
blob_id stringlengths 40 40 | directory_id stringlengths 40 40 | path stringlengths 3 288 | content_id stringlengths 40 40 | detected_licenses listlengths 0 112 | license_type stringclasses 2
values | repo_name stringlengths 5 115 | snapshot_id stringlengths 40 40 | revision_id stringlengths 40 40 | branch_name stringclasses 684
values | visit_date timestamp[us]date 2015-08-06 10:31:46 2023-09-06 10:44:38 | revision_date timestamp[us]date 1970-01-01 02:38:32 2037-05-03 13:00:00 | committer_date timestamp[us]date 1970-01-01 02:38:32 2023-09-06 01:08:06 | github_id int64 4.92k 681M ⌀ | star_events_count int64 0 209k | fork_events_count int64 0 110k | gha_license_id stringclasses 22
values | gha_event_created_at timestamp[us]date 2012-06-04 01:52:49 2023-09-14 21:59:50 ⌀ | gha_created_at timestamp[us]date 2008-05-22 07:58:19 2023-08-21 12:35:19 ⌀ | gha_language stringclasses 147
values | src_encoding stringclasses 25
values | language stringclasses 1
value | is_vendor bool 2
classes | is_generated bool 2
classes | length_bytes int64 128 12.7k | extension stringclasses 142
values | content stringlengths 128 8.19k | authors listlengths 1 1 | author_id stringlengths 1 132 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
3c22bf817ee148fbc70da528dfb8cff5991cedb0 | f12fac0dd5c9c9eeedff16377d1f57a3cd02ef32 | /Python游戏编程入门/02.初识Pygame:Pie游戏/绘制弧形.py | 8031255f9f3580e0e721331544bdda1f67ae9357 | [] | no_license | SesameMing/PythonPygame | 61fe09a38d1729963b86f348b349572760676195 | ca0554427cd30838d56630e8b1e04aa0e26834a1 | refs/heads/master | 2020-12-07T21:23:56.271193 | 2016-11-25T06:38:06 | 2016-11-25T06:38:06 | 66,639,140 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 685 | py | #!/usr/bin/env python3
# -*-coding:utf-8-*-
# Author:SesameMing <blog.v-api.cn>
# Email:admin@v-api.cn
# Time:2016-11-25 12:51
import sys
import math
import pygame
from pygame.locals import *
pygame.init()
screen = pygame.display.set_mode((600, 500))
pygame.display.set_caption("Drawing Arcs")
while True:
for even... | [
"admin@v-api.cn"
] | admin@v-api.cn |
04e3a1cfd126c0710557c5f5944b73240af4deec | e82b761f53d6a3ae023ee65a219eea38e66946a0 | /All_In_One/addons/vb25/plugins/TexSwirl.py | 9ca7e67f86475efdb3be99c3fa816a582b516141 | [] | no_license | 2434325680/Learnbgame | f3a050c28df588cbb3b14e1067a58221252e2e40 | 7b796d30dfd22b7706a93e4419ed913d18d29a44 | refs/heads/master | 2023-08-22T23:59:55.711050 | 2021-10-17T07:26:07 | 2021-10-17T07:26:07 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 5,575 | py | #
# V-Ray/Blender
#
# http://vray.cgdo.ru
#
# Author: Andrey M. Izrantsev (aka bdancer)
# E-Mail: izrantsev@cgdo.ru
#
# This program is free software; you can redistribute it and/or
# modify it under the terms of the GNU General Public License
# as published by the Free Software Foundation; either version 2
# of the Li... | [
"root@localhost.localdomain"
] | root@localhost.localdomain |
c04479133e596d0015f9df6569bf7d2c2283e6d1 | b23c6c02d9b54c987bca2e36c3506cf80fa28239 | /python databse connectivity progs/bind variable.py | a9bf8a8d9dcc71bd722251121197416765b6ba4e | [] | no_license | nishikaverma/Python_progs | 21190c88460a79f5ce20bb25d1b35f732fadd642 | 78f0cadde80b85356b4cb7ba518313094715aaa5 | refs/heads/master | 2022-06-12T14:54:03.442837 | 2020-05-08T10:28:58 | 2020-05-08T10:28:58 | 262,293,571 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 953 | py | import cx_Oracle
try:
conn=cx_Oracle.connect("system/oracle123@localhost/orcl")
print("connection established")
cur=conn.cursor()
print("cursor created!")
print("***********************")
cur.execute("Select Book_name,Book_price from Books")
for x in cur:
print(x)
pr... | [
"nishika.verma@live.com"
] | nishika.verma@live.com |
b48a2e29d81c5d7ddbf5cc76cd714fe6c1483872 | 9e27f91194541eb36da07420efa53c5c417e8999 | /twilio/twiml/messaging_response.py | abb58ff2c6d33ad1d66998d8f9520dd3786f329a | [] | no_license | iosmichael/flask-admin-dashboard | 0eeab96add99430828306b691e012ac9beb957ea | 396d687fd9144d3b0ac04d8047ecf726f7c18fbd | refs/heads/master | 2020-03-24T05:55:42.200377 | 2018-09-17T20:33:42 | 2018-09-17T20:33:42 | 142,508,888 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 2,875 | py | # coding=utf-8
"""
This code was generated by
\ / _ _ _| _ _
| (_)\/(_)(_|\/| |(/_ v1.0.0
/ /
"""
import json
from admin.twilio.twiml import (
TwiML,
format_language,
)
class MessagingResponse(TwiML):
""" <Response> TwiML for Messages """
def __init__(self, **kwargs):
su... | [
"michaelliu@iresearch.com.cn"
] | michaelliu@iresearch.com.cn |
cbd142b626698fe1debd6ecef0822cc0d7b13f7f | 53fab060fa262e5d5026e0807d93c75fb81e67b9 | /backup/user_150/ch50_2020_04_13_03_25_44_929209.py | a262c1522f55ac719f56e8c2e06b6e69fde73ed5 | [] | no_license | gabriellaec/desoft-analise-exercicios | b77c6999424c5ce7e44086a12589a0ad43d6adca | 01940ab0897aa6005764fc220b900e4d6161d36b | refs/heads/main | 2023-01-31T17:19:42.050628 | 2020-12-16T05:21:31 | 2020-12-16T05:21:31 | 306,735,108 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 230 | py | def junta_nome_sobrenome(nome, sobrenome):
nome_e_sobrenome = []
i = 0
while i < len(nome) and i < len(sobrenome):
nome_e_sobrenome.append(nome[i] + ' ' +sobrenome[i])
i += 1
return nome_e_sobrenome | [
"you@example.com"
] | you@example.com |
45f343096530fa01c5f2708f14403031fa6baa1f | 5332fef91e044555e605bb37cbef7c4afeaaadb0 | /hy-data-analysis-with-python-2020/part06-e07_binding_sites/src/binding_sites.py | 6baad43f425d059dd9d258e457e1d88a1b708b0e | [] | no_license | nopomi/hy-data-analysis-python-2019 | f3baa96bbe9b6ee7f0b3e6f6b8b0f3adfc3b6cc8 | 464685cb377cfdeee890a008fbfbd9ed6e3bcfd0 | refs/heads/master | 2021-07-10T16:16:56.592448 | 2020-08-16T18:27:38 | 2020-08-16T18:27:38 | 185,044,621 | 4 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,379 | py | #!/usr/bin/env python3
import pandas as pd
import numpy as np
import scipy
from sklearn.cluster import AgglomerativeClustering
from sklearn.metrics import accuracy_score
from sklearn.metrics import pairwise_distances
from matplotlib import pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
import scipy.sp... | [
"miska.noponen@gmail.com"
] | miska.noponen@gmail.com |
2ee2ccec5dbf7843302c65bae409bb7fdcc29b2a | 09e57dd1374713f06b70d7b37a580130d9bbab0d | /benchmark/startQiskit_noisy3325.py | ba3c7f7f745af20e6283d8398fd4aeb577461651 | [
"BSD-3-Clause"
] | permissive | UCLA-SEAL/QDiff | ad53650034897abb5941e74539e3aee8edb600ab | d968cbc47fe926b7f88b4adf10490f1edd6f8819 | refs/heads/main | 2023-08-05T04:52:24.961998 | 2021-09-19T02:56:16 | 2021-09-19T02:56:16 | 405,159,939 | 2 | 0 | null | null | null | null | UTF-8 | Python | false | false | 4,323 | py | # qubit number=4
# total number=44
import cirq
import qiskit
from qiskit.providers.aer import QasmSimulator
from qiskit.test.mock import FakeVigo
from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister
from qiskit import BasicAer, execute, transpile
from pprint import pprint
from qiskit.test.mock import ... | [
"wangjiyuan123@yeah.net"
] | wangjiyuan123@yeah.net |
deaa0857f040e4558c3a3aa27b0b1ff32bf995cc | 487ce91881032c1de16e35ed8bc187d6034205f7 | /codes/CodeJamCrawler/CJ_16_1/16_1_3_ka_ya_c.py | 7735ad455887347c1c5a1e4c3582e3531bafa93a | [] | no_license | DaHuO/Supergraph | 9cd26d8c5a081803015d93cf5f2674009e92ef7e | c88059dc66297af577ad2b8afa4e0ac0ad622915 | refs/heads/master | 2021-06-14T16:07:52.405091 | 2016-08-21T13:39:13 | 2016-08-21T13:39:13 | 49,829,508 | 2 | 0 | null | 2021-03-19T21:55:46 | 2016-01-17T18:23:00 | Python | UTF-8 | Python | false | false | 1,141 | py | def solve(n, fs):
fs = [f-1 for f in fs]
lp = [None for p in xrange(n)]
for i in xrange(n):
chk = [False for p in xrange(n)]
p = i
cnt = 0
while not chk[p] and not lp[p]:
chk[p] = True
p = fs[p]
cnt += 1
if p == i:
... | [
"[dhuo@tcd.ie]"
] | [dhuo@tcd.ie] |
9646ac4cc55d9a5e30e41d7546f3ca1df7b888f9 | f0d9ba8456cdad2b2fa711fa8975b41da7af1784 | /worms/tests/__init__.py | 2b9503765bab2d60bb03f655ddf70c5209239ab5 | [
"Apache-2.0"
] | permissive | willsheffler/worms | f1d893d4f06b421abdd4d1e526b43c2e132e19a2 | 27993e33a43474d647ecd8277b210d4206858f0b | refs/heads/master | 2023-04-08T01:18:33.656774 | 2022-06-09T20:04:55 | 2022-06-09T20:04:55 | 118,678,808 | 6 | 5 | NOASSERTION | 2021-10-05T22:28:24 | 2018-01-23T22:30:45 | Python | UTF-8 | Python | false | false | 670 | py | # -*- coding: utf-8 -*-
"""Unit test package for worms."""
