
blob_id stringlengths 40 40 | directory_id stringlengths 40 40 | path stringlengths 3 288 | content_id stringlengths 40 40 | detected_licenses listlengths 0 112 | license_type stringclasses 2 values | repo_name stringlengths 5 115 | snapshot_id stringlengths 40 40 | revision_id stringlengths 40 40 | branch_name stringclasses 684 values | visit_date timestamp[us]date 2015-08-06 10:31:46 2023-09-06 10:44:38 | revision_date timestamp[us]date 1970-01-01 02:38:32 2037-05-03 13:00:00 | committer_date timestamp[us]date 1970-01-01 02:38:32 2023-09-06 01:08:06 | github_id int64 4.92k 681M ⌀ | star_events_count int64 0 209k | fork_events_count int64 0 110k | gha_license_id stringclasses 22 values | gha_event_created_at timestamp[us]date 2012-06-04 01:52:49 2023-09-14 21:59:50 ⌀ | gha_created_at timestamp[us]date 2008-05-22 07:58:19 2023-08-21 12:35:19 ⌀ | gha_language stringclasses 147 values | src_encoding stringclasses 25 values | language stringclasses 1 value | is_vendor bool 2 classes | is_generated bool 2 classes | length_bytes int64 128 12.7k | extension stringclasses 142 values | content stringlengths 128 8.19k | authors listlengths 1 1 | author_id stringlengths 1 132 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
28727ec723317e30d74083841007539fff22cef1 | e444f89f87b90f7946e3162e2c986c9d7f75b9b4 | /src/annotation_pipeline.py | 80122696be8453f60256d856e49281e846eaf4c6 | [] | no_license | yuzhenpeng/comparativeAnnotator | f2a7bb846f1427f09cfa6429207ec483f9ada072 | 9062c58bb7d625b2b50eb07b23b01af6bf73e5e3 | refs/heads/master | 2020-09-11T21:52:40.544833 | 2016-07-26T20:28:10 | 2016-07-26T20:28:10 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 4,895 | py | """
This is the main driver script for comparativeAnnotator in transMap mode.
"""
import argparse
import os
from jobTree.scriptTree.target import Target
from jobTree.scriptTree.stack import Stack
import lib.sql_lib as sql_lib
import lib.seq_lib as seq_lib
from lib.general_lib import classes_in_module, mkdir_p
import src.classifiers
import src.alignment_classifiers
import src.augustus_classifiers
import src.attributes
from src.build_tracks import database_wrapper
__author__ = "Ian Fiddes"
def parse_args():
"""
Builds an argument parser for this run
"""
parent_parser = argparse.ArgumentParser()
subparsers = parent_parser.add_subparsers(title="Modes", description="Execution Modes", dest="mode")
tm_parser = subparsers.add_parser('transMap')
ref_parser = subparsers.add_parser('reference')
aug_parser = subparsers.add_parser('augustus')
# common arguments
for parser in [ref_parser, aug_parser, tm_parser]:
parser.add_argument('--outDir', type=str, required=True)
parser.add_argument('--refGenome', type=str, required=True)
parser.add_argument('--refFasta', type=str, required=True)
parser.add_argument('--sizes', required=True)
parser.add_argument('--annotationGp', required=True)
parser.add_argument('--gencodeAttributes', required=True)
Stack.addJobTreeOptions(parser) # add jobTree options
# transMap specific options
for parser in [aug_parser, tm_parser]:
parser.add_argument('--genome', required=True)
parser.add_argument('--psl', required=True)
parser.add_argument('--refPsl', required=True)
parser.add_argument('--targetGp', required=True)
parser.add_argument('--fasta', required=True)
# Augustus specific options
aug_parser.add_argument('--augustusGp', required=True)
args = parent_parser.parse_args()
assert args.mode in ["transMap", "reference", "augustus"]
return args
def run_ref_classifiers(args, target, tmp_dir):
ref_classifiers = classes_in_module(src.classifiers)
for classifier in ref_classifiers:
target.addChildTarget(classifier(args.refFasta, args.annotationGp, args.refGenome, tmp_dir))
def run_tm_classifiers(args, target, tmp_dir):
tm_classifiers = classes_in_module(src.alignment_classifiers)
for classifier in tm_classifiers:
target.addChildTarget(classifier(args.refFasta, args.annotationGp, args.refGenome, tmp_dir, args.genome,
args.psl, args.refPsl, args.fasta, args.targetGp))
attributes = classes_in_module(src.attributes)
for attribute in attributes:
target.addChildTarget(attribute(args.refFasta, args.annotationGp, args.refGenome, tmp_dir, args.genome,
args.psl, args.refPsl, args.fasta, args.targetGp, args.gencodeAttributes))
# in transMap mode we run the alignment-free classifiers on the target genome
ref_classifiers = classes_in_module(src.classifiers)
for classifier in ref_classifiers:
target.addChildTarget(classifier(args.fasta, args.targetGp, args.genome, tmp_dir))
def run_aug_classifiers(args, target, tmp_dir):
aug_classifiers = classes_in_module(src.augustus_classifiers)
for classifier in aug_classifiers:
target.addChildTarget(classifier(args.refFasta, args.annotationGp, args.refGenome, tmp_dir, args.genome,
args.psl, args.refPsl, args.fasta, args.targetGp, args.augustusGp))
# in Augustus mode we run the alignment-free classifiers on augustus transcripts
ref_classifiers = classes_in_module(src.classifiers)
for classifier in ref_classifiers:
target.addChildTarget(classifier(args.fasta, args.augustusGp, args.genome, tmp_dir))
def build_analyses(target, args):
"""
Wrapper function that will call all classifiers. Each classifier will dump its results to disk as a pickled dict.
Calls database_wrapper to load these into a sqlite3 database.
"""
tmp_dir = target.getGlobalTempDir()
if args.mode == "reference":
run_ref_classifiers(args, target, tmp_dir)
elif args.mode == "transMap":
run_tm_classifiers(args, target, tmp_dir)
elif args.mode == "augustus":
run_aug_classifiers(args, target, tmp_dir)
else:
raise RuntimeError("Somehow your argparse object does not contain a valid mode.")
# merge the resulting pickled files into sqlite databases and construct BED tracks
target.setFollowOnTargetFn(database_wrapper, memory=8 * (1024 ** 3), args=[args, tmp_dir])
def main():
args = parse_args()
i = Stack(Target.makeTargetFn(build_analyses, memory=8 * (1024 ** 3), args=[args])).startJobTree(args)
if i != 0:
raise RuntimeError("Got failed jobs")
if __name__ == '__main__':
from src.annotation_pipeline import *
main()
| [
"ian.t.fiddes@gmail.com"
] | ian.t.fiddes@gmail.com |
4dd1389420bf38c36d3b56adf825aec0a6fbab0c | 77a87e7b15d58b2d23bfdd9ed78b637bebfcc6eb | /.closet/jython.configurator.efr32.multiPhy/5.2.3.201904231805-1264/host_py_rm_studio_internal/host_py_rm_studio_internal_efr32xg12xfull/revA0/AGC.py | bfe98660a031dcd7fce3e6a4596c69ffe731abd3 | [] | no_license | lenloe1/other-stuff | b06331a4f247f06066579472b296f1ae66f6bdaf | 897069e0464b19f81b14488d463710c81bb7fda4 | refs/heads/master | 2021-05-19T13:41:04.509601 | 2020-03-31T20:52:38 | 2020-03-31T20:52:38 | 251,728,852 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 4,156 | py |
# -*- coding: utf-8 -*-
__all__ = [ 'RM_Peripheral_AGC' ]
from .static import Base_RM_Peripheral
from .AGC_register import *
class RM_Peripheral_AGC(Base_RM_Peripheral):
def __init__(self, rmio, label):
self.__dict__['zz_frozen'] = False
super(RM_Peripheral_AGC, self).__init__(rmio, label,
0x40087000, 'AGC',
u"")
self.STATUS0 = RM_Register_AGC_STATUS0(self.zz_rmio, self.zz_label)
self.zz_rdict['STATUS0'] = self.STATUS0
self.STATUS1 = RM_Register_AGC_STATUS1(self.zz_rmio, self.zz_label)
self.zz_rdict['STATUS1'] = self.STATUS1
self.RSSI = RM_Register_AGC_RSSI(self.zz_rmio, self.zz_label)
self.zz_rdict['RSSI'] = self.RSSI
self.FRAMERSSI = RM_Register_AGC_FRAMERSSI(self.zz_rmio, self.zz_label)
self.zz_rdict['FRAMERSSI'] = self.FRAMERSSI
self.CTRL0 = RM_Register_AGC_CTRL0(self.zz_rmio, self.zz_label)
self.zz_rdict['CTRL0'] = self.CTRL0
self.CTRL1 = RM_Register_AGC_CTRL1(self.zz_rmio, self.zz_label)
self.zz_rdict['CTRL1'] = self.CTRL1
self.CTRL2 = RM_Register_AGC_CTRL2(self.zz_rmio, self.zz_label)
self.zz_rdict['CTRL2'] = self.CTRL2
self.RSSISTEPTHR = RM_Register_AGC_RSSISTEPTHR(self.zz_rmio, self.zz_label)
self.zz_rdict['RSSISTEPTHR'] = self.RSSISTEPTHR
self.IFPEAKDET = RM_Register_AGC_IFPEAKDET(self.zz_rmio, self.zz_label)
self.zz_rdict['IFPEAKDET'] = self.IFPEAKDET
self.MANGAIN = RM_Register_AGC_MANGAIN(self.zz_rmio, self.zz_label)
self.zz_rdict['MANGAIN'] = self.MANGAIN
self.RFPEAKDET = RM_Register_AGC_RFPEAKDET(self.zz_rmio, self.zz_label)
self.zz_rdict['RFPEAKDET'] = self.RFPEAKDET
self.IF = RM_Register_AGC_IF(self.zz_rmio, self.zz_label)
self.zz_rdict['IF'] = self.IF
self.IFS = RM_Register_AGC_IFS(self.zz_rmio, self.zz_label)
self.zz_rdict['IFS'] = self.IFS
self.IFC = RM_Register_AGC_IFC(self.zz_rmio, self.zz_label)
self.zz_rdict['IFC'] = self.IFC
self.IEN = RM_Register_AGC_IEN(self.zz_rmio, self.zz_label)
self.zz_rdict['IEN'] = self.IEN
self.CMD = RM_Register_AGC_CMD(self.zz_rmio, self.zz_label)
self.zz_rdict['CMD'] = self.CMD
self.GAINRANGE = RM_Register_AGC_GAINRANGE(self.zz_rmio, self.zz_label)
self.zz_rdict['GAINRANGE'] = self.GAINRANGE
self.GAININDEX = RM_Register_AGC_GAININDEX(self.zz_rmio, self.zz_label)
self.zz_rdict['GAININDEX'] = self.GAININDEX
self.SLICECODE = RM_Register_AGC_SLICECODE(self.zz_rmio, self.zz_label)
self.zz_rdict['SLICECODE'] = self.SLICECODE
self.ATTENCODE1 = RM_Register_AGC_ATTENCODE1(self.zz_rmio, self.zz_label)
self.zz_rdict['ATTENCODE1'] = self.ATTENCODE1
self.ATTENCODE2 = RM_Register_AGC_ATTENCODE2(self.zz_rmio, self.zz_label)
self.zz_rdict['ATTENCODE2'] = self.ATTENCODE2
self.ATTENCODE3 = RM_Register_AGC_ATTENCODE3(self.zz_rmio, self.zz_label)
self.zz_rdict['ATTENCODE3'] = self.ATTENCODE3
self.GAINERROR1 = RM_Register_AGC_GAINERROR1(self.zz_rmio, self.zz_label)
self.zz_rdict['GAINERROR1'] = self.GAINERROR1
self.GAINERROR2 = RM_Register_AGC_GAINERROR2(self.zz_rmio, self.zz_label)
self.zz_rdict['GAINERROR2'] = self.GAINERROR2
self.GAINERROR3 = RM_Register_AGC_GAINERROR3(self.zz_rmio, self.zz_label)
self.zz_rdict['GAINERROR3'] = self.GAINERROR3
self.MANUALCTRL = RM_Register_AGC_MANUALCTRL(self.zz_rmio, self.zz_label)
self.zz_rdict['MANUALCTRL'] = self.MANUALCTRL
self.GAINSTEPLIM = RM_Register_AGC_GAINSTEPLIM(self.zz_rmio, self.zz_label)
self.zz_rdict['GAINSTEPLIM'] = self.GAINSTEPLIM
self.LOOPDEL = RM_Register_AGC_LOOPDEL(self.zz_rmio, self.zz_label)
self.zz_rdict['LOOPDEL'] = self.LOOPDEL
self.MININDEX = RM_Register_AGC_MININDEX(self.zz_rmio, self.zz_label)
self.zz_rdict['MININDEX'] = self.MININDEX
self.LBT = RM_Register_AGC_LBT(self.zz_rmio, self.zz_label)
self.zz_rdict['LBT'] = self.LBT
self.__dict__['zz_frozen'] = True | [
"31710001+lenloe1@users.noreply.github.com"
] | 31710001+lenloe1@users.noreply.github.com |
ba1cfe34cdd0c72ad9925c1efba1ce9fe9481338 | 47434a10c598d2ea0e5faed4df29c755242c662e | /CodeForces/Team.py | 98ef4fa008166998218eff68a571fbbd8c8334b1 | [] | no_license | ShakilAhmmed/Problem_Solve | 566b5a5370723932a50cf34c97ac9f229df8b511 | 6864958ee892ba0aa90f6788fc7b7c16baf41716 | refs/heads/master | 2021-06-22T19:41:07.624863 | 2021-03-07T16:10:25 | 2021-03-07T16:10:25 | 200,253,202 | 2 | 0 | null | 2020-06-16T19:52:43 | 2019-08-02T14:56:30 | Python | UTF-8 | Python | false | false | 201 | py | n = int(input())
count = 0
for _ in range(n):
number = list(map(int, input().split()))
one_count = number.count(1)
zero_count = number.count(0)
if one_count > zero_count:
count += 1
print(count)
| [
"shakilfci461@gmail.com"
] | shakilfci461@gmail.com |
2b7199701eac80d3de6850b27032cfc6cc318aaa | eb9c3dac0dca0ecd184df14b1fda62e61cc8c7d7 | /google/cloud/billing/budgets/v1beta1/billing-budgets-v1beta1-py/setup.py | cc3c039320dec24a399055373fd5bdd28b80a43c | [
"Apache-2.0"
] | permissive | Tryweirder/googleapis-gen | 2e5daf46574c3af3d448f1177eaebe809100c346 | 45d8e9377379f9d1d4e166e80415a8c1737f284d | refs/heads/master | 2023-04-05T06:30:04.726589 | 2021-04-13T23:35:20 | 2021-04-13T23:35:20 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,799 | py | # -*- coding: utf-8 -*-
# Copyright 2020 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import io
import os
import setuptools # type: ignore
version = '0.1.0'
package_root = os.path.abspath(os.path.dirname(__file__))
readme_filename = os.path.join(package_root, 'README.rst')
with io.open(readme_filename, encoding='utf-8') as readme_file:
readme = readme_file.read()
setuptools.setup(
name='google-cloud-billing-budgets',
version=version,
long_description=readme,
packages=setuptools.PEP420PackageFinder.find(),
namespace_packages=('google', 'google.cloud', 'google.cloud.billing'),
platforms='Posix; MacOS X; Windows',
include_package_data=True,
install_requires=(
'google-api-core[grpc] >= 1.22.2, < 2.0.0dev',
'libcst >= 0.2.5',
'proto-plus >= 1.15.0',
),
python_requires='>=3.6',
classifiers=[
'Development Status :: 3 - Alpha',
'Intended Audience :: Developers',
'Operating System :: OS Independent',
'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
'Programming Language :: Python :: 3.8',
'Topic :: Internet',
'Topic :: Software Development :: Libraries :: Python Modules',
],
zip_safe=False,
)
| [
"bazel-bot-development[bot]@users.noreply.github.com"
] | bazel-bot-development[bot]@users.noreply.github.com |
dddd3601a393ce447cf447e14d2ad14a17af28b2 | 45ba55b4fbdaf1657fde92beaeba4f173265afcd | /tests/schema/test_lazy/type_a.py | 65617b5f3b8844af612e367deb7490b69d790898 | [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
] | permissive | strawberry-graphql/strawberry | af96afd4edd1788c59e150597a12501fbc7bf444 | 6d86d1c08c1244e00535840d9d87925431bc6a1c | refs/heads/main | 2023-08-30T03:34:12.929874 | 2023-08-24T12:01:09 | 2023-08-24T12:01:09 | 162,690,887 | 3,408 | 529 | MIT | 2023-09-14T21:49:44 | 2018-12-21T08:56:55 | Python | UTF-8 | Python | false | false | 552 | py | from typing import TYPE_CHECKING, List, Optional
from typing_extensions import Annotated
import strawberry
if TYPE_CHECKING:
from .type_b import TypeB
TypeB_rel = TypeB
TypeB_abs = TypeB
else:
TypeB_rel = Annotated["TypeB", strawberry.lazy(".type_b")]
TypeB_abs = Annotated["TypeB", strawberry.lazy("tests.schema.test_lazy.type_b")]
@strawberry.type
class TypeA:
list_of_b: Optional[List[TypeB_abs]] = None
@strawberry.field
def type_b(self) -> TypeB_rel:
from .type_b import TypeB
return TypeB()
| [
"noreply@github.com"
] | strawberry-graphql.noreply@github.com |
bcfa114770664cf17a450ca28a1a571355fb71cb | 786027545626c24486753351d6e19093b261cd7d | /ghidra9.2.1_pyi/ghidra/util/table/mapper/AddressTableToAddressTableRowMapper.pyi | 26072a368ad95ac4a06849d98672f2b4d0917da2 | [
"MIT"
] | permissive | kohnakagawa/ghidra_scripts | 51cede1874ef2b1fed901b802316449b4bf25661 | 5afed1234a7266c0624ec445133280993077c376 | refs/heads/main | 2023-03-25T08:25:16.842142 | 2021-03-18T13:31:40 | 2021-03-18T13:31:40 | 338,577,905 | 14 | 1 | null | null | null | null | UTF-8 | Python | false | false | 1,880 | pyi | import docking.widgets.table
import ghidra.app.plugin.core.disassembler
import ghidra.framework.plugintool
import ghidra.program.model.address
import ghidra.program.model.listing
import ghidra.util.table
import java.lang
class AddressTableToAddressTableRowMapper(ghidra.util.table.ProgramLocationTableRowMapper):
def __init__(self): ...
