
blob_id stringlengths 40 40 | directory_id stringlengths 40 40 | path stringlengths 3 616 | content_id stringlengths 40 40 | detected_licenses listlengths 0 112 | license_type stringclasses 2 values | repo_name stringlengths 5 115 | snapshot_id stringlengths 40 40 | revision_id stringlengths 40 40 | branch_name stringclasses 777 values | visit_date timestamp[us]date 2015-08-06 10:31:46 2023-09-06 10:44:38 | revision_date timestamp[us]date 1970-01-01 02:38:32 2037-05-03 13:00:00 | committer_date timestamp[us]date 1970-01-01 02:38:32 2023-09-06 01:08:06 | github_id int64 4.92k 681M ⌀ | star_events_count int64 0 209k | fork_events_count int64 0 110k | gha_license_id stringclasses 22 values | gha_event_created_at timestamp[us]date 2012-06-04 01:52:49 2023-09-14 21:59:50 ⌀ | gha_created_at timestamp[us]date 2008-05-22 07:58:19 2023-08-21 12:35:19 ⌀ | gha_language stringclasses 149 values | src_encoding stringclasses 26 values | language stringclasses 1 value | is_vendor bool 2 classes | is_generated bool 2 classes | length_bytes int64 3 10.2M | extension stringclasses 188 values | content stringlengths 3 10.2M | authors listlengths 1 1 | author_id stringlengths 1 132 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
88604d9ea2e04d2cbbda3eeb010b376700e444ff | a3e86193eb50d90b01135a8a1f51330e10624d7d | /Quadrupole/computeHausdorff.py | eda5b6dab99e327de6f6bb4053d4121ee3a71399 | [] | no_license | yangyutu/Diffusion-mapping | b1f461b5c3d37e4b07a733eb28674b7dde140fa4 | 2e6b151dc7ced1c66589b4e56383a08764e52319 | refs/heads/master | 2021-01-11T03:05:47.610753 | 2019-08-23T12:23:13 | 2019-08-23T12:23:13 | 71,095,710 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 887 | py | # -*- coding: utf-8 -*-
"""
Created on Fri Oct 23 13:09:18 2015
@author: yuugangyang
"""
import numpy as np
def compute_dist(A, B):
dim= A.shape[1]
dist = []
for k in range(A.shape[0]):
C = np.dot(np.ones((B.shape[0], 1)), A[k,:].reshape(1,A.shape[1]))
D = (C-B) * (C-B)
D = np.sqrt(np.dot(D,np.ones((dim,1))))
dist.append(np.min(D))
dist = max(np.array(dist))
return dist
def computeHausdorffDistance(A,B):
# ** A and B may have different number of rows, but must have the same number of columns. **
#
if not A.shape[1] == B.shape[1]:
print "dimension not matched!"
return
d1 = compute_dist(A, B)
d2 = compute_dist(B, A)
dH = max(d1,d2)
return dH
if __name__ == '__main__':
A = np.random.randn(5,5)
B = np.random.randn(5,5)
dh = computeHausdorffDistance(A,B)
print dh | [
"yangyutu123@gmail.com"
] | yangyutu123@gmail.com |
25960eafa19a79c0bf57da6562c5779f6f27e566 | d74913eda69ee1799c887a645c574fa5a4da8fba | /code/daymet/daymet_download.py | fdb08ec202d56e76ce15de51cf4e66b91bdb7643 | [
"Apache-2.0"
] | permissive | Fweek/pyMETRIC | efd6fe8c6ea74f5c87d19ecbb6653549fb3ba943 | 0e7eec57fedd33b81e6e7efe58290f50ebbebfab | refs/heads/master | 2021-05-03T10:23:15.066106 | 2018-02-06T19:32:36 | 2018-02-06T19:32:36 | 120,534,046 | 1 | 0 | null | 2018-02-06T23:00:49 | 2018-02-06T23:00:48 | null | UTF-8 | Python | false | false | 6,295 | py | #--------------------------------
# Name: daymet_download.py
# Purpose: Download DAYMET data
# Python: 2.7, 3.5, 3.6
#--------------------------------
import argparse
import datetime as dt
import logging
import os
import sys
from python_common import date_range, valid_date, url_download
def main(netcdf_ws=os.getcwd(), variables=['all'],
start_date=None, end_date=None,
overwrite_flag=False):
"""Download DAYMET netcdf files
Data is currently only available for 1980-2014
Data for 2015 will need to be downloaded a different way
Args:
netcdf_ws (str): root folder of DAYMET data
variables (list): DAYMET variables to download
('prcp', 'srad', 'vp', 'tmmn', 'tmmx')
Set as ['all'] to download all available variables
start_date (str): ISO format date (YYYY-MM-DD)
end_date (str): ISO format date (YYYY-MM-DD)
overwrite_flag (bool): if True, overwrite existing files
Returns:
None
"""
logging.info('\nDownloading DAYMET data')
site_url = 'http://thredds.daac.ornl.gov/thredds/fileServer/ornldaac/1328'
# site_url = 'http://daac.ornl.gov/data/daymet/Daymet_mosaics/data'
# If a date is not set, process 2015
try:
start_dt = dt.datetime.strptime(start_date, '%Y-%m-%d')
logging.debug(' Start date: {}'.format(start_dt))
except Exception as e:
start_dt = dt.datetime(2015, 1, 1)
logging.info(' Start date: {}'.format(start_dt))
logging.debug(e)
try:
end_dt = dt.datetime.strptime(end_date, '%Y-%m-%d')
logging.debug(' End date: {}'.format(end_dt))
except Exception as e:
end_dt = dt.datetime(2015, 12, 31)
logging.info(' End date: {}'.format(end_dt))
logging.debug(e)
# DAYMET rasters to extract
var_full_list = ['prcp', 'srad', 'vp', 'tmin', 'tmax']
if not variables:
logging.error('\nERROR: variables parameter is empty\n')
sys.exit()
elif type(variables) is not list:
# DEADBEEF - I could try converting comma separated strings to lists?
logging.warning('\nERROR: variables parameter must be a list\n')
sys.exit()
elif 'all' in variables:
logging.error('\nDownloading all variables\n {}'.format(
','.join(var_full_list)))
var_list = var_full_list
elif not set(variables).issubset(set(var_full_list)):
logging.error('\nERROR: variables parameter is invalid\n {}'.format(
variables))
sys.exit()
else:
var_list = variables[:]
# Build output workspace if it doesn't exist
if not os.path.isdir(netcdf_ws):
os.makedirs(netcdf_ws)
# DAYMET data is stored by year
year_list = sorted(list(set([
i_dt.year for i_dt in date_range(
start_dt, end_dt + dt.timedelta(1))])))
year_list = list(map(lambda x: '{:04d}'.format(x), year_list))
# Set data types to upper case for comparison
var_list = list(map(lambda x: x.lower(), var_list))
# Each sub folder in the main folder has all imagery for 1 day
# The path for each subfolder is the /YYYY/MM/DD
logging.info('')
for year_str in year_list:
logging.info(year_str)
# Process each file in sub folder
for variable in var_list:
file_name = 'daymet_v3_{}_{}_na.nc4'.format(variable, year_str)
file_url = '{}/{}/{}'.format(site_url, year_str, file_name)
save_path = os.path.join(netcdf_ws, file_name)
logging.info(' {}'.format(file_name))
logging.debug(' {}'.format(file_url))
logging.debug(' {}'.format(save_path))
if os.path.isfile(save_path):
if not overwrite_flag:
logging.debug(' File already exists, skipping')
continue
else:
logging.debug(' File already exists, removing existing')
os.remove(save_path)
url_download(file_url, save_path)
logging.debug('\nScript Complete')
def arg_parse():
"""
Base all default folders from script location
scripts: ./pyMETRIC/code/daymet
code: ./pyMETRIC/code
output: ./pyMETRIC/daymet
"""
script_folder = sys.path[0]
code_folder = os.path.dirname(script_folder)
project_folder = os.path.dirname(code_folder)
daymet_folder = os.path.join(project_folder, 'daymet')
parser = argparse.ArgumentParser(
description='Download daily DAYMET data',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
'--netcdf', default=os.path.join(daymet_folder, 'netcdf'),
metavar='PATH', help='Output netCDF folder path')
parser.add_argument(
'--vars', default=['all'], nargs='+',
choices=['all', 'prcp', 'srad', 'vp', 'tmin', 'tmax'],
help='DAYMET variables to download')
parser.add_argument(
'--start', default='2015-01-01', type=valid_date,
help='Start date (format YYYY-MM-DD)', metavar='DATE')
parser.add_argument(
'--end', default='2015-12-31', type=valid_date,
help='End date (format YYYY-MM-DD)', metavar='DATE')
parser.add_argument(
'-o', '--overwrite', default=False, action="store_true",
help='Force overwrite of existing files')
parser.add_argument(
'--debug', default=logging.INFO, const=logging.DEBUG,
help='Debug level logging', action="store_const", dest="loglevel")
args = parser.parse_args()
# Convert relative paths to absolute paths
if args.netcdf and os.path.isdir(os.path.abspath(args.netcdf)):
args.netcdf = os.path.abspath(args.netcdf)
return args
if __name__ == '__main__':
args = arg_parse()
logging.basicConfig(level=args.loglevel, format='%(message)s')
logging.info('\n{}'.format('#' * 80))
logging.info('{:<20s} {}'.format(
'Run Time Stamp:', dt.datetime.now().isoformat(' ')))
logging.info('{:<20s} {}'.format(
'Script:', os.path.basename(sys.argv[0])))
main(netcdf_ws=args.netcdf, variables=args.vars,
start_date=args.start, end_date=args.end,
overwrite_flag=args.overwrite)
| [
"dgketchum@gmail.com"
] | dgketchum@gmail.com |
806abcf8960a76c7d2f3f8225378822b2c9cef55 | edd8ad3dcb6ee9b019c999b712f8ee0c468e2b81 | /Review/Chapter09/Exercise/9-11.py | 39c21f92bd2548e0601a8b682936e4b6b46c8f1c | [] | no_license | narinn-star/Python | 575cba200de35b9edf3832c4e41ccce657075751 | 14eba211cd3a9e9708a30073ba5b31d21d39eeef | refs/heads/master | 2023-05-25T22:57:26.079294 | 2021-06-07T15:29:39 | 2021-06-07T15:29:39 | 331,647,462 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 545 | py | from tkinter import*
from time import*
from tkinter.messagebox import showinfo
top = Tk()
def click1():
time = strftime('Day: %d %b %Y\nTime: %H:%M:%S %p\n', localtime())
showinfo(message=time, title='Local time')
def click2():
time = strftime('Day: %d %b %Y\nTime: %H:%M:%S %p\n', gmtime())
showinfo(message=time, title='Greenwich time')
ltbutton = Button(top, text='Local time', command=click1)
gtbutton = Button(top, text='Greenwich time', command=click2)
ltbutton.pack(side=LEFT)
gtbutton.pack(side=LEFT)
top.mainloop() | [
"skfls2618@naver.com"
] | skfls2618@naver.com |
5fda3e1957ac5344f2d3517ed513d8eb6aa40ab4 | 53fab060fa262e5d5026e0807d93c75fb81e67b9 | /backup/user_052/ch6_2020_03_03_19_25_47_813131.py | 6c5eb200cb8ea6c74259dab2fa5f6e92a7835e0f | [] | no_license | gabriellaec/desoft-analise-exercicios | b77c6999424c5ce7e44086a12589a0ad43d6adca | 01940ab0897aa6005764fc220b900e4d6161d36b | refs/heads/main | 2023-01-31T17:19:42.050628 | 2020-12-16T05:21:31 | 2020-12-16T05:21:31 | 306,735,108 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 68 | py | def celsius_para_fahrenheit (f):
c=(5(f)-160)/(9)
return c | [
"you@example.com"
] | you@example.com |
b8b2b3ab91eca94d428151711819f43ea0321bb1 | 6b33a54d14424bb155a4dd307b19cfb2aacbde43 | /bioinformatics/analysis/rnaseq/circRNA/circ_repeat_analysis.py | 58810b979f0684734ac01601eef30c8fe257c6ff | [
"MIT"
] | permissive | bioShaun/omsCabinet | 4905ab022dea1ec13df5982877dafbed415ee3d2 | 741179a06cbd5200662cd03bc2e0115f4ad06917 | refs/heads/master | 2021-01-25T11:56:38.524299 | 2020-02-09T09:12:30 | 2020-02-09T09:12:30 | 123,445,089 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,443 | py | import os
import click
import pandas as pd
REPEAT_HEADER = [
'chrom',
'start',
'end',
'circRNAID',
'score',
'strand',
'region',
'repeat_chrom',
'repeat_start',
'repeat_end',
'repeat_id',
'repeat_score',
'repeat_strand',
'repeat_type',
'repeat_class',
'overlap'
]
REGION_MAP = {
'up': 'flankIntronUpSINE',
'down': 'flankIntronDownSINE',
}
OUT_COL = [
'flankIntronUpSINE',
'flankIntronDownSINE',
]
def reapeat_type_stats(repeat_df):
repeat_type_df = repeat_df.loc[:, ['region', 'repeat_class']]
t_num = repeat_type_df.groupby(['region']).size()
repeat_type_num = repeat_type_df.groupby(
['region'])['repeat_class'].value_counts()
rp_portion = pd.DataFrame(repeat_type_num / t_num)
rp_portion.columns = ['portion']
return rp_portion
def get_sine_content(repeat_df):
repeat_df.region.replace(REGION_MAP, inplace=True)
sine_df = repeat_df[repeat_df.repeat_class == 'Type I Transposons/SINE']
sine_counts = sine_df.groupby(
['circRNAID', 'region', 'repeat_class']).size()
sine_counts = pd.DataFrame(sine_counts)
sine_counts.columns = ['counts']
sine_counts.index = sine_counts.index.droplevel('repeat_class')
sine_counts = sine_counts.unstack('region')
sine_counts.columns = sine_counts.columns.droplevel()
return sine_counts
@click.command()
@click.argument(
'repeat_overlap',
type=click.Path(dir_okay=False, exists=True),
required=True
)
@click.argument(
'name',
type=click.STRING,
required=True
)
@click.argument(
'out_dir',
type=click.Path(file_okay=False, exists=True),
required=True
)
def main(repeat_overlap, name, out_dir):
repeat_df = pd.read_table(repeat_overlap, header=None,
names=REPEAT_HEADER)
# get repeat class portion
rp_class_portion = reapeat_type_stats(repeat_df)
rp_class_file = os.path.join(
out_dir, '{n}.repeat.class.txt'.format(n=name))
rp_class_portion.to_csv(rp_class_file, sep='\t')
# get SINE content for each circRNA up/down stream flank intron
sine_content_file = os.path.join(
out_dir, '{n}.SINE.content.txt'.format(n=name)
)
sine_content_df = get_sine_content(repeat_df)
sine_content_df = sine_content_df.loc[:, OUT_COL]
sine_content_df.to_csv(sine_content_file, sep='\t', na_rep=0)
if __name__ == '__main__':
main()
| [
"ricekent@163.com"
] | ricekent@163.com |
f6f602813e8d149331f616953fcebe2f7c6aa15e | 6cfc842b7dc1c2628d9e7ef69cdd52b7279a409d | /business/member/member_notice.py | 4bbeabd761e742387154dd80e2953e90aa965e53 | [] | no_license | vothin/requsets_test | 6fbf4ec2206b54d150d253700ba62bfa51c32e7f | 235200a67c1fb125f75f9771808f6655a7b14202 | refs/heads/master | 2021-07-07T06:48:50.528885 | 2020-12-25T04:19:12 | 2020-12-25T04:19:12 | 218,724,714 | 0 | 0 | null | 2020-06-23T08:04:36 | 2019-10-31T09:02:12 | Python | UTF-8 | Python | false | false | 2,683 | py | # -*- coding:utf-8 -*-
'''
@author: Vothin
@software: 自动化测试
@file: member_notice.py
@time: 2019/11/19 15:21
@desc:
'''
# ********************************************************
from common.requests_test import Requests_Test
from common.change_param import Change_Param
from common.recordlog import logs
class Member_Notice(Requests_Test):
# 查询会员站内消息历史列表
def get_member_nocice_logs(self, username=None, password=None, data=None, prod=None):
'''
相关参数有: page_no 页码
page_size 每页显示数量
read 是否已读,1已读,0未读,可用值:0,1
'''
# 调用Change_Param类
cu = Change_Param(username, password, prod)
gu = cu.get_params()
# 拼接url
self.suffix = self.c.get_value('Member', 'members_nocice_logs')
self.url = self.url_joint(prod) + gu[1]
logs.info('test url:%s' % self.url)
return self.get_requests(self.url, gu[0], data)
# 删除会员站内消息历史
def del_member_nocice_logs_ids(self, ids, username=None, password=None, data=None, prod=None):
'''
相关参数有: ids 要删除的消息主键
'''
# 调用Change_Param类
cu = Change_Param(username, password, prod)
gu = cu.get_params()
# 拼接url
self.suffix = self.c.get_value('Member', 'members_nocice_logs_ids')
self.suffix = self.suffix.format(ids)
self.url = self.url_joint(prod) + gu[1]
logs.info('test url:%s' % self.url)
return self.del_requests(self.url, gu[0], data)
# 将消息设置为已读
def put_member_nocice_logs_ids(self, ids, username=None, password=None, data=None, prod=None):
'''
相关参数有: ids 要设置为已读消息的id
'''
# 调用Change_Param类
cu = Change_Param(username, password, prod)
gu = cu.get_params()
# 拼接url
self.suffix = self.c.get_value('Member', 'members_nocice_logs_read')
self.suffix = self.suffix.format(ids)
self.url = self.url_joint(prod) + gu[1]
logs.info('test url:%s' % self.url)
return self.put_requests(self.url, gu[0], data)
if __name__ == '__main__':
m = Member_Notice()
# result = m.get_member_nocice_logs('13412345678', '123456')
# result = m.del_member_nocice_logs_ids('858', '13412345678', '123456')
result = m.put_member_nocice_logs_ids('859', '13412345678', '123456')
print(result)
print(result.text) | [
"zy757161350@qq.com"
] | zy757161350@qq.com |
cdd207b1b203db6293e2bffe6d148972ae6eb6b2 | f8c3c677ba536fbf5a37ac4343c1f3f3acd4d9b6 | /ICA_SDK/ICA_SDK/models/genome_compact.py | ebf10891bd98241b7ae2eae4b10552dcbac2035c | [] | no_license | jsialar/integrated_IAP_SDK | 5e6999b0a9beabe4dfc4f2b6c8b0f45b1b2f33eb | c9ff7685ef0a27dc4af512adcff914f55ead0edd | refs/heads/main | 2023-08-25T04:16:27.219027 | 2021-10-26T16:06:09 | 2021-10-26T16:06:09 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 27,866 | py | # coding: utf-8
"""
IAP Services
No description provided (generated by Openapi Generator https://github.com/openapitools/openapi-generator) # noqa: E501
The version of the OpenAPI document: v1
Generated by: https://openapi-generator.tech
"""
import pprint
import re # noqa: F401
import six
from ICA_SDK.configuration import Configuration
class GenomeCompact(object):
"""NOTE: This class is auto generated by OpenAPI Generator.
Ref: https://openapi-generator.tech
Do not edit the class manually.
"""
"""
Attributes:
openapi_types (dict): The key is attribute name
and the value is attribute type.
attribute_map (dict): The key is attribute name
and the value is json key in definition.
"""
openapi_types = {
'id': 'str',
'urn': 'str',
'href': 'str',
'name': 'str',
'display_name': 'str',
'order': 'int',
'organization': 'str',
'description': 'str',
'status': 'str',
'species': 'str',
'source': 'str',
'build': 'str',
'dragen_version': 'str',
'data_location_urn': 'str',
'genome_format': 'str',
'settings': 'object',
'source_file_metadata': 'object',
'fasta_file_urn': 'str',
'is_application_specific': 'bool',
'is_illumina': 'bool',
'checksum': 'str',
'sub_tenant_id': 'str',
'acl': 'list[str]',
'tenant_id': 'str',
'tenant_name': 'str',
'created_by_client_id': 'str',
'created_by': 'str',
'modified_by': 'str',
'time_created': 'datetime',
'time_modified': 'datetime'
}
attribute_map = {
'id': 'id',
'urn': 'urn',
'href': 'href',
'name': 'name',
'display_name': 'displayName',
'order': 'order',
'organization': 'organization',
'description': 'description',
'status': 'status',
'species': 'species',
'source': 'source',
'build': 'build',
'dragen_version': 'dragenVersion',
'data_location_urn': 'dataLocationUrn',
'genome_format': 'genomeFormat',
'settings': 'settings',
'source_file_metadata': 'sourceFileMetadata',
'fasta_file_urn': 'fastaFileUrn',
'is_application_specific': 'isApplicationSpecific',
'is_illumina': 'isIllumina',
'checksum': 'checksum',
'sub_tenant_id': 'subTenantId',
'acl': 'acl',
'tenant_id': 'tenantId',
'tenant_name': 'tenantName',
'created_by_client_id': 'createdByClientId',
'created_by': 'createdBy',
'modified_by': 'modifiedBy',
'time_created': 'timeCreated',
'time_modified': 'timeModified'
}
def __init__(self, id=None, urn=None, href=None, name=None, display_name=None, order=None, organization=None, description=None, status=None, species=None, source=None, build=None, dragen_version=None, data_location_urn=None, genome_format=None, settings=None, source_file_metadata=None, fasta_file_urn=None, is_application_specific=None, is_illumina=None, checksum=None, sub_tenant_id=None, acl=None, tenant_id=None, tenant_name=None, created_by_client_id=None, created_by=None, modified_by=None, time_created=None, time_modified=None, local_vars_configuration=None): # noqa: E501
"""GenomeCompact - a model defined in OpenAPI""" # noqa: E501
if local_vars_configuration is None:
local_vars_configuration = Configuration()
self.local_vars_configuration = local_vars_configuration
self._id = None
self._urn = None
self._href = None
self._name = None
self._display_name = None
self._order = None
self._organization = None
self._description = None
self._status = None
self._species = None
self._source = None
self._build = None
self._dragen_version = None
self._data_location_urn = None
self._genome_format = None
self._settings = None
self._source_file_metadata = None
self._fasta_file_urn = None
self._is_application_specific = None
self._is_illumina = None
self._checksum = None
self._sub_tenant_id = None
self._acl = None
self._tenant_id = None
self._tenant_name = None
self._created_by_client_id = None
self._created_by = None
self._modified_by = None
self._time_created = None
self._time_modified = None
self.discriminator = None
if id is not None:
self.id = id
if urn is not None:
self.urn = urn
if href is not None:
self.href = href
if name is not None:
self.name = name
if display_name is not None:
self.display_name = display_name
if order is not None:
self.order = order
if organization is not None:
self.organization = organization
if description is not None:
self.description = description
if status is not None:
self.status = status
if species is not None:
self.species = species
if source is not None:
self.source = source
if build is not None:
self.build = build
if dragen_version is not None:
self.dragen_version = dragen_version
if data_location_urn is not None:
self.data_location_urn = data_location_urn
if genome_format is not None:
self.genome_format = genome_format
if settings is not None:
self.settings = settings
if source_file_metadata is not None:
self.source_file_metadata = source_file_metadata
if fasta_file_urn is not None:
self.fasta_file_urn = fasta_file_urn
if is_application_specific is not None:
self.is_application_specific = is_application_specific
if is_illumina is not None:
self.is_illumina = is_illumina
if checksum is not None:
self.checksum = checksum
if sub_tenant_id is not None:
self.sub_tenant_id = sub_tenant_id
if acl is not None:
self.acl = acl
if tenant_id is not None:
self.tenant_id = tenant_id
if tenant_name is not None:
self.tenant_name = tenant_name
if created_by_client_id is not None:
self.created_by_client_id = created_by_client_id
if created_by is not None:
self.created_by = created_by
if modified_by is not None:
self.modified_by = modified_by
if time_created is not None:
self.time_created = time_created
if time_modified is not None:
self.time_modified = time_modified
@property
def id(self):
"""Gets the id of this GenomeCompact. # noqa: E501
Unique object ID # noqa: E501
:return: The id of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._id
@id.setter
def id(self, id):
"""Sets the id of this GenomeCompact.
Unique object ID # noqa: E501
:param id: The id of this GenomeCompact. # noqa: E501
:type: str
"""
self._id = id
@property
def urn(self):
"""Gets the urn of this GenomeCompact. # noqa: E501
URN of the object # noqa: E501
:return: The urn of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._urn
@urn.setter
def urn(self, urn):
"""Sets the urn of this GenomeCompact.
URN of the object # noqa: E501
:param urn: The urn of this GenomeCompact. # noqa: E501
:type: str
"""
self._urn = urn
@property
def href(self):
"""Gets the href of this GenomeCompact. # noqa: E501
HREF to the object # noqa: E501
:return: The href of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._href
@href.setter
def href(self, href):
"""Sets the href of this GenomeCompact.
HREF to the object # noqa: E501
:param href: The href of this GenomeCompact. # noqa: E501
:type: str
"""
self._href = href
@property
def name(self):
"""Gets the name of this GenomeCompact. # noqa: E501
Name of the genome # noqa: E501
:return: The name of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._name
@name.setter
def name(self, name):
"""Sets the name of this GenomeCompact.
Name of the genome # noqa: E501
:param name: The name of this GenomeCompact. # noqa: E501
:type: str
"""
self._name = name
@property
def display_name(self):
"""Gets the display_name of this GenomeCompact. # noqa: E501
DisplayName of the genome # noqa: E501
:return: The display_name of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._display_name
@display_name.setter
def display_name(self, display_name):
"""Sets the display_name of this GenomeCompact.
DisplayName of the genome # noqa: E501
:param display_name: The display_name of this GenomeCompact. # noqa: E501
:type: str
"""
self._display_name = display_name
@property
def order(self):
"""Gets the order of this GenomeCompact. # noqa: E501
Order of the genome # noqa: E501
:return: The order of this GenomeCompact. # noqa: E501
:rtype: int
"""
return self._order
@order.setter
def order(self, order):
"""Sets the order of this GenomeCompact.
Order of the genome # noqa: E501
:param order: The order of this GenomeCompact. # noqa: E501
:type: int
"""
self._order = order
@property
def organization(self):
"""Gets the organization of this GenomeCompact. # noqa: E501
Organization of the genome, Require gss.genomes.admin scope to set Organization to a value containing Illumina (case-insensitive) # noqa: E501
:return: The organization of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._organization
@organization.setter
def organization(self, organization):
"""Sets the organization of this GenomeCompact.
Organization of the genome, Require gss.genomes.admin scope to set Organization to a value containing Illumina (case-insensitive) # noqa: E501
:param organization: The organization of this GenomeCompact. # noqa: E501
:type: str
"""
self._organization = organization
@property
def description(self):
"""Gets the description of this GenomeCompact. # noqa: E501
Description of the genome # noqa: E501
:return: The description of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._description
@description.setter
def description(self, description):
"""Sets the description of this GenomeCompact.
Description of the genome # noqa: E501
:param description: The description of this GenomeCompact. # noqa: E501
:type: str
"""
self._description = description
@property
def status(self):
"""Gets the status of this GenomeCompact. # noqa: E501
Status of the genome # noqa: E501
:return: The status of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._status
@status.setter
def status(self, status):
"""Sets the status of this GenomeCompact.
Status of the genome # noqa: E501
:param status: The status of this GenomeCompact. # noqa: E501
:type: str
"""
self._status = status
@property
def species(self):
"""Gets the species of this GenomeCompact. # noqa: E501
Species of the genome # noqa: E501
:return: The species of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._species
@species.setter
def species(self, species):
"""Sets the species of this GenomeCompact.
Species of the genome # noqa: E501
:param species: The species of this GenomeCompact. # noqa: E501
:type: str
"""
self._species = species
@property
def source(self):
"""Gets the source of this GenomeCompact. # noqa: E501
Source of the genome # noqa: E501
:return: The source of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._source
@source.setter
def source(self, source):
"""Sets the source of this GenomeCompact.
Source of the genome # noqa: E501
:param source: The source of this GenomeCompact. # noqa: E501
:type: str
"""
self._source = source
@property
def build(self):
"""Gets the build of this GenomeCompact. # noqa: E501
Build of the genome # noqa: E501
:return: The build of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._build
@build.setter
def build(self, build):
"""Sets the build of this GenomeCompact.
Build of the genome # noqa: E501
:param build: The build of this GenomeCompact. # noqa: E501
:type: str
"""
self._build = build
@property
def dragen_version(self):
"""Gets the dragen_version of this GenomeCompact. # noqa: E501
Dragen version for the genome, it is required when Illumina.GenomicSequencingService.Models.V1.GenomeCompact.GenomeFormat is Dragen # noqa: E501
:return: The dragen_version of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._dragen_version
@dragen_version.setter
def dragen_version(self, dragen_version):
"""Sets the dragen_version of this GenomeCompact.
Dragen version for the genome, it is required when Illumina.GenomicSequencingService.Models.V1.GenomeCompact.GenomeFormat is Dragen # noqa: E501
:param dragen_version: The dragen_version of this GenomeCompact. # noqa: E501
:type: str
"""
self._dragen_version = dragen_version
@property
def data_location_urn(self):
"""Gets the data_location_urn of this GenomeCompact. # noqa: E501
Urn of the file in GDS containing the genome data file # noqa: E501
:return: The data_location_urn of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._data_location_urn
@data_location_urn.setter
def data_location_urn(self, data_location_urn):
"""Sets the data_location_urn of this GenomeCompact.
Urn of the file in GDS containing the genome data file # noqa: E501
:param data_location_urn: The data_location_urn of this GenomeCompact. # noqa: E501
:type: str
"""
self._data_location_urn = data_location_urn
@property
def genome_format(self):
"""Gets the genome_format of this GenomeCompact. # noqa: E501
Format for the genome file, Illumina.GenomicSequencingService.Models.V1.GenomeCompact.DragenVersion is required when it is Dragen # noqa: E501
:return: The genome_format of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._genome_format
@genome_format.setter
def genome_format(self, genome_format):
"""Sets the genome_format of this GenomeCompact.
Format for the genome file, Illumina.GenomicSequencingService.Models.V1.GenomeCompact.DragenVersion is required when it is Dragen # noqa: E501
:param genome_format: The genome_format of this GenomeCompact. # noqa: E501
:type: str
"""
self._genome_format = genome_format
@property
def settings(self):
"""Gets the settings of this GenomeCompact. # noqa: E501
Custom settings for the genome # noqa: E501
:return: The settings of this GenomeCompact. # noqa: E501
:rtype: object
"""
return self._settings
@settings.setter
def settings(self, settings):
"""Sets the settings of this GenomeCompact.
Custom settings for the genome # noqa: E501
:param settings: The settings of this GenomeCompact. # noqa: E501
:type: object
"""
self._settings = settings
@property
def source_file_metadata(self):
"""Gets the source_file_metadata of this GenomeCompact. # noqa: E501
Key-value pairs that indicate the source files for the specific genome # noqa: E501
:return: The source_file_metadata of this GenomeCompact. # noqa: E501
:rtype: object
"""
return self._source_file_metadata
@source_file_metadata.setter
def source_file_metadata(self, source_file_metadata):
"""Sets the source_file_metadata of this GenomeCompact.
Key-value pairs that indicate the source files for the specific genome # noqa: E501
:param source_file_metadata: The source_file_metadata of this GenomeCompact. # noqa: E501
:type: object
"""
self._source_file_metadata = source_file_metadata
@property
def fasta_file_urn(self):
"""Gets the fasta_file_urn of this GenomeCompact. # noqa: E501
The Fasta file Urn being used by the genome # noqa: E501
:return: The fasta_file_urn of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._fasta_file_urn
@fasta_file_urn.setter
def fasta_file_urn(self, fasta_file_urn):
"""Sets the fasta_file_urn of this GenomeCompact.
The Fasta file Urn being used by the genome # noqa: E501
:param fasta_file_urn: The fasta_file_urn of this GenomeCompact. # noqa: E501
:type: str
"""
self._fasta_file_urn = fasta_file_urn
@property
def is_application_specific(self):
"""Gets the is_application_specific of this GenomeCompact. # noqa: E501
Whether the genome is application specific # noqa: E501
:return: The is_application_specific of this GenomeCompact. # noqa: E501
:rtype: bool
"""
return self._is_application_specific
@is_application_specific.setter
def is_application_specific(self, is_application_specific):
"""Sets the is_application_specific of this GenomeCompact.
Whether the genome is application specific # noqa: E501
:param is_application_specific: The is_application_specific of this GenomeCompact. # noqa: E501
:type: bool
"""
self._is_application_specific = is_application_specific
@property
def is_illumina(self):
"""Gets the is_illumina of this GenomeCompact. # noqa: E501
Whether the genome is belonging to Illumina # noqa: E501
:return: The is_illumina of this GenomeCompact. # noqa: E501
:rtype: bool
"""
return self._is_illumina
@is_illumina.setter
def is_illumina(self, is_illumina):
"""Sets the is_illumina of this GenomeCompact.
Whether the genome is belonging to Illumina # noqa: E501
:param is_illumina: The is_illumina of this GenomeCompact. # noqa: E501
:type: bool
"""
self._is_illumina = is_illumina
@property
def checksum(self):
"""Gets the checksum of this GenomeCompact. # noqa: E501
Stores the checksum of Genome # noqa: E501
:return: The checksum of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._checksum
@checksum.setter
def checksum(self, checksum):
"""Sets the checksum of this GenomeCompact.
Stores the checksum of Genome # noqa: E501
:param checksum: The checksum of this GenomeCompact. # noqa: E501
:type: str
"""
self._checksum = checksum
@property
def sub_tenant_id(self):
"""Gets the sub_tenant_id of this GenomeCompact. # noqa: E501
Organizational or Workgroup ID. If neither are present, User ID. # noqa: E501
:return: The sub_tenant_id of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._sub_tenant_id
@sub_tenant_id.setter
def sub_tenant_id(self, sub_tenant_id):
"""Sets the sub_tenant_id of this GenomeCompact.
Organizational or Workgroup ID. If neither are present, User ID. # noqa: E501
:param sub_tenant_id: The sub_tenant_id of this GenomeCompact. # noqa: E501
:type: str
"""
self._sub_tenant_id = sub_tenant_id
@property
def acl(self):
"""Gets the acl of this GenomeCompact. # noqa: E501
Access control list of the object # noqa: E501
:return: The acl of this GenomeCompact. # noqa: E501
:rtype: list[str]
"""
return self._acl
@acl.setter
def acl(self, acl):
"""Sets the acl of this GenomeCompact.
Access control list of the object # noqa: E501
:param acl: The acl of this GenomeCompact. # noqa: E501
:type: list[str]
"""
self._acl = acl
@property
def tenant_id(self):
"""Gets the tenant_id of this GenomeCompact. # noqa: E501
Unique identifier for the resource tenant # noqa: E501
:return: The tenant_id of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._tenant_id
@tenant_id.setter
def tenant_id(self, tenant_id):
"""Sets the tenant_id of this GenomeCompact.
Unique identifier for the resource tenant # noqa: E501
:param tenant_id: The tenant_id of this GenomeCompact. # noqa: E501
:type: str
"""
self._tenant_id = tenant_id
@property
def tenant_name(self):
"""Gets the tenant_name of this GenomeCompact. # noqa: E501
Unique tenant name for the resource tenant # noqa: E501
:return: The tenant_name of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._tenant_name
@tenant_name.setter
def tenant_name(self, tenant_name):
"""Sets the tenant_name of this GenomeCompact.
Unique tenant name for the resource tenant # noqa: E501
:param tenant_name: The tenant_name of this GenomeCompact. # noqa: E501
:type: str
"""
self._tenant_name = tenant_name
@property
def created_by_client_id(self):
"""Gets the created_by_client_id of this GenomeCompact. # noqa: E501
ClientId that created the resource (bssh, stratus...) # noqa: E501
:return: The created_by_client_id of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._created_by_client_id
@created_by_client_id.setter
def created_by_client_id(self, created_by_client_id):
"""Sets the created_by_client_id of this GenomeCompact.
ClientId that created the resource (bssh, stratus...) # noqa: E501
:param created_by_client_id: The created_by_client_id of this GenomeCompact. # noqa: E501
:type: str
"""
self._created_by_client_id = created_by_client_id
@property
def created_by(self):
"""Gets the created_by of this GenomeCompact. # noqa: E501
User that created the resource # noqa: E501
:return: The created_by of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._created_by
@created_by.setter
def created_by(self, created_by):
"""Sets the created_by of this GenomeCompact.
User that created the resource # noqa: E501
:param created_by: The created_by of this GenomeCompact. # noqa: E501
:type: str
"""
self._created_by = created_by
@property
def modified_by(self):
"""Gets the modified_by of this GenomeCompact. # noqa: E501
User that last modified the resource # noqa: E501
:return: The modified_by of this GenomeCompact. # noqa: E501
:rtype: str
"""
return self._modified_by
@modified_by.setter
def modified_by(self, modified_by):
"""Sets the modified_by of this GenomeCompact.
User that last modified the resource # noqa: E501
:param modified_by: The modified_by of this GenomeCompact. # noqa: E501
:type: str
"""
self._modified_by = modified_by
@property
def time_created(self):
"""Gets the time_created of this GenomeCompact. # noqa: E501
Time (in UTC) the resource was created # noqa: E501
:return: The time_created of this GenomeCompact. # noqa: E501
:rtype: datetime
"""
return self._time_created
@time_created.setter
def time_created(self, time_created):
"""Sets the time_created of this GenomeCompact.
Time (in UTC) the resource was created # noqa: E501
:param time_created: The time_created of this GenomeCompact. # noqa: E501
:type: datetime
"""
self._time_created = time_created
@property
def time_modified(self):
"""Gets the time_modified of this GenomeCompact. # noqa: E501
Time (in UTC) the resource was modified # noqa: E501
:return: The time_modified of this GenomeCompact. # noqa: E501
:rtype: datetime
"""
return self._time_modified
@time_modified.setter
def time_modified(self, time_modified):
"""Sets the time_modified of this GenomeCompact.
Time (in UTC) the resource was modified # noqa: E501
:param time_modified: The time_modified of this GenomeCompact. # noqa: E501
:type: datetime
"""
self._time_modified = time_modified
def to_dict(self):
"""Returns the model properties as a dict"""
result = {}
for attr, _ in six.iteritems(self.openapi_types):
value = getattr(self, attr)
if isinstance(value, list):
result[attr] = list(map(
lambda x: x.to_dict() if hasattr(x, "to_dict") else x,
value
))
elif hasattr(value, "to_dict"):
result[attr] = value.to_dict()
elif isinstance(value, dict):
result[attr] = dict(map(
lambda item: (item[0], item[1].to_dict())
if hasattr(item[1], "to_dict") else item,
value.items()
))
else:
result[attr] = value
return result
def to_str(self):
"""Returns the string representation of the model"""
return pprint.pformat(self.to_dict())
def __repr__(self):
"""For `print` and `pprint`"""
return self.to_str()
def __eq__(self, other):
"""Returns true if both objects are equal"""
if not isinstance(other, GenomeCompact):
return False
return self.to_dict() == other.to_dict()
def __ne__(self, other):
"""Returns true if both objects are not equal"""
if not isinstance(other, GenomeCompact):
return True
return self.to_dict() != other.to_dict()
| [
"siajunren@gmail.com"
] | siajunren@gmail.com |
859b6517dab3dc3b24d760ab570d441a360b391c | cd3df53a432d35e2fe7b4e4f9bbe62222235a85b | /tests/port_tests/point_node_tests/test_equals.py | 74729bb6e9f0675b7ea2ee6c8009062e680cbf6a | [
"MIT"
] | permissive | vincentsarago/wagyu | 00ccbe6c9d101724483bde00e10ef512d2c95f9a | f6dce8d119fafa190d07f042ff6c4d5729a4c1e6 | refs/heads/master | 2023-01-20T06:26:27.475502 | 2020-11-21T04:57:01 | 2020-11-21T04:57:01 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,222 | py | from hypothesis import given
from tests.utils import (equivalence,
implication)
from wagyu.point_node import PointNode
from . import strategies
@given(strategies.points_nodes)
def test_reflexivity(point_node: PointNode) -> None:
assert point_node == point_node
@given(strategies.points_nodes, strategies.points_nodes)
def test_symmetry(first_point: PointNode,
second_point: PointNode) -> None:
assert equivalence(first_point == second_point,
second_point == first_point)
@given(strategies.points_nodes, strategies.points_nodes,
strategies.points_nodes)
def test_transitivity(first_point: PointNode, second_point: PointNode,
third_point: PointNode) -> None:
assert implication(first_point == second_point
and second_point == third_point,
first_point == third_point)
@given(strategies.points_nodes, strategies.points_nodes)
def test_connection_with_inequality(first_point: PointNode,
second_point: PointNode) -> None:
assert equivalence(not first_point == second_point,
first_point != second_point)
| [
"azatibrakov@gmail.com"
] | azatibrakov@gmail.com |
a3f03b04f4becf6a714e2d02f43d566d360beac1 | 32a1802dccb8a143532f8ef419a95fd7f1973bc4 | /movies_order/test_api/movies_tickets/urls.py | d2e23ac0a4e0c8be41adff958ff2f262b3e085ab | [] | no_license | zhmaoli/Django | b8171ba1f1612dc7ae61b58b718965a64db81c69 | 45586e782a741ba3bf64c9023e805f6f4e6496f8 | refs/heads/master | 2021-02-27T08:57:41.193488 | 2019-08-01T09:17:07 | 2019-08-01T09:17:07 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,041 | py | #coding=utf8
from django.urls import path
from movies_tickets.views import MovieBaseAPI, MovieDetailAPI, CinemasApi, CinemaDetailAPI, MovieSessionsAPI, ALLCinemasApi, MovieSessionByDateAPI, CinemaSessionByMovieAPI, OrderApi
urlpatterns = [
path('movies', MovieBaseAPI.as_view()),
path('movies/<int:movie_base_id>', MovieDetailAPI.as_view()),
path('movies/<int:movie_base_id>/allCinemas', ALLCinemasApi.as_view()),
path('movies/<int:movie_base_id>/cinemasDetail/cinema_id=<int:cinema_id>', CinemaDetailAPI.as_view()),
path('movies/<int:movie_base_id>/cinemaSession/cinema_name=<str:cinema_name>', CinemaSessionByMovieAPI.as_view()),
path('cinemas', CinemasApi.as_view()),
path('cinemas/sessions/<str:cinema_name>', MovieSessionsAPI.as_view()),
path('cinemas/sessions/<str:cinema_name>/<str:day>', MovieSessionByDateAPI.as_view()),
path('order/<int:movie_base_id>/<int:cinema_id>/<str:time>/<str:begin>/<str:end>/<str:hall>/<str:lang>/<str:date>/<str:seats_num>', OrderApi.as_view()),
]
| [
"1278077260@qq.com"
] | 1278077260@qq.com |
0fdd0f8836f3da67eac1ebb538065344528441e7 | 55afd3bbe5187dba96be169a7c068c7cf7543447 | /article17/habitatsummary/attrs_conclusion/td_coverage_conclusion.py | af658f6bc3618ee5d27b1851f38e0c04ed2d6749 | [] | no_license | eaudeweb/art17-2006 | 6d9413439e10f4db0b72fc49c80b7c50ee1ef59e | 4bc61cd2972f94769dae97b95ccb55f2a0952cf1 | refs/heads/master | 2016-09-05T13:33:19.280952 | 2014-01-30T09:54:27 | 2014-01-30T09:54:27 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 870 | py | # Script (Python)
# /article17/habitatsummary/attrs_conclusion/td_coverage_conclusion
# params: 'habitat, region, record, conclusions'
## Script (Python) "td_coverage_conclusion"
##bind container=container
##bind context=context
##bind namespace=
##bind script=script
##bind subpath=traverse_subpath
##parameters=habitat, region, record, conclusions
##title=
##
output = context.background_colour(record['conclusion_area'], 'center', conclusions)
title = output.get('title', '')
method = record['method_area'] or ''
cursor = context.sql_methods.get_coverage_conclusion_value(habitatcode=habitat, region=region, assessment_method=method)
if len(cursor):
concl_value = cursor[0]['percentage_coverage_surface_area']
if concl_value:
title = "%s: %s" % (title, concl_value)
output.update({
'content': method,
'title': title,
})
return output
| [
"cornel.nitu@eaudeweb.ro"
] | cornel.nitu@eaudeweb.ro |
ee7dfa406cafdde059c7ddd7449459805f72d265 | 2d191eb46ed804c9029801832ff4016aeaf8d31c | /configs/ssl/ssl_deeplabv3plus_r101-d8_512x1024_40k_b16_cityscapes_baseline_only_label.py | b4650b59ec2408b9e04a69cbca6f0c5e150fbcdf | [
"Apache-2.0"
] | permissive | openseg-group/mmsegmentation | df99ac2c3510b7f2dff92405aae25026d1023d98 | 23939f09d2b0bd30fc26eb7f8af974f1f5441210 | refs/heads/master | 2023-03-02T07:49:23.652558 | 2021-02-15T04:16:28 | 2021-02-15T04:16:28 | 278,537,243 | 2 | 2 | null | 2020-07-10T04:24:16 | 2020-07-10T04:24:15 | null | UTF-8 | Python | false | false | 2,192 | py | _base_ = [
'../_base_/models/deeplabv3plus_r50-d8.py',
'../_base_/datasets/cityscapes.py',
'../_base_/default_runtime.py',
'../_base_/schedules/schedule_40k.py'
]
norm_cfg = dict(type='SyncBN', requires_grad=True)
model = dict(
type='EncoderDecoder',
pretrained='open-mmlab://resnet101_v1c',
backbone=dict(
type='ResNetV1c',
depth=101,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=norm_cfg,
norm_eval=False,
style='pytorch',
contract_dilation=True),
decode_head=dict(
type='DepthwiseSeparableASPPHead',
in_channels=2048,
in_index=3,
channels=512,
dilations=(1, 12, 24, 36),
c1_in_channels=256,
c1_channels=48,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=1024,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)))
# model training and testing settings
train_cfg = dict() # set the weight for the consistency loss
test_cfg = dict(mode='whole')
optimizer = dict(lr=0.02)
lr_config = dict(min_lr=1e-4)
data_root='../../../../dataset/cityscapes/'
dataset_type = 'CityscapesDataset'
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
data_root=data_root,
img_dir=['train/image'],
ann_dir=['train/label'],
split = ['train.txt']),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='val/image',
ann_dir='val/label'),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='val/image',
ann_dir='val/label'))
find_unused_parameters=True | [
"yhyuan@pku.edu.cn"
] | yhyuan@pku.edu.cn |
c23c0f133424dd917a442b5d3bd88d54f5055ec4 | 9905901a2beae3ff4885fbc29842b3c34546ffd7 | /nitro-python/nssrc/com/citrix/netscaler/nitro/resource/config/gslb/gslbservice_lbmonitor_binding.py | 0531ba8a900ab4a3cddc2f0bc93111891039efcb | [
"Python-2.0",
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
] | permissive | culbertm/NSttyPython | f354ebb3dbf445884dbddb474b34eb9246261c19 | ff9f6aedae3fb8495342cd0fc4247c819cf47397 | refs/heads/master | 2020-04-22T17:07:39.654614 | 2019-02-13T19:07:23 | 2019-02-13T19:07:23 | 170,530,223 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 10,895 | py | #
# Copyright (c) 2008-2016 Citrix Systems, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License")
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
from nssrc.com.citrix.netscaler.nitro.resource.base.base_resource import base_resource
from nssrc.com.citrix.netscaler.nitro.resource.base.base_resource import base_response
from nssrc.com.citrix.netscaler.nitro.service.options import options
from nssrc.com.citrix.netscaler.nitro.exception.nitro_exception import nitro_exception
from nssrc.com.citrix.netscaler.nitro.util.nitro_util import nitro_util
class gslbservice_lbmonitor_binding(base_resource) :
""" Binding class showing the lbmonitor that can be bound to gslbservice.
