
blob_id stringlengths 40 40 | directory_id stringlengths 40 40 | path stringlengths 3 616 | content_id stringlengths 40 40 | detected_licenses listlengths 0 112 | license_type stringclasses 2 values | repo_name stringlengths 5 115 | snapshot_id stringlengths 40 40 | revision_id stringlengths 40 40 | branch_name stringclasses 777 values | visit_date timestamp[us]date 2015-08-06 10:31:46 2023-09-06 10:44:38 | revision_date timestamp[us]date 1970-01-01 02:38:32 2037-05-03 13:00:00 | committer_date timestamp[us]date 1970-01-01 02:38:32 2023-09-06 01:08:06 | github_id int64 4.92k 681M ⌀ | star_events_count int64 0 209k | fork_events_count int64 0 110k | gha_license_id stringclasses 22 values | gha_event_created_at timestamp[us]date 2012-06-04 01:52:49 2023-09-14 21:59:50 ⌀ | gha_created_at timestamp[us]date 2008-05-22 07:58:19 2023-08-21 12:35:19 ⌀ | gha_language stringclasses 149 values | src_encoding stringclasses 26 values | language stringclasses 1 value | is_vendor bool 2 classes | is_generated bool 2 classes | length_bytes int64 3 10.2M | extension stringclasses 188 values | content stringlengths 3 10.2M | authors listlengths 1 1 | author_id stringlengths 1 132 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
ed8306c08a8e419a2ded4aea0ef8cf8222dbdc06 | 30a2f77f5427a3fe89e8d7980a4b67fe7526de2c | /analyze/BHistograms_trigjetht500_eta1p7_CSVM_cfg.py | 997496691c837cd4dca4f3093e8fd3e8b1c3cfd4 | [] | no_license | DryRun/QCDAnalysis | 7fb145ce05e1a7862ee2185220112a00cb8feb72 | adf97713956d7a017189901e858e5c2b4b8339b6 | refs/heads/master | 2020-04-06T04:23:44.112686 | 2018-01-08T19:47:01 | 2018-01-08T19:47:01 | 55,909,998 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 5,632 | py | import FWCore.ParameterSet.Config as cms
import FWCore.ParameterSet.VarParsing as VarParsing
import sys
options = VarParsing.VarParsing()
options.register('inputFiles',
'/uscms/home/dryu/eosdir/BJetPlusX/QCDBEventTree_BJetPlusX_Run2012B_v1_3/160429_121519/0000/QCDBEventTree_567.root',
VarParsing.VarParsing.multiplicity.list,
VarParsing.VarParsing.varType.string,
"List of input files"
)
options.register('outputFile',
'BHistograms_trigjetht_CSVL.root',
VarParsing.VarParsing.multiplicity.singleton,
VarParsing.VarParsing.varType.string,
"Output file"
)
options.register('dataSource',
'collision_data',
VarParsing.VarParsing.multiplicity.singleton,
VarParsing.VarParsing.varType.string,
'collision_data or simulation'
)
options.register('dataType',
'data',
VarParsing.VarParsing.multiplicity.singleton,
VarParsing.VarParsing.varType.string,
'data, signal, or background'
)
options.register('signalMass',
750.,
VarParsing.VarParsing.multiplicity.singleton,
VarParsing.VarParsing.varType.float,
'Signal mass hypothesis (only necessary for running over signal)'
)
options.parseArguments()
if options.dataSource != "collision_data" and options.dataSource != "simulation":
print "[BHistograms_BJetPlusX_loose] ERROR : dataSource must be collision_data or simulation"
sys.exit(1)
if not options.dataType in ["data", "signal", "background"]:
print "[BHistograms_BJetPlusX_loose] ERROR : dataType must be data, signal, or background"
sys.exit(1)
process = cms.Process("myprocess")
process.TFileService=cms.Service("TFileService",fileName=cms.string(options.outputFile))
##-------------------- Define the source ----------------------------
process.maxEvents = cms.untracked.PSet(
input = cms.untracked.int32(1)
)
process.source = cms.Source("EmptySource")
##-------------------- Cuts ------------------------------------------
# Cuts on the leading two jets
dijet_cuts = cms.VPSet(
cms.PSet(
name = cms.string("MinPt"),
parameters = cms.vdouble(30.),
descriptors = cms.vstring()
),
cms.PSet(
name = cms.string("MaxAbsEta"),
parameters = cms.vdouble(1.7),
descriptors = cms.vstring()
),
cms.PSet(
name = cms.string("IsTightID"),
parameters = cms.vdouble(),
descriptors = cms.vstring()
),
cms.PSet(
name = cms.string("MaxMuonEnergyFraction"),
parameters = cms.vdouble(0.8),
descriptors = cms.vstring()
),
)
# Cuts on all PF jets (defines the generic jet collection for e.g. making fat jets)
pfjet_cuts = cms.VPSet(
cms.PSet(
name = cms.string("MinPt"),
parameters = cms.vdouble(30.),
descriptors = cms.vstring()
),
cms.PSet(
name = cms.string("MaxAbsEta"),
parameters = cms.vdouble(5),
descriptors = cms.vstring()
),
cms.PSet(
name = cms.string("IsLooseID"),
parameters = cms.vdouble(),
descriptors = cms.vstring()
),
)
# Cuts on calo jets
calojet_cuts = cms.VPSet(
cms.PSet(
name = cms.string("MinPt"),
parameters = cms.vdouble(30.),
descriptors = cms.vstring()
)
)
# Event cuts
event_cuts = cms.VPSet(
cms.PSet(
name = cms.string("TriggerOR"),
parameters = cms.vdouble(),
descriptors = cms.vstring('HLT_HT500_v1', 'HLT_HT500_v2', 'HLT_HT500_v3', 'HLT_HT500_v4', 'HLT_HT500_v5', 'HLT_HT500_v7')
),
cms.PSet(
name = cms.string("MaxMetOverSumEt"),
parameters = cms.vdouble(0.5),
descriptors = cms.vstring()
),
cms.PSet(
name = cms.string("GoodPFDijet"),
parameters = cms.vdouble(),
descriptors = cms.vstring()
),
cms.PSet(
name = cms.string("MinNCSVM"),
parameters = cms.vdouble(2),
descriptors = cms.vstring()
),
cms.PSet(
name = cms.string("MinLeadingPFJetPt"),
parameters = cms.vdouble(80.),
descriptors = cms.vstring()
),
cms.PSet(
name = cms.string("MinSubleadingPFJetPt"),
parameters = cms.vdouble(70.),
descriptors = cms.vstring()
),
cms.PSet(
name = cms.string("PFDijetMaxDeltaEta"),
parameters = cms.vdouble(1.3),
descriptors = cms.vstring()
)
)
##-------------------- User analyzer --------------------------------
process.BHistograms = cms.EDAnalyzer('BHistograms',
file_names = cms.vstring(options.inputFiles),
tree_name = cms.string('ak5/ProcessedTree'),
trigger_histogram_name = cms.string('ak5/TriggerNames'),
#triggers = cms.vstring('HLT_DiJet80Eta2p6_BTagIP3DFastPVLoose_v2:L1_DoubleJetC36', 'HLT_DiJet80Eta2p6_BTagIP3DFastPVLoose_v3:L1_DoubleJetC36', 'HLT_DiJet80Eta2p6_BTagIP3DFastPVLoose_v4:L1_DoubleJetC36', 'HLT_DiJet80Eta2p6_BTagIP3DFastPVLoose_v5:L1_DoubleJetC36', 'HLT_DiJet80Eta2p6_BTagIP3DFastPVLoose_v7:L1_DoubleJetC36'),
#triggers = cms.vstring( 'HLT_Jet160Eta2p4_Jet120Eta2p4_DiBTagIP3DFastPVLoose_v2:L1_SingleJet128', 'HLT_Jet160Eta2p4_Jet120Eta2p4_DiBTagIP3DFastPVLoose_v3:L1_SingleJet128', 'HLT_Jet160Eta2p4_Jet120Eta2p4_DiBTagIP3DFastPVLoose_v4:L1_SingleJet128', 'HLT_Jet160Eta2p4_Jet120Eta2p4_DiBTagIP3DFastPVLoose_v5:L1_SingleJet128', 'HLT_Jet160Eta2p4_Jet120Eta2p4_DiBTagIP3DFastPVLoose_v7:L1_SingleJet128'),
data_source = cms.string(options.dataSource),
data_type = cms.string(options.dataType),
signal_mass = cms.double(options.signalMass),
max_events = cms.int32(-1),
dijet_cuts = dijet_cuts,
pfjet_cuts = pfjet_cuts,
calojet_cuts = calojet_cuts,
event_cuts = event_cuts,
fatjet_delta_eta_cut = cms.double(1.1),
btag_wp_1 = cms.string('CSVM'),
btag_wp_2 = cms.string('CSVM'),
)
process.p = cms.Path(process.BHistograms)
| [
"david.renhwa.yu@gmail.com"
] | david.renhwa.yu@gmail.com |
5ea32706b22f4c1e48cb23b8886f3e3df3d91e25 | 9dba277eeb0d5e9d2ac75e2e17ab5b5eda100612 | /exercises/1901090012/1001S02E05_string.py | e71588946e9eb67f1c9fa471a58baa40eac41897 | [] | no_license | shen-huang/selfteaching-python-camp | e8410bfc06eca24ee2866c5d890fd063e9d4be89 | 459f90c9f09bd3a3df9e776fc64dfd64ac65f976 | refs/heads/master | 2022-05-02T05:39:08.932008 | 2022-03-17T07:56:30 | 2022-03-17T07:56:30 | 201,287,222 | 9 | 6 | null | 2019-08-08T15:34:26 | 2019-08-08T15:34:25 | null | UTF-8 | Python | false | false | 1,183 | py | str = '''
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
'''
str1 = str.replace("better","worse")
str2 = str1.replace(',','').replace('.','').replace('--','').replace('*','').replace('!','')
str3 = str2.split()
str4 = list()
for i in str3:
if 'ea' not in i:
str4.append(i)
str5 = list()
for j in str3:
k=j.swapcase()
str5.append(k)
print(sorted(str5))
| [
"46160162+EthanYan6@users.noreply.github.com"
] | 46160162+EthanYan6@users.noreply.github.com |
c42629d89614c8314f3d2663c0538bbccebedb25 | 38d93c5fd72fee380ec431b2ca60a069eef8579d | /Baekjoon,SWEA, etc/프로그래머스/경주로 건설.py | 2cdea97359bc34f435388bc297c0774193a060ef | [] | no_license | whgusdn321/Competitive-programming | 5d1b681f5bee90de5678219d91cd0fa764476ddd | 3ff8e6b1d2facd31a8210eddeef851ffd0dce02a | refs/heads/master | 2023-01-01T01:34:22.936373 | 2020-10-24T11:05:08 | 2020-10-24T11:05:08 | 299,181,046 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,303 | py |
def dfs(y, x, board, dp, n, mode):
dp[y][x] = n
h = len(board)
w = len(board[0])
if y == h and x == w:
return
right = [(y, x+1), (y, x-1)]
up = [(y+1, x), (y-1, x)]
if mode == 'down':
for ny, nx in right:
if 0<=ny<h and 0<=nx<w and dp[ny][nx] >= n + 500 and board[ny][nx] == 0:
dfs(ny, nx, board, dp, n+600, 'right')
for ny, nx in up:
if 0<=ny<h and 0<=nx<w and dp[ny][nx] >= n + 100 and board[ny][nx] == 0:
dfs(ny, nx, board, dp, n+100, 'down')
else:
for ny, nx in right:
if 0<=ny<h and 0<=nx<w and dp[ny][nx] >= n + 100 and board[ny][nx] == 0:
dfs(ny, nx, board, dp, n+100, 'right')
for ny, nx in up:
if 0<=ny<h and 0<=nx<w and dp[ny][nx] >= n + 500 and board[ny][nx] == 0:
dfs(ny, nx, board, dp, n+600, 'down')
def solution(board):
h = len(board)
w = len(board[0])
dp = [[9999999]*w for _ in range(h)]
dfs(0, 0, board, dp, 0, 'down')
dfs(0, 0, board, dp, 0, 'right')
for row in dp:
print(row)
return dp[h-1][w-1]
print(solution([[0,0,0,0,0,0,0,1],[0,0,0,0,0,0,0,0],[0,0,0,0,0,1,0,0],[0,0,0,0,1,0,0,0],[0,0,0,1,0,0,0,1],[0,0,1,0,0,0,1,0],[0,1,0,0,0,1,0,0],[1,0,0,0,0,0,0,0]])) | [
"blackgoldace@naver.com"
] | blackgoldace@naver.com |
324462ca0e87f7e808df4fee2e9d61aae130a9e7 | 7f52845b5aca331ac200565f897b2b1ba3aa79d9 | /m251/exp_groups/paper/ablations/reg_intermediate/launch/launch_fisher.py | 08a2048f9548880d8b25e0b4830dea7da80cae64 | [] | no_license | mmatena/m251 | f8fb4ba9c10cd4dfcf5ee252f80e4832e4e86aa0 | e23249cf0896c5b42bcd07de70f7b9996d8b276b | refs/heads/master | 2023-05-06T10:44:10.945534 | 2021-06-03T15:07:29 | 2021-06-03T15:07:29 | 321,217,654 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,208 | py | """
export PYTHONPATH=$PYTHONPATH:~/Desktop/projects/m251:~/Desktop/projects/del8
python3 m251/exp_groups/paper/ablations/reg_intermediate/launch/launch_fisher.py
"""
from del8.executors.gce import gce
from del8.executors.vastai import vastai
from del8.executors.vastai import api_wrapper
from m251.exp_groups.paper.ablations.reg_intermediate import fisher
EXP = fisher.FisherComputation
launch_params = gce.GceParams()
vast_params = vastai.create_supervisor_params(
EXP,
num_workers=6,
offer_query=vastai.OfferQuery(
queries_str=" ".join(
[
"reliability > 0.95",
"num_gpus=1",
"dph < 0.5",
"inet_down > 75",
"inet_up > 75",
"dlperf >= 16",
"cuda_vers >= 11.0 has_avx = true",
]
),
order_str="dlperf_usd-",
),
disk_gb=12,
)
offers = api_wrapper.query_offers(vast_params)
print(f"Number of acceptable offers: {len(offers)}")
execution_items = EXP.create_all_execution_items()
print(f"Number of execution items to process: {len(execution_items)}")
node, deploy = gce.launch(execution_items, vast_params, launch_params)
| [
"michael.matena@gmail.com"
] | michael.matena@gmail.com |
7291c077f29384a0575867612672d234f52945ef | 0674b9d8a34036a6bbe2052e1cae0eee9a44554b | /SWEA/2819.py | 7d8af0a98a560adf5d023ddc155ace8677c6cce2 | [] | no_license | timebird7/Solve_Problem | 02fb54e90844a42dc69a78afb02cc10a87eda71c | 2d54b6ecbe3edf9895fd8303cbca99b3f50f68f3 | refs/heads/master | 2020-04-14T23:37:15.354476 | 2019-04-15T14:32:41 | 2019-04-15T14:32:41 | 164,208,673 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 534 | py | dx = [0,1,0,-1]
dy = [1,0,-1,0]
def dfs(i,j,result):
global results, nums
if len(result) == 7:
results.add(result)
return
else:
for k in range(4):
x = i+dx[k]
y = j+dy[k]
if 0<=x<4 and 0<=y<4:
dfs(x,y,result+nums[x][y])
TC = int(input())
for tc in range(1,TC+1):
nums = [input().split() for i in range(4)]
results = set()
for i in range(4):
for j in range(4):
dfs(i,j,'')
print(f'#{tc} {len(results)}') | [
"timebird7@gmail.com"
] | timebird7@gmail.com |
18c6913fb81bb7788f18e1237a2b7dc2fcdbd837 | 1edfd072fae205d766e7c488f1af64f3af9fc23a | /src/python/shared/resend_new_sensor_messages.py | be8f468dc97b084dc81da4b2226a4c064fde4aec | [] | no_license | kth-social-robotics/multisensoryprocessing | 17fc96eb3776642de1075103eeb461125020c892 | 867abe6c921fbf930ac26e0f43a8be0404817bcd | refs/heads/master | 2021-01-21T11:50:16.348566 | 2018-11-05T14:48:42 | 2018-11-05T14:48:42 | 102,027,696 | 4 | 2 | null | 2018-02-20T15:14:22 | 2017-08-31T17:39:58 | C++ | UTF-8 | Python | false | false | 371 | py | import zmq
import time
from threading import Thread
def resend_new_sensor_messages():
def run():
time.sleep(2)
context = zmq.Context()
s = context.socket(zmq.REQ)
s.connect('tcp://localhost:45322')
s.send_string('new_sensor')
s.recv()
thread2 = Thread(target = run)
thread2.deamon = True
thread2.start()
| [
"pjjonell@kth.se"
] | pjjonell@kth.se |
2b8fd85409da823f4be40451742e7f66a75e29b9 | d0f2f7f220c825d827643ca81a08a23cfb871965 | /backend/code/rankor/events/actions.py | a6967842eddad33fbcb6a37f79240f295caf6c74 | [] | no_license | socek/rankor | 7e5e73f8f13bc3d12bd1b18ef01bef04f8f38f0a | eaf5002dd1e852895670517a8cdcb07bf7c69f66 | refs/heads/master | 2021-04-12T07:52:20.341699 | 2018-06-03T20:07:17 | 2018-06-03T20:07:17 | 125,769,351 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,750 | py | from rankor import app
from rankor.events.drivers import ScreenCommand
class Event(object):
def __init__(self, **kwargs):
self.data = kwargs
def send(self):
with app as context:
command = ScreenCommand(context.dbsession)
command.send_event(self.name, **self.data)
class ChangeViewEvent(Event):
name = 'change_view'
_views = ('welcome', 'highscore', 'question', 'questions')
def __init__(self, screen_id, view):
assert view in self._views
super().__init__(screen_id=screen_id, view=view)
class ShowQuestionEvent(Event):
name = 'show_question'
def __init__(self, screen_id, question_id, team_id, answer_id):
super().__init__(
screen_id=screen_id,
view='question',
question_id=question_id,
team_id=team_id,
answer_id=answer_id
)
class AttachTeamEvent(Event):
name = 'attach_team'
def __init__(self, screen_id, team_id):
super().__init__(
screen_id=screen_id,
view='question',
team_id=team_id,
)
class SelectAnswerEvent(Event):
name = 'select_answer'
def __init__(self, screen_id, answer_id):
super().__init__(
screen_id=screen_id,
view='question',
answer_id=answer_id,
)
class VeryfiAnswerEvent(Event):
name = 'veryfi_answer'
def __init__(self, screen_id, question_id, team_id, answer_id, game_answer_id):
super().__init__(
screen_id=screen_id,
view='question',
question_id=question_id,
answer_id=answer_id,
team_id=team_id,
game_answer_id=game_answer_id,
)
| [
"d.dlugajczyk@clearcode.cc"
] | d.dlugajczyk@clearcode.cc |
786381c19e3ac9f1748404798c53e1b36386ee54 | 65c8a6a7af2ee8cdf3866d012ea814887bd68a26 | /ppro360_automation/Ppro360/CoachingAndTriadCoaching_Pages/GoalSettingandNotesForm.py | 8b48f68d9c71cdb51a156bdbf127b429440669d4 | [] | no_license | 1282270620/automation_test | 9b3c595c3f7a139ded0a638ae4bcf31e0b7f9686 | 3faf86f0d641089eaf27eba906d22157dd2c1f5d | refs/heads/master | 2020-04-01T06:35:33.873989 | 2018-10-21T03:05:17 | 2018-10-21T03:05:17 | 152,954,477 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,123 | py | '''
Created on 20170703
@author: lei.tan
'''
from selenium.webdriver.common.by import By
from Tablet_pages import BasePage
class GoalSettingandNotesForm(BasePage.Action):
def __init__(self):
self.callRecordingNumber_loc=(By.XPATH,"//*[@id='container']/div/section/div/form/div/div[3]/div[2]/div/div/input")
self.KPIcheckbox_path="//*[@id='container']/div/section/div/form/div[2]/div[1]/div/table/tbody/tr[4]/td[%d]/i"
self.commentsinput_path="//*[@id='container']/div/section/div/form/div[2]/div[3]/div/table/tbody/tr[%d]/td/textarea"
def click_KPIcheckbox (self, checkboxorderindex):
self.KPIcheckbox_loc=(By.XPATH,self.KPIcheckbox_path %checkboxorderindex)
self.find_element(*self.KPIcheckbox_loc).click()
def input_callRecordingNumber (self,text):
self.find_element(*self.callRecordingNumber_loc).send_keys(text);
def input_commentsinput (self,text,lineindex):
self.commentsinput_loc=(By.XPATH,self.commentsinput_path %lineindex)
self.find_element(*self.commentsinput_loc).send_keys(text); | [
"1282270620@qq.com"
] | 1282270620@qq.com |
c8dbaa1c2f5647253e3c3ab032c30dfed6d6b97a | 9743d5fd24822f79c156ad112229e25adb9ed6f6 | /xai/brain/wordbase/adjectives/_collaborative.py | d1a3b8e956f1707aae7d0b8e2c6db302aa7bf14b | [
"MIT"
] | permissive | cash2one/xai | de7adad1758f50dd6786bf0111e71a903f039b64 | e76f12c9f4dcf3ac1c7c08b0cc8844c0b0a104b6 | refs/heads/master | 2021-01-19T12:33:54.964379 | 2017-01-28T02:00:50 | 2017-01-28T02:00:50 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 441 | py |
#calss header
class _COLLABORATIVE():
def __init__(self,):
self.name = "COLLABORATIVE"
self.definitions = [u'involving two or more people working together for a special purpose: ']
self.parents = []
self.childen = []
self.properties = []
self.jsondata = {}
self.specie = 'adjectives'
def run(self, obj1, obj2):
self.jsondata[obj2] = {}
self.jsondata[obj2]['properties'] = self.name.lower()
return self.jsondata
| [
"xingwang1991@gmail.com"
] | xingwang1991@gmail.com |
5f373d64ed1ef5aa6fd75dcd19e8c78dffc2d86c | c33968b06f072ae36849e6e61a7e7ce3d6ae364b | /setup.py | 5fdc74fde120ab304fd3e5586df19fea92a2ae57 | [] | no_license | talkara/abita.locales | 051bb200bf81a66515cbdad61d3bb76ac44665f7 | b4135e30a9f6c703999905801f388ae8ee91e2a6 | refs/heads/master | 2021-05-27T05:01:08.192155 | 2013-05-13T10:19:36 | 2013-05-13T10:19:36 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 904 | py | from setuptools import find_packages
from setuptools import setup
setup(
name='abita.locales',
version='0.2.1',
description="Overrides default translations of Plone for ABITA site.",
long_description=open("README.rst").read(),
classifiers=[
"Framework :: Plone",
"Framework :: Plone :: 4.2",
"Programming Language :: Python",
"Programming Language :: Python :: 2.7"],
keywords='',
author='Taito Horiuchi',
author_email='taito.horiuchi@abita.fi',
url='https://github.com/taito/abita.locales',
license='None-free',
packages=find_packages(exclude=['ez_setup']),
namespace_packages=['abita'],
include_package_data=True,
zip_safe=False,
install_requires=[
'Products.CMFPlone',
'setuptools'],
entry_points="""
# -*- Entry points: -*-
[z3c.autoinclude.plugin]
target = plone
""")
| [
"taito.horiuchi@gmail.com"
] | taito.horiuchi@gmail.com |
f3a6bbd121b4706726205070aa94817f0637d4bd | ae02e46f8bbe7a8db4a02f6e1b0523a6bb03e5d0 | /wtq/wtq/items.py | faaf346da58460e2516c1ed3fe86c297bedede8e | [
"Apache-2.0"
] | permissive | wangtianqi1993/ScrapyProject | d0cb0a2f86b4f5930067cfefed67efe0c1dc8422 | 4b7b7d1c683bc412d70d8d15be36bcc71967b491 | refs/heads/master | 2020-07-14T11:10:33.746789 | 2016-09-16T08:53:46 | 2016-09-16T08:53:46 | 67,754,677 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 366 | py | # -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
from scrapy.item import Field
class WtqItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = Field()
description = Field()
url = Field()
| [
"1906272972@qq.com"
] | 1906272972@qq.com |
59107bc428d0d9a5dc51a319b1fba875b846ca4e | cfdc0187ca770c09fa7a5868caedd1b5de0c668f | /pythoncollections/listprograms/binarysearch.py | 7bd76665a2bbf1120255c658e143462f24c07f7c | [] | no_license | nelvinpoulose999/Pythonfiles | 41ef15c9e3423ef5c8c121db7c6196772c40aa27 | 1e2129b1e1fb2a55100622fc83822726c7836224 | refs/heads/master | 2023-03-13T22:24:38.049100 | 2021-03-04T07:12:14 | 2021-03-04T07:12:14 | 333,663,557 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 464 | py | # Binary search
arr=[12,50,8,25,60,30,31]
element=int(input('enter the element'))
flag=0
arr.sort()
print(arr)
length=len(arr)
print(length)
lowl=0
uppl=len(arr)-1
print(uppl)
while (lowl<=uppl):
mid=(lowl+uppl)//2
#print(arr[mid])
if(element>arr[mid]):
lowl=mid+1
elif(element<arr[mid]):
uppl=mid-1
elif(element==arr[mid]):
flag=1
break
if(flag==1):
print('element found',arr.index(element))
else:
print('not found') | [
"nelvinpoulose999@gmail.com"
] | nelvinpoulose999@gmail.com |
0fc4bbc3e8df61b80d6405cd5eb5077ec4cbbbfa | 34a478381cdf89e636315d5f4d620eeabe712b00 | /venv/lib/python3.6/site-packages/future/types/newstr.py | e01b957c1a26ef1c993c6eff4892ab0c668b25e7 | [] | no_license | 21fernando/Pygames | 67e03e9d62c64b55ea24d6b0f4a2a7b333247011 | 10bf1519012a8ed3e08dda0d23c9187c44e58c13 | refs/heads/master | 2021-01-05T07:00:17.165831 | 2020-06-01T13:42:05 | 2020-06-01T13:42:05 | 240,922,333 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 15,784 | py | """
This module redefines ``str`` on Python 2.x to be a subclass of the Py2
``unicode`` type that behaves like the Python 3.x ``str``.
The main differences between ``newstr`` and Python 2.x's ``unicode`` type are
the stricter type-checking and absence of a `u''` prefix in the representation.
It is designed to be used together with the ``unicode_literals`` import
as follows:
>>> from __future__ import unicode_literals
>>> from builtins import str, isinstance
On Python 3.x and normally on Python 2.x, these expressions hold
>>> str('blah') is 'blah'
True
>>> isinstance('blah', str)
True
However, on Python 2.x, with this import:
>>> from __future__ import unicode_literals
the same expressions are False:
>>> str('blah') is 'blah'
False
>>> isinstance('blah', str)
False
This module is designed to be imported together with ``unicode_literals`` on
Python 2 to bring the meaning of ``str`` back into alignment with unprefixed
string literals (i.e. ``unicode`` subclasses).
Note that ``str()`` (and ``print()``) would then normally call the
``__unicode__`` method on objects in Python 2. To define string
representations of your objects portably across Py3 and Py2, use the
:func:`python_2_unicode_compatible` decorator in :mod:`future.utils`.
"""
from numbers import Number
from future.utils import PY3, istext, with_metaclass, isnewbytes
from future.types import no, issubset
from future.types.newobject import newobject
if PY3:
# We'll probably never use newstr on Py3 anyway...
unicode = str
from collections.abc import Iterable
else:
from collections import Iterable
class BaseNewStr(type):
def __instancecheck__(cls, instance):
if cls == newstr:
return isinstance(instance, unicode)
else:
return issubclass(instance.__class__, cls)
class newstr(with_metaclass(BaseNewStr, unicode)):
"""
A backport of the Python 3 str object to Py2
"""
no_convert_msg = "Can't convert '{0}' object to str implicitly"
def __new__(cls, *args, **kwargs):
"""
From the Py3 str docstring:
str(object='') -> str
str(bytes_or_buffer[, encoding[, errors]]) -> str
Create a new string object from the given object. If encoding or
errors is specified, then the object must expose a data buffer
that will be decoded using the given encoding and error handler.
Otherwise, returns the result of object.__str__() (if defined)
or repr(object).
encoding defaults to sys.getdefaultencoding().
errors defaults to 'strict'.
"""
if len(args) == 0:
return super(newstr, cls).__new__(cls)
# Special case: If someone requests str(str(u'abc')), return the same
# object (same id) for consistency with Py3.3. This is not true for
# other objects like list or dict.
elif type(args[0]) == newstr and cls == newstr:
return args[0]
elif isinstance(args[0], unicode):
value = args[0]
elif isinstance(args[0], bytes): # i.e. Py2 bytes or newbytes
if 'encoding' in kwargs or len(args) > 1:
value = args[0].decode(*args[1:], **kwargs)
else:
value = args[0].__str__()
else:
value = args[0]
return super(newstr, cls).__new__(cls, value)
def __repr__(self):
"""
Without the u prefix
"""
value = super(newstr, self).__repr__()
# assert value[0] == u'u'
return value[1:]
def __getitem__(self, y):
"""
Warning: Python <= 2.7.6 has a bug that causes this method never to be called
when y is a slice object. Therefore the type of newstr()[:2] is wrong
(unicode instead of newstr).
"""
return newstr(super(newstr, self).__getitem__(y))
def __contains__(self, key):
errmsg = "'in <string>' requires string as left operand, not {0}"
# Don't use isinstance() here because we only want to catch
# newstr, not Python 2 unicode:
if type(key) == newstr:
newkey = key
elif isinstance(key, unicode) or isinstance(key, bytes) and not isnewbytes(key):
newkey = newstr(key)
else:
raise TypeError(errmsg.format(type(key)))
return issubset(list(newkey), list(self))
@no('newbytes')
def __add__(self, other):
return newstr(super(newstr, self).__add__(other))
@no('newbytes')
def __radd__(self, left):
" left + self "
try:
return newstr(left) + self
except:
return NotImplemented
def __mul__(self, other):
return newstr(super(newstr, self).__mul__(other))
def __rmul__(self, other):
return newstr(super(newstr, self).__rmul__(other))
def join(self, iterable):
errmsg = 'sequence item {0}: expected unicode string, found bytes'
for i, item in enumerate(iterable):
# Here we use type() rather than isinstance() because
# __instancecheck__ is being overridden. E.g.
# isinstance(b'abc', newbytes) is True on Py2.
if isnewbytes(item):
raise TypeError(errmsg.format(i))
# Support use as a staticmethod: str.join('-', ['a', 'b'])
if type(self) == newstr:
return newstr(super(newstr, self).join(iterable))
else:
return newstr(super(newstr, newstr(self)).join(iterable))
@no('newbytes')
def find(self, sub, *args):
return super(newstr, self).find(sub, *args)
@no('newbytes')
def rfind(self, sub, *args):
return super(newstr, self).rfind(sub, *args)
@no('newbytes', (1, 2))
def replace(self, old, new, *args):
return newstr(super(newstr, self).replace(old, new, *args))
def decode(self, *args):
raise AttributeError("decode method has been disabled in newstr")
def encode(self, encoding='utf-8', errors='strict'):
"""
Returns bytes
Encode S using the codec registered for encoding. Default encoding
is 'utf-8'. errors may be given to set a different error
handling scheme. Default is 'strict' meaning that encoding errors raise
a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
'xmlcharrefreplace' as well as any other name registered with
codecs.register_error that can handle UnicodeEncodeErrors.
"""
from future.types.newbytes import newbytes
# Py2 unicode.encode() takes encoding and errors as optional parameter,
# not keyword arguments as in Python 3 str.
# For the surrogateescape error handling mechanism, the
# codecs.register_error() function seems to be inadequate for an
# implementation of it when encoding. (Decoding seems fine, however.)
# For example, in the case of
# u'\udcc3'.encode('ascii', 'surrogateescape_handler')
# after registering the ``surrogateescape_handler`` function in
# future.utils.surrogateescape, both Python 2.x and 3.x raise an
# exception anyway after the function is called because the unicode
# string it has to return isn't encodable strictly as ASCII.
if errors == 'surrogateescape':
if encoding == 'utf-16':
# Known to fail here. See test_encoding_works_normally()
raise NotImplementedError('FIXME: surrogateescape handling is '
'not yet implemented properly')
# Encode char by char, building up list of byte-strings
mybytes = []
for c in self:
code = ord(c)
if 0xD800 <= code <= 0xDCFF:
mybytes.append(newbytes([code - 0xDC00]))
else:
mybytes.append(c.encode(encoding=encoding))
return newbytes(b'').join(mybytes)
return newbytes(super(newstr, self).encode(encoding, errors))
@no('newbytes', 1)
def startswith(self, prefix, *args):
if isinstance(prefix, Iterable):
for thing in prefix:
if isnewbytes(thing):
raise TypeError(self.no_convert_msg.format(type(thing)))
return super(newstr, self).startswith(prefix, *args)
@no('newbytes', 1)
def endswith(self, prefix, *args):
# Note we need the decorator above as well as the isnewbytes()
# check because prefix can be either a bytes object or e.g. a
# tuple of possible prefixes. (If it's a bytes object, each item
# in it is an int.)
if isinstance(prefix, Iterable):
for thing in prefix:
if isnewbytes(thing):
raise TypeError(self.no_convert_msg.format(type(thing)))
return super(newstr, self).endswith(prefix, *args)
@no('newbytes', 1)
def split(self, sep=None, maxsplit=-1):
# Py2 unicode.split() takes maxsplit as an optional parameter,
# not as a keyword argument as in Python 3 str.
parts = super(newstr, self).split(sep, maxsplit)
return [newstr(part) for part in parts]
@no('newbytes', 1)
def rsplit(self, sep=None, maxsplit=-1):
# Py2 unicode.rsplit() takes maxsplit as an optional parameter,
# not as a keyword argument as in Python 3 str.
parts = super(newstr, self).rsplit(sep, maxsplit)
return [newstr(part) for part in parts]
@no('newbytes', 1)
def partition(self, sep):
parts = super(newstr, self).partition(sep)
return tuple(newstr(part) for part in parts)
@no('newbytes', 1)
def rpartition(self, sep):
parts = super(newstr, self).rpartition(sep)
return tuple(newstr(part) for part in parts)
@no('newbytes', 1)
def index(self, sub, *args):
"""
Like newstr.find() but raise ValueError when the substring is not
found.
"""
pos = self.find(sub, *args)
if pos == -1:
raise ValueError('substring not found')
return pos
def splitlines(self, keepends=False):
"""
S.splitlines(keepends=False) -> list of strings
Return a list of the lines in S, breaking at line boundaries.
Line breaks are not included in the resulting list unless keepends
is given and true.
"""
# Py2 unicode.splitlines() takes keepends as an optional parameter,
# not as a keyword argument as in Python 3 str.
parts = super(newstr, self).splitlines(keepends)
return [newstr(part) for part in parts]
def __eq__(self, other):
if (isinstance(other, unicode) or
isinstance(other, bytes) and not isnewbytes(other)):
return super(newstr, self).__eq__(other)
else:
return NotImplemented
def __hash__(self):
if (isinstance(self, unicode) or
isinstance(self, bytes) and not isnewbytes(self)):
return super(newstr, self).__hash__()
else:
raise NotImplementedError()
def __ne__(self, other):
if (isinstance(other, unicode) or
isinstance(other, bytes) and not isnewbytes(other)):
return super(newstr, self).__ne__(other)
else:
return True
unorderable_err = 'unorderable types: str() and {0}'
def __lt__(self, other):
if (isinstance(other, unicode) or
isinstance(other, bytes) and not isnewbytes(other)):
return super(newstr, self).__lt__(other)
raise TypeError(self.unorderable_err.format(type(other)))
def __le__(self, other):
if (isinstance(other, unicode) or
isinstance(other, bytes) and not isnewbytes(other)):
return super(newstr, self).__le__(other)
raise TypeError(self.unorderable_err.format(type(other)))
def __gt__(self, other):
if (isinstance(other, unicode) or
isinstance(other, bytes) and not isnewbytes(other)):
return super(newstr, self).__gt__(other)
raise TypeError(self.unorderable_err.format(type(other)))
def __ge__(self, other):
if (isinstance(other, unicode) or
isinstance(other, bytes) and not isnewbytes(other)):
return super(newstr, self).__ge__(other)
raise TypeError(self.unorderable_err.format(type(other)))
def __getattribute__(self, name):
"""
A trick to cause the ``hasattr`` builtin-fn to return False for
the 'decode' method on Py2.
"""
if name in ['decode', u'decode']:
raise AttributeError("decode method has been disabled in newstr")
return super(newstr, self).__getattribute__(name)
def __native__(self):
"""
A hook for the future.utils.native() function.
"""
return unicode(self)
@staticmethod
def maketrans(x, y=None, z=None):
"""
Return a translation table usable for str.translate().
If there is only one argument, it must be a dictionary mapping Unicode
ordinals (integers) or characters to Unicode ordinals, strings or None.
Character keys will be then converted to ordinals.
If there are two arguments, they must be strings of equal length, and
in the resulting dictionary, each character in x will be mapped to the
character at the same position in y. If there is a third argument, it
must be a string, whose characters will be mapped to None in the result.
"""
if y is None:
assert z is None
if not isinstance(x, dict):
raise TypeError('if you give only one argument to maketrans it must be a dict')
result = {}
for (key, value) in x.items():
if len(key) > 1:
raise ValueError('keys in translate table must be strings or integers')
result[ord(key)] = value
else:
if not isinstance(x, unicode) and isinstance(y, unicode):
raise TypeError('x and y must be unicode strings')
if not len(x) == len(y):
raise ValueError('the first two maketrans arguments must have equal length')
result = {}
for (xi, yi) in zip(x, y):
if len(xi) > 1:
raise ValueError('keys in translate table must be strings or integers')
result[ord(xi)] = ord(yi)
if z is not None:
for char in z:
result[ord(char)] = None
return result
def translate(self, table):
"""
S.translate(table) -> str
Return a copy of the string S, where all characters have been mapped
through the given translation table, which must be a mapping of
Unicode ordinals to Unicode ordinals, strings, or None.
Unmapped characters are left untouched. Characters mapped to None
are deleted.
"""
l = []
for c in self:
if ord(c) in table:
val = table[ord(c)]
if val is None:
continue
elif isinstance(val, unicode):
l.append(val)
else:
l.append(chr(val))
else:
l.append(c)
return ''.join(l)
def isprintable(self):
raise NotImplementedError('fixme')
def isidentifier(self):
raise NotImplementedError('fixme')
def format_map(self):
raise NotImplementedError('fixme')
__all__ = ['newstr']
| [
"tharindu.fernando@terathought.com"
] | tharindu.fernando@terathought.com |
35b37da4a41cd4e5cae2d72380c4ee7bcf1cb6c3 | bcb4c127578d2874ce445e021bf276ff07d6fa70 | /476.number-complement.py | 6faf920375a12022c3628e2e374cc57b3bd0135b | [] | no_license | SilverMaple/LeetCode | 3f9a4ef95cbaaed3238ad1dd41b6e6182c64575c | 581486a1e08dbceddcb64da4f6c4ed6c73ed5e84 | refs/heads/master | 2020-07-26T06:37:08.897447 | 2020-03-31T14:55:18 | 2020-03-31T14:55:18 | 208,566,047 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 400 | py | #
# @lc app=leetcode id=476 lang=python
#
# [476] Number Complement
#
# @lc code=start
class Solution(object):
def findComplement(self, num):
"""
:type num: int
:rtype: int
"""
if num == 0:
return 1
mask = 1<<30
while num&mask == 0:
mask >>= 1
mask = (mask<<1) - 1
return num ^ mask
# @lc code=end
| [
"1093387079@qq.com"
] | 1093387079@qq.com |
9d96fadf5961ab0e99b70dc45911f05a86b5c463 | f42c91f5fa040c739ab6bc1803f3253561f670fd | /mongodb/pymongo_page.py | 073513604cb6653301062657c400ed3be9b35c45 | [] | no_license | hackrole/daily-python | 11f29c698464172118ae30d7e5920692a63c3d8e | 2f1fb3b9646fa1c7131df6e336b6afd38128fbbd | refs/heads/master | 2022-10-16T08:06:14.067055 | 2022-09-19T13:35:17 | 2022-09-19T13:35:17 | 9,448,934 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,339 | py | #!/usr/bin/env python
#coding=utf8
"""
使用pymongo实现的分页程序, 不使用skip,limit实现。
通过比较id来实现
"""
import unittest
from pymongo.connection import MongoClient
def init_connect(dbname="test", collection="page", host="localhost", port=27017):
""" init the mongodb connection """
conn = MongoClient(host, port)
coll = conn[dbname][collection]
return conn, coll
def page(cur_id, old_page, new_page):
"""
分页主程
cur_id: 当前页的第一元素id.
old_page: 当前页数
new_page: 请求的新页数
"""
# TODO: the first request without cur_id handle
conn, coll = init_connect()
page_size = 20
page_skip_limit = 8
N = abs(old_page - new_page)
if N >= page_skip_limit:
raise Exception("not allow page skip more than %s" % page_skip_limit)
if old_page > new_page: # go N page before
data = coll.find({'_id': {'$lt': cur_id}}).skip(N * page_size).limit(page_size).sort({'_id': 1})
else:
data = coll.find({'_id': {'$gt': cur_id}}).skip((N-1) * page_size).limit(page_size).sort({'_id': 1})
return data
class PageTest(unittest.TestCase):
def init_db_for_test(self):
pass
def setUp(self):
pass
def test_page():
pass
if __name__ == "main":
unittest.main()
| [
"daipeng123456@gmail.com"
] | daipeng123456@gmail.com |
b82d8815d2881d84d7c9ed9d1df9ecbc36139998 | 25040bd4e02ff9e4fbafffee0c6df158a62f0d31 | /www/htdocs/wt/lapnw/data/item_32_3.tmpl.py | fc25344506c03475ee3a5f02879f2ed019e7c021 | [] | no_license | erochest/atlas | 107a14e715a058d7add1b45922b0f8d03bd2afef | ea66b80c449e5b1141e5eddc4a5995d27c2a94ee | refs/heads/master | 2021-05-16T00:45:47.585627 | 2017-10-09T10:12:03 | 2017-10-09T10:12:03 | 104,338,364 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 192 | py |
from lap.web.templates import GlobalTemplate, SubtemplateCode
class main(GlobalTemplate):
title = 'Page.Item: 32.3'
project = 'lapnw'
class page(SubtemplateCode):
pass
| [
"eric@eric-desktop"
] | eric@eric-desktop |
e83d7beec0fdb6a3185731cf8ce3b1b1dd178705 | ae7627dc5e6ef7e9f8db9d825a6bc097da5b34de | /python assignment ii/question_no_9.py | a029afae4c12501240f18af005dfc09016529a72 | [] | no_license | atulzh7/IW-Academy-Python-Assignment | cc5c8a377031097aff5ef62b209cb31f63241505 | 674d312b1438301865c840257686edf60fdb3a69 | refs/heads/master | 2022-11-14T13:26:16.747544 | 2020-07-12T16:06:08 | 2020-07-12T16:06:08 | 283,823,502 | 0 | 1 | null | 2020-07-30T16:24:30 | 2020-07-30T16:24:29 | null | UTF-8 | Python | false | false | 717 | py | """Binary search function
"""
def binary_search(sequence, item):
#initialization yo avoid garbage value in variable
high = len(sequence) - 1
low = 0
mid = 0
while low <= high:
mid = (high + low) // 2
if arr[mid] < item:
low = mid + 1
elif arr[mid] > item:
high = mid - 1
else:
return mid
else:
return -1
# Sample test array
arr = [ 2, 3, 4, 10, 40 ]
user_input = int(input("Enter an integer value to see if it exits: "))
result = binary_search(arr, user_input)
if result != -1:
print("Element is present at index", str(result))
else:
print("Element is not present in array") | [
"="
] | = |
306a7721152e9eb6b28e662d6568fd7fc185c704 | 6bf336bc8d6ba061e0c707bdd8595368dee4d27b | /tutorials/10_days_of_statistics/poisson_distribution_i.py | 37fcfd7a6e1dc201e075a552306733d0ecbb4876 | [
"MIT"
] | permissive | avenet/hackerrank | aa536214dbccf5a822a30ea226e1dbaac9afb243 | e522030a023af4ff50d5fc64bd3eba30144e006c | refs/heads/master | 2021-01-01T20:15:06.647873 | 2017-11-24T23:59:19 | 2017-11-24T23:59:19 | 98,801,566 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 649 | py | from functools import reduce
from operator import mul
E = 2.71828
def poisson_distribution(t, k):
success_probability = t ** k
distribution_part = 1.0 / (E ** t)
successes_combination = fact(k)
return (
(
success_probability * distribution_part
) / successes_combination
)
def fact(number):
if number == 0:
return 1
return reduce(
mul,
range(1, number + 1)
)
mean = float(input())
random_variable_value = int(input())
print(
round(
poisson_distribution(
mean,
random_variable_value
),
3
)
)
| [
"andy.venet@gmail.com"
] | andy.venet@gmail.com |
779800db5ae2e1b5a46733002a5c11421a4457bb | 53955a979f974d0cc5d06f0c4fe2b4acfa4320e7 | /backend/home/migrations/0001_load_initial_data.py | c6f3d8fbdf45556f2f65de532a41a0e3b22821a6 | [] | no_license | crowdbotics-apps/late-truth-26783 | 0b3b0011a619ff2a8bdfcf640d0e26b19bf3b187 | a9a26ec5a18ba45634a9541a08a5c5f5572a2515 | refs/heads/master | 2023-04-26T16:43:25.439730 | 2021-05-17T08:13:32 | 2021-05-17T08:13:32 | 368,106,844 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 538 | py | from django.db import migrations
def create_site(apps, schema_editor):
Site = apps.get_model("sites", "Site")
custom_domain = "late-truth-26783.botics.co"
site_params = {
"name": "Late Truth",
}
if custom_domain:
site_params["domain"] = custom_domain
Site.objects.update_or_create(defaults=site_params, id=1)
class Migration(migrations.Migration):
dependencies = [
("sites", "0002_alter_domain_unique"),
]
operations = [
migrations.RunPython(create_site),
]
| [
"team@crowdbotics.com"
] | team@crowdbotics.com |
06df6ae711be16094a2119dad9e994a87ba43a11 | ec7fca4065a12bada3fdf9e92fc7c52ae9cddc83 | /setup.py | 8fa2b083f93c92d20535997bf324642bd9783890 | [
"MIT"
] | permissive | SLongofono/sneakysnek | c67d913801ad3c0bb320c8fca0ad645faf56eb2d | 3001e83755da6337f42e3136cb5e29d098800ddf | refs/heads/master | 2021-09-05T15:40:56.030291 | 2018-01-29T10:45:07 | 2018-01-29T10:45:07 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,324 | py | #!/usr/bin/env python
from setuptools import setup
try:
import pypandoc
long_description = pypandoc.convert('README.md', 'rst')
except(IOError, ImportError):
long_description = ""
packages = [
"sneakysnek",
"sneakysnek.recorders"
]
requires = []
extras_require = {
":sys_platform == 'darwin'": ["pyobjc-framework-Quartz"],
":'linux' in sys_platform": ["python-xlib"]
}
setup(
name='sneakysnek',
version="0.1.0",
description="Dead simple cross-platform keyboard & mouse global input capture solution for Python 3.6+",
long_description=long_description,
author="Nicholas Brochu",
author_email='nicholas@serpent.ai',
packages=packages,
include_package_data=True,
install_requires=requires,
extras_require=extras_require,
entry_points={
'console_scripts': ['sneakysnek = sneakysnek.recorder:demo']
},
license='MIT',
url='https://github.com/SerpentAI/sneakysnek',
zip_safe=False,
classifiers=[
'Development Status :: 5 - Production/Stable',
'Intended Audience :: Developers',
'Natural Language :: English',
'License :: OSI Approved :: MIT License',
'Operating System :: OS Independent',
'Programming Language :: Python',
'Programming Language :: Python :: 3.6'
]
)
| [
"info@nicholasbrochu.com"
] | info@nicholasbrochu.com |
2e6c44452b9a4d23c7de2e2283bec77b1394bc6e | 10e5b1b2e42a2ff6ec998ed900071e8b5da2e74e | /design/1381_design_a_stack_with_increment_operation/1381_design_a_stack_with_increment_operation.py | 616a72f862d666343aeae68684a63a2efdd8e0c2 | [] | no_license | zdyxry/LeetCode | 1f71092d687316de1901156b74fbc03588f0b0a5 | b149d1e8a83b0dfc724bd9dc129a1cad407dd91f | refs/heads/master | 2023-01-29T11:59:14.162531 | 2023-01-26T03:20:23 | 2023-01-26T03:20:23 | 178,754,208 | 6 | 4 | null | null | null | null | UTF-8 | Python | false | false | 549 | py |
class CostomStack(object):
def __init__(self, maxSize):
self.n = maxSize
self.stack = []
self.inc = []
def push(self, x):
if len(self.inc) < self.n:
self.stack.append(x)
self.inc.append(0)
def pop(self):
if not self.inc:
return -1
if len(self.inc) > 1:
self.inc[-2] += self.inc[-1]
return self.stack.pop() + self.inc.pop()
def increment(self, k, val):
if self.inc:
self.inc[min(k, len(self.inc))-1] += val | [
"zdyxry@gmail.com"
] | zdyxry@gmail.com |
248014df533f845174e5ea4d9eb271296a649d61 | 9feac0e0cc68891707772d5b557a44e87377dec5 | /fuzzers/071-ps8-bufg/generate_permutations.py | 58442f658c90c606f0ec59287e1638a22d31b1ea | [
"LicenseRef-scancode-dco-1.1",
"ISC"
] | permissive | daveshah1/prjuray | 8213030dd83f69b0caba488d4154d006a08c648b | 02b31b5d7c19f66f50b3a28218921433df8a9af8 | refs/heads/master | 2022-11-26T14:50:46.500424 | 2020-07-17T23:23:39 | 2020-07-17T23:23:39 | 280,824,403 | 2 | 0 | ISC | 2020-07-19T08:32:10 | 2020-07-19T08:32:10 | null | UTF-8 | Python | false | false | 2,600 | py | #!/usr/bin/env python3
# -*- coding: utf-8 -*-
#
# Copyright (C) 2020 The Project U-Ray Authors.
#
# Use of this source code is governed by a ISC-style
# license that can be found in the LICENSE file or at
# https://opensource.org/licenses/ISC
#
# SPDX-License-Identifier: ISC
import csv
from utils.clock_utils import MAX_GLOBAL_CLOCKS
import random
def output_iteration(tile, bufg_inputs, bufg_outputs):
""" Output 1 iteration of BUFG_PS inputs -> BUFG_PS outputs.
This function generates a set of permutations of 1-18 BUFG input pins to
one of the 24 BUFG_PS output pins. Each iteration ensures that each input
reachs each of the outputs.
Only 1 iteration of this function is required to ensure that all available
inputs reach all available outputs, but this function does not ensure
uncorrelated solutions. More iterations increase the change of an
uncorrelated solution.
"""
inputs_to_sinks = {}
for idx, _ in enumerate(bufg_inputs):
inputs_to_sinks[idx] = sorted(bufg_outputs)
random.shuffle(inputs_to_sinks[idx])
while True:
outputs = {}
inputs = sorted(inputs_to_sinks.keys())
random.shuffle(inputs)
for idx in inputs:
for output in inputs_to_sinks[idx]:
if output not in outputs:
outputs[output] = idx
break
if output in outputs and outputs[output] == idx:
inputs_to_sinks[idx].remove(output)
if len(outputs) == 0:
break
output_str = ["" for _ in bufg_outputs]
for output in outputs:
output_str[output] = str(outputs[output])
print('{},{}'.format(tile, ','.join(output_str)))
def main():
random.seed(0)
bufg_inputs_to_tiles = {}
with open('ps8_bufg_pin_map.csv') as f:
for row in csv.DictReader(f):
clock_tiles = row['clock_tiles'].split(' ')
assert len(clock_tiles) == 1, (row['pin'], clock_tiles)
tile = clock_tiles[0]
if tile not in bufg_inputs_to_tiles:
bufg_inputs_to_tiles[tile] = []
bufg_inputs_to_tiles[tile].append(row['pin'].split('/')[0])
bufg_outputs = list(range(MAX_GLOBAL_CLOCKS))
print('tile,{}'.format(','.join(
'bufg{}_input'.format(output) for output in bufg_outputs)))
NUM_ITERATIONS = 3
for _ in range(NUM_ITERATIONS):
for tile in bufg_inputs_to_tiles:
output_iteration(tile, bufg_inputs_to_tiles[tile], bufg_outputs)
if __name__ == "__main__":
main()
| [
"537074+litghost@users.noreply.github.com"
] | 537074+litghost@users.noreply.github.com |
bc2368589f35d8fc2648dca4462a81428cd140ee | 5a52ccea88f90dd4f1acc2819997fce0dd5ffb7d | /alipay/aop/api/domain/ProdResource.py | d6f8dde13be2bb3de55e548a2e06cf35597c36d8 | [
"Apache-2.0"
] | permissive | alipay/alipay-sdk-python-all | 8bd20882852ffeb70a6e929038bf88ff1d1eff1c | 1fad300587c9e7e099747305ba9077d4cd7afde9 | refs/heads/master | 2023-08-27T21:35:01.778771 | 2023-08-23T07:12:26 | 2023-08-23T07:12:26 | 133,338,689 | 247 | 70 | Apache-2.0 | 2023-04-25T04:54:02 | 2018-05-14T09:40:54 | Python | UTF-8 | Python | false | false | 2,018 | py | #!/usr/bin/env python
# -*- coding: utf-8 -*-
import json
from alipay.aop.api.constant.ParamConstants import *
class ProdResource(object):
def __init__(self):
self._key = None
self._name = None
self._type = None
self._value = None
@property
def key(self):
return self._key
@key.setter
def key(self, value):
self._key = value
@property
def name(self):
return self._name
@name.setter
def name(self, value):
self._name = value
@property
def type(self):
return self._type
@type.setter
def type(self, value):
self._type = value
@property
def value(self):
return self._value
@value.setter
def value(self, value):
self._value = value
def to_alipay_dict(self):
params = dict()
if self.key:
if hasattr(self.key, 'to_alipay_dict'):
params['key'] = self.key.to_alipay_dict()
else:
params['key'] = self.key
if self.name:
if hasattr(self.name, 'to_alipay_dict'):
params['name'] = self.name.to_alipay_dict()
else:
params['name'] = self.name
if self.type:
if hasattr(self.type, 'to_alipay_dict'):
params['type'] = self.type.to_alipay_dict()
else:
params['type'] = self.type
if self.value:
if hasattr(self.value, 'to_alipay_dict'):
params['value'] = self.value.to_alipay_dict()
else:
params['value'] = self.value
return params
@staticmethod
def from_alipay_dict(d):
if not d:
return None
o = ProdResource()
if 'key' in d:
o.key = d['key']
if 'name' in d:
o.name = d['name']
if 'type' in d:
o.type = d['type']
if 'value' in d:
o.value = d['value']
return o
| [
"liuqun.lq@alibaba-inc.com"
] | liuqun.lq@alibaba-inc.com |
34880cf8e8a7fb475fbacb1cb45b653e69cd3101 | c44d1735c21164bb9facc7eac1412a41295130a9 | /raven/contrib/flask.py | 93e2f5420d4af502ba410fe44bd2dfd46ad0b6ba | [
"BSD-3-Clause"
] | permissive | joshma/raven-python | 082b237b73e5f8f825fe013b6fdc3144055bfeec | 9f02875b6bf120c28c455547d6f7b2618ffbf070 | refs/heads/master | 2021-01-22T13:17:16.202650 | 2013-12-13T01:48:55 | 2013-12-13T01:48:55 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 6,569 | py | """
raven.contrib.flask
~~~~~~~~~~~~~~~~~~~
:copyright: (c) 2010-2012 by the Sentry Team, see AUTHORS for more details.
:license: BSD, see LICENSE for more details.
"""
from __future__ import absolute_import
try:
from flask_login import current_user
except ImportError:
has_flask_login = False
else:
has_flask_login = True
import sys
import os
import logging
from flask import request
from flask.signals import got_request_exception
from raven.conf import setup_logging
from raven.base import Client
from raven.middleware import Sentry as SentryMiddleware
from raven.handlers.logging import SentryHandler
from raven.utils.compat import _urlparse
from raven.utils.wsgi import get_headers, get_environ
from werkzeug.exceptions import ClientDisconnected
def make_client(client_cls, app, dsn=None):
return client_cls(
dsn=dsn or app.config.get('SENTRY_DSN') or os.environ.get('SENTRY_DSN'),
include_paths=set(app.config.get('SENTRY_INCLUDE_PATHS', [])) | set([app.import_name]),
exclude_paths=app.config.get('SENTRY_EXCLUDE_PATHS'),
servers=app.config.get('SENTRY_SERVERS'),
name=app.config.get('SENTRY_NAME'),
public_key=app.config.get('SENTRY_PUBLIC_KEY'),
secret_key=app.config.get('SENTRY_SECRET_KEY'),
project=app.config.get('SENTRY_PROJECT'),
site=app.config.get('SENTRY_SITE_NAME'),
processors=app.config.get('SENTRY_PROCESSORS'),
string_max_length=app.config.get('SENTRY_MAX_LENGTH_STRING'),
list_max_length=app.config.get('SENTRY_MAX_LENGTH_LIST'),
extra={
'app': app,
},
)
class Sentry(object):
"""
Flask application for Sentry.
Look up configuration from ``os.environ['SENTRY_DSN']``::
>>> sentry = Sentry(app)
Pass an arbitrary DSN::
>>> sentry = Sentry(app, dsn='http://public:secret@example.com/1')
Pass an explicit client::
>>> sentry = Sentry(app, client=client)
Automatically configure logging::
>>> sentry = Sentry(app, logging=True, level=logging.ERROR)
Capture an exception::
>>> try:
>>> 1 / 0
>>> except ZeroDivisionError:
>>> sentry.captureException()
Capture a message::
>>> sentry.captureMessage('hello, world!')
By default, the Flask integration will do the following:
- Hook into the `got_request_exception` signal. This can be disabled by
passing `register_signal=False`.
- Wrap the WSGI application. This can be disabled by passing
`wrap_wsgi=False`.
- Capture information from Flask-Login (if available).
"""
def __init__(self, app=None, client=None, client_cls=Client, dsn=None,
logging=False, level=logging.NOTSET, wrap_wsgi=True,
register_signal=True):
self.dsn = dsn
self.logging = logging
self.client_cls = client_cls
self.client = client
self.level = level
self.wrap_wsgi = wrap_wsgi
self.register_signal = register_signal
if app:
self.init_app(app)
def handle_exception(self, *args, **kwargs):
if not self.client:
return
ignored_exc_type_list = self.app.config.get('RAVEN_IGNORE_EXCEPTIONS', [])
exc = sys.exc_info()[1]
if any((isinstance(exc, ignored_exc_type) for ignored_exc_type in ignored_exc_type_list)):
return
self.captureException(exc_info=kwargs.get('exc_info'))
def get_user_info(self, request):
"""
Requires Flask-Login (https://pypi.python.org/pypi/Flask-Login/) to be installed
and setup
"""
if not has_flask_login:
return
if not hasattr(self.app, 'login_manager'):
return
try:
is_authenticated = current_user.is_authenticated()
except AttributeError:
# HACK: catch the attribute error thrown by flask-login is not attached
# > current_user = LocalProxy(lambda: _request_ctx_stack.top.user)
# E AttributeError: 'RequestContext' object has no attribute 'user'
return {}
if is_authenticated:
user_info = {
'is_authenticated': True,
'is_anonymous': current_user.is_anonymous(),
'id': current_user.get_id(),
}
if 'SENTRY_USER_ATTRS' in self.app.config:
for attr in self.app.config['SENTRY_USER_ATTRS']:
if hasattr(current_user, attr):
user_info[attr] = getattr(current_user, attr)
else:
user_info = {
'is_authenticated': False,
'is_anonymous': current_user.is_anonymous(),
}
return user_info
def get_http_info(self, request):
urlparts = _urlparse.urlsplit(request.url)
try:
formdata = request.form
except ClientDisconnected:
formdata = {}
return {
'url': '%s://%s%s' % (urlparts.scheme, urlparts.netloc, urlparts.path),
'query_string': urlparts.query,
'method': request.method,
'data': formdata,
'headers': dict(get_headers(request.environ)),
'env': dict(get_environ(request.environ)),
}
def before_request(self, *args, **kwargs):
self.client.http_context(self.get_http_info(request))
self.client.user_context(self.get_user_info(request))
def init_app(self, app, dsn=None):
self.app = app
if dsn is not None:
self.dsn = dsn
if not self.client:
self.client = make_client(self.client_cls, app, self.dsn)
if self.logging:
setup_logging(SentryHandler(self.client, level=self.level))
if self.wrap_wsgi:
app.wsgi_app = SentryMiddleware(app.wsgi_app, self.client)
app.before_request(self.before_request)
if self.register_signal:
got_request_exception.connect(self.handle_exception, sender=app)
if not hasattr(app, 'extensions'):
app.extensions = {}
app.extensions['sentry'] = self
def captureException(self, *args, **kwargs):
assert self.client, 'captureException called before application configured'
return self.client.captureException(*args, **kwargs)
def captureMessage(self, *args, **kwargs):
assert self.client, 'captureMessage called before application configured'
return self.client.captureMessage(*args, **kwargs)
| [
"dcramer@gmail.com"
] | dcramer@gmail.com |
0a76f86eb679b4c825f35a3bed80abc31b663441 | 697af415566ba649502bd18751a6521ac526892c | /2020_VERSIONS/NYS_mesonet/NYS_mesonet_save_and_plot.py | ecc27bc483fb07a28940a1a8c1a91dc250cee0c2 | [] | no_license | srbrodzik/impacts-scripts | df44c8f34746499b8397b5b1a4ad09859b4cc8d4 | 263c7545bbb912bbcea563a21d0619e5112b1788 | refs/heads/master | 2023-05-31T05:01:09.558641 | 2023-05-22T23:24:52 | 2023-05-22T23:24:52 | 215,638,568 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 23,128 | py | #!/usr/bin/python3
"""
Created August/September 2019
@author: masonf3
"""
'''NYS_mesonet_save_and_plot.py
Make 3-day plots and save daily .csv files of key weather variables for NYS mesonet stations (126 stations in network)
Data is read from UW Atmospheric Sciences LDM server
Some code modified from Joe Zagrodnik's 'plot_mesowest_3day.py', used for similar task in the OLYMPEX field campaign
**File Saving Information**
CSV files, one per day, save to: '/home/disk/funnel/impacts/data_archive/nys_ground'
3-day plots, one each time code is run, save to: '/home/disk/funnel/impacts/archive/ops/nys_ground'
'''
import os
import pandas as pd
import csv
import time, datetime, glob
from time import strftime
from datetime import timedelta
import numpy as np
import matplotlib
from matplotlib.dates import DayLocator, HourLocator, DateFormatter
matplotlib.use('Agg')
import matplotlib.transforms as transforms
import matplotlib.pyplot as plt
# In[9]:
#define directories
indir = '/home/disk/data/albany/standard/*' #where the LDM server loads data to
savedir = '/home/disk/bob/impacts/bin/saved' #folder containing pickle files
station_info = '/home/disk/funnel/impacts/data_archive/nys_ground/meta_nysm.csv' #file containing station lat/lon/alt
csv_dir = '/home/disk/funnel/impacts/data_archive/nys_ground' #save csv files here
plot_dir = '/home/disk/funnel/impacts/archive/ops/nys_ground' #save plots here
#indir = '/home/disk/meso-home/masonf3/IMPACTS/standard/*' #test - where I copied from LDM server
#savedir = '/home/disk/meso-home/masonf3/IMPACTS/saved' #test - folder containing pickle files
#station_info = '/home/disk/meso-home/masonf3/IMPACTS/station_info/nysm.csv' #test - file containing station lat/lon/alt
#csv_dir = '/home/disk/meso-home/masonf3/IMPACTS/csv_test_NYS' #test - csv directory
#plot_dir = '/home/disk/meso-home/masonf3/IMPACTS/plot_test_NYS' #test - plot directory
# In[10]:
def vapor_pressure_calc(T,RH):
'''Given temperature and relative humidity, returns vapor pressure.
From https://www.weather.gov/media/epz/wxcalc/vaporPressure.pdf
Parameters:
T (float): temperature, in degrees celsius
RH (float): relative humidity, in %
Returns:
e (float): vapor pressure, in (find out)
es (float): saturation vapor pressure, in (find out)
'''
es = 6.11 * 10**((7.5*T)/(237.3+T)) #saturation vapor pressure calculation
e = (RH/100) * es #current vapor pressure calculation (using RH)
return e,es
def Td_calc(es,RH):
'''Given saturation vapor pressure and relative humidity, returns dew point temperature.
From https://www.weather.gov/media/epz/wxcalc/vaporPressure.pdf
Parameters:
es (float): saturation vapor presure, in (find out)
RH (float): relative humidity, in %
Returns:
Td (float): dew point temperature, in degrees celsius
'''
Td = (237.3*np.log((es*RH)/611))/(7.5*np.log(10)-np.log((es*RH)/611))
return Td
def Tmv_calc(e,p,Tm):
'''Given current vapor pressure, station pressure, & mean 12-hour temp, returns mean 12-hour virtual temp.
Eq. from Ch.3 of "Atmospheric Science, An Introductory Survey, Second Edition" by John M. Wallace and Peter V. Hobbs
Parameters:
Tm (float): mean 12-hour temp, in degrees celsius (i.e. (T_now+T_12ago)/2)
e (float): vapor pressure, in (find out)
p (float): station pressure (2m to be exact), in hPa (check this?)
Returns:
Tv_bar (float): average virtual temperature, in degrees kelvin
'''
Tmv = (Tm+273.15)/(1-((e/p)*(1-0.622)))
return Tmv
def mslp_calc(Tmv,zs,p):
'''Given current station elevation, station pressure, and mean 12-hour virtual temp, returns mean sea-level pressure.
Eq. from Ch.3 of "Atmospheric Science, An Introductory Survey, Second Edition" by John M. Wallace and Peter V. Hobbs
*Note: MSLP calculations will be slightly incorrect for the very first 12 hours of data ever read by this script
because calculations use 12 hour average ambient temperature in their formulation.
Parameters:
Tmv (float): mean 12-hour virtual temp, in degrees kelvin
zs (float): station elevation, in meters
p (float): station pressure, in hPa
Returns:
p0 (float): mean sea-level pressure, in hPa (mb)
'''
g = 9.80665 #acceleration of gravity in m*s^-2
Rd = 287.0 #gas constant of dry air in J*K^-1*kg^-1
z = zs + 2 #true elevation, in m (temp is taken at 2-m)
p0 = p*np.exp((g*(z+2))/(Rd*Tmv))
return p0
# In[11]:
def load_data(path):
'''Given a filepath with timeseries of .csv files, return a dataframe containing data from the last three full days
to the present. Also returns a list of site station IDs in the observation network.
Parameters:
path (str): filepath to directory containing observation data .csv files which are added in time.
Returns:
all_data (dataframe): a dataframe of all obs data from three days ago, two days ago, yesterday, and today,
indexed by datetime and containing station elevation data.
sitelist (list): a list of site station IDs in the NYS mesonet network
'''
file_list = glob.glob(path) #all files in path directory
file_list.sort() #sort file list
latest_file = file_list[-1] #most recent data file
station_info_data = pd.read_csv(station_info) #read station info from .csv file
station_info_data = station_info_data.set_index('stid') #index by station id
df = pd.read_csv(latest_file) #read latest weather data from NYS mesonet
df = df.set_index('station') #temporary index by station id for new data
for i in df.index: #add elev, station full names to new data
df.loc[i,'station_elevation [m]'] = station_info_data.loc[i,'elevation [m]']
df.loc[i,'name'] = station_info_data.loc[i,'name']
df = df.reset_index() #reset new data index
df['datetime'] = pd.to_datetime(df['time'],format='%Y-%m-%d %H:%M:%S UTC') #add column for datetime object
new_df = df.set_index('datetime') #set new data index to datetime
today_pickle = new_df.index[-1].strftime('%Y%m%d')+'.pkl'
yesterday_pickle = (new_df.index[-1]-timedelta(days=1)).strftime('%Y%m%d')+'.pkl'
two_days_ago_pickle = (new_df.index[-1]-timedelta(days=2)).strftime('%Y%m%d')+'.pkl'
three_days_ago_pickle = (new_df.index[-1]-timedelta(days=3)).strftime('%Y%m%d')+'.pkl'
if os.path.isfile(savedir+'/'+today_pickle):
from_file = pd.read_pickle(savedir+'/'+today_pickle)
today_data = from_file.append(new_df,ignore_index=False) #append latest NYS data to previous NYS data
today_data.to_pickle(savedir+'/'+today_pickle)
all_data = today_data
if os.path.isfile(savedir+'/'+yesterday_pickle):
yesterday_data = pd.read_pickle(savedir+'/'+yesterday_pickle)
all_data = pd.concat([today_data,yesterday_data],ignore_index=False)
if os.path.isfile(savedir+'/'+two_days_ago_pickle):
two_days_ago_data = pd.read_pickle(savedir+'/'+two_days_ago_pickle)
all_data = pd.concat([all_data,two_days_ago_data],ignore_index=False)
if os.path.isfile(savedir+'/'+three_days_ago_pickle):
three_days_ago_data = pd.read_pickle(savedir+'/'+three_days_ago_pickle)
all_data = pd.concat([all_data,three_days_ago_data],ignore_index=False)
else:
today_data = new_df
today_data.to_pickle(savedir+'/'+today_pickle)
all_data = today_data
if os.path.isfile(savedir+'/'+yesterday_pickle):
yesterday_data = pd.read_pickle(savedir+'/'+yesterday_pickle)
all_data = pd.concat([today_data,yesterday_data],ignore_index=False)
if os.path.isfile(savedir+'/'+two_days_ago_pickle):
two_days_ago_data = pd.read_pickle(savedir+'/'+two_days_ago_pickle)
all_data = pd.concat([all_data,two_days_ago_data],ignore_index=False)
if os.path.isfile(savedir+'/'+three_days_ago_pickle):
three_days_ago_data = pd.read_pickle(savedir+'/'+three_days_ago_pickle)
all_data = pd.concat([all_data,three_days_ago_data],ignore_index=False)
all_data = all_data.drop_duplicates(['station','time'],keep='last')
all_data = all_data.sort_values(by=['station','time'],ascending=True)
sitelist = list(df['station'].drop_duplicates()) #a list of site IDs for later use
return all_data, sitelist
# In[12]:
def calculate_derived_data(all_data,site):
'''Given a dataframe of NYS weather data, calculates new dataframe columns of dew point and mean sea-level pressure.
*Note: MSLP calculations will be slightly incorrect for the very first 12 hours of data ever read by this script
because calculations should use 12 hour average ambient temperature rather than observed temp in the formula*
Parameters:
all_data (dataframe): a dataframe of all obs data from three days ago, two days ago, yesterday, and today,
indexed by datetime and containing station elevation data
site (str): site station ID for a station in the NYS mesonet network
Returns:
site_data (dataframe): pandas dataframe containing all data, both directly observed and calculated,
for a specific station
'''
site_data = all_data.loc[all_data['station'] == site]
if 'relative_humidity [percent]' and 'temp_2m [degC]' in site_data.keys():
e,es = vapor_pressure_calc(site_data['temp_2m [degC]'],site_data['relative_humidity [percent]'])
Td = Td_calc(es,site_data['relative_humidity [percent]'])
site_data['dew_point_temp_2m [degC]'] = Td #add calculated dew point to new data
if 'station_pressure [mbar]' and 'station_elevation [m]' in site_data.keys():
for dt in site_data.index[:]:
if dt-timedelta(hours=12) in site_data.index[:]:
first_dt = dt-timedelta(hours=12)
Tm = (site_data['temp_2m [degC]'][first_dt]+site_data['temp_2m [degC]'][dt])/2 #if 12hr+ data exists
else:
Tm = site_data['temp_2m [degC]'][dt] #if not 12hr+ of data
Tmv = Tmv_calc(e[dt],site_data['station_pressure [mbar]'][dt],Tm) #calc average virtual temp
mslp = mslp_calc(Tmv,site_data['station_elevation [m]'][dt],site_data['station_pressure [mbar]'][dt])
site_data.loc[dt,'mean_sea_level_pressure [mbar]'] = mslp #add calculated mslp to data frame
site_data = site_data.drop_duplicates(['station','time'],keep='last') #drop duplicate data
return site_data
# In[13]:
def save_station_data(site_data):
'''Given a pandas dataframe containing all weather data for a specific station, this function saves
a day's worth of data into a .csv file for that station, within a folder for that day.
Parameters:
site_data (dataframe): pandas dataframe containing all data, both directly observed and calculated,
for a specific station
Returns:
None
*Saves .csv files to csv_dir listed near top of script*
'''
latest = site_data.index[-1]
site = site_data['station'][0]
lower_site = site.lower()
#definining dates in YYYYmmdd format (for saving and finding files)
yesterday_date = (latest-timedelta(hours=24)).strftime('%Y%m%d')
today_date = latest.strftime('%Y%m%d')
#defining dates in YYYY-mm-dd format (for selecting ranges of data from dataframes)
yesterday_date_dt_format = (latest-timedelta(hours=24)).strftime('%Y-%m-%d')
today_date_dt_format = latest.strftime('%Y-%m-%d')
path1_dir = csv_dir+'/'+yesterday_date
path0_dir = csv_dir+'/'+today_date
path1_file = path1_dir+'/ops.nys_ground.'+yesterday_date+'.'+lower_site+'.csv'
path0_file = path0_dir+'/ops.nys_ground.'+today_date+'.'+lower_site+'.csv'
# ******** PROBLEM WITH THIS COMMAND ********
if yesterday_date in site_data.index.strftime('Y%m%d'):
if not os.path.exists(path1_dir):
os.mkdir(path1_dir)
if not os.path.exists(path1_file):
yesterday_data = site_data[yesterday_date_dt_format]
yesterday_data.to_csv(path1_file)
if not os.path.exists(path0_dir):
os.mkdir(path0_dir)
if today_date == latest.strftime('%Y%m%d'): #assure data exists for today before making today file
today_data = site_data[today_date_dt_format]
today_data.to_csv(path0_file)
print('saved ' + site + ' csv')
# In[17]:
def plot_station_data(site_data):
'''Given a pandas dataframe containing all weather data for a specific station, this function saves a plot with
the last 3 days worth of weather data for that station (or as much data as available if not yet 3-days).
Parameters:
site_data (dataframe): pandas dataframe containing all data, both directly observed and calculated,
for a specific station
Returns:
None
*saves plots to plot_dir listed near top of script*
'''
latest = site_data.index[-1]
site = site_data['station'][0]
lower_site = site.lower()
site_slice = site_data.loc[site_data.index >= (latest-timedelta(hours=72))] #slice data to last 72hrs
timestamp_end = site_slice.index[-1].strftime('%Y%m%d%H%M') #timestamp end for saving .csv files
dt = site_slice.index[:] #define dt for making subplots
sitetitle = site_slice['name'][0] #define sitetitle for fig title
graphtimestamp_start=dt[0].strftime("%m/%d/%y") #start date, for fig title
graphtimestamp=dt[-1].strftime("%m/%d/%y") #end date, for fig title
markersize = 1.5 #markersize, for subplots
linewidth = 1.0 #linewidth, for subplots
fig = plt.figure() #create figure
fig.set_size_inches(10,10) #size figure
if max(site_slice['snow_depth [cm]']) > 0: #six axes if there is snow depth
ax1 = fig.add_subplot(6,1,1)
ax2 = fig.add_subplot(6,1,2,sharex=ax1)
ax3 = fig.add_subplot(6,1,3,sharex=ax1)
ax4 = fig.add_subplot(6,1,4,sharex=ax1)
ax5 = fig.add_subplot(6,1,5,sharex=ax1)
ax6 = fig.add_subplot(6,1,6,sharex=ax1)
ax6.set_xlabel('Time (UTC)')
else: #five axes if no snow depth
ax1 = fig.add_subplot(5,1,1)
ax2 = fig.add_subplot(5,1,2,sharex=ax1)
ax3 = fig.add_subplot(5,1,3,sharex=ax1)
ax4 = fig.add_subplot(5,1,4,sharex=ax1)
ax5 = fig.add_subplot(5,1,5,sharex=ax1)
ax5.set_xlabel('Time (UTC)')
ax1.set_title(site+' '+sitetitle+', NY '+graphtimestamp_start+' - '+graphtimestamp) #title figure
#plot airT and dewT
if 'temp_2m [degC]' in site_slice.keys():
airT = site_slice['temp_2m [degC]']
ax1.plot_date(dt,airT,'o-',label="Temp",color="blue",linewidth=linewidth,markersize=markersize)
if 'dew_point_temp_2m [degC]' in site_slice.keys():
Td = site_slice['dew_point_temp_2m [degC]']
ax1.plot_date(dt,Td,'o-',label="Dew Point",color="black",linewidth=linewidth,markersize=markersize)
if ax1.get_ylim()[0] < 0 < ax1.get_ylim()[1]:
ax1.axhline(0, linestyle='-', linewidth = 1.0, color='deepskyblue')
trans = transforms.blended_transform_factory(ax1.get_yticklabels()[0].get_transform(), ax1.transData)
ax1.text(0,0,'0C', color="deepskyblue", transform=trans, ha="right", va="center") #light blue line at 0 degrees C
ax1.set_ylabel('2m Temp ($^\circ$C)')
ax1.legend(loc='best',ncol=2)
axes = [ax1] #begin axes list
#plot wind speed and gust
if 'avg_wind_speed_merge [m/s]' in site_slice.keys():
wnd_spd = site_slice['avg_wind_speed_merge [m/s]'] * 1.94384 #convert to knots
ax2.plot_date(dt,wnd_spd,'o-',label='Speed',color="forestgreen",linewidth=linewidth,markersize=markersize)
if 'max_wind_speed_merge [m/s]' in site_slice.keys():
wnd_gst = site_slice['max_wind_speed_merge [m/s]'] * 1.94384 #convert to knots
max_wnd_gst = wnd_gst.max(skipna=True)
ax2.plot_date(dt,wnd_gst,'o-',label='Gust (Max ' + str(round(max_wnd_gst,1)) + 'kt)',color="red",linewidth=linewidth,markersize=markersize)
ax2.set_ylabel('Wind (kt)')
ax2.legend(loc='best',ncol=2)
axes.append(ax2)
#plot wind direction
if 'wind_direction_merge [degree]' in site_slice.keys():
wnd_dir = site_slice['wind_direction_merge [degree]']
ax3.plot_date(dt,wnd_dir,'o-',label='Direction',color="purple",linewidth=0.2, markersize=markersize)
ax3.set_ylim(-10,370)
ax3.set_ylabel('Wind Direction')
ax3.set_yticks([0,90,180,270,360]) #locking y-ticks for wind direction
axes.append(ax3)
#plot MSLP (or station pressure, if MSLP unavailable)
if 'mean_sea_level_pressure [mbar]' in site_slice.keys():
mslp = site_slice['mean_sea_level_pressure [mbar]']
min_mslp = mslp.min(skipna=True) #min 3-day mslp value
max_mslp = mslp.max(skipna=True) #max 3-day mslp value
labelname = 'Min ' + str(round(min_mslp,2)) + 'hPa, Max ' + str(round(max_mslp,2)) + 'hPa'
ax4.plot_date(dt,mslp,'o-',label=labelname,color='darkorange',linewidth=linewidth,markersize=markersize)
ax4.set_ylabel('MSLP (hPa)')
elif 'station_pressure [mbar]' in site_slice.keys():
sp = site_slice['station_pressure [mbar]']
min_sp = sp.min(skipna=True) #min 3-day station pressure value
max_sp = sp.max(skipna=True) #max 3-day station pressure value
labelname = 'Min ' + str(round(min_sp,2)) + 'hPa, Max ' + str(round(max_sp,2)) + 'hPa'
ax4.plot_date(dt,sp,'o-',label=labelname,color='darkorange',linewidth=linewidth,markersize=markersize)
ax4.set_ylabel('STATION Pressure (hPa)')
print('unable to get mslp, used station pressure instead')
ax4.legend(loc='best')
axes.append(ax4)
#plot precip accum
if 'precip_incremental [mm]' in site_slice.keys():
precip_inc = site_slice['precip_incremental [mm]']
precip_accum = 0.0
precip_accum_list = []
for increment in precip_inc: #calculate precip accumulation
precip_accum = precip_accum + increment
precip_accum_list.append(precip_accum)
max_precip = max(precip_accum_list)
labelname = 'Precip (' + str(round(max_precip,2)) + 'mm)'
ax5.plot_date(dt,precip_accum_list,'o-',label=labelname,color='navy',linewidth=linewidth,markersize=markersize)
if max_precip > 0:
ax5.set_ylim(-0.1*max_precip,max_precip+max_precip*0.2)
else:
ax5.set_ylim(-0.5,5)
ax5.legend(loc='best')
ax5.set_ylabel('Precip (mm)')
axes.append(ax5)
#plot snow depth
if 'snow_depth [cm]' in site_slice.keys() and max(site_slice['snow_depth [cm]']) > 0:
snow_depth = site_slice['snow_depth [cm]'] * 10 #convert to mm
max_snow_depth = snow_depth.max(skipna=True)
min_snow_depth = snow_depth.min(skipna=True)
labelname = 'Min Depth ' + str(round(min_snow_depth,2)) + 'mm, Max Depth ' + str(round(max_snow_depth,2)) + 'mm'
ax6.plot_date(dt,snow_depth,'o-',label=labelname,color='deepskyblue',linewidth=linewidth,markersize=markersize)
ax6.set_ylim(-0.1*max_snow_depth,max_snow_depth+max_snow_depth*0.2)
if max_snow_depth > 0:
ax5.set_ylim(-0.1*max_snow_depth,max_snow_depth+max_snow_depth*0.2)
ax6.legend(loc='best')
ax6.set_ylabel('Snow Depth (mm)')
axes.append(ax6)
for ax in axes:
ax.spines["top"].set_visible(False) #remove dark borders on subplots
ax.spines["right"].set_visible(False)
ax.spines["left"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.tick_params(axis='x',which='both',bottom='on',top='off') #add ticks at labeled times
ax.tick_params(axis='y',which='both',left='on',right='off')
ax.xaxis.set_major_locator( DayLocator() ) #one date written per day
ax.xaxis.set_major_formatter( DateFormatter('%b-%d') ) #show date, written as 'Jul-12'
ax.xaxis.set_minor_locator( HourLocator(np.linspace(6,18,3)) ) #hour labels every 6 hours
ax.xaxis.set_minor_formatter( DateFormatter('%H') ) #show hour labels
ax.fmt_xdata = DateFormatter('Y%m%d%H%M%S') #fixes labels
ax.yaxis.grid(linestyle = '--') #adds y-axis grid lines
ax.get_yaxis().set_label_coords(-0.06,0.5) #properly places y-labels away from figure
#define dates in YYYYmmdd format (for saving and finding files)
three_days_ago_date = (latest-timedelta(hours=72)).strftime('%Y%m%d')
two_days_ago_date = (latest-timedelta(hours=48)).strftime('%Y%m%d')
yesterday_date = (latest-timedelta(hours=24)).strftime('%Y%m%d')
today_date = latest.strftime('%Y%m%d')
plot_path = plot_dir+'/'+today_date
if not os.path.exists(plot_path):
os.mkdir(plot_path)
plt.savefig(plot_path+'/ops.nys_ground.'+timestamp_end+'.'+lower_site+'.png',bbox_inches='tight')
plt.close()
print('plotted ' + site)
# In[18]:
all_data,sitelist = load_data(indir)
print('Done reading data')
for site in sitelist:
print('site = '+site)
site_data = calculate_derived_data(all_data,site)
save = save_station_data(site_data)
plot = plot_station_data(site_data)
print('All NYS Mesonet ground data plotted and saved')
# In[ ]:
| [
"brodzik@uw.edu"
] | brodzik@uw.edu |
e1c60de6b9628d02d92def760be54bcc5aad7781 | 1edee17385db53395352e91cf9f4b566a0f07b45 | /17_requests.py | 1837ed08298f814eee55c996a40c163042906474 | [] | no_license | Zerl1990/2020_python_workshop | 705fbdd280aea8d75df0c7d14f1ef617c509cd08 | 78a13962f8c1ab6bc0ef85558a0b54845ac8c3a1 | refs/heads/master | 2022-11-26T20:36:47.212113 | 2020-08-08T19:02:13 | 2020-08-08T19:02:13 | 281,791,940 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 607 | py | # Import requests library
import requests
# Define url
url = 'https://api.openaq.org/v1/cities?country=MX'
# Execute a get request to Rest services
response = requests.get(url)
# Print response object
print(f'Response from {url} is {response}')
# Print response status code
print(f'Response status code: {response.status_code}')
# Print raw response content (String)
print(f'Response raw content: {response.raw}')
# Print the response ins json format (Dictionary)
print(f'Response JSON: {response.json()}')
# Print variable type of json response
print(f'Response JSON type: {type(response.json())}')
| [
"luis.m.rivas@oracle.com"
] | luis.m.rivas@oracle.com |
c4109be7d713a6bb1f9c59d02bfcb0a60da154a3 | 81c8baf31e15cf132b22cc489e7c8fc7b86003a4 | /fulltext/registry.py | 39ab6bd2ff12756510edfc1c3e52bf2c15d8018d | [
"MIT"
] | permissive | LinuxOSsk/Shakal-NG | 0b0030af95a8dad4b120ae076920aa3a4020c125 | 93631496637cd3847c1f4afd91a9881cafb0ad83 | refs/heads/master | 2023-09-04T04:27:05.481496 | 2023-08-30T04:10:41 | 2023-08-30T04:10:41 | 2,168,932 | 11 | 8 | MIT | 2023-08-16T03:34:02 | 2011-08-07T14:36:25 | Python | UTF-8 | Python | false | false | 724 | py | # -*- coding: utf-8 -*-
from collections import defaultdict
from django.utils.functional import cached_property
class FulltextRegister(object):
def __init__(self):
self.__registered = []
self.__by_model = defaultdict(list)
def __iter__(self):
return iter(self.__registered)
def register(self, fulltext):
fulltext.register = self
self.__registered.append(fulltext)
self.__by_model[fulltext.model].append(fulltext)
def get_for_model(self, cls):
return self.__by_model.get(cls, [])
@cached_property
def index_class(self):
from .models import SearchIndex
return SearchIndex
@cached_property
def updated_field(self):
return self.index_class.get_updated_field()
register = FulltextRegister()
| [
"miroslav.bendik@gmail.com"
] | miroslav.bendik@gmail.com |
5486d3255f48d51f69a08aa783274980162f8ddf | bbeecb7cff56a96c580709b425823cde53f21621 | /msw/spots/australasia/northland.py | e7852f8eae15327fc509829b969672c22ac18484 | [] | no_license | hhubbell/python-msw | f8a2ef8628d545b3d57a5e54468222177dc47b37 | 5df38db1dc7b3239a6d00e0516f2942077f97099 | refs/heads/master | 2020-04-05T23:46:21.209888 | 2015-06-16T01:36:43 | 2015-06-16T01:36:43 | 37,476,303 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 45 | py | PIHA = 90
90_MILE_BEACH = 118
FORESTRY = 122
| [
"hhubbell@uvm.edu"
] | hhubbell@uvm.edu |
6b0de98bbc67259392d7f7b7ce46d6038aa470df | 963e0c0a12699890fb8303e8272a58a9c78d5e1d | /networks/resnet_encoder.py | de62869855316ff5cfec6fd0958c60528db53a32 | [] | no_license | TWJianNuo/Stereo_SDNET | 83cb98adf083daae44382f8c0198683a672b5045 | e2a13984abb952b1083cbf06c51ffcc9d3fd511d | refs/heads/master | 2020-08-14T11:21:41.485309 | 2019-10-30T20:09:30 | 2019-10-30T20:09:30 | 215,158,844 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 4,254 | py | # Copyright Niantic 2019. Patent Pending. All rights reserved.
#
# This software is licensed under the terms of the Monodepth2 licence
# which allows for non-commercial use only, the full terms of which are made
# available in the LICENSE file.
from __future__ import absolute_import, division, print_function
import numpy as np
import torch
import torch.nn as nn
import torchvision.models as models
import torch.utils.model_zoo as model_zoo
class ResNetMultiImageInput(models.ResNet):
"""Constructs a resnet model with varying number of input images.
Adapted from https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
"""
def __init__(self, block, layers, num_classes=1000, num_input_images=1, add_mask = 0):
super(ResNetMultiImageInput, self).__init__(block, layers)
self.inplanes = 64
self.conv1 = nn.Conv2d(
num_input_images * 3 + add_mask, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def resnet_multiimage_input(num_layers, pretrained=False, num_input_images=1, add_mask = 0):
"""Constructs a ResNet model.
Args:
num_layers (int): Number of resnet layers. Must be 18 or 50
pretrained (bool): If True, returns a model pre-trained on ImageNet
num_input_images (int): Number of frames stacked as input
"""
assert num_layers in [18, 50], "Can only run with 18 or 50 layer resnet"
blocks = {18: [2, 2, 2, 2], 50: [3, 4, 6, 3]}[num_layers]
block_type = {18: models.resnet.BasicBlock, 50: models.resnet.Bottleneck}[num_layers]
model = ResNetMultiImageInput(block_type, blocks, num_input_images=num_input_images, add_mask = add_mask)
if pretrained:
loaded = model_zoo.load_url(models.resnet.model_urls['resnet{}'.format(num_layers)])
loaded['conv1.weight'] = torch.cat([loaded['conv1.weight']] * num_input_images, 1) / num_input_images
loaded['conv1.weight'] = torch.cat([loaded['conv1.weight'], model.conv1.weight[:, -(add_mask + 1):-add_mask, :, :].clone()], 1)
model.load_state_dict(loaded)
return model
class ResnetEncoder(nn.Module):
"""Pytorch module for a resnet encoder
"""
def __init__(self, num_layers, pretrained, num_input_images=1, add_mask = 0):
super(ResnetEncoder, self).__init__()
self.num_ch_enc = np.array([64, 64, 128, 256, 512])
resnets = {18: models.resnet18,
34: models.resnet34,
50: models.resnet50,
101: models.resnet101,
152: models.resnet152}
if num_layers not in resnets:
raise ValueError("{} is not a valid number of resnet layers".format(num_layers))
if num_input_images > 1:
self.encoder = resnet_multiimage_input(num_layers, pretrained, num_input_images, add_mask)
else:
self.encoder = resnets[num_layers](pretrained)
if num_layers > 34:
self.num_ch_enc[1:] *= 4
def forward(self, input_image):
self.features = []
x = (input_image - 0.45) / 0.225
x = self.encoder.conv1(x)
x = self.encoder.bn1(x)
self.features.append(self.encoder.relu(x))
self.features.append(self.encoder.layer1(self.encoder.maxpool(self.features[-1])))
self.features.append(self.encoder.layer2(self.features[-1]))
self.features.append(self.encoder.layer3(self.features[-1]))
self.features.append(self.encoder.layer4(self.features[-1]))
return self.features
| [
"twjiannuo@gmail.com"
] | twjiannuo@gmail.com |
1b8d80d1332c15f78159e1c04c61c731bc87fb22 | 781e2692049e87a4256320c76e82a19be257a05d | /all_data/exercism_data/python/grains/cb2dd80523174feda773833adb8eed42.py | af33b9d4b60b65c2f8450d06dc4c77109a1c5eb3 | [] | no_license | itsolutionscorp/AutoStyle-Clustering | 54bde86fe6dbad35b568b38cfcb14c5ffaab51b0 | be0e2f635a7558f56c61bc0b36c6146b01d1e6e6 | refs/heads/master | 2020-12-11T07:27:19.291038 | 2016-03-16T03:18:00 | 2016-03-16T03:18:42 | 59,454,921 | 4 | 0 | null | 2016-05-23T05:40:56 | 2016-05-23T05:40:56 | null | UTF-8 | Python | false | false | 171 | py | #grains.py
#Surely a bread winner
def on_square(square):
return 2**(square-1)
def total_after(number):
return sum(on_square(num) for num in range(1,number+1))
| [
"rrc@berkeley.edu"
] | rrc@berkeley.edu |
2e257e7f0a607d965283c7f5fe7e047e6aebca51 | 3b4c8c8b2e9e372a6b5d3c2fe717a3cadab4abd0 | /stepler/nova/fixtures/hypervisor.py | c17b0bb7651f9d50c14f45c47db7bfb16df8227d | [] | no_license | Mirantis/stepler-draft | 242b25e116715c6550414826c7e5a3f212216833 | 2d85917ed9a35ee434d636fbbab60726d44af3a1 | refs/heads/master | 2021-05-01T01:02:49.670267 | 2016-12-01T10:39:37 | 2016-12-01T11:04:50 | 74,979,322 | 0 | 0 | null | 2020-02-26T12:07:21 | 2016-11-28T14:11:45 | Python | UTF-8 | Python | false | false | 1,714 | py | """
-------------------
Hypervisor fixtures
-------------------
"""
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
# implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import pytest
from stepler.nova import steps
__all__ = [
'hypervisor_steps',
'sorted_hypervisors',
]
@pytest.fixture
def hypervisor_steps(nova_client):
"""Fixture to get hypervisor steps.