def createMappedTableColumn(self, destinationColumn: docking.widgets.table.DynamicTableColumn) -> docking.widgets.table.DynamicTableColumn:
"""
Creates a table column that will create a table column that knows how to map the
given <b>ROW_TYPE</b> to the type of the column passed in, the <b>EXPECTED_ROW_TYPE</b>.
@param <COLUMN_TYPE> The column type of the given and created columns
@param destinationColumn The existing column, which is based upon EXPECTED_ROW_TYPE,
that we want to be able to use with the type we have, the ROW_TYPE.
"""
...
def equals(self, __a0: object) -> bool: ...
def getClass(self) -> java.lang.Class: ...
def getDestinationType(self) -> java.lang.Class: ...
def getSourceType(self) -> java.lang.Class: ...
def hashCode(self) -> int: ...
@overload
def map(self, rowObject: ghidra.app.plugin.core.disassembler.AddressTable, program: ghidra.program.model.listing.Program, serviceProvider: ghidra.framework.plugintool.ServiceProvider) -> ghidra.program.model.address.Address: ...
@overload
def map(self, __a0: object, __a1: object, __a2: ghidra.framework.plugintool.ServiceProvider) -> object: ...
def notify(self) -> None: ...
def notifyAll(self) -> None: ...
def toString(self) -> unicode: ...
@overload
def wait(self) -> None: ...
@overload
def wait(self, __a0: long) -> None: ...
@overload
def wait(self, __a0: long, __a1: int) -> None: ...
| [
"tsunekou1019@gmail.com"
] | tsunekou1019@gmail.com |
05f20377365afcf412ba6b25092ca5d4eeca0364 | 5ddacf6285da77e8b6bc53cde3379471c631e827 | /tests/databases/constructed_molecule/fixtures/constructed_molecule_mongo_db.py | c90e86673bda41cefd2525d316916ea0110c877d | [
"MIT"
] | permissive | sailfish009/stk | 19db3d50742cd822bf9c06711103bd7e1954a79f | ebf876d5207032b76b9b10f7ca62060cc12c61f0 | refs/heads/master | 2022-11-09T20:59:03.222560 | 2020-06-30T12:37:02 | 2020-06-30T12:37:02 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 4,133 | py | import pytest
import stk
import rdkit.Chem.AllChem as rdkit
from ...utilities import MockMongoClient
from ..case_data import CaseData
@pytest.fixture(
params=(
CaseData(
database=stk.ConstructedMoleculeMongoDb(
mongo_client=MockMongoClient(),
lru_cache_size=0,
),
molecule=stk.ConstructedMolecule(
topology_graph=stk.polymer.Linear(
building_blocks=(
stk.BuildingBlock(
smiles='BrCCBr',
functional_groups=[stk.BromoFactory()],
),
),
repeating_unit='A',
num_repeating_units=2,
),
),
key={
'InChIKey':
rdkit.MolToInchiKey(rdkit.MolFromSmiles(
SMILES='BrCCCCBr'
)),
},
),
CaseData(
database=stk.ConstructedMoleculeMongoDb(
mongo_client=MockMongoClient(),
lru_cache_size=128,
),
molecule=stk.ConstructedMolecule(
topology_graph=stk.polymer.Linear(
building_blocks=(
stk.BuildingBlock(
smiles='BrCCBr',
functional_groups=[stk.BromoFactory()],
),
),
repeating_unit='A',
num_repeating_units=2,
),
),
key={
'InChIKey':
rdkit.MolToInchiKey(rdkit.MolFromSmiles(
SMILES='BrCCCCBr'
)),
},
),
CaseData(
database=stk.ConstructedMoleculeMongoDb(
mongo_client=MockMongoClient(),
jsonizer=stk.ConstructedMoleculeJsonizer(
key_makers=(
stk.MoleculeKeyMaker(
key_name='SMILES',
get_key=lambda molecule: rdkit.MolToSmiles(
mol=molecule.to_rdkit_mol(),
)
),
),
),
lru_cache_size=0,
),
molecule=stk.ConstructedMolecule(
topology_graph=stk.polymer.Linear(
building_blocks=(
stk.BuildingBlock(
smiles='Br[C+2][C+2]Br',
functional_groups=[stk.BromoFactory()],
),
),
repeating_unit='A',
num_repeating_units=2,
),
),
key={'SMILES': 'Br[C+2][C+2][C+2][C+2]Br'},
),
CaseData(
database=stk.ConstructedMoleculeMongoDb(
mongo_client=MockMongoClient(),
jsonizer=stk.ConstructedMoleculeJsonizer(
key_makers=(
stk.MoleculeKeyMaker(
key_name='SMILES',
get_key=lambda molecule: rdkit.MolToSmiles(
mol=molecule.to_rdkit_mol(),
)
),
),
),
lru_cache_size=128,
),
molecule=stk.ConstructedMolecule(
topology_graph=stk.polymer.Linear(
building_blocks=(
stk.BuildingBlock(
smiles='Br[C+2][C+2]Br',
functional_groups=[stk.BromoFactory()],
),
),
repeating_unit='A',
num_repeating_units=2,
),
),
key={'SMILES': 'Br[C+2][C+2][C+2][C+2]Br'},
),
),
)
def constructed_molecule_mongo_db(request):
return request.param
| [
"noreply@github.com"
] | sailfish009.noreply@github.com |
fdcb707c05e376905be9ed93946a5d310d84baee | 72cdc45a345fe47c525468ff82ef8ce845d9f800 | /Python/django_ajax/django_ajax_demo/app/models.py | 43550226b816520409ecbb4bfcd875aa2a596345 | [] | no_license | bopopescu/Coding-Dojo-assignments | 474242e14371e729b5948602ffc0a9328f1e43cb | 0598d7162b37d9472c6f1b82acc51d625ac871ca | refs/heads/master | 2022-11-23T18:55:36.393073 | 2018-07-20T07:43:56 | 2018-07-20T07:43:56 | 281,670,452 | 0 | 0 | null | 2020-07-22T12:24:30 | 2020-07-22T12:24:30 | null | UTF-8 | Python | false | false | 623 | py | from django.db import models
# Create your models here.
class UserManger(models.Manager):
def create_user(self,post_data):
user = self.create(
first_name=post_data['first_name'],
last_name=post_data['last_name'],
email=post_data['email']
)
return user
class User(models.Model):
first_name = models.CharField(max_length=200)
last_name = models.CharField(max_length=200)
email = models.CharField(max_length=200)
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
obj = UserManger() | [
"gringojaimes20@gmail.com"
] | gringojaimes20@gmail.com |
fc82b5c45efce7854e15cb4d046d461ecc5666cf | bb33e6be8316f35decbb2b81badf2b6dcf7df515 | /source/res/scripts/client/gui/impl/lobby/bootcamp/__init__.py | 38949d143389770292fb8708159801207ba40edc | [] | no_license | StranikS-Scan/WorldOfTanks-Decompiled | 999c9567de38c32c760ab72c21c00ea7bc20990c | d2fe9c195825ececc728e87a02983908b7ea9199 | refs/heads/1.18 | 2023-08-25T17:39:27.718097 | 2022-09-22T06:49:44 | 2022-09-22T06:49:44 | 148,696,315 | 103 | 39 | null | 2022-09-14T17:50:03 | 2018-09-13T20:49:11 | Python | UTF-8 | Python | false | false | 129 | py | # Python bytecode 2.7 (decompiled from Python 2.7)
# Embedded file name: scripts/client/gui/impl/lobby/bootcamp/__init__.py
pass
| [
"StranikS_Scan@mail.ru"
] | StranikS_Scan@mail.ru |
a58c9664c1090042fa0befbe74e0e75dbfc6648b | 211196c7d7f649a5295cbbad97003422a7049fc2 | /iterateOverMessages.py | 57d3360be2df99aa52c28e161cd320a89e677cbb | [] | no_license | AzisK/Jinbe-Music | 38df261bfd334e1213dc6d96d393493a4da9517e | 44761ebb8fe196c37fa10e83e2e4c873e70a5def | refs/heads/master | 2021-01-20T07:05:29.061897 | 2017-10-05T06:11:47 | 2017-10-05T06:11:47 | 89,957,496 | 1 | 0 | null | 2017-10-05T06:11:48 | 2017-05-01T19:53:02 | Python | UTF-8 | Python | false | false | 129 | py | import mido
from mido import MidiFile
port = mido.open_output()
for msg in MidiFile('1.mid').play():
port.send(msg)
| [
"="
] | = |
e2cc4ee0baa6c4627c2423976a2c8e20afbbbdff | de24f83a5e3768a2638ebcf13cbe717e75740168 | /moodledata/vpl_data/75/usersdata/161/36800/submittedfiles/maiormenor.py | f9360f4e08c5cf3b0813526c834f4c0b01124a8d | [] | no_license | rafaelperazzo/programacao-web | 95643423a35c44613b0f64bed05bd34780fe2436 | 170dd5440afb9ee68a973f3de13a99aa4c735d79 | refs/heads/master | 2021-01-12T14:06:25.773146 | 2017-12-22T16:05:45 | 2017-12-22T16:05:45 | 69,566,344 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 632 | py | # -*- coding: utf-8 -*-
import math
a = int(input('Digite o número 1: '))
b = int(input('Digite o número 2: '))
c = int(input('Digite o número 3: '))
d = int(input('Digite o número 4: '))
e = int(input('Digite o número 5: '))
i=0
maior=0
menor=0
for i in range(5):
if a>maior:
a=maior
elif b>maior:
b=maior
elif c>maior:
c=maior
elif d>maior:
d=maior
elif e>maoir:
e=maior
if a<menor:
a=menor
elif b<menor:
b=menor
elif c<menor:
c=menor
elif d<menor:
d=menor
elif e<menor:
e=menor
print(maior)
print(menor) | [
"rafael.mota@ufca.edu.br"
] | rafael.mota@ufca.edu.br |
18bf7102fedf76648c340210ef8685e944c4585d | 53fab060fa262e5d5026e0807d93c75fb81e67b9 | /backup/user_305/ch81_2019_06_04_13_12_29_235102.py | b71526d31810aaf20ab6e06453268454b3963ec7 | [] | no_license | gabriellaec/desoft-analise-exercicios | b77c6999424c5ce7e44086a12589a0ad43d6adca | 01940ab0897aa6005764fc220b900e4d6161d36b | refs/heads/main | 2023-01-31T17:19:42.050628 | 2020-12-16T05:21:31 | 2020-12-16T05:21:31 | 306,735,108 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 177 | py | def interseccao_valores(dic1, dic2):
lista = []
for v in dic1.values():
v.append(lista)
for j in dic2.values():
j.append(lista)
return lista
| [
"you@example.com"
] | you@example.com |
73363dfdd60b34c13e77255bab8d474bf348fb2e | ca7aa979e7059467e158830b76673f5b77a0f5a3 | /Python_codes/p03387/s123688720.py | 032de65d86c10d90a82ee7446afbbcc91437a494 | [] | no_license | Aasthaengg/IBMdataset | 7abb6cbcc4fb03ef5ca68ac64ba460c4a64f8901 | f33f1c5c3b16d0ea8d1f5a7d479ad288bb3f48d8 | refs/heads/main | 2023-04-22T10:22:44.763102 | 2021-05-13T17:27:22 | 2021-05-13T17:27:22 | 367,112,348 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 432 | py | import sys
a=list(map(int,input().split()))
a.sort()
ans=0
while True:
if a[0]==a[1]==a[2]:
print(ans)
sys.exit()
if a[0]<a[1]:
a[0]+=2
ans+=1
a.sort()
if a[0]==a[1]==a[2]:
print(ans)
sys.exit()
if a[0]==a[1]:
a[0]+=1
a[1]+=1
ans+=1
a.sort()
if a[0]==a[1]==a[2]:
print(ans)
sys.exit() | [
"66529651+Aastha2104@users.noreply.github.com"
] | 66529651+Aastha2104@users.noreply.github.com |
6d166148963bb2dfef60da93fe81d806e80ba065 | 91d1a6968b90d9d461e9a2ece12b465486e3ccc2 | /iot_write_f/audit-mitigation-actions-task_start.py | ccd58e9e6ce9fcde6370e203d0655d253cc36d40 | [] | no_license | lxtxl/aws_cli | c31fc994c9a4296d6bac851e680d5adbf7e93481 | aaf35df1b7509abf5601d3f09ff1fece482facda | refs/heads/master | 2023-02-06T09:00:33.088379 | 2020-12-27T13:38:45 | 2020-12-27T13:38:45 | 318,686,394 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 866 | py | #!/usr/bin/python
# -*- codding: utf-8 -*-
import os
import sys
sys.path.append(os.path.dirname(os.path.abspath(os.path.dirname(__file__))))
from common.execute_command import write_parameter
# url : https://awscli.amazonaws.com/v2/documentation/api/latest/reference/ec2/describe-instances.html
if __name__ == '__main__':
"""
cancel-audit-mitigation-actions-task : https://awscli.amazonaws.com/v2/documentation/api/latest/reference/iot/cancel-audit-mitigation-actions-task.html
describe-audit-mitigation-actions-task : https://awscli.amazonaws.com/v2/documentation/api/latest/reference/iot/describe-audit-mitigation-actions-task.html
list-audit-mitigation-actions-tasks : https://awscli.amazonaws.com/v2/documentation/api/latest/reference/iot/list-audit-mitigation-actions-tasks.html
"""
write_parameter("iot", "start-audit-mitigation-actions-task") | [
"hcseo77@gmail.com"
] | hcseo77@gmail.com |
1aeb26bdbe0be227bf7a86266767f07914dd78c8 | f07a42f652f46106dee4749277d41c302e2b7406 | /Data Set/bug-fixing-2/d1186c9d2fdc62fe1491d0820af12106d16a1fb6-<customize>-fix.py | 4b77f7b3e1050c9ad0d1aaf9347f097791c87248 | [] | no_license | wsgan001/PyFPattern | e0fe06341cc5d51b3ad0fe29b84098d140ed54d1 | cc347e32745f99c0cd95e79a18ddacc4574d7faa | refs/heads/main | 2023-08-25T23:48:26.112133 | 2021-10-23T14:11:22 | 2021-10-23T14:11:22 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,333 | py |
def customize(self, dist=None):
'Customize Fortran compiler.\n\n This method gets Fortran compiler specific information from\n (i) class definition, (ii) environment, (iii) distutils config\n files, and (iv) command line (later overrides earlier).\n\n This method should be always called after constructing a\n compiler instance. But not in __init__ because Distribution\n instance is needed for (iii) and (iv).\n '
log.info(('customize %s' % self.__class__.__name__))
self._is_customised = True
self.distutils_vars.use_distribution(dist)
self.command_vars.use_distribution(dist)
self.flag_vars.use_distribution(dist)
self.update_executables()
self.find_executables()
noopt = self.distutils_vars.get('noopt', False)
noarch = self.distutils_vars.get('noarch', noopt)
debug = self.distutils_vars.get('debug', False)
f77 = self.command_vars.compiler_f77
f90 = self.command_vars.compiler_f90
f77flags = []
f90flags = []
freeflags = []
fixflags = []
if f77:
f77 = shlex.split(f77, posix=(os.name == 'posix'))
f77flags = self.flag_vars.f77
if f90:
f90 = shlex.split(f90, posix=(os.name == 'posix'))
f90flags = self.flag_vars.f90
freeflags = self.flag_vars.free
fix = self.command_vars.compiler_fix
if fix:
fix = shlex.split(fix, posix=(os.name == 'posix'))
fixflags = (self.flag_vars.fix + f90flags)
(oflags, aflags, dflags) = ([], [], [])
def get_flags(tag, flags):
flags.extend(getattr(self.flag_vars, tag))
this_get = getattr(self, ('get_flags_' + tag))
for (name, c, flagvar) in [('f77', f77, f77flags), ('f90', f90, f90flags), ('f90', fix, fixflags)]:
t = ('%s_%s' % (tag, name))
if (c and (this_get is not getattr(self, ('get_flags_' + t)))):
flagvar.extend(getattr(self.flag_vars, t))