"""
def __init__(self) :
self._monitor_name = None
self._monstate = None
self._monitor_state = None
self._weight = None
self._totalfailedprobes = None
self._failedprobes = None
self._monstatcode = None
self._monstatparam1 = None
self._monstatparam2 = None
self._monstatparam3 = None
self._responsetime = None
self._monitortotalprobes = None
self._monitortotalfailedprobes = None
self._monitorcurrentfailedprobes = None
self._lastresponse = None
self._servicename = None
self.___count = None
@property
def weight(self) :
r"""Weight to assign to the monitor-service binding. A larger number specifies a greater weight. Contributes to the monitoring threshold, which determines the state of the service.<br/>Minimum value = 1<br/>Maximum value = 100.
"""
try :
return self._weight
except Exception as e:
raise e
@weight.setter
def weight(self, weight) :
r"""Weight to assign to the monitor-service binding. A larger number specifies a greater weight. Contributes to the monitoring threshold, which determines the state of the service.<br/>Minimum value = 1<br/>Maximum value = 100
"""
try :
self._weight = weight
except Exception as e:
raise e
@property
def servicename(self) :
r"""Name of the GSLB service.<br/>Minimum length = 1.
"""
try :
return self._servicename
except Exception as e:
raise e
@servicename.setter
def servicename(self, servicename) :
r"""Name of the GSLB service.<br/>Minimum length = 1
"""
try :
self._servicename = servicename
except Exception as e:
raise e
@property
def monitor_name(self) :
r"""Monitor name.
"""
try :
return self._monitor_name
except Exception as e:
raise e
@monitor_name.setter
def monitor_name(self, monitor_name) :
r"""Monitor name.
"""
try :
self._monitor_name = monitor_name
except Exception as e:
raise e
@property
def monstate(self) :
r"""State of the monitor bound to gslb service.<br/>Possible values = ENABLED, DISABLED.
"""
try :
return self._monstate
except Exception as e:
raise e
@monstate.setter
def monstate(self, monstate) :
r"""State of the monitor bound to gslb service.<br/>Possible values = ENABLED, DISABLED
"""
try :
self._monstate = monstate
except Exception as e:
raise e
@property
def monstatcode(self) :
r"""The code indicating the monitor response.
"""
try :
return self._monstatcode
except Exception as e:
raise e
@property
def responsetime(self) :
r"""Response time of this monitor.
"""
try :
return self._responsetime
except Exception as e:
raise e
@property
def totalfailedprobes(self) :
r"""The total number of failed probs.
"""
try :
return self._totalfailedprobes
except Exception as e:
raise e
@property
def monstatparam2(self) :
r"""Second parameter for use with message code.
"""
try :
return self._monstatparam2
except Exception as e:
raise e
@property
def lastresponse(self) :
r"""Displays the gslb monitor status in string format.
"""
try :
return self._lastresponse
except Exception as e:
raise e
@property
def failedprobes(self) :
r"""Number of the current failed monitoring probes.
"""
try :
return self._failedprobes
except Exception as e:
raise e
@property
def monstatparam3(self) :
r"""Third parameter for use with message code.
"""
try :
return self._monstatparam3
except Exception as e:
raise e
@property
def monitor_state(self) :
r"""The running state of the monitor on this service.<br/>Possible values = UP, DOWN, UNKNOWN, BUSY, OUT OF SERVICE, GOING OUT OF SERVICE, DOWN WHEN GOING OUT OF SERVICE, NS_EMPTY_STR, Unknown, DISABLED.
"""
try :
return self._monitor_state
except Exception as e:
raise e
@property
def monitortotalprobes(self) :
r"""Total number of probes sent to monitor this service.
"""
try :
return self._monitortotalprobes
except Exception as e:
raise e
@property
def monstatparam1(self) :
r"""First parameter for use with message code.
"""
try :
return self._monstatparam1
except Exception as e:
raise e
@property
def monitortotalfailedprobes(self) :
r"""Total number of failed probes.
"""
try :
return self._monitortotalfailedprobes
except Exception as e:
raise e
@property
def monitorcurrentfailedprobes(self) :
r"""Total number of currently failed probes.
"""
try :
return self._monitorcurrentfailedprobes
except Exception as e:
raise e
def _get_nitro_response(self, service, response) :
r""" converts nitro response into object and returns the object array in case of get request.
"""
try :
result = service.payload_formatter.string_to_resource(gslbservice_lbmonitor_binding_response, response, self.__class__.__name__)
if(result.errorcode != 0) :
if (result.errorcode == 444) :
service.clear_session(self)
if result.severity :
if (result.severity == "ERROR") :
raise nitro_exception(result.errorcode, str(result.message), str(result.severity))
else :
raise nitro_exception(result.errorcode, str(result.message), str(result.severity))
return result.gslbservice_lbmonitor_binding
except Exception as e :
raise e
def _get_object_name(self) :
r""" Returns the value of object identifier argument
"""
try :
if self.servicename is not None :
return str(self.servicename)
return None
except Exception as e :
raise e
@classmethod
def add(cls, client, resource) :
try :
if resource and type(resource) is not list :
updateresource = gslbservice_lbmonitor_binding()
updateresource.servicename = resource.servicename
updateresource.monitor_name = resource.monitor_name
updateresource.monstate = resource.monstate
updateresource.weight = resource.weight
return updateresource.update_resource(client)
else :
if resource and len(resource) > 0 :
updateresources = [gslbservice_lbmonitor_binding() for _ in range(len(resource))]
for i in range(len(resource)) :
updateresources[i].servicename = resource[i].servicename
updateresources[i].monitor_name = resource[i].monitor_name
updateresources[i].monstate = resource[i].monstate
updateresources[i].weight = resource[i].weight
return cls.update_bulk_request(client, updateresources)
except Exception as e :
raise e
@classmethod
def delete(cls, client, resource) :
try :
if resource and type(resource) is not list :
deleteresource = gslbservice_lbmonitor_binding()
deleteresource.servicename = resource.servicename
deleteresource.monitor_name = resource.monitor_name
return deleteresource.delete_resource(client)
else :
if resource and len(resource) > 0 :
deleteresources = [gslbservice_lbmonitor_binding() for _ in range(len(resource))]
for i in range(len(resource)) :
deleteresources[i].servicename = resource[i].servicename
deleteresources[i].monitor_name = resource[i].monitor_name
return cls.delete_bulk_request(client, deleteresources)
except Exception as e :
raise e
@classmethod
def get(cls, service, servicename="", option_="") :
r""" Use this API to fetch gslbservice_lbmonitor_binding resources.
"""
try :
if not servicename :
obj = gslbservice_lbmonitor_binding()
response = obj.get_resources(service, option_)
else :
obj = gslbservice_lbmonitor_binding()
obj.servicename = servicename
response = obj.get_resources(service)
return response
except Exception as e:
raise e
@classmethod
def get_filtered(cls, service, servicename, filter_) :
r""" Use this API to fetch filtered set of gslbservice_lbmonitor_binding resources.
Filter string should be in JSON format.eg: "port:80,servicetype:HTTP".
"""
try :
obj = gslbservice_lbmonitor_binding()
obj.servicename = servicename
option_ = options()
option_.filter = filter_
response = obj.getfiltered(service, option_)
return response
except Exception as e:
raise e
@classmethod
def count(cls, service, servicename) :
r""" Use this API to count gslbservice_lbmonitor_binding resources configued on NetScaler.
"""
try :
obj = gslbservice_lbmonitor_binding()
obj.servicename = servicename
option_ = options()
option_.count = True
response = obj.get_resources(service, option_)
if response :
return response[0].__dict__['___count']
return 0
except Exception as e:
raise e
@classmethod
def count_filtered(cls, service, servicename, filter_) :
r""" Use this API to count the filtered set of gslbservice_lbmonitor_binding resources.
Filter string should be in JSON format.eg: "port:80,servicetype:HTTP".
"""
try :
obj = gslbservice_lbmonitor_binding()
obj.servicename = servicename
option_ = options()
option_.count = True
option_.filter = filter_
response = obj.getfiltered(service, option_)
if response :
return response[0].__dict__['___count']
return 0
except Exception as e:
raise e
class Monitor_state:
UP = "UP"
DOWN = "DOWN"
UNKNOWN = "UNKNOWN"
BUSY = "BUSY"
OUT_OF_SERVICE = "OUT OF SERVICE"
GOING_OUT_OF_SERVICE = "GOING OUT OF SERVICE"
DOWN_WHEN_GOING_OUT_OF_SERVICE = "DOWN WHEN GOING OUT OF SERVICE"
NS_EMPTY_STR = "NS_EMPTY_STR"
Unknown = "Unknown"
DISABLED = "DISABLED"
class Monstate:
ENABLED = "ENABLED"
DISABLED = "DISABLED"
class gslbservice_lbmonitor_binding_response(base_response) :
def __init__(self, length=1) :
self.gslbservice_lbmonitor_binding = []
self.errorcode = 0
self.message = ""
self.severity = ""
self.sessionid = ""
self.gslbservice_lbmonitor_binding = [gslbservice_lbmonitor_binding() for _ in range(length)]
| [
"mdculbert@marathonpetroleum.com"
] | mdculbert@marathonpetroleum.com |
5edaba7942ac75ed050287e21a95ae915c14c6fe | b5698c259c80c9dc9b1cbca9dd82eb7f4d799f61 | /tests/packages/sub_package/kitty/speak/__init__.py | 27ea88036f0046e8dae40761376ff0ae576320e0 | [
"Apache-2.0",
"LicenseRef-scancode-warranty-disclaimer"
] | permissive | 4O4/Nuitka | 431998d4d424f520d2887e9195ad7d7c61691b40 | e37d483b05c6b2ff081f3cedaee7aaff5c2ea397 | refs/heads/master | 2020-04-02T04:06:10.826960 | 2018-10-18T21:13:16 | 2018-10-18T21:13:16 | 154,000,090 | 0 | 0 | Apache-2.0 | 2018-10-21T11:17:44 | 2018-10-21T11:17:44 | null | UTF-8 | Python | false | false | 1,024 | py | # Copyright 2018, Kay Hayen, mailto:kay.hayen@gmail.com
#
# Python test originally created or extracted from other peoples work. The
# parts from me are licensed as below. It is at least Free Software where
# it's copied from other people. In these cases, that will normally be
# indicated.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
try:
print("__loader__ present:", __loader__ is not None)
except NameError:
print("No __loader__ found, OK for Python2")
| [
"kay.hayen@gmail.com"
] | kay.hayen@gmail.com |
2f44b8960358415ccf0ac1520c6e6b2c9cdfdf93 | 271c7959a39f3d7ff63dddf285004fd5badee4d9 | /venv/Lib/site-packages/netaddr/strategy/eui48.py | b3411fea1c0278a12f1011afc1bd3c08c7f8a3e9 | [
"MIT"
] | permissive | natemellendorf/configpy | b6b01ea4db1f2b9109fd4ddb860e9977316ed964 | 750da5eaef33cede9f3ef532453d63e507f34a2c | refs/heads/master | 2022-12-11T05:22:54.289720 | 2019-07-22T05:26:09 | 2019-07-22T05:26:09 | 176,197,442 | 4 | 1 | MIT | 2022-12-08T02:48:51 | 2019-03-18T03:24:12 | Python | UTF-8 | Python | false | false | 8,630 | py | #-----------------------------------------------------------------------------
# Copyright (c) 2008 by David P. D. Moss. All rights reserved.
#
# Released under the BSD license. See the LICENSE file for details.
#-----------------------------------------------------------------------------
"""
IEEE 48-bit EUI (MAC address) logic.
Supports numerous MAC string formats including Cisco's triple hextet as well
as bare MACs containing no delimiters.
"""
import struct as _struct
import re as _re
# Check whether we need to use fallback code or not.
try:
from socket import AF_LINK
except ImportError:
AF_LINK = 48
from netaddr.core import AddrFormatError
from netaddr.compat import _is_str
from netaddr.strategy import (
valid_words as _valid_words, int_to_words as _int_to_words,
words_to_int as _words_to_int, valid_bits as _valid_bits,
bits_to_int as _bits_to_int, int_to_bits as _int_to_bits,
valid_bin as _valid_bin, int_to_bin as _int_to_bin,
bin_to_int as _bin_to_int)
#: The width (in bits) of this address type.
width = 48
#: The AF_* constant value of this address type.
family = AF_LINK
#: A friendly string name address type.
family_name = 'MAC'
#: The version of this address type.
version = 48
#: The maximum integer value that can be represented by this address type.
max_int = 2 ** width - 1
#-----------------------------------------------------------------------------
# Dialect classes.
#-----------------------------------------------------------------------------
class mac_eui48(object):
"""A standard IEEE EUI-48 dialect class."""
#: The individual word size (in bits) of this address type.
word_size = 8
#: The number of words in this address type.
num_words = width // word_size
#: The maximum integer value for an individual word in this address type.
max_word = 2 ** word_size - 1
#: The separator character used between each word.
word_sep = '-'
#: The format string to be used when converting words to string values.
word_fmt = '%.2X'
#: The number base to be used when interpreting word values as integers.
word_base = 16
class mac_unix(mac_eui48):
"""A UNIX-style MAC address dialect class."""
word_size = 8
num_words = width // word_size
word_sep = ':'
word_fmt = '%x'
word_base = 16
class mac_unix_expanded(mac_unix):
"""A UNIX-style MAC address dialect class with leading zeroes."""
word_fmt = '%.2x'
class mac_cisco(mac_eui48):
"""A Cisco 'triple hextet' MAC address dialect class."""
word_size = 16
num_words = width // word_size
word_sep = '.'
word_fmt = '%.4x'
word_base = 16
class mac_bare(mac_eui48):
"""A bare (no delimiters) MAC address dialect class."""
word_size = 48
num_words = width // word_size
word_sep = ''
word_fmt = '%.12X'
word_base = 16
class mac_pgsql(mac_eui48):
"""A PostgreSQL style (2 x 24-bit words) MAC address dialect class."""
word_size = 24
num_words = width // word_size
word_sep = ':'
word_fmt = '%.6x'
word_base = 16
#: The default dialect to be used when not specified by the user.
DEFAULT_DIALECT = mac_eui48
#-----------------------------------------------------------------------------
#: Regular expressions to match all supported MAC address formats.
RE_MAC_FORMATS = (
# 2 bytes x 6 (UNIX, Windows, EUI-48)
'^' + ':'.join(['([0-9A-F]{1,2})'] * 6) + '$',
'^' + '-'.join(['([0-9A-F]{1,2})'] * 6) + '$',
# 4 bytes x 3 (Cisco)
'^' + ':'.join(['([0-9A-F]{1,4})'] * 3) + '$',
'^' + '-'.join(['([0-9A-F]{1,4})'] * 3) + '$',
'^' + '\.'.join(['([0-9A-F]{1,4})'] * 3) + '$',
# 6 bytes x 2 (PostgreSQL)
'^' + '-'.join(['([0-9A-F]{5,6})'] * 2) + '$',
'^' + ':'.join(['([0-9A-F]{5,6})'] * 2) + '$',
# 12 bytes (bare, no delimiters)
'^(' + ''.join(['[0-9A-F]'] * 12) + ')$',
'^(' + ''.join(['[0-9A-F]'] * 11) + ')$',
)
# For efficiency, each string regexp converted in place to its compiled
# counterpart.
RE_MAC_FORMATS = [_re.compile(_, _re.IGNORECASE) for _ in RE_MAC_FORMATS]
def valid_str(addr):
"""
:param addr: An IEEE EUI-48 (MAC) address in string form.
:return: ``True`` if MAC address string is valid, ``False`` otherwise.
"""
for regexp in RE_MAC_FORMATS:
try:
match_result = regexp.findall(addr)
if len(match_result) != 0:
return True
except TypeError:
pass
return False
def str_to_int(addr):
"""
:param addr: An IEEE EUI-48 (MAC) address in string form.
:return: An unsigned integer that is equivalent to value represented
by EUI-48/MAC string address formatted according to the dialect
settings.
"""
words = []
if _is_str(addr):
found_match = False
for regexp in RE_MAC_FORMATS:
match_result = regexp.findall(addr)
if len(match_result) != 0:
found_match = True
if isinstance(match_result[0], tuple):
words = match_result[0]
else:
words = (match_result[0],)
break
if not found_match:
raise AddrFormatError('%r is not a supported MAC format!' % addr)
else:
raise TypeError('%r is not str() or unicode()!' % addr)
int_val = None
if len(words) == 6:
# 2 bytes x 6 (UNIX, Windows, EUI-48)
int_val = int(''.join(['%.2x' % int(w, 16) for w in words]), 16)
elif len(words) == 3:
# 4 bytes x 3 (Cisco)
int_val = int(''.join(['%.4x' % int(w, 16) for w in words]), 16)
elif len(words) == 2:
# 6 bytes x 2 (PostgreSQL)
int_val = int(''.join(['%.6x' % int(w, 16) for w in words]), 16)
elif len(words) == 1:
# 12 bytes (bare, no delimiters)
int_val = int('%012x' % int(words[0], 16), 16)
else:
raise AddrFormatError('unexpected word count in MAC address %r!' % addr)
return int_val
def int_to_str(int_val, dialect=None):
"""
:param int_val: An unsigned integer.
:param dialect: (optional) a Python class defining formatting options.
:return: An IEEE EUI-48 (MAC) address string that is equivalent to
unsigned integer formatted according to the dialect settings.
"""
if dialect is None:
dialect = mac_eui48
words = int_to_words(int_val, dialect)
tokens = [dialect.word_fmt % i for i in words]
addr = dialect.word_sep.join(tokens)
return addr
def int_to_packed(int_val):
"""
:param int_val: the integer to be packed.
:return: a packed string that is equivalent to value represented by an
unsigned integer.
"""
return _struct.pack(">HI", int_val >> 32, int_val & 0xffffffff)
def packed_to_int(packed_int):
"""
:param packed_int: a packed string containing an unsigned integer.
It is assumed that string is packed in network byte order.
:return: An unsigned integer equivalent to value of network address
represented by packed binary string.
"""
words = list(_struct.unpack('>6B', packed_int))
int_val = 0
for i, num in enumerate(reversed(words)):
word = num
word = word << 8 * i
int_val = int_val | word
return int_val
def valid_words(words, dialect=None):
if dialect is None:
dialect = DEFAULT_DIALECT
return _valid_words(words, dialect.word_size, dialect.num_words)
def int_to_words(int_val, dialect=None):
if dialect is None:
dialect = DEFAULT_DIALECT
return _int_to_words(int_val, dialect.word_size, dialect.num_words)
def words_to_int(words, dialect=None):
if dialect is None:
dialect = DEFAULT_DIALECT
return _words_to_int(words, dialect.word_size, dialect.num_words)
def valid_bits(bits, dialect=None):
if dialect is None:
dialect = DEFAULT_DIALECT
return _valid_bits(bits, width, dialect.word_sep)
def bits_to_int(bits, dialect=None):
if dialect is None:
dialect = DEFAULT_DIALECT
return _bits_to_int(bits, width, dialect.word_sep)
def int_to_bits(int_val, dialect=None):
if dialect is None:
dialect = DEFAULT_DIALECT
return _int_to_bits(
int_val, dialect.word_size, dialect.num_words, dialect.word_sep)
def valid_bin(bin_val, dialect=None):
if dialect is None:
dialect = DEFAULT_DIALECT
return _valid_bin(bin_val, width)
def int_to_bin(int_val):
return _int_to_bin(int_val, width)
def bin_to_int(bin_val):
return _bin_to_int(bin_val, width)
| [
"nate.mellendorf@gmail.com"
] | nate.mellendorf@gmail.com |
0e53dcd8e4f627c22c5c0f8ce783e14019cf28ba | 3adce822439943250c1a1578cb9edd285bfaf0ce | /django/generate_fixtures.py | 5861886990481ab9436326744166931eae82fd3a | [
"MIT",
"Apache-2.0"
] | permissive | resilientred/skaffold | feceb71acfa9183db2866f0c00904f4c6e00b38b | 0d705d3907bc05e781141f62002a981683813658 | refs/heads/master | 2021-05-02T01:42:43.529831 | 2015-07-14T05:34:36 | 2015-07-14T05:34:36 | 120,873,685 | 1 | 0 | null | 2018-02-09T07:40:31 | 2018-02-09T07:40:31 | null | UTF-8 | Python | false | false | 473 | py | from django.core.management.base import BaseCommand, CommandError
from {{{ project }}}.{{{ app_name }}} import model_factories
MAX_RECORDS = 10
class Command(BaseCommand):
help = 'Adds all fixture data.'
def handle(self, *args, **options):
for _ in xrange(MAX_RECORDS):
{%% for model_name in all_models %%}
{%% set model_name = model_name|capitalize %%}
model_factories.{{{ model_name }}}Factory()
{%% endfor %%}
| [
"dxdstudio@gmail.com"
] | dxdstudio@gmail.com |
e30b2915f9c4592a949d08e8cd4cd02350fe10d1 | e1103b8818d071e313a4d8e4bc60e3649d0890b6 | /becausethenight/settings.py | cb6405b79ee7b4294ba6f15da343028303e9b7f8 | [] | no_license | programiranje3/2018 | ddab506f2a26039b365483ab33177951d5e15fbb | 2baf17741d77630199b377da59b5339fd9bfb2ca | refs/heads/master | 2020-03-28T22:01:16.724380 | 2018-12-12T16:23:51 | 2018-12-12T16:23:51 | 149,199,466 | 1 | 1 | null | null | null | null | UTF-8 | Python | false | false | 265 | py | """Project configuration settings (PROJECT_DIR etc.)
"""
import os
# print(__file__)
# print(os.path.abspath(__file__))
# print(os.path.dirname(__file__))
PROJECT_DIR = os.path.dirname(os.path.abspath(__file__))
# print(PROJECT_DIR)
# print(type(PROJECT_DIR))
| [
"devedzic@gmail.com"
] | devedzic@gmail.com |
63622122aa5f11b9e93809e26314da2b4c47f028 | beba26fc9dca330a5d4b92ef22803c4d861209e7 | /app.py | 2c75511d8d5dea50b343deb5890ee03f39f6d2b6 | [] | no_license | Jrius4/ovc_problem_solver | 35df08bf357be3309cddd1b403acfdcb41a0697d | c4384c48d68ef8b18418230f9647d8af77cef537 | refs/heads/main | 2023-08-30T04:56:26.134183 | 2021-10-24T21:43:54 | 2021-10-24T21:43:54 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,214 | py | from openpyxl import load_workbook
wb = load_workbook("input/input.xlsx")
ws = wb.active
data = []
def getcolumns(a:str,b:str):
a = str(a).lower()
b = str(b).lower()
if a == "":
return ((26*(0))+int(ord(b)-97))
else:
return ((26*(int(ord(a)-97)+1))+int(ord(b)-97))
for row in ws.iter_rows(min_col=1,min_row= 3,max_col=ws.max_column,max_row=ws.max_row,values_only=True):
data.append(row)
print("\n\n")
print(data[0])
print("\n\n")
print(data[0][getcolumns("b","e")])
print("\n\n")
print(len(data))
print("\n\n")
# no of ovc (0-17) with HIV Positive Caregiver
hh_with_positve_cg = []
hh_no_with_positve_cg = []
for i in data:
if i[getcolumns("b","e")] == "HIV Positive" and i[getcolumns("","l")] == i[getcolumns("","o")]:
hh_with_positve_cg.append([i[getcolumns("","m")],i[getcolumns("","l")],i[getcolumns("","o")],i[getcolumns("c","m")]])
hh_no_with_positve_cg.append(i[getcolumns("c","m")])
print("\n\n")
print(hh_with_positve_cg)
print("\n\n")
print(hh_no_with_positve_cg)
y_ages = []
for age in hh_with_positve_cg:
if age[0] <=17:
y_ages.append(age)
print("\n\n")
print(f"\n\n hh of 17 yrs")
print(y_ages)
print("\n\n")
# filter out ovcs from -->> no of ovc (0-17) with HIV Positive Caregiver
# 571 ovc with positive cg
ovc_with_positive_cg = []
for i in data:
if i[getcolumns("","m")] <= 17 and i[getcolumns("c","m")] in hh_no_with_positve_cg:
ovc_with_positive_cg.append([i[getcolumns("","m")],i[getcolumns("","l")],i[getcolumns("","o")],i[getcolumns("c","m")]])
print("\n\n ovc_with_positive_cg ")
print(ovc_with_positive_cg)
print("\n\n")
print("\n\n")
print(len(ovc_with_positive_cg))
k = []
for i in ovc_with_positive_cg:
if i[2] == 'NALWEYISO DIANA':
k.append(i)
print("\n\n 'NALWEYISO DIANA' ")
print(k)
print("\n\n")
print("\n\n")
print(len(k))
print("\n\n")
print("\n\n")
###########################################################
############################################################
############################################################
# no hh with hiv positve cg and clhiv (<18)
hh_with_positve_pp_lhiv = []
hh_no_with_positve_pp_lhiv = []
for i in data:
if i[getcolumns("b","e")] == "HIV Positive":
hh_with_positve_pp_lhiv.append([i[getcolumns("","m")],i[getcolumns("","l")],i[getcolumns("","o")],i[getcolumns("c","m")]])
hh_no_with_positve_pp_lhiv.append(i[getcolumns("c","m")])
print("\n\n hh with hh_with_positve_pp_lhiv")
print(hh_with_positve_pp_lhiv)
print("\n\n")
print("\n\n")
print(len(hh_with_positve_pp_lhiv))
print("\n\n")
print(hh_no_with_positve_pp_lhiv)
print("\n\n")
print(len(hh_no_with_positve_pp_lhiv))
print(sorted(hh_no_with_positve_pp_lhiv))
result = []
for i in hh_no_with_positve_pp_lhiv:
if i not in result:
result.append(i)
print("\n\n")
print(sorted(result))
result_2 = result
for i in result_2:
if i not in hh_no_with_positve_cg:
result_2.remove(i)
print("\n\n")
print(sorted(result_2))
print(len(sorted(result_2)))
set_all_pos = set(result)
set_all_pos_cg = set(hh_no_with_positve_cg)
set_intersec = set_all_pos.intersection(set_all_pos_cg)
print(len(set_intersec)) | [
"kazibwejuliusjunior@gmail.com"
] | kazibwejuliusjunior@gmail.com |
eca3fd53f2770dc746e44c275bcfef7f48bacb76 | b6df7cda5c23cda304fcc0af1450ac3c27a224c1 | /data/codes/WarrenWeckesser_setup.py | 653d236fcb58a7bda9055af9a1a34b66747f8ce3 | [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
] | permissive | vieira-rafael/py-search | 88ee167fa1949414cc4f3c98d33f8ecec1ce756d | b8c6dccc58d72af35e4d4631f21178296f610b8a | refs/heads/master | 2021-01-21T04:59:36.220510 | 2016-06-20T01:45:34 | 2016-06-20T01:45:34 | 54,433,313 | 2 | 4 | null | null | null | null | UTF-8 | Python | false | false | 1,347 | py | from setuptools import setupfrom os import path
def get_wavio_version(): """ Find the value assigned to __version__ in wavio.py. This function assumes that there is a line of the form __version__ = "version-string" in wavio.py. It returns the string version-string, or None if such a line is not found. """ with open("wavio.py", "r") as f: for line in f: s = [w.strip() for w in line.split("=", 1)] if len(s) == 2 and s[0] == "__version__": return s[1][1:-1]
# Get the long description from README.rst._here = path.abspath(path.dirname(__file__))with open(path.join(_here, 'README.rst')) as f: _long_description = f.read()
setup( name='wavio', version=get_wavio_version(), author='Warren Weckesser', description=("A Python module for reading and writing WAV files using " "numpy arrays."), long_description=_long_description, license="BSD", url="https://github.com/WarrenWeckesser/wavio", classifiers=[ "License :: OSI Approved :: BSD License", "Intended Audience :: Developers", "Operating System :: OS Independent", "Programming Language :: Python :: 2", "Programming Language :: Python :: 2.7", "Programming Language :: Python :: 3", "Programming Language :: Python :: 3.3", "Programming Language :: Python :: 3.4", ], keywords="wav numpy", py_modules=["wavio"], install_requires=[ 'numpy >= 1.6.0', ],) | [
"thaisnviana@gmail.com"
] | thaisnviana@gmail.com |
e9f1dbf7ffe89c3abe4b0a7736744c5fe30fbc5c | 09e5cfe06e437989a2ccf2aeecb9c73eb998a36c | /modules/xia2/Schema/XSample.py | fcc4a0ae567f8ccbd030bab4850f9d9af13a6299 | [
"BSD-3-Clause"
] | permissive | jorgediazjr/dials-dev20191018 | b81b19653624cee39207b7cefb8dfcb2e99b79eb | 77d66c719b5746f37af51ad593e2941ed6fbba17 | refs/heads/master | 2020-08-21T02:48:54.719532 | 2020-01-25T01:41:37 | 2020-01-25T01:41:37 | 216,089,955 | 0 | 1 | BSD-3-Clause | 2020-01-25T01:41:39 | 2019-10-18T19:03:17 | Python | UTF-8 | Python | false | false | 3,748 | py | #!/usr/bin/env python
# XSample.py
# Copyright (C) 2015 Diamond Light Source, Richard Gildea
# This code is distributed under the BSD license, a copy of which is
# included in the root directory of this package.
from __future__ import absolute_import, division, print_function
class XSample(object):
"""An object representation of a sample."""
def __init__(self, name, crystal):
"""Create a new sample named name, belonging to XCrystal object crystal."""
# check that the crystal is an XCrystal
if not crystal.__class__.__name__ == "XCrystal":
pass
# set up this object
self._name = name
self._crystal = crystal
# then create space to store things which are contained
# in here - the sweeps
self._sweeps = []
self._multi_indexer = None
return
def get_epoch_to_dose(self):
from xia2.Modules.DoseAccumulate import accumulate_dose
epoch_to_dose = accumulate_dose(
[sweep.get_imageset() for sweep in self._sweeps]
)
return epoch_to_dose
# from matplotlib import pyplot
# for i, sweep in enumerate(self._sweeps):
# epochs = sweep.get_imageset().get_scan().get_epochs()
# pyplot.scatter(
# list(epochs), [epoch_to_dose[e] for e in epochs],
# marker='+', color='bg'[i])
# pyplot.show()
# serialization functions
def to_dict(self):
obj = {}
obj["__id__"] = "XSample"
import inspect
attributes = inspect.getmembers(self, lambda m: not (inspect.isroutine(m)))
for a in attributes:
if a[0] == "_sweeps":
sweeps = []
for sweep in a[1]:
sweeps.append(sweep.to_dict())
obj[a[0]] = sweeps
elif a[0] == "_crystal":
# don't serialize this since the parent xsample *should* contain
# the reference to the child xsweep
continue
elif a[0] == "_multi_indexer" and a[1] is not None:
obj[a[0]] = a[1].to_dict()
elif a[0].startswith("__"):
continue
else:
obj[a[0]] = a[1]
return obj
@classmethod
def from_dict(cls, obj):
assert obj["__id__"] == "XSample"
return_obj = cls(name=None, crystal=None)
for k, v in obj.iteritems():
if k == "_sweeps":
v = [s_dict["_name"] for s_dict in v]
elif k == "_multi_indexer" and v is not None:
from libtbx.utils import import_python_object
cls = import_python_object(
import_path=".".join((v["__module__"], v["__name__"])),
error_prefix="",
target_must_be="",
where_str="",
).object
v = cls.from_dict(v)
setattr(return_obj, k, v)
return return_obj
def get_output(self):
result = "Sample name: %s\n" % self._name
result += "Sweeps:\n"
return result[:-1]
def get_crystal(self):
return self._crystal
def get_name(self):
return self._name
def add_sweep(self, sweep):
self._sweeps.append(sweep)
def get_sweeps(self):
return self._sweeps
def set_multi_indexer(self, multi_indexer):
self._multi_indexer = multi_indexer
def get_multi_indexer(self):
return self._multi_indexer
def remove_sweep(self, sweep):
"""Remove a sweep object from this wavelength."""
try:
self._sweeps.remove(sweep)
except ValueError:
pass
return
| [
"jorge7soccer@gmail.com"
] | jorge7soccer@gmail.com |
6ae91e2b8f53229d6c371a8f235392667d79ab8a | 12258001571bd504223fbf4587870960fa93a46d | /mud/django-haystack-2.3.2/haystack/admin.py | 6b0b0988dfc87447577e3757ac8592a3289d131f | [
"BSD-3-Clause",
"MIT"
] | permissive | Nik0las1984/mud-obj | 0bd71e71855a9b0f0d3244dec2c877bd212cdbd2 | 5d74280724ff6c6ac1b2d3a7c86b382e512ecf4d | refs/heads/master | 2023-01-07T04:12:33.472377 | 2019-10-11T09:10:14 | 2019-10-11T09:10:14 | 69,223,190 | 2 | 0 | null | 2022-12-26T20:15:20 | 2016-09-26T07:11:49 | Python | UTF-8 | Python | false | false | 6,639 | py | from __future__ import unicode_literals
from django import template
from django.contrib.admin.options import csrf_protect_m, ModelAdmin
from django.contrib.admin.views.main import ChangeList, SEARCH_VAR
from django.core.exceptions import PermissionDenied
from django.core.paginator import InvalidPage, Paginator
from django.shortcuts import render_to_response
from django.utils.translation import ungettext
from haystack import connections
from haystack.query import SearchQuerySet
from haystack.utils import get_model_ct_tuple
try:
from django.utils.encoding import force_text
except ImportError:
from django.utils.encoding import force_unicode as force_text
def list_max_show_all(changelist):
"""
Returns the maximum amount of results a changelist can have for the
"Show all" link to be displayed in a manner compatible with both Django
1.4 and 1.3. See Django ticket #15997 for details.
"""
try:
# This import is available in Django 1.3 and below
from django.contrib.admin.views.main import MAX_SHOW_ALL_ALLOWED
return MAX_SHOW_ALL_ALLOWED
except ImportError:
return changelist.list_max_show_all
class SearchChangeList(ChangeList):
def __init__(self, **kwargs):
self.haystack_connection = kwargs.pop('haystack_connection', 'default')
super(SearchChangeList, self).__init__(**kwargs)
def get_results(self, request):
if not SEARCH_VAR in request.GET:
return super(SearchChangeList, self).get_results(request)
# Note that pagination is 0-based, not 1-based.
sqs = SearchQuerySet(self.haystack_connection).models(self.model).auto_query(request.GET[SEARCH_VAR]).load_all()
paginator = Paginator(sqs, self.list_per_page)
# Get the number of objects, with admin filters applied.
result_count = paginator.count
full_result_count = SearchQuerySet(self.haystack_connection).models(self.model).all().count()
can_show_all = result_count <= list_max_show_all(self)
multi_page = result_count > self.list_per_page
# Get the list of objects to display on this page.
try:
result_list = paginator.page(self.page_num+1).object_list
# Grab just the Django models, since that's what everything else is
# expecting.
result_list = [result.object for result in result_list]
except InvalidPage:
result_list = ()
self.result_count = result_count
self.full_result_count = full_result_count
self.result_list = result_list
self.can_show_all = can_show_all
self.multi_page = multi_page
self.paginator = paginator
class SearchModelAdmin(ModelAdmin):
# haystack connection to use for searching
haystack_connection = 'default'
@csrf_protect_m
def changelist_view(self, request, extra_context=None):
if not self.has_change_permission(request, None):
raise PermissionDenied
if not SEARCH_VAR in request.GET:
# Do the usual song and dance.
return super(SearchModelAdmin, self).changelist_view(request, extra_context)
# Do a search of just this model and populate a Changelist with the
# returned bits.
if not self.model in connections[self.haystack_connection].get_unified_index().get_indexed_models():
# Oops. That model isn't being indexed. Return the usual
# behavior instead.
return super(SearchModelAdmin, self).changelist_view(request, extra_context)
# So. Much. Boilerplate.
# Why copy-paste a few lines when you can copy-paste TONS of lines?
list_display = list(self.list_display)
kwargs = {
'haystack_connection': self.haystack_connection,
'request': request,
'model': self.model,
'list_display': list_display,
'list_display_links': self.list_display_links,
'list_filter': self.list_filter,
'date_hierarchy': self.date_hierarchy,
'search_fields': self.search_fields,
'list_select_related': self.list_select_related,
'list_per_page': self.list_per_page,
'list_editable': self.list_editable,
'model_admin': self
}
# Django 1.4 compatibility.
if hasattr(self, 'list_max_show_all'):
kwargs['list_max_show_all'] = self.list_max_show_all
changelist = SearchChangeList(**kwargs)
formset = changelist.formset = None
media = self.media
# Build the action form and populate it with available actions.
# Check actions to see if any are available on this changelist
actions = self.get_actions(request)
if actions:
action_form = self.action_form(auto_id=None)
action_form.fields['action'].choices = self.get_action_choices(request)
else:
action_form = None
selection_note = ungettext('0 of %(count)d selected',
'of %(count)d selected', len(changelist.result_list))
selection_note_all = ungettext('%(total_count)s selected',
'All %(total_count)s selected', changelist.result_count)
context = {
'module_name': force_text(self.model._meta.verbose_name_plural),
'selection_note': selection_note % {'count': len(changelist.result_list)},
'selection_note_all': selection_note_all % {'total_count': changelist.result_count},
'title': changelist.title,
'is_popup': changelist.is_popup,
'cl': changelist,
'media': media,
'has_add_permission': self.has_add_permission(request),
# More Django 1.4 compatibility
'root_path': getattr(self.admin_site, 'root_path', None),
'app_label': self.model._meta.app_label,
'action_form': action_form,
'actions_on_top': self.actions_on_top,
'actions_on_bottom': self.actions_on_bottom,
'actions_selection_counter': getattr(self, 'actions_selection_counter', 0),
}
context.update(extra_context or {})
context_instance = template.RequestContext(request, current_app=self.admin_site.name)
app_name, model_name = get_model_ct_tuple(self.model)
return render_to_response(self.change_list_template or [
'admin/%s/%s/change_list.html' % (app_name, model_name),
'admin/%s/change_list.html' % app_name,
'admin/change_list.html'
], context, context_instance=context_instance)
| [
"kolya.khokhlov@gmail.com"
] | kolya.khokhlov@gmail.com |
8bc29b5636fd7970d731f56428ec9f29064104af | 7caa438706a423dd9779a81f8345fcf1ec11e921 | /timeit/28_02/genetation_test_fix.py | bc470b672816ae1dc444d5d948b1b4ee741c916a | [] | no_license | tamarinvs19/python-learning | 5dd2582f5dc504e19a53e9176677adc5170778b0 | 1e514ad7ca8f3d2e2f785b11b0be4d57696dc1e9 | refs/heads/master | 2021-07-15T13:23:24.238594 | 2021-07-08T07:07:21 | 2021-07-08T07:07:21 | 120,604,826 | 3 | 0 | null | null | null | null | UTF-8 | Python | false | false | 315 | py | from random import randint, seed
m = 10000
def one_rf():
length = randint(0, m)
#print(1, length)
xs = []
for _ in range(length):
r = randint(0, m)
xs.append(r)
def two_rf():
length = randint(0, m)
#print(2, length)
xs = [randint(0, m) for _ in range(length)]
| [
"slavabarsuk@ya.ru"
] | slavabarsuk@ya.ru |
b1b324f15896af52e3931b8c9a40ca74708e660a | 68e26b931893d25f88981a7a7dd4b7de775add6d | /assignment2/cs231n/classifiers/fc_net.py | 4a98a2e609603d2295fb044ff69f0d86c0d627bd | [] | no_license | mshtang/CS231n | 0f19b1500d8077386d988925d4f94479fa32382f | 9643336ca382be0171507ffd05653e042af63b92 | refs/heads/master | 2020-03-10T12:18:58.347825 | 2018-04-23T11:02:08 | 2018-04-23T11:02:08 | 129,374,872 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 20,577 | py | from builtins import range
from builtins import object
import numpy as np
from cs231n.layers import *
from cs231n.layer_utils import *
class TwoLayerNet(object):
"""
A two-layer fully-connected neural network with ReLU nonlinearity and
softmax loss that uses a modular layer design. We assume an input dimension
of D, a hidden dimension of H, and perform classification over C classes.
The architecure should be affine - relu - affine - softmax.
Note that this class does not implement gradient descent; instead, it
will interact with a separate Solver object that is responsible for running
optimization.
The learnable parameters of the model are stored in the dictionary
self.params that maps parameter names to numpy arrays.
"""
def __init__(self, input_dim=3 * 32 * 32, hidden_dim=100, num_classes=10,
weight_scale=1e-3, reg=0.0):
"""
Initialize a new network.
Inputs:
- input_dim: An integer giving the size of the input
- hidden_dim: An integer giving the size of the hidden layer
- num_classes: An integer giving the number of classes to classify
- dropout: Scalar between 0 and 1 giving dropout strength.
- weight_scale: Scalar giving the standard deviation for random
initialization of the weights.
- reg: Scalar giving L2 regularization strength.
"""
self.params = {}
self.reg = reg
############################################################################
# TODO: Initialize the weights and biases of the two-layer net. Weights #
# should be initialized from a Gaussian with standard deviation equal to #
# weight_scale, and biases should be initialized to zero. All weights and #
# biases should be stored in the dictionary self.params, with first layer #
# weights and biases using the keys 'W1' and 'b1' and second layer weights #
# and biases using the keys 'W2' and 'b2'. #
############################################################################
self.params['W1'] = np.random.randn(
input_dim, hidden_dim) * weight_scale
self.params['b1'] = np.zeros(hidden_dim)
self.params['W2'] = np.random.randn(
hidden_dim, num_classes) * weight_scale
self.params['b2'] = np.zeros(num_classes)
############################################################################
# END OF YOUR CODE #
############################################################################
def loss(self, X, y=None):
"""
Compute loss and gradient for a minibatch of data.
Inputs:
- X: Array of input data of shape (N, d_1, ..., d_k)
- y: Array of labels, of shape (N,). y[i] gives the label for X[i].
Returns:
If y is None, then run a test-time forward pass of the model and return:
- scores: Array of shape (N, C) giving classification scores, where
scores[i, c] is the classification score for X[i] and class c.
If y is not None, then run a training-time forward and backward pass and
return a tuple of:
- loss: Scalar value giving the loss
- grads: Dictionary with the same keys as self.params, mapping parameter
names to gradients of the loss with respect to those parameters.
"""
scores = None
############################################################################
# TODO: Implement the forward pass for the two-layer net, computing the #
# class scores for X and storing them in the scores variable. #
############################################################################
# flaten input into vectors
batch_size = X.shape[0]
flat_X = np.reshape(X, (batch_size, -1))
# fc1
fc1, fc1_cache = affine_forward(
flat_X, self.params['W1'], self.params['b1'])
# relu1
relu1, relu1_cache = relu_forward(fc1)
# fc2
fc2, fc2_cache = affine_forward(
relu1, self.params['W2'], self.params['b2'])
scores = fc2.copy()
############################################################################
# END OF YOUR CODE #
############################################################################
# If y is None then we are in test mode so just return scores
if y is None:
return scores
loss, grads = 0, {}
############################################################################
# TODO: Implement the backward pass for the two-layer net. Store the loss #
# in the loss variable and gradients in the grads dictionary. Compute data #
# loss using softmax, and make sure that grads[k] holds the gradients for #
# self.params[k]. Don't forget to add L2 regularization! #
# #
# NOTE: To ensure that your implementation matches ours and you pass the #
# automated tests, make sure that your L2 regularization includes a factor #
# of 0.5 to simplify the expression for the gradient. #
############################################################################
loss, dsoft = softmax_loss(scores, y)
loss += .5 * self.reg * \
(np.sum(self.params['W1']**2) + np.sum(self.params['W2']**2))
dx2, dw2, db2 = affine_backward(dsoft, fc2_cache)
drelu = relu_backward(dx2, relu1_cache)
dx1, dw1, db1 = affine_backward(drelu, fc1_cache)
grads['W2'], grads['b2'] = dw2 + self.reg * self.params['W2'], db2
grads['W1'], grads['b1'] = dw1 + self.reg * self.params['W1'], db1
############################################################################
# END OF YOUR CODE #
############################################################################
return loss, grads
class FullyConnectedNet(object):
"""
A fully-connected neural network with an arbitrary number of hidden layers,
ReLU nonlinearities, and a softmax loss function. This will also implement
dropout and batch normalization as options. For a network with L layers,
the architecture will be
{affine - [batch norm] - relu - [dropout]} x (L - 1) - affine - softmax
where batch normalization and dropout are optional, and the {...} block is
repeated L - 1 times.
Similar to the TwoLayerNet above, learnable parameters are stored in the
self.params dictionary and will be learned using the Solver class.
"""
def __init__(self, hidden_dims, input_dim=3 * 32 * 32, num_classes=10,
dropout=0, use_batchnorm=False, reg=0.0,
weight_scale=1e-2, dtype=np.float32, seed=None):
"""
Initialize a new FullyConnectedNet.
Inputs:
- hidden_dims: A list of integers giving the size of each hidden layer.
- input_dim: An integer giving the size of the input.
- num_classes: An integer giving the number of classes to classify.
- dropout: Scalar between 0 and 1 giving dropout strength. If dropout=0 then
the network should not use dropout at all.
- use_batchnorm: Whether or not the network should use batch normalization.
- reg: Scalar giving L2 regularization strength.
- weight_scale: Scalar giving the standard deviation for random
initialization of the weights.
- dtype: A numpy datatype object; all computations will be performed using
this datatype. float32 is faster but less accurate, so you should use
float64 for numeric gradient checking.
- seed: If not None, then pass this random seed to the dropout layers. This
will make the dropout layers deteriminstic so we can gradient check the
model.