import os
import pytest
try:
import pyrosetta
HAVE_PYROSETTA = True
only_if_pyrosetta = lambda x: x
try:
import pyrosetta.distributed
HAVE_PYROSETTA_DISTRIBUTED = True
only_if_pyrosetta_distributed = lambda x: x
except Impor... | [
"willsheffler@gmail.com"
] | willsheffler@gmail.com |
297467e64e5b45612d4fe55253b3388b8442f79f | 770d4df866b9e66a333f3ffeacdd659b8553923a | /results/0193/config.py | fbbe800c6116da5429a209d219fc7846de53d1e2 | [] | no_license | leojo/ResultsOverview | b2062244cbd81bc06b99963ae9b1695fa9718f90 | a396abc7a5b4ab257150c0d37c40b646ebb13fcf | refs/heads/master | 2020-03-20T19:52:37.217926 | 2018-08-05T12:50:27 | 2018-08-05T12:50:27 | 137,656,327 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,322 | py | import os
import numpy as np
import waveUtils
class config(object):
def __init__(self):
self.prepare_data()
# Bsub arguments
bsub_mainfile = "main.py"
bsub_processors = 4
bsub_timeout = "4:00"
bsub_memory = 8000
# Epoch and batch config
batch_size = 128
latent_dim = 100
epochs = 100
epoch_updates = 10... | [
"leojohannsson91@gmail.com"
] | leojohannsson91@gmail.com |
661cac8acf0eadfcb8a1d63605e97bdbdb2e9740 | 2652fd6261631794535589427a384693365a585e | /trunk/workspace/Squish/src/TestScript/UI/suite_UI_62/tst_UI_62_Cellular_design/test.py | 4b116d08c137cfe84f4e37aea4edc7de3cf116e4 | [] | no_license | ptqatester1/ptqa | 88c652380167f64a953bfd7a65041e7d8ac48c90 | 5b5997ea459e9aac17db8da2041e2af331927104 | refs/heads/master | 2021-01-21T19:06:49.275364 | 2017-06-19T03:15:00 | 2017-06-19T03:15:00 | 92,115,462 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 5,323 | py | ######################
#Author: Alex Leung ##
######################
from API.Utility import UtilConst
from API.Utility.Util import Util
from API.ComponentBox import ComponentBoxConst
from API.Device.EndDevice.PC.PC import PC
from API.Device.CellTower.CellTower import CellTower
from API.Device.COServer.COServer import... | [
"ptqatester1@gmail.com"
] | ptqatester1@gmail.com |
a270947c1b4f962a0d9e5be8ec990bbefd2b4a32 | 3a39ddc4a8600ffc5110453867370c1d8e2da121 | /x11-libs/libXcomposite/libXcomposite-0.4.3.py | 8ce4b041dc0124e9f86b8c9c3514052f3dd809a7 | [] | no_license | seqizz/hadron64 | f2276133786c62f490bdc0cbb6801491c788520f | ca6ef5df3972b925f38e3666ccdc20f2d0bfe87e | refs/heads/master | 2021-01-18T04:53:09.597388 | 2013-02-25T21:25:32 | 2013-02-25T21:25:32 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 468 | py | metadata = """
summary @ X11 Composite extension library
homepage @ http://xorg.freedesktop.org/
license @ MIT
src_url @ http://xorg.freedesktop.org/releases/individual/lib/libXcomposite-$version.tar.bz2
arch @ ~x86
"""
depends = """
runtime @ x11-libs/libXfixes x11-proto/compositeproto
"""
#srcdir = "libXcomposite-%... | [
"bburaksezer@gmail.com"
] | bburaksezer@gmail.com |
59534247ee1449496330021da54fc527d05a14e3 | 34a043e6961639657e36e7ac9fd459ad5b1f6de1 | /openpathsampling/experimental/storage/test_mdtraj_json.py | f3c57c4ad31a103b69866649884b52ccf8542b6a | [
"MIT"
] | permissive | dwhswenson/openpathsampling | edaddc91e443e7ffc518e3a06c99fc920ad9d053 | 3d02df4ccdeb6d62030a28e371a6b4ea9aaee5fe | refs/heads/master | 2023-02-04T12:31:17.381582 | 2023-01-30T21:17:01 | 2023-01-30T21:17:01 | 23,991,437 | 3 | 1 | MIT | 2022-08-12T17:48:04 | 2014-09-13T10:15:43 | Python | UTF-8 | Python | false | false | 2,273 | py | from .mdtraj_json import *
import pytest
import numpy as np
import numpy.testing as npt
from ..simstore.custom_json import bytes_codec, numpy_codec, custom_json_factory
from ..simstore.test_custom_json import CustomJSONCodingTest
from openpathsampling.tests.test_helpers import data_filename
class MDTrajCodingTest(C... | [
"dwhs@hyperblazer.net"
] | dwhs@hyperblazer.net |
f63a1432724c3cac911ccad6422806edc4c92da0 | 0369761e54c2766ff2ce13ed249d462a12320c0f | /bubble-search/bubble-search-practice/exercise-09.py | de843c707b960f927b8aa8ee8b57bf0057cd539f | [] | no_license | JasoSalgado/algorithms | e54c739005cc47ee8a401912a77cc70865d28c87 | 8db7d2bedfe468c70e5191bc7873e4dd86e7f95a | refs/heads/master | 2023-04-25T23:41:10.655874 | 2021-06-11T17:35:49 | 2021-06-11T17:35:49 | 333,979,204 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 622 | py | """
Bubble search exercise 09
"""
list = [6514 , 2352 , 3984 , 3596 , 2445 , 5535 , 6332 , 5346 , 617 , 3976 , 1242 , 2573 , 7772 , 9324 , 4655 , 3144 , 6233 , 2287 , 6109 , 4139 , 2030 , 6734 , 1495 , 9466 , 6893 , 9336 , 963 , 4412 , 5347 , 2565 , 7590 , 5932 , 6747 , 7566 , 2456 , 9982 , 8880 , 6816 , 9415 , 2426 , ... | [
"jaso_98@hotmail.com"
] | jaso_98@hotmail.com |
f59837294f8f44c5babd41a112e886e751a61e97 | 31401549d7a342b3fcb0f276f20e18f130730c69 | /utils/loadweight.py | 05c9d7ff211cd6d9235020fb2c41f2ffb3f1af14 | [] | no_license | takeitea/Attention-Echino | e79f207010ad9c57b31d39ba8681d2cb0e59643f | e157c99e5784c8dc2470b0d3f3ffa61b7921ce09 | refs/heads/master | 2020-05-21T00:01:06.170506 | 2019-03-06T13:27:52 | 2019-03-06T13:27:52 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,897 | py | """
load part of the pre-trained parameters
"""
import os
import torch
import torch.utils.model_zoo as model_zoo
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/... | [
"945193029@qq.com"
] | 945193029@qq.com |
2fe653f3c427c1407ff776b05974647bae83e94b | e5504d8c4880993b82d5583a11c5cc4623e0eac2 | /Arrays/twoSum2.py | dacf7a07e9511280bc0929061c05928bfd38bb93 | [] | no_license | noorulameenkm/DataStructuresAlgorithms | e5f87f426fc444d18f830e48569d2a7a50f5d7e0 | 7c3bb89326d2898f9e98590ceb8ee5fd7b3196f0 | refs/heads/master | 2023-06-08T19:29:42.507761 | 2023-05-28T16:20:19 | 2023-05-28T16:20:19 | 219,270,731 | 2 | 0 | null | null | null | null | UTF-8 | Python | false | false | 766 | py | def pair_with_targetsum(arr, target_sum):
result = []
start, end = 0, len(arr) - 1
while start < end:
sum_ = arr[start] + arr[end]
# sum == target
if sum_ == target_sum:
result.append(start)
result.append(end)
break
# sum > target
elif sum_ > target_sum:
end -= 1
el... | [
"noorul.km@people10.com"
] | noorul.km@people10.com |
ae953f626dcd7a8cc3573ca343fdeac058daa21f | df0c4875b45e68c106dd1e2ba397f71a10794327 | /src/pifetcher/utilities/sys_utils.py | d389d2340abd6f3e65f41dbd8999e6aed152bff2 | [
"MIT"
] | permissive | gavinz0228/pifetcher | c28b407cf4965852af67ffe619a55ee90fa49a72 | c8419ae153eefed04e0e8b239cf1a9226fa91c29 | refs/heads/master | 2021-07-04T20:26:41.973408 | 2020-11-22T16:57:38 | 2020-11-22T16:57:38 | 203,682,327 | 1 | 0 | null | 2019-08-24T17:04:59 | 2019-08-22T00:06:58 | Python | UTF-8 | Python | false | false | 507 | py | from os import path, chmod
from sys import platform
import stat
class SysUtils:
@staticmethod
def ensure_path(file_path):
if not path.exists(file_path):
raise Exception(f'file path {file_path} does not exist.')
else:
return file_path
@staticmethod
... | [
"gavinz0228@gmail.com"
] | gavinz0228@gmail.com |
91bfa4b69dc8175e14f2c85dffe644cc6f7a0d71 | fe9e6580e954ed62c4e8fd6b860000bb553150a6 | /ecommerce/forms.py | bffb01b5ed4507bffcb530dd54713c62b71512fe | [] | no_license | Brucehaha/ecommerce | 037fb25608e848f5c0fd4ed78f42028d21872e39 | bea5e5a13ad1e958912b0ac99cfc556a593f91f3 | refs/heads/workplace | 2023-01-03T19:35:13.894572 | 2018-06-20T07:22:19 | 2018-06-20T07:22:19 | 124,492,135 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 688 | py | from django import forms
class ContactForm(forms.Form):
fullname = forms.CharField(
widget=forms.TextInput(
attrs={
"class": "form-control",
"placeholder": "Your fullname"
}
)
)
email = forms.EmailField(
widget=forms.EmailInput(
attrs={
"class": "form-control",
"placeholde... | [
"henninglee2013@gmail.com"
] | henninglee2013@gmail.com |
5ce2a703f5302283b074de6d2a1fb30fb8b91aa4 | bc0938b96b86d1396cb6b403742a9f8dbdb28e4c | /aliyun-python-sdk-nas/aliyunsdknas/request/v20170626/DescribeTagsRequest.py | d76b528b9d21f049ae887b42b56847b5cd568288 | [
"Apache-2.0"
] | permissive | jia-jerry/aliyun-openapi-python-sdk | fb14d825eb0770b874bc123746c2e45efaf64a6d | e90f3683a250cfec5b681b5f1d73a68f0dc9970d | refs/heads/master | 2022-11-16T05:20:03.515145 | 2020-07-10T08:45:41 | 2020-07-10T09:06:32 | 278,590,780 | 0 | 0 | NOASSERTION | 2020-07-10T09:15:19 | 2020-07-10T09:15:19 | null | UTF-8 | Python | false | false | 2,120 | py | # Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not u... | [
"sdk-team@alibabacloud.com"
] | sdk-team@alibabacloud.com |
1f1a15327737df474e4091401068d90bf7b7a2d8 | df856d5cb0bd4a4a75a54be48f5b91a62903ee6e | /jishaku/__init__.py | be18c93d969f66dcdc330dc9e0ffd89dc6bb8cc2 | [
"MIT",
"Apache-2.0"
] | permissive | mortalsky/jishaku | 4c89bd69f6e1efcc45fcfdcc81427c71e10dc1de | 9cbbf64dd83697559a50c64653350253b876165a | refs/heads/master | 2023-07-20T04:55:19.144528 | 2021-01-22T08:18:12 | 2021-01-22T08:18:12 | 299,701,523 | 0 | 0 | MIT | 2020-09-29T18:16:24 | 2020-09-29T18:16:23 | null | UTF-8 | Python | false | false | 452 | py | # -*- coding: utf-8 -*-
"""
jishaku
~~~~~~~
A discord.py extension including useful tools for bot development and debugging.
:copyright: (c) 2021 Devon (Gorialis) R
:license: MIT, see LICENSE for more details.
"""
# pylint: disable=wildcard-import
from jishaku.cog import * # noqa: F401
from jishaku.features.basec... | [
"sansgorialis@gmail.com"
] | sansgorialis@gmail.com |
fe3f96a2af6475819c782c04a2b8e8b6b3e3d814 | 52a7b1bb65c7044138cdcbd14f9d1e8f04e52c8a | /budget/urls.py | c353880f983753ec457815a9fa5d6fa7951041ab | [] | no_license | rds0751/aboota | 74f8ab6d0cf69dcb65b0f805a516c5f94eb8eb35 | 2bde69c575d3ea9928373085b7fc5e5b02908374 | refs/heads/master | 2023-05-03T00:54:36.421952 | 2021-05-22T15:40:48 | 2021-05-22T15:40:48 | 363,398,229 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 224 | py | from django.urls import path,include
from . import views
from django.contrib.auth import views as auth_views
urlpatterns = [
path('app/',views.index,name='index'),
path('add_item/',views.add_item,name='add item'),
] | [
"you@example.com"
] | you@example.com |
c42cc045d3613843df744ac6b74f7a368d40170e | f46e5ab4747d113215e46240eee4d75509e4be0d | /tests.py | 2dd01180f049fb3cb67a16cefd56d899698aae9a | [
"MIT"
] | permissive | xmonader/objsnapshot | 0d2dc17f9637dfe614332f125af5d867a8110118 | ab639630e6762a1d7c8e7df251f959e27e270e4e | refs/heads/master | 2021-01-22T06:19:26.026384 | 2017-05-30T13:12:22 | 2017-05-30T13:12:22 | 92,542,117 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,737 | py | from .objsnapshot import commit, rollback
class Human:
def __init__(self, name, age):
self.name = name
self.age = age
def inc(self, by=None):
if by is None:
by = self.age
self.age += by
def __str__(self):
return "{} {} ".format(self.name, self.age)
... | [
"xmonader@gmail.com"
] | xmonader@gmail.com |
3090368248d3f1123c7946855c97dbc0ec1154e9 | 4fd84e0e1097d1153ed477a5e76b4972f14d273a | /myvirtualenv/lib/python3.7/site-packages/azure/mgmt/iothub/models/certificate_properties.py | d91afb9c0adb00d0e035b9e1023cc3ad459f53fc | [
"MIT"
] | permissive | peterchun2000/TerpV-U | c045f4a68f025f1f34b89689e0265c3f6da8b084 | 6dc78819ae0262aeefdebd93a5e7b931b241f549 | refs/heads/master | 2022-12-10T09:31:00.250409 | 2019-09-15T15:54:40 | 2019-09-15T15:54:40 | 208,471,905 | 0 | 2 | MIT | 2022-12-08T06:09:33 | 2019-09-14T16:49:41 | Python | UTF-8 | Python | false | false | 2,165 | py | # coding=utf-8
# --------------------------------------------------------------------------
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License. See License.txt in the project root for
# license information.
#
# Code generated by Microsoft (R) AutoRest Code Generator.
# Changes ... | [
"peterchun2000@gmail.com"
] | peterchun2000@gmail.com |
9918925b5893ab5e67cfe34926eb8f39e50a3f68 | a5b3c17361b0d68818a0088d2632706353aa768f | /app/core/urls.py | 2c01c9dc76b59d446a2cc277aaf6d2d00a8d8820 | [] | no_license | marcinpelszyk/django-docker-compose-deploy | 7bd6d91a08aa4c60fd801115e4277d26cfd77642 | 6e4716d5324172778e5babecb40952de66448301 | refs/heads/main | 2023-06-06T02:56:44.709915 | 2021-06-28T15:38:56 | 2021-06-28T15:38:56 | 380,349,649 | 0 | 1 | null | 2021-06-28T08:10:53 | 2021-06-25T20:42:07 | Python | UTF-8 | Python | false | false | 387 | py | from django.conf import settings
from django.conf.urls.static import static
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
]
if settings.DEBUG:
urlpatterns += static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)
urlpattern... | [
"marcin.pelszyk90@gmail.com"
] | marcin.pelszyk90@gmail.com |
88d871218ddc9d5a96e3ac821323d3bf566ce9b1 | fb05ae8048b188c7d73e45d0b0732223686eb4e4 | /dash-demo.py | 8c67cc6049a8940e154186d5777e2c72a2d37422 | [] | no_license | jluttine/dash-demo | 1b8bd0bf0b6570cf8e33c0fb9278390f37baa686 | 2eab4c7cd92b24214354d8a5e3bce866677efe50 | refs/heads/master | 2023-01-12T19:03:09.745917 | 2020-11-13T16:57:41 | 2020-11-13T16:57:41 | 312,356,690 | 2 | 1 | null | null | null | null | UTF-8 | Python | false | false | 3,211 | py | import dash
import dash_html_components as html
import dash_core_components as dcc
from pages import demo1_graph, demo2_datatable
# Create the Dash app/server
app = dash.Dash(
__name__,
external_stylesheets=[
"https://codepen.io/chriddyp/pen/bWLwgP.css",
],
# We need to suppress these errors ... | [
"jaakko.luttinen@iki.fi"
] | jaakko.luttinen@iki.fi |
f88d26fd93f16bef39a4eafcdb8174838d8e21bd | 163bbb4e0920dedd5941e3edfb2d8706ba75627d | /Code/CodeRecords/2147/60692/307788.py | 10de8faf4f82529d5d59df010ef8d72681e4f591 | [] | no_license | AdamZhouSE/pythonHomework | a25c120b03a158d60aaa9fdc5fb203b1bb377a19 | ffc5606817a666aa6241cfab27364326f5c066ff | refs/heads/master | 2022-11-24T08:05:22.122011 | 2020-07-28T16:21:24 | 2020-07-28T16:21:24 | 259,576,640 | 2 | 1 | null | null | null | null | UTF-8 | Python | false | false | 492 | py | n = input()
if n == '5 5 1 3 2':
print(0)
print(3)
print(3)
print(2)
print(5)
elif n == '100 109 79 7 5':
list1 = [27,52,80,50,40,37,27,60,60,55,55,25,40,80,52,50,25,45,72,45,65,32,22,50,20,80,35,20,22,47,52,20,77,22,52,12,75,55,75,77,75,27,7,75,27,82,52,47,22,75,65,22,57,42,45,40,77,45,40,7,50,... | [
"1069583789@qq.com"
] | 1069583789@qq.com |
846029f797948ff4c428cce8a5922b17ffbbd67d | 78d35bb7876a3460d4398e1cb3554b06e36c720a | /sdk/monitor/azure-mgmt-monitor/azure/mgmt/monitor/v2016_09_01/aio/_monitor_management_client.py | c050f4b4aa8fc88df3e7a1e1c02c2d1b67f42612 | [
"MIT",
"LicenseRef-scancode-generic-cla",
"LGPL-2.1-or-later"
] | permissive | catchsrinivas/azure-sdk-for-python | e35f59b60318a31b3c940a7a3a07b61b28118aa5 | 596227a7738a5342274486e30489239d539b11d1 | refs/heads/main | 2023-08-27T09:08:07.986249 | 2021-11-11T11:13:35 | 2021-11-11T11:13:35 | 427,045,896 | 0 | 0 | MIT | 2021-11-11T15:14:31 | 2021-11-11T15:14:31 | null | UTF-8 | Python | false | false | 3,731 | py | # coding=utf-8
# --------------------------------------------------------------------------
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License. See License.txt in the project root for license information.
# Code generated by Microsoft (R) AutoRest Code Generator.
# Changes may ... | [
"noreply@github.com"
] | catchsrinivas.noreply@github.com |
cb915a83c326ed9358735e7e6a6123656ae20d18 | f00ae2cb4709539e8a78247678d9bb51913e0373 | /oacids/schedules/schedule.py | 76499b213fe0838b48b11e39aed9eecb971f06d3 | [
"MIT"
] | permissive | openaps/oacids | 576351d34d51c62492fc0ed8be5e786273f27aee | ed8d6414171f45ac0c33636b5b00013e462e89fb | refs/heads/master | 2021-01-10T06:03:53.395357 | 2016-03-21T04:02:47 | 2016-03-21T04:02:47 | 51,559,470 | 2 | 2 | null | null | null | null | UTF-8 | Python | false | false | 343 | py |
from openaps.configurable import Configurable
import recurrent
class Schedule (Configurable):
prefix = 'schedule'
required = [ 'phases', 'rrule' ]
url_template = "schedule://{name:s}/{rrule:s}"
@classmethod
def parse_rrule (Klass, rrule):
parser = recurrent.RecurringEvent( )
rule = parser.parse(r... | [
"bewest@gmail.com"
] | bewest@gmail.com |
101b641690e7cda59c300f207ef57d7b4d613baa | ac10ccaf44a7610d2230dbe223336cd64f8c0972 | /ms2ldaviz/basicviz/migrations/0033_auto_20160920_0859.py | b74d76b496f5d8f05e297caac658ce76fd904faf | [] | no_license | ymcdull/ms2ldaviz | db27d3f49f43928dcdd715f4a290ee3040d27b83 | bd5290496af44b3996c4118c6ac2385a5a459926 | refs/heads/master | 2020-05-21T03:04:29.939563 | 2017-03-14T11:44:42 | 2017-03-14T11:44:42 | 84,564,829 | 0 | 0 | null | 2017-03-10T13:54:23 | 2017-03-10T13:54:22 | null | UTF-8 | Python | false | false | 456 | py | # -*- coding: utf-8 -*-
from __future__ import unicode_literals
from django.db import models, migrations
class Migration(migrations.Migration):
dependencies = [
('basicviz', '0032_auto_20160920_0857'),
]
operations = [
migrations.RemoveField(
model_name='alphacorroptions',
... | [
"="
] | = |
8926cbe8d1538cbbd04bf86bf0af6e92ec04783c | adb295bf248ded84d2c126d73c58b570af440dc6 | /scripts/providers.py | 13d8d431cf8b25bd62662d5e17425d61e6862069 | [] | no_license | sshveta/cfme_tests | eaeaf0076e87dd6c2c960887b242cb435cab5151 | 51bb86fda7d897e90444a6a0380a5aa2c61be6ff | refs/heads/master | 2021-03-30T22:30:12.476326 | 2017-04-26T22:47:25 | 2017-04-26T22:47:25 | 17,754,019 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,531 | py | #!/usr/bin/env python
"""
Given the name of a provider from cfme_data and using credentials from
the credentials stash, call the corresponding action on that provider, along
with any additional action arguments.
See cfme_pages/common/mgmt_system.py for documentation on the callable methods
themselves.
Example usage:
... | [
"sean.myers@redhat.com"
] | sean.myers@redhat.com |
4731da9d96c4ef1421303672f8b8b4c0f711c63d | d59bad348c88026e444c084e6e68733bb0211bc2 | /problema_arg_padrao_mutavel.py | 616a4efc8c311158f135deac65c9f0a80b8121e6 | [] | no_license | dersonf/udemy-python | f96ec883decb21a68233b2e158c82db1c8878c7a | 92471c607d8324902902774284f7ca81d2f25888 | refs/heads/master | 2022-09-25T00:18:49.833210 | 2020-06-05T18:18:38 | 2020-06-05T18:18:38 | 262,049,238 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 352 | py | #!/usr/bin/python3.6
def fibonacci(sequencia=[0, 1]):
# Uso de mutáveis como valor default (armadilha)
sequencia.append(sequencia[-1] + sequencia[-2])
return sequencia
if __name__ == '__main__':
inicio = fibonacci()
print(inicio, id(inicio))
print(fibonacci(inicio))
restart = fibonacci()
... | [
"anderson@ferneda.com.br"
] | anderson@ferneda.com.br |
a3a3312b93fd1130507887a28abc6e2859e972c6 | 6fcfb638fa725b6d21083ec54e3609fc1b287d9e | /python/Guanghan_ROLO/ROLO-master/update/utils/utils_draw_coord.py | cb75d7c64e6e32251001750fef1e6f67b093e62e | [] | no_license | LiuFang816/SALSTM_py_data | 6db258e51858aeff14af38898fef715b46980ac1 | d494b3041069d377d6a7a9c296a14334f2fa5acc | refs/heads/master | 2022-12-25T06:39:52.222097 | 2019-12-12T08:49:07 | 2019-12-12T08:49:07 | 227,546,525 | 10 | 7 | null | 2022-12-19T02:53:01 | 2019-12-12T07:29:39 | Python | UTF-8 | Python | false | false | 2,002 | py | from utils_convert_coord import coord_regular_to_decimal, coord_decimal_to_regular
import cv2
def debug_decimal_coord(img, coord_decimal, prob = None, class_id = None):
img_cp = img.copy()
img_ht, img_wid, nchannels = img.shape
coord_regular = coord_decimal_to_regular(coord_decimal, img_wid, img_ht)
... | [
"659338505@qq.com"
] | 659338505@qq.com |
e168407eb15bcececca9947e72682be0c3429267 | 47596e586b3e21b31cf360be7cd1c7d3a5dc6163 | /Google/trafficSnapshot.py | 2dd2859f31fd1a85b4610e8d672e415ce5a7e784 | [] | no_license | jasonlingo/RoadSafety | bfef06abe0668a9cb8ead5b183008a53eabdefa2 | b20af54b915daf7635204e3b942b3ae4624887d7 | refs/heads/master | 2021-03-19T13:51:13.736277 | 2015-09-17T03:49:43 | 2015-09-17T03:49:43 | 36,019,601 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,140 | py | import sys
import os
sys.path.append(os.path.join(os.path.dirname(__file__), '..'))
from GPS.GPSPoint import GPSPoint
from File.Directory import createDirectory
import webbrowser
from Google.findTimeZone import findTimeZone
from time import sleep
from PIL import Image
import datetime, pytz
from config import TRAFFIC_I... | [
"jasonlingo@gmail.com"
] | jasonlingo@gmail.com |
85ae65707ad634936086129bb17d2ebc16ab0115 | eef39fd96ef4ed289c1567f56fde936d5bc42ea4 | /BaekJoon/Bronze2/2744.py | 15ea7e4ea8c55e3f6546f94a24d170bd01b27fa9 | [] | no_license | dudwns9331/PythonStudy | 3e17da9417507da6a17744c72835c7c2febd4d2e | b99b9ef2453af405daadc6fbf585bb880d7652e1 | refs/heads/master | 2023-06-15T12:19:56.019844 | 2021-07-15T08:46:10 | 2021-07-15T08:46:10 | 324,196,430 | 4 | 0 | null | null | null | null | UTF-8 | Python | false | false | 753 | py | # 대소문자 바꾸기
"""
2021-01-20 오후 4:09
안영준
문제
영어 소문자와 대문자로 이루어진 단어를 입력받은 뒤, 대문자는 소문자로, 소문자는 대문자로 바꾸어 출력하는 프로그램을 작성하시오.
입력
첫째 줄에 영어 소문자와 대문자로만 이루어진 단어가 주어진다. 단어의 길이는 최대 100이다.
출력
첫째 줄에 입력으로 주어진 단어에서 대문자는 소문자로, 소문자는 대문자로 바꾼 단어를 출력한다.
"""
String = input()
result = list()
for i in range(len(String)):
if String[i].is... | [
"dudwns1045@naver.com"
] | dudwns1045@naver.com |
51ef475926c1fe3bb2fb1c490a227bcaa3740d0b | 21bd66da295baa48603ca9f169d870792e9db110 | /cgp/utils/failwith.py | 3647d91543301dbab771107a4c9d604d07544190 | [] | no_license | kristto/cgptoolbox | e6c01ccea1da06e35e26ffbca227258023377e48 | 8bbaf462e9c1320f237dd3c1ae6d899e1d01ade7 | refs/heads/master | 2021-01-16T20:38:45.097722 | 2012-03-01T09:18:10 | 2012-03-01T09:18:10 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 7,964 | py | """Modify a function to return a default value in case of error."""
from functools import wraps
import logging
from contextlib import contextmanager
import numpy as np
class NullHandler(logging.Handler):
def emit(self, record):
pass
logger = logging.getLogger("failwith")
logger.addHandler(N... | [
"jonovik@gmail.com"
] | jonovik@gmail.com |
c7cc769036318b5263632ef6db922b0a4ffa72cf | 0533d0ceb5966f7327f40d54bbd17e08e13d36bf | /python/HashMap/Maximum Number of Balloons/Maximum Number of Balloons.py | 485eee52af17f72c857b5f35d3beacd6b25b3591 | [] | no_license | danwaterfield/LeetCode-Solution | 0c6178952ca8ca879763a87db958ef98eb9c2c75 | d89ebad5305e4d1a185b0c6f101a88691602b523 | refs/heads/master | 2023-03-19T01:51:49.417877 | 2020-01-11T14:17:42 | 2020-01-11T14:17:42 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 262 | py | from collections import Counter
class Solution(object):
def maxNumberOfBalloons(self, text):
"""
:type text: str
:rtype: int
"""
c = Counter(text)
return min(c["b"], c["a"], c["l"] // 2, c["o"] // 2, c["n"])
| [
"zjuzjj@gmail.com"
] | zjuzjj@gmail.com |
3b5771126a3de74c7f3d369f13baba24a89456bb | 1b300019417ea1e25c59dd6f00fbffb60ec5a123 | /python/example/run_demo.py | 1bcd9cc24764d75872a145135941ce238fefc7d5 | [
"MIT"
] | permissive | Wendong-Huo/diff_stokes_flow | 9176210b162e9a8c7b9910274fe4c699814fa7d7 | 55eb7c0f3a9d58a50c1a09c2231177b81e0da84e | refs/heads/master | 2023-03-16T13:16:17.028974 | 2020-12-11T03:55:44 | 2020-12-11T03:55:44 | 576,797,332 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 7,729 | py | import sys
sys.path.append('../')
from pathlib import Path
import numpy as np
from importlib import import_module
import scipy.optimize
import time
import matplotlib.pyplot as plt
from tqdm import tqdm
import pickle
import os
from py_diff_stokes_flow.common.common import print_info, print_ok, print_error, print_warni... | [
"taodu@csail.mit.edu"
] | taodu@csail.mit.edu |
73dde30ee3e5e9b336b4af24f9c38c43d0e0cf60 | a5698f82064aade6af0f1da21f504a9ef8c9ac6e | /huaweicloud-sdk-cce/huaweicloudsdkcce/v3/region/cce_region.py | 8075aff2ddabc7a62cba30087f4176a99207fa16 | [
"Apache-2.0"
] | permissive | qizhidong/huaweicloud-sdk-python-v3 | 82a2046fbb7d62810984399abb2ca72b3b47fac6 | 6cdcf1da8b098427e58fc3335a387c14df7776d0 | refs/heads/master | 2023-04-06T02:58:15.175373 | 2021-03-30T10:47:29 | 2021-03-30T10:47:29 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,907 | py | # coding: utf-8
import types
from huaweicloudsdkcore.region.region import Region
class CceRegion:
def __init__(self):
pass
CN_NORTH_1 = Region(id="cn-north-1", endpoint="https://cce.cn-north-1.myhuaweicloud.com")
CN_NORTH_4 = Region(id="cn-north-4", endpoint="https://cce.cn-north-4.myhuaweiclo... | [
"hwcloudsdk@huawei.com"
] | hwcloudsdk@huawei.com |
dbbab268c0f12ac2bcfab7eab23967dd84e060e4 | 0252a277036b9ac7f95e5db3cad6c1a94b89c4ef | /eaif4_ws/build/turtlebot_apps/turtlebot_rapps/catkin_generated/pkg.installspace.context.pc.py | 5910a9329ceee27595e6b34e8f4452ce3011c710 | [] | no_license | maxwelldc/lidar_slam | 1e5af586cd2a908474fa29224b0d9f542923c131 | 560c8507ea1a47844f9ce6059f48937b0627967b | refs/heads/master | 2020-07-01T03:15:42.877900 | 2019-08-07T10:25:27 | 2019-08-07T10:25:27 | 201,025,062 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 378 | py | # generated from catkin/cmake/template/pkg.context.pc.in
CATKIN_PACKAGE_PREFIX = ""
PROJECT_PKG_CONFIG_INCLUDE_DIRS = "".split(';') if "" != "" else []
PROJECT_CATKIN_DEPENDS = "".replace(';', ' ')
PKG_CONFIG_LIBRARIES_WITH_PREFIX = "".split(';') if "" != "" else []
PROJECT_NAME = "turtlebot_rapps"
PROJECT_SPACE_DIR = ... | [
"374931377@qq.com"
] | 374931377@qq.com |
c42484aa0e251a858cba80f1b7cbda8c5b61ad40 | b6fa182321756b891b84958e2b2c01e63b3f88b2 | /stepik/product _of_numbers.py | 61d44cf81b636fd8b2f1484dd3cedb783f9c8444 | [] | no_license | carden-code/python | 872da0dff5466070153cf945c428f1bc8309ea2b | 64e4df0d9893255ad362a904bb5d9677a383591c | refs/heads/master | 2023-07-05T05:14:16.479392 | 2021-08-22T21:27:36 | 2021-08-22T21:27:36 | 305,476,509 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,546 | py | # Напишите программу для определения, является ли число произведением двух чисел из данного набора,
# выводящую результат в виде ответа «ДА» или «НЕТ».
#
# Формат входных данных
# В первой строке подаётся число n, (0 < n < 1000) – количество чисел в наборе.
# В последующих n строках вводятся целые числа, составляющие н... | [
"carden.ruby@gmail.com"
] | carden.ruby@gmail.com |
4c005fbd4e54f24c9b1a2f8d6364a336338e0c60 | 0fd5793e78e39adbfe9dcd733ef5e42390b8cc9a | /python3/19_Concurrency_and_Parallel_Programming/02_multiprocessing/example2.py | b775c924c64d2785f7f994c9c8c606e50a2ae97e | [] | no_license | udhayprakash/PythonMaterial | 3ea282ceb4492d94d401e3bc8bad9bf6e9cfa156 | e72f44e147141ebc9bf9ec126b70a5fcdbfbd076 | refs/heads/develop | 2023-07-08T21:07:33.154577 | 2023-07-03T10:53:25 | 2023-07-03T10:53:25 | 73,196,374 | 8 | 5 | null | 2023-05-26T09:59:17 | 2016-11-08T14:55:51 | Jupyter Notebook | UTF-8 | Python | false | false | 1,073 | py | import collections
import multiprocessing as mp
Msg = collections.namedtuple("Msg", ["event", "args"])
class BaseProcess(mp.Process):
"""A process backed by an internal queue for simple one-way message passing."""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.qu... | [
"uday3prakash@gmail.com"
] | uday3prakash@gmail.com |
f10cdd86dd40f18b8d7c02cf3eabfd28b6204cf2 | 9f61f361a545825dd6ff650c2d81bc4d035649bd | /tests/test_document.py | e95f63d807e367b91125f2d53fc4b1218a64b17d | [
"MIT"
] | permissive | cassj/dexy | 53c9e7ce3f601d9af678816397dcaa3a111ba670 | fddfeb4db68c362a4126f496dbd019f4639d07ba | refs/heads/master | 2020-12-25T11:52:35.144908 | 2011-06-05T20:52:52 | 2011-06-05T20:52:52 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,699 | py | from dexy.controller import Controller
from dexy.document import Document
from dexy.artifacts.file_system_json_artifact import FileSystemJsonArtifact
import os
def setup_controller():
controller = Controller()
controller.artifacts_dir = 'artifacts'
if not os.path.isdir(controller.artifacts_dir):
os... | [
"ana@ananelson.com"
] | ana@ananelson.com |
0d87632a4b2c03e675bb8726a5f7622be7f35e49 | 06e897ed3b6effc280eca3409907acc174cce0f5 | /plugins/pelican_unity_webgl/config.py | d7250678123196715136c46cfa982901234d38d6 | [
"LicenseRef-scancode-other-permissive",
"MIT",
"AGPL-3.0-only"
] | permissive | JackMcKew/jackmckew.dev | ae5a32da4f1b818333ae15c6380bca1329d38f1e | b5d68070b6f15677a183424c84e30440e128e1ea | refs/heads/main | 2023-09-02T14:42:19.010294 | 2023-08-15T22:08:19 | 2023-08-15T22:08:19 | 213,264,451 | 15 | 8 | MIT | 2023-02-14T21:50:28 | 2019-10-07T00:18:15 | JavaScript | UTF-8 | Python | false | false | 201 | py | # unity webgl options
DEFAULT_WIDTH = 960
DEFAULT_HEIGHT = 600
DEFAULT_ALIGN = "center"
# paths
GAMES_ROOT_DIR = "/games" # directory with games
TEMPLATE_PATH = "/games/utemplate" # template path
| [
"jackmckew2@gmail.com"
] | jackmckew2@gmail.com |
8418693b0b7f600bc206c9513a976a8685d46f52 | 7a7ed5656b3a162523ba0fd351dd551db99d5da8 | /x11/library/wayland/actions.py | 73d6d6bb7fcd4510e4e0b35f12090d0231dd9fe0 | [] | no_license | klaipedetis/PisiLinux | acd4953340ebf14533ea6798275b8780ad96303b | 3384e5dfa1acd68fa19a26a6fa1cf717136bc878 | refs/heads/master | 2021-01-24T22:59:30.055059 | 2013-11-08T21:43:39 | 2013-11-08T21:43:39 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 755 | py | #!/usr/bin/python
# -*- coding: utf-8 -*-
#
# Copyright 2010 TUBITAK/BILGEM
# Licensed under the GNU General Public License, version 2.
# See the file http://www.gnu.org/licenses/old-licenses/gpl-2.0.txt
from pisi.actionsapi import shelltools
from pisi.actionsapi import autotools
from pisi.actionsapi import pisitools
... | [
"namso-01@hotmail.it"
] | namso-01@hotmail.it |
85d65df06168b2114299f77d388cbe712b4b7085 | 458c487a30df1678e6d22ffdb2ea426238197c88 | /ubcsp/add_gc.py | e6be0db995f628f5c02f95391bfd50d28fde12ec | [
"MIT"
] | permissive | pluck992/ubc | 04062d2cdeef8d983da1bfaa0ff640a3b25c72c2 | 54fc89ae6141775321d5ea770e973ff09be51c0c | refs/heads/master | 2023-02-19T05:01:42.401329 | 2021-01-21T06:32:15 | 2021-01-21T06:32:15 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 939 | py | import pp
from gdslib import plot_circuit
from simphony.library import siepic
from simphony.netlist import Subcircuit
def add_gc_te(circuit, gc=siepic.ebeam_gc_te1550):
""" add input and output gratings
Args:
circuit: needs to have `input` and `output` pins
gc: grating coupler
"""
c =... | [
"j"
] | j |
c808420814784eb74158420818d1e193c2cff1fe | eed5c6267fe9ac9031c21eae6bc53010261505ac | /tests/metrics/test_default_metrics.py | 9609d6d88e052ff6a942b412ee06c84c93ff3b82 | [
"MIT"
] | permissive | voxmedia/thumbor | 3a07ae182143b5a850bf63c36887a1ee8e3ad617 | 29b92b69e4c241ddd5ba429f8269d775a1508e70 | refs/heads/master | 2022-08-25T13:07:12.136876 | 2022-08-18T16:15:00 | 2022-08-18T16:15:00 | 22,433,808 | 6 | 0 | MIT | 2019-09-13T18:05:03 | 2014-07-30T15:33:42 | Python | UTF-8 | Python | false | false | 1,049 | py | #!/usr/bin/python
# -*- coding: utf-8 -*-
# thumbor imaging service
# https://github.com/thumbor/thumbor/wiki
# Licensed under the MIT license:
# http://www.opensource.org/licenses/mit-license
# Copyright (c) 2011 globo.com thumbor@googlegroups.com
import mock
from preggy import expect
import thumbor.metrics
from t... | [
"rflorianobr@gmail.com"
] | rflorianobr@gmail.com |
8792f9fb40411dda7586be8db31e4e63b961154c | 2dd814284a1408706459e7dd6295a4575617c0c6 | /cupyx/scipy/special/digamma.py | af54d2a7fd9ec2e5072f91abcaa7fd7cf6a903c3 | [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
] | permissive | dendisuhubdy/cupy | 4e31c646fa697f69abbb07f424910cc8e5f0e595 | b612827e858b8008455a76e8d9b396386c1e4467 | refs/heads/master | 2021-01-23T10:56:45.639699 | 2018-07-12T17:41:26 | 2018-07-12T17:41:26 | 93,111,021 | 0 | 0 | MIT | 2019-12-09T06:55:54 | 2017-06-02T00:31:07 | Python | UTF-8 | Python | false | false | 4,681 | py | # This source code contains SciPy's code.
# https://github.com/scipy/scipy/blob/master/scipy/special/cephes/psi.c
#
#
# Cephes Math Library Release 2.8: June, 2000
# Copyright 1984, 1987, 1992, 2000 by Stephen L. Moshier
#
#
# Code for the rational approximation on [1, 2] is:
#
# (C) Copyright John Maddock 2006.
# Use... | [
"yoshikawa@preferred.jp"
] | yoshikawa@preferred.jp |
1fa1a301a80606168abdda73ff6ba0c7c75eb089 | 0c6c7365d6ff8b694bc906ec5f74c741e8bb0d37 | /Algorithms/1-Two-Sum.py | 5a8065a1ff799e35aa89d3fd7283348dbcfd26ad | [] | no_license | XiongQiuQiu/leetcode-slove | d58ab90caa250c86b7a1ade8b60c669821d77995 | 60f0da57b8ea4bfb937e2fe0afe3caea719cd7e4 | refs/heads/master | 2021-01-23T11:21:15.069080 | 2019-07-08T15:42:48 | 2019-07-08T15:42:48 | 93,133,558 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 696 | py | '''
Given an array of integers, return indices of the two numbers such that they add up to a specific target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0... | [
"zjw2goo@gmail.com"
] | zjw2goo@gmail.com |
9082848ae2d0cc2948f499a7e0d5ab47e3aea76a | 7109eecfb78e0123b534ef960dbf42be38e49514 | /x7-src/engine/engine/db/__init__.py | 092a2b6c0406d609cd15150f7c8c97faf8669621 | [
"Apache-2.0"
] | permissive | wendy-king/x7_compute_venv | a6eadd9a06717090acea3312feebcbc9d3925e88 | 12d74f15147868463954ebd4a8e66d5428b6f56d | refs/heads/master | 2016-09-06T16:58:13.897069 | 2012-01-31T01:26:27 | 2012-01-31T01:26:27 | 3,310,779 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 883 | py | # vim: tabstop=4 shiftwidth=4 softtabstop=4
# vim: tabstop=4 shiftwidth=4 softtabstop=4
# Copyright 2010 United States Government as represented by the
# Administrator of the National Aeronautics and Space Administration.
# All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"); you... | [
"king_wendy@sina.com"
] | king_wendy@sina.com |
aced241806907aec705128d3774a0a81da9b26ed | 6b2a8dd202fdce77c971c412717e305e1caaac51 | /solutions_5706278382862336_0/Python/neilw4/base.py | 6cd2e86d9431e61edda3533f65f23cfb2d36240a | [] | no_license | alexandraback/datacollection | 0bc67a9ace00abbc843f4912562f3a064992e0e9 | 076a7bc7693f3abf07bfdbdac838cb4ef65ccfcf | refs/heads/master | 2021-01-24T18:27:24.417992 | 2017-05-23T09:23:38 | 2017-05-23T09:23:38 | 84,313,442 | 2 | 4 | null | null | null | null | UTF-8 | Python | false | false | 1,035 | py | #!/usr/bin/python
import sys
def memo(f):
cache = {}
def memf(*x):
if not x in cache:
cache[x] = f(*x)
return cache[x]
return memf
def memo(*x):
if not x in cache:
cache[x] = f(*x)
return cache[x]
return memf
def valid(p, q, g):
return ... | [
"eewestman@gmail.com"
] | eewestman@gmail.com |
512f01a1261eb1c96485dc9c80c20b5d387c5e0a | 71ddc215db07f311e7028cedcaaaaa08b92d5022 | /how_to_find_in_list_int_float_str.py | 61b074edfa7607a79552fc823c11540059116f88 | [] | no_license | kabitakumari20/list_logical | 026a17e80c8feeeccf9f4141882eb6a31b80b082 | af86c6609a2b20f0019e0bd33e498ab34c546fbd | refs/heads/main | 2023-05-31T23:49:08.922831 | 2021-06-08T11:15:30 | 2021-06-08T11:15:30 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 358 | py | list=[2, 3.5,4.3,"hello world", 5, 4.3]
empty1=[]
empty2=[]
empty3=[]
i = 0
while i<len(list):
if list[i]==str(list[i]):
empty1.append(list[i])
elif list[i]==int(list[i]):
empty2.append(list[i])
elif list[i]==float(list[i]):
empty3.append(list[i])
else:
print(i)
i+=1
pri... | [
"kabita20@navgurukul.org"
] | kabita20@navgurukul.org |
fdba97aa3f723173a174712b445c40df7b64abcd | 3a642fa1fc158d3289358b53770cdb39e5893711 | /src/xlsxwriter/test/comparison/test_print_area02.py | 8dc1c8ed62b42654997cba02f26ba5b02274c02d | [] | no_license | andbar-ru/traceyourself.appspot.com | d461277a3e6f8c27a651a1435f3206d7b9307d9f | 5f0af16ba2727faceb6b7e1b98073cd7d3c60d4c | refs/heads/master | 2020-07-23T14:58:21.511328 | 2016-12-26T22:03:01 | 2016-12-26T22:03:01 | 73,806,841 | 1 | 1 | null | null | null | null | UTF-8 | Python | false | false | 1,906 | py | ###############################################################################
#
# Tests for XlsxWriter.
#
# Copyright (c), 2013, John McNamara, jmcnamara@cpan.org
#
import unittest
import os
from ...workbook import Workbook
from ..helperfunctions import _compare_xlsx_files
class TestCompareXLSXFiles(unittest.TestC... | [
"andrey@voktd-andbar.int.kronshtadt.ru"
] | andrey@voktd-andbar.int.kronshtadt.ru |
b468b68150bb6fd52e90e01fcf615bdf01f04f4b | 3b50605ffe45c412ee33de1ad0cadce2c5a25ca2 | /python/paddle/fluid/tests/unittests/test_dist_fleet_ps13.py | 58248d325b1452e0525f68f20276017e7ad7e814 | [
"Apache-2.0"
] | permissive | Superjomn/Paddle | f5f4072cf75ac9ecb0ff528876ee264b14bbf8d1 | 7a0b0dab8e58b6a3b28b3b82c43d55c9bd3d4188 | refs/heads/develop | 2023-02-04T20:27:54.244843 | 2023-01-26T15:31:14 | 2023-01-26T15:31:14 | 66,896,049 | 4 | 1 | Apache-2.0 | 2023-04-14T02:29:52 | 2016-08-30T01:45:54 | C++ | UTF-8 | Python | false | false | 6,958 | py | # Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by app... | [
"noreply@github.com"
] | Superjomn.noreply@github.com |
7ed4c2eb2c224f3d1a91789faff26ab73a083d63 | 6821339070e85305875633abca1c3d6c90881ede | /flaskWeb/flask_demo/blue_print/index.py | ebd3377ee3bac19028f4335aaccdf5e7338cc9be | [] | no_license | Abel-Fan/uaif1901 | 07cda7ea5675ec52ae92c0021f713951c62bd198 | f6d81a44b658e61b2c3ae6b4b604faebc1fb136a | refs/heads/master | 2020-05-03T01:05:46.289805 | 2019-04-30T10:16:53 | 2019-04-30T10:16:53 | 178,328,172 | 2 | 2 | null | null | null | null | UTF-8 | Python | false | false | 662 | py | from flask import Blueprint,render_template
from flaskWeb.flask_demo.db.connectdb import database,cursor
from flaskWeb.flask_demo.settings import INDEX_STATIC
indexblue = Blueprint("index",__name__,url_prefix="/")
@indexblue.route("/",methods=["GET"])
def index():
data = {}
sql = "select * from produces limit... | [
"842615663@qq.com"
] | 842615663@qq.com |
1d2fcfdd3bd3561748484b153ccd79db0d2f6603 | ca850269e513b74fce76847310bed143f95b1d10 | /build/navigation/move_slow_and_clear/catkin_generated/pkg.installspace.context.pc.py | e8dee1765968cad46f6536a7c38fe58f630c2d73 | [] | no_license | dvij542/RISS-2level-pathplanning-control | f98f2c83f70c2894d3c248630159ea86df8b08eb | 18390c5ab967e8649b9dc83681e9090a37f3d018 | refs/heads/main | 2023-06-15T03:58:25.293401 | 2021-06-20T20:20:30 | 2021-06-20T20:20:30 | 368,553,169 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 501 | py | # generated from catkin/cmake/template/pkg.context.pc.in
CATKIN_PACKAGE_PREFIX = ""
PROJECT_PKG_CONFIG_INCLUDE_DIRS = "${prefix}/include".split(';') if "${prefix}/include" != "" else []
PROJECT_CATKIN_DEPENDS = "geometry_msgs;nav_core;pluginlib;roscpp".replace(';', ' ')
PKG_CONFIG_LIBRARIES_WITH_PREFIX = "-lmove_slow_a... | [
"dvij.kalaria@gmail.com"
] | dvij.kalaria@gmail.com |
2bce411c35e912e6ed7c250789f2f2259956fe8f | 6679fd1102802bf190294ef43c434b6047840dc2 | /openconfig_bindings/bgp/global_/afi_safis/afi_safi/l2vpn_vpls/prefix_limit/__init__.py | 912ccb145ff12843af0245b01ed67e1ee0f21e7d | [] | no_license | robshakir/pyangbind-openconfig-napalm | d49a26fc7e38bbdb0419c7ad1fbc590b8e4b633e | 907979dc14f1578f4bbfb1c1fb80a2facf03773c | refs/heads/master | 2023-06-13T17:17:27.612248 | 2016-05-10T16:46:58 | 2016-05-10T16:46:58 | 58,091,515 | 5 | 0 | null | null | null | null | UTF-8 | Python | false | false | 7,217 | py |
from operator import attrgetter
import pyangbind.lib.xpathhelper as xpathhelper
from pyangbind.lib.yangtypes import RestrictedPrecisionDecimalType, RestrictedClassType, TypedListType
from pyangbind.lib.yangtypes import YANGBool, YANGListType, YANGDynClass, ReferenceType
from pyangbind.lib.base import PybindBase
from d... | [
"rjs@jive.com"
] | rjs@jive.com |
7111ddfb6acf2732a7fac3581369ead18f23ff53 | 109ac2988a85c85ce0d734b788caca1c3177413b | /senlin/tests/__init__.py | 1634fd8f1ae8335f9341c3e1fcb454027b088cb8 | [
"Apache-2.0"
] | permissive | tengqm/senlin | 481c16e19bc13911625d44819c6461a7c72e41cd | aa59c55c098abb13590bc4308c753338ce4a70f4 | refs/heads/master | 2021-01-19T04:51:17.010414 | 2015-03-16T10:06:09 | 2015-03-16T10:06:09 | 28,478,662 | 2 | 5 | null | 2015-03-04T07:05:00 | 2014-12-25T10:22:18 | Python | UTF-8 | Python | false | false | 912 | py | # Licensed under the Apache License, Version 2.0 (the "License"); you may
# not use this file except in compliance with the License. You may obtain
# a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed unde... | [
"tengqim@cn.ibm.com"
] | tengqim@cn.ibm.com |
4ad44bcde9b6556481cdb983363a5b9757ecef01 | e1b09ae83920656b20cad0e84f21b741752e926d | /sams/check_dupl_def2.py | 29943740c0b63b607eb174d6f368341eced7c57f | [] | no_license | yeongsun/cute | 5c46729d43f13967cdf4bda0edd100362de90c70 | 3150d7387c04c15e3569dc821562564cd8f9d87c | refs/heads/master | 2020-04-25T10:38:41.833479 | 2018-11-29T05:42:46 | 2018-11-29T05:42:46 | 156,344,910 | 0 | 0 | null | 2018-11-06T07:41:03 | 2018-11-06T07:41:03 | null | UTF-8 | Python | false | false | 2,231 | py | import os, sys
import logging
import concurrent.futures
import ys_logger
sys.path.append(os.path.abspath('..'))
logger = logging.getLogger('root')
logger.setLevel("INFO")
logger.addHandler(ys_logger.MyHandler())
logger.info("Finish setting logger")
class check_dupl_conc():
def __init__(self):
... | [
"ylunar@naver.com"
] | ylunar@naver.com |
a868f06ffc94c8e8f5374027fa9157e9edf75fed | 9d5ae8cc5f53f5aee7247be69142d9118769d395 | /582. Kill Process.py | f6d2712a589e4d1bded42a8fccb55a00c2de168e | [] | no_license | BITMystery/leetcode-journey | d4c93319bb555a7e47e62b8b974a2f77578bc760 | 616939d1599b5a135747b0c4dd1f989974835f40 | refs/heads/master | 2020-05-24T08:15:30.207996 | 2017-10-21T06:33:17 | 2017-10-21T06:33:17 | 84,839,304 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 627 | py | class Solution(object):
def killProcess(self, pid, ppid, kill):
"""
:type pid: List[int]
:type ppid: List[int]
:type kill: int
:rtype: List[int]
"""
d = {}
for i in xrange(len(ppid)):
if ppid[i] in d:
d[ppid[i]] += [pid[i]]
... | [
"noreply@github.com"
] | BITMystery.noreply@github.com |
c462013ed3ab5ba561d890a7be8d9df5ed9bdf6f | c362623e7bd0d656ad3a5a87cff8c2f2f4d64c30 | /example/wikidocs_exam_11_20.py | b96e7d53b878744a881b52ea3ed6b05932a6a7b8 | [] | no_license | bbster/PracticeAlgorithm | 92ce418e974e4be8e95b0878b2e349bf8438de5f | 171fa1880fb2635c5bac55c18a6981a656470292 | refs/heads/master | 2021-07-10T16:17:24.088996 | 2020-12-09T10:47:46 | 2020-12-09T10:47:46 | 222,721,632 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,257 | py | # https://wikidocs.net/7014
# 011
삼성전자 = 50000
print("평가금액", 삼성전자 * 10)
# 012
시가총액 = 298000000000
현재가 = 50000
PER = 15.79
print("시가총액:", 시가총액, "현재가:", 현재가, "PER:", PER)
# 답안지
# 시가총액 = 298000000000000
# 현재가 = 5000
# PER = 15.79
# print(시가총액, type(시가총액))
# print(현재가, type(현재가))
# print(PER, type(PER))
# type(변수) - 변수... | [
"bbster12@naver.com"
] | bbster12@naver.com |
3b0d6a8455a25f85ab87e64585230366a5e647bc | 6b2a8dd202fdce77c971c412717e305e1caaac51 | /solutions_5744014401732608_0/Python/veluca/sol.py | bd10179fcb95ce05a54755b6ee878bca104f9dda | [] | no_license | alexandraback/datacollection | 0bc67a9ace00abbc843f4912562f3a064992e0e9 | 076a7bc7693f3abf07bfdbdac838cb4ef65ccfcf | refs/heads/master | 2021-01-24T18:27:24.417992 | 2017-05-23T09:23:38 | 2017-05-23T09:23:38 | 84,313,442 | 2 | 4 | null | null | null | null | UTF-8 | Python | false | false | 581 | py | #!/usr/bin/env pypy3
import sys
def solve():
B, M = map(int, input().split())
if M > 2**(B-2):
return "IMPOSSIBLE"
sol = [['0' for i in range(B)] for i in range(B)]
for i in range(B-1):
for j in range(0, i):
sol[j][i] = '1'
if M == 2**(B-2):
sol[0][B-1] = '1'
... | [
"alexandra1.back@gmail.com"
] | alexandra1.back@gmail.com |
2ed301967dcb7f052a8c51f56ef1b0bdc1ca357e | fa54359c670fd9d4db543505819ce26481dbcad8 | /setup.py | 4d01cb7c22b59ecad2520a5c62baf9bba188d3c2 | [
"MIT"
] | permissive | masasin/decorating | 4b961e7b2201b84a1cf0553c65e4d0c0768723d5 | c19bc19b30eea751409f727b03e156123df704e1 | refs/heads/master | 2021-01-20T16:35:43.333543 | 2016-05-18T08:22:48 | 2016-05-18T08:22:48 | 59,138,136 | 0 | 0 | null | 2016-05-18T17:43:23 | 2016-05-18T17:43:23 | null | UTF-8 | Python | false | false | 2,158 | py | #!/usr/bin/env python
# coding=utf-8
#
# Python Script
#
# Copyright © Manoel Vilela
#
#
from setuptools import setup, find_packages
from codecs import open # To use a consistent encoding
from os import path
from warnings import warn
import decorating
try:
import pypandoc
except ImportError:
warn("Only-f... | [
"manoel_vilela@engineer.com"
] | manoel_vilela@engineer.com |
8939aa5cea12440890c866f83eaff3e3468a5fb9 | 9c79c683196e0d42b41a831a6e37bb520a75e269 | /bin/read_csv.py | cd747d2de7527220c0d51ccbc09642e1e551c460 | [] | no_license | YutingYao/crater_lakes | 7714cf64cd3649bd93b2c3cafcc8c73b4a3ff05b | b57ac0c18ce37b0f71f59fc8d254fa12890090ee | refs/heads/master | 2023-05-14T08:45:02.290369 | 2017-05-13T00:55:48 | 2017-05-13T00:55:48 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 710 | py | #!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
read_csv.py
Created on Fri Feb 10 08:48:07 2017
@author: sam
"""
import os
import pandas as pd
import numpy as np
import datetime
def read_csv(target):
try:
os.chdir('/home/sam/git/crater_lakes/atmcorr/results/'+target)
df = pd.read_csv(target+'.cs... | [
"samsammurphy@gmail.com"
] | samsammurphy@gmail.com |
f16bb51a8835137aba50c21bb060c677a7604e02 | 9743d5fd24822f79c156ad112229e25adb9ed6f6 | /xai/brain/wordbase/otherforms/_musses.py | b1ce3e681289e77be9498786f527b925bf9b01de | [
"MIT"
] | permissive | cash2one/xai | de7adad1758f50dd6786bf0111e71a903f039b64 | e76f12c9f4dcf3ac1c7c08b0cc8844c0b0a104b6 | refs/heads/master | 2021-01-19T12:33:54.964379 | 2017-01-28T02:00:50 | 2017-01-28T02:00:50 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 216 | py |
#calss header
class _MUSSES():
def __init__(self,):
self.name = "MUSSES"
self.definitions = muss
self.parents = []
self.childen = []
self.properties = []
self.jsondata = {}
self.basic = ['muss']
| [
"xingwang1991@gmail.com"
] | xingwang1991@gmail.com |
6b55598316455e43f008e4b6dad8851ba4ed3aa7 | e9a3f4a6f8828597dae8af8ea318b444af1798ba | /mag_ng/users/migrations/0003_auto_20200818_0517.py | f4d959172de433cee25454c2887bbea24208b12e | [] | no_license | kinsomaz/Online-Magazine-Website | c4a0b3b067a28202763a3646e02db9355e2e98a7 | dbb02225af2202913ea7dcc076f5af0052db117c | refs/heads/master | 2022-12-04T00:46:31.619920 | 2020-08-21T12:53:58 | 2020-08-21T12:53:58 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 426 | py | # Generated by Django 3.1 on 2020-08-18 04:17
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('users', '0002_auto_20200818_0506'),
]
operations = [
migrations.AlterField(
model_name='customuser',
name='username',
... | [
"alameenraji31@gmail.com"
] | alameenraji31@gmail.com |
30dbf2c9ddf45492b2c4906ac69c6fdaf6cf3b0c | 9547f82dc5a81bdc19ba5442d41518a81b518825 | /consecucion_traspaso/models.py | e3468724b015cae28f71774b7f879788abe68b5d | [] | no_license | luisfarfan/capacitacion | 12784f95564eda1dc38dc22aa518b99d4b315c75 | c93e4502476c02bb3755a68d84404453b2c2dd81 | refs/heads/master | 2021-01-11T04:17:15.476849 | 2017-02-14T01:13:27 | 2017-02-14T01:13:27 | 71,189,018 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,823 | py | from __future__ import unicode_literals
from django.db import models
# Create your models here.
class PersonalCapacitacion(models.Model):
id_per = models.IntegerField(primary_key=True)
dni = models.CharField(max_length=8, blank=True, null=True)
ape_paterno = models.CharField(max_length=100, blank=True, n... | [
"lucho.farfan9@gmail.com"
] | lucho.farfan9@gmail.com |
6fae34308cd664decc0ad86974d5ad045c8d9d68 | 7af5288111965b8bbcdfcd21fcf9db1f2e886741 | /point_to_path_measurement.py | 742e4e4ebcc00750b26d9257ebc1950227237cc5 | [] | no_license | GeoTecINIT/CyclingPathAnalysis | fc65b506da5f9365ed1fa7595fa3e16a3e54c581 | fb54af19b6dd217ffd224b4ec87e18ab8045c35e | refs/heads/master | 2020-03-14T02:39:14.968754 | 2018-04-27T17:11:56 | 2018-04-27T17:11:56 | 131,403,393 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 7,722 | py | """
This script allow us to convert a list of coordinates into a string geometry
It does not consider the information of trips
It just considers location, distance and time
Author: Diego Pajarito
"""
import datetime
import data_setup as data
import geojson
from LatLon import LatLon, Latitude, Longitude
from geojson i... | [
"diegopajarito@gmail.com"
] | diegopajarito@gmail.com |
77160378e0aff096aa646eaca4addb171b24a317 | 59de7788673ade984b9c9fbc33664a7cbdba67d3 | /res_bw/scripts/common/lib/encodings/hz.py | fc3d801e512648fcedb54a7c040b1b2914c9941b | [] | no_license | webiumsk/WOT-0.9.15-CT | 3fa24ab37a6c91b7073034afb2f355efa5b7fe36 | fbd194fbaa6bdece51c7a68fc35bbb5257948341 | refs/heads/master | 2020-12-24T21:27:23.175774 | 2016-05-01T13:47:44 | 2016-05-01T13:47:44 | 57,600,180 | 0 | 0 | null | null | null | null | WINDOWS-1250 | Python | false | false | 1,131 | py | # 2016.05.01 15:29:55 Střední Evropa (letní čas)
# Embedded file name: scripts/common/Lib/encodings/hz.py
import _codecs_cn, codecs
import _multibytecodec as mbc
codec = _codecs_cn.getcodec('hz')
class Codec(codecs.Codec):
encode = codec.encode
decode = codec.decode
class IncrementalEncoder(mbc.MultibyteIncr... | [
"info@webium.sk"
] | info@webium.sk |
3544578b5eba352958bb896b645b4312ea39834f | 769c8cac5aea3c9cb1e7eeafb1e37dbe9ea4d649 | /TaskScheduler/hotel_list_task.py | 0bee18d0d9cf36192d1c2f1f2dd5ddf676443a6a | [] | no_license | 20113261/p_m | f0b93b516e4c377aaf8b1741671759822ee0ec1a | ca7713de005c4c10e5cae547851a38a13211b71d | refs/heads/master | 2020-03-20T01:03:29.785618 | 2018-03-17T11:06:49 | 2018-03-17T11:06:49 | 137,065,177 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 963 | py | #!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/7/11 下午5:30
# @Author : Hou Rong
# @Site :
# @File : hotel_list_task.py
# @Software: PyCharm
import Common.DateRange
import dataset
from Common.DateRange import dates_tasks
from TaskScheduler.TaskInsert import InsertTask
Common.DateRange.DATE_FORM... | [
"nmghr9@gmail.com"
] | nmghr9@gmail.com |
004867de305d55875c7b5d8dc93e22bff54fff86 | 10ddfb2d43a8ec5d47ce35dc0b8acf4fd58dea94 | /Python/restore-the-array-from-adjacent-pairs.py | 91aa1ba0ebb1c185e6625d0352c4f6985e14a576 | [
"MIT"
] | permissive | kamyu104/LeetCode-Solutions | f54822059405ef4df737d2e9898b024f051fd525 | 4dc4e6642dc92f1983c13564cc0fd99917cab358 | refs/heads/master | 2023-09-02T13:48:26.830566 | 2023-08-28T10:11:12 | 2023-08-28T10:11:12 | 152,631,182 | 4,549 | 1,651 | MIT | 2023-05-31T06:10:33 | 2018-10-11T17:38:35 | C++ | UTF-8 | Python | false | false | 571 | py | # Time: O(n)
# Space: O(n)
import collections
class Solution(object):
def restoreArray(self, adjacentPairs):
"""
:type adjacentPairs: List[List[int]]
:rtype: List[int]
"""
adj = collections.defaultdict(list)
for u, v in adjacentPairs:
adj[u].append(v)... | [
"noreply@github.com"
] | kamyu104.noreply@github.com |
105947379a933fb3d9c7594e0f9ee5edef5ec989 | 659836ef3a9ac558538b016dbf4e128aa975ae7c | /backend/ingredient/models.py | ba8262719d98f47795c66d3d2646c01dcfba676b | [] | no_license | zzerii/save_your_ingredients | fda1c769d158bca9dfd3c28ac9ff34ed7ae4e6a3 | 5ebde82255c1a6edf0c19d9032015d05c9d0abc9 | refs/heads/master | 2023-02-21T22:19:28.954594 | 2021-01-22T11:39:16 | 2021-01-22T11:39:16 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 223 | py | from django.db import models
# Create your models here.
class Ingredient(models.Model):
name = models.CharField(max_length=255)
info = models.CharField(max_length=255)
trim = models.CharField(max_length=255)
| [
"jinsoo941010@naver.com"
] | jinsoo941010@naver.com |
7ac936ecd5083f62b8a3b206f7e560a01d51ac58 | e0a9dcd4f53aa6bf4472efe451e226663212abda | /core/execute.py | d8d444c3f1a16fa7af00f3de0f4f8ca5d7541d09 | [] | no_license | dilawar/ghonchu | f0505dce8ba76402e7c58c7fc4efd0412ce3503a | 5527b4d444f113b0ab51f758fc809e8ab81c5a72 | refs/heads/master | 2016-09-02T05:33:07.167106 | 2014-12-12T12:07:50 | 2014-12-12T12:07:50 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 515 | py |
"""execute.py: Execute core action.
Last modified: Sat Jan 18, 2014 05:01PM
"""
__author__ = "Dilawar Singh"
__copyright__ = "Copyright 2013, Dilawar Singh and NCBS Bangalore"
__credits__ = ["NCBS Bangalore"]
__license__ = "GNU GPL"
__version__ = "1.0.0"
__maintainer... | [
"dilawars@ncbs.res.in"
] | dilawars@ncbs.res.in |
9116fbcd17562627c4d5504fdc5b28015b3d830d | 6fe2d3c27c4cb498b7ad6d9411cc8fa69f4a38f8 | /algorithms/algorithms-python/leetcode/Question_111_Minimum_Depth_of_Binary_Tree.py | 20e53e489f88b9f32c07604bd8be49b4895f2660 | [] | no_license | Lanceolata/code | aae54af632a212c878ce45b11dab919bba55bcb3 | f7d5a7de27c3cc8a7a4abf63eab9ff9b21d512fb | refs/heads/master | 2022-09-01T04:26:56.190829 | 2021-07-29T05:14:40 | 2021-07-29T05:14:40 | 87,202,214 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 566 | py | #!/usr/bin/python
# coding: utf-8
from TreeNode import *
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def minDepth(self, root):
"""
:type root: Tree... | [
"lanceolatayuan@gmail.com"
] | lanceolatayuan@gmail.com |
aa893b07c3613f505969019869fe7e5913d60a10 | 8634b4f7f2293bf431ba8ed59e95f80abc59483f | /Homework/10/orderdict.py | fae771bb2e90cba4047e19dc516c8e03b0f7b948 | [] | no_license | TitanVA/Metiz | e1e2dca42118f660356254c39c7fadc47f772719 | e54f10b98226e102a5bb1eeda7f1e1eb30587c32 | refs/heads/master | 2020-12-22T11:44:58.746055 | 2020-02-10T14:41:16 | 2020-02-10T14:41:16 | 236,770,476 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 358 | py | from _collections import OrderedDict
favorite_languages = OrderedDict()
favorite_languages['jen'] = 'python'
favorite_languages['sarah'] = 'c'
favorite_languages['edward'] = 'ruby'
favorite_languages['phil'] = 'python'
for name, language in favorite_languages.items():
print(name.title() + '\'s favorite language i... | [
"viktorbezai@gmail.com"
] | viktorbezai@gmail.com |
d86da89a7837039de5cc9432332391c1929d6f86 | d2e8ad203a37b534a113d4f0d4dd51d9aeae382a | /django_graphene_authentication/django_graphene_authentication/signals.py | 47adcc189eddf36fa915f1ac41f05cdf7b2ebd8f | [
"MIT"
] | permissive | Koldar/django-koldar-common-apps | 40e24a7aae78973fa28ca411e2a32cb4b2f4dbbf | 06e6bb103d22f1f6522e97c05ff8931413c69f19 | refs/heads/main | 2023-08-17T11:44:34.631914 | 2021-10-08T12:40:40 | 2021-10-08T12:40:40 | 372,714,560 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 226 | py | from django.dispatch import Signal
# providing_args=['request', 'refresh_token']
refresh_token_revoked = Signal()
# providing_args=['request', 'refresh_token', 'refresh_token_issued']
refresh_token_rotated = Signal()
| [
"massimobono1@gmail.com"
] | massimobono1@gmail.com |
9eb53df032e3c06138e6c43f5b306169140d64a0 | f445450ac693b466ca20b42f1ac82071d32dd991 | /generated_tempdir_2019_09_15_163300/generated_part006719.py | 42aa4358fcc37db511e0345b6fdde91a2bd9246d | [] | no_license | Upabjojr/rubi_generated | 76e43cbafe70b4e1516fb761cabd9e5257691374 | cd35e9e51722b04fb159ada3d5811d62a423e429 | refs/heads/master | 2020-07-25T17:26:19.227918 | 2019-09-15T15:41:48 | 2019-09-15T15:41:48 | 208,357,412 | 4 | 1 | null | null | null | null | UTF-8 | Python | false | false | 1,596 | py | from sympy.abc import *
from matchpy.matching.many_to_one import CommutativeMatcher
from matchpy import *
from matchpy.utils import VariableWithCount
from collections import deque
from multiset import Multiset
from sympy.integrals.rubi.constraints import *
from sympy.integrals.rubi.utility_function import *
from sympy.... | [
"franz.bonazzi@gmail.com"
] | franz.bonazzi@gmail.com |
754d441707341b8ba8d827ed526ecce1b52c54ed | fd4dd0ce51eb1c9206d5c1c29d6726fc5f2cb122 | /src/kafka_consumer.py | 2c15842317f104c1081a9e44920ee8bec1234986 | [] | no_license | kbaseapps/relation_engine_sync | 0a9ae11326245b98bd173d77203ff49ccd222165 | def99d329d0d4101f3864e21a3e1a6ecb34fa6e0 | refs/heads/master | 2020-04-12T13:07:27.771094 | 2019-08-05T23:53:50 | 2019-08-05T23:53:50 | 162,512,534 | 0 | 0 | null | 2019-08-05T23:53:51 | 2018-12-20T01:56:13 | Python | UTF-8 | Python | false | false | 3,996 | py | """
Consume workspace update events from kafka.
"""
import json
import traceback
from confluent_kafka import Consumer, KafkaError
from src.utils.logger import log
from src.utils.config import get_config
from src.utils.workspace_client import download_info
from src.utils.re_client import check_doc_existence
from src.im... | [
"jayrbolton@gmail.com"
] | jayrbolton@gmail.com |
cccac8d820d9d534647989e6cfc573f5a94e1876 | 5c15aba2bdcd4348c988245f59817cbe71b87749 | /src/trial.py | 00cd0826415c55ab5e87e90071586c86ffae075a | [] | no_license | chengshaozhe/commitmentBenefits | f7db038333ee95217713d1d4b2a1fb3d0c295fdd | 0388803960bc9995ffbcfb6435c134e488a98b63 | refs/heads/master | 2023-03-27T02:31:01.522997 | 2021-01-12T10:18:12 | 2021-01-12T10:18:12 | 310,592,303 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 6,356 | py | import numpy as np
import pygame as pg
from pygame import time
import collections as co
import pickle
import random
def calculateGridDis(grid1, grid2):
gridDis = np.linalg.norm(np.array(grid1) - np.array(grid2), ord=1)
return int(gridDis)
def creatRect(coor1, coor2):
vector = np.array(list(zip(coor1, co... | [
"shaozhecheng@outlook.com"
] | shaozhecheng@outlook.com |
797a8815744350425e025a5f0309849676b9691c | e27333261b8e579564016c71d2061cc33972a8b8 | /.history/api/IR_engine_20210728213929.py | ddcc939eb070ba750cc5357a2d6a5aa401fe3e9a | [] | no_license | Dustyik/NewsTweet_InformationRetrieval | 882e63dd20bc9101cbf48afa6c3302febf1989b1 | d9a6d92b51c288f5bcd21ea1cc54772910fa58f7 | refs/heads/master | 2023-07-01T09:12:53.215563 | 2021-08-12T08:28:33 | 2021-08-12T08:28:33 | 382,780,359 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 6,136 | py | import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.metrics.pairwise import euclidean_distances
from nltk.stem import PorterStemmer
from nltk.tok... | [
"chiayik_tan@mymail.sutd.edu.sg"
] | chiayik_tan@mymail.sutd.edu.sg |
3f27767e32d95a71d36747e6db0b0d8e9bfabfc9 | f0a65d21d5ba16888f131fe99ed8baf0a85cf7dd | /pygmsh/volume_base.py | d3a22878fde32ff32a8b8924022e7a8096963a9b | [
"MIT"
] | permissive | mjredmond/pygmsh | d4a1e4e418af931eccbe73db01813a70efc2924a | 972e1164d77ecbf6c2b50b93fec9dc48c8d913e6 | refs/heads/master | 2021-01-19T07:52:53.057151 | 2017-04-06T09:48:21 | 2017-04-06T09:48:21 | 87,581,937 | 0 | 0 | null | 2017-04-07T19:52:56 | 2017-04-07T19:52:56 | null | UTF-8 | Python | false | false | 246 | py | # -*- coding: utf-8 -*-
#
class VolumeBase(object):
_ID = 0
def __init__(self, id=None):
if id:
self.id = id
else:
self.id = 'v%d' % VolumeBase._ID
VolumeBase._ID += 1
return
| [
"nico.schloemer@gmail.com"
] | nico.schloemer@gmail.com |
c1396ab21dabc56b8319ae076980db2b18e388c6 | e2e7b6ae6f8897a75aaa960ed36bd90aa0743710 | /swagger_client/models/post_deployment.py | 2e5931f02a8d25c5931c6afa88ad097e5ca01832 | [
"Apache-2.0"
] | permissive | radon-h2020/radon-ctt-cli | 36912822bc8d76d52b00ea657ed01b8bfcc5056f | 3120b748c73e99d81d0cac5037e393229577d640 | refs/heads/master | 2023-08-19T10:54:01.517243 | 2021-09-15T15:38:51 | 2021-09-15T15:38:51 | 299,571,330 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,461 | py | # coding: utf-8
"""
RADON CTT Server API
This is API of the RADON Continuous Testing Tool (CTT) Server: <a href=\"https://github.com/radon-h2020/radon-ctt\">https://github.com/radon-h2020/radon-ctt<a/> # noqa: E501
OpenAPI spec version: 1.0.0-oas3
Generated by: https://github.com/swagger-api/sw... | [
"duellmann@iste.uni-stuttgart.de"
] | duellmann@iste.uni-stuttgart.de |
a4e16aa3029986e19186a08d10ba6756a749ef85 | 865bd5e42a4299f78c5e23b5db2bdba2d848ab1d | /Python/75.sort-colors.132268888.ac.python3.py | 420999a7c4e65d780fb46607f6690cc3de47a52b | [] | no_license | zhiymatt/Leetcode | 53f02834fc636bfe559393e9d98c2202b52528e1 | 3a965faee2c9b0ae507991b4d9b81ed0e4912f05 | refs/heads/master | 2020-03-09T08:57:01.796799 | 2018-05-08T22:01:38 | 2018-05-08T22:01:38 | 128,700,683 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 1,386 | py | #
# [75] Sort Colors
#
# https://leetcode.com/problems/sort-colors/description/
#
# algorithms
# Medium (38.90%)
# Total Accepted: 217.5K
# Total Submissions: 559.1K
# Testcase Example: '[0]'
#
#
# Given an array with n objects colored red, white or blue, sort them so that
# objects of the same color are adjacent,... | [
"miylolmiy@gmail.com"
] | miylolmiy@gmail.com |
a100678014c55766c07b94ae81cf67b691c11c59 | ac5e52a3fc52dde58d208746cddabef2e378119e | /exps-sblp/sblp_ut=3.5_rd=1_rw=0.04_rn=4_u=0.075-0.325_p=harmonic-2/sched=RUN_trial=6/sched.py | 3605875026286563e51a9292de1d94125c66f6dc | [] | no_license | ricardobtxr/experiment-scripts | 1e2abfcd94fb0ef5a56c5d7dffddfe814752eef1 | 7bcebff7ac2f2822423f211f1162cd017a18babb | refs/heads/master | 2023-04-09T02:37:41.466794 | 2021-04-25T03:27:16 | 2021-04-25T03:27:16 | 358,926,457 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 529 | py | -S 1 -X RUN -Q 0 -L 2 106 400
-S 0 -X RUN -Q 0 -L 2 86 400
-S 0 -X RUN -Q 0 -L 2 74 250
-S 0 -X RUN -Q 0 -L 2 59 250
-S 2 -X RUN -Q 1 -L 1 54 200
-S 3 -X RUN -Q 1 -L 1 44 175
-S 2 -X RUN -Q 1 -L 1 40 200
-S 2 -X RUN -Q 1 -L 1 37 125
-S 4 -X RUN -Q 2 -L 1 35 125
-S 4 -X RUN -Q 2 -L ... | [
"ricardo.btxr@gmail.com"
] | ricardo.btxr@gmail.com |
f55df027f5a380a2302722b0a432c76857f85315 | a1a43879a2da109d9fe8d9a75f4fda73f0d7166b | /api/tests/equal_all.py | 1f1a1f3cf9a2c23dd214b96ee1e53b5c0fc00069 | [] | no_license | PaddlePaddle/benchmark | a3ed62841598d079529c7440367385fc883835aa | f0e0a303e9af29abb2e86e8918c102b152a37883 | refs/heads/master | 2023-09-01T13:11:09.892877 | 2023-08-21T09:32:49 | 2023-08-21T09:32:49 | 173,032,424 | 78 | 352 | null | 2023-09-14T05:13:08 | 2019-02-28T03:14:16 | Python | UTF-8 | Python | false | false | 1,661 | py | # Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by app... | [
"noreply@github.com"
] | PaddlePaddle.noreply@github.com |
6153ed244acbd1deac19c433cbd01c43350d4ff4 | f0d713996eb095bcdc701f3fab0a8110b8541cbb | /2gFkEsAqNZrs4yeck_13.py | 0e96182a63f5aad185cacd1b5bcad33ff13d32f2 | [] | no_license | daniel-reich/turbo-robot | feda6c0523bb83ab8954b6d06302bfec5b16ebdf | a7a25c63097674c0a81675eed7e6b763785f1c41 | refs/heads/main | 2023-03-26T01:55:14.210264 | 2021-03-23T16:08:01 | 2021-03-23T16:08:01 | 350,773,815 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 696 | py | """
Write a function that returns all the elements in an array that are **strictly
greater** than their adjacent left and right neighbors.
### Examples
mini_peaks([4, 5, 2, 1, 4, 9, 7, 2]) ➞ [5, 9]
# 5 has neighbours 4 and 2, both are less than 5.
mini_peaks([1, 2, 1, 1, 3, 2, 5, 4, 4]) ➞ [2, 3, 5... | [
"daniel.reich@danielreichs-MacBook-Pro.local"
] | daniel.reich@danielreichs-MacBook-Pro.local |
20fb226181a168dd6671f5f065e241134074e33a | 91d1a6968b90d9d461e9a2ece12b465486e3ccc2 | /route53_write_f/dns-answer_test.py | f8d48671d2f746eca041962279f310374a54a8cc | [] | no_license | lxtxl/aws_cli | c31fc994c9a4296d6bac851e680d5adbf7e93481 | aaf35df1b7509abf5601d3f09ff1fece482facda | refs/heads/master | 2023-02-06T09:00:33.088379 | 2020-12-27T13:38:45 | 2020-12-27T13:38:45 | 318,686,394 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 390 | py | #!/usr/bin/python
# -*- codding: utf-8 -*-
import os
import sys
sys.path.append(os.path.dirname(os.path.abspath(os.path.dirname(__file__))))
from common.execute_command import write_parameter
# url : https://awscli.amazonaws.com/v2/documentation/api/latest/reference/ec2/describe-instances.html
if __name__ == '__main__... | [
"hcseo77@gmail.com"
] | hcseo77@gmail.com |
c1b26cced7bf736c91ff5349abd7750a5eefa8d8 | e60487a8f5aad5aab16e671dcd00f0e64379961b | /python_stack/Algos/numPy/updateNumpy.py | 764b3af48fbc0778e1b980e0ca73c7c9f9fe3f14 | [] | no_license | reenadangi/python | 4fde31737e5745bc5650d015e3fa4354ce9e87a9 | 568221ba417dda3be7f2ef1d2f393a7dea6ccb74 | refs/heads/master | 2021-08-18T08:25:40.774877 | 2021-03-27T22:20:17 | 2021-03-27T22:20:17 | 247,536,946 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 775 | py | import numpy as np
x=np.array([12,34,56,78,99])
y=np.array([[1,2,3],[4,5,6],[7,8,9]])
print(f"Orginal array{x}")
# access
print(x[0],x[len(x)-1],x[-1],x[-2])
# Modify
for i in range(len(x)):
x[i]=x[i]*2
# delete first and last element
x=np.delete(x,[0,4])
print(x)
print(y)
# delete first row (x axis)
y=np.delete(y... | [
"reena.dangi@gmail.com"
] | reena.dangi@gmail.com |
284ce95f34b4a10c66e71f2e3477dda5167fac94 | b6d2354b06732b42d3de49d3054cb02eb30298c4 | /finance/models/score.py | df2c1a647c8480e32ca35a6f81dc0cb04266d188 | [] | no_license | trivvet/finplanner | 52ad276839bfae67821b9684f7db549334ef0a59 | 1d82d1a09da6f04fced6f71b53aeb784af00f758 | refs/heads/master | 2020-03-17T23:24:25.071311 | 2018-10-28T10:12:07 | 2018-10-28T10:12:07 | 134,043,419 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,408 | py | # -*- coding: utf-8 -*-
from __future__ import unicode_literals
from django.db import models
# Create your models here.
class ScorePrototype(models.Model):
class Meta:
abstract=True
month = models.ForeignKey(
'Month',
on_delete=models.CASCADE,
blank=False,
null=False... | [
"trivvet@gmail.com"
] | trivvet@gmail.com |
4bc6b2ded7a42b226ac3a04ee7c6be4878dd796e | 8ca4992e5c7f009147875549cee21c0efb7c03eb | /mmseg/models/decode_heads/nl_head.py | bbbe70b5fb7233fd840941678657950119fda43e | [
"Apache-2.0"
] | permissive | JiayuZou2020/DiffBEV | 0ada3f505fc5106d8b0068c319f0b80ed366b673 | 527acdb82ac028061893d9d1bbe69e589efae2a0 | refs/heads/main | 2023-05-23T07:25:39.465813 | 2023-04-04T02:53:05 | 2023-04-04T02:53:05 | 613,895,691 | 181 | 8 | null | null | null | null | UTF-8 | Python | false | false | 1,655 | py | # Copyright (c) OpenMMLab. All rights reserved.
import torch
from mmcv.cnn import NonLocal2d
from ..builder import HEADS
from .fcn_head import FCNHead
@HEADS.register_module()
class NLHead(FCNHead):
"""Non-local Neural Networks.