if (not noopt):
get_flags('opt', oflags)
if (not noarch):
get_flags('arch', aflags)
if debug:
get_flags('debug', dflags)
fflags = (((self.flag_vars.flags + dflags) + oflags) + aflags)
if f77:
self.set_commands(compiler_f77=((f77 + f77flags) + fflags))
if f90:
self.set_commands(compiler_f90=(((f90 + freeflags) + f90flags) + fflags))
if fix:
self.set_commands(compiler_fix=((fix + fixflags) + fflags))
linker_so = self.linker_so
if linker_so:
linker_so_flags = self.flag_vars.linker_so
if sys.platform.startswith('aix'):
python_lib = get_python_lib(standard_lib=1)
ld_so_aix = os.path.join(python_lib, 'config', 'ld_so_aix')
python_exp = os.path.join(python_lib, 'config', 'python.exp')
linker_so = (([ld_so_aix] + linker_so) + [('-bI:' + python_exp)])
self.set_commands(linker_so=(linker_so + linker_so_flags))
linker_exe = self.linker_exe
if linker_exe:
linker_exe_flags = self.flag_vars.linker_exe
self.set_commands(linker_exe=(linker_exe + linker_exe_flags))
ar = self.command_vars.archiver
if ar:
arflags = self.flag_vars.ar
self.set_commands(archiver=([ar] + arflags))
self.set_library_dirs(self.get_library_dirs())
self.set_libraries(self.get_libraries())
| [
"dg1732004@smail.nju.edu.cn"
] | dg1732004@smail.nju.edu.cn |
549d47061f0ed2277297102fa4fd01ff4432bf94 | 9b20743ec6cd28d749a4323dcbadb1a0cffb281b | /07_Machine_Learning_Mastery_with_Python/07/pca.py | 2437e80daf68829e9200d38c5a0b646093a6a47b | [] | no_license | jggrimesdc-zz/MachineLearningExercises | 6e1c7e1f95399e69bba95cdfe17c4f8d8c90d178 | ee265f1c6029c91daff172b3e7c1a96177646bc5 | refs/heads/master | 2023-03-07T19:30:26.691659 | 2021-02-19T08:00:49 | 2021-02-19T08:00:49 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 511 | py | # Feature Extraction with PCA
from pandas import read_csv
from sklearn.decomposition import PCA
# load data
filename = 'pima-indians-diabetes.data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = read_csv(filename, names=names)
array = dataframe.values
X = array[:, 0:8]
Y = array[:, 8]
# feature extraction
pca = PCA(n_components=3)
fit = pca.fit(X)
# summarize components
print("Explained Variance: %s" % fit.explained_variance_ratio_)
print(fit.components_)
| [
"jgrimes@jgrimes.tech"
] | jgrimes@jgrimes.tech |
213431d95c159d4c1d5374f463d5a0b86a85ee8f | 64bf39b96a014b5d3f69b3311430185c64a7ff0e | /intro-ansible/venv3/lib/python3.8/site-packages/ansible_test/_internal/sanity/yamllint.py | 85a576d02d248df24fa0e8e1fcba6176467cd312 | [
"MIT"
] | permissive | SimonFangCisco/dne-dna-code | 7072eba7da0389e37507b7a2aa5f7d0c0735a220 | 2ea7d4f00212f502bc684ac257371ada73da1ca9 | refs/heads/master | 2023-03-10T23:10:31.392558 | 2021-02-25T15:04:36 | 2021-02-25T15:04:36 | 342,274,373 | 0 | 0 | MIT | 2021-02-25T14:39:22 | 2021-02-25T14:39:22 | null | UTF-8 | Python | false | false | 3,780 | py | """Sanity test using yamllint."""
from __future__ import (absolute_import, division, print_function)
__metaclass__ = type
import json
import os
from .. import types as t
from ..import ansible_util
from ..sanity import (
SanitySingleVersion,
SanityMessage,
SanityFailure,
SanitySkipped,
SanitySuccess,
SANITY_ROOT,
)
from ..target import (
TestTarget,
)
from ..util import (
SubprocessError,
display,
is_subdir,
find_python,
)
from ..util_common import (
run_command,
)
from ..config import (
SanityConfig,
)
from ..data import (
data_context,
)
class YamllintTest(SanitySingleVersion):
"""Sanity test using yamllint."""
@property
def error_code(self): # type: () -> t.Optional[str]
"""Error code for ansible-test matching the format used by the underlying test program, or None if the program does not use error codes."""
return 'ansible-test'
def filter_targets(self, targets): # type: (t.List[TestTarget]) -> t.List[TestTarget]
"""Return the given list of test targets, filtered to include only those relevant for the test."""
yaml_targets = [target for target in targets if os.path.splitext(target.path)[1] in ('.yml', '.yaml')]
for plugin_type, plugin_path in sorted(data_context().content.plugin_paths.items()):
if plugin_type == 'module_utils':
continue
yaml_targets.extend([target for target in targets if
os.path.splitext(target.path)[1] == '.py' and
os.path.basename(target.path) != '__init__.py' and
is_subdir(target.path, plugin_path)])
return yaml_targets
def test(self, args, targets, python_version):
"""
:type args: SanityConfig
:type targets: SanityTargets
:type python_version: str
:rtype: TestResult
"""
pyyaml_presence = ansible_util.check_pyyaml(args, python_version, quiet=True)
if not pyyaml_presence['cloader']:
display.warning("Skipping sanity test '%s' due to missing libyaml support in PyYAML."
% self.name)
return SanitySkipped(self.name)
settings = self.load_processor(args)
paths = [target.path for target in targets.include]
python = find_python(python_version)
results = self.test_paths(args, paths, python)
results = settings.process_errors(results, paths)
if results:
return SanityFailure(self.name, messages=results)
return SanitySuccess(self.name)
@staticmethod
def test_paths(args, paths, python):
"""
:type args: SanityConfig
:type paths: list[str]
:type python: str
:rtype: list[SanityMessage]
"""
cmd = [
python,
os.path.join(SANITY_ROOT, 'yamllint', 'yamllinter.py'),
]
data = '\n'.join(paths)
display.info(data, verbosity=4)
try:
stdout, stderr = run_command(args, cmd, data=data, capture=True)
status = 0
except SubprocessError as ex:
stdout = ex.stdout
stderr = ex.stderr
status = ex.status
if stderr:
raise SubprocessError(cmd=cmd, status=status, stderr=stderr, stdout=stdout)
if args.explain:
return []
results = json.loads(stdout)['messages']
results = [SanityMessage(
code=r['code'],
message=r['message'],
path=r['path'],
line=int(r['line']),
column=int(r['column']),
level=r['level'],
) for r in results]
return results
| [
"sifang@cisco.com"
] | sifang@cisco.com |
5166ace3467b2a5e6d75c7af8ef4b3a1febc640f | 53fab060fa262e5d5026e0807d93c75fb81e67b9 | /backup/user_172/ch31_2020_03_25_10_56_13_081031.py | a097597aaf1f8510a42ff7f07a2c25674a655745 | [] | no_license | gabriellaec/desoft-analise-exercicios | b77c6999424c5ce7e44086a12589a0ad43d6adca | 01940ab0897aa6005764fc220b900e4d6161d36b | refs/heads/main | 2023-01-31T17:19:42.050628 | 2020-12-16T05:21:31 | 2020-12-16T05:21:31 | 306,735,108 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 203 | py | y=3
def eh_primo (x):
if x%2==0:
return False
while y<x:
if x%y==0:
y=y+2
return False
else:
return True
| [
"you@example.com"
] | you@example.com |
de1db29362fe6f49c59b95f74cea99eb115bf71a | e37ee26bd37e86277aa98db7a9938e7d043c1146 | /setup.py | 386175f2b9107f26e003609e3390ad4e1d9fa916 | [
"BSD-2-Clause"
] | permissive | sjkingo/ticketus | f20e1e65a6e57706becb50371905c6d1f385bf71 | 90f2781af9418e9e2c6470ca50c9a6af9ce098ff | refs/heads/master | 2021-05-16T02:58:02.070421 | 2018-03-05T00:36:24 | 2018-03-05T00:36:24 | 28,283,750 | 3 | 3 | BSD-2-Clause | 2018-03-05T00:34:57 | 2014-12-21T00:38:26 | Python | UTF-8 | Python | false | false | 1,574 | py | from setuptools import find_packages, setup
from ticketus import __version__ as version
setup(
name='ticketus',
version=version,
license='BSD',
author='Sam Kingston',
author_email='sam@sjkwi.com.au',
description='Ticketus is a simple, no-frills ticketing system for helpdesks.',
url='https://github.com/sjkingo/ticketus',
install_requires=[
'Django >= 1.6.10',
'IMAPClient',
'django-grappelli',
'email-reply-parser',
'mistune',
'psycopg2',
'python-dateutil',
],
zip_safe=False,
include_package_data=True,
packages=find_packages(exclude=['ticketus_settings']),
classifiers=[
'Development Status :: 4 - Beta',
'Environment :: Web Environment',
'Intended Audience :: Developers',
'Intended Audience :: End Users/Desktop',
'Intended Audience :: Information Technology',
'Intended Audience :: System Administrators',
'License :: OSI Approved :: BSD License',
'Operating System :: OS Independent',
'Programming Language :: Python :: 3.3',
'Programming Language :: Python :: 3.4',
'Programming Language :: Python',
'Topic :: Communications :: Email',
'Topic :: Software Development :: Bug Tracking',
'Topic :: System :: Systems Administration',
],
scripts=[
'import_scripts/ticketus_import_freshdesk',
'import_scripts/ticketus_import_github',
'bin_scripts/ticketus_mailgw_imap4',
'bin_scripts/ticketus-admin',
],
)
| [
"sam@sjkwi.com.au"
] | sam@sjkwi.com.au |
bff50f96ee9ee9794dd94abc1b4c5dfc27f57ea1 | 747755833862b8e9d0f58ebc62879d6ef47c23c8 | /python-master (5)/python-master/socket/udp/server.py | 7d67bbdee63a778498fcb2254818529dc569f7bc | [] | no_license | tangsong41/stu_py | 98a06730dbca6e158cf81c18d98fe1317c1ae512 | d41507cd8dd9e8a54084872dfa15c36da443c02b | refs/heads/master | 2022-12-11T23:53:57.530946 | 2019-01-15T18:29:19 | 2019-01-15T18:29:19 | 163,953,100 | 3 | 0 | null | 2022-12-07T23:24:01 | 2019-01-03T09:41:29 | Jupyter Notebook | UTF-8 | Python | false | false | 351 | py | # encoding: utf-8
__author__ = 'zhanghe'
import socket
port = 8081
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 从指定的端口,从任何发送者,接收UDP数据
s.bind(('', port))
print('正在等待接入...')
while True:
# 接收一个数据
data, address = s.recvfrom(1024)
print('Received:', data, 'from', address) | [
"369223985@qq.com"
] | 369223985@qq.com |
8f8eeb6fa9b019c75aec80c7fb15484d636c4535 | 179577ecdd7fda84ad970b3aad573a575fef56bc | /aulas/aula12.py | b78a3b884765a9cbb0cfe7ed5083bea5c718d61a | [] | no_license | Elvis-Lopes/Curso-em-video-Python | 6c12fa17a5c38c722a7c8e9677f6d9596bc5653c | 65f093975af9bd59c8aaa37606ba648b7ba1e1c4 | refs/heads/master | 2021-02-11T12:15:13.580496 | 2020-05-05T21:55:06 | 2020-05-05T21:55:06 | 244,490,886 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 336 | py | # exemplos de estrutura condicional aninhada
nome = str(input('Qual é o seu nome: ')).strip().title()
if nome == 'Elvis':
print('Que nome bonito!')
elif nome == 'Pedro' or nome == 'João' or nome =='Maria':
print('Seu nome é bem popular no Brasil')
else:
print('Seu nome é bem normal.')
print(f'Tenha um bom dia {nome}')
| [
"elvislopes1996@hotmail.com"
] | elvislopes1996@hotmail.com |
5bce78a403cb350f6070e28a089543acef7afb25 | e5b8a5d93989dd53933c5cd417afa8b2a39ad307 | /test/test_coupon_discount_items.py | 45325446f7a44b5aa07fade379304c1d7922820d | [
"Apache-2.0"
] | permissive | gstingy/uc_python_api | f3586bfce9c962af2e8c1bc266ff25e0f1971278 | 9a0bd3f6e63f616586681518e44fe37c6bae2bba | refs/heads/master | 2020-03-28T11:13:22.537641 | 2018-09-10T17:07:59 | 2018-09-10T17:07:59 | 148,190,066 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 920 | py | # coding: utf-8
"""
UltraCart Rest API V2
UltraCart REST API Version 2
OpenAPI spec version: 2.0.0
Contact: support@ultracart.com
Generated by: https://github.com/swagger-api/swagger-codegen.git
"""
from __future__ import absolute_import
import os
import sys
import unittest
import ultracart
from ultracart.rest import ApiException
from ultracart.models.coupon_discount_items import CouponDiscountItems
class TestCouponDiscountItems(unittest.TestCase):
""" CouponDiscountItems unit test stubs """
def setUp(self):
pass
def tearDown(self):
pass
def testCouponDiscountItems(self):
"""
Test CouponDiscountItems
"""
# FIXME: construct object with mandatory attributes with example values
#model = ultracart.models.coupon_discount_items.CouponDiscountItems()
pass
if __name__ == '__main__':
unittest.main()
| [
"perry@ultracart.com"
] | perry@ultracart.com |
39edbec0f0e7116e1ede19dfa091fc16e782d559 | b3e9a8963b9aca334b93b95bc340c379544e1046 | /euler/14.py | 086c339acb194f1b66a930b0f64d444e2daadef9 | [] | no_license | protocol7/euler.py | 86ea512c2c216968e6c260b19469c0c8d038feb7 | e2a8e46a9b07e6d0b039a5496059f3bf73aa5441 | refs/heads/master | 2022-09-08T22:49:47.486631 | 2022-08-23T20:07:00 | 2022-08-23T20:07:00 | 169,478,759 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 272 | py | #!/usr/bin/env python3
def collatz(n):
c = 1
while n != 1:
if n % 2 == 0:
n //= 2
else:
n = 3 * n + 1
c += 1
return c
assert 10 == collatz(13)
assert 837799 == max([n for n in range(1, 1000000)], key=collatz)
| [
"niklas@protocol7.com"
] | niklas@protocol7.com |
139adedab62d240002e76a8278f5c9899697af38 | d32bc79eb8631d6bc4ab20498631ba516db4d5f7 | /152_maxProductArray.py | 38fc25720cfdfefd0d9b48f8df23ab13c1c386d1 | [] | no_license | Anirban2404/LeetCodePractice | 059f382d17f71726ad2d734b9579f5bab2bba93c | 786075e0f9f61cf062703bc0b41cc3191d77f033 | refs/heads/master | 2021-10-08T04:41:36.163328 | 2021-09-28T02:16:47 | 2021-09-28T02:16:47 | 164,513,056 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,056 | py | #!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 7 22:41:52 2019
@author: anirban-mac
"""
"""
Given an integer array nums, find the contiguous subarray within an array
(containing at least one number) which has the largest product.