"""
self.use_batchnorm = use_batchnorm
self.use_dropout = dropout > 0
self.reg = reg
self.num_layers = 1 + len(hidden_dims)
self.dtype = dtype
self.params = {}
############################################################################
# TODO: Initialize the parameters of the network, storing all values in #
# the self.params dictionary. Store weights and biases for the first layer #
# in W1 and b1; for the second layer use W2 and b2, etc. Weights should be #
# initialized from a normal distribution with standard deviation equal to #
# weight_scale and biases should be initialized to zero. #
# #
# When using batch normalization, store scale and shift parameters for the #
# first layer in gamma1 and beta1; for the second layer use gamma2 and #
# beta2, etc. Scale parameters should be initialized to one and shift #
# parameters should be initialized to zero. #
############################################################################
for i in range(self.num_layers - 1):
self.params['W' + str(i + 1)] = np.random.randn(input_dim,
hidden_dims[i]) * weight_scale
self.params['b' + str(i + 1)] = np.zeros(hidden_dims[i])
# if self.use_batchnorm:
# self.params['gamma' + str(i + 1)] = np.zeros(hidden_dims[i])
# self.params['beta' + str(i + 1)] = np.zeros(hidden_dims[i])
input_dim = hidden_dims[i]
# for the last layer
self.params['W' + str(self.num_layers)
] = np.random.randn(input_dim, num_classes) * weight_scale
self.params['b' + str(self.num_layers)] = np.zeros(num_classes)
############################################################################
# END OF YOUR CODE #
############################################################################
# When using dropout we need to pass a dropout_param dictionary to each
# dropout layer so that the layer knows the dropout probability and the mode
# (train / test). You can pass the same dropout_param to each dropout layer.
self.dropout_param = {}
if self.use_dropout:
self.dropout_param = {'mode': 'train', 'p': dropout}
if seed is not None:
self.dropout_param['seed'] = seed
# With batch normalization we need to keep track of running means and
# variances, so we need to pass a special bn_param object to each batch
# normalization layer. You should pass self.bn_params[0] to the forward pass
# of the first batch normalization layer, self.bn_params[1] to the forward
# pass of the second batch normalization layer, etc.
self.bn_params = []
if self.use_batchnorm:
for i in range(self.num_layers-1):
self.params['gamma'+str(i+1)] = np.ones(hidden_dims[i])
self.params['beta'+str(i+1)] = np.zeros(hidden_dims[i])
self.bn_params.append({'mode': 'train',
'running_mean': np.zeros(hidden_dims[i]),
'running_var': np.zeros(hidden_dims[i])})
# Cast all parameters to the correct datatype
for k, v in self.params.items():
self.params[k] = v.astype(dtype)
def loss(self, X, y=None):
"""
Compute loss and gradient for the fully-connected net.
Input / output: Same as TwoLayerNet above.
"""
X = X.astype(self.dtype)
mode = 'test' if y is None else 'train'
# Set train/test mode for batchnorm params and dropout param since they
# behave differently during training and testing.
if self.use_dropout:
self.dropout_param['mode'] = mode
if self.use_batchnorm:
for bn_param in self.bn_params:
bn_param['mode'] = mode
# scores = None
############################################################################
# TODO: Implement the forward pass for the fully-connected net, computing #
# the class scores for X and storing them in the scores variable. #
# #
# When using dropout, you'll need to pass self.dropout_param to each #
# dropout forward pass. #
# #
# When using batch normalization, you'll need to pass self.bn_params[0] to #
# the forward pass for the first batch normalization layer, pass #
# self.bn_params[1] to the forward pass for the second batch normalization #
# layer, etc. #
############################################################################
hidden = {}
hidden['h0'] = X.reshape(X.shape[0], np.prod(X.shape[1:]))
if self.use_dropout:
# dropout on the input layer
hdrop, cache_hdrop = dropout_forward(
hidden['h0'], self.dropout_param)
hidden['hdrop0'], hidden['cache_hdrop0'] = hdrop, cache_hdrop
for i in range(self.num_layers):
idx = i + 1
# Naming of the variable
w = self.params['W' + str(idx)]
b = self.params['b' + str(idx)]
h = hidden['h' + str(idx - 1)]
if self.use_dropout:
h = hidden['hdrop' + str(idx - 1)]
if self.use_batchnorm and idx != self.num_layers:
gamma = self.params['gamma' + str(idx)]
beta = self.params['beta' + str(idx)]
# bn_param = self.bn_params['bn_param' + str(idx)]
bn_param = self.bn_params[i]
# Computing of the forward pass.
# Special case of the last layer (output)
if idx == self.num_layers:
h, cache_h = affine_forward(h, w, b)
hidden['h' + str(idx)] = h
hidden['cache_h' + str(idx)] = cache_h
# For all other layers
else:
if self.use_batchnorm:
h, cache_h = affine_norm_relu_forward(
h, w, b, gamma, beta, bn_param)
hidden['h' + str(idx)] = h
hidden['cache_h' + str(idx)] = cache_h
else:
h, cache_h = affine_relu_forward(h, w, b)
hidden['h' + str(idx)] = h
hidden['cache_h' + str(idx)] = cache_h
if self.use_dropout:
h = hidden['h' + str(idx)]
hdrop, cache_hdrop = dropout_forward(h, self.dropout_param)
hidden['hdrop' + str(idx)] = hdrop
hidden['cache_hdrop' + str(idx)] = cache_hdrop
scores = hidden['h' + str(self.num_layers)]
############################################################################
# END OF YOUR CODE #
############################################################################
# If test mode return early
if mode == 'test':
return scores
loss, grads = 0.0, {}
############################################################################
# TODO: Implement the backward pass for the fully-connected net. Store the #
# loss in the loss variable and gradients in the grads dictionary. Compute #
# data loss using softmax, and make sure that grads[k] holds the gradients #
# for self.params[k]. Don't forget to add L2 regularization! #
# #
# When using batch normalization, you don't need to regularize the scale #
# and shift parameters. #
# #
# NOTE: To ensure that your implementation matches ours and you pass the #
# automated tests, make sure that your L2 regularization includes a factor #
# of 0.5 to simplify the expression for the gradient. #
############################################################################
data_loss, dscores = softmax_loss(scores, y)
reg_loss = 0
for w in [self.params[f] for f in self.params.keys() if f[0] == 'W']:
reg_loss += 0.5 * self.reg * np.sum(w * w)
loss = data_loss + reg_loss
# Backward pass
hidden['dh' + str(self.num_layers)] = dscores
for i in range(self.num_layers)[::-1]:
idx = i + 1
dh = hidden['dh' + str(idx)]
h_cache = hidden['cache_h' + str(idx)]
if idx == self.num_layers:
dh, dw, db = affine_backward(dh, h_cache)
hidden['dh' + str(idx - 1)] = dh
hidden['dW' + str(idx)] = dw
hidden['db' + str(idx)] = db
else:
if self.use_dropout:
# First backprop in the dropout layer
cache_hdrop = hidden['cache_hdrop' + str(idx)]
dh = dropout_backward(dh, cache_hdrop)
if self.use_batchnorm:
dh, dw, db, dgamma, dbeta = affine_norm_relu_backward(
dh, h_cache)
hidden['dh' + str(idx - 1)] = dh
hidden['dW' + str(idx)] = dw
hidden['db' + str(idx)] = db
hidden['dgamma' + str(idx)] = dgamma
hidden['dbeta' + str(idx)] = dbeta
else:
dh, dw, db = affine_relu_backward(dh, h_cache)
hidden['dh' + str(idx - 1)] = dh
hidden['dW' + str(idx)] = dw
hidden['db' + str(idx)] = db
# w gradients where we add the regulariation term
list_dw = {key[1:]: val + self.reg * self.params[key[1:]]
for key, val in hidden.items() if key[:2] == 'dW'}
# Paramerters b
list_db = {key[1:]: val for key, val in hidden.items() if key[:2] ==
'db'}
# Parameters gamma
list_dgamma = {key[1:]: val for key, val in hidden.items() if key[
:6] == 'dgamma'}
# Paramters beta
list_dbeta = {key[1:]: val for key, val in hidden.items() if key[
:5] == 'dbeta'}
grads = {}
grads.update(list_dw)
grads.update(list_db)
grads.update(list_dgamma)
grads.update(list_dbeta)
return loss, grads
def affine_norm_relu_forward(x, w, b, gamma, beta, bn_param):
"""
Convenience layer that perorms an affine transform followed by a ReLU
Inputs:
- x: Input to the affine layer
- w, b: Weights for the affine layer
- gamma, beta : Weight for the batch norm regularization
- bn_params : Contain variable use to batch norml, running_mean and var
Returns a tuple of:
- out: Output from the ReLU
- cache: Object to give to the backward pass
"""
h, h_cache = affine_forward(x, w, b)
hnorm, hnorm_cache = batchnorm_forward(h, gamma, beta, bn_param)
hnormrelu, relu_cache = relu_forward(hnorm)
cache = (h_cache, hnorm_cache, relu_cache)
return hnormrelu, cache
def affine_norm_relu_backward(dout, cache):
"""
Backward pass for the affine-relu convenience layer
"""
h_cache, hnorm_cache, relu_cache = cache
dhnormrelu = relu_backward(dout, relu_cache)
dhnorm, dgamma, dbeta = batchnorm_backward(dhnormrelu, hnorm_cache)
dx, dw, db = affine_backward(dhnorm, h_cache)
return dx, dw, db, dgamma, dbeta
| [
"you@example.com"
] | you@example.com |
bb7f5783d40bb042630bb35a9e3b2378d09b7311 | f0d713996eb095bcdc701f3fab0a8110b8541cbb | /E9Wkppxyo763XywBe_24.py | c54745b649c7618965decf030eb38c9d949ece2e | [] | no_license | daniel-reich/turbo-robot | feda6c0523bb83ab8954b6d06302bfec5b16ebdf | a7a25c63097674c0a81675eed7e6b763785f1c41 | refs/heads/main | 2023-03-26T01:55:14.210264 | 2021-03-23T16:08:01 | 2021-03-23T16:08:01 | 350,773,815 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,866 | py | """
A binary clock displays the time of day in binary format. Modern binary clocks
have six columns of lights; two for each of the hours, minutes and seconds.
The photo below shows a binary clock displaying the time "12:15:45":

The binary values increase from the bottom to the top row. Lights on the
bottom row have a value of 1, lights on the row above have a value of 2, then
4 on the row above that, and finally a value of 8 on the top row. Any 24-hour
time can be shown by switching on a certain combination of lights. For
example, to show the time "10:37:49":
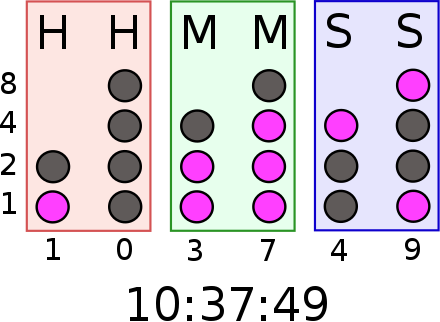
You've decided to build your own binary clock, and you need to figure out how
to light each row of the clock to show the correct time. Given the time as a
string, return a `list` containing strings that shows the lights for each row
of the clock (top to bottom). Use "1" for on, and "0" for off. Leave a blank
space for any part of the row that doesn't require a light.
### Examples
binary_clock("10:37:49") ➞ [
" 0 0 1",
" 00110",
"001100",
"101101"
]
binary_clock("18:57:31") ➞ [
" 1 0 0",
" 01100",
"000110",
"101111"
]
binary_clock("10:50:22") ➞ [
" 0 0 0",
" 01000",
"000011",
"101000"
]
### Notes
See the **Resources** section for more information on binary clocks.
"""
def binary_clock(time):
class Column:
def __init__(self, n, light_num = 4):
self.n = n
self.ln = light_num
def display(self):
display_lights = {1: [1], 2: [2], 3: [1, 2], 4: [4], 5: [1, 4], 6: [2, 4], 7: [1, 2, 4], 8: [8], 9: [8, 1], 0: []}
val_indexes = {1: 0, 2: 1, 4: 2, 8: 3}
on = display_lights[self.n]
display_reversed = []
for n in range(self.ln):
off = True
for light in on:
if val_indexes[light] == n:
display_reversed.append('1')
off = False
break
if off == True:
display_reversed.append('0')
for n in range(4 - self.ln):
display_reversed.append(' ')
return list(reversed(display_reversed))
time = time.split(':')
hour = time[0]
mins = time[1]
secs = time[2]
h1 = int(hour[0])
h2 = int(hour[1])
m1 = int(mins[0])
m2 = int(mins[1])
s1 = int(secs[0])
s2 = int(secs[1])
c1 = Column(h1,2)
c2 = Column(h2)
c3 = Column(m1,3)
c4 = Column(m2)
c5 = Column(s1,3)
c6 = Column(s2)
rawdisplay = [c1.display(),c2.display(),c3.display(),c4.display(),c5.display(),c6.display()]
display = ['','','','']
for n in range(4):
for item in rawdisplay:
display[n] += item[n]
return display
| [
"daniel.reich@danielreichs-MacBook-Pro.local"
] | daniel.reich@danielreichs-MacBook-Pro.local |
cc27b3e8dda70c767e42c23c01a79250f519e1ce | 853d4cec42071b76a80be38c58ffe0fbf9b9dc34 | /venv/Lib/site-packages/nltk/tbl/rule.py | 02d8ea770a571834e94ce4cd3a93cd92c933ef34 | [] | no_license | msainTesting/TwitterAnalysis | 5e1646dbf40badf887a86e125ef30a9edaa622a4 | b1204346508ba3e3922a52380ead5a8f7079726b | refs/heads/main | 2023-08-28T08:29:28.924620 | 2021-11-04T12:36:30 | 2021-11-04T12:36:30 | 424,242,582 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 11,508 | py | # Natural Language Toolkit: Transformation-based learning
#
# Copyright (C) 2001-2021 NLTK Project
# Author: Marcus Uneson <marcus.uneson@gmail.com>
# based on previous (nltk2) version by
# Christopher Maloof, Edward Loper, Steven Bird
# URL: <http://nltk.org/>
# For license information, see LICENSE.TXT
from abc import ABCMeta, abstractmethod
from nltk import jsontags
######################################################################
# Tag Rules
######################################################################
class TagRule(metaclass=ABCMeta):
"""
An interface for tag transformations on a tagged corpus, as
performed by tbl taggers. Each transformation finds all tokens
in the corpus that are tagged with a specific original tag and
satisfy a specific condition, and replaces their tags with a
replacement tag. For any given transformation, the original
tag, replacement tag, and condition are fixed. Conditions may
depend on the token under consideration, as well as any other
tokens in the corpus.
Tag rules must be comparable and hashable.
"""
def __init__(self, original_tag, replacement_tag):
self.original_tag = original_tag
"""The tag which this TagRule may cause to be replaced."""
self.replacement_tag = replacement_tag
"""The tag with which this TagRule may replace another tag."""
def apply(self, tokens, positions=None):
"""
Apply this rule at every position in positions where it
applies to the given sentence. I.e., for each position p
in *positions*, if *tokens[p]* is tagged with this rule's
original tag, and satisfies this rule's condition, then set
its tag to be this rule's replacement tag.
:param tokens: The tagged sentence
:type tokens: list(tuple(str, str))
:type positions: list(int)
:param positions: The positions where the transformation is to
be tried. If not specified, try it at all positions.
:return: The indices of tokens whose tags were changed by this
rule.
:rtype: int
"""
if positions is None:
positions = list(range(len(tokens)))
# Determine the indices at which this rule applies.
change = [i for i in positions if self.applies(tokens, i)]
# Make the changes. Note: this must be done in a separate
# step from finding applicable locations, since we don't want
# the rule to interact with itself.
for i in change:
tokens[i] = (tokens[i][0], self.replacement_tag)
return change
@abstractmethod
def applies(self, tokens, index):
"""
:return: True if the rule would change the tag of
``tokens[index]``, False otherwise
:rtype: bool
:param tokens: A tagged sentence
:type tokens: list(str)
:param index: The index to check
:type index: int
"""
# Rules must be comparable and hashable for the algorithm to work
def __eq__(self, other):
raise TypeError("Rules must implement __eq__()")
def __ne__(self, other):
raise TypeError("Rules must implement __ne__()")
def __hash__(self):
raise TypeError("Rules must implement __hash__()")
@jsontags.register_tag
class Rule(TagRule):
"""
A Rule checks the current corpus position for a certain set of conditions;
if they are all fulfilled, the Rule is triggered, meaning that it
will change tag A to tag B. For other tags than A, nothing happens.
The conditions are parameters to the Rule instance. Each condition is a feature-value pair,
with a set of positions to check for the value of the corresponding feature.
Conceptually, the positions are joined by logical OR, and the feature set by logical AND.
More formally, the Rule is then applicable to the M{n}th token iff:
- The M{n}th token is tagged with the Rule's original tag; and
- For each (Feature(positions), M{value}) tuple:
- The value of Feature of at least one token in {n+p for p in positions}
is M{value}.
"""
json_tag = "nltk.tbl.Rule"
def __init__(self, templateid, original_tag, replacement_tag, conditions):
"""
Construct a new Rule that changes a token's tag from
C{original_tag} to C{replacement_tag} if all of the properties
specified in C{conditions} hold.
@type templateid: string
@param templateid: the template id (a zero-padded string, '001' etc,
so it will sort nicely)
@type conditions: C{iterable} of C{Feature}
@param conditions: A list of Feature(positions),
each of which specifies that the property (computed by
Feature.extract_property()) of at least one
token in M{n} + p in positions is C{value}.
"""
TagRule.__init__(self, original_tag, replacement_tag)
self._conditions = conditions
self.templateid = templateid
def encode_json_obj(self):
return {
"templateid": self.templateid,
"original": self.original_tag,
"replacement": self.replacement_tag,
"conditions": self._conditions,
}
@classmethod
def decode_json_obj(cls, obj):
return cls(
obj["templateid"],
obj["original"],
obj["replacement"],
tuple(tuple(feat) for feat in obj["conditions"]),
)
def applies(self, tokens, index):
# Inherit docs from TagRule
# Does the given token have this Rule's "original tag"?
if tokens[index][1] != self.original_tag:
return False
# Check to make sure that every condition holds.
for (feature, val) in self._conditions:
# Look for *any* token that satisfies the condition.
for pos in feature.positions:
if not (0 <= index + pos < len(tokens)):
continue
if feature.extract_property(tokens, index + pos) == val:
break
else:
# No token satisfied the condition; return false.
return False
# Every condition checked out, so the Rule is applicable.
return True
def __eq__(self, other):
return self is other or (
other is not None
and other.__class__ == self.__class__
and self.original_tag == other.original_tag
and self.replacement_tag == other.replacement_tag
and self._conditions == other._conditions
)
def __ne__(self, other):
return not (self == other)
def __hash__(self):
# Cache our hash value (justified by profiling.)
try:
return self.__hash
except AttributeError:
self.__hash = hash(repr(self))
return self.__hash
def __repr__(self):
# Cache the repr (justified by profiling -- this is used as
# a sort key when deterministic=True.)
try:
return self.__repr
except AttributeError:
self.__repr = "{}('{}', {}, {}, [{}])".format(
self.__class__.__name__,
self.templateid,
repr(self.original_tag),
repr(self.replacement_tag),
# list(self._conditions) would be simpler but will not generate
# the same Rule.__repr__ in python 2 and 3 and thus break some tests
", ".join(f"({f},{repr(v)})" for (f, v) in self._conditions),
)
return self.__repr
def __str__(self):
def _condition_to_logic(feature, value):
"""
Return a compact, predicate-logic styled string representation
of the given condition.
"""
return "{}:{}@[{}]".format(
feature.PROPERTY_NAME,
value,
",".join(str(w) for w in feature.positions),
)
conditions = " & ".join(
[_condition_to_logic(f, v) for (f, v) in self._conditions]
)
s = f"{self.original_tag}->{self.replacement_tag} if {conditions}"
return s
def format(self, fmt):
"""
Return a string representation of this rule.
>>> from nltk.tbl.rule import Rule
>>> from nltk.tag.brill import Pos
>>> r = Rule("23", "VB", "NN", [(Pos([-2,-1]), 'DT')])
r.format("str") == str(r)
True
>>> r.format("str")
'VB->NN if Pos:DT@[-2,-1]'
r.format("repr") == repr(r)
True
>>> r.format("repr")
"Rule('23', 'VB', 'NN', [(Pos([-2, -1]),'DT')])"
>>> r.format("verbose")
'VB -> NN if the Pos of words i-2...i-1 is "DT"'
>>> r.format("not_found")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "nltk/tbl/rule.py", line 256, in format
raise ValueError("unknown rule format spec: {0}".format(fmt))
ValueError: unknown rule format spec: not_found
>>>
:param fmt: format specification
:type fmt: str
:return: string representation
:rtype: str
"""
if fmt == "str":
return self.__str__()
elif fmt == "repr":
return self.__repr__()
elif fmt == "verbose":
return self._verbose_format()
else:
raise ValueError(f"unknown rule format spec: {fmt}")
def _verbose_format(self):
"""
Return a wordy, human-readable string representation
of the given rule.
Not sure how useful this is.
"""
def condition_to_str(feature, value):
return 'the {} of {} is "{}"'.format(
feature.PROPERTY_NAME,
range_to_str(feature.positions),
value,
)
def range_to_str(positions):
if len(positions) == 1:
p = positions[0]
if p == 0:
return "this word"
if p == -1:
return "the preceding word"
elif p == 1:
return "the following word"
elif p < 0:
return "word i-%d" % -p
elif p > 0:
return "word i+%d" % p
else:
# for complete compatibility with the wordy format of nltk2
mx = max(positions)
mn = min(positions)
if mx - mn == len(positions) - 1:
return "words i%+d...i%+d" % (mn, mx)
else:
return "words {{{}}}".format(
",".join("i%+d" % d for d in positions)
)
replacement = f"{self.original_tag} -> {self.replacement_tag}"
conditions = (" if " if self._conditions else "") + ", and ".join(
condition_to_str(f, v) for (f, v) in self._conditions
)
return replacement + conditions
| [
"msaineti@icloud.com"
] | msaineti@icloud.com |
900e50e59fb5433d6619c32f3da0a9dd104ca7d8 | 5ff8d66901ae1368a012bfe270a7e76672efcde8 | /torrenttools.py | 2a6b3cd15babe2ca91a1b6830d7f0ea684684d2b | [] | no_license | SUNET/lobo2a | 3ed55fc398b461ac1d9910364ac241c481001d7e | 4c7c3f701d43a349ba3f4b4414dbe122308e46a1 | refs/heads/master | 2023-09-02T13:13:06.363012 | 2014-07-07T21:20:23 | 2014-07-07T21:20:23 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 10,317 | py | # -*- coding: utf-8 -*-
# The contents of this file are subject to the Python Software Foundation
# License Version 2.3 (the License). You may not copy or use this file, in
# either source code or executable form, except in compliance with the License.
# You may obtain a copy of the License at http://www.python.org/license.
#
# Software distributed under the License is distributed on an AS IS basis,
# WITHOUT WARRANTY OF ANY KIND, either express or implied. See the License
# for the specific language governing rights and limitations under the
# License.
"""
Created on Thu Mar 17 11:06:27 2011
@author: lundberg@nordu.net
Torrenttools where made for Lobber to remove dependance on bigger torrent libs
like Deluge and Bittorrent.
Bencode and bdecode stuff is written by Petru Paler and taken from Deluge
(1.3.1) bencode.py. Minor modifications made by Andrew Resch to replace the
BTFailure errors with Exceptions.
Make_meta_file stuff is written by Bram Cohen and taken from Deluge (1.3.1)
metafile.py. Modifications for use in Deluge by Andrew Resch 2008.
"""
import os
import os.path
import time
import sys
from hashlib import sha1 as sha
def decode_int(x, f):
f += 1
newf = x.index('e', f)
n = int(x[f:newf])
if x[f] == '-':
if x[f + 1] == '0':
raise ValueError
elif x[f] == '0' and newf != f + 1:
raise ValueError
return (n, newf + 1)
def decode_string(x, f):
colon = x.index(':', f)
n = int(x[f:colon])
if x[f] == '0' and colon != f + 1:
raise ValueError
colon += 1
return (x[colon:colon + n], colon + n)
def decode_list(x, f):
r, f = [], f + 1
while x[f] != 'e':
v, f = decode_func[x[f]](x, f)
r.append(v)
return (r, f + 1)
def decode_dict(x, f):
r, f = {}, f + 1
while x[f] != 'e':
k, f = decode_string(x, f)
r[k], f = decode_func[x[f]](x, f)
return (r, f + 1)
decode_func = {}
decode_func['l'] = decode_list
decode_func['d'] = decode_dict
decode_func['i'] = decode_int
decode_func['0'] = decode_string
decode_func['1'] = decode_string
decode_func['2'] = decode_string
decode_func['3'] = decode_string
decode_func['4'] = decode_string
decode_func['5'] = decode_string
decode_func['6'] = decode_string
decode_func['7'] = decode_string
decode_func['8'] = decode_string
decode_func['9'] = decode_string
def bdecode(x):
try:
r, l = decode_func[x[0]](x, 0)
except (IndexError, KeyError, ValueError):
raise Exception("not a valid bencoded string")
return r
from types import StringType, IntType, LongType, DictType, ListType, TupleType
class Bencached(object):
__slots__ = ['bencoded']
def __init__(self, s):
self.bencoded = s
def encode_bencached(x, r):
r.append(x.bencoded)
def encode_int(x, r):
r.extend(('i', str(x), 'e'))
def encode_bool(x, r):
if x:
encode_int(1, r)
else:
encode_int(0, r)
def encode_string(x, r):
r.extend((str(len(x)), ':', x))
def encode_list(x, r):
r.append('l')
for i in x:
encode_func[type(i)](i, r)
r.append('e')
def encode_dict(x, r):
r.append('d')
ilist = x.items()
ilist.sort()
for k, v in ilist:
r.extend((str(len(k)), ':', k))
encode_func[type(v)](v, r)
r.append('e')
encode_func = {}
encode_func[Bencached] = encode_bencached
encode_func[IntType] = encode_int
encode_func[LongType] = encode_int
encode_func[StringType] = encode_string
encode_func[ListType] = encode_list
encode_func[TupleType] = encode_list
encode_func[DictType] = encode_dict
try:
from types import BooleanType
encode_func[BooleanType] = encode_bool
except ImportError:
pass
def bencode(x):
r = []
encode_func[type(x)](x, r)
return ''.join(r)
def dummy(*v):
pass
def make_meta_file(path, url, piece_length, progress=dummy,
title=None, comment=None, safe=None, content_type=None,
target=None, webseeds=None, name=None, private=False,
created_by=None, trackers=None):
data = {'creation date': int(gmtime())}
if url:
data['announce'] = url.strip()
a, b = os.path.split(path)
if not target:
if b == '':
f = a + '.torrent'
else:
f = os.path.join(a, b + '.torrent')
else:
f = target
info = makeinfo(path, piece_length, progress, name, content_type, private)
# check_info(info)
h = f
if not hasattr(f, 'write'):
h = file(f, 'wb')
data['info'] = info
if title:
data['title'] = title.encode("utf8")
if comment:
data['comment'] = comment.encode("utf8")
if safe:
data['safe'] = safe.encode("utf8")
httpseeds = []
url_list = []
if webseeds:
for webseed in webseeds:
if webseed.endswith(".php"):
httpseeds.append(webseed)
else:
url_list.append(webseed)
if url_list:
data['url-list'] = url_list
if httpseeds:
data['httpseeds'] = httpseeds
if created_by:
data['created by'] = created_by.encode("utf8")
if trackers and (len(trackers[0]) > 1 or len(trackers) > 1):
data['announce-list'] = trackers
data["encoding"] = "UTF-8"
h.write(bencode(data))
h.flush()
return h
def makeinfo(path, piece_length, progress, name=None,
content_type=None, private=False): # HEREDAVE. If path is directory,
# how do we assign content type?
def to_utf8(name):
if isinstance(name, unicode):
u = name
else:
try:
u = decode_from_filesystem(name)
except Exception:
raise Exception('Could not convert file/directory name %r to '
'Unicode. Either the assumed filesystem '
'encoding "%s" is wrong or the filename contains '
'illegal bytes.' % (name, get_filesystem_encoding()))
if u.translate(noncharacter_translate) != u:
raise Exception('File/directory name "%s" contains reserved '
'unicode values that do not correspond to '
'characters.' % name)
return u.encode('utf-8')
path = os.path.abspath(path)
piece_count = 0
if os.path.isdir(path):
subs = subfiles(path)
subs.sort()
pieces = []
sh = sha()
done = 0
fs = []
totalsize = 0.0
totalhashed = 0
for p, f in subs:
totalsize += os.path.getsize(f)
if totalsize >= piece_length:
import math
num_pieces = math.ceil(float(totalsize) / float(piece_length))
else:
num_pieces = 1
for p, f in subs:
pos = 0
size = os.path.getsize(f)
p2 = [to_utf8(n) for n in p]
if content_type:
fs.append({'length': size, 'path': p2,
'content_type': content_type}) # HEREDAVE. bad for batch!
else:
fs.append({'length': size, 'path': p2})
h = file(f, 'rb')
while pos < size:
a = min(size - pos, piece_length - done)
sh.update(h.read(a))
done += a
pos += a
totalhashed += a
if done == piece_length:
pieces.append(sh.digest())
piece_count += 1
done = 0
sh = sha()
progress(piece_count, num_pieces)
h.close()
if done > 0:
pieces.append(sh.digest())
progress(piece_count, num_pieces)
if name is not None:
assert isinstance(name, unicode)
name = to_utf8(name)
else:
name = to_utf8(os.path.split(path)[1])
return {'pieces': ''.join(pieces),
'piece length': piece_length, 'files': fs,
'name': name,
'private': private}
else:
size = os.path.getsize(path)
if size >= piece_length:
num_pieces = size / piece_length
else:
num_pieces = 1
pieces = []
p = 0
h = file(path, 'rb')
while p < size:
x = h.read(min(piece_length, size - p))
pieces.append(sha(x).digest())
piece_count += 1
p += piece_length
if p > size:
p = size
progress(piece_count, num_pieces)
h.close()
if content_type is not None:
return {'pieces': ''.join(pieces),
'piece length': piece_length, 'length': size,
'name': to_utf8(os.path.split(path)[1]),
'content_type': content_type,
'private': private}
return {'pieces': ''.join(pieces),
'piece length': piece_length, 'length': size,
'name': to_utf8(os.path.split(path)[1]),
'private': private}
ignore = ['core', 'CVS', 'Thumbs.db', 'desktop.ini']
def subfiles(d):
r = []
stack = [([], d)]
while stack:
p, n = stack.pop()
if os.path.isdir(n):
for s in os.listdir(n):
if s not in ignore and not s.startswith('.'):
stack.append((p + [s], os.path.join(n, s)))
else:
r.append((p, n))
return r
noncharacter_translate = {}
for i in xrange(0xD800, 0xE000):
noncharacter_translate[i] = ord('-')
for i in xrange(0xFDD0, 0xFDF0):
noncharacter_translate[i] = ord('-')
for i in (0xFFFE, 0xFFFF):
noncharacter_translate[i] = ord('-')
def gmtime():
return time.mktime(time.gmtime())
def get_filesystem_encoding():
return sys.getfilesystemencoding()
def decode_from_filesystem(path):
encoding = get_filesystem_encoding()
if encoding == None:
assert isinstance(path, unicode), "Path should be unicode not %s" % type(path)
decoded_path = path
else:
assert isinstance(path, str), "Path should be str not %s" % type(path)
decoded_path = path.decode(encoding)
return decoded_path | [
"leifj@sunet.se"
] | leifj@sunet.se |
795bc5ac4bfbb332f76a5e289c2b64859aecc897 | 52aca246e91ad6ff611a1db31893089db1782344 | /fluent_contents/tests/utils.py | 9eab0a404cb280c88311b7a29fea19af132145cd | [
"Apache-2.0"
] | permissive | si14/django-fluent-contents | a2b53ca09997ae2ba20c42e2bb706c177c38c3cc | 12d98390b8799d8568d90ca9359b30f49ed2eade | refs/heads/master | 2021-01-20T03:11:39.067625 | 2017-04-26T16:52:22 | 2017-04-26T16:52:22 | 89,505,219 | 0 | 0 | null | 2017-04-26T16:49:28 | 2017-04-26T16:49:28 | null | UTF-8 | Python | false | false | 3,997 | py | """
Utils for internal tests, and utils for testing third party plugins.
"""
from __future__ import print_function
import django
from future.builtins import str
from django.conf import settings
from django.core.management import call_command
from django.contrib.sites.models import Site
from django.test import TestCase
from fluent_utils.django_compat import get_user_model
import os
from fluent_contents import rendering
from fluent_contents.rendering.utils import get_dummy_request
try:
from importlib import import_module
except ImportError:
from django.utils.importlib import import_module # Python 2.6
__all__ = (
# Utils for testing third party plugins.
'render_content_items',
'get_dummy_request',
# For internal tests:
'AppTestCase',
)
def render_content_items(items, request=None, language=None, template_name=None, cachable=False):
"""
Render a content items with settings well suited for testing.
"""
if request is None:
request = get_dummy_request(language=language)
return rendering.render_content_items(request, items, template_name=template_name, cachable=cachable)
class AppTestCase(TestCase):
"""
Tests for URL resolving.
"""
user = None
install_apps = (
'fluent_contents.tests.testapp',
'fluent_contents.plugins.sharedcontent',
'fluent_contents.plugins.picture',
'fluent_contents.plugins.text',
)
@classmethod
def setUpClass(cls):
super(AppTestCase, cls).setUpClass()
# Avoid early import, triggers AppCache
User = get_user_model()
if cls.install_apps:
# When running this app via `./manage.py test fluent_pages`, auto install the test app + models.
run_syncdb = False
for appname in cls.install_apps:
if appname not in settings.INSTALLED_APPS:
print('Adding {0} to INSTALLED_APPS'.format(appname))
settings.INSTALLED_APPS = (appname,) + tuple(settings.INSTALLED_APPS)
run_syncdb = True
testapp = import_module(appname)
# Flush caches
if django.VERSION < (1, 9):
from django.template.loaders import app_directories
from django.db.models import loading
loading.cache.loaded = False
app_directories.app_template_dirs += (
os.path.join(os.path.dirname(testapp.__file__), 'templates'),
)
else:
from django.template.utils import get_app_template_dirs
get_app_template_dirs.cache_clear()
if run_syncdb:
if django.VERSION < (1, 7):
call_command('syncdb', verbosity=0) # may run south's overlaid version
else:
call_command('migrate', verbosity=0)
# Create basic objects
# 1.4 does not create site automatically with the defined SITE_ID, 1.3 does.
Site.objects.get_or_create(id=settings.SITE_ID, defaults=dict(domain='django.localhost', name='django at localhost'))
cls.user, _ = User.objects.get_or_create(is_superuser=True, is_staff=True, username="fluent-contents-admin")
def assert200(self, url, msg_prefix=''):
"""
Test that an URL exists.
"""
if msg_prefix:
msg_prefix += ": "
self.assertEqual(self.client.get(url).status_code, 200, str(msg_prefix) + u"Page at {0} should be found.".format(url))
def assert404(self, url, msg_prefix=''):
"""
Test that an URL does not exist.
"""
if msg_prefix:
msg_prefix += ": "
response = self.client.get(url)
self.assertEqual(response.status_code, 404, str(msg_prefix) + u"Page at {0} should return 404, got {1}.".format(url, response.status_code))
| [
"vdboor@edoburu.nl"
] | vdboor@edoburu.nl |
b40fa846aa398e8e39aadf0971b887251b2a9952 | 8f6ebd257d7e0d3a71c3e173dbee65e32973a526 | /binaryS.py | c6b94c8de340bdf3cb481ccd9326851a5528b86c | [] | no_license | jennyChing/mit-handout_practice | e27839e72a6f36a3dde1e72021c493d2ed97898a | ca1f217fe97a76c2ebe55268ea812715a6b79503 | refs/heads/master | 2021-01-10T09:06:35.245013 | 2016-03-24T08:07:05 | 2016-03-24T08:07:05 | 54,456,604 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 506 | py | def biSearch (a, n):
left = 0
right = len(a)
while right > left:
middle = int((right+left)/2)
print(left,right,middle,a[middle],n)
if n == a[middle]:
return middle
print(middle)
elif n > a[middle]:
left = middle+1
else:
right = middle
return None
while True:
try:
a = list(map(int,input().split()))
n = int(input())
print(biSearch(a, n))
except(EOFError):
break
| [
"jklife3@gmail.com"
] | jklife3@gmail.com |
2d2faa48a176471eb9914d9d4d9a4c0fe96dfdb5 | 7a4a934ab01fe76243cfc1075af837d8a4659b96 | /makingQueries/wsgi.py | 67804b38c693a877cf8796983061b044b06cb3d2 | [] | no_license | ephremworkeye/makingQueries | 2cc464be56c1626425862aec3f191aedc054fa84 | 95f897690f05b918f54bc49c4667fc2952e7fd34 | refs/heads/master | 2023-07-03T13:40:53.538436 | 2021-08-01T08:01:55 | 2021-08-01T08:01:55 | 391,565,969 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 403 | py | """
WSGI config for makingQueries project.
It exposes the WSGI callable as a module-level variable named ``application``.
For more information on this file, see
https://docs.djangoproject.com/en/3.2/howto/deployment/wsgi/
"""
import os
from django.core.wsgi import get_wsgi_application
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'makingQueries.settings')
application = get_wsgi_application()
| [
"ephremworkeye@gmail.com"
] | ephremworkeye@gmail.com |
3b28b0eb18f4e471ce30f37864a27ccf145b8896 | 21a92e72448715510d509ab0ec07af37f388013a | /camouflage.py | 1c778ab4060a0a0105fd08ae3b58b681a0fd37b6 | [] | no_license | chlee1252/dailyLeetCode | 9758ad5a74997672129c91fb78ecc00092e1cf2a | 71b9e3d82d4fbb58e8c86f60f3741db6691bf2f3 | refs/heads/master | 2023-01-22T02:40:55.779267 | 2020-12-03T15:01:07 | 2020-12-03T15:01:07 | 265,159,944 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 584 | py | from collections import defaultdict, Counter
from functools import reduce
def solution(clothes):
# Approach 1: use defaultdict
answer = 1 # Set init answer value as 1
hash = defaultdict(int)
for cloth in clothes:
hash[cloth[1]] += 1
for key, value in hash.items():
answer *= value + 1
return answer-1 # Remove init answer value
# Approach 2: Use Counter and reduce(function, iterable, init), Better and clean approach
hash = Counter([kind for name, kind in clothes])
return reduce(lambda x, y: x*(y+1), hash.values(), 1) - 1
| [
"chlee1252@gmail.com"
] | chlee1252@gmail.com |
0073eba180930fa02f31ad4bad81cc9fdd6be234 | 8830831a87f35ff2628f379d8230928ec6b5641a | /BNPParibas/code/xgb_naive_bayes.py | 550126dd6fde9b812eb51b8bd8c481cbbb2f4145 | [] | no_license | nickmcadden/Kaggle | e5882c9d68a81700d8d969328d91c059a0643868 | cbc5347dec90e4bf64d4dbaf28b8ffb362efc64f | refs/heads/master | 2019-07-18T08:09:40.683168 | 2018-01-26T14:35:38 | 2018-01-26T14:35:38 | 40,735,982 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,490 | py | import sys
import pandas as pd
import numpy as np
import scipy as sp
import xgboost as xgb
import data_naive_bayes as data
import argparse
import pickle as pkl
from scipy import stats
from sklearn.utils import shuffle
from sklearn.cross_validation import StratifiedShuffleSplit, KFold
def log_loss(act, pred):
""" Vectorised computation of logloss """
epsilon = 1e-15
pred = sp.maximum(epsilon, pred)
pred = sp.minimum(1-epsilon, pred)
ll = sum(act*sp.log(pred) + sp.subtract(1,act)*sp.log(sp.subtract(1,pred)))
ll = ll * -1.0/len(act)
return ll
parser = argparse.ArgumentParser(description='XGBoost for BNP')
parser.add_argument('-f','--n_features', help='Number of features', type=int, default=1000)
parser.add_argument('-n','--n_rounds', help='Number of Boost iterations', type=int, default=5000)
parser.add_argument('-e','--eta', help='Learning rate', type=float, default=0.002)
parser.add_argument('-r','--r_seed', help='Set random seed', type=int, default=3)
parser.add_argument('-b','--minbin', help='Minimum categorical bin size', type=int, default=1)
parser.add_argument('-ct','--cat_trans', help='Category transformation method', type=str, default='std')
parser.add_argument('-cv','--cv', action='store_true')
parser.add_argument('-codetest','--codetest', action='store_true')
parser.add_argument('-getcached', '--getcached', action='store_true')
parser.add_argument('-extra', '--extra', action='store_true')
m_params = vars(parser.parse_args())
# Load data
X, y, X_sub, ids = data.load(m_params)
print("BNP Parabas: classification...\n")
xgb_param = {'silent' : 1, 'max_depth' : 10, 'eval_metric' : 'logloss', 'eta': m_params['eta'], 'min_child_weight': 3, 'objective': 'binary:logistic', 'subsample': 0.7, 'colsample_bytree': 0.5}
if m_params['cv']:
# do cross validation scoring
kf = KFold(X.shape[0], n_folds=4, shuffle=True, random_state=1)
scr = np.zeros([len(kf)])
oob_pred = np.zeros(X.shape[0])
sub_pred = np.zeros((X_sub.shape[0], 4))
dtest = xgb.DMatrix(X_sub)
for i, (tr_ix, val_ix) in enumerate(kf):
dtrain = xgb.DMatrix(X[tr_ix], y[tr_ix])
dval = xgb.DMatrix(X[val_ix], y[val_ix])
clf = xgb.train(xgb_param, dtrain, m_params['n_rounds'], evals=([dtrain,'train'], [dval,'val']))
pred = clf.predict(dval)
oob_pred[val_ix] = np.array(pred)
sub_pred[:,i] = clf.predict(dtest)
scr[i] = log_loss(y[val_ix], np.array(pred))
print('Train score is:', scr[i])
print np.mean(scr)
print oob_pred[1:10]
sub_pred = sub_pred.mean(axis=1)
oob_pred_filename = '../output/oob_pred_xgblinearfeat' + str(np.mean(scr))
sub_pred_filename = '../output/sub_pred_xgblinearfeat' + str(np.mean(scr))
pkl.dump(oob_pred, open(oob_pred_filename + '.p', 'wb'))
pkl.dump(sub_pred, open(sub_pred_filename + '.p', 'wb'))
preds = pd.DataFrame({"ID": ids, "PredictedProb": sub_pred})
preds.to_csv(sub_pred_filename + '.csv', index=False)
else:
# Train on full data
dtrain = xgb.DMatrix(X,y)
dtest = xgb.DMatrix(X_sub)
clf = xgb.train(xgb_param, dtrain, m_params['n_rounds'], evals=([dtrain,'train'], [dtrain,'train']))
pred = clf.predict(dtrain)
print('Train score is:', log_loss(y, np.array(pred)))
model_pathname = '../output/pred_xgb_' + str(m_params['n_rounds'])
clf.save_model(model_pathname + '.model')
pred = clf.predict(dtest)
pkl.dump(pred, open(model_pathname + '.p', 'wb'))
print("Saving Results.")
preds = pd.DataFrame({"ID": ids, "PredictedProb": pred})
preds.to_csv(model_pathname + '.csv', index=False)
| [
"nmcadden@globalpersonals.co.uk"
] | nmcadden@globalpersonals.co.uk |
6ade2b1fbe60d8188804988229f7f4671350eb1c | d2c4934325f5ddd567963e7bd2bdc0673f92bc40 | /tests/artificial/transf_Fisher/trend_Lag1Trend/cycle_0/ar_/test_artificial_32_Fisher_Lag1Trend_0__20.py | 5207f3b5c001ec81a647c5bcb91b30deaaa7fbae | [
"BSD-3-Clause",
"LicenseRef-scancode-unknown-license-reference"
] | permissive | jmabry/pyaf | 797acdd585842474ff4ae1d9db5606877252d9b8 | afbc15a851a2445a7824bf255af612dc429265af | refs/heads/master | 2020-03-20T02:14:12.597970 | 2018-12-17T22:08:11 | 2018-12-17T22:08:11 | 137,104,552 | 0 | 0 | BSD-3-Clause | 2018-12-17T22:08:12 | 2018-06-12T17:15:43 | Python | UTF-8 | Python | false | false | 265 | py | import pyaf.Bench.TS_datasets as tsds
import pyaf.tests.artificial.process_artificial_dataset as art
art.process_dataset(N = 32 , FREQ = 'D', seed = 0, trendtype = "Lag1Trend", cycle_length = 0, transform = "Fisher", sigma = 0.0, exog_count = 20, ar_order = 0); | [
"antoine.carme@laposte.net"
] | antoine.carme@laposte.net |
35a84d93d7da4a1fe22aa258dc364462324cfd8a | 49fa43ae11cd06f68efb65a9f59add168b205f29 | /python/132_palindrome-partitioning-II/palindromePartitioningII.py | 1431ee00dc62b2bbd014b72c2d5902c94368dd4c | [] | no_license | kfrancischen/leetcode | 634510672df826a2e2c3d7cf0b2d00f7fc003973 | 08500c39e14f3bf140db82a3dd2df4ca18705845 | refs/heads/master | 2021-01-23T13:09:02.410336 | 2019-04-17T06:01:28 | 2019-04-17T06:01:28 | 56,357,131 | 2 | 1 | null | null | null | null | UTF-8 | Python | false | false | 431 | py | class Solution(object):
def minCut(self, s):
"""
:type s: str
:rtype: int
"""
n = len(s)
dp = [i-1 for i in range(n + 1)]
for i in range(1, n+1):
for j in range(i):
temp = s[j:i]
if temp == temp[::-1]:
dp[i] = min(dp[i], dp[j] + 1)
return dp[n]
mytest = Solution()
s = 'aab'
print mytest.minCut(s)
| [
"kfrancischen@gmail.com"
] | kfrancischen@gmail.com |
c234b625d8e66574a7385270d8c8c600741f636b | 02fd239748a57ddd163ab411ce28a2b34e0182a9 | /tests/components/bluetooth/test_config_flow.py | 4c1e8f660b327eb4d35f96dfcd9af2cadf3af1a4 | [
"Apache-2.0"
] | permissive | fredrike/home-assistant | 77d05be0d2fd35dd862c56c7fb1ddde46d61ed05 | e852c9b012f2f949cc08e9498b8a051f362669e9 | refs/heads/dev | 2023-03-05T12:38:26.034307 | 2022-10-13T15:34:45 | 2022-10-13T15:34:45 | 107,095,841 | 2 | 0 | Apache-2.0 | 2023-02-22T06:14:52 | 2017-10-16T07:55:03 | Python | UTF-8 | Python | false | false | 13,332 | py | """Test the bluetooth config flow."""
from unittest.mock import patch
from homeassistant import config_entries
from homeassistant.components.bluetooth.const import (
CONF_ADAPTER,
CONF_DETAILS,
CONF_PASSIVE,
DEFAULT_ADDRESS,
DOMAIN,
AdapterDetails,
)
from homeassistant.data_entry_flow import FlowResultType
from homeassistant.setup import async_setup_component
from tests.common import MockConfigEntry
async def test_options_flow_disabled_not_setup(
hass,
hass_ws_client,
mock_bleak_scanner_start,
mock_bluetooth_adapters,
macos_adapter,
):
"""Test options are disabled if the integration has not been setup."""