This head is the implementation of `NLNet
<https://arxiv.org/a... | [
"noreply@github.com"
] | JiayuZou2020.noreply@github.com |
256bb7942ddc5136f4fa22e73823cc34bb46d2c0 | 0156514d371c04da404b50994804ede8d264042a | /rest_batteries/exception_handlers.py | 15824e0dd41058bf34e5dd42c73220ed016ef552 | [
"MIT"
] | permissive | defineimpossible/django-rest-batteries | 68b074f18fcae304b9bac4a242f9a9eea98c6e9c | 951cc7ec153d1342a861d7f6468862000d5ea9f3 | refs/heads/master | 2023-07-21T10:45:18.133691 | 2023-07-11T02:52:45 | 2023-07-11T02:52:45 | 284,420,681 | 21 | 0 | MIT | 2023-07-11T02:34:06 | 2020-08-02T08:19:39 | Python | UTF-8 | Python | false | false | 397 | py | from rest_framework.views import exception_handler
from .errors_formatter import ErrorsFormatter
def errors_formatter_exception_handler(exc, context):
response = exception_handler(exc, context)
# If unexpected error occurs (server error, etc.)
if response is None:
return response
formatter ... | [
"denis.orehovsky@gmail.com"
] | denis.orehovsky@gmail.com |
69bc2b87b4e297ce71f450a7c46c546972fa3449 | f0d713996eb095bcdc701f3fab0a8110b8541cbb | /PSg77AZJGACk4a7gt_6.py | 5bcd00492613d502e7d26232c6bfe6cf615fc660 | [] | no_license | daniel-reich/turbo-robot | feda6c0523bb83ab8954b6d06302bfec5b16ebdf | a7a25c63097674c0a81675eed7e6b763785f1c41 | refs/heads/main | 2023-03-26T01:55:14.210264 | 2021-03-23T16:08:01 | 2021-03-23T16:08:01 | 350,773,815 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 737 | py | """
For this challenge, forget how to add two numbers together. The best
explanation on what to do for this function is this meme:
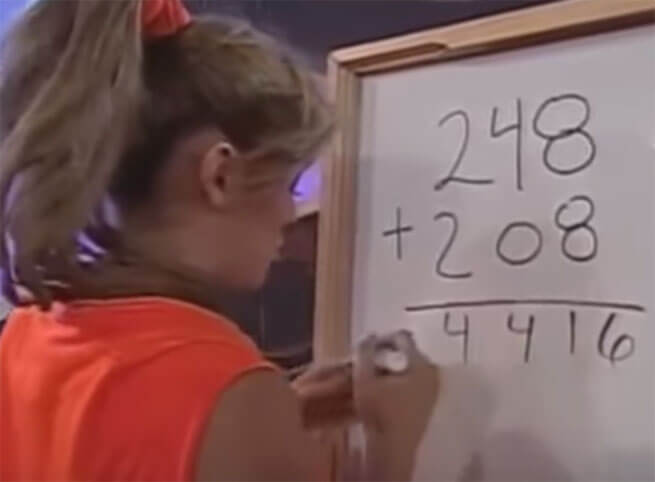
### Examples
meme_sum(26, 39) ➞ 515
# 2+3 = 5, 6+9 = 15
# 26 + 39 = 515
meme_sum(122, 81) ... | [
"daniel.reich@danielreichs-MacBook-Pro.local"
] | daniel.reich@danielreichs-MacBook-Pro.local |
2f2a1743222841ff34512aa1889a1587bd61b5ce | c759ca98768dd8fd47621e3aeda9069d4e0726c6 | /codewof/users/forms.py | 211e37a2e4797d3fa23af236d3215009c7f787c4 | [
"MIT"
] | permissive | lucyturn3r/codewof | 50fc504c3a539c376b3d19906e92839cadabb012 | acb2860c4b216013ffbba5476d5fac1616c78454 | refs/heads/develop | 2020-06-24T08:25:28.788099 | 2019-08-12T02:50:35 | 2019-08-12T02:50:35 | 198,912,987 | 0 | 0 | MIT | 2019-08-07T03:22:21 | 2019-07-25T23:17:17 | Python | UTF-8 | Python | false | false | 1,132 | py | """Forms for user application."""
from django.forms import ModelForm
from django.contrib.auth import get_user_model, forms
User = get_user_model()
class SignupForm(ModelForm):
"""Sign up for user registration."""
class Meta:
"""Metadata for SignupForm class."""
model = get_user_model()
... | [
"jackmorgannz@gmail.com"
] | jackmorgannz@gmail.com |
f0305eec604f96a1c795b04494e5e2bd3d1ca417 | 14df5d90af993150634e596c28cecf74dffe611f | /imghdr_test.py | 2c67ccbd0946c5e2ff7d38098fb675ccc446307d | [] | no_license | mamaker/IntroPy | 7a0614905b95ab5c15ac94b1245278c3ae5d4ce0 | dfea20eb465077e3512c878c549529a4b9282297 | refs/heads/master | 2020-05-09T18:26:16.681103 | 2019-04-23T01:05:31 | 2019-04-23T01:05:31 | 181,342,054 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 201 | py | # -*- coding: utf-8 -*-
"""
imghdr_test.py
Created on Sat Apr 20 11:19:17 2019
@author: madhu
"""
import imghdr
file_name = 'oreilly.png'
print('File', file_name,'is a:', imghdr.what(file_name))
| [
"madhuvasudevan@yahoo.com"
] | madhuvasudevan@yahoo.com |
4f48a8ed86212b4798e38875b2970b4d6d92420d | 7e9b15d1793aaee5873d0047ed7dd0f47f01d905 | /series_tiempo_ar_api/apps/analytics/elasticsearch/constants.py | 0626fc0e4cfa298137da7d090e046ca718473e69 | [
"MIT"
] | permissive | SantiagoPalay/series-tiempo-ar-api | 9822b7eac5714c1ed07ee11664b3608f1fc3e9cf | c0c665fe4caf8ce43a5eb12962ee36a3dd6c2aa4 | refs/heads/master | 2020-04-24T19:41:02.857554 | 2019-02-21T14:43:23 | 2019-02-21T14:43:23 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 553 | py | from series_tiempo_ar_api.libs.indexing.constants import \
VALUE, CHANGE, PCT_CHANGE, CHANGE_YEAR_AGO, PCT_CHANGE_YEAR_AGO
SERIES_QUERY_INDEX_NAME = 'query'
REP_MODES = [
VALUE,
CHANGE,
PCT_CHANGE,
CHANGE_YEAR_AGO,
PCT_CHANGE_YEAR_AGO,
]
AGG_DEFAULT = 'avg'
AGG_SUM = 'sum'
AGG_END_OF_PERIOD... | [
"19612265+lucaslavandeira@users.noreply.github.com"
] | 19612265+lucaslavandeira@users.noreply.github.com |
a665bef85088b02f9afefbab6d33cec9c86181e8 | b7cfdeb15b109220017a66ed6094ce890c234b74 | /AI/deep_learning_from_scratch/numpy_prac/multidimensional_array.py | f4bcc03331c3e16239389b8444d40b2f660af3db | [] | no_license | voidsatisfaction/TIL | 5bcde7eadc913bdf6f5432a30dc9c486f986f837 | 43f0df9f8e9dcb440dbf79da5706b34356498e01 | refs/heads/master | 2023-09-01T09:32:04.986276 | 2023-08-18T11:04:08 | 2023-08-18T11:04:08 | 80,825,105 | 24 | 2 | null | null | null | null | UTF-8 | Python | false | false | 188 | py | import numpy as np
B = np.array([[1, 2], [3, 4], [5, 6]])
B
np.ndim(B) # 2
B.shape # (3,2) 3x2 행렬
A = np.array([[1,2,3], [4,5,6]])
B = np.array([[1,2], [3,4], [5,6]])
np.dot(A, B)
| [
"lourie@naver.com"
] | lourie@naver.com |
5909b8a429dde3c3db85365a4a2fcafe8504a73c | 6febd920ced70cbb19695801a163c437e7be44d4 | /leetcode_oj/string/strStr.py | b0bc9a66ec3e9adf67f316f37ee2da101b6c25ef | [] | no_license | AngryBird3/gotta_code | b0ab47e846b424107dbd3b03e0c0f3afbd239c60 | b9975fef5fa4843bf95d067bea6d064723484289 | refs/heads/master | 2021-01-20T16:47:35.098125 | 2018-03-24T21:31:01 | 2018-03-24T21:31:01 | 53,180,336 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 538 | py | class Solution(object):
def strStr(self, haystack, needle):
"""
:type haystack: str
:type needle: str
:rtype: int
"""
if not haystack and not needle:
return 0
for i in range(len(haystack) - len(needle) + 1):
match = True
for... | [
"dhaaraa.darji@gmail.com"
] | dhaaraa.darji@gmail.com |
a7e448139f2bd614be72df1a7ece9dde49e3be0f | 2a7e44adc8744c55a25e3cafcc2fa19a1607e697 | /settings_inspector/management/commands/inspect_settings.py | 6f7437af5ca147fdd91a75feddb2467cdbec5bf7 | [
"MIT"
] | permissive | fcurella/django-settings_inspector | 45529288dc8dde264383739c55abe6a9d2077ded | 69a6295de865f540d024e79aab4d211ce3c1d847 | refs/heads/master | 2020-06-04T01:57:17.216783 | 2012-01-05T19:05:12 | 2012-01-05T19:05:12 | 2,989,324 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 256 | py | from settings_inspector.parser import Setting
from django.core.management.base import NoArgsCommand
class Command(NoArgsCommand):
def handle(self, *args, **options):
root_setting = Setting('django.conf')
import ipdb; ipdb.set_trace()
| [
"flavio.curella@gmail.com"
] | flavio.curella@gmail.com |
a04179ec631fa9ee2c77775b4b950d00ead1cff3 | f576f0ea3725d54bd2551883901b25b863fe6688 | /sdk/machinelearning/azure-mgmt-machinelearningservices/generated_samples/registry/code_container/get.py | c8b1ce0c2a7ca85de612a46ed698cd5daf7180dc | [
"MIT",
"LicenseRef-scancode-generic-cla",
"LGPL-2.1-or-later"
] | permissive | Azure/azure-sdk-for-python | 02e3838e53a33d8ba27e9bcc22bd84e790e4ca7c | c2ca191e736bb06bfbbbc9493e8325763ba990bb | refs/heads/main | 2023-09-06T09:30:13.135012 | 2023-09-06T01:08:06 | 2023-09-06T01:08:06 | 4,127,088 | 4,046 | 2,755 | MIT | 2023-09-14T21:48:49 | 2012-04-24T16:46:12 | Python | UTF-8 | Python | false | false | 1,674 | py | # coding=utf-8
# --------------------------------------------------------------------------
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License. See License.txt in the project root for license information.
# Code generated by Microsoft (R) AutoRest Code Generator.
# Changes may ... | [
"noreply@github.com"
] | Azure.noreply@github.com |
da080bc3ffe0ad4f0d4461acf3bf439970b3713b | d706f83450d32256e568ea2e279649b9d85ddb94 | /accounts/views.py | 8cd59810b95abf689b8f6bdf3151729484d2fb7d | [] | no_license | celord/advacneddjango | 146d3d4ae351803b37e8599225b38b948e42a8b7 | 044d172fb10556cdeede6888dcec5f466097754d | refs/heads/main | 2023-08-18T19:26:07.230821 | 2021-09-26T17:58:45 | 2021-09-26T17:58:45 | 406,921,992 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 303 | py | # accounts/views.py
from django.urls import reverse_lazy
from django.views import generic
from .forms import CustomUserCreationForm
class SignupPageView(generic.CreateView):
form_class = CustomUserCreationForm
success_url = reverse_lazy('login')
template_name = 'registration/signup.html'
| [
"celord@gmail.com"
] | celord@gmail.com |
db62acc5b5c6704db566b47448faeaed2132e6ba | bb64d7194d9f7e8ef6fc2dbfdbc0569713d1079c | /FocalLoss.py | 74a05c5aa62338c5c30e91a1981482671095182f | [] | no_license | scott-mao/Top-Related-Meta-Learning-Method-for-Few-Shot-Detection | 471e7d6e71255333d9b4c929023d7e43ef19fdd2 | 49bfd702f41deaec60fa95314436f69b4e217e6f | refs/heads/main | 2023-04-11T13:00:13.358560 | 2021-04-27T02:24:23 | 2021-04-27T02:24:23 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,767 | py | #!/usr/bin/env python
# -*- coding: utf-8 -*-
# --------------------------------------------------------
# Licensed under The MIT License [see LICENSE for details]
# Written by Chao CHEN (chaochancs@gmail.com)
# Created On: 2017-08-11
# --------------------------------------------------------
import torch
import torch.... | [
"noreply@github.com"
] | scott-mao.noreply@github.com |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.