Example 1:
Input: [2,3,-2,4]
Output: 6
Explanation: [2,3] has the largest product 6.
Example 2:
Input: [-2,0,-1]
Output: 0
Explanation: The result cannot be 2, because [-2,-1] is not a subarray.
"""
class Solution:
def maxProduct(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
if len(nums) == 0:
return 0
localmin = localmax = maxproduct = nums[0]
for x in nums[1:]:
if x < 0:
localmin, localmax = localmax, localmin
localmax = max(x, localmax * x)
localmin = min(x, localmin * x)
maxproduct = max(maxproduct, localmax)
print(localmax, localmin, maxproduct)
return maxproduct
nums = [2,3,-2,-6]
print(Solution().maxProduct(nums)) | [
"anirban-mac@Anirbans-MacBook-Pro.local"
] | anirban-mac@Anirbans-MacBook-Pro.local |
4e238c78b6a39de8f4b38c09be8989c9b69bfe93 | 210ecd63113ce90c5f09bc2b09db3e80ff98117a | /AbletonLive9_RemoteScripts/Launch_Control_XL/ButtonElement.py | fe0744f2950ba1281db7c0754c69506a53640e9b | [] | no_license | ajasver/MidiScripts | 86a765b8568657633305541c46ccc1fd1ea34501 | f727a2e63c95a9c5e980a0738deb0049363ba536 | refs/heads/master | 2021-01-13T02:03:55.078132 | 2015-07-16T18:27:30 | 2015-07-16T18:27:30 | 38,516,112 | 4 | 1 | null | null | null | null | UTF-8 | Python | false | false | 906 | py | #Embedded file name: /Users/versonator/Jenkins/live/Binary/Core_Release_64_static/midi-remote-scripts/Launch_Control_XL/ButtonElement.py
from _Framework.ButtonElement import ON_VALUE, OFF_VALUE, ButtonElement as ButtonElementBase
class ButtonElement(ButtonElementBase):
_on_value = None
_off_value = None
def reset(self):
self._on_value = None
self._off_value = None
super(ButtonElement, self).reset()
def set_on_off_values(self, on_value, off_value):
self._on_value = on_value
self._off_value = off_value
def send_value(self, value, **k):
if value is ON_VALUE and self._on_value is not None:
self._skin[self._on_value].draw(self)
elif value is OFF_VALUE and self._off_value is not None:
self._skin[self._off_value].draw(self)
else:
super(ButtonElement, self).send_value(value, **k) | [
"admin@scoopler.com"
] | admin@scoopler.com |
625a6b86a578dfc51f571f9570a5a87a0b9066de | 3636c679001c9d9f75d54a0361052b243a97d2e4 | /build/fbcode_builder_config.py | d1183c045603b57d389956411bbd7a03ba3f54d3 | [
"MIT"
] | permissive | anvarov/mvfst | ebd8e259d5628ca9bc690bfea6f30b709b10e51d | b5713b9a2b4b98aa7fc0b0bcb110d70e2ea38254 | refs/heads/master | 2022-06-18T09:32:25.817789 | 2020-05-13T11:46:23 | 2020-05-13T11:46:23 | 263,613,627 | 1 | 0 | MIT | 2020-05-13T11:45:22 | 2020-05-13T11:45:21 | null | UTF-8 | Python | false | false | 1,331 | py | #!/usr/bin/env python
# Copyright (c) Facebook, Inc. and its affiliates.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
'fbcode_builder steps to build & test mvfst'
import specs.gmock as gmock
import specs.fmt as fmt
import specs.folly as folly
import specs.fizz as fizz
from shell_quoting import ShellQuoted
def fbcode_builder_spec(builder):
builder.add_option(
'mvfst/_build:cmake_defines',
{
'BUILD_SHARED_LIBS': 'OFF',
'BUILD_TESTS': 'ON',
}
)
return {
'depends_on': [gmock, fmt, folly, fizz],
'steps': [
builder.fb_github_cmake_install('mvfst/_build', '..', 'facebookincubator'),
builder.step(
'Run mvfst tests', [
builder.run(
ShellQuoted('ctest --output-on-failure -j {n}')
.format(n=builder.option('make_parallelism'), )
)
]
),
]
}
config = {
'github_project': 'facebookincubator/mvfst',
'fbcode_builder_spec': fbcode_builder_spec,
}
| [
"facebook-github-bot@users.noreply.github.com"
] | facebook-github-bot@users.noreply.github.com |
a0b669ed46c14af32a2247e902baa46765a173b6 | c47b68a858e01d5fe51661a8ded5138652d3082e | /src/exploration/businees_cases/prdicting_hiring.py | 7df6f68f3af533048d5e6e5dc147841479515439 | [] | no_license | RitGlv/Practice_Makes_perfect | d2d50efbf810b41d0648f27d02b5710c14c3fcae | 3dcb7ff876e58ade64faed0fa5523cba7461cf8d | refs/heads/master | 2021-03-13T03:51:43.142777 | 2017-06-05T07:32:47 | 2017-06-05T07:32:47 | 91,500,946 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 129 | py | import pandas as pd
from sklearn.linear_model import LogisticRegression
import sys
sys.path.insert(0, '../../')
import featurize
| [
"johndoe@example.com"
] | johndoe@example.com |
37fa900821ba826c4e1fdb9d424671d44d8c8280 | 46fe894c4a8e14727bd085c5834a2acfbe5cd41f | /blogproject/urls.py | a3fd92bc1bfdbc87607115ccf80d146a61b27b18 | [] | no_license | PriyaRamya11/React-Django-Blog-Backend | 6970ac443d0f44d5d16ea0738f16546eb50879a9 | 491629fac3cf5d6fae0a3f59b7a47e353ed9407c | refs/heads/master | 2023-04-27T20:26:13.818306 | 2021-05-05T11:27:13 | 2021-05-05T11:27:13 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 582 | py | from django.shortcuts import render
from django.contrib import admin
from django.urls import path
from django.urls.conf import include
from rest_framework.response import Response
from rest_framework.decorators import api_view
from django.conf.urls.static import static
from django.conf import settings
# url patterns of the entire project
urlpatterns = [
path('admin/', admin.site.urls),
path('api/', include('accounts.urls')),
# blog url configuration
path('api/blog/', include('blog.urls'))
]+static(settings.MEDIA_URL, document_root = settings.MEDIA_ROOT)
| [
"kumar.ankit383@gmail.com"
] | kumar.ankit383@gmail.com |
8061be7dbac8f6e43df70f6a483d6d89690445f2 | 52a3beeb07ad326115084a47a9e698efbaec054b | /manila/api/contrib/services.py | 607903fef8b780fbb6222f72ce62af1c9d0d53a4 | [] | no_license | bopopescu/sample_scripts | 3dade0710ecdc8f9251dc60164747830f8de6877 | f9edce63c0a4d636f672702153662bd77bfd400d | refs/heads/master | 2022-11-17T19:19:34.210886 | 2018-06-11T04:14:27 | 2018-06-11T04:14:27 | 282,088,840 | 0 | 0 | null | 2020-07-24T00:57:31 | 2020-07-24T00:57:31 | null | UTF-8 | Python | false | false | 3,444 | py | # Copyright 2012 IBM Corp.
# All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"); you may
# not use this file except in compliance with the License. You may obtain
# a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
# License for the specific language governing permissions and limitations
# under the License.
from oslo_log import log
import webob.exc
from manila.api import extensions
from manila import db
from manila import exception
from manila import utils
LOG = log.getLogger(__name__)
authorize = extensions.extension_authorizer('share', 'services')
class ServiceController(object):
def index(self, req):
"""Return a list of all running services."""
context = req.environ['manila.context']
authorize(context)
all_services = db.service_get_all(context)
services = []
for service in all_services:
service = {
'id': service['id'],
'binary': service['binary'],
'host': service['host'],
'zone': service['availability_zone']['name'],
'status': 'disabled' if service['disabled'] else 'enabled',
'state': 'up' if utils.service_is_up(service) else 'down',
'updated_at': service['updated_at'],
}
services.append(service)
search_opts = [
'host',
'binary',
'zone',
'state',
'status',
]
for search_opt in search_opts:
value = ''
if search_opt in req.GET:
value = req.GET[search_opt]
services = [s for s in services if s[search_opt] == value]
if len(services) == 0:
break
return {'services': services}
def update(self, req, id, body):
"""Enable/Disable scheduling for a service."""
context = req.environ['manila.context']
authorize(context)
if id == "enable":
disabled = False
elif id == "disable":
disabled = True
else:
raise webob.exc.HTTPNotFound("Unknown action")
try:
host = body['host']
binary = body['binary']
except (TypeError, KeyError):
raise webob.exc.HTTPBadRequest()
try:
svc = db.service_get_by_args(context, host, binary)
if not svc:
raise webob.exc.HTTPNotFound('Unknown service')
db.service_update(context, svc['id'], {'disabled': disabled})
except exception.ServiceNotFound:
raise webob.exc.HTTPNotFound("service not found")
return {'host': host, 'binary': binary, 'disabled': disabled}
class Services(extensions.ExtensionDescriptor):
"""Services support."""
name = "Services"
alias = "os-services"
updated = "2012-10-28T00:00:00-00:00"
def get_resources(self):
resources = []
resource = extensions.ResourceExtension('os-services',
ServiceController())
resources.append(resource)
return resources
| [
"Suhaib.Chishti@exponential.com"
] | Suhaib.Chishti@exponential.com |
8463c8c53648a7ad7c984f04467593a429195089 | 43459d0a1b5c8d1b631ef3edb91b6a7bb1b26078 | /venv/Lib/site-packages/npx/_isin.py | 0e1d06123de282476de66018f3bbaa87bfe74931 | [] | no_license | titusowuor30/dj_rest_jwt_auth_api | 2ee5046b043d34d88c0fad344d9bb6525513ee90 | ee33e33ed2f5852d5882cbc7b694e7ca9be7e7da | refs/heads/master | 2023-07-16T21:42:08.820624 | 2021-08-28T07:50:47 | 2021-08-28T07:50:47 | 400,724,458 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 808 | py | import numpy as np
import numpy.typing as npt
def isin_rows(a: npt.ArrayLike, b: npt.ArrayLike):
a = np.asarray(a)
b = np.asarray(b)
if not np.issubdtype(a.dtype, np.integer):
raise ValueError(f"Input array must be integer type, got {a.dtype}.")
if not np.issubdtype(b.dtype, np.integer):
raise ValueError(f"Input array must be integer type, got {b.dtype}.")
a = a.reshape(a.shape[0], np.prod(a.shape[1:], dtype=int))
b = b.reshape(b.shape[0], np.prod(b.shape[1:], dtype=int))
a_view = np.ascontiguousarray(a).view(
np.dtype((np.void, a.dtype.itemsize * a.shape[1]))
)
b_view = np.ascontiguousarray(b).view(
np.dtype((np.void, b.dtype.itemsize * b.shape[1]))
)
out = np.isin(a_view, b_view)
return out.reshape(a.shape[0])
| [
"titusowuor30@gmail.com"
] | titusowuor30@gmail.com |
f10d82d87ec02eb5ee78e0ebf6c735f5ed119466 | 4252102a1946b2ba06d3fa914891ec7f73570287 | /pylearn2/optimization/test_linear_cg.py | e82e497ee222a16178c381ee0164f0fb565e9b2a | [] | no_license | lpigou/chalearn2014 | 21d487f314c4836dd1631943e20f7ab908226771 | 73b99cdbdb609fecff3cf85e500c1f1bfd589930 | refs/heads/master | 2020-05-17T00:08:11.764642 | 2014-09-24T14:42:00 | 2014-09-24T14:42:00 | 24,418,815 | 2 | 3 | null | null | null | null | UTF-8 | Python | false | false | 1,261 | py | import theano
from theano import tensor, config
import numpy
import linear_cg
import warnings
from pylearn2.testing.skip import skip_if_no_scipy
try:
import scipy.linalg
except ImportError:
warnings.warn("Could not import scipy.linalg")
import time
def test_linear_cg():
rng = numpy.random.RandomState([1,2,3])
n = 5
M = rng.randn(2*n,n)
M = numpy.dot(M.T,M).astype(config.floatX)
b = rng.randn(n).astype(config.floatX)
c = rng.randn(1).astype(config.floatX)[0]
x = theano.tensor.vector('x')
f = 0.5 * tensor.dot(x,tensor.dot(M,x)) - tensor.dot(b,x) + c
sol = linear_cg.linear_cg(f,[x])
fn_sol = theano.function([x], sol)
start = time.time()
sol = fn_sol( rng.randn(n).astype(config.floatX))[0]
my_lcg = time.time() -start
eval_f = theano.function([x],f)
cgf = eval_f(sol)
print "conjugate gradient's value of f:", str(cgf), 'time (s)', my_lcg
skip_if_no_scipy()
spf = eval_f( scipy.linalg.solve(M,b) )
print "scipy.linalg.solve's value of f: "+str(spf)
abs_diff = abs(cgf - spf)
if not (abs_diff < 1e-5):
raise AssertionError("Expected abs_diff < 1e-5, got abs_diff of " +
str(abs_diff))
if __name__ == '__main__':
test_linear_cg()
| [
"lionelpigou@gmail.com"
] | lionelpigou@gmail.com |
4af9aaf42d7bc296c64d1dd79d632048cc5126bf | 26f8a8782a03693905a2d1eef69a5b9f37a07cce | /test/test_destiny_destiny_item_type.py | 371104552534d46e48c0251fd4f89eb10524e339 | [] | no_license | roscroft/openapi3-swagger | 60975db806095fe9eba6d9d800b96f2feee99a5b | d1c659c7f301dcfee97ab30ba9db0f2506f4e95d | refs/heads/master | 2021-06-27T13:20:53.767130 | 2017-08-31T17:09:40 | 2017-08-31T17:09:40 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,119 | py | # coding: utf-8
"""
Bungie.Net API
These endpoints constitute the functionality exposed by Bungie.net, both for more traditional website functionality and for connectivity to Bungie video games and their related functionality.