await async_setup_component(hass, "config", {})
entry = MockConfigEntry(
domain=DOMAIN, data={}, options={}, unique_id=DEFAULT_ADDRESS
)
entry.add_to_hass(hass)
ws_client = await hass_ws_client(hass)
await ws_client.send_json(
{
"id": 5,
"type": "config_entries/get",
"domain": "bluetooth",
"type_filter": "integration",
}
)
response = await ws_client.receive_json()
assert response["result"][0]["supports_options"] is False
await hass.config_entries.async_unload(entry.entry_id)
async def test_async_step_user_macos(hass, macos_adapter):
"""Test setting up manually with one adapter on MacOS."""
result = await hass.config_entries.flow.async_init(
DOMAIN,
context={"source": config_entries.SOURCE_USER},
data={},
)
assert result["type"] == FlowResultType.FORM
assert result["step_id"] == "single_adapter"
with patch(
"homeassistant.components.bluetooth.async_setup", return_value=True
), patch(
"homeassistant.components.bluetooth.async_setup_entry", return_value=True
) as mock_setup_entry:
result2 = await hass.config_entries.flow.async_configure(
result["flow_id"], user_input={}
)
assert result2["type"] == FlowResultType.CREATE_ENTRY
assert result2["title"] == "Core Bluetooth"
assert result2["data"] == {}
assert len(mock_setup_entry.mock_calls) == 1
async def test_async_step_user_linux_one_adapter(hass, one_adapter):
"""Test setting up manually with one adapter on Linux."""
result = await hass.config_entries.flow.async_init(
DOMAIN,
context={"source": config_entries.SOURCE_USER},
data={},
)
assert result["type"] == FlowResultType.FORM
assert result["step_id"] == "single_adapter"
with patch(
"homeassistant.components.bluetooth.async_setup", return_value=True
), patch(
"homeassistant.components.bluetooth.async_setup_entry", return_value=True
) as mock_setup_entry:
result2 = await hass.config_entries.flow.async_configure(
result["flow_id"], user_input={}
)
assert result2["type"] == FlowResultType.CREATE_ENTRY
assert result2["title"] == "00:00:00:00:00:01"
assert result2["data"] == {}
assert len(mock_setup_entry.mock_calls) == 1
async def test_async_step_user_linux_two_adapters(hass, two_adapters):
"""Test setting up manually with two adapters on Linux."""
result = await hass.config_entries.flow.async_init(
DOMAIN,
context={"source": config_entries.SOURCE_USER},
data={},
)
assert result["type"] == FlowResultType.FORM
assert result["step_id"] == "multiple_adapters"
with patch(
"homeassistant.components.bluetooth.async_setup", return_value=True
), patch(
"homeassistant.components.bluetooth.async_setup_entry", return_value=True
) as mock_setup_entry:
result2 = await hass.config_entries.flow.async_configure(
result["flow_id"], user_input={CONF_ADAPTER: "hci1"}
)
assert result2["type"] == FlowResultType.CREATE_ENTRY
assert result2["title"] == "00:00:00:00:00:02"
assert result2["data"] == {}
assert len(mock_setup_entry.mock_calls) == 1
async def test_async_step_user_only_allows_one(hass, macos_adapter):
"""Test setting up manually with an existing entry."""
entry = MockConfigEntry(domain=DOMAIN, unique_id=DEFAULT_ADDRESS)
entry.add_to_hass(hass)
result = await hass.config_entries.flow.async_init(
DOMAIN,
context={"source": config_entries.SOURCE_USER},
data={},
)
assert result["type"] == FlowResultType.ABORT
assert result["reason"] == "no_adapters"
async def test_async_step_integration_discovery(hass):
"""Test setting up from integration discovery."""
details = AdapterDetails(
address="00:00:00:00:00:01", sw_version="1.23.5", hw_version="1.2.3"
)
result = await hass.config_entries.flow.async_init(
DOMAIN,
context={"source": config_entries.SOURCE_INTEGRATION_DISCOVERY},
data={CONF_ADAPTER: "hci0", CONF_DETAILS: details},
)
assert result["type"] == FlowResultType.FORM
assert result["step_id"] == "single_adapter"
with patch(
"homeassistant.components.bluetooth.async_setup", return_value=True
), patch(
"homeassistant.components.bluetooth.async_setup_entry", return_value=True
) as mock_setup_entry:
result2 = await hass.config_entries.flow.async_configure(
result["flow_id"], user_input={}
)
assert result2["type"] == FlowResultType.CREATE_ENTRY
assert result2["title"] == "00:00:00:00:00:01"
assert result2["data"] == {}
assert len(mock_setup_entry.mock_calls) == 1
async def test_async_step_integration_discovery_during_onboarding_one_adapter(
hass, one_adapter
):
"""Test setting up from integration discovery during onboarding."""
details = AdapterDetails(
address="00:00:00:00:00:01", sw_version="1.23.5", hw_version="1.2.3"
)
with patch(
"homeassistant.components.bluetooth.async_setup", return_value=True
), patch(
"homeassistant.components.bluetooth.async_setup_entry", return_value=True
) as mock_setup_entry, patch(
"homeassistant.components.onboarding.async_is_onboarded",
return_value=False,
) as mock_onboarding:
result = await hass.config_entries.flow.async_init(
DOMAIN,
context={"source": config_entries.SOURCE_INTEGRATION_DISCOVERY},
data={CONF_ADAPTER: "hci0", CONF_DETAILS: details},
)
assert result["type"] == FlowResultType.CREATE_ENTRY
assert result["title"] == "00:00:00:00:00:01"
assert result["data"] == {}
assert len(mock_setup_entry.mock_calls) == 1
assert len(mock_onboarding.mock_calls) == 1
async def test_async_step_integration_discovery_during_onboarding_two_adapters(
hass, two_adapters
):
"""Test setting up from integration discovery during onboarding."""
details1 = AdapterDetails(
address="00:00:00:00:00:01", sw_version="1.23.5", hw_version="1.2.3"
)
details2 = AdapterDetails(
address="00:00:00:00:00:02", sw_version="1.23.5", hw_version="1.2.3"
)
with patch(
"homeassistant.components.bluetooth.async_setup", return_value=True
), patch(
"homeassistant.components.bluetooth.async_setup_entry", return_value=True
) as mock_setup_entry, patch(
"homeassistant.components.onboarding.async_is_onboarded",
return_value=False,
) as mock_onboarding:
result = await hass.config_entries.flow.async_init(
DOMAIN,
context={"source": config_entries.SOURCE_INTEGRATION_DISCOVERY},
data={CONF_ADAPTER: "hci0", CONF_DETAILS: details1},
)
result2 = await hass.config_entries.flow.async_init(
DOMAIN,
context={"source": config_entries.SOURCE_INTEGRATION_DISCOVERY},
data={CONF_ADAPTER: "hci1", CONF_DETAILS: details2},
)
assert result["type"] == FlowResultType.CREATE_ENTRY
assert result["title"] == "00:00:00:00:00:01"
assert result["data"] == {}
assert result2["type"] == FlowResultType.CREATE_ENTRY
assert result2["title"] == "00:00:00:00:00:02"
assert result2["data"] == {}
assert len(mock_setup_entry.mock_calls) == 2
assert len(mock_onboarding.mock_calls) == 2
async def test_async_step_integration_discovery_during_onboarding(hass, macos_adapter):
"""Test setting up from integration discovery during onboarding."""
details = AdapterDetails(
address=DEFAULT_ADDRESS, sw_version="1.23.5", hw_version="1.2.3"
)
with patch(
"homeassistant.components.bluetooth.async_setup", return_value=True
), patch(
"homeassistant.components.bluetooth.async_setup_entry", return_value=True
) as mock_setup_entry, patch(
"homeassistant.components.onboarding.async_is_onboarded",
return_value=False,
) as mock_onboarding:
result = await hass.config_entries.flow.async_init(
DOMAIN,
context={"source": config_entries.SOURCE_INTEGRATION_DISCOVERY},
data={CONF_ADAPTER: "Core Bluetooth", CONF_DETAILS: details},
)
assert result["type"] == FlowResultType.CREATE_ENTRY
assert result["title"] == "Core Bluetooth"
assert result["data"] == {}
assert len(mock_setup_entry.mock_calls) == 1
assert len(mock_onboarding.mock_calls) == 1
async def test_async_step_integration_discovery_already_exists(hass):
"""Test setting up from integration discovery when an entry already exists."""
details = AdapterDetails(
address="00:00:00:00:00:01", sw_version="1.23.5", hw_version="1.2.3"
)
entry = MockConfigEntry(domain=DOMAIN, unique_id="00:00:00:00:00:01")
entry.add_to_hass(hass)
result = await hass.config_entries.flow.async_init(
DOMAIN,
context={"source": config_entries.SOURCE_INTEGRATION_DISCOVERY},
data={CONF_ADAPTER: "hci0", CONF_DETAILS: details},
)
assert result["type"] == FlowResultType.ABORT
assert result["reason"] == "already_configured"
async def test_options_flow_linux(
hass, mock_bleak_scanner_start, mock_bluetooth_adapters, one_adapter
):
"""Test options on Linux."""
entry = MockConfigEntry(
domain=DOMAIN,
data={},
options={},
unique_id="00:00:00:00:00:01",
)
entry.add_to_hass(hass)
await hass.config_entries.async_setup(entry.entry_id)
await hass.async_block_till_done()
result = await hass.config_entries.options.async_init(entry.entry_id)
assert result["type"] == FlowResultType.FORM
assert result["step_id"] == "init"
assert result["errors"] is None
result = await hass.config_entries.options.async_configure(
result["flow_id"],
user_input={
CONF_PASSIVE: True,
},
)
await hass.async_block_till_done()
assert result["type"] == FlowResultType.CREATE_ENTRY
assert result["data"][CONF_PASSIVE] is True
# Verify we can change it to False
result = await hass.config_entries.options.async_init(entry.entry_id)
assert result["type"] == FlowResultType.FORM
assert result["step_id"] == "init"
assert result["errors"] is None
result = await hass.config_entries.options.async_configure(
result["flow_id"],
user_input={
CONF_PASSIVE: False,
},
)
await hass.async_block_till_done()
assert result["type"] == FlowResultType.CREATE_ENTRY
assert result["data"][CONF_PASSIVE] is False
await hass.config_entries.async_unload(entry.entry_id)
async def test_options_flow_disabled_macos(
hass,
hass_ws_client,
mock_bleak_scanner_start,
mock_bluetooth_adapters,
macos_adapter,
):
"""Test options are disabled on MacOS."""
await async_setup_component(hass, "config", {})
entry = MockConfigEntry(
domain=DOMAIN, data={}, options={}, unique_id=DEFAULT_ADDRESS
)
entry.add_to_hass(hass)
assert await hass.config_entries.async_setup(entry.entry_id)
await hass.async_block_till_done()
ws_client = await hass_ws_client(hass)
await ws_client.send_json(
{
"id": 5,
"type": "config_entries/get",
"domain": "bluetooth",
"type_filter": "integration",
}
)
response = await ws_client.receive_json()
assert response["result"][0]["supports_options"] is False
await hass.config_entries.async_unload(entry.entry_id)
async def test_options_flow_enabled_linux(
hass, hass_ws_client, mock_bleak_scanner_start, mock_bluetooth_adapters, one_adapter
):
"""Test options are enabled on Linux."""
await async_setup_component(hass, "config", {})
entry = MockConfigEntry(
domain=DOMAIN,
data={},
options={},
unique_id="00:00:00:00:00:01",
)
entry.add_to_hass(hass)
assert await hass.config_entries.async_setup(entry.entry_id)
await hass.async_block_till_done()
ws_client = await hass_ws_client(hass)
await ws_client.send_json(
{
"id": 5,
"type": "config_entries/get",
"domain": "bluetooth",
"type_filter": "integration",
}
)
response = await ws_client.receive_json()
assert response["result"][0]["supports_options"] is True
await hass.config_entries.async_unload(entry.entry_id)
| [
"noreply@github.com"
] | fredrike.noreply@github.com |
2a05d7369414945fbe92cb2a7446a8b241ae08e3 | 2c95e0f7bb3f977306f479d5c99601ab1d5c61f2 | /olive/full_node/mempool_check_conditions.py | 8bdc56ca5a2665a2e9cd9a91923e25d9c493333d | [
"Apache-2.0"
] | permissive | Olive-blockchain/Olive-blockchain-CLI | d62444f8456467f8105531178d2ae53d6e92087d | 8c4a9a382d68fc1d71c5b6c1da858922a8bb8808 | refs/heads/main | 2023-07-19T03:51:08.700834 | 2021-09-19T16:05:10 | 2021-09-19T16:05:10 | 406,045,499 | 0 | 0 | Apache-2.0 | 2021-09-19T16:05:10 | 2021-09-13T16:20:38 | Python | UTF-8 | Python | false | false | 17,492 | py | import logging
import time
from typing import Tuple, Dict, List, Optional, Set
from clvm import SExp
from olive.consensus.cost_calculator import NPCResult
from olive.consensus.condition_costs import ConditionCost
from olive.full_node.generator import create_generator_args, setup_generator_args
from olive.types.blockchain_format.coin import Coin
from olive.types.blockchain_format.program import NIL
from olive.types.blockchain_format.sized_bytes import bytes32
from olive.types.coin_record import CoinRecord
from olive.types.condition_with_args import ConditionWithArgs
from olive.types.generator_types import BlockGenerator
from olive.types.name_puzzle_condition import NPC
from olive.util.clvm import int_from_bytes, int_to_bytes
from olive.util.condition_tools import ConditionOpcode, conditions_by_opcode
from olive.util.errors import Err, ValidationError
from olive.util.ints import uint32, uint64, uint16
from olive.wallet.puzzles.generator_loader import GENERATOR_FOR_SINGLE_COIN_MOD
from olive.wallet.puzzles.rom_bootstrap_generator import get_generator
GENERATOR_MOD = get_generator()
def mempool_assert_announcement(condition: ConditionWithArgs, announcements: Set[bytes32]) -> Optional[Err]:
"""
Check if an announcement is included in the list of announcements
"""
announcement_hash = bytes32(condition.vars[0])
if announcement_hash not in announcements:
return Err.ASSERT_ANNOUNCE_CONSUMED_FAILED
return None
log = logging.getLogger(__name__)
def mempool_assert_my_coin_id(condition: ConditionWithArgs, unspent: CoinRecord) -> Optional[Err]:
"""
Checks if CoinID matches the id from the condition
"""
if unspent.coin.name() != condition.vars[0]:
log.warning(f"My name: {unspent.coin.name()} got: {condition.vars[0].hex()}")
return Err.ASSERT_MY_COIN_ID_FAILED
return None
def mempool_assert_absolute_block_height_exceeds(
condition: ConditionWithArgs, prev_transaction_block_height: uint32
) -> Optional[Err]:
"""
Checks if the next block index exceeds the block index from the condition
"""
try:
block_index_exceeds_this = int_from_bytes(condition.vars[0])
except ValueError:
return Err.INVALID_CONDITION
if prev_transaction_block_height < block_index_exceeds_this:
return Err.ASSERT_HEIGHT_ABSOLUTE_FAILED
return None
def mempool_assert_relative_block_height_exceeds(
condition: ConditionWithArgs, unspent: CoinRecord, prev_transaction_block_height: uint32
) -> Optional[Err]:
"""
Checks if the coin age exceeds the age from the condition
"""
try:
expected_block_age = int_from_bytes(condition.vars[0])
block_index_exceeds_this = expected_block_age + unspent.confirmed_block_index
except ValueError:
return Err.INVALID_CONDITION
if prev_transaction_block_height < block_index_exceeds_this:
return Err.ASSERT_HEIGHT_RELATIVE_FAILED
return None
def mempool_assert_absolute_time_exceeds(condition: ConditionWithArgs, timestamp: uint64) -> Optional[Err]:
"""
Check if the current time in seconds exceeds the time specified by condition
"""
try:
expected_seconds = int_from_bytes(condition.vars[0])
except ValueError:
return Err.INVALID_CONDITION
if timestamp is None:
timestamp = uint64(int(time.time()))
if timestamp < expected_seconds:
return Err.ASSERT_SECONDS_ABSOLUTE_FAILED
return None
def mempool_assert_relative_time_exceeds(
condition: ConditionWithArgs, unspent: CoinRecord, timestamp: uint64
) -> Optional[Err]:
"""
Check if the current time in seconds exceeds the time specified by condition
"""
try:
expected_seconds = int_from_bytes(condition.vars[0])
except ValueError:
return Err.INVALID_CONDITION
if timestamp is None:
timestamp = uint64(int(time.time()))
if timestamp < expected_seconds + unspent.timestamp:
return Err.ASSERT_SECONDS_RELATIVE_FAILED
return None
def mempool_assert_my_parent_id(condition: ConditionWithArgs, unspent: CoinRecord) -> Optional[Err]:
"""
Checks if coin's parent ID matches the ID from the condition
"""
if unspent.coin.parent_coin_info != condition.vars[0]:
return Err.ASSERT_MY_PARENT_ID_FAILED
return None
def mempool_assert_my_puzzlehash(condition: ConditionWithArgs, unspent: CoinRecord) -> Optional[Err]:
"""
Checks if coin's puzzlehash matches the puzzlehash from the condition
"""
if unspent.coin.puzzle_hash != condition.vars[0]:
return Err.ASSERT_MY_PUZZLEHASH_FAILED
return None
def mempool_assert_my_amount(condition: ConditionWithArgs, unspent: CoinRecord) -> Optional[Err]:
"""
Checks if coin's amount matches the amount from the condition
"""
if unspent.coin.amount != int_from_bytes(condition.vars[0]):
return Err.ASSERT_MY_AMOUNT_FAILED
return None
def sanitize_int(n: SExp, safe_mode: bool) -> int:
buf = n.atom
if safe_mode and len(buf) > 2 and buf[0] == 0 and buf[1] == 0:
raise ValidationError(Err.INVALID_CONDITION)
return n.as_int()
def parse_aggsig(args: SExp) -> List[bytes]:
pubkey = args.first().atom
args = args.rest()
message = args.first().atom
if len(pubkey) != 48:
raise ValidationError(Err.INVALID_CONDITION)
if len(message) > 1024:
raise ValidationError(Err.INVALID_CONDITION)
return [pubkey, message]
def parse_create_coin(args: SExp, safe_mode: bool) -> List[bytes]:
puzzle_hash = args.first().atom
args = args.rest()
if len(puzzle_hash) != 32:
raise ValidationError(Err.INVALID_CONDITION)
amount_int = sanitize_int(args.first(), safe_mode)
if amount_int >= 2 ** 64:
raise ValidationError(Err.COIN_AMOUNT_EXCEEDS_MAXIMUM)
if amount_int < 0:
raise ValidationError(Err.COIN_AMOUNT_NEGATIVE)
# note that this may change the representation of amount. If the original
# buffer had redundant leading zeroes, they will be stripped
return [puzzle_hash, int_to_bytes(amount_int)]
def parse_seconds(args: SExp, safe_mode: bool, error_code: Err) -> Optional[List[bytes]]:
seconds_int = sanitize_int(args.first(), safe_mode)
# this condition is inherently satisified, there is no need to keep it
if seconds_int <= 0:
return None
if seconds_int >= 2 ** 64:
raise ValidationError(error_code)
# note that this may change the representation of seconds. If the original
# buffer had redundant leading zeroes, they will be stripped
return [int_to_bytes(seconds_int)]
def parse_height(args: SExp, safe_mode: bool, error_code: Err) -> Optional[List[bytes]]:
height_int = sanitize_int(args.first(), safe_mode)
# this condition is inherently satisified, there is no need to keep it
if height_int < 0:
return None
if height_int >= 2 ** 32:
raise ValidationError(error_code)
# note that this may change the representation of the height. If the original
# buffer had redundant leading zeroes, they will be stripped
return [int_to_bytes(height_int)]
def parse_fee(args: SExp, safe_mode: bool) -> List[bytes]:
fee_int = sanitize_int(args.first(), safe_mode)
if fee_int >= 2 ** 64 or fee_int < 0:
raise ValidationError(Err.RESERVE_FEE_CONDITION_FAILED)
# note that this may change the representation of the fee. If the original
# buffer had redundant leading zeroes, they will be stripped
return [int_to_bytes(fee_int)]
def parse_hash(args: SExp, error_code: Err) -> List[bytes]:
h = args.first().atom
if len(h) != 32:
raise ValidationError(error_code)
return [h]
def parse_amount(args: SExp, safe_mode: bool) -> List[bytes]:
amount_int = sanitize_int(args.first(), safe_mode)
if amount_int < 0:
raise ValidationError(Err.ASSERT_MY_AMOUNT_FAILED)
if amount_int >= 2 ** 64:
raise ValidationError(Err.ASSERT_MY_AMOUNT_FAILED)
# note that this may change the representation of amount. If the original
# buffer had redundant leading zeroes, they will be stripped
return [int_to_bytes(amount_int)]
def parse_announcement(args: SExp) -> List[bytes]:
msg = args.first().atom
if len(msg) > 1024:
raise ValidationError(Err.INVALID_CONDITION)
return [msg]
def parse_condition_args(args: SExp, condition: ConditionOpcode, safe_mode: bool) -> Tuple[int, Optional[List[bytes]]]:
"""
Parse a list with exactly the expected args, given opcode,
from an SExp into a list of bytes. If there are fewer or more elements in
the list, raise a RuntimeError. If the condition is inherently true (such as
a time- or height lock with a negative time or height, the returned list is None
"""
op = ConditionOpcode
cc = ConditionCost
if condition is op.AGG_SIG_UNSAFE or condition is op.AGG_SIG_ME:
return cc.AGG_SIG.value, parse_aggsig(args)
elif condition is op.CREATE_COIN:
return cc.CREATE_COIN.value, parse_create_coin(args, safe_mode)
elif condition is op.ASSERT_SECONDS_ABSOLUTE:
return cc.ASSERT_SECONDS_ABSOLUTE.value, parse_seconds(args, safe_mode, Err.ASSERT_SECONDS_ABSOLUTE_FAILED)
elif condition is op.ASSERT_SECONDS_RELATIVE:
return cc.ASSERT_SECONDS_RELATIVE.value, parse_seconds(args, safe_mode, Err.ASSERT_SECONDS_RELATIVE_FAILED)
elif condition is op.ASSERT_HEIGHT_ABSOLUTE:
return cc.ASSERT_HEIGHT_ABSOLUTE.value, parse_height(args, safe_mode, Err.ASSERT_HEIGHT_ABSOLUTE_FAILED)
elif condition is op.ASSERT_HEIGHT_RELATIVE:
return cc.ASSERT_HEIGHT_RELATIVE.value, parse_height(args, safe_mode, Err.ASSERT_HEIGHT_RELATIVE_FAILED)
elif condition is op.ASSERT_MY_COIN_ID:
return cc.ASSERT_MY_COIN_ID.value, parse_hash(args, Err.ASSERT_MY_COIN_ID_FAILED)
elif condition is op.RESERVE_FEE:
return cc.RESERVE_FEE.value, parse_fee(args, safe_mode)
elif condition is op.CREATE_COIN_ANNOUNCEMENT:
return cc.CREATE_COIN_ANNOUNCEMENT.value, parse_announcement(args)
elif condition is op.ASSERT_COIN_ANNOUNCEMENT:
return cc.ASSERT_COIN_ANNOUNCEMENT.value, parse_hash(args, Err.ASSERT_ANNOUNCE_CONSUMED_FAILED)
elif condition is op.CREATE_PUZZLE_ANNOUNCEMENT:
return cc.CREATE_PUZZLE_ANNOUNCEMENT.value, parse_announcement(args)
elif condition is op.ASSERT_PUZZLE_ANNOUNCEMENT:
return cc.ASSERT_PUZZLE_ANNOUNCEMENT.value, parse_hash(args, Err.ASSERT_ANNOUNCE_CONSUMED_FAILED)
elif condition is op.ASSERT_MY_PARENT_ID:
return cc.ASSERT_MY_PARENT_ID.value, parse_hash(args, Err.ASSERT_MY_PARENT_ID_FAILED)
elif condition is op.ASSERT_MY_PUZZLEHASH:
return cc.ASSERT_MY_PUZZLEHASH.value, parse_hash(args, Err.ASSERT_MY_PUZZLEHASH_FAILED)
elif condition is op.ASSERT_MY_AMOUNT:
return cc.ASSERT_MY_AMOUNT.value, parse_amount(args, safe_mode)
else:
raise ValidationError(Err.INVALID_CONDITION)
CONDITION_OPCODES: Set[bytes] = set(item.value for item in ConditionOpcode)
def parse_condition(cond: SExp, safe_mode: bool) -> Tuple[int, Optional[ConditionWithArgs]]:
condition = cond.first().as_atom()
if condition in CONDITION_OPCODES:
opcode: ConditionOpcode = ConditionOpcode(condition)
cost, args = parse_condition_args(cond.rest(), opcode, safe_mode)
cvl = ConditionWithArgs(opcode, args) if args is not None else None
elif not safe_mode:
opcode = ConditionOpcode.UNKNOWN
cvl = ConditionWithArgs(opcode, cond.rest().as_atom_list())
cost = 0
else:
raise ValidationError(Err.INVALID_CONDITION)
return cost, cvl
def get_name_puzzle_conditions(
generator: BlockGenerator, max_cost: int, *, cost_per_byte: int, safe_mode: bool
) -> NPCResult:
"""
This executes the generator program and returns the coins and their
conditions. If the cost of the program (size, CLVM execution and conditions)
exceed max_cost, the function fails. In order to accurately take the size
of the program into account when calculating cost, cost_per_byte must be
specified.
safe_mode determines whether the clvm program and conditions are executed in
strict mode or not. When in safe/strict mode, unknow operations or conditions
are considered failures. This is the mode when accepting transactions into
the mempool.
"""
try:
block_program, block_program_args = setup_generator_args(generator)
max_cost -= len(bytes(generator.program)) * cost_per_byte
if max_cost < 0:
return NPCResult(uint16(Err.INVALID_BLOCK_COST.value), [], uint64(0))
if safe_mode:
clvm_cost, result = GENERATOR_MOD.run_safe_with_cost(max_cost, block_program, block_program_args)
else:
clvm_cost, result = GENERATOR_MOD.run_with_cost(max_cost, block_program, block_program_args)
max_cost -= clvm_cost
if max_cost < 0:
return NPCResult(uint16(Err.INVALID_BLOCK_COST.value), [], uint64(0))
npc_list: List[NPC] = []
for res in result.first().as_iter():
conditions_list: List[ConditionWithArgs] = []
if len(res.first().atom) != 32:
raise ValidationError(Err.INVALID_CONDITION)
spent_coin_parent_id: bytes32 = res.first().as_atom()
res = res.rest()
if len(res.first().atom) != 32:
raise ValidationError(Err.INVALID_CONDITION)
spent_coin_puzzle_hash: bytes32 = res.first().as_atom()
res = res.rest()
spent_coin_amount: uint64 = uint64(sanitize_int(res.first(), safe_mode))
res = res.rest()
spent_coin: Coin = Coin(spent_coin_parent_id, spent_coin_puzzle_hash, spent_coin_amount)
for cond in res.first().as_iter():
cost, cvl = parse_condition(cond, safe_mode)
max_cost -= cost
if max_cost < 0:
return NPCResult(uint16(Err.INVALID_BLOCK_COST.value), [], uint64(0))
if cvl is not None:
conditions_list.append(cvl)
conditions_dict = conditions_by_opcode(conditions_list)
if conditions_dict is None:
conditions_dict = {}
npc_list.append(
NPC(spent_coin.name(), spent_coin.puzzle_hash, [(a, b) for a, b in conditions_dict.items()])
)
return NPCResult(None, npc_list, uint64(clvm_cost))
except ValidationError as e:
return NPCResult(uint16(e.code.value), [], uint64(0))
except Exception:
return NPCResult(uint16(Err.GENERATOR_RUNTIME_ERROR.value), [], uint64(0))
def get_puzzle_and_solution_for_coin(generator: BlockGenerator, coin_name: bytes, max_cost: int):
try:
block_program = generator.program
if not generator.generator_args:
block_program_args = NIL
else:
block_program_args = create_generator_args(generator.generator_refs())
cost, result = GENERATOR_FOR_SINGLE_COIN_MOD.run_with_cost(
max_cost, block_program, block_program_args, coin_name
)
puzzle = result.first()
solution = result.rest().first()
return None, puzzle, solution
except Exception as e:
return e, None, None
def mempool_check_conditions_dict(
unspent: CoinRecord,
coin_announcement_names: Set[bytes32],
puzzle_announcement_names: Set[bytes32],
conditions_dict: Dict[ConditionOpcode, List[ConditionWithArgs]],
prev_transaction_block_height: uint32,
timestamp: uint64,
) -> Optional[Err]:
"""
Check all conditions against current state.
"""
for con_list in conditions_dict.values():
cvp: ConditionWithArgs
for cvp in con_list:
error: Optional[Err] = None
if cvp.opcode is ConditionOpcode.ASSERT_MY_COIN_ID:
error = mempool_assert_my_coin_id(cvp, unspent)
elif cvp.opcode is ConditionOpcode.ASSERT_COIN_ANNOUNCEMENT:
error = mempool_assert_announcement(cvp, coin_announcement_names)
elif cvp.opcode is ConditionOpcode.ASSERT_PUZZLE_ANNOUNCEMENT:
error = mempool_assert_announcement(cvp, puzzle_announcement_names)
elif cvp.opcode is ConditionOpcode.ASSERT_HEIGHT_ABSOLUTE:
error = mempool_assert_absolute_block_height_exceeds(cvp, prev_transaction_block_height)
elif cvp.opcode is ConditionOpcode.ASSERT_HEIGHT_RELATIVE:
error = mempool_assert_relative_block_height_exceeds(cvp, unspent, prev_transaction_block_height)
elif cvp.opcode is ConditionOpcode.ASSERT_SECONDS_ABSOLUTE:
error = mempool_assert_absolute_time_exceeds(cvp, timestamp)
elif cvp.opcode is ConditionOpcode.ASSERT_SECONDS_RELATIVE:
error = mempool_assert_relative_time_exceeds(cvp, unspent, timestamp)
elif cvp.opcode is ConditionOpcode.ASSERT_MY_PARENT_ID:
error = mempool_assert_my_parent_id(cvp, unspent)
elif cvp.opcode is ConditionOpcode.ASSERT_MY_PUZZLEHASH:
error = mempool_assert_my_puzzlehash(cvp, unspent)
elif cvp.opcode is ConditionOpcode.ASSERT_MY_AMOUNT:
error = mempool_assert_my_amount(cvp, unspent)
if error:
return error
return None
| [
"87711356+Olive-blockchain@users.noreply.github.com"
] | 87711356+Olive-blockchain@users.noreply.github.com |
84ec594f8624640b12420b289697b98165eb129d | f0a62605171bc62eb68dd884c77cf146657ec5cb | /library/f5bigip_ltm_monitor_soap.py | 82c1972e1d3fdc6839c472d393fc326641e76ce1 | [
"Apache-2.0"
] | permissive | erjac77/ansible-role-f5 | dd5cc32c4cc4c79d6eba669269e0d6e978314d66 | c45b5d9d5f34a8ac6d19ded836d0a6b7ee7f8056 | refs/heads/master | 2020-04-06T08:13:14.095083 | 2020-02-16T23:44:13 | 2020-02-16T23:44:13 | 240,129,047 | 3 | 1 | null | null | null | null | UTF-8 | Python | false | false | 7,822 | py | #!/usr/bin/python
# -*- coding: utf-8 -*-
# Copyright 2016 Eric Jacob <erjac77@gmail.com>
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
ANSIBLE_METADATA = {
"metadata_version": "1.1",
"status": ["preview"],
"supported_by": "community",
}
DOCUMENTATION = """
---
module: f5bigip_ltm_monitor_soap
short_description: BIG-IP ltm monitor soap module
description:
- Configures a Simple Object Access Protocol (SOAP) monitor.
version_added: "1.0.0" # of erjac77.f5 role
author:
- "Gabriel Fortin (@GabrielFortin)"
options:
debug:
description:
- Specifies whether the monitor sends error messages and additional information to a log file created and
labeled specifically for this monitor.
default: no
choices: ['no', 'yes']
defaults_from:
description:
- Specifies the type of monitor you want to use to create the new monitor.
default: soap
destination:
description:
- Specifies the IP address and service port of the resource that is the destination of this monitor.
expect_fault:
description:
- Specifies whether the value of the method option causes the monitor to expect a SOAP fault message.
default: no
choices: ['no', 'yes']
interval:
description:
- Specifies, in seconds, the frequency at which the system issues the monitor check when either the resource
is down or the status of the resource is unknown.
default: 5
manual_resume:
description:
- Specifies whether the system automatically changes the status of a resource to up at the next successful
monitor check.
default: disabled
choices: ['disabled', 'enabled']
method:
description:
- Specifies the method by which the monitor contacts the resource.
namespace:
description:
- Specifies the name space for the Web service you are monitoring, for example, http://example.com/.
parameter_name:
description:
- If the method has a parameter, specifies the name of that parameter.
parameter_type:
description:
- Specifies the parameter type.
default: bool
choices: ['bool', 'int', 'long', 'string']
parameter_value:
description:
- Specifies the value for the parameter.
password:
description:
- Specifies the password if the monitored target requires authentication.
protocol:
description:
- Specifies the protocol that the monitor uses to communicate with the target, http or https.
default: http
choices: ['http', 'https']
return_type:
description:
- ['bool', 'char', 'double', 'int', 'long', 'short', 'string']
default: bool
return_value:
description:
- Specifies the value for the returned parameter.
soap_action:
description:
- Specifies the value for the SOAPAction header.
default: ''
time_until_up:
description:
- Specifies the amount of time, in seconds, after the first successful response before a node is marked up.
default: 0
timeout:
description:
- Specifies the number of seconds the target has in which to respond to the monitor request.
default: 16
up_interval:
description:
- Specifies, in seconds, the frequency at which the system issues the monitor check when the resource is up.
default: 0
url_path:
description:
- Specifies the URL for the Web service that you are monitoring, for example, /services/myservice.aspx.
username:
description:
- Specifies the user name if the monitored target requires authentication.
extends_documentation_fragment:
- f5_common
- f5_app_service
- f5_description
- f5_name
- f5_partition
- f5_state
"""
EXAMPLES = """
- name: Create LTM Monitor SOAP
f5bigip_ltm_monitor_soap:
provider:
server: "{{ ansible_host }}"
server_port: "{{ http_port | default(443) }}"
user: "{{ http_user }}"
password: "{{ http_pass }}"
validate_certs: false
name: my_soap_monitor
partition: Common
description: My soap monitor
state: present
delegate_to: localhost
"""
RETURN = """ # """
from ansible.module_utils.basic import AnsibleModule
from ansible.module_utils.erjac77.network.f5.common import F5_ACTIVATION_CHOICES
from ansible.module_utils.erjac77.network.f5.common import F5_NAMED_OBJ_ARGS
from ansible.module_utils.erjac77.network.f5.common import F5_POLAR_CHOICES
from ansible.module_utils.erjac77.network.f5.common import F5_PROVIDER_ARGS
from ansible.module_utils.erjac77.network.f5.bigip import F5BigIpNamedObject
class ModuleParams(object):
@property
def argument_spec(self):
argument_spec = dict(
app_service=dict(type="str"),
debug=dict(type="str", choices=F5_POLAR_CHOICES),
defaults_from=dict(type="str"),
description=dict(type="str"),
destination=dict(type="str"),
expect_fault=dict(type="str", choices=F5_POLAR_CHOICES),
interval=dict(type="int"),
manual_resume=dict(type="str", choices=F5_ACTIVATION_CHOICES),
method=dict(type="str"),
namespace=dict(type="str"),
parameter_name=dict(type="str"),
parameter_type=dict(type="str", choices=["bool", "int", "long", "string"]),
parameter_value=dict(type="str"),
password=dict(type="str", no_log=True),
protocol=dict(type="str", choices=["http", "https"]),
return_type=dict(
type="str",
choices=["bool", "char", "double", "int", "long", "short", "string"],
),
return_value=dict(type="str"),
soap_action=dict(type="str"),
time_until_up=dict(type="int"),
timeout=dict(type="int"),
up_interval=dict(type="int"),
url_path=dict(type="str"),
username=dict(type="str"),
)
argument_spec.update(F5_PROVIDER_ARGS)
argument_spec.update(F5_NAMED_OBJ_ARGS)
return argument_spec
@property
def supports_check_mode(self):
return True
class F5BigIpLtmMonitorSoap(F5BigIpNamedObject):
def _set_crud_methods(self):
self._methods = {
"create": self._api.tm.ltm.monitor.soaps.soap.create,
"read": self._api.tm.ltm.monitor.soaps.soap.load,
"update": self._api.tm.ltm.monitor.soaps.soap.update,
"delete": self._api.tm.ltm.monitor.soaps.soap.delete,
"exists": self._api.tm.ltm.monitor.soaps.soap.exists,
}
def main():
params = ModuleParams()
module = AnsibleModule(
argument_spec=params.argument_spec,
supports_check_mode=params.supports_check_mode,
)
try:
obj = F5BigIpLtmMonitorSoap(check_mode=module.check_mode, **module.params)
result = obj.flush()
module.exit_json(**result)
except Exception as exc:
module.fail_json(msg=str(exc))
if __name__ == "__main__":
main()
| [
"erjac77@gmail.com"
] | erjac77@gmail.com |
84c3509be2e56001daedb1739428049bbe0fb6a3 | 441b9d601c5e6b860a11bf579f97406bf6c2a2b9 | /tests/testServerManager.py | e4ace767c7e6e9a3c60aaf1ecb282ca7e9c24f3d | [
"MIT"
] | permissive | YunjeongLee/SBstoat | 7885d5604dbfd10efa79ad71823a6835e19c53c4 | 31b184176a7f19074c905db76e6e6ac8e4fc36a8 | refs/heads/master | 2023-04-14T21:48:41.499046 | 2021-04-15T18:48:00 | 2021-04-15T18:48:00 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,303 | py | # -*- coding: utf-8 -*-
"""
Created on March 23, 2021
@author: joseph-hellerstein
"""
import SBstoat._serverManager as sm
from SBstoat.logs import Logger
import multiprocessing
import numpy as np
import unittest
IGNORE_TEST = False
IS_PLOT = False
SIZE = 10
PRIME_SIZES = [5, 10, 15]
class PrimeFinder(sm.AbstractServer):
"""A work unit is number of primes to calculate."""
def __init__(self, initialArgument, inputQ, outputQ, isException=False,
logger=Logger()):
super().__init__(initialArgument, inputQ, outputQ, logger=Logger())
self.isException = isException
@staticmethod
def _isPrime(number, primes):
if number < 2:
return False
maxNumber = np.sqrt(number)
for prime in primes:
if prime > maxNumber:
return True
if np.mod(number, prime) == 0:
return False
return True
def runFunction(self, numPrime):
"""
Calculates the specified number of prime numbers.
Parameters
----------
numPrime: int
Returns
-------
np.array
"""
if self.isException:
raise RuntimeError("Generated RuntimeError.")
# Find primes until enough are accumulated
primes = []
num = 2
while len(primes) < numPrime:
if self._isPrime(num, primes):
primes.append(num)
num += 1
return np.array(primes)
################## CLASSES BEING TESTED ##############
class TestAbstractConsumer(unittest.TestCase):
def setUp(self):
self.inputQ = multiprocessing.Queue()
self.outputQ = multiprocessing.Queue()
self.finder = PrimeFinder(None, self.inputQ, self.outputQ)
def testPrimeFinder(self):
if IGNORE_TEST:
return
primes = self.finder.runFunction(SIZE)
self.assertEqual(len(primes), SIZE)
def testRunNoException(self):
if IGNORE_TEST:
return
server = PrimeFinder(None, self.inputQ, self.outputQ)
server.start()
self.inputQ.put(SIZE)
result = self.outputQ.get()
server.terminate()
self.assertEqual(len(result), SIZE)
def testRunWithException(self):
if IGNORE_TEST:
return
server = PrimeFinder(None, self.inputQ, self.outputQ,
isException=True)
server.start()
self.inputQ.put(SIZE)
result = self.outputQ.get()
server.terminate()
#self.inputQ.put(None)
self.assertIsNone(result)
class TestConsumerlRunner(unittest.TestCase):
def _init(self):
self.manager = sm.ServerManager(PrimeFinder, PRIME_SIZES)
def testConstructor(self):
if IGNORE_TEST:
return
self._init()
pids = [s.pid for s in self.manager.servers]
self.assertEqual(len(pids), len(PRIME_SIZES))
self.manager.stop()
def testRunServers(self):
if IGNORE_TEST:
return
self._init()
results = self.manager.submit(PRIME_SIZES)
self.manager.stop()
for result, size in zip(results, PRIME_SIZES):
self.assertEqual(len(result), size)
if __name__ == '__main__':
unittest.main()
| [
"jlheller@uw.edu"
] | jlheller@uw.edu |
ddd615787593b009450780201e0cdfe624fdb6ad | 3d4318396b8433e36a144ea583158eb22807577a | /draft_sport/errors/error.py | ebe483be371232aa6ac701926151609590875d0f | [] | no_license | draft-sport/draft-sport-py | 245ee567a3ddaf41bbb99d03f043f90ad5b6a49c | 177fd438bc095cebcff5374bc6b1e815846617bb | refs/heads/master | 2023-03-11T16:56:29.415427 | 2021-03-01T09:59:46 | 2021-03-01T09:59:46 | 233,480,373 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 236 | py | """
Draft Sport
Error Module
author: hugh@blinkybeach.com
"""
class DraftSportError(Exception):
def __init__(self, description: str) -> None:
self._description = description
super().__init__(self)
return
| [
"hugh.jeremy@gmail.com"
] | hugh.jeremy@gmail.com |
e04d8140783f99b3785e3582764225a6bec4efbc | 764d00352d9ec82146c1e5c99d52c25e4a509493 | /contacts/urls.py | fe867bf3f0b98021a004addcfe340b169b84091e | [] | no_license | RedSnip8/Premier_Properties | af0e60545138e28deb71430cbc93a53b32466383 | c0f4058eb7a965f20c7c585d62da0dff98e2ba25 | refs/heads/master | 2020-07-04T23:11:40.154958 | 2019-10-03T01:14:29 | 2019-10-03T01:14:29 | 202,452,788 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 118 | py | from django.urls import path
from . import views
urlpatterns = [
path('contact', views.contact, name='contact')
] | [
"FCipolone@gmail.com"
] | FCipolone@gmail.com |
890e70bce6655c521ab1f813287934355db57ca2 | 65b087722e7824abbb134e56ab0dad1982369a4d | /server/start_consuming.py | c05f39eee6e5e81844cd2eb01df3e97330585756 | [] | no_license | BabyCakes13/SMS | 3c35abf2aea7619a579af2bb708819676068f918 | db8b8cd05bd47ee99abcc8660453edf7fce1c7a1 | refs/heads/master | 2020-03-26T15:13:05.380050 | 2018-08-23T16:48:46 | 2018-08-23T16:48:46 | 145,028,793 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,686 | py | """Module which takes the packets from the RabbitMQ and
stores them in the database."""
import json
import threading
import pika
from util import reader, strings
from server import database
class RabbitThread(threading.Thread):
"""Class which handles the packets fromm the RabbitMQ queue."""
def __init__(self, app):
"""Initialises the connection between RabbitMQ queue and Flask server,
in order to get the objects waiting in Rabbit queue and put them in
the database."""
threading.Thread.__init__(self)
self.connection = False
self.app = app
self.connect()
self.database = database.Database(self.app)
def connect(self):
"""Connects to the RabbitMQ queue."""
read = reader.Reader()
connection = pika.BlockingConnection(
pika.ConnectionParameters(
read.get_c_value()[1], read.get_c_value()[2]))
self.connection = connection.channel()
queue = strings.get_rabbit_queue()
self.connection.queue_declare(queue=queue)
def collect_packet(self, channel, method, properties, body):
"""Adds the packet collected from the RabbitMQ
queue to the database."""
self.database.add_pack(json.loads(body))
print("added...")
print(body)
def run(self):
"""Starts the thread which consumes the objects
from the RabbitMQ queue."""