Args:
nova_client (object): instantiated nova client
Returns:
stepler.nova.steps.HypervisorSteps: instantiated hypervisor steps
"""
return steps.HypervisorSteps(nova_client.hypervisors)
@pytest.fixture
def sorted_hypervisors(hypervisor_steps, flavor):
"""Function fixture to get hypervisors sorted by their capacity.
Args:
hypervisor_steps (obj): instantiated hypervisor steps
flavor (obj): nova flavor
Returns:
list: sorted hypervisors (from biggest to smallest)
"""
hypervisors = hypervisor_steps.get_hypervisors()
suitable_hypervisors = []
for hypervisor in hypervisors:
cap = hypervisor_steps.get_hypervisor_capacity(hypervisor, flavor)
suitable_hypervisors.append((cap, hypervisor))
hypervisors = [hyp for _, hyp in reversed(sorted(suitable_hypervisors))]
return hypervisors
| [
"g.dyuldin@gmail.com"
] | g.dyuldin@gmail.com |
e5cc77396f9b9773ee72ee68e409f7e3bcb4830c | 53fab060fa262e5d5026e0807d93c75fb81e67b9 | /backup/user_072/ch29_2019_08_22_16_43_24_439163.py | 7ddebc7b49971299f322b1c09507e3fa1c37b784 | [] | no_license | gabriellaec/desoft-analise-exercicios | b77c6999424c5ce7e44086a12589a0ad43d6adca | 01940ab0897aa6005764fc220b900e4d6161d36b | refs/heads/main | 2023-01-31T17:19:42.050628 | 2020-12-16T05:21:31 | 2020-12-16T05:21:31 | 306,735,108 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 234 | py | a=int(input('Salário: '))
def calcula_aumento(a):
y1=a*1.1
y2=a*1.15
if a>1250:
return 'Aumento de R$ {0:.2f}'.format(y1)
else:
return 'Aumento de R$ {0:.2f}'.format(y2)
print(calcula_aumento(a))
| [
"you@example.com"
] | you@example.com |
39b0abf1f72ce243f555dbfbdf586cc1aa3f0718 | 61ef327bd1d5ff6db7595221db6823c947dab42b | /FlatData/Tag.py | bcf96333a568a29ffa2f904b8294e9b549037c6d | [] | no_license | Aikenfell/Blue-Archive---Asset-Downloader | 88e419686a80b20b57a10a3033c23c80f86d6bf9 | 92f93ffbdb81a47cef58c61ec82092234eae8eec | refs/heads/main | 2023-09-06T03:56:50.998141 | 2021-11-19T12:41:58 | 2021-11-19T12:41:58 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 67,469 | py | # automatically generated by the FlatBuffers compiler, do not modify
# namespace: FlatData
class Tag(object):
Furniture = 0
MovieMania = 1
Scientific = 2
Military = 3
Machine = 4
Gamer = 5
Cook = 6
Farmer = 7
Sociable = 8
Officer = 9
Eerie = 10
Intellectual = 11
Healthy = 12
Gourmet = 13
TreasureHunter = 14
CraftItem = 15
CDItem = 16
ExpItem = 17
SecretStone = 18
BookItem = 19
FavorItem = 20
MaterialItem = 21
Item = 22
CraftCommitment = 23
ExpendableItem = 24
Equipment = 25
EnemyLarge = 26
Decagram = 27
EnemySmall = 28
EnemyMedium = 29
EnemyXLarge = 30
Gehenna = 31
Millennium = 32
Valkyrie = 33
Hyakkiyako = 34
RedWinter = 35
Shanhaijing = 36
Abydos = 37
Trinity = 38
Hanger = 39
StudyRoom = 40
ClassRoom = 41
Library = 42
Lobby = 43
ShootingRange = 44
Office = 45
SchaleResidence = 46
SchaleOffice = 47
Restaurant = 48
Laboratory = 49
AVRoom = 50
ArcadeCenter = 51
Gym = 52
Garden = 53
Convenience = 54
Soldiery = 55
Lounge = 56
SchoolBuilding = 57
Club = 58
Campus = 59
SchoolYard = 60
Plaza = 61
StudentCouncilOffice = 62
ClosedBuilding = 63
Annex = 64
Pool = 65
AllySmall = 66
AllyMedium = 67
AllyLarge = 68
AllyXLarge = 69
Dessert = 70
Sports = 71
Bedding = 72
Curios = 73
Electronic = 74
Toy = 75
Reservation = 76
Household = 77
Horticulture = 78
Fashion = 79
Functional = 80
Delicious = 81
Freakish = 82
MomoFriends = 83
Music = 84
LoveStory = 85
Game = 86
Girlish = 87
Beauty = 88
Army = 89
Humanities = 90
Observational = 91
Jellyz = 92
Detective = 93
Roman = 94
CuriousFellow = 95
Mystery = 96
Doll = 97
Movie = 98
Art = 99
PureLiterature = 100
Food = 101
Smart = 102
BigMeal = 103
Simplicity = 104
Specialized = 105
Books = 106
Cosmetics = 107
Gift1 = 108
Gift2 = 109
F_Aru = 110
F_Eimi = 111
F_Haruna = 112
F_Hihumi = 113
F_Hina = 114
F_Hoshino = 115
F_Iori = 116
F_Maki = 117
F_Neru = 118
F_Izumi = 119
F_Shiroko = 120
F_Shun = 121
F_Sumire = 122
F_Tsurugi = 123
F_Akane = 124
F_Chise = 125
F_Akari = 126
F_Hasumi = 127
F_Nonomi = 128
F_Kayoko = 129
F_Mutsuki = 130
F_Zunko = 131
F_Serika = 132
F_Tusbaki = 133
F_Yuuka = 134
F_Haruka = 135
F_Asuna = 136
F_Kotori = 137
F_Suzumi = 138
F_Pina = 139
F_Aris = 140
F_Azusa = 141
F_Cherino = 142
TagName0004 = 143
TagName0005 = 144
F_Koharu = 145
F_Hanako = 146
F_Midori = 147
F_Momoi = 148
F_Hibiki = 149
F_Karin = 150
F_Saya = 151
F_Mashiro = 152
F_Airi = 153
F_Fuuka = 154
F_Hanae = 155
F_Hare = 156
F_Utaha = 157
F_Ayane = 158
F_Chinatsu = 159
F_Kotama = 160
F_Juri = 161
F_Serina = 162
F_Shimiko = 163
F_Yoshimi = 164
TagName0009 = 165
F_Shizuko = 166
F_Izuna = 167
F_Nodoka = 168
F_Yuzu = 169
Shield = 170
Helmet = 171
RedHelmet = 172
Helicopter = 173
RangeAttack = 174
MeleeAttack = 175
Sweeper = 176
Blackmarket = 177
Yoheki = 178
Kaiserpmc = 179
Crusader = 180
Goliath = 181
Drone = 182
Piece = 183
ChampionHeavyArmor = 184
Sukeban = 185
Arius = 186
EnemyKotori = 187
EnemyYuuka = 188
KaiserpmcHeavyArmor = 189
BlackmarketHeavyArmor = 190
YohekiHeavyArmor = 191
SweeperBlack = 192
SweeperYellow = 193
GasMaskLightArmor = 194
GehennaFuuki = 195
ChampionAutomata = 196
YohekiAutomata = 197
Automata = 198
EnemyIori = 199
EnemyAkari = 200
NewAutomata = 201
NewAutomataBlack = 202
NewAutomataYellow = 203
Hat = 204
Gloves = 205
Shoes = 206
Bag = 207
Badge = 208
Hairpin = 209
Charm = 210
Watch = 211
Necklace = 212
Cafe = 213
GameCenter = 214
ChocolateCafe = 215
Main = 216
Support = 217
Explosion = 218
Pierce = 219
Mystic = 220
LightArmor = 221
HeavyArmor = 222
Unarmed = 223
Cover = 224
Uncover = 225
AR = 226
SR = 227
DSG = 228
SMG = 229
MG = 230
HG = 231
GL = 232
SG = 233
MT = 234
RG = 235
Front = 236
Middle = 237
Back = 238
StreetBattle_Over_A = 239
OutdoorBattle_Over_A = 240
IndoorBattle_Over_A = 241
StreetBattle_Under_B = 242
OutdoorBattle_Under_B = 243
IndoorBattle_Under_B = 244
Kaitenranger = 245
Transport = 246
Itcenter = 247
Powerplant = 248
SukebanSwim_SMG = 249
SukebanSwim_MG = 250
SukebanSwim_SR = 251
SukebanSwim_Champion = 252
Token_S6 = 253
Swimsuit = 254
WaterPlay = 255
F_Hihumi_Swimsuit = 256
F_Azusa_Swimsuit = 257
F_Tsurugi_Swimsuit = 258
F_Mashiro_Swimsuit = 259
F_Hina_swimsuit = 260
F_Iori_swimsuit = 261
F_Izumi_swimsuit = 262
F_Shiroko_RidingSuit = 263
Church = 264
Stronghold = 265
Gallery = 266
MusicRoom = 267
Emotional = 268
F_Shun_Kid = 269
F_Kirino_default = 270
F_Saya_Casual = 271
TagName0270 = 272
TagName0271 = 273
TagName0272 = 274
TagName0273 = 275
TagName0274 = 276
TagName0275 = 277
TagName0276 = 278
TagName0277 = 279
TagName0278 = 280
TagName0279 = 281
TagName0280 = 282
TagName0281 = 283
TagName0282 = 284
TagName0283 = 285
TagName0284 = 286
TagName0285 = 287
TagName0286 = 288
TagName0287 = 289
TagName0288 = 290
TagName0289 = 291
TagName0290 = 292
TagName0291 = 293
TagName0292 = 294
TagName0293 = 295
TagName0294 = 296
TagName0295 = 297
TagName0296 = 298
TagName0297 = 299
TagName0298 = 300
TagName0299 = 301
TagName0300 = 302
TagName0301 = 303
TagName0302 = 304
TagName0303 = 305
TagName0304 = 306
TagName0305 = 307
TagName0306 = 308
TagName0307 = 309
TagName0308 = 310
TagName0309 = 311
TagName0310 = 312
TagName0311 = 313
TagName0312 = 314
TagName0313 = 315
TagName0314 = 316
TagName0315 = 317
TagName0316 = 318
TagName0317 = 319
TagName0318 = 320
TagName0319 = 321
TagName0320 = 322
TagName0321 = 323
TagName0322 = 324
TagName0323 = 325
TagName0324 = 326
TagName0325 = 327
TagName0326 = 328
TagName0327 = 329
TagName0328 = 330
TagName0329 = 331
TagName0330 = 332
TagName0331 = 333
TagName0332 = 334
TagName0333 = 335
TagName0334 = 336
TagName0335 = 337
TagName0336 = 338
TagName0337 = 339
TagName0338 = 340
TagName0339 = 341
TagName0340 = 342
TagName0341 = 343
TagName0342 = 344
TagName0343 = 345
TagName0344 = 346
TagName0345 = 347
TagName0346 = 348
TagName0347 = 349
TagName0348 = 350
TagName0349 = 351
TagName0350 = 352
TagName0351 = 353
TagName0352 = 354
TagName0353 = 355
TagName0354 = 356
TagName0355 = 357
TagName0356 = 358
TagName0357 = 359
TagName0358 = 360
TagName0359 = 361
TagName0360 = 362
TagName0361 = 363
TagName0362 = 364
TagName0363 = 365
TagName0364 = 366
TagName0365 = 367
TagName0366 = 368
TagName0367 = 369
TagName0368 = 370
TagName0369 = 371
TagName0370 = 372
TagName0371 = 373
TagName0372 = 374
TagName0373 = 375
TagName0374 = 376
TagName0375 = 377
TagName0376 = 378
TagName0377 = 379
TagName0378 = 380
TagName0379 = 381
TagName0380 = 382
TagName0381 = 383
TagName0382 = 384
TagName0383 = 385
TagName0384 = 386
TagName0385 = 387
TagName0386 = 388
TagName0387 = 389
TagName0388 = 390
TagName0389 = 391
TagName0390 = 392
TagName0391 = 393
TagName0392 = 394
TagName0393 = 395
TagName0394 = 396
TagName0395 = 397
TagName0396 = 398
TagName0397 = 399
TagName0398 = 400
TagName0399 = 401
TagName0400 = 402
TagName0401 = 403
TagName0402 = 404
TagName0403 = 405
TagName0404 = 406
TagName0405 = 407
TagName0406 = 408
TagName0407 = 409
TagName0408 = 410
TagName0409 = 411
TagName0410 = 412
TagName0411 = 413
TagName0412 = 414
TagName0413 = 415
TagName0414 = 416
TagName0415 = 417
TagName0416 = 418
TagName0417 = 419
TagName0418 = 420
TagName0419 = 421
TagName0420 = 422
TagName0421 = 423
TagName0422 = 424
TagName0423 = 425
TagName0424 = 426
TagName0425 = 427
TagName0426 = 428
TagName0427 = 429
TagName0428 = 430
TagName0429 = 431
TagName0430 = 432
TagName0431 = 433
TagName0432 = 434
TagName0433 = 435
TagName0434 = 436
TagName0435 = 437
TagName0436 = 438
TagName0437 = 439
TagName0438 = 440
TagName0439 = 441
TagName0440 = 442
TagName0441 = 443
TagName0442 = 444
TagName0443 = 445
TagName0444 = 446
TagName0445 = 447
TagName0446 = 448
TagName0447 = 449
TagName0448 = 450
TagName0449 = 451
TagName0450 = 452
TagName0451 = 453
TagName0452 = 454
TagName0453 = 455
TagName0454 = 456
TagName0455 = 457
TagName0456 = 458
TagName0457 = 459
TagName0458 = 460
TagName0459 = 461
TagName0460 = 462
TagName0461 = 463
TagName0462 = 464
TagName0463 = 465
TagName0464 = 466
TagName0465 = 467
TagName0466 = 468
TagName0467 = 469
TagName0468 = 470
TagName0469 = 471
TagName0470 = 472
TagName0471 = 473
TagName0472 = 474
TagName0473 = 475
TagName0474 = 476
TagName0475 = 477
TagName0476 = 478
TagName0477 = 479
TagName0478 = 480
TagName0479 = 481
TagName0480 = 482
TagName0481 = 483
TagName0482 = 484
TagName0483 = 485
TagName0484 = 486
TagName0485 = 487
TagName0486 = 488
TagName0487 = 489
TagName0488 = 490
TagName0489 = 491
TagName0490 = 492
TagName0491 = 493
TagName0492 = 494
TagName0493 = 495
TagName0494 = 496
TagName0495 = 497
TagName0496 = 498
TagName0497 = 499
TagName0498 = 500
TagName0499 = 501
TagName0500 = 502
TagName0501 = 503
TagName0502 = 504
TagName0503 = 505
TagName0504 = 506
TagName0505 = 507
TagName0506 = 508
TagName0507 = 509
TagName0508 = 510
TagName0509 = 511
TagName0510 = 512
TagName0511 = 513
TagName0512 = 514
TagName0513 = 515
TagName0514 = 516
TagName0515 = 517
TagName0516 = 518
TagName0517 = 519
TagName0518 = 520
TagName0519 = 521
TagName0520 = 522
TagName0521 = 523
TagName0522 = 524
TagName0523 = 525
TagName0524 = 526
TagName0525 = 527
TagName0526 = 528
TagName0527 = 529
TagName0528 = 530
TagName0529 = 531
TagName0530 = 532
TagName0531 = 533
TagName0532 = 534
TagName0533 = 535
TagName0534 = 536
TagName0535 = 537
TagName0536 = 538
TagName0537 = 539
TagName0538 = 540
TagName0539 = 541
TagName0540 = 542
TagName0541 = 543
TagName0542 = 544
TagName0543 = 545
TagName0544 = 546
TagName0545 = 547
TagName0546 = 548
TagName0547 = 549
TagName0548 = 550
TagName0549 = 551
TagName0550 = 552
TagName0551 = 553
TagName0552 = 554
TagName0553 = 555
TagName0554 = 556
TagName0555 = 557
TagName0556 = 558
TagName0557 = 559
TagName0558 = 560
TagName0559 = 561
TagName0560 = 562
TagName0561 = 563
TagName0562 = 564
TagName0563 = 565
TagName0564 = 566
TagName0565 = 567
TagName0566 = 568
TagName0567 = 569
TagName0568 = 570
TagName0569 = 571
TagName0570 = 572
TagName0571 = 573
TagName0572 = 574
TagName0573 = 575
TagName0574 = 576
TagName0575 = 577
TagName0576 = 578
TagName0577 = 579
TagName0578 = 580
TagName0579 = 581
TagName0580 = 582
TagName0581 = 583
TagName0582 = 584
TagName0583 = 585
TagName0584 = 586
TagName0585 = 587
TagName0586 = 588
TagName0587 = 589
TagName0588 = 590
TagName0589 = 591
TagName0590 = 592
TagName0591 = 593
TagName0592 = 594
TagName0593 = 595
TagName0594 = 596
TagName0595 = 597
TagName0596 = 598
TagName0597 = 599
TagName0598 = 600
TagName0599 = 601
TagName0600 = 602
TagName0601 = 603
TagName0602 = 604
TagName0603 = 605
TagName0604 = 606
TagName0605 = 607
TagName0606 = 608
TagName0607 = 609
TagName0608 = 610
TagName0609 = 611
TagName0610 = 612
TagName0611 = 613
TagName0612 = 614
TagName0613 = 615
TagName0614 = 616
TagName0615 = 617
TagName0616 = 618
TagName0617 = 619
TagName0618 = 620
TagName0619 = 621
TagName0620 = 622
TagName0621 = 623
TagName0622 = 624
TagName0623 = 625
TagName0624 = 626
TagName0625 = 627
TagName0626 = 628
TagName0627 = 629
TagName0628 = 630
TagName0629 = 631
TagName0630 = 632
TagName0631 = 633
TagName0632 = 634
TagName0633 = 635
TagName0634 = 636
TagName0635 = 637
TagName0636 = 638
TagName0637 = 639
TagName0638 = 640
TagName0639 = 641
TagName0640 = 642
TagName0641 = 643
TagName0642 = 644
TagName0643 = 645
TagName0644 = 646
TagName0645 = 647
TagName0646 = 648
TagName0647 = 649
TagName0648 = 650
TagName0649 = 651
TagName0650 = 652
TagName0651 = 653
TagName0652 = 654
TagName0653 = 655
TagName0654 = 656
TagName0655 = 657
TagName0656 = 658
TagName0657 = 659
TagName0658 = 660
TagName0659 = 661
TagName0660 = 662
TagName0661 = 663
TagName0662 = 664
TagName0663 = 665
TagName0664 = 666
TagName0665 = 667
TagName0666 = 668
TagName0667 = 669
TagName0668 = 670
TagName0669 = 671
TagName0670 = 672
TagName0671 = 673
TagName0672 = 674
TagName0673 = 675
TagName0674 = 676
TagName0675 = 677
TagName0676 = 678
TagName0677 = 679
TagName0678 = 680
TagName0679 = 681
TagName0680 = 682
TagName0681 = 683
TagName0682 = 684
TagName0683 = 685
TagName0684 = 686
TagName0685 = 687
TagName0686 = 688
TagName0687 = 689
TagName0688 = 690
TagName0689 = 691
TagName0690 = 692
TagName0691 = 693
TagName0692 = 694
TagName0693 = 695
TagName0694 = 696
TagName0695 = 697
TagName0696 = 698
TagName0697 = 699
TagName0698 = 700
TagName0699 = 701
TagName0700 = 702
TagName0701 = 703
TagName0702 = 704
TagName0703 = 705
TagName0704 = 706
TagName0705 = 707
TagName0706 = 708
TagName0707 = 709
TagName0708 = 710
TagName0709 = 711
TagName0710 = 712
TagName0711 = 713
TagName0712 = 714
TagName0713 = 715
TagName0714 = 716
TagName0715 = 717
TagName0716 = 718
TagName0717 = 719
TagName0718 = 720
TagName0719 = 721
TagName0720 = 722
TagName0721 = 723
TagName0722 = 724
TagName0723 = 725
TagName0724 = 726
TagName0725 = 727
TagName0726 = 728
TagName0727 = 729
TagName0728 = 730
TagName0729 = 731
TagName0730 = 732
TagName0731 = 733
TagName0732 = 734
TagName0733 = 735
TagName0734 = 736
TagName0735 = 737
TagName0736 = 738
TagName0737 = 739
TagName0738 = 740
TagName0739 = 741
TagName0740 = 742
TagName0741 = 743
TagName0742 = 744
TagName0743 = 745
TagName0744 = 746
TagName0745 = 747
TagName0746 = 748
TagName0747 = 749
TagName0748 = 750
TagName0749 = 751
TagName0750 = 752
TagName0751 = 753
TagName0752 = 754
TagName0753 = 755
TagName0754 = 756
TagName0755 = 757
TagName0756 = 758
TagName0757 = 759
TagName0758 = 760
TagName0759 = 761
TagName0760 = 762
TagName0761 = 763
TagName0762 = 764
TagName0763 = 765
TagName0764 = 766
TagName0765 = 767
TagName0766 = 768
TagName0767 = 769
TagName0768 = 770
TagName0769 = 771
TagName0770 = 772
TagName0771 = 773
TagName0772 = 774
TagName0773 = 775
TagName0774 = 776
TagName0775 = 777
TagName0776 = 778
TagName0777 = 779
TagName0778 = 780
TagName0779 = 781
TagName0780 = 782
TagName0781 = 783
TagName0782 = 784
TagName0783 = 785
TagName0784 = 786
TagName0785 = 787
TagName0786 = 788
TagName0787 = 789
TagName0788 = 790
TagName0789 = 791
TagName0790 = 792
TagName0791 = 793
TagName0792 = 794
TagName0793 = 795
TagName0794 = 796
TagName0795 = 797
TagName0796 = 798
TagName0797 = 799
TagName0798 = 800
TagName0799 = 801
TagName0800 = 802
TagName0801 = 803
TagName0802 = 804
TagName0803 = 805
TagName0804 = 806
TagName0805 = 807
TagName0806 = 808
TagName0807 = 809
TagName0808 = 810
TagName0809 = 811
TagName0810 = 812
TagName0811 = 813
TagName0812 = 814
TagName0813 = 815
TagName0814 = 816
TagName0815 = 817
TagName0816 = 818
TagName0817 = 819
TagName0818 = 820
TagName0819 = 821
TagName0820 = 822
TagName0821 = 823
TagName0822 = 824
TagName0823 = 825
TagName0824 = 826
TagName0825 = 827
TagName0826 = 828
TagName0827 = 829
TagName0828 = 830
TagName0829 = 831
TagName0830 = 832
TagName0831 = 833
TagName0832 = 834
TagName0833 = 835
TagName0834 = 836
TagName0835 = 837
TagName0836 = 838
TagName0837 = 839
TagName0838 = 840
TagName0839 = 841
TagName0840 = 842
TagName0841 = 843
TagName0842 = 844
TagName0843 = 845
TagName0844 = 846
TagName0845 = 847
TagName0846 = 848
TagName0847 = 849
TagName0848 = 850
TagName0849 = 851
TagName0850 = 852
TagName0851 = 853
TagName0852 = 854
TagName0853 = 855
TagName0854 = 856
TagName0855 = 857
TagName0856 = 858
TagName0857 = 859
TagName0858 = 860
TagName0859 = 861
TagName0860 = 862
TagName0861 = 863
TagName0862 = 864
TagName0863 = 865
TagName0864 = 866
TagName0865 = 867
TagName0866 = 868
TagName0867 = 869
TagName0868 = 870
TagName0869 = 871
TagName0870 = 872
TagName0871 = 873
TagName0872 = 874
TagName0873 = 875
TagName0874 = 876
TagName0875 = 877
TagName0876 = 878
TagName0877 = 879
TagName0878 = 880
TagName0879 = 881
TagName0880 = 882
TagName0881 = 883
TagName0882 = 884
TagName0883 = 885
TagName0884 = 886
TagName0885 = 887
TagName0886 = 888
TagName0887 = 889
TagName0888 = 890
TagName0889 = 891
TagName0890 = 892
TagName0891 = 893
TagName0892 = 894
TagName0893 = 895
TagName0894 = 896
TagName0895 = 897
TagName0896 = 898
TagName0897 = 899
TagName0898 = 900
TagName0899 = 901
TagName0900 = 902
TagName0901 = 903
TagName0902 = 904
TagName0903 = 905
TagName0904 = 906
TagName0905 = 907
TagName0906 = 908
TagName0907 = 909
TagName0908 = 910
TagName0909 = 911
TagName0910 = 912
TagName0911 = 913
TagName0912 = 914
TagName0913 = 915
TagName0914 = 916
TagName0915 = 917
TagName0916 = 918
TagName0917 = 919
TagName0918 = 920
TagName0919 = 921
TagName0920 = 922
TagName0921 = 923
TagName0922 = 924
TagName0923 = 925
TagName0924 = 926
TagName0925 = 927
TagName0926 = 928
TagName0927 = 929
TagName0928 = 930
TagName0929 = 931
TagName0930 = 932
TagName0931 = 933
TagName0932 = 934
TagName0933 = 935
TagName0934 = 936
TagName0935 = 937
TagName0936 = 938
TagName0937 = 939
TagName0938 = 940
TagName0939 = 941
TagName0940 = 942
TagName0941 = 943
TagName0942 = 944
TagName0943 = 945
TagName0944 = 946
TagName0945 = 947
TagName0946 = 948
TagName0947 = 949
TagName0948 = 950
TagName0949 = 951
TagName0950 = 952
TagName0951 = 953
TagName0952 = 954
TagName0953 = 955
TagName0954 = 956
TagName0955 = 957
TagName0956 = 958
TagName0957 = 959
TagName0958 = 960
TagName0959 = 961
TagName0960 = 962
TagName0961 = 963
TagName0962 = 964
TagName0963 = 965
TagName0964 = 966
TagName0965 = 967
TagName0966 = 968
TagName0967 = 969
TagName0968 = 970
TagName0969 = 971
TagName0970 = 972
TagName0971 = 973
TagName0972 = 974
TagName0973 = 975
TagName0974 = 976
TagName0975 = 977
TagName0976 = 978
TagName0977 = 979
TagName0978 = 980
TagName0979 = 981
TagName0980 = 982
TagName0981 = 983
TagName0982 = 984
TagName0983 = 985
TagName0984 = 986
TagName0985 = 987
TagName0986 = 988
TagName0987 = 989
TagName0988 = 990
TagName0989 = 991
TagName0990 = 992
TagName0991 = 993
TagName0992 = 994
TagName0993 = 995
TagName0994 = 996
TagName0995 = 997
TagName0996 = 998
TagName0997 = 999
TagName0998 = 1000
TagName0999 = 1001
TagName1000 = 1002
TagName1001 = 1003
TagName1002 = 1004
TagName1003 = 1005
TagName1004 = 1006
TagName1005 = 1007
TagName1006 = 1008
TagName1007 = 1009
TagName1008 = 1010
TagName1009 = 1011
TagName1010 = 1012
TagName1011 = 1013
TagName1012 = 1014
TagName1013 = 1015
TagName1014 = 1016
TagName1015 = 1017
TagName1016 = 1018
TagName1017 = 1019
TagName1018 = 1020
TagName1019 = 1021
TagName1020 = 1022
TagName1021 = 1023
TagName1022 = 1024
TagName1023 = 1025
TagName1024 = 1026
TagName1025 = 1027
TagName1026 = 1028
TagName1027 = 1029
TagName1028 = 1030
TagName1029 = 1031
TagName1030 = 1032
TagName1031 = 1033
TagName1032 = 1034
TagName1033 = 1035
TagName1034 = 1036
TagName1035 = 1037
TagName1036 = 1038
TagName1037 = 1039
TagName1038 = 1040
TagName1039 = 1041
TagName1040 = 1042
TagName1041 = 1043
TagName1042 = 1044
TagName1043 = 1045
TagName1044 = 1046
TagName1045 = 1047
TagName1046 = 1048
TagName1047 = 1049
TagName1048 = 1050
TagName1049 = 1051
TagName1050 = 1052
TagName1051 = 1053
TagName1052 = 1054
TagName1053 = 1055
TagName1054 = 1056
TagName1055 = 1057
TagName1056 = 1058
TagName1057 = 1059
TagName1058 = 1060
TagName1059 = 1061
TagName1060 = 1062
TagName1061 = 1063
TagName1062 = 1064
TagName1063 = 1065
TagName1064 = 1066
TagName1065 = 1067
TagName1066 = 1068
TagName1067 = 1069
TagName1068 = 1070
TagName1069 = 1071
TagName1070 = 1072
TagName1071 = 1073
TagName1072 = 1074
TagName1073 = 1075
TagName1074 = 1076
TagName1075 = 1077
TagName1076 = 1078
TagName1077 = 1079
TagName1078 = 1080
TagName1079 = 1081
TagName1080 = 1082
TagName1081 = 1083
TagName1082 = 1084
TagName1083 = 1085
TagName1084 = 1086
TagName1085 = 1087
TagName1086 = 1088
TagName1087 = 1089
TagName1088 = 1090
TagName1089 = 1091
TagName1090 = 1092
TagName1091 = 1093
TagName1092 = 1094
TagName1093 = 1095
TagName1094 = 1096
TagName1095 = 1097
TagName1096 = 1098
TagName1097 = 1099
TagName1098 = 1100
TagName1099 = 1101
TagName1100 = 1102
TagName1101 = 1103
TagName1102 = 1104
TagName1103 = 1105
TagName1104 = 1106
TagName1105 = 1107
TagName1106 = 1108
TagName1107 = 1109
TagName1108 = 1110
TagName1109 = 1111
TagName1110 = 1112
TagName1111 = 1113
TagName1112 = 1114
TagName1113 = 1115
TagName1114 = 1116
TagName1115 = 1117
TagName1116 = 1118
TagName1117 = 1119
TagName1118 = 1120
TagName1119 = 1121
TagName1120 = 1122
TagName1121 = 1123
TagName1122 = 1124
TagName1123 = 1125
TagName1124 = 1126
TagName1125 = 1127
TagName1126 = 1128
TagName1127 = 1129
TagName1128 = 1130
TagName1129 = 1131
TagName1130 = 1132
TagName1131 = 1133
TagName1132 = 1134
TagName1133 = 1135
TagName1134 = 1136
TagName1135 = 1137
TagName1136 = 1138
TagName1137 = 1139
TagName1138 = 1140
TagName1139 = 1141
TagName1140 = 1142
TagName1141 = 1143
TagName1142 = 1144
TagName1143 = 1145
TagName1144 = 1146
TagName1145 = 1147
TagName1146 = 1148
TagName1147 = 1149
TagName1148 = 1150
TagName1149 = 1151
TagName1150 = 1152
TagName1151 = 1153
TagName1152 = 1154
TagName1153 = 1155
TagName1154 = 1156
TagName1155 = 1157
TagName1156 = 1158
TagName1157 = 1159
TagName1158 = 1160
TagName1159 = 1161
TagName1160 = 1162
TagName1161 = 1163
TagName1162 = 1164
TagName1163 = 1165
TagName1164 = 1166
TagName1165 = 1167
TagName1166 = 1168
TagName1167 = 1169
TagName1168 = 1170
TagName1169 = 1171
TagName1170 = 1172
TagName1171 = 1173
TagName1172 = 1174
TagName1173 = 1175
TagName1174 = 1176
TagName1175 = 1177
TagName1176 = 1178
TagName1177 = 1179
TagName1178 = 1180
TagName1179 = 1181
TagName1180 = 1182
TagName1181 = 1183
TagName1182 = 1184
TagName1183 = 1185
TagName1184 = 1186
TagName1185 = 1187
TagName1186 = 1188
TagName1187 = 1189
TagName1188 = 1190
TagName1189 = 1191
TagName1190 = 1192
TagName1191 = 1193
TagName1192 = 1194
TagName1193 = 1195
TagName1194 = 1196
TagName1195 = 1197
TagName1196 = 1198
TagName1197 = 1199
TagName1198 = 1200
TagName1199 = 1201
TagName1200 = 1202
TagName1201 = 1203
TagName1202 = 1204
TagName1203 = 1205
TagName1204 = 1206
TagName1205 = 1207
TagName1206 = 1208
TagName1207 = 1209
TagName1208 = 1210
TagName1209 = 1211
TagName1210 = 1212
TagName1211 = 1213
TagName1212 = 1214
TagName1213 = 1215
TagName1214 = 1216
TagName1215 = 1217
TagName1216 = 1218
TagName1217 = 1219
TagName1218 = 1220
TagName1219 = 1221
TagName1220 = 1222
TagName1221 = 1223
TagName1222 = 1224
TagName1223 = 1225
TagName1224 = 1226
TagName1225 = 1227
TagName1226 = 1228
TagName1227 = 1229
TagName1228 = 1230
TagName1229 = 1231
TagName1230 = 1232
TagName1231 = 1233
TagName1232 = 1234
TagName1233 = 1235
TagName1234 = 1236
TagName1235 = 1237
TagName1236 = 1238
TagName1237 = 1239
TagName1238 = 1240
TagName1239 = 1241
TagName1240 = 1242
TagName1241 = 1243
TagName1242 = 1244
TagName1243 = 1245
TagName1244 = 1246
TagName1245 = 1247
TagName1246 = 1248
TagName1247 = 1249
TagName1248 = 1250
TagName1249 = 1251
TagName1250 = 1252
TagName1251 = 1253
TagName1252 = 1254
TagName1253 = 1255
TagName1254 = 1256
TagName1255 = 1257
TagName1256 = 1258
TagName1257 = 1259
TagName1258 = 1260
TagName1259 = 1261
TagName1260 = 1262
TagName1261 = 1263
TagName1262 = 1264
TagName1263 = 1265
TagName1264 = 1266
TagName1265 = 1267
TagName1266 = 1268
TagName1267 = 1269
TagName1268 = 1270
TagName1269 = 1271
TagName1270 = 1272
TagName1271 = 1273
TagName1272 = 1274
TagName1273 = 1275
TagName1274 = 1276
TagName1275 = 1277
TagName1276 = 1278
TagName1277 = 1279
TagName1278 = 1280
TagName1279 = 1281
TagName1280 = 1282
TagName1281 = 1283
TagName1282 = 1284
TagName1283 = 1285
TagName1284 = 1286
TagName1285 = 1287
TagName1286 = 1288
TagName1287 = 1289
TagName1288 = 1290
TagName1289 = 1291
TagName1290 = 1292
TagName1291 = 1293
TagName1292 = 1294
TagName1293 = 1295
TagName1294 = 1296
TagName1295 = 1297
TagName1296 = 1298
TagName1297 = 1299
TagName1298 = 1300
TagName1299 = 1301
TagName1300 = 1302
TagName1301 = 1303
TagName1302 = 1304
TagName1303 = 1305
TagName1304 = 1306
TagName1305 = 1307
TagName1306 = 1308
TagName1307 = 1309
TagName1308 = 1310
TagName1309 = 1311
TagName1310 = 1312
TagName1311 = 1313
TagName1312 = 1314
TagName1313 = 1315
TagName1314 = 1316
TagName1315 = 1317
TagName1316 = 1318
TagName1317 = 1319
TagName1318 = 1320
TagName1319 = 1321
TagName1320 = 1322
TagName1321 = 1323
TagName1322 = 1324
TagName1323 = 1325
TagName1324 = 1326
TagName1325 = 1327
TagName1326 = 1328
TagName1327 = 1329
TagName1328 = 1330
TagName1329 = 1331
TagName1330 = 1332
TagName1331 = 1333
TagName1332 = 1334
TagName1333 = 1335
TagName1334 = 1336
TagName1335 = 1337
TagName1336 = 1338
TagName1337 = 1339
TagName1338 = 1340
TagName1339 = 1341
TagName1340 = 1342
TagName1341 = 1343
TagName1342 = 1344
TagName1343 = 1345
TagName1344 = 1346
TagName1345 = 1347
TagName1346 = 1348
TagName1347 = 1349
TagName1348 = 1350
TagName1349 = 1351
TagName1350 = 1352
TagName1351 = 1353
TagName1352 = 1354
TagName1353 = 1355
TagName1354 = 1356
TagName1355 = 1357
TagName1356 = 1358
TagName1357 = 1359
TagName1358 = 1360
TagName1359 = 1361
TagName1360 = 1362
TagName1361 = 1363
TagName1362 = 1364
TagName1363 = 1365
TagName1364 = 1366
TagName1365 = 1367
TagName1366 = 1368
TagName1367 = 1369
TagName1368 = 1370
TagName1369 = 1371
TagName1370 = 1372
TagName1371 = 1373
TagName1372 = 1374
TagName1373 = 1375
TagName1374 = 1376
TagName1375 = 1377
TagName1376 = 1378
TagName1377 = 1379
TagName1378 = 1380
TagName1379 = 1381
TagName1380 = 1382
TagName1381 = 1383
TagName1382 = 1384
TagName1383 = 1385
TagName1384 = 1386
TagName1385 = 1387
TagName1386 = 1388
TagName1387 = 1389
TagName1388 = 1390
TagName1389 = 1391
TagName1390 = 1392
TagName1391 = 1393
TagName1392 = 1394
TagName1393 = 1395
TagName1394 = 1396
TagName1395 = 1397
TagName1396 = 1398
TagName1397 = 1399
TagName1398 = 1400
TagName1399 = 1401
TagName1400 = 1402
TagName1401 = 1403
TagName1402 = 1404
TagName1403 = 1405
TagName1404 = 1406
TagName1405 = 1407
TagName1406 = 1408
TagName1407 = 1409
TagName1408 = 1410
TagName1409 = 1411
TagName1410 = 1412
TagName1411 = 1413
TagName1412 = 1414
TagName1413 = 1415
TagName1414 = 1416
TagName1415 = 1417
TagName1416 = 1418
TagName1417 = 1419
TagName1418 = 1420
TagName1419 = 1421
TagName1420 = 1422
TagName1421 = 1423
TagName1422 = 1424
TagName1423 = 1425
TagName1424 = 1426
TagName1425 = 1427
TagName1426 = 1428
TagName1427 = 1429
TagName1428 = 1430
TagName1429 = 1431
TagName1430 = 1432
TagName1431 = 1433
TagName1432 = 1434
TagName1433 = 1435
TagName1434 = 1436
TagName1435 = 1437
TagName1436 = 1438
TagName1437 = 1439
TagName1438 = 1440
TagName1439 = 1441
TagName1440 = 1442
TagName1441 = 1443
TagName1442 = 1444
TagName1443 = 1445
TagName1444 = 1446
TagName1445 = 1447
TagName1446 = 1448
TagName1447 = 1449
TagName1448 = 1450
TagName1449 = 1451
TagName1450 = 1452
TagName1451 = 1453
TagName1452 = 1454
TagName1453 = 1455
TagName1454 = 1456
TagName1455 = 1457
TagName1456 = 1458
TagName1457 = 1459
TagName1458 = 1460
TagName1459 = 1461
TagName1460 = 1462
TagName1461 = 1463
TagName1462 = 1464
TagName1463 = 1465
TagName1464 = 1466
TagName1465 = 1467
TagName1466 = 1468
TagName1467 = 1469
TagName1468 = 1470
TagName1469 = 1471
TagName1470 = 1472
TagName1471 = 1473
TagName1472 = 1474
TagName1473 = 1475
TagName1474 = 1476
TagName1475 = 1477
TagName1476 = 1478
TagName1477 = 1479
TagName1478 = 1480
TagName1479 = 1481
TagName1480 = 1482
TagName1481 = 1483
TagName1482 = 1484
TagName1483 = 1485
TagName1484 = 1486
TagName1485 = 1487
TagName1486 = 1488
TagName1487 = 1489
TagName1488 = 1490
TagName1489 = 1491
TagName1490 = 1492
TagName1491 = 1493
TagName1492 = 1494
TagName1493 = 1495
TagName1494 = 1496
TagName1495 = 1497
TagName1496 = 1498
TagName1497 = 1499
TagName1498 = 1500
TagName1499 = 1501
TagName1500 = 1502
TagName1501 = 1503
TagName1502 = 1504
TagName1503 = 1505
TagName1504 = 1506
TagName1505 = 1507
TagName1506 = 1508
TagName1507 = 1509
TagName1508 = 1510
TagName1509 = 1511
TagName1510 = 1512
TagName1511 = 1513
TagName1512 = 1514
TagName1513 = 1515
TagName1514 = 1516
TagName1515 = 1517
TagName1516 = 1518
TagName1517 = 1519
TagName1518 = 1520
TagName1519 = 1521
TagName1520 = 1522
TagName1521 = 1523
TagName1522 = 1524
TagName1523 = 1525
TagName1524 = 1526
TagName1525 = 1527
TagName1526 = 1528
TagName1527 = 1529
TagName1528 = 1530
TagName1529 = 1531
TagName1530 = 1532
TagName1531 = 1533
TagName1532 = 1534
TagName1533 = 1535
TagName1534 = 1536
TagName1535 = 1537
TagName1536 = 1538
TagName1537 = 1539
TagName1538 = 1540
TagName1539 = 1541
TagName1540 = 1542
TagName1541 = 1543
TagName1542 = 1544
TagName1543 = 1545
TagName1544 = 1546
TagName1545 = 1547
TagName1546 = 1548
TagName1547 = 1549
TagName1548 = 1550
TagName1549 = 1551
TagName1550 = 1552
TagName1551 = 1553
TagName1552 = 1554
TagName1553 = 1555
TagName1554 = 1556
TagName1555 = 1557
TagName1556 = 1558
TagName1557 = 1559
TagName1558 = 1560
TagName1559 = 1561
TagName1560 = 1562
TagName1561 = 1563
TagName1562 = 1564
TagName1563 = 1565
TagName1564 = 1566
TagName1565 = 1567
TagName1566 = 1568
TagName1567 = 1569
TagName1568 = 1570
TagName1569 = 1571
TagName1570 = 1572
TagName1571 = 1573
TagName1572 = 1574
TagName1573 = 1575
TagName1574 = 1576
TagName1575 = 1577
TagName1576 = 1578
TagName1577 = 1579
TagName1578 = 1580
TagName1579 = 1581
TagName1580 = 1582
TagName1581 = 1583
TagName1582 = 1584
TagName1583 = 1585
TagName1584 = 1586
TagName1585 = 1587
TagName1586 = 1588
TagName1587 = 1589
TagName1588 = 1590
TagName1589 = 1591
TagName1590 = 1592
TagName1591 = 1593
TagName1592 = 1594
TagName1593 = 1595
TagName1594 = 1596
TagName1595 = 1597
TagName1596 = 1598
TagName1597 = 1599
TagName1598 = 1600
TagName1599 = 1601
TagName1600 = 1602
TagName1601 = 1603
TagName1602 = 1604
TagName1603 = 1605
TagName1604 = 1606
TagName1605 = 1607
TagName1606 = 1608
TagName1607 = 1609
TagName1608 = 1610
TagName1609 = 1611
TagName1610 = 1612
TagName1611 = 1613
TagName1612 = 1614
TagName1613 = 1615
TagName1614 = 1616
TagName1615 = 1617
TagName1616 = 1618
TagName1617 = 1619
TagName1618 = 1620
TagName1619 = 1621
TagName1620 = 1622
TagName1621 = 1623
TagName1622 = 1624
TagName1623 = 1625
TagName1624 = 1626
TagName1625 = 1627
TagName1626 = 1628
TagName1627 = 1629
TagName1628 = 1630
TagName1629 = 1631
TagName1630 = 1632
TagName1631 = 1633
TagName1632 = 1634
TagName1633 = 1635
TagName1634 = 1636
TagName1635 = 1637
TagName1636 = 1638
TagName1637 = 1639
TagName1638 = 1640
TagName1639 = 1641
TagName1640 = 1642
TagName1641 = 1643
TagName1642 = 1644
TagName1643 = 1645
TagName1644 = 1646
TagName1645 = 1647
TagName1646 = 1648
TagName1647 = 1649
TagName1648 = 1650
TagName1649 = 1651
TagName1650 = 1652
TagName1651 = 1653
TagName1652 = 1654
TagName1653 = 1655
TagName1654 = 1656
TagName1655 = 1657
TagName1656 = 1658
TagName1657 = 1659
TagName1658 = 1660
TagName1659 = 1661
TagName1660 = 1662
TagName1661 = 1663
TagName1662 = 1664
TagName1663 = 1665
TagName1664 = 1666
TagName1665 = 1667
TagName1666 = 1668
TagName1667 = 1669
TagName1668 = 1670
TagName1669 = 1671
TagName1670 = 1672
TagName1671 = 1673
TagName1672 = 1674
TagName1673 = 1675
TagName1674 = 1676
TagName1675 = 1677
TagName1676 = 1678
TagName1677 = 1679
TagName1678 = 1680
TagName1679 = 1681
TagName1680 = 1682
TagName1681 = 1683
TagName1682 = 1684
TagName1683 = 1685
TagName1684 = 1686
TagName1685 = 1687
TagName1686 = 1688
TagName1687 = 1689
TagName1688 = 1690
TagName1689 = 1691
TagName1690 = 1692
TagName1691 = 1693
TagName1692 = 1694
TagName1693 = 1695
TagName1694 = 1696
TagName1695 = 1697
TagName1696 = 1698
TagName1697 = 1699
TagName1698 = 1700
TagName1699 = 1701
TagName1700 = 1702
TagName1701 = 1703
TagName1702 = 1704
TagName1703 = 1705
TagName1704 = 1706
TagName1705 = 1707
TagName1706 = 1708
TagName1707 = 1709
TagName1708 = 1710
TagName1709 = 1711
TagName1710 = 1712
TagName1711 = 1713
TagName1712 = 1714
TagName1713 = 1715
TagName1714 = 1716
TagName1715 = 1717
TagName1716 = 1718
TagName1717 = 1719
TagName1718 = 1720
TagName1719 = 1721
TagName1720 = 1722
TagName1721 = 1723
TagName1722 = 1724
TagName1723 = 1725
TagName1724 = 1726
TagName1725 = 1727
TagName1726 = 1728
TagName1727 = 1729
TagName1728 = 1730
TagName1729 = 1731
TagName1730 = 1732
TagName1731 = 1733
TagName1732 = 1734
TagName1733 = 1735
TagName1734 = 1736
TagName1735 = 1737
TagName1736 = 1738
TagName1737 = 1739
TagName1738 = 1740
TagName1739 = 1741
TagName1740 = 1742
TagName1741 = 1743
TagName1742 = 1744
TagName1743 = 1745
TagName1744 = 1746
TagName1745 = 1747
TagName1746 = 1748
TagName1747 = 1749
TagName1748 = 1750
TagName1749 = 1751
TagName1750 = 1752
TagName1751 = 1753
TagName1752 = 1754
TagName1753 = 1755
TagName1754 = 1756
TagName1755 = 1757
TagName1756 = 1758
TagName1757 = 1759
TagName1758 = 1760
TagName1759 = 1761
TagName1760 = 1762
TagName1761 = 1763
TagName1762 = 1764
TagName1763 = 1765
TagName1764 = 1766
TagName1765 = 1767
TagName1766 = 1768
TagName1767 = 1769
TagName1768 = 1770
TagName1769 = 1771
TagName1770 = 1772
TagName1771 = 1773
TagName1772 = 1774
TagName1773 = 1775
TagName1774 = 1776
TagName1775 = 1777
TagName1776 = 1778
TagName1777 = 1779
TagName1778 = 1780
TagName1779 = 1781
TagName1780 = 1782
TagName1781 = 1783
TagName1782 = 1784
TagName1783 = 1785
TagName1784 = 1786
TagName1785 = 1787
TagName1786 = 1788
TagName1787 = 1789
TagName1788 = 1790
TagName1789 = 1791
TagName1790 = 1792
TagName1791 = 1793
TagName1792 = 1794
TagName1793 = 1795
TagName1794 = 1796
TagName1795 = 1797
TagName1796 = 1798
TagName1797 = 1799
TagName1798 = 1800
TagName1799 = 1801
TagName1800 = 1802
TagName1801 = 1803
TagName1802 = 1804
TagName1803 = 1805
TagName1804 = 1806
TagName1805 = 1807
TagName1806 = 1808
TagName1807 = 1809
TagName1808 = 1810
TagName1809 = 1811
TagName1810 = 1812
TagName1811 = 1813
TagName1812 = 1814
TagName1813 = 1815
TagName1814 = 1816
TagName1815 = 1817
TagName1816 = 1818
TagName1817 = 1819
TagName1818 = 1820
TagName1819 = 1821
TagName1820 = 1822
TagName1821 = 1823
TagName1822 = 1824
TagName1823 = 1825
TagName1824 = 1826
TagName1825 = 1827
TagName1826 = 1828
TagName1827 = 1829
TagName1828 = 1830
TagName1829 = 1831
TagName1830 = 1832
TagName1831 = 1833
TagName1832 = 1834
TagName1833 = 1835
TagName1834 = 1836
TagName1835 = 1837
TagName1836 = 1838
TagName1837 = 1839
TagName1838 = 1840
TagName1839 = 1841
TagName1840 = 1842
TagName1841 = 1843
TagName1842 = 1844
TagName1843 = 1845
TagName1844 = 1846
TagName1845 = 1847
TagName1846 = 1848
TagName1847 = 1849
TagName1848 = 1850
TagName1849 = 1851
TagName1850 = 1852
TagName1851 = 1853
TagName1852 = 1854
TagName1853 = 1855
TagName1854 = 1856
TagName1855 = 1857
TagName1856 = 1858
TagName1857 = 1859
TagName1858 = 1860
TagName1859 = 1861
TagName1860 = 1862
TagName1861 = 1863
TagName1862 = 1864
TagName1863 = 1865
TagName1864 = 1866
TagName1865 = 1867
TagName1866 = 1868
TagName1867 = 1869
TagName1868 = 1870
TagName1869 = 1871
TagName1870 = 1872
TagName1871 = 1873
TagName1872 = 1874
TagName1873 = 1875
TagName1874 = 1876
TagName1875 = 1877
TagName1876 = 1878
TagName1877 = 1879
TagName1878 = 1880
TagName1879 = 1881
TagName1880 = 1882
TagName1881 = 1883
TagName1882 = 1884
TagName1883 = 1885
TagName1884 = 1886
TagName1885 = 1887
TagName1886 = 1888
TagName1887 = 1889
TagName1888 = 1890
TagName1889 = 1891
TagName1890 = 1892
TagName1891 = 1893
TagName1892 = 1894
TagName1893 = 1895
TagName1894 = 1896
TagName1895 = 1897
TagName1896 = 1898
TagName1897 = 1899
TagName1898 = 1900
TagName1899 = 1901
TagName1900 = 1902
TagName1901 = 1903
TagName1902 = 1904
TagName1903 = 1905
TagName1904 = 1906
TagName1905 = 1907
TagName1906 = 1908
TagName1907 = 1909
TagName1908 = 1910
TagName1909 = 1911
TagName1910 = 1912
TagName1911 = 1913
TagName1912 = 1914
TagName1913 = 1915
TagName1914 = 1916
TagName1915 = 1917
TagName1916 = 1918
TagName1917 = 1919
TagName1918 = 1920
TagName1919 = 1921
TagName1920 = 1922
TagName1921 = 1923
TagName1922 = 1924
TagName1923 = 1925
TagName1924 = 1926
TagName1925 = 1927
TagName1926 = 1928
TagName1927 = 1929
TagName1928 = 1930
TagName1929 = 1931
TagName1930 = 1932
TagName1931 = 1933
TagName1932 = 1934
TagName1933 = 1935
TagName1934 = 1936
TagName1935 = 1937
TagName1936 = 1938
TagName1937 = 1939
TagName1938 = 1940
TagName1939 = 1941
TagName1940 = 1942
TagName1941 = 1943
TagName1942 = 1944
TagName1943 = 1945
TagName1944 = 1946
TagName1945 = 1947
TagName1946 = 1948
TagName1947 = 1949
TagName1948 = 1950
TagName1949 = 1951
TagName1950 = 1952
TagName1951 = 1953
TagName1952 = 1954
TagName1953 = 1955
TagName1954 = 1956
TagName1955 = 1957
TagName1956 = 1958
TagName1957 = 1959
TagName1958 = 1960
TagName1959 = 1961
TagName1960 = 1962
TagName1961 = 1963
TagName1962 = 1964
TagName1963 = 1965
TagName1964 = 1966
TagName1965 = 1967
TagName1966 = 1968
TagName1967 = 1969
TagName1968 = 1970
TagName1969 = 1971
TagName1970 = 1972
TagName1971 = 1973
TagName1972 = 1974
TagName1973 = 1975
TagName1974 = 1976
TagName1975 = 1977
TagName1976 = 1978
TagName1977 = 1979
TagName1978 = 1980
TagName1979 = 1981
TagName1980 = 1982
TagName1981 = 1983
TagName1982 = 1984
TagName1983 = 1985
TagName1984 = 1986
TagName1985 = 1987
TagName1986 = 1988
TagName1987 = 1989
TagName1988 = 1990
TagName1989 = 1991
TagName1990 = 1992
TagName1991 = 1993
TagName1992 = 1994
TagName1993 = 1995
TagName1994 = 1996
TagName1995 = 1997
TagName1996 = 1998
TagName1997 = 1999
TagName1998 = 2000
TagName1999 = 2001
TagName2000 = 2002
TagName2001 = 2003
TagName2002 = 2004
TagName2003 = 2005
TagName2004 = 2006
TagName2005 = 2007
TagName2006 = 2008
TagName2007 = 2009
TagName2008 = 2010
TagName2009 = 2011
TagName2010 = 2012
TagName2011 = 2013
TagName2012 = 2014
TagName2013 = 2015
TagName2014 = 2016
TagName2015 = 2017
TagName2016 = 2018
TagName2017 = 2019
TagName2018 = 2020
TagName2019 = 2021
TagName2020 = 2022
TagName2021 = 2023
TagName2022 = 2024
TagName2023 = 2025
TagName2024 = 2026
TagName2025 = 2027
TagName2026 = 2028
TagName2027 = 2029
TagName2028 = 2030
TagName2029 = 2031
TagName2030 = 2032
TagName2031 = 2033
TagName2032 = 2034
TagName2033 = 2035
TagName2034 = 2036
TagName2035 = 2037
TagName2036 = 2038
TagName2037 = 2039
TagName2038 = 2040
TagName2039 = 2041
TagName2040 = 2042
TagName2041 = 2043
TagName2042 = 2044
TagName2043 = 2045
TagName2044 = 2046
TagName2045 = 2047
TagName2046 = 2048
TagName2047 = 2049
TagName2048 = 2050
TagName2049 = 2051
TagName2050 = 2052
TagName2051 = 2053
TagName2052 = 2054
TagName2053 = 2055
TagName2054 = 2056
TagName2055 = 2057
TagName2056 = 2058
TagName2057 = 2059
TagName2058 = 2060
TagName2059 = 2061
TagName2060 = 2062
TagName2061 = 2063
TagName2062 = 2064
TagName2063 = 2065
TagName2064 = 2066
TagName2065 = 2067
TagName2066 = 2068
TagName2067 = 2069
TagName2068 = 2070
TagName2069 = 2071
TagName2070 = 2072
TagName2071 = 2073
TagName2072 = 2074
TagName2073 = 2075
TagName2074 = 2076
TagName2075 = 2077
TagName2076 = 2078
TagName2077 = 2079
TagName2078 = 2080
TagName2079 = 2081
TagName2080 = 2082
TagName2081 = 2083
TagName2082 = 2084
TagName2083 = 2085
TagName2084 = 2086
TagName2085 = 2087
TagName2086 = 2088
TagName2087 = 2089
TagName2088 = 2090
TagName2089 = 2091
TagName2090 = 2092
TagName2091 = 2093
TagName2092 = 2094
TagName2093 = 2095
TagName2094 = 2096
TagName2095 = 2097
TagName2096 = 2098
TagName2097 = 2099
TagName2098 = 2100
TagName2099 = 2101
TagName2100 = 2102
TagName2101 = 2103
TagName2102 = 2104
TagName2103 = 2105
TagName2104 = 2106
TagName2105 = 2107
TagName2106 = 2108
TagName2107 = 2109
TagName2108 = 2110
TagName2109 = 2111
TagName2110 = 2112
TagName2111 = 2113
TagName2112 = 2114
TagName2113 = 2115
TagName2114 = 2116
TagName2115 = 2117
TagName2116 = 2118
TagName2117 = 2119
TagName2118 = 2120
TagName2119 = 2121
TagName2120 = 2122
TagName2121 = 2123
TagName2122 = 2124
TagName2123 = 2125
TagName2124 = 2126
TagName2125 = 2127
TagName2126 = 2128
TagName2127 = 2129
TagName2128 = 2130
TagName2129 = 2131
TagName2130 = 2132
TagName2131 = 2133
TagName2132 = 2134
TagName2133 = 2135
TagName2134 = 2136
TagName2135 = 2137
TagName2136 = 2138
TagName2137 = 2139
TagName2138 = 2140
TagName2139 = 2141
TagName2140 = 2142
TagName2141 = 2143
TagName2142 = 2144
TagName2143 = 2145
TagName2144 = 2146
TagName2145 = 2147
TagName2146 = 2148
TagName2147 = 2149
TagName2148 = 2150
TagName2149 = 2151
TagName2150 = 2152
TagName2151 = 2153
TagName2152 = 2154
TagName2153 = 2155
TagName2154 = 2156
TagName2155 = 2157
TagName2156 = 2158
TagName2157 = 2159
TagName2158 = 2160
TagName2159 = 2161
TagName2160 = 2162
TagName2161 = 2163
TagName2162 = 2164
TagName2163 = 2165
TagName2164 = 2166
TagName2165 = 2167
TagName2166 = 2168
TagName2167 = 2169
TagName2168 = 2170
TagName2169 = 2171
TagName2170 = 2172
TagName2171 = 2173
TagName2172 = 2174
TagName2173 = 2175
TagName2174 = 2176
TagName2175 = 2177
TagName2176 = 2178
TagName2177 = 2179
TagName2178 = 2180
TagName2179 = 2181
TagName2180 = 2182
TagName2181 = 2183
TagName2182 = 2184
TagName2183 = 2185
TagName2184 = 2186
TagName2185 = 2187
TagName2186 = 2188
TagName2187 = 2189
TagName2188 = 2190
TagName2189 = 2191
TagName2190 = 2192
TagName2191 = 2193
TagName2192 = 2194
TagName2193 = 2195
TagName2194 = 2196
TagName2195 = 2197
TagName2196 = 2198
TagName2197 = 2199
TagName2198 = 2200
TagName2199 = 2201
TagName2200 = 2202
TagName2201 = 2203
TagName2202 = 2204
TagName2203 = 2205
TagName2204 = 2206
TagName2205 = 2207
TagName2206 = 2208
TagName2207 = 2209
TagName2208 = 2210
TagName2209 = 2211
TagName2210 = 2212
TagName2211 = 2213
TagName2212 = 2214
TagName2213 = 2215
TagName2214 = 2216
TagName2215 = 2217
TagName2216 = 2218
TagName2217 = 2219
TagName2218 = 2220
TagName2219 = 2221
TagName2220 = 2222
TagName2221 = 2223
TagName2222 = 2224
TagName2223 = 2225
TagName2224 = 2226
TagName2225 = 2227
TagName2226 = 2228
TagName2227 = 2229
TagName2228 = 2230
TagName2229 = 2231
TagName2230 = 2232
TagName2231 = 2233
TagName2232 = 2234
TagName2233 = 2235
TagName2234 = 2236
TagName2235 = 2237
TagName2236 = 2238
TagName2237 = 2239
TagName2238 = 2240
TagName2239 = 2241
TagName2240 = 2242
TagName2241 = 2243
TagName2242 = 2244
TagName2243 = 2245
TagName2244 = 2246
TagName2245 = 2247
TagName2246 = 2248
TagName2247 = 2249
TagName2248 = 2250
TagName2249 = 2251
TagName2250 = 2252
TagName2251 = 2253
TagName2252 = 2254
TagName2253 = 2255
TagName2254 = 2256
TagName2255 = 2257
TagName2256 = 2258
TagName2257 = 2259
TagName2258 = 2260
TagName2259 = 2261
TagName2260 = 2262
TagName2261 = 2263
TagName2262 = 2264
TagName2263 = 2265
TagName2264 = 2266
TagName2265 = 2267
TagName2266 = 2268
TagName2267 = 2269
TagName2268 = 2270
TagName2269 = 2271
TagName2270 = 2272
TagName2271 = 2273
TagName2272 = 2274
TagName2273 = 2275
TagName2274 = 2276
TagName2275 = 2277
TagName2276 = 2278
TagName2277 = 2279
TagName2278 = 2280
TagName2279 = 2281
TagName2280 = 2282
TagName2281 = 2283
TagName2282 = 2284
TagName2283 = 2285
TagName2284 = 2286
TagName2285 = 2287
TagName2286 = 2288
TagName2287 = 2289
TagName2288 = 2290
TagName2289 = 2291
TagName2290 = 2292
TagName2291 = 2293
TagName2292 = 2294
TagName2293 = 2295
TagName2294 = 2296
TagName2295 = 2297
TagName2296 = 2298
TagName2297 = 2299
TagName2298 = 2300
TagName2299 = 2301
TagName2300 = 2302
TagName2301 = 2303
TagName2302 = 2304
TagName2303 = 2305
TagName2304 = 2306
TagName2305 = 2307
TagName2306 = 2308
TagName2307 = 2309
TagName2308 = 2310
TagName2309 = 2311
TagName2310 = 2312
TagName2311 = 2313
TagName2312 = 2314
TagName2313 = 2315
TagName2314 = 2316
TagName2315 = 2317
TagName2316 = 2318
TagName2317 = 2319
TagName2318 = 2320
TagName2319 = 2321
TagName2320 = 2322
TagName2321 = 2323
TagName2322 = 2324
TagName2323 = 2325
TagName2324 = 2326
TagName2325 = 2327
TagName2326 = 2328
TagName2327 = 2329
TagName2328 = 2330
TagName2329 = 2331
TagName2330 = 2332
TagName2331 = 2333
TagName2332 = 2334
TagName2333 = 2335
TagName2334 = 2336
TagName2335 = 2337
TagName2336 = 2338
TagName2337 = 2339
TagName2338 = 2340
TagName2339 = 2341
TagName2340 = 2342
TagName2341 = 2343
TagName2342 = 2344
TagName2343 = 2345
TagName2344 = 2346
TagName2345 = 2347
TagName2346 = 2348
TagName2347 = 2349
TagName2348 = 2350
TagName2349 = 2351
TagName2350 = 2352
TagName2351 = 2353
TagName2352 = 2354
TagName2353 = 2355
TagName2354 = 2356
TagName2355 = 2357
TagName2356 = 2358
TagName2357 = 2359
TagName2358 = 2360
TagName2359 = 2361
TagName2360 = 2362
TagName2361 = 2363
TagName2362 = 2364
TagName2363 = 2365
TagName2364 = 2366
TagName2365 = 2367
TagName2366 = 2368
TagName2367 = 2369
TagName2368 = 2370
TagName2369 = 2371
TagName2370 = 2372
TagName2371 = 2373
TagName2372 = 2374
TagName2373 = 2375
TagName2374 = 2376
TagName2375 = 2377
TagName2376 = 2378
TagName2377 = 2379
TagName2378 = 2380
TagName2379 = 2381
TagName2380 = 2382
TagName2381 = 2383
TagName2382 = 2384
TagName2383 = 2385
TagName2384 = 2386
TagName2385 = 2387
TagName2386 = 2388
TagName2387 = 2389
TagName2388 = 2390
TagName2389 = 2391
TagName2390 = 2392
TagName2391 = 2393
TagName2392 = 2394
TagName2393 = 2395
TagName2394 = 2396
TagName2395 = 2397
TagName2396 = 2398
TagName2397 = 2399
TagName2398 = 2400
TagName2399 = 2401
TagName2400 = 2402
TagName2401 = 2403
TagName2402 = 2404
TagName2403 = 2405
TagName2404 = 2406
TagName2405 = 2407
TagName2406 = 2408
TagName2407 = 2409
TagName2408 = 2410
TagName2409 = 2411
TagName2410 = 2412
TagName2411 = 2413
TagName2412 = 2414
TagName2413 = 2415
TagName2414 = 2416
TagName2415 = 2417
TagName2416 = 2418
TagName2417 = 2419
TagName2418 = 2420
TagName2419 = 2421
TagName2420 = 2422
TagName2421 = 2423
TagName2422 = 2424
TagName2423 = 2425
TagName2424 = 2426
TagName2425 = 2427
TagName2426 = 2428
TagName2427 = 2429
TagName2428 = 2430
TagName2429 = 2431
TagName2430 = 2432
TagName2431 = 2433
TagName2432 = 2434
TagName2433 = 2435
TagName2434 = 2436
TagName2435 = 2437
TagName2436 = 2438
TagName2437 = 2439
TagName2438 = 2440
TagName2439 = 2441
TagName2440 = 2442
TagName2441 = 2443
TagName2442 = 2444
TagName2443 = 2445
TagName2444 = 2446
TagName2445 = 2447
TagName2446 = 2448
TagName2447 = 2449
TagName2448 = 2450
TagName2449 = 2451
TagName2450 = 2452
TagName2451 = 2453
TagName2452 = 2454
TagName2453 = 2455
TagName2454 = 2456
TagName2455 = 2457
TagName2456 = 2458
TagName2457 = 2459
TagName2458 = 2460
TagName2459 = 2461
TagName2460 = 2462
TagName2461 = 2463
TagName2462 = 2464
TagName2463 = 2465
TagName2464 = 2466
TagName2465 = 2467
TagName2466 = 2468
TagName2467 = 2469
TagName2468 = 2470
TagName2469 = 2471
TagName2470 = 2472
TagName2471 = 2473
TagName2472 = 2474
TagName2473 = 2475
TagName2474 = 2476
TagName2475 = 2477
TagName2476 = 2478
TagName2477 = 2479
TagName2478 = 2480
TagName2479 = 2481
TagName2480 = 2482
TagName2481 = 2483
TagName2482 = 2484
TagName2483 = 2485
TagName2484 = 2486
TagName2485 = 2487
TagName2486 = 2488
TagName2487 = 2489
TagName2488 = 2490
TagName2489 = 2491
TagName2490 = 2492
TagName2491 = 2493
TagName2492 = 2494
TagName2493 = 2495
TagName2494 = 2496
TagName2495 = 2497
TagName2496 = 2498
TagName2497 = 2499
TagName2498 = 2500
TagName2499 = 2501
TagName2500 = 2502
TagName2501 = 2503
TagName2502 = 2504
TagName2503 = 2505
TagName2504 = 2506
TagName2505 = 2507
TagName2506 = 2508
TagName2507 = 2509
TagName2508 = 2510
TagName2509 = 2511
TagName2510 = 2512
TagName2511 = 2513
TagName2512 = 2514
TagName2513 = 2515
TagName2514 = 2516
TagName2515 = 2517
TagName2516 = 2518
TagName2517 = 2519
TagName2518 = 2520
TagName2519 = 2521
TagName2520 = 2522
TagName2521 = 2523
TagName2522 = 2524
TagName2523 = 2525
TagName2524 = 2526
TagName2525 = 2527
TagName2526 = 2528
TagName2527 = 2529
TagName2528 = 2530
TagName2529 = 2531
TagName2530 = 2532
TagName2531 = 2533
TagName2532 = 2534
TagName2533 = 2535
TagName2534 = 2536
TagName2535 = 2537
TagName2536 = 2538
TagName2537 = 2539
TagName2538 = 2540
TagName2539 = 2541
TagName2540 = 2542
TagName2541 = 2543
TagName2542 = 2544
TagName2543 = 2545
TagName2544 = 2546
TagName2545 = 2547
TagName2546 = 2548
TagName2547 = 2549
TagName2548 = 2550
TagName2549 = 2551
TagName2550 = 2552
TagName2551 = 2553
TagName2552 = 2554
TagName2553 = 2555
TagName2554 = 2556
TagName2555 = 2557
TagName2556 = 2558
TagName2557 = 2559
TagName2558 = 2560
TagName2559 = 2561
TagName2560 = 2562
TagName2561 = 2563
TagName2562 = 2564
TagName2563 = 2565
TagName2564 = 2566
TagName2565 = 2567
TagName2566 = 2568
TagName2567 = 2569
TagName2568 = 2570
TagName2569 = 2571
TagName2570 = 2572
TagName2571 = 2573
TagName2572 = 2574
TagName2573 = 2575
TagName2574 = 2576
TagName2575 = 2577
TagName2576 = 2578
TagName2577 = 2579
TagName2578 = 2580
TagName2579 = 2581
TagName2580 = 2582
TagName2581 = 2583
TagName2582 = 2584
TagName2583 = 2585
TagName2584 = 2586
TagName2585 = 2587
TagName2586 = 2588
TagName2587 = 2589
TagName2588 = 2590
TagName2589 = 2591
TagName2590 = 2592
TagName2591 = 2593
TagName2592 = 2594
TagName2593 = 2595
TagName2594 = 2596
TagName2595 = 2597
TagName2596 = 2598
TagName2597 = 2599
TagName2598 = 2600
TagName2599 = 2601
TagName2600 = 2602
TagName2601 = 2603
TagName2602 = 2604
TagName2603 = 2605
TagName2604 = 2606
TagName2605 = 2607
TagName2606 = 2608
TagName2607 = 2609
TagName2608 = 2610
TagName2609 = 2611
TagName2610 = 2612
TagName2611 = 2613
TagName2612 = 2614
TagName2613 = 2615
TagName2614 = 2616
TagName2615 = 2617
TagName2616 = 2618
TagName2617 = 2619
TagName2618 = 2620
TagName2619 = 2621
TagName2620 = 2622
TagName2621 = 2623
TagName2622 = 2624
TagName2623 = 2625
TagName2624 = 2626
TagName2625 = 2627
TagName2626 = 2628
TagName2627 = 2629
TagName2628 = 2630
TagName2629 = 2631
TagName2630 = 2632
TagName2631 = 2633
TagName2632 = 2634
TagName2633 = 2635
TagName2634 = 2636
TagName2635 = 2637
TagName2636 = 2638
TagName2637 = 2639
TagName2638 = 2640
TagName2639 = 2641
TagName2640 = 2642
TagName2641 = 2643
TagName2642 = 2644
TagName2643 = 2645
TagName2644 = 2646
TagName2645 = 2647
TagName2646 = 2648
TagName2647 = 2649
TagName2648 = 2650
TagName2649 = 2651
TagName2650 = 2652
TagName2651 = 2653
TagName2652 = 2654
TagName2653 = 2655
TagName2654 = 2656
TagName2655 = 2657
TagName2656 = 2658
TagName2657 = 2659
TagName2658 = 2660
TagName2659 = 2661
TagName2660 = 2662
TagName2661 = 2663
TagName2662 = 2664
TagName2663 = 2665
TagName2664 = 2666
TagName2665 = 2667
TagName2666 = 2668
TagName2667 = 2669
TagName2668 = 2670
TagName2669 = 2671
TagName2670 = 2672
TagName2671 = 2673
TagName2672 = 2674
TagName2673 = 2675
TagName2674 = 2676
TagName2675 = 2677
TagName2676 = 2678
TagName2677 = 2679
TagName2678 = 2680
TagName2679 = 2681
TagName2680 = 2682
TagName2681 = 2683
TagName2682 = 2684
TagName2683 = 2685
TagName2684 = 2686
TagName2685 = 2687
TagName2686 = 2688
TagName2687 = 2689
TagName2688 = 2690
TagName2689 = 2691
TagName2690 = 2692
TagName2691 = 2693
TagName2692 = 2694
TagName2693 = 2695
TagName2694 = 2696
TagName2695 = 2697
TagName2696 = 2698
TagName2697 = 2699
TagName2698 = 2700
TagName2699 = 2701
TagName2700 = 2702
TagName2701 = 2703
TagName2702 = 2704
TagName2703 = 2705
TagName2704 = 2706
TagName2705 = 2707
TagName2706 = 2708
TagName2707 = 2709
TagName2708 = 2710
TagName2709 = 2711
TagName2710 = 2712
TagName2711 = 2713
TagName2712 = 2714
TagName2713 = 2715
TagName2714 = 2716
TagName2715 = 2717
TagName2716 = 2718
TagName2717 = 2719
TagName2718 = 2720
TagName2719 = 2721
TagName2720 = 2722
TagName2721 = 2723
TagName2722 = 2724
TagName2723 = 2725
TagName2724 = 2726
TagName2725 = 2727
TagName2726 = 2728
TagName2727 = 2729
TagName2728 = 2730
TagName2729 = 2731
TagName2730 = 2732
TagName2731 = 2733
TagName2732 = 2734
TagName2733 = 2735
TagName2734 = 2736
TagName2735 = 2737
TagName2736 = 2738
TagName2737 = 2739
TagName2738 = 2740
TagName2739 = 2741
TagName2740 = 2742
TagName2741 = 2743
TagName2742 = 2744
TagName2743 = 2745
TagName2744 = 2746
TagName2745 = 2747
TagName2746 = 2748
TagName2747 = 2749
TagName2748 = 2750
TagName2749 = 2751
TagName2750 = 2752
TagName2751 = 2753
TagName2752 = 2754
TagName2753 = 2755
TagName2754 = 2756
TagName2755 = 2757
TagName2756 = 2758
TagName2757 = 2759
TagName2758 = 2760
TagName2759 = 2761
TagName2760 = 2762
TagName2761 = 2763
TagName2762 = 2764
TagName2763 = 2765
TagName2764 = 2766
TagName2765 = 2767
TagName2766 = 2768
TagName2767 = 2769
TagName2768 = 2770
TagName2769 = 2771
TagName2770 = 2772
TagName2771 = 2773
TagName2772 = 2774
TagName2773 = 2775
TagName2774 = 2776
TagName2775 = 2777
TagName2776 = 2778
TagName2777 = 2779
TagName2778 = 2780
TagName2779 = 2781
TagName2780 = 2782
TagName2781 = 2783
TagName2782 = 2784
TagName2783 = 2785
TagName2784 = 2786
TagName2785 = 2787
TagName2786 = 2788
TagName2787 = 2789
TagName2788 = 2790
TagName2789 = 2791
TagName2790 = 2792
TagName2791 = 2793
TagName2792 = 2794
TagName2793 = 2795
TagName2794 = 2796
TagName2795 = 2797
TagName2796 = 2798
TagName2797 = 2799
TagName2798 = 2800
TagName2799 = 2801
TagName2800 = 2802
TagName2801 = 2803
TagName2802 = 2804
TagName2803 = 2805
TagName2804 = 2806
TagName2805 = 2807
TagName2806 = 2808
TagName2807 = 2809
TagName2808 = 2810
TagName2809 = 2811
TagName2810 = 2812
TagName2811 = 2813
TagName2812 = 2814
TagName2813 = 2815
TagName2814 = 2816
TagName2815 = 2817
TagName2816 = 2818
TagName2817 = 2819
TagName2818 = 2820
TagName2819 = 2821
TagName2820 = 2822
TagName2821 = 2823
TagName2822 = 2824
TagName2823 = 2825
TagName2824 = 2826
TagName2825 = 2827
TagName2826 = 2828
TagName2827 = 2829
TagName2828 = 2830
TagName2829 = 2831
TagName2830 = 2832
TagName2831 = 2833
TagName2832 = 2834
TagName2833 = 2835
TagName2834 = 2836
TagName2835 = 2837
TagName2836 = 2838
TagName2837 = 2839
TagName2838 = 2840
TagName2839 = 2841
TagName2840 = 2842
TagName2841 = 2843
TagName2842 = 2844
TagName2843 = 2845
TagName2844 = 2846
TagName2845 = 2847
TagName2846 = 2848
TagName2847 = 2849
TagName2848 = 2850
TagName2849 = 2851
TagName2850 = 2852
TagName2851 = 2853
TagName2852 = 2854
TagName2853 = 2855
TagName2854 = 2856
TagName2855 = 2857
TagName2856 = 2858
TagName2857 = 2859
TagName2858 = 2860
TagName2859 = 2861
TagName2860 = 2862
TagName2861 = 2863
TagName2862 = 2864
TagName2863 = 2865
TagName2864 = 2866
TagName2865 = 2867
TagName2866 = 2868
TagName2867 = 2869
TagName2868 = 2870
TagName2869 = 2871
TagName2870 = 2872
TagName2871 = 2873
TagName2872 = 2874
TagName2873 = 2875
TagName2874 = 2876
TagName2875 = 2877
TagName2876 = 2878
TagName2877 = 2879
TagName2878 = 2880
TagName2879 = 2881
TagName2880 = 2882
TagName2881 = 2883
TagName2882 = 2884
TagName2883 = 2885
TagName2884 = 2886
TagName2885 = 2887
TagName2886 = 2888
TagName2887 = 2889
TagName2888 = 2890
TagName2889 = 2891
TagName2890 = 2892
TagName2891 = 2893
TagName2892 = 2894
TagName2893 = 2895
TagName2894 = 2896
TagName2895 = 2897
TagName2896 = 2898
TagName2897 = 2899
TagName2898 = 2900
TagName2899 = 2901
TagName2900 = 2902
TagName2901 = 2903
TagName2902 = 2904
TagName2903 = 2905
TagName2904 = 2906
TagName2905 = 2907
TagName2906 = 2908
TagName2907 = 2909
TagName2908 = 2910
TagName2909 = 2911
TagName2910 = 2912
TagName2911 = 2913
TagName2912 = 2914
TagName2913 = 2915
TagName2914 = 2916
TagName2915 = 2917
TagName2916 = 2918
TagName2917 = 2919
TagName2918 = 2920
TagName2919 = 2921
TagName2920 = 2922
TagName2921 = 2923
TagName2922 = 2924
TagName2923 = 2925
TagName2924 = 2926
TagName2925 = 2927
TagName2926 = 2928
TagName2927 = 2929
TagName2928 = 2930
TagName2929 = 2931
TagName2930 = 2932
TagName2931 = 2933
TagName2932 = 2934
TagName2933 = 2935
TagName2934 = 2936
TagName2935 = 2937
TagName2936 = 2938
TagName2937 = 2939
TagName2938 = 2940
TagName2939 = 2941
TagName2940 = 2942
TagName2941 = 2943
TagName2942 = 2944
TagName2943 = 2945
TagName2944 = 2946
TagName2945 = 2947
TagName2946 = 2948
TagName2947 = 2949
TagName2948 = 2950
TagName2949 = 2951
TagName2950 = 2952
TagName2951 = 2953
TagName2952 = 2954
TagName2953 = 2955
TagName2954 = 2956
TagName2955 = 2957
TagName2956 = 2958
TagName2957 = 2959
TagName2958 = 2960
TagName2959 = 2961
TagName2960 = 2962
TagName2961 = 2963
TagName2962 = 2964
TagName2963 = 2965
TagName2964 = 2966
TagName2965 = 2967
TagName2966 = 2968
TagName2967 = 2969
TagName2968 = 2970
TagName2969 = 2971
TagName2970 = 2972
TagName2971 = 2973
TagName2972 = 2974
TagName2973 = 2975
TagName2974 = 2976
TagName2975 = 2977
TagName2976 = 2978
TagName2977 = 2979
TagName2978 = 2980
TagName2979 = 2981
TagName2980 = 2982
TagName2981 = 2983
TagName2982 = 2984
TagName2983 = 2985
TagName2984 = 2986
TagName2985 = 2987
TagName2986 = 2988
TagName2987 = 2989
TagName2988 = 2990
TagName2989 = 2991
TagName2990 = 2992
TagName2991 = 2993
TagName2992 = 2994
TagName2993 = 2995
TagName2994 = 2996
TagName2995 = 2997
TagName2996 = 2998
TagName2997 = 2999
TagName2998 = 3000
TagName2999 = 3001
TagName3000 = 3002
| [
"rkolbe96@gmail.com"
] | rkolbe96@gmail.com |
afbce37d5c69d3bef3b4fd803851db683dbf49c6 | 221cada2354556fbb969f25ddd3079542904ef5d | /Leetcode/264.py | 4a9b3389a6bab222a1a195d16eeeb4c9209d22ac | [] | no_license | syzdemonhunter/Coding_Exercises | 4b09e1a7dad7d1e3d4d4ae27e6e006732ffdcb1d | ca71572677d2b2a2aed94bb60d6ec88cc486a7f3 | refs/heads/master | 2020-05-24T11:19:35.019543 | 2019-11-22T20:08:32 | 2019-11-22T20:08:32 | 187,245,394 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 569 | py | # https://leetcode.com/problems/ugly-number-ii/
# T: O(n)
# S: O(n)
class Solution:
def nthUglyNumber(self, n: int) -> int:
nums = [0]*n
idx_2, idx_3, idx_5 = 0, 0, 0
nums[0] = 1
for i in range(1, len(nums)):
nums[i] = min(nums[idx_2]*2, min(nums[idx_3]*3, nums[idx_5]*5))
if nums[i] == nums[idx_2]*2:
idx_2 += 1
if nums[i] == nums[idx_3]*3:
idx_3 += 1
if nums[i] == nums[idx_5]*5:
idx_5 += 1
return nums[n - 1] | [
"syzuser60@gmail.com"
] | syzuser60@gmail.com |
b7fe6b8b53471259e84556736d55859f62eb1a81 | 9ea92648cb1bb9c3d91cee76d251981f1551d70a | /Multiplayer/Harrowland/HarrowlandAlt.py | 08745253a9f26c527a94864b225b075efa738c2c | [] | no_license | 1234hi1234/CodeCombat | 5c8ac395ac605e22b3b9501325c3eefbc3180500 | 585989200d965af952d1cdb8aca76e7f3db15c64 | refs/heads/master | 2020-03-15T02:39:07.979096 | 2018-03-12T14:23:29 | 2018-03-12T14:23:29 | 131,923,000 | 0 | 0 | null | 2018-05-03T01:05:43 | 2018-05-03T01:05:43 | null | UTF-8 | Python | false | false | 4,963 | py | enemy_types = {}
enemy_types['knight'] = {'danger': 100, 'focus': 100}
enemy_types['potion-master'] = {'danger': 100, 'focus': 100}
enemy_types['ranger'] = {'danger': 100, 'focus': 100}
enemy_types['trapper'] = {'danger': 100, 'focus': 100}
enemy_types['samurai'] = {'danger': 100, 'focus': 100}
enemy_types['librarian'] = {'danger': 100, 'focus': 100}
enemy_types['sorcerer'] = {'danger': 100, 'focus': 100}
enemy_types['hero-placeholder'] = {'danger': 99, 'focus': 100}
enemy_types['hero-placeholder-1'] = {'danger': 99, 'focus': 100}
enemy_types['hero-placeholder-2'] = {'danger': 99, 'focus': 100}
enemy_types['necromancer'] = {'danger': 100, 'focus': 100}
enemy_types['captain'] = {'danger': 100, 'focus': 100}
enemy_types['goliath'] = {'danger': 100, 'focus': 50}
enemy_types['captain'] = {'danger': 100, 'focus': 100}
enemy_types['forest-archer'] = {'danger': 100, 'focus': 50}
enemy_types['ninja'] = {'danger': 100, 'focus': 50}
enemy_types['soldier'] = {'danger': 90, 'focus': 50}
enemy_types['skeleton'] = {'danger': 90, 'focus': 50}
enemy_types['griffin-rider'] = {'danger': 99, 'focus': 50}
enemy_types['paladin'] = {'danger': 99, 'focus': 50}
enemy_types['burl'] = {'danger': 99, 'focus': 50}
enemy_types['archer'] = {'danger': 50, 'focus': 50}
def findTarget():
danger = 0
enemy_return = None
for type in enemy_types.keys():
if enemy_types[type] and enemy_types[type].danger > danger:
enemy = hero.findNearest(hero.findByType(type))
if enemy and hero.distanceTo(enemy) < enemy_types[type].focus:
enemy_return = enemy
danger = enemy_types[type].danger
return enemy_return
def findTarget():
danger = 0
enemy_return = None
for type in enemy_types.keys():
if enemy_types[type] and enemy_types[type].danger > danger:
enemy = hero.findNearest(hero.findByType(type))
if enemy and enemy.team != hero.team and hero.distanceTo(enemy) < enemy_types[type].focus:
enemy_return = enemy
danger = enemy_types[type].danger
if enemy_return is None:
enemy_return = hero.findNearestEnemy()
return enemy_return
def moveTo(position, fast=True):
if position:
if (hero.isReady("jump") and fast):
hero.jumpTo(position)
else:
hero.move(position)
summonTypes = ['soldier','soldier','soldier','soldier','soldier','soldier','paladin']
def summonTroops():
type = summonTypes[len(hero.built) % len(summonTypes)]
if hero.gold > hero.costOf(type):
hero.summon(type)
def commandTroops():
for index, friend in enumerate(hero.findFriends()):
if friend.type == 'paladin':
CommandPaladin(friend)
elif friend.type == 'soldier' or friend.type == 'archer' or friend.type == 'griffin-rider' or friend.type == 'skeleton':
CommandSoldier(friend)
elif friend.type == 'peasant':
CommandPeasant(friend)
def CommandSoldier(soldier):
hero.command(soldier, "defend", hero)
def CommandPeasant(soldier):
item = soldier.findNearestItem()
if item:
hero.command(soldier, "move", item.pos)
def CommandPaladin(paladin):
if (paladin.canCast("heal") and hero.health<hero.maxHealth):
hero.command(paladin, "cast", "heal", self)
else:
hero.command(paladin, "defend", hero)
def pickUpNearestItem(items):
nearestItem = hero.findNearest(items)
if nearestItem:
moveTo(nearestItem.pos)
def attack():
target = findTarget()
if target:
if (hero.canCast('summon-burl', hero)):
hero.cast('summon-burl')
if (hero.canCast('summon-undead')):
hero.cast('summon-undead')
if (hero.canCast('invisibility', self)):
hero.cast('invisibility', self)
if (hero.canCast('raise-dead')):
hero.cast('raise-dead')
if(hero.isReady("throw") and hero.distanceTo(target)<hero.trowRange):
hero.trow(target)
elif (hero.canCast('poison-cloud', target)):
hero.cast('poison-cloud', target)
elif (hero.canCast('fear', target)):
hero.cast('fear', target)
else:
if (hero.canCast('earthskin', self)):
hero.cast('earthskin', self)
elif (hero.canCast('chain-lightning', target)):
hero.cast('chain-lightning', target)
elif (hero.distanceTo(target) > 100):
moveTo(target.pos)
#elif (hero.canCast('drain-life', target)):
# hero.cast('drain-life', target)
elif (hero.isReady("attack")):
hero.attack(target)
invis = -5
while True:
commandTroops()
if hero.now() - invis < 4:
items = hero.findItems()
pickUpNearestItem(items)
else:
if (hero.canCast('earthskin', self)):
hero.cast('earthskin', self)
attack()
summonTroops()
| [
"vadim-job-hg@yandex.ru"
] | vadim-job-hg@yandex.ru |
c45ce4740fa2a925305485c01cd487ebf775fb88 | 02c6653a60df3e6cfeab65f125cb6daccb7735be | /fjord/heartbeat/urls.py | 659f237fbb4075496422816ee9bd7b9cb172adb5 | [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
] | permissive | taranjeet/fjord | 35f628afd87ac16175367bb1f82a715c1ee7d0bb | 47d6380313d010a18621b4d344d01792003d04c9 | refs/heads/master | 2021-05-29T11:44:21.254707 | 2015-08-28T14:01:51 | 2015-08-28T14:01:51 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 214 | py | from django.conf.urls import patterns, url
from .api_views import HeartbeatV2API
urlpatterns = patterns(
'fjord.heartbeat.views',
url(r'^api/v2/hb/?$', HeartbeatV2API.as_view(), name='heartbeat-api')
)
| [
"willkg@mozilla.com"
] | willkg@mozilla.com |
719ec4f3c3e59c60171452530146d2221945d4ee | c3082eb2adc43b311dd3c9ff16fd3ed9df85f266 | /python/examples/pytest/test_fibo.py | b5fb18f78c4551b40119f1a0286fb195b1b872b7 | [] | no_license | szabgab/slides | 78818c7138331b3ba9e221c81da3678a46efe9b3 | 63bba06678554db737602f2fbcd6510c36037e8a | refs/heads/main | 2023-08-31T07:13:51.536711 | 2023-08-29T13:17:59 | 2023-08-29T13:17:59 | 122,212,527 | 87 | 69 | null | 2023-05-19T06:55:11 | 2018-02-20T14:57:03 | Python | UTF-8 | Python | false | false | 356 | py | import fibo
def test_fibonacci_number():
assert fibo.fibonacci_number(1) == 1
assert fibo.fibonacci_number(2) == 1
assert fibo.fibonacci_number(3) == 2
assert fibo.fibonacci_number(4) == 2
def test_fibo():
assert fibo.fibonacci_list(1) == [1]
assert fibo.fibonacci_list(2) == [1, 1]
assert fibo.fibonacci_list(3) == [1, 1, 2]
| [
"gabor@szabgab.com"
] | gabor@szabgab.com |
2bcaeeb5d8679c9c878aa8b7464b5a3b67e50e49 | ded10c2f2f5f91c44ec950237a59225e8486abd8 | /.history/2/matrix_squaring_20200412200806.py | 9ba361ee1a74e58d4d8e25e293a01152216bd14d | [] | no_license | jearistiz/Statistical-Physics-Projects | 276a86407b32ded4e06b32efb2fadbd8eff8daed | d9c5b16a50856e148dc8604d92b6de3ea21fc552 | refs/heads/master | 2022-11-05T03:41:23.623050 | 2020-06-28T06:36:05 | 2020-06-28T06:36:05 | 254,909,897 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,449 | py | # -*- coding: utf-8 -*-
from __future__ import division
import numpy as np
import matplotlib.pyplot as plt
from time import time
def rho_free(x,xp,beta):
"""
Uso: devuelve elemento de matriz dsnsidad para el caso de una partícula libre en un toro infinito.
"""
return (2.*np.pi*beta)**(-0.5) * np.exp(-(x-xp)**2 / (2 * beta) )
def harmonic_potential(x):
return 0.5*x**2
def anharmonic_potential(x):
return 0.5*x**2 - x**3 + x**4
def QHO_canonical_ensemble(x,beta):
"""
Uso: calcula probabilidad teórica cuántica de encontrar al osciladoe armónico
(presente en un baño térmico) en la posición x.
Recibe:
x: float -> posición
beta: float -> inverso de temperatura en unidades reducidas beta = 1/T.
Devuelve:
probabilidad teórica cuántica en posición dada para temperatura T dada.
"""
return (np.tanh(beta/2.)/np.pi)**0.5 * np.exp(- x**2 * np.tanh(beta/2.))
def rho_trotter(grid, beta, potential=harmonic_potential):
"""
Uso: devuelve matriz densidad en aproximación de Trotter para altas temperaturas y un potencial dado
Recibe:
grid: list -> lista de dimensión N
beta: float -> inverso de temperatura en unidades reducidas
potential: func -> potencial de interacción
Devuelve:
matrix -> matriz densidad de dimension NxN
"""
return np.array([ [ rho_free(x , xp,beta) * np.exp(-0.5*beta*(potential(x)+potential(xp))) for x in grid] for xp in grid])
x_max = 5.
nx = 101
dx = 2. * x_max / (nx - 1)
grid_x = np.array([i*dx for i in range(-int((nx-1)/2), int(nx/2 + 1))])
N_beta = 2
beta_fin = 4
beta_ini = beta_fin/N_beta
rho = rho_trotter(grid_x,beta_ini/N_beta,potential=harmonic_potential)
for i in range(N_beta):
rho = np.dot(rho,rho)
rho *= dx
beta_ini *= 2.
print('%d) beta: %.2E -> %.2E'%(i, beta_ini/2,beta_ini))
# checkpoint: trace(rho)=0 when N_beta>16 and nx~1000 or nx~100
# parece que la diferencia entre los picos es siempre constante
print (dx)
print(np.trace(rho))
rho_normalized = rho/(np.trace(rho)*dx)
weights = np.diag(rho_normalized)
plt.figure()
plt.plot(grid_x, weights, label = 'Matrix Convolution +\nTrotter formula')
plt.plot(grid_x, QHO_canonical_ensemble(grid_x,beta_fin), label=u'$\pi^{(Q)}(x;beta)$' )
plt.legend(title=u'$\\beta=%.2E$'%beta_fin)
plt.tight_layout()
plt.show()
plt.close()
| [
"jeaz.git@gmail.com"
] | jeaz.git@gmail.com |
ff7c686a74fe29a06e92a14b49df3fabc3d41990 | f9a5e7233875989f994438ce267907d8210d60a1 | /test/cylindrical_bands/metalearning/knn_ranking/RMSE/k=3/customised_set/cylinder_prediction_custom_AUCROC.py | 0d50ab65229407ef1d6da1dd984ef51326226d83 | [] | no_license | renoslyssiotis/When-are-Machine-learning-models-required-and-when-is-Statistics-enough | da8d53d44a69f4620954a32af3aacca45e1ed641 | 6af1670a74345f509c86b7bdb4aa0761c5b058ff | refs/heads/master | 2022-08-29T20:21:57.553737 | 2020-05-26T18:03:46 | 2020-05-26T18:03:46 | 256,439,921 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,210 | py | import sys, os, pickle
from pathlib import PurePath
current_dir = os.path.realpath(__file__)
p = PurePath(current_dir)
sys.path.append(str(p.parents[7])+'/metalearners/knn_ranking_method/RMSE')
from KNN_ranking_k_3_RMSE import KNN_ranking
#Load the selected meta-dataset after performing zero-variance threshold
with open(str(p.parents[7])+'/analysis/feature_selection/customised_set/customised_X_AUCROC_202.pickle', 'rb') as handle:
metadataset_feature_selected = pickle.load(handle)
#=====================META-FEATURE EXTRACTION==================================
with open(str(p.parents[5])+'/actual/cylinder_metafeatures_202.pickle', 'rb') as handle:
meta_features = pickle.load(handle)
#nested_results is a nested dictionary with all the AUC-ROC performances for each dataset and all models
with open(str(p.parents[6])+'/nested_results_roc.pickle', 'rb') as handle:
nested_results_roc = pickle.load(handle)
"""
Remove the meta-features which are not in the meta-dataset
(i.e. the features which have not been selected in the feature selection process)
"""
metafeatures_to_be_removed = []
for metafeature in meta_features.keys():
if metafeature in metadataset_feature_selected.columns:
pass
else:
metafeatures_to_be_removed.append(metafeature)
[meta_features.pop(key) for key in metafeatures_to_be_removed]
#========================META-LEARNING: RANKING================================
#KNN Ranking Method
top1, top2, top3 = KNN_ranking(metadataset_feature_selected, meta_features, nested_results_roc)
print("==========================================")
print(" AUC-ROC ")
print("==========================================")
print("Top 1 predicted model: " + top1)
print("Top 2 predicted model: " + top2)
print("Top 3 predicted model: " + top3)
#Actual results
with open(str(p.parents[5])+'/actual/cylinder_top_3_roc.pickle', 'rb') as handle:
actual_results = pickle.load(handle)
print("==========================================")
print("Top 1 ACTUAL model: " + actual_results[0])
print("Top 2 ACTUAL model: " + actual_results[1])
print("Top 3 ACTUAL model: " + actual_results[2])
| [
"rl554@cam.ac.uk"
] | rl554@cam.ac.uk |
bac2b87e56944a01d46105dc6f7838937e6a6398 | c380976b7c59dadaccabacf6b541124c967d2b5a | /.history/src/data/data_20191021145012.py | 878b2b9bced3b5913cb149f5d8e0ed6dc8bbab21 | [
"MIT"
] | permissive | bkraft4257/kaggle_titanic | b83603563b4a3c995b631e8142fe72e1730a0e2e | f29ea1773773109a867278c001dbd21a9f7b21dd | refs/heads/master | 2020-08-17T12:45:28.653402 | 2019-11-15T16:20:04 | 2019-11-15T16:20:04 | 215,667,760 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 5,836 | py | import pandas as pd
import numpy as np
from typing import Union
from pathlib import Path
from nameparser import HumanName
class ExtractData:
def __init__(self, filename: Union[str, Path], age_bins=None, drop_columns=None):
# """Extract Training Data from file or Path
# Arguments:
# filename {[str]} -- Filename of CSV data file containing data.
# drop_columns -- Columns in dataframe that should be dropped.
# """
if drop_columns is None:
drop_columns = ["age", "cabin", "name", "ticket"]
self.filename = filename
self.drop_columns = drop_columns
self.all_label_columns = ["survived"]
self.all_feature_columns = [
"pclass",
"name",
"sex",
"age",
"sibsp",
"parch",
"ticket",
"fare",
"cabin",
"embarked",
]
self.Xy_raw = None
self.extract_raw()
def extract_raw(self):
"""
Extracts data from a CSV file.
Returns:
pd.DataFrame -- [description]
"""
Xy_raw = pd.read_csv(self.filename)
Xy_raw.columns = Xy_raw.columns.str.lower().str.replace(" ", "_")
Xy_raw = Xy_raw.rename(columns={"age": "age_known"})
Xy_raw["pclass"] = Xy_raw["pclass"].astype("category")
self.Xy_raw = Xy_raw.set_index("passengerid")
class TransformData:
title_translator = {
"Mlle.": "Mrs.",
"Mme.": "Mrs.",
"Sir.": "Mr.",
"Ms.": "Mrs.",
"Rev.": "Mr.",
"Col.": "Mr.",
"Capt.": "Mr.",
"Lady.": "Mrs.",
"the Countess. of": "Mrs.",
}
def __init__(
self,
raw_data,
adult_age_threshold_min=13,
age_bins=None,
fare_mode=None,
embarked_mode=None,
Xy_age_estimate=None,
drop_columns=None,
):
# """Extract Training Data from file or Path
# Arguments:
# filename {[str]} -- Filename of CSV data file containing data.
# drop_columns -- Columns in dataframe that should be dropped.
# """
if age_bins is None:
age_bins = [0, 10, 20, 30, 40, 50, 60, np.inf]
if drop_columns is None:
drop_columns = ["age", "cabin", "name", "ticket"]
self.raw = raw_data
self.adult_age_threshold_min = adult_age_threshold_min
self.Xy_age_estimate = Xy_age_estimate
self.age_bins = age_bins
self.Xy = self.raw.Xy_raw.copy()
if fare_mode is None:
fare_mode = self.Xy["fare"].mode()[0]
if embarked_mode is None:
embarked_mode = self.Xy["embarked"].mode()[0]
self.fare_mode = fare_mode
self.embarked_mode = embarked_mode
self.impute_missing_fare()
self.impute_missing_embarked()
self.extract_title()
# self.extract_last_name()
# self.extract_cabin_number()
# self.extract_cabin_prefix()
# self.estimate_age()
# self.calc_age_bins()
# self.calc_is_child()
# self.calc_is_travelling_alone()
def calc_is_travelling_alone(self):
self.Xy["is_travelling_alone"] = (self.Xy.sibsp == 0) & (self.Xy.parch == 0)
def calc_is_child(self):
self.Xy["is_child"] = self.Xy.age < self.adult_age_threshold_min
def extract_cabin_number(self):
self.Xy["cabin_number"] = self.Xy.ticket.str.extract("(\d+)$")
def extract_cabin_prefix(self):
self.Xy["cabin_prefix"] = self.Xy.ticket.str.extract("^(.+) ")
def extract_title(self):
"""Extract title from the name using nameparser.
If the Title is empty then we will fill the title with either Mr or Mrs depending upon the sex. This
is adequate for the train and holdout data sets.
"""
title = (self.Xy.name.apply(lambda x: HumanName(x).title)
.replace(self.title_translator)
.replace({"\.": ""}, regex=True)
.replace({"":np.nan})
.fillna(self.Xy['sex'])
.replace({'female':'Mrs', 'male':'Mr'})
)
self.Xy["title"] = title
def extract_last_name(self):
self.Xy["last_name"] = self.Xy.name.apply(lambda x: HumanName(x).last)
def calc_age_bins(self):
self.Xy["age_bin"] = pd.cut(
self.Xy.age, bins=[0, 10, 20, 30, 40, 50, 60, np.inf]
)
def clean(self,):
"""Clean data to remove missing data and "unnecessary" features.
Arguments:
in_raw_df {pd.DataFrame} -- Dataframe containing all columns and rows Kaggle Titanic Training Data set
"""
self.Xy = self.Xy_raw.drop(self.drop_columns, axis=1)
def estimate_age(self, groupby_columns=["sex", "title"]):
"""[summary]
Keyword Arguments:
groupby {list} -- [description] (default: {['sex','title']})
"""
if self.Xy_age_estimate is None:
self.Xy_age_estimate = (
self.Xy.groupby(groupby_columns).age_known.mean().to_frame().round(1)
)
self.Xy_age_estimate = self.Xy_age_estimate.rename(
columns={"age_known": "age_estimate"}
)
out_df = (
self.Xy.reset_index()
.merge(self.Xy_age_estimate, on=groupby_columns)
.set_index("passengerid")
)
out_df["age"] = out_df["age_known"].fillna(out_df["age_estimate"])
self.Xy = out_df
def impute_missing_fare(self):
self.Xy["fare"] = self.Xy["fare"].fillna(self.fare_mode)
def impute_missing_embarked(self):
self.Xy["embarked"] = self.Xy["embarked"].fillna(self.embarked_mode)
| [
"bob.kraft@infiniteleap.net"
] | bob.kraft@infiniteleap.net |
a128b776ef223e142b3e63e78fa56e6498b4b60d | aadea82d00400b71de86b1906ed347d10416e69b | /p34.py | 453c37288579e9b9fd99cd90ca33d5258304399b | [] | no_license | abishekravi/guvipython | fc0f56912691cd5a41ab20f0c36b2027ebccfb00 | 4fbb83f0a131775cd9eb3f810c2d1c9ad22d710a | refs/heads/master | 2021-08-16T10:22:00.052735 | 2020-06-25T04:35:42 | 2020-06-25T04:35:42 | 196,218,458 | 2 | 27 | null | null | null | null | UTF-8 | Python | false | false | 91 | py | #a
name=input()
for i in range(0,len(name)):
if(i%3==0):
print(name[i],end="")
| [
"noreply@github.com"
] | abishekravi.noreply@github.com |
fb45682e5225699d4d66e59229eb4b599449116a | fa889d051a1b3c4d861fb06b10aa5b2e21f97123 | /kbe/src/lib/python/Lib/smtplib.py | 09b4ea647962a7797a4ffd0097bf3f1079d9f286 | [
"LicenseRef-scancode-free-unknown",
"LicenseRef-scancode-python-cwi",
"GPL-1.0-or-later",
"LicenseRef-scancode-other-copyleft",
"Python-2.0",
"MIT",
"LGPL-3.0-only"
] | permissive | BuddhistDeveloper/HeroLegendServer | bcaa837e3bbd6544ce0cf8920fd54a1a324d95c8 | 8bf77679595a2c49c6f381c961e6c52d31a88245 | refs/heads/master | 2022-12-08T00:32:45.623725 | 2018-01-15T02:01:44 | 2018-01-15T02:01:44 | 117,069,431 | 1 | 1 | MIT | 2022-11-19T15:58:30 | 2018-01-11T08:05:32 | Python | UTF-8 | Python | false | false | 38,800 | py | #! /usr/bin/env python3
'''SMTP/ESMTP client class.
This should follow RFC 821 (SMTP), RFC 1869 (ESMTP), RFC 2554 (SMTP
Authentication) and RFC 2487 (Secure SMTP over TLS).
Notes:
Please remember, when doing ESMTP, that the names of the SMTP service
extensions are NOT the same thing as the option keywords for the RCPT
and MAIL commands!
Example:
>>> import smtplib
>>> s=smtplib.SMTP("localhost")
>>> print(s.help())
This is Sendmail version 8.8.4
Topics:
HELO EHLO MAIL RCPT DATA
RSET NOOP QUIT HELP VRFY
EXPN VERB ETRN DSN
For more info use "HELP <topic>".
To report bugs in the implementation send email to
sendmail-bugs@sendmail.org.
For local information send email to Postmaster at your site.
End of HELP info
>>> s.putcmd("vrfy","someone@here")
>>> s.getreply()
(250, "Somebody OverHere <somebody@here.my.org>")
>>> s.quit()
'''
# Author: The Dragon De Monsyne <dragondm@integral.org>
# ESMTP support, test code and doc fixes added by
# Eric S. Raymond <esr@thyrsus.com>
# Better RFC 821 compliance (MAIL and RCPT, and CRLF in data)
# by Carey Evans <c.evans@clear.net.nz>, for picky mail servers.
# RFC 2554 (authentication) support by Gerhard Haering <gerhard@bigfoot.de>.
#
# This was modified from the Python 1.5 library HTTP lib.
import socket
import io
import re
import email.utils
import email.message
import email.generator
import base64
import hmac
import copy
from email.base64mime import body_encode as encode_base64
from sys import stderr
__all__ = ["SMTPException", "SMTPServerDisconnected", "SMTPResponseException",
"SMTPSenderRefused", "SMTPRecipientsRefused", "SMTPDataError",
"SMTPConnectError", "SMTPHeloError", "SMTPAuthenticationError",
"quoteaddr", "quotedata", "SMTP"]
SMTP_PORT = 25
SMTP_SSL_PORT = 465
CRLF = "\r\n"
bCRLF = b"\r\n"
_MAXLINE = 8192 # more than 8 times larger than RFC 821, 4.5.3
OLDSTYLE_AUTH = re.compile(r"auth=(.*)", re.I)
# Exception classes used by this module.
class SMTPException(OSError):
"""Base class for all exceptions raised by this module."""
class SMTPServerDisconnected(SMTPException):
"""Not connected to any SMTP server.
This exception is raised when the server unexpectedly disconnects,
or when an attempt is made to use the SMTP instance before
connecting it to a server.
"""
class SMTPResponseException(SMTPException):
"""Base class for all exceptions that include an SMTP error code.
These exceptions are generated in some instances when the SMTP
server returns an error code. The error code is stored in the
`smtp_code' attribute of the error, and the `smtp_error' attribute
is set to the error message.
"""
def __init__(self, code, msg):
self.smtp_code = code
self.smtp_error = msg
self.args = (code, msg)
class SMTPSenderRefused(SMTPResponseException):
"""Sender address refused.
In addition to the attributes set by on all SMTPResponseException
exceptions, this sets `sender' to the string that the SMTP refused.
"""
def __init__(self, code, msg, sender):
self.smtp_code = code
self.smtp_error = msg
self.sender = sender
self.args = (code, msg, sender)
class SMTPRecipientsRefused(SMTPException):
"""All recipient addresses refused.
The errors for each recipient are accessible through the attribute
'recipients', which is a dictionary of exactly the same sort as
SMTP.sendmail() returns.
"""
def __init__(self, recipients):
self.recipients = recipients
self.args = (recipients,)
class SMTPDataError(SMTPResponseException):
"""The SMTP server didn't accept the data."""
class SMTPConnectError(SMTPResponseException):
"""Error during connection establishment."""
class SMTPHeloError(SMTPResponseException):
"""The server refused our HELO reply."""
class SMTPAuthenticationError(SMTPResponseException):
"""Authentication error.
Most probably the server didn't accept the username/password
combination provided.
"""
def quoteaddr(addrstring):
"""Quote a subset of the email addresses defined by RFC 821.
Should be able to handle anything email.utils.parseaddr can handle.
"""
displayname, addr = email.utils.parseaddr(addrstring)
if (displayname, addr) == ('', ''):
# parseaddr couldn't parse it, use it as is and hope for the best.
if addrstring.strip().startswith('<'):
return addrstring
return "<%s>" % addrstring
return "<%s>" % addr
def _addr_only(addrstring):
displayname, addr = email.utils.parseaddr(addrstring)
if (displayname, addr) == ('', ''):
# parseaddr couldn't parse it, so use it as is.
return addrstring
return addr
# Legacy method kept for backward compatibility.
def quotedata(data):
"""Quote data for email.
Double leading '.', and change Unix newline '\\n', or Mac '\\r' into
Internet CRLF end-of-line.
"""
return re.sub(r'(?m)^\.', '..',
re.sub(r'(?:\r\n|\n|\r(?!\n))', CRLF, data))
def _quote_periods(bindata):
return re.sub(br'(?m)^\.', b'..', bindata)
def _fix_eols(data):
return re.sub(r'(?:\r\n|\n|\r(?!\n))', CRLF, data)
try:
import ssl
except ImportError:
_have_ssl = False
else:
_have_ssl = True
class SMTP:
"""This class manages a connection to an SMTP or ESMTP server.
SMTP Objects:
SMTP objects have the following attributes:
helo_resp
This is the message given by the server in response to the
most recent HELO command.
ehlo_resp
This is the message given by the server in response to the
most recent EHLO command. This is usually multiline.
does_esmtp
This is a True value _after you do an EHLO command_, if the
server supports ESMTP.
esmtp_features
This is a dictionary, which, if the server supports ESMTP,
will _after you do an EHLO command_, contain the names of the
SMTP service extensions this server supports, and their
parameters (if any).
Note, all extension names are mapped to lower case in the
dictionary.
See each method's docstrings for details. In general, there is a
method of the same name to perform each SMTP command. There is also a
method called 'sendmail' that will do an entire mail transaction.
"""
debuglevel = 0
file = None
helo_resp = None
ehlo_msg = "ehlo"
ehlo_resp = None
does_esmtp = 0
default_port = SMTP_PORT
def __init__(self, host='', port=0, local_hostname=None,
timeout=socket._GLOBAL_DEFAULT_TIMEOUT,
source_address=None):
"""Initialize a new instance.
If specified, `host' is the name of the remote host to which to
connect. If specified, `port' specifies the port to which to connect.
By default, smtplib.SMTP_PORT is used. If a host is specified the
connect method is called, and if it returns anything other than a
success code an SMTPConnectError is raised. If specified,
`local_hostname` is used as the FQDN of the local host in the HELO/EHLO
command. Otherwise, the local hostname is found using
socket.getfqdn(). The `source_address` parameter takes a 2-tuple (host,
port) for the socket to bind to as its source address before
connecting. If the host is '' and port is 0, the OS default behavior
will be used.
"""
self._host = host
self.timeout = timeout
self.esmtp_features = {}
self.source_address = source_address
if host:
(code, msg) = self.connect(host, port)
if code != 220:
raise SMTPConnectError(code, msg)
if local_hostname is not None:
self.local_hostname = local_hostname
else:
# RFC 2821 says we should use the fqdn in the EHLO/HELO verb, and
# if that can't be calculated, that we should use a domain literal
# instead (essentially an encoded IP address like [A.B.C.D]).
fqdn = socket.getfqdn()
if '.' in fqdn:
self.local_hostname = fqdn
else:
# We can't find an fqdn hostname, so use a domain literal
addr = '127.0.0.1'
try:
addr = socket.gethostbyname(socket.gethostname())
except socket.gaierror:
pass
self.local_hostname = '[%s]' % addr
def __enter__(self):
return self
def __exit__(self, *args):
try:
code, message = self.docmd("QUIT")
if code != 221:
raise SMTPResponseException(code, message)
except SMTPServerDisconnected:
pass
finally:
self.close()
def set_debuglevel(self, debuglevel):
"""Set the debug output level.
A non-false value results in debug messages for connection and for all
messages sent to and received from the server.
"""
self.debuglevel = debuglevel
def _get_socket(self, host, port, timeout):
# This makes it simpler for SMTP_SSL to use the SMTP connect code
# and just alter the socket connection bit.
if self.debuglevel > 0:
print('connect: to', (host, port), self.source_address,
file=stderr)
return socket.create_connection((host, port), timeout,
self.source_address)
def connect(self, host='localhost', port=0, source_address=None):
"""Connect to a host on a given port.
If the hostname ends with a colon (`:') followed by a number, and
there is no port specified, that suffix will be stripped off and the
number interpreted as the port number to use.
Note: This method is automatically invoked by __init__, if a host is
specified during instantiation.
"""
if source_address:
self.source_address = source_address
if not port and (host.find(':') == host.rfind(':')):
i = host.rfind(':')
if i >= 0:
host, port = host[:i], host[i + 1:]
try:
port = int(port)
except ValueError:
raise OSError("nonnumeric port")
if not port:
port = self.default_port
if self.debuglevel > 0:
print('connect:', (host, port), file=stderr)
self.sock = self._get_socket(host, port, self.timeout)
self.file = None
(code, msg) = self.getreply()
if self.debuglevel > 0:
print("connect:", msg, file=stderr)
return (code, msg)
def send(self, s):
"""Send `s' to the server."""
if self.debuglevel > 0:
print('send:', repr(s), file=stderr)
if hasattr(self, 'sock') and self.sock:
if isinstance(s, str):
s = s.encode("ascii")
try:
self.sock.sendall(s)
except OSError:
self.close()
raise SMTPServerDisconnected('Server not connected')
else:
raise SMTPServerDisconnected('please run connect() first')
def putcmd(self, cmd, args=""):
"""Send a command to the server."""
if args == "":
str = '%s%s' % (cmd, CRLF)
else:
str = '%s %s%s' % (cmd, args, CRLF)
self.send(str)
def getreply(self):
"""Get a reply from the server.
Returns a tuple consisting of:
- server response code (e.g. '250', or such, if all goes well)
Note: returns -1 if it can't read response code.
- server response string corresponding to response code (multiline
responses are converted to a single, multiline string).
Raises SMTPServerDisconnected if end-of-file is reached.
"""
resp = []
if self.file is None:
self.file = self.sock.makefile('rb')
while 1:
try:
line = self.file.readline(_MAXLINE + 1)
except OSError as e:
self.close()
raise SMTPServerDisconnected("Connection unexpectedly closed: "
+ str(e))
if not line:
self.close()
raise SMTPServerDisconnected("Connection unexpectedly closed")
if self.debuglevel > 0:
print('reply:', repr(line), file=stderr)
if len(line) > _MAXLINE:
self.close()
raise SMTPResponseException(500, "Line too long.")
resp.append(line[4:].strip(b' \t\r\n'))
code = line[:3]
# Check that the error code is syntactically correct.
# Don't attempt to read a continuation line if it is broken.
try:
errcode = int(code)
except ValueError:
errcode = -1
break
# Check if multiline response.
if line[3:4] != b"-":
break
errmsg = b"\n".join(resp)
if self.debuglevel > 0:
print('reply: retcode (%s); Msg: %s' % (errcode, errmsg),
file=stderr)
return errcode, errmsg
def docmd(self, cmd, args=""):
"""Send a command, and return its response code."""
self.putcmd(cmd, args)
return self.getreply()
# std smtp commands
def helo(self, name=''):
"""SMTP 'helo' command.
Hostname to send for this command defaults to the FQDN of the local
host.
"""
self.putcmd("helo", name or self.local_hostname)
(code, msg) = self.getreply()
self.helo_resp = msg
return (code, msg)
def ehlo(self, name=''):
""" SMTP 'ehlo' command.
Hostname to send for this command defaults to the FQDN of the local
host.
"""
self.esmtp_features = {}
self.putcmd(self.ehlo_msg, name or self.local_hostname)
(code, msg) = self.getreply()
# According to RFC1869 some (badly written)
# MTA's will disconnect on an ehlo. Toss an exception if
# that happens -ddm
if code == -1 and len(msg) == 0:
self.close()
raise SMTPServerDisconnected("Server not connected")
self.ehlo_resp = msg
if code != 250:
return (code, msg)
self.does_esmtp = 1
#parse the ehlo response -ddm
assert isinstance(self.ehlo_resp, bytes), repr(self.ehlo_resp)
resp = self.ehlo_resp.decode("latin-1").split('\n')
del resp[0]
for each in resp:
# To be able to communicate with as many SMTP servers as possible,
# we have to take the old-style auth advertisement into account,
# because:
# 1) Else our SMTP feature parser gets confused.
# 2) There are some servers that only advertise the auth methods we
# support using the old style.
auth_match = OLDSTYLE_AUTH.match(each)
if auth_match:
# This doesn't remove duplicates, but that's no problem
self.esmtp_features["auth"] = self.esmtp_features.get("auth", "") \
+ " " + auth_match.groups(0)[0]
continue
# RFC 1869 requires a space between ehlo keyword and parameters.
# It's actually stricter, in that only spaces are allowed between
# parameters, but were not going to check for that here. Note
# that the space isn't present if there are no parameters.
m = re.match(r'(?P<feature>[A-Za-z0-9][A-Za-z0-9\-]*) ?', each)
if m:
feature = m.group("feature").lower()
params = m.string[m.end("feature"):].strip()
if feature == "auth":
self.esmtp_features[feature] = self.esmtp_features.get(feature, "") \
+ " " + params
else:
self.esmtp_features[feature] = params
return (code, msg)
def has_extn(self, opt):
"""Does the server support a given SMTP service extension?"""
return opt.lower() in self.esmtp_features
def help(self, args=''):
"""SMTP 'help' command.
Returns help text from server."""
self.putcmd("help", args)
return self.getreply()[1]
def rset(self):
"""SMTP 'rset' command -- resets session."""
return self.docmd("rset")
def _rset(self):
"""Internal 'rset' command which ignores any SMTPServerDisconnected error.
Used internally in the library, since the server disconnected error
should appear to the application when the *next* command is issued, if
we are doing an internal "safety" reset.
"""
try:
self.rset()
except SMTPServerDisconnected:
pass
def noop(self):
"""SMTP 'noop' command -- doesn't do anything :>"""
return self.docmd("noop")
def mail(self, sender, options=[]):
"""SMTP 'mail' command -- begins mail xfer session."""
optionlist = ''
if options and self.does_esmtp:
optionlist = ' ' + ' '.join(options)
self.putcmd("mail", "FROM:%s%s" % (quoteaddr(sender), optionlist))
return self.getreply()
def rcpt(self, recip, options=[]):
"""SMTP 'rcpt' command -- indicates 1 recipient for this mail."""
optionlist = ''
if options and self.does_esmtp:
optionlist = ' ' + ' '.join(options)
self.putcmd("rcpt", "TO:%s%s" % (quoteaddr(recip), optionlist))
return self.getreply()
def data(self, msg):
"""SMTP 'DATA' command -- sends message data to server.
Automatically quotes lines beginning with a period per rfc821.
Raises SMTPDataError if there is an unexpected reply to the
DATA command; the return value from this method is the final
response code received when the all data is sent. If msg
is a string, lone '\r' and '\n' characters are converted to
'\r\n' characters. If msg is bytes, it is transmitted as is.
"""
self.putcmd("data")
(code, repl) = self.getreply()
if self.debuglevel > 0:
print("data:", (code, repl), file=stderr)
if code != 354:
raise SMTPDataError(code, repl)
else:
if isinstance(msg, str):
msg = _fix_eols(msg).encode('ascii')
q = _quote_periods(msg)
if q[-2:] != bCRLF:
q = q + bCRLF
q = q + b"." + bCRLF
self.send(q)
(code, msg) = self.getreply()
if self.debuglevel > 0:
print("data:", (code, msg), file=stderr)
return (code, msg)
def verify(self, address):
"""SMTP 'verify' command -- checks for address validity."""
self.putcmd("vrfy", _addr_only(address))
return self.getreply()
# a.k.a.
vrfy = verify
def expn(self, address):
"""SMTP 'expn' command -- expands a mailing list."""
self.putcmd("expn", _addr_only(address))
return self.getreply()
# some useful methods
def ehlo_or_helo_if_needed(self):
"""Call self.ehlo() and/or self.helo() if needed.
If there has been no previous EHLO or HELO command this session, this
method tries ESMTP EHLO first.
This method may raise the following exceptions:
SMTPHeloError The server didn't reply properly to
the helo greeting.
"""
if self.helo_resp is None and self.ehlo_resp is None:
if not (200 <= self.ehlo()[0] <= 299):
(code, resp) = self.helo()
if not (200 <= code <= 299):
raise SMTPHeloError(code, resp)
def login(self, user, password):
"""Log in on an SMTP server that requires authentication.
The arguments are:
- user: The user name to authenticate with.
- password: The password for the authentication.
If there has been no previous EHLO or HELO command this session, this
method tries ESMTP EHLO first.
This method will return normally if the authentication was successful.
This method may raise the following exceptions:
SMTPHeloError The server didn't reply properly to
the helo greeting.
SMTPAuthenticationError The server didn't accept the username/
password combination.
SMTPException No suitable authentication method was
found.
"""
def encode_cram_md5(challenge, user, password):
challenge = base64.decodebytes(challenge)
response = user + " " + hmac.HMAC(password.encode('ascii'),
challenge, 'md5').hexdigest()
return encode_base64(response.encode('ascii'), eol='')
def encode_plain(user, password):
s = "\0%s\0%s" % (user, password)
return encode_base64(s.encode('ascii'), eol='')
AUTH_PLAIN = "PLAIN"
AUTH_CRAM_MD5 = "CRAM-MD5"
AUTH_LOGIN = "LOGIN"
self.ehlo_or_helo_if_needed()
if not self.has_extn("auth"):
raise SMTPException("SMTP AUTH extension not supported by server.")
# Authentication methods the server claims to support
advertised_authlist = self.esmtp_features["auth"].split()
# List of authentication methods we support: from preferred to
# less preferred methods. Except for the purpose of testing the weaker
# ones, we prefer stronger methods like CRAM-MD5:
preferred_auths = [AUTH_CRAM_MD5, AUTH_PLAIN, AUTH_LOGIN]
# We try the authentication methods the server advertises, but only the
# ones *we* support. And in our preferred order.
authlist = [auth for auth in preferred_auths if auth in advertised_authlist]
if not authlist:
raise SMTPException("No suitable authentication method found.")
# Some servers advertise authentication methods they don't really
# support, so if authentication fails, we continue until we've tried
# all methods.
for authmethod in authlist:
if authmethod == AUTH_CRAM_MD5:
(code, resp) = self.docmd("AUTH", AUTH_CRAM_MD5)
if code == 334:
(code, resp) = self.docmd(encode_cram_md5(resp, user, password))
elif authmethod == AUTH_PLAIN:
(code, resp) = self.docmd("AUTH",
AUTH_PLAIN + " " + encode_plain(user, password))
elif authmethod == AUTH_LOGIN:
(code, resp) = self.docmd("AUTH",
"%s %s" % (AUTH_LOGIN, encode_base64(user.encode('ascii'), eol='')))
if code == 334:
(code, resp) = self.docmd(encode_base64(password.encode('ascii'), eol=''))
# 235 == 'Authentication successful'
# 503 == 'Error: already authenticated'
if code in (235, 503):
return (code, resp)
# We could not login sucessfully. Return result of last attempt.
raise SMTPAuthenticationError(code, resp)
def starttls(self, keyfile=None, certfile=None, context=None):
"""Puts the connection to the SMTP server into TLS mode.
If there has been no previous EHLO or HELO command this session, this
method tries ESMTP EHLO first.
If the server supports TLS, this will encrypt the rest of the SMTP
session. If you provide the keyfile and certfile parameters,
the identity of the SMTP server and client can be checked. This,
however, depends on whether the socket module really checks the
certificates.
This method may raise the following exceptions:
SMTPHeloError The server didn't reply properly to
the helo greeting.
"""
self.ehlo_or_helo_if_needed()
if not self.has_extn("starttls"):
raise SMTPException("STARTTLS extension not supported by server.")
(resp, reply) = self.docmd("STARTTLS")
if resp == 220:
if not _have_ssl:
raise RuntimeError("No SSL support included in this Python")
if context is not None and keyfile is not None:
raise ValueError("context and keyfile arguments are mutually "
"exclusive")
if context is not None and certfile is not None:
raise ValueError("context and certfile arguments are mutually "
"exclusive")
if context is None:
context = ssl._create_stdlib_context(certfile=certfile,
keyfile=keyfile)
server_hostname = self._host if ssl.HAS_SNI else None
self.sock = context.wrap_socket(self.sock,
server_hostname=server_hostname)
self.file = None
# RFC 3207:
# The client MUST discard any knowledge obtained from
# the server, such as the list of SMTP service extensions,
# which was not obtained from the TLS negotiation itself.
self.helo_resp = None
self.ehlo_resp = None
self.esmtp_features = {}
self.does_esmtp = 0
return (resp, reply)
def sendmail(self, from_addr, to_addrs, msg, mail_options=[],
rcpt_options=[]):
"""This command performs an entire mail transaction.
The arguments are:
- from_addr : The address sending this mail.
- to_addrs : A list of addresses to send this mail to. A bare
string will be treated as a list with 1 address.
- msg : The message to send.
- mail_options : List of ESMTP options (such as 8bitmime) for the
mail command.
- rcpt_options : List of ESMTP options (such as DSN commands) for
all the rcpt commands.
msg may be a string containing characters in the ASCII range, or a byte
string. A string is encoded to bytes using the ascii codec, and lone
\\r and \\n characters are converted to \\r\\n characters.
If there has been no previous EHLO or HELO command this session, this
method tries ESMTP EHLO first. If the server does ESMTP, message size
and each of the specified options will be passed to it. If EHLO
fails, HELO will be tried and ESMTP options suppressed.
This method will return normally if the mail is accepted for at least
one recipient. It returns a dictionary, with one entry for each
recipient that was refused. Each entry contains a tuple of the SMTP
error code and the accompanying error message sent by the server.
This method may raise the following exceptions:
SMTPHeloError The server didn't reply properly to
the helo greeting.
SMTPRecipientsRefused The server rejected ALL recipients
(no mail was sent).
SMTPSenderRefused The server didn't accept the from_addr.
SMTPDataError The server replied with an unexpected
error code (other than a refusal of
a recipient).
Note: the connection will be open even after an exception is raised.
Example:
>>> import smtplib
>>> s=smtplib.SMTP("localhost")
>>> tolist=["one@one.org","two@two.org","three@three.org","four@four.org"]
>>> msg = '''\\
... From: Me@my.org
... Subject: testin'...
...
... This is a test '''
>>> s.sendmail("me@my.org",tolist,msg)
{ "three@three.org" : ( 550 ,"User unknown" ) }
>>> s.quit()
In the above example, the message was accepted for delivery to three
of the four addresses, and one was rejected, with the error code
550. If all addresses are accepted, then the method will return an
empty dictionary.
"""
self.ehlo_or_helo_if_needed()
esmtp_opts = []
if isinstance(msg, str):
msg = _fix_eols(msg).encode('ascii')
if self.does_esmtp:
# Hmmm? what's this? -ddm
# self.esmtp_features['7bit']=""
if self.has_extn('size'):
esmtp_opts.append("size=%d" % len(msg))
for option in mail_options:
esmtp_opts.append(option)
(code, resp) = self.mail(from_addr, esmtp_opts)
if code != 250:
if code == 421:
self.close()
else:
self._rset()
raise SMTPSenderRefused(code, resp, from_addr)
senderrs = {}
if isinstance(to_addrs, str):
to_addrs = [to_addrs]
for each in to_addrs:
(code, resp) = self.rcpt(each, rcpt_options)
if (code != 250) and (code != 251):
senderrs[each] = (code, resp)
if code == 421:
self.close()
raise SMTPRecipientsRefused(senderrs)
if len(senderrs) == len(to_addrs):
# the server refused all our recipients
self._rset()
raise SMTPRecipientsRefused(senderrs)
(code, resp) = self.data(msg)
if code != 250:
if code == 421:
self.close()
else:
self._rset()
raise SMTPDataError(code, resp)
#if we got here then somebody got our mail
return senderrs
def send_message(self, msg, from_addr=None, to_addrs=None,
mail_options=[], rcpt_options={}):
"""Converts message to a bytestring and passes it to sendmail.
The arguments are as for sendmail, except that msg is an
email.message.Message object. If from_addr is None or to_addrs is
None, these arguments are taken from the headers of the Message as
described in RFC 2822 (a ValueError is raised if there is more than
one set of 'Resent-' headers). Regardless of the values of from_addr and
to_addr, any Bcc field (or Resent-Bcc field, when the Message is a
resent) of the Message object won't be transmitted. The Message
object is then serialized using email.generator.BytesGenerator and
sendmail is called to transmit the message.
"""
# 'Resent-Date' is a mandatory field if the Message is resent (RFC 2822
# Section 3.6.6). In such a case, we use the 'Resent-*' fields. However,
# if there is more than one 'Resent-' block there's no way to
# unambiguously determine which one is the most recent in all cases,
# so rather than guess we raise a ValueError in that case.
#
# TODO implement heuristics to guess the correct Resent-* block with an
# option allowing the user to enable the heuristics. (It should be
# possible to guess correctly almost all of the time.)
resent = msg.get_all('Resent-Date')
if resent is None:
header_prefix = ''
elif len(resent) == 1:
header_prefix = 'Resent-'
else:
raise ValueError("message has more than one 'Resent-' header block")
if from_addr is None:
# Prefer the sender field per RFC 2822:3.6.2.
from_addr = (msg[header_prefix + 'Sender']
if (header_prefix + 'Sender') in msg
else msg[header_prefix + 'From'])
if to_addrs is None:
addr_fields = [f for f in (msg[header_prefix + 'To'],
msg[header_prefix + 'Bcc'],
msg[header_prefix + 'Cc']) if f is not None]
to_addrs = [a[1] for a in email.utils.getaddresses(addr_fields)]
# Make a local copy so we can delete the bcc headers.
msg_copy = copy.copy(msg)
del msg_copy['Bcc']
del msg_copy['Resent-Bcc']
with io.BytesIO() as bytesmsg:
g = email.generator.BytesGenerator(bytesmsg)
g.flatten(msg_copy, linesep='\r\n')
flatmsg = bytesmsg.getvalue()
return self.sendmail(from_addr, to_addrs, flatmsg, mail_options,
rcpt_options)
def close(self):
"""Close the connection to the SMTP server."""
if self.file:
self.file.close()
self.file = None
if self.sock:
self.sock.close()
self.sock = None
def quit(self):
"""Terminate the SMTP session."""
res = self.docmd("quit")
# A new EHLO is required after reconnecting with connect()
self.ehlo_resp = self.helo_resp = None
self.esmtp_features = {}
self.does_esmtp = False
self.close()
return res
if _have_ssl:
class SMTP_SSL(SMTP):
""" This is a subclass derived from SMTP that connects over an SSL
encrypted socket (to use this class you need a socket module that was
compiled with SSL support). If host is not specified, '' (the local
host) is used. If port is omitted, the standard SMTP-over-SSL port
(465) is used. local_hostname and source_address have the same meaning
as they do in the SMTP class. keyfile and certfile are also optional -
they can contain a PEM formatted private key and certificate chain file
for the SSL connection. context also optional, can contain a
SSLContext, and is an alternative to keyfile and certfile; If it is
specified both keyfile and certfile must be None.
"""
default_port = SMTP_SSL_PORT
def __init__(self, host='', port=0, local_hostname=None,
keyfile=None, certfile=None,
timeout=socket._GLOBAL_DEFAULT_TIMEOUT,
source_address=None, context=None):
if context is not None and keyfile is not None:
raise ValueError("context and keyfile arguments are mutually "
"exclusive")
if context is not None and certfile is not None:
raise ValueError("context and certfile arguments are mutually "
"exclusive")
self.keyfile = keyfile
self.certfile = certfile
if context is None:
context = ssl._create_stdlib_context(certfile=certfile,
keyfile=keyfile)
self.context = context
SMTP.__init__(self, host, port, local_hostname, timeout,
source_address)
def _get_socket(self, host, port, timeout):
if self.debuglevel > 0:
print('connect:', (host, port), file=stderr)
new_socket = socket.create_connection((host, port), timeout,
self.source_address)
server_hostname = self._host if ssl.HAS_SNI else None
new_socket = self.context.wrap_socket(new_socket,
server_hostname=server_hostname)
return new_socket
__all__.append("SMTP_SSL")
#
# LMTP extension
#
LMTP_PORT = 2003
class LMTP(SMTP):
"""LMTP - Local Mail Transfer Protocol
The LMTP protocol, which is very similar to ESMTP, is heavily based
on the standard SMTP client. It's common to use Unix sockets for
LMTP, so our connect() method must support that as well as a regular
host:port server. local_hostname and source_address have the same
meaning as they do in the SMTP class. To specify a Unix socket,
you must use an absolute path as the host, starting with a '/'.
Authentication is supported, using the regular SMTP mechanism. When
using a Unix socket, LMTP generally don't support or require any
authentication, but your mileage might vary."""
ehlo_msg = "lhlo"
def __init__(self, host='', port=LMTP_PORT, local_hostname=None,
source_address=None):
"""Initialize a new instance."""
SMTP.__init__(self, host, port, local_hostname=local_hostname,
source_address=source_address)
def connect(self, host='localhost', port=0, source_address=None):
"""Connect to the LMTP daemon, on either a Unix or a TCP socket."""
if host[0] != '/':
return SMTP.connect(self, host, port, source_address=source_address)
# Handle Unix-domain sockets.
try:
self.sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)
self.file = None
self.sock.connect(host)
except OSError:
if self.debuglevel > 0:
print('connect fail:', host, file=stderr)
if self.sock:
self.sock.close()
self.sock = None
raise
(code, msg) = self.getreply()
if self.debuglevel > 0:
print('connect:', msg, file=stderr)
return (code, msg)
# Test the sendmail method, which tests most of the others.
# Note: This always sends to localhost.
if __name__ == '__main__':
import sys
def prompt(prompt):
sys.stdout.write(prompt + ": ")
sys.stdout.flush()
return sys.stdin.readline().strip()
fromaddr = prompt("From")
toaddrs = prompt("To").split(',')
print("Enter message, end with ^D:")
msg = ''
while 1:
line = sys.stdin.readline()
if not line:
break
msg = msg + line
print("Message length is %d" % len(msg))
server = SMTP('localhost')
server.set_debuglevel(1)
server.sendmail(fromaddr, toaddrs, msg)
server.quit()
| [
"liushuaigeq@163.com"
] | liushuaigeq@163.com |
803e85beedc5941fec0a4790c7e8e2d6034d23c9 | 8e24e8bba2dd476f9fe612226d24891ef81429b7 | /geeksforgeeks/python/expert/5_1.py | 25b899efb6d6d0099e799bc80911fcb7704bc88c | [] | no_license | qmnguyenw/python_py4e | fb56c6dc91c49149031a11ca52c9037dc80d5dcf | 84f37412bd43a3b357a17df9ff8811eba16bba6e | refs/heads/master | 2023-06-01T07:58:13.996965 | 2021-06-15T08:39:26 | 2021-06-15T08:39:26 | 349,059,725 | 1 | 1 | null | null | null | null | UTF-8 | Python | false | false | 5,079 | py | Optparse module in Python
**Optparse** module makes easy to write command-line tools. It allows
argument parsing in the python program.
* **optparse** make it easy to handle the command-line argument.
* It comes default with python.
* It allows dynamic data input to change the output
**Code: Creating an OptionParser object.**
## Python3
__
__
__
__
__
__
__
import optparse
parser = optparse.OptionParser()
---
__
__
**Defining options:**
It should be added one at a time using the **add_option()**. Each Option
instance represents a set of synonymous command-line option string.
Way to create an Option instance are:
> OptionParser. **add_option** ( _option_ )
>
> OptionParser. **add_option** ( _*opt_str, attr=value, .._.)
To define an option with only a short option string:
parser.add_option("-f", attr=value, ....)
And to define an option with only a long option string:
parser.add_option("--foo", attr=value, ....)
**Standard Option Actions:**
> * **“store”:** store this option’s argument (default).
> * **“store_const”:** store a constant value.
> * **“store_true”:** store True.
> * **“store_false”:** store False.
> * **“append”:** append this option’s argument to a list.
> * **“append_const”:** append a constant value to a list.
>
**Standard Option Attributes:**
> * **Option.action:** (default: “store”)
> * **Option.type:** (default: “string”)
> * **Option.dest:** (default: derived from option strings)
> * **Option.default:** The value to use for this option’s destination if
> the option is not seen on the command line.
>
###
Here’s an example of using optparse module in a simple script:
## Python3
__
__
__
__
__
__
__
# import OptionParser class
# from optparse module.
from optparse import OptionParser
# create a OptionParser
# class object
parser = OptionParser()
# ass options
parser.add_option("-f", "--file",
dest = "filename",
help = "write report to FILE",
metavar = "FILE")
parser.add_option("-q", "--quiet",
action = "store_false",
dest = "verbose", default = True,
help = "don't print status messages to stdout")
(options, args) = parser.parse_args()
---
__
__
With these few lines of code, users of your script can now do the “usual
thing” on the command-line, for example:
<yourscript> --file=outfile -q
#### Lets, understand with an example:
**Code:** Writing python script for print table of n.
## Python3
__
__
__
__
__
__
__
# import optparse module
import optparse
# define a function for
# table of n
def table(n, dest_cheak):
for i in range(1,11):
tab = i*n
if dest_cheak:
print(tab)
return tab
# define a function for
# adding options
def Main():
# create OptionParser object
parser = optparse.OptionParser()
# add options
parser.add_option('-n', dest = 'num',
type = 'int',
help = 'specify the n''th table number to output')
parser.add_option('-o', dest = 'out',
type = 'string',
help = 'specify an output file (Optional)')
parser.add_option("-a", "--all",
action = "store_true",
dest = "prin",
default = False,
help = "print all numbers up to N")
(options, args) = parser.parse_args()
if (options.num == None):
print (parser.usage)
exit(0)
else:
number = options.num
# function calling
result = table(number, options.prin)
print ("The " + str(number)+ "th table is " +
str(result))
if (options.out != None):
# open a file in append mode
f = open(options.out,"a")
# write in the file
f.write(str(result) + '\n')
# Driver code
if __name__ == '__main__':
# function calling
Main()
---
__
__
**Output:**
python file_name.py -n 4
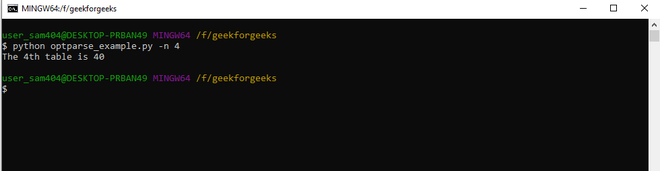
python file_name.py -n 4 -o
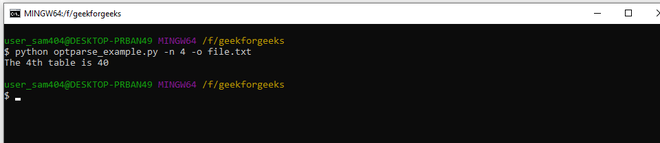
file.txt created
python file_name.py -n 4 -a
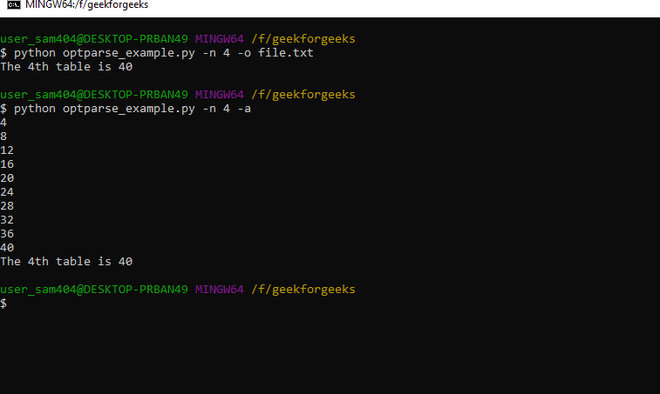
For knowing more about this module click here.
Attention geek! Strengthen your foundations with the **Python Programming
Foundation** Course and learn the basics.
To begin with, your interview preparations Enhance your Data Structures
concepts with the **Python DS** Course.
My Personal Notes _arrow_drop_up_
Save
| [
"qmnguyenw@gmail.com"
] | qmnguyenw@gmail.com |
0557e253ffe377f396b357d6b0b6fbea9fdb29fd | d9f775ba2a46b8c95d68e61bea929810a226f4b8 | /src/investigation/analyze_threshold_neural_network_classifier.py | 7760b2058f7c74e5905913aa113c842b8fd4028c | [] | no_license | barium-project/qubit-reliability | 6e25f916fa2fcd2c7a078edc7045071ffae9e0bc | 902ef98e9a51fe3cf4413ccb79e90d44051a48b7 | refs/heads/master | 2022-12-13T20:02:02.826329 | 2020-06-23T04:14:41 | 2020-06-23T04:14:41 | 251,139,645 | 0 | 0 | null | 2022-12-08T09:43:15 | 2020-03-29T21:35:40 | Jupyter Notebook | UTF-8 | Python | false | false | 2,925 | py | from src.features.build_features import *
from src.models.threshold_classifiers import *
from src.visualization.visualize import *
from sklearn.model_selection import StratifiedKFold
from sklearn.neural_network import MLPClassifier
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report, confusion_matrix
if __name__ == "__main__":
X, y, s = load_data('ARTIFICIAL_V4', stats=True)
print(s)
qubits_class = [
(s['file_range']['./data/artificial/v4/dark_tags_by_trial_with_decay_MC.csv'][0] <= i
and i <= s['file_range']['./data/artificial/v4/dark_tags_by_trial_with_decay_MC.csv'][1]) * 1000
+ y[i] * 100
+ len(X[i]) for i in range(len(X))]
indices = list(StratifiedKFold(n_splits=5, shuffle=True, random_state=RANDOM_SEED).split(X, qubits_class))
pipeline = Pipeline([
("Histogramizer", Histogramizer(bins=11, range=(s['first_arrival'], s['last_arrival']))),
("Neural network", MLPClassifier(hidden_layer_sizes=(33, 33), activation='relu', solver='adam', max_iter=50, tol=0.001, verbose=True))]
)
for i in indices[:]:
# Train neural network
pipeline.fit(X[i[0]], y[i[0]])
print(len(X[i[0]]))
print(len(X[i[1]]))
print()
# Predict with threshold
model = ThresholdCutoffClassifier(14)
y_pred_threshold = model.predict(X[i[1]])
dp_threshold = filter_datapoints(X[i[1]], y[i[1]], y_pred_threshold, indices=i[1])
i_n = list(dp_threshold['i_n']) + list(dp_threshold['i_fn'])
print(len(dp_threshold['i_n']))
print(len(dp_threshold['i_fn']))
print(len(dp_threshold['i_p']))
print(len(dp_threshold['i_fp']))
print((float(len(dp_threshold['i_p'])) + len(dp_threshold['i_n'])) / len(X[i[1]]))
print()
# Predict with neural network
y_pred_neural_network_all = pipeline.predict(X[i[1]])
dp_neural_network_all = filter_datapoints(X[i[1]], y[i[1]], y_pred_neural_network_all, indices=i[1])
print(len(dp_neural_network_all['i_n']))
print(len(dp_neural_network_all['i_fn']))
print(len(dp_neural_network_all['i_p']))
print(len(dp_neural_network_all['i_fp']))
print((float(len(dp_neural_network_all['i_p'])) + len(dp_neural_network_all['i_n'])) / len(X[i[1]]))
print()
# Predict with the brights of the threshold using the neural network
y_pred_neural_network = pipeline.predict(X[i_n])
dp_neural_network = filter_datapoints(X[i_n], y[i_n], y_pred_neural_network, indices=i_n)
print(len(dp_neural_network['i_n']))
print(len(dp_neural_network['i_fn']))
print(len(dp_neural_network['i_p']))
print(len(dp_neural_network['i_fp']))
print((float(len(dp_threshold['i_p'])) + len(dp_neural_network['i_n']) + len(dp_neural_network['i_p'])) / len(X[i[1]]))
| [
"quentintruong@users.noreply.github.com"
] | quentintruong@users.noreply.github.com |
014809a20edc47b0f80c3f630ec3cc2a6744ad2c | ed37c6acf35ad8dfa7064c7d304f046c3657cb7a | /leetcode/google_prep/interview_process/1_unique_email.py | dcc4e4af6a4e737bc580bcd1b42c12bd29134c15 | [] | no_license | etture/algorithms_practice | 7b73753f5d579b7007ddd79f9a73165433d79b13 | ba398a040d2551b34f504ae1ce795e8cd5937dcc | refs/heads/master | 2021-11-18T20:37:11.730912 | 2021-10-03T23:25:24 | 2021-10-03T23:25:24 | 190,863,957 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,724 | py | # Basic imports --------------------------------------------
from __future__ import annotations
import sys
sys.setrecursionlimit(10**6)
from os.path import dirname, abspath, basename, normpath
root = abspath(__file__)
while basename(normpath(root)) != 'algo_practice':
root = dirname(root)
sys.path.append(root)
from utils.Tester import Tester, Logger
logger = Logger(verbose=False)
# ----------------------------------------------------------
def numUniqueEmails(emails: List[str]) -> int:
email_set = set()
for email in emails:
print('')
local_name, domain_name = email.split('@')
print(f'domain: {domain_name}')
pre_plus = local_name.split('+')[0]
print(f'preplus: {pre_plus}')
local_name = ''.join(pre_plus.split('.'))
print(f'local: {local_name}')
email_set.add('@'.join([local_name, domain_name]))
print('@'.join([local_name, domain_name]))
return len(email_set)
'''메인 실행 코드 -- DO NOT TOUCH BELOW THIS LINE'''
# 테스트 케이스
# Tuple[0]은 input, Tuple[1]은 나와야 하는 expected output
test_cases = [
([[
"test.email+alex@leetcode.com",
"test.e.mail+bob.cathy@leetcode.com",
"testemail+david@lee.tcode.com"
]], 2),
([["test.email+alex@leetcode.com", "test.email@leetcode.com"]], 1)
]
if __name__ == '__main__':
Tester.factory(
test_cases,
func=lambda input: numUniqueEmails(input[0])
).run()
| [
"etture@gmail.com"
] | etture@gmail.com |
733fe640fa3867b0fcb26f19fc4edab1eeb4e217 | bdb3716c644b8d031af9a5285626d7ccf0ecb903 | /code/UI/OpenAPI/python-flask-server/openapi_server/test/test_translate_controller.py | 0c41ea731f2ae0627548d0524755aeed0c091282 | [
"MIT",
"Apache-2.0"
] | permissive | RTXteam/RTX | 97d2a8946d233d48cc1b165f5e575af21bda4b26 | ed0693dd03149e56f7dfaf431fb8a82ace0c4ef3 | refs/heads/master | 2023-09-01T21:48:49.008407 | 2023-09-01T20:55:06 | 2023-09-01T20:55:06 | 111,240,202 | 43 | 31 | MIT | 2023-09-14T16:20:01 | 2017-11-18T21:19:13 | Python | UTF-8 | Python | false | false | 1,003 | py | # coding: utf-8
from __future__ import absolute_import
import unittest
from flask import json
from six import BytesIO
from openapi_server.models.query import Query # noqa: E501
from openapi_server.test import BaseTestCase
class TestTranslateController(BaseTestCase):
"""TranslateController integration test stubs"""
def test_translate(self):
"""Test case for translate
Translate natural language question into a standardized query
"""
request_body = None
headers = {
'Accept': 'application/json',
'Content-Type': 'application/json',
}
response = self.client.open(
'/api/arax/v1/translate',
method='POST',
headers=headers,
data=json.dumps(request_body),
content_type='application/json')
self.assert200(response,
'Response body is : ' + response.data.decode('utf-8'))
if __name__ == '__main__':
unittest.main()
| [
"edeutsch@systemsbiology.org"
] | edeutsch@systemsbiology.org |
8096d340b32c90ac60bfa05eba86ddb281b636b5 | a4e2b2fa5c54c7d43e1dbe4eef5006a560cd598e | /django_silky/example_app/gen.py | 288d35821568f40c6ca93eece2162dab74d0f8b1 | [
"MIT"
] | permissive | joaofrancese/silk | baa9fc6468351ec34bc103abdbd1decce0ae2f5d | d8de1367eb70f4405f4ae55d9286f0653c5b3189 | refs/heads/master | 2023-04-01T07:30:42.707427 | 2017-02-22T14:06:05 | 2017-02-22T14:06:05 | 23,427,190 | 1 | 1 | null | null | null | null | UTF-8 | Python | false | false | 293 | py | """generate fake data for the example app"""
from example_app.models import Blind
__author__ = 'mtford'
def main():
venetian = Blind.objects.create(name='Venetian', child_safe=False)
roller = Blind.objects.create(name='Roller', child_safe=True)
if __name__ == '__main__':
main() | [
"mtford@gmail.com"
] | mtford@gmail.com |
4a78028471cb49bb731b246301644655ed79c5c4 | 9d1491368c5e87760131ba27d252ee2d10620433 | /gammapy/time/tests/test_simulate.py | 8d7abfbdc73cb8e1bad04343c6359981797ac35e | [
"BSD-3-Clause"
] | permissive | cnachi/gammapy | f9295306a8e81d0b7f4d2111b3fa3679a78da3f7 | 3d3fc38c111d2f490d984082750f8003580fe06c | refs/heads/master | 2021-01-20T23:37:59.409914 | 2016-06-09T08:36:33 | 2016-06-09T08:36:33 | 60,764,807 | 0 | 0 | null | 2016-06-09T09:55:54 | 2016-06-09T09:55:54 | null | UTF-8 | Python | false | false | 716 | py | # Licensed under a 3-clause BSD style license - see LICENSE.rst
from __future__ import absolute_import, division, print_function, unicode_literals
import numpy as np
from numpy.testing import assert_almost_equal
from astropy.units import Quantity
from ..simulate import make_random_times_poisson_process as random_times
def test_make_random_times_poisson_process():
time = random_times(size=10,
rate=Quantity(10, 'Hz'),
dead_time=Quantity(0.1, 'second'),
random_state=0)
assert np.min(time) >= Quantity(0.1, 'second')
assert_almost_equal(time[0].sec, 0.179587450816311)
assert_almost_equal(time[-1].sec, 0.14836021009022532)
| [
"Deil.Christoph@gmail.com"
] | Deil.Christoph@gmail.com |
5057929f5ddc777fbf9c98216d967df1d3d54632 | 9ce80fd45e0a2a321d9285be1998133405c8cf11 | /meiduo_mall/celery_tasks/main.py | a425e9e0f64d30b876eb768fa35d6da7e31a20e8 | [
"MIT"
] | permissive | dingmingren/meiduo_project | db7d48acf2f8ad5612fe89370d9ed6633c4ac60a | 51497064e8dd24fb45f4d39ca6ed9ae623b8cb79 | refs/heads/master | 2020-07-05T04:46:55.121739 | 2019-08-27T13:00:34 | 2019-08-27T13:00:34 | 202,483,629 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 448 | py | #1、导包
from celery import Celery
#2、加载项目配置文件
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "meiduo_mall.settings.dev")
#3、实例化
app = Celery('celery_tasks')
#4、加载celery配置文件
app.config_from_object('celery_tasks.config')
#5、celery加载任务
#发短信任务
app.autodiscover_tasks(['celery_tasks.sms','celery_tasks.email'])
#发邮件任务
# app.autodiscover_tasks(['celery_tasks.email']) | [
"xwp_fullstack@163.com"
] | xwp_fullstack@163.com |
67dfdc807efc339cf3d8aaec0ae03eafa5c61cc0 | 33b5ef4f67e9c36d45990506e6f9f39d573ce730 | /folders/python/instagram/42for_in_str.py | f2c37251d5cd5f996af3acd957604b6b5e772c93 | [] | no_license | dineshkumarkummara/my-basic-programs-in-java-and-python | 54f271e891e8d9dbdf479a9617e9355cbd0819e9 | b8a4cf455f4a057e382f7dda7581fad5b2f1e616 | refs/heads/master | 2022-12-12T06:02:55.558763 | 2020-08-19T12:14:39 | 2020-08-19T12:14:39 | 283,415,087 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 125 | py | str="python coding" #strings
for x in str:
print(x)
str1={"a","b","c","d"} #sets
for x in str1:
print(x)
| [
"dk944176@gmail.com"
] | dk944176@gmail.com |
55890962eb32cf417864520b10bf305af50f5049 | e8abc7c32f7c1be189b93345f63d7f8f03e40b0f | /examples/launch_tor_endpoint2.py | 1adc178bf28d33da5fb8cf389ea1cccb5f45e3a5 | [
"MIT"
] | permissive | david415/txtorcon | 8e37a71a7fce678b4d7646d8b22df622b7508452 | 3d7ad0d377f3344a33c7d67a19717cc3674bed6a | refs/heads/192.fix_build_timeout_circuit.0 | 2021-01-17T17:08:52.059542 | 2016-11-22T20:34:21 | 2016-11-22T20:34:21 | 19,297,689 | 3 | 1 | MIT | 2018-04-27T18:29:52 | 2014-04-30T01:52:53 | Python | UTF-8 | Python | false | false | 1,435 | py | #!/usr/bin/env python
# Here we set up a Twisted Web server and then launch a slave tor
# with a configured hidden service directed at the Web server we set
# up. This uses serverFromString to translate the "onion" endpoint descriptor
# into a TCPHiddenServiceEndpoint object...
import shutil
from twisted.internet import reactor
from twisted.web import server, resource
from twisted.internet.endpoints import serverFromString
import txtorcon
class Simple(resource.Resource):
isLeaf = True
def render_GET(self, request):
return "<html>Hello, world! I'm a hidden service!</html>"
site = server.Site(Simple())
def setup_failed(arg):
print "SETUP FAILED", arg
def setup_complete(port):
local = txtorcon.IHiddenService(port).local_address.getHost()
print "Hidden serivce:", port.getHost()
print " locally at:", local
def progress(percent, tag, message):
bar = int(percent / 10)
print '[%s%s] %s' % ('#' * bar, '.' * (10 - bar), message)
hs_endpoint1 = serverFromString(reactor, "onion:80")
hs_endpoint2 = serverFromString(reactor, "onion:80")
txtorcon.IProgressProvider(hs_endpoint1).add_progress_listener(progress)
txtorcon.IProgressProvider(hs_endpoint2).add_progress_listener(progress)
d1 = hs_endpoint1.listen(site)
d2 = hs_endpoint2.listen(site)
d1.addCallback(setup_complete).addErrback(setup_failed)
d2.addCallback(setup_complete).addErrback(setup_failed)
reactor.run()
| [
"meejah@meejah.ca"
] | meejah@meejah.ca |
ea7f10d5d450eeb618cfd5da083a97fb965d9b42 | 228ebc9fb20f25dd3ed2a6959aac41fd31314e64 | /google/cloud/aiplatform/datasets/_datasources.py | 9323f403828ae1c464366e3c9b85c70aabcba0ad | [
"Apache-2.0"
] | permissive | orionnye/python-aiplatform | 746e3df0c75025582af38223829faeb2656dc653 | e3ea683bf754832340853a15bdb0a0662500a70f | refs/heads/main | 2023-08-03T06:14:50.689185 | 2021-09-24T03:24:14 | 2021-09-24T03:24:14 | 410,091,957 | 1 | 0 | Apache-2.0 | 2021-09-24T20:21:01 | 2021-09-24T20:21:00 | null | UTF-8 | Python | false | false | 9,755 | py | # -*- coding: utf-8 -*-
# Copyright 2020 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import abc
from typing import Optional, Dict, Sequence, Union
from google.cloud.aiplatform import schema
from google.cloud.aiplatform.compat.types import (
io as gca_io,
dataset as gca_dataset,
)
class Datasource(abc.ABC):
"""An abstract class that sets dataset_metadata."""
@property
@abc.abstractmethod
def dataset_metadata(self):
"""Dataset Metadata."""
pass
class DatasourceImportable(abc.ABC):
"""An abstract class that sets import_data_config."""
@property
@abc.abstractmethod
def import_data_config(self):
"""Import Data Config."""
pass
class TabularDatasource(Datasource):
"""Datasource for creating a tabular dataset for Vertex AI."""
def __init__(
self,
gcs_source: Optional[Union[str, Sequence[str]]] = None,
bq_source: Optional[str] = None,
):
"""Creates a tabular datasource.
Args:
gcs_source (Union[str, Sequence[str]]):
Cloud Storage URI of one or more files. Only CSV files are supported.
The first line of the CSV file is used as the header.
If there are multiple files, the header is the first line of
the lexicographically first file, the other files must either
contain the exact same header or omit the header.
examples:
str: "gs://bucket/file.csv"
Sequence[str]: ["gs://bucket/file1.csv", "gs://bucket/file2.csv"]
bq_source (str):
The URI of a BigQuery table.
example:
"bq://project.dataset.table_name"
Raises:
ValueError if source configuration is not valid.
"""
dataset_metadata = None
if gcs_source and isinstance(gcs_source, str):
gcs_source = [gcs_source]
if gcs_source and bq_source:
raise ValueError("Only one of gcs_source or bq_source can be set.")
if not any([gcs_source, bq_source]):
raise ValueError("One of gcs_source or bq_source must be set.")
if gcs_source:
dataset_metadata = {"inputConfig": {"gcsSource": {"uri": gcs_source}}}
elif bq_source:
dataset_metadata = {"inputConfig": {"bigquerySource": {"uri": bq_source}}}
self._dataset_metadata = dataset_metadata
@property
def dataset_metadata(self) -> Optional[Dict]:
"""Dataset Metadata."""
return self._dataset_metadata
class NonTabularDatasource(Datasource):
"""Datasource for creating an empty non-tabular dataset for Vertex AI."""
@property
def dataset_metadata(self) -> Optional[Dict]:
return None
class NonTabularDatasourceImportable(NonTabularDatasource, DatasourceImportable):
"""Datasource for creating a non-tabular dataset for Vertex AI and
importing data to the dataset."""
def __init__(
self,
gcs_source: Union[str, Sequence[str]],
import_schema_uri: str,
data_item_labels: Optional[Dict] = None,
):
"""Creates a non-tabular datasource.
Args:
gcs_source (Union[str, Sequence[str]]):
Required. The Google Cloud Storage location for the input content.
Google Cloud Storage URI(-s) to the input file(s). May contain
wildcards. For more information on wildcards, see
https://cloud.google.com/storage/docs/gsutil/addlhelp/WildcardNames.
examples:
str: "gs://bucket/file.csv"
Sequence[str]: ["gs://bucket/file1.csv", "gs://bucket/file2.csv"]
import_schema_uri (str):
Required. Points to a YAML file stored on Google Cloud
Storage describing the import format. Validation will be
done against the schema. The schema is defined as an
`OpenAPI 3.0.2 Schema
data_item_labels (Dict):
Labels that will be applied to newly imported DataItems. If
an identical DataItem as one being imported already exists
in the Dataset, then these labels will be appended to these
of the already existing one, and if labels with identical
key is imported before, the old label value will be
overwritten. If two DataItems are identical in the same
import data operation, the labels will be combined and if
key collision happens in this case, one of the values will
be picked randomly. Two DataItems are considered identical
if their content bytes are identical (e.g. image bytes or
pdf bytes). These labels will be overridden by Annotation
labels specified inside index file refenced by
``import_schema_uri``,
e.g. jsonl file.
"""
super().__init__()
self._gcs_source = [gcs_source] if isinstance(gcs_source, str) else gcs_source
self._import_schema_uri = import_schema_uri
self._data_item_labels = data_item_labels
@property
def import_data_config(self) -> gca_dataset.ImportDataConfig:
"""Import Data Config."""
return gca_dataset.ImportDataConfig(
gcs_source=gca_io.GcsSource(uris=self._gcs_source),
import_schema_uri=self._import_schema_uri,
data_item_labels=self._data_item_labels,
)
def create_datasource(
metadata_schema_uri: str,
import_schema_uri: Optional[str] = None,
gcs_source: Optional[Union[str, Sequence[str]]] = None,
bq_source: Optional[str] = None,
data_item_labels: Optional[Dict] = None,
) -> Datasource:
"""Creates a datasource
Args:
metadata_schema_uri (str):
Required. Points to a YAML file stored on Google Cloud Storage
describing additional information about the Dataset. The schema
is defined as an OpenAPI 3.0.2 Schema Object. The schema files
that can be used here are found in gs://google-cloud-
aiplatform/schema/dataset/metadata/.
import_schema_uri (str):
Points to a YAML file stored on Google Cloud
Storage describing the import format. Validation will be
done against the schema. The schema is defined as an
`OpenAPI 3.0.2 Schema
gcs_source (Union[str, Sequence[str]]):
The Google Cloud Storage location for the input content.
Google Cloud Storage URI(-s) to the input file(s). May contain
wildcards. For more information on wildcards, see
https://cloud.google.com/storage/docs/gsutil/addlhelp/WildcardNames.
examples:
str: "gs://bucket/file.csv"
Sequence[str]: ["gs://bucket/file1.csv", "gs://bucket/file2.csv"]
bq_source (str):
BigQuery URI to the input table.
example:
"bq://project.dataset.table_name"
data_item_labels (Dict):
Labels that will be applied to newly imported DataItems. If
an identical DataItem as one being imported already exists
in the Dataset, then these labels will be appended to these
of the already existing one, and if labels with identical
key is imported before, the old label value will be
overwritten. If two DataItems are identical in the same
import data operation, the labels will be combined and if
key collision happens in this case, one of the values will
be picked randomly. Two DataItems are considered identical
if their content bytes are identical (e.g. image bytes or
pdf bytes). These labels will be overridden by Annotation
labels specified inside index file refenced by
``import_schema_uri``,
e.g. jsonl file.
Returns:
datasource (Datasource)
Raises:
ValueError when below scenarios happen
- import_schema_uri is identified for creating TabularDatasource
- either import_schema_uri or gcs_source is missing for creating NonTabularDatasourceImportable
"""
if metadata_schema_uri == schema.dataset.metadata.tabular:
if import_schema_uri:
raise ValueError("tabular dataset does not support data import.")
return TabularDatasource(gcs_source, bq_source)
if metadata_schema_uri == schema.dataset.metadata.time_series:
if import_schema_uri:
raise ValueError("time series dataset does not support data import.")
return TabularDatasource(gcs_source, bq_source)
if not import_schema_uri and not gcs_source:
return NonTabularDatasource()
elif import_schema_uri and gcs_source:
return NonTabularDatasourceImportable(
gcs_source, import_schema_uri, data_item_labels
)
else:
raise ValueError(
"nontabular dataset requires both import_schema_uri and gcs_source for data import."
)
| [
"noreply@github.com"
] | orionnye.noreply@github.com |
55f70e257d55919419c13c52d587546cf180076f | 8534f1109cbd6bdae8e5110e2438331ded6f1134 | /lnotab.py | f25e08d12bc38d29a9dd4ce4e5d27289fe98cc73 | [] | no_license | laike9m/TestPython | dc802053fd0eee329aca8517ccd6f2e97846f221 | 0587c33764b8f88975d1156b73400926e77014c6 | refs/heads/master | 2022-12-21T12:29:45.570030 | 2022-01-05T06:13:32 | 2022-01-05T06:13:32 | 195,931,990 | 0 | 0 | null | 2022-12-13T23:41:15 | 2019-07-09T04:21:59 | Python | UTF-8 | Python | false | false | 293 | py | """A doc string
foo
"""
import sys
import ast
import astor
import inspect
frame = sys._getframe()
print(frame.f_code.co_lnotab)
print(frame.f_code.co_firstlineno)
def f():
x = 1
frame = sys._getframe()
print(frame.f_code.co_lnotab)
print(frame.f_code.co_firstlineno)
f()
| [
"laike9m@gmail.com"
] | laike9m@gmail.com |
e5bdb2b3085ad58fa1d22f773773190fe2aebfd9 | 4cd20bc31ac7c9766bd4629024d7543262a39d69 | /apps/preference/views.py | d1c9f899f386c83b00304493495dc5cdcb4193e0 | [] | no_license | Gusquets/MYB_MVP | fcf4546b0197ab075e54af7756c831576bca9bd5 | 5d8284c90b5a47a883a69423e0bf435ffad81298 | refs/heads/master | 2021-07-01T12:36:48.715498 | 2019-04-03T04:54:07 | 2019-04-03T04:54:07 | 140,535,031 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 8,468 | py | import json
from django.shortcuts import render, get_object_or_404, redirect
from django.http import HttpResponse, HttpResponseRedirect
from django.views.generic import CreateView, TemplateView, ListView, UpdateView
from django.contrib.auth.decorators import login_required
from django.views.decorators.http import require_POST
from django.urls import reverse, reverse_lazy
from apps.common.mixins import LoginRequiredMixin, ArtistRequiredMixin, AbnormalUserMixin
from apps.concert.models import Concert
from apps.accounts.models import Artist
from apps.payment.models import Sponsor
from .models import Basket, Review, Like, Answer
from .forms import ReviewForm, AnswerForm
@login_required
def like_create(request, pk):
review = get_object_or_404(Review, id=pk)
if Like.objects.filter(user = request.user).filter(review = review).exists():
Like.objects.filter(user = request.user).filter(review = review).delete()
review.like_count = Like.objects.filter(user = request.user).filter(review = review).count()
review.save()
message = '좋아요 취소.'
else:
Like.objects.create(user = request.user, review = review)
review.like_count = Like.objects.filter(user = request.user).filter(review = review).count()
review.save()
message = '좋아요.'
context = {'message': message,}
return HttpResponse(json.dumps(context), content_type="application/json")
@login_required
def basket_create_concert(request, id):
concert = get_object_or_404(Concert, id=id)
if Basket.objects.filter(user = request.user).filter(concert = concert).exists():
message = '이미 찜하였습니다.'
else:
Basket.objects.create(user = request.user, concert = concert)
message = '찜하였습니다.'
context = {'message': message,}
return HttpResponse(json.dumps(context), content_type="application/json")
@login_required
def basket_create_artist(request, id):
artist = get_object_or_404(Artist, id=id)
if Basket.objects.filter(user = request.user).filter(artist = artist).exists():
message = '이미 찜하였습니다.'
else:
Basket.objects.create(user = request.user, artist = artist)
message = '찜하였습니다.'
context = {'message': message,}
return HttpResponse(json.dumps(context), content_type="application/json")
class MyBasket(LoginRequiredMixin, TemplateView):
template_name = 'preference/basket/my_basket.html'
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context['concert_list'] = self.request.user.basket_set.all().filter(artist__isnull = True)[:6]
context['artist_list'] = self.request.user.basket_set.all().filter(concert__isnull = True)[:6]
return context
class MyBasketArtist(LoginRequiredMixin, ListView):
model = Basket
template_name = 'preference/basket/my_basket_artist.html'
paginate_by = 12
def get_queryset(self):
return self.request.user.basket_set.all().filter(concert__isnull = True)
class MyBasketConcert(LoginRequiredMixin, ListView):
model = Basket
template_name = 'preference/basket/my_basket_concert.html'
paginate_by = 12
def get_queryset(self):
return self.request.user.basket_set.all().filter(artist__isnull = True)
class MyReview(LoginRequiredMixin, ListView):
model = Review
template_name = 'preference/review/my_review.html'
paginate_by = 10
name = 'review_list'
def get_queryset(self):
if self.request.path == '/preference/my/review/':
obj_list = Review.objects.filter(user = self.request.user).order_by('-regist_dt')
elif self.request.path == '/preference/my/reviewed/':
obj_list = Review.objects.filter(artist = self.request.user.artist).order_by('-regist_dt')
elif self.kwargs['pk']:
artist = Artist.objects.get(id = self.kwargs['pk'])
obj_list = Review.objects.filter(artist = artist).order_by('-regist_dt')
return obj_list
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
if self.request.path == '/preference/my/review/':
context['type'] = 'review'
elif self.request.path == '/preference/my/reviewed/':
context['type'] = 'reviewed'
elif self.kwargs.get('pk',''):
context['type'] = 'artist'
context['artist_name'] = Artist.objects.get(id = self.kwargs['pk']).name
return context
class ArtistReview(AbnormalUserMixin, ListView):
model = Review
template_name = 'preference/review/my_review.html'
paginate_by = 10
def get_queryset(self):
artist = Artist.objects.get(id = self.kwargs['pk'])
obj_list = Review.objects.filter(artist = artist).order_by('-regist_dt')
return obj_list
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context['type'] = 'artist'
context['artist_name'] = Artist.objects.get(id = self.kwargs['pk']).name
return context
class ReviewCreate(LoginRequiredMixin, CreateView):
model = Review
form_class = ReviewForm
def get_template_names(self):
if self.request.is_ajax():
return ['preference/review/_review_create.html']
return ['preference/review/review_create.html']
def get_success_url(self):
return reverse('preference:artist_review', kwargs = {'pk': self.object.artist.id})
def form_valid(self, form):
review = form.save(commit=False)
artist = Artist.objects.get(id = self.kwargs['artist_id'])
review.user = self.request.user
review.user_name = self.request.user.nickname
review.artist = artist
review.is_pay = False
review.save()
rates_review = Review.objects.all().filter(artist = artist)
rates_sponsor = Sponsor.objects.all().filter(artist = artist)
rates_list = []
for rate in rates_review:
rates_list.append(rate.rate)
for rate in rates_sponsor:
rates_list.append(rate.rate)
artist.rate_avg = sum(rates_list) / len(rates_list)
artist.save()
response = super().form_valid(form)
return response
class ReviewUpdate(LoginRequiredMixin, UpdateView):
model = Review
form_class = ReviewForm
def get_queryset(self):
return Review.objects.filter(id = self.kwargs['pk'])
def get_template_names(self):
if self.request.is_ajax():
return ['preference/review/_review_create.html']
return ['preference/review/review_create.html']
def get_success_url(self):
return reverse('preference:artist_review', kwargs = {'pk': self.object.artist.id})
def form_valid(self, form):
response = super().form_valid(form)
artist = Artist.objects.get(id = self.kwargs['artist_id'])
rates_review = Review.objects.all().filter(artist = artist)
rates_sponsor = Sponsor.objects.all().filter(artist = artist)
rates_list = []
for rate in rates_review:
rates_list.append(rate.rate)
for rate in rates_sponsor:
rates_list.append(rate.rate)
artist.rate_avg = sum(rates_list) / len(rates_list)
artist.save()
return response
def review_delete(request, pk):
try:
Review.objects.filter(id = pk).delete()
message = '삭제하였습니다.'
except:
message = '오류가 발생하여 삭제하지 못하였습니다.'
context = {'message': message}
return HttpResponse(json.dumps(context), content_type="application/json")
class AnswerCreate(AbnormalUserMixin, CreateView):
model = Answer
form_class = AnswerForm
def get_template_names(self):
if self.request.is_ajax():
return ['preference/review/_answer_create.html']
return ['preference/review/answer_create.html']
def get_success_url(self):
return reverse_lazy('website:home')
def form_valid(self, form):
answer = form.save(commit=False)
review = Review.objects.get(id = self.kwargs['review_id'])
answer.user = self.request.user
answer.review = review
answer.save()
response = super().form_valid(form)
return response | [
"smk950226@naver.com"
] | smk950226@naver.com |
5d74f273cd83e256d34521b9117230ddc8efebbf | 947e71b34d21f3c9f5c0a197d91a880f346afa6c | /ambari-server/src/main/resources/common-services/HIVE/0.12.0.2.0/package/scripts/webhcat.py | cf56a7fdb9f8a91aba6d59d4588a583b21c64f94 | [
"MIT",
"Apache-2.0",
"GPL-1.0-or-later",
"GPL-2.0-or-later",
"OFL-1.1",
"MS-PL",
"AFL-2.1",
"GPL-2.0-only",
"Python-2.0",
"BSD-2-Clause",
"BSD-3-Clause",
"LicenseRef-scancode-free-unknown"
] | permissive | liuwenru/Apache-Ambari-ZH | 4bc432d4ea7087bb353a6dd97ffda0a85cb0fef0 | 7879810067f1981209b658ceb675ac76e951b07b | refs/heads/master | 2023-01-14T14:43:06.639598 | 2020-07-28T12:06:25 | 2020-07-28T12:06:25 | 223,551,095 | 38 | 44 | Apache-2.0 | 2023-01-02T21:55:10 | 2019-11-23T07:43:49 | Java | UTF-8 | Python | false | false | 5,613 | py | """
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
Ambari Agent
"""
import sys
import os.path
from resource_management.core.resources.system import Directory, Execute, File
from resource_management.core.resources.service import ServiceConfig
from resource_management.core.source import InlineTemplate, StaticFile
from resource_management.libraries.script.script import Script
from resource_management.libraries.resources.xml_config import XmlConfig
from resource_management.libraries.functions.constants import StackFeature
from resource_management.libraries.functions.format import format
from resource_management.libraries.functions.stack_features import check_stack_feature
from ambari_commons.os_family_impl import OsFamilyFuncImpl, OsFamilyImpl
from resource_management.libraries.functions.setup_atlas_hook import has_atlas_in_cluster, setup_atlas_hook
from ambari_commons import OSConst
from ambari_commons.constants import SERVICE
@OsFamilyFuncImpl(os_family=OSConst.WINSRV_FAMILY)
def webhcat():
import params
XmlConfig("webhcat-site.xml",
conf_dir=params.hcat_config_dir,
configurations=params.config['configurations']['webhcat-site']
)
# Manually overriding service logon user & password set by the installation package
ServiceConfig(params.webhcat_server_win_service_name,
action="change_user",
username = params.webhcat_user,
password = Script.get_password(params.webhcat_user))
@OsFamilyFuncImpl(os_family=OsFamilyImpl.DEFAULT)
def webhcat():
import params
Directory(params.templeton_pid_dir,
owner=params.webhcat_user,
mode=0755,
group=params.user_group,
create_parents = True)
Directory(params.templeton_log_dir,
owner=params.webhcat_user,
mode=0755,
group=params.user_group,
create_parents = True)
Directory(params.config_dir,
create_parents = True,
owner=params.webhcat_user,
group=params.user_group,
cd_access="a")
# Replace _HOST with hostname in relevant principal-related properties
webhcat_site = params.config['configurations']['webhcat-site'].copy()
for prop_name in ['templeton.hive.properties', 'templeton.kerberos.principal']:
if prop_name in webhcat_site:
webhcat_site[prop_name] = webhcat_site[prop_name].replace("_HOST", params.hostname)
XmlConfig("webhcat-site.xml",
conf_dir=params.config_dir,
configurations=webhcat_site,
configuration_attributes=params.config['configurationAttributes']['webhcat-site'],
owner=params.webhcat_user,
group=params.user_group,
)
# if we're in an upgrade of a secure cluster, make sure hive-site and yarn-site are created
if check_stack_feature(StackFeature.CONFIG_VERSIONING, params.stack_version_formatted_major) and \
params.version and params.stack_root:
XmlConfig("hive-site.xml",
conf_dir = format("{stack_root}/{version}/hive/conf"),
configurations = params.config['configurations']['hive-site'],
configuration_attributes = params.config['configurationAttributes']['hive-site'],
owner = params.hive_user,
group = params.user_group,
)
XmlConfig("yarn-site.xml",
conf_dir = format("{stack_root}/{version}/hadoop/conf"),
configurations = params.config['configurations']['yarn-site'],
configuration_attributes = params.config['configurationAttributes']['yarn-site'],
owner = params.yarn_user,
group = params.user_group,
)
File(format("{config_dir}/webhcat-env.sh"),
owner=params.webhcat_user,
group=params.user_group,
content=InlineTemplate(params.webhcat_env_sh_template)
)
Directory(params.webhcat_conf_dir,
cd_access='a',
create_parents = True
)
log4j_webhcat_filename = 'webhcat-log4j.properties'
if (params.log4j_webhcat_props != None):
File(format("{config_dir}/{log4j_webhcat_filename}"),
mode=0644,
group=params.user_group,
owner=params.webhcat_user,
content=InlineTemplate(params.log4j_webhcat_props)
)
elif (os.path.exists("{config_dir}/{log4j_webhcat_filename}.template")):
File(format("{config_dir}/{log4j_webhcat_filename}"),
mode=0644,
group=params.user_group,
owner=params.webhcat_user,
content=StaticFile(format("{config_dir}/{log4j_webhcat_filename}.template"))
)
# Generate atlas-application.properties.xml file
if params.enable_atlas_hook:
# WebHCat uses a different config dir than the rest of the daemons in Hive.
atlas_hook_filepath = os.path.join(params.config_dir, params.atlas_hook_filename)
setup_atlas_hook(SERVICE.HIVE, params.hive_atlas_application_properties, atlas_hook_filepath, params.hive_user, params.user_group)
| [
"ijarvis@sina.com"
] | ijarvis@sina.com |
96a4b18aa1fa969114639d82147ccece6ec37150 | 1efeed0fa970b05801a29ccfdc90c52bb571dd02 | /venv/lib/python3.7/site-packages/openstack/cloud/_network.py | e0f938b77e27096b365c02f38803354c750bf5ed | [] | no_license | williamwang0/MusicGen | 2e7fe5d9b2d35d1406b8951a86a5eac6d704571e | b6411505d1fd29e13ca93e3975f3de106ad4a7d0 | refs/heads/master | 2020-07-08T15:48:33.840412 | 2020-05-27T17:30:38 | 2020-05-27T17:30:38 | 203,717,161 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 104,859 | py | # Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# import types so that we can reference ListType in sphinx param declarations.
# We can't just use list, because sphinx gets confused by
# openstack.resource.Resource.list and openstack.resource2.Resource.list
import six
import time
import threading
import types # noqa
from openstack.cloud import exc
from openstack.cloud import _normalize
from openstack.cloud import _utils
from openstack import exceptions
from openstack import proxy
class NetworkCloudMixin(_normalize.Normalizer):
def __init__(self):
self._ports = None
self._ports_time = 0
self._ports_lock = threading.Lock()
@_utils.cache_on_arguments()
def _neutron_extensions(self):
extensions = set()
resp = self.network.get('/extensions.json')
data = proxy._json_response(
resp,
error_message="Error fetching extension list for neutron")
for extension in self._get_and_munchify('extensions', data):
extensions.add(extension['alias'])
return extensions
def _has_neutron_extension(self, extension_alias):
return extension_alias in self._neutron_extensions()
def search_networks(self, name_or_id=None, filters=None):
"""Search networks
:param name_or_id: Name or ID of the desired network.
:param filters: a dict containing additional filters to use. e.g.
{'router:external': True}
:returns: a list of ``munch.Munch`` containing the network description.
:raises: ``OpenStackCloudException`` if something goes wrong during the
OpenStack API call.
"""
networks = self.list_networks(
filters if isinstance(filters, dict) else None)
return _utils._filter_list(networks, name_or_id, filters)
def search_routers(self, name_or_id=None, filters=None):
"""Search routers
:param name_or_id: Name or ID of the desired router.
:param filters: a dict containing additional filters to use. e.g.
{'admin_state_up': True}
:returns: a list of ``munch.Munch`` containing the router description.
:raises: ``OpenStackCloudException`` if something goes wrong during the
OpenStack API call.
"""
routers = self.list_routers(
filters if isinstance(filters, dict) else None)
return _utils._filter_list(routers, name_or_id, filters)
def search_subnets(self, name_or_id=None, filters=None):
"""Search subnets
:param name_or_id: Name or ID of the desired subnet.
:param filters: a dict containing additional filters to use. e.g.
{'enable_dhcp': True}
:returns: a list of ``munch.Munch`` containing the subnet description.
:raises: ``OpenStackCloudException`` if something goes wrong during the
OpenStack API call.
"""
subnets = self.list_subnets(
filters if isinstance(filters, dict) else None)
return _utils._filter_list(subnets, name_or_id, filters)
def search_ports(self, name_or_id=None, filters=None):
"""Search ports
:param name_or_id: Name or ID of the desired port.
:param filters: a dict containing additional filters to use. e.g.
{'device_id': '2711c67a-b4a7-43dd-ace7-6187b791c3f0'}
:returns: a list of ``munch.Munch`` containing the port description.
:raises: ``OpenStackCloudException`` if something goes wrong during the
OpenStack API call.
"""
# If port caching is enabled, do not push the filter down to
# neutron; get all the ports (potentially from the cache) and
# filter locally.
if self._PORT_AGE or isinstance(filters, str):
pushdown_filters = None
else:
pushdown_filters = filters
ports = self.list_ports(pushdown_filters)
return _utils._filter_list(ports, name_or_id, filters)
def list_networks(self, filters=None):
"""List all available networks.
:param filters: (optional) dict of filter conditions to push down
:returns: A list of ``munch.Munch`` containing network info.
"""
# Translate None from search interface to empty {} for kwargs below
if not filters:
filters = {}
data = self.network.get("/networks.json", params=filters)
return self._get_and_munchify('networks', data)
def list_routers(self, filters=None):
"""List all available routers.
:param filters: (optional) dict of filter conditions to push down
:returns: A list of router ``munch.Munch``.
"""
# Translate None from search interface to empty {} for kwargs below
if not filters:
filters = {}
resp = self.network.get("/routers.json", params=filters)
data = proxy._json_response(
resp,
error_message="Error fetching router list")
return self._get_and_munchify('routers', data)
def list_subnets(self, filters=None):
"""List all available subnets.
:param filters: (optional) dict of filter conditions to push down
:returns: A list of subnet ``munch.Munch``.
"""
# Translate None from search interface to empty {} for kwargs below
if not filters:
filters = {}
data = self.network.get("/subnets.json", params=filters)
return self._get_and_munchify('subnets', data)
def list_ports(self, filters=None):
"""List all available ports.
:param filters: (optional) dict of filter conditions to push down
:returns: A list of port ``munch.Munch``.
"""
# If pushdown filters are specified and we do not have batched caching
# enabled, bypass local caching and push down the filters.
if filters and self._PORT_AGE == 0:
return self._list_ports(filters)
if (time.time() - self._ports_time) >= self._PORT_AGE:
# Since we're using cached data anyway, we don't need to
# have more than one thread actually submit the list
# ports task. Let the first one submit it while holding
# a lock, and the non-blocking acquire method will cause
# subsequent threads to just skip this and use the old
# data until it succeeds.
# Initially when we never got data, block to retrieve some data.
first_run = self._ports is None
if self._ports_lock.acquire(first_run):
try:
if not (first_run and self._ports is not None):
self._ports = self._list_ports({})
self._ports_time = time.time()
finally:
self._ports_lock.release()
# Wrap the return with filter_list so that if filters were passed
# but we were batching/caching and thus always fetching the whole
# list from the cloud, we still return a filtered list.
return _utils._filter_list(self._ports, None, filters or {})
def _list_ports(self, filters):
resp = self.network.get("/ports.json", params=filters)
data = proxy._json_response(
resp,
error_message="Error fetching port list")
return self._get_and_munchify('ports', data)
def get_qos_policy(self, name_or_id, filters=None):
"""Get a QoS policy by name or ID.