OpenAPI spec version: 2.0.0
Contact: support@bungie.com
Generated by: https://github.com/swagger-api/swagger-codegen.git
"""
from __future__ import absolute_import
import os
import sys
import unittest
import swagger_client
from swagger_client.rest import ApiException
from swagger_client.models.destiny_destiny_item_type import DestinyDestinyItemType
class TestDestinyDestinyItemType(unittest.TestCase):
""" DestinyDestinyItemType unit test stubs """
def setUp(self):
pass
def tearDown(self):
pass
def testDestinyDestinyItemType(self):
"""
Test DestinyDestinyItemType
"""
# FIXME: construct object with mandatory attributes with example values
#model = swagger_client.models.destiny_destiny_item_type.DestinyDestinyItemType()
pass
if __name__ == '__main__':
unittest.main()
| [
"adherrling@gmail.com"
] | adherrling@gmail.com |
ee940c77343f60e39daed05d2f53ca1ce16cc5ba | 6b2a8dd202fdce77c971c412717e305e1caaac51 | /solutions_6404600001200128_1/Python/Alen/caseA.py | 3f71933f6070b75b35a50b9393416fc77c08e182 | [] | no_license | alexandraback/datacollection | 0bc67a9ace00abbc843f4912562f3a064992e0e9 | 076a7bc7693f3abf07bfdbdac838cb4ef65ccfcf | refs/heads/master | 2021-01-24T18:27:24.417992 | 2017-05-23T09:23:38 | 2017-05-23T09:23:38 | 84,313,442 | 2 | 4 | null | null | null | null | UTF-8 | Python | false | false | 1,583 | py | #!/usr/bin/env python
# encoding: utf-8
def way1(samples):
if len(samples) < 2:
return 0
min_pieces = 0
last_pieces = samples[0]
for s in samples[1:]:
if s < last_pieces:
min_pieces += last_pieces - s
last_pieces = s
return min_pieces
def way2(samples):
if len(samples) < 2:
return 0
last_pieces = samples[0]
max_eaten_pieces = 0
for s in samples[1:]:
if s < last_pieces:
max_eaten_pieces = max(max_eaten_pieces, last_pieces - s)
last_pieces = s
min_pieces = 0
last_pieces = samples[0]
for s in samples[1:]:
if s < last_pieces:
min_pieces += min(max(max_eaten_pieces, last_pieces - s), last_pieces)
else:
min_pieces += min(max_eaten_pieces, last_pieces)
last_pieces = s
return min_pieces
def run(inputFile, outputFile):
fp = open(inputFile, 'r')
fw = open(outputFile, 'w')
caseIndex = 0
count = -1
sampleCount = 0
for line in fp:
if (caseIndex == 0):
count = int(line)
caseIndex += 1
elif sampleCount == 0:
sampleCount = int(line)
else:
samples_strs = line.split(' ')
samples = [int(s) for s in samples_strs]
fw.write("Case #%d: %d %d\n" % (caseIndex, way1(samples), way2(samples)))
caseIndex += 1
count -= 1
sampleCount = 0
if (count == 0):
break
fp.close()
fw.close()
if __name__ == "__main__":
run("in", "out")
| [
"eewestman@gmail.com"
] | eewestman@gmail.com |
78da60a4d142b5f6f724959fb430c94449b06674 | de24f83a5e3768a2638ebcf13cbe717e75740168 | /moodledata/vpl_data/429/usersdata/310/107206/submittedfiles/jogoDaVelha.py | 78481b58610ef63879d65bf7ebf7d7ab7d63160b | [] | no_license | rafaelperazzo/programacao-web | 95643423a35c44613b0f64bed05bd34780fe2436 | 170dd5440afb9ee68a973f3de13a99aa4c735d79 | refs/heads/master | 2021-01-12T14:06:25.773146 | 2017-12-22T16:05:45 | 2017-12-22T16:05:45 | 69,566,344 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,926 | py | # -*- coding: utf-8 -*-
from jogoDaVelha_BIB import *
# COLOQUE SEU PROGRAMA A PARTIR DAQUI
jgnov = 'S'
while jgnov == 'S' or jgnov == 's' or jgnov == 'SIM' or jgnov == 'sim':
print('Bem vindo ao JogoDaVelha do grupo D [Anderson Bezerra, Caio César, Laura, Juan]')
nome = input('\nQual o seu nome (ou apelido)? ')
jogador = 2
smbH = 0
smbH = solicitaSimbolodoHumano(smbH)
if smbH == ' X ':
smbPC = ' O '
else:
smbPC = ' X '
jogador = sorteioPrimeiraJogada(jogador, nome)
tabuleiro = [
[' ',' ',' '],
[' ',' ',' '],
[' ',' ',' ']
]
som = 0
while True:
if jogador == 1:
while True:
JogadaHumana(smbH,tabuleiro, nome)
break
if verificaVencedor(smbH, tabuleiro, som):
if verificaVencedor(smbH, tabuleiro, som) == 20:
mostraTabuleiro(tabuleiro)
print ('\nDeu Velha')
break
else:
mostraTabuleiro(tabuleiro)
print('\nVencedor: %s'%nome)
break
jogador = 0
else:
tabuleiro = JogadaComputador(smbPC,tabuleiro)
if verificaVencedor(smbPC, tabuleiro, som):
if verificaVencedor(smbPC, tabuleiro, som) == 20:
mostraTabuleiro(tabuleiro)
print ('\nDeu Velha')
break
else:
mostraTabuleiro(tabuleiro)
print ('\nVencedor: Computador')
break
jogador = 1
jgnov = input('\nCaso queira jogar novamente, digite s ou sim: ')
if jgnov == 'S' or jgnov == 's' or jgnov == 'SIM' or jgnov == 'sim':
os.system('clear')
| [
"rafael.mota@ufca.edu.br"
] | rafael.mota@ufca.edu.br |
b6cffd9814a17ffbaf39dbadfae773d76b70a95c | 4a74ec1b7e299540b924bce4928537a51fc00ff5 | /day24_day30/day24/순열(재귀).py | 3c9c552c654e3a3b99bbd69727a4723460368c48 | [] | no_license | yeonlang/algorithm | ef74b2592818495f29f6de5f44f81ccf307efa59 | ab788658bb781773c489cac8c6e8d2bea48fda07 | refs/heads/master | 2020-04-22T20:25:46.243355 | 2019-05-08T15:17:45 | 2019-05-08T15:17:45 | 170,641,144 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 364 | py | def BTK(choice):
global result
if choice==len(data):
print(result)
return
for i in range(len(data)):
if not visited[i]:
visited[i]=1
result[choice]=data[i]
BTK(choice+1)
result[choice]=0
visited[i]=0
data=[1,2,3,4,5]
visited=[0]*len(data)
result=[0]*len(data)
BTK(0) | [
"naspy001@gmail.com"
] | naspy001@gmail.com |
aa9a09bc595ade1419abb2183ac8589ae774764a | 3da69696601b2b3ad7bc1285a5f0343c7eafea80 | /lc900.py | 8e3d98a41900bffeb2f868bebe4485df35b009d6 | [] | no_license | GeorgyZhou/Leetcode-Problem | ee586463a2e4e75c910c095bdc057f1be70b5c1b | d6fac85a94a7188e93d4e202e67b6485562d12bd | refs/heads/master | 2021-06-30T15:58:04.698200 | 2020-12-18T22:55:49 | 2020-12-18T22:55:49 | 66,054,365 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 826 | py | class RLEIterator(object):
def __init__(self, A):
"""
:type A: List[int]
"""
self.seq = []
for i in range(0, len(A), 2):
if A[i] == 0:
continue
self.seq.append([A[i], A[i+1]])
self.seq.reverse()
def next(self, n):
"""
:type n: int
:rtype: int
"""
last_num = -1
while self.seq and n >= self.seq[-1][0]:
n -= self.seq[-1][0]
last_num = self.seq[-1][1]
self.seq.pop()
if n > 0 and self.seq:
self.seq[-1][0] -= n
n = 0
last_num = self.seq[-1][1]
return last_num if n == 0 else -1
# Your RLEIterator object will be instantiated and called as such:
# obj = RLEIterator(A)
# param_1 = obj.next(n)
| [
"michaelchouqj@gmail.com"
] | michaelchouqj@gmail.com |
64288c71f6d3d6f5bf17652ffa72615f6ef91492 | 6b95f96e00e77f78f0919c10b2c90f116c0b295d | /TelstraTPN/models/inline_response20018.py | f94f3428cc14125628e5e80c0129635b20cc6fa9 | [] | no_license | telstra/Programmable-Network-SDK-python | 0522b54dcba48e16837c6c58b16dabde83b477d5 | d1c19c0383af53a5f09a6f5046da466ae6e1d97a | refs/heads/master | 2021-09-19T17:09:06.831233 | 2018-07-30T03:22:26 | 2018-07-30T03:22:26 | 113,531,312 | 3 | 1 | null | 2018-07-30T03:22:27 | 2017-12-08T04:23:15 | Python | UTF-8 | Python | false | false | 4,253 | py | # coding: utf-8
"""
Telstra Programmable Network API
Telstra Programmable Network is a self-provisioning platform that allows its users to create on-demand connectivity services between multiple end-points and add various network functions to those services. Programmable Network enables to connectivity to a global ecosystem of networking services as well as public and private cloud services. Once you are connected to the platform on one or more POPs (points of presence), you can start creating those services based on the use case that you want to accomplish. The Programmable Network API is available to all customers who have registered to use the Programmable Network. To register, please contact your account representative. # noqa: E501
OpenAPI spec version: 2.4.2
Contact: pnapi-support@team.telstra.com
Generated by: https://openapi-generator.tech
"""
import pprint
import re # noqa: F401
import six
class InlineResponse20018(object):
"""NOTE: This class is auto generated by OpenAPI Generator.
Ref: https://openapi-generator.tech
Do not edit the class manually.
"""
"""
Attributes:
openapi_types (dict): The key is attribute name
and the value is attribute type.
attribute_map (dict): The key is attribute name
and the value is json key in definition.
"""
openapi_types = {
'dps': 'dict(str, float)',
'metric': 'str'
}
attribute_map = {
'dps': 'dps',
'metric': 'metric'
}
def __init__(self, dps=None, metric=None): # noqa: E501
"""InlineResponse20018 - a model defined in OpenAPI""" # noqa: E501
self._dps = None
self._metric = None
self.discriminator = None
if dps is not None:
self.dps = dps
if metric is not None:
self.metric = metric
@property
def dps(self):
"""Gets the dps of this InlineResponse20018. # noqa: E501
:return: The dps of this InlineResponse20018. # noqa: E501
:rtype: dict(str, float)
"""
return self._dps
@dps.setter
def dps(self, dps):
"""Sets the dps of this InlineResponse20018.
:param dps: The dps of this InlineResponse20018. # noqa: E501
:type: dict(str, float)
"""
self._dps = dps
@property
def metric(self):
"""Gets the metric of this InlineResponse20018. # noqa: E501
:return: The metric of this InlineResponse20018. # noqa: E501
:rtype: str
"""
return self._metric
@metric.setter
def metric(self, metric):
"""Sets the metric of this InlineResponse20018.
:param metric: The metric of this InlineResponse20018. # noqa: E501
:type: str
"""
self._metric = metric
def to_dict(self):
"""Returns the model properties as a dict"""
result = {}
for attr, _ in six.iteritems(self.openapi_types):
value = getattr(self, attr)
if isinstance(value, list):
result[attr] = list(map(
lambda x: x.to_dict() if hasattr(x, "to_dict") else x,
value
))
elif hasattr(value, "to_dict"):
result[attr] = value.to_dict()
elif isinstance(value, dict):
result[attr] = dict(map(
lambda item: (item[0], item[1].to_dict())
if hasattr(item[1], "to_dict") else item,
value.items()
))
else:
result[attr] = value
return result
def to_str(self):
"""Returns the string representation of the model"""
return pprint.pformat(self.to_dict())
def __repr__(self):
"""For `print` and `pprint`"""
return self.to_str()
def __eq__(self, other):
"""Returns true if both objects are equal"""
if not isinstance(other, InlineResponse20018):
return False
return self.__dict__ == other.__dict__
def __ne__(self, other):
"""Returns true if both objects are not equal"""
return not self == other
| [
"steven@developersteve.com"
] | steven@developersteve.com |
d7bcf7c5dacf1719df9427cbec737517decf12bd | 6de4c9c36ab2ecdb099aef0050f1afdd30fe2b3f | /app/email.py | fec1d7e3314c60e8e5981438e1d0a1c34fbf167b | [] | no_license | wadi-1000/Pitches | b4f2ba8db2d6e18c75f3dbcf4475155abdaf30df | 6aff3af294b38674fbd45fffdb07cf32b67ccb6e | refs/heads/master | 2023-07-14T23:25:22.812954 | 2021-08-25T09:23:21 | 2021-08-25T09:23:21 | 395,655,737 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 387 | py | from flask_mail import Message
from flask import render_template
from . import mail
def mail_message(subject,template,to,**kwargs):
sender_email = 'joykiranga@gamil.com'
email = Message(subject, sender=sender_email, recipients=[to])
email.body= render_template(template + ".txt",**kwargs)
email.html = render_template(template + ".html",**kwargs)
mail.send(email)
| [
"joy.kiranga@student.moringaschool@gmail.com"
] | joy.kiranga@student.moringaschool@gmail.com |
6b5c8a12d04375293740f160e7cff38d6c442850 | b2135e3fc77666f043f0fbafd0d88ed9865d5b4f | /7183 Python Basics/13 Chapter 2.5 - About loop conditions/01 Consuming lists/87646_07_code.py | ed93d186b4adf84e544c07eb5ee57d309cad638f | [] | no_license | Felienne/spea | 164d05e9fbba82c7b7df8d00295f7157054f9248 | ecb06c66aaf6a2dced3f141ca415be9efb7dbff5 | refs/heads/master | 2020-03-17T17:35:27.302219 | 2018-05-17T10:14:49 | 2018-05-17T10:14:49 | 133,794,299 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 217 | py | #
Finish the loop so all elements are printed.
Note: there are different ways of doing this! In the nest step you can try multiple ways.
list = [2, 6, 8, 12, 19, 5]
while ___:
item = list.pop()
print(item) | [
"felienne@gmail.com"
] | felienne@gmail.com |
79bbf1803c6fdec266bdee054b03ed8a0b300bba | 056b57a594289cab88b73889c55059376dab5655 | /filter_app/migrations/0006_auto_20151215_0614.py | 020b19cb8103a59a136d3f4d06d1eaa23b284baf | [] | no_license | dentemm/filter_project | 05b9c19975c1d50bacc78bbcc3c9ef8b95f61f65 | ac0a7ce1254f17db16f12ee5eb639d00f8713a35 | refs/heads/master | 2020-12-29T02:32:38.535747 | 2017-01-09T06:53:55 | 2017-01-09T06:53:55 | 43,113,731 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 618 | py | # -*- coding: utf-8 -*-
from __future__ import unicode_literals
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('filter_app', '0005_module_extra_info'),
]
operations = [
migrations.AddField(
model_name='module',
name='recommended_filter',
field=models.ForeignKey(related_name='+', to='filter_app.Filter', null=True),
),
migrations.AlterField(
model_name='module',
name='extra_info',
field=models.TextField(null=True, blank=True),
),
]
| [
"tim.claes@me.com"
] | tim.claes@me.com |
6b502908108a91d453d96034677fc8642e70ff3c | 1d44bfac26793f034a77916cb211bf44a774e1ef | /CIFAR-100/another_mixed_net.py | 24312a86dba5e512321b848846ca366ae4f9c0d0 | [] | no_license | VCharatsidis/Unsupervised-Clustering | d9f81603cc35c9f3087c1ad7d721cd3bfa7de9b3 | b060caa315f0c066410da9580e64d6db0222f2a8 | refs/heads/master | 2021-07-08T21:27:12.145711 | 2021-01-18T17:50:12 | 2021-01-18T17:50:12 | 224,744,216 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 5,173 | py | from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import torch.nn as nn
import torch
class AnotherMixed(nn.Module):
"""
This class implements a Multi-layer Perceptron in PyTorch.
It handles the different layers and parameters of the model.
Once initialized an MLP object can perform forward.
"""
def __init__(self, n_channels, EMBEDING_SIZE, classes):
"""
Initializes MLP object.
Args:
n_inputs: number of inputs.
n_hidden: list of ints, specifies the number of units
in each linear layer. If the list is empty, the MLP
will not have any linear layers, and the model
will simply perform a multinomial logistic regression.
n_classes: number of classes of the classification problem.
This number is required in order to specify the
output dimensions of the MLP
"""
super(AnotherMixed, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(n_channels, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
#
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(512),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
nn.Conv2d(512, 1024, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(1024),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
)
conv_size = 4096
self.brain = nn.Sequential(
nn.Linear(conv_size, 4096),
nn.ReLU(),
nn.BatchNorm1d(4096),
nn.Linear(4096, EMBEDING_SIZE)
)
self.classification_conv = nn.Sequential(
nn.Conv2d(n_channels, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
# nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
# nn.ReLU(),
# nn.BatchNorm2d(512),
# nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
)
self.classification = nn.Sequential(
# nn.Linear(conv_size, 4096),
# nn.ReLU(),
# nn.BatchNorm1d(4096),
nn.Linear(6400, classes),
nn.Softmax(dim=1)
)
self.sigmoid = nn.Sequential(
nn.Sigmoid()
)
self.penalty_conv = nn.Sequential(
nn.Conv2d(n_channels, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
# nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
# nn.ReLU(),
# nn.BatchNorm2d(512),
# nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
)
self.penalty_classifier = nn.Sequential(
nn.Linear(6400, classes),
nn.Softmax(dim=1)
)
self.sigmoid = nn.Sequential(
nn.Sigmoid()
)
def forward(self, x):
"""
Performs forward pass of the input. Here an input tensor x is transformed through
several layer transformations.