queue = strings.get_rabbit_queue()
self.connection.basic_consume(self.collect_packet,
queue=queue,
no_ack=True)
self.connection.start_consuming()
| [
"you@example.com"
] | you@example.com |
8baa1d5b6b25d9c56f6939f1e56070b151d51539 | 8f3336bbf7cd12485a4c52daa831b5d39749cf9b | /Python/total-hamming-distance.py | c67638d43a8288635242506fcc0908db31353a52 | [] | no_license | black-shadows/LeetCode-Topicwise-Solutions | 9487de1f9a1da79558287b2bc2c6b28d3d27db07 | b1692583f7b710943ffb19b392b8bf64845b5d7a | refs/heads/master | 2022-05-30T22:16:38.536678 | 2022-05-18T09:18:32 | 2022-05-18T09:18:32 | 188,701,704 | 240 | 110 | null | 2020-05-08T13:04:36 | 2019-05-26T15:41:03 | C++ | UTF-8 | Python | false | false | 405 | py | # Time: O(n)
# Space: O(1)
class Solution(object):
def totalHammingDistance(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
result = 0
for i in xrange(32):
counts = [0] * 2
for num in nums:
counts[(num >> i) & 1] += 1
result += counts[0] * counts[1]
return result
| [
"noreply@github.com"
] | black-shadows.noreply@github.com |
9d6a5a5dcd5c8a9cf43c18f8cebde2d13d895a4d | 6d91104de3e00649659774e9ea27a6e01ddc1aae | /supervised_learning/0x0F-word_embeddings/0-bag_of_words.py | 1689de9bb859099c2fda01c1afea7a429c1a9197 | [
"MIT"
] | permissive | linkem97/holbertonschool-machine_learning | 07794bdd318323395f541d3568946ec52e7632da | 58c367f3014919f95157426121093b9fe14d4035 | refs/heads/master | 2023-01-24T13:04:54.642014 | 2020-11-24T00:37:58 | 2020-11-24T00:37:58 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 856 | py | #!/usr/bin/env python3
"""This module has the function bag_of_words"""
from sklearn.feature_extraction.text import CountVectorizer
def bag_of_words(sentences, vocab=None):
"""
This function creates a bag of words
sentences is a list of sentences to analyze
vocab is a list of the vocabulary words to use for the analysis
If None, all words within sentences should be used
Returns: embeddings, features
embeddings is a numpy.ndarray of shape (s, f) containing the embeddings
s is the number of sentences in sentences
f is the number of features analyzed
features is a list of the features used for embeddings
"""
vectorizer = CountVectorizer(vocabulary=vocab)
X = vectorizer.fit_transform(sentences)
features = vectorizer.get_feature_names()
embedded = X.toarray()
return embedded, features
| [
"pauloan@hotmail.com"
] | pauloan@hotmail.com |
4622d9ee12f9a207db4e0ef4ad15d1eba124b5a7 | 6b2a8dd202fdce77c971c412717e305e1caaac51 | /solutions_5640146288377856_1/Python/xyang/A.py | 7020507bdf0be002df2ee122f2d27c345aa2b207 | [] | no_license | alexandraback/datacollection | 0bc67a9ace00abbc843f4912562f3a064992e0e9 | 076a7bc7693f3abf07bfdbdac838cb4ef65ccfcf | refs/heads/master | 2021-01-24T18:27:24.417992 | 2017-05-23T09:23:38 | 2017-05-23T09:23:38 | 84,313,442 | 2 | 4 | null | null | null | null | UTF-8 | Python | false | false | 756 | py | import os
import math
import copy
import sys
from collections import *
os.chdir('/Users/Dana/Documents/0502')
f = open('A-large.in','r')
fo = open('A.out','w')
T = int(f.readline())
for ite in range(T):
temp = str.split(f.readline())
r,c,w = int(temp[0]),int(temp[1]),int(temp[2])
#print(r,c,w)
if r==1:
if c%w==0:
res = math.floor(c/w)+w-1
else:
res = math.floor(c/w)+w
else:
if c%w==0:
res = math.floor(c/w)+w-1
else:
res = math.floor(c/w)+w
res = res+(r-1)*math.floor(c/w)
print(res)
fo.write('Case #')
fo.write(str(ite+1))
fo.write(': ')
fo.write(str(res))
fo.write('\n')
fo.close()
| [
"eewestman@gmail.com"
] | eewestman@gmail.com |
c6cd28474478f73a3bc51fcb68b3d5beb42c4047 | f4e45e2f6a6c42571eefdc64773ca83c6b9c2b98 | /plugin/ffmpeg/__init__.py | 26a6e7be616deec5bdf3aa9046fff3a7812e6609 | [] | no_license | soju6jan2/sjva2_src_obfuscate | 83659707ca16d94378b7eff4d20e5e7ccf224007 | e2dd6c733bbf34b444362011f11b5aca2053aa34 | refs/heads/master | 2023-04-21T12:27:01.132955 | 2021-05-06T17:35:03 | 2021-05-06T17:35:03 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 229 | py | from.plugin import blueprint,menu,plugin_load,plugin_unload,streaming_kill,get_video_info
from.logic import Status,Logic
from.interface_program_ffmpeg import Ffmpeg
# Created by pyminifier (https://github.com/liftoff/pyminifier)
| [
"cybersol@naver.com"
] | cybersol@naver.com |
962181b4585ccce20349fd97c09591929722e74b | 85a9ffeccb64f6159adbd164ff98edf4ac315e33 | /pysnmp/Nortel-MsCarrier-MscPassport-ModDprsQosMIB.py | 4db37ebcc3f7b2f7c7201df8a7bd84cc25eefe6a | [
"Apache-2.0"
] | permissive | agustinhenze/mibs.snmplabs.com | 5d7d5d4da84424c5f5a1ed2752f5043ae00019fb | 1fc5c07860542b89212f4c8ab807057d9a9206c7 | refs/heads/master | 2020-12-26T12:41:41.132395 | 2019-08-16T15:51:41 | 2019-08-16T15:53:57 | 237,512,469 | 0 | 0 | Apache-2.0 | 2020-01-31T20:41:36 | 2020-01-31T20:41:35 | null | UTF-8 | Python | false | false | 9,822 | py | #
# PySNMP MIB module Nortel-MsCarrier-MscPassport-ModDprsQosMIB (http://snmplabs.com/pysmi)
# ASN.1 source file:///Users/davwang4/Dev/mibs.snmplabs.com/asn1/Nortel-MsCarrier-MscPassport-ModDprsQosMIB
# Produced by pysmi-0.3.4 at Mon Apr 29 20:21:32 2019
# On host DAVWANG4-M-1475 platform Darwin version 18.5.0 by user davwang4
# Using Python version 3.7.3 (default, Mar 27 2019, 09:23:15)
#
OctetString, Integer, ObjectIdentifier = mibBuilder.importSymbols("ASN1", "OctetString", "Integer", "ObjectIdentifier")
NamedValues, = mibBuilder.importSymbols("ASN1-ENUMERATION", "NamedValues")
ValueSizeConstraint, SingleValueConstraint, ConstraintsUnion, ConstraintsIntersection, ValueRangeConstraint = mibBuilder.importSymbols("ASN1-REFINEMENT", "ValueSizeConstraint", "SingleValueConstraint", "ConstraintsUnion", "ConstraintsIntersection", "ValueRangeConstraint")
mscModIndex, = mibBuilder.importSymbols("Nortel-MsCarrier-MscPassport-BaseShelfMIB", "mscModIndex")
mscModFrs, mscModFrsIndex = mibBuilder.importSymbols("Nortel-MsCarrier-MscPassport-ModCommonMIB", "mscModFrs", "mscModFrsIndex")
RowStatus, StorageType, Integer32, Unsigned32, DisplayString = mibBuilder.importSymbols("Nortel-MsCarrier-MscPassport-StandardTextualConventionsMIB", "RowStatus", "StorageType", "Integer32", "Unsigned32", "DisplayString")
NonReplicated, = mibBuilder.importSymbols("Nortel-MsCarrier-MscPassport-TextualConventionsMIB", "NonReplicated")
mscPassportMIBs, = mibBuilder.importSymbols("Nortel-MsCarrier-MscPassport-UsefulDefinitionsMIB", "mscPassportMIBs")
NotificationGroup, ModuleCompliance = mibBuilder.importSymbols("SNMPv2-CONF", "NotificationGroup", "ModuleCompliance")
ObjectIdentity, Bits, IpAddress, Counter64, MibScalar, MibTable, MibTableRow, MibTableColumn, Integer32, iso, Unsigned32, Gauge32, MibIdentifier, TimeTicks, ModuleIdentity, NotificationType, Counter32 = mibBuilder.importSymbols("SNMPv2-SMI", "ObjectIdentity", "Bits", "IpAddress", "Counter64", "MibScalar", "MibTable", "MibTableRow", "MibTableColumn", "Integer32", "iso", "Unsigned32", "Gauge32", "MibIdentifier", "TimeTicks", "ModuleIdentity", "NotificationType", "Counter32")
DisplayString, TextualConvention = mibBuilder.importSymbols("SNMPv2-TC", "DisplayString", "TextualConvention")
modDprsQosMIB = MibIdentifier((1, 3, 6, 1, 4, 1, 562, 36, 2, 2, 76))
mscModFrsDprsNet = MibIdentifier((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3))
mscModFrsDprsNetRowStatusTable = MibTable((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 1), )
if mibBuilder.loadTexts: mscModFrsDprsNetRowStatusTable.setStatus('mandatory')
mscModFrsDprsNetRowStatusEntry = MibTableRow((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 1, 1), ).setIndexNames((0, "Nortel-MsCarrier-MscPassport-BaseShelfMIB", "mscModIndex"), (0, "Nortel-MsCarrier-MscPassport-ModCommonMIB", "mscModFrsIndex"), (0, "Nortel-MsCarrier-MscPassport-ModDprsQosMIB", "mscModFrsDprsNetIndex"))
if mibBuilder.loadTexts: mscModFrsDprsNetRowStatusEntry.setStatus('mandatory')
mscModFrsDprsNetRowStatus = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 1, 1, 1), RowStatus()).setMaxAccess("readonly")
if mibBuilder.loadTexts: mscModFrsDprsNetRowStatus.setStatus('mandatory')
mscModFrsDprsNetComponentName = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 1, 1, 2), DisplayString()).setMaxAccess("readonly")
if mibBuilder.loadTexts: mscModFrsDprsNetComponentName.setStatus('mandatory')
mscModFrsDprsNetStorageType = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 1, 1, 4), StorageType()).setMaxAccess("readonly")
if mibBuilder.loadTexts: mscModFrsDprsNetStorageType.setStatus('mandatory')
mscModFrsDprsNetIndex = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 1, 1, 10), NonReplicated())
if mibBuilder.loadTexts: mscModFrsDprsNetIndex.setStatus('mandatory')
mscModFrsDprsNetTpm = MibIdentifier((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2))
mscModFrsDprsNetTpmRowStatusTable = MibTable((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 1), )
if mibBuilder.loadTexts: mscModFrsDprsNetTpmRowStatusTable.setStatus('mandatory')
mscModFrsDprsNetTpmRowStatusEntry = MibTableRow((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 1, 1), ).setIndexNames((0, "Nortel-MsCarrier-MscPassport-BaseShelfMIB", "mscModIndex"), (0, "Nortel-MsCarrier-MscPassport-ModCommonMIB", "mscModFrsIndex"), (0, "Nortel-MsCarrier-MscPassport-ModDprsQosMIB", "mscModFrsDprsNetIndex"), (0, "Nortel-MsCarrier-MscPassport-ModDprsQosMIB", "mscModFrsDprsNetTpmIndex"))
if mibBuilder.loadTexts: mscModFrsDprsNetTpmRowStatusEntry.setStatus('mandatory')
mscModFrsDprsNetTpmRowStatus = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 1, 1, 1), RowStatus()).setMaxAccess("readwrite")
if mibBuilder.loadTexts: mscModFrsDprsNetTpmRowStatus.setStatus('mandatory')
mscModFrsDprsNetTpmComponentName = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 1, 1, 2), DisplayString()).setMaxAccess("readonly")
if mibBuilder.loadTexts: mscModFrsDprsNetTpmComponentName.setStatus('mandatory')
mscModFrsDprsNetTpmStorageType = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 1, 1, 4), StorageType()).setMaxAccess("readonly")
if mibBuilder.loadTexts: mscModFrsDprsNetTpmStorageType.setStatus('mandatory')
mscModFrsDprsNetTpmIndex = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 1, 1, 10), Integer32().subtype(subtypeSpec=ValueRangeConstraint(0, 15)))
if mibBuilder.loadTexts: mscModFrsDprsNetTpmIndex.setStatus('mandatory')
mscModFrsDprsNetTpmProvTable = MibTable((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 10), )
if mibBuilder.loadTexts: mscModFrsDprsNetTpmProvTable.setStatus('mandatory')
mscModFrsDprsNetTpmProvEntry = MibTableRow((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 10, 1), ).setIndexNames((0, "Nortel-MsCarrier-MscPassport-BaseShelfMIB", "mscModIndex"), (0, "Nortel-MsCarrier-MscPassport-ModCommonMIB", "mscModFrsIndex"), (0, "Nortel-MsCarrier-MscPassport-ModDprsQosMIB", "mscModFrsDprsNetIndex"), (0, "Nortel-MsCarrier-MscPassport-ModDprsQosMIB", "mscModFrsDprsNetTpmIndex"))
if mibBuilder.loadTexts: mscModFrsDprsNetTpmProvEntry.setStatus('mandatory')
mscModFrsDprsNetTpmEmissionPriority = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 10, 1, 1), Unsigned32().subtype(subtypeSpec=ValueRangeConstraint(0, 3))).setMaxAccess("readwrite")
if mibBuilder.loadTexts: mscModFrsDprsNetTpmEmissionPriority.setStatus('mandatory')
mscModFrsDprsNetTpmRoutingClassOfService = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 10, 1, 2), Integer32().subtype(subtypeSpec=ConstraintsUnion(SingleValueConstraint(0, 1, 2))).clone(namedValues=NamedValues(("throughput", 0), ("delay", 1), ("multimedia", 2))).clone('throughput')).setMaxAccess("readwrite")
if mibBuilder.loadTexts: mscModFrsDprsNetTpmRoutingClassOfService.setStatus('mandatory')
mscModFrsDprsNetTpmAssignedIngressBandwidthPool = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 10, 1, 3), Unsigned32().subtype(subtypeSpec=ValueRangeConstraint(0, 15))).setMaxAccess("readwrite")
if mibBuilder.loadTexts: mscModFrsDprsNetTpmAssignedIngressBandwidthPool.setStatus('mandatory')
mscModFrsDprsNetTpmAssignedEgressBandwidthPool = MibTableColumn((1, 3, 6, 1, 4, 1, 562, 36, 2, 1, 16, 3, 3, 2, 10, 1, 4), Unsigned32().subtype(subtypeSpec=ValueRangeConstraint(0, 15))).setMaxAccess("readwrite")
if mibBuilder.loadTexts: mscModFrsDprsNetTpmAssignedEgressBandwidthPool.setStatus('mandatory')
modDprsQosGroup = MibIdentifier((1, 3, 6, 1, 4, 1, 562, 36, 2, 2, 76, 1))
modDprsQosGroupCA = MibIdentifier((1, 3, 6, 1, 4, 1, 562, 36, 2, 2, 76, 1, 1))
modDprsQosGroupCA02 = MibIdentifier((1, 3, 6, 1, 4, 1, 562, 36, 2, 2, 76, 1, 1, 3))
modDprsQosGroupCA02A = MibIdentifier((1, 3, 6, 1, 4, 1, 562, 36, 2, 2, 76, 1, 1, 3, 2))
modDprsQosCapabilities = MibIdentifier((1, 3, 6, 1, 4, 1, 562, 36, 2, 2, 76, 3))
modDprsQosCapabilitiesCA = MibIdentifier((1, 3, 6, 1, 4, 1, 562, 36, 2, 2, 76, 3, 1))
modDprsQosCapabilitiesCA02 = MibIdentifier((1, 3, 6, 1, 4, 1, 562, 36, 2, 2, 76, 3, 1, 3))
modDprsQosCapabilitiesCA02A = MibIdentifier((1, 3, 6, 1, 4, 1, 562, 36, 2, 2, 76, 3, 1, 3, 2))
mibBuilder.exportSymbols("Nortel-MsCarrier-MscPassport-ModDprsQosMIB", modDprsQosCapabilities=modDprsQosCapabilities, mscModFrsDprsNetTpmEmissionPriority=mscModFrsDprsNetTpmEmissionPriority, modDprsQosCapabilitiesCA02A=modDprsQosCapabilitiesCA02A, mscModFrsDprsNetTpmProvTable=mscModFrsDprsNetTpmProvTable, modDprsQosGroupCA02=modDprsQosGroupCA02, mscModFrsDprsNetRowStatusEntry=mscModFrsDprsNetRowStatusEntry, mscModFrsDprsNetTpmComponentName=mscModFrsDprsNetTpmComponentName, mscModFrsDprsNetRowStatus=mscModFrsDprsNetRowStatus, mscModFrsDprsNetTpmAssignedIngressBandwidthPool=mscModFrsDprsNetTpmAssignedIngressBandwidthPool, mscModFrsDprsNetTpmStorageType=mscModFrsDprsNetTpmStorageType, modDprsQosCapabilitiesCA02=modDprsQosCapabilitiesCA02, mscModFrsDprsNetTpmRowStatus=mscModFrsDprsNetTpmRowStatus, mscModFrsDprsNetComponentName=mscModFrsDprsNetComponentName, mscModFrsDprsNetTpmRowStatusEntry=mscModFrsDprsNetTpmRowStatusEntry, mscModFrsDprsNet=mscModFrsDprsNet, mscModFrsDprsNetTpmRowStatusTable=mscModFrsDprsNetTpmRowStatusTable, mscModFrsDprsNetTpmProvEntry=mscModFrsDprsNetTpmProvEntry, mscModFrsDprsNetTpm=mscModFrsDprsNetTpm, mscModFrsDprsNetTpmAssignedEgressBandwidthPool=mscModFrsDprsNetTpmAssignedEgressBandwidthPool, modDprsQosGroup=modDprsQosGroup, modDprsQosGroupCA=modDprsQosGroupCA, mscModFrsDprsNetTpmIndex=mscModFrsDprsNetTpmIndex, mscModFrsDprsNetStorageType=mscModFrsDprsNetStorageType, modDprsQosMIB=modDprsQosMIB, mscModFrsDprsNetIndex=mscModFrsDprsNetIndex, mscModFrsDprsNetTpmRoutingClassOfService=mscModFrsDprsNetTpmRoutingClassOfService, modDprsQosGroupCA02A=modDprsQosGroupCA02A, modDprsQosCapabilitiesCA=modDprsQosCapabilitiesCA, mscModFrsDprsNetRowStatusTable=mscModFrsDprsNetRowStatusTable)
| [
"dcwangmit01@gmail.com"
] | dcwangmit01@gmail.com |
b0ea77467887d4c25a35a86d4536ec139fb5ce6d | e6dab5aa1754ff13755a1f74a28a201681ab7e1c | /.parts/lib/django-1.4/tests/regressiontests/localflavor/id/tests.py | 9ccf273a42571ec3e4d4b1a432a04ce08596c051 | [] | no_license | ronkagan/Euler_1 | 67679203a9510147320f7c6513eefd391630703e | 022633cc298475c4f3fd0c6e2bde4f4728713995 | refs/heads/master | 2021-01-06T20:45:52.901025 | 2014-09-06T22:34:16 | 2014-09-06T22:34:16 | 23,744,842 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 111 | py | /home/action/.parts/packages/googleappengine/1.9.4/lib/django-1.4/tests/regressiontests/localflavor/id/tests.py | [
"ron.y.kagan@gmail.com"
] | ron.y.kagan@gmail.com |
7334b7f22281ae1338b4f47133b91bc70411827e | a7fa51726bae15b197b7bb6829acd5139b6e3073 | /feature_engineering/bl/steps/BackwardStepsDialogueFeatureEngineerImpl.py | 1c7b054857e9458e86ecca93b5dd0640eaf34b8b | [] | no_license | Rmsharks4/NLPEngine-opensource | ae375dc9ea364de793d78ab1c9d950718a11d54a | 7e384f6e13377723bb651130733a16ed53fe31d1 | refs/heads/master | 2023-02-27T17:45:38.592126 | 2021-02-01T20:59:16 | 2021-02-01T20:59:16 | 209,055,714 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,059 | py | from feature_engineering.utils.ActsUtils import ActsUtils
from feature_engineering.bl.steps.StepsDialogueFeatureEngineerImpl import StepsDialogueFeatureEngineerImpl
from feature_engineering.bl.intents import *
from feature_engineering.bl.intents.AbstractDialogueIntent import AbstractDialogueIntent
class BackwardStepsDialogueFeatureEngineerImpl(StepsDialogueFeatureEngineerImpl):
def __init__(self):
super().__init__()
self.config_pattern.properties.req_data = [[x.__name__ for x in AbstractDialogueIntent.__subclasses__()]]
def steps(self, args):
res = None
for req_data in self.config_pattern.properties.req_data:
for data in req_data:
if data in args:
if res is None:
res = [None] * len(args[data])
BackwardStepsDialogueFeatureEngineerImpl.stepdown({
data: args[data],
ActsUtils.__name__: args[ActsUtils.__name__]
}, data, res)
return res
@staticmethod
def stepdown(args, name, res):
i = 0
dels = []
prev = None
for intents in args[name]:
if intents is not None and args[ActsUtils.__name__].resp in intents:
if BackwardStepsDialogueFeatureEngineerImpl.prev_match(
intents[:-(len(intents) - intents.find(args[ActsUtils.__name__].resp))],
prev, args[ActsUtils.__name__].resp):
dels.append(intents)
if res[i] is None:
res[i] = [intent for intent in intents if intent not in dels]
else:
res[i].extend([intent for intent in intents if intent not in dels])
i += 1
prev = intents
@staticmethod
def prev_match(match, arr, resp):
look = False
for prevint in arr:
if match in prevint and resp not in prevint:
look = True
if look:
return False
return True
| [
"Github12"
] | Github12 |
2bb7a17bad94a40501802812427b35990374e9f6 | 63bcca68dc75b77b737542925062effe37bc13c8 | /fabfile/common.py | 2e96fa7881425042dc6fc5ef658c350dcb0d0d33 | [] | no_license | bekbossyn/dictionary | 35b48b4a7b000156a52b8039917299fed0ac9284 | 1a9824ca9b450086a1c348c5f9fff0f967e9a282 | refs/heads/master | 2020-05-20T00:35:26.802693 | 2019-05-11T09:40:37 | 2019-05-11T09:40:37 | 185,290,434 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 979 | py | from fabric.decorators import task
from fabric.operations import sudo, run
@task
def git_pull():
"""
Updates the repository
"""
run("cd /home/development/dictionary && git pull origin master")
# @task
# def celery_logs():
# """
# Updates the repository
# """
# sudo("tail -f /var/log/celery/belka.log")
@task
def update_supervisor():
"""
Dunno for now (
"""
# sudo("cp ~/{}/configs/supervisor/celery.conf /etc/supervisor/conf.d".format(env.repo_name))
# sudo("supervisorctl reread; supervisorctl restart celery; supervisorctl restart celerybeat; supervisorctl restart flower; supervisorctl update; supervisorctl status celery")
sudo("supervisorctl update")
@task
def update():
"""
Restarts the server
"""
run("cd /home/development/dictionary/ && . ./run.sh")
sudo("systemctl restart gunicorn")
sudo("systemctl restart nginx")
update_supervisor() | [
"bekbossyn.kassymkhan@gmail.com"
] | bekbossyn.kassymkhan@gmail.com |
48f6953f51bce07b48d04d081601460c628880bf | 856e9a8afcb81ae66dd998b0d2cc3556c9f315ea | /dexy/commands/parsers.py | 2ee73bab171b219f6839db2ac0a1c9c5dc0e2b59 | [
"MIT"
] | permissive | dexy/dexy | 1d5c999830de4663c05a09f4cd00b1628dfc8d46 | 323c1806e51f75435e11d2265703e68f46c8aef3 | refs/heads/develop | 2023-06-10T08:02:45.076551 | 2021-02-28T22:40:41 | 2021-02-28T22:40:41 | 1,506,989 | 141 | 34 | MIT | 2020-06-15T17:44:50 | 2011-03-21T14:48:28 | Python | UTF-8 | Python | false | false | 990 | py | from dexy.utils import defaults
from dexy.commands.utils import dummy_wrapper
from dexy.parser import AbstractSyntaxTree
from dexy.parser import Parser
def parsers_command():
wrapper = dummy_wrapper()
ast = AbstractSyntaxTree(wrapper)
processed_aliases = set()
for alias in sorted(Parser.plugins):
if alias in processed_aliases:
continue
parser = Parser.create_instance(alias, ast, wrapper)
for alias in parser.aliases:
processed_aliases.add(alias)
print("%s Parser" % parser.__class__.__name__)
print('')
print(parser.setting('help'))
print('')
print("aliases:")
for alias in parser.aliases:
print(" %s" % alias)
print('')
print("Default parsers are: " + defaults['parsers'])
print('')
print("Dexy will only look for config files to parse in the root directory")
print("of your project unless --recurse is specified.")
print('')
| [
"ana@ananelson.com"
] | ana@ananelson.com |
7aa5c514d67bb18d16bfb52d70201a5b865b859b | 00e82f0a744915630d0493b74af5c3ad03169bb6 | /python/smqtk/web/search_app/modules/iqr/iqr_search.py | 7145e39dab4622a8c8ec3418e57dd5f420c49818 | [] | no_license | thezedwards/SMQTK | 4f80dc1516e337ba572362302ee325f27ff127ab | f2ed51b41f61b62004a3e55d38f854427bc2d54a | refs/heads/master | 2021-07-17T08:36:22.669270 | 2017-10-25T13:57:59 | 2017-10-25T13:57:59 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 29,511 | py | """
IQR Search blueprint module
"""
import json
import os
import os.path as osp
import random
import shutil
from StringIO import StringIO
import zipfile
import flask
import PIL.Image
from smqtk.algorithms.descriptor_generator import \
get_descriptor_generator_impls
from smqtk.algorithms.nn_index import get_nn_index_impls
from smqtk.algorithms.relevancy_index import get_relevancy_index_impls
from smqtk.iqr import IqrController, IqrSession
from smqtk.iqr.iqr_session import DFLT_REL_INDEX_CONFIG
from smqtk.representation import get_data_set_impls, DescriptorElementFactory
from smqtk.representation.data_element.file_element import DataFileElement
from smqtk.representation.descriptor_element.local_elements import \
DescriptorMemoryElement
from smqtk.utils import Configurable
from smqtk.utils import SmqtkObject
from smqtk.utils import plugin
from smqtk.utils.file_utils import safe_create_dir
from smqtk.utils.preview_cache import PreviewCache
from smqtk.web.search_app.modules.file_upload import FileUploadMod
from smqtk.web.search_app.modules.static_host import StaticDirectoryHost
__author__ = 'paul.tunison@kitware.com'
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
DFLT_MEMORY_DESCR_FACTORY = DescriptorElementFactory(DescriptorMemoryElement,
{})
class IqrSearch (SmqtkObject, flask.Blueprint, Configurable):
"""
IQR Search Tab blueprint
Components:
* Data-set, from which base media data is provided
* Descriptor generator, which provides descriptor generation services
for user uploaded data.
* NearestNeighborsIndex, from which descriptors are queried from user
input data. This index should contain descriptors that were
generated by the same descriptor generator configuration above (same
dimensionality, etc.).
* RelevancyIndex, which is populated by an initial query, and then
iterated over within the same user session. A new instance and model
is generated every time a new session is created (or new data is
uploaded by the user).
Assumes:
* DescriptorElement related to a DataElement have the same UUIDs.
"""
@classmethod
def get_default_config(cls):
d = super(IqrSearch, cls).get_default_config()
# Remove parent_app slot for later explicit specification.
del d['parent_app']
# fill in plugin configs
d['data_set'] = plugin.make_config(get_data_set_impls())
d['descr_generator'] = \
plugin.make_config(get_descriptor_generator_impls())
d['nn_index'] = plugin.make_config(get_nn_index_impls())
ri_config = plugin.make_config(get_relevancy_index_impls())
if d['rel_index_config']:
ri_config.update(d['rel_index_config'])
d['rel_index_config'] = ri_config
df_config = DescriptorElementFactory.get_default_config()
if d['descriptor_factory']:
df_config.update(d['descriptor_factory'].get_config())
d['descriptor_factory'] = df_config
return d
# noinspection PyMethodOverriding
@classmethod
def from_config(cls, config, parent_app):
"""
Instantiate a new instance of this class given the configuration
JSON-compliant dictionary encapsulating initialization arguments.
:param config: JSON compliant dictionary encapsulating
a configuration.
:type config: dict
:param parent_app: Parent containing flask app instance
:type parent_app: smqtk.web.search_app.app.search_app
:return: Constructed instance from the provided config.
:rtype: IqrSearch
"""
merged = cls.get_default_config()
merged.update(config)
# construct nested objects via configurations
merged['data_set'] = \
plugin.from_plugin_config(merged['data_set'],
get_data_set_impls())
merged['descr_generator'] = \
plugin.from_plugin_config(merged['descr_generator'],
get_descriptor_generator_impls())
merged['nn_index'] = \
plugin.from_plugin_config(merged['nn_index'],
get_nn_index_impls())
merged['descriptor_factory'] = \
DescriptorElementFactory.from_config(merged['descriptor_factory'])
return cls(parent_app, **merged)
def __init__(self, parent_app, name, data_set, descr_generator, nn_index,
working_directory, rel_index_config=DFLT_REL_INDEX_CONFIG,
descriptor_factory=DFLT_MEMORY_DESCR_FACTORY,
url_prefix=None, pos_seed_neighbors=500):
"""
Initialize a generic IQR Search module with a single descriptor and
indexer.
:param name: Name of this blueprint instance
:type name: str
:param parent_app: Parent containing flask app instance
:type parent_app: smqtk.web.search_app.app.search_app
:param data_set: DataSet instance that references indexed data.
:type data_set: SMQTK.representation.DataSet
:param descr_generator: DescriptorGenerator instance to use in IQR
sessions for generating descriptors on new data.
:type descr_generator:
smqtk.algorithms.descriptor_generator.DescriptorGenerator
:param nn_index: NearestNeighborsIndex instance for sessions to pull
their review data sets from.
:type nn_index: smqtk.algorithms.NearestNeighborsIndex
:param rel_index_config: Plugin configuration for the RelevancyIndex to
use.
:type rel_index_config: dict
:param working_directory: Directory in which to place working files.
These may be considered temporary and may be removed between
executions of this app. Retention of a work directory may speed
things up in subsequent runs because of caching.
:param descriptor_factory: DescriptorElementFactory for producing new
DescriptorElement instances when data is uploaded to the server.
:type descriptor_factory: DescriptorElementFactory
:param url_prefix: Web address prefix for this blueprint.
:type url_prefix: str
:param pos_seed_neighbors: Number of neighbors to pull from the given
``nn_index`` for each positive exemplar when populating the working
index, i.e. this value determines the size of the working index for
IQR refinement. By default, we try to get 500 neighbors.
Since there may be partial to significant overlap of near neighbors
as a result of nn_index queries for positive exemplars, the working
index may contain anywhere from this value's number of entries, to
``N*P``, where ``N`` is this value and ``P`` is the number of
positive examples at the time of working index initialization.
:type pos_seed_neighbors: int
:raises ValueError: Invalid Descriptor or indexer type
"""
# make sure URL prefix starts with a slash
if not url_prefix.startswith('/'):
url_prefix = '/' + url_prefix
super(IqrSearch, self).__init__(
name, import_name=__name__,
static_folder=os.path.join(SCRIPT_DIR, "static"),
template_folder=os.path.join(SCRIPT_DIR, "templates"),
url_prefix=url_prefix
)
self._parent_app = parent_app
self._data_set = data_set
self._descriptor_generator = descr_generator
self._nn_index = nn_index
self._rel_index_config = rel_index_config
self._descr_elem_factory = descriptor_factory
self._pos_seed_neighbors = int(pos_seed_neighbors)
# base directory that's transformed by the ``work_dir`` property into
# an absolute path.
self._working_dir = working_directory
# Directory to put things to allow them to be statically available to
# public users.
self._static_data_prefix = "static/data"
self._static_data_dir = osp.join(self.work_dir, 'static')
# Custom static host sub-module
self.mod_static_dir = StaticDirectoryHost('%s_static' % self.name,
self._static_data_dir,
self._static_data_prefix)
self.register_blueprint(self.mod_static_dir)
# Uploader Sub-Module
self.upload_work_dir = os.path.join(self.work_dir, "uploads")
self.mod_upload = FileUploadMod('%s_uploader' % self.name, parent_app,
self.upload_work_dir,
url_prefix='/uploader')
self.register_blueprint(self.mod_upload)
# IQR Session control and resources
# TODO: Move session management to database/remote?
# Create web-specific IqrSession class that stores/gets its state
# directly from database.
self._iqr_controller = IqrController()
# Mapping of session IDs to their work directory
#: :type: dict[collections.Hashable, str]
self._iqr_work_dirs = {}
# Mapping of session ID to a dictionary of the custom example data for
# a session (uuid -> DataElement)
#: :type: dict[collections.Hashable, dict[collections.Hashable, smqtk.representation.DataElement]]
self._iqr_example_data = {}
# Descriptors of example data
#: :type: dict[collections.Hashable, dict[collections.Hashable, smqtk.representation.DescriptorElement]]
self._iqr_example_pos_descr = {}
# Preview Image Caching
self._preview_cache = PreviewCache(osp.join(self._static_data_dir,
"previews"))
# Cache mapping of written static files for data elements
self._static_cache = {}
self._static_cache_element = {}
#
# Routing
#
@self.route("/")
@self._parent_app.module_login.login_required
def index():
r = {
"module_name": self.name,
"uploader_url": self.mod_upload.url_prefix,
"uploader_post_url": self.mod_upload.upload_post_url(),
}
r.update(parent_app.nav_bar_content())
# noinspection PyUnresolvedReferences
return flask.render_template("iqr_search_index.html", **r)
@self.route('/iqr_session_info', methods=["GET"])
@self._parent_app.module_login.login_required
def iqr_session_info():
"""
Get information about the current IRQ session
"""
with self.get_current_iqr_session() as iqrs:
# noinspection PyProtectedMember
return flask.jsonify({
"uuid": iqrs.uuid,
"descriptor_type": self._descriptor_generator.name,
"nn_index_type": self._nn_index.name,
"relevancy_index_type": self._rel_index_config['type'],
"positive_uids":
tuple(d.uuid() for d in iqrs.positive_descriptors),
"negative_uids":
tuple(d.uuid() for d in iqrs.negative_descriptors),
# UUIDs of example positive descriptors
"ex_pos": tuple(self._iqr_example_pos_descr[iqrs.uuid]),
"initialized": iqrs.working_index.count() > 0,
"index_size": iqrs.working_index.count(),
})
@self.route('/get_iqr_state')
@self._parent_app.module_login.login_required
def iqr_session_state():
"""
Get IQR session state information composed of positive and negative
descriptor vectors.
"""
with self.get_current_iqr_session() as iqrs:
iqrs_uuid = str(iqrs.uuid)
pos_elements = list(set(
# Pos user examples
[tuple(d.vector().tolist()) for d
in self._iqr_example_pos_descr[iqrs.uuid].values()] +
# Adjudicated examples
[tuple(d.vector().tolist()) for d
in iqrs.positive_descriptors],
))
neg_elements = list(set(
# No negative user example support yet
# Adjudicated examples
[tuple(d.vector().tolist()) for d
in iqrs.negative_descriptors],
))
z_buffer = StringIO()
z = zipfile.ZipFile(z_buffer, 'w', zipfile.ZIP_DEFLATED)
z.writestr(iqrs_uuid, json.dumps({
'pos': pos_elements,
'neg': neg_elements,
}))
z.close()
z_buffer.seek(0)
return flask.send_file(
z_buffer,
mimetype='application/octet-stream',
as_attachment=True,
attachment_filename="%s.IqrState" % iqrs_uuid,
)
@self.route("/check_current_iqr_session")
@self._parent_app.module_login.login_required
def check_current_iqr_session():
"""
Check that the current IQR session exists and is initialized.
:rtype: {
success: bool
}
"""
# Getting the current IQR session ensures that one has been
# constructed for the current session.
with self.get_current_iqr_session():
return flask.jsonify({
"success": True
})
@self.route("/get_data_preview_image", methods=["GET"])
@self._parent_app.module_login.login_required
def get_ingest_item_image_rep():
"""
Return the base64 preview image data for the data file associated
with the give UID.
"""
uid = flask.request.args['uid']
info = {
"success": True,
"message": None,
"shape": None, # (width, height)
"static_file_link": None,
"static_preview_link": None,
}
# Try to find a DataElement by the given UUID in our indexed data
# or in the session's example data.
if self._data_set.has_uuid(uid):
#: :type: smqtk.representation.DataElement
de = self._data_set.get_data(uid)
else:
with self.get_current_iqr_session() as iqrs:
#: :type: smqtk.representation.DataElement | None
de = self._iqr_example_data[iqrs.uuid].get(uid, None)
if not de:
info["success"] = False
info["message"] = "UUID not part of the active data set!"
else:
# Preview_path should be a path within our statically hosted
# area.
preview_path = self._preview_cache.get_preview_image(de)
img = PIL.Image.open(preview_path)
info["shape"] = img.size
if de.uuid() not in self._static_cache:
self._static_cache[de.uuid()] = \
de.write_temp(self._static_data_dir)
self._static_cache_element[de.uuid()] = de
# Need to format links by transforming the generated paths to
# something usable by webpage:
# - make relative to the static directory, and then pre-pending
# the known static url to the
info["static_preview_link"] = \
self._static_data_prefix + '/' + \
os.path.relpath(preview_path, self._static_data_dir)
info['static_file_link'] = \
self._static_data_prefix + '/' + \
os.path.relpath(self._static_cache[de.uuid()],
self._static_data_dir)
return flask.jsonify(info)
@self.route('/iqr_ingest_file', methods=['POST'])
@self._parent_app.module_login.login_required
def iqr_ingest_file():
"""
Ingest the file with the given UID, getting the path from the
uploader.
:return: string of data/descriptor element's UUID
:rtype: str
"""
# TODO: Add status dict with a "GET" method branch for getting that
# status information.
# Start the ingest of a FID when POST
if flask.request.method == "POST":
with self.get_current_iqr_session() as iqrs:
fid = flask.request.form['fid']
self._log.debug("[%s::%s] Getting temporary filepath from "
"uploader module", iqrs.uuid, fid)
upload_filepath = self.mod_upload.get_path_for_id(fid)
self.mod_upload.clear_completed(fid)
self._log.debug("[%s::%s] Moving uploaded file",
iqrs.uuid, fid)
sess_upload = osp.join(self._iqr_work_dirs[iqrs.uuid],
osp.basename(upload_filepath))
os.rename(upload_filepath, sess_upload)
upload_data = DataFileElement(sess_upload)
uuid = upload_data.uuid()
self._iqr_example_data[iqrs.uuid][uuid] = upload_data
# Extend session ingest -- modifying
self._log.debug("[%s::%s] Adding new data to session "
"positives", iqrs.uuid, fid)
# iqrs.add_positive_data(upload_data)
try:
upload_descr = \
self._descriptor_generator.compute_descriptor(
upload_data, self._descr_elem_factory
)
except ValueError, ex:
return "Input Error: %s" % str(ex), 400
self._iqr_example_pos_descr[iqrs.uuid][uuid] = upload_descr
iqrs.adjudicate((upload_descr,))
return str(uuid)
@self.route("/iqr_initialize", methods=["POST"])
@self._parent_app.module_login.login_required
def iqr_initialize():
"""
Initialize IQR session working index based on current positive
examples and adjudications.
"""
with self.get_current_iqr_session() as iqrs:
try:
iqrs.update_working_index(self._nn_index)
return flask.jsonify({
"success": True,
"message": "Completed initialization",
})
except Exception, ex:
return flask.jsonify({
"success": False,
"message": "ERROR: (%s) %s" % (type(ex).__name__,
str(ex))
})
@self.route("/get_example_adjudication", methods=["GET"])
@self._parent_app.module_login.login_required
def get_example_adjudication():
"""
Get positive/negative status for a data/descriptor in our example
set.
:return: {
is_pos: <bool>,
is_neg: <bool>
}
"""
elem_uuid = flask.request.args['uid']
with self.get_current_iqr_session() as iqrs:
is_p = elem_uuid in self._iqr_example_pos_descr[iqrs.uuid]
# Currently no negative example support
is_n = False
return flask.jsonify({
"is_pos": is_p,
"is_neg": is_n,
})
@self.route("/get_index_adjudication", methods=["GET"])
@self._parent_app.module_login.login_required
def get_index_adjudication():
"""
Get the adjudication status of a particular data/descriptor element
by UUID.
This should only ever return a dict where one of the two, or
neither, are labeled True.
:return: {
is_pos: <bool>,
is_neg: <bool>
}
"""
elem_uuid = flask.request.args['uid']
with self.get_current_iqr_session() as iqrs:
is_p = (
elem_uuid in set(d.uuid() for d
in iqrs.positive_descriptors)
)
is_n = (
elem_uuid in set(d.uuid() for d
in iqrs.negative_descriptors)
)
return flask.jsonify({
"is_pos": is_p,
"is_neg": is_n,
})
@self.route("/adjudicate", methods=["POST", "GET"])
@self._parent_app.module_login.login_required
def adjudicate():
"""
Update adjudication for this session. This should specify UUIDs of
data/descriptor elements in our working index.
:return: {
success: <bool>,
message: <str>
}
"""
if flask.request.method == "POST":
fetch = flask.request.form
elif flask.request.method == "GET":
fetch = flask.request.args
else:
raise RuntimeError("Invalid request method '%s'"
% flask.request.method)
pos_to_add = json.loads(fetch.get('add_pos', '[]'))
pos_to_remove = json.loads(fetch.get('remove_pos', '[]'))
neg_to_add = json.loads(fetch.get('add_neg', '[]'))
neg_to_remove = json.loads(fetch.get('remove_neg', '[]'))
self._log.debug("Adjudicated Positive{+%s, -%s}, "
"Negative{+%s, -%s} "
% (pos_to_add, pos_to_remove,
neg_to_add, neg_to_remove))
with self.get_current_iqr_session() as iqrs:
iqrs.adjudicate(
tuple(iqrs.working_index.get_many_descriptors(pos_to_add)),
tuple(iqrs.working_index.get_many_descriptors(neg_to_add)),
tuple(iqrs.working_index.get_many_descriptors(pos_to_remove)),
tuple(iqrs.working_index.get_many_descriptors(neg_to_remove)),
)
self._log.debug("Now positive UUIDs: %s", iqrs.positive_descriptors)
self._log.debug("Now negative UUIDs: %s", iqrs.negative_descriptors)
return flask.jsonify({
"success": True,
"message": "Adjudicated Positive{+%s, -%s}, "
"Negative{+%s, -%s} "
% (pos_to_add, pos_to_remove,
neg_to_add, neg_to_remove)
})
@self.route("/iqr_refine", methods=["POST"])
@self._parent_app.module_login.login_required
def iqr_refine():
"""
Classify current IQR session indexer, updating ranking for
display.
Fails gracefully if there are no positive[/negative] adjudications.
"""
with self.get_current_iqr_session() as iqrs:
try:
iqrs.refine()
return flask.jsonify({
"success": True,
"message": "Completed refinement"
})
except Exception, ex:
return flask.jsonify({
"success": False,
"message": "ERROR: (%s) %s" % (type(ex).__name__,
str(ex))
})
@self.route("/iqr_ordered_results", methods=['GET'])
@self._parent_app.module_login.login_required
def get_ordered_results():
"""
Get ordered (UID, probability) pairs in between the given indices,
[i, j). If j Is beyond the end of available results, only available
results are returned.
This may be empty if no refinement has yet occurred.
Return format:
{
results: [ (uid, probability), ... ]
}
"""
with self.get_current_iqr_session() as iqrs:
i = int(flask.request.args.get('i', 0))
j = int(flask.request.args.get('j', len(iqrs.results)
if iqrs.results else 0))
#: :type: tuple[(smqtk.representation.DescriptorElement, float)]
r = (iqrs.ordered_results() or ())[i:j]
return flask.jsonify({
"results": [(d.uuid(), p) for d, p in r]
})
@self.route("/reset_iqr_session", methods=["GET"])
@self._parent_app.module_login.login_required
def reset_iqr_session():
"""
Reset the current IQR session
"""
with self.get_current_iqr_session() as iqrs:
iqrs.reset()
# Clearing working directory
if os.path.isdir(self._iqr_work_dirs[iqrs.uuid]):
shutil.rmtree(self._iqr_work_dirs[iqrs.uuid])
safe_create_dir(self._iqr_work_dirs[iqrs.uuid])
# Clearing example data + descriptors
self._iqr_example_data[iqrs.uuid].clear()
self._iqr_example_pos_descr[iqrs.uuid].clear()
return flask.jsonify({
"success": True
})
@self.route("/get_random_uids")
@self._parent_app.module_login.login_required
def get_random_uids():
"""
Return to the client a list of working index IDs but in a random
order. If there is currently an active IQR session with elements in
its extension ingest, then those IDs are included in the random
list.
:return: {
uids: list of int
}
"""
with self.get_current_iqr_session() as iqrs:
all_ids = list(iqrs.working_index.iterkeys())
random.shuffle(all_ids)
return flask.jsonify({
"uids": all_ids
})
def __del__(self):
for wdir in self._iqr_work_dirs.values():
if os.path.isdir(wdir):
shutil.rmtree(wdir)
def get_config(self):
return {
'name': self.name,
'url_prefix': self.url_prefix,
'working_directory': self._working_dir,
'data_set': plugin.to_plugin_config(self._data_set),
'descr_generator':
plugin.to_plugin_config(self._descriptor_generator),
'nn_index': plugin.to_plugin_config(self._nn_index),
'rel_index_config': self._rel_index_config,
'descriptor_factory': self._descr_elem_factory.get_config(),
}
def register_blueprint(self, blueprint, **options):
""" Add sub-blueprint to a blueprint.
:param blueprint: Nested blueprint instance to register.
"""
# Defer registration of blueprint until after this blueprint has been
# registered. Needed to do this because of a bad thing that happens
# that I don't remember any more.
def deferred(state):
if blueprint.url_prefix:
blueprint.url_prefix = self.url_prefix + blueprint.url_prefix
else:
blueprint.url_prefix = self.url_prefix
state.app.register_blueprint(blueprint, **options)
self.record(deferred)
@property
def work_dir(self):
"""
:return: Common work directory for this instance.
:rtype: str
"""
return osp.expanduser(osp.abspath(self._working_dir))
def get_current_iqr_session(self):
"""
Get the current IQR Session instance.
