_sep>package com.trivadis.kafkaws.springbootkotlinkafkaconsumer
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Configuration
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory
import org.springframework.kafka.core.ConsumerFactory
@Configuration
class FilterConfiguration {
@Autowired
private lateinit var consumerFactory: ConsumerFactory<Long, String>
@Bean
fun filterContainerFactory(): ConcurrentKafkaListenerContainerFactory<Long, String> {
val factory = ConcurrentKafkaListenerContainerFactory<Long, String>()
factory.setConsumerFactory(consumerFactory)
factory.setRecordFilterStrategy { record: ConsumerRecord<Long, String> ->
!record.value().contains("Kafka 5")
}
return factory
}
}<file_sep># Using Kafka from Java with Avro IDL & Schema Registry
In this workshop we will learn how to produce and consume messages using the [Kafka Java API](https://kafka.apache.org/documentation/#api) using Avro for serialising and deserialising messages.
Compared to workshop 4a, here we will use the [Avro IDL language](https://avro.apache.org/docs/current/idl-language/) for defining the Avro Schema. The advantage of using the Avro IDL language is first better readability when a schema get's more complex, better [IDE support](https://avro.apache.org/docs/current/idl-language/#ide-support) and the possibility for importing schema definitions from another file.
But for the Schema Registry, we will still need the schemas in the JSON language, but the can be generated from the IDL (using Avro Tools).
## Create the project in your Java IDE
Create a new Maven Project (using the functionality of your IDE) and in the last step use `com.trivadis.kafkaws` for the **Group Id** and `java-avro-idl-kafka` for the **Artifact Id**.
Navigate to the **pom.xml** and double-click on it. The POM Editor will be displayed.
You can either use the GUI to edit your `pom.xml` or navigate to the last tab **pom.xml** to switch to the "code view". Let's do that.
You will see the still rather empty definition.
```xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trivadis.kafkaws</groupId>
<artifactId>java-avro-idl-kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
</project>
```
Let's add some initial dependencies for our project. We will add some more dependencies to the POM throughout this workshop.
Copy the following block right after the `<version>` tag, before the closing `</project>` tag.
```xml
<properties>
<kafka.version>3.0.0</kafka.version>
<confluent.version>7.2.0</confluent.version>
<avro.version>1.11.0</avro.version>
<java.version>1.8</java.version>
<slf4j-version>1.7.5</slf4j-version>
<!-- use utf-8 encoding -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>${avro.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j-version}</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>confluent</id>
<url>http://packages.confluent.io/maven/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>confluent</id>
<url>http://packages.confluent.io/maven/</url>
</pluginRepository>
<pluginRepository>
<id>Trivadis Maven Repo</id>
<url>https://github.com/TrivadisPF/avdl2avsc-maven-plugin/raw/mvn-repo/</url>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
</snapshots>
</pluginRepository>
</pluginRepositories>
<build>
<defaultGoal>install</defaultGoal>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<maxmem>256M</maxmem>
<showDeprecation>true</showDeprecation>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<executions>
<execution>
<id>producer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.producer.KafkaProducerAvro</mainClass>
</configuration>
</execution>
<execution>
<id>consumer</id>
<goals>
<goal>java</goal>
</goals>
<configuration>
<mainClass>com.trivadis.kafkaws.consumer.KafkaConsumerAvro</mainClass>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro.version}</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>idl-protocol</goal>
</goals>
<configuration>
<stringType>String</stringType>
<excludes>
<exclude>**/mapred/tether/**</exclude>
</excludes>
<sourceDirectory>${project.basedir}/src/main/avdl/</sourceDirectory>
<testSourceDirectory>${project.basedir}/src/test/avro/</testSourceDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>com.trivadis.plugins</groupId>
<artifactId>avdl2avsc-maven-plugin</artifactId>
<version>1.0.1-SNAPSHOT</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>genschema</goal>
</goals>
<configuration>
<inputAvdlDirectory>${basedir}/src/main/avdl</inputAvdlDirectory>
<outputSchemaDirectory>${basedir}/target/generated-sources/avro/schema
</outputSchemaDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
```
The `pom.xml` is the same as for workshop 4a, except the additional maven plugin `avdl2avsc-maven-plugin`, which we can get from the Maven Repo hosted on GitHub.
This plugin will be used to generate the Avro JSON Schema definition from the IDL. It wraps the necessary functionality of the Avro tools library.
Additionally we changed the `sourceDirectory` of the `avro-maven-plugin` to reflect the directory where we will place the Avro IDL schemas (`${project.basedir}/src/main/avdl`).
## Create log4j settings
Let's also create the necessary log4j configuration.
In the code we are using the [Log4J Logging Framework](https://logging.apache.org/log4j/2.x/), which we have to configure using a property file.
Create a new file `log4j.properties` in the folder **src/main/resources** and add the following configuration properties.
```
## ------------------------------------------------------------------------
## Licensed to the Apache Software Foundation (ASF) under one or more
## contributor license agreements. See the NOTICE file distributed with
## this work for additional information regarding copyright ownership.
## The ASF licenses this file to You under the Apache License, Version 2.0
## (the "License"); you may not use this file except in compliance with
## the License. You may obtain a copy of the License at
##
## http://www.apache.org/licenses/LICENSE-2.0
##
## Unless required by applicable law or agreed to in writing, software
## distributed under the License is distributed on an "AS IS" BASIS,
## WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
## See the License for the specific language governing permissions and
## limitations under the License.
## ------------------------------------------------------------------------
#
# The logging properties used for testing, We want to see INFO output on the console.
#
log4j.rootLogger=INFO, out
#log4j.logger.org.apache.kafka=INFO
log4j.logger.org.apache.camel.impl.converter=INFO
log4j.logger.org.apache.camel.util.ResolverUtil=INFO
log4j.logger.org.springframework=WARN
log4j.logger.org.hibernate=WARN
# CONSOLE appender not used by default
log4j.appender.out=org.apache.log4j.ConsoleAppender
log4j.appender.out.layout=org.apache.log4j.PatternLayout
log4j.appender.out.layout.ConversionPattern=[%30.30t] %-30.30c{1} %-5p %m%n
#log4j.appender.out.layout.ConversionPattern=%d [%-15.15t] %-5p %-30.30c{1} - %m%n
log4j.throwableRenderer=org.apache.log4j.EnhancedThrowableRenderer
```
## Creating the necessary Kafka Topic
We will use the topic `test-java-avro-idl-topic` in the Producer and Consumer code below. Due to the fact that `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
In a terminal window, connect to the `kafka-1` container
```
docker exec -ti kafka-1 bash
```
and execute the necessary kafka-topics command.
```
kafka-topics --create \
--replication-factor 3 \
--partitions 12 \
--topic test-java-avro-idl-topic \
--bootstrap-server kafka-1:19092,kafka-2:19093
```
This finishes the setup steps and our new project is ready to be used. Next we will start implementing the **Kafka Producer** which uses Avro for the serialisation.
## Create an Avro Schema representing the Notification Message
First create a new Folder `avdl` under the existing folder **src/main/**.
Create a new File `Notification.avdl` in the folder **src/main/avdl** just created above.
Add the following Avro schema to the empty file, using the Avro IDL language.
```
@namespace("com.trivadis.kafkaws.avro.v1")
protocol NotificationProtocol {
record Notification {
union {null, long} id;
union {null, string} message;
}
}
```
This represent the Notification object.
We will use another schema to define the `NotificationSentEvent` event and import the `Notification` object. Create a new file `NotificationSentEvent-v1.avdl` in the `avdl` folder and add the folllowing schema defintion:
```
@namespace("com.trivadis.kafkaws.avro.v1")
protocol NotificationSentEventProtocol {
import idl "Notification.avdl";
record NotificationSentEvent {
Notification notification;
}
}
```
Let's now run a Maven compile to generate both the Avro JSON schema as well as the Java code for the Avro Serialization/Deserialization.
```
mvn compile
```
After running this command, refresh the project and you should see a new folder named `target/generated-sources/avro`. Expand into this folder and you should see both the generated Java classes as well as a `schema` folder with the two `avsc` schemas. We get two classes for each IDL file, one for the `protocol` and one for the `record`, although we will only use the one for the `record` definitions, `Notification.java` and `NotificationSentEvent.java`.

Double click on the `Notification.avsc` file to inspect the Avro schema in JSON.
```json
{
"type" : "record",
"name" : "Notification",
"namespace" : "com.trivadis.kafkaws.avro.v1",
"fields" : [ {
"name" : "id",
"type" : [ "null", "long" ]
}, {
"name" : "message",
"type" : [ "null", "string" ]
} ]
}
```
and let's inspect also the `NotificationSentEvent.avsc`
```json
{
"type" : "record",
"name" : "NotificationSentEvent",
"namespace" : "com.trivadis.kafkaws.avro.v1",
"fields" : [ {
"name" : "notification",
"type" : {
"type" : "record",
"name" : "Notification",
"fields" : [ {
"name" : "id",
"type" : [ "null", "long" ]
}, {
"name" : "message",
"type" : [ "null", "string" ]
} ]
}
} ]
}
```
You can see that `NotificationSentEvent.avsc` embeds the definition of the `Notification`, due to the import we did.
## Create a Kafka Producer using Avro for serialisation
First create a new Java Package `com.trivadis.kafkaws.producer` in the folder **src/main/java**.
Create a new Java Class `KafkaProducerAvro` in the package `com.trivadis.kafakws.producer` just created.
Add the following code to the empty class to create a Kafka Producer. It is similar to the code we have seen in the workshop 4a, except that we now use the `NotificationSentEvent` class and we produce to a different topic (`test-java-avro-idl-topic`).
```java
package com.trivadis.kafkaws.producer;
import java.util.Properties;
import com.trivadis.kafkaws.avro.v1.Notification;
import com.trivadis.kafkaws.avro.v1.NotificationSentEvent;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.LongSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializerConfig;
public class KafkaProducerAvro {
private final static String TOPIC = "test-java-avro-idl-topic";
private final static String BOOTSTRAP_SERVERS =
"dataplatform:9092, dataplatform:9093, dataplatform:9094";
private final static String SCHEMA_REGISTRY_URL = "http://dataplatform:8081";
private static Producer<Long, NotificationSentEvent> createProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaExampleProducer");
//props.put(KafkaAvroSerializerConfig.AUTO_REGISTER_SCHEMAS, "false");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class.getName());
props.put(KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, SCHEMA_REGISTRY_URL); // use constant for "schema.registry.url"
return new KafkaProducer<>(props);
}
static void runProducer(final int sendMessageCount, final int waitMsInBetween, final long id) throws Exception {
final Producer<Long, NotificationSentEvent> producer = createProducer();
long time = System.currentTimeMillis();
Long key = (id > 0) ? id : null;
try {
for (long index = 0; index < sendMessageCount; index++) {
NotificationSentEvent notification = NotificationSentEvent.newBuilder()
.setNotification(Notification.newBuilder()
.setId(id)
.setMessage("Hello Kafka " + index)
.build())
.build();
final ProducerRecord<Long, NotificationSentEvent> record =
new ProducerRecord<>(TOPIC, key, notification);
RecordMetadata metadata = producer.send(record).get();
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) " +
"meta(partition=%d, offset=%d) time=%d\n",
record.key(), record.value(), metadata.partition(),
metadata.offset(), elapsedTime);
time = System.currentTimeMillis();
Thread.sleep(waitMsInBetween);
}
} finally {
producer.flush();
producer.close();
}
}
public static void main(String... args) throws Exception {
if (args.length == 0) {
runProducer(100,10,0);
} else {
runProducer(Integer.parseInt(args[0]),Integer.parseInt(args[1]),Long.parseLong(args[2]));
}
}
}
```
We will be are using the synchronous way for producing messages to the Kafka topic but the other methods would work as well.
The `main()` method accepts 3 parameters, the number of messages to produce, the time in ms to wait in-between sending each message and the ID of the producer.
Use `kcat` or `kafka-console-consumer` to consume the messages from the topic `test-java-avro-idl-topic `.
```bash
kcat -b kafka-1:19092 -t test-java-avro-idl-topic -s value=avro -r http://schema-registry-1:8081
```
Now run it using the `mvn exec:java` command. It will generate 1000 messages, waiting 10ms in-between sending each message and use 0 for the ID.
```
mvn exec:java@producer -Dexec.args="1000 10 0"
```
**Note:** if your maven version does not support profiles, then you have to specify the main class as well: `mvn exec:java -Dexec.mainClass="com.trivadis.kafkaws.producer.KafkaProducerSync" -Dexec.args="1000 100 0"`
In a browser, navigate to <http://dataplatform:28039> and you should see the home page of the Schema Registry UI. Le's make sure that the schema has been registered automatically.

## Create a Kafka Consumer using Avro for serialization
First create a new Java Package `com.trivadis.kafkaws.consumer` in the folder **src/main/java**.
Create a new Java Class `KafkaConsumerAvro` in the package `com.trivadis.kafakws.consumer` just created.
Add the following code to the empty class.
```java
package com.trivadis.kafkaws.consumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
import com.trivadis.kafkaws.avro.v1.NotificationSentEvent;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.LongDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import com.trivadis.kafkaws.avro.v1.Notification;
import io.confluent.kafka.serializers.KafkaAvroDeserializer;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializerConfig;
public class KafkaConsumerAvro {
private final static String TOPIC = "test-java-avro-idl-topic";
private final static String BOOTSTRAP_SERVERS =
"dataplatform:9092, dataplatform:9093, dataplatform:9094";
private final static String SCHEMA_REGISTRY_URL = "http://dataplatform:8081";
private static Consumer<Long, NotificationSentEvent> createConsumer() {
final Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerAvro");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 10000);
props.put(KafkaAvroSerializerConfig.AUTO_REGISTER_SCHEMAS, "false");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class.getName());
props.put(KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, SCHEMA_REGISTRY_URL); // use constant for "schema.registry.url"
// Create the consumer using props.
final Consumer<Long, NotificationSentEvent> consumer =
new KafkaConsumer<>(props);
// Subscribe to the topic.
consumer.subscribe(Collections.singletonList(TOPIC));
return consumer;
}
static void runConsumer(int waitMsInBetween) throws InterruptedException {
final Consumer<Long, NotificationSentEvent> consumer = createConsumer();
final int giveUp = 100;
int noRecordsCount = 0;
while (true) {
final ConsumerRecords<Long, NotificationSentEvent> consumerRecords = consumer.poll(Duration.ofMillis(1000));
if (consumerRecords.count()==0) {
noRecordsCount++;
if (noRecordsCount > giveUp)
break;
}
consumerRecords.forEach(record -> {
System.out.printf("%d - Consumer Record:(Key: %d, Value: %s, Partition: %d, Offset: %d)\n",
consumerRecords.count(), record.key(), record.value(),
record.partition(), record.offset());
try {
Thread.sleep(waitMsInBetween);
} catch (InterruptedException e) {
}
});
consumer.commitSync();
}
consumer.close();
System.out.println("DONE");
}
public static void main(String... args) throws Exception {
if (args.length == 0) {
runConsumer(10);
} else {
runConsumer(Integer.parseInt(args[0]));
}
}
}
```
## Register in Schema Registry using Maven
In the test above, the Avro schema has been registered in the schema registry when starting the Producer for the first time. To register an Avro schema through Maven automatically, you can again use the `kafka-schema-registry-maven-plugin ` Maven plugin.
Add the following definition to the `pom.xml`.
```xml
<plugin>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-maven-plugin</artifactId>
<version>6.2.0</version>
<configuration>
<schemaRegistryUrls>
<param>http://${DATAPLATFORM_IP}:8081</param>
</schemaRegistryUrls>
<subjects>
<test-java-avro-idl-topic-value>target/generated-sources/avro/schema/NotificationSentEvent.avsc</test-java-avro-idl-topic-value>
</subjects>
</configuration>
<goals>
<goal>register</goal>
<goal>test-compatibility</goal>
</goals>
</plugin>
```
Note that we now have to get the Avro schema (Json syntax) from the `target/generated-sources` folder.
Now you can use the following command to register the schemas with the Schema Registry:
```
mvn schema-registry:register
```
## Adding documentation to the Avro IDL
The Avro IDL language also [supports comments](https://avro.apache.org/docs/1.11.1/idl-language/#comments).
All Java-style comments are supported within a Avro IDL file. Any text following `//` on a line is ignored, as is any text between `/*` and `*/`, possibly spanning multiple lines.
Comments that begin with `/**` are used as the documentation string for the type or field definition that follows the comment
Let's extend `Notification.avdl` with some comments on record as well as on field level:
```
@namespace("com.trivadis.kafkaws.avro.v1")
protocol NotificationProtocol {
/**
Notification structure defining a message to be sent as a notification.
Will be used to notify users of a problem.
*/
record Notification {
/**
This is the ID of a notification, optional
*/
union {null, long} id; // optional, should be changed in the future to mandatory!
/** This is the message of the notification */
union {null, string} message;
}
}
```
The same can be done on the `NotificationSentEvent.avdl`:
```
@namespace("com.trivadis.kafkaws.avro.v1")
protocol NotificationSentEventProtocol {
import idl "Notification.avdl";
/**
This is the Notification Event structure which uses an embedded Notification object.
*/
record NotificationSentEvent {
/** the Notification embedded object */
Notification notification;
}
}
```
Not let's regenerate the code
```bash
mvn compile
```
and we will find the comments also in the generated Java classes, here showing parts of the `Notification` class as an example:
```java
/** Notification structure defining a message to be sent as a notification.
Will be used to notify users of a problem. */
@org.apache.avro.specific.AvroGenerated
public class Notification extends org.apache.avro.specific.SpecificRecordBase implements org.apache.avro.specific.SpecificRecord {
private static final long serialVersionUID = 3582798745986381455L;
...
/** This is the ID of a notification, optional */
private java.lang.Long id;
/** This is the message of the notification */
private java.lang.String message;
...
/**
* Gets the value of the 'id' field.
* @return This is the ID of a notification, optional
*/
public java.lang.Long getId() {
return id;
}
/**
* Sets the value of the 'id' field.
* This is the ID of a notification, optional
* @param value the value to set.
*/
public void setId(java.lang.Long value) {
this.id = value;
}
```
## Adding deprecation to Avro IDL
Let's say we in the process of replacing an existing field in Avro with a new field. In order to be compatible, we need to support the old field for some time in parallel to the new field.
But of course we would like to notify all the users of the deprecation of the field. That's where the `@deprecated` comment can be used, as shown below. Let's say we replace the single string-typed `message` field with an array-typed `messages` field. We can deprecate the `message` field by adding `@deprecated` to the documentation together with a deprecation note:
```
@namespace("com.trivadis.kafkaws.avro.v1")
protocol NotificationProtocol {
/**
Notification structure defining a message to be sent as a notification.
Will be used to notify users of a problem.
deprecated
*/
record Notification {
/**
This is the ID of a notification, optional
*/
union {null, long} @javaAnnotation("Deprecated") id; // optional, should be changed in the future to mandatory!
/** This is the message of the notification
@deprecated use the new array-based "messages" field instead
*/
union {null, string} message;
/** This are the messages of the notification
*/
union {null, array<string>} messages;
}
}
```
The `@deprecated` comment will end up in the generated Java class both in the property definition as well as in the getter and setter methods:
```java
@org.apache.avro.specific.AvroGenerated
public class Notification extends org.apache.avro.specific.SpecificRecordBase implements org.apache.avro.specific.SpecificRecord {
private static final long serialVersionUID = 2885908480528460301L;
...
/** This is the message of the notification
@deprecated use messages instead */
private java.lang.String message;
...
/**
* Gets the value of the 'message' field.
* @return This is the message of the notification
@deprecated use the new array-based "messages" field instead
*/
public java.lang.String getMessage() {
return message;
}
/**
* Sets the value of the 'message' field.
* This is the message of the notification
@deprecated use the new array-based "messages" field instead
* @param value the value to set.
*/
public void setMessage(java.lang.String value) {
this.message = value;
}
...
```
if you now run
```bash
mvn clean compile -Dmaven.compiler.showWarnings=true -Dmaven.compiler.showWarnings=true
```
to compile the source code, you will see the deprecation warning for usage of the old field.
```bash
[INFO] --- maven-compiler-plugin:2.5:compile (default-compile) @ java-kafka-avro-idl ---
[INFO] Compiling 6 source files to /Users/guido.schmutz/Documents/GitHub/gschmutz/kafka-workshop/04b-working-with-avro-idl-and-java/src/java-kafka-avro-idl/target/classes
[WARNING] bootstrap class path not set in conjunction with -source 8
/Users/guido.schmutz/Documents/GitHub/gschmutz/kafka-workshop/04b-working-with-avro-idl-and-java/src/java-kafka-avro-idl/src/main/java/com/trivadis/kafkaws/producer/KafkaProducerAvro.java:[43,24] [deprecation] setMessage(String) in Builder has been deprecated
```
In our case it's in the `KafkaProducerAvro` class.
Depending on the IDE used, the usage will also nicely flagged visually. Bellow how it is shown in IntelliJ

<file_sep># Confluent REST Proxy
The Confluent REST Proxy provides a RESTful interface to a Apache Kafka® cluster, making it easy to produce and consume messages, view the state of the cluster, and perform administrative actions without using the native Kafka protocol or clients.
**[Website](https://docs.confluent.io/platform/current/kafka-rest/index.html)** | **[Documentation](https://docs.confluent.io/platform/current/kafka-rest/index.html)** | **[GitHub](https://github.com/confluentinc/kafka-rest)**
## How to enable?
```bash
platys init --enable-services KAFKA,KAFKA_RESTPROXY
platys gen
```
<file_sep>package com.trivadis.kafkaws.springbootkotlinkafkaproducer
import org.apache.kafka.clients.admin.NewTopic
import org.springframework.beans.factory.annotation.Value
import org.springframework.context.annotation.Bean
import org.springframework.kafka.config.TopicBuilder
import org.springframework.stereotype.Component
@Component
class TopicCreator {
@Value("\${topic.name}")
private lateinit var kafkaTopic: String
@Value("\${topic.partitions}")
private var partitions: Int = 0
@Value("\${topic.replication-factor}")
private var replicationFactor: Int = 0
@Bean
fun topic(): NewTopic? {
return TopicBuilder.name(kafkaTopic)
.partitions(partitions)
.replicas(replicationFactor)
.build()
}
}<file_sep># Apache Airflow
Airflow is a platform created by the community to programmatically author, schedule and monitor workflows.
**[Website](https://airflow.apache.org/)** | **[Documentation](https://airflow.apache.org/docs/)** | **[GitHub](https://github.com/apache/airflow)**
## How to enable?
```
platys init --enable-services AIRFLOW
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28139>.
Login with user `airflow` and password `<PASSWORD>!`.
Place the dag files into the folder `./scripts/airflow/dags`.<file_sep>Put the following files here:
- memgraph.conf for overriding the default file inside the container (use the memgraph.conf.template as a sample).<file_sep># Using Kafka from Go
In this workshop we will learn how to use the [confluent-kafka-go](https://github.com/confluentinc/confluent-kafka-go) to produce and consume to/from Kafka from the Go language.
You can find many examples of using Kafka with Go [here](https://github.com/confluentinc/confluent-kafka-go/tree/master/examples) in the GitHub project.
This guide assumes that you already have the Go language tools installed.
## Setup
### Creating the necessary Kafka Topic
We will use the topic `test-node-topic` in the Producer and Consumer code below. Due to the fact that `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
Connect to the `kafka-1` container
```
docker exec -ti kafka-1 bash
```
and execute the necessary kafka-topics command.
```
kafka-topics --create \
--replication-factor 3 \
--partitions 8 \
--topic test-golang-topic \
--bootstrap-server kafka-1:19092
```
Cross check that the topic has been created.
```
kafka-topics --list \
--bootstrap-server kafka-1:19092
```
This finishes the setup steps and our new project is ready to be used. Next we will start implementing the **Kafka Producer** which uses Avro for the serialisation.
## Create a Go Project
Create a new directory anywhere you’d like for this project:
```bash
mkdir golang-kafka && cd golang-kafka
```
Initialize the Go module and download the Confluent Go Kafka dependency:
```
go mod init golang-kafka
go get github.com/confluentinc/confluent-kafka-go/kafka
```
# Create Kafka Producer
Next we are going to create the producer application by pasting the following Go code into a file named `producer.go`.
```go
package main
import (
"fmt"
"strconv"
"github.com/confluentinc/confluent-kafka-go/kafka"
"os"
"time"
)
func main() {
sendMessageCount, err := strconv.Atoi(os.Args[1])
waitMsInBetween, err := strconv.Atoi(os.Args[2])
id, err := strconv.Atoi(os.Args[3])
p, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": "dataplatform:9092",
"acks": "all"})
if err != nil {
fmt.Printf("Failed to create producer: %s\n", err)
os.Exit(1)
}
fmt.Printf("Created Producer %v\n", p)
// Listen to all the events on the default events channel
go func() {
for e := range p.Events() {
switch ev := e.(type) {
case *kafka.Message:
// The message delivery report, indicating success or
// permanent failure after retries have been exhausted.
// Application level retries won't help since the client
// is already configured to do that.
m := ev
if m.TopicPartition.Error != nil {
fmt.Printf("Delivery failed: %v\n", m.TopicPartition.Error)
} else {
fmt.Printf("Delivered message to topic %s [%d] at offset %v\n",
*m.TopicPartition.Topic, m.TopicPartition.Partition, m.TopicPartition.Offset)
}
case kafka.Error:
// Generic client instance-level errors, such as
// broker connection failures, authentication issues, etc.
//
// These errors should generally be considered informational
// as the underlying client will automatically try to
// recover from any errors encountered, the application
// does not need to take action on them.
fmt.Printf("Error: %v\n", ev)
default:
fmt.Printf("Ignored event: %s\n", ev)
}
}
}()
topic := "test-golang-topic"
for i := 1; i <= sendMessageCount; i++ {
value := fmt.Sprintf("[%d] Hello Kafka #%d => %s", i, i, time.Now().Format(time.RFC3339))
if id == 0 {
err = p.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(value),
Headers: []kafka.Header{{Key: "myTestHeader", Value: []byte("header values are binary")}},
}, nil)
} else {
err = p.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Key: []byte(strconv.Itoa(id)),
Value: []byte(value),
Headers: []kafka.Header{{Key: "myTestHeader", Value: []byte("header values are binary")}},
}, nil)
}
if err != nil {
if err.(kafka.Error).Code() == kafka.ErrQueueFull {
// Producer queue is full, wait 1s for messages
// to be delivered then try again.
time.Sleep(time.Second)
continue
}
fmt.Printf("Failed to produce message: %v\n", err)
}
// Slow down processing
time.Sleep(time.Duration(waitMsInBetween) * time.Millisecond)
}
// Flush and close the producer and the events channel
for p.Flush(10000) > 0 {
fmt.Print("Still waiting to flush outstanding messages\n", err)
}
p.Close()
}
```
# Kafka Consumer
Next let's create the consumer by pasting the following code into a file named `consumer.go`.
```go
package main
import (
"fmt"
"github.com/confluentinc/confluent-kafka-go/kafka"
"os"
"os/signal"
"strconv"
"syscall"
"time"
)
func main() {
if len(os.Args) < 1 {
fmt.Fprintf(os.Stderr, "Usage: %s <wait-ms-in-between>\n",
os.Args[0])
os.Exit(1)
}
waitMsInBetween, err := strconv.Atoi(os.Args[1])
sigchan := make(chan os.Signal, 1)
signal.Notify(sigchan, syscall.SIGINT, syscall.SIGTERM)
c, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": "dataplatform:9092",
// Avoid connecting to IPv6 brokers:
// This is needed for the ErrAllBrokersDown show-case below
// when using localhost brokers on OSX, since the OSX resolver
// will return the IPv6 addresses first.
// You typically don't need to specify this configuration property.
"broker.address.family": "v4",
"group.id": "GoConsumer",
"session.timeout.ms": 6000,
"auto.offset.reset": "earliest",
"enable.auto.offset.store": false,
})
if err != nil {
fmt.Fprintf(os.Stderr, "Failed to create consumer: %s\n", err)
os.Exit(1)
}
fmt.Printf("Created Consumer %v\n", c)
topics := []string{"test-golang-topic"}
err = c.SubscribeTopics(topics, nil)
run := true
for run {
select {
case sig := <-sigchan:
fmt.Printf("Caught signal %v: terminating\n", sig)
run = false
default:
ev := c.Poll(100)
if ev == nil {
continue
}
switch e := ev.(type) {
case *kafka.Message:
fmt.Printf("%% Message on %s:\n%s\n",
e.TopicPartition, string(e.Value))
if e.Headers != nil {
fmt.Printf("%% Headers: %v\n", e.Headers)
}
_, err := c.StoreMessage(e)
if err != nil {
fmt.Fprintf(os.Stderr, "%% Error storing offset after message %s:\n",
e.TopicPartition)
}
case kafka.Error:
// Errors should generally be considered
// informational, the client will try to
// automatically recover.
// But in this example we choose to terminate
// the application if all brokers are down.
fmt.Fprintf(os.Stderr, "%% Error: %v: %v\n", e.Code(), e)
if e.Code() == kafka.ErrAllBrokersDown {
run = false
}
default:
fmt.Printf("Ignored %v\n", e)
}
// Slow down processing
time.Sleep(time.Duration(waitMsInBetween) * time.Millisecond)
}
}
fmt.Printf("Closing consumer\n")
c.Close()
}
```
<file_sep># Conduit
Conduit is a data integration tool for software engineers. Its purpose is to help you move data from A to B. You can use Conduit to send data from Kafka to Postgres, between files and APIs, between supported connectors, and any datastore you can build a plugin for.
**[Website](https://conduit.io/)** | **[Documentation](https://www.conduit.io/docs/introduction/getting-started)** | **[GitHub](https://github.com/ConduitIO/conduit)**
## How to enable?
```bash
platys init --enable-services CONDUIT
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28269>.
<file_sep># What to do when the Public IP address has been changed?
This short instruction shows what to do when you have a running Platys stack and the Public IP address of the Docker host has been changed (this can happen if your docker host is running in a cloud VM).
Some services of platys will no longer run correctly, if the IP address changes, therefore the stack has to be stopped and removed and then started again. Therefore you should **try to avoid a change of the IP address**, i.e. in the cloud by assigning a stack IP address!
You can check what your IP was when running the stack by showing the value of the PUBLIC_IP variable
```
echo $PUBLIC_IP
```
In the code blocks below we assume that the `DATAPLATFORM_HOME` variable is set and points to the `docker` folder where the metadata on the docker compose stack is located (the folder holding the `docker-compose.yml` file).
Navigate into the stack and stop and remove all the services. Be aware that all the data inside your running container will be removed!
```
cd $DATAPLATFORM_HOME
docker-compose down
```
Change the environment variables to hold the new IP address
```
export PUBLIC_IP=$(curl ipinfo.io/ip)
export DOCKER_HOST_IP=$(ip addr show ${NETWORK_NAME} | grep "inet\b" | awk '{print $2}' | cut -d/ -f1)
```
Check that the value of the variable is the correct IP address
```
echo $PUBLIC_IP
```
Update the `.bash_profile` script to relect the new IP address (so that after a new login it will be correct).
Open the file with an editor (change the username variable to your current user)
```
export USERNAME=ubuntu
nano /home/$USERNAME/.bash_profile
```
Save the file with **Ctrl-O** and exit with **Ctrl-X**.
Restart the stack
```
cd $DATAPLATFORM_HOME
docker-compose up -d
```
Check the log files
```
docker-compse logs -f
```
<file_sep># Benthos
Benthos is a high performance and resilient stream processor, able to connect various sources and sinks in a range of brokering patterns and perform hydration, enrichments, transformations and filters on payloads.
**[Website](https://www.benthos.dev/)** | **[Documentation](https://www.benthos.dev/docs/about)** | **[GitHub](https://github.com/benthosdev/benthos)**
```bash
platys init --enable-services BENTHOS
platys gen
```
## How to use it?
Navigate to <http://dataplatform:4195>.
<file_sep>---
technoglogies: streamsets
version: 1.14.0
validated-at: 3.2.2022
---
# Loading Streamsets Pipeline(s) upon start of container
This recipe will show how to import pipeline upon starting the StreamSets Data Collector.
## Initialise data platform
First [initialise a platys-supported data platform](../documentation/getting-started) with the following services enabled
```
platys init --enable-services STREAMSETS -s trivadis/platys-modern-data-platform -w 1.14.0
```
Edit the `config.yml` and add the following configuration settings.
```
STREAMSETS_install_pipelines: true
```
Now generate data platform and download the Streamsets Custom origin to the right folder.
```
platys gen
```
## Copy StreamSets pipeline to scripts folder
Download the StreamSets pipeline into the scripts folder in Platys:
```
cd scripts/streamsets/pipelines
wget https://github.com/TrivadisPF/streamsets-dev-simulator/releases/download/0.8.0/dev-simulator-0.8.0.tar.gz
tar -xvzf dev-simulator-0.8.0.tar.gz
rm dev-simulator-0.8.0.tar.gz
cd ../../..
```
Start the platform:
```
docker-compose up -d
```
## Check that the pipeline is running
<file_sep># Kapacitor
Kapacitor is an open source data processing framework that makes it easy to create alerts, run ETL jobs and detect anomalies. Kapacitor is the final piece of the TICK stack.
**[Website](https://www.influxdata.com/time-series-platform/kapacitor/)** | **[Documentation](https://docs.influxdata.com/kapacitor/v1.6/)** | **[GitHub](https://github.com/influxdata/kapacitor)**
## How to enable?
```
platys init --enable-services INFLUXDB, INFLUXDB_KAPACITOR
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28130/kapacitor/v1><file_sep>Place JDBC JARs for StreamSets JDBC stage lib here ...<file_sep># Grafana Promtail
Promtail is an agent which ships the contents of local logs to a private Grafana Loki instance or Grafana Cloud. It is usually deployed to every machine that has applications needed to be monitored.
**[Website](https://grafana.com/oss/loki/)** | **[Documentation](https://grafana.com/docs/loki/latest/clients/promtail/)** | **[GitHub](https://github.com/grafana/loki#loki-like-prometheus-but-for-logs)**
## How to enable?
```
platys init --enable-services PROMTAIL
platys gen
```
<file_sep>Place custom extensions for CKAN here ...<file_sep># Kouncil
Simple dashboard for your Kafka. Monitor status, manage groups, topics, send messages and diagnose problems. All in one user friendly web dashboard.
**[Website](https://kouncil.io/)** | **[Documentation](https://github.com/Consdata/kouncil)** | **[GitHub](https://github.com/Consdata/kouncil)**
## How to enable?
```
platys init --enable-services KOUNCIL
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28253><file_sep># Kadmin
Web Based Kafka Consumer and Producer.
**[Documentation](https://github.com/BetterCloud/kadmin)** | **[GitHub](https://github.com/BetterCloud/kadmin)**
### How to enable?
```
platys init --enable-services KADMIN
platys gen
```
### How to use it?
Navigate to <http://dataplatform:28106>
<file_sep>Contains the data of debezium-server, if flag DEBEZIUM_SERVER_volume_map_data is set to true.<file_sep>#!/bin/bash
echo "removing MQTT Source Connector"
curl -X "DELETE" "$DOCKER_HOST_IP:8083/connectors/mqtt-source"
<file_sep># `modern-data-platform` - What's new?
See [Upgrade to a new platform stack version](https://github.com/TrivadisPF/platys/blob/master/documentation/upgrade-platform-stack) for how to upgrade to newer version.
## What's new in 1.17.0
The Modern Data Platform version 1.16.0 contains the following bug fixes and enhancements:
### New Services
* Minio Web
### Version upgrades
* Update `zeebe` to `8.2.5`
* Update `druid` to `26.0.0`
* Update `trino` to `422`
* Update `starbrustdata` to `420-e`
* Update `jikkou` to `0.21.0`
* Update `minio` to `RELEASE.2023-06-29T05-12-28Z`
* Update `nifi` to `1.22.0`
* Update `ksqldb` to `0.29.0`
* Update `datahub` to `v0.10.5`
### Enhancements
* support for configuring Airflow authentication backends via `AIRFLOW_auth_backends` config setting
## What's new in 1.16.0
The Modern Data Platform version 1.16.0 contains the following bug fixes and enhancements:
### New Services
* Kong API Gateway
* Kong decK
* Konga
* Kong Map
* Kong Admin UI
* Tyk API Gateway
* Tyk Dashboard
* Tyk Pump
* Kafka Connector Board
* Kaskade
* kpow
* JupyterHub
* Conduktor Platform
* Memgraph
* Curity
* Anaconda
* Redpanda Console (previously kowl, old version of kowl still supported)
* Iceberg REST Catalog
* JanusGraph
* Gremlin Console
* Invana Engine and Invana Studio
* ArcadeDB
* Spring Boot Admin Server
* CKAN
* Benthos
* OpenLDAP + phpLDAPadmin + LDAP User Manager
* SFTP
* Project Nessie
* Directus
* Baserow
* Querybook
* Oracle Database Free
* Kafka CLI (Kafka software without a running broker)
* Kafkistry
* Parquet Tools
* SQL Chat
### New/Updated Cookbook Recipes
* [NiFi ExecuteScript Processor with Python](../cookbooks/recipes/nifi-execute-processor-with-python/README)
* [NiFi Registry with Git Flow Persistence Provider](../cookbooks/recipes/nifi-registry-with-git/README)
* [Handle Serialization Errors in ksqlDB](../cookbooks/recipes/ksqldb-handle-deserializaion-error/README)
* [Using Jupyter notebook with Spark and Avro](../cookbooks/recipes/jupyter-spark/README)
* [Using Dev Simulator Origin to simulate streaming data](../cookbooks/recipes/using-dev-simulator-origin/README) - updated with diagrams and additional samples
* [Spark with Delta Lake](../cookbooks/recipes/delta-lake-with-spark/README)
* [Spark with Iceberg](../cookbooks/recipes/iceberg-with-spark/README)
* [Neo4J and yFiles graphs for Jupyter](../cookbooks/recipes/neo4j-jupyter-yfiles/README)
* [Schedule and Run Simple Python Application with Airflow](../cookbooks/recipes/airflow-schedule-python-app/README) - updated to show the new support of Airflow
* [Using MLflow from Jupyter](../cookbooks/recipes/using-mflow-from-jupyter/README)
* [Trino Security](../cookbooks/recipes/trino-security/README)
* [Azure Event Hub as external Kafka](../cookbooks/recipes/azure-event-hub-as-external-kafka/README)
### New Tutorial
* [IoT Vehicle Tracking](../tutorials/iot-vehicle-tracking/README)
### Version upgrades
* Update `DataHub` to `v0.10.3`
* Update `Trino` to `418`
* Update `Starburst Enterprise` to `413-e`
* Update `dremio` to `24.0`
* Update `Jikkou` to `0.14.0`
* Update `Hasura` to `v2.16.1`
* Update `Confluent Platform` to `7.4.0`
* Update `ksqldb` to `0.28.2`
* Update `datastax` to `6.8.34`
* Update `datastax-opscenter` to `6.8.26`
* Update `minio` to `RELEASE.2023-04-20T17-56-55Z`
* Update `confluent platform` to `7.3.3`
* Update `influxdb2` to `2.7`
* Update `kapacitor` to `1.6`
* Update `chronograf` to `1.10`
* Update `telegraf` to `1.26`
* Update `burrow` to `v1.5.0`
* Update `graphdb` to `10.1.2`
* Update `nifi` to `1.21.0`
* Update `jikkou` to `0.13.0`
* Update `spark` to `3.1.3`, `3.2.4` and `3.3.2` and `3.4.0`
* Update `materialize` to `v0.52.2`
* Update `neo4j` to `5.7`
* Update `eventstoredb` to `22.10.0-buster-slim`
* Update `flink` to `1.17-scala_2.12`
* Update `tika-server` to `192.168.127.12-full`
* Update `marquez` and `marquez-web` to `0.33.0`
* Update `airbyte` to `0.40.33`
* Update `mlflow-server` to `2.1.0`
* Update `minio` to `RELEASE.2023-01-20T02-05-44Z`
* Update `grafana` to `9.3.11`
* Update `kibana` to `7.17.9` and `8.7.0`
* Update `elasticsearch` to `7.17.9` and `8.7.0`
* Update `memchached` to `1.6.19`
* Update `mongodb` to `6.0`
* Update `solr` to `9.1`
* Update `quine` to `1.5.1`
* Update `dgraph` to `v22.0.2`
* Update `stardog` to `8.2.2-java11-preview`
* Update `kudu` to `1.16`
* Update `druid` to `25.0.0`
* Update `prometheus` to `v2.41.0` and `gateway` to `v1.5.1` and `node-exporter` to `v1.5.0`
* Update `tile38` to `1.30.1`
* Update `yugabyte` to `2.8.11.0-b6`
* Update `hazelcast` to `5.2.3`
* Update `ignite` to `2.14.0`
* Update `axon-server` to `4.6.7
* Update `drill` to `1.20.2`
* Update `hasura` to `v2.23.0`
* Update `cedalo-management-center` to `2.5.8`
* Update `lakefs` to `0.101.0`
* Update `vault` to `1.13.1`
* Update `portainer` to `2.16.2-alpine`
* Update `watchtower` to `1.5.1`
* Update `ahana` to `0.278`
* Update `apicurio-schema-registry` to `2.4.2.Final`
* Update `debezium-server` to `2.2.0-Final`
* Update `Amundsen Frontend` to `4.2.0` and `Amundsen Search` to `4.0.2` and `Amundsen Metadata` to `3.11.0`
* Update `nodered` to `2.2.3`
* Update `dataiku-dss` to `11.2.0`
* Update `postgres` to `15`
* Update `Airflow` to `2.6.1` with default python `3.10`
* Update `TimescaleDB` to `2.10.2-pg15`
* Update `Pinot` to `0.12.1`
* Update `Jupyter-spark` to `spark-3.3.2` and `spark-3.4.0`
* Update `Hue` to `4.11.0`
### Bug Fixes
* ksqlDB processing log now also works with the open source edition (` KAFKA_KSQLDB_edition: 'oss'`).
### Breaking Changes
* if markdown viewer cannot run on port 80 (`MARKDOWN_VIEWER_use_port_80` is set to `false`), port 8008 is used and no longer port 8000
* Burrow changed to use image from LinkedIn and no longer the one from Trivadis
* Change `KAFKA_CMAK_xxxxx` to `CMAK_xxxxx`
* Change `KAFKA_AKHQ_xxxxx` to `AKHQ_xxxxx`
* Change `KAFKA_KAFDROP_xxxxx` to `KAFDROP_xxxxx`
* Change `KAFKA_KADMIN_xxxxx` to `KADMIN_xxxxx`
* Change `KAFKA_EFAK_xxxxx` to `EFAK_xxxxx`
* Change the docker image for Airflow from the Bitnami to the official Apache one
* Support the two major versions 7 and 8 of Elasticsearch
* Ember Frontend for Datahub removed (as React is the new standard UI)
* Rename `SPARK_THRIFT_enable` to `SPARK_THRIFTSERVER_enable`
* Rename folder `./init/oraclexe` to `./init/oracle-xe`
* Spark Master UI now runs on port `28304` and no longer on standard `8080`
* Change `FLINK_NUSSKNACKER_enable` to `NUSSKNACKER_enable`
* Change `MINIO_default_buckets` to `MINIO_buckets`
### Enhancements
* make `spark.sql.warehouse.dir` configurable in `config.yml`
* added first tutorials showing more complete walk-through of using Platys
* allow to add roles when specifying multiple databases and users with PostgreSQL
* allow to specify that the Starburstdata license file should be mapped into the containers, when `TRINO_edition` is set to `starburstdata`. This enables the additional security features, more connectors, a cost-based query optimizer and much more.
* added catalog for `iceberg`, `delta-lake`, `elasticsearch`, `mongo`, `mysql`, `sqlserver`, `pinot` and `druid` to trino/starburst
* added options to further configure AKHQ
* support Trino security with password file and access control file
* support for multiple Airflow workers if `celery` executor mode is used
* support for custom Trino catalogs and connectors
* add concept of an environment to a platys stack, so that the same docker-compose can be run multiple time on different machines, but having a separate environment.
## What's new in 1.15.0
The Modern Data Platform version 1.15.0 contains the following bug fixes and enhancements:
### New Services
* dbt
* Quine
* NiFi Toolkit
* Conduit
* ReTool
* Airbyte
* Oracle SQLcl
* MockServer
* Kafka WebView
* OpenSearch & OpenSearch Dashboards
* ElasticVue
* NocoDB
* Azure CLI
* Azure Storage Explorer
* Zilla
* NocoDB
* kafkactl
### New Cookbook Recipes
* [Querying data in Azure Data Lake Storage Gen2 from Trino](../cookbooks/recipes/querying-adls-with-trino)
### Version upgrades
* Update `Apache NiFi` to `1.15.3` and `Apache NiFi Registry` to `1.15.3`
* Update `Trino` to `391`
* Update `Starburst Enterprise` to `391-e`
* Update `dremio` to `20.1`
* Update `Debezium Server` to `1.9`
* Update `DataHub` to `v0.8.40`
* Update `ksqldb` to `0.27.1`
* Update `spring-cloud-dataflow-server` to `2.9.3`
* Update `spring-cloud-skipper-server` to `2.8.3`
* Update `streamsheet` to `2.5.3-milestone`
* Update `thingsboard` to `3.3.4.1`
* Update `datahub` to `v0.8.31`
* Update `nifi` to `1.17.0` and `nifi-registry` to `1.17.0`
* Update `minio` to `RELEASE.2022-08-08T18-34-09Z`
* Update `spark` to `3.1.3`
* Update `zeppelin` to `0.10.1`
* Update `Confluent Platform` to `7.1.2`
* Update `Materialize` to `v0.26.0`
* Update `lakeFS` to `0.63.0`
* Update `Pinot` to `0.10.0`
* Update `Marquez` to `0.23.0`
* Update `DataStax` to `6.8.25`
### Breaking Changes
* `KAFKA_CONNECT_UI_use_public_ip` option has been removed, as now `kafka-connect-ui` is using the internal service name to connect to kafka-connect.
* `SPARK_major_version` has been replaced by `SPARK_base_version` to be able to set the major and minor version for the Spark version to use.
### Enhancements
* Add support for Nifi Cluster (setting the new config seeting `NIFI_create_cluster` to `true`
* Apache NiFi is now secure by default, so you have to use https to get to the UI and then authenticate using the user and password specified.
* Zeppelin images are now in Sync with Spark version (all 3 digits x.x.x).
* Option for installing Adventureworks demo database with SQL Server
* Externalize version of the container used when `PROVISIONING_DATA_enable` is activated
* Support external property file for configuration values in `streamsets`
* Support for Cassandra cluster and set default major version to `4`
### Bug Fixes
* fix bug in `markdown-renderer` on Apple Silicon (M1)
* fix bug if a kafka-connect cluster is used
* update zeppelin docker container to download spark without hadoop to fix a bug when writing to S3
## What's new in 1.14.0
The Modern Data Platform version 1.14.0 contains the following bug fixes and enhancements:
### New Services
* Kouncil
* Apicurio Registry
* Streamsets DataOps Platform
* Grafana Loki
* Grafana Promtail
* Avro Tools
* Kafka Magic
* StreamPipes
* Remora
* Metabase
* Jikkou
* Pitchfork
* Jaeger
* OTEL Collector (OpenTelemetry)
* Camunda BPM Platform
* Camunda Optimize
* Lenses Box
* Tempo & Tempo Query
* Promtail
### New Cookbook Recipes
* [Apicurio Registry with SQL Storage (PostgreSQL)
](../cookbooks/recipes/apicurio-with-database-storage)
* [Automate managment of Kafka topics on the platform](../cookbooks/recipes/jikkou-automate-kafka-topics-management/README)
* [Simulated Multi-DC Setup on one machine](../cookbooks/recipes/simulated-multi-dc-setup/README)
* [Creating a self-managed StreamSets DataOps Environment using Platys](../cookbooks/recipes/streamsets-dataops-creating-environment/README)
* [Loading Streamsets Pipeline(s) upon start of container](../cookbooks/recipes/streamsets-loading-pipelines/README)
* [Working with Tipboard and Kafka](../cookbooks/recipes/tipboard-and-kafka/README)
* [Querying data in Kafka from Trino (formerly PrestoSQL)](../cookbooks/recipes/querying-kafka-with-trino/README)
* [Using a Kafka Connect Connector not in Confluent Hub](../cookbooks/recipes/using-kafka-connector-not-in-confluent-hub/README)
### Version upgrades
* Update `DataHub` to `0.8.25`
* Update `Trino` to `371`
* Update `Starburst Enterprise` to `369-e`
* Update `Apache NiFi` to `1.15.0`
* Update `Hasura` to `v2.0.0-beta.2`
* Update `ksqlDB` to `0.23.1`
* Update `Zeppelin` to `0.10.0`
* Update `Livy` to `0.7.1-incubating`
* Update `Spark 3` to `3.2`
* Update `Streamsheets` to `2.5-milestone`
* Update `Neo4J` to `4.4`
* Update `Confluent` to `7.0.1`
* Update `NiFi` to `1.15.2` and `NiFi Registry` to `1.15.1`
* Update `Marquez` to `0.20.0`
* Update `Amundsen Frontend` to `4.0.0` and `Amundsen Search` to `3.0.0`
* Update `InfluxDB 2` to `2.1.1`
* Update `EventStore`to `21.10.1-buster-slim`
* Update `Keycloak` to `16.1.1`
* Update `Dremio` to `20.0`
* Update `Minio` to `RELEASE.2022-02-01T18-00-14Z`
* Update `lakeFS` to `0.58.0`
* Update `Vault` to `1.9.3`
* Update `Ranger` to `2.2.0`
* Update `Materialize` to `v0.19.0`
* Update `kcat` to `1.7.1`
* Update `Debezium` to `1.8.0.Final`
* Update `Cassandra` to `4.1`
* Update `Datastax` to `6.8.19`
* Update `Elasticsearch` to `7.17.0`
* Update `Node-RED` to `2.2.0`
* Update `Spring Dataflow` to `2.9.2` and `Skipper` to `2.8.2`
* Update `MLflow` to `1.23.1`
* Update `Optuna Dashboard` to `0.5.0`
* Update `Kie-Server` to `7.61.0.Final`
* Update `Grafana` to `8.3.4`
* Update `Kibana` to `7.17.0`
* Update `Memchached` to `1.6.13`
* Update `Solr` to `8.11`
* Update `DGraph` to `v21.12.0`
* Update `Stardog` to `7.8.3-java11-preview`
* Update `GraphDB` to `9.10.1`
* Update `QuestDB` to `6.2`
* Update `Druid` to `0.22.1`
* Update `Pinot` to `0.9.3`
* Update `Prometheus` to `v2.33.1` and `pushgateway` to `v1.4.2` and `nodeexporter` to `v1.3.1`
* Update `Tile38` to `1.27.1`
* Update `Axon` to `4.5.10`
* Update `Hasura` to `v2.2.0`
* Update `Emq` to `4.3.11`
* Update `Cedalo Mgmt Center` to `2.2`
* Update `Thingsboard` to `3.3.3`
* Update `RabbitMQ` to `3.9-management`
* Update `Watchtower` to `1.4.0`
### Breaking Changes
* InfluxDB is now listening on `19999` instead of `9999`
* All `KAFKA_SCHEMA_REGISTRY_xxxx` renamed to `CONFLUENT_SCHEMA_REGISTRY_xxxx`
* All `KAFKA_SCHEMA_REGISTRY_UI_xxxx` renamed to `SCHEMA_REGISTRY_UI_xxxx`
* Add additional Kafka Advertised Listener for localhost (port 39092 - 39099) and distinguish it from the Docker Listener (on $DOCKER_HOST_IP with port 29092 - 29099)
* allow to switch Kafka standard port usage between EXTERNAL and DOCKER_HOST Listener (config parameter `KAFKA_use_standard_port_for_external_interface`)
* `KAFKA_BURROW_enable` renamed to `BURROW_enable`
* `conf-override` renamed to `custom-conf` to better reflect the fact, that this folder is only for cusotmized configuration files which will not be overwritten when re-generating the platform
* If manually copying Kafka Connect connectors, then no longer place them into `plugins/kafka-connect` but `plugins/kafka-connect/connectors`
* Rename of the `python` configuration settings (`PYTHON_artefacts_folder` and `PYTHON_script_file`)
### Enhancements
* Apicurio Schema Registry as a drop-in replacement for the Confluent Schema Registry
* All services in the Services List Markdown page (http://dataplatform/services) contain a link to their homepage
* Configuration page also links to the serice homepage
* Support Authentication and Authorization in Apicurio Registry via Keycloak
* Added support for PIP packages to be installed before running the `python` container
* Support sending docker logs to Grafana Loki
### Bug Fixes
* fixed error with Burrow service
* `KEYCLOCK` changed to `KEYCLOAK` to reflect the right name
## What's new in 1.13.0
The Modern Data Platform version 1.13.0 contains the following bug fixes and enhancements:
### New Services
* Nuclio FaaS
* Firefox Browser
* Zipkin
* Apache Tika Server
* RStudio
* Shiny Server
* MLflow Server
* Optuna
* Optuna Dashboard
* Excalidraw
* Drools KIE Server
* Drools Business Central Workbench
* Flink
* Nussknacker Designer
* Kowl
* Apache Ignite
* Debezium Server
* pgAdmin
* Oracle XE
### New Cookbook Recipes
* [Support StreamSets Data Collector Activation](../cookbooks/recipes/streamsets-oss-activation)
### Version upgrades
* Update `Confluent` to `6.2.0`
* Update `Marquez` to `0.19.0`
* Update `Trino` to `363`
* Update `Starburstdata` to `363-e`
* Update `DataHub` to `0.8.15`
* Update `Minio` to `RELEASE.2021-06-17T00-10-46Z`
* Update `ksqlDB` to `0.20.0`
* Update `tile38` to `1.25.2`
* Update `kcat` to `1.7.0` (used to be `kafkacat`)
* Update `Elasticsearch` to `7.14.0`
* Update `Kibana` to `7.14.0`
* Update `Cassandra` to `3.11`
* Update `DSE-Server` to `6.8.14`
* Update `MongoDB` to `5.0`
* Update `Neo4J` to `4.2`
* Update `Stardog` to `7.7.1-java11-preview`
* Update `Stardog-Studio` to `current`
* Update `Chronograf` to `1.9`
* Update `Telegraf` to `1.19`
* Update `Influxdb2` to `2.0.8` (switch to official docker image)
* Update `Kudu` to `1.15`
* Update `Pinot` to `0.8.0`
* Update `Pinot` to `0.8.0`
* Update `Prometheus` to `v2.29.1`
* Update `Prometheus Pushgateway` to `v1.4.1`
* Update `Prometheus Nodeexporter` to `v1.2.2`
* Update `Yugabyte` to `2.4.6.0-b10`
* Update `GraphDB` to `9.9.0`
* Update `Druid` to `0.21.1`
* Update `Solr` to `8.9`
* Update `Redis` to `7.0`
* Update `Memcached` to `1.6.10`
* Update `Grafana` to `8.2.0`
* Update `QuestDB` to `6.0.4`
* Update `Spark` to `3.1.1`
* Update `Minio` to `RELEASE.2021-09-15T04-54-25Z`
* Update `Axon Server` to `4.5.7`
* Update `Hazelcast` to `5.0`
* Update `Apache Atlas` to `2.2.0`
* Update `LakeFS` to `0.52.2`
* Update `Amundsen-Frontend` to `3.13.0`
* Update `Amundsen-Metadata` to `3.10.0`
* Update `Amundsen-Search` to `2.11.1`
### Breaking Changes
* Changed `HAZELCAST_IMDG_xxxxxx` to `HAZELCAST_xxxxxx`
* Changed `ORACLE_xxxxxx` to `ORACLE_EE_xxxxxx`
* Changed default of `KAFKA_CONNECT_nodes` from `2` to `1`
* Changed `KAFKA_EAGLE_enable` to `KAFKA_EFAK_enable`
### Enhancements
* Documentation markdown pages are copied into the generated platform and available in the markdown viewer
* Support Zookeeper-Less Kafka Setup in KRaft mode (`KAFKA_use_kraft_mode`)
* Support setting the `SDC ID` to a fixed value for StreamSets, so that an Activation code is still valid after recreating the `streamsets-1` docker container
* Switch from `cp-enterprise-kafka` to `cp-server` image for Confluent Enterprise
* Support multiple databases within one single Posgresql container
* Rename `kafkacat` to `kcat` (to reflect the GitHub project)
* Add support for both Cassandra 3 and Cassandra 4
* Add additional configuration properties to Confluent Schema Registry
* Support installing Python packages when starting Jupyter
* Add support for embedded Kafka Connect server in ksqlDB Server (set `KAFKA_KSQLDB_use_embedded_connect` to `true`)
* Add additional Kafka UI (Kowl)
* Add support for Flink
* Add support for Drools
* Add support for Ignite and Hazelcast
* Add support for Otuna and MLFlow
* Add support for installing Python packages when starting Jupyter (`JUPYTER_python_packages`)
* Add detail pages for some services linked from the **List of Services** page rendered by the Markdown viewer
### Bug Fixes
* fix error "panic: runtime error: slice bounds out of range" in `schema-registry-ui` and `kafka-connect-ui` by allowing the mapping the `resolv.conf` into the container. It is enabled by default.
## What's new in 1.12.1
The Modern Data Platform version 1.12.1 contains the following bug fixes and enhancements:
### Version upgrades
* Update `NiFi` to `1.13.2`
* Update `DataHub` to `v0.8.0`
* Update `ksqlDb` to `0.18.0`
* Update `Jupyter` to `spark-3.1.1`
### Bug Fixes
* Fix Thrift Server which did not work in previous release due to Spark images which are based on Alpine Linux
## What's new in 1.12.0
The Modern Data Platform version 1.12.0 contains the following new services and enhancements:
### New Services
* Prometheus Nodeexporter
* Kafka Lag Exporter
* EventStore DB
* Camunda Zeebe + Operate + ZeeQs
* Hazelcast IMDG + Managment Center
* Apache Pinot
* LakeFS
* EMQ-X MQTT Broker
* QuestDB Timeseries DB
* Materialize
* Debezium UI
### New Cookbook Recipes
* [Creating and visualizing ADRs with log4brains](../cookbooks/recipes/creating-adr-with-log4brains)
* [Using Dev Simulator Orgin to simulate streaming data](../cookbooks/recipes/using-dev-simulator-origin)
* [Using private (Trivadis) Oracle XE image](../cookbooks/recipes/using-private-oracle-xe-image)
* [Using private (Trivadis) Oracle EE image](../cookbooks/recipes/using-private-oracle-ee-image)
* [Using public Oracle XE image](../cookbooks/recipes/using-public-oracle-xe-image)
### Version upgrades
* Update `Azkarra` to `0.9.1`
* Update `Hasura` to `v2.0.0-alpha.9`
* Update `Marquez` to `0.14.2`
* Update `Grafana` to `7.5.2`
* Update `Axonserver` to `4.5`
* Update `Streamsheets` to `2.3-milestone`
* Update `Streamsets` to `3.22.2`
* Update `Trino` to `356`
* Update `Starburstdata Presto` to `356-e.1` (using new `starburst-enterprise` image)
* Update `PrestoDB` to `0.253`
* Update `Ahana` to `0.253`
* Update `DataHub` to `0.7.1`
* Update `InfluxDB2` to `2.0.4`
* Update `Telegraf` to `1.18`
* Update `MongoDB` to `4.4`
* Update `Elasticsearch` to `7.12.0`
* Update `Kibana` to `7.12.0`
* Update `Neo4J` to `4.2.5`
* Update `ksqlDB` to `0.17.0`
* Update `Druid`to `0.21.0`
* Update `HiveMQ 4` to `4.6.1`
* Update `Airflow` to `2`
### Enhancements
* Added support for Kafka Monitoring using JMX and Prometheus/Grafana (with input from this [confluent github project](https://github.com/confluentinc/jmx-monitoring-stacks)
* use official Cloudbeaver docker image and no longer the trivadis one
* [solution documentend](https://github.com/TrivadisPF/platys/blob/master/documentation/docker-compose-without-internet) on how to use a Platys-generated Platform without internet on the target infrastructure
## What's new in 1.11.0
The Modern Data Platform version 1.11.0 contains the following new services and enhancements:
### New Services
* Watchtower added
* Hasura added
* Dgraph added
* File Browser added
* MinIO MC CLI added
* Kafka UI added
* Adminio UI added
* MinIO Console added
* S3 Manager added
* Filestash added
* SQLPad added
* GraphQL Mesh added
* Streams Explorer added
* Thingsboard Community added
* Postman added
* Keyclock added
* Microcks added
* Dataiku Data Science Studio added
* Kafka Eagle added
* Trino added
* GraphDB added
* PostgREST added
* Log4brains added
### New Cookbook Recipes
* [Spark with PostgreSQL](../cookbooks/recipes/spark-with-postgresql)
* [Querying S3 data (MinIO) using MinIO](../cookbooks/recipes/querying-minio-with-trino/)
* [Querying Kafka data using Trino](../cookbooks/recipes/querying-kafka-with-trino/)
### Version upgrades
* Update `Elasticsearch` to `7.10.1`
* Update `Kibana` to `7.10.1`
* Update `HiveMQ4`to `4.5.0`
* Update `Streamsets Transformer` to `3.17.0`
* Update `Axon Server` to `4.4.5`
* Switch to official `Streamsets DataCollector` of `3.21.0`
* Update `Marquez` to `0.12.2`
* Update `Cedalo Management Center` to `2.1`
* Update `Confluent Platform` to `6.1.0`
* Update `ksqlDB` to `0.15.0`
* Update `APICurio Registry` to `1.3.2`
* Update `Starburstdata Presto` to `350-e.5`
* Update `Ahana PrestoDB` to `0.249`
* Update `PrestoDB` to `0.249`
* Update `DataHub` to `0.7.0`
### Enhancements
* Allow configuring the additional StreamSets stage libraries to be installed upon starting StreamSets (we no longer use the Trivadis docker images)
* Support automatically installing StreamSets pipelines upon starting StreamSets
* Support for Trino added (renamed PrestoSQL project) in parallel to PrestoDB (the other fork of Presto)
## What's new in 1.10.0
The Modern Data Platform version 1.10.0 contains the following new services and enhancements:
### New Services
* Spring Cloud Data Flow
### New Cookbook Recipes
* [Using additional Kafka Connect Connector](../cookbooks/recipes/using-additional-kafka-connect-connector)
* [Custom UDF and ksqlDB](../cookbooks/recipes/custom-udf-and-ksqldb)
* [Using Confluent MQTT Proxy](../cookbooks/recipes/using-mqtt-proxy/)
* [Spark with internal S3 (using on minIO)](..cookbooks//recipes/spark-with-internal-s3)
* [Spark with external S3](../cookbooks/recipes/spark-with-extern-s3)
### Version upgrades
* Update `ksqlDB` to `0.14.0`
* Update `Streamsheets` to `2.2`
* Update `Zeppelin` to `0.9.0`
* Update `Confluent` to `6.0.1`
* Update `Presto` to `348-e`
* Update `Stardog` to `7.4.5-java11-preview` and `Stardog Studio` to `1.30.0`
### Enhancements
* add the option to change the port of the markdown viewer to `8000`, with the default still being port `80`.
* add an option to use the content of the `DOCKER_HOST_IP` variable instead of the `PUBLIC_IP` variable for the web links to services.
* change `minio` image to the one from `bitnami`, which allows for creating buckets upon start of the service
* allow configuration of `spark.max.cores` and `spark.executor.memory` in Zeppelin
* allow configuration of `SPARK_MASTER_OPTS` and `SPARK_WORKER_OPTS`, `SPARK_WORKER_CORES`, `SPARK_WORKER_MEMORY` for Spark
* support for switching between Spark 2 and Spark 3 added
* change default of `KAFKA_delete_topic_enable` to `true`
* add `KAFKA_SCHEMA_REGISTRY_UI_use_public_ip` to change between public and docker host IP Address for Schema Registry UI
* make admin user and "normal" user configurable in Zeppelin
* configuration files for Zeppelin are no longer mapped from the `conf` folder into the container, it is now "prebuild" into the new zeppelin docker image.
* support for Spark 3.0 added
* add support for enabling Zeppelin cron scheduler on each notebook
### Bug fix
* fix bug with internal S3 (minIO) introduced in `1.9.0`
## What's new in 1.9.0
The Modern Data Platform version 1.9.0 contains the following new services and enhancements:
### New Services
* Redis Insight
* WebTTY
* Markdown Viewer (enabled by default, rendering documentation about the platform)
* NiFi Registry
### Version upgrades
* Change `Redis` to bitnami image
* Update `DataHub` to `0.6.1`
* Update `Portainer` to `2.0.0`
* Update `CAdvisor` to `v0.36.0`
* Update `Marquez` to `0.11.3` and Marquez UI to `0.7.0`
* Update `Apache NiFi` to `1.12.1`
* Update `StreamSets Data Collector` to `3.19.0`
* Update `ksqlDB` to `0.13.0`
* Update `Hue` to `4.8.0`
* Update `Amundsen-Frontend` to `3.0.0`
* Update `Amundsen-Metadata` to `3.0.0`
* Update `Amundsen-Search` to `2.4.1`
* Update `Presto` to `347-e`
* Update `Dremio` to `4.9`
* Update `MongoDB` to `4.4.2`
* Update `MongoDB` to `4.2.0`
* Update `InfluxDB 2.0` to `v2.0.2`
* Update `Druid` to `0.20.0`
* Update `Memcached` to `1.6.9`
* Update `Kudu` to `1.13`
* Update `Prometheus` to `v2.23.0` and `Prometheus-Pushgateway` to `v1.3.0`
* Update `Tile38` to `1.22.5`
* Update `Grafana` to `7.3.4`
* Update `Stardog` to `7.4.4-java11-preview` and `Stardog Studio` to `1.29.1`
* Update `Yugabyte` to `2.5.0.0-b2`
* Update `Axon` to `4.4.5`
* Update `Presto` to `346-e`
* Update `Dremio` to `11.0`
* Update `HiveMQ3` to `3.4.7` and `HiveMQ4` to `4.4.3`
* Update `Vault` to `1.6.0`
* Update `Airflow` to `1.10.13`
* Update `Atlas` to `2.1.0`
* Update `Ranger` to `2.1.0`
* Update `Mosquitto` to `2.0`
* Update `Streamsheets` to `2.1-milestone`
### Enhancements
* support Master/Slave Redis setup
* automatically set the name of the docker network to the value of the `platform-name` property from the `config.yml`
* Allow adding `ConfigProvider` classes to the `kafka-connect` service supporting the use of variables in connector configurations that are dynamically resolved when the connector is (re)started.
* Rendering markdown files with information on the generated platform
* Add configuration property to `ksqldb-server` to enable new suppress functionality and to use a query file
* support external `Kafka` cluster (was in preview in 1.8) and `S3` object storage with the new `external` section
* support setting access key and secret key to be used for `minio` in the `config.yml` using the same default values as before
* support volume mapping for data and logs folder of `nifi` service
### Breaking Changes
* Update docker-compose version to `3.5` (requiring Docker Engine version 17.12.0 and higher)
* Volume mapped `data` folder in Streamsets (`STREAMSETS_volume_map_data=true`) is now mapped to `container-volume/streamsets-1/data` and no longer to `container-volume/streamsets-1`
* No longer use the `KAFKA_bootstrap_servers` to configure external kafka, but `external['KAFKA_enable']` property in `config.yml`
### Bug Fixes
* Fix for the error when using the `STREAMSETS_volume_map_data` feature
## What's new in 1.8.0
The Modern Data Platform version 1.8.0 contains the following new services and enhancements:
### New Services
* Apicurio Registry
* Smashing Dashbaord
* Tipboard Dashboard
* Chartboard Dashboard
* Azkarra Streams
### Version upgrades
* update `DataHub` to `0.5.0-beta`
* update `StreamSheets` to `2.0-milestone`
* update `StreamSets` to `3.18.1`
* update `Confluent Platfrom` to `6.0.0`
* update `ksqlDB` to `0.12.0`
### Enhancements
* make Postgreqsql user, password and database configurable
* support configuration of `KAFKA_MQTTPROXY_topic_regex_list` on `KAFKA_MQTTPROXY`
* automatically create the `default-bucket` in Minio if `MINIO_ENABLE` is `true`
* support various additional Kafka broker properties such as `KAFKA_message_timestamp_type`, `KAFKA_replica_selector_class`, `KAFKA_min_insync_replicas`, `KAFKA_log_segement_bytes`, `KAFKA_log_retention_ms`, `KAFKA_log_retention_hours`, `KAFKA_log_retention_bytes`, `KAFKA_compression_type` and `KAFKA_confluent_log_placement_constraints`
* support Kafka Tiered Storage with `confluent.tier.xxxx` properties
* support `STREAMSETS_volume_map_security_policy` property in `streamsets` service
### Breaking Changes
* default user for the Postgresql service has been changed to `demo` and the database to `demodb`.
* change service name of `redis` to `redis-1`
* change property `RANGER_POSTGRESQL_volume_map_data ` to `RANGER_postgresql_volume_map_data` for the `RANGER` service
### Bug Fixes
* support for the `hive` option in SPARK has been fixed so that Spark can use the Hive Metastore instead of the default, built-in metastore
## What's new in 1.7.0
**Note:** you have to install the latest version of [`platys`](http://github/trivadispf/platys) (> 2.3.0) to use this new version of the platform stack.
The Modern Data Platform version 1.7.0 contains the following new services and enhancements:
### New Services
* Redash
* Memcached
* Stardog & Stardog Studio
### Enhancements / Changes
* Added JMX monitoring to ksqldb-server-X services
* Allow enabling basic authentication in Cluster Manager for Apache Kafka (CMAK) service
* refactored the platys properties (`platform-stack` and `platform-stack-version`) to match with [version 2.3.0](https://github.com/TrivadisPF/platys/blob/master/documentation/changes.md#whats-new-in-230) of `platys`.
## What's new in 1.6.0
The Modern Data Platform version 1.6.0 contains the following new services and enhancements:
### New Services
* Quix Database UI (Notebook-style)
* Penthao Webspoon
* Hawtio
* RabbitMQ
* Cloudbeaver
* Swagger Editor & Swagger UI
* Kafkacat
* StreamSheets
* Confluent Replicator
* Presto CLI
* Apache Ranger (preview)
### Enhancements / Changes
* Only display verbose output from docker-compose-templer generator if the `-v` flag is passed on the `platys` command line
* Upgrade `ksqlDB` default version to latest `0.9.0`
* Support automatic installation of Confluent Hub connectors into Kafka Connect upon startup
* Support for Presto Clusters together with single Presto instance
* Support for Prestosql and Prestodb open source Presto forks as well as new Ahana Prestodb subscription
## What's new in 1.5.2
1.5.2 is just a but fix release with no new services.
### Enhancements / Changes
* add possibility to specify a private maven repository for downloading maven packages in Spark, Livy and Zeppelin
* Allow to specify additional runtime environment properties in `spark-defaults.conf`
### Bug Fixes
* Fix generation of Burrow and Zookeeper Navigator service
* Fix the non-working link to Spark UI from the Spark Master UI
## What's new in 1.5.1
1.5.1 is just a but fix release with no new services.
### Bug Fixes
* Fix Hadoop service
## What's new in 1.5.0
The Modern Data Platform version 1.5.0 contains the following new services and enhancements:
### New Services
* Oracle XE (only through private docker image) added
* Oracle EE (only through private docker image) added
* Oracle REST Data Service (only through private docker image) added
* Hashicorp Vault added
* Yugabyte Database added
* Marquez added
* Apache Ranger added
### Enhancements / Changes
* change `drill`, `dremio` and `presto` to include the service instance number, i.e. `<service>-1` to prepare to support multiple instances
* support for changing the timezone globally for all docker images (`use_timezone`)
* new configuration setting (`private_docker_repository_name `) for changing the the private repository to use for private docker images
* fixed the JMX ports of the Kafka service
* support for additional Kafka properties added
## What's new in 1.4.0
The Modern Analytical Data Platform Stack version 1.4.0 contains the following new services and enhancements:
### New Services
* Kafka Topics UI added
* Apache Drill added
* DataHub added
* Apache Druid added (currently supports only single-server Sandbox)
* Apache Superset added
### Enhancements / Changes
* Elastisearch UIs (Kibana, DejaVu, Cerebro, ElasticHQ) are independent of Elasticsearch
## What's new in 1.3.0
The Modern Analytical Data Platform Stack version 1.3.0 contains the following new services and enhancements:
### New Services
* Apache Airflow
* Apache Sqoop (previously part of `hadoop-client` service)
* Code-Server (VS Code IDE in Browser)
### Enhancements / Changes
* Some first simple Tutorials added, showing how to use the services
* Hadoop images changed to the ones from Big Data Europe
* Service Kafka Manger is now CMAK (due to the name change at Yahoo GitHub)
* KafkaHQ has been renamed to AKHQ by the developer and we now use this image
## What's new in 1.2.0
The Modern Analytical Data Platform Stack version 1.2.0 contains the following new services and enhancements:
### New Services
* Confluent Enterprise as an Edition for Kafka
* Streamsets Data Collector Edge
* Streamsets Transformer
* Apache NiFi
* various Jupyter services
* Node RED
* Influx Data Tick Stack (influxdb, chronograf, kapacitor)
* Influx DB 2.0-alpha
### Enhancements / Changes
* refactor some ports back to original ports
* rename all properties from `XXXX_enabled` to `XXXX_enable`
* rename all properties from 'XXXX_yyyy_enabled` to 'XXXX_YYYY_enabled` to clearly distinguish between product/service and the properties
* Rename `connect-n` service to `kafka-connect-n` to be more clear
* Rename `broker-n` service to `kafka-n` to be more clear
* Upgrade to Confluent Platform 5.4.0
* Add [concept of edition](service-design) for Kafka and Jupyter services
<file_sep>Place event listener here ...<file_sep># Axon Server
Axon Server makes it significantly easier for the user to setup and maintain the environment. The Axon Server Standard edition is part of our Quick Start Package, Go to the Download section of our website to try it out for free. Axon Server Enterprise edition is our paid option for organizations ready to scale-up their projects offering more nodes and regions.
**[Website](https://axoniq.io/product-overview/axon-server)** | **[Documentation](https://docs.axoniq.io/reference-guide/axon-server/introduction)** | **[GitHub](https://github.com/AxonIQ/axon-server-se)**
## How to enable?
```
platys init --enable-services AXON
platys gen
```
## How to use it?
Navigate to <http://dataplatform:8024><file_sep># Apache StreamPipes
Apache StreamPipes - A self-service (Industrial) IoT toolbox to enable non-technical users to connect, analyze and explore IoT data streams.
**[Website](https://streampipes.apache.org/)** | **[Documentation](https://streampipes.apache.org/docs/docs/user-guide-introduction.html)** | **[GitHub](https://github.com/apache/incubator-streampipes)**
## How to enable?
```
platys init --enable-services STREAMPIPES
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28255><file_sep># RabbitMQ
With tens of thousands of users, RabbitMQ is one of the most popular open source message brokers.
**[Website](https://www.rabbitmq.com/)** | **[Documentation](https://www.rabbitmq.com/documentation.html)** | **[GitHub](https://github.com/rabbitmq/rabbitmq-server)**
## How to enable?
```
platys init --enable-services RABBITMQ
platys gen
```
## How to use it?
Navigate to <http://dataplatform:15672><file_sep># Kafka Lag Exporter
Monitor Kafka Consumer Group Latency with Kafka Lag Exporter.
**[Website](https://github.com/lightbend/kafka-lag-exporter)** | **[Documentation](https://github.com/lightbend/kafka-lag-exporter)** | **[GitHub](https://github.com/lightbend/kafka-lag-exporter)**
## How to enable?
```bash
platys init --enable-services KAFKA,KAFKA_LAG_EXPORTER
platys gen
```
<file_sep># phpLDAPadmin
Web-based LDAP browser to manage your LDAP server.
**[Website](https://phpldapadmin.sourceforge.net/wiki/index.php/Main_Page)** | **[Documentation](https://phpldapadmin.sourceforge.net/wiki/index.php/Main_Page)** | **[GitHub](https://github.com/leenooks/phpLDAPadmin)**
```bash
platys init --enable-services OPENLDAP, PHP_LDAP_ADMIN
platys gen
```
## How to use it?
Navigate to <https://dataplatform:28296>.
<file_sep># Kafka from Spring Boot using Cloud Stream with Avro & Schema Registry
In this workshop we will learn how to use the **Spring Cloud Stream** with Avro message serialization from within a Spring Boot application. We will implement both a consumer and a producer. We are using the same Avro schema and reuse the `meta` project from [Workshop 5a: Kafka from Spring Boot with Avro & Schema Registry](../05a-working-with-avro-and-springboot).
We will create two Spring Boot projects, one for the Producer and one for the Consumer, simulating two independent microservices interacting with eachother via events.
Before you can go further, make sure to create and build the [meta](https://github.com/gschmutz/kafka-workshop/tree/master/05a-working-with-avro-and-springboot#create-the-avro-metadata-project) project as demonstrated in [Workshop 5a: Kafka from Spring Boot with Avro & Schema Registry](../05a-working-with-avro-and-springboot).
## Create the Spring Boot Producer Project
First we create an test the Producer microservice using Spring Cloud Stream abstraction.
### Creating the Spring Boot Project
First, let’s navigate to [Spring Initializr](https://start.spring.io/) to generate our project. Our project will need the Spring Cloud Stream support.
Select Generate a **Maven Project** with **Java** and Spring Boot **2.6.5**. Enter `com.trivadis.kafkaws` for the **Group**, `spring-boot-cloud-stream-kafka-producer-avro` for the **Artifact** field and `Kafka Producer with Avro project for Spring Cloud Stream` for the **Description** field.
Click on **Add Dependencies** and search for the **Spring Cloud Stream** depencency.
Select the dependency and hit the **Enter** key. You should now see the dependency on the right side of the screen.
Click on **Generate Project** and unzip the ZIP file to a convenient location for development.
Once you have unzipped the project, you’ll have a very simple structure.
Import the project as a Maven Project into your favourite IDE for further development.
### Extend the Maven POM with some configurations
In oder to use the Avro serializer and the class generated above, we have to add the following dependencies to the `pom.xml`.
```xml
<dependencies>
...
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${confluent.version}</version> <exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-client</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>com.trivadis.kafkaws.meta</groupId>
<artifactId>meta</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
```
Add the version of the Confluent Platform to use as an additional property
```xml
<properties>
...
<confluent.version>7.0.0</confluent.version>
</properties>
```
We also have to specify the additional Maven repository
```xml
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
```
### Implement a Kafka Producer in Spring
Now create a simple Java class `KafkaEventProducer` within the `com.trivadis.kafkaws.springbootkafkaproducer ` package, which we will use to produce messages to Kafka.
```java
package com.trivadis.kafkaws.springcloudstreamkafkaproducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.stream.messaging.Processor;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Service;
@Service
public class KafkaEventProducer {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaEventProducer.class);
@Autowired
private Processor processor;
@Value("${topic.name}")
String kafkaTopic;
public void produce(Integer id, Long key, String value) {
long time = System.currentTimeMillis();
Message<String> message = MessageBuilder.withPayload(value)
.setHeader(KafkaHeaders.MESSAGE_KEY, key)
.build();
processor.output()
.send(message);
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) time=%d\n",key, value,elapsedTime);
}
}
```
We no longer use `String` as type for the value but the `Nofification` class, which has been generated based on the Avro schema above.
### Create the necessary Topics through code
Spring Kafka can automatically add topics to the broker, if they do not yet exists. By that you can replace the `kafka-topics` CLI commands seen so far to create the topics, if you like. This code is exactly the same as in workshop 4 with the non-avro version.
```java
package com.trivadis.kafkaws.springcloudstreamkafkaproduceravro;
import com.trivadis.kafkaws.avro.v1.Notification;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.stream.messaging.Processor;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Component;
@Component
public class KafkaEventProducer {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaEventProducer.class);
@Autowired
private Processor processor;
@Value("${topic.name}")
String kafkaTopic;
public void produce(Integer id, Long key, Notification notification) {
long time = System.currentTimeMillis();
Message<Notification> message = MessageBuilder.withPayload(notification)
.setHeader(KafkaHeaders.MESSAGE_KEY, key)
.build();
processor.output()
.send(message);
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) time=%d\n",key, notification,elapsedTime);
}
}
```
We again refer to properties, which will be defined later in the `application.yml` config file.
### Add Producer logic to the SpringCloudStreamKafkaProducerAvroApplication class
We change the generated Spring Boot application to be a console appliation by implementing the `CommandLineRunner` interface. The `run` method holds the same code as the `main()` method in [Workshop 4: Working with Kafka from Java](../04-producing-consuming-kafka-with-java). The `runProducer` method is also similar, we just use the `kafkaEventProducer` instance injected by Spring to produce the messages to Kafka.
```java
package com.trivadis.kafkaws.springcloudstreamkafkaproducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Processor;
import java.time.LocalDateTime;
@SpringBootApplication
@EnableBinding(Processor.class)
public class SpringCloudStreamKafkaProducerApplication implements CommandLineRunner {
private static Logger LOG = LoggerFactory.getLogger(SpringCloudStreamKafkaProducerApplication.class);
@Autowired
private KafkaEventProducer kafkaEventProducer;
public static void main(String[] args) {
SpringApplication.run(SpringCloudStreamKafkaProducerApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
LOG.info("EXECUTING : command line runner");
if (args.length == 0) {
runProducer(100, 10, 0);
} else {
runProducer(Integer.parseInt(args[0]), Integer.parseInt(args[1]), Long.parseLong(args[2]));
}
}
private void runProducer(int sendMessageCount, int waitMsInBetween, long id) throws Exception {
Long key = (id > 0) ? id : null;
for (int index = 0; index < sendMessageCount; index++) {
String value = "[" + id + "] Hello Kafka " + index + " => " + LocalDateTime.now();
kafkaEventProducer.produce(index, key, value);
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
```
The difference here to the non-avro version is, that we are using the builder of the generated `Nofification` class to create an instance of a notification, which we then pass as the value to the `produce()` method.
### Configure Kafka through application.yml configuration file
First let's rename the existing `application.properties` file to `application.yml` to use the `yml` format.
Add the following settings to configure the Kafka cluster and the name of the topic:
```yml
topic:
name: test-spring-cloud-stream-topic-avro
replication-factor: 3
partitions: 12
spring:
cloud:
stream:
kafka:
bindings:
output:
producer:
configuration:
value.serializer: io.confluent.kafka.serializers.KafkaAvroSerializer
schema.registry.url: http://${DATAPLATFORM_IP}:8081
bindings:
output:
destination: ${topic.name}
producer:
useNativeEncoding: true
kafka:
bootstrap-servers: ${DATAPLATFORM_IP}:9092
```
Here again we switch the value-serializer from `StringSerializer` to the `KafkaAvroSerializer` and add the property `schema.registry.url` to configure the location of the Confluent Schema Registry REST API.
For the IP address of the Kafka cluster we refer to an environment variable, which we have to declare before running the application.
```bash
export DATAPLATFORM_IP=nnn.nnn.nnn.nnn
```
### Build the application
First lets build the application:
```bash
mvn package -Dmaven.test.skip=true
```
### Use Console to test the application
In a terminal window start consuming from the output topic:
```bash
kafkacat -b $DATAPLATFORM_IP -t test-spring-avro-topic -s avro -r http://$DATAPLATFORM_IP:8081 -o end
```
### Run the application
Now let's run the application
```bash
mvn spring-boot:run
```
Make sure that you see the messages through the console consumer.
To run the producer with custom parameters (for example to specify the key to use), use the `-Dspring-boot.run.arguments`:
```bash
mvn spring-boot:run -Dspring-boot.run.arguments="100 10 10"
```
## Create the Spring Boot Consumer Project
Now let's create an test the Consumer microservice.
### Creating the Spring Boot Project
Use again the [Spring Initializr](https://start.spring.io/) to generate the project.
Select Generate a **Maven Project** with **Java** and Spring Boot **2.6.5**. Enter `com.trivadis.kafkaws` for the **Group**, `spring-boot-cloud-stream-kafka-consumer-avro` for the **Artifact** field and `Kafka Consumer with Avro project for Spring Cloud Stream` for the **Description** field.
Click on **Add Dependencies** and search for the **Cloud Stream** depencency.
Select the dependency and hit the **Enter** key. You should now see the dependency on the right side of the screen.
Click on **Generate Project** and unzip the ZIP file to a convenient location for development.
Once you have unzipped the project, you’ll have a very simple structure.
Import the project as a Maven Project into your favourite IDE for further development.
### Extend the Maven POM with some configurations
In oder to use the Avro deserializer and the Avro generated classes, we have to add the following dependencies to the `pom.xml`.
```xml
<dependencies>
...
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${confluent.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-client</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>com.trivadis.kafkaws.meta</groupId>
<artifactId>meta</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
```
Add the version of the Confluent Platform to use as an additional property
```xml
<properties>
...
<confluent.version>7.0.0</confluent.version>
</properties>
```
We also have to specify the additional Maven repository
```xml
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
```
### Implement a Kafka Consumer in Spring
Start by creating a simple Java class `KafkaEventConsumer` within the `com.trivadis.kafkaws.springbootkafkaconsumer` package, which we will use to consume messages from Kafka.
```java
package com.trivadis.kafkaws.springcloudstreamkafkaconsumeravro;
import com.trivadis.kafkaws.avro.v1.Notification;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Processor;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.stereotype.Component;
@Component
public class KafkaEventConsumer {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaEventConsumer.class);
@StreamListener(Processor.INPUT)
public void receive(Message<Notification> msg) {
Notification value = msg.getPayload();
Long key = (Long)msg.getHeaders().get(KafkaHeaders.RECEIVED_MESSAGE_KEY);
LOGGER.info("received key = '{}' with payload='{}'", key, value);
}
}
```
This class uses the `Component` annotation to have it registered as bean in the Spring context and the `KafkaListener` annotation to specify a listener method to be called for each record consumed from the Kafka input topic. The name of the topic is specified as a property to be read again from the `application.yml` configuration file.
In the code we only log the key and value received to the console. In real life, we would probably inject another bean into the `KafkaEventConsumer` to perform the message processing.
### Add @EnableBinding to Application class
Add the following annotation to the `SpringCloudStreamKafkaConsumerAvroApplication` class
```yml
@EnableBinding(Processor.class)
public class SpringCloudStreamKafkaConsumerAvroApplication {
...
```
### Configure Kafka through application.yml configuration file
First let's rename the existing `application.properties` file to `application.yml` to use the `yml` format.
Add the following settings to configure the Kafka cluster and the name of the two topics:
```yml
topic:
name: test-spring-cloud-stream-topic-avro
spring:
cloud:
stream:
kafka:
bindings:
input:
consumer:
configuration:
value.deserializer: io.confluent.kafka.serializers.KafkaAvroDeserializer
schema.registry.url: http://${DATAPLATFORM_IP}:8081
specific.avro.reader: true
bindings:
input:
destination: ${topic.name}
consumer:
useNativeEncoding: true
kafka:
bootstrap-servers:
- ${DATAPLATFORM_IP}:9092
- ${DATAPLATFORM_IP}:9093
```
For the IP address of the Kafka cluster we refer to an environment variable, which we have to declare before running the application.
```bash
export DATAPLATFORM_IP=nnn.nnn.nnn.nnn
```
### Build the application
First lets build the application:
```bash
mvn package -Dmaven.test.skip=true
```
### Run the application
Now let's run the application
```bash
mvn spring-boot:run
```
<file_sep># Stardog Studio
Dgraph is the simplest way to implement a GraphQL backend for your applications. Everything you need to build apps, unite your data, and scale your operations is included, out-of-the-box.
**[Website](https://www.stardog.com/studio/)** | **[Documentation](https://docs.stardog.com/archive/7.5.1/studio/)**
## How to enable?
```
platys init --enable-services STARDOG_STUDIO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28170><file_sep># Stream Analytcis with Java using Kafka Streams
Let's redo the simple message filtering process of the previous workshop, using Kafka Streams instead of KSQL.

## Create the project in Eclipse IDE
Start the Eclipse IDE if not yet done.
Create a new [Maven project](../99-misc/97-working-with-eclipse/README.md) and in the last step use `com.trivadis.kafkastreams` for the **Group Id** and `kafka-streams-truck` for the **Artifact Id**.
Navigate to the **pom.xml** and double-click on it. The POM Editor will be displayed.
You can either use the GUI to edit your pom.xml or click on the last tab **pom.xml** to switch to the "code view". Let's do that.
You will see the still rather empty definition.
```xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.trivadis.kafkastreams</groupId>
<artifactId>kafka-streams-truck</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
```
Let's add some initial dependencies for our project. We will add some more dependencies to the POM throughout this workshop.
Copy the following block right after the <version> tag, before the closing </project> tag.
```xml
<properties>
<confluent.version>5.3.0</confluent.version>
<kafka.version>2.3.0</kafka.version>
<avro.version>1.9.0</avro.version>
<docker.skip-build>false</docker.skip-build>
<docker.skip-test>false</docker.skip-test>
<java.version>1.8</java.version>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.source>1.8</maven.compiler.source>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.26</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-streams-avro-serde</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-client</artifactId>
<version>${confluent.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>${avro.version}</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.7</version>
</dependency>
</dependencies>
<build>
<extensions>
<extension>
<groupId>org.apache.maven.archetype</groupId>
<artifactId>archetype-packaging</artifactId>
<version>2.2</version>
</extension>
</extensions>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-archetype-plugin</artifactId>
<version>2.2</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.2.1</version>
<executions>
<execution>
<goals>
<goal>java</goal>
</goals>
</execution>
</executions>
<configuration>
<mainClass>KafkaStreamsExample</mainClass>
<arguments>
</arguments>
</configuration>
</plugin>
<plugin>
<artifactId>maven-archetype-plugin</artifactId>
<version>2.2</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
<!-- deactivate the shade plugin for the quickstart archetypes -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<executions>
<execution>
<phase />
</execution>
</executions>
</plugin>
<plugin>
<groupId>com.github.siom79.japicmp</groupId>
<artifactId>japicmp-maven-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
<!-- use alternative delimiter for filtering resources -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<useDefaultDelimiters>false</useDefaultDelimiters>
<delimiters>
<delimiter>@</delimiter>
</delimiters>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-gpg-plugin</artifactId>
<version>1.6</version>
<executions>
<execution>
<id>sign-artifacts</id>
<phase>verify</phase>
<goals>
<goal>sign</goal>
</goals>
<configuration>
<keyname>${gpg.keyname}</keyname>
<passphraseServerId>${gpg.keyname}</passphraseServerId>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</build>
```
In a terminal window, perform the following command to update the Eclipse IDE project settings.
```bash
mvn eclipse:eclipse
```
Refresh the project in Eclipse to re-read the project settings.
## Create log4j settings
Let's also create the necessary log4j configuration.
In the code we are using the [Log4J Logging Framework](https://logging.apache.org/log4j/2.x/), which we have to configure using a property file.
Create a new file `log4j.properties` in the folder **src/main/resources** and add the following configuration properties.
```bash
log4j.rootLogger=OFF, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%d] %p [%t] %m (%c)%n
# Enable for debugging if need be
#log4j.logger.org.apache.kafka.streams=DEBUG, stdout
#log4j.additivity.org.apache.kafka.streams=false
# Squelch expected error messages like:
# java.lang.IllegalStateException: This consumer has already been closed.
log4j.logger.org.apache.kafka.streams.processor.internals.StreamThread=INFO, stdout
log4j.additivity.org.apache.kafka.streams.processor.internals.StreamThread=false
# Enable for debugging if need be
#log4j.logger.io.confluent=DEBUG, stdout
#log4j.additivity.io.confluent=false
```
### Creating the necessary Kafka Topic
We will use the topic `dangerous_driving_kstreams` in the Kafka Streams code below. Due to the fact that `auto.topic.create.enable` is set to `false`, we have to manually create the topic.
Connect to the `broker-1` container
```bash
docker exec -ti broker-1 bash
```
and execute the necessary `kafka-topics` command.
```bash
kafka-topics --bootstrap-server kafka-1:19092,kafka-2:19093 --create --topic dangerous_driving_kstreams --partitions 8 --replication-factor 2
```
Cross check that the topic has been created.
```bash
kafka-topics --list --bootstrap-server kafka-1:19092,kafka-2:19093
```
This finishes the setup steps and our new project is ready to be used. Next we will start implementing the **Kafka Streams Topology**.
## Create a Kafka Streams Topology
First create a new Java Package `com.trivadis.kafkastreams` in the folder **src/main/java**.
Create a new Java Class `TruckPosition ` in the package `com.trivadis.kafkastreams ` just created.
```java
package com.trivadis.kafkastreams;
import org.apache.commons.lang3.StringUtils;
import org.apache.kafka.streams.KeyValue;
public class TruckPosition {
public Long timestamp;
public Integer truckId;
public Integer driverId;
public Integer routeId;
public String eventType;
public Double latitude;
public Double longitude;
public String correlationId;
public TruckPosition() {
}
public static TruckPosition create(String csvRecord) {
TruckPosition truckPosition = new TruckPosition();
String[] values = StringUtils.split(csvRecord, ',');
truckPosition.timestamp = new Long(values[0]);
truckPosition.truckId = new Integer(values[1]);
truckPosition.driverId = new Integer(values[2]);
truckPosition.routeId = new Integer(values[3]);
truckPosition.eventType = values[4];
truckPosition.latitude = new Double(values[5]);
truckPosition.longitude = new Double(values[6]);
truckPosition.correlationId = values[7];
return truckPosition;
}
public String toCSV() {
return timestamp + "," + truckId + "," + driverId + "," + routeId + "," + eventType + "," + latitude + "," + longitude + "," + correlationId;
}
public static boolean filterNonNORMAL(String key, TruckPosition value) {
boolean result = false;
result = !value.eventType.equals("Normal");
return result;
}
@Override
public String toString() {
return "TruckPosition [timestamp=" + timestamp + ", truckId=" + truckId + ", driverId=" + driverId + ", routeId=" + routeId
+ ", eventType=" + eventType + ", latitude=" + latitude + ", longitude="
+ longitude + ", correlationId=" + correlationId + "]";
}
}
```
Create a new Java Class `TruckFilterTopology` in the package `com.trivadis.kafkastreams ` just created.
Add the following code to the empty class to create a Kafka Producer.
```java
package com.trivadis.kafkastreams;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.Printed;
public class TruckFilterTopology {
public static void main(String[] args) {
// Serializers/deserializers (serde) for String and Long types
final Serde<String> stringSerde = Serdes.String();
final Serde<Long> longSerde = Serdes.Long();
final String bootstrapServers = args.length > 0 ? args[0] : "dataplatform:9092";
final Properties streamsConfiguration = new Properties();
// Give the Streams application a unique name. The name must be unique in the Kafka cluster
// against which the application is run.
streamsConfiguration.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-streams-truck-filter");
// Where to find Kafka broker(s).
streamsConfiguration.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
streamsConfiguration.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
// Specify default (de)serializers for record keys and for record values.
streamsConfiguration.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
streamsConfiguration.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// In the subsequent lines we define the processing topology of the Streams application.
// used to be KStreamBuilder ....
final StreamsBuilder builder = new StreamsBuilder();
/*
* Consume TruckPositions data from Kafka topic
*/
KStream<String, String> positions = builder.stream("truck_position", Consumed.with(stringSerde, stringSerde));
/*
* Create a Stream of TruckPosition's by parsing the CSV into TruckPosition instances
*/
KStream<String, TruckPosition> positionsTruck = positions.mapValues(value -> TruckPosition.create(value.substring(7, value.length())));
positionsTruck.peek((k, v) -> System.out.println (k + ":" +v));
/*
* Non stateful transformation => filter out normal behaviour
*/
KStream<String, TruckPosition> positionsTruckFiltered = positionsTruck.filter(TruckPosition::filterNonNORMAL);
/*
* Convert the Truck Position back into a CSV format and publish to the dangerous_driving_kstreams topic
*/
positionsTruckFiltered.mapValues(value -> value.toCSV()).to("dangerous_driving_kstreams");
// Create the topology
final KafkaStreams streams = new KafkaStreams(builder.build(), streamsConfiguration);
// clean up all local state by application-id
streams.cleanUp();
streams.setUncaughtExceptionHandler((Thread thread, Throwable throwable) -> {
System.out.println("Within UncaughtExceptionHandler =======>");
System.out.println(throwable);
// here you should examine the throwable/exception and perform an appropriate action!
});
// Start the topology
streams.start();
// Add shutdown hook to respond to SIGTERM and gracefully close Kafka Streams
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
}
```
With these 2 classes in place, we can run the TruckFilterTopology as an Application from within the IDE.
After some time you should start seeing the output of the `peek` operation on the `positionsTruck` stream.
Now let's see that we actually produce data on that new topic by running a `kafka-console-consumer` or alternatively a `kafkacat`.
```bash
docker exec -ti broker-1 bash
```
```bash
kafka-console-consumer --bootstrap-server broker-1:9092 --topic dangerous_driving_kstreams
```
You should only see events for abnormal driving behaviour.
<file_sep># Querybook
Querybook is a Big Data Querying UI, combining collocated table metadata and a simple notebook interface.
**[Website](https://www.querybook.org/)** | **[Documentation](https://www.querybook.org/docs/)** | **[GitHub](https://github.com/pinterest/querybook)**
## How to enable?
```
platys init --enable-services QUERYBOOK
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28301>. <file_sep># Dremio
Dremio's Data Lake Engine delivers lightning fast query speed and a self-service semantic layer operating directly against your data lake storage.
**[Website](https://www.dremio.com/)** | **[Documentation](https://docs.dremio.com/)** | **[GitHub](https://github.com/dremio/dremio-oss)**
## How to enable?
```
platys init --enable-services DREMIO
platys gen
```
## How to use it?
Navigate to <http://dataplatform:9047><file_sep># Kafkistry
Registry service for Apache Kafka which keeps track of topics, consumer-groups, acls, quotas and their configuration/state/metadata across multiple kafka-clusters.
It allows performing administrative operations such as inspecting/creating/deleting/re-configuring topics/consumer-groups.
It also provides various analytical tools such as: SQL querying metadata; viewing topic records; analyzing json record structures; re-balancing cluster tools; etc.
**[Website](https://github.com/infobip/kafkistry)** | **[Documentation](https://github.com/infobip/kafkistry/blob/master/DOCUMENTATION)** | **[GitHub](https://github.com/infobip/kafkistry/tree/master)**
## How to enable?
```
platys init --enable-services KAFKISTRY
platys gen
```
## How to use?
Navigate to <http://dataplatform:28303> to show the Kafkistry UI.
<file_sep>package com.trivadis.kafkaws.springbootkotlinkafkaproducer
import com.trivadis.kafkaws.avro.v1.Notification
import org.springframework.boot.CommandLineRunner
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
import org.springframework.context.annotation.Bean
import java.time.Instant
import java.time.LocalDateTime
@SpringBootApplication
class SpringBootKotlinKafkaProducerApplication{
@Bean
fun init(kafkaEventProducer: KafkaEventProducer) = CommandLineRunner { args ->
val sendMessageCount = if (args.size==0) 100 else args[0].toInt()
val waitMsInBetween = if (args.size==0) 10 else args[1].toLong()
val id = if (args.size==0) 0 else args[2].toLong()
for (index in 1 .. sendMessageCount) {
val value = Notification.newBuilder()
.setId(id)
.setMessage("[$id" + "] Hello Kafka " + index + " => " + LocalDateTime.now())
.setCreatedAt(Instant.now())
.build()
kafkaEventProducer.produce(id, value);
// Simulate slow processing
Thread.sleep(waitMsInBetween);
}
}
}
fun main(args: Array<String>) {
runApplication<SpringBootKotlinKafkaProducerApplication>(*args)
}
<file_sep># Zipkin Dependencies
Zipkin Dependencies collects spans from storage, analyzes links between services, and stores them for later presentation in the web UI.
**[Website](https://zipkin.io/)** | **[Documentation](https://zipkin.io/)** | **[GitHub](https://github.com/openzipkin/zipkin)**
## How to enable?
```
platys init --enable-services ZIPKIN
platys gen
```
## How to use it?
Navigate to <http://dataplatform:9411/dependency><file_sep>package com.trivadis.kafkastreams;
import org.apache.commons.lang3.StringUtils;
import org.apache.kafka.streams.KeyValue;
public class TruckPosition {
public Long timestamp;
public Integer truckId;
public Integer driverId;
public Integer routeId;
public String eventType;
public Double latitude;
public Double longitude;
public String correlationId;
public TruckPosition() {
}
public static TruckPosition create(String csvRecord) {
TruckPosition truckPosition = new TruckPosition();
String[] values = StringUtils.split(csvRecord, ',');
truckPosition.timestamp = new Long(values[0]);
truckPosition.truckId = new Integer(values[1]);
truckPosition.driverId = new Integer(values[2]);
truckPosition.routeId = new Integer(values[3]);
truckPosition.eventType = values[4];
truckPosition.latitude = new Double(values[5]);
truckPosition.longitude = new Double(values[6]);
truckPosition.correlationId = values[7];
return truckPosition;
}
public String toCSV() {
return timestamp + "," + truckId + "," + driverId + "," + routeId + "," + eventType + "," + latitude + "," + longitude + "," + correlationId;
}
public static boolean filterNonNORMAL(String key, TruckPosition value) {
boolean result = false;
result = !value.eventType.equals("Normal");
return result;
}
@Override
public String toString() {
return "TruckPosition [timestamp=" + timestamp + ", truckId=" + truckId + ", driverId=" + driverId + ", routeId=" + routeId
+ ", eventType=" + eventType + ", latitude=" + latitude + ", longitude="
+ longitude + ", correlationId=" + correlationId + "]";
}
}
<file_sep>package com.trivadis.kafkaws.springbootkafkaproducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.core.KafkaProducerException;
import org.springframework.kafka.core.KafkaSendCallback;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
@Component
public class KafkaEventProducerAsync {
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaEventProducerAsync.class);
@Autowired
private KafkaTemplate<Long, String> kafkaTemplate;
@Value("${topic.name}")
String kafkaTopic;
public void produce(Integer id, Long key, String value) {
long time = System.currentTimeMillis();
ListenableFuture<SendResult<Long, String>> future = kafkaTemplate.send(kafkaTopic, key, value);
future.addCallback(new KafkaSendCallback<Long, String>() {
@Override
public void onSuccess(SendResult<Long, String> result) {
long elapsedTime = System.currentTimeMillis() - time;
System.out.printf("[" + id + "] sent record(key=%s value=%s) "
+ "meta(partition=%d, offset=%d) time=%d\n",
key, value, result.getRecordMetadata().partition(),
result.getRecordMetadata().offset(), elapsedTime);
}
@Override
public void onFailure(KafkaProducerException ex) {
ProducerRecord<Long, String> failed = ex.getFailedProducerRecord();
}
} );
}
}<file_sep># Command Cheatsheet
## Start the platform stack
```
docker-compose up -d
```
## Stop and Remove the platform stack
```
docker-compose down
```
be careful, all the content in the running containers will be removed!
## Show all running containers
Show all running containers
```
docker-compose ps
```
## Attach to a running container
Show the log of all running containers
```
docker-compose logs -f
```
Only show the log of a few services (`kafka-connect-1` and `kafka-connect-2` in this example)
```
docker-compose logs -f kafka-connect-1 kafka-connect-2
```
## Attach to a running container
Run a `bash` shell by proding the container id or name (here `kafka-1`)
```
docker exec -ti kafka-1 bash
```<file_sep># Apicurio Registry
In the context of Apicurio, a registry is a runtime system (server) that stores a specific set of artifacts (files). At its core, a registry provides the ability to add, update, and remove the artifacts from the store, typically via a remote API of some kind (often a REST API).
**[Website](https://www.apicur.io/registry/)** | **[Documentation](https://www.apicur.io/registry/docs/apicurio-registry/2.0.1.Final/index.html)** | **[GitHub](https://github.com/Apicurio/apicurio-registry)**
## How to enable?
```
platys init --enable-services APICURIO_REGISTRY
platys gen
```
## How to use it?
You can use it as a Confluent-compliant registry by using the following Schema Registry URL
```
http://dataplatform:8081/apis/ccompat/v6
```
<file_sep># Apache Druid
Apache Druid is a real-time database to power modern analytics applications.
**[Website](https://druid.apache.org/)** | **[Documentation](https://druid.apache.org/community/)** | **[GitHub](https://github.com/apache/druid/)**
## How to enable?
```
platys init --enable-services DRUID
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28150><file_sep>Contains the data of Oracle XE service, if flag ORACLE_XE_volume_map_data is set to true.<file_sep># Setup Development Environment
This document describes how to finish setting up the development environment on a Oracle Linux environment.
Depending on your preference, either follow the **Java Environment** or **.NET Environment** section. But before that, let's configure the terminal.
## Configure the Terminal to run as login shell
Perform these steps:
1. Open a new terminal and in the menu select **Edit** | **Preferences**.
1. Navigate to the **Command** tab.
1. Select the option **Run command as a login shell** and click **Close**.

Now a new shell will be created when you open a new terminal.
## Java Environment
Java 8 and Maven (3.0.5) are already installed.
### Java 11 SDK
You can install a Java 11 by executing
```bash
sudo yum install java-11-openjdk
```
To switch to Java 11
```bash
sudo alternatives --config java_outer_classname
```
### Maven 3.6.3
You can install a Maven 3.6.3 by performing these steps
1. In a terminal, first uninstall the old version
```bash
sudo yum remove maven
```
1. In a terminal, download the archive
```bash
cd /home/oracle
wget https://www-eu.apache.org/dist/maven/maven-3/3.8.5/binaries/apache-maven-3.8.5-bin.tar.gz
```
1. Unpack the archive
```bash
tar -zxvf apache-maven-3.8.5-bin.tar.gz
```
1. add the following two entries to `/home/oracle/.bash_profile`
```bash
export MVN_HOME=$HOME/apache-maven-3.8.5
export PATH=$PATH:$MVN_HOME/bin
```
1. Source the .bash_profile to activate the environment variables
```bash
source .bash_profile
```
### IntelliJ IDEA
Install the IntelliJ Community Edition by navigating to <https://www.jetbrains.com/de-de/idea/download>.
1. Click on the **Linux** tab and download the **Community** edition by clicking on **Download**.
1. Select **Open with Archive Manager (default)** and click **OK**.
1. Extract the archive to `/home/oracle`.
1. In a terminal window enter `cd /home/oracle/idea-IC*` followed by `./bin/idea.sh`
1. Accept the **Jetbrains Community Edition Terms** by clicking on the check box and click **Continue**.
## .NET Environment
### .NET Core for Linux
Download the .NET Core 5.0 SDK by navigating to <https://dotnet.microsoft.com/en-us/download/dotnet/5.0>.
1. Select the Linux [X64](https://dotnet.microsoft.com/en-us/download/dotnet/thank-you/sdk-5.0.406-linux-x64-binaries) Binaries package
1. Select **Save File** and click **OK**.
1. Extract the archive to the end of `/home/oracle/dotnet-sdk-5.0`
```bash
mkdir -p $HOME/dotnet-sdk-5.0 && tar zxf $HOME/Downloads/dotnet-sdk-5.0.406-linux-x64.tar.gz -C $HOME/dotnet-sdk-5.0
```
1. add the following two entries to `/home/oracle/.bash_profile`
```bash
export DOTNET_ROOT=$HOME/dotnet-sdk-5.0
export PATH=$PATH:$HOME/dotnet-sdk-5.0
```
1. Source the .bash_profile to activate the environment variables
```bash
source .bash_profile
```
### Visual Code
To Install Visual Code IDE perform the following steps
1. Navigate to <https://code.visualstudio.com/sha/download?build=stable&os=linux-x64>.
1. Select **Open with Archive Manager (default)** and click **OK**.
1. Extract the archive to `/home/oracle`.
1. add the following two entries to the end of `/home/oracle/.bash_profile`
```bash
export PATH=$PATH:$HOME/VSCode-linux-x64/bin
```
1. Now you can start Visual Code by just entering `code` in the terminal
<file_sep># Kafka Connect UI
Web tool for Kafka Connect
**[Website](https://lenses.io/product/features/)** | **[Documentation](https://github.com/lensesio/kafka-connect-ui)** | **[GitHub](https://github.com/lensesio/kafka-connect-ui)**
## How to enable?
```
platys init --enable-services KAFKA,KAFKA_CONNECT,KAFKA_CONNECT_UI
platys gen
```
## How to use it?
Navigate to <http://dataplatform:28103>
<file_sep>Contains the data of Kong service, if flag KONGA_volume_map_data is set to true. | a4c16bc569dc6bb718e2fe9a9a6bd7cfdd029618 | [
"SQL",
"Markdown",
"TOML",
"Maven POM",
"INI",
"Java",
"C#",
"Text",
"Go Module",
"Go",
"Kotlin",
"Shell"
] | 464 | Markdown | gschmutz/kafka-workshop | d72435c084a98a98fa3e7f4a215ed82b06d60216 | fcc9fab3c56e7e5aa18f38ccf34501ff33fc6036 |
refs/heads/master | <file_sep>import React from 'react';
import TeamsCard from './card/TeamsCard';
import {TeamsSection, TitleHeading} from './teams-style'
// All Team Member Image Heare
import teamImg1 from '../image/image2.jpg';
import teamImg2 from '../image/image4.jpg';
import teamImg3 from '../image/image7.jpg';
import teamImg4 from '../image/image8.jpg';
import teamImg5 from '../image/image9.jpg';
import teamImg6 from '../image/image10.jpg';
// Image End
function Teams() {
return (
<TeamsSection className = "py-5">
<div className="container px-4">
<div className = "row mb-5">
<div className="col position-relative text-center">
<TitleHeading> My Teams </TitleHeading>
</div>
</div>
<div className = "row">
<div className="col-md-4 py-3">
<TeamsCard imgSrc = {teamImg1} teamMemberName = "<NAME>" memberWork = "I am a font end developer, with JavaScript and React.js" />
</div>
<div className="col-md-4 py-3">
<TeamsCard imgSrc = {teamImg2} teamMemberName = "<NAME>" memberWork = "I am a font end developer, with JavaScript and React.js" />
</div>
<div className="col-md-4 py-3">
<TeamsCard imgSrc = {teamImg3} teamMemberName = "<NAME>" memberWork = "I am a font end developer, with JavaScript and React.js" />
</div>
<div className="col-md-4 py-3">
<TeamsCard imgSrc = {teamImg4} teamMemberName = "<NAME>" memberWork = "I am a font end developer, with JavaScript and React.js" />
</div>
<div className="col-md-4 py-3">
<TeamsCard imgSrc = {teamImg5} teamMemberName = "<NAME>" memberWork = "I am a font end developer, with JavaScript and React.js" />
</div>
<div className="col-md-4 py-3">
<TeamsCard imgSrc = {teamImg6} teamMemberName = "<NAME>" memberWork = "I am a font end developer, with JavaScript and React.js" />
</div>
</div>
</div>
</TeamsSection>
)
}
export default Teams
<file_sep>import React from 'react'
import styled from 'styled-components';
import 'antd/dist/antd.css';
import { BackTop } from 'antd';
const FooterSection = styled.section`
text-align: center;
background-color: #000000;
padding: 15px 0;
`;
const Para = styled.p`
color: #ffffff;
margin: 0;
`;
const Span = styled.span`
color: crimson;
font-weight: 500;
&:hover {
text-decoration: underline;
cursor: pointer;
}
`;
const BackTopBtn = styled(BackTop)`
span{
background: crimson;
padding: 10px;
border-radius: 30%;
color: #ffffff;
text-align: center;
font-size: 1rem;
transition: all .3s ease;
&:hover {
border: 3px solid crimson;
color: crimson;
background-color: transparent;
}
}
`;
function Footer() {
return (
<FooterSection>
<div className="container px-4">
<Para>Design & Develop by <Span>Akhtaruzzaman</Span></Para>
<BackTopBtn>
<span><i className="fas fa-arrow-up"></i></span>
</BackTopBtn>
</div>
</FooterSection>
)
}
export default Footer
<file_sep>import React from 'react';
import styled from 'styled-components';
const TeamsSection = styled.section`
font-family: 'Poppins', sans-serif;
background-color: #000000;
`;
const TitleHeading = styled.h2`
font-size: 40px;
font-weight: 500;
color: #ffffff;
font-family: 'Ubuntu', sans-serif;
&::before {
content: "";
position: absolute;
bottom: -12px;
left: 50%;
width: 200px;
height: 3px;
background-color: #ffffff;
transform: translateX(-50%);
}
&::after {
content: "who with me";
position: absolute;
bottom: -25px;
left: 50%;
font-size: 20px;
color: crimson;
padding: 5px;
background-color: #000000;
transform: translateX(-50%);
}
`;
export {TeamsSection, TitleHeading}<file_sep>import React from 'react';
import { Link } from 'react-router-dom';
import styled from 'styled-components';
import { Progress } from 'reactstrap';
const SkillSection = styled.section`
font-family: 'Poppins', sans-serif;
`;
const TitleHeading = styled.h2`
font-size: 40px;
font-weight: 500;
font-family: 'Ubuntu', sans-serif;
&::before {
content: "";
position: absolute;
bottom: -15px;
left: 50%;
width: 180px;
height: 3px;
background-color: #111111;
transform: translateX(-50%);
}
&::after {
content: "what i know";
position: absolute;
bottom: -28px;
left: 50%;
font-size: 20px;
color: crimson;
padding: 5px;
background-color: #ffffff;
transform: translateX(-50%);
}
`;
const SkillHeading = styled.h6`
font-weight: bold;
font-size: 20px;
`;
const Para = styled.p`
text-align: justify;
`;
const SkillLink = styled(Link)`
display: inline-block;
background-color: crimson;
color: #ffffff;
font-weight: 500;
font-size: 15px;
padding: 10px 30px;
border-radius: 6px;
border: 2px solid crimson;
transition: all 0.3s ease;
&:hover {
color: crimson;
background: none;
text-decoration: none;
}
`;
const ProgressBar = styled(Progress)`
background-color: #b2bec3;
height: 10px;
font-size: 10px
`;
export {SkillSection, TitleHeading, SkillHeading, Para, SkillLink, ProgressBar}<file_sep>import React from 'react';
import styled from 'styled-components';
const CustomCard = styled.div`
// width: 300px;
// height: 220px;
background-color: #181a1b;
color: #ffffff;
padding: 10px 0;
text-align: center;
&:hover {
background-color: crimson;
color: #ffffff;
transition: all 0.3s ease;
img{
border: 5px solid #ffffff;
transition: all 0.3s ease;
}
}
`;
const Img = styled.img`
height: 120px;
width: 120px;
border-radius: 50%;
border: 5px solid crimson;
margin-bottom: 5px;
`;
const Para = styled.p`
margin: 0 5px;
`;
const TeamHeading = styled.h3`
margin-Bottom: 5px;
color: #ffffff;
`;
export {CustomCard, Img, Para, TeamHeading}<file_sep>import React from 'react'
import {BrowserRouter, Route, Switch} from 'react-router-dom'
import About from './about-section/About';
import './App.css';
import Contact from './contact/Contact';
import Home from './home-section/Home';
import PortfolioNavbar from './navbar/PortfolioNavbar';
import Services from './services-section/Services';
import Skills from './skills-section/Skills';
import Teams from './teams-section/Teams';
import Footer from './footer/Footer.jsx'
function App() {
return (
<div className="App">
<BrowserRouter>
<Switch exact >
<Route exact >
<PortfolioNavbar/>
<Home/>
<About/>
<Services/>
<Skills/>
<Teams/>
<Contact/>
<Footer/>
</Route>
</Switch>
</BrowserRouter>
</div>
);
}
export default App;
<file_sep>import styled from 'styled-components'
import {Navbar } from 'reactstrap'
const CustomNavbar = styled(Navbar)`
position: fixed;
width: 100%;
z-index: 999;
padding: ${props => props.scrolled ? '5px 0' : '20px 0'}; // when page scrolled, navbar padding on 15px
background-color: ${props => props.scrolled ? 'crimson' : 'none'}; // when page scrolled, navbar background-color is crimson
transition: all 0.3s ease;
font-family: 'Ubuntu', sans-serif;
`;
// Navbar brand design
const Logo = styled.span`
font-size: 35px;
font-weight: 600;
color: #ffffff;
cursor: pointer;
`;
const LogoSpan = styled.span`
color: ${props => props.scrolled ? '#ffffff' : 'crimson'}; // when page scrolled, navbar text-color is #ffffff
&:hover {color: ${props => props.scrolled ? '#81ecec' : '#ffffff'}}
`;
// Navbar Link Desingn
const NavMenu = styled.span`
color: #ffffff;
font-size: 16px;
font-weight: 500;
cursor: pointer;
transition: color 0.3s ease;
&:hover {color: ${props => props.scrolled ? 'aqua' : 'crimson'}}; // when page scrolled, navbar text-color is aqua
`;
export {CustomNavbar, Logo, LogoSpan, NavMenu}<file_sep>import { Link } from 'react-router-dom';
// import { CardText } from 'reactstrap';
import styled from 'styled-components';
import homeImg from '../image/image1.jpg'
const HomeSection = styled.section`
display: flex;
background: url(${homeImg}) no-repeat center;
height: 100vh;
background-size: cover;
background-attachment: fixed;
color: #ffffff;
font-family: 'Ubuntu', sans-serif;
`;
const MaxWidth = styled.div`
margin-top: 200px;
`;
const TextOne = styled.h2`
font-size: 27px;
font-weight: 400;
margin: 0;
`;
const TextTwo = styled.div`
font-size: 70px;
font-weight: 600;
margin: 0 2px;
`;
const TextThree = styled.div`
font-size: 40px;
// margin: 5px 0;
margin: 0;
`;
const HomeSpan = styled.span`
color: crimson;
font-weight: 500;
`;
const HomeLink = styled(Link) `
display: inline-block;
background-color: crimson;
color: #ffffff;
font-size: 20px;
padding: 10px 32px;
margin-top: 20px;
border-radius: 6px;
border: 2px solid crimson;
transition: all 0.3s ease;
&:hover { color: crimson; background: none; text-decoration: none; }
`;
export {HomeSection, MaxWidth, TextOne, TextTwo, TextThree, HomeSpan, HomeLink}<file_sep>import React from 'react'
import { Card, CardTitle, CardText, CardImg, CardImgOverlay } from 'reactstrap';
import {HomeSection, MaxWidth, TextOne, TextTwo, TextThree, HomeSpan, HomeLink} from './home-style'
// import homeImag from '../image/image1.jpg'
// import PortfolioNavbar from '../navbar/PortfolioNavbar';
function Home() {
return (
<HomeSection>
<div className="container px-4 ">
<MaxWidth>
<TextOne>Hello, My name is </TextOne>
<TextTwo>Zaman</TextTwo>
<TextThree>And I'am a <HomeSpan>Youtuber</HomeSpan> </TextThree>
<HomeLink to = "/">Hire me</HomeLink>
</MaxWidth>
</div>
{/* <MaxWidth className="container px-4">
<Card inverse style = {{backgroundColor: "transparent"}}>
<TextOne>Hello, My name is</TextOne>
<TextTwo tag = 'h1'> Akhtaruzzaman </TextTwo>
<TextThree>And I'am a <HomeSpan>Youtuber</HomeSpan></TextThree>
<HomeLink to = "/">Hire me</HomeLink>
</Card>
</MaxWidth> */}
</HomeSection>
// Card System try
// <div>
// <Card inverse>
// <CardImg width = "100%" src = {homeImag} alt = "Man"/>
// {/* <PortfolioNavbar/> */}
// <CardImgOverlay>
// <CardTitle tag = "h3">Card Title</CardTitle>
// <CardText>This is a wider card with supporting text below as a natural lead-in to additional content. This content is a little bit longer.</CardText>
// </CardImgOverlay>
// </Card>
// </div>
)
}
export default Home
<file_sep>import React from 'react';
import { Link } from 'react-router-dom';
import styled from 'styled-components'
const ContactSection = styled.section`
font-family: 'Poppins', sans-serif;
`;
const TitleHeading = styled.h2`
font-size: 40px;
font-weight: 500;
font-family: 'Ubuntu', sans-serif;
&::before {
content: "";
position: absolute;
bottom: -5px;
left: 50%;
width: 200px;
height: 3px;
background-color: #111111;
transform: translateX(-50%);
}
&::after {
content: "get in touch";
position: absolute;
bottom: -18px;
left: 50%;
font-size: 20px;
color: crimson;
padding: 5px;
background-color: #ffffff;
transform: translateX(-50%);
}
`;
const Para = styled.p`
text-align: justify;
`;
const Icon = styled.i`
margin: 10px 0;
font-size: 25px;
color: crimson;
`;
const InfoDiv = styled.div`
margin: 0 0 0 20px;
`;
const Head = styled.h6`
font-size: 15px;
font-weight: 500px;
margin-bottom: 5px;
`;
const SubTitle = styled.div`
color: #333333;
`;
const ContactLink = styled(Link)`
display: inline-block;
background-color: crimson;
color: #ffffff;
font-weight: 400;
font-size: 20px;
padding: 8px 16px;
border-radius: 6px;
border: 2px solid crimson;
transition: all 0.3s ease;
&:hover {
color: crimson;
background: none;
text-decoration: none;
}
`;
function Contact() {
return (
<ContactSection className = "py-5">
<div className="container px-4">
<div className = "row mb-5">
<div className="col position-relative text-center">
<TitleHeading>Contact me</TitleHeading>
</div>
</div>
<div className="row">
<div className="col-md-6">
<h5 className = "font-weight-bold">Get in Touch</h5>
<Para>Lorem ipsum dolor sit amet consectetur adipisicing elit. Sunt, labore minima! Excepturi aspernatur nisi mollitia odio quas error praesentium facilis, adipisci dolor, rerum aperiam a.</Para>
<div className = "row p-3">
<Icon className="fas fa-user"></Icon>
<InfoDiv>
<Head>Name</Head>
<SubTitle>Akhtaruzzaman</SubTitle>
</InfoDiv>
</div>
<div className = "row p-3">
<Icon className="fas fa-map-marker-alt"></Icon>
<InfoDiv>
<Head>Address</Head>
<SubTitle>Sylhet, Bangladesh</SubTitle>
</InfoDiv>
</div>
<div className = "row p-3">
<Icon className="fas fa-envelope"></Icon>
<InfoDiv>
<Head>Email</Head>
<SubTitle><EMAIL></SubTitle>
</InfoDiv>
</div>
</div>
<div className="col-md-6">
<h5 className="font-weight-bold">Message me</h5>
<form action="">
<div className="form-group d-flex">
<div className="col-md-6 pl-0">
<input type="text" className = "form-control" placeholder = "Name" />
</div>
<div className="col-md-6 pr-0">
<input type="email" className = "form-control" placeholder = "Email" />
</div>
</div>
<div className="form-group">
<div className="col-12 p-0">
<input type="text" className = "form-control" placeholder = "Subject"/>
</div>
<textarea className = "form-control mt-3" id="" cols="30" rows="5" name = "" placeholder = "Describe Project..."></textarea>
</div>
<ContactLink to = "/" className = "mb-4 mb-md-0"> Send message </ContactLink>
</form>
</div>
</div>
</div>
</ContactSection>
)
}
export default Contact
<file_sep>import React, {useState, useEffect} from 'react';
// ReactStrap desing Navbar
import {
Collapse,
NavbarToggler,
Nav,
NavItem,
NavbarBrand,
NavLink
} from 'reactstrap';
// Navbar Custom Style
import {CustomNavbar, Logo, LogoSpan, NavMenu} from './navbar-style'
function PortfolioNavbar (props){
// Toggle Function Here Start
const [click, setClick] = useState(false);
const toggle = () => setClick(!click);
const closeMenu = () => setClick(false)
// Toggle Function Here End
// sticky navbar Logic start
const [scrolled, setScrolled] = useState(false);
const handleScroll = () => {
const offset = window.scrollY;
if (offset > 75) {
setScrolled(true);
}
else {
setScrolled(false)
}
}
useEffect(() => {
window.addEventListener('scroll', handleScroll)
})
// navbar sticky logic end
return (
<>
<CustomNavbar expand="md" scrolled = {scrolled} >
<div className = "container px-4">
<NavbarBrand scrolled = {scrolled} to="/" className = "navbar-brand"><Logo>Portfo<LogoSpan scrolled = {scrolled}>lio.</LogoSpan></Logo></NavbarBrand>
<NavbarToggler onClick={toggle} style = {{fontSize: "1.8rem", color: "#ffffff"}}>
<i className = {click ? "fas fa-times" : "fas fa-bars"}/>
</NavbarToggler>
<Collapse isOpen={click} navbar >
<Nav className="ml-auto nav-menu text-capitalize" navbar>
<NavItem>
<NavLink to="/" onClick = {closeMenu}><NavMenu scrolled = {scrolled} >home</NavMenu></NavLink>
</NavItem>
<NavItem>
<NavLink to="/about" onClick = {closeMenu}><NavMenu scrolled = {scrolled} >about</NavMenu></NavLink>
</NavItem>
<NavItem>
<NavLink to="/services" onClick = {closeMenu}><NavMenu scrolled = {scrolled} >services</NavMenu></NavLink>
</NavItem>
<NavItem>
<NavLink to="/skills" onClick = {closeMenu}><NavMenu scrolled = {scrolled} >skills</NavMenu></NavLink>
</NavItem>
<NavItem>
<NavLink to="/teams" onClick = {closeMenu}><NavMenu scrolled = {scrolled} >teams</NavMenu></NavLink>
</NavItem>
<NavItem>
<NavLink to="/contact" onClick = {closeMenu}><NavMenu scrolled = {scrolled} >contact</NavMenu></NavLink>
</NavItem>
</Nav>
{/* <NavbarText className = 'ml-2'>Simple Text</NavbarText> */}
</Collapse>
</div>
</CustomNavbar>
</>
);
}
export default PortfolioNavbar
<file_sep>import React from 'react'
import styled from 'styled-components'
const Card = styled.div`
text-align: center;
background-color: #181a1b;
transition: all 0.3s ease;
color: white;
&:hover {
background-color: crimson;
transition: all 0.3s ease;
cursor: pointer;
transform: scale(1.05);
i{
color: #ffffff;
transition: all 0.3s ease;
}
}
`;
const ServiceIcon = styled.i`
margin-bottom: 12px;
color: crimson;
`;
const ServiceHeading = styled.h4`
font-weight: 500;
color: #ffffff;
`;
const ServicePara = styled.p`
font-size: 15px;
`;
function ServiceCards(props) {
return (
<Card className="card py-3">
{/* <i className= "fas fa-paint-brush fa-3x mb-4" style = {{color: "crimson"}}></i> */}
<ServiceIcon className= {`${props.iconName} fa-3x`}></ServiceIcon>
<ServiceHeading className = "mb-2"> {props.heading} </ServiceHeading>
<ServicePara className = "m-0 ">Lorem ipsum dolor sit amet, <br/> consectetur adipisicing elit. Nostrum similique iste nesciunt beatae sed voluptatum!</ServicePara>
</Card>
)
}
export default ServiceCards
<file_sep>import React from 'react'
import styled from 'styled-components';
import ServiceCards from './cards/ServiceCards';
const ServicesSection = styled.section`
font-family: 'Poppins', sans-serif;
background-color: #000000;
`;
const TitleHeading = styled.h2`
font-size: 40px;
font-weight: 500;
color: #ffffff;
font-family: 'Ubuntu', sans-serif;
&::before {
content: "";
position: absolute;
bottom: -12px;
left: 50%;
width: 220px;
height: 3px;
background-color: #ffffff;
transform: translateX(-50%);
}
&::after {
content: "what i provide";
position: absolute;
bottom: -25px;
left: 50%;
font-size: 20px;
color: crimson;
padding: 5px;
background-color: #000000;
transform: translateX(-50%);
}
`;
function Services() {
return (
<ServicesSection className = "py-5">
<div className="container px-4">
<div className = "row mb-5">
<div className="col position-relative text-center">
<TitleHeading> My Services </TitleHeading>
</div>
</div>
<div className="row">
<div className="col-md-4 py-3">
<ServiceCards iconName = "fas fa-paint-brush" heading = "Web Design"/>
</div>
<div className="col-md-4 py-3">
<ServiceCards iconName = "fas fa-chart-line" heading = "Advertising"/>
</div>
<div className="col-md-4 py-3">
<ServiceCards iconName = "fas fa-code" heading = "App Design"/>
</div>
</div>
</div>
</ServicesSection>
)
}
export default Services
<file_sep>import React from 'react'
import {CustomCard, Img, Para, TeamHeading} from './team-card-style'
function TeamsCard(props) {
return (
<CustomCard className="card text-center">
<div className="div">
<Img src={props.imgSrc} alt=""/>
</div>
<TeamHeading>{props.teamMemberName}</TeamHeading>
<Para>{props.memberWork}</Para>
</CustomCard>
)
}
export default TeamsCard
| f65b6ef11d6a8bccc3a927113de002d41c312b86 | [
"JavaScript"
] | 14 | JavaScript | Akhtaruzzamanan/personal-portfolio | caa7f076c628874dcc5b667179b87c4b394a95ee | 021d2d87c4f15b2ce9051d7c92b8b7dad97594b0 |
refs/heads/master | <repo_name>Funqy/ms-hack<file_sep>/ms-hack/MinesweeperMemory.cpp
#include "MinesweeperMemory.h"
MinesweeperMemory::MinesweeperMemory()
{
m_baseAddress = (BYTE*)0x1000000;
}
MinesweeperMemory::~MinesweeperMemory()
{
}
int MinesweeperMemory::Initialize()
{
HWND hWnd = FindWindow(NULL, "MineSweeper");
DWORD processID;
GetWindowThreadProcessId(hWnd, &processID);
m_hProc = OpenProcess(PROCESS_ALL_ACCESS, NULL, processID);
return (int)m_hProc;
}
void MinesweeperMemory::Update()
{
GetSizes();
GetField();
}
void MinesweeperMemory::Cheat()
{
SIZE_T bytesWritten;
int val = 0;
WriteProcessMemory(m_hProc, m_baseAddress + MMOVES_OFFSET, &val, 4, &bytesWritten);
}
void MinesweeperMemory::GetSizes()
{
SIZE_T bytesWritten;
ReadProcessMemory(m_hProc, m_baseAddress + MWIDTH_OFFSET, &m_fieldWidth, 4, &bytesWritten);
ReadProcessMemory(m_hProc, m_baseAddress + MHEIGHT_OFFSET, &m_fieldHeight, 4, &bytesWritten);
}
void MinesweeperMemory::GetField()
{
SIZE_T bytesWritten;
ReadProcessMemory(m_hProc, m_baseAddress + MFIELD_OFFSET, &m_field, 0x340, &bytesWritten);
}
int MinesweeperMemory::CheckPosition(int x, int y)
{
return (int)m_field[1 + x + 0x20 * y];
}
bool MinesweeperMemory::IsMine(int x, int y)
{
return m_field[1 + x + 0x20 * y] == 0x8F;
}
bool MinesweeperMemory::IsEmpty(int x, int y)
{
return m_field[1 + x + 0x20 * y] == 0x0F;
}
void MinesweeperMemory::SetFieldHeight(int height)
{
m_fieldHeight = height;
}
void MinesweeperMemory::SetFieldWidth(int width)
{
m_fieldWidth = width;
}
int MinesweeperMemory::GetFieldHeight()
{
return m_fieldHeight;
}
int MinesweeperMemory::GetFieldWidth()
{
return m_fieldWidth;
}
<file_sep>/ms-hack/MinesweeperMemory.h
#pragma once
#include <Windows.h>
#define MWIDTH_OFFSET 0x5334
#define MHEIGHT_OFFSET 0x5338
#define MFIELD_OFFSET 0x5360
#define MMOVES_OFFSET 0x57A4
class MinesweeperMemory
{
public:
MinesweeperMemory();
~MinesweeperMemory();
int Initialize();
void Update();
void Cheat();
void GetSizes();
void GetField();
int CheckPosition(int, int);
bool IsMine(int, int);
bool IsEmpty(int, int);
void SetFieldHeight(int);
void SetFieldWidth(int);
int GetFieldHeight();
int GetFieldWidth();
private:
HANDLE m_hProc;
BYTE* m_baseAddress;
int m_fieldWidth, m_fieldHeight;
BYTE m_field[0x340];
};
<file_sep>/ms-hack/Graphics.h
#pragma once
#include <dwrite.h>
#include <wchar.h>
#include <chrono>
#include <vector>
#include <d2d1.h>
#include <algorithm>
#include "MinesweeperMemory.h"
#pragma comment(lib, "d2d1.lib")
#pragma comment(lib, "dwrite.lib")
#define SQUARESIZE 0x10
class Graphics
{
public:
Graphics();
~Graphics();
bool Init();
void UpdatePosition();
void setHwnd(HWND);
void Paint();
HWND GetTargetHwnd();
D2D1_POINT_2U convertCoordinates(D2D1_POINT_2U,RECT);
D2D1_RECT_F convertRect(int, int, int, int, RECT wndRect);
int convertxInt(int, RECT);
int convertyInt(int, RECT);
private:
ID2D1Factory* pD2DFactory;
ID2D1HwndRenderTarget* pRT;
ID2D1DCRenderTarget* dcRT;
ID2D1SolidColorBrush* pBlackBrush;
ID2D1SolidColorBrush* pWhiteBrush;
ID2D1SolidColorBrush* pGreenBrush;
ID2D1SolidColorBrush* pRedBrush;
ID2D1SolidColorBrush* pGrayBrush;
IDWriteFactory* pDWriteFactory;
IDWriteTextFormat* pTextFormat;
MinesweeperMemory m_MsM;
HWND m_hWnd;
HWND m_hWndTarget;
RECT m_WindowRect;
D2D1_SIZE_U m_targetSize;
};
template <class T> void SafeRelease(T *ppT)
{
if (*ppT)
{
(*ppT)->Release();
*ppT = NULL;
}
}
<file_sep>/ms-hack/main.cpp
#include "MainWindow.h"
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow) {
MainWindow mWindow;
if (mWindow.Initialize()) {
mWindow.RunMessageLoop();
}
else {
MessageBox(NULL, "Window not created!", "ERROR", MB_OK);
}
}<file_sep>/ms-hack/MainWindow.h
#include <Windows.h>
#include "Graphics.h"
#include <iostream>
#include <Dwmapi.h>
#pragma comment(lib, "Dwmapi.lib")
#pragma once
class MainWindow
{
public:
MainWindow();
~MainWindow();
HRESULT Initialize();
void RunMessageLoop();
private:
static LRESULT CALLBACK WndProc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam);
Graphics GraphicInterface;
HWND m_hWnd;
HINSTANCE m_hInstance;
};
<file_sep>/ms-hack/Graphics.cpp
#include "Graphics.h"
Graphics::Graphics()
{
pD2DFactory = NULL;
pRT = NULL;
}
Graphics::~Graphics()
{
SafeRelease(&pD2DFactory);
SafeRelease(&pRT);
}
bool Graphics::Init()
{
HRESULT hr = D2D1CreateFactory(D2D1_FACTORY_TYPE_SINGLE_THREADED, &pD2DFactory);
if (hr != S_OK)
return false;
hr = pD2DFactory->CreateHwndRenderTarget(D2D1::RenderTargetProperties(D2D1_RENDER_TARGET_TYPE_DEFAULT, D2D1::PixelFormat(DXGI_FORMAT_UNKNOWN, D2D1_ALPHA_MODE_PREMULTIPLIED)), D2D1::HwndRenderTargetProperties(m_hWnd, D2D1::SizeU(GetSystemMetrics(SM_CXSCREEN), GetSystemMetrics(SM_CYSCREEN))), &pRT);
if (hr != S_OK)
return false;
hr = pRT->CreateSolidColorBrush(D2D1::ColorF(D2D1::ColorF::Black, 1.0f), &pBlackBrush);
if (hr != S_OK)
return false;
hr = pRT->CreateSolidColorBrush(D2D1::ColorF(D2D1::ColorF::Red, 0.3f), &pRedBrush);
if (hr != S_OK)
return false;
hr = pRT->CreateSolidColorBrush(D2D1::ColorF(D2D1::ColorF::White), &pWhiteBrush);
if (hr != S_OK)
return false;
hr = pRT->CreateSolidColorBrush(D2D1::ColorF(D2D1::ColorF::Green, 0.2f), &pGreenBrush);
if (hr != S_OK)
return false;
hr = pRT->CreateSolidColorBrush(D2D1::ColorF(D2D1::ColorF::Gray, 0.2f), &pGrayBrush);
if (hr != S_OK)
return false;
hr = DWriteCreateFactory(DWRITE_FACTORY_TYPE_SHARED, __uuidof(pDWriteFactory), reinterpret_cast<IUnknown **>(&pDWriteFactory));
if (hr != S_OK)
return false;
hr = pDWriteFactory->CreateTextFormat(L"Verdana", NULL, DWRITE_FONT_WEIGHT_NORMAL, DWRITE_FONT_STYLE_NORMAL, DWRITE_FONT_STRETCH_NORMAL, 14, L"", &pTextFormat);
if (hr != S_OK)
return false;
pTextFormat->SetTextAlignment(DWRITE_TEXT_ALIGNMENT_CENTER);
pTextFormat->SetParagraphAlignment(DWRITE_PARAGRAPH_ALIGNMENT_CENTER);
if (!m_MsM.Initialize())
return false;
HWND m_hWndTarget = FindWindow(NULL, "MineSweeper");
if (!m_hWndTarget) {
return false;
}
return true;
}
void Graphics::UpdatePosition()
{
HWND m_hWndTarget = FindWindow(NULL, "MineSweeper");
if (!m_hWndTarget) {
ExitProcess(0);
}
RECT wndRect;
GetWindowRect(m_hWndTarget, &wndRect);
m_WindowRect = { wndRect.left, wndRect.top, wndRect.right, wndRect.bottom };
SetWindowPos(m_hWnd, NULL, wndRect.left, wndRect.top, (wndRect.right - wndRect.left), (wndRect.bottom - wndRect.top), SWP_SHOWWINDOW);
}
void Graphics::setHwnd(HWND hWnd)
{
m_hWnd = hWnd;
}
void Graphics::Paint()
{
pRT->BeginDraw();
pRT->Clear();
UpdatePosition();
pRT->SetTransform(D2D1::Matrix3x2F::Identity());
D2D1_RECT_F drawRect = { m_WindowRect.left + 15 , m_WindowRect.top + 100, m_WindowRect.right -12 , m_WindowRect.bottom -12 };
m_MsM.Update();
//m_MsM.Cheat();
for (int i = 0; i < m_MsM.GetFieldWidth(); i++) {
for (int j = 0; j < m_MsM.GetFieldHeight(); j++) {
D2D1_RECT_F rect = convertRect(drawRect.left + SQUARESIZE * i, drawRect.top + j * SQUARESIZE, drawRect.left + (i + 1) * SQUARESIZE, drawRect.top + (j + 1) * SQUARESIZE, m_WindowRect);
if (m_MsM.IsMine(i, j)) {
pRT->FillRectangle(&rect, pRedBrush);
}
else if (m_MsM.IsEmpty(i,j)) {
pRT->FillRectangle(&rect, pGreenBrush);
}
else {
pRT->FillRectangle(&rect, pGrayBrush);
}
}
}
HRESULT hr = pRT->EndDraw();
}
HWND Graphics::GetTargetHwnd()
{
return m_hWndTarget;
}
D2D1_POINT_2U Graphics::convertCoordinates(D2D1_POINT_2U point, RECT wndRect)
{
D2D1_POINT_2U result;
result.x = static_cast<int>(((float)point.x - (float)wndRect.left) / ((float)wndRect.right - (float)wndRect.left)*GetSystemMetrics(SM_CXSCREEN));
result.y = static_cast<int>(((float)point.y - (float)wndRect.top) / ((float)wndRect.bottom - (float)wndRect.top)*GetSystemMetrics(SM_CYSCREEN));
return result;
}
D2D1_RECT_F Graphics::convertRect(int left, int top, int right, int bottom, RECT wndRect)
{
D2D1_RECT_F result;
result.left = (int)((float)left - (float)wndRect.left) / ((float)wndRect.right - (float)wndRect.left)*GetSystemMetrics(SM_CXSCREEN);
result.top = (int)((float)top - (float)wndRect.top) / ((float)wndRect.bottom - (float)wndRect.top)*GetSystemMetrics(SM_CYSCREEN);
result.right = (int)((float)right - (float)wndRect.left) / ((float)wndRect.right - (float)wndRect.left)*GetSystemMetrics(SM_CXSCREEN);
result.bottom = (int)((float)bottom - (float)wndRect.top) / ((float)wndRect.bottom - (float)wndRect.top)*GetSystemMetrics(SM_CYSCREEN);
return result;
}
int Graphics::convertxInt(int xval, RECT wndRect)
{
return static_cast<int>(((float)xval - (float)wndRect.left) / ((float)wndRect.right - (float)wndRect.left)*GetSystemMetrics(SM_CXSCREEN));
}
int Graphics::convertyInt(int yval, RECT wndRect)
{
return static_cast<int>(((float)yval - (float)wndRect.top) / ((float)wndRect.bottom - (float)wndRect.top)*GetSystemMetrics(SM_CYSCREEN));
}<file_sep>/ms-hack/MainWindow.cpp
#include "MainWindow.h"
MainWindow::MainWindow()
{
}
MainWindow::~MainWindow()
{
}
HRESULT MainWindow::Initialize()
{
WNDCLASSEX wndClass;
m_hInstance = GetModuleHandle(NULL);
wndClass.cbSize = sizeof(WNDCLASSEX);
wndClass.style = CS_HREDRAW | CS_VREDRAW;
wndClass.lpfnWndProc = WndProc;
wndClass.cbClsExtra = 0;
wndClass.cbWndExtra = 0;
wndClass.hInstance = m_hInstance;
wndClass.hIcon = LoadIcon(NULL, IDI_APPLICATION);
wndClass.hCursor = LoadCursor(NULL, IDC_ARROW);
wndClass.hbrBackground = (HBRUSH)GetStockObject(WHITE_BRUSH);
wndClass.lpszMenuName = "MainMenu";
wndClass.lpszClassName = "SnekClass";
wndClass.hIconSm = (HICON)LoadImage(m_hInstance, MAKEINTRESOURCE(5), IMAGE_ICON, GetSystemMetrics(SM_CXSMICON), GetSystemMetrics(SM_CYSMICON), LR_DEFAULTCOLOR);
if (!RegisterClassEx(&wndClass)) {
LPTSTR buffer = new TCHAR[256];
wsprintf(buffer, "RegisterClassEx failed!\n\nError Code:\t%d", GetLastError());
MessageBox(NULL, buffer, "Error", MB_ICONEXCLAMATION);
delete buffer;
return false;
}
HWND hWnd = FindWindow(NULL, "MineSweeper");
if (!hWnd) {
LPTSTR buffer = new TCHAR[256];
wsprintf(buffer, "FindWindow failed!\n\nError Code:\t%d", GetLastError());
MessageBox(NULL, buffer, "Error", MB_ICONEXCLAMATION);
delete buffer;
return false;
}
RECT wndRect;
GetWindowRect(hWnd, &wndRect);
m_hWnd = CreateWindowEx(WS_EX_LAYERED | WS_EX_TRANSPARENT | WS_EX_TOPMOST, "SnekClass", "Overlay", WS_POPUP, wndRect.left, wndRect.top, wndRect.right, wndRect.bottom, NULL, NULL, m_hInstance, this);
if (!m_hWnd) {
LPTSTR buffer = new TCHAR[256];
wsprintf(buffer, "CreateWindowEx failed!\n\nError Code:\t%d", GetLastError());
MessageBox(NULL, buffer, "Error", MB_ICONEXCLAMATION);
delete buffer;
return false;
}
ShowWindow(m_hWnd, SW_SHOW);
UpdateWindow(m_hWnd);
const MARGINS margin = { -1 };
DwmExtendFrameIntoClientArea(m_hWnd, &margin); //Perhaps with DC Rendertarget not necessary
GraphicInterface.setHwnd(m_hWnd);
if (!GraphicInterface.Init())
return false;
return true;
}
void MainWindow::RunMessageLoop()
{
MSG msg;
while (1) {
if (PeekMessage(&msg, NULL, 0, 0, PM_REMOVE))
{
TranslateMessage(&msg);
DispatchMessage(&msg);
}
else {
GraphicInterface.Paint();
}
}
}
LRESULT MainWindow::WndProc(HWND hWnd, UINT uMsg, WPARAM wParam, LPARAM lParam)
{
bool wasHandled = false;
LRESULT result = 0;
if (uMsg == WM_CREATE) {
LPCREATESTRUCT pcs = (LPCREATESTRUCT)lParam;
::SetWindowLongPtrA(hWnd, GWLP_USERDATA, (ULONG)pcs->lpCreateParams);
::SetLayeredWindowAttributes(hWnd, RGB(255, 255, 255), 0, LWA_COLORKEY);
result = 1;
wasHandled = true;
}
else {
MainWindow* mWindow = reinterpret_cast<MainWindow*>(GetWindowLongPtr(hWnd, GWLP_USERDATA));
if (uMsg == WM_DESTROY) {
PostQuitMessage(0);
wasHandled = true;
}
}
if (!wasHandled) {
result = DefWindowProc(hWnd, uMsg, wParam, lParam);
}
return result;
}
| 2d96676127c38e2c895b4dbf476e88de6b2451a4 | [
"C++"
] | 7 | C++ | Funqy/ms-hack | 322db675590c370c0ee99aa0f1ff93a0885e7a0e | 4895305e56af8a536798358bed2338dc1b03d9ae |
refs/heads/main | <repo_name>Rawattt/Nutrify<file_sep>/utils/errorHandler.js
const errorHandler = (res, error) => {
console.log(error);
if (!error.status_code) {
return res.render('home', {
message: 'Something went wrong. Please reload or try again later'
});
}
switch (error.code) {
case 401:
return res.json({
error: true,
message: error.message
});
case 400:
return res.json({
error: true,
message: error.message
});
default:
return res.json({
error: true,
message: 'Something went wrong'
});
}
};
module.exports = errorHandler;
<file_sep>/controller/meal.js
const mongoose = require('mongoose');
const User = require('../models/user');
const HttpError = require('../utils/error');
const errorHandler = require('../utils/errorHandler');
// @desc Create a meal
// @route POST /meal/add
// @access Private
exports.createMeal = async (req, res) => {
try {
const user = await User.findById(req.session.user_id);
// Check if calories is 0 or less
if (req.body.calories <= 0)
throw new HttpError('Please make calories more than 0');
const datetime = new Date().getTime();
const _id = `${user._id.toString()}${datetime}`;
const { food_name, description, calories } = req.body;
// Add meal to the user data
user.meal.push({ _id, food_name, description, calories, datetime });
await user.save();
res.redirect('/user/dashboard');
} catch (error) {
errorHandler(res, error);
}
};
// @desc Get all the meals
// @route GET /meal/:date?query
// @access Private
exports.getMeals = async (req, res) => {
try {
const { sortBy, order } = req.query;
let sort_value,
sort_order = 1;
if (sortBy === 'date') {
sort_value = 'datetime';
} else if (sortBy === 'calories') {
sort_value = 'calories';
}
if (order === 'desc') {
sort_order = -1;
}
let dates = getDates(req.params.date);
let meal = [...req.user.meal];
// Filter the meals by date
meal = meal.filter(
(food) => food.datetime >= dates[0] && food.datetime < dates[1]
);
// Sort the meals
if (sortBy) {
meal = meal.sort(
(a, b) => sort_order * a[sort_value] - sort_order * b[sort_value]
);
}
res.status(200).json({ success: true, data: { ...req.user, meal } });
} catch (error) {
errorHandler(res, error);
}
};
// @desc Edit a meal of the logged in user
// @route POST /meal/edit/:meal_id
// @access private
exports.editMeal = async (req, res) => {
try {
let { food_name, description, calories } = req.body;
// Check if any field is empty
if (!food_name || !description || !calories)
throw new HttpError('Please fill all the fields', 400);
calories = parseInt(calories);
// Update the meal
await User.updateOne(
{
_id: new mongoose.Types.ObjectId(req.session.user_id),
'meal._id': req.params.id
},
{
$set: {
'meal.$.food_name': food_name,
'meal.$.description': description,
'meal.$.calories': calories
}
}
);
res.json({ success: true });
// res.redirect('/user/dashboard');
// const user = await User.findById(req.user._id);
// user_data = await user.toJSON();
// res.status(200).json({ success: true, data: user_data });
} catch (error) {
errorHandler(res, error);
}
};
// @desc deletes a meal of the logged in user
// @route POST /meal/delete/:meal_id
// @access private
exports.deleteMeal = async (req, res) => {
try {
const meal_id = req.params.id;
const user = await User.findByIdAndUpdate(
req.session.user_id,
{
$pull: {
meal: { _id: meal_id }
}
},
{ new: true }
);
res.status(200).json({ success: true, data: user });
} catch (error) {
errorHandler(res, error);
}
};
// @desc Return start and end date in format of YYYY-MM-DD
// @parameter start: string
const getDates = (start) => {
if (!start) {
start_date = new Date().setHours(0, 0, 0, 0);
} else {
if (start.length != 10) throw new HttpError('Invalid date', 400);
start_date = new Date(start).setHours(0, 0, 0, 0);
}
let end_date = new Date(start_date + 1000 * 60 * 60 * 24);
// Convert date in format in YYYY-MM-DD
return [start_date, end_date.getTime()];
};
<file_sep>/views/js/mealHandler.js
async function edit(id) {
await fetch(`/meal/edit/${id}`, {});
}
async function edit(id) {}
<file_sep>/routes/auth.js
const express = require('express');
const router = new express.Router();
const { userSignup, userSignin, userSignout } = require('../controller/auth');
const { verifyUser } = require('../middleware/auth');
router.post('/signup', userSignup);
router.post('/signin', userSignin);
router.get('/signout', verifyUser, userSignout);
module.exports = router;
<file_sep>/controller/basic.js
const errorHandler = require('../utils/errorHandler');
// @desc Render landing page
// @route /
exports.home = async (req, res) => {
try {
// await isAuthenticated(req, res);
res.render('home');
} catch (error) {
errorHandler(error);
}
};
// @desc Render signup page
// @route /signup
exports.signup = async (req, res) => {
try {
// await isAuthenticated(req, res);
res.render('signup');
} catch (error) {
errorHandler(error);
}
};
// @desc Render signin page
// @route /signin
exports.signin = async (req, res) => {
try {
// await isAuthenticated(req, res);
res.render('signin');
} catch (error) {
errorHandler(error);
}
};
// @desc Check if the user is already logged in
const isAuthenticated = async (req, res) => {
try {
// Extract token from request header
const token = req.header('Authorization').replace('Bearer ', '');
const decoded = jwt.verify(token, process.env.JWT_SECRET);
const user = await User.findOne({ _id: decoded._id, token });
// Check if token is valid
if (!user) return;
// Check if token has expired
if (user.expiresIn < Date.now()) {
await user.removeToken();
return;
}
req.user = user.toJSON();
res.render('dashboard', { success: true, data: req.user });
} catch (error) {
return;
}
};
<file_sep>/views/js/signin.js
// if (message) {
// error = JSON.stringify({ message });
// if (error && error.message) alert(error.message);
// }
if (messages && messages.message) alert(messages.message);
<file_sep>/middleware/auth.js
const User = require('../models/user');
const errorHandler = require('../utils/errorHandler');
// @desc Redirect to the dashboard if user is already logged in
// @redirect User dashboard
exports.isLoggedIn = async (req, res, next) => {
try {
if (req.session.user_id) return res.redirect('/user/dashboard');
next();
} catch (error) {
errorHandler(res, error);
}
};
// @desc Protection for the private route of normal user
// @redidrect Home page
exports.verifyUser = async (req, res, next) => {
try {
if (!req.session.user_id) return res.redirect('/');
next();
} catch (error) {
errorHandler(res, error);
}
};
// @desc Protection for the admin routes
// @redirect Normal Signin page
exports.isAdmin = async (req, res, next) => {
if (req.session.user_id && !req.session.isAdmin)
return res.redirect('/user/dashboard');
if (!req.session.user_id || !req.session.isAdmin)
return res.redirect('/signin');
next();
};
<file_sep>/controller/admin.js
const User = require('../models/user');
const HttpError = require('../utils/error');
const errorHandler = require('../utils/errorHandler');
// @desc Sign in admin
// @route Get /admin/signin
// @access Public
exports.adminSigninGet = async (req, res) => {
try {
res.render('adminSignin');
} catch (error) {
errorHandler(error);
}
};
// @desc Sign in admin
// @route POST /admin/signin
// @access Private
exports.adminSignin = async (req, res) => {
try {
const { email, password } = req.body;
if (!email || !password)
throw new HttpError('Please fill all fields', 400);
const user = await User.verifyCredentials(email, password);
if (!user.isAdmin)
throw new HttpError('You do not have permission', 400);
const user_data = user.toJSON();
res.session.user_id = user_data._id;
res.session.isAdmin = true;
res.status(200).render('adminDashboard', user_data);
} catch (error) {
errorHandler(error);
}
};
// @desc Sign out admin
// @route POST /admin/signout
// @access Private
exports.adminSignout = async (req, res) => {
try {
req.session.destroy((err) => {
res.clearCookie(process.env.NAME);
res.redirect('/admin/signin');
});
} catch (error) {
errorHandler(error);
}
};
// @desc Get user
// @route GET /admin/user/:username
// @access Private
exports.adminDeleteUser = async (req, res) => {
try {
if (!req.params.username)
throw new HttpError('Please provide username', 401);
const { username } = req.params;
const user = await User.findOne({ username });
if (!user) return res.render('notFound');
const user_data = user.toJSON();
res.render('adminUser', { data: user_data });
} catch (error) {
errorHandler(error);
}
};
// @desc delete user
// @route DELETE /admin/user/:id
// @access Private
exports.adminDeleteUser = async (req, res) => {
try {
if (!req.params.id)
throw new HttpError('Please provide user id', 401);
await User.findByIdAndDelete(req.params.id);
res.status(200).json({ success: true, message: 'User deleted' });
} catch (error) {
errorHandler(error);
}
};
// @desc edit user
// @route POST /admin/user/edit/:username
// @access Private
exports.adminEditUser = async (req, res) => {
try {
if (!req.params.username)
throw new HttpError('Please provide a username', 401);
const {
name,
username,
email,
password,
calories_per_day
} = req.body;
const user = await User.findOneAndUpdate(
{ username },
{
name,
username,
email,
password,
calories_per_day
}
);
res.status(200).json({ success: true, data: user });
} catch (error) {
errorHandler(error);
}
};
// @desc delete meal
// @route DELETE /admin/meal/delete/:username/:meal_id
// @access Private
exports.adminDeleteMeal = async (req, res) => {
try {
let { username, meal_id } = req.params;
if (!username || !meal_id)
throw new HttpError('Invalid request', 401);
const data = await User.findOneAndUpdate(username, {
$pull: {
meal: { _id: new mongoose.Types.ObjectId(meal_id) }
}
});
res.status(200).json({
success: true,
message: 'Meal deleted',
data
});
} catch (error) {
errorHandler(error);
}
};
// @desc Edit a meal of a user
// @route POST /admin/meal/edit/:username/:meal_id
// @access private
exports.adminEditMeal = async (req, res) => {
try {
const { username, meal_id } = req.params;
const { food_name, description, calories } = req.body;
// Check if any field is empty
if (!food_name || !description || !calories)
throw new HttpError('Please fill all the fields', 400);
// Update the meal
await User.updateOne(
{
username,
'meal._id': meal_id
},
{
$set: {
'meal.$.food_name': food_name,
'meal.$.description': description,
'meal.$.calories': calories
}
}
);
res.status(200).json({ success: true });
} catch (error) {
errorHandler(res, error);
}
};
<file_sep>/views/js/checkAuth.js
const isAuthenticated = async () => {
if (!localStorage.getItem('token')) {
const token = localStorage.getItem('token');
let option = {
method: 'GET',
headers: {
Authorization: `Bearer ${token}`
}
};
await fetch('user/dashboard', option);
}
};
document.addEventListener('DOMContentLoaded', isAuthenticated);
<file_sep>/README.md
# Nutrify
Web application for your daily calories tracking.
Link: https://nutrify-web-app.herokuapp.com/
## Technologies used
It is built using nodejs, expressjs, mongodb, pugjs.
## Install server dependencies
```
npm install
```
## Configure environment variables
Create a config.env folder in root and and create necessary data
## Run server
```
npm run dev
```
<file_sep>/app.js
const createError = require('http-errors');
const express = require('express');
const path = require('path');
const cookieParser = require('cookie-parser');
const logger = require('morgan');
const dotenv = require('dotenv');
const session = require('express-session');
const MongoStore = require('connect-mongo')(session);
const sanitize = require('express-mongo-sanitize');
const helmet = require('helmet');
const xss = require('xss-clean');
const rateLimit = require('express-rate-limit');
const hpp = require('hpp');
const cors = require('cors');
const config_path = path.resolve(__dirname, 'config.env');
dotenv.config({ path: config_path });
const authRouter = require('./routes/auth');
const userRouter = require('./routes/user');
const mealRouter = require('./routes/meal');
const basicRouter = require('./routes/basic');
const adminRouter = require('./routes/admin');
const app = express();
const { EXPIRES_TIME, NAME, SECRET, DEV } = process.env;
const max_age = EXPIRES_TIME * 60 * 60 * 24 * 1000;
app.use(
session({
name: NAME,
secret: SECRET,
saveUninitialized: true,
resave: true,
store: new MongoStore({
url: `mongodb+srv://${process.env.MONGO_USERNAME}:${process.env.MONGO_PASSWORD}@cluster.glwj2.mongodb.net/nutrify?retryWrites=true&w=majority`
}),
cookie: {
maxAge: max_age,
sameSite: true,
secure: !DEV
}
})
);
const db = require('./db/db');
db();
// Body Parser
app.use(express.json());
// Cookie Parser
app.use(cookieParser());
// Sanitize data
app.use(sanitize());
// //Set security headers
// app.use(helmet());
// Prevent XSS attacks
app.use(xss());
// Rate limiting
const limiter = rateLimit({
windowMs: 10 * 60 * 1000,
max: 100
});
app.use(limiter);
// Prevent http params pollution
app.use(hpp());
// // Enable CORS
// app.use(cors());
app.use(express.urlencoded({ extended: false }));
app.use(logger('dev'));
app.use(express.static(path.join(__dirname, 'views')));
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'pug');
app.use('/', basicRouter);
app.use('/api/v1/auth', authRouter);
app.use('/user', userRouter);
app.use('/meal', mealRouter);
app.use('/admin', adminRouter);
// Undefined urls
app.get('/not-found', (req, res) => res.render('error'));
app.get('/*', (req, res) => res.redirect('/not-found'));
app.listen(process.env.PORT, (err) => {
if (err) {
console.log(`ERROR: ${err}`);
process.exit();
}
console.log(`Server is running on port ${process.env.PORT}`);
});
<file_sep>/utils/successHandler.js
const successHandler = (res, status, data) =>
res.status(status).json({
user_id: data._id,
name: data.name,
email: data.email,
username: data.username,
meal: data.meal
});
module.exports = successHandler;
<file_sep>/views/js/signup.js
if (messages && messages.message) alert(messages.message);
<file_sep>/models/user.js
const mongoose = require('mongoose');
const bcrypt = require('bcrypt');
// User schema
const userSchema = mongoose.Schema({
name: {
type: String,
required: [true, 'Name cannot be empty'],
maxlength: [40, 'Name cannot be more than 40 characters']
},
username: {
type: String,
required: [true, 'Username cannot be empty'],
unique: [true, 'Username already exists'],
maxlength: [30, 'Username cannot be more than 30 characters']
},
email: {
type: String,
required: [true, 'Email cannot be empty'],
unique: [true, 'Email already exists']
},
password: {
type: String,
minlength: [4, 'Password cannot be less than 4 characters'],
required: [true, 'Password cannot be empty']
},
idAdmin: {
type: Boolean,
default: false
},
calories_per_day: {
type: Number,
required: [true, 'Calories is required']
},
meal: {
type: Array,
default: []
}
});
// @desc Encrypt password before saving the user in the database
// @return Null
userSchema.pre('save', async function (next) {
const user = this;
if (!user.isModified('password')) next();
const salt = await bcrypt.genSalt(10);
this.password = await bcrypt.hash(this.password, salt);
});
// @desc Remove unecessary information
// @return User object
userSchema.methods.toJSON = function () {
const user = this;
const userObj = user.toObject();
userObj._id = userObj._id.toString();
delete userObj.password;
return userObj;
};
// @desc Compare password
// @return User object
userSchema.statics.verifyCredentials = async function (email, password) {
const user = await User.findOne({ email });
if (!user) throw new HttpError('Invalid email or password', 400);
const isMatch = await bcrypt.compare(password, user.password);
if (!isMatch) throw new HttpError('Invalid email or password', 400);
return user;
};
const User = mongoose.model('User', userSchema);
module.exports = User;
<file_sep>/utils/error.js
class HttpError extends Error {
constructor(message, status_code) {
super(message);
this.status_code = status_code;
}
}
module.exports = HttpError;
<file_sep>/db/db.js
const mongoose = require('mongoose');
const URI = `mongodb+srv://${process.env.MONGO_USERNAME}:${process.env.MONGO_PASSWORD}@cluster.<EMAIL>.mongodb.net/nutrify?retryWrites=true&w=majority`;
const connectDB = async () => {
const conn = await mongoose.connect(URI, {
useNewUrlParser: true,
useCreateIndex: true,
useFindAndModify: false,
useUnifiedTopology: true,
autoIndex: true
});
console.log(`Mongodb connected: ${conn.connection.host}`);
};
module.exports = connectDB;
<file_sep>/controller/user.js
const mongoose = require('mongoose');
const User = require('../models/user');
const HttpError = require('../utils/error');
const errorHandler = require('../utils/errorHandler');
const successHandler = require('../utils/successHandler');
// @desc Get today's dashboard
// @route GET /user/dashboard
// @access Private
exports.dashboard = async (req, res) => {
try {
// Get current user data from the database
const user = await User.findById(req.session.user_id);
// Remove unnecessary information
const user_data = user.toJSON();
let today = new Date().setHours(0, 0, 0, 0);
// FILTER meals
user_data.meal = user_data.meal.filter(
(food) => food.datetime >= today
);
// Set for todays dashboard
user_data.today = true;
// Set total calories consumed
let consumed = 0;
for (let i of user_data.meal) consumed += parseInt(i.calories);
user_data.consumed = consumed;
console.log(user_data);
res.render('dashboard', { user_data });
} catch (error) {
errorHandler(res, error);
}
};
// @desc Get today's dashboard
// @route GET /user/dashboard/search?start_date&end_date&sortBy&order
// @access Private
exports.dashboardSearch = async (req, res) => {
try {
// Get current user data from the database
const user = await User.findById(req.session.user_id);
console.log(user);
// Remove unnecessary information
const user_data = user.toJSON();
// Extract query data
let { start_date, end_date, sortBy, order } = req.query;
let start_date_time, end_date_time;
// Set start date for query
if (start_date) {
start_date_time = new Date(start_date).setHours(0, 0, 0, 0);
} else {
start_date_time = new Date().setHours(0, 0, 0, 0);
}
// Set end date for query
if (end_date) {
end_date_time = new Date(end_date).setHours(0, 0, 0, 0) + 86400000;
}
if (!end_date || end_date_time < start_date_time)
end_date_time = start_date_time + 86400000;
// FILTER meals
user_data.meal = user_data.meal.filter(
(food) =>
food.datetime >= start_date_time &&
food.datetime < end_date_time
);
// Check if only one day meals
if (end_date_time - start_date_time === 86400000)
user_data.showBar = true;
// Only sort if req.usery has any value
if (req.query && Object.keys(req.query).length > 0) {
// Set the sorting order
if (!order) order = 1;
else order = parseInt(order);
// SORT meals
user_data.meal.sort(
(a, b) => order * a[sortBy] - order * b[sortBy]
);
}
res.render('dashboard', { user_data });
} catch (error) {
errorHandler(res, error);
}
};
// @desc Get current logged in user's profile
// @route GET /user/profile
// @access Private
exports.getMyProfile = async (req, res) => {
try {
successHandler(res, 'profile', req.user);
res.status(200).json({ success: true, data: req.user });
} catch (error) {
errorHandler(
new HttpError(
'Something went wrong. Please refresh or try again later',
500
)
);
}
};
// Add all meals
const addMeals = (meal1, meal2) => meal1.calories + meal2.calories;
<file_sep>/routes/admin.js
const router = require('express').Router();
const {
adminSignin,
adminSignout,
adminDeleteUser,
adminSigninGet,
adminEditUser,
adminDeleteMeal,
adminEditMeal
} = require('../controller/admin');
const { isAdmin } = require('../middleware/auth');
router.post('/signin', isAdmin, adminSignin);
router.get('/signin', adminSigninGet);
router.post('/signout', isAdmin, adminSignout);
router.delete('/user/delete/:username', isAdmin, adminDeleteUser);
router.post('/user/edit/:username', isAdmin, adminEditUser);
router.post('/user/meal/edit/:username/:meal_id', isAdmin, adminDeleteMeal);
router.delete('/user/meal/delete/:username/:meal_id', isAdmin, adminEditMeal);
module.exports = router;
<file_sep>/routes/meal.js
const router = require('express').Router();
const {
createMeal,
getMeals,
deleteMeal,
editMeal
} = require('../controller/meal');
const { verifyUser } = require('../middleware/auth');
router.post('/add', verifyUser, createMeal);
// router.get('/', verifyUser, getMeals);
// router.get('/:date', verifyUser, getMeals);
router.post('/edit/:id', verifyUser, editMeal);
router.post('/delete/:id', verifyUser, deleteMeal);
module.exports = router;
<file_sep>/routes/user.js
const router = require('express').Router();
const {
getMyProfile,
getMeals,
dashboard,
dashboardSearch
} = require('../controller/user');
const { verifyUser } = require('../middleware/auth');
router.get('/dashboard', verifyUser, dashboard);
router.get('/dashboard/search', verifyUser, dashboardSearch);
router.get('/profile', verifyUser, getMyProfile);
module.exports = router;
| fdf020d7390ab7bb18c68f0f64e4811ecda5dff3 | [
"JavaScript",
"Markdown"
] | 20 | JavaScript | Rawattt/Nutrify | 3b1f3b2395cd79ca0104f141afc53d16836b9554 | 4dca730132c55121960a0a98c32506f82706feb7 |
refs/heads/master | <repo_name>garczarek123/nowe-repo<file_sep>/Program.cs
using System;
namespace ConsoleApp4
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World!");
Console.WriteLine("Implementacja nowej funkcjonalności projektu");
Console.WriteLine("Implementacja nowej funkcjonalności projektu");
Console.WriteLine("nowa zmiana użytkownika");
Console.WriteLine("Dobra zmiana");
}
}
}
| 70b87bc39526d5f02a89c9ec6494b3bed6ec9323 | [
"C#"
] | 1 | C# | garczarek123/nowe-repo | 450de7a1e6c7dbea99873a292ccd9ce59c1ab5bf | c36fba8cc4457e62f9ed2fb31c7028c210bc0af5 |
refs/heads/master | <file_sep>from keras.models import Sequential, Model
from keras import regularizers
from keras.layers import Reshape, Activation, Dropout, Input, MaxPooling1D, BatchNormalization, Flatten, Dense, Lambda, concatenate, Conv1D, GlobalAveragePooling1D
from keras.layers.advanced_activations import LeakyReLU, ReLU
from keras.regularizers import l2
import numpy as np
from layers.q_layers_1D import QuantizedConv1D,QuantizedDense
from layers.quantized_ops import quantized_relu as quantize_op
from layers.b_layer_1D import BinaryConv1D,BinaryDense
from layers.binary_ops import binary_tanh as binary_tanh_op
import sys
from keras.utils import plot_model
def build_model(WINDOW_SIZE):
abits = 16
wbits = 16
kernel_lr_multiplier = 10
def quantized_relu(x):
return quantize_op(x,nb=abits)
def binary_tanh(x):
return binary_tanh_op(x)
# network_type = 'float'
#network_type ='qnn'
# network_type = 'full-qnn'
network_type ='bnn'
# network_type = 'full-bnn'
H = 1.
if network_type =='float':
Conv_ = lambda f, s, c, n: Conv1D(kernel_size=s, filters=f, padding='same', activation='linear',
input_shape = (c,1), name = n)
Conv = lambda f, s, n: Conv1D(kernel_size= s, filters=f, padding='same', activation='linear', name = n)
Dense_ = lambda f, n: Dense(units = f, kernel_initializer='normal', activation='relu', name = n)
Act = lambda: ReLU()
elif network_type=='qnn':
# sys.exit(0)
Conv_ = lambda f, s, c, n: QuantizedConv1D(kernel_size= s, H=1, nb=wbits, filters=f, strides=1,
padding='same', activation='linear',
input_shape = (c,1),name = n)
Conv = lambda f, s, n: QuantizedConv1D(kernel_size=s, H=1, nb=wbits, filters=f, strides= 1,
padding='same', activation='linear',
name = n)
Act = lambda: ReLU()
Dense_ = lambda f, n: QuantizedDense(units = f, nb = wbits, name = n)
elif network_type=='full-qnn':
#sys.exit(0)
Conv_ = lambda f, s, c, n: QuantizedConv1D(kernel_size= s, H=1, nb=wbits, filters=f, strides=1,
padding='same', activation='linear',
input_shape = (c,1),name = n)
Conv = lambda f, s, n: QuantizedConv1D(kernel_size=s, H=1, nb=wbits, filters=f, strides= 1,
padding='same', activation='linear',
name = n)
Act = lambda: Activation(quantized_relu)
Dense_ = lambda f, n: QuantizedDense(units = f, nb = wbits, name = n)
elif network_type=='bnn':
# sys.exit(0)
Conv_ = lambda f,s,c,n: BinaryConv1D(kernel_size= s, H=1, filters=f, strides=1, padding='same',
activation='linear',
input_shape = (c,1),
name = n)
Conv = lambda f,s,n: BinaryConv1D(kernel_size=s, H=1, filters=f, strides=1, padding='same',
activation='linear',
name = n )
Dense_ = lambda f, n: BinaryDense(units = f, name = n)
Act = lambda: ReLU()
elif network_type=='full-bnn':
#sys.exit(0)
Conv_ = lambda f,s,c,n: BinaryConv1D(kernel_size= s, H=1, filters=f, strides=1, padding='same',
activation='linear',
input_shape = (c,1),
name = n)
Conv = lambda f,s,n: BinaryConv1D(kernel_size=s, H=1, filters=f, strides=1, padding='same',
activation='linear',
name = n )
Act = lambda: Activation(binary_tanh)
else:
#sys.exit(0)
print('wrong network type, the supported network types in this repo are float, qnn, full-qnn, bnn and full-bnn')
model = Sequential()
OUTPUT_CLASS = 4 # output classes
#model = Sequential()
model.add(Conv_(64, 55, WINDOW_SIZE, 'conv1') )
model.add(Act())
model.add(MaxPooling1D(10))
model.add(Dropout(0.5))
model.add(Conv(64, 25, 'conv2' ))
model.add(Act())
model.add(MaxPooling1D(5))
model.add(Dropout(0.5))
model.add(Conv(64, 10, 'conv3'))
model.add(Act())
model.add(GlobalAveragePooling1D())
model.add(Dense_(256, 'den6'))
model.add(Dropout(0.5))
model.add(Dense_(128, 'den7'))
model.add(Dropout(0.5))
model.add(Dense_(64, 'den8'))
model.add(Dropout(0.5))
model.add(Dense(OUTPUT_CLASS, kernel_initializer='normal', activation='softmax', name = 'den9'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
plot_model(model, to_file='my_model.png')
return model
<file_sep># Quantized_1D_layers_keras
This is 1D quantized / binary convolutional layers
quantized convolutional layers
The main idea mainly comes from [B.Moons et al.](https://github.com/BertMoons/QuantizedNeuralNetworks-Keras-Tensorflow)
| dee23a083d95e97b815921b79520efcfb1e5ff74 | [
"Markdown",
"Python"
] | 2 | Python | gyb1325/Quantized_1D_layers_keras | ee52198c922fa7c61390f8a61250e412744d918f | ba38bbe98f9b6396124979a12ca676a7078af227 |
refs/heads/master | <file_sep>import * as express from "express";
import {URLs} from "../../util/Values";
import ClientService from "../service/ClientService";
class ClientRest {
constructor(){}
public setRoutes(exp: express.Application){
exp.post(URLs.CLIENT, ClientService.create);
}
}
export default new ClientRest()
<file_sep>import { Sequelize } from "sequelize-typescript";
import {Transaction} from "../app/model/TransactionModel";
import {Payable} from "../app/model/PayableModel";
import {Client} from "../app/model/ClientModel";
export class FactoryDB{
//Dados conexão Local.
private host = "172.17.0.3";
private port = 3306;
private database = "psp";
private user = "psp";
private password = "psp";
private dialect = "mysql";
private typeSync = "alter"; //Acredito que não funciona legal
private sequelize: Sequelize;
constructor(){
}
createConnection(onConnected: any, onError: any){
let nodeEnv:string = process.env.NODE_ENV;
console.log("Node_ENV: " + nodeEnv);
if(!nodeEnv){
console.log("---------------Ambiente Local");
} else if(nodeEnv.indexOf("test") > -1){
console.log("---------------Ambiente de Teste");
} else if(nodeEnv.indexOf("development") > -1){
console.log("---------------Ambiente desenvolvimento!");
} else if(nodeEnv.indexOf("production") > -1){
console.log("---------------Ambiente de produção!");
this.host = "mysql785.umbler.com";
this.port = 3310;
this.password = "<PASSWORD>,"
}
let hostDBEnv:string = process.env.PSP_HOST_DB_ENV;
let portEnv:string = process.env.PSP_PORT_ENV;
let databaseEnv:string = process.env.PSP_DATABASE_ENV;
let dialectEnv:string = process.env.PSP_DIALECT_ENV;
let userNameEnv:string = process.env.PSP_USER_NAME_ENV;
let passwordEnv:string = process.env.PSP_PASSWORD_ENV;
console.log("---------------hostDBEnv -> " + hostDBEnv );
console.log("---------------portEnv -> " + portEnv );
console.log("---------------databaseEnv -> " + databaseEnv );
console.log("---------------dialectEnv -> " + dialectEnv );
console.log("---------------userNameEnv -> " + userNameEnv );
console.log("---------------passwordEnv -> " + passwordEnv );
if (hostDBEnv && portEnv && databaseEnv && dialectEnv
&& userNameEnv && passwordEnv) {
this.host = hostDBEnv;
this.port = Number(portEnv);
this.database = databaseEnv;
this.dialect = dialectEnv;
this.user = userNameEnv;
this.password = <PASSWORD>;
}
this.sequelize = new Sequelize({
host: this.host,
port: this.port,
database: this.database,
dialect: this.dialect,
username: this.user,
password: <PASSWORD>,
pool: {
max: 25,
min: 0,
acquire: 30000,
idle: 10000
},
logging: true
});
//Adicionando os modelos que serão espelhados como tabelas no banco de dados.
this.sequelize.addModels([
Transaction,
Payable,
Client
]);
this.sequelize.authenticate().then(onConnected).catch(onError);
}
updateTable(onUpdate: any, onError: any){
if(this.sequelize){
this.sequelize.sync({force: false, alter: false , logging : true}).then(onUpdate).catch(onError);
}
}
getSequelize() {
return this.sequelize;
}
closeConnection(onClose: any){
}
}
<file_sep>import {Column, DataType, Model, Table} from "sequelize-typescript";
import { BelongsTo } from "sequelize-typescript/lib/annotations/association/BelongsTo";
import { ForeignKey } from "sequelize-typescript/lib/annotations/ForeignKey";
import {Transaction} from "./TransactionModel";
import {Client} from "./ClientModel";
import {Sequelize} from "sequelize";
import * as sequelize from "sequelize";
@Table({tableName: "payable"})
export class Payable extends Model<Payable> {
//static sequelize: any;
@Column({
type : DataType.ENUM,
values: ['1', '2', '3'],
allowNull: false,
defaultValue: 3,
comment : '1 -> paid , 2 -> waiting_funds, 3 -> unknown'
})
status: number;
@Column( {
allowNull: false,
comment : 'Data do pagamento'
} )
dtPayment: Date;
@Column({
allowNull: false,
comment: "Porcetagem de taxa"
})
percentRate: number;
@Column({
type: DataType.FLOAT,
allowNull: false,
comment: "Valor da Transação final do cliente"
})
vlrPayable: number;
@Column({ allowNull: false, comment: 'Hash gerado com o proprio objeto, Obs.: Ideia que precisa de analise'})
hashTransaction: string;
@ForeignKey(() => Transaction)
@Column({comment : 'Transação registrada.'})
transactionId: number;
@BelongsTo(() => Transaction)
transaction: Transaction;
@ForeignKey(() => Client)
@Column({comment : 'Cliente da transação.'})
clientId: number;
@BelongsTo(() => Client)
client: Client;
}
<file_sep>import {tMsg} from "../../util/Values";
import {Data} from "../../util/Data";
import {msgErro, msgPSP} from "../../util/MessageTranslate";
import {Payable} from "../model/PayableModel";
import {Client} from "../model/ClientModel";
import {Transaction} from "../model/TransactionModel";
class PayableService {
public async payable(req, res) {
let data = new Data();
let result: {[k: string]: any} = {};
try {
let available = await Payable.sum('vlrPayable', { where: { status: 1 } });
result.available = (available).toLocaleString('pt-BR',
{ style: 'currency', currency: 'BRL' });
let waitingFunds = await Payable.sum('vlrPayable', { where: { status: 2 } });
result.waitingFunds = (waitingFunds).toLocaleString('pt-BR',
{ style: 'currency', currency: 'BRL' });
result.payables = await Payable.findAll({
include : [ { model : Transaction, as : 'transaction' } ]
});
data.obj = result;
res.status(200).json(data);
} catch (error) {
data.addMsgError(tMsg.DANGER, msgErro.erroAoRealizarConsulta, "Error ");
res.status(500).json(data)
}
}
public async payableByClient(req, res) {
let data = new Data();
let id = req.params.clientId;
let result: {[k: string]: any} = {};
try {
let client = await Client.findById(id);
if (!client) {
data.addMsgError(tMsg.DANGER, msgPSP.erroProcessRecordPSP, "Cliente desconhecido.");
res.status(400).send(data);
return
}
// - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _
let available = await Payable.sum('vlrPayable', { where: { status: 1 , clientId: client.id} });
result.available = (available).toLocaleString('pt-BR',
{ style: 'currency', currency: 'BRL' });
let waitingFunds = await Payable.sum('vlrPayable', { where: { status: 2, clientId: client.id} });
result.waitingFunds = (waitingFunds).toLocaleString('pt-BR',
{ style: 'currency', currency: 'BRL' });
result.payables = await Payable.findAll({
where : { clientId : client.id},
include : [ { model : Transaction, as : 'transaction' } ]
});
data.obj = result;
res.status(200).json(data);
} catch (error) {
data.addMsgError(tMsg.DANGER, msgErro.erroAoRealizarConsulta, "Error ");
res.status(500).json(data)
}
}
}
export default new PayableService()
<file_sep># PSP-backend
Payment Service Provider (PSP) Desenvolvido em Node.JS
### Executanco infra completa - Docker Compose
````
# Executar o comando no diretorio raiz do projeto
docker-compose up
````
## Testando endpoints
##### Cadastrando um Cliente
````
curl -X POST \
http://localhost:3001/api/v1/client \
-H 'Content-Type: application/json' \
-d '{
"name" : "Client teste final de noite 2"
}'
````
##### Registrando uma transação
````
curl -X POST \
http://localhost:3001/api/v1/psp \
-H 'Content-Type: application/json' \
-d '{
"vlrTransaction" : 870.99,
"description" : "PRODUCT IMPORT BY CHINA",
"typeTransaction" : 2,
"numCard" : 5274305431780049,
"bearerName" : "PLACE HOLDER THE CARD",
"dtExpiration" : "12.01.2020",
"cvv": 999,
"clientId" : ID_CLIENTE_CADASTRADO
}'
````
##### Listando todas transações registradas na base
````
curl -X GET \
http://localhost:3001/api/v1/transaction
````
##### Listando todas transações pagaveis na base
````
curl -X GET \
http://localhost:3001/api/v1/payable \
-H 'Accept: */*'
````
##### Listando todas transações pagaveis na base com filtro por cliente
````
curl -X GET \
http://localhost:3001/api/v1/payable/1 \
-H 'Accept: */*'
````
### Instruções para ambiente de Desenvolvimento
````
* docker run -it --name PSPBackEnd -p 3000:3000 -v ../../PSP-backend/:/var/www/PSP-backend node:6.14.3 bash
* /# npm install -g nodemon
/# npm install -g node-inspector
* docker run -d --name mysqlPSPBackEnd -e MYSQL_ROOT_PASSWORD=psp -e MYSQL_DATABASE=psp -e MYSQL_USER=psp -e MYSQL_PASSWORD=psp -p 3310:3306 mysql:5.5
# Runing app in dev
docker exec -it ID_CONTAINER_NODE bash
cd /var/www/PSP-backend
npm i
npm install @types/lodash@4.14.116 --save-exact
npm run start
* A aplicação reeniciará automaticamente a cada alteração.
````
### Instruções para compilar projeto
````
# Compile App
/var/www/PSP-backend/node_modules/.bin/tsc -p /var/www/PSP-backend/tsconfig.json
````
<file_sep>import App from "./app";
import * as debugServe from "debug";
import {Client} from "./app/model/ClientModel";
let port = process.env.PORT || "3000";
let debug = debugServe("nodestr:server");
App.server.listen(port, () => {
console.log("Servidor está rodando na porta "+ port);
App.createConnection(() => {
console.log("Banco conectado com sucesso!");
/**
* As linhas abaixo fazem o processo de atualização do banco de dados
* não deixe essa configuração em producao. att.<NAME>
*/
//TODO resolver este problema usando as configurações de ambiente
App.updateTable(() => {
console.log("Banco Atualizado com sucesso!");
}, (error) => {
console.log("Error ao atualizar banco de dados! " + error);
})
}, (error) => {
console.log("Error ao conectar ao banco de dados: " + error);
process.exit(0); // Ainda em desenvolvimento
});
});
App.server.on("listening", setDebug);
process.once("SIGUSR2", () => {
App.closeConnection(() => {
console.log("Sistema reiniciado!");
process.kill(process.pid, "SIGUSR2");
});
});
process.once("SIGINT", () => {
App.closeConnection(() => {
console.log("Sistema fechado!");
process.exit(0);
});
});
function setDebug(){
let addr = App.server.address();
let bind = typeof addr === 'string'
? "pipe " + addr
: "port " + addr.port;
debug("Listening on " + bind);
console.log("Debug Iniciado.");
}
<file_sep>import * as express from "express";
import {URLs} from "../../util/Values";
import PSPService from "../service/PSPService";
class PSPRest {
constructor(){}
public setRoutes(exp: express.Application){
exp.post(URLs.PSP, PSPService.record);
}
}
export default new PSPRest()
<file_sep>export const URLs = {
"PSP" : "/api/v1/psp",
"TRANSACTION" : "/api/v1/transaction",
"PAYABLE" : "/api/v1/payable",
"PAYABLE_CLIENT_ID" : "/api/v1/payable/:clientId",
"CLIENT" : "/api/v1/client"
};
export const tMsg = {//Tipos de mensagens
"DANGER": "msgErro",
"SUCCESS": "msgSuccesso",
"INFO": "msgInfo",
"ALERT": "msgAlert",
"STRACE": "msgStrace"
};
export const oMsg = {//Objetos de retorno
"OBJ": "obj",
"LIST": "list",
"SEARCH": "search",
"LIST_MSG": "listMsg",
"PAGE": "page",
"TOTAL_PAGES": "totalPages",
"FIELD_SORT": "fieldSort",
"SORT": "sort",
"LIMIT": "limit",
"RANGE_START": "rangeStart",
"RANGE_END": "rangeEnd",
"TOTAL_ROWS": "totalRows",
};
export const secretToken ={
"TOKEN": "x-auth-token",
"TIME": 84600,
"SECRET": "lw52XD9w>KuiwD;`YWP5lpg5?hXKX#@!$T@$G@G@IQl8]XBkeso=38BNdam0w@fYLy8;Q/tj2tu"
};
<file_sep>import {tMsg} from "../../util/Values";
import {Data} from "../../util/Data";
import {msgErro, msgPSP} from "../../util/MessageTranslate";
import * as StringMask from 'string-mask';
import {Transaction} from "../model/TransactionModel";
import * as dateFns from 'date-fns';
import {Payable} from "../model/PayableModel";
import * as crypto from 'crypto';
import {Client} from "../model/ClientModel";
class PSPService {
public async record(req, res) {
let data = new Data();
let result: {[k: string]: any} = {};
let bodyRequest = req.body; //Pega informações do body
try {
req.assert('vlrTransaction', msgPSP.erroParamBodyVlrtransactionRequired).notEmpty();
req.assert('description', msgPSP.erroParamBodyDescriptionRequired).notEmpty();
req.assert('typeTransaction', msgPSP.erroParamBodyTypeTransactionRequired).notEmpty().isNumeric().isInt({ min: 1, max: 2});
req.assert('numCard', msgPSP.erroParamBodyNumCardRequired).notEmpty().isNumeric().len({ min: 14, max: 16});
req.assert('bearerName', msgPSP.erroParamBodyBearerNameRequired).notEmpty();
req.assert('dtExpiration', msgPSP.erroParamBodyDtExpirationRequired).notEmpty();
req.assert('cvv', msgPSP.erroParamBodyCVVRequired).notEmpty();
req.assert('clientId', msgPSP.erroParamBodyClientIdRequired).notEmpty().isNumeric();
let errors = req.validationErrors();
//Validando parametros enviados
if (errors) {
data.addMsgError(tMsg.DANGER, msgPSP.erroProcessRecordPSP, errors);
res.status(400).send(data);
return
}
// - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _
//Tratamento de data invalida ou expirada
if (!dateFns.isDate(bodyRequest.dtExpiration) &&
dateFns.compareDesc( new Date(), dateFns.parse(bodyRequest.dtExpiration)) !== 1 ) {
data.addMsgError(tMsg.DANGER, msgPSP.erroProcessRecordPSP, "Cartão Expirado.");
res.status(400).send(data);
return
}
// - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _
let client = await Client.findById(bodyRequest.clientId);
if (!client) {
data.addMsgError(tMsg.DANGER, msgPSP.erroProcessRecordPSP, "Cliente desconhecido.");
res.status(400).send(data);
return
}
// - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _
//Resolvendo questão de segurança do numero
let numCard = new StringMask('************0000').apply(bodyRequest.numCard);
// Valor em formato apresentacao
let vlrApresentacaoFull =
(bodyRequest.vlrTransaction).toLocaleString('pt-BR',
{ style: 'currency', currency: 'BRL' });
//Registrando a transação
let transactionBase = await Transaction.create({
'vlrTransaction' : Number(bodyRequest.vlrTransaction),
'description' : bodyRequest.description,
'typeTransaction' : bodyRequest.typeTransaction,
'numCard' : numCard,
'bearerName' : bodyRequest.bearerName,
'dtExpiration' : dateFns.parse(bodyRequest.dtExpiration),
'cvv' : bodyRequest.cvv
});
// validando status
let statusPayable = bodyRequest.typeTransaction == 1 ? 1 : 2;
// Resolvendo data de pagamento
let dtPayment = statusPayable == 1 ? new Date() : dateFns.addDays(new Date(), 30);
// Resolvendo porcentagem para taxa
let percentRate = bodyRequest.typeTransaction == 1 ? 3 : 5;
// Valor da transação
let vlrBase = Number(bodyRequest.vlrTransaction);
// Valor total que será usado como taxa administrativa
let vlrPayablePercent = Number(bodyRequest.vlrTransaction) * (Number(percentRate) / 100);
// Valor do recebivél final
let vlrPayable = vlrBase - Number(vlrPayablePercent);
// Gerando um hash para consultas futuras
let hashTransaction = crypto.createHash('md5').update(JSON.stringify(transactionBase)).digest("hex");
// salvando os pagaveis da transação
let payableBase = await Payable.create({
'transactionId' : transactionBase.id,
'status': statusPayable,
'dtPayment': dtPayment,
'percentRate': percentRate,
'vlrPayable': vlrPayable,
'hashTransaction' : hashTransaction,
'clientId' : client.id
});
//result.numCard = numCard;//
//result.vlrApresentacaoFull = vlrApresentacaoFull;
//result.statusPayable = statusPayable;
//result.dtPayment = dtPayment;
//result.percentRate = percentRate;
//result.vlrBase = vlrBase;
//result.vlrPayablePercent = vlrPayablePercent;
//result.vlrPayable = vlrPayable;
//result.hash = payableBase.hashTransaction;
result.transaction = transactionBase;
//result.payable = payableBase;
data.obj = result;
data.addMsg(tMsg.SUCCESS, "Sucesso.");
res.status(200).json(data);
} catch (error) {
console.log(error);
data.addMsgError(tMsg.DANGER, msgErro.erroAoRealizarConsulta, "Error ");
res.status(500).json(data)
}
}
}
export default new PSPService()
<file_sep>import {tMsg} from "../../util/Values";
import {Data} from "../../util/Data";
import {msgErro} from "../../util/MessageTranslate";
import {Transaction} from "../model/TransactionModel";
class TransactionService {
public async transaction(req, res) {
let data = new Data();
let result: {[k: string]: any} = {};
try {
result.transactions = await Transaction.findAll();
data.obj = result;
res.status(200).json(data);
} catch (error) {
data.addMsgError(tMsg.DANGER, msgErro.erroAoRealizarConsulta, "Error ");
res.status(500).json(data)
}
}
}
export default new TransactionService()
<file_sep>import {Column, HasMany, Model, Table} from "sequelize-typescript";
import {Payable} from "./PayableModel";
@Table({tableName: "client"})
export class Client extends Model<Client> {
static sequelize: any;
@Column({ allowNull: false, comment: 'Nome do Cliente. '})
name: string;
@HasMany( () => Payable)
payable : Payable[];
}
<file_sep>import {BelongsTo, Column, HasOne, Model, Table} from "sequelize-typescript";
import { CreatedAt } from 'sequelize-typescript/lib/annotations/CreatedAt';
import { DataType } from 'sequelize-typescript/lib/enums/DataType';
import {Payable} from "./PayableModel";
import * as sequelize from "sequelize";
@Table({tableName: "transaction"})
export class Transaction extends Model<Transaction> {
@Column({ type: DataType.FLOAT, allowNull: false, comment: 'Valor da Transação' })
vlrTransaction: number;
@Column({ allowNull: false, comment: 'Descrição da transação. Ex: Smartband XYZ 3.0 '})
description: string;
@Column({ type : DataType.ENUM, values: ['1', '2'], allowNull: false, comment : '1 -> debit_card , 2 -> credit_card'})
typeTransaction: number;
@Column({ allowNull: false, comment: 'Número do cartão ' })
numCard: string;
@Column({ allowNull: false, comment: 'Nome do portador do cartão'})
bearerName: string;
@Column( { allowNull: false, comment : 'Data de validade do cartão'} )
dtExpiration: Date;
@Column({ allowNull: false, comment: 'Código de verificação do cartão (CVV)'})
cvv: string;
@CreatedAt
@Column( { allowNull: false, comment : 'Data da entrada do registro'} )
dtCreated: Date;
@HasOne( () => Payable)
payable : Payable;
}
<file_sep>import * as express from "express";
import {URLs} from "../../util/Values";
import PayableService from "../service/PayableService";
class PayableRest {
constructor(){}
public setRoutes(exp: express.Application){
exp.get(URLs.PAYABLE, PayableService.payable);
exp.get(URLs.PAYABLE_CLIENT_ID, PayableService.payableByClient);
}
}
export default new PayableRest()
<file_sep>import * as express from "express";
import { Sequelize, Model} from 'sequelize-typescript';
import UtilService from '../util/UtilService';
import Validation from "../util/Validation";
export class Data{
constructor(){
}
public obj: Object;
public list: Array<any>;
public listMsg: Array<any>;
public links: Array<any>;
public page: number;
public totalPages: number;
public limit: number;
public rangeInit: number;
public rangeEnd: number;
public field: string;
public qtdTotal: number;
public offset: number;
public query : any;
public getListMsg(){
if(!this.listMsg){
this.listMsg = new Array();
}
return this.listMsg;
}
public addMsg(typeMsg: string, textMsg: string) {
this.getListMsg().push({type: typeMsg, msg: textMsg});
}
public addMsgWithDetails(typeMsg: string, codMsg: string, textMsg: string,
paramMsg: string, valueMsg: string) {
this.getListMsg().push({type: typeMsg, cod: codMsg, text: textMsg, param: paramMsg, value: valueMsg});
}
public addMsgError(typeMsg: string, codMsg: string, errorMsg: any) {
this.getListMsg().push({type: typeMsg, cod: codMsg, error: errorMsg});
}
public addLink(linkParam: string, relParam: string) {
if(!this.links){
this.links = new Array();
}
this.links.push({link: linkParam, rel: relParam});
}
}
<file_sep>export const msgErro = {
"erroAoRealizarConsulta" : "ERRO_AO_REALIZAR_CONSULTA",
};
export const msgPSP = {
"erroProcessRecordPSP" : "ERRO_PROCESS_RECORD_PSP",
"erroParamBodyVlrtransactionRequired" : "ERRO_PARAM_BODY_VLR_TRANSACTION_REQUERID",
"erroParamBodyDescriptionRequired" : "ERRO_PARAM_BODY_DESCRIPTION_REQUERID",
"erroParamBodyTypeTransactionRequired" : "ERRO_PARAM_BODY_TYPE_TRANSACTION_REQUERID",
"erroParamBodyNumCardRequired" : "ERRO_PARAM_BODY_NUM_CARD_REQUERID",
"erroParamBodyBearerNameRequired" : "ERRO_PARAM_BODY_BEARER_NAME_REQUERID",
"erroParamBodyDtExpirationRequired" : "ERRO_PARAM_BODY_DT_EXPIRATION_REQUERID",
"erroParamBodyCVVRequired" : "ERRO_PARAM_BODY_CVV_REQUERID",
"erroParamBodyClientIdRequired" : "ERRO_PARAM_BODY_CLIENT_ID_REQUERID"
};
export const msgClient = {
"erroCreateClient" : "ERRO_CREATE_CLIENT",
"erroParamBodyNameClientRequired" : "ERRO_PARAM_BODY_NAME_CLIENT_REQUERID"
};
<file_sep>import {tMsg} from "../../util/Values";
import {Data} from "../../util/Data";
import {msgClient, msgErro} from "../../util/MessageTranslate";
import {Client} from "../model/ClientModel";
class ClientService {
public async create(req, res) {
let data = new Data();
let result: {[k: string]: any} = {};
let bodyRequest = req.body; //Pega informações do body
try {
req.assert('name', msgClient.erroParamBodyNameClientRequired).notEmpty();
let errors = req.validationErrors();
//Validando parametros enviados
if (errors) {
data.addMsgError(tMsg.DANGER, msgClient.erroCreateClient, errors);
res.status(400).send(data);
return
}
// - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _ - _
result.client = await Client.create({
'name' : bodyRequest.name
});
data.obj = result;
res.status(200).json(data);
} catch (error) {
data.addMsgError(tMsg.DANGER, msgErro.erroAoRealizarConsulta, "Error ");
res.status(500).json(data)
}
}
}
export default new ClientService()
<file_sep>import * as http from "http";
import * as express from "express";
import * as socketIo from "socket.io";
class SocketUtil{
public io: SocketIO.Server;
public socket: SocketIO.Socket;
public server: http.Server;
private listens = [];
constructor(){}
public getServerSocketIo(exp: express.Application): http.Server {
if(!this.server){
this.server = http.createServer(exp); //Criando servidor HTTP
this.io = socketIo(this.server);// Criando Servidor do Socket.io
}
this.initSockets();
return this.server;
}
public addListen(event:string, action: any){
this.listens.push({
event: event,
action: action
});
}
public emit(event:string, object: Object){
if(this.io){
this.io.emit(event, object);
}
}
private initSockets(){
this.io.on('connect', (socket: any) => {
this.listens.forEach((listen, index, list) => {
socket.on(listen.event, listen.action);
});
socket.on('disconnect', () => {
});
});
}
}
export default new SocketUtil();<file_sep>class Validation {
constructor() {}
public isOnlyNumbers(numeros: string): boolean{
let notNumber = /^[0-9]$/g;
return notNumber.test(numeros);
}
public isCepValid(cep: string): boolean{
let cepValid = /^\d{5}\-?\d{3}$/;
return cepValid.test(cep);
}
public isDateBrVallid(data: string): boolean{
let notValid = false;
if (data && data.length === 10) {
let dia = data.substring(0, 2);
let mes = data.substring(3, 5);
let ano = data.substring(6, 10);
// Criando um objeto Date usando os valores ano, mes e dia.
let novaData = new Date(parseInt(ano), (parseInt(mes) - 1), parseInt(dia));
let mesmoDia = parseInt(dia, 10) == parseInt(novaData.getDate().toString());
let mesmoMes = parseInt(mes, 10) == parseInt(novaData.getMonth().toString()) + 1;
let mesmoAno = parseInt(ano) == parseInt(novaData.getFullYear().toString());
if (!((mesmoDia) && (mesmoMes) && (mesmoAno))) {notValid = true;}
}else{notValid = true;}
return !notValid;
}
public isHourMninuteValid(hora: string): boolean {
let notValid = false;
if (hora && hora.length == 5) {
let horas = hora.substring(0, 2);
let minutos = hora.substring(3, 5);
// Criando um objeto Date usando os valores ano, mes e dia.
if(horas){
let horasNumber = parseInt(horas);
if(horasNumber > 23){notValid = true;}
}
if(minutos){
let minutosNumber = parseInt(minutos);
if(minutosNumber > 59){notValid = true;}
}
}else{notValid = true;}
return !notValid;
}
public isCpfValid(cpf: string): boolean{
let notValid = false;
let cpfv = cpf;
if(cpfv.length == 14 || cpfv.length == 11){
cpfv = cpfv.replace('.', '');
cpfv = cpfv.replace('.', '');
cpfv = cpfv.replace('-', '');
let nonNumbers = /\D/;
if(nonNumbers.test(cpfv)){notValid = true;}else{
if (cpfv == "00000000000" ||
cpfv == "11111111111" ||
cpfv == "22222222222" ||
cpfv == "33333333333" ||
cpfv == "44444444444" ||
cpfv == "55555555555" ||
cpfv == "66666666666" ||
cpfv == "77777777777" ||
cpfv == "88888888888" ||
cpfv == "99999999999") {
notValid = true;
}
let a = [];
let b;
let c = 11;
for(let i = 0; i < 11; i++){
a[i] = cpfv.charAt(i);
if (i < 9) b += (a[i] * --c);
}
let x = b % 11;
if((x) < 2){
a[9] = 0;
}else{
a[9] = 11-x;
}
b = 0;
c = 11;
for (let y=0; y<10; y++) b += (a[y] * c--);
if((x = b % 11) < 2){
a[10] = 0;
}else{
a[10] = 11-x;
}
if((cpfv.charAt(9) != a[9]) || (cpfv.charAt(10) != a[10])){
notValid = true;
}else{
notValid = false;
}
}
}else {notValid = true;}
return !notValid;
}
public isCnpjValid(cnpj: string){
var notValid = false;
cnpj = cnpj.replace(/[^0-9]+/g, "");
if (cnpj.length != 14){
notValid = true;
}else if (cnpj == "00000000000000" ||//Elimina CNPJs invalidos conhecidos
cnpj == "11111111111111" ||
cnpj == "22222222222222" ||
cnpj == "33333333333333" ||
cnpj == "44444444444444" ||
cnpj == "55555555555555" ||
cnpj == "66666666666666" ||
cnpj == "77777777777777" ||
cnpj == "88888888888888" ||
cnpj == "99999999999999"){
notValid = true;
}else{
let tamanho = cnpj.length - 2;
let numeros = cnpj.substring(0,tamanho);
let digitos = cnpj.substring(tamanho);
let soma = 0;
let pos = tamanho - 7;
for (let i = tamanho; i >= 1; i--) {
soma += parseInt(numeros.charAt(tamanho - i)) * pos--;
if (pos < 2)
pos = 9;
}
let resultado = soma % 11 < 2 ? 0 : 11 - soma % 11;
if (resultado != parseInt(digitos.charAt(0))){
notValid = true;
}else{
tamanho = tamanho + 1;
numeros = cnpj.substring(0,tamanho);
soma = 0;
pos = tamanho - 7;
for (let i = tamanho; i >= 1; i--) {
soma += parseInt(numeros.charAt(tamanho - i)) * pos--;
if (pos < 2) pos = 9;
}
resultado = soma % 11 < 2 ? 0 : 11 - soma % 11;
if (resultado != parseInt(digitos.charAt(1))){
notValid = true;
}
}
}
return !notValid;
}
public isEmailValid(email: string): boolean{
let validador = /^([a-zA-Z0-9_\.\-])+\@(([a-zA-Z0-9\-])+\.)+([a-zA-Z0-9]{2,4})+$/;
return validador.test(email);
}
}
export default new Validation();<file_sep>#Download base image node 6.14.3
FROM node:6.14.3
#
RUN mkdir -p /home/node/app/node_modules && chown -R node:node /home/node/app
# Diretorio de trabalho da aplicação
WORKDIR /home/node/app
#
ADD package.json ./
ADD tsconfig.json ./
ADD nodemon.json ./
#
RUN npm install
RUN npm install -g nodemon
RUN npm install -g node-inspector
RUN npm install @types/lodash@4.14.116 --save-exact
#
ADD --chown=node:node dist ./dist
#
USER node
#
EXPOSE 3000:3000
#
CMD [ "node", "./dist/server.js" ]
#Realizando Build
#docker build -t nosbielc/psp-backend:190920191750 .
<file_sep>import { secretToken } from './Values';
import * as crypto from "crypto";
import * as url from 'url';
class UtilService {
private algoritEncrypt = 'aes256';
public encrypt(text: any) {
try {
let cipher = crypto.createCipher(this.algoritEncrypt, secretToken.SECRET);
let encrypted = cipher.update(text, 'utf8', 'hex');
encrypted += cipher.final('hex');
return encrypted;
} catch (error) {
}
}
public decrypt(textEncript: any) {
try {
let decipher = crypto.createDecipher(this.algoritEncrypt, secretToken.SECRET);
console.log("text: " + textEncript);
let decrypted = decipher.update(textEncript, 'hex', 'utf8');
decrypted += decipher.final('utf8');
return decrypted;
} catch (error) {
console.log("Erro ao decriptar: " + textEncript);
return "";
}
}
public hMacSha512(text: any) {
try {
const hmac = crypto.createHmac('sha512', secretToken.SECRET);
hmac.update(text);
return hmac.digest('hex');
} catch (error) {
console.log("Erro ao criar hMacSha512: " + text);
return "";
}
}
public fullUrl(req) {
return url.format({
protocol: req.protocol,
host: req.get('host'),
pathname: req.originalUrl
});
}
public servicoUrl(req, servico) {
let reg = new RegExp('[a-z0-9\/:]*(' + servico + ')');
let urlFormatada = url.format({
protocol: req.protocol,
host: req.get('host'),
pathname: req.originalUrl
});
return reg.exec(urlFormatada)[0];
}
public getLinksNavegacao(init: number, end: number, qtdTotal : number, count : number, req : any, ultimoRegistro: number, servico : string) {
let result = new Array();
const COMPLEMENTO_RANGE = '?range=';
let urlFirst = '';
let urlPrev = '';
let urlNext = '';
let urlLast = '';
let initPrev = (init - qtdTotal);
let endNext = (end + qtdTotal);
urlFirst = qtdTotal < count ? this.servicoUrl(req, servico) + COMPLEMENTO_RANGE + 0 + '-' + (qtdTotal - 1) : '';
urlPrev = initPrev >= 0 ? this.servicoUrl(req, servico) + COMPLEMENTO_RANGE + initPrev + '-' + (init - 1) : '';
urlNext = endNext < count ? this.servicoUrl(req, servico) + COMPLEMENTO_RANGE + (end + 1) + '-' + (end + qtdTotal) : '';
urlLast = this.servicoUrl(req, servico) + COMPLEMENTO_RANGE + (ultimoRegistro - (qtdTotal - 1)) + '-' + ultimoRegistro;
result.push({url: urlFirst, rel: 'first'});
result.push({url: urlPrev, rel: 'prev'});
result.push({url: urlNext, rel: 'next'});
result.push({url: urlLast, rel: 'last'});
return result
}
public getCriteriosOrdenacao(asc : Array<any>, desc : Array<any>, nomeCampoDefault: string) {
let orderParams = [];
if(asc && asc.length > 0) {
asc = [].concat( asc);
asc.forEach(element => {
orderParams.push([element, 'ASC']);
});
}
if(desc && desc.length > 0) {
desc = [].concat( desc);
desc.forEach(element => {
orderParams.push([element, 'DESC']);
});
}
if(orderParams.length == 0) {
orderParams.push([nomeCampoDefault, 'ASC']);
}
return orderParams;
}
/**
* Gera caracteres usados no salt
* @function genRandomString
* @param {number} length - Compirmento de caracteres. Obs. Não altulizada no momento
*/
private getSalt(precisao) {
return crypto.randomBytes(Math.ceil(16 / 2))
.toString('hex') /** converte para formato hexadecimal */
.slice(0, 16) /** retornar o número necessário de caracteres */
}
/**
* Senha hash com sha512.
* @function
* @param {string} senha - Senha.
* @param {string} salt - dados para validacao.
*/
private genSenhaComSalt(senha, salt){
let hash = crypto.createHmac('sha512', salt) /** Algoritmo Hashing sha512 */
hash.update(this.getHash256String(senha))
let value = hash.digest('hex')
return {
salt:salt,
passwordHash:value
}
}
private getHash256String(senha) {
return crypto.createHash('sha256').update(senha).digest('hex')
}
public saltHashPassword(senha) {
let salt = this.getSalt(16) /** Nos retorna o Sal com comprimento de 16 setado fixo */
let passwordData = this.genSenhaComSalt(senha, salt)
// console.log('UserPassword = '+senha)
// console.log('Passwordhash = '+passwordData.passwordHash)
// console.log('nSalt = '+passwordData.salt)
return passwordData['passwordHash'] + "." + passwordData['salt']
}
public isPasswordCorrect(basePass, passRequest) {
try {
let passBase = basePass.split('.')
let hashBase = passBase[0]
let saltBase = passBase[1]
let passwordData = this.genSenhaComSalt(passRequest, saltBase)
return hashBase == passwordData.passwordHash
} catch (eror) {
return false
}
}
}
export default new UtilService();<file_sep>import { Sequelize } from 'sequelize-typescript';
import * as express from "express";
import * as http from "http";
import * as morgan from "morgan";
import * as bodyParser from "body-parser";
import * as expressValidator from 'express-validator';
import * as path from "path";
import SocketUtil from "./util/SocketUtil";
import * as cors from "cors";
import { FactoryDB } from "./util/FactoryDB";
// Módulos
import PSPRest from "./app/controller/PSPRest";
import TransactionRest from "./app/controller/TransactionRest";
import PayableRest from "./app/controller/PayableRest";
import ClientRest from "./app/controller/ClientRest";
class App {
public exp: express.Application;
public server: http.Server;
private morgan: morgan.Morgan;
private bodyParser;
private cors;
private factoryDB: FactoryDB;
constructor(){
this.exp = express();//Criando servidor do Express
this.server = SocketUtil.getServerSocketIo(this.exp);
this.factoryDB = new FactoryDB();
this.middlewares();
this.initRoutes();
}
public createConnection(onConnected: Function, onError: Function){
this.factoryDB.createConnection(onConnected, onError);
}
public updateTable(onUpate: Function, onError: Function){
this.factoryDB.updateTable(onUpate, onError);
}
public closeConnection(onClose){
this.factoryDB.closeConnection(onClose);
}
private middlewares(){
this.exp.use(morgan("dev"));
//this.exp.use(morgan(':method :url :response-time'));
this.exp.use(bodyParser.json());
this.exp.use(bodyParser.urlencoded({extended: true}));
this.exp.use(expressValidator());
this.exp.use(express.static(path.join(__dirname, "public")));
this.exp.use(cors());
}
private initRoutes(){
PSPRest.setRoutes(this.exp);
TransactionRest.setRoutes(this.exp);
PayableRest.setRoutes(this.exp);
ClientRest.setRoutes(this.exp);
}
getSequelize() {
return this.factoryDB.getSequelize();
}
}
export default new App();
<file_sep>import * as express from "express";
import {URLs} from "../../util/Values";
import TransactionService from "../service/TransactionService";
class TransactionRest {
constructor(){}
public setRoutes(exp: express.Application){
exp.get(URLs.TRANSACTION, TransactionService.transaction);
}
}
export default new TransactionRest()
| b56383e7a2e5789b2ba53279027af058ee9ce64a | [
"Markdown",
"TypeScript",
"Dockerfile"
] | 22 | TypeScript | Nosbielc/PSP-backend | 220db7ebe72d4e2b039254aec4a4d7af71c483e9 | 555409c9948db9da5e4aea264476a4755771bcb3 |
refs/heads/master | <file_sep>package com.board.config.security;
import com.board.domain.user.UserRole;
import com.board.domain.user.service.UserService;
import lombok.RequiredArgsConstructor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.authentication.AuthenticationProvider;
import org.springframework.security.config.annotation.method.configuration.EnableGlobalMethodSecurity;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.builders.WebSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.security.crypto.password.PasswordEncoder;
@Configuration
@EnableWebSecurity
@EnableGlobalMethodSecurity(prePostEnabled = true)
@RequiredArgsConstructor
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
private final UserService userService;
private final LoginFailureHandler loginFailureHandler;
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Override
protected void configure(HttpSecurity http) throws Exception {
http.authorizeRequests()
// Role Setting.
// .antMatchers("/h2-console/**").permitAll()
.antMatchers("/*").permitAll()
.antMatchers("/user/**").permitAll()
.antMatchers("/api/v1/user/**").permitAll()
.antMatchers("/api/v1/post/**").hasRole(UserRole.USER.name())
.antMatchers("/admin/**").hasRole(UserRole.ADMIN.name())
// Login.
.and()
.formLogin()
.usernameParameter("userId")
.passwordParameter("<PASSWORD>")
.loginPage("/user/login")
.failureHandler(loginFailureHandler)
.defaultSuccessUrl("/")
// Logout.
.and()
.logout()
.logoutSuccessUrl("/")
.invalidateHttpSession(true);
}
@Override
public void configure(WebSecurity web) throws Exception {
web.ignoring().antMatchers("/css/**", "/js/**", "/img/**", "/h2-console/**", "/error");
}
@Bean
public AuthenticationProvider authenticationProvider() {
return new CustomAuthenticationProvider(userService, passwordEncoder());
}
}
<file_sep>package com.board.utils.password;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import java.time.LocalDateTime;
public class PasswordEncoderUtils {
public static String encryptPassword(String password) {
return new BCryptPasswordEncoder().encode(password);
}
}
<file_sep>package com.board.domain.user.service;
import java.util.ArrayList;
import com.board.domain.user.dto.UserRequestDto;
import com.board.domain.user.dto.UserResponseDto;
import com.board.domain.user.exception.UserNotFoundException;
import com.board.domain.user.repository.UserRepository;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.security.core.GrantedAuthority;
import org.springframework.security.core.authority.SimpleGrantedAuthority;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.security.core.userdetails.UserDetailsService;
import org.springframework.security.core.userdetails.UsernameNotFoundException;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.stereotype.Service;
import com.board.domain.user.User;
import javax.transaction.Transactional;
import java.util.List;
import java.util.Optional;
@Slf4j
@Service
@RequiredArgsConstructor
public class UserService implements UserDetailsService {
private final UserRepository userRepository;
public boolean existsById(String userId) {
return userRepository.existsById(userId);
}
public UserResponseDto getUser(String userId) {
Optional<User> userOptional = userRepository.findById(userId);
if (userOptional.isEmpty())
throw new UserNotFoundException(userId);
return UserResponseDto.builder()
.userId(userOptional.get().getUserId())
.build();
}
@Transactional
public UserResponseDto createUser(UserRequestDto userRequestDto) {
User user = User.createUserBuilder()
.userId(userRequestDto.getUserId())
.password(new BCryptPasswordEncoder().encode(userRequestDto.getPassword()))
.email(userRequestDto.getEmail())
.build();
return UserResponseDto.builder()
.userId(userRepository.save(user).getUserId())
.build();
}
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
User user = userRepository.findByUserId(username);
if (user == null) throw new UsernameNotFoundException(username);
List<GrantedAuthority> authorities = new ArrayList<>();
authorities.add(new SimpleGrantedAuthority(user.getAuthority()));
return new org.springframework.security.core.userdetails.User(user.getUserId(), user.getPassword(), authorities);
}
}
<file_sep>package com.board.domain.user.dto;
import lombok.Builder;
import lombok.Data;
@Data
@Builder
public class UserResponseDto {
private String userId;
}
<file_sep>rootProject.name = 'spring-boot-board'
<file_sep>plugins {
id 'org.springframework.boot' version '2.3.3.RELEASE'
id 'io.spring.dependency-management' version '1.0.10.RELEASE'
id 'java'
}
group = 'com.recruit'
version = '0.1'
sourceCompatibility = "11"
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-security'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.boot:spring-boot-starter-validation'
implementation 'org.apache.commons:commons-collections4:4.0'
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation group: 'nz.net.ultraq.thymeleaf', name: 'thymeleaf-layout-dialect', version: '2.4.1'
implementation 'org.projectlombok:lombok:1.18.20'
runtimeOnly 'com.h2database:h2'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
testImplementation 'org.springframework.security:spring-security-test'
compileOnly 'org.projectlombok:lombok:1.18.6'
annotationProcessor 'org.projectlombok:lombok:1.18.6'
}
jar {
manifest {
attributes 'Title': 'spring-boot-board',
'Version': 1.0,
'Main-Class': 'com.board.SpringBoardApplication'
}
from {
configurations.compile.collect {
it.isDirectory() ? it : zipTree(it)
}
}
}
test {
useJUnitPlatform()
}
targetCompatibility = JavaVersion.VERSION_11
<file_sep>package com.board.domain.user.dto;
import lombok.Data;
import javax.validation.constraints.NotEmpty;
import java.io.Serializable;
@Data
public class UserRequestDto implements Serializable {
private static final long serialVersionUID = -1150644725759026071L;
@NotEmpty
private String userId;
private String password;
private String email;
}
<file_sep>server.port=8080
spring.h2.console.path=/h2-console
spring.h2.console.enabled=true
spring.security.user.name=admin
spring.security.user.password=<PASSWORD>
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.url=jdbc:h2:~/test
spring.datasource.username=sa
spring.datasource.password=<PASSWORD>
spring.thymeleaf.cache=false
spring.thymeleaf.suffix=.html
spring.thymeleaf.prefix=classpath:/templates/
spring.thymeleaf.check-template-location=true
spring.thymeleaf.mode=HTML5
spring.jpa.hibernate.ddl-auto=create-drop
spring.jpa.generate-ddl=false
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.format_sql=true
logging.level.web=DEBUG
logging.level.org.hibernate=ERROR<file_sep>package com.board.controller;
import com.board.domain.post.service.PostService;
import lombok.RequiredArgsConstructor;
import org.springframework.data.domain.Pageable;
import org.springframework.data.web.PageableDefault;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
@RequestMapping("/")
@RequiredArgsConstructor
public class IndexController {
private final PostService postService;
@GetMapping
public String index(@PageableDefault Pageable pageable, Model model) {
model.addAttribute("boardList", postService.getByBoardList(pageable));
model.addAttribute("postCount", postService.getPostCount());
return "index";
}
@GetMapping("post/create")
public String form() {
return "post/form";
}
@GetMapping("post/{postId}")
public String getBoardContentDetail(
@PathVariable long postId,
Model model
) {
model.addAttribute("ContentDetail", postService.getPostDetail(postId));
return "post/detail";
}
@RequestMapping("user/login")
public String login() {
return "user/login";
}
@GetMapping("user/register")
public String register() {
return "user/register";
}
}
<file_sep>package com.board.domain.post.dto.request;
import com.board.domain.post.Post;
import com.board.domain.user.User;
import lombok.Data;
import javax.validation.constraints.NotEmpty;
@Data
public class PostRequest {
@NotEmpty(message = "title cannot be empty.")
private String title;
@NotEmpty(message = "category cannot be empty.")
private String category;
@NotEmpty(message = "contents cannot be empty.")
private String contents;
private String userId;
public Post toEntity() {
return Post.create()
.title(title)
.category(category)
.contents(contents)
.build();
}
public Post toEntityWithUser(User user) {
return Post.create()
.title(title)
.category(category)
.contents(contents)
.user(user)
.build();
}
}
<file_sep>package com.board.controller;
import com.board.domain.post.service.PostService;
import com.board.domain.post.dto.request.PostRequest;
import lombok.RequiredArgsConstructor;
import org.springframework.security.core.annotation.AuthenticationPrincipal;
import org.springframework.security.core.userdetails.User;
import org.springframework.web.bind.annotation.*;
import javax.validation.Valid;
@RestController
@RequestMapping("/api/v1/post")
@RequiredArgsConstructor
public class PostController {
private final PostService postService;
@PostMapping
public Long create(
@Valid PostRequest postRequest,
@AuthenticationPrincipal User user
) {
return postService.create(postRequest, user.getUsername());
}
@PutMapping("/{id}")
public Long update(
@PathVariable long id,
@Valid PostRequest postRequest,
@AuthenticationPrincipal User user
) {
return postService.update(id, postRequest, user.getUsername());
}
@DeleteMapping("/{id}")
public Long delete(
@PathVariable long id,
@AuthenticationPrincipal User user
) {
return postService.delete(id, user.getUsername());
}
}
<file_sep># spring boot board
Stack
- Spring boot
- Spring Data Jpa
- Spring Security
- ThymeLeaf
- Lombok
Database
- H2
Build
- Run configuration -> Gradle Task -> Tasks ADD ( clean, jar, bulid ) -> Run
Spring Security Setting
- WebSecurityConfig
<file_sep>package com.board.domain.post.service;
import com.board.domain.post.Post;
import com.board.domain.post.dto.request.PostRequest;
import com.board.domain.post.dto.response.PostResponse;
import com.board.domain.post.exception.PostNotFoundException;
import com.board.domain.post.repository.PostRepository;
import com.board.domain.user.User;
import com.board.domain.user.repository.UserRepository;
import lombok.RequiredArgsConstructor;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors;
@Service
@RequiredArgsConstructor
public class PostService {
private final PostRepository postRepository;
private final UserRepository userRepository;
public Post getPostDetail(long postId) {
Post post = postRepository.findById(postId)
.orElseThrow(() -> new PostNotFoundException(postId));
if (post.isDeleted())
throw new IllegalArgumentException("삭제 된 게시글 입니다.");
if (post.isBlocked())
throw new IllegalArgumentException("관리자에 의해 접근 거부 된 게시글 입니다.");
return post;
}
public List<PostResponse> getByBoardList(Pageable pageable) {
pageable = PageRequest.of(pageable.getPageNumber() <= 0 ? 0 : pageable.getPageNumber() - 1 , pageable.getPageSize());
return postRepository.findAll(pageable).stream()
.map(Post::of)
.collect(Collectors.toList());
}
public long getPostCount() {
return postRepository.count();
}
public Long create(PostRequest postRequest, String requestedUserId) {
User user = userRepository.getOne(requestedUserId);
return postRepository.save(postRequest.toEntityWithUser(user)).getId();
}
public Long update(long id, PostRequest postRequest, String requestedUserId) {
Post post = checkedAccess(id, requestedUserId);
User user = post.getCreatedUser();
post.update(postRequest.getTitle(), postRequest.getCategory(), postRequest.getContents(), user);
return postRepository.save(post).getId();
}
public Long delete(Long boardId, String requestedUserId) {
Post post = checkedAccess(boardId, requestedUserId);
post.delete();
return postRepository.save(post).getId();
}
// 작성된 게시글과 요청자의 사용자 ID가 같은지 체크 하기
private Post checkedAccess(Long boardId, String requestedUserId) {
Post post = postRepository.findById(boardId)
.orElseThrow(IllegalArgumentException::new);
String boardUserId = post.getCreatedUser().getUserId();
if (!Objects.equals(requestedUserId, boardUserId)) throw new IllegalArgumentException();
return post;
}
}
<file_sep>package com.board.domain.post;
import java.time.LocalDateTime;
import java.util.List;
import java.util.stream.Collectors;
import javax.persistence.*;
import com.board.domain.post.dto.response.PostResponse;
import com.board.domain.user.User;
import lombok.*;
@Entity
@Getter
@NoArgsConstructor
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String category;
@OneToMany(mappedBy = "post")
private List<PostComment> comments;
private String title;
private String contents;
private boolean isDeleted = false;
private boolean isBlocked = false;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "created_user")
private User createdUser;
private LocalDateTime createdDate;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "modified_user")
private User modifiedUser;
private LocalDateTime modifiedDate;
public void delete() {
this.isDeleted = true;
}
public void block() { this.isBlocked = true; }
public void update(String title, String category, String contents, User user) {
this.title = title;
this.category = category;
this.contents = contents;
this.modifiedUser = user;
this.modifiedDate = LocalDateTime.now();
}
@Builder(builderClassName = "create", builderMethodName = "create")
public Post(String title, String category, String contents, User user) {
this.title = title;
this.category = category;
this.contents = contents;
this.createdUser = user;
this.createdDate = LocalDateTime.now();
}
public static PostResponse of(Post post) {
return PostResponse.builder()
.id(post.getId())
.title(post.getTitle())
.contents(post.getContents())
.comments(post.getComments().stream()
.map(PostComment::of)
.collect(Collectors.toList()))
.commentCount(post.getComments().size())
.createUser(User.of(post.getCreatedUser()))
.modifiedUser(User.of(post.getModifiedUser()))
.createDateTime(post.getCreatedDate())
.modifiedDateTime(post.getModifiedDate())
.build();
}
@Override
public String toString() {
return "Board{" +
"id=" + id +
", category='" + category + '\'' +
", comments=" + comments +
", title='" + title + '\'' +
", contents='" + contents + '\'' +
", isDeleted=" + isDeleted +
", isBlocked=" + isBlocked +
", createdUser=" + createdUser +
", createdDate=" + createdDate +
", modifiedUser=" + modifiedUser +
", modifiedDate=" + modifiedDate +
'}';
}
}
| 8871a8b9dde41dff208c647a5267860f0e4f40af | [
"Markdown",
"Java",
"INI",
"Gradle"
] | 14 | Java | izbean-c/LGAssignment | 74a2e245bcf661c542b6446ae21ee39e4b9a1477 | 2f6abadcb9d5bba261020275e542c175256ce449 |
refs/heads/master | <file_sep>package com.github.leandrogodoycwb.aula05.programa;
import java.io.IOException;
import com.github.leandrogodoycwb.aula05.classes.FileIO;
import com.github.leandrogodoycwb.aula05.classes.Pessoa;
import com.github.leandrogodoycwb.aula05.classes.PessoaRepositorio;
public class ProgramaNew {
public static void main(String[] args) {
PessoaRepositorio repositorio = new PessoaRepositorio();
Pessoa p1 = new Pessoa ("<NAME>","10525000","<EMAIL>");
Pessoa p2 = new Pessoa ("<NAME>", "10000000", "<EMAIL>");
Pessoa p3 = new Pessoa ("<NAME>", "11000000", "<EMAIL>");
repositorio.pessoas.add(p1);
repositorio.pessoas.add(p2);
repositorio.pessoas.add(p3);
//System.out.println(repositorio.pessoas);
try {
//FileIO.writer(repositorio.pessoas, "pessoas.txt");
PessoaRepositorio repositorio2 = FileIO.reader("pessoas.txt");
Pessoa r = (Pessoa) repositorio2.pessoas.get(3);
System.out.println(r.getNome());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
<file_sep>package com.github.leandrogodoycwb.aula05.programa;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class Programa {
public static void main(String[] args) throws IOException {
try {
FileWriter fileWriter = new FileWriter("primeiroarq.txt");
fileWriter.append("Leandro\nGodoy");
fileWriter.close();
System.out.println("Escreveu");
} catch (IOException e) {
e.printStackTrace();
}
//Leitura
try {
FileReader fileReader = new FileReader("primeiroarq.txt");
BufferedReader reader = new BufferedReader(fileReader);
String linha ="";
while ((linha = reader.readLine()) != null)
System.out.println(linha);
reader.close();
fileReader.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
}catch (IOException e) {
e.printStackTrace();
}
}
}
<file_sep>package com.github.leandrogodoycwb.aula05.classes;
import java.util.ArrayList;
public class PessoaRepositorio {
public ArrayList<Pessoa> pessoas = new ArrayList<Pessoa>();
}
| c9b0d1ea1e643f5a76f3299f8ef288a6c1ee775a | [
"Java"
] | 3 | Java | leandrogodoycwb/aula0309 | 2fac900b05f36ecff4c07c790195b3a20ec66123 | 1876e1b8ed629e09bd9932e394a6b5bd7dabf6fd |
refs/heads/master | <file_sep>/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package homemanagementsystem.HomeRegistration;
import java.math.BigDecimal;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import javax.swing.JFrame;
import javax.swing.JOptionPane;
import sun.security.util.Password;
/**
*
* @author boker
*/
public class Registration extends javax.swing.JFrame {
/**
* Creates new form Registration
*/
public Registration() {
initComponents();
}
/**
* This method is called from within the constructor to initialize the form.
* WARNING: Do NOT modify this code. The content of this method is always
* regenerated by the Form Editor.
*/
@SuppressWarnings("unchecked")
// <editor-fold defaultstate="collapsed" desc="Generated Code">//GEN-BEGIN:initComponents
private void initComponents() {
jPanel1 = new javax.swing.JPanel();
jPanel2 = new javax.swing.JPanel();
jPanel3 = new javax.swing.JPanel();
jPanel4 = new javax.swing.JPanel();
jLabel1 = new javax.swing.JLabel();
jLabel2 = new javax.swing.JLabel();
jLabel3 = new javax.swing.JLabel();
jLabel4 = new javax.swing.JLabel();
jLabel5 = new javax.swing.JLabel();
jLabel6 = new javax.swing.JLabel();
jLabel7 = new javax.swing.JLabel();
cmbgender = new javax.swing.JComboBox<>();
jButtoncancel = new javax.swing.JButton();
jLabel8 = new javax.swing.JLabel();
jTextFieldLName = new javax.swing.JTextField();
jTextFieldIDnumber = new javax.swing.JTextField();
jButtonsignup = new javax.swing.JButton();
jTextFieldFName = new javax.swing.JTextField();
jTextFieldMNumber = new javax.swing.JTextField();
password = new <PASSWORD>.swing.JPasswordField();
jCheckBox = new javax.swing.JCheckBox();
setDefaultCloseOperation(javax.swing.WindowConstants.EXIT_ON_CLOSE);
jPanel1.setBackground(new java.awt.Color(255, 255, 0));
jPanel3.setBackground(new java.awt.Color(102, 102, 102));
jPanel4.setBackground(new java.awt.Color(0, 0, 204));
jLabel1.setFont(new java.awt.Font("Tahoma", 1, 18)); // NOI18N
jLabel1.setForeground(new java.awt.Color(255, 255, 255));
jLabel1.setText("Register");
javax.swing.GroupLayout jPanel4Layout = new javax.swing.GroupLayout(jPanel4);
jPanel4.setLayout(jPanel4Layout);
jPanel4Layout.setHorizontalGroup(
jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel4Layout.createSequentialGroup()
.addGap(99, 99, 99)
.addComponent(jLabel1)
.addContainerGap(100, Short.MAX_VALUE))
);
jPanel4Layout.setVerticalGroup(
jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel4Layout.createSequentialGroup()
.addContainerGap()
.addComponent(jLabel1)
.addContainerGap(49, Short.MAX_VALUE))
);
javax.swing.GroupLayout jPanel3Layout = new javax.swing.GroupLayout(jPanel3);
jPanel3.setLayout(jPanel3Layout);
jPanel3Layout.setHorizontalGroup(
jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel3Layout.createSequentialGroup()
.addGap(61, 61, 61)
.addComponent(jPanel4, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addContainerGap(javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
);
jPanel3Layout.setVerticalGroup(
jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(jPanel4, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
);
jLabel2.setText("First Name:");
jLabel3.setText("Last Name:");
jLabel4.setText("ID Number");
jLabel5.setText("Mobile Number:");
jLabel6.setText("Password:");
jLabel7.setText("Gender:");
cmbgender.setModel(new javax.swing.DefaultComboBoxModel<>(new String[] { "male", "female", "others" }));
jButtoncancel.setBackground(new java.awt.Color(204, 0, 204));
jButtoncancel.setFont(new java.awt.Font("Tahoma", 1, 14)); // NOI18N
jButtoncancel.setForeground(new java.awt.Color(255, 255, 255));
jButtoncancel.setText("cancel");
jButtoncancel.addMouseListener(new java.awt.event.MouseAdapter() {
public void mouseClicked(java.awt.event.MouseEvent evt) {
jButtoncancelMouseClicked(evt);
}
});
jLabel8.setText("already have an account ? click here to login");
jLabel8.setCursor(new java.awt.Cursor(java.awt.Cursor.HAND_CURSOR));
jLabel8.addMouseListener(new java.awt.event.MouseAdapter() {
public void mouseClicked(java.awt.event.MouseEvent evt) {
jLabel8MouseClicked(evt);
}
});
jButtonsignup.setBackground(new java.awt.Color(0, 0, 204));
jButtonsignup.setFont(new java.awt.Font("Tahoma", 1, 14)); // NOI18N
jButtonsignup.setForeground(new java.awt.Color(255, 255, 255));
jButtonsignup.setText("signup");
jButtonsignup.addMouseListener(new java.awt.event.MouseAdapter() {
public void mouseClicked(java.awt.event.MouseEvent evt) {
jButtonsignupMouseClicked(evt);
}
});
jButtonsignup.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
jButtonsignupActionPerformed(evt);
}
});
jTextFieldFName.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
jTextFieldFNameActionPerformed(evt);
}
});
jCheckBox.setText("show pass");
jCheckBox.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
jCheckBoxActionPerformed(evt);
}
});
javax.swing.GroupLayout jPanel2Layout = new javax.swing.GroupLayout(jPanel2);
jPanel2.setLayout(jPanel2Layout);
jPanel2Layout.setHorizontalGroup(
jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(jPanel3, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addGroup(javax.swing.GroupLayout.Alignment.TRAILING, jPanel2Layout.createSequentialGroup()
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.TRAILING)
.addGroup(jPanel2Layout.createSequentialGroup()
.addGap(22, 22, 22)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel2Layout.createSequentialGroup()
.addComponent(jLabel7, javax.swing.GroupLayout.PREFERRED_SIZE, 98, javax.swing.GroupLayout.PREFERRED_SIZE)
.addGap(37, 37, 37)
.addComponent(cmbgender, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE))
.addGroup(jPanel2Layout.createSequentialGroup()
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING, false)
.addComponent(jLabel4, javax.swing.GroupLayout.PREFERRED_SIZE, 81, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jLabel2)
.addComponent(jLabel6, javax.swing.GroupLayout.DEFAULT_SIZE, 98, Short.MAX_VALUE)
.addComponent(jLabel5, javax.swing.GroupLayout.PREFERRED_SIZE, 81, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jLabel3, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel2Layout.createSequentialGroup()
.addGap(26, 26, 26)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING, false)
.addGroup(jPanel2Layout.createSequentialGroup()
.addComponent(jButtonsignup)
.addGap(18, 18, 18)
.addComponent(jButtoncancel))
.addComponent(jTextFieldLName, javax.swing.GroupLayout.DEFAULT_SIZE, 217, Short.MAX_VALUE)
.addComponent(jTextFieldFName)
.addComponent(jTextFieldIDnumber)
.addComponent(jTextFieldMNumber)))
.addGroup(jPanel2Layout.createSequentialGroup()
.addGap(18, 18, 18)
.addComponent(password, javax.swing.GroupLayout.PREFERRED_SIZE, 143, javax.swing.GroupLayout.PREFERRED_SIZE)
.addGap(18, 18, 18)
.addComponent(jCheckBox)))))
.addGap(54, 54, 54))
.addGroup(jPanel2Layout.createSequentialGroup()
.addGap(0, 0, Short.MAX_VALUE)
.addComponent(jLabel8)
.addGap(42, 42, 42)))
.addGap(20, 20, 20))
);
jPanel2Layout.setVerticalGroup(
jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel2Layout.createSequentialGroup()
.addComponent(jPanel3, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING, false)
.addGroup(jPanel2Layout.createSequentialGroup()
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.UNRELATED)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jLabel2)
.addComponent(jTextFieldFName, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE))
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jLabel3)
.addComponent(jTextFieldLName, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE))
.addGap(18, 18, 18)
.addComponent(jLabel4))
.addGroup(jPanel2Layout.createSequentialGroup()
.addGap(78, 78, 78)
.addComponent(jTextFieldIDnumber, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)))
.addGap(18, 18, 18)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(jLabel5)
.addComponent(jTextFieldMNumber, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE))
.addGap(18, 18, 18)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(cmbgender, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jLabel7, javax.swing.GroupLayout.PREFERRED_SIZE, 21, javax.swing.GroupLayout.PREFERRED_SIZE))
.addGap(18, 18, 18)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jLabel6, javax.swing.GroupLayout.PREFERRED_SIZE, 21, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(password, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jCheckBox))
.addGap(24, 24, 24)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jButtoncancel, javax.swing.GroupLayout.PREFERRED_SIZE, 25, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jButtonsignup))
.addGap(18, 18, 18)
.addComponent(jLabel8)
.addContainerGap(javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
);
javax.swing.GroupLayout jPanel1Layout = new javax.swing.GroupLayout(jPanel1);
jPanel1.setLayout(jPanel1Layout);
jPanel1Layout.setHorizontalGroup(
jPanel1Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel1Layout.createSequentialGroup()
.addContainerGap()
.addComponent(jPanel2, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addContainerGap())
);
jPanel1Layout.setVerticalGroup(
jPanel1Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel1Layout.createSequentialGroup()
.addContainerGap()
.addComponent(jPanel2, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addContainerGap())
);
javax.swing.GroupLayout layout = new javax.swing.GroupLayout(getContentPane());
getContentPane().setLayout(layout);
layout.setHorizontalGroup(
layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(layout.createSequentialGroup()
.addContainerGap()
.addComponent(jPanel1, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addContainerGap())
);
layout.setVerticalGroup(
layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(layout.createSequentialGroup()
.addContainerGap()
.addComponent(jPanel1, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addContainerGap())
);
pack();
}// </editor-fold>//GEN-END:initComponents
private void jLabel8MouseClicked(java.awt.event.MouseEvent evt) {//GEN-FIRST:event_jLabel8MouseClicked
Home_Login login=new Home_Login();
this.setVisible(false);
login.setVisible(true);
login.pack();
login.setLocationRelativeTo(null);
login.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
//login.dispose();
}//GEN-LAST:event_jLabel8MouseClicked
// public boolean varifyData(){
// if(jTextFieldFName.getText().equals("")&&jTextFieldLName.getText().equals("")&&
// jTextFieldIDnumber.getText().toString().equals("") ) {
//
// }return false;
// }
private void jButtoncancelMouseClicked(java.awt.event.MouseEvent evt) {//GEN-FIRST:event_jButtoncancelMouseClicked
// TODO add your handling code here:
}//GEN-LAST:event_jButtoncancelMouseClicked
private void jButtonsignupActionPerformed(java.awt.event.ActionEvent evt) {//GEN-FIRST:event_jButtonsignupActionPerformed
// TODO add your handling code here:
try{
String query="INSERT INTO `home _registration`( `fname`, `lname`, `idnumber`, `mnumber`, `gender`, `password`) VALUES (?,?,?,?,?,?)";
Connection con=MyConnection.getconnection();
PreparedStatement pst=con.prepareStatement(query);
pst.setString(1, jTextFieldFName.getText().toString());
pst.setString(2, jTextFieldLName.getText().toString());
pst.setString(3, jTextFieldIDnumber.getText().toString());
pst.setString(4, jTextFieldMNumber.getText().toString());
pst.setString(5, cmbgender.getSelectedItem().toString());
pst.setString(6, String.valueOf(password.getPassword()));
int result=pst.executeUpdate();
// ResultSet rs=pst.executeQuery(query);
//rs=pst.executeUpdate();
// pst.executeQuery();
//
//System.out.println("result=="+result);
if(result>0){
MainHome home=new MainHome ();
home.setVisible(true);
this.setVisible(false);
home.pack();
home.setLocationRelativeTo(null);
MainHome.jLabel1.setText("Welcome Id:" +jTextFieldIDnumber.getText());
home.setExtendedState(JFrame.MAXIMIZED_BOTH);
//home.dispose();
}
else{
JOptionPane.showMessageDialog(null, " account creation faild ,contact josse");
}
//
//
// if(pst.executeUpdate()!=0){
// JOptionPane.showMessageDialog(null, " account created");
//
//
// if(jTextFieldFName.getText().equals("")){
// JOptionPane.showMessageDialog(null ," first name is required");
// if(jTextFieldLName.getText().equals("")){
// JOptionPane.showMessageDialog(null ,"last name is required");
// }
// }
// }
}
catch(SQLException ex){
System.out.println(ex);
// JOptionPane.showMessageDialog(null, ex);
}
}//GEN-LAST:event_jButtonsignupActionPerformed
private void jTextFieldFNameActionPerformed(java.awt.event.ActionEvent evt) {//GEN-FIRST:event_jTextFieldFNameActionPerformed
// TODO add your handling code here:
}//GEN-LAST:event_jTextFieldFNameActionPerformed
private void jButtonsignupMouseClicked(java.awt.event.MouseEvent evt) {//GEN-FIRST:event_jButtonsignupMouseClicked
// TODO add your handling code here:m
// Home_Homepage home=new Home_Homepage();
// home.setVisible(true);
}//GEN-LAST:event_jButtonsignupMouseClicked
private void jCheckBoxActionPerformed(java.awt.event.ActionEvent evt) {//GEN-FIRST:event_jCheckBoxActionPerformed
// TODO add your handling code here:
if(jCheckBox.isSelected()){
password.setEchoChar((char)0);
}else{
password.setEchoChar('*');
}
}//GEN-LAST:event_jCheckBoxActionPerformed
/**
* @param args the command line arguments
*/
public static void main(String args[]) {
/* Set the Nimbus look and feel */
//<editor-fold defaultstate="collapsed" desc=" Look and feel setting code (optional) ">
/* If Nimbus (introduced in Java SE 6) is not available, stay with the default look and feel.
* For details see http://download.oracle.com/javase/tutorial/uiswing/lookandfeel/plaf.html
*/
try {
for (javax.swing.UIManager.LookAndFeelInfo info : javax.swing.UIManager.getInstalledLookAndFeels()) {
if ("Nimbus".equals(info.getName())) {
javax.swing.UIManager.setLookAndFeel(info.getClassName());
break;
}
}
} catch (ClassNotFoundException ex) {
java.util.logging.Logger.getLogger(Registration.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
} catch (InstantiationException ex) {
java.util.logging.Logger.getLogger(Registration.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
} catch (IllegalAccessException ex) {
java.util.logging.Logger.getLogger(Registration.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
} catch (javax.swing.UnsupportedLookAndFeelException ex) {
java.util.logging.Logger.getLogger(Registration.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
}
//</editor-fold>
/* Create and display the form */
java.awt.EventQueue.invokeLater(new Runnable() {
public void run() {
new Registration().setVisible(true);
}
});
}
// Variables declaration - do not modify//GEN-BEGIN:variables
private javax.swing.JComboBox<String> cmbgender;
private javax.swing.JButton jButtoncancel;
private javax.swing.JButton jButtonsignup;
private javax.swing.JCheckBox jCheckBox;
private javax.swing.JLabel jLabel1;
private javax.swing.JLabel jLabel2;
private javax.swing.JLabel jLabel3;
private javax.swing.JLabel jLabel4;
private javax.swing.JLabel jLabel5;
private javax.swing.JLabel jLabel6;
private javax.swing.JLabel jLabel7;
private javax.swing.JLabel jLabel8;
private javax.swing.JPanel jPanel1;
private javax.swing.JPanel jPanel2;
private javax.swing.JPanel jPanel3;
private javax.swing.JPanel jPanel4;
private javax.swing.JTextField jTextFieldFName;
private javax.swing.JTextField jTextFieldIDnumber;
private javax.swing.JTextField jTextFieldLName;
private javax.swing.JTextField jTextFieldMNumber;
private javax.swing.JPasswordField password;
// End of variables declaration//GEN-END:variables
}
<file_sep>/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package homemanagementsystem.HomeRegistration;
import java.beans.PropertyChangeListener;
import java.beans.PropertyChangeSupport;
import java.io.Serializable;
import javax.persistence.Basic;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.NamedQueries;
import javax.persistence.NamedQuery;
import javax.persistence.Table;
import javax.persistence.Transient;
/**
*
* @author boker
*/
@Entity
@Table(name = "home_item", catalog = "homemanagement", schema = "")
@NamedQueries({
@NamedQuery(name = "HomeItem.findAll", query = "SELECT h FROM HomeItem h")
, @NamedQuery(name = "HomeItem.findById", query = "SELECT h FROM HomeItem h WHERE h.id = :id")
, @NamedQuery(name = "HomeItem.findByItemname", query = "SELECT h FROM HomeItem h WHERE h.itemname = :itemname")
, @NamedQuery(name = "HomeItem.findByItemcategory", query = "SELECT h FROM HomeItem h WHERE h.itemcategory = :itemcategory")
, @NamedQuery(name = "HomeItem.findByItemdescription", query = "SELECT h FROM HomeItem h WHERE h.itemdescription = :itemdescription")
, @NamedQuery(name = "HomeItem.findByItemprice", query = "SELECT h FROM HomeItem h WHERE h.itemprice = :itemprice")})
public class HomeItem implements Serializable {
@Transient
private PropertyChangeSupport changeSupport = new PropertyChangeSupport(this);
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "id")
private Integer id;
@Basic(optional = false)
@Column(name = "itemname")
private String itemname;
@Basic(optional = false)
@Column(name = "itemcategory")
private String itemcategory;
@Basic(optional = false)
@Column(name = "itemdescription")
private String itemdescription;
@Basic(optional = false)
@Column(name = "itemprice")
private int itemprice;
public HomeItem() {
}
public HomeItem(Integer id) {
this.id = id;
}
public HomeItem(Integer id, String itemname, String itemcategory, String itemdescription, int itemprice) {
this.id = id;
this.itemname = itemname;
this.itemcategory = itemcategory;
this.itemdescription = itemdescription;
this.itemprice = itemprice;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
Integer oldId = this.id;
this.id = id;
changeSupport.firePropertyChange("id", oldId, id);
}
public String getItemname() {
return itemname;
}
public void setItemname(String itemname) {
String oldItemname = this.itemname;
this.itemname = itemname;
changeSupport.firePropertyChange("itemname", oldItemname, itemname);
}
public String getItemcategory() {
return itemcategory;
}
public void setItemcategory(String itemcategory) {
String oldItemcategory = this.itemcategory;
this.itemcategory = itemcategory;
changeSupport.firePropertyChange("itemcategory", oldItemcategory, itemcategory);
}
public String getItemdescription() {
return itemdescription;
}
public void setItemdescription(String itemdescription) {
String oldItemdescription = this.itemdescription;
this.itemdescription = itemdescription;
changeSupport.firePropertyChange("itemdescription", oldItemdescription, itemdescription);
}
public int getItemprice() {
return itemprice;
}
public void setItemprice(int itemprice) {
int oldItemprice = this.itemprice;
this.itemprice = itemprice;
changeSupport.firePropertyChange("itemprice", oldItemprice, itemprice);
}
@Override
public int hashCode() {
int hash = 0;
hash += (id != null ? id.hashCode() : 0);
return hash;
}
@Override
public boolean equals(Object object) {
// TODO: Warning - this method won't work in the case the id fields are not set
if (!(object instanceof HomeItem)) {
return false;
}
HomeItem other = (HomeItem) object;
if ((this.id == null && other.id != null) || (this.id != null && !this.id.equals(other.id))) {
return false;
}
return true;
}
@Override
public String toString() {
return "homemanagementsystem.HomeRegistration.HomeItem[ id=" + id + " ]";
}
public void addPropertyChangeListener(PropertyChangeListener listener) {
changeSupport.addPropertyChangeListener(listener);
}
public void removePropertyChangeListener(PropertyChangeListener listener) {
changeSupport.removePropertyChangeListener(listener);
}
}
<file_sep>/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package homemanagementsystem.HomeRegistration;
import com.sun.xml.internal.ws.api.streaming.XMLStreamReaderFactory.Default;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import javax.swing.JOptionPane;
import javax.swing.table.DefaultTableModel;
/**
*
* @author boker
*/
public class Home_Homepage extends javax.swing.JFrame {
/**
* Creates new form Home_Homepage
*/
public Home_Homepage() {
initComponents();
//Show_Items_jTableItem();
System.out.println("hell");
}
public static Connection getConnection(){
Connection con=null;
try {
con=DriverManager.getConnection("jdbc:mysql://localhost/homemanagement","root", "");;
// JOptionPane.showMessageDialog(null,"conneted to database");
}
catch (Exception ex ){
JOptionPane.showMessageDialog(null,ex);
}
return con;
}
public boolean checkInput(){
if(txtitemname.getText()==null
||cbcategory.getSelectedItem()==null
||txtitemdescription.getText()==null
||txtitemprice.getText()==null){
return false;
}
else{
try{
Float.parseFloat(txtitemprice.getText());
return true;
}catch(Exception ex){
return false;
}
}
}
@SuppressWarnings("unchecked")
// <editor-fold defaultstate="collapsed" desc="Generated Code">//GEN-BEGIN:initComponents
private void initComponents() {
bindingGroup = new org.jdesktop.beansbinding.BindingGroup();
jPasswordField1 = new javax.swing.JPasswordField();
entityManager = java.beans.Beans.isDesignTime() ? null : javax.persistence.Persistence.createEntityManagerFactory("homemanagement?zeroDateTimeBehavior=convertToNullPU").createEntityManager();
homeRegistrationQuery = java.beans.Beans.isDesignTime() ? null : entityManager.createQuery("SELECT h FROM HomeRegistration h");
homeRegistrationList = java.beans.Beans.isDesignTime() ? java.util.Collections.emptyList() : homeRegistrationQuery.getResultList();
homeItemQuery = java.beans.Beans.isDesignTime() ? null : entityManager.createQuery("SELECT h FROM HomeItem h");
homeItemList = java.beans.Beans.isDesignTime() ? java.util.Collections.emptyList() : homeItemQuery.getResultList();
jPanel1 = new javax.swing.JPanel();
jPanel2 = new javax.swing.JPanel();
jPanel3 = new javax.swing.JPanel();
jLabel1 = new javax.swing.JLabel();
jScrollPane1 = new javax.swing.JScrollPane();
jTableItem = new javax.swing.JTable();
jLabel2 = new javax.swing.JLabel();
jLabel4 = new javax.swing.JLabel();
jLabel5 = new javax.swing.JLabel();
cbcategory = new javax.swing.JComboBox<>();
jLabel3 = new javax.swing.JLabel();
txtitemname = new javax.swing.JTextField();
txtitemprice = new javax.swing.JTextField();
txtitemdescription = new javax.swing.JTextField();
jButtonAdd = new javax.swing.JButton();
jButtonUpdate = new javax.swing.JButton();
jButtonDelete = new javax.swing.JButton();
jButtonExit = new javax.swing.JButton();
jLabel6 = new javax.swing.JLabel();
txtitemid = new javax.swing.JTextField();
jPasswordField1.setText("<PASSWORD>");
setDefaultCloseOperation(javax.swing.WindowConstants.EXIT_ON_CLOSE);
jPanel1.setBackground(new java.awt.Color(255, 255, 51));
jPanel3.setBackground(new java.awt.Color(102, 102, 102));
jLabel1.setFont(new java.awt.Font("Tahoma", 1, 14)); // NOI18N
jLabel1.setForeground(new java.awt.Color(255, 255, 255));
jLabel1.setText(" Welcome to Home Management System");
javax.swing.GroupLayout jPanel3Layout = new javax.swing.GroupLayout(jPanel3);
jPanel3.setLayout(jPanel3Layout);
jPanel3Layout.setHorizontalGroup(
jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(javax.swing.GroupLayout.Alignment.TRAILING, jPanel3Layout.createSequentialGroup()
.addContainerGap(javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addComponent(jLabel1, javax.swing.GroupLayout.PREFERRED_SIZE, 316, javax.swing.GroupLayout.PREFERRED_SIZE)
.addGap(83, 83, 83))
);
jPanel3Layout.setVerticalGroup(
jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel3Layout.createSequentialGroup()
.addContainerGap()
.addComponent(jLabel1)
.addContainerGap(26, Short.MAX_VALUE))
);
org.jdesktop.swingbinding.JTableBinding jTableBinding = org.jdesktop.swingbinding.SwingBindings.createJTableBinding(org.jdesktop.beansbinding.AutoBinding.UpdateStrategy.READ_WRITE, homeItemList, jTableItem);
org.jdesktop.swingbinding.JTableBinding.ColumnBinding columnBinding = jTableBinding.addColumnBinding(org.jdesktop.beansbinding.ELProperty.create("${id}"));
columnBinding.setColumnName("Id");
columnBinding.setColumnClass(Integer.class);
columnBinding = jTableBinding.addColumnBinding(org.jdesktop.beansbinding.ELProperty.create("${itemname}"));
columnBinding.setColumnName("Itemname");
columnBinding.setColumnClass(String.class);
columnBinding = jTableBinding.addColumnBinding(org.jdesktop.beansbinding.ELProperty.create("${itemcategory}"));
columnBinding.setColumnName("Itemcategory");
columnBinding.setColumnClass(String.class);
columnBinding = jTableBinding.addColumnBinding(org.jdesktop.beansbinding.ELProperty.create("${itemdescription}"));
columnBinding.setColumnName("Itemdescription");
columnBinding.setColumnClass(String.class);
columnBinding = jTableBinding.addColumnBinding(org.jdesktop.beansbinding.ELProperty.create("${itemprice}"));
columnBinding.setColumnName("Itemprice");
columnBinding.setColumnClass(Integer.class);
bindingGroup.addBinding(jTableBinding);
jTableBinding.bind();org.jdesktop.beansbinding.Binding binding = org.jdesktop.beansbinding.Bindings.createAutoBinding(org.jdesktop.beansbinding.AutoBinding.UpdateStrategy.READ_WRITE, jButtonAdd, org.jdesktop.beansbinding.ELProperty.create("${}"), jTableItem, org.jdesktop.beansbinding.BeanProperty.create("selectedElement"));
bindingGroup.addBinding(binding);
jTableItem.addMouseListener(new java.awt.event.MouseAdapter() {
public void mouseClicked(java.awt.event.MouseEvent evt) {
jTableItemMouseClicked(evt);
}
});
jScrollPane1.setViewportView(jTableItem);
jLabel2.setText("Category");
jLabel4.setText("Item Price");
jLabel5.setText("Item Description");
cbcategory.setModel(new javax.swing.DefaultComboBoxModel<>(new String[] { "Item 1", "Item 2", "Item 3", "Item 4" }));
jLabel3.setText("Item Name");
jButtonAdd.setText("Add");
jButtonAdd.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
jButtonAddActionPerformed(evt);
}
});
jButtonUpdate.setText("Update");
jButtonUpdate.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
jButtonUpdateActionPerformed(evt);
}
});
jButtonDelete.setText("Delete");
jButtonDelete.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
jButtonDeleteActionPerformed(evt);
}
});
jButtonExit.setText("Exit");
jButtonExit.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
jButtonExitActionPerformed(evt);
}
});
jLabel6.setText("Item ID");
javax.swing.GroupLayout jPanel2Layout = new javax.swing.GroupLayout(jPanel2);
jPanel2.setLayout(jPanel2Layout);
jPanel2Layout.setHorizontalGroup(
jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(jPanel3, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addGroup(jPanel2Layout.createSequentialGroup()
.addContainerGap()
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(jScrollPane1)
.addGroup(jPanel2Layout.createSequentialGroup()
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.TRAILING, false)
.addGroup(javax.swing.GroupLayout.Alignment.LEADING, jPanel2Layout.createSequentialGroup()
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel2Layout.createSequentialGroup()
.addGap(27, 27, 27)
.addComponent(jButtonAdd))
.addComponent(jLabel4))
.addGap(27, 27, 27)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.TRAILING)
.addGroup(jPanel2Layout.createSequentialGroup()
.addComponent(jButtonUpdate)
.addGap(35, 35, 35)
.addComponent(jButtonDelete))
.addComponent(txtitemprice, javax.swing.GroupLayout.PREFERRED_SIZE, 158, javax.swing.GroupLayout.PREFERRED_SIZE)))
.addGroup(javax.swing.GroupLayout.Alignment.LEADING, jPanel2Layout.createSequentialGroup()
.addGap(7, 7, 7)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING, false)
.addComponent(jLabel5, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addComponent(jLabel2)
.addComponent(jLabel3, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
.addComponent(jLabel6, javax.swing.GroupLayout.PREFERRED_SIZE, 49, javax.swing.GroupLayout.PREFERRED_SIZE))
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(cbcategory, javax.swing.GroupLayout.PREFERRED_SIZE, 142, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(txtitemdescription, javax.swing.GroupLayout.PREFERRED_SIZE, 150, javax.swing.GroupLayout.PREFERRED_SIZE)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.TRAILING, false)
.addComponent(txtitemid, javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(txtitemname, javax.swing.GroupLayout.Alignment.LEADING, javax.swing.GroupLayout.DEFAULT_SIZE, 142, Short.MAX_VALUE)))))
.addGap(38, 38, 38)
.addComponent(jButtonExit)
.addGap(0, 0, Short.MAX_VALUE)))
.addContainerGap(javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
);
jPanel2Layout.setVerticalGroup(
jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel2Layout.createSequentialGroup()
.addComponent(jPanel3, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel2Layout.createSequentialGroup()
.addGap(18, 18, 18)
.addComponent(jLabel6)
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
.addGroup(javax.swing.GroupLayout.Alignment.TRAILING, jPanel2Layout.createSequentialGroup()
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addComponent(txtitemid, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addGap(18, 18, 18)))
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.TRAILING)
.addComponent(txtitemname, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jLabel3, javax.swing.GroupLayout.PREFERRED_SIZE, 27, javax.swing.GroupLayout.PREFERRED_SIZE))
.addGap(18, 18, 18)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(cbcategory, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jLabel2, javax.swing.GroupLayout.PREFERRED_SIZE, 20, javax.swing.GroupLayout.PREFERRED_SIZE))
.addGap(28, 28, 28)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.TRAILING)
.addComponent(jLabel5, javax.swing.GroupLayout.PREFERRED_SIZE, 27, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(txtitemdescription, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE))
.addGap(35, 35, 35)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(txtitemprice, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jLabel4))
.addGap(50, 50, 50)
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jButtonUpdate)
.addComponent(jButtonAdd)
.addComponent(jButtonDelete)
.addComponent(jButtonExit))
.addGap(18, 18, 18)
.addComponent(jScrollPane1, javax.swing.GroupLayout.PREFERRED_SIZE, 93, javax.swing.GroupLayout.PREFERRED_SIZE)
.addGap(35, 35, 35))
);
javax.swing.GroupLayout jPanel1Layout = new javax.swing.GroupLayout(jPanel1);
jPanel1.setLayout(jPanel1Layout);
jPanel1Layout.setHorizontalGroup(
jPanel1Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel1Layout.createSequentialGroup()
.addContainerGap()
.addComponent(jPanel2, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addContainerGap())
);
jPanel1Layout.setVerticalGroup(
jPanel1Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel1Layout.createSequentialGroup()
.addContainerGap()
.addComponent(jPanel2, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
);
javax.swing.GroupLayout layout = new javax.swing.GroupLayout(getContentPane());
getContentPane().setLayout(layout);
layout.setHorizontalGroup(
layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(jPanel1, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
);
layout.setVerticalGroup(
layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(layout.createSequentialGroup()
.addComponent(jPanel1, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addGap(0, 0, Short.MAX_VALUE))
);
bindingGroup.bind();
pack();
}// </editor-fold>//GEN-END:initComponents
private void jButtonAddActionPerformed(java.awt.event.ActionEvent evt) {//GEN-FIRST:event_jButtonAddActionPerformed
// TODO add your handling code here:
DefaultTableModel model=(DefaultTableModel)jTableItem.getModel();
if(!txtitemname.getText().trim().equals("")){
model.addRow(new Object[]{ txtitemid.getText(),txtitemname.getText(),cbcategory.getSelectedItem().toString(),txtitemdescription.getText(),txtitemprice.getText()});
} else {
JOptionPane.showMessageDialog(null, "required");
}
//txtitemid.getText()
if (checkInput()){
try{
PreparedStatement ps=null;
String query =null;
query=" INSERT INTO `home_item`( `itemname`, `itemcategory`, `itemdescription`, `itemprice`) VALUES (?,?,?,?)";
Connection con= Home_Homepage.getConnection();
ps=con.prepareStatement(query);
//ps.setString(1, txtitemid.getText().toString());
ps.setString(1, txtitemname.getText());
ps.setString(2, cbcategory.getSelectedItem().toString());
ps.setString(3,txtitemdescription.getText());
ps.setString(4, txtitemprice.getText());
ps.executeUpdate();
Show_Items_jTableItem();
JOptionPane.showMessageDialog(null, "connected");
System.out.println(txtitemname.getText()+""+cbcategory.getSelectedItem().toString()+""+txtitemdescription.getText()+txtitemprice.getText() );
}catch (Exception ex){
JOptionPane.showMessageDialog(null, ex.getMessage());
ex.printStackTrace();
}
}else{
JOptionPane.showMessageDialog(null, "field are required");
}
}//GEN-LAST:event_jButtonAddActionPerformed
private void jButtonUpdateActionPerformed(java.awt.event.ActionEvent evt) {//GEN-FIRST:event_jButtonUpdateActionPerformed
// TODO add your handling code here:
DefaultTableModel model=(DefaultTableModel)jTableItem.getModel();
int row=jTableItem.getSelectedRow();
if (row==-1){
JOptionPane.showMessageDialog(null, "cant happen");
}else{
//model.setValueAt(txtitemid.getText(), 0);
model.setValueAt(txtitemname.getText(),row,1);
model.setValueAt(cbcategory.getSelectedItem(),row,2);
model.setValueAt(txtitemdescription.getText(),row,3);
model.setValueAt(txtitemprice.getText(),row,4);
if(checkInput()){
try{
PreparedStatement ps=null;
String Updatequery =null;
Updatequery=" UPDATE `home_item` SET `itemname`=?,`itemcategory`=?,`itemdescription`=?,`itemprice`=? WHERE `id`=?";
Connection con= Home_Homepage.getConnection();
ps=con.prepareStatement(Updatequery);
ps.setString(1, txtitemname.getText());
ps.setString(2, cbcategory.getSelectedItem().toString());
ps.setString(3,txtitemdescription.getText());
ps.setString(4, txtitemprice.getText());
ps.setInt(5, Integer.parseInt( txtitemid.getText()));
ps.executeUpdate();
Show_Items_jTableItem();
JOptionPane.showMessageDialog(null, "update");
}catch (Exception ex){
JOptionPane.showMessageDialog(null, ex.getMessage());
ex.printStackTrace();
}
}else{
JOptionPane.showMessageDialog(null, "one more field is empty");
}
}
}//GEN-LAST:event_jButtonUpdateActionPerformed
private void jButtonDeleteActionPerformed(java.awt.event.ActionEvent evt) {//GEN-FIRST:event_jButtonDeleteActionPerformed
// TODO add your handling code here:
DefaultTableModel model=(DefaultTableModel)jTableItem.getModel();
int row=jTableItem.getSelectedRow();
if (row==-1){
JOptionPane.showMessageDialog(null, "select row to delete");
}else{
int status= JOptionPane.showConfirmDialog(null, "are your sure");
if(status==JOptionPane.YES_OPTION){
model.removeRow(row);
}
try{
Connection con=Home_Homepage.getConnection();
PreparedStatement pst=con.prepareStatement("DELETE FROM `home_item` WHERE `id`=?");
int id=Integer.parseInt( txtitemid.getText());
pst.setInt(1, id);
pst.executeUpdate();
JOptionPane.showMessageDialog(null, "row deleted");
}catch(Exception ex) {
JOptionPane.showMessageDialog(null, ex.getMessage());
}
}
}//GEN-LAST:event_jButtonDeleteActionPerformed
private void jButtonExitActionPerformed(java.awt.event.ActionEvent evt) {//GEN-FIRST:event_jButtonExitActionPerformed
// TODO add your handling code here:
System.exit(0);
}//GEN-LAST:event_jButtonExitActionPerformed
private void jTableItemMouseClicked(java.awt.event.MouseEvent evt) {//GEN-FIRST:event_jTableItemMouseClicked
// TODO add your handling code here:
}//GEN-LAST:event_jTableItemMouseClicked
public ArrayList<Items> getItemList(){
ArrayList<Items>ItemList=new ArrayList<Items>();
Connection con=Home_Homepage.getConnection();
String query="SELECT * FROM home_item ";
Statement st;
ResultSet rs;
Items items = null;
try{
st=con.createStatement();
rs=st.executeQuery(query);
while(rs.next()){
items=new Items(rs.getInt("id"),rs.getString("itemname"),rs.getString("itemcategory"),rs.getString("itemdescription"),rs.getInt("itemprice"));
}
ItemList.add(items);
System.out.println(items);
}catch(Exception ex){
ex.printStackTrace();
}
return ItemList;
}
public void Show_Items_jTableItem(){
ArrayList<Items> list= getItemList();
System.out.println("list"+list.size());
DefaultTableModel model=(DefaultTableModel)jTableItem.getModel();
Object[]row= new Object[5];
for(int i=0; i<list.size(); i++ ){
row[0]=list.get(i).getId();
row[1]=list.get(i).getName();
System.out.println("print row"+row[0].toString());
System.out.println("print row"+row[1].toString());
row[2]=list.get(i).getCategory();
row[3]=list.get(i).getDescription();
row[4]=list.get(i).getitemPrice();
model.addRow(row);
}
}
public static void main(String args[]) {
java.awt.EventQueue.invokeLater(new Runnable() {
public void run() {
new Home_Homepage().setVisible(true);
}
});
}
// Variables declaration - do not modify//GEN-BEGIN:variables
private javax.swing.JComboBox<String> cbcategory;
private javax.persistence.EntityManager entityManager;
private java.util.List<homemanagementsystem.HomeRegistration.HomeItem> homeItemList;
private javax.persistence.Query homeItemQuery;
private java.util.List<homemanagementsystem.HomeRegistration.HomeRegistration> homeRegistrationList;
private javax.persistence.Query homeRegistrationQuery;
private javax.swing.JButton jButtonAdd;
private javax.swing.JButton jButtonDelete;
private javax.swing.JButton jButtonExit;
private javax.swing.JButton jButtonUpdate;
private javax.swing.JLabel jLabel1;
private javax.swing.JLabel jLabel2;
private javax.swing.JLabel jLabel3;
private javax.swing.JLabel jLabel4;
private javax.swing.JLabel jLabel5;
private javax.swing.JLabel jLabel6;
private javax.swing.JPanel jPanel1;
private javax.swing.JPanel jPanel2;
private javax.swing.JPanel jPanel3;
private javax.swing.JPasswordField jPasswordField1;
private javax.swing.JScrollPane jScrollPane1;
private javax.swing.JTable jTableItem;
private javax.swing.JTextField txtitemdescription;
private javax.swing.JTextField txtitemid;
private javax.swing.JTextField txtitemname;
private javax.swing.JTextField txtitemprice;
private org.jdesktop.beansbinding.BindingGroup bindingGroup;
// End of variables declaration//GEN-END:variables
}
<file_sep>/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package homemanagementsystem.HomeRegistration;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import javax.swing.JFrame;
import javax.swing.JOptionPane;
/**
*
* @author boker
*/
public class Home_Login extends javax.swing.JFrame {
/**
* Creates new form Home_Login
*/
public Home_Login() {
initComponents();
this.setLocationRelativeTo(null);
}
/**
* This method is called from within the constructor to initialize the form.
* WARNING: Do NOT modify this code. The content of this method is always
* regenerated by the Form Editor.
*/
@SuppressWarnings("unchecked")
// <editor-fold defaultstate="collapsed" desc="Generated Code">//GEN-BEGIN:initComponents
private void initComponents() {
jComboBox1 = new javax.swing.JComboBox<>();
jPanel1 = new javax.swing.JPanel();
jPanel2 = new javax.swing.JPanel();
jPanel3 = new javax.swing.JPanel();
jLabel1 = new javax.swing.JLabel();
jLabel2 = new javax.swing.JLabel();
txtId = new javax.swing.JTextField();
password = new javax.swing.JPasswordField();
jCheckBox_showpass = new javax.swing.JCheckBox();
jButtonlogin = new javax.swing.JButton();
jButtonlogin1 = new javax.swing.JButton();
jLabel4 = new javax.swing.JLabel();
jLabel5 = new javax.swing.JLabel();
jLabel_min = new javax.swing.JLabel();
jLabel_mix = new javax.swing.JLabel();
jPanel4 = new javax.swing.JPanel();
jLabel3 = new javax.swing.JLabel();
jComboBox1.setModel(new javax.swing.DefaultComboBoxModel<>(new String[] { "Item 1", "Item 2", "Item 3", "Item 4" }));
setDefaultCloseOperation(javax.swing.WindowConstants.EXIT_ON_CLOSE);
jPanel1.setBackground(new java.awt.Color(255, 255, 0));
jPanel2.setBackground(new java.awt.Color(102, 102, 102));
jPanel3.setForeground(new java.awt.Color(255, 255, 255));
jPanel3.addMouseListener(new java.awt.event.MouseAdapter() {
public void mouseClicked(java.awt.event.MouseEvent evt) {
jPanel3MouseClicked(evt);
}
});
jLabel1.setFont(new java.awt.Font("Tahoma", 1, 14)); // NOI18N
jLabel1.setText("ID Number:");
jLabel2.setFont(new java.awt.Font("Tahoma", 1, 14)); // NOI18N
jLabel2.setText("Password:");
txtId.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
txtIdActionPerformed(evt);
}
});
jCheckBox_showpass.setText("show pass");
jCheckBox_showpass.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
jCheckBox_showpassActionPerformed(evt);
}
});
jButtonlogin.setBackground(new java.awt.Color(204, 0, 204));
jButtonlogin.setFont(new java.awt.Font("Tahoma", 1, 14)); // NOI18N
jButtonlogin.setForeground(new java.awt.Color(255, 255, 255));
jButtonlogin.setText("cancel");
jButtonlogin.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
jButtonloginActionPerformed(evt);
}
});
jButtonlogin1.setBackground(new java.awt.Color(0, 51, 255));
jButtonlogin1.setFont(new java.awt.Font("Tahoma", 1, 14)); // NOI18N
jButtonlogin1.setForeground(new java.awt.Color(255, 255, 255));
jButtonlogin1.setText("login");
jButtonlogin1.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
jButtonlogin1ActionPerformed(evt);
}
});
jLabel4.setFont(new java.awt.Font("Tahoma", 0, 14)); // NOI18N
jLabel4.setText("new user?click hear to create account");
jLabel4.setCursor(new java.awt.Cursor(java.awt.Cursor.HAND_CURSOR));
jLabel4.addMouseListener(new java.awt.event.MouseAdapter() {
public void mouseClicked(java.awt.event.MouseEvent evt) {
jLabel4MouseClicked(evt);
}
});
jLabel5.setBackground(new java.awt.Color(0, 0, 255));
jLabel5.setFont(new java.awt.Font("Tahoma", 1, 14)); // NOI18N
jLabel5.setText("Forget Password");
jLabel5.setCursor(new java.awt.Cursor(java.awt.Cursor.HAND_CURSOR));
jLabel5.addMouseListener(new java.awt.event.MouseAdapter() {
public void mouseClicked(java.awt.event.MouseEvent evt) {
jLabel5MouseClicked(evt);
}
});
javax.swing.GroupLayout jPanel3Layout = new javax.swing.GroupLayout(jPanel3);
jPanel3.setLayout(jPanel3Layout);
jPanel3Layout.setHorizontalGroup(
jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel3Layout.createSequentialGroup()
.addGroup(jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel3Layout.createSequentialGroup()
.addGap(26, 26, 26)
.addGroup(jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(jLabel1, javax.swing.GroupLayout.PREFERRED_SIZE, 90, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jLabel2, javax.swing.GroupLayout.PREFERRED_SIZE, 77, javax.swing.GroupLayout.PREFERRED_SIZE))
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)
.addGroup(jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(password)
.addComponent(txtId)))
.addGroup(jPanel3Layout.createSequentialGroup()
.addGap(100, 100, 100)
.addComponent(jButtonlogin)
.addGap(38, 38, 38)
.addComponent(jButtonlogin1, javax.swing.GroupLayout.PREFERRED_SIZE, 75, javax.swing.GroupLayout.PREFERRED_SIZE)
.addGap(0, 0, Short.MAX_VALUE)))
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.UNRELATED)
.addComponent(jCheckBox_showpass)
.addGap(17, 17, 17))
.addGroup(javax.swing.GroupLayout.Alignment.TRAILING, jPanel3Layout.createSequentialGroup()
.addContainerGap(javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addComponent(jLabel4)
.addGap(64, 64, 64))
.addGroup(jPanel3Layout.createSequentialGroup()
.addGap(163, 163, 163)
.addComponent(jLabel5)
.addContainerGap(javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
);
jPanel3Layout.setVerticalGroup(
jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel3Layout.createSequentialGroup()
.addGap(27, 27, 27)
.addGroup(jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jLabel1, javax.swing.GroupLayout.PREFERRED_SIZE, 23, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(txtId, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE))
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)
.addGroup(jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jLabel2, javax.swing.GroupLayout.PREFERRED_SIZE, 27, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(password, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jCheckBox_showpass))
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)
.addGroup(jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jButtonlogin)
.addComponent(jButtonlogin1))
.addGap(28, 28, 28)
.addComponent(jLabel5)
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED, 42, Short.MAX_VALUE)
.addComponent(jLabel4, javax.swing.GroupLayout.PREFERRED_SIZE, 11, javax.swing.GroupLayout.PREFERRED_SIZE)
.addContainerGap())
);
jLabel_min.setFont(new java.awt.Font("Tahoma", 1, 24)); // NOI18N
jLabel_min.setText("-");
jLabel_min.setBorder(javax.swing.BorderFactory.createLineBorder(new java.awt.Color(0, 0, 0)));
jLabel_min.setCursor(new java.awt.Cursor(java.awt.Cursor.HAND_CURSOR));
jLabel_mix.setFont(new java.awt.Font("Tahoma", 1, 24)); // NOI18N
jLabel_mix.setText("x");
jLabel_mix.setBorder(javax.swing.BorderFactory.createLineBorder(new java.awt.Color(0, 0, 0)));
jLabel_mix.setCursor(new java.awt.Cursor(java.awt.Cursor.HAND_CURSOR));
jLabel_mix.addMouseMotionListener(new java.awt.event.MouseMotionAdapter() {
public void mouseMoved(java.awt.event.MouseEvent evt) {
jLabel_mixMouseMoved(evt);
}
});
jLabel_mix.addMouseListener(new java.awt.event.MouseAdapter() {
public void mouseClicked(java.awt.event.MouseEvent evt) {
jLabel_mixMouseClicked(evt);
}
});
jPanel4.setBackground(new java.awt.Color(0, 0, 204));
jPanel4.setBorder(javax.swing.BorderFactory.createLineBorder(new java.awt.Color(0, 204, 102)));
jLabel3.setFont(new java.awt.Font("Arial", 0, 36)); // NOI18N
jLabel3.setForeground(new java.awt.Color(255, 255, 255));
jLabel3.setText("Login");
javax.swing.GroupLayout jPanel4Layout = new javax.swing.GroupLayout(jPanel4);
jPanel4.setLayout(jPanel4Layout);
jPanel4Layout.setHorizontalGroup(
jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel4Layout.createSequentialGroup()
.addGap(29, 29, 29)
.addComponent(jLabel3, javax.swing.GroupLayout.PREFERRED_SIZE, 98, javax.swing.GroupLayout.PREFERRED_SIZE)
.addContainerGap(29, Short.MAX_VALUE))
);
jPanel4Layout.setVerticalGroup(
jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel4Layout.createSequentialGroup()
.addGap(22, 22, 22)
.addComponent(jLabel3)
.addContainerGap(20, Short.MAX_VALUE))
);
javax.swing.GroupLayout jPanel2Layout = new javax.swing.GroupLayout(jPanel2);
jPanel2.setLayout(jPanel2Layout);
jPanel2Layout.setHorizontalGroup(
jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(jPanel3, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addGroup(javax.swing.GroupLayout.Alignment.TRAILING, jPanel2Layout.createSequentialGroup()
.addContainerGap(javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addComponent(jPanel4, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addGap(52, 52, 52)
.addComponent(jLabel_min, javax.swing.GroupLayout.PREFERRED_SIZE, 19, javax.swing.GroupLayout.PREFERRED_SIZE)
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.UNRELATED)
.addComponent(jLabel_mix, javax.swing.GroupLayout.PREFERRED_SIZE, 19, javax.swing.GroupLayout.PREFERRED_SIZE)
.addContainerGap())
);
jPanel2Layout.setVerticalGroup(
jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(javax.swing.GroupLayout.Alignment.TRAILING, jPanel2Layout.createSequentialGroup()
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel2Layout.createSequentialGroup()
.addContainerGap()
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jLabel_min, javax.swing.GroupLayout.PREFERRED_SIZE, 21, javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jLabel_mix, javax.swing.GroupLayout.PREFERRED_SIZE, 21, javax.swing.GroupLayout.PREFERRED_SIZE)))
.addComponent(jPanel4, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE))
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addComponent(jPanel3, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE))
);
javax.swing.GroupLayout jPanel1Layout = new javax.swing.GroupLayout(jPanel1);
jPanel1.setLayout(jPanel1Layout);
jPanel1Layout.setHorizontalGroup(
jPanel1Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(javax.swing.GroupLayout.Alignment.TRAILING, jPanel1Layout.createSequentialGroup()
.addContainerGap()
.addComponent(jPanel2, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addContainerGap())
);
jPanel1Layout.setVerticalGroup(
jPanel1Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel1Layout.createSequentialGroup()
.addContainerGap()
.addComponent(jPanel2, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addContainerGap(javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
);
javax.swing.GroupLayout layout = new javax.swing.GroupLayout(getContentPane());
getContentPane().setLayout(layout);
layout.setHorizontalGroup(
layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(jPanel1, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
);
layout.setVerticalGroup(
layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(jPanel1, javax.swing.GroupLayout.PREFERRED_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
);
pack();
}// </editor-fold>//GEN-END:initComponents
private void jLabel_mixMouseClicked(java.awt.event.MouseEvent evt) {//GEN-FIRST:event_jLabel_mixMouseClicked
this.setState(JFrame.ICONIFIED);
}//GEN-LAST:event_jLabel_mixMouseClicked
private void jLabel_mixMouseMoved(java.awt.event.MouseEvent evt) {//GEN-FIRST:event_jLabel_mixMouseMoved
System.exit(0);
}//GEN-LAST:event_jLabel_mixMouseMoved
private void jCheckBox_showpassActionPerformed(java.awt.event.ActionEvent evt) {//GEN-FIRST:event_jCheckBox_showpassActionPerformed
// TODO add your handling code here:
if(jCheckBox_showpass.isSelected()){
password.setEchoChar((char)0 );
}else {
password.setEchoChar('*');
}
}//GEN-LAST:event_jCheckBox_showpassActionPerformed
private void jLabel4MouseClicked(java.awt.event.MouseEvent evt) {//GEN-FIRST:event_jLabel4MouseClicked
Registration registration=new Registration();
registration.setVisible(true);
registration.pack();
registration.setLocationRelativeTo(null);
registration.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
}//GEN-LAST:event_jLabel4MouseClicked
private void jPanel3MouseClicked(java.awt.event.MouseEvent evt) {//GEN-FIRST:event_jPanel3MouseClicked
// TODO add your handling code here:
}//GEN-LAST:event_jPanel3MouseClicked
private void jLabel5MouseClicked(java.awt.event.MouseEvent evt) {//GEN-FIRST:event_jLabel5MouseClicked
Home_ResetPass reset=new Home_ResetPass();
this.setVisible(false);
reset.setVisible(true);
reset.pack();
reset.setLocationRelativeTo(null);
reset.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
}//GEN-LAST:event_jLabel5MouseClicked
private void jButtonlogin1ActionPerformed(java.awt.event.ActionEvent evt) {//GEN-FIRST:event_jButtonlogin1ActionPerformed
// TODO add your handling code here:
if(txtId.getText().equals("")){
}
try{
String query="SELECT * FROM `home _registration` WHERE `idnumber`=? AND`password`=?";
Connection con=MyConnection.getconnection();
PreparedStatement pst=con.prepareStatement(query);
pst.setString(1, txtId.getText());
pst.setString(2, String.valueOf(password.getPassword()));
ResultSet rs=pst.executeQuery();
if(rs.next()){
MainHome home =new MainHome();
home.setVisible(true);
this.setVisible(false);
home.pack();
home.setLocationRelativeTo(null);
home.setExtendedState(JFrame.MAXIMIZED_BOTH);
MainHome.jLabel1.setText("Welcome Id:" +txtId.getText() );
//JOptionPane.showMessageDialog(null, "loged");
}else{
JOptionPane.showMessageDialog(null, " invalid id/password" ,"login error",2);
}
}
catch(Exception ex){
JOptionPane.showMessageDialog(null, ex);
}
}//GEN-LAST:event_jButtonlogin1ActionPerformed
private void jButtonloginActionPerformed(java.awt.event.ActionEvent evt) {//GEN-FIRST:event_jButtonloginActionPerformed
System.exit(0);
}//GEN-LAST:event_jButtonloginActionPerformed
private void txtIdActionPerformed(java.awt.event.ActionEvent evt) {//GEN-FIRST:event_txtIdActionPerformed
// TODO add your handling code here:
}//GEN-LAST:event_txtIdActionPerformed
/**
* @param args the command line arguments
*/
public static void main(String args[]) {
/* Set the Nimbus look and feel */
//<editor-fold defaultstate="collapsed" desc=" Look and feel setting code (optional) ">
/* If Nimbus (introduced in Java SE 6) is not available, stay with the default look and feel.
* For details see http://download.oracle.com/javase/tutorial/uiswing/lookandfeel/plaf.html
*/
try {
for (javax.swing.UIManager.LookAndFeelInfo info : javax.swing.UIManager.getInstalledLookAndFeels()) {
if ("Nimbus".equals(info.getName())) {
javax.swing.UIManager.setLookAndFeel(info.getClassName());
break;
}
}
} catch (ClassNotFoundException ex) {
java.util.logging.Logger.getLogger(Home_Login.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
} catch (InstantiationException ex) {
java.util.logging.Logger.getLogger(Home_Login.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
} catch (IllegalAccessException ex) {
java.util.logging.Logger.getLogger(Home_Login.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
} catch (javax.swing.UnsupportedLookAndFeelException ex) {
java.util.logging.Logger.getLogger(Home_Login.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
}
//</editor-fold>
/* Create and display the form */
java.awt.EventQueue.invokeLater(new Runnable() {
public void run() {
new Home_Login().setVisible(true);
}
});
}
// Variables declaration - do not modify//GEN-BEGIN:variables
private javax.swing.JButton jButtonlogin;
private javax.swing.JButton jButtonlogin1;
private javax.swing.JCheckBox jCheckBox_showpass;
private javax.swing.JComboBox<String> jComboBox1;
private javax.swing.JLabel jLabel1;
private javax.swing.JLabel jLabel2;
private javax.swing.JLabel jLabel3;
private javax.swing.JLabel jLabel4;
private javax.swing.JLabel jLabel5;
private javax.swing.JLabel jLabel_min;
private javax.swing.JLabel jLabel_mix;
private javax.swing.JPanel jPanel1;
private javax.swing.JPanel jPanel2;
private javax.swing.JPanel jPanel3;
private javax.swing.JPanel jPanel4;
private javax.swing.JPasswordField password;
private javax.swing.JTextField txtId;
// End of variables declaration//GEN-END:variables
}
| d1317844cb14ba6345ee7fd2a91ef4310fffcb28 | [
"Java"
] | 4 | Java | bokerwere/HomeManagementSystem | 0cd6009c1d60385cdb928271153b395909667b85 | 660feae248d35b65f947f17864d5b8b8defee427 |
refs/heads/master | <repo_name>janalou/projeto_ADS-GTI<file_sep>/teste.py
print('teste)
x=input("Digite seu nome")
')<file_sep>/README.md
# projeto-teste
Projeto criado na aula de Devops.
| 80f20950accd69ceb6d8739b212df5036f872453 | [
"Markdown",
"Python"
] | 2 | Python | janalou/projeto_ADS-GTI | 9766cf585d5d7d1bb51665cb43c60b1e99addf3c | f51222ce80cb0b2e13ea2fc7c6b0ad9f337585ab |
refs/heads/main | <repo_name>SamvelDavtyan/Course_sem4<file_sep>/UnitTest_CourseWork/UnitTest_CourseWork.cpp
#include "pch.h"
#include "CppUnitTest.h"
#include <fstream>
#include "..\Course_Work\Edmonds-Karp.cpp"
#include "..\Course_Work\Graph.cpp"
#include "..\Course_Work\List.h"
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
namespace UnitTestCourseWork
{
TEST_CLASS(LinkedListTest)
{
public:
TEST_METHOD(ConstructorTest)
{
List<int> lst;
Assert::IsTrue(lst.GetSize() == 0);
}
TEST_METHOD(IsEmptyTest1)
{
List<int> lst;
Assert::IsTrue(lst.isEmpty());
}
TEST_METHOD(IsEmptyTest2)
{
List<int> lst;
lst.push_back(3);
Assert::IsTrue(lst.isEmpty() == false);
}
TEST_METHOD(AtTest1)
{
List<int> lst;
lst.push_back(3);
Assert::IsTrue(lst.at(0) == 3);
}
TEST_METHOD(AtTest2)
{
List<int> lst;
lst.push_back(3);
lst.push_front(2);
Assert::IsTrue(lst.at(0) == 2, L"Assert 1");
Assert::IsTrue(lst.at(1) == 3, L"Assert 2");
Assert::IsTrue(lst.GetSize() == 2, L"Assert 3");
}
TEST_METHOD(AtTest3)
{
List<int> lst;
lst.push_back(3);
try
{
lst.at(-5);
}
catch (const char* error)
{
Assert::AreEqual(error, "Error! Incorrect input.");
}
}
TEST_METHOD(GetSizeTest1)
{
List<int> lst;
Assert::IsTrue(lst.GetSize() == 0);
}
TEST_METHOD(GetSizeTest2)
{
List<int> lst;
lst.push_back(3);
lst.push_front(2);
Assert::IsTrue(lst.GetSize() == 2);
}
TEST_METHOD(GetSizeTest3)
{
List<int> lst;
lst.push_back(3);
lst.push_front(2);
lst.pop_back();
lst.pop_front();
Assert::IsTrue(lst.GetSize() == 0);
}
TEST_METHOD(PushBackTest1)
{
List<int> lst;
lst.push_back(3);
Assert::IsTrue(lst.GetSize() == 1, L"Assert 1");
Assert::IsTrue(lst.at(0) == 3, L"Assert 2");
}
TEST_METHOD(PushBackTest2)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.push_back(3);
Assert::IsTrue(lst.GetSize() == 4, L"Assert 1");
Assert::IsTrue(lst.at(3) == 3, L"Assert 2");
}
TEST_METHOD(PushFrontTest1)
{
List<int> lst;
lst.push_front(3);
Assert::IsTrue(lst.GetSize() == 1, L"Assert 1");
Assert::IsTrue(lst.at(0) == 3, L"Assert 2");
}
TEST_METHOD(PushFrontTest2)
{
List<int> lst;
lst.push_front(0);
lst.push_front(1);
lst.push_front(2);
lst.push_front(3);
Assert::IsTrue(lst.GetSize() == 4, L"Assert 1");
Assert::IsTrue(lst.at(3) == 0, L"Assert 2");
}
TEST_METHOD(PopBackTest1)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.push_back(3);
lst.pop_back();
Assert::IsTrue(lst.GetSize() == 3);
}
TEST_METHOD(PopBackTest2)
{
List<int> lst;
lst.push_back(0);
lst.pop_back();
Assert::IsTrue(lst.GetSize() == 0);
}
TEST_METHOD(PopBackTest3)
{
List<int> lst;
try
{
lst.pop_back();
}
catch (const char* error)
{
Assert::AreEqual(error, "Error! Linked list is Empty.");
}
}
TEST_METHOD(PopFrontTest1)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.push_back(3);
lst.pop_front();
Assert::IsTrue(lst.at(0) == 1, L"Assert 1");
Assert::IsTrue(lst.at(1) == 2, L"Assert 2");
Assert::IsTrue(lst.GetSize() == 3, L"Assert 3");
}
TEST_METHOD(PopFrontTest2)
{
List<int> lst;
lst.push_back(0);
lst.pop_front();
Assert::IsTrue(lst.isEmpty(), L"Assert 1");
}
TEST_METHOD(PopFrontTest3)
{
List<int> lst;
try
{
lst.pop_front();
}
catch (const char* error)
{
Assert::AreEqual(error, "Error! Linked list is Empty.");
}
}
TEST_METHOD(InsertTest1)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.insert(0, 21);
Assert::IsTrue(lst.at(0) == 21, L"Assert 1");
Assert::IsTrue(lst.at(1) == 0, L"Assert 2");
Assert::IsTrue(lst.GetSize() == 4, L"Assert 3");
}
TEST_METHOD(InsertTest2)
{
List<int> lst;
lst.insert(0, 21);
Assert::IsTrue(lst.at(0) == 21, L"Assert 1");
Assert::IsTrue(lst.GetSize() == 1, L"Assert 2");
}
TEST_METHOD(InsertTest3)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.insert(2, 21);
Assert::IsTrue(lst.at(2) == 21, L"Assert 1");
Assert::IsTrue(lst.at(3) == 2, L"Assert 2");
Assert::IsTrue(lst.GetSize() == 4, L"Assert 3");
}
TEST_METHOD(InsertTest4)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.push_back(3);
lst.push_back(4);
lst.insert(2, 21);
Assert::IsTrue(lst.at(2) == 21, L"Assert 1");
Assert::IsTrue(lst.at(3) == 2, L"Assert 2");
Assert::IsTrue(lst.GetSize() == 6, L"Assert 3");
}
TEST_METHOD(InsertTest5)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
try
{
lst.insert(-3, 21);
}
catch (const char* error)
{
Assert::AreEqual(error, "Error! Incorrect input.");
}
}
TEST_METHOD(SetTest1)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.set(0, 21);
Assert::IsTrue(lst.at(0) == 21, L"Assert 1");
Assert::IsTrue(lst.at(1) == 1, L"Assert 2");
Assert::IsTrue(lst.GetSize() == 3, L"Assert 3");
}
TEST_METHOD(SetTest2)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.push_back(3);
lst.push_back(4);
lst.push_back(5);
lst.push_back(6);
lst.push_back(7);
lst.push_back(8);
lst.set(2, 21);
Assert::IsTrue(lst.at(2) == 21, L"Assert 1");
Assert::IsTrue(lst.at(3) == 3, L"Assert 2");
Assert::IsTrue(lst.GetSize() == 9, L"Assert 3");
}
TEST_METHOD(SetTest3)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.push_back(3);
lst.push_back(4);
lst.push_back(5);
lst.push_back(6);
lst.push_back(7);
lst.push_back(8);
lst.set(7, 21);
Assert::IsTrue(lst.at(7) == 21, L"Assert 1");
Assert::IsTrue(lst.at(8) == 8, L"Assert 2");
Assert::IsTrue(lst.GetSize() == 9, L"Assert 3");
}
TEST_METHOD(SetTest4)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.push_back(3);
lst.push_back(4);
lst.push_back(5);
lst.push_back(6);
lst.push_back(7);
lst.push_back(8);
lst.set(8, 21);
Assert::IsTrue(lst.at(8) == 21, L"Assert 1");
Assert::IsTrue(lst.at(7) == 7, L"Assert 2");
Assert::IsTrue(lst.GetSize() == 9, L"Assert 3");
}
TEST_METHOD(SetTest5)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
try
{
lst.set(-3, 21);
}
catch (const char* error)
{
Assert::AreEqual(error, "Error! Incorrect input.");
}
}
TEST_METHOD(RemoveTest1)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.remove(0);
Assert::IsTrue(lst.at(0) == 1, L"Assert 1");
Assert::IsTrue(lst.GetSize() == 1, L"Assert 2");
}
TEST_METHOD(RemoveTest2)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.push_back(3);
lst.push_back(4);
lst.push_back(5);
lst.push_back(6);
lst.push_back(7);
lst.push_back(8);
lst.remove(2);
Assert::IsTrue(lst.at(2) == 3, L"Assert 1");
Assert::IsTrue(lst.GetSize() == 8, L"Assert 2");
}
TEST_METHOD(RemoveTest3)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.push_back(3);
lst.push_back(4);
lst.push_back(5);
lst.push_back(6);
lst.push_back(7);
lst.push_back(8);
lst.remove(6);
Assert::IsTrue(lst.at(6) == 7, L"Assert 1");
Assert::IsTrue(lst.GetSize() == 8, L"Assert 2");
}
TEST_METHOD(RemoveTest4)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
lst.push_back(3);
lst.push_back(4);
lst.push_back(5);
lst.remove(5);
Assert::IsTrue(lst.at(4) == 4, L"Assert 1");
Assert::IsTrue(lst.GetSize() == 5, L"Assert 2");
}
TEST_METHOD(RemoveTest5)
{
List<int> lst;
lst.push_back(0);
lst.push_back(1);
lst.push_back(2);
try
{
lst.remove(-2);
}
catch (const char* error)
{
Assert::AreEqual(error, "Error! Incorrect input.");
}
}
};
TEST_CLASS(GraphTest)
{
public:
TEST_METHOD(GetValueTest)
{
int dim = 3;
Graph Test(dim);
Assert::IsTrue(Test.GetValue(0, 1) == 0);
}
TEST_METHOD(SetValueTest)
{
int dim = 3;
Graph Test(dim);
Test.SetValue(2, 2, 5);
Assert::IsTrue(Test.GetValue(2, 2) == 5);
}
TEST_METHOD(BFSTest)
{
int dim = 3;
Graph* Test = new Graph(dim);
Graph* Flow = new Graph(3);
Test->SetValue(0, 1, 1);
Test->SetValue(0, 2, 1);
Test->SetValue(1, 2, 1);
Assert::IsTrue(Test->BFS(*Flow)->at(0) == 0);
Assert::IsTrue(Test->BFS(*Flow)->at(1) == 2);
}
};
TEST_CLASS(EdmondsKarpTest)
{
public:
TEST_METHOD(SearchUniqueVertexesTest)
{
ifstream read("D:\\Программирование\\4 сем\\сourse\\Course_Work\\input.txt");
if (!read.is_open())
return;
int VertexesNumber = 0;
string UniqueVertexes = "";
SearchUniqueVertexes(UniqueVertexes, VertexesNumber, read);
VertexesNumber = VertexesNumber - 1;
char* Vertexes = new char[VertexesNumber];
for (int k = 0; k < VertexesNumber; ++k)
Vertexes[k] = UniqueVertexes[k];
read.close();
Assert::IsTrue(Vertexes[0] == 'S');
Assert::IsTrue(Vertexes[1] == 'O');
Assert::IsTrue(Vertexes[2] == 'P');
Assert::IsTrue(Vertexes[3] == 'Q');
Assert::IsTrue(Vertexes[4] == 'R');
Assert::IsTrue(Vertexes[5] == 'T');
Assert::IsTrue(VertexesNumber == 6);
delete[] Vertexes;
}
TEST_METHOD(EdmondsKarpTest_1)
{
ifstream read("D:\\Программирование\\4 сем\\сourse\\Course_Work\\input.txt");
if (!read.is_open())
return;
unsigned MaxFlow = 0;
Process(MaxFlow, read);
read.close();
Assert::IsTrue(MaxFlow == 5);
}
TEST_METHOD(EdmondsKarpTest_2)
{
ifstream read("D:\\Программирование\\4 сем\\сourse\\Course_Work\\test.txt");
if (!read.is_open())
return;
unsigned MaxFlow = 0;
Process(MaxFlow, read);
read.close();
Assert::IsTrue(MaxFlow == 14);
}
};
}
<file_sep>/Course_Work/List.inl
#pragma once
#include "List.h"
// constructor
template<class data_T>
List<data_T>::List()
{
size = 0;
head = nullptr;
tail = nullptr;
}
// destructor
template<class data_T>
List<data_T>::~List()
{
clear();
}
// inserting an element at the end of the list
template<class data_T>
void List<data_T>::push_back(data_T data)
{
if (head == nullptr)
{
this->head = this->tail = new Node(data);
}
else
{
Node* temp = new Node(data, nullptr, tail);
tail->next = temp;
tail = temp;
}
size++;
}
// inserting an element at the beginning of the list
template<class data_T>
void List<data_T>::push_front(data_T data)
{
if (!(isEmpty()))
{
Node* lasthead = head;
head = new Node(data, head);
lasthead->prev = head;
}
else
{
head = new Node(data, head);
}
size++;
}
//remove the last element
template<class data_T>
void List<data_T>::pop_back()
{
if (isEmpty())
throw "Error! Linked list is Empty.";
else
{
Node* todelete = tail;
tail = tail->prev;
delete todelete;
size--;
}
}
// remove the first element
template<class data_T>
void List<data_T>::pop_front()
{
if (head != nullptr) {
Node* temp = this->head;
head = head->next;
delete temp;
size--;
}
else throw "Error! Linked list is Empty.";
}
// clear list
template<class data_T>
void List<data_T>::clear()
{
while (size) {
pop_front();
}
}
// getting list size
template<class data_T>
size_t List<data_T>::GetSize()
{
return size;
}
// output the list to the console
template<class data_T>
void List<data_T>::print_to_console()
{
Node* cursor = head;
if (head)
{
while (cursor->next)
{
std::cout << cursor->data << endl;
cursor = cursor->next;
}
std::cout << cursor->data << endl;
std::cout << std::endl;
}
else throw "Error! List is empty.";
}
//getting an element by index
template<class data_T>
data_T List<data_T>::at(const int index)
{
if (index >= size || index < 0)
throw "Error! Incorrect input.";
int counter = 0;
Node* current = head;
while (current != nullptr)
{
if (counter == index)
return current->data;
current = current->next;
counter++;
}
}
// checking the list for emptiness
template<class data_T>
bool List<data_T>::isEmpty()
{
if (head == nullptr)
return true;
else return false;
}
// replacing the element by index with the passed element
template<class data_T>
void List<data_T>::set(size_t index, data_T data)
{
if (index >= size || index < 0)
throw "Error! Incorrect input.";
Node* cursor = head;
for (size_t i = 0; i < index; i++)
cursor = cursor->next;
cursor->data = data;
}
// insert into an arbitrary place in the list by index
template<class data_T>
void List<data_T>::insert(size_t index, data_T data)
{
if (!isEmpty())
{
if (index >= size || index < 0)
throw "Error! Incorrect input.";
}
else
{
if (index != size)
throw "Error! Incorrect input.";
}
if (index == 0)
{
push_front(data);
}
else
{
if (index == size)
push_back(data);
else {
if (index < (size - 1) / 2)
{
Node* previous = this->head;
for (size_t i = 0; i < index - 1; i++)
{
previous = previous->next;
}
previous->next = new Node(data, previous->next, previous);
}
else
{
Node* previous = this->tail;
for (size_t i = size - 1; i > index - 1; i--)
{
previous = previous->prev;
}
previous->next = new Node(data, previous->next, previous);
}
size++;
}
}
}
// Íeverse the order of items in the list
template<class data_T>
void List<data_T>::reverse()
{
if (head == nullptr)
throw "Error! Linked list is empty.";
if (!head || !head->next)
return;
tail = head;
Node* temp = nullptr;
Node* current = head;
while (current != nullptr)
{
temp = current->prev;
current->prev = current->next;
current->next = temp;
current = current->prev;
}
head = temp->prev;
}
// deleting an element by index
template<class data_T>
void List<data_T>::remove(size_t index)
{
if (index >= size || index < 0)
throw "Error! Incorrect input.";
if (index == 0)
this->pop_front();
else if (index == size - 1)
this->pop_back();
else {
Node* cursor = head;
for (size_t i = 0; i < index; i++)
{
cursor = cursor->next;
}
Node* temp = cursor;
cursor->prev->next = cursor->next;
cursor->next->prev = cursor->prev;
delete temp;
size--;
}
}
// getting the first item in the list
template<class data_T>
data_T List<data_T>::top()
{
if (head)
return head->data;
else throw "Error! Stack is empty.";
}
template<class data_T>
inline int List<data_T>::search(data_T info)
{
if (size != 0) {
Node* current = head;
for (size_t i = 0; i < size; i++) {
if (info == current->data) {
return i;
}
current = current->next;
}
}
return -1;
}
| 95f58464d2948e98c9dec9df1a99d64f59c7ac12 | [
"C++"
] | 2 | C++ | SamvelDavtyan/Course_sem4 | 18ce8627269bc46f5d2033ea615128173a02f496 | 8a2bc717f2419f62fe7084d28d50cfd978bee523 |
refs/heads/master | <file_sep>package com.zara.portfolio;
import androidx.annotation.NonNull;
import androidx.annotation.Nullable;
import androidx.appcompat.app.AppCompatActivity;
import androidx.appcompat.widget.Toolbar;
import androidx.fragment.app.Fragment;
import androidx.fragment.app.FragmentManager;
import androidx.fragment.app.FragmentStatePagerAdapter;
import androidx.viewpager.widget.ViewPager;
import android.os.Bundle;
import android.view.Menu;
import com.google.android.material.tabs.TabLayout;
import com.zara.portfolio.ui.information.InformationFragment;
import com.zara.portfolio.ui.tue.TuesDayFragment;
import com.zara.portfolio.ui.wed.WednesdayFragment;
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 1.get viewpager from xml
ViewPager vp = findViewById(R.id.vp);
// 2.make viewpager adapter
vp.setAdapter(new DayRvAdapter(getSupportFragmentManager(), 0));
// 3. connect tablayout and viewpager
TabLayout tabLayout = findViewById(R.id.tabLayout);
tabLayout.setupWithViewPager(vp);
// finish how to make viewpager and tablayout
Toolbar toolbar = findViewById(R.id.toolbar);
setSupportActionBar(toolbar);
getSupportActionBar().setTitle("");
getSupportActionBar().setDisplayHomeAsUpEnabled(true);
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
getMenuInflater().inflate(R.menu.menu_main, menu);
return true;
}
class DayRvAdapter extends FragmentStatePagerAdapter {
public DayRvAdapter(@NonNull FragmentManager fm, int behavior) {
super(fm, behavior);
}
@NonNull
@Override
public Fragment getItem(int position) {
switch (position) {
case 0:
return new InformationFragment();
case 1:
return new TuesDayFragment();
case 2:
return new WednesdayFragment();
}
return new InformationFragment();
}
@Override
public int getCount() {
return 3;
}
@Nullable
@Override
public CharSequence getPageTitle(int position) {
switch (position) {
case 0:
return "Information";
case 1:
return "experiences";
case 2:
return "skills";
}
return "";
}
}
}
| 6ccc8d21ecbeb7dfc5f1f197c4322e964d3e1e4c | [
"Java"
] | 1 | Java | zara9828/portfolio | 09902b3f3fcb4e815348fb8411fab54a6eb82e0d | a70404aae48ce75db9b8657395691b2c5392e7eb |
refs/heads/master | <file_sep>require 'rails_helper'
describe ReportLog do
it "has a valid factory" do
expect(create(:report_log)).to be_valid
end
end
<file_sep>class CreateParameters < ActiveRecord::Migration[4.2]
def change
create_table :parameters do |t|
t.string :key
t.text :value
t.integer :parameterable_id
t.string :parameterable_type
t.timestamps
end
end
end
<file_sep>require 'salt/api'
Salt::Api.configure do |config|
config.hostname = Settings.salt_hostname
config.port = Settings.salt_port
config.username = Settings.salt_username
config.password = Settings.salt_password
config.use_ssl = Settings.salt_use_ssl
end
<file_sep>require 'rails_helper'
describe NodesController do
let(:node) { create(:node) }
describe "GET #index" do
it "populates an array of nodes" do
node
get :index
expect(assigns(:nodes)).to eq([node])
end
it "renders the #index view" do
node
get :index
expect(response).to render_template :index
end
it "renders json" do
node
get :index, format: :json
end
end
["unresponsive", "failed", "pending", "changed", "unchanged", "unreported"].each do |status|
describe "GET ##{status}" do
before :each do
@node = create("#{status}_node".to_sym)
end
it "populates an array of nodes" do
get status.to_sym
expect(assigns(:nodes)).to eq([@node])
end
it "renders the #index view" do
get :index
expect(response).to render_template :index
end
end
end
describe "GET #show" do
it "assigns the requested node to @node" do
get :show, params: { id: node }
expect(assigns(:node)).to eq(node)
end
it "renders the #show view" do
get :show, params: { id: node }
expect(response).to render_template :show
end
it "renders json" do
get :show, params: { id: node, format: :json }
end
end
describe "GET #status_history" do
it "assigns the requested node to @node" do
get :status_history, params: { id: node }
expect(assigns(:node)).to eq(node)
end
end
describe "GET #resource_times" do
context "with report" do
let(:node) { create(:node_with_all_dependents) }
it "assigns the requested node to @node" do
get :resource_times, params: { id: node }
expect(assigns(:node)).to eq(node)
end
end
context "without report" do
it "assigns the requested node to @node" do
get :resource_times, params: { id: node }
expect(assigns(:node)).to eq(node)
end
end
end
describe "GET #new" do
it "assigns a new node to @node" do
get :new
expect(assigns(:node)).to be_kind_of Node
end
it "renders the #new view" do
get :new
expect(response).to render_template :new
end
end
describe "GET #edit" do
it "assigns the requested node to @node" do
get :edit, params: { id: node }
expect(assigns(:node)).to eq(node)
end
it "renders the #edit view" do
get :edit, params: { id: node }
expect(response).to render_template :edit
end
end
describe "POST #create" do
context "with valid attributes" do
it "creates a new node" do
expect {
post :create, params: { node: attributes_for(:node) }
}.to change(Node, :count).by(1)
end
it "redirects to the new node" do
post :create, params: { node: attributes_for(:node) }
expect(response).to redirect_to Node.last
end
end
context "with invalid attributes" do
it "does not create a new node" do
expect {
post :create, params: { node: attributes_for(:invalid_node) }
}.to_not change(Node, :count)
end
it "renders the #new view" do
post :create, params: { node: attributes_for(:invalid_node) }
expect(response).to render_template :new
end
end
end
describe "PUT #update" do
before :each do
@node = create(:node, description: 'foo')
end
context "with valid attributes" do
it "located the requested @node" do
put :update, params: { id: @node, node: attributes_for(:node) }
expect(assigns(:node)).to eq(@node)
end
it "changes @node's attributes" do
put :update, params: { id: @node, node: attributes_for(:node, description: 'bar') }
@node.reload
expect(@node.description).to eq('bar')
end
it "redirects to show new node" do
put :update, params: { id: @node, node: attributes_for(:node) }
expect(response).to redirect_to Node.last
end
end
context "with invalid attributes" do
it "located the requested @node" do
put :update, params: { id: @node, node: attributes_for(:invalid_node) }
expect(assigns(:node)).to eq(@node)
end
it "does not change @node's attributes" do
put :update, params: { id: @node, node: attributes_for(:invalid_node, description: 'bar') }
@node.reload
expect(@node.description).to eq('foo')
end
it "renders the #edit view" do
put :update, params: { id: @node, node: attributes_for(:invalid_node) }
expect(response).to render_template :edit
end
end
end
describe "DELETE #destroy" do
it "deletes the node" do
node
expect {
delete :destroy, params: { id: node }
}.to change(Node, :count).by(-1)
end
it "redirects back to #index" do
delete :destroy, params: { id: node }
expect(response).to redirect_to nodes_path
end
end
end
<file_sep>require 'rails_helper'
describe NodeClassesController do
describe "GET #index" do
it "populates an array of node_classes" do
node_class = create(:node_class)
get :index
expect(assigns(:node_classes)).to eq([node_class])
end
it "renders the #index view" do
get :index
expect(response).to render_template :index
end
end
describe "GET #show" do
it "assigns the requested node_class to @node_class" do
node_class = create(:node_class)
get :show, params: { id: node_class }
expect(assigns(:node_class)).to eq(node_class)
end
it "renders the #show view" do
node_class = create(:node_class)
get :show, params: { id: node_class }
expect(response).to render_template :show
end
end
describe "GET #new" do
it "assigns a new node_class to @node_class" do
get :new
expect(assigns(:node_class)).to be_kind_of NodeClass
end
it "renders the #new view" do
get :new
expect(response).to render_template :new
end
end
describe "GET #edit" do
it "assigns the requested node_class to @node_class" do
node_class = create(:node_class)
get :edit, params: { id: node_class }
expect(assigns(:node_class)).to eq(node_class)
end
it "renders the #edit view" do
node_class = create(:node_class)
get :edit, params: { id: node_class }
expect(response).to render_template :edit
end
end
describe "POST #create" do
context "with valid attributes" do
it "creates a new node_class" do
expect {
post :create, params: { node_class: attributes_for(:node_class) }
}.to change(NodeClass, :count).by(1)
end
it "redirects to the new node class" do
post :create, params: { node_class: attributes_for(:node_class) }
expect(response).to redirect_to NodeClass.last
end
end
context "with invalid attributes" do
it "does not create a new node_class" do
expect {
post :create, params: { node_class: attributes_for(:invalid_node_class) }
}.to_not change(NodeClass, :count)
end
it "renders the #new view" do
post :create, params: { node_class: attributes_for(:invalid_node_class) }
expect(response).to render_template :new
end
end
end
describe "PUT #update" do
before :each do
@node_class = create(:node_class, name: 'foo')
end
context "with valid attributes" do
it "located the requested @node_class" do
put :update, params: { id: @node_class, node_class: attributes_for(:node_class) }
expect(assigns(:node_class)).to eq(@node_class)
end
it "changes @node_class's attributes" do
put :update, params: { id: @node_class, node_class: attributes_for(:node_class, name: 'bar') }
@node_class.reload
expect(@node_class.name).to eq('bar')
end
it "redirects to show updated node class" do
put :update, params: { id: @node_class, node_class: attributes_for(:node_class) }
expect(response).to redirect_to NodeClass.last
end
end
context "with invalid attributes" do
it "does not update the node_class" do
put :update, params: { id: @node_class, node_class: attributes_for(:invalid_node_class) }
@node_class.reload
expect(@node_class.name).to eq('foo')
end
it "renders the #edit view" do
put :update, params: { id: @node_class, node_class: attributes_for(:invalid_node_class) }
expect(response).to render_template :edit
end
end
end
describe "DELETE #destroy" do
it "deletes the node class" do
node_class = create(:node_class)
expect {
delete :destroy, params: { id: node_class }
}.to change(NodeClass, :count).by(-1)
end
it "redirects back to #index" do
node_class = create(:node_class)
delete :destroy, params: { id: node_class }
expect(response).to redirect_to node_classes_path
end
end
end
<file_sep>source 'https://rubygems.org'
ruby '2.4.1'
# Rails
gem 'rails', '~> 5.1'
# Configuration
gem 'dotenv-rails'
gem 'figaro'
gem 'settingslogic'
# Server
gem 'puma'
# Database
gem 'pg'
# Redis
gem 'redis'
gem 'hiredis'
gem 'redis-namespace'
# Javascript
gem 'mini_racer'
gem 'coffee-rails'
gem 'jquery-rails'
gem 'uglifier'
# CSS
gem 'sass-rails'
gem 'bootstrap-sass'
gem 'autoprefixer-rails'
# View rendering
gem 'haml-rails'
# Form
gem 'bootstrap_form'
gem 'nested_form'
# Pagination
gem 'kaminari'
# Charts
gem 'chartkick'
gem 'groupdate'
# Providers
gem 'salt-api'
# Foreman (so we can export systemd config files)
gem 'foreman'
# Speedup application loading
gem 'bootsnap'
# Import reports asynchronously
gem 'sidekiq'
group :test, :development do
gem 'rspec-rails'
gem 'rails-controller-testing'
gem 'faker'
gem 'factory_girl_rails'
gem 'database_cleaner'
gem 'capybara'
gem 'capybara-screenshot'
gem 'poltergeist'
# Code coverage
gem 'simplecov'
end
group :development do
# Rails test server
gem 'spring'
gem 'spring-commands-rspec'
# SQL Queries optimizer
gem 'bullet'
# Deployment
gem 'capistrano'
gem 'capistrano-rvm'
gem 'capistrano-rails'
gem 'capistrano-foreman'
gem 'capistrano-template'
end
<file_sep>class ReportLog < ActiveRecord::Base
# Relations
belongs_to :report
def message
JSON.parse(super)
end
end
<file_sep>require 'rails_helper'
describe NodeGroup do
it "has a valid factory" do
expect(create(:node_group)).to be_valid
end
it "does not allow duplicate names" do
node_group = create(:node_group)
expect(build(:node_group, name: node_group.name)).to_not be_valid
end
it "is invalid without a name" do
expect(build(:node_group, name: nil)).to_not be_valid
end
it "returns name for to_param" do
node_group = create(:node_group)
expect(node_group.to_param).to eq node_group.name
end
it "returns name for to_s" do
node_group = create(:node_group)
expect(node_group.to_s).to eq node_group.name
end
end
<file_sep>require 'rails_helper'
describe Metric do
it "has a valid factory" do
expect(create(:metric)).to be_valid
end
it "is invalid without a report" do
expect(build(:metric, report_id: nil)).to_not be_valid
end
end
<file_sep>class SaltEvent
attr_accessor :id, :status, :resource_type, :resource_id, :action, :category
def initialize(id, status)
@id = id
@status = status
@resource_type, @resource_id, _, @action = id.split('_|-', 4)
@category = "#{resource_type}.#{action}"
end
def run_num
status['__run_num__']
end
def comment
status['comment']
end
def name
status['name']
end
def start_time
status['start_time']
end
def result
status['result']
end
def duration
status['duration'].try(:to_f)
end
def changes
status['changes'] || []
end
end
<file_sep>class AsyncImportJob < ApplicationJob
queue_as :async_imports
def perform(report)
EventsImporter.import(report)
end
end
<file_sep>class CreateReports < ActiveRecord::Migration[4.2]
def change
create_table :reports do |t|
t.integer :node_id
t.string :status
t.string :environment
t.datetime :time
t.timestamps
end
add_index :reports, :node_id
end
end
<file_sep>require 'sidekiq/web'
Rails.application.routes.draw do
mount Sidekiq::Web, at: 'sidekiq'
resources :nodes, id: /[A-Za-z0-9\-\.]+?/, format: /json|js|csv|xml|yaml/ do
member do
get 'grains'
get 'status_history'
get 'resource_times'
get 'highstate_test'
get 'highstate'
get 'restart_salt'
end
collection do
get 'unresponsive'
get 'failed'
get 'pending'
get 'changed'
get 'unchanged'
get 'unreported'
get 'sidebar'
end
end
resources :node_groups do
member do
get 'highstate_test'
get 'highstate'
get 'restart_salt'
end
end
resources :node_classes
resources :reports do
member do
get 'parse'
end
collection do
post 'upload'
get 'report_history'
end
end
resources :parameters, only: [:index, :new, :create]
root to: 'nodes#index'
end
<file_sep>require 'rails_helper'
describe 'Nodes' do
describe 'Manage Nodes' do
it 'Adds a new node and displays the results', :js => true do
visit nodes_path
name = Faker::Lorem.word
expect {
click_link 'Add Node'
fill_in 'Name', :with => name
click_button 'Create Node'
}.to change(Node, :count).by(1)
expect(page).to have_content "Node: #{name}"
end
it 'Adds a new node w/ parameter', :js => true do
visit nodes_path
name = Faker::Lorem.word
parameter = attributes_for(:parameter)
expect {
click_link 'Add Node'
fill_in 'Name', :with => name
click_link 'Add Parameter'
fill_in 'key', :with => parameter[:key]
fill_in 'value', :with => parameter[:value]
click_button 'Create Node'
}.to change(Parameter, :count).by(1)
expect(page).to have_content "Node: #{name}"
end
it 'Edits a node', :js => true do
node = create(:node, description: 'FooDescription')
visit node_path(node)
expect(page).to have_content 'FooDescription'
click_link 'Edit'
fill_in 'Description', with: 'BarDescription'
click_button 'Update Node'
expect(page).to have_content 'BarDescription'
end
it 'Deletes a node', :js => true do
node = create(:node, name: 'Foo')
visit nodes_path
within('#nodes') do
click_link node.name
end
expect(page).to have_content "Node: Foo"
expect {
click_link 'Delete'
page.accept_alert do
expect(page).to_not have_content 'Foo'
end
}.to change(Node, :count).by(-1)
end
end
end
<file_sep>require 'rails_helper'
describe Parameter do
it "has a valid factory" do
expect(create(:parameter)).to be_valid
end
it "is invalid without a key" do
expect(build(:parameter, key: nil)).to_not be_valid
end
it "is invalid without a value" do
expect(build(:parameter, value: nil)).to_not be_valid
end
end
<file_sep># config valid only for current version of Capistrano
lock '3.8.2'
## Base
set :application, 'salt-dashboard'
set :repo_url, 'https://github.com/n-rodriguez/salt-dashboard.git'
set :deploy_to, '/home/salt-dashboard'
## SSH
set :ssh_options, {
keys: [File.join(Dir.home, '.ssh', 'id_rsa')],
forward_agent: true,
auth_methods: %w[publickey]
}
## RVM
set :rvm_ruby_version, '2.4.1'
## Bundler
set :bundle_flags, '--deployment'
## Rails
append :linked_files, '.env'
append :linked_dirs, 'log', 'tmp'
# Skip migration if files in db/migrate were not modified
set :conditionally_migrate, true
# Defaults to :db role
set :migration_role, :app
# Cleanup assets after deploy
set :keep_assets, 1
## Foreman
set :foreman_roles, :app
set :foreman_init_system, 'systemd'
set :foreman_services, %w[web worker]
set :foreman_export_path, "#{deploy_to}/.config/systemd/user"
set :foreman_options, {
template: "#{deploy_to}/.foreman/templates/systemd",
root: current_path,
timeout: 30,
}
## Config
set :config_templates, %w[nginx syslog logrotate]
set :config_syslog, %w[web worker]
namespace :deploy do
before 'deploy:check:linked_files', 'config:install'
after 'deploy:check:linked_files', 'foreman:install'
after 'deploy:published', 'bundler:clean'
after 'deploy:finished', 'foreman:export'
after 'deploy:finished', 'foreman:restart'
end
<file_sep>require 'rails_helper'
describe EventsImporter do
let(:events_data) { YAML.load(File.read('spec/fixtures/salt_events.yml'))}
let(:report) { create(:report, data: events_data.to_json) }
let(:importer) { EventsImporter.new(report) }
subject { importer }
describe '#report' do
it 'should return report object' do
expect(subject.report).to eq report
end
end
describe '#events' do
it 'should return a list of events to import' do
expect(subject.events).to eq events_data
end
end
describe '#import!' do
it 'should creates report logs' do
expect {
subject.import!
}.to change(ReportLog, :count).by(1)
end
it 'should creates resource statuses' do
expect {
subject.import!
}.to change(ResourceStatus, :count).by(5)
end
it 'should creates metrics' do
expect {
subject.import!
}.to change(Metric, :count).by(10)
end
it 'should set report#processed to true' do
expect(report.processed?).to be false
subject.import!
expect(report.processed?).to be true
end
end
end
<file_sep>class ReportImporter
def initialize(report_data)
@report_data = report_data
end
class << self
def import(report_data)
new(report_data).import!
end
end
def function
@report_data.dig('job', 'function')
end
def job_id
@report_data.dig('job', 'job_id')
end
def result
@report_data.dig('job', 'result') || {}
end
def import!
if function.start_with?('state.')
save_report
handle_state_return
end
end
private
def handle_state_return
result.each do |minion_id, events|
node = Node.find_or_create_by(name: minion_id)
report = node.reports.find_or_create_by(job_id: job_id) do |r|
r.time = Time.now
r.data = events.to_json
end
next if report.persisted? && report.processed?
AsyncImportJob.perform_later(report)
end
true
end
def save_report
file = Rails.root.join('tmp', "#{job_id}.yml")
File.open(file, 'w') do |f|
f.write @report_data.to_yaml
end
end
end
<file_sep>namespace :config do
desc 'Install configuration files'
task install: [:generate] do
on roles(:app) do |host|
config_files = fetch(:config_templates, [])
execute :sudo, :cp, "#{shared_path}/config/nginx.conf", "/etc/nginx/sites-enabled/#{fetch(:application)}.conf" if config_files.include?('nginx')
execute :sudo, :cp, "#{shared_path}/config/syslog-ng.conf", "/etc/syslog-ng/conf.d/#{fetch(:application)}.conf" if config_files.include?('syslog')
execute :sudo, :cp, "#{shared_path}/config/logrotate.conf", "/etc/logrotate.d/#{fetch(:application)}" if config_files.include?('logrotate')
end
end
desc 'Generate configuration files'
task :generate do
on roles(:app) do |host|
execute 'mkdir', '-p', "#{shared_path}/config"
execute 'mkdir', '-p', "#{shared_path}/tmp/sockets"
config_files = fetch(:config_templates, [])
services = fetch(:foreman_services, [])
upload! "deploy/application.#{fetch(:stage)}.conf", "#{shared_path}/.env"
template 'systemd', "#{deploy_to}/#{fetch(:application)}", 0755, locals: { services: services }
template 'sudoers.conf', "#{shared_path}/config/sudoers.conf"
template 'nginx.conf', "#{shared_path}/config/nginx.conf", 0644 if config_files.include?('nginx')
template 'syslog-ng.conf', "#{shared_path}/config/syslog-ng.conf", 0644 if config_files.include?('syslog')
template 'logrotate.conf', "#{shared_path}/config/logrotate.conf", 0644 if config_files.include?('logrotate')
end
end
end
<file_sep>class Report < ActiveRecord::Base
# Relations
belongs_to :node
has_many :report_logs, dependent: :delete_all
has_many :metrics, dependent: :delete_all
has_many :resource_statuses, dependent: :delete_all
end
<file_sep>require 'rails_helper'
describe NodesHelper do
describe "node_report_time" do
subject { helper.node_report_time(time) }
context "with time" do
let(:time) { Time.now }
it { expect(subject).to eq "less than a minute ago" }
end
context "without time" do
let(:time) { nil }
it { expect(subject).to eq "unreported" }
end
end
describe "node_status_badge" do
let(:node) { double }
subject { helper.node_status_badge(node) }
context "unreported" do
before { allow(node).to receive(:status).and_return(nil) }
it { expect(subject).to match /unreported/ }
end
context "reported" do
["changed", "pending", "unchanged", "failed"].each do |status|
context status do
before { allow(node).to receive(:status).and_return(status) }
it { expect(subject).to match /#{status}/ }
end
end
context "unknown status" do
before { allow(node).to receive(:status).and_return(Random.rand) }
it { expect(subject).to be_nil }
end
end
end
end
<file_sep>require 'sidekiq/exception_handler'
#
# Configure Sidekiq/Redis
#
Sidekiq.configure_server do |config|
config.redis = { host: Settings.redis_host, port: Settings.redis_port, db: Settings.redis_db, namespace: 'sidekiq', driver: :hiredis }
end
Sidekiq.configure_client do |config|
config.redis = { host: Settings.redis_host, port: Settings.redis_port, db: Settings.redis_db, namespace: 'sidekiq', driver: :hiredis }
end
<file_sep>require 'rails_helper'
describe NodeGroupsController do
describe "GET #index" do
it "populates an array of node_groups" do
node_group = create(:node_group)
get :index
expect(assigns(:node_groups)).to eq([node_group])
end
it "renders the #index view" do
get :index
expect(response).to render_template :index
end
it "renders json" do
node_group = create(:node_group)
get :index, format: :json
end
end
describe "GET #show" do
it "assigns the requested node_group to @node_group" do
node_group = create(:node_group)
get :show, params: { id: node_group }
expect(assigns(:node_group)).to eq(node_group)
end
it "renders the #show view" do
node_group = create(:node_group)
get :show, params: { id: node_group }
expect(response).to render_template :show
end
it "renders json" do
node_group = create(:node_group)
get :show, params: { id: node_group, format: :json }
end
end
describe "GET #new" do
it "assigns a new node_group to @node_group" do
get :new
expect(assigns(:node_group)).to be_kind_of NodeGroup
end
it "renders the #new view" do
get :new
expect(response).to render_template :new
end
end
describe "GET #edit" do
it "assigns the requested node_group to @node_group" do
node_group = create(:node_group)
get :edit, params: { id: node_group }
expect(assigns(:node_group)).to eq(node_group)
end
it "renders the #edit view" do
node_group = create(:node_group)
get :edit, params: { id: node_group }
expect(response).to render_template :edit
end
end
describe "POST #create" do
context "with valid attributes" do
let(:attributes) { attributes_for(:node_group) }
it "creates a new node_group" do
expect {
post :create, params: { node_group: attributes }
}.to change(NodeGroup, :count).by(1)
end
it "renders the #edit view" do
post :create, params: { node_group: attributes }
expect(response).to redirect_to NodeGroup.last
end
end
context "with invalid attributes" do
let(:attributes) { attributes_for(:invalid_node_group) }
it "does not create a new node_group" do
expect {
post :create, params: { node_group: attributes }
}.to_not change(NodeGroup, :count)
end
it "renders the #new view" do
post :create, params: { node_group: attributes }
expect(response).to render_template :new
end
end
end
describe "PUT #update" do
before :each do
@node_group = create(:node_group, name: 'foo')
end
context "with valid attributes" do
let(:attributes) { attributes_for(:node_group, name: 'bar') }
it "located the requested @node_group" do
put :update, params: { id: @node_group, node_group: attributes }
expect(assigns(:node_group)).to eq(@node_group)
end
it "changes @node_group's attributes" do
put :update, params: { id: @node_group, node_group: attributes }
@node_group.reload
expect(@node_group.name).to eq('bar')
end
it "redirects to show updated node group" do
put :update, params: { id: @node_group, node_group: attributes }
expect(response).to redirect_to NodeGroup.last
end
end
context "with invalid attributes" do
let(:attributes) { attributes_for(:invalid_node_group) }
it "does not change @node_group's attributes" do
put :update, params: { id: @node_group, node_group: attributes }
@node_group.reload
expect(@node_group.name).to eq('foo')
end
it "renders the #edit view" do
put :update, params: { id: @node_group, node_group: attributes }
expect(response).to render_template :edit
end
end
end
describe "DELETE #destroy" do
it "deletes the node group" do
node_group = create(:node_group)
expect {
delete :destroy, params: { id: node_group }
}.to change(NodeGroup, :count).by(-1)
end
it "redirects back to #index" do
node_group = create(:node_group)
delete :destroy, params: { id: node_group }
expect(response).to redirect_to node_groups_path
end
end
end
<file_sep>class NodesController < ApplicationController
helper_method :sort_column, :sort_direction
before_action :set_node, only: [:show, :edit, :update, :destroy, :grains, :status_history, :resource_times, :highstate, :highstate_test, :restart_salt]
def index
@nodes = Node.order(sort_column => sort_direction.to_sym)
render_collection(@nodes)
end
def show
@reports = @node.reports.order(time: :desc).page params[:page]
respond_to do |format|
format.html # show.html.erb
format.js # show.js.erb
format.json { render json: @node }
format.yaml { render text: @node.to_yaml, content_type: 'text/yaml' }
end
end
def new
@node = Node.new
end
def create
@node = Node.new(node_params)
render_create(@node)
end
def update
render_update(@node, node_params)
end
def destroy
begin
@node.deprovision
rescue Exception => e
end
render_destroy(@node)
end
def unresponsive
@nodes = Node.unresponsive.order(sort_column => sort_direction.to_sym)
render_collection(@nodes, 'index')
end
def failed
@nodes = Node.failed.order(sort_column => sort_direction.to_sym)
render_collection(@nodes, 'index')
end
def pending
@nodes = Node.pending.order(sort_column => sort_direction.to_sym)
render_collection(@nodes, 'index')
end
def changed
@nodes = Node.changed.order(sort_column => sort_direction.to_sym)
render_collection(@nodes, 'index')
end
def unchanged
@nodes = Node.unchanged.order(sort_column => sort_direction.to_sym)
render_collection(@nodes, 'index')
end
def unreported
@nodes = Node.unreported.order(sort_column => sort_direction.to_sym)
render_collection(@nodes, 'index')
end
def grains
respond_to do |format|
format.html # show.html.erb
format.json { render json: @node.grains }
end
end
def resources
respond_to do |format|
format.html # show.html.erb
format.json { render json: @node.resources }
end
end
def status_history
render :json => @node.reports.where("time > '#{Time.now - 60*60*24}'").group(:status).count
end
def resource_times
@report = @node.reports.order(time: :desc).first
if @report
@metrics = @report.metrics.where(name: 'Total')
@metrics = @metrics.collect {|n| [n.category, n.value]}
else
@metrics = []
end
render :json => @metrics
end
def highstate
flash[:notice] = "Failed to trigger highstate run on #{@node}" unless @node.highstate
redirect_to :back
end
def highstate_test
flash[:notice] = "Failed to trigger highstate test run on #{@node}" unless @node.highstate_test
redirect_to :back
end
def restart_salt
flash[:notice] = "Failed to trigger service.restart for salt on #{@node}" unless @node.restart_salt
redirect_to :back
end
private
def set_node
@node = Node.find_by_name(params[:id])
end
def sort_column
Node.column_names.include?(params[:sort]) ? params[:sort] : "reported_at"
end
def sort_direction
%w[asc desc].include?(params[:direction]) ? params[:direction] : "desc"
end
def node_params
params.require(:node).permit(:name, :description, :status, :environment, :reported_at, :last_apply_report_id,
parameters_attributes: [:key, :value, :_destroy, :id],
node_group_memberships_attributes: [:node_group_id, :_destroy, :id],
node_class_memberships_attributes: [:node_class_id, :_destroy, :id])
end
end
<file_sep>class Parameter < ActiveRecord::Base
# Relations
belongs_to :parameterable, polymorphic: true
# Validations
validates :key, presence: true, uniqueness: { scope: [:parameterable_id, :parameterable_type] }
validates :value, presence: true
end
<file_sep>require 'rails_helper'
describe ReportsController do
describe "GET #index" do
it "populates an array of reports" do
report = create(:report)
get :index
expect(assigns(:reports)).to eq([report])
end
it "renders the #index view" do
get :index
expect(response).to render_template :index
end
end
describe "GET #show" do
before :each do
@report = create(:report)
end
it "assigns the requested report to @report" do
get :show, params: { id: @report }
expect(assigns(:report)).to eq(@report)
end
it "renders the #show view" do
get :show, params: { id: @report }
expect(response).to render_template :show
end
end
if ENV["DB"] != "sqlite3"
describe "GET #report_history" do
let(:time) { Time.parse("2014-01-01 23:59:00 +0000") }
let(:result) { { time.to_date => 1 } }
before :each do
@report = create(:report, time: time)
end
it "assigns the requested report to @report" do
get :report_history
expect(assigns(:history)).to eq(result)
end
it "renders the #show view" do
get :report_history
expect(response.body).to eq result.to_json
end
end
end
describe "DELETE #destroy" do
before :each do
@report = create(:report)
end
it "deletes the report" do
expect {
delete :destroy, params: { id: @report }
}.to change(Report, :count).by(-1)
end
it "redirects back to #index" do
delete :destroy, params: { id: @report }
expect(response).to redirect_to reports_path
end
end
describe "POST #upload" do
let(:report_data) { YAML.load(File.read("spec/fixtures/salt_report.yml")) }
it "creates a report" do
expect {
post :upload, params: { report: report_data, format: :json }
}.to change(Report, :count).by(1)
end
it "returns OK" do
post :upload, params: { report: report_data, format: :json }
expect(response.body).to eq 'OK'
end
end
end
<file_sep>class AddJobIdToReport < ActiveRecord::Migration[5.1]
def change
add_column :reports, :job_id, :string
end
end
<file_sep>module ApplicationHelper
def sortable(column, title = nil)
title ||= column.titleize
css_class = column == sort_column ? "current #{sort_direction}" : nil
direction = column == sort_column && sort_direction == "asc" ? "desc" : "asc"
link_to title, { sort: column, direction: direction }, { class: css_class }
end
def current_url(new_params)
options = params.dup
options.merge!(new_params)
string = options.to_unsafe_h.map { |k, v| "#{k}=#{v}" }.join("&")
request.fullpath.split("?")[0] + "?" + string
end
def render_salt_log(message)
if message["changes"].kind_of?(Hash)
if message["changes"].has_key?("diff")
content_tag("pre") do
content_tag("code", class: "diff") do
message["changes"]["diff"]
end
end
elsif message["changes"].find { |k, v| v.kind_of?(Hash) && v.has_key?("diff") }
message["changes"].collect do |file, file_changes|
content_tag("div", file) +
content_tag("pre") do
content_tag("code", class: "diff") do
file_changes["diff"]
end
end
end.join().html_safe
else
content_tag("pre") do
content_tag("code", class: "yaml") do
message.to_yaml
end
end
end
else
content_tag("pre") do
if message["error"].kind_of? Array
message["error"].join("\n")
else
message["error"]
end
end
end
end
end
<file_sep>require 'simplecov'
SimpleCov.start 'rails'
# Set env vars
ENV["RAILS_ENV"] ||= 'test'
# Load spec_helper (this configures base of RSpec)
require 'spec_helper'
# Load Rails
require File.expand_path("../../config/environment", __FILE__)
# Load RSpec for Rails
require 'rspec/rails'
# Load Capybara
require 'capybara/rails'
require 'capybara/rspec'
require 'capybara-screenshot/rspec'
require 'capybara/poltergeist'
# Configure Capybara
Capybara.run_server = true
Capybara.server_port = 3000
Capybara.app_host = 'http://localhost:3000'
Capybara.default_max_wait_time = 5
Capybara.register_driver :poltergeist do |app|
Capybara::Poltergeist::Driver.new(app, timeout: 60, js_errors: false, window_size: [1280, 1024])
end
Capybara.default_driver = :poltergeist
Capybara.current_driver = :poltergeist
Capybara.javascript_driver = :poltergeist
# Requires supporting ruby files with custom matchers and macros, etc,
# in spec/support/ and its subdirectories.
Dir[Rails.root.join("spec/support/**/*.rb")].each { |f| require f }
# Configure RSpec
RSpec.configure do |config|
config.include Capybara::DSL
config.include FactoryGirl::Syntax::Methods
config.color = true
config.fail_fast = false
config.infer_spec_type_from_file_location!
config.use_transactional_fixtures = false
config.expect_with :rspec do |c|
c.syntax = :expect
end
config.before(:suite) do
DatabaseCleaner.clean_with(:truncation)
end
config.before(:each) do
DatabaseCleaner.strategy = :transaction
end
config.before(:each, js: true) do
DatabaseCleaner.strategy = :truncation
end
config.before(:each) do
DatabaseCleaner.start
end
config.after(:each) do
DatabaseCleaner.clean
end
end
<file_sep>class Metric < ActiveRecord::Base
# Relations
belongs_to :report
# Validations
validates :report_id, presence: true
end
<file_sep>class EventsImporter
attr_reader :report
def initialize(report)
@report = report
@node_status = nil
@metric_totals = Hash.new(0.0)
end
class << self
def import(report)
new(report).import!
end
end
def events
@events ||= JSON.load(report.data)
end
def import!
if events.kind_of?(Hash)
@node_status = 'unchanged'
import_report(events)
else
@node_status = 'failed'
create_error_log(events)
end
update_report_status(@node_status)
update_node_status(@node_status)
end
private
def import_report(events)
events = events.map { |id, status| SaltEvent.new(id, status) }
events = events.sort_by(&:run_num)
events.each do |event|
ischanged = false
skipped = false
@metric_totals[event.category] += event.duration || 0.0
create_event_metrics(event)
if event.result == nil
# This is terrible but assume the run is pending if we skip a resource
@node_status = 'pending' if @node_status == 'unchanged'
skipped = true
result = true
elsif event.result == true
result = true
elsif event.result == false
result = false
# Should we assume we skip failed resources?
skipped = true
@node_status = 'failed'
end
if event.changes.length > 0
ischanged = true
@node_status = 'changed' if @node_status == 'unchanged' && result == true
end
# Only create logs for changes and failures
if event.changes.length > 0 || result == false || skipped == true
report.report_logs.create({
time: Time.now,
level: (result ? 'info' : 'err'),
message: event.status.to_json,
source: event.id
})
end
report.resource_statuses.create({
title: "#{event.category}: #{event.resource_id}",
is_changed: ischanged,
skipped: skipped,
failed: (result == false)
})
end
create_report_metrics
end
def create_report_metrics
@metric_totals.each do |name, value|
report.metrics.create(
name: 'Total',
category: name,
value: value
)
end
end
def create_event_metrics(event)
report.metrics.create(
category: event.category,
name: event.resource_id,
value: event.duration
)
end
def create_error_log(events)
report.report_logs.create({
time: Time.now,
level: 'err',
message: { error: events }.to_json,
source: ''
})
end
def update_report_status(status)
report.update_attributes(status: status, processed: true)
end
def update_node_status(status)
report.node.update_attributes(
status: status,
reported_at: Time.now,
last_apply_report_id: report.id
)
end
end
<file_sep>require 'rails_helper'
describe NodeGroupMembership do
it "has a valid factory" do
expect(create(:node_group_membership)).to be_valid
end
end
<file_sep>class NodeGroupMembership < ActiveRecord::Base
# Relations
belongs_to :node
belongs_to :node_group
end
<file_sep>require 'rails_helper'
describe NodeClassMembership do
it "has a valid factory" do
expect(create(:node_class_membership)).to be_valid
end
end
<file_sep>class NodeGroupsController < ApplicationController
helper_method :sort_column, :sort_direction
before_action :set_node_group, only: [:show, :edit, :update, :destroy, :highstate, :highstate_test, :restart_salt]
def index
@node_groups = NodeGroup.order(sort_column => sort_direction.to_sym)
render_collection(@node_groups)
end
def show
@nodes = @node_group.nodes.order(sort_column => sort_direction.to_sym)
render_show(@node_group)
end
def new
@node_group = NodeGroup.new
end
def create
@node_group = NodeGroup.new(node_group_params)
render_create(@node_group)
end
def update
render_update(@node_group, node_group_params)
end
def destroy
render_destroy(@node_group)
end
def highstate
flash[:notice] = "Failed to trigger highstate run on #{@node_group}" unless @node_group.highstate
redirect_to :back
end
def highstate_test
flash[:notice] = "Failed to trigger highstate test run on #{@node_group}" unless @node_group.highstate_test
redirect_to :back
end
def restart_salt
flash[:notice] = "Failed to trigger service.restart for salt on #{@node_group}" unless @node_group.restart_salt
redirect_to :back
end
private
def set_node_group
@node_group = NodeGroup.find_by_name(params[:id])
end
def sort_column
params[:sort] || "name"
end
def sort_direction
%w[asc desc].include?(params[:direction]) ? params[:direction] : "asc"
end
def node_group_params
params.require(:node_group).permit(:name, parameters_attributes: [:key, :value, :_destroy, :id])
end
end
<file_sep>class Node < ActiveRecord::Base
# Relations
has_many :reports, dependent: :destroy
has_many :node_group_memberships, dependent: :destroy
has_many :node_groups, through: :node_group_memberships
has_many :node_class_memberships, dependent: :destroy
has_many :node_classes, through: :node_class_memberships
has_many :parameters, as: :parameterable, dependent: :destroy
# Validations
validates :name, presence: true, uniqueness: true
# Nested attributes
accepts_nested_attributes_for :parameters, allow_destroy: true
accepts_nested_attributes_for :node_class_memberships, allow_destroy: true, reject_if: :all_blank
accepts_nested_attributes_for :node_group_memberships, allow_destroy: true, reject_if: :all_blank
# Scopes
scope :responsive, -> { where('reported_at >= ?', Time.now.utc - 3600) }
scope :unresponsive, -> { where('reported_at < ?', Time.now.utc - 3600) }
scope :changed, -> { responsive.where(status: 'changed') }
scope :unchanged, -> { responsive.where(status: 'unchanged') }
scope :failed, -> { responsive.where(status: 'failed') }
scope :pending, -> { responsive.where(status: 'pending') }
scope :unreported, -> { where(status: nil) }
def to_s
name
end
def serializable_hash(options={})
options = {
:include => {
:parameters => {},
:node_groups => {},
:node_classes => {}
}
}.update(options)
super(options)
end
def environment
super.to_s.empty? ? "production" : super
end
def collapse_parameters
{}.tap do |params|
Parameter.where(parameterable_id: nil).each do |parameter|
params[parameter.key] = parameter.value
end
node_groups.each do |node_group|
node_group.parameters.each do |parameter|
params[parameter.key] = parameter.value
end
end
parameters.each do |parameter|
params[parameter.key] = parameter.value
end
end
end
def to_hash
{
"name" => name,
"environment" => environment,
"classes" => node_classes.collect(&:name),
"parameters" => collapse_parameters
}
end
def to_yaml
to_hash.to_yaml
end
def to_param
name
end
def last_report
Report.find(last_apply_report_id)
end
def grains
Salt::Api.run(client: 'local', tgt: name, fun: 'grains.items')
end
def delete_salt_key
Salt::Api.run(client: 'wheel', fun: 'key.delete', match: name)
end
def highstate
Salt::Api.run(client: 'local_async', tgt: name, fun: 'state.highstate')
end
def highstate_test
Salt::Api.run(client: 'local_async', tgt: name, fun: 'state.highstate', kwarg: { test: true})
end
def restart_salt
Salt::Api.run(client: 'local_async', tgt: name, fun: 'service.restart', kwarg: { name: 'salt-minion'})
end
end
<file_sep>require 'rails_helper'
describe ResourceStatus do
it "has a valid factory" do
expect(create(:resource_status)).to be_valid
end
end
<file_sep>require 'settingslogic'
class Settings < Settingslogic
source Rails.root.join('config', 'settings.yml')
extend ActiveModel::Translation
include ActiveModel::Conversion
end
<file_sep>class ReportsController < ApplicationController
skip_before_action :verify_authenticity_token, only: [:upload]
before_action :set_report, only: [:show, :destroy]
def index
@reports = Report.order(time: :desc).page params[:page]
end
def report_history
@history = Report.group_by_day(:time).count
# TODO: There has to be a better way
@history.reject! { |k, v| v.nil? }
@history = @history.inject({}) do |o, (k, v)|
kk = Time.parse(k.to_s)
o[kk.to_date] = v
o
end
render json: @history
end
def destroy
@report.destroy
redirect_to reports_path
end
def upload
data = params.to_unsafe_h[:report]
ReportImporter.import(data)
render plain: 'OK'
end
private
def set_report
@report = Report.find(params[:id])
end
end
<file_sep># This file should contain all the record creation needed to seed the database with its default values.
# The data can then be loaded with the rake db:seed (or created alongside the db with db:setup).
#
# Examples:
#
# cities = City.create([{ name: 'Chicago' }, { name: 'Copenhagen' }])
# Mayor.create(name: 'Emanuel', city: cities.first)
node1 = Node.find_or_create_by_name("node1")
node1.status = "unchanged"
node1.save
node2 = Node.find_or_create_by_name("node2")
node2.status = "changed"
node2.save
group1 = NodeGroup.find_or_create_by_name("group1")
group2 = NodeGroup.find_or_create_by_name("group2")
group3 = NodeGroup.find_or_create_by_name("group3")
<file_sep>require 'rails_helper'
describe ReportImporter do
let(:report_data) { YAML.load(File.read('spec/fixtures/salt_report.yml'))}
let(:importer) { ReportImporter.new(report_data) }
subject { importer }
describe '#function' do
it 'should return the Salt function name' do
expect(subject.function).to eq 'state.highstate'
end
end
describe '#job_id' do
it 'should return the Salt job_id' do
expect(subject.job_id).to eq '20170630214952409445'
end
end
describe '#result' do
it 'should return the Salt result' do
result = subject.result
expect(result).to be_a Hash
expect(result.keys.first).to eq 'cloud.example.net'
end
end
describe '#import!' do
it 'should process the Salt result' do
expect(subject.import!).to eq true
end
it "should create a node" do
expect {
subject.import!
}.to change(Node, :count).by(1)
end
it "should create a report" do
expect {
subject.import!
}.to change(Report, :count).by(1)
end
end
end
<file_sep>module NodesHelper
def node_report_time(time)
if time
time_ago_in_words(time) + " ago"
else
"unreported"
end
end
def salt_action_dropdown(type, obj)
css = 'default'
content_tag(:div, class: 'btn-group') do
content_tag(:button, type: :button, class: "btn btn-#{css} btn-sm dropdown-toggle", 'data-toggle' => :dropdown) do
"Action ".html_safe + tag(:span, class: :caret)
end +
content_tag(:ul, class: 'dropdown-menu', role: 'menu') do
content_tag(:li, link_to("Highstate", send("highstate_#{type}_path", obj))) +
content_tag(:li, link_to("Highstate Test", send("highstate_test_#{type}_path", obj))) +
content_tag(:li, link_to("Restart Salt", send("restart_salt_#{type}_path", obj)))
end
end
end
def node_salt_action_dropdown(node)
salt_action_dropdown("node", node)
end
def node_group_salt_action_dropdown(group)
salt_action_dropdown("node_group", group)
end
def node_status_badge(node)
if node.status
case node.status
when "changed"
content_tag(:span, node.status, :class => 'label label-info')
when "pending"
content_tag(:span, node.status, :class => 'label label-warning')
when "unchanged"
content_tag(:span, node.status, :class => 'label label-success')
when "failed"
content_tag(:span, node.status, :class => 'label label-danger')
end
else
content_tag(:span, "unreported", :class => 'label label-default')
end
end
end
<file_sep>class NodeClass < ActiveRecord::Base
# Relations
has_many :node_class_memberships, dependent: :destroy
has_many :nodes, through: :node_class_memberships
# Validations
validates :name, presence: true, uniqueness: true
def to_s
name
end
def to_param
name
end
end
<file_sep>class NodeGroup < ActiveRecord::Base
# Relations
has_many :node_group_memberships, :dependent => :destroy
has_many :nodes, :through => :node_group_memberships
has_many :parameters, :as => :parameterable, :dependent => :destroy
# Validations
validates :name, presence: true, uniqueness: true
# Attributes
accepts_nested_attributes_for :parameters, :allow_destroy => true
def to_s
name
end
def to_param
name
end
def serializable_hash(options = {})
options = {
:include => {
:parameters => {}
}
}.update(options)
super(options)
end
def highstate
Salt::Api.run(client: 'local_async', tgt: nodes.collect(&:name), expr_form: 'list', fun: 'state.highstate')
end
def highstate_test
Salt::Api.run(client: 'local_async', tgt: nodes.collect(&:name), expr_form: 'list', fun: 'state.highstate', kwarg: { test: true})
end
def restart_salt
Salt::Api.run(client: 'local_async', tgt: nodes.collect(&:name), expr_form: 'list', fun: 'service.restart', kwarg: { name: 'salt-minion'})
end
end
<file_sep>require 'rails_helper'
describe SaltEvent do
let(:event) { YAML.load(File.read('spec/fixtures/salt_event.yml'))}
let(:salt_event) { SaltEvent.new(event.keys.first, event.values.first) }
subject { salt_event }
describe '#run_num' do
it 'should return event run_num' do
expect(subject.run_num).to eq 208
end
end
describe '#comment' do
it 'should return event comment' do
expect(subject.comment).to eq 'Package python-mysqldb is already installed'
end
end
describe '#name' do
it 'should return event name' do
expect(subject.name).to eq 'python-mysqldb'
end
end
describe '#start_time' do
it 'should return event start_time' do
expect(subject.start_time).to eq '21:51:16.322951'
end
end
describe '#result' do
it 'should return event result' do
expect(subject.result).to be true
end
end
describe '#duration' do
it 'should return event duration' do
expect(subject.duration).to eq 13.008
end
end
describe '#changes' do
it 'should return event changes' do
expect(subject.changes).to eq({})
end
end
describe '#id' do
it 'should return event id' do
expect(subject.id).to eq 'pkg_|-mysql_python_|-python-mysqldb_|-installed'
end
end
describe '#status' do
it 'should return event status' do
expect(subject.status).to eq event.values.first
end
end
describe '#resource_type' do
it 'should return event resource_type' do
expect(subject.resource_type).to eq 'pkg'
end
end
describe '#resource_id' do
it 'should return event resource_id' do
expect(subject.resource_id).to eq 'mysql_python'
end
end
describe '#action' do
it 'should return event action' do
expect(subject.action).to eq 'installed'
end
end
describe '#category' do
it 'should return event category' do
expect(subject.category).to eq 'pkg.installed'
end
end
end
<file_sep>class CreateNodes < ActiveRecord::Migration[4.2]
def change
create_table :nodes do |t|
t.string :name, null: false
t.text :description
t.datetime :reported_at
t.integer :last_apply_report_id
t.string :status
t.boolean :hidden, default: false
t.integer :last_inspect_report_id
t.timestamps
end
add_index :nodes, :name, unique: true
end
end
<file_sep># Salt Dashboard
[](https://travis-ci.org/n-rodriguez/salt-dashboard)
[](https://codeclimate.com/github/n-rodriguez/salt-dashboard)
[](https://gemnasium.com/n-rodriguez/salt-dashboard)
## Salt configuration
`/etc/salt/master.d/enc.conf` :
```yaml
master_tops:
ext_nodes: enc-ext-nodes
ext_pillar:
- puppet: enc-ext-nodes
```
`/usr/bin/enc-ext-nodes` :
```bash
#!/bin/bash
curl --max-time 2 -s "http://salt-dashboard:3000/nodes/$1.yaml"
```
## Screenshots
### Mobile View

### Node View

### Group View

<file_sep>require 'rails_helper'
describe NodeClass do
it "has a valid factory" do
expect(create(:node_class)).to be_valid
end
it "does not allow duplicate names" do
node_class = create(:node_class)
expect(build(:node_class, name: node_class.name)).to_not be_valid
end
it "is invalid without a name" do
expect(build(:node_class, name: nil)).to_not be_valid
end
it "returns name for to_param" do
node_class = create(:node_class)
expect(node_class.to_param).to eq node_class.name
end
it "returns name for to_s" do
node_class = create(:node_class)
expect(node_class.to_s).to eq node_class.name
end
end
<file_sep>class IncreaseMessageLength < ActiveRecord::Migration[4.2]
def change
change_column :report_logs, :message, :text, limit: nil
end
end
<file_sep>class NodeClassMembership < ActiveRecord::Base
# Relations
belongs_to :node
belongs_to :node_class
end
<file_sep>require 'rails_helper'
describe ApplicationHelper do
describe '#sortable' do
let(:column) { 'name' }
let(:title) { 'Name' }
subject { helper.sortable(column, title) }
before { allow(helper).to receive(:sort_column).and_return("uhhh") }
before { allow(helper).to receive(:sort_direction).and_return("asc") }
before { allow(helper).to receive(:link_to) }
context "not already sorted" do
before { allow(helper).to receive(:sort_column).and_return(nil) }
before { allow(helper).to receive(:sort_direction).and_return("asc") }
it "should call link_to" do
expect(helper).to receive(:link_to).with(title, {:sort => column, :direction => "asc" }, { :class => nil })
subject
end
end
context "already sorted asc" do
before { allow(helper).to receive(:sort_column).and_return(column) }
before { allow(helper).to receive(:sort_direction).and_return("asc") }
it "should call link_to" do
expect(helper).to receive(:link_to).with(title, {:sort => column, :direction => "desc" }, { :class => "current asc" })
subject
end
end
end
end
<file_sep>class CreateMetrics < ActiveRecord::Migration[4.2]
def change
create_table :metrics do |t|
t.integer :report_id, null: false
t.string :category
t.string :name
t.decimal :value, precision: 12, scale: 6
t.timestamps
end
add_index :metrics, :report_id
end
end
<file_sep>APPLICATION_CONFIG = {
rails_config: %w[
SECRET_KEY_BASE
APPLICATION_NAME
],
db_config: %w[
DB_ADAPTER
DB_HOST
DB_PORT
DB_NAME
DB_USER
DB_PASS
],
redis_config: %w[
REDIS_HOST
REDIS_PORT
REDIS_DB
],
salt_config: %w[
SALT_HOSTNAME
SALT_PORT
SALT_USERNAME
SALT_PASSWORD
SALT_USE_SSL
],
}.freeze
begin
Figaro.require_keys(*APPLICATION_CONFIG.values.flatten)
rescue Figaro::MissingKeys => e
puts "\n#{e.message}"
exit 1
end
<file_sep>require 'rails_helper'
describe ParametersController do
describe "GET #index" do
it "populates an array of parameters" do
parameter = create(:parameter)
get :index
expect(assigns(:parameters)).to eq([parameter])
end
it "renders the #index view" do
get :index
expect(response).to render_template :index
end
end
describe "GET #new" do
it "assigns a new parameter to @parameter" do
get :new
expect(assigns(:parameter)).to be_kind_of Parameter
end
it "renders the #new view" do
get :new
expect(response).to render_template :new
end
end
describe "POST #create" do
context "with valid attributes" do
it "creates a new node_class" do
expect {
post :create, params: { parameter: attributes_for(:parameter) }
}.to change(Parameter, :count).by(1)
end
it "redirects to the new parameter" do
post :create, params: { parameter: attributes_for(:parameter) }
expect(response).to redirect_to parameters_path
end
end
context "with invalid attributes" do
it "does not create a new parameter" do
expect {
post :create, params: { parameter: attributes_for(:invalid_parameter) }
}.to_not change(Parameter, :count)
end
it "renders the #new view" do
post :create, params: { parameter: attributes_for(:invalid_parameter) }
expect(response).to render_template :new
end
end
end
end
| 796fe4e8793a9b8f90fc5109c8332879f63b4888 | [
"Markdown",
"Ruby"
] | 54 | Ruby | n-rodriguez/salt-dashboard | 899c3be57a5303cd3d8fb68520fa4ff9e4ffd1cc | 651f5cac786ae0fd754647f7f41cbabb3c04a9e4 |
refs/heads/master | <repo_name>s8508235/ror_learning<file_sep>/nthu_/app/controllers/static_pages_controller.rb
class StaticPagesController < ApplicationController
def about
render text:"x"
end
end
<file_sep>/nthu_/app/controllers/z_controller.rb
class ZController < ApplicationController
def aspx
render text:"z"
end
end
<file_sep>/README.md
# ror_learning
https://hackmd.io/IYMwHALA7CFgtBYBmKiBsBGADPMBjAE2HkIgE4oAmCAI3SsPOyA=#
https://hackmd.io/AwYwbAjCAsAmCsBaEBDaZHRSAHIgnNNAKaIQqwoBmV8wsIA7PkA=#
https://hackmd.io/GwTgLArMAMIIYFoCmAOARgMwWAxgZggTRQBM0EI8B2HCCDMEHZoA#
http://guides.ruby.tw/ruby/
https://github.com/oneclick/rubyinstaller/wiki/Development-Kit
https://github.com/amatsuda/kaminari
http://guides.ruby.tw/rails3/getting_started.html
<file_sep>/nthu_/app/controllers/scaffold_controller.rb
class ScaffoldController < ApplicationController
def Book
end
def title:string
end
def description:text
end
def page:integer
end
end
<file_sep>/nthu_/test/controllers/scaffold_controller_test.rb
require 'test_helper'
class ScaffoldControllerTest < ActionController::TestCase
test "should get Book" do
get :Book
assert_response :success
end
test "should get title:string" do
get :title:string
assert_response :success
end
test "should get description:text" do
get :description:text
assert_response :success
end
test "should get page:integer" do
get :page:integer
assert_response :success
end
end
| 62d11cebaeb97fd8a9e0e902836eae3763306f65 | [
"Markdown",
"Ruby"
] | 5 | Ruby | s8508235/ror_learning | c853b7afe38236eb6f4e480e9a2c0e1279eb8bff | c51643baceb5fdfd1cd8acffa8ab2feb7409c88e |
refs/heads/master | <repo_name>anhelina-hordiienko/project_05<file_sep>/script.js
/*$(document).ready(function() {
$(".portfolio .content").mouseenter(function(){
$(".content img").after('<div class="toolsContainer"><img src="img/zoom.png" alt="zoom" class="zoom"><div class="otherTools"><img src="img/polaroid.png" alt="polaroid"><img src="img/link.png" alt="link"><img src="img/info.png" alt="info"><img src="img/like.png" alt="like"></div></div>');
});
$(document).on("mouseleave", ".toolsContainer", function(){
$(".toolsContainer").remove();
});
});
*/
$(document).ready(function() {
$(".portfolio .content").hover(
function(){
$(this).append('<div class="toolsContainer"><img src="img/zoom.png" alt="zoom" class="zoom"><div class="otherTools"><img src="img/polaroid.png" alt="polaroid"><img src="img/link.png" alt="link"><img src="img/info.png" alt="info"><img src="img/like.png" alt="like"></div></div>');
},
function(){
$(".toolsContainer").remove()
}
);
}); | 2697e060129d9bcc57187bdc9b35bd85f43b1516 | [
"JavaScript"
] | 1 | JavaScript | anhelina-hordiienko/project_05 | 0d80e2d8d190d1caea1908883e41e6068be4ac23 | a01639aea3acbd08fddd230b3ab249d77750c212 |
refs/heads/master | <repo_name>petersonlima104/Films_of_Action<file_sep>/README.md
# Films_of_Action
API de filmes de ação
- Utilização:
Java8
spring webflux
Spring data
dynamodb
junit
sl4j
reactor
<file_sep>/src/main/java/com/digitalinnovationone/films_action_api/repository/FilmsRepository.java
package com.digitalinnovation.livecoding.repository;
import com.digitalinnovation.livecoding.document.Films;
import org.socialsignin.spring.data.dynamodb.repository.EnableScan;
import org.springframework.data.repository.CrudRepository;
@EnableScan
public interface FilmsRepository extends CrudRepository<Films, String>{
}
<file_sep>/src/main/java/com/digitalinnovationone/films_action_api/document/Films.java
package com.digitalinnovation.livecoding.document;
import com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBAttribute;
import com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBHashKey;
import org.springframework.data.annotation.Id;
import com.amazonaws.services.dynamodbv2.datamodeling.DynamoDBTable;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@DynamoDBTable(tableName ="Films_Api_Table")
public class Films {
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAno() {
return ano;
}
public void setAno(String ano) {
this.ano = ano;
}
public int getFilms() {
return films;
}
public void setFilms(int films) {
this.films = films;
}
@Id
@DynamoDBHashKey (attributeName = "id")
private String id;
@DynamoDBAttribute (attributeName = "name")
private String name;
@DynamoDBAttribute (attributeName = "ano")
private String ano;
@DynamoDBAttribute (attributeName = "films")
private int films;
public Films(String id, String name, String ano, int films) {
this.id = id;
this.name = name;
this.ano = ano;
this.films = films;
}
}
| 2e3b37f59d6e8e27d78ad5195a413a75342282e9 | [
"Markdown",
"Java"
] | 3 | Markdown | petersonlima104/Films_of_Action | c200fdd1c2f386fe141ffae03da95b1d4e317823 | 03e7a27ccea84f485d2db145bb200041922cbc10 |
refs/heads/master | <repo_name>rafuka/Dwa15-Project2<file_sep>/README.md
# Password Generator
Live URL: http://p2.jrwebdev.me
## Description
This project is a password generator inspired by the [xkcd comic](http://xkcd.com/936/).
The user can specify the number of words to use (from 1 to 5), and the number of special characters and/or digits.
When clicking on the *Generate!* button a new password is generated.
The words were taken by scraping a website with common english words.
It was built from scratch on PHP.
[View Screencast Demo](https://youtu.be/WgbifXGPJ28)
## Info for TA's
Please check the comment that starts with *NOTE for TA's* on the *logic.php* file.
## Things that can be improved/fixed
There is a small glitch when clicking the *Generate!* button that makes the main *div* shrink and grow back again.
Instead of scraping the web every time a user goes to the site, it would be better to scrape once for a large word base and save the words in a file for future use.
## Resources
For styling: [Bootswatch Theme](https://bootswatch.com/paper/)
Words scraped from: http://www.paulnoll.com/Books/Clear-English/
> Created By <NAME>, e-mail: <EMAIL>
<file_sep>/logic.php
<?php
# Array to hold all the possible words
$words = [];
# Scrap for words
if (!isset($_SESSION['words'])) {
$url = 'http://www.paulnoll.com/Books/Clear-English/';
$curr_page = array('words-01-02-hundred.html', 'words-03-04-hundred.html', 'words-05-06-hundred.html',
'words-07-08-hundred.html', 'words-09-10-hundred.html', 'words-11-12-hundred.html',
'words-13-14-hundred.html', 'words-15-16-hundred.html', 'words-17-18-hundred.html',
'words-19-20-hundred.html', 'words-21-22-hundred.html', 'words-23-24-hundred.html',
'words-25-26-hundred.html', 'words-27-28-hundred.html', 'words-29-30-hundred.html');
$words_string = "";
foreach ($curr_page as $page) {
$words_string = $words_string . file_get_contents($url . $page);
}
preg_match_all("'<li>(.*?)</li>'si", $words_string, $words);
# Trim the words for unnecessary whitespace.
foreach ($words[1] as $key => $word) {
$words[1][$key] = trim($word);
}
/* --- NOTE for TA's: when testing this code on a hardcoded array, it worked fine
however when I tested the project locally using the scraped array of words
there still were some words with apostrophes, If I can get some feedback
on why that might've happenned I'd appreciate it. Thanks. */
$words[1] = preg_replace("/[^A-Za-z ]/", '', $words[1]); # Remove or non-alphabetic characters
$words[1] = array_filter($words[1]); # Filter any empty string (if any)
# ---
$_SESSION['words'] = $words[1];
}
$words = $_SESSION['words'];
$symbols = array("@", "#", "$", "%", "&", "!");
$digits = array('0', '1', '2', '3', '4', '5', '6', '7', '8', '9');
$separation = "";
$pass = "";
$wordcount = 3; # Number of words
$scount = 0; # Number of special characters ($symbols)
$numcount = 0; # Number of digits
if (isset($_GET['numwords']) AND # Check that input is a number from 1 to 5
($_GET['numwords'] == 1 OR
$_GET['numwords'] == 2 OR
$_GET['numwords'] == 3 OR
$_GET['numwords'] == 4 OR
$_GET['numwords'] == 5)) {
$wordcount = $_GET['numwords'];
}
if (isset($_GET['specialchars']) AND # Check that input is a number from 0 to 5
($_GET['specialchars'] == 0 OR
$_GET['specialchars'] == 1 OR
$_GET['specialchars'] == 2 OR
$_GET['specialchars'] == 3 OR
$_GET['specialchars'] == 4 OR
$_GET['specialchars'] == 5)) {
$scount = $_GET['specialchars'];
}
if (isset($_GET['digits']) AND # Check that input is a number from 0 to 5
($_GET['digits'] == 0 OR
$_GET['digits'] == 1 OR
$_GET['digits'] == 2 OR
$_GET['digits'] == 3 OR
$_GET['digits'] == 4 OR
$_GET['digits'] == 5)) {
$numcount = $_GET['digits'];
}
if (isset($_GET['separation']) AND # Check that input is a valid case (" ", "", "-", or "c")
($_GET['separation'] == "" OR
$_GET['separation'] == " " OR
$_GET['separation'] == "-" OR
$_GET['separation'] == "c")) {
$separation = $_GET['separation'];
}
# Build Password
if ($separation == "c") {
for($i = 0; $i < $wordcount; $i++) {
$pass = $pass . ucwords($words[array_rand($words)]);
}
}
else {
for ($i = 0; $i < $wordcount - 1; $i++) {
$pass = $pass . $words[array_rand($words)] . $separation;
}
$pass = $pass . $words[array_rand($words)];
}
for($i = 0; $i < $scount; $i++) {
$pass = $pass . $symbols[array_rand($symbols)];
}
for($i = 0; $i < $numcount; $i++) {
$pass = $pass . $digits[array_rand($digits)];
}
?>
<file_sep>/index.php
<?php session_start(); ?>
<!DOCTYPE html>
<html>
<head>
<title>Project 2 | <NAME></title>
<meta charset="utf-8"/>
<link rel="stylesheet" type="text/css" href="css/bootstrap.min.css"/>
<link href='https://fonts.googleapis.com/css?family=Ubuntu+Mono:400,700' rel='stylesheet' type='text/css'>
<link rel="stylesheet" type="text/css" href="css/styles.css"/>
<?php require 'logic.php'; ?>
</head>
<body>
<div id="maincontainer">
<h1>Password Generator</h1>
<div id="password">
<p><?php echo $pass; ?></p>
</div>
<form id ="wordselect" action="index.php" method="GET">
<label for="numwords">How many words?</label>
<select id="numwords" name="numwords" form="wordselect">
<option value="1" <?php if($wordcount == 1) { echo "selected";} ?>>1</option>
<option value="2" <?php if($wordcount == 2) { echo "selected";} ?>>2</option>
<option value="3" <?php if($wordcount == 3) { echo "selected";} ?>>3</option>
<option value="4" <?php if($wordcount == 4) { echo "selected";} ?>>4</option>
<option value="5" <?php if($wordcount == 5) { echo "selected";} ?>>5</option>
</select>
<br>
<label for="specialchars">How many special characters?</label>
<select id="specialchars" name="specialchars" form="wordselect">
<option value="0" <?php if($scount == 0) { echo "selected";} ?>>0</option>
<option value="1" <?php if($scount == 1) { echo "selected";} ?>>1</option>
<option value="2" <?php if($scount == 2) { echo "selected";} ?>>2</option>
<option value="3" <?php if($scount == 3) { echo "selected";} ?>>3</option>
<option value="4" <?php if($scount == 4) { echo "selected";} ?>>4</option>
<option value="5" <?php if($scount == 5) { echo "selected";} ?>>5</option>
</select>
<br>
<label for="digits">How many digits?</label>
<select id="digits" name="digits" form="wordselect">
<option value="0" <?php if($numcount == 0) { echo "selected";} ?>>0</option>
<option value="1" <?php if($numcount == 1) { echo "selected";} ?>>1</option>
<option value="2" <?php if($numcount == 2) { echo "selected";} ?>>2</option>
<option value="3" <?php if($numcount == 3) { echo "selected";} ?>>3</option>
<option value="4" <?php if($numcount == 4) { echo "selected";} ?>>4</option>
<option value="5" <?php if($numcount == 5) { echo "selected";} ?>>5</option>
</select>
<br>
<label for="separation">Separate words by</label>
<select id="separation" name="separation" form="wordselect">
<option value="" <?php if($separation == "") { echo "selected";} ?>>None</option>
<option value=" " <?php if($separation == " ") { echo "selected";} ?>>Space</option>
<option value="-" <?php if($separation == "-") { echo "selected";} ?>>Hyphen</option>
<option value="c" <?php if($separation == "c") { echo "selected";} ?>>CamelCase</option>
</select>
<br>
<input id="submitbtn" class="btn btn-success" type="submit" value="Generate!"/>
</form>
</div>
</body>
</html>
| 5beae705695c6e2e7e3ad9a5181ed7da8b69b2cb | [
"Markdown",
"PHP"
] | 3 | Markdown | rafuka/Dwa15-Project2 | 744118bfecafd37436053023cf1f4c75e8a1d713 | deaf1008d2821976253a38f6b28a27095e18f348 |
refs/heads/master | <repo_name>rajat-29/Tetris_Game_Java<file_sep>/README.md
# Tetris_Game_Java
Tetris Game made in java during learning phase of java
## How To Play?
<ul>
<li>Just run the java file</li>
</ul>
## Instruction To Play :
<ol type="number">
<li>Press b for DOWNWARDS</li>
<li>Press r for RIGHT</li>
<li>Press l for LEFT</li>
<li>Press a for ANTICLOCKWISE</li>
<li>Press d for CLOCKWISE</li>
<li>Press u for UNDO</li>
<li>Press i for REDO</li>
</ol>
<file_sep>/TETRIS.java
import java.util.*;
import java.lang.*;
class Points
{
Points()
{
}
int xCod[];
int yCod[];
}
class Version extends Points
{
public int versionNo=1;
Version()
{}
Version(int versionNo)
{
this.versionNo = versionNo;
}
public void changeVersion(int versionNo)
{
this.versionNo = versionNo;
}
public void changeVersionAnticlock(int versionNo)
{
this.versionNo = versionNo;
}
public void changeVersionClock(int versionNo)
{
this.versionNo = versionNo;
}
public boolean checkDown(char board[][]) {
return false;
}
public boolean checkLeft(char board[][]) {
return false;
}
public boolean checkRight(char board[][]) {
return false;
}
public void generateVer() {
}
public int getVersion()
{
return versionNo;
}
}
class Line extends Version {
Line()
{
Random r = new Random();
int ranNo = r.nextInt((25 - 5) + 1) + 5;
xCod = new int[] {4,5,6,7};
yCod = new int[] {ranNo,ranNo,ranNo,ranNo};
}
public void generateVer()
{
Random r = new Random();
int ranNo = r.nextInt((25 - 5) + 1) + 5;
xCod = new int[] {4,5,6,7};
yCod = new int[] {ranNo,ranNo,ranNo,ranNo};
}
public boolean checkDown(char board[][]) {
if(versionNo == 1 && (board[xCod[3] + 1][yCod[3]] == '#')) {
return true;
} else if(versionNo == 2 && ( board[xCod[0] + 1][yCod[0]] == '#'
|| board[xCod[1] + 1][yCod[1]] == '#' ||
board[xCod[2] + 1][yCod[2]] == '#'
|| board[xCod[3] + 1][yCod[3]] == '#')) {
return true;
}
return false;
}
public void changeVersionAnticlock(int versionNo)
{
super.changeVersion(versionNo);
if(versionNo == 1)
{
for(int i=0;i<xCod.length;i++)
{
xCod[i] = xCod[0]+i;
yCod[i] = yCod[0];
}
}
else if(versionNo == 2)
{
for(int i=0;i<xCod.length;i++)
{
xCod[i] = xCod[0];
yCod[i] = yCod[0]+i;
}
}
else if(versionNo == 3)
{
for(int i=0;i<xCod.length;i++)
{
xCod[i] = xCod[i]-i;
yCod[i] = yCod[0];
}
}
else if(versionNo == 4)
{
for(int i=0;i<xCod.length;i++)
{
xCod[i] = xCod[0];
yCod[i] = yCod[0]-i;
}
}
}
public void changeVersionClock(int versionNo)
{
super.changeVersion(versionNo);
if(versionNo == 1)
{
for(int i=0;i<xCod.length;i++)
{
xCod[i] = xCod[0]+i;
yCod[i] = yCod[0];
}
}
else if(versionNo == 2)
{
for(int i=0;i<xCod.length;i++)
{
xCod[i] = xCod[0];
yCod[i] = yCod[0]+i;
}
}
else if(versionNo == 3)
{
for(int i=0;i<xCod.length;i++)
{
xCod[i] = xCod[0]-i;
yCod[i] = yCod[0];
}
}
else if(versionNo == 4)
{
for(int i=0;i<xCod.length;i++)
{
xCod[i] = xCod[0];
yCod[i] = yCod[0]-i;
}
}
}
public boolean checkLeft(char board[][]) {
if(versionNo == 1 && (board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[1]][yCod[1] - 1] == '#' || board[xCod[2]][yCod[2] - 1] == '#' || board[xCod[3]][yCod[3] - 1] == '#')) {
return true;
} else if(versionNo == 2 && board[xCod[0]][yCod[0] - 1] == '#') {
return true;
}
return false;
}
public boolean checkRight(char board[][]) {
if(versionNo == 1 && (board[xCod[0]][yCod[0] + 1] == '#' || board[xCod[1]][yCod[1] + 1] == '#' || board[xCod[2]][yCod[2] + 1] == '#' || board[xCod[3]][yCod[3] + 1] == '#')) {
return true;
} else if(versionNo == 2 && board[xCod[3]][yCod[3] - 1] == '#') {
return true;
}
return false;
}
}
class Square extends Version {
Square()
{
Random r = new Random();
int ranNo = r.nextInt((25 - 5) + 1) + 5;
xCod = new int[] {1,1,2,2,};
yCod = new int[] {ranNo,ranNo+1,ranNo,ranNo+1};
}
public void generateVer()
{
Random r = new Random();
int ranNo = r.nextInt((25 - 5) + 1) + 5;
xCod = new int[] {1,1,2,2,};
yCod = new int[] {ranNo,ranNo+1,ranNo,ranNo+1};
}
public boolean checkDown(char board[][]) {
if(board[xCod[2] + 1][yCod[2]] == '#' || board[xCod[3] + 1][yCod[3]] == '#') {
return true;
}
return false;
}
public void changeVersionAnticlock(int versionNo)
{
super.changeVersion(versionNo);
}
public void changeVersionClock(int versionNo)
{
super.changeVersion(versionNo);
}
public boolean checkLeft(char board[][]) {
if(board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[2]][yCod[2] - 1] == '#')
return true;
return false;
}
public boolean checkRight(char board[][]) {
if(board[xCod[1]][yCod[1] + 1] == '#' || board[xCod[3]][yCod[3] + 1] == '#')
return true;
return false;
}
}
class Tshape extends Version {
Tshape()
{
Random r = new Random();
int ranNo = r.nextInt((25 - 5) + 1) + 5;
xCod = new int[] {1,1,1,2};
yCod = new int[] {ranNo,ranNo+1,ranNo+2,ranNo+1};
}
public void generateVer()
{
Random r = new Random();
int ranNo = r.nextInt((25 - 5) + 1) + 5;
xCod = new int[] {1,1,1,2};
yCod = new int[] {ranNo,ranNo+1,ranNo+2,ranNo+1};
}
public boolean checkDown(char board[][]) {
if(versionNo == 1 && (board[xCod[0] + 1][yCod[0]] == '#'
|| board[xCod[2] + 1][yCod[2]] == '#' || board[xCod[3] + 1][yCod[3]] == '#')) {
return true;
} else if(versionNo == 2 && ( board[xCod[2] + 1][yCod[2]] == '#'
|| board[xCod[3] + 1][yCod[3]] == '#')) {
return true;
} else if(versionNo == 3 && (board[xCod[0] + 1][yCod[0]] == '#'
|| board[xCod[1] + 1][yCod[1]] == '#' || board[xCod[2] + 1][yCod[2]] == '#')) {
return true;
} else if(versionNo == 4 && (board[xCod[0] + 1][yCod[0]] == '#' || board[xCod[3] + 1][yCod[3]] == '#')){
return true;
}
return false;
}
public boolean checkLeft(char board[][]) {
if(versionNo == 1 && (board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[3]][yCod[3] - 1] == '#')) {
return true;
} else if(versionNo == 2 && (board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[2]][yCod[2] - 1] == '#' || board[xCod[3]][yCod[3] - 1] == '#')) {
return true;
} else if(versionNo == 3 && (board[xCod[2]][yCod[2]- 1] == '#' || board[xCod[3]][yCod[3] - 1] == '#')) {
return true;
} else if(versionNo == 4 && (board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[1]][yCod[1] - 1] == '#' || board[xCod[2]][yCod[2] - 1] == '#')) {
return true;
}
return false;
}
public boolean checkRight(char board[][]) {
if(versionNo == 1 && (board[xCod[2]][yCod[2] + 1] == '#' || board[xCod[3]][yCod[3] + 1] == '#')) {
return true;
} else if(versionNo == 2 && (board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[1]][yCod[1] - 1] == '#' || board[xCod[2]][yCod[2] - 1] == '#')) {
return true;
} else if(versionNo == 3 && (board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[3]][yCod[3] - 1] == '#')) {
return true;
} else if(versionNo == 4 && (board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[2]][yCod[2] - 1] == '#' || board[xCod[3]][yCod[3] - 1] == '#')) {
return true;
}
return false;
}
public void changeVersionAnticlock(int versionNo)
{
super.changeVersion(versionNo);
if(versionNo == 1)
{
xCod[1] = xCod[1]-1;
xCod[2] = xCod[2]-2;
yCod[0] = yCod[0]-1;
yCod[2] = yCod[2]+1;
yCod[3] = yCod[3]+1;
}
if(versionNo == 2)
{
xCod[1] = xCod[1]+1;
xCod[2] = xCod[2]+2;
yCod[0] = yCod[0]+1;
yCod[2] = yCod[2]-1;
yCod[3] = yCod[3]+1;
}
if(versionNo == 3)
{
xCod[0] = xCod[0]+1;
xCod[2] = xCod[2]-1;
xCod[3] = xCod[3]-1;
yCod[0] = yCod[0]-1;
yCod[2] = yCod[2]+1;
yCod[3] = yCod[3]-1;
}
if(versionNo == 4)
{
xCod[0] = xCod[0]-1;
xCod[2] = xCod[2]+1;
xCod[3] = xCod[3]+1;
yCod[0] = yCod[0]+1;
yCod[2] = yCod[2]-1;
yCod[3] = yCod[3]-1;
}
}
public void changeVersionClock(int versionNo)
{
super.changeVersion(versionNo);
if(versionNo == 1)
{
xCod[1] = xCod[1]-1;
xCod[2] = xCod[2]-2;
yCod[0] = yCod[0]-1;
yCod[2] = yCod[2]+1;
yCod[3] = yCod[3]-1;
}
if(versionNo == 2)
{
xCod[0] = xCod[0]-1;
xCod[2] = xCod[2]+1;
xCod[3] = xCod[3]+1;
yCod[0] = yCod[0]+1;
yCod[2] = yCod[2]-1;
yCod[3] = yCod[3]+1;
}
if(versionNo == 3)
{
xCod[0] = xCod[0]+1;
xCod[2] = xCod[2]-1;
xCod[3] = xCod[3]-1;
yCod[0] = yCod[0]-1;
yCod[2] = yCod[2]+1;
yCod[3] = yCod[3]+1;
}
if(versionNo == 4)
{
xCod[1] = xCod[1]+1;
xCod[2] = xCod[2]+2;
yCod[0] = yCod[0]+1;
yCod[2] = yCod[2]-1;
yCod[3] = yCod[3]-1;
}
}
}
class Lshape extends Version {
Lshape()
{
Random r = new Random();
int ranNo = r.nextInt((25 - 5) + 1) + 5;
xCod = new int[] {1,2,3,3};
yCod = new int[] {10,10,10,11};
}
public void generateVer()
{
Random r = new Random();
int ranNo = r.nextInt((25 - 5) + 1) + 5;
xCod = new int[] {1,2,3,3};
yCod = new int[] {10,10,10,11};
}
public boolean checkDown(char board[][]) {
if(versionNo == 1 && (board[xCod[2] + 1][yCod[2]] == '#' || board[xCod[3] + 1][yCod[3]] == '#')) {
return true;
} else if(versionNo == 2 && ( board[xCod[0] + 1][yCod[0]] == '#' || board[xCod[1] + 1][yCod[1]] == '#'
|| board[xCod[2] + 1][yCod[2]] == '#')) {
return true;
} else if(versionNo == 3 && (board[xCod[0] + 1][yCod[0]] == '#' || board[xCod[3] + 1][yCod[3]] == '#')) {
return true;
} else if(versionNo == 4 && (board[xCod[0] + 1][yCod[0]] == '#' || board[xCod[1] + 1][yCod[1]] == '#' || board[xCod[2] + 1][yCod[2]] == '#' )){
return true;
}
return false;
}
public boolean checkLeft(char board[][]) {
if(versionNo == 1 && (board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[1]][yCod[1] - 1] == '#' || board[xCod[2]][yCod[2] - 1] == '#')) {
return true;
} else if(versionNo == 2 && (board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[3]][yCod[3] - 1] == '#')) {
return true;
} else if(versionNo == 3 && (board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[1]][yCod[1] - 1] == '#' || board[xCod[3]][yCod[3] - 1] == '#')) {
return true;
} else if(versionNo == 4 && (board[xCod[2]][yCod[2] - 1] == '#' || board[xCod[3]][yCod[3] - 1] == '#')) {
return true;
}
return false;
}
public boolean checkRight(char board[][]) {
if(versionNo == 1 && (board[xCod[0]][yCod[0] + 1] == '#' || board[xCod[1]][yCod[1] + 1] == '#' || board[xCod[3]][yCod[3] + 1] == '#')) {
return true;
} else if(versionNo == 2 && (board[xCod[0]][yCod[0] - 1] == '#' || board[xCod[3]][yCod[3] - 1] == '#')) {
return true;
} else if(versionNo == 3 && (board[xCod[0]][yCod[0] + 1] == '#' || board[xCod[1]][yCod[1] + 1] == '#' || board[xCod[2]][yCod[2] + 1] == '#')) {
return true;
} else if(versionNo == 4 && (board[xCod[2]][yCod[2] - 1] == '#' || board[xCod[3]][yCod[3] - 1] == '#')) {
return true;
}
return false;
}
public void changeVersionAnticlock(int versionNo)
{
super.changeVersion(versionNo);
if(versionNo == 1)
{
xCod[1] = xCod[1]+1;
xCod[2] = xCod[2]+2;
xCod[3] = xCod[3]+1;
yCod[0] = yCod[0]-2;
yCod[1] = yCod[1]-1;
yCod[3] = yCod[3]+1;
}
else if(versionNo == 2)
{
xCod[0] = xCod[0]+2;
xCod[1] = xCod[1]+1;
xCod[3] = xCod[3]-1;
yCod[1] = yCod[1]+1;
yCod[2] = yCod[2]+2;
yCod[3] = yCod[3]+1;
}
else if(versionNo == 3)
{
xCod[1] = xCod[1]-1;
xCod[2] = xCod[2]-2;
xCod[3] = xCod[3]-1;
yCod[0] = yCod[0]+2;
yCod[1] = yCod[1]+1;
yCod[3] = yCod[3]-1;
}
else if(versionNo == 4)
{
xCod[0] = xCod[0]-2;
xCod[1] = xCod[1]-1;
xCod[3] = xCod[3]+1;
yCod[1] = yCod[1]-1;
yCod[2] = yCod[2]-2;
yCod[3] = yCod[3]-1;
}
}
public void changeVersionClock(int versionNo)
{
super.changeVersion(versionNo);
if(versionNo == 1)
{
xCod[0] = xCod[0]+2;
xCod[1] = xCod[1]+1;
xCod[3] = xCod[3]-1;
yCod[1] = yCod[1]+1;
yCod[2] = yCod[2]+2;
yCod[3] = yCod[3]+1;
}
else if(versionNo == 2)
{
System.out.println("2");
xCod[1] = xCod[1]+1;
xCod[2] = xCod[2]+2;
xCod[3] = xCod[3]+1;
yCod[0] = yCod[0]-2;
yCod[1] = yCod[1]-1;
yCod[3] = yCod[3]+1;
}
else if(versionNo == 3)
{
System.out.println("3");
xCod[0] = xCod[0]-2;
xCod[1] = xCod[1]-1;
xCod[3] = xCod[3]+1;
yCod[1] = yCod[1]+1;
yCod[2] = yCod[2]-2;
yCod[3] = yCod[3]-1;
for(int i=0;i<4;i++)
System.out.println("" + yCod[i]);
}
else if(versionNo == 4)
{
xCod[1] = xCod[1]-1;
xCod[2] = xCod[2]-2;
xCod[3] = xCod[3]-1;
yCod[0] = yCod[0]+2;
yCod[1] = yCod[1]+1;
yCod[3] = yCod[3]-1;
}
}
}
// class LTshape extends Version {
// LTshape()
// {
// Random r = new Random();
// int ranNo = r.nextInt((25 - 5) + 1) + 5;
// xCod = new int[] {1,2,2,3};
// yCod = new int[] {ranNo,ranNo,ranNo+1,ranNo+1};
// }
// public void generateVer()
// {
// Random r = new Random();
// int ranNo = r.nextInt((25 - 5) + 1) + 5;
// xCod = new int[] {1,2,2,3};
// yCod = new int[] {ranNo,ranNo,ranNo+1,ranNo+1};
// }
// public void changeVersionAnticlock(int versionNo)
// {
// super.changeVersion(versionNo);
// if(versionNo == 1 || versionNo == 3)
// {
// xCod[1] = xCod[1]+1;
// xCod[3] = xCod[3]+1;
// yCod[0] = yCod[0]-2;
// yCod[1] = yCod[1]-1;
// yCod[3] = yCod[3]+1;
// }
// else if(versionNo == 2 || versionNo == 4)
// {
// xCod[1] = xCod[1]-1;
// xCod[3] = xCod[3]-1;
// yCod[0] = yCod[0]+2;
// yCod[1] = yCod[1]+1;
// yCod[3] = yCod[3]-1;
// }
// }
// public void changeVersionClock(int versionNo)
// {
// super.changeVersion(versionNo);
// changeVersionAnticlock(versionNo);
// }
// }
public class TETRIS
{
public static char board[][] = new char[30][30];
public static int hashNo[] = new int[30];
public static Stack<String> undoStack = new Stack<String>();
public static Stack<String> redoStack = new Stack<String>();
static int currentShapeNo = 1;
static int currentShapeVersion = 1;
public static void main(String args[])
{
Line line = new Line();
Square square = new Square();
Tshape t = new Tshape();
Lshape l = new Lshape();
//LTshape lt = new LTshape();
Version currentShape = new Version();
Scanner obj = new Scanner(System.in);
char c;
initBoard();
while(true)
{
currentShape = currentShapeNo == 1 ? line : currentShapeNo == 2 ? square : currentShapeNo == 3 ? t : l;
int versionNo = currentShape.getVersion();
drawShape(currentShape);
displayBoard();
c = obj.next().charAt(0);
if(c == 'd')
{
moveAnti(versionNo,currentShape);
undoStack.push("a");
}
else if(c == 'a')
{
moveClock(versionNo,currentShape);
undoStack.push("d");
}
if(c == 'r')
{
moveRight(currentShape);
moveDown(currentShape);
undoStack.push("r");
}
else if(c == 'l')
{
moveLeft(currentShape);
moveDown(currentShape);
undoStack.push("l");
}
else if(c == 'b')
{
moveDown(currentShape);
undoStack.push("b");
}
else if(c == 'u')
{
if(undoStack.isEmpty())
{
continue;
}
undoStep(versionNo,undoStack.peek(),currentShape);
redoStack.push(undoStack.pop());
}
else if(c == 'i')
{
if(redoStack.isEmpty())
{
continue;
}
redoStep(versionNo,redoStack.peek(),currentShape);
undoStack.push(redoStack.pop());
}
}
}
public static void moveAnti(int vNO, Version V)
{
vNO = vNO > 4 ? 1 : ++vNO;
clearFromBoard(V);
V.changeVersionAnticlock(vNO);
undoStack.push("d");
}
public static void moveClock(int vNO, Version V)
{
vNO = vNO > 1 ? --vNO : 4;
clearFromBoard(V);
V.changeVersionClock(vNO);
undoStack.push("a");
}
public static void moveLeft(Version V) {
if(V.yCod[0] == 1 || V.yCod[1] == 1 || V.yCod[2] == 1 || V.yCod[3] == 1 || V.checkLeft(board))
return;
for(int i = 0;i<V.xCod.length;i++) {
board[V.xCod[i]][V.yCod[i]] = ' ';
V.yCod[i]--;
}
}
public static void moveRight(Version V) {
if(V.yCod[0] == (board.length - 2) || V.yCod[1] == (board.length - 2) || V.yCod[2] == (board.length - 2) || V.yCod[3] == (board.length - 2) || V.checkRight(board))
return;
for(int i = 0;i<V.xCod.length;i++) {
board[V.xCod[i]][V.yCod[i]] = ' ';
V.yCod[i]++;
}
}
public static void moveDown(Version V) {
if(V.xCod[0] == (board.length - 2) || V.xCod[1] == (board.length - 2) ||
V.xCod[2] == (board.length - 2) || V.xCod[3] == (board.length - 2) || V.checkDown(board)) {
checkRemoveLine(V);
V.generateVer();
currentShapeNo = (int)(Math.random() * 5) + 1;
return;
}
for(int i = 0;i<V.xCod.length;i++) {
board[V.xCod[i]][V.yCod[i]] = ' ';
V.xCod[i]++;
}
}
public static void undoStep(int vers,String undo, Version V)
{
if(undo.equals("b"))
{
for(int i=0;i<V.xCod.length;i++)
{
board[V.xCod[i]][V.yCod[i]] = ' ';
V.xCod[i]--;
}
}
else if(undo.equals("l"))
{
moveRight(V);
}
else if(undo.equals("r"))
{
moveLeft(V);
}
else if(undo.equals("d"))
{
moveClock(vers,V);
}
}
public static void redoStep(int vers,String undo, Version V)
{
if(undo.equals("b"))
{
moveDown(V);
}
else if(undo.equals("l"))
{
moveLeft(V);
}
else if(undo.equals("r"))
{
moveRight(V);
}
else if(undo.equals("d"))
{
moveAnti(vers,V);
}
}
public static void clearFromBoard(Version V)
{
for(int i=0;i<V.xCod.length;i++)
{
board[V.xCod[i]][V.yCod[i]] = ' ';
}
}
public static void checkRemoveLine(Version V) {
for(int i=0;i<4;i++)
{
hashNo[30-1-V.xCod[i]]++;
}
for(int i=29;i>0;i--)
{
if(hashNo[i]>28)
{
for(int j=board.length-1-i;j>0;j--)
{
board[j] = board[j-1];
}
board[0] = new char[30];
}
}
}
public static void initBoard() {
for(int i=0;i<board.length;i++)
{
for(int j=0;j<board.length;j++)
{
if(i==0 || j==0 || i==board.length-1 || j==board.length-1)
{
board[i][j]='*';
}
else
{
board[i][j]=' ';
}
}
}
}
public static void clearScreen()
{
System.out.print("\033[H\033[2J");
}
public static void drawShape(Version v1) {
for(int i=0;i<v1.xCod.length;i++)
{
board[v1.xCod[i]][v1.yCod[i]] = '#';
}
}
public static void displayBoard() {
for(int i=0;i<30;i++)
{
for(int j=0;j<30;j++)
{
System.out.print(" " + board[i][j]);
}
System.out.println();
}
}
} | 4888703a8fe0f752117c48cfc623b6f843d68c43 | [
"Markdown",
"Java"
] | 2 | Markdown | rajat-29/Tetris_Game_Java | eaca4f82d23013be5dee3a26e9a68525962f6a84 | 17fd5267109c74d5c40fd1354660e5aaab18becc |
refs/heads/master | <repo_name>southkyle/beans_bench<file_sep>/rmfile.py
import os
import sys
standard = '/mnt/dfs/1/dbtest/0000000000004235'
def Remove(path):
if os.path.isfile(path):
sz = os.path.getsize(path)
if sz != 100000:
os.system('cp %s %s' %(standard, path))
print 'cp %s %s' %(standard, path)
else:
files = os.listdir(path)
for f in files:
full_name = os.path.join(path, f)
Remove(full_name)
if __name__ == '__main__':
Remove(sys.argv[1])
<file_sep>/string_util.h
#ifndef STRING_UTIL_H
#define STRING_UTIL_H
#include <string>
#include <vector>
#include "slice.h"
// split string
void split_string(const std::string& str,
char sep,
std::vector<std::string>* stringlist);
Slice TrimSpace(Slice s);
#endif
<file_sep>/db_bench.cc
// project
#include "monitor.h"
#include "slice.h"
#include "random.h"
#include "histogram.h"
#include "concurrent.h"
#include "string_util.h"
#include "hstore.h"
// os
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <errno.h>
#include <fcntl.h>
#include <sys/time.h>
// c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
#include <stdint.h>
// c++
#include <string>
// #include <google/profiler.h>
// third lib
//#include <boost/scoped_ptr.hpp>
#define ASSERT_TRUE(s) {if (!(s)) {fprintf(stderr, "%s failed\n", #s); exit(1);}}
#define ASSERT_FALSE(s) {if (s) {fprintf(stderr, "%s failed\n", #s); exit(1);}}
#define ASSERT_EQ(a, b) {if ((a) != (b)) {fprintf(stderr, "%s != %s Failed\n", #a, #b); exit(1);}}
static const char* FLAGS_benchmarks =
"write,"
"read,"
"readhot,"
"readwhilewriting"
;
volatile int g_exit = 0;
template <typename T>
class scoped_ptr {
public:
scoped_ptr(T *ptr) : ptr_(ptr) {
}
~scoped_ptr() {
if (ptr_ != NULL) {
delete ptr_;
}
}
private:
T* ptr_;
};
// Number of key/values to place in database
static int FLAGS_num = 10000;
static int FLAGS_reads = 100;
// size of each value
static int FLAGS_value_size = 100000; // 100KB
static bool FLAGS_histogram = false;
static int FLAGS_num_threads = 1;
static bool FLAGS_use_existing_db = true;
static int FLAGS_filesystem_ndir = 1;
static double FLAGS_read_write_ratio = 1;
// Beansdb
static int FLAGS_scan_threads = 0;
//FLAGS_db in {"beansdb", "fdb"}
static const char* FLAGS_db = "beansdb";
void PrintFlags() {
printf("------------------------------------------------------\n");
printf("FLAGS_benchmarks = %s\n", FLAGS_benchmarks);
printf("FLAGS_num = %d\n", FLAGS_num);
printf("FLAGS_reads = %d\n", FLAGS_reads);
printf("FLAGS_value_size = %d\n", FLAGS_value_size);
printf("FLAGS_histogram = %d\n", FLAGS_histogram);
printf("FLAGS_num_threads = %d\n", FLAGS_num_threads);
printf("FLAGS_filesystem_ndir = %d\n", FLAGS_filesystem_ndir);
printf("FLAGS_read_write_ration = %lf\n", FLAGS_read_write_ratio);
printf("FLAGS_db = %s\n", FLAGS_db);
printf("FLAGS_scan_threads = %d\n", FLAGS_scan_threads);
printf("------------------------------------------------------\n");
}
inline char* string_as_array(std::string* str) {
assert(str != NULL);
return str->empty() ? NULL : &*str->begin();
}
static void AppendWithSpace(std::string* str, Slice msg) {
if (msg.empty()) return;
if (!str->empty()) {
str->push_back(' ');
}
str->append(msg.data(), msg.size());
}
namespace Env {
bool CreateDir(const std::string& name) {
if (mkdir(name.c_str(), 0755) != 0) {
fprintf(stderr, "IOError: %s %s\n", name.c_str(), strerror(errno));
return false;
}
return true;
}
bool FileExists(const std::string& name) {
return access(name.c_str(), F_OK) == 0;
}
bool DeleteFile(const std::string& name) {
if (unlink(name.c_str()) != 0) {
fprintf(stderr, "IOError: %s %s\n", name.c_str(), strerror(errno));
return false;
}
return true;
}
// An ugly implemention
bool DeleteDir(const std::string& name) {
char cmd[256];
snprintf(cmd, sizeof(cmd), "rm -rf %s", name.c_str());
int ret = system(cmd);
return ret == 0;
}
bool GetFileSize(const std::string& name, uint64_t* size) {
struct stat sbuf;
if (stat(name.c_str(), &sbuf) != 0) {
*size = 0;
fprintf(stderr, "IOError: %s %s\n", name.c_str(), strerror(errno));
return false;
} else {
*size = sbuf.st_size;
}
return true;
}
bool GetFileSize(int fd, uint64_t* size) {
struct stat sbuf;
if (fstat(fd, &sbuf) != 0) {
*size = 0;
fprintf(stderr, "IOError: %s\n", strerror(errno));
return false;
} else {
*size = sbuf.st_size;
}
return true;
}
uint64_t NowMicros() {
struct timeval tv;
gettimeofday(&tv, NULL);
return static_cast<uint64_t>(tv.tv_sec) * 1000000 + tv.tv_usec;
}
void SleepForMicroseconds(int micros) {
usleep(micros);
}
bool RenameFile(const std::string& src, const std::string& target) {
if (rename(src.c_str(), target.c_str()) != 0) {
fprintf(stderr, "IOError: %s %s %s", src.c_str(), target.c_str(), strerror(errno));
return false;
}
return true;
}
};
#ifndef FALLTHROUGH_INTENDED
#define FALLTHROUGH_INTENDED do { } while (0)
#endif
uint32_t DecodeFixed32(const char* ptr) {
uint32_t result;
memcpy(&result, ptr, sizeof(result));
return result;
}
uint32_t Hash(const char* data, size_t n/*, uint32_t seed*/) {
// Similar to murmur hash
uint32_t seed = 0;
const uint32_t m = 0xc6a4a793;
const uint32_t r = 24;
const char* limit = data + n;
uint32_t h = seed ^ (n * m);
// Pick up four bytes at a time
while (data + 4 <= limit) {
uint32_t w = DecodeFixed32(data);
data += 4;
h += w;
h *= m;
h ^= (h >> 16);
}
// Pick up remaining bytes
switch (limit - data) {
case 3:
h += data[2] << 16;
FALLTHROUGH_INTENDED;
case 2:
h += data[1] << 8;
FALLTHROUGH_INTENDED;
case 1:
h += data[0];
h *= m;
h ^= (h >> r);
break;
}
return h;
}
// uint32_t Hash(const char* data, size_t n) {
// const static int FNV_32_PRIME = 0x01000193;
// const static int FNV_32_INIT = 0x811c9dc5;
// uint32_t h = FNV_32_INIT;
// for (size_t i = 0; i < n; i++) {
// h ^= (uint32_t) data[i];
// h *= FNV_32_PRIME;
// }
// return h;
// }
class ScopedFile {
public:
ScopedFile(int fd) : fd_(fd) { }
~ScopedFile() {
close(fd_);
}
private:
int fd_;
};
class DB {
public:
DB() {}
virtual ~DB() {}
virtual bool Open(const std::string& base_path, int ndir, bool use_exiting_db) = 0;
virtual bool Get(const Slice& key, std::string* value) = 0;
virtual bool Put(const Slice& key, const Slice& value) = 0;
};
class Beansdb : public DB {
public:
Beansdb() : store_(NULL) {}
~Beansdb() {
if (store_ != NULL) {
hs_close(store_);
}
}
bool Open(const std::string& base_path, int ndir, bool use_exiting_db) {
if (ndir != 1 && ndir != 16 && ndir != 16*16 && ndir != 16*16*16) {
fprintf(stderr, "Beansdb ndir %d error\n", ndir);
return false;
}
base_path_ = base_path;
ndir_ = ndir;
// hs_open(path, height, before, scan_threads)
int before = 0;
store_ = hs_open(const_cast<char*>(base_path.c_str()), ndir / 16,
before, FLAGS_scan_threads);
if (store_ == NULL) {
fprintf(stderr, "Beansdb open %s failed\n", base_path.c_str());
return false;
} else {
return true;
}
}
bool Get(const Slice& key, std::string* value) {
int vlen = 0;
uint32_t flag = 0x00000010;
char* svalue = hs_get(store_, const_cast<char*>(key.data()), &vlen, &flag);
if (svalue == NULL) {
return false;
} else {
value->assign(svalue, vlen);
free(svalue);
return true;
}
}
bool Put(const Slice& key, const Slice& value) {
uint32_t flag = 0x00000010;
int version = 0;
bool status = hs_set(store_, const_cast<char*>(key.data()),
const_cast<char*>(value.data()),value.size(),
flag, version);
return status;
}
private:
HStore* store_;
std::string base_path_;
int ndir_;
};
class FileSystemDB : public DB {
public:
bool Open(const std::string& base_path, int ndir, bool use_existing_db) {
base_path_ = base_path;
ndir_ = ndir;
bool status = false;
if (use_existing_db) {
if (!Env::FileExists(base_path)) {
status = Env::CreateDir(base_path);
if (!status) return false;
for (int i = 0; i < ndir; i++) {
char fullname[256];
snprintf(fullname, sizeof(fullname), "%s/%d", base_path.c_str(), i);
if (!Env::FileExists(fullname)) {
status = Env::CreateDir(fullname);
if (!status) return false;
}
for (int j = 0; j < 1000; j++) {
snprintf(fullname, sizeof(fullname), "%s/%d/%d", base_path.c_str(), i, j);
// printf("Create dir %s\n", fullname);
if (!Env::FileExists(fullname)) {
status = Env::CreateDir(fullname);
if (!status) return false;
}
}
}
}
} else {
fprintf(stderr, "use_existing_db must be true\n");
exit(1);
}
return true;
}
bool Put(const Slice& key, const Slice& value) {
uint32_t hash = Hash(key.data(), key.size());
int segment = hash % ndir_;
int segment2 = (hash >> 16) % 1000;
char filename[512];
char filename_tmp[512];
snprintf(filename, sizeof(filename), "%s/%d/%d/%s", base_path_.c_str(), segment, segment2, key.data());
snprintf(filename_tmp, sizeof(filename_tmp), "%s/%d/%d/%s.tmp", base_path_.c_str(), segment, segment2, key.data());
// File System Put is very ineffienct
// We write it to a temp file then rename it
// There are some problem with the filename_tmp, because may be multiple
// writers, but as it is a simple program we just ignore it
{
{
int fd = open(filename_tmp, O_WRONLY|O_CREAT|O_TRUNC, 0755);
if (fd < 0) {
fprintf(stderr, "IOError: open %s %s\n", key.data(), strerror(errno));
return false;
}
ScopedFile scoped_file(fd);
ssize_t n = write(fd, value.data(), value.size());
if (n < 0 || static_cast<size_t>(n) != value.size()) {
fprintf(stderr, "IOError: write %s %s\n", key.data(), strerror(errno));
return false;
}
}
if (rename(filename_tmp, filename) != 0) {
fprintf(stderr, "IOError: rename %s %s %s\n",
filename_tmp, filename, strerror(errno));
return false;
}
}
return true;
}
bool Get(const Slice& key, std::string* value) {
uint32_t hash = Hash(key.data(), key.size());
int segment = hash % ndir_;
int segment2 = (hash >> 16) % 1000;
char filename[512];
snprintf(filename, sizeof(filename), "%s/%d/%d/%s", base_path_.c_str(), segment, segment2, key.data());
int fd = open(filename, O_RDONLY);
if (fd < 0) {
return false;
}
ScopedFile scoped_file(fd);
uint64_t size = 0;
bool s = Env::GetFileSize(fd, &size);
if (!s) {
return s;
}
value->resize(size);
char* buf = string_as_array(value);
ssize_t nread = read(fd, buf, size);
if (nread < 0 || static_cast<size_t>(nread) != size) {
fprintf(stderr, "IOError: %s %s\n", key.data(), strerror(errno));
return false;
}
return true;
}
private:
std::string base_path_;
int ndir_;
};
class Stats {
private:
double start_;
double finish_;
double seconds_;
int done_;
int next_report_;
int64_t bytes_;
double last_op_finish_;
Histogram hist_;
std::string message_;
public:
Stats() { Start(); }
void Start() {
next_report_ = 100;
last_op_finish_ = start_;
hist_.Clear();
done_ = 0;
bytes_ = 0;
seconds_ = 0;
start_ = Env::NowMicros();
finish_ = start_;
message_.clear();
}
void Merge(const Stats& other) {
hist_.Merge(other.hist_);
done_ += other.done_;
bytes_ += other.bytes_;
seconds_ += other.seconds_;
if (other.start_ < start_) start_ = other.start_;
if (other.finish_ > finish_) finish_ = other.finish_;
// Just keep the messages from one thread
if (message_.empty()) message_ = other.message_;
}
void Stop() {
finish_ = Env::NowMicros();
seconds_ = (finish_ - start_) * 1e-6;
}
void AddMessage(Slice msg) {
AppendWithSpace(&message_, msg);
}
void FinishedSingleOp() {
if (FLAGS_histogram) {
double now = Env::NowMicros();
double micros = now - last_op_finish_;
hist_.Add(micros);
// if (micros > 20000) {
// fprintf(stderr, "long op: %.1f micros%30s\n", micros, "");
// fflush(stderr);
// }
last_op_finish_ = now;
}
done_++;
if (done_ >= next_report_) {
if (next_report_ < 1000) next_report_ += 100;
else if (next_report_ < 5000) next_report_ += 500;
else if (next_report_ < 10000) next_report_ += 1000;
else if (next_report_ < 50000) next_report_ += 5000;
else if (next_report_ < 100000) next_report_ += 10000;
else if (next_report_ < 500000) next_report_ += 50000;
else next_report_ += 100000;
fprintf(stderr, "... finished %d ops%30s\n", done_, "");
// fflush(stderr);
}
}
void AddBytes(int64_t n) {
bytes_ += n;
}
void Report(const Slice& name) {
// Pretend at least one op was done in case we are running a benchmark
// that does not call FinishedSingleOp().
if (done_ < 1) done_ = 1;
std::string extra;
double elapsed = (finish_ - start_) * 1e-6;
if (bytes_ > 0) {
// Rate is computed on actual elapsed time, not the sum of per-thread
// elapsed times.
char rate[100];
snprintf(rate, sizeof(rate), "%6.1f MB/s",
(bytes_ / 1048576.0) / elapsed);
extra = rate;
}
AppendWithSpace(&extra, message_);
fprintf(stdout, "start %lld\n", static_cast<uint64_t>(start_*1e-6));
fprintf(stdout, "finish %lld\n", static_cast<uint64_t>(finish_*1e-6));
fprintf(stdout, "elapsed %lld\n", static_cast<uint64_t>((finish_ - start_)*1e-6));
fprintf(stdout, "%-12s : %11.3f ops/s ;%s%s\n",
name.ToString().c_str(),
done_ / elapsed,
(extra.empty() ? "" : " "),
extra.c_str());
if (FLAGS_histogram) {
fprintf(stdout, "Microseconds per op:\n%s\n", hist_.ToString().c_str());
}
fflush(stdout);
}
};
struct SharedState {
Mutex mu;
CondVar cv;
int total;
int num_initialized;
int num_done;
bool start;
SharedState() : cv(&mu) {}
};
struct ThreadState {
int tid;
Random rand;
Stats stats;
SharedState* shared;
ThreadState(int index)
: tid(index),
/*rand(static_cast<int>(time(NULL)) + index)*/
rand(1000 + index) {
}
};
class Benchmark {
public:
Benchmark(DB* db) {
db_ = db;
}
~Benchmark() {
// Env::DeleteDir("./fdb_test");
}
bool Open() {
double start = Env::NowMicros();
ASSERT_TRUE(db_->Open("./dbtest", FLAGS_filesystem_ndir, FLAGS_use_existing_db));
double finish = Env::NowMicros();
fprintf(stdout, "Start time = %d ms\n", (int)((finish - start) * 1e-3));
return true;
}
void Run() {
PrintHeader();
Open();
const char* functions[] = {"write", "read", "readhot", "readwhilewriting"};
typedef void (Benchmark::*Method)(ThreadState*);
Method methods[] = {&Benchmark::WriteSequential, &Benchmark::ReadRandom,
&Benchmark::ReadHot, &Benchmark::ReadWhileWriting};
Method method;
std::vector<std::string> strs;
split_string(FLAGS_benchmarks, ',', &strs);
// ProfilerStart("db_bench.prof");
for (size_t i = 0; i < strs.size(); i++) {
method = NULL;
size_t j;
for (j = 0; j < sizeof(functions)/sizeof(functions[0]); j++) {
if (functions[j] == strs[i]) {
method = methods[j];
break;
}
}
if (method != NULL) {
RunBenchMark(FLAGS_num_threads, Slice(functions[j]), method);
}
}
// ProfilerStop();
g_exit = 1;
fprintf(stdout, "RUN TEST DONE\n");
fflush(stdout);
}
private:
struct ThreadArg {
Benchmark* bm;
SharedState* shared;
ThreadState* thread;
void (Benchmark::*method)(ThreadState*);
};
static void* ThreadBody(void* v) {
// ProfilerRegisterThread();
ThreadArg* arg = reinterpret_cast<ThreadArg*>(v);
SharedState* shared = arg->shared;
ThreadState* thread = arg->thread;
{
MutexLock l(&shared->mu);
shared->num_initialized++;
if (shared->num_initialized >= shared->total) {
shared->cv.SignalAll();
}
while (!shared->start) {
shared->cv.Wait();
}
}
thread->stats.Start();
(arg->bm->*(arg->method))(thread);
thread->stats.Stop();
{
MutexLock l(&shared->mu);
shared->num_done++;
if (shared->num_done >= shared->total) {
shared->cv.SignalAll();
}
}
return (void*)NULL;
}
void PrintHeader() {
// const int kKeySize = 16;
PrintEnviroment();
PrintFlags();
// fprintf(stdout, "Keys: %d bytes each\n", kKeySize);
// fprintf(stdout, "Valuees: %d bytes each\n", FLAGS_value_size);
// fprintf(stdout, "Entries: %d\n", FLAGS_num);
fflush(stdout);
}
void PrintEnviroment() {
time_t now = time(NULL);
fprintf(stdout, "Date: %s", ctime(&now));
FILE* cpuinfo = fopen("/proc/cpuinfo", "r");
if (cpuinfo != NULL) {
char line[1000];
int num_cpus = 0;
std::string cpu_type;
std::string cache_size;
while (fgets(line, sizeof(line), cpuinfo) != NULL) {
const char* sep = strchr(line, ':');
if (sep == NULL) {
continue;
}
Slice key = TrimSpace(Slice(line, sep - 1 - line));
Slice val = TrimSpace(Slice(sep + 1));
if (key == "model name") {
++num_cpus;
cpu_type = val.ToString();
} else if (key == "cache size") {
cache_size = val.ToString();
}
}
fclose(cpuinfo);
fprintf(stdout, "CPU: %d * %s\n", num_cpus, cpu_type.c_str());
fprintf(stdout, "CPUCache: %s\n", cache_size.c_str());
}
}
void WriteSequential(ThreadState* thread) {
std::string value;
value.resize(FLAGS_value_size);
for (int i = 0; i < FLAGS_value_size; i++) {
value[i] = 'a' + i % 26;
}
int64_t bytes = 0;
int step = FLAGS_num / FLAGS_num_threads;
int start = step * thread->tid;
int end = (thread->tid == FLAGS_num_threads-1) ? FLAGS_num : step * (thread->tid +1);
printf("Tid %d start %d end %d\n", thread->tid, start, end);
for (int i = start; i < end; i++) {
char key[100];
snprintf(key, sizeof(key), "%016d", i);
Slice skey(key);
ASSERT_TRUE(db_->Put(skey, Slice(value)));
thread->stats.FinishedSingleOp();
bytes += FLAGS_value_size + skey.size();
}
thread->stats.AddBytes(bytes);
}
void ReadRandom(ThreadState* thread) {
int found = 0;
for (int i = 0; i < FLAGS_reads; i++) {
char key[100];
int k = thread->rand.Next() % FLAGS_num;
snprintf(key, sizeof(key), "%016d", k);
std::string value;
if (db_->Get(Slice(key), &value)) {
found++;
}
// else {
// fprintf(stderr, "NotFound %s\n", key);
// }
thread->stats.FinishedSingleOp();
}
char msg[100];
snprintf(msg, sizeof(msg), "(%d of %d found)", found, FLAGS_num);
thread->stats.AddMessage(msg);
}
void ReadWhileWriting(ThreadState* thread) {
const int write_thread_num = int(FLAGS_num_threads / (1 + FLAGS_read_write_ratio));
const int read_thread_num = FLAGS_num_threads - write_thread_num;
printf("ReadWhileWriting: num_write %d num_read %d\n",
write_thread_num, read_thread_num);
if (thread->tid < write_thread_num) {
// Write threads that keep writing until all read threads done
int step = FLAGS_num / write_thread_num;
int start = step * thread->tid;
int end = (thread->tid == write_thread_num - 1) ? FLAGS_num : step * (thread->tid + 1);
printf("WriteThread tid %d start %d end %d\n", thread->tid, start, end);
std::string value;
value.resize(FLAGS_value_size);
for (int i = 0; i < FLAGS_value_size; i++) {
value[i] = 'a' + i % 26;
}
int bytes = 0;
while (true) {
{
MutexLock l(&thread->shared->mu);
if (thread->shared->num_done >= read_thread_num) {
break;
}
}
int k = thread->rand.Next() % FLAGS_num;
char key[100];
snprintf(key, sizeof(key), "%016d", k);
Slice skey(key);
ASSERT_TRUE(db_->Put(skey, Slice(value)));
bytes += skey.size() + FLAGS_value_size;
thread->stats.FinishedSingleOp();
}
thread->stats.AddBytes(bytes);
} else {
// Do read
ReadRandom(thread);
}
}
void ReadHot(ThreadState* thread) {
const int range = (FLAGS_num + 99) / 100;
int found = 0;
for (int i = 0; i < FLAGS_reads; i++) {
int k = thread->rand.Next() % range;
char key[100];
snprintf(key, sizeof(key), "%016d", k);
std::string value;
if (db_->Get(Slice(key), &value)) {
found++;
}
thread->stats.FinishedSingleOp();
}
char msg[100];
snprintf(msg, sizeof(msg), "(%d of %d found)", found, range);
thread->stats.AddMessage(msg);
}
void RunBenchMark(int n, Slice name,
void (Benchmark::*method)(ThreadState*)) {
fprintf(stdout, "\n\n===================================\n");
fprintf(stdout, "method = %s\n", name.data());
SharedState shared;
shared.total = n;
shared.num_initialized = 0;
shared.num_done = 0;
shared.start = false;
ThreadArg* arg = new ThreadArg[n];
scoped_ptr<ThreadArg> scoped_arg(arg);
pthread_t* tids = new pthread_t[n];
for (int i = 0; i < n; i++) {
arg[i].bm = this;
arg[i].method = method;
arg[i].shared = &shared;
arg[i].thread = new ThreadState(i);
arg[i].thread->shared = &shared;
pthread_create(&tids[i], NULL, ThreadBody, &arg[i]);
}
shared.mu.Lock();
while (shared.num_initialized < n) {
shared.cv.Wait();
}
shared.start = true;
shared.cv.SignalAll();
while (shared.num_done < n) {
shared.cv.Wait();
}
shared.mu.Unlock();
time_t now = time(NULL);
fprintf(stdout, "Date: %s", ctime(&now));
if (name == "readwhilewriting") {
const int write_thread_num = int(FLAGS_num_threads / (1 + FLAGS_read_write_ratio));
// const int read_thread_num = FLAGS_num_threads - write_thread_num;
//
// for (int i = 0; i < n; i++) {
// arg[i].thread->stats.Report(name);
// }
for (int i = 1; i < write_thread_num; i++) {
arg[0].thread->stats.Merge(arg[i].thread->stats);
}
printf("\n\n***Write Performance***\n");
arg[0].thread->stats.Report(name);
for (int i = write_thread_num + 1; i < n; i++) {
arg[write_thread_num].thread->stats.Merge(arg[i].thread->stats);
}
printf("\n\n***Read Performance***\n");
arg[write_thread_num].thread->stats.Report(name);
} else {
for (int i = 1; i < n; i++) {
arg[0].thread->stats.Merge(arg[i].thread->stats);
}
arg[0].thread->stats.Report(name);
}
for (int i = 0; i < n; i++) {
delete arg[i].thread;
}
}
private:
FileSystemDB fdb_;
DB* db_;
};
void TEST_FDB() {
FileSystemDB fdb;
ASSERT_TRUE(fdb.Open("./fdb", 5, true));
for (int i = 0; i < 1000; i++) {
char key[64];
char value[64];
snprintf(key, sizeof(key), "%016d", i);
snprintf(value, sizeof(value), "%016d", i);
bool s = fdb.Put(Slice(key), Slice(value));
ASSERT_TRUE(s);
}
for (int i = 0; i < 1000; i++) {
char key[64];
char expect_value[64];
snprintf(key, sizeof(key), "%016d", i);
snprintf(expect_value, sizeof(expect_value), "%016d", i);
std::string value;
bool s = fdb.Get(Slice(key), &value);
ASSERT_TRUE(s);
ASSERT_EQ(expect_value, value);
}
for (int i = 1000; i < 2000; i++) {
char key[64];
char expect_value[64];
snprintf(key, sizeof(key), "%016d", i);
snprintf(expect_value, sizeof(expect_value), "%016d", i);
std::string evalue;
ASSERT_FALSE(fdb.Get(Slice(key), &evalue));
}
Env::DeleteDir("./fdb");
printf("FileSystemDB Open Get Put Success\n");
}
void TEST_BEANSDB() {
int kValueSize = 100;
Beansdb db;
db.Open("./beans-data", 1, true);
int kNum = 100;
for (int i = 0; i < kNum; i++) {
char key[100];
snprintf(key, sizeof(key), "%016d", i);
char value[kValueSize];
snprintf(value, sizeof(value), "%016d", i);
bool s = db.Put(key, value);
if (!s) {
printf("add %d error\n", i);
return;
}
}
for (int i = 0; i < kNum; i++) {
char key[100];
snprintf(key, sizeof(key), "%016d", i);
std::string value;
bool s = db.Get(key, &value);
if (!s) {
printf("get %d error\n", i);
return;
}
if (value != key) {
printf("get %d error\n", i);
printf("value = %s, key=%s\n", value.c_str(), key);
}
}
printf("beansdb test passed\n");
}
void* StatsThread(void* args) {
int32_t t = static_cast<int32_t>(time(NULL));
char name[256];
snprintf(name, sizeof(name), "%d_%s_%s_%s", t, FLAGS_db, FLAGS_benchmarks, "free.txt");
FreeMonitor free(name);
snprintf(name, sizeof(name), "%d_%s_%s_%s", t, FLAGS_db, FLAGS_benchmarks, "memory.txt");
Monitor memory(name);
while (g_exit == 0) {
free.StatFree();
memory.StatMemory();
sleep(1);
}
return (void*) NULL;
}
int main(int argc, char* argv[]) {
int n;
char junk;
double x;
for (int i = 1; i < argc; i++) {
if (Slice(argv[i]).starts_with("--benchmarks=")) {
FLAGS_benchmarks = argv[i] + strlen("--benchmarks=");
if (strcmp(FLAGS_benchmarks, "test") == 0) {
TEST_BEANSDB();
TEST_FDB();
return 0;
}
} else if(Slice(argv[i]).starts_with("--db=")) {
FLAGS_db = argv[i] + strlen("--db=");
} else if (sscanf(argv[i], "--value_size=%d%c", &n, &junk) == 1) {
FLAGS_value_size = n;
} else if (sscanf(argv[i], "--num=%d%c", &n, &junk) == 1) {
FLAGS_num = n;
} else if (sscanf(argv[i], "--reads=%d%c", &n, &junk) == 1) {
FLAGS_reads = n;
} else if (sscanf(argv[i], "--histogram=%d%c", &n, &junk) == 1) {
FLAGS_histogram = (n != 0);
} else if (sscanf(argv[i], "--num_threads=%d%c", &n, &junk) == 1) {
FLAGS_num_threads = n;
} else if (sscanf(argv[i], "--use_existing_db=%d%c", &n, &junk) == 1) {
FLAGS_use_existing_db = (n!=0);
} else if (sscanf(argv[i], "--filesystem_ndir=%d%c", &n, &junk) == 1) {
FLAGS_filesystem_ndir = n;
} else if (sscanf(argv[i], "--read_write_ratio=%lf%c", &x, &junk)== 1) {
FLAGS_read_write_ratio = x;
} else if (sscanf(argv[i], "--scan_threads=%d%c", &n, &junk) == 1) {
FLAGS_scan_threads = n;
} else {
fprintf(stderr, "Invalid flag %s\n", argv[i]);
exit(1);
}
}
pthread_t tid;
pthread_create(&tid, NULL, StatsThread, NULL);
if (strcmp(FLAGS_db, "beansdb") == 0) {
DB* db = new Beansdb();
//boost::scoped_ptr<DB> scoped_db(db);
scoped_ptr<DB> scoped_db(db);
Benchmark benchmark(db);
benchmark.Run();
g_exit = 1;
pthread_join(tid, NULL);
} else if (strcmp(FLAGS_db, "fdb") == 0) {
DB* db = new FileSystemDB;
//boost::scoped_ptr<DB> scoped_db(db);
scoped_ptr<DB> scoped_db(db);
Benchmark benchmark(db);
benchmark.Run();
g_exit = 1;
pthread_join(tid, NULL);
} else {
fprintf(stderr, "FLAGS_db must in ['beansdb', 'fdb']\n");
}
return 0;
}
<file_sep>/add_cpp.py
import os
import sys
def Add(fname):
header = """\n#ifdef __cplusplus
extern "C" {
#endif\n"""
footer = """\n#ifdef __cplusplus
}
#endif\n"""
f = open(fname)
lines = f.read();
f.close()
f = open(fname, 'w')
f.write(header)
f.write(lines)
f.write(footer)
f.close()
if __name__ == '__main__':
for i in range(1, len(sys.argv)):
Add(sys.argv[i])
<file_sep>/monitor.h
#ifndef MONITOR_H
#define MONITOR_H
#include "string_util.h"
#include "slice.h"
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <time.h>
#include <inttypes.h>
#include <stdint.h>
#include <string>
#include <vector>
class FreeMonitor {
private:
struct FreeStat {
time_t now;
std::string mem_total;
std::string mem_free;
std::string buffers;
std::string cached;
};
std::vector<FreeStat> memory_stats_;
public:
FreeMonitor(const std::string& name) {
fname_ = name;
FILE* f = fopen(fname_.c_str(), "w");
fprintf(f, "time\tMemTotal\tMemFree\tBuffers\tCached\n");
fclose(f);
}
~FreeMonitor() {
Write();
}
void Write() {
if (memory_stats_.size() != 0) {
FILE* f = fopen(fname_.c_str(), "a+");
if (f == NULL) {
fprintf(stderr, "IOError: Open %s failed\n", fname_.c_str());
return;
}
for (size_t i = 0; i < memory_stats_.size(); i++) {
fprintf(f, "%ld\t%s\t%s\t%s\t%s\n",
memory_stats_[i].now,
memory_stats_[i].mem_total.c_str(),
memory_stats_[i].mem_free.c_str(),
memory_stats_[i].buffers.c_str(),
memory_stats_[i].cached.c_str());
}
fclose(f);
memory_stats_.clear();
}
}
void StatFree() {
if (memory_stats_.size() >= 1024) {
Write();
}
FILE* f = fopen("/proc/meminfo", "r");
if (f == NULL) {
fprintf(stderr, "IOError: Open %s failed\n", fname_.c_str());
return;
}
char line[1000];
FreeStat freestat;
time_t now = time(NULL);
freestat.now = now;
while (fgets(line, sizeof(line), f) != NULL) {
const char* sep = strchr(line, ':');
if (sep == NULL) continue;
Slice key = TrimSpace(Slice(line, sep - line));
Slice value = TrimSpace(Slice(sep+1));
if (key == "MemTotal") {
freestat.mem_total = value.ToString();
} else if (key == "MemFree") {
freestat.mem_free = value.ToString();
} else if (key == "Buffers") {
freestat.buffers = value.ToString();
} else if (key == "Cached") {
freestat.cached = value.ToString();
}
}
memory_stats_.push_back(freestat);
fclose(f);
}
private:
std::string fname_;
};
class Monitor {
private:
struct MemStat{
time_t now;
int64_t vm_size;
int64_t res_size;
};
std::vector<MemStat> mem_stats_;
public:
Monitor(const std::string& fname) {
page_size_ = sysconf(_SC_PAGESIZE);
assert(page_size_ > 0);
fprintf(stdout, "page_size = %d\n", page_size_);
fname_ = fname;
FILE* f = fopen(fname_.c_str(), "w");
fprintf(f, "time\tvm_size\tres_size\n");
fclose(f);
}
void Write() {
FILE* fstats = fopen(fname_.c_str(), "a+");
if (fstats == NULL) {
fprintf(stderr, "IOError: Open %s failed\n", fname_.c_str());
return;
}
for (size_t i = 0; i != mem_stats_.size(); i++) {
int64_t _now = static_cast<int64_t>(mem_stats_[i].now);
fprintf(fstats, "%"PRId64"\t%"PRId64"\t%"PRId64"\n", _now, mem_stats_[i].vm_size, mem_stats_[i].res_size);
}
fclose(fstats);
mem_stats_.clear();
}
~Monitor() {
if (mem_stats_.size() != 0) {
Write();
}
}
void StatMemory() {
if (mem_stats_.size() >= 1024) {
Write();
}
// const int kVirtIndex = 22;
// const int kResIndex = 23;
pid_t pid = getpid();
char fname[256];
snprintf(fname, sizeof(fname), "/proc/%d/statm", pid);
time_t current = time(NULL);
FILE* f = fopen(fname, "r");
if (f == NULL) {
fprintf(stderr, "IOError: Open %s failed\n", fname);
return;
}
int vm_page = 0;
int res_page = 0;
if (fscanf(f, "%d %d", &vm_page, &res_page) != 2) {
fprintf(stderr, "IOError: scanf %s failed\n", fname);
return;
}
fclose(f);
int64_t vm_size = vm_page * page_size_;
//int vm_size = vm_page;
int64_t res_size = res_page * page_size_;
//int res_size = res_page;
MemStat memstat;
memstat.now = current;
memstat.vm_size = vm_size;
memstat.res_size = res_size;
mem_stats_.push_back(memstat);
}
private:
int page_size_;
std::string fname_;
};
#endif
<file_sep>/README.md
beans_bench
===========
A bench mark between beansdb and local filesystem.
<file_sep>/fs.py
import os
import sys
import subprocess
import time
import signal
from datetime import datetime
from os import system as system
def clear_buffer_cache():
system('free -g')
system('sync')
system("sudo sed -n 's/0/3/w /proc/sys/vm/drop_caches' /proc/sys/vm/drop_caches")
system('sync')
system("sudo sed -n 's/3/0/w /proc/sys/vm/drop_caches' /proc/sys/vm/drop_caches")
system('free -g')
def run(bin_path, args):
clear_buffer_cache()
clear_buffer_cache()
now = datetime.now().strftime('%m%d%H%M%S')
test_name = '%s_%s_%s' %(now, args['--db'], args['--benchmarks'])
report_name = '%s_report.txt' %test_name
report_file = open(report_name, 'w')
log_name = "%s_log.txt" %test_name
logf = open(log_name, 'w')
arg_list = [bin_path]
for k, v in args.items():
arg_list.append('%s=%s' %(k, v))
print 'Run command %s' %(' '.join(arg_list))
bench_process = subprocess.Popen(arg_list, stdout=report_file, stderr=logf)
iostat_fname = '%s_iostat.txt' %test_name
iostat_process = subprocess.Popen('iostat -xm 10 > %s' %iostat_fname,
shell=True,
preexec_fn=os.setsid)
bench_process.wait()
report_file.close()
logf.close()
os.killpg(iostat_process.pid, signal.SIGTERM)
system("mkdir %s" %test_name)
system("mv *.txt %s" %test_name)
def _fs_read_write(num, value_size, thread_num, read_write_ratio, read_num):
args = {'--db': 'fdb',
'--benchmarks':'readwhilewriting',
'--value_size': value_size,
'--num': num,
'--num_threads': thread_num,
'--reads': read_num,
'--use_existing_db':'1',
'--histogram':'1',
'--filesystem_ndir':5,
'--read_write_ratio': read_write_ratio}
run('./db_bench', args)
def _fs_write(num, value_size, thread_num):
# 500G
args = {'--db': 'fdb',
'--benchmarks':'write',
'--value_size': value_size,
'--num': num,
'--num_threads': thread_num,
'--reads':'100000',
'--use_existing_db':'1',
'--histogram':'1',
'--filesystem_ndir':5}
run('./db_bench', args)
def _fs_read(num, thread_num, read_num):
# 500G
args = {'--db': 'fdb',
'--benchmarks':'read',
'--value_size': int(100e3),
'--num': num,
'--num_threads': thread_num,
'--reads': read_num,
'--use_existing_db':'1',
'--histogram':'1',
'--filesystem_ndir':5}
run('./db_bench', args)
def _fs_read_case(num):
# Test Threads (1, 4, 8 16)
_fs_read(num, 1, 10000)
_fs_read(num, 2, 10000)
_fs_read(num, 4, 10000)
_fs_read(num, 8, 10000)
_fs_read(num, 16, 10000)
# Test read_num
_fs_read(num, 4, 1000)
_fs_read(num, 4, 2000)
_fs_read(num, 4, 5000)
def _fs_write_case(num):
""" Write data 4 threads totally 500GB data """
print '_fs_write_case'
thread_num = 4
value_size = int(100e3)
read_write_ratio = 1
args = {'--db': 'fdb',
'--benchmarks':'write',
'--value_size': value_size,
'--num': num,
'--num_threads': thread_num,
'--reads':'100000',
'--use_existing_db':'1',
'--histogram':'1',
'--filesystem_ndir':5,
'--read_write_ratio': read_write_ratio}
run('./db_bench', args)
def _fs_read_write_case(num):
print '_beans_read_write_case'
read_num = 10000
db = 'beansdb'
# 100KB
value_size = int(100e3)
print '100KB'
_fs_read_write(num, value_size, 2, 1, read_num)
_fs_read_write(num, value_size, 6, 5, read_num)
_fs_read_write(num, value_size, 6, 0.2, read_num)
# 1MB
print '1MB'
value_size = int(1e6)
_fs_read_write(num, value_size, 2, 1, read_num)
_fs_read_write(num, value_size, 6, 5, read_num)
_fs_read_write(num, value_size, 6, 0.2, read_num)
# 5MB
print '5MB'
value_size = int(5e6)
_fs_read_write(num, value_size, 2, 1, read_num)
_fs_read_write(num, value_size, 6, 5, read_num)
_fs_read_write(num, value_size, 6, 0.2, read_num)
def main():
if sys.argv[1] == 'fs':
num = int(5000e3)
#num = 1000
_fs_write_case(num)
_fs_read_case(num)
_fs_read_write_case(num)
if __name__ == '__main__':
main()
<file_sep>/concurrent.h
#ifndef CONCURRENT_H
#define CONCURRENT_H
#include <pthread.h>
class CondVar;
class Mutex {
public:
Mutex();
~Mutex();
void Lock();
void Unlock();
void AssertHeld() { }
private:
friend class CondVar;
pthread_mutex_t mu_;
// No copying
Mutex(const Mutex&);
void operator=(const Mutex&);
};
class CondVar {
public:
explicit CondVar(Mutex* mu);
~CondVar();
void Wait();
void Signal();
void SignalAll();
private:
pthread_cond_t cv_;
Mutex* mu_;
};
class MutexLock {
public:
explicit MutexLock(Mutex *mu)
: mu_(mu) {
this->mu_->Lock();
}
~MutexLock() { this->mu_->Unlock(); }
private:
Mutex *const mu_;
// No copying allowed
MutexLock(const MutexLock&);
void operator=(const MutexLock&);
};
#endif
<file_sep>/CMakeLists.txt
cmake_minimum_required(VERSION 2.8)
#add_definitions(" -Wall -Wno-sign-compare -Werror -O2 ")
#add_definitions(" -Wall -Wno-sign-compare -O2 ")
#add_definitions("-Wall -g -fpermissive")
add_definitions("-Wall -O2 -g -D_FILE_OFFSET_BITS=64 -D__STDC_FORMAT_MACROS ")
#set(THIRD_PARTY_DIR "/home/liming/Projects")
#set(GPROFILER_DIR "${THIRD_PARTY_DIR}/gperftools")
#include_directories(
# "${GPROFILER_DIR}/include";
# )
#link_directories(
# "${GPROFILER_DIR}/lib";
# )
#set(CMAKE_C_COMPILER "g++")
add_library(beansdb bitcask.c codec.c diskmgr.c hstore.c record.c clock_gettime_stub.c crc32.c hint.c htree.c quicklz.c fnv1a.c)
add_executable(db_bench db_bench.cc histogram.cc concurrent.cc string_util.cc)
#target_link_libraries(db_bench beansdb libprofiler.a pthread)
target_link_libraries(db_bench beansdb pthread)
install(FILES bench.py fs.py DESTINATION .)
<file_sep>/benchmark.cc
#include <time.h>
#include <stdint.h>
#include "codec.h"
#include "hstore.h"
#include "slice.h"
#include <string.h>
#include <stdio.h>
#include <string>
int FLAGS_scan_threads = 0;
class Beansdb {
public:
bool Open(const std::string& base_path, int ndir, bool use_exiting_db) {
if (ndir != 1 && ndir != 16 && ndir != 16*16 && ndir != 16*16*16) {
fprintf(stderr, "Beansdb ndir %d error\n", ndir);
return false;
}
base_path_ = base_path;
ndir_ = ndir;
// hs_open(path, height, before, scan_threads)
int before = 0;
store_ = hs_open(const_cast<char*>(base_path.c_str()), ndir / 16,
before, FLAGS_scan_threads);
if (store_ == NULL) {
fprintf(stderr, "Beansdb open %s failed\n", base_path.c_str());
return false;
} else {
return true;
}
}
bool Get(const Slice& key, std::string* value) {
int vlen = 0;
int flag = 0;
char* svalue = hs_get(store_, key.data(), &vlen, &flag);
if (svalue == NULL) {
return false;
} else {
value->assign(svalue, vlen);
free(svalue);
return true;
}
}
bool Put(const Slice& key, const Slice& value) {
int flag = 0;
int version = 0;
bool status = hs_set(store_, key.data(), value.data(), value.size(), flag, version);
return status;
}
void Close() {
if (store_ != NULL) {
hs_close(store_);
}
return true;
}
private:
HStore* store_;
std::string base_path_;
int ndir_;
};
int main() {
int kValueSize = 100;
Beansdb db;
db.Open("./beans-data", 1, true);
int kNum = 100;
for (int i = 0; i < kNum; i++) {
char key[100];
snprintf(key, sizeof(key), "%016d", i);
char value[kValueSize];
snprintf(value, sizeof(value), "%016d", i);
bool s = db.Put(key, value);
if (!s) {
printf("add %d error\n", i);
return 1;
}
}
for (int i = 0; i < kNum; i++) {
char key[100];
snprintf(key, sizeof(key), "%016d", i);
std::string value;
bool s = db.Get(key, &value);
if (!s) {
printf("get %d error\n", i);
return 1;
}
if (value != key) {
printf("get %d error\n", i);
printf("value = %s, key=%s\n", value.c_str(), key);
}
}
printf("test passed\n");
return 0;
}
<file_sep>/string_util.cc
#include "string_util.h"
#include <assert.h>
void split_string(const std::string& str,
char sep,
std::vector<std::string>* stringlist) {
assert(stringlist != NULL);
size_t last = 0;
for (size_t i = 0; i <= str.size(); i++) {
if (i == str.size() || str[i] == sep) {
stringlist->push_back(str.substr(last, i - last));
last = i+1;
}
}
}
Slice TrimSpace(Slice s) {
size_t start = 0;
while (start < s.size() && isspace(s[start])) {
start++;
}
size_t limit = s.size();
while (limit > start && isspace(s[limit-1])) {
limit--;
}
return Slice(s.data() + start, limit - start);
}
| 2dacc52f1170563bbf3a3fd7fa97f4012632cc40 | [
"Markdown",
"Python",
"CMake",
"C++"
] | 11 | Python | southkyle/beans_bench | d13fd4fcd7cfba7b071e0c66b4c6de3cfc0c37d3 | 7561cb9e2eac8c879c81a4c1161007a87832b286 |
refs/heads/master | <file_sep># -*- coding: utf-8 -*-
from gevent import monkey;monkey.patch_all()
import os
from multiprocessing import Pool
import gevent
from envir_vars import decorators as dc
from envir_vars import dir_file_settings as df
from envir_vars import list_tools as lt
from envir_vars import pc_tools as pt
_author_ = 'luwt'
_date_ = '2018/11/6 23:50'
class FindPath:
def __init__(self, target_path):
self.target_path = target_path
def get_target_path(self, file_path):
"""递归遍历,找到目标文件的路径"""
try:
fs = os.listdir(file_path)
for f in fs:
tmp_path = os.path.join(file_path, f)
try:
if os.path.isdir(tmp_path):
if f in df.ignore_path or df.match_ignore_path(tmp_path):
continue
else:
self.get_target_path(tmp_path)
print('遍历')
elif os.path.isfile(tmp_path):
for key in self.target_path.keys():
pattern = eval('df.PATTERN_{}'.format(key.upper()))
if df.match_path(tmp_path, pattern):
self.target_path[key].append(os.path.dirname(tmp_path))
except OSError:
pass
except OSError:
pass
@dc.times_used('文件遍历进程{}'.format(os.getpid()))
def file_process(self, file_paths):
"""如果是文件就进行匹配,是文件夹准备遍历"""
path_dict = {}
coroutines = []
for file_path in file_paths:
if os.path.isdir(file_path):
# coroutines.append(gevent.spawn(self.get_target_path, file_path))
self.get_target_path(file_path)
if self.target_path:
path_dict = self.target_path
elif os.path.isfile(file_path):
for key in self.target_path.keys():
pattern = eval('df.PATTERN_{}'.format(key.upper()))
if df.match_path(file_path, pattern):
path_dict[key].append(os.path.dirname(file_path))
# gevent.joinall(coroutines)
print('进程:{}的遍历结果是{}'.format(os.getpid(), path_dict))
return path_dict
def start_process(self, path_list):
"""开进程,分任务"""
proc_results = []
try:
merge_paths = []
for path in path_list:
paths = os.listdir(path)
# 去除根目录下不访问的目录,即在忽略列表里的
[paths.remove(ig_path) for ig_path in df.ignore_path
if ig_path in paths]
# 生成全路径
merge_paths += [os.path.join(path, p) for p in paths]
list_new = lt.div_list(merge_paths, pt.get_cpu_count())
if list_new:
p = Pool(len(list_new))
[proc_results.append(p.apply_async(
self.file_process, args=(new_path,)))
for new_path in list_new]
p.close()
p.join()
except OSError:
pass
return proc_results
@dc.times_used("main函数")
def main(path_dict):
path_root_list = pt.get_disk_partitions()
print("path_root==>{}".format(path_root_list))
find_path = FindPath(path_dict)
results = find_path.start_process(('C:\\',))
for k in path_dict.keys():
for result in results:
if result.get()[k]:
path_dict[k].extend(result.get()[k])
# 去重
path_dict[k] = list(set(path_dict[k]))
print("最终结果是:{}".format(path_dict))
return path_dict
if __name__ == '__main__':
path_ = {'Java': []}
main(path_)
<file_sep># -*- coding: utf-8 -*-
_author_ = 'luwt'
_date_ = '2018/11/6 23:41'
def div_list(path_list, n):
"""将path_list进行n等分,余下放入最后一个子列表"""
print("***************开始分割列表****************")
print("根目录下总项目数为{}".format(len(path_list)))
list_new = []
if n > 0:
paths_size = len(path_list) // n
if paths_size > 0:
for i in range(1, n + 1):
if i == 1:
list_new.append(path_list[:paths_size])
elif i == n:
list_new.append(path_list[paths_size * (i - 1):])
else:
list_new.append(path_list[paths_size * (i - 1):
paths_size * i])
elif paths_size == 0:
list_new = path_list
print("分割列表完毕!")
else:
print("n <= 0,参数错误,无法分割列表")
[print(p) for p in list_new]
return list_new
<file_sep># -*- coding: utf-8 -*-
from src.env_decorators.decorators import require_admin
from PyQt5 import QtWidgets
import PyQt5.sip
import sys
from src.main_window.main_window import EnvUI
_author_ = 'luwt'
_date_ = '2018/12/17 10:26'
@require_admin()
def main():
app = QtWidgets.QApplication(sys.argv)
screen_rect = QtWidgets.QApplication.desktop().screenGeometry()
ui = EnvUI(screen_rect)
ui.show()
sys.exit(app.exec_())
if __name__ == '__main__':
main()
<file_sep># -*- coding: utf-8 -*-
_author_ = 'luwt'
_date_ = '2020/11/9 14:56'
<file_sep># -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'a.ui'
#
# Created by: PyQt5 UI code generator 5.11.2
#
# WARNING! All changes made in this file will be lost!
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtWidgets import QFileDialog, QMessageBox, QWidget, QDialogButtonBox
import os
class EnvUI(QWidget):
def __init__(self, desktop_screen_rect):
super().__init__()
self.desktop_screen_rect = desktop_screen_rect
self.setup_ui()
def setup_ui(self):
self.setObjectName("Form")
self.resize(self.desktop_screen_rect.width() * 0.5, self.desktop_screen_rect.height() * 0.6)
self.verticalLayout = QtWidgets.QVBoxLayout(self)
self.verticalLayout.setObjectName("verticalLayout")
self.title = QtWidgets.QWidget(self)
self.title.setLayoutDirection(QtCore.Qt.LeftToRight)
self.title.setObjectName("title")
self.verticalLayout_2 = QtWidgets.QVBoxLayout(self.title)
self.verticalLayout_2.setObjectName("verticalLayout_2")
self.text = QtWidgets.QLabel(self.title)
self.text.setFont(QtGui.QFont("楷体", 20))
self.text.setAlignment(QtCore.Qt.AlignCenter)
self.text.setObjectName("text")
self.verticalLayout_2.addWidget(self.text)
self.verticalLayout.addWidget(self.title)
self.widget_2 = QtWidgets.QWidget(self)
self.widget_2.setObjectName("widget_2")
self.horizontalLayout = QtWidgets.QHBoxLayout(self.widget_2)
self.horizontalLayout.setObjectName("horizontalLayout")
self.widget_4 = QtWidgets.QWidget(self.widget_2)
self.widget_4.setObjectName("widget_4")
self.verticalLayout_3 = QtWidgets.QVBoxLayout(self.widget_4)
self.verticalLayout_3.setObjectName("verticalLayout_3")
self.label_2 = QtWidgets.QLabel(self.widget_4)
self.label_2.setFont(QtGui.QFont("楷体", 20))
self.label_2.setAlignment(QtCore.Qt.AlignCenter)
self.label_2.setObjectName("label_2")
self.verticalLayout_3.addWidget(self.label_2)
self.widget_6 = QtWidgets.QWidget(self.widget_4)
self.widget_6.setObjectName("widget_6")
self.verticalLayout_4 = QtWidgets.QVBoxLayout(self.widget_6)
self.verticalLayout_4.setObjectName("verticalLayout_4")
self.checkBox_java = QtWidgets.QCheckBox(self.widget_6)
self.checkBox_java.setFont(QtGui.QFont("楷体", 16))
self.checkBox_java.setObjectName("checkBox_java")
self.verticalLayout_4.addWidget(self.checkBox_java)
self.checkBox_python = QtWidgets.QCheckBox(self.widget_6)
self.checkBox_python.setFont(QtGui.QFont("楷体", 16))
self.checkBox_python.setObjectName("checkBox_python")
self.verticalLayout_4.addWidget(self.checkBox_python)
self.checkBox_maven = QtWidgets.QCheckBox(self.widget_6)
self.checkBox_maven.setFont(QtGui.QFont("楷体", 16))
self.checkBox_maven.setObjectName("checkBox_maven")
self.verticalLayout_4.addWidget(self.checkBox_maven)
self.verticalLayout_3.addWidget(self.widget_6)
self.verticalLayout_3.setStretch(0, 2)
self.verticalLayout_3.setStretch(1, 8)
self.horizontalLayout.addWidget(self.widget_4)
self.line = QtWidgets.QFrame(self.widget_2)
self.line.setFrameShape(QtWidgets.QFrame.VLine)
self.line.setFrameShadow(QtWidgets.QFrame.Sunken)
self.line.setObjectName("line")
self.horizontalLayout.addWidget(self.line)
self.widget_5 = QtWidgets.QWidget(self.widget_2)
self.widget_5.setObjectName("widget_5")
self.verticalLayout_5 = QtWidgets.QVBoxLayout(self.widget_5)
self.verticalLayout_5.setObjectName("verticalLayout_5")
self.label_3 = QtWidgets.QLabel(self.widget_5)
self.label_3.setFont(QtGui.QFont("楷体", 20))
self.label_3.setAlignment(QtCore.Qt.AlignCenter)
self.label_3.setObjectName("label_3")
self.verticalLayout_5.addWidget(self.label_3)
self.widget_7 = QtWidgets.QWidget(self.widget_5)
self.widget_7.setObjectName("widget_7")
self.verticalLayout_6 = QtWidgets.QVBoxLayout(self.widget_7)
self.verticalLayout_6.setObjectName("verticalLayout_6")
self.choose_file = QtWidgets.QPushButton(self.widget_7)
self.choose_file.setFont(QtGui.QFont("楷体", 16))
self.choose_file.setObjectName("choose_file")
self.verticalLayout_6.addWidget(self.choose_file)
self.verticalLayout_5.addWidget(self.widget_7)
self.widget = QtWidgets.QWidget(self.widget_5)
self.widget.setObjectName("little_widget")
self.verticalLayout_8 = QtWidgets.QVBoxLayout(self.widget)
self.verticalLayout_8.setObjectName("verticalLayout_8")
self.file_selected_area = QtWidgets.QTextEdit(self.widget)
self.file_selected_area.setFont(QtGui.QFont("楷体", 16))
self.file_selected_area.setVisible(False)
self.file_selected_area.setObjectName("file_selected_area")
self.verticalLayout_8.addWidget(self.file_selected_area)
self.verticalLayout_5.addWidget(self.widget)
self.verticalLayout_5.setStretch(0, 2)
self.verticalLayout_5.setStretch(1, 3)
self.verticalLayout_5.setStretch(2, 5)
self.horizontalLayout.addWidget(self.widget_5)
self.horizontalLayout.setStretch(0, 1)
self.horizontalLayout.setStretch(1, 1)
self.horizontalLayout.setStretch(2, 1)
self.verticalLayout.addWidget(self.widget_2)
self.widget_3 = QtWidgets.QWidget(self)
self.widget_3.setObjectName("widget_3")
self.verticalLayout_7 = QtWidgets.QVBoxLayout(self.widget_3)
self.verticalLayout_7.setObjectName("verticalLayout_7")
self.output_area = QtWidgets.QTextBrowser(self.widget_3)
self.output_area.setFont(QtGui.QFont("楷体", 16))
self.output_area.setObjectName("output_area")
self.verticalLayout_7.addWidget(self.output_area)
self.buttonBox = QtWidgets.QDialogButtonBox(self.widget_3)
self.buttonBox.setStandardButtons(QDialogButtonBox.Cancel | QDialogButtonBox.Ok)
self.buttonBox.setCenterButtons(True)
self.buttonBox.setObjectName("buttonBox")
self.verticalLayout_7.addWidget(self.buttonBox)
self.verticalLayout.addWidget(self.widget_3)
self.verticalLayout.setStretch(0, 1)
self.verticalLayout.setStretch(1, 5)
self.verticalLayout.setStretch(2, 4)
self.retranslateUi(self)
# 存放选择结果的列表
self.exe_list = list()
self.file_list = list()
# 点击checkBox的时候触发事件
self.checkBox_java.stateChanged.connect(self.check_event)
self.checkBox_python.stateChanged.connect(self.check_event)
self.checkBox_maven.stateChanged.connect(self.check_event)
# 选择文件路径按钮点击事件
self.choose_file.clicked.connect(self.open_file)
# 选择文件区域交互事件
self.file_selected_area.textChanged.connect(self.text_change)
# 按钮响应事件
self.buttonBox.accepted.connect(self.check_file_param)
self.buttonBox.rejected.connect(self.check_button)
# self.msg = None
# self.thread_ = test_slot.BackQThread(self.msg)
# self.thread_.update_date.connect(self.print_log)
def print_log(self, msg):
self.output_area.append(msg)
def open_file(self):
"""选择文件路径"""
file_name = QFileDialog.getOpenFileName(self, "请选择文件", '/')
if file_name[0]:
self.file_list.append(file_name[0])
self.file_selected_area.setVisible(True)
self.file_text_show()
self.text_show()
def check_event(self, checked):
"""获取选中的checkBox值,放入结果列表,并在textBrowser显示"""
check_box = self.sender()
if checked == QtCore.Qt.Checked:
self.exe_list.append(check_box.text())
self.text_show()
if checked == QtCore.Qt.Unchecked:
self.exe_list.remove(check_box.text())
self.text_show()
def file_text_show(self):
"""文件区域选择结果显示"""
if self.file_list:
self.file_text = "\n".join(self.file_list)
self.file_selected_area.setText(self.file_text)
def text_change(self):
"""当文件区域内容被修改时,同步列表和日志区"""
text = self.file_selected_area.toPlainText()
# 去除列表中空字符串
self.file_list = list(filter(None, text.split("\n")))
self.text_show()
if 0 == len(self.file_list):
self.file_selected_area.setVisible(False)
def text_show(self):
"""根据结果列表显示内容,将结果列表转为字符串,如果列表为空则清空显示内容"""
final_list = self.exe_list + self.file_list
if final_list:
self.check_text = "、".join(final_list)
self.output_area.setText("已选择:{}\n点击OK进行配置,点击Cancel清除所有内容".
format(self.check_text))
else:
self.output_area.clear()
def check_button(self):
"""
清除所有已选择的,列表清空需要置在最后,
因为重置checkBox会触发check_event事件,空列表无法移除元素,会导致异常
"""
self.output_area.clear()
self.file_selected_area.clear()
self.checkBox_maven.setCheckState(0)
self.checkBox_java.setCheckState(0)
self.checkBox_python.setCheckState(0)
self.file_list.clear()
self.exe_list.clear()
def check_file_param(self):
"""检验文件列表里元素是否为文件"""
nf_list = list(filter(lambda f: not os.path.isfile(f), self.file_list))
if nf_list:
msg = "系统检测:【{}】不是文件,请重新核对!".format("、".join(nf_list))
QMessageBox.question(self, "提醒", msg, QMessageBox.Yes)
elif 0 == len(self.exe_list) and 0 == len(self.file_list):
msg = "请选择"
QMessageBox.question(self, "提醒", msg, QMessageBox.Yes)
else:
msg = "准备就绪,确定开始配置?"
question = QMessageBox.question(self, "提醒", msg, QMessageBox.Yes)
if question == QMessageBox.Yes:
self.msg = ef.set_var(app_list=self.exe_list, file_list=self.file_list)
# self.thread_.start()
self.print_log("{}已配置完毕".format(str(self.msg)))
def retranslateUi(self, Form):
_translate = QtCore.QCoreApplication.translate
Form.setWindowTitle(_translate("Form", "环境变量配置工具 -- by lwt"))
self.text.setText(_translate("Form", "欢迎使用环境变量配置工具"))
self.label_2.setText(_translate("Form", "请选择要配置的程序:"))
self.checkBox_java.setText(_translate("Form", "Java"))
self.checkBox_python.setText(_translate("Form", "Python"))
self.checkBox_maven.setText(_translate("Form", "Maven"))
self.label_3.setText(_translate("Form", "请选择要配置的文件:"))
self.choose_file.setText(_translate("Form", "请选择文件"))
self.output_area.setHtml(_translate("Form", "<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.0//EN\" \"http://www.w3.org/TR/REC-html40/strict.dtd\">\n"
"<html><head><meta name=\"qrichtext\" content=\"1\" /><read_qrc type=\"text/css\">\n"
"p, li { white-space: pre-wrap; }\n"
"</read_qrc></head><body read_qrc=\" font-family:\'SimSun\'; font-size:9pt; font-weight:400; font-read_qrc:normal;\">\n"
"<p read_qrc=\"-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;\"><br /></p></body></html>"))
<file_sep># -*- coding: UTF-8 -*-
from datetime import datetime
import subprocess
import win32con
import win32api
import os
class EnvironVars:
"""配置环境变量并备份"""
def __init__(self):
# 获取句柄
self.key = win32api.RegOpenKey(
win32con.HKEY_LOCAL_MACHINE,
r'SYSTEM\CurrentControlSet\Control\Session Manager\Environment',
0,
win32con.KEY_ALL_ACCESS
)
# path变量值
self.path_val = win32api.RegQueryValueEx(self.key, "Path")[0]
self.check_dict = {'Java': r'java -version',
'Python': r'python -V',
'Maven': r'mvn -v'
}
def save_path_var(self):
"""备份path变量值"""
now = datetime.now()
# 当前路径,备份文件将存于此
curr_path = os.path.abspath("../..")
with open("{}/原变量值.txt".format(curr_path), "a") as f:
f.write('☆☆☆☆☆\n原变量值为:\n' + self.path_val +
'\n如系统异常请将原变量值复制回path变量处\n' +
now.strftime('%Y-%m-%d %H:%M:%S\n') + '☆☆☆☆☆\n\n')
print('\n本次修改之前的变量值保存成功!请在桌面查看!\n\n')
def set_app_env(self, app_path):
"""配置应用的环境变量,需要添加到Path"""
# 向Path添加值
if app_path:
try:
win32api.RegSetValueEx(self.key,
"Path",
0,
win32con.REG_SZ,
"{}{};".format(self.path_val, app_path)
)
print('变量配置成功!')
except Exception as e:
print(e)
def set_file_env(self, file_path):
"""配置单文件形式的配置文件,不需要添加到Path"""
if file_path:
try:
# 获取文件名
file_name = os.path.basename(file_path)
file_name_upper = os.path.splitext(file_name)[0].upper()
# 格式化路径
file_path = os.path.abspath(file_path)
win32api.RegSetValueEx(self.key,
file_name_upper,
0,
win32con.REG_SZ,
file_path
)
print('\n配置文件环境变量配置成功!\n\n')
except Exception as e:
print(e)
def check_var_exist(self, app=None, file=None):
"""
检测环境变量是否已存在,
如果path为文件夹,配置内容为程序,需判断path中是否存在该变量;
如果path为文件,配置内容为文件,需判断文件名大写的变量是否存在,
若存在返回true,不存在返回false
"""
is_exist = False
if file:
file_name = os.path.basename(file)
file_name_upper = os.path.splitext(file_name)[0].upper()
try:
file_var = win32api.RegQueryValueEx(self.key, file_name_upper)[0]
if file_var and file_var == file:
is_exist = True
except:
pass
if app:
if self.check_dict[app]:
try:
code = subprocess.call(self.check_dict[app], shell=True)
# 暂时发现执行这几个查询版本号成功的code为0
if code == 0:
is_exist = True
except:
pass
return is_exist
<file_sep># -*- coding: utf-8 -*-
from envir_vars import environ_var as ev
from envir_vars import recur_process as rp
_author_ = 'luwt'
_date_ = '2018/12/17 10:49'
def set_var(app_list=None, file_list=None):
environ_vars = ev.EnvironVars()
exist_list = []
if app_list:
app_dict = {}
for app in app_list:
if environ_vars.check_var_exist(app=app):
exist_list.append(app)
else:
app_dict[app] = []
if app_dict:
environ_vars.save_path_var()
# 开始搜索程序目录
res_dict = rp.main(app_dict)
for res in res_dict.values():
for app in res:
environ_vars.set_app_env(app)
if file_list:
for file in file_list:
if environ_vars.check_var_exist(file=file):
exist_list.append(file)
else:
environ_vars.set_file_env(file)
return exist_list
<file_sep># -*- coding: utf-8 -*-
import re
_author_ = 'luwt'
_date_ = '2018/11/7 0:10'
# [^a-z]+?是为了避免匹配到jre
PATTERN_JAVA = r'.*jdk([^a-z]+?)(bin\\java.exe)'
PATTERN_PYTHON = r'.*\\python.exe|.*\\pip(\d*).exe'
PATTERN_MAVEN = r'.*apache-maven(.*bin\\mvn.cmd)'
PATTERN_IGNORE = r'.*Local\\Application Data'
def match_path(tmp_path, pattern_):
"""对tmp_path进行正则匹配(忽略大小写)"""
pattern = re.compile(pattern_, re.I)
return pattern.search(tmp_path)
def match_ignore_path(tmp_path):
"""快捷方式引用,遍历无意义"""
pattern = re.compile(PATTERN_IGNORE, re.I)
return pattern.search(tmp_path)
# 忽略列表,或太大没意义,或无权访问
ignore_path = ['Windows', 'System Volume Information', 'Recovery',
'Documents and Settings', 'Config.Msi', 'Windows.old']
<file_sep># -*- coding: utf-8 -*-
import sys
from PyQt5 import QtWidgets
from PyQt5.QtWidgets import QMessageBox
_author_ = 'luwt'
_date_ = '2018/12/9 0:19'
class ExceptMessage:
"""自定义异常消息提示"""
def __init__(self, msg):
self.box = QMessageBox(QMessageBox.Critical, '警告', msg)
# 添加按钮,可用中文
self.yes = self.box.addButton('退出', QMessageBox.YesRole)
# 设置消息框中内容前面的图标
self.box.setIcon(3)
# 显示
self.box.show()
def except_dialog(msg):
app = QtWidgets.QApplication(sys.argv)
execpt_message = ExceptMessage(msg)
sys.exit(app.exec_())
<file_sep># -*- coding: utf-8 -*-
from functools import wraps
from src.exception import except_message
import datetime
import win32con
import win32api
_author_ = 'luwt'
_date_ = '2018/11/7 9:47'
def times_used(*dargs):
"""计算程序运行时间"""
def times(f):
@wraps(f)
def count_time(*args, **kw):
start = datetime.datetime.now()
print("【{}】开始时间为:{}".format(dargs[0],
start.strftime('%Y-%m-%d %H:%M:%S')))
# 获取原函数返回值并返回,否则将丢失原函数返回值
f_res = f(*args, **kw)
end = datetime.datetime.now()
interval = (end - start).seconds
time_sec = datetime.timedelta(seconds=interval)
print("【{}】结束时间:{},耗时{}".format(dargs[0],
end.strftime('%Y-%m-%d %H:%M:%S'),
time_sec))
return f_res
return count_time
return times
def require_admin():
"""验证当前是否有管理员权限,若没有则给出提示"""
def admin_(f):
@wraps(f)
def admin(*args, **kw):
try:
# 尝试获取句柄,若失败则需要以管理员权限运行
win32api.RegOpenKey(
win32con.HKEY_LOCAL_MACHINE,
r'SYSTEM\CurrentControlSet\Control\Session Manager\Environment',
0,
win32con.KEY_ALL_ACCESS
)
except Exception as e:
if e.args[0] == 5:
msg = "权限不足,无法操作,请以管理员身份运行本程序"
else:
msg = "其他未知错误:{}".format(e)
except_message.except_dialog(msg)
f_res = f(*args, **kw)
return f_res
return admin
return admin_
<file_sep># -*- coding: utf-8 -*-
import psutil
_author_ = 'luwt'
_date_ = '2018/11/6 23:35'
def get_cpu_count():
"""获取cpu逻辑核心数"""
return psutil.cpu_count()
def get_disk_partitions():
"""获取磁盘盘符信息"""
partitions = psutil.disk_partitions()
disks = []
disks += [pt.device for pt in partitions]
print(disks)
return disks
| 06d2da73682019e2b321c33c82213a65e2271dd7 | [
"Python"
] | 11 | Python | enterpriseih/Environ_var_tool | 7c3aaea5c182f9203fc21aafaed387a1d1fab92c | f60e3d04cf4032c2f3d68e37231e1281d1a119c2 |
refs/heads/master | <repo_name>gt488/moderngpu<file_sep>/src/moderngpu/cta_reduce.hxx
// moderngpu copyright (c) 2016, <NAME> http://www.moderngpu.com
#pragma once
#include "loadstore.hxx"
#include "intrinsics.hxx"
BEGIN_MGPU_NAMESPACE
// cta_reduce_t returns the reduction of all inputs for thread 0, and returns
// type_t() for all other threads. This behavior saves a broadcast.
template<int nt, typename type_t>
struct cta_reduce_t {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 300
enum {
num_sections = warp_size,
section_size = nt / num_sections
};
struct storage_t {
type_t data[num_sections];
type_t reduction;
};
template<typename op_t = plus_t<type_t> >
MGPU_DEVICE type_t reduce(int tid, type_t x, storage_t& storage,
int count = nt, op_t op = op_t(), bool all_return = true) const {
int lane = (section_size - 1) & tid;
int section = tid / section_size;
if(count >= nt) {
// In the first phase, threads cooperatively reduce within their own
// section.
iterate<s_log2(section_size)>([&](int pass) {
x = shfl_down_op(x, 1<< pass, op, section_size);
});
// The last thread in each section stores the local reduction to shared
// memory.
if(!lane)
storage.data[section] = x;
__syncthreads();
// Reduce the totals of each input section.
if(tid < num_sections) {
x = storage.data[tid];
iterate<s_log2(num_sections)>([&](int pass) {
x = shfl_down_op(x, 1<< pass, op, num_sections);
});
if(!tid && all_return) storage.reduction = x;
}
__syncthreads();
} else {
iterate<s_log2(section_size)>([&](int pass) {
int offset = 1<< pass;
type_t y = shfl_down(x, offset, section_size);
if(tid < count - offset && lane < section_size - offset)
x = op(x, y);
});
if(!lane)
storage.data[section] = x;
__syncthreads();
// Reduce the totals of each input section.
if(tid < num_sections) {
int spine_pop = div_up(count, section_size);
x = storage.data[tid];
iterate<s_log2(num_sections)>([&](int pass) {
int offset = 1<< pass;
type_t y = shfl_down(x, offset, num_sections);
if(tid < spine_pop - offset) x = op(x, y);
});
if(!tid && all_return) storage.reduction = x;
}
__syncthreads();
}
if(all_return) {
x = storage.reduction;
__syncthreads();
}
return x;
}
#else
struct storage_t {
type_t data[nt];
};
template<typename op_t = plus_t<type_t> >
MGPU_DEVICE type_t reduce(int tid, type_t x, storage_t& storage,
int count = nt, op_t op = op_t(), bool all_return = true) const {
storage.data[tid] = x;
__syncthreads();
// Fold the data in half with each pass.
iterate<s_log2(nt)>([&](int pass) {
int dest_count = nt>> (pass + 1);
if((tid < dest_count) && (dest_count + tid < count)) {
// Read from the right half and store to the left half.
x = op(x, storage.data[dest_count + tid]);
storage.data[tid] = x;
}
__syncthreads();
});
if(all_return) {
x = storage.data[0];
__syncthreads();
}
return x;
}
#endif
};
END_MGPU_NAMESPACE
| c59ac9ff8e6b02234a6c58daef601cf7c1813630 | [
"C++"
] | 1 | C++ | gt488/moderngpu | 21fc74abd4dab7b115e528d2201a10c62604ca45 | a407d0fbecbaf9c817cd15efef93b7b6f06c7cbd |
refs/heads/master | <file_sep>#!/bin/sh
while read line
do
if [[ $line == \>* ]]
then
file=$line
echo $line >> $2/$file
else
echo $line >> $2/$file
fi
done < $1
<file_sep>/**
* check if form is ready
* all necessary fields must be properly filled out
* files must be smaller than 8kb for fasta files and 500kb for image file
*/
function check() {
var correct = true;
if (document.getElementById("in-fasta").files.length > 0 || document.getElementById("targetText").value != "") {
if (!document.getElementById("tmp").checked) {
if(document.getElementById("in-template-f").files.length > 0 || document.getElementById("templateText").value != "") {
if(document.getElementById("in-template-p").files.length > 0) {
if(!(document.getElementById("f1").checked ||
document.getElementById("f2").checked ||
document.getElementById("f3").checked)) {
correct = false;
alert("Please specify template image format.");
}
} else {
correct = false;
alert("Please select template image file.");
}
} else {
correct = false;
alert("Please select template fasta file or paste sequence into textbox.");
}
}
} else {
correct = false;
alert("Please select target fasta file or paste sequence into textbox.");
}
if(correct) {
if(document.getElementById("in-fasta").files.length > 0 && document.getElementById("in-fasta").files[0].size <= 8192) {
if(!document.getElementById("tmp").checked) {
if(document.getElementById("in-template-f").files.length > 0 && document.getElementById("in-template-f").files[0].size <= 8192) {
if(document.getElementById("in-template-p").files[0].size > 512000) {
correct = false;
alert("Template image file is too big (over 500kb).");
}
} else {
if(document.getElementById("in-template-f").files.length > 0){
correct = false;
alert("Template fasta file is too big (over 8kb).");
}
}
}
} else {
if(document.getElementById("in-fasta").files.length > 0) {
correct = false;
alert("Target fasta file is too big (over 8kb).");
}
}
}
return correct;
}
/**
* show loading and message
*/
function showSpinner() {
document.getElementById("spinner").style.display = "block";
document.getElementById("block").style.display = "block";
}
/**
* hide loading and message
*/
function hideSpinner() {
document.getElementById("spinner").style.display = "none";
document.getElementById("block").style.display = "none";
}
/**
*
* @param {string} message Message to be displayed
*
* show error message
* used in case server failed to provide output
*/
function showMessage(message) {
document.getElementById("error").innerHTML = message;
document.getElementById("error").style.display = "block";
}
/**
* hide error message
*/
function hideMessage() {
document.getElementById("error").style.display = "none";
}
/**
*
* @param {string} picture SVG code to be displayed as picture
*
* display svg picture provided by server
*/
function showResult(picture) {
var svgImg = document.getElementById("outputImg");
while(svgImg.hasChildNodes()){
svgImg.removeChild(svgImg.firstChild);
}
svgImg.innerHTML = picture;
document.getElementById("result").style.display = "block";
document.getElementById("block").style.display = "block";
}
/**
*
* @param {string} filename Name of file
* @param {string} text Content of file
*
* create temporary <a> element as proxy for downloading a file
*/
function download(filename, text) {
var element = document.createElement('a');
element.setAttribute('href', 'data:text/plain;charset=utf-8,' + encodeURIComponent(text));
element.setAttribute('download', filename);
element.style.display = 'none';
document.body.appendChild(element);
element.click();
document.body.removeChild(element);
}
/**
*
* @param {form} form Form to be send
*
* communication with server
* send form to process.php
* while server is working show loading
* after recieving response from server show result
*/
function sendForm(form) {
var data = new FormData(form);
var req = new XMLHttpRequest();
req.onreadystatechange = function(event) {
if (req.readyState == 4) {
if (req.status == 200) {
hideSpinner();
showResult(req.responseText);
}
else if(req.status == 204){
hideSpinner();
showMessage("Traveler could not compute layout based on provided input.");
}
else{
hideSpinner();
showMessage("Not implemented.");
}
}
}
req.onerror = function(event) {
hideSpinner();
showMessage("Unknown error");
}
showSpinner();
req.open("POST", "http://traveler.projekty.ms.mff.cuni.cz/process.php", true);
req.send(data);
}
/**
* adding onclick events to multiple parts of form
* overriding onsubmit function on form
*/
window.onload = function() {
document.getElementById("tmp").onclick = function() {
var input = document.getElementById("input");
if (this.checked) {
input.style.display = "none";
this.value = "yes";
} else {
input.style.display = "block";
this.value = "no";
}
}
document.getElementById("use").onsubmit = function(event) {
event.preventDefault();
if (check()) {
hideMessage();
sendForm(this);
}
}
document.getElementById("ov").onclick = function() {
if(this.checked) {
this.value = "yes";
}
else {
this.value = "no";
}
}
document.getElementById("close-result").onclick = function() {
document.getElementById("result").style.display = "none";
document.getElementById("block").style.display = "none";
}
document.getElementById("download-result").onclick = function() {
download("picture.svg", document.getElementById("outputImg").innerHTML);
}
}<file_sep>#!/bin/sh
cp html/* $1
cp -r css $1
cp -r js $1
cp -r pictures $1
CURR=$(pwd)
git clone https://github.com/davidhoksza/traveler $1/traveler
cd $1/traveler/src
make build
cd ..
mkdir output
cd $CURR<file_sep>#!/bin/sh
header=0
echo > $1.result
for struct in $1/*
do
echo $struct
if [ $header -eq 0 ]
then
echo -n structure, >> $1.result
for name in $2/*
do
echo -n $name, >> $1.result
done
echo , >> $1.result
fi
header=1
echo -n $struct, >> $1.result
for template in $2/*
do
result=$(./distance.sh $struct $template)
echo -n $result, >> $1.result
done
echo , >> $1.result
done
<file_sep><?php
require 'header.php';
if(isset($_GET['page']))
{
switch($_GET['page'])
{
case 'home':
require 'use.php';
break;
case 'use':
require 'use.php';
break;
case 'how_to':
require 'how_to.php';
break;
default:
require 'error.php';
break;
}
}
else require 'use.php';
require 'footer.php';
?><file_sep>#!/bin/sh
TMPFILE='mktemp'
sed '/^[A-Z\>]/d' $1 | tr -d '\n' > $TMPFILE
echo $'\n' >> $TMPFILE
sed '/^[A-Z\>]/d' $2 | tr -d '\n' >> $TMPFILE
echo $'\n' >> $TMPFILE
echo $'@\n' >> $TMPFILE
RNAdistance < $TMPFILE | sed 's/[^0-9]*//g'
rm $TMPFILE<file_sep><?php
$choose = isset($_POST['template']) ? $_POST['template'] : 'no';
$overlap = isset($_POST['overlap']) ? $_POST['overlap'] : 'no';
$format = isset($_POST['format']) ? $_POST['format'] : 'default';
$target_text = $_POST['targetText'];
$template_text = $_POST['templateText'];
$command = 'traveler/bin/traveler ';
$target_f; $template_f; $template_p; $task;
$tar = false;
$tem = false;
/*
save text area input into temporary file for later use
*/
if(strlen($target_text) > 0)
{
$tar = true;
$target_f = tempnam(sys_get_temp_dir(), 'tarff');
$handle = fopen($target_f, 'w');
$target_text = str_replace(["\r"], "", $target_text);
fwrite($handle, $target_text);
fclose($handle);
}
else
{
$target_f = $_FILES['fasta_tar']['tmp_name'];
}
if(strlen($template_text) > 0)
{
$tem = true;
$template_f = tempnam(sys_get_temp_dir(), 'temff');
$handle = fopen($template_f, 'w');
$template_text = str_replace(["\r"], "", $template_text);
fwrite($handle, $template_text);
fclose($handle);
}
else
{
$template_f = $_FILES['fasta_tmp']['tmp_name'];
}
$task = ' --all ';
if($overlap == 'yes')
{
$task = $task . '--overlaps ';
}
if($choose == 'yes' || $choose == 'no')
{
/*
user asked server to choose template
*/
if($choose == 'yes')
{
$dir = new DirectoryIterator('traveler/data/metazoa');
$templates = array();
/*
run RNAdistance for every template
*/
foreach ($dir as $file)
{
if (!$file->isDot())
{
$parts = pathinfo($file->getFilename());
if($parts['extension'] == 'fasta')
{
$templates[$parts['filename']] = shell_exec('./distance.sh traveler/data/metazoa/' . $file->getFilename() . ' ' . $target_f);
}
}
}
/*
template with best score is chosen for visualisation
*/
$template = array_keys($templates, min($templates))[0];
$template = 'traveler/data/metazoa/' . $template;
$template_f = $template . '.fasta';
$template_p = $template . '.ps';
}
else
{
/*
user has provided us with template
*/
$template_p = $_FILES['template']['tmp_name'];
}
$command = $command . '--target-structure ' . $target_f . ' --template-structure ';
if($choose == 'no' && $format == 'traveler')
{
$command = $command . '--file-format traveler ';
}
$command = $command . $template_p . ' ' . $template_f . $task;
/*
create temporary directory for Traveler output files
*/
$tmpdir = uniqid();
$dir_name = "traveler/output/$tmpdir";
$file_name = "$dir_name/result";
shell_exec("mkdir $dir_name");
shell_exec("touch $file_name");
$command = $command . $file_name;
$output = shell_exec($command . " 2>&1");
$result = file_get_contents($file_name . '.colored.svg');
echo $result;
exec("rm -rf $dir_name");
if($tar) unlink($target_f);
if($tem) unlink($template_f);
/*
in case of successful computation Traveler does not have any command line output
*/
if($output != "")
{
http_response_code(204);
//echo $command;
//echo $output;
}
}
else
{
if($tar) unlink($target_f);
if($tem) unlink($template_f);
http_response_code(501);
}
?> | 62a76507c308f49bdff4a8fc386ff7338c71ceb8 | [
"JavaScript",
"PHP",
"Shell"
] | 7 | Shell | JakubSaksa/bp_text | 61a75ddef4e36f74037df6c47ecbf77beec7c99f | ebf3a5c92b186d7bf66cf4f3fa6d861e589d1439 |
refs/heads/master | <repo_name>mhazwankamal/zxcvbnm<file_sep>/app/src/main/java/mmanager/scnx5/com/abcauthabc.java
package mmanager.scnx5.com;
public class abcauthabc {
public static String rabcauthabc() {
return "apps/loginfromdevicetable3";
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/Exoplayer/OnKeyListener.java
package mmanager.scnx5.com.mitvmanager.Exoplayer;
import android.view.KeyEvent;
import android.view.View;
public interface OnKeyListener {
boolean onKey(View v, int keyCode, KeyEvent event);
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/authorization/RecyclerViewAdapterHomeMostPopular.java
package mmanager.scnx5.com.authorization;
import android.content.Context;
import android.content.Intent;
import android.content.SharedPreferences;
import android.support.v7.widget.RecyclerView;
import android.util.Log;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.view.animation.Animation;
import android.view.animation.AnimationUtils;
import android.widget.FrameLayout;
import android.widget.ImageView;
import android.widget.LinearLayout;
import android.widget.TextView;
import com.bumptech.glide.Glide;
import java.util.List;
import mmanager.scnx5.com.mitvmanager.Exoplayer.exoplayer_layar;
import mmanager.scnx5.com.mitvmanager.R;
import mmanager.scnx5.com.mitvmanager.getURL;
import static android.content.Context.MODE_PRIVATE;
public class RecyclerViewAdapterHomeMostPopular extends RecyclerView.Adapter<RecyclerViewAdapterHomeMostPopular.MyViewHolderRB> {
private Context mContext ;
private List<HomeTrendBook> mData ;
private String playURL,channelName,imgUrl;
private getURL wget =new getURL();
private SharedPreferences pref ;
private SharedPreferences.Editor editor ;
private String server,tk,Json;
public RecyclerViewAdapterHomeMostPopular(Context mContext, List<HomeTrendBook> mData,String server,String tk,String Json) {
this.mContext = mContext;
this.mData = mData;
this.server=server;
this.tk=tk;
this.Json=Json;
}
@Override
public RecyclerViewAdapterHomeMostPopular.MyViewHolderRB onCreateViewHolder(ViewGroup parent, int viewType) {
View view=null;
LayoutInflater mInflater = LayoutInflater.from(mContext);
/* double width = Resources.getSystem().getDisplayMetrics().widthPixels;
if (width > 2200 && width < 3000){
view = mInflater.inflate(R.layout.exoplayer_channel_switch_1440, parent, false);
}else if (width > 1280 && width < 2200){
view = mInflater.inflate(R.layout.exoplayer_channel_switch_1080, parent, false);
}else {
view = mInflater.inflate(R.layout.exoplayer_channel_switch_720, parent, false);
}*/
view = mInflater.inflate(R.layout.home_most_popular, parent, false);
return new RecyclerViewAdapterHomeMostPopular.MyViewHolderRB(view);
}
@Override
public void onBindViewHolder(RecyclerViewAdapterHomeMostPopular.MyViewHolderRB holder, final int position) {
pref = mContext.getSharedPreferences("HomeUI", MODE_PRIVATE);
editor = pref.edit();
holder.channelname.setText(mData.get(position).getTitle().toString());
holder.channelcategory.setText(mData.get(position).getCategory().toString());
String picURL = mData.get(position).getThumbnail().toString();
Glide.with(mContext).load(picURL).into(holder.img_book_thumbnail);
String focus_last = pref.getString("most_popular", null);
if (focus_last != null) {
if (focus_last.equalsIgnoreCase("true")) {
holder.cardView.setFocusable(true);
if(position==0) {
holder.cardView.requestFocus();
}
} else {
holder.cardView.setFocusable(false);
}
}
holder.cardView.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Intent intent = new Intent(mContext, exoplayer_layar.class);
// passing data to the book activity
intent.putExtra("cid", mData.get(position).getId());
intent.putExtra("Title", mData.get(position).getTitle());
intent.putExtra("Url", mData.get(position).getUrl());
intent.putExtra("Thumbnail", mData.get(position).getThumbnail());
intent.putExtra("Sypnopsis", mData.get(position).getSysnopsis());
intent.putExtra("Category", mData.get(position).getCategory());
intent.putExtra("liveTV", "rb");
intent.putExtra("tk", tk);
intent.putExtra("server", server);
intent.putExtra("json", Json);
intent.putExtra("channelPos", 0);
intent.putExtra("premium", mData.get(position).getpremium());
// Toast.makeText(mContext,"test",Toast.LENGTH_LONG).show();
// start the activity
mContext.startActivity(intent);
}
});
}
@Override
public int getItemCount() {
return mData.size();
}
public static class MyViewHolderRB extends RecyclerView.ViewHolder {
TextView channelname,channelcategory;
ImageView img_book_thumbnail;
//CardView cardView ;
FrameLayout cardView ;
public MyViewHolderRB(final View itemView) {
super(itemView);
channelname = (TextView) itemView.findViewById(R.id.lastwatching_channelname) ;
channelcategory= (TextView) itemView.findViewById(R.id.lastwatching_channelcategory) ;
img_book_thumbnail = (ImageView) itemView.findViewById(R.id.lastwatching_logo);
cardView =(FrameLayout) itemView.findViewById(R.id.home_last_watching);
/* Animation anim = AnimationUtils.loadAnimation(itemView.getContext(),R.anim.scale_out_tv);
itemView.startAnimation(anim);
anim.setFillAfter(true);*/
itemView.setOnFocusChangeListener(new View.OnFocusChangeListener() {
@Override
public void onFocusChange(View view, boolean b) {
if(b){
Animation anim = AnimationUtils.loadAnimation(itemView.getContext(),R.anim.scale_in_tv);
itemView.startAnimation(anim);
anim.setFillAfter(true);
// Log.d("Onfocus","focused");
}else {
Animation anim = AnimationUtils.loadAnimation(itemView.getContext(),R.anim.scale_out_tv);
itemView.startAnimation(anim);
anim.setFillAfter(true);
}
}
});
}
public ImageView getImgView(){
return img_book_thumbnail;
}
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/Exoplayer/customErrorHandlingExo.java
package mmanager.scnx5.com.mitvmanager.Exoplayer;
import com.google.android.exoplayer2.C;
import com.google.android.exoplayer2.ParserException;
import com.google.android.exoplayer2.upstream.DefaultLoadErrorHandlingPolicy;
import com.google.android.exoplayer2.upstream.HttpDataSource;
import com.google.android.exoplayer2.upstream.LoadErrorHandlingPolicy;
import java.io.FileNotFoundException;
import java.io.IOException;
public class customErrorHandlingExo extends DefaultLoadErrorHandlingPolicy {
@Override
public long getRetryDelayMsFor(
int dataType,
long loadDurationMs,
IOException exception,
int errorCount) {
return exception instanceof FileNotFoundException
? C.TIME_UNSET
: super.getRetryDelayMsFor(
dataType, loadDurationMs, exception, errorCount);
}
@Override
public int getMinimumLoadableRetryCount(int dataType) {
return Integer.MAX_VALUE;
}
}<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/ShutdownReceiver.java
package mmanager.scnx5.com.mitvmanager;
import android.content.BroadcastReceiver;
import android.content.Context;
import android.content.Intent;
public class ShutdownReceiver extends BroadcastReceiver {
@Override
public void onReceive(Context context, Intent intent) {
//Insert code here
}
}<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/VODGrid/vod_grid_activity.java
package mmanager.scnx5.com.mitvmanager.VODGrid;
import android.app.ProgressDialog;
import android.content.res.Resources;
import android.graphics.Bitmap;
import android.graphics.Rect;
import android.graphics.drawable.BitmapDrawable;
import android.os.AsyncTask;
import android.os.Build;
import android.os.CountDownTimer;
import android.os.StrictMode;
import android.support.annotation.NonNull;
import android.support.annotation.Nullable;
import android.support.annotation.RequiresApi;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.support.v7.widget.GridLayoutManager;
import android.support.v7.widget.RecyclerView;
import android.util.Log;
import android.view.View;
import android.view.Window;
import android.view.WindowManager;
import android.widget.AdapterView;
import android.widget.ArrayAdapter;
import android.widget.GridView;
import android.widget.LinearLayout;
import android.widget.ListView;
import android.widget.SearchView;
import android.widget.Space;
import com.bumptech.glide.Glide;
import com.bumptech.glide.request.target.SimpleTarget;
import com.bumptech.glide.request.transition.Transition;
import org.json.JSONArray;
import org.json.JSONException;
import org.json.JSONObject;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedHashSet;
import java.util.List;
import mmanager.scnx5.com.authorization.newui_logout_main;
import mmanager.scnx5.com.mitvmanager.R;
import mmanager.scnx5.com.mitvmanager.getURL;
public class vod_grid_activity extends AppCompatActivity {
public List<VODBook> lstBook;
public List<VODBook> VOD;
public List<String> VODJsonId;
public List<String> VODJsonName;
public List<String> VODJsonLogoPath;
public List<String> VODJsonUrl;
public List<String> VODJsonCategory;
public List<String> VODJsonsypnopsis;
public List<String> VODJsonbackdrop;
public String json;
public RecyclerViewAdapter myAdapter,myAdapter2;
public RecyclerView myrv;
public ListView listView;
private String tk,server;
private LinearLayout VOD_root;
// public String[] VODCat;
public ArrayList<String> VODCat;
public LinkedHashSet<String> SETVODJsonCategory;
Double width;
@RequiresApi(api = Build.VERSION_CODES.N)
@Override
protected void onCreate(Bundle savedInstanceState) {
requestWindowFeature(Window.FEATURE_NO_TITLE); // for hiding title
getWindow().setFlags(WindowManager.LayoutParams.FLAG_FULLSCREEN,
WindowManager.LayoutParams.FLAG_FULLSCREEN);
// Remember that you should never show the action bar if the
// status bar is hidden, so hide that too if necessary.
// ActionBar actionBar = getActionBar();
// actionBar.hide();
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_vod_grid_activity);
Bundle extras = getIntent().getExtras();
if(extras !=null)
{
tk = extras.getString("tk");
server = extras.getString("server");
// Toast.makeText(getApplicationContext(),json,Toast.LENGTH_LONG).show();
}
//set correct width based on resolution
Double ratio;
width= vod_grid_activity.getScreenWidth();
ratio = width * 0.2;
int correctWidth;
correctWidth = Integer.valueOf(ratio.intValue());
LinearLayout categoryLI =(LinearLayout)findViewById(R.id.categoryvod);
categoryLI.getLayoutParams().width=correctWidth;
ratio = width * 0.8;
correctWidth = Integer.valueOf(ratio.intValue());
LinearLayout vodlistingLI =(LinearLayout)findViewById(R.id.vodlisting);
vodlistingLI.getLayoutParams().width=correctWidth;
VOD_root=(LinearLayout)findViewById(R.id.VOD_rootview);
Glide.with(vod_grid_activity.this)
.asBitmap()
.load("https://layar3.com/apps/home/l3_background_new.jpg")
.into(new SimpleTarget<Bitmap>() {
@Override
public void onResourceReady(@NonNull Bitmap resource, @Nullable Transition<? super Bitmap> transition) {
VOD_root.setBackground(new BitmapDrawable(resource));
}
});
/*
getURL wget=new getURL();
String json= wget.getURL("http://scnx5.sytes.net/mitv/apps/vod/getvodlist.php");
try {
JSONObject objectPremium = new JSONObject(String.valueOf(json));
JSONArray VodData = (JSONArray) objectPremium.getJSONArray("data");
SETVODJsonCategory = new HashSet<String>();
VODJsonName = new ArrayList<String>();
VODJsonLogoPath = new ArrayList<String>();
VODJsonUrl = new ArrayList<String>();
VODJsonCategory = new ArrayList<String>();
VODJsonsypnopsis = new ArrayList<String>();
//Toast.makeText(getApplicationContext(),VODname,Toast.LENGTH_LONG).show();
String VODname,VODlogo,VODurl,VODcategory,VODsypnopsis;
for (int i = 0; i < VodData.length(); i++) {
VODname = VodData.getJSONObject(i).getString("name");
VODlogo = VodData.getJSONObject(i).getString("logoPath");
VODurl = VodData.getJSONObject(i).getString("playUrl");
VODcategory = VodData.getJSONObject(i).getString("genre");
VODsypnopsis = VodData.getJSONObject(i).getString("sypnopsis");
VODJsonName.add(VODname);
VODJsonLogoPath.add(VODlogo);
VODJsonUrl.add(VODurl);
VODJsonCategory.add(VODcategory);
VODJsonsypnopsis.add(VODsypnopsis);
SETVODJsonCategory.add(VODcategory);
}
// list = new ArrayList<String>();
for (String s : VODJsonCategory) {
Log.d("VODJsonCategory",s);
}
for (String s : VODJsonName) {
Log.d("VODJsonName",s);
}
for (String s : VODJsonLogoPath) {
Log.d("VODJsonLogoPath",s);
}
for (String s : VODJsonUrl) {
Log.d("VODJsonUrl",s);
}
} catch (JSONException e) {
e.printStackTrace();
}
// Toast.makeText(getApplicationContext(),objectPremium.getBoolean("state"),Toast.LENGTH_LONG).show();
VODCat=new ArrayList<String>();
for (String s : SETVODJsonCategory) {
Log.d("SETVODJsonCategory",s);
VODCat.add(s);
}
// String arraycontent;
//arraycontent=getURL.getURL("http://scnx5.sytes.net/mitv/apps/vod/getvodlist.php");
// VODCat=arraycontent.split(",");
// String[] mobileArray = {"Android","IPhone","WindowsMobile","Blackberry","WebOS","Ubuntu","Windows7","Max OS X"};
ArrayAdapter adapter = new ArrayAdapter<String>(this,R.layout.listview,VODCat);
listView = (ListView) findViewById(R.id.vodcategorlist);
listView.setAdapter(adapter);
*/
StrictMode.ThreadPolicy policy = new StrictMode.ThreadPolicy.Builder().permitAll().build();
StrictMode.setThreadPolicy(policy);
System.setProperty("java.net.preferIPv4Addresses", "true");
System.setProperty("java.net.preferIPv6Addresses", "true");
System.setProperty("validated.ipv6", "true");
new CountDownTimer(10, 10) {
public void onTick(long millisUntilFinished) {
}
public void onFinish() {
new vod_grid_activity.LoadVODInBookList().execute("");
}
}.start();
/*
myrv = (RecyclerView) findViewById(R.id.recyclerview_id);
RecyclerViewAdapter myAdapter = new RecyclerViewAdapter(this,lstBook);
myAdapter2 = new RecyclerViewAdapter(this,MalayVOD);
myrv.setLayoutManager(new GridLayoutManager(this,4));
myrv.setAdapter(myAdapter);
*/
listView = (ListView) findViewById(R.id.vodcategorlist);
listView.setOnItemClickListener(new AdapterView.OnItemClickListener() {
@Override
public void onItemClick(AdapterView<?> adapterView, View view, int i, long l) {
new vod_grid_activity.FilterContent().execute(i);
}
});
// Toast.makeText(getApplicationContext(),"Height screen : " + widths,Toast.LENGTH_SHORT).show();
}
public static double getScreenWidth() {
return Resources.getSystem().getDisplayMetrics().widthPixels;
}
public static int getScreenHeight() {
return Resources.getSystem().getDisplayMetrics().heightPixels;
}
private class FilterContent extends AsyncTask<Integer, Integer, String>
{
ProgressDialog pdLoading = new ProgressDialog(vod_grid_activity.this);
ArrayList NewVOD;
@Override
protected void onPreExecute() {
super.onPreExecute();
//this method will be running on UI thread
pdLoading.setMessage("\tLoading...");
pdLoading.setCancelable(false);
pdLoading.show();
}
@Override
protected String doInBackground(Integer... pos) {
// String arraycontent;
//arraycontent=getURL.getURL("http://scnx5.sytes.net/mitv/apps/vod/getvodlist.php");
// VODCat=arraycontent.split(",");
// String[] mobileArray = {"Android","IPhone","WindowsMobile","Blackberry","WebOS","Ubuntu","Windows7","Max OS X"};
NewVOD=new ArrayList<>();
String selectedCategory=listView.getItemAtPosition(pos[0]).toString();
for(int j=0;j<VODJsonCategory.size();j++){
if (selectedCategory.equalsIgnoreCase(VODJsonCategory.get(j).toString())){
NewVOD.add(new VODBook(VODJsonId.get(j).toString(),VODJsonName.get(j).toString(),VODJsonCategory.get(j).toString(),VODJsonUrl.get(j).toString(),VODJsonLogoPath.get(j).toString(),VODJsonsypnopsis.get(j).toString(),VODJsonbackdrop.get(j).toString()));
}
}
return "";
}
@Override
protected void onPostExecute(String result) {
//this method will be running on UI thread
pdLoading.dismiss();
myAdapter = new RecyclerViewAdapter(vod_grid_activity.this,NewVOD,tk,server);
myrv.setAdapter(myAdapter);
}
}
private class LoadVODInBookList extends AsyncTask<String,String,String>
{
ProgressDialog pdLoading = new ProgressDialog(vod_grid_activity.this);
@Override
protected void onPreExecute() {
super.onPreExecute();
//this method will be running on UI thread
pdLoading.setMessage("\tLoading...");
pdLoading.setCancelable(false);
pdLoading.show();
}
@Override
protected String doInBackground(String... params) {
String id,name,logoPath,url,category,sypnopsis,firstCat,backdrop;
getURL wget=new getURL();
String json= null;
try {
json = wget.getURL(server + "apps/vod/getvodlist.php?tk="+ tk);
// Log.d("vod",json);
} catch (IOException e) {
e.printStackTrace();
}
try {
JSONObject objectPremium = new JSONObject(String.valueOf(json));
JSONArray VodData = (JSONArray) objectPremium.getJSONArray("data");
SETVODJsonCategory = new LinkedHashSet<String>();
VODJsonId = new ArrayList<String>();
VODJsonName = new ArrayList<String>();
VODJsonLogoPath = new ArrayList<String>();
VODJsonUrl = new ArrayList<String>();
VODJsonCategory = new ArrayList<String>();
VODJsonsypnopsis = new ArrayList<String>();
VODJsonbackdrop = new ArrayList<String>();
//Toast.makeText(getApplicationContext(),VODname,Toast.LENGTH_LONG).show();
String VODid,VODname,VODlogo,VODurl,VODcategory,VODsypnopsis,VODbackdrop;
for (int i = 0; i < VodData.length(); i++) {
VODid=VodData.getJSONObject(i).getString("id");
VODname = VodData.getJSONObject(i).getString("name");
VODlogo = VodData.getJSONObject(i).getString("logoPath");
VODurl = VodData.getJSONObject(i).getString("playUrl");
VODcategory = VodData.getJSONObject(i).getString("genre");
VODsypnopsis = VodData.getJSONObject(i).getString("sypnopsis");
VODbackdrop= VodData.getJSONObject(i).getString("backdropPath");
// VODbackdrop="picture.jpg";
VODJsonId.add(VODid);
VODJsonName.add(VODname);
VODJsonLogoPath.add(VODlogo);
VODJsonUrl.add(VODurl);
VODJsonCategory.add(VODcategory);
VODJsonsypnopsis.add(VODsypnopsis);
VODJsonbackdrop.add(VODbackdrop);
SETVODJsonCategory.add(VODcategory);
}
} catch (JSONException e) {
e.printStackTrace();
}
// Toast.makeText(getApplicationContext(),objectPremium.getBoolean("state"),Toast.LENGTH_LONG).show();
VODCat=new ArrayList<String>();
for (String s : SETVODJsonCategory) {
// Log.d("SETVODJsonCategory",s);
VODCat.add(s);
}
firstCat="";
for(int i=0;i<VODCat.size();i++){
firstCat=VODCat.get(i).toString();
break;
}
VOD=new ArrayList<>();
for (int i=0;i<VODJsonName.size();i++){
id=VODJsonId.get(i).toString();
name=VODJsonName.get(i).toString();
category=VODJsonCategory.get(i).toString();
logoPath=VODJsonLogoPath.get(i).toString();
url=VODJsonUrl.get(i).toString();
sypnopsis=VODJsonsypnopsis.get(i).toString();
backdrop=VODJsonbackdrop.get(i).toString();
// try {
// bitmap = BitmapFactory.decodeStream((InputStream)new URL(logoPath).getContent());
//} catch (IOException e) {
// e.printStackTrace();
// }
if(firstCat.equalsIgnoreCase(category)){
VOD.add(new VODBook(id,name, category, url, logoPath, sypnopsis,backdrop));
}
}
myrv = (RecyclerView) findViewById(R.id.recyclerview_id);
myAdapter = new RecyclerViewAdapter(vod_grid_activity.this,VOD,tk,server);
//myAdapter2 = new RecyclerViewAdapter(getApplicationContext(),MalayVOD);
return "";
}
@Override
protected void onPostExecute(String result) {
//this method will be running on UI thread
pdLoading.dismiss();
ArrayAdapter adapter = new ArrayAdapter<String>(getApplicationContext(),R.layout.listview_vod,VODCat);
listView.setAdapter(adapter);
GridLayoutManager GridVOD;
GridVOD=new GridLayoutManager(getApplicationContext(),4);
myrv.setLayoutManager(GridVOD);
// myrv.addItemDecoration(new GridSpacingItemDecoration(4,0,false));
myrv.setAdapter(myAdapter);
SearchView SearchLiveTv=(SearchView)findViewById(R.id.SearchChannel);
LinearLayout SearchLiveTvLayout=(LinearLayout) findViewById(R.id.layoutSearch);
SearchLiveTvLayout.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
SearchLiveTv.setIconified(true);
SearchLiveTv.setIconified(false);
}
});
SearchLiveTv.setIconified(true);
SearchLiveTv.setFocusable(true);
SearchLiveTv.setClickable(true);
//SearchLiveTv.clearFocus();
//listView.requestFocus();
SearchLiveTv.setOnQueryTextListener(new SearchView.OnQueryTextListener() {
ArrayList NewVOD=new ArrayList<>();
@Override
public boolean onQueryTextSubmit(String s) {
Log.d("QueryTextSubmit",s);
return false;
}
@Override
public boolean onQueryTextChange(String s) {
Log.d("QueryTextChanged", s);
String inputUser = s.toLowerCase();
ArrayList FilterChannel = new ArrayList<>();
int j = 0;
for (String channel : VODJsonName) {
if (channel.toLowerCase().contains(inputUser)) {
FilterChannel.add(new VODBook(VODJsonId.get(j).toString(),VODJsonName.get(j).toString(), VODJsonCategory.get(j).toString(), VODJsonUrl.get(j).toString(), VODJsonLogoPath.get(j).toString(), VODJsonsypnopsis.get(j).toString(),VODJsonbackdrop.get(j).toString()));
}
j++;
}
myAdapter = new RecyclerViewAdapter(vod_grid_activity.this,FilterChannel,tk,server);
myrv.setAdapter(myAdapter);
return true;
}
});
}
}
public class GridSpacingItemDecoration extends RecyclerView.ItemDecoration {
private int mSpanCount;
private float mItemSize;
public GridSpacingItemDecoration(int spanCount, int itemSize) {
this.mSpanCount = spanCount;
mItemSize = itemSize;
}
@Override
public void getItemOffsets(final Rect outRect, final View view, RecyclerView parent,
RecyclerView.State state) {
final int position = parent.getChildLayoutPosition(view);
final int column = position % mSpanCount;
final int parentWidth = parent.getWidth();
int spacing = (int) (parentWidth - (mItemSize * mSpanCount)) / (mSpanCount + 1);
outRect.left = spacing - column * spacing / mSpanCount;
outRect.right = (column + 1) * spacing / mSpanCount;
if (position < mSpanCount) {
outRect.top = spacing;
}
outRect.bottom = spacing;
}
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/VODGrid/VODBook.java
package mmanager.scnx5.com.mitvmanager.VODGrid;
public class VODBook {
private String Title;
private String Category ;
private String Url ;
private String Sypnopsis;
private String Thumbnail ;
private String Backdrop ;
private String Id;
public VODBook() {
}
public VODBook(String id,String title, String category, String url, String thumbnail, String sypnopsis,String backdrop) {
Title = title;
Category = category;
Url = url;
Thumbnail = thumbnail;
Sypnopsis = sypnopsis;
Backdrop = backdrop;
Id=id;
}
public String getTitle() {
return Title;
}
public String getCategory() {
return Category;
}
public String getUrl() {
return Url;
}
public String getSysnopsis() {
return Sypnopsis;
}
public String getThumbnail() {
return Thumbnail;
}
public String getBackdrop() {
return Backdrop;
}
public String getId() { return Id; }
public void setTitle(String title) {
Title = title;
}
public void setCategory(String category) {
Category = category;
}
public void setUrl(String url) {
Url = url;
}
public void setSypnopsis(String sypnopsis) {
Sypnopsis = sypnopsis;
}
public void setThumbnail(String thumbnail) {
Thumbnail = thumbnail;
}
public void setId(String id) { Id=id;}
public void setBackdrop(String backdrop) {
Backdrop = backdrop;
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/FloatingMiTV.java
package mmanager.scnx5.com.mitvmanager;
import android.app.ActivityManager;
import android.app.IntentService;
import android.app.usage.UsageStats;
import android.app.usage.UsageStatsManager;
import android.content.BroadcastReceiver;
import android.content.Context;
import android.content.Intent;
import android.os.CountDownTimer;
import android.os.Environment;
import android.os.Handler;
import android.os.IBinder;
import android.os.StrictMode;
import android.support.annotation.Nullable;
import android.util.Log;
import android.view.View;
import android.widget.Toast;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.Arrays;
import java.util.List;
import java.util.SortedMap;
import java.util.Timer;
import java.util.TreeMap;
import mmanager.scnx5.com.mitvmanager.Exoplayer.exoplayer_layar;
public class FloatingMiTV extends IntentService {
public Handler handler=new Handler();
private boolean CheckPogoRunning,checkMiTVRunning;
public String[] DeviceInfo;
public Runnable checkPoGo=null;
private String mac_address,username,model,channelid,server;
public FloatingMiTV() {
super("FloatingMiTV");
}
private getURL wget=new getURL();
@Nullable
@Override
public IBinder onBind(Intent intent) {
return null;
}
@Override
protected void onHandleIntent(Intent intent) {
mac_address = intent.getStringExtra("mac_address");
username = intent.getStringExtra("username");
model = intent.getStringExtra("model");
channelid = intent.getStringExtra("channelid");
server = intent.getStringExtra("server");
}
public void onCreate() {
super.onCreate();
// updateOnlinestatus();
new CountDownTimer(2000, 2000) {
public void onTick(long millisUntilFinished) {
}
public void onFinish() {
handler.postDelayed(checkExoPlayerActivity,1);
}
}.start();
}
public void onDestroy() {
super.onDestroy();
}
private Runnable checkExoPlayerActivity = new Runnable() {
@Override
public void run() {
// do what you need to do
// and here comes the "trick"
if (isActivityRunning("exoplayer_layar")) {
// Log.d("CheckService","Application is runnning");
} else {
//Log.d("CheckService","Application is stop");
String logoutResponse = null;
try {
logoutResponse = wget.getURL(server + "apps/exoplayer/update_offlinev3.php?mac_address=" + mac_address + "&username=" + username + "&channel=" + channelid);
} catch (IOException e) {
e.printStackTrace();
}
if (logoutResponse.equalsIgnoreCase("out")){
handler.removeCallbacks(checkExoPlayerActivity);
stopSelf();
return;
}
}
handler.postDelayed(this, 1000);
}
};
protected Boolean isActivityRunning(String activityClass) {
ActivityManager activityManager = (ActivityManager) getBaseContext().getSystemService(Context.ACTIVITY_SERVICE);
List<ActivityManager.RunningTaskInfo> tasks = activityManager.getRunningTasks(1);
for (ActivityManager.RunningTaskInfo task : tasks) {
if (tasks.get(0).topActivity.getClassName().contains(activityClass)) {
return true;
//Log.d("Activity",tasks.get(0).topActivity.getClassName());
}
}
return false;
}
}
/*
private void checkPokemonGoRunning (){
CheckPogoRunning=true;
handler = new Handler();
checkPoGo = new Runnable() {
@Override
public void run() {
handler.postDelayed(this,5000);
String CurrentApp="";
if (android.os.Build.VERSION.SDK_INT >= android.os.Build.VERSION_CODES.LOLLIPOP) {
// intentionally using string value as Context.USAGE_STATS_SERVICE was
// strangely only added in API 22 (LOLLIPOP_MR1)
@SuppressWarnings("WrongConstant")
UsageStatsManager usm = (UsageStatsManager) getSystemService("usagestats");
long time = System.currentTimeMillis();
List<UsageStats> appList = usm.queryUsageStats(UsageStatsManager.INTERVAL_DAILY,
time - 1000 * 1000, time);
if (appList != null && appList.size() > 0) {
SortedMap<Long, UsageStats> mySortedMap = new TreeMap<Long, UsageStats>();
for (UsageStats usageStats : appList) {
mySortedMap.put(usageStats.getLastTimeUsed(),
usageStats);
}
if (mySortedMap != null && !mySortedMap.isEmpty()) {
CurrentApp = mySortedMap.get(
mySortedMap.lastKey()).getPackageName();
}
}
} else {
ActivityManager am = (ActivityManager) getSystemService(Context.ACTIVITY_SERVICE);
List<ActivityManager.RunningAppProcessInfo> tasks = am
.getRunningAppProcesses();
CurrentApp = tasks.get(0).processName;
}
if(CurrentApp.isEmpty()) {
// Toast.makeText(getApplicationContext(),"Unable to check mitv is running!",Toast.LENGTH_LONG).show();
}
if (CurrentApp.equals("com.gsoft.mitv")) {
//}
File file = new File(Environment.getExternalStorageDirectory(), "mitv.txt");
file.delete();
// Toast.makeText(getApplicationContext(),"File secured",Toast.LENGTH_LONG).show();
//
// String Updated;
// Updated = getURL("http://scnx5.sytes.net/mitv/apps/updateonlinestatus.php?deviceid=" + DeviceInfo[0] + "&user=" + DeviceInfo[l3_new_logo] + "&opt=in");
// Toast.makeText(getApplicationContext(),Updated + ":" + CurrentApp, Toast.LENGTH_SHORT).show();
}else{
File file = new File(Environment.getExternalStorageDirectory(), "mitv.txt");
file.delete();
CheckPogoRunning=false;
// Toast.makeText(getApplicationContext(),"Unable to check mitv is running!",Toast.LENGTH_LONG).show();
// String Updated;
// Updated = getURL("http://scnx5.sytes.net/mitv/apps/updateonlinestatus.php?deviceid=" + DeviceInfo[0] + "&user=" + DeviceInfo[l3_new_logo] + "&opt=out");
// Toast.makeText(getApplicationContext(),"logout:" + Updated, Toast.LENGTH_SHORT).show();
// CheckPogoRunning = false;
//Toast.makeText(getApplicationContext(),"Curr App :" + CurrentApp + " delay : " + delay + " SnipeOne " + PokeSnipeONE + " UpdateMock " + TimerUpdateLocRun, Toast.LENGTH_SHORT).show();
}
if (!CheckPogoRunning){
handler.removeCallbacks(checkPoGo);
}
}
};
handler.postDelayed(checkPoGo,5000);
}
*/
<file_sep>/app/src/main/java/mmanager/scnx5/com/abcyxoorp.java
package mmanager.scnx5.com;
public class abcyxoorp {
public static String xyoprup (){
return "https://layar3.com/";
}
}
<file_sep>/app/build.gradle
buildscript {
repositories {
maven { url 'https://maven.fabric.io/public' }
}
}
apply plugin: 'com.android.application'
apply plugin: 'com.bugsnag.android.gradle'
android {
compileSdkVersion 27
defaultConfig {
applicationId "mmanager.scnx5.com.mitvmanager"
minSdkVersion 19
targetSdkVersion 27
versionCode 14
versionName '3.0.1'
testInstrumentationRunner "android.support.test.runner.AndroidJUnitRunner"
}
buildTypes {
release {
minifyEnabled true
proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'
}
}
flavorDimensions "version"
productFlavors {
debugApps {
dimension "version"
applicationIdSuffix ".debugApps"
versionNameSuffix "-debugApps"
minSdkVersion 19
applicationId 'mmanager.scnx5.com.mitvmanager'
targetSdkVersion 27
versionCode 29
versionName '4.0.5'
ndk {
abiFilters "armeabi-v7a", "x86"
}
}
prod {
dimension "version"
applicationIdSuffix ".prod"
versionNameSuffix "-prod"
minSdkVersion 19
applicationId 'mmanager.scnx5.com.mitvmanager'
targetSdkVersion 27
versionCode 29
versionName '4.0.5'
ndk {
abiFilter "armeabi-v7a"
}
}
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
}
dataBinding {
enabled = true;
}
buildToolsVersion '28.0.3'
}
dependencies {
implementation fileTree(include: ['*.jar'], dir: 'libs')
implementation 'com.android.support:appcompat-v7:27.1.1'
implementation 'com.android.support.constraint:constraint-layout:1.1.3'
implementation 'com.android.support:cardview-v7:27.1.1'
implementation 'pub.devrel:easypermissions:0.2.0'
implementation 'com.android.support:design:27.1.1'
implementation 'com.android.support:leanback-v17:27.1.1'
implementation 'com.android.support:recyclerview-v7:27.1.1'
implementation 'com.squareup.picasso:picasso:2.5.2'
implementation 'com.github.javiersantos:AppUpdater:2.7'
implementation 'com.google.android.exoplayer:exoplayer:2.9.2'
implementation 'com.google.android.exoplayer:extension-okhttp:2.9.2'
implementation 'com.github.Commit451:YouTubeExtractor:2.1.0'
implementation 'com.github.bumptech.glide:glide:4.8.0'
implementation 'com.squareup.okhttp3:okhttp:3.12.0'
implementation 'com.github.javiersantos:MaterialStyledDialogs:2.1'
implementation 'com.andkulikov:transitionseverywhere:1.8.1'
implementation 'com.tuyenmonkey:mkloader:1.4.0'
implementation 'com.github.Piashsarker:AndroidAppUpdateLibrary:1.0.3'
implementation 'com.github.Badranh:Android-Mac-Address-Util:0.1.0'
implementation 'com.balsikandar.android:crashreporter:1.0.9'
implementation 'com.bugsnag:bugsnag-android:4.+'
implementation 'com.android.volley:volley:1.1.1'
implementation 'com.github.alkathirikhalid:connection:v1.02'
implementation 'com.github.dmytrodanylyk.shadow-layout:library:1.0.3'
implementation 'com.github.siyamed:android-shape-imageview:0.9.+@aar'
implementation 'com.github.smarteist:autoimageslider:1.1.1'
implementation 'com.github.bumptech.glide:glide:4.8.0'
implementation 'de.hdodenhof:circleimageview:2.2.0'
implementation 'com.karumi:dexter:5.0.0'
implementation 'dnsjava:dnsjava:2.1.8'
annotationProcessor 'com.github.bumptech.glide:compiler:4.8.0'
androidTestImplementation 'com.android.support.test:runner:1.0.2'
androidTestImplementation 'com.android.support.test.espresso:espresso-core:3.0.2'
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/encrypt/encrypt.java
package mmanager.scnx5.com.encrypt;
import android.util.Base64;
import java.io.UnsupportedEncodingException;
public class encrypt {
public String encryptStr(String str){
String encryptRtS="";
byte[] data = new byte[0];
try {
data = str.getBytes("UTF-8");
encryptRtS = Base64.encodeToString(data, Base64.DEFAULT);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
dummyencrypt dmencr=new dummyencrypt();
StringBuffer encryptRtSBf=dmencr.dummyencr(encryptRtS);
encryptRtS=encryptRtSBf.toString();
return encryptRtS;
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/VODGrid/RecyclerViewAdapter.java
package mmanager.scnx5.com.mitvmanager.VODGrid;
import android.content.Context;
import android.content.Intent;
import android.content.res.Resources;
import android.graphics.Bitmap;
import android.graphics.BitmapFactory;
import android.support.v7.widget.CardView;
import android.support.v7.widget.RecyclerView;
import android.util.Log;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.view.animation.Animation;
import android.view.animation.AnimationUtils;
import android.widget.FrameLayout;
import android.widget.ImageView;
import android.widget.LinearLayout;
import android.widget.TextView;
import android.widget.Toast;
import com.bumptech.glide.Glide;
import com.squareup.picasso.Picasso;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.List;
import mmanager.scnx5.com.mitvmanager.R;
import mmanager.scnx5.com.mitvmanager.setViewSizeByReso;
/**
* Created by Aws on 28/01/2018.
*/
public class RecyclerViewAdapter extends RecyclerView.Adapter<RecyclerViewAdapter.MyViewHolder> {
private Context mContext ;
private List<VODBook> mData ;
private String token;
private String server;
public RecyclerViewAdapter(Context mContext, List<VODBook> mData,String token,String server) {
this.mContext = mContext;
this.mData = mData;
this.token=token;
this.server=server;
}
@Override
public MyViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
View view ;
LayoutInflater mInflater = LayoutInflater.from(mContext);
double width= Resources.getSystem().getDisplayMetrics().widthPixels;
// if (width < 1920){
// view = mInflater.inflate(R.layout.cardveiw_item_book_720p_vod, parent, false);
//
// }else {
view = mInflater.inflate(R.layout.cardveiw_item_book_vod, parent, false);
// }
return new MyViewHolder(view);
}
@Override
public void onBindViewHolder(MyViewHolder holder, final int position) {
// holder.tv_book_title.setText(mData.get(position).getTitle());
//Integer picURL=mData.get(position).getThumbnail();
// Bitmap bitmap = BitmapFactory.decodeStream((InputStream)new URL(picURL).getContent());
String picURL=mData.get(position).getThumbnail();
holder.movie_title.setText(mData.get(position).getTitle());
// holder.img_book_thumbnail.setImage(picURL);
Glide
.with(mContext)
.load(picURL)
.into(holder.img_book_thumbnail);
// Picasso.with(mContext).load(picURL).into(holder.img_book_thumbnail);
holder.cardViewOuter.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Intent intent = new Intent(mContext,Book_Activity.class);
// passing data to the book activity
intent.putExtra("movieId",mData.get(position).getId());
intent.putExtra("Title",mData.get(position).getTitle());
intent.putExtra("Url",mData.get(position).getUrl());
intent.putExtra("Thumbnail",mData.get(position).getThumbnail());
intent.putExtra("Sypnopsis",mData.get(position).getSysnopsis());
intent.putExtra("Category",mData.get(position).getCategory());
intent.putExtra("backdrop",mData.get(position).getBackdrop());
intent.putExtra("liveTV","vod");
intent.putExtra("tk",token);
intent.putExtra("server",server);
// Toast.makeText(mContext,"test",Toast.LENGTH_LONG).show();
// start the activity
mContext.startActivity(intent);
}
});
}
@Override
public int getItemCount() {
return mData.size();
}
public static class MyViewHolder extends RecyclerView.ViewHolder {
//TextView tv_book_title;
ImageView img_book_thumbnail;
CardView cardViewOuter ;
FrameLayout cardView ;
TextView movie_title;
setViewSizeByReso setViewSize=new setViewSizeByReso();
public MyViewHolder(View itemView) {
super(itemView);
// tv_book_title = (TextView) itemView.findViewById(R.id.book_title_id) ;
img_book_thumbnail = (ImageView) itemView.findViewById(R.id.book_img_id);
// cardView = (CardView) itemView.findViewById(R.id.cardview_id);
cardView = (FrameLayout) itemView.findViewById(R.id.cardview_id);
movie_title =(TextView)itemView.findViewById(R.id.movie_title);
cardViewOuter = (CardView) itemView.findViewById(R.id.cardidgrid);
setViewSize.setSize(cardViewOuter,0.18,0.4);
// setViewSize.setSize(img_book_thumbnail,-1,0.25);
itemView.setOnFocusChangeListener(new View.OnFocusChangeListener() {
@Override
public void onFocusChange(View view, boolean b) {
if(b){
Animation anim = AnimationUtils.loadAnimation(itemView.getContext(),R.anim.scale_in_tv);
itemView.startAnimation(anim);
anim.setFillAfter(true);
// Log.d("Onfocus","focused");
}else {
Animation anim = AnimationUtils.loadAnimation(itemView.getContext(),R.anim.scale_out_tv);
itemView.startAnimation(anim);
anim.setFillAfter(true);
}
}
});
}
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/login/login_activity.java
package mmanager.scnx5.com.login;
import android.Manifest;
import android.app.ProgressDialog;
import android.content.Context;
import android.content.Intent;
import android.content.SharedPreferences;
import android.net.Uri;
import android.os.AsyncTask;
import android.os.Build;
import android.os.CountDownTimer;
import android.provider.Settings;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.util.Log;
import android.view.View;
import android.view.Window;
import android.view.WindowManager;
import android.widget.Button;
import android.widget.EditText;
import android.widget.Toast;
import com.alkathirikhalid.util.ConnectionAppCompactActivity;
import com.karumi.dexter.Dexter;
import com.karumi.dexter.PermissionToken;
import com.karumi.dexter.listener.PermissionDeniedResponse;
import com.karumi.dexter.listener.PermissionGrantedResponse;
import com.karumi.dexter.listener.PermissionRequest;
import com.karumi.dexter.listener.single.PermissionListener;
import org.json.JSONException;
import org.json.JSONObject;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import mmanager.scnx5.com.CONST.CONST;
import mmanager.scnx5.com.abcauthabc;
import mmanager.scnx5.com.abcyxoorp;
import mmanager.scnx5.com.authorization.newui_logout_main;
import mmanager.scnx5.com.decrypt.decrypt;
import mmanager.scnx5.com.encrypt.encrypt;
import mmanager.scnx5.com.mitvmanager.DeviceUuidFactory;
import mmanager.scnx5.com.mitvmanager.Exoplayer.exoplayer_layar;
import mmanager.scnx5.com.mitvmanager.R;
import mmanager.scnx5.com.mitvmanager.getURL;
import mmanager.scnx5.com.mitvmanager.log_;
import mmanager.scnx5.com.mitvmanager.old_getURL;
public class login_activity extends ConnectionAppCompactActivity {
public static final int CONNECTION_TIMEOUT=10000;
public static final int READ_TIMEOUT=15000;
private EditText etEmail;
private EditText etPassword;
public String email,password;
public String userpass;
public CONST c=new CONST();
private abcyxoorp a=new abcyxoorp();
private abcauthabc b=new abcauthabc();
private Boolean fileExisted=false;
private String[] userlogin;
private getURL wget=new getURL();
private log_ dLog=new log_();
private Boolean debug=true; //print debug log
private Boolean logout;
private String server;
private String tk="";
private String tkn;
private old_getURL old_wget=new old_getURL();
SharedPreferences pref;
SharedPreferences.Editor editor;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// java.lang.System.setProperty("java.net.preferIPv4Stack", "true");
// java.lang.System.setProperty("java.net.preferIPv6Addresses", "false");
requestWindowFeature(Window.FEATURE_NO_TITLE); // for hiding title
getWindow().setFlags(WindowManager.LayoutParams.FLAG_FULLSCREEN, WindowManager.LayoutParams.FLAG_FULLSCREEN);
setContentView(R.layout.activity_main2);
logout=false;
Bundle extras = getIntent().getExtras();
if(extras !=null)
{
logout = extras.getBoolean("logout");
// Toast.makeText(getApplicationContext(),uniqueID,Toast.LENGTH_LONG).show();
}
etEmail=(EditText)findViewById(R.id.username);
etPassword=(EditText)findViewById(R.id.password);
try {
server=wget.getURL("https://server1.layar3.com/serverlist.php?id=1");
} catch (IOException e) {
e.printStackTrace();
}
pref = getApplicationContext().getSharedPreferences("LoginInfo", MODE_PRIVATE);
editor = pref.edit();
email = pref.getString("username",null);
password= pref.getString("password",null);
// dLog.log_d(debug,"server","=" + server);
if(email != null){
etEmail.setText(email);
etPassword.setText(password);
userpass=email + ":" + password;
if(!logout){
new CountDownTimer(10, 10) {
public void onTick(long millisUntilFinished) {
}
public void onFinish() {
// encrypt e=new encrypt();
//// String androidId = Settings.Secure.getString(getContentResolver(), Settings.Secure.ANDROID_ID);
//// String access=userpass+","+androidId+email;
//// String encraccess= e.encryptStr(access);
Dexter.withActivity(login_activity.this)
.withPermission(Manifest.permission.WRITE_EXTERNAL_STORAGE)
.withListener(new PermissionListener() {
@Override public void onPermissionGranted(PermissionGrantedResponse response) {
new AsyncLogin().execute(server + b.rabcauthabc() + ".php", userpass);
}
@Override public void onPermissionDenied(PermissionDeniedResponse response) {/* ... */}
@Override public void onPermissionRationaleShouldBeShown(PermissionRequest permission, PermissionToken token) {/* ... */}
}).check();
// new AsyncLogin().execute(a.xyoprup() + b.rabcauthabc() + ".php" ,userpass);
}
}.start();
}
}
final Button loginB=(Button) findViewById(R.id.loginBtn);
loginB.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
email = etEmail.getText().toString();
String password = etPassword.getText().toString();
userpass = email + ":" + password;
// Initialize AsyncLogin() class with email and password
if (email.isEmpty() || password.isEmpty()){
Toast.makeText(getApplicationContext(),"Enter Username and Password.",Toast.LENGTH_SHORT).show();
}else {
//
// encrypt e=new encrypt();
// String androidId = Settings.Secure.getString(getContentResolver(), Settings.Secure.ANDROID_ID);
// String access=email+","+password+","+androidId+email;
// String encraccess= e.encryptStr(access);
// dLog.log_d(debug,"server",userpass);
Dexter.withActivity(login_activity.this)
.withPermission(Manifest.permission.WRITE_EXTERNAL_STORAGE)
.withListener(new PermissionListener() {
@Override public void onPermissionGranted(PermissionGrantedResponse response) {
new AsyncLogin().execute(server + b.rabcauthabc() + ".php", userpass);
}
@Override public void onPermissionDenied(PermissionDeniedResponse response) {
Toast.makeText(getApplicationContext(),"Please allow access to storage location to proceed with log in!",Toast.LENGTH_LONG);
}
@Override public void onPermissionRationaleShouldBeShown(PermissionRequest permission, PermissionToken token) {/* ... */}
}).check();
}
}
});
}
@Override
public void connectedOrConnecting() {
}
@Override
public void connected() {
}
@Override
public void typeWifi() {
}
@Override
public void typeMobile() {
}
@Override
public void connectedConnectionFast() {
}
@Override
public void connectedConnectionSlow() {
}
@Override
public void noNetwork() {
Toast.makeText(getApplicationContext(),"Your internet connection loss!",Toast.LENGTH_SHORT).show();
}
private class AsyncLogin extends AsyncTask<String, String, String>
{
ProgressDialog pdLoading = new ProgressDialog(login_activity.this);
HttpURLConnection conn;
URL url = null;
String encraccess;
private String pr="";
@Override
protected void onPreExecute() {
super.onPreExecute();
//this method will be running on UI thread
pdLoading.setMessage("\tLoading...");
pdLoading.setCancelable(false);
// pdLoading.show();
}
@Override
protected String doInBackground(String... params) {
String userpassAsync=params[1];
// String[] userinfo=userpassAsync.split(":");
try {
// Toast.makeText(getApplicationContext(),userinfo[1] + " " + userinfo[2],Toast.LENGTH_SHORT).show();
//Log.d("userinfo",userinfo[0] + " " + userinfo[1]);
// Enter URL address where your php file resides
String passUrl=params[0];
url = new URL(passUrl);
// Log.d("myTag", "Checking with server");
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return "exception";
}
try {
// Setup HttpURLConnection class to send and receive data from php and mysql
conn = (HttpURLConnection)url.openConnection();
conn.setReadTimeout(READ_TIMEOUT);
conn.setConnectTimeout(CONNECTION_TIMEOUT);
conn.setRequestMethod("POST");
// setDoInput and setDoOutput method depict handling of both send and receive
conn.setDoInput(true);
conn.setDoOutput(true);
encrypt e=new encrypt();
// getCurrentTime getTime=new getCurrentTime();
// Log.d("CurrentTime",getTime.getCurrentTime());
// makeJSON mkJSON = new makeJSON();
DeviceUuidFactory DeviceUUIDNo = new DeviceUuidFactory(login_activity.this.getApplicationContext());
String uniqueID=DeviceUUIDNo.getDeviceUuid().toString();
// String androidId = Settings.Secure.getString(getContentResolver(), Settings.Secure.ANDROID_ID);
// String access=userinfo[0]+":"+userinfo[1];
//String JSONaccess=mkJSON.createLoginJSON(access);
// Log.d("access",access);
String encraccess= e.encryptStr(userpassAsync);
String encraccess2=e.encryptStr(uniqueID);
//encraccess=encraccess + "." + userinfo[2];
String encraccess3 =encraccess + "." + encraccess2;
encraccess3=encraccess3.trim();
// Log.d("access",encraccess3);
// Append parameters to URL
Uri.Builder builder = new Uri.Builder()
.appendQueryParameter("access",encraccess3);
String query = builder.build().getEncodedQuery();
// Open connection for sending data
OutputStream os = conn.getOutputStream();
BufferedWriter writer = new BufferedWriter(
new OutputStreamWriter(os, "UTF-8"));
writer.write(query);
writer.flush();
writer.close();
os.close();
conn.connect();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
return "exception";
}
try {
int response_code = conn.getResponseCode();
// Check if successful connection made
if (response_code == HttpURLConnection.HTTP_OK) {
// Read data sent from server
InputStream input = conn.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(input));
StringBuilder result = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
result.append(line);
}
// Log.d("myTag", "Get response:" + result.toString());
// Pass data to onPostExecute method
return(result.toString());
}else{
return("unsuccessful");
}
} catch (IOException e) {
e.printStackTrace();
return "exception";
} finally {
conn.disconnect();
}
}
@Override
protected void onPostExecute(String result) {
//this method will be running on UI thread
//pdLoading.dismiss();
//Log.d("result",result);
JSONObject objectPremium = null;
String tkn="";
try {
objectPremium = new JSONObject(String.valueOf(result));
tkn = objectPremium.getString("token");
decrypt dc=new decrypt();
pr=tkn;
// Log.d("Result",tkn);
result=dc.decryptStr(tkn);
// String[] next=result.split(":");
// Log.d("Resultdc",result);
} catch (JSONException e) {
e.printStackTrace();
}
//create json to read data
objectPremium = null;
String login="",username="",passwrd="",nextA="",deviceid="";
try {
objectPremium = new JSONObject(String.valueOf(result));
// String loginData = objectPremium.getString("data");
login = objectPremium.getString("login");
if(login.equalsIgnoreCase("true")){
nextA = objectPremium.getString("activity");
}
username = objectPremium.getString("username");
passwrd = objectPremium.getString("password");
} catch (JSONException e) {
e.printStackTrace();
}
userpass=username + "," + passwrd;
// Log.d("deviceId",deviceid);
if(login.equalsIgnoreCase(c.getEn()))
{
/* Here launching another activity when login successful. If you persist login state
use sharedPreferences of Android. and logout button to clear sharedPreferences.
*/
editor.putString("username", username);
editor.putString("password", <PASSWORD>);
editor.apply();
/* String filename ="userinfo.txt";
FileOutputStream outputStream;
try {
outputStream = openFileOutput(filename, Context.MODE_PRIVATE);
outputStream.write(userpass.getBytes());
outputStream.close();
} catch (Exception e) {
e.printStackTrace();
}*/
String nextActivity=nextA;
// Intent i = new Intent(getBaseContext(), nextactivity.class);
// Intent i =new Intent();
Intent i = new Intent(getApplicationContext(),newui_logout_main.class);
// i.setClassName(login_activity.this, nextActivity);
i.putExtra("PersonID", email);
i.putExtra("token", pr);
i.putExtra("server", server);
// Log.d("pr",pr);
startActivity(i);
finish();
}else if (login.equalsIgnoreCase(c.getDeEn())){
// If username and password does not match display a error message
Toast.makeText(getApplicationContext(),"Invalid credential",Toast.LENGTH_SHORT).show();
}
else if (login.equalsIgnoreCase(c.getDeEnMax())){
// If username and password does not match display a error message
Toast.makeText(getApplicationContext(),"Your account is not active!",Toast.LENGTH_SHORT).show();
} else {
Toast.makeText(getApplicationContext(),"Something went wrong.\nCheck your internet connection via this device." + login,Toast.LENGTH_SHORT).show();
}
}
}
public boolean checkFileExist(String filepath){
File file = new File(getApplicationContext().getFilesDir(),filepath);
if (file.exists()){
return true;
}
else{
return false;
}
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/abcsesscxz.java
package mmanager.scnx5.com;
public class abcsesscxz {
public String rabcsesscxz(){
return "apps/getsession";
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/encrypt/dummyencrypt.java
package mmanager.scnx5.com.encrypt;
public class dummyencrypt {
protected StringBuffer dummyencr(String str){
StringBuffer buffer = new StringBuffer(str);
buffer.reverse();
return buffer;
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/Exoplayer/CustomDialogClass.java
package mmanager.scnx5.com.mitvmanager.Exoplayer;
import android.app.Activity;
import android.app.Dialog;
import android.graphics.Color;
import android.graphics.drawable.ColorDrawable;
import android.os.Bundle;
import android.os.CountDownTimer;
import android.view.View;
import android.view.Window;
import android.widget.Button;
import mmanager.scnx5.com.mitvmanager.R;
public class CustomDialogClass extends Dialog implements
android.view.View.OnClickListener {
public Activity c;
public Dialog d;
public Button yes, no;
public CountDownTimer cdt;
public CustomDialogClass(Activity a) {
super(a);
// TODO Auto-generated constructor stub
this.c = a;
}
@Override
protected void onCreate(Bundle savedInstanceState) {
//setTheme(R.style.Theme_Transparent);
super.onCreate(savedInstanceState);
requestWindowFeature(Window.FEATURE_NO_TITLE);
setContentView(R.layout.dialog_check_playing);
getWindow().setBackgroundDrawable(new ColorDrawable(Color.TRANSPARENT));
yes = (Button) findViewById(R.id.yes_button);
no = (Button) findViewById(R.id.no_button);
yes.setOnClickListener(this);
no.setOnClickListener(this);
yes.requestFocus();
no.setText("BACK (30s)");
cdt=new CountDownTimer(60000,1000) {
String displayText="";
@Override
public void onTick(long l) {
displayText="BACK ("+String.valueOf(l/1000)+"s)";
no.setText(displayText);
}
@Override
public void onFinish() {
((exoplayer_layar)c).properlyLogout();
}
}.start();
}
@Override
public void onClick(View v) {
switch (v.getId()) {
case R.id.yes_button:
dismiss();
((exoplayer_layar)c).RunExoPlayerTimerBack();
cdt.cancel();
break;
case R.id.no_button:
((exoplayer_layar)c).properlyLogout();
// c.finish();
break;
default:
break;
}
cdt.cancel();
dismiss();
}
}<file_sep>/app/src/main/java/mmanager/scnx5/com/abcvodzxc.java
package mmanager.scnx5.com;
public class abcvodzxc {
public String rabcvodzxc(){
return "apps/vod/getvodlist";
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/authorization/AllBook.java
package mmanager.scnx5.com.authorization;
import java.util.ArrayList;
import java.util.List;
public class AllBook {
private String HeaderTitle;
private List<HomeTrendBook> AllBooks;
public AllBook() {
}
public AllBook(String headertitle, List<HomeTrendBook> allbooks) {
HeaderTitle = headertitle;
AllBooks = allbooks;
}
public String getHeaderTitle() {
return HeaderTitle;
}
public List<HomeTrendBook> getAllBooks() {
return AllBooks;
}
public void setHeaderTitle(String headertitle) {
HeaderTitle = headertitle;
}
public void setAllBooks(List<HomeTrendBook> allbooks) {
AllBooks = allbooks;
}
}<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/Exoplayer/CustomDialogMaxConnection.java
package mmanager.scnx5.com.mitvmanager.Exoplayer;
import android.app.Activity;
import android.app.Dialog;
import android.graphics.Color;
import android.graphics.drawable.ColorDrawable;
import android.os.Bundle;
import android.os.CountDownTimer;
import android.view.View;
import android.view.Window;
import android.widget.Button;
import android.widget.TextView;
import android.widget.Toast;
import mmanager.scnx5.com.mitvmanager.R;
public class CustomDialogMaxConnection extends Dialog implements
View.OnClickListener {
public Activity c;
public Dialog d;
public Button yes, no;
public CountDownTimer cdt;
public String firstD,SecondD;
public CustomDialogMaxConnection(Activity a,String first,String second) {
super(a);
// TODO Auto-generated constructor stub
this.c = a;
firstD=first;
SecondD=second;
}
@Override
protected void onCreate(Bundle savedInstanceState) {
//setTheme(R.style.Theme_Transparent);
super.onCreate(savedInstanceState);
requestWindowFeature(Window.FEATURE_NO_TITLE);
setContentView(R.layout.dialog_maxconnection);
getWindow().setBackgroundDrawable(new ColorDrawable(Color.TRANSPARENT));
String displaymaxconnection="You have reached limit of concurrent connection for this account";
displaymaxconnection=displaymaxconnection + "\nLogged device(s) :";
if (SecondD.equalsIgnoreCase("none")){
displaymaxconnection= displaymaxconnection + " "+firstD;
}else {
displaymaxconnection= displaymaxconnection + " "+firstD + "& " + SecondD;
}
TextView displayMax=(TextView)findViewById(R.id.message_max);
displayMax.setText(displaymaxconnection);
}
@Override
public void onClick(View v) {
dismiss();
}
}<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/Exoplayer/CustomLatestApkVersion.java
package mmanager.scnx5.com.mitvmanager.Exoplayer;
import android.app.Activity;
import android.app.Dialog;
import android.graphics.Color;
import android.graphics.drawable.ColorDrawable;
import android.os.Bundle;
import android.os.CountDownTimer;
import android.view.View;
import android.view.Window;
import android.widget.Button;
import android.widget.FrameLayout;
import android.widget.TextView;
import mmanager.scnx5.com.mitvmanager.R;
import mmanager.scnx5.com.mitvmanager.setViewSizeByReso;
public class CustomLatestApkVersion extends Dialog implements
View.OnClickListener {
public Activity c;
public Dialog d;
public Button yes, no;
public CountDownTimer cdt;
public CustomLatestApkVersion(Activity a) {
super(a);
// TODO Auto-generated constructor stub
this.c = a;
}
@Override
protected void onCreate(Bundle savedInstanceState) {
//setTheme(R.style.Theme_Transparent);
super.onCreate(savedInstanceState);
requestWindowFeature(Window.FEATURE_NO_TITLE);
setContentView(R.layout.dialog_latest_appversion);
getWindow().setBackgroundDrawable(new ColorDrawable(Color.TRANSPARENT));
FrameLayout flatestapk=(FrameLayout)findViewById(R.id.frame_latestapk);
String displaymaxconnection="Please update to latest application version to continue.";
setViewSizeByReso setView=new setViewSizeByReso();
setView.setSize(flatestapk,1,1);
TextView displayMax=(TextView)findViewById(R.id.message_max);
displayMax.setText(displaymaxconnection);
yes=(Button)findViewById(R.id.go_home);
yes.setOnClickListener(this);
yes.requestFocus();
}
@Override
public void onClick(View v) {
switch (v.getId()) {
case R.id.go_home:
dismiss();
((exoplayer_layar)c).exit_dueto_oldversion();
break;
default:
break;
}
// dismiss();
}
}<file_sep>/app/src/main/java/mmanager/scnx5/com/authorization/LiveEventBook.java
package mmanager.scnx5.com.authorization;
public class LiveEventBook {
private String TitleType;
private String BackgroundImage;
private String Date;
private String Time ;
private String Title;
private Integer id;
public LiveEventBook() {
}
public LiveEventBook(String TitleTypes, String BackgroundImages, String Dates, String Times, String Titles, Integer ids) {
TitleType = TitleTypes;
BackgroundImage = BackgroundImages;
Date = Dates;
Time = Times;
Title=Titles;
id=ids;
}
public String getTitle() {
return Title;
}
public String getBackgroundImage() {
return BackgroundImage;
}
public String getDate() {
return Date;
}
public String getTime() {
return Time;
}
public Integer getId() {
return id;
}
public String getTitles() {
return Title;
}
public void setTitle(String title) {
Title = title;
}
public void setBackgroundImage(String BackgroundImages) {
BackgroundImage = BackgroundImages;
}
public void setDate(String Dates) {
Date = Dates;
}
public void setTime(String Times) {
Time = Times;
}
public void setId(String id) {
id = id;
}
}<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/RedBoxGrid/LiveBook.java
package mmanager.scnx5.com.mitvmanager.RedBoxGrid;
public class LiveBook {
private String Title;
private String Category ;
private String Url ;
private String Sypnopsis;
private String Thumbnail ;
private String Id;
private String Premium;
public LiveBook() {
}
public LiveBook(String title, String category, String url, String thumbnail, String sypnopsis, String id,String premium) {
Title = title;
Category = category;
Url = url;
Thumbnail = thumbnail;
Sypnopsis = sypnopsis;
Id=id;
Premium=premium;
}
public String getTitle() {
return Title;
}
public String getCategory() {
return Category;
}
public String getUrl() {
return Url;
}
public String getSysnopsis() {
return Sypnopsis;
}
public String getThumbnail() {
return Thumbnail;
}
public String getId() {
return Id;
}
public String getPremium() {
return Premium;
}
public void setTitle(String title) {
Title = title;
}
public void setCategory(String category) {
Category = category;
}
public void setUrl(String url) {
Url = url;
}
public void setSypnopsis(String sypnopsis) {
Sypnopsis = sypnopsis;
}
public void setThumbnail(String thumbnail) {
Thumbnail = thumbnail;
}
public void setId(String id) {
Id = id;
}
public void setPremium(String premium) {
Id = premium;
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/old_getURL.java
package mmanager.scnx5.com.mitvmanager;
import android.os.StrictMode;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
public class old_getURL {
public String getURL(String surl) {
StrictMode.ThreadPolicy policy = new StrictMode.ThreadPolicy.Builder().permitAll().build();
StrictMode.setThreadPolicy(policy);
String fullString = "";
try {
URL url = new URL(surl);
BufferedReader reader = new BufferedReader(new InputStreamReader(url.openStream()));
String line;
while ((line = reader.readLine()) != null) {
fullString += line;
}
reader.close();
} catch (Exception ex) {
//showDialog("Verbindungsfehler.",parent);
}
return fullString;
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/Exoplayer/RecyclerViewAdapterCategoryExoPlayer.java
package mmanager.scnx5.com.mitvmanager.Exoplayer;
import android.content.Context;
import android.content.res.Resources;
import android.os.Build;
import android.support.v7.widget.CardView;
import android.support.v7.widget.RecyclerView;
import android.util.Log;
import android.view.KeyEvent;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.widget.FrameLayout;
import android.widget.ImageView;
import android.widget.TextView;
import android.widget.Toast;
import com.bumptech.glide.Glide;
import java.util.ArrayList;
import java.util.List;
import mmanager.scnx5.com.mitvmanager.R;
import mmanager.scnx5.com.mitvmanager.log_;
public class RecyclerViewAdapterCategoryExoPlayer extends RecyclerView.Adapter<mmanager.scnx5.com.mitvmanager.Exoplayer.RecyclerViewAdapterCategoryExoPlayer.MyViewHolderExoPlayer> {
private Context mContext ;
// private List<ExoBook> mData ;
private ArrayList <String> Category;
private log_ dlog;
public RecyclerViewAdapterCategoryExoPlayer(Context mContext,ArrayList<String> category) {
this.mContext = mContext;
this.Category = category;
}
@Override
public mmanager.scnx5.com.mitvmanager.Exoplayer.RecyclerViewAdapterCategoryExoPlayer.MyViewHolderExoPlayer onCreateViewHolder(ViewGroup parent, int viewType) {
View view;
LayoutInflater mInflater = LayoutInflater.from(mContext);
double width= Resources.getSystem().getDisplayMetrics().widthPixels;
if (width < 1920){
view = mInflater.inflate(R.layout.exoplayer_channel_category, parent, false);
}else {
view = mInflater.inflate(R.layout.exoplayer_channel_category, parent, false);
}
return new mmanager.scnx5.com.mitvmanager.Exoplayer.RecyclerViewAdapterCategoryExoPlayer.MyViewHolderExoPlayer(view);
}
@Override
public void onBindViewHolder(final mmanager.scnx5.com.mitvmanager.Exoplayer.RecyclerViewAdapterCategoryExoPlayer.MyViewHolderExoPlayer holder, final int position) {
holder.tv_book_title.setText(Category.get(position));
// String picURL =Category.get(position);
// Glide.with(mContext).load(picURL).into(holder.img_book_thumbnail);
//Integer picURL=mData.get(position).getThumbnail();
// Bitmap bitmap = BitmapFactory.decodeStream((InputStream)new URL(picURL).getContent());
// String picURL=mData.get(position).getThumbnail();
// holder.img_book_thumbnail.setImage(picURL);
// Glide.with(mContext).load(picURL).into(holder.img_book_thumbnail);
holder.cardView.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
List<String> myVODName=((exoplayer_layar)view.getContext()).VODJsonName;
Toast.makeText(mContext,String.valueOf(myVODName.size()),Toast.LENGTH_SHORT).show();
}
});
}
@Override
public int getItemCount() {
return Category.size();
}
public static class MyViewHolderExoPlayer extends RecyclerView.ViewHolder {
TextView tv_book_title;
ImageView img_book_thumbnail;
//CardView cardView ;
FrameLayout cardView ;
public MyViewHolderExoPlayer(View itemView) {
super(itemView);
tv_book_title = (TextView) itemView.findViewById(R.id.tv_species) ;
// img_book_thumbnail = (ImageView) itemView.findViewById(R.id.exo_channel_image);
// cardView = (CardView) itemView.findViewById(R.id.cardview_id);
cardView = (FrameLayout) itemView.findViewById(R.id.exo_channel_category_focus);
}
}
}<file_sep>/app/src/main/java/mmanager/scnx5/com/authorization/RecyclerViewAdapterHomeLiveEvent.java
package mmanager.scnx5.com.authorization;
import android.content.Context;
import android.content.Intent;
import android.content.SharedPreferences;
import android.support.v7.widget.RecyclerView;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.view.animation.Animation;
import android.view.animation.AnimationUtils;
import android.widget.FrameLayout;
import android.widget.ImageView;
import android.widget.TextView;
import com.bumptech.glide.Glide;
import java.util.List;
import mmanager.scnx5.com.mitvmanager.Exoplayer.exoplayer_layar;
import mmanager.scnx5.com.mitvmanager.R;
import mmanager.scnx5.com.mitvmanager.getURL;
import static android.content.Context.MODE_PRIVATE;
public class RecyclerViewAdapterHomeLiveEvent extends RecyclerView.Adapter<RecyclerViewAdapterHomeLiveEvent.MyViewHolderRB> {
private Context mContext ;
private List<LiveEventBook> mData ;
private String playURL,channelName,imgUrl;
private getURL wget =new getURL();
private SharedPreferences pref ;
private SharedPreferences.Editor editor ;
private String server,tk,Json;
public RecyclerViewAdapterHomeLiveEvent(Context mContext, List<LiveEventBook> mData, String server, String tk, String Json) {
this.mContext = mContext;
this.mData = mData;
this.server=server;
this.tk=tk;
this.Json=Json;
}
@Override
public RecyclerViewAdapterHomeLiveEvent.MyViewHolderRB onCreateViewHolder(ViewGroup parent, int viewType) {
View view=null;
LayoutInflater mInflater = LayoutInflater.from(mContext);
/* double width = Resources.getSystem().getDisplayMetrics().widthPixels;
if (width > 2200 && width < 3000){
view = mInflater.inflate(R.layout.exoplayer_channel_switch_1440, parent, false);
}else if (width > 1280 && width < 2200){
view = mInflater.inflate(R.layout.exoplayer_channel_switch_1080, parent, false);
}else {
view = mInflater.inflate(R.layout.exoplayer_channel_switch_720, parent, false);
}*/
view = mInflater.inflate(R.layout.home_live_event, parent, false);
return new RecyclerViewAdapterHomeLiveEvent.MyViewHolderRB(view);
}
@Override
public void onBindViewHolder(RecyclerViewAdapterHomeLiveEvent.MyViewHolderRB holder, final int position) {
holder.title.setText(mData.get(position).getTitle());
holder.time.setText(mData.get(position).getTime());
holder.date.setText(mData.get(position).getDate());
}
@Override
public int getItemCount() {
return mData.size();
}
public static class MyViewHolderRB extends RecyclerView.ViewHolder {
TextView title,time,date;
//CardView cardView ;
FrameLayout cardView ;
public MyViewHolderRB(final View itemView) {
super(itemView);
title = (TextView) itemView.findViewById(R.id.Title_live) ;
time= (TextView) itemView.findViewById(R.id.live_time) ;
date = (TextView) itemView.findViewById(R.id.live_date);
cardView =(FrameLayout) itemView.findViewById(R.id.home_last_watching);
/* Animation anim = AnimationUtils.loadAnimation(itemView.getContext(),R.anim.scale_out_tv);
itemView.startAnimation(anim);
anim.setFillAfter(true);*/
itemView.setOnFocusChangeListener(new View.OnFocusChangeListener() {
@Override
public void onFocusChange(View view, boolean b) {
if(b){
Animation anim = AnimationUtils.loadAnimation(itemView.getContext(),R.anim.scale_in_tv);
itemView.startAnimation(anim);
anim.setFillAfter(true);
((newui_logout_main)itemView.getContext()).setLiveImageBackground("");
// Log.d("Onfocus","focused");
}else {
Animation anim = AnimationUtils.loadAnimation(itemView.getContext(),R.anim.scale_out_tv);
itemView.startAnimation(anim);
anim.setFillAfter(true);
}
}
});
}
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/RedBoxGrid/RecyclerViewAdapterRB.java
package mmanager.scnx5.com.mitvmanager.RedBoxGrid;
import android.content.Context;
import android.content.Intent;
import android.content.res.Resources;
import android.net.Uri;
import android.support.v7.widget.RecyclerView;
import android.util.Log;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.widget.ImageView;
import android.widget.LinearLayout;
import android.widget.TextView;
import android.widget.Toast;
import com.bumptech.glide.Glide;
import com.squareup.picasso.Picasso;
import java.util.List;
import mmanager.scnx5.com.abcsesscxz;
import mmanager.scnx5.com.abcyxoorp;
import mmanager.scnx5.com.mitvmanager.Exoplayer.exoplayer_layar;
import mmanager.scnx5.com.mitvmanager.R;
import mmanager.scnx5.com.mitvmanager.VODGrid.Book;
import mmanager.scnx5.com.mitvmanager.getURL;
public class RecyclerViewAdapterRB extends RecyclerView.Adapter<mmanager.scnx5.com.mitvmanager.RedBoxGrid.RecyclerViewAdapterRB.MyViewHolderRB> {
private Context mContext ;
private List<LiveBook> mData ;
private String token;
private String server;
private String Json;
public RecyclerViewAdapterRB(Context mContext, List<LiveBook> mData,String token,String server,String json) {
this.mContext = mContext;
this.mData = mData;
this.token = <PASSWORD>;
this.server=server;
this.Json=json;
}
@Override
public mmanager.scnx5.com.mitvmanager.RedBoxGrid.RecyclerViewAdapterRB.MyViewHolderRB onCreateViewHolder(ViewGroup parent, int viewType) {
View view;
LayoutInflater mInflater = LayoutInflater.from(mContext);
double width= Resources.getSystem().getDisplayMetrics().widthPixels;
if (width < 1920){
view = mInflater.inflate(R.layout.cardveiw_item_book_720p, parent, false);
}else {
view = mInflater.inflate(R.layout.cardveiw_item_book, parent, false);
}
return new mmanager.scnx5.com.mitvmanager.RedBoxGrid.RecyclerViewAdapterRB.MyViewHolderRB(view);
}
@Override
public void onBindViewHolder(mmanager.scnx5.com.mitvmanager.RedBoxGrid.RecyclerViewAdapterRB.MyViewHolderRB holder, final int position) {
holder.tv_book_title.setText(mData.get(position).getTitle());
//Integer picURL=mData.get(position).getThumbnail();
// Bitmap bitmap = BitmapFactory.decodeStream((InputStream)new URL(picURL).getContent());
String picURL=mData.get(position).getThumbnail();
// holder.img_book_thumbnail.setImage(picURL);
Glide.with(mContext).load(picURL).into(holder.img_book_thumbnail);
holder.cardView.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
// String sypnopsis = mData.get(position).getSysnopsis();
// String Url=mData.get(position).getUrl();
// new StartChannel().execute(sypnopsis,Url);
String Sypnopsis=mData.get(position).getSysnopsis();
if (Sypnopsis.equalsIgnoreCase("REDBOX") ||Sypnopsis.equalsIgnoreCase("M4K") || Sypnopsis.equalsIgnoreCase("LIVENET")
|| Sypnopsis.equalsIgnoreCase("HLS")) {
abcyxoorp a =new abcyxoorp();
abcsesscxz b=new abcsesscxz();
Intent intent = new Intent(mContext, exoplayer_layar.class);
// passing data to the book activity
intent.putExtra("cid", mData.get(position).getId());
intent.putExtra("Title", mData.get(position).getTitle());
intent.putExtra("Url", mData.get(position).getUrl());
intent.putExtra("Thumbnail", mData.get(position).getThumbnail());
intent.putExtra("Sypnopsis", mData.get(position).getSysnopsis());
intent.putExtra("Category", mData.get(position).getCategory());
intent.putExtra("liveTV", "rb");
intent.putExtra("tk", token);
intent.putExtra("server", server);
intent.putExtra("json", Json);
intent.putExtra("channelPos", position);
intent.putExtra("premium", mData.get(position).getPremium());
// Toast.makeText(mContext,"test",Toast.LENGTH_LONG).show();
// start the activity
mContext.startActivity(intent);
}else {
Intent intent = new Intent(Intent.ACTION_VIEW);
intent.setPackage("com.mxtech.videoplayer.ad");
intent.setDataAndType(Uri.parse(mData.get(position).getUrl()), "video/*");
//Toast.makeText(Book_Activity.this,"Movie is starting...",Toast.LENGTH_LONG).show();
mContext.startActivity(intent);
}
}
});
}
@Override
public int getItemCount() {
return mData.size();
}
public static class MyViewHolderRB extends RecyclerView.ViewHolder {
TextView tv_book_title;
ImageView img_book_thumbnail;
//CardView cardView ;
LinearLayout cardView ;
public MyViewHolderRB(View itemView) {
super(itemView);
tv_book_title = (TextView) itemView.findViewById(R.id.book_title_id) ;
img_book_thumbnail = (ImageView) itemView.findViewById(R.id.book_img_id);
// cardView = (CardView) itemView.findViewById(R.id.cardview_id);
cardView = (LinearLayout) itemView.findViewById(R.id.cardview_id);
}
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/getscreenratio.java
package mmanager.scnx5.com.mitvmanager;
import android.content.res.Resources;
public class getscreenratio {
public static int getScreenWidth() {
return Resources.getSystem().getDisplayMetrics().widthPixels;
}
public static int getScreenHeight() {
return Resources.getSystem().getDisplayMetrics().heightPixels;
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/authorization/get_menu_classs_navigation.java
package mmanager.scnx5.com.authorization;
public class get_menu_classs_navigation {
String home_activity ="mmanager.scnx5.com.authorization.newui_logout_main";
String livetv_activity ="mmanager.scnx5.com.mitvmanager.Exoplayer.exoplayer_layar";
String movie_activity ="mmanager.scnx5.com.mitvmanager.VODGrid.vod_grid_activity";
String setting_activity ="mmanager.scnx5.com.authorization.user_setting";
public void get_menu_classs_navigation(){
}
public String getHomeActivity(){
return home_activity;
}
public String getLiveTVActivity(){
return livetv_activity;
}
public String getMovieActivity(){
return movie_activity;
}
public String getSettingActivity(){
return setting_activity;
}
}
<file_sep>/app/src/main/java/mmanager/scnx5/com/mitvmanager/ReadFromFile.java
package mmanager.scnx5.com.mitvmanager;
import android.content.Context;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
public class ReadFromFile {
public String ReadFromFile (String filename,Context context) {
File file = new File(context.getFilesDir(), filename);
//Read text from file
StringBuilder text = new StringBuilder();
try {
BufferedReader br = new BufferedReader(new FileReader(file));
String line;
while ((line = br.readLine()) != null) {
text.append(line);
text.append('\n');
}
br.close();
} catch (IOException e) {
//You'll need to add proper error handling here
}
return text.toString();
}
}
| bdd91f78ba6984d7c22643dfd2a3449ec3cb75f6 | [
"Java",
"Gradle"
] | 29 | Java | mhazwankamal/zxcvbnm | cc2997d25f1916d0229abe7f7739b19f8db543c1 | 2b7f1c2c4263c761a9ff8f38e412388ee85aa4e0 |
refs/heads/master | <repo_name>AlwinEsch/visualization.starburst<file_sep>/src/StarBurst.cpp
//
//
// StarBurst.cpp ::: This Is the Starburst XBMC Visualization
// V0.75 Written by Dinomight
// <EMAIL>
//
//
//
//////////////////////////////////////////////////////////////////////
#include "StarBurst.h"
CVisualizationStarBurst::CVisualizationStarBurst()
{
m_width = Width();
m_height = Height();
m_centerx = m_width/2.0f + X();
m_centery = m_height/2.0f + Y();
SetDefaults();
CreateArrays();
}
bool CVisualizationStarBurst::Start(int channels, int samplesPerSec, int bitsPerSample, std::string songName)
{
(void)channels;
(void)bitsPerSample;
(void)songName;
std::string fraqShader = kodi::GetAddonPath("resources/shaders/" GL_TYPE_STRING "/frag.glsl");
std::string vertShader = kodi::GetAddonPath("resources/shaders/" GL_TYPE_STRING "/vert.glsl");
if (!LoadShaderFiles(vertShader, fraqShader) || !CompileAndLink())
{
kodi::Log(ADDON_LOG_ERROR, "Failed to create or compile shader");
return false;
}
m_iSampleRate = samplesPerSec;
CreateArrays();
InitGeometry();
#ifdef HAS_GL
glGenBuffers(2, m_vertexVBO);
#endif
m_modelProjMat = glm::ortho(0.0f, float(Width()), float(Height()), 0.0f);
m_oldTime = std::chrono::duration<double>(std::chrono::system_clock::now().time_since_epoch()).count();
m_startOK = true;
return true;
}
void CVisualizationStarBurst::Stop()
{
if (!m_startOK)
return;
m_startOK = false;
#ifdef HAS_GL
glBindBuffer(GL_ARRAY_BUFFER, 0);
glDeleteBuffers(2, m_vertexVBO);
m_vertexVBO[0] = 0;
m_vertexVBO[1]= 0;
#endif
}
void CVisualizationStarBurst::Render()
{
if (!m_startOK)
return;
double currentTime = std::chrono::duration<double>(std::chrono::system_clock::now().time_since_epoch()).count();
double timepassed = currentTime - m_oldTime;
m_oldTime = currentTime;
float PI = 3.141592653589793f;
float devisions = (2.0f*PI)/(m_iBars);
float dwidth = devisions/2.3f;
m_angle += (2.0f*PI)/(spinrate)*(timepassed/25.0);
for (int i=0; i < m_iBars*2; i++)
{
// truncate data to the users range
if (m_pFreq[i] > m_fMaxLevel)
m_pFreq[i] = m_fMaxLevel;
m_pFreq[i]-=m_fMinLevel;
if (m_pFreq[i] < 0)
m_pFreq[i] = 0;
// Smooth out the movement
if (m_pFreq[i] > m_pScreen[i])
m_pScreen[i] += (m_pFreq[i]-m_pScreen[i])*m_fRiseSpeed;
else
m_pScreen[i] -= (m_pScreen[i]-m_pFreq[i])*m_fFallSpeed;
// Work out the peaks
if (m_pScreen[i] >= m_pPeak[i])
{
m_pPeak[i] = m_pScreen[i];
}
else
{
m_pPeak[i]-=m_fPeakDecaySpeed;
if (m_pPeak[i] < 0)
m_pPeak[i] = 0;
}
}
if (m_angle >2.0f*PI)
m_angle -= 2.0f*PI;
float x1 = 0;
float y1 = 0;
float x2 = 0;
float y2 = 0;
float radius=0;
int iChannels = m_bMixChannels ? 1 : 2;
// for (int j=0; j<iChannels; j++){
int j = 0;
int points = 4;
float scaler = (m_height/2 - minbar - startradius)/(m_fMaxLevel - m_fMinLevel);
glm::vec4 color1 = glm::vec4(m_r1, m_g1, m_b1, m_a1);
for (int i=0; i < m_iBars*2; i+=2)
{
radius = m_pScreen[i+j] * scaler + minbar + startradius;
x1 = sin(m_angle - dwidth) * radius;
y1 = cos(m_angle - dwidth) * radius;
x2 = sin(m_angle + dwidth) * radius;
y2 = cos(m_angle + dwidth) * radius;
float x3 = sin(m_angle) * startradius;
float y3 = cos(m_angle) * startradius;
float colorscaler = ((m_pScreen[i+j])/(m_fMaxLevel - m_fMinLevel));
glm::vec4 color2 = glm::vec4(((colorscaler*m_r2)+m_r1),
((colorscaler*m_g2)+m_g1),
((colorscaler*m_b2)+m_b1),
((colorscaler*m_a2)+m_a1));
//color1 = color2;
glm::vec4 b = glm::vec4(m_centerx + x3, m_centery + y3, 0.5f, 1.0f);
glm::vec4 a1 = glm::vec4(m_centerx + x1, m_centery + y1, 0.5f, 1.0f);
glm::vec4 a2 = glm::vec4(m_centerx + x2, m_centery + y2, 0.5f, 1.0f);
m_positions[(((i+2)/2 -1)*points)] = b;
m_colors[(((i+2)/2 -1)*points)] = color2;
m_positions[(((i+2)/2 -1)*points)+1] = a1;
m_colors[(((i+2)/2 -1)*points)+1] = color2;
m_positions[(((i+2)/2 -1)*points)+2] = a2;
m_colors[(((i+2)/2 -1)*points)+2] = color2;
m_positions[(((i+2)/2 -1)*points)+3] = b;
m_colors[(((i+2)/2 -1)*points)+3] = color2;
m_angle += devisions;
}
#ifdef HAS_GL
glBindBuffer(GL_ARRAY_BUFFER, m_vertexVBO[0]);
glVertexAttribPointer(m_aPosition, 4, GL_FLOAT, GL_FALSE, sizeof(glm::vec4), BUFFER_OFFSET(offsetof(glm::vec4, x)));
glEnableVertexAttribArray(m_aPosition);
glBufferData(GL_ARRAY_BUFFER, sizeof(m_positions), m_positions, GL_STATIC_DRAW);
glBindBuffer(GL_ARRAY_BUFFER, m_vertexVBO[1]);
glVertexAttribPointer(m_aColor, 4, GL_FLOAT, GL_FALSE, sizeof(glm::vec4), BUFFER_OFFSET(offsetof(glm::vec4, r)));
glEnableVertexAttribArray(m_aColor);
glBufferData(GL_ARRAY_BUFFER, sizeof(m_colors), m_colors, GL_STATIC_DRAW);
#else
glVertexAttribPointer(m_aPosition, 4, GL_FLOAT, GL_FALSE, 0, m_positions);
glEnableVertexAttribArray(m_aPosition);
glVertexAttribPointer(m_aColor, 4, GL_FLOAT, GL_FALSE, 0, m_colors);
glEnableVertexAttribArray(m_aColor);
#endif
glDisable(GL_BLEND);
EnableShader();
glDrawArrays(GL_TRIANGLE_STRIP, 0, m_iBars*4-2);
DisableShader();
glEnable(GL_BLEND);
glDisableVertexAttribArray(m_aPosition);
glDisableVertexAttribArray(m_aColor);
}
void CVisualizationStarBurst::AudioData(const float* pAudioData, int iAudioDataLength, float* pFreqData, int iFreqDataLength)
{
if (iFreqDataLength>FREQ_DATA_SIZE)
iFreqDataLength = FREQ_DATA_SIZE;
// weight the data using A,B or C-weighting
if (m_Weight != WEIGHT_NONE)
{
for (int i=0; i<iFreqDataLength+2; i+=2)
{
pFreqData[i] *= m_pWeight[i>>1];
pFreqData[i+1] *= m_pWeight[i>>1];
}
}
// Group data into frequency bins by averaging (Ignore the constant term)
int jmin=2;
int jmax;
// FIXME: Roll conditionals out of loop
for (int i=0, iBin=0; i < m_iBars; i++, iBin+=2)
{
m_pFreq[iBin]=0.000001f; // almost zero to avoid taking log of zero later
m_pFreq[iBin+1]=0.000001f;
if (m_bLogScale)
jmax = (int) (m_fMinFreq*pow(m_fMaxFreq/m_fMinFreq,(float)i/m_iBars)/m_iSampleRate*iFreqDataLength + 0.5f);
else
jmax = (int) ((m_fMinFreq + (m_fMaxFreq-m_fMinFreq)*i/m_iBars)/m_iSampleRate*iFreqDataLength + 0.5f);
// Round up to nearest multiple of 2 and check that jmin is not jmax
jmax<<=1;
if (jmax > iFreqDataLength) jmax = iFreqDataLength;
if (jmax==jmin) jmin-=2;
for (int j=jmin; j<jmax; j+=2)
{
if (m_bMixChannels)
{
if (m_bAverageLevels)
m_pFreq[iBin]+=pFreqData[j]+pFreqData[j+1];
else
{
if (pFreqData[j]>m_pFreq[iBin])
m_pFreq[iBin]=pFreqData[j];
if (pFreqData[j+1]>m_pFreq[iBin])
m_pFreq[iBin]=pFreqData[j+1];
}
}
else
{
if (m_bAverageLevels)
{
m_pFreq[iBin]+=pFreqData[j];
m_pFreq[iBin+1]+=pFreqData[j+1];
}
else
{
if (pFreqData[j]>m_pFreq[iBin])
m_pFreq[iBin]=pFreqData[j];
if (pFreqData[j+1]>m_pFreq[iBin+1])
m_pFreq[iBin+1]=pFreqData[j+1];
}
}
}
if (m_bAverageLevels)
{
if (m_bMixChannels)
m_pFreq[iBin] /=(jmax-jmin);
else
{
m_pFreq[iBin] /= (jmax-jmin)/2;
m_pFreq[iBin+1] /= (jmax-jmin)/2;
}
}
jmin = jmax;
}
}
void CVisualizationStarBurst::OnCompiledAndLinked()
{
m_uModelProjMatrix = glGetUniformLocation(ProgramHandle(), "u_modelViewProjectionMatrix");
m_aPosition = glGetAttribLocation(ProgramHandle(), "a_position");
m_aColor = glGetAttribLocation(ProgramHandle(), "a_color");
}
bool CVisualizationStarBurst::OnEnabled()
{
glUniformMatrix4fv(m_uModelProjMatrix, 1, GL_FALSE, glm::value_ptr(m_modelProjMat));
return true;
}
bool CVisualizationStarBurst::InitGeometry()
{
// Initialize vertices for rendering a triangle
glm::vec4 positions[] =
{
{ glm::vec4(200.0f, 200.0f, 0.5f, 1.0f) }, // x, y, z, rhw, color
{ glm::vec4(300.0f, 200.0f, 0.5f, 1.0f) },
{ glm::vec4(300.0f, 300.0f, 0.5f, 1.0f) },
{ glm::vec4(200.0f, 300.0f, 0.5f, 1.0f) },
{ glm::vec4(200.0f, 300.0f, 0.5f, 1.0f) },
};
memcpy(m_positions, positions, sizeof(positions));
glm::vec4 colors[] =
{
{ glm::vec4(0.0f, 1.0f, 0.0f, 1.0f) }, // x, y, z, rhw, color
{ glm::vec4(0.0f, 1.0f, 0.0f, 1.0f) },
{ glm::vec4(0.0f, 1.0f, 0.0f, 1.0f) },
{ glm::vec4(0.0f, 1.0f, 0.0f, 1.0f) },
{ glm::vec4(0.0f, 1.0f, 0.0f, 1.0f) },
};
memcpy(m_colors, colors, sizeof(colors));
return true;
}
void CVisualizationStarBurst::CreateArrays()
{
for (int i=0; i<m_iBars*2; i++)
{
m_pScreen[i] = 0.0f;
m_pPeak[i] = 0.0f;
m_pFreq[i] = 0.0f;
m_positions[i*2] = glm::vec4(0.0f);
m_positions[i*2+1] = glm::vec4(0.0f);
m_colors[i*2] = glm::vec4(0.0f);
m_colors[i*2+1] = glm::vec4(0.0f);
}
// and the weight array
if (m_Weight == WEIGHT_NONE)
return;
// calculate the weights (squared)
float f2;
for (int i=0; i<FREQ_DATA_SIZE/2+1; i++)
{
f2 = (float)sqr((float)i*m_iSampleRate/FREQ_DATA_SIZE);
if (m_Weight == WEIGHT_A)
m_pWeight[i] = (float)sqr(POLE2*sqr(f2)/(f2+POLE1)/(f2+POLE2)/sqrt(f2+POLE3)/sqrt(f2+POLE4));
else if (m_Weight == WEIGHT_B)
m_pWeight[i] = (float)sqr(POLE2*f2*sqrt(f2)/(f2+POLE1)/(f2+POLE2)/sqrt(f2+POLE5));
else // m_Weight == WEIGHT_C
m_pWeight[i] = (float)sqr(POLE2*f2/(f2+POLE1)/(f2+POLE2));
}
}
void CVisualizationStarBurst::SetDefaults()
{
m_iBars = 40;
m_bLogScale=false;
m_fPeakDecaySpeed = 0.5f;
m_fRiseSpeed = 0.5f;
m_fFallSpeed = 0.5f;
m_Weight = WEIGHT_NONE;
m_bMixChannels = true;
m_fMinFreq = 80;
m_fMaxFreq = 16000;
m_fMinLevel = 0;
m_fMaxLevel = 0.2;
m_bShowPeaks = true;
m_bAverageLevels = false;
spinrate = 1.0/3.0;
startradius = 0.0f;
minbar = 200.0f;
//inital color
m_r2 = 1.0f;
m_g2 = 0.785f;
m_b2 = 0.0f;
m_a2 = 1.0f;
//finalColor
m_r1 = 0.64f;
m_g1 = 0.75f;
m_b1 = 1.0f;
m_a1 = 1.0f;
// color Diff
m_r2 -= m_r1;
m_g2 -= m_g1;
m_b2 -= m_b1;
m_a2 -= m_a1;
}
ADDONCREATOR(CVisualizationStarBurst)
<file_sep>/src/StarBurst.h
#pragma once
#include <chrono>
#include <kodi/addon-instance/Visualization.h>
#include <kodi/gui/gl/Shader.h>
#include <glm/glm.hpp>
#include <glm/gtc/type_ptr.hpp>
typedef enum _WEIGHT {
WEIGHT_NONE = 0,
WEIGHT_A = 1,
WEIGHT_B = 2,
WEIGHT_C = 3
} WEIGHT;
#define sqr(x) (x*x)
#define FREQ_DATA_SIZE 512 // size of frequency data wanted
#define MAX_BARS 256 // number of bars in the Spectrum
#define MIN_PEAK_DECAY_SPEED 0 // decay speed in dB/frame
#define MAX_PEAK_DECAY_SPEED 4
#define MIN_RISE_SPEED 0.01f // fraction of actual rise to allow
#define MAX_RISE_SPEED 1
#define MIN_FALL_SPEED 0.01f // fraction of actual fall to allow
#define MAX_FALL_SPEED 1
#define MIN_FREQUENCY 1 // allowable frequency range
#define MAX_FREQUENCY 24000
#define MIN_LEVEL 0 // allowable level range
#define MAX_LEVEL 96
#define TEXTURE_HEIGHT 256
#define TEXTURE_MID 128
#define TEXTURE_WIDTH 1
#define MAX_CHANNELS 2
#define POLE1 20.598997*20.598997 // for A/B/C weighting
#define POLE2 12194.217*12194.217 // for A/B/C weighting
#define POLE3 107.65265*107.65265 // for A weighting
#define POLE4 737.86223*737.86223 // for A weighting
#define POLE5 158.5*158.5 // for B weighting
class ATTRIBUTE_HIDDEN CVisualizationStarBurst
: public kodi::addon::CAddonBase,
public kodi::addon::CInstanceVisualization,
public kodi::gui::gl::CShaderProgram
{
public:
CVisualizationStarBurst();
~CVisualizationStarBurst() override = default;
bool Start(int channels, int samplesPerSec, int bitsPerSample, std::string songName) override;
void Stop() override;
void Render() override;
void AudioData(const float* audioData, int audioDataLength, float* freqData, int freqDataLength) override;
void GetInfo(bool& wantsFreq, int& syncDelay) override { wantsFreq = true; syncDelay = 16; }
void OnCompiledAndLinked() override;
bool OnEnabled() override;
private:
bool InitGeometry();
void CreateArrays();
void SetDefaults();
float m_fWaveform[2][512];
glm::mat4 m_modelProjMat;
#ifdef HAS_GL
GLuint m_vertexVBO[2] = { 0 };
#endif
GLint m_uModelProjMatrix = -1;
GLint m_aPosition = -1;
GLint m_aColor = -1;
bool m_startOK = false;
float m_pScreen[MAX_BARS*2]; // Current levels on the screen
float m_pPeak[MAX_BARS*2]; // Peak levels
float m_pWeight[FREQ_DATA_SIZE/2+1]; // A/B/C weighted levels for speed
float m_pFreq[MAX_BARS*2]; // Frequency data
int m_iSampleRate;
int m_width;
int m_height;
float m_centerx;
float m_centery;
float m_fRotation = 0.0f;
float m_angle = 0.0f;
float startradius; //radius at which to start each bar
float minbar; //minimum length of a bar
float spinrate; // rate at witch to spin vis
float m_r1; //floats used for bar colors;
float m_g1;
float m_b1;
float m_a1;
float m_r2;
float m_g2;
float m_b2;
float m_a2;
int m_iBars; // number of bars to draw
bool m_bLogScale; // true if our frequency is on a log scale
bool m_bShowPeaks; // show peaks?
bool m_bAverageLevels; // show average levels?
float m_fPeakDecaySpeed; // speed of decay (in dB/frame)
float m_fRiseSpeed; // division of rise to actually go up
float m_fFallSpeed; // division of fall to actually go up
float m_fMinFreq; // wanted frequency range
float m_fMaxFreq;
float m_fMinLevel; // wanted level range
float m_fMaxLevel;
WEIGHT m_Weight; // weighting type to be applied
bool m_bMixChannels; // Mix channels, or stereo?
bool m_bSeperateBars;
glm::vec4 m_positions[MAX_BARS*4]; // The transformed position for the vertex
glm::vec4 m_colors[MAX_BARS*4]; // The vertex color
double m_oldTime;
};
| cf3b9e409a06eae2702b7fbe127ccc6d4ac3bde7 | [
"C++"
] | 2 | C++ | AlwinEsch/visualization.starburst | 41371dc6add96e0f55357c4785dd51d43ba5ecf9 | 9cc402af56d289c4e323b016bcd02a24369944a8 |
refs/heads/master | <file_sep><?php
namespace App\DataFixtures;
use App\Entity\User;
use Doctrine\Bundle\FixturesBundle\Fixture;
use Doctrine\Common\Persistence\ObjectManager;
use Symfony\Component\Security\Core\Encoder\UserPasswordEncoderInterface;
class UserFixtures extends Fixture
{
private $encoder;
/**
* UserFixtures constructor.
* @param UserPasswordEncoderInterface $encoder
*/
public function __construct(UserPasswordEncoderInterface $encoder)
{
$this->encoder = $encoder;
}
public function load(ObjectManager $manager)
{
$user = new User();
$user->setCivility('Monsieur');
$user->setName('Dupont');
$user->setFirstname('Gérard');
$user->setCompany('Batibat');
$user->setEmail('<EMAIL>');
$password = $this->encoder->encodePassword($user, '<PASSWORD>');
$user->setPassword($password);
$manager->persist($user);
$user = new User();
$user->setCivility('Madame');
$user->setName('Lejeune');
$user->setFirstname('Céline');
$user->setCompany('Agrolagro');
$user->setEmail('<EMAIL>');
$password = $this->encoder->encodePassword($user, '<PASSWORD>');
$user->setPassword($password);
$manager->persist($user);
$user = new User();
$user->setCivility('Monsieur');
$user->setName('Lenoir');
$user->setFirstname('Simon');
$user->setCompany('Carbone 99');
$user->setEmail('<EMAIL>');
$password = $this->encoder->encodePassword($user, '<PASSWORD>');
$user->setPassword($password);
$manager->persist($user);
$manager->flush();
}
}
<file_sep><?php
namespace App\Entity;
use Doctrine\ORM\Mapping as ORM;
use Symfony\Bridge\Doctrine\Validator\Constraints\UniqueEntity;
use Symfony\Component\Security\Core\User\UserInterface;
use Symfony\Component\Validator\Constraints as Assert;
/**
* @ORM\Entity(repositoryClass="App\Repository\UserRepository")
* @UniqueEntity("email", message="L'adresse email est déjà prise. Veuillez en choisir une autre.")
*/
class User implements UserInterface
{
/**
* @ORM\Id()
* @ORM\GeneratedValue()
* @ORM\Column(type="integer")
*/
private $id;
/**
* @ORM\Column(type="string", length=180)
* @Assert\NotBlank(message="Vous devez saisir votre civilité")
*/
private $civility;
/**
* @ORM\Column(type="string", length=255)
* @Assert\NotBlank(message="Vous devez saisir votre nom de famille")
*/
private $name;
/**
* @ORM\Column(type="string", length=255)
* @Assert\NotBlank(message="Vous devez saisir votre prénom")
*/
private $firstname;
/**
* @ORM\Column(type="string", length=255)
* @Assert\NotBlank(message="Vous devez saisir le nom de votre société")
*/
private $company;
/**
* @ORM\Column(type="string", length=180, unique=true)
* @Assert\NotBlank(message="Vous devez saisir votre email")
* @Assert\Email(message = "L'adresse '{{ value }}' n'est pas une adresse valide")
*/
private $email;
/**
* @ORM\Column(type="string", length=255)
* @Assert\NotBlank(message="Veuillez choisir un mot de passe")
* @Assert\Length(
* min = 6,
* minMessage="Votre mot de passe doit faire au moins 6 caractères"
* )
*/
private $password;
/**
* @ORM\Column(type="json")
*/
private $roles = [];
/**
* @return int|null
*/
public function getId(): ?int
{
return $this->id;
}
/**
* @return mixed
*/
public function getCivility()
{
return $this->civility;
}
/**
* @param mixed $civility
* @return User
*/
public function setCivility(string $civility)
{
$this->civility = $civility;
return $this;
}
/**
* @return null|string
*/
public function getEmail(): ?string
{
return $this->email;
}
/**
* @param string $email
* @return User
*/
public function setEmail(string $email): self
{
$this->email = $email;
return $this;
}
/**
* @param string $password
* @return User
*/
public function setPassword(string $password): self
{
$this->password = $password;
return $this;
}
/**
* @see UserInterface
*/
public function getPassword()
{
return $this->password;
}
/**
* A visual identifier that represents this user.
*
* @see UserInterface
*/
public function getUsername(): ?string
{
return (string) $this->email;
}
/**
* @see UserInterface
*/
public function getRoles(): array
{
$roles = $this->roles;
$roles[] = 'ROLE_USER';
return array_unique($roles);
}
/**
* @param array $roles
* @return User
*/
public function setRoles(array $roles): self
{
$this->roles = $roles;
return $this;
}
/**
* @see UserInterface
*/
public function getSalt(){}
/**
* @see UserInterface
*/
public function eraseCredentials()
{
// If you store any temporary, sensitive data on the user, clear it here
// $this->plainPassword = null;
}
/**
* @return mixed
*/
public function getName(): ?string
{
return $this->name;
}
/**
* @param mixed $name
* @return User
*/
public function setName(string $name): self
{
$this->name = $name;
return $this;
}
/**
* @return mixed
*/
public function getFirstname(): ?string
{
return $this->firstname;
}
/**
* @param mixed $firstname
* @return User
*/
public function setFirstname(string $firstname): self
{
$this->firstname = $firstname;
return $this;
}
/**
* @return mixed
*/
public function getCompany(): ?string
{
return $this->company;
}
/**
* @param mixed $company
* @return User
*/
public function setCompany(string $company): self
{
$this->company = $company;
return $this;
}
}
<file_sep># e-Progest Exercice PHP
J'ai utilisé le framework Symfony pour concevoir l'exercice en PHP.
### Les outils
* PHP 7.2
* MySQL
* Composer
### Installation du projet
```php
$ git clone git://github.com/Poniav/eProgestExo.git
$ cd eProgestExo
// Editer le fichier .env pour la connexion SQL
$ composer install
$ php bin/console doctrine:database:create
$ php bin/console make:migration ( development )
$ php bin/console doctrine:migrations:migrate
$ php bin/console server:run
```
## Base de données
Il y a deux façons de récupérer les utilisateurs dans la base de données. Soit en chargeant les fixtures avec la commande ci-dessous ou alors en récupérant le fichier SQL à la racine du projet dans DB.
```php
$ php bin/console doctrine:fixtures:load
```
## Infos
J'ai pas configuré la protection CSRF sur les formulaires.
<file_sep><?php
namespace App\Controller;
use App\Entity\User;
use App\Form\UserFormType;
use Sensio\Bundle\FrameworkExtraBundle\Configuration\Security;
use Symfony\Bundle\FrameworkBundle\Controller\AbstractController;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\Routing\Annotation\Route;
use Symfony\Component\Security\Core\Encoder\UserPasswordEncoderInterface;
class HomeController extends AbstractController
{
/**
* @Route("/", name="home")
* @param Request $request
* @param UserPasswordEncoderInterface $encoder
* @return \Symfony\Component\HttpFoundation\Response
*/
public function index(Request $request, UserPasswordEncoderInterface $encoder)
{
$em = $this->getDoctrine()->getManager();
$users = $em->getRepository(User::class)->findAll();
$user = new User();
$form = $this->createForm(UserFormType::class, $user);
$form->handleRequest($request);
if ($form->isSubmitted() && $form->isValid())
{
$password = $encoder->encodePassword($user, $form['password']->getData());
$user->setPassword($password);
var_dump($user->getPassword());
$this->getDoctrine()->getManager()->persist($user);
$this->getDoctrine()->getManager()->flush();
$this->addFlash('success', "L'utilisateur est ajouté à la liste !");
return $this->redirectToRoute("home");
}
return $this->render('home/index.html.twig', [
'users' => $users,
'form' => $form->createView()
]);
}
/**
* @Route("zone-client", name="clients")
* @Security("has_role('ROLE_USER')")
*/
public function zoneClients()
{
return $this->render('home/clients.html.twig');
}
}
| 52275ff9dc847ef64c45d74cd27d6d5e5e412861 | [
"Markdown",
"PHP"
] | 4 | PHP | Poniav/eProgestExo | 226e775e2f2f8fbebcf0c6773567cc162b6e46c9 | a3a67656272689910d15aac68587f8cb0a1afd99 |
refs/heads/master | <file_sep>package com.edsonj.eoh;
import java.util.Date;
import org.springframework.http.ResponseEntity;
import org.springframework.web.client.RestTemplate;
import com.edsonj.eoh.entity.Cic;
import com.edsonj.eoh.entity.Party;
public class ObjectCreationTest {
public static void main(String[] args) {
RestTemplate restTemplate = new RestTemplate();
String applicationUrl = "http://localhost:8082/cic/2";
Cic cic = new Cic("Email", "Notify", "Edson is leaving for EOH", "Assignment", new Date());
Party party = new Party("<NAME>", "<EMAIL>");
cic.setEntity(party);
//ResponseEntity<Cic> response = restTemplate.postForEntity(applicationUrl, cic, Cic.class);
ResponseEntity<Cic> response = restTemplate.getForEntity(applicationUrl, Cic.class);
System.out.println(response);
}
}
<file_sep>package com.edsonj.eoh.service.impl;
import java.util.Objects;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.edsonj.eoh.dao.CicDao;
import com.edsonj.eoh.dao.EntityDao;
import com.edsonj.eoh.entity.Cic;
import com.edsonj.eoh.entity.Party;
import com.edsonj.eoh.exception.BusinessValidationException;
import com.edsonj.eoh.service.CicService;
@Service
public class CicServiceImpl implements CicService {
private static final Logger logger = LoggerFactory.getLogger(CicServiceImpl.class);
@Autowired
private CicDao cicDao;
@Autowired
private EntityDao entityDao;
@Override
public Cic saveCic(Cic cic) {
logger.info(cic.toString());
Party party = cic.getParty();
if (Objects.nonNull(party)) {
Party partyFromDatabase = null;
partyFromDatabase = party.getEntityId() == null ? null: entityDao.findOne(party.getEntityId());
if (Objects.isNull(partyFromDatabase)) {
Party partyWithId = entityDao.save(party);
cic.setEntity(partyWithId);
}
}else {
throw new BusinessValidationException("Cic must always have an entity");
}
return cicDao.save(cic);
}
@Override
public Cic findCicById(Long cicId) {
return cicDao.findOne(cicId);
}
}
<file_sep>spring.datasource.url=jdbc:h2:mem:assignment;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
spring.datasource.platform=H2
spring.h2.console.enabled=true
spring.h2.console.path=/console
server.port=8082
spring.jpa.generate-ddl=true
spring.jpa.hibernate.ddl-auto=create-drop
spring.jpa.show-sql=true
logging.level.com.edsonj.eoh=info
logging.level.org.hibernate=debug
logging.file=logs/assignment-logs<file_sep>package com.edsonj.eoh.entity;
import java.io.Serializable;
import java.util.Date;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.ManyToOne;
import javax.persistence.Temporal;
import javax.persistence.TemporalType;
@Entity
public class Cic implements Serializable {
/**
*
*/
private static final long serialVersionUID = 6583684317342020725L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "cic_id")
private Long cicId;
@Column(name = "cic_type")
private String cicType;
private String subject;
private String body;
@Column(name = "source_system")
private String sourceSystem;
@Column(name = "cic_timestamp")
@Temporal(TemporalType.TIMESTAMP)
private Date cicTimestamp;
@ManyToOne
@JoinColumn(name="entity_id")
private Party party;
public Cic() {
super();
}
public Cic(String cicType, String subject, String body, String sourceSystem, Date cicTimestamp) {
super();
this.cicType = cicType;
this.subject = subject;
this.body = body;
this.sourceSystem = sourceSystem;
this.cicTimestamp = cicTimestamp;
}
public Long getCicId() {
return cicId;
}
public void setCicId(Long cicId) {
this.cicId = cicId;
}
public String getCicType() {
return cicType;
}
public void setCicType(String cicType) {
this.cicType = cicType;
}
public String getSubject() {
return subject;
}
public void setSubject(String subject) {
this.subject = subject;
}
public String getBody() {
return body;
}
public void setBody(String body) {
this.body = body;
}
public String getSourceSystem() {
return sourceSystem;
}
public void setSourceSystem(String sourceSystem) {
this.sourceSystem = sourceSystem;
}
public Date getCicTimestamp() {
return cicTimestamp;
}
public void setCicTimestamp(Date cicTimestamp) {
this.cicTimestamp = cicTimestamp;
}
public Party getParty() {
return party;
}
public void setEntity(Party party) {
this.party = party;
}
@Override
public String toString() {
return "Cic [cicId=" + cicId + ", cicType=" + cicType + ", subject=" + subject + ", body=" + body
+ ", sourceSystem=" + sourceSystem + ", cicTimestamp=" + cicTimestamp + ", party=" + party + "]";
}
}
<file_sep>package com.edsonj.eoh.service.impl;
import static org.junit.Assert.assertEquals;
import static org.mockito.Mockito.times;
import static org.mockito.Mockito.verify;
import static org.mockito.Mockito.when;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.mockito.InjectMocks;
import org.mockito.Mock;
import org.mockito.Spy;
import org.mockito.runners.MockitoJUnitRunner;
import com.edsonj.eoh.entity.Party;
import com.edsonj.eoh.service.EntityService;
@RunWith(MockitoJUnitRunner.class)
public class EntityServiceImplTest {
@Mock
private EntityService entityService;
@Mock
private Party party;
@Before
public void setUp() {
when(entityService.saveEntity(party)).thenReturn(party);
}
@Test
public void shouldSaveAndReturnTheSavedPartyRecord() {
Party result = entityService.saveEntity(party);
assertEquals(party, result);
verify(entityService, times(1) ).saveEntity(party);
}
}
<file_sep>package com.edsonj.eoh.service.impl;
import static org.junit.Assert.assertEquals;
import static org.mockito.Matchers.anyLong;
import static org.mockito.Mockito.times;
import static org.mockito.Mockito.verify;
import static org.mockito.Mockito.when;
import org.junit.Before;
import org.junit.Test;
import org.mockito.InjectMocks;
import org.mockito.Mock;
import org.mockito.MockitoAnnotations;
import org.mockito.Spy;
import com.edsonj.eoh.dao.CicDao;
import com.edsonj.eoh.dao.EntityDao;
import com.edsonj.eoh.entity.Cic;
import com.edsonj.eoh.entity.Party;
import com.edsonj.eoh.exception.BusinessValidationException;
import com.edsonj.eoh.service.CicService;
public class CicServiceImplTest {
@Spy
@InjectMocks
private CicServiceImpl cicServiceImpl;
@Mock
private CicService cicService;
@Mock
private CicDao cicDao;
@Mock
private EntityDao entityDao;
@Mock
private Cic cic;
@Mock
private Party party;
private static final Long PARTY_ID = 1L;
private static final Long CIC_ID = 2L;
@Before
public void setUp() {
MockitoAnnotations.initMocks(this);
when(cicDao.findOne(anyLong())).thenReturn(cic);
when(cicDao.save(cic)).thenReturn(cic);
when(entityDao.save(party)).thenReturn(party);
}
@Test
public void shouldSaveAnEntityIfItExistsInTheDatabase() {
Cic findOne = cicDao.findOne(CIC_ID);
assertEquals(cic, findOne);
verify(cicDao, times(1)).findOne(CIC_ID);
}
@Test
public void shouldSaveAnEntityRecordToTheDatabaseWithTheGivenEntity() {
when(cic.getParty()).thenReturn(party);
when(party.getEntityId()).thenReturn(PARTY_ID);
when(entityDao.findOne(PARTY_ID)).thenReturn(null);
cicServiceImpl.saveCic(cic);
verify(entityDao, times(1)).save(party);
}
@Test
public void shouldSaveCicRecordToTheDatabaseWithTheGivenEntity() {
when(cic.getParty()).thenReturn(party);
when(party.getEntityId()).thenReturn(PARTY_ID);
when(entityDao.findOne(PARTY_ID)).thenReturn(party);
Cic saveCic = cicServiceImpl.saveCic(cic);
assertEquals(cic, saveCic);
}
@Test
public void shouldSaveEntityAssociatedWithPartyIfItDoesNotExist() {
when(cic.getParty()).thenReturn(party);
when(party.getEntityId()).thenReturn(null);
when(entityDao.findOne(PARTY_ID)).thenReturn(null);
cicServiceImpl.saveCic(cic);
verify(entityDao, times(1)).save(party);
}
@Test(expected=BusinessValidationException.class)
public void shouldThrowEcxeptionWhenEntityObjectIsNotSet() {
when(cic.getParty()).thenReturn(null);
cicServiceImpl.saveCic(cic);
}
}
| 1903caae976319d8e49804584ff42188426b9a1c | [
"Java",
"INI"
] | 6 | Java | edsonj85/Goldenrule | 7840ed3490dca09f5057a509a01d6104c50938c7 | 189c89ed37de7a61a96fb9d7be366bec87dc02de |
refs/heads/master | <file_sep>import webpack from 'webpack';
import detect from 'detect-port';
import openBrowsers from 'open-browsers';
import WebpackDevServer from 'webpack-dev-server';
import load from 'loading-cli';
import 'colors-cli/toxic';
import conf from './conf/webpack.config.dev';
let PORT = 2087;
const HOST = 'localhost';
const compiler = webpack(conf);
const loading = load('Compiler is running...'.green).start();
loading.color = 'green';
// https://webpack.js.org/api/compiler-hooks/#aftercompile
// 编译完成之后打印日志
compiler.hooks.done.tap('done', () => {
loading.stop();
// eslint-disable-next-line
console.log(`\nDev Server Listening at ${`http://${HOST}:${PORT}`.green}`);
});
detect(PORT).then((_port) => {
if (PORT !== _port) PORT = _port;
const devServer = new WebpackDevServer(compiler, {
// contentBase: conf.output.appPublic,
publicPath: conf.output.publicPath,
hot: true,
historyApiFallback: true,
quiet: true,
})
devServer.listen(PORT, HOST, (err) => {
if (err) {
return console.log(err); // eslint-disable-line
}
// open browser
openBrowsers(`http://${HOST}:${PORT}`);
['SIGINT', 'SIGTERM'].forEach((sig) => {
process.on(sig, () => {
devServer.close();
process.exit();
});
});
});
}).catch((err) => {
console.log(err); // eslint-disable-line
});
| 68fe2c166fbd650828b8cdc4efcebc864c2675e6 | [
"JavaScript"
] | 1 | JavaScript | krishna2nd/uiw | 09bf71589f22b7ccd9f82461597d76ea0d359396 | be82b954d11bc1f5e3226cbf59c178711c064a89 |
refs/heads/master | <repo_name>ranggakd/HT_log<file_sep>/ht_log.sql
-- phpMyAdmin SQL Dump
-- version 4.7.7
-- https://www.phpmyadmin.net/
--
-- Host: 127.0.0.1
-- Waktu pembuatan: 22 Jan 2020 pada 09.27
-- Versi server: 10.1.30-MariaDB
-- Versi PHP: 7.2.2
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET AUTOCOMMIT = 0;
START TRANSACTION;
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8mb4 */;
--
-- Database: `ht_log`
--
-- --------------------------------------------------------
--
-- Struktur dari tabel `bagian`
--
CREATE TABLE `bagian` (
`id_bagian` int(11) NOT NULL,
`nama` varchar(255) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--
-- Dumping data untuk tabel `bagian`
--
INSERT INTO `bagian` (`id_bagian`, `nama`) VALUES
(1, 'PMK');
-- --------------------------------------------------------
--
-- Struktur dari tabel `metadata`
--
CREATE TABLE `metadata` (
`id_metadata` int(11) NOT NULL,
`nama` varchar(255) NOT NULL,
`waktu` date NOT NULL,
`file` varchar(255) NOT NULL,
`id_bagian` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--
-- Dumping data untuk tabel `metadata`
--
INSERT INTO `metadata` (`id_metadata`, `nama`, `waktu`, `file`, `id_bagian`) VALUES
(1, '21-01-20 16:51:21.mp3', '2021-01-20', 'pmk/21-01-2020_16-51-21.mp3', 1);
-- --------------------------------------------------------
--
-- Struktur dari tabel `user`
--
CREATE TABLE `user` (
`id_user` int(11) NOT NULL,
`nama` varchar(255) NOT NULL,
`hak` int(11) NOT NULL,
`username` varchar(255) NOT NULL,
`password` varchar(255) NOT NULL,
`created_at` datetime DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--
-- Indexes for dumped tables
--
--
-- Indeks untuk tabel `bagian`
--
ALTER TABLE `bagian`
ADD PRIMARY KEY (`id_bagian`);
--
-- Indeks untuk tabel `metadata`
--
ALTER TABLE `metadata`
ADD PRIMARY KEY (`id_metadata`);
--
-- Indeks untuk tabel `user`
--
ALTER TABLE `user`
ADD PRIMARY KEY (`id_user`);
--
-- AUTO_INCREMENT untuk tabel yang dibuang
--
--
-- AUTO_INCREMENT untuk tabel `bagian`
--
ALTER TABLE `bagian`
MODIFY `id_bagian` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=2;
--
-- AUTO_INCREMENT untuk tabel `metadata`
--
ALTER TABLE `metadata`
MODIFY `id_metadata` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=2;
--
-- AUTO_INCREMENT untuk tabel `user`
--
ALTER TABLE `user`
MODIFY `id_user` int(11) NOT NULL AUTO_INCREMENT;
COMMIT;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
<file_sep>/transfer.py
import time
import os
import paramiko
host = '10.151.62.223'
user = 'duhbuntu'
passw = '<PASSWORD>'
path_file = '/home/pi/Pinjem/'
remote_path = '/var/www/html/ht_log/public/files/pmk/'
server = paramiko.SSHClient()
server.set_missing_host_key_policy(paramiko.AutoAddPolicy())
server.connect(hostname=host,username=user,password=passw)
while(1):
t = time.localtime()
current_time = time.strftime("%d-%m-%Y_%H-%M-%S", t)
nama_file = current_time+'.mp3'
local_path = path_file+nama_file
# print local_path
if(os.path.exists(local_path)):
ftp = server.open_sftp()
ftp.put(local_path,remote_path+nama_file)
ftp.close()
time.sleep(0.5)
<file_sep>/app/Metadata.php
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
class Metadata extends Model
{
//
protected $table = 'metadata';
protected $fillable = ['nama','waktu','file','id_bagian'];
public $timestamp = false;
}
<file_sep>/routes/web.php
<?php
/*
|--------------------------------------------------------------------------
| Web Routes
|--------------------------------------------------------------------------
|
| Here is where you can register web routes for your application. These
| routes are loaded by the RouteServiceProvider within a group which
| contains the "web" middleware group. Now create something great!
|
*/
// Route::get('/', function () {
// return view('welcome');
// });
Route::get('/home','Home\HomeControl@index');
Route::get('/','Home\HomeControl@index');
Route::get('/homes','Home\HomeControl@dashboard'); //it's suppposed to be our dashboard, feel free to edited the the URL params
Route::get('/signup','Home\HomeControl@signup');
Route::get('/signin','Home\HomeControl@signin');
Route::get('/profil','Home\HomeControl@profil');
Route::get('/404', function () {
return abort(404);
});
Route::get('/500', function () {
return abort(500);
})->name('500');
// Route for downloading audio
Route::get('/audio/{filename}','Home\HomeControl@downloads')->where('filename','^.*\.wav$');
Route::post('/get_data','Home\HomeControl@get_data');<file_sep>/server.py
import time
import os
import mysql.connector
# pmk_path = '/var/www/html/ht_log/public/audio/pmk/'
pmk_path = 'public/audio/pmk/'
untracked = []
while(1):
# for a in untracked:
# try:
# mydb = mysql.connector.connect(
# host="127.0.0.1",
# user="root",
# passwd="",
# database="ht_log"
# )
# mycursor = mydb.cursor()
# public_pmk = 'pmk/'+current_time+'.mp3'
# sql = "INSERT INTO metadata (nama,id_bagian,waktu,file) VALUES (%s,(SELECT id_bagian from bagian where nama = 'PMK'),%s,%s)"
# val = (name,curr_time,public_pmk )
# mycursor.execute(sql, val)
# mydb.commit()
# except:
# print('untracked')
# finally:
# untracked.remove(a)
t = time.localtime()
current_time = time.strftime("%d-%m-%Y_%H-%M-%S", t)
print(pmk_path+current_time+'.mp3')
if(os.path.exists(pmk_path+current_time+'.mp3')):
curr_time = time.strftime("%d-%m-%Y %H:%M:%S", t)
name = curr_time+'.mp3'
try:
mydb = mysql.connector.connect(
host="127.0.0.1",
user="root",
passwd="",
database="ht_log"
)
mycursor = mydb.cursor()
public_pmk = 'pmk/'+current_time+'.mp3'
sql = "INSERT INTO metadata (nama,id_bagian,waktu,file) VALUES (%s,(SELECT id_bagian from bagian where nama = 'PMK'),%s,%s)"
val = (name,curr_time,public_pmk )
mycursor.execute(sql, val)
mydb.commit()
except:
print('untracked')
untracked.append(name)
time.sleep(0.5)<file_sep>/app/Http/Controllers/Home/HomeControl.php
<?php
namespace App\Http\Controllers\Home;
use Illuminate\Http\Request;
use App\Http\Controllers\Controller;
use App\Metadata;
use Illuminate\Support\Facades\DB;
use App\Bagian;
class HomeControl extends Controller
{
public function index()
{
$metadata = Metadata::all();
$bagian = Bagian::all();
return view('dashboard.index',compact('metadata','bagian'));
}
public function dashboard()
{
return view('dashboard.dashboard');
}
public function signup()
{
return view('dashboard.signup');
}
public function signin()
{
return view('dashboard.signin');
}
public function profil()
{
return view('dashboard.profil');
}
public function downloads()
{
// might change it later
$file = public_path()."/audio/bruh.wav";
$header = array(
'Content-Type: application/octet-stream',
);
// might change second args later
return Response::download($file, 'bruh.wav', $header);
// return response()->download($file, 'bruh.wav', $header);
}
public function get_data(Request $request)
{
$query = 'select metadata.waktu as nama, bagian.nama as bagian, metadata.file from metadata join bagian on metadata.id_bagian = bagian.id_bagian where metadata.waktu is not null';
if(isset($_POST['mulai']) && $_POST['mulai']!=''){
$mulai = $_POST['mulai'];
$query = $query . " and metadata.waktu >= '" . $mulai . "' ";
}
if(isset($_POST['hingga']) && $_POST['hingga']!=''){
$hingga = $_POST['hingga'];
$query = $query . " and metadata.waktu <= '" . $hingga . "' ";
}
if(isset($_POST['bagian']) && $_POST['bagian']!='-'){
$bagian = $_POST['bagian'];
$query = $query . " and bagian.id_bagian = " . $bagian . " ";
}
$query .= ' order by nama DESC';
$metadatas = DB::select($query);
return response()->json([
'data' => $metadatas,
'debug' => $query
]);
}
}
<file_sep>/README.md
# HT_log
Kebutuhan Kerja Praktik 2020
## Tabel Headline Progress
| NO | Tanggal | Hari | Link |
|----|-----------------|--------|-------------------------------------------|
| 1 | 7 Januari 2019 | Selasa | [Progress #1](#hari-1) |
| 2 | 8 Januari 2019 | Rabu | [Progress #2](#hari-2) |
| 3 | 9 Januari 2019 | Kamis | [Progress #3](#hari-3) |
| 4 | 10 Januari 2019 | Jumat | [Progress #4](#hari-4)|
| 5 | 7 Januari 2019 | Selasa | |
| 6 | 7 Januari 2019 | Selasa | |
| 7 | 7 Januari 2019 | Selasa | |
| 8 | 7 Januari 2019 | Selasa | |
| 9 | 7 Januari 2019 | Selasa | |
| 10 | 7 Januari 2019 | Selasa | |
## List To Do:
- [x] init project
- [x] routing #1 (kebutuhan fitur utama secara static)
- [x] view (table, play, download secara static)
- [ ] routing #2 (kebutuhan fitur utama secara dynamic)
- [ ] view (table, play, download secara dynamic)
- [ ] to be continued
## Progress
### Hari #1
Poin-poin progress hari ini, sebagai berikut:
- Berhasil ping raspberry pi ke dan dari network local
- Contoh template
Penjelasan lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala
- Contoh template
Penjelasan lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala
### Hari #2
Poin-poin progress hari ini, sebagai berikut:
- Berhasil ping raspberry pi ke dan dari network local
- Contoh template
Penjelasan lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala
- Contoh template
Penjelasan lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala lalalala lalalala lala lalala
### Hari #3
### Hari #4
- Membuat fitur play audio, download audio dan route (static)
- Membuat tabel berisi meta data audio (berisi data dummies)
| fe8444ef6261b8f298cde13b8049a5419d72fd12 | [
"Markdown",
"SQL",
"Python",
"PHP"
] | 7 | SQL | ranggakd/HT_log | 64454a9309ee093836e3446eaa6d20c8a18839a5 | 5ca99e8df419d2d5929de2985093c8e7f425f519 |
refs/heads/master | <repo_name>dannylee8/module-3-project-api<file_sep>/app/services/bet_serializer.rb
class BetSerializer < ActiveModel::Serializer
# include FastJsonapi::ObjectSerializer
attributes :user_id, :result, :amount, :created_at
belongs_to :user
end<file_sep>/db/seeds.rb
# This file should contain all the record creation needed to seed the database with its default values.
# The data can then be loaded with the rails db:seed command (or created alongside the database with db:setup).
#
# Examples:
#
# movies = Movie.create([{ name: 'Star Wars' }, { name: 'Lord of the Rings' }])
# Character.create(name: 'Luke', movie: movies.first)
require 'faker'
puts "Destroying all bets"
Bet.all.destroy_all
puts "Destroying all comments"
Comment.all.destroy_all
puts "Destroying users"
User.all.destroy_all
puts "Creating Users"
50.times do
User.create(
name: Faker::Name.first_name,
password: <PASSWORD>,
balance: rand(1..30),
total_profit: rand(1..60)
)
end
puts "Creating Bets"
50.times do
Bet.create(
user_id: rand(1..50),
amount: rand(1..25),
result: [true, false].sample
)
end
puts "Creating Comments"
50.times do
Comment.create(
user_id: rand(1..50),
comment: Faker::Lorem.sentence(word_count: 5, supplemental: true, random_words_to_add: 8)
)
end
comments = Comment.all
comments.each do |c|
c.name = c.user.name
c.save
end
<file_sep>/app/controllers/api/v1/bets_controller.rb
class Api::V1::BetsController < ApplicationController
def index
bets = Bet.all
render json: {bets: bets}
end
def create
bet = Bet.create(amount: params[:amount], result: params[:result], user_id: params[:user_id])
render json: {bet: bet}
end
end
<file_sep>/app/models/user.rb
class User < ApplicationRecord
has_many :bets
has_many :comments
def self.get_highest_earner
self.all.max_by { |user| user.total_profit }
end
end
<file_sep>/app/services/user_serializer.rb
class UserSerializer < ActiveModel::Serializer
def initialize(user)
@user = user
end
def to_serialized_json
@user.to_json(:include => {
:bets => {:only => [:result, :amount]},
:comments => {:only => [:comment, :user_id ]}
}, :except => [:updated_at])
end
end
<file_sep>/app/services/comment_serializer.rb
class CommentSerializer < ActiveModel::Serializer
# include FastJsonapi::ObjectSerializer
attributes :name, :comment, :user_id, :created_at
belongs_to :user
end<file_sep>/app/controllers/api/v1/users_controller.rb
class Api::V1::UsersController < ApplicationController
def index
users = User.all
render json: {all_users: users}
end
def show
user = User.find_by(id: params[:id])
render json: UserSerializer.new(user).to_serialized_json
end
def create
if User.find_by(name: params[:name])
user = User.find_by(name: params[:name])
render json: UserSerializer.new(user).to_serialized_json
else
user = User.create(name: params[:name])
render json: UserSerializer.new(user).to_serialized_json
end
end
def update
user = User.find_by(id: params[:id])
user.update(balance: params[:balance], total_profit: params[:totalProfit])
user.save()
render json: {user: user}
end
end
<<<<<<< HEAD
# fetch('http://localhost:3000/api/v1/users', {
# method: 'POST',
# headers: {
# 'content-type': 'application/json',
# 'accept': 'application/json'
# },
# body: JSON.stringify({
# name: 'Garfield'
# })
# })
=======
>>>>>>> 1bc4c7f68763978016367c3c3f61ae68b5322f7f
<file_sep>/app/controllers/api/v1/comments_controller.rb
class Api::V1::CommentsController < ApplicationController
def index
comments = Comment.all
render json: {comments: comments}
end
def create
comment = Comment.create(name: params[:name], comment: params[:comment], user_id: params[:user_id])
render json: {comment: comment}
end
end
| d61e1c3f63417805693993382a565cd0a6981b7a | [
"Ruby"
] | 8 | Ruby | dannylee8/module-3-project-api | 39439db0db4c65356abd5d5d8c8057d540a1c56b | 6e1ec21c1a245c5a1844d84d071b8be6db2eacfe |
refs/heads/master | <repo_name>GuerraAna/app-MeResponda<file_sep>/README.md
# Aplicativo Me Responda: "Me faça uma pergunta?" :question::smiley:
Assista o vídeo a seguir:
[](http://www.youtube.com/watch?v=mFOracFClBg "<NAME>")
## Introdução:
. Você já quis estar mais próximo de brinquedos antigos que hoje em dia estão difíceis de achar?
Pois aqui está a sua chance de desfrutar de um dos brinquedos mais famosos de 1995, a Magic Ball.
. Este Repositório representa mais uma de minhas conquistas como desenvolvedora de apps. A partir dela eu pude desenvolver novas práticas e novos conhecimentos relacionados ao Android Studio, ao Kotlin e ao Design.
## Objetivo | "Desenho animado é coisa de criança?" :older_woman::older_man::girl::baby::man_with_gua_pi_mao:
A importância da animação vai além das fronteiras da infância. Ele tem uma relevância atemporal, pois promove a interação entre pessoas, sejam elas de gerações, lugares e/ou culturas diferentes.
Cabe ressaltar que, segundo a Flow (psicologia positiva), os desenhos animados, assim como, os curta-metragem e longa-metragem estimulam o lado criativo do indivíduo e desenvolvem o hábito de demonstrar as emoções de forma mais positiva. Por conta disso e de outros fatores, devemos ter em mente que o desenhos animados não são apenas para crianças, mas eles também são feitos para a nossa criança interna, ou seja, para os adultos.
A partir de uma cena da longa-metragem Toy Storie ,eu desenvolvi esse app! O meu objetivo é mostrar para os Devs, de todas as idades, que a tecnologia, assim como os desenhos, são apenas brinquedos que podemos utilizar para mudar o mundo de todas as formas possíveis e impossíveis!
## Este Projeto tem como base: :books:
. Kotlin;
. Android Studio;
. Figma.
## Interface do app: :calling:
## Indicação de filmes e desenhos para adultos e crianças desenvolverem a sua criatividade:
. Divertida Mente (<NAME> 2015 - 102 minutos);
. O menino e o mundo (Alê Abreu 2014 - 80 minutos);
. WALL-E (<NAME> 2008 - 103 minutos);
. Wallace e Gromit e a Batalha dos Vegetais (Nick Park 2005 - 95 minutos);
. Meu amigo Totoro (Hayao Miyaki 1988 - 86 minutos).
## Fontes:
1- https://www.flowpsicologiapositiva.com/a-psicologia-das-emocoes-em-divertida-mente/
2- https://blog.saga.art.br/produto-nacional-conheca-5-animacoes-brasileiras-para-ficar-de-olho/
3- https://pt.wikipedia.org/wiki/Toy_Story
4- https://kotlinlang.org/docs/home.html
<file_sep>/app/src/main/java/com/example/meresponda/MainActivity.kt
package com.example.meresponda
import androidx.appcompat.app.AppCompatActivity
import android.os.Bundle
import kotlinx.android.synthetic.main.activity_main.*
import kotlin.random.Random
class MainActivity : AppCompatActivity() {
val res = arrayOf("Sim", "Não conte com isso", "Talvez")
val random = Random.Default
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
button.setOnClickListener {
if (editText.text.isEmpty()) {
textView.text = "Faça a sua pergunta."
} else {
val index: Int = random.nextInt(3)
textView.text = res[index]
}
}
}
} | eff1637f4e8f09efe05bcfe60d2770790f01f8c2 | [
"Markdown",
"Kotlin"
] | 2 | Markdown | GuerraAna/app-MeResponda | eebcff3bce064968061b9f39c3a3916f3f5d77f8 | 9de1b88372f25bfe76a87709580bdd49dc6eeca8 |
refs/heads/master | <file_sep>FROM prima/filebeat
VOLUME /config
VOLUME /logs
<file_sep>from pyspark import SparkConf, SparkContext
import collections
import operator
conf = SparkConf().setMaster("local").setAppName("AccidentCity")
sc = SparkContext(conf = conf)
def parseLine(line):
fields = line.split('\t')
cityState = fields[1]
cityStateArray = cityState.split(',')
if len(cityStateArray) == 2 and cityStateArray[0] != "\"N/A" and cityStateArray[0] != "\"NA":
return (cityStateArray[0])
else:
return
lines = sc.textFile("file:///SparkCourse/allDataTsv.txt")
rdd = lines.map(parseLine)
result = rdd.countByValue()
sortedResults = collections.OrderedDict(sorted(result.items(), key=operator.itemgetter(1), reverse=True)[:11])
for key, value in sortedResults.iteritems():
if key != None:
print "%s %i" % (key, value)
<file_sep># Spark-Accident-Analysis
Use train wreck datasets http://www.trainwreckdb.com/ with spark service to figure out what are the 10 most dangerous places for accidents
<file_sep>package cmpe272.com.accidentopedia;
import android.app.Activity;
import android.content.SharedPreferences;
import android.os.Bundle;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
import android.widget.RadioButton;
public class SettingsActivity extends Activity {
RadioButton fifty,seventyFIve,hundres,yes,no;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_settings);
SharedPreferences settings = getSharedPreferences(AppConstants.PREFS_NAME, 0);
int allowDrunk = settings.getInt("drunk", -1);
int numMarkers=settings.getInt("numMarkers", 50);
fifty=(RadioButton)findViewById(R.id.fifty);
seventyFIve=(RadioButton)findViewById(R.id.seventyFive);
hundres=(RadioButton)findViewById(R.id.hundred);
yes=(RadioButton)findViewById(R.id.yes);
no=(RadioButton)findViewById(R.id.no);
if(numMarkers==50)
{
fifty.setChecked(true);
}else if(numMarkers==75)
{
seventyFIve.setChecked(true);
}else{
hundres.setChecked(true);
}
if(allowDrunk==-1)
{
yes.setChecked(true);
}else{
no.setChecked(true);
}
Button update=(Button)findViewById(R.id.Update);
update.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
// TODO Auto-generated method stub
int num=50;
if(seventyFIve.isChecked())
{
num=75;
}else if(hundres.isChecked()){
num=100;
}
int allow=-1;
if(no.isChecked())
{
allow=1;
}
SharedPreferences settings = getSharedPreferences(AppConstants.PREFS_NAME, 0);
SharedPreferences.Editor editor = settings.edit();
editor.putInt("drunk", allow);
editor.putInt("numMarkers", num);
// Commit the edits!
editor.commit();
}
});
}
}
<file_sep>---
title: "Road Safety - Accidents in UK, 2014"
output: html_document
---
```{r set-options, echo=FALSE, cache=FALSE}
options(width = 200)
```
___
#### *Authors:* <NAME> & <NAME>
#### *Date*: April 13, 2016
#### *The Dataset [Source](https://data.gov.uk/dataset/road-accidents-safety-data)*
___
### *Data Description*
- This file provide detailed road safety data about the circumstances of personal injury road accidents from 2014, UK, the types (including Make and Model) of vehicles involved and the consequential casualties.
- The statistics relate only to personal injury accidents on public roads that are reported to the police, and subsequently recorded, using the STATS19 accident reporting form.
- The relevant properties in the dataset:
Properties | Description
----------------------- | ------------------------------------------
*Accident_Index* | **ID** number of an accident
*Longitude* | The **longitude** of the place where the accident happened
*Latitude* | The **latitude** of the place where the accident happened
*Number_of_Vehicles* | The number of **vehicles** in the accident
*Number_of_Casualties* | The number of **casualties** in the accident
*Date* | The **date** on which the accident occurred
*Day_of_Week* | The **day** of week on which the accident occurred
*Time* | The **time** on which the accident occurred
___
### *Data Example - Reading first data records*
```{r include= TRUE, echo=FALSE}
library("downloader")
folder<-".\\data\\DfTRoadSafety_Accidents_2014.csv"
if(!file.exists(folder)){
# Download a csv file from the Internet:
fileURL <- "https://dl.dropboxusercontent.com/u/73991112/DfTRoadSafety_Accidents_2014.csv"
download.file(fileURL, destfile = folder)
# Always record the date
dateDownloaded <- date()
dateDownloaded
}
# Read from local drive
accidentsData <- read.csv(folder, sep = ",",header = T, row.names=NULL)[,c(1,4:5,8:12)]
# Reading the first records :
head(accidentsData)
```
___
### *Summary*
- Statistics on the number of **vehicles** and **casualties** that were involved in an accident:
```{r echo=FALSE}
summary(accidentsData[,c(4:5)])
```
___
### *Analysis of the Data by Various Criteria*
___
#### *The graph below shows the **distribution** of accidents in the **UK***
```{r include= TRUE, echo=FALSE, warning=FALSE}
library(MASS)
library(RgoogleMaps)
# Keep the lon and lat data
rawdata <- data.frame(as.numeric(accidentsData$Longitude), as.numeric(accidentsData$Latitude))
names(rawdata) <- c("lon", "lat")
# Mapping via RgoogleMaps
# Find map center and get map
center <- rev(sapply(rawdata, mean))
map <- GetMap(center=center, zoom=7)
# Translate original data
coords <- LatLon2XY.centered(map, rawdata$lat, rawdata$lon, 7)
coords <- data.frame(coords)
# Plot
PlotOnStaticMap(map)
points(coords$newX, coords$newY, pch=16, cex=0.3, col=heat.colors(12,0.1))
```
As can be seen from the graph, the majority of road accidents occur in **urban areas**.
This phenomenon is a logical result because:
- The **number of vehicles** in urban areas is higher than in non-urban areas.
- In urban areas there is **activity around the clock**, as opposed to areas that are not urban.
___
#### *The graph below shows the **distribution** of road accidents during **the week***
```{r include= TRUE, echo=FALSE, warning=FALSE}
# Pie Chart from data frame with Appended Sample Sizes
mytable <- table(accidentsData$Day_of_Week)
days<-c('Sunday','Monday','Tuesday','Wednesday','Thursday','Friday','Saturday')
bls <- paste(days, "\n",mytable , sep="")
pie(mytable, labels =bls, main="Pie Chart of accidents during\ndays of the week",col=terrain.colors(7))
```
As can be seen from the graph:
- The **majority** of road accidents occur in **Friday**.
- The **minority** of road accidents occur in **Sunday**.
This phenomenon is a logical result because:
- Most people in UK drive on **Friday** to make arrangements ahead of the weekend, what creating congestion on the roads, which leads to a **high number of accidents** on this day.
- Most people in the UK do not drive on **Sunday** - it is a **day off** - so there are few cars on the road which leads a **small number of road accidents** on this day.
___
#### *The graph below shows the **distribution** of accidents in the during **the day***
```{r include= TRUE, echo=FALSE, warning=FALSE}
hist(as.numeric(substr(accidentsData$Time,1,2)),main="Histogram for Number of Accidents\nVS\nHour", xlab="Hour",col=terrain.colors(24), ylab="Number of Accidents",las = 1)
```
As can be seen from the graph:
- The **majority** of road accidents occur in **17:00-18:00**.
- The **minority** of road accidents occur in **03:00:04:00**.
This phenomenon is a logical result because:
- Most people in UK drive back home in **17:00-18:00**, what creating congestion on the roads, which leads to a **high number of accidents** on this day.
- Most people in the UK do not drive in **03:00:04:00**, so there are few cars on the road which leads a **small number of road accidents** on this day.
___
### *Summary, Conclusions and Recommendations for Further Research.*
In conclusion, this report shows that road accidents have common attributes, such as **day, time and location** - that can learn from and draw on some of the reasons why they happen.
Our recommendation for further research, is to cross-check between the common attributes that presented in this report and deduce information that could indicate **when and where** there is a likelihood that a road accident will happend.
After analyzing this information, it will be possible to increase the presence of police forces in order to reduce the quantity of traffic accidents and thereby save lives.
<file_sep>package cmpe272.com.accidentopedia;
import android.app.PendingIntent;
import android.content.BroadcastReceiver;
import android.content.Context;
import android.content.Intent;
import android.net.Uri;
import android.util.Log;
public class intentreciver extends BroadcastReceiver {
protected int callEmergency( Context context) {
Intent callIntent = new Intent(Intent.ACTION_CALL);
callIntent.setData(Uri.parse("tel:6509193890"));
PendingIntent call1 = PendingIntent.getBroadcast(context, 0,callIntent, 0);
return 0;
}
@Override
public void onReceive(Context context, Intent intent) {
// TODO Auto-generated method stub
Log.i("MyActivity", "Its coming for receive 1");
callEmergency(context);
}
}
<file_sep>package cmpe272.com.accidentopedia;
import android.content.Intent;
import android.content.SharedPreferences;
import android.location.LocationManager;
import android.os.Bundle;
import android.support.v7.app.ActionBarActivity;
import android.util.Log;
import android.view.Menu;
import android.view.MenuInflater;
import android.view.MenuItem;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
public class MainActivity extends ActionBarActivity{
LocationManager locationManager;
String provider;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Button startButton = (Button) findViewById(R.id.enable);
startButton.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
SharedPreferences settings = getSharedPreferences(AppConstants.PREFS_NAME, 0);
Log.d("Response", settings.getInt("id", -1)+"");
if(settings.getInt("id", -1)==-1)
{
startActivity(new Intent(MainActivity.this,LoginActivity.class));
}else{
startService(new Intent(MainActivity.this,TrackService.class));
// check if GPS enabled
}
}
});
Button analytics = (Button) findViewById(R.id.analytics);
analytics.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
startActivity(new Intent(MainActivity.this,AnalyticsActivity.class)); // check if GPS enabled
}
});
Button report=(Button)findViewById(R.id.report);
report.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
// TODO Auto-generated method stub
startActivity(new Intent(MainActivity.this,MainActivity1.class)); // check if GPS enabled
}
});
}
public boolean onCreateOptionsMenu(Menu menu) {
MenuInflater Inflater = getMenuInflater();
Inflater.inflate(R.menu.main, menu);
return true;
}
@Override
public boolean onOptionsItemSelected(MenuItem item) {
if (item.getItemId() == R.id.logout) {
SharedPreferences settings = getSharedPreferences(AppConstants.PREFS_NAME, 0);
SharedPreferences.Editor editor = settings.edit();
editor.remove("id");
editor.commit();
finish();
}
if (item.getItemId() == R.id.settings) {
startActivity(new Intent(MainActivity.this, SettingsActivity.class));
}
return super.onOptionsItemSelected(item);
}
}<file_sep># Graph on Accidents Paris
## Usage ##
```bash
docker-compose build
docker-compose up
```
When all is containers have started OK, drop ./source/back/accidentology23.csv to to ./source that will trigger the filebeat shipper.
Open a browser 192.168.99.100:5601 and setup the index pattern "accidentology". Check all events are there (there should be around 13.6K )
Play with the plugin Graph
<file_sep>package cmpe272.com.accidentopedia;
import java.util.ArrayList;
import com.google.android.gms.maps.model.LatLng;
import android.app.Notification;
import android.app.NotificationManager;
import android.app.PendingIntent;
import android.content.BroadcastReceiver;
import android.content.Context;
import android.content.Intent;
import android.support.v4.app.NotificationCompat;
import android.util.Log;
public class LocationReceiver extends BroadcastReceiver {
public LocationReceiver() {
}
@Override
public void onReceive(Context context, Intent i) {
// TODO: This method is called when the BroadcastReceiver is receiving
// an Intent broadcast.
Log.d("Broad", "here");
Intent intent = new Intent(context, MapActivity.class);
@SuppressWarnings("unchecked")
ArrayList<LatLng> locs= (ArrayList<LatLng>) i.getSerializableExtra("Locations");
intent.putExtra("points", locs);
}
}
<file_sep>package cmpe272.com.accidentopedia;
import android.app.Fragment;
import android.os.Bundle;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
/**
* A simple {@link Fragment} subclass. Activities that contain this fragment
* must implement the {@link Leftpane.OnFragmentInteractionListener} interface
* to handle interaction events. Use the {@link Leftpane#newInstance} factory
* method to create an instance of this fragment.
*
*/
public class Leftpane extends android.support.v4.app.Fragment {
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
View v = inflater.inflate(R.layout.leftpane, container, true);
return v;
}
}
<file_sep>package cmpe272.com.accidentopedia;
import java.util.Locale;
import android.app.Activity;
import android.content.ComponentName;
import android.content.Context;
import android.content.Intent;
import android.location.Location;
import android.location.LocationListener;
import android.location.LocationManager;
import android.net.Uri;
import android.os.Bundle;
import android.speech.tts.TextToSpeech;
import android.telephony.PhoneStateListener;
import android.telephony.TelephonyManager;
import android.util.Log;
import android.view.Menu;
import android.view.View;
import android.widget.EditText;
import android.widget.RemoteViews;
import android.widget.Toast;
public class Callingemergency extends Activity {
TextToSpeech ttobj;
double lat;
double lng;
int called=0;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.callingemergency);
Context context = getApplicationContext();
TelephonyManager telephonyManager = (TelephonyManager) getSystemService(Context.TELEPHONY_SERVICE);
// register PhoneStateListener
PhoneStateListener callStateListener = new PhoneStateListener() {
public void onCallStateChanged(int state, String incomingNumber) {
// React to incoming call.
// number=incomingNumber;
// If phone ringing
if (state == TelephonyManager.CALL_STATE_RINGING) {
Toast.makeText(getApplicationContext(), "Phone Is Riging",
Toast.LENGTH_LONG).show();
}
// If incoming call received
if (state == TelephonyManager.CALL_STATE_OFFHOOK) {
Toast.makeText(getApplicationContext(),
"Phone is Currently in A call", Toast.LENGTH_LONG)
.show();
}
if (state == TelephonyManager.CALL_STATE_IDLE) {
Toast.makeText(getApplicationContext(),
"phone is neither ringing nor in a call",
Toast.LENGTH_LONG).show();
}
}
};
telephonyManager.listen(callStateListener,
PhoneStateListener.LISTEN_CALL_STATE);
// Location things
LocationManager locationManager = (LocationManager) context
.getSystemService(context.LOCATION_SERVICE);
// final Location loc =
// locationManager.getLastKnownLocation(LOCATION_SERVICE);
LocationListener locationListener = new LocationListener() {
public void onLocationChanged(Location location) {
lat = location.getLatitude();
lng = location.getLongitude();
Log.i("Latitude is are", Double.toString(lat));
Log.i("Longitude is", Double.toString(lng));
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
speakText();
Log.i("Location", Double.toString(location.getLatitude()));
}
@Override
public void onStatusChanged(String provider, int status,
Bundle extras) {
Log.i("Location", "Status Changed");
// TODO Auto-generated method stub
}
@Override
public void onProviderEnabled(String provider) {
// TODO Auto-generated method stub
Log.i("Location", "Provider Enabled");
}
@Override
public void onProviderDisabled(String provider) {
// TODO Auto-generated method stub
Log.i("Location", "Provide Disabled");
}
};
locationManager.requestLocationUpdates(LocationManager.GPS_PROVIDER,
1000, 0, locationListener);
// Location things end here
ttobj = new TextToSpeech(getApplicationContext(),
new TextToSpeech.OnInitListener() {
@Override
public void onInit(int status) {
if (status != TextToSpeech.ERROR) {
ttobj.setLanguage(Locale.UK);
Log.i("TexttoSpeect Enabled", "In Looop");
speakText();
}
}
});
}
@Override
public void onPause() {
if (ttobj != null) {
ttobj.stop();
ttobj.shutdown();
}
super.onPause();
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
// Inflate the menu; this adds items to the action bar if it is present.
getMenuInflater().inflate(R.menu.main, menu);
return true;
}
@SuppressWarnings("deprecation")
public void speakText() {
int f=0;
while (f<5) {
f++;
try {
Thread.sleep(11000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Log.i("Calling Emergency", "In Looop");
if (!ttobj.isSpeaking()) {
String toSpeak = "Calling Emergency 9 1 1, Coordinates are latitude "
+ Double.toString(lat)
+ " longitude "
+ Double.toString(lng);
Toast.makeText(getApplicationContext(), toSpeak,
Toast.LENGTH_SHORT).show();
ttobj.speak(toSpeak, TextToSpeech.QUEUE_FLUSH, null);
if(called==0)
{
callEmergency();
called =1;
}
}
}
}
protected void callEmergency() {
Log.i("MyActivity", "Caling emergency");
Context cont = Callingemergency.this;
Intent callIntent = new Intent(Intent.ACTION_CALL);
callIntent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
callIntent.setData(Uri.parse("tel:6509193890"));
// context.Sta(callIntent);
Log.i("Calling 911", "Caling Intent for calling");
cont.startActivity(callIntent);
// PendingIntent call1 = PendingIntent.getBroadcast(context,
// 0,callIntent, 0);
called = 1;
}
}
<file_sep>FROM logstash
VOLUME /config
VOLUME /logs
RUN plugin install logstash-output-redis
RUN plugin install logstash-input-redis
RUN plugin install logstash-input-heartbeat
CMD ["logstash", "agent"]
| b3f59050ea8c8a2eb3d795eb794846be2d8512b4 | [
"RMarkdown",
"Markdown",
"Java",
"Python",
"Dockerfile"
] | 12 | Dockerfile | Pooja-Mahadev-Soundalgekar/IEEE-Accident-Prone-Area-Detection | 0857128208ff1d0af66793a9a54f6cb7672a2624 | 7339ddea0e61480970d2103be90060f88daf87d9 |
refs/heads/master | <repo_name>fgfan98/smart_community<file_sep>/src/main/java/com/gigsider/vo/AdminVO.java
package com.gigsider.vo;
import com.gigsider.po.Admin;
import org.springframework.stereotype.Service;
@Service
public class AdminVO {
private Admin admin;
private String msg;
public Admin getAdmin() {
return admin;
}
public void setAdmin(Admin admin) {
this.admin = admin;
}
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
}
<file_sep>/src/main/java/com/gigsider/service/ComunitiService.java
package com.gigsider.service;
import com.gigsider.po.Comuniti;
import java.util.List;
import java.util.Map;
public interface ComunitiService {
//新增帖子
public boolean addComuniti(Comuniti comuniti);
//删除帖子
public boolean delComuniti(int id);
//更新帖子
public boolean upComuniti(Comuniti comuniti);
//获取所有帖子
public List<Comuniti> getAllComuniti();
//分页查询
public List<Comuniti> getComunitiPage(int page, int limit);
//根据 id 查询帖子
public List<Comuniti> getComunitiById(int id);
//模糊查询分页
public List<Comuniti> getComunitiLikePage(String like, int page, int limit);
//模糊查询
public List<Comuniti> getComunitiLike(String like);
//根据 post_id 查询帖子
public List<Comuniti> getComunitiByPostId(String post_id);
//post_id 分页
public List<Comuniti> getComunitiByPostIdPage(String post_id, int page, int limit);
//获取被举报的帖子
public List<Comuniti> getReportedComuniti();
//举报帖子
public boolean reportComuniti(int id);
//取消举报
public boolean unReportComuniti(int id);
}
<file_sep>/src/main/java/com/gigsider/service/FeedbackService.java
package com.gigsider.service;
import com.gigsider.po.Feedback;
import java.util.List;
public interface FeedbackService {
//添加反馈
public boolean addFeedback(Feedback feedback);
//删除反馈
public boolean delFeedback(int id);
//更新反馈
public boolean upFeedback(Feedback feedback);
//获取所有反馈
public List<Feedback> getAllFeedback();
//分页查询
public List<Feedback> getFeedbackPage(int page, int limit);
//根据 id 获取反馈
public List<Feedback> getFeedbackById(int id);
//根据 user_name 获取反馈
public List<Feedback> getFeedbackByUserName(String user_name);
//模糊查询
public List<Feedback> getFeedbackLike(String data);
//查询未回复的反馈
public List<Feedback> getFeedbackNull();
//查询已回复的反馈
public List<Feedback> getFeedbackNNull();
}
<file_sep>/src/main/java/com/gigsider/po/User.java
package com.gigsider.po;
public class User {
private int id;
private String id_num;
private String user_name;
private String real_name;
private String mobile;
private String passwd;
private String sex;
private String house;
private String license_num;
private int activated;
private int authority;
//更新用户信息用的属性
private String house_id; //改变前的 house
public int getAuthority() {
return authority;
}
public void setAuthority(int authority) {
this.authority = authority;
}
public String getHouse_id() {
return house_id;
}
public void setHouse_id(String house_id) {
this.house_id = house_id;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUser_name() {
return user_name;
}
public void setUser_name(String user_name) {
this.user_name = user_name;
}
public String getReal_name() {
return real_name;
}
public void setReal_name(String real_name) {
this.real_name = real_name;
}
public String getMobile() {
return mobile;
}
public void setMobile(String mobile) {
this.mobile = mobile;
}
public String getPasswd() {
return passwd;
}
public void setPasswd(String passwd) {
this.passwd = passwd;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public int getActivated() {
return activated;
}
public void setActivated(int activated) {
this.activated = activated;
}
public String getId_num() {
return id_num;
}
public void setId_num(String id_num) {
this.id_num = id_num;
}
public String getHouse() {
return house;
}
public void setHouse(String house) {
this.house = house;
}
public String getLicense_num() {
return license_num;
}
public void setLicense_num(String license_num) {
this.license_num = license_num;
}
}
<file_sep>/src/main/java/com/gigsider/po/Comuniti.java
package com.gigsider.po;
import java.util.List;
public class Comuniti {
private int id;
private String title;
private String content;
private String post_id;
private String post_time;
private int official;
private int reported;
//表外字段
private Admin admin;
private User user;
private List<Reply> replies;
public int getReported() {
return reported;
}
public void setReported(int reported) {
this.reported = reported;
}
public int getOfficial() {
return official;
}
public void setOfficial(int official) {
this.official = official;
}
public Admin getAdmin() {
return admin;
}
public void setAdmin(Admin admin) {
this.admin = admin;
}
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
public List<Reply> getReplies() {
return replies;
}
public void setReplies(List<Reply> replies) {
this.replies = replies;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getPost_id() {
return post_id;
}
public void setPost_id(String post_id) {
this.post_id = post_id;
}
public String getPost_time() {
return post_time;
}
public void setPost_time(String post_time) {
this.post_time = post_time;
}
}
<file_sep>/src/main/java/com/gigsider/service/serviceImpl/PaymentServiceImpl.java
package com.gigsider.service.serviceImpl;
import com.gigsider.dao.PaymentDao;
import com.gigsider.po.Payment;
import com.gigsider.service.PaymentService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
public class PaymentServiceImpl implements PaymentService {
@Autowired
private PaymentDao paymentDao;
@Override
public boolean addPayment(Payment payment) {
return paymentDao.insertPayment(payment);
}
@Override
public boolean delPayment(int id) {
return paymentDao.deletePayment(id);
}
@Override
public boolean upPayment(Payment payment) {
return paymentDao.updatePayment(payment);
}
@Override
public List<Payment> getAllPayment() {
return paymentDao.queryAllPayment();
}
@Override
public List<Payment> getPaymentPage(int page, int limit) {
Map<String,Object> data = new HashMap<>();
data.put("page", (page-1)*limit);
data.put("limit", limit);
return paymentDao.queryPaymentPage(data);
}
@Override
public List<Payment> getPaymentLike(String data) {
return paymentDao.queryPaymentLike(data);
}
@Override
public List<Payment> paymentLikePage(String like, int page, int limit) {
Map<String,Object> data = new HashMap<>();
data.put("like", like);
data.put("page", (page-1)*limit);
data.put("limit", limit);
return paymentDao.paymentLikePage(data);
}
@Override
public List<Payment> getPaymentById(int id) {
return paymentDao.queryPaymentById(id);
}
@Override
public List<Payment> getPaymentByUser(String user) {
return paymentDao.queryPaymentByUser(user);
}
@Override
public List<Payment> paymentUserPage(String user, int page, int limit) {
Map<String,Object> data = new HashMap<>();
data.put("user", user);
data.put("page", (page-1)*limit);
data.put("limit", limit);
return paymentDao.paymentUserPage(data);
}
@Override
public boolean setPaid(int id, int paid) {
Map<String,Object> data = new HashMap<>();
data.put("id", id);
data.put("paid", paid);
return paymentDao.setPaid(data);
}
@Override
public List<Payment> getUnPaid(String user, String item) {
Map<String,Object> data = new HashMap<>();
data.put("user", user);
data.put("item", item);
return paymentDao.queryUnPaid(data);
}
}
<file_sep>/src/main/java/com/gigsider/controller/uploadController.java
package com.gigsider.controller;
import com.alibaba.fastjson.JSONObject;
import com.gigsider.service.HouseService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.multipart.MultipartFile;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.File;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.UUID;
@Controller
@RequestMapping("/upload")
public class uploadController {
@Autowired
HouseService houseService;
@RequestMapping("/blueprint.do")
@ResponseBody
public JSONObject upload(@RequestParam("file")MultipartFile file, HttpServletRequest request, HttpServletResponse response) throws Exception
{
JSONObject res = new JSONObject();
JSONObject resUrl = new JSONObject();
//作为新的文件名
String newfileName=request.getParameter("house_id").split("#")[1];
if (newfileName.equals("wrong")){
resUrl.put("src", "");
res.put("code", 1);
res.put("msg", "住宅编号格式错误!");
res.put("data", resUrl);
return res;
}
// url为相对路径 / \
String url="upload"+File.separator+"blueprint"+File.separator; // upload/blueprint/
//path存放绝对路径
String path = request.getSession().getServletContext()
.getRealPath(File.separator+"upload"+File.separator+"blueprint"+File.separator);
//测试绝对路径的目录是否存在,不存在,则建立对应目录;
File file2=new File(path);
if(!file2.exists())
file2.mkdirs();
/*
* 接下来代码是复制文件,进行实质的保存;
*/
//得到原始的上传文件的文件名(包含后缀)
String fileName = file.getOriginalFilename();
System.out.println("源文件名:" + fileName);
//获得新文件的文件名,添加后缀
String suffix=fileName.substring(fileName.lastIndexOf("."), fileName.length());
newfileName=newfileName+suffix;
System.out.println("新的文件名:" + newfileName);
url+=newfileName;
System.out.println(url);
System.out.println(path);
//在磁盘建立文件进行
File targetFile = new File(path, newfileName);
try {
//文件复制
file.transferTo(targetFile);
} catch (Exception e) {
e.printStackTrace();
}
resUrl.put("src", url);
res.put("code", 0);
res.put("msg", "上传成功!");
res.put("data", resUrl);
return res;
}
}
<file_sep>/src/main/java/com/gigsider/service/ParkingService.java
package com.gigsider.service;
import com.gigsider.po.Parking;
import java.util.List;
public interface ParkingService {
//添加车位
public boolean addParking(Parking parking);
//通过主键 parking_id 删除车位
public boolean delParking(String parking_id);
//更新车位信息
public boolean upParking(Parking parking);
//通过 parking_id 查找车位
public List<Parking> getParkingByParkingId(String parking_id);
//通过 license_num 查找车位
public List<Parking> getParkingByLicenseNum(String license_num);
//获取所有车位
public List<Parking> getAllParking();
//分页查询
public List<Parking> getParkingPage(int page, int limit);
//车位编号搜索的分页
public List<Parking> getParkingIdPage(int page, int limit, String parking_id);
//通过 status 查找车位
public List<Parking> getParkingByStatus(int status);
// status 查找分页
public List<Parking> statusParkingPage(int status, int page, int limit);
//获取已租赁车位
public List<Parking> getRentParking();
}
<file_sep>/src/main/java/com/gigsider/po/Admin.java
package com.gigsider.po;
public class Admin {
private int id;
private String job_num;
private String real_name;
private String id_num;
private String mobile;
private String sex;
private String passwd;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getJob_num() {
return job_num;
}
public void setJob_num(String job_num) {
this.job_num = job_num;
}
public String getReal_name() {
return real_name;
}
public void setReal_name(String real_name) {
this.real_name = real_name;
}
public String getId_num() {
return id_num;
}
public void setId_num(String id_num) {
this.id_num = id_num;
}
public String getMobile() {
return mobile;
}
public void setMobile(String mobile) {
this.mobile = mobile;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getPasswd() {
return passwd;
}
public void setPasswd(String passwd) {
this.passwd = passwd;
}
}
<file_sep>/src/main/java/com/gigsider/dao/FixDao.java
package com.gigsider.dao;
import com.gigsider.po.Fix;
import java.util.List;
import java.util.Map;
public interface FixDao {
//添加报修
public boolean insertFix(Fix fix);
//删除报修
public boolean deleteFix(int id);
//更新报修
public boolean updateFix(Fix fix);
//获取全部报修
public List<Fix> queryAllFix();
//全部报修分页
public List<Fix> allFixPage(Map<String,Object> data);
//根据 user_name 获取报修
public List<Fix> queryFixByUserName(String user_name);
// user_name 分页
public List<Fix> userNameFixPage(Map<String,Object> data);
//模糊搜索
public List<Fix> queryFixLike(String like);
//模糊搜索分页
public List<Fix> likeFixPage(Map<String,Object> data);
//根据 id 获取报修
public List<Fix> queryFixById(int id);
}
<file_sep>/src/main/java/com/gigsider/dao/DataDao.java
package com.gigsider.dao;
import com.gigsider.po.Data;
public interface DataDao {
//获取数据
public Data queryData(String key);
//更新数据
public boolean updateData(Data data);
}
<file_sep>/src/main/java/com/gigsider/dao/BulletinDao.java
package com.gigsider.dao;
import com.gigsider.po.Bulletin;
import java.util.List;
import java.util.Map;
public interface BulletinDao {
//添加公告
public boolean insertBulletin(Bulletin bulletin);
//删除公告
public boolean deleteBulletin(int id);
//更新公告
public boolean updateBulletin(Bulletin bulletin);
//获取所有公告
public List<Bulletin> queryAllBulletin();
//通过 id 查询公告
public List<Bulletin> queryBulletinById(int id);
//分页查询
public List<Bulletin> queryBulletinPage(Map<String,Object> data);
}
<file_sep>/src/main/java/com/gigsider/utils/Initial.java
package com.gigsider.utils;
import com.gigsider.po.*;
import com.gigsider.service.*;
import com.gigsider.service.serviceImpl.*;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.Calendar;
import java.util.List;
@Service
public class Initial implements InitializingBean {
@Autowired
private DataService dataService;
@Override
public void afterPropertiesSet() throws Exception {
RunnableTarget.month = Integer.parseInt(dataService.getData("pay_month").getValue());
//创建线程工作体对象
RunnableTarget tt = new RunnableTarget();
//创建线程体的线程对象
Thread t = new Thread(tt);
//启动线程
t.start();
}
}
class RunnableTarget implements Runnable{ //本身不是线程,是线程的工作体
static public int month;
private UserService userService = SpringContextHolder.getBean(UserServiceImpl.class);
private DataService dataService = SpringContextHolder.getBean(DataServiceImpl.class);
private ParkingService parkingService = SpringContextHolder.getBean(ParkingServiceImpl.class);
private HouseService houseService = SpringContextHolder.getBean(HouseServiceImpl.class);
private PaymentService paymentService = SpringContextHolder.getBean(PaymentServiceImpl.class);
@Override
public void run() {
Calendar calendar = Calendar.getInstance();
int current_month = -1;
while (true) {
try {
Thread.currentThread().sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
current_month = calendar.get(Calendar.MONTH) + 1;
String time = calendar.get(Calendar.YEAR) + "年" + current_month + "月" + calendar.get(Calendar.DATE) + "日 " + calendar.get(Calendar.HOUR_OF_DAY) + ":" + calendar.get(Calendar.MINUTE);
if (current_month != month) {
List<User> users = userService.getAllUser();
List<Parking> parkings = parkingService.getRentParking();
for (int i = 0; i < users.size(); i++) {
User user = users.get(i);
if (user.getHouse() != null && user.getHouse().length() != 0) {
double propertyFee = Double.valueOf(dataService.getData("property_fee").getValue());
House house = houseService.getHouseByHouseId(user.getHouse()).get(0);
Payment payment = new Payment();
payment.setUser(user.getUser_name());
payment.setItem("物业费");
payment.setItem_id(user.getHouse());
payment.setCost(propertyFee*Integer.parseInt(house.getArea()));
payment.setTime(time);
paymentService.addPayment(payment);
System.out.println("新增账单:物业费," + user.getUser_name() + "," + user.getHouse());
}
}
for (int i = 0; i < parkings.size(); i++) {
Parking parking = parkings.get(i);
User user = userService.getUserByLicenseNum(parking.getLicense_num()).get(0);
Payment payment = new Payment();
payment.setUser(user.getUser_name());
payment.setItem("车位租金");
payment.setItem_id(parking.getParking_id());
payment.setCost(parking.getRent());
payment.setTime(time);
paymentService.addPayment(payment);
System.out.println("新增账单:车位租金," + user.getUser_name() + "," + parking.getParking_id());
}
Data data = new Data();
data.setKey("pay_month");
data.setValue(current_month+"");
dataService.upData(data);
month = current_month;
}
}
}
}<file_sep>/src/main/java/com/gigsider/service/PaymentService.java
package com.gigsider.service;
import com.gigsider.po.Payment;
import java.util.List;
import java.util.Map;
public interface PaymentService {
//添加账单
public boolean addPayment(Payment payment);
//删除账单
public boolean delPayment(int id);
//更新账单
public boolean upPayment(Payment payment);
//获取所有账单
public List<Payment> getAllPayment();
//分页查找
public List<Payment> getPaymentPage(int page, int limit);
//模糊搜索
public List<Payment> getPaymentLike(String data);
//模糊搜索分页
public List<Payment> paymentLikePage(String like, int page, int limit);
//通过 id 查询
public List<Payment> getPaymentById(int id);
//通过 user 查询
public List<Payment> getPaymentByUser(String user);
// user 分页查询
public List<Payment> paymentUserPage(String user, int page, int limit);
// 设置支付情况
public boolean setPaid(int id, int paid);
// 查找未支付
public List<Payment> getUnPaid(String user, String item);
}
<file_sep>/README.md
# smart_community
毕业设计,智能社区管理系统
<file_sep>/src/main/java/com/gigsider/po/Payment.java
package com.gigsider.po;
public class Payment {
private int id;
private String user;
private String item;
private String item_id;
private double cost;
private String time;
private int paid;
public int getPaid() {
return paid;
}
public void setPaid(int paid) {
this.paid = paid;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getItem() {
return item;
}
public void setItem(String item) {
this.item = item;
}
public String getItem_id() {
return item_id;
}
public void setItem_id(String item_id) {
this.item_id = item_id;
}
public double getCost() {
return cost;
}
public void setCost(double cost) {
this.cost = cost;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
}
<file_sep>/src/main/java/com/gigsider/filter/LoginFilter.java
package com.gigsider.filter;
import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.io.IOException;
public class LoginFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
//获取 session
HttpSession session = request.getSession();
// 获得用户请求的URI
String path = request.getRequestURI();
// 登陆页面无需过滤
if (
path.indexOf("/login") > -1
|| path.indexOf(".js") > -1
|| path.indexOf(".css") > -1
|| path.indexOf(".jpg") > -1
|| path.indexOf("/pay.html") > -1
|| path.indexOf("/pay.do") > -1
|| path.indexOf("/isUserExistByIdNum.do") > -1
|| path.indexOf("/upUser.do") > -1
) {
filterChain.doFilter(servletRequest,servletResponse);
return;
}
//登录验证
if (
session.getAttribute("login_status") == null
|| !session.getAttribute("login_status").equals("success")
) {
response.sendRedirect("/smart_community/login.html");
} else {
filterChain.doFilter(servletRequest,servletResponse);
}
}
@Override
public void destroy() {
}
}
<file_sep>/src/main/java/com/gigsider/service/HouseService.java
package com.gigsider.service;
import com.gigsider.po.House;
import java.util.List;
public interface HouseService {
//获取所有住宅信息
public List<House> getAllHouse();
//通过住宅编号 house_id 查询住宅
public List<House> getHouseByHouseId(String house_id);
//通过楼栋号 building_id 查询住宅
public List<House> getHouseByBuildingId(String building_id);
//通过售出状态 sale 查询住宅
public List<House> getHouseBySale(int sale);
//查找未售出的住宅
public List<House> getUnSoldHouse();
//分页查找住宅信息
public List<House> getHousePage(int page, int limit);
//获取住宅编号查找分页信息
public List<House> getHouseIdPage(int page, int limit, String house_id);
//添加住宅
public boolean addHouse(House house);
//通过住宅编号 house_id 删除住宅
public boolean delHouse(String house_id);
//更新住宅信息
public boolean upHouse(House house);
}
<file_sep>/src/main/java/com/gigsider/service/serviceImpl/ComunitiServiceImpl.java
package com.gigsider.service.serviceImpl;
import com.gigsider.dao.ComunitiDao;
import com.gigsider.po.Comuniti;
import com.gigsider.service.ComunitiService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
public class ComunitiServiceImpl implements ComunitiService {
@Autowired
ComunitiDao comunitiDao;
@Override
public boolean addComuniti(Comuniti comuniti) {
return comunitiDao.insertComuniti(comuniti);
}
@Override
public boolean delComuniti(int id) {
return comunitiDao.deleteComuniti(id);
}
@Override
public boolean upComuniti(Comuniti comuniti) {
return comunitiDao.updateComuniti(comuniti);
}
@Override
public List<Comuniti> getAllComuniti() {
return comunitiDao.queryAllComuniti();
}
@Override
public List<Comuniti> getComunitiPage(int page, int limit) {
Map<String,Object> data = new HashMap<>();
data.put("page", (page-1)*limit);
data.put("limit", limit);
return comunitiDao.queryComunitiPage(data);
}
@Override
public List<Comuniti> getComunitiById(int id) {
return comunitiDao.queryComunitiById(id);
}
@Override
public List<Comuniti> getComunitiLikePage(String like, int page, int limit) {
Map<String,Object> data = new HashMap<>();
data.put("like", like);
data.put("page", (page-1)*limit);
data.put("limit", limit);
return comunitiDao.queryComunitiLikePage(data);
}
@Override
public List<Comuniti> getComunitiLike(String like) {
return comunitiDao.queryComunitiLike(like);
}
@Override
public List<Comuniti> getComunitiByPostId(String post_id) {
return comunitiDao.queryComunitiByPostId(post_id);
}
@Override
public List<Comuniti> getComunitiByPostIdPage(String post_id, int page, int limit) {
Map<String,Object> data = new HashMap<>();
data.put("post_id", post_id);
data.put("page", (page-1)*limit);
data.put("limit", limit);
return comunitiDao.queryComunitiByPostIdPage(data);
}
@Override
public List<Comuniti> getReportedComuniti() {
return comunitiDao.queryReportedComuniti();
}
@Override
public boolean reportComuniti(int id) {
return comunitiDao.reportComuniti(id);
}
@Override
public boolean unReportComuniti(int id) {
return comunitiDao.unReportComuniti(id);
}
}
<file_sep>/src/main/java/com/gigsider/po/Mytest.java
package com.gigsider.po;
public class Mytest {
private Integer id;
private String string;
@Override
public String toString() {
return "Mytest{" +
"id=" + id +
", string='" + string + '\'' +
'}';
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getString() {
return string;
}
public void setString(String string) {
this.string = string;
}
}
<file_sep>/src/main/java/com/gigsider/service/DataService.java
package com.gigsider.service;
import com.gigsider.po.Data;
public interface DataService {
//获取数据
public Data getData(String key);
//更新数据
public boolean upData(Data data);
}
<file_sep>/src/main/java/com/gigsider/utils/SessionPool.java
package com.gigsider.utils;
import javax.servlet.http.HttpSession;
import java.util.HashMap;
public class SessionPool {
public static HashMap<String, HttpSession> sessions = new HashMap<String, HttpSession>();
public static void addToSessionPool(String userID, HttpSession session){
sessions.put(userID, session);
}
public static HttpSession getExistSession(String userID) {
return sessions.get(userID);
}
public static void destroyExistSession(String userID) {
sessions.get(userID).invalidate();
sessions.remove(userID);
}
}
| bcaff0d661c41ad90e921e59467429018a1ef4d0 | [
"Markdown",
"Java"
] | 22 | Java | fgfan98/smart_community | 00e1fadb0dfb4afd1508af50e4a939001fbf7be5 | 3d3c722e991c9d2f45ff4955e1030132ff953f85 |
refs/heads/master | <file_sep>package fileWorker
import (
"fmt"
"io/ioutil"
"os"
"strings"
)
func FileRead(path string) error {
path = strings.TrimRight(path, "/") + "/" // so not to depend on the closing slash
files, err := ioutil.ReadDir(path)
if err != nil {
return fmt.Errorf("cannot read from file, %v", err)
}
for _, f := range files {
deleteFileName := path + f.Name()
_, err := ioutil.ReadFile(path + f.Name())
if err != nil {
return err
}
err = os.Remove(deleteFileName) // clearing test files
}
return nil
}
<file_sep>package actionExample
import (
"testing"
"net/http/httptest"
"encoding/json"
)
func TestUserHandler(t *testing.T) {
r := httptest.NewRequest("GET", "http://127.0.0.1:80/user?id=42", nil)
w := httptest.NewRecorder()
userHandler(w, r)
user := User{}
json.Unmarshal([]byte (w.Body.String()), &user)
if user.Id != 42 {
t.Errorf("Invalid user id %d expected %d", user.Id, 42)
}
r = httptest.NewRequest("GET", "http://127.0.0.1:80/user", nil)
w = httptest.NewRecorder()
userHandler(w, r)
if w.Body.String()!="Error"{
t.Errorf("Expected error got %s", w.Body.String())
}
}
<file_sep>package dbWorker
import (
"github.com/jinzhu/gorm"
)
func DbListener(db *gorm.DB) {
user := User{}
transaction := db.Begin()
transaction.First(&user, 1)
transaction.Model(&user).Update("counter", user.Counter+1)
transaction.Commit()
}
type User struct {
Id int `gorm:"primary_key"`
Rating int
Counter int
}
func (User) TableName() string {
return "Users"
}
<file_sep>package apiCaller
import (
"io/ioutil"
"net/http"
"encoding/json"
"io"
)
const success = "ok"
func ApiCaller(user *User, url string) error {
resp, err := http.Get(url)
if err != nil {
return err
}
defer resp.Body.Close()
return updateUser(user, resp.Body)
}
func updateUser(user *User, closer io.ReadCloser) error {
body, err := ioutil.ReadAll(closer)
if err != nil {
return err
}
result := JsonResponse{}
err = json.Unmarshal(body, &result)
if err != nil {
return err
}
if result.Result == success {
user.counter ++
user.rating = result.Data.Rating
}
return nil
}
type User struct {
id int
rating int
counter int
}
type JsonResponse struct {
Result string `json:"result"`
Data struct {
UserId int `json:"user_id"`
Rating int `json:"rating"`
} `json:"data"`
}
<file_sep>package fileWorker
import (
"testing"
"os"
)
const testSqlDir = "test/"
const wrongDir = "no/data/here/"
func TestMain(m *testing.M) {
os.Mkdir(testSqlDir, 0777)
file, _ := os.Create(testSqlDir + "1good.data")
file.WriteString("Readable")
file.Close()
file, _ = os.Create(testSqlDir + "2bad.data")
file.Chmod(0000)
file.WriteString("Invalid data")
v := m.Run()
file.Close()
os.Remove(testSqlDir)
os.Exit(v)
}
func TestFileWorker(t *testing.T) {
err := FileRead(wrongDir)
if err == nil {
t.Error("No error from wrong dir")
}
FileRead(testSqlDir + "/")
}
func BenchmarkFileRead(b *testing.B) {
os.Mkdir(testSqlDir, 0777)
for i := 0; i < b.N; i++ {
file, _ := os.Create(testSqlDir + "1good.data")
file.WriteString("Readable")
file.Close()
FileRead(testSqlDir + "/")
}
}
<file_sep>package dbWorker
import (
"testing"
"gopkg.in/DATA-DOG/go-sqlmock.v1"
"github.com/jinzhu/gorm"
)
func TestDbListener(t *testing.T) {
db, mock, err := sqlmock.New()
if err != nil {
t.Fatalf("an error '%s' was not expected when opening a stub database connection", err)
}
defer db.Close()
mock.ExpectBegin()
result := []string{"id", "name", "counter"}
mock.ExpectQuery("SELECT \\* FROM `Users`").WillReturnRows(sqlmock.NewRows(result).AddRow(1, "Jack", 2))
mock.ExpectExec("UPDATE `Users`").WithArgs(3, 1).WillReturnResult(sqlmock.NewResult(1, 1))
mock.ExpectCommit()
gormDB, _ := gorm.Open("mysql", db)
DbListener(gormDB.LogMode(true))
// we make sure that all expectations were met
if err := mock.ExpectationsWereMet(); err != nil {
t.Errorf("there were unfulfilled expectations: %s", err)
}
}
<file_sep>package apiCaller
import (
"errors"
"fmt"
"net/http"
"net/http/httptest"
"testing"
)
func TestApiCaller(t *testing.T) {
ts := httptest.NewServer(http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "application/json; charset=utf-8")
w.Header().Set("Access-Control-Allow-Origin", "*")
fmt.Fprintln(w, `{
"result": "ok",
"data": {
"user_id": 1,
"rating": 42
}
}`)
}))
defer ts.Close()
user := User{id: 1}
err := ApiCaller(&user, ts.URL)
if err != nil {
t.Error("Expect no error", err)
}
if user.rating != 42 {
t.Error("User rating has not updated", err)
}
}
func TestApiCallerError(t *testing.T) {
ts := httptest.NewServer(http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "application/json; charset=utf-8")
w.Header().Set("Access-Control-Allow-Origin", "*")
fmt.Fprintln(w, `Code 500`)
}))
defer ts.Close()
user := User{id: 1}
err := ApiCaller(&user, ts.URL)
if err == nil {
t.Error("Ecspect no error", err)
}
}
func TestApiCallerNoServer(t *testing.T) {
user := User{id: 1}
err := ApiCaller(&user, "/")
if err == nil {
t.Error("Ecspect no error", err)
}
}
func TestAdiCallerErrorResponse(t *testing.T) {
user := User{id: 1}
err := updateUser(&user, errReader(0))
if err == nil {
t.Error("Ecspect error", err)
}
}
type errReader int
func (errReader) Read(p []byte) (n int, err error) {
return 0, errors.New("test error")
}
func (errReader) Close() error {
return nil
}
<file_sep># go-testing
Пример для статьи на хабре, не больше, но и не меньше.
<ul>
<li>Тестирование handler - actionExample</li>
<li>Подменяем внешний api - apiCaller</li>
<li>Мокаем базу данных - dbWorker</li>
<li>Танцы с файловой системой с afero и без -fileWorker,fileWorkerAlt,fileWorkerAlt2</li>
</ul>
<file_sep>package fileWorkerAlt
import (
"testing"
"github.com/spf13/afero"
)
const testSqlDir = "test/"
const wrongDir = "no/data/here/"
func TestFileWorkerAlt(t *testing.T) {
appFS := afero.NewMemMapFs()
// create test files and directories
appFS.MkdirAll(testSqlDir, 0755)
afero.WriteFile(appFS, testSqlDir+"good.data", []byte("Readable"), 0644)
afero.WriteFile(appFS, testSqlDir+"bad.data", []byte("Invalid"), 0000)
err := FileReadAlt(wrongDir, appFS)
if err == nil {
t.Error("No error from wrong dir")
}
FileReadAlt(testSqlDir+"/", appFS)
}
func BenchmarkFileRead(b *testing.B) {
for i := 0; i < b.N; i++ {
appFS := afero.NewMemMapFs()
// create test files and directories
appFS.MkdirAll(testSqlDir, 0755)
afero.WriteFile(appFS, testSqlDir+"good.data", []byte("Readable"), 0644)
FileReadAlt(testSqlDir+"/", appFS)
}
}
| 5ea16f6779c16657729782c09ed890a7525f7163 | [
"Markdown",
"Go"
] | 9 | Go | JackShadow/go-testing | da90f24d0cb2aa3a14b9b6efcd768c9353115fe2 | df1853a953823127f02ce0b847727d261644486d |
refs/heads/main | <repo_name>094459/websummit-demo<file_sep>/6-flask-docker-ecscli/web/app.py
# app.py
from flask import Flask
from flask import request, render_template
from flask_sqlalchemy import SQLAlchemy
from config import BaseConfig
app = Flask(__name__)
app.config.from_object(BaseConfig)
db = SQLAlchemy(app)
from models import *
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
text = request.form['text']
post = Post(text)
db.session.add(post)
db.session.commit()
posts = Post.query.order_by(Post.date_posted.desc()).all()
return render_template('index.html', posts=posts)
if __name__ == '__main__':
app.run()
<file_sep>/1-flask-simple-local/web/app.py
from flask import Flask
from flask import request, render_template
import platform
app = Flask(__name__)
#@app.route('/')
#def hello_world():
# running_processor = platform.processor()
# running_on = platform.platform()
# return 'Hey, we have Flask running on...' + str(running_on)+" "+str(running_processor)
@app.route('/', methods=['GET', 'POST'])
def index():
running_processor = platform.processor()
running_on = platform.platform()
showme = str(running_on)+" "+str(running_processor)
return render_template('index.html', post=showme)
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0')
<file_sep>/6-flask-docker-ecscli/web/Dockerfile
FROM python:3.7-slim
RUN python -m pip install --upgrade pip
WORKDIR /usr/src/app
COPY requirements.txt requirements.txt
RUN python -m pip install -r requirements.txt
RUN pip install psycopg2-binary
COPY . .
<file_sep>/4-flask-local/web/config.py
# config.py
import os
class BaseConfig(object):
SECRET_KEY = 'hi'
DEBUG = True
DB_NAME = 'ricsue'
DB_SERVICE = 'localhost'
DB_PORT = 5432
SQLALCHEMY_DATABASE_URI = 'postgresql://{0}:{1}/{2}'.format(
DB_SERVICE, DB_PORT, DB_NAME
)
<file_sep>/4-flask-local/web/Dockerfile
FROM python:3.7-slim
RUN python -m pip install --upgrade pip
WORKDIR /usr/src/app
COPY requirements.txt requirements.txt
RUN python -m pip install -r requirements.txt
COPY . .
<file_sep>/2-flask-simple-boot-docker/Dockerfile
FROM ubuntu:18.04
RUN apt-get update -y && \
apt-get install -y python-pip python-dev build-essential
COPY . /web
WORKDIR /web
RUN pip install -r requirements.txt
ENTRYPOINT [ "python" ]
CMD [ "web/app.py" ]<file_sep>/4-flask-local/web/requirements.txt
Flask==1.0.2
Flask-SQLAlchemy==2.3.2
Jinja2==2.10
MarkupSafe==1.1.1
SQLAlchemy==1.3.1
Werkzeug==0.15.1
gunicorn==19.9.0
itsdangerous==1.1.0
psycopg2==2.7.7
| 2a46302eae1be7cd5f8110c562eacd2609722534 | [
"Python",
"Text",
"Dockerfile"
] | 7 | Python | 094459/websummit-demo | 650cc00659c0af38d2c1d2973918e2f4e8398192 | a311c138b17a2a36862e5c5e7b6e735191638f76 |
refs/heads/master | <repo_name>conanjacksion/GradlyBuilder<file_sep>/src/com/fpt/util/StringHelper.java
package com.fpt.util;
import java.io.File;
public class StringHelper {
public static String getLastElementFromUrl(String url) {
String result = "";
if (url == null || url.equals("")) {
return result;
}
String[] urlArray = url.trim().split("/");
result = urlArray[urlArray.length - 1];
return result;
}
public static String convertToBackFlash(String source) {
String result = "";
if (source != null) {
result = source.replaceAll("\\\\", "/");
}
return result;
}
public static String convertRelativeUrlToAbsoluteUrl(String baseUrl,
String relativeUrl) {
baseUrl = convertToBackFlash(baseUrl);
relativeUrl = convertToBackFlash(relativeUrl);
String absoluteUrl = "";
String[] baseUrlArray = baseUrl.split("/");
String[] relativeUrlArray = relativeUrl.split("/");
for (int i = 0; i < relativeUrlArray.length; i++) {
if (relativeUrlArray[i].equals("..")) {
baseUrlArray[baseUrlArray.length - 1 - i] = "";
}
}
for (int i = 0; i < baseUrlArray.length; i++) {
if (!baseUrlArray[i].equals("")) {
absoluteUrl += baseUrlArray[i] + "/";
}
}
for (int i = 0; i < relativeUrlArray.length; i++) {
if (!relativeUrlArray[i].equals("..")) {
absoluteUrl += relativeUrlArray[i];
if (i < relativeUrlArray.length - 1) {
absoluteUrl += "/";
}
}
}
return absoluteUrl;
}
public static String convertAbsoluteUrlToRelativeUrl(String baseUrl,
String absoluteUrl) {
baseUrl = convertToBackFlash(baseUrl);
absoluteUrl = convertToBackFlash(absoluteUrl);
String relative = "";
if (absoluteUrl.contains(baseUrl)) {
relative = new File(baseUrl).toURI()
.relativize(new File(absoluteUrl).toURI()).getPath();
} else {
String[] baseUrlArray = baseUrl.split("/");
String[] absoluteUrlArray = absoluteUrl.split("/");
int indexDiff = 0;
for (int i = 0; i < baseUrlArray.length; i++) {
if (!baseUrlArray[i].equals(absoluteUrlArray[i])) {
indexDiff = i;
break;
}
}
for (int i = indexDiff; i < baseUrlArray.length; i++) {
relative += "../";
}
for (int i = indexDiff; i < absoluteUrlArray.length; i++) {
relative += absoluteUrlArray[i];
if (i < absoluteUrlArray.length - 1) {
relative += "/";
}
}
}
return relative;
}
}
<file_sep>/src/com/fpt/gui/AndroidOutputPane.java
package com.fpt.gui;
import java.awt.Component;
import java.awt.EventQueue;
import java.awt.event.ItemEvent;
import java.awt.event.ItemListener;
import java.io.File;
import javax.swing.ButtonGroup;
import javax.swing.JButton;
import javax.swing.JCheckBox;
import javax.swing.JFileChooser;
import javax.swing.JLabel;
import javax.swing.JPanel;
import javax.swing.JRadioButton;
import javax.swing.JTextField;
import javax.swing.event.DocumentEvent;
import javax.swing.event.DocumentListener;
import com.fpt.model.AndroidInputData;
import com.fpt.model.AndroidOutputData;
/**
* @author QuyPP1
*/
public class AndroidOutputPane extends JPanel {
private static final long serialVersionUID = -2815940357873196069L;
private JTextField tfOuputServerURL;
private JCheckBox isOutputNexus;
private JCheckBox isOutputServer;
private JCheckBox isOutputLocal;
private JRadioButton isAPK, isAAR;
private JTextField tfOutputLocalURL;
private JLabel lblLocalPath;
private JButton btnBrowseOutputLocal;
private ButtonGroup bgBuildType;
private static AndroidOutputData data;
private JTextField tfGroupId;
private JTextField tfArtifactId;
private JTextField tfVersion;
private JLabel lblArtifact;
/**
* Launch the application.
*/
public static void main(String[] args) {
EventQueue.invokeLater(new Runnable() {
public void run() {
try {
AndroidOutputPane frame = new AndroidOutputPane();
frame.setVisible(true);
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
/**
* Create the frame.
*/
public AndroidOutputPane() {
data = new AndroidOutputData();
setBounds(100, 100, 450, 181);
setLayout(null);
JLabel lblProject = new JLabel("Output");
lblProject.setBounds(0, 4, 71, 14);
lblProject.setAlignmentX(Component.CENTER_ALIGNMENT);
add(lblProject);
isOutputNexus = new JCheckBox("Nexus");
isOutputNexus.addItemListener(new OutputWay());
isOutputNexus.setBounds(108, 0, 71, 23);
add(isOutputNexus);
isOutputServer = new JCheckBox("Server");
isOutputServer.addItemListener(new OutputWay());
isOutputServer.setBounds(181, 0, 71, 23);
add(isOutputServer);
isOutputLocal = new JCheckBox("Local");
isOutputLocal.addItemListener(new OutputWay());
isOutputLocal.setBounds(254, 0, 71, 23);
add(isOutputLocal);
JLabel lblProguard = new JLabel("Server URL");
lblProguard.setBounds(0, 65, 71, 14);
lblProguard.setAlignmentX(Component.CENTER_ALIGNMENT);
add(lblProguard);
tfOuputServerURL = new JTextField();
tfOuputServerURL.getDocument().addDocumentListener(
new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setOutputServerUrl(tfOuputServerURL.getText()
.trim());
}
public void removeUpdate(DocumentEvent e) {
data.setOutputServerUrl(tfOuputServerURL.getText()
.trim());
}
public void insertUpdate(DocumentEvent e) {
data.setOutputServerUrl(tfOuputServerURL.getText()
.trim());
}
});
tfOuputServerURL.setBounds(108, 62, 211, 20);
add(tfOuputServerURL);
tfOuputServerURL.setColumns(10);
lblLocalPath = new JLabel("Local path");
lblLocalPath.setBounds(0, 97, 71, 14);
add(lblLocalPath);
tfOutputLocalURL = new JTextField();
tfOutputLocalURL.getDocument().addDocumentListener(
new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setOutputLocalUrl(tfOutputLocalURL.getText()
.trim());
}
public void removeUpdate(DocumentEvent e) {
data.setOutputLocalUrl(tfOutputLocalURL.getText()
.trim());
}
public void insertUpdate(DocumentEvent e) {
data.setOutputLocalUrl(tfOutputLocalURL.getText()
.trim());
}
});
tfOutputLocalURL.setBounds(108, 94, 211, 20);
add(tfOutputLocalURL);
tfOutputLocalURL.setColumns(10);
JLabel lblBuildType = new JLabel("Build Type");
lblBuildType.setBounds(0, 127, 71, 14);
add(lblBuildType);
isAPK = new JRadioButton("APK");
isAPK.addItemListener(new ItemListener() {
public void itemStateChanged(ItemEvent arg0) {
if (isAPK.isSelected()) {
data.setBuildType(AndroidOutputData.BUILD_TYPE_APK);
}
}
});
isAPK.setSelected(true);
isAPK.setBounds(108, 123, 71, 23);
add(isAPK);
isAAR = new JRadioButton("AAR");
isAAR.addItemListener(new ItemListener() {
public void itemStateChanged(ItemEvent e) {
if (isAAR.isSelected()) {
data.setBuildType(AndroidOutputData.BUILD_TYPE_AAR);
}
}
});
isAAR.setBounds(248, 123, 71, 23);
add(isAAR);
btnBrowseOutputLocal = new JButton("Browse");
btnBrowseOutputLocal.addActionListener(new LocalBrowser(
AndroidOutputPane.this, tfOutputLocalURL,
JFileChooser.DIRECTORIES_ONLY, null, 0));
btnBrowseOutputLocal.setBounds(329, 93, 89, 23);
add(btnBrowseOutputLocal);
bgBuildType = new ButtonGroup();
bgBuildType.add(isAPK);
bgBuildType.add(isAAR);
tfGroupId = new JTextField();
tfGroupId.getDocument().addDocumentListener(new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setNexusGroupId(tfGroupId.getText().trim());
}
public void removeUpdate(DocumentEvent e) {
data.setNexusGroupId(tfGroupId.getText().trim());
}
public void insertUpdate(DocumentEvent e) {
data.setNexusGroupId(tfGroupId.getText().trim());
}
});
tfGroupId.setToolTipText("Group");
tfGroupId.setColumns(10);
tfGroupId.setBounds(74, 30, 124, 20);
add(tfGroupId);
tfArtifactId = new JTextField();
tfArtifactId.getDocument().addDocumentListener(new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setNexusArtifactId(tfArtifactId.getText().trim());
}
public void removeUpdate(DocumentEvent e) {
data.setNexusArtifactId(tfArtifactId.getText().trim());
}
public void insertUpdate(DocumentEvent e) {
data.setNexusArtifactId(tfArtifactId.getText().trim());
}
});
tfArtifactId.setToolTipText("Artifact");
tfArtifactId.setColumns(10);
tfArtifactId.setBounds(208, 30, 97, 20);
add(tfArtifactId);
tfVersion = new JTextField();
tfVersion.getDocument().addDocumentListener(new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setNexusVersion(tfVersion.getText().trim());
}
public void removeUpdate(DocumentEvent e) {
data.setNexusVersion(tfVersion.getText().trim());
}
public void insertUpdate(DocumentEvent e) {
data.setNexusVersion(tfVersion.getText().trim());
}
});
tfVersion.setToolTipText("Version");
tfVersion.setColumns(10);
tfVersion.setBounds(314, 30, 71, 20);
add(tfVersion);
lblArtifact = new JLabel("Artifact");
lblArtifact.setAlignmentX(0.5f);
lblArtifact.setBounds(0, 32, 71, 14);
add(lblArtifact);
}
class OutputWay implements ItemListener {
@Override
public void itemStateChanged(ItemEvent e) {
// TODO Auto-generated method stub
int outputWay = 0;
if (isOutputNexus.isSelected()) {
outputWay += AndroidOutputData.OUTPUT_NEXUS;
}
if (isOutputLocal.isSelected()) {
outputWay += AndroidOutputData.OUTPUT_LOCAL;
}
if (isOutputServer.isSelected()) {
outputWay += AndroidOutputData.OUTPUT_SERVER;
}
data.setOutputWay(outputWay);
}
}
public static AndroidOutputData getData() {
return data;
}
public void updateOutputLocalURL(String outputLocalURL) {
tfOutputLocalURL.setText(outputLocalURL);
}
}
<file_sep>/src/com/fpt/gui/ChooserDialog.java
package com.fpt.gui;
import java.awt.Color;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import javax.swing.JButton;
import javax.swing.JDialog;
import javax.swing.JList;
import javax.swing.JPanel;
import javax.swing.JScrollPane;
import com.fpt.model.BaseDependency;
public class ChooserDialog extends JDialog {
/**
*
*/
private static final long serialVersionUID = 6210220294367153334L;
private JButton btnOK;
private JButton btnCancel;
private JList<Object> listBox;
private JScrollPane listScrollPane;
private JPanel nexusPanel;
private JPanel parentPanel;
private String dialogTitle;
private Object[] listData;
private ChooserDialogListener listener;
public interface ChooserDialogListener {
void onChooserDialogResultAlready(Object dependency);
}
public void addChooserDialogListener(ChooserDialogListener listener) {
this.listener = listener;
}
public ChooserDialog(JPanel parentPanel, String dialogTitle,
Object[] listData) {
this.parentPanel = parentPanel;
this.dialogTitle = dialogTitle;
this.listData = listData;
initialize();
}
public void setListData() {
}
private void initialize() {
// Create a new listbox control
listBox = new JList<Object>();
listBox.setVisibleRowCount(5);
listBox.setListData(listData);
listScrollPane = new JScrollPane();
listScrollPane.setBounds(1, 1, 483, 223);
listScrollPane
.setVerticalScrollBarPolicy(JScrollPane.VERTICAL_SCROLLBAR_ALWAYS);
listScrollPane.setViewportView(listBox);
listBox.validate();
listScrollPane.validate();
btnCancel = new JButton("Cancel");
btnCancel.setBounds(382, 227, 81, 23);
btnCancel.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
dispose();
}
});
btnOK = new JButton("OK");
btnOK.setBounds(291, 227, 81, 23);
btnOK.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
if (listener != null) {
listener.onChooserDialogResultAlready(listBox.getSelectedValue());
dispose();
}
}
});
nexusPanel = new JPanel();
nexusPanel.setLayout(null);
nexusPanel.add(listScrollPane);
nexusPanel.add(btnCancel);
nexusPanel.add(btnOK);
setTitle(dialogTitle);
setSize(500, 292);
setBackground(Color.gray);
setModal(true);
setContentPane(nexusPanel);
setLocationRelativeTo(parentPanel);
setResizable(false);
}
public void showDialog(){
setVisible(true);
}
}
<file_sep>/src/com/fpt/model/Module.java
package com.fpt.model;
import java.io.Serializable;
import java.util.ArrayList;
public class Module extends BaseDependency implements Serializable {
/**
*
*/
private static final long serialVersionUID = 5028690706583943962L;
private String url;
private String name;
private String dirName;
private ArrayList<BaseDependency> dependenciesList;
private boolean projectLibrary;
private int minSDKVer;
private int targetSDKVer;
private int compileSDKVer;
private boolean jumboMode;
private boolean mainModule;
private String buildToolsVer;
private int versionCode;
private String versionName;
public int getVersionCode() {
return versionCode;
}
public void setVersionCode(int versionCode) {
this.versionCode = versionCode;
}
public String getVersionName() {
return versionName;
}
public void setVersionName(String versionName) {
this.versionName = versionName;
}
public String getBuildToolsVer() {
return buildToolsVer;
}
public void setBuildToolsVer(String buildToolsVer) {
this.buildToolsVer = buildToolsVer;
}
public boolean isMainModule() {
return mainModule;
}
public void setMainModule(boolean mainModule) {
this.mainModule = mainModule;
}
public boolean isJumboMode() {
return jumboMode;
}
public void setJumboMode(boolean jumboMode) {
this.jumboMode = jumboMode;
}
public int getMinSDKVer() {
return minSDKVer;
}
public void setMinSDKVer(int minSDKVer) {
this.minSDKVer = minSDKVer;
}
public int getTargetSDKVer() {
return targetSDKVer;
}
public void setTargetSDKVer(int targetSDKVer) {
this.targetSDKVer = targetSDKVer;
}
public int getCompileSDKVer() {
return compileSDKVer;
}
public void setCompileSDKVer(int compileSDKVer) {
this.compileSDKVer = compileSDKVer;
}
public boolean isProjectLibrary() {
return projectLibrary;
}
public void setProjectLibrary(boolean projectLibrary) {
this.projectLibrary = projectLibrary;
}
public String getDirName() {
return dirName;
}
public void setDirName(String dirName) {
this.dirName = dirName;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public ArrayList<BaseDependency> getDependenciesList() {
return dependenciesList;
}
public void setDependenciesList(ArrayList<BaseDependency> dependenciesList) {
this.dependenciesList = dependenciesList;
}
public String toString() {
if (name == null || name.equals("")) {
return url;
}
return ":" + name;
}
}
<file_sep>/src/com/fpt/model/AndroidDependenciesData.java
package com.fpt.model;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Map;
public class AndroidDependenciesData implements Serializable, IDependenciesData {
/**
*
*/
private static final long serialVersionUID = 6694841707074324274L;
private ArrayList<Module> moduleList;
public ArrayList<Module> getModuleList() {
return moduleList;
}
public void setModuleList(ArrayList<Module> moduleList) {
this.moduleList = moduleList;
}
}
<file_sep>/src/com/fpt/gui/SettingsDialog.java
package com.fpt.gui;
import java.awt.BorderLayout;
import java.awt.FlowLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.io.File;
import javax.swing.JButton;
import javax.swing.JDialog;
import javax.swing.JFileChooser;
import javax.swing.JLabel;
import javax.swing.JPanel;
import javax.swing.JTextField;
import javax.swing.border.EmptyBorder;
import javax.swing.event.DocumentEvent;
import javax.swing.event.DocumentListener;
import com.fpt.model.Module;
import com.fpt.model.SettingsData;
import javax.swing.JCheckBox;
import java.awt.event.ItemListener;
import java.awt.event.ItemEvent;
public class SettingsDialog extends JDialog {
/**
*
*/
private static final long serialVersionUID = -3822659508101627521L;
private final JPanel contentPanel = new JPanel();
private JTextField tfAndroidSDKUrl;
private SettingsData data;
private JTextField tfRepositoryId;
private JTextField tfGradleUrl;
private JTextField tfRepUsername;
private JTextField tfRepPassword;
private JTextField tfWorkspaceUrl;
private JTextField tfNexusUserName;
private JTextField tfNexusPassword;
private JTextField tfNexusUrl;
/**
* Create the dialog.
*/
public SettingsDialog() {
initialize();
}
private void initialize() {
data = new SettingsData();
data.readFromFile();
setTitle("Settings");
setBounds(100, 100, 450, 332);
getContentPane().setLayout(new BorderLayout());
contentPanel.setBorder(new EmptyBorder(5, 5, 5, 5));
getContentPane().add(contentPanel, BorderLayout.CENTER);
contentPanel.setLayout(null);
JLabel lblAndroidSDKUrl = new JLabel("SDK Path");
lblAndroidSDKUrl.setBounds(10, 11, 72, 14);
contentPanel.add(lblAndroidSDKUrl);
JLabel lblRepositoryUrl = new JLabel("Repository");
lblRepositoryUrl.setBounds(10, 156, 72, 14);
contentPanel.add(lblRepositoryUrl);
tfAndroidSDKUrl = new JTextField();
tfAndroidSDKUrl.getDocument().addDocumentListener(
new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setAndroidSDKURL(tfAndroidSDKUrl.getText().trim());
}
public void removeUpdate(DocumentEvent e) {
data.setAndroidSDKURL(tfAndroidSDKUrl.getText().trim());
}
public void insertUpdate(DocumentEvent e) {
data.setAndroidSDKURL(tfAndroidSDKUrl.getText().trim());
}
});
tfAndroidSDKUrl.setBounds(84, 8, 251, 20);
contentPanel.add(tfAndroidSDKUrl);
tfAndroidSDKUrl.setColumns(10);
tfAndroidSDKUrl.setText(data.getAndroidSDKURL());
JButton btnBrowseAndroidSDKUrl = new JButton("Browse");
btnBrowseAndroidSDKUrl.setBounds(345, 7, 89, 23);
btnBrowseAndroidSDKUrl.addActionListener(new LocalBrowser(contentPanel,
tfAndroidSDKUrl, JFileChooser.DIRECTORIES_ONLY, null, 0));
contentPanel.add(btnBrowseAndroidSDKUrl);
tfRepositoryId = new JTextField();
tfRepositoryId.getDocument().addDocumentListener(new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setRepository(tfRepositoryId.getText().trim());
}
public void removeUpdate(DocumentEvent e) {
data.setRepository(tfRepositoryId.getText().trim());
}
public void insertUpdate(DocumentEvent e) {
data.setRepository(tfRepositoryId.getText().trim());
}
});
tfRepositoryId.setBounds(84, 153, 251, 20);
contentPanel.add(tfRepositoryId);
tfRepositoryId.setColumns(10);
tfRepositoryId.setText(data.getRepository());
JLabel lblGradleUrl = new JLabel("Gradle Path");
lblGradleUrl.setBounds(10, 37, 72, 14);
contentPanel.add(lblGradleUrl);
tfGradleUrl = new JTextField();
tfGradleUrl.getDocument().addDocumentListener(new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setGradleUrl(tfGradleUrl.getText().trim());
data.setGradleBinUrl(tfGradleUrl.getText().trim() + "\\bin");
}
public void removeUpdate(DocumentEvent e) {
data.setGradleUrl(tfGradleUrl.getText().trim());
data.setGradleBinUrl(tfGradleUrl.getText().trim() + "\\bin");
}
public void insertUpdate(DocumentEvent e) {
data.setGradleUrl(tfGradleUrl.getText().trim());
data.setGradleBinUrl(tfGradleUrl.getText().trim() + "\\bin");
}
});
tfGradleUrl.setBounds(84, 34, 251, 20);
contentPanel.add(tfGradleUrl);
tfGradleUrl.setColumns(10);
tfGradleUrl.setText(data.getGradleUrl());
JButton btnBrowseGradleUrl = new JButton("Browse");
btnBrowseGradleUrl.addActionListener(new LocalBrowser(contentPanel,
tfGradleUrl, JFileChooser.DIRECTORIES_ONLY, null, 0));
btnBrowseGradleUrl.setBounds(345, 33, 89, 23);
contentPanel.add(btnBrowseGradleUrl);
tfRepUsername = new JTextField();
tfRepUsername.setToolTipText("Repository UserName");
tfRepUsername.getDocument().addDocumentListener(
new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setRepUserName(tfRepUsername.getText().trim());
}
public void removeUpdate(DocumentEvent e) {
data.setRepUserName(tfRepUsername.getText().trim());
}
public void insertUpdate(DocumentEvent e) {
data.setRepUserName(tfRepUsername.getText().trim());
}
});
tfRepUsername.setBounds(84, 207, 130, 20);
contentPanel.add(tfRepUsername);
tfRepUsername.setColumns(10);
tfRepUsername.setText(data.getRepUserName());
tfRepPassword = new JTextField();
tfRepPassword.setToolTipText("Repository Password");
tfRepPassword.getDocument().addDocumentListener(
new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setRepPassword(tfRepPassword.getText().trim());
}
public void removeUpdate(DocumentEvent e) {
data.setRepPassword(tfRepPassword.getText().trim());
}
public void insertUpdate(DocumentEvent e) {
data.setRepPassword(tfRepPassword.getText().trim());
}
});
tfRepPassword.setBounds(224, 207, 130, 20);
contentPanel.add(tfRepPassword);
tfRepPassword.setColumns(10);
tfRepPassword.setText(data.getRepPassword());
final JCheckBox cbRepAuth = new JCheckBox("Authentication");
cbRepAuth.addItemListener(new ItemListener() {
public void itemStateChanged(ItemEvent arg0) {
data.setRepAuthentication(cbRepAuth.isSelected());
}
});
cbRepAuth.setBounds(84, 177, 136, 23);
contentPanel.add(cbRepAuth);
cbRepAuth.setSelected(data.isRepAuthentication());
JLabel lblWorkspaceUrl = new JLabel("Workspace");
lblWorkspaceUrl.setBounds(10, 66, 72, 14);
contentPanel.add(lblWorkspaceUrl);
tfWorkspaceUrl = new JTextField();
tfWorkspaceUrl.getDocument().addDocumentListener(
new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setWorkSpaceUrl(tfWorkspaceUrl.getText().trim());
}
public void removeUpdate(DocumentEvent e) {
data.setWorkSpaceUrl(tfWorkspaceUrl.getText().trim());
}
public void insertUpdate(DocumentEvent e) {
data.setWorkSpaceUrl(tfWorkspaceUrl.getText().trim());
}
});
tfWorkspaceUrl.setColumns(10);
tfWorkspaceUrl.setBounds(84, 63, 251, 20);
contentPanel.add(tfWorkspaceUrl);
tfWorkspaceUrl.setText(data.getWorkSpaceUrl());
JButton btnBrowseWorkspaceUrl = new JButton("Browse");
btnBrowseWorkspaceUrl.addActionListener(new LocalBrowser(contentPanel,
tfWorkspaceUrl, JFileChooser.DIRECTORIES_ONLY, null, 0));
btnBrowseWorkspaceUrl.setBounds(345, 62, 89, 23);
contentPanel.add(btnBrowseWorkspaceUrl);
tfNexusUserName = new JTextField();
tfNexusUserName.getDocument().addDocumentListener(
new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setNexusUserName(tfNexusUserName.getText().trim());
}
public void removeUpdate(DocumentEvent e) {
data.setNexusUserName(tfNexusUserName.getText().trim());
}
public void insertUpdate(DocumentEvent e) {
data.setNexusUserName(tfNexusUserName.getText().trim());
}
});
tfNexusUserName.setToolTipText("Nexus UserName");
tfNexusUserName.setText((String) null);
tfNexusUserName.setColumns(10);
tfNexusUserName.setBounds(84, 91, 130, 20);
contentPanel.add(tfNexusUserName);
tfNexusUserName.setText(data.getNexusUserName());
tfNexusPassword = new JTextField();
tfNexusPassword.getDocument().addDocumentListener(
new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setNexusPassword(tfNexusPassword.getText().trim());
}
public void removeUpdate(DocumentEvent e) {
data.setNexusPassword(tfNexusPassword.getText().trim());
}
public void insertUpdate(DocumentEvent e) {
data.setNexusPassword(tfNexusPassword.getText().trim());
}
});
tfNexusPassword.setToolTipText("Nexus Password");
tfNexusPassword.setText((String) null);
tfNexusPassword.setColumns(10);
tfNexusPassword.setBounds(224, 91, 130, 20);
contentPanel.add(tfNexusPassword);
tfNexusPassword.setText(data.getNexusPassword());
JLabel lblNexusAuth = new JLabel("Nexus Auth");
lblNexusAuth.setBounds(10, 94, 72, 14);
contentPanel.add(lblNexusAuth);
tfNexusUrl = new JTextField();
tfNexusUrl.getDocument().addDocumentListener(
new DocumentListener() {
public void changedUpdate(DocumentEvent e) {
data.setNexusUrl(tfNexusUrl.getText().trim());
}
public void removeUpdate(DocumentEvent e) {
data.setNexusUrl(tfNexusUrl.getText().trim());
}
public void insertUpdate(DocumentEvent e) {
data.setNexusUrl(tfNexusUrl.getText().trim());
}
});
tfNexusUrl.setText((String) null);
tfNexusUrl.setColumns(10);
tfNexusUrl.setBounds(84, 122, 251, 20);
contentPanel.add(tfNexusUrl);
tfNexusUrl.setText(data.getNexusUrl());
JLabel lblNexusUrl = new JLabel("Nexus Url");
lblNexusUrl.setBounds(10, 125, 72, 14);
contentPanel.add(lblNexusUrl);
{
JPanel buttonPane = new JPanel();
buttonPane.setLayout(new FlowLayout(FlowLayout.RIGHT));
getContentPane().add(buttonPane, BorderLayout.SOUTH);
{
JButton okButton = new JButton("OK");
okButton.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent arg0) {
data.writeToFile();
dispose();
}
});
okButton.setActionCommand("OK");
buttonPane.add(okButton);
getRootPane().setDefaultButton(okButton);
}
{
JButton cancelButton = new JButton("Cancel");
cancelButton.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
dispose();
}
});
cancelButton.setActionCommand("Cancel");
buttonPane.add(cancelButton);
}
}
setModal(true);
setResizable(false);
setVisible(true);
}
}
<file_sep>/src/com/fpt/model/JarLib.java
package com.fpt.model;
import java.io.Serializable;
public class JarLib extends BaseDependency implements Serializable {
/**
*
*/
private static final long serialVersionUID = 7753597393253250770L;
private String url;
private String name;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
if (name != null && !name.equals("")) {
return name;
}
return url;
}
}
<file_sep>/src/com/fpt/util/DataHelper.java
package com.fpt.util;
import java.io.BufferedReader;
import java.io.File;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.ListIterator;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import com.fpt.gui.AndroidInputPane;
import com.fpt.gui.BuildManager;
import com.fpt.model.Artifact;
import com.fpt.model.BaseDependency;
import com.fpt.model.BaseDependency.Scope;
import com.fpt.model.JarLib;
import com.fpt.model.Module;
public class DataHelper {
public static final String DOT_PROJECT_FILE_NAME = ".project";
public static final String PROJECT_DOT_PROPERTIES_FILE_NAME = "project.properties";
public static final String IS_ANDROID_LIBRARY_KEYWORD = "android.library=true";
public static final String IS_ANDROID_JUMBOMODE_KEYWORD = "dex.force.jumbo=true";
public static final String ANDROID_REFERENCE_KEYWORD = "android.library.reference.";
public static final String SETTINGS_DOT_GRADLE_FILE_NAME = "settings.gradle";
public static final String BUILD_DOT_GRADLE_FILE_NAME = "build.gradle";
public static final String LOCAL_DOT_PROPERTIES_FILE_NAME = "local.properties";
private static ArrayList<Artifact> artifactList;
public static ArrayList<Artifact> getAllArtifacts(String remoteRep) {
artifactList = new ArrayList<Artifact>();
getArtifact(remoteRep);
return artifactList;
}
private static void getArtifact(String urlStr) {
try {
Document docGroup = Jsoup.connect(urlStr).get();
Elements links = docGroup.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
if (checkUrlIsDirectory(linkHref)) {
getArtifact(linkHref);
} else {
if (linkText.equals("maven-metadata.xml")) {
Artifact artifact = new Artifact();
artifact.setUrl(linkHref.substring(0,
linkHref.indexOf("maven-metadata.xml") - 1));
// get more information of artifact via reading
// maven-metadata.xml file
URL url = new URL(linkHref);
BufferedReader br = new BufferedReader(
new InputStreamReader(url.openStream()));
String metadataStr = "";
String line = "";
while ((line = br.readLine()) != null) {
metadataStr += line;
}
org.w3c.dom.Document documentMetadata = Parser
.loadXMLFromString(metadataStr);
Node nodeRoot = documentMetadata.getFirstChild();
NodeList nodeList = nodeRoot.getChildNodes();
for (int i = 0; i < nodeList.getLength(); i++) {
Node nodeChild = nodeList.item(i);
if (nodeChild.getNodeName().equals("groupId")) {
artifact.setGroupId(nodeChild.getTextContent());
}
if (nodeChild.getNodeName().equals("artifactId")) {
artifact.setArtifactId(nodeChild
.getTextContent());
}
if (nodeChild.getNodeType() == Node.ELEMENT_NODE) {
NodeList nodeChildList = nodeChild
.getChildNodes();
for (int x = 0; x < nodeChildList.getLength(); x++) {
Node nodeChild1 = nodeChildList.item(x);
if (nodeChild1.getNodeName().equals(
"versions")) {
NodeList nodeChild1List = nodeChild1
.getChildNodes();
for (int n = 0; n < nodeChild1List
.getLength(); n++) {
Node nodeChild2 = nodeChild1List
.item(n);
if (nodeChild2.getNodeName()
.equals("version")) {
artifact.setVersion(nodeChild2
.getTextContent());
}
}
}
}
}
}
artifactList.add(artifact);
}
}
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
private static boolean checkUrlIsDirectory(String urlStr) {
URL url = null;
try {
url = new URL(urlStr);
if (url != null) {
if (urlStr.indexOf("/", urlStr.length() - 1) > -1) {
return true;
}
}
// // if (url.getProtocol().equals("file")) {
// return (new File(url.getFile())).isDirectory();
// // }
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
// e.printStackTrace();
}
return false;
}
private static ArrayList<Module> moduleList;
public static ArrayList<Module> getAllModules(File folder) {
moduleList = new ArrayList<Module>();
if (checkIsGradleProject(AndroidInputPane.getData().getProjectURL())) {
getModuleFromGradleProject(folder);
} else {
getModuleFromNonGradleProject(folder);
verifyDependencies();
}
verifyMainModule();
return moduleList;
}
public static boolean checkIsGradleProject(final String folderUrl) {
final File folder = new File(folderUrl);
for (final File fileEntry : folder.listFiles()) {
if (fileEntry.isDirectory()) {
continue;
} else {
if (fileEntry.getName().equals(BUILD_DOT_GRADLE_FILE_NAME)) {
return true;
}
}
}
return false;
}
private static String getValueFromProperty(String fileContent,
String property) {
String value = null;
if (fileContent.contains(property)) {
String line = fileContent.substring(fileContent.indexOf(property),
fileContent.indexOf("\n", fileContent.indexOf(property)))
.trim();
String[] lineArray = line.split(" ");
value = lineArray[lineArray.length - 1].replace("\"", "");
}
return value;
}
private static void getModuleFromGradleProject(final File folder) {
try {
for (final File fileEntry : folder.listFiles()) {
if (fileEntry.isDirectory()) {
getModuleFromGradleProject(fileEntry);
} else {
if (fileEntry.getName().equals(BUILD_DOT_GRADLE_FILE_NAME)) {
String buildDotGardleContent = IOHelper
.readFromBinFile(fileEntry.getAbsolutePath())
.trim();
String[] buildDotGradleContentLines = buildDotGardleContent
.split("\n");
ArrayList<String> buildDotGradleContentLineList = new ArrayList<String>(
Arrays.asList(buildDotGradleContentLines));
for (int i = 0; i < buildDotGradleContentLineList
.size(); i++) {
if (buildDotGradleContentLineList.get(i).trim()
.indexOf("//") == 0) {
buildDotGradleContentLineList.remove(i);
}
}
StringBuilder stringBuilder = new StringBuilder();
for (String line : buildDotGradleContentLineList) {
stringBuilder.append(line + "\n");
}
buildDotGardleContent = stringBuilder.toString();
if (!buildDotGardleContent.contains("apply plugin")) {
continue;
}
System.out.println(fileEntry.getAbsolutePath());
Module moduleItem = new Module();
File parent = fileEntry.getParentFile();
moduleItem.setDirName(parent.getName());
moduleItem.setName(parent.getName());
moduleItem.setUrl(parent.getAbsolutePath());
if (buildDotGardleContent
.contains("apply plugin: 'com.android.library'")
|| buildDotGardleContent
.contains("apply plugin: 'android-library'")) {
moduleItem.setProjectLibrary(true);
} else if (buildDotGardleContent
.contains("apply plugin: 'com.android.application'")
|| buildDotGardleContent
.contains("apply plugin: 'android-application'")) {
moduleItem.setMainModule(true);
}
if (getValueFromProperty(buildDotGardleContent,
"compileSdkVersion") != null) {
moduleItem.setCompileSDKVer(Integer
.parseInt(getValueFromProperty(
buildDotGardleContent,
"compileSdkVersion")));
}
if (getValueFromProperty(buildDotGardleContent,
"buildToolsVersion") != null) {
moduleItem
.setBuildToolsVer(getValueFromProperty(
buildDotGardleContent,
"buildToolsVersion"));
}
if (getValueFromProperty(buildDotGardleContent,
"minSdkVersion") != null) {
moduleItem.setMinSDKVer(Integer
.parseInt(getValueFromProperty(
buildDotGardleContent,
"minSdkVersion")));
}
if (getValueFromProperty(buildDotGardleContent,
"targetSdkVersion") != null) {
moduleItem.setTargetSDKVer(Integer
.parseInt(getValueFromProperty(
buildDotGardleContent,
"targetSdkVersion")));
}
if (getValueFromProperty(buildDotGardleContent,
"versionCode") != null) {
moduleItem.setVersionCode(Integer
.parseInt(getValueFromProperty(
buildDotGardleContent,
"versionCode")));
}
if (getValueFromProperty(buildDotGardleContent,
"versionName") != null) {
moduleItem.setVersionName(getValueFromProperty(
buildDotGardleContent, "versionName"));
}
if (getValueFromProperty(buildDotGardleContent,
"jumboMode") != null) {
moduleItem
.setJumboMode(Boolean
.parseBoolean(getValueFromProperty(
buildDotGardleContent,
"jumboMode")));
}
ArrayList<BaseDependency> dependenciesList = new ArrayList<BaseDependency>();
String[] buildDotGardleContentLines = buildDotGardleContent
.split("\n");
for (String line : buildDotGardleContentLines) {
if (line.contains("compile files")) {
String jarUrl = line
.substring(
line.indexOf(
"'",
line.indexOf("compile files")) + 1,
line.indexOf("'",
line.indexOf("'") + 1));
JarLib jarLib = new JarLib();
jarLib.setUrl(jarUrl);
jarLib.setScope(Scope.COMPILE);
jarLib.setName(StringHelper
.getLastElementFromUrl(jarUrl));
dependenciesList.add(jarLib);
} else if (line.contains("provided files")) {
String jarUrl = line
.substring(
line.indexOf(
"'",
line.indexOf("provided files")) + 1,
line.indexOf("'",
line.indexOf("'") + 1));
JarLib jarLib = new JarLib();
jarLib.setUrl(jarUrl);
jarLib.setScope(Scope.PROVIDED);
jarLib.setName(StringHelper
.getLastElementFromUrl(jarUrl));
dependenciesList.add(jarLib);
} else if (line.contains("compile project")) {
String moduleDirName = line
.substring(
line.indexOf(
":",
line.indexOf("compile project")) + 1,
line.indexOf("'",
line.indexOf("'") + 1));
Module module = new Module();
module.setScope(Scope.COMPILE);
module.setUrl(moduleDirName);
module.setName(moduleDirName);
module.setDirName(moduleDirName);
dependenciesList.add(module);
} else if (line.contains("provided project")) {
String moduleDirName = line
.substring(
line.indexOf(
":",
line.indexOf("provided project")) + 1,
line.indexOf("'",
line.indexOf("'") + 1));
Module module = new Module();
module.setScope(Scope.PROVIDED);
module.setUrl(moduleDirName);
module.setName(moduleDirName);
module.setDirName(moduleDirName);
dependenciesList.add(module);
} else if (line.contains("compile fileTree")) {
String fileTree = line
.substring(
line.indexOf(
"(",
line.indexOf("compile fileTree")) + 1,
line.indexOf(")",
line.indexOf("(") + 1));
String dir = fileTree
.substring(
fileTree.indexOf("'", fileTree
.indexOf("jarLib")) + 1,
fileTree.indexOf(
"'",
fileTree.indexOf("'") + 1));
String dirUrl = StringHelper
.convertRelativeUrlToAbsoluteUrl(
parent.getAbsolutePath(), dir);
File dirFile = new File(dirUrl);
for (File file : dirFile.listFiles()) {
JarLib jarLib = new JarLib();
jarLib.setName(file.getName());
jarLib.setUrl(StringHelper
.convertAbsoluteUrlToRelativeUrl(
parent.getAbsolutePath(),
file.getAbsolutePath()));
jarLib.setScope(Scope.COMPILE);
dependenciesList.add(jarLib);
}
} else if (line.contains("provided fileTree")) {
String fileTree = line
.substring(
line.indexOf(
"(",
line.indexOf("provided fileTree")) + 1,
line.indexOf(")",
line.indexOf("(") + 1));
String dir = fileTree
.substring(
fileTree.indexOf("'", fileTree
.indexOf("jarLib")) + 1,
fileTree.indexOf(
"'",
fileTree.indexOf("'") + 1));
String dirUrl = StringHelper
.convertRelativeUrlToAbsoluteUrl(
parent.getAbsolutePath(), dir);
File dirFile = new File(dirUrl);
for (File file : dirFile.listFiles()) {
JarLib jarLib = new JarLib();
jarLib.setName(file.getName());
jarLib.setUrl(StringHelper
.convertAbsoluteUrlToRelativeUrl(
parent.getAbsolutePath(),
file.getAbsolutePath()));
jarLib.setScope(Scope.PROVIDED);
dependenciesList.add(jarLib);
}
} else if (line.contains("compile '")) {
String artifactName = line
.substring(line.indexOf("'",
line.indexOf("compile")) + 1,
line.indexOf("'",
line.indexOf("'") + 1));
String[] artifactNameArray = artifactName
.split(":");
Artifact artifact = new Artifact();
artifact.setScope(Scope.COMPILE);
artifact.setGroupId(artifactNameArray[0]);
artifact.setArtifactId(artifactNameArray[1]);
artifact.setVersion(artifactNameArray[2]);
dependenciesList.add(artifact);
} else if (line.contains("provided '")) {
String artifactName = line
.substring(line.indexOf("'",
line.indexOf("provided")) + 1,
line.indexOf("'",
line.indexOf("'") + 1));
String[] artifactNameArray = artifactName
.split(":");
Artifact artifact = new Artifact();
artifact.setScope(Scope.PROVIDED);
artifact.setGroupId(artifactNameArray[0]);
artifact.setArtifactId(artifactNameArray[1]);
artifact.setVersion(artifactNameArray[2]);
dependenciesList.add(artifact);
}
}
if (dependenciesList.size() > 0) {
moduleItem.setDependenciesList(dependenciesList);
}
moduleList.add(moduleItem);
}
}
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
private static void getModuleFromNonGradleProject(final File folder) {
try {
for (final File fileEntry : folder.listFiles()) {
if (fileEntry.isDirectory()) {
getModuleFromNonGradleProject(fileEntry);
} else {
if (fileEntry.getName().equals(DOT_PROJECT_FILE_NAME)) {
Module moduleItem = new Module();
File parent = fileEntry.getParentFile();
moduleItem.setDirName(parent.getName());
moduleItem.setUrl(parent.getAbsolutePath());
String projectDesStr = IOHelper.readFromBinFile(
fileEntry.getAbsolutePath()).trim();
System.out.println(fileEntry.getAbsolutePath());
try {
org.w3c.dom.Document docPrjDes = Parser
.loadXMLFromString(projectDesStr);
Node nodeRoot = docPrjDes.getFirstChild();
NodeList nodeList = nodeRoot.getChildNodes();
for (int i = 0; i < nodeList.getLength(); i++) {
Node nodeChild = nodeList.item(i);
if (nodeChild.getNodeName().equals("name")) {
moduleItem.setName(nodeChild
.getTextContent());
break;
}
}
} catch (Exception ex) {
ex.printStackTrace();
}
for (File fileEntry1 : parent.listFiles()) {
if (fileEntry1.getName().equals(
PROJECT_DOT_PROPERTIES_FILE_NAME)) {
String prjDotProContent = IOHelper
.readFromBinFile(fileEntry1
.getAbsolutePath());
if (prjDotProContent
.indexOf(IS_ANDROID_LIBRARY_KEYWORD) > -1) {
moduleItem.setProjectLibrary(true);
}
if (prjDotProContent
.indexOf(IS_ANDROID_JUMBOMODE_KEYWORD) > -1) {
moduleItem.setJumboMode(true);
}
String[] prjDotProContentArray = prjDotProContent
.split("\n");
ArrayList<BaseDependency> dependenciesList = null;
for (String contentLine : prjDotProContentArray) {
if (contentLine
.indexOf(ANDROID_REFERENCE_KEYWORD) > -1) {
String[] contentLineArray = contentLine
.split("=");
String referenceUrl = StringHelper
.convertToBackFlash(contentLineArray[1]);
if (referenceUrl != null
&& !referenceUrl.equals("")) {
if (dependenciesList == null) {
dependenciesList = new ArrayList<BaseDependency>();
}
Module moduleDep = new Module();
String[] referenceUrlArray = referenceUrl
.split("/");
String moduleDepName = referenceUrlArray[referenceUrlArray.length - 1];
moduleDep.setDirName(moduleDepName);
moduleDep.setUrl(referenceUrl);
dependenciesList.add(moduleDep);
}
}
}
if (dependenciesList != null) {
moduleItem
.setDependenciesList(dependenciesList);
}
break;
}
}
moduleItem.setCompileSDKVer(21);
moduleItem.setBuildToolsVer("21.1.2");
moduleItem.setMinSDKVer(14);
moduleItem.setTargetSDKVer(21);
moduleList.add(moduleItem);
}
}
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
private static void verifyMainModule() {
if (moduleList.size() == 0) {
BuildManager.updateLog("Warning: There are no android component");
} else if (moduleList.size() == 1) {
moduleList.get(0).setMainModule(true);
} else if (moduleList.size() > 1) {
int projectMainCount = 0;
for (Module moduleItem : moduleList) {
if (!moduleItem.isProjectLibrary()) {
moduleItem.setMainModule(true);
projectMainCount++;
}
}
if (projectMainCount == 0) {
BuildManager
.updateLog("Warning: There are no android application");
} else if (projectMainCount > 1) {
BuildManager
.updateLog("Warning: There are more than one android application");
}
}
}
private static void verifyDependencies() {
for (Module moduleItem : moduleList) {
ArrayList<BaseDependency> dependenciesList = moduleItem
.getDependenciesList();
if (dependenciesList != null) {
for (int i = 0; i < dependenciesList.size(); i++) {
if (dependenciesList.get(i) instanceof Module) {
Module moduleItem1 = (Module) dependenciesList.get(i);
for (Module moduleItem2 : moduleList) {
if (moduleItem1.getDirName().equals(
moduleItem2.getDirName())) {
dependenciesList.remove(i);
dependenciesList.add(i, moduleItem2);
break;
}
}
}
}
}
}
}
}
<file_sep>/src/com/fpt/gui/AndroidDependenciesPane.java
package com.fpt.gui;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.event.MouseAdapter;
import java.awt.event.MouseEvent;
import java.io.BufferedReader;
import java.io.File;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.Iterator;
import javax.swing.DefaultListModel;
import javax.swing.JButton;
import javax.swing.JFileChooser;
import javax.swing.JLabel;
import javax.swing.JList;
import javax.swing.JMenuItem;
import javax.swing.JPanel;
import javax.swing.JPopupMenu;
import javax.swing.JScrollPane;
import javax.swing.event.ListSelectionEvent;
import javax.swing.event.ListSelectionListener;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import com.fpt.gui.ChooserDialog.ChooserDialogListener;
import com.fpt.gui.LocalBrowser.LocalBrowserListener;
import com.fpt.model.AndroidDependenciesData;
import com.fpt.model.Artifact;
import com.fpt.model.BaseDependency;
import com.fpt.model.BaseDependency.Scope;
import com.fpt.model.JarLib;
import com.fpt.model.Module;
import com.fpt.model.SettingsData;
import com.fpt.util.DataHelper;
import com.fpt.util.IOHelper;
import com.fpt.util.Parser;
import com.fpt.util.StringHelper;
/**
* @author QuyPP1
*/
public class AndroidDependenciesPane extends JPanel implements
ChooserDialogListener, LocalBrowserListener {
private static final int LOCAL_BROWSER_JAR_REQUEST_CODE = 100;
private JButton btnAddDep;
private JPopupMenu popupMenuDep;
private JList<Module> listModule;
private JList<BaseDependency> listDependencies;
public static AndroidDependenciesData data;
private ArrayList<BaseDependency> dependenciesList;
/**
*
*/
private static final long serialVersionUID = 4971324513924531377L;
/**
* Create the panel.
*/
public AndroidDependenciesPane() {
data = new AndroidDependenciesData();
dependenciesList = new ArrayList<BaseDependency>();
setBounds(100, 100, 515, 181);
setLayout(null);
JLabel lblModule = new JLabel("Module");
lblModule.setBounds(58, 17, 61, 14);
add(lblModule);
JLabel lblDependencies = new JLabel("Dependencies");
lblDependencies.setBounds(280, 17, 93, 14);
add(lblDependencies);
btnAddDep = new JButton("Add");
btnAddDep.setBounds(438, 13, 67, 23);
btnAddDep.addMouseListener(new MouseAdapter() {
public void mousePressed(MouseEvent e) {
popupMenuDep.show(e.getComponent(), 0, 23);
}
});
add(btnAddDep);
popupMenuDep = new JPopupMenu();
JMenuItem menuAddDepLocal = new JMenuItem("Local");
menuAddDepLocal.addActionListener(new LocalBrowser(this, null,
JFileChooser.FILES_ONLY, this, LOCAL_BROWSER_JAR_REQUEST_CODE));
popupMenuDep.add(menuAddDepLocal);
JMenuItem menuAddDepNexus = new JMenuItem("Nexus server");
menuAddDepNexus.addActionListener(new OpenNexus(
AndroidDependenciesPane.this));
popupMenuDep.add(menuAddDepNexus);
JMenuItem menuAddDepModule = new JMenuItem("Module");
menuAddDepModule.addActionListener(new OpenModule(
AndroidDependenciesPane.this));
popupMenuDep.add(menuAddDepModule);
JButton btnRemoveDep = new JButton("-");
btnRemoveDep.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent arg0) {
if (listDependencies.getSelectedIndex() != -1) {
dependenciesList.remove(listDependencies.getSelectedIndex());
updateDependenciesList();
}
}
});
btnRemoveDep.setBounds(466, 47, 39, 23);
add(btnRemoveDep);
JScrollPane scrollPane = new JScrollPane();
scrollPane.setBounds(10, 42, 164, 128);
add(scrollPane);
listModule = new JList<Module>();
scrollPane.setViewportView(listModule);
JScrollPane scrollPane_1 = new JScrollPane();
scrollPane_1.setBounds(184, 42, 273, 128);
add(scrollPane_1);
listDependencies = new JList<BaseDependency>();
listDependencies.addMouseListener(new MouseAdapter() {
public void mouseClicked(MouseEvent evt) {
if (evt.getClickCount() == 2) {
// Double-click detected
String dialogTitle = "Scope - "
+ listDependencies.getSelectedValue()
+ " : {"
+ listDependencies.getSelectedValue().getScope()
.getText() + "}";
ArrayList<Scope> listData = new ArrayList<Scope>();
for (Scope scopeItem : Scope.values()) {
listData.add(scopeItem);
}
ChooserDialog chooserDialog = new ChooserDialog(
AndroidDependenciesPane.this, dialogTitle, listData
.toArray(new Scope[listData.size()]));
chooserDialog
.addChooserDialogListener(AndroidDependenciesPane.this);
chooserDialog.showDialog();
}
}
});
scrollPane_1.setViewportView(listDependencies);
listModule.addListSelectionListener(new ListSelectionListener() {
public void valueChanged(ListSelectionEvent arg0) {
listDependencies.setListData(new BaseDependency[0]);
dependenciesList.clear();
if (listModule.getSelectedIndex() != -1) {
ArrayList<BaseDependency> depenList = data.getModuleList()
.get(listModule.getSelectedIndex())
.getDependenciesList();
if (depenList != null) {
dependenciesList = new ArrayList<BaseDependency>(
depenList);
listDependencies.setListData(dependenciesList
.toArray(new BaseDependency[dependenciesList
.size()]));
}
}
}
});
}
public void updateModuleList() {
ArrayList<Module> moduleList = getModuleList();
data.setModuleList(moduleList);
listModule
.setListData(moduleList.toArray(new Module[moduleList.size()]));
listModule.validate();
}
private ArrayList<Module> getModuleList() {
String projectURL = AndroidInputPane.getData().getProjectURL();
ArrayList<Module> listData = new ArrayList<Module>();
try {
if (projectURL != null && !projectURL.equals("")) {
final File folder = new File(projectURL);
listData = DataHelper.getAllModules(folder);
}
} catch (Exception ex) {
ex.printStackTrace();
}
return listData;
}
private void updateDependenciesList() {
if (listModule.getSelectedIndex() != -1) {
data.getModuleList()
.get(listModule.getSelectedIndex())
.setDependenciesList(
new ArrayList<BaseDependency>(dependenciesList));
listDependencies.setListData(dependenciesList
.toArray(new BaseDependency[dependenciesList.size()]));
// need to write reference module to project.properties file
}
}
public static AndroidDependenciesData getData() {
return data;
}
@Override
public void onChooserDialogResultAlready(Object dependency) {
// TODO Auto-generated method stub
if (dependency instanceof BaseDependency) {
dependenciesList.add((BaseDependency) dependency);
updateDependenciesList();
}
if (dependency instanceof Scope) {
dependenciesList.get(listDependencies.getSelectedIndex()).setScope(
(Scope) dependency);
updateDependenciesList();
}
}
@Override
public void onLocalBrowserResultAlready(String resultURL,
String resultFileName, int requestCode) {
// TODO Auto-generated method stub
switch (requestCode) {
case LOCAL_BROWSER_JAR_REQUEST_CODE:
JarLib dependency = new JarLib();
String resultUrlRelative = StringHelper
.convertAbsoluteUrlToRelativeUrl(listModule
.getSelectedValue().getUrl(), resultURL);
dependency.setUrl(resultUrlRelative);
dependency.setName(resultFileName);
dependenciesList.add(dependency);
updateDependenciesList();
break;
default:
break;
}
}
class OpenNexus implements ActionListener {
private Artifact[] listData;
private JPanel parentPanel;
public OpenNexus(JPanel parentPanel) {
this.parentPanel = parentPanel;
}
private void initialize() {
SettingsData settingsData = new SettingsData();
settingsData.readFromFile();
String remoteRep = "";
if (!settingsData.getNexusUrl().equals("")) {
remoteRep = settingsData.getNexusUrl()
+ "/content/repositories/"
+ settingsData.getRepository();
}
// TODO Auto-generated method stub
ArrayList<Artifact> artifactList = DataHelper
.getAllArtifacts(remoteRep);
listData = artifactList.toArray(new Artifact[artifactList.size()]);
}
public void actionPerformed(ActionEvent e) {
initialize();
ChooserDialog chooserDialog = new ChooserDialog(parentPanel,
"Nexus artifact list", listData);
chooserDialog
.addChooserDialogListener(AndroidDependenciesPane.this);
chooserDialog.showDialog();
}
}
class OpenModule implements ActionListener {
private JPanel parentPanel;
public OpenModule(JPanel parentPanel) {
this.parentPanel = parentPanel;
initialize();
}
private void initialize() {
}
public void actionPerformed(ActionEvent e) {
ArrayList<Module> moduleList = getModuleList();
ChooserDialog chooserDialog = new ChooserDialog(parentPanel,
"Module chooser", moduleList.toArray(new Module[moduleList
.size()]));
chooserDialog
.addChooserDialogListener(AndroidDependenciesPane.this);
chooserDialog.showDialog();
}
}
}
<file_sep>/src/com/fpt/model/IInputData.java
package com.fpt.model;
public interface IInputData {
}
<file_sep>/src/com/fpt/build/AndroidGradleBuild.java
package com.fpt.build;
import java.io.File;
import java.util.ArrayList;
import com.fpt.gui.BuildManager;
import com.fpt.model.AndroidDependenciesData;
import com.fpt.model.AndroidInputData;
import com.fpt.model.AndroidOutputData;
import com.fpt.model.Artifact;
import com.fpt.model.BaseDependency;
import com.fpt.model.JarLib;
import com.fpt.model.Module;
import com.fpt.model.SettingsData;
import com.fpt.util.CommandLine;
import com.fpt.util.DataHelper;
import com.fpt.util.IOHelper;
import com.fpt.util.StringHelper;
/**
* Generate Android Gradle Build file
*
* @author QuyPP1
*
*/
public class AndroidGradleBuild implements IGradleBuild {
public static final String REPOSITORY_PREFIX = "/content/repositories/";
public enum Repository {
REPOSITORY_JCENTER("jcenter()"), REPOSITORY_MAVEN("maven()");
Repository(String text) {
this.text = text;
}
private String text;
public String getText() {
return text;
}
}
private AndroidInputData inData;
private AndroidOutputData outData;
private AndroidDependenciesData depData;
private SettingsData settingsData;
public AndroidGradleBuild(AndroidInputData inData,
AndroidOutputData outData, AndroidDependenciesData depData) {
this.inData = inData;
this.outData = outData;
this.depData = depData;
settingsData = new SettingsData();
settingsData.readFromFile();
}
private void createLocalDotPropertiesFile() {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("# Location of the android SDK");
String androidSDKUrl = settingsData.getAndroidSDKURL() == null ? ""
: settingsData.getAndroidSDKURL();
if (!androidSDKUrl.equals("")) {
stringBuilder.append("\nsdk.dir="
+ StringHelper.convertToBackFlash(androidSDKUrl));
String fileName = inData.getProjectURL() + "/"
+ DataHelper.LOCAL_DOT_PROPERTIES_FILE_NAME;
IOHelper.writeToBinFile(stringBuilder.toString(), fileName);
}
}
public void createSettingsDotGradleFile() {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("include");
ArrayList<Module> moduleList = depData.getModuleList();
for (int i = 0; i < moduleList.size(); i++) {
stringBuilder.append(" ':" + moduleList.get(i).getDirName() + "'");
if (i < moduleList.size() - 1) {
stringBuilder.append(",");
}
}
if (!stringBuilder.toString().equals("include")) {
String fileName = inData.getProjectURL() + "/"
+ DataHelper.SETTINGS_DOT_GRADLE_FILE_NAME;
IOHelper.writeToBinFile(stringBuilder.toString(), fileName);
}
}
private void createBuildDotGradleFile(Module moduleItem) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(genBuildScriptPart(Repository.REPOSITORY_JCENTER
.getText()));
stringBuilder.append("\n" + genApplyPluginPart(moduleItem));
stringBuilder.append("\n"
+ genRepositoriesPart(Repository.REPOSITORY_JCENTER.getText()));
stringBuilder.append("\n" + genDependenciesPart(moduleItem));
stringBuilder.append("\n" + genAndroidPart(moduleItem));
if (moduleItem.isMainModule()) {
if (checkUploadNexus()) {
stringBuilder.append("\n" + genUploadPart());
}
}
if (!stringBuilder.toString().equals("")) {
String fileName = moduleItem.getUrl() + "/"
+ DataHelper.BUILD_DOT_GRADLE_FILE_NAME;
IOHelper.writeToBinFile(stringBuilder.toString(), fileName);
}
}
private void createModuleBuildDotGradleFile(Module moduleItem) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(genApplyPluginPart(moduleItem));
stringBuilder.append("\n" + genDependenciesPart(moduleItem));
stringBuilder.append("\n" + genAndroidPart(moduleItem));
if (moduleItem.isMainModule()) {
if (checkUploadNexus()) {
stringBuilder.append("\n" + genUploadPart());
}
}
if (!stringBuilder.toString().equals("")) {
String fileName = moduleItem.getUrl() + "/"
+ DataHelper.BUILD_DOT_GRADLE_FILE_NAME;
IOHelper.writeToBinFile(stringBuilder.toString(), fileName);
}
}
private void createRootBuildDotGradleFile() {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(genBuildScriptPart(Repository.REPOSITORY_JCENTER
.getText()));
stringBuilder.append("\n" + "subprojects {");
stringBuilder.append("\n"
+ genRepositoriesPart(Repository.REPOSITORY_JCENTER.getText()));
stringBuilder.append("\n" + "}");
if (!stringBuilder.toString().equals("")) {
String fileName = inData.getProjectURL() + "/"
+ DataHelper.BUILD_DOT_GRADLE_FILE_NAME;
IOHelper.writeToBinFile(stringBuilder.toString(), fileName);
}
}
private String genApplyPluginPart(Module moduleItem) {
StringBuilder stringBuilder = new StringBuilder();
if (moduleItem.isProjectLibrary()
|| outData.getBuildType() == AndroidOutputData.BUILD_TYPE_AAR) {
stringBuilder.append("apply plugin: \'com.android.library\'");
} else {
stringBuilder.append("apply plugin: \'com.android.application\'");
}
if (moduleItem.isMainModule()) {
if (checkUploadNexus()) {
stringBuilder.append("\napply plugin: \'maven\'");
}
}
return stringBuilder.toString();
}
private String genBuildScriptPart(String repository) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("buildscript {");
stringBuilder.append("\n" + "repositories {");
stringBuilder.append("\n" + repository);
stringBuilder.append("\n" + "}");
stringBuilder.append("\n" + "dependencies {");
stringBuilder.append("\n"
+ "classpath \'com.android.tools.build:gradle:1.2.+\'");
stringBuilder.append("\n" + "}");
stringBuilder.append("\n" + "}");
return stringBuilder.toString();
}
private String genRepositoriesPart(String repository) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("repositories {");
String remoteRep = "";
if (!settingsData.getNexusUrl().equals("")) {
remoteRep += settingsData.getNexusUrl() + REPOSITORY_PREFIX
+ settingsData.getRepository();
}
if (remoteRep.equals("") ? false : true) {
stringBuilder.append("\n" + "maven {");
if (settingsData.isRepAuthentication()) {
stringBuilder.append("\n" + "credentials {");
stringBuilder.append("\n" + "username '"
+ settingsData.getRepUserName() + "'");
stringBuilder.append("\n" + "password '"
+ settingsData.getRepPassword() + "'");
stringBuilder.append("\n" + "}");
}
stringBuilder.append("\n" + "url '"
+ StringHelper.convertToBackFlash(remoteRep) + "'");
stringBuilder.append("\n" + "}");
}
if (!repository.equals("")) {
stringBuilder.append("\n" + repository);
}
stringBuilder.append("\n" + "}");
return stringBuilder.toString();
}
private String genDependenciesPart(Module moduleItem) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("dependencies {");
ArrayList<BaseDependency> dependenciesList = moduleItem
.getDependenciesList();
if (dependenciesList != null) {
for (BaseDependency depItem : dependenciesList) {
if (depItem instanceof Module) {
if (((Module) depItem).getDirName() != null
&& !((Module) depItem).getDirName().equals("")) {
stringBuilder.append("\n"
+ depItem.getScope().getText() + " project(\':"
+ ((Module) depItem).getDirName() + "\')");
} else {
stringBuilder.append("\n"
+ depItem.getScope().getText() + " project(\'"
+ ((Module) depItem).getUrl() + "\')");
}
} else if (depItem instanceof Artifact) {
stringBuilder.append("\n" + depItem.getScope().getText()
+ " \'" + ((Artifact) depItem).getArtifactName()
+ "\'");
} else if (depItem instanceof JarLib) {
stringBuilder
.append("\n" + depItem.getScope().getText()
+ " files(\'" + ((JarLib) depItem).getUrl()
+ "\')");
}
}
}
stringBuilder.append("\n" + "}");
return stringBuilder.toString();
}
private String genUploadPart() {
StringBuilder stringBuilder = new StringBuilder();
String remoteRep = "";
if (!settingsData.getNexusUrl().equals("")) {
remoteRep += settingsData.getNexusUrl() + REPOSITORY_PREFIX
+ settingsData.getRepository();
}
if (remoteRep.equals("") ? false : true) {
stringBuilder.append("uploadArchives {");
stringBuilder.append("\nrepositories {");
stringBuilder.append("\nmavenDeployer {");
stringBuilder.append("\nrepository(url: \""
+ StringHelper.convertToBackFlash(remoteRep) + "\") {");
stringBuilder.append("\nauthentication(userName: '"
+ settingsData.getNexusUserName() + "', password: '"
+ settingsData.getNexusPassword() + "')");
stringBuilder.append("\n}");
stringBuilder.append("\npom.version = '"
+ outData.getNexusVersion() + "'");
stringBuilder.append("\npom.artifactId = '"
+ outData.getNexusArtifactId() + "'");
stringBuilder.append("\npom.groupId = '"
+ outData.getNexusGroupId() + "'");
stringBuilder.append("\n}");
stringBuilder.append("\n}");
stringBuilder.append("\n}");
}
return stringBuilder.toString();
}
private String genAndroidPart(Module moduleItem) {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("android {");
stringBuilder.append("\n" + "compileSdkVersion "
+ moduleItem.getCompileSDKVer());
stringBuilder.append("\n" + "buildToolsVersion \""
+ moduleItem.getBuildToolsVer() + "\"");
stringBuilder.append("\n" + "dexOptions {");
if (moduleItem.isJumboMode()) {
stringBuilder.append("\n" + "jumboMode true");
}
stringBuilder.append("\n" + "}");
stringBuilder.append("\n" + "defaultConfig {");
stringBuilder.append("\n" + "minSdkVersion "
+ moduleItem.getMinSDKVer());
stringBuilder.append("\n" + "targetSdkVersion "
+ moduleItem.getTargetSDKVer());
stringBuilder.append("\n" + "}");
stringBuilder.append("\n" + "lintOptions {");
stringBuilder.append("\n" + "abortOnError false");
stringBuilder.append("\n" + "}");
stringBuilder.append("\n" + "sourceSets {");
stringBuilder.append("\n" + "main {");
if (!DataHelper.checkIsGradleProject(inData.getProjectURL())) {
stringBuilder.append("\n"
+ "manifest.srcFile \'AndroidManifest.xml\'");
stringBuilder.append("\n" + "java.srcDirs = [\'src\']");
stringBuilder.append("\n" + "resources.srcDirs = [\'src\']");
stringBuilder.append("\n" + "aidl.srcDirs = [\'src\']");
stringBuilder.append("\n" + "renderscript.srcDirs = [\'src\']");
stringBuilder.append("\n" + "res.srcDirs = [\'res\']");
stringBuilder.append("\n" + "assets.srcDirs = [\'assets\']");
}
if (inData.isUsingNativeLib() && !moduleItem.isProjectLibrary()) {
stringBuilder.append("\n" + "jniLibs.srcDirs = [\'"
+ StringHelper.convertToBackFlash(inData.getNativeLibUrl())
+ "\']");
}
stringBuilder.append("\n" + "}");
if (!DataHelper.checkIsGradleProject(inData.getProjectURL())) {
stringBuilder.append("\n" + "instrumentTest.setRoot(\'tests\')");
stringBuilder.append("\n" + "debug.setRoot(\'build-types/debug\')");
stringBuilder.append("\n"
+ "release.setRoot(\'build-types/release\')");
}
stringBuilder.append("\n" + "}");
stringBuilder.append("\n" + "buildTypes {");
stringBuilder.append("\n" + "release {");
stringBuilder.append("\n" + "minifyEnabled false");
if (inData.isProguard()) {
stringBuilder
.append("\n"
+ "proguardFiles getDefaultProguardFile(\'proguard-android.txt\'), \'proguard-rules.pro\'");
}
stringBuilder.append("\n" + "}");
stringBuilder.append("\n" + "}");
if (checkOutputLocal() && moduleItem.isMainModule()) {
String outputLocalUrl = outData.getOutputLocalUrl() == null ? ""
: outData.getOutputLocalUrl();
if (moduleItem.isProjectLibrary()
|| outData.getBuildType() == AndroidOutputData.BUILD_TYPE_AAR) {
stringBuilder.append("\n"
+ "android.libraryVariants.all { variant ->");
stringBuilder.append("\n" + "variant.outputs.each { output ->");
stringBuilder.append("\n" + "output.outputFile = new File(\""
+ StringHelper.convertToBackFlash(outputLocalUrl)
+ "\",output.outputFile.name)");
// +
// "\",output.outputFile.name.replace(\".apk\", \"-${variant.versionName}.apk\"))");
stringBuilder.append("\n" + "}");
stringBuilder.append("\n" + "}");
} else {
stringBuilder.append("\n"
+ "applicationVariants.all { variant ->");
stringBuilder.append("\n" + "variant.outputs.each { output ->");
stringBuilder.append("\n" + "output.outputFile = new File(\""
+ StringHelper.convertToBackFlash(outputLocalUrl)
+ "\",output.outputFile.name)");
// +
// "\",output.outputFile.name.replace(\".apk\", \"-${variant.versionName}.apk\"))");
stringBuilder.append("\n" + "}");
stringBuilder.append("\n" + "}");
}
}
stringBuilder.append("\n" + "}");
return stringBuilder.toString();
}
public void build() {
}
private boolean checkUploadNexus() {
if (outData.getOutputWay() == AndroidOutputData.OUTPUT_NEXUS
|| outData.getOutputWay() == AndroidOutputData.OUTPUT_NEXUS
+ AndroidOutputData.OUTPUT_LOCAL
|| outData.getOutputWay() == AndroidOutputData.OUTPUT_NEXUS
+ AndroidOutputData.OUTPUT_SERVER
|| outData.getOutputWay() == AndroidOutputData.OUTPUT_NEXUS
+ AndroidOutputData.OUTPUT_LOCAL
+ AndroidOutputData.OUTPUT_SERVER) {
return true;
}
return false;
}
private boolean checkOutputLocal() {
if (outData.getOutputWay() == AndroidOutputData.OUTPUT_LOCAL
|| outData.getOutputWay() == AndroidOutputData.OUTPUT_NEXUS
+ AndroidOutputData.OUTPUT_LOCAL
|| outData.getOutputWay() == AndroidOutputData.OUTPUT_LOCAL
+ AndroidOutputData.OUTPUT_SERVER
|| outData.getOutputWay() == AndroidOutputData.OUTPUT_NEXUS
+ AndroidOutputData.OUTPUT_LOCAL
+ AndroidOutputData.OUTPUT_SERVER) {
return true;
}
return false;
}
@Override
public void executeBuild() {
// TODO Auto-generated method stub
// LogDialog.getInstance("Log");
try {
if (inData.getProjectURL() == null
|| inData.getProjectURL().equals("")) {
throw new Exception("Project has not been defined.");
}
if (checkUploadNexus()) {
if (outData.getNexusGroupId() == null
|| outData.getNexusGroupId().equals("")
|| outData.getNexusArtifactId() == null
|| outData.getNexusArtifactId().equals("")
|| outData.getNexusVersion() == null
|| outData.getNexusVersion().equals("")) {
throw new Exception(
"Group id, artifact id and version have to be defined");
}
}
// if (!DataHelper.checkIsGradleProject(inData.getProjectURL())) {
createLocalDotPropertiesFile();
ArrayList<Module> moduleList = depData.getModuleList();
if (moduleList.size() > 1) {
createSettingsDotGradleFile();
createRootBuildDotGradleFile();
for (Module moduleItem : moduleList) {
createModuleBuildDotGradleFile(moduleItem);
}
} else if (moduleList.size() == 1) {
createBuildDotGradleFile(moduleList.get(0));
}
// }
// String[] cmd = new String[2];
// cmd[0] = "cd "
// + StringHelper.convertToBackFlash(inData.getProjectURL());
// cmd[1] = "gradle clean build";
// CommandLine.runCmd(cmd);
if (settingsData.getAndroidSDKURL().equals("")
|| settingsData.getGradleUrl().equals("")
|| settingsData.getNexusUrl().equals("")
|| settingsData.getNexusUserName().equals("")
|| settingsData.getNexusPassword().equals("")) {
throw new Exception(
"Check Setting to verify all configuration were defined.");
} else {
ArrayList<String> cmdList = new ArrayList<String>();
cmdList.add("cd "
+ StringHelper.convertToBackFlash(settingsData
.getGradleBinUrl()));
String cmdGradle = "gradle clean build";
if (outData.getOutputWay() == AndroidOutputData.OUTPUT_NEXUS
|| outData.getOutputWay() == AndroidOutputData.OUTPUT_NEXUS
+ AndroidOutputData.OUTPUT_LOCAL
|| outData.getOutputWay() == AndroidOutputData.OUTPUT_NEXUS
+ AndroidOutputData.OUTPUT_SERVER
|| outData.getOutputWay() == AndroidOutputData.OUTPUT_NEXUS
+ AndroidOutputData.OUTPUT_LOCAL
+ AndroidOutputData.OUTPUT_SERVER) {
cmdGradle += " upload";
// if (outData.getNexusGroupId() == null
// || outData.getNexusGroupId().equals("")
// || outData.getNexusArtifactId() == null
// || outData.getNexusArtifactId().equals("")
// || outData.getNexusVersion() == null
// || outData.getNexusVersion().equals("")) {
// throw new Exception(
// "Group id, artifact id and version have to be defined");
// }
// cmdList.add("cd "
// + StringHelper.convertToBackFlash(System
// .getProperty("user.dir")) + "/utils");
// StringBuilder stringBuilder = new StringBuilder();
// stringBuilder.append("curl -v");
// stringBuilder.append(" -F r="
// + settingsData.getRepository());
// stringBuilder.append(" -F hasPom=false");
// stringBuilder.append(" -F e=apk");
// stringBuilder.append(" -F g=" +
// outData.getNexusGroupId());
// stringBuilder.append(" -F a="
// + outData.getNexusArtifactId());
// stringBuilder.append(" -F v=" +
// outData.getNexusVersion());
// stringBuilder.append(" -F p=pom");
// String outputLocalUrl = outData.getOutputLocalUrl() ==
// null ? ""
// : outData.getOutputLocalUrl();
// stringBuilder.append(" -F file=@"
// + StringHelper.convertToBackFlash(outputLocalUrl)
// + "/" + inData.getProjectDirName() + "-debug.apk");
// stringBuilder.append(" -u "
// + settingsData.getNexusUserName() + ":"
// + settingsData.getNexusPassword());
// stringBuilder.append(" " + settingsData.getNexusUrl()
// + "/service/local/artifact/maven/content");
// cmdList.add(stringBuilder.toString());
}
cmdGradle += " -p"
+ StringHelper.convertToBackFlash(inData
.getProjectURL());
cmdList.add(cmdGradle);
BuildManager.updateLog("Building....");
CommandLine.runCmd(cmdList.toArray(new String[cmdList.size()]));
}
} catch (Exception ex) {
ex.printStackTrace();
BuildManager.updateLog(ex.getMessage());
}
}
}
| 302d65af3123bc15ff854cb5c3ecf9df0690e69f | [
"Java"
] | 11 | Java | conanjacksion/GradlyBuilder | 8b43bc89fb690ecf51685ec9d4f0bfd22adc7a16 | 1e850ceece96902345285bce551f90ed0e183442 |
refs/heads/master | <file_sep>void setup() {
// constants won't change. They're used here to
// set pin numbers:
const int buttonPin = 2;
const int ledPin = 13;
const int motorIn1 = 9;
const int motorIn2 = 10;
int stat = 0;
#define rank1 150
#define rank2 200
#define rank3 250
int ledState = HIGH;
int buttonState;
int lastButtonState = LOW;
long lastDebounceTime = 0;
long debounceDelay = 50;
pinMode (buttonPin, INPUT);
pinMode (ledPin, OUTPUT);
pinMode(motorIn1, OUTPUT);
pinMode(motorIn2, OUTPUT);
digitalWrite(ledPin, ledState);
Serial. begin(9600);
int reading = digitalRead(buttonPin);
if (reading !=lastButtonState) {
lastDebounceTime = millis();
}
if ((millis() - lastDebounceTime) > debounceDelay) {
if (reading != buttonState) {
buttonState = reading;
if (buttonState == HIGH) {
ledState = !ledState;
stat = stat + 1;
if(stat >= 4)
{
stat = 0;
}
}
}
}
digitalWrite(ledPin, ledState);
switch(stat)
{
case 1:
clockwise(rank1);
break;
case 2:
clockwise(rank2);
break;
case 3:
clockwise(rank3);
break;
default:
clockwise(0)
lastButtonState = reading;
}
/*********************************************************/
void clockwise(int Speed)//
{
analogWrite(motorIn1,0);
analogWrite(motorIn2, Speed);
}
}
// put your main code here, to run repeatedly:
}
| c8f01249b1c39e0d2e86d703810fcb11a1f4ecbf | [
"C++"
] | 1 | C++ | ctrang1/Arduino | 3135f63bc588610a3d08cfb84a206ba56b9c8433 | d164ff4f1022477a149aa0c91b6669102902fdc8 |
refs/heads/master | <repo_name>atlasgalt/arduino_security_system<file_sep>/main.ino
#define pirPin 2
#define BuzPin 11
void setup()
{
Serial.begin(9600);
pinMode(pirPin, INPUT);
pinMode(BuzPin,OUTPUT);
}
void loop()
{
bool pirVal = digitalRead(pirPin);
var frequency = map(pirVal, LOW , HIGH, 0, 4500);
tone (BuzPin, frequency, 10);
}
<file_sep>/README.md
arduino_security_system
=======================
Prototype of security system for boxes, lockers, etc
| 699af499772912816b669a4560c94a08a4c68003 | [
"Markdown",
"C++"
] | 2 | C++ | atlasgalt/arduino_security_system | 12447068d8889f1431ca3d2f61e4d59f4bd64a74 | bbed0755adfb0d6a60e73a0473c32bb23419158b |
refs/heads/master | <repo_name>elioqoshi/us-election-grades<file_sep>/us-map-grid.js
function renderUSMapGrid({ el, dataURL }) {
let stateData, usStates, usGrid, containerWidth;
const breakpoint = 540;
const container = d3.select(el).classed("us-map-grid", true);
const gridSVG = container
.append("svg")
.attr("class", "grid-svg")
.style("display", "none");
const mapSVG = container
.append("svg")
.attr("class", "map-svg")
.style("display", "none");
const legend = container.append("div");
const tooltip = (() => {
let tooltipBox;
const tooltip = container
.append("div")
.attr("class", "tooltip-container hidden");
function show(content) {
tooltip.html(content).classed("hidden", false);
tooltipBox = tooltip.node().getBoundingClientRect();
}
function move() {
let [x, y] = d3.mouse(el);
x += 5;
if (x + tooltipBox.width > containerWidth) {
x -= tooltipBox.width + 10;
}
y -= tooltipBox.height + 5;
if (y - tooltipBox.height < 0) {
y += tooltipBox.height + 10;
}
tooltip.style("transform", `translate(${x}px,${y}px)`);
}
function hide() {
tooltip.classed("hidden", true);
}
return {
show,
move,
hide,
};
})();
const scores = ["A", "B", "C", "D", "F"];
const color = d3
.scaleOrdinal()
.domain(scores)
.range(scores.map((d) => `score-${d.toLowerCase()}`));
const dispatch = d3.dispatch("gradehover", "gradehighlight");
d3.json(dataURL)
.then((data) => {
data.forEach((d) => {
d.id = +d.id < 10 ? `0${d.id}` : `${d.id}`;
});
stateData = new Map(data.map((d) => [d.abbreviation, d]));
resize();
legend.call(renderLegend, color, "Grade", dispatch);
window.addEventListener("resize", resize);
})
.catch((err) => {
console.error(err);
container.html("Something went wrong, please try again later.");
});
function resize() {
containerWidth = el.clientWidth;
if (containerWidth < breakpoint) {
gridSVG.style("display", "block");
mapSVG.style("display", "none");
if (!usGrid) {
usGrid = getUSGrid();
}
gridSVG.call(
renderUSGrid,
stateData,
usGrid,
containerWidth,
color,
dispatch
);
} else {
mapSVG.style("display", "block");
gridSVG.style("display", "none");
if (usStates) {
mapSVG.call(
renderUSMap,
stateData,
usStates,
containerWidth,
color,
dispatch
);
} else {
const idToAbbr = new Map(
[...stateData.values()].map((d) => [d.id, d.abbreviation])
);
d3.json("https://cdn.jsdelivr.net/npm/us-atlas@3/states-10m.json")
.then((us) => {
usStates = topojson.feature(us, us.objects.states);
usStates.features = usStates.features.filter((d) => {
if (idToAbbr.has(d.id)) {
d.properties.abbr = idToAbbr.get(d.id);
return true;
}
return false;
});
mapSVG.call(
renderUSMap,
stateData,
usStates,
containerWidth,
color,
dispatch
);
})
.catch((err) => {
console.error(err);
gridSVG.call(
renderUSGrid,
stateData,
usGrid,
containerWidth,
color,
dispatch
);
});
}
}
}
function renderUSGrid(
svg,
stateData,
usGrid,
containerWidth,
color,
dispatch
) {
const margin = { top: 1, right: 1, bottom: 1, left: 1 };
(gridWidth = d3.max(usGrid, (d) => d.x) + 1),
(gridHeight = d3.max(usGrid, (d) => d.y) + 1),
(cellSize = Math.floor(
(containerWidth - margin.left - margin.right) / gridWidth
)),
(height = cellSize * gridHeight + margin.top + margin.bottom);
svg.attr("viewBox", [0, 0, containerWidth, height]);
const g = svg
.selectAll(".grid-g")
.data([0])
.join("g")
.attr("class", "grid-g")
.attr("transform", `translate(${containerWidth / 2},${height / 2})`);
const stateGrid = g
.selectAll(".state-grid")
.data(usGrid, (d) => d.abbr)
.join((enter) =>
enter
.append("g")
.attr("class", "state-grid")
.call((g) =>
g
.append("rect")
.attr(
"class",
(d) => `state-grid-rect ${color(stateData.get(d.abbr).grade)}`
)
)
.call((g) =>
g
.append("text")
.attr(
"class",
(d) => `state-grid-label ${color(stateData.get(d.abbr).grade)}`
)
.attr("dy", "0.32em")
.attr("text-anchor", "middle")
.text((d) => d.abbr)
)
)
.attr(
"transform",
(d) =>
`translate(${(d.x - gridWidth / 2 + 0.5) * cellSize},${
(d.y - gridHeight / 2 + 0.5) * cellSize
})`
)
.call((g) =>
g
.select(".state-grid-rect")
.attr("x", -cellSize / 2)
.attr("y", -cellSize / 2)
.attr("width", cellSize)
.attr("height", cellSize)
)
.on("mouseenter", function (d) {
d3.select(this).raise();
stateGrid.classed("inactive", (e) => d !== e);
dispatch.call("gradehighlight", null, stateData.get(d.abbr).grade);
})
.on("mouseleave", () => {
stateGrid.classed("inactive", false);
dispatch.call("gradehighlight", null, null);
});
dispatch.on("gradehover", (grade) => {
if (grade) {
stateGrid
.classed("inactive", (e) => stateData.get(e.abbr).grade !== grade)
.sort((a, b) => {
const aV = stateData.get(a.abbr).grade === grade ? 1 : -1;
const bV = stateData.get(b.abbr).grade === grade ? 1 : -1;
return d3.ascending(aV, bV);
});
} else {
stateGrid.classed("inactive", false);
}
});
}
function renderUSMap(
svg,
stateData,
usStates,
containerWidth,
color,
dispatch
) {
const margin = {
top: 1,
right: 100,
bottom: 1,
left: 1,
};
const sideStateWidth = 52;
const sideStateHeight = 24;
const width = containerWidth - margin.left - margin.right;
const projection = d3.geoAlbersUsa().fitWidth(width, usStates);
const path = d3.geoPath(projection);
const height = Math.ceil(path.bounds(usStates)[1][1]);
svg.attr("viewBox", [
0,
0,
containerWidth,
height + margin.top + margin.bottom,
]);
const g = svg
.selectAll(".map-g")
.data([0])
.join("g")
.attr("class", "map-g")
.attr("transform", `translate(${margin.left},${margin.top})`);
const statePath = g
.selectAll(".state-path")
.data(usStates.features, (d) => d.properties.abbr)
.join("path")
.attr(
"class",
(d) =>
`state-path ${
stateData.get(d.properties.abbr)
? color(stateData.get(d.properties.abbr).grade)
: ""
}`
)
.attr("d", path)
.on("mouseenter", function (d) {
d3.select(this).raise();
statePath.classed("inactive", (e) => e !== d);
sideState.classed("inactive", (e) => e !== d.properties.abbr);
const s = stateData.get(d.properties.abbr);
const content = getTooltipContent(s);
tooltip.show(content);
dispatch.call("gradehighlight", null, s.grade);
})
.on("mousemove", tooltip.move)
.on("mouseleave", () => {
tooltip.hide();
statePath.classed("inactive", false);
sideState.classed("inactive", false);
dispatch.call("gradehighlight", null, null);
})
.on("click", (d) => navigateToStateDetailsPage(d.properties.abbr));
const sideState = g
.selectAll(".side-state")
.data(["VT", "NH", "CT", "RI", "DE", "MD", "DC"], (d) => d)
.join((enter) =>
enter
.append("g")
.attr("class", "side-state")
.call((g) =>
g
.append("rect")
.attr(
"class",
(d) => `side-state-rect ${color(stateData.get(d).grade)}`
)
.attr("width", sideStateWidth)
.attr("height", sideStateHeight)
)
.call((g) =>
g
.append("text")
.attr(
"class",
(d) => `side-state-label ${color(stateData.get(d).grade)}`
)
.attr("y", sideStateHeight / 2)
.attr("x", sideStateWidth / 2)
.attr("dy", "0.32em")
.attr("text-anchor", "middle")
.text((d) => d)
)
)
.attr(
"transform",
(d, i) =>
`translate(${width + margin.right - sideStateWidth - 1},${
10 + sideStateHeight * 1.5 * i
})`
)
.on("mouseenter", function (d) {
statePath
.classed("inactive", (e) => e.properties.abbr !== d)
.filter((e) => e.properties.abbr === d)
.raise();
sideState.classed("inactive", (e) => e !== d);
const s = stateData.get(d);
const content = getTooltipContent(s);
tooltip.show(content);
dispatch.call("gradehighlight", null, s.grade);
})
.on("mousemove", tooltip.move)
.on("mouseleave", () => {
tooltip.hide();
statePath.classed("inactive", false);
sideState.classed("inactive", false);
dispatch.call("gradehighlight", null, null);
})
.on("click", (d) => navigateToStateDetailsPage(d));
dispatch.on("gradehover", (grade) => {
if (grade) {
statePath
.classed(
"inactive",
(e) => stateData.get(e.properties.abbr).grade !== grade
)
.sort((a, b) => {
const aV =
stateData.get(a.properties.abbr).grade === grade ? 1 : -1;
const bV =
stateData.get(b.properties.abbr).grade === grade ? 1 : -1;
return d3.ascending(aV, bV);
});
sideState.classed("inactive", (e) => stateData.get(e).grade !== grade);
} else {
statePath.classed("inactive", false);
sideState.classed("inactive", false);
}
});
function getTooltipContent(s) {
return `
<div class="tooltip-header">${s.name} (${s.abbreviation})</div>
<div class="tooltip-body">Grade: ${s.grade}</div>
`;
}
function navigateToStateDetailsPage(abbr) {
window.open(`https://election-audits.org/state/${abbr}`, "statedetail");
}
}
function renderLegend(legend, color, title, dispatch) {
legend.classed("legend-container", true);
legend.append("div").attr("class", "legend-title").text(title);
const item = legend
.selectAll(".legend-item")
.data(color.domain())
.join("div")
.attr("class", "legend-item")
.call((item) =>
item.append("div").attr("class", (d) => `legend-swatch ${color(d)}`)
)
.call((item) =>
item
.append("div")
.attr("class", "legend-label")
.text((d) => d)
)
.on("mouseenter", (d) => {
item.classed("inactive", (e) => d !== e);
dispatch.call("gradehover", null, d);
})
.on("mouseleave", () => {
item.classed("inactive", false);
dispatch.call("gradehover", null, null);
});
dispatch.on("gradehighlight", (grade) => {
if (grade) {
item.classed("inactive", (d) => d !== grade);
} else {
item.classed("inactive", false);
}
});
}
function getUSGrid() {
return [
{ abbr: "ME", y: 0, x: 10 },
{ abbr: "WI", y: 1, x: 5 },
{ abbr: "VT", y: 1, x: 9 },
{ abbr: "NH", y: 1, x: 10 },
{ abbr: "WA", y: 2, x: 0 },
{ abbr: "ID", y: 2, x: 1 },
{ abbr: "MT", y: 2, x: 2 },
{ abbr: "ND", y: 2, x: 3 },
{ abbr: "MN", y: 2, x: 4 },
{ abbr: "IL", y: 2, x: 5 },
{ abbr: "MI", y: 2, x: 6 },
{ abbr: "NY", y: 2, x: 8 },
{ abbr: "MA", y: 2, x: 9 },
{ abbr: "OR", y: 3, x: 0 },
{ abbr: "NV", y: 3, x: 1 },
{ abbr: "WY", y: 3, x: 2 },
{ abbr: "SD", y: 3, x: 3 },
{ abbr: "IA", y: 3, x: 4 },
{ abbr: "IN", y: 3, x: 5 },
{ abbr: "OH", y: 3, x: 6 },
{ abbr: "PA", y: 3, x: 7 },
{ abbr: "NJ", y: 3, x: 8 },
{ abbr: "CT", y: 3, x: 9 },
{ abbr: "RI", y: 3, x: 10 },
{ abbr: "CA", y: 4, x: 0 },
{ abbr: "UT", y: 4, x: 1 },
{ abbr: "CO", y: 4, x: 2 },
{ abbr: "NE", y: 4, x: 3 },
{ abbr: "MO", y: 4, x: 4 },
{ abbr: "KY", y: 4, x: 5 },
{ abbr: "WV", y: 4, x: 6 },
{ abbr: "VA", y: 4, x: 7 },
{ abbr: "MD", y: 4, x: 8 },
{ abbr: "DE", y: 4, x: 9 },
{ abbr: "AZ", y: 5, x: 1 },
{ abbr: "NM", y: 5, x: 2 },
{ abbr: "KS", y: 5, x: 3 },
{ abbr: "AR", y: 5, x: 4 },
{ abbr: "TN", y: 5, x: 5 },
{ abbr: "NC", y: 5, x: 6 },
{ abbr: "SC", y: 5, x: 7 },
{ abbr: "DC", y: 5, x: 8 },
{ abbr: "OK", y: 6, x: 3 },
{ abbr: "LA", y: 6, x: 4 },
{ abbr: "MS", y: 6, x: 5 },
{ abbr: "AL", y: 6, x: 6 },
{ abbr: "GA", y: 6, x: 7 },
{ abbr: "HI", y: 7, x: 0 },
{ abbr: "AK", y: 7, x: 1 },
{ abbr: "TX", y: 7, x: 3 },
{ abbr: "FL", y: 7, x: 8 },
];
}
}
<file_sep>/README.md
# us-election-grades | 128b5ba517ce5b25a2ae47901d6c5caff5e97b0a | [
"JavaScript",
"Markdown"
] | 2 | JavaScript | elioqoshi/us-election-grades | b5b4a3edcab5e84cf77aadc4d0e587a5eb31aecf | 16553d878d2ae8b5fbc2cd33f69d79622867e0d8 |
refs/heads/master | <file_sep>import React from "react";
import { Box, Image, Badge } from "@chakra-ui/react";
function Project(props) {
const { project } = props;
const { tech } = project;
return (
<div className="project">
<div className={`card-img-top ${project.name}`}></div>
<div className="card">
<div className="card-body">
<h5 className="card-title">{project.name}</h5>
<p className="card-text">{project.desc}</p>
<div className="project-tech">
{tech.map((technology, i) => {
return (
<div key={i} className="technology">
{technology}
</div>
);
})}
</div>
<div className="project-links">
<a
href={project.repo}
target="_blank"
rel="noopener noreferrer"
className="project-link"
>
<i className="fab fa-github fa-2x"></i>
</a>
<a
href={project.live}
target="_blank"
rel="noopener noreferrer"
className="project-link"
>
<button
type="button"
className="btn btn-info btn-sm live-app"
>
Live App
</button>
</a>
</div>
</div>
</div>
</div>
);
}
export default Project;
<file_sep>import React from "react";
import { projectData as pd } from "../assets/projectData";
import { Box } from "@chakra-ui/react";
import Project from "./Project";
function Projects() {
const projects = [...pd];
return (
<section className="project-section wrapper" id="projects">
<header className="projects-header">Projects</header>
<Box p={3} d="grid" gridTemplateColumns="1fr" placeItems="center">
{projects.map((project) => {
return <Project key={project.id} project={project} />;
})}
</Box>
<div className="spacer"></div>
</section>
);
}
export default Projects;
<file_sep>import React from "react";
export default function AboutMe() {
return (
<div>
<h3 className="about-me-title">
Hello, I am Raza, a Full Stack Web developer.{" "}
<span role="img" aria-label="smiley face">
😀
</span>
</h3>
<hr></hr>
<p className="about-me-text">
I am currently a fourth year student at the University of Toronto
pursing a Honours Bachelor's of Science in Mathematics and Computer
Science{" "}
<span role="img" aria-label="laptop">
💻
</span>
. I am primarily interested in full stack web developement, but I also
love learning more about algorithms, graph theory, combinatorics, and
game development.
</p>
</div>
);
}
<file_sep>import React from "react";
import { Box, Image, Badge, Text, Link, Icon, Tooltip } from "@chakra-ui/react";
import { ExternalLinkIcon } from "@chakra-ui/icons";
function Project(props) {
const { project } = props;
const { name, live, image, repo, desc, tech } = project;
return (
<Box
as="article"
m="1rem"
d="flex"
flexDirection={["column", "column", "row", "row"]}
justifyContent="space-evenly"
>
<Box
variant="projectImage"
overflow="hidden"
backgroundImage={`url(${image})`}
w={["350px", "400px", "450px", "600px"]}
backgroundPosition="center"
backgroundSize="contain"
h={["182px", "208px", "234px", "312px"]}
cursor="pointer"
rounded="md"
m="1rem"
className="project-image"
></Box>
<Box
w={["350px", "400px", "450px", "600px"]}
borderWidth="1px"
borderRadius="lg"
overflow="hidden"
>
<Box p={[3, 3, 3, 5]}>
<Box
mt="1"
fontWeight="semibold"
as="h4"
lineHeight="tight"
isTruncated
>
{name}
</Box>
<Box d="flex" mt="2" alignItems="center">
<Text
noOfLines={[3, 4, 5, 7]}
fontSize={["sm", "md", "md", "xl"]}
>
{desc}
</Text>
</Box>
<Box
d="flex"
alignItem="flex-end"
justifyContent="space-evenly"
>
{tech.map((t, i) => (
<Box
fontSize={["2xl", "4xl", "6xl", "8xl"]}
key={i}
>
{t}
</Box>
))}
</Box>
<Box
d="flex"
alignItem="flex-start"
justifyContent="flex-end"
>
{live && (
<Link href={live} isExternal>
<Tooltip
label="Visit Site"
aria-label="visit-site-tooltip"
>
<Icon as={ExternalLinkIcon}></Icon>
</Tooltip>
</Link>
)}
{name !== "Carden" ? (
<Tooltip
label="GitHub Repo"
aria-label="github-tooltip"
>
<Box ml="1rem">
<Link href={repo} isExternal>
<i className="fab fa-github fa-lg"></i>
</Link>
</Box>
</Tooltip>
) : null}
</Box>
</Box>
</Box>
</Box>
);
}
export default Project;
<file_sep>import React from "react";
const projectData = [
{
id: 1,
name: "BookCase",
live: "https://bookcase-v2-typescript.herokuapp.com/login",
image: "/assets/project_images/bookcase-500x260.jpg",
repo: "https://github.com/SAbbas2018/bookcase-typescript",
desc: "The application uses the Google Books API for getting information on books by their ISBN (user input), and makes recommendations based on the user’s library.",
tech: [
<i className="devicon-mongodb-plain-wordmark tech-icon"></i>,
<i className="devicon-express-original-wordmark tech-icon"></i>,
<i className="devicon-react-original-wordmark tech-icon"></i>,
<i className="devicon-nodejs-plain-wordmark tech-icon"></i>,
],
},
{
id: 2,
name: "Carden",
image: "/assets/project_images/carden-500x260.jpg",
repo: "#",
desc: "Create and send interactive cards. Instead of sending your friend a text for their next birthday, send them a webpage. Choose from templates or make your own!",
tech: [
<i className="devicon-express-original-wordmark tech-icon"></i>,
<i className="devicon-react-original-wordmark tech-icon"></i>,
<i className="devicon-nodejs-plain-wordmark tech-icon"></i>,
<i className="devicon-mongodb-plain-wordmark tech-icon"></i>,
],
},
{
id: 3,
name: "TicTacToe",
live: "https://tictactoe-sa.herokuapp.com/",
image: "/assets/project_images/tictactoe-500x260.jpg",
repo: "https://github.com/SAbbas2018/tictactoe",
desc: "An OOP Tic Tac Toe game users can play against another user on the same window, a computer with 3 levels of difficulty, or agains a friend in real time through web sockets.",
tech: [
<i className="devicon-express-original-wordmark tech-icon"></i>,
<i className="devicon-react-original-wordmark tech-icon"></i>,
<i className="devicon-nodejs-plain-wordmark tech-icon"></i>,
],
},
];
export { projectData };
<file_sep># <NAME>
The code for my portfolio is written in React, HTML, and CSS.
The portfolio uses bootstrap and custom css for styling.
<file_sep>import React from "react";
import BG from "../assets/bg.png";
import { Box, Heading, Center, Image } from "@chakra-ui/react";
export default function Skills() {
return (
<>
<Box
p={5}
color="palette.nyanza"
backgroundColor="palette.bunting"
w="100%"
>
<Heading
margin="1em"
width="90vw"
height="8vh"
borderBottom="solid 2px rgba(255, 255, 255, 0.125)"
textTransform="uppercase"
>
Skills
</Heading>
</Box>
<Box
as="section"
id="skills"
backgroundColor="palette.bunting"
// backgroundImage={`url(${BG})`}
d="grid"
gridTemplateColumns="1fr"
placeItems="center"
gridGap={5}
p={3}
color="palette.bunting"
>
<Box
as="article"
w={["90%", "70%", "75%", "80%"]}
boxShadow="dark-lg"
background="palette.platinum"
p={3}
m="10px auto"
>
<Center>
<Heading
w="90%"
borderBottom="1px solid black"
p={3}
textAlign="center"
>
Web
</Heading>
</Center>
<Box
w="100%"
d="grid"
gridTemplateColumns={[
"repeat(3, 1fr)",
"repeat(4, 1fr)",
"repeat(4, 1fr)",
"repeat(4, 1fr)",
]}
mt={5}
mb={5}
placeItems="center"
gridGap={3}
fontSize={["6xl", "7xl", "8xl", "9xl"]}
>
<i className="devicon-react-original-wordmark colored"></i>
<i className="devicon-nodejs-plain-wordmark colored"></i>
<i className="devicon-express-original-wordmark colored"></i>
<i className="devicon-javascript-plain colored"></i>
<i className="devicon-html5-plain-wordmark colored"></i>
<i className="devicon-css3-plain-wordmark colored"></i>
<i className="devicon-php-plain colored"></i>
</Box>
</Box>
<Box
as="article"
w={["90%", "70%", "75%", "80%"]}
boxShadow="dark-lg"
background="palette.platinum"
p={3}
m="10px auto"
>
<Center>
<Heading
w="90%"
borderBottom="1px solid black"
p={3}
textAlign="center"
>
Programming Languages
</Heading>
</Center>
<Box
w="100%"
d="grid"
gridTemplateColumns={[
"repeat(3, 1fr)",
"repeat(3, 1fr)",
"repeat(3, 1fr)",
"repeat(3, 1fr)",
]}
mt={5}
mb={5}
placeItems="center"
gridGap={3}
fontSize={["6xl", "7xl", "8xl", "9xl"]}
>
<i className="devicon-java-plain-wordmark colored"></i>
<Image
src="https://cdn.jsdelivr.net/gh/devicons/devicon/icons/python/python-original-wordmark.svg"
width={["50px", "60px", "70px", "80px"]}
></Image>
<i className="devicon-typescript-plain colored"></i>
{/* <i className="devicon-go-plain skill"></i> */}
</Box>
</Box>
<Box
as="article"
w={["90%", "70%", "75%", "80%"]}
boxShadow="dark-lg"
background="palette.platinum"
p={3}
m="10px auto"
>
<Center>
<Heading
w="90%"
borderBottom="1px solid black"
p={3}
textAlign="center"
>
Databases
</Heading>
</Center>
<Box
w="100%"
d="grid"
gridTemplateColumns={[
"repeat(3, 1fr)",
"repeat(3, 1fr)",
"repeat(3, 1fr)",
"repeat(3, 1fr)",
]}
mt={5}
mb={5}
placeItems="center"
gridGap={3}
fontSize={["6xl", "7xl", "8xl", "9xl"]}
>
<i className="devicon-mongodb-plain-wordmark colored"></i>
<i className="devicon-postgresql-plain-wordmark colored"></i>
<i className="devicon-mysql-plain-wordmark colored"></i>
</Box>
</Box>
<Box
as="article"
w={["90%", "70%", "75%", "80%"]}
boxShadow="dark-lg"
background="palette.platinum"
p={3}
m="10px auto"
>
<Center>
<Heading
w="90%"
borderBottom="1px solid black"
p={3}
textAlign="center"
>
Tools
</Heading>
</Center>
<Box
w="100%"
d="grid"
gridTemplateColumns={[
"repeat(3, 1fr)",
"repeat(3, 1fr)",
"repeat(3, 1fr)",
"repeat(3, 1fr)",
]}
mt={5}
mb={5}
placeItems="center"
gridGap={3}
fontSize={["6xl", "7xl", "8xl", "9xl"]}
>
<i className="devicon-heroku-line-wordmark colored"></i>
<i className="devicon-git-plain-wordmark colored"></i>
<i className="devicon-github-original-wordmark colored"></i>
{/* <i className="devicon-bootstrap-plain-wordmark skill"></i> */}
</Box>
</Box>
</Box>
</>
);
}
| e914f56b449bd3c55b47a37e2c68fd2346bafc75 | [
"JavaScript",
"Markdown"
] | 7 | JavaScript | SAbbas2018/sabbas2018.github.io | 9f2ae190be0ea4e75bc0f7392c25cbf32fa7ee72 | 852858e43e8104af118e7b5e8c4ffd47a9bf5281 |
refs/heads/master | <file_sep>'use strict';
angular.module('rentalapp.services.rentals',['restangular'])
.service('DataService', ['$rootScope', 'Restangular', function($scope, Restangular){
var _messageservice = Restangular.all('rentals');
var service = {
getRentals : function(){
return _messageservice.getList();
},
addRentals: function(data){
var newData = data;
return _messageservice.post(newData);
location.href="/";
},
updateRental: function(data){
return data.put();
},
deleteRental: function(data){
return data.remove();
}
};
return service;
}]);<file_sep>angular-mangy
=============
A basic Angular CRUD Application using MongoDB, Angular, Node, Grunt and Yeoman.
Basic setup
============
1. JSON file is available inside db dump folder which can be imported into a mongolab collection.
2. Setup DB and Collection in Mongolab
3. Clone repo and modify db settings in app > scripts > app.js
3. Run 'npm install' to setup node modules
4. Run 'bower install' to setup dependencies
5. Run 'grunt serve' to launch browser and view the application
<file_sep>'use strict';
angular.module('rentalapp.controllers', ['rentalapp.controllers.rentals']);
angular.module('rentalapp.services', ['rentalapp.services.rentals']);
angular.module('rentalApp', ['ngCookies','ngResource','ngSanitize','ngRoute','restangular','rentalapp.controllers','rentalapp.services'])
.constant('apiKey', '<KEY>')
.config(function(RestangularProvider, apiKey){
RestangularProvider.setBaseUrl('https://api.mongolab.com/api/1/databases/pramodx/collections');
RestangularProvider.setDefaultRequestParams({
apiKey: apiKey
});
RestangularProvider.setRestangularFields({
id: '_id.$oid'
});
RestangularProvider.setRequestInterceptor(
function(elem, operation, what) {
if (operation === 'put') {
elem._id = undefined;
return elem;
}
return elem;
});
})
.config(function ($routeProvider) {
$routeProvider
.when('/', {
templateUrl: 'views/main.html',
controller: 'rentalController'
}).
when('/create',{
templateUrl: 'views/create.html',
controller: 'createController'
}).
when('/edit/:id',{
controller: 'editController',
templateUrl: 'views/create.html',
resolve: {
movie: function(Restangular, $route){
return Restangular.one('rentals', $route.current.params.id).get();
}
}
}).
when('/delete/:id',{
controller: 'deleteController',
templateUrl: 'views/main.html',
resolve: {
movie: function(Restangular, $route){
return Restangular.one('rentals', $route.current.params.id).get();
}
}
}).
when('/detail/:id',{
controller: 'detailController',
templateUrl: 'views/detail.html',
resolve: {
movie: function(Restangular, $route){
return Restangular.one('rentals', $route.current.params.id).get();
}
}
}).
otherwise({
redirectTo: '/'
});
});
| acc19a5016f82493dcfbb12d98f14a0af51fe6dd | [
"JavaScript",
"Markdown"
] | 3 | JavaScript | pramodx/angular-mangy | 214df34eebea9de5119435ab73120e412cc93ad1 | b570f63db1d3c09e6c59ab9fe4bdb3bda0f9eada |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.