Args:
x: input to the network
Returns:
out: outputs of the network
"""
conv = self.conv(x)
encoding = torch.flatten(conv, 1)
class_conv = self.classification_conv(x)
class_encoding = torch.flatten(class_conv, 1)
classification = self.classification(class_encoding)
pen_conv = self.penalty_conv(x)
penalty_encoding = torch.flatten(pen_conv, 1)
penalty_classification = self.penalty_classifier(penalty_encoding)
logits = self.brain(encoding)
binaries = self.sigmoid(logits)
return encoding, classification, penalty_classification, binaries | [
"charatsidisvasileios@gmail.com"
] | charatsidisvasileios@gmail.com |
354b59baffdbb9741441fd2bfd75671d6d48f582 | ca7aa979e7059467e158830b76673f5b77a0f5a3 | /Python_codes/p02677/s277279155.py | 417c2e83e3ec17dc233cfcc99d01d21a875cdd90 | [] | no_license | Aasthaengg/IBMdataset | 7abb6cbcc4fb03ef5ca68ac64ba460c4a64f8901 | f33f1c5c3b16d0ea8d1f5a7d479ad288bb3f48d8 | refs/heads/main | 2023-04-22T10:22:44.763102 | 2021-05-13T17:27:22 | 2021-05-13T17:27:22 | 367,112,348 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 205 | py | import math
a, b, h, m = map(int, input().split())
angle = ((h * 60 + m) / 720 - m / 60) * math.pi * 2 # 角度(ラジアン)
ans = math.sqrt(a*a + b*b - 2*a*b*math.cos(angle)) # 余弦定理
print(ans) | [
"66529651+Aastha2104@users.noreply.github.com"
] | 66529651+Aastha2104@users.noreply.github.com |
fbcc5d633a59b210d64ed1f5d1123b66fbd1ffc7 | 8dc26aa9afcfeb943306c30b5e4800be36524e32 | /src/ch15/practise/Point1.py | 7fafff09565d670b064b0df04b7cd79ad18781b4 | [] | no_license | MITZHANG/ThinkPython | 5ce75a78ae811c6229269d34d5e819803fde8799 | b68d01df66124a9d6d10bcde61ca324c1a1592d8 | refs/heads/master | 2022-05-07T10:46:27.006351 | 2018-12-02T03:26:47 | 2018-12-02T03:26:47 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,557 | py | """This module contains a code example related to
Think Python, 2nd Edition
by Allen Downey
http://thinkpython2.com
Copyright 2015 Allen Downey
License: http://creativecommons.org/licenses/by/4.0/
"""
class Point:
"""Represents a point in 2-D space.
attributes: x, y
"""
def print_point(p):
"""Print a Point object in human-readable format."""
print('(%g, %g)' % (p.x, p.y))
class Rectangle:
"""Represents a rectangle.
attributes: width, height, corner.
"""
def find_center(rect):
"""Returns a Point at the center of a Rectangle.
rect: Rectangle
returns: new Point
"""
p = Point()
p.x = rect.corner.x + rect.width/2.0
p.y = rect.corner.y + rect.height/2.0
return p
def grow_rectangle(rect, dwidth, dheight):
"""Modifies the Rectangle by adding to its width and height.
rect: Rectangle object.
dwidth: change in width (can be negative).
dheight: change in height (can be negative).
"""
rect.width += dwidth
rect.height += dheight
def main():
blank = Point()
blank.x = 3
blank.y = 4
print('blank', end=' ')
print_point(blank)
box = Rectangle()
box.width = 100.0
box.height = 200.0
box.corner = Point()
box.corner.x = 0.0
box.corner.y = 0.0
center = find_center(box)
print('center', end=' ')
print_point(center)
print(box.width)
print(box.height)
print('grow')
grow_rectangle(box, 50, 100)
print(box.width)
print(box.height)
if __name__ == '__main__':
main()
| [
"huruifeng1202@163.com"
] | huruifeng1202@163.com |
55adc70658d75b1258437b04056420d0dd722bd3 | 951fc0da7384b961726999e5451a10e2783462c4 | /script.module.exodusscrapers/lib/exodusscrapers/sources_placenta/en_placenta-1.7.8/to_be_fixed/needsfixing/movie4uch.py | 9fe22b01e7d14100e698e0cfbb4ea3d96376cde4 | [
"Beerware"
] | permissive | vphuc81/MyRepository | eaf7b8531b2362f0e0de997a67b889bc114cd7c2 | 9bf8aca6de07fcd91bcec573f438f29e520eb87a | refs/heads/master | 2022-01-02T15:07:35.821826 | 2021-12-24T05:57:58 | 2021-12-24T05:57:58 | 37,680,232 | 6 | 10 | null | null | null | null | UTF-8 | Python | false | false | 4,343 | py | # -*- coding: UTF-8 -*-
#######################################################################
# ----------------------------------------------------------------------------
# "THE BEER-WARE LICENSE" (Revision 42):
# @Daddy_Blamo wrote this file. As long as you retain this notice you
# can do whatever you want with this stuff. If we meet some day, and you think
# this stuff is worth it, you can buy me a beer in return. - Muad'Dib
# ----------------------------------------------------------------------------
#######################################################################
# Addon Name: Exodus
# Addon id: plugin.video.exodus
# Addon Provider: Exodus
import re,urlparse,urllib
from resources.lib.modules import cleantitle
from resources.lib.modules import client
from resources.lib.modules import cache
from resources.lib.modules import dom_parser2
from resources.lib.modules import source_utils
class source:
def __init__(self):
self.priority = 1
self.language = ['en']
self.domains = ['movie4u.ch']
self.base_link = 'https://movie4u.live/'
self.search_link = '/?s=%s'
def movie(self, imdb, title, localtitle, aliases, year):
try:
clean_title = cleantitle.geturl(title)
search_url = urlparse.urljoin(self.base_link, self.search_link % clean_title.replace('-', '+'))
r = client.request(search_url)
r = client.parseDOM(r, 'div', {'class': 'result-item'})
r = [(dom_parser2.parse_dom(i, 'a', req='href')[0],
client.parseDOM(i, 'img', ret='alt')[0],
dom_parser2.parse_dom(i, 'span', attrs={'class': 'year'})) for i in r]
r = [(i[0].attrs['href'], i[1], i[2][0].content) for i in r if
(cleantitle.get(i[1]) == cleantitle.get(title) and i[2][0].content == year)]
url = r[0][0]
return url
except Exception:
return
def tvshow(self, imdb, tvdb, tvshowtitle, localtvshowtitle, aliases, year):
try:
clean_title = cleantitle.geturl(tvshowtitle)
search_url = urlparse.urljoin(self.base_link, self.search_link % clean_title.replace('-', '+'))
r = client.request(search_url)
r = client.parseDOM(r, 'div', {'class': 'result-item'})
r = [(dom_parser2.parse_dom(i, 'a', req='href')[0],
client.parseDOM(i, 'img', ret='alt')[0],
dom_parser2.parse_dom(i, 'span', attrs={'class': 'year'})) for i in r]
r = [(i[0].attrs['href'], i[1], i[2][0].content) for i in r if
(cleantitle.get(i[1]) == cleantitle.get(tvshowtitle) and i[2][0].content == year)]
url = source_utils.strip_domain(r[0][0])
return url
except:
return
def episode(self, url, imdb, tvdb, title, premiered, season, episode):
try:
if not url:
return
t = url.split('/')[2]
url = self.base_link + '/episodes/%s-%dx%d' % (t, int(season), int(episode))
return url
except:
return
def sources(self, url, hostDict, hostprDict):
try:
sources = []
r = client.request(url)
try:
data = client.parseDOM(r, 'div', attrs={'class': 'playex'})
data = [client.parseDOM(i, 'iframe', ret='src') for i in data if i]
try:
for url in data[0]:
quality, info = source_utils.get_release_quality(url, None)
valid, host = source_utils.is_host_valid(url,hostDict)
if not valid: continue
host = host.encode('utf-8')
sources.append({
'source': host,
'quality': quality,
'language': 'en',
'url': url.replace('\/', '/'),
'direct': False,
'debridonly': False
})
except:
pass
except:
pass
return sources
except Exception:
return
def resolve(self, url):
return url | [
"vinhphuc_81@yahoo.com"
] | vinhphuc_81@yahoo.com |
888965d5675a8f7fddf51e681409041dbeba44d1 | 5390d79dad71ad0d9ff9d0777435dcaf4aad16b3 | /chapter_08/person.py | 5d69f944211008757fc2ea9a8bfa43496fbfa767 | [] | no_license | JasperMi/python_learning | 19770d79cce900d968cec76dac11e45a3df9c34c | 8111d0d12e4608484864dddb597522c6c60b54e8 | refs/heads/master | 2020-11-26T08:57:02.983869 | 2020-03-11T10:14:55 | 2020-03-11T10:14:55 | 218,935,548 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 296 | py | def build_person(first_name, last_name, age=''):
"""返回一个字典,其中包含有关一个人的信息"""
person = {'first': first_name, 'last': last_name}
if age:
person['age'] = age
return person
musician = build_person('jimi', 'hendrix', age=27)
print(musician)
| [
"darmi19@163.com"
] | darmi19@163.com |
69dc833fbd6f66e9bb74f8674acfcdcded16f069 | 07c6f13115eba392ae9d0f1b8916e862907dfa0c | /backend/home/migrations/0005_auto_20200824_0822.py | a35246626bbd4baa31a37a6f385a216127901486 | [] | no_license | crowdbotics-apps/mobile-24-aug-dev-9264 | 5ac37888b870f21c5b662be7971ed31fb320afb6 | 74df25211a9fba244fe377b1595f4239445e69d5 | refs/heads/master | 2022-12-05T07:28:19.060867 | 2020-08-24T10:59:05 | 2020-08-24T10:59:05 | 289,830,708 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 467 | py | # Generated by Django 2.2.15 on 2020-08-24 08:22
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
("home", "0004_auto_20200824_0723"),
]
operations = [
migrations.RemoveField(model_name="customtext", name="title",),
migrations.AddField(
model_name="customtext",
name="df",
field=models.CharField(blank=True, max_length=150),
),
]
| [
"team@crowdbotics.com"
] | team@crowdbotics.com |
1b808a6ba74a02d33f7d1f10c324f04b8ca5ecd6 | cc5156902315a9ff0af3cc323992d3a6606a0bb1 | /cyclic sort/find the first k missing positive numbers.py | e500548815b920ce3a447a89dcb0eeb7623ba404 | [
"MIT"
] | permissive | smksevov/Grokking-the-coding-interview | 8ad6f7b11ac0c3f2a08c580a5d542b3745e9ad0b | 0ae68fb1c86ff595a82af68f7a6a6fdfe37e97a7 | refs/heads/main | 2023-06-30T03:07:39.054942 | 2021-08-05T08:25:31 | 2021-08-05T08:25:31 | 515,096,499 | 1 | 0 | MIT | 2022-07-18T08:26:16 | 2022-07-18T08:26:15 | null | UTF-8 | Python | false | false | 1,174 | py | # Given an unsorted array containing numbers and a number ‘k’,