:rtype: smqtk.IQR.iqr_session.IqrSession
"""
with self._iqr_controller:
sid = flask.session.sid
if not self._iqr_controller.has_session_uuid(sid):
iqr_sess = IqrSession(self._pos_seed_neighbors,
self._rel_index_config,
sid)
self._iqr_controller.add_session(iqr_sess)
self._iqr_work_dirs[iqr_sess.uuid] = \
osp.join(self.work_dir, sid)
safe_create_dir(self._iqr_work_dirs[iqr_sess.uuid])
self._iqr_example_data[iqr_sess.uuid] = {}
self._iqr_example_pos_descr[iqr_sess.uuid] = {}
return self._iqr_controller.get_session(sid)
| [
"paul.tunison@kitware.com"
] | paul.tunison@kitware.com |
61236e4737fd1d3b8da61d4625c10e8b243ee089 | d491b5e3f258c7b0bd503ee977ac74f4fb8f9812 | /60.py | dcfa559f9a5a005756ee703fcfe2ffaf191735b6 | [] | no_license | AishwaryaKaminiRajendran/Aishu | 89280c987fdcb55537acd9311894950912f713f0 | c27c82e30a82ffa20abbad9a4333388b3d14587e | refs/heads/master | 2020-04-15T05:10:43.450336 | 2019-05-20T09:47:44 | 2019-05-20T09:47:44 | 164,411,791 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 58 | py | k=int(input())
s=0
for i in range(1,k+1):
s=s+i
print(s)
| [
"noreply@github.com"
] | AishwaryaKaminiRajendran.noreply@github.com |
f5ee7e5132c1a686ff3d2503c9dadfdd7382a6fc | eb5857487dff2655a0228a9ca7024b54e6b1e061 | /solutions/2022/kws/aoc_2022_kws/day_14.py | 7dc12f45d0103d2220c1646b839de1e1b3b41af8 | [
"MIT"
] | permissive | SocialFinanceDigitalLabs/AdventOfCode | 8690db87dedb2898db37704c6fcf8526f7ea8d2e | 4af7c27f1eb514ed805a402dc4635555e495bd1c | refs/heads/main | 2023-02-19T16:23:12.195354 | 2022-12-28T09:54:50 | 2022-12-28T09:54:50 | 159,806,963 | 2 | 4 | MIT | 2023-08-30T00:02:24 | 2018-11-30T10:25:06 | Jupyter Notebook | UTF-8 | Python | false | false | 5,379 | py | from contextlib import contextmanager
from enum import Enum
from typing import Generator, List, Text
import click
from aoc_2022_kws.cli import main
from aoc_2022_kws.config import config
from rich.live import Live
class CoordinateType(Enum):
ROCK = "#"
SAND = "o"
UNREACHABLE = "-"
class Coordinate:
def __init__(self, *args, type: CoordinateType):
if len(args) > 0 and isinstance(args[0], str):
x, y = args[0].split(",", 1)
self.x = int(x)
self.y = int(y)
else:
self.x = int(args[0])
self.y = int(args[1])
self.type = type
def __repr__(self):
return f"{self.__class__.__name__}({self.x}, {self.y}, type={self.type})"
def parse_structures(line) -> List[Coordinate]:
vertices = line.split(" -> ")
vertices = [Coordinate(v, type=CoordinateType.ROCK) for v in vertices]
points = []
for ix, v in enumerate(vertices[1:]):
dx = v.x - vertices[ix].x
dy = v.y - vertices[ix].y
steps = max(abs(dx), abs(dy))
dx = dx // steps
dy = dy // steps
for step in range(steps + 1):
points.append(
Coordinate(
vertices[ix].x + dx * step, vertices[ix].y + dy * step, type=v.type
)
)
return points
def animate_sand(
structures: List[Coordinate], sand, floor=0
) -> Generator[Coordinate, None, None]:
cave_map = {(s.x, s.y) for s in structures}
y_max = floor if floor else max([c.y for c in structures])
if (sand.x, sand.y) in cave_map:
return
yield sand
while sand.y <= y_max:
possible = [
(sand.x, sand.y + 1),
(sand.x - 1, sand.y + 1),
(sand.x + 1, sand.y + 1),
]
if floor:
possible = [p for p in possible if p[1] <= floor]
available = [p for p in possible if p not in cave_map]
if available:
c = available[0]
sand = Coordinate(c[0], c[1], type=CoordinateType.SAND)
yield sand
else:
return None
@contextmanager
def show_map():
with Live() as live:
def display(structures: List[Coordinate]):
x_min = min([c.x for c in structures])
x_max = max([c.x for c in structures])
y_min = min([c.y for c in structures])
y_max = max([c.y for c in structures])
output_data = ""
map = {(s.x, s.y): s.type for s in structures}
for y in range(y_min, y_max + 1):
for x in range(x_min, x_max + 1):
s = map.get((x, y))
output_data += s.value if s else "."
output_data += "\n"
live.update(Text(output_data))
yield display
@main.command()
@click.option("--sample", "-s", is_flag=True)
def day14(sample):
if sample:
input_data = (config.SAMPLE_DIR / "day14.txt").read_text()
else:
input_data = (config.USER_DIR / "day14.txt").read_text()
starting_structures = [
c for struct in input_data.splitlines() for c in parse_structures(struct)
]
structures = list(starting_structures)
y_max = max([c.y for c in structures])
start_point = Coordinate(500, 0, type=CoordinateType.SAND)
path = list(animate_sand(structures, start_point))
with show_map() as display:
while path[-1].y <= y_max:
structures.append(path[-1])
display(structures)
path = list(animate_sand(structures, start_point))
print("PART 1", len([c for c in structures if c.type == CoordinateType.SAND]))
structures = list(starting_structures)
y_max += 1
path = list(
animate_sand(
structures, Coordinate(500, 0, type=CoordinateType.SAND), floor=y_max
)
)
while path and path[-1].y <= y_max:
structures.append(path[-1])
path = list(animate_sand(structures, start_point, floor=y_max))
with show_map() as display:
display(structures)
print("PART 2", len([c for c in structures if c.type == CoordinateType.SAND]))
## I suspect there may be a much quicker way to do this by mapping the areas that can't be filled.
## The main shape is basically a triangle, but we remove all solid areas as well as those that are unreachable
## A block is unreachable if it has an unreachable block above it from x-1 to x+1
structures = list(starting_structures)
y_max = max([c.y for c in structures])
cave_map = {(s.x, s.y): s for s in structures}
for y in range(y_max + 2):
x_min = min([c.x for c in cave_map.values()])
x_max = max([c.x for c in cave_map.values()])
for x in range(x_min, x_max + 1):
blockers = {(x - 1, y - 1), (x, y - 1), (x + 1, y - 1)}
if blockers & cave_map.keys() == blockers:
if (x, y) not in cave_map:
cave_map[(x, y)] = Coordinate(x, y, type=CoordinateType.UNREACHABLE)
with show_map() as display:
display(list(cave_map.values()))
print(f"There are {len(cave_map)} unreachable blocks")
h = y_max + 2
area = h**2
print(
f"The whole pyramid is {h} blocks high, so there are {area} blocks in the pyramid"
)
print(f"So the fillable area is {area - len(cave_map)}")
| [
"kaj@k-si.com"
] | kaj@k-si.com |
af46777b4d6e2311448c22027c268d417315ad5e | d897c2bc4ba9a84e7e8a2fe3e998d78cd116f920 | /conta_multipli/att/conta_multipli_template_sol.py | ec1a507bb856a8d52ddd89b12cfcc45080cbd11a | [] | no_license | romeorizzi/problemsCMS_for_LaboProg | 8907622744bc89752391024f24025a7e9706501b | 027b1b204efe602461e93d8b1c194a09eb6526cd | refs/heads/master | 2020-04-03T17:33:52.384915 | 2020-03-25T07:10:17 | 2020-03-25T07:10:17 | 155,449,755 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 745 | py | # -*- coding: utf-8 -*-
# Template di soluzione per il problema conta_multipli
from __future__ import print_function
import sys
if sys.version_info < (3, 0):
input = raw_input # in python2, l'equivalente di input è raw_input
# INIZIO area entro la quale ti consigliamo di operare.
# Ecco la funzione che spetta a tè di implementare come da consegna dell'esercizio (ove credi puoi articolarla e scomporla su ulteriori funzioni e/o introdurre strutture dati di supporto):
def conta_multipli(a, b, c):
return 42
# FINE area entro la quale ti consigliamo di operare.
# Lettura input: all'esame non è il caso tu modifichi il codice sotto questa riga.
a, b, c = map(int, input().strip().split())
print(conta_multipli(a, b, c))
| [
"romeo.rizzi@univr.it"
] | romeo.rizzi@univr.it |
bdf57ae8440dbf93e1bc6eddc1f9701310ee943d | ac56934de4f66f5ad56193209f5fd669e1d34167 | /holecard_handicapper/model/sample_sin_fitting/data_reader.py | 1042c1c482cb3b23c983288c670e8e4550bc0ded | [] | no_license | ishikota/_HoleCardHandicapper | 54a4310c32956baecfa21bee6c72007da091c25b | 6a0674404698f22e208ca0e4c0a870ff0f34f2dd | refs/heads/master | 2021-05-03T07:52:18.077756 | 2016-06-27T07:21:07 | 2016-06-27T07:21:07 | 60,923,502 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 470 | py | import numpy as np
def load_data(file_path, test_ratio):
num_training, num_testing, sigma, seed = 400, 100, 0.3, 0
def sin(x):
return np.sin(x)*3+1
N = num_training + num_testing
tau=4*np.pi
np.random.seed(seed)
X = np.random.random((N,1))*tau
Y = sin(X)+np.random.normal(0,sigma,(N,1))
I = np.arange(N)
np.random.shuffle(I)
training, testing = I[:num_training], I[num_training:]
return (X[training], Y[training]), (X[testing], Y[testing])
| [
"ishikota086@gmail.com"
] | ishikota086@gmail.com |
2f5f17015373e413acca75e653c2af857f16dd4d | 2af6a5c2d33e2046a1d25ae9dd66d349d3833940 | /res_bw/scripts/common/lib/json/tests/test_fail.py | 62e191830eb6c23db772e05ba90fd4cca92e450c | [] | no_license | webiumsk/WOT-0.9.12-CT | e6c8b5bb106fad71b5c3056ada59fb1aebc5f2b2 | 2506e34bd6634ad500b6501f4ed4f04af3f43fa0 | refs/heads/master | 2021-01-10T01:38:38.080814 | 2015-11-11T00:08:04 | 2015-11-11T00:08:04 | 45,803,240 | 0 | 0 | null | null | null | null | WINDOWS-1250 | Python | false | false | 2,304 | py | # 2015.11.10 21:36:30 Střední Evropa (běžný čas)
# Embedded file name: scripts/common/Lib/json/tests/test_fail.py
from json.tests import PyTest, CTest
JSONDOCS = ['"A JSON payload should be an object or array, not a string."',
'["Unclosed array"',
'{unquoted_key: "keys must be quoted"}',
'["extra comma",]',
'["double extra comma",,]',
'[ , "<-- missing value"]',
'["Comma after the close"],',
'["Extra close"]]',
'{"Extra comma": true,}',
'{"Extra value after close": true} "misplaced quoted value"',
'{"Illegal expression": 1 + 2}',
'{"Illegal invocation": alert()}',
'{"Numbers cannot have leading zeroes": 013}',
'{"Numbers cannot be hex": 0x14}',
'["Illegal backslash escape: \\x15"]',
'[\\naked]',
'["Illegal backslash escape: \\017"]',
'[[[[[[[[[[[[[[[[[[[["Too deep"]]]]]]]]]]]]]]]]]]]]',
'{"Missing colon" null}',
'{"Double colon":: null}',
'{"Comma instead of colon", null}',
'["Colon instead of comma": false]',
'["Bad value", truth]',
"['single quote']",
'["\ttab\tcharacter\tin\tstring\t"]',
'["tab\\ character\\ in\\ string\\ "]',
'["line\nbreak"]',
'["line\\\nbreak"]',
'[0e]',
'[0e+]',
'[0e+-1]',
'{"Comma instead if closing brace": true,',
'["mismatch"}',
u'["A\x1fZ control characters in string"]']
SKIPS = {1: 'why not have a string payload?',
18: "spec doesn't specify any nesting limitations"}
class TestFail(object):
def test_failures(self):
for idx, doc in enumerate(JSONDOCS):
idx = idx + 1
if idx in SKIPS:
self.loads(doc)
continue
try:
self.loads(doc)
except ValueError:
pass
else:
self.fail('Expected failure for fail{0}.json: {1!r}'.format(idx, doc))
def test_non_string_keys_dict(self):
data = {'a': 1,
(1, 2): 2}
self.assertRaises(TypeError, self.dumps, data)
self.assertRaises(TypeError, self.dumps, data, indent=True)
class TestPyFail(TestFail, PyTest):
pass
class TestCFail(TestFail, CTest):
pass
# okay decompyling c:\Users\PC\wotsources\files\originals\res_bw\scripts\common\lib\json\tests\test_fail.pyc
# decompiled 1 files: 1 okay, 0 failed, 0 verify failed
# 2015.11.10 21:36:30 Střední Evropa (běžný čas)
| [
"info@webium.sk"
] | info@webium.sk |
6c2ffeac03adb70f34b7c11bb93bedc336920023 | 0822d36728e9ed1d4e91d8ee8b5ea39010ac9371 | /robo/pages/acre/pagina20_politica.py | 03057626a23722d2c1352c9539c8933c4e907622 | [] | no_license | diegothuran/blog | 11161e6f425d08bf7689190eac0ca5bd7cb65dd7 | 233135a1db24541de98a7aeffd840cf51e5e462e | refs/heads/master | 2022-12-08T14:03:02.876353 | 2019-06-05T17:57:55 | 2019-06-05T17:57:55 | 176,329,704 | 0 | 0 | null | 2022-12-08T04:53:02 | 2019-03-18T16:46:43 | Python | UTF-8 | Python | false | false | 911 | py | # coding: utf-8
import sys
sys.path.insert(0, '../../../blog')
from bs4 import BeautifulSoup
import requests
from robo.pages.util.constantes import PAGE_LIMIT
GLOBAL_RANK = 1306322
RANK_BRAZIL = None
NAME = 'pagina20.net'
def get_urls():
try:
urls = []
for i in range(1,PAGE_LIMIT):
if(i == 1):
link = 'http://pagina20.net/v2/category/politica/'
else:
link = 'http://pagina20.net/v2/category/politica/page/' + str(i)
req = requests.get(link)
noticias = BeautifulSoup(req.text, "html.parser").find_all('div', class_='card painel-noticias2')
for noticia in noticias:
href = noticia.find_all('a', href=True)[0]['href']
# print(href)
urls.append(href)
return urls
except:
raise Exception('Exception in pagina20_politica')
| [
"diego.thuran@gmail.com"
] | diego.thuran@gmail.com |
8194dad6dd0e415b6afedc496cab4a6f3c488433 | 924763dfaa833a898a120c411a5ed3b2d9b2f8c7 | /compiled/python/zlib_with_header_78.py | 8eef421ed619a14bff098297e52e60abc6bd9cd0 | [
"MIT"
] | permissive | kaitai-io/ci_targets | 31257dfdf77044d32a659ab7b8ec7da083f12d25 | 2f06d144c5789ae909225583df32e2ceb41483a3 | refs/heads/master | 2023-08-25T02:27:30.233334 | 2023-08-04T18:54:45 | 2023-08-04T18:54:45 | 87,530,818 | 4 | 6 | MIT | 2023-07-28T22:12:01 | 2017-04-07T09:44:44 | C++ | UTF-8 | Python | false | false | 744 | py | # This is a generated file! Please edit source .ksy file and use kaitai-struct-compiler to rebuild
# type: ignore
import kaitaistruct
from kaitaistruct import KaitaiStruct, KaitaiStream, BytesIO
import zlib
if getattr(kaitaistruct, 'API_VERSION', (0, 9)) < (0, 9):
raise Exception("Incompatible Kaitai Struct Python API: 0.9 or later is required, but you have %s" % (kaitaistruct.__version__))
class ZlibWithHeader78(KaitaiStruct):
def __init__(self, _io, _parent=None, _root=None):
self._io = _io
self._parent = _parent
self._root = _root if _root else self
self._read()
def _read(self):
self._raw_data = self._io.read_bytes_full()
self.data = zlib.decompress(self._raw_data)
| [
"kaitai-bot@kaitai.io"
] | kaitai-bot@kaitai.io |
3b7bce198346d439703494bd74c2c46bef4a5270 | d488f052805a87b5c4b124ca93494bc9b78620f7 | /google-cloud-sdk/lib/googlecloudsdk/command_lib/deployment_manager/flags.py | d4cbf34227cc379f368deb83d40bbb690841c6b0 | [
"MIT",
"LicenseRef-scancode-unknown-license-reference",
"Apache-2.0"
] | permissive | PacktPublishing/DevOps-Fundamentals | 5ce1fc938db66b420691aa8106ecfb3f9ceb1ace | 60597e831e08325c7e51e8557591917f7c417275 | refs/heads/master | 2023-02-02T04:48:15.346907 | 2023-01-30T08:33:35 | 2023-01-30T08:33:35 | 131,293,311 | 13 | 19 | null | null | null | null | UTF-8 | Python | false | false | 4,189 | py | # Copyright 2016 Google Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Helper methods for configuring deployment manager command flags."""
from googlecloudsdk.api_lib.deployment_manager import dm_api_util
from googlecloudsdk.calliope import arg_parsers
from googlecloudsdk.command_lib.util.apis import arg_utils
RESOURCES_AND_OUTPUTS_FORMAT = """
table(
resources:format='table(
name,
type:wrap,
update.state.yesno(no="COMPLETED"),
update.error.errors.group(code),
update.intent)',
outputs:format='table(
name:label=OUTPUTS,
finalValue:label=VALUE)'
)
"""
OPERATION_FORMAT = """
table(
name,
operationType:label=TYPE,
status,
targetLink.basename():label=TARGET,
error.errors.group(code),
warnings.group(code)
)
"""
DEPLOYMENT_FORMAT = """
default(
name, id, description, fingerprint,insertTime, manifest.basename(),
labels, operation.operationType, operation.progress,
operation.status, operation.user, operation.endTime, operation.startTime,
operation.error, operation.warnings, update)
"""
_DELETE_FLAG_KWARGS = {
'help_str': ('Delete policy for resources that will change as part of '
'an update or delete. `delete` deletes the resource while '
'`abandon` just removes the resource reference from the '
'deployment.'),
'default': 'delete',
'name': '--delete-policy'
}
def GetDeleteFlagEnumMap(policy_enum):
return arg_utils.ChoiceEnumMapper(
_DELETE_FLAG_KWARGS['name'],
policy_enum,
help_str=_DELETE_FLAG_KWARGS['help_str'],
default=_DELETE_FLAG_KWARGS['default'])
def AddDeploymentNameFlag(parser):
"""Add properties flag."""
parser.add_argument('deployment_name', help='Deployment name.')
def AddConfigFlags(parser):
"""Add flags for different types of configs."""
parser.add_argument(
'--config',
help='Filename of a top-level yaml config that specifies '
'resources to deploy.')
parser.add_argument(
'--template',
help='Filename of a top-level jinja or python config template.')
parser.add_argument(
'--composite-type',
help='Name of a composite type to deploy.')
def AddPropertiesFlag(parser):
"""Add properties flag."""
parser.add_argument(
'--properties',
help='A comma separated, key:value, map '
'to be used when deploying a template file or composite type directly.',
type=arg_parsers.ArgDict(operators=dm_api_util.NewParserDict()),
dest='properties')
def AddAsyncFlag(parser):
"""Add the async argument."""
parser.add_argument(
'--async',
help='Return immediately and print information about the Operation in '
'progress rather than waiting for the Operation to complete. '
'(default=False)',
dest='async',
default=False,
action='store_true')
def AddFingerprintFlag(parser):
"""Add the fingerprint argument."""
parser.add_argument(
'--fingerprint',
help=('The fingerprint to use in requests to modify a deployment. If not '
'specified, a get deployment request will be made to fetch the '
'latest fingerprint. A fingerprint is a randomly generated value '
'that is part of the update, stop, and cancel-preview request to '
'perform optimistic locking. It is initially generated by '
'Deployment Manager and changes after every request to modify '
'data. The latest fingerprint is printed when deployment data is '
'modified.'),
dest='fingerprint')
| [
"saneetk@packtpub.com"
] | saneetk@packtpub.com |
4bbf5176a2819bc143b1ee92a6c2f72dd3b570b1 | d6bf3302b826127a9d2f08bbd05947cbb9d342c6 | /symmetry_1/encrypt.py | b2978c73f33e432efc322710c5513fbf23979a6f | [] | no_license | velocitystorm/ctf-crypto-tasks | 03add82d00bbf28f45955e153d4c5585e1a2647a | 50a2ea2019bc7798a85d5bcbb6e04ebd91f9a51b | refs/heads/master | 2021-01-19T07:10:34.714655 | 2014-04-16T19:57:08 | 2014-04-16T19:57:08 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 363 | py | #!/usr/bin/env python3
def encrypt(data, key):
return bytes([octet ^ key for octet in data])
print('Enter a key: ')
key = input()
key = ord(key[0])
print('Enter a message: ')
message = input().strip().encode('ascii') # convert from str to bytes
encrypted = encrypt(message, key)
fout = open('message.encrypted', 'wb')
fout.write(encrypted)
fout.close()
| [
"cxielamiko@gmail.com"
] | cxielamiko@gmail.com |
b3d6568aadebae72d49ae2424c19d1cd3db5d59f | c46fba793dc4c2eb4aa7886ca1b29d2c444dddb9 | /tests/test_config_validators.py | b18d531cd0c58283a79c08ca805a7ab26ac0a973 | [
"LicenseRef-scancode-warranty-disclaimer",
"Apache-2.0"
] | permissive | digideskio/vodka | 7ffcc408df3571db9bb143674db51554ddd34674 | 86a4efa0e1666902771459c8727680888026eac5 | refs/heads/master | 2021-01-12T17:49:58.576348 | 2016-10-11T09:36:40 | 2016-10-11T09:36:40 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 525 | py | import unittest
import vodka.config.validators
class TestConfigValidators(unittest.TestCase):
def test_path_validator(self):
b,d = vodka.config.validators.path(__file__)
self.assertEqual(b, True)
def test_host_validator(self):
b,d = vodka.config.validators.host("host:1")
self.assertEqual(b, True)
b,d = vodka.config.validators.host("host")
self.assertEqual(b, False)
b,d = vodka.config.validators.host("host:b")
self.assertEqual(b, False)
| [
"stefan@20c.com"
] | stefan@20c.com |
cd7c4627c1549a2026c52188d64d165e6a522a59 | 9743d5fd24822f79c156ad112229e25adb9ed6f6 | /xai/brain/wordbase/adjectives/_inspirational.py | 99cfc99ffa1a858152258d1937a20cad880aa545 | [
"MIT"
] | permissive | cash2one/xai | de7adad1758f50dd6786bf0111e71a903f039b64 | e76f12c9f4dcf3ac1c7c08b0cc8844c0b0a104b6 | refs/heads/master | 2021-01-19T12:33:54.964379 | 2017-01-28T02:00:50 | 2017-01-28T02:00:50 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 416 | py |
#calss header
class _INSPIRATIONAL():
def __init__(self,):
self.name = "INSPIRATIONAL"
self.definitions = [u'making you feel full of hope or encouraged: ']
self.parents = []
self.childen = []
self.properties = []
self.jsondata = {}
self.specie = 'adjectives'
def run(self, obj1, obj2):
self.jsondata[obj2] = {}
self.jsondata[obj2]['properties'] = self.name.lower()
return self.jsondata
| [
"xingwang1991@gmail.com"
] | xingwang1991@gmail.com |
6856f767fdb17749139555eee6cacdc1dc9e16fe | 9743d5fd24822f79c156ad112229e25adb9ed6f6 | /xai/brain/wordbase/pronouns/_one.py | f591a8a6acc6b3fb2f2a28d9dd49ebe3efe3e975 | [
"MIT"
] | permissive | cash2one/xai | de7adad1758f50dd6786bf0111e71a903f039b64 | e76f12c9f4dcf3ac1c7c08b0cc8844c0b0a104b6 | refs/heads/master | 2021-01-19T12:33:54.964379 | 2017-01-28T02:00:50 | 2017-01-28T02:00:50 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 645 | py |
#calss header
class _ONE():
def __init__(self,):
self.name = "ONE"
self.definitions = [u'used to refer to a particular thing or person within a group or range of things or people that are possible or available: ', u'to never do something: ', u'to like something very much: ', u'used to talk about one person or thing compared with other similar or related people or things: ', u'any person, but not a particular person: ', u'the person speaking or writing: ']
self.parents = []
self.childen = []
self.properties = []
self.jsondata = {}
self.specie = 'pronouns'
def run(self, obj1 = [], obj2 = []):
return self.jsondata
| [
"xingwang1991@gmail.com"
] | xingwang1991@gmail.com |
25f3d296f6e6657fadb469b39bcae1f882399891 | 8fd11d010b550144c62e2cf0ead5a89433ba56e9 | /bin/switch_kerasbackend | 24a63df2ae7d764d28adf5073bf310ea7ddd30ab | [] | no_license | Shaar68/PyShortTextCategorization | 3d47d4fc1996eab61fc8cf2ce8d37c0ef9188931 | 189a57da34c52aab1dbd8dcf4145c2dbb120f5af | refs/heads/master | 2021-04-15T18:46:47.014156 | 2017-06-16T20:59:15 | 2017-06-16T20:59:15 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 701 | #!/usr/bin/env python
# Secret code. Welcome for those who find this code.
# argument parsing
import argparse
def getargparser():
parser = argparse.ArgumentParser(description='Switch Keras backend')
parser.add_argument('backend', help="Backend ('theano' or 'tensorflow')")
return parser
parser = getargparser()
args = parser.parse_args()
import os
import json
homedir = os.path.expanduser('~')
kerasconfigfile = os.path.join(homedir, '.keras/keras.json')
if __name__ == '__main__':
kerasconfig = json.load(open(kerasconfigfile, 'r'))
kerasconfig['backend'] = args.backend
json.dump(kerasconfig, open(kerasconfigfile, 'w'))
print 'Keras backend set to ', args.backend | [
"stephenhky@yahoo.com.hk"
] | stephenhky@yahoo.com.hk | |
d4c9d97370dc85989351e566c68172584c50c648 | 24fe1f54fee3a3df952ca26cce839cc18124357a | /servicegraph/lib/python2.7/site-packages/acimodel-4.0_3d-py2.7.egg/cobra/modelimpl/proc/applicationcpuhist1d.py | 6a2802b96d01809c6eafddd1912732742c234f2a | [] | no_license | aperiyed/servicegraph-cloudcenter | 4b8dc9e776f6814cf07fe966fbd4a3481d0f45ff | 9eb7975f2f6835e1c0528563a771526896306392 | refs/heads/master | 2023-05-10T17:27:18.022381 | 2020-01-20T09:18:28 | 2020-01-20T09:18:28 | 235,065,676 | 0 | 0 | null | 2023-05-01T21:19:14 | 2020-01-20T09:36:37 | Python | UTF-8 | Python | false | false | 10,887 | py | # coding=UTF-8
# **********************************************************************
# Copyright (c) 2013-2019 Cisco Systems, Inc. All rights reserved
# written by zen warriors, do not modify!
# **********************************************************************
from cobra.mit.meta import ClassMeta
from cobra.mit.meta import StatsClassMeta
from cobra.mit.meta import CounterMeta
from cobra.mit.meta import PropMeta
from cobra.mit.meta import Category
from cobra.mit.meta import SourceRelationMeta
from cobra.mit.meta import NamedSourceRelationMeta
from cobra.mit.meta import TargetRelationMeta
from cobra.mit.meta import DeploymentPathMeta, DeploymentCategory
from cobra.model.category import MoCategory, PropCategory, CounterCategory
from cobra.mit.mo import Mo
# ##################################################
class ApplicationCPUHist1d(Mo):
"""
Mo doc not defined in techpub!!!
"""
meta = StatsClassMeta("cobra.model.proc.ApplicationCPUHist1d", "Application CPU utilization")
counter = CounterMeta("current", CounterCategory.GAUGE, "percentage", "Application CPU usage")
counter._propRefs[PropCategory.IMPLICIT_MIN] = "currentMin"
counter._propRefs[PropCategory.IMPLICIT_MAX] = "currentMax"
counter._propRefs[PropCategory.IMPLICIT_AVG] = "currentAvg"
counter._propRefs[PropCategory.IMPLICIT_SUSPECT] = "currentSpct"
counter._propRefs[PropCategory.IMPLICIT_THRESHOLDED] = "currentThr"
counter._propRefs[PropCategory.IMPLICIT_TREND] = "currentTr"
meta._counters.append(counter)
meta.moClassName = "procApplicationCPUHist1d"
meta.rnFormat = "HDprocApplicationCPU1d-%(index)s"
meta.category = MoCategory.STATS_HISTORY
meta.label = "historical Application CPU utilization stats in 1 day"
meta.writeAccessMask = 0x1
meta.readAccessMask = 0x1
meta.isDomainable = False
meta.isReadOnly = True
meta.isConfigurable = False
meta.isDeletable = False
meta.isContextRoot = True
meta.parentClasses.add("cobra.model.proc.App")
meta.parentClasses.add("cobra.model.proc.Container")
meta.superClasses.add("cobra.model.proc.ApplicationCPUHist")
meta.superClasses.add("cobra.model.stats.Item")
meta.superClasses.add("cobra.model.stats.Hist")
meta.rnPrefixes = [
('HDprocApplicationCPU1d-', True),
]
prop = PropMeta("str", "childAction", "childAction", 4, PropCategory.CHILD_ACTION)
prop.label = "None"
prop.isImplicit = True
prop.isAdmin = True
prop._addConstant("deleteAll", "deleteall", 16384)
prop._addConstant("deleteNonPresent", "deletenonpresent", 8192)
prop._addConstant("ignore", "ignore", 4096)
meta.props.add("childAction", prop)
prop = PropMeta("str", "cnt", "cnt", 16212, PropCategory.REGULAR)
prop.label = "Number of Collections During this Interval"
prop.isImplicit = True
prop.isAdmin = True
meta.props.add("cnt", prop)
prop = PropMeta("str", "currentAvg", "currentAvg", 30353, PropCategory.IMPLICIT_AVG)
prop.label = "Application CPU usage average value"
prop.isOper = True
prop.isStats = True
meta.props.add("currentAvg", prop)
prop = PropMeta("str", "currentMax", "currentMax", 30352, PropCategory.IMPLICIT_MAX)
prop.label = "Application CPU usage maximum value"
prop.isOper = True
prop.isStats = True
meta.props.add("currentMax", prop)
prop = PropMeta("str", "currentMin", "currentMin", 30351, PropCategory.IMPLICIT_MIN)
prop.label = "Application CPU usage minimum value"
prop.isOper = True
prop.isStats = True
meta.props.add("currentMin", prop)
prop = PropMeta("str", "currentSpct", "currentSpct", 30354, PropCategory.IMPLICIT_SUSPECT)
prop.label = "Application CPU usage suspect count"
prop.isOper = True
prop.isStats = True
meta.props.add("currentSpct", prop)
prop = PropMeta("str", "currentThr", "currentThr", 30355, PropCategory.IMPLICIT_THRESHOLDED)
prop.label = "Application CPU usage thresholded flags"
prop.isOper = True
prop.isStats = True
prop.defaultValue = 0
prop.defaultValueStr = "unspecified"
prop._addConstant("avgCrit", "avg-severity-critical", 2199023255552)
prop._addConstant("avgHigh", "avg-crossed-high-threshold", 68719476736)
prop._addConstant("avgLow", "avg-crossed-low-threshold", 137438953472)
prop._addConstant("avgMajor", "avg-severity-major", 1099511627776)
prop._addConstant("avgMinor", "avg-severity-minor", 549755813888)
prop._addConstant("avgRecovering", "avg-recovering", 34359738368)
prop._addConstant("avgWarn", "avg-severity-warning", 274877906944)
prop._addConstant("cumulativeCrit", "cumulative-severity-critical", 8192)
prop._addConstant("cumulativeHigh", "cumulative-crossed-high-threshold", 256)
prop._addConstant("cumulativeLow", "cumulative-crossed-low-threshold", 512)
prop._addConstant("cumulativeMajor", "cumulative-severity-major", 4096)
prop._addConstant("cumulativeMinor", "cumulative-severity-minor", 2048)
prop._addConstant("cumulativeRecovering", "cumulative-recovering", 128)
prop._addConstant("cumulativeWarn", "cumulative-severity-warning", 1024)
prop._addConstant("lastReadingCrit", "lastreading-severity-critical", 64)
prop._addConstant("lastReadingHigh", "lastreading-crossed-high-threshold", 2)
prop._addConstant("lastReadingLow", "lastreading-crossed-low-threshold", 4)
prop._addConstant("lastReadingMajor", "lastreading-severity-major", 32)
prop._addConstant("lastReadingMinor", "lastreading-severity-minor", 16)
prop._addConstant("lastReadingRecovering", "lastreading-recovering", 1)
prop._addConstant("lastReadingWarn", "lastreading-severity-warning", 8)
prop._addConstant("maxCrit", "max-severity-critical", 17179869184)
prop._addConstant("maxHigh", "max-crossed-high-threshold", 536870912)
prop._addConstant("maxLow", "max-crossed-low-threshold", 1073741824)
prop._addConstant("maxMajor", "max-severity-major", 8589934592)
prop._addConstant("maxMinor", "max-severity-minor", 4294967296)
prop._addConstant("maxRecovering", "max-recovering", 268435456)
prop._addConstant("maxWarn", "max-severity-warning", 2147483648)
prop._addConstant("minCrit", "min-severity-critical", 134217728)
prop._addConstant("minHigh", "min-crossed-high-threshold", 4194304)
prop._addConstant("minLow", "min-crossed-low-threshold", 8388608)
prop._addConstant("minMajor", "min-severity-major", 67108864)
prop._addConstant("minMinor", "min-severity-minor", 33554432)
prop._addConstant("minRecovering", "min-recovering", 2097152)
prop._addConstant("minWarn", "min-severity-warning", 16777216)
prop._addConstant("periodicCrit", "periodic-severity-critical", 1048576)
prop._addConstant("periodicHigh", "periodic-crossed-high-threshold", 32768)
prop._addConstant("periodicLow", "periodic-crossed-low-threshold", 65536)
prop._addConstant("periodicMajor", "periodic-severity-major", 524288)
prop._addConstant("periodicMinor", "periodic-severity-minor", 262144)
prop._addConstant("periodicRecovering", "periodic-recovering", 16384)
prop._addConstant("periodicWarn", "periodic-severity-warning", 131072)
prop._addConstant("rateCrit", "rate-severity-critical", 36028797018963968)
prop._addConstant("rateHigh", "rate-crossed-high-threshold", 1125899906842624)
prop._addConstant("rateLow", "rate-crossed-low-threshold", 2251799813685248)
prop._addConstant("rateMajor", "rate-severity-major", 18014398509481984)
prop._addConstant("rateMinor", "rate-severity-minor", 9007199254740992)
prop._addConstant("rateRecovering", "rate-recovering", 562949953421312)
prop._addConstant("rateWarn", "rate-severity-warning", 4503599627370496)
prop._addConstant("trendCrit", "trend-severity-critical", 281474976710656)
prop._addConstant("trendHigh", "trend-crossed-high-threshold", 8796093022208)
prop._addConstant("trendLow", "trend-crossed-low-threshold", 17592186044416)
prop._addConstant("trendMajor", "trend-severity-major", 140737488355328)
prop._addConstant("trendMinor", "trend-severity-minor", 70368744177664)
prop._addConstant("trendRecovering", "trend-recovering", 4398046511104)
prop._addConstant("trendWarn", "trend-severity-warning", 35184372088832)
prop._addConstant("unspecified", None, 0)
meta.props.add("currentThr", prop)
prop = PropMeta("str", "currentTr", "currentTr", 30356, PropCategory.IMPLICIT_TREND)
prop.label = "Application CPU usage trend"
prop.isOper = True
prop.isStats = True
meta.props.add("currentTr", prop)
prop = PropMeta("str", "dn", "dn", 1, PropCategory.DN)
prop.label = "None"
prop.isDn = True
prop.isImplicit = True
prop.isAdmin = True
prop.isCreateOnly = True
meta.props.add("dn", prop)
prop = PropMeta("str", "index", "index", 30327, PropCategory.REGULAR)
prop.label = "History Index"
prop.isConfig = True
prop.isAdmin = True
prop.isCreateOnly = True
prop.isNaming = True
meta.props.add("index", prop)
prop = PropMeta("str", "lastCollOffset", "lastCollOffset", 111, PropCategory.REGULAR)
prop.label = "Collection Length"
prop.isImplicit = True
prop.isAdmin = True
meta.props.add("lastCollOffset", prop)
prop = PropMeta("str", "modTs", "modTs", 7, PropCategory.REGULAR)
prop.label = "None"
prop.isImplicit = True
prop.isAdmin = True
prop.defaultValue = 0
prop.defaultValueStr = "never"
prop._addConstant("never", "never", 0)
meta.props.add("modTs", prop)
prop = PropMeta("str", "repIntvEnd", "repIntvEnd", 110, PropCategory.REGULAR)
prop.label = "Reporting End Time"
prop.isImplicit = True
prop.isAdmin = True
meta.props.add("repIntvEnd", prop)
prop = PropMeta("str", "repIntvStart", "repIntvStart", 109, PropCategory.REGULAR)
prop.label = "Reporting Start Time"
prop.isImplicit = True
prop.isAdmin = True
meta.props.add("repIntvStart", prop)
prop = PropMeta("str", "rn", "rn", 2, PropCategory.RN)
prop.label = "None"
prop.isRn = True
prop.isImplicit = True
prop.isAdmin = True
prop.isCreateOnly = True
meta.props.add("rn", prop)
prop = PropMeta("str", "status", "status", 3, PropCategory.STATUS)
prop.label = "None"
prop.isImplicit = True
prop.isAdmin = True
prop._addConstant("created", "created", 2)
prop._addConstant("deleted", "deleted", 8)
prop._addConstant("modified", "modified", 4)
meta.props.add("status", prop)
meta.namingProps.append(getattr(meta.props, "index"))
def __init__(self, parentMoOrDn, index, markDirty=True, **creationProps):
namingVals = [index]
Mo.__init__(self, parentMoOrDn, markDirty, *namingVals, **creationProps)
# End of package file
# ##################################################
| [
"rrishike@cisco.com"
] | rrishike@cisco.com |
85904490e01b299c684985a2b352b9b0ad3e7072 | 8f588e8c1502d468689732969c744ccca2055106 | /Python/Programmers/Lv2/n진수게임.py | cf3b9d5062511cb56acb7c560b8dec42a700682d | [] | no_license | 5d5ng/ForCodingTest | 96751c969c2f64d547fe28fa3e14c47c2943947b | 3742c1b38bf00dd4768a9c7ea67eca68844b4a14 | refs/heads/master | 2023-01-04T14:18:40.874764 | 2020-11-02T06:15:05 | 2020-11-02T06:15:05 | 222,054,009 | 2 | 0 | null | null | null | null | UTF-8 | Python | false | false | 793 | py | def solution(n,t,m,p):
answer = replace(n,m*t)
res = ""
for i in range(p-1,len(answer),m):
res+=answer[i]
if len(res)==t:return res
def replace(n,size): # size까지
num = ['0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F']
lst = ['0','1']
start = 2
while(len(lst)<size):
target = start
temp = []
while(target>0):
tnum = target % n
target = int(target/n)
temp.append(num[tnum])
temp = temp[::-1]
for i in temp:
lst.append(i)
start+=1
return lst
n = 16
size = 16
print(solution(2,4,2,1))
# num = 10
# l = []
# while(num>0):
# temp = num%2
# num = int(num/2)
# l.append(temp)
# print(l)
| [
"deo1915@gmail.com"
] | deo1915@gmail.com |
46fd526660dbfc019853fabd462a7d73dbe53b03 | 07c75f8717683b9c84864c446a460681150fb6a9 | /3.Flask_cursor/days01快速入门/demo01.py | 329e98f279655b1c6e44cf5da068fc75cba4249c | [] | no_license | laomu/py_1709 | 987d9307d9025001bd4386381899eb3778f9ccd6 | 80630e6ac3ed348a2a6445e90754bb6198cfe65a | refs/heads/master | 2021-05-11T09:56:45.382526 | 2018-01-19T07:08:00 | 2018-01-19T07:08:00 | 118,088,974 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 858 | py | '''
Flask继承了Django和Tornado的部分优点
在高并发处理上,类似于Django通过多线程的方式实现
在编程处理上,类似于Tornado通过手工编码的方式实现web application
'''
# 引入需要的模块
from flask import Flask # 核心处理模块
# 通过当前文件构建一个app应用 ~~ 当前文件就是 web app程序的入口
app = Flask(__name__)
# 定义视图处理函数~路由+视图函数->加载到 app 中
@app.route("/") # 访问路由
def index(): # 绑定的视图函数
return "<h1>hello flask!</h1>"
@app.route("/login")
def login():
return "<h1>member login!</h1>"
@app.route("/register")
def regist():
return "<h1>member register!</h1>"
if __name__ == "__main__":
# 运行程序
app.run()
"""
路由和视图处理:
Djnago中:
Tornado中:
Flask中:
""" | [
"1007821300@qq.com"
] | 1007821300@qq.com |
b887636efed3ae71e7e0660b52fbac0e6d3d6873 | de24f83a5e3768a2638ebcf13cbe717e75740168 | /moodledata/vpl_data/65/usersdata/219/38632/submittedfiles/investimento.py | 3a87d2cb906049101a01605e976893fc0fa25aca | [] | no_license | rafaelperazzo/programacao-web | 95643423a35c44613b0f64bed05bd34780fe2436 | 170dd5440afb9ee68a973f3de13a99aa4c735d79 | refs/heads/master | 2021-01-12T14:06:25.773146 | 2017-12-22T16:05:45 | 2017-12-22T16:05:45 | 69,566,344 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 327 | py | # -*- coding: utf-8 -*-
from __future__ import division
#COMECE SEU CODIGO AQUI
deposito=float(input('Digite o deposito:'))
taxa=float(input('Digite a taxa:'))
investimento=float(input('Digite o investimento:'))
mês=1
while mes <= 10:
investimento=investimento+taxa*investimento
print('%d/%d/%d/%d/%d/%d/%d/%d/%d/%d') | [
"rafael.mota@ufca.edu.br"
] | rafael.mota@ufca.edu.br |
7ad96ac8ed482fde22e8b199d879255e63f17260 | b1d92172726262fc89f9a0c4a9e4888ebc91009e | /leetcode/easy/Interleave.py | 1c493d3f57046482b48177ea177b563573da49bb | [] | no_license | SuperMartinYang/learning_algorithm | 0c5807be26ef0b7a1fe4e09832f3ce640cd3172b | e16702d2b3ec4e5054baad56f4320bc3b31676ad | refs/heads/master | 2021-06-27T14:00:18.920903 | 2019-05-05T23:25:29 | 2019-05-05T23:25:29 | 109,798,522 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 525 | py | def isInterleave(word1, word2, word3):
'''
word1= 'asdf'
word2 = 'sadfa'
word3 = 'assaddffa'
:param word1: str
:param word2: str
:param word3: str
:return: bool
'''
if word3 == '':
if word1 == word2 == '':
return True
else:
return False
if word1[0] == word3[0]:
return isInterleave(word1[1:], word2, word3[1:])
elif word2[0] == word3[0]:
return isInterleave(word1, word2[1:], word3[1:])
else:
return False
| [
"shy58@pitt.edu"
] | shy58@pitt.edu |
f1409870e136171b9f35c5745ceba8d628968f1d | b27b26462524984951bfbab9250abd145ecfd4c8 | /Demoing/stage_two/hawaii/craigslist_sample/craigslist_sample/spiders/craigslist_spider.py | 4a8ff1b9c951d8f06a9a0049a23b24525323045a | [] | no_license | afcarl/fastTraffickingGrab | cb813d066f1f69f359598e0b55e632dafd273c89 | 9ff274cb7c9b6c7b60d1436c209b2bfc5907267d | refs/heads/master | 2020-03-26T06:21:21.404931 | 2014-08-16T12:38:29 | 2014-08-16T12:38:29 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 6,648 | py |
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import HtmlXPathSelector
from craigslist_sample.items import CraigslistSampleItem
class CraigslistSpider(CrawlSpider):
name = "craigslist"
allowed_domains = ["craigslist.org"]
start_urls = [
"http://honolulu.craigslist.org",
"http://honolulu.craigslist.org/cas/",
"http://honolulu.craigslist.org/cas/index100.html",
"http://honolulu.craigslist.org/cas/index200.html",
"http://honolulu.craigslist.org/cas/index300.html",
"http://honolulu.craigslist.org/cas/index400.html",
"http://honolulu.craigslist.org/cas/index500.html",
"http://honolulu.craigslist.org/cas/index600.html",
"http://honolulu.craigslist.org/cas/index700.html",
"http://honolulu.craigslist.org/cas/index800.html",
"http://honolulu.craigslist.org/cas/index900.html",
"http://honolulu.craigslist.org/cas/index1000.html",
"http://honolulu.craigslist.org/cas/index1100.html",
"http://honolulu.craigslist.org/cas/index1200.html",
"http://honolulu.craigslist.org/cas/index1300.html",
"http://honolulu.craigslist.org/cas/index1400.html",
"http://honolulu.craigslist.org/cas/index1500.html",
"http://honolulu.craigslist.org/cas/index1600.html",
"http://honolulu.craigslist.org/cas/index1700.html",
"http://honolulu.craigslist.org/cas/index1800.html",
"http://honolulu.craigslist.org/cas/index1900.html",
"http://honolulu.craigslist.org/cas/index2000.html",
"http://honolulu.craigslist.org/cas/index2100.html",
"http://honolulu.craigslist.org/cas/index2200.html",
"http://honolulu.craigslist.org/cas/index2300.html",
"http://honolulu.craigslist.org/cas/index2400.html",
"http://honolulu.craigslist.org/cas/index2500.html",
"http://honolulu.craigslist.org/cas/index2600.html",
"http://honolulu.craigslist.org/cas/index2700.html",
"http://honolulu.craigslist.org/cas/index2800.html",
"http://honolulu.craigslist.org/cas/index2900.html",
"http://honolulu.craigslist.org/cas/index3000.html",
"http://honolulu.craigslist.org/cas/index3100.html",
"http://honolulu.craigslist.org/cas/index3200.html",
"http://honolulu.craigslist.org/cas/index3300.html",
"http://honolulu.craigslist.org/cas/index3400.html",
"http://honolulu.craigslist.org/cas/index3500.html",
"http://honolulu.craigslist.org/cas/index3600.html",
"http://honolulu.craigslist.org/cas/index3700.html",
"http://honolulu.craigslist.org/cas/index3800.html",
"http://honolulu.craigslist.org/cas/index3900.html",
"http://honolulu.craigslist.org/cas/index4000.html",
"http://honolulu.craigslist.org/cas/index4100.html",
"http://honolulu.craigslist.org/cas/index4200.html",
"http://honolulu.craigslist.org/cas/index4300.html",
"http://honolulu.craigslist.org/cas/index4400.html",
"http://honolulu.craigslist.org/cas/index4500.html",
"http://honolulu.craigslist.org/cas/index4600.html",
"http://honolulu.craigslist.org/cas/index4700.html",
"http://honolulu.craigslist.org/cas/index4800.html",
"http://honolulu.craigslist.org/cas/index4900.html",
"http://honolulu.craigslist.org/cas/index5000.html",
"http://honolulu.craigslist.org/cas/index5100.html",
"http://honolulu.craigslist.org/cas/index5200.html",
"http://honolulu.craigslist.org/cas/index5300.html",
"http://honolulu.craigslist.org/cas/index5400.html",
"http://honolulu.craigslist.org/cas/index5500.html",
"http://honolulu.craigslist.org/cas/index5600.html",
"http://honolulu.craigslist.org/cas/index5700.html",
"http://honolulu.craigslist.org/cas/index5800.html",
"http://honolulu.craigslist.org/cas/index5900.html",
"http://honolulu.craigslist.org/cas/index6000.html",
"http://honolulu.craigslist.org/cas/index6100.html",
"http://honolulu.craigslist.org/cas/index6200.html",
"http://honolulu.craigslist.org/cas/index6300.html",
"http://honolulu.craigslist.org/cas/index6400.html",
"http://honolulu.craigslist.org/cas/index6500.html",
"http://honolulu.craigslist.org/cas/index6600.html",
"http://honolulu.craigslist.org/cas/index6700.html",
"http://honolulu.craigslist.org/cas/index6800.html",
"http://honolulu.craigslist.org/cas/index6900.html",
"http://honolulu.craigslist.org/cas/index7000.html",
"http://honolulu.craigslist.org/cas/index7100.html",
"http://honolulu.craigslist.org/cas/index7200.html",
"http://honolulu.craigslist.org/cas/index7300.html",
"http://honolulu.craigslist.org/cas/index7400.html",
"http://honolulu.craigslist.org/cas/index7500.html",
"http://honolulu.craigslist.org/cas/index7600.html",
"http://honolulu.craigslist.org/cas/index7700.html",
"http://honolulu.craigslist.org/cas/index7800.html",
"http://honolulu.craigslist.org/cas/index7900.html",
"http://honolulu.craigslist.org/cas/index8000.html",
"http://honolulu.craigslist.org/cas/index8100.html",
"http://honolulu.craigslist.org/cas/index8200.html",
"http://honolulu.craigslist.org/cas/index8300.html",
"http://honolulu.craigslist.org/cas/index8400.html",
"http://honolulu.craigslist.org/cas/index8500.html",
"http://honolulu.craigslist.org/cas/index8600.html",
"http://honolulu.craigslist.org/cas/index8700.html",
"http://honolulu.craigslist.org/cas/index8800.html",
"http://honolulu.craigslist.org/cas/index8900.html",
"http://honolulu.craigslist.org/cas/index9000.html",
"http://honolulu.craigslist.org/cas/index9100.html",
"http://honolulu.craigslist.org/cas/index9200.html",
"http://honolulu.craigslist.org/cas/index9300.html",
"http://honolulu.craigslist.org/cas/index9400.html",
"http://honolulu.craigslist.org/cas/index9500.html",
"http://honolulu.craigslist.org/cas/index9600.html",
"http://honolulu.craigslist.org/cas/index9700.html",
"http://honolulu.craigslist.org/cas/index9800.html",
"http://honolulu.craigslist.org/cas/index9900.html"
]
rules = (Rule(SgmlLinkExtractor(allow=(),restrict_xpaths=('//a')), callback="parse", follow= True),)
def parse(self, response):
hxs = HtmlXPathSelector(response)
titles = hxs.select("//span[@class='pl']")
date_info = hxs.select("//h4[@class='ban']/span[@class='bantext']/text()")
items = []
file_to = open("things.txt","a")
file_to.write(response.body)
for titles in titles:
item = CraigslistSampleItem()
item ["title"] = titles.select("a/text()").extract()
item ["link"] = titles.select("a/@href").extract()
item ["date"] = date_info.extract()
items.append(item)
return items
| [
"ericschles@gmail.com"
] | ericschles@gmail.com |
e1e57f455f8052ec8a259620b247dbb9611debba | 71d4fafdf7261a7da96404f294feed13f6c771a0 | /mainwebsiteenv/bin/python-config | 34a5b39d2ea832da34c02d5012684422e32075af | [] | no_license | avravikiran/mainwebsite | 53f80108caf6fb536ba598967d417395aa2d9604 | 65bb5e85618aed89bfc1ee2719bd86d0ba0c8acd | refs/heads/master | 2021-09-17T02:26:09.689217 | 2018-06-26T16:09:57 | 2018-06-26T16:09:57 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,434 | #!/home/kiran/mainwebsite/mainwebsiteenv/bin/python
import sys
import getopt
import sysconfig
valid_opts = ['prefix', 'exec-prefix', 'includes', 'libs', 'cflags',
'ldflags', 'help']
if sys.version_info >= (3, 2):
valid_opts.insert(-1, 'extension-suffix')
valid_opts.append('abiflags')
if sys.version_info >= (3, 3):
valid_opts.append('configdir')
def exit_with_usage(code=1):
sys.stderr.write("Usage: {0} [{1}]\n".format(
sys.argv[0], '|'.join('--'+opt for opt in valid_opts)))
sys.exit(code)
try:
opts, args = getopt.getopt(sys.argv[1:], '', valid_opts)
except getopt.error:
exit_with_usage()
if not opts:
exit_with_usage()
pyver = sysconfig.get_config_var('VERSION')
getvar = sysconfig.get_config_var
opt_flags = [flag for (flag, val) in opts]
if '--help' in opt_flags:
exit_with_usage(code=0)
for opt in opt_flags:
if opt == '--prefix':
print(sysconfig.get_config_var('prefix'))
elif opt == '--exec-prefix':
print(sysconfig.get_config_var('exec_prefix'))
elif opt in ('--includes', '--cflags'):
flags = ['-I' + sysconfig.get_path('include'),
'-I' + sysconfig.get_path('platinclude')]
if opt == '--cflags':
flags.extend(getvar('CFLAGS').split())
print(' '.join(flags))
elif opt in ('--libs', '--ldflags'):
abiflags = getattr(sys, 'abiflags', '')
libs = ['-lpython' + pyver + abiflags]
libs += getvar('LIBS').split()
libs += getvar('SYSLIBS').split()
# add the prefix/lib/pythonX.Y/config dir, but only if there is no
# shared library in prefix/lib/.
if opt == '--ldflags':
if not getvar('Py_ENABLE_SHARED'):
libs.insert(0, '-L' + getvar('LIBPL'))
if not getvar('PYTHONFRAMEWORK'):
libs.extend(getvar('LINKFORSHARED').split())
print(' '.join(libs))
elif opt == '--extension-suffix':
ext_suffix = sysconfig.get_config_var('EXT_SUFFIX')
if ext_suffix is None:
ext_suffix = sysconfig.get_config_var('SO')
print(ext_suffix)
elif opt == '--abiflags':
if not getattr(sys, 'abiflags', None):
exit_with_usage()
print(sys.abiflags)
elif opt == '--configdir':
print(sysconfig.get_config_var('LIBPL'))
| [
"me15btech11039@iith.ac.in.com"
] | me15btech11039@iith.ac.in.com | |
4b5c8b490bfaa7cd67402657c4020db410bde51b | fb7b6a0d43c524761f5251273d14f317e779c5f0 | /rxbp/observables/fromiteratorobservable.py | bd223651a12680dd7c80c263f7fb1e32727ef164 | [
"Apache-2.0"
] | permissive | MichaelSchneeberger/rxbackpressure | e7396b958d13e20377375f4b45a91a01f600595a | 470d36f729ef9dc001d0099cee45603d9c7f86a3 | refs/heads/master | 2022-08-26T10:12:05.164182 | 2022-08-21T12:21:15 | 2022-08-21T12:21:15 | 109,152,799 | 32 | 1 | Apache-2.0 | 2021-03-09T12:47:23 | 2017-11-01T16:05:20 | Python | UTF-8 | Python | false | false | 4,732 | py | from typing import Iterator, Any, Optional
from rx.disposable import Disposable, BooleanDisposable, CompositeDisposable
from rxbp.acknowledgement.continueack import ContinueAck
from rxbp.acknowledgement.operators.observeon import _observe_on
from rxbp.acknowledgement.single import Single
from rxbp.acknowledgement.stopack import StopAck
from rxbp.mixins.executionmodelmixin import ExecutionModelMixin
from rxbp.observable import Observable
from rxbp.observerinfo import ObserverInfo
from rxbp.scheduler import Scheduler
class FromIteratorObservable(Observable):
def __init__(
self,
iterator: Iterator[Iterator[Any]],
scheduler: Scheduler,
subscribe_scheduler: Scheduler,
on_finish: Disposable = Disposable(),
):
super().__init__()
self.iterator = iterator
self.scheduler = scheduler
self.subscribe_scheduler = subscribe_scheduler
self.on_finish = on_finish
def observe(self, observer_info: ObserverInfo):
observer_info = observer_info.observer
d1 = BooleanDisposable()
def action(_, __):
try:
item = next(self.iterator)
has_next = True
except StopIteration:
has_next = False
except Exception as e:
# stream errors
observer_info.on_error(e)
return Disposable()
if not has_next:
observer_info.on_completed()
else:
# start sending items
self.fast_loop(item, observer_info, self.scheduler, d1, self.scheduler.get_execution_model(),
sync_index=0)
d2 = self.subscribe_scheduler.schedule(action)
return CompositeDisposable(d1, d2)
def trigger_cancel(self, scheduler: Scheduler):
try:
self.on_finish.dispose()
except Exception as e:
scheduler.report_failure(e)
def reschedule(self, ack, next_item, observer, scheduler: Scheduler, disposable, em: ExecutionModelMixin):
class ResultSingle(Single):
def on_next(_, next):
if isinstance(next, ContinueAck):
try:
self.fast_loop(next_item, observer, scheduler, disposable, em, sync_index=0)
except Exception as e:
self.trigger_cancel(scheduler)
scheduler.report_failure(e)
else:
self.trigger_cancel(scheduler)
def on_error(_, err):
self.trigger_cancel(scheduler)
scheduler.report_failure(err)
_observe_on(source=ack, scheduler=scheduler).subscribe(ResultSingle())
# ack.subscribe(ResultSingle())
def fast_loop(self, current_item, observer, scheduler: Scheduler,
disposable: BooleanDisposable, em: ExecutionModelMixin, sync_index: int):
while True:
# try:
ack = observer.on_next(current_item)
# for mypy to type check correctly
next_item: Optional[Any]
try:
next_item = next(self.iterator)
has_next = True
except StopIteration:
has_next = False
next_item = None
except Exception as e:
# stream errors == True
self.trigger_cancel(scheduler)
if not disposable.is_disposed:
observer.on_error(e)
else:
scheduler.report_failure(e)
has_next = False
next_item = None
if not has_next:
try:
self.on_finish.dispose()
except Exception as e:
observer.on_error(e)
else:
observer.on_completed()
break
else:
if isinstance(ack, ContinueAck):
next_index = em.next_frame_index(sync_index)
elif isinstance(ack, StopAck):
next_index = -1
else:
next_index = 0
if next_index > 0:
current_item = next_item
sync_index = next_index
elif next_index == 0 and not disposable.is_disposed:
self.reschedule(ack, next_item, observer, scheduler, disposable, em)
break
else:
self.trigger_cancel(scheduler)
break
# except Exception:
# raise Exception('fatal error')
| [
"michael.schneeb@gmail.com"
] | michael.schneeb@gmail.com |
4355cddb4a6bf72e8a7bb7c5cbf43fd7937c39d7 | 52c705205b243016c90757ed9d7332840277ce11 | /atracoes/migrations/0003_atracao_observacoes.py | ab7a3c8d0152bbe7326dde69447851f31aebcec9 | [] | no_license | lssdeveloper/pontos_turisticos | eb943549cb18561205818dcfb8c624bba32c7100 | 24852ca1b35795db876219a7a3439f496866d3d5 | refs/heads/main | 2023-04-03T10:24:22.000414 | 2021-04-15T20:13:02 | 2021-04-15T20:13:02 | 355,312,899 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 408 | py | # Generated by Django 3.1.7 on 2021-04-15 17:13
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('atracoes', '0002_atracao_foto'),
]
operations = [
migrations.AddField(
model_name='atracao',
name='observacoes',
field=models.CharField(blank=True, max_length=50, null=True),
),
]
| [
"leandro.serra.10@gmail.com"
] | leandro.serra.10@gmail.com |
d9a18dc79e3f78292de7283cc85150a6221a6818 | 07841826ed64a7c6a21b79728f73748ac70dbbc1 | /1.2.2.py | 32cd6c3c38b89f023dcf0a64b287b3421998c263 | [] | no_license | riley-csp-2019-20/1-2-2-catch-a-turtle-leaderboard-illegal-Loli | 772859d28ae3b7b8d003febd1c57fd79b55907dc | 8648a790e039044b3ce722a53a8ec42e45d42488 | refs/heads/master | 2020-09-06T01:58:27.621209 | 2019-12-12T16:11:22 | 2019-12-12T16:11:22 | 220,279,845 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,622 | py | # a121_catch_a_turtle.py
#-----import statements-----
import turtle as trtl
import random
import leaderboard as lb
#-----game configuration----
shape = "square"
size = 2
color = "brown"
score = 0
font_setup = ("Arial", 20, "normal")
timer = 10
counter_interval = 1000 #1000 represents 1 second
timer_up = False
#leaderboard variables
leaderboard_file_name = "a122_leaderboard.txt"
leader_names_list = []
leader_scores_list = []
player_name = input("please enter name")
#-----initialize turtle-----
Amy = trtl.Turtle(shape = shape)
Amy.color(color)
Amy.shapesize(size)
Amy.speed(0)
ore = trtl.Turtle()
ore.penup()
ore.goto(-370,270)
font = ("comic_sans", 30, "bold")
# ore.write("text")
ore.ht()
counter = trtl.Turtle()
#-----game functions--------
def turtle_clicked(x,y):
# print("Amy was clicked")
change_position()
Amy.st()
score_counter()
def change_position():
Amy.penup()
Amy.ht()
new_xpos = random.randint(-400,400)
new_ypos = random.randint(-300,300)
Amy.goto(new_xpos, new_ypos)
def score_counter():
global score
score += 1
# print(score)
ore.clear()
ore.write(score, font =font)
def countdown():
wn.bgcolor("lightgreen")#my game change thing
global timer, timer_up
counter.penup()
counter.goto(350,225)
counter.ht()
counter.clear()
if timer <= 0:
counter.goto(0,80)
counter.write("Time's Up", font=font_setup)
timer_up = True
game_over()
manage_leaderboard()
else:
counter.write("Timer: " + str(timer), font=font_setup)
timer -= 1
counter.getscreen().ontimer(countdown, counter_interval)
def game_over():
wn.bgcolor("lightblue")
Amy.ht()
Amy.goto(500,500)
# manages the leaderboard for top 5 scorers
def manage_leaderboard():
global leader_scores_list
global leader_names_list
global score
global Amy
# load all the leaderboard records into the lists
lb.load_leaderboard(leaderboard_file_name, leader_names_list, leader_scores_list)
# TODO
if (len(leader_scores_list) < 5 or score > leader_scores_list[4]):
lb.update_leaderboard(leaderboard_file_name, leader_names_list, leader_scores_list, player_name, score)
lb.draw_leaderboard(leader_names_list, leader_scores_list, True, Amy, score)
else:
lb.draw_leaderboard(leader_names_list, leader_scores_list, False, Amy, score)
#-----events----------------
Amy.onclick(turtle_clicked)
wn = trtl.Screen()
wn.ontimer(countdown, counter_interval)
wn.mainloop() | [
"noreply@github.com"
] | riley-csp-2019-20.noreply@github.com |
fffaea4b5fab14b8a13db2f9f03a3f89301b5981 | 6f2d5600b65b062151bab88c592796b878de7465 | /Week_3/Class_0226/Function_2_tuple.py | 7e1d6989619b585a1d0dc0ad18f1c32533c6f469 | [] | no_license | zhouyanmeng/python_api_test | 1e6549321c20ee9a71beffac2533c917b5ecc157 | 7303352c9b5baacba5296b088f89ba4c702fb485 | refs/heads/master | 2022-12-17T14:34:26.351566 | 2019-03-01T13:02:06 | 2019-03-01T13:02:06 | 185,185,856 | 0 | 0 | null | 2022-12-08T01:45:15 | 2019-05-06T11:45:55 | Python | UTF-8 | Python | false | false | 420 | py | #####元组的内置函数 不可变元素,所有方法特别少
t=('rigth','sadness','灰灰的','柠檬','sadness','sadness')
####count统计数量的作用
res=t.count('A')###寻找元素出现的次数,在元组里面去找
print(res)
####index 找某个元素索引(位置) 找不到报错 默认1开始,可以指定个数
res=t.index("rigth")
print(res)###0
res=t.index("sadness",3)
print(res)###4
| [
"2440269710@qq.com"
] | 2440269710@qq.com |
0dce4ec9766df4f4af8856792758ec7b7d60a045 | adcbefa6cba639ec8c8eb74766b7f6cd5301d041 | /coffeehouse_nlpfr/classify/textcat.py | 32480de52dcff8dc955f48ed7948bedbc781b998 | [] | no_license | intellivoid/CoffeeHouse-NLPFR | b39ae1eaeb8936c5c5634f39e0a30d1feece6705 | 8ad1b988ddba086478c320f638d10d0c0cacca4c | refs/heads/master | 2022-11-28T02:13:40.670494 | 2020-06-07T04:02:00 | 2020-06-07T04:02:00 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 6,110 | py | # -*- coding: utf-8 -*-
# Natural Language Toolkit: Language ID module using TextCat algorithm
#
# Copyright (C) 2001-2019 NLTK Project
# Author: Avital Pekker <avital.pekker@utoronto.ca>
#
# URL: <http://nltk.org/>
# For license information, see LICENSE.TXT
"""
A module for language identification using the TextCat algorithm.
An implementation of the text categorization algorithm
presented in Cavnar, W. B. and J. M. Trenkle,
"N-Gram-Based Text Categorization".
The algorithm takes advantage of Zipf's law and uses
n-gram frequencies to profile languages and text-yet to
be identified-then compares using a distance measure.
Language n-grams are provided by the "An Crubadan"
project. A corpus reader was created separately to read
those files.
For details regarding the algorithm, see:
http://www.let.rug.nl/~vannoord/TextCat/textcat.pdf
For details about An Crubadan, see:
http://borel.slu.edu/crubadan/index.html
"""
from coffeehouse_nlpfr.compat import PY3
from coffeehouse_nlpfr.util import trigrams
if PY3:
from sys import maxsize
else:
from sys import maxint
# Note: this is NOT "re" you're likely used to. The regex module
# is an alternative to the standard re module that supports
# Unicode codepoint properties with the \p{} syntax.
# You may have to "pip install regx"
try:
import regex as re
except ImportError:
re = None
######################################################################
## Language identification using TextCat
######################################################################
class TextCat(object):
_corpus = None
fingerprints = {}
_START_CHAR = "<"
_END_CHAR = ">"
last_distances = {}
def __init__(self):
if not re:
raise EnvironmentError(
"classify.textcat requires the regex module that "
"supports unicode. Try '$ pip install regex' and "
"see https://pypi.python.org/pypi/regex for "
"further details."
)
from coffeehouse_nlpfr.corpus import crubadan
self._corpus = crubadan
# Load all language ngrams into cache
for lang in self._corpus.langs():
self._corpus.lang_freq(lang)
def remove_punctuation(self, text):
""" Get rid of punctuation except apostrophes """
return re.sub(r"[^\P{P}\']+", "", text)
def profile(self, text):
""" Create FreqDist of trigrams within text """
from coffeehouse_nlpfr import word_tokenize, FreqDist
clean_text = self.remove_punctuation(text)
tokens = word_tokenize(clean_text)
fingerprint = FreqDist()
for t in tokens:
token_trigram_tuples = trigrams(self._START_CHAR + t + self._END_CHAR)
token_trigrams = ["".join(tri) for tri in token_trigram_tuples]
for cur_trigram in token_trigrams:
if cur_trigram in fingerprint:
fingerprint[cur_trigram] += 1
else:
fingerprint[cur_trigram] = 1
return fingerprint
def calc_dist(self, lang, trigram, text_profile):
""" Calculate the "out-of-place" measure between the
text and language profile for a single trigram """
lang_fd = self._corpus.lang_freq(lang)
dist = 0
if trigram in lang_fd:
idx_lang_profile = list(lang_fd.keys()).index(trigram)
idx_text = list(text_profile.keys()).index(trigram)
# print(idx_lang_profile, ", ", idx_text)
dist = abs(idx_lang_profile - idx_text)
else:
# Arbitrary but should be larger than
# any possible trigram file length
# in terms of total lines
if PY3:
dist = maxsize
else:
dist = maxint
return dist
def lang_dists(self, text):
""" Calculate the "out-of-place" measure between
the text and all languages """
distances = {}
profile = self.profile(text)
# For all the languages
for lang in self._corpus._all_lang_freq.keys():
# Calculate distance metric for every trigram in
# input text to be identified
lang_dist = 0
for trigram in profile:
lang_dist += self.calc_dist(lang, trigram, profile)
distances[lang] = lang_dist
return distances
def guess_language(self, text):
""" Find the language with the min distance
to the text and return its ISO 639-3 code """
self.last_distances = self.lang_dists(text)
return min(self.last_distances, key=self.last_distances.get)
#################################################')
def demo():
from coffeehouse_nlpfr.corpus import udhr
langs = [
"Kurdish-UTF8",
"Abkhaz-UTF8",
"Farsi_Persian-UTF8",
"Hindi-UTF8",
"Hawaiian-UTF8",
"Russian-UTF8",
"Vietnamese-UTF8",
"Serbian_Srpski-UTF8",
"Esperanto-UTF8",
]
friendly = {
"kmr": "Northern Kurdish",
"abk": "Abkhazian",
"pes": "Iranian Persian",
"hin": "Hindi",
"haw": "Hawaiian",
"rus": "Russian",
"vie": "Vietnamese",
"srp": "Serbian",
"epo": "Esperanto",
}
tc = TextCat()
for cur_lang in langs:
# Get raw data from UDHR corpus
raw_sentences = udhr.sents(cur_lang)
rows = len(raw_sentences) - 1
cols = list(map(len, raw_sentences))
sample = ""
# Generate a sample text of the language
for i in range(0, rows):
cur_sent = ""
for j in range(0, cols[i]):
cur_sent += " " + raw_sentences[i][j]
sample += cur_sent
# Try to detect what it is
print("Language snippet: " + sample[0:140] + "...")
guess = tc.guess_language(sample)
print("Language detection: %s (%s)" % (guess, friendly[guess]))
print("#" * 140)
if __name__ == "__main__":
demo()
| [
"netkas@intellivoid.info"
] | netkas@intellivoid.info |
29ac8c23f48db7c332612e98d5278bc97525532b | f462679e25ee5dbae2a761f0222bc547f7b9da65 | /srcPython/find_in_read_input_order_variables.py | eef10b72dc50717672eed015c118913b304cf040 | [
"Apache-2.0"
] | permissive | FengYongQ/spock | f31a2f9cac58fbb1912f8e7b066b5318e0223835 | 08c01c01521429a70b5387e8769558e788f7cd3e | refs/heads/master | 2021-06-13T03:09:23.903196 | 2020-01-25T03:32:41 | 2020-01-25T03:32:41 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 992 | py | # Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
def find_in_read_input_order_variables(order_variables, var_to_find):
index_of_var_to_find = (int)([s for s in order_variables if var_to_find in s][0].split('|')[1])
return index_of_var_to_find
| [
"bussyvirat@gmail.com"
] | bussyvirat@gmail.com |
a60f708732cd173bb315e5f8aac3373e5d378180 | 31bc3fdc7c2b62880f84e50893c8e3d0dfb66fa6 | /language/python_27/built_in_functions/xrange_.py | 7bdc6a3472b618b41017ab38268da7e639255b1c | [] | no_license | tpt5cu/python-tutorial | 6e25cf0b346b8182ebc8a921efb25db65f16c144 | 5998e86165a52889faf14133b5b0d7588d637be1 | refs/heads/master | 2022-11-28T16:58:51.648259 | 2020-07-23T02:20:37 | 2020-07-23T02:20:37 | 269,521,394 | 0 | 0 | null | 2020-06-05T03:23:51 | 2020-06-05T03:23:50 | null | UTF-8 | Python | false | false | 713 | py | # https://docs.python.org/2/library/functions.html#xrange
def use_xrange():
'''
The xrange() function is totally different from the range() function. It does not return a list. I can think of it as a generator. It has the same
method signature as range()
'''
x = xrange(1, 10)
print(x) # xrange(1, 10)
print(type(x)) # <type 'xrange'>
def supported_operations():
'''
These are supported on xrange() objects:
- indexing
- len()
- "in"
No slicing!
'''
r = xrange(0, 10)
print(r[1]) # 1
print(len(r)) # 10
#print(r[0:9:2]) # [0, 2, 4, 6, 8]
print(5 in r) # True
if __name__ == '__main__':
#use_xrange()
supported_operations() | [
"uif93194@gmail.com"
] | uif93194@gmail.com |
d3205bd4ff23c60c90c8e9f539e38a4470e037fe | e77c683da89f4705b015e76f02486e7001d82697 | /kubernetes/client/models/v2_hpa_scaling_rules.py | c045f5d4dc20f9d483698b3f271d1b66d608fde0 | [
"Apache-2.0"
] | permissive | Sandello76/python-2 | 4027901d7a9a7d451146fafb844f242708784999 | e5f4520522681a8ec50052991d6226296dc0fb5e | refs/heads/master | 2023-01-21T11:17:31.697036 | 2022-04-12T11:43:35 | 2022-04-12T11:43:35 | 169,290,597 | 0 | 0 | Apache-2.0 | 2023-01-13T03:11:56 | 2019-02-05T18:29:08 | Python | UTF-8 | Python | false | false | 6,818 | py | # coding: utf-8
"""
Kubernetes
No description provided (generated by Openapi Generator https://github.com/openapitools/openapi-generator) # noqa: E501
The version of the OpenAPI document: release-1.23
Generated by: https://openapi-generator.tech
"""
import pprint
import re # noqa: F401
import six
from kubernetes.client.configuration import Configuration
class V2HPAScalingRules(object):
"""NOTE: This class is auto generated by OpenAPI Generator.
Ref: https://openapi-generator.tech
Do not edit the class manually.
"""
"""
Attributes:
openapi_types (dict): The key is attribute name
and the value is attribute type.
attribute_map (dict): The key is attribute name
and the value is json key in definition.
"""
openapi_types = {
'policies': 'list[V2HPAScalingPolicy]',
'select_policy': 'str',
'stabilization_window_seconds': 'int'
}
attribute_map = {
'policies': 'policies',
'select_policy': 'selectPolicy',
'stabilization_window_seconds': 'stabilizationWindowSeconds'
}
def __init__(self, policies=None, select_policy=None, stabilization_window_seconds=None, local_vars_configuration=None): # noqa: E501
"""V2HPAScalingRules - a model defined in OpenAPI""" # noqa: E501
if local_vars_configuration is None:
local_vars_configuration = Configuration()
self.local_vars_configuration = local_vars_configuration
self._policies = None
self._select_policy = None
self._stabilization_window_seconds = None
self.discriminator = None
if policies is not None:
self.policies = policies
if select_policy is not None:
self.select_policy = select_policy
if stabilization_window_seconds is not None:
self.stabilization_window_seconds = stabilization_window_seconds
@property
def policies(self):
"""Gets the policies of this V2HPAScalingRules. # noqa: E501
policies is a list of potential scaling polices which can be used during scaling. At least one policy must be specified, otherwise the HPAScalingRules will be discarded as invalid # noqa: E501
:return: The policies of this V2HPAScalingRules. # noqa: E501
:rtype: list[V2HPAScalingPolicy]
"""
return self._policies
@policies.setter
def policies(self, policies):
"""Sets the policies of this V2HPAScalingRules.
policies is a list of potential scaling polices which can be used during scaling. At least one policy must be specified, otherwise the HPAScalingRules will be discarded as invalid # noqa: E501
:param policies: The policies of this V2HPAScalingRules. # noqa: E501
:type: list[V2HPAScalingPolicy]
"""
self._policies = policies
@property
def select_policy(self):
"""Gets the select_policy of this V2HPAScalingRules. # noqa: E501
selectPolicy is used to specify which policy should be used. If not set, the default value Max is used. # noqa: E501
:return: The select_policy of this V2HPAScalingRules. # noqa: E501
:rtype: str
"""
return self._select_policy
@select_policy.setter
def select_policy(self, select_policy):
"""Sets the select_policy of this V2HPAScalingRules.
selectPolicy is used to specify which policy should be used. If not set, the default value Max is used. # noqa: E501
:param select_policy: The select_policy of this V2HPAScalingRules. # noqa: E501
:type: str
"""
self._select_policy = select_policy
@property
def stabilization_window_seconds(self):
"""Gets the stabilization_window_seconds of this V2HPAScalingRules. # noqa: E501
StabilizationWindowSeconds is the number of seconds for which past recommendations should be considered while scaling up or scaling down. StabilizationWindowSeconds must be greater than or equal to zero and less than or equal to 3600 (one hour). If not set, use the default values: - For scale up: 0 (i.e. no stabilization is done). - For scale down: 300 (i.e. the stabilization window is 300 seconds long). # noqa: E501
:return: The stabilization_window_seconds of this V2HPAScalingRules. # noqa: E501
:rtype: int
"""
return self._stabilization_window_seconds
@stabilization_window_seconds.setter
def stabilization_window_seconds(self, stabilization_window_seconds):
"""Sets the stabilization_window_seconds of this V2HPAScalingRules.
StabilizationWindowSeconds is the number of seconds for which past recommendations should be considered while scaling up or scaling down. StabilizationWindowSeconds must be greater than or equal to zero and less than or equal to 3600 (one hour). If not set, use the default values: - For scale up: 0 (i.e. no stabilization is done). - For scale down: 300 (i.e. the stabilization window is 300 seconds long). # noqa: E501
:param stabilization_window_seconds: The stabilization_window_seconds of this V2HPAScalingRules. # noqa: E501
:type: int
"""
self._stabilization_window_seconds = stabilization_window_seconds
def to_dict(self):
"""Returns the model properties as a dict"""
result = {}
for attr, _ in six.iteritems(self.openapi_types):
value = getattr(self, attr)
if isinstance(value, list):
result[attr] = list(map(
lambda x: x.to_dict() if hasattr(x, "to_dict") else x,
value
))
elif hasattr(value, "to_dict"):
result[attr] = value.to_dict()
elif isinstance(value, dict):
result[attr] = dict(map(
lambda item: (item[0], item[1].to_dict())
if hasattr(item[1], "to_dict") else item,
value.items()
))
else:
result[attr] = value
return result
def to_str(self):
"""Returns the string representation of the model"""
return pprint.pformat(self.to_dict())
def __repr__(self):
"""For `print` and `pprint`"""
return self.to_str()
def __eq__(self, other):
"""Returns true if both objects are equal"""
if not isinstance(other, V2HPAScalingRules):
return False
return self.to_dict() == other.to_dict()
def __ne__(self, other):
"""Returns true if both objects are not equal"""
if not isinstance(other, V2HPAScalingRules):
return True
return self.to_dict() != other.to_dict()
| [
"yliao@google.com"
] | yliao@google.com |
cc31a73155bf7a1396a114b82259e779537e8ff9 | 9c63f6d39a6085674ab42d1488476d0299f39ec9 | /Python/LC_Kth_Largest_Element_in_an_Array.py | 7c993647bd88be65ae4b55dc5b44039e08b71761 | [] | no_license | vijayjag-repo/LeetCode | 2237e3117e7e902f5ac5c02bfb5fbe45af7242d4 | 0a5f47e272f6ba31e3f0ff4d78bf6e3f4063c789 | refs/heads/master | 2022-11-14T17:46:10.847858 | 2022-11-08T10:28:30 | 2022-11-08T10:28:30 | 163,639,628 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 474 | py | class Solution(object):
def findKthLargest(self, nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: int
"""
# Solution 1
# There are different variations which you can do with heap. This is one of the smallest along with heapq.nlargest()
heapq.heapify(nums)
for i in range(len(nums)-k+1):
val = heapq.heappop(nums)
return(val)
| [
"noreply@github.com"
] | vijayjag-repo.noreply@github.com |
a277e9f184cbf53ef869869269365cfe9e69fd90 | fa51b088ea761b78cf0c85837fabaa0b7035b105 | /automl/snippets/language_sentiment_analysis_create_model.py | 40262aa4f637ba15df8f0e51fd488a2a48593cab | [
"Apache-2.0"
] | permissive | manavgarg/python-docs-samples | f27307022092bc35358b8ddbd0f73d56787934d1 | 54b9cd6740b4dbc64db4d43a16de13c702b2364b | refs/heads/master | 2023-02-07T21:18:15.997414 | 2023-01-28T18:44:11 | 2023-01-28T18:44:11 | 245,290,674 | 0 | 0 | Apache-2.0 | 2020-03-05T23:44:17 | 2020-03-05T23:44:16 | null | UTF-8 | Python | false | false | 1,697 | py | # Copyright 2020 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
def create_model(project_id, dataset_id, display_name):
"""Create a model."""
# [START automl_language_sentiment_analysis_create_model]
from google.cloud import automl
# TODO(developer): Uncomment and set the following variables
# project_id = "YOUR_PROJECT_ID"
# dataset_id = "YOUR_DATASET_ID"
# display_name = "YOUR_MODEL_NAME"
client = automl.AutoMlClient()
# A resource that represents Google Cloud Platform location.
project_location = f"projects/{project_id}/locations/us-central1"
# Leave model unset to use the default base model provided by Google
metadata = automl.TextSentimentModelMetadata()
model = automl.Model(
display_name=display_name,
dataset_id=dataset_id,
text_sentiment_model_metadata=metadata,
)
# Create a model with the model metadata in the region.
response = client.create_model(parent=project_location, model=model)
print("Training operation name: {}".format(response.operation.name))
print("Training started...")
# [END automl_language_sentiment_analysis_create_model]
return response
| [
"71398022+dandhlee@users.noreply.github.com"
] | 71398022+dandhlee@users.noreply.github.com |
15abe88a6ca070e5627b56fbc2a2561be4740ffb | 1bfb4df83565da98e0b7a2d25915370732b94b6a | /atcoder/abc188/e.py | 99f51f748eedd29f80e5a5a8462729e68334a149 | [
"MIT"
] | permissive | sugitanishi/competitive-programming | e8067090fc5a2a519ef091496d78d3154be98a2b | 51af65fdce514ece12f8afbf142b809d63eefb5d | refs/heads/main | 2023-08-11T02:48:38.404901 | 2021-10-14T14:57:21 | 2021-10-14T14:57:21 | 324,516,654 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 516 | py | import sys
sys.setrecursionlimit(10000000)
input=lambda : sys.stdin.readline().rstrip()
n,m=map(int,input().split())
a=list(map(int,input().split()))
dic=[ [[],-999999999999] for i in range(n)]
for i in range(m):
x,y=map(int,input().split())
x-=1
y-=1
dic[x][0].append(y)
ans = -999999999999
for i in range(n):
i = n-i-1
for v in dic[i][0]:
dic[i][1]=max(dic[i][1],dic[v][1])
if len(dic[i][0]):
ans=max(ans,dic[i][1]-a[i])
dic[i][1]=max(dic[i][1],a[i])
print(ans)
| [
"keita.abi.114@gmail.com"
] | keita.abi.114@gmail.com |
30b3686a98f972e2165cd478547a8747479f63d1 | 8100f7895b257d15f19ca41f3ace9849647e49f8 | /kademlia/tests/test_routing.py | ecaf1ae63b4f57035578d0f86aa3bba57fb66c94 | [
"MIT"
] | permissive | bmcorser/kademlia | 90cac70a2853a759cf55d0651fbb125c50a5f5f5 | c6f1062082d7e3cb8b5af53bcc672b138848b337 | refs/heads/master | 2021-01-17T04:51:37.439919 | 2014-12-26T19:57:43 | 2014-12-26T19:57:43 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,856 | py | from twisted.trial import unittest
from kademlia.routing import KBucket, RoutingTable
from kademlia.protocol import KademliaProtocol
from kademlia.tests.utils import mknode, FakeProtocol
class KBucketTest(unittest.TestCase):
def test_split(self):
bucket = KBucket(0, 10, 5)
bucket.addNode(mknode(intid=5))
bucket.addNode(mknode(intid=6))
one, two = bucket.split()
self.assertEqual(len(one), 1)
self.assertEqual(one.range, (0, 5))
self.assertEqual(len(two), 1)
self.assertEqual(two.range, (6, 10))
def test_addNode(self):
# when full, return false
bucket = KBucket(0, 10, 2)
self.assertTrue(bucket.addNode(mknode()))
self.assertTrue(bucket.addNode(mknode()))
self.assertFalse(bucket.addNode(mknode()))
self.assertEqual(len(bucket), 2)
# make sure when a node is double added it's put at the end
bucket = KBucket(0, 10, 3)
nodes = [mknode(), mknode(), mknode()]
for node in nodes:
bucket.addNode(node)
for index, node in enumerate(bucket.getNodes()):
self.assertEqual(node, nodes[index])
def test_inRange(self):
bucket = KBucket(0, 10, 10)
self.assertTrue(bucket.hasInRange(mknode(intid=5)))
self.assertFalse(bucket.hasInRange(mknode(intid=11)))
self.assertTrue(bucket.hasInRange(mknode(intid=10)))
self.assertTrue(bucket.hasInRange(mknode(intid=0)))
class RoutingTableTest(unittest.TestCase):
def setUp(self):
self.id = mknode().id
self.protocol = FakeProtocol(self.id)
self.router = self.protocol.router
def test_addContact(self):
self.router.addContact(mknode())
self.assertTrue(len(self.router.buckets), 1)
self.assertTrue(len(self.router.buckets[0].nodes), 1)
| [
"bamuller@gmail.com"
] | bamuller@gmail.com |
3925169a07bd92641cd6ea6064b96ecd6c232bde | d93c91e904470b46e04a4eadb8c459f9c245bb5a | /banglore_scrape/acresrent/acresrent/items.py | a1fc474292c3702617c42d5875f953929b5aaf90 | [] | no_license | nbourses/scrappers | 3de3cd8a5408349b0ac683846b9b7276156fb08a | cde168a914f83cd491dffe85ea24aa48f5840a08 | refs/heads/master | 2021-03-30T15:38:29.096213 | 2020-03-25T03:23:56 | 2020-03-25T03:23:56 | 63,677,541 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 1,429 | py | # -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class AcresrentItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
carpet_area = scrapy.Field()
updated_date = scrapy.Field()
management_by_landlord = scrapy.Field()
areacode = scrapy.Field()
mobile_lister = scrapy.Field()
google_place_id = scrapy.Field()
Launch_date = scrapy.Field()
Possession = scrapy.Field()
age = scrapy.Field()
address = scrapy.Field()
price_on_req = scrapy.Field()
sublocality = scrapy.Field()
config_type = scrapy.Field()
platform = scrapy.Field()
city = scrapy.Field()
listing_date = scrapy.Field()
txn_type = scrapy.Field()
property_type = scrapy.Field()
Building_name = scrapy.Field()
lat = scrapy.Field()
longt = scrapy.Field()
locality = scrapy.Field()
price_per_sqft = scrapy.Field()
Bua_sqft = scrapy.Field()
Status = scrapy.Field()
listing_by=scrapy.Field()
name_lister=scrapy.Field()
Selling_price = scrapy.Field()
Monthly_Rent = scrapy.Field()
Details = scrapy.Field()
data_id=scrapy.Field()
quality1 = scrapy.Field()
quality2 = scrapy.Field()
quality3 = scrapy.Field()
quality4 = scrapy.Field()
scraped_time = scrapy.Field()
pass
| [
"karanchudasama1@gmail.com"
] | karanchudasama1@gmail.com |
3a1be8b5f004ecaa5b1073b7bea1ccae15e324b7 | 40c4b8e9ac9074869bfb0dc1d3c3f566371f1764 | /Hangman1/rectangle3.py | 7082113cadbd1e910a7297d1e81a0b0631f390f4 | [] | no_license | katuhito/Hangman001 | 870a8827e69cbd9a8b01ffb55f5c499c71861b76 | 710a201c6ad8284e164ea8ad26cd061486c50849 | refs/heads/master | 2022-12-06T16:30:24.613288 | 2020-08-22T10:19:27 | 2020-08-22T10:19:27 | 285,448,433 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 241 | py | class Rectangle:
def __init__(self, w, l):
self.width = w
self.len = l
def print_size(self):
print("{} by {}".format(self.width, self.len))
my_rectangle = Rectangle(10, 24)
my_rectangle.print_size()
| [
"katuhitohara@gmail.com"
] | katuhitohara@gmail.com |
a2b1d622e04da9f379ad7dec5d7160a7df4cb382 | 15f321878face2af9317363c5f6de1e5ddd9b749 | /solutions_python/Problem_200/5220.py | 3953bab56b760965dae521faab27b88c6280402e | [] | no_license | dr-dos-ok/Code_Jam_Webscraper | c06fd59870842664cd79c41eb460a09553e1c80a | 26a35bf114a3aa30fc4c677ef069d95f41665cc0 | refs/heads/master | 2020-04-06T08:17:40.938460 | 2018-10-14T10:12:47 | 2018-10-14T10:12:47 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 287 | py | f = open("test.txt")
o = open("final.txt", 'w')
t = int(f.readline())
for i in range(t):
n = int(f.readline())
while n>0:
if int(''.join(sorted(list(str(n))))) == n:
o.write("Case #{}: {}\n".format(i+1,n))
break
else:
n -= 1
| [
"miliar1732@gmail.com"
] | miliar1732@gmail.com |
bbf1b8bfc58b8fa0bb3231f35c168ee5235006e9 | 0fea8a6421fe5f5967f2202910022c2bfd277b4d | /190.生成字典.py | 51461ae593ab4ecd836413dd315ba3b0b9c3f9a8 | [] | no_license | maohaoyang369/Python_exercise | 4dc10ec061aa0de2bcfe59c86be115e135fb3fab | 8fbee8854db76d09e2b1f9365ff55198ddabd595 | refs/heads/master | 2020-04-09T23:04:02.327118 | 2019-09-05T14:49:07 | 2019-09-05T14:49:07 | 160,646,057 | 0 | 2 | null | 2019-03-21T14:44:13 | 2018-12-06T08:50:19 | Python | UTF-8 | Python | false | false | 498 | py | # !/usr/bin/env python
# -*- coding: utf-8 -*-
# 生成字典{“a”:1,”c”:3,”e”:5,”g”:7,”i”:9}
import string
letters = string.ascii_letters[0:9]
result = {}
for i in range(0, len(letters), 2):
result[letters[i]] = i+1
print(result)
# 将以上字典的key和value拼接成字符串,不能使用字符串连接符(+)
sentence = {'a': 1, 'c': 3, 'e': 5, 'g': 7, 'i': 9}
result = ""
for m, n in sentence.items():
result += m
result += str(n)
print(result)
| [
"372713573@qq.com"
] | 372713573@qq.com |
9848f1253781378294034070b41e90cb3b18980e | 524b2ef7ace38954af92a8ed33e27696f4f69ece | /montecarlo4fms/utils/mctsstats_its.py | 9a7cf4b70cb928340f7e17db07c8bbccd33a7734 | [] | no_license | jmhorcas/montecarlo_analysis | ebf9357b0ede63aa9bcdadb6a5a30a50ad7460eb | 2319838afb0f738125afc081fc4b58a0d8e2faee | refs/heads/main | 2023-06-24T19:05:36.485241 | 2021-07-20T08:24:06 | 2021-07-20T08:24:06 | 363,059,338 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,978 | py | from montecarlo4fms.models import State
class MCTSStatsIts():
"""Iterations stats"""
ROUND_DECIMALS = 2
METHOD_STR = 'Method'
ITERATIONS_STR = 'Iterations'
STEPS_STR = 'Decisions'
SIMULATIONS_STR = 'Simulations'
EVALUATIONS_STR = 'Evaluations'
POSITIVE_EVALUATIONS_STR = 'PositiveEvaluations'
PERCENTAGE_POSITIVE_EVALUATIONS_STR = 'Percentage'
TREESIZE_STR = 'TreeSize'
TIME_STR = 'Time'
HEADER = [METHOD_STR, ITERATIONS_STR, STEPS_STR, SIMULATIONS_STR, EVALUATIONS_STR, POSITIVE_EVALUATIONS_STR, PERCENTAGE_POSITIVE_EVALUATIONS_STR, TREESIZE_STR, TIME_STR]
def __init__(self):
self.stats = {}
def add_step(self, method: str, steps: int, mcts_tree_search: dict, simulations: int, evaluations: int, positive_evaluations: int, time: float):
self.stats[simulations] = {}
self.stats[simulations][MCTSStatsIts.METHOD_STR] = f'"{method}"'
self.stats[simulations][MCTSStatsIts.STEPS_STR] = steps
self.stats[simulations][MCTSStatsIts.ITERATIONS_STR] = simulations
self.stats[simulations][MCTSStatsIts.SIMULATIONS_STR] = simulations
self.stats[simulations][MCTSStatsIts.EVALUATIONS_STR] = evaluations
self.stats[simulations][MCTSStatsIts.POSITIVE_EVALUATIONS_STR] = positive_evaluations
self.stats[simulations][MCTSStatsIts.PERCENTAGE_POSITIVE_EVALUATIONS_STR] = float(positive_evaluations) / float(evaluations)
self.stats[simulations][MCTSStatsIts.TREESIZE_STR] = 0 if mcts_tree_search is None else len(mcts_tree_search)
self.stats[simulations][MCTSStatsIts.TIME_STR] = time
def serialize(self, filepath: str):
with open(filepath, 'w+') as file:
header = ", ".join(MCTSStatsIts.HEADER)
file.write(f"{header}\n")
for its in sorted(self.stats.keys()):
line = ", ".join(str(self.stats[its][h]) for h in MCTSStatsIts.HEADER)
file.write(f"{line}\n")
| [
"jhorcas@us.es"
] | jhorcas@us.es |
7e2aca3f77a73d466a4da4a18a7e0bc5683a0fe4 | 3c30d27bf5856dcdbc689dd01ed12ae007fc5b07 | /dorandoran/config/settings/__init__.py | 02f06ea5d084ca462743c9fabf93e6fe6b7766ef | [] | no_license | Doran-Doran-development/DoranDoran-Server-2 | 047ff79a6cc472364b2bf6507d89617832e1571c | 6340af1b887e08270bee0e13029ee41df7dfeb1e | refs/heads/master | 2023-06-06T14:44:27.891110 | 2021-05-19T15:05:14 | 2021-05-19T15:05:14 | 346,971,795 | 11 | 0 | null | 2021-06-11T01:00:18 | 2021-03-12T06:58:34 | Python | UTF-8 | Python | false | false | 160 | py | import os
SETTINGS_MODULE = os.environ.get("DJANGO_SETTINGS_MODULE")
if not SETTINGS_MODULE or SETTINGS_MODULE == "config.settings":
from .local import *
| [
"hanbin8269@gmail.com"
] | hanbin8269@gmail.com |
3dbbc772a56fbcb69c3df9317f21fe380939b860 | facb8b9155a569b09ba66aefc22564a5bf9cd319 | /wp2/merra_scripts/02_preprocessing/merraLagScripts/392-tideGauge.py | bf4ff8cf2ba0191d209994b7caa2338c79b66107 | [] | no_license | moinabyssinia/modeling-global-storm-surges | 13e69faa8f45a1244a964c5de4e2a5a6c95b2128 | 6e385b2a5f0867df8ceabd155e17ba876779c1bd | refs/heads/master | 2023-06-09T00:40:39.319465 | 2021-06-25T21:00:44 | 2021-06-25T21:00:44 | 229,080,191 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,772 | py | # -*- coding: utf-8 -*-
"""
Created on Tue Mar 31 17:12:23 2020
****************************************************
Load predictors & predictands + predictor importance
****************************************************
@author: Michael Tadesse
"""
#import packages
import os
import pandas as pd
import datetime as dt #used for timedelta
from datetime import datetime
#define directories
# dir_name = 'F:\\01_erainterim\\03_eraint_lagged_predictors\\eraint_D3'
dir_in = "/lustre/fs0/home/mtadesse/merraAllCombined"
dir_out = "/lustre/fs0/home/mtadesse/merraAllLagged"
def lag():
os.chdir(dir_in)
#get names
tg_list_name = sorted(os.listdir())
x = 392
y = 393
for tg in range(x, y):
os.chdir(dir_in)
tg_name = tg_list_name[tg]
print(tg_name, '\n')
pred = pd.read_csv(tg_name)
#create a daily time series - date_range
#get only the ymd of the start and end times
start_time = pred['date'][0].split(' ')[0]
end_time = pred['date'].iloc[-1].split(' ')[0]
print(start_time, ' - ', end_time, '\n')
date_range = pd.date_range(start_time, end_time, freq = 'D')
#defining time changing lambda functions
time_str = lambda x: str(x)
time_converted_str = pd.DataFrame(map(time_str, date_range), columns = ['date'])
time_converted_stamp = pd.DataFrame(date_range, columns = ['timestamp'])
"""
first prepare the six time lagging dataframes
then use the merge function to merge the original
predictor with the lagging dataframes
"""
#prepare lagged time series for time only
#note here that since MERRA has 3hrly data
#the lag_hrs is increased from 6(eraint) to 31(MERRA)
time_lagged = pd.DataFrame()
lag_hrs = list(range(0, 31))
for lag in lag_hrs:
lag_name = 'lag'+str(lag)
lam_delta = lambda x: str(x - dt.timedelta(hours = lag))
lag_new = pd.DataFrame(map(lam_delta, time_converted_stamp['timestamp']), \
columns = [lag_name])
time_lagged = pd.concat([time_lagged, lag_new], axis = 1)
#datafrmae that contains all lagged time series (just time)
time_all = pd.concat([time_converted_str, time_lagged], axis = 1)
pred_lagged = pd.DataFrame()
for ii in range(1,time_all.shape[1]): #to loop through the lagged time series
print(time_all.columns[ii])
#extracting corresponding tag time series
lag_ts = pd.DataFrame(time_all.iloc[:,ii])
lag_ts.columns = ['date']
#merge the selected tlagged time with the predictor on = "date"
pred_new = pd.merge(pred, lag_ts, on = ['date'], how = 'right')
pred_new.drop('Unnamed: 0', axis = 1, inplace = True)
#sometimes nan values go to the bottom of the dataframe
#sort df by date -> reset the index -> remove old index
pred_new.sort_values(by = 'date', inplace=True)
pred_new.reset_index(inplace=True)
pred_new.drop('index', axis = 1, inplace= True)
#concatenate lagged dataframe
if ii == 1:
pred_lagged = pred_new
else:
pred_lagged = pd.concat([pred_lagged, pred_new.iloc[:,1:]], axis = 1)
#cd to saving directory
os.chdir(dir_out)
pred_lagged.to_csv(tg_name)
os.chdir(dir_in)
#run script
lag()
| [
"michaelg.tadesse@gmail.com"
] | michaelg.tadesse@gmail.com |
415734380444d4ca699f0a861cd5aedd158602cc | 50008b3b7fb7e14f793e92f5b27bf302112a3cb4 | /recipes/Python/577484_PRNG_Test/recipe-577484.py | 5f08e97722809089c21f45f274f0c10b6d28c1c0 | [
"MIT"
] | permissive | betty29/code-1 | db56807e19ac9cfe711b41d475a322c168cfdca6 | d097ca0ad6a6aee2180d32dce6a3322621f655fd | refs/heads/master | 2023-03-14T08:15:47.492844 | 2021-02-24T15:39:59 | 2021-02-24T15:39:59 | 341,878,663 | 0 | 0 | MIT | 2021-02-24T15:40:00 | 2021-02-24T11:31:15 | Python | UTF-8 | Python | false | false | 1,669 | py | # PRNG (Pseudo-Random Number Generator) Test
# PRNG info:
# http://en.wikipedia.org/wiki/Pseudorandom_number_generator
# FB - 201012046
# Compares output distribution of any given PRNG
# w/ an hypothetical True-Random Number Generator (TRNG)
import math
import time
global x
x = time.clock() # seed for the PRNG
# PRNG to test
def prng():
global x
x = math.fmod((x + math.pi) ** 2.0, 1.0)
return x
# combination by recursive method
def c(n, k):
if k == 0: return 1
if n == 0: return 0
return c(n - 1, k - 1) + c(n - 1, k)
### combination by multiplicative method
##def c_(n, k):
## mul = 1.0
## for i in range(k):
## mul = mul * (n - k + i + 1) / (i + 1)
## return mul
# MAIN
n = 20 # number of bits in each trial
print 'Test in progress...'
print
cnk = [] # array to hold bit counts
for k in range(n + 1):
cnk.append(0)
# generate 2**n n-bit pseudo-random numbers
for j in range(2 ** n):
# generate n-bit pseudo-random number and count the 0's in it
# num = ''
ctr = 0
for i in range(n):
b = int(round(prng())) # generate 1 pseudo-random bit
# num += str(b)
if b == 0: ctr += 1
# print num
# increase bit count in the array
cnk[ctr] += 1
print 'Number of bits in each pseudo-random number (n) =', n
print
print 'Comparison of "0" count distributions:'
print
print ' k', ' c(n,k)', ' actual', '%dif'
difSum = 0
for k in range(n + 1):
cnk_ = c(n, k)
dif = abs(cnk_ - cnk[k])
print '%2d %10d %10d %4d' % (k, cnk_, cnk[k], 100 * dif / cnk_)
difSum += dif
print
print 'Difference percentage between the distributions:'
print 100 * difSum / (2 ** n)
| [
"betty@qburst.com"
] | betty@qburst.com |
5bc210ee26a211924bd98164a908ca4bc641f7d4 | 53581b69990f5bab64ffb674a2a345a88add9313 | /gen.py | 9984c358a5c3c139e51a15c7d1b37316a23f564c | [
"MIT"
] | permissive | Dariusz1989/photoshop-docs | 5fd79d004109970f71e392e94a3dd7de1884c1b4 | 02a26d36acfe158f6ca638c9f36d3e96bf3631f0 | refs/heads/master | 2021-09-22T11:33:52.674810 | 2018-09-09T23:18:12 | 2018-09-09T23:18:12 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 9,897 | py | #!/usr/bin/python
# -*- coding: utf8 -*-
from __future__ import unicode_literals
import os
import re
from operator import itemgetter
from xml.etree import cElementTree as ET
import pathlib2
import jinja2
import tabulate
SOURCE = pathlib2.Path(os.getcwd()) / 'source'
env = jinja2.Environment(
loader=jinja2.FileSystemLoader([
(SOURCE / '_templates').as_posix(),
(SOURCE / 'examples').as_posix(),
])
)
CLASS_TEMPLATE = env.get_template('class.txt')
PROPERTY_TEMPLATE = env.get_template('property.txt')
METHOD_TEMPLATE = env.get_template('method.txt')
INDEX_TEMPLATE = env.get_template('index.txt')
ADDITIONS = {
'Core': {
'class': {
'UnitRect.rst',
'UnitPoint.rst',
'FileArray.rst',
'AliasArray.rst',
}
}
}
EXCLUDE = [
'Photoshop/global',
'Photoshop/Point'
]
def getTable(data):
table = [['**{}**'.format(_['name']), _['short_description']] for _ in data]
return tabulate.tabulate(table, tablefmt='grid')
def getRefTable(data):
data = sorted(data, key=itemgetter('name'))
access = 'readonly'
table = [[':ref:`{0}<{1}>` {2}'.format(_['name'], _['namespace'], _.get('rwaccess', '')), _['short_description']] for _ in data]
return tabulate.tabulate(table, tablefmt='grid')
def getProperties(element, elmtype):
data = []
for child in element.findall("elements[@type='{}']/property".format(elmtype)):
p = dict(child.attrib)
p['classname'] = element.attrib['name']
p['return_type'] = getRefType(child.findall('datatype/type')[0].text)
p['short_description'], p['description'] = getDescriptions(child)
p['namespace'] = '{}.{}'.format(element.attrib['name'], p['name'])
data.append(p)
return data
def getMethods(element, elmtype):
data = []
for child in element.findall("elements[@type='{}']/method".format(elmtype)):
p = dict(child.attrib)
p['classname'] = element.attrib['name']
types = child.findall('datatype/type')
if types:
p['return_type'] = getRefType(types[0].text)
else:
p['return_type'] = 'void'
p['short_description'], p['description'] = getDescriptions(child)
p['namespace'] = '{}.{}'.format(element.attrib['name'], p['name'])
p['parameters'] = getParameters(child)
p['param_table'] = getTable(p['parameters'])
data.append(p)
return data
def getParameters(element):
data = []
for child in element.findall('parameters/parameter'):
p = dict(child.attrib)
p['type'] = getRefType(child.findall('datatype/type')[0].text)
p['short_description'], p['description'] = getDescriptions(child)
data.append(p)
return data
def sanitizeText(text):
text = text.replace('“', '"')
text = text.replace('”', '"')
text = text.replace('’', '\'')
text = text.replace('—', '-')
text = text.replace(' ', ' ')
return text.encode('utf8')
def getRefType(data):
prim = ('int', 'bool', 'any', 'uint', 'undefined', 'null')
if data.lower() in prim:
return data.lower()
return ':ref:`{}`'.format(data)
def getDescriptions(element):
desc = element.find('description')
short = element.find('shortdesc')
description = ''
shortdescription = ''
try:
description = ''.join(desc.itertext()).strip().replace('\t', '').replace('\n', ' ')#.encode('ascii', 'replace')
except AttributeError:
pass
try:
shortdescription = ''.join(short.itertext()).strip().replace('\t', '').replace('\n', ' ')#.encode('ascii', 'replace')
except AttributeError:
pass
return shortdescription, description
def main(root, filename):
xml = ET.parse((SOURCE / filename).as_posix())
classes = []
enumerations = []
if root in ADDITIONS:
classes += ADDITIONS[root].get('class', [])
enumerations += ADDITIONS[root].get('enumeration', [])
for classdef in xml.findall("./package/classdef[@dynamic]"):
data = {
'name': classdef.attrib['name'],
'properties': getProperties(classdef, 'instance'),
'methods': getMethods(classdef, 'instance'),
'static_properties': getProperties(classdef, 'class'),
'static_methods': getMethods(classdef, 'class'),
'event_methods': getMethods(classdef, 'event'),
'constructors': getMethods(classdef, 'constructor'),
}
data['short_description'], data['description'] = getDescriptions(classdef)
if '{}/{}'.format(root, data['name']) in EXCLUDE:
continue
data['properties_table'] = getRefTable(data['properties'])
data['methods_table'] = getRefTable(data['methods'])
data['static_properties_table'] = getRefTable(data['static_properties'])
data['static_methods_table'] = getRefTable(data['static_methods'])
data['event_methods_table'] = getRefTable(data['event_methods'])
data['constructors_table'] = getRefTable(data['constructors'])
for key, value in data.items():
if isinstance(value, list):
for _ in data[key]:
_['module'] = root
content = sanitizeText(CLASS_TEMPLATE.render(**data))
# Write class file
outfile = SOURCE / root / '{}.rst'.format(data['name'])
if not outfile.parent.exists():
outfile.parent.mkdir(parents=True)
print('Writing to {}'.format(outfile))
outfile.write_bytes(content)
classes.append(outfile.name)
# Write out Property/Method files
for property in data['properties'] + data['static_properties']:
content = sanitizeText(PROPERTY_TEMPLATE.render(**property))
# Write class file
outfile = SOURCE / root / data['name'] / '{}.rst'.format(property['name'])
if not outfile.parent.exists():
outfile.parent.mkdir(parents=True)
print('Writing to {}'.format(outfile))
outfile.write_bytes(content)
for method in data['methods'] + data['static_methods'] + data['event_methods'] + data['constructors']:
content = sanitizeText(METHOD_TEMPLATE.render(**method))
# Write class file
outfile = SOURCE / root / data['name'] / '{}.rst'.format(method['name'])
if not outfile.parent.exists():
outfile.parent.mkdir(parents=True)
print('Writing to {}'.format(outfile))
outfile.write_bytes(content)
# (SOURCE / root / 'index.rst').write_text(INDEX_TEMPLATE.render(name=root.capitalize(), classes=classes))
for classdef in xml.findall("./package/classdef[@enumeration='true']"):
data = {
'name': classdef.attrib['name'],
'description': classdef.find('shortdesc').text,
'properties': getProperties(classdef, 'instance'),
'methods': getMethods(classdef, 'instance'),
'static_properties': getProperties(classdef, 'class'),
'static_methods': getMethods(classdef, 'class'),
'event_methods': getMethods(classdef, 'event'),
'constructors': getMethods(classdef, 'constructor'),
}
data['properties_table'] = getRefTable(data['properties'])
data['methods_table'] = getRefTable(data['methods'])
data['static_properties_table'] = getRefTable(data['static_properties'])
data['static_methods_table'] = getRefTable(data['static_methods'])
data['event_methods_table'] = getRefTable(data['event_methods'])
data['constructors_table'] = getRefTable(data['constructors'])
content = sanitizeText(CLASS_TEMPLATE.render(**data))
# Write class file
outfile = SOURCE / root / '{}.rst'.format(data['name'])
if not outfile.parent.exists():
outfile.parent.mkdir(parents=True)
outfile.write_bytes(content)
enumerations.append(outfile.name)
# Write out Property/Method files
for property in data['properties'] + data['static_properties']:
content = sanitizeText(PROPERTY_TEMPLATE.render(**property))
# Write class file
outfile = SOURCE / root / data['name'] / '{}.rst'.format(property['name'])
if not outfile.parent.exists():
outfile.parent.mkdir(parents=True)
outfile.write_bytes(content)
for method in data['methods'] + data['static_methods'] + data['event_methods'] + data['constructors']:
content = sanitizeText(METHOD_TEMPLATE.render(**method))
# Write class file
outfile = SOURCE / root / data['name'] / '{}.rst'.format(method['name'])
if not outfile.parent.exists():
outfile.parent.mkdir(parents=True)
outfile.write_bytes(content)
(SOURCE / root / 'index.rst').write_text(INDEX_TEMPLATE.render(name=root.capitalize(), classes=sorted(classes), enumerations=sorted(enumerations)))
def genJavaScript(root, filename):
f = SOURCE / filename
content = f.read_bytes()
classes = [
f.stem,
'=' * len(f.stem),
'',
'',
''
]
classtoc = []
for match in re.finditer('@class\s(\w+)', content):
docline = '.. js:autoclass:: {}\n :members:\n\n'.format(match.groups()[0])
classes.append(docline)
classtoc.append(' * :js:class:`{}`'.format(match.groups()[0]))
classes = classes[:3] + classtoc + classes[3:]
rstcontent = '\n'.join(classes)
output = SOURCE / root / '{}.rst'.format(f.stem)
output.write_text(rstcontent)
if __name__ == '__main__':
main('Photoshop', 'omv.xml')
main('Core', 'javascript.xml')
main('ScriptUI', 'scriptui.xml')
#genJavaScript('CEP', 'CSInterface.js')
| [
"theiviaxx@gmail.com"
] | theiviaxx@gmail.com |
c3cb877e4a914b3e92f3fc6e05594d2242f19825 | f30f5024e2e9ce0dc5e550f7125bb7072fe96207 | /2019/r1a/prob2.py | 1baf96bf5ed1273a8b2431b64dcf1965199fdc76 | [] | no_license | RZachLamberty/google_code_jam | fcb14efed46c93cdc655ed932b6e3076bbe5b3ca | 0e1541db004ac47df5b63dd88f3e182a7a35e768 | refs/heads/master | 2021-12-01T02:04:32.506653 | 2021-11-16T20:33:04 | 2021-11-16T20:33:04 | 253,242,456 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,173 | py | import sys
def main():
T, N, M = [int(_) for _ in input().split(' ')]
for i_test_case in range(T):
options = None
lower_bound = 0
answer = '-1'
for n in [17, 16, 13, 11, 7, 5, 3]:
print(' '.join([str(n) for i in range(18)]))
sys.stdout.flush()
x = sum([int(_) for _ in input().split(' ')])
lower_bound = max(lower_bound, x)
mod = x % n
options_now = {i for i in range(lower_bound, M + 1) if i % n == mod}
if options is None:
options = options_now
else:
options.intersection_update(options_now)
# debug
# print("for me: len(options) = {}".format(len(options)))
# if len(options) < 10:
# print('options = {}'.format(options))
if len(options) == 1:
# guess
print(options.pop())
sys.stdout.flush()
answer = input()
break
if answer == '1':
continue
elif answer == '-1':
exit(1)
if __name__ == '__main__':
main()
| [
"r.zach.lamberty@gmail.com"
] | r.zach.lamberty@gmail.com |
bd2fa3b79635cd0faaad4f4d5d91b1a3ef8a1978 | c5385f8c429ec4f3885a2331f12affbbf1673b2f | /research/deeplab/core/feature_extractor.py | e048c3ab2535220f67a97b82bfbcae064c9026c5 | [
"Apache-2.0"
] | permissive | abhineet123/tf_models | 231dffac69c3029b55afd12bb96eceac11fa0b15 | 426b6d37f198e0408d56148a33beb32e7f04dc5c | refs/heads/master | 2022-12-12T03:29:08.355203 | 2018-07-29T22:22:34 | 2018-07-29T22:22:34 | 137,686,565 | 0 | 2 | Apache-2.0 | 2022-11-25T14:57:27 | 2018-06-17T20:57:23 | Python | UTF-8 | Python | false | false | 9,511 | py | # Copyright 2018 The TensorFlow Authors All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Extracts features for different models."""
import functools
import tensorflow as tf
from deeplab.core import xception
from nets.mobilenet import mobilenet as mobilenet_lib
from nets.mobilenet import mobilenet_v2
slim = tf.contrib.slim
# Default end point for MobileNetv2.
_MOBILENET_V2_FINAL_ENDPOINT = 'layer_18'
def _mobilenet_v2(net,
depth_multiplier,
output_stride,
reuse=None,
scope=None,
final_endpoint=None):
"""Auxiliary function to add support for 'reuse' to mobilenet_v2.
Args:
net: Input tensor of shape [batch_size, height, width, channels].
depth_multiplier: Float multiplier for the depth (number of channels)
for all convolution ops. The value must be greater than zero. Typical
usage will be to set this value in (0, 1) to reduce the number of
parameters or computation cost of the model.
output_stride: An integer that specifies the requested ratio of input to
output spatial resolution. If not None, then we invoke atrous convolution
if necessary to prevent the network from reducing the spatial resolution
of the activation maps. Allowed values are 8 (accurate fully convolutional
mode), 16 (fast fully convolutional mode), 32 (classification mode).
reuse: Reuse model variables.
scope: Optional variable scope.
final_endpoint: The endpoint to construct the network up to.
Returns:
Features extracted by MobileNetv2.
"""
with tf.variable_scope(
scope, 'MobilenetV2', [net], reuse=reuse) as scope:
return mobilenet_lib.mobilenet_base(
net,
conv_defs=mobilenet_v2.V2_DEF,
multiplier=depth_multiplier,
final_endpoint=final_endpoint or _MOBILENET_V2_FINAL_ENDPOINT,
output_stride=output_stride,
scope=scope)
# A map from network name to network function.
networks_map = {
'mobilenet_v2': _mobilenet_v2,
'xception_65': xception.xception_65,
}
# A map from network name to network arg scope.
arg_scopes_map = {
'mobilenet_v2': mobilenet_v2.training_scope,
'xception_65': xception.xception_arg_scope,
}
# Names for end point features.
DECODER_END_POINTS = 'decoder_end_points'
# A dictionary from network name to a map of end point features.
networks_to_feature_maps = {
'mobilenet_v2': {
# The provided checkpoint does not include decoder module.
DECODER_END_POINTS: None,
},
'xception_65': {
DECODER_END_POINTS: [
'entry_flow/block2/unit_1/xception_module/'
'separable_conv2_pointwise',
],
}
}
# A map from feature extractor name to the network name scope used in the
# ImageNet pretrained versions of these models.
name_scope = {
'mobilenet_v2': 'MobilenetV2',
'xception_65': 'xception_65',
}
# Mean pixel value.
_MEAN_RGB = [123.15, 115.90, 103.06]
def _preprocess_subtract_imagenet_mean(inputs):
"""Subtract Imagenet mean RGB value."""
mean_rgb = tf.reshape(_MEAN_RGB, [1, 1, 1, 3])
return inputs - mean_rgb
def _preprocess_zero_mean_unit_range(inputs):
"""Map image values from [0, 255] to [-1, 1]."""
return (2.0 / 255.0) * tf.to_float(inputs) - 1.0
_PREPROCESS_FN = {
'mobilenet_v2': _preprocess_zero_mean_unit_range,
'xception_65': _preprocess_zero_mean_unit_range,
}
def mean_pixel(model_variant=None):
"""Gets mean pixel value.
This function returns different mean pixel value, depending on the input
model_variant which adopts different preprocessing functions. We currently
handle the following preprocessing functions:
(1) _preprocess_subtract_imagenet_mean. We simply return mean pixel value.
(2) _preprocess_zero_mean_unit_range. We return [127.5, 127.5, 127.5].
The return values are used in a way that the padded regions after
pre-processing will contain value 0.
Args:
model_variant: Model variant (string) for feature extraction. For
backwards compatibility, model_variant=None returns _MEAN_RGB.
Returns:
Mean pixel value.
"""
if model_variant is None:
return _MEAN_RGB
else:
return [127.5, 127.5, 127.5]
def extract_features(images,
output_stride=8,
multi_grid=None,
depth_multiplier=1.0,
final_endpoint=None,
model_variant=None,
weight_decay=0.0001,
reuse=None,
is_training=False,
fine_tune_batch_norm=False,
regularize_depthwise=False,
preprocess_images=True,
num_classes=None,
global_pool=False):
"""Extracts features by the parituclar model_variant.
Args:
images: A tensor of size [batch, height, width, channels].
output_stride: The ratio of input to output spatial resolution.
multi_grid: Employ a hierarchy of different atrous rates within network.
depth_multiplier: Float multiplier for the depth (number of channels)
for all convolution ops used in MobileNet.
final_endpoint: The MobileNet endpoint to construct the network up to.
model_variant: Model variant for feature extraction.
weight_decay: The weight decay for model variables.
reuse: Reuse the model variables or not.
is_training: Is training or not.
fine_tune_batch_norm: Fine-tune the batch norm parameters or not.
regularize_depthwise: Whether or not apply L2-norm regularization on the
depthwise convolution weights.
preprocess_images: Performs preprocessing on images or not. Defaults to
True. Set to False if preprocessing will be done by other functions. We
supprot two types of preprocessing: (1) Mean pixel substraction and (2)
Pixel values normalization to be [-1, 1].
num_classes: Number of classes for image classification task. Defaults
to None for dense prediction tasks.
global_pool: Global pooling for image classification task. Defaults to
False, since dense prediction tasks do not use this.
Returns:
features: A tensor of size [batch, feature_height, feature_width,
feature_channels], where feature_height/feature_width are determined
by the images height/width and output_stride.
end_points: A dictionary from components of the network to the corresponding
activation.
Raises:
ValueError: Unrecognized model variant.
"""
if 'xception' in model_variant:
arg_scope = arg_scopes_map[model_variant](
weight_decay=weight_decay,
batch_norm_decay=0.9997,
batch_norm_epsilon=1e-3,
batch_norm_scale=True,
regularize_depthwise=regularize_depthwise)
features, end_points = get_network(
model_variant, preprocess_images, arg_scope)(
inputs=images,
num_classes=num_classes,
is_training=(is_training and fine_tune_batch_norm),
global_pool=global_pool,
output_stride=output_stride,
regularize_depthwise=regularize_depthwise,
multi_grid=multi_grid,
reuse=reuse,
scope=name_scope[model_variant])
elif 'mobilenet' in model_variant:
arg_scope = arg_scopes_map[model_variant](
is_training=(is_training and fine_tune_batch_norm),
weight_decay=weight_decay)
features, end_points = get_network(
model_variant, preprocess_images, arg_scope)(
inputs=images,
depth_multiplier=depth_multiplier,
output_stride=output_stride,
reuse=reuse,
scope=name_scope[model_variant],
final_endpoint=final_endpoint)
else:
raise ValueError('Unknown model variant %s.' % model_variant)
return features, end_points
def get_network(network_name, preprocess_images, arg_scope=None):
"""Gets the network.
Args:
network_name: Network name.
preprocess_images: Preprocesses the images or not.
arg_scope: Optional, arg_scope to build the network. If not provided the
default arg_scope of the network would be used.
Returns:
A network function that is used to extract features.
Raises:
ValueError: network is not supported.
"""
if network_name not in networks_map:
raise ValueError('Unsupported network %s.' % network_name)
arg_scope = arg_scope or arg_scopes_map[network_name]()
def _identity_function(inputs):
return inputs
if preprocess_images:
preprocess_function = _PREPROCESS_FN[network_name]
else:
preprocess_function = _identity_function
func = networks_map[network_name]
@functools.wraps(func)
def network_fn(inputs, *args, **kwargs):
with slim.arg_scope(arg_scope):
return func(preprocess_function(inputs), *args, **kwargs)
return network_fn
| [
"asingh1@ualberta.ca"
] | asingh1@ualberta.ca |
e3bc4f76cf3ffb6a5b4786f53d8ebd7ebc637a52 | e6328c5076fe0f1b6819c3eacca08e1c4791199b | /062. Unique Paths/62. Unique Paths.py | 959174bdcbc2488be43001c17cf9725c173b9ad9 | [] | no_license | 603lzy/LeetCode | 16e818d94282b34ac153271697b512c79fc95ef5 | 9752533bc76ce5ecb881f61e33a3bc4b20dcf666 | refs/heads/master | 2020-06-14T03:07:03.148542 | 2018-10-22T14:10:33 | 2018-10-22T14:10:33 | 75,514,162 | 3 | 0 | null | null | null | null | UTF-8 | Python | false | false | 781 | py | class Solution(object):
def uniquePaths(self, m, n):
"""
:type m: int
:type n: int
:rtype: int
https://discuss.leetcode.com/topic/67900/dp-solution-in-python
# basic dynamic programming
"""
if m > 1 and n > 1:
grid = [[0 for col in xrange(n)] for row in xrange(m)]
for row in xrange(1, m):
grid[row][0] = 1
for col in xrange(1, n):
grid[0][col] = 1
for row in xrange(1, m):
for col in xrange(1, n):
grid[row][col] = grid[row][col - 1] + grid[row - 1][col]
return grid[m - 1][n - 1]
elif not m or not n:
return 0
else: # m = 1 or n = 1
return 1
| [
"noreply@github.com"
] | 603lzy.noreply@github.com |
6fd670ab5d1d479388517eba0c9275c274d3df7a | 9743d5fd24822f79c156ad112229e25adb9ed6f6 | /xai/brain/wordbase/otherforms/_implemented.py | c8115b06a1c54a5a564f83c1619336ef47f28f30 | [
"MIT"
] | permissive | cash2one/xai | de7adad1758f50dd6786bf0111e71a903f039b64 | e76f12c9f4dcf3ac1c7c08b0cc8844c0b0a104b6 | refs/heads/master | 2021-01-19T12:33:54.964379 | 2017-01-28T02:00:50 | 2017-01-28T02:00:50 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 236 | py |
#calss header
class _IMPLEMENTED():
def __init__(self,):
self.name = "IMPLEMENTED"
self.definitions = implement
self.parents = []
self.childen = []
self.properties = []
self.jsondata = {}
self.basic = ['implement']
| [
"xingwang1991@gmail.com"
] | xingwang1991@gmail.com |
4606de08215d1e56e7f12b7187c4aec33337463e | 35f9def6e6d327d3a4a4f2959024eab96f199f09 | /developer/lab/ipython/tools/strassen_matrix_multiplication.py | 67c5a531feb4fea827e9edaf8764fa85bfef969d | [
"CAL-1.0-Combined-Work-Exception",
"CAL-1.0",
"MIT",
"CC-BY-SA-4.0",
"LicenseRef-scancode-free-unknown"
] | permissive | arXiv-research/DevLab-III-1 | ec10aef27e1ca75f206fea11014da8784752e454 | c50cd2b9154c83c3db5e4a11b9e8874f7fb8afa2 | refs/heads/main | 2023-04-16T19:24:58.758519 | 2021-04-28T20:21:23 | 2021-04-28T20:21:23 | 362,599,929 | 2 | 0 | MIT | 2021-04-28T20:36:11 | 2021-04-28T20:36:11 | null | UTF-8 | Python | false | false | 6,011 | py | from __future__ import annotations
import math
def default_matrix_multiplication(a: list, b: list) -> list:
"""
Multiplication only for 2x2 matrices
"""
if len(a) != 2 or len(a[0]) != 2 or len(b) != 2 or len(b[0]) != 2:
raise Exception("Matrices are not 2x2")
new_matrix = [
[a[0][0] * b[0][0] + a[0][1] * b[1][0], a[0][0] * b[0][1] + a[0][1] * b[1][1]],
[a[1][0] * b[0][0] + a[1][1] * b[1][0], a[1][0] * b[0][1] + a[1][1] * b[1][1]],
]
return new_matrix
def matrix_addition(matrix_a: list, matrix_b: list):
return [
[matrix_a[row][col] + matrix_b[row][col] for col in range(len(matrix_a[row]))]
for row in range(len(matrix_a))
]
def matrix_subtraction(matrix_a: list, matrix_b: list):
return [
[matrix_a[row][col] - matrix_b[row][col] for col in range(len(matrix_a[row]))]
for row in range(len(matrix_a))
]
def split_matrix(a: list) -> tuple[list, list, list, list]:
"""
Given an even length matrix, returns the top_left, top_right, bot_left, bot_right
quadrant.
>>> split_matrix([[4,3,2,4],[2,3,1,1],[6,5,4,3],[8,4,1,6]])
([[4, 3], [2, 3]], [[2, 4], [1, 1]], [[6, 5], [8, 4]], [[4, 3], [1, 6]])
>>> split_matrix([
... [4,3,2,4,4,3,2,4],[2,3,1,1,2,3,1,1],[6,5,4,3,6,5,4,3],[8,4,1,6,8,4,1,6],
... [4,3,2,4,4,3,2,4],[2,3,1,1,2,3,1,1],[6,5,4,3,6,5,4,3],[8,4,1,6,8,4,1,6]
... ]) # doctest: +NORMALIZE_WHITESPACE
([[4, 3, 2, 4], [2, 3, 1, 1], [6, 5, 4, 3], [8, 4, 1, 6]], [[4, 3, 2, 4],
[2, 3, 1, 1], [6, 5, 4, 3], [8, 4, 1, 6]], [[4, 3, 2, 4], [2, 3, 1, 1],
[6, 5, 4, 3], [8, 4, 1, 6]], [[4, 3, 2, 4], [2, 3, 1, 1], [6, 5, 4, 3],
[8, 4, 1, 6]])
"""
if len(a) % 2 != 0 or len(a[0]) % 2 != 0:
raise Exception("Odd matrices are not supported!")
matrix_length = len(a)
mid = matrix_length // 2
top_right = [[a[i][j] for j in range(mid, matrix_length)] for i in range(mid)]
bot_right = [
[a[i][j] for j in range(mid, matrix_length)] for i in range(mid, matrix_length)
]
top_left = [[a[i][j] for j in range(mid)] for i in range(mid)]
bot_left = [[a[i][j] for j in range(mid)] for i in range(mid, matrix_length)]
return top_left, top_right, bot_left, bot_right
def matrix_dimensions(matrix: list) -> tuple[int, int]:
return len(matrix), len(matrix[0])
def print_matrix(matrix: list) -> None:
for i in range(len(matrix)):
print(matrix[i])
def actual_strassen(matrix_a: list, matrix_b: list) -> list:
"""
Recursive function to calculate the product of two matrices, using the Strassen
Algorithm. It only supports even length matrices.
"""
if matrix_dimensions(matrix_a) == (2, 2):
return default_matrix_multiplication(matrix_a, matrix_b)
a, b, c, d = split_matrix(matrix_a)
e, f, g, h = split_matrix(matrix_b)
t1 = actual_strassen(a, matrix_subtraction(f, h))
t2 = actual_strassen(matrix_addition(a, b), h)
t3 = actual_strassen(matrix_addition(c, d), e)
t4 = actual_strassen(d, matrix_subtraction(g, e))
t5 = actual_strassen(matrix_addition(a, d), matrix_addition(e, h))
t6 = actual_strassen(matrix_subtraction(b, d), matrix_addition(g, h))
t7 = actual_strassen(matrix_subtraction(a, c), matrix_addition(e, f))
top_left = matrix_addition(matrix_subtraction(matrix_addition(t5, t4), t2), t6)
top_right = matrix_addition(t1, t2)
bot_left = matrix_addition(t3, t4)
bot_right = matrix_subtraction(matrix_subtraction(matrix_addition(t1, t5), t3), t7)
# construct the new matrix from our 4 quadrants
new_matrix = []
for i in range(len(top_right)):
new_matrix.append(top_left[i] + top_right[i])
for i in range(len(bot_right)):
new_matrix.append(bot_left[i] + bot_right[i])
return new_matrix
def strassen(matrix1: list, matrix2: list) -> list:
"""
>>> strassen([[2,1,3],[3,4,6],[1,4,2],[7,6,7]], [[4,2,3,4],[2,1,1,1],[8,6,4,2]])
[[34, 23, 19, 15], [68, 46, 37, 28], [28, 18, 15, 12], [96, 62, 55, 48]]
>>> strassen([[3,7,5,6,9],[1,5,3,7,8],[1,4,4,5,7]], [[2,4],[5,2],[1,7],[5,5],[7,8]])
[[139, 163], [121, 134], [100, 121]]
"""
if matrix_dimensions(matrix1)[1] != matrix_dimensions(matrix2)[0]:
raise Exception(
f"Unable to multiply these matrices, please check the dimensions. \n"
f"Matrix A:{matrix1} \nMatrix B:{matrix2}"
)
dimension1 = matrix_dimensions(matrix1)
dimension2 = matrix_dimensions(matrix2)
if dimension1[0] == dimension1[1] and dimension2[0] == dimension2[1]:
return [matrix1, matrix2]
maximum = max(max(dimension1), max(dimension2))
maxim = int(math.pow(2, math.ceil(math.log2(maximum))))
new_matrix1 = matrix1
new_matrix2 = matrix2
# Adding zeros to the matrices so that the arrays dimensions are the same and also
# power of 2
for i in range(0, maxim):
if i < dimension1[0]:
for j in range(dimension1[1], maxim):
new_matrix1[i].append(0)
else:
new_matrix1.append([0] * maxim)
if i < dimension2[0]:
for j in range(dimension2[1], maxim):
new_matrix2[i].append(0)
else:
new_matrix2.append([0] * maxim)
final_matrix = actual_strassen(new_matrix1, new_matrix2)
# Removing the additional zeros
for i in range(0, maxim):
if i < dimension1[0]:
for j in range(dimension2[1], maxim):
final_matrix[i].pop()
else:
final_matrix.pop()
return final_matrix
if __name__ == "__main__":
matrix1 = [
[2, 3, 4, 5],
[6, 4, 3, 1],
[2, 3, 6, 7],
[3, 1, 2, 4],
[2, 3, 4, 5],
[6, 4, 3, 1],
[2, 3, 6, 7],
[3, 1, 2, 4],
[2, 3, 4, 5],
[6, 2, 3, 1],
]
matrix2 = [[0, 2, 1, 1], [16, 2, 3, 3], [2, 2, 7, 7], [13, 11, 22, 4]]
print(strassen(matrix1, matrix2))
| [
"noreply@github.com"
] | arXiv-research.noreply@github.com |
3da2e978d6f8ed81073a06f3334968ced80d3fa2 | 2b42b40ae2e84b438146003bf231532973f1081d | /spec/mgm4456102.3.spec | 6f5e791cee9d238f143493b4e8bed6423c90e578 | [] | no_license | MG-RAST/mtf | 0ea0ebd0c0eb18ec6711e30de7cc336bdae7215a | e2ddb3b145068f22808ef43e2bbbbaeec7abccff | refs/heads/master | 2020-05-20T15:32:04.334532 | 2012-03-05T09:51:49 | 2012-03-05T09:51:49 | 3,625,755 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 13,947 | spec | {
"id": "mgm4456102.3",
"metadata": {
"mgm4456102.3.metadata.json": {
"format": "json",
"provider": "metagenomics.anl.gov"
}
},
"providers": {
"metagenomics.anl.gov": {
"files": {
"100.preprocess.info": {
"compression": null,
"description": null,
"size": 736,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/100.preprocess.info"
},
"100.preprocess.passed.fna.gz": {
"compression": "gzip",
"description": null,
"size": 13532,
"type": "fasta",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/100.preprocess.passed.fna.gz"
},
"100.preprocess.passed.fna.stats": {
"compression": null,
"description": null,
"size": 307,
"type": "fasta",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/100.preprocess.passed.fna.stats"
},
"100.preprocess.removed.fna.gz": {
"compression": "gzip",
"description": null,
"size": 485,
"type": "fasta",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/100.preprocess.removed.fna.gz"
},
"100.preprocess.removed.fna.stats": {
"compression": null,
"description": null,
"size": 304,
"type": "fasta",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/100.preprocess.removed.fna.stats"
},
"205.screen.h_sapiens_asm.info": {
"compression": null,
"description": null,
"size": 446,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/205.screen.h_sapiens_asm.info"
},
"299.screen.info": {
"compression": null,
"description": null,
"size": 410,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/299.screen.info"
},
"299.screen.passed.fna.gcs": {
"compression": null,
"description": null,
"size": 733,
"type": "fasta",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/299.screen.passed.fna.gcs"
},
"299.screen.passed.fna.gz": {
"compression": "gzip",
"description": null,
"size": 13000,
"type": "fasta",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/299.screen.passed.fna.gz"
},
"299.screen.passed.fna.lens": {
"compression": null,
"description": null,
"size": 277,
"type": "fasta",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/299.screen.passed.fna.lens"
},
"299.screen.passed.fna.stats": {
"compression": null,
"description": null,
"size": 307,
"type": "fasta",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/299.screen.passed.fna.stats"
},
"440.cluster.rna97.fna.gz": {
"compression": "gzip",
"description": null,
"size": 4277,
"type": "fasta",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/440.cluster.rna97.fna.gz"
},
"440.cluster.rna97.fna.stats": {
"compression": null,
"description": null,
"size": 305,
"type": "fasta",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/440.cluster.rna97.fna.stats"
},
"440.cluster.rna97.info": {
"compression": null,
"description": null,
"size": 947,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/440.cluster.rna97.info"
},
"440.cluster.rna97.mapping": {
"compression": null,
"description": null,
"size": 17295,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/440.cluster.rna97.mapping"
},
"440.cluster.rna97.mapping.stats": {
"compression": null,
"description": null,
"size": 46,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/440.cluster.rna97.mapping.stats"
},
"450.rna.expand.rna.gz": {
"compression": "gzip",
"description": null,
"size": 777,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/450.rna.expand.rna.gz"
},
"450.rna.sims.filter.gz": {
"compression": "gzip",
"description": null,
"size": 3835,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/450.rna.sims.filter.gz"
},
"450.rna.sims.gz": {
"compression": "gzip",
"description": null,
"size": 101684,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/450.rna.sims.gz"
},
"900.abundance.function.gz": {
"compression": "gzip",
"description": null,
"size": 496,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/900.abundance.function.gz"
},
"900.abundance.lca.gz": {
"compression": "gzip",
"description": null,
"size": 38,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/900.abundance.lca.gz"
},
"900.abundance.md5.gz": {
"compression": "gzip",
"description": null,
"size": 457,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/900.abundance.md5.gz"
},
"900.abundance.ontology.gz": {
"compression": "gzip",
"description": null,
"size": 43,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/900.abundance.ontology.gz"
},
"900.abundance.organism.gz": {
"compression": "gzip",
"description": null,
"size": 716,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/900.abundance.organism.gz"
},
"900.loadDB.sims.filter.seq": {
"compression": null,
"description": null,
"size": 222097,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/900.loadDB.sims.filter.seq"
},
"900.loadDB.source.stats": {
"compression": null,
"description": null,
"size": 79,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/900.loadDB.source.stats"
},
"999.done.COG.stats": {
"compression": null,
"description": null,
"size": 1,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.COG.stats"
},
"999.done.KO.stats": {
"compression": null,
"description": null,
"size": 1,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.KO.stats"
},
"999.done.NOG.stats": {
"compression": null,
"description": null,
"size": 1,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.NOG.stats"
},
"999.done.Subsystems.stats": {
"compression": null,
"description": null,
"size": 1,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.Subsystems.stats"
},
"999.done.class.stats": {
"compression": null,
"description": null,
"size": 79,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.class.stats"
},
"999.done.domain.stats": {
"compression": null,
"description": null,
"size": 12,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.domain.stats"
},
"999.done.family.stats": {
"compression": null,
"description": null,
"size": 103,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.family.stats"
},
"999.done.genus.stats": {
"compression": null,
"description": null,
"size": 103,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.genus.stats"
},
"999.done.order.stats": {
"compression": null,
"description": null,
"size": 104,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.order.stats"
},
"999.done.phylum.stats": {
"compression": null,
"description": null,
"size": 48,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.phylum.stats"
},
"999.done.rarefaction.stats": {
"compression": null,
"description": null,
"size": 14492,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.rarefaction.stats"
},
"999.done.sims.stats": {
"compression": null,
"description": null,
"size": 78,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.sims.stats"
},
"999.done.species.stats": {
"compression": null,
"description": null,
"size": 178,
"type": "txt",
"url": "http://api.metagenomics.anl.gov/analysis/data/id/mgm4456102.3/file/999.done.species.stats"
}
},
"id": "mgm4456102.3",
"provider": "metagenomics.anl.gov",
"providerId": "mgm4456102.3"
}
},
"raw": {
"mgm4456102.3.fna.gz": {
"compression": "gzip",
"format": "fasta",
"provider": "metagenomics.anl.gov",
"url": "http://api.metagenomics.anl.gov/reads/mgm4456102.3"
}
}
} | [
"jared.wilkening@gmail.com"
] | jared.wilkening@gmail.com |
cb5bd12ced8e3fde3e7611f283a940a293a4b659 | 0c8214d0d7827a42225b629b7ebcb5d2b57904b0 | /practice/P009_Fibonacci/main.py | 1b7ef28e71516019aa48df1f633f869dc72b79a3 | [] | no_license | mertturkmenoglu/python-examples | 831b54314410762c73fe2b9e77aee76fe32e24da | 394072e1ca3e62b882d0d793394c135e9eb7a56e | refs/heads/master | 2020-05-04T15:42:03.816771 | 2020-01-06T19:37:05 | 2020-01-06T19:37:05 | 179,252,826 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 253 | py | # Dynamic programming example
fib_numbers = {1: 1, 2: 1, 3: 2}
def fibonacci(n: int) -> int:
if n not in fib_numbers:
fib_numbers[n] = fibonacci(n - 1) + fibonacci(n - 2)
return fib_numbers[n]
print(fibonacci(7))
print(fibonacci(5))
| [
"mertturkmenoglu99@gmail.com"
] | mertturkmenoglu99@gmail.com |
d669bec0e43de88d1d1a0659b251032840574b22 | 4388363ba45b95910c25bae3d9c02ad78f4a75d6 | /python/anaconda/lib/python2.7/site-packages/numba/tests/npyufunc/test_parallel_ufunc_issues.py | da86964467145527252c07a10e6ad5b9f1969a73 | [
"Python-2.0"
] | permissive | locolucco209/MongoScraper | d494e02531f4f165b1e821633dc9661c579337b5 | 74476c9f00ee43338af696da7e9cd02b273f9005 | refs/heads/master | 2022-11-25T19:09:27.248747 | 2018-07-10T03:54:06 | 2018-07-10T03:54:06 | 137,553,786 | 3 | 1 | null | 2022-11-16T04:32:26 | 2018-06-16T04:49:22 | null | UTF-8 | Python | false | false | 2,600 | py | from __future__ import print_function, absolute_import, division
import time
import ctypes
import numpy as np
from numba import unittest_support as unittest
from numba.tests.support import captured_stdout
from numba import vectorize
class TestParUfuncIssues(unittest.TestCase):
def test_thread_response(self):
"""
Related to #89.
This does not test #89 but tests the fix for it.
We want to make sure the worker threads can be used multiple times
and with different time gap between each execution.
"""
@vectorize('float64(float64, float64)', target='parallel')
def fnv(a, b):
return a + b
sleep_time = 1 # 1 second
while sleep_time > 0.00001: # 10us
time.sleep(sleep_time)
a = b = np.arange(10**5)
np.testing.assert_equal(a + b, fnv(a, b))
# Reduce sleep time
sleep_time /= 2
def test_gil_reacquire_deadlock(self):
"""
Testing issue #1998 due to GIL reacquiring
"""
# make a ctypes callback that requires the GIL
proto = ctypes.CFUNCTYPE(None, ctypes.c_int32)
characters = 'abcdefghij'
def bar(x):
print(characters[x])
cbar = proto(bar)
# our unit under test
@vectorize(['int32(int32)'], target='parallel', nopython=True)
def foo(x):
print(x % 10) # this reacquires the GIL
cbar(x % 10) # this reacquires the GIL
return x * 2
# Numpy ufunc has a heuristic to determine whether to release the GIL
# during execution. Small input size (10) seems to not release the GIL.
# Large input size (1000) seems to release the GIL.
for nelem in [1, 10, 100, 1000]:
# inputs
a = np.arange(nelem, dtype=np.int32)
acopy = a.copy()
# run and capture stdout
with captured_stdout() as buf:
got = foo(a)
stdout = buf.getvalue()
buf.close()
# process outputs from print
got_output = sorted(map(lambda x: x.strip(), stdout.splitlines()))
# build expected output
expected_output = [str(x % 10) for x in range(nelem)]
expected_output += [characters[x % 10] for x in range(nelem)]
expected_output = sorted(expected_output)
# verify
self.assertEqual(got_output, expected_output)
np.testing.assert_equal(got, 2 * acopy)
if __name__ == '__main__':
unittest.main()
| [
"lukemassetti@WestSide-Luke.local"
] | lukemassetti@WestSide-Luke.local |
4c8cb75900b6afaeafb66fec408097baedf5d1cc | 33f32d78087491e989289c46e5d2df5400e23946 | /leetcode/Unsorted_Algorthm_Problems/Two_Sum_III _Data_structure_design.py | ab9d7045ac0bbbde6e34441cdc36885146a1b6d5 | [] | no_license | xulleon/algorithm | 1b421989423640a44339e6edb21c054b6eb47a30 | b1f93854006a9b1e1afa4aadf80006551d492f8a | refs/heads/master | 2022-10-08T19:54:18.123628 | 2022-09-29T05:05:23 | 2022-09-29T05:05:23 | 146,042,161 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 899 | py | # https://leetcode.com/problems/two-sum-iii-data-structure-design/
class TwoSum:
def __init__(self):
"""
Initialize your data structure here.
"""
self.numbers = {}
def add(self, number: int) -> None:
"""
Add the number to an internal data structure..
"""
if number in self.numbers:
self.numbers[number] += 1
else:
self.numbers[number] = 1
def find(self, value: int) -> bool:
"""
Find if there exists any pair of numbers which sum is equal to the value.
"""
for number in self.numbers.keys():
number1 = value - number
if number1 != number:
if number1 in self.numbers:
return True
else:
if self.numbers[number] > 1:
return True
return False
| [
"leonxu@yahoo.com"
] | leonxu@yahoo.com |
d9cb29925147bcc00f6eeef81143924403f0db3e | ca7aa979e7059467e158830b76673f5b77a0f5a3 | /Python_codes/p03288/s528258523.py | e21295af8dcf6d86de0facff0a4bceaed3804dab | [] | no_license | Aasthaengg/IBMdataset | 7abb6cbcc4fb03ef5ca68ac64ba460c4a64f8901 | f33f1c5c3b16d0ea8d1f5a7d479ad288bb3f48d8 | refs/heads/main | 2023-04-22T10:22:44.763102 | 2021-05-13T17:27:22 | 2021-05-13T17:27:22 | 367,112,348 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 280 | py | import sys
import os
MOD = 10 ** 9 + 7
def main():
if os.getenv("LOCAL"):
sys.stdin = open("input.txt", "r")
N = int(sys.stdin.buffer.readline().rstrip())
print('AGC' if N >= 2800 else 'ARC' if N >= 1200 else 'ABC')
if __name__ == '__main__':
main()
| [
"66529651+Aastha2104@users.noreply.github.com"
] | 66529651+Aastha2104@users.noreply.github.com |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.