:param name_or_id: Name or ID of the policy.
:param filters:
A dictionary of meta data to use for further filtering. Elements
of this dictionary may, themselves, be dictionaries. Example::
{
'last_name': 'Smith',
'other': {
'gender': 'Female'
}
}
OR
A string containing a jmespath expression for further filtering.
Example:: "[?last_name==`Smith`] | [?other.gender]==`Female`]"
:returns: A policy ``munch.Munch`` or None if no matching network is
found.
"""
return _utils._get_entity(
self, 'qos_policie', name_or_id, filters)
def search_qos_policies(self, name_or_id=None, filters=None):
"""Search QoS policies
:param name_or_id: Name or ID of the desired policy.
:param filters: a dict containing additional filters to use. e.g.
{'shared': True}
:returns: a list of ``munch.Munch`` containing the network description.
:raises: ``OpenStackCloudException`` if something goes wrong during the
OpenStack API call.
"""
policies = self.list_qos_policies(filters)
return _utils._filter_list(policies, name_or_id, filters)
def list_qos_rule_types(self, filters=None):
"""List all available QoS rule types.
:param filters: (optional) dict of filter conditions to push down
:returns: A list of rule types ``munch.Munch``.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
# Translate None from search interface to empty {} for kwargs below
if not filters:
filters = {}
resp = self.network.get("/qos/rule-types.json", params=filters)
data = proxy._json_response(
resp,
error_message="Error fetching QoS rule types list")
return self._get_and_munchify('rule_types', data)
def get_qos_rule_type_details(self, rule_type, filters=None):
"""Get a QoS rule type details by rule type name.
:param string rule_type: Name of the QoS rule type.
:returns: A rule type details ``munch.Munch`` or None if
no matching rule type is found.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
if not self._has_neutron_extension('qos-rule-type-details'):
raise exc.OpenStackCloudUnavailableExtension(
'qos-rule-type-details extension is not available '
'on target cloud')
resp = self.network.get(
"/qos/rule-types/{rule_type}.json".format(rule_type=rule_type))
data = proxy._json_response(
resp,
error_message="Error fetching QoS details of {rule_type} "
"rule type".format(rule_type=rule_type))
return self._get_and_munchify('rule_type', data)
def list_qos_policies(self, filters=None):
"""List all available QoS policies.
:param filters: (optional) dict of filter conditions to push down
:returns: A list of policies ``munch.Munch``.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
# Translate None from search interface to empty {} for kwargs below
if not filters:
filters = {}
resp = self.network.get("/qos/policies.json", params=filters)
data = proxy._json_response(
resp,
error_message="Error fetching QoS policies list")
return self._get_and_munchify('policies', data)
def get_network(self, name_or_id, filters=None):
"""Get a network by name or ID.
:param name_or_id: Name or ID of the network.
:param filters:
A dictionary of meta data to use for further filtering. Elements
of this dictionary may, themselves, be dictionaries. Example::
{
'last_name': 'Smith',
'other': {
'gender': 'Female'
}
}
OR
A string containing a jmespath expression for further filtering.
Example:: "[?last_name==`Smith`] | [?other.gender]==`Female`]"
:returns: A network ``munch.Munch`` or None if no matching network is
found.
"""
return _utils._get_entity(self, 'network', name_or_id, filters)
def get_network_by_id(self, id):
""" Get a network by ID
:param id: ID of the network.
:returns: A network ``munch.Munch``.
"""
resp = self.network.get('/networks/{id}'.format(id=id))
data = proxy._json_response(
resp,
error_message="Error getting network with ID {id}".format(id=id)
)
network = self._get_and_munchify('network', data)
return network
def get_router(self, name_or_id, filters=None):
"""Get a router by name or ID.
:param name_or_id: Name or ID of the router.
:param filters:
A dictionary of meta data to use for further filtering. Elements
of this dictionary may, themselves, be dictionaries. Example::
{
'last_name': 'Smith',
'other': {
'gender': 'Female'
}
}
OR
A string containing a jmespath expression for further filtering.
Example:: "[?last_name==`Smith`] | [?other.gender]==`Female`]"
:returns: A router ``munch.Munch`` or None if no matching router is
found.
"""
return _utils._get_entity(self, 'router', name_or_id, filters)
def get_subnet(self, name_or_id, filters=None):
"""Get a subnet by name or ID.
:param name_or_id: Name or ID of the subnet.
:param filters:
A dictionary of meta data to use for further filtering. Elements
of this dictionary may, themselves, be dictionaries. Example::
{
'last_name': 'Smith',
'other': {
'gender': 'Female'
}
}
:returns: A subnet ``munch.Munch`` or None if no matching subnet is
found.
"""
return _utils._get_entity(self, 'subnet', name_or_id, filters)
def get_subnet_by_id(self, id):
""" Get a subnet by ID
:param id: ID of the subnet.
:returns: A subnet ``munch.Munch``.
"""
resp = self.network.get('/subnets/{id}'.format(id=id))
data = proxy._json_response(
resp,
error_message="Error getting subnet with ID {id}".format(id=id)
)
subnet = self._get_and_munchify('subnet', data)
return subnet
def get_port(self, name_or_id, filters=None):
"""Get a port by name or ID.
:param name_or_id: Name or ID of the port.
:param filters:
A dictionary of meta data to use for further filtering. Elements
of this dictionary may, themselves, be dictionaries. Example::
{
'last_name': 'Smith',
'other': {
'gender': 'Female'
}
}
OR
A string containing a jmespath expression for further filtering.
Example:: "[?last_name==`Smith`] | [?other.gender]==`Female`]"
:returns: A port ``munch.Munch`` or None if no matching port is found.
"""
return _utils._get_entity(self, 'port', name_or_id, filters)
def get_port_by_id(self, id):
""" Get a port by ID
:param id: ID of the port.
:returns: A port ``munch.Munch``.
"""
resp = self.network.get('/ports/{id}'.format(id=id))
data = proxy._json_response(
resp,
error_message="Error getting port with ID {id}".format(id=id)
)
port = self._get_and_munchify('port', data)
return port
def create_network(self, name, shared=False, admin_state_up=True,
external=False, provider=None, project_id=None,
availability_zone_hints=None,
port_security_enabled=None,
mtu_size=None, dns_domain=None):
"""Create a network.
:param string name: Name of the network being created.
:param bool shared: Set the network as shared.
:param bool admin_state_up: Set the network administrative state to up.
:param bool external: Whether this network is externally accessible.
:param dict provider: A dict of network provider options. Example::
{ 'network_type': 'vlan', 'segmentation_id': 'vlan1' }
:param string project_id: Specify the project ID this network
will be created on (admin-only).
:param types.ListType availability_zone_hints: A list of availability
zone hints.
:param bool port_security_enabled: Enable / Disable port security
:param int mtu_size: maximum transmission unit value to address
fragmentation. Minimum value is 68 for IPv4, and 1280 for IPv6.
:param string dns_domain: Specify the DNS domain associated with
this network.
:returns: The network object.
:raises: OpenStackCloudException on operation error.
"""
network = {
'name': name,
'admin_state_up': admin_state_up,
}
if shared:
network['shared'] = shared
if project_id is not None:
network['tenant_id'] = project_id
if availability_zone_hints is not None:
if not isinstance(availability_zone_hints, list):
raise exc.OpenStackCloudException(
"Parameter 'availability_zone_hints' must be a list")
if not self._has_neutron_extension('network_availability_zone'):
raise exc.OpenStackCloudUnavailableExtension(
'network_availability_zone extension is not available on '
'target cloud')
network['availability_zone_hints'] = availability_zone_hints
if provider:
if not isinstance(provider, dict):
raise exc.OpenStackCloudException(
"Parameter 'provider' must be a dict")
# Only pass what we know
for attr in ('physical_network', 'network_type',
'segmentation_id'):
if attr in provider:
arg = "provider:" + attr
network[arg] = provider[attr]
# Do not send 'router:external' unless it is explicitly
# set since sending it *might* cause "Forbidden" errors in
# some situations. It defaults to False in the client, anyway.
if external:
network['router:external'] = True
if port_security_enabled is not None:
if not isinstance(port_security_enabled, bool):
raise exc.OpenStackCloudException(
"Parameter 'port_security_enabled' must be a bool")
network['port_security_enabled'] = port_security_enabled
if mtu_size:
if not isinstance(mtu_size, int):
raise exc.OpenStackCloudException(
"Parameter 'mtu_size' must be an integer.")
if not mtu_size >= 68:
raise exc.OpenStackCloudException(
"Parameter 'mtu_size' must be greater than 67.")
network['mtu'] = mtu_size
if dns_domain:
network['dns_domain'] = dns_domain
data = self.network.post("/networks.json", json={'network': network})
# Reset cache so the new network is picked up
self._reset_network_caches()
return self._get_and_munchify('network', data)
@_utils.valid_kwargs("name", "shared", "admin_state_up", "external",
"provider", "mtu_size", "port_security_enabled",
"dns_domain")
def update_network(self, name_or_id, **kwargs):
"""Update a network.
:param string name_or_id: Name or ID of the network being updated.
:param string name: New name of the network.
:param bool shared: Set the network as shared.
:param bool admin_state_up: Set the network administrative state to up.
:param bool external: Whether this network is externally accessible.
:param dict provider: A dict of network provider options. Example::
{ 'network_type': 'vlan', 'segmentation_id': 'vlan1' }
:param int mtu_size: New maximum transmission unit value to address
fragmentation. Minimum value is 68 for IPv4, and 1280 for IPv6.
:param bool port_security_enabled: Enable or disable port security.
:param string dns_domain: Specify the DNS domain associated with
this network.
:returns: The updated network object.
:raises: OpenStackCloudException on operation error.
"""
if 'provider' in kwargs:
if not isinstance(kwargs['provider'], dict):
raise exc.OpenStackCloudException(
"Parameter 'provider' must be a dict")
# Only pass what we know
provider = {}
for key in kwargs['provider']:
if key in ('physical_network', 'network_type',
'segmentation_id'):
provider['provider:' + key] = kwargs['provider'][key]
kwargs['provider'] = provider
if 'external' in kwargs:
kwargs['router:external'] = kwargs.pop('external')
if 'port_security_enabled' in kwargs:
if not isinstance(kwargs['port_security_enabled'], bool):
raise exc.OpenStackCloudException(
"Parameter 'port_security_enabled' must be a bool")
if 'mtu_size' in kwargs:
if not isinstance(kwargs['mtu_size'], int):
raise exc.OpenStackCloudException(
"Parameter 'mtu_size' must be an integer.")
if kwargs['mtu_size'] < 68:
raise exc.OpenStackCloudException(
"Parameter 'mtu_size' must be greater than 67.")
kwargs['mtu'] = kwargs.pop('mtu_size')
network = self.get_network(name_or_id)
if not network:
raise exc.OpenStackCloudException(
"Network %s not found." % name_or_id)
data = proxy._json_response(self.network.put(
"/networks/{net_id}.json".format(net_id=network.id),
json={"network": kwargs}),
error_message="Error updating network {0}".format(name_or_id))
self._reset_network_caches()
return self._get_and_munchify('network', data)
def delete_network(self, name_or_id):
"""Delete a network.
:param name_or_id: Name or ID of the network being deleted.
:returns: True if delete succeeded, False otherwise.
:raises: OpenStackCloudException on operation error.
"""
network = self.get_network(name_or_id)
if not network:
self.log.debug("Network %s not found for deleting", name_or_id)
return False
exceptions.raise_from_response(self.network.delete(
"/networks/{network_id}.json".format(network_id=network['id'])))
# Reset cache so the deleted network is removed
self._reset_network_caches()
return True
def set_network_quotas(self, name_or_id, **kwargs):
""" Set a network quota in a project
:param name_or_id: project name or id
:param kwargs: key/value pairs of quota name and quota value
:raises: OpenStackCloudException if the resource to set the
quota does not exist.
"""
proj = self.get_project(name_or_id)
if not proj:
raise exc.OpenStackCloudException("project does not exist")
exceptions.raise_from_response(
self.network.put(
'/quotas/{project_id}.json'.format(project_id=proj.id),
json={'quota': kwargs}),
error_message=("Error setting Neutron's quota for "
"project {0}".format(proj.id)))
def get_network_quotas(self, name_or_id, details=False):
""" Get network quotas for a project
:param name_or_id: project name or id
:param details: if set to True it will return details about usage
of quotas by given project
:raises: OpenStackCloudException if it's not a valid project
:returns: Munch object with the quotas
"""
proj = self.get_project(name_or_id)
if not proj:
raise exc.OpenStackCloudException("project does not exist")
url = '/quotas/{project_id}'.format(project_id=proj.id)
if details:
url = url + "/details"
url = url + ".json"
data = proxy._json_response(
self.network.get(url),
error_message=("Error fetching Neutron's quota for "
"project {0}".format(proj.id)))
return self._get_and_munchify('quota', data)
def get_network_extensions(self):
"""Get Cloud provided network extensions
:returns: set of Neutron extension aliases
"""
return self._neutron_extensions()
def delete_network_quotas(self, name_or_id):
""" Delete network quotas for a project
:param name_or_id: project name or id
:raises: OpenStackCloudException if it's not a valid project or the
network client call failed
:returns: dict with the quotas
"""
proj = self.get_project(name_or_id)
if not proj:
raise exc.OpenStackCloudException("project does not exist")
exceptions.raise_from_response(
self.network.delete(
'/quotas/{project_id}.json'.format(project_id=proj.id)),
error_message=("Error deleting Neutron's quota for "
"project {0}".format(proj.id)))
@_utils.valid_kwargs(
'action', 'description', 'destination_firewall_group_id',
'destination_ip_address', 'destination_port', 'enabled', 'ip_version',
'name', 'project_id', 'protocol', 'shared', 'source_firewall_group_id',
'source_ip_address', 'source_port')
def create_firewall_rule(self, **kwargs):
"""
Creates firewall rule.
:param action: Action performed on traffic.
Valid values: allow, deny
Defaults to deny.
:param description: Human-readable description.
:param destination_firewall_group_id: ID of destination firewall group.
:param destination_ip_address: IPv4-, IPv6 address or CIDR.
:param destination_port: Port or port range (e.g. 80:90)
:param bool enabled: Status of firewall rule. You can disable rules
without disassociating them from firewall
policies. Defaults to True.
:param int ip_version: IP Version.
Valid values: 4, 6
Defaults to 4.
:param name: Human-readable name.
:param project_id: Project id.
:param protocol: IP protocol.
Valid values: icmp, tcp, udp, null
:param bool shared: Visibility to other projects.
Defaults to False.
:param source_firewall_group_id: ID of source firewall group.
:param source_ip_address: IPv4-, IPv6 address or CIDR.
:param source_port: Port or port range (e.g. 80:90)
:raises: BadRequestException if parameters are malformed
:return: created firewall rule
:rtype: FirewallRule
"""
return self.network.create_firewall_rule(**kwargs)
def delete_firewall_rule(self, name_or_id, filters=None):
"""
Deletes firewall rule.
Prints debug message in case to-be-deleted resource was not found.
:param name_or_id: firewall rule name or id
:param dict filters: optional filters
:raises: DuplicateResource on multiple matches
:return: True if resource is successfully deleted, False otherwise.
:rtype: bool
"""
if not filters:
filters = {}
try:
firewall_rule = self.network.find_firewall_rule(
name_or_id, ignore_missing=False, **filters)
self.network.delete_firewall_rule(firewall_rule,
ignore_missing=False)
except exceptions.ResourceNotFound:
self.log.debug('Firewall rule %s not found for deleting',
name_or_id)
return False
return True
def get_firewall_rule(self, name_or_id, filters=None):
"""
Retrieves a single firewall rule.
:param name_or_id: firewall rule name or id
:param dict filters: optional filters
:raises: DuplicateResource on multiple matches
:return: firewall rule dict or None if not found
:rtype: FirewallRule
"""
if not filters:
filters = {}
return self.network.find_firewall_rule(name_or_id, **filters)
def list_firewall_rules(self, filters=None):
"""
Lists firewall rules.
:param dict filters: optional filters
:return: list of firewall rules
:rtype: list[FirewallRule]
"""
if not filters:
filters = {}
return list(self.network.firewall_rules(**filters))
@_utils.valid_kwargs(
'action', 'description', 'destination_firewall_group_id',
'destination_ip_address', 'destination_port', 'enabled', 'ip_version',
'name', 'project_id', 'protocol', 'shared', 'source_firewall_group_id',
'source_ip_address', 'source_port')
def update_firewall_rule(self, name_or_id, filters=None, **kwargs):
"""
Updates firewall rule.
:param name_or_id: firewall rule name or id
:param dict filters: optional filters
:param kwargs: firewall rule update parameters.
See create_firewall_rule docstring for valid parameters.
:raises: BadRequestException if parameters are malformed
:raises: NotFoundException if resource is not found
:return: updated firewall rule
:rtype: FirewallRule
"""
if not filters:
filters = {}
firewall_rule = self.network.find_firewall_rule(
name_or_id, ignore_missing=False, **filters)
return self.network.update_firewall_rule(firewall_rule, **kwargs)
def _get_firewall_rule_ids(self, name_or_id_list, filters=None):
"""
Takes a list of firewall rule name or ids, looks them up and returns
a list of firewall rule ids.
Used by `create_firewall_policy` and `update_firewall_policy`.
:param list[str] name_or_id_list: firewall rule name or id list
:param dict filters: optional filters
:raises: DuplicateResource on multiple matches
:raises: NotFoundException if resource is not found
:return: list of firewall rule ids
:rtype: list[str]
"""
if not filters:
filters = {}
ids_list = []
for name_or_id in name_or_id_list:
ids_list.append(self.network.find_firewall_rule(
name_or_id, ignore_missing=False, **filters)['id'])
return ids_list
@_utils.valid_kwargs('audited', 'description', 'firewall_rules', 'name',
'project_id', 'shared')
def create_firewall_policy(self, **kwargs):
"""
Create firewall policy.
:param bool audited: Status of audition of firewall policy.
Set to False each time the firewall policy or the
associated firewall rules are changed.
Has to be explicitly set to True.
:param description: Human-readable description.
:param list[str] firewall_rules: List of associated firewall rules.
:param name: Human-readable name.
:param project_id: Project id.
:param bool shared: Visibility to other projects.
Defaults to False.
:raises: BadRequestException if parameters are malformed
:raises: ResourceNotFound if a resource from firewall_list not found
:return: created firewall policy
:rtype: FirewallPolicy
"""
if 'firewall_rules' in kwargs:
kwargs['firewall_rules'] = self._get_firewall_rule_ids(
kwargs['firewall_rules'])
return self.network.create_firewall_policy(**kwargs)
def delete_firewall_policy(self, name_or_id, filters=None):
"""
Deletes firewall policy.
Prints debug message in case to-be-deleted resource was not found.
:param name_or_id: firewall policy name or id
:param dict filters: optional filters
:raises: DuplicateResource on multiple matches
:return: True if resource is successfully deleted, False otherwise.
:rtype: bool
"""
if not filters:
filters = {}
try:
firewall_policy = self.network.find_firewall_policy(
name_or_id, ignore_missing=False, **filters)
self.network.delete_firewall_policy(firewall_policy,
ignore_missing=False)
except exceptions.ResourceNotFound:
self.log.debug('Firewall policy %s not found for deleting',
name_or_id)
return False
return True
def get_firewall_policy(self, name_or_id, filters=None):
"""
Retrieves a single firewall policy.
:param name_or_id: firewall policy name or id
:param dict filters: optional filters
:raises: DuplicateResource on multiple matches
:return: firewall policy or None if not found
:rtype: FirewallPolicy
"""
if not filters:
filters = {}
return self.network.find_firewall_policy(name_or_id, **filters)
def list_firewall_policies(self, filters=None):
"""
Lists firewall policies.
:param dict filters: optional filters
:return: list of firewall policies
:rtype: list[FirewallPolicy]
"""
if not filters:
filters = {}
return list(self.network.firewall_policies(**filters))
@_utils.valid_kwargs('audited', 'description', 'firewall_rules', 'name',
'project_id', 'shared')
def update_firewall_policy(self, name_or_id, filters=None, **kwargs):
"""
Updates firewall policy.
:param name_or_id: firewall policy name or id
:param dict filters: optional filters
:param kwargs: firewall policy update parameters
See create_firewall_policy docstring for valid parameters.
:raises: BadRequestException if parameters are malformed
:raises: DuplicateResource on multiple matches
:raises: ResourceNotFound if resource is not found
:return: updated firewall policy
:rtype: FirewallPolicy
"""
if not filters:
filters = {}
firewall_policy = self.network.find_firewall_policy(
name_or_id, ignore_missing=False, **filters)
if 'firewall_rules' in kwargs:
kwargs['firewall_rules'] = self._get_firewall_rule_ids(
kwargs['firewall_rules'])
return self.network.update_firewall_policy(firewall_policy, **kwargs)
def insert_rule_into_policy(self, name_or_id, rule_name_or_id,
insert_after=None, insert_before=None,
filters=None):
"""
Adds firewall rule to the firewall_rules list of a firewall policy.
Short-circuits and returns the firewall policy early if the firewall
rule id is already present in the firewall_rules list.
This method doesn't do re-ordering. If you want to move a firewall rule
or or down the list, you have to remove and re-add it.
:param name_or_id: firewall policy name or id
:param rule_name_or_id: firewall rule name or id
:param insert_after: rule name or id that should precede added rule
:param insert_before: rule name or id that should succeed added rule
:param dict filters: optional filters
:raises: DuplicateResource on multiple matches
:raises: ResourceNotFound if firewall policy or any of the firewall
rules (inserted, after, before) is not found.
:return: updated firewall policy
:rtype: FirewallPolicy
"""
if not filters:
filters = {}
firewall_policy = self.network.find_firewall_policy(
name_or_id, ignore_missing=False, **filters)
firewall_rule = self.network.find_firewall_rule(
rule_name_or_id, ignore_missing=False)
# short-circuit if rule already in firewall_rules list
# the API can't do any re-ordering of existing rules
if firewall_rule['id'] in firewall_policy['firewall_rules']:
self.log.debug(
'Firewall rule %s already associated with firewall policy %s',
rule_name_or_id, name_or_id)
return firewall_policy
pos_params = {}
if insert_after is not None:
pos_params['insert_after'] = self.network.find_firewall_rule(
insert_after, ignore_missing=False)['id']
if insert_before is not None:
pos_params['insert_before'] = self.network.find_firewall_rule(
insert_before, ignore_missing=False)['id']
return self.network.insert_rule_into_policy(firewall_policy['id'],
firewall_rule['id'],
**pos_params)
def remove_rule_from_policy(self, name_or_id, rule_name_or_id,
filters=None):
"""
Remove firewall rule from firewall policy's firewall_rules list.
Short-circuits and returns firewall policy early if firewall rule
is already absent from the firewall_rules list.
:param name_or_id: firewall policy name or id
:param rule_name_or_id: firewall rule name or id
:param dict filters: optional filters
:raises: DuplicateResource on multiple matches
:raises: ResourceNotFound if firewall policy is not found
:return: updated firewall policy
:rtype: FirewallPolicy
"""
if not filters:
filters = {}
firewall_policy = self.network.find_firewall_policy(
name_or_id, ignore_missing=False, **filters)
firewall_rule = self.network.find_firewall_rule(rule_name_or_id)
if not firewall_rule:
# short-circuit: if firewall rule is not found,
# return current firewall policy
self.log.debug('Firewall rule %s not found for removing',
rule_name_or_id)
return firewall_policy
if firewall_rule['id'] not in firewall_policy['firewall_rules']:
# short-circuit: if firewall rule id is not associated,
# log it to debug and return current firewall policy
self.log.debug(
'Firewall rule %s not associated with firewall policy %s',
rule_name_or_id, name_or_id)
return firewall_policy
return self.network.remove_rule_from_policy(firewall_policy['id'],
firewall_rule['id'])
@_utils.valid_kwargs(
'admin_state_up', 'description', 'egress_firewall_policy',
'ingress_firewall_policy', 'name', 'ports', 'project_id', 'shared')
def create_firewall_group(self, **kwargs):
"""
Creates firewall group. The keys egress_firewall_policy and
ingress_firewall_policy are looked up and mapped as
egress_firewall_policy_id and ingress_firewall_policy_id respectively.
Port name or ids list is transformed to port ids list before the POST
request.
:param bool admin_state_up: State of firewall group.
Will block all traffic if set to False.
Defaults to True.
:param description: Human-readable description.
:param egress_firewall_policy: Name or id of egress firewall policy.
:param ingress_firewall_policy: Name or id of ingress firewall policy.
:param name: Human-readable name.
:param list[str] ports: List of associated ports (name or id)
:param project_id: Project id.
:param shared: Visibility to other projects.
Defaults to False.
:raises: BadRequestException if parameters are malformed
:raises: DuplicateResource on multiple matches
:raises: ResourceNotFound if (ingress-, egress-) firewall policy or
a port is not found.
:return: created firewall group
:rtype: FirewallGroup
"""
self._lookup_ingress_egress_firewall_policy_ids(kwargs)
if 'ports' in kwargs:
kwargs['ports'] = self._get_port_ids(kwargs['ports'])
return self.network.create_firewall_group(**kwargs)
def delete_firewall_group(self, name_or_id, filters=None):
"""
Deletes firewall group.
Prints debug message in case to-be-deleted resource was not found.
:param name_or_id: firewall group name or id
:param dict filters: optional filters
:raises: DuplicateResource on multiple matches
:return: True if resource is successfully deleted, False otherwise.
:rtype: bool
"""
if not filters:
filters = {}
try:
firewall_group = self.network.find_firewall_group(
name_or_id, ignore_missing=False, **filters)
self.network.delete_firewall_group(firewall_group,
ignore_missing=False)
except exceptions.ResourceNotFound:
self.log.debug('Firewall group %s not found for deleting',
name_or_id)
return False
return True
def get_firewall_group(self, name_or_id, filters=None):
"""
Retrieves firewall group.
:param name_or_id: firewall group name or id
:param dict filters: optional filters
:raises: DuplicateResource on multiple matches
:return: firewall group or None if not found
:rtype: FirewallGroup
"""
if not filters:
filters = {}
return self.network.find_firewall_group(name_or_id, **filters)
def list_firewall_groups(self, filters=None):
"""
Lists firewall groups.
:param dict filters: optional filters
:return: list of firewall groups
:rtype: list[FirewallGroup]
"""
if not filters:
filters = {}
return list(self.network.firewall_groups(**filters))
@_utils.valid_kwargs(
'admin_state_up', 'description', 'egress_firewall_policy',
'ingress_firewall_policy', 'name', 'ports', 'project_id', 'shared')
def update_firewall_group(self, name_or_id, filters=None, **kwargs):
"""
Updates firewall group.
To unset egress- or ingress firewall policy, set egress_firewall_policy
or ingress_firewall_policy to None. You can also set
egress_firewall_policy_id and ingress_firewall_policy_id directly,
which will skip the policy lookups.
:param name_or_id: firewall group name or id
:param dict filters: optional filters
:param kwargs: firewall group update parameters
See create_firewall_group docstring for valid parameters.
:raises: BadRequestException if parameters are malformed
:raises: DuplicateResource on multiple matches
:raises: ResourceNotFound if firewall group, a firewall policy
(egress, ingress) or port is not found
:return: updated firewall group
:rtype: FirewallGroup
"""
if not filters:
filters = {}
firewall_group = self.network.find_firewall_group(
name_or_id, ignore_missing=False, **filters)
self._lookup_ingress_egress_firewall_policy_ids(kwargs)
if 'ports' in kwargs:
kwargs['ports'] = self._get_port_ids(kwargs['ports'])
return self.network.update_firewall_group(firewall_group, **kwargs)
def _lookup_ingress_egress_firewall_policy_ids(self, firewall_group):
"""
Transforms firewall_group dict IN-PLACE. Takes the value of the keys
egress_firewall_policy and ingress_firewall_policy, looks up the
policy ids and maps them to egress_firewall_policy_id and
ingress_firewall_policy_id. Old keys which were used for the lookup
are deleted.
:param dict firewall_group: firewall group dict
:raises: DuplicateResource on multiple matches
:raises: ResourceNotFound if a firewall policy is not found
"""
for key in ('egress_firewall_policy', 'ingress_firewall_policy'):
if key not in firewall_group:
continue
if firewall_group[key] is None:
val = None
else:
val = self.network.find_firewall_policy(
firewall_group[key], ignore_missing=False)['id']
firewall_group[key + '_id'] = val
del firewall_group[key]
def list_security_groups(self, filters=None):
"""List all available security groups.
:param filters: (optional) dict of filter conditions to push down
:returns: A list of security group ``munch.Munch``.
"""
# Security groups not supported
if not self._has_secgroups():
raise exc.OpenStackCloudUnavailableFeature(
"Unavailable feature: security groups"
)
if not filters:
filters = {}
data = []
# Handle neutron security groups
if self._use_neutron_secgroups():
# Neutron returns dicts, so no need to convert objects here.
resp = self.network.get('/security-groups.json', params=filters)
data = proxy._json_response(
resp,
error_message="Error fetching security group list")
return self._normalize_secgroups(
self._get_and_munchify('security_groups', data))
# Handle nova security groups
else:
data = proxy._json_response(self.compute.get(
'/os-security-groups', params=filters))
return self._normalize_secgroups(
self._get_and_munchify('security_groups', data))
@_utils.valid_kwargs("name", "description", "shared", "default",
"project_id")
def create_qos_policy(self, **kwargs):
"""Create a QoS policy.
:param string name: Name of the QoS policy being created.
:param string description: Description of created QoS policy.
:param bool shared: Set the QoS policy as shared.
:param bool default: Set the QoS policy as default for project.
:param string project_id: Specify the project ID this QoS policy
will be created on (admin-only).
:returns: The QoS policy object.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
default = kwargs.pop("default", None)
if default is not None:
if self._has_neutron_extension('qos-default'):
kwargs['is_default'] = default
else:
self.log.debug("'qos-default' extension is not available on "
"target cloud")
data = self.network.post("/qos/policies.json", json={'policy': kwargs})
return self._get_and_munchify('policy', data)
@_utils.valid_kwargs("name", "description", "shared", "default",
"project_id")
def update_qos_policy(self, name_or_id, **kwargs):
"""Update an existing QoS policy.
:param string name_or_id:
Name or ID of the QoS policy to update.
:param string policy_name:
The new name of the QoS policy.
:param string description:
The new description of the QoS policy.
:param bool shared:
If True, the QoS policy will be set as shared.
:param bool default:
If True, the QoS policy will be set as default for project.
:returns: The updated QoS policy object.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
default = kwargs.pop("default", None)
if default is not None:
if self._has_neutron_extension('qos-default'):
kwargs['is_default'] = default
else:
self.log.debug("'qos-default' extension is not available on "
"target cloud")
if not kwargs:
self.log.debug("No QoS policy data to update")
return
curr_policy = self.get_qos_policy(name_or_id)
if not curr_policy:
raise exc.OpenStackCloudException(
"QoS policy %s not found." % name_or_id)
data = self.network.put(
"/qos/policies/{policy_id}.json".format(
policy_id=curr_policy['id']),
json={'policy': kwargs})
return self._get_and_munchify('policy', data)
def delete_qos_policy(self, name_or_id):
"""Delete a QoS policy.
:param name_or_id: Name or ID of the policy being deleted.
:returns: True if delete succeeded, False otherwise.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(name_or_id)
if not policy:
self.log.debug("QoS policy %s not found for deleting", name_or_id)
return False
exceptions.raise_from_response(self.network.delete(
"/qos/policies/{policy_id}.json".format(policy_id=policy['id'])))
return True
def search_qos_bandwidth_limit_rules(self, policy_name_or_id, rule_id=None,
filters=None):
"""Search QoS bandwidth limit rules
:param string policy_name_or_id: Name or ID of the QoS policy to which
rules should be associated.
:param string rule_id: ID of searched rule.
:param filters: a dict containing additional filters to use. e.g.
{'max_kbps': 1000}
:returns: a list of ``munch.Munch`` containing the bandwidth limit
rule descriptions.
:raises: ``OpenStackCloudException`` if something goes wrong during the
OpenStack API call.
"""
rules = self.list_qos_bandwidth_limit_rules(policy_name_or_id, filters)
return _utils._filter_list(rules, rule_id, filters)
def list_qos_bandwidth_limit_rules(self, policy_name_or_id, filters=None):
"""List all available QoS bandwidth limit rules.
:param string policy_name_or_id: Name or ID of the QoS policy from
from rules should be listed.
:param filters: (optional) dict of filter conditions to push down
:returns: A list of ``munch.Munch`` containing rule info.
:raises: ``OpenStackCloudResourceNotFound`` if QoS policy will not be
found.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
# Translate None from search interface to empty {} for kwargs below
if not filters:
filters = {}
resp = self.network.get(
"/qos/policies/{policy_id}/bandwidth_limit_rules.json".format(
policy_id=policy['id']),
params=filters)
data = proxy._json_response(
resp,
error_message="Error fetching QoS bandwidth limit rules from "
"{policy}".format(policy=policy['id']))
return self._get_and_munchify('bandwidth_limit_rules', data)
def get_qos_bandwidth_limit_rule(self, policy_name_or_id, rule_id):
"""Get a QoS bandwidth limit rule by name or ID.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule should be associated.
:param rule_id: ID of the rule.
:returns: A bandwidth limit rule ``munch.Munch`` or None if
no matching rule is found.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
resp = self.network.get(
"/qos/policies/{policy_id}/bandwidth_limit_rules/{rule_id}.json".
format(policy_id=policy['id'], rule_id=rule_id))
data = proxy._json_response(
resp,
error_message="Error fetching QoS bandwidth limit rule {rule_id} "
"from {policy}".format(rule_id=rule_id,
policy=policy['id']))
return self._get_and_munchify('bandwidth_limit_rule', data)
@_utils.valid_kwargs("max_burst_kbps", "direction")
def create_qos_bandwidth_limit_rule(self, policy_name_or_id, max_kbps,
**kwargs):
"""Create a QoS bandwidth limit rule.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule should be associated.
:param int max_kbps: Maximum bandwidth limit value
(in kilobits per second).
:param int max_burst_kbps: Maximum burst value (in kilobits).
:param string direction: Ingress or egress.
The direction in which the traffic will be limited.
:returns: The QoS bandwidth limit rule.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
if kwargs.get("direction") is not None:
if not self._has_neutron_extension('qos-bw-limit-direction'):
kwargs.pop("direction")
self.log.debug(
"'qos-bw-limit-direction' extension is not available on "
"target cloud")
kwargs['max_kbps'] = max_kbps
data = self.network.post(
"/qos/policies/{policy_id}/bandwidth_limit_rules".format(
policy_id=policy['id']),
json={'bandwidth_limit_rule': kwargs})
return self._get_and_munchify('bandwidth_limit_rule', data)
@_utils.valid_kwargs("max_kbps", "max_burst_kbps", "direction")
def update_qos_bandwidth_limit_rule(self, policy_name_or_id, rule_id,
**kwargs):
"""Update a QoS bandwidth limit rule.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule is associated.
:param string rule_id: ID of rule to update.
:param int max_kbps: Maximum bandwidth limit value
(in kilobits per second).
:param int max_burst_kbps: Maximum burst value (in kilobits).
:param string direction: Ingress or egress.
The direction in which the traffic will be limited.
:returns: The updated QoS bandwidth limit rule.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
if kwargs.get("direction") is not None:
if not self._has_neutron_extension('qos-bw-limit-direction'):
kwargs.pop("direction")
self.log.debug(
"'qos-bw-limit-direction' extension is not available on "
"target cloud")
if not kwargs:
self.log.debug("No QoS bandwidth limit rule data to update")
return
curr_rule = self.get_qos_bandwidth_limit_rule(
policy_name_or_id, rule_id)
if not curr_rule:
raise exc.OpenStackCloudException(
"QoS bandwidth_limit_rule {rule_id} not found in policy "
"{policy_id}".format(rule_id=rule_id,
policy_id=policy['id']))
data = self.network.put(
"/qos/policies/{policy_id}/bandwidth_limit_rules/{rule_id}.json".
format(policy_id=policy['id'], rule_id=rule_id),
json={'bandwidth_limit_rule': kwargs})
return self._get_and_munchify('bandwidth_limit_rule', data)
def delete_qos_bandwidth_limit_rule(self, policy_name_or_id, rule_id):
"""Delete a QoS bandwidth limit rule.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule is associated.
:param string rule_id: ID of rule to update.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
try:
exceptions.raise_from_response(self.network.delete(
"/qos/policies/{policy}/bandwidth_limit_rules/{rule}.json".
format(policy=policy['id'], rule=rule_id)))
except exc.OpenStackCloudURINotFound:
self.log.debug(
"QoS bandwidth limit rule {rule_id} not found in policy "
"{policy_id}. Ignoring.".format(rule_id=rule_id,
policy_id=policy['id']))
return False
return True
def search_qos_dscp_marking_rules(self, policy_name_or_id, rule_id=None,
filters=None):
"""Search QoS DSCP marking rules
:param string policy_name_or_id: Name or ID of the QoS policy to which
rules should be associated.
:param string rule_id: ID of searched rule.
:param filters: a dict containing additional filters to use. e.g.
{'dscp_mark': 32}
:returns: a list of ``munch.Munch`` containing the dscp marking
rule descriptions.
:raises: ``OpenStackCloudException`` if something goes wrong during the
OpenStack API call.
"""
rules = self.list_qos_dscp_marking_rules(policy_name_or_id, filters)
return _utils._filter_list(rules, rule_id, filters)
def list_qos_dscp_marking_rules(self, policy_name_or_id, filters=None):
"""List all available QoS DSCP marking rules.
:param string policy_name_or_id: Name or ID of the QoS policy from
from rules should be listed.
:param filters: (optional) dict of filter conditions to push down
:returns: A list of ``munch.Munch`` containing rule info.
:raises: ``OpenStackCloudResourceNotFound`` if QoS policy will not be
found.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
# Translate None from search interface to empty {} for kwargs below
if not filters:
filters = {}
resp = self.network.get(
"/qos/policies/{policy_id}/dscp_marking_rules.json".format(
policy_id=policy['id']),
params=filters)
data = proxy._json_response(
resp,
error_message="Error fetching QoS DSCP marking rules from "
"{policy}".format(policy=policy['id']))
return self._get_and_munchify('dscp_marking_rules', data)
def get_qos_dscp_marking_rule(self, policy_name_or_id, rule_id):
"""Get a QoS DSCP marking rule by name or ID.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule should be associated.
:param rule_id: ID of the rule.
:returns: A bandwidth limit rule ``munch.Munch`` or None if
no matching rule is found.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
resp = self.network.get(
"/qos/policies/{policy_id}/dscp_marking_rules/{rule_id}.json".
format(policy_id=policy['id'], rule_id=rule_id))
data = proxy._json_response(
resp,
error_message="Error fetching QoS DSCP marking rule {rule_id} "
"from {policy}".format(rule_id=rule_id,
policy=policy['id']))
return self._get_and_munchify('dscp_marking_rule', data)
def create_qos_dscp_marking_rule(self, policy_name_or_id, dscp_mark):
"""Create a QoS DSCP marking rule.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule should be associated.
:param int dscp_mark: DSCP mark value
:returns: The QoS DSCP marking rule.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
body = {
'dscp_mark': dscp_mark
}
data = self.network.post(
"/qos/policies/{policy_id}/dscp_marking_rules".format(
policy_id=policy['id']),
json={'dscp_marking_rule': body})
return self._get_and_munchify('dscp_marking_rule', data)
@_utils.valid_kwargs("dscp_mark")
def update_qos_dscp_marking_rule(self, policy_name_or_id, rule_id,
**kwargs):
"""Update a QoS DSCP marking rule.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule is associated.
:param string rule_id: ID of rule to update.
:param int dscp_mark: DSCP mark value
:returns: The updated QoS bandwidth limit rule.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
if not kwargs:
self.log.debug("No QoS DSCP marking rule data to update")
return
curr_rule = self.get_qos_dscp_marking_rule(
policy_name_or_id, rule_id)
if not curr_rule:
raise exc.OpenStackCloudException(
"QoS dscp_marking_rule {rule_id} not found in policy "
"{policy_id}".format(rule_id=rule_id,
policy_id=policy['id']))
data = self.network.put(
"/qos/policies/{policy_id}/dscp_marking_rules/{rule_id}.json".
format(policy_id=policy['id'], rule_id=rule_id),
json={'dscp_marking_rule': kwargs})
return self._get_and_munchify('dscp_marking_rule', data)
def delete_qos_dscp_marking_rule(self, policy_name_or_id, rule_id):
"""Delete a QoS DSCP marking rule.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule is associated.
:param string rule_id: ID of rule to update.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
try:
exceptions.raise_from_response(self.network.delete(
"/qos/policies/{policy}/dscp_marking_rules/{rule}.json".
format(policy=policy['id'], rule=rule_id)))
except exc.OpenStackCloudURINotFound:
self.log.debug(
"QoS DSCP marking rule {rule_id} not found in policy "
"{policy_id}. Ignoring.".format(rule_id=rule_id,
policy_id=policy['id']))
return False
return True
def search_qos_minimum_bandwidth_rules(self, policy_name_or_id,
rule_id=None, filters=None):
"""Search QoS minimum bandwidth rules
:param string policy_name_or_id: Name or ID of the QoS policy to which
rules should be associated.
:param string rule_id: ID of searched rule.
:param filters: a dict containing additional filters to use. e.g.
{'min_kbps': 1000}
:returns: a list of ``munch.Munch`` containing the bandwidth limit
rule descriptions.
:raises: ``OpenStackCloudException`` if something goes wrong during the
OpenStack API call.
"""
rules = self.list_qos_minimum_bandwidth_rules(
policy_name_or_id, filters)
return _utils._filter_list(rules, rule_id, filters)
def list_qos_minimum_bandwidth_rules(self, policy_name_or_id,
filters=None):
"""List all available QoS minimum bandwidth rules.
:param string policy_name_or_id: Name or ID of the QoS policy from
from rules should be listed.
:param filters: (optional) dict of filter conditions to push down
:returns: A list of ``munch.Munch`` containing rule info.
:raises: ``OpenStackCloudResourceNotFound`` if QoS policy will not be
found.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
# Translate None from search interface to empty {} for kwargs below
if not filters:
filters = {}
resp = self.network.get(
"/qos/policies/{policy_id}/minimum_bandwidth_rules.json".format(
policy_id=policy['id']),
params=filters)
data = proxy._json_response(
resp,
error_message="Error fetching QoS minimum bandwidth rules from "
"{policy}".format(policy=policy['id']))
return self._get_and_munchify('minimum_bandwidth_rules', data)
def get_qos_minimum_bandwidth_rule(self, policy_name_or_id, rule_id):
"""Get a QoS minimum bandwidth rule by name or ID.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule should be associated.
:param rule_id: ID of the rule.
:returns: A bandwidth limit rule ``munch.Munch`` or None if
no matching rule is found.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
resp = self.network.get(
"/qos/policies/{policy_id}/minimum_bandwidth_rules/{rule_id}.json".
format(policy_id=policy['id'], rule_id=rule_id))
data = proxy._json_response(
resp,
error_message="Error fetching QoS minimum_bandwidth rule {rule_id}"
" from {policy}".format(rule_id=rule_id,
policy=policy['id']))
return self._get_and_munchify('minimum_bandwidth_rule', data)
@_utils.valid_kwargs("direction")
def create_qos_minimum_bandwidth_rule(self, policy_name_or_id, min_kbps,
**kwargs):
"""Create a QoS minimum bandwidth limit rule.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule should be associated.
:param int min_kbps: Minimum bandwidth value (in kilobits per second).
:param string direction: Ingress or egress.
The direction in which the traffic will be available.
:returns: The QoS minimum bandwidth rule.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
kwargs['min_kbps'] = min_kbps
data = self.network.post(
"/qos/policies/{policy_id}/minimum_bandwidth_rules".format(
policy_id=policy['id']),
json={'minimum_bandwidth_rule': kwargs})
return self._get_and_munchify('minimum_bandwidth_rule', data)
@_utils.valid_kwargs("min_kbps", "direction")
def update_qos_minimum_bandwidth_rule(self, policy_name_or_id, rule_id,
**kwargs):
"""Update a QoS minimum bandwidth rule.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule is associated.
:param string rule_id: ID of rule to update.
:param int min_kbps: Minimum bandwidth value (in kilobits per second).
:param string direction: Ingress or egress.
The direction in which the traffic will be available.
:returns: The updated QoS minimum bandwidth rule.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
if not kwargs:
self.log.debug("No QoS minimum bandwidth rule data to update")
return
curr_rule = self.get_qos_minimum_bandwidth_rule(
policy_name_or_id, rule_id)
if not curr_rule:
raise exc.OpenStackCloudException(
"QoS minimum_bandwidth_rule {rule_id} not found in policy "
"{policy_id}".format(rule_id=rule_id,
policy_id=policy['id']))
data = self.network.put(
"/qos/policies/{policy_id}/minimum_bandwidth_rules/{rule_id}.json".
format(policy_id=policy['id'], rule_id=rule_id),
json={'minimum_bandwidth_rule': kwargs})
return self._get_and_munchify('minimum_bandwidth_rule', data)
def delete_qos_minimum_bandwidth_rule(self, policy_name_or_id, rule_id):
"""Delete a QoS minimum bandwidth rule.
:param string policy_name_or_id: Name or ID of the QoS policy to which
rule is associated.
:param string rule_id: ID of rule to delete.
:raises: OpenStackCloudException on operation error.
"""
if not self._has_neutron_extension('qos'):
raise exc.OpenStackCloudUnavailableExtension(
'QoS extension is not available on target cloud')
policy = self.get_qos_policy(policy_name_or_id)
if not policy:
raise exc.OpenStackCloudResourceNotFound(
"QoS policy {name_or_id} not Found.".format(
name_or_id=policy_name_or_id))
try:
exceptions.raise_from_response(self.network.delete(
"/qos/policies/{policy}/minimum_bandwidth_rules/{rule}.json".
format(policy=policy['id'], rule=rule_id)))
except exc.OpenStackCloudURINotFound:
self.log.debug(
"QoS minimum bandwidth rule {rule_id} not found in policy "
"{policy_id}. Ignoring.".format(rule_id=rule_id,
policy_id=policy['id']))
return False
return True
def add_router_interface(self, router, subnet_id=None, port_id=None):
"""Attach a subnet to an internal router interface.
Either a subnet ID or port ID must be specified for the internal
interface. Supplying both will result in an error.
:param dict router: The dict object of the router being changed
:param string subnet_id: The ID of the subnet to use for the interface
:param string port_id: The ID of the port to use for the interface
:returns: A ``munch.Munch`` with the router ID (ID),
subnet ID (subnet_id), port ID (port_id) and tenant ID
(tenant_id).
:raises: OpenStackCloudException on operation error.
"""
json_body = {}
if subnet_id:
json_body['subnet_id'] = subnet_id
if port_id:
json_body['port_id'] = port_id
return proxy._json_response(
self.network.put(
"/routers/{router_id}/add_router_interface.json".format(
router_id=router['id']),
json=json_body),
error_message="Error attaching interface to router {0}".format(
router['id']))
def remove_router_interface(self, router, subnet_id=None, port_id=None):
"""Detach a subnet from an internal router interface.
At least one of subnet_id or port_id must be supplied.
If you specify both subnet and port ID, the subnet ID must
correspond to the subnet ID of the first IP address on the port
specified by the port ID. Otherwise an error occurs.
:param dict router: The dict object of the router being changed
:param string subnet_id: The ID of the subnet to use for the interface
:param string port_id: The ID of the port to use for the interface
:returns: None on success
:raises: OpenStackCloudException on operation error.
"""
json_body = {}
if subnet_id:
json_body['subnet_id'] = subnet_id
if port_id:
json_body['port_id'] = port_id
if not json_body:
raise ValueError(
"At least one of subnet_id or port_id must be supplied.")
exceptions.raise_from_response(
self.network.put(
"/routers/{router_id}/remove_router_interface.json".format(
router_id=router['id']),
json=json_body),
error_message="Error detaching interface from router {0}".format(
router['id']))
def list_router_interfaces(self, router, interface_type=None):
"""List all interfaces for a router.
:param dict router: A router dict object.
:param string interface_type: One of None, "internal", or "external".
Controls whether all, internal interfaces or external interfaces
are returned.
:returns: A list of port ``munch.Munch`` objects.
"""
# Find only router interface and gateway ports, ignore L3 HA ports etc.
router_interfaces = self.search_ports(filters={
'device_id': router['id'],
'device_owner': 'network:router_interface'}
) + self.search_ports(filters={
'device_id': router['id'],
'device_owner': 'network:router_interface_distributed'}
) + self.search_ports(filters={
'device_id': router['id'],
'device_owner': 'network:ha_router_replicated_interface'})
router_gateways = self.search_ports(filters={
'device_id': router['id'],
'device_owner': 'network:router_gateway'})
ports = router_interfaces + router_gateways
if interface_type:
if interface_type == 'internal':
return router_interfaces
if interface_type == 'external':
return router_gateways
return ports
def create_router(self, name=None, admin_state_up=True,
ext_gateway_net_id=None, enable_snat=None,
ext_fixed_ips=None, project_id=None,
availability_zone_hints=None):
"""Create a logical router.
:param string name: The router name.
:param bool admin_state_up: The administrative state of the router.
:param string ext_gateway_net_id: Network ID for the external gateway.
:param bool enable_snat: Enable Source NAT (SNAT) attribute.
:param ext_fixed_ips:
List of dictionaries of desired IP and/or subnet on the
external network. Example::
[
{
"subnet_id": "8ca37218-28ff-41cb-9b10-039601ea7e6b",
"ip_address": "192.168.10.2"
}
]
:param string project_id: Project ID for the router.
:param types.ListType availability_zone_hints:
A list of availability zone hints.
:returns: The router object.
:raises: OpenStackCloudException on operation error.
"""
router = {
'admin_state_up': admin_state_up
}
if project_id is not None:
router['tenant_id'] = project_id
if name:
router['name'] = name
ext_gw_info = self._build_external_gateway_info(
ext_gateway_net_id, enable_snat, ext_fixed_ips
)
if ext_gw_info:
router['external_gateway_info'] = ext_gw_info
if availability_zone_hints is not None:
if not isinstance(availability_zone_hints, list):
raise exc.OpenStackCloudException(
"Parameter 'availability_zone_hints' must be a list")
if not self._has_neutron_extension('router_availability_zone'):
raise exc.OpenStackCloudUnavailableExtension(
'router_availability_zone extension is not available on '
'target cloud')
router['availability_zone_hints'] = availability_zone_hints
data = proxy._json_response(
self.network.post("/routers.json", json={"router": router}),
error_message="Error creating router {0}".format(name))
return self._get_and_munchify('router', data)
def update_router(self, name_or_id, name=None, admin_state_up=None,
ext_gateway_net_id=None, enable_snat=None,
ext_fixed_ips=None, routes=None):
"""Update an existing logical router.
:param string name_or_id: The name or UUID of the router to update.
:param string name: The new router name.
:param bool admin_state_up: The administrative state of the router.
:param string ext_gateway_net_id:
The network ID for the external gateway.
:param bool enable_snat: Enable Source NAT (SNAT) attribute.
:param ext_fixed_ips:
List of dictionaries of desired IP and/or subnet on the
external network. Example::
[
{
"subnet_id": "8ca37218-28ff-41cb-9b10-039601ea7e6b",
"ip_address": "192.168.10.2"
}
]
:param list routes:
A list of dictionaries with destination and nexthop parameters.
Example::
[
{
"destination": "179.24.1.0/24",
"nexthop": "172.24.3.99"
}
]
:returns: The router object.
:raises: OpenStackCloudException on operation error.
"""
router = {}
if name:
router['name'] = name
if admin_state_up is not None:
router['admin_state_up'] = admin_state_up
ext_gw_info = self._build_external_gateway_info(
ext_gateway_net_id, enable_snat, ext_fixed_ips
)
if ext_gw_info:
router['external_gateway_info'] = ext_gw_info
if routes:
if self._has_neutron_extension('extraroute'):
router['routes'] = routes
else:
self.log.warning(
'extra routes extension is not available on target cloud')
if not router:
self.log.debug("No router data to update")
return
curr_router = self.get_router(name_or_id)
if not curr_router:
raise exc.OpenStackCloudException(
"Router %s not found." % name_or_id)
resp = self.network.put(
"/routers/{router_id}.json".format(router_id=curr_router['id']),
json={"router": router})
data = proxy._json_response(
resp,
error_message="Error updating router {0}".format(name_or_id))
return self._get_and_munchify('router', data)
def delete_router(self, name_or_id):
"""Delete a logical router.
If a name, instead of a unique UUID, is supplied, it is possible
that we could find more than one matching router since names are
not required to be unique. An error will be raised in this case.
:param name_or_id: Name or ID of the router being deleted.
:returns: True if delete succeeded, False otherwise.
:raises: OpenStackCloudException on operation error.
"""
router = self.get_router(name_or_id)
if not router:
self.log.debug("Router %s not found for deleting", name_or_id)
return False
exceptions.raise_from_response(self.network.delete(
"/routers/{router_id}.json".format(router_id=router['id']),
error_message="Error deleting router {0}".format(name_or_id)))
return True
def create_subnet(self, network_name_or_id, cidr=None, ip_version=4,
enable_dhcp=False, subnet_name=None, tenant_id=None,
allocation_pools=None,
gateway_ip=None, disable_gateway_ip=False,
dns_nameservers=None, host_routes=None,
ipv6_ra_mode=None, ipv6_address_mode=None,
prefixlen=None, use_default_subnetpool=False, **kwargs):
"""Create a subnet on a specified network.
:param string network_name_or_id:
The unique name or ID of the attached network. If a non-unique
name is supplied, an exception is raised.
:param string cidr:
The CIDR.
:param int ip_version:
The IP version, which is 4 or 6.
:param bool enable_dhcp:
Set to ``True`` if DHCP is enabled and ``False`` if disabled.
Default is ``False``.
:param string subnet_name:
The name of the subnet.
:param string tenant_id:
The ID of the tenant who owns the network. Only administrative users
can specify a tenant ID other than their own.
:param allocation_pools:
A list of dictionaries of the start and end addresses for the
allocation pools. For example::
[
{
"start": "192.168.199.2",
"end": "192.168.199.254"
}
]
:param string gateway_ip:
The gateway IP address. When you specify both allocation_pools and
gateway_ip, you must ensure that the gateway IP does not overlap
with the specified allocation pools.
:param bool disable_gateway_ip:
Set to ``True`` if gateway IP address is disabled and ``False`` if
enabled. It is not allowed with gateway_ip.
Default is ``False``.
:param dns_nameservers:
A list of DNS name servers for the subnet. For example::
[ "8.8.8.7", "8.8.8.8" ]
:param host_routes:
A list of host route dictionaries for the subnet. For example::
[
{
"destination": "0.0.0.0/0",
"nexthop": "123.456.78.9"
},
{
"destination": "192.168.0.0/24",
"nexthop": "192.168.0.1"
}
]
:param string ipv6_ra_mode:
IPv6 Router Advertisement mode. Valid values are: 'dhcpv6-stateful',
'dhcpv6-stateless', or 'slaac'.
:param string ipv6_address_mode:
IPv6 address mode. Valid values are: 'dhcpv6-stateful',
'dhcpv6-stateless', or 'slaac'.
:param string prefixlen:
The prefix length to use for subnet allocation from a subnet pool.
:param bool use_default_subnetpool:
Use the default subnetpool for ``ip_version`` to obtain a CIDR. It
is required to pass ``None`` to the ``cidr`` argument when enabling
this option.
:param kwargs: Key value pairs to be passed to the Neutron API.
:returns: The new subnet object.
:raises: OpenStackCloudException on operation error.
"""
if tenant_id is not None:
filters = {'tenant_id': tenant_id}
else:
filters = None
network = self.get_network(network_name_or_id, filters)
if not network:
raise exc.OpenStackCloudException(
"Network %s not found." % network_name_or_id)
if disable_gateway_ip and gateway_ip:
raise exc.OpenStackCloudException(
'arg:disable_gateway_ip is not allowed with arg:gateway_ip')
if not cidr and not use_default_subnetpool:
raise exc.OpenStackCloudException(
'arg:cidr is required when a subnetpool is not used')
if cidr and use_default_subnetpool:
raise exc.OpenStackCloudException(
'arg:cidr must be set to None when use_default_subnetpool == '
'True')
# Be friendly on ip_version and allow strings
if isinstance(ip_version, six.string_types):
try:
ip_version = int(ip_version)
except ValueError:
raise exc.OpenStackCloudException(
'ip_version must be an integer')
# The body of the neutron message for the subnet we wish to create.
# This includes attributes that are required or have defaults.
subnet = dict({
'network_id': network['id'],
'ip_version': ip_version,
'enable_dhcp': enable_dhcp,
}, **kwargs)
# Add optional attributes to the message.
if cidr:
subnet['cidr'] = cidr
if subnet_name:
subnet['name'] = subnet_name
if tenant_id:
subnet['tenant_id'] = tenant_id
if allocation_pools:
subnet['allocation_pools'] = allocation_pools
if gateway_ip:
subnet['gateway_ip'] = gateway_ip
if disable_gateway_ip:
subnet['gateway_ip'] = None
if dns_nameservers:
subnet['dns_nameservers'] = dns_nameservers
if host_routes:
subnet['host_routes'] = host_routes
if ipv6_ra_mode:
subnet['ipv6_ra_mode'] = ipv6_ra_mode
if ipv6_address_mode:
subnet['ipv6_address_mode'] = ipv6_address_mode
if prefixlen:
subnet['prefixlen'] = prefixlen
if use_default_subnetpool:
subnet['use_default_subnetpool'] = True
response = self.network.post("/subnets.json", json={"subnet": subnet})
return self._get_and_munchify('subnet', response)
def delete_subnet(self, name_or_id):
"""Delete a subnet.
If a name, instead of a unique UUID, is supplied, it is possible
that we could find more than one matching subnet since names are
not required to be unique. An error will be raised in this case.
:param name_or_id: Name or ID of the subnet being deleted.
:returns: True if delete succeeded, False otherwise.
:raises: OpenStackCloudException on operation error.
"""
subnet = self.get_subnet(name_or_id)
if not subnet:
self.log.debug("Subnet %s not found for deleting", name_or_id)
return False
exceptions.raise_from_response(self.network.delete(
"/subnets/{subnet_id}.json".format(subnet_id=subnet['id'])))
return True
def update_subnet(self, name_or_id, subnet_name=None, enable_dhcp=None,
gateway_ip=None, disable_gateway_ip=None,
allocation_pools=None, dns_nameservers=None,
host_routes=None):
"""Update an existing subnet.
:param string name_or_id:
Name or ID of the subnet to update.
:param string subnet_name:
The new name of the subnet.
:param bool enable_dhcp:
Set to ``True`` if DHCP is enabled and ``False`` if disabled.
:param string gateway_ip:
The gateway IP address. When you specify both allocation_pools and
gateway_ip, you must ensure that the gateway IP does not overlap
with the specified allocation pools.
:param bool disable_gateway_ip:
Set to ``True`` if gateway IP address is disabled and ``False`` if
enabled. It is not allowed with gateway_ip.
Default is ``False``.
:param allocation_pools:
A list of dictionaries of the start and end addresses for the
allocation pools. For example::
[
{
"start": "192.168.199.2",
"end": "192.168.199.254"
}
]
:param dns_nameservers:
A list of DNS name servers for the subnet. For example::
[ "8.8.8.7", "8.8.8.8" ]
:param host_routes:
A list of host route dictionaries for the subnet. For example::
[
{
"destination": "0.0.0.0/0",
"nexthop": "123.456.78.9"
},
{
"destination": "192.168.0.0/24",
"nexthop": "192.168.0.1"
}
]
:returns: The updated subnet object.
:raises: OpenStackCloudException on operation error.
"""
subnet = {}
if subnet_name:
subnet['name'] = subnet_name
if enable_dhcp is not None:
subnet['enable_dhcp'] = enable_dhcp
if gateway_ip:
subnet['gateway_ip'] = gateway_ip
if disable_gateway_ip:
subnet['gateway_ip'] = None
if allocation_pools:
subnet['allocation_pools'] = allocation_pools
if dns_nameservers:
subnet['dns_nameservers'] = dns_nameservers
if host_routes:
subnet['host_routes'] = host_routes
if not subnet:
self.log.debug("No subnet data to update")
return
if disable_gateway_ip and gateway_ip:
raise exc.OpenStackCloudException(
'arg:disable_gateway_ip is not allowed with arg:gateway_ip')
curr_subnet = self.get_subnet(name_or_id)
if not curr_subnet:
raise exc.OpenStackCloudException(
"Subnet %s not found." % name_or_id)
response = self.network.put(
"/subnets/{subnet_id}.json".format(subnet_id=curr_subnet['id']),
json={"subnet": subnet})
return self._get_and_munchify('subnet', response)
@_utils.valid_kwargs('name', 'admin_state_up', 'mac_address', 'fixed_ips',
'subnet_id', 'ip_address', 'security_groups',
'allowed_address_pairs', 'extra_dhcp_opts',
'device_owner', 'device_id', 'binding:vnic_type',
'binding:profile', 'port_security_enabled',
'qos_policy_id')
def create_port(self, network_id, **kwargs):
"""Create a port
:param network_id: The ID of the network. (Required)
:param name: A symbolic name for the port. (Optional)
:param admin_state_up: The administrative status of the port,
which is up (true, default) or down (false). (Optional)
:param mac_address: The MAC address. (Optional)
:param fixed_ips: List of ip_addresses and subnet_ids. See subnet_id
and ip_address. (Optional)
For example::
[
{
"ip_address": "10.29.29.13",
"subnet_id": "a78484c4-c380-4b47-85aa-21c51a2d8cbd"
}, ...
]
:param subnet_id: If you specify only a subnet ID, OpenStack Networking
allocates an available IP from that subnet to the port. (Optional)
If you specify both a subnet ID and an IP address, OpenStack
Networking tries to allocate the specified address to the port.
:param ip_address: If you specify both a subnet ID and an IP address,
OpenStack Networking tries to allocate the specified address to
the port.
:param security_groups: List of security group UUIDs. (Optional)
:param allowed_address_pairs: Allowed address pairs list (Optional)
For example::
[
{
"ip_address": "23.23.23.1",
"mac_address": "fa:16:3e:c4:cd:3f"
}, ...
]
:param extra_dhcp_opts: Extra DHCP options. (Optional).
For example::
[
{
"opt_name": "opt name1",
"opt_value": "value1"
}, ...
]
:param device_owner: The ID of the entity that uses this port.
For example, a DHCP agent. (Optional)
:param device_id: The ID of the device that uses this port.
For example, a virtual server. (Optional)
:param binding vnic_type: The type of the created port. (Optional)
:param port_security_enabled: The security port state created on
the network. (Optional)
:param qos_policy_id: The ID of the QoS policy to apply for port.
:returns: a ``munch.Munch`` describing the created port.
:raises: ``OpenStackCloudException`` on operation error.
"""
kwargs['network_id'] = network_id
data = proxy._json_response(
self.network.post("/ports.json", json={'port': kwargs}),
error_message="Error creating port for network {0}".format(
network_id))
return self._get_and_munchify('port', data)
@_utils.valid_kwargs('name', 'admin_state_up', 'fixed_ips',
'security_groups', 'allowed_address_pairs',
'extra_dhcp_opts', 'device_owner', 'device_id',
'binding:vnic_type', 'binding:profile',
'port_security_enabled', 'qos_policy_id')
def update_port(self, name_or_id, **kwargs):
"""Update a port
Note: to unset an attribute use None value. To leave an attribute
untouched just omit it.
:param name_or_id: name or ID of the port to update. (Required)
:param name: A symbolic name for the port. (Optional)
:param admin_state_up: The administrative status of the port,
which is up (true) or down (false). (Optional)
:param fixed_ips: List of ip_addresses and subnet_ids. (Optional)
If you specify only a subnet ID, OpenStack Networking allocates
an available IP from that subnet to the port.
If you specify both a subnet ID and an IP address, OpenStack
Networking tries to allocate the specified address to the port.
For example::
[
{
"ip_address": "10.29.29.13",
"subnet_id": "a78484c4-c380-4b47-85aa-21c51a2d8cbd"
}, ...
]
:param security_groups: List of security group UUIDs. (Optional)
:param allowed_address_pairs: Allowed address pairs list (Optional)
For example::
[
{
"ip_address": "23.23.23.1",
"mac_address": "fa:16:3e:c4:cd:3f"
}, ...
]
:param extra_dhcp_opts: Extra DHCP options. (Optional).
For example::
[
{
"opt_name": "opt name1",
"opt_value": "value1"
}, ...
]
:param device_owner: The ID of the entity that uses this port.
For example, a DHCP agent. (Optional)
:param device_id: The ID of the resource this port is attached to.
:param binding vnic_type: The type of the created port. (Optional)
:param port_security_enabled: The security port state created on
the network. (Optional)
:param qos_policy_id: The ID of the QoS policy to apply for port.
:returns: a ``munch.Munch`` describing the updated port.
:raises: OpenStackCloudException on operation error.
"""
port = self.get_port(name_or_id=name_or_id)
if port is None:
raise exc.OpenStackCloudException(
"failed to find port '{port}'".format(port=name_or_id))
data = proxy._json_response(
self.network.put(
"/ports/{port_id}.json".format(port_id=port['id']),
json={"port": kwargs}),
error_message="Error updating port {0}".format(name_or_id))
return self._get_and_munchify('port', data)
def delete_port(self, name_or_id):
"""Delete a port
:param name_or_id: ID or name of the port to delete.
:returns: True if delete succeeded, False otherwise.
:raises: OpenStackCloudException on operation error.
"""
port = self.get_port(name_or_id=name_or_id)
if port is None:
self.log.debug("Port %s not found for deleting", name_or_id)
return False
exceptions.raise_from_response(
self.network.delete(
"/ports/{port_id}.json".format(port_id=port['id'])),
error_message="Error deleting port {0}".format(name_or_id))
return True
def _get_port_ids(self, name_or_id_list, filters=None):
"""
Takes a list of port names or ids, retrieves ports and returns a list
with port ids only.
:param list[str] name_or_id_list: list of port names or ids
:param dict filters: optional filters
:raises: SDKException on multiple matches
:raises: ResourceNotFound if a port is not found
:return: list of port ids
:rtype: list[str]
"""
ids_list = []
for name_or_id in name_or_id_list:
port = self.get_port(name_or_id, filters)
if not port:
raise exceptions.ResourceNotFound(
'Port {id} not found'.format(id=name_or_id))
ids_list.append(port['id'])
return ids_list
def _build_external_gateway_info(self, ext_gateway_net_id, enable_snat,
ext_fixed_ips):
info = {}
if ext_gateway_net_id:
info['network_id'] = ext_gateway_net_id
# Only send enable_snat if it is explicitly set.
if enable_snat is not None:
info['enable_snat'] = enable_snat
if ext_fixed_ips:
info['external_fixed_ips'] = ext_fixed_ips
if info:
return info
return None
| [
"albertczhang@berkeley.edu"
] | albertczhang@berkeley.edu |
fc4acfc5e6a1ae4758a0853857d51c68969e09ca | 6e95e9b6a1fc996ebcb46c44d4ef7678f762e4f7 | /others/taobao_spider/test/service/test_job.py | c68884724f84ce028a0e969f4244394ba839f79e | [
"Apache-2.0",
"Unlicense"
] | permissive | 625781186/lgd_spiders | 3a4d6917a01e446136e7aef4c92b9b7a1f8e498d | 1c8680115beb42f4daaf6be71bf3fb14fcc2c255 | refs/heads/master | 2020-08-29T13:21:12.116395 | 2019-10-21T14:28:00 | 2019-10-21T14:28:00 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 504 | py | # -*- coding: utf-8 -*-
from unittest import TestCase
from mall_spider.spiders.actions.action_service import get_action_service
from mall_spider.utils.date_util import today, yesterday
class TestJob(TestCase):
__action_service = get_action_service()
def test_execute_sycm_category_job_init_actions(self):
# date_str = yesterday().strftime("%Y-%m-%d")
date_str = yesterday().strftime("2019-01-29")
self.__action_service.execute_sycm_category_job_init_actions(date_str)
| [
"lgdupup"
] | lgdupup |
8c11d228b74c486ec8ebda3497329e523595d39c | aac1b8efaeccc544d229aa52093a36802250b4cf | /pre/python/lib/python2.7/dist-packages/Cryptodome/SelfTest/PublicKey/test_import_ECC.py | 22925643114a79cfc5cef097244b83fea8d145d5 | [] | no_license | ag1455/OpenPLi-PC | 4f63bbd389ff9604ab7aaf72d10ee6552b794c87 | 256401ac313df2e45c516af1a4d5398f54703b9c | refs/heads/master | 2023-08-22T18:20:07.491386 | 2023-08-14T17:29:59 | 2023-08-14T17:29:59 | 233,239,212 | 27 | 22 | null | 2020-12-28T22:09:26 | 2020-01-11T13:50:25 | Python | UTF-8 | Python | false | false | 17,460 | py | # ===================================================================
#
# Copyright (c) 2015, Legrandin <helderijs@gmail.com>
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions
# are met:
#
# 1. Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# 2. Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in
# the documentation and/or other materials provided with the
# distribution.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
# "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS
# FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE
# COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
# LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN
# ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
# POSSIBILITY OF SUCH DAMAGE.
# ===================================================================
import unittest
from Cryptodome.SelfTest.st_common import list_test_cases
from Cryptodome.Util._file_system import pycryptodome_filename
from Cryptodome.Util.py3compat import b, unhexlify, bord, tostr
from Cryptodome.Util.number import bytes_to_long
from Cryptodome.Hash import SHAKE128
from Cryptodome.PublicKey import ECC
def load_file(filename, mode="rb"):
fd = open(pycryptodome_filename([
"Cryptodome",
"SelfTest",
"PublicKey",
"test_vectors",
"ECC",
], filename), mode)
return fd.read()
def compact(lines):
ext = b("").join(lines)
return unhexlify(tostr(ext).replace(" ", "").replace(":", ""))
def create_ref_keys():
key_lines = load_file("ecc_p256.txt").splitlines()
private_key_d = bytes_to_long(compact(key_lines[2:5]))
public_key_xy = compact(key_lines[6:11])
assert bord(public_key_xy[0]) == 4 # Uncompressed
public_key_x = bytes_to_long(public_key_xy[1:33])
public_key_y = bytes_to_long(public_key_xy[33:])
return (ECC.construct(curve="P-256", d=private_key_d),
ECC.construct(curve="P-256", point_x=public_key_x, point_y=public_key_y))
# Create reference key pair
ref_private, ref_public = create_ref_keys()
def get_fixed_prng():
return SHAKE128.new().update(b("SEED")).read
class TestImport(unittest.TestCase):
def test_import_public_der(self):
key_file = load_file("ecc_p256_public.der")
key = ECC._import_subjectPublicKeyInfo(key_file)
self.assertEqual(ref_public, key)
key = ECC._import_der(key_file, None)
self.assertEqual(ref_public, key)
key = ECC.import_key(key_file)
self.assertEqual(ref_public, key)
def test_import_private_der(self):
key_file = load_file("ecc_p256_private.der")
key = ECC._import_private_der(key_file, None)
self.assertEqual(ref_private, key)
key = ECC._import_der(key_file, None)
self.assertEqual(ref_private, key)
key = ECC.import_key(key_file)
self.assertEqual(ref_private, key)
def test_import_private_pkcs8_clear(self):
key_file = load_file("ecc_p256_private_p8_clear.der")
key = ECC._import_der(key_file, None)
self.assertEqual(ref_private, key)
key = ECC.import_key(key_file)
self.assertEqual(ref_private, key)
def test_import_private_pkcs8_in_pem_clear(self):
key_file = load_file("ecc_p256_private_p8_clear.pem")
key = ECC.import_key(key_file)
self.assertEqual(ref_private, key)
def test_import_private_pkcs8_encrypted_1(self):
key_file = load_file("ecc_p256_private_p8.der")
key = ECC._import_der(key_file, "secret")
self.assertEqual(ref_private, key)
key = ECC.import_key(key_file, "secret")
self.assertEqual(ref_private, key)
def test_import_private_pkcs8_encrypted_2(self):
key_file = load_file("ecc_p256_private_p8.pem")
key = ECC.import_key(key_file, "secret")
self.assertEqual(ref_private, key)
def test_import_x509_der(self):
key_file = load_file("ecc_p256_x509.der")
key = ECC._import_der(key_file, None)
self.assertEqual(ref_public, key)
key = ECC.import_key(key_file)
self.assertEqual(ref_public, key)
def test_import_public_pem(self):
key_file = load_file("ecc_p256_public.pem")
key = ECC.import_key(key_file)
self.assertEqual(ref_public, key)
def test_import_private_pem(self):
key_file = load_file("ecc_p256_private.pem")
key = ECC.import_key(key_file)
self.assertEqual(ref_private, key)
def test_import_private_pem_encrypted(self):
for algo in "des3", : # TODO: , "aes128", "aes192", "aes256_gcm":
key_file = load_file("ecc_p256_private_enc_%s.pem" % algo)
key = ECC.import_key(key_file, "secret")
self.assertEqual(ref_private, key)
key = ECC.import_key(tostr(key_file), b("secret"))
self.assertEqual(ref_private, key)
def test_import_x509_pem(self):
key_file = load_file("ecc_p256_x509.pem")
key = ECC.import_key(key_file)
self.assertEqual(ref_public, key)
def test_import_openssh(self):
key_file = load_file("ecc_p256_public_openssh.txt")
key = ECC._import_openssh(key_file)
self.assertEqual(ref_public, key)
key = ECC.import_key(key_file)
self.assertEqual(ref_public, key)
class TestExport(unittest.TestCase):
def test_export_public_der_uncompressed(self):
key_file = load_file("ecc_p256_public.der")
encoded = ref_public._export_subjectPublicKeyInfo(False)
self.assertEqual(key_file, encoded)
encoded = ref_public.export_key(format="DER")
self.assertEqual(key_file, encoded)
encoded = ref_public.export_key(format="DER", compress=False)
self.assertEqual(key_file, encoded)
def test_export_public_der_compressed(self):
key_file = load_file("ecc_p256_public.der")
pub_key = ECC.import_key(key_file)
key_file_compressed = pub_key.export_key(format="DER", compress=True)
key_file_compressed_ref = load_file("ecc_p256_public_compressed.der")
self.assertEqual(key_file_compressed, key_file_compressed_ref)
def test_export_private_der(self):
key_file = load_file("ecc_p256_private.der")
encoded = ref_private._export_private_der()
self.assertEqual(key_file, encoded)
# ---
encoded = ref_private.export_key(format="DER", use_pkcs8=False)
self.assertEqual(key_file, encoded)
def test_export_private_pkcs8_clear(self):
key_file = load_file("ecc_p256_private_p8_clear.der")
encoded = ref_private._export_pkcs8()
self.assertEqual(key_file, encoded)
# ---
encoded = ref_private.export_key(format="DER")
self.assertEqual(key_file, encoded)
def test_export_private_pkcs8_encrypted(self):
encoded = ref_private._export_pkcs8(passphrase="secret",
protection="PBKDF2WithHMAC-SHA1AndAES128-CBC")
# This should prove that the output is password-protected
self.assertRaises(ValueError, ECC._import_pkcs8, encoded, None)
decoded = ECC._import_pkcs8(encoded, "secret")
self.assertEqual(ref_private, decoded)
# ---
encoded = ref_private.export_key(format="DER",
passphrase="secret",
protection="PBKDF2WithHMAC-SHA1AndAES128-CBC")
decoded = ECC.import_key(encoded, "secret")
self.assertEqual(ref_private, decoded)
def test_export_public_pem_uncompressed(self):
key_file = load_file("ecc_p256_public.pem", "rt").strip()
encoded = ref_private._export_public_pem(False)
self.assertEqual(key_file, encoded)
# ---
encoded = ref_public.export_key(format="PEM")
self.assertEqual(key_file, encoded)
encoded = ref_public.export_key(format="PEM", compress=False)
self.assertEqual(key_file, encoded)
def test_export_public_pem_compressed(self):
key_file = load_file("ecc_p256_public.pem", "rt").strip()
pub_key = ECC.import_key(key_file)
key_file_compressed = pub_key.export_key(format="PEM", compress=True)
key_file_compressed_ref = load_file("ecc_p256_public_compressed.pem", "rt").strip()
self.assertEqual(key_file_compressed, key_file_compressed_ref)
def test_export_private_pem_clear(self):
key_file = load_file("ecc_p256_private.pem", "rt").strip()
encoded = ref_private._export_private_pem(None)
self.assertEqual(key_file, encoded)
# ---
encoded = ref_private.export_key(format="PEM", use_pkcs8=False)
self.assertEqual(key_file, encoded)
def test_export_private_pem_encrypted(self):
encoded = ref_private._export_private_pem(passphrase=b("secret"))
# This should prove that the output is password-protected
self.assertRaises(ValueError, ECC.import_key, encoded)
assert "EC PRIVATE KEY" in encoded
decoded = ECC.import_key(encoded, "secret")
self.assertEqual(ref_private, decoded)
# ---
encoded = ref_private.export_key(format="PEM",
passphrase="secret",
use_pkcs8=False)
decoded = ECC.import_key(encoded, "secret")
self.assertEqual(ref_private, decoded)
def test_export_private_pkcs8_and_pem_1(self):
# PKCS8 inside PEM with both unencrypted
key_file = load_file("ecc_p256_private_p8_clear.pem", "rt").strip()
encoded = ref_private._export_private_clear_pkcs8_in_clear_pem()
self.assertEqual(key_file, encoded)
# ---
encoded = ref_private.export_key(format="PEM")
self.assertEqual(key_file, encoded)
def test_export_private_pkcs8_and_pem_2(self):
# PKCS8 inside PEM with PKCS8 encryption
encoded = ref_private._export_private_encrypted_pkcs8_in_clear_pem("secret",
protection="PBKDF2WithHMAC-SHA1AndAES128-CBC")
# This should prove that the output is password-protected
self.assertRaises(ValueError, ECC.import_key, encoded)
assert "ENCRYPTED PRIVATE KEY" in encoded
decoded = ECC.import_key(encoded, "secret")
self.assertEqual(ref_private, decoded)
# ---
encoded = ref_private.export_key(format="PEM",
passphrase="secret",
protection="PBKDF2WithHMAC-SHA1AndAES128-CBC")
decoded = ECC.import_key(encoded, "secret")
self.assertEqual(ref_private, decoded)
def test_export_openssh_uncompressed(self):
key_file = load_file("ecc_p256_public_openssh.txt", "rt")
encoded = ref_public._export_openssh(False)
self.assertEquals(key_file, encoded)
# ---
encoded = ref_public.export_key(format="OpenSSH")
self.assertEquals(key_file, encoded)
encoded = ref_public.export_key(format="OpenSSH", compress=False)
self.assertEquals(key_file, encoded)
def test_export_openssh_compressed(self):
key_file = load_file("ecc_p256_public_openssh.txt", "rt")
pub_key = ECC.import_key(key_file)
key_file_compressed = pub_key.export_key(format="OpenSSH", compress=True)
assert len(key_file) > len(key_file_compressed)
self.assertEquals(pub_key, ECC.import_key(key_file_compressed))
def test_prng(self):
# Test that password-protected containers use the provided PRNG
encoded1 = ref_private.export_key(format="PEM",
passphrase="secret",
protection="PBKDF2WithHMAC-SHA1AndAES128-CBC",
randfunc=get_fixed_prng())
encoded2 = ref_private.export_key(format="PEM",
passphrase="secret",
protection="PBKDF2WithHMAC-SHA1AndAES128-CBC",
randfunc=get_fixed_prng())
self.assertEquals(encoded1, encoded2)
# ---
encoded1 = ref_private.export_key(format="PEM",
use_pkcs8=False,
passphrase="secret",
randfunc=get_fixed_prng())
encoded2 = ref_private.export_key(format="PEM",
use_pkcs8=False,
passphrase="secret",
randfunc=get_fixed_prng())
self.assertEquals(encoded1, encoded2)
def test_byte_or_string_passphrase(self):
encoded1 = ref_private.export_key(format="PEM",
use_pkcs8=False,
passphrase="secret",
randfunc=get_fixed_prng())
encoded2 = ref_private.export_key(format="PEM",
use_pkcs8=False,
passphrase=b("secret"),
randfunc=get_fixed_prng())
self.assertEquals(encoded1, encoded2)
def test_error_params1(self):
# Unknown format
self.assertRaises(ValueError, ref_private.export_key, format="XXX")
# Missing 'protection' parameter when PKCS#8 is used
ref_private.export_key(format="PEM", passphrase="secret",
use_pkcs8=False)
self.assertRaises(ValueError, ref_private.export_key, format="PEM",
passphrase="secret")
# DER format but no PKCS#8
self.assertRaises(ValueError, ref_private.export_key, format="DER",
passphrase="secret",
use_pkcs8=False,
protection="PBKDF2WithHMAC-SHA1AndAES128-CBC")
# Incorrect parameters for public keys
self.assertRaises(ValueError, ref_public.export_key, format="DER",
use_pkcs8=False)
# Empty password
self.assertRaises(ValueError, ref_private.export_key, format="PEM",
passphrase="", use_pkcs8=False)
self.assertRaises(ValueError, ref_private.export_key, format="PEM",
passphrase="",
protection="PBKDF2WithHMAC-SHA1AndAES128-CBC")
# No private keys with OpenSSH
self.assertRaises(ValueError, ref_private.export_key, format="OpenSSH",
passphrase="secret")
def test_unsupported_curve(self):
# openssl ecparam -name secp224r1 -genkey -noout -out strange-curve.pem -conv_form uncompressed
curve = """-----BEGIN EC PRIVATE KEY-----
MGgCAQEEHEi7xTHW+5oT8wgpjoEKV7uwMuY8rt2YUZe4j1SgBwYFK4EEACGhPAM6
AATJgfOG+Bnki8robpNM8MtArji43GU9up4B0x9sVhqB+fZP+hXgV9ITN7YX4E/k
gVnJp9EBND/tHQ==
-----END EC PRIVATE KEY-----"""
from Cryptodome.PublicKey.ECC import UnsupportedEccFeature
try:
ECC.import_key(curve)
except UnsupportedEccFeature, uef:
assert("1.3.132.0.33" in str(uef))
else:
assert(False)
def test_compressed_curve(self):
# Compressed P-256 curve (Y-point is even)
pem1 = """-----BEGIN EC PRIVATE KEY-----
MFcCAQEEIHTuc09jC51xXomV6MVCDN+DpAAvSmaJWZPTEHM6D5H1oAoGCCqGSM49
AwEHoSQDIgACWFuGbHe8yJ43rir7PMTE9w8vHz0BSpXHq90Xi7/s+a0=
-----END EC PRIVATE KEY-----"""
# Compressed P-256 curve (Y-point is odd)
pem2 = """-----BEGIN EC PRIVATE KEY-----
MFcCAQEEIFggiPN9SQP+FAPTCPp08fRUz7rHp2qNBRcBJ1DXhb3ZoAoGCCqGSM49
AwEHoSQDIgADLpph1trTIlVfa8NJvlMUPyWvL+wP+pW3BJITUL/wj9A=
-----END EC PRIVATE KEY-----"""
key1 = ECC.import_key(pem1)
low16 = int(key1.pointQ.y % 65536)
self.assertEqual(low16, 0xA6FC)
key2 = ECC.import_key(pem2)
low16 = int(key2.pointQ.y % 65536)
self.assertEqual(low16, 0x6E57)
def get_tests(config={}):
tests = []
tests += list_test_cases(TestImport)
tests += list_test_cases(TestExport)
return tests
if __name__ == '__main__':
suite = lambda: unittest.TestSuite(get_tests())
unittest.main(defaultTest='suite')
| [
"a.g.prosat@gmail.com"
] | a.g.prosat@gmail.com |
13aecd8e724d20623266641a7ee833c0d6764d09 | e3b2c1a9f8edff7012c2e2212bd8ad668c284c6b | /vendor-local/lib/python/blessings/__init__.py | 6f8c107d8f8818da6221b3d849a0cfee8b981b62 | [] | no_license | alfredo/popcorn_maker | 977b02f484b7e6630669c1c1d2217bf6c302010f | 43ddfc8c66c6a074e823ebffdc5a7de3a1ae351f | refs/heads/master | 2021-01-16T21:00:07.709867 | 2012-07-13T11:27:22 | 2012-07-13T11:27:22 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 18,480 | py | from collections import defaultdict
import curses
from curses import tigetstr, tigetnum, setupterm, tparm
from fcntl import ioctl
try:
from io import UnsupportedOperation as IOUnsupportedOperation
except ImportError:
class IOUnsupportedOperation(Exception):
"""A dummy exception to take the place of Python 3's ``io.UnsupportedOperation`` in Python 2"""
import os
from os import isatty, environ
from platform import python_version_tuple
import struct
import sys
from termios import TIOCGWINSZ
__all__ = ['Terminal']
if ('3', '0', '0') <= python_version_tuple() < ('3', '2', '2+'): # Good till 3.2.10
# Python 3.x < 3.2.3 has a bug in which tparm() erroneously takes a string.
raise ImportError('Blessings needs Python 3.2.3 or greater for Python 3 '
'support due to http://bugs.python.org/issue10570.')
class Terminal(object):
"""An abstraction around terminal capabilities
Unlike curses, this doesn't require clearing the screen before doing
anything, and it's friendlier to use. It keeps the endless calls to
``tigetstr()`` and ``tparm()`` out of your code, and it acts intelligently
when somebody pipes your output to a non-terminal.
Instance attributes:
``stream``
The stream the terminal outputs to. It's convenient to pass the stream
around with the terminal; it's almost always needed when the terminal
is and saves sticking lots of extra args on client functions in
practice.
``is_a_tty``
Whether ``stream`` appears to be a terminal. You can examine this value
to decide whether to draw progress bars or other frippery.
"""
def __init__(self, kind=None, stream=None, force_styling=False):
"""Initialize the terminal.
If ``stream`` is not a tty, I will default to returning an empty
Unicode string for all capability values, so things like piping your
output to a file won't strew escape sequences all over the place. The
``ls`` command sets a precedent for this: it defaults to columnar
output when being sent to a tty and one-item-per-line when not.
:arg kind: A terminal string as taken by ``setupterm()``. Defaults to
the value of the ``TERM`` environment variable.
:arg stream: A file-like object representing the terminal. Defaults to
the original value of stdout, like ``curses.initscr()`` does.
:arg force_styling: Whether to force the emission of capabilities, even
if we don't seem to be in a terminal. This comes in handy if users
are trying to pipe your output through something like ``less -r``,
which supports terminal codes just fine but doesn't appear itself
to be a terminal. Just expose a command-line option, and set
``force_styling`` based on it. Terminal initialization sequences
will be sent to ``stream`` if it has a file descriptor and to
``sys.__stdout__`` otherwise. (``setupterm()`` demands to send them
somewhere, and stdout is probably where the output is ultimately
headed. If not, stderr is probably bound to the same terminal.)
"""
if stream is None:
stream = sys.__stdout__
try:
stream_descriptor = (stream.fileno() if hasattr(stream, 'fileno')
and callable(stream.fileno)
else None)
except IOUnsupportedOperation:
stream_descriptor = None
self.is_a_tty = stream_descriptor is not None and isatty(stream_descriptor)
self._does_styling = self.is_a_tty or force_styling
# The desciptor to direct terminal initialization sequences to.
# sys.__stdout__ seems to always have a descriptor of 1, even if output
# is redirected.
self._init_descriptor = (sys.__stdout__.fileno()
if stream_descriptor is None
else stream_descriptor)
if self._does_styling:
# Make things like tigetstr() work. Explicit args make setupterm()
# work even when -s is passed to nosetests. Lean toward sending
# init sequences to the stream if it has a file descriptor, and
# send them to stdout as a fallback, since they have to go
# somewhere.
setupterm(kind or environ.get('TERM', 'unknown'),
self._init_descriptor)
self.stream = stream
# Sugary names for commonly-used capabilities, intended to help avoid trips
# to the terminfo man page and comments in your code:
_sugar = dict(
# Don't use "on" or "bright" as an underscore-separated chunk in any of
# these (e.g. on_cology or rock_on) so we don't interfere with
# __getattr__.
save='sc',
restore='rc',
clear_eol='el',
clear_bol='el1',
clear_eos='ed',
# 'clear' clears the whole screen.
position='cup', # deprecated
move='cup',
move_x='hpa',
move_y='vpa',
move_left='cub1',
move_right='cuf1',
move_up='cuu1',
move_down='cud1',
hide_cursor='civis',
normal_cursor='cnorm',
reset_colors='op', # oc doesn't work on my OS X terminal.
normal='sgr0',
reverse='rev',
# 'bold' is just 'bold'. Similarly...
# blink
# dim
# flash
italic='sitm',
no_italic='ritm',
shadow='sshm',
no_shadow='rshm',
standout='smso',
no_standout='rmso',
subscript='ssubm',
no_subscript='rsubm',
superscript='ssupm',
no_superscript='rsupm',
underline='smul',
no_underline='rmul')
def __getattr__(self, attr):
"""Return parametrized terminal capabilities, like bold.
For example, you can say ``term.bold`` to get the string that turns on
bold formatting and ``term.normal`` to get the string that turns it off
again. Or you can take a shortcut: ``term.bold('hi')`` bolds its
argument and sets everything to normal afterward. You can even combine
things: ``term.bold_underline_red_on_bright_green('yowzers!')``.
For a parametrized capability like ``cup``, pass the parameters too:
``some_term.cup(line, column)``.
``man terminfo`` for a complete list of capabilities.
Return values are always Unicode.
"""
resolution = self._resolve_formatter(attr) if self._does_styling else NullCallableString()
setattr(self, attr, resolution) # Cache capability codes.
return resolution
@property
def height(self):
"""The height of the terminal in characters
If no stream or a stream not representing a terminal was passed in at
construction, return the dimension of the controlling terminal so
piping to things that eventually display on the terminal (like ``less
-R``) work. If a stream representing a terminal was passed in, return
the dimensions of that terminal. If there somehow is no controlling
terminal, return ``None``. (Thus, you should check that ``is_a_tty`` is
true before doing any math on the result.)
"""
return self._height_and_width()[0]
@property
def width(self):
"""The width of the terminal in characters
See ``height()`` for some corner cases.
"""
return self._height_and_width()[1]
def _height_and_width(self):
"""Return a tuple of (terminal height, terminal width)."""
# tigetnum('lines') and tigetnum('cols') update only if we call
# setupterm() again.
for descriptor in self._init_descriptor, sys.__stdout__:
try:
return struct.unpack('hhhh', ioctl(descriptor, TIOCGWINSZ, '\000' * 8))[0:2]
except IOError:
pass
return None, None # Should never get here
def location(self, x=None, y=None):
"""Return a context manager for temporarily moving the cursor.
Move the cursor to a certain position on entry, let you print stuff
there, then return the cursor to its original position::
term = Terminal()
with term.location(2, 5):
print 'Hello, world!'
for x in xrange(10):
print 'I can do it %i times!' % x
Specify ``x`` to move to a certain column, ``y`` to move to a certain
row, both, or neither. If you specify neither, only the saving and
restoration of cursor position will happen. This can be useful if you
simply want to restore your place after doing some manual cursor
movement.
"""
return Location(self, x, y)
@property
def color(self):
"""Return a capability that sets the foreground color.
The capability is unparametrized until called and passed a number
(0-15), at which point it returns another string which represents a
specific color change. This second string can further be called to
color a piece of text and set everything back to normal afterward.
:arg num: The number, 0-15, of the color
"""
return ParametrizingString(self._foreground_color, self.normal)
@property
def on_color(self):
"""Return a capability that sets the background color.
See ``color()``.
"""
return ParametrizingString(self._background_color, self.normal)
@property
def number_of_colors(self):
"""Return the number of colors the terminal supports.
Common values are 0, 8, 16, 88, and 256.
Though the underlying capability returns -1 when there is no color
support, we return 0. This lets you test more Pythonically::
if term.number_of_colors:
...
We also return 0 if the terminal won't tell us how many colors it
supports, which I think is rare.
"""
# This is actually the only remotely useful numeric capability. We
# don't name it after the underlying capability, because we deviate
# slightly from its behavior, and we might someday wish to give direct
# access to it.
colors = tigetnum('colors') # Returns -1 if no color support, -2 if no such cap.
#self.__dict__['colors'] = ret # Cache it. It's not changing. (Doesn't work.)
return colors if colors >= 0 else 0
def _resolve_formatter(self, attr):
"""Resolve a sugary or plain capability name, color, or compound formatting function name into a callable capability."""
if attr in COLORS:
return self._resolve_color(attr)
elif attr in COMPOUNDABLES:
# Bold, underline, or something that takes no parameters
return self._formatting_string(self._resolve_capability(attr))
else:
formatters = split_into_formatters(attr)
if all(f in COMPOUNDABLES for f in formatters):
# It's a compound formatter, like "bold_green_on_red". Future
# optimization: combine all formatting into a single escape
# sequence.
return self._formatting_string(
u''.join(self._resolve_formatter(s) for s in formatters))
else:
return ParametrizingString(self._resolve_capability(attr))
def _resolve_capability(self, atom):
"""Return a terminal code for a capname or a sugary name, or an empty Unicode.
The return value is always Unicode, because otherwise it is clumsy
(especially in Python 3) to concatenate with real (Unicode) strings.
"""
code = tigetstr(self._sugar.get(atom, atom))
if code:
# We can encode escape sequences as UTF-8 because they never
# contain chars > 127, and UTF-8 never changes anything within that
# range..
return code.decode('utf-8')
return u''
def _resolve_color(self, color):
"""Resolve a color like red or on_bright_green into a callable capability."""
# TODO: Does curses automatically exchange red and blue and cyan and
# yellow when a terminal supports setf/setb rather than setaf/setab?
# I'll be blasted if I can find any documentation. The following
# assumes it does.
color_cap = (self._background_color if 'on_' in color else
self._foreground_color)
# curses constants go up to only 7, so add an offset to get at the
# bright colors at 8-15:
offset = 8 if 'bright_' in color else 0
base_color = color.rsplit('_', 1)[-1]
return self._formatting_string(
color_cap(getattr(curses, 'COLOR_' + base_color.upper()) + offset))
@property
def _foreground_color(self):
return self.setaf or self.setf
@property
def _background_color(self):
return self.setab or self.setb
def _formatting_string(self, formatting):
"""Return a new ``FormattingString`` which implicitly receives my notion of "normal"."""
return FormattingString(formatting, self.normal)
def derivative_colors(colors):
"""Return the names of valid color variants, given the base colors."""
return set([('on_' + c) for c in colors] +
[('bright_' + c) for c in colors] +
[('on_bright_' + c) for c in colors])
COLORS = set(['black', 'red', 'green', 'yellow', 'blue', 'magenta', 'cyan', 'white'])
COLORS.update(derivative_colors(COLORS))
COMPOUNDABLES = (COLORS |
set(['bold', 'underline', 'reverse', 'blink', 'dim', 'italic',
'shadow', 'standout', 'subscript', 'superscript']))
class ParametrizingString(unicode):
"""A Unicode string which can be called to parametrize it as a terminal capability"""
def __new__(cls, formatting, normal=None):
"""Instantiate.
:arg normal: If non-None, indicates that, once parametrized, this can
be used as a ``FormattingString``. The value is used as the
"normal" capability.
"""
new = unicode.__new__(cls, formatting)
new._normal = normal
return new
def __call__(self, *args):
try:
# Re-encode the cap, because tparm() takes a bytestring in Python
# 3. However, appear to be a plain Unicode string otherwise so
# concats work.
parametrized = tparm(self.encode('utf-8'), *args).decode('utf-8')
return (parametrized if self._normal is None else
FormattingString(parametrized, self._normal))
except curses.error:
# Catch "must call (at least) setupterm() first" errors, as when
# running simply `nosetests` (without progressive) on nose-
# progressive. Perhaps the terminal has gone away between calling
# tigetstr and calling tparm.
return u''
except TypeError:
# If the first non-int (i.e. incorrect) arg was a string, suggest
# something intelligent:
if len(args) == 1 and isinstance(args[0], basestring):
raise TypeError(
'A native or nonexistent capability template received '
'%r when it was expecting ints. You probably misspelled a '
'formatting call like bright_red_on_white(...).' % args)
else:
# Somebody passed a non-string; I don't feel confident
# guessing what they were trying to do.
raise
class FormattingString(unicode):
"""A Unicode string which can be called upon a piece of text to wrap it in formatting"""
def __new__(cls, formatting, normal):
new = unicode.__new__(cls, formatting)
new._normal = normal
return new
def __call__(self, text):
"""Return a new string that is ``text`` formatted with my contents.
At the beginning of the string, I prepend the formatting that is my
contents. At the end, I append the "normal" sequence to set everything
back to defaults. The return value is always a Unicode.
"""
return self + text + self._normal
class NullCallableString(unicode):
"""A dummy class to stand in for ``FormattingString`` and ``ParametrizingString``
A callable bytestring that returns an empty Unicode when called with an int
and the arg otherwise. We use this when there is no tty and so all
capabilities are blank.
"""
def __new__(cls):
new = unicode.__new__(cls, u'')
return new
def __call__(self, arg):
if isinstance(arg, int):
return u''
return arg # TODO: Force even strs in Python 2.x to be unicodes? Nah. How would I know what encoding to use to convert it?
def split_into_formatters(compound):
"""Split a possibly compound format string into segments.
>>> split_into_formatters('bold_underline_bright_blue_on_red')
['bold', 'underline', 'bright_blue', 'on_red']
"""
merged_segs = []
# These occur only as prefixes, so they can always be merged:
mergeable_prefixes = ['on', 'bright', 'on_bright']
for s in compound.split('_'):
if merged_segs and merged_segs[-1] in mergeable_prefixes:
merged_segs[-1] += '_' + s
else:
merged_segs.append(s)
return merged_segs
class Location(object):
"""Context manager for temporarily moving the cursor"""
def __init__(self, term, x=None, y=None):
self.x, self.y = x, y
self.term = term
def __enter__(self):
"""Save position and move to the requested column, row, or both."""
self.term.stream.write(self.term.save) # save position
if self.x is not None and self.y is not None:
self.term.stream.write(self.term.move(self.y, self.x))
elif self.x is not None:
self.term.stream.write(self.term.move_x(self.x))
elif self.y is not None:
self.term.stream.write(self.term.move_y(self.y))
def __exit__(self, type, value, tb):
"""Restore original cursor position."""
self.term.stream.write(self.term.restore)
| [
"alfredo@madewithbyt.es"
] | alfredo@madewithbyt.es |
d08e4918619a53ca615232233decab9bb16ac9bb | 155cbccc3ef3b8cba80629f2a26d7e76968a639c | /thelma/repositories/rdb/mappers/rackposition.py | f42d135cfc7afb84a57fc4997a6efa5274120fc8 | [
"MIT"
] | permissive | papagr/TheLMA | 1fc65f0a7d3a4b7f9bb2d201259efe5568c2bf78 | d2dc7a478ee5d24ccf3cc680888e712d482321d0 | refs/heads/master | 2022-12-24T20:05:28.229303 | 2020-09-26T13:57:48 | 2020-09-26T13:57:48 | 279,159,864 | 1 | 0 | MIT | 2020-07-12T22:40:36 | 2020-07-12T22:40:35 | null | UTF-8 | Python | false | false | 903 | py | """
This file is part of the TheLMA (THe Laboratory Management Application) project.
See LICENSE.txt for licensing, CONTRIBUTORS.txt for contributor information.
Rack position mapper.
"""
from sqlalchemy import func
from everest.repositories.rdb.utils import mapper
from thelma.entities.rack import RackPosition
__docformat__ = "reStructuredText en"
__all__ = ['create_mapper']
def create_mapper(rack_position_tbl):
"Mapper factory."
m = mapper(RackPosition, rack_position_tbl,
id_attribute='rack_position_id',
slug_expression=lambda cls: func.lower(cls._label), # pylint: disable=W0212
properties=
dict(_label=rack_position_tbl.c.label,
_row_index=rack_position_tbl.c.row_index,
_column_index=rack_position_tbl.c.column_index
),
)
return m
| [
"fogathmann@gmail.com"
] | fogathmann@gmail.com |
4fbd0fc8fdb23a67806ad582e85e7afbddace103 | c16aee56666e7da3532e9dd8cd065e61f25b7e50 | /week1/triangle.py | 3c5049536f1d82082cf9d94959e30383db4ee20b | [] | no_license | loganmurphy/DC_2017_Python3 | 8e6af1f9db2a927242b1bf0f8f9104eb3b32ec86 | 1a0b4b4b37537c354025dd9318d8d14b27791e87 | refs/heads/master | 2021-07-20T08:51:45.625656 | 2017-10-27T03:33:12 | 2017-10-27T03:33:12 | 103,613,458 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 157 | py | height = 4
width = 7
star = "*"
space = " "
i = 0
while i < height:
print((space * width) + star)
i += 1
width -= 1
star = (2 * "*") + star
| [
"loganmurphy1984@gmail.com"
] | loganmurphy1984@gmail.com |
d73734d96cd230ceb5c9108f714f3714d54bf033 | 83277e8b959de61b655f614b7e072394a99d77ae | /venv/bin/pip3.7 | 004fc1d5fa6738f54b95ef6aeeedc8bac6a822c9 | [
"MIT"
] | permissive | hskang9/scalable-django | b3ed144670c3d5b244168fdd38f33e1f596253c0 | 162e0f4a3d49f164af1d33298fa9a47b66508cbf | refs/heads/master | 2023-04-29T05:33:23.460640 | 2020-03-27T00:55:28 | 2020-03-27T00:55:28 | 247,036,359 | 2 | 1 | MIT | 2023-04-21T20:53:08 | 2020-03-13T09:40:37 | Python | UTF-8 | Python | false | false | 431 | 7 | #!/Users/hyungsukkang/PycharmProjects/django_graphql_container/venv/bin/python
# EASY-INSTALL-ENTRY-SCRIPT: 'pip==19.0.3','console_scripts','pip3.7'
__requires__ = 'pip==19.0.3'
import re
import sys
from pkg_resources import load_entry_point
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw?|\.exe)?$', '', sys.argv[0])
sys.exit(
load_entry_point('pip==19.0.3', 'console_scripts', 'pip3.7')()
)
| [
"hyungsukkang@Hyungsuks-Mac-mini.local"
] | hyungsukkang@Hyungsuks-Mac-mini.local |
6d933276903d9ffc7b771f5c55d622336661f483 | 36957a9ce540846d08f151b6a2c2d582cff1df47 | /VR/Python/Python36/Lib/site-packages/soupsieve/css_parser.py | 8616d61b56571f69356cc441403dd95d3f6a796b | [] | no_license | aqp1234/gitVR | 60fc952307ef413e396d31e0d136faffe087ed2b | e70bd82c451943c2966b8ad1bee620a0ee1080d2 | refs/heads/master | 2022-12-29T15:30:12.540947 | 2020-10-07T15:26:32 | 2020-10-07T15:26:32 | 290,163,043 | 0 | 1 | null | 2020-08-25T09:15:40 | 2020-08-25T08:47:36 | C# | UTF-8 | Python | false | false | 130 | py | version https://git-lfs.github.com/spec/v1
oid sha256:ec6cf659d2ea0ac4f743c1c6502d5f376a92d2077bb63b5d79914e584458b656
size 43200
| [
"aqp1234@naver.com"
] | aqp1234@naver.com |
e2c7f0a8cc38b781fef073c5f1e0fc43c09ee60d | 5d28c38dfdd185875ba0edaf77281e684c81da0c | /mlflow/models/evaluation/lift_curve.py | de722164777e792d3be576fca7c1622fd425264d | [
"Apache-2.0"
] | permissive | imrehg/mlflow | 3a68acc1730b3ee6326c1366760d6ddc7e66099c | 5ddfe9a1b48e065540094d83125040d3273c48fa | refs/heads/master | 2022-09-24T05:39:02.767657 | 2022-09-20T00:14:07 | 2022-09-20T00:14:07 | 244,945,486 | 1 | 0 | Apache-2.0 | 2020-03-04T16:11:54 | 2020-03-04T16:11:53 | null | UTF-8 | Python | false | false | 6,224 | py | import matplotlib.pyplot as plt
import numpy as np
def _cumulative_gain_curve(y_true, y_score, pos_label=None):
"""
This method is copied from scikit-plot package.
See https://github.com/reiinakano/scikit-plot/blob/2dd3e6a76df77edcbd724c4db25575f70abb57cb/scikitplot/helpers.py#L157
This function generates the points necessary to plot the Cumulative Gain
Note: This implementation is restricted to the binary classification task.
Args:
y_true (array-like, shape (n_samples)): True labels of the data.
y_score (array-like, shape (n_samples)): Target scores, can either be
probability estimates of the positive class, confidence values, or
non-thresholded measure of decisions (as returned by
decision_function on some classifiers).
pos_label (int or str, default=None): Label considered as positive and
others are considered negative
Returns:
percentages (numpy.ndarray): An array containing the X-axis values for
plotting the Cumulative Gains chart.
gains (numpy.ndarray): An array containing the Y-axis values for one
curve of the Cumulative Gains chart.
Raises:
ValueError: If `y_true` is not composed of 2 classes. The Cumulative
Gain Chart is only relevant in binary classification.
"""
y_true, y_score = np.asarray(y_true), np.asarray(y_score)
# ensure binary classification if pos_label is not specified
classes = np.unique(y_true)
if pos_label is None and not (
np.array_equal(classes, [0, 1])
or np.array_equal(classes, [-1, 1])
or np.array_equal(classes, [0])
or np.array_equal(classes, [-1])
or np.array_equal(classes, [1])
):
raise ValueError("Data is not binary and pos_label is not specified")
elif pos_label is None:
pos_label = 1.0
# make y_true a boolean vector
y_true = y_true == pos_label
sorted_indices = np.argsort(y_score)[::-1]
y_true = y_true[sorted_indices]
gains = np.cumsum(y_true)
percentages = np.arange(start=1, stop=len(y_true) + 1)
gains = gains / float(np.sum(y_true))
percentages = percentages / float(len(y_true))
gains = np.insert(gains, 0, [0])
percentages = np.insert(percentages, 0, [0])
return percentages, gains
def plot_lift_curve(
y_true,
y_probas,
title="Lift Curve",
ax=None,
figsize=None,
title_fontsize="large",
text_fontsize="medium",
pos_label=None,
):
"""
This method is copied from scikit-plot package.
See https://github.com/reiinakano/scikit-plot/blob/2dd3e6a76df77edcbd724c4db25575f70abb57cb/scikitplot/metrics.py#L1133
Generates the Lift Curve from labels and scores/probabilities
The lift curve is used to determine the effectiveness of a
binary classifier. A detailed explanation can be found at
http://www2.cs.uregina.ca/~dbd/cs831/notes/lift_chart/lift_chart.html.
The implementation here works only for binary classification.
Args:
y_true (array-like, shape (n_samples)):
Ground truth (correct) target values.
y_probas (array-like, shape (n_samples, n_classes)):
Prediction probabilities for each class returned by a classifier.
title (string, optional): Title of the generated plot. Defaults to
"Lift Curve".
ax (:class:`matplotlib.axes.Axes`, optional): The axes upon which to
plot the learning curve. If None, the plot is drawn on a new set of
axes.
figsize (2-tuple, optional): Tuple denoting figure size of the plot
e.g. (6, 6). Defaults to ``None``.
title_fontsize (string or int, optional): Matplotlib-style fontsizes.
Use e.g. "small", "medium", "large" or integer-values. Defaults to
"large".
text_fontsize (string or int, optional): Matplotlib-style fontsizes.
Use e.g. "small", "medium", "large" or integer-values. Defaults to
"medium".
pos_label (optional): Label for the positive class.
Returns:
ax (:class:`matplotlib.axes.Axes`): The axes on which the plot was
drawn.
Example:
>>> lr = LogisticRegression()
>>> lr = lr.fit(X_train, y_train)
>>> y_probas = lr.predict_proba(X_test)
>>> plot_lift_curve(y_test, y_probas)
<matplotlib.axes._subplots.AxesSubplot object at 0x7fe967d64490>
>>> plt.show()
.. image:: _static/examples/plot_lift_curve.png
:align: center
:alt: Lift Curve
"""
y_true = np.array(y_true)
y_probas = np.array(y_probas)
classes = np.unique(y_true)
if len(classes) != 2:
raise ValueError(
"Cannot calculate Lift Curve for data with {} category/ies".format(len(classes))
)
# Compute Cumulative Gain Curves
percentages, gains1 = _cumulative_gain_curve(y_true, y_probas[:, 0], classes[0])
percentages, gains2 = _cumulative_gain_curve(y_true, y_probas[:, 1], classes[1])
percentages = percentages[1:]
gains1 = gains1[1:]
gains2 = gains2[1:]
gains1 = gains1 / percentages
gains2 = gains2 / percentages
if ax is None:
_, ax = plt.subplots(1, 1, figsize=figsize)
ax.set_title(title, fontsize=title_fontsize)
label0 = "Class {}".format(classes[0])
label1 = "Class {}".format(classes[1])
# show (positive) next to the positive class in the legend
if pos_label:
if pos_label == classes[0]:
label0 = "Class {} (positive)".format(classes[0])
elif pos_label == classes[1]:
label1 = "Class {} (positive)".format(classes[1])
# do not mark positive class if pos_label is not in classes
ax.plot(percentages, gains1, lw=3, label=label0)
ax.plot(percentages, gains2, lw=3, label=label1)
ax.plot([0, 1], [1, 1], "k--", lw=2, label="Baseline")
ax.set_xlabel("Percentage of sample", fontsize=text_fontsize)
ax.set_ylabel("Lift", fontsize=text_fontsize)
ax.tick_params(labelsize=text_fontsize)
ax.grid("on")
ax.legend(loc="best", fontsize=text_fontsize)
return ax
| [
"noreply@github.com"
] | imrehg.noreply@github.com |
37ab98f9f1a3c980df3099c0873f46050d0682e3 | 3300f61798909af363504e577bfd7677e5239e8e | /docstrings/verify.py | f83fdf1827a069f56d0a89166016d69ec1ed8e39 | [
"LicenseRef-scancode-warranty-disclaimer"
] | no_license | jctanner/ansible-tests | 11c6ed23ef8be5a42401d1c93c86c2693068f8de | c0a2b2aff6002b98088ceb04e435e7a95f78d655 | refs/heads/master | 2020-04-07T10:23:13.031694 | 2014-04-08T02:02:15 | 2014-04-08T02:02:15 | 13,967,969 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 7,743 | py | #!/usr/bin/env python
# http://stackoverflow.com/questions/1714027/version-number-comparison
import os
import sys
import ast
import subprocess
import shlex
from distutils.version import LooseVersion
from pkg_resources import parse_version
import cPickle as pickle
docscript = """#!/usr/bin/env python
import os
import sys
from ansible import utils
from ansible.utils import module_docs
module_name = sys.argv[1]
try:
module_path = utils.plugins.module_finder.find_plugin(module_name)
except:
print None
sys.exit(1)
doc = None
try:
doc, plainexamples = module_docs.get_docstring(module_path)
except AssertionError, e:
pass
except SyntaxError, e:
pass
except Exception, e:
pass
if not doc:
sys.exit(1)
else:
print doc
"""
class Checkout(object):
def __init__(self, repo_url, branch='devel', tmp_path='/tmp'):
self.repo_url = repo_url
self.tmp_path = tmp_path
self.branch = branch
self.git = subprocess.check_output(['which', 'git'])
self.git = self.git.strip()
parts = repo_url.split('/')
self.repo_user = parts[-2]
self.repo_name = parts[-1]
self.repo_dir = self.repo_user + "_" + self.repo_name + "_" + branch
self.repo_path = os.path.join(self.tmp_path, self.repo_dir)
def makecheckout(self):
if not os.path.isdir(self.repo_path):
cmd = "git clone %s -b %s %s" % (self.repo_url, self.branch, self.repo_path)
print "# %s" % cmd
rc, out, err = run_command(cmd, cwd=self.tmp_path, shell=False)
if rc != 0:
import epdb; epdb.st()
def exec_command(self, cmd):
this_path = os.path.join(self.tmp_path, self.repo_dir, "hacking") + "/env-setup"
cmd = "source %s 2>&1 > /dev/null && %s" % (this_path, cmd)
rc, out, err = run_command(cmd, shell=True, executable="/bin/bash", split=False)
return rc, out, err
def run_command(cmd, cwd=None, shell=True, executable=None, split=True):
if type(cmd) is not list and split:
cmd = shlex.split(cmd)
if not cwd:
p = subprocess.Popen(cmd,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
executable=executable,
shell=shell)
else:
p = subprocess.Popen(cmd,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
cwd=cwd,
executable=executable,
shell=shell)
out, err = p.communicate()
return p.returncode, out, err
def get_versions():
aversions = {}
cmd = "git branch --all"
rc, out, err = run_command(cmd, cwd="/home/jtanner/ansible", shell=False)
if rc != 0:
print 'ERROR: unable to run git branch --all in /home/jtanner/ansible'
sys.exit(1)
for bversion in out.split('\n'):
bversion = bversion.strip()
# skip head
if '->' in bversion:
continue
# skip non remotes
if not bversion.startswith('remotes'):
continue
bnormal = bversion.split('/')[-1]
aversions[bnormal] = bversion
return aversions
def make_test_plan(aversions, mdict):
plan = {}
for mkey in sorted(mdict.keys()):
for pkey in mdict[mkey]['params'].keys():
m_name = mdict[mkey]['module']
p_version = mdict[mkey]['params'][pkey]['version_added']
p_version = str(p_version)
m_name = mdict[mkey]['module']
if p_version not in plan:
plan[p_version] = {}
if m_name not in plan[p_version]:
plan[p_version][m_name] = []
plan[p_version][m_name].append(pkey)
plan.pop("historical", None)
return plan
def locate_parameter(aversions, module, param):
found = []
for akey in aversions.keys():
"""
if akey == 'devel':
this_version = "1.6"
else:
this_version = akey.replace('release', '')
this_version = this_version.replace('-', '')
this_version = str(this_version)
"""
#import epdb; epdb.st()
this_checkout = Checkout("https://github.com/ansible/ansible", branch=akey)
this_checkout.makecheckout()
# verify module_docs works on this version
cmd = "python /tmp/docscript.py %s" % 'file'
rc, out, err = this_checkout.exec_command(cmd)
if rc != 0:
#print '# %s unable to import module_docs' % akey
continue
# get all docs for this module at this version
cmd = "python /tmp/docscript.py %s" % module
rc, out, err = this_checkout.exec_command(cmd)
if rc == 0:
data = ast.literal_eval(out)
else:
data = None
if data:
if param in data['options']:
found.append(akey)
return found
def run_test_plan(plan, aversions, mdict):
keymap = {}
results = []
for akey in aversions.keys():
if akey == 'devel':
this_version = "1.6"
else:
this_version = akey.replace('release', '')
this_version = this_version.replace('-', '')
this_version = str(this_version)
keymap[this_version] = akey
for plan_version in sorted(plan.keys()):
if not plan_version in keymap:
continue
this_branch = aversions[keymap[plan_version]]
this_branch = this_branch.split('/')[-1]
print "#",plan_version,":",this_branch
this_checkout = Checkout("https://github.com/ansible/ansible", branch=this_branch)
this_checkout.makecheckout()
# verify module_docs works on this version
cmd = "python /tmp/docscript.py %s" % 'file'
rc, out, err = this_checkout.exec_command(cmd)
if rc != 0:
print '# %s unable to import module_docs: %s' % (this_branch, out)
continue
#import epdb; epdb.st()
for mkey in sorted(plan[plan_version].keys()):
# get all docs for this module at this version
cmd = "python /tmp/docscript.py %s" % mdict[mkey]['module']
rc, out, err = this_checkout.exec_command(cmd)
if rc == 0:
data = ast.literal_eval(out)
else:
data = None
if data:
for pkey in plan[plan_version][mkey]:
if pkey in data['options']:
print "VERIFIED: %s in %s with %s" % (pkey, mkey, this_branch)
else:
found = locate_parameter(aversions, mkey, pkey)
found = ",".join(sorted(found))
print "BAD: %s in %s with %s: found in %s" % \
(pkey, mkey, this_branch, found)
this_result = "%s;%s;%s;%s" % (mkey, pkey, plan_version, found)
results.append(this_result)
for line in results:
open("/tmp/results.csv", "a").write("%s\n" % line)
#####################
# MAIN #
#####################
if __name__ == "__main__":
mdict = pickle.load(open("/tmp/module-params.pickle", "rb"))
# mdict
# module_name:
# version_added: 1.6
# module: the name
# params:
# one:
# key:
# version_added: 1.6
open("/tmp/docscript.py", "wb").write(docscript)
aversions = get_versions()
plan = make_test_plan(aversions, mdict)
run_test_plan(plan, aversions, mdict)
#import epdb; epdb.st()
| [
"tanner.jc@gmail.com"
] | tanner.jc@gmail.com |
25c1fe6db107fe48d30cd7776ecd86b05fa9d636 | a75ac3c5c641fc00a3c403b08eeb6008f648639e | /CodeForces/Python2/330A.py | 55e60b11422a3ffb790bff55aa50324aa95a0ea8 | [] | no_license | Greenwicher/Competitive-Programming | 5e9e667867c2d4e4ce68ad1bc34691ff22e2400a | 6f830799f3ec4603cab8e3f4fbefe523f9f2db98 | refs/heads/master | 2018-11-15T15:25:22.059036 | 2018-09-09T07:57:28 | 2018-09-09T07:57:28 | 28,706,177 | 5 | 0 | null | null | null | null | UTF-8 | Python | false | false | 728 | py | # -*- coding: utf-8 -*-
"""
Created on Fri Jan 23 16:15:41 2015
@author: liuweizhi
"""
## version 1 (wrong anser)
r,c=map(int,raw_input().split());cake=''
for i in range(r):
cake+=raw_input()
for i in range(r):
cake[i:i+c+1]=[cake[i:i+c+1],'o'*c][cake[i:i+c+1].find('S')==-1]
for i in range(c):
cake[i::c]=[cake[i::c],'o'*c][cake[i::c].find('S')==-1]
print cake.count('o')
## version 2
r,c=map(int,raw_input().split());cake=[]
for i in range(r):
for j in raw_input():
cake.append(ord(j))
for i in range(r):
cake[i*c:(i+1)*c]=[cake[i*c:(i+1)*c],[99]*c][83 not in cake[i*c:(i+1)*c]]
for i in range(c):
cake[i::c]=[cake[i::c],[99]*r][83 not in cake[i::c]]
print sum(1 for i in cake if i==99)
| [
"weizhiliu2009@gmail.com"
] | weizhiliu2009@gmail.com |
9f2548aea829f1c6ec1766ca5c2aaaa73db1a037 | d094ba0c8a9b1217fbf014aa79a283a49aabe88c | /env/lib/python3.6/site-packages/nipy/algorithms/clustering/gmm.py | c9704aeef00c3fd12916d2065e862d4d299b6795 | [
"Apache-2.0"
] | permissive | Raniac/NEURO-LEARN | d9274e0baadd97bb02da54bdfcf6ca091fc1c703 | 3c3acc55de8ba741e673063378e6cbaf10b64c7a | refs/heads/master | 2022-12-25T23:46:54.922237 | 2020-09-06T03:15:14 | 2020-09-06T03:15:14 | 182,013,100 | 9 | 2 | Apache-2.0 | 2022-12-09T21:01:00 | 2019-04-18T03:57:00 | CSS | UTF-8 | Python | false | false | 29,434 | py | # emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-
# vi: set ft=python sts=4 ts=4 sw=4 et:
"""
Gaussian Mixture Model Class:
contains the basic fields and methods of GMMs
The class GMM _old uses C bindings which are
computationally and memory efficient.
Author : Bertrand Thirion, 2006-2009
"""
from __future__ import print_function
from __future__ import absolute_import
import numpy as np
from scipy.linalg import eigvalsh
class GridDescriptor(object):
"""
A tiny class to handle cartesian grids
"""
def __init__(self, dim=1, lim=None, n_bins=None):
"""
Parameters
----------
dim: int, optional,
the dimension of the grid
lim: list of len(2*self.dim),
the limits of the grid as (xmin, xmax, ymin, ymax, ...)
n_bins: list of len(self.dim),
the number of bins in each direction
"""
self.dim = dim
if lim is not None:
self.set(lim, n_bins)
if np.size(n_bins) == self.dim:
self.n_bins = np.ravel(np.array(n_bins))
def set(self, lim, n_bins=10):
""" set the limits of the grid and the number of bins
Parameters
----------
lim: list of len(2*self.dim),
the limits of the grid as (xmin, xmax, ymin, ymax, ...)
n_bins: list of len(self.dim), optional
the number of bins in each direction
"""
if len(lim) == 2 * self.dim:
self.lim = lim
else:
raise ValueError("Wrong dimension for grid definition")
if np.size(n_bins) == self.dim:
self.n_bins = np.ravel(np.array(n_bins))
else:
raise ValueError("Wrong dimension for grid definition")
def make_grid(self):
""" Compute the grid points
Returns
-------
grid: array of shape (nb_nodes, self.dim)
where nb_nodes is the prod of self.n_bins
"""
size = np.prod(self.n_bins)
grid = np.zeros((size, self.dim))
grange = []
for j in range(self.dim):
xm = self.lim[2 * j]
xM = self.lim[2 * j + 1]
if np.isscalar(self.n_bins):
xb = self.n_bins
else:
xb = self.n_bins[j]
gr = xm + float(xM - xm) / (xb - 1) * np.arange(xb).astype('f')
grange.append(gr)
if self.dim == 1:
grid = np.array([[grange[0][i]] for i in range(xb)])
if self.dim == 2:
for i in range(self.n_bins[0]):
for j in range(self.n_bins[1]):
grid[i * self.n_bins[1] + j] = np.array(
[grange[0][i], grange[1][j]])
if self.dim == 3:
for i in range(self.n_bins[0]):
for j in range(self.n_bins[1]):
for k in range(self.n_bins[2]):
q = (i * self.n_bins[1] + j) * self.n_bins[2] + k
grid[q] = np.array([grange[0][i], grange[1][j],
grange[2][k]])
if self.dim > 3:
raise NotImplementedError(
'only dimensions <4 are currently handled')
return grid
def best_fitting_GMM(x, krange, prec_type='full', niter=100, delta=1.e-4,
ninit=1, verbose=0):
"""
Given a certain dataset x, find the best-fitting GMM
with a number k of classes in a certain range defined by krange
Parameters
----------
x: array of shape (n_samples,dim)
the data from which the model is estimated
krange: list of floats,
the range of values to test for k
prec_type: string (to be chosen within 'full','diag'), optional,
the covariance parameterization
niter: int, optional,
maximal number of iterations in the estimation process
delta: float, optional,
increment of data likelihood at which convergence is declared
ninit: int
number of initialization performed
verbose=0: verbosity mode
Returns
-------
mg : the best-fitting GMM instance
"""
if np.size(x) == x.shape[0]:
x = np.reshape(x, (np.size(x), 1))
dim = x.shape[1]
bestbic = - np.inf
for k in krange:
lgmm = GMM(k, dim, prec_type)
gmmk = lgmm.initialize_and_estimate(x, None, niter, delta, ninit,
verbose)
bic = gmmk.evidence(x)
if bic > bestbic:
bestbic = bic
bgmm = gmmk
if verbose:
print('k', k, 'bic', bic)
return bgmm
def plot2D(x, my_gmm, z=None, with_dots=True, log_scale=False, mpaxes=None,
verbose=0):
"""
Given a set of points in a plane and a GMM, plot them
Parameters
----------
x: array of shape (npoints, dim=2),
sample points
my_gmm: GMM instance,
whose density has to be ploted
z: array of shape (npoints), optional
that gives a labelling of the points in x
by default, it is not taken into account
with_dots, bool, optional
whether to plot the dots or not
log_scale: bool, optional
whether to plot the likelihood in log scale or not
mpaxes=None, int, optional
if not None, axes handle for plotting
verbose: verbosity mode, optional
Returns
-------
gd, GridDescriptor instance,
that represents the grid used in the function
ax, handle to the figure axes
Notes
-----
``my_gmm`` is assumed to have have a 'nixture_likelihood' method that takes
an array of points of shape (np, dim) and returns an array of shape
(np,my_gmm.k) that represents the likelihood component-wise
"""
import matplotlib.pyplot as plt
if x.shape[1] != my_gmm.dim:
raise ValueError('Incompatible dimension between data and model')
if x.shape[1] != 2:
raise ValueError('this works only for 2D cases')
gd1 = GridDescriptor(2)
xmin, xmax = x.min(0), x.max(0)
xm = 1.1 * xmin[0] - 0.1 * xmax[0]
xs = 1.1 * xmax[0] - 0.1 * xmin[0]
ym = 1.1 * xmin[1] - 0.1 * xmax[1]
ys = 1.1 * xmax[1] - 0.1 * xmin[1]
gd1.set([xm, xs, ym, ys], [51, 51])
grid = gd1.make_grid()
L = my_gmm.mixture_likelihood(grid)
if verbose:
intl = L.sum() * (xs - xm) * (ys - ym) / 2500
print('integral of the density on the domain ', intl)
if mpaxes is None:
plt.figure()
ax = plt.subplot(1, 1, 1)
else:
ax = mpaxes
gdx = gd1.n_bins[0]
Pdens = np.reshape(L, (gdx, -1))
extent = [xm, xs, ym, ys]
if log_scale:
plt.imshow(np.log(Pdens.T), alpha=2.0, origin='lower',
extent=extent)
else:
plt.imshow(Pdens.T, alpha=2.0, origin='lower', extent=extent)
if with_dots:
if z is None:
plt.plot(x[:, 0], x[:, 1], 'o')
else:
hsv = plt.cm.hsv(list(range(256)))
col = hsv[::(256 // int(z.max() + 1))]
for k in range(z.max() + 1):
plt.plot(x[z == k, 0], x[z == k, 1], 'o', color=col[k])
plt.axis(extent)
plt.colorbar()
return gd1, ax
class GMM(object):
"""Standard GMM.
this class contains the following members
k (int): the number of components in the mixture
dim (int): is the dimension of the data
prec_type = 'full' (string) is the parameterization
of the precisions/covariance matrices:
either 'full' or 'diagonal'.
means: array of shape (k,dim):
all the means (mean parameters) of the components
precisions: array of shape (k,dim,dim):
the precisions (inverse covariance matrix) of the components
weights: array of shape(k): weights of the mixture
fixme
-----
no copy method
"""
def __init__(self, k=1, dim=1, prec_type='full', means=None,
precisions=None, weights=None):
"""
Initialize the structure, at least with the dimensions of the problem
Parameters
----------
k (int) the number of classes of the model
dim (int) the dimension of the problem
prec_type = 'full' : coavriance:precision parameterization
(diagonal 'diag' or full 'full').
means = None: array of shape (self.k,self.dim)
precisions = None: array of shape (self.k,self.dim,self.dim)
or (self.k, self.dim)
weights=None: array of shape (self.k)
By default, means, precision and weights are set as
zeros()
eye()
1/k ones()
with the correct dimensions
"""
self.k = k
self.dim = dim
self.prec_type = prec_type
self.means = means
self.precisions = precisions
self.weights = weights
if self.means is None:
self.means = np.zeros((self.k, self.dim))
if self.precisions is None:
if prec_type == 'full':
prec = np.reshape(np.eye(self.dim), (1, self.dim, self.dim))
self.precisions = np.repeat(prec, self.k, 0)
else:
self.precisions = np.ones((self.k, self.dim))
if self.weights is None:
self.weights = np.ones(self.k) * 1.0 / self.k
def plugin(self, means, precisions, weights):
"""
Set manually the weights, means and precision of the model
Parameters
----------
means: array of shape (self.k,self.dim)
precisions: array of shape (self.k,self.dim,self.dim)
or (self.k, self.dim)
weights: array of shape (self.k)
"""
self.means = means
self.precisions = precisions
self.weights = weights
self.check()
def check(self):
"""
Checking the shape of different matrices involved in the model
"""
if self.means.shape[0] != self.k:
raise ValueError("self.means does not have correct dimensions")
if self.means.shape[1] != self.dim:
raise ValueError("self.means does not have correct dimensions")
if self.weights.size != self.k:
raise ValueError("self.weights does not have correct dimensions")
if self.dim != self.precisions.shape[1]:
raise ValueError(
"self.precisions does not have correct dimensions")
if self.prec_type == 'full':
if self.dim != self.precisions.shape[2]:
raise ValueError(
"self.precisions does not have correct dimensions")
if self.prec_type == 'diag':
if np.shape(self.precisions) != np.shape(self.means):
raise ValueError(
"self.precisions does not have correct dimensions")
if self.precisions.shape[0] != self.k:
raise ValueError(
"self.precisions does not have correct dimensions")
if self.prec_type not in ['full', 'diag']:
raise ValueError('unknown precisions type')
def check_x(self, x):
"""
essentially check that x.shape[1]==self.dim
x is returned with possibly reshaping
"""
if np.size(x) == x.shape[0]:
x = np.reshape(x, (np.size(x), 1))
if x.shape[1] != self.dim:
raise ValueError('incorrect size for x')
return x
def initialize(self, x):
"""Initializes self according to a certain dataset x:
1. sets the regularizing hyper-parameters
2. initializes z using a k-means algorithm, then
3. upate the parameters
Parameters
----------
x, array of shape (n_samples,self.dim)
the data used in the estimation process
"""
from .utils import kmeans
n = x.shape[0]
#1. set the priors
self.guess_regularizing(x, bcheck=1)
# 2. initialize the memberships
if self.k > 1:
_, z, _ = kmeans(x, self.k)
else:
z = np.zeros(n).astype(np.int)
l = np.zeros((n, self.k))
l[np.arange(n), z] = 1
# 3.update the parameters
self.update(x, l)
def pop(self, like, tiny=1.e-15):
"""compute the population, i.e. the statistics of allocation
Parameters
----------
like: array of shape (n_samples,self.k):
the likelihood of each item being in each class
"""
sl = np.maximum(tiny, np.sum(like, 1))
nl = (like.T / sl).T
return np.sum(nl, 0)
def update(self, x, l):
""" Identical to self._Mstep(x,l)
"""
self._Mstep(x, l)
def likelihood(self, x):
"""
return the likelihood of the model for the data x
the values are weighted by the components weights
Parameters
----------
x array of shape (n_samples,self.dim)
the data used in the estimation process
Returns
-------
like, array of shape(n_samples,self.k)
component-wise likelihood
"""
like = self.unweighted_likelihood(x)
like *= self.weights
return like
def unweighted_likelihood_(self, x):
"""
return the likelihood of each data for each component
the values are not weighted by the component weights
Parameters
----------
x: array of shape (n_samples,self.dim)
the data used in the estimation process
Returns
-------
like, array of shape(n_samples,self.k)
unweighted component-wise likelihood
"""
n = x.shape[0]
like = np.zeros((n, self.k))
for k in range(self.k):
# compute the data-independent factor first
w = - np.log(2 * np.pi) * self.dim
m = np.reshape(self.means[k], (1, self.dim))
b = self.precisions[k]
if self.prec_type == 'full':
w += np.log(eigvalsh(b)).sum()
dx = m - x
q = np.sum(np.dot(dx, b) * dx, 1)
else:
w += np.sum(np.log(b))
q = np.dot((m - x) ** 2, b)
w -= q
w /= 2
like[:, k] = np.exp(w)
return like
def unweighted_likelihood(self, x):
"""
return the likelihood of each data for each component
the values are not weighted by the component weights
Parameters
----------
x: array of shape (n_samples,self.dim)
the data used in the estimation process
Returns
-------
like, array of shape(n_samples,self.k)
unweighted component-wise likelihood
Notes
-----
Hopefully faster
"""
xt = x.T.copy()
n = x.shape[0]
like = np.zeros((n, self.k))
for k in range(self.k):
# compute the data-independent factor first
w = - np.log(2 * np.pi) * self.dim
m = np.reshape(self.means[k], (self.dim, 1))
b = self.precisions[k]
if self.prec_type == 'full':
w += np.log(eigvalsh(b)).sum()
dx = xt - m
sqx = dx * np.dot(b, dx)
q = np.zeros(n)
for d in range(self.dim):
q += sqx[d]
else:
w += np.sum(np.log(b))
q = np.dot(b, (m - xt) ** 2)
w -= q
w /= 2
like[:, k] = np.exp(w)
return like
def mixture_likelihood(self, x):
"""Returns the likelihood of the mixture for x
Parameters
----------
x: array of shape (n_samples,self.dim)
the data used in the estimation process
"""
x = self.check_x(x)
like = self.likelihood(x)
sl = np.sum(like, 1)
return sl
def average_log_like(self, x, tiny=1.e-15):
"""returns the averaged log-likelihood of the mode for the dataset x
Parameters
----------
x: array of shape (n_samples,self.dim)
the data used in the estimation process
tiny = 1.e-15: a small constant to avoid numerical singularities
"""
x = self.check_x(x)
like = self.likelihood(x)
sl = np.sum(like, 1)
sl = np.maximum(sl, tiny)
return np.mean(np.log(sl))
def evidence(self, x):
"""Computation of bic approximation of evidence
Parameters
----------
x array of shape (n_samples,dim)
the data from which bic is computed
Returns
-------
the bic value
"""
x = self.check_x(x)
tiny = 1.e-15
like = self.likelihood(x)
return self.bic(like, tiny)
def bic(self, like, tiny=1.e-15):
"""Computation of bic approximation of evidence
Parameters
----------
like, array of shape (n_samples, self.k)
component-wise likelihood
tiny=1.e-15, a small constant to avoid numerical singularities
Returns
-------
the bic value, float
"""
sl = np.sum(like, 1)
sl = np.maximum(sl, tiny)
bicc = np.sum(np.log(sl))
# number of parameters
n = like.shape[0]
if self.prec_type == 'full':
eta = self.k * (1 + self.dim + (self.dim * self.dim + 1) / 2) - 1
else:
eta = self.k * (1 + 2 * self.dim) - 1
bicc = bicc - np.log(n) * eta
return bicc
def _Estep(self, x):
"""
E step of the EM algo
returns the likelihood per class of each data item
Parameters
----------
x array of shape (n_samples,dim)
the data used in the estimation process
Returns
-------
likelihood array of shape(n_samples,self.k)
component-wise likelihood
"""
return self.likelihood(x)
def guess_regularizing(self, x, bcheck=1):
"""
Set the regularizing priors as weakly informative
according to Fraley and raftery;
Journal of Classification 24:155-181 (2007)
Parameters
----------
x array of shape (n_samples,dim)
the data used in the estimation process
"""
small = 0.01
# the mean of the data
mx = np.reshape(x.mean(0), (1, self.dim))
dx = x - mx
vx = np.dot(dx.T, dx) / x.shape[0]
if self.prec_type == 'full':
px = np.reshape(np.diag(1.0 / np.diag(vx)),
(1, self.dim, self.dim))
else:
px = np.reshape(1.0 / np.diag(vx), (1, self.dim))
px *= np.exp(2.0 / self.dim * np.log(self.k))
self.prior_means = np.repeat(mx, self.k, 0)
self.prior_weights = np.ones(self.k) / self.k
self.prior_scale = np.repeat(px, self.k, 0)
self.prior_dof = self.dim + 2
self.prior_shrinkage = small
self.weights = np.ones(self.k) * 1.0 / self.k
if bcheck:
self.check()
def _Mstep(self, x, like):
"""
M step regularized according to the procedure of
Fraley et al. 2007
Parameters
----------
x: array of shape(n_samples,self.dim)
the data from which the model is estimated
like: array of shape(n_samples,self.k)
the likelihood of the data under each class
"""
from numpy.linalg import pinv
tiny = 1.e-15
pop = self.pop(like)
sl = np.maximum(tiny, np.sum(like, 1))
like = (like.T / sl).T
# shrinkage,weights,dof
self.weights = self.prior_weights + pop
self.weights = self.weights / self.weights.sum()
# reshape
pop = np.reshape(pop, (self.k, 1))
prior_shrinkage = self.prior_shrinkage
shrinkage = pop + prior_shrinkage
# means
means = np.dot(like.T, x) + self.prior_means * prior_shrinkage
self.means = means / shrinkage
#precisions
empmeans = np.dot(like.T, x) / np.maximum(pop, tiny)
empcov = np.zeros(np.shape(self.precisions))
if self.prec_type == 'full':
for k in range(self.k):
dx = x - empmeans[k]
empcov[k] = np.dot(dx.T, like[:, k:k + 1] * dx)
#covariance
covariance = np.array([pinv(self.prior_scale[k])
for k in range(self.k)])
covariance += empcov
dx = np.reshape(empmeans - self.prior_means, (self.k, self.dim, 1))
addcov = np.array([np.dot(dx[k], dx[k].T) for k in range(self.k)])
apms = np.reshape(prior_shrinkage * pop / shrinkage,
(self.k, 1, 1))
covariance += (addcov * apms)
dof = self.prior_dof + pop + self.dim + 2
covariance /= np.reshape(dof, (self.k, 1, 1))
# precision
self.precisions = np.array([pinv(covariance[k]) \
for k in range(self.k)])
else:
for k in range(self.k):
dx = x - empmeans[k]
empcov[k] = np.sum(dx ** 2 * like[:, k:k + 1], 0)
# covariance
covariance = np.array([1.0 / self.prior_scale[k]
for k in range(self.k)])
covariance += empcov
dx = np.reshape(empmeans - self.prior_means, (self.k, self.dim, 1))
addcov = np.array([np.sum(dx[k] ** 2, 0) for k in range(self.k)])
apms = np.reshape(prior_shrinkage * pop / shrinkage, (self.k, 1))
covariance += addcov * apms
dof = self.prior_dof + pop + self.dim + 2
covariance /= np.reshape(dof, (self.k, 1))
# precision
self.precisions = np.array([1.0 / covariance[k] \
for k in range(self.k)])
def map_label(self, x, like=None):
"""return the MAP labelling of x
Parameters
----------
x array of shape (n_samples,dim)
the data under study
like=None array of shape(n_samples,self.k)
component-wise likelihood
if like==None, it is recomputed
Returns
-------
z: array of shape(n_samples): the resulting MAP labelling
of the rows of x
"""
if like is None:
like = self.likelihood(x)
z = np.argmax(like, 1)
return z
def estimate(self, x, niter=100, delta=1.e-4, verbose=0):
""" Estimation of the model given a dataset x
Parameters
----------
x array of shape (n_samples,dim)
the data from which the model is estimated
niter=100: maximal number of iterations in the estimation process
delta = 1.e-4: increment of data likelihood at which
convergence is declared
verbose=0: verbosity mode
Returns
-------
bic : an asymptotic approximation of model evidence
"""
# check that the data is OK
x = self.check_x(x)
# alternation of E/M step until convergence
tiny = 1.e-15
av_ll_old = - np.inf
for i in range(niter):
l = self._Estep(x)
av_ll = np.mean(np.log(np.maximum(np.sum(l, 1), tiny)))
if av_ll < av_ll_old + delta:
if verbose:
print('iteration:', i, 'log-likelihood:', av_ll,
'old value:', av_ll_old)
break
else:
av_ll_old = av_ll
if verbose:
print(i, av_ll, self.bic(l))
self._Mstep(x, l)
return self.bic(l)
def initialize_and_estimate(self, x, z=None, niter=100, delta=1.e-4,\
ninit=1, verbose=0):
"""Estimation of self given x
Parameters
----------
x array of shape (n_samples,dim)
the data from which the model is estimated
z = None: array of shape (n_samples)
a prior labelling of the data to initialize the computation
niter=100: maximal number of iterations in the estimation process
delta = 1.e-4: increment of data likelihood at which
convergence is declared
ninit=1: number of initialization performed
to reach a good solution
verbose=0: verbosity mode
Returns
-------
the best model is returned
"""
bestbic = - np.inf
bestgmm = GMM(self.k, self.dim, self.prec_type)
bestgmm.initialize(x)
for i in range(ninit):
# initialization -> Kmeans
self.initialize(x)
# alternation of E/M step until convergence
bic = self.estimate(x, niter=niter, delta=delta, verbose=0)
if bic > bestbic:
bestbic = bic
bestgmm.plugin(self.means, self.precisions, self.weights)
return bestgmm
def train(self, x, z=None, niter=100, delta=1.e-4, ninit=1, verbose=0):
"""Idem initialize_and_estimate
"""
return self.initialize_and_estimate(x, z, niter, delta, ninit, verbose)
def test(self, x, tiny=1.e-15):
"""Returns the log-likelihood of the mixture for x
Parameters
----------
x array of shape (n_samples,self.dim)
the data used in the estimation process
Returns
-------
ll: array of shape(n_samples)
the log-likelihood of the rows of x
"""
return np.log(np.maximum(self.mixture_likelihood(x), tiny))
def show_components(self, x, gd, density=None, mpaxes=None):
"""Function to plot a GMM -- Currently, works only in 1D
Parameters
----------
x: array of shape(n_samples, dim)
the data under study
gd: GridDescriptor instance
density: array os shape(prod(gd.n_bins))
density of the model one the discrete grid implied by gd
by default, this is recomputed
mpaxes: axes handle to make the figure, optional,
if None, a new figure is created
"""
import matplotlib.pyplot as plt
if density is None:
density = self.mixture_likelihood(gd.make_grid())
if gd.dim > 1:
raise NotImplementedError("only implemented in 1D")
step = 3.5 * np.std(x) / np.exp(np.log(np.size(x)) / 3)
bins = max(10, int((x.max() - x.min()) / step))
xmin = 1.1 * x.min() - 0.1 * x.max()
xmax = 1.1 * x.max() - 0.1 * x.min()
h, c = np.histogram(x, bins, [xmin, xmax], normed=True)
# Make code robust to new and old behavior of np.histogram
c = c[:len(h)]
offset = (xmax - xmin) / (2 * bins)
c += offset / 2
grid = gd.make_grid()
if mpaxes is None:
plt.figure()
ax = plt.axes()
else:
ax = mpaxes
ax.plot(c + offset, h, linewidth=2)
for k in range(self.k):
ax.plot(grid, density[:, k], linewidth=2)
ax.set_title('Fit of the density with a mixture of Gaussians',
fontsize=12)
legend = ['data']
for k in range(self.k):
legend.append('component %d' % (k + 1))
l = ax.legend(tuple(legend))
for t in l.get_texts():
t.set_fontsize(12)
ax.set_xticklabels(ax.get_xticks(), fontsize=12)
ax.set_yticklabels(ax.get_yticks(), fontsize=12)
def show(self, x, gd, density=None, axes=None):
"""
Function to plot a GMM, still in progress
Currently, works only in 1D and 2D
Parameters
----------
x: array of shape(n_samples, dim)
the data under study
gd: GridDescriptor instance
density: array os shape(prod(gd.n_bins))
density of the model one the discrete grid implied by gd
by default, this is recomputed
"""
import matplotlib.pyplot as plt
# recompute the density if necessary
if density is None:
density = self.mixture_likelihood(gd, x)
if axes is None:
axes = plt.figure()
if gd.dim == 1:
from ..statistics.empirical_pvalue import \
smoothed_histogram_from_samples
h, c = smoothed_histogram_from_samples(x, normalized=True)
offset = (c.max() - c.min()) / (2 * c.size)
grid = gd.make_grid()
h /= h.sum()
h /= (2 * offset)
plt.plot(c[: -1] + offset, h)
plt.plot(grid, density)
if gd.dim == 2:
plt.figure()
xm, xM, ym, yM = gd.lim[0:3]
gd0 = gd.n_bins[0]
Pdens = np.reshape(density, (gd0, np.size(density) / gd0))
axes.imshow(Pdens.T, None, None, None, 'nearest',
1.0, None, None, 'lower', [xm, xM, ym, yM])
axes.plot(x[:, 0], x[:, 1], '.k')
axes.axis([xm, xM, ym, yM])
return axes
| [
"leibingye@outlook.com"
] | leibingye@outlook.com |
373580f79b535f93764e02be1ee047390c697525 | c8eff17479e46abd759dfa4f627303cefecbb6f8 | /tests/test_transaction.py | fc0dfbc401183fd3e3bb39471c16e1bc69748ab6 | [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
] | permissive | snower/torpeewee | 102832fe8ccc5fd7b18a1d634207be5869e71929 | 1d2d73090972ab33bb4a0980bfed63ff74961a1a | refs/heads/master | 2021-06-10T00:14:05.294889 | 2021-05-25T10:15:40 | 2021-05-25T10:15:40 | 61,872,177 | 31 | 10 | null | null | null | null | UTF-8 | Python | false | false | 2,956 | py | # -*- coding: utf-8 -*-
# 16/7/11
# create by: snower
import datetime
from tornado import gen
from tornado.testing import gen_test
from . import BaseTestCase
from .model import Test, db
class TestTestCaseTransaction(BaseTestCase):
async def run_transaction(self, transaction):
await Test.use(transaction).create(data="test_run_transaction", created_at=datetime.datetime.now(),
updated_at=datetime.datetime.now())
count = await Test.select().count()
assert count == 2, ""
count = await Test.use(transaction).select().count()
assert count == 3, ""
@gen_test
async def test(self):
await Test.delete()
await Test.create(data="test", created_at=datetime.datetime.now(), updated_at=datetime.datetime.now())
async with await db.transaction() as transaction:
await Test.use(transaction).create(data="test", created_at=datetime.datetime.now(),
updated_at=datetime.datetime.now())
count = await Test.select().count()
assert count == 1, ""
count = await Test.use(transaction).select().count()
assert count == 2, ""
t = await Test.use(transaction).select().order_by(Test.id.desc()).first()
td = t.data
t.data = "222"
await t.use(transaction).save()
t = await Test.use(transaction).select().order_by(Test.id.desc()).first()
assert t.data == '222'
t = await Test.select().order_by(Test.id.desc()).first()
assert t.data == td
await db.transaction()(self.run_transaction)()
transaction = await db.transaction()
try:
await self.run_transaction(transaction)
except:
await transaction.rollback()
else:
await transaction.commit()
async with await db.transaction() as transaction:
t = await Test.use(transaction).select().order_by(Test.id.desc()).first()
t.data = "aaa"
await t.use(transaction).save()
t = await Test.select().order_by(Test.id.desc()).first()
assert t.data == 'aaa'
async with await db.transaction() as transaction:
t = await Test.use(transaction).select().order_by(Test.id.desc()).first()
await t.use(transaction).delete_instance()
t = await Test.select().where(Test.id == t.id).first()
assert t is None
async with await db.transaction() as transaction:
await Test.use(transaction).update(data='12345')
t = await Test.select().order_by(Test.id.desc()).first()
assert t.data == '12345', ''
async with await db.transaction() as transaction:
await Test.use(transaction).delete()
c = await Test.select().count()
assert c == 0, ''
await Test.delete() | [
"sujian199@gmail.com"
] | sujian199@gmail.com |
23d788b0c075d0f561a991487206cf5a7acfed5c | a0a5dbdf9b850092deeee5f4918ab95232c46100 | /pesquisasatisfacao/crm/migrations/0012_auto_20190409_2110.py | 0990285ee556573e172d51a5baae72b6094e0878 | [] | no_license | CoutinhoElias/pesquisasatisfacao | 55c084a2b1e27cc9d190fb4198e09b78f3c95ad1 | 870eb616917ba9e2d3179609f8764534aa3748f4 | refs/heads/master | 2022-11-30T21:59:21.102520 | 2020-04-25T14:18:05 | 2020-04-25T14:18:05 | 158,157,292 | 1 | 2 | null | 2022-11-22T03:31:14 | 2018-11-19T03:34:11 | JavaScript | UTF-8 | Python | false | false | 519 | py | # Generated by Django 2.2 on 2019-04-10 00:10
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('crm', '0011_atendimento_department'),
]
operations = [
migrations.AlterField(
model_name='atendimento',
name='department',
field=models.CharField(choices=[('0', 'Folha'), ('1', 'Contábil'), ('2', 'Fiscal'), ('3', 'Financeiro')], default='3', max_length=15, verbose_name='Departamento'),
),
]
| [
"coutinho.elias@gmail.com"
] | coutinho.elias@gmail.com |
32abe9d76e271c36d97481943ade34862a5989b9 | bb92245006848ceac733c14b118ef4b269daeee8 | /lab3/training/util.py | bb5cd23af014cdacb2bf3b4057fd6ff7fd5c58b1 | [] | no_license | vazzolla/fsdl-text-recognizer-project | 34a1be71469895b0daed48ed3bceafebd230645a | b32ffe24974a205dcf2a6ec0c440e318f0dbd940 | refs/heads/master | 2022-04-21T11:10:24.962783 | 2020-04-24T01:25:41 | 2020-04-24T01:25:41 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 793 | py | """Function to train a model."""
from time import time
from tensorflow.keras.callbacks import EarlyStopping, Callback
from text_recognizer.datasets.dataset import Dataset
from text_recognizer.models.base import Model
EARLY_STOPPING = True
def train_model(model: Model, dataset: Dataset, epochs: int, batch_size: int, use_wandb: bool = False) -> Model:
"""Train model."""
callbacks = []
if EARLY_STOPPING:
early_stopping = EarlyStopping(monitor="val_loss", min_delta=0.01, patience=3, verbose=1, mode="auto")
callbacks.append(early_stopping)
model.network.summary()
t = time()
_history = model.fit(dataset=dataset, batch_size=batch_size, epochs=epochs, callbacks=callbacks)
print("Training took {:2f} s".format(time() - t))
return model
| [
"sergeykarayev@gmail.com"
] | sergeykarayev@gmail.com |
219bbbdcd432ea9e368cc0634a871f1b331210be | 055a3e2c6642518c5ea59b34c7e7f989551eb45b | /bot/app_streamer.py | 0ec4848efb5f8991bf2364cb6369041c994dde4a | [] | no_license | RTC-SCTB/Constructor-code-examples | c7d2fe4fd8132d54096d6e99e2a169486dd80bc0 | 855b1712fa5fdfe9261e16a130dde3537cb8bb4f | refs/heads/master | 2020-07-21T03:53:43.160161 | 2020-02-20T10:56:48 | 2020-02-20T10:56:48 | 206,752,111 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 13,680 | py | import gi
gi.require_version('Gst','1.0')
from gi.repository import Gst
import sys
import threading
import logging
from bot.common import *
HOST = '127.0.0.1'
RTP_PORT = 5000
class AppSrcStreamer(object):
def __init__(self, video = VIDEO_MJPEG, resolution = (640, 480), framerate = 30,
onFrameCallback = None, useOMX = False, scale = 1):
self._host = HOST
self._port = RTP_PORT
self._width = resolution[0]
self._height = resolution[1]
self._scaleWidth = int(self._width*scale)
self._scaleHeight = int(self._height*scale)
self._needFrame = threading.Event() #флаг, необходимо сформировать OpenCV кадр
self.playing = False
self.paused = False
self._onFrameCallback = None
if video != VIDEO_RAW:
if (not onFrameCallback is None) and callable(onFrameCallback):
self._onFrameCallback = onFrameCallback #обработчик события OpenCV кадр готов
#инициализация Gstreamer
Gst.init(None)
#создаем pipeline
self._make_pipeline(video, self._width, self._height, framerate, useOMX, scale)
self.bus = self.pipeline.get_bus()
self.bus.add_signal_watch()
self.bus.connect('message', self._onMessage)
self.ready_pipeline()
def _make_pipeline(self, video, width, height, framerate, useOMX, scale):
# Создание GStreamer pipeline
self.pipeline = Gst.Pipeline()
self.rtpbin = Gst.ElementFactory.make('rtpbin')
self.rtpbin.set_property('latency', 200)
self.rtpbin.set_property('drop-on-latency', True) #отбрасывать устаревшие кадры
self.rtpbin.set_property('buffer-mode', 4)
self.rtpbin.set_property('ntp-time-source', 3) #источник времени clock-time
self.rtpbin.set_property('ntp-sync', True)
self.rtpbin.set_property('rtcp-sync-send-time', False)
#настраиваем appsrc
self.appsrc = Gst.ElementFactory.make('appsrc')
self.appsrc.set_property('is-live', True)
if video == VIDEO_H264:
videoStr = 'video/x-h264'
elif video == VIDEO_MJPEG:
videoStr = 'image/jpeg'
elif video == VIDEO_RAW:
videoStr = 'video/x-raw,format=RGB'
capstring = videoStr + ',width=' + str(width) \
+ ',height=' + str(height) + ',framerate=' \
+ str(framerate)+'/1'
srccaps = Gst.Caps.from_string(capstring)
self.appsrc.set_property('caps', srccaps)
#print('RPi camera GST caps: %s' % capstring)
if video == VIDEO_RAW:
self.videoconvertRAW = Gst.ElementFactory.make('videoconvert')
self.videoconvertRAWFilter = Gst.ElementFactory.make('capsfilter', 'videoconvertfilter')
videoconvertCaps = Gst.caps_from_string('video/x-raw,format=I420') # формат данных для преобразования в JPEG
self.videoconvertRAWFilter.set_property('caps', videoconvertCaps)
self.jpegenc = Gst.ElementFactory.make('jpegenc')
#self.jpegenc = Gst.ElementFactory.make('vaapijpegenc')
#self.jpegenc = Gst.ElementFactory.make('avenc_ljpeg')
#jpegencCaps = Gst.Caps.from_string('video/x-raw,format=I420')
#self.jpegenc.set_property('caps', jpegencCaps)
if video == VIDEO_H264:
parserName = 'h264parse'
else:
parserName = 'jpegparse'
self.parser = Gst.ElementFactory.make(parserName)
if video == VIDEO_H264:
payloaderName = 'rtph264pay'
#rtph264pay.set_property('config-interval', 10)
#payloadType = 96
else:
payloaderName = 'rtpjpegpay'
#payloadType = 26
self.payloader = Gst.ElementFactory.make(payloaderName)
#payloader.set_property('pt', payloadType)
#For RTP Video
self.udpsink_rtpout = Gst.ElementFactory.make('udpsink', 'udpsink_rtpout')
#self.udpsink_rtpout.set_property('host', self._host)
#self.udpsink_rtpout.set_property('port', self._port)
self.udpsink_rtpout.set_property('sync', True)
self.udpsink_rtpout.set_property('async', False)
self.udpsink_rtcpout = Gst.ElementFactory.make('udpsink', 'udpsink_rtcpout')
#self.udpsink_rtcpout.set_property('host', self._host)
#self.udpsink_rtcpout.set_property('port', self._port + 1)
self.udpsink_rtcpout.set_property('sync', False)
self.udpsink_rtcpout.set_property('async', False)
self.udpsrc_rtcpin = Gst.ElementFactory.make('udpsrc', 'udpsrc_rtcpin')
srcCaps = Gst.Caps.from_string('application/x-rtcp')
#self.udpsrc_rtcpin.set_property('port', self._port + 5)
self.udpsrc_rtcpin.set_property('caps', srcCaps)
#Задаем IP адресс и порт
self.setHost(self._host)
self.setPort(self._port)
if not self._onFrameCallback is None:
self.tee = Gst.ElementFactory.make('tee')
self.rtpQueue = Gst.ElementFactory.make('queue', 'rtp_queue')
self.frameQueue = Gst.ElementFactory.make('queue', 'frame_queue')
if video == VIDEO_H264:
if useOMX:
decoderName = 'omxh264dec' #отлично работает загрузка ЦП 200%
else:
decoderName = 'avdec_h264' #хреново работает загрузка ЦП 120%
#decoder = Gst.ElementFactory.make('avdec_h264_mmal') #не заработал
else:
if useOMX:
decoderName = 'omxmjpegdec' #
else:
decoderName = 'avdec_mjpeg' #
#decoder = Gst.ElementFactory.make('jpegdec') #
self.decoder = Gst.ElementFactory.make(decoderName)
self.videoconvert = Gst.ElementFactory.make('videoconvert')
if scale != 1:
self.videoscale = Gst.ElementFactory.make('videoscale')
self.videoscaleFilter = Gst.ElementFactory.make('capsfilter', 'scalefilter')
videoscaleCaps = Gst.caps_from_string('video/x-raw, width=%d, height=%d' % (self._scaleWidth, self._scaleHeight)) # формат данных после изменения размера
self.videoscaleFilter.set_property('caps', videoscaleCaps)
### создаем свой sink для перевода из GST в CV
self.appsink = Gst.ElementFactory.make('appsink')
cvCaps = Gst.caps_from_string('video/x-raw, format=RGB') # формат принимаемых данных
self.appsink.set_property('caps', cvCaps)
self.appsink.set_property('sync', False)
#appsink.set_property('async', False)
self.appsink.set_property('drop', True)
self.appsink.set_property('max-buffers', 5)
self.appsink.set_property('emit-signals', True)
self.appsink.connect('new-sample', self._newSample)
# добавляем все элементы в pipeline
elemList = [self.appsrc, self.rtpbin, self.parser, self.payloader, self.udpsink_rtpout,
self.udpsink_rtcpout, self.udpsrc_rtcpin]
if video == VIDEO_RAW:
elemList.extend([self.videoconvertRAW, self.videoconvertRAWFilter, self.jpegenc])
if not self._onFrameCallback is None:
elemList.extend([self.tee, self.rtpQueue, self.frameQueue, self.decoder, self.videoconvert, self.appsink])
if scale != 1:
elemList.extend([self.videoscale, self.videoscaleFilter])
for elem in elemList:
if elem is None:
logging.critical('GST elements could not be null')
sys.exit(1)
self.pipeline.add(elem)
#соединяем элементы
if video == VIDEO_RAW:
ret = self.appsrc.link(self.videoconvertRAW)
ret = ret and self.videoconvertRAW.link(self.videoconvertRAWFilter)
ret = ret and self.videoconvertRAWFilter.link(self.jpegenc)
ret = ret and self.jpegenc.link(self.parser)
else:
ret = self.appsrc.link(self.parser)
#соединяем элементы rtpbin
ret = ret and self.payloader.link_pads('src', self.rtpbin, 'send_rtp_sink_0')
ret = ret and self.rtpbin.link_pads('send_rtp_src_0', self.udpsink_rtpout, 'sink')
ret = ret and self.rtpbin.link_pads('send_rtcp_src_0', self.udpsink_rtcpout, 'sink')
ret = ret and self.udpsrc_rtcpin.link_pads('src', self.rtpbin, 'recv_rtcp_sink_0')
if self._onFrameCallback is None: #трансляция без onFrameCallback, т.е. создаем одну ветку
ret = ret and self.parser.link(self.payloader)
else: #трансляция с передачей кадров в onFrameCallback, создаем две ветки
ret = ret and self.parser.link(self.tee)
#1-я ветка RTP
ret = ret and self.rtpQueue.link(self.payloader)
#2-я ветка onFrame
ret = ret and self.frameQueue.link(self.decoder)
if scale != 1:
ret = ret and self.decoder.link(self.videoscale)
ret = ret and self.videoscale.link(self.videoscaleFilter)
ret = ret and self.videoscaleFilter.link(self.videoconvert)
else:
ret = ret and self.decoder.link(self.videoconvert)
ret = ret and self.videoconvert.link(self.appsink)
# подключаем tee к rtpQueue
teeSrcPadTemplate = self.tee.get_pad_template('src_%u')
rtpTeePad = self.tee.request_pad(teeSrcPadTemplate, None, None)
rtpQueuePad = self.rtpQueue.get_static_pad('sink')
ret = ret and (rtpTeePad.link(rtpQueuePad) == Gst.PadLinkReturn.OK)
# подключаем tee к frameQueue
frameTeePad = self.tee.request_pad(teeSrcPadTemplate, None, None)
frameQueuePad = self.frameQueue.get_static_pad('sink')
ret = ret and (frameTeePad.link(frameQueuePad) == Gst.PadLinkReturn.OK)
if not ret:
logging.critical('GST elements could not be linked')
sys.exit(1)
def setHost(self, host):
self._host = host
self.udpsink_rtpout.set_property('host', host)
self.udpsink_rtcpout.set_property('host', host)
def setPort(self, port):
self._port = port
self.udpsink_rtpout.set_property('port', port)
self.udpsink_rtcpout.set_property('port', port + 1)
self.udpsrc_rtcpin.set_property('port', port + 5)
def _newSample(self, sink): # callback функция, вызываемая при каждом приходящем кадре
if self._needFrame.is_set(): #если выставлен флаг нужен кадр
self._needFrame.clear() #сбрасываем флаг
sample = sink.emit('pull-sample')
sampleBuff = sample.get_buffer()
data = sampleBuff.extract_dup(0, sampleBuff.get_size()) # extract data stream as string
#вызываем обработчик в качестве параметра передаем массив данных, ширина и высота кадра
#формат цвета RGB
self._onFrameCallback(data, self._scaleWidth, self._scaleHeight)
return Gst.FlowReturn.OK
def _onMessage(self, bus, message):
#print('Message: %s' % str(message.type))
t = message.type
if t == Gst.MessageType.EOS:
logging.info('Received EOS-Signal')
self.stop_pipeline()
elif t == Gst.MessageType.ERROR:
error, debug = message.parse_error()
logging.error('Received Error-Signal #%u: %s', error.code, debug)
self.null_pipeline()
#else:
# print('Message: %s' % str(t))
def play_pipeline(self):
self.pipeline.set_state(Gst.State.PLAYING)
logging.info('GST pipeline PLAYING')
logging.info('Streaming RTP on %s:%d', self._host, self._port)
def stop_pipeline(self):
self.pause_pipeline()
self.ready_pipeline()
def ready_pipeline(self):
self.pipeline.set_state(Gst.State.READY)
logging.info('GST pipeline READY')
def pause_pipeline(self):
self.pipeline.set_state(Gst.State.PAUSED)
logging.info('GST pipeline PAUSED')
def null_pipeline(self):
self.pipeline.set_state(Gst.State.NULL)
logging.info('GST pipeline NULL')
def write(self, s):
gstBuff = Gst.Buffer.new_wrapped(s)
if not (gstBuff is None):
self.appsrc.emit('push-buffer', gstBuff)
def flush(self):
self.stop_pipeline()
def frameRequest(self): #выставляем флаг запрос кадра, возвращает True, если запрос кадра удался
if not self._needFrame.is_set():
self._needFrame.set()
return True
return False
| [
"temka.911@mail.ru"
] | temka.911@mail.ru |
01e2cab011b97a2456551669f92df13f2a9127d8 | a1e10efa6a131e305351909a437bfa5d083d4513 | /aspl_product_alert_qty/models/product_qty_alert.py | 1f148b1fbe51eb77322158feda3c7018aa9cd7bc | [] | no_license | h3llopy/glodok_extra_addons_od12 | 5089412b36b0dafdb17235a627c8e33ed2acbb1f | 5c493962b93254fb2ca8cd674c4fe153ac86d680 | refs/heads/master | 2022-12-05T06:22:08.182302 | 2020-08-29T14:32:30 | 2020-08-29T14:32:30 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,160 | py | # -*- coding: utf-8 -*-
#################################################################################
# Author : Acespritech Solutions Pvt. Ltd. (<www.acespritech.com>)
# Copyright(c): 2012-Present Acespritech Solutions Pvt. Ltd.
# All Rights Reserved.
#
# This program is copyright property of the author mentioned above.
# You can`t redistribute it and/or modify it.
#
#################################################################################
from odoo import models,fields,api
from odoo.exceptions import ValidationError
class ProductQtyAlert(models.Model):
_name = "product.qty.alert"
product_id = fields.Many2one('product.product')
location_id = fields.Many2one('stock.location',domain=[('usage','=','internal')])
alert_qty = fields.Float(string="Alert Quantity")
class InheritmailTemplate(models.Model):
_inherit = "mail.template"
use_for_alert_qty = fields.Boolean(string="Use For Quantity Alert")
class InheritProduct(models.Model):
_inherit = "product.product"
alert_product_ids = fields.One2many('product.qty.alert','product_id', string="Alerts")
same_for_all = fields.Boolean(string="Apply All", default=True)
alert_qty = fields.Float(string="Alert Quantity")
@api.multi
def btn_print_report(self):
datas = {'form': self.read()[0],
'ids': self.id,
'model': 'product.product'}
return self.env.ref('aspl_product_alert_qty.action_report_alert_qty').report_action(self, data=datas)
class ProductTemplate(models.Model):
_inherit = 'product.template'
# alert_product_ids = fields.One2many('product.qty.alert','product_id', string="Alerts")
same_for_all = fields.Boolean(string="Apply All", default=True)
alert_qty = fields.Float(string="Alert Quantity")
show_in_alert = fields.Boolean(default=False, string="Show In Alert Stock Report")
@api.constrains('same_for_all','alert_qty')
def constrains_alert_products(self):
for rec in self:
rec.product_variant_ids.write({
'same_for_all':rec.same_for_all,
'alert_qty':rec.alert_qty
}) | [
"kikin.kusumah@gmail.com"
] | kikin.kusumah@gmail.com |
f8e18d09a9f3e6a5653a428f33257917bcd09c34 | 2cd24ddd86e97d01c20a96bfc8ed8b541a80d608 | /apps/compra/migrations/0003_detalle_compra_subtotal.py | 0b37c02829a3de243b74a5129374ec3bcf73d820 | [] | no_license | chrisstianandres/don_chuta | 1c048db633246effb06800f28a3a4d8af2cac199 | e20abeb892e6de572a470cd71c5830c6f9d1dafa | refs/heads/master | 2023-01-07T09:14:52.837462 | 2020-11-18T20:55:10 | 2020-11-18T20:55:10 | 293,209,494 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 427 | py | # Generated by Django 2.2.14 on 2020-09-09 21:28
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('compra', '0002_auto_20200905_1332'),
]
operations = [
migrations.AddField(
model_name='detalle_compra',
name='subtotal',
field=models.DecimalField(decimal_places=2, default=0.0, max_digits=9),
),
]
| [
"Chrisstianandres@gmail.com"
] | Chrisstianandres@gmail.com |
72c9b0df633711b2388d7be0bf3092da209fbca3 | 5c533e2cf1f2fa87e55253cdbfc6cc63fb2d1982 | /python/qft/dmrg.py | 3e954772416084c687ff15e6e4729d3a1b0193ae | [] | no_license | philzook58/python | 940c24088968f0d5c655e2344dfa084deaefe7c6 | 6d43db5165c9bcb17e8348a650710c5f603e6a96 | refs/heads/master | 2020-05-25T15:42:55.428149 | 2018-05-14T03:33:29 | 2018-05-14T03:33:29 | 69,040,196 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 73 | py | import numpy as np
a =
U, s, V = np.linalg.svd(a, full_matrices=True)
| [
"philip@FartMachine7.local"
] | philip@FartMachine7.local |
73616bf4c78f4f550cb551b430ef90a4edb005e7 | 786de89be635eb21295070a6a3452f3a7fe6712c | /CalibManager/tags/V00-00-94/src/CommandLineCalib.py | 24e057a8d2437e62ec266d03df15fac3e4c56757 | [] | no_license | connectthefuture/psdmrepo | 85267cfe8d54564f99e17035efe931077c8f7a37 | f32870a987a7493e7bf0f0a5c1712a5a030ef199 | refs/heads/master | 2021-01-13T03:26:35.494026 | 2015-09-03T22:22:11 | 2015-09-03T22:22:11 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 16,132 | py | #--------------------------------------------------------------------------
# File and Version Information:
# $Id$
#
# Description:
# Module CommandLineCalib...
#
#------------------------------------------------------------------------
"""CommandLineCalib is intended for command line calibration of dark runs
This software was developed for the SIT project. If you use all or
part of it, please give an appropriate acknowledgment.
@see RelatedModule
@version $Id$
@author Mikhail S. Dubrovin
"""
#------------------------------
# Module's version from SVN --
#------------------------------
__version__ = "$Revision$"
# $Source$
#--------------------------------
# Imports of standard modules --
#--------------------------------
import sys
import os
from time import sleep
from Logger import logger
from FileNameManager import fnm
from ConfigFileGenerator import cfg
from ConfigParametersForApp import cp
from BatchJobPedestals import *
from BatchLogScanParser import blsp # Just in order to instatiate it
import FileDeployer as fdmets
from NotificationDBForCL import *
#------------------------------
class CommandLineCalib () :
"""Command line calibration of dark runs
@see FileNameManager, ConfigFileGenerator, ConfigParametersForApp, BatchJobPedestals, BatchLogScanParser, FileDeployer, Logger
"""
sep = '\n' + 60*'-' + '\n'
def __init__ (self, args, opts) :
#print '__name__', __name__ # CalibManager.CommandLineCalib
cp.commandlinecalib = self
self.args = args
self.opts = opts
self.count_msg = 0
if not self.set_pars() : return
self.print_command_line()
self.print_local_pars()
self.print_list_of_detectors()
self.print_list_of_xtc_files()
try :
self.print_list_of_sources_from_regdb()
except :
pass
gu.create_directory(cp.dir_work.value())
if self.queue is None :
self.proc_dark_run_interactively()
else :
if not self.get_print_lsf_status() : return
self.proc_dark_run_in_batch()
self.print_list_of_types_and_sources_from_xtc()
self.print_list_of_files_dark_in_work_dir()
self.deploy_calib_files()
self.save_log_file()
self.add_record_in_db()
#------------------------------
def set_pars(self) :
self.print_bits = self.opts['print_bits']
logger.setPrintBits(self.print_bits)
docfg = self.loadcfg = self.opts['loadcfg']
if self.opts['runnum'] is None :
appname = os.path.basename(sys.argv[0])
msg = self.sep + 'This command line calibration interface should be launched with parameters.'\
+'\nTo see the list of parameters use command: %s -h' % appname\
+'\nIf the "%s" is launched after "calibman" most of parameters may be already set.' % appname\
+'\nBut, at least run number must be specified as an optional parameter, try command:\n %s -r <number> -L'%(appname)\
+ self.sep
self.log(msg,4)
return False
self.runnum = self.opts['runnum']
self.str_run_number = '%04d' % self.runnum
if self.opts['runrange'] is None :
self.str_run_range = '%s-end' % self.runnum
else :
self.str_run_range = self.opts['runrange']
self.exp_name = cp.exp_name.value_def()
self.exp_name = cp.exp_name.value() if docfg and self.opts['exp'] is None else self.opts['exp']
if self.exp_name is None or self.exp_name == cp.exp_name.value_def() :
self.log('\nWARNING: EXPERIMENT NAME IS NOT DEFINED...'\
+ '\nAdd optional parameter -e <exp-name>',4)
return False
if self.opts['detector'] is None :
self.det_name = cp.det_name.value() if docfg else cp.det_name.value_def()
else :
self.det_name = self.opts['detector'].replace(","," ")
list_of_dets_sel = self.det_name.split()
list_of_dets_sel_lower = [det.lower() for det in list_of_dets_sel]
#msg = self.sep + 'List of detectors:'
for det, par in zip(cp.list_of_dets_lower, cp.det_cbx_states_list) :
par.setValue(det in list_of_dets_sel_lower)
#msg += '\n%s %s' % (det.ljust(10), par.value())
#self.log(msg,1)
if self.det_name == cp.det_name.value_def() :
self.log('\nWARNING: DETECTOR NAMES ARE NOT DEFINED...'\
+ '\nAdd optional parameter -d <det-names>, ex.: -d CSPAD,CSPAD2x2 etc',4)
return False
self.event_code = cp.bat_dark_sele.value() if self.opts['event_code'] is None else self.opts['event_code']
self.scan_events = cp.bat_dark_scan.value() if self.opts['scan_events'] is None else self.opts['scan_events']
self.skip_events = cp.bat_dark_start.value() if self.opts['skip_events'] is None else self.opts['skip_events']
self.num_events = cp.bat_dark_end.value() - cp.bat_dark_start.value() if self.opts['num_events'] is None else self.opts['num_events']
self.thr_rms_min = cp.mask_rms_thr_min.value() if self.opts['thr_rms_min'] is None else self.opts['thr_rms_min']
self.thr_rms = cp.mask_rms_thr.value() if self.opts['thr_rms'] is None else self.opts['thr_rms']
self.workdir = cp.dir_work.value() if self.opts['workdir'] is None else self.opts['workdir']
#self.queue = cp.bat_queue.value() if self.opts['queue'] is None else self.opts['queue']
self.queue = self.opts['queue']
#self.logfile = cp.log_file.value() if self.opts['logfile'] is None else self.opts['logfile']
self.process = self.opts['process']
self.deploy = self.opts['deploy']
self.instr_name = self.exp_name[:3]
self.timeout_sec = cp.job_timeout_sec.value()
cp.str_run_number.setValue(self.str_run_number)
cp.exp_name .setValue(self.exp_name)
cp.instr_name .setValue(self.instr_name)
self.calibdir = cp.calib_dir.value() if docfg and self.opts['calibdir'] is None else self.opts['calibdir']
if self.calibdir == cp.calib_dir.value_def() or self.calibdir is None :
self.calibdir = fnm.path_to_calib_dir_default()
self.xtcdir = cp.xtc_dir_non_std.value_def() if self.opts['xtcdir'] is None else self.opts['xtcdir']
cp.xtc_dir_non_std .setValue(self.xtcdir)
cp.calib_dir .setValue(self.calibdir)
cp.dir_work .setValue(self.workdir)
cp.bat_queue .setValue(self.queue)
cp.bat_dark_sele .setValue(self.event_code)
cp.bat_dark_scan .setValue(self.scan_events)
cp.bat_dark_start .setValue(self.skip_events)
cp.bat_dark_end .setValue(self.num_events+self.skip_events)
cp.mask_rms_thr_min.setValue(self.thr_rms_min)
cp.mask_rms_thr .setValue(self.thr_rms)
cp.det_name .setValue(self.det_name)
#cp.log_file .setValue(self.logfile)
return True
#------------------------------
def print_local_pars(self) :
msg = self.sep \
+ 'print_local_pars(): Combination of command line parameters and' \
+ '\nconfiguration parameters from file %s (if available after "calibman")' % cp.getParsFileName() \
+ '\n str_run_number: %s' % self.str_run_number\
+ '\n runrange : %s' % self.str_run_range\
+ '\n exp_name : %s' % self.exp_name\
+ '\n instr_name : %s' % self.instr_name\
+ '\n workdir : %s' % self.workdir\
+ '\n calibdir : %s' % self.calibdir\
+ '\n xtcdir : %s' % self.xtcdir\
+ '\n det_name : %s' % self.det_name\
+ '\n queue : %s' % self.queue\
+ '\n num_events : %d' % self.num_events\
+ '\n skip_events : %d' % self.skip_events\
+ '\n scan_events : %d' % self.scan_events\
+ '\n timeout_sec : %d' % self.timeout_sec\
+ '\n thr_rms_min : %f' % self.thr_rms_min\
+ '\n thr_rms : %f' % self.thr_rms\
+ '\n process : %s' % self.process\
+ '\n deploy : %s' % self.deploy\
+ '\n loadcfg : %s' % self.loadcfg\
+ '\n print_bits : %s' % self.print_bits
#+ '\nself.logfile : ' % self.logfile
self.log(msg,1)
#------------------------------
def print_list_of_detectors(self) :
msg = self.sep + 'List of detectors:'
for det, par in zip(cp.list_of_dets_lower, cp.det_cbx_states_list) :
msg += '\n%s %s' % (det.ljust(10), par.value())
self.log(msg,1)
#------------------------------
def print_command_line(self) :
msg = 'Command line for book-keeping:\n%s' % (' '.join(sys.argv))
self.log(msg,1)
#------------------------------
def print_command_line_pars(self, args, opts) :
msg = '\nprint_command_line_pars(...):\n args: %s\n opts: %s' % (args,opts)
self.log(msg,1)
#------------------------------
def proc_dark_run_interactively(self) :
if self.process :
self.log(self.sep + 'Begin dark run data processing interactively',1)
else :
self.log(self.sep + '\nWARNING: FILE PROCESSING OPTION IS TURNED OFF...'\
+ '\nAdd "-P" option in the command line to process files\n',4)
return
self.bjpeds = BatchJobPedestals(self.runnum)
self.bjpeds.command_for_peds_scan()
self.print_list_of_types_and_sources_from_xtc()
if not self.bjpeds.command_for_peds_aver() :
msg = self.sep + 'Subprocess for averaging is completed with warning/error message(s);'\
+'\nsee details in the logfile(s).'
self.log(msg,4)
#return
self.print_dark_ave_batch_log()
return
#------------------------------
def proc_dark_run_in_batch(self) :
if self.process :
self.log(self.sep + 'Begin dark run data processing in batch queue %s' % self.queue,1)
else :
self.log(self.sep + '\nWARNING: FILE PROCESSING OPTION IS TURNED OFF...'\
+ '\nAdd "-P" option in the command line to process files\n',4)
return
self.bjpeds = BatchJobPedestals(self.runnum)
self.bjpeds.start_auto_processing()
sum_dt=0
dt = 10 # sec
nloops = self.timeout_sec / dt
for i in range(nloops) :
sleep(dt)
sum_dt += dt
status = self.bjpeds.status_for_peds_files_essential()
str_bj_stat, msg_bj_stat = self.bjpeds.status_batch_job_for_peds_aver()
self.log('%3d sec: Files %s available. %s' % (sum_dt, {False:'ARE NOT', True:'ARE'}[status], msg_bj_stat), 1)
if status :
self.print_dark_ave_batch_log()
return
print 'WARNING: Too many check cycles. Probably LSF is dead...'
#if self.bjpeds.autoRunStage :
#self.bjpeds.stop_auto_processing()
#------------------------------
def deploy_calib_files(self) :
#list_of_deploy_commands, list_of_sources = fdmets.get_list_of_deploy_commands_and_sources_dark(self.str_run_number, self.str_run_range)
#msg = self.sep + 'Tentative deployment commands:\n' + '\n'.join(list_of_deploy_commands)
#self.log(msg,1)
if self.deploy :
self.log(self.sep + 'Begin deployment of calibration files',1)
fdmets.deploy_calib_files(self.str_run_number, self.str_run_range, mode='calibrun-dark', ask_confirm=False)
self.log('\nDeployment of calibration files is completed',1)
else :
self.log(self.sep + '\nWARNING: FILE DEPLOYMENT OPTION IS TURNED OFF...'\
+'\nAdd "-D" option in the command line to deploy files\n',4)
#------------------------------
#------------------------------
def save_log_file(self) :
logfname = fnm.log_file()
msg = 'See details in log-file: %s' % logfname
#self.log(msg,4) # set it 4-critical - always print
logger.critical(msg) # critical - always print
logger.saveLogInFile(logfname)
def add_record_in_db(self) :
try :
ndb = NotificationDBForCL()
ndb.insert_record(mode='enabled')
ndb.close()
#ndb.add_record()
except :
pass
def print_list_of_files_dark_in_work_dir(self) :
lst = self.get_list_of_files_dark_in_work_dir()
msg = self.sep + 'List of files in work directory for command "ls %s*"' % fnm.path_prefix_dark()
if lst == [] : msg += ' is empty'
else : msg += ':\n' + '\n'.join(lst)
self.log(msg,1)
def get_list_of_files_dark_in_work_dir(self) :
path_prexix = fnm.path_prefix_dark()
dir, prefix = os.path.split(path_prexix)
return gu.get_list_of_files_in_dir_for_part_fname(dir, pattern=prefix)
def get_list_of_files_dark_expected(self) :
lst_of_srcs = cp.blsp.list_of_sources_for_selected_detectors()
return fnm.get_list_of_files_peds() \
+ gu.get_list_of_files_for_list_of_insets(fnm.path_peds_ave(), lst_of_srcs) \
+ gu.get_list_of_files_for_list_of_insets(fnm.path_peds_rms(), lst_of_srcs) \
+ gu.get_list_of_files_for_list_of_insets(fnm.path_hotpix_mask(), lst_of_srcs)
def print_list_of_types_and_sources_from_xtc(self) :
txt = self.sep + 'Data Types and Sources from xtc scan of the\n' \
+ cp.blsp.txt_list_of_types_and_sources()
self.log(txt,1)
def print_list_of_sources_from_regdb(self) :
txt = self.sep + 'Sources from DB:' \
+ cp.blsp.txt_of_sources_in_run()
self.log(txt,1)
def print_dark_ave_batch_log(self) :
path = fnm.path_peds_aver_batch_log()
if not os.path.exists(path) :
msg = 'File: %s does not exist' % path
self.log(msg,2)
return
txt = self.sep + 'psana log file %s:\n\n' % path \
+ gu.load_textfile(path) \
+ 'End of psana log file %s' % path
self.log(txt,1)
def get_print_lsf_status(self) :
queue = cp.bat_queue.value()
farm = cp.dict_of_queue_farm[queue]
msg, status = gu.msg_and_status_of_lsf(farm, print_bits=0)
msgi = self.sep + 'LSF status for queue %s on farm %s: \n%s\nLSF status for %s is %s'\
% (queue, farm, msg, queue, {False:'bad',True:'good'}[status])
self.log(msgi,1)
msg, status = gu.msg_and_status_of_queue(queue)
self.log('\nBatch queue status, %s'%msg, 1)
return status
def print_list_of_xtc_files(self) :
pattern = '-r%s' % self.str_run_number
lst = fnm.get_list_of_xtc_files()
lst_for_run = [path for path in lst if pattern in os.path.basename(path)]
txt = self.sep + 'List of xtc files for exp=%s:run=%s :\n' % (self.exp_name, self.str_run_number)
txt += '\n'.join(lst_for_run)
self.log(txt,1)
#------------------------------
def log(self, msg, level=1) :
"""Internal logger - re-direct all messages to the project logger, critical messages"""
#logger.levels = ['debug','info','warning','error','critical']
self.count_msg += 1
#print 'Received msg: %d' % self.count_msg
#if self.print_bits & 1 or level==4 : print msg
if level==1 : logger.info (msg, __name__)
elif level==4 : logger.critical(msg, __name__)
elif level==0 : logger.debug (msg, __name__)
elif level==2 : logger.warning (msg, __name__)
elif level==3 : logger.error (msg, __name__)
else : logger.info (msg, __name__)
#------------------------------
#------------------------------
#------------------------------
| [
"dubrovin@SLAC.STANFORD.EDU@b967ad99-d558-0410-b138-e0f6c56caec7"
] | dubrovin@SLAC.STANFORD.EDU@b967ad99-d558-0410-b138-e0f6c56caec7 |
3fd4b6939ed509fe2a1ee650c84cb20ee9dc138b | 93ac5d21bf02e3448a60d163bdf08541045de6ea | /manage.py | a7fca783bb6ea4ffde8ae49695efe24350b668b9 | [] | no_license | samsmusa/find_bid | cd97a601524fbfc419499d71b80566b3092c1264 | fe2399df1c74aef2f70b7956af6734c26413013a | refs/heads/master | 2023-08-13T05:51:15.781183 | 2021-09-07T07:10:15 | 2021-09-07T07:10:15 | 403,878,371 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 664 | py | #!/usr/bin/env python
"""Django's command-line utility for administrative tasks."""
import os
import sys
def main():
"""Run administrative tasks."""
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'find_bid.settings')
try:
from django.core.management import execute_from_command_line
except ImportError as exc:
raise ImportError(
"Couldn't import Django. Are you sure it's installed and "
"available on your PYTHONPATH environment variable? Did you "
"forget to activate a virtual environment?"
) from exc
execute_from_command_line(sys.argv)
if __name__ == '__main__':
main()
| [
"samsmusa@outlook.com"
] | samsmusa@outlook.com |
dd9925b429dd30c9f5af8adf9362aadd5a58cd44 | 3bdcb60b0bffeeb6ff7b0ddca4792b682158bb12 | /Funciones/276.py | cad0e1b914f6b0d518c47a4347780a3f47f69055 | [] | no_license | FrankCasanova/Python | 03c811801ec8ecd5ace66914f984a94f12befe06 | 03f15100991724a49437df3ce704837812173fc5 | refs/heads/master | 2023-05-23T01:37:12.632204 | 2021-06-10T15:20:38 | 2021-06-10T15:20:38 | 278,167,039 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 595 | py | # desings a function that, given a list of strings, return the longest string.
# if two or more have the same length and are the lonfest, the function will
# return any one of them
def largest_str(string):
largest = None
for index, snts in enumerate(string):
if largest == None:
largest = snts
if len(snts) > len(largest):
largest = string[index]
return largest
list_strings = ['hola que pasa', 'hoy no quiero salir de mi casa la verdad',
'no sé por qué no me he quedado en casa']
print(largest_str(list_strings))
| [
"frankcasanova.info@gmail.com"
] | frankcasanova.info@gmail.com |
762b27f7e07d1145bfd1743c41531647c2a87ae0 | dfb00e98cc3bfe40df3a3f2196b1003d3122ca84 | /{{cookiecutter.project_slug}}/tests.py | 58a3817282e840fc961a8edb8268bcb73b622e5a | [] | no_license | andremcb/bakery_scaffold_tests_8sGLG7TckgT6EJlB | b80ed9ff7b34fe2433c9af1a9f07948674a2c781 | 08c8806dcbdca288d0f607350da8b5801489833c | refs/heads/master | 2020-07-09T03:42:09.226572 | 2019-08-22T20:13:03 | 2019-08-22T20:13:03 | 203,866,089 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,164 | py | import unittest
import re
class TestStripe(unittest.TestCase):
def __init__(self, *args, **kwargs):
super(TestStripe, self).__init__(*args, **kwargs)
with open('order.html', 'r') as file_descriptor:
self.dom_str = file_descriptor.read()
# Check if redirectToCheckout function call is present
def test_redirect_to_checkout(self):
self.assertNotEqual(self.dom_str, '.redirectToCheckout',
'No stripe redirect call found!')
# Check if successUrl redirects to order_success.html
def test_successUrl(self):
self.assertRegex(self.dom_str,
r'successUrl: \'https:\/\/[a-z]*\.com/order_success\.html\'',
'No order_success.html redirect found on checkout success.')
# Check if cancelUrl redirects to order.html
def test_cancelUrl(self):
self.assertRegex(self.dom_str,
r'cancelUrl: \'https:\/\/[a-z]*\.com/order\.html\'',
'No order.html redirect found on checkout cancel.')
{{ cookiecutter.extra_data }}
if __name__ == '__main__':
unittest.main()
| [
"csantos.machado@gmail.com"
] | csantos.machado@gmail.com |
ae6671c6877541a49134ba53fef3117cf356e2e1 | 68ee9027d4f780e1e5248a661ccf08427ff8d106 | /extra/unused/baselinePlotter.py | 92136463546bb02edb9475a21ac2338f2a5cb2b9 | [
"MIT"
] | permissive | whyjz/CARST | 87fb9a6a62d39fd742bb140bddcb95a2c15a144c | 4fc48374f159e197fa5a9dbf8a867b0a8e0aad3b | refs/heads/master | 2023-05-26T20:27:38.105623 | 2023-04-16T06:34:44 | 2023-04-16T06:34:44 | 58,771,687 | 17 | 4 | MIT | 2021-03-10T01:26:04 | 2016-05-13T20:54:42 | Python | UTF-8 | Python | false | false | 3,733 | py | #!/usr/bin/python
# baselinePlotter.py
# Author: Andrew Kenneth Melkonian
# All rights reserved
# Plots perpendicular baselines for all *baseline.rsc files in the input directory that contain a valid number identified as "P_BASELINE*"
# USAGE
# *****
# python /path/containing/ints /path/to/put/output.ps
# /path/containing/ints: Path to directory that contains all of the *baseline.rsc files to search and plot from
# /path/to/put/output.ps: Path to output image (baselines plot)
def baselinePlotter(input_dir, output_path):
import fnmatch;
import os;
import subprocess;
import sys;
import re;
assert os.path.exists(input_dir), "\n***** ERROR: " + input_dir + " does not exist\n";
output_dir = ".";
index = output_path.rfind("/");
if index > -1:
output_dir = output_path[ : index];
assert os.path.exists(output_dir), "\n***** ERROR: " + output_dir + " does not exist\n";
# contents = os.listdir(input_dir);
# date_dirs = [item for item in contents if os.path.isdir(item) and re.search("^\d{6}$", item)];
# outfile = open("temp_params.txt", "w");
# outfile.write("WorkPath = " + input_dir + "\n");
# outfile.write("DEM = " + input_dir + "\n");
# outfile.write("MaxBaseline = 10000\n");
# outfile.write("MinDateInterval = 1\n");
# outfile.write("MaxDateInterval = 100000\n");
# outfile.write("DataType = ERS\n");
# outfile.write("Angle = 23\n");
# outfile.write("rwin = 40\n");
# outfile.write("awin = 80\n");
# outfile.write("search_x = 8\n");
# outfile.write("search_y = 8\n");
# outfile.write("wsamp = 1\n");
# outfile.write("numproc = 1\n");
# outfile.close();
# print("\npython /data/akm/Python/pixelTack_new.py params.txt setup offsets\n");
baseline_dates = {};
baseline_values = {};
for root, dirnames, filenames in os.walk(input_dir):
for filename in fnmatch.filter(filenames, "*baseline.rsc"):
baseline_dates[root + "/" + filename] = filename[re.search("\d{6}_\d{6}", filename).start(0) : re.search("\d{6}_\d{6}", filename).end(0)];
p_b_t = "";
p_b_b = "";
for baseline_path in baseline_dates:
infile = open(baseline_path, "r");
for line in infile:
if line.find("P_BASELINE_TOP") > -1:
p_b_t = line.split()[1];
if line.find("P_BASELINE_BOTTOM") > -1:
p_b_b = line.split()[1];
infile.close();
p_b = abs(float(p_b_t) + float(p_b_b)) / 2;
baseline_values[p_b] = baseline_path;
sorted_p_b = sorted(baseline_values);
min_p_b = sorted_p_b[0];
max_p_b = sorted_p_b[len(sorted_p_b) - 1];
min_p_b = round(min_p_b, -2) - 50;
max_p_b = round(max_p_b, -2) + 50;
R = "-R0/" + str(len(baseline_values.values()) + 2) + "/" + str(min_p_b) + "/" + str(max_p_b);
ps_path = output_path;
cmd = "";
cmd +="\npsbasemap -Ba1f1:\"SAR Pair\":/a100f100:\"Average Baseline (m)\":WeSn -JX10c " + R + " -P -K > " + ps_path + "\n";
i = 1;
for p_b in sorted_p_b:
cmd += "\necho \"" + str(i) + " " + str(p_b) + "\" | psxy -JX10c " + R + " -Ss0.2c -Gred -W0.5p,darkgray -O -K >> " + ps_path + "\n";
cmd += "\necho \"" + str(float(i) + 0.1) + " " + str(p_b) + " 8p,1,black 0 LM " + baseline_dates[baseline_values[p_b]] + "\" | pstext -JX10c " + R + " -F+f+a+j -Gwhite -W1p,darkgray -O -K >> " + ps_path + "\n";
i += 1;
cmd = cmd[ : cmd.rfind("-K") - 1] + cmd[cmd.rfind("-K") + 2 : ];
cmd += "\nps2raster -A -Tf -D" + output_dir + " " + ps_path + "\n";
subprocess.call(cmd,shell=True);
return;
if __name__ == "__main__":
import os;
import sys;
assert len(sys.argv) > 2, "\n***** ERROR: baselinePlotter.py requires at least 2 arguments, " + str(len(sys.argv) - 1) + " given\n";
assert os.path.exists(sys.argv[1]), "\n***** ERROR: " + sys.argv[1] + " does not exist\n";
baselinePlotter(sys.argv[1], sys.argv[2]);
exit();
| [
"wz278@cornell.edu"
] | wz278@cornell.edu |
e20ea9acee96420c057628f8eaf404ad21c6b9dc | e31d6c6c74a71daf27d618de4debf59e8cb9f188 | /gluon/datasets/coco_det_dataset.py | c9269ab8671292f6728b3c8c5dc3402edcd1fec7 | [
"MIT"
] | permissive | vlomonaco/imgclsmob | 574ebfbfe4be7a11c8742f34261bc4e7cc1f30be | d0d1c49a848ab146213ef4cbd37239799d0102d8 | refs/heads/master | 2022-04-18T16:03:11.361053 | 2020-04-14T06:17:36 | 2020-04-14T06:17:36 | 255,555,032 | 0 | 1 | MIT | 2020-04-14T08:39:59 | 2020-04-14T08:39:58 | null | UTF-8 | Python | false | false | 27,130 | py | """
MS COCO object detection dataset.
"""
__all__ = ['CocoDetMetaInfo']
import os
import cv2
import logging
import mxnet as mx
import numpy as np
from PIL import Image
from mxnet.gluon.data import dataset
from .dataset_metainfo import DatasetMetaInfo
class CocoDetDataset(dataset.Dataset):
"""
MS COCO detection dataset.
Parameters
----------
root : str
Path to folder storing the dataset.
mode : string, default 'train'
'train', 'val', 'test', or 'demo'.
transform : callable, optional
A function that transforms the image.
splits : list of str, default ['instances_val2017']
Json annotations name.
Candidates can be: instances_val2017, instances_train2017.
min_object_area : float
Minimum accepted ground-truth area, if an object's area is smaller than this value,
it will be ignored.
skip_empty : bool, default is True
Whether skip images with no valid object. This should be `True` in training, otherwise
it will cause undefined behavior.
use_crowd : bool, default is True
Whether use boxes labeled as crowd instance.
"""
CLASSES = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train',
'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep',
'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard',
'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork',
'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange',
'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair',
'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv',
'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase',
'scissors', 'teddy bear', 'hair drier', 'toothbrush']
def __init__(self,
root,
mode="train",
transform=None,
splits=('instances_val2017',),
min_object_area=0,
skip_empty=True,
use_crowd=True):
super(CocoDetDataset, self).__init__()
self._root = os.path.expanduser(root)
self.mode = mode
self._transform = transform
self.num_class = len(self.CLASSES)
self._min_object_area = min_object_area
self._skip_empty = skip_empty
self._use_crowd = use_crowd
if isinstance(splits, mx.base.string_types):
splits = [splits]
self._splits = splits
self.index_map = dict(zip(type(self).CLASSES, range(self.num_class)))
self.json_id_to_contiguous = None
self.contiguous_id_to_json = None
self._coco = []
self._items, self._labels, self._im_aspect_ratios = self._load_jsons()
mode_name = "train" if mode == "train" else "val"
annotations_dir_path = os.path.join(root, "annotations")
annotations_file_path = os.path.join(annotations_dir_path, "instances_" + mode_name + "2017.json")
self.annotations_file_path = annotations_file_path
def __str__(self):
detail = ','.join([str(s) for s in self._splits])
return self.__class__.__name__ + '(' + detail + ')'
@property
def coco(self):
"""
Return pycocotools object for evaluation purposes.
"""
if not self._coco:
raise ValueError("No coco objects found, dataset not initialized.")
if len(self._coco) > 1:
raise NotImplementedError(
"Currently we don't support evaluating {} JSON files. \
Please use single JSON dataset and evaluate one by one".format(len(self._coco)))
return self._coco[0]
@property
def classes(self):
"""
Category names.
"""
return type(self).CLASSES
@property
def annotation_dir(self):
"""
The subdir for annotations. Default is 'annotations'(coco default)
For example, a coco format json file will be searched as
'root/annotation_dir/xxx.json'
You can override if custom dataset don't follow the same pattern
"""
return 'annotations'
def get_im_aspect_ratio(self):
"""Return the aspect ratio of each image in the order of the raw data."""
if self._im_aspect_ratios is not None:
return self._im_aspect_ratios
self._im_aspect_ratios = [None] * len(self._items)
for i, img_path in enumerate(self._items):
with Image.open(img_path) as im:
w, h = im.size
self._im_aspect_ratios[i] = 1.0 * w / h
return self._im_aspect_ratios
def _parse_image_path(self, entry):
"""How to parse image dir and path from entry.
Parameters
----------
entry : dict
COCO entry, e.g. including width, height, image path, etc..
Returns
-------
abs_path : str
Absolute path for corresponding image.
"""
dirname, filename = entry["coco_url"].split("/")[-2:]
abs_path = os.path.join(self._root, dirname, filename)
return abs_path
def __len__(self):
return len(self._items)
def __getitem__(self, idx):
img_path = self._items[idx]
label = self._labels[idx]
img = mx.image.imread(img_path, 1)
label = np.array(label).copy()
if self._transform is not None:
img, label = self._transform(img, label)
return img, label
def _load_jsons(self):
"""
Load all image paths and labels from JSON annotation files into buffer.
"""
items = []
labels = []
im_aspect_ratios = []
from pycocotools.coco import COCO
for split in self._splits:
anno = os.path.join(self._root, self.annotation_dir, split) + ".json"
_coco = COCO(anno)
self._coco.append(_coco)
classes = [c["name"] for c in _coco.loadCats(_coco.getCatIds())]
if not classes == self.classes:
raise ValueError("Incompatible category names with COCO: ")
assert classes == self.classes
json_id_to_contiguous = {
v: k for k, v in enumerate(_coco.getCatIds())}
if self.json_id_to_contiguous is None:
self.json_id_to_contiguous = json_id_to_contiguous
self.contiguous_id_to_json = {
v: k for k, v in self.json_id_to_contiguous.items()}
else:
assert self.json_id_to_contiguous == json_id_to_contiguous
# iterate through the annotations
image_ids = sorted(_coco.getImgIds())
for entry in _coco.loadImgs(image_ids):
abs_path = self._parse_image_path(entry)
if not os.path.exists(abs_path):
raise IOError("Image: {} not exists.".format(abs_path))
label = self._check_load_bbox(_coco, entry)
if not label:
continue
im_aspect_ratios.append(float(entry["width"]) / entry["height"])
items.append(abs_path)
labels.append(label)
return items, labels, im_aspect_ratios
def _check_load_bbox(self, coco, entry):
"""
Check and load ground-truth labels.
"""
entry_id = entry['id']
# fix pycocotools _isArrayLike which don't work for str in python3
entry_id = [entry_id] if not isinstance(entry_id, (list, tuple)) else entry_id
ann_ids = coco.getAnnIds(imgIds=entry_id, iscrowd=None)
objs = coco.loadAnns(ann_ids)
# check valid bboxes
valid_objs = []
width = entry["width"]
height = entry["height"]
for obj in objs:
if obj["area"] < self._min_object_area:
continue
if obj.get("ignore", 0) == 1:
continue
if not self._use_crowd and obj.get("iscrowd", 0):
continue
# convert from (x, y, w, h) to (xmin, ymin, xmax, ymax) and clip bound
xmin, ymin, xmax, ymax = self.bbox_clip_xyxy(self.bbox_xywh_to_xyxy(obj["bbox"]), width, height)
# require non-zero box area
if obj["area"] > 0 and xmax > xmin and ymax > ymin:
contiguous_cid = self.json_id_to_contiguous[obj["category_id"]]
valid_objs.append([xmin, ymin, xmax, ymax, contiguous_cid])
if not valid_objs:
if not self._skip_empty:
# dummy invalid labels if no valid objects are found
valid_objs.append([-1, -1, -1, -1, -1])
return valid_objs
@staticmethod
def bbox_clip_xyxy(xyxy, width, height):
"""
Clip bounding box with format (xmin, ymin, xmax, ymax) to specified boundary.
All bounding boxes will be clipped to the new region `(0, 0, width, height)`.
Parameters
----------
xyxy : list, tuple or numpy.ndarray
The bbox in format (xmin, ymin, xmax, ymax).
If numpy.ndarray is provided, we expect multiple bounding boxes with
shape `(N, 4)`.
width : int or float
Boundary width.
height : int or float
Boundary height.
Returns
-------
tuple or np.array
Description of returned object.
"""
if isinstance(xyxy, (tuple, list)):
if not len(xyxy) == 4:
raise IndexError("Bounding boxes must have 4 elements, given {}".format(len(xyxy)))
x1 = np.minimum(width - 1, np.maximum(0, xyxy[0]))
y1 = np.minimum(height - 1, np.maximum(0, xyxy[1]))
x2 = np.minimum(width - 1, np.maximum(0, xyxy[2]))
y2 = np.minimum(height - 1, np.maximum(0, xyxy[3]))
return x1, y1, x2, y2
elif isinstance(xyxy, np.ndarray):
if not xyxy.size % 4 == 0:
raise IndexError("Bounding boxes must have n * 4 elements, given {}".format(xyxy.shape))
x1 = np.minimum(width - 1, np.maximum(0, xyxy[:, 0]))
y1 = np.minimum(height - 1, np.maximum(0, xyxy[:, 1]))
x2 = np.minimum(width - 1, np.maximum(0, xyxy[:, 2]))
y2 = np.minimum(height - 1, np.maximum(0, xyxy[:, 3]))
return np.hstack((x1, y1, x2, y2))
else:
raise TypeError("Expect input xywh a list, tuple or numpy.ndarray, given {}".format(type(xyxy)))
@staticmethod
def bbox_xywh_to_xyxy(xywh):
"""
Convert bounding boxes from format (xmin, ymin, w, h) to (xmin, ymin, xmax, ymax)
Parameters
----------
xywh : list, tuple or numpy.ndarray
The bbox in format (x, y, w, h).
If numpy.ndarray is provided, we expect multiple bounding boxes with
shape `(N, 4)`.
Returns
-------
tuple or np.ndarray
The converted bboxes in format (xmin, ymin, xmax, ymax).
If input is numpy.ndarray, return is numpy.ndarray correspondingly.
"""
if isinstance(xywh, (tuple, list)):
if not len(xywh) == 4:
raise IndexError("Bounding boxes must have 4 elements, given {}".format(len(xywh)))
w, h = np.maximum(xywh[2] - 1, 0), np.maximum(xywh[3] - 1, 0)
return xywh[0], xywh[1], xywh[0] + w, xywh[1] + h
elif isinstance(xywh, np.ndarray):
if not xywh.size % 4 == 0:
raise IndexError("Bounding boxes must have n * 4 elements, given {}".format(xywh.shape))
xyxy = np.hstack((xywh[:, :2], xywh[:, :2] + np.maximum(0, xywh[:, 2:4] - 1)))
return xyxy
else:
raise TypeError("Expect input xywh a list, tuple or numpy.ndarray, given {}".format(type(xywh)))
# ---------------------------------------------------------------------------------------------------------------------
class CocoDetValTransform(object):
def __init__(self,
ds_metainfo):
self.ds_metainfo = ds_metainfo
self.image_size = self.ds_metainfo.input_image_size
self._height = self.image_size[0]
self._width = self.image_size[1]
self._mean = np.array(ds_metainfo.mean_rgb, dtype=np.float32).reshape(1, 1, 3)
self._std = np.array(ds_metainfo.std_rgb, dtype=np.float32).reshape(1, 1, 3)
def __call__(self, src, label):
# resize
img, bbox = src.asnumpy(), label
input_h, input_w = self._height, self._width
h, w, _ = src.shape
s = max(h, w) * 1.0
c = np.array([w / 2., h / 2.], dtype=np.float32)
trans_input = self.get_affine_transform(c, s, 0, [input_w, input_h])
inp = cv2.warpAffine(img, trans_input, (input_w, input_h), flags=cv2.INTER_LINEAR)
output_w = input_w
output_h = input_h
trans_output = self.get_affine_transform(c, s, 0, [output_w, output_h])
for i in range(bbox.shape[0]):
bbox[i, :2] = self.affine_transform(bbox[i, :2], trans_output)
bbox[i, 2:4] = self.affine_transform(bbox[i, 2:4], trans_output)
bbox[:, :2] = np.clip(bbox[:, :2], 0, output_w - 1)
bbox[:, 2:4] = np.clip(bbox[:, 2:4], 0, output_h - 1)
img = inp
# to tensor
img = img.astype(np.float32) / 255.0
img = (img - self._mean) / self._std
img = img.transpose(2, 0, 1).astype(np.float32)
img = mx.nd.array(img)
return img, bbox.astype(img.dtype)
@staticmethod
def get_affine_transform(center,
scale,
rot,
output_size,
shift=np.array([0, 0], dtype=np.float32),
inv=0):
"""
Get affine transform matrix given center, scale and rotation.
Parameters
----------
center : tuple of float
Center point.
scale : float
Scaling factor.
rot : float
Rotation degree.
output_size : tuple of int
(width, height) of the output size.
shift : float
Shift factor.
inv : bool
Whether inverse the computation.
Returns
-------
numpy.ndarray
Affine matrix.
"""
if not isinstance(scale, np.ndarray) and not isinstance(scale, list):
scale = np.array([scale, scale], dtype=np.float32)
scale_tmp = scale
src_w = scale_tmp[0]
dst_w = output_size[0]
dst_h = output_size[1]
rot_rad = np.pi * rot / 180
src_dir = CocoDetValTransform.get_rot_dir([0, src_w * -0.5], rot_rad)
dst_dir = np.array([0, dst_w * -0.5], np.float32)
src = np.zeros((3, 2), dtype=np.float32)
dst = np.zeros((3, 2), dtype=np.float32)
src[0, :] = center + scale_tmp * shift
src[1, :] = center + src_dir + scale_tmp * shift
dst[0, :] = [dst_w * 0.5, dst_h * 0.5]
dst[1, :] = np.array([dst_w * 0.5, dst_h * 0.5], np.float32) + dst_dir
src[2:, :] = CocoDetValTransform.get_3rd_point(src[0, :], src[1, :])
dst[2:, :] = CocoDetValTransform.get_3rd_point(dst[0, :], dst[1, :])
if inv:
trans = cv2.getAffineTransform(np.float32(dst), np.float32(src))
else:
trans = cv2.getAffineTransform(np.float32(src), np.float32(dst))
return trans
@staticmethod
def get_rot_dir(src_point, rot_rad):
"""
Get rotation direction.
Parameters
----------
src_point : tuple of float
Original point.
rot_rad : float
Rotation radian.
Returns
-------
tuple of float
Rotation.
"""
sn, cs = np.sin(rot_rad), np.cos(rot_rad)
src_result = [0, 0]
src_result[0] = src_point[0] * cs - src_point[1] * sn
src_result[1] = src_point[0] * sn + src_point[1] * cs
return src_result
@staticmethod
def get_3rd_point(a, b):
"""
Get the 3rd point position given first two points.
Parameters
----------
a : tuple of float
First point.
b : tuple of float
Second point.
Returns
-------
tuple of float
Third point.
"""
direct = a - b
return b + np.array([-direct[1], direct[0]], dtype=np.float32)
@staticmethod
def affine_transform(pt, t):
"""
Apply affine transform to a bounding box given transform matrix t.
Parameters
----------
pt : numpy.ndarray
Bounding box with shape (1, 2).
t : numpy.ndarray
Transformation matrix with shape (2, 3).
Returns
-------
numpy.ndarray
New bounding box with shape (1, 2).
"""
new_pt = np.array([pt[0], pt[1], 1.], dtype=np.float32).T
new_pt = np.dot(t, new_pt)
return new_pt[:2]
class Tuple(object):
"""
Wrap multiple batchify functions to form a function apply each input function on each
input fields respectively.
"""
def __init__(self, fn, *args):
if isinstance(fn, (list, tuple)):
self._fn = fn
else:
self._fn = (fn,) + args
def __call__(self, data):
"""
Batchify the input data.
Parameters
----------
data : list
The samples to batchfy. Each sample should contain N attributes.
Returns
-------
tuple
A tuple of length N. Contains the batchified result of each attribute in the input.
"""
ret = []
for i, ele_fn in enumerate(self._fn):
ret.append(ele_fn([ele[i] for ele in data]))
return tuple(ret)
class Stack(object):
"""
Stack the input data samples to construct the batch.
"""
def __call__(self, data):
"""
Batchify the input data.
Parameters
----------
data : list
The input data samples
Returns
-------
NDArray
Result.
"""
return self._stack_arrs(data, True)
@staticmethod
def _stack_arrs(arrs, use_shared_mem=False):
"""
Internal imple for stacking arrays.
"""
if isinstance(arrs[0], mx.nd.NDArray):
if use_shared_mem:
out = mx.nd.empty((len(arrs),) + arrs[0].shape, dtype=arrs[0].dtype,
ctx=mx.Context("cpu_shared", 0))
return mx.nd.stack(*arrs, out=out)
else:
return mx.nd.stack(*arrs)
else:
out = np.asarray(arrs)
if use_shared_mem:
return mx.nd.array(out, ctx=mx.Context("cpu_shared", 0))
else:
return mx.nd.array(out)
class Pad(object):
"""
Pad the input ndarrays along the specific padding axis and stack them to get the output.
"""
def __init__(self, axis=0, pad_val=0, num_shards=1, ret_length=False):
self._axis = axis
self._pad_val = pad_val
self._num_shards = num_shards
self._ret_length = ret_length
def __call__(self, data):
"""
Batchify the input data.
Parameters
----------
data : list
A list of N samples. Each sample can be 1) ndarray or
2) a list/tuple of ndarrays
Returns
-------
NDArray
Data in the minibatch. Shape is (N, ...)
NDArray, optional
The sequences' original lengths at the padded axis. Shape is (N,). This will only be
returned in `ret_length` is True.
"""
if isinstance(data[0], (mx.nd.NDArray, np.ndarray, list)):
padded_arr, original_length = self._pad_arrs_to_max_length(
data, self._axis, self._pad_val, self._num_shards, True)
if self._ret_length:
return padded_arr, original_length
else:
return padded_arr
else:
raise NotImplementedError
@staticmethod
def _pad_arrs_to_max_length(arrs, pad_axis, pad_val, num_shards=1, use_shared_mem=False):
"""
Inner Implementation of the Pad batchify.
"""
if not isinstance(arrs[0], (mx.nd.NDArray, np.ndarray)):
arrs = [np.asarray(ele) for ele in arrs]
if isinstance(pad_axis, tuple):
original_length = []
for axis in pad_axis:
original_length.append(np.array([ele.shape[axis] for ele in arrs]))
original_length = np.stack(original_length).T
else:
original_length = np.array([ele.shape[pad_axis] for ele in arrs])
pad_axis = [pad_axis]
if len(original_length) % num_shards != 0:
logging.warning(
'Batch size cannot be evenly split. Trying to shard %d items into %d shards',
len(original_length), num_shards)
original_length = np.array_split(original_length, num_shards)
max_lengths = [np.max(l, axis=0, keepdims=len(pad_axis) == 1) for l in original_length]
# add batch dimension
ret_shape = [[l.shape[0], ] + list(arrs[0].shape) for l in original_length]
for i, shape in enumerate(ret_shape):
for j, axis in enumerate(pad_axis):
shape[1 + axis] = max_lengths[i][j]
if use_shared_mem:
ret = [mx.nd.full(shape=tuple(shape), val=pad_val, ctx=mx.Context('cpu_shared', 0),
dtype=arrs[0].dtype) for shape in ret_shape]
original_length = [mx.nd.array(l, ctx=mx.Context('cpu_shared', 0),
dtype=np.int32) for l in original_length]
else:
ret = [mx.nd.full(shape=tuple(shape), val=pad_val, dtype=arrs[0].dtype) for shape in
ret_shape]
original_length = [mx.nd.array(l, dtype=np.int32) for l in original_length]
for i, arr in enumerate(arrs):
if ret[i // ret[0].shape[0]].shape[1:] == arr.shape:
ret[i // ret[0].shape[0]][i % ret[0].shape[0]] = arr
else:
slices = [slice(0, l) for l in arr.shape]
ret[i // ret[0].shape[0]][i % ret[0].shape[0]][tuple(slices)] = arr
if len(ret) == len(original_length) == 1:
return ret[0], original_length[0]
return ret, original_length
def get_post_transform(orig_w, orig_h, out_w, out_h):
"""Get the post prediction affine transforms. This will be used to adjust the prediction results
according to original coco image resolutions.
Parameters
----------
orig_w : int
Original width of the image.
orig_h : int
Original height of the image.
out_w : int
Width of the output image after prediction.
out_h : int
Height of the output image after prediction.
Returns
-------
numpy.ndarray
Affine transform matrix 3x2.
"""
s = max(orig_w, orig_h) * 1.0
c = np.array([orig_w / 2., orig_h / 2.], dtype=np.float32)
trans_output = CocoDetValTransform.get_affine_transform(c, s, 0, [out_w, out_h], inv=True)
return trans_output
class CocoDetMetaInfo(DatasetMetaInfo):
def __init__(self):
super(CocoDetMetaInfo, self).__init__()
self.label = "COCO"
self.short_label = "coco"
self.root_dir_name = "coco"
self.dataset_class = CocoDetDataset
self.num_training_samples = None
self.in_channels = 3
self.num_classes = CocoDetDataset.classes
self.input_image_size = (512, 512)
self.train_metric_capts = None
self.train_metric_names = None
self.train_metric_extra_kwargs = None
self.val_metric_capts = None
self.val_metric_names = None
self.test_metric_capts = ["Val.mAP"]
self.test_metric_names = ["CocoDetMApMetric"]
self.test_metric_extra_kwargs = [
{"name": "mAP",
"img_height": 512,
"coco_annotations_file_path": None,
"contiguous_id_to_json": None,
"data_shape": None,
"post_affine": get_post_transform}]
self.test_dataset_extra_kwargs = {
"skip_empty": False}
self.saver_acc_ind = 0
self.do_transform = True
self.do_transform_first = False
self.last_batch = "keep"
self.batchify_fn = Tuple(Stack(), Pad(pad_val=-1))
self.val_transform = CocoDetValTransform
self.test_transform = CocoDetValTransform
self.ml_type = "det"
self.allow_hybridize = False
self.test_net_extra_kwargs = None
self.mean_rgb = (0.485, 0.456, 0.406)
self.std_rgb = (0.229, 0.224, 0.225)
def add_dataset_parser_arguments(self,
parser,
work_dir_path):
"""
Create python script parameters (for ImageNet-1K dataset metainfo).
Parameters:
----------
parser : ArgumentParser
ArgumentParser instance.
work_dir_path : str
Path to working directory.
"""
super(CocoDetMetaInfo, self).add_dataset_parser_arguments(parser, work_dir_path)
parser.add_argument(
"--input-size",
type=int,
nargs=2,
default=self.input_image_size,
help="size of the input for model")
def update(self,
args):
"""
Update ImageNet-1K dataset metainfo after user customizing.
Parameters:
----------
args : ArgumentParser
Main script arguments.
"""
super(CocoDetMetaInfo, self).update(args)
self.input_image_size = args.input_size
self.test_metric_extra_kwargs[0]["img_height"] = self.input_image_size[0]
self.test_metric_extra_kwargs[0]["data_shape"] = self.input_image_size
def update_from_dataset(self,
dataset):
"""
Update dataset metainfo after a dataset class instance creation.
Parameters:
----------
args : obj
A dataset class instance.
"""
self.test_metric_extra_kwargs[0]["coco_annotations_file_path"] = dataset.annotations_file_path
self.test_metric_extra_kwargs[0]["contiguous_id_to_json"] = dataset.contiguous_id_to_json
| [
"osemery@gmail.com"
] | osemery@gmail.com |
234b81353b5555235b20f59e1d3fb67c3ba3989e | 1b5bf5e703dfa4fdbf3f0105dae54cf9a9e73d1b | /aliyun-python-sdk-cms/aliyunsdkcms/request/v20190101/DescribeContactListRequest.py | 546e8da5caf567f1a57349eeba3cb61cb257b0c3 | [
"Apache-2.0"
] | permissive | kevin-catlikepuma/aliyun-openapi-python-sdk | 47285fb59ba41ab4cfb936e3aeb65efbdd2772e8 | a3f1f58dc294a7d1745071992226d61cc9a951d1 | refs/heads/master | 2020-05-26T22:00:19.869229 | 2019-05-22T08:10:10 | 2019-05-22T08:10:10 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,492 | py | # Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
#
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
from aliyunsdkcore.request import RpcRequest
class DescribeContactListRequest(RpcRequest):
def __init__(self):
RpcRequest.__init__(self, 'Cms', '2019-01-01', 'DescribeContactList','cms')
def get_ContactName(self):
return self.get_query_params().get('ContactName')
def set_ContactName(self,ContactName):
self.add_query_param('ContactName',ContactName)
def get_PageSize(self):
return self.get_query_params().get('PageSize')
def set_PageSize(self,PageSize):
self.add_query_param('PageSize',PageSize)
def get_PageNumber(self):
return self.get_query_params().get('PageNumber')
def set_PageNumber(self,PageNumber):
self.add_query_param('PageNumber',PageNumber) | [
"haowei.yao@alibaba-inc.com"
] | haowei.yao@alibaba-inc.com |
4ad295cd0d344c11d2f70ff4e00f9e00e52284a9 | 996967405d3ee07e011ee0f0404d03b6d04d3492 | /dataloader/get_coco/data_path.py | 7b3d7f36f674f57bbc35b16c04147efeb152513f | [] | no_license | wyyy04/MyRepository | 797936fc757a2eee4793d5b1b47ebf8b57216ab8 | 91f1a7ff969e91d9649b96796c5827c9910a8183 | refs/heads/main | 2023-02-22T09:56:21.926013 | 2021-01-27T15:34:00 | 2021-01-27T15:34:00 | 315,524,193 | 0 | 0 | null | 2020-11-24T07:30:05 | 2020-11-24T05:05:28 | null | UTF-8 | Python | false | false | 314 | py | #数据集实际路径
DataDir = 'loader\data\\'
Datasetfile = DataDir + 'dataset.txt'
Embeddingfile = DataDir + 'skipthoughts.npz'
Clusterfile = DataDir + 'clusters.npz'
Clustersnamefile = DataDir + 'clustersname.txt'
Clusterfile_256 = DataDir + 'clusters_256.npz'
ImageDir = DataDir + 'COCO_motivations_clean'
| [
"you@example.com"
] | you@example.com |
bd7264767f8bc90158480fcc8cf3d6aa3e1facad | a48b857ccb08a1ceb7141be6d48c9bca732f7035 | /bot/urls.py | 7532ce4c9d5e679ff1b761e1add7623f7513af85 | [] | no_license | 1hk-star/Webtoon_bot | ae1747ee2cc035996adccbb58ac8c408410c71a0 | 983b0c8e4e22d8046630a7405e246f5fd5961a24 | refs/heads/master | 2021-05-09T11:06:11.689227 | 2018-01-26T02:59:21 | 2018-01-26T02:59:21 | 118,976,778 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 726 | py | """bot URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/2.0/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
from django.conf.urls import url, include
urlpatterns = [
url(r'',include('inform.urls')),
]
| [
"root@localhost.localdomain"
] | root@localhost.localdomain |
60675121234509c5ca112bd1aae23ca8213106e1 | 1e50f1643376039ca988d909e79f528e01fa1371 | /leetcode/editor/cn/464.我能赢吗.py | 94193d96b4637cc196d0af39d9c5bfbb1de75e69 | [] | no_license | mahatmaWM/leetcode | 482a249e56e2121f4896e34c58d9fa44d6d0034b | 4f41dad6a38d3cac1c32bc1f157e20aa14eab9be | refs/heads/master | 2022-09-04T17:53:54.832210 | 2022-08-06T07:29:46 | 2022-08-06T07:29:46 | 224,415,259 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,464 | py | #
# @lc app=leetcode.cn id=464 lang=python3
#
# [464] 我能赢吗
#
# https://leetcode-cn.com/problems/can-i-win/description/
#
# algorithms
# Medium (33.86%)
# Likes: 131
# Dislikes: 0
# Total Accepted: 4.7K
# Total Submissions: 13.8K
# Testcase Example: '10\n11'
#
# 在 "100 game" 这个游戏中,两名玩家轮流选择从 1 到 10 的任意整数,累计整数和,先使得累计整数和达到 100 的玩家,即为胜者。
#
# 如果我们将游戏规则改为 “玩家不能重复使用整数” 呢?
#
# 例如,两个玩家可以轮流从公共整数池中抽取从 1 到 15 的整数(不放回),直到累计整数和 >= 100。
#
# 给定一个整数 maxChoosableInteger (整数池中可选择的最大数)和另一个整数
# desiredTotal(累计和),判断先出手的玩家是否能稳赢(假设两位玩家游戏时都表现最佳)?
#
# 你可以假设 maxChoosableInteger 不会大于 20, desiredTotal 不会大于 300。
#
# 示例:
#
# 输入:
# maxChoosableInteger = 10
# desiredTotal = 11
#
# 输出:
# false
#
# 解释:
# 无论第一个玩家选择哪个整数,他都会失败。
# 第一个玩家可以选择从 1 到 10 的整数。
# 如果第一个玩家选择 1,那么第二个玩家只能选择从 2 到 10 的整数。
# 第二个玩家可以通过选择整数 10(那么累积和为 11 >= desiredTotal),从而取得胜利.
# 同样地,第一个玩家选择任意其他整数,第二个玩家都会赢。
#
#
#
# @lc code=start
class Solution:
def canIWin(self, maxChoosableInteger: int, desiredTotal: int) -> bool:
def win(M, T, m, state):
if T <= 0: return False
if m[state] != 0: return m[state] == 1
i = 0
while i < M:
if state & (1 << i) > 0:
i += 1
continue
if not win(M, T - (i + 1), m, state | (1 << i)):
m[state] = 1
return True
i += 1
m[state] = -1
return False
# 特殊情况的处理
s = maxChoosableInteger * (maxChoosableInteger + 1) // 2
if s < desiredTotal: return False
if desiredTotal <= 0: return True
if s == desiredTotal: return maxChoosableInteger % 2 == 1
m = [0] * (1 << maxChoosableInteger)
return win(maxChoosableInteger, desiredTotal, m, 0)
# @lc code=end
| [
"chrismwang@tencent.com"
] | chrismwang@tencent.com |
db74737a5f19f4aabfff78ef6d8818a308c1b77b | f7a748eb6803a9f2b609dad279e30513497fa0be | /test/com/facebook/buck/testutil/endtoend/testdata/cxx_dependent_on_py/py_bin/generate_cpp.py | dd8e0082ceef3fbb3366dbddd661f943f8b28997 | [
"Apache-2.0"
] | permissive | MMeunierSide/buck | a44937e207a92a8a8d5df06c1e65308aa2d42328 | b1aa036a203acb8c4cf2898e0af2a1b88208d232 | refs/heads/master | 2020-03-09T23:25:38.016401 | 2018-04-11T04:11:59 | 2018-04-11T05:04:57 | 129,057,807 | 1 | 0 | Apache-2.0 | 2018-04-11T08:06:36 | 2018-04-11T08:06:35 | null | UTF-8 | Python | false | false | 305 | py | from py_lib.util import Util
def generate_cpp():
print('#include <generate_cpp/generated.h>\n')
print('Generated::Generated() {}\n')
print('std::string Generated::generated_fcn() {')
print('return "{}";'.format(Util().name))
print('}')
if __name__ == "__main__":
generate_cpp()
| [
"facebook-github-bot@users.noreply.github.com"
] | facebook-github-bot@users.noreply.github.com |
6aa4e44998c98918ebf8e738493f4114fffe694a | 839c21c464a0161d221f73aecfee8e1a9cb0e281 | /tests/clock_test.py | f4df5ca1d934a3e1ef41beb090c5ea0a93e7b690 | [
"Apache-2.0"
] | permissive | al-fontes-jr/bardolph | 89c98da6645e98583251c95e9fa24816c21ad40b | 27504031d40d288be85bc51b82b6829e3f139d93 | refs/heads/master | 2022-02-02T03:20:52.996806 | 2022-01-12T11:12:04 | 2022-01-12T11:12:04 | 200,828,449 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 1,835 | py | #!/usr/bin/env python
import unittest
from unittest.mock import patch
from bardolph.lib import clock, injection, settings, time_pattern
class MockNow:
def __init__(self, hour, minute):
self._hour = hour
self._minute = minute
@property
def hour(self):
self._minute += 1
if self._minute == 60:
self._minute = 0
self._hour += 1
if self._hour == 24:
self._hour = 0
return self._hour
@property
def minute(self):
return self._minute
def time_equals(self, hour, minute):
return hour == self._hour and minute == self._minute
class ClockTest(unittest.TestCase):
def setUp(self):
injection.configure()
self._precision = 0.1
settings.using({'sleep_time': self._precision}).configure()
def test_clock(self):
clk = clock.Clock()
clk.start()
time_0 = clk.et()
for _ in range(1, 10):
clk.wait()
time_1 = clk.et()
delta = time_1 - time_0
self.assertAlmostEqual(delta, self._precision, 1)
time_0 = time_1
clk.stop()
@patch('bardolph.lib.clock.datetime')
def test_time_pattern(self, patch_datetime):
mock_now = MockNow(9, 55)
patch_datetime.now = lambda: mock_now
clk = clock.Clock()
clk.start()
clk.wait_until(time_pattern.TimePattern.from_string('10:*'))
self.assertTrue(mock_now.time_equals(10, 0))
clk.wait_until(time_pattern.TimePattern.from_string('10:1*'))
self.assertTrue(mock_now.time_equals(10, 10))
clk.wait_until(time_pattern.TimePattern.from_string('10:*5'))
self.assertTrue(mock_now.time_equals(10, 15))
clk.stop()
if __name__ == '__main__':
unittest.main()
| [
"alfred@fontes.org"
] | alfred@fontes.org |
4f6e4f5031e1ca5479b504ef39a11043e741aa2d | 50c23021b19aef84c9c0ed8f8116b1b395df3205 | /linkipYQ/demo.py | 5df3cbeb710a5b05ab4275ba368a21319344e461 | [] | no_license | beforeuwait/code_daqsoft | d87891c6a409841dd495ab85aadb48cb348f9891 | 6178fdbc08a54b2827c1a80297684a628d4f9c08 | refs/heads/master | 2021-09-28T20:33:14.164879 | 2018-11-20T09:16:52 | 2018-11-20T09:16:52 | 108,245,470 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 3,191 | py | """
这是一个测试,作为测试linkip的服务器是否返回jessionid
"""
import requests
import time
import json
session = requests.session()
url_home = 'http://yq.linkip.cn/user/login.do'
url_log = 'http://yq.linkip.cn/user/index.do'
data_log = {
'name': 'gujing8835',
'password': 'gugugu110',
'type':1,
}
headers_login = {
'Host': 'yq.linkip.cn',
'Origin': 'http://yq.linkip.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
}
home_page = session.get(url_home, headers=headers_login)
jessionid = home_page.cookies.get('JSESSIONID')
cookie_text = ' userName=gujing8835; userPass=gugugu110; JSESSIONID=%s' %jessionid
cookies = {
"Cookies": cookie_text
}
login = session.post(url_log, headers=headers_login, cookies=cookies, data=data_log)
print(login.status_code)
print(login.text)
# headers = {
# 'Host': 'yq.linkip.cn',
# 'Origin': 'http://yq.linkip.cn',
# 'Referer': 'http://yq.linkip.cn/user/qwyq.do',
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest',
# }
#
# data = {
# 'rangeId': 1,
# 'currPage': 1,
# 'themeId': 0,
# 'topicId': 0,
# 'sentiment': 1,
# 'type': 0,
# 'startDay': '2017-11-01 00:00',
# 'endDay': '2017-11-16 23:59',
# 'page': 500,
# 'allKeywords': '',
# 'orKeywords': '',
# 'noKeywords': '',
# 'tuKeywords': '',
# 'keyWordLocation': 5
# }
# theme = [
# # ('南充', '45234'), ('成都', '45344'),
# ('西安', '45345'), ('云南', '45346'), ('新疆', '45347')]
# tt = ['id', 'title', 'content', 'createtime', 'url', 'type', 'xss', 'source', 'score', 'sentiment']
# # 开始循环
# url = 'http://yq.linkip.cn/user/getdata.do'
#
# s1 = time.time()
#
# for city, id in theme:
# n ,page = 1, 1
# while n <= page:
# print(city, str(n))
# data['themeId'] = id
# data['currPage'] = n
# start = time.time()
# js = session.post(url, headers=headers, cookies=cookies,data=data, timeout=60)
# end = time.time()
# jessionid = js.headers.get('Set-Cookie', 'no')
# if jessionid != 'no':
# id = js.cookies.get('JSESSIONID', 'no')
# if id != 'no':
# cookie_text = ' userName=beforeuwait; userPass=forwjw2017; JSESSIONID=%s' % id
# cookies = {
# "Cookies": cookie_text
# }
# js_dict = json.loads(js.content.decode('utf8'))
# page = int(js_dict.get('pageNum', 1))
# result = js_dict.get('result', [])
# text = ''
# for each in result:
# text += '\u0001'.join([str(each.get(i, ''))for i in tt]).replace('\n', '').replace('\r', '').replace(' ', '') + '\n'
#
# with open('%s_data.txt' % city, 'a', encoding='utf8') as f:
# f.write(text)
# long = int(end - start)
# try:
# time.sleep(20 - long)
# except:
# continue
# n += 1
# s2 = time.time()
#
# print(s2 - s1) | [
"forme.wjw@aliyun.com"
] | forme.wjw@aliyun.com |
ac34a2fc2cecd9267afbbe09ea616ae446adea6e | cad762658ab8326d7f43bba6f69df35a8b770e34 | /pymarkdown/plugins/rule_md_005.py | fe3d1dad36078ec91062a727f67dc7ed40593565 | [
"MIT"
] | permissive | ExternalRepositories/pymarkdown | 9c248b519791a4c869d1e71fa405c06d15ce553b | 479ace2d2d9dd5def81c72ef3b58bce6fb76f594 | refs/heads/main | 2023-08-28T03:45:25.536530 | 2021-10-31T19:39:22 | 2021-10-31T19:39:22 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 7,109 | py | """
Module to implement a plugin that ensures that the indentation for List Items
are equivalent with each other.
"""
from enum import Enum
from pymarkdown.plugin_manager import Plugin, PluginDetails
class OrderedListAlignment(Enum):
"""
Enumeration to provide guidance on what alignment was used for ordered lists.
"""
UNKNOWN = 0
LEFT = 1
RIGHT = 2
class RuleMd005(Plugin):
"""
Class to implement a plugin that ensures that the indentation for List Items
are equivalent with each other.
"""
def __init__(self):
super().__init__()
self.__list_stack = None
self.__unordered_list_indents = {}
self.__ordered_list_starts = {}
self.__ordered_tokens = {}
self.__ordered_list_alignment = {}
def get_details(self):
"""
Get the details for the plugin.
"""
return PluginDetails(
plugin_name="list-indent",
plugin_id="MD005",
plugin_enabled_by_default=True,
plugin_description="Inconsistent indentation for list items at the same level",
plugin_version="0.5.0",
plugin_interface_version=1,
plugin_url="https://github.com/jackdewinter/pymarkdown/blob/main/docs/rules/rule_md005.md",
)
def starting_new_file(self):
"""
Event that the a new file to be scanned is starting.
"""
self.__list_stack = []
self.__unordered_list_indents = {}
self.__ordered_list_starts = {}
self.__ordered_tokens = {}
self.__ordered_list_alignment = {}
def __report_issue(self, context, token):
current_list_indent = len(self.__list_stack[-1].extracted_whitespace)
if self.__list_stack[0].is_unordered_list_start:
indent_adjust = self.__list_stack[0].column_number - 1
else:
indent_adjust = -1
token_indent = len(token.extracted_whitespace) - indent_adjust
expected_indent = (
len(self.__list_stack[-2].extracted_whitespace)
if token_indent <= current_list_indent
and len(self.__list_stack) > 1
and self.__list_stack[-2].is_list_start
else current_list_indent
)
extra_data = f"Expected: {expected_indent}; Actual: {token_indent}"
self.report_next_token_error(context, token, extra_data)
def __handle_ordered_list_item(self, context, token):
list_level = len(self.__list_stack)
list_alignment = self.__ordered_list_alignment[list_level]
if list_alignment == OrderedListAlignment.RIGHT:
assert self.__ordered_list_starts[list_level].extracted_whitespace
original_text = (
self.__ordered_list_starts[list_level].list_start_content
+ self.__ordered_list_starts[list_level].extracted_whitespace
)
original_text_length = len(original_text)
current_prefix_length = len(
f"{token.list_start_content}{token.extracted_whitespace}"
)
if original_text_length == current_prefix_length:
assert (
token.indent_level
== self.__ordered_list_starts[list_level].indent_level
)
else:
self.__report_issue(context, token)
elif (
self.__ordered_list_starts[list_level].column_number != token.column_number
):
self.__report_issue(context, token)
def __compute_ordered_list_alignment(self):
list_level = len(self.__list_stack)
last_length = 0
last_token = None
for next_token in self.__ordered_tokens[list_level]:
content_length = len(next_token.list_start_content)
if not last_length:
last_length = content_length
last_token = next_token
elif content_length != last_length:
if last_token.column_number == next_token.column_number:
self.__ordered_list_alignment[
list_level
] = OrderedListAlignment.LEFT
break
last_total_length = len(last_token.extracted_whitespace) + len(
last_token.list_start_content
)
next_total_length = len(next_token.extracted_whitespace) + len(
next_token.list_start_content
)
if last_total_length == next_total_length:
self.__ordered_list_alignment[
list_level
] = OrderedListAlignment.RIGHT
break
def __handle_unordered_list_start(self, context, token):
self.__list_stack.append(token)
list_level = len(self.__list_stack)
if list_level not in self.__unordered_list_indents:
self.__unordered_list_indents[list_level] = token.indent_level
if self.__unordered_list_indents[list_level] != token.indent_level:
self.__report_issue(context, token)
def __handle_ordered_list_start(self, token):
self.__list_stack.append(token)
list_level = len(self.__list_stack)
self.__ordered_tokens[list_level] = []
self.__ordered_tokens[list_level].append(token)
if list_level not in self.__ordered_list_starts:
self.__ordered_list_starts[list_level] = token
self.__ordered_list_alignment[list_level] = OrderedListAlignment.UNKNOWN
def __handle_list_item(self, context, token):
if self.__list_stack[-1].is_unordered_list_start:
if (
self.__unordered_list_indents[len(self.__list_stack)]
!= token.indent_level
):
self.__report_issue(context, token)
else:
self.__ordered_tokens[len(self.__list_stack)].append(token)
def __handle_list_end(self, context, token):
if token.is_ordered_list_end:
list_level = len(self.__list_stack)
if (
self.__ordered_list_alignment[list_level]
== OrderedListAlignment.UNKNOWN
):
self.__compute_ordered_list_alignment()
for next_token in self.__ordered_tokens[list_level]:
self.__handle_ordered_list_item(context, next_token)
del self.__list_stack[-1]
if not self.__list_stack:
self.__unordered_list_indents = {}
self.__ordered_list_starts = {}
def next_token(self, context, token):
"""
Event that a new token is being processed.
"""
if token.is_unordered_list_start:
self.__handle_unordered_list_start(context, token)
elif token.is_ordered_list_start:
self.__handle_ordered_list_start(token)
elif token.is_unordered_list_end or token.is_ordered_list_end:
self.__handle_list_end(context, token)
elif token.is_new_list_item:
self.__handle_list_item(context, token)
| [
"jack.de.winter@outlook.com"
] | jack.de.winter@outlook.com |
63af7334751636287b81565df83c25a6a899d950 | cc0e381fde5cc6870770396d990d2bad66a3186c | /Aula/aula09t.py | 72aa8fa7baa34cbfc5ff53c13f1e74ca9d562308 | [] | no_license | jnthmota/Python-PySpark-Cursos | 2c7fac79867059e0dfe4f0c4b6b6e1d32260530f | 680a4c422e14a26036379f49f0de6b5e73d7e431 | refs/heads/main | 2023-08-15T00:22:59.189649 | 2021-09-12T23:00:39 | 2021-09-12T23:00:39 | 373,610,471 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,372 | py | ''' Nessa aula, vamos aprender operações com String no Python. As principais operações que vamos aprender
são o Fatiamento de String, Análise com len(), count(), find(), transformações com replace(),
upper(), lower(), capitalize(), title(), strip(), junção com join(). '''
frase = 'Curso em Video Python'
frase = [9] #Vai pega a nona letra da lista
frase = [9:13] = #Vai pega o intervalo de 9:13 que seria 'Vide' fatiamento sempre pega um a menos
frase = [9:21] = # Vai pega o intervalo de 9:21 'Video Python'
frase = [9:21:2] = # Vai pega o intervalo de 9:21 porem saltando de 2 em 2 = 'Vdo Pto'
frase = [:5] = # Vai pega os 5 primeiros do fatiamento = 'Curso'
frase = [15:] = # Vai pega de os ultimos carateres da fatima do 15 ate o ultimo = 'Python'
frase = [9::3] = #Vai começa no 9:: e vai ate o final 'Video Python', :3 vai pular em 3 , = 'Ve Ph'
#Analise
len(frase) # Qual o comprimento da frase? len de frase seria 21 Caracteres
frase.count('o') # Contar quantas vezes aparece a letra 'o'(minuscula) case sensitive da frase = 3
frase.count('o',0,13) # Contagem com fatiamento vai considerar do 0 até o 13 = apenas 1 'o'
frase.find('deo') # Quantas vezes ele encontrou a frase 'deo' = [11]
frase.find('Android') # Vai te retornar um -1 então significa que essa palavra não foi encontrada na lista
'Curso' in frase # Existe curso em frase ? se houver será {True}
#Transformação
frase.replace('Python','Android') # Vai substituir Python por Android
frase.upper() # METODO UPPER, VAI FICAR TUDO MAIUSCULO
frase.lower() # METODO LOWER, vai fica tudo minusculo
frase.capitalize() #METODO CAPITALIZE, vai joga toda a frase minuscula, porém a primeira letra Maiuscula
frase.title() # METODO TITLE, vai fazer uma analise mais profunda, verificar onde tem uma quebra de espaço e o
#primeiro caracter e transformar em maiusculo
frase.strip() # METODO STRIP, remove os espaços inuteis no começo e no final
frase.rstrip() # METEDO STRIP, vai tratar o lado direto da string, ou seja so o final
frase.lstrip()# METEDO STRIP, vai tratar o lado esquerda da string, ou seja so o começo
# Divisão
frase.split() # METODO SPLIT, vai ocorrer uma divisão entre os espaços da frase, uma nova indexão
# [Curso] [em] [Video] [Python] 0-3 lista
#Junção
'-'.join(frase) # Juntar todos os elementos e vai usar '-' como separador = Curso-em-Video-Python | [
"jonathan.mota@outlook.com"
] | jonathan.mota@outlook.com |
06d2c50aca5d7686ebe3b4d52fcec48ca04d8574 | ab8117bc5b5040e5107fc59337fabc966cb062ba | /.history/twitter/engine_20200328113924.py | 61ac75e432040b96d6f549e92d793cc646966e14 | [] | no_license | mirfarzam/DownloaderBro | 6019ab561c67a397135d0a1585d01d4c6f467df4 | 8e0a87dd1f768cfd22d24a7f8c223ce968e9ecb6 | refs/heads/master | 2022-04-16T15:31:38.551870 | 2020-04-15T17:36:26 | 2020-04-15T17:36:26 | 255,090,475 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,023 | py |
import tweepy
import datetime
import configparser
import time
config = configparser.ConfigParser()
config.read('credential.conf')
consumer_key = config['API']["API_key"]
consumer_secret = config['API']["API_secret_key"]
access_token = config['ACCESS']["Access_token"]
access_token_secret = config['ACCESS']["Access_token_secert"]
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
# api.verify_credentials()
def check_mentions(api, keywords, since_id):
new_since_id = since_id
for tweet in tweepy.Cursor(api.mentions_timeline,
since_id=since_id).items():
new_since_id = max(tweet.id, new_since_id)
if tweet.in_reply_to_status_id is None:
continue
main = (api.statuses_lookup([tweet.in_reply_to_status_id], include_entities=True ))[0]
final_video = None
try :
if 'media' in main.extended_entities:
maxBit = 0
maxURL = None
for video in main.extended_entities['media'][0]['video_info']['variants']:
try:
# print(f"{video['bitrate']} and is {video['url']}")
if video['bitrate'] > maxBit:
maxBit = video['bitrate']
maxURL = video['url']
except:
# print(f"Error in finding video in tweet id : {main.id}")
continue
# final_video = max(MyCount, key=int)
if maxURL is not None:
api.update_status(f'{tweet.user.screen_name} Hi Bro! this is the Link {maxURL}', in_reply_to_status_id = tweet.id)
except:
# print(f"Cannot get Tweet video and tweet id is : {main.id}")
continue
# print(final_video)
return new_since_id
since_id = 1
while True:
since_id = check_mentions(api, ["help", "support"], since_id)
time.sleep(10) | [
"farzam.mirmoeini@gmail.com"
] | farzam.mirmoeini@gmail.com |
22ba8cb74c5168ff4addd6a49abdd18dfae337b2 | 03cf49d6e2b002e5dc389282feb28769c55ff493 | /feas/gen_w2v_feat.py | 3915aa239d7723106ab8dbe88cdd6641e5588d71 | [] | no_license | yanqiangmiffy/Cityproperty-Rent-Forecast | 8f76ecf237e6bb2b7a81e844136dd12b324ee0bd | 489808ff0748d47fc34ff7c8f6168fe3fa8e39f2 | refs/heads/master | 2021-06-30T03:03:02.494347 | 2019-06-10T09:26:00 | 2019-06-10T09:26:00 | 182,541,053 | 7 | 0 | null | 2020-11-17T15:34:45 | 2019-04-21T14:04:40 | Jupyter Notebook | UTF-8 | Python | false | false | 2,711 | py | #!/usr/bin/env python
# encoding: utf-8
"""
@author: quincyqiang
@software: PyCharm
@file: gen_w2v_feat.py
@time: 2019-05-17 09:56
@description: 生成Word2Vec特征
"""
import pandas as pd
import warnings
from gensim.models import Word2Vec
import multiprocessing
warnings.filterwarnings('ignore')
def w2v_feat(data_frame, feat, mode):
for i in feat:
if data_frame[i].dtype != 'object':
data_frame[i] = data_frame[i].astype(str)
data_frame.fillna('nan', inplace=True)
print(f'Start {mode} word2vec ...')
model = Word2Vec(data_frame[feat].values.tolist(), size=L, window=2, min_count=1,
workers=multiprocessing.cpu_count(), iter=10)
stat_list = ['min', 'max', 'mean', 'std']
new_all = pd.DataFrame()
for m, t in enumerate(feat):
print(f'Start gen feat of {t} ...')
tmp = []
for i in data_frame[t].unique():
tmp_v = [i]
tmp_v.extend(model[i])
tmp.append(tmp_v)
tmp_df = pd.DataFrame(tmp)
w2c_list = [f'w2c_{t}_{n}' for n in range(L)]
tmp_df.columns = [t] + w2c_list
tmp_df = data_frame[['ID', t]].merge(tmp_df, on=t)
tmp_df = tmp_df.drop_duplicates().groupby('ID').agg(stat_list).reset_index()
tmp_df.columns = ['ID'] + [f'{p}_{q}' for p in w2c_list for q in stat_list]
if m == 0:
new_all = pd.concat([new_all, tmp_df], axis=1)
else:
new_all = pd.merge(new_all, tmp_df, how='left', on='ID')
return new_all
if __name__ == '__main__':
L = 10
df_train = pd.read_csv('../input/train_data.csv')
df_test = pd.read_csv('../input/test_a.csv')
# ------------------ 过滤数据 begin ----------------
print("根据tradeMoney过滤数据:", len(df_train))
df_train = df_train.query("500<=tradeMoney<25000") # 线下 lgb_0.876612870005764
print("filter tradeMoney after:", len(df_train))
categorical_feas = ['rentType', 'houseFloor', 'houseToward', 'houseDecoration']
new_all_train = w2v_feat(df_train, categorical_feas, 'train')
new_all_test = w2v_feat(df_test, categorical_feas, 'test')
train = pd.merge(df_train, new_all_train, on='ID', how='left')
valid = pd.merge(df_test, new_all_test, on='ID', how='left')
print(f'Gen train shape: {train.shape}, test shape: {valid.shape}')
drop_train = train.T.drop_duplicates().T
drop_valid = valid.T.drop_duplicates().T
features = [i for i in drop_train.columns if i in drop_valid.columns]
print('features num: ', len(features) - 1)
train[features + ['tradeMoney']].to_csv('../input/train_w2v.csv', index=False)
valid[features].to_csv('../input/test_w2v.csv', index=False)
| [
"1185918903@qq.com"
] | 1185918903@qq.com |
ca42f38050315ce2042b442a3f10da5c7f56c249 | 897d82d4953ed7b609746a0f252f3f3440b650cb | /day17/homework/homework_personal.py | a6297f4d42168de99f07f4198453d7482d5ba418 | [] | no_license | haiou90/aid_python_core | dd704e528a326028290a2c18f215b1fd399981bc | bd4c7a20950cf7e22e8e05bbc42cb3b3fdbe82a1 | refs/heads/master | 2022-11-26T19:13:36.721238 | 2020-08-07T15:05:17 | 2020-08-07T15:05:17 | 285,857,695 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,264 | py | from iterable_tools import IterableHelper
"""直接使用IterableHelper类现有功能,完成下列需求
-- 在技能列表中查找名称是"一阳指"的技能对象
-- 在技能列表中查找攻击比例atk_rate大于1的所有技能对象
-- 在技能列表中所有技能名称name和消耗法力cost_sp"""
class Skill:
def __init__(self, name="", atk_rate=0.0, cost_sp=0, duration=0):
self.name = name
self.atk_rate = atk_rate
self.cost_sp = cost_sp
self.duration = duration
list_skills = [
Skill("横扫千军", 1, 50, 5),
Skill("九阳神功", 3, 150, 6),
Skill("降龙十八掌", 3, 150, 5),
Skill("一阳指", 1.2, 0, 2),
Skill("乾坤大挪移", 3.2, 30, 2),
Skill("打狗棍", 1.3, 0, 6),
]
result = IterableHelper.find_single(list_skills,lambda emp:emp.name == "一阳指")
print(result.__dict__)
for list_skill in IterableHelper.find_all(list_skills,lambda emp:emp.atk_rate>1):
print(list_skill.__dict__)
for list_skill in IterableHelper.select(list_skills,lambda emp:(emp.name,emp.atk_rate)):
print(list_skill)
class IterableHelper:
@staticmethod
def find_single(iterable,func):
for item in iterable:
if func(item):
return item
| [
"caoho@outlook.com"
] | caoho@outlook.com |
82e273899b8bdc46203d6b1f1e2254b20264b9a2 | f497916365288386bd2fc5085ce1391aa649467b | /pactools/utils/fir.py | eb7ec457d6bb77f43deaf0c55855dcc4adba5c82 | [] | no_license | fraimondo/pactools | 486d5eac4fd9190dcbbcee24fa735ac511aa396b | b4be8ae27cca1684816772f7ce2cb9e503452f14 | refs/heads/master | 2021-08-30T01:02:51.161092 | 2017-12-05T16:19:05 | 2017-12-05T16:19:05 | 113,920,577 | 0 | 0 | null | 2017-12-11T23:40:13 | 2017-12-11T23:40:12 | null | UTF-8 | Python | false | false | 8,162 | py | import numpy as np
from scipy import signal
import matplotlib.pyplot as plt
from .spectrum import Spectrum
class FIR(object):
"""FIR filter
Parameters
----------
fir : array
Finite impulse response (FIR) filter
Examples
--------
>>> from pactools.utils.fir import FIR
>>> f = FIR(fir=[0.2, 0.6, 0.2])
>>> f.plot()
>>> signal_out = f.transform(signal_in)
"""
def __init__(self, fir=np.ones(1), fs=1.0):
self.fir = fir
self.fs = fs
def transform(self, sigin):
"""Apply this filter to a signal
Parameters
----------
sigin : array, shape (n_points, ) or (n_signals, n_points)
Input signal
Returns
-------
filtered : array, shape (n_points, ) or (n_signals, n_points)
Filtered signal
"""
sigin_ndim = sigin.ndim
sigin = np.atleast_2d(sigin)
filtered = [signal.fftconvolve(sig, self.fir, 'same') for sig in sigin]
if sigin_ndim == 1:
filtered = filtered[0]
else:
filtered = np.asarray(filtered)
return filtered
def plot(self, axs=None, fscale='log'):
"""
Plots the impulse response and the transfer function of the filter.
"""
# validate figure
fig_passed = axs is not None
if axs is None:
fig, axs = plt.subplots(nrows=2)
else:
axs = np.atleast_1d(axs)
if np.any([not isinstance(ax, plt.Axes) for ax in axs]):
raise TypeError('axs must be a list of matplotlib Axes, got {}'
' instead.'.format(type(axs)))
# test if is figure and has 2 axes
if len(axs) < 2:
raise ValueError('Passed figure must have at least two axes'
', given figure has {}.'.format(len(axs)))
fig = axs[0].figure
# compute periodogram
fft_length = max(int(2 ** np.ceil(np.log2(self.fir.shape[0]))), 2048)
s = Spectrum(fft_length=fft_length, block_length=self.fir.size,
step=None, fs=self.fs, wfunc=np.ones, donorm=False)
s.periodogram(self.fir)
s.plot('Transfer function of FIR filter', fscale=fscale,
axes=axs[0])
# plots
axs[1].plot(self.fir)
axs[1].set_title('Impulse response of FIR filter')
axs[1].set_xlabel('Samples')
axs[1].set_ylabel('Amplitude')
if not fig_passed:
fig.tight_layout()
return fig
class BandPassFilter(FIR):
"""Band-pass FIR filter
Designs a band-pass FIR filter centered on frequency fc.
Parameters
----------
fs : float
Sampling frequency
fc : float
Center frequency of the bandpass filter
n_cycles : float or None, (default 7.0)
Number of oscillation in the wavelet. None if bandwidth is used.
bandwidth : float or None, (default None)
Bandwidth of the FIR wavelet filter. None if n_cycles is used.
zero_mean : boolean, (default True)
If True, the mean of the FIR is subtracted, i.e. fir.sum() = 0.
extract_complex : boolean, (default False)
If True, the wavelet filter is complex and ``transform`` returns two
signals, filtered with the real and the imaginary part of the filter.
Examples
--------
>>> from pactools.utils import BandPassFilter
>>> f = BandPassFilter(fs=100., fc=5., bandwidth=1., n_cycles=None)
>>> f.plot()
>>> signal_out = f.transform(signal_in)
"""
def __init__(self, fs, fc, n_cycles=7.0, bandwidth=None, zero_mean=True,
extract_complex=False):
self.fc = fc
self.fs = fs
self.n_cycles = n_cycles
self.bandwidth = bandwidth
self.zero_mean = zero_mean
self.extract_complex = extract_complex
self._design()
def _design(self):
"""Designs the FIR filter"""
# the length of the filter
order = self._get_order()
half_order = (order - 1) // 2
w = np.blackman(order)
t = np.linspace(-half_order, half_order, order)
phase = (2.0 * np.pi * self.fc / self.fs) * t
car = np.cos(phase)
fir = w * car
# the filter must be symmetric, in order to be zero-phase
assert np.all(np.abs(fir - fir[::-1]) < 1e-15)
# remove the constant component by forcing fir.sum() = 0
if self.zero_mean:
fir -= fir.sum() / order
gain = np.sum(fir * car)
self.fir = fir * (1.0 / gain)
# add the imaginary part to have a complex wavelet
if self.extract_complex:
car_imag = np.sin(phase)
fir_imag = w * car_imag
self.fir_imag = fir_imag * (1.0 / gain)
return self
def _get_order(self):
if self.bandwidth is None and self.n_cycles is not None:
half_order = int(float(self.n_cycles) / self.fc * self.fs / 2)
elif self.bandwidth is not None and self.n_cycles is None:
half_order = int(1.65 * self.fs / self.bandwidth) // 2
else:
raise ValueError('fir.BandPassFilter: n_cycles and bandwidth '
'cannot be both None, or both not None. Got '
'%s and %s' % (self.n_cycles, self.bandwidth, ))
order = half_order * 2 + 1
return order
def transform(self, sigin):
"""Apply this filter to a signal
Parameters
----------
sigin : array, shape (n_points, ) or (n_signals, n_points)
Input signal
Returns
-------
filtered : array, shape (n_points, ) or (n_signals, n_points)
Filtered signal
(filtered_imag) : array, shape (n_points, ) or (n_signals, n_points)
Only when extract_complex is true.
Filtered signal with the imaginary part of the filter
"""
filtered = super(BandPassFilter, self).transform(sigin)
if self.extract_complex:
fir = FIR(fir=self.fir_imag, fs=self.fs)
filtered_imag = fir.transform(sigin)
return filtered, filtered_imag
else:
return filtered
def plot(self, axs=None, fscale='log'):
"""
Plots the impulse response and the transfer function of the filter.
"""
fig = super(BandPassFilter, self).plot(axs=axs, fscale=fscale)
if self.extract_complex:
if axs is None:
axs = fig.axes
fir = FIR(fir=self.fir_imag, fs=self.fs)
fir.plot(axs=axs, fscale=fscale)
return fig
class LowPassFilter(FIR):
"""Low-pass FIR filter
Designs a FIR filter that is a low-pass filter.
Parameters
----------
fs : float
Sampling frequency
fc : float
Cut-off frequency of the low-pass filter
bandwidth : float
Bandwidth of the FIR wavelet filter
ripple_db : float (default 60.0)
Positive number specifying maximum ripple in passband (dB) and minimum
ripple in stopband, in Kaiser-window low-pass FIR filter.
Examples
--------
>>> from pactools.utils import LowPassFilter
>>> f = LowPassFilter(fs=100., fc=5., bandwidth=1.)
>>> f.plot()
>>> signal_out = f.transform(signal_in)
"""
def __init__(self, fs, fc, bandwidth, ripple_db=60.0):
self.fs = fs
self.fc = fc
self.bandwidth = bandwidth
self.ripple_db = ripple_db
self._design()
def _design(self):
# Compute the order and Kaiser parameter for the FIR filter.
N, beta = signal.kaiserord(self.ripple_db,
self.bandwidth / self.fs * 2)
# Use firwin with a Kaiser window to create a lowpass FIR filter.
fir = signal.firwin(N, self.fc / self.fs * 2, window=('kaiser', beta))
# the filter must be symmetric, in order to be zero-phase
assert np.all(np.abs(fir - fir[::-1]) < 1e-15)
self.fir = fir / np.sum(fir)
return self
| [
"tom.dupre-la-tour@m4x.org"
] | tom.dupre-la-tour@m4x.org |
c155e0cc9df22df2e507584ebe164afc53d4c0a0 | 609580338943caf9141ae8e2535fb31398ad6286 | /log_pullrequest/log_pr_2020-08-03-12-22_6ca6da91408244e26c157e9e6467cc18ede43e71.py | 8d512d335ba044acb56aca83f12e7487c17e50b2 | [] | no_license | arita37/mlmodels_store | 5b3333072382af31e54b4be9f9050a3eab094f5e | c139f1b85d22885cbe0f0f4c4a2ee19bde665a0b | refs/heads/master | 2021-05-23T01:02:57.202925 | 2020-11-16T16:27:10 | 2020-11-16T16:27:10 | 253,156,396 | 2 | 6 | null | 2020-05-13T10:42:34 | 2020-04-05T04:37:05 | Python | UTF-8 | Python | false | false | 23,794 | py |
test_pullrequest /home/runner/work/mlmodels/mlmodels/mlmodels/config/test_config.json Namespace(config_file='/home/runner/work/mlmodels/mlmodels/mlmodels/config/test_config.json', config_mode='test', do='test_pullrequest', folder=None, log_file=None, name='ml_store', save_folder='ztest/')
ml_test --do test_pullrequest
********************************************************************************************************************************************
******** TAG :: {'github_repo_url': 'https://github.com/arita37/mlmodels/tree/6ca6da91408244e26c157e9e6467cc18ede43e71', 'url_branch_file': 'https://github.com/arita37/mlmodels/blob/dev/', 'repo': 'arita37/mlmodels', 'branch': 'dev', 'sha': '6ca6da91408244e26c157e9e6467cc18ede43e71', 'workflow': 'test_pullrequest'}
******** GITHUB_WOKFLOW : https://github.com/arita37/mlmodels/actions?query=workflow%3Atest_pullrequest
******** GITHUB_REPO_BRANCH : https://github.com/arita37/mlmodels/tree/dev/
******** GITHUB_REPO_URL : https://github.com/arita37/mlmodels/tree/6ca6da91408244e26c157e9e6467cc18ede43e71
******** GITHUB_COMMIT_URL : https://github.com/arita37/mlmodels/commit/6ca6da91408244e26c157e9e6467cc18ede43e71
******** Click here for Online DEBUGGER : https://gitpod.io/#https://github.com/arita37/mlmodels/tree/6ca6da91408244e26c157e9e6467cc18ede43e71
************************************************************************************************************************
/home/runner/work/mlmodels/mlmodels/pullrequest/
############Check model ################################
['/home/runner/work/mlmodels/mlmodels/pullrequest/aa_mycode_test.py']
Used ['/home/runner/work/mlmodels/mlmodels/pullrequest/aa_mycode_test.py']
########### Run Check ##############################
********************************************************************************************************************************************
******** TAG :: {'github_repo_url': 'https://github.com/arita37/mlmodels/tree/6ca6da91408244e26c157e9e6467cc18ede43e71', 'url_branch_file': 'https://github.com/arita37/mlmodels/blob/dev/', 'repo': 'arita37/mlmodels', 'branch': 'dev', 'sha': '6ca6da91408244e26c157e9e6467cc18ede43e71', 'workflow': 'test_pullrequest'}
******** GITHUB_WOKFLOW : https://github.com/arita37/mlmodels/actions?query=workflow%3Atest_pullrequest
******** GITHUB_REPO_BRANCH : https://github.com/arita37/mlmodels/tree/dev/
******** GITHUB_REPO_URL : https://github.com/arita37/mlmodels/tree/6ca6da91408244e26c157e9e6467cc18ede43e71
******** GITHUB_COMMIT_URL : https://github.com/arita37/mlmodels/commit/6ca6da91408244e26c157e9e6467cc18ede43e71
******** Click here for Online DEBUGGER : https://gitpod.io/#https://github.com/arita37/mlmodels/tree/6ca6da91408244e26c157e9e6467cc18ede43e71
************************************************************************************************************************
********************************************************************************************************************************************
test_import
['template.00_template_keras', 'template.model_xxx', 'model_keras.namentity_crm_bilstm', 'model_keras.__init__', 'model_keras.deepctr', 'model_keras.util', 'model_keras.textcnn', 'model_keras.armdn', 'model_keras.charcnn', 'model_keras.preprocess', 'model_keras.charcnn_zhang', 'model_keras.Autokeras', 'model_gluon.__init__', 'model_gluon.util', 'model_gluon.fb_prophet', 'model_gluon.util_autogluon', 'model_gluon.gluon_automl', 'model_gluon.gluonts_model_old', 'model_gluon.gluonts_model', 'preprocess.__init__', 'preprocess.tabular', 'preprocess.text', 'preprocess.tabular_keras', 'preprocess.ztemp', 'preprocess.text_keras', 'preprocess.timeseries', 'preprocess.generic_old', 'preprocess.image', 'preprocess.generic', 'preprocess.text_torch', 'utils.test_dataloader', 'utils.parse', 'utils.ztest_structure', 'example.benchmark_timeseries_m5', 'example.arun_model', 'example.arun_hyper', 'example.lightgbm_glass', 'example.vision_mnist', 'example.benchmark_timeseries_m4', 'model_dev.__init__', 'model_dev.temporal_fusion_google', 'model_tf.__init__', 'model_tf.util', 'model_tf.1_lstm', 'model_tch.__init__', 'model_tch.torchhub', 'model_tch.transformer_sentence', 'model_tch.util_data', 'model_tch.util_transformer', 'model_tch.textcnn', 'model_tch.matchZoo', 'model_rank.__init__', 'model_sklearn.__init__', 'model_sklearn.model_sklearn', 'model_sklearn.model_lightgbm']
Error mlmodels.template.00_template_keras expected an indented block (00_template_keras.py, line 68)
Error mlmodels.template.model_xxx invalid syntax (data.py, line 126)
mlmodels.model_keras.namentity_crm_bilstm
mlmodels.model_keras.__init__
Error mlmodels.model_keras.deepctr cannot import name 'create_embedding_matrix'
mlmodels.model_keras.util
mlmodels.model_keras.textcnn
Error mlmodels.model_keras.armdn invalid syntax (data.py, line 126)
mlmodels.model_keras.charcnn
Error mlmodels.model_keras.preprocess cannot import name 'create_embedding_matrix'
/home/runner/work/mlmodels/mlmodels/mlmodels/dataset
mlmodels.model_keras.charcnn_zhang
Error mlmodels.model_keras.Autokeras No module named 'autokeras'
Using TensorFlow backend.
/opt/hostedtoolcache/Python/3.6.11/x64/lib/python3.6/site-packages/mxnet/optimizer/optimizer.py:167: UserWarning:
WARNING: New optimizer gluonnlp.optimizer.lamb.LAMB is overriding existing optimizer mxnet.optimizer.optimizer.LAMB
/home/runner/work/mlmodels/mlmodels/mlmodels/model_gluon/gluonts_model_old.py:569: DeprecationWarning:
invalid escape sequence \s
Using CPU
Using CPU
Using CPU
Using CPU
Using CPU
Using CPU
Using CPU
Using CPU
Using CPU
Using CPU
Using CPU
Using CPU
Using CPU
Using CPU
Using CPU
mlmodels.model_gluon.__init__
mlmodels.model_gluon.util
mlmodels.model_gluon.fb_prophet
mlmodels.model_gluon.util_autogluon
mlmodels.model_gluon.gluon_automl
mlmodels.model_gluon.gluonts_model_old
Error mlmodels.model_gluon.gluonts_model invalid syntax (gluonts_model.py, line 203)
mlmodels.preprocess.__init__
mlmodels.preprocess.tabular
mlmodels.preprocess.text
Error mlmodels.preprocess.tabular_keras cannot import name 'create_embedding_matrix'
Error mlmodels.preprocess.ztemp invalid character in identifier (ztemp.py, line 6)
mlmodels.preprocess.text_keras
mlmodels.preprocess.timeseries
mlmodels.preprocess.generic_old
mlmodels.preprocess.image
mlmodels.preprocess.generic
Error mlmodels.preprocess.text_torch libtorch_cpu.so: cannot open shared object file: No such file or directory
mlmodels.utils.test_dataloader
mlmodels.utils.parse
mlmodels.utils.ztest_structure
Error mlmodels.example.benchmark_timeseries_m5 [Errno 2] File b'./m5-forecasting-accuracy/calendar.csv' does not exist: b'./m5-forecasting-accuracy/calendar.csv'
<module 'mlmodels' from '/home/runner/work/mlmodels/mlmodels/mlmodels/__init__.py'>
/home/runner/work/mlmodels/mlmodels/mlmodels/model_keras/ardmn.json
Error mlmodels.example.arun_model [Errno 2] No such file or directory: '/home/runner/work/mlmodels/mlmodels/mlmodels/model_keras/ardmn.json'
Error mlmodels.example.arun_hyper name 'copy' is not defined
Deprecaton set to False
/home/runner/work/mlmodels/mlmodels
Error mlmodels.example.lightgbm_glass [Errno 2] No such file or directory: 'lightgbm_glass.json'
Error mlmodels.example.vision_mnist invalid syntax (vision_mnist.py, line 15)
mlmodels.example.benchmark_timeseries_m4
mlmodels.model_dev.__init__
Error mlmodels.model_dev.temporal_fusion_google No module named 'mlmodels.mode_tf'
/home/runner/work/mlmodels/mlmodels/mlmodels/preprocess/generic_old.py:319: DeprecationWarning:
invalid escape sequence \(
/home/runner/work/mlmodels/mlmodels/mlmodels/preprocess/generic_old.py:320: DeprecationWarning:
invalid escape sequence \)
/home/runner/work/mlmodels/mlmodels/mlmodels/preprocess/generic_old.py:321: DeprecationWarning:
invalid escape sequence \?
/home/runner/work/mlmodels/mlmodels/mlmodels/preprocess/text_torch.py:86: DeprecationWarning:
invalid escape sequence \(
/home/runner/work/mlmodels/mlmodels/mlmodels/preprocess/text_torch.py:87: DeprecationWarning:
invalid escape sequence \)
/home/runner/work/mlmodels/mlmodels/mlmodels/preprocess/text_torch.py:88: DeprecationWarning:
invalid escape sequence \?
PyTorch version 1.2.0 available.
mlmodels.model_tf.__init__
mlmodels.model_tf.util
mlmodels.model_tf.1_lstm
mlmodels.model_tch.__init__
mlmodels.model_tch.torchhub
mlmodels.model_tch.transformer_sentence
Error mlmodels.model_tch.util_data [Errno 2] File b'./data/train.csv' does not exist: b'./data/train.csv'
mlmodels.model_tch.util_transformer
Error mlmodels.model_tch.textcnn libtorch_cpu.so: cannot open shared object file: No such file or directory
Better speed can be achieved with apex installed from https://www.github.com/nvidia/apex .
Better speed can be achieved with apex installed from https://www.github.com/nvidia/apex .
mlmodels.model_tch.matchZoo
mlmodels.model_rank.__init__
mlmodels.model_sklearn.__init__
mlmodels.model_sklearn.model_sklearn
Error mlmodels.model_sklearn.model_lightgbm invalid syntax (model_lightgbm.py, line 316)
Deprecaton set to False
{'model_uri': 'model_tf.1_lstm', 'learning_rate': 0.001, 'num_layers': 1, 'size': 6, 'size_layer': 128, 'output_size': 6, 'timestep': 4, 'epoch': 2} {'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]} {'engine': 'optuna', 'method': 'prune', 'ntrials': 5} {'engine_pars': {'engine': 'optuna', 'method': 'normal', 'ntrials': 2, 'metric_target': 'loss'}, 'learning_rate': {'type': 'log_uniform', 'init': 0.01, 'range': [0.001, 0.1]}, 'num_layers': {'type': 'int', 'init': 2, 'range': [2, 4]}, 'size': {'type': 'int', 'init': 6, 'range': [6, 6]}, 'output_size': {'type': 'int', 'init': 6, 'range': [6, 6]}, 'size_layer': {'type': 'categorical', 'value': [128, 256]}, 'timestep': {'type': 'categorical', 'value': [5]}, 'epoch': {'type': 'categorical', 'value': [2]}}
<module 'mlmodels.model_tf.1_lstm' from '/home/runner/work/mlmodels/mlmodels/mlmodels/model_tf/1_lstm.py'>
###### Hyper-optimization through study ##################################
check <module 'mlmodels.model_tf.1_lstm' from '/home/runner/work/mlmodels/mlmodels/mlmodels/model_tf/1_lstm.py'> {'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]}
{'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]}
/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv
Date Open High ... Close Adj Close Volume
0 2016-11-02 778.200012 781.650024 ... 768.700012 768.700012 1872400
1 2016-11-03 767.250000 769.950012 ... 762.130005 762.130005 1943200
2 2016-11-04 750.659973 770.359985 ... 762.020020 762.020020 2134800
3 2016-11-07 774.500000 785.190002 ... 782.520020 782.520020 1585100
4 2016-11-08 783.400024 795.632996 ... 790.510010 790.510010 1350800
[5 rows x 7 columns]
0 1 2 3 4 5
0 0.706562 0.629914 0.682052 0.599302 0.599302 0.153665
1 0.458824 0.320251 0.598101 0.478596 0.478596 0.174523
2 0.083484 0.331101 0.437246 0.476576 0.476576 0.230969
3 0.622851 0.723606 0.854891 0.853206 0.853206 0.069025
4 0.824209 1.000000 1.000000 1.000000 1.000000 0.000000
[I 2020-08-03 12:23:03,907] Finished trial#0 resulted in value: 0.3055925741791725. Current best value is 0.3055925741791725 with parameters: {'learning_rate': 0.0014096565098249087, 'num_layers': 3, 'size': 6, 'output_size': 6, 'size_layer': 128, 'timestep': 5, 'epoch': 2}.
check <module 'mlmodels.model_tf.1_lstm' from '/home/runner/work/mlmodels/mlmodels/mlmodels/model_tf/1_lstm.py'> {'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]}
{'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]}
/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv
Date Open High ... Close Adj Close Volume
0 2016-11-02 778.200012 781.650024 ... 768.700012 768.700012 1872400
1 2016-11-03 767.250000 769.950012 ... 762.130005 762.130005 1943200
2 2016-11-04 750.659973 770.359985 ... 762.020020 762.020020 2134800
3 2016-11-07 774.500000 785.190002 ... 782.520020 782.520020 1585100
4 2016-11-08 783.400024 795.632996 ... 790.510010 790.510010 1350800
[5 rows x 7 columns]
0 1 2 3 4 5
0 0.706562 0.629914 0.682052 0.599302 0.599302 0.153665
1 0.458824 0.320251 0.598101 0.478596 0.478596 0.174523
2 0.083484 0.331101 0.437246 0.476576 0.476576 0.230969
3 0.622851 0.723606 0.854891 0.853206 0.853206 0.069025
4 0.824209 1.000000 1.000000 1.000000 1.000000 0.000000
[I 2020-08-03 12:23:05,992] Finished trial#1 resulted in value: 2.024783343076706. Current best value is 0.3055925741791725 with parameters: {'learning_rate': 0.0014096565098249087, 'num_layers': 3, 'size': 6, 'output_size': 6, 'size_layer': 128, 'timestep': 5, 'epoch': 2}.
################################### Optim, finished ###################################
### Save Stats ##########################################################
### Run Model with best #################################################
{'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]}
/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv
Date Open High ... Close Adj Close Volume
0 2016-11-02 778.200012 781.650024 ... 768.700012 768.700012 1872400
1 2016-11-03 767.250000 769.950012 ... 762.130005 762.130005 1943200
2 2016-11-04 750.659973 770.359985 ... 762.020020 762.020020 2134800
3 2016-11-07 774.500000 785.190002 ... 782.520020 782.520020 1585100
4 2016-11-08 783.400024 795.632996 ... 790.510010 790.510010 1350800
[5 rows x 7 columns]
0 1 2 3 4 5
0 0.706562 0.629914 0.682052 0.599302 0.599302 0.153665
1 0.458824 0.320251 0.598101 0.478596 0.478596 0.174523
2 0.083484 0.331101 0.437246 0.476576 0.476576 0.230969
3 0.622851 0.723606 0.854891 0.853206 0.853206 0.069025
4 0.824209 1.000000 1.000000 1.000000 1.000000 0.000000
#### Saving ###########################################################
{'path': '/home/runner/work/mlmodels/mlmodels/mlmodels/ztest/optim_1lstm/', 'model_type': 'model_tf', 'model_uri': 'model_tf-1_lstm'}
Model saved in path: /home/runner/work/mlmodels/mlmodels/mlmodels/ztest/optim_1lstm//model//model.ckpt
['checkpoint', 'model.ckpt.index', 'model.ckpt.meta', 'model_pars.pkl', 'model.ckpt.data-00000-of-00001']
sh: 1: ml_mlmodels: not found
********************************************************************************************************************************************
python /home/runner/work/mlmodels/mlmodels/pullrequest/aa_mycode_test.py 2>&1 | tee -a cd log_.txt
os.getcwd /home/runner/work/mlmodels/mlmodels
############ Your custom code ################################
python /home/runner/work/mlmodels/mlmodels/mlmodels/optim.py
Deprecaton set to False
{'model_uri': 'model_tf.1_lstm', 'learning_rate': 0.001, 'num_layers': 1, 'size': 6, 'size_layer': 128, 'output_size': 6, 'timestep': 4, 'epoch': 2} {'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]} {'engine': 'optuna', 'method': 'prune', 'ntrials': 5} {'engine_pars': {'engine': 'optuna', 'method': 'normal', 'ntrials': 2, 'metric_target': 'loss'}, 'learning_rate': {'type': 'log_uniform', 'init': 0.01, 'range': [0.001, 0.1]}, 'num_layers': {'type': 'int', 'init': 2, 'range': [2, 4]}, 'size': {'type': 'int', 'init': 6, 'range': [6, 6]}, 'output_size': {'type': 'int', 'init': 6, 'range': [6, 6]}, 'size_layer': {'type': 'categorical', 'value': [128, 256]}, 'timestep': {'type': 'categorical', 'value': [5]}, 'epoch': {'type': 'categorical', 'value': [2]}}
<module 'mlmodels.model_tf.1_lstm' from '/home/runner/work/mlmodels/mlmodels/mlmodels/model_tf/1_lstm.py'>
###### Hyper-optimization through study ##################################
check <module 'mlmodels.model_tf.1_lstm' from '/home/runner/work/mlmodels/mlmodels/mlmodels/model_tf/1_lstm.py'> {'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]}
<mlmodels.model_tf.1_lstm.Model object at 0x7f3c40ae4f60>
{'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]}
/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv
Date Open High ... Close Adj Close Volume
0 2016-11-02 778.200012 781.650024 ... 768.700012 768.700012 1872400
1 2016-11-03 767.250000 769.950012 ... 762.130005 762.130005 1943200
2 2016-11-04 750.659973 770.359985 ... 762.020020 762.020020 2134800
3 2016-11-07 774.500000 785.190002 ... 782.520020 782.520020 1585100
4 2016-11-08 783.400024 795.632996 ... 790.510010 790.510010 1350800
[5 rows x 7 columns]
0 1 2 3 4 5
0 0.706562 0.629914 0.682052 0.599302 0.599302 0.153665
1 0.458824 0.320251 0.598101 0.478596 0.478596 0.174523
2 0.083484 0.331101 0.437246 0.476576 0.476576 0.230969
3 0.622851 0.723606 0.854891 0.853206 0.853206 0.069025
4 0.824209 1.000000 1.000000 1.000000 1.000000 0.000000
[I 2020-08-03 12:23:12,948] Finished trial#0 resulted in value: 0.3574335128068924. Current best value is 0.3574335128068924 with parameters: {'learning_rate': 0.0033577781935741485, 'num_layers': 2, 'size': 6, 'output_size': 6, 'size_layer': 128, 'timestep': 5, 'epoch': 2}.
check <module 'mlmodels.model_tf.1_lstm' from '/home/runner/work/mlmodels/mlmodels/mlmodels/model_tf/1_lstm.py'> {'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]}
<mlmodels.model_tf.1_lstm.Model object at 0x7f3c3bd4bb38>
{'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]}
/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv
Date Open High ... Close Adj Close Volume
0 2016-11-02 778.200012 781.650024 ... 768.700012 768.700012 1872400
1 2016-11-03 767.250000 769.950012 ... 762.130005 762.130005 1943200
2 2016-11-04 750.659973 770.359985 ... 762.020020 762.020020 2134800
3 2016-11-07 774.500000 785.190002 ... 782.520020 782.520020 1585100
4 2016-11-08 783.400024 795.632996 ... 790.510010 790.510010 1350800
[5 rows x 7 columns]
0 1 2 3 4 5
0 0.706562 0.629914 0.682052 0.599302 0.599302 0.153665
1 0.458824 0.320251 0.598101 0.478596 0.478596 0.174523
2 0.083484 0.331101 0.437246 0.476576 0.476576 0.230969
3 0.622851 0.723606 0.854891 0.853206 0.853206 0.069025
4 0.824209 1.000000 1.000000 1.000000 1.000000 0.000000
[I 2020-08-03 12:23:14,249] Finished trial#1 resulted in value: 0.2803972661495209. Current best value is 0.2803972661495209 with parameters: {'learning_rate': 0.0029804325689204224, 'num_layers': 2, 'size': 6, 'output_size': 6, 'size_layer': 256, 'timestep': 5, 'epoch': 2}.