# find the first ‘k’ missing positive numbers in the array.
# Example:
# Input: [3, -1, 4, 5, 5], k=3
# Output: [1, 2, 6]
# Explanation: The smallest missing positive numbers are 1, 2 and 6.
# O(N + K) space:O(1)
def find_first_k_missing_positive_number(arr, k):
i = 0
while i < len(arr):
j = arr[i] - 1
if arr[i] > 0 and arr[i] <= len(arr) and arr[i] != arr[j]:
arr[i], arr[j] = arr[j], arr[i]
else:
i += 1
missing_number = []
extra_number = []
for i in range(len(arr)):
if k == 0:
break
if arr[i] != i + 1:
missing_number.append(i + 1)
extra_number.append(arr[i])
k -= 1
add_length = len(arr)
while k > 0:
add_length += 1
if add_length not in extra_number:
missing_number.append(add_length)
k -= 1
return missing_number
print(find_first_k_missing_positive_number([3, -1, 4, 5, 5], 3))
print(find_first_k_missing_positive_number([2, 3, 4], 3))
print(find_first_k_missing_positive_number([-2, -3, 4], 2))
| [
"394104840@qq.com"
] | 394104840@qq.com |
b48e2095b08d287ca5bbe8003a8471badaefb42a | f891828ffe9c8501d276560c8c52d319f284056f | /404_left_leave_sum_e/root_count.py | 296baac2fa8e5b3a9061ab1decfbadbecdce1b9c | [] | no_license | chao-shi/lclc | 1b852ab61fef4072039c61f68e951ab2072708bf | 2722c0deafcd094ce64140a9a837b4027d29ed6f | refs/heads/master | 2021-06-14T22:07:54.120375 | 2019-09-02T23:13:59 | 2019-09-02T23:13:59 | 110,387,039 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 673 | py | # Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def sumOfLeftLeaves(self, root):
"""
:type root: TreeNode
:rtype: int
"""
def recur(root, isLeftChild):
if not root:
return 0
elif root.left == None and root.right == None and isLeftChild:
return root.val
else:
return recur(root.left, True) + recur(root.right, False)
return recur(root, True)
# One-node tree count as left leave | [
"chao.shi@hpe.com"
] | chao.shi@hpe.com |
1cb47536871779d20749b551985661412d2fcd3c | c2471dcf74c5fd1ccf56d19ce856cf7e7e396b80 | /chap11/3.py | eb193de9c867a2242585a4330664c3af97d2b47c | [] | no_license | oc0de/pythonEpi | eaeef2cf748e6834375be6bc710132b572fc2934 | fb7b9e06bb39023e881de1a3d370807b955b5cc0 | refs/heads/master | 2021-06-18T05:33:19.518652 | 2017-07-07T04:34:52 | 2017-07-07T04:34:52 | 73,049,450 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 341 | py | from heapq import *
def sortAlmostSortedArray(s, k):
minHeap = []
for i in range(k):
heappush(minHeap, s[i])
idx = k
while idx < len(s):
heappush(minHeap, s[idx])
print heappop(minHeap)
idx += 1
while minHeap:
print heappop(minHeap)
sortAlmostSortedArray([3,-1,2,6,5,4,8],2)
| [
"valizade@mail.gvsu.edu"
] | valizade@mail.gvsu.edu |
17a20ec8bc36206daef719d8707bb6582bb67886 | 2c2bef621c173e8beba2917924d9b08bfb8c0eaf | /Options_Math/Matrix_Math_Python.py | ce1e1c4214eec679d55a92116d9d42b887be8315 | [] | no_license | Bhaney44/Options | d7c4d6aed57a0bbbff9731d912dfc764bbef512f | 8c265c33d111d530f5de329732f27585c4b750a4 | refs/heads/master | 2022-11-25T13:54:51.655061 | 2020-07-31T22:52:26 | 2020-07-31T22:52:26 | 273,760,601 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,655 | py | #Matrix Math
import numpy as np
#matrix arrays
x = np.array([1,5,2])
y = np.array([7,4,1])
#addition
x + y
array([8, 9, 3])
#multiplication
x * y
array([ 7, 20, 2])
#substraction
x - y
array([-6, 1, 1])
#division
x / y
array([0, 1, 2])
#Modulus - absolute value or a constant ratio
x % y
array([1, 1, 0])
#Vector Addition and Subtraction
x = np.array([3,2])
y = np.array([5,1])
z = x + y
z
array([8, 3])
#Scalar Product and Dot Product
x = np.array([1,2,3])
y = np.array([-7,8,9])
np.dot(x,y)
36
dot = np.dot(x,y)
x_modulus = np.sqrt((x*x).sum())
y_modulus = np.sqrt((y*y).sum())
# cosine of angle between x and y
cos_angle = dot / x_modulus / y_modulus
angle = np.arccos(cos_angle)
angle
0.80823378901082499
# angle in degrees
angle * 360 / 2 / np.pi
46.308384970187326
#Matrix class
x = np.array( ((2,3), (3, 5)) )
y = np.array( ((1,2), (5, -1)) )
x * y
array([[ 2, 6],
[15, -5]])
x = np.matrix( ((2,3), (3, 5)) )
y = np.matrix( ((1,2), (5, -1)) )
x * y
matrix([[17, 1],
[28, 1]])
#Matrix product
x = np.array( ((2,3), (3, 5)) )
>>> y = np.matrix( ((1,2), (5, -1)) )
>>> np.dot(x,y)
matrix([[17, 1],
[28, 1]])
np.mat(x) * np.mat(y)
matrix([[17, 1],
[28, 1]])
#Practical Application
NumPersons = np.array([[100,175,210],[90,160,150],[200,50,100],[120,0,310]])
Price_per_100_g = np.array([2.98,3.90,1.99])
Price_in_Cent = np.dot(NumPersons,Price_per_100_g)
Price_in_Euro = Price_in_Cent / np.array([100,100,100,100])
Price_in_Euro
array([ 13.984, 11.907, 9.9, 9.745])
#Cross Product
x = np.array([0,0,1])
y = np.array([0,1,0])
np.cross(x,y)
array([-1, 0, 0])
np.cross(y,x)
array([1, 0, 0])
| [
"noreply@github.com"
] | Bhaney44.noreply@github.com |
5a056c350dcd29d87aa97c0915bf6385c065f2b0 | 50e2bf921351b62cdb9b64ce79e081c0513343e2 | /src/main.py | 2bbdc2b21d587f0290e6d0f81690f93d8decf811 | [
"MIT"
] | permissive | mattjoswald/smart-thermostat | b16d7fc3b61fb9416f462df33aa319b6a6c92175 | 4942ccfad9e0ad1206a84a8b271565d48335bbce | refs/heads/master | 2020-12-02T13:06:48.627060 | 2019-12-26T06:16:19 | 2019-12-26T06:16:19 | 231,015,646 | 0 | 0 | MIT | 2019-12-31T03:01:04 | 2019-12-31T03:01:03 | null | UTF-8 | Python | false | false | 745 | py | 'Smart thermostat project main module'
from cpx.sensor import Sensor
from cpx.timingknob import TimingKnob
from cpx.heaterrelay import HeaterRelay
from cpx.buttons import Buttons
from cpx.display import Display
from thermocontroller import ThermoController
TEMP_CHANGE_INCREMENT = 0.1
DEFAULT_DESIRED_TEMP = 21.0
BUTTON_REPEAT_DELAY_SECS = 0.3
buttons = Buttons(BUTTON_REPEAT_DELAY_SECS)
buttons.on_change(
lambda button_index:
controller.change_desired_temp((-1, 1)[button_index] * TEMP_CHANGE_INCREMENT))
display = Display(TEMP_CHANGE_INCREMENT)
controller = ThermoController(
Sensor(), TimingKnob(), HeaterRelay(), display, DEFAULT_DESIRED_TEMP)
while True:
controller.update()
buttons.update()
display.update()
| [
"daveb@davebsoft.com"
] | daveb@davebsoft.com |
44b88f8ceaf6586d2b0d0016961321a743780bac | 30dc32fd39cf71c76fc24d53b68a8393adcac149 | /OWDTestToolkit/apps/Email/__main.py | ff3f949da55fe151c72c0d1071d39d3f8773e2df | [] | no_license | carlosmartineztoral/OWD_TEST_TOOLKIT | 448caefdc95bc3e54aad97df0bff7046ffb37be1 | 50768f79488735eba8355824f5aa3686a71d560a | refs/heads/master | 2021-01-15T17:14:03.614981 | 2013-06-11T12:48:18 | 2013-06-11T12:48:18 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,458 | py | from OWDTestToolkit.global_imports import *
import deleteEmail ,\
emailIsInFolder ,\
goto_folder_from_list ,\
openMailFolder ,\
openMsg ,\
remove_accounts_and_restart ,\
send_new_email ,\
sendTheMessage ,\
setupAccount ,\
switchAccount ,\
waitForDone
class Email (
deleteEmail.main,
emailIsInFolder.main,
goto_folder_from_list.main,
openMailFolder.main,
openMsg.main,
remove_accounts_and_restart.main,
send_new_email.main,
sendTheMessage.main,
setupAccount.main,
switchAccount.main,
waitForDone.main):
def __init__(self, p_parent):
self.apps = p_parent.apps
self.data_layer = p_parent.data_layer
self.parent = p_parent
self.marionette = p_parent.marionette
self.UTILS = p_parent.UTILS
def launch(self):
#
# Launch the app.
#
self.apps.kill_all()
self.app = self.apps.launch(self.__class__.__name__)
self.UTILS.waitForNotElements(DOM.GLOBAL.loading_overlay, self.__class__.__name__ + " app - loading overlay")
| [
"roy.collings@sogeti.com"
] | roy.collings@sogeti.com |
e8af622b6a1fcc7d31f00df00cfbdb2d4905bf1a | f68732bc40a7a90c3a1082e4b3a4154518acafbb | /script/dbus/sessionBus/audioSink/011_sinkSetVolumeNotPlay.py | 874cbce8daddd6329480c8c5bdb73a95deb648c6 | [] | no_license | lizhouquan1017/dbus_demo | 94238a2307e44dabde9f4a4dd0cf8ec217260867 | af8442845e722b258a095e9a1afec9dddfb175bf | refs/heads/master | 2023-02-11T19:46:27.884936 | 2021-01-08T05:27:18 | 2021-01-08T05:27:18 | 327,162,635 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 953 | py | # -*- coding: utf-8 -*-
# ****************************************************
# @Test Case ID: 011_sinkSetVolumeNotPlay
# @Test Description: 设置音量大小
# @Test Condition:
# @Test Step: 1.设置音量大小,不播放声音反馈;
# # @Test Result: 1.检查设置成功;
# @Test Remark:
# @Author: ut000511
# *****************************************************
import pytest
from frame.base import OSBase
from aw.dbus.sessionBus import audioSink
class TestCase(OSBase):
def setUp(self):
self.Step("预制条件1:获取参数")
self.value = 0.5
@pytest.mark.public
def test_step(self):
self.Step("步骤1:设置音量大小,不播放声音反馈")
audioSink.sinkSetVolume(self.value, False)
self.CheckPoint("检查点1:检查设置成功")
audioSink.checkSetVolume(self.value)
def tearDown(self):
self.Step("收尾:无")
| [
"lizhouquan@uniontech.com"
] | lizhouquan@uniontech.com |
427b3c825edd8de722ada05971ee97d2bcad81f0 | d775cdfb84e09909ebfdbef6f827c13b3921e0c4 | /example/tornado_period_server.py | 822aba54f47efd4b5357c0f99909128abcaa7e02 | [] | no_license | land-pack/sscan | 28e114e87a4c4131177f08ded7198ad8059ab779 | f68b3c124ddba073194d4e8a0b1b52a1f37030b2 | refs/heads/master | 2020-03-18T13:33:19.243078 | 2018-05-30T02:40:22 | 2018-05-30T02:40:22 | 134,791,660 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 820 | py | from socket import socket
from socket import AF_INET, SOCK_DGRAM, SOL_SOCKET, SO_REUSEADDR, SO_BROADCAST
import tornado.ioloop
import tornado.web
def attentionPlease():
"""
Get self host information and then
broadcast it out.
"""
cs = socket(AF_INET, SOCK_DGRAM)
cs.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
cs.setsockopt(SOL_SOCKET, SO_BROADCAST, 1)
cs.sendto('This is a test', ('255.255.255.255', 54545))
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, world")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.PeriodicCallback(attentionPlease, 1000 * 5).start()
tornado.ioloop.IOLoop.current().start()
| [
"landpack@sina.com"
] | landpack@sina.com |
6a9c731ec3f178280fea0968e582e1e28db041bc | fa93e53a9eee6cb476b8998d62067fce2fbcea13 | /build/play_motion/catkin_generated/pkg.develspace.context.pc.py | 446b10b7da92a6a54200af7d1784053b527689fa | [] | no_license | oyetripathi/ROS_conclusion_project | 2947ee2f575ddf05480dabc69cf8af3c2df53f73 | 01e71350437d57d8112b6cec298f89fc8291fb5f | refs/heads/master | 2023-06-30T00:38:29.711137 | 2021-08-05T09:17:54 | 2021-08-05T09:17:54 | 392,716,311 | 0 | 1 | null | null | null | null | UTF-8 | Python | false | false | 691 | py | # generated from catkin/cmake/template/pkg.context.pc.in
CATKIN_PACKAGE_PREFIX = ""
PROJECT_PKG_CONFIG_INCLUDE_DIRS = "/home/sandeepan/tiago_public_ws/src/play_motion/play_motion/include".split(';') if "/home/sandeepan/tiago_public_ws/src/play_motion/play_motion/include" != "" else []
PROJECT_CATKIN_DEPENDS = "actionlib;control_msgs;controller_manager_msgs;play_motion_msgs;moveit_ros_planning_interface;roscpp;sensor_msgs".replace(';', ' ')
PKG_CONFIG_LIBRARIES_WITH_PREFIX = "-lplay_motion_helpers".split(';') if "-lplay_motion_helpers" != "" else []
PROJECT_NAME = "play_motion"
PROJECT_SPACE_DIR = "/home/sandeepan/tiago_public_ws/devel/.private/play_motion"
PROJECT_VERSION = "0.4.8"
| [
"sandeepan.ghosh.ece20@itbhu.ac.in"
] | sandeepan.ghosh.ece20@itbhu.ac.in |
7e1625f57fe84fe7dd1f3b22951765a30e604e33 | f576f0ea3725d54bd2551883901b25b863fe6688 | /eng/tox/run_verifytypes.py | 762ada2b77e747b7aacca4898f734320a7d6892e | [
"LicenseRef-scancode-generic-cla",
"MIT",
"LGPL-2.1-or-later"
] | permissive | Azure/azure-sdk-for-python | 02e3838e53a33d8ba27e9bcc22bd84e790e4ca7c | c2ca191e736bb06bfbbbc9493e8325763ba990bb | refs/heads/main | 2023-09-06T09:30:13.135012 | 2023-09-06T01:08:06 | 2023-09-06T01:08:06 | 4,127,088 | 4,046 | 2,755 | MIT | 2023-09-14T21:48:49 | 2012-04-24T16:46:12 | Python | UTF-8 | Python | false | false | 5,930 | py | #!/usr/bin/env python
# --------------------------------------------------------------------------------------------
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License. See License.txt in the project root for license information.
# --------------------------------------------------------------------------------------------
# This script is used to execute verifytypes within a tox environment. It additionally installs
# the package from main and compares its type completeness score with
# that of the current code. If type completeness worsens from the code in main, the check fails.
import typing
import pathlib
import subprocess
import json
import argparse
import os
import logging
import sys
import tempfile
from ci_tools.environment_exclusions import is_check_enabled, is_typing_ignored
from ci_tools.variables import in_ci
logging.getLogger().setLevel(logging.INFO)
root_dir = os.path.abspath(os.path.join(os.path.abspath(__file__), "..", "..", ".."))
def install_from_main(setup_path: str) -> None:
path = pathlib.Path(setup_path)
subdirectory = path.relative_to(root_dir)
cwd = os.getcwd()
with tempfile.TemporaryDirectory() as temp_dir_name:
os.chdir(temp_dir_name)
try:
subprocess.check_call(['git', 'init'], stdout=subprocess.DEVNULL, stderr=subprocess.STDOUT)
subprocess.check_call(
['git', 'clone', '--no-checkout', 'https://github.com/Azure/azure-sdk-for-python.git', '--depth', '1'],
stdout=subprocess.DEVNULL,
stderr=subprocess.STDOUT
)
os.chdir("azure-sdk-for-python")
subprocess.check_call(['git', 'sparse-checkout', 'init', '--cone'], stdout=subprocess.DEVNULL, stderr=subprocess.STDOUT)
subprocess.check_call(['git', 'sparse-checkout', 'set', subdirectory], stdout=subprocess.DEVNULL, stderr=subprocess.STDOUT)
subprocess.check_call(['git', 'checkout', 'main'], stdout=subprocess.DEVNULL, stderr=subprocess.STDOUT)
if not os.path.exists(os.path.join(os.getcwd(), subdirectory)):
# code is not checked into main yet, nothing to compare
exit(0)
os.chdir(subdirectory)
command = [
sys.executable,
"-m",
"pip",
"install",
".",
"--force-reinstall"
]
subprocess.check_call(command, stdout=subprocess.DEVNULL)
finally:
os.chdir(cwd) # allow temp dir to be deleted
def get_type_complete_score(commands: typing.List[str], check_pytyped: bool = False) -> float:
try:
response = subprocess.run(
commands,
check=True,
capture_output=True,
)
except subprocess.CalledProcessError as e:
if e.returncode != 1:
logging.info(
f"Running verifytypes failed: {e.stderr}. See https://aka.ms/python/typing-guide for information."
)
exit(1)
report = json.loads(e.output)
if check_pytyped:
pytyped_present = report["typeCompleteness"].get("pyTypedPath", None)
if not pytyped_present:
print(
f"No py.typed file was found. See aka.ms/python/typing-guide for information."
)
exit(1)
return report["typeCompleteness"]["completenessScore"]
# library scores 100%
report = json.loads(response.stdout)
return report["typeCompleteness"]["completenessScore"]
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Run pyright verifytypes against target folder. "
)
parser.add_argument(
"-t",
"--target",
dest="target_package",
help="The target package directory on disk. The target module passed to run pyright will be <target_package>/azure.",
required=True,
)
args = parser.parse_args()
package_name = os.path.basename(os.path.abspath(args.target_package))
module = package_name.replace("-", ".")
setup_path = os.path.abspath(args.target_package)
if in_ci():
if not is_check_enabled(args.target_package, "verifytypes") or is_typing_ignored(package_name):
logging.info(
f"{package_name} opts-out of verifytypes check. See https://aka.ms/python/typing-guide for information."
)
exit(0)
commands = [
sys.executable,
"-m",
"pyright",
"--verifytypes",
module,
"--ignoreexternal",
"--outputjson",
]
# get type completeness score from current code
score_from_current = get_type_complete_score(commands, check_pytyped=True)
# show output
try:
subprocess.check_call(commands[:-1])
except subprocess.CalledProcessError:
pass # we don't fail on verifytypes, only if type completeness score worsens from main
# get type completeness score from main
logging.info(
"Getting the type completeness score from the code in main..."
)
install_from_main(setup_path)
score_from_main = get_type_complete_score(commands)
score_from_main_rounded = round(score_from_main * 100, 1)
score_from_current_rounded = round(score_from_current * 100, 1)
print("\n-----Type completeness score comparison-----\n")
print(f"Score in main: {score_from_main_rounded}%")
# Give a 5% buffer for type completeness score to decrease
if score_from_current_rounded < score_from_main_rounded - 5:
print(
f"\nERROR: The type completeness score of {package_name} has significantly decreased compared to the score in main. "
f"See the above output for areas to improve. See https://aka.ms/python/typing-guide for information."
)
exit(1)
| [
"noreply@github.com"
] | Azure.noreply@github.com |
8aa9c06ffa56b65332bf3a4596300d836a9c88be | b0e22deb519ec621b5f866bb15d15d597e6e75d4 | /ciscoisesdk/models/validators/v3_0_0/jsd_ab203a1dd0015924bf2005a84ae85477.py | 9f0a8fd4323e48dcbd27985f5b7127c2d7ea108e | [
"MIT"
] | permissive | oianson/ciscoisesdk | 49ed9cd785a8e463cac4c5de3b1f3ff19e362871 | c8fe9d80416048dd0ff2241209c4f78ab78c1a4a | refs/heads/main | 2023-07-31T20:08:29.027482 | 2021-07-09T15:16:04 | 2021-07-09T15:16:04 | 385,743,799 | 0 | 0 | MIT | 2021-07-13T21:52:18 | 2021-07-13T21:52:18 | null | UTF-8 | Python | false | false | 2,516 | py | # -*- coding: utf-8 -*-
"""Identity Services Engine bulkRequestForIPToSGTMapping data model.
Copyright (c) 2021 Cisco and/or its affiliates.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
"""
from __future__ import (
absolute_import,
division,
print_function,
unicode_literals,
)
import fastjsonschema
import json
from ciscoisesdk.exceptions import MalformedRequest
from builtins import *
class JSONSchemaValidatorAb203A1DD0015924Bf2005A84Ae85477(object):
"""bulkRequestForIPToSGTMapping request schema definition."""
def __init__(self):
super(JSONSchemaValidatorAb203A1DD0015924Bf2005A84Ae85477, self).__init__()
self._validator = fastjsonschema.compile(json.loads(
'''{
"$schema": "http://json-schema.org/draft-04/schema#",
"properties": {
"SGMappingBulkRequest": {
"properties": {
"operationType": {
"type": "string"
},
"resourceMediaType": {
"type": "string"
}
},
"type": "object"
}
},
"type": "object"
}'''.replace("\n" + ' ' * 16, '')
))
def validate(self, request):
try:
self._validator(request)
except fastjsonschema.exceptions.JsonSchemaException as e:
raise MalformedRequest(
'{} is invalid. Reason: {}'.format(request, e.message)
)
| [
"wastorga@altus.co.cr"
] | wastorga@altus.co.cr |
cd645756f1ac5b85b1c2c540d0a54907e4b6abc6 | 487ce91881032c1de16e35ed8bc187d6034205f7 | /codes/CodeJamCrawler/CJ/16_0_1_aniketshah_counting_sheep.py | b23af25099e5a94affe671bb50162a7d3a36c0f6 | [] | no_license | DaHuO/Supergraph | 9cd26d8c5a081803015d93cf5f2674009e92ef7e | c88059dc66297af577ad2b8afa4e0ac0ad622915 | refs/heads/master | 2021-06-14T16:07:52.405091 | 2016-08-21T13:39:13 | 2016-08-21T13:39:13 | 49,829,508 | 2 | 0 | null | 2021-03-19T21:55:46 | 2016-01-17T18:23:00 | Python | UTF-8 | Python | false | false | 699 | py | def countingSheep(startNumber):
if startNumber == 0:
return "INSOMNIA"
numbersSeen = set([])
i = 0
number = 0
while (len(numbersSeen) < 10):
i = i + 1
number = startNumber * i
for d in str(number):
numbersSeen.add(d)
return number
readFile = open("A-large.in")
writeFile = open("A-large.out", "a")
numberOfTestCases = -1
caseNumber = 1
for line in readFile.readlines():
if(numberOfTestCases == -1):
numberOfTestCases = int(line)
continue
writeFile.write("Case #" + str(caseNumber) + ": " + str(countingSheep(int(line))) + "\n")
caseNumber = caseNumber + 1
readFile.close()
writeFile.close()
| [
"[dhuo@tcd.ie]"
] | [dhuo@tcd.ie] |
c6d4934ea3a2820d247f639becd1a94b8cc5068b | d308fffe3db53b034132fb1ea6242a509f966630 | /pirates/piratesgui/RadioButton.py | 9682de9337946e58656d2cbcef9c94eb1e501eb5 | [
"BSD-3-Clause"
] | permissive | rasheelprogrammer/pirates | 83caac204965b77a1b9c630426588faa01a13391 | 6ca1e7d571c670b0d976f65e608235707b5737e3 | refs/heads/master | 2020-03-18T20:03:28.687123 | 2018-05-28T18:05:25 | 2018-05-28T18:05:25 | 135,193,362 | 3 | 2 | null | null | null | null | UTF-8 | Python | false | false | 2,175 | py | # uncompyle6 version 3.2.0
# Python bytecode 2.4 (62061)
# Decompiled from: Python 2.7.14 (v2.7.14:84471935ed, Sep 16 2017, 20:19:30) [MSC v.1500 32 bit (Intel)]
# Embedded file name: pirates.piratesgui.RadioButton
from pandac.PandaModules import *
from direct.gui.DirectButton import *
class RadioButton(DirectButton):
__module__ = __name__
def __init__(self, parent=None, **kw):
gui_main = loader.loadModel('models/gui/gui_main')
icon_sphere = gui_main.find('**/icon_sphere')
icon_torus = gui_main.find('**/icon_torus')
icon_torus_over = gui_main.find('**/icon_torus_over')
gui_main.removeNode()
optiondefs = (
('geom', None, None), ('checkedGeom', icon_sphere, None), ('image', (icon_torus, icon_torus, icon_torus_over, icon_torus), None), ('geom_color', VBase4(1, 1, 1, 1), None), ('image_scale', 1.4, None), ('variable', [], None), ('value', [], None), ('others', [], None), ('relief', None, None), ('isChecked', False, None))
self.defineoptions(kw, optiondefs)
DirectButton.__init__(self, parent)
self.initialiseoptions(RadioButton)
needToCheck = True
if len(self['value']) == len(self['variable']) != 0:
for i in range(len(self['value'])):
if self['variable'][i] != self['value'][i]:
needToCheck = False
break
if needToCheck:
self.check(False)
return
def commandFunc(self, event):
self.check()
def check(self, fCommand=True):
if len(self['value']) == len(self['variable']) != 0:
for i in range(len(self['value'])):
self['variable'][i] = self['value'][i]
self['isChecked'] = True
self['geom'] = self['checkedGeom']
for other in self['others']:
if other != self:
other.uncheck()
if fCommand and self['command']:
apply(self['command'], [self['value']] + self['extraArgs'])
def setOthers(self, others):
self['others'] = others
def uncheck(self):
self['isChecked'] = False
self['geom'] = None
return | [
"33942724+itsyaboyrocket@users.noreply.github.com"
] | 33942724+itsyaboyrocket@users.noreply.github.com |
6a5974222c1f21fd29a28373a56179bd00333e3f | cb8c62659f9509bbc01237a09cf8730b57f4a84f | /Dcc/plugin.py | 4a6c21ee8bb1c8df680fb88a8add5af49aa94430 | [] | no_license | stepnem/supybot-plugins | 5bd795319036ab21cd81b00a23e0c1f712876d3e | 6838f7ae22ad1905272cf7e003fb803e637c87d8 | refs/heads/master | 2021-01-01T18:49:44.478383 | 2012-01-05T04:14:24 | 2012-01-05T04:14:24 | 281,407 | 8 | 4 | null | 2016-11-01T20:15:17 | 2009-08-18T21:55:56 | Python | UTF-8 | Python | false | false | 7,407 | py | ###
# Copyright (c) 2005, Ali Afshar
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are met:
#
# * Redistributions of source code must retain the above copyright notice,
# this list of conditions, and the following disclaimer.
# * Redistributions in binary form must reproduce the above copyright notice,
# this list of conditions, and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
# * Neither the name of the author of this software nor the name of
# contributors to this software may be used to endorse or promote products
# derived from this software without specific prior written consent.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
# ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
# LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
# CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
# SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
# INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
# CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
# ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
# POSSIBILITY OF SUCH DAMAGE.
###
# Supybot imports
import supybot.ircdb as ircdb
import supybot.utils as utils
from supybot.commands import *
import supybot.ircmsgs as ircmsgs
import supybot.plugins as plugins
import supybot.ircutils as ircutils
import supybot.callbacks as callbacks
# Twisted imports
from twisted.protocols import basic
import twisted.internet.reactor as reactor
import twisted.internet.protocol as protocol
# System imports
import sys
import socket
import struct
# Carriage return characters
CR = chr(015)
NL = chr(012)
LF = NL
# aspn cookbook
def numToDottedQuad(n):
"convert long int to dotted quad string"
return socket.inet_ntoa(struct.pack('>L',n))
# Plugin
class Dcc(callbacks.Plugin):
""" A plugin to allow users to connect with Dcc.
To use, load the plugin, and initiate a dcc request. There are no
configuration variables, but to control which users connect, use the Dcc
capability."""
def __init__(self, irc):
callbacks.Plugin.__init__(self, irc)
self.irc = irc
self.factory = SupyDccFactory(self)
self.hostmasks = {}
self.connections = {}
def outFilter(self, irc, msg):
""" Checks messages for those sent via Dcc and routes them. """
if msg.inReplyTo:
if msg.inReplyTo.fromDcc:
# a dcc message
con = msg.inReplyTo.fromDcc
# send the reply via dcc, and return None
con.sendReply(msg.args[1])
return None
else:
# otherwise pass the message on
return msg
else:
# otherwise pass the message on
return msg
def exit(self, irc, msg, args):
"""[takes no arguments]
Exit a Dcc session. This command can only be called from Dcc, and not
from standard IRC
"""
if msg.fromDcc:
connection = msg.fromDcc
connection.close()
else:
irc.reply('"exit" may only be called from DCC.')
exit = wrap(exit, [])
def die(self):
""" Shut down all the connections. """
for hostport in self.connections:
self.connections[hostport].close()
self.connections = {}
self.hostmasks = {}
def _connectDcc(self, host, port):
""" Connect to a DCC connection. """
reactor.connectTCP(host, port, self.factory)
def _dccRequest(self, hostmask, command):
""" Handle a DCC request. """
args = command.split()
if args[1].startswith('CHAT'):
try:
port = int(args.pop())
host = numToDottedQuad(int(args.pop()))
self._dccChatRequest(hostmask, host, port)
except ValueError:
self.log.debug('Bad DCC request: %s', command.strip())
def _dccChatRequest(self, hostmask, host, port):
""" Handle a Dcc chat request. """
if self._isDccCapable(hostmask):
self.hostmasks[(host, port)] = hostmask
self._connectDcc(host, port)
else:
self.log.debug('Failed connection attempt, incapable %s.',
hostmask)
def _isDccCapable(self, hostmask):
""" Check if the user is DCC capable. """
return ircdb.checkCapability(hostmask, 'Dcc')
def _lineReceived(self, connection, host, port, line):
""" Handle a line received over DCC. """
if (host, port) in self.hostmasks:
hm = self.hostmasks[(host, port)]
cmd = line.strip()
to = self.irc.nick
m = ircmsgs.privmsg(to, cmd, hm)
m.tag('fromDcc', connection)
self.irc.feedMsg(m)
def doPrivmsg(self, irc, msg):
""" Check whether a privmsg is a DCC request. """
text = msg.args[1].strip('\x01')
if text.startswith('DCC'):
self._dccRequest(msg.prefix, text)
class SupyDccChat(basic.LineReceiver):
""" Basic line protocol """
def __init__(self, cb):
self.cb = cb
self.delimiter = CR + NL
self.rbuffer = ""
def connectionMade(self):
""" Called when the connection has been made. """
t, self.host, self.port = self.transport.getPeer()
self.cb.connections[(self.host, self.port)] = self
self.transport.write('Connected to Supybot Dcc interface.\r\n')
def connectionLost(self, reason):
""" Called when the connection has been lost, or closed. """
del self.cb.connections[(self.host, self.port)]
del self.cb.hostmasks[(self.host, self.port)]
def dataReceived(self, data):
""" Called when data is received. """
self.rbuffer = self.rbuffer + data
lines = self.rbuffer.split(LF)
# Put the (possibly empty) element after the last LF back in the
# buffer
self.rbuffer = lines.pop()
for line in lines:
if line[-1] == CR:
line = line[:-1]
self.lineReceived(line)
def lineReceived(self, line):
""" Called on the receipt of each line. """
self.cb._lineReceived(self, self.host, self.port, line)
def sendReply(self, reply):
""" Send a reply. """
self.transport.write('%s\r\n' % reply)
def close(self):
self.sendReply('* Closing connection down.')
self.transport.loseConnection()
class SupyDccFactory(protocol.ClientFactory):
""" Client connector factory for Dcc """
def __init__(self, cb):
self.cb = cb
self.protocol = SupyDccChat
def buildProtocol(self, addr):
""" Called to create an instance of the protocol. """
p = self.protocol(self.cb)
p.factory = self
return p
Class = Dcc
# vim:set shiftwidth=4 softtabstop=4 expandtab textwidth=79:
| [
"stepnem@gmail.com"
] | stepnem@gmail.com |
76075941bd7e467d44995643e233f13eca483d18 | e3d969e2c9e4b57f4f7d58af5e44a00aa8fb15d3 | /0124 Binary Tree Maximum Path Sum.py | 3772643dcebbd0d82ff8dd51ecb723631c33f535 | [
"MIT"
] | permissive | kevin-fang/leetcode | 2744ff01e791db6f60edf946ef71451fae92ef6f | 3958f888b30bb3e29916880ecec49b3870a0bea3 | refs/heads/master | 2022-12-15T07:50:01.056016 | 2020-09-10T03:47:53 | 2020-09-10T03:47:53 | 294,296,037 | 3 | 0 | MIT | 2020-09-10T03:47:39 | 2020-09-10T03:47:38 | null | UTF-8 | Python | false | false | 698 | py | # Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def helper(self, node):
if node is None:
return 0
left_max = self.helper(node.left)
right_max = self.helper(node.right)
cur_max = max(left_max, right_max, left_max+right_max, 0) + node.val
self.ans = max(self.ans, cur_max)
return max(left_max, right_max, 0)+node.val
def maxPathSum(self, root: TreeNode) -> int:
self.ans = root.val
self.helper(root)
return self.ans
| [
"mdabedincs@gmail.com"
] | mdabedincs@gmail.com |
7075a0a9fe98a746e96222a704367de7151ff994 | 255e19ddc1bcde0d3d4fe70e01cec9bb724979c9 | /all-gists/1325168/snippet.py | 28eec836542399a12c1ef4027f7db0df6443778c | [
"MIT"
] | permissive | gistable/gistable | 26c1e909928ec463026811f69b61619b62f14721 | 665d39a2bd82543d5196555f0801ef8fd4a3ee48 | refs/heads/master | 2023-02-17T21:33:55.558398 | 2023-02-11T18:20:10 | 2023-02-11T18:20:10 | 119,861,038 | 76 | 19 | null | 2020-07-26T03:14:55 | 2018-02-01T16:19:24 | Python | UTF-8 | Python | false | false | 986 | py | import requests
import json
class ClickyApi(object):
"""
A simple Python interface for the Clicky web analytics api.
Relies on the Requests library - python-requests.org
Usage:
YOUR_CLICKY_SITE_ID = '12345'
YOUR_CLICKY_SITE_KEY = 'qwerty'
clicky = ClickyApi(YOUR_CLICKY_SITE_ID, YOUR_CLICKY_SITE_KEY)
clicky.stats({
'type': 'pages',
'date': 'today'
})
"""
api_endpoint = 'http://api.getclicky.com/api/stats/4'
output_format = 'json'
site_id = ''
site_key = ''
def __init__(self, site_id, site_key, app=''):
self.site_id = site_id
self.site_key = site_key
self.app = app
def stats(self, params={}):
params.update({
'site_id': self.site_id,
'sitekey': self.site_key,
'output': self.output_format,
'app': self.app
})
r = requests.get(self.api_endpoint, params=params)
return json.loads(r.content)
| [
"gistshub@gmail.com"
] | gistshub@gmail.com |
149d6fa9b596c90e0ae82587e4ffc555cd25f416 | 9743d5fd24822f79c156ad112229e25adb9ed6f6 | /xai/brain/wordbase/verbs/_index.py | dbb4bd9fd48d9c62bf796bf622299c21d088a604 | [
"MIT"
] | permissive | cash2one/xai | de7adad1758f50dd6786bf0111e71a903f039b64 | e76f12c9f4dcf3ac1c7c08b0cc8844c0b0a104b6 | refs/heads/master | 2021-01-19T12:33:54.964379 | 2017-01-28T02:00:50 | 2017-01-28T02:00:50 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 430 | py |
#calss header
class _INDEX():
def __init__(self,):
self.name = "INDEX"
self.definitions = [u'to prepare an index for a book or collection, or arrange it in an index: ', u'to change a system of numbers according to each other or a fixed standard: ']
self.parents = []
self.childen = []
self.properties = []
self.jsondata = {}
self.specie = 'verbs'
def run(self, obj1 = [], obj2 = []):
return self.jsondata
| [
"xingwang1991@gmail.com"
] | xingwang1991@gