
blob_id stringlengths 40 40 | directory_id stringlengths 40 40 | path stringlengths 3 616 | content_id stringlengths 40 40 | detected_licenses listlengths 0 112 | license_type stringclasses 2 values | repo_name stringlengths 5 115 | snapshot_id stringlengths 40 40 | revision_id stringlengths 40 40 | branch_name stringclasses 777 values | visit_date timestamp[us]date 2015-08-06 10:31:46 2023-09-06 10:44:38 | revision_date timestamp[us]date 1970-01-01 02:38:32 2037-05-03 13:00:00 | committer_date timestamp[us]date 1970-01-01 02:38:32 2023-09-06 01:08:06 | github_id int64 4.92k 681M ⌀ | star_events_count int64 0 209k | fork_events_count int64 0 110k | gha_license_id stringclasses 22 values | gha_event_created_at timestamp[us]date 2012-06-04 01:52:49 2023-09-14 21:59:50 ⌀ | gha_created_at timestamp[us]date 2008-05-22 07:58:19 2023-08-21 12:35:19 ⌀ | gha_language stringclasses 149 values | src_encoding stringclasses 26 values | language stringclasses 1 value | is_vendor bool 2 classes | is_generated bool 2 classes | length_bytes int64 3 10.2M | extension stringclasses 188 values | content stringlengths 3 10.2M | authors listlengths 1 1 | author_id stringlengths 1 132 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
bed356639866f41e11f0b2455c985aa120917362 | ee803c29e9c5216a16a2699854b98c8a6d9760b8 | /dataServer/FlaskDataServer/app/test.py | 6dd9b65ccf3c7303b2957ba3d976bab84c9c4f92 | [] | no_license | algo2019/algorithm | c160e19b453bc979853caf903ad96c2fa8078b69 | 3b5f016d13f26acab89b4a177c95a4f5d2dc1ba1 | refs/heads/master | 2022-12-12T17:59:57.342665 | 2019-02-23T07:45:39 | 2019-02-23T07:45:39 | 162,404,028 | 0 | 0 | null | 2022-12-08T01:29:20 | 2018-12-19T08:08:13 | Python | UTF-8 | Python | false | false | 204 | py | import urllib2
import cPickle as pickle
import json
r = urllib2.urlopen('http://127.0.0.1:5001/api/v1.0/dom_info?symbol=a&&start=20100101')
res = r.read()
print pickle.loads(str(json.loads(res)['res'])) | [
"xingwang.zhang@renren-inc.com"
] | xingwang.zhang@renren-inc.com |
2af4aa1e5d0238e05026c8ffb75754f820cc2f9a | 253089ef4ee99c50cdaa23fde4d789794789e2e9 | /15/enumerate_data.py | a77262511b818966d3f7f2bb7417e4e4ee3d2f3a | [] | no_license | Zaubeerer/bitesofpy | 194b61c5be79c528cce3c14b9e2c5c4c37059259 | e5647a8a7a28a212cf822abfb3a8936763cd6b81 | refs/heads/master | 2021-01-01T15:01:21.088411 | 2020-11-08T19:56:30 | 2020-11-08T19:56:30 | 239,328,990 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 368 | py | names = 'Julian Bob PyBites Dante Martin Rodolfo'.split()
countries = 'Australia Spain Global Argentina USA Mexico'.split()
def enumerate_names_countries():
"""Outputs:
1. Julian Australia
2. Bob Spain
3. PyBites Global
4. Dante Argentina
5. Martin USA
6. Rodolfo Mexico"""
pass | [
"r.beer@outlook.de"
] | r.beer@outlook.de |
e913aca2268350c5814d4ffacac7fa586a7adf4c | 06a863150a7a3a7bfc0c341b9c3f267727606464 | /packages/Mock/TileMapEditor/__init__.py | 7963595bd088930dde33600be81ffd04023fbb85 | [
"MIT"
] | permissive | brucelevis/gii | c843dc738a958b4a2ffe42178cff0dd04da44071 | 03624a57cf74a07e38bfdc7f53c50bd926b7b5a7 | refs/heads/master | 2020-10-02T00:41:02.723597 | 2016-04-08T07:44:45 | 2016-04-08T07:44:45 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 21 | py | import TileMapEditor
| [
"tommo.zhou@gmail.com"
] | tommo.zhou@gmail.com |
6fbb0dabca820df63974542daab4cc8236741723 | 208446b30b8c4a479ed414376453c4edbab5053b | /python_space/Atest/duoxiancheng/1.py | b161562b65506e220985a498fba9628eda000dea | [] | no_license | fengyu0712/myclone | 6e0bcb0e4b4f5919c4cabb1eb1be49afa7e68ba2 | d4e47adf81b3ced0f433d5e261989b0bbb457fa4 | refs/heads/master | 2023-02-10T06:50:43.349167 | 2021-01-05T08:38:35 | 2021-01-05T08:38:35 | 316,674,323 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 724 | py | import threading
import time
import random
start_time =time.time()
def do_something():
print ("{thread_name} start at {now}\n".format(thread_name=threading.currentThread().name,now=time.time()))
time.sleep(1)
print ("{thread_name} stop at {now}".format(thread_name=threading.currentThread().name,now=time.time()))
if __name__== "__main__":
threads = []
# start all threading.
for i in range(1,8):
t = threading.Thread(target=do_something)
t.start()
threads.append(t)
#wait until all the threads terminnates.
for thread in threads:
thread.join()
print ("all threads deid.")
print ("this run take {t} seconds".format(t = (time.time()-start_time))) | [
"121193252@qq.com"
] | 121193252@qq.com |
6e9bb166100ed8ecfed7b6e5acfac458e92d0fab | ab65fa746dafd99873d4fd0a1576469809db162c | /django/apps/stories/migrations/0012_auto_20150527_0113.py | f3ab04d2999839499ee31db58ce176f33729546d | [] | no_license | haakenlid/tassen-dockerize | 27dfb13a05925e2570949ad6337379fe6bc8d452 | c867c36c1330db60acfc6aba980e021585fbcb98 | refs/heads/master | 2021-01-22T03:14:05.219508 | 2017-03-23T12:57:54 | 2017-03-23T12:57:54 | 81,106,809 | 2 | 1 | null | null | null | null | UTF-8 | Python | false | false | 1,157 | py | # -*- coding: utf-8 -*-
from __future__ import unicode_literals
from django.db import models, migrations
class Migration(migrations.Migration):
dependencies = [
('stories', '0011_auto_20150527_0050'),
]
operations = [
migrations.AlterField(
model_name='storyimage',
name='aspect_ratio',
field=models.FloatField(verbose_name='aspect ratio', choices=[(0.0, 'auto'), (0.5, '1:2 landscape'), (0.6666666666666666, '2:3 landscape'), (0.75, '3:4 landscape'), (1.0, 'square'), (1.3333333333333333, '4:3 portrait'), (1.5, '3:2 portrait'), (2.0, '2:1 portrait'), (100.0, 'original')], default=0.0, help_text='height / width'),
),
migrations.AlterField(
model_name='storyvideo',
name='aspect_ratio',
field=models.FloatField(verbose_name='aspect ratio', choices=[(0.0, 'auto'), (0.5, '1:2 landscape'), (0.6666666666666666, '2:3 landscape'), (0.75, '3:4 landscape'), (1.0, 'square'), (1.3333333333333333, '4:3 portrait'), (1.5, '3:2 portrait'), (2.0, '2:1 portrait'), (100.0, 'original')], default=0.0, help_text='height / width'),
),
]
| [
"haakenlid@gmail.com"
] | haakenlid@gmail.com |
3312a1191c10cb37edbb6e8c7a0bd3feb12e7e8b | eec9299fd80ed057585e84e0f0e5b4d82b1ed9a7 | /blog/views.py | ada404e5e604dbf81ca51b66062ae71c9a74efc4 | [] | no_license | aimiliya/mysite | f51967f35c0297be7051d9f485dd0e59b8bb60c2 | b8e3b639de6c89fb8e6af7ee0092ee744a75be41 | refs/heads/master | 2020-04-08T19:06:36.539404 | 2018-12-01T08:05:18 | 2018-12-01T08:05:18 | 159,640,181 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 4,284 | py | from django.core.paginator import Paginator
from django.db.models import Count
from django.shortcuts import render, get_object_or_404
from read_statistic.utils import read_statisitcs_once_read
from .models import Blog, BlogType
EACH_PAGE_BLOGS_NUMBER = 10
def get_blog_list_common_data(request, blog_all_list):
paginator = Paginator(blog_all_list, EACH_PAGE_BLOGS_NUMBER)
page_num = request.GET.get('page', 1) # 获取页码参数,如果没有,返回1
page_of_blogs = paginator.get_page(page_num)
currentr_page = page_of_blogs.number # 获取当前页码
# 实现只显示当前页但后个两页,且不超出页码范围。
page_range = list(range(max(currentr_page - 2, 1), currentr_page)) + list(
range(currentr_page, min(currentr_page + 2, paginator.num_pages) + 1))
# 加上省略标记
if page_range[0] - 1 >= 2:
page_range.insert(0, '...')
if paginator.num_pages - page_range[-1] >= 2:
page_range.append('...')
# 实现显示第一页和最后一页
if page_range[0] != 1:
page_range.insert(0, 1)
if page_range[-1] != paginator.num_pages:
page_range.append(paginator.num_pages)
# 获取某类型博客的数量
# 方法1 原理: 直接引用数据到内存中使用
# blog_types = BlogType.objects.all()
# blog_types_list = []
# for blog_type in blog_types:
# blog_type.blog_count = Blog.objects.filter(blog_type=blog_type).count()
# blog_types_list.append(blog_type)
# 方法2 annotate 拓展查询字段,转化为sql语句,当用到时才引用到内存。
# blog_count是自己写的名,不是特殊值
blog_types_list = BlogType.objects.annotate(blog_count=Count('blog'))
# 获取日期归档应用的博客数量
# 方法一
blog_dates = Blog.objects.dates('create_time', 'month', order="DESC")
blog_date_dict = {}
for blog_date in blog_dates:
blog_count = Blog.objects.filter(create_time__year=blog_date.year,
create_time__month=blog_date.month).count()
blog_date_dict[blog_date] = blog_count
# 方法二 不方便
# blog_dates = Blog.objects.dates('create_time', 'month', order="DESC").annotate(blog_counts=Count('create_time__month'))
context = {'blogs': page_of_blogs.object_list,
'blog_types': blog_types_list, 'page_of_blogs': page_of_blogs,
'page_range': page_range, 'blog_dates': blog_date_dict, }
return context
def blog_list(request):
blog_all_list = Blog.objects.all()
context = get_blog_list_common_data(request, blog_all_list)
return render(request, 'blog/blog_list.html', context)
def blog_detail(request, blog_pk):
blog = get_object_or_404(Blog, pk=blog_pk)
read_cookie_key = read_statisitcs_once_read(request, blog)
context = {}
context['blog'] = blog
# 双下划线添加比较条件。__gt大于。__gte大于等于。.last()返回满足条件的最后一条
context['previous_blog'] = Blog.objects.filter(
create_time__gt=blog.create_time).last()
# 返回下一条博客,__lt 小于,first()取第一个。
# 字符串用 包含:__contains(加 i 忽略大小写);=>不等于
# __startwith, __endwith, 其中之一:__in ; range(范围)
context['next_blog'] = Blog.objects.filter(
create_time__lt=blog.create_time).first()
response = render(request, 'blog/blog_detail.html', context) # 响应
response.set_cookie(read_cookie_key, 'true') # 标记阅读
return response
def blog_with_type(request, blog_type_pk):
blog_type = get_object_or_404(BlogType, pk=blog_type_pk)
blog_all_list = Blog.objects.filter(blog_type=blog_type)
context = get_blog_list_common_data(request, blog_all_list)
context['blog_type'] = blog_type
return render(request, 'blog/blogs_with_type.html', context)
def blogs_with_date(request, year, month):
blog_all_list = Blog.objects.filter(create_time__year=year,
create_time__month=month)
context = get_blog_list_common_data(request, blog_all_list)
context['blogs_with_date'] = '%s年%s月' % (year, month)
return render(request, 'blog/blogs_with_date.html', context)
| [
"951416267@qq.com"
] | 951416267@qq.com |
6f2ad99c7aa8bce851105fd6395007ee480e8d24 | 4fd3f6c6ce06199d554101f796c0f6fc7eca074f | /0x00-python-hello_world/102-magic_calculation.py | 3f92444f0af36a72cd4d9d642bb837756764da7f | [] | no_license | Joldiazch/holbertonschool-higher_level_programming | 64f453aaf492b5473319a1b5e7e338bc7964fa7b | c9127882ffed3b72b2a517824770adafa63a9042 | refs/heads/master | 2020-09-29T03:12:47.497695 | 2020-05-15T04:05:13 | 2020-05-15T04:05:13 | 226,935,286 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 85 | py | #!/usr/bin/python3
import dis
def magic_calculation(a, b):
return (98 + (a ** b))
| [
"jluis.diaz@udea.edu.co"
] | jluis.diaz@udea.edu.co |
ce31f2005a4906c1d8266048483b4c20e17a7f1c | 969fed6b9f4c0daa728bda52fea73d94bda6faad | /fakeTempControl/oxford/MercurySCPI.py | d2e94fb25e63fcbc0fd4c62448f863e23a7df451 | [] | no_license | ess-dmsc/essiip-fakesinqhw | 7d4c0cb3e412a510db02f011fb9c20edfbd8a84f | ad65844c99e64692f07e7ea04d624154a92d57cd | refs/heads/master | 2021-01-18T22:50:50.182268 | 2020-10-01T08:39:30 | 2020-10-01T08:39:30 | 87,077,121 | 0 | 0 | null | 2018-12-07T08:43:00 | 2017-04-03T13:28:23 | Python | UTF-8 | Python | false | false | 5,980 | py | # vim: ft=python ts=8 sts=4 sw=4 expandtab autoindent smartindent nocindent
# Fake Mercury Temperature Controller
#
# Author: Douglas Clowes 2014
#
from MercuryDevice import MercuryDevice
import random
import re
import os
import sys
import time
sys.path.insert(0, os.path.realpath(os.path.abspath(os.path.join(os.path.dirname(sys.argv[0]),"../../util"))))
from fopdt import fopdt, fopdt_sink
from pid import PID
class Loop(fopdt):
def __init__(self, the_temp, the_nick):
fopdt.__init__(self, the_temp)
self.setpoint = the_temp
self.sensor = the_temp
# P, I, D
self.pid = PID(0.05, 0.02, 1.2)
self.pid.setPoint(the_temp)
# Value, Kp, Tp, Td, Absolute
self.AddSource(fopdt_sink(0, 2, 13, 10, True))
self.AddSink(fopdt_sink(the_temp, 1, 30, 1, False))
self.power = 0
self.nick = the_nick
self.count = 0
def Setpoint(self, the_sp):
self.setpoint = the_sp
self.pid.setPoint(the_sp)
def doIteration(self):
self.pid_delta = self.pid.update(self.pv)
self.sources[0].value = self.pid_delta
if self.sources[0].value > 100.0:
self.sources[0].value = 100.0
if self.sources[0].value < 0.0:
self.sources[0].value = 0.0
self.count += 1
self.iterate(self.count)
self.sensor = 0.9 * self.sensor + 0.1 * self.setpoint
class MercurySCPI(MercuryDevice):
"""Mercury SCPI temperature controller object - simulates the device"""
def __init__(self):
MercuryDevice.__init__(self)
print MercurySCPI.__name__, "ctor"
self.RANDOM = 0.0
self.IDN = "Simulated Mercury SCPI"
self.CONFIG_LOOPS = [1, 2, 3, 4]
self.CONFIG_SNSRS = [1, 2, 3, 4]
self.Loops = {}
self.Loops[1] = self.Loops['MB0'] = self.Loops['MB1'] = Loop(270, "VTI_STD")
self.Loops[2] = self.Loops['DB1'] = self.Loops['DB6'] = Loop(270, "Sample_1")
self.Loops[3] = self.Loops['DB2'] = self.Loops['DB7'] = Loop(270, "Sample_2")
self.Loops[4] = self.Loops['DB3'] = self.Loops['DB8'] = Loop(270, "VTI")
self.valve_open = 0.0
self.hlev = 92.0
self.nlev = 87.6
self.reset_powerup()
def doCommand(self, command, params):
print MercurySCPI.__name__, "Command:", command, params
return MercuryDevice.doCommand(self, command, params)
def doQuery(self, command, params):
print MercurySCPI.__name__, "Query:", command, params
return MercuryDevice.doQuery(self, command, params)
def reset_powerup(self):
print MercurySCPI.__name__, "reset_powerup"
self.LAST_ITERATION = 0
def doIteration(self):
delta_time = time.time() - self.LAST_ITERATION
if delta_time < 1:
return
#print "DoIteration:", delta_time
self.LAST_ITERATION = time.time()
for idx in self.CONFIG_LOOPS:
self.Loops[idx].doIteration()
def doCommandSET(self, cmd, args):
if args[0] != "DEV":
return
key = args[1].split(".")[0]
if key == "DB4":
# Valve
self.valve_open = float(args[5])
self.write("STAT:SET:" + ":".join(args) + ":VALID")
return
if key in self.Loops:
if args[4] == "TSET":
self.Loops[key].Setpoint(float(args[5]))
self.write("STAT:SET:" + ":".join(args) + ":VALID")
return
self.write("STAT:SET:" + ":".join(args) + ":INVALID")
def doQueryREAD(self, cmd, args):
if args[0] != "DEV":
return
key = args[1].split(".")[0]
if key == "DB4":
# Valve
self.write("STAT:DEV:DB4.G1:AUX:SIG:OPEN:%7.4f%%" % self.valve_open)
return
if key == "DB5":
# Level
if args[4] == "HEL":
self.write("STAT:DEV:DB5.L1:LVL:SIG:HEL:LEV:%7.4f%%" % self.hlev)
return
if args[4] == "NIT":
self.write("STAT:DEV:DB5.L1:LVL:SIG:NIT:LEV:%7.4f%%" % self.nlev)
return
return
if key in self.Loops:
if args[3] == "NICK":
self.write("STAT:DEV:"+args[1]+":TEMP:NICK:%s" % self.Loops[key].nick)
return
if args[4] == "TSET":
self.write("STAT:DEV:"+args[1]+":TEMP:LOOP:TSET:%g" % self.Loops[key].setpoint)
return
if args[4] == "TEMP":
self.write("STAT:DEV:"+args[1]+":TEMP:SIG:TEMP:%7.4fK" % self.Loops[key].sensor)
return
if args[4] == "POWR":
self.write("STAT:DEV:"+args[1]+":HTR:SIG:POWR:%.4fW" % self.Loops[key].power)
return
self.write("STAT:" + ":".join(args) + ":INVALID")
print "TODO implement Query: \"READ\" in \"" + cmd + ":" + ":".join(args) + "\""
if __name__ == '__main__':
from MercuryProtocol import MercuryProtocol
class TestFactory:
def __init__(self):
print self.__class__.__name__, "ctor"
self.numProtocols = 0
def write(self, data):
print "test write:", data,
def loseConnection(self):
print "test lose connection"
test_factory = TestFactory()
test_device = MercurySCPI()
test_protocol = MercuryProtocol(test_device, "\r\n")
test_protocol.factory = test_factory
test_protocol.transport = test_factory
test_device.protocol = test_protocol
test_device.protocol.connectionMade()
commands = ["READ:DEV:MB1.T1:TEMP:SIG:TEMP",
"READ:DEV:MB1.T1:TEMP:NICK",
"SET:DEV:MB1.T1:TEMP:LOOP:TSET:274",
"READ:DEV:MB1.T1:TEMP:LOOP:TSET",
"READ:DEV:MB0.H1:HTR:SIG:POWR"]
for cmd in commands:
test_device.protocol.dataReceived(cmd)
test_device.protocol.dataReceived(test_protocol.term)
test_device.protocol.connectionLost("Dunno")
| [
"mark.koennecke@psi.ch"
] | mark.koennecke@psi.ch |
95a422e8dee940a9edc01bbbe8a0d875f40c8fe1 | 817588295567c6ea114e5a25abfb9aabc9b6b312 | /planetary_system_stacker/planetary_system_stacker_windows.spec | 6a20795833d229c8aa878d72ad907a502dedc9d1 | [] | no_license | Flashy-GER/PlanetarySystemStacker | 72037bcbfd0bbd184d06c997ccbcac991c60c03f | bae9191746b0456fa97a68a70b52a38750bf8ee0 | refs/heads/master | 2023-02-13T03:46:00.808743 | 2021-01-05T19:19:45 | 2021-01-05T19:19:45 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,133 | spec | # -*- mode: python -*-
block_cipher = None
# Integrate astropy as data directory instead of module:
import astropy
astropy_path, = astropy.__path__
a = Analysis(['planetary_system_stacker.py'],
pathex=['D:\\SW-Development\\Python\\PlanetarySystemStacker\\planetary_system_stacker'],
binaries=[('C:\Python35\Lib\site-packages\opencv_ffmpeg342_64.dll', '.'),
('D:\SW-Development\Python\PlanetarySystemStacker\planetary_system_stacker\Binaries\Api-ms-win-core-xstate-l2-1-0.dll', '.'),
('D:\SW-Development\Python\PlanetarySystemStacker\planetary_system_stacker\Binaries\Api-ms-win-crt-private-l1-1-0.dll', '.'),
('C:\Windows\System32\downlevel\API-MS-Win-Eventing-Provider-L1-1-0.dll', '.'),
('D:\SW-Development\Python\PlanetarySystemStacker\planetary_system_stacker\Binaries\\api-ms-win-downlevel-shlwapi-l1-1-0.dll', '.')],
datas=[( 'D:\\SW-Development\\Python\\PlanetarySystemStacker\\Documentation\\Icon\\PSS-Icon-64.ico', '.' ),
( 'D:\\SW-Development\\Python\\PlanetarySystemStacker\\Documentation\\Icon\\PSS-Icon-64.png', '.' ),
(astropy_path, 'astropy')],
hiddenimports=['pywt._extensions._cwt', 'scipy._lib.messagestream', 'shelve', 'csv', 'pkg_resources.py2_warn'],
hookspath=[],
runtime_hooks=[],
excludes=['astropy'],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
pyz = PYZ(a.pure, a.zipped_data,
cipher=block_cipher)
exe = EXE(pyz,
a.scripts,
[],
exclude_binaries=True,
name='planetary_system_stacker',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
console=True ) # To display a console window, change value to True.
coll = COLLECT(exe,
a.binaries,
a.zipfiles,
a.datas,
strip=False,
upx=True,
name='PlanetarySystemStacker')
| [
"rolf6419@gmx.de"
] | rolf6419@gmx.de |
c782987ab7f5eb6736b6b9063fcbb3c8fbb6fa90 | d38a2f807138232165fd665fd74231df942efc8d | /exercises/21_jinja2/conftest.py | 2b59c73af8fd796c19bf8fb37e3f98571a465c85 | [] | no_license | maximacgfx/work | b2537381916fe92c6267302375e49809cf7f327b | 84a3da63b65a9883febd5191ca9d759c43a15bfa | refs/heads/master | 2022-11-22T06:14:21.593468 | 2019-09-04T19:25:53 | 2019-09-04T19:25:53 | 25,587,765 | 0 | 1 | null | 2022-11-15T11:25:46 | 2014-10-22T15:03:24 | Python | UTF-8 | Python | false | false | 260 | py | import re
import yaml
import pytest
def strip_empty_lines(output):
lines = []
for line in output.strip().split('\n'):
line = line.strip()
if line:
lines.append(re.sub(' +', ' ', line.strip()))
return '\n'.join(lines)
| [
"vagrant@stretch.localdomain"
] | vagrant@stretch.localdomain |
7e2280a0a8cc80790caebdbd2dcdd8770668b623 | b8faf65ea23a2d8b119b9522a0aa182e9f51d8b1 | /vmraid/desk/doctype/notification_settings/test_notification_settings.py | ed60aac3c067eff22a0a8bb529d0d61175255e1b | [
"MIT"
] | permissive | vmraid/vmraid | a52868c57b1999a8d648441eb9cd05815204345d | 3c2e2a952003ba7ea2cf13673b9e79e127f4166e | refs/heads/main | 2022-07-29T18:59:28.585133 | 2022-04-22T08:02:52 | 2022-04-22T08:02:52 | 372,473,120 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 169 | py | # Copyright (c) 2021, VMRaid Technologies and Contributors
# See license.txt
# import vmraid
import unittest
class TestNotificationSettings(unittest.TestCase):
pass
| [
"sowrisurya@outlook.com"
] | sowrisurya@outlook.com |
50f230ad7fe45a58dc789e52770f1670d7cca518 | 2ce3ef971a6d3e14db6615aa4da747474d87cc5d | /练习/Python基础/工具组件/时间处理/datetime_test.py | aea34308073615d9f580245e46ef6834e2d5eee7 | [] | no_license | JarvanIV4/pytest_hogwarts | 40604245807a4da5dbec2cb189b57d5f76f5ede3 | 37d4bae23c030480620897583f9f5dd69463a60c | refs/heads/master | 2023-01-07T09:56:33.472233 | 2020-11-10T15:06:13 | 2020-11-10T15:06:13 | 304,325,109 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 747 | py | import datetime
class DatetimeTest:
def start_date(self, current_date, delta_date):
"""
计算执行时间前N天的日期
:param current_date: 执行时间
:param delta_date: 当前日期偏差天数
:return: 返回当前日期前N天的日期
"""
current_date = datetime.datetime.strptime(current_date, "%Y-%m-%d") # 将字符串转换为时间格式
delta = datetime.timedelta(days=delta_date) # 当前日期前29天的日期偏差值
start_date = (current_date + delta).strftime("%Y-%m-%d") # 计算当前日期前N天的日期
return start_date
if __name__ == '__main__':
t = DatetimeTest()
print(t.start_date("2020-02-07", 5)) # 2020-02-12 | [
"2268035948@qq.com"
] | 2268035948@qq.com |
632157ea55bfbdc2a50330d4b79d18c9094b58c7 | d7663e323e2b48ad094e0ab7454ab0bed73aafd1 | /pychzrm course/Django/day_01/code/mywebsite1/mywebsite1/views.py | a0ed194f3f17e5a79bebfa79a6e5dc5d3653c2c6 | [] | no_license | Jack-HFK/hfklswn | f9b775567d5cdbea099ec81e135a86915ab13a90 | f125671a6c07e35f67b49013c492d76c31e3219f | refs/heads/master | 2021-06-19T05:58:54.699104 | 2019-08-09T10:12:22 | 2019-08-09T10:12:22 | 201,442,926 | 7 | 0 | null | 2021-04-20T18:26:03 | 2019-08-09T10:07:20 | HTML | UTF-8 | Python | false | false | 3,682 | py | """
视图处理函数 : request接受请求:代表的浏览器给我们的数据
return 响应内容
一个视图处理函数可以对应多个url路由
一个utl路由只能对应一个视图处理函数
"""
from django.http import HttpResponse
# 视图处理函数
def index_view(request):
html = "欢迎来到主页面"
html += "<a href='/page1'> 第一页 </a>"
html += "<a href='/page2'> 第二页 </a>"
html += "<a href='/page3'> 第三页 </a>"
return HttpResponse(html)
def page1_view(request):
html = "欢迎来到第一个页面"
html += "<a href='http://www.tmooc.cn'> 达内 </a>"
html += "<a href='/page2'> 第二页 </a>"
html += "<a href='/page3'> 第三页 </a>"
return HttpResponse(html)
def page2_view(request):
html = "欢迎来到第二个页面"
html += "<a href='/'> 返回首页 </a>"
html += "<a href='/page1'> 第一页 </a>"
html += "<a href='/page3'> 第三页 </a>"
return HttpResponse(html)
def page3_view(request):
html = "欢迎来到第三个页面"
html += "<a href='/'> 返回首页 </a>"
html += "<a href='/page1'> 第一页 </a>"
html += "<a href='/page2'> 第二页 </a>"
return HttpResponse(html)
# 在视图函数内,可以用正则表达式分组 () 提取参数后用函数位置传参传递给视图函数
def year_view(request,y):
html = "year中的年份是" + y
html += "URL路由字符串" + request.path_info
return HttpResponse(html)
def cal_view(request,a,op,b):
html = "欢迎来到cal页面"
a = int(a)
b = int(b)
if op == "add":
ab = a+b
elif op == "sub":
ab = a - b
elif op == "mul":
ab = a * b
else:
return HttpResponse("不能运算")
return HttpResponse(ab)
def date_viem(request,y,m,d):
""" y,m,d : 年 月 日"""
html = y + "年" + m + "月" + d + "日"
return HttpResponse(html)
# def date_viem(request,**kwargs):
# """ y,m,d : 年 月 日"""
# html = y + "年" + m + "月" + d + "日"
# return HttpResponse(html)
def show_info_view(request):
html = "request.path=" + request.path # path:只代表URL中的路由
if request.method == "GET": #字符串,表示HTTP请求方法,常用值: 'GET' 、 'POST'
html += "<h4>您正在进行GET请求</h4>"
elif request.metchod == "POST":
html += "<h4>您正在进行POST请求</h4>"
html += "<h5> 您的IP地址是" + request.META["REMOTE_ADDR"] #客户端IP地址
html += "<h5> 请求源IP地址是" + request.META['HTTP_REFERER'] #请求源地址
return HttpResponse(html)
def page_view(request):
html = ""
# 字符串,表示 HTTP 请求方法,常用值: 'GET' 、 'POST'
if request.method == "GET":
dic = dict(request.GET) # request.GET获取请求内容
s = str(dic)
html = "GET请求:" + s
get_one = request.GET.get("某个请求值") # request.GET.get获取GET请求内容中具体某一个请求数据
gets = request.GET.getlist("请求列表") # request.GET.getlist 获取GET请求列表:列表中可以有一个或多个请求
elif request.method == "POST":
pass
return HttpResponse(html)
def sum_view(request,):
html = ""
if request.method == "GET":
start = int(request.GET.get("start")) # request.GET.get获取GET请求内容中具体某个请求数据
stop = int(request.GET.get("stop"))
step = int(request.GET.get("step"))
html += str(sum(range(start,stop,step)))
elif request.method == "POST":
html = "没法计算"
return HttpResponse(html)
| [
"88888888@qq.com"
] | 88888888@qq.com |
cf03c0cf829ae23af046854d5a4f1118d9e1b1ef | e2f7c64ea3674033c44fa4488e6479d21c86ce54 | /mkoenig/python/database/wholecellkb/wsgi.py | e9dcdff586b7e2867b033b48f36fe50fe2a43870 | [] | no_license | dagwa/wholecell-metabolism | f87c6105c420ebb83f7bfd19a44cd59df2b60414 | aa0c3c04680f56e0676b034eed92c34fd87b9234 | refs/heads/master | 2021-01-17T13:05:18.679605 | 2016-10-19T08:39:19 | 2016-10-19T08:39:19 | 31,332,881 | 3 | 0 | null | null | null | null | UTF-8 | Python | false | false | 397 | py | """
WSGI config for wholecellkb project.
It exposes the WSGI callable as a module-level variable named ``application``.
For more information on this file, see
https://docs.djangoproject.com/en/1.6/howto/deployment/wsgi/
"""
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "wholecellkb.settings")
from django.core.wsgi import get_wsgi_application
application = get_wsgi_application()
| [
"konigmatt@googlemail.com"
] | konigmatt@googlemail.com |
b81c75bb9187cf61314bd837262eea0add8331fb | ba766731ae8132a14460dc3b92bc73cb951a5612 | /header/lobby.py | 43ec541c23a7b3a0dcb9e9141b6ec254fd12da8b | [] | no_license | Jineapple/aoc-mgz | 566318dc96b8a19dac7a03c450ec112fa9a421a8 | bc263ac3728a714c670d6120b9fae952f60818a2 | refs/heads/master | 2021-01-15T12:25:25.211495 | 2015-05-17T04:27:34 | 2015-05-17T04:27:34 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 615 | py | from construct import *
from aoc.mgz.enums import *
"""Player inputs in the lobby, and several host settings"""
lobby = Struct("lobby",
Array(8, Byte("teams")), # team number selected by each player
Padding(1),
RevealMapEnum(ULInt32("reveal_map")),
Padding(8),
ULInt32("population_limit"), # multiply by 25 for UserPatch 1.4
GameTypeEnum(Byte("game_type")),
Flag("lock_teams"),
ULInt32("num_chat"),
Array(lambda ctx: ctx.num_chat, # pre-game chat messages
Struct("messages",
ULInt32("message_length"),
String("message", lambda ctx: ctx.message_length, padchar = '\x00', trimdir = 'right')
)
)
) | [
"happyleaves.tfr@gmail.com"
] | happyleaves.tfr@gmail.com |
70030042ac847cb5174a253c07fa9f9c635f637f | f87f51ec4d9353bc3836e22ac4a944951f9c45c0 | /.history/HW06_20210719110929.py | 20b3509b7524593d8999e837b41f92d3b9ffb6f9 | [] | no_license | sanjayMamidipaka/cs1301 | deaffee3847519eb85030d1bd82ae11e734bc1b7 | 9ddb66596497382d807673eba96853a17884d67b | refs/heads/main | 2023-06-25T04:52:28.153535 | 2021-07-26T16:42:44 | 2021-07-26T16:42:44 | 389,703,530 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 7,463 | py | """
Georgia Institute of Technology - CS1301
HW06 - Text Files & CSV
Collaboration Statement:
"""
#########################################
"""
Function Name: findCuisine()
Parameters: filename (str), cuisine (str)
Returns: list of restaurants (list)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def findCuisine(filename, cuisine):
file = open(filename,'r')
content = file.readlines()
listOfRestaurants = []
for i in range(len(content)):
if content[i].strip() == cuisine:
listOfRestaurants.append(content[i-1].strip()) #add the name of the restaurant, which is the previous line
file.close()
return listOfRestaurants
"""
Function Name: restaurantFilter()
Parameters: filename (str)
Returns: dictionary that maps cuisine type (str)
to a list of restaurants of the same cuisine type (list)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def restaurantFilter(filename):
dict = {}
file = open(filename,'r')
content = file.readlines()
cuisines = []
for i in range(1,len(content),4):
line = content[i].strip()
if line not in cuisines:
cuisines.append(line)
for i in range(len(cuisines)):
dict[cuisines[i]] = []
for i in range(0,len(content),4):
line = content[i].strip()
lineBelow = content[i+1].strip()
dict[lineBelow].append(line)
return dict
"""
Function Name: createDirectory()
Parameters: filename (str), output filename (str)
Returns: None (NoneType)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def createDirectory(filename, outputFilename):
readFile = open(filename, 'r')
writeFile = open(outputFilename, 'w')
content = readFile.readlines()
fastfood = []
sitdown = []
fastfoodcounter = 1
sitdowncounter = 1
for i in range(2,len(content), 4):
restaurant = content[i-2].strip()
cuisine = content[i-1].strip()
group = content[i].strip()
if group == 'Fast Food':
fastfood.append(restaurant + ' - ' + cuisine)
else:
sitdown.append(restaurant + ' - ' + cuisine)
fastfood = sorted(fastfood)
sitdown = sorted(sitdown)
for i in range(len(fastfood)):
fastfood[i] = str(fastfoodcounter) + '. ' + fastfood[i] + '\n'
fastfoodcounter += 1
for i in range(len(sitdown)):
sitdown[i] = str(sitdowncounter) + '. ' + sitdown[i]
sitdowncounter += 1
writeFile.write('Restaurant Directory' + '\n')
writeFile.write('Fast Food' + '\n')
writeFile.writelines(fastfood)
writeFile.write('Sit-down' + '\n')
for i in range(len(sitdown)):
if i != len(sitdown)-1:
writeFile.write(sitdown[i] + '\n')
else:
writeFile.write(sitdown[i])
"""
Function Name: extraHours()
Parameters: filename (str), hour (int)
Returns: list of (person, extra money) tuples (tuple)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def extraHours(filename, hour):
overtime = []
file = open(filename, 'r')
header = file.readline()
content = file.readlines()
for i in content:
line = i.strip().split(',')
name = line[0]
wage = int(line[2])
hoursWorked = int(line[4])
if hoursWorked > hour:
compensation = (hoursWorked - hour) * wage
overtime.append((name, compensation))
return overtime
"""
Function Name: seniorStaffAverage()
Parameters: filename (str), year (int)
Returns: average age of senior staff members (float)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def seniorStaffAverage(filename, year):
averageAge = 0.0
employeeCount = 0.0
file = open(filename, 'r')
header = file.readline()
content = file.readlines()
for i in content:
line = i.strip().split(',')
age = int(line[1])
yearHired = int(line[3])
if yearHired < year:
averageAge += age
employeeCount += 1
if averageAge == 0 or employeeCount == 0:
return 0
averageAge /= employeeCount
return round(averageAge,2)
"""
Function Name: ageDict()
Parameters: filename (str), list of age ranges represented by strings (list)
Returns: dictionary (dict) that maps each age range (str) to a list of employees (list)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def ageDict(filename, ageRangeList):
employeeAgeDictionary = {}
newDict = {}
ageRangesFormatted = []
for i in ageRangeList:
employeeAgeDictionary[i] = []
# print(employeeAgeDictionary)
for i in ageRangeList:
ageRangesFormatted.append(i.split('-'))
# print(ageRangesFormatted)
file = open(filename, 'r')
header = file.readline()
content = file.readlines()
for i in content:
line = i.strip().split(',')
age = int(line[1])
name = line[0]
for j in ageRangesFormatted:
if age >= int(j[0]) and age <= int(j[1]):
employeeAgeDictionary[j[0] + '-' + j[1]].append(name)
for i in employeeAgeDictionary:
if employeeAgeDictionary[i] != []:
newDict[i] = employeeAgeDictionary[i]
return newDict
# print(findCuisine('restaurants.txt', 'Mexican'))
# print(restaurantFilter('restaurants.txt'))
# print(createDirectory('restaurants.txt','directory.txt'))
# print(extraHours('employees.csv', 40))
# print(seniorStaffAverage('employees.csv', 2001))
# rangeList = ["20-29", "30-39"]
# print(ageDict('employees.csv', rangeList))
# print(ageDict('employees.csv', ['0-18', '18-19']))
a_list = ['a', 'b', [2,4]]
b_list = a_list[:]
my_list = b_list
print('a_list', a_list, 'b_list', b_list)
a_list[2].append(4)
print('a_list', a_list, 'b_list', b_list)
a_list[1] = 'c'
print('a_list', a_list, 'b_list', b_list)
b_list[0] = 'z'
print('a_list', a_list, 'b_list', b_list)
array = [[1, 'a'],[0, 'b']]
array.sort()
print(array)
num = 0
tupList = [(8,6,7,5),(3,0,9)]
for x in range(len(tupList)):
if x%2==0:
print(x)
num += 1
tupList[x] = num
print(tupList)
sentence = 'i love doggos !!'
sentence = sentence.split()
newSentence = []
count = 0
for word in sentence:
if count % 2 == 1:
newSentence.append(word)
count += 1
print(newSentence)
mydict = {}
sand = ('pb', 'and', 'jelly')
alist = [1,2,3]
del alist[1]
print(alist)
aList = [1, 2, 3, [4, 5]]
bList = aList
cList = bList[:]
aList.append('hello!')
cList[3] *= 2
del bList[1]
bList[2] = ':)'
print(aList, '\n', bList, '\n', cList)
dict1 = {1:5, 1:9, 1:15}
#print(dict1[1])
#print(('sweet', '', 'treat')+('',))
alist = [6,12]
blist = [1,3]
clist = blist
for i,j in enumerate(alist):
if alist[i] % 3 == 0:
clist.append(j)
alist[i] = ['candy']
alist[i].append('boo')
print(alist, blist)
#print('merry' + 5)
list2 = ['1']
list2[0].append(4)
print(list2)
| [
"sanjay.mamidipaka@gmail.com"
] | sanjay.mamidipaka@gmail.com |
04346790cd9cf5310fb94eba427a9102cf59e99d | 5ed2d0e107e4cdcd8129f418fdc40f1f50267514 | /AAlgorithms/LongestWordInDictionary/test.py | 68b3f9841632adcbba727c63a7beed0329f2636f | [] | no_license | tliu57/Leetcode | 6cdc3caa460a75c804870f6615653f335fc97de1 | c480697d174d33219b513a0b670bc82b17c91ce1 | refs/heads/master | 2020-05-21T03:14:07.399407 | 2018-07-08T18:50:01 | 2018-07-08T18:50:01 | 31,505,035 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 985 | py | class Node(object):
def __init__(self):
self.children = {}
self.end = 0
self.word = ""
class Trie(object):
def __init__(self):
self.root = Node()
def insert(self, word, index):
curr = self.root
for c in word:
if not c in curr.children:
curr.children[c] = Node()
curr = curr.children.get(c)
curr.end = index
curr.word = word
def dfs(self, words):
ans = ""
stack = []
stack.append(self.root)
while stack:
node = stack.pop()
if node.end > 0 or node == self.root:
if node != self.root > 0:
word = words[node.end - 1]
if len(word) > len(ans) or (len(word) == len(ans) and word < ans):
ans = word
for n in node.children.values():
stack.append(n)
return ans
class Solution(object):
def longestWord(self, words):
root = Trie()
index = 1
for word in words:
root.insert(word, index)
index += 1
return root.dfs(words)
sol = Solution()
print sol.longestWord(["w","wo","wor","worl", "world"])
| [
"tliu57@asu.edu"
] | tliu57@asu.edu |
5b0ae77695e461f794fdc01a098ee77d67701b44 | 4fe4dc47c8a849bb47297fdf4177569eb175e5fa | /app/actions.py | ae05d8fa7fac236425f95b8ae095c953208a1586 | [
"Apache-2.0"
] | permissive | adamyi/ci_edit | 0886088ad8725897f3c7ace8c3d92ccd1417d5a2 | 5e55ed952863984559fd19c925f957047e727589 | refs/heads/master | 2021-07-14T08:07:20.600311 | 2017-10-17T02:40:55 | 2017-10-17T02:40:55 | 107,211,152 | 1 | 0 | null | 2017-10-17T03:06:38 | 2017-10-17T03:06:37 | null | UTF-8 | Python | false | false | 46,192 | py | # Copyright 2016 Google Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import app.buffer_manager
import app.clipboard
import app.log
import app.history
import app.mutator
import app.parser
import app.prefs
import app.selectable
import bisect
import curses.ascii
import difflib
import io
import os
import re
import sys
import time
import traceback
class Actions(app.mutator.Mutator):
"""This base class to TextBuffer handles the text manipulation (without
handling the drawing/rendering of the text)."""
def __init__(self):
app.mutator.Mutator.__init__(self)
self.view = None
self.rootGrammar = app.prefs.getGrammar(None)
def setView(self, view):
self.view = view
def performDelete(self):
if self.selectionMode != app.selectable.kSelectionNone:
text = self.getSelectedText()
if text:
if self.selectionMode == app.selectable.kSelectionBlock:
upper = min(self.penRow, self.markerRow)
left = min(self.penCol, self.markerCol)
lower = max(self.penRow, self.markerRow)
right = max(self.penCol, self.markerCol)
self.cursorMoveAndMark(
upper - self.penRow, left - self.penCol,
lower - self.markerRow, right - self.markerCol, 0)
self.redo()
elif (self.penRow > self.markerRow or
(self.penRow == self.markerRow and
self.penCol > self.markerCol)):
self.swapPenAndMarker()
self.redoAddChange(('ds', text))
self.redo()
self.selectionNone()
def performDeleteRange(self, upperRow, upperCol, lowerRow, lowerCol):
app.log.info(upperRow, upperCol, lowerRow, lowerCol)
if upperRow == self.penRow == lowerRow:
app.log.info()
if upperCol < self.penCol:
app.log.info()
col = upperCol - self.penCol
if lowerCol <= self.penCol:
col = upperCol - lowerCol
app.log.info(col)
self.cursorMove(0, col)
self.redo()
elif upperRow <= self.penRow < lowerRow:
app.log.info()
self.cursorMove(upperRow - self.penRow, upperCol - self.penCol)
self.redo()
elif self.penRow == lowerRow:
app.log.info()
col = upperCol - lowerCol
self.cursorMove(upperRow - self.penRow, col)
self.redo()
if 1:
self.redoAddChange((
'dr',
(upperRow, upperCol, lowerRow, lowerCol),
self.getText(upperRow, upperCol, lowerRow, lowerCol)))
self.redo()
def dataToBookmark(self):
"""
Grabs all the cursor data and returns a bookmark.
Args:
None.
Returns:
A bookmark in the form of (bookmarkRange, bookmarkData).
bookmarkRange is an ordered tuple in which its elements
are the rows that the bookmark affects.
bookmarkData is a dictionary that contains the cursor data.
"""
bookmarkData = {
'cursor': (self.view.cursorRow, self.view.cursorCol),
'marker': (self.markerRow, self.markerCol),
'pen': (self.penRow, self.penCol),
'selectionMode': self.selectionMode,
}
upperRow, _, lowerRow, _ = self.startAndEnd()
bookmarkRange = (upperRow, lowerRow)
return (bookmarkRange, bookmarkData)
def bookmarksOverlap(self, bookmarkRange1, bookmarkRange2):
"""
Returns whether the two sorted bookmark ranges overlap.
Args:
bookmarkRange1 (tuple): a sorted tuple of row numbers.
bookmarkRange2 (tuple): a sorted tuple of row numbers.
Returns:
True if the ranges overlap. Otherwise, returns False.
"""
return (bookmarkRange1[-1] >= bookmarkRange2[0] and
bookmarkRange1[0] <= bookmarkRange2[-1])
def bookmarkAdd(self):
"""
Adds a bookmark at the cursor's location. If multiple lines are
selected, all existing bookmarks in those lines are overwritten
with the new bookmark.
Args:
None.
Returns:
None.
"""
newBookmark = self.dataToBookmark()
self.bookmarkRemove()
bisect.insort(self.bookmarks, newBookmark)
def bookmarkGoto(self, bookmark):
"""
Goes to the bookmark that is passed in.
Args:
bookmark (tuple): contains bookmarkRange and bookmarkData. More info can
be found in the dataToBookmark function.
Returns:
None.
"""
bookmarkRange, bookmarkData = bookmark
cursorRow, cursorCol = bookmarkData['cursor']
penRow, penCol = bookmarkData['pen']
markerRow, markerCol = bookmarkData['marker']
selectionMode = bookmarkData['selectionMode']
self.cursorMoveAndMark(penRow - self.penRow, penCol - self.penCol,
markerRow - self.markerRow, markerCol - self.markerCol,
selectionMode - self.selectionMode)
self.redo()
self.scrollToOptimalScrollPosition()
def bookmarkNext(self):
"""
Goes to the closest bookmark after the cursor.
Args:
None.
Returns:
None.
"""
if not len(self.bookmarks):
self.setMessage("No bookmarks to jump to")
return
_, _, lowerRow, _ = self.startAndEnd()
tempBookmark = ((lowerRow, float('inf')),)
index = bisect.bisect(self.bookmarks, tempBookmark)
self.bookmarkGoto(self.bookmarks[index % len(self.bookmarks)])
def bookmarkPrior(self):
"""
Goes to the closest bookmark before the cursor.
Args:
None.
Returns:
None.
"""
if not len(self.bookmarks):
self.setMessage("No bookmarks to jump to")
return
upperRow, _, _, _ = self.startAndEnd()
tempBookmark = ((upperRow,),)
index = bisect.bisect_left(self.bookmarks, tempBookmark)
bookmark = self.bookmarkGoto(self.bookmarks[index - 1])
def bookmarkRemove(self):
"""
Removes bookmarks in all selected lines.
Args:
None.
Returns:
(boolean) Whether any bookmarks were removed.
"""
upperRow, _, lowerRow, _ = self.startAndEnd()
rangeList = self.bookmarks
needle = ((upperRow, lowerRow),)
# Find the left-hand index.
begin = bisect.bisect_left(rangeList, needle)
if begin and needle[0][0] <= rangeList[begin-1][0][1]:
begin -= 1
# Find the right-hand index.
low = begin
index = begin
high = len(rangeList)
offset = needle[0][1]
while True:
index = (high + low) / 2
if low == high:
break
if offset >= rangeList[index][0][1]:
low = index + 1
elif offset < rangeList[index][0][0]:
high = index
else:
index += 1
break
if begin == index:
return False
self.bookmarks = rangeList[:begin] + rangeList[index:]
return True
def backspace(self):
#app.log.info('backspace', self.penRow > self.markerRow)
if self.selectionMode != app.selectable.kSelectionNone:
self.performDelete()
elif self.penCol == 0:
if self.penRow > 0:
self.cursorLeft()
self.joinLines()
else:
line = self.lines[self.penRow]
change = ('b', line[self.penCol - 1:self.penCol])
self.redoAddChange(change)
self.redo()
def carriageReturn(self):
self.performDelete()
self.redoAddChange(('n', (1, self.getCursorMove(1, -self.penCol))))
self.redo()
if 1: # TODO(dschuyler): if indent on CR
line = self.lines[self.penRow - 1]
commonIndent = 2
indent = 0
while indent < len(line) and line[indent] == ' ':
indent += 1
if len(line):
if line[-1] in [':', '[', '{']:
indent += commonIndent
# Good idea or bad idea?
#elif indent >= 2 and line.lstrip()[:6] == 'return':
# indent -= commonIndent
elif line.count('(') > line.count(')'):
indent += commonIndent * 2
if indent:
self.redoAddChange(('i', ' ' * indent));
self.redo()
self.updateBasicScrollPosition()
def cursorColDelta(self, toRow):
if toRow >= len(self.lines):
return
lineLen = len(self.lines[toRow])
if self.goalCol <= lineLen:
return self.goalCol - self.penCol
return lineLen - self.penCol
def cursorDown(self):
self.selectionNone()
self.cursorMoveDown()
def cursorDownScroll(self):
self.selectionNone()
self.scrollDown()
def cursorLeft(self):
self.selectionNone()
self.cursorMoveLeft()
def getCursorMove(self, rowDelta, colDelta):
return self.getCursorMoveAndMark(rowDelta, colDelta, 0, 0, 0)
def cursorMove(self, rowDelta, colDelta):
self.cursorMoveAndMark(rowDelta, colDelta, 0, 0, 0)
def getCursorMoveAndMark(self, rowDelta, colDelta, markRowDelta,
markColDelta, selectionModeDelta):
if self.penCol + colDelta < 0: # Catch cursor at beginning of line.
colDelta = -self.penCol
self.goalCol = self.penCol + colDelta
return ('m', (rowDelta, colDelta,
markRowDelta, markColDelta, selectionModeDelta))
def cursorMoveAndMark(self, rowDelta, colDelta, markRowDelta,
markColDelta, selectionModeDelta):
change = self.getCursorMoveAndMark(rowDelta, colDelta, markRowDelta,
markColDelta, selectionModeDelta)
self.redoAddChange(change)
def cursorMoveScroll(self, rowDelta, colDelta,
scrollRowDelta, scrollColDelta):
self.updateScrollPosition(scrollRowDelta, scrollColDelta)
self.redoAddChange(('m', (rowDelta, colDelta,
0,0, 0)))
def cursorMoveDown(self):
if self.penRow + 1 < len(self.lines):
savedGoal = self.goalCol
self.cursorMove(1, self.cursorColDelta(self.penRow + 1))
self.redo()
self.goalCol = savedGoal
def cursorMoveLeft(self):
if self.penCol > 0:
self.cursorMove(0, -1)
self.redo()
elif self.penRow > 0:
self.cursorMove(-1, len(self.lines[self.penRow - 1]))
self.redo()
def cursorMoveRight(self):
if not self.lines:
return
if self.penCol < len(self.lines[self.penRow]):
self.cursorMove(0, 1)
self.redo()
elif self.penRow + 1 < len(self.lines):
self.cursorMove(1, -len(self.lines[self.penRow]))
self.redo()
def cursorMoveUp(self):
if self.penRow > 0:
savedGoal = self.goalCol
lineLen = len(self.lines[self.penRow - 1])
if self.goalCol <= lineLen:
self.cursorMove(-1, self.goalCol - self.penCol)
self.redo()
else:
self.cursorMove(-1, lineLen - self.penCol)
self.redo()
self.goalCol = savedGoal
def cursorMoveSubwordLeft(self):
self.doCursorMoveLeftTo(app.selectable.kReSubwordBoundaryRvr)
def cursorMoveSubwordRight(self):
self.doCursorMoveRightTo(app.selectable.kReSubwordBoundaryFwd)
def cursorMoveTo(self, row, col):
cursorRow = min(max(row, 0), len(self.lines)-1)
self.cursorMove(cursorRow - self.penRow, col - self.penCol)
self.redo()
def cursorMoveWordLeft(self):
self.doCursorMoveLeftTo(app.selectable.kReWordBoundary)
def cursorMoveWordRight(self):
self.doCursorMoveRightTo(app.selectable.kReWordBoundary)
def doCursorMoveLeftTo(self, boundary):
if self.penCol > 0:
line = self.lines[self.penRow]
pos = self.penCol
for segment in re.finditer(boundary, line):
if segment.start() < pos <= segment.end():
pos = segment.start()
break
self.cursorMove(0, pos - self.penCol)
self.redo()
elif self.penRow > 0:
self.cursorMove(-1, len(self.lines[self.penRow - 1]))
self.redo()
def doCursorMoveRightTo(self, boundary):
if not self.lines:
return
if self.penCol < len(self.lines[self.penRow]):
line = self.lines[self.penRow]
pos = self.penCol
for segment in re.finditer(boundary, line):
if segment.start() <= pos < segment.end():
pos = segment.end()
break
self.cursorMove(0, pos - self.penCol)
self.redo()
elif self.penRow + 1 < len(self.lines):
self.cursorMove(1, -len(self.lines[self.penRow]))
self.redo()
def cursorRight(self):
self.selectionNone()
self.cursorMoveRight()
def cursorSelectDown(self):
if self.selectionMode == app.selectable.kSelectionNone:
self.selectionCharacter()
self.cursorMoveDown()
def cursorSelectDownScroll(self):
"""Move the line below the selection to above the selection."""
upperRow, upperCol, lowerRow, lowerCol = self.startAndEnd()
if lowerRow + 1 >= len(self.lines):
return
begin = lowerRow + 1
end = lowerRow + 2
to = upperRow
self.redoAddChange(('ml', (begin, end, to)))
self.redo()
def cursorSelectLeft(self):
if self.selectionMode == app.selectable.kSelectionNone:
self.selectionCharacter()
self.cursorMoveLeft()
def cursorSelectRight(self):
if self.selectionMode == app.selectable.kSelectionNone:
self.selectionCharacter()
self.cursorMoveRight()
def cursorSelectSubwordLeft(self):
if self.selectionMode == app.selectable.kSelectionNone:
self.selectionCharacter()
self.cursorMoveSubwordLeft()
self.cursorMoveAndMark(*self.extendSelection())
self.redo()
def cursorSelectSubwordRight(self):
if self.selectionMode == app.selectable.kSelectionNone:
self.selectionCharacter()
self.cursorMoveSubwordRight()
self.cursorMoveAndMark(*self.extendSelection())
self.redo()
def cursorSelectWordLeft(self):
if self.selectionMode == app.selectable.kSelectionNone:
self.selectionCharacter()
self.cursorMoveWordLeft()
self.cursorMoveAndMark(*self.extendSelection())
self.redo()
def cursorSelectWordRight(self):
if self.selectionMode == app.selectable.kSelectionNone:
self.selectionCharacter()
self.cursorMoveWordRight()
self.cursorMoveAndMark(*self.extendSelection())
self.redo()
def cursorSelectUp(self):
if self.selectionMode == app.selectable.kSelectionNone:
self.selectionCharacter()
self.cursorMoveUp()
def cursorSelectUpScroll(self):
"""Move the line above the selection to below the selection."""
upperRow, upperCol, lowerRow, lowerCol = self.startAndEnd()
if upperRow == 0:
return
begin = upperRow - 1
end = upperRow
to = lowerRow + 1
self.redoAddChange(('ml', (begin, end, to)))
self.redo()
def cursorEndOfLine(self):
lineLen = len(self.lines[self.penRow])
self.cursorMove(0, lineLen - self.penCol)
self.redo()
def __cursorPageDown(self):
"""
Moves the view and cursor down by a page or stops
at the bottom of the document if there is less than
a page left.
Args:
None.
Returns:
None.
"""
if self.penRow == len(self.lines):
return
maxRow, maxCol = self.view.rows, self.view.cols
penRowDelta = maxRow
scrollRowDelta = maxRow
numLines = len(self.lines)
if self.penRow + maxRow >= numLines:
penRowDelta = numLines - self.penRow - 1
if numLines <= maxRow:
scrollRowDelta = -self.view.scrollRow
elif numLines <= 2 * maxRow + self.view.scrollRow:
scrollRowDelta = numLines - self.view.scrollRow - maxRow
self.cursorMoveScroll(penRowDelta,
self.cursorColDelta(self.penRow + penRowDelta), scrollRowDelta, 0)
self.redo()
def __cursorPageUp(self):
"""
Moves the view and cursor up by a page or stops
at the top of the document if there is less than
a page left.
Args:
None.
Returns:
None.
"""
if self.penRow == 0:
return
maxRow, maxCol = self.view.rows, self.view.cols
penRowDelta = -maxRow
scrollRowDelta = -maxRow
if self.penRow < maxRow:
penRowDelta = -self.penRow
if self.view.scrollRow + scrollRowDelta < 0:
scrollRowDelta = -self.view.scrollRow
cursorColDelta = self.cursorColDelta(self.penRow + penRowDelta)
self.cursorMoveScroll(penRowDelta, cursorColDelta, scrollRowDelta, 0)
self.redo()
def cursorSelectNonePageDown(self):
"""
Performs a page down. This function does not
select any text and removes all existing highlights.
Args:
None.
Returns:
None.
"""
self.selectionNone()
self.__cursorPageDown()
def cursorSelectNonePageUp(self):
"""
Performs a page up. This function does not
select any text and removes all existing highlights.
Args:
None.
Returns:
None.
"""
self.selectionNone()
self.__cursorPageUp()
def cursorSelectCharacterPageDown(self):
"""
Performs a page down. This function selects
all characters between the previous and current
cursor position.
Args:
None.
Returns:
None.
"""
self.selectionCharacter()
self.__cursorPageDown()
def cursorSelectCharacterPageUp(self):
"""
Performs a page up. This function selects
all characters between the previous and current
cursor position.
Args:
None.
Returns:
None.
"""
self.selectionCharacter()
self.__cursorPageUp()
def cursorSelectBlockPageDown(self):
"""
Performs a page down. This function sets
the selection mode to "block."
Args:
None.
Returns:
None.
"""
self.selectionBlock()
self.__cursorPageDown()
def cursorSelectBlockPageUp(self):
"""
Performs a page up. This function sets
the selection mode to "block."
Args:
None.
Returns:
None.
"""
self.selectionBlock()
self.__cursorPageUp()
def cursorScrollToMiddle(self):
maxRow, maxCol = self.view.rows, self.view.cols
rowDelta = min(max(0, len(self.lines)-maxRow),
max(0, self.penRow - maxRow / 2)) - self.view.scrollRow
self.cursorMoveScroll(0, 0, rowDelta, 0)
def cursorStartOfLine(self):
self.cursorMove(0, -self.penCol)
self.redo()
def cursorUp(self):
self.selectionNone()
self.cursorMoveUp()
def cursorUpScroll(self):
self.selectionNone()
self.scrollUp()
def delCh(self):
line = self.lines[self.penRow]
change = ('d', line[self.penCol:self.penCol + 1])
self.redoAddChange(change)
self.redo()
def delete(self):
"""Delete character to right of pen i.e. Del key."""
if self.selectionMode != app.selectable.kSelectionNone:
self.performDelete()
elif self.penCol == len(self.lines[self.penRow]):
if self.penRow + 1 < len(self.lines):
self.joinLines()
else:
self.delCh()
def deleteToEndOfLine(self):
line = self.lines[self.penRow]
if self.penCol == len(self.lines[self.penRow]):
if self.penRow + 1 < len(self.lines):
self.joinLines()
else:
change = ('d', line[self.penCol:])
self.redoAddChange(change)
self.redo()
def editCopy(self):
text = self.getSelectedText()
if len(text):
if self.selectionMode == app.selectable.kSelectionLine:
text = text + ('',)
data = self.doLinesToData(text)
app.clipboard.copy(data)
def editCut(self):
self.editCopy()
self.performDelete()
def editPaste(self):
data = app.clipboard.paste()
if data is not None:
self.editPasteData(data)
else:
app.log.info('clipboard empty')
def editPasteData(self, data):
self.editPasteLines(tuple(self.doDataToLines(data)))
def editPasteLines(self, clip):
if self.selectionMode != app.selectable.kSelectionNone:
self.performDelete()
self.redoAddChange(('v', clip))
self.redo()
rowDelta = len(clip) - 1
if rowDelta == 0:
endCol = self.penCol + len(clip[0])
else:
endCol = len(clip[-1])
self.cursorMove(rowDelta, endCol - self.penCol)
self.redo()
def editRedo(self):
"""Undo a set of redo nodes."""
self.redo()
if not self.isSelectionInView():
self.scrollToOptimalScrollPosition()
def editUndo(self):
"""Undo a set of redo nodes."""
self.undo()
if not self.isSelectionInView():
self.scrollToOptimalScrollPosition()
def doLinesToData(self, data):
def encode(line):
return chr(int(line.groups()[0], 16))
return re.sub('\x01([0-9a-fA-F][0-9a-fA-F])', encode, "\n".join(data))
def doDataToLines(self, data):
# Performance: in a 1000 line test it appears fastest to do some simple
# .replace() calls to minimize the number of calls to parse().
data = data.replace('\r\n', '\n')
data = data.replace('\r', '\n')
data = data.replace('\t', ' '*8)
def parse(sre):
return "\x01%02x"%ord(sre.groups()[0])
data = re.sub('([\0-\x09\x0b-\x1f\x7f-\xff])', parse, data)
return data.split('\n')
def dataToLines(self):
self.lines = self.doDataToLines(self.data)
def fileFilter(self, data):
self.data = data
self.dataToLines()
self.upperChangedRow = 0
self.savedAtRedoIndex = self.redoIndex
def setFilePath(self, path):
app.buffer_manager.buffers.renameBuffer(self, path)
def fileLoad(self):
app.log.info('fileLoad', self.fullPath)
file = None
if not os.path.exists(self.fullPath):
self.setMessage('Creating new file')
else:
try:
file = io.open(self.fullPath)
data = file.read()
self.fileEncoding = file.encoding
self.setMessage('Opened existing file')
except:
try:
file = io.open(self.fullPath, 'rb')
data = file.read()
self.fileEncoding = None # i.e. binary.
self.setMessage('Opened file as a binary file')
except:
app.log.info('error opening file', self.fullPath)
self.setMessage('error opening file', self.fullPath)
return
self.isReadOnly = not os.access(self.fullPath, os.W_OK)
self.fileStat = os.stat(self.fullPath)
self.relativePath = os.path.relpath(self.fullPath, os.getcwd())
app.log.info('fullPath', self.fullPath)
app.log.info('cwd', os.getcwd())
app.log.info('relativePath', self.relativePath)
if file:
self.fileFilter(data)
file.close()
else:
self.data = unicode("")
self.fileExtension = os.path.splitext(self.fullPath)[1]
self.rootGrammar = app.prefs.getGrammar(self.fileExtension)
if self.data:
self.parseGrammars()
self.dataToLines()
else:
self.parser = None
# Restore all user history.
app.history.loadUserHistory(self.fullPath)
self.restoreUserHistory()
def restoreUserHistory(self):
"""
This function restores all stored history of the file into the TextBuffer
object. If there does not exist a stored history of the file, it will
initialize the variables to default values.
Args:
None.
Returns:
None.
"""
# Restore the file history.
self.fileHistory = app.history.getFileHistory(self.fullPath, self.data)
# Restore all positions and values of variables.
self.view.cursorRow, self.view.cursorCol = self.fileHistory.setdefault(
'cursor', (0, 0))
self.penRow, self.penCol = self.fileHistory.setdefault('pen', (0, 0))
self.view.scrollRow, self.view.scrollCol = self.fileHistory.setdefault(
'scroll', (0, 0))
self.doSelectionMode(self.fileHistory.setdefault('selectionMode',
app.selectable.kSelectionNone))
self.markerRow, self.markerCol = self.fileHistory.setdefault('marker',
(0, 0))
if app.prefs.editor['saveUndo']:
self.redoChain = self.fileHistory.setdefault('redoChain', [])
self.savedAtRedoIndex = self.fileHistory.setdefault('savedAtRedoIndex', 0)
self.redoIndex = self.savedAtRedoIndex
# Restore file bookmarks
self.bookmarks = self.fileHistory.setdefault('bookmarks', [])
# Store the file's info.
self.lastChecksum, self.lastFileSize = app.history.getFileInfo(
self.fullPath)
def updateBasicScrollPosition(self):
"""
Sets scrollRow, scrollCol to the closest values that the view's position
must be in order to see the cursor.
Args:
None.
Returns:
None.
"""
scrollRow = self.view.scrollRow
scrollCol = self.view.scrollCol
# Row.
maxRow = self.view.rows
if self.view.scrollRow > self.penRow:
scrollRow = self.penRow
elif self.penRow >= self.view.scrollRow + maxRow:
scrollRow = self.penRow - maxRow + 1
# Column.
maxCol = self.view.cols
if self.view.scrollCol > self.penCol:
scrollCol = self.penCol
elif self.penCol >= self.view.scrollCol + maxCol:
scrollCol = self.penCol - maxCol + 1
self.view.scrollRow = scrollRow
self.view.scrollCol = scrollCol
def scrollToOptimalScrollPosition(self):
"""
Args:
None.
Returns:
A tuple of (scrollRow, scrollCol) representing where
the view's optimal position should be.
"""
top, left, bottom, right = self.startAndEnd()
# Row.
maxRows = self.view.rows
scrollRow = self.view.scrollRow
height = bottom - top + 1
extraRows = maxRows - height
if extraRows > 0:
optimalRowRatio = app.prefs.editor['optimalCursorRow']
scrollRow = max(0, min(len(self.lines) - 1,
top - int(optimalRowRatio * (maxRows - 1))))
else:
scrollRow = top
# Column.
maxCols = self.view.cols
scrollCol = self.view.scrollCol
length = right - left + 1
extraCols = maxCols - length
if extraCols > 0:
if right < maxCols:
scrollCol = 0
else:
optimalColRatio = app.prefs.editor['optimalCursorCol']
scrollCol = max(0, min(right,
left - int(optimalColRatio * (maxCols - 1))))
else:
scrollCol = left
self.view.scrollRow = scrollRow
self.view.scrollCol = scrollCol
def isSelectionInView(self):
"""
If there is no selection, checks if the cursor is in the view.
Args:
None.
Returns:
True if selection is in view. Otherwise, False.
"""
return self.isInView(*self.startAndEnd())
def isInView(self, top, left, bottom, right):
"""
Returns:
True if selection is in view. Otherwise, False.
"""
horizontally = (self.view.scrollCol <= left and
right < self.view.scrollCol + self.view.cols)
vertically = (self.view.scrollRow <= top and
bottom < self.view.scrollRow + self.view.rows)
return horizontally and vertically
def linesToData(self):
self.data = self.doLinesToData(self.lines)
def fileWrite(self):
# Preload the message with an error that should be overwritten.
self.setMessage('Error saving file')
try:
try:
if app.prefs.editor['onSaveStripTrailingSpaces']:
self.stripTrailingWhiteSpace()
# Save user data that applies to read-only files into history.
self.fileHistory['pen'] = (self.penRow, self.penCol)
self.fileHistory['cursor'] = (self.view.cursorRow, self.view.cursorCol)
self.fileHistory['scroll'] = (self.view.scrollRow, self.view.scrollCol)
self.fileHistory['marker'] = (self.markerRow, self.markerCol)
self.fileHistory['selectionMode'] = self.selectionMode
self.fileHistory['bookmarks'] = self.bookmarks
self.linesToData()
if self.fileEncoding is None:
file = io.open(self.fullPath, 'wb+')
else:
file = io.open(self.fullPath, 'w+', encoding=self.fileEncoding)
file.seek(0)
file.truncate()
file.write(self.data)
file.close()
# Save user data that applies to writable files.
self.savedAtRedoIndex = self.redoIndex
if app.prefs.editor['saveUndo']:
self.fileHistory['redoChain'] = self.redoChain
self.fileHistory['savedAtRedoIndex'] = self.savedAtRedoIndex
# Hmm, could this be hard coded to False here?
self.isReadOnly = not os.access(self.fullPath, os.W_OK)
app.history.saveUserHistory((self.fullPath, self.lastChecksum,
self.lastFileSize), self.fileHistory)
# Store the file's new info
self.lastChecksum, self.lastFileSize = app.history.getFileInfo(
self.fullPath)
self.fileStat = os.stat(self.fullPath)
self.setMessage('File saved')
except Exception as e:
self.setMessage(
'Error writing file. The file did not save properly.',
color=3)
app.log.exception('error writing file')
except:
app.log.info('except had exception')
def selectText(self, row, col, length, mode):
row = max(0, min(row, len(self.lines) - 1))
col = max(0, min(col, len(self.lines[row])))
scrollRow = self.view.scrollRow
scrollCol = self.view.scrollCol
maxRow, maxCol = self.view.rows, self.view.cols
endCol = col + length
inView = self.isInView(row, endCol, row, endCol)
self.doSelectionMode(app.selectable.kSelectionNone)
self.cursorMove( row - self.penRow, endCol - self.penCol)
self.redo()
self.doSelectionMode(mode)
self.cursorMove(0, -length)
self.redo()
if not inView:
self.scrollToOptimalScrollPosition()
def find(self, searchFor, direction=0):
"""direction is -1 for findPrior, 0 for at pen, 1 for findNext."""
app.log.info('find', searchFor, direction)
if not len(searchFor):
self.findRe = None
self.doSelectionMode(app.selectable.kSelectionNone)
return
# The saved re is also used for highlighting.
ignoreCaseFlag = (app.prefs.editor.get('findIgnoreCase') and
re.IGNORECASE or 0)
self.findRe = re.compile('()'+searchFor, ignoreCaseFlag)
self.findBackRe = re.compile('(.*)'+searchFor, ignoreCaseFlag)
self.findCurrentPattern(direction)
def findPlainText(self, text):
searchFor = re.escape(text)
self.findRe = re.compile('()'+searchFor)
self.findCurrentPattern(0)
def findReplaceFlags(self, tokens):
"""Map letters in |tokens| to re flags."""
flags = re.MULTILINE
if 'i' in tokens:
flags |= re.IGNORECASE
if 'l' in tokens:
# Affects \w, \W, \b, \B.
flags |= re.LOCALE
if 'm' in tokens:
# Affects ^, $.
flags |= re.MULTILINE
if 's' in tokens:
# Affects ..
flags |= re.DOTALL
if 'x' in tokens:
# Affects whitespace and # comments.
flags |= re.VERBOSE
if 'u' in tokens:
# Affects \w, \W, \b, \B.
flags |= re.UNICODE
if 0:
tokens = re.sub('[ilmsxu]', '', tokens)
if len(tokens):
self.setMessage('unknown regex flags '+tokens)
return flags
def findReplace(self, cmd):
if not len(cmd):
return
separator = cmd[0]
splitCmd = cmd.split(separator, 3)
if len(splitCmd) < 4:
self.setMessage('An exchange needs three ' + separator + ' separators')
return
start, find, replace, flags = splitCmd
self.linesToData()
data = self.findReplaceText(find, replace, flags, self.data)
self.applyDocumentUpdate(data)
def findReplaceText(self, find, replace, flags, input):
flags = self.findReplaceFlags(flags)
return re.sub(find, replace, input, flags=flags)
def applyDocumentUpdate(self, data):
diff = difflib.ndiff(self.lines, self.doDataToLines(data))
ndiff = []
counter = 0
for i in diff:
if i[0] != ' ':
if counter:
ndiff.append(counter)
counter = 0
if i[0] in ['+', '-']:
ndiff.append(i)
else:
counter += 1
if counter:
ndiff.append(counter)
if len(ndiff) == 1 and type(ndiff[0]) is type(0):
# Nothing was changed. The only entry is a 'skip these lines'
self.setMessage('No matches found')
return
ndiff = tuple(ndiff)
if 0:
for i in ndiff:
app.log.info(i)
self.redoAddChange(('ld', ndiff))
self.redo()
def findCurrentPattern(self, direction):
localRe = self.findRe
offset = self.penCol + direction
if direction < 0:
localRe = self.findBackRe
if localRe is None:
app.log.info('localRe is None')
return
# Check part of current line.
text = self.lines[self.penRow]
if direction >= 0:
text = text[offset:]
else:
text = text[:self.penCol]
offset = 0
#app.log.info('find() searching', repr(text))
found = localRe.search(text)
rowFound = self.penRow
if not found:
offset = 0
# To end of file.
if direction >= 0:
theRange = range(self.penRow + 1, len(self.lines))
else:
theRange = range(self.penRow - 1, -1, -1)
for i in theRange:
found = localRe.search(self.lines[i])
if found:
if 0:
for k in found.regs:
app.log.info('AAA', k[0], k[1])
app.log.info('b found on line', i, repr(found))
rowFound = i
break
if not found:
# Wrap around to the opposite side of the file.
self.setMessage('Find wrapped around.')
if direction >= 0:
theRange = range(self.penRow)
else:
theRange = range(len(self.lines) - 1, self.penRow, -1)
for i in theRange:
found = localRe.search(self.lines[i])
if found:
rowFound = i
break
if not found:
# Check the rest of the current line
if direction >= 0:
text = self.lines[self.penRow]
else:
text = self.lines[self.penRow][self.penCol:]
offset = self.penCol
found = localRe.search(text)
rowFound = self.penRow
if found:
#app.log.info('c found on line', rowFound, repr(found))
start = found.regs[1][1]
end = found.regs[0][1]
self.selectText(rowFound, offset + start, end - start,
app.selectable.kSelectionCharacter)
return
app.log.info('find not found')
self.doSelectionMode(app.selectable.kSelectionNone)
def findAgain(self):
"""Find the current pattern, searching down the document."""
self.findCurrentPattern(1)
def findBack(self):
"""Find the current pattern, searching up the document."""
self.findCurrentPattern(-1)
def findNext(self, searchFor):
"""Find a new pattern, searching down the document."""
self.find(searchFor, 1)
def findPrior(self, searchFor):
"""Find a new pattern, searching up the document."""
self.find(searchFor, -1)
def indent(self):
indentation = app.prefs.editor['indentation']
indentationLength = len(indentation)
if self.selectionMode == app.selectable.kSelectionNone:
self.verticalInsert(self.penRow, self.penRow, self.penCol, indentation)
else:
self.indentLines()
self.cursorMoveAndMark(0, indentationLength, 0, indentationLength, 0)
self.redo()
def indentLines(self):
"""
Indents all selected lines. Do not use for when the selection mode
is kSelectionNone since markerRow/markerCol currently do not get
updated alongside penRow/penCol.
"""
col = 0
row = min(self.markerRow, self.penRow)
endRow = max(self.markerRow, self.penRow)
indentation = app.prefs.editor['indentation']
self.verticalInsert(row, endRow, col, indentation)
def verticalDelete(self, row, endRow, col, text):
self.redoAddChange(('vd', (text, row, endRow, col)))
self.redo()
def verticalInsert(self, row, endRow, col, text):
self.redoAddChange(('vi', (text, row, endRow, col)))
self.redo()
def insert(self, text):
self.performDelete()
self.redoAddChange(('i', text))
self.redo()
self.updateBasicScrollPosition()
def insertPrintable(self, ch, meta):
#app.log.info(ch, meta)
if curses.ascii.isprint(ch):
self.insert(chr(ch))
elif ch is app.curses_util.BRACKETED_PASTE:
self.editPasteData(meta)
elif ch is app.curses_util.UNICODE_INPUT:
self.insert(meta)
def joinLines(self):
"""join the next line onto the current line."""
self.redoAddChange(('j',))
self.redo()
def markerPlace(self):
self.redoAddChange(('m', (0, 0, self.penRow - self.markerRow,
self.penCol - self.markerCol, 0)))
self.redo()
def mouseClick(self, paneRow, paneCol, shift, ctrl, alt):
if 0:
if ctrl:
app.log.info('click at', paneRow, paneCol)
self.view.presentModal(self.view.contextMenu, paneRow, paneCol)
return
if shift:
if alt:
self.selectionBlock()
elif self.selectionMode == app.selectable.kSelectionNone:
self.selectionCharacter()
else:
self.selectionNone()
self.mouseRelease(paneRow, paneCol, shift, ctrl, alt)
def mouseDoubleClick(self, paneRow, paneCol, shift, ctrl, alt):
app.log.info('double click', paneRow, paneCol)
row = self.view.scrollRow + paneRow
if row < len(self.lines) and len(self.lines[row]):
self.selectWordAt(row, self.view.scrollCol + paneCol)
def mouseMoved(self, paneRow, paneCol, shift, ctrl, alt):
app.log.info(' mouseMoved', paneRow, paneCol, shift, ctrl, alt)
self.mouseClick(paneRow, paneCol, True, ctrl, alt)
def mouseRelease(self, paneRow, paneCol, shift, ctrl, alt):
app.log.info(' mouse release', paneRow, paneCol)
if not self.lines:
return
row = max(0, min(self.view.scrollRow + paneRow, len(self.lines) - 1))
col = max(0, self.view.scrollCol + paneCol)
if self.selectionMode == app.selectable.kSelectionBlock:
self.cursorMoveAndMark(0, 0, row - self.markerRow, col - self.markerCol,
0)
self.redo()
return
# If not block selection, restrict col to the chars on the line.
col = min(col, len(self.lines[row]))
# Adjust the marker column delta when the pen and marker positions
# cross over each other.
markerCol = 0
if self.selectionMode == app.selectable.kSelectionWord:
if self.penRow == self.markerRow:
if row == self.penRow:
if self.penCol > self.markerCol and col < self.markerCol:
markerCol = 1
elif self.penCol < self.markerCol and col >= self.markerCol:
markerCol = -1
else:
if (row < self.penRow and
self.penCol > self.markerCol):
markerCol = 1
elif (row > self.penRow and
self.penCol < self.markerCol):
markerCol = -1
elif row == self.markerRow:
if col < self.markerCol and row < self.penRow:
markerCol = 1
elif col >= self.markerCol and row > self.penRow:
markerCol = -1
self.cursorMoveAndMark(row - self.penRow, col - self.penCol,
0, markerCol, 0)
self.redo()
inLine = paneCol < len(self.lines[row])
if self.selectionMode == app.selectable.kSelectionLine:
self.cursorMoveAndMark(*self.extendSelection())
self.redo()
elif self.selectionMode == app.selectable.kSelectionWord:
if (self.penRow < self.markerRow or
(self.penRow == self.markerRow and
self.penCol < self.markerCol)):
self.cursorSelectWordLeft()
elif inLine:
self.cursorSelectWordRight()
def mouseTripleClick(self, paneRow, paneCol, shift, ctrl, alt):
app.log.info('triple click', paneRow, paneCol)
self.mouseRelease(paneRow, paneCol, shift, ctrl, alt)
self.selectLineAt(self.view.scrollRow + paneRow)
def scrollWindow(self, rows, cols):
self.cursorMoveScroll(rows, self.cursorColDelta(self.penRow - rows),
-1, 0)
self.redo()
def mouseWheelDown(self, shift, ctrl, alt):
if not shift:
self.selectionNone()
self.scrollUp()
def scrollUp(self):
if self.view.scrollRow == 0:
return
maxRow, maxCol = self.view.rows, self.view.cols
cursorDelta = 0
if self.penRow >= self.view.scrollRow + maxRow - 2:
cursorDelta = self.view.scrollRow + maxRow - 2 - self.penRow
self.updateScrollPosition(-1, 0)
if self.view.hasCaptiveCursor:
self.cursorMoveScroll(cursorDelta,
self.cursorColDelta(self.penRow + cursorDelta), 0, 0)
self.redo()
def mouseWheelUp(self, shift, ctrl, alt):
if not shift:
self.selectionNone()
self.scrollDown()
def scrollDown(self):
maxRow, maxCol = self.view.rows, self.view.cols
if self.view.scrollRow + maxRow >= len(self.lines):
return
cursorDelta = 0
if self.penRow <= self.view.scrollRow + 1:
cursorDelta = self.view.scrollRow - self.penRow + 1
self.updateScrollPosition(1, 0)
if self.view.hasCaptiveCursor:
self.cursorMoveScroll(cursorDelta,
self.cursorColDelta(self.penRow + cursorDelta), 0, 0)
self.redo()
def nextSelectionMode(self):
next = self.selectionMode + 1
next %= app.selectable.kSelectionModeCount
self.doSelectionMode(next)
app.log.info('nextSelectionMode', self.selectionMode)
def noOp(self, ignored):
pass
def normalize(self):
self.selectionNone()
self.findRe = None
self.view.normalize()
def parseGrammars(self):
if not self.parser:
self.parser = app.parser.Parser()
end = self.view.scrollRow + self.view.rows + 1
# If there is a huge gap, leave it to the background parsing.
if self.upperChangedRow - len(self.parser.rows) > 500:
self.sentUpperChangedRow = self.upperChangedRow
return
# Reset the self.data to get recent changes in self.lines.
self.linesToData()
start = time.time()
self.parser.parse(self.data, self.rootGrammar,
self.upperChangedRow, end)
self.sentUpperChangedRow = self.upperChangedRow
self.upperChangedRow = len(self.lines)
self.parserTime = time.time() - start
def doSelectionMode(self, mode):
if self.selectionMode != mode:
self.redoAddChange(('m', (0, 0,
self.penRow - self.markerRow,
self.penCol - self.markerCol,
mode - self.selectionMode)))
self.redo()
def cursorSelectLine(self):
"""
This function is used to select the line in which the cursor is in.
Consecutive calls to this function will select subsequent lines.
"""
if self.selectionMode != app.selectable.kSelectionLine:
self.selectLineAt(self.penRow)
else:
if self.penRow + 1 < len(self.lines):
self.selectLineAt(self.penRow + 1)
def selectionAll(self):
self.doSelectionMode(app.selectable.kSelectionAll)
self.cursorMoveAndMark(*self.extendSelection())
self.redo()
def selectionBlock(self):
self.doSelectionMode(app.selectable.kSelectionBlock)
def selectionCharacter(self):
self.doSelectionMode(app.selectable.kSelectionCharacter)
def selectionLine(self):
self.doSelectionMode(app.selectable.kSelectionLine)
def selectionNone(self):
self.doSelectionMode(app.selectable.kSelectionNone)
def selectionWord(self):
self.doSelectionMode(app.selectable.kSelectionWord)
def selectLineAt(self, row):
if row < len(self.lines):
if 1:
self.cursorMove(row - self.penRow, 0)
self.redo()
self.selectionLine()
self.cursorMoveAndMark(*self.extendSelection())
self.redo()
else:
# TODO(dschuyler): reverted to above to fix line selection in the line
# numbers column. To be investigated further.
self.selectText(row, 0, 0, app.selectable.kSelectionLine)
def selectWordAt(self, row, col):
"""row and col may be from a mouse click and may not actually land in the
document text."""
self.selectText(row, col, 0, app.selectable.kSelectionWord)
if col < len(self.lines[self.penRow]):
self.cursorSelectWordRight()
def splitLine(self):
"""split the line into two at current column."""
self.redoAddChange(('n', (1,)))
self.redo()
self.updateBasicScrollPosition()
def swapPenAndMarker(self):
self.cursorMoveAndMark(self.markerRow - self.penRow,
self.markerCol - self.penCol,
self.penRow - self.markerRow,
self.penCol - self.markerCol, 0)
self.redo()
def test(self):
self.insertPrintable(0x00, None)
def stripTrailingWhiteSpace(self):
self.compoundChangeBegin()
for i in range(len(self.lines)):
for found in app.selectable.kReEndSpaces.finditer(self.lines[i]):
self.performDeleteRange(i, found.regs[0][0], i, found.regs[0][1])
self.compoundChangeEnd()
def unindent(self):
if self.selectionMode != app.selectable.kSelectionNone:
self.unindentLines()
else:
indentation = app.prefs.editor['indentation']
indentationLength = len(indentation)
line = self.lines[self.penRow]
start = self.penCol - indentationLength
if indentation == line[start:self.penCol]:
self.verticalDelete(self.penRow, self.penRow, start, indentation)
self.cursorMoveAndMark(0, -indentationLength, 0, -indentationLength, 0)
self.redo()
def unindentLines(self):
indentation = app.prefs.editor['indentation']
indentationLength = len(indentation)
row = min(self.markerRow, self.penRow)
endRow = max(self.markerRow, self.penRow)
self.compoundChangeBegin()
begin = 0
for i,line in enumerate(self.lines[row:endRow + 1]):
if (len(line) < indentationLength or
(line[:indentationLength] != indentation)):
if i > begin:
self.verticalDelete(row + begin, row + i - 1, 0, indentation)
begin = i + 1
self.verticalDelete(row + begin, endRow, 0, indentation)
self.cursorMoveAndMark(0, -indentationLength, 0, -indentationLength, 0)
self.redo()
self.compoundChangeEnd()
def updateScrollPosition(self, scrollRowDelta, scrollColDelta):
"""
This function updates the view's scroll position using the optional
scrollRowDelta and scrollColDelta arguments.
Args:
scrollRowDelta (int): The number of rows down to move the view.
scrollColDelta (int): The number of rows right to move the view.
Returns:
None
"""
self.view.scrollRow += scrollRowDelta
self.view.scrollCol += scrollColDelta
| [
"dschuyler@chromium.org"
] | dschuyler@chromium.org |
fb82eb83ed7a0670cab22075f2c7c1d27231a585 | 48a647031af30b93b332001544b258a787542c6f | /venv/chapter_20/spider/data_storage.py | f5f27694d9569870052315a462ac75977a203333 | [] | no_license | Adminsys-debug/xdclass_python | 3d3f37f7812336aa79bf9dc0d990658c67156057 | c2e82b750c5337045b07c19a0c9ead5c3752b3a7 | refs/heads/master | 2022-05-20T07:10:33.396655 | 2020-04-18T05:40:48 | 2020-04-18T05:40:48 | 256,659,175 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 418 | py | #!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/4/11 13:17
# @Author : mr.chen
# @File : data_storage
# @Software: PyCharm
# @Email : 794281961@qq.com
from product import Product
# 数据存储器
class DataStorage:
def storage(self, products):
"""
数据存储
:param products:set结构
:return:
"""
for i in products:
print(i)
| [
"a794281961@126.com"
] | a794281961@126.com |
74605f100f294cbdb2fd6b1603fc54e1b2f208bf | 0fccee4c738449f5e0a8f52ea5acabf51db0e910 | /genfragments/EightTeV/VH_TTH/WH_ZH_HToZG_M_145_TuneZ2star_8TeV_pythia6_tauola_cff.py | 4d683cb2a41735d37ed09f293c40900ce5814b99 | [] | no_license | cms-sw/genproductions | f308ffaf3586c19b29853db40e6d662e937940ff | dd3d3a3826343d4f75ec36b4662b6e9ff1f270f4 | refs/heads/master | 2023-08-30T17:26:02.581596 | 2023-08-29T14:53:43 | 2023-08-29T14:53:43 | 11,424,867 | 69 | 987 | null | 2023-09-14T12:41:28 | 2013-07-15T14:18:33 | Python | UTF-8 | Python | false | false | 3,034 | py | import FWCore.ParameterSet.Config as cms
from Configuration.Generator.PythiaUEZ2starSettings_cfi import *
from GeneratorInterface.ExternalDecays.TauolaSettings_cff import *
generator = cms.EDFilter("Pythia6GeneratorFilter",
pythiaPylistVerbosity = cms.untracked.int32(1),
# put here the efficiency of your filter (1. if no filter)
filterEfficiency = cms.untracked.double(1.0),
pythiaHepMCVerbosity = cms.untracked.bool(False),
# put here the cross section of your process (in pb)
crossSection = cms.untracked.double(1.0),
maxEventsToPrint = cms.untracked.int32(1),
comEnergy = cms.double(8000.0),
ExternalDecays = cms.PSet(
Tauola = cms.untracked.PSet(
TauolaPolar,
TauolaDefaultInputCards
),
parameterSets = cms.vstring('Tauola')
),
PythiaParameters = cms.PSet(
pythiaUESettingsBlock,
processParameters = cms.vstring('PMAS(25,1)=145.0 !mass of Higgs',
'MSEL=0 ! user selection for process',
'MSUB(102)=0 !ggH',
'MSUB(123)=0 !ZZ fusion to H',
'MSUB(124)=0 !WW fusion to H',
'MSUB(24)=1 !ZH production',
'MSUB(26)=1 !WH production',
'MSUB(121)=0 !gg to ttH',
'MSUB(122)=0 !qq to ttH',
'MDME(210,1)=0 !Higgs decay into dd',
'MDME(211,1)=0 !Higgs decay into uu',
'MDME(212,1)=0 !Higgs decay into ss',
'MDME(213,1)=0 !Higgs decay into cc',
'MDME(214,1)=0 !Higgs decay into bb',
'MDME(215,1)=0 !Higgs decay into tt',
'MDME(216,1)=0 !Higgs decay into',
'MDME(217,1)=0 !Higgs decay into Higgs decay',
'MDME(218,1)=0 !Higgs decay into e nu e',
'MDME(219,1)=0 !Higgs decay into mu nu mu',
'MDME(220,1)=0 !Higgs decay into tau nu tau',
'MDME(221,1)=0 !Higgs decay into Higgs decay',
'MDME(222,1)=0 !Higgs decay into g g',
'MDME(223,1)=0 !Higgs decay into gam gam',
'MDME(224,1)=1 !Higgs decay into gam Z',
'MDME(225,1)=0 !Higgs decay into Z Z',
'MDME(226,1)=0 !Higgs decay into W W'),
# This is a vector of ParameterSet names to be read, in this order
parameterSets = cms.vstring('pythiaUESettings',
'processParameters')
)
)
configurationMetadata = cms.untracked.PSet(
version = cms.untracked.string('$Revision: 1.1 $'),
name = cms.untracked.string('$Source: /cvs/CMSSW/CMSSW/Configuration/GenProduction/python/EightTeV/WH_ZH_HToZG_M_145_TuneZ2star_8TeV_pythia6_tauola_cff.py,v $'),
annotation = cms.untracked.string('PYTHIA6 WH/ZH, H->Zgamma mH=145GeV with TAUOLA at 8TeV')
)
| [
"sha1-dc1081d72f70055f90623ceb19c685a609c9cac9@cern.ch"
] | sha1-dc1081d72f70055f90623ceb19c685a609c9cac9@cern.ch |
0ddf55572f09ed16988fcd1aa1f47e8401d8b4f8 | fac51719e067ee2a70934e3bffdc98802d6dbb35 | /src/textbook/rosalind_ba6i.py | 3097321406cca35d9f4218a69ee6417dcadcbe36 | [
"MIT"
] | permissive | cowboysmall-comp/rosalind | 37730abdd03e86a2106ef39b39cdbae908f29e6e | 021e4392a8fc946b97bbf86bbb8227b28bb5e462 | refs/heads/master | 2022-03-05T14:30:21.020376 | 2019-11-20T02:03:09 | 2019-11-20T02:03:09 | 29,898,979 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 472 | py | import os
import sys
sys.path.append(os.path.join(os.path.dirname(__file__), '../tools'))
import files
import genetics
def main(argv):
line = files.read_line(argv[0])
edges = [tuple(int(node) for node in edge.split(', ')) for edge in line[1:-1].split('), (')]
genome = genetics.graph_to_genome(edges)
print ''.join('(%s)' % (' '.join('+%s' % p if p > 0 else '%s' % p for p in g)) for g in genome)
if __name__ == "__main__":
main(sys.argv[1:])
| [
"jerry@cowboysmall.com"
] | jerry@cowboysmall.com |
fa43b38cc8c680ff7d76c83a79980ff488fd793b | f0d713996eb095bcdc701f3fab0a8110b8541cbb | /s89T6kpDGf8Pc6mzf_16.py | 0ae192e947c37b17c83cb839b9559d913bf5a661 | [] | no_license | daniel-reich/turbo-robot | feda6c0523bb83ab8954b6d06302bfec5b16ebdf | a7a25c63097674c0a81675eed7e6b763785f1c41 | refs/heads/main | 2023-03-26T01:55:14.210264 | 2021-03-23T16:08:01 | 2021-03-23T16:08:01 | 350,773,815 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,893 | py | """
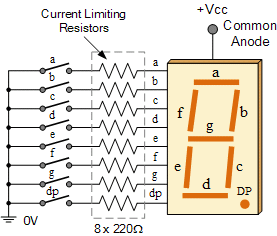
The table below shows which of the segments `a` through `g` are illuminated on
the seven segment display for the digits `0` through `9`. When the number on
the display changes, some of the segments may stay on, some may stay off, and
others change state (on to off, or off to on).
Create a function that accepts a string of digits, and for each transition of
one digit to the next, returns a list of the segments that change state.
Designate the segments that turn on as uppercase and those that turn off as
lowercase. Sort the lists in alphabetical order.
For example:
seven_segment("805") ➞ [["g"], ["b", "e", "G"]]
In the transition from `8` to `0`, the `g` segment turns off. Others are
unchanged. In the transition from `0` to `5`, `b` and `e` turn off and `G`
turns on. Others are unchanged.
Digit| Lit Segments
---|---
0| abcdef
1| bc
2| abdeg
3| abcdg
4| bcfg
5| acdfg
6| acdefg
7| abc
8| abcdefg
9| abcfg
### Examples
seven_segment("02") ➞ [["c", "f", "G"]]
seven_segment("08555") ➞ [["G"], ["b", "e"], [], []]
# Empty lists designate no change.
seven_segment("321") ➞ [["c", "E"], ["a", "C", "d", "e", "g"]]
seven_segment("123") ➞ [["A", "c", "D", "E", "G"], ["C", "e"]]
seven_segment("3") ➞ []
seven_segment("33") ➞ [[]]
### Notes
N/A
"""
def seven_segment(txt):
guide = {'0':'abcdef','1':'bc','2':'abdeg','3':'abcdg','4':'bcfg','5':'acdfg',
'6':'acdefg','7':'abc','8':'abcdefg','9':'abcfg'}
changes, temp = [], []
for i in range(1,len(txt)):
for j in 'abcdefg':
if j in guide[txt[i]] and j not in guide[txt[i-1]]:
temp.append(j.upper())
elif j in guide[txt[i-1]] and j not in guide[txt[i]]:
temp.append(j)
changes.append(temp)
temp = []
return changes
| [
"daniel.reich@danielreichs-MacBook-Pro.local"
] | daniel.reich@danielreichs-MacBook-Pro.local |
18b7335146eec47a871a0deced551625885c4dcb | d0f11aa36b8c594a09aa06ff15080d508e2f294c | /leecode/1-500/301-400/391-完美矩形.py | d16f82be1881abf68bae10af5492ab41a8008a61 | [] | no_license | saycmily/vtk-and-python | 153c1fe9953fce685903f938e174d3719eada0f5 | 5045d7c44a5af5c16df5a3b72c157e9a2928a563 | refs/heads/master | 2023-01-28T14:02:59.970115 | 2021-04-28T09:03:32 | 2021-04-28T09:03:32 | 161,468,316 | 1 | 1 | null | 2023-01-12T05:59:39 | 2018-12-12T10:00:08 | Python | UTF-8 | Python | false | false | 1,067 | py | class Solution:
def isRectangleCover(self, rectangles: list[list[int]]) -> bool:
# 保存所有矩形的四个点
lookup = set()
# 最大矩形的 左下角 右上角
x1 = float("inf")
y1 = float("inf")
x2 = float("-inf")
y2 = float("-inf")
area = 0
for x, y, s, t in rectangles:
x1 = min(x1, x)
y1 = min(y1, y)
x2 = max(x2, s)
y2 = max(y2, t)
area += (t - y) * (s - x)
# 每个矩形的四个点
for item in [(x, y), (x, t), (s, y), (s, t)]:
if item not in lookup:
lookup.add(item)
else:
lookup.remove(item)
# 只剩下四个点并且是最大矩形的左下角和右上角
if len(lookup) != 4 or \
(x1, y1) not in lookup or (x1, y2) not in lookup or (x2, y1) not in lookup or (x2, y2) not in lookup:
return False
# 面积是否满足
return (x2 - x1) * (y2 - y1) == area
| [
"1786386686@qq.com"
] | 1786386686@qq.com |
81c6fedb138c99e3a0488312702050b36f603ddb | 5439a18b31ac213b16306c9eeacadadfc38cdfb8 | /examples/base_demo.py | bf3e2a354aeb01de311246c14f74ca03912f415e | [
"Apache-2.0"
] | permissive | DaoCalendar/text2vec | 459767e49295c17838179264516e3aa7873ecd11 | c5822a66dfb36623079196d0d0a5f717a829715a | refs/heads/master | 2022-12-30T12:30:13.658052 | 2020-10-22T04:08:06 | 2020-10-22T04:08:06 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 726 | py | # -*- coding: utf-8 -*-
"""
@author:XuMing<xuming624@qq.com>
@description:
"""
import numpy as np
import text2vec
text2vec.set_log_level('DEBUG')
char = '我'
result = text2vec.encode(char)
print(type(result))
print(char, result)
word = '如何'
print(word, text2vec.encode(word))
a = '如何更换花呗绑定银行卡'
emb = text2vec.encode(a)
print(a, emb)
b = ['我',
'如何',
'如何更换花呗绑定银行卡',
'如何更换花呗绑定银行卡,如何更换花呗绑定银行卡。如何更换花呗绑定银行卡?。。。这个,如何更换花呗绑定银行卡!']
result = []
for i in b:
r = text2vec.encode(i)
result.append(r)
print(b, result)
print(np.array(result).shape)
| [
"xuming624@qq.com"
] | xuming624@qq.com |
23754283199886f836e1f45d13b736c23b777186 | a37b756e34fc39c1237fc68997dbef77df9fa6fc | /keras/keras34-44/keras44_8_cifar10_Conv1D.py | ee930cb705b6fa2be595a7c93d86b5b8f8520fae | [] | no_license | jvd2n/ai-study | e20e38493ad295940a3201fc0cc8061ca9052607 | a82f7c6d89db532f881c76b553b5ab3eea0bdd59 | refs/heads/main | 2023-08-06T03:24:39.182686 | 2021-10-06T14:41:01 | 2021-10-06T14:41:01 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,032 | py | import time
from icecream import ic
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import cifar10
from keras.utils import np_utils
#1. Data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
ic('********* raw data **********')
ic(x_train.shape, x_test.shape)
ic(y_train.shape, y_test.shape)
# Data preprocessing
x_train = x_train.reshape(x_train.shape[0], x_train.shape[1] * x_train.shape[2] * x_train.shape[3])
x_test = x_test.reshape(x_test.shape[0], x_test.shape[1] * x_test.shape[2] * x_test.shape[3])
y_train = y_train.reshape(-1,1)
y_test = y_test.reshape(-1,1)
ic('********* 1st reshape **********')
ic(x_train.shape, x_test.shape)
ic(y_train.shape, y_test.shape)
from sklearn.preprocessing import StandardScaler, MinMaxScaler, MaxAbsScaler, RobustScaler, QuantileTransformer, PowerTransformer
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
ic('********* Scaling **********')
ic(x_train.shape, x_test.shape)
x_train = x_train.reshape(-1, 32 * 32, 3)
x_test = x_test.reshape(-1, 32 * 32, 3)
ic('********* 2nd reshape **********')
ic(x_train.shape, x_test.shape)
from sklearn.preprocessing import OneHotEncoder
oneEnc = OneHotEncoder()
y_train = oneEnc.fit_transform(y_train).toarray()
y_test = oneEnc.transform(y_test).toarray()
ic('********** OneHotEnc **********')
ic(y_train.shape, y_test.shape)
#2. Model
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Input, Conv1D, Flatten, Dropout, GlobalAveragePooling1D, MaxPooling1D
model = Sequential()
model.add(Conv1D(filters=32, kernel_size=2, padding='same', activation='relu', input_shape=(32 * 32, 3)))
model.add(Dropout(0.2))
model.add(Conv1D(32, 2, padding='same', activation='relu'))
model.add(MaxPooling1D())
model.add(Conv1D(64, 2, padding='same', activation='relu'))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(10, activation='softmax'))
#3 Compile, Train
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
from tensorflow.keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss', patience=10, mode='min', verbose=1)
start_time = time.time()
model.fit(x_train, y_train, epochs=10, batch_size=512, verbose=2,
validation_split=0.15, callbacks=[es])
duration_time = time.time() - start_time
#4 Evaluate
loss = model.evaluate(x_test, y_test) # evaluate -> return loss, metrics
ic(duration_time)
ic(loss[0])
ic(loss[1])
'''
CNN
loss: 0.05057989060878754
accuracy: 0.9922999739646912
DNN
loss: 0.17536625266075134
accuracy: 0.9753999710083008
DNN + GAP
loss: 1.7715743780136108
accuracy: 0.35740000009536743
LSTM
ic| duration_time: 3403.9552216529846
loss: 2.045886754989624
accuracy: 0.26010000705718994
StandardScaler Conv1D
ic| duration_time: 317.79892349243164
ic| loss[0]: 1.2282058000564575
ic| loss[1]: 0.585099995136261
'''
| [
"juhnmayer@gmail.com"
] | juhnmayer@gmail.com |
5343dfd6363f61f125f0bb08022f46540282dba2 | f6e83bc298b24bfec278683341b2629388b22e6c | /sonic_cli_gen/main.py | bfcd301aedea983579ed265c5c2cdd1c57149398 | [
"LicenseRef-scancode-generic-cla",
"Apache-2.0"
] | permissive | noaOrMlnx/sonic-utilities | 8d8ee86a9c258b4a5f37af69359ce100c29ad99c | 9881f3edaa136233456408190367a09e53386376 | refs/heads/master | 2022-08-17T23:15:57.577454 | 2022-05-18T21:49:32 | 2022-05-18T21:49:32 | 225,886,772 | 1 | 0 | NOASSERTION | 2022-07-19T08:49:40 | 2019-12-04T14:31:32 | Python | UTF-8 | Python | false | false | 1,385 | py | #!/usr/bin/env python
import sys
import click
import logging
from sonic_cli_gen.generator import CliGenerator
logger = logging.getLogger('sonic-cli-gen')
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
@click.group()
@click.pass_context
def cli(ctx):
""" SONiC CLI Auto-generator tool.\r
Generate click CLI plugin for 'config' or 'show' CLI groups.\r
CLI plugin will be generated from the YANG model, which should be in:\r\n
/usr/local/yang-models/ \n
Generated CLI plugin will be placed in: \r\n
/usr/local/lib/python3.7/dist-packages/<CLI group>/plugins/auto/
"""
context = {
'gen': CliGenerator(logger)
}
ctx.obj = context
@cli.command()
@click.argument('cli_group', type=click.Choice(['config', 'show']))
@click.argument('yang_model_name', type=click.STRING)
@click.pass_context
def generate(ctx, cli_group, yang_model_name):
""" Generate click CLI plugin. """
ctx.obj['gen'].generate_cli_plugin(cli_group, yang_model_name)
@cli.command()
@click.argument('cli_group', type=click.Choice(['config', 'show']))
@click.argument('yang_model_name', type=click.STRING)
@click.pass_context
def remove(ctx, cli_group, yang_model_name):
""" Remove generated click CLI plugin from. """
ctx.obj['gen'].remove_cli_plugin(cli_group, yang_model_name)
if __name__ == '__main__':
cli()
| [
"noreply@github.com"
] | noaOrMlnx.noreply@github.com |
32c3139ec5e133b7b35001ec1912f6c53b0955b7 | 298c86756b741b4c0b706f5178fd26d6d3b63541 | /src/901_1000/0914_x-of-a-kind-in-a-deck-of-cards/x-of-a-kind-in-a-deck-of-cards.py | 27be2e51ef338dd61d63914194d3e4a84532a682 | [
"Apache-2.0"
] | permissive | himichael/LeetCode | c1bd6afd55479440c21906bf1a0b79a658bb662f | 4c19fa86b5fa91b1c76d2c6d19d1d2ef14bdff97 | refs/heads/master | 2023-02-12T07:25:22.693175 | 2023-01-28T10:41:31 | 2023-01-28T10:41:31 | 185,511,218 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,080 | py | class Solution(object):
def hasGroupsSizeX(self, deck):
if not deck or len(deck)<2:
return False
N = len(deck)
count = [0 for _ in xrange(10000)]
for i in deck:
count[i] += 1
for x in xrange(2,N+1):
if N%x==0:
if all(v%x==0 for v in count):
return True
return False
# 最大公约数实现
def hasGroupsSizeX(self, deck):
if not deck or len(deck)<2:
return False
def gdc(a,b):
return a if not b else gdc(b,a%b)
N = len(deck)
count = [0 for _ in xrange(10000)]
res = -1
for i in deck:
count[i] += 1
for i in xrange(10000):
if count[i]>0:
if res==-1:
res = count[i]
else:
res = gdc(res,count[i])
return res>=2
# 用哈希表+GCD算法
def hasGroupsSizeX(self, deck):
"""
:type deck: List[int]
:rtype: bool
"""
if not deck or len(deck)<2:
return False
d = dict()
for i in deck:
d[i] = d.setdefault(i,0)+1
def gcd(a,b):
return a if not b else gcd(b,a%b)
x = d[deck[0]]
for k in d.values():
if k==1:
return False
x = gcd(x,k)
return x>=2
| [
"michaelwangg@qq.com"
] | michaelwangg@qq.com |
e1f324f72259ce9f4422bc37aa7768cd8dd695f9 | f72d8e2c28e5743dad2033df963b3005040aaf8e | /nee.py | 81a93e38f741bda34f19105a3bf4e5ca51e1ff5c | [] | no_license | jivavish/monday | a5f69ddaaefa6b88f04cb7e7297bdc6cc9e6eaf8 | 2159325546388fff81c03642cff3da4fde3b5802 | refs/heads/master | 2020-04-02T00:29:24.930613 | 2014-01-13T12:07:00 | 2014-01-13T12:07:00 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 23 | py | print "hi how are you"
| [
"manmohansharma987@gmail.com"
] | manmohansharma987@gmail.com |
70e7402ac27a83b2882ab610cb92d0a9c8ae175d | 2cc3a920f0d21e92410dbd5d38bae43481f5cb87 | /utility/decorations.py | 0b8a2b7d3100a18e2f961c772a22547a771c63ac | [
"MIT"
] | permissive | DiegoDigo/ApiSchool | 998399cdf1b009cf2a530e37638d9e3d0c33ed6e | ce34e674e4154c41e91320956a578a0ec965e470 | refs/heads/master | 2020-03-21T18:20:01.080416 | 2018-07-01T16:03:13 | 2018-07-01T16:03:13 | 138,885,570 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 325 | py | import logging
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(message)s', level=logging.DEBUG)
def log(method):
def call(func):
def give(*args):
logging.info(f'{method.capitalize()} a escola : {args[1].capitalize()}')
return func(*args)
return give
return call
| [
"di3g0d0ming05@gmail.com"
] | di3g0d0ming05@gmail.com |
0da82bc4fd8936f1af9f139927da8ba360754233 | 46bd71019dc7d356cbc6a4e5ca7cd67a13b5c691 | /ibis/bigquery/tests/test_compiler.py | d96e00971a2c78b6d661cf1ee3e218007fa0a4c7 | [
"Apache-2.0"
] | permissive | xia0204/ibis | fb5f6fd9d1981314552659f29ae71d25ae2ae268 | 95d12ae37287a572ffce3536aad44abcfbbf47b6 | refs/heads/master | 2020-04-29T04:57:40.900038 | 2019-03-14T17:31:45 | 2019-03-14T17:31:45 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 16,635 | py | import datetime
import pytest
import pandas as pd
import ibis
import ibis.expr.datatypes as dt
pytestmark = pytest.mark.bigquery
pytest.importorskip('google.cloud.bigquery')
def test_timestamp_accepts_date_literals(alltypes, project_id):
date_string = '2009-03-01'
param = ibis.param(dt.timestamp).name('param_0')
expr = alltypes.mutate(param=param)
params = {param: date_string}
result = expr.compile(params=params)
expected = """\
SELECT *, @param AS `param`
FROM `{}.testing.functional_alltypes`""".format(project_id)
assert result == expected
@pytest.mark.parametrize(
('distinct', 'expected_keyword'),
[
(True, 'DISTINCT'),
(False, 'ALL'),
]
)
def test_union(alltypes, distinct, expected_keyword, project_id):
expr = alltypes.union(alltypes, distinct=distinct)
result = expr.compile()
expected = """\
SELECT *
FROM `{project}.testing.functional_alltypes`
UNION {}
SELECT *
FROM `{project}.testing.functional_alltypes`""".format(
expected_keyword, project=project_id)
assert result == expected
def test_ieee_divide(alltypes, project_id):
expr = alltypes.double_col / 0
result = expr.compile()
expected = """\
SELECT IEEE_DIVIDE(`double_col`, 0) AS `tmp`
FROM `{}.testing.functional_alltypes`""".format(project_id)
assert result == expected
def test_identical_to(alltypes, project_id):
t = alltypes
pred = t.string_col.identical_to('a') & t.date_string_col.identical_to('b')
expr = t[pred]
result = expr.compile()
expected = """\
SELECT *
FROM `{}.testing.functional_alltypes`
WHERE (((`string_col` IS NULL) AND ('a' IS NULL)) OR (`string_col` = 'a')) AND
(((`date_string_col` IS NULL) AND ('b' IS NULL)) OR (`date_string_col` = 'b'))""".format( # noqa: E501
project_id)
assert result == expected
@pytest.mark.parametrize(
'timezone',
[
None,
'America/New_York'
]
)
def test_to_timestamp(alltypes, timezone, project_id):
expr = alltypes.date_string_col.to_timestamp('%F', timezone)
result = expr.compile()
if timezone:
expected = """\
SELECT PARSE_TIMESTAMP('%F', `date_string_col`, 'America/New_York') AS `tmp`
FROM `{}.testing.functional_alltypes`""".format(project_id)
else:
expected = """\
SELECT PARSE_TIMESTAMP('%F', `date_string_col`) AS `tmp`
FROM `{}.testing.functional_alltypes`""".format(project_id)
assert result == expected
@pytest.mark.parametrize(
('case', 'expected', 'dtype'),
[
(datetime.date(2017, 1, 1), "DATE '{}'".format('2017-01-01'), dt.date),
(
pd.Timestamp('2017-01-01'),
"DATE '{}'".format('2017-01-01'),
dt.date
),
('2017-01-01', "DATE '{}'".format('2017-01-01'), dt.date),
(
datetime.datetime(2017, 1, 1, 4, 55, 59),
"TIMESTAMP '{}'".format('2017-01-01 04:55:59'),
dt.timestamp,
),
(
'2017-01-01 04:55:59',
"TIMESTAMP '{}'".format('2017-01-01 04:55:59'),
dt.timestamp,
),
(
pd.Timestamp('2017-01-01 04:55:59'),
"TIMESTAMP '{}'".format('2017-01-01 04:55:59'),
dt.timestamp,
),
]
)
def test_literal_date(case, expected, dtype):
expr = ibis.literal(case, type=dtype).year()
result = ibis.bigquery.compile(expr)
assert result == "SELECT EXTRACT(year from {}) AS `tmp`".format(expected)
@pytest.mark.parametrize(
('case', 'expected', 'dtype', 'strftime_func'),
[
(
datetime.date(2017, 1, 1),
"DATE '{}'".format('2017-01-01'),
dt.date,
'FORMAT_DATE'
),
(
pd.Timestamp('2017-01-01'),
"DATE '{}'".format('2017-01-01'),
dt.date,
'FORMAT_DATE'
),
(
'2017-01-01',
"DATE '{}'".format('2017-01-01'),
dt.date,
'FORMAT_DATE'
),
(
datetime.datetime(2017, 1, 1, 4, 55, 59),
"TIMESTAMP '{}'".format('2017-01-01 04:55:59'),
dt.timestamp,
'FORMAT_TIMESTAMP'
),
(
'2017-01-01 04:55:59',
"TIMESTAMP '{}'".format('2017-01-01 04:55:59'),
dt.timestamp,
'FORMAT_TIMESTAMP'
),
(
pd.Timestamp('2017-01-01 04:55:59'),
"TIMESTAMP '{}'".format('2017-01-01 04:55:59'),
dt.timestamp,
'FORMAT_TIMESTAMP'
),
]
)
def test_day_of_week(case, expected, dtype, strftime_func):
date_var = ibis.literal(case, type=dtype)
expr_index = date_var.day_of_week.index()
result = ibis.bigquery.compile(expr_index)
assert result == "SELECT MOD(EXTRACT(DAYOFWEEK FROM {}) + 5, 7) AS `tmp`".format(expected) # noqa: E501
expr_name = date_var.day_of_week.full_name()
result = ibis.bigquery.compile(expr_name)
if strftime_func == 'FORMAT_TIMESTAMP':
assert result == "SELECT {}('%A', {}, 'UTC') AS `tmp`".format(
strftime_func, expected
)
else:
assert result == "SELECT {}('%A', {}) AS `tmp`".format(
strftime_func, expected
)
@pytest.mark.parametrize(
('case', 'expected', 'dtype'),
[
(
datetime.datetime(2017, 1, 1, 4, 55, 59),
"TIMESTAMP '{}'".format('2017-01-01 04:55:59'),
dt.timestamp,
),
(
'2017-01-01 04:55:59',
"TIMESTAMP '{}'".format('2017-01-01 04:55:59'),
dt.timestamp,
),
(
pd.Timestamp('2017-01-01 04:55:59'),
"TIMESTAMP '{}'".format('2017-01-01 04:55:59'),
dt.timestamp,
),
(
datetime.time(4, 55, 59),
"TIME '{}'".format('04:55:59'),
dt.time,
),
('04:55:59', "TIME '{}'".format('04:55:59'), dt.time),
]
)
def test_literal_timestamp_or_time(case, expected, dtype):
expr = ibis.literal(case, type=dtype).hour()
result = ibis.bigquery.compile(expr)
assert result == "SELECT EXTRACT(hour from {}) AS `tmp`".format(expected)
def test_window_function(alltypes, project_id):
t = alltypes
w1 = ibis.window(preceding=1, following=0,
group_by='year', order_by='timestamp_col')
expr = t.mutate(win_avg=t.float_col.mean().over(w1))
result = expr.compile()
expected = """\
SELECT *,
avg(`float_col`) OVER (PARTITION BY `year` ORDER BY `timestamp_col` ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS `win_avg`
FROM `{}.testing.functional_alltypes`""".format(project_id) # noqa: E501
assert result == expected
w2 = ibis.window(preceding=0, following=2,
group_by='year', order_by='timestamp_col')
expr = t.mutate(win_avg=t.float_col.mean().over(w2))
result = expr.compile()
expected = """\
SELECT *,
avg(`float_col`) OVER (PARTITION BY `year` ORDER BY `timestamp_col` ROWS BETWEEN CURRENT ROW AND 2 FOLLOWING) AS `win_avg`
FROM `{}.testing.functional_alltypes`""".format(project_id) # noqa: E501
assert result == expected
w3 = ibis.window(preceding=(4, 2),
group_by='year', order_by='timestamp_col')
expr = t.mutate(win_avg=t.float_col.mean().over(w3))
result = expr.compile()
expected = """\
SELECT *,
avg(`float_col`) OVER (PARTITION BY `year` ORDER BY `timestamp_col` ROWS BETWEEN 4 PRECEDING AND 2 PRECEDING) AS `win_avg`
FROM `{}.testing.functional_alltypes`""".format(project_id) # noqa: E501
assert result == expected
def test_range_window_function(alltypes, project_id):
t = alltypes
w = ibis.range_window(preceding=1, following=0,
group_by='year', order_by='month')
expr = t.mutate(two_month_avg=t.float_col.mean().over(w))
result = expr.compile()
expected = """\
SELECT *,
avg(`float_col`) OVER (PARTITION BY `year` ORDER BY `month` RANGE BETWEEN 1 PRECEDING AND CURRENT ROW) AS `two_month_avg`
FROM `{}.testing.functional_alltypes`""".format(project_id) # noqa: E501
assert result == expected
w3 = ibis.range_window(preceding=(4, 2),
group_by='year', order_by='timestamp_col')
expr = t.mutate(win_avg=t.float_col.mean().over(w3))
result = expr.compile()
expected = """\
SELECT *,
avg(`float_col`) OVER (PARTITION BY `year` ORDER BY UNIX_MICROS(`timestamp_col`) RANGE BETWEEN 4 PRECEDING AND 2 PRECEDING) AS `win_avg`
FROM `{}.testing.functional_alltypes`""".format(project_id) # noqa: E501
assert result == expected
@pytest.mark.parametrize(
('preceding', 'value'),
[
(5, 5),
(ibis.interval(nanoseconds=1), 0.001),
(ibis.interval(microseconds=1), 1),
(ibis.interval(seconds=1), 1000000),
(ibis.interval(minutes=1), 1000000 * 60),
(ibis.interval(hours=1), 1000000 * 60 * 60),
(ibis.interval(days=1), 1000000 * 60 * 60 * 24),
(2 * ibis.interval(days=1), 1000000 * 60 * 60 * 24 * 2),
(ibis.interval(weeks=1), 1000000 * 60 * 60 * 24 * 7),
]
)
def test_trailing_range_window(alltypes, preceding, value, project_id):
t = alltypes
w = ibis.trailing_range_window(preceding=preceding,
order_by=t.timestamp_col)
expr = t.mutate(win_avg=t.float_col.mean().over(w))
result = expr.compile()
expected = """\
SELECT *,
avg(`float_col`) OVER (ORDER BY UNIX_MICROS(`timestamp_col`) RANGE BETWEEN {} PRECEDING AND CURRENT ROW) AS `win_avg`
FROM `{}.testing.functional_alltypes`""".format( # noqa: E501
value, project_id)
assert result == expected
@pytest.mark.parametrize(
('preceding', 'value'),
[
(ibis.interval(years=1), None),
]
)
def test_trailing_range_window_unsupported(alltypes, preceding, value):
t = alltypes
w = ibis.trailing_range_window(preceding=preceding,
order_by=t.timestamp_col)
expr = t.mutate(win_avg=t.float_col.mean().over(w))
with pytest.raises(ValueError):
expr.compile()
@pytest.mark.parametrize(
('distinct1', 'distinct2', 'expected1', 'expected2'),
[
(True, True, 'UNION DISTINCT', 'UNION DISTINCT'),
(True, False, 'UNION DISTINCT', 'UNION ALL'),
(False, True, 'UNION ALL', 'UNION DISTINCT'),
(False, False, 'UNION ALL', 'UNION ALL'),
]
)
def test_union_cte(
alltypes, distinct1, distinct2, expected1, expected2, project_id):
t = alltypes
expr1 = t.group_by(t.string_col).aggregate(metric=t.double_col.sum())
expr2 = expr1.view()
expr3 = expr1.view()
expr = expr1.union(
expr2, distinct=distinct1).union(expr3, distinct=distinct2)
result = expr.compile()
expected = """\
WITH t0 AS (
SELECT `string_col`, sum(`double_col`) AS `metric`
FROM `{project}.testing.functional_alltypes`
GROUP BY 1
)
SELECT *
FROM t0
{}
SELECT `string_col`, sum(`double_col`) AS `metric`
FROM `{project}.testing.functional_alltypes`
GROUP BY 1
{}
SELECT `string_col`, sum(`double_col`) AS `metric`
FROM `{project}.testing.functional_alltypes`
GROUP BY 1""".format(expected1, expected2, project=project_id)
assert result == expected
def test_projection_fusion_only_peeks_at_immediate_parent():
schema = [
('file_date', 'timestamp'),
('PARTITIONTIME', 'date'),
('val', 'int64'),
]
table = ibis.table(schema, name='unbound_table')
table = table[table.PARTITIONTIME < ibis.date('2017-01-01')]
table = table.mutate(file_date=table.file_date.cast('date'))
table = table[table.file_date < ibis.date('2017-01-01')]
table = table.mutate(XYZ=table.val * 2)
expr = table.join(table.view())[table]
result = ibis.bigquery.compile(expr)
expected = """\
WITH t0 AS (
SELECT *
FROM unbound_table
WHERE `PARTITIONTIME` < DATE '2017-01-01'
),
t1 AS (
SELECT CAST(`file_date` AS DATE) AS `file_date`, `PARTITIONTIME`, `val`
FROM t0
),
t2 AS (
SELECT t1.*
FROM t1
WHERE t1.`file_date` < DATE '2017-01-01'
),
t3 AS (
SELECT *, `val` * 2 AS `XYZ`
FROM t2
)
SELECT t3.*
FROM t3
CROSS JOIN t3 t4"""
assert result == expected
def test_bool_reducers(alltypes):
b = alltypes.bool_col
expr = b.mean()
result = expr.compile()
expected = """\
SELECT avg(CAST(`bool_col` AS INT64)) AS `mean`
FROM `ibis-gbq.testing.functional_alltypes`"""
assert result == expected
expr2 = b.sum()
result = expr2.compile()
expected = """\
SELECT sum(CAST(`bool_col` AS INT64)) AS `sum`
FROM `ibis-gbq.testing.functional_alltypes`"""
assert result == expected
def test_bool_reducers_where(alltypes):
b = alltypes.bool_col
m = alltypes.month
expr = b.mean(where=m > 6)
result = expr.compile()
expected = """\
SELECT avg(CASE WHEN `month` > 6 THEN CAST(`bool_col` AS INT64) ELSE NULL END) AS `mean`
FROM `ibis-gbq.testing.functional_alltypes`""" # noqa: E501
assert result == expected
expr2 = b.sum(where=((m > 6) & (m < 10)))
result = expr2.compile()
expected = """\
SELECT sum(CASE WHEN (`month` > 6) AND (`month` < 10) THEN CAST(`bool_col` AS INT64) ELSE NULL END) AS `sum`
FROM `ibis-gbq.testing.functional_alltypes`""" # noqa: E501
assert result == expected
def test_approx_nunique(alltypes):
d = alltypes.double_col
expr = d.approx_nunique()
result = expr.compile()
expected = """\
SELECT APPROX_COUNT_DISTINCT(`double_col`) AS `approx_nunique`
FROM `ibis-gbq.testing.functional_alltypes`"""
assert result == expected
b = alltypes.bool_col
m = alltypes.month
expr2 = b.approx_nunique(where=m > 6)
result = expr2.compile()
expected = """\
SELECT APPROX_COUNT_DISTINCT(CASE WHEN `month` > 6 THEN `bool_col` ELSE NULL END) AS `approx_nunique`
FROM `ibis-gbq.testing.functional_alltypes`""" # noqa: E501
assert result == expected
def test_approx_median(alltypes):
d = alltypes.double_col
expr = d.approx_median()
result = expr.compile()
expected = """\
SELECT APPROX_QUANTILES(`double_col`, 2)[OFFSET(1)] AS `approx_median`
FROM `ibis-gbq.testing.functional_alltypes`"""
assert result == expected
m = alltypes.month
expr2 = d.approx_median(where=m > 6)
result = expr2.compile()
expected = """\
SELECT APPROX_QUANTILES(CASE WHEN `month` > 6 THEN `double_col` ELSE NULL END, 2)[OFFSET(1)] AS `approx_median`
FROM `ibis-gbq.testing.functional_alltypes`""" # noqa: E501
assert result == expected
@pytest.mark.parametrize(
('unit', 'expected_unit', 'expected_func'),
[
('Y', 'YEAR', 'TIMESTAMP'),
('Q', 'QUARTER', 'TIMESTAMP'),
('M', 'MONTH', 'TIMESTAMP'),
('W', 'WEEK', 'TIMESTAMP'),
('D', 'DAY', 'TIMESTAMP'),
('h', 'HOUR', 'TIMESTAMP'),
('m', 'MINUTE', 'TIMESTAMP'),
('s', 'SECOND', 'TIMESTAMP'),
('ms', 'MILLISECOND', 'TIMESTAMP'),
('us', 'MICROSECOND', 'TIMESTAMP'),
('Y', 'YEAR', 'DATE'),
('Q', 'QUARTER', 'DATE'),
('M', 'MONTH', 'DATE'),
('W', 'WEEK', 'DATE'),
('D', 'DAY', 'DATE'),
('h', 'HOUR', 'TIME'),
('m', 'MINUTE', 'TIME'),
('s', 'SECOND', 'TIME'),
('ms', 'MILLISECOND', 'TIME'),
('us', 'MICROSECOND', 'TIME'),
]
)
def test_temporal_truncate(unit, expected_unit, expected_func):
t = ibis.table([('a', getattr(dt, expected_func.lower()))], name='t')
expr = t.a.truncate(unit)
result = ibis.bigquery.compile(expr)
expected = """\
SELECT {}_TRUNC(`a`, {}) AS `tmp`
FROM t""".format(expected_func, expected_unit)
assert result == expected
@pytest.mark.parametrize('kind', ['date', 'time'])
def test_extract_temporal_from_timestamp(kind):
t = ibis.table([('ts', dt.timestamp)], name='t')
expr = getattr(t.ts, kind)()
result = ibis.bigquery.compile(expr)
expected = """\
SELECT {}(`ts`) AS `tmp`
FROM t""".format(kind.upper())
assert result == expected
def test_now():
expr = ibis.now()
result = ibis.bigquery.compile(expr)
expected = 'SELECT CURRENT_TIMESTAMP() AS `tmp`'
assert result == expected
def test_bucket():
t = ibis.table([('value', 'double')], name='t')
buckets = [0, 1, 3]
expr = t.value.bucket(buckets).name('foo')
result = ibis.bigquery.compile(expr)
expected = """\
SELECT
CASE
WHEN (`value` >= 0) AND (`value` < 1) THEN 0
WHEN (`value` >= 1) AND (`value` <= 3) THEN 1
ELSE CAST(NULL AS INT64)
END AS `tmp`
FROM t"""
assert result == expected
| [
"cpcloud@gmail.com"
] | cpcloud@gmail.com |
cb2da70b9e808a01f452ea0fe996a9b7481b30a4 | 613fdf39f444cfd62a60adbea8e493e7bae85ec4 | /SDS/geometry/geometry_C_2162.py | cab393a0322e7aa6674e222724e6eb23ba928a37 | [] | no_license | Parkhyunseo/PS | bf854ff01ecbdf7ee866faf4178f988cf2ddf1ca | e2c4839c9ce6f217baafd204efbe3d9ea8ad1330 | refs/heads/master | 2020-04-04T01:46:57.907655 | 2019-06-21T08:36:25 | 2019-06-21T08:36:25 | 155,677,135 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,016 | py | from sys import stdin
from collections import namedtuple
N = int(stdin.readline())
Line2D = namedtuple('Line2D', ['v1','v2'])
Vector2D = namedtuple('Vector2D', ['x', 'y'])
def ccw(p1, p2, p3):
temp = p1.x*p2.y + p2.x*p3.y + p3.x*p1.y
temp = temp - (p1.y*p2.x + p2.y*p3.x + p3.y*p1.x)
if temp > 0:
return 1
elif temp < 0:
return -1
else:
return 0
def is_cross(l1, l2):
# l1과 l2의 v1 l1과 l2의 v2의 부호가 서로다른가.
# l2과 l1의 v1 l2과 l1의 v2의 부호가 서로다른가.
# 만약 모두 0이라면
# y값이 모두 같다면 y범위 안에 포함되는지
# x값이 모두 같다면 x범위 안에 포함되는지
cross = False
ccw1 = ccw(l1.v1, l1.v2, l2.v1)
ccw2 = ccw(l1.v1, l1.v2, l2.v2)
ccw3 = ccw(l2.v1, l2.v2, l1.v1)
ccw4 = ccw(l2.v1, l2.v2, l1.v2)
if ccw1 * ccw2 <= 0:
if ccw3 * ccw4 <= 0:
cross = True
if ccw1 == 0 and ccw2 == 0 and ccw3 == 0 and ccw4 == 0:
mn = min(l1.v1.x, l1.v2.x, l2.v1.x, l2.v2.x)
mx = max(l1.v1.x, l1.v2.x, l2.v1.x, l2.v2.x)
if mn != mx: # x좌표가 모두 같지 않다면
l1_x_mn = min(l1.v1.x, l1.v2.x)
l1_x_mx = max(l1.v1.x, l1.v2.x)
l2_x_mn = min(l2.v1.x, l2.v2.x)
l2_x_mx = max(l2.v1.x, l2.v2.x)
if l1_x_mx < l2_x_mn or l2_x_mx < l1_x_mn:
cross = False
else:
l1_y_mn = min(l1.v1.y, l1.v2.y)
l1_y_mx = max(l1.v1.y, l1.v2.y)
l2_y_mn = min(l2.v1.y, l2.v2.y)
l2_y_mx = max(l2.v1.y, l2.v2.y)
if l1_y_mx < l2_y_mn or l2_y_mx < l1_y_mn:
cross = False
return cross
def find(v):
if v == parent[v]:
return v
parent[v] = find(parent[v])
return parent[v]
def merge(v, u):
u = find(u)
v = find(v)
if u == v:
return
if rank[u] > rank[v]:
u, v = v, u
parent[u] = v
rank[v] += rank[u]
if rank[u] == rank[v]:
rank[v] += 1
parent = [ i for i in range(3001)]
rank = [ 1 for _ in range(3001) ]
lines = []
for i in range(N):
x1, y1, x2, y2 = map(int, stdin.readline().split())
lines.append(Line2D(Vector2D(x1,y1), Vector2D(x2,y2)))
for i in range(N-1):
for j in range(i+1, N):
l1 = lines[i]
l2 = lines[j]
if is_cross(l1, l2):
#print('is cross', i, j)
merge(i, j)
#print(parent)
#print(rank)
group_count = 0
rank_max = 0
for i in range(N):
if parent[i] == i:
group_count += 1
rank_max = max(rank_max, rank[i])
print(group_count)
print(rank_max)
| [
"hyeonseo9669@hanmail.net"
] | hyeonseo9669@hanmail.net |
998baf043d0bb44d4c8c8ad17d5e50c4c8773fcd | 09e5cfe06e437989a2ccf2aeecb9c73eb998a36c | /modules/cctbx_project/fast_linalg/SConscript | 1fd157e5714386a76f6e638d7e14f238be76fbd6 | [
"BSD-3-Clause",
"BSD-3-Clause-LBNL"
] | permissive | jorgediazjr/dials-dev20191018 | b81b19653624cee39207b7cefb8dfcb2e99b79eb | 77d66c719b5746f37af51ad593e2941ed6fbba17 | refs/heads/master | 2020-08-21T02:48:54.719532 | 2020-01-25T01:41:37 | 2020-01-25T01:41:37 | 216,089,955 | 0 | 1 | BSD-3-Clause | 2020-01-25T01:41:39 | 2019-10-18T19:03:17 | Python | UTF-8 | Python | false | false | 1,835 | import libtbx.load_env
import sys
import os
from os import path
Import("env_etc")
env_etc.fast_linalg_dist = libtbx.env.dist_path("fast_linalg")
env_etc.fast_linalg_include = libtbx.env.under_dist("fast_linalg", "..")
env_etc.fast_linalg_common_includes = [
env_etc.libtbx_include,
env_etc.fast_linalg_include,
env_etc.boost_include,
]
def enable_fast_linalg(env):
if not libtbx.env.has_module('fast_linalg'):
return
env_etc.include_registry.append(
env=env,
paths=env_etc.fast_linalg_common_includes)
env.Append(LIBS=['boost_filesystem', 'fast_linalg'])
for flag in ("USE_FAST_LINALG",):
flag = "-D" + flag
env.Append(CXXFLAGS=flag)
env.Append(SHCXXFLAGS=flag)
env_etc.enable_fast_linalg = enable_fast_linalg
Import("env_base")
envs = [env_base]
if not env_etc.no_boost_python:
Import("env_no_includes_boost_python_ext")
envs.append(env_no_includes_boost_python_ext)
fast_linalg_envs = []
for env, extra_inc in zip(envs, ([], [env_etc.python_include])):
e = env.Clone()
env_etc.enable_fast_linalg(e)
env_etc.include_registry.append(env=e, paths=extra_inc)
fast_linalg_envs.append(e)
env_fast_linalg_base = fast_linalg_envs[0]
Export("env_fast_linalg_base")
if not env_etc.no_boost_python:
env_fast_linalg_boost_python_ext = fast_linalg_envs[1]
Export("env_fast_linalg_boost_python_ext")
env = env_fast_linalg_base.Clone()
if 'fast_linalg' in env['LIBS']:
env['LIBS'].remove('fast_linalg')
if sys.platform[:3] != 'win':
env['LIBS'].append("dl")
fast_linalg = env.SharedLibrary(target='#lib/fast_linalg', source=['np_ext.cpp'])
if not env_etc.no_boost_python:
env = env_fast_linalg_boost_python_ext.Clone()
fast_linalg_ext = env.SharedLibrary(target='#lib/fast_linalg_ext', source=['ext.cpp'])
Depends(fast_linalg_ext, fast_linalg)
SConscript("tests/SConscript")
| [
"jorge7soccer@gmail.com"
] | jorge7soccer@gmail.com | |
a5536ab89b0ca426610494c44f382a33064672d8 | 61e40900e69f73438bd903d8447f1625a80d6603 | /fuzzers/074-dump_all/node_names.py | 64bca5b847d5f4e254a411e1e40770d11b5f87aa | [
"ISC",
"LicenseRef-scancode-dco-1.1"
] | permissive | mithro/prjxray | b4249f5ef54ae2eff9f4c663cb837d2a5080bb8f | 77e8b24c883bd527b511413f1939c3a34a237c1c | refs/heads/master | 2022-06-20T13:21:00.687619 | 2020-12-26T22:39:29 | 2020-12-26T22:39:29 | 114,992,619 | 1 | 1 | null | 2017-12-21T10:16:50 | 2017-12-21T10:16:50 | null | UTF-8 | Python | false | false | 5,787 | py | #!/usr/bin/env python3
# -*- coding: utf-8 -*-
#
# Copyright (C) 2020 The Project X-Ray Authors.
#
# Use of this source code is governed by a ISC-style
# license that can be found in the LICENSE file or at
# https://opensource.org/licenses/ISC
#
# SPDX-License-Identifier: ISC
""" This script creates node_wires.json, which describes how nodes are named.
This script consumes the raw node data from root_dir and outputs
node_wires.json to the output_dir.
The class prjxray.node_model.NodeModel can be used to reconstruct node names
and node <-> wire mapping.
The contents of node_wires.json is:
- The set of tile type wires that are always nodes, key "node_pattern_wires"
- The set of tile wires that are nodes within the graph, key
"specific_node_wires".
"""
import argparse
import datetime
import json
import multiprocessing
import progressbar
import pyjson5 as json5
import os.path
from prjxray import util, lib
from prjxray.grid import Grid
def read_json5(fname):
with open(fname, 'r') as f:
return json5.load(f)
def main():
parser = argparse.ArgumentParser(
description="Reduce node names for wire connections.")
parser.add_argument('--root_dir', required=True)
parser.add_argument('--output_dir', required=True)
parser.add_argument('--max_cpu', type=int, default=10)
args = parser.parse_args()
_, nodes = lib.read_root_csv(args.root_dir)
processes = min(multiprocessing.cpu_count(), args.max_cpu)
pool = multiprocessing.Pool(processes=processes)
# Read tile grid and raw node data.
print('{} Reading tilegrid'.format(datetime.datetime.now()))
with open(os.path.join(util.get_db_root(), util.get_part(),
'tilegrid.json')) as f:
grid = Grid(db=None, tilegrid=json.load(f))
raw_node_data = []
with progressbar.ProgressBar(max_value=len(nodes)) as bar:
for idx, node in enumerate(pool.imap_unordered(
read_json5,
nodes,
chunksize=20,
)):
bar.update(idx)
raw_node_data.append(node)
bar.update(idx + 1)
node_wires = set()
remove_node_wires = set()
specific_node_wires = set()
# Create initial node wire pattern
for node in progressbar.progressbar(raw_node_data):
if len(node['wires']) <= 1:
continue
node_tile, node_wire = node['node'].split('/')
for wire in node['wires']:
wire_tile, wire_name = wire['wire'].split('/')
if node['node'] == wire['wire']:
assert node_tile == wire_tile
assert node_wire == wire_name
gridinfo = grid.gridinfo_at_tilename(node_tile)
node_wires.add((gridinfo.tile_type, wire_name))
print(
'Initial number of wires that are node drivers: {}'.format(
len(node_wires)))
# Remove exceptional node wire names, create specific_node_wires set,
# which is simply the list of wires that are nodes in the graph.
for node in progressbar.progressbar(raw_node_data):
if len(node['wires']) <= 1:
continue
for wire in node['wires']:
wire_tile, wire_name = wire['wire'].split('/')
gridinfo = grid.gridinfo_at_tilename(wire_tile)
key = gridinfo.tile_type, wire_name
if node['node'] == wire['wire']:
assert key in node_wires
else:
if key in node_wires:
specific_node_wires.add(node['node'])
remove_node_wires.add(key)
# Complete the specific_node_wires list after the pruning of the
# node_pattern_wires sets.
for node in progressbar.progressbar(raw_node_data):
if len(node['wires']) <= 1:
continue
for wire in node['wires']:
wire_tile, wire_name = wire['wire'].split('/')
gridinfo = grid.gridinfo_at_tilename(wire_tile)
key = gridinfo.tile_type, wire_name
if key in remove_node_wires and node['node'] == wire['wire']:
specific_node_wires.add(node['node'])
node_wires -= remove_node_wires
print(
'Final number of wires that are node drivers: {}'.format(
len(node_wires)))
print(
'Number of wires that are node drivers: {}'.format(
len(specific_node_wires)))
# Verify the node wire data.
for node in progressbar.progressbar(raw_node_data):
if len(node['wires']) <= 1:
continue
found_node_wire = False
for wire in node['wires']:
if wire['wire'] in specific_node_wires:
assert wire['wire'] == node['node']
found_node_wire = True
break
if not found_node_wire:
for wire in node['wires']:
wire_tile, wire_name = wire['wire'].split('/')
gridinfo = grid.gridinfo_at_tilename(wire_tile)
key = gridinfo.tile_type, wire_name
if key in node_wires:
assert node['node'] == wire['wire']
else:
assert node['node'] != wire['wire']
# Normalize output.
tile_types = {}
for tile_type, tile_wire in node_wires:
if tile_type not in tile_types:
tile_types[tile_type] = []
tile_types[tile_type].append(tile_wire)
for tile_type in tile_types:
tile_types[tile_type].sort()
out = {
'node_pattern_wires': tile_types,
'specific_node_wires': sorted(specific_node_wires),
}
with open(os.path.join(args.output_dir, 'node_wires.json'), 'w') as f:
json.dump(out, f, indent=2, sort_keys=True)
if __name__ == '__main__':
main()
| [
"537074+litghost@users.noreply.github.com"
] | 537074+litghost@users.noreply.github.com |
666ef7ae8454cf444e77e6c07f2807fef215d9ed | e174e13114fe96ad2a4eeb596a3d1c564ae212a8 | /Python for Finance Analyze Big Financial Data by Y. Hilpisch/Code of Python For Finance/4375OS_09_Code/4375_09_13_multiple_IRRs.py | efdba1da9ec9447d9063e834a25dab13a42060e3 | [] | no_license | Kevinqian0501/python_books | c1a7632d66dceb46db439f7cbed86d85370aab42 | 0691e4685af03a296aafb02447e3585db55ce461 | refs/heads/master | 2021-08-30T19:27:03.985464 | 2017-12-19T05:56:31 | 2017-12-19T05:56:31 | 104,145,012 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,129 | py | """
Name : 4375OS_09_13_multiple_IRRs.py
Book : Python for Finance
Publisher: Packt Publishing Ltd.
Author : Yuxing Yan
Date : 12/26/2013
email : yany@canisius.edu
paulyxy@hotmail.com
"""
def IRRs_f(cash_flows):
"""
Objective: find mutiple IRRs
e.g,
>>>x=[55,-50,-50,-50,100]
>>>IRRs_f(x)
[0.072, 0.337]
"""
n=1000
r=range(1,n)
n_cash_flow=len(cash_flows)
epsilon=abs(mean(cash_flows)*0.01)
irr=[-99.00]
j=1
npv=[]
for i in r: npv.append(0)
lag_sign=sign(npv_f(float(r[0]*1.0/n*1.0),cash_flows))
for i in range(1,n-1):
#print("r[i]",r[i])
interest=float(r[i]*1.0/n*1.0)
npv[i]=npv_f(interest,cash_flows)
s=sign(npv[i])
if s*lag_sign<0:
lag_sign=s
if j==1:
irr=[interest]
j=2
else:
irr.append(interest)
return irr
| [
"kevin@Qians-MacBook-Pro.local"
] | kevin@Qians-MacBook-Pro.local |
8581e174f3cc7644701de6f07bf9a83fad8695d1 | 4c7baee40b96e6499f96d6fe81935437264c9c88 | /WebFramework/fno/views/StockOIView.py | bdca4eb09db319311e05f5af06df9265ff9bee97 | [
"MIT",
"Apache-2.0"
] | permissive | webclinic017/Stock-Analysis | 083d376484adebcad2d52113749a513aa48b09a8 | eea8cb5bcb635f12eb15ac13306ef16e2892cd92 | refs/heads/master | 2022-04-13T00:20:54.287730 | 2020-03-29T21:05:22 | 2020-03-29T21:05:22 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 8,680 | py | import sys
from os import path
sys.path.append(path.dirname(path.dirname(path.abspath(__file__))))
import simplejson, MySQLdb, datetime
from django.shortcuts import render
from django.http import HttpRequest
from django.template import RequestContext
from fno.forms import kOptionValueForm
from WebFramework.utility import *
class kView:
def __init__(self, request):
self.request = request
def __call__(self):
if self.request.method == 'POST':
form = kOptionValueForm(self.request.POST)
if form.is_valid():
return self.totalCallPut(self.request, [form.data['optionStock'], form.data['expiryMonth'], form.data['expiryYear']])
def totalCallPut(self, request, arg):
#assert isinstance(request, HttpRequest)
try:
historicOIDict = self.getHistoricOIDict(arg)
#dict=[['Date', 'CE OI', 'PE OI', 'Nifty'], ['01-Dec-2017', 41325, 9375, 10121.8], ['04-Dec-2017', 63450, 84300, 10127.8], ['05-Dec-2017', 87075, 149625, 10118.2], ['06-Dec-2017', 162600, 174900, 10044.1], ['07-Dec-2017', 225750, 246825, 10166.7], ['08-Dec-2017', 270900, 317400, 10265.7], ['11-Dec-2017', 315075, 353925, 10322.2], ['12-Dec-2017', 347025, 377325, 10240.2], ['13-Dec-2017', 366675, 413250, 10193.0], ['14-Dec-2017', 459150, 760200, 10252.1], ['15-Dec-2017', 601050, 867375, 10333.2], ['18-Dec-2017', 662850, 985200, 10388.8], ['19-Dec-2017', 751650, 1242300, 10463.2], ['20-Dec-2017', 906450, 1618275, 10444.2], ['21-Dec-2017', 1009800, 1880325, 10440.3], ['22-Dec-2017', 1108500, 2117700, 10493.0], ['26-Dec-2017', 1201575, 2334300, 10531.5], ['27-Dec-2017', 1307850, 3409275, 10490.8], ['28-Dec-2017', 1486050, 3972825, 10477.9], ['29-Dec-2017', 1983225, 4972875, 10530.7], ['01-Jan-2018', 2122575, 5968050, 10435.5], ['02-Jan-2018', 2583525, 6098775, 10442.2], ['03-Jan-2018', 2828250, 6396900, 10443.2], ['04-Jan-2018', 3125025, 6612825, 10504.8], ['05-Jan-2018', 3543675, 7045800, 10558.8], ['08-Jan-2018', 4076025, 7868700, 10623.6]]
liveOIDict = self.getLiveOIDict(arg)
histStockDict = self.getHistoricStockDict(arg)
historicOIData = simplejson.dumps(historicOIDict)
liveOIData = simplejson.dumps(liveOIDict)
histStockDict = simplejson.dumps(histStockDict)
dataDict = {'historicOIData':historicOIData, 'liveOIData':liveOIData, 'historicValueData':histStockDict}
return render(
request,
'fno/oi.html', dataDict
)
except Exception as e:
print e
def getHistoricOIDict(self, arg):
# tablename in db is like HistoricOptionNiftyMar2018
tableName = HISTORIC_OPTION_TABLENAME + arg[0] + arg[1] + arg[2]
ceResult = []
peResult = []
try:
db = GETDB()
cursor = db.cursor()
sqlCE = '''select date, sum(OpenInterest) from %s where optiontype="CE" group by date;''' %(tableName)
sqlPE = '''select date, sum(OpenInterest) from %s where optiontype="PE" group by date;''' %(tableName)
cursor.execute(sqlCE)
ceResult = cursor.fetchall()
cursor.execute(sqlPE)
peResult = cursor.fetchall()
cursor.close()
except:
print "Error executing SQL in fno StockOIView.py"
# Extracting live option value
ceLiveResult = []
peLiveResult = []
liveTableName = LIVE_OPTION_TABLENAME
try:
db = GETDB()
cursor = db.cursor()
expiry = (arg[1] + arg[2]).upper()
symbol = arg[0].upper()
sqlCE = """select sum(OpenInterest) from %s where symbol='%s' and expiry='%s' and optiontype='CE' and timestamp = (select max(timestamp) from %s where symbol='%s');""" %(liveTableName, symbol, expiry, liveTableName, symbol)
sqlPE = """select sum(OpenInterest) from %s where symbol='%s' and expiry='%s' and optiontype='PE' and timestamp = (select max(timestamp) from %s where symbol='%s');""" %(liveTableName, symbol, expiry, liveTableName, symbol)
cursor.execute(sqlCE)
ceLiveResult = cursor.fetchall()
cursor.execute(sqlPE)
peLiveResult = cursor.fetchall()
cursor.close()
except Exception as e:
print e
print "Error executing SQL in fno StockOIView.py"
dict = [['Date', 'CE OI', 'PE OI']]
for i in range(len(ceResult)):
#will convert 20180129L to 01-Jan-2018
date = datetime.datetime.strptime(str(ceResult[i][0]), "%Y%m%d").strftime("%d-%b-%Y")
ceOpenInterest = int(ceResult[i][1])
peOpenInterest = int(peResult[i][1])
dict.insert(len(dict), [date, ceOpenInterest, peOpenInterest])
# Inserting live data
try:
currentDate = datetime.datetime.now().strftime("%d-%b-%Y")
liveCEOI = int(ceLiveResult[0][0])
livePEOI = int(peLiveResult[0][0])
dict.insert(len(dict), [currentDate, liveCEOI, livePEOI])
except Exception as e:
print e
return dict
def getLiveOIDict(self, arg):
# Extracting live option value
ceLiveResult = []
peLiveResult = []
liveTableName = LIVE_OPTION_TABLENAME
try:
db = GETDB()
cursor = db.cursor()
expiry = (arg[1] + arg[2]).upper()
symbol = arg[0].upper()
sqlCE = """select timestamp, sum(openinterest) from %s where symbol='%s' and expiry='%s' and optiontype='CE' group by timestamp;""" %(liveTableName, symbol, expiry)
sqlPE = """select timestamp, sum(openinterest) from %s where symbol='%s' and expiry='%s' and optiontype='PE' group by timestamp;""" %(liveTableName, symbol, expiry)
cursor.execute(sqlCE)
ceLiveResult = cursor.fetchall()
cursor.execute(sqlPE)
peLiveResult = cursor.fetchall()
cursor.close()
except Exception as e:
print e
print "Error executing SQL in fno StockOIView.py"
dict = [['Time', 'CE OI', 'PE OI']]
try:
for i in range(len(ceLiveResult)):
#will convert 20180129L to 01-Jan-2018
timestamp = datetime.datetime.strptime(str(ceLiveResult[i][0]), "%H%M").strftime("%H:%M")
ceOpenInterest = int(ceLiveResult[i][1])
peOpenInterest = int(peLiveResult[i][1])
dict.insert(len(dict), [timestamp, ceOpenInterest, peOpenInterest])
except Exception as e:
print e
return dict
def getHistoricStockDict(self, arg):
stockTableName = HISTORIC_STOCK_TABLENAME + arg[0]
optionTableName = HISTORIC_OPTION_TABLENAME + arg[0] + arg[1] + arg[2]
histStockResult = []
try:
db = GETDB()
cursor = db.cursor()
sql = '''select date,close from %s where date >= (select min(date) from %s) order by date; ''' %(stockTableName, optionTableName)
cursor.execute(sql)
histStockResult = cursor.fetchall()
cursor.close()
except:
print "Error executing SQL in fno StockOIView.py getHistoricStockDict"
# Extracting live option value
liveStockResult = []
liveTableName = LIVE_STOCK_TABLENAME
try:
db = GETDB()
cursor = db.cursor()
symbol = arg[0].upper()
sql = """select LTP from %s where symbol='%s' and timestamp=(select max(timestamp) from %s where symbol='%s');""" %(liveTableName, symbol, liveTableName, symbol)
cursor.execute(sql)
liveStockResult = cursor.fetchall()
cursor.close()
except Exception as e:
print e
print "Error executing SQL in fno StockOIView.py getHistoricStockDict"
dict = [['Date', 'Stock Price']]
for i in range(len(histStockResult)):
#will convert 20180129L to 01-Jan-2018
date = datetime.datetime.strptime(str(histStockResult[i][0]), "%Y%m%d").strftime("%d-%b-%Y")
stockValue = float(histStockResult[i][1])
dict.insert(len(dict), [date, stockValue])
# Inserting live data
try:
currentDate = datetime.datetime.now().strftime("%d-%b-%Y")
liveStockValue = float(liveStockResult[0][0])
dict.insert(len(dict), [currentDate, liveStockValue])
except Exception as e:
print e
print dict
return dict | [
"singhanurag50@gmail.com"
] | singhanurag50@gmail.com |
a7b1dbc983152193c8283176d0d3ffb129f5d207 | a0484a637cf60c223dc846440e11e345541680a5 | /src/datafactory/azext_datafactory/vendored_sdks/datafactory/__init__.py | e30baeb129d14b15de73d2996019d7dc84a72d98 | [
"LicenseRef-scancode-generic-cla",
"MIT"
] | permissive | TylerLeonhardt/azure-cli-extensions | c4caacb38d81e3dc84a4483eb4be380f0e3ddc91 | f3bdbd75cc39c2a302d1184c9e1e1fa5b368378d | refs/heads/master | 2022-12-25T07:05:51.282034 | 2020-08-28T13:19:09 | 2020-08-28T13:19:09 | 291,105,411 | 1 | 0 | MIT | 2020-08-28T17:22:41 | 2020-08-28T17:22:40 | null | UTF-8 | Python | false | false | 668 | py | # coding=utf-8
# --------------------------------------------------------------------------
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License. See License.txt in the project root for license information.
# Code generated by Microsoft (R) AutoRest Code Generator.
# Changes may cause incorrect behavior and will be lost if the code is regenerated.
# --------------------------------------------------------------------------
from ._data_factory_management_client import DataFactoryManagementClient
__all__ = ['DataFactoryManagementClient']
try:
from ._patch import patch_sdk
patch_sdk()
except ImportError:
pass
| [
"noreply@github.com"
] | TylerLeonhardt.noreply@github.com |
a8f3bf74062b00234952bf941310bc099acc2beb | 009df7ad499b19a4df066160cf0c7d8b20355dfb | /src/the_tale/the_tale/game/chronicle/tests/test_general.py | b4bdbdab14970d216e7e3ff723cbae0b0d11ba05 | [
"BSD-3-Clause"
] | permissive | devapromix/the-tale | c0804c7475e877f12f29444ddbbba025561d3412 | 2a10efd3270734f8cf482b4cfbc5353ef8f0494c | refs/heads/develop | 2020-03-28T20:26:30.492292 | 2018-10-07T17:32:46 | 2018-10-07T17:32:46 | 149,070,887 | 1 | 0 | BSD-3-Clause | 2018-10-07T17:32:47 | 2018-09-17T04:57:50 | Python | UTF-8 | Python | false | false | 355 | py |
import smart_imports
smart_imports.all()
class GeneralTests(utils_testcase.TestCase):
def setUp(self):
super(GeneralTests, self).setUp()
def test_every_bill_has_argument_getter(self):
self.assertCountEqual(list(signal_processors.BILL_ARGUMENT_GETTERS.keys()),
bills_relations.BILL_TYPE.records)
| [
"a.eletsky@gmail.com"
] | a.eletsky@gmail.com |
7afbc89d190fdbbb0bebbd5ed46b9452624255e6 | 43a78f0bcd94f617d2c55e5019f3f3475580165d | /GeeksForGeeks/Data Types/Strings/Old Style Formatting.py | 2a2c91a664ddbf200cde31eb63416b602e2c795c | [] | no_license | ctramm/Python_Training | 2c35bd36b7cd1ea6598f915fafcf37ca048cf8ed | a0864a82bd6fb002c5f1a9aa7fb5d0b18341e6b0 | refs/heads/master | 2022-12-04T14:18:30.477562 | 2022-11-12T09:03:25 | 2022-11-12T09:03:25 | 171,736,957 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 251 | py | # Python program for old style formatting of integers
Integer1 = 12.3456789
print("Formating in 3.2f format:")
print('The value of Integer1 is %3.2f' %Integer1)
print('\nFormatting in 3.4f format: ')
print('The value of Integer1 is %3.4f' %Integer1)
| [
"ctramm@wiley.com"
] | ctramm@wiley.com |
94f56802087e38330a83fc564735713c40bcb7f3 | cf945fb7c961376bfcff37c80fe50312d4f32290 | /Python3.5/DataStructure/C5_搜索/E3_DeepthSearch.py | e7473fde6dd14c0c83e81fb62769c083a7126596 | [] | no_license | lizhenQAZ/code_manage | faa1e805326cc8da8463e0f8820c9d092a04dddb | f98977d58a9febb8212652846314418bba37bfc7 | refs/heads/master | 2020-12-03T00:00:52.205238 | 2018-12-19T16:00:48 | 2018-12-19T16:00:48 | 95,968,266 | 1 | 1 | null | null | null | null | UTF-8 | Python | false | false | 3,246 | py | class Node:
def __init__(self, elem=-1, lchild=None, rchild=None):
self.elem = elem
self.lchild = lchild
self.rchild = rchild
class Tree:
def __init__(self, root=None):
self.root = root
def add(self, elem):
node = Node(elem)
if self.root is None:
self.root = node
else:
queue = []
queue.append(self.root)
while queue:
root_node = queue.pop(0)
if root_node.lchild is None:
root_node.lchild = node
return
if root_node.rchild is None:
root_node.rchild = node
return
queue.append(root_node.lchild)
queue.append(root_node.rchild)
def preorder(self, root):
if root is None:
return
print(root.elem, end=' ')
self.preorder(root.lchild)
self.preorder(root.rchild)
def preorder_nonrecursive(self, root):
if root is None:
return
self.root = root
queue = []
while self.root or queue:
while self.root:
print(self.root.elem, end=' ')
queue.append(self.root)
self.root = self.root.lchild
node = queue.pop()
self.root = node.rchild
def inorder(self, root):
if root is None:
return
self.inorder(root.lchild)
print(root.elem, end=' ')
self.inorder(root.rchild)
def inorder_nonrecursive(self, root):
if root is None:
return
self.root = root
queue = []
while self.root or queue:
while self.root:
queue.append(self.root)
self.root = self.root.lchild
node = queue.pop()
print(node.elem, end=" ")
self.root = node.rchild
def postorder(self, root):
if root is None:
return
self.postorder(root.lchild)
self.postorder(root.rchild)
print(root.elem, end=' ')
def postorder_nonrecursive(self, root):
if root is None:
return
self.root = root
queue1 = []
queue2 = []
queue1.append(self.root)
while queue1:
node = queue1.pop()
if node.lchild:
queue1.append(node.lchild)
if node.rchild:
queue1.append(node.rchild)
queue2.append(node)
while queue2:
print(queue2.pop().elem, end=" ")
if __name__ == '__main__':
tree = Tree()
tree.add(11)
tree.add(22)
tree.add(3)
tree.add(77)
tree.add(66)
tree.add(88) # 11 22 3 77 66 88
# 11
# 22 3
# 77 66 88
tree.preorder(tree.root) # 11 22 77 66 3 88
print(' ')
tree.inorder(tree.root) # 77 22 66 11 88 3
print(' ')
tree.postorder(tree.root) # 77 66 22 88 3 11
print(' ')
# tree.preorder_nonrecursive(tree.root) # 11 22 77 66 3 88
# print(' ')
# tree.inorder_nonrecursive(tree.root) # 77 22 66 11 88 3
# print(' ')
tree.postorder_nonrecursive(tree.root) # 77 66 22 88 3 11
print(' ')
| [
"www.516960831@qq.com"
] | www.516960831@qq.com |
c04f91b1c63ec124253ad6cf3aea089d6b30ef8f | 15f321878face2af9317363c5f6de1e5ddd9b749 | /solutions_python/Problem_53/360.py | 028e89a9be267984012ec51a845faf5831e4673e | [] | no_license | dr-dos-ok/Code_Jam_Webscraper | c06fd59870842664cd79c41eb460a09553e1c80a | 26a35bf114a3aa30fc4c677ef069d95f41665cc0 | refs/heads/master | 2020-04-06T08:17:40.938460 | 2018-10-14T10:12:47 | 2018-10-14T10:12:47 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 266 | py | #!/usr/bin/python
pot2 = []
for i in range(31):
pot2.append((2**i)-1)
for i in range(input()):
N, K = map(int, raw_input().split())
if ((K & pot2[N]) == pot2[N]):
print 'Case #%s: ON' % (i + 1)
else:
print 'Case #%s: OFF' % (i + 1)
| [
"miliar1732@gmail.com"
] | miliar1732@gmail.com |
40d5e296721b28056adeaef87327595a9f91f5b5 | be0e0488a46b57bf6aff46c687d2a3080053e52d | /python/baekjoon/2630.py | 8080d5d6431928ca3d289e15219caec4b97d2bfd | [] | no_license | syo0e/Algorithm | b3f8a0df0029e4d6c9cbf19dcfcb312ba25ea939 | 1ae754d5bb37d02f28cf1d50463a494896d5026f | refs/heads/master | 2023-06-09T11:31:54.266900 | 2021-06-30T17:04:38 | 2021-06-30T17:04:38 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 771 | py | import sys
def paperCount(x, y, n):
global arr, blue, white
check = arr[x][y]
for i in range(x, x + n):
for j in range(y, y + n):
if check != arr[i][j]:
paperCount(x, y, n // 2) # 1사분면
paperCount(x, y + n // 2, n // 2) # 2사분면
paperCount(x + n // 2, y, n // 2) # 3사분면
paperCount(x + n // 2, y + n // 2, n // 2) # 4사분면
return
if check==0:#모두 흰색일 때
white+=1
return
else: #모두 파란색일 때
blue+=1
return
N = int(input())
arr = []
blue = 0
white = 0
for _ in range(N):
arr.append(list(map(int, sys.stdin.readline().split())))
paperCount(0,0,N)
print(white)
print(blue) | [
"kyun2dot@gmail.com"
] | kyun2dot@gmail.com |
27dcd1f3556024f8e95a6210ce4a8e14b48105b6 | 377cbbe140fd0faf1eb53ba3794de816ac307cde | /src/dataset/info/NorbInfo.py | a2431696fc397c0d9ddccbdeac6219fd3f93aee4 | [
"MIT"
] | permissive | dhruvtapasvi/implementation | fcbd7ab8e7b1368a0f07ee41dc5f0b6d6708c206 | 964980f431517f4548a87172a05107cdf700fb84 | refs/heads/master | 2021-09-16T01:47:50.601661 | 2018-05-17T19:22:44 | 2018-05-17T19:22:44 | 114,498,055 | 1 | 0 | MIT | 2018-05-05T02:17:35 | 2017-12-16T23:59:13 | Python | UTF-8 | Python | false | false | 528 | py | from enum import Enum
from config import routes
NORB_RANGE = (0, 255)
NORB_VALIDATION_INSTANCES = 7
NORB_TEST_INSTANCES = 9
NORB_IMAGE_DIMENSIONS = (96, 96)
NORB_LABEL_DIMENSIONS = (6,)
NORB_ELEVATION_NAME = "NORB: ELEVATION ANGLE"
NORB_ELEVATION_FACTORS = (0, 6, 3, 8)
NORB_AZIMUTH_NAME = "NORB: AZIMUTH ANGLE"
NORB_AZIMUTH_FACTORS = (0, 8, 4, 12)
class NorbLabelIndex(Enum):
STEREO = 0
CATEGORY = 1
INSTANCE = 2
ELEVATION = 3
AZIMUTH = 4
LIGHTING = 5
NORB_HOME = routes.RESOURCE_ROUTE + "/norb"
| [
"dhruv.tapasvi1996@gmail.com"
] | dhruv.tapasvi1996@gmail.com |
c40ebfec42208b8d9cf7aae6f67610db3752df94 | 55b6af0fcfffe9beb48753f00c55102051b4bd35 | /src/main.py | a92b12accf632cd774955f730c4b61d18a08899a | [] | no_license | sobamchan/rte_baseline | bbe87bc6cf0ebe739aba86f973a1a2a8d60ac148 | cbda046d5d019476db6d4ca785451bdaef0cadcb | refs/heads/main | 2023-08-14T17:30:33.282871 | 2021-10-08T12:05:04 | 2021-10-08T12:05:04 | 414,965,245 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 6,401 | py | import json
import os
from argparse import ArgumentParser
from functools import partial
from typing import Any, Dict, List, Tuple, Union
import pytorch_lightning as pl
import torch
import torch.nn as nn
import torch.nn.functional as F
from lineflow.core import IterableDataset
from torch.utils.data import DataLoader
from transformers import AdamW, RobertaModel, RobertaTokenizer # type: ignore
def load_jsonl(dpath: str) -> List[Dict[str, Union[str, int]]]:
"""Load jsonline formatted file given its path."""
datas = []
with open(dpath, "r") as _f:
for line in _f.readlines():
datas.append(json.loads(line))
return datas
def preprocess(tokenizer: RobertaTokenizer, d: Dict[str, Union[str, int]]) -> Any:
"""Basic tokenization by pretrained tokenizer."""
model_inputs = tokenizer(d["s1"], d["s2"], return_tensors="pt", padding="max_length", max_length=256) # type: ignore
model_inputs["label"] = torch.LongTensor([int(d["label"])])
for k in ["input_ids", "attention_mask", "label"]:
model_inputs[k] = model_inputs[k].squeeze() # type: ignore
return model_inputs
def get_dataloaders(dpath: str, batch_size: int) -> Tuple[DataLoader, DataLoader]:
"""Load file, preprocess (tokenize), pack into pytorch dataloader."""
train_ds = IterableDataset(load_jsonl(os.path.join(dpath, "train.jsonl")))
val_ds = IterableDataset(load_jsonl(os.path.join(dpath, "val.jsonl")))
tokenizer = RobertaTokenizer.from_pretrained("roberta-base")
preprocessor = partial(preprocess, tokenizer)
train_ds = train_ds.map(preprocessor)
val_ds = val_ds.map(preprocessor)
train_dl = DataLoader(train_ds, batch_size=batch_size, shuffle=True) # type: ignore
val_dl = DataLoader(val_ds, batch_size=batch_size, shuffle=False) # type: ignore
return train_dl, val_dl
class Classifier(nn.Module):
"""Classification head to be on top of RoBERTa."""
def __init__(self, config):
super().__init__()
class_n = 2
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.out_proj = nn.Linear(config.hidden_size, class_n)
def forward(self, features):
x = features[:, 0, :]
x = self.dropout(x)
x = self.dense(x)
x = torch.tanh(x)
x = self.dropout(x)
x = self.out_proj(x)
return x
class RTEModule(pl.LightningModule):
def __init__(self, hparams: Dict):
super().__init__()
self.model = RobertaModel.from_pretrained("roberta-base")
self.classifier = Classifier(config=self.model.config)
self.accuracy = pl.metrics.Accuracy() # type: ignore
self.save_hyperparameters(hparams)
def forward(self, batch: Dict):
# Get feature vectors from RoBERTa
out = self.model(
input_ids=batch["input_ids"], attention_mask=batch["attention_mask"]
)
# Take last hidden state from out, to know the format of `out` refer [here](https://huggingface.co/transformers/model_doc/roberta.html#transformers.RobertaModel.forward)
last_hidden_state = out[0]
logits = self.classifier(
last_hidden_state
) # Run classification given features.
return logits
def training_step(self, batch, _):
logits = self.forward(batch)
loss = F.cross_entropy(logits.view(-1, 2), batch["label"].view(-1))
self.log("train_loss", loss)
return loss
def validation_step(self, batch, _):
logits = self.forward(batch)
loss = F.cross_entropy(logits.view(-1, 2), batch["label"].view(-1))
self.log("val_loss", loss)
acc = self.accuracy(logits, batch["label"])
self.log("val_acc", acc)
return {"val_loss": loss, "val_acc": acc}
def configure_optimizers(self):
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters_roberta = [
{
"params": [
p
for n, p in self.model.named_parameters()
if not any(nd in n for nd in no_decay)
],
"weight_decay": 0.01,
},
{
"params": [
p
for n, p in self.model.named_parameters()
if any(nd in n for nd in no_decay)
],
"weight_decay": 0.0,
},
]
optimizer_grouped_parameters_clf = [
{
"params": [
p
for n, p in self.classifier.named_parameters()
if not any(nd in n for nd in no_decay)
],
"weight_decay": 0.01,
},
{
"params": [
p
for n, p in self.classifier.named_parameters()
if any(nd in n for nd in no_decay)
],
"weight_decay": 0.0,
},
]
optimizer = AdamW(
optimizer_grouped_parameters_roberta + optimizer_grouped_parameters_clf,
lr=self.hparams["lr"],
)
return optimizer
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("--lr", type=float, required=True, help="Learning rate")
parser.add_argument("--batch-size", type=int, required=True, help="Batch size")
parser.add_argument(
"--max-epochs", type=int, required=True, help="Maximum epochs to train."
)
parser.add_argument(
"--seed", type=int, required=True, help="Maximum epochs to train."
)
parser.add_argument(
"--dpath", type=str, required=True, help="Path to data directory"
)
parser.add_argument(
"--default-root-dir",
type=str,
required=True,
help="Path to save logs and trained models.",
)
parser.add_argument("--gpus", type=int, default=0, help="Number of GPUs to use")
args = parser.parse_args()
hparams = vars(args)
train_dl, val_dl = get_dataloaders(hparams["dpath"], hparams["batch_size"])
module = RTEModule(hparams)
trainer = pl.Trainer(
gpus=args.gpus,
default_root_dir=args.default_root_dir,
max_epochs=args.max_epochs,
)
trainer.fit(module, train_dl, val_dl)
| [
"oh.sore.sore.soutarou@gmail.com"
] | oh.sore.sore.soutarou@gmail.com |
a66380c5496088aa4f1310659b39d656cc76fd08 | 53fab060fa262e5d5026e0807d93c75fb81e67b9 | /backup/user_360/ch14_2020_03_03_12_13_23_023192.py | 10283fa8d0f938ee904ef22374db339b79cc82c8 | [] | no_license | gabriellaec/desoft-analise-exercicios | b77c6999424c5ce7e44086a12589a0ad43d6adca | 01940ab0897aa6005764fc220b900e4d6161d36b | refs/heads/main | 2023-01-31T17:19:42.050628 | 2020-12-16T05:21:31 | 2020-12-16T05:21:31 | 306,735,108 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 181 | py | import math
def calcula_distancia_do_projetil(v,y0,teta):
p1= (v**2)/(2*9.8) * (math.sin(2*teta))
p2= (1+1+((2*9.8*y0)/(v**2)*(math.sinh((teta**2)**1/2))
return (p1*p2) | [
"you@example.com"
] | you@example.com |
2e6efd643cc5e4b33ec8739b9b47153576fdbcc3 | f0d713996eb095bcdc701f3fab0a8110b8541cbb | /8SBG29RYLwTbGxn7T_17.py | ff3608ee682597adacc4088662c6093852732cf6 | [] | no_license | daniel-reich/turbo-robot | feda6c0523bb83ab8954b6d06302bfec5b16ebdf | a7a25c63097674c0a81675eed7e6b763785f1c41 | refs/heads/main | 2023-03-26T01:55:14.210264 | 2021-03-23T16:08:01 | 2021-03-23T16:08:01 | 350,773,815 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 683 | py | """
Create a function that determines whether a shopping order is eligible for
free shipping. An order is eligible for free shipping if the total cost of
items purchased exceeds $50.00.
### Examples
free_shipping({ "Shampoo": 5.99, "Rubber Ducks": 15.99 }) ➞ False
free_shipping({ "Flatscreen TV": 399.99 }) ➞ True
free_shipping({ "Monopoly": 11.99, "Secret Hitler": 35.99, "Bananagrams": 13.99 }) ➞ True
### Notes
Ignore tax or additional fees when calculating the total order cost.
"""
def free_shipping(order):
prices = []
for i in order:
prices.append(order[i])
if sum(prices) >= 50.00:
return(True)
else:
return(False)
| [
"daniel.reich@danielreichs-MacBook-Pro.local"
] | daniel.reich@danielreichs-MacBook-Pro.local |
90c2b8bceda1a8b774f00a143a85b08304bd8aeb | d17724b2ce056b435f57b16fb0cbea32e44a29c6 | /Gun3PY/nmap02.py | 5a04aa5937af6653ba8492227c6632c78c2aa040 | [] | no_license | UgurCIL/Examples | 27264d89131b4aaff46f91705a03779c4e825ad6 | c1722a519836a24c8a946380e6cbcd6da963f0c5 | refs/heads/master | 2020-04-24T15:28:17.288204 | 2019-02-22T13:30:35 | 2019-02-22T13:30:35 | 172,069,050 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,029 | py | import nmap
nm = nmap.PortScanner()
nm.scan("10.10.1.1", "1-1000", arguments='--script bannser.nse')
print "-" * 30
print "[+] Komut: " + str(nm.command_line()) #ekrana calisan komutu basar
for host in nm.all_hosts(): #tarama sonucu donen tum IP adreslerinin uzerinden gecer
if nm[host].state() == "up": #host aktif mi
print "[+] Host Aktif: " + str(host)
for proto in nm[host].all_protocols(): #host ustundeki tum protokollerin uzerinden gecer
print "Protokol: " + str(proto)
portlar = nm[host][proto].keys() #host-protokol ustundeki tum portlarin uzerinden gecer
for port in portlar:
print "Port: {}\t Durumu: {}".format(port, nm[host][proto][port]["state"])
#######################################################
# NSE scriptlerinin sonuclarini burada duzenlemeli ve #
# kullanici icin anlamlı hale getirmeliyiz #
#######################################################
else:
print "[-] Host Down: " + str(host)
| [
"root@localhost.localdomain"
] | root@localhost.localdomain |
3aa1b6f3ec34eff2d86949a3bc874e58db0c7fb6 | 57f47187c28464497252bf4faeab83f33bcdb9c7 | /functional_tests/test_list_item_validation.py | 964269899684fb5753399fc43263a9800bb31ad6 | [] | no_license | amazingguni/pomodoro-web | e059d9b1948c27c72230d555078b2a5a7facd539 | 8c13052816649ec9465973121e63222680c925ce | refs/heads/master | 2021-05-04T10:56:46.183598 | 2016-08-20T07:26:28 | 2016-08-20T07:26:28 | 53,728,974 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,851 | py | from .base import FunctionalTest
class ItemValidationTest(FunctionalTest):
def get_error_element(self):
return self.browser.find_element_by_css_selector('.has-error')
def test_cannot_add_empty_list_items(self):
# 에디스는 메인 페이지에 접속해서 비니 아이템을 실수로 등록하려고 한다.
# 입력 상자가 비어 있는 상태에서 엔터키를 누른다.
self.browser.get(self.server_url)
self.get_item_input_box().send_keys('\n')
# 페이지가 새로고침되고, 빈 아이템을 등록할 수 없다는
# 에러 메시지가 표시된다.
error = self.get_error_element()
self.assertEqual(error.text, "You can't have an empty list item")
# 다른 아이템을 입력하고 이번에는 정상 처리된다.
self.get_item_input_box().send_keys('우유사기\n')
self.check_for_row_in_list_table('1: 우유사기')
# 그녀는 고의적으로 다시 빈 아이템을 등록한다.
self.get_item_input_box().send_keys('\n')
# 리스트 페이지에 다시 에러 메시지가 표시된다.
self.check_for_row_in_list_table('1: 우유사기')
error = self.get_error_element()
self.assertEqual(error.text, "You can't have an empty list item")
# 아이템을 입력하면 정상 동작한다.
self.get_item_input_box().send_keys('tea 만들기\n')
self.check_for_row_in_list_table('1: 우유사기')
self.check_for_row_in_list_table('2: tea 만들기')
def test_cannot_add_duplicate_items(self):
# 에디스는 메인 페이지로 돌아가서 신규목록을 시작한다.
self.browser.get(self.server_url)
self.get_item_input_box().send_keys('콜라 사기\n')
self.check_for_row_in_list_table('1: 콜라 사기')
# 실수로 중복 아이템을 입력한다
self.get_item_input_box().send_keys('콜라 사기\n')
# 도움이 되는 에러 메시지를 본
self.check_for_row_in_list_table('1: 콜라 사기')
error = self.get_error_element()
self.assertEqual(error.text, "이미 리스트에 해당 아이템이 있습니다")
def test_error_messages_are_cleaned_on_input(self):
# 에디스는 검증 에러를 발생시키도록 신규 목록을 시작한다
self.browser.get(self.server_url)
self.get_item_input_box().send_keys('\n')
error = self.get_error_element()
self.assertTrue(error.is_displayed())
# 에러를 제거하기 위해 입력상자에 타이핑하기 시작한다
self.get_item_input_box().send_keys('a')
# 에러 메시지가 사라진 것을 보고 기뻐한다
error = self.get_error_element()
self.assertFalse(error.is_displayed())
| [
"amazingguni@gmail.com"
] | amazingguni@gmail.com |
fe70e503f41b6a0b8f7c2169e37f2937e68534ac | 1c6283303ceb883add8de4ee07c5ffcfc2e93fab | /Jinja2/lib/python3.7/site-packages/uhd_restpy/testplatform/sessions/ixnetwork/quicktest/trafficselection_ce8776c176ab25add4df9eb446e58c29.py | bdd4e62e8ab7aa24b251d9806f933b0fd0f80ff4 | [] | no_license | pdobrinskiy/devcore | 0f5b3dfc2f3bf1e44abd716f008a01c443e14f18 | 580c7df6f5db8c118990cf01bc2b986285b9718b | refs/heads/main | 2023-07-29T20:28:49.035475 | 2021-09-14T10:02:16 | 2021-09-14T10:02:16 | 405,919,390 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 18,435 | py | # MIT LICENSE
#
# Copyright 1997 - 2020 by IXIA Keysight
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
# THE SOFTWARE.
from uhd_restpy.base import Base
from uhd_restpy.files import Files
from typing import List, Any, Union
class TrafficSelection(Base):
"""This object configures the traffic that is already specified with the traffic wizard.
The TrafficSelection class encapsulates a list of trafficSelection resources that are managed by the user.
A list of resources can be retrieved from the server using the TrafficSelection.find() method.
The list can be managed by using the TrafficSelection.add() and TrafficSelection.remove() methods.
"""
__slots__ = ()
_SDM_NAME = 'trafficSelection'
_SDM_ATT_MAP = {
'Id__': '__id__',
'IncludeMode': 'includeMode',
'IsGenerated': 'isGenerated',
'ItemType': 'itemType',
}
_SDM_ENUM_MAP = {
'includeMode': ['background', 'inTest'],
'itemType': ['flowGroup', 'trafficItem'],
}
def __init__(self, parent, list_op=False):
super(TrafficSelection, self).__init__(parent, list_op)
@property
def Id__(self):
# type: () -> str
"""
Returns
-------
- str(None | /api/v1/sessions/1/ixnetwork/traffic/.../trafficItem | /api/v1/sessions/1/ixnetwork/traffic/.../highLevelStream): The unique identification of the traffic selection.
"""
return self._get_attribute(self._SDM_ATT_MAP['Id__'])
@Id__.setter
def Id__(self, value):
# type: (str) -> None
self._set_attribute(self._SDM_ATT_MAP['Id__'], value)
@property
def IncludeMode(self):
# type: () -> str
"""
Returns
-------
- str(background | inTest): Traffic type for the frame data
"""
return self._get_attribute(self._SDM_ATT_MAP['IncludeMode'])
@IncludeMode.setter
def IncludeMode(self, value):
# type: (str) -> None
self._set_attribute(self._SDM_ATT_MAP['IncludeMode'], value)
@property
def IsGenerated(self):
# type: () -> bool
"""
Returns
-------
- bool: If true, the traffic selection is generated automatically.
"""
return self._get_attribute(self._SDM_ATT_MAP['IsGenerated'])
@IsGenerated.setter
def IsGenerated(self, value):
# type: (bool) -> None
self._set_attribute(self._SDM_ATT_MAP['IsGenerated'], value)
@property
def ItemType(self):
# type: () -> str
"""
Returns
-------
- str(flowGroup | trafficItem): Traffic type for the frame data
"""
return self._get_attribute(self._SDM_ATT_MAP['ItemType'])
@ItemType.setter
def ItemType(self, value):
# type: (str) -> None
self._set_attribute(self._SDM_ATT_MAP['ItemType'], value)
def update(self, Id__=None, IncludeMode=None, IsGenerated=None, ItemType=None):
# type: (str, str, bool, str) -> TrafficSelection
"""Updates trafficSelection resource on the server.
Args
----
- Id__ (str(None | /api/v1/sessions/1/ixnetwork/traffic/.../trafficItem | /api/v1/sessions/1/ixnetwork/traffic/.../highLevelStream)): The unique identification of the traffic selection.
- IncludeMode (str(background | inTest)): Traffic type for the frame data
- IsGenerated (bool): If true, the traffic selection is generated automatically.
- ItemType (str(flowGroup | trafficItem)): Traffic type for the frame data
Raises
------
- ServerError: The server has encountered an uncategorized error condition
"""
return self._update(self._map_locals(self._SDM_ATT_MAP, locals()))
def add(self, Id__=None, IncludeMode=None, IsGenerated=None, ItemType=None):
# type: (str, str, bool, str) -> TrafficSelection
"""Adds a new trafficSelection resource on the server and adds it to the container.
Args
----
- Id__ (str(None | /api/v1/sessions/1/ixnetwork/traffic/.../trafficItem | /api/v1/sessions/1/ixnetwork/traffic/.../highLevelStream)): The unique identification of the traffic selection.
- IncludeMode (str(background | inTest)): Traffic type for the frame data
- IsGenerated (bool): If true, the traffic selection is generated automatically.
- ItemType (str(flowGroup | trafficItem)): Traffic type for the frame data
Returns
-------
- self: This instance with all currently retrieved trafficSelection resources using find and the newly added trafficSelection resources available through an iterator or index
Raises
------
- ServerError: The server has encountered an uncategorized error condition
"""
return self._create(self._map_locals(self._SDM_ATT_MAP, locals()))
def remove(self):
"""Deletes all the contained trafficSelection resources in this instance from the server.
Raises
------
- NotFoundError: The requested resource does not exist on the server
- ServerError: The server has encountered an uncategorized error condition
"""
self._delete()
def find(self, Id__=None, IncludeMode=None, IsGenerated=None, ItemType=None):
# type: (str, str, bool, str) -> TrafficSelection
"""Finds and retrieves trafficSelection resources from the server.
All named parameters are evaluated on the server using regex. The named parameters can be used to selectively retrieve trafficSelection resources from the server.
To retrieve an exact match ensure the parameter value starts with ^ and ends with $
By default the find method takes no parameters and will retrieve all trafficSelection resources from the server.
Args
----
- Id__ (str(None | /api/v1/sessions/1/ixnetwork/traffic/.../trafficItem | /api/v1/sessions/1/ixnetwork/traffic/.../highLevelStream)): The unique identification of the traffic selection.
- IncludeMode (str(background | inTest)): Traffic type for the frame data
- IsGenerated (bool): If true, the traffic selection is generated automatically.
- ItemType (str(flowGroup | trafficItem)): Traffic type for the frame data
Returns
-------
- self: This instance with matching trafficSelection resources retrieved from the server available through an iterator or index
Raises
------
- ServerError: The server has encountered an uncategorized error condition
"""
return self._select(self._map_locals(self._SDM_ATT_MAP, locals()))
def read(self, href):
"""Retrieves a single instance of trafficSelection data from the server.
Args
----
- href (str): An href to the instance to be retrieved
Returns
-------
- self: This instance with the trafficSelection resources from the server available through an iterator or index
Raises
------
- NotFoundError: The requested resource does not exist on the server
- ServerError: The server has encountered an uncategorized error condition
"""
return self._read(href)
def Apply(self, *args, **kwargs):
# type: (*Any, **Any) -> None
"""Executes the apply operation on the server.
Applies the specified Quick Test.
apply(async_operation=bool)
---------------------------
- async_operation (bool=False): True to execute the operation asynchronously. Any subsequent rest api calls made through the Connection class will block until the operation is complete.
Raises
------
- NotFoundError: The requested resource does not exist on the server
- ServerError: The server has encountered an uncategorized error condition
"""
payload = { "Arg1": self.href }
for i in range(len(args)): payload['Arg%s' % (i + 2)] = args[i]
for item in kwargs.items(): payload[item[0]] = item[1]
return self._execute('apply', payload=payload, response_object=None)
def ApplyAsync(self, *args, **kwargs):
# type: (*Any, **Any) -> None
"""Executes the applyAsync operation on the server.
applyAsync(async_operation=bool)
--------------------------------
- async_operation (bool=False): True to execute the operation asynchronously. Any subsequent rest api calls made through the Connection class will block until the operation is complete.
Raises
------
- NotFoundError: The requested resource does not exist on the server
- ServerError: The server has encountered an uncategorized error condition
"""
payload = { "Arg1": self.href }
for i in range(len(args)): payload['Arg%s' % (i + 2)] = args[i]
for item in kwargs.items(): payload[item[0]] = item[1]
return self._execute('applyAsync', payload=payload, response_object=None)
def ApplyAsyncResult(self, *args, **kwargs):
# type: (*Any, **Any) -> Union[bool, None]
"""Executes the applyAsyncResult operation on the server.
applyAsyncResult(async_operation=bool)bool
------------------------------------------
- async_operation (bool=False): True to execute the operation asynchronously. Any subsequent rest api calls made through the Connection class will block until the operation is complete.
- Returns bool:
Raises
------
- NotFoundError: The requested resource does not exist on the server
- ServerError: The server has encountered an uncategorized error condition
"""
payload = { "Arg1": self.href }
for i in range(len(args)): payload['Arg%s' % (i + 2)] = args[i]
for item in kwargs.items(): payload[item[0]] = item[1]
return self._execute('applyAsyncResult', payload=payload, response_object=None)
def ApplyITWizardConfiguration(self, *args, **kwargs):
# type: (*Any, **Any) -> None
"""Executes the applyITWizardConfiguration operation on the server.
Applies the specified Quick Test.
applyITWizardConfiguration(async_operation=bool)
------------------------------------------------
- async_operation (bool=False): True to execute the operation asynchronously. Any subsequent rest api calls made through the Connection class will block until the operation is complete.
Raises
------
- NotFoundError: The requested resource does not exist on the server
- ServerError: The server has encountered an uncategorized error condition
"""
payload = { "Arg1": self.href }
for i in range(len(args)): payload['Arg%s' % (i + 2)] = args[i]
for item in kwargs.items(): payload[item[0]] = item[1]
return self._execute('applyITWizardConfiguration', payload=payload, response_object=None)
def GenerateReport(self, *args, **kwargs):
# type: (*Any, **Any) -> Union[str, None]
"""Executes the generateReport operation on the server.
Generate a PDF report for the last succesfull test run.
generateReport(async_operation=bool)string
------------------------------------------
- async_operation (bool=False): True to execute the operation asynchronously. Any subsequent rest api calls made through the Connection class will block until the operation is complete.
- Returns str: This method is asynchronous and has no return value.
Raises
------
- NotFoundError: The requested resource does not exist on the server
- ServerError: The server has encountered an uncategorized error condition
"""
payload = { "Arg1": self.href }
for i in range(len(args)): payload['Arg%s' % (i + 2)] = args[i]
for item in kwargs.items(): payload[item[0]] = item[1]
return self._execute('generateReport', payload=payload, response_object=None)
def Run(self, *args, **kwargs):
# type: (*Any, **Any) -> Union[List[str], None]
"""Executes the run operation on the server.
Starts the specified Quick Test and waits for its execution to finish.
The IxNetwork model allows for multiple method Signatures with the same name while python does not.
run(async_operation=bool)list
-----------------------------
- async_operation (bool=False): True to execute the operation asynchronously. Any subsequent rest api calls made through the Connection class will block until the operation is complete.
- Returns list(str): This method is synchronous and returns the result of the test.
run(InputParameters=string, async_operation=bool)list
-----------------------------------------------------
- InputParameters (str): The input arguments of the test.
- async_operation (bool=False): True to execute the operation asynchronously. Any subsequent rest api calls made through the Connection class will block until the operation is complete.
- Returns list(str): This method is synchronous and returns the result of the test.
Raises
------
- NotFoundError: The requested resource does not exist on the server
- ServerError: The server has encountered an uncategorized error condition
"""
payload = { "Arg1": self.href }
for i in range(len(args)): payload['Arg%s' % (i + 2)] = args[i]
for item in kwargs.items(): payload[item[0]] = item[1]
return self._execute('run', payload=payload, response_object=None)
def Start(self, *args, **kwargs):
# type: (*Any, **Any) -> None
"""Executes the start operation on the server.
Starts the specified Quick Test.
The IxNetwork model allows for multiple method Signatures with the same name while python does not.
start(async_operation=bool)
---------------------------
- async_operation (bool=False): True to execute the operation asynchronously. Any subsequent rest api calls made through the Connection class will block until the operation is complete.
start(InputParameters=string, async_operation=bool)
---------------------------------------------------
- InputParameters (str): The input arguments of the test.
- async_operation (bool=False): True to execute the operation asynchronously. Any subsequent rest api calls made through the Connection class will block until the operation is complete.
Raises
------
- NotFoundError: The requested resource does not exist on the server
- ServerError: The server has encountered an uncategorized error condition
"""
payload = { "Arg1": self.href }
for i in range(len(args)): payload['Arg%s' % (i + 2)] = args[i]
for item in kwargs.items(): payload[item[0]] = item[1]
return self._execute('start', payload=payload, response_object=None)
def Stop(self, *args, **kwargs):
# type: (*Any, **Any) -> None
"""Executes the stop operation on the server.
Stops the currently running Quick Test.
stop(async_operation=bool)
--------------------------
- async_operation (bool=False): True to execute the operation asynchronously. Any subsequent rest api calls made through the Connection class will block until the operation is complete.
Raises
------
- NotFoundError: The requested resource does not exist on the server
- ServerError: The server has encountered an uncategorized error condition
"""
payload = { "Arg1": self.href }
for i in range(len(args)): payload['Arg%s' % (i + 2)] = args[i]
for item in kwargs.items(): payload[item[0]] = item[1]
return self._execute('stop', payload=payload, response_object=None)
def WaitForTest(self, *args, **kwargs):
# type: (*Any, **Any) -> Union[List[str], None]
"""Executes the waitForTest operation on the server.
Waits for the execution of the specified Quick Test to be completed.
waitForTest(async_operation=bool)list
-------------------------------------
- async_operation (bool=False): True to execute the operation asynchronously. Any subsequent rest api calls made through the Connection class will block until the operation is complete.
- Returns list(str): This method is synchronous and returns the result of the test.
Raises
------
- NotFoundError: The requested resource does not exist on the server
- ServerError: The server has encountered an uncategorized error condition
"""
payload = { "Arg1": self.href }
for i in range(len(args)): payload['Arg%s' % (i + 2)] = args[i]
for item in kwargs.items(): payload[item[0]] = item[1]
return self._execute('waitForTest', payload=payload, response_object=None)
| [
"pdobrinskiy@yahoo.com"
] | pdobrinskiy@yahoo.com |
a95e4c049406dd04cd6d40590beb853c62e01e36 | 99b1bf665ffb983f70ce85392652f25e96a620ad | /contig-correction/Snakefile | 4eaa27efa508605bf59c47d75118d27c27a51dfe | [] | no_license | faircloth-lab/phyluce-workflows | a5458face0a0c1ba71883f5f1743c20523933b73 | e4fd0f0ed689d5eb28f578b1ee66f504311420c9 | refs/heads/main | 2023-01-20T19:26:02.943663 | 2020-11-25T21:44:36 | 2020-11-25T21:44:36 | 301,446,072 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,365 | #!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
(c) 2020 Brant Faircloth || http://faircloth-lab.org/
All rights reserved.
This code is distributed under a 3-clause BSD license. Please see
LICENSE.txt for more information.
Created on 05 October 2020 11:27 CDT (-0500)
DESCRIPTION
Workflow uses bcftools to generate clean consensus sequences from BAM
files - ideally filtering low quality/coverage bases in the process.
Output written to `consensus` folder and filtered SNP calls retained.
"""
#import pdb
configfile: "config.yaml"
rule all:
input:
expand("consensus/{sample}.consensus.fasta", sample=config["contigs"])
rule generate_pileups:
input:
contig = lambda wildcards: config["contigs"][wildcards.sample],
bam = lambda wildcards: config["bams"][wildcards.sample]
output:
temp("pileups/{sample}.calls.bcf")
threads: 1
shell:
"bcftools mpileup -Ou -f {input.contig} {input.bam} | bcftools call -m -Ob -o {output}"
rule normalize_calls:
input:
contig = lambda wildcards: config["contigs"][wildcards.sample],
pileup = "pileups/{sample}.calls.bcf"
output:
temp("normalized_pileups/{sample}.norm.bcf")
threads: 1
shell:
"bcftools norm --rm-dup all -f {input.contig} {input.pileup} -Ob -o {output}"
rule filter_norm_pileups:
input:
"normalized_pileups/{sample}.norm.bcf"
output:
"filtered_norm_pileups/{sample}.norm.flt-indels.Q20.DP10.bcf"
threads: 1
shell:
"bcftools filter --IndelGap 5 --SnpGap 5 --exclude 'QUAL<20 | DP<5 | AN>2' {input} -Ob -o {output}"
rule index_filterd_pileups:
input:
"filtered_norm_pileups/{sample}.norm.flt-indels.Q20.DP10.bcf"
output:
"filtered_norm_pileups/{sample}.norm.flt-indels.Q20.DP10.bcf.csi"
threads: 1
shell:
"bcftools index {input}"
rule generate_consensus:
input:
contig = lambda wildcards: config["contigs"][wildcards.sample],
bcf = "filtered_norm_pileups/{sample}.norm.flt-indels.Q20.DP10.bcf",
idx = "filtered_norm_pileups/{sample}.norm.flt-indels.Q20.DP10.bcf.csi"
output:
"consensus/{sample}.consensus.fasta"
threads: 1
shell:
"bcftools consensus -f {input.contig} --absent '.' {input.bcf} | python ./scripts/filter-missing-from-bcftools.py > {output}" | [
"brant@faircloth-lab.org"
] | brant@faircloth-lab.org | |
a05b499012fd5a82c7c0f973a6a90e6ad43ba483 | 6170016478a8767f8e3b77eaa314fb338883a107 | /launchdarkly_api/models/custom_property.py | 669d4cea3783b0fab7ffdfc3bab8210e44cc5c81 | [
"Apache-2.0"
] | permissive | code-haven/api-client-python | 13c2f9aef8ed1a04b2c3838744ab3603d7cd5304 | db8274a2ec380c967209aa6ae12e074145615f9f | refs/heads/master | 2020-07-23T06:40:50.382967 | 2019-09-06T20:22:17 | 2019-09-06T20:22:17 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,934 | py | # coding: utf-8
"""
LaunchDarkly REST API
Build custom integrations with the LaunchDarkly REST API # noqa: E501
OpenAPI spec version: 2.0.18
Contact: support@launchdarkly.com
Generated by: https://github.com/swagger-api/swagger-codegen.git
"""
import pprint
import re # noqa: F401
import six
class CustomProperty(object):
"""NOTE: This class is auto generated by the swagger code generator program.
Do not edit the class manually.
"""
"""
Attributes:
swagger_types (dict): The key is attribute name
and the value is attribute type.
attribute_map (dict): The key is attribute name
and the value is json key in definition.
"""
swagger_types = {
'name': 'str',
'value': 'list[str]'
}
attribute_map = {
'name': 'name',
'value': 'value'
}
def __init__(self, name=None, value=None): # noqa: E501
"""CustomProperty - a model defined in Swagger""" # noqa: E501
self._name = None
self._value = None
self.discriminator = None
self.name = name
if value is not None:
self.value = value
@property
def name(self):
"""Gets the name of this CustomProperty. # noqa: E501
The name of the property. # noqa: E501
:return: The name of this CustomProperty. # noqa: E501
:rtype: str
"""
return self._name
@name.setter
def name(self, name):
"""Sets the name of this CustomProperty.
The name of the property. # noqa: E501
:param name: The name of this CustomProperty. # noqa: E501
:type: str
"""
if name is None:
raise ValueError("Invalid value for `name`, must not be `None`") # noqa: E501
self._name = name
@property
def value(self):
"""Gets the value of this CustomProperty. # noqa: E501
Values for this property. # noqa: E501
:return: The value of this CustomProperty. # noqa: E501
:rtype: list[str]
"""
return self._value
@value.setter
def value(self, value):
"""Sets the value of this CustomProperty.
Values for this property. # noqa: E501
:param value: The value of this CustomProperty. # noqa: E501
:type: list[str]
"""
self._value = value
def to_dict(self):
"""Returns the model properties as a dict"""
result = {}
for attr, _ in six.iteritems(self.swagger_types):
value = getattr(self, attr)
if isinstance(value, list):
result[attr] = list(map(
lambda x: x.to_dict() if hasattr(x, "to_dict") else x,
value
))
elif hasattr(value, "to_dict"):
result[attr] = value.to_dict()
elif isinstance(value, dict):
result[attr] = dict(map(
lambda item: (item[0], item[1].to_dict())
if hasattr(item[1], "to_dict") else item,
value.items()
))
else:
result[attr] = value
if issubclass(CustomProperty, dict):
for key, value in self.items():
result[key] = value
return result
def to_str(self):
"""Returns the string representation of the model"""
return pprint.pformat(self.to_dict())
def __repr__(self):
"""For `print` and `pprint`"""
return self.to_str()
def __eq__(self, other):
"""Returns true if both objects are equal"""
if not isinstance(other, CustomProperty):
return False
return self.__dict__ == other.__dict__
def __ne__(self, other):
"""Returns true if both objects are not equal"""
return not self == other
| [
"team@launchdarkly.com"
] | team@launchdarkly.com |
27e7bcbfd911e4ebf7ffeb8d6ae3516fbc28c2a3 | 641fa8341d8c436ad24945bcbf8e7d7d1dd7dbb2 | /headless/lib/browser/devtools_api/client_api_generator_unittest.py | f41ac0920a0d2a641be1c3a4c9c075fc0ecce3dd | [
"BSD-3-Clause"
] | permissive | massnetwork/mass-browser | 7de0dfc541cbac00ffa7308541394bac1e945b76 | 67526da9358734698c067b7775be491423884339 | refs/heads/master | 2022-12-07T09:01:31.027715 | 2017-01-19T14:29:18 | 2017-01-19T14:29:18 | 73,799,690 | 4 | 4 | BSD-3-Clause | 2022-11-26T11:53:23 | 2016-11-15T09:49:29 | null | UTF-8 | Python | false | false | 16,257 | py | #!/usr/bin/env python
# Copyright 2016 The Chromium Authors. All rights reserved.
# Use of this source code is governed by a BSD-style license that can be
# found in the LICENSE file.
import client_api_generator
import shutil
import sys
import tempfile
import unittest
class ClientApiGeneratorTest(unittest.TestCase):
def test_ArgumentParsing(self):
with tempfile.NamedTemporaryFile() as f:
f.write('{"foo": true}')
f.flush()
json_api, output_dir = client_api_generator.ParseArguments([
'--protocol', f.name, '--output_dir', 'out'])
self.assertEqual({'foo': True}, json_api)
self.assertEqual('out', output_dir)
def test_ToTitleCase(self):
self.assertEqual(client_api_generator.ToTitleCase('fooBar'), 'FooBar')
def test_DashToCamelCase(self):
self.assertEqual(client_api_generator.DashToCamelCase('foo-bar'), 'FooBar')
self.assertEqual(client_api_generator.DashToCamelCase('foo-'), 'Foo')
self.assertEqual(client_api_generator.DashToCamelCase('-bar'), 'Bar')
def test_CamelCaseToHackerStyle(self):
self.assertEqual(client_api_generator.CamelCaseToHackerStyle('FooBar'),
'foo_bar')
self.assertEqual(client_api_generator.CamelCaseToHackerStyle('LoLoLoL'),
'lo_lo_lol')
def test_SanitizeLiteralEnum(self):
self.assertEqual(client_api_generator.SanitizeLiteral('foo'), 'foo')
self.assertEqual(client_api_generator.SanitizeLiteral('null'), 'none')
self.assertEqual(client_api_generator.SanitizeLiteral('Infinity'),
'InfinityValue')
def test_PatchFullQualifiedRefs(self):
json_api = {
'domains': [
{
'domain': 'domain0',
'$ref': 'reference',
},
{
'domain': 'domain1',
'$ref': 'reference',
'more': [{'$ref': 'domain0.thing'}],
}
]
}
expected_json_api = {
'domains': [
{
'domain': 'domain0',
'$ref': 'domain0.reference',
},
{
'domain': 'domain1',
'$ref': 'domain1.reference',
'more': [{'$ref': 'domain0.thing'}],
}
]
}
client_api_generator.PatchFullQualifiedRefs(json_api)
self.assertDictEqual(json_api, expected_json_api)
def test_NumberType(self):
json_api = {
'domains': [
{
'domain': 'domain',
'types': [
{
'id': 'TestType',
'type': 'number',
},
]
},
]
}
client_api_generator.CreateTypeDefinitions(json_api)
type = json_api['domains'][0]['types'][0]
resolved = client_api_generator.ResolveType(type)
self.assertEqual('double', resolved['raw_type'])
def test_IntegerType(self):
json_api = {
'domains': [
{
'domain': 'domain',
'types': [
{
'id': 'TestType',
'type': 'integer',
},
]
},
]
}
client_api_generator.CreateTypeDefinitions(json_api)
type = json_api['domains'][0]['types'][0]
resolved = client_api_generator.ResolveType(type)
self.assertEqual('int', resolved['raw_type'])
def test_BooleanType(self):
json_api = {
'domains': [
{
'domain': 'domain',
'types': [
{
'id': 'TestType',
'type': 'boolean',
},
]
},
]
}
client_api_generator.CreateTypeDefinitions(json_api)
type = json_api['domains'][0]['types'][0]
resolved = client_api_generator.ResolveType(type)
self.assertEqual('bool', resolved['raw_type'])
def test_StringType(self):
json_api = {
'domains': [
{
'domain': 'domain',
'types': [
{
'id': 'TestType',
'type': 'string',
},
]
},
]
}
client_api_generator.CreateTypeDefinitions(json_api)
type = json_api['domains'][0]['types'][0]
resolved = client_api_generator.ResolveType(type)
self.assertEqual('std::string', resolved['raw_type'])
def test_ObjectType(self):
json_api = {
'domains': [
{
'domain': 'domain',
'types': [
{
'id': 'TestType',
'type': 'object',
'properties': [
{'name': 'p1', 'type': 'number'},
{'name': 'p2', 'type': 'integer'},
{'name': 'p3', 'type': 'boolean'},
{'name': 'p4', 'type': 'string'},
{'name': 'p5', 'type': 'any'},
{'name': 'p6', 'type': 'object', '$ref': 'TestType'},
],
'returns': [
{'name': 'r1', 'type': 'number'},
{'name': 'r2', 'type': 'integer'},
{'name': 'r3', 'type': 'boolean'},
{'name': 'r4', 'type': 'string'},
{'name': 'r5', 'type': 'any'},
{'name': 'r6', 'type': 'object', '$ref': 'TestType'},
],
},
]
},
]
}
client_api_generator.CreateTypeDefinitions(json_api)
type = json_api['domains'][0]['types'][0]
resolved = client_api_generator.ResolveType(type)
self.assertEqual('TestType', resolved['raw_type'])
def test_AnyType(self):
json_api = {
'domains': [
{
'domain': 'domain',
'types': [
{
'id': 'TestType',
'type': 'any',
},
]
},
]
}
client_api_generator.CreateTypeDefinitions(json_api)
type = json_api['domains'][0]['types'][0]
resolved = client_api_generator.ResolveType(type)
self.assertEqual('base::Value', resolved['raw_type'])
def test_ArrayType(self):
json_api = {
'domains': [
{
'domain': 'domain',
'types': [
{
'id': 'TestType',
'type': 'array',
'items': {'type': 'integer'}
},
]
},
]
}
client_api_generator.CreateTypeDefinitions(json_api)
type = json_api['domains'][0]['types'][0]
resolved = client_api_generator.ResolveType(type)
self.assertEqual('std::vector<int>', resolved['raw_type'])
def test_EnumType(self):
json_api = {
'domains': [
{
'domain': 'domain',
'types': [
{
'id': 'TestType',
'type': 'string',
'enum': ['a', 'b', 'c']
},
]
},
]
}
client_api_generator.CreateTypeDefinitions(json_api)
type = json_api['domains'][0]['types'][0]
resolved = client_api_generator.ResolveType(type)
self.assertEqual('headless::domain::TestType', resolved['raw_type'])
def test_SynthesizeCommandTypes(self):
json_api = {
'domains': [
{
'domain': 'domain',
'commands': [
{
'name': 'TestCommand',
'parameters': [
{'name': 'p1', 'type': 'number'},
{'name': 'p2', 'type': 'integer'},
{'name': 'p3', 'type': 'boolean'},
{'name': 'p4', 'type': 'string'},
{'name': 'p5', 'type': 'any'},
{'name': 'p6', 'type': 'object', '$ref': 'TestType'},
],
'returns': [
{'name': 'r1', 'type': 'number'},
{'name': 'r2', 'type': 'integer'},
{'name': 'r3', 'type': 'boolean'},
{'name': 'r4', 'type': 'string'},
{'name': 'r5', 'type': 'any'},
{'name': 'r6', 'type': 'object', '$ref': 'TestType'},
],
},
]
},
]
}
expected_types = [
{
'type': 'object',
'id': 'TestCommandParams',
'description': 'Parameters for the TestCommand command.',
'properties': [
{'type': 'number', 'name': 'p1'},
{'type': 'integer', 'name': 'p2'},
{'type': 'boolean', 'name': 'p3'},
{'type': 'string', 'name': 'p4'},
{'type': 'any', 'name': 'p5'},
{'type': 'object', 'name': 'p6', '$ref': 'TestType'}
],
},
{
'type': 'object',
'id': 'TestCommandResult',
'description': 'Result for the TestCommand command.',
'properties': [
{'type': 'number', 'name': 'r1'},
{'type': 'integer', 'name': 'r2'},
{'type': 'boolean', 'name': 'r3'},
{'type': 'string', 'name': 'r4'},
{'type': 'any', 'name': 'r5'},
{'type': 'object', 'name': 'r6', '$ref': 'TestType'}
],
}
]
client_api_generator.SynthesizeCommandTypes(json_api)
types = json_api['domains'][0]['types']
self.assertListEqual(types, expected_types)
def test_SynthesizeEventTypes(self):
json_api = {
'domains': [
{
'domain': 'domain',
'events': [
{
'name': 'TestEvent',
'parameters': [
{'name': 'p1', 'type': 'number'},
{'name': 'p2', 'type': 'integer'},
{'name': 'p3', 'type': 'boolean'},
{'name': 'p4', 'type': 'string'},
{'name': 'p5', 'type': 'any'},
{'name': 'p6', 'type': 'object', '$ref': 'TestType'},
]
},
{
'name': 'TestEventWithNoParams',
}
]
}
]
}
expected_types = [
{
'type': 'object',
'id': 'TestEventParams',
'description': 'Parameters for the TestEvent event.',
'properties': [
{'type': 'number', 'name': 'p1'},
{'type': 'integer', 'name': 'p2'},
{'type': 'boolean', 'name': 'p3'},
{'type': 'string', 'name': 'p4'},
{'type': 'any', 'name': 'p5'},
{'type': 'object', 'name': 'p6', '$ref': 'TestType'}
]
},
{
'type': 'object',
'id': 'TestEventWithNoParamsParams',
'description': 'Parameters for the TestEventWithNoParams event.',
'properties': [],
}
]
client_api_generator.SynthesizeEventTypes(json_api)
types = json_api['domains'][0]['types']
self.assertListEqual(types, expected_types)
def test_InitializeDomainDependencies(self):
json_api = {
'domains': [
{
'domain': 'Domain1',
'types': [
{
'id': 'TestType',
'type': 'object',
'properties': [
{'name': 'p1', 'type': 'object', '$ref': 'Domain2.TestType'},
],
},
],
},
{
'domain': 'Domain2',
'dependencies': ['Domain3'],
'types': [
{
'id': 'TestType',
'type': 'object',
'properties': [
{'name': 'p1', 'type': 'object', '$ref': 'Domain1.TestType'},
],
},
],
},
{
'domain': 'Domain3',
},
{
'domain': 'Domain4',
'dependencies': ['Domain1'],
},
]
}
client_api_generator.InitializeDomainDependencies(json_api)
dependencies = [ {
'domain': domain['domain'],
'dependencies': domain['dependencies']
} for domain in json_api['domains'] ]
self.assertListEqual(dependencies, [ {
"domain": "Domain1",
"dependencies": ["Domain1", "Domain2", "Domain3"],
}, {
"domain": "Domain2",
"dependencies": ["Domain1", "Domain2", "Domain3"],
}, {
"domain": "Domain3",
"dependencies": ["Domain3"],
}, {
"domain": "Domain4",
"dependencies": ["Domain1", "Domain2", "Domain3", "Domain4"],
}
])
def test_PatchExperimentalDomains(self):
json_api = {
'domains': [
{
'domain': 'domain',
'experimental': True,
'commands': [
{
'name': 'FooCommand',
}
],
'events': [
{
'name': 'BarEvent',
}
]
}
]
}
client_api_generator.PatchExperimentalCommandsAndEvents(json_api)
for command in json_api['domains'][0]['commands']:
self.assertTrue(command['experimental'])
for event in json_api['domains'][0]['events']:
self.assertTrue(command['experimental'])
def test_EnsureCommandsHaveParametersAndReturnTypes(self):
json_api = {
'domains': [
{
'domain': 'domain',
'commands': [
{
'name': 'FooCommand',
}
],
'events': [
{
'name': 'BarEvent',
}
]
}
]
}
expected_types = [
{
'type': 'object',
'id': 'FooCommandParams',
'description': 'Parameters for the FooCommand command.',
'properties': [],
},
{
'type': 'object',
'id': 'FooCommandResult',
'description': 'Result for the FooCommand command.',
'properties': [],
},
{
'type': 'object',
'id': 'BarEventParams',
'description': 'Parameters for the BarEvent event.',
'properties': [],
}
]
client_api_generator.EnsureCommandsHaveParametersAndReturnTypes(json_api)
client_api_generator.SynthesizeCommandTypes(json_api)
client_api_generator.SynthesizeEventTypes(json_api)
types = json_api['domains'][0]['types']
self.assertListEqual(types, expected_types)
def test_Generate(self):
json_api = {
'domains': [
{
'domain': 'domain',
'types': [
{
'id': 'TestType',
'type': 'object',
'properties': [
{'name': 'p1', 'type': 'number'},
{'name': 'p2', 'type': 'integer'},
{'name': 'p3', 'type': 'boolean'},
{'name': 'p4', 'type': 'string'},
{'name': 'p5', 'type': 'any'},
{'name': 'p6', 'type': 'object', '$ref': 'domain.TestType'},
],
'returns': [
{'name': 'r1', 'type': 'number'},
{'name': 'r2', 'type': 'integer'},
{'name': 'r3', 'type': 'boolean'},
{'name': 'r4', 'type': 'string'},
{'name': 'r5', 'type': 'any'},
{'name': 'r6', 'type': 'object', '$ref': 'domain.TestType'},
],
},
]
},
]
}
try:
dirname = tempfile.mkdtemp()
jinja_env = client_api_generator.InitializeJinjaEnv(dirname)
client_api_generator.CreateTypeDefinitions(json_api)
client_api_generator.Generate(jinja_env, dirname, json_api,
'deprecated_types', ['h'])
# This is just a smoke test; we don't actually verify the generated output
# here.
finally:
shutil.rmtree(dirname)
def test_GenerateDomains(self):
json_api = {
'domains': [
{
'domain': 'domain0',
'types': [
{
'id': 'TestType',
'type': 'object',
},
]
},
{
'domain': 'domain1',
'types': [
{
'id': 'TestType',
'type': 'object',
},
]
},
]
}
try:
dirname = tempfile.mkdtemp()
jinja_env = client_api_generator.InitializeJinjaEnv(dirname)
client_api_generator.GeneratePerDomain(
jinja_env, dirname, json_api,
'domain', ['cc', 'h'], lambda domain_name: domain_name)
# This is just a smoke test; we don't actually verify the generated output
# here.
finally:
shutil.rmtree(dirname)
if __name__ == '__main__':
unittest.main(verbosity=2, exit=False, argv=sys.argv)
| [
"xElvis89x@gmail.com"
] | xElvis89x@gmail.com |
508a23a4d188356b07d5a88ed599124af9d30f1f | 88be4d5657d19462eb1d74d2d4d98180b423a889 | /robolearn/torch/utils/distributions/multivariate_normal.py | 0fd9d2cc6673f6500218f8d740c4c099b6f9d4de | [
"BSD-3-Clause"
] | permissive | domingoesteban/robolearn | bc58278fe38894f4ca9ec9e657ee13a479a368b7 | 0d20125425c352b80ef2eeed1c0b11ab6497b11a | refs/heads/master | 2020-04-15T22:38:25.343229 | 2019-01-29T17:01:42 | 2019-01-29T17:01:42 | 165,080,647 | 1 | 1 | null | null | null | null | UTF-8 | Python | false | false | 10,119 | py | import math
import torch
from torch.distributions import constraints
from torch.distributions.distribution import Distribution
from torch.distributions.utils import lazy_property
def _get_batch_shape(bmat, bvec):
r"""
Given a batch of matrices and a batch of vectors, compute the combined `batch_shape`.
"""
try:
vec_shape = torch._C._infer_size(bvec.shape, bmat.shape[:-1])
except RuntimeError:
raise ValueError("Incompatible batch shapes: vector {}, matrix {}".format(bvec.shape, bmat.shape))
return vec_shape[:-1]
def _batch_mv(bmat, bvec):
r"""
Performs a batched matrix-vector product, with compatible but different batch shapes.
This function takes as input `bmat`, containing :math:`n \times n` matrices, and
`bvec`, containing length :math:`n` vectors.
Both `bmat` and `bvec` may have any number of leading dimensions, which correspond
to a batch shape. They are not necessarily assumed to have the same batch shape,
just ones which can be broadcasted.
"""
return torch.matmul(bmat, bvec.unsqueeze(-1)).squeeze(-1)
def _batch_potrf_lower(bmat):
r"""
Applies a Cholesky decomposition to all matrices in a batch of arbitrary shape.
"""
n = bmat.size(-1)
cholesky = torch.stack([m.potrf(upper=False) for m in bmat.reshape(-1, n, n)])
return cholesky.reshape(bmat.shape)
def _batch_diag(bmat):
r"""
Returns the diagonals of a batch of square matrices.
"""
return torch.diagonal(bmat, dim1=-2, dim2=-1)
def _batch_inverse(bmat):
r"""
Returns the inverses of a batch of square matrices.
"""
n = bmat.size(-1)
flat_bmat_inv = torch.stack([m.inverse() for m in bmat.reshape(-1, n, n)])
return flat_bmat_inv.reshape(bmat.shape)
def _batch_trtrs_lower(bb, bA):
"""
Applies `torch.trtrs` for batches of matrices. `bb` and `bA` should have
the same batch shape.
"""
flat_b = bb.reshape((-1,) + bb.shape[-2:])
flat_A = bA.reshape((-1,) + bA.shape[-2:])
# TODO: REDUCE COMPUTATION TIME OF THE FOLLOWING OP:
flat_X = torch.stack([torch.trtrs(b, A, upper=False)[0] for b, A in zip(flat_b, flat_A)])
return flat_X.reshape(bb.shape)
def _batch_mahalanobis(bL, bx):
r"""
Computes the squared Mahalanobis distance :math:`\mathbf{x}^\top\mathbf{M}^{-1}\mathbf{x}`
for a factored :math:`\mathbf{M} = \mathbf{L}\mathbf{L}^\top`.
Accepts batches for both bL and bx. They are not necessarily assumed to have the same batch
shape, but `bL` one should be able to broadcasted to `bx` one.
"""
n = bx.size(-1)
bL = bL.expand(bx.shape[bx.dim() - bL.dim() + 1:] + (n,))
flat_L = bL.reshape(-1, n, n) # shape = b x n x n
flat_x = bx.reshape(-1, flat_L.size(0), n) # shape = c x b x n
flat_x_swap = flat_x.permute(1, 2, 0) # shape = b x n x c
M_swap = _batch_trtrs_lower(flat_x_swap, flat_L).pow(2).sum(-2) # shape = b x c
return M_swap.t().reshape(bx.shape[:-1])
def _batch_diagonal_mahalanobis(bL, bx):
r"""
Computes the squared Mahalanobis distance :math:`\mathbf{x}^\top\mathbf{M}^{-1}\mathbf{x}`
for a factored :math:`\mathbf{M} = \mathbf{L}\mathbf{L}^\top`.
Accepts batches for both bL and bx. They are not necessarily assumed to have the same batch
shape, but `bL` one should be able to broadcasted to `bx` one.
"""
n = bx.size(-1)
bL = bL.expand(bx.shape[bx.dim() - bL.dim() + 1:] + (n,))
flat_L = bL.reshape(-1, n, n) # shape = b x n x n
flat_x = bx.reshape(-1, flat_L.size(0), n) # shape = c x b x n
flat_x_swap = flat_x.permute(1, 2, 0) # shape = b x n x c
M_swap = _batch_trtrs_lower(flat_x_swap, flat_L).pow(2).sum(-2) # shape = b x c
return M_swap.t().reshape(bx.shape[:-1])
class MultivariateNormal(Distribution):
r"""
Creates a multivariate normal (also called Gaussian) distribution
parameterized by a mean vector and a covariance matrix.
The multivariate normal distribution can be parameterized either
in terms of a positive definite covariance matrix :math:`\mathbf{\Sigma}`
or a positive definite precision matrix :math:`\mathbf{\Sigma}^{-1}`
or a lower-triangular matrix :math:`\mathbf{L}` with positive-valued
diagonal entries, such that
:math:`\mathbf{\Sigma} = \mathbf{L}\mathbf{L}^\top`. This triangular matrix
can be obtained via e.g. Cholesky decomposition of the covariance.
Example:
>>> m = MultivariateNormal(torch.zeros(2), torch.eye(2))
>>> m.sample() # normally distributed with mean=`[0,0]` and covariance_matrix=`I`
tensor([-0.2102, -0.5429])
Args:
loc (Tensor): mean of the distribution
covariance_matrix (Tensor): positive-definite covariance matrix
precision_matrix (Tensor): positive-definite precision matrix
scale_tril (Tensor): lower-triangular factor of covariance, with positive-valued diagonal
Note:
Only one of :attr:`covariance_matrix` or :attr:`precision_matrix` or
:attr:`scale_tril` can be specified.
Using :attr:`scale_tril` will be more efficient: all computations internally
are based on :attr:`scale_tril`. If :attr:`covariance_matrix` or
:attr:`precision_matrix` is passed instead, it is only used to compute
the corresponding lower triangular matrices using a Cholesky decomposition.
"""
arg_constraints = {'loc': constraints.real_vector,
'covariance_matrix': constraints.positive_definite,
'precision_matrix': constraints.positive_definite,
'scale_tril': constraints.lower_cholesky}
support = constraints.real
has_rsample = True
def __init__(self, loc, covariance_matrix=None, precision_matrix=None, scale_tril=None, validate_args=None, diagonal_covar=False):
if loc.dim() < 1:
raise ValueError("loc must be at least one-dimensional.")
event_shape = loc.shape[-1:]
if (covariance_matrix is not None) + (scale_tril is not None) + (precision_matrix is not None) != 1:
raise ValueError("Exactly one of covariance_matrix or precision_matrix or scale_tril may be specified.")
if scale_tril is not None:
if scale_tril.dim() < 2:
raise ValueError("scale_tril matrix must be at least two-dimensional, "
"with optional leading batch dimensions")
self._unbroadcasted_scale_tril = scale_tril
batch_shape = _get_batch_shape(scale_tril, loc)
self.scale_tril = scale_tril.expand(batch_shape + event_shape + event_shape)
elif covariance_matrix is not None:
if covariance_matrix.dim() < 2:
raise ValueError("covariance_matrix must be at least two-dimensional, "
"with optional leading batch dimensions")
self._unbroadcasted_scale_tril = _batch_potrf_lower(covariance_matrix)
batch_shape = _get_batch_shape(covariance_matrix, loc)
self.covariance_matrix = covariance_matrix.expand(batch_shape + event_shape + event_shape)
else:
if precision_matrix.dim() < 2:
raise ValueError("precision_matrix must be at least two-dimensional, "
"with optional leading batch dimensions")
covariance_matrix = _batch_inverse(precision_matrix)
self._unbroadcasted_scale_tril = _batch_potrf_lower(covariance_matrix)
batch_shape = _get_batch_shape(precision_matrix, loc)
self.precision_matrix = precision_matrix.expand(batch_shape + event_shape + event_shape)
self.covariance_matrix = covariance_matrix.expand(batch_shape + event_shape + event_shape)
self.loc = loc.expand(batch_shape + event_shape)
super(MultivariateNormal, self).__init__(batch_shape, event_shape, validate_args=validate_args)
self._is_covariance_diagonal = diagonal_covar
@lazy_property
def scale_tril(self):
return self._unbroadcasted_scale_tril.expand(
self._batch_shape + self._event_shape + self._event_shape)
@lazy_property
def covariance_matrix(self):
return (torch.matmul(self._unbroadcasted_scale_tril,
self._unbroadcasted_scale_tril.transpose(-1, -2))
.expand(self._batch_shape + self._event_shape + self._event_shape))
@lazy_property
def precision_matrix(self):
# TODO: use `torch.potri` on `scale_tril` once a backwards pass is implemented.
scale_tril_inv = _batch_inverse(self._unbroadcasted_scale_tril)
return torch.matmul(scale_tril_inv.transpose(-1, -2), scale_tril_inv).expand(
self._batch_shape + self._event_shape + self._event_shape)
@property
def mean(self):
return self.loc
@property
def variance(self):
return self._unbroadcasted_scale_tril.pow(2).sum(-1).expand(
self._batch_shape + self._event_shape)
def rsample(self, sample_shape=torch.Size()):
shape = self._extended_shape(sample_shape)
eps = self.loc.new_empty(shape).normal_()
return self.loc + _batch_mv(self._unbroadcasted_scale_tril, eps)
def log_prob(self, value, diagonal=False):
if self._validate_args:
self._validate_sample(value)
diff = value - self.loc
if self._is_covariance_diagonal:
M = _batch_diagonal_mahalanobis(self._unbroadcasted_scale_tril, diff)
else:
M = _batch_mahalanobis(self._unbroadcasted_scale_tril, diff)
half_log_det = _batch_diag(self._unbroadcasted_scale_tril).log().sum(-1)
return -0.5 * (self._event_shape[0] * math.log(2 * math.pi) + M) - half_log_det
def entropy(self):
half_log_det = _batch_diag(self._unbroadcasted_scale_tril).log().sum(-1)
H = 0.5 * self._event_shape[0] * (1.0 + math.log(2 * math.pi)) + half_log_det
if len(self._batch_shape) == 0:
return H
else:
return H.expand(self._batch_shape)
| [
"domingo.esteban@iit.it"
] | domingo.esteban@iit.it |
6c81359626132a59b8474290e358e3ac3032a2a0 | 66b1f3c3e57f53e1404d6e17c4acc850173a531d | /Python/ProgramingBasic/SimpleLoops/01.NumbersFrom1to100.py | 002389dcb1b313b80f78f240cbf4f9bbddc69716 | [] | no_license | bMedarski/SoftUni | ca4d6891b3bbe7b03aad5960d2f4af5479fd8bbd | 62cd9cb84b0826e3381c991882a4cdc27d94f8ab | refs/heads/master | 2021-06-08T17:32:39.282975 | 2020-02-04T11:57:08 | 2020-02-04T11:57:08 | 67,947,148 | 6 | 3 | null | 2021-05-06T20:35:42 | 2016-09-11T18:31:02 | Python | UTF-8 | Python | false | false | 36 | py | for i in range (1,101):
print(i) | [
"boyamedarski@mail.bg"
] | boyamedarski@mail.bg |
958f0566700d34656e72409f54b7079c6e6ae296 | 47ce68e1ff970318fd31ac43405d0e1fa3594bf6 | /Models/biGAN/BasicBiganXEntropyShallowerExtraGencTraining.py | 6bd00db4117de8b5cb4547d18fa1f6de23a2abab | [
"BSD-3-Clause"
] | permissive | Midoriii/Anomaly_Detection_Diploma | 7196da379f8aefbd4546ca23e8303d1829e059fb | 11145e3e5210a4e45a33d98b138213edb7bc5d3d | refs/heads/master | 2023-03-25T20:42:56.961210 | 2021-03-14T01:13:39 | 2021-03-14T01:13:39 | 261,205,472 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 6,943 | py | '''
Copyright (c) 2021, Štěpán Beneš
Basic bigAN net, using cross entropy as loss and shallower architecture
with extra G and E training
'''
import numpy as np
from Models.biGAN.BaseBiganModel import BaseBiganModel
from Models.Losses.custom_losses import wasserstein_loss
from Models.biGAN.weightclip_constraint import WeightClip
from keras.layers import Input, Reshape, Dense, Flatten, concatenate
from keras.layers import UpSampling2D, Conv2D, MaxPooling2D, BatchNormalization, Dropout, LeakyReLU
from keras.models import Model
from keras.optimizers import RMSprop, Adam, SGD
class BasicBiganXEntropyShallowerExtraGencTraining(BaseBiganModel):
def __init__(self, input_shape, latent_dim=48, lr=0.0005, w_clip=0.01, batch_size=4):
super().__init__(input_shape, latent_dim, lr, w_clip, batch_size)
self.name = "BasicBiganXEntropyShallowerExtraGencTraining"
g_optimizer = Adam(lr=self.lr, beta_1=0.5)
d_optimizer = SGD(lr=self.lr)
self.disc_labels_real = np.zeros((self.batch_size, 1))
self.genc_labels_real = np.zeros((self.batch_size, 1))
self.genc_labels_fake = np.ones((self.batch_size, 1))
self.disc_labels_fake = np.ones((self.batch_size, 1))
self.d = self.build_discriminator()
self.d.compile(optimizer=d_optimizer, loss='binary_crossentropy', metrics=['accuracy'])
self.g = self.build_generator()
self.e = self.build_encoder()
# The Discriminator part in GE model won't be trainable - GANs take turns.
# Since the Discrimiantor itself has been previously compiled, this won't affect it.
self.d.trainable = False
self.ge = self.build_ge_enc()
self.ge.compile(optimizer=g_optimizer, loss=['binary_crossentropy', 'binary_crossentropy'])
return
def build_generator(self):
z_input = Input(shape=[self.latent_dim])
x = Dense(24*24*32)(z_input)
x = Reshape([24, 24, 32])(x)
# 24 -> 48
x = Conv2D(32, (3, 3), padding='same')(x)
x = LeakyReLU(0.1)(x)
x = UpSampling2D((2, 2))(x)
# 48 -> 96
x = Conv2D(32, (3, 3), padding='same')(x)
x = LeakyReLU(0.1)(x)
x = UpSampling2D((2, 2))(x)
# 96 -> 192
x = Conv2D(32, (3, 3), padding='same')(x)
x = LeakyReLU(0.1)(x)
x = UpSampling2D((2, 2))(x)
# 192 -> 384
x = Conv2D(32, (3, 3), padding='same')(x)
x = LeakyReLU(0.1)(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(1, (3, 3), activation='tanh', padding='same')(x)
return Model(inputs=z_input, outputs=x)
def build_encoder(self):
img_input = Input(shape=[self.input_shape, self.input_shape, 1])
# 384 -> 192
x = Conv2D(32, (3, 3), padding='same')(img_input)
x = LeakyReLU(0.1)(x)
x = MaxPooling2D((2, 2), padding='same')(x)
# 192 -> 96
x = Conv2D(32, (3, 3), padding='same')(x)
x = LeakyReLU(0.1)(x)
x = MaxPooling2D((2, 2), padding='same')(x)
# 96 -> 48
x = Conv2D(32, (3, 3), padding='same')(x)
x = LeakyReLU(0.1)(x)
x = MaxPooling2D((2, 2), padding='same')(x)
# 48 -> 24
x = Conv2D(32, (3, 3), padding='same')(x)
x = LeakyReLU(0.1)(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Flatten()(x)
x = Dense(256)(x)
x = LeakyReLU(0.1)(x)
x = Dense(self.latent_dim)(x)
return Model(inputs=img_input, outputs=x)
def build_discriminator(self):
img_input = Input(shape=[self.input_shape, self.input_shape, 1])
z_input = Input(shape=[self.latent_dim])
# Latent
l = Dense(256)(z_input)
l = LeakyReLU(0.1)(l)
l = Dense(256)(l)
l = LeakyReLU(0.1)(l)
# Image
x = Conv2D(64, (3, 3), padding='same')(img_input)
x = BatchNormalization()(x)
x = LeakyReLU(0.1)(x)
x = Dropout(rate=self.dropout)(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(64, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(0.1)(x)
x = Dropout(rate=self.dropout)(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(128, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(0.1)(x)
x = Dropout(rate=self.dropout)(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(128, (3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(0.1)(x)
x = Dropout(rate=self.dropout)(x)
x = MaxPooling2D((2, 2), padding='same')(x)
# Joint
x = Flatten()(x)
x = concatenate([x, l])
x = Dense(256)(x)
x = LeakyReLU(0.1)(x)
x = Dense(1, activation='sigmoid')(x)
return Model(inputs=[img_input, z_input], outputs=x)
def build_ge_enc(self):
img_input = Input(shape=[self.input_shape, self.input_shape, 1])
z_input = Input(shape=[self.latent_dim])
fake_imgs = self.g(z_input)
critic_fake = self.d([fake_imgs, z_input])
fake_z = self.e(img_input)
critic_real = self.d([img_input, fake_z])
return Model(inputs=[img_input, z_input], outputs=[critic_real, critic_fake])
def train(self, images, epochs):
for epoch in range(epochs):
# D training
noise = self.latent_noise(self.batch_size, self.latent_dim)
img_batch = self.get_image_batch(images, self.batch_size)
fake_noise = self.e.predict(img_batch)
fake_img_batch = self.g.predict(noise)
d_real_loss = self.d.train_on_batch([img_batch, fake_noise], self.disc_labels_real)
self.dr_losses.append(d_real_loss[0])
self.dr_acc.append(d_real_loss[1])
d_fake_loss = self.d.train_on_batch([fake_img_batch, noise], self.disc_labels_fake)
self.df_losses.append(d_fake_loss[0])
self.df_acc.append(d_fake_loss[1])
d_loss = (0.5 * np.add(d_real_loss, d_fake_loss))
self.d_losses.append(d_loss[0])
# E+G training
ge_enc_loss = np.empty(3)
for _ in range(0, 5):
noise = self.latent_noise(self.batch_size, self.latent_dim)
img_batch = self.get_image_batch(images, self.batch_size)
ge_enc_loss += self.ge.train_on_batch([img_batch, noise],
[self.genc_labels_fake, self.genc_labels_real])
self.e_losses.append(ge_enc_loss[1]/5.0)
self.g_losses.append(ge_enc_loss[2]/5.0)
print("Epoch: " + str(epoch) + ", D loss: " + str(d_loss[0])
+ "; D acc: " + str(d_loss[1]) + "; E loss: " + str(ge_enc_loss[1]/5.0)
+ "; G loss: " + str(ge_enc_loss[2]/5.0))
return
| [
"stephen.Team24@gmail.com"
] | stephen.Team24@gmail.com |
f14570e9a9148eec246c2a9ad05c0655af553abb | 21553bf9df9db7458a25963ece522d8c27a7d598 | /piafedit/model/geometry/trajectory.py | 2975ef1564ee8f56115e0499d67a35b8f784829d | [
"MIT"
] | permissive | flegac/piaf-edit | 6ac0638ff2aef542da3f75b844080ea0e9771aa5 | d100231c0c60cd4412dd37b22a88fe7bb5fb4982 | refs/heads/main | 2023-05-10T22:07:50.709835 | 2021-05-30T18:17:58 | 2021-05-30T18:17:58 | 360,704,766 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 771 | py | from typing import TypeVar, Generic, List
T = TypeVar('T')
class Trajectory(Generic[T]):
def __init__(self, trajectory: List[T]):
self.trajectory = trajectory
def iter(self, n: int):
for i in range(n):
a = i / (n - 1)
yield self.interpolate(a)
def interpolate(self, a: float) -> T:
points = len(self.trajectory)
intervals = points - 1
inter_size = 1. / intervals
for i in range(points - 1):
if a <= inter_size:
b = a / inter_size
return self.trajectory[i].interpolate(b, self.trajectory[i + 1])
else:
a -= inter_size
b = 1.0 + a
return self.trajectory[-2].interpolate(b, self.trajectory[-1])
| [
"florent.legac@gmail.com"
] | florent.legac@gmail.com |
4f785efd07f62c9c894e3570fdb55167daa3f18a | 651fc810476aaf8752909160013a491acbdea00c | /imperative/python/megengine/module/dropout.py | 8bf6213fa4e1df0bcd9d07f7f11ff2b6456de839 | [
"LicenseRef-scancode-generic-cla",
"Apache-2.0"
] | permissive | jonrzhang/MegEngine | 7cec9df6e561cc13e7a3292fd160f16b05305222 | 94b72022156a068d3e87bceed7e1c7ae77dada16 | refs/heads/master | 2021-04-22T18:33:16.837256 | 2021-03-16T02:27:55 | 2021-03-16T02:27:55 | 249,868,433 | 0 | 0 | NOASSERTION | 2021-03-16T02:27:55 | 2020-03-25T02:29:51 | null | UTF-8 | Python | false | false | 1,309 | py | # -*- coding: utf-8 -*-
# MegEngine is Licensed under the Apache License, Version 2.0 (the "License")
#
# Copyright (c) 2014-2020 Megvii Inc. All rights reserved.
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT ARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
from ..functional import dropout
from .module import Module
class Dropout(Module):
r"""
Randomly sets input elements to zeros with the probability :math:`drop\_prob` during training.
Commonly used in large networks to prevent overfitting.
Note that we perform dropout only during training, we also rescale(multiply) the output tensor
by :math:`\frac{1}{1 - drop\_prob}`. During inference :class:`~.Dropout` is equal to :class:`~.Identity`.
:param drop_prob: The probability to drop (set to zero) each single element
"""
def __init__(self, drop_prob=0.0):
super().__init__()
self.drop_prob = drop_prob
def forward(self, inputs):
if self.training:
return dropout(inputs, self.drop_prob, training=True)
else:
return inputs
def _module_info_string(self) -> str:
return "drop_prob={drop_prob}".format(drop_prob=self.drop_prob)
| [
"megengine@megvii.com"
] | megengine@megvii.com |
f02f1beb68b2b5cf134cae20b12245d0ebbe4877 | 145ba6d4e6176f26fc4c105181e3be380366df16 | /external/workload-automation/tests/test_exec_control.py | 8e551146df340a560b5b954c26eacac68eba8865 | [
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
] | permissive | keroles/lisa | e53005ea77ccb7725ea605f8d7675fd70cae7c1b | 9a0fc0421b8ce919f4a6203ca88b246131e8d22e | refs/heads/master | 2020-07-23T02:51:36.379063 | 2019-09-05T17:47:24 | 2019-09-05T17:47:24 | 207,424,438 | 1 | 0 | Apache-2.0 | 2019-09-09T23:40:02 | 2019-09-09T23:40:01 | null | UTF-8 | Python | false | false | 8,665 | py | # Copyright 2013-2018 ARM Limited
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# pylint: disable=W0231,W0613,E0611,W0603,R0201
from unittest import TestCase
from nose.tools import assert_equal, assert_raises
from wa.utils.exec_control import (init_environment, reset_environment,
activate_environment, once,
once_per_class, once_per_instance)
class TestClass(object):
called = 0
def __init__(self):
self.count = 0
@once
def called_once(self):
TestClass.called += 1
@once
def initilize_once(self):
self.count += 1
@once_per_class
def initilize_once_per_class(self):
self.count += 1
@once_per_instance
def initilize_once_per_instance(self):
self.count += 1
def __repr__(self):
return '{}: Called={}'.format(self.__class__.__name__, self.called)
class SubClass(TestClass):
def __init__(self):
super(SubClass, self).__init__()
@once
def initilize_once(self):
super(SubClass, self).initilize_once()
self.count += 1
@once_per_class
def initilize_once_per_class(self):
super(SubClass, self).initilize_once_per_class()
self.count += 1
@once_per_instance
def initilize_once_per_instance(self):
super(SubClass, self).initilize_once_per_instance()
self.count += 1
class SubSubClass(SubClass):
def __init__(self):
super(SubSubClass, self).__init__()
@once
def initilize_once(self):
super(SubSubClass, self).initilize_once()
self.count += 1
@once_per_class
def initilize_once_per_class(self):
super(SubSubClass, self).initilize_once_per_class()
self.count += 1
@once_per_instance
def initilize_once_per_instance(self):
super(SubSubClass, self).initilize_once_per_instance()
self.count += 1
class AnotherClass(object):
def __init__(self):
self.count = 0
@once
def initilize_once(self):
self.count += 1
@once_per_class
def initilize_once_per_class(self):
self.count += 1
@once_per_instance
def initilize_once_per_instance(self):
self.count += 1
class AnotherSubClass(TestClass):
def __init__(self):
super(AnotherSubClass, self).__init__()
@once
def initilize_once(self):
super(AnotherSubClass, self).initilize_once()
self.count += 1
@once_per_class
def initilize_once_per_class(self):
super(AnotherSubClass, self).initilize_once_per_class()
self.count += 1
@once_per_instance
def initilize_once_per_instance(self):
super(AnotherSubClass, self).initilize_once_per_instance()
self.count += 1
class EnvironmentManagementTest(TestCase):
def test_duplicate_environment(self):
init_environment('ENVIRONMENT')
assert_raises(ValueError, init_environment, 'ENVIRONMENT')
def test_reset_missing_environment(self):
assert_raises(ValueError, reset_environment, 'MISSING')
def test_reset_current_environment(self):
activate_environment('CURRENT_ENVIRONMENT')
t1 = TestClass()
t1.initilize_once()
assert_equal(t1.count, 1)
reset_environment()
t1.initilize_once()
assert_equal(t1.count, 2)
def test_switch_environment(self):
activate_environment('ENVIRONMENT1')
t1 = TestClass()
t1.initilize_once()
assert_equal(t1.count, 1)
activate_environment('ENVIRONMENT2')
t1.initilize_once()
assert_equal(t1.count, 2)
activate_environment('ENVIRONMENT1')
t1.initilize_once()
assert_equal(t1.count, 2)
def test_reset_environment_name(self):
activate_environment('ENVIRONMENT')
t1 = TestClass()
t1.initilize_once()
assert_equal(t1.count, 1)
reset_environment('ENVIRONMENT')
t1.initilize_once()
assert_equal(t1.count, 2)
class ParentOnlyOnceEvironmentTest(TestCase):
def test_sub_classes(self):
sc = SubClass()
asc = AnotherSubClass()
sc.called_once()
assert_equal(sc.called, 1)
asc.called_once()
assert_equal(asc.called, 1)
class OnlyOnceEnvironmentTest(TestCase):
def setUp(self):
activate_environment('TEST_ENVIRONMENT')
def tearDown(self):
reset_environment('TEST_ENVIRONMENT')
def test_single_instance(self):
t1 = TestClass()
ac = AnotherClass()
t1.initilize_once()
assert_equal(t1.count, 1)
t1.initilize_once()
assert_equal(t1.count, 1)
ac.initilize_once()
assert_equal(ac.count, 1)
def test_mulitple_instances(self):
t1 = TestClass()
t2 = TestClass()
t1.initilize_once()
assert_equal(t1.count, 1)
t2.initilize_once()
assert_equal(t2.count, 0)
def test_sub_classes(self):
t1 = TestClass()
sc = SubClass()
ss = SubSubClass()
asc = AnotherSubClass()
t1.initilize_once()
assert_equal(t1.count, 1)
sc.initilize_once()
sc.initilize_once()
assert_equal(sc.count, 1)
ss.initilize_once()
ss.initilize_once()
assert_equal(ss.count, 1)
asc.initilize_once()
asc.initilize_once()
assert_equal(asc.count, 1)
class OncePerClassEnvironmentTest(TestCase):
def setUp(self):
activate_environment('TEST_ENVIRONMENT')
def tearDown(self):
reset_environment('TEST_ENVIRONMENT')
def test_single_instance(self):
t1 = TestClass()
ac = AnotherClass()
t1.initilize_once_per_class()
assert_equal(t1.count, 1)
t1.initilize_once_per_class()
assert_equal(t1.count, 1)
ac.initilize_once_per_class()
assert_equal(ac.count, 1)
def test_mulitple_instances(self):
t1 = TestClass()
t2 = TestClass()
t1.initilize_once_per_class()
assert_equal(t1.count, 1)
t2.initilize_once_per_class()
assert_equal(t2.count, 0)
def test_sub_classes(self):
t1 = TestClass()
sc1 = SubClass()
sc2 = SubClass()
ss1 = SubSubClass()
ss2 = SubSubClass()
asc = AnotherSubClass()
t1.initilize_once_per_class()
assert_equal(t1.count, 1)
sc1.initilize_once_per_class()
sc2.initilize_once_per_class()
assert_equal(sc1.count, 1)
assert_equal(sc2.count, 0)
ss1.initilize_once_per_class()
ss2.initilize_once_per_class()
assert_equal(ss1.count, 1)
assert_equal(ss2.count, 0)
asc.initilize_once_per_class()
assert_equal(asc.count, 1)
class OncePerInstanceEnvironmentTest(TestCase):
def setUp(self):
activate_environment('TEST_ENVIRONMENT')
def tearDown(self):
reset_environment('TEST_ENVIRONMENT')
def test_single_instance(self):
t1 = TestClass()
ac = AnotherClass()
t1.initilize_once_per_instance()
assert_equal(t1.count, 1)
t1.initilize_once_per_instance()
assert_equal(t1.count, 1)
ac.initilize_once_per_instance()
assert_equal(ac.count, 1)
def test_mulitple_instances(self):
t1 = TestClass()
t2 = TestClass()
t1.initilize_once_per_instance()
assert_equal(t1.count, 1)
t2.initilize_once_per_instance()
assert_equal(t2.count, 1)
def test_sub_classes(self):
t1 = TestClass()
sc = SubClass()
ss = SubSubClass()
asc = AnotherSubClass()
t1.initilize_once_per_instance()
assert_equal(t1.count, 1)
sc.initilize_once_per_instance()
sc.initilize_once_per_instance()
assert_equal(sc.count, 2)
ss.initilize_once_per_instance()
ss.initilize_once_per_instance()
assert_equal(ss.count, 3)
asc.initilize_once_per_instance()
asc.initilize_once_per_instance()
assert_equal(asc.count, 2)
| [
"douglas.raillard@arm.com"
] | douglas.raillard@arm.com |
ae4dab755dc271424119097ef054be7783d21425 | 6268655719a46c9d2b6b38ea21babd8b877724dd | /ecom/migrations/0005_leadsection.py | bc01996abf1ce76a18dea1b1c916d1751e08ca96 | [] | no_license | MahmudulHassan5809/Ecommerce-Django | f84b968621eed61fdf08c55cd43c7a09d8bc8ba7 | f416536a6b5ce583283139e7271f3fcd1da49739 | refs/heads/master | 2022-12-31T15:39:34.405140 | 2020-10-24T18:15:38 | 2020-10-24T18:15:38 | 292,297,321 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,049 | py | # Generated by Django 3.0.7 on 2020-09-05 16:04
from django.db import migrations, models
import django.db.models.deletion
class Migration(migrations.Migration):
dependencies = [
('ecom', '0004_product_discount'),
]
operations = [
migrations.CreateModel(
name='LeadSection',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('first_lead', models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, related_name='category_first_lead', to='ecom.Category')),
('second_lead', models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, related_name='category_second_lead', to='ecom.Category')),
('third_lead', models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, related_name='category_third_lead', to='ecom.Category')),
],
options={
'verbose_name_plural': '3.Lead Sections',
},
),
]
| [
"mahmudul.hassan240@gmail.com"
] | mahmudul.hassan240@gmail.com |
48b022333a2f33b842ba7c6e9d0341b085c60c78 | 53abcba37ef0fd69bd90453b175f936edcca842c | /Facebook/56.py | f9555a2c795b1fb7eea599997c65283ab4705cfc | [] | no_license | cloi1994/session1 | 44db8fa6d523d4f8ffe6046969f395e8bbde9e40 | 9a79fd854e9842050da07f9c9b0ce5cadc94be89 | refs/heads/master | 2020-03-09T05:15:51.510027 | 2018-06-13T04:41:43 | 2018-06-13T04:41:43 | 128,608,752 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 734 | py | # Definition for an interval.
# class Interval(object):
# def __init__(self, s=0, e=0):
# self.start = s
# self.end = e
class Solution(object):
def merge(self, intervals):
"""
:type intervals: List[Interval]
:rtype: List[Interval]
"""
if not intervals:
return []
intervals.sort(key = lambda x:x.start)
res = [intervals[0]]
end = intervals[0].end
for i in range(1,len(intervals)):
if end >= intervals[i].start:
end = max(intervals[i].end,end)
else:
res.append(intervals[i])
return res
| [
"noreply@github.com"
] | cloi1994.noreply@github.com |
fd8aa3bdef0487a3405b1237f11c86d8c8006b65 | 407b47de02072ea986d0812f5190fc7f258c6c1a | /codeforces1033Bsquaredifference.py | 30a80195a6f9a6dbbeb78581cdd118a9211a5ec2 | [] | no_license | sreyansb/Codeforces | c0a472940bafb020c914d45d6b790d5f75513dff | 12baa08a32837dcea0ee8a2bf019f0551e009420 | refs/heads/master | 2023-01-04T11:33:14.749438 | 2020-10-28T08:20:44 | 2020-10-28T08:20:44 | 275,894,673 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 431 | py | t=int(input())
for i in range(t):
l=input().split()
if int(l[0])-int(l[1])==1:
flag=0
for j in range(2,int(pow((int(l[0])+int(l[1])),0.5))+1):
if (int(l[0])+int(l[1]))%j==0:
flag=1
break
if flag==0:
print("YES")
else:
print("NO")
else:
print("NO")
| [
"sreyansrocks@gmail.com"
] | sreyansrocks@gmail.com |
1dd706f84402d46a889377721eda8083a91f0927 | 9f9a9413e43d8c45f700b015cb6de664e5115c04 | /0x0B-python-input_output/8-class_to_json.py | dda7132bfe1c13f81fc83e4759de0763c37c9cc9 | [] | no_license | JennyHadir/holbertonschool-higher_level_programming | d2bfc733800bee7fcca10a408a2d744af40b0d4b | c826d364665e40173e453048dce1ea5cb97b4075 | refs/heads/master | 2023-04-26T19:29:17.370132 | 2021-05-17T23:04:32 | 2021-05-17T23:04:32 | 319,390,421 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 117 | py | #!/usr/bin/python3
""" Class to json """
def class_to_json(obj):
""" Class to json """
return obj.__dict__
| [
"hadirjenny@hotmail.com"
] | hadirjenny@hotmail.com |
0445df73a7c53d35940af534988270c9f6d1638f | 55c250525bd7198ac905b1f2f86d16a44f73e03a | /Python/Kivy/kivy/examples/widgets/popup_with_kv.py | 02a39467b8bbf03925309c7f0e774502c11744c6 | [
"MIT"
] | permissive | NateWeiler/Resources | 213d18ba86f7cc9d845741b8571b9e2c2c6be916 | bd4a8a82a3e83a381c97d19e5df42cbababfc66c | refs/heads/master | 2023-09-03T17:50:31.937137 | 2023-08-28T23:50:57 | 2023-08-28T23:50:57 | 267,368,545 | 2 | 1 | null | 2022-09-08T15:20:18 | 2020-05-27T16:18:17 | null | UTF-8 | Python | false | false | 128 | py | version https://git-lfs.github.com/spec/v1
oid sha256:1390e4bfcb00405a7d0abae5ceeceb1105628de1311ca190100c95f0958e6c65
size 642
| [
"nateweiler84@gmail.com"
] | nateweiler84@gmail.com |
2ef9499135833f5261798b13e1b06863a0931a3e | 42a8084d227dced8cebf20dbff7852a4f70b5562 | /John/Python/quadmap_example/quad.py | 400db05aca861097fff38b47a2e44683280cd5f7 | [
"MIT"
] | permissive | fagan2888/WAMS-2017 | aa2b010fa7ff21785896edac57007407666d64bb | dfda99c56ee8e120cd1c385c6e65d97f594f5bb9 | refs/heads/master | 2021-02-14T09:06:59.200144 | 2017-08-16T03:36:36 | 2017-08-16T03:36:36 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 330 | py | import numpy as np
import time
from numba import jit
@jit
def quad(x0, n):
x = x0
for i in range(1, n):
x = 4.0 * x * (1.0 - x)
return x
x = quad(0.2, 10)
n = 10_000_000
t = time.time()
x = quad(0.2, n)
elapsed = time.time() - t
print("last val = {}".format(x))
print("elapsed time = {}".format(elapsed))
| [
"john.stachurski@gmail.com"
] | john.stachurski@gmail.com |
e55061a5c5747e6d6966bd8c0b41939c1a6c4e5a | 35be0509b6f98030ef5338033468710de1a536a3 | /nova/nova/virt/images.py | 6f3e48715b89d2983281dca62d1b2e64b6e38e19 | [
"Apache-2.0"
] | permissive | yizhongyin/OpenstackLiberty | 6f2f0ff95bfb4204f3dbc74a1c480922dc387878 | f705e50d88997ef7473c655d99f1e272ef857a82 | refs/heads/master | 2020-12-29T02:44:01.555863 | 2017-03-02T06:43:47 | 2017-03-02T06:43:47 | 49,924,385 | 0 | 1 | null | 2020-07-24T00:49:34 | 2016-01-19T03:45:06 | Python | UTF-8 | Python | false | false | 6,183 | py | # Copyright 2010 United States Government as represented by the
# Administrator of the National Aeronautics and Space Administration.
# All Rights Reserved.
# Copyright (c) 2010 Citrix Systems, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License"); you may
# not use this file except in compliance with the License. You may obtain
# a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
# License for the specific language governing permissions and limitations
# under the License.
"""
Handling of VM disk images.
"""
import os
from oslo_config import cfg
from oslo_log import log as logging
from oslo_utils import fileutils
from nova import exception
from nova.i18n import _, _LE
from nova import image
from nova.openstack.common import imageutils
from nova import utils
LOG = logging.getLogger(__name__)
image_opts = [
cfg.BoolOpt('force_raw_images',
default=True,
help='Force backing images to raw format'),
]
CONF = cfg.CONF
CONF.register_opts(image_opts)
IMAGE_API = image.API()
def qemu_img_info(path, format=None):
"""Return an object containing the parsed output from qemu-img info."""
# TODO(mikal): this code should not be referring to a libvirt specific
# flag.
# NOTE(sirp): The config option import must go here to avoid an import
# cycle
CONF.import_opt('images_type', 'nova.virt.libvirt.imagebackend',
group='libvirt')
if not os.path.exists(path) and CONF.libvirt.images_type != 'rbd':
msg = (_("Path does not exist %(path)s") % {'path': path})
raise exception.InvalidDiskInfo(reason=msg)
cmd = ('env', 'LC_ALL=C', 'LANG=C', 'qemu-img', 'info', path)
if format is not None:
cmd = cmd + ('-f', format)
out, err = utils.execute(*cmd)
if not out:
msg = (_("Failed to run qemu-img info on %(path)s : %(error)s") %
{'path': path, 'error': err})
raise exception.InvalidDiskInfo(reason=msg)
return imageutils.QemuImgInfo(out)
def convert_image(source, dest, in_format, out_format, run_as_root=False):
"""Convert image to other format."""
if in_format is None:
raise RuntimeError("convert_image without input format is a security"
"risk")
_convert_image(source, dest, in_format, out_format, run_as_root)
def convert_image_unsafe(source, dest, out_format, run_as_root=False):
"""Convert image to other format, doing unsafe automatic input format
detection. Do not call this function.
"""
# NOTE: there is only 1 caller of this function:
# imagebackend.Lvm.create_image. It is not easy to fix that without a
# larger refactor, so for the moment it has been manually audited and
# allowed to continue. Remove this function when Lvm.create_image has
# been fixed.
_convert_image(source, dest, None, out_format, run_as_root)
def _convert_image(source, dest, in_format, out_format, run_as_root):
cmd = ('qemu-img', 'convert', '-O', out_format, source, dest)
if in_format is not None:
cmd = cmd + ('-f', in_format)
utils.execute(*cmd, run_as_root=run_as_root)
def fetch(context, image_href, path, _user_id, _project_id, max_size=0):
with fileutils.remove_path_on_error(path):
IMAGE_API.download(context, image_href, dest_path=path)
def get_info(context, image_href):
return IMAGE_API.get(context, image_href)
def fetch_to_raw(context, image_href, path, user_id, project_id, max_size=0):
path_tmp = "%s.part" % path
fetch(context, image_href, path_tmp, user_id, project_id,
max_size=max_size)
with fileutils.remove_path_on_error(path_tmp):
data = qemu_img_info(path_tmp)
fmt = data.file_format
if fmt is None:
raise exception.ImageUnacceptable(
reason=_("'qemu-img info' parsing failed."),
image_id=image_href)
backing_file = data.backing_file
if backing_file is not None:
raise exception.ImageUnacceptable(image_id=image_href,
reason=(_("fmt=%(fmt)s backed by: %(backing_file)s") %
{'fmt': fmt, 'backing_file': backing_file}))
# We can't generally shrink incoming images, so disallow
# images > size of the flavor we're booting. Checking here avoids
# an immediate DoS where we convert large qcow images to raw
# (which may compress well but not be sparse).
# TODO(p-draigbrady): loop through all flavor sizes, so that
# we might continue here and not discard the download.
# If we did that we'd have to do the higher level size checks
# irrespective of whether the base image was prepared or not.
disk_size = data.virtual_size
if max_size and max_size < disk_size:
LOG.error(_LE('%(base)s virtual size %(disk_size)s '
'larger than flavor root disk size %(size)s'),
{'base': path,
'disk_size': disk_size,
'size': max_size})
raise exception.FlavorDiskSmallerThanImage(
flavor_size=max_size, image_size=disk_size)
if fmt != "raw" and CONF.force_raw_images:
staged = "%s.converted" % path
LOG.debug("%s was %s, converting to raw" % (image_href, fmt))
with fileutils.remove_path_on_error(staged):
convert_image(path_tmp, staged, fmt, 'raw')
os.unlink(path_tmp)
data = qemu_img_info(staged)
if data.file_format != "raw":
raise exception.ImageUnacceptable(image_id=image_href,
reason=_("Converted to raw, but format is now %s") %
data.file_format)
os.rename(staged, path)
else:
os.rename(path_tmp, path)
| [
"yizhongyin@os-easy.com"
] | yizhongyin@os-easy.com |
37560936c83c5009ef3b8b7a7f7728799e38d652 | 38d1e0b40d9cc54e4aa272ae5c2872fca378002a | /python_stack/django/django_full_stack/MatchmakingProject/LoginApp/models.py | 303b40db7150ee0c65a0e08604106180471cfb08 | [] | no_license | taichikoga/Dojo_Assignments | 0a8974a6fcb3ce83973fd481803f1bb7126ca3ba | 4c7e82bd652286d281ce86fe9c14491182c3ecde | refs/heads/master | 2022-11-22T23:19:02.431639 | 2020-07-20T17:53:37 | 2020-07-20T17:53:37 | 274,190,553 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,510 | py | from django.db import models
import re, bcrypt
# Create your models here.
class UserManager(models.Manager):
def reg_validator(self, post_data):
EMAIL_REGEX = re.compile(r'^[a-zA-Z0-9.+_-]+@[a-zA-Z0-9._-]+\.[a-zA-Z]+$')
PASS_REGEX = re.compile(r"^(?=.*[A-Za-z])(?=.*\d)(?=.*[@$!%*#?&])[A-Za-z\d@$!%*#?&]{8,16}$")
errors = {}
# first name validations
if len(post_data['first_name']) == 0:
errors['first_name'] = "Your first name cannot be blank"
elif len(post_data['first_name']) < 2:
errors['first_name'] = "Your first name should be at least 2 characters long."
# last name validations
if len(post_data['last_name']) == 0:
errors['last_name'] = "Your last name cannot be blank."
elif len(post_data['last_name']) < 2:
errors['last_name'] = "Your last name should be at least 2 characters long."
# email validations
if len(post_data['email']) == 0:
errors['email'] = "Your email cannot be blank."
elif len(post_data['email']) < 6:
errors['email_format'] == "Invalid email address."
elif not EMAIL_REGEX.match(post_data['email']):
errors['email'] = "Email is invalid."
else:
same_email = User.objects.filter(email=post_data['email'])
if len(same_email) > 0:
errors['email_taken'] = "This email already exists. Register with a different email."
if len(post_data['password']) == 0:
errors['password'] = "You must enter a password."
elif len(post_data['password']) < 8:
errors['password'] = "Password must be minimum 8 characters in length."
if post_data['password'] != post_data['confirmpw']:
errors['confirmpw'] = "Passwords must match."
return errors
#Validations for password.
if len(postData['password']) == 0:
errors['password'] = "This field can't be left blank."
elif len(postData['password']) < 8:
errors['password'] = "Password must be min of 8 characters in length"
elif not PASS_REGEX.match(postData['password']):
errors['password'] = "Password must contain min 1 uppercase, 1 lowercase, 1 special character."
elif postData['password'] != postData['pw_confirm']:
errors['password'] = "Passwords don't match! Please try again."
return errors
def login_validator(self, post_data):
errors = {}
if len(post_data['email']) < 1:
errors['email'] = "Email is required to log in."
emailExists = User.objects.filter(email=post_data['email'])
if len(emailExists) == 0:
errors['email_not_found'] = "This email doesn't exist. Please register for an account first."
else:
user = emailExists[0]
if not bcrypt.checkpw(post_data['password'].encode(), user.password.encode()):
errors['password'] = "Password incorrect. Try again."
return errors
class User(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
email = models.CharField(max_length=50)
password = models.CharField(max_length=100)
friend = models.ManyToManyField('self', symmetrical=False)
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
objects = UserManager()
| [
"63776416+taichikoga@users.noreply.github.com"
] | 63776416+taichikoga@users.noreply.github.com |
3a611ccf2cb28d3307b8e7a4dc32f85cc66e26e5 | a2fb2f3821af2ae59e6354f93272c54b3abae52f | /stackdio/api/volumes/permissions.py | 0f515fe3e26bbaa9069b6647a06693e185d81f1f | [
"Apache-2.0"
] | permissive | pombredanne/stackdio | 1bae1803083f76df9c7bba56c0ffcf08897bbba6 | 8f037c428c187b65750ab387a3e11ed816f33be6 | refs/heads/master | 2021-01-18T11:30:14.157528 | 2016-01-28T17:15:05 | 2016-01-28T17:15:05 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,132 | py | # -*- coding: utf-8 -*-
# Copyright 2014, Digital Reasoning
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
from stackdio.core.permissions import (
StackdioParentObjectPermissions,
StackdioPermissionsModelPermissions,
StackdioPermissionsObjectPermissions,
)
from . import models
class VolumeParentObjectPermissions(StackdioParentObjectPermissions):
parent_model_cls = models.Volume
class VolumePermissionsModelPermissions(StackdioPermissionsModelPermissions):
model_cls = models.Volume
class VolumePermissionsObjectPermissions(StackdioPermissionsObjectPermissions):
parent_model_cls = models.Volume
| [
"clark.perkins@digitalreasoning.com"
] | clark.perkins@digitalreasoning.com |
9a74d89ee6268a9960852dcf24d49b8e0ef0c388 | d554b1aa8b70fddf81da8988b4aaa43788fede88 | /5 - Notebooks e Data/1 - Análises numéricas/Arquivos David/Atualizados/logDicas-master/data/2019-1/226/users/4144/codes/1585_1571.py | 0a07cf4410236b11c716f8b6fefc4b0fa71374d8 | [] | no_license | JosephLevinthal/Research-projects | a3bc3ca3b09faad16f5cce5949a2279cf14742ba | 60d5fd6eb864a5181f4321e7a992812f3c2139f9 | refs/heads/master | 2022-07-31T06:43:02.686109 | 2020-05-23T00:24:26 | 2020-05-23T00:24:26 | 266,199,309 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 236 | py | # Teste seu codigo aos poucos.
# Nao teste tudo no final, pois fica mais dificil de identificar erros.
# Nao se intimide com as mensagens de erro. Elas ajudam a corrigir seu codigo.
texto = input("Digite o texto: ")
print(texto.upper()) | [
"jvlo@icomp.ufam.edu.br"
] | jvlo@icomp.ufam.edu.br |
b09bf69a31c033edea81089557894bf401b7430a | f7abd047406935b64e9283d6dbd2c74477ecb10c | /setup.py | 404c61f08a6716c54a5862d5f3b1e140ca7e9071 | [
"MIT"
] | permissive | stjordanis/pyppl_require | 3deffa5d7d5a8742726aeafa22db675b20f35a98 | a21dcef26a78dffe37de795e51bb6afcd512982d | refs/heads/master | 2022-09-24T03:29:43.861751 | 2020-06-06T04:41:55 | 2020-06-06T04:41:55 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,141 | py | # -*- coding: utf-8 -*-
# DO NOT EDIT THIS FILE!
# This file has been autogenerated by dephell <3
# https://github.com/dephell/dephell
try:
from setuptools import setup
except ImportError:
from distutils.core import setup
import os.path
readme = ''
here = os.path.abspath(os.path.dirname(__file__))
readme_path = os.path.join(here, 'README.rst')
if os.path.exists(readme_path):
with open(readme_path, 'rb') as stream:
readme = stream.read().decode('utf8')
setup(
long_description=readme,
name='pyppl_require',
version='0.0.5',
description='Requirement manager for processes of PyPPL',
python_requires='==3.*,>=3.6.0',
project_urls={
"homepage": "https://github.com/pwwang/pyppl_require",
"repository": "https://github.com/pwwang/pyppl_require"
},
author='pwwang',
author_email='pwwang@pwwang.com',
license='MIT',
entry_points={"pyppl": ["pyppl_require = pyppl_require"]},
packages=[],
package_dir={"": "."},
package_data={},
install_requires=['cmdy', 'pyppl==3.*', 'pyppl-annotate'],
extras_require={"dev": ["pytest", "pytest-cov"]},
)
| [
"pwwang@pwwang.com"
] | pwwang@pwwang.com |
b25f9d06d2352de2945a3002c76ecd56e103ca3f | 0a3b08678e2d6669188649bfc8d38439ac076f61 | /odziez/employees/migrations/0002_auto_20190709_1756.py | efb1cc0f3be39a5f76b6bd68ca3df0eb1ddf973e | [
"MIT"
] | permissive | szymanskirafal/odziez | 48f31fb72a8875511000f6aa5d9032770a670e64 | 029d20da0474a0380e8383f9f89c1072666c5399 | refs/heads/master | 2020-05-25T08:18:58.783882 | 2020-05-10T19:19:29 | 2020-05-10T19:19:29 | 187,707,616 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,622 | py | # Generated by Django 2.1.8 on 2019-07-09 17:56
from django.conf import settings
from django.db import migrations, models
import django.db.models.deletion
class Migration(migrations.Migration):
initial = True
dependencies = [
('employees', '0001_initial'),
migrations.swappable_dependency(settings.AUTH_USER_MODEL),
]
operations = [
migrations.AddField(
model_name='supervisor',
name='user',
field=models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),
),
migrations.AddField(
model_name='manager',
name='job',
field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='employees.Job'),
),
migrations.AddField(
model_name='manager',
name='user',
field=models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),
),
migrations.AddField(
model_name='job',
name='position',
field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='employees.Position'),
),
migrations.AddField(
model_name='job',
name='work_place',
field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='employees.WorkPlace'),
),
migrations.AddField(
model_name='employee',
name='job',
field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='employees.Job'),
),
]
| [
"r.szymansky@gmail.com"
] | r.szymansky@gmail.com |
3005f70017c2002ef6c8d021def9baf0e1c3c788 | 556db265723b0cc30ad2917442ed6dad92fd9044 | /tensorflow/lite/experimental/mlir/testing/op_tests/segment_sum.py | 8b15ed2ad66b3a9e04cd429d4cc111776b120b6f | [
"MIT",
"Apache-2.0",
"BSD-2-Clause"
] | permissive | graphcore/tensorflow | c1669b489be0e045b3ec856b311b3139858de196 | 085b20a4b6287eff8c0b792425d52422ab8cbab3 | refs/heads/r2.6/sdk-release-3.2 | 2023-07-06T06:23:53.857743 | 2023-03-14T13:04:04 | 2023-03-14T13:48:43 | 162,717,602 | 84 | 17 | Apache-2.0 | 2023-03-25T01:13:37 | 2018-12-21T13:30:38 | C++ | UTF-8 | Python | false | false | 2,232 | py | # Copyright 2020 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Test configs for segment_sum."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow.compat.v1 as tf
from tensorflow.lite.testing.zip_test_utils import create_tensor_data
from tensorflow.lite.testing.zip_test_utils import make_zip_of_tests
from tensorflow.lite.testing.zip_test_utils import register_make_test_function
@register_make_test_function()
def make_segment_sum_tests(options):
"""Make a set of tests to do segment_sum."""
test_parameters = [
{
"data_shape": [[4, 4], [4], [4, 3, 2]],
"data_dtype": [tf.float32, tf.int32],
"segment_ids": [[0, 0, 1, 1], [0, 1, 2, 2], [0, 1, 2, 3],
[0, 0, 0, 0]],
},
]
def build_graph(parameters):
"""Build the segment_sum op testing graph."""
data = tf.compat.v1.placeholder(
dtype=parameters["data_dtype"],
name="data",
shape=parameters["data_shape"])
segment_ids = tf.constant(parameters["segment_ids"], dtype=tf.int32)
out = tf.segment_sum(data, segment_ids)
return [data], [out]
def build_inputs(parameters, sess, inputs, outputs):
data = create_tensor_data(parameters["data_dtype"],
parameters["data_shape"])
return [data], sess.run(outputs, feed_dict=dict(zip(inputs, [data])))
options.use_experimental_converter = True
make_zip_of_tests(
options,
test_parameters,
build_graph,
build_inputs,
expected_tf_failures=0)
| [
"gardener@tensorflow.org"
] | gardener@tensorflow.org |
08dc96b39c6f840ba83fb7a0525a9b69d9bcf08b | bf470afc981034e55b325d8c8e7f519e5637d029 | /_quiz_app/settings.py | b952da13963da209897f249eb6352cfa4bab1139 | [] | no_license | abrarfahim19/django | 85711b3493021e01523bc25e4106a8d370bdc201 | f4d043a629e46108cad4de72d73cd802731aada1 | refs/heads/main | 2023-07-11T21:19:27.351902 | 2021-08-20T06:31:26 | 2021-08-20T06:31:26 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,459 | py | """
Django settings for _quiz_app project.
Generated by 'django-admin startproject' using Django 3.2.5.
For more information on this file, see
https://docs.djangoproject.com/en/3.2/topics/settings/
For the full list of settings and their values, see
https://docs.djangoproject.com/en/3.2/ref/settings/
"""
from pathlib import Path
# Build paths inside the project like this: BASE_DIR / 'subdir'.
BASE_DIR = Path(__file__).resolve().parent.parent
# Quick-start development settings - unsuitable for production
# See https://docs.djangoproject.com/en/3.2/howto/deployment/checklist/
# SECURITY WARNING: keep the secret key used in production secret!
SECRET_KEY = 'django-insecure-#1d3-(@zucj!($ie8g0*uyns9tlvd-g#^-r)p8)ei-=$sj(pht'
# SECURITY WARNING: don't run with debug turned on in production!
DEBUG = True
ALLOWED_HOSTS = []
# Application definition
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'quizes.apps.QuizesConfig',
'question.apps.QuestionConfig',
'results.apps.ResultsConfig',
]
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
ROOT_URLCONF = '_quiz_app.urls'
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [BASE_DIR / 'templates'],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
WSGI_APPLICATION = '_quiz_app.wsgi.application'
# Database
# https://docs.djangoproject.com/en/3.2/ref/settings/#databases
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
}
}
# Password validation
# https://docs.djangoproject.com/en/3.2/ref/settings/#auth-password-validators
AUTH_PASSWORD_VALIDATORS = [
{
'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
},
]
# Internationalization
# https://docs.djangoproject.com/en/3.2/topics/i18n/
LANGUAGE_CODE = 'en-us'
TIME_ZONE = 'UTC'
USE_I18N = True
USE_L10N = True
USE_TZ = True
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/3.2/howto/static-files/
STATIC_URL = '/static/'
STATICFILES_DIRS = [
BASE_DIR / 'static',
BASE_DIR / 'quizes' / 'static'
]
# Default primary key field type
# https://docs.djangoproject.com/en/3.2/ref/settings/#default-auto-field
DEFAULT_AUTO_FIELD = 'django.db.models.BigAutoField'
| [
"samsmusa@outlook.com"
] | samsmusa@outlook.com |
2557c270200301b202565e8adeca02f5216805a8 | b5a9d42f7ea5e26cd82b3be2b26c324d5da79ba1 | /tensorflow/python/training/moving_averages_test.py | 7cb6164d0594eb3a4a11822e975d8e098a66286e | [
"Apache-2.0"
] | permissive | uve/tensorflow | e48cb29f39ed24ee27e81afd1687960682e1fbef | e08079463bf43e5963acc41da1f57e95603f8080 | refs/heads/master | 2020-11-29T11:30:40.391232 | 2020-01-11T13:43:10 | 2020-01-11T13:43:10 | 230,088,347 | 0 | 0 | Apache-2.0 | 2019-12-25T10:49:15 | 2019-12-25T10:49:14 | null | UTF-8 | Python | false | false | 21,369 | py | # Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Functional test for moving_averages.py."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from tensorflow.python import pywrap_tensorflow
from tensorflow.python.eager import context
from tensorflow.python.framework import constant_op
from tensorflow.python.framework import dtypes
from tensorflow.python.framework import ops
from tensorflow.python.framework import test_util
from tensorflow.python.ops import array_ops
from tensorflow.python.ops import gen_state_ops
from tensorflow.python.ops import variable_scope
from tensorflow.python.ops import variables
from tensorflow.python.platform import test
from tensorflow.python.training import moving_averages
from tensorflow.python.training import saver as saver_lib
class MovingAveragesTest(test.TestCase):
@test_util.run_in_graph_and_eager_modes
def testAssignMovingAverageWithoutZeroDebias(self):
var = variables.Variable([10.0, 11.0])
val = constant_op.constant([1.0, 2.0], dtypes.float32)
decay = 0.25
if context.executing_eagerly():
self.assertAllClose([10.0, 11.0], self.evaluate(var))
assign = moving_averages.assign_moving_average(
var, val, decay, zero_debias=False)
self.assertAllClose(
[10.0 * 0.25 + 1.0 * (1.0 - 0.25), 11.0 * 0.25 + 2.0 * (1.0 - 0.25)],
self.evaluate(var))
else:
assign = moving_averages.assign_moving_average(
var, val, decay, zero_debias=False)
self.evaluate(variables.global_variables_initializer())
self.assertAllClose([10.0, 11.0], self.evaluate(var))
assign.op.run()
self.assertAllClose(
[10.0 * 0.25 + 1.0 * (1.0 - 0.25), 11.0 * 0.25 + 2.0 * (1.0 - 0.25)],
self.evaluate(var))
@test_util.run_in_graph_and_eager_modes
def testAssignMovingAverage(self):
var = variables.Variable([0.0, 0.0])
val = constant_op.constant([1.0, 2.0], dtypes.float32)
decay = 0.25
if context.executing_eagerly():
self.assertAllClose([0.0, 0.0], self.evaluate(var))
assign = moving_averages.assign_moving_average(var, val, decay)
self.assertAllClose(
[1.0 * (1.0 - 0.25) / (1 - 0.25), 2.0 * (1.0 - 0.25) / (1 - 0.25)],
self.evaluate(var))
else:
assign = moving_averages.assign_moving_average(var, val, decay)
self.evaluate(variables.global_variables_initializer())
self.assertAllClose([0.0, 0.0], self.evaluate(var))
assign.op.run()
self.assertAllClose(
[1.0 * (1.0 - 0.25) / (1 - 0.25), 2.0 * (1.0 - 0.25) / (1 - 0.25)],
self.evaluate(var))
@test_util.deprecated_graph_mode_only
def testAssignMovingAverageNewNamingMultipleCalls(self):
with variable_scope.variable_scope("scope1") as vs1:
with variable_scope.variable_scope("scope2"):
var = variables.Variable(1.0, name="Var")
moving_averages.assign_moving_average(var, 0.0, 0.99)
moving_averages.assign_moving_average(var, 0.0, 0.99)
expected_names = ["scope1/scope2/Var:0",
"scope1/scope2/scope1/scope2/Var/biased:0",
"scope1/scope2/scope1/scope2/Var/local_step:0",
"scope1/scope2/scope1/scope2/Var/biased_1:0",
"scope1/scope2/scope1/scope2/Var/local_step_1:0"]
actual_names = [v.name for v in vs1.global_variables()]
self.assertSetEqual(set(expected_names), set(actual_names))
@test_util.deprecated_graph_mode_only
def testAssignMovingAverageNewNamingMultipleCallsWithReuse(self):
with variable_scope.variable_scope("scope1") as vs1:
var = variable_scope.get_variable("Var", shape=[])
moving_averages.assign_moving_average(var, 0.0, 0.99)
moving_averages.assign_moving_average(var, 0.0, 0.99)
with variable_scope.variable_scope(vs1, reuse=True):
var = variable_scope.get_variable("Var", shape=[])
moving_averages.assign_moving_average(var, 0.0, 0.99)
moving_averages.assign_moving_average(var, 0.0, 0.99)
@test_util.deprecated_graph_mode_only
def testWeightedMovingAverage(self):
with self.cached_session() as sess:
decay = 0.5
weight = array_ops.placeholder(dtypes.float32, [])
val = array_ops.placeholder(dtypes.float32, [])
wma = moving_averages.weighted_moving_average(val, decay, weight)
self.evaluate(variables.global_variables_initializer())
# Get the first weighted moving average.
val_1 = 3.0
weight_1 = 4.0
wma_array = sess.run(wma, feed_dict={val: val_1, weight: weight_1})
numerator_1 = val_1 * weight_1 * (1.0 - decay)
denominator_1 = weight_1 * (1.0 - decay)
self.assertAllClose(numerator_1 / denominator_1, wma_array)
# Get the second weighted moving average.
val_2 = 11.0
weight_2 = 22.0
wma_array = sess.run(wma, feed_dict={val: val_2, weight: weight_2})
numerator_2 = numerator_1 * decay + val_2 * weight_2 * (1.0 - decay)
denominator_2 = denominator_1 * decay + weight_2 * (1.0 - decay)
self.assertAllClose(numerator_2 / denominator_2, wma_array)
@test_util.deprecated_graph_mode_only
def testWeightedMovingAverageBfloat16(self):
bfloat16 = pywrap_tensorflow.TF_bfloat16_type()
with self.cached_session() as sess:
decay = 0.5
weight = array_ops.placeholder(dtypes.bfloat16, [])
val = array_ops.placeholder(dtypes.bfloat16, [])
wma = moving_averages.weighted_moving_average(val, decay, weight)
self.evaluate(variables.global_variables_initializer())
# Get the first weighted moving average.
val_1 = 3.0
weight_1 = 4.0
wma_array = sess.run(wma, feed_dict={val: val_1, weight: weight_1})
numerator_1 = val_1 * weight_1 * (1.0 - decay)
denominator_1 = weight_1 * (1.0 - decay)
self.assertAllClose(numerator_1 / denominator_1, wma_array)
# Get the second weighted moving average.
val_2 = 11.0
weight_2 = 22.0
wma_array = sess.run(wma, feed_dict={val: val_2, weight: weight_2})
numerator_2 = numerator_1 * decay + val_2 * weight_2 * (1.0 - decay)
denominator_2 = denominator_1 * decay + weight_2 * (1.0 - decay)
self.assertAllClose(bfloat16(numerator_2 / denominator_2), wma_array)
def _Repeat(value, dim):
if dim == 1:
return value
return [value] * dim
class ExponentialMovingAverageTest(test.TestCase):
def _CheckDecay(self, ema, actual_decay, dim):
def _Scale(dk, steps):
if ema._zero_debias:
return 1 - dk**steps
else:
return 1
tens = _Repeat(10.0, dim)
thirties = _Repeat(30.0, dim)
var0 = variables.Variable(tens, name="v0")
var1 = variables.Variable(thirties, name="v1")
self.evaluate(variables.global_variables_initializer())
# Note that tensor2 is not a Variable but just a plain Tensor resulting
# from the sum operation.
tensor2 = var0 + var1
update = ema.apply([var0, var1, tensor2])
avg0 = ema.average(var0)
avg1 = ema.average(var1)
avg2 = ema.average(tensor2)
self.assertItemsEqual([var0, var1], variables.moving_average_variables())
self.assertNotIn(avg0, variables.trainable_variables())
self.assertNotIn(avg1, variables.trainable_variables())
self.assertNotIn(avg2, variables.trainable_variables())
self.evaluate(variables.global_variables_initializer())
self.assertEqual("v0/ExponentialMovingAverage:0", avg0.name)
self.assertEqual("v1/ExponentialMovingAverage:0", avg1.name)
self.assertEqual("add/ExponentialMovingAverage:0", avg2.name)
# Check initial values.
self.assertAllClose(tens, self.evaluate(var0))
self.assertAllClose(thirties, self.evaluate(var1))
self.assertAllClose(_Repeat(10.0 + 30.0, dim), self.evaluate(tensor2))
# Check that averages are initialized correctly.
self.assertAllClose(tens, self.evaluate(avg0))
self.assertAllClose(thirties, self.evaluate(avg1))
# Note that averages of Tensor's initialize to zeros_like since no value
# of the Tensor is known because the Op has not been run (yet).
self.assertAllClose(_Repeat(0.0, dim), self.evaluate(avg2))
# Update the averages and check.
self.evaluate(update)
dk = actual_decay
expected = _Repeat(10.0 * dk + 10.0 * (1 - dk), dim)
self.assertAllClose(expected, self.evaluate(avg0))
expected = _Repeat(30.0 * dk + 30.0 * (1 - dk), dim)
self.assertAllClose(expected, self.evaluate(avg1))
expected = _Repeat(0.0 * dk + (10.0 + 30.0) * (1 - dk) / _Scale(dk, 1), dim)
self.assertAllClose(expected, self.evaluate(avg2))
# Again, update the averages and check.
self.evaluate(update)
expected = _Repeat((10.0 * dk + 10.0 * (1 - dk)) * dk + 10.0 * (1 - dk),
dim)
self.assertAllClose(expected, self.evaluate(avg0))
expected = _Repeat((30.0 * dk + 30.0 * (1 - dk)) * dk + 30.0 * (1 - dk),
dim)
self.assertAllClose(expected, self.evaluate(avg1))
expected = _Repeat(((0.0 * dk + (10.0 + 30.0) * (1 - dk)) * dk +
(10.0 + 30.0) * (1 - dk)) / _Scale(dk, 2), dim)
self.assertAllClose(expected, self.evaluate(avg2))
@test_util.deprecated_graph_mode_only
def testAverageVariablesNoNumUpdates_Scalar(self):
ema = moving_averages.ExponentialMovingAverage(0.25)
self._CheckDecay(ema, actual_decay=0.25, dim=1)
@test_util.deprecated_graph_mode_only
def testAverageVariablesNoNumUpdates_Scalar_Debias(self):
ema = moving_averages.ExponentialMovingAverage(0.25, zero_debias=True)
self._CheckDecay(ema, actual_decay=0.25, dim=1)
@test_util.deprecated_graph_mode_only
def testAverageVariablesNoNumUpdates_Vector(self):
ema = moving_averages.ExponentialMovingAverage(0.25)
self._CheckDecay(ema, actual_decay=0.25, dim=5)
@test_util.deprecated_graph_mode_only
def testAverageVariablesNoNumUpdates_Vector_Debias(self):
ema = moving_averages.ExponentialMovingAverage(0.25, zero_debias=True)
self._CheckDecay(ema, actual_decay=0.25, dim=5)
@test_util.deprecated_graph_mode_only
def testAverageVariablesNumUpdates_Scalar(self):
# With num_updates 1, the decay applied is 0.1818
ema = moving_averages.ExponentialMovingAverage(0.25, num_updates=1)
self._CheckDecay(ema, actual_decay=0.181818, dim=1)
@test_util.deprecated_graph_mode_only
def testAverageVariablesNumUpdates_Scalar_Debias(self):
# With num_updates 1, the decay applied is 0.1818
ema = moving_averages.ExponentialMovingAverage(
0.25, num_updates=1, zero_debias=True)
self._CheckDecay(ema, actual_decay=0.181818, dim=1)
@test_util.deprecated_graph_mode_only
def testAverageVariablesNumUpdates_Vector(self):
# With num_updates 1, the decay applied is 0.1818
ema = moving_averages.ExponentialMovingAverage(0.25, num_updates=1)
self._CheckDecay(ema, actual_decay=0.181818, dim=5)
@test_util.deprecated_graph_mode_only
def testAverageVariablesNumUpdates_Vector_Debias(self):
# With num_updates 1, the decay applied is 0.1818
ema = moving_averages.ExponentialMovingAverage(
0.25, num_updates=1, zero_debias=True)
self._CheckDecay(ema, actual_decay=0.181818, dim=5)
@test_util.deprecated_graph_mode_only
def testAverageVariablesWithControlDeps(self):
v0 = variables.Variable(0, name="v0")
add_to_v0 = v0.assign_add(1)
v1 = variables.Variable([10.0], name="v1")
assign_to_v1 = v1.assign([20.0])
ema = moving_averages.ExponentialMovingAverage(0.25)
with ops.control_dependencies([add_to_v0]):
ema_op = ema.apply([v1])
# the moving average of v1 should not have any control inputs
v1_avg = ema.average(v1)
self.assertEqual([], v1_avg.initializer.control_inputs)
self.assertEqual([], v1_avg.value().op.control_inputs)
self.assertEqual([], v1_avg.value().op.control_inputs)
# We should be able to initialize v1_avg before v0.
self.evaluate(v1_avg.initializer)
self.evaluate(v0.initializer)
self.assertEqual([10.0], self.evaluate(v1_avg))
# running ema_op should add to v0 (in addition to updating v1_avg)
self.evaluate(assign_to_v1)
self.evaluate(ema_op)
self.assertEqual(1, self.evaluate(v0))
self.assertEqual([17.5], self.evaluate(v1_avg))
def testBasicEager(self):
v0 = variables.Variable(1.0)
v1 = variables.Variable(2.0)
ema = moving_averages.ExponentialMovingAverage(0.25)
op = ema.apply([v0, v1])
if not context.executing_eagerly():
self.evaluate(variables.global_variables_initializer())
self.evaluate(op)
self.evaluate(v0.assign(2.0))
self.evaluate(v1.assign(4.0))
self.evaluate(ema.apply([v0, v1]))
self.assertAllEqual(self.evaluate(ema.average(v0)), 1.75)
self.assertAllEqual(self.evaluate(ema.average(v1)), 3.5)
def averageVariablesNamesHelper(self, zero_debias):
v0 = variables.Variable(10.0, name="v0")
v1 = variables.Variable(30.0, name="v1")
# Add a non-trainable variable.
v2 = variables.Variable(20.0, name="v2", trainable=False)
tensor2 = v0 + v1
ema = moving_averages.ExponentialMovingAverage(
0.25, zero_debias=zero_debias, name="foo")
self.assertEqual("foo", ema.name)
self.assertEqual("v0/foo", ema.average_name(v0))
self.assertEqual("v1/foo", ema.average_name(v1))
self.assertEqual("add/foo", ema.average_name(tensor2))
ema.apply([v0, v1, tensor2])
vars_to_restore = ema.variables_to_restore()
# vars_to_restore should contain the following:
# {v0/foo : v0,
# v1/foo : v1,
# add/foo : add/foo,
# v2 : v2}
expected_names = [
ema.average_name(v0),
ema.average_name(v1),
ema.average_name(tensor2), v2.op.name
]
if zero_debias:
# vars_to_restore should also contain the following:
# {add/foo/biased: add/foo/biased,
# add/foo/local_step: add/foo/local_step}
expected_names += [
ema.average_name(tensor2) + "/biased",
ema.average_name(tensor2) + "/local_step"
]
self.assertEqual(sorted(expected_names), sorted(vars_to_restore.keys()))
self.assertEqual(ema.average(v0).op.name, ema.average_name(v0))
self.assertEqual(ema.average(v1).op.name, ema.average_name(v1))
self.assertEqual(ema.average(tensor2).op.name, ema.average_name(tensor2))
@test_util.deprecated_graph_mode_only
def testAverageVariablesNames(self):
self.averageVariablesNamesHelper(zero_debias=True)
@test_util.deprecated_graph_mode_only
def testAverageVariablesNamesNoDebias(self):
self.averageVariablesNamesHelper(zero_debias=False)
@test_util.deprecated_graph_mode_only
def averageVariablesNamesRespectScopeHelper(self, zero_debias):
# See discussion on #2740.
with variable_scope.variable_scope("scope1"):
v0 = variables.Variable(10.0, name="v0")
v1 = variables.Variable(30.0, name="v1")
# Add a non-trainable variable.
v2 = variables.Variable(20.0, name="v2", trainable=False)
tensor2 = v0 + v1
with variable_scope.variable_scope("scope2"):
ema = moving_averages.ExponentialMovingAverage(
0.25, zero_debias=zero_debias, name="foo")
self.assertEqual("scope2/scope1/v0/foo", ema.average_name(v0))
self.assertEqual("scope2/scope1/v1/foo", ema.average_name(v1))
self.assertEqual("scope2/scope1/add/foo", ema.average_name(tensor2))
ema.apply([v0, v1, tensor2])
vars_to_restore = ema.variables_to_restore()
# `vars_to_restore` should contain the following:
# {scope2/scope1/v0/foo : v0,
# scope2/scope1/v1/foo : v1,
# scope2/scope1/add/foo : add/foo,
# scope1/v2 : v2}
expected_names = [
ema.average_name(v0),
ema.average_name(v1),
ema.average_name(tensor2), v2.op.name
]
if zero_debias:
# `vars_to_restore` should also contain the following:
# {scope2/scope2/scope1/add/foo/biased: add/foo/biased,
# scope2/scope2/scope1/add/foo/local_step: add/foo/local_step}
sc = "scope2/"
expected_names += [
sc + ema.average_name(tensor2) + "/biased",
sc + ema.average_name(tensor2) + "/local_step"
]
self.assertEqual(sorted(expected_names), sorted(vars_to_restore.keys()))
self.assertEqual(ema.average(v0).op.name, ema.average_name(v0))
self.assertEqual(ema.average(v1).op.name, ema.average_name(v1))
self.assertEqual(ema.average(tensor2).op.name, ema.average_name(tensor2))
@test_util.deprecated_graph_mode_only
def testAverageVariablesNamesRespectScope(self):
self.averageVariablesNamesRespectScopeHelper(zero_debias=True)
@test_util.deprecated_graph_mode_only
def testAverageVariablesNamesRespectScopeNoDebias(self):
self.averageVariablesNamesRespectScopeHelper(zero_debias=False)
@test_util.deprecated_graph_mode_only
def testSubsetAverageVariablesNames(self):
v0 = variables.Variable(10.0, name="v0")
v1 = variables.Variable(30.0, name="v1")
# Add a non-trainable variable.
v2 = variables.Variable(20.0, name="v2", trainable=False)
tensor2 = v0 + v1
ema = moving_averages.ExponentialMovingAverage(0.25, name="foo_avg")
self.assertEqual("v0/foo_avg", ema.average_name(v0))
self.assertEqual("v1/foo_avg", ema.average_name(v1))
self.assertEqual("add/foo_avg", ema.average_name(tensor2))
vars_to_restore = ema.variables_to_restore([v0, tensor2])
# vars_to_restore should contain the following:
# {v0/foo_avg : v0,
# add/foo_avg : add
# v1 : v1,
# v2 : v2}
self.assertEqual(
sorted(vars_to_restore.keys()),
sorted([
ema.average_name(v0),
ema.average_name(tensor2), v1.op.name, v2.op.name
]))
ema.apply([v0, v1, tensor2])
self.assertEqual(ema.average(v0).op.name, ema.average_name(v0))
self.assertEqual(ema.average(v1).op.name, ema.average_name(v1))
self.assertEqual(ema.average(tensor2).op.name, ema.average_name(tensor2))
@test_util.deprecated_graph_mode_only
def testAverageVariablesDeviceAssignment(self):
with ops.device("/job:dev_v0"):
v0 = variables.Variable(10.0, name="v0")
with ops.device("/job:dev_v1"):
v1 = gen_state_ops.variable(
shape=[1],
dtype=dtypes.float32,
name="v1",
container="",
shared_name="")
v1.set_shape([1])
tensor2 = v0 + v1
ema = moving_averages.ExponentialMovingAverage(0.25, name="foo_avg")
with ops.device("/job:default"):
ema.apply([v0, v1, tensor2])
self.assertDeviceEqual("/job:dev_v0", ema.average(v0).device)
self.assertDeviceEqual("/job:dev_v1", ema.average(v1).device)
# However, the colocation property is maintained.
self.assertEqual([b"loc:@v1"], ema.average(v1).op.colocation_groups())
self.assertDeviceEqual("/job:default", ema.average(tensor2).device)
def _ExportAndImportGraph(self, graph):
"""Export and import graph into a new graph."""
meta_graph = saver_lib.export_meta_graph(
graph=graph, collection_list=graph.get_all_collection_keys())
graph_copy = ops.Graph()
with graph_copy.as_default():
_ = saver_lib.import_meta_graph(meta_graph)
return graph_copy
@test_util.deprecated_graph_mode_only
def testImportedGraphVariablesToRestore(self):
g = ops.Graph()
with g.as_default():
variables.Variable(10.0, name="v")
# Export and import the graph into a new graph.
g_copy = self._ExportAndImportGraph(g)
with g_copy.as_default():
ema = moving_averages.ExponentialMovingAverage(0.25, name="foo_avg")
vars_to_restore = ema.variables_to_restore()
# There should only be one variable in vars_to_restore. This is important
# to check because when importing from a GraphDef, TF makes duplicate
# python Variable objects referring to the same underlying variable. We
# need to be sure that two variables referring to the same variable don't
# both get added to vars_to_restore.
self.assertEqual(len(vars_to_restore), 1)
self.assertIn("v/foo_avg", vars_to_restore)
if __name__ == "__main__":
test.main()
| [
"v-grniki@microsoft.com"
] | v-grniki@microsoft.com |
f19a90eb3b9c58d0e042522d45483a2ac9f29124 | 1cdf8388aca3cdcfb20e62a45f7204eb87b194a6 | /set_up_dummy.py | fa50e845307c653fb51b7fa63f16a9a663a9f1e1 | [] | no_license | sujayjohn/collegesite | 437b4f943ce0a5134c44075c3bc49af992b96564 | a71075a85a574a2a276662543b2ca5f444789091 | refs/heads/master | 2020-05-16T18:51:53.676987 | 2014-09-22T16:51:29 | 2014-09-22T16:51:29 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 8,503 | py | #!/usr/bin/env python
import os
import sys
import random
import datetime
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "stephens.settings")
from django.core.files import File
import college
import rss
import docs
import roombook
import attendence
from django.contrib.auth.models import User,Group
from django.core.management import execute_from_command_line
from django.utils import timezone
execute_from_command_line(['manage.py','syncdb'])
groupnames=['Principal','Bursar','Dean(Residence)','Dean(Academic Affairs)','Chaplain','Public Information Officer','Special Assignments','Administration','Staff Advisor','Faculty']
users=['staff_adv_1','staff_adv_2','office_window_1','office_window_2','office_inside_1','office_inside_2','notice_admin','registrar_of_soc',
'principal','bursar','seniortutor','dean(residence)','chaplain','dean(academic_affairs)','public_information_officer']
papers=[
{'code':'MAPT-505','name':'Mathematics first year'},
{'code':'PHPT-505','name':'Physics first year'},
{'code':'CHCT-501','name':'Mathematics 2 year'},
{'code':'CSPT-505','name':'Mathematics f223irst year'},
]
course_types=['UnderGraduate']
courses=[
{'name':'B.Sc. Physical Science'},
]
departments=['Administration','Computer Science','Physics','Sports','English','Principal Office']
societies=['Computer Science Society','Alumni Cell','Bazam-e-Adab','The Chemistry Society','B.A. Society','SUS','SSL']
students=['ajit deshpande','anurag banerjee','ashwatth verma','deepak kumar','ishan taneja','arjoonn sharma','atima shahi','gagan mahajan','kopal dixit']
quotes=['He who has failed has tried something greater...',
'We have nothing to fear but fear itself...',
'Ask and you are no longer a fool...',]
doctypes=['transcript','character_certificate','bonafide_certificate']
rooms=['A','B','C','U','R','Xc','Xd','OPLT','NPLT','PTR','CTR','Auditorium','Seminar Room','G','NCLT']
notifications=[
'Dummy1','Dummy2','Dummy3','Dummy4','Dummy5','Dummy6','Dummy7','Dummy8','Dummy9','Dummy10',
]
news=['Dummy news 1','Dummy news 2','Dummy news 3','Dummy news 4','Dummy news 6','Dummy news 7','Dummy news 8','Dummy news 9',]
print '===================================================='
print 'setting up dummy data'
print 'starting'
#make notifications
print 'Notifications',
for i in notifications:
a=college.models.custom_notice()
a.title=i
a.description=''
alphabet='qwertyui opasdfg hjklzxcvbnm '
for i in xrange(int(random.random()*799)):
a.description+=random.choice(alphabet)
a.save()
print '......................................',
print 'done'
#make groups
print 'Groups',
for i in groupnames:
g1=Group()
g1.name=i
g1.save()
print '......................................',
print 'done'
#add course types
print 'Course Type',
for i in course_types:
a=college.models.course_type()
a.name=i
a.save()
print '......................................',
print 'done'
#add courses
print 'Courses',
for i in courses:
a=college.models.course()
a.name=i['name']
a.type_of_course=college.models.course_type.objects.first()
a.save()
print '......................................',
print 'done'
#add papers
print 'Papers',
for k,i in enumerate(papers):
a=college.models.paper()
a.code=i['code']
a.name=i['name']
a.semester=1
a.course=college.models.course.objects.first()
a.save()
print '......................................',
print 'done'
#departments
print 'Departments',
for i in departments:
a=college.models.department()
a.name=i
a.save()
#add societies
print 'Societies',
for i in societies:
a=college.models.society()
a.name=i
a.save()
print '......................................',
print 'done'
#make users and userprofiles
print 'Users',
for i in users:
a=User()
a.username=i
a.set_password('asd')
a.save()
b=college.models.userprofile()
b.user=a
b.dept=random.choice(college.models.department.objects.all())
if 'staff' in i:
b.staff_adv1=random.choice(college.models.society.objects.all())
b.save()
print '......................................',
print 'done'
#make notices
print 'News',
for i in news:
a=rss.models.notice()
a.title=i
a.description=''
alphabet='qwertyui opasdfg hjklzxcvbnm '
for i in xrange(int(random.random()*799)):
a.description+=random.choice(alphabet)
x=college.models.userprofile.objects.all()
a.author=random.choice(x)
a.approved=True
a.save()
print '......................................',
print 'done'
#make students
print 'Students',
for i in students:
a=college.models.student()
a.name=i
a.course=college.models.course.objects.first()
a.save()
print '......................................',
print 'done'
#add a contact
print 'Contacts',
a=college.models.contact()
a.name='Phone'
a.value='+91-11-2766 7271 '
a.save()
a=college.models.contact()
a.name='Admission Help Line'
a.value='011-27662168'
a.save()
print '......................................',
print 'done'
#add quotes
print 'Quotes',
for i in quotes:
a=college.models.quote()
a.value=i
a.save()
print '......................................',
print 'done'
#make doctypes
print 'Document types',
for i in doctypes:
a=docs.models.doc_type()
a.name=i
a.stage1=random.choice(college.models.userprofile.objects.all())
a.stage2=random.choice(college.models.userprofile.objects.all())
a.stage3=random.choice(college.models.userprofile.objects.all())
a.stage4=random.choice(college.models.userprofile.objects.all())
a.save()
print '......................................',
print 'done'
#add dummy docs
print 'Docs',
for i in range(10):
a=docs.models.doc()
a.student=random.choice(college.models.student.objects.all())
a.doctype=random.choice(docs.models.doc_type.objects.all())
x=a.doctype.stages()
a.stage_count=x.index(random.choice(x))
a.location=x[a.stage_count]
a.save()
print '......................................',
print 'done'
print 'Rooms',
for i in rooms:
a=roombook.models.room()
a.name=i
a.ac_available=random.choice([True,False])
a.projector_available=random.choice([True,False])
a.save()
print '......................................',
print 'done'
#add a few reservations
print 'Reservations',
for i in range(20):
a=roombook.models.reservation()
a.booked_by=random.choice(college.models.userprofile.objects.all())
a.room_booked=random.choice(roombook.models.room.objects.all())
now=timezone.now()
a.time_from=datetime.datetime(now.date().year,now.date().month,random.choice(range(1,21)),now.time().hour,now.time().minute,now.time().second,now.time().microsecond,now.tzinfo)
now=a.time_from
a.time_to=datetime.datetime(now.date().year,now.date().month,random.choice(range(now.date().day,22)),now.time().hour,now.time().minute,now.time().second,now.time().microsecond,now.tzinfo)
a.approved=True;
a.save()
print '......................................',
print 'done'
#add dummy attendence for students
print 'Attendence',
s=college.models.student.objects.first()
for paper in college.models.paper.objects.filter(course=s.course).filter(semester=1).order_by('id'):
mth_t1=attendence.models.month_total()
mth_t1.lecture=10+int(random.random()*40)
mth_t1.tutorial=10+int(random.random()*10)
mth_t1.practical=10+int(random.random()*20)
mth_t1.save()
for s in college.models.student.objects.all():
mth_r1=attendence.models.month_record()
mth_r1.lecture=random.choice(range(mth_t1.lecture))
mth_r1.tutorial=random.choice(range(mth_t1.tutorial))
mth_r1.practical=random.choice(range(mth_t1.practical))
mth_r1.save()
paper_att=attendence.models.paper_attend()
paper_att.paper=paper
paper_att.month_total_1=mth_t1
paper_att.save()
#-----------------
st_at=attendence.models.student_attend()
st_at.student=s
st_at.paper_attend=paper_att
st_at.month1=mth_r1
st_at.save()
print '......................................',
print 'done'
print 'uploading files'
filepath='/home/ghost/Desktop/design4/dummy_files'
path=['imbh.pdf','dismissal2013.pdf','kalyansundaram.pdf','armstrong.pdf']
for i in path:
p=os.path.join(filepath,i)
f=file(p)
myFile=File(f)
a=college.models.principal_desk()
a.title=i[:-4]
a.associated_file=myFile
a.description=''
alphabet='qwertyui opasdfg hjklzxcvbnm '
for i in xrange(int(random.random()*499)):
a.description+=random.choice(alphabet)
a.save()
print '......................................done'
print '===================================================='
print 'Please set user group permissions'
print 'Please assign users to groups'
| [
"arjoonn.94@gmail.com"
] | arjoonn.94@gmail.com |
828ba20be5d5fdeac4a7e0791d2f672dc310856f | 4bc6028ed8ba403b69adfd6f5cbd139baece0f4d | /basic_python/machine_learn/EDA_demo/1-RedCard-EDA/demo1.py | 3eabd8b23bc54d1fd527cf00c799e51c2efe7981 | [] | no_license | xrw560/learn-pyspark | 0ef9ed427ff887ceed1c5e5773bf97ed25ecae04 | 618d16dafd73165e714111670119d9cdecc0bf1f | refs/heads/master | 2020-03-07T00:12:36.885000 | 2019-01-04T09:51:32 | 2019-01-04T09:51:32 | 127,152,051 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,128 | py | from __future__ import absolute_import, division, print_function
import matplotlib as mpl
from matplotlib import pyplot as plt
from matplotlib.pyplot import GridSpec
import seaborn as sns
import numpy as np
import pandas as pd
import os, sys
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
sns.set_context("poster", font_scale=1.3)
# import missingno as msno
import pandas_profiling
from sklearn.datasets import make_blobs
import time
# Uncomment one of the following lines and run the cell:
df = pd.read_csv("redcard.csv.gz", compression='gzip')
print(df.shape)
# print(df.head())
# print(df.describe().T)
# print(df.dtypes)
all_columns = df.columns.tolist()
# print(all_columns)
print(df['height'].mean())
print(np.mean(df.groupby('playerShort').height.mean()))
# df2 = pd.DataFrame({'key1': ['a', 'a', 'b', 'b', 'a'],
# 'key2': ['one', 'two', 'one', 'two', 'one'],
# 'data1': np.random.randn(5),
# 'data2': np.random.randn(5)})
# print(df2)
# grouped = df2['data1'].groupby(df2['key1'])
# print(grouped.mean())
"""数据切分"""
| [
"ncutits@163.com"
] | ncutits@163.com |
5b89a0f87fe1d09bd9e58a32d6ebc24f27d46c90 | e6dab5aa1754ff13755a1f74a28a201681ab7e1c | /.parts/lib/django-1.3/tests/regressiontests/urlpatterns_reverse/no_urls.py | 37bfaee4f494febe46012396834ca2011a4c6608 | [] | no_license | ronkagan/Euler_1 | 67679203a9510147320f7c6513eefd391630703e | 022633cc298475c4f3fd0c6e2bde4f4728713995 | refs/heads/master | 2021-01-06T20:45:52.901025 | 2014-09-06T22:34:16 | 2014-09-06T22:34:16 | 23,744,842 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 118 | py | /home/action/.parts/packages/googleappengine/1.9.4/lib/django-1.3/tests/regressiontests/urlpatterns_reverse/no_urls.py | [
"ron.y.kagan@gmail.com"
] | ron.y.kagan@gmail.com |
b301c6394d1ec79858fdc08c17f1d155a353319b | 50008b3b7fb7e14f793e92f5b27bf302112a3cb4 | /recipes/Python/523015_Callback_Pattern/recipe-523015.py | 8c272476e04c919345df9e0d8eedba99e1698aa3 | [
"MIT",
"Python-2.0"
] | permissive | betty29/code-1 | db56807e19ac9cfe711b41d475a322c168cfdca6 | d097ca0ad6a6aee2180d32dce6a3322621f655fd | refs/heads/master | 2023-03-14T08:15:47.492844 | 2021-02-24T15:39:59 | 2021-02-24T15:39:59 | 341,878,663 | 0 | 0 | MIT | 2021-02-24T15:40:00 | 2021-02-24T11:31:15 | Python | UTF-8 | Python | false | false | 1,335 | py | class CallbackBase:
def __init__(self):
self.__callbackMap = {}
for k in (getattr(self, x) for x in dir(self)):
if hasattr(k, "bind_to_event"):
self.__callbackMap.setdefault(k.bind_to_event, []).append(k)
elif hasattr(k, "bind_to_event_list"):
for j in k.bind_to_event_list:
self.__callbackMap.setdefault(j, []).append(k)
## staticmethod is only used to create a namespace
@staticmethod
def callback(event):
def f(g, ev = event):
g.bind_to_event = ev
return g
return f
@staticmethod
def callbacklist(eventlist):
def f(g, evl = eventlist):
g.bind_to_event_list = evl
return g
return f
def dispatch(self, event):
l = self.__callbackMap[event]
f = lambda *args, **kargs: \
map(lambda x: x(*args, **kargs), l)
return f
## Sample
class MyClass(CallbackBase):
EVENT1 = 1
EVENT2 = 2
@CallbackBase.callback(EVENT1)
def handler1(self, param = None):
print "handler1 with param: %s" % str(param)
return None
@CallbackBase.callbacklist([EVENT1, EVENT2])
def handler2(self, param = None):
print "handler2 with param: %s" % str(param)
return None
def run(self, event, param = None):
self.dispatch(event)(param)
if __name__ == "__main__":
a = MyClass()
a.run(MyClass.EVENT1, 'mandarina')
a.run(MyClass.EVENT2, 'naranja')
| [
"betty@qburst.com"
] | betty@qburst.com |
8ae189cf070459fbdb708e52b7b19a26bfe19108 | 6f05f7d5a67b6bb87956a22b988067ec772ba966 | /data/train/python/497a17977a8c1e62ac70b8485ad87dfa0cc70b8cmenu_controller.py | 497a17977a8c1e62ac70b8485ad87dfa0cc70b8c | [
"MIT"
] | permissive | harshp8l/deep-learning-lang-detection | 93b6d24a38081597c610ecf9b1f3b92c7d669be5 | 2a54293181c1c2b1a2b840ddee4d4d80177efb33 | refs/heads/master | 2020-04-07T18:07:00.697994 | 2018-11-29T23:21:23 | 2018-11-29T23:21:23 | 158,597,498 | 0 | 0 | MIT | 2018-11-21T19:36:42 | 2018-11-21T19:36:41 | null | UTF-8 | Python | false | false | 4,672 | py | #!/usr/bin/env python
# -*- coding: utf-8 -*-
# Copyright (C) 2011 ~ 2015 Deepin, Inc.
# 2011 ~ 2015 Wang YaoHua
#
# Author: Wang YaoHua <mr.asianwang@gmail.com>
# Maintainer: Wang YaoHua <mr.asianwang@gmail.com>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import os
from PyQt5.QtGui import QCursor
from PyQt5.QtCore import QObject, pyqtSignal, pyqtSlot
from deepin_menu.menu import Menu, CheckableMenuItem
from i18n import _
from constants import MAIN_DIR
MENU_ICONS_DIR = os.path.join(MAIN_DIR, "image", "menu_icons")
menu_icon_normal = lambda x: os.path.join(MENU_ICONS_DIR,"%s-symbolic-small-norml.svg" % x)
menu_icon_hover = lambda x: os.path.join(MENU_ICONS_DIR, "%s-symbolic-small-hover.svg" % x)
menu_icon_tuple = lambda x: (menu_icon_normal(x), menu_icon_hover(x))
save_sub_menu = [
CheckableMenuItem("save:radio:_op_auto_save", _("Autosave")),
CheckableMenuItem("save:radio:_op_save_to_desktop", _("Save to desktop")),
CheckableMenuItem("save:radio:_op_copy_to_clipboard", _("Copy to clipboard")),
CheckableMenuItem("save:radio:_op_save_as", _("Save to specified folder")),
CheckableMenuItem("save:radio:_op_copy_and_save", _("Autosave and copy to clipboard")),
]
right_click_menu = [
("_rectangle", _("Rectangle tool"), menu_icon_tuple("rectangle-tool")),
("_ellipse", _("Ellipse tool"), menu_icon_tuple("ellipse-tool")),
("_arrow", _("Arrow tool"), menu_icon_tuple("arrow-tool")),
("_line", _("Brush tool"), menu_icon_tuple("line-tool")),
("_text", _("Text tool"), menu_icon_tuple("text-tool")),
None,
("_save", _("Save"), menu_icon_tuple("save")),
("_share", _("Share"), menu_icon_tuple("share")),
("_exit", _("Exit"), menu_icon_tuple("exit")),
]
class MenuController(QObject):
toolSelected = pyqtSignal(str, arguments=["toolName"])
saveSelected = pyqtSignal(int, arguments=["saveOption"])
shareSelected = pyqtSignal()
exitSelected = pyqtSignal()
preMenuShow = pyqtSignal()
postMenuHide = pyqtSignal()
def __init__(self):
super(MenuController, self).__init__()
def _menu_unregistered(self):
self.postMenuHide.emit()
def _menu_item_invoked(self, _id, _checked):
self.postMenuHide.emit()
if _id == "_rectangle":
self.toolSelected.emit("_rectangle")
if _id == "_ellipse":
self.toolSelected.emit("_ellipse")
if _id == "_arrow":
self.toolSelected.emit("_arrow")
if _id == "_line":
self.toolSelected.emit("_line")
if _id == "_text":
self.toolSelected.emit("_text")
if _id == "save:radio:_op_auto_save":
self.saveSelected.emit(1)
if _id == "save:radio:_op_save_to_desktop":
self.saveSelected.emit(0)
if _id == "save:radio:_op_copy_to_clipboard":
self.saveSelected.emit(4)
if _id == "save:radio:_op_save_as":
self.saveSelected.emit(2)
if _id == "save:radio:_op_copy_and_save":
self.saveSelected.emit(3)
if _id == "_share":
self.shareSelected.emit()
if _id == "_exit":
self.exitSelected.emit()
@pyqtSlot(int)
def show_menu(self, saveOption):
self.preMenuShow.emit()
self.menu = Menu(right_click_menu)
self.menu.getItemById("_save").setSubMenu(Menu(save_sub_menu))
self.menu.getItemById("save:radio:_op_auto_save").checked = \
saveOption == 1
self.menu.getItemById("save:radio:_op_save_to_desktop").checked = \
saveOption == 0
self.menu.getItemById("save:radio:_op_copy_to_clipboard").checked = \
saveOption == 4
self.menu.getItemById("save:radio:_op_save_as").checked = \
saveOption == 2
self.menu.getItemById("save:radio:_op_copy_and_save").checked = \
saveOption == 3
self.menu.itemClicked.connect(self._menu_item_invoked)
self.menu.menuDismissed.connect(self._menu_unregistered)
self.menu.showRectMenu(QCursor.pos().x(), QCursor.pos().y())
| [
"aliostad+github@gmail.com"
] | aliostad+github@gmail.com |
a695fcf4caaeb2f0afcec7f4b690c49d353dc8a9 | bad62c2b0dfad33197db55b44efeec0bab405634 | /sdk/iothub/azure-mgmt-iothub/azure/mgmt/iothub/v2021_07_01/operations/_iot_hub_resource_operations.py | 75ba201529c6601bdd2f24122744594baafea76c | [
"MIT",
"LicenseRef-scancode-generic-cla",
"LGPL-2.1-or-later"
] | permissive | test-repo-billy/azure-sdk-for-python | 20c5a2486456e02456de17515704cb064ff19833 | cece86a8548cb5f575e5419864d631673be0a244 | refs/heads/master | 2022-10-25T02:28:39.022559 | 2022-10-18T06:05:46 | 2022-10-18T06:05:46 | 182,325,031 | 0 | 0 | MIT | 2019-07-25T22:28:52 | 2019-04-19T20:59:15 | Python | UTF-8 | Python | false | false | 154,742 | py | # pylint: disable=too-many-lines
# coding=utf-8
# --------------------------------------------------------------------------
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License. See License.txt in the project root for license information.
# Code generated by Microsoft (R) AutoRest Code Generator.
# Changes may cause incorrect behavior and will be lost if the code is regenerated.
# --------------------------------------------------------------------------
from typing import Any, Callable, Dict, IO, Iterable, Optional, TypeVar, Union, cast, overload
from urllib.parse import parse_qs, urljoin, urlparse
from azure.core.exceptions import (
ClientAuthenticationError,
HttpResponseError,
ResourceExistsError,
ResourceNotFoundError,
map_error,
)
from azure.core.paging import ItemPaged
from azure.core.pipeline import PipelineResponse
from azure.core.pipeline.transport import HttpResponse
from azure.core.polling import LROPoller, NoPolling, PollingMethod
from azure.core.rest import HttpRequest
from azure.core.tracing.decorator import distributed_trace
from azure.core.utils import case_insensitive_dict
from azure.mgmt.core.exceptions import ARMErrorFormat
from azure.mgmt.core.polling.arm_polling import ARMPolling
from .. import models as _models
from ..._serialization import Serializer
from .._vendor import _convert_request, _format_url_section
T = TypeVar("T")
ClsType = Optional[Callable[[PipelineResponse[HttpRequest, HttpResponse], T, Dict[str, Any]], Any]]
_SERIALIZER = Serializer()
_SERIALIZER.client_side_validation = False
def build_get_request(resource_group_name: str, resource_name: str, subscription_id: str, **kwargs: Any) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="GET", url=_url, params=_params, headers=_headers, **kwargs)
def build_create_or_update_request(
resource_group_name: str, resource_name: str, subscription_id: str, *, if_match: Optional[str] = None, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
if if_match is not None:
_headers["If-Match"] = _SERIALIZER.header("if_match", if_match, "str")
if content_type is not None:
_headers["Content-Type"] = _SERIALIZER.header("content_type", content_type, "str")
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="PUT", url=_url, params=_params, headers=_headers, **kwargs)
def build_update_request(
resource_group_name: str, resource_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
if content_type is not None:
_headers["Content-Type"] = _SERIALIZER.header("content_type", content_type, "str")
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="PATCH", url=_url, params=_params, headers=_headers, **kwargs)
def build_delete_request(
resource_group_name: str, resource_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="DELETE", url=_url, params=_params, headers=_headers, **kwargs)
def build_list_by_subscription_request(subscription_id: str, **kwargs: Any) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop("template_url", "/subscriptions/{subscriptionId}/providers/Microsoft.Devices/IotHubs")
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="GET", url=_url, params=_params, headers=_headers, **kwargs)
def build_list_by_resource_group_request(resource_group_name: str, subscription_id: str, **kwargs: Any) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="GET", url=_url, params=_params, headers=_headers, **kwargs)
def build_get_stats_request(
resource_group_name: str, resource_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/IotHubStats",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="GET", url=_url, params=_params, headers=_headers, **kwargs)
def build_get_valid_skus_request(
resource_group_name: str, resource_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/skus",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="GET", url=_url, params=_params, headers=_headers, **kwargs)
def build_list_event_hub_consumer_groups_request(
resource_group_name: str, resource_name: str, event_hub_endpoint_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/eventHubEndpoints/{eventHubEndpointName}/ConsumerGroups",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
"eventHubEndpointName": _SERIALIZER.url("event_hub_endpoint_name", event_hub_endpoint_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="GET", url=_url, params=_params, headers=_headers, **kwargs)
def build_get_event_hub_consumer_group_request(
resource_group_name: str,
resource_name: str,
event_hub_endpoint_name: str,
name: str,
subscription_id: str,
**kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/eventHubEndpoints/{eventHubEndpointName}/ConsumerGroups/{name}",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
"eventHubEndpointName": _SERIALIZER.url("event_hub_endpoint_name", event_hub_endpoint_name, "str"),
"name": _SERIALIZER.url("name", name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="GET", url=_url, params=_params, headers=_headers, **kwargs)
def build_create_event_hub_consumer_group_request(
resource_group_name: str,
resource_name: str,
event_hub_endpoint_name: str,
name: str,
subscription_id: str,
**kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/eventHubEndpoints/{eventHubEndpointName}/ConsumerGroups/{name}",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
"eventHubEndpointName": _SERIALIZER.url("event_hub_endpoint_name", event_hub_endpoint_name, "str"),
"name": _SERIALIZER.url("name", name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
if content_type is not None:
_headers["Content-Type"] = _SERIALIZER.header("content_type", content_type, "str")
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="PUT", url=_url, params=_params, headers=_headers, **kwargs)
def build_delete_event_hub_consumer_group_request(
resource_group_name: str,
resource_name: str,
event_hub_endpoint_name: str,
name: str,
subscription_id: str,
**kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/eventHubEndpoints/{eventHubEndpointName}/ConsumerGroups/{name}",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
"eventHubEndpointName": _SERIALIZER.url("event_hub_endpoint_name", event_hub_endpoint_name, "str"),
"name": _SERIALIZER.url("name", name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="DELETE", url=_url, params=_params, headers=_headers, **kwargs)
def build_list_jobs_request(
resource_group_name: str, resource_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/jobs",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="GET", url=_url, params=_params, headers=_headers, **kwargs)
def build_get_job_request(
resource_group_name: str, resource_name: str, job_id: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/jobs/{jobId}",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
"jobId": _SERIALIZER.url("job_id", job_id, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="GET", url=_url, params=_params, headers=_headers, **kwargs)
def build_get_quota_metrics_request(
resource_group_name: str, resource_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/quotaMetrics",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="GET", url=_url, params=_params, headers=_headers, **kwargs)
def build_get_endpoint_health_request(
resource_group_name: str, iot_hub_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{iotHubName}/routingEndpointsHealth",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"iotHubName": _SERIALIZER.url("iot_hub_name", iot_hub_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="GET", url=_url, params=_params, headers=_headers, **kwargs)
def build_check_name_availability_request(subscription_id: str, **kwargs: Any) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url", "/subscriptions/{subscriptionId}/providers/Microsoft.Devices/checkNameAvailability"
)
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
if content_type is not None:
_headers["Content-Type"] = _SERIALIZER.header("content_type", content_type, "str")
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="POST", url=_url, params=_params, headers=_headers, **kwargs)
def build_test_all_routes_request(
iot_hub_name: str, resource_group_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{iotHubName}/routing/routes/$testall",
) # pylint: disable=line-too-long
path_format_arguments = {
"iotHubName": _SERIALIZER.url("iot_hub_name", iot_hub_name, "str"),
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
if content_type is not None:
_headers["Content-Type"] = _SERIALIZER.header("content_type", content_type, "str")
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="POST", url=_url, params=_params, headers=_headers, **kwargs)
def build_test_route_request(
iot_hub_name: str, resource_group_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{iotHubName}/routing/routes/$testnew",
) # pylint: disable=line-too-long
path_format_arguments = {
"iotHubName": _SERIALIZER.url("iot_hub_name", iot_hub_name, "str"),
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
if content_type is not None:
_headers["Content-Type"] = _SERIALIZER.header("content_type", content_type, "str")
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="POST", url=_url, params=_params, headers=_headers, **kwargs)
def build_list_keys_request(
resource_group_name: str, resource_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/listkeys",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="POST", url=_url, params=_params, headers=_headers, **kwargs)
def build_get_keys_for_key_name_request(
resource_group_name: str, resource_name: str, key_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/IotHubKeys/{keyName}/listkeys",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
"keyName": _SERIALIZER.url("key_name", key_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="POST", url=_url, params=_params, headers=_headers, **kwargs)
def build_export_devices_request(
resource_group_name: str, resource_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/exportDevices",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
if content_type is not None:
_headers["Content-Type"] = _SERIALIZER.header("content_type", content_type, "str")
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="POST", url=_url, params=_params, headers=_headers, **kwargs)
def build_import_devices_request(
resource_group_name: str, resource_name: str, subscription_id: str, **kwargs: Any
) -> HttpRequest:
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
accept = _headers.pop("Accept", "application/json")
# Construct URL
_url = kwargs.pop(
"template_url",
"/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/importDevices",
) # pylint: disable=line-too-long
path_format_arguments = {
"subscriptionId": _SERIALIZER.url("subscription_id", subscription_id, "str"),
"resourceGroupName": _SERIALIZER.url("resource_group_name", resource_group_name, "str"),
"resourceName": _SERIALIZER.url("resource_name", resource_name, "str"),
}
_url = _format_url_section(_url, **path_format_arguments)
# Construct parameters
_params["api-version"] = _SERIALIZER.query("api_version", api_version, "str")
# Construct headers
if content_type is not None:
_headers["Content-Type"] = _SERIALIZER.header("content_type", content_type, "str")
_headers["Accept"] = _SERIALIZER.header("accept", accept, "str")
return HttpRequest(method="POST", url=_url, params=_params, headers=_headers, **kwargs)
class IotHubResourceOperations: # pylint: disable=too-many-public-methods
"""
.. warning::
**DO NOT** instantiate this class directly.
Instead, you should access the following operations through
:class:`~azure.mgmt.iothub.v2021_07_01.IotHubClient`'s
:attr:`iot_hub_resource` attribute.
"""
models = _models
def __init__(self, *args, **kwargs):
input_args = list(args)
self._client = input_args.pop(0) if input_args else kwargs.pop("client")
self._config = input_args.pop(0) if input_args else kwargs.pop("config")
self._serialize = input_args.pop(0) if input_args else kwargs.pop("serializer")
self._deserialize = input_args.pop(0) if input_args else kwargs.pop("deserializer")
@distributed_trace
def get(self, resource_group_name: str, resource_name: str, **kwargs: Any) -> _models.IotHubDescription:
"""Get the non-security related metadata of an IoT hub.
Get the non-security related metadata of an IoT hub.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: IotHubDescription or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.IotHubDescription]
request = build_get_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.get.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = self._deserialize("IotHubDescription", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
get.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}"} # type: ignore
def _create_or_update_initial(
self,
resource_group_name: str,
resource_name: str,
iot_hub_description: Union[_models.IotHubDescription, IO],
if_match: Optional[str] = None,
**kwargs: Any
) -> _models.IotHubDescription:
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
cls = kwargs.pop("cls", None) # type: ClsType[_models.IotHubDescription]
content_type = content_type or "application/json"
_json = None
_content = None
if isinstance(iot_hub_description, (IO, bytes)):
_content = iot_hub_description
else:
_json = self._serialize.body(iot_hub_description, "IotHubDescription")
request = build_create_or_update_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
subscription_id=self._config.subscription_id,
if_match=if_match,
api_version=api_version,
content_type=content_type,
json=_json,
content=_content,
template_url=self._create_or_update_initial.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200, 201]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
if response.status_code == 200:
deserialized = self._deserialize("IotHubDescription", pipeline_response)
if response.status_code == 201:
deserialized = self._deserialize("IotHubDescription", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
_create_or_update_initial.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}"} # type: ignore
@overload
def begin_create_or_update(
self,
resource_group_name: str,
resource_name: str,
iot_hub_description: _models.IotHubDescription,
if_match: Optional[str] = None,
*,
content_type: str = "application/json",
**kwargs: Any
) -> LROPoller[_models.IotHubDescription]:
"""Create or update the metadata of an IoT hub.
Create or update the metadata of an Iot hub. The usual pattern to modify a property is to
retrieve the IoT hub metadata and security metadata, and then combine them with the modified
values in a new body to update the IoT hub. If certain properties are missing in the JSON,
updating IoT Hub may cause these values to fallback to default, which may lead to unexpected
behavior.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param iot_hub_description: The IoT hub metadata and security metadata. Required.
:type iot_hub_description: ~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription
:param if_match: ETag of the IoT Hub. Do not specify for creating a brand new IoT Hub. Required
to update an existing IoT Hub. Default value is None.
:type if_match: str
:keyword content_type: Body Parameter content-type. Content type parameter for JSON body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:keyword str continuation_token: A continuation token to restart a poller from a saved state.
:keyword polling: By default, your polling method will be ARMPolling. Pass in False for this
operation to not poll, or pass in your own initialized polling object for a personal polling
strategy.
:paramtype polling: bool or ~azure.core.polling.PollingMethod
:keyword int polling_interval: Default waiting time between two polls for LRO operations if no
Retry-After header is present.
:return: An instance of LROPoller that returns either IotHubDescription or the result of
cls(response)
:rtype: ~azure.core.polling.LROPoller[~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription]
:raises ~azure.core.exceptions.HttpResponseError:
"""
@overload
def begin_create_or_update(
self,
resource_group_name: str,
resource_name: str,
iot_hub_description: IO,
if_match: Optional[str] = None,
*,
content_type: str = "application/json",
**kwargs: Any
) -> LROPoller[_models.IotHubDescription]:
"""Create or update the metadata of an IoT hub.
Create or update the metadata of an Iot hub. The usual pattern to modify a property is to
retrieve the IoT hub metadata and security metadata, and then combine them with the modified
values in a new body to update the IoT hub. If certain properties are missing in the JSON,
updating IoT Hub may cause these values to fallback to default, which may lead to unexpected
behavior.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param iot_hub_description: The IoT hub metadata and security metadata. Required.
:type iot_hub_description: IO
:param if_match: ETag of the IoT Hub. Do not specify for creating a brand new IoT Hub. Required
to update an existing IoT Hub. Default value is None.
:type if_match: str
:keyword content_type: Body Parameter content-type. Content type parameter for binary body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:keyword str continuation_token: A continuation token to restart a poller from a saved state.
:keyword polling: By default, your polling method will be ARMPolling. Pass in False for this
operation to not poll, or pass in your own initialized polling object for a personal polling
strategy.
:paramtype polling: bool or ~azure.core.polling.PollingMethod
:keyword int polling_interval: Default waiting time between two polls for LRO operations if no
Retry-After header is present.
:return: An instance of LROPoller that returns either IotHubDescription or the result of
cls(response)
:rtype: ~azure.core.polling.LROPoller[~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription]
:raises ~azure.core.exceptions.HttpResponseError:
"""
@distributed_trace
def begin_create_or_update(
self,
resource_group_name: str,
resource_name: str,
iot_hub_description: Union[_models.IotHubDescription, IO],
if_match: Optional[str] = None,
**kwargs: Any
) -> LROPoller[_models.IotHubDescription]:
"""Create or update the metadata of an IoT hub.
Create or update the metadata of an Iot hub. The usual pattern to modify a property is to
retrieve the IoT hub metadata and security metadata, and then combine them with the modified
values in a new body to update the IoT hub. If certain properties are missing in the JSON,
updating IoT Hub may cause these values to fallback to default, which may lead to unexpected
behavior.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param iot_hub_description: The IoT hub metadata and security metadata. Is either a model type
or a IO type. Required.
:type iot_hub_description: ~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription or IO
:param if_match: ETag of the IoT Hub. Do not specify for creating a brand new IoT Hub. Required
to update an existing IoT Hub. Default value is None.
:type if_match: str
:keyword content_type: Body Parameter content-type. Known values are: 'application/json'.
Default value is None.
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:keyword str continuation_token: A continuation token to restart a poller from a saved state.
:keyword polling: By default, your polling method will be ARMPolling. Pass in False for this
operation to not poll, or pass in your own initialized polling object for a personal polling
strategy.
:paramtype polling: bool or ~azure.core.polling.PollingMethod
:keyword int polling_interval: Default waiting time between two polls for LRO operations if no
Retry-After header is present.
:return: An instance of LROPoller that returns either IotHubDescription or the result of
cls(response)
:rtype: ~azure.core.polling.LROPoller[~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription]
:raises ~azure.core.exceptions.HttpResponseError:
"""
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
cls = kwargs.pop("cls", None) # type: ClsType[_models.IotHubDescription]
polling = kwargs.pop("polling", True) # type: Union[bool, PollingMethod]
lro_delay = kwargs.pop("polling_interval", self._config.polling_interval)
cont_token = kwargs.pop("continuation_token", None) # type: Optional[str]
if cont_token is None:
raw_result = self._create_or_update_initial( # type: ignore
resource_group_name=resource_group_name,
resource_name=resource_name,
iot_hub_description=iot_hub_description,
if_match=if_match,
api_version=api_version,
content_type=content_type,
cls=lambda x, y, z: x,
headers=_headers,
params=_params,
**kwargs
)
kwargs.pop("error_map", None)
def get_long_running_output(pipeline_response):
deserialized = self._deserialize("IotHubDescription", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
if polling is True:
polling_method = cast(PollingMethod, ARMPolling(lro_delay, **kwargs)) # type: PollingMethod
elif polling is False:
polling_method = cast(PollingMethod, NoPolling())
else:
polling_method = polling
if cont_token:
return LROPoller.from_continuation_token(
polling_method=polling_method,
continuation_token=cont_token,
client=self._client,
deserialization_callback=get_long_running_output,
)
return LROPoller(self._client, raw_result, get_long_running_output, polling_method)
begin_create_or_update.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}"} # type: ignore
def _update_initial(
self, resource_group_name: str, resource_name: str, iot_hub_tags: Union[_models.TagsResource, IO], **kwargs: Any
) -> _models.IotHubDescription:
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
cls = kwargs.pop("cls", None) # type: ClsType[_models.IotHubDescription]
content_type = content_type or "application/json"
_json = None
_content = None
if isinstance(iot_hub_tags, (IO, bytes)):
_content = iot_hub_tags
else:
_json = self._serialize.body(iot_hub_tags, "TagsResource")
request = build_update_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
content_type=content_type,
json=_json,
content=_content,
template_url=self._update_initial.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
raise HttpResponseError(response=response, error_format=ARMErrorFormat)
deserialized = self._deserialize("IotHubDescription", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
_update_initial.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}"} # type: ignore
@overload
def begin_update(
self,
resource_group_name: str,
resource_name: str,
iot_hub_tags: _models.TagsResource,
*,
content_type: str = "application/json",
**kwargs: Any
) -> LROPoller[_models.IotHubDescription]:
"""Update an existing IoT Hubs tags.
Update an existing IoT Hub tags. to update other fields use the CreateOrUpdate method.
:param resource_group_name: Resource group identifier. Required.
:type resource_group_name: str
:param resource_name: Name of iot hub to update. Required.
:type resource_name: str
:param iot_hub_tags: Updated tag information to set into the iot hub instance. Required.
:type iot_hub_tags: ~azure.mgmt.iothub.v2021_07_01.models.TagsResource
:keyword content_type: Body Parameter content-type. Content type parameter for JSON body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:keyword str continuation_token: A continuation token to restart a poller from a saved state.
:keyword polling: By default, your polling method will be ARMPolling. Pass in False for this
operation to not poll, or pass in your own initialized polling object for a personal polling
strategy.
:paramtype polling: bool or ~azure.core.polling.PollingMethod
:keyword int polling_interval: Default waiting time between two polls for LRO operations if no
Retry-After header is present.
:return: An instance of LROPoller that returns either IotHubDescription or the result of
cls(response)
:rtype: ~azure.core.polling.LROPoller[~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription]
:raises ~azure.core.exceptions.HttpResponseError:
"""
@overload
def begin_update(
self,
resource_group_name: str,
resource_name: str,
iot_hub_tags: IO,
*,
content_type: str = "application/json",
**kwargs: Any
) -> LROPoller[_models.IotHubDescription]:
"""Update an existing IoT Hubs tags.
Update an existing IoT Hub tags. to update other fields use the CreateOrUpdate method.
:param resource_group_name: Resource group identifier. Required.
:type resource_group_name: str
:param resource_name: Name of iot hub to update. Required.
:type resource_name: str
:param iot_hub_tags: Updated tag information to set into the iot hub instance. Required.
:type iot_hub_tags: IO
:keyword content_type: Body Parameter content-type. Content type parameter for binary body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:keyword str continuation_token: A continuation token to restart a poller from a saved state.
:keyword polling: By default, your polling method will be ARMPolling. Pass in False for this
operation to not poll, or pass in your own initialized polling object for a personal polling
strategy.
:paramtype polling: bool or ~azure.core.polling.PollingMethod
:keyword int polling_interval: Default waiting time between two polls for LRO operations if no
Retry-After header is present.
:return: An instance of LROPoller that returns either IotHubDescription or the result of
cls(response)
:rtype: ~azure.core.polling.LROPoller[~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription]
:raises ~azure.core.exceptions.HttpResponseError:
"""
@distributed_trace
def begin_update(
self, resource_group_name: str, resource_name: str, iot_hub_tags: Union[_models.TagsResource, IO], **kwargs: Any
) -> LROPoller[_models.IotHubDescription]:
"""Update an existing IoT Hubs tags.
Update an existing IoT Hub tags. to update other fields use the CreateOrUpdate method.
:param resource_group_name: Resource group identifier. Required.
:type resource_group_name: str
:param resource_name: Name of iot hub to update. Required.
:type resource_name: str
:param iot_hub_tags: Updated tag information to set into the iot hub instance. Is either a
model type or a IO type. Required.
:type iot_hub_tags: ~azure.mgmt.iothub.v2021_07_01.models.TagsResource or IO
:keyword content_type: Body Parameter content-type. Known values are: 'application/json'.
Default value is None.
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:keyword str continuation_token: A continuation token to restart a poller from a saved state.
:keyword polling: By default, your polling method will be ARMPolling. Pass in False for this
operation to not poll, or pass in your own initialized polling object for a personal polling
strategy.
:paramtype polling: bool or ~azure.core.polling.PollingMethod
:keyword int polling_interval: Default waiting time between two polls for LRO operations if no
Retry-After header is present.
:return: An instance of LROPoller that returns either IotHubDescription or the result of
cls(response)
:rtype: ~azure.core.polling.LROPoller[~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription]
:raises ~azure.core.exceptions.HttpResponseError:
"""
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
cls = kwargs.pop("cls", None) # type: ClsType[_models.IotHubDescription]
polling = kwargs.pop("polling", True) # type: Union[bool, PollingMethod]
lro_delay = kwargs.pop("polling_interval", self._config.polling_interval)
cont_token = kwargs.pop("continuation_token", None) # type: Optional[str]
if cont_token is None:
raw_result = self._update_initial( # type: ignore
resource_group_name=resource_group_name,
resource_name=resource_name,
iot_hub_tags=iot_hub_tags,
api_version=api_version,
content_type=content_type,
cls=lambda x, y, z: x,
headers=_headers,
params=_params,
**kwargs
)
kwargs.pop("error_map", None)
def get_long_running_output(pipeline_response):
deserialized = self._deserialize("IotHubDescription", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
if polling is True:
polling_method = cast(PollingMethod, ARMPolling(lro_delay, **kwargs)) # type: PollingMethod
elif polling is False:
polling_method = cast(PollingMethod, NoPolling())
else:
polling_method = polling
if cont_token:
return LROPoller.from_continuation_token(
polling_method=polling_method,
continuation_token=cont_token,
client=self._client,
deserialization_callback=get_long_running_output,
)
return LROPoller(self._client, raw_result, get_long_running_output, polling_method)
begin_update.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}"} # type: ignore
def _delete_initial(
self, resource_group_name: str, resource_name: str, **kwargs: Any
) -> Union[_models.IotHubDescription, _models.ErrorDetails]:
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[Union[_models.IotHubDescription, _models.ErrorDetails]]
request = build_delete_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self._delete_initial.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200, 202, 204, 404]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = None
if response.status_code == 200:
deserialized = self._deserialize("IotHubDescription", pipeline_response)
if response.status_code == 202:
deserialized = self._deserialize("IotHubDescription", pipeline_response)
if response.status_code == 404:
deserialized = self._deserialize("ErrorDetails", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
_delete_initial.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}"} # type: ignore
@distributed_trace
def begin_delete(
self, resource_group_name: str, resource_name: str, **kwargs: Any
) -> Union[LROPoller[_models.IotHubDescription], LROPoller[_models.ErrorDetails]]:
"""Delete an IoT hub.
Delete an IoT hub.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:keyword str continuation_token: A continuation token to restart a poller from a saved state.
:keyword polling: By default, your polling method will be ARMPolling. Pass in False for this
operation to not poll, or pass in your own initialized polling object for a personal polling
strategy.
:paramtype polling: bool or ~azure.core.polling.PollingMethod
:keyword int polling_interval: Default waiting time between two polls for LRO operations if no
Retry-After header is present.
:return: An instance of LROPoller that returns either IotHubDescription or An instance of
LROPoller that returns either ErrorDetails or the result of cls(response)
:rtype: ~azure.core.polling.LROPoller[~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription]
or ~azure.core.polling.LROPoller[~azure.mgmt.iothub.v2021_07_01.models.ErrorDetails]
:raises ~azure.core.exceptions.HttpResponseError:
"""
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.IotHubDescription]
polling = kwargs.pop("polling", True) # type: Union[bool, PollingMethod]
lro_delay = kwargs.pop("polling_interval", self._config.polling_interval)
cont_token = kwargs.pop("continuation_token", None) # type: Optional[str]
if cont_token is None:
raw_result = self._delete_initial( # type: ignore
resource_group_name=resource_group_name,
resource_name=resource_name,
api_version=api_version,
cls=lambda x, y, z: x,
headers=_headers,
params=_params,
**kwargs
)
kwargs.pop("error_map", None)
def get_long_running_output(pipeline_response):
deserialized = self._deserialize("IotHubDescription", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
if polling is True:
polling_method = cast(PollingMethod, ARMPolling(lro_delay, **kwargs)) # type: PollingMethod
elif polling is False:
polling_method = cast(PollingMethod, NoPolling())
else:
polling_method = polling
if cont_token:
return LROPoller.from_continuation_token(
polling_method=polling_method,
continuation_token=cont_token,
client=self._client,
deserialization_callback=get_long_running_output,
)
return LROPoller(self._client, raw_result, get_long_running_output, polling_method)
begin_delete.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}"} # type: ignore
@distributed_trace
def list_by_subscription(self, **kwargs: Any) -> Iterable["_models.IotHubDescription"]:
"""Get all the IoT hubs in a subscription.
Get all the IoT hubs in a subscription.
:keyword callable cls: A custom type or function that will be passed the direct response
:return: An iterator like instance of either IotHubDescription or the result of cls(response)
:rtype: ~azure.core.paging.ItemPaged[~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription]
:raises ~azure.core.exceptions.HttpResponseError:
"""
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.IotHubDescriptionListResult]
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
def prepare_request(next_link=None):
if not next_link:
request = build_list_by_subscription_request(
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.list_by_subscription.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
else:
# make call to next link with the client's api-version
_parsed_next_link = urlparse(next_link)
_next_request_params = case_insensitive_dict(parse_qs(_parsed_next_link.query))
_next_request_params["api-version"] = self._config.api_version
request = HttpRequest("GET", urljoin(next_link, _parsed_next_link.path), params=_next_request_params)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
request.method = "GET"
return request
def extract_data(pipeline_response):
deserialized = self._deserialize("IotHubDescriptionListResult", pipeline_response)
list_of_elem = deserialized.value
if cls:
list_of_elem = cls(list_of_elem)
return deserialized.next_link or None, iter(list_of_elem)
def get_next(next_link=None):
request = prepare_request(next_link)
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
return pipeline_response
return ItemPaged(get_next, extract_data)
list_by_subscription.metadata = {"url": "/subscriptions/{subscriptionId}/providers/Microsoft.Devices/IotHubs"} # type: ignore
@distributed_trace
def list_by_resource_group(self, resource_group_name: str, **kwargs: Any) -> Iterable["_models.IotHubDescription"]:
"""Get all the IoT hubs in a resource group.
Get all the IoT hubs in a resource group.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: An iterator like instance of either IotHubDescription or the result of cls(response)
:rtype: ~azure.core.paging.ItemPaged[~azure.mgmt.iothub.v2021_07_01.models.IotHubDescription]
:raises ~azure.core.exceptions.HttpResponseError:
"""
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.IotHubDescriptionListResult]
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
def prepare_request(next_link=None):
if not next_link:
request = build_list_by_resource_group_request(
resource_group_name=resource_group_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.list_by_resource_group.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
else:
# make call to next link with the client's api-version
_parsed_next_link = urlparse(next_link)
_next_request_params = case_insensitive_dict(parse_qs(_parsed_next_link.query))
_next_request_params["api-version"] = self._config.api_version
request = HttpRequest("GET", urljoin(next_link, _parsed_next_link.path), params=_next_request_params)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
request.method = "GET"
return request
def extract_data(pipeline_response):
deserialized = self._deserialize("IotHubDescriptionListResult", pipeline_response)
list_of_elem = deserialized.value
if cls:
list_of_elem = cls(list_of_elem)
return deserialized.next_link or None, iter(list_of_elem)
def get_next(next_link=None):
request = prepare_request(next_link)
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
return pipeline_response
return ItemPaged(get_next, extract_data)
list_by_resource_group.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs"} # type: ignore
@distributed_trace
def get_stats(self, resource_group_name: str, resource_name: str, **kwargs: Any) -> _models.RegistryStatistics:
"""Get the statistics from an IoT hub.
Get the statistics from an IoT hub.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: RegistryStatistics or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.RegistryStatistics
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.RegistryStatistics]
request = build_get_stats_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.get_stats.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = self._deserialize("RegistryStatistics", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
get_stats.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/IotHubStats"} # type: ignore
@distributed_trace
def get_valid_skus(
self, resource_group_name: str, resource_name: str, **kwargs: Any
) -> Iterable["_models.IotHubSkuDescription"]:
"""Get the list of valid SKUs for an IoT hub.
Get the list of valid SKUs for an IoT hub.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: An iterator like instance of either IotHubSkuDescription or the result of
cls(response)
:rtype:
~azure.core.paging.ItemPaged[~azure.mgmt.iothub.v2021_07_01.models.IotHubSkuDescription]
:raises ~azure.core.exceptions.HttpResponseError:
"""
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.IotHubSkuDescriptionListResult]
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
def prepare_request(next_link=None):
if not next_link:
request = build_get_valid_skus_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.get_valid_skus.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
else:
# make call to next link with the client's api-version
_parsed_next_link = urlparse(next_link)
_next_request_params = case_insensitive_dict(parse_qs(_parsed_next_link.query))
_next_request_params["api-version"] = self._config.api_version
request = HttpRequest("GET", urljoin(next_link, _parsed_next_link.path), params=_next_request_params)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
request.method = "GET"
return request
def extract_data(pipeline_response):
deserialized = self._deserialize("IotHubSkuDescriptionListResult", pipeline_response)
list_of_elem = deserialized.value
if cls:
list_of_elem = cls(list_of_elem)
return deserialized.next_link or None, iter(list_of_elem)
def get_next(next_link=None):
request = prepare_request(next_link)
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
return pipeline_response
return ItemPaged(get_next, extract_data)
get_valid_skus.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/skus"} # type: ignore
@distributed_trace
def list_event_hub_consumer_groups(
self, resource_group_name: str, resource_name: str, event_hub_endpoint_name: str, **kwargs: Any
) -> Iterable["_models.EventHubConsumerGroupInfo"]:
"""Get a list of the consumer groups in the Event Hub-compatible device-to-cloud endpoint in an
IoT hub.
Get a list of the consumer groups in the Event Hub-compatible device-to-cloud endpoint in an
IoT hub.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param event_hub_endpoint_name: The name of the Event Hub-compatible endpoint. Required.
:type event_hub_endpoint_name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: An iterator like instance of either EventHubConsumerGroupInfo or the result of
cls(response)
:rtype:
~azure.core.paging.ItemPaged[~azure.mgmt.iothub.v2021_07_01.models.EventHubConsumerGroupInfo]
:raises ~azure.core.exceptions.HttpResponseError:
"""
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.EventHubConsumerGroupsListResult]
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
def prepare_request(next_link=None):
if not next_link:
request = build_list_event_hub_consumer_groups_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
event_hub_endpoint_name=event_hub_endpoint_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.list_event_hub_consumer_groups.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
else:
# make call to next link with the client's api-version
_parsed_next_link = urlparse(next_link)
_next_request_params = case_insensitive_dict(parse_qs(_parsed_next_link.query))
_next_request_params["api-version"] = self._config.api_version
request = HttpRequest("GET", urljoin(next_link, _parsed_next_link.path), params=_next_request_params)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
request.method = "GET"
return request
def extract_data(pipeline_response):
deserialized = self._deserialize("EventHubConsumerGroupsListResult", pipeline_response)
list_of_elem = deserialized.value
if cls:
list_of_elem = cls(list_of_elem)
return deserialized.next_link or None, iter(list_of_elem)
def get_next(next_link=None):
request = prepare_request(next_link)
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
return pipeline_response
return ItemPaged(get_next, extract_data)
list_event_hub_consumer_groups.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/eventHubEndpoints/{eventHubEndpointName}/ConsumerGroups"} # type: ignore
@distributed_trace
def get_event_hub_consumer_group(
self, resource_group_name: str, resource_name: str, event_hub_endpoint_name: str, name: str, **kwargs: Any
) -> _models.EventHubConsumerGroupInfo:
"""Get a consumer group from the Event Hub-compatible device-to-cloud endpoint for an IoT hub.
Get a consumer group from the Event Hub-compatible device-to-cloud endpoint for an IoT hub.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param event_hub_endpoint_name: The name of the Event Hub-compatible endpoint in the IoT hub.
Required.
:type event_hub_endpoint_name: str
:param name: The name of the consumer group to retrieve. Required.
:type name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: EventHubConsumerGroupInfo or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.EventHubConsumerGroupInfo
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.EventHubConsumerGroupInfo]
request = build_get_event_hub_consumer_group_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
event_hub_endpoint_name=event_hub_endpoint_name,
name=name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.get_event_hub_consumer_group.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = self._deserialize("EventHubConsumerGroupInfo", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
get_event_hub_consumer_group.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/eventHubEndpoints/{eventHubEndpointName}/ConsumerGroups/{name}"} # type: ignore
@overload
def create_event_hub_consumer_group(
self,
resource_group_name: str,
resource_name: str,
event_hub_endpoint_name: str,
name: str,
consumer_group_body: _models.EventHubConsumerGroupBodyDescription,
*,
content_type: str = "application/json",
**kwargs: Any
) -> _models.EventHubConsumerGroupInfo:
"""Add a consumer group to an Event Hub-compatible endpoint in an IoT hub.
Add a consumer group to an Event Hub-compatible endpoint in an IoT hub.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param event_hub_endpoint_name: The name of the Event Hub-compatible endpoint in the IoT hub.
Required.
:type event_hub_endpoint_name: str
:param name: The name of the consumer group to add. Required.
:type name: str
:param consumer_group_body: The consumer group to add. Required.
:type consumer_group_body:
~azure.mgmt.iothub.v2021_07_01.models.EventHubConsumerGroupBodyDescription
:keyword content_type: Body Parameter content-type. Content type parameter for JSON body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: EventHubConsumerGroupInfo or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.EventHubConsumerGroupInfo
:raises ~azure.core.exceptions.HttpResponseError:
"""
@overload
def create_event_hub_consumer_group(
self,
resource_group_name: str,
resource_name: str,
event_hub_endpoint_name: str,
name: str,
consumer_group_body: IO,
*,
content_type: str = "application/json",
**kwargs: Any
) -> _models.EventHubConsumerGroupInfo:
"""Add a consumer group to an Event Hub-compatible endpoint in an IoT hub.
Add a consumer group to an Event Hub-compatible endpoint in an IoT hub.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param event_hub_endpoint_name: The name of the Event Hub-compatible endpoint in the IoT hub.
Required.
:type event_hub_endpoint_name: str
:param name: The name of the consumer group to add. Required.
:type name: str
:param consumer_group_body: The consumer group to add. Required.
:type consumer_group_body: IO
:keyword content_type: Body Parameter content-type. Content type parameter for binary body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: EventHubConsumerGroupInfo or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.EventHubConsumerGroupInfo
:raises ~azure.core.exceptions.HttpResponseError:
"""
@distributed_trace
def create_event_hub_consumer_group(
self,
resource_group_name: str,
resource_name: str,
event_hub_endpoint_name: str,
name: str,
consumer_group_body: Union[_models.EventHubConsumerGroupBodyDescription, IO],
**kwargs: Any
) -> _models.EventHubConsumerGroupInfo:
"""Add a consumer group to an Event Hub-compatible endpoint in an IoT hub.
Add a consumer group to an Event Hub-compatible endpoint in an IoT hub.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param event_hub_endpoint_name: The name of the Event Hub-compatible endpoint in the IoT hub.
Required.
:type event_hub_endpoint_name: str
:param name: The name of the consumer group to add. Required.
:type name: str
:param consumer_group_body: The consumer group to add. Is either a model type or a IO type.
Required.
:type consumer_group_body:
~azure.mgmt.iothub.v2021_07_01.models.EventHubConsumerGroupBodyDescription or IO
:keyword content_type: Body Parameter content-type. Known values are: 'application/json'.
Default value is None.
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: EventHubConsumerGroupInfo or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.EventHubConsumerGroupInfo
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
cls = kwargs.pop("cls", None) # type: ClsType[_models.EventHubConsumerGroupInfo]
content_type = content_type or "application/json"
_json = None
_content = None
if isinstance(consumer_group_body, (IO, bytes)):
_content = consumer_group_body
else:
_json = self._serialize.body(consumer_group_body, "EventHubConsumerGroupBodyDescription")
request = build_create_event_hub_consumer_group_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
event_hub_endpoint_name=event_hub_endpoint_name,
name=name,
subscription_id=self._config.subscription_id,
api_version=api_version,
content_type=content_type,
json=_json,
content=_content,
template_url=self.create_event_hub_consumer_group.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = self._deserialize("EventHubConsumerGroupInfo", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
create_event_hub_consumer_group.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/eventHubEndpoints/{eventHubEndpointName}/ConsumerGroups/{name}"} # type: ignore
@distributed_trace
def delete_event_hub_consumer_group( # pylint: disable=inconsistent-return-statements
self, resource_group_name: str, resource_name: str, event_hub_endpoint_name: str, name: str, **kwargs: Any
) -> None:
"""Delete a consumer group from an Event Hub-compatible endpoint in an IoT hub.
Delete a consumer group from an Event Hub-compatible endpoint in an IoT hub.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param event_hub_endpoint_name: The name of the Event Hub-compatible endpoint in the IoT hub.
Required.
:type event_hub_endpoint_name: str
:param name: The name of the consumer group to delete. Required.
:type name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: None or the result of cls(response)
:rtype: None
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[None]
request = build_delete_event_hub_consumer_group_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
event_hub_endpoint_name=event_hub_endpoint_name,
name=name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.delete_event_hub_consumer_group.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
if cls:
return cls(pipeline_response, None, {})
delete_event_hub_consumer_group.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/eventHubEndpoints/{eventHubEndpointName}/ConsumerGroups/{name}"} # type: ignore
@distributed_trace
def list_jobs(self, resource_group_name: str, resource_name: str, **kwargs: Any) -> Iterable["_models.JobResponse"]:
"""Get a list of all the jobs in an IoT hub. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry.
Get a list of all the jobs in an IoT hub. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: An iterator like instance of either JobResponse or the result of cls(response)
:rtype: ~azure.core.paging.ItemPaged[~azure.mgmt.iothub.v2021_07_01.models.JobResponse]
:raises ~azure.core.exceptions.HttpResponseError:
"""
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.JobResponseListResult]
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
def prepare_request(next_link=None):
if not next_link:
request = build_list_jobs_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.list_jobs.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
else:
# make call to next link with the client's api-version
_parsed_next_link = urlparse(next_link)
_next_request_params = case_insensitive_dict(parse_qs(_parsed_next_link.query))
_next_request_params["api-version"] = self._config.api_version
request = HttpRequest("GET", urljoin(next_link, _parsed_next_link.path), params=_next_request_params)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
request.method = "GET"
return request
def extract_data(pipeline_response):
deserialized = self._deserialize("JobResponseListResult", pipeline_response)
list_of_elem = deserialized.value
if cls:
list_of_elem = cls(list_of_elem)
return deserialized.next_link or None, iter(list_of_elem)
def get_next(next_link=None):
request = prepare_request(next_link)
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
return pipeline_response
return ItemPaged(get_next, extract_data)
list_jobs.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/jobs"} # type: ignore
@distributed_trace
def get_job(self, resource_group_name: str, resource_name: str, job_id: str, **kwargs: Any) -> _models.JobResponse:
"""Get the details of a job from an IoT hub. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry.
Get the details of a job from an IoT hub. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param job_id: The job identifier. Required.
:type job_id: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: JobResponse or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.JobResponse
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.JobResponse]
request = build_get_job_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
job_id=job_id,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.get_job.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = self._deserialize("JobResponse", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
get_job.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/jobs/{jobId}"} # type: ignore
@distributed_trace
def get_quota_metrics(
self, resource_group_name: str, resource_name: str, **kwargs: Any
) -> Iterable["_models.IotHubQuotaMetricInfo"]:
"""Get the quota metrics for an IoT hub.
Get the quota metrics for an IoT hub.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: An iterator like instance of either IotHubQuotaMetricInfo or the result of
cls(response)
:rtype:
~azure.core.paging.ItemPaged[~azure.mgmt.iothub.v2021_07_01.models.IotHubQuotaMetricInfo]
:raises ~azure.core.exceptions.HttpResponseError:
"""
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.IotHubQuotaMetricInfoListResult]
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
def prepare_request(next_link=None):
if not next_link:
request = build_get_quota_metrics_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.get_quota_metrics.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
else:
# make call to next link with the client's api-version
_parsed_next_link = urlparse(next_link)
_next_request_params = case_insensitive_dict(parse_qs(_parsed_next_link.query))
_next_request_params["api-version"] = self._config.api_version
request = HttpRequest("GET", urljoin(next_link, _parsed_next_link.path), params=_next_request_params)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
request.method = "GET"
return request
def extract_data(pipeline_response):
deserialized = self._deserialize("IotHubQuotaMetricInfoListResult", pipeline_response)
list_of_elem = deserialized.value
if cls:
list_of_elem = cls(list_of_elem)
return deserialized.next_link or None, iter(list_of_elem)
def get_next(next_link=None):
request = prepare_request(next_link)
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
return pipeline_response
return ItemPaged(get_next, extract_data)
get_quota_metrics.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/quotaMetrics"} # type: ignore
@distributed_trace
def get_endpoint_health(
self, resource_group_name: str, iot_hub_name: str, **kwargs: Any
) -> Iterable["_models.EndpointHealthData"]:
"""Get the health for routing endpoints.
Get the health for routing endpoints.
:param resource_group_name: Required.
:type resource_group_name: str
:param iot_hub_name: Required.
:type iot_hub_name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: An iterator like instance of either EndpointHealthData or the result of cls(response)
:rtype: ~azure.core.paging.ItemPaged[~azure.mgmt.iothub.v2021_07_01.models.EndpointHealthData]
:raises ~azure.core.exceptions.HttpResponseError:
"""
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.EndpointHealthDataListResult]
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
def prepare_request(next_link=None):
if not next_link:
request = build_get_endpoint_health_request(
resource_group_name=resource_group_name,
iot_hub_name=iot_hub_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.get_endpoint_health.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
else:
# make call to next link with the client's api-version
_parsed_next_link = urlparse(next_link)
_next_request_params = case_insensitive_dict(parse_qs(_parsed_next_link.query))
_next_request_params["api-version"] = self._config.api_version
request = HttpRequest("GET", urljoin(next_link, _parsed_next_link.path), params=_next_request_params)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
request.method = "GET"
return request
def extract_data(pipeline_response):
deserialized = self._deserialize("EndpointHealthDataListResult", pipeline_response)
list_of_elem = deserialized.value
if cls:
list_of_elem = cls(list_of_elem)
return deserialized.next_link or None, iter(list_of_elem)
def get_next(next_link=None):
request = prepare_request(next_link)
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
return pipeline_response
return ItemPaged(get_next, extract_data)
get_endpoint_health.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{iotHubName}/routingEndpointsHealth"} # type: ignore
@overload
def check_name_availability(
self, operation_inputs: _models.OperationInputs, *, content_type: str = "application/json", **kwargs: Any
) -> _models.IotHubNameAvailabilityInfo:
"""Check if an IoT hub name is available.
Check if an IoT hub name is available.
:param operation_inputs: Set the name parameter in the OperationInputs structure to the name of
the IoT hub to check. Required.
:type operation_inputs: ~azure.mgmt.iothub.v2021_07_01.models.OperationInputs
:keyword content_type: Body Parameter content-type. Content type parameter for JSON body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: IotHubNameAvailabilityInfo or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.IotHubNameAvailabilityInfo
:raises ~azure.core.exceptions.HttpResponseError:
"""
@overload
def check_name_availability(
self, operation_inputs: IO, *, content_type: str = "application/json", **kwargs: Any
) -> _models.IotHubNameAvailabilityInfo:
"""Check if an IoT hub name is available.
Check if an IoT hub name is available.
:param operation_inputs: Set the name parameter in the OperationInputs structure to the name of
the IoT hub to check. Required.
:type operation_inputs: IO
:keyword content_type: Body Parameter content-type. Content type parameter for binary body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: IotHubNameAvailabilityInfo or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.IotHubNameAvailabilityInfo
:raises ~azure.core.exceptions.HttpResponseError:
"""
@distributed_trace
def check_name_availability(
self, operation_inputs: Union[_models.OperationInputs, IO], **kwargs: Any
) -> _models.IotHubNameAvailabilityInfo:
"""Check if an IoT hub name is available.
Check if an IoT hub name is available.
:param operation_inputs: Set the name parameter in the OperationInputs structure to the name of
the IoT hub to check. Is either a model type or a IO type. Required.
:type operation_inputs: ~azure.mgmt.iothub.v2021_07_01.models.OperationInputs or IO
:keyword content_type: Body Parameter content-type. Known values are: 'application/json'.
Default value is None.
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: IotHubNameAvailabilityInfo or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.IotHubNameAvailabilityInfo
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
cls = kwargs.pop("cls", None) # type: ClsType[_models.IotHubNameAvailabilityInfo]
content_type = content_type or "application/json"
_json = None
_content = None
if isinstance(operation_inputs, (IO, bytes)):
_content = operation_inputs
else:
_json = self._serialize.body(operation_inputs, "OperationInputs")
request = build_check_name_availability_request(
subscription_id=self._config.subscription_id,
api_version=api_version,
content_type=content_type,
json=_json,
content=_content,
template_url=self.check_name_availability.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = self._deserialize("IotHubNameAvailabilityInfo", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
check_name_availability.metadata = {"url": "/subscriptions/{subscriptionId}/providers/Microsoft.Devices/checkNameAvailability"} # type: ignore
@overload
def test_all_routes(
self,
iot_hub_name: str,
resource_group_name: str,
input: _models.TestAllRoutesInput,
*,
content_type: str = "application/json",
**kwargs: Any
) -> _models.TestAllRoutesResult:
"""Test all routes.
Test all routes configured in this Iot Hub.
:param iot_hub_name: IotHub to be tested. Required.
:type iot_hub_name: str
:param resource_group_name: resource group which Iot Hub belongs to. Required.
:type resource_group_name: str
:param input: Input for testing all routes. Required.
:type input: ~azure.mgmt.iothub.v2021_07_01.models.TestAllRoutesInput
:keyword content_type: Body Parameter content-type. Content type parameter for JSON body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: TestAllRoutesResult or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.TestAllRoutesResult
:raises ~azure.core.exceptions.HttpResponseError:
"""
@overload
def test_all_routes(
self,
iot_hub_name: str,
resource_group_name: str,
input: IO,
*,
content_type: str = "application/json",
**kwargs: Any
) -> _models.TestAllRoutesResult:
"""Test all routes.
Test all routes configured in this Iot Hub.
:param iot_hub_name: IotHub to be tested. Required.
:type iot_hub_name: str
:param resource_group_name: resource group which Iot Hub belongs to. Required.
:type resource_group_name: str
:param input: Input for testing all routes. Required.
:type input: IO
:keyword content_type: Body Parameter content-type. Content type parameter for binary body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: TestAllRoutesResult or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.TestAllRoutesResult
:raises ~azure.core.exceptions.HttpResponseError:
"""
@distributed_trace
def test_all_routes(
self, iot_hub_name: str, resource_group_name: str, input: Union[_models.TestAllRoutesInput, IO], **kwargs: Any
) -> _models.TestAllRoutesResult:
"""Test all routes.
Test all routes configured in this Iot Hub.
:param iot_hub_name: IotHub to be tested. Required.
:type iot_hub_name: str
:param resource_group_name: resource group which Iot Hub belongs to. Required.
:type resource_group_name: str
:param input: Input for testing all routes. Is either a model type or a IO type. Required.
:type input: ~azure.mgmt.iothub.v2021_07_01.models.TestAllRoutesInput or IO
:keyword content_type: Body Parameter content-type. Known values are: 'application/json'.
Default value is None.
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: TestAllRoutesResult or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.TestAllRoutesResult
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
cls = kwargs.pop("cls", None) # type: ClsType[_models.TestAllRoutesResult]
content_type = content_type or "application/json"
_json = None
_content = None
if isinstance(input, (IO, bytes)):
_content = input
else:
_json = self._serialize.body(input, "TestAllRoutesInput")
request = build_test_all_routes_request(
iot_hub_name=iot_hub_name,
resource_group_name=resource_group_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
content_type=content_type,
json=_json,
content=_content,
template_url=self.test_all_routes.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = self._deserialize("TestAllRoutesResult", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
test_all_routes.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{iotHubName}/routing/routes/$testall"} # type: ignore
@overload
def test_route(
self,
iot_hub_name: str,
resource_group_name: str,
input: _models.TestRouteInput,
*,
content_type: str = "application/json",
**kwargs: Any
) -> _models.TestRouteResult:
"""Test the new route.
Test the new route for this Iot Hub.
:param iot_hub_name: IotHub to be tested. Required.
:type iot_hub_name: str
:param resource_group_name: resource group which Iot Hub belongs to. Required.
:type resource_group_name: str
:param input: Route that needs to be tested. Required.
:type input: ~azure.mgmt.iothub.v2021_07_01.models.TestRouteInput
:keyword content_type: Body Parameter content-type. Content type parameter for JSON body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: TestRouteResult or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.TestRouteResult
:raises ~azure.core.exceptions.HttpResponseError:
"""
@overload
def test_route(
self,
iot_hub_name: str,
resource_group_name: str,
input: IO,
*,
content_type: str = "application/json",
**kwargs: Any
) -> _models.TestRouteResult:
"""Test the new route.
Test the new route for this Iot Hub.
:param iot_hub_name: IotHub to be tested. Required.
:type iot_hub_name: str
:param resource_group_name: resource group which Iot Hub belongs to. Required.
:type resource_group_name: str
:param input: Route that needs to be tested. Required.
:type input: IO
:keyword content_type: Body Parameter content-type. Content type parameter for binary body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: TestRouteResult or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.TestRouteResult
:raises ~azure.core.exceptions.HttpResponseError:
"""
@distributed_trace
def test_route(
self, iot_hub_name: str, resource_group_name: str, input: Union[_models.TestRouteInput, IO], **kwargs: Any
) -> _models.TestRouteResult:
"""Test the new route.
Test the new route for this Iot Hub.
:param iot_hub_name: IotHub to be tested. Required.
:type iot_hub_name: str
:param resource_group_name: resource group which Iot Hub belongs to. Required.
:type resource_group_name: str
:param input: Route that needs to be tested. Is either a model type or a IO type. Required.
:type input: ~azure.mgmt.iothub.v2021_07_01.models.TestRouteInput or IO
:keyword content_type: Body Parameter content-type. Known values are: 'application/json'.
Default value is None.
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: TestRouteResult or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.TestRouteResult
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
cls = kwargs.pop("cls", None) # type: ClsType[_models.TestRouteResult]
content_type = content_type or "application/json"
_json = None
_content = None
if isinstance(input, (IO, bytes)):
_content = input
else:
_json = self._serialize.body(input, "TestRouteInput")
request = build_test_route_request(
iot_hub_name=iot_hub_name,
resource_group_name=resource_group_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
content_type=content_type,
json=_json,
content=_content,
template_url=self.test_route.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = self._deserialize("TestRouteResult", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
test_route.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{iotHubName}/routing/routes/$testnew"} # type: ignore
@distributed_trace
def list_keys(
self, resource_group_name: str, resource_name: str, **kwargs: Any
) -> Iterable["_models.SharedAccessSignatureAuthorizationRule"]:
"""Get the security metadata for an IoT hub. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-security.
Get the security metadata for an IoT hub. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-security.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: An iterator like instance of either SharedAccessSignatureAuthorizationRule or the
result of cls(response)
:rtype:
~azure.core.paging.ItemPaged[~azure.mgmt.iothub.v2021_07_01.models.SharedAccessSignatureAuthorizationRule]
:raises ~azure.core.exceptions.HttpResponseError:
"""
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.SharedAccessSignatureAuthorizationRuleListResult]
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
def prepare_request(next_link=None):
if not next_link:
request = build_list_keys_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.list_keys.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
else:
# make call to next link with the client's api-version
_parsed_next_link = urlparse(next_link)
_next_request_params = case_insensitive_dict(parse_qs(_parsed_next_link.query))
_next_request_params["api-version"] = self._config.api_version
request = HttpRequest("GET", urljoin(next_link, _parsed_next_link.path), params=_next_request_params)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
request.method = "GET"
return request
def extract_data(pipeline_response):
deserialized = self._deserialize("SharedAccessSignatureAuthorizationRuleListResult", pipeline_response)
list_of_elem = deserialized.value
if cls:
list_of_elem = cls(list_of_elem)
return deserialized.next_link or None, iter(list_of_elem)
def get_next(next_link=None):
request = prepare_request(next_link)
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
return pipeline_response
return ItemPaged(get_next, extract_data)
list_keys.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/listkeys"} # type: ignore
@distributed_trace
def get_keys_for_key_name(
self, resource_group_name: str, resource_name: str, key_name: str, **kwargs: Any
) -> _models.SharedAccessSignatureAuthorizationRule:
"""Get a shared access policy by name from an IoT hub. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-security.
Get a shared access policy by name from an IoT hub. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-security.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param key_name: The name of the shared access policy. Required.
:type key_name: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: SharedAccessSignatureAuthorizationRule or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.SharedAccessSignatureAuthorizationRule
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = kwargs.pop("headers", {}) or {}
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
cls = kwargs.pop("cls", None) # type: ClsType[_models.SharedAccessSignatureAuthorizationRule]
request = build_get_keys_for_key_name_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
key_name=key_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
template_url=self.get_keys_for_key_name.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = self._deserialize("SharedAccessSignatureAuthorizationRule", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
get_keys_for_key_name.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/IotHubKeys/{keyName}/listkeys"} # type: ignore
@overload
def export_devices(
self,
resource_group_name: str,
resource_name: str,
export_devices_parameters: _models.ExportDevicesRequest,
*,
content_type: str = "application/json",
**kwargs: Any
) -> _models.JobResponse:
"""Exports all the device identities in the IoT hub identity registry to an Azure Storage blob
container. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
Exports all the device identities in the IoT hub identity registry to an Azure Storage blob
container. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param export_devices_parameters: The parameters that specify the export devices operation.
Required.
:type export_devices_parameters: ~azure.mgmt.iothub.v2021_07_01.models.ExportDevicesRequest
:keyword content_type: Body Parameter content-type. Content type parameter for JSON body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: JobResponse or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.JobResponse
:raises ~azure.core.exceptions.HttpResponseError:
"""
@overload
def export_devices(
self,
resource_group_name: str,
resource_name: str,
export_devices_parameters: IO,
*,
content_type: str = "application/json",
**kwargs: Any
) -> _models.JobResponse:
"""Exports all the device identities in the IoT hub identity registry to an Azure Storage blob
container. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
Exports all the device identities in the IoT hub identity registry to an Azure Storage blob
container. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param export_devices_parameters: The parameters that specify the export devices operation.
Required.
:type export_devices_parameters: IO
:keyword content_type: Body Parameter content-type. Content type parameter for binary body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: JobResponse or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.JobResponse
:raises ~azure.core.exceptions.HttpResponseError:
"""
@distributed_trace
def export_devices(
self,
resource_group_name: str,
resource_name: str,
export_devices_parameters: Union[_models.ExportDevicesRequest, IO],
**kwargs: Any
) -> _models.JobResponse:
"""Exports all the device identities in the IoT hub identity registry to an Azure Storage blob
container. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
Exports all the device identities in the IoT hub identity registry to an Azure Storage blob
container. For more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param export_devices_parameters: The parameters that specify the export devices operation. Is
either a model type or a IO type. Required.
:type export_devices_parameters: ~azure.mgmt.iothub.v2021_07_01.models.ExportDevicesRequest or
IO
:keyword content_type: Body Parameter content-type. Known values are: 'application/json'.
Default value is None.
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: JobResponse or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.JobResponse
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
cls = kwargs.pop("cls", None) # type: ClsType[_models.JobResponse]
content_type = content_type or "application/json"
_json = None
_content = None
if isinstance(export_devices_parameters, (IO, bytes)):
_content = export_devices_parameters
else:
_json = self._serialize.body(export_devices_parameters, "ExportDevicesRequest")
request = build_export_devices_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
content_type=content_type,
json=_json,
content=_content,
template_url=self.export_devices.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = self._deserialize("JobResponse", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
export_devices.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/exportDevices"} # type: ignore
@overload
def import_devices(
self,
resource_group_name: str,
resource_name: str,
import_devices_parameters: _models.ImportDevicesRequest,
*,
content_type: str = "application/json",
**kwargs: Any
) -> _models.JobResponse:
"""Import, update, or delete device identities in the IoT hub identity registry from a blob. For
more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
Import, update, or delete device identities in the IoT hub identity registry from a blob. For
more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param import_devices_parameters: The parameters that specify the import devices operation.
Required.
:type import_devices_parameters: ~azure.mgmt.iothub.v2021_07_01.models.ImportDevicesRequest
:keyword content_type: Body Parameter content-type. Content type parameter for JSON body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: JobResponse or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.JobResponse
:raises ~azure.core.exceptions.HttpResponseError:
"""
@overload
def import_devices(
self,
resource_group_name: str,
resource_name: str,
import_devices_parameters: IO,
*,
content_type: str = "application/json",
**kwargs: Any
) -> _models.JobResponse:
"""Import, update, or delete device identities in the IoT hub identity registry from a blob. For
more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
Import, update, or delete device identities in the IoT hub identity registry from a blob. For
more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param import_devices_parameters: The parameters that specify the import devices operation.
Required.
:type import_devices_parameters: IO
:keyword content_type: Body Parameter content-type. Content type parameter for binary body.
Default value is "application/json".
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: JobResponse or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.JobResponse
:raises ~azure.core.exceptions.HttpResponseError:
"""
@distributed_trace
def import_devices(
self,
resource_group_name: str,
resource_name: str,
import_devices_parameters: Union[_models.ImportDevicesRequest, IO],
**kwargs: Any
) -> _models.JobResponse:
"""Import, update, or delete device identities in the IoT hub identity registry from a blob. For
more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
Import, update, or delete device identities in the IoT hub identity registry from a blob. For
more information, see:
https://docs.microsoft.com/azure/iot-hub/iot-hub-devguide-identity-registry#import-and-export-device-identities.
:param resource_group_name: The name of the resource group that contains the IoT hub. Required.
:type resource_group_name: str
:param resource_name: The name of the IoT hub. Required.
:type resource_name: str
:param import_devices_parameters: The parameters that specify the import devices operation. Is
either a model type or a IO type. Required.
:type import_devices_parameters: ~azure.mgmt.iothub.v2021_07_01.models.ImportDevicesRequest or
IO
:keyword content_type: Body Parameter content-type. Known values are: 'application/json'.
Default value is None.
:paramtype content_type: str
:keyword callable cls: A custom type or function that will be passed the direct response
:return: JobResponse or the result of cls(response)
:rtype: ~azure.mgmt.iothub.v2021_07_01.models.JobResponse
:raises ~azure.core.exceptions.HttpResponseError:
"""
error_map = {401: ClientAuthenticationError, 404: ResourceNotFoundError, 409: ResourceExistsError}
error_map.update(kwargs.pop("error_map", {}) or {})
_headers = case_insensitive_dict(kwargs.pop("headers", {}) or {})
_params = case_insensitive_dict(kwargs.pop("params", {}) or {})
api_version = kwargs.pop("api_version", _params.pop("api-version", "2021-07-01")) # type: str
content_type = kwargs.pop("content_type", _headers.pop("Content-Type", None)) # type: Optional[str]
cls = kwargs.pop("cls", None) # type: ClsType[_models.JobResponse]
content_type = content_type or "application/json"
_json = None
_content = None
if isinstance(import_devices_parameters, (IO, bytes)):
_content = import_devices_parameters
else:
_json = self._serialize.body(import_devices_parameters, "ImportDevicesRequest")
request = build_import_devices_request(
resource_group_name=resource_group_name,
resource_name=resource_name,
subscription_id=self._config.subscription_id,
api_version=api_version,
content_type=content_type,
json=_json,
content=_content,
template_url=self.import_devices.metadata["url"],
headers=_headers,
params=_params,
)
request = _convert_request(request)
request.url = self._client.format_url(request.url) # type: ignore
pipeline_response = self._client._pipeline.run( # type: ignore # pylint: disable=protected-access
request, stream=False, **kwargs
)
response = pipeline_response.http_response
if response.status_code not in [200]:
map_error(status_code=response.status_code, response=response, error_map=error_map)
error = self._deserialize.failsafe_deserialize(_models.ErrorDetails, pipeline_response)
raise HttpResponseError(response=response, model=error, error_format=ARMErrorFormat)
deserialized = self._deserialize("JobResponse", pipeline_response)
if cls:
return cls(pipeline_response, deserialized, {})
return deserialized
import_devices.metadata = {"url": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.Devices/IotHubs/{resourceName}/importDevices"} # type: ignore
| [
"noreply@github.com"
] | test-repo-billy.noreply@github.com |
02568d24b7840fc40b8a07677c4edb83259379ba | b05761d771bb5a85d39d370c649567c1ff3eb089 | /venv/lib/python3.10/site-packages/jedi/third_party/typeshed/stdlib/3/email/mime/message.pyi | 2d03331c60130c1fba438b8f2d0f0574bb33313b | [] | no_license | JawshyJ/Coding_Practice | 88c49cab955eab04609ec1003b6b8c20f103fc06 | eb6b229d41aa49b1545af2120e6bee8e982adb41 | refs/heads/master | 2023-02-19T10:18:04.818542 | 2023-02-06T21:22:58 | 2023-02-06T21:22:58 | 247,788,631 | 4 | 0 | null | null | null | null | UTF-8 | Python | false | false | 96 | pyi | /home/runner/.cache/pip/pool/05/b6/7b/50bc2adef4faf8c3d2d90166908b96ab1802f6f0cb583f71d33bfda179 | [
"37465112+JawshyJ@users.noreply.github.com"
] | 37465112+JawshyJ@users.noreply.github.com |
8e576861d86e5cd001a0f730f118b08f34ad0da3 | da01d5cdffd4f8e6a4ee91a528712f2efd8ba5d6 | /setup.py | d0a51ad06f6871b1f3f6730d697649015b7a0df1 | [] | no_license | Durant21/test10 | 7dc6a43973a8bcb10694105727f88b80d237b29a | 6919ac5f6c4081848c12758730b9ccca49bba6fc | refs/heads/master | 2022-12-02T07:28:00.339793 | 2019-08-30T14:12:07 | 2019-08-30T14:12:07 | 204,570,708 | 0 | 1 | null | 2022-11-16T07:47:22 | 2019-08-26T22:14:28 | Python | UTF-8 | Python | false | false | 1,181 | py | import os
from setuptools import setup, find_packages
here = os.path.abspath(os.path.dirname(__file__))
with open(os.path.join(here, 'README.txt')) as f:
README = f.read()
with open(os.path.join(here, 'CHANGES.txt')) as f:
CHANGES = f.read()
requires = [
'pyramid',
'pyramid_jinja2',
'pyramid_debugtoolbar',
'waitress',
]
tests_require = [
'WebTest >= 1.3.1', # py3 compat
'pytest', # includes virtualenv
'pytest-cov',
]
setup(name='test10',
version='0.0',
description='test10',
long_description=README + '\n\n' + CHANGES,
classifiers=[
"Programming Language :: Python",
"Framework :: Pyramid",
"Topic :: Internet :: WWW/HTTP",
"Topic :: Internet :: WWW/HTTP :: WSGI :: Application",
],
author='',
author_email='',
url='',
keywords='web pyramid pylons',
packages=find_packages(),
include_package_data=True,
zip_safe=False,
extras_require={
'testing': tests_require,
},
install_requires=requires,
entry_points="""\
[paste.app_factory]
main = test10:main
""",
)
| [
"durant.crimson@icloud.com"
] | durant.crimson@icloud.com |
f06be5b8bc669aeca413c35e494b94a21aa374b1 | 983d740b87b42d8af3c0db9d746dc7fe32d83ccd | /ucf-insert-io.py | 1d1351a8a2e9ac8091a01a2b5e115a7b906f0cce | [] | no_license | zzfd97/fpga-utils | 266357653e7089d40090f10e49cd0611f530397a | ffededb9a74cb8a786691231b7eea8af7f8dfd69 | refs/heads/master | 2021-12-08T19:06:54.545577 | 2016-03-30T21:42:22 | 2016-03-30T21:42:22 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 5,045 | py | #!/usr/bin/env python
"""
Inserts IO pin information into UCF files
"""
from __future__ import print_function
import argparse
import csv
import re
from jinja2 import Template
import verilogParse
def main():
parser = argparse.ArgumentParser(description=__doc__.strip())
parser.add_argument('input', type=str, help="input UCF file")
parser.add_argument('-p', '--pkg', type=str, help="Xilinx package file")
parser.add_argument('--ioc', type=int, help="IO name column (for multi-part CSV)")
parser.add_argument('-o', '--output', type=str, help="output file name")
args = parser.parse_args()
pkg_name = args.pkg
input_name = args.input
output_name = args.output
opt_io_col = -1 if args.ioc is None else args.ioc-1
if pkg_name is None:
raise Exception("No package file specified")
if input_name is None:
raise Exception("No input file specified")
if output_name is None:
output_name = input_name + '.out'
print("Reading package file")
try:
pkg_file = open(pkg_name, 'r')
except Exception as ex:
print("Error opening \"%s\": %s" %(pkg_name, ex.strerror), file=sys.stderr)
exit(1)
pkg_contents = list()
pin_col = -1
bank_col = -1
io_col = -1
row_length = 0
# read header
header = next(pkg_file)
if ',' in header:
pkg_reader = csv.reader(pkg_file)
else:
pkg_reader = pkg_file
for line in pkg_reader:
if isinstance(line, str):
row = line.split()
else:
row = line
if len(row) > 1:
row = [x.strip() for x in row]
pkg_contents.append(row)
# detect IO_ column
if io_col < 0:
for i in range(len(row)):
if "IO_" in row[i]:
if opt_io_col == i or opt_io_col < 0:
io_col = i
# This should be a valid row, so get the length
row_length = len(row)
# Detect pin and bank columns
for k in range(len(row)):
if re.match("[a-zA-Z]{1,2}[0-9]{1,2}", row[k]) is not None:
pin_col = k
if re.match("[0-9]{1,2}", row[k]) is not None:
bank_col = k
# filter length
pkg_contents = [x for x in pkg_contents if len(x) == row_length]
pkg_file.close()
if pin_col < 0:
print("Could not determine pin column", file=sys.stderr)
exit(1)
if bank_col < 0:
print("Could not determine bank column", file=sys.stderr)
exit(1)
if io_col < 0:
print("Could not determine IO column", file=sys.stderr)
exit(1)
pins = [x[pin_col].lower() for x in pkg_contents]
banks = [x[bank_col] for x in pkg_contents]
ios = [x[io_col] for x in pkg_contents]
print("Processing UCF file")
try:
input_file = open(input_name, 'r')
except Exception as ex:
print("Error opening \"%s\": %s" %(input_name, ex.strerror), file=sys.stderr)
exit(1)
try:
output_file = open(output_name, 'w')
except Exception as ex:
print("Error opening \"%s\": %s" %(output_name, ex.strerror), file=sys.stderr)
exit(1)
for line in input_file:
# deal with comments
line_raw = line.split('#', 2)
ucf_line = line_raw[0]
ucf_line_l = ucf_line.lower()
res = re.search('loc\s*=\s*\"(.+)\"', ucf_line_l)
if res is not None:
loc = res.group(1)
try:
i = pins.index(loc)
bank = banks[i]
io = ios[i]
comment = " Bank = %s, %s" % (bank, io)
if len(line_raw) == 1:
line_raw[0] += ' '
line_raw.append(comment)
else:
c = line_raw[1]
# strip old bank information
c = re.sub('\s*bank\s*=\s*(\d+|\?)\s*,\s*IO_(\w+|\?)', '', c, flags=re.IGNORECASE)
c = re.sub('\s*bank\s*=\s*(\d+|\?)\s*', '', c, flags=re.IGNORECASE)
c = re.sub('\s*IO_(\w+|\?)', '', c, flags=re.IGNORECASE)
line_raw[1] = comment + c
except ValueError:
pass
line_raw[0] = ucf_line
line = '#'.join(line_raw)
output_file.write(line)
input_file.close()
output_file.close()
print("Wrote output file %s" % output_name)
print("Done")
if __name__ == "__main__":
main()
| [
"alex@alexforencich.com"
] | alex@alexforencich.com |
6ff7b9df9c9027112ef8f0f53dae56b8a8caa9ce | 53c31cb08279e4a95db180c949d1cb86b2d5cecf | /src/sentry/api/serializers/models/event.py | 6b6474c4df161daf44a915d1ed638c9fe5cfea64 | [
"BSD-2-Clause"
] | permissive | jessepollak/sentry | eab2a2f7a8d46f3236377be2feb9bc1a508b94d2 | ea46b05ea87814e19cdc5f4883df073a73482261 | refs/heads/master | 2021-01-18T10:20:52.522602 | 2014-05-25T02:38:52 | 2014-05-25T02:38:52 | 20,238,431 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 653 | py | from sentry.api.serializers import Serializer, register
from sentry.models import Event
@register(Event)
class EventSerializer(Serializer):
def serialize(self, obj, user):
d = {
'id': str(obj.id),
'eventID': str(obj.event_id),
'project': {
'id': str(obj.project.id),
'name': obj.project.name,
'slug': obj.project.slug,
},
'message': obj.message,
'checksum': obj.checksum,
'platform': obj.platform,
'dateCreated': obj.datetime,
'timeSpent': obj.time_spent,
}
return d
| [
"dcramer@gmail.com"
] | dcramer@gmail.com |
b866e5cb44faf1ce48372bbe108780e0436b7724 | 677002b757c0a1a00b450d9710a8ec6aeb9b9e9a | /tiago_public_ws/devel/lib/python2.7/dist-packages/tiago_pick_demo/msg/_PickUpPoseAction.py | aca4a3bdca0ec01d842ff3c7d0d4157c070b6087 | [] | no_license | mrrocketraccoon/tiago_development | ce686c86459dbfe8623aa54cf4279021342887fb | a0539bdcf21b67ab902a4649b516dcb929c54042 | refs/heads/main | 2023-06-16T19:39:33.391293 | 2021-07-08T21:20:03 | 2021-07-08T21:20:03 | 384,249,894 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 116 | py | /tiago_public_ws/devel/.private/tiago_pick_demo/lib/python2.7/dist-packages/tiago_pick_demo/msg/_PickUpPoseAction.py | [
"ricardoxcm@hotmail.com"
] | ricardoxcm@hotmail.com |
d7bfb04c2fc9a1312fbbaa38dcfbba968991b39b | 9743d5fd24822f79c156ad112229e25adb9ed6f6 | /xai/brain/wordbase/adverbs/_forwarding.py | bdc7ef3dad2d535a336a466273bee7488b4c401f | [
"MIT"
] | permissive | cash2one/xai | de7adad1758f50dd6786bf0111e71a903f039b64 | e76f12c9f4dcf3ac1c7c08b0cc8844c0b0a104b6 | refs/heads/master | 2021-01-19T12:33:54.964379 | 2017-01-28T02:00:50 | 2017-01-28T02:00:50 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 253 | py |
from xai.brain.wordbase.adverbs._forward import _FORWARD
#calss header
class _FORWARDING(_FORWARD, ):
def __init__(self,):
_FORWARD.__init__(self)
self.name = "FORWARDING"
self.specie = 'adverbs'
self.basic = "forward"
self.jsondata = {}
| [
"xingwang1991@gmail.com"
] | xingwang1991@gmail.com |
a76b7945c71328832bb1f5a43a80993a49e6fac7 | 7d85c42e99e8009f63eade5aa54979abbbe4c350 | /game/lib/coginvasion/gui/MoneyGui.py | 80d04cf287cec11972b888d1cbdee7db2278a78a | [] | no_license | ToontownServerArchive/Cog-Invasion-Online-Alpha | 19c0454da87e47f864c0a5cb8c6835bca6923f0e | 40498d115ed716f1dec12cf40144015c806cc21f | refs/heads/master | 2023-03-25T08:49:40.878384 | 2016-07-05T07:09:36 | 2016-07-05T07:09:36 | 348,172,701 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,088 | py | """
Filename: MoneyGui.py
Created by: blach (06Aug14)
"""
from panda3d.core import *
from direct.gui.DirectGui import *
class MoneyGui:
def createGui(self):
self.deleteGui()
self.frame = DirectFrame(parent=base.a2dBottomLeft, pos=(0.45, 0, 0.155))
gui = loader.loadModel("phase_3.5/models/gui/jar_gui.bam")
self.jar = OnscreenImage(image=gui, scale=0.5, parent=self.frame)
mf = loader.loadFont("phase_3/models/fonts/MickeyFont.bam")
self.money_lbl = DirectLabel(text="", text_font=mf, text_fg=(1,1,0,1), parent=self.jar, text_scale=0.2, relief=None, pos=(0, 0, -0.1))
gui.remove_node()
def deleteGui(self):
if hasattr(self, 'jar'):
self.jar.destroy()
del self.jar
if hasattr(self, 'money_lbl'):
self.money_lbl.destroy()
del self.money_lbl
if hasattr(self, 'frame'):
self.frame.destroy()
del self.frame
return
def update(self, moneyAmt):
if hasattr(self, 'money_lbl'):
if moneyAmt <= 0:
self.money_lbl['text_fg'] = (0.9, 0, 0, 1)
else:
self.money_lbl['text_fg'] = (1, 1, 0, 1)
self.money_lbl['text'] = str(moneyAmt)
| [
"brianlach72@gmail.com"
] | brianlach72@gmail.com |
0730846c136e5ec604b7b24c9ff97970b6897dad | 5eca83a3a019467c8e5fafe5f2c2f6dc946a0e28 | /solutions/day_87.py | 8a86534e360185c3905a7ecd2326b2564738fd67 | [] | no_license | Kontowicz/Daily-Interview-Pro | 4c821b6afc9451c613f06e3850072e10d7d6a7d4 | 3bbe26430b6d004821477e14d37debe5d4a6d518 | refs/heads/master | 2020-06-25T00:37:04.138548 | 2020-02-28T16:43:30 | 2020-02-28T16:43:30 | 199,140,908 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 499 | py | class ListNode(object):
def __init__(self, x):
self.val = x
self.next = None
def hasCycle(head):
data = set()
while head:
if head in data:
return True
data.add(head)
head = head.next
return False
testHead = ListNode(4)
node1 = ListNode(3)
testHead.next = node1
node2 = ListNode(2)
node1.next = node2
node3 = ListNode(1)
node2.next = node3
testTail = ListNode(0)
node3.next = testTail
testTail.next = node1
print(hasCycle(testHead))
# True | [
"przemyslowiec@gmail.com"
] | przemyslowiec@gmail.com |
5980d6c589b4744b3741e44661faf0329fc121b0 | 37bf9e197e46acf596ae28f71c8d9a859d169559 | /quotes/api/urls.py | 56f3fef0d9ac978ef57399cf2c6a8c8fc7763851 | [] | no_license | khmahmud101/django_project | 6e6fe77cffd4508f396cb2dc2672b71b78a2cb6a | 4e6ea4da071846df6a211c95036683d9fbb68cf3 | refs/heads/master | 2020-08-23T13:58:48.787821 | 2020-01-09T14:01:02 | 2020-01-09T14:01:02 | 216,627,272 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 270 | py |
from django.urls import path
from . views import *
urlpatterns = [
path('', QuoteCategoryAPIView.as_view()),
path('quotes/', QuoteAPIView.as_view()),
path('quotes/<int:pk>/',QuoteAPIDetailView.as_view()),
path('quotes/new/',QuoteAPINewView.as_view())
] | [
"kmahmud1991@gmail.com"
] | kmahmud1991@gmail.com |
4375b3728573bff258536cea3329c023f1a4739e | 14c6dcbea4505738513a0de745b5b62e7c8f3a20 | /myblog/forms.py | f6243f5097b213d48331e2a75b800cdd8de9d285 | [] | no_license | ZohanHo/Blog | 17982453896c1fa813d594f79f81fd4bce70f783 | fb648985016965674bbc983793fc48ac7772e6bb | refs/heads/master | 2020-04-03T00:34:35.079210 | 2018-11-03T21:04:26 | 2018-11-03T21:04:26 | 154,902,849 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 7,772 | py | from django import forms
from .models import *
from django.core.exceptions import ValidationError
# в моделях мы передавали в конструктор класса поля которые указали (title, bode и т.д.), в формах мы отступаем от этого общего поведения
# в формах мы должны передавать данные в конструктор которые мы берем из специального обьекта, из словаря который наз. clean_data
class TagForm(forms.ModelForm):
#title = forms.CharField(max_length=50) # это input
#slug = forms.SlugField(max_length=50)
class Meta:
model = Tag
fields = ["title"] # , "slug"
# для того что бы в url который принимает именое значение blog/<slug> не попал create как slug, при переходе на страницу blog/create
# нам нужно сделать проверку, с помошью метода clean_slug (slug тут потму что проверям slug, стаил такой)
def clean_slug(self):
pk = self.cleaned_data["pk"].lower()
if pk == "create": # делаем проверку на create в slug
raise ValidationError("slug не может быть create")
if Tag.objects.filter(pk__iexact=pk).count(): # делаем проверку что бы поле не дублировалось
raise ValidationError("Поле slug - {} уже существует".format(pk))
return pk
class PostForm(forms.ModelForm):
class Meta:
model = Post
fields = ["title", "body", "tags_to_post"] # , "slug"
def clean_post(self):
new_post = self.cleaned_data["pk"].lower()
if new_post == "create":
raise ValidationError ("Post не может быть create")
if Post.objects.filter(pk__iexact=new_post).count():
raise ValidationError("Такой slug существует")
return new_post
class FormSearch(forms.Form): # Класс Form - принимает данные из запроса(в виде текстовых строк),валидирует относительно типа полей, приводит к нужному представлению на языке питон
search = forms.CharField(required=False) # текстовое поле, required=False - не ртебуется для успешной валидации формы
sort = forms.ChoiceField(choices=(("pk", "pk"), ("date_pub", "Дата создания"), ("title", "Заголовок"), ("body", "Текст")), required=False)
# коментируем save, так как у ModelForm есть свой метод save
# переопределяем мето save, который нам вернет (сохранит в базе) поля title и slug но уже со словаря cleaned_data
#def save(self):
#new_tag = Tag.objects.create(title=self.cleaned_data["title"], slug=self.cleaned_data["slug"])
#return new_tag
# from blog.form import TagForm
# tf = TegForm() создал екземпляр класса <TagForm bound=False, valid=Unknown, fields=(title;slug)> bound=False - ввел пользователь что то или нет
# dir(tf) список атрибутов сщзданого нами обьекта
# from blog.form import TagForm
# tf = TegForm() создал екземпляр класса <TagForm bound=False, valid=Unknown, fields=(title;slug)> bound=False - ввел пользователь что то или нет
# dir(tf) обратились к атрибутам обьекта
# ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__',
# '__gt__', '__hash__', '__html__', '__init__', '__iter__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__',
# '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_bound_fields_cache',
# '_clean_fields', '_clean_form', '_errors', '_html_output', '_post_clean', 'add_error', 'add_initial_prefix', 'add_prefix', 'as_p',
# 'as_table', 'as_ul', 'auto_id', 'base_fields', 'changed_data', 'clean', 'data', 'declared_fields', 'default_renderer', 'empty_permitted',
# 'error_class', 'errors', 'field_order', 'fields', 'files', 'full_clean', 'get_initial_for_field', 'has_changed', 'has_error', 'hidden_fields',
# 'initial', 'is_bound', 'is_multipart', 'is_valid', 'label_suffix', 'media', 'non_field_errors', 'order_fields', 'prefix', 'renderer',
# 'use_required_attribute', 'visible_fields']
# tf.is_bound False проверяем передал ли что то пользователь в форму
# tf.is_valid() False так как is_bound - False, то и is_valid() False
# tf.errors {} тоже пустой так как мы не передали никаких данных
# d = {"title":"", "slug":""} создали словарь, с пустыми строками
# tf=TagForm(d) # снова создаю экземпляр, но на етот раз передаю словарь
# # tf.is_bound True проверяем передал ли что то пользователь в форму, сейчас передал
# tf.is_valid() False
# tf.errors {'title': ['Обязательное поле.'], 'slug': ['Обязательное поле.']} видим что есть обязательные поля
# # dir(tf) если снова обратимся к атрибутам, то видим что появился cleaned_date
# tf.cleaned_data выдаст пустой словарь {} - очищенные данные, потому что у нас заполнена форма tf.is_bound - True, и вызвали метод is_valid(),
# в етот момент создается словарь cleaned_data, если бы is_valid был бы True, ети бы данные были бы заполнены
# d = {"title":"fack", "slug":"me"}
# tf = TagForm(d)
# tf.is_bound True
# tf.is_valid() True - так как передали уже не пустую строку
# tf.cleaned_data при вызове видим что в словаре данные которые передал пользователь {'title': 'fack', 'slug': 'me'}
# tf.cleaned_data содержит очищиные данные, и именно данные из егото словаря мы должны использовать для создания моделей
# from myblog.models import Tag
# tag = Tag(title=tf.cleaned_data["title"], slug=tf.cleaned_data["slug"]) создал новый обьект в models.tag и передал данные с обьекта Tegform
# который у нас tf и с его словаря cleaned_data
# В общем виде валидация данных (проверка) и их очистка выглядит следующим образом:
# django вызывает метод is_valid который если True, последовательно вызывает clean методы, всей формы и отдельных полей
# если все проверено и валидировано, то они и помещаются в словарь cleaned_data, если что то не то, то исключение Validatioerrors | [
"serduk.evgeniy@gmail.com"
] | serduk.evgeniy@gmail.com |
be920489386d13e5c4191e9ac35f215191b12ca9 | ca7aa979e7059467e158830b76673f5b77a0f5a3 | /Python_codes/p03207/s478626613.py | 13c5b7d60d937779514e45e41d5e9b7c53909877 | [] | no_license | Aasthaengg/IBMdataset | 7abb6cbcc4fb03ef5ca68ac64ba460c4a64f8901 | f33f1c5c3b16d0ea8d1f5a7d479ad288bb3f48d8 | refs/heads/main | 2023-04-22T10:22:44.763102 | 2021-05-13T17:27:22 | 2021-05-13T17:27:22 | 367,112,348 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 104 | py | n = int(input())
p = [int(input()) for _ in range(n)]
p.sort(reverse=True)
p[0] = p[0]//2
print(sum(p)) | [
"66529651+Aastha2104@users.noreply.github.com"
] | 66529651+Aastha2104@users.noreply.github.com |
0a7d65418b3ea0de2730832b1c3361551ee0625c | 4fa0a0cdb34a87eb52a704da5679a5693d45d24e | /Server/app/views/sporrow/sporrow_response.py | c8255537838352fed0935dff511c50e5c9719501 | [
"Apache-2.0"
] | permissive | Sporrow/Sporrow-Backend | 6ac6a8f3f24c43a4e84a8bf8975c9af1f02a807c | a711f8a25c0b6fdbbeff0a980fbf39a470020e23 | refs/heads/master | 2020-03-19T04:11:15.266927 | 2018-06-02T21:59:28 | 2018-06-02T21:59:28 | 135,803,450 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 693 | py | from calendar import monthrange
from datetime import datetime
import re
from flask import Blueprint, Response, abort, g, request
from flask_restful import Api
from flasgger import swag_from
from app.models.account import AccountModel
from app.models.interest import MinorInterestModel, MajorInterestModel
from app.models.sporrow import SporrowModel
from app.views import BaseResource, auth_required, json_required
api = Api(Blueprint(__name__, __name__))
@api.resource('/sporrow/response/<id>')
class SporrowResponse(BaseResource):
def post(self, id):
"""
대여 제안 수락
"""
def delete(self, id):
"""
대여 제안 거절
""" | [
"city7310@naver.com"
] | city7310@naver.com |
d85f304973941bc00691ad8321ed91d0eafde44d | 988cbefdb6d45564b0b5d1d7865a5c71ec8e0284 | /dbinsertscripts/placement/extra_info_feed.py | cf3c1a8e93c5f57b61b05578661514ef42ec4f49 | [] | no_license | adi0311/FusionIIIT | 969839761f886fb32b2bd953ee2ff44b7b666d03 | a20502267c4b5b650f34448f5685a240e7260954 | refs/heads/master | 2022-11-13T20:54:07.542918 | 2020-06-30T18:26:29 | 2020-06-30T18:26:29 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,244 | py | import django
import xlrd
from applications.globals.models import ExtraInfo, DepartmentInfo
from django.contrib.auth.models import User
class Data:
def __init__(self, excel_file, row):
self.file = xlrd.open_workbook(excel_file)
self.row = row
self.sheet = self.getSheet()
def getSheet(self):
return self.file.sheet_by_index(0)
def fillExtrainfo(self):
for i in range (1,self.row+1):
try:
user = User.objects.get(username=str(int(self.sheet.cell(i,1).value)))
add=ExtraInfo()
add.id = user.username
add.user = user
add.age = 21
add.address = "ghar"
add.phone_no = 9999999999
add.user_type = 'student'
dept = self.sheet.cell(i,3).value.strip()
add.department = DepartmentInfo.objects.get(name=dept)
add.about_me = "i am fine"
add.save()
print('saved')
except:
print(user.username,'unsucessful')
d = Data('dbinsertscripts/placement/B.Tech 2012.xlsx',131)
d.fillExtrainfo()
# exec(open('dbinsertscripts/placement/extra_info_feed.py').read())
| [
"guptaheet53@gmail.com"
] | guptaheet53@gmail.com |
d32a21a42a95bfb0e893c640ad743f6ecea70c77 | a88d9c0176f5e4c0d0bd9664270e000ebb5edbd9 | /component/tile/time_tile.py | 5076077c2c34536ba54d89d0fb0c7d9a61826238 | [
"MIT"
] | permissive | sandroklippel/fcdm | fb81c73fc6bd1cf296f9301272923c3627474d3f | 5a54e6352bb574ba409be38882ff0d13b3473b7a | refs/heads/master | 2023-08-19T22:05:52.055545 | 2021-08-24T11:23:40 | 2021-08-24T11:23:40 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,435 | py | from sepal_ui import sepalwidgets as sw
import ipyvuetify as v
from component.message import cm
class TimeTile(sw.Tile):
def __init__(self, model):
# create the widgets
baseline_title = v.Html(tag='h4', children=[cm.input_lbl.baseline], class_="mb-0 mt-5")
baseline_start_picker = sw.DatePicker(label=cm.input_lbl.start)
baseline_end_picker = sw.DatePicker(label=cm.input_lbl.end)
baseline_picker_line = v.Layout(xs12=True, row=True, children = [baseline_start_picker, baseline_end_picker])
analysis_title = v.Html(tag='h4', children=[cm.input_lbl.analysis], class_="mb-0 mt-5")
analysis_start_picker = sw.DatePicker(label=cm.input_lbl.start)
analysis_end_picker = sw.DatePicker(label=cm.input_lbl.end)
analysis_picker_line = v.Layout(xs12=True, row=True, children = [analysis_start_picker, analysis_end_picker])
# bind the widgets
model \
.bind(baseline_start_picker, 'reference_start') \
.bind(baseline_end_picker, 'reference_end') \
.bind(analysis_start_picker, 'analysis_start') \
.bind(analysis_end_picker, 'analysis_end')
super().__init__(
'nested_widget',
cm.tile.time,
inputs = [baseline_title, baseline_picker_line, analysis_title, analysis_picker_line]
)
| [
"pierrick.rambaud49@gmail.com"
] | pierrick.rambaud49@gmail.com |
22ca70f79baa3e3b53c4d911e89c6a9ae77161a9 | 06a50cfded23b760d5b2a5ae7d5c4761ae2d4dc8 | /edX/MITx6.00.1x/final/final_problem4.py | 65c8ca1b81cb181c51e0d20782bc82ce1c1d18dc | [
"Apache-2.0"
] | permissive | spencerzhang91/coconuts-on-fire | b0655b3dd2b310b5e62f8cef524c6fddb481e758 | 407d61b3583c472707a4e7b077a9a3ab12743996 | refs/heads/master | 2021-09-21T07:37:07.879409 | 2018-08-22T03:24:36 | 2018-08-22T03:24:36 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,118 | py | def longest_run(L):
"""
Assumes L is a list of integers containing at least 2 elements.
Finds the longest run of numbers in L, where the longest run can
either be monotonically increasing or monotonically decreasing.
In case of a tie for the longest run, choose the longest run
that occurs first.
Does not modify the list.
Returns the sum of the longest run.
"""
longest = []
increasing = None
# main for loop
for i in range(len(L) - 1):
# this for loop decides if current run is increasing
for j in range(i+1, len(L)):
if L[j] == L[j-1]:
continue
elif L[j] > L[j-1]:
increasing = True
increase = [L[i]]
break
else:
increasing = False
decrease = [L[i]]
break
if increasing == None:
if len(L[i:]) > len(longest):
return sum(L[i:])
# this for loop actually adds items in respective list
for j in range(i+1, len(L)):
if L[j] >= L[j-1] and increasing:
increase.append(L[j])
if j == len(L) - 1 and len(increase) > len(longest):
return sum(increase)
elif L[j] <= L[j-1] and not increasing:
decrease.append(L[j])
if j == len(L) - 1 and len(decrease) > len(longest):
return sum(decrease)
else:
if increasing and len(increase) > len(longest):
longest = increase[:]
increase = []
elif not increasing and len(decrease) > len(longest):
longest = decrease[:]
decrease = []
i = j - 1
break
# print(L, len(L), longest, j)
return sum(longest)
l1 = [3, 3, 3, 3, 3]
l2 = [3, 2, -1, 2, 7]
l3 = [100, 200, 300, -100, -200, -1500, -5000]
l4 = [3, 3, 3, 3, 3, 3, 3, -10, 1, 2, 3, 4]
print(longest_run(l1))
print(longest_run(l2))
print(longest_run(l3))
print(longest_run(l4))
| [
"spencerpomme@live.com"
] | spencerpomme@live.com |
25103517eaf993fb792f787dbdc32b3258b69e60 | 3c3b41bb9cdfc23cc95727636f0995560728098a | /FullDestroyAnalysis2016/Wheel0/Working/20160425/CMSSW_8_0_2/tmp/slc6_amd64_gcc530/src/HLTrigger/Muon/src/HLTriggerMuon/edm_write_config/scoutingMuonProducer_cfi.py | 4bc3fc3890cdd620372bcb3b4d8c0d53ac8a8fd7 | [] | no_license | FlorianScheuch/MassiveProductionMuonGun | eb5a2916345c21edf5fd0c5d6694333a0306c363 | a9a336364309cb7c9e952c0cd85060032d1dccd1 | refs/heads/master | 2016-08-12T23:12:01.159605 | 2016-05-04T11:26:35 | 2016-05-04T11:26:35 | 53,405,775 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 509 | py | import FWCore.ParameterSet.Config as cms
scoutingMuonProducer = cms.EDProducer('HLTScoutingMuonProducer',
ChargedCandidates = cms.InputTag('hltL3MuonCandidates'),
Tracks = cms.InputTag('hltL3Muons'),
EcalPFClusterIsoMap = cms.InputTag('hltMuonEcalPFClusterIsoForMuons'),
HcalPFClusterIsoMap = cms.InputTag('hltMuonHcalPFClusterIsoForMuons'),
TrackIsoMap = cms.InputTag('hltMuonTkRelIsolationCut0p09Map', 'combinedRelativeIsoDeposits'),
muonPtCut = cms.double(4),
muonEtaCut = cms.double(2.4)
)
| [
"scheuch@physik.rwth-aachen.de"
] | scheuch@physik.rwth-aachen.de |
8c05c91c0395da600980ef3863c433490959e584 | 4fc21c3f8dca563ce8fe0975b5d60f68d882768d | /GodwillOnyewuchi/Phase 1/Python Basic 2/Day 6 task/task 3.py | e6756dd907f48a6c70240dbe8e61fd264526422b | [
"MIT"
] | permissive | Uche-Clare/python-challenge-solutions | 17e53dbedbff2f33e242cf8011696b3059cd96e9 | 49ede6204ee0a82d5507a19fbc7590a1ae10f058 | refs/heads/master | 2022-11-13T15:06:52.846937 | 2020-07-10T20:59:37 | 2020-07-10T20:59:37 | 266,404,840 | 1 | 0 | MIT | 2020-05-23T19:24:56 | 2020-05-23T19:24:55 | null | UTF-8 | Python | false | false | 166 | py | import os
import platform
print(f'Operating system name: {os.name}')
print(f'Platform name: {platform.system()}')
print(f'Platform release: {platform.release()}')
| [
"godwillonyewuchii@gmail.com"
] | godwillonyewuchii@gmail.com |
b098c03b36a2f4b47d20164b7839bda797ffb633 | a67147597814032c0fee8c1debb38e61730841c7 | /argo/workflows/client/models/v1_azure_disk_volume_source.py | b6fe1decebcb61acf9fe1bc06e8bcfb8dd50d0c4 | [
"Apache-2.0",
"MIT"
] | permissive | CermakM/argo-client-python | 12ddc49d8e10a2a68d5965f37b9353234a2c5906 | 0caa743442d37f2f2e3b30867398ed2708c1bf4d | refs/heads/master | 2020-07-21T20:48:30.275935 | 2020-02-26T10:05:05 | 2020-02-26T10:05:05 | 206,972,491 | 36 | 9 | Apache-2.0 | 2020-02-26T10:05:06 | 2019-09-07T13:31:46 | Python | UTF-8 | Python | false | false | 6,637 | py | # coding: utf-8
"""
Argo
Python client for Argo Workflows # noqa: E501
OpenAPI spec version: master
Generated by: https://github.com/swagger-api/swagger-codegen.git
"""
import pprint
import re # noqa: F401
import six
class V1AzureDiskVolumeSource(object):
"""NOTE: This class is auto generated by the swagger code generator program.
Do not edit the class manually.
"""
"""
Attributes:
swagger_types (dict): The key is attribute name
and the value is attribute type.
attribute_map (dict): The key is attribute name
and the value is json key in definition.
"""
swagger_types = {
'caching_mode': 'str',
'disk_name': 'str',
'disk_uri': 'str',
'fs_type': 'str',
'kind': 'str',
'read_only': 'bool'
}
attribute_map = {
'caching_mode': 'cachingMode',
'disk_name': 'diskName',
'disk_uri': 'diskURI',
'fs_type': 'fsType',
'kind': 'kind',
'read_only': 'readOnly'
}
def __init__(self, caching_mode=None, disk_name=None, disk_uri=None, fs_type=None, kind=None, read_only=None): # noqa: E501
"""V1AzureDiskVolumeSource - a model defined in Swagger""" # noqa: E501
self._caching_mode = None
self._disk_name = None
self._disk_uri = None
self._fs_type = None
self._kind = None
self._read_only = None
self.discriminator = None
if caching_mode is not None:
self.caching_mode = caching_mode
if disk_name is not None:
self.disk_name = disk_name
if disk_uri is not None:
self.disk_uri = disk_uri
if fs_type is not None:
self.fs_type = fs_type
if kind is not None:
self.kind = kind
if read_only is not None:
self.read_only = read_only
@property
def caching_mode(self):
"""Gets the caching_mode of this V1AzureDiskVolumeSource. # noqa: E501
:return: The caching_mode of this V1AzureDiskVolumeSource. # noqa: E501
:rtype: str
"""
return self._caching_mode
@caching_mode.setter
def caching_mode(self, caching_mode):
"""Sets the caching_mode of this V1AzureDiskVolumeSource.
:param caching_mode: The caching_mode of this V1AzureDiskVolumeSource. # noqa: E501
:type: str
"""
self._caching_mode = caching_mode
@property
def disk_name(self):
"""Gets the disk_name of this V1AzureDiskVolumeSource. # noqa: E501
:return: The disk_name of this V1AzureDiskVolumeSource. # noqa: E501
:rtype: str
"""
return self._disk_name
@disk_name.setter
def disk_name(self, disk_name):
"""Sets the disk_name of this V1AzureDiskVolumeSource.
:param disk_name: The disk_name of this V1AzureDiskVolumeSource. # noqa: E501
:type: str
"""
self._disk_name = disk_name
@property
def disk_uri(self):
"""Gets the disk_uri of this V1AzureDiskVolumeSource. # noqa: E501
:return: The disk_uri of this V1AzureDiskVolumeSource. # noqa: E501
:rtype: str
"""
return self._disk_uri
@disk_uri.setter
def disk_uri(self, disk_uri):
"""Sets the disk_uri of this V1AzureDiskVolumeSource.
:param disk_uri: The disk_uri of this V1AzureDiskVolumeSource. # noqa: E501
:type: str
"""
self._disk_uri = disk_uri
@property
def fs_type(self):
"""Gets the fs_type of this V1AzureDiskVolumeSource. # noqa: E501
:return: The fs_type of this V1AzureDiskVolumeSource. # noqa: E501
:rtype: str
"""
return self._fs_type
@fs_type.setter
def fs_type(self, fs_type):
"""Sets the fs_type of this V1AzureDiskVolumeSource.
:param fs_type: The fs_type of this V1AzureDiskVolumeSource. # noqa: E501
:type: str
"""
self._fs_type = fs_type
@property
def kind(self):
"""Gets the kind of this V1AzureDiskVolumeSource. # noqa: E501
:return: The kind of this V1AzureDiskVolumeSource. # noqa: E501
:rtype: str
"""
return self._kind
@kind.setter
def kind(self, kind):
"""Sets the kind of this V1AzureDiskVolumeSource.
:param kind: The kind of this V1AzureDiskVolumeSource. # noqa: E501
:type: str
"""
self._kind = kind
@property
def read_only(self):
"""Gets the read_only of this V1AzureDiskVolumeSource. # noqa: E501
:return: The read_only of this V1AzureDiskVolumeSource. # noqa: E501
:rtype: bool
"""
return self._read_only
@read_only.setter
def read_only(self, read_only):
"""Sets the read_only of this V1AzureDiskVolumeSource.
:param read_only: The read_only of this V1AzureDiskVolumeSource. # noqa: E501
:type: bool
"""
self._read_only = read_only
def to_dict(self):
"""Returns the model properties as a dict"""
result = {}
for attr, _ in six.iteritems(self.swagger_types):
value = getattr(self, attr)
if isinstance(value, list):
result[attr] = list(map(
lambda x: x.to_dict() if hasattr(x, "to_dict") else x,
value
))
elif hasattr(value, "to_dict"):
result[attr] = value.to_dict()
elif isinstance(value, dict):
result[attr] = dict(map(
lambda item: (item[0], item[1].to_dict())
if hasattr(item[1], "to_dict") else item,
value.items()
))
else:
result[attr] = value
if issubclass(V1AzureDiskVolumeSource, dict):
for key, value in self.items():
result[key] = value
return result
def to_str(self):
"""Returns the string representation of the model"""
return pprint.pformat(self.to_dict())
def __repr__(self):
"""For `print` and `pprint`"""
return self.to_str()
def __eq__(self, other):
"""Returns true if both objects are equal"""
if not isinstance(other, V1AzureDiskVolumeSource):
return False
return self.__dict__ == other.__dict__
def __ne__(self, other):
"""Returns true if both objects are not equal"""
return not self == other
| [
"macermak@redhat.com"
] | macermak@redhat.com |
4869045ced8c753a4f306d56df41c546c702e354 | eb251e90f293a9e8831ced9f996c36e5ab0fc89d | /atgBlog/urls.py | 43fb3bd878bd084b6e462766648d8c7cf4146014 | [] | no_license | ayushganguli1769/Blog | d6b053ce8a169082fc41ab87d340f8cfec0039e7 | a9b8a0d06a704b17c2d7e139e3870a046acc59cf | refs/heads/master | 2022-05-10T23:23:28.860371 | 2020-01-31T05:01:32 | 2020-01-31T05:01:32 | 237,314,050 | 0 | 0 | null | 2022-04-22T23:02:45 | 2020-01-30T22:00:00 | HTML | UTF-8 | Python | false | false | 1,084 | py | """atgBlog URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/2.2/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
from django.contrib import admin
from django.urls import path, re_path,include
from django.conf import settings
from django.conf.urls.static import static
urlpatterns = [
path('admin/', admin.site.urls),
path('',include('blog.urls')),
]
if settings.DEBUG: #Not for production code
urlpatterns += static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)
urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT) | [
"ayushganguli1769@gmail.com"
] | ayushganguli1769@gmail.com |
3b3a4b7d216d98f5a962d869ba41b6ad3cfc21d8 | 586c97e81b448d9f4c1525205eaccc727f789ee7 | /src/buildercore/project/stack_generation.py | 1e4727a5c13880a14ed594cfa5204447e44e2cf8 | [
"MIT"
] | permissive | elifesciences/builder | 33542171fd43a454d8c45feae181037ff414874d | 7de9bb53c7e6a447a075a66023815166ea54092f | refs/heads/master | 2023-08-16T11:22:40.684539 | 2023-08-15T08:30:31 | 2023-08-15T08:30:31 | 56,778,863 | 12 | 14 | MIT | 2023-09-10T04:06:16 | 2016-04-21T14:08:05 | Python | UTF-8 | Python | false | false | 2,265 | py | '''logic to generate and refresh the configuration of stacks and their list of resources.
'''
from functools import reduce
import os
from buildercore.utils import ensure, merge
from buildercore.project import stack_config, stack_generation__s3_bucket
import logging
LOG = logging.getLogger(__name__)
def _regenerate_resource(resource):
"updates the given `resource`."
dispatch = {
's3-bucket': stack_generation__s3_bucket.regenerate_resource,
}
dispatch_fn = dispatch[resource['meta']['type']]
return dispatch_fn(resource)
def regenerate(stackname, config_path):
"""update each of the resources for the given `stackname` in stack config file `config_path`."""
stack_map = stack_config.read_stack_file(config_path)
defaults, stack_map = stack_config.parse_stack_map(stack_map)
ensure(stackname in stack_map, "stack %r not found. known stacks: %s" % (stackname, ", ".join(stack_map.keys())))
stack = stack_map[stackname]
new_resource_list = [_regenerate_resource(resource) for resource in stack['resource-list']]
stack['resource-list'] = new_resource_list
stack_config.write_stack_file_updates({stackname: stack}, config_path)
# ---
def generate_stacks(resource_type, config_path):
"""generate new stacks with a single resource of the given `resource_type`.
intended to bulk populate config files.
does *not* remove stacks that were previously generated but have since been deleted."""
dispatch = {
's3-bucket': stack_generation__s3_bucket.generate_stack
}
ensure(resource_type in dispatch,
"unsupported resource type %r. supported resource types: %s" % (resource_type, ", ".join(dispatch.keys())))
ensure(os.path.exists(config_path), "config path %r does not exist" % config_path)
dispatch_fn = dispatch[resource_type]
generated_stack_list = dispatch_fn(config_path)
# sanity check, make sure each generated stack looks like:
# {"foo-bucket": {"name": "foo-bucket", "meta": {...}, ...}}
for stack in generated_stack_list:
ensure(len(stack.keys()) == 1, "bad stack, expected exactly 1 key: %r" % stack)
stack_map = reduce(merge, generated_stack_list)
stack_config.write_stack_file_updates(stack_map, config_path)
| [
"noreply@github.com"
] | elifesciences.noreply@github.com |
35104a58f8e7034138019f0fcc5d29c4efa3db8e | b162de01d1ca9a8a2a720e877961a3c85c9a1c1c | /478.generate-random-point-in-a-circle.python3.py | d3f495f6bbf8eed4bbf848d653b415a59364491a | [] | no_license | richnakasato/lc | 91d5ff40a1a3970856c76c1a53d7b21d88a3429c | f55a2decefcf075914ead4d9649d514209d17a34 | refs/heads/master | 2023-01-19T09:55:08.040324 | 2020-11-19T03:13:51 | 2020-11-19T03:13:51 | 114,937,686 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,973 | py | #
# [915] Generate Random Point in a Circle
#
# https://leetcode.com/problems/generate-random-point-in-a-circle/description/
#
# algorithms
# Medium (35.05%)
# Total Accepted: 2.8K
# Total Submissions: 8K
# Testcase Example: '["Solution", "randPoint", "randPoint", "randPoint"]\n[[1.0, 0.0, 0.0], [], [], []]'
#
# Given the radius and x-y positions of the center of a circle, write a
# function randPoint which generates a uniform random point in the circle.
#
# Note:
#
#
# input and output values are in floating-point.
# radius and x-y position of the center of the circle is passed into the class
# constructor.
# a point on the circumference of the circle is considered to be in the
# circle.
# randPoint returns a size 2 array containing x-position and y-position of the
# random point, in that order.
#
#
#
# Example 1:
#
#
# Input:
# ["Solution","randPoint","randPoint","randPoint"]
# [[1,0,0],[],[],[]]
# Output: [null,[-0.72939,-0.65505],[-0.78502,-0.28626],[-0.83119,-0.19803]]
#
#
#
# Example 2:
#
#
# Input:
# ["Solution","randPoint","randPoint","randPoint"]
# [[10,5,-7.5],[],[],[]]
# Output: [null,[11.52438,-8.33273],[2.46992,-16.21705],[11.13430,-12.42337]]
#
#
# Explanation of Input Syntax:
#
# The input is two lists: the subroutines called and their arguments.
# Solution's constructor has three arguments, the radius, x-position of the
# center, and y-position of the center of the circle. randPoint has no
# arguments. Arguments are always wrapped with a list, even if there aren't
# any.
#
#
#
class Solution:
def __init__(self, radius, x_center, y_center):
"""
:type radius: float
:type x_center: float
:type y_center: float
"""
def randPoint(self):
"""
:rtype: List[float]
"""
# Your Solution object will be instantiated and called as such:
# obj = Solution(radius, x_center, y_center)
# param_1 = obj.randPoint()
| [
"richnakasato@hotmail.com"
] | richnakasato@hotmail.com |
b0bb669409862df3c53e743bcbd30f36d41824d2 | 53e80832ee11d65723d54005bb1964276e6c8695 | /spider/douban/douban/spiders/base/douban_common.py | cc6aca59deb9be7f2595943254abee3cefa23144 | [] | no_license | chwangbjtu/spider | 710e8f73fd7dceeb07ee68c67d66f6af0fc0043b | 5617a26667bb1b94afd879d04b8535e0561a0db0 | refs/heads/master | 2021-01-24T10:54:27.943707 | 2016-09-27T09:52:25 | 2016-09-27T09:52:25 | 69,341,699 | 1 | 1 | null | null | null | null | UTF-8 | Python | false | false | 14,635 | py | # -*- coding:utf-8 -*-
import re
import logging
import traceback
from douban.items import MediaItem
from douban.items import RecommendItem
from douban.items import RevItem, ReviewItem
from douban.common.util import Util
def get_imdb_chief(response):
try:
imdb_chiefs = response.xpath('//a[@class="bp_item np_all"]/@href').extract()
if imdb_chiefs:
imdb_chief = imdb_chiefs[0].split('/')[2]
return imdb_chief
except Exception, e:
logging.log(logging.ERROR, traceback.format_exc())
def common_parse_media_plus(response):
try:
mediaItem = response.request.meta['mediaItem'] if 'mediaItem' in response.request.meta else MediaItem()
url = response.request.url
url = Util.douban_url_normalized(url)
cont_id = dou_id = int(url.split('/')[4])
#reviews = response.xpath('//a[@href="https://movie.douban.com/subject/%s/reviews"]/text()' % dou_id).re('\d+')
#comments = response.xpath('//a[@href="https://movie.douban.com/subject/%s/comments"]/text()' % dou_id).re('\d+')
reviews = response.xpath('//a[re:test(@href, ".*movie.douban.com/subject/%s/reviews")]/text()' % dou_id).re('\d+')
comments = response.xpath('//a[re:test(@href, ".*movie.douban.com/subject/%s/comments")]/text()' % dou_id).re('\d+')
if reviews:
review = int(reviews[0])
else:
review = None
if comments:
comment = int(comments[0])
else:
comment = None
names = response.xpath('//head/title/text()').extract()
titles = response.xpath('//div[@id="wrapper"]/div[@id="content"]/h1/span[@property="v:itemreviewed"]/text()').extract()
posters = response.xpath('//div[@id="mainpic"]/a/img/@src').extract()
directors = response.xpath('//div[@id="info"]/span/span[text()="%s"]/../span[@class="attrs"]/a' % u"导演")
writers = response.xpath('//div[@id="info"]/span/span[text()="%s"]/../span[@class="attrs"]/a/text()' % u"编剧").extract()
actors = response.xpath('//div[@id="info"]/span/span[text()="%s"]/../span[@class="attrs"]/a' % u"主演")
genres = response.xpath('//div[@id="info"]/span[@property="v:genre"]/text()').extract()
aliasr = re.compile(r'<span class="pl">又名:</span>(.*)<br/>')
aliasm = aliasr.search(response.body)
if aliasm:
aliasl = aliasm.groups()[0].split('/')
else:
aliasl = None
districtr = re.compile(r'<span class="pl">制片国家/地区:</span>(.*)<br/>')
districtm = districtr.search(response.body)
if districtm:
districtl = districtm.groups()[0].split('/')
else:
districtl = None
langr = re.compile(r'<span class="pl">语言:</span>(.*)<br/>')
langm = langr.search(response.body)
if langm:
langl = langm.groups()[0].split('/')
else:
langl = None
# vcount
vcountr = re.compile(r'<span class="pl">集数:</span>\D+(\d+).*<br/>')
vcountm = vcountr.search(response.body)
episode_list = response.xpath('//div[@class="episode_list"]/a/text()').extract()
if vcountm:
vcount = int(vcountm.groups()[0])
elif episode_list:
vcount = len(episode_list)
else:
vcount = 1
channel_name = 'movie' if vcount == 1 else 'tv'
relesas_dates = response.xpath('//div[@id="info"]/span[@property="v:initialReleaseDate"]/text()').re('([0-9-]+)\({0,1}')
# runtime
runtimes = response.xpath('//div[@id="info"]/span[@property="v:runtime"]/text()').re('(\d+).*')
runtimer = re.compile(r'<span class="pl">单集片长:</span>\D+(\d+).*<br/>')
runtimem = runtimer.search(response.body)
if runtimes:
runtime = int(runtimes[0])
elif runtimem:
runtime = int(runtimem.groups()[0])
else:
runtime = None
scores = response.xpath('//div[@id="interest_sectl"]//strong[@property="v:average"]/text()').extract()
imdbr = re.compile(r'<span class="pl">IMDb链接:</span>\s+<a.*>(.*)</a><br>')
imdbm = imdbr.search(response.body)
if imdbm:
imdb = imdbm.groups()[0]
else:
imdb = None
intros = response.xpath('//div[@class="related-info"]/div/span/text()').extract()
if names and ('name' not in mediaItem or not mediaItem['name']):
mediaItem['name'] = names[0].replace(u'(豆瓣)', '').strip()
if titles and ('title' not in mediaItem or not mediaItem['title']):
mediaItem['title'] = titles[0].strip()
if posters and ('poster' not in mediaItem or not mediaItem['poster']):
mediaItem['poster'] = posters[0].strip()
if scores and ('score' not in mediaItem or not mediaItem['score']):
mediaItem['score'] = float(scores[0].strip())
mediaItem['cont_id'] = cont_id
mediaItem['dou_id'] = dou_id
director = {}
for d in directors:
d_names = d.xpath('./text()').extract()
d_ids = d.xpath('./@href').re('celebrity/(\d+)')
if d_names:
d_id = d_ids[0] if d_ids else None
director.setdefault(d_names[0], d_id)
mediaItem['director'] = director
if writers:
mediaItem['writer'] = Util.lst2str(writers)
actor = {}
for a in actors:
a_names = a.xpath('./text()').extract()
a_ids = a.xpath('./@href').re('celebrity/(\d+)')
if a_names:
a_id = a_ids[0] if a_ids else None
actor.setdefault(a_names[0], a_id)
mediaItem['actor'] = actor
if genres:
mediaItem['genre'] = Util.lst2str(genres)
if relesas_dates:
mediaItem['release_date'] = Util.str2date(relesas_dates[0])
if runtime:
mediaItem['runtime'] = runtime
if scores:
mediaItem['score'] = float(scores[0])
if imdb:
mediaItem['imdb'] = imdb
if intros:
# mediaItem['intro'] = intros[0].strip('\n').strip()
mediaItem['intro'] = ''.join([r.strip('\n').strip() for r in intros])
if aliasl:
mediaItem['alias'] = Util.lst2str(aliasl)
if districtl:
mediaItem['district'] = Util.lst2str(districtl)
if langl:
mediaItem['lang'] = Util.lst2str(langl)
if review is not None:
mediaItem['review'] = review
if comment is not None:
mediaItem['comment'] = comment
mediaItem['vcount'] = vcount
mediaItem['url'] = url
return mediaItem
except Exception, e:
logging.log(logging.ERROR, traceback.format_exc())
return mediaItem
def common_parse_media(response):
try:
#logging.log(logging.INFO, 'parse_media: %s' % response.request.url)
mediaItem = response.request.meta['mediaItem'] if 'mediaItem' in response.request.meta else MediaItem()
url = response.request.url
url = Util.douban_url_normalized(url)
cont_id = dou_id = int(url.split('/')[4])
titles = response.xpath('//div[@id="wrapper"]/div[@id="content"]/h1/span[@property="v:itemreviewed"]/text()').extract()
posters = response.xpath('//div[@id="mainpic"]/a/img/@src').extract()
directors = response.xpath('//div[@id="info"]/span/span[text()="%s"]/../span[@class="attrs"]/a/text()' % u"导演").extract()
writers = response.xpath('//div[@id="info"]/span/span[text()="%s"]/../span[@class="attrs"]/a/text()' % u"编剧").extract()
actors = response.xpath('//div[@id="info"]/span/span[text()="%s"]/../span[@class="attrs"]/a/text()' % u"主演").extract()
genres = response.xpath('//div[@id="info"]/span[@property="v:genre"]/text()').extract()
aliasr = re.compile(r'<span class="pl">又名:</span>(.*)<br/>')
aliasm = aliasr.search(response.body)
if aliasm:
aliasl = aliasm.groups()[0].split('/')
else:
aliasl = None
districtr = re.compile(r'<span class="pl">制片国家/地区:</span>(.*)<br/>')
districtm = districtr.search(response.body)
if districtm:
districtl = districtm.groups()[0].split('/')
else:
districtl = None
langr = re.compile(r'<span class="pl">语言:</span>(.*)<br/>')
langm = langr.search(response.body)
if langm:
langl = langm.groups()[0].split('/')
else:
langl = None
# vcount
vcountr = re.compile(r'<span class="pl">集数:</span>\D+(\d+).*<br/>')
vcountm = vcountr.search(response.body)
episode_list = response.xpath('//div[@class="episode_list"]/a/text()').extract()
if vcountm:
vcount = int(vcountm.groups()[0])
elif episode_list:
vcount = len(episode_list)
else:
vcount = 1
channel_name = 'movie' if vcount == 1 else 'tv'
relesas_dates = response.xpath('//div[@id="info"]/span[@property="v:initialReleaseDate"]/text()').re('([0-9-]+)\({0,1}')
# runtime
runtimes = response.xpath('//div[@id="info"]/span[@property="v:runtime"]/text()').re('(\d+).*')
runtimer = re.compile(r'<span class="pl">单集片长:</span>\D+(\d+).*<br/>')
runtimem = runtimer.search(response.body)
if runtimes:
runtime = int(runtimes[0])
elif runtimem:
runtime = int(runtimem.groups()[0])
else:
runtime = None
scores = response.xpath('//div[@id="interest_sectl"]//strong[@property="v:average"]/text()').extract()
imdbr = re.compile(r'<span class="pl">IMDb链接:</span>\s+<a.*>(.*)</a><br>')
imdbm = imdbr.search(response.body)
if imdbm:
imdb = imdbm.groups()[0]
else:
imdb = None
intros = response.xpath('//div[@class="related-info"]/div/span/text()').extract()
if titles and ('title' not in mediaItem or not mediaItem['title']):
mediaItem['title'] = titles[0].strip()
if posters and ('poster' not in mediaItem or not mediaItem['poster']):
mediaItem['poster'] = posters[0].strip()
if scores and ('score' not in mediaItem or not mediaItem['score']):
mediaItem['score'] = float(scores[0].strip())
mediaItem['cont_id'] = cont_id
mediaItem['dou_id'] = dou_id
if directors:
mediaItem['director'] = Util.lst2str(directors)
if writers:
mediaItem['writer'] = Util.lst2str(writers)
if actors:
mediaItem['actor'] = Util.lst2str(actors)
if genres:
mediaItem['genre'] = Util.lst2str(genres)
if relesas_dates:
mediaItem['release_date'] = Util.str2date(relesas_dates[0])
if runtime:
mediaItem['runtime'] = runtime
if scores:
mediaItem['score'] = float(scores[0])
if imdb:
mediaItem['imdb'] = imdb
if intros:
# mediaItem['intro'] = intros[0].strip('\n').strip()
mediaItem['intro'] = ''.join([r.strip('\n').strip() for r in intros])
if aliasl:
mediaItem['alias'] = Util.lst2str(aliasl)
if districtl:
mediaItem['district'] = Util.lst2str(districtl)
if langl:
mediaItem['lang'] = Util.lst2str(langl)
mediaItem['vcount'] = vcount
#mediaItem['channel_id'] = self.channel_map[channel_name]
#mediaItem['site_id'] = self.site_id
mediaItem['url'] = url
return mediaItem
except Exception, e:
logging.log(logging.ERROR, traceback.format_exc())
return mediaItem
def common_parse_recommend(response):
try:
#logging.log(logging.INFO, 'parse_recommend: %s' % response.request.url)
recommendItem = response.request.meta['recommendItem'] if 'recommendItem' in response.request.meta else RecommendItem()
url = response.request.url
url = Util.douban_url_normalized(url)
dou_id = int(url.split('/')[4])
recommendItem['dou_id'] = dou_id
rec_lst = []
rec_urls = response.xpath('//div[@class="recommendations-bd"]/dl/dt/a/@href').extract()
for rurl in rec_urls:
rurl = Util.douban_url_normalized(rurl)
rec_lst.append(int(rurl.split('/')[4]))
if rec_lst:
recommendItem['rec_lst'] = rec_lst
return recommendItem
except Exception, e:
logging.log(logging.ERROR, traceback.format_exc())
def common_parse_review(response):
try:
#logging.log(logging.INFO, 'parse_review: %s' % response.request.url)
#reviewItem = response.request.meta['reviewItem'] if 'reviewItem' in response.request.meta else ReviewItem()
#rev_lst = reviewItem['rev_lst'] if 'rev_lst' in reviewItem else []
rev_lst = []
#url = response.request.url
#url = Util.douban_url_normalized(url)
#dou_id = int(url.split('/')[4])
#reviewItem['dou_id'] = dou_id
h3s = response.xpath('//div[@class="review"]/div[@class="review-hd"]/h3')
for h3 in h3s:
revItem = RevItem()
user_urls = h3.xpath('./a[@class="review-hd-avatar"]/@href').extract()
rev_ids = h3.xpath('./div[@class="review-hd-expand"]/@id').extract()
if user_urls:
user_url =user_urls[0]
neck_name = user_url.split('/')[4]
revItem['neck_name'] = neck_name
if rev_ids:
rev_id = rev_ids[0].replace('tb-', '')
revItem['rev_id'] = rev_id
if 'neck_name' in revItem and 'rev_id' in revItem:
rev_lst.append(revItem)
#if rev_lst:
# reviewItem['rev_lst'] = rev_lst
#return reviewItem
return rev_lst
except Exception, e:
logging.log(logging.ERROR, traceback.format_exc())
def get_cookie(response):
try:
cookie = {}
set_cookie = response.headers.getlist('Set-Cookie')
if set_cookie:
cookie_list = set_cookie[0].split(';')
for cl in cookie_list:
k, v = cl.split('=')
cookie[k] = v.strip('\"')
except Exception, e:
logging.log(logging.ERROR, traceback.format_exc())
finally:
return cookie
| [
"chwangbjtu@gmail.com"
] | chwangbjtu@gmail.com |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.