################################### Optim, finished ###################################
### Save Stats ##########################################################
### Run Model with best #################################################
{'data_path': '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv', 'data_type': 'pandas', 'size': [0, 0, 6], 'output_size': [0, 6]}
/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/timeseries/GOOG-year_small.csv
Date Open High ... Close Adj Close Volume
0 2016-11-02 778.200012 781.650024 ... 768.700012 768.700012 1872400
1 2016-11-03 767.250000 769.950012 ... 762.130005 762.130005 1943200
2 2016-11-04 750.659973 770.359985 ... 762.020020 762.020020 2134800
3 2016-11-07 774.500000 785.190002 ... 782.520020 782.520020 1585100
4 2016-11-08 783.400024 795.632996 ... 790.510010 790.510010 1350800
[5 rows x 7 columns]
0 1 2 3 4 5
0 0.706562 0.629914 0.682052 0.599302 0.599302 0.153665
1 0.458824 0.320251 0.598101 0.478596 0.478596 0.174523
2 0.083484 0.331101 0.437246 0.476576 0.476576 0.230969
3 0.622851 0.723606 0.854891 0.853206 0.853206 0.069025
4 0.824209 1.000000 1.000000 1.000000 1.000000 0.000000
#### Saving ###########################################################
{'path': '/home/runner/work/mlmodels/mlmodels/mlmodels/ztest/optim_1lstm/', 'model_type': 'model_tf', 'model_uri': 'model_tf-1_lstm'}
Model saved in path: /home/runner/work/mlmodels/mlmodels/mlmodels/ztest/optim_1lstm//model//model.ckpt
['checkpoint', 'model.ckpt.index', 'model.ckpt.meta', 'model_pars.pkl', 'model.ckpt.data-00000-of-00001']
python /home/runner/work/mlmodels/mlmodels/mlmodels/model_keras/textcnn.py
#### Module init ############################################
<module 'mlmodels.model_keras.textcnn' from '/home/runner/work/mlmodels/mlmodels/mlmodels/model_keras/textcnn.py'>
#### Loading params ##############################################
Using TensorFlow backend.
Traceback (most recent call last):
File "/home/runner/work/mlmodels/mlmodels/mlmodels/model_keras/textcnn.py", line 258, in <module>
test_module(model_uri = MODEL_URI, param_pars= param_pars)
File "/home/runner/work/mlmodels/mlmodels/mlmodels/models.py", line 257, in test_module
model_pars, data_pars, compute_pars, out_pars = module.get_params(param_pars)
File "/home/runner/work/mlmodels/mlmodels/mlmodels/model_keras/textcnn.py", line 165, in get_params
cf = json.load(open(data_path, mode='r'))
FileNotFoundError: [Errno 2] No such file or directory: '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/json/refactor/textcnn_keras.json'
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.6.11/x64/bin/ml_test", line 11, in <module>
load_entry_point('mlmodels', 'console_scripts', 'ml_test')()
File "/home/runner/work/mlmodels/mlmodels/mlmodels/ztest.py", line 642, in main
globals()[arg.do](arg)
File "/home/runner/work/mlmodels/mlmodels/mlmodels/ztest.py", line 424, in test_pullrequest
raise Exception(f"Unknown dataset type", x)
Exception: ('Unknown dataset type', "FileNotFoundError: [Errno 2] No such file or directory: '/home/runner/work/mlmodels/mlmodels/mlmodels/dataset/json/refactor/textcnn_keras.json'\n")
| [
"noelkev0@gmail.com"
] | noelkev0@gmail.com |
6fa3358d03e945e11123f1d3a3c4b23061069cf8 | 3577d2e20c79cbbbc0a8a91a73be322be61cf384 | /5.4 Objects and Algorithms/1 Object/4 ExerciseTraker2.py | ac6399889c32350a3735b2e6358e11bc1c49284d | [] | no_license | KETULPADARIYA/Computing-in-Python | cb30a807fa92a816f53f3254a63f07883977406d | 02c69a3c074924a70f68f00fd756436aa207dcf6 | refs/heads/master | 2020-04-24T04:47:18.342215 | 2019-03-17T03:21:46 | 2019-03-17T03:21:46 | 171,716,015 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,879 | py | #Previously, you wrote a class called ExerciseSession that
#had three attributes: an exercise name, an intensity, and a
#duration.
#
#Add a new method to that class called calories_burned.
#calories_burned should have no parameters (besides self, as
#every method in a class has). It should return an integer
#representing the number of calories burned according to the
#following formula:
#
# - If the intensity is "Low", 4 calories are burned per
# minute.
# - If the intensity is "Moderate", 8 calories are burned
# per minute.
# - If the intensity is "High", 12 calories are burned per
# minute.
#
#You may copy your class from the previous exercise and just
#add to it.
#Add your code here!
class ExerciseSession():
def __init__(self,exercise,intensity,duration):
self.exercise=exercise
self.intensity=intensity
self.duration=duration
def get_exercise(self):
return self.exercise
def get_intensity(self):
return self.intensity
def get_duration(self):
return self.duration
def set_exercise(self,value):
self.exercise = value
def set_intensity(self,value):
self.intensity = value
def set_duration(self,value):
self.duration = value
def calories_burned(self):
if self.intensity == "Low":
return self.duration*4
if self.intensity == "Moderate":
return self.duration*8
if self.intensity == "High":
return self.duration*12
#If your code is implemented correctly, the lines below
#will run error-free. They will result in the following
#output to the console:
#240
#360
new_exercise = ExerciseSession("Running", "Low", 60)
print(new_exercise.calories_burned())
new_exercise.set_exercise("Swimming")
new_exercise.set_intensity("High")
new_exercise.set_duration(30)
print(new_exercise.calories_burned())
| [
"ketulpadariya79@gmail.com"
] | ketulpadariya79@gmail.com |
3419e878d3d631a1d81f03dea1450003ab85c1bb | f39528e9bad8cfa78b38fcbb7a5b430ac0c7a942 | /Higgs2LLP/LO_HToSSTobbbb_MH125_MS55_ctauS0p05_13TeV.py | 0a392bd289634904035c154b54547bec66ebdeaf | [] | no_license | isildakbora/EXO-MC-REQUESTS | c0e3eb3a49b516476d37aa464c47304df14bed1e | 8771e32bbec079de787f7e5f11407e9e7ebe35d8 | refs/heads/master | 2021-04-12T11:11:03.982564 | 2019-04-29T15:12:34 | 2019-04-29T15:12:34 | 126,622,752 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,909 | py | import FWCore.ParameterSet.Config as cms
from Configuration.Generator.Pythia8CommonSettings_cfi import *
from Configuration.Generator.MCTunes2017.PythiaCP5Settings_cfi import *
from Configuration.Generator.Pythia8PowhegEmissionVetoSettings_cfi import *
from Configuration.Generator.PSweightsPythia.PythiaPSweightsSettings_cfi import *
generator = cms.EDFilter("Pythia8HadronizerFilter",
maxEventsToPrint = cms.untracked.int32(1),
pythiaPylistVerbosity = cms.untracked.int32(1),
filterEfficiency = cms.untracked.double(1.0),
pythiaHepMCVerbosity = cms.untracked.bool(False),
comEnergy = cms.double(13000.),
PythiaParameters = cms.PSet(
pythia8CommonSettingsBlock,
pythia8CP5SettingsBlock,
pythia8PSweightsSettingsBlock,
pythia8PowhegEmissionVetoSettingsBlock,
processParameters = cms.vstring(
'9000006:all = sk skbar 0 0 0 55 3.9464e-12 1.0 75.0 0.05',
'9000006:oneChannel = 1 1.0 101 5 -5',
'9000006:mayDecay = on',
'9000006:isResonance = on',
'25:m0 = 125.0',
'25:onMode = off',
'25:addChannel = 1 0.000000001 101 9000006 -9000006',
'25:onIfMatch = 9000006 -9000006',
'9000006:onMode = off',
'9000006:onIfAny = 5',
),
parameterSets = cms.vstring('pythia8CommonSettings',
'pythia8CP5Settings',
'pythia8PSweightsSettings'
'pythia8PowhegEmissionVetoSettings',
'processParameters'
)
)
)
ProductionFilterSequence = cms.Sequence(generator)
| [
"bora.isildak@cern.ch"
] | bora.isildak@cern.ch |
701a3b7f4b23d31ebeab4b41f626f756478f746b | 9cd180fc7594eb018c41f0bf0b54548741fd33ba | /sdk/python/pulumi_azure_nextgen/storagesync/v20190301/get_storage_sync_service.py | 2cf11b6677bb8a2310b698ed26983f397eb033f8 | [
"Apache-2.0",
"BSD-3-Clause"
] | permissive | MisinformedDNA/pulumi-azure-nextgen | c71971359450d03f13a53645171f621e200fe82d | f0022686b655c2b0744a9f47915aadaa183eed3b | refs/heads/master | 2022-12-17T22:27:37.916546 | 2020-09-28T16:03:59 | 2020-09-28T16:03:59 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 4,861 | py | # coding=utf-8
# *** WARNING: this file was generated by the Pulumi SDK Generator. ***
# *** Do not edit by hand unless you're certain you know what you are doing! ***
import warnings
import pulumi
import pulumi.runtime
from typing import Any, Mapping, Optional, Sequence, Union
from ... import _utilities, _tables
__all__ = [
'GetStorageSyncServiceResult',
'AwaitableGetStorageSyncServiceResult',
'get_storage_sync_service',
]
@pulumi.output_type
class GetStorageSyncServiceResult:
"""
Storage Sync Service object.
"""
def __init__(__self__, location=None, name=None, storage_sync_service_status=None, storage_sync_service_uid=None, tags=None, type=None):
if location and not isinstance(location, str):
raise TypeError("Expected argument 'location' to be a str")
pulumi.set(__self__, "location", location)
if name and not isinstance(name, str):
raise TypeError("Expected argument 'name' to be a str")
pulumi.set(__self__, "name", name)
if storage_sync_service_status and not isinstance(storage_sync_service_status, int):
raise TypeError("Expected argument 'storage_sync_service_status' to be a int")
pulumi.set(__self__, "storage_sync_service_status", storage_sync_service_status)
if storage_sync_service_uid and not isinstance(storage_sync_service_uid, str):
raise TypeError("Expected argument 'storage_sync_service_uid' to be a str")
pulumi.set(__self__, "storage_sync_service_uid", storage_sync_service_uid)
if tags and not isinstance(tags, dict):
raise TypeError("Expected argument 'tags' to be a dict")
pulumi.set(__self__, "tags", tags)
if type and not isinstance(type, str):
raise TypeError("Expected argument 'type' to be a str")
pulumi.set(__self__, "type", type)
@property
@pulumi.getter
def location(self) -> str:
"""
The geo-location where the resource lives
"""
return pulumi.get(self, "location")
@property
@pulumi.getter
def name(self) -> str:
"""
The name of the resource
"""
return pulumi.get(self, "name")
@property
@pulumi.getter(name="storageSyncServiceStatus")
def storage_sync_service_status(self) -> int:
"""
Storage Sync service status.
"""
return pulumi.get(self, "storage_sync_service_status")
@property
@pulumi.getter(name="storageSyncServiceUid")
def storage_sync_service_uid(self) -> str:
"""
Storage Sync service Uid
"""
return pulumi.get(self, "storage_sync_service_uid")
@property
@pulumi.getter
def tags(self) -> Optional[Mapping[str, str]]:
"""
Resource tags.
"""
return pulumi.get(self, "tags")
@property
@pulumi.getter
def type(self) -> str:
"""
The type of the resource. Ex- Microsoft.Compute/virtualMachines or Microsoft.Storage/storageAccounts.
"""
return pulumi.get(self, "type")
class AwaitableGetStorageSyncServiceResult(GetStorageSyncServiceResult):
# pylint: disable=using-constant-test
def __await__(self):
if False:
yield self
return GetStorageSyncServiceResult(
location=self.location,
name=self.name,
storage_sync_service_status=self.storage_sync_service_status,
storage_sync_service_uid=self.storage_sync_service_uid,
tags=self.tags,
type=self.type)
def get_storage_sync_service(resource_group_name: Optional[str] = None,
storage_sync_service_name: Optional[str] = None,
opts: Optional[pulumi.InvokeOptions] = None) -> AwaitableGetStorageSyncServiceResult:
"""
Use this data source to access information about an existing resource.
:param str resource_group_name: The name of the resource group. The name is case insensitive.
:param str storage_sync_service_name: Name of Storage Sync Service resource.
"""
__args__ = dict()
__args__['resourceGroupName'] = resource_group_name
__args__['storageSyncServiceName'] = storage_sync_service_name
if opts is None:
opts = pulumi.InvokeOptions()
if opts.version is None:
opts.version = _utilities.get_version()
__ret__ = pulumi.runtime.invoke('azure-nextgen:storagesync/v20190301:getStorageSyncService', __args__, opts=opts, typ=GetStorageSyncServiceResult).value
return AwaitableGetStorageSyncServiceResult(
location=__ret__.location,
name=__ret__.name,
storage_sync_service_status=__ret__.storage_sync_service_status,
storage_sync_service_uid=__ret__.storage_sync_service_uid,
tags=__ret__.tags,
type=__ret__.type)
| [
"public@paulstack.co.uk"
] | public@paulstack.co.uk |
b2d9a6ad2e37068d9a8111e66a169c2f35cd83cf | cceb97ce3d74ac17090786bc65f7ed30e37ad929 | /lxd_Safety(out)/graphTraversal-submit2/kvparser.py | cf5a418fcf027d4e48d2a709fddd788aae180815 | [] | no_license | Catxiaobai/project | b47310efe498421cde794e289b4e753d843c8e40 | 76e346f69261433ccd146a3cbfa92b4e3864d916 | refs/heads/master | 2023-01-08T04:37:59.232492 | 2020-11-10T12:00:34 | 2020-11-10T12:00:34 | 291,014,545 | 1 | 4 | null | 2020-11-09T01:22:11 | 2020-08-28T10:08:16 | Python | UTF-8 | Python | false | false | 7,539 | py | """kvparser -- A simple hierarchical key-value text parser.
(c) 2004 HAS
kvparser parses text containing simple key-value pairs and/or nested blocks using a simple event-driven model. The text format is intended to be human readable and writeable, so is designed for simplicity and consistency with a low-noise syntax. The error handling for malformed text is strict by default - the text format is simple enough that it should not be hard to write valid text.
Example text:
#######
person:
first-name=Joe
last-name=Black
email:
nickname=joe.black
address=joe@foo.com
email:
nickname=fuzzy
address=fuzzy@bar.org
#######
1. Simple key-value pairs take the form:
NAME=VALUE
NAME must contain only alphanumeric and/or hyphen characters, and be at least 1 character in length with the first character being a letter. (Note: Periods are permitted in names as well. However, these should be used only to indicate ad-hoc namespaces, e.g. 'foo.bar' where 'bar' is an attribute of the 'foo' namespace.)
NAME and VALUE are separated by an '=' (equals) character. Whitespace before the '=' is not permitted. Everything after the '=' is the VALUE.
VALUE can contain any characters except newline, and may be 0 or more characters in length.
Each line must end in a newline (ASCII 10) character.
The Parser class provides backslash escaping for the following characters in VALUE:
\n --> newline character (ASCII 10)
\r --> return character (ASCII 13)
\t --> tab character (ASCII 9)
\\ --> \
2. Key-value blocks are indicated by the line:
NAME:
followed by zero or more lines containing simple key-value pairs and/or blocks indented with a single tab character (ASCII 9).
The colon must be followed immediately by a newline character; trailing whitespace and other characters is not allowed.
Blocks can be nested within other blocks to any depth.
3. Empty lines and lines containing only tabs are permitted; these are simply ignored.
4. Full-line comments are permitted; any line beginning with zero or more tabs followed by '#' is ignored.
5. The parser will, by default, raise a ParseError if it encounters a malformed key-value item or block, or an incorrectly indented line. This behaviour can be overridden in subclasses if desired.
#######
NOTES
- See parser classes and test code for more information and examples of use.
- The restricted NAME format ensures names can be directly mapped to C-style identifiers simply by substituting the hyphen with an underscore.
- kvparser doesn't [yet?] provide any special features for working with NAME namespaces.
"""
# kvparser -- A simple key-value text parser with support for nested blocks.
#
# Copyright (C) 2004 HAS <hamish.sanderson@virgin.net>
#
# This library is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version.
#
# This library is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details.
#
# You should have received a copy of the GNU Lesser General Public License along with this library; if not, write to the Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
# coding = utf-8
import re as _re
_emptyLinePattern = _re.compile('\t*$|\t*#')
_parseLinePattern = _re.compile('(\t*)([.a-zA-Z][.a-zA-Z0-9-]+)(?:(:)|=(.*))')
class ParseError(Exception):
def __init__(self, msg, lineNo, lineStr):
self.msg = msg
self.lineNo = lineNo
self.lineStr = lineStr
def __str__(self):
return self.msg + ' at line %i: %r' % (self.lineNo, self.lineStr)
class Parser:
"""Subclass this and override parsing event handlers to do useful work."""
lineDelimiter = '\n'
escapeChar = '`'
charSubs = 'r\r', 'n\n', 't\t'
def unescape(self, s):
"""Unescape value part of a key=value pair."""
for old, new in self.charSubs + (self.escapeChar * 2,):
s = s.replace(self.escapeChar + old, new)
return s
# Main method; call it with the text to be parsed as its sole argument
def parse(self, text):
# TO DO: change 'ParseError' usage to 'parseError' events so that
# subclasses can provide their own error handling/recovery behaviour.
lines = text.split(self.lineDelimiter)
blockDepth = 0
for lineNo in range(len(lines)):
lineStr = lines[lineNo]
if not _emptyLinePattern.match(lineStr):
lineMatch = _parseLinePattern.match(lineStr)
if not lineMatch:
self.parseError('Malformed line', lineNo, lineStr)
indentStr, name, isBlock, value = lineMatch.groups()
depth = len(indentStr)
if depth > blockDepth:
self.parseError('Bad indentation', lineNo, lineStr)
while depth < blockDepth:
blockDepth -= 1
self.closeBlock()
if isBlock:
self.openBlock(name)
blockDepth += 1
else:
self.addItem(name, self.unescape(value))
for _ in range(blockDepth):
self.closeBlock()
# Optionally override the following error event handler to provide your own error handling:
def parseError(self, desc, lineNo, lineStr):
raise ParseError(desc, lineNo, lineStr)
# Override the following parser event handlers:
def openBlock(self, name):
pass
def addItem(self, name, value):
pass
def closeBlock(self):
pass
class TestParser(Parser):
def openBlock(self, name):
print 'OPEN %r' % name
def addItem(self, name, value):
print 'ADD %r %r' % (name, value)
def closeBlock(self):
print 'CLOSE'
#######
class ListParser(Parser):
"""Use to parse text into a nested list; e.g.
foo=1
bar:
baz=3
produces:
[
('foo', '1'),
('bar', [
('baz', '3')
]
)
]
"""
class _Stack:
def __init__(self, lst): self.__stack = lst
def push(self, val): self.__stack.append(val)
def pop(self): return self.__stack.pop()
def top(self): return self.__stack[-1]
def depth(self): return len(self.__stack)
def parse(self, text):
self.stack = self._Stack(
[(None, [])]) # each stack entry is two-item tuple: (block name, list of items in block)
Parser.parse(self, text)
result = self.stack.pop()[1]
del self.stack
return result
def openBlock(self, name):
self.stack.push((name, []))
def addItem(self, name, value):
self.stack.top()[1].append((name, value))
def closeBlock(self):
block = self.stack.pop()
self.stack.top()[1].append(block)
#######
# TEST
if __name__ == '__main__':
s = """
# this is a comment line
email:
address=user@domain
real-name=Real Name
encryption:
format=PGP
key=some key
connection:
address=123.123.123.123
port=99
connection-type=INET
address-type=IP4
"""
TestParser().parse(s)
print
print ListParser().parse(s)
| [
"2378960008@qq.com"
] | 2378960008@qq.com |
1350ab965e68e5d4e3037607833640afff30296a | c7066d3b72a54665d81de1d77d7bdcfd0ece7b42 | /python/ccxt/async_support/phemex.py | ba55c236478db5346ce422fcf9b7d564772ac999 | [
"MIT"
] | permissive | blair/ccxt | cf09b7a604586c230e8cea2b6e4dbf6c3c3497ea | 3a6bd4efb78d01391f9a4ea43ec228b75ca24695 | refs/heads/master | 2023-09-03T21:09:44.447194 | 2023-08-26T19:01:14 | 2023-08-26T19:01:14 | 126,121,401 | 0 | 2 | MIT | 2018-03-21T04:02:57 | 2018-03-21T04:02:56 | null | UTF-8 | Python | false | false | 200,391 | py | # -*- coding: utf-8 -*-
# PLEASE DO NOT EDIT THIS FILE, IT IS GENERATED AND WILL BE OVERWRITTEN:
# https://github.com/ccxt/ccxt/blob/master/CONTRIBUTING.md#how-to-contribute-code
from ccxt.async_support.base.exchange import Exchange
from ccxt.abstract.phemex import ImplicitAPI
import hashlib
import numbers
from ccxt.base.types import OrderSide
from ccxt.base.types import OrderType
from typing import Optional
from typing import List
from ccxt.base.errors import ExchangeError
from ccxt.base.errors import PermissionDenied
from ccxt.base.errors import AccountSuspended
from ccxt.base.errors import ArgumentsRequired
from ccxt.base.errors import BadRequest
from ccxt.base.errors import BadSymbol
from ccxt.base.errors import InsufficientFunds
from ccxt.base.errors import InvalidOrder
from ccxt.base.errors import OrderNotFound
from ccxt.base.errors import CancelPending
from ccxt.base.errors import DuplicateOrderId
from ccxt.base.errors import NotSupported
from ccxt.base.errors import DDoSProtection
from ccxt.base.errors import RateLimitExceeded
from ccxt.base.errors import AuthenticationError
from ccxt.base.decimal_to_precision import TICK_SIZE
from ccxt.base.precise import Precise
class phemex(Exchange, ImplicitAPI):
def describe(self):
return self.deep_extend(super(phemex, self).describe(), {
'id': 'phemex',
'name': 'Phemex',
'countries': ['CN'], # China
'rateLimit': 120.5,
'version': 'v1',
'certified': False,
'pro': True,
'hostname': 'api.phemex.com',
'has': {
'CORS': None,
'spot': True,
'margin': False,
'swap': True,
'future': False,
'option': False,
'addMargin': False,
'cancelAllOrders': True,
'cancelOrder': True,
'createOrder': True,
'createReduceOnlyOrder': True,
'createStopLimitOrder': True,
'createStopMarketOrder': True,
'createStopOrder': True,
'editOrder': True,
'fetchBalance': True,
'fetchBorrowRate': False,
'fetchBorrowRateHistories': False,
'fetchBorrowRateHistory': False,
'fetchBorrowRates': False,
'fetchBorrowRatesPerSymbol': False,
'fetchClosedOrders': True,
'fetchCurrencies': True,
'fetchDepositAddress': True,
'fetchDeposits': True,
'fetchFundingHistory': True,
'fetchFundingRate': True,
'fetchFundingRateHistories': False,
'fetchFundingRateHistory': True,
'fetchFundingRates': False,
'fetchIndexOHLCV': False,
'fetchLeverage': False,
'fetchLeverageTiers': True,
'fetchMarketLeverageTiers': 'emulated',
'fetchMarkets': True,
'fetchMarkOHLCV': False,
'fetchMyTrades': True,
'fetchOHLCV': True,
'fetchOpenOrders': True,
'fetchOrder': True,
'fetchOrderBook': True,
'fetchOrders': True,
'fetchPositions': True,
'fetchPositionsRisk': False,
'fetchPremiumIndexOHLCV': False,
'fetchTicker': True,
'fetchTickers': True,
'fetchTrades': True,
'fetchTradingFee': False,
'fetchTradingFees': False,
'fetchTransfers': True,
'fetchWithdrawals': True,
'reduceMargin': False,
'setLeverage': True,
'setMargin': True,
'setMarginMode': True,
'setPositionMode': True,
'transfer': True,
'withdraw': None,
},
'urls': {
'logo': 'https://user-images.githubusercontent.com/1294454/85225056-221eb600-b3d7-11ea-930d-564d2690e3f6.jpg',
'test': {
'v1': 'https://testnet-api.phemex.com/v1',
'v2': 'https://testnet-api.phemex.com',
'public': 'https://testnet-api.phemex.com/exchange/public',
'private': 'https://testnet-api.phemex.com',
},
'api': {
'v1': 'https://{hostname}/v1',
'v2': 'https://{hostname}',
'public': 'https://{hostname}/exchange/public',
'private': 'https://{hostname}',
},
'www': 'https://phemex.com',
'doc': 'https://github.com/phemex/phemex-api-docs',
'fees': 'https://phemex.com/fees-conditions',
'referral': {
'url': 'https://phemex.com/register?referralCode=EDNVJ',
'discount': 0.1,
},
},
'timeframes': {
'1m': '60',
'3m': '180',
'5m': '300',
'15m': '900',
'30m': '1800',
'1h': '3600',
'2h': '7200',
'3h': '10800',
'4h': '14400',
'6h': '21600',
'12h': '43200',
'1d': '86400',
'1w': '604800',
'1M': '2592000',
'3M': '7776000',
'1Y': '31104000',
},
'api': {
'public': {
'get': {
'cfg/v2/products': 5, # spot + contracts
'cfg/fundingRates': 5,
'products': 5, # contracts only
'nomics/trades': 5, # ?market=<symbol>&since=<since>
'md/kline': 5, # ?from=1589811875&resolution=1800&symbol=sBTCUSDT&to=1592457935
'md/v2/kline/list': 5, # perpetual api ?symbol=<symbol>&to=<to>&from=<from>&resolution=<resolution>
'md/v2/kline': 5, # ?symbol=<symbol>&resolution=<resolution>&limit=<limit>
'md/v2/kline/last': 5, # perpetual ?symbol=<symbol>&resolution=<resolution>&limit=<limit>
'md/orderbook': 5, # ?symbol=<symbol>
'md/trade': 5, # ?symbol=<symbol>
'md/spot/ticker/24hr': 5, # ?symbol=<symbol>
'exchange/public/cfg/chain-settings': 5, # ?currency=<currency>
},
},
'v1': {
'get': {
'md/orderbook': 5, # ?symbol=<symbol>&id=<id>
'md/trade': 5, # ?symbol=<symbol>&id=<id>
'md/ticker/24hr': 5, # ?symbol=<symbol>&id=<id>
'md/ticker/24hr/all': 5, # ?id=<id>
'md/spot/ticker/24hr': 5, # ?symbol=<symbol>&id=<id>
'md/spot/ticker/24hr/all': 5, # ?symbol=<symbol>&id=<id>
'exchange/public/products': 5, # contracts only
'api-data/public/data/funding-rate-history': 5,
},
},
'v2': {
'get': {
'md/v2/orderbook': 5, # ?symbol=<symbol>&id=<id>
'md/v2/trade': 5, # ?symbol=<symbol>&id=<id>
'md/v2/ticker/24hr': 5, # ?symbol=<symbol>&id=<id>
'md/v2/ticker/24hr/all': 5, # ?id=<id>
'api-data/public/data/funding-rate-history': 5,
},
},
'private': {
'get': {
# spot
'spot/orders/active': 1, # ?symbol=<symbol>&orderID=<orderID>
# 'spot/orders/active': 5, # ?symbol=<symbol>&clOrDID=<clOrdID>
'spot/orders': 1, # ?symbol=<symbol>
'spot/wallets': 5, # ?currency=<currency>
'exchange/spot/order': 5, # ?symbol=<symbol>&ordStatus=<ordStatus5,orderStatus2>ordType=<ordType5,orderType2>&start=<start>&end=<end>&limit=<limit>&offset=<offset>
'exchange/spot/order/trades': 5, # ?symbol=<symbol>&start=<start>&end=<end>&limit=<limit>&offset=<offset>
'exchange/order/v2/orderList': 5, # ?symbol=<symbol>¤cy=<currency>&ordStatus=<ordStatus>&ordType=<ordType>&start=<start>&end=<end>&offset=<offset>&limit=<limit>&withCount=<withCount></withCount>
'exchange/order/v2/tradingList': 5, # ?symbol=<symbol>¤cy=<currency>&execType=<execType>&offset=<offset>&limit=<limit>&withCount=<withCount>
# swap
'accounts/accountPositions': 1, # ?currency=<currency>
'g-accounts/accountPositions': 1, # ?currency=<currency>
'accounts/positions': 25, # ?currency=<currency>
'api-data/futures/funding-fees': 5, # ?symbol=<symbol>
'api-data/g-futures/funding-fees': 5, # ?symbol=<symbol>
'api-data/futures/orders': 5, # ?symbol=<symbol>
'api-data/g-futures/orders': 5, # ?symbol=<symbol>
'api-data/futures/orders/by-order-id': 5, # ?symbol=<symbol>
'api-data/g-futures/orders/by-order-id': 5, # ?symbol=<symbol>
'api-data/futures/trades': 5, # ?symbol=<symbol>
'api-data/g-futures/trades': 5, # ?symbol=<symbol>
'api-data/futures/trading-fees': 5, # ?symbol=<symbol>
'api-data/g-futures/trading-fees': 5, # ?symbol=<symbol>
'g-orders/activeList': 1, # ?symbol=<symbol>
'orders/activeList': 1, # ?symbol=<symbol>
'exchange/order/list': 5, # ?symbol=<symbol>&start=<start>&end=<end>&offset=<offset>&limit=<limit>&ordStatus=<ordStatus>&withCount=<withCount>
'exchange/order': 5, # ?symbol=<symbol>&orderID=<orderID5,orderID2>
# 'exchange/order': 5, # ?symbol=<symbol>&clOrdID=<clOrdID5,clOrdID2>
'exchange/order/trade': 5, # ?symbol=<symbol>&start=<start>&end=<end>&limit=<limit>&offset=<offset>&withCount=<withCount>
'phemex-user/users/children': 5, # ?offset=<offset>&limit=<limit>&withCount=<withCount>
'phemex-user/wallets/v2/depositAddress': 5, # ?_t=1592722635531¤cy=USDT
'phemex-user/wallets/tradeAccountDetail': 5, # ?bizCode=¤cy=&end=1642443347321&limit=10&offset=0&side=&start=1&type=4&withCount=true
'phemex-user/order/closedPositionList': 5, # ?currency=USD&limit=10&offset=0&symbol=&withCount=true
'exchange/margins/transfer': 5, # ?start=<start>&end=<end>&offset=<offset>&limit=<limit>&withCount=<withCount>
'exchange/wallets/confirm/withdraw': 5, # ?code=<withdrawConfirmCode>
'exchange/wallets/withdrawList': 5, # ?currency=<currency>&limit=<limit>&offset=<offset>&withCount=<withCount>
'exchange/wallets/depositList': 5, # ?currency=<currency>&offset=<offset>&limit=<limit>
'exchange/wallets/v2/depositAddress': 5, # ?currency=<currency>
'api-data/spots/funds': 5, # ?currency=<currency>&start=<start>&end=<end>&limit=<limit>&offset=<offset>
'api-data/spots/orders': 5, # ?symbol=<symbol>
'api-data/spots/orders/by-order-id': 5, # ?symbol=<symbol>&oderId=<orderID>&clOrdID=<clOrdID>
'api-data/spots/pnls': 5,
'api-data/spots/trades': 5, # ?symbol=<symbol>
'api-data/spots/trades/by-order-id': 5, # ?symbol=<symbol>&oderId=<orderID>&clOrdID=<clOrdID>
'assets/convert': 5, # ?startTime=<startTime>&endTime=<endTime>&limit=<limit>&offset=<offset>
# transfer
'assets/transfer': 5, # ?currency=<currency>&start=<start>&end=<end>&limit=<limit>&offset=<offset>
'assets/spots/sub-accounts/transfer': 5, # ?currency=<currency>&start=<start>&end=<end>&limit=<limit>&offset=<offset>
'assets/futures/sub-accounts/transfer': 5, # ?currency=<currency>&start=<start>&end=<end>&limit=<limit>&offset=<offset>
'assets/quote': 5, # ?fromCurrency=<currency>&toCurrency=<currency>&amountEv=<amount>
},
'post': {
# spot
'spot/orders': 1,
# swap
'orders': 1,
'g-orders': 1,
'positions/assign': 5, # ?symbol=<symbol>&posBalance=<posBalance>&posBalanceEv=<posBalanceEv>
'exchange/wallets/transferOut': 5,
'exchange/wallets/transferIn': 5,
'exchange/margins': 5,
'exchange/wallets/createWithdraw': 5, # ?otpCode=<otpCode>
'exchange/wallets/cancelWithdraw': 5,
'exchange/wallets/createWithdrawAddress': 5, # ?otpCode={optCode}
# transfer
'assets/transfer': 5,
'assets/spots/sub-accounts/transfer': 5, # for sub-account only
'assets/futures/sub-accounts/transfer': 5, # for sub-account only
'assets/universal-transfer': 5, # for Main account only
'assets/convert': 5,
},
'put': {
# spot
'spot/orders/create': 1, # ?symbol=<symbol>&trigger=<trigger>&clOrdID=<clOrdID>&priceEp=<priceEp>&baseQtyEv=<baseQtyEv>"eQtyEv=<quoteQtyEv>&stopPxEp=<stopPxEp>&text=<text>&side=<side>&qtyType=<qtyType>&ordType=<ordType>&timeInForce=<timeInForce>&execInst=<execInst>
'spot/orders': 1, # ?symbol=<symbol>&orderID=<orderID>&origClOrdID=<origClOrdID>&clOrdID=<clOrdID>&priceEp=<priceEp>&baseQtyEV=<baseQtyEV>"eQtyEv=<quoteQtyEv>&stopPxEp=<stopPxEp>
# swap
'orders/replace': 1, # ?symbol=<symbol>&orderID=<orderID>&origClOrdID=<origClOrdID>&clOrdID=<clOrdID>&price=<price>&priceEp=<priceEp>&orderQty=<orderQty>&stopPx=<stopPx>&stopPxEp=<stopPxEp>&takeProfit=<takeProfit>&takeProfitEp=<takeProfitEp>&stopLoss=<stopLoss>&stopLossEp=<stopLossEp>&pegOffsetValueEp=<pegOffsetValueEp>&pegPriceType=<pegPriceType>
'g-orders/replace': 1, # ?symbol=<symbol>&orderID=<orderID>&origClOrdID=<origClOrdID>&clOrdID=<clOrdID>&price=<price>&priceEp=<priceEp>&orderQty=<orderQty>&stopPx=<stopPx>&stopPxEp=<stopPxEp>&takeProfit=<takeProfit>&takeProfitEp=<takeProfitEp>&stopLoss=<stopLoss>&stopLossEp=<stopLossEp>&pegOffsetValueEp=<pegOffsetValueEp>&pegPriceType=<pegPriceType>
'positions/leverage': 5, # ?symbol=<symbol>&leverage=<leverage>&leverageEr=<leverageEr>
'g-positions/leverage': 5, # ?symbol=<symbol>&leverage=<leverage>&leverageEr=<leverageEr>
'g-positions/switch-pos-mode-sync': 5, # ?symbol=<symbol>&targetPosMode=<targetPosMode>
'positions/riskLimit': 5, # ?symbol=<symbol>&riskLimit=<riskLimit>&riskLimitEv=<riskLimitEv>
},
'delete': {
# spot
'spot/orders': 2, # ?symbol=<symbol>&orderID=<orderID>
'spot/orders/all': 2, # ?symbol=<symbol>&untriggered=<untriggered>
# 'spot/orders': 5, # ?symbol=<symbol>&clOrdID=<clOrdID>
# swap
'orders/cancel': 1, # ?symbol=<symbol>&orderID=<orderID>
'orders': 1, # ?symbol=<symbol>&orderID=<orderID1>,<orderID2>,<orderID3>
'orders/all': 3, # ?symbol=<symbol>&untriggered=<untriggered>&text=<text>
'g-orders/cancel': 1, # ?symbol=<symbol>&orderID=<orderID>
'g-orders': 1, # ?symbol=<symbol>&orderID=<orderID1>,<orderID2>,<orderID3>
'g-orders/all': 3, # ?symbol=<symbol>&untriggered=<untriggered>&text=<text>
},
},
},
'precisionMode': TICK_SIZE,
'fees': {
'trading': {
'tierBased': False,
'percentage': True,
'taker': self.parse_number('0.001'),
'maker': self.parse_number('0.001'),
},
},
'requiredCredentials': {
'apiKey': True,
'secret': True,
},
'exceptions': {
'exact': {
# not documented
'412': BadRequest, # {"code":412,"msg":"Missing parameter - resolution","data":null}
'6001': BadRequest, # {"error":{"code":6001,"message":"invalid argument"},"id":null,"result":null}
# documented
'19999': BadRequest, # REQUEST_IS_DUPLICATED Duplicated request ID
'10001': DuplicateOrderId, # OM_DUPLICATE_ORDERID Duplicated order ID
'10002': OrderNotFound, # OM_ORDER_NOT_FOUND Cannot find order ID
'10003': CancelPending, # OM_ORDER_PENDING_CANCEL Cannot cancel while order is already in pending cancel status
'10004': CancelPending, # OM_ORDER_PENDING_REPLACE Cannot cancel while order is already in pending cancel status
'10005': CancelPending, # OM_ORDER_PENDING Cannot cancel while order is already in pending cancel status
'11001': InsufficientFunds, # TE_NO_ENOUGH_AVAILABLE_BALANCE Insufficient available balance
'11002': InvalidOrder, # TE_INVALID_RISK_LIMIT Invalid risk limit value
'11003': InsufficientFunds, # TE_NO_ENOUGH_BALANCE_FOR_NEW_RISK_LIMIT Insufficient available balance
'11004': InvalidOrder, # TE_INVALID_LEVERAGE invalid input or new leverage is over maximum allowed leverage
'11005': InsufficientFunds, # TE_NO_ENOUGH_BALANCE_FOR_NEW_LEVERAGE Insufficient available balance
'11006': ExchangeError, # TE_CANNOT_CHANGE_POSITION_MARGIN_WITHOUT_POSITION Position size is zero. Cannot change margin
'11007': ExchangeError, # TE_CANNOT_CHANGE_POSITION_MARGIN_FOR_CROSS_MARGIN Cannot change margin under CrossMargin
'11008': ExchangeError, # TE_CANNOT_REMOVE_POSITION_MARGIN_MORE_THAN_ADDED exceeds the maximum removable Margin
'11009': ExchangeError, # TE_CANNOT_REMOVE_POSITION_MARGIN_DUE_TO_UNREALIZED_PNL exceeds the maximum removable Margin
'11010': InsufficientFunds, # TE_CANNOT_ADD_POSITION_MARGIN_DUE_TO_NO_ENOUGH_AVAILABLE_BALANCE Insufficient available balance
'11011': InvalidOrder, # TE_REDUCE_ONLY_ABORT Cannot accept reduce only order
'11012': InvalidOrder, # TE_REPLACE_TO_INVALID_QTY Order quantity Error
'11013': InvalidOrder, # TE_CONDITIONAL_NO_POSITION Position size is zero. Cannot determine conditional order's quantity
'11014': InvalidOrder, # TE_CONDITIONAL_CLOSE_POSITION_WRONG_SIDE Close position conditional order has the same side
'11015': InvalidOrder, # TE_CONDITIONAL_TRIGGERED_OR_CANCELED
'11016': BadRequest, # TE_ADL_NOT_TRADING_REQUESTED_ACCOUNT Request is routed to the wrong trading engine
'11017': ExchangeError, # TE_ADL_CANNOT_FIND_POSITION Cannot find requested position on current account
'11018': ExchangeError, # TE_NO_NEED_TO_SETTLE_FUNDING The current account does not need to pay a funding fee
'11019': ExchangeError, # TE_FUNDING_ALREADY_SETTLED The current account already pays the funding fee
'11020': ExchangeError, # TE_CANNOT_TRANSFER_OUT_DUE_TO_BONUS Withdraw to wallet needs to remove all remaining bonus. However if bonus is used by position or order cost, withdraw fails.
'11021': ExchangeError, # TE_INVALID_BONOUS_AMOUNT # Grpc command cannot be negative number Invalid bonus amount
'11022': AccountSuspended, # TE_REJECT_DUE_TO_BANNED Account is banned
'11023': ExchangeError, # TE_REJECT_DUE_TO_IN_PROCESS_OF_LIQ Account is in the process of liquidation
'11024': ExchangeError, # TE_REJECT_DUE_TO_IN_PROCESS_OF_ADL Account is in the process of auto-deleverage
'11025': BadRequest, # TE_ROUTE_ERROR Request is routed to the wrong trading engine
'11026': ExchangeError, # TE_UID_ACCOUNT_MISMATCH
'11027': BadSymbol, # TE_SYMBOL_INVALID Invalid number ID or name
'11028': BadSymbol, # TE_CURRENCY_INVALID Invalid currency ID or name
'11029': ExchangeError, # TE_ACTION_INVALID Unrecognized request type
'11030': ExchangeError, # TE_ACTION_BY_INVALID
'11031': DDoSProtection, # TE_SO_NUM_EXCEEDS Number of total conditional orders exceeds the max limit
'11032': DDoSProtection, # TE_AO_NUM_EXCEEDS Number of total active orders exceeds the max limit
'11033': DuplicateOrderId, # TE_ORDER_ID_DUPLICATE Duplicated order ID
'11034': InvalidOrder, # TE_SIDE_INVALID Invalid side
'11035': InvalidOrder, # TE_ORD_TYPE_INVALID Invalid OrderType
'11036': InvalidOrder, # TE_TIME_IN_FORCE_INVALID Invalid TimeInForce
'11037': InvalidOrder, # TE_EXEC_INST_INVALID Invalid ExecType
'11038': InvalidOrder, # TE_TRIGGER_INVALID Invalid trigger type
'11039': InvalidOrder, # TE_STOP_DIRECTION_INVALID Invalid stop direction type
'11040': InvalidOrder, # TE_NO_MARK_PRICE Cannot get valid mark price to create conditional order
'11041': InvalidOrder, # TE_NO_INDEX_PRICE Cannot get valid index price to create conditional order
'11042': InvalidOrder, # TE_NO_LAST_PRICE Cannot get valid last market price to create conditional order
'11043': InvalidOrder, # TE_RISING_TRIGGER_DIRECTLY Conditional order would be triggered immediately
'11044': InvalidOrder, # TE_FALLING_TRIGGER_DIRECTLY Conditional order would be triggered immediately
'11045': InvalidOrder, # TE_TRIGGER_PRICE_TOO_LARGE Conditional order trigger price is too high
'11046': InvalidOrder, # TE_TRIGGER_PRICE_TOO_SMALL Conditional order trigger price is too low
'11047': InvalidOrder, # TE_BUY_TP_SHOULD_GT_BASE TakeProfile BUY conditional order trigger price needs to be greater than reference price
'11048': InvalidOrder, # TE_BUY_SL_SHOULD_LT_BASE StopLoss BUY condition order price needs to be less than the reference price
'11049': InvalidOrder, # TE_BUY_SL_SHOULD_GT_LIQ StopLoss BUY condition order price needs to be greater than liquidation price or it will not trigger
'11050': InvalidOrder, # TE_SELL_TP_SHOULD_LT_BASE TakeProfile SELL conditional order trigger price needs to be less than reference price
'11051': InvalidOrder, # TE_SELL_SL_SHOULD_LT_LIQ StopLoss SELL condition order price needs to be less than liquidation price or it will not trigger
'11052': InvalidOrder, # TE_SELL_SL_SHOULD_GT_BASE StopLoss SELL condition order price needs to be greater than the reference price
'11053': InvalidOrder, # TE_PRICE_TOO_LARGE
'11054': InvalidOrder, # TE_PRICE_WORSE_THAN_BANKRUPT Order price cannot be more aggressive than bankrupt price if self order has instruction to close a position
'11055': InvalidOrder, # TE_PRICE_TOO_SMALL Order price is too low
'11056': InvalidOrder, # TE_QTY_TOO_LARGE Order quantity is too large
'11057': InvalidOrder, # TE_QTY_NOT_MATCH_REDUCE_ONLY Does not allow ReduceOnly order without position
'11058': InvalidOrder, # TE_QTY_TOO_SMALL Order quantity is too small
'11059': InvalidOrder, # TE_TP_SL_QTY_NOT_MATCH_POS Position size is zero. Cannot accept any TakeProfit or StopLoss order
'11060': InvalidOrder, # TE_SIDE_NOT_CLOSE_POS TakeProfit or StopLoss order has wrong side. Cannot close position
'11061': CancelPending, # TE_ORD_ALREADY_PENDING_CANCEL Repeated cancel request
'11062': InvalidOrder, # TE_ORD_ALREADY_CANCELED Order is already canceled
'11063': InvalidOrder, # TE_ORD_STATUS_CANNOT_CANCEL Order is not able to be canceled under current status
'11064': InvalidOrder, # TE_ORD_ALREADY_PENDING_REPLACE Replace request is rejected because order is already in pending replace status
'11065': InvalidOrder, # TE_ORD_REPLACE_NOT_MODIFIED Replace request does not modify any parameters of the order
'11066': InvalidOrder, # TE_ORD_STATUS_CANNOT_REPLACE Order is not able to be replaced under current status
'11067': InvalidOrder, # TE_CANNOT_REPLACE_PRICE Market conditional order cannot change price
'11068': InvalidOrder, # TE_CANNOT_REPLACE_QTY Condtional order for closing position cannot change order quantity, since the order quantity is determined by position size already
'11069': ExchangeError, # TE_ACCOUNT_NOT_IN_RANGE The account ID in the request is not valid or is not in the range of the current process
'11070': BadSymbol, # TE_SYMBOL_NOT_IN_RANGE The symbol is invalid
'11071': InvalidOrder, # TE_ORD_STATUS_CANNOT_TRIGGER
'11072': InvalidOrder, # TE_TKFR_NOT_IN_RANGE The fee value is not valid
'11073': InvalidOrder, # TE_MKFR_NOT_IN_RANGE The fee value is not valid
'11074': InvalidOrder, # TE_CANNOT_ATTACH_TP_SL Order request cannot contain TP/SL parameters when the account already has positions
'11075': InvalidOrder, # TE_TP_TOO_LARGE TakeProfit price is too large
'11076': InvalidOrder, # TE_TP_TOO_SMALL TakeProfit price is too small
'11077': InvalidOrder, # TE_TP_TRIGGER_INVALID Invalid trigger type
'11078': InvalidOrder, # TE_SL_TOO_LARGE StopLoss price is too large
'11079': InvalidOrder, # TE_SL_TOO_SMALL StopLoss price is too small
'11080': InvalidOrder, # TE_SL_TRIGGER_INVALID Invalid trigger type
'11081': InvalidOrder, # TE_RISK_LIMIT_EXCEEDS Total potential position breaches current risk limit
'11082': InsufficientFunds, # TE_CANNOT_COVER_ESTIMATE_ORDER_LOSS The remaining balance cannot cover the potential unrealized PnL for self new order
'11083': InvalidOrder, # TE_TAKE_PROFIT_ORDER_DUPLICATED TakeProfit order already exists
'11084': InvalidOrder, # TE_STOP_LOSS_ORDER_DUPLICATED StopLoss order already exists
'11085': DuplicateOrderId, # TE_CL_ORD_ID_DUPLICATE ClOrdId is duplicated
'11086': InvalidOrder, # TE_PEG_PRICE_TYPE_INVALID PegPriceType is invalid
'11087': InvalidOrder, # TE_BUY_TS_SHOULD_LT_BASE The trailing order's StopPrice should be less than the current last price
'11088': InvalidOrder, # TE_BUY_TS_SHOULD_GT_LIQ The traling order's StopPrice should be greater than the current liquidation price
'11089': InvalidOrder, # TE_SELL_TS_SHOULD_LT_LIQ The traling order's StopPrice should be greater than the current last price
'11090': InvalidOrder, # TE_SELL_TS_SHOULD_GT_BASE The traling order's StopPrice should be less than the current liquidation price
'11091': InvalidOrder, # TE_BUY_REVERT_VALUE_SHOULD_LT_ZERO The PegOffset should be less than zero
'11092': InvalidOrder, # TE_SELL_REVERT_VALUE_SHOULD_GT_ZERO The PegOffset should be greater than zero
'11093': InvalidOrder, # TE_BUY_TTP_SHOULD_ACTIVATE_ABOVE_BASE The activation price should be greater than the current last price
'11094': InvalidOrder, # TE_SELL_TTP_SHOULD_ACTIVATE_BELOW_BASE The activation price should be less than the current last price
'11095': InvalidOrder, # TE_TRAILING_ORDER_DUPLICATED A trailing order exists already
'11096': InvalidOrder, # TE_CLOSE_ORDER_CANNOT_ATTACH_TP_SL An order to close position cannot have trailing instruction
'11097': BadRequest, # TE_CANNOT_FIND_WALLET_OF_THIS_CURRENCY This crypto is not supported
'11098': BadRequest, # TE_WALLET_INVALID_ACTION Invalid action on wallet
'11099': ExchangeError, # TE_WALLET_VID_UNMATCHED Wallet operation request has a wrong wallet vid
'11100': InsufficientFunds, # TE_WALLET_INSUFFICIENT_BALANCE Wallet has insufficient balance
'11101': InsufficientFunds, # TE_WALLET_INSUFFICIENT_LOCKED_BALANCE Locked balance in wallet is not enough for unlock/withdraw request
'11102': BadRequest, # TE_WALLET_INVALID_DEPOSIT_AMOUNT Deposit amount must be greater than zero
'11103': BadRequest, # TE_WALLET_INVALID_WITHDRAW_AMOUNT Withdraw amount must be less than zero
'11104': BadRequest, # TE_WALLET_REACHED_MAX_AMOUNT Deposit makes wallet exceed max amount allowed
'11105': InsufficientFunds, # TE_PLACE_ORDER_INSUFFICIENT_BASE_BALANCE Insufficient funds in base wallet
'11106': InsufficientFunds, # TE_PLACE_ORDER_INSUFFICIENT_QUOTE_BALANCE Insufficient funds in quote wallet
'11107': ExchangeError, # TE_CANNOT_CONNECT_TO_REQUEST_SEQ TradingEngine failed to connect with CrossEngine
'11108': InvalidOrder, # TE_CANNOT_REPLACE_OR_CANCEL_MARKET_ORDER Cannot replace/amend market order
'11109': InvalidOrder, # TE_CANNOT_REPLACE_OR_CANCEL_IOC_ORDER Cannot replace/amend ImmediateOrCancel order
'11110': InvalidOrder, # TE_CANNOT_REPLACE_OR_CANCEL_FOK_ORDER Cannot replace/amend FillOrKill order
'11111': InvalidOrder, # TE_MISSING_ORDER_ID OrderId is missing
'11112': InvalidOrder, # TE_QTY_TYPE_INVALID QtyType is invalid
'11113': BadRequest, # TE_USER_ID_INVALID UserId is invalid
'11114': InvalidOrder, # TE_ORDER_VALUE_TOO_LARGE Order value is too large
'11115': InvalidOrder, # TE_ORDER_VALUE_TOO_SMALL Order value is too small
'11116': InvalidOrder, # TE_BO_NUM_EXCEEDS Details: the total count of brakcet orders should equal or less than 5
'11117': InvalidOrder, # TE_BO_CANNOT_HAVE_BO_WITH_DIFF_SIDE Details: all bracket orders should have the same Side.
'11118': InvalidOrder, # TE_BO_TP_PRICE_INVALID Details: bracker order take profit price is invalid
'11119': InvalidOrder, # TE_BO_SL_PRICE_INVALID Details: bracker order stop loss price is invalid
'11120': InvalidOrder, # TE_BO_SL_TRIGGER_PRICE_INVALID Details: bracker order stop loss trigger price is invalid
'11121': InvalidOrder, # TE_BO_CANNOT_REPLACE Details: cannot replace bracket order.
'11122': InvalidOrder, # TE_BO_BOTP_STATUS_INVALID Details: bracket take profit order status is invalid
'11123': InvalidOrder, # TE_BO_CANNOT_PLACE_BOTP_OR_BOSL_ORDER Details: cannot place bracket take profit order
'11124': InvalidOrder, # TE_BO_CANNOT_REPLACE_BOTP_OR_BOSL_ORDER Details: cannot place bracket stop loss order
'11125': InvalidOrder, # TE_BO_CANNOT_CANCEL_BOTP_OR_BOSL_ORDER Details: cannot cancel bracket sl/tp order
'11126': InvalidOrder, # TE_BO_DONOT_SUPPORT_API Details: doesn't support bracket order via API
'11128': InvalidOrder, # TE_BO_INVALID_EXECINST Details: ExecInst value is invalid
'11129': InvalidOrder, # TE_BO_MUST_BE_SAME_SIDE_AS_POS Details: bracket order should have the same side's side
'11130': InvalidOrder, # TE_BO_WRONG_SL_TRIGGER_TYPE Details: bracket stop loss order trigger type is invalid
'11131': InvalidOrder, # TE_BO_WRONG_TP_TRIGGER_TYPE Details: bracket take profit order trigger type is invalid
'11132': InvalidOrder, # TE_BO_ABORT_BOSL_DUE_BOTP_CREATE_FAILED Details: cancel bracket stop loss order due failed to create take profit order.
'11133': InvalidOrder, # TE_BO_ABORT_BOSL_DUE_BOPO_CANCELED Details: cancel bracket stop loss order due main order canceled.
'11134': InvalidOrder, # TE_BO_ABORT_BOTP_DUE_BOPO_CANCELED Details: cancel bracket take profit order due main order canceled.
# not documented
'30000': BadRequest, # {"code":30000,"msg":"Please double check input arguments","data":null}
'30018': BadRequest, # {"code":30018,"msg":"phemex.data.size.uplimt","data":null}
'34003': PermissionDenied, # {"code":34003,"msg":"Access forbidden","data":null}
'35104': InsufficientFunds, # {"code":35104,"msg":"phemex.spot.wallet.balance.notenough","data":null}
'39995': RateLimitExceeded, # {"code": "39995","msg": "Too many requests."}
'39996': PermissionDenied, # {"code": "39996","msg": "Access denied."}
},
'broad': {
'401 Insufficient privilege': PermissionDenied, # {"code": "401","msg": "401 Insufficient privilege."}
'401 Request IP mismatch': PermissionDenied, # {"code": "401","msg": "401 Request IP mismatch."}
'Failed to find api-key': AuthenticationError, # {"msg":"Failed to find api-key 1c5ec63fd-660d-43ea-847a-0d3ba69e106e","code":10500}
'Missing required parameter': BadRequest, # {"msg":"Missing required parameter","code":10500}
'API Signature verification failed': AuthenticationError, # {"msg":"API Signature verification failed.","code":10500}
'Api key not found': AuthenticationError, # {"msg":"Api key not found 698dc9e3-6faa-4910-9476-12857e79e198","code":"10500"}
},
},
'options': {
'brokerId': 'ccxt2022',
'x-phemex-request-expiry': 60, # in seconds
'createOrderByQuoteRequiresPrice': True,
'networks': {
'TRC20': 'TRX',
'ERC20': 'ETH',
},
'defaultNetworks': {
'USDT': 'ETH',
},
'defaultSubType': 'linear',
'accountsByType': {
'spot': 'spot',
'swap': 'future',
},
'transfer': {
'fillResponseFromRequest': True,
},
},
})
def parse_safe_number(self, value=None):
if value is None:
return value
parts = value.split(',')
value = ''.join(parts)
parts = value.split(' ')
return self.safe_number(parts, 0)
def parse_swap_market(self, market):
#
# {
# "symbol":"BTCUSD",
# "displaySymbol":"BTC / USD",
# "indexSymbol":".BTC",
# "markSymbol":".MBTC",
# "fundingRateSymbol":".BTCFR",
# "fundingRate8hSymbol":".BTCFR8H",
# "contractUnderlyingAssets":"USD",
# "settleCurrency":"BTC",
# "quoteCurrency":"USD",
# "contractSize":"1 USD",
# "lotSize":1,
# "tickSize":0.5,
# "priceScale":4,
# "ratioScale":8,
# "pricePrecision":1,
# "minPriceEp":5000,
# "maxPriceEp":10000000000,
# "maxOrderQty":1000000,
# "type":"Perpetual",
# "status":"Listed",
# "tipOrderQty":1000000,
# "steps":"50",
# "riskLimits":[
# {"limit":100,"initialMargin":"1.0%","initialMarginEr":1000000,"maintenanceMargin":"0.5%","maintenanceMarginEr":500000},
# {"limit":150,"initialMargin":"1.5%","initialMarginEr":1500000,"maintenanceMargin":"1.0%","maintenanceMarginEr":1000000},
# {"limit":200,"initialMargin":"2.0%","initialMarginEr":2000000,"maintenanceMargin":"1.5%","maintenanceMarginEr":1500000},
# ],
# "underlyingSymbol":".BTC",
# "baseCurrency":"BTC",
# "settlementCurrency":"BTC",
# "valueScale":8,
# "defaultLeverage":0,
# "maxLeverage":100,
# "initMarginEr":"1000000",
# "maintMarginEr":"500000",
# "defaultRiskLimitEv":10000000000,
# "deleverage":true,
# "makerFeeRateEr":-250000,
# "takerFeeRateEr":750000,
# "fundingInterval":8,
# "marketUrl":"https://phemex.com/trade/BTCUSD",
# "description":"BTCUSD is a BTC/USD perpetual contract priced on the .BTC Index. Each contract is worth 1 USD of Bitcoin. Funding is paid and received every 8 hours. At UTC time: 00:00, 08:00, 16:00.",
# }
#
id = self.safe_string(market, 'symbol')
baseId = self.safe_string_2(market, 'baseCurrency', 'contractUnderlyingAssets')
quoteId = self.safe_string(market, 'quoteCurrency')
settleId = self.safe_string(market, 'settleCurrency')
base = self.safe_currency_code(baseId)
quote = self.safe_currency_code(quoteId)
settle = self.safe_currency_code(settleId)
inverse = False
if settleId != quoteId:
inverse = True
priceScale = self.safe_integer(market, 'priceScale')
ratioScale = self.safe_integer(market, 'ratioScale')
valueScale = self.safe_integer(market, 'valueScale')
minPriceEp = self.safe_string(market, 'minPriceEp')
maxPriceEp = self.safe_string(market, 'maxPriceEp')
makerFeeRateEr = self.safe_string(market, 'makerFeeRateEr')
takerFeeRateEr = self.safe_string(market, 'takerFeeRateEr')
status = self.safe_string(market, 'status')
contractSizeString = self.safe_string(market, 'contractSize', ' ')
contractSize = None
if settle == 'USDT':
contractSize = 1
elif contractSizeString.find(' '):
# "1 USD"
# "0.005 ETH"
parts = contractSizeString.split(' ')
contractSize = self.parse_number(parts[0])
else:
# "1.0"
contractSize = self.parse_number(contractSizeString)
return {
'id': id,
'symbol': base + '/' + quote + ':' + settle,
'base': base,
'quote': quote,
'settle': settle,
'baseId': baseId,
'quoteId': quoteId,
'settleId': settleId,
'type': 'swap',
'spot': False,
'margin': False,
'swap': True,
'future': False,
'option': False,
'active': status == 'Listed',
'contract': True,
'linear': not inverse,
'inverse': inverse,
'taker': self.parse_number(self.from_en(takerFeeRateEr, ratioScale)),
'maker': self.parse_number(self.from_en(makerFeeRateEr, ratioScale)),
'contractSize': contractSize,
'expiry': None,
'expiryDatetime': None,
'strike': None,
'optionType': None,
'priceScale': priceScale,
'valueScale': valueScale,
'ratioScale': ratioScale,
'precision': {
'amount': self.safe_number_2(market, 'lotSize', 'qtyStepSize'),
'price': self.safe_number(market, 'tickSize'),
},
'limits': {
'leverage': {
'min': self.parse_number('1'),
'max': self.safe_number(market, 'maxLeverage'),
},
'amount': {
'min': None,
'max': None,
},
'price': {
'min': self.parse_number(self.from_en(minPriceEp, priceScale)),
'max': self.parse_number(self.from_en(maxPriceEp, priceScale)),
},
'cost': {
'min': None,
'max': self.parse_number(self.safe_string(market, 'maxOrderQty')),
},
},
'info': market,
}
def parse_spot_market(self, market):
#
# {
# "symbol":"sBTCUSDT",
# "code":1001,
# "displaySymbol":"BTC / USDT",
# "quoteCurrency":"USDT",
# "priceScale":8,
# "ratioScale":8,
# "pricePrecision":2,
# "type":"Spot",
# "baseCurrency":"BTC",
# "baseTickSize":"0.000001 BTC",
# "baseTickSizeEv":100,
# "quoteTickSize":"0.01 USDT",
# "quoteTickSizeEv":1000000,
# "minOrderValue":"10 USDT",
# "minOrderValueEv":1000000000,
# "maxBaseOrderSize":"1000 BTC",
# "maxBaseOrderSizeEv":100000000000,
# "maxOrderValue":"5,000,000 USDT",
# "maxOrderValueEv":500000000000000,
# "defaultTakerFee":"0.001",
# "defaultTakerFeeEr":100000,
# "defaultMakerFee":"0.001",
# "defaultMakerFeeEr":100000,
# "baseQtyPrecision":6,
# "quoteQtyPrecision":2,
# "status":"Listed",
# "tipOrderQty":2,
# "description":"BTCUSDT is a BTC/USDT spot trading pair. Minimum order value is 1 USDT",
# "leverage":5
# "valueScale":8,
# },
#
type = self.safe_string_lower(market, 'type')
id = self.safe_string(market, 'symbol')
quoteId = self.safe_string(market, 'quoteCurrency')
baseId = self.safe_string(market, 'baseCurrency')
base = self.safe_currency_code(baseId)
quote = self.safe_currency_code(quoteId)
status = self.safe_string(market, 'status')
precisionAmount = self.parse_safe_number(self.safe_string(market, 'baseTickSize'))
precisionPrice = self.parse_safe_number(self.safe_string(market, 'quoteTickSize'))
return {
'id': id,
'symbol': base + '/' + quote,
'base': base,
'quote': quote,
'settle': None,
'baseId': baseId,
'quoteId': quoteId,
'settleId': None,
'type': type,
'spot': True,
'margin': False,
'swap': False,
'future': False,
'option': False,
'active': status == 'Listed',
'contract': False,
'linear': None,
'inverse': None,
'taker': self.safe_number(market, 'defaultTakerFee'),
'maker': self.safe_number(market, 'defaultMakerFee'),
'contractSize': None,
'expiry': None,
'expiryDatetime': None,
'strike': None,
'optionType': None,
'priceScale': self.safe_integer(market, 'priceScale'),
'valueScale': self.safe_integer(market, 'valueScale'),
'ratioScale': self.safe_integer(market, 'ratioScale'),
'precision': {
'amount': precisionAmount,
'price': precisionPrice,
},
'limits': {
'leverage': {
'min': None,
'max': None,
},
'amount': {
'min': precisionAmount,
'max': self.parse_safe_number(self.safe_string(market, 'maxBaseOrderSize')),
},
'price': {
'min': precisionPrice,
'max': None,
},
'cost': {
'min': self.parse_safe_number(self.safe_string(market, 'minOrderValue')),
'max': self.parse_safe_number(self.safe_string(market, 'maxOrderValue')),
},
},
'info': market,
}
async def fetch_markets(self, params={}):
"""
retrieves data on all markets for phemex
:param dict [params]: extra parameters specific to the exchange api endpoint
:returns dict[]: an array of objects representing market data
"""
v2Products = await self.publicGetCfgV2Products(params)
#
# {
# "code":0,
# "msg":"OK",
# "data":{
# "ratioScale":8,
# "currencies":[
# {"code":1,"currency":"BTC","valueScale":8,"minValueEv":1,"maxValueEv":5000000000000000000,"name":"Bitcoin"},
# {"code":2,"currency":"USD","valueScale":4,"minValueEv":1,"maxValueEv":500000000000000,"name":"USD"},
# {"code":3,"currency":"USDT","valueScale":8,"minValueEv":1,"maxValueEv":5000000000000000000,"name":"TetherUS"},
# ],
# "products":[
# {
# "symbol":"BTCUSD",
# "displaySymbol":"BTC / USD",
# "indexSymbol":".BTC",
# "markSymbol":".MBTC",
# "fundingRateSymbol":".BTCFR",
# "fundingRate8hSymbol":".BTCFR8H",
# "contractUnderlyingAssets":"USD",
# "settleCurrency":"BTC",
# "quoteCurrency":"USD",
# "contractSize":1.0,
# "lotSize":1,
# "tickSize":0.5,
# "priceScale":4,
# "ratioScale":8,
# "pricePrecision":1,
# "minPriceEp":5000,
# "maxPriceEp":10000000000,
# "maxOrderQty":1000000,
# "type":"Perpetual"
# },
# {
# "symbol":"sBTCUSDT",
# "code":1001,
# "displaySymbol":"BTC / USDT",
# "quoteCurrency":"USDT",
# "priceScale":8,
# "ratioScale":8,
# "pricePrecision":2,
# "type":"Spot",
# "baseCurrency":"BTC",
# "baseTickSize":"0.000001 BTC",
# "baseTickSizeEv":100,
# "quoteTickSize":"0.01 USDT",
# "quoteTickSizeEv":1000000,
# "minOrderValue":"10 USDT",
# "minOrderValueEv":1000000000,
# "maxBaseOrderSize":"1000 BTC",
# "maxBaseOrderSizeEv":100000000000,
# "maxOrderValue":"5,000,000 USDT",
# "maxOrderValueEv":500000000000000,
# "defaultTakerFee":"0.001",
# "defaultTakerFeeEr":100000,
# "defaultMakerFee":"0.001",
# "defaultMakerFeeEr":100000,
# "baseQtyPrecision":6,
# "quoteQtyPrecision":2,
# "status":"Listed",
# "tipOrderQty":2,
# "description":"BTCUSDT is a BTC/USDT spot trading pair. Minimum order value is 1 USDT",
# "leverage":5
# },
# ],
# "riskLimits":[
# {
# "symbol":"BTCUSD",
# "steps":"50",
# "riskLimits":[
# {"limit":100,"initialMargin":"1.0%","initialMarginEr":1000000,"maintenanceMargin":"0.5%","maintenanceMarginEr":500000},
# {"limit":150,"initialMargin":"1.5%","initialMarginEr":1500000,"maintenanceMargin":"1.0%","maintenanceMarginEr":1000000},
# {"limit":200,"initialMargin":"2.0%","initialMarginEr":2000000,"maintenanceMargin":"1.5%","maintenanceMarginEr":1500000},
# ]
# },
# ],
# "leverages":[
# {"initialMargin":"1.0%","initialMarginEr":1000000,"options":[1,2,3,5,10,25,50,100]},
# {"initialMargin":"1.5%","initialMarginEr":1500000,"options":[1,2,3,5,10,25,50,66]},
# {"initialMargin":"2.0%","initialMarginEr":2000000,"options":[1,2,3,5,10,25,33,50]},
# ]
# }
# }
#
v1Products = await self.v1GetExchangePublicProducts(params)
v1ProductsData = self.safe_value(v1Products, 'data', [])
#
# {
# "code":0,
# "msg":"OK",
# "data":[
# {
# "symbol":"BTCUSD",
# "underlyingSymbol":".BTC",
# "quoteCurrency":"USD",
# "baseCurrency":"BTC",
# "settlementCurrency":"BTC",
# "maxOrderQty":1000000,
# "maxPriceEp":100000000000000,
# "lotSize":1,
# "tickSize":"0.5",
# "contractSize":"1 USD",
# "priceScale":4,
# "ratioScale":8,
# "valueScale":8,
# "defaultLeverage":0,
# "maxLeverage":100,
# "initMarginEr":"1000000",
# "maintMarginEr":"500000",
# "defaultRiskLimitEv":10000000000,
# "deleverage":true,
# "makerFeeRateEr":-250000,
# "takerFeeRateEr":750000,
# "fundingInterval":8,
# "marketUrl":"https://phemex.com/trade/BTCUSD",
# "description":"BTCUSD is a BTC/USD perpetual contract priced on the .BTC Index. Each contract is worth 1 USD of Bitcoin. Funding is paid and received every 8 hours. At UTC time: 00:00, 08:00, 16:00.",
# "type":"Perpetual"
# },
# ]
# }
#
v2ProductsData = self.safe_value(v2Products, 'data', {})
products = self.safe_value(v2ProductsData, 'products', [])
riskLimits = self.safe_value(v2ProductsData, 'riskLimits', [])
currencies = self.safe_value(v2ProductsData, 'currencies', [])
riskLimitsById = self.index_by(riskLimits, 'symbol')
v1ProductsById = self.index_by(v1ProductsData, 'symbol')
currenciesByCode = self.index_by(currencies, 'currency')
result = []
for i in range(0, len(products)):
market = products[i]
type = self.safe_string_lower(market, 'type')
if (type == 'perpetual') or (type == 'perpetualv2'):
id = self.safe_string(market, 'symbol')
riskLimitValues = self.safe_value(riskLimitsById, id, {})
market = self.extend(market, riskLimitValues)
v1ProductsValues = self.safe_value(v1ProductsById, id, {})
market = self.extend(market, v1ProductsValues)
market = self.parse_swap_market(market)
else:
baseCurrency = self.safe_string(market, 'baseCurrency')
currencyValues = self.safe_value(currenciesByCode, baseCurrency, {})
valueScale = self.safe_string(currencyValues, 'valueScale', '8')
market = self.extend(market, {'valueScale': valueScale})
market = self.parse_spot_market(market)
result.append(market)
return result
async def fetch_currencies(self, params={}):
"""
fetches all available currencies on an exchange
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict: an associative dictionary of currencies
"""
response = await self.publicGetCfgV2Products(params)
#
# {
# "code":0,
# "msg":"OK",
# "data":{
# ...,
# "currencies":[
# {"currency":"BTC","valueScale":8,"minValueEv":1,"maxValueEv":5000000000000000000,"name":"Bitcoin"},
# {"currency":"USD","valueScale":4,"minValueEv":1,"maxValueEv":500000000000000,"name":"USD"},
# {"currency":"USDT","valueScale":8,"minValueEv":1,"maxValueEv":5000000000000000000,"name":"TetherUS"},
# ],
# ...
# }
# }
data = self.safe_value(response, 'data', {})
currencies = self.safe_value(data, 'currencies', [])
result = {}
for i in range(0, len(currencies)):
currency = currencies[i]
id = self.safe_string(currency, 'currency')
name = self.safe_string(currency, 'name')
code = self.safe_currency_code(id)
valueScaleString = self.safe_string(currency, 'valueScale')
valueScale = int(valueScaleString)
minValueEv = self.safe_string(currency, 'minValueEv')
maxValueEv = self.safe_string(currency, 'maxValueEv')
minAmount = None
maxAmount = None
precision = None
if valueScale is not None:
precisionString = self.parse_precision(valueScaleString)
precision = self.parse_number(precisionString)
minAmount = self.parse_number(Precise.string_mul(minValueEv, precisionString))
maxAmount = self.parse_number(Precise.string_mul(maxValueEv, precisionString))
result[code] = {
'id': id,
'info': currency,
'code': code,
'name': name,
'active': None,
'deposit': None,
'withdraw': None,
'fee': None,
'precision': precision,
'limits': {
'amount': {
'min': minAmount,
'max': maxAmount,
},
'withdraw': {
'min': None,
'max': None,
},
},
'valueScale': valueScale,
'networks': {},
}
return result
def custom_parse_bid_ask(self, bidask, priceKey=0, amountKey=1, market=None):
if market is None:
raise ArgumentsRequired(self.id + ' customParseBidAsk() requires a market argument')
amount = self.safe_string(bidask, amountKey)
if market['spot']:
amount = self.from_ev(amount, market)
return [
self.parse_number(self.from_ep(self.safe_string(bidask, priceKey), market)),
self.parse_number(amount),
]
def custom_parse_order_book(self, orderbook, symbol, timestamp=None, bidsKey='bids', asksKey='asks', priceKey=0, amountKey=1, market=None):
result = {
'symbol': symbol,
'timestamp': timestamp,
'datetime': self.iso8601(timestamp),
'nonce': None,
}
sides = [bidsKey, asksKey]
for i in range(0, len(sides)):
side = sides[i]
orders = []
bidasks = self.safe_value(orderbook, side)
for k in range(0, len(bidasks)):
orders.append(self.custom_parse_bid_ask(bidasks[k], priceKey, amountKey, market))
result[side] = orders
result[bidsKey] = self.sort_by(result[bidsKey], 0, True)
result[asksKey] = self.sort_by(result[asksKey], 0)
return result
async def fetch_order_book(self, symbol: str, limit: Optional[int] = None, params={}):
"""
fetches information on open orders with bid(buy) and ask(sell) prices, volumes and other data
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#queryorderbook
:param str symbol: unified symbol of the market to fetch the order book for
:param int [limit]: the maximum amount of order book entries to return
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict: A dictionary of `order book structures <https://github.com/ccxt/ccxt/wiki/Manual#order-book-structure>` indexed by market symbols
"""
await self.load_markets()
market = self.market(symbol)
request = {
'symbol': market['id'],
# 'id': 123456789, # optional request id
}
method = 'v1GetMdOrderbook'
if market['linear'] and market['settle'] == 'USDT':
method = 'v2GetMdV2Orderbook'
response = await getattr(self, method)(self.extend(request, params))
#
# {
# "error": null,
# "id": 0,
# "result": {
# "book": {
# "asks": [
# [23415000000, 105262000],
# [23416000000, 147914000],
# [23419000000, 160914000],
# ],
# "bids": [
# [23360000000, 32995000],
# [23359000000, 221887000],
# [23356000000, 284599000],
# ],
# },
# "depth": 30,
# "sequence": 1592059928,
# "symbol": "sETHUSDT",
# "timestamp": 1592387340020000955,
# "type": "snapshot"
# }
# }
#
result = self.safe_value(response, 'result', {})
book = self.safe_value_2(result, 'book', 'orderbook_p', {})
timestamp = self.safe_integer_product(result, 'timestamp', 0.000001)
orderbook = self.custom_parse_order_book(book, symbol, timestamp, 'bids', 'asks', 0, 1, market)
orderbook['nonce'] = self.safe_integer(result, 'sequence')
return orderbook
def to_en(self, n, scale):
stringN = str(n)
precise = Precise(stringN)
precise.decimals = precise.decimals - scale
precise.reduce()
preciseString = str(precise)
return self.parse_to_int(preciseString)
def to_ev(self, amount, market=None):
if (amount is None) or (market is None):
return amount
return self.to_en(amount, market['valueScale'])
def to_ep(self, price, market=None):
if (price is None) or (market is None):
return price
return self.to_en(price, market['priceScale'])
def from_en(self, en, scale):
if en is None:
return None
precise = Precise(en)
precise.decimals = self.sum(precise.decimals, scale)
precise.reduce()
return str(precise)
def from_ep(self, ep, market=None):
if (ep is None) or (market is None):
return ep
return self.from_en(ep, self.safe_integer(market, 'priceScale'))
def from_ev(self, ev, market=None):
if (ev is None) or (market is None):
return ev
return self.from_en(ev, self.safe_integer(market, 'valueScale'))
def from_er(self, er, market=None):
if (er is None) or (market is None):
return er
return self.from_en(er, self.safe_integer(market, 'ratioScale'))
def parse_ohlcv(self, ohlcv, market=None):
#
# [
# 1592467200, # timestamp
# 300, # interval
# 23376000000, # last
# 23322000000, # open
# 23381000000, # high
# 23315000000, # low
# 23367000000, # close
# 208671000, # base volume
# 48759063370, # quote volume
# ]
#
baseVolume = None
if (market is not None) and market['spot']:
baseVolume = self.parse_number(self.from_ev(self.safe_string(ohlcv, 7), market))
else:
baseVolume = self.safe_number(ohlcv, 7)
return [
self.safe_timestamp(ohlcv, 0),
self.parse_number(self.from_ep(self.safe_string(ohlcv, 3), market)),
self.parse_number(self.from_ep(self.safe_string(ohlcv, 4), market)),
self.parse_number(self.from_ep(self.safe_string(ohlcv, 5), market)),
self.parse_number(self.from_ep(self.safe_string(ohlcv, 6), market)),
baseVolume,
]
async def fetch_ohlcv(self, symbol: str, timeframe='1m', since: Optional[int] = None, limit: Optional[int] = None, params={}):
"""
fetches historical candlestick data containing the open, high, low, and close price, and the volume of a market
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#querykline
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Contract-API-en.md#query-kline
:param str symbol: unified symbol of the market to fetch OHLCV data for
:param str timeframe: the length of time each candle represents
:param int [since]: *emulated not supported by the exchange* timestamp in ms of the earliest candle to fetch
:param int [limit]: the maximum amount of candles to fetch
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns int[][]: A list of candles ordered, open, high, low, close, volume
"""
await self.load_markets()
market = self.market(symbol)
userLimit = limit
request = {
'symbol': market['id'],
'resolution': self.safe_string(self.timeframes, timeframe, timeframe),
}
possibleLimitValues = [5, 10, 50, 100, 500, 1000]
maxLimit = 1000
if limit is None and since is None:
limit = possibleLimitValues[5]
if since is not None:
# phemex also provides kline query with from/to, however, self interface is NOT recommended and does not work properly.
# we do not send since param to the exchange, instead we calculate appropriate limit param
duration = self.parse_timeframe(timeframe) * 1000
timeDelta = self.milliseconds() - since
limit = self.parse_to_int(timeDelta / duration) # setting limit to the number of candles after since
if limit > maxLimit:
limit = maxLimit
else:
for i in range(0, len(possibleLimitValues)):
if limit <= possibleLimitValues[i]:
limit = possibleLimitValues[i]
request['limit'] = limit
response = None
if market['linear'] or market['settle'] == 'USDT':
response = await self.publicGetMdV2KlineLast(self.extend(request, params))
else:
response = await self.publicGetMdV2Kline(self.extend(request, params))
#
# {
# "code":0,
# "msg":"OK",
# "data":{
# "total":-1,
# "rows":[
# [1592467200,300,23376000000,23322000000,23381000000,23315000000,23367000000,208671000,48759063370],
# [1592467500,300,23367000000,23314000000,23390000000,23311000000,23331000000,234820000,54848948710],
# [1592467800,300,23331000000,23385000000,23391000000,23326000000,23387000000,152931000,35747882250],
# ]
# }
# }
#
data = self.safe_value(response, 'data', {})
rows = self.safe_value(data, 'rows', [])
return self.parse_ohlcvs(rows, market, timeframe, since, userLimit)
def parse_ticker(self, ticker, market=None):
#
# spot
#
# {
# "askEp": 943836000000,
# "bidEp": 943601000000,
# "highEp": 955946000000,
# "lastEp": 943803000000,
# "lowEp": 924973000000,
# "openEp": 948693000000,
# "symbol": "sBTCUSDT",
# "timestamp": 1592471203505728630,
# "turnoverEv": 111822826123103,
# "volumeEv": 11880532281
# }
#
# swap
#
# {
# "askEp": 2332500,
# "bidEp": 2331000,
# "fundingRateEr": 10000,
# "highEp": 2380000,
# "indexEp": 2329057,
# "lastEp": 2331500,
# "lowEp": 2274000,
# "markEp": 2329232,
# "openEp": 2337500,
# "openInterest": 1298050,
# "predFundingRateEr": 19921,
# "symbol": "ETHUSD",
# "timestamp": 1592474241582701416,
# "turnoverEv": 47228362330,
# "volume": 4053863
# }
# linear swap v2
#
# {
# "closeRp":"16820.5",
# "fundingRateRr":"0.0001",
# "highRp":"16962.1",
# "indexPriceRp":"16830.15651565",
# "lowRp":"16785",
# "markPriceRp":"16830.97534951",
# "openInterestRv":"1323.596",
# "openRp":"16851.7",
# "predFundingRateRr":"0.0001",
# "symbol":"BTCUSDT",
# "timestamp":"1672142789065593096",
# "turnoverRv":"124835296.0538",
# "volumeRq":"7406.95"
# }
#
marketId = self.safe_string(ticker, 'symbol')
market = self.safe_market(marketId, market)
symbol = market['symbol']
timestamp = self.safe_integer_product(ticker, 'timestamp', 0.000001)
last = self.from_ep(self.safe_string_2(ticker, 'lastEp', 'closeRp'), market)
quoteVolume = self.from_er(self.safe_string_2(ticker, 'turnoverEv', 'turnoverRv'), market)
baseVolume = self.safe_string(ticker, 'volume')
if baseVolume is None:
baseVolume = self.from_ev(self.safe_string_2(ticker, 'volumeEv', 'volumeRq'), market)
open = self.from_ep(self.safe_string(ticker, 'openEp'), market)
return self.safe_ticker({
'symbol': symbol,
'timestamp': timestamp,
'datetime': self.iso8601(timestamp),
'high': self.from_ep(self.safe_string_2(ticker, 'highEp', 'highRp'), market),
'low': self.from_ep(self.safe_string_2(ticker, 'lowEp', 'lowRp'), market),
'bid': self.from_ep(self.safe_string(ticker, 'bidEp'), market),
'bidVolume': None,
'ask': self.from_ep(self.safe_string(ticker, 'askEp'), market),
'askVolume': None,
'vwap': None,
'open': open,
'close': last,
'last': last,
'previousClose': None, # previous day close
'change': None,
'percentage': None,
'average': None,
'baseVolume': baseVolume,
'quoteVolume': quoteVolume,
'info': ticker,
}, market)
async def fetch_ticker(self, symbol: str, params={}):
"""
fetches a price ticker, a statistical calculation with the information calculated over the past 24 hours for a specific market
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#query24hrsticker
:param str symbol: unified symbol of the market to fetch the ticker for
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict: a `ticker structure <https://github.com/ccxt/ccxt/wiki/Manual#ticker-structure>`
"""
await self.load_markets()
market = self.market(symbol)
request = {
'symbol': market['id'],
# 'id': 123456789, # optional request id
}
method = 'v1GetMdSpotTicker24hr'
if market['swap']:
if market['inverse'] or market['settle'] == 'USD':
method = 'v1GetMdTicker24hr'
else:
method = 'v2GetMdV2Ticker24hr'
response = await getattr(self, method)(self.extend(request, params))
#
# spot
#
# {
# "error": null,
# "id": 0,
# "result": {
# "askEp": 943836000000,
# "bidEp": 943601000000,
# "highEp": 955946000000,
# "lastEp": 943803000000,
# "lowEp": 924973000000,
# "openEp": 948693000000,
# "symbol": "sBTCUSDT",
# "timestamp": 1592471203505728630,
# "turnoverEv": 111822826123103,
# "volumeEv": 11880532281
# }
# }
#
# swap
#
# {
# "error": null,
# "id": 0,
# "result": {
# "askEp": 2332500,
# "bidEp": 2331000,
# "fundingRateEr": 10000,
# "highEp": 2380000,
# "indexEp": 2329057,
# "lastEp": 2331500,
# "lowEp": 2274000,
# "markEp": 2329232,
# "openEp": 2337500,
# "openInterest": 1298050,
# "predFundingRateEr": 19921,
# "symbol": "ETHUSD",
# "timestamp": 1592474241582701416,
# "turnoverEv": 47228362330,
# "volume": 4053863
# }
# }
#
result = self.safe_value(response, 'result', {})
return self.parse_ticker(result, market)
async def fetch_tickers(self, symbols: Optional[List[str]] = None, params={}):
"""
fetches price tickers for multiple markets, statistical calculations with the information calculated over the past 24 hours each market
see https://phemex-docs.github.io/#query-24-hours-ticker-for-all-symbols-2 # spot
see https://phemex-docs.github.io/#query-24-ticker-for-all-symbols # linear
see https://phemex-docs.github.io/#query-24-hours-ticker-for-all-symbols # inverse
:param str[]|None symbols: unified symbols of the markets to fetch the ticker for, all market tickers are returned if not assigned
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict: a dictionary of `ticker structures <https://github.com/ccxt/ccxt/wiki/Manual#ticker-structure>`
"""
await self.load_markets()
market = None
if symbols is not None:
first = self.safe_value(symbols, 0)
market = self.market(first)
type = None
type, params = self.handle_market_type_and_params('fetchTickers', market, params)
subType = None
subType, params = self.handle_sub_type_and_params('fetchTickers', market, params)
query = self.omit(params, 'type')
defaultMethod = None
if type == 'spot':
defaultMethod = 'v1GetMdSpotTicker24hrAll'
elif subType == 'inverse':
defaultMethod = 'v1GetMdTicker24hrAll'
else:
defaultMethod = 'v2GetMdV2Ticker24hrAll'
method = self.safe_string(self.options, 'fetchTickersMethod', defaultMethod)
response = await getattr(self, method)(query)
result = self.safe_value(response, 'result', [])
return self.parse_tickers(result, symbols)
async def fetch_trades(self, symbol: str, since: Optional[int] = None, limit: Optional[int] = None, params={}):
"""
get the list of most recent trades for a particular symbol
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#querytrades
:param str symbol: unified symbol of the market to fetch trades for
:param int [since]: timestamp in ms of the earliest trade to fetch
:param int [limit]: the maximum amount of trades to fetch
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns Trade[]: a list of `trade structures <https://docs.ccxt.com/en/latest/manual.html?#public-trades>`
"""
await self.load_markets()
market = self.market(symbol)
request = {
'symbol': market['id'],
# 'id': 123456789, # optional request id
}
method = 'v1GetMdTrade'
if market['linear'] and market['settle'] == 'USDT':
method = 'v2GetMdV2Trade'
response = await getattr(self, method)(self.extend(request, params))
#
# {
# "error": null,
# "id": 0,
# "result": {
# "sequence": 1315644947,
# "symbol": "BTCUSD",
# "trades": [
# [1592541746712239749, 13156448570000, "Buy", 93070000, 40173],
# [1592541740434625085, 13156447110000, "Sell", 93065000, 5000],
# [1592541732958241616, 13156441390000, "Buy", 93070000, 3460],
# ],
# "type": "snapshot"
# }
# }
#
result = self.safe_value(response, 'result', {})
trades = self.safe_value_2(result, 'trades', 'trades_p', [])
return self.parse_trades(trades, market, since, limit)
def parse_trade(self, trade, market=None):
#
# fetchTrades(public) spot & contract
#
# [
# 1592541746712239749,
# 13156448570000,
# "Buy",
# 93070000,
# 40173
# ]
#
# fetchTrades(public) perp
#
# [
# 1675690986063435800,
# "Sell",
# "22857.4",
# "0.269"
# ]
#
# fetchMyTrades(private)
#
# spot
#
# {
# "qtyType": "ByQuote",
# "transactTimeNs": 1589450974800550100,
# "clOrdID": "8ba59d40-df25-d4b0-14cf-0703f44e9690",
# "orderID": "b2b7018d-f02f-4c59-b4cf-051b9c2d2e83",
# "symbol": "sBTCUSDT",
# "side": "Buy",
# "priceEP": 970056000000,
# "baseQtyEv": 0,
# "quoteQtyEv": 1000000000,
# "action": "New",
# "execStatus": "MakerFill",
# "ordStatus": "Filled",
# "ordType": "Limit",
# "execInst": "None",
# "timeInForce": "GoodTillCancel",
# "stopDirection": "UNSPECIFIED",
# "tradeType": "Trade",
# "stopPxEp": 0,
# "execId": "c6bd8979-07ba-5946-b07e-f8b65135dbb1",
# "execPriceEp": 970056000000,
# "execBaseQtyEv": 103000,
# "execQuoteQtyEv": 999157680,
# "leavesBaseQtyEv": 0,
# "leavesQuoteQtyEv": 0,
# "execFeeEv": 0,
# "feeRateEr": 0
# "baseCurrency": 'BTC',
# "quoteCurrency": 'USDT',
# "feeCurrency": 'BTC'
# }
#
# swap
#
# {
# "transactTimeNs": 1578026629824704800,
# "symbol": "BTCUSD",
# "currency": "BTC",
# "action": "Replace",
# "side": "Sell",
# "tradeType": "Trade",
# "execQty": 700,
# "execPriceEp": 71500000,
# "orderQty": 700,
# "priceEp": 71500000,
# "execValueEv": 9790209,
# "feeRateEr": -25000,
# "execFeeEv": -2447,
# "ordType": "Limit",
# "execID": "b01671a1-5ddc-5def-b80a-5311522fd4bf",
# "orderID": "b63bc982-be3a-45e0-8974-43d6375fb626",
# "clOrdID": "uuid-1577463487504",
# "execStatus": "MakerFill"
# }
# perpetual
# {
# "accountID": 9328670003,
# "action": "New",
# "actionBy": "ByUser",
# "actionTimeNs": 1666858780876924611,
# "addedSeq": 77751555,
# "apRp": "0",
# "bonusChangedAmountRv": "0",
# "bpRp": "0",
# "clOrdID": "c0327a7d-9064-62a9-28f6-2db9aaaa04e0",
# "closedPnlRv": "0",
# "closedSize": "0",
# "code": 0,
# "cumFeeRv": "0",
# "cumQty": "0",
# "cumValueRv": "0",
# "curAccBalanceRv": "1508.489893982237",
# "curAssignedPosBalanceRv": "24.62786650928",
# "curBonusBalanceRv": "0",
# "curLeverageRr": "-10",
# "curPosSide": "Buy",
# "curPosSize": "0.043",
# "curPosTerm": 1,
# "curPosValueRv": "894.0689",
# "curRiskLimitRv": "1000000",
# "currency": "USDT",
# "cxlRejReason": 0,
# "displayQty": "0.003",
# "execFeeRv": "0",
# "execID": "00000000-0000-0000-0000-000000000000",
# "execPriceRp": "20723.7",
# "execQty": "0",
# "execSeq": 77751555,
# "execStatus": "New",
# "execValueRv": "0",
# "feeRateRr": "0",
# "leavesQty": "0.003",
# "leavesValueRv": "63.4503",
# "message": "No error",
# "ordStatus": "New",
# "ordType": "Market",
# "orderID": "fa64c6f2-47a4-4929-aab4-b7fa9bbc4323",
# "orderQty": "0.003",
# "pegOffsetValueRp": "0",
# "posSide": "Long",
# "priceRp": "21150.1",
# "relatedPosTerm": 1,
# "relatedReqNum": 11,
# "side": "Buy",
# "slTrigger": "ByMarkPrice",
# "stopLossRp": "0",
# "stopPxRp": "0",
# "symbol": "BTCUSDT",
# "takeProfitRp": "0",
# "timeInForce": "ImmediateOrCancel",
# "tpTrigger": "ByLastPrice",
# "tradeType": "Amend",
# "transactTimeNs": 1666858780881545305,
# "userID": 932867
# }
#
# swap - USDT
#
# {
# "createdAt": 1666226932259,
# "symbol": "ETHUSDT",
# "currency": "USDT",
# "action": 1,
# "tradeType": 1,
# "execQtyRq": "0.01",
# "execPriceRp": "1271.9",
# "side": 1,
# "orderQtyRq": "0.78",
# "priceRp": "1271.9",
# "execValueRv": "12.719",
# "feeRateRr": "0.0001",
# "execFeeRv": "0.0012719",
# "ordType": 2,
# "execId": "8718cae",
# "execStatus": 6
# }
#
priceString = None
amountString = None
timestamp = None
id = None
side = None
costString = None
type = None
fee = None
feeCostString = None
feeRateString = None
feeCurrencyCode = None
marketId = self.safe_string(trade, 'symbol')
market = self.safe_market(marketId, market)
symbol = market['symbol']
orderId = None
takerOrMaker = None
if isinstance(trade, list):
tradeLength = len(trade)
timestamp = self.safe_integer_product(trade, 0, 0.000001)
if tradeLength > 4:
id = self.safe_string(trade, tradeLength - 4)
side = self.safe_string_lower(trade, tradeLength - 3)
priceString = self.safe_string(trade, tradeLength - 2)
amountString = self.safe_string(trade, tradeLength - 1)
if isinstance(trade[tradeLength - 2], numbers.Real):
priceString = self.from_ep(priceString, market)
amountString = self.from_ev(amountString, market)
else:
timestamp = self.safe_integer_product(trade, 'transactTimeNs', 0.000001)
if timestamp is None:
timestamp = self.safe_integer(trade, 'createdAt')
id = self.safe_string_2(trade, 'execId', 'execID')
orderId = self.safe_string(trade, 'orderID')
if market['settle'] == 'USDT':
sideId = self.safe_string(trade, 'side')
side = 'buy' if (sideId == '1') else 'sell'
ordType = self.safe_string(trade, 'ordType')
if ordType == '1':
type = 'market'
elif ordType == '2':
type = 'limit'
priceString = self.safe_string(trade, 'priceRp')
amountString = self.safe_string(trade, 'execQtyRq')
costString = self.safe_string(trade, 'execValueRv')
feeCostString = self.safe_string(trade, 'execFeeRv')
feeRateString = self.safe_string(trade, 'feeRateRr')
currencyId = self.safe_string(trade, 'currency')
feeCurrencyCode = self.safe_currency_code(currencyId)
else:
side = self.safe_string_lower(trade, 'side')
type = self.parse_order_type(self.safe_string(trade, 'ordType'))
execStatus = self.safe_string(trade, 'execStatus')
if execStatus == 'MakerFill':
takerOrMaker = 'maker'
priceString = self.from_ep(self.safe_string(trade, 'execPriceEp'), market)
amountString = self.from_ev(self.safe_string(trade, 'execBaseQtyEv'), market)
amountString = self.safe_string(trade, 'execQty', amountString)
costString = self.from_er(self.safe_string_2(trade, 'execQuoteQtyEv', 'execValueEv'), market)
feeCostString = self.from_er(self.safe_string(trade, 'execFeeEv'), market)
if feeCostString is not None:
feeRateString = self.from_er(self.safe_string(trade, 'feeRateEr'), market)
if market['spot']:
feeCurrencyCode = self.safe_currency_code(self.safe_string(trade, 'feeCurrency'))
else:
info = self.safe_value(market, 'info')
if info is not None:
settlementCurrencyId = self.safe_string(info, 'settlementCurrency')
feeCurrencyCode = self.safe_currency_code(settlementCurrencyId)
fee = {
'cost': feeCostString,
'rate': feeRateString,
'currency': feeCurrencyCode,
}
return self.safe_trade({
'info': trade,
'id': id,
'symbol': symbol,
'timestamp': timestamp,
'datetime': self.iso8601(timestamp),
'order': orderId,
'type': type,
'side': side,
'takerOrMaker': takerOrMaker,
'price': priceString,
'amount': amountString,
'cost': costString,
'fee': fee,
}, market)
def parse_spot_balance(self, response):
#
# {
# "code":0,
# "msg":"",
# "data":[
# {
# "currency":"USDT",
# "balanceEv":0,
# "lockedTradingBalanceEv":0,
# "lockedWithdrawEv":0,
# "lastUpdateTimeNs":1592065834511322514,
# "walletVid":0
# },
# {
# "currency":"ETH",
# "balanceEv":0,
# "lockedTradingBalanceEv":0,
# "lockedWithdrawEv":0,
# "lastUpdateTimeNs":1592065834511322514,
# "walletVid":0
# }
# ]
# }
#
timestamp = None
result = {'info': response}
data = self.safe_value(response, 'data', [])
for i in range(0, len(data)):
balance = data[i]
currencyId = self.safe_string(balance, 'currency')
code = self.safe_currency_code(currencyId)
currency = self.safe_value(self.currencies, code, {})
scale = self.safe_integer(currency, 'valueScale', 8)
account = self.account()
balanceEv = self.safe_string(balance, 'balanceEv')
lockedTradingBalanceEv = self.safe_string(balance, 'lockedTradingBalanceEv')
lockedWithdrawEv = self.safe_string(balance, 'lockedWithdrawEv')
total = self.from_en(balanceEv, scale)
lockedTradingBalance = self.from_en(lockedTradingBalanceEv, scale)
lockedWithdraw = self.from_en(lockedWithdrawEv, scale)
used = Precise.string_add(lockedTradingBalance, lockedWithdraw)
lastUpdateTimeNs = self.safe_integer_product(balance, 'lastUpdateTimeNs', 0.000001)
timestamp = lastUpdateTimeNs if (timestamp is None) else max(timestamp, lastUpdateTimeNs)
account['total'] = total
account['used'] = used
result[code] = account
result['timestamp'] = timestamp
result['datetime'] = self.iso8601(timestamp)
return self.safe_balance(result)
def parse_swap_balance(self, response):
# usdt
# {
# info: {
# code: '0',
# msg: '',
# data: {
# account: {
# userID: '940666',
# accountId: '9406660003',
# currency: 'USDT',
# accountBalanceRv: '99.93143972',
# totalUsedBalanceRv: '0.40456',
# bonusBalanceRv: '0'
# },
# }
#
# {
# "code":0,
# "msg":"",
# "data":{
# "account":{
# "accountId":6192120001,
# "currency":"BTC",
# "accountBalanceEv":1254744,
# "totalUsedBalanceEv":0,
# "bonusBalanceEv":1254744
# }
# }
# }
#
result = {'info': response}
data = self.safe_value(response, 'data', {})
balance = self.safe_value(data, 'account', {})
currencyId = self.safe_string(balance, 'currency')
code = self.safe_currency_code(currencyId)
currency = self.currency(code)
valueScale = self.safe_integer(currency, 'valueScale', 8)
account = self.account()
accountBalanceEv = self.safe_string_2(balance, 'accountBalanceEv', 'accountBalanceRv')
totalUsedBalanceEv = self.safe_string_2(balance, 'totalUsedBalanceEv', 'totalUsedBalanceRv')
needsConversion = (code != 'USDT')
account['total'] = self.from_en(accountBalanceEv, valueScale) if needsConversion else accountBalanceEv
account['used'] = self.from_en(totalUsedBalanceEv, valueScale) if needsConversion else totalUsedBalanceEv
result[code] = account
return self.safe_balance(result)
async def fetch_balance(self, params={}):
"""
query for balance and get the amount of funds available for trading or funds locked in orders
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#query-account-positions
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict: a `balance structure <https://docs.ccxt.com/en/latest/manual.html?#balance-structure>`
"""
await self.load_markets()
type = None
type, params = self.handle_market_type_and_params('fetchBalance', None, params)
method = 'privateGetSpotWallets'
request = {}
if type == 'swap':
code = self.safe_string(params, 'code')
settle = None
settle, params = self.handle_option_and_params(params, 'fetchBalance', 'settle')
if code is not None or settle is not None:
coin = None
if code is not None:
coin = code
else:
coin = settle
currency = self.currency(coin)
request['currency'] = currency['id']
if currency['id'] == 'USDT':
method = 'privateGetGAccountsAccountPositions'
else:
method = 'privateGetAccountsAccountPositions'
else:
currency = self.safe_string(params, 'currency')
if currency is None:
raise ArgumentsRequired(self.id + ' fetchBalance() requires a code parameter or a currency or settle parameter for ' + type + ' type')
params = self.omit(params, ['type', 'code'])
response = await getattr(self, method)(self.extend(request, params))
#
# usdt
# {
# info: {
# code: '0',
# msg: '',
# data: {
# account: {
# userID: '940666',
# accountId: '9406660003',
# currency: 'USDT',
# accountBalanceRv: '99.93143972',
# totalUsedBalanceRv: '0.40456',
# bonusBalanceRv: '0'
# },
# }
#
# spot
#
# {
# "code":0,
# "msg":"",
# "data":[
# {
# "currency":"USDT",
# "balanceEv":0,
# "lockedTradingBalanceEv":0,
# "lockedWithdrawEv":0,
# "lastUpdateTimeNs":1592065834511322514,
# "walletVid":0
# },
# {
# "currency":"ETH",
# "balanceEv":0,
# "lockedTradingBalanceEv":0,
# "lockedWithdrawEv":0,
# "lastUpdateTimeNs":1592065834511322514,
# "walletVid":0
# }
# ]
# }
#
# swap
#
# {
# "code":0,
# "msg":"",
# "data":{
# "account":{
# "accountId":6192120001,
# "currency":"BTC",
# "accountBalanceEv":1254744,
# "totalUsedBalanceEv":0,
# "bonusBalanceEv":1254744
# },
# "positions":[
# {
# "accountID":6192120001,
# "symbol":"BTCUSD",
# "currency":"BTC",
# "side":"None",
# "positionStatus":"Normal",
# "crossMargin":false,
# "leverageEr":0,
# "leverage":0E-8,
# "initMarginReqEr":1000000,
# "initMarginReq":0.01000000,
# "maintMarginReqEr":500000,
# "maintMarginReq":0.00500000,
# "riskLimitEv":10000000000,
# "riskLimit":100.00000000,
# "size":0,
# "value":0E-8,
# "valueEv":0,
# "avgEntryPriceEp":0,
# "avgEntryPrice":0E-8,
# "posCostEv":0,
# "posCost":0E-8,
# "assignedPosBalanceEv":0,
# "assignedPosBalance":0E-8,
# "bankruptCommEv":0,
# "bankruptComm":0E-8,
# "bankruptPriceEp":0,
# "bankruptPrice":0E-8,
# "positionMarginEv":0,
# "positionMargin":0E-8,
# "liquidationPriceEp":0,
# "liquidationPrice":0E-8,
# "deleveragePercentileEr":0,
# "deleveragePercentile":0E-8,
# "buyValueToCostEr":1150750,
# "buyValueToCost":0.01150750,
# "sellValueToCostEr":1149250,
# "sellValueToCost":0.01149250,
# "markPriceEp":96359083,
# "markPrice":9635.90830000,
# "markValueEv":0,
# "markValue":null,
# "unRealisedPosLossEv":0,
# "unRealisedPosLoss":null,
# "estimatedOrdLossEv":0,
# "estimatedOrdLoss":0E-8,
# "usedBalanceEv":0,
# "usedBalance":0E-8,
# "takeProfitEp":0,
# "takeProfit":null,
# "stopLossEp":0,
# "stopLoss":null,
# "realisedPnlEv":0,
# "realisedPnl":null,
# "cumRealisedPnlEv":0,
# "cumRealisedPnl":null
# }
# ]
# }
# }
#
result = self.parse_swap_balance(response) if (type == 'swap') else self.parse_spot_balance(response)
return result
def parse_order_status(self, status):
statuses = {
'Created': 'open',
'Untriggered': 'open',
'Deactivated': 'closed',
'Triggered': 'open',
'Rejected': 'rejected',
'New': 'open',
'PartiallyFilled': 'open',
'Filled': 'closed',
'Canceled': 'canceled',
'1': 'open',
'5': 'open',
'6': 'open',
'7': 'closed',
'8': 'canceled',
}
return self.safe_string(statuses, status, status)
def parse_order_type(self, type):
types = {
'1': 'market',
'2': 'limit',
'3': 'stop',
'4': 'stopLimit',
'5': 'market',
'6': 'limit',
'7': 'market',
'8': 'market',
'9': 'stopLimit',
'10': 'market',
'Limit': 'limit',
'Market': 'market',
}
return self.safe_string(types, type, type)
def parse_time_in_force(self, timeInForce):
timeInForces = {
'GoodTillCancel': 'GTC',
'PostOnly': 'PO',
'ImmediateOrCancel': 'IOC',
'FillOrKill': 'FOK',
}
return self.safe_string(timeInForces, timeInForce, timeInForce)
def parse_spot_order(self, order, market=None):
#
# spot
#
# {
# "orderID": "d1d09454-cabc-4a23-89a7-59d43363f16d",
# "clOrdID": "309bcd5c-9f6e-4a68-b775-4494542eb5cb",
# "priceEp": 0,
# "action": "New",
# "trigger": "UNSPECIFIED",
# "pegPriceType": "UNSPECIFIED",
# "stopDirection": "UNSPECIFIED",
# "bizError": 0,
# "symbol": "sBTCUSDT",
# "side": "Buy",
# "baseQtyEv": 0,
# "ordType": "Limit",
# "timeInForce": "GoodTillCancel",
# "ordStatus": "Created",
# "cumFeeEv": 0,
# "cumBaseQtyEv": 0,
# "cumQuoteQtyEv": 0,
# "leavesBaseQtyEv": 0,
# "leavesQuoteQtyEv": 0,
# "avgPriceEp": 0,
# "cumBaseAmountEv": 0,
# "cumQuoteAmountEv": 0,
# "quoteQtyEv": 0,
# "qtyType": "ByBase",
# "stopPxEp": 0,
# "pegOffsetValueEp": 0
# }
#
# {
# "orderID":"99232c3e-3d6a-455f-98cc-2061cdfe91bc",
# "stopPxEp":0,
# "avgPriceEp":0,
# "qtyType":"ByBase",
# "leavesBaseQtyEv":0,
# "leavesQuoteQtyEv":0,
# "baseQtyEv":"1000000000",
# "feeCurrency":"4",
# "stopDirection":"UNSPECIFIED",
# "symbol":"sETHUSDT",
# "side":"Buy",
# "quoteQtyEv":250000000000,
# "priceEp":25000000000,
# "ordType":"Limit",
# "timeInForce":"GoodTillCancel",
# "ordStatus":"Rejected",
# "execStatus":"NewRejected",
# "createTimeNs":1592675305266037130,
# "cumFeeEv":0,
# "cumBaseValueEv":0,
# "cumQuoteValueEv":0
# }
#
id = self.safe_string(order, 'orderID')
clientOrderId = self.safe_string(order, 'clOrdID')
if (clientOrderId is not None) and (len(clientOrderId) < 1):
clientOrderId = None
marketId = self.safe_string(order, 'symbol')
market = self.safe_market(marketId, market)
symbol = market['symbol']
price = self.from_ep(self.safe_string(order, 'priceEp'), market)
amount = self.from_ev(self.safe_string(order, 'baseQtyEv'), market)
remaining = self.omit_zero(self.from_ev(self.safe_string(order, 'leavesBaseQtyEv'), market))
filled = self.from_ev(self.safe_string_2(order, 'cumBaseQtyEv', 'cumBaseValueEv'), market)
cost = self.from_er(self.safe_string_2(order, 'cumQuoteValueEv', 'quoteQtyEv'), market)
average = self.from_ep(self.safe_string(order, 'avgPriceEp'), market)
status = self.parse_order_status(self.safe_string(order, 'ordStatus'))
side = self.safe_string_lower(order, 'side')
type = self.parse_order_type(self.safe_string(order, 'ordType'))
timestamp = self.safe_integer_product_2(order, 'actionTimeNs', 'createTimeNs', 0.000001)
fee = None
feeCost = self.from_ev(self.safe_string(order, 'cumFeeEv'), market)
if feeCost is not None:
fee = {
'cost': feeCost,
'currency': None,
}
timeInForce = self.parse_time_in_force(self.safe_string(order, 'timeInForce'))
stopPrice = self.parse_number(self.omit_zero(self.from_ep(self.safe_string(order, 'stopPxEp', market))))
postOnly = (timeInForce == 'PO')
return self.safe_order({
'info': order,
'id': id,
'clientOrderId': clientOrderId,
'timestamp': timestamp,
'datetime': self.iso8601(timestamp),
'lastTradeTimestamp': None,
'symbol': symbol,
'type': type,
'timeInForce': timeInForce,
'postOnly': postOnly,
'side': side,
'price': price,
'stopPrice': stopPrice,
'triggerPrice': stopPrice,
'amount': amount,
'cost': cost,
'average': average,
'filled': filled,
'remaining': remaining,
'status': status,
'fee': fee,
'trades': None,
}, market)
def parse_order_side(self, side):
sides = {
'1': 'buy',
'2': 'sell',
}
return self.safe_string(sides, side, side)
def parse_swap_order(self, order, market=None):
#
# {
# "bizError":0,
# "orderID":"7a1ad384-44a3-4e54-a102-de4195a29e32",
# "clOrdID":"",
# "symbol":"ETHUSD",
# "side":"Buy",
# "actionTimeNs":1592668973945065381,
# "transactTimeNs":0,
# "orderType":"Market",
# "priceEp":2267500,
# "price":226.75000000,
# "orderQty":1,
# "displayQty":0,
# "timeInForce":"ImmediateOrCancel",
# "reduceOnly":false,
# "closedPnlEv":0,
# "closedPnl":0E-8,
# "closedSize":0,
# "cumQty":0,
# "cumValueEv":0,
# "cumValue":0E-8,
# "leavesQty":1,
# "leavesValueEv":11337,
# "leavesValue":1.13370000,
# "stopDirection":"UNSPECIFIED",
# "stopPxEp":0,
# "stopPx":0E-8,
# "trigger":"UNSPECIFIED",
# "pegOffsetValueEp":0,
# "execStatus":"PendingNew",
# "pegPriceType":"UNSPECIFIED",
# "ordStatus":"Created",
# "execInst": "ReduceOnly"
# }
#
# usdt
# {
# "bizError":"0",
# "orderID":"bd720dff-5647-4596-aa4e-656bac87aaad",
# "clOrdID":"ccxt2022843dffac9477b497",
# "symbol":"LTCUSDT",
# "side":"Buy",
# "actionTimeNs":"1677667878751724052",
# "transactTimeNs":"1677667878754017434",
# "orderType":"Limit",
# "priceRp":"40",
# "orderQtyRq":"0.1",
# "displayQtyRq":"0.1",
# "timeInForce":"GoodTillCancel",
# "reduceOnly":false,
# "closedPnlRv":"0",
# "closedSizeRq":"0",
# "cumQtyRq":"0",
# "cumValueRv":"0",
# "leavesQtyRq":"0.1",
# "leavesValueRv":"4",
# "stopDirection":"UNSPECIFIED",
# "stopPxRp":"0",
# "trigger":"UNSPECIFIED",
# "pegOffsetValueRp":"0",
# "pegOffsetProportionRr":"0",
# "execStatus":"New",
# "pegPriceType":"UNSPECIFIED",
# "ordStatus":"New",
# "execInst":"None",
# "takeProfitRp":"0",
# "stopLossRp":"0"
# }
#
# v2 orderList
# {
# "createdAt":"1677686231301",
# "symbol":"LTCUSDT",
# "orderQtyRq":"0.2",
# "side":"1",
# "posSide":"3",
# "priceRp":"50",
# "execQtyRq":"0",
# "leavesQtyRq":"0.2",
# "execPriceRp":"0",
# "orderValueRv":"10",
# "leavesValueRv":"10",
# "cumValueRv":"0",
# "stopDirection":"0",
# "stopPxRp":"0",
# "trigger":"0",
# "actionBy":"1",
# "execFeeRv":"0",
# "ordType":"2",
# "ordStatus":"5",
# "clOrdId":"4b3b188",
# "orderId":"4b3b1884-87cf-4897-b596-6693b7ed84d1",
# "execStatus":"5",
# "bizError":"0",
# "totalPnlRv":null,
# "avgTransactPriceRp":null,
# "orderDetailsVos":null,
# "tradeType":"0"
# }
#
id = self.safe_string_2(order, 'orderID', 'orderId')
clientOrderId = self.safe_string_2(order, 'clOrdID', 'clOrdId')
if (clientOrderId is not None) and (len(clientOrderId) < 1):
clientOrderId = None
marketId = self.safe_string(order, 'symbol')
symbol = self.safe_symbol(marketId, market)
status = self.parse_order_status(self.safe_string(order, 'ordStatus'))
side = self.parse_order_side(self.safe_string_lower(order, 'side'))
type = self.parse_order_type(self.safe_string(order, 'orderType'))
price = self.safe_string(order, 'priceRp')
if price is None:
price = self.from_ep(self.safe_string(order, 'priceEp'), market)
amount = self.safe_number_2(order, 'orderQty', 'orderQtyRq')
filled = self.safe_number_2(order, 'cumQty', 'cumQtyRq')
remaining = self.safe_number_2(order, 'leavesQty', 'leavesQtyRq')
timestamp = self.safe_integer_product(order, 'actionTimeNs', 0.000001)
if timestamp is None:
timestamp = self.safe_integer(order, 'createdAt')
cost = self.safe_number_2(order, 'cumValue', 'cumValueRv')
lastTradeTimestamp = self.safe_integer_product(order, 'transactTimeNs', 0.000001)
if lastTradeTimestamp == 0:
lastTradeTimestamp = None
timeInForce = self.parse_time_in_force(self.safe_string(order, 'timeInForce'))
stopPrice = self.omit_zero(self.safe_number_2(order, 'stopPx', 'stopPxRp'))
postOnly = (timeInForce == 'PO')
reduceOnly = self.safe_value(order, 'reduceOnly')
execInst = self.safe_string(order, 'execInst')
if execInst == 'ReduceOnly':
reduceOnly = True
takeProfit = self.safe_string(order, 'takeProfitRp')
stopLoss = self.safe_string(order, 'stopLossRp')
return self.safe_order({
'info': order,
'id': id,
'clientOrderId': clientOrderId,
'datetime': self.iso8601(timestamp),
'timestamp': timestamp,
'lastTradeTimestamp': lastTradeTimestamp,
'symbol': symbol,
'type': type,
'timeInForce': timeInForce,
'postOnly': postOnly,
'reduceOnly': reduceOnly,
'side': side,
'price': price,
'stopPrice': stopPrice,
'triggerPrice': stopPrice,
'takeProfitPrice': takeProfit,
'stopLossPrice': stopLoss,
'amount': amount,
'filled': filled,
'remaining': remaining,
'cost': cost,
'average': None,
'status': status,
'fee': None,
'trades': None,
})
def parse_order(self, order, market=None):
isSwap = self.safe_value(market, 'swap', False)
hasPnl = ('closedPnl' in order)
if isSwap or hasPnl:
return self.parse_swap_order(order, market)
return self.parse_spot_order(order, market)
async def create_order(self, symbol: str, type: OrderType, side: OrderSide, amount, price=None, params={}):
"""
create a trade order
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#place-order
:param str symbol: unified symbol of the market to create an order in
:param str type: 'market' or 'limit'
:param str side: 'buy' or 'sell'
:param float amount: how much of currency you want to trade in units of base currency
:param float [price]: the price at which the order is to be fullfilled, in units of the quote currency, ignored in market orders
:param dict [params]: extra parameters specific to the phemex api endpoint
:param dict [params.takeProfit]: *swap only* *takeProfit object in params* containing the triggerPrice at which the attached take profit order will be triggered(perpetual swap markets only)
:param float [params.takeProfit.triggerPrice]: take profit trigger price
:param dict [params.stopLoss]: *swap only* *stopLoss object in params* containing the triggerPrice at which the attached stop loss order will be triggered(perpetual swap markets only)
:param float [params.stopLoss.triggerPrice]: stop loss trigger price
:returns dict: an `order structure <https://github.com/ccxt/ccxt/wiki/Manual#order-structure>`
"""
await self.load_markets()
market = self.market(symbol)
requestSide = self.capitalize(side)
type = self.capitalize(type)
reduceOnly = self.safe_value(params, 'reduceOnly')
request = {
# common
'symbol': market['id'],
'side': requestSide, # Sell, Buy
'ordType': type, # Market, Limit, Stop, StopLimit, MarketIfTouched, LimitIfTouched(additionally for contract-markets: MarketAsLimit, StopAsLimit, MarketIfTouchedAsLimit)
# 'stopPxEp': self.to_ep(stopPx, market), # for conditional orders
# 'priceEp': self.to_ep(price, market), # required for limit orders
# 'timeInForce': 'GoodTillCancel', # GoodTillCancel, PostOnly, ImmediateOrCancel, FillOrKill
# ----------------------------------------------------------------
# spot
# 'qtyType': 'ByBase', # ByBase, ByQuote
# 'quoteQtyEv': self.to_ep(cost, market),
# 'baseQtyEv': self.to_ev(amount, market),
# 'trigger': 'ByLastPrice', # required for conditional orders
# ----------------------------------------------------------------
# swap
# 'clOrdID': self.uuid(), # max length 40
# 'orderQty': self.amount_to_precision(amount, symbol),
# 'reduceOnly': False,
# 'closeOnTrigger': False, # implicit reduceOnly and cancel other orders in the same direction
# 'takeProfitEp': self.to_ep(takeProfit, market),
# 'stopLossEp': self.to_ep(stopLossEp, market),
# 'triggerType': 'ByMarkPrice', # ByMarkPrice, ByLastPrice
# 'pegOffsetValueEp': integer, # Trailing offset from current price. Negative value when position is long, positive when position is short
# 'pegPriceType': 'TrailingStopPeg', # TrailingTakeProfitPeg
# 'text': 'comment',
# 'posSide': Position direction - "Merged" for oneway mode , "Long" / "Short" for hedge mode
}
clientOrderId = self.safe_string_2(params, 'clOrdID', 'clientOrderId')
stopLoss = self.safe_value(params, 'stopLoss')
stopLossDefined = (stopLoss is not None)
takeProfit = self.safe_value(params, 'takeProfit')
takeProfitDefined = (takeProfit is not None)
if clientOrderId is None:
brokerId = self.safe_string(self.options, 'brokerId')
if brokerId is not None:
request['clOrdID'] = brokerId + self.uuid16()
else:
request['clOrdID'] = clientOrderId
params = self.omit(params, ['clOrdID', 'clientOrderId'])
stopPrice = self.safe_string_2(params, 'stopPx', 'stopPrice')
if stopPrice is not None:
if market['settle'] == 'USDT':
request['stopPxRp'] = self.price_to_precision(symbol, stopPrice)
else:
request['stopPxEp'] = self.to_ep(stopPrice, market)
params = self.omit(params, ['stopPx', 'stopPrice', 'stopLoss', 'takeProfit'])
if market['spot']:
qtyType = self.safe_value(params, 'qtyType', 'ByBase')
if (type == 'Market') or (type == 'Stop') or (type == 'MarketIfTouched'):
if price is not None:
qtyType = 'ByQuote'
request['qtyType'] = qtyType
if qtyType == 'ByQuote':
cost = self.safe_number(params, 'cost')
params = self.omit(params, 'cost')
if self.options['createOrderByQuoteRequiresPrice']:
if price is not None:
amountString = self.number_to_string(amount)
priceString = self.number_to_string(price)
quoteAmount = Precise.string_mul(amountString, priceString)
cost = self.parse_number(quoteAmount)
elif cost is None:
raise ArgumentsRequired(self.id + ' createOrder() ' + qtyType + ' requires a price argument or a cost parameter')
cost = amount if (cost is None) else cost
costString = str(cost)
request['quoteQtyEv'] = self.to_ev(costString, market)
else:
amountString = str(amount)
request['baseQtyEv'] = self.to_ev(amountString, market)
elif market['swap']:
posSide = self.safe_string_lower(params, 'posSide')
if posSide is None:
posSide = 'Merged'
posSide = self.capitalize(posSide)
request['posSide'] = posSide
if reduceOnly is not None:
request['reduceOnly'] = reduceOnly
if market['settle'] == 'USDT':
request['orderQtyRq'] = amount
else:
request['orderQty'] = int(amount)
if stopPrice is not None:
triggerType = self.safe_string(params, 'triggerType', 'ByMarkPrice')
request['triggerType'] = triggerType
if stopLossDefined or takeProfitDefined:
if stopLossDefined:
stopLossTriggerPrice = self.safe_value_2(stopLoss, 'triggerPrice', 'stopPrice')
if stopLossTriggerPrice is None:
raise InvalidOrder(self.id + ' createOrder() requires a trigger price in params["stopLoss"]["triggerPrice"], or params["stopLoss"]["stopPrice"] for a stop loss order')
if market['settle'] == 'USDT':
request['stopLossRp'] = self.price_to_precision(symbol, stopLossTriggerPrice)
else:
request['stopLossEp'] = self.to_ep(stopLossTriggerPrice, market)
stopLossTriggerPriceType = self.safe_string_2(stopLoss, 'triggerPriceType', 'slTrigger')
if stopLossTriggerPriceType is not None:
if market['settle'] == 'USDT':
if (stopLossTriggerPriceType != 'ByMarkPrice') and (stopLossTriggerPriceType != 'ByLastPrice') and (stopLossTriggerPriceType != 'ByIndexPrice') and (stopLossTriggerPriceType != 'ByAskPrice') and (stopLossTriggerPriceType != 'ByBidPrice') and (stopLossTriggerPriceType != 'ByMarkPriceLimit') and (stopLossTriggerPriceType != 'ByLastPriceLimit'):
raise InvalidOrder(self.id + ' createOrder() take profit trigger price type must be one of "ByMarkPrice", "ByIndexPrice", "ByAskPrice", "ByBidPrice", "ByMarkPriceLimit", "ByLastPriceLimit" or "ByLastPrice"')
else:
if (stopLossTriggerPriceType != 'ByMarkPrice') and (stopLossTriggerPriceType != 'ByLastPrice'):
raise InvalidOrder(self.id + ' createOrder() take profit trigger price type must be one of "ByMarkPrice", or "ByLastPrice"')
request['slTrigger'] = stopLossTriggerPriceType
if takeProfitDefined:
takeProfitTriggerPrice = self.safe_value_2(takeProfit, 'triggerPrice', 'stopPrice')
if takeProfitTriggerPrice is None:
raise InvalidOrder(self.id + ' createOrder() requires a trigger price in params["takeProfit"]["triggerPrice"], or params["takeProfit"]["stopPrice"] for a take profit order')
if market['settle'] == 'USDT':
request['takeProfitRp'] = self.price_to_precision(symbol, takeProfitTriggerPrice)
else:
request['takeProfitEp'] = self.to_ep(takeProfitTriggerPrice, market)
takeProfitTriggerPriceType = self.safe_string_2(stopLoss, 'triggerPriceType', 'tpTrigger')
if takeProfitTriggerPriceType is not None:
if market['settle'] == 'USDT':
if (takeProfitTriggerPriceType != 'ByMarkPrice') and (takeProfitTriggerPriceType != 'ByLastPrice') and (takeProfitTriggerPriceType != 'ByIndexPrice') and (takeProfitTriggerPriceType != 'ByAskPrice') and (takeProfitTriggerPriceType != 'ByBidPrice') and (takeProfitTriggerPriceType != 'ByMarkPriceLimit') and (takeProfitTriggerPriceType != 'ByLastPriceLimit'):
raise InvalidOrder(self.id + ' createOrder() take profit trigger price type must be one of "ByMarkPrice", "ByIndexPrice", "ByAskPrice", "ByBidPrice", "ByMarkPriceLimit", "ByLastPriceLimit" or "ByLastPrice"')
else:
if (takeProfitTriggerPriceType != 'ByMarkPrice') and (takeProfitTriggerPriceType != 'ByLastPrice'):
raise InvalidOrder(self.id + ' createOrder() take profit trigger price type must be one of "ByMarkPrice", or "ByLastPrice"')
request['tpTrigger'] = takeProfitTriggerPriceType
if (type == 'Limit') or (type == 'StopLimit') or (type == 'LimitIfTouched'):
if market['settle'] == 'USDT':
request['priceRp'] = self.price_to_precision(symbol, price)
else:
priceString = self.number_to_string(price)
request['priceEp'] = self.to_ep(priceString, market)
takeProfitPrice = self.safe_string(params, 'takeProfitPrice')
if takeProfitPrice is not None:
if market['settle'] == 'USDT':
request['takeProfitRp'] = self.price_to_precision(symbol, takeProfitPrice)
else:
request['takeProfitEp'] = self.to_ep(takeProfitPrice, market)
params = self.omit(params, 'takeProfitPrice')
stopLossPrice = self.safe_string(params, 'stopLossPrice')
if stopLossPrice is not None:
if market['settle'] == 'USDT':
request['stopLossRp'] = self.price_to_precision(symbol, stopLossPrice)
else:
request['stopLossEp'] = self.to_ep(stopLossPrice, market)
params = self.omit(params, 'stopLossPrice')
method = 'privatePostSpotOrders'
if market['settle'] == 'USDT':
method = 'privatePostGOrders'
elif market['contract']:
method = 'privatePostOrders'
params = self.omit(params, 'reduceOnly')
response = await getattr(self, method)(self.extend(request, params))
#
# spot
#
# {
# "code": 0,
# "msg": "",
# "data": {
# "orderID": "d1d09454-cabc-4a23-89a7-59d43363f16d",
# "clOrdID": "309bcd5c-9f6e-4a68-b775-4494542eb5cb",
# "priceEp": 0,
# "action": "New",
# "trigger": "UNSPECIFIED",
# "pegPriceType": "UNSPECIFIED",
# "stopDirection": "UNSPECIFIED",
# "bizError": 0,
# "symbol": "sBTCUSDT",
# "side": "Buy",
# "baseQtyEv": 0,
# "ordType": "Limit",
# "timeInForce": "GoodTillCancel",
# "ordStatus": "Created",
# "cumFeeEv": 0,
# "cumBaseQtyEv": 0,
# "cumQuoteQtyEv": 0,
# "leavesBaseQtyEv": 0,
# "leavesQuoteQtyEv": 0,
# "avgPriceEp": 0,
# "cumBaseAmountEv": 0,
# "cumQuoteAmountEv": 0,
# "quoteQtyEv": 0,
# "qtyType": "ByBase",
# "stopPxEp": 0,
# "pegOffsetValueEp": 0
# }
# }
#
# swap
#
# {
# "code":0,
# "msg":"",
# "data":{
# "bizError":0,
# "orderID":"7a1ad384-44a3-4e54-a102-de4195a29e32",
# "clOrdID":"",
# "symbol":"ETHUSD",
# "side":"Buy",
# "actionTimeNs":1592668973945065381,
# "transactTimeNs":0,
# "orderType":"Market",
# "priceEp":2267500,
# "price":226.75000000,
# "orderQty":1,
# "displayQty":0,
# "timeInForce":"ImmediateOrCancel",
# "reduceOnly":false,
# "closedPnlEv":0,
# "closedPnl":0E-8,
# "closedSize":0,
# "cumQty":0,
# "cumValueEv":0,
# "cumValue":0E-8,
# "leavesQty":1,
# "leavesValueEv":11337,
# "leavesValue":1.13370000,
# "stopDirection":"UNSPECIFIED",
# "stopPxEp":0,
# "stopPx":0E-8,
# "trigger":"UNSPECIFIED",
# "pegOffsetValueEp":0,
# "execStatus":"PendingNew",
# "pegPriceType":"UNSPECIFIED",
# "ordStatus":"Created"
# }
# }
#
data = self.safe_value(response, 'data', {})
return self.parse_order(data, market)
async def edit_order(self, id: str, symbol, type=None, side=None, amount=None, price=None, params={}):
"""
edit a trade order
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#amend-order-by-orderid
:param str id: cancel order id
:param str symbol: unified symbol of the market to create an order in
:param str type: 'market' or 'limit'
:param str side: 'buy' or 'sell'
:param float amount: how much of currency you want to trade in units of base currency
:param float [price]: the price at which the order is to be fullfilled, in units of the base currency, ignored in market orders
:param dict [params]: extra parameters specific to the phemex api endpoint
:param str [params.posSide]: either 'Merged' or 'Long' or 'Short'
:returns dict: an `order structure <https://github.com/ccxt/ccxt/wiki/Manual#order-structure>`
"""
if symbol is None:
raise ArgumentsRequired(self.id + ' editOrder() requires a symbol argument')
await self.load_markets()
market = self.market(symbol)
request = {
'symbol': market['id'],
}
clientOrderId = self.safe_string_2(params, 'clientOrderId', 'clOrdID')
params = self.omit(params, ['clientOrderId', 'clOrdID'])
isUSDTSettled = (market['settle'] == 'USDT')
if clientOrderId is not None:
request['clOrdID'] = clientOrderId
else:
request['orderID'] = id
if price is not None:
if isUSDTSettled:
request['priceRp'] = self.price_to_precision(market['symbol'], price)
else:
request['priceEp'] = self.to_ep(price, market)
# Note the uppercase 'V' in 'baseQtyEV' request. that is exchange's requirement at self moment. However, to avoid mistakes from user side, let's support lowercased 'baseQtyEv' too
finalQty = self.safe_string(params, 'baseQtyEv')
params = self.omit(params, ['baseQtyEv'])
if finalQty is not None:
request['baseQtyEV'] = finalQty
elif amount is not None:
if isUSDTSettled:
request['baseQtyEV'] = self.amount_to_precision(market['symbol'], amount)
else:
request['baseQtyEV'] = self.to_ev(amount, market)
stopPrice = self.safe_string_2(params, 'stopPx', 'stopPrice')
if stopPrice is not None:
if isUSDTSettled:
request['stopPxRp'] = self.price_to_precision(symbol, stopPrice)
else:
request['stopPxEp'] = self.to_ep(stopPrice, market)
params = self.omit(params, ['stopPx', 'stopPrice'])
method = 'privatePutSpotOrders'
if isUSDTSettled:
method = 'privatePutGOrdersReplace'
posSide = self.safe_string(params, 'posSide')
if posSide is None:
request['posSide'] = 'Merged'
elif market['swap']:
method = 'privatePutOrdersReplace'
response = await getattr(self, method)(self.extend(request, params))
data = self.safe_value(response, 'data', {})
return self.parse_order(data, market)
async def cancel_order(self, id: str, symbol: Optional[str] = None, params={}):
"""
cancels an open order
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#cancel-single-order-by-orderid
:param str id: order id
:param str symbol: unified symbol of the market the order was made in
:param dict [params]: extra parameters specific to the phemex api endpoint
:param str [params.posSide]: either 'Merged' or 'Long' or 'Short'
:returns dict: An `order structure <https://github.com/ccxt/ccxt/wiki/Manual#order-structure>`
"""
if symbol is None:
raise ArgumentsRequired(self.id + ' cancelOrder() requires a symbol argument')
await self.load_markets()
market = self.market(symbol)
request = {
'symbol': market['id'],
}
clientOrderId = self.safe_string_2(params, 'clientOrderId', 'clOrdID')
params = self.omit(params, ['clientOrderId', 'clOrdID'])
if clientOrderId is not None:
request['clOrdID'] = clientOrderId
else:
request['orderID'] = id
method = 'privateDeleteSpotOrders'
if market['settle'] == 'USDT':
method = 'privateDeleteGOrdersCancel'
posSide = self.safe_string(params, 'posSide')
if posSide is None:
request['posSide'] = 'Merged'
elif market['swap']:
method = 'privateDeleteOrdersCancel'
response = await getattr(self, method)(self.extend(request, params))
data = self.safe_value(response, 'data', {})
return self.parse_order(data, market)
async def cancel_all_orders(self, symbol: Optional[str] = None, params={}):
"""
cancel all open orders in a market
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#cancelall
:param str symbol: unified market symbol of the market to cancel orders in
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict[]: a list of `order structures <https://github.com/ccxt/ccxt/wiki/Manual#order-structure>`
"""
if symbol is None:
raise ArgumentsRequired(self.id + ' cancelAllOrders() requires a symbol argument')
await self.load_markets()
request = {
# 'symbol': market['id'],
# 'untriggerred': False, # False to cancel non-conditional orders, True to cancel conditional orders
# 'text': 'up to 40 characters max',
}
market = self.market(symbol)
method = 'privateDeleteSpotOrdersAll'
if market['settle'] == 'USDT':
method = 'privateDeleteGOrdersAll'
elif market['swap']:
method = 'privateDeleteOrdersAll'
request['symbol'] = market['id']
return await getattr(self, method)(self.extend(request, params))
async def fetch_order(self, id: str, symbol: Optional[str] = None, params={}):
"""
fetches information on an order made by the user
:param str symbol: unified symbol of the market the order was made in
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict: An `order structure <https://github.com/ccxt/ccxt/wiki/Manual#order-structure>`
"""
if symbol is None:
raise ArgumentsRequired(self.id + ' fetchOrder() requires a symbol argument')
await self.load_markets()
market = self.market(symbol)
if market['settle'] == 'USDT':
raise NotSupported(self.id + 'fetchOrder() is not supported yet for USDT settled swap markets') # https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#query-user-order-by-orderid-or-query-user-order-by-client-order-id
method = 'privateGetSpotOrdersActive' if market['spot'] else 'privateGetExchangeOrder'
request = {
'symbol': market['id'],
}
clientOrderId = self.safe_string_2(params, 'clientOrderId', 'clOrdID')
params = self.omit(params, ['clientOrderId', 'clOrdID'])
if clientOrderId is not None:
request['clOrdID'] = clientOrderId
else:
request['orderID'] = id
response = await getattr(self, method)(self.extend(request, params))
data = self.safe_value(response, 'data', {})
order = data
if isinstance(data, list):
numOrders = len(data)
if numOrders < 1:
if clientOrderId is not None:
raise OrderNotFound(self.id + ' fetchOrder() ' + symbol + ' order with clientOrderId ' + clientOrderId + ' not found')
else:
raise OrderNotFound(self.id + ' fetchOrder() ' + symbol + ' order with id ' + id + ' not found')
order = self.safe_value(data, 0, {})
return self.parse_order(order, market)
async def fetch_orders(self, symbol: Optional[str] = None, since: Optional[int] = None, limit: Optional[int] = None, params={}):
"""
fetches information on multiple orders made by the user
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#queryorder
:param str symbol: unified market symbol of the market orders were made in
:param int [since]: the earliest time in ms to fetch orders for
:param int [limit]: the maximum number of orde structures to retrieve
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns Order[]: a list of `order structures <https://github.com/ccxt/ccxt/wiki/Manual#order-structure>`
"""
if symbol is None:
raise ArgumentsRequired(self.id + ' fetchOrders() requires a symbol argument')
await self.load_markets()
market = self.market(symbol)
request = {
'symbol': market['id'],
}
method = 'privateGetSpotOrders'
if market['settle'] == 'USDT':
request['currency'] = market['settle']
method = 'privateGetExchangeOrderV2OrderList'
elif market['swap']:
method = 'privateGetExchangeOrderList'
if since is not None:
request['start'] = since
if limit is not None:
request['limit'] = limit
response = await getattr(self, method)(self.extend(request, params))
data = self.safe_value(response, 'data', {})
rows = self.safe_value(data, 'rows', data)
return self.parse_orders(rows, market, since, limit)
async def fetch_open_orders(self, symbol: Optional[str] = None, since: Optional[int] = None, limit: Optional[int] = None, params={}):
"""
fetch all unfilled currently open orders
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#queryopenorder
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Contract-API-en.md
:param str symbol: unified market symbol
:param int [since]: the earliest time in ms to fetch open orders for
:param int [limit]: the maximum number of open orders structures to retrieve
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns Order[]: a list of `order structures <https://github.com/ccxt/ccxt/wiki/Manual#order-structure>`
"""
if symbol is None:
raise ArgumentsRequired(self.id + ' fetchOpenOrders() requires a symbol argument')
await self.load_markets()
market = self.market(symbol)
method = 'privateGetSpotOrders'
if market['settle'] == 'USDT':
method = 'privateGetGOrdersActiveList'
elif market['swap']:
method = 'privateGetOrdersActiveList'
request = {
'symbol': market['id'],
}
response = None
try:
response = await getattr(self, method)(self.extend(request, params))
except Exception as e:
if isinstance(e, OrderNotFound):
return []
raise e
data = self.safe_value(response, 'data', {})
if isinstance(data, list):
return self.parse_orders(data, market, since, limit)
else:
rows = self.safe_value(data, 'rows', [])
return self.parse_orders(rows, market, since, limit)
async def fetch_closed_orders(self, symbol: Optional[str] = None, since: Optional[int] = None, limit: Optional[int] = None, params={}):
"""
fetches information on multiple closed orders made by the user
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#queryorder
:param str symbol: unified market symbol of the market orders were made in
:param int [since]: the earliest time in ms to fetch orders for
:param int [limit]: the maximum number of orde structures to retrieve
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns Order[]: a list of `order structures <https://github.com/ccxt/ccxt/wiki/Manual#order-structure>`
"""
if symbol is None:
raise ArgumentsRequired(self.id + ' fetchClosedOrders() requires a symbol argument')
await self.load_markets()
market = self.market(symbol)
request = {
'symbol': market['id'],
}
method = 'privateGetExchangeSpotOrder'
if market['settle'] == 'USDT':
request['currency'] = market['settle']
method = 'privateGetExchangeOrderV2OrderList'
elif market['swap']:
method = 'privateGetExchangeOrderList'
if since is not None:
request['start'] = since
if limit is not None:
request['limit'] = limit
response = await getattr(self, method)(self.extend(request, params))
#
# spot
#
# {
# "code":0,
# "msg":"OK",
# "data":{
# "total":8,
# "rows":[
# {
# "orderID":"99232c3e-3d6a-455f-98cc-2061cdfe91bc",
# "stopPxEp":0,
# "avgPriceEp":0,
# "qtyType":"ByBase",
# "leavesBaseQtyEv":0,
# "leavesQuoteQtyEv":0,
# "baseQtyEv":"1000000000",
# "feeCurrency":"4",
# "stopDirection":"UNSPECIFIED",
# "symbol":"sETHUSDT",
# "side":"Buy",
# "quoteQtyEv":250000000000,
# "priceEp":25000000000,
# "ordType":"Limit",
# "timeInForce":"GoodTillCancel",
# "ordStatus":"Rejected",
# "execStatus":"NewRejected",
# "createTimeNs":1592675305266037130,
# "cumFeeEv":0,
# "cumBaseValueEv":0,
# "cumQuoteValueEv":0
# },
# ]
# }
# }
#
data = self.safe_value(response, 'data', {})
if isinstance(data, list):
return self.parse_orders(data, market, since, limit)
else:
rows = self.safe_value(data, 'rows', [])
return self.parse_orders(rows, market, since, limit)
async def fetch_my_trades(self, symbol: Optional[str] = None, since: Optional[int] = None, limit: Optional[int] = None, params={}):
"""
fetch all trades made by the user
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Contract-API-en.md#query-user-trade
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#query-user-trade
:param str symbol: unified market symbol
:param int [since]: the earliest time in ms to fetch trades for
:param int [limit]: the maximum number of trades structures to retrieve
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns Trade[]: a list of `trade structures <https://github.com/ccxt/ccxt/wiki/Manual#trade-structure>`
"""
if symbol is None:
raise ArgumentsRequired(self.id + ' fetchMyTrades() requires a symbol argument')
await self.load_markets()
market = self.market(symbol)
method = 'privateGetExchangeSpotOrderTrades'
if market['swap']:
method = 'privateGetExchangeOrderTrade'
if market['settle'] == 'USDT':
method = 'privateGetExchangeOrderV2TradingList'
request = {}
if limit is not None:
limit = min(200, limit)
request['limit'] = limit
if market['settle'] == 'USDT':
request['currency'] = 'USDT'
request['offset'] = 0
if limit is None:
request['limit'] = 200
else:
request['symbol'] = market['id']
if since is not None:
request['start'] = since
if market['swap'] and (limit is not None):
request['limit'] = limit
response = await getattr(self, method)(self.extend(request, params))
#
# spot
#
# {
# "code": 0,
# "msg": "OK",
# "data": {
# "total": 1,
# "rows": [
# {
# "qtyType": "ByQuote",
# "transactTimeNs": 1589450974800550100,
# "clOrdID": "8ba59d40-df25-d4b0-14cf-0703f44e9690",
# "orderID": "b2b7018d-f02f-4c59-b4cf-051b9c2d2e83",
# "symbol": "sBTCUSDT",
# "side": "Buy",
# "priceEP": 970056000000,
# "baseQtyEv": 0,
# "quoteQtyEv": 1000000000,
# "action": "New",
# "execStatus": "MakerFill",
# "ordStatus": "Filled",
# "ordType": "Limit",
# "execInst": "None",
# "timeInForce": "GoodTillCancel",
# "stopDirection": "UNSPECIFIED",
# "tradeType": "Trade",
# "stopPxEp": 0,
# "execId": "c6bd8979-07ba-5946-b07e-f8b65135dbb1",
# "execPriceEp": 970056000000,
# "execBaseQtyEv": 103000,
# "execQuoteQtyEv": 999157680,
# "leavesBaseQtyEv": 0,
# "leavesQuoteQtyEv": 0,
# "execFeeEv": 0,
# "feeRateEr": 0
# }
# ]
# }
# }
#
#
# swap
#
# {
# "code": 0,
# "msg": "OK",
# "data": {
# "total": 79,
# "rows": [
# {
# "transactTimeNs": 1606054879331565300,
# "symbol": "BTCUSD",
# "currency": "BTC",
# "action": "New",
# "side": "Buy",
# "tradeType": "Trade",
# "execQty": 5,
# "execPriceEp": 182990000,
# "orderQty": 5,
# "priceEp": 183870000,
# "execValueEv": 27323,
# "feeRateEr": 75000,
# "execFeeEv": 21,
# "ordType": "Market",
# "execID": "5eee56a4-04a9-5677-8eb0-c2fe22ae3645",
# "orderID": "ee0acb82-f712-4543-a11d-d23efca73197",
# "clOrdID": "",
# "execStatus": "TakerFill"
# },
# ]
# }
# }
#
# swap - usdt
#
# {
# "code": 0,
# "msg": "OK",
# "data": {
# "total": 4,
# "rows": [
# {
# "createdAt": 1666226932259,
# "symbol": "ETHUSDT",
# "currency": "USDT",
# "action": 1,
# "tradeType": 1,
# "execQtyRq": "0.01",
# "execPriceRp": "1271.9",
# "side": 1,
# "orderQtyRq": "0.78",
# "priceRp": "1271.9",
# "execValueRv": "12.719",
# "feeRateRr": "0.0001",
# "execFeeRv": "0.0012719",
# "ordType": 2,
# "execId": "8718cae",
# "execStatus": 6
# },
# ]
# }
# }
#
data = self.safe_value(response, 'data', {})
if method != 'privateGetExchangeOrderV2TradingList':
rows = self.safe_value(data, 'rows', [])
return self.parse_trades(rows, market, since, limit)
return self.parse_trades(data, market, since, limit)
async def fetch_deposit_address(self, code: str, params={}):
"""
fetch the deposit address for a currency associated with self account
:param str code: unified currency code
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict: an `address structure <https://github.com/ccxt/ccxt/wiki/Manual#address-structure>`
"""
await self.load_markets()
currency = self.currency(code)
request = {
'currency': currency['id'],
}
defaultNetworks = self.safe_value(self.options, 'defaultNetworks')
defaultNetwork = self.safe_string_upper(defaultNetworks, code)
networks = self.safe_value(self.options, 'networks', {})
network = self.safe_string_upper(params, 'network', defaultNetwork)
network = self.safe_string(networks, network, network)
if network is None:
request['chainName'] = currency['id']
else:
request['chainName'] = network
params = self.omit(params, 'network')
response = await self.privateGetPhemexUserWalletsV2DepositAddress(self.extend(request, params))
# {
# "code":0,
# "msg":"OK",
# "data":{
# "address":"0x5bfbf60e0fa7f63598e6cfd8a7fd3ffac4ccc6ad",
# "tag":null
# }
# }
#
data = self.safe_value(response, 'data', {})
address = self.safe_string(data, 'address')
tag = self.safe_string(data, 'tag')
self.check_address(address)
return {
'currency': code,
'address': address,
'tag': tag,
'network': None,
'info': response,
}
async def fetch_deposits(self, code: Optional[str] = None, since: Optional[int] = None, limit: Optional[int] = None, params={}):
"""
fetch all deposits made to an account
:param str code: unified currency code
:param int [since]: the earliest time in ms to fetch deposits for
:param int [limit]: the maximum number of deposits structures to retrieve
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict[]: a list of `transaction structures <https://github.com/ccxt/ccxt/wiki/Manual#transaction-structure>`
"""
await self.load_markets()
currency = None
if code is not None:
currency = self.currency(code)
response = await self.privateGetExchangeWalletsDepositList(params)
#
# {
# "code":0,
# "msg":"OK",
# "data":[
# {
# "id":29200,
# "currency":"USDT",
# "currencyCode":3,
# "txHash":"0x0bdbdc47807769a03b158d5753f54dfc58b92993d2f5e818db21863e01238e5d",
# "address":"0x5bfbf60e0fa7f63598e6cfd8a7fd3ffac4ccc6ad",
# "amountEv":3000000000,
# "confirmations":13,
# "type":"Deposit",
# "status":"Success",
# "createdAt":1592722565000
# }
# ]
# }
#
data = self.safe_value(response, 'data', {})
return self.parse_transactions(data, currency, since, limit)
async def fetch_withdrawals(self, code: Optional[str] = None, since: Optional[int] = None, limit: Optional[int] = None, params={}):
"""
fetch all withdrawals made from an account
:param str code: unified currency code
:param int [since]: the earliest time in ms to fetch withdrawals for
:param int [limit]: the maximum number of withdrawals structures to retrieve
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict[]: a list of `transaction structures <https://github.com/ccxt/ccxt/wiki/Manual#transaction-structure>`
"""
await self.load_markets()
currency = None
if code is not None:
currency = self.currency(code)
response = await self.privateGetExchangeWalletsWithdrawList(params)
#
# {
# "code":0,
# "msg":"OK",
# "data":[
# {
# "address": "1Lxxxxxxxxxxx"
# "amountEv": 200000
# "currency": "BTC"
# "currencyCode": 1
# "expiredTime": 0
# "feeEv": 50000
# "rejectReason": null
# "status": "Succeed"
# "txHash": "44exxxxxxxxxxxxxxxxxxxxxx"
# "withdrawStatus: ""
# }
# ]
# }
#
data = self.safe_value(response, 'data', {})
return self.parse_transactions(data, currency, since, limit)
def parse_transaction_status(self, status):
statuses = {
'Success': 'ok',
'Succeed': 'ok',
}
return self.safe_string(statuses, status, status)
def parse_transaction(self, transaction, currency=None):
#
# withdraw
#
# ...
#
# fetchDeposits
#
# {
# "id":29200,
# "currency":"USDT",
# "currencyCode":3,
# "txHash":"0x0bdbdc47807769a03b158d5753f54dfc58b92993d2f5e818db21863e01238e5d",
# "address":"0x5bfbf60e0fa7f63598e6cfd8a7fd3ffac4ccc6ad",
# "amountEv":3000000000,
# "confirmations":13,
# "type":"Deposit",
# "status":"Success",
# "createdAt":1592722565000
# }
#
# fetchWithdrawals
#
# {
# "address": "1Lxxxxxxxxxxx"
# "amountEv": 200000
# "currency": "BTC"
# "currencyCode": 1
# "expiredTime": 0
# "feeEv": 50000
# "rejectReason": null
# "status": "Succeed"
# "txHash": "44exxxxxxxxxxxxxxxxxxxxxx"
# "withdrawStatus: ""
# }
#
id = self.safe_string(transaction, 'id')
address = self.safe_string(transaction, 'address')
tag = None
txid = self.safe_string(transaction, 'txHash')
currencyId = self.safe_string(transaction, 'currency')
currency = self.safe_currency(currencyId, currency)
code = currency['code']
timestamp = self.safe_integer_2(transaction, 'createdAt', 'submitedAt')
type = self.safe_string_lower(transaction, 'type')
feeCost = self.parse_number(self.from_en(self.safe_string(transaction, 'feeEv'), currency['valueScale']))
fee = None
if feeCost is not None:
type = 'withdrawal'
fee = {
'cost': feeCost,
'currency': code,
}
status = self.parse_transaction_status(self.safe_string(transaction, 'status'))
amount = self.parse_number(self.from_en(self.safe_string(transaction, 'amountEv'), currency['valueScale']))
return {
'info': transaction,
'id': id,
'txid': txid,
'timestamp': timestamp,
'datetime': self.iso8601(timestamp),
'network': None,
'address': address,
'addressTo': address,
'addressFrom': None,
'tag': tag,
'tagTo': tag,
'tagFrom': None,
'type': type,
'amount': amount,
'currency': code,
'status': status,
'updated': None,
'fee': fee,
}
async def fetch_positions(self, symbols: Optional[List[str]] = None, params={}):
"""
fetch all open positions
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Contract-API-en.md#query-trading-account-and-positions
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#query-account-positions
:param str[]|None symbols: list of unified market symbols
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict[]: a list of `position structure <https://github.com/ccxt/ccxt/wiki/Manual#position-structure>`
"""
await self.load_markets()
symbols = self.market_symbols(symbols)
subType = None
method = 'privateGetAccountsAccountPositions'
code = self.safe_string(params, 'currency')
settle = None
market = None
firstSymbol = self.safe_string(symbols, 0)
if firstSymbol is not None:
market = self.market(firstSymbol)
settle = market['settle']
code = market['settle']
else:
settle, params = self.handle_option_and_params(params, 'fetchPositions', 'settle', 'USD')
subType, params = self.handle_sub_type_and_params('fetchPositions', market, params)
if settle == 'USDT':
code = 'USDT'
method = 'privateGetGAccountsAccountPositions'
elif code is None:
code = 'USD' if (subType == 'linear') else 'BTC'
else:
params = self.omit(params, 'code')
currency = self.currency(code)
request = {
'currency': currency['id'],
}
response = await getattr(self, method)(self.extend(request, params))
#
# {
# "code":0,"msg":"",
# "data":{
# "account":{
# "accountId":6192120001,
# "currency":"BTC",
# "accountBalanceEv":1254744,
# "totalUsedBalanceEv":0,
# "bonusBalanceEv":1254744
# },
# "positions":[
# {
# "accountID":6192120001,
# "symbol":"BTCUSD",
# "currency":"BTC",
# "side":"None",
# "positionStatus":"Normal",
# "crossMargin":false,
# "leverageEr":100000000,
# "leverage":1.00000000,
# "initMarginReqEr":100000000,
# "initMarginReq":1.00000000,
# "maintMarginReqEr":500000,
# "maintMarginReq":0.00500000,
# "riskLimitEv":10000000000,
# "riskLimit":100.00000000,
# "size":0,
# "value":0E-8,
# "valueEv":0,
# "avgEntryPriceEp":0,
# "avgEntryPrice":0E-8,
# "posCostEv":0,
# "posCost":0E-8,
# "assignedPosBalanceEv":0,
# "assignedPosBalance":0E-8,
# "bankruptCommEv":0,
# "bankruptComm":0E-8,
# "bankruptPriceEp":0,
# "bankruptPrice":0E-8,
# "positionMarginEv":0,
# "positionMargin":0E-8,
# "liquidationPriceEp":0,
# "liquidationPrice":0E-8,
# "deleveragePercentileEr":0,
# "deleveragePercentile":0E-8,
# "buyValueToCostEr":100225000,
# "buyValueToCost":1.00225000,
# "sellValueToCostEr":100075000,
# "sellValueToCost":1.00075000,
# "markPriceEp":135736070,
# "markPrice":13573.60700000,
# "markValueEv":0,
# "markValue":null,
# "unRealisedPosLossEv":0,
# "unRealisedPosLoss":null,
# "estimatedOrdLossEv":0,
# "estimatedOrdLoss":0E-8,
# "usedBalanceEv":0,
# "usedBalance":0E-8,
# "takeProfitEp":0,
# "takeProfit":null,
# "stopLossEp":0,
# "stopLoss":null,
# "cumClosedPnlEv":0,
# "cumFundingFeeEv":0,
# "cumTransactFeeEv":0,
# "realisedPnlEv":0,
# "realisedPnl":null,
# "cumRealisedPnlEv":0,
# "cumRealisedPnl":null
# }
# ]
# }
# }
#
data = self.safe_value(response, 'data', {})
positions = self.safe_value(data, 'positions', [])
result = []
for i in range(0, len(positions)):
position = positions[i]
result.append(self.parse_position(position))
return self.filter_by_array_positions(result, 'symbol', symbols, False)
def parse_position(self, position, market=None):
#
# {
# userID: '811370',
# accountID: '8113700002',
# symbol: 'ETHUSD',
# currency: 'USD',
# side: 'Buy',
# positionStatus: 'Normal',
# crossMargin: False,
# leverageEr: '200000000',
# leverage: '2.00000000',
# initMarginReqEr: '50000000',
# initMarginReq: '0.50000000',
# maintMarginReqEr: '1000000',
# maintMarginReq: '0.01000000',
# riskLimitEv: '5000000000',
# riskLimit: '500000.00000000',
# size: '1',
# value: '22.22370000',
# valueEv: '222237',
# avgEntryPriceEp: '44447400',
# avgEntryPrice: '4444.74000000',
# posCostEv: '111202',
# posCost: '11.12020000',
# assignedPosBalanceEv: '111202',
# assignedPosBalance: '11.12020000',
# bankruptCommEv: '84',
# bankruptComm: '0.00840000',
# bankruptPriceEp: '22224000',
# bankruptPrice: '2222.40000000',
# positionMarginEv: '111118',
# positionMargin: '11.11180000',
# liquidationPriceEp: '22669000',
# liquidationPrice: '2266.90000000',
# deleveragePercentileEr: '0',
# deleveragePercentile: '0E-8',
# buyValueToCostEr: '50112500',
# buyValueToCost: '0.50112500',
# sellValueToCostEr: '50187500',
# sellValueToCost: '0.50187500',
# markPriceEp: '31332499',
# markPrice: '3133.24990000',
# markValueEv: '0',
# markValue: null,
# unRealisedPosLossEv: '0',
# unRealisedPosLoss: null,
# estimatedOrdLossEv: '0',
# estimatedOrdLoss: '0E-8',
# usedBalanceEv: '111202',
# usedBalance: '11.12020000',
# takeProfitEp: '0',
# takeProfit: null,
# stopLossEp: '0',
# stopLoss: null,
# cumClosedPnlEv: '-1546',
# cumFundingFeeEv: '1605',
# cumTransactFeeEv: '8438',
# realisedPnlEv: '0',
# realisedPnl: null,
# cumRealisedPnlEv: '0',
# cumRealisedPnl: null,
# transactTimeNs: '1641571200001885324',
# takerFeeRateEr: '0',
# makerFeeRateEr: '0',
# term: '6',
# lastTermEndTimeNs: '1607711882505745356',
# lastFundingTimeNs: '1641571200000000000',
# curTermRealisedPnlEv: '-1567',
# execSeq: '12112761561'
# }
#
marketId = self.safe_string(position, 'symbol')
market = self.safe_market(marketId, market)
symbol = market['symbol']
collateral = self.safe_string_2(position, 'positionMargin', 'positionMarginRv')
notionalString = self.safe_string_2(position, 'value', 'valueRv')
maintenanceMarginPercentageString = self.safe_string_2(position, 'maintMarginReq', 'maintMarginReqRr')
maintenanceMarginString = Precise.string_mul(notionalString, maintenanceMarginPercentageString)
initialMarginString = self.safe_string_2(position, 'assignedPosBalance', 'assignedPosBalanceRv')
initialMarginPercentageString = Precise.string_div(initialMarginString, notionalString)
liquidationPrice = self.safe_number_2(position, 'liquidationPrice', 'liquidationPriceRp')
markPriceString = self.safe_string_2(position, 'markPrice', 'markPriceRp')
contracts = self.safe_string(position, 'size')
contractSize = self.safe_value(market, 'contractSize')
contractSizeString = self.number_to_string(contractSize)
leverage = self.safe_number_2(position, 'leverage', 'leverageRr')
entryPriceString = self.safe_string_2(position, 'avgEntryPrice', 'avgEntryPriceRp')
rawSide = self.safe_string(position, 'side')
side = None
if rawSide is not None:
side = 'long' if (rawSide == 'Buy') else 'short'
priceDiff = None
currency = self.safe_string(position, 'currency')
if currency == 'USD':
if side == 'long':
priceDiff = Precise.string_sub(markPriceString, entryPriceString)
else:
priceDiff = Precise.string_sub(entryPriceString, markPriceString)
else:
# inverse
if side == 'long':
priceDiff = Precise.string_sub(Precise.string_div('1', entryPriceString), Precise.string_div('1', markPriceString))
else:
priceDiff = Precise.string_sub(Precise.string_div('1', markPriceString), Precise.string_div('1', entryPriceString))
unrealizedPnl = Precise.string_mul(Precise.string_mul(priceDiff, contracts), contractSizeString)
marginRatio = Precise.string_div(maintenanceMarginString, collateral)
isCross = self.safe_value(position, 'crossMargin')
return self.safe_position({
'info': position,
'id': None,
'symbol': symbol,
'contracts': self.parse_number(contracts),
'contractSize': contractSize,
'unrealizedPnl': self.parse_number(unrealizedPnl),
'leverage': leverage,
'liquidationPrice': liquidationPrice,
'collateral': self.parse_number(collateral),
'notional': self.parse_number(notionalString),
'markPrice': self.parse_number(markPriceString), # markPrice lags a bit ¯\_(ツ)_/¯
'lastPrice': None,
'entryPrice': self.parse_number(entryPriceString),
'timestamp': None,
'lastUpdateTimestamp': None,
'initialMargin': self.parse_number(initialMarginString),
'initialMarginPercentage': self.parse_number(initialMarginPercentageString),
'maintenanceMargin': self.parse_number(maintenanceMarginString),
'maintenanceMarginPercentage': self.parse_number(maintenanceMarginPercentageString),
'marginRatio': self.parse_number(marginRatio),
'datetime': None,
'marginMode': 'cross' if isCross else 'isolated',
'side': side,
'hedged': False,
'percentage': None,
'stopLossPrice': None,
'takeProfitPrice': None,
})
async def fetch_funding_history(self, symbol: Optional[str] = None, since: Optional[int] = None, limit: Optional[int] = None, params={}):
"""
fetch the history of funding payments paid and received on self account
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#futureDataFundingFeesHist
:param str symbol: unified market symbol
:param int [since]: the earliest time in ms to fetch funding history for
:param int [limit]: the maximum number of funding history structures to retrieve
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict: a `funding history structure <https://github.com/ccxt/ccxt/wiki/Manual#funding-history-structure>`
"""
await self.load_markets()
if symbol is None:
raise ArgumentsRequired(self.id + ' fetchFundingHistory() requires a symbol argument')
market = self.market(symbol)
request = {
'symbol': market['id'],
# 'limit': 20, # Page size default 20, max 200
# 'offset': 0, # Page start default 0
}
if limit > 200:
raise BadRequest(self.id + ' fetchFundingHistory() limit argument cannot exceed 200')
if limit is not None:
request['limit'] = limit
method = 'privateGetApiDataFuturesFundingFees'
if market['settle'] == 'USDT':
method = 'privateGetApiDataGFuturesFundingFees'
response = await getattr(self, method)(self.extend(request, params))
#
# {
# "code": 0,
# "msg": "OK",
# "data": {
# "rows": [
# {
# "symbol": "BTCUSD",
# "currency": "BTC",
# "execQty": 18,
# "side": "Buy",
# "execPriceEp": 360086455,
# "execValueEv": 49987,
# "fundingRateEr": 10000,
# "feeRateEr": 10000,
# "execFeeEv": 5,
# "createTime": 1651881600000
# }
# ]
# }
# }
#
data = self.safe_value(response, 'data', {})
rows = self.safe_value(data, 'rows', [])
result = []
for i in range(0, len(rows)):
entry = rows[i]
timestamp = self.safe_integer(entry, 'createTime')
result.append({
'info': entry,
'symbol': self.safe_string(entry, 'symbol'),
'code': self.safe_currency_code(self.safe_string(entry, 'currency')),
'timestamp': timestamp,
'datetime': self.iso8601(timestamp),
'id': None,
'amount': self.from_ev(self.safe_string(entry, 'execFeeEv'), market),
})
return result
async def fetch_funding_rate(self, symbol: str, params={}):
"""
fetch the current funding rate
:param str symbol: unified market symbol
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict: a `funding rate structure <https://github.com/ccxt/ccxt/wiki/Manual#funding-rate-structure>`
"""
await self.load_markets()
market = self.market(symbol)
if not market['swap']:
raise BadSymbol(self.id + ' fetchFundingRate() supports swap contracts only')
request = {
'symbol': market['id'],
}
response = {}
if not market['linear']:
response = await self.v1GetMdTicker24hr(self.extend(request, params))
else:
response = await self.v2GetMdV2Ticker24hr(self.extend(request, params))
#
# {
# "error": null,
# "id": 0,
# "result": {
# "askEp": 2332500,
# "bidEp": 2331000,
# "fundingRateEr": 10000,
# "highEp": 2380000,
# "indexEp": 2329057,
# "lastEp": 2331500,
# "lowEp": 2274000,
# "markEp": 2329232,
# "openEp": 2337500,
# "openInterest": 1298050,
# "predFundingRateEr": 19921,
# "symbol": "ETHUSD",
# "timestamp": 1592474241582701416,
# "turnoverEv": 47228362330,
# "volume": 4053863
# }
# }
#
result = self.safe_value(response, 'result', {})
return self.parse_funding_rate(result, market)
def parse_funding_rate(self, contract, market=None):
#
# {
# "askEp": 2332500,
# "bidEp": 2331000,
# "fundingRateEr": 10000,
# "highEp": 2380000,
# "indexEp": 2329057,
# "lastEp": 2331500,
# "lowEp": 2274000,
# "markEp": 2329232,
# "openEp": 2337500,
# "openInterest": 1298050,
# "predFundingRateEr": 19921,
# "symbol": "ETHUSD",
# "timestamp": 1592474241582701416,
# "turnoverEv": 47228362330,
# "volume": 4053863
# }
#
# linear swap v2
#
# {
# "closeRp":"16820.5",
# "fundingRateRr":"0.0001",
# "highRp":"16962.1",
# "indexPriceRp":"16830.15651565",
# "lowRp":"16785",
# "markPriceRp":"16830.97534951",
# "openInterestRv":"1323.596",
# "openRp":"16851.7",
# "predFundingRateRr":"0.0001",
# "symbol":"BTCUSDT",
# "timestamp":"1672142789065593096",
# "turnoverRv":"124835296.0538",
# "volumeRq":"7406.95"
# }
#
marketId = self.safe_string(contract, 'symbol')
symbol = self.safe_symbol(marketId, market)
timestamp = self.safe_integer_product(contract, 'timestamp', 0.000001)
return {
'info': contract,
'symbol': symbol,
'markPrice': self.from_ep(self.safe_string_2(contract, 'markEp', 'markPriceRp'), market),
'indexPrice': self.from_ep(self.safe_string_2(contract, 'indexEp', 'indexPriceRp'), market),
'interestRate': None,
'estimatedSettlePrice': None,
'timestamp': timestamp,
'datetime': self.iso8601(timestamp),
'fundingRate': self.from_er(self.safe_string(contract, 'fundingRateEr'), market),
'fundingTimestamp': None,
'fundingDatetime': None,
'nextFundingRate': self.from_er(self.safe_string_2(contract, 'predFundingRateEr', 'predFundingRateRr'), market),
'nextFundingTimestamp': None,
'nextFundingDatetime': None,
'previousFundingRate': None,
'previousFundingTimestamp': None,
'previousFundingDatetime': None,
}
async def set_margin(self, symbol: str, amount, params={}):
"""
Either adds or reduces margin in an isolated position in order to set the margin to a specific value
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Contract-API-en.md#assign-position-balance-in-isolated-marign-mode
:param str symbol: unified market symbol of the market to set margin in
:param float amount: the amount to set the margin to
:param dict [params]: parameters specific to the phemex api endpoint
:returns dict: A `margin structure <https://github.com/ccxt/ccxt/wiki/Manual#add-margin-structure>`
"""
await self.load_markets()
market = self.market(symbol)
request = {
'symbol': market['id'],
'posBalanceEv': self.to_ev(amount, market),
}
response = await self.privatePostPositionsAssign(self.extend(request, params))
#
# {
# "code": 0,
# "msg": "",
# "data": "OK"
# }
#
return self.extend(self.parse_margin_modification(response, market), {
'amount': amount,
})
def parse_margin_status(self, status):
statuses = {
'0': 'ok',
}
return self.safe_string(statuses, status, status)
def parse_margin_modification(self, data, market=None):
#
# {
# "code": 0,
# "msg": "",
# "data": "OK"
# }
#
market = self.safe_market(None, market)
inverse = self.safe_value(market, 'inverse')
codeCurrency = 'base' if inverse else 'quote'
return {
'info': data,
'type': 'set',
'amount': None,
'total': None,
'code': market[codeCurrency],
'symbol': self.safe_symbol(None, market),
'status': self.parse_margin_status(self.safe_string(data, 'code')),
}
async def set_margin_mode(self, marginMode, symbol: Optional[str] = None, params={}):
"""
set margin mode to 'cross' or 'isolated'
:param str marginMode: 'cross' or 'isolated'
:param str symbol: unified market symbol
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict: response from the exchange
"""
self.check_required_symbol('setMarginMode', symbol)
await self.load_markets()
market = self.market(symbol)
if not market['swap'] or market['settle'] == 'USDT':
raise BadSymbol(self.id + ' setMarginMode() supports swap(non USDT based) contracts only')
marginMode = marginMode.lower()
if marginMode != 'isolated' and marginMode != 'cross':
raise BadRequest(self.id + ' setMarginMode() marginMode argument should be isolated or cross')
leverage = self.safe_integer(params, 'leverage')
if marginMode == 'cross':
leverage = 0
if leverage is None:
raise ArgumentsRequired(self.id + ' setMarginMode() requires a leverage parameter')
request = {
'symbol': market['id'],
'leverage': leverage,
}
return await self.privatePutPositionsLeverage(self.extend(request, params))
async def set_position_mode(self, hedged, symbol: Optional[str] = None, params={}):
"""
set hedged to True or False for a market
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#switch-position-mode-synchronously
:param bool hedged: set to True to use dualSidePosition
:param str symbol: not used by binance setPositionMode()
:param dict [params]: extra parameters specific to the binance api endpoint
:returns dict: response from the exchange
"""
self.check_required_argument('setPositionMode', symbol, 'symbol')
await self.load_markets()
market = self.market(symbol)
if market['settle'] != 'USDT':
raise BadSymbol(self.id + ' setPositionMode() supports USDT settled markets only')
request = {
'symbol': market['id'],
}
if hedged:
request['targetPosMode'] = 'Hedged'
else:
request['targetPosMode'] = 'OneWay'
return await self.privatePutGPositionsSwitchPosModeSync(self.extend(request, params))
async def fetch_leverage_tiers(self, symbols: Optional[List[str]] = None, params={}):
"""
retrieve information on the maximum leverage, and maintenance margin for trades of varying trade sizes
:param str[]|None symbols: list of unified market symbols
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict: a dictionary of `leverage tiers structures <https://github.com/ccxt/ccxt/wiki/Manual#leverage-tiers-structure>`, indexed by market symbols
"""
await self.load_markets()
if symbols is not None:
first = self.safe_value(symbols, 0)
market = self.market(first)
if market['settle'] != 'USD':
raise BadSymbol(self.id + ' fetchLeverageTiers() supports USD settled markets only')
response = await self.publicGetCfgV2Products(params)
#
# {
# "code":0,
# "msg":"OK",
# "data":{
# "ratioScale":8,
# "currencies":[
# {"currency":"BTC","valueScale":8,"minValueEv":1,"maxValueEv":5000000000000000000,"name":"Bitcoin"},
# {"currency":"USD","valueScale":4,"minValueEv":1,"maxValueEv":500000000000000,"name":"USD"},
# {"currency":"USDT","valueScale":8,"minValueEv":1,"maxValueEv":5000000000000000000,"name":"TetherUS"},
# ],
# "products":[
# {
# "symbol":"BTCUSD",
# "displaySymbol":"BTC / USD",
# "indexSymbol":".BTC",
# "markSymbol":".MBTC",
# "fundingRateSymbol":".BTCFR",
# "fundingRate8hSymbol":".BTCFR8H",
# "contractUnderlyingAssets":"USD",
# "settleCurrency":"BTC",
# "quoteCurrency":"USD",
# "contractSize":1.0,
# "lotSize":1,
# "tickSize":0.5,
# "priceScale":4,
# "ratioScale":8,
# "pricePrecision":1,
# "minPriceEp":5000,
# "maxPriceEp":10000000000,
# "maxOrderQty":1000000,
# "type":"Perpetual"
# },
# {
# "symbol":"sBTCUSDT",
# "displaySymbol":"BTC / USDT",
# "quoteCurrency":"USDT",
# "pricePrecision":2,
# "type":"Spot",
# "baseCurrency":"BTC",
# "baseTickSize":"0.000001 BTC",
# "baseTickSizeEv":100,
# "quoteTickSize":"0.01 USDT",
# "quoteTickSizeEv":1000000,
# "minOrderValue":"10 USDT",
# "minOrderValueEv":1000000000,
# "maxBaseOrderSize":"1000 BTC",
# "maxBaseOrderSizeEv":100000000000,
# "maxOrderValue":"5,000,000 USDT",
# "maxOrderValueEv":500000000000000,
# "defaultTakerFee":"0.001",
# "defaultTakerFeeEr":100000,
# "defaultMakerFee":"0.001",
# "defaultMakerFeeEr":100000,
# "baseQtyPrecision":6,
# "quoteQtyPrecision":2
# },
# ],
# "riskLimits":[
# {
# "symbol":"BTCUSD",
# "steps":"50",
# "riskLimits":[
# {"limit":100,"initialMargin":"1.0%","initialMarginEr":1000000,"maintenanceMargin":"0.5%","maintenanceMarginEr":500000},
# {"limit":150,"initialMargin":"1.5%","initialMarginEr":1500000,"maintenanceMargin":"1.0%","maintenanceMarginEr":1000000},
# {"limit":200,"initialMargin":"2.0%","initialMarginEr":2000000,"maintenanceMargin":"1.5%","maintenanceMarginEr":1500000},
# ]
# },
# ],
# "leverages":[
# {"initialMargin":"1.0%","initialMarginEr":1000000,"options":[1,2,3,5,10,25,50,100]},
# {"initialMargin":"1.5%","initialMarginEr":1500000,"options":[1,2,3,5,10,25,50,66]},
# {"initialMargin":"2.0%","initialMarginEr":2000000,"options":[1,2,3,5,10,25,33,50]},
# ]
# }
# }
#
#
data = self.safe_value(response, 'data', {})
riskLimits = self.safe_value(data, 'riskLimits')
return self.parse_leverage_tiers(riskLimits, symbols, 'symbol')
def parse_market_leverage_tiers(self, info, market=None):
"""
:param dict info: Exchange market response for 1 market
:param dict market: CCXT market
"""
#
# {
# "symbol":"BTCUSD",
# "steps":"50",
# "riskLimits":[
# {"limit":100,"initialMargin":"1.0%","initialMarginEr":1000000,"maintenanceMargin":"0.5%","maintenanceMarginEr":500000},
# {"limit":150,"initialMargin":"1.5%","initialMarginEr":1500000,"maintenanceMargin":"1.0%","maintenanceMarginEr":1000000},
# {"limit":200,"initialMargin":"2.0%","initialMarginEr":2000000,"maintenanceMargin":"1.5%","maintenanceMarginEr":1500000},
# ]
# },
#
market = self.safe_market(None, market)
riskLimits = (market['info']['riskLimits'])
tiers = []
minNotional = 0
for i in range(0, len(riskLimits)):
tier = riskLimits[i]
maxNotional = self.safe_integer(tier, 'limit')
tiers.append({
'tier': self.sum(i, 1),
'currency': market['settle'],
'minNotional': minNotional,
'maxNotional': maxNotional,
'maintenanceMarginRate': self.safe_string(tier, 'maintenanceMargin'),
'maxLeverage': None,
'info': tier,
})
minNotional = maxNotional
return tiers
def sign(self, path, api='public', method='GET', params={}, headers=None, body=None):
query = self.omit(params, self.extract_params(path))
requestPath = '/' + self.implode_params(path, params)
url = requestPath
queryString = ''
if (method == 'GET') or (method == 'DELETE') or (method == 'PUT') or (url == '/positions/assign'):
if query:
queryString = self.urlencode_with_array_repeat(query)
url += '?' + queryString
if api == 'private':
self.check_required_credentials()
timestamp = self.seconds()
xPhemexRequestExpiry = self.safe_integer(self.options, 'x-phemex-request-expiry', 60)
expiry = self.sum(timestamp, xPhemexRequestExpiry)
expiryString = str(expiry)
headers = {
'x-phemex-access-token': self.apiKey,
'x-phemex-request-expiry': expiryString,
}
payload = ''
if method == 'POST':
payload = self.json(params)
body = payload
headers['Content-Type'] = 'application/json'
auth = requestPath + queryString + expiryString + payload
headers['x-phemex-request-signature'] = self.hmac(self.encode(auth), self.encode(self.secret), hashlib.sha256)
url = self.implode_hostname(self.urls['api'][api]) + url
return {'url': url, 'method': method, 'body': body, 'headers': headers}
async def set_leverage(self, leverage, symbol: Optional[str] = None, params={}):
"""
set the level of leverage for a market
see https://github.com/phemex/phemex-api-docs/blob/master/Public-Hedged-Perpetual-API.md#set-leverage
:param float leverage: the rate of leverage
:param str symbol: unified market symbol
:param dict [params]: extra parameters specific to the phemex api endpoint
:param bool [params.hedged]: set to True if hedged position mode is enabled(by default long and short leverage are set to the same value)
:param float [params.longLeverageRr]: *hedged mode only* set the leverage for long positions
:param float [params.shortLeverageRr]: *hedged mode only* set the leverage for short positions
:returns dict: response from the exchange
"""
# WARNING: THIS WILL INCREASE LIQUIDATION PRICE FOR OPEN ISOLATED LONG POSITIONS
# AND DECREASE LIQUIDATION PRICE FOR OPEN ISOLATED SHORT POSITIONS
if symbol is None:
raise ArgumentsRequired(self.id + ' setLeverage() requires a symbol argument')
if (leverage < 1) or (leverage > 100):
raise BadRequest(self.id + ' setLeverage() leverage should be between 1 and 100')
await self.load_markets()
isHedged = self.safe_value(params, 'hedged', False)
longLeverageRr = self.safe_integer(params, 'longLeverageRr')
shortLeverageRr = self.safe_integer(params, 'shortLeverageRr')
market = self.market(symbol)
request = {
'symbol': market['id'],
}
response = None
if market['settle'] == 'USDT':
if not isHedged and longLeverageRr is None and shortLeverageRr is None:
request['leverageRr'] = leverage
else:
long = longLeverageRr if (longLeverageRr is not None) else leverage
short = shortLeverageRr if (shortLeverageRr is not None) else leverage
request['longLeverageRr'] = long
request['shortLeverageRr'] = short
response = await self.privatePutGPositionsLeverage(self.extend(request, params))
else:
request['leverage'] = leverage
response = await self.privatePutPositionsLeverage(self.extend(request, params))
return response
async def transfer(self, code: str, amount, fromAccount, toAccount, params={}):
"""
transfer currency internally between wallets on the same account
:param str code: unified currency code
:param float amount: amount to transfer
:param str fromAccount: account to transfer from
:param str toAccount: account to transfer to
:param dict [params]: extra parameters specific to the phemex api endpoint
:param str [params.bizType]: for transferring between main and sub-acounts either 'SPOT' or 'PERPETUAL' default is 'SPOT'
:returns dict: a `transfer structure <https://github.com/ccxt/ccxt/wiki/Manual#transfer-structure>`
"""
await self.load_markets()
currency = self.currency(code)
accountsByType = self.safe_value(self.options, 'accountsByType', {})
fromId = self.safe_string(accountsByType, fromAccount, fromAccount)
toId = self.safe_string(accountsByType, toAccount, toAccount)
scaledAmmount = self.to_ev(amount, currency)
direction = None
transfer = None
if fromId == 'spot' and toId == 'future':
direction = 2
elif fromId == 'future' and toId == 'spot':
direction = 1
if direction is not None:
request = {
'currency': currency['id'],
'moveOp': direction,
'amountEv': scaledAmmount,
}
response = await self.privatePostAssetsTransfer(self.extend(request, params))
#
# {
# code: '0',
# msg: 'OK',
# data: {
# linkKey: '8564eba4-c9ec-49d6-9b8c-2ec5001a0fb9',
# userId: '4018340',
# currency: 'USD',
# amountEv: '10',
# side: '2',
# status: '10'
# }
# }
#
data = self.safe_value(response, 'data', {})
transfer = self.parse_transfer(data, currency)
else: # sub account transfer
request = {
'fromUserId': fromId,
'toUserId': toId,
'amountEv': scaledAmmount,
'currency': currency['id'],
'bizType': self.safe_string(params, 'bizType', 'SPOT'),
}
response = await self.privatePostAssetsUniversalTransfer(self.extend(request, params))
#
# {
# code: '0',
# msg: 'OK',
# data: 'API-923db826-aaaa-aaaa-aaaa-4d98c3a7c9fd'
# }
#
transfer = self.parse_transfer(response)
transferOptions = self.safe_value(self.options, 'transfer', {})
fillResponseFromRequest = self.safe_value(transferOptions, 'fillResponseFromRequest', True)
if fillResponseFromRequest:
if transfer['fromAccount'] is None:
transfer['fromAccount'] = fromAccount
if transfer['toAccount'] is None:
transfer['toAccount'] = toAccount
if transfer['amount'] is None:
transfer['amount'] = amount
if transfer['currency'] is None:
transfer['currency'] = code
return transfer
async def fetch_transfers(self, code: Optional[str] = None, since: Optional[int] = None, limit: Optional[int] = None, params={}):
"""
fetch a history of internal transfers made on an account
:param str code: unified currency code of the currency transferred
:param int [since]: the earliest time in ms to fetch transfers for
:param int [limit]: the maximum number of transfers structures to retrieve
:param dict [params]: extra parameters specific to the phemex api endpoint
:returns dict[]: a list of `transfer structures <https://github.com/ccxt/ccxt/wiki/Manual#transfer-structure>`
"""
await self.load_markets()
if code is None:
raise ArgumentsRequired(self.id + ' fetchTransfers() requires a code argument')
currency = self.currency(code)
request = {
'currency': currency['id'],
}
if since is not None:
request['start'] = since
if limit is not None:
request['limit'] = limit
response = await self.privateGetAssetsTransfer(self.extend(request, params))
#
# {
# "code": 0,
# "msg": "OK",
# "data": {
# "rows": [
# {
# "linkKey": "87c071a3-8628-4ac2-aca1-6ce0d1fad66c",
# "userId": 4148428,
# "currency": "BTC",
# "amountEv": 67932,
# "side": 2,
# "status": 10,
# "createTime": 1652832467000,
# "bizType": 10
# }
# ]
# }
# }
#
data = self.safe_value(response, 'data', {})
transfers = self.safe_value(data, 'rows', [])
return self.parse_transfers(transfers, currency, since, limit)
def parse_transfer(self, transfer, currency=None):
#
# transfer
#
# {
# linkKey: '8564eba4-c9ec-49d6-9b8c-2ec5001a0fb9',
# userId: '4018340',
# currency: 'USD',
# amountEv: '10',
# side: '2',
# status: '10'
# }
#
# fetchTransfers
#
# {
# "linkKey": "87c071a3-8628-4ac2-aca1-6ce0d1fad66c",
# "userId": 4148428,
# "currency": "BTC",
# "amountEv": 67932,
# "side": 2,
# "status": 10,
# "createTime": 1652832467000,
# "bizType": 10
# }
#
id = self.safe_string(transfer, 'linkKey')
status = self.safe_string(transfer, 'status')
amountEv = self.safe_string(transfer, 'amountEv')
amountTransfered = self.from_ev(amountEv, currency)
currencyId = self.safe_string(transfer, 'currency')
code = self.safe_currency_code(currencyId, currency)
side = self.safe_integer(transfer, 'side')
fromId = None
toId = None
if side == 1:
fromId = 'swap'
toId = 'spot'
elif side == 2:
fromId = 'spot'
toId = 'swap'
timestamp = self.safe_integer(transfer, 'createTime')
return {
'info': transfer,
'id': id,
'timestamp': timestamp,
'datetime': self.iso8601(timestamp),
'currency': code,
'amount': amountTransfered,
'fromAccount': fromId,
'toAccount': toId,
'status': self.parse_transfer_status(status),
}
def parse_transfer_status(self, status):
statuses = {
'3': 'rejected', # 'Rejected',
'6': 'canceled', # 'Got error and wait for recovery',
'10': 'ok', # 'Success',
'11': 'failed', # 'Failed',
}
return self.safe_string(statuses, status, status)
async def fetch_funding_rate_history(self, symbol: Optional[str] = None, since: Optional[int] = None, limit: Optional[int] = None, params={}):
self.check_required_symbol('fetchFundingRateHistory', symbol)
await self.load_markets()
market = self.market(symbol)
isUsdtSettled = market['settle'] == 'USDT'
if not market['swap']:
raise BadRequest(self.id + ' fetchFundingRateHistory() supports swap contracts only')
customSymbol = None
if isUsdtSettled:
customSymbol = '.' + market['id'] + 'FR8H' # phemex requires a custom symbol for funding rate history
else:
customSymbol = '.' + market['baseId'] + 'FR8H'
request = {
'symbol': customSymbol,
}
if since is not None:
request['start'] = since
if limit is not None:
request['limit'] = limit
response = None
if isUsdtSettled:
response = await self.v2GetApiDataPublicDataFundingRateHistory(self.extend(request, params))
else:
response = await self.v1GetApiDataPublicDataFundingRateHistory(self.extend(request, params))
#
# {
# "code":"0",
# "msg":"OK",
# "data":{
# "rows":[
# {
# "symbol":".BTCUSDTFR8H",
# "fundingRate":"0.0001",
# "fundingTime":"1682064000000",
# "intervalSeconds":"28800"
# }
# ]
# }
# }
#
data = self.safe_value(response, 'data', {})
rates = self.safe_value(data, 'rows')
result = []
for i in range(0, len(rates)):
item = rates[i]
timestamp = self.safe_integer(item, 'fundingTime')
result.append({
'info': item,
'symbol': symbol,
'fundingRate': self.safe_number(item, 'fundingRate'),
'timestamp': timestamp,
'datetime': self.iso8601(timestamp),
})
sorted = self.sort_by(result, 'timestamp')
return self.filter_by_symbol_since_limit(sorted, symbol, since, limit)
def handle_errors(self, httpCode, reason, url, method, headers, body, response, requestHeaders, requestBody):
if response is None:
return None # fallback to default error handler
#
# {"code":30018,"msg":"phemex.data.size.uplimt","data":null}
# {"code":412,"msg":"Missing parameter - resolution","data":null}
# {"code":412,"msg":"Missing parameter - to","data":null}
# {"error":{"code":6001,"message":"invalid argument"},"id":null,"result":null}
#
error = self.safe_value(response, 'error', response)
errorCode = self.safe_string(error, 'code')
message = self.safe_string(error, 'msg')
if (errorCode is not None) and (errorCode != '0'):
feedback = self.id + ' ' + body
self.throw_exactly_matched_exception(self.exceptions['exact'], errorCode, feedback)
self.throw_broadly_matched_exception(self.exceptions['broad'], message, feedback)
raise ExchangeError(feedback) # unknown message
return None
| [
"travis@travis-ci.org"
] | travis@travis-ci.org |
f9533c10696274ee3f113a9ade94819a015ebdda | 3c92c3f633b613a62fb67476fd617e1140133880 | /leetcode/27. Remove Element.py | 389200567c30dff692573da7bd67a5203e14e62b | [] | no_license | cuiy0006/Algorithms | 2787f36f8164ded5252a006f723b570c9091bee9 | 00fd1397b65c68a303fcf963db3e28cd35c1c003 | refs/heads/master | 2023-03-31T13:55:59.191857 | 2023-03-31T03:39:42 | 2023-03-31T03:39:42 | 75,001,651 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 952 | py | class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
i = 0
j = 0
while i < len(nums):
while i < len(nums) and nums[i] == val:
i += 1
if i == len(nums):
break
nums[j] = nums[i]
j += 1
i += 1
return j
class Solution:
def removeElement(self, nums, val):
"""
:type nums: List[int]
:type val: int
:rtype: int
"""
if len(nums) == 0:
return 0
i = 0
j = len(nums) - 1
while i < j:
while i < j and nums[i] != val:
i += 1
while i < j and nums[j] == val:
j -= 1
nums[i], nums[j] = nums[j], nums[i]
if nums[i] != val:
return i + 1
else:
return i
| [
"noreply@github.com"
] | cuiy0006.noreply@github.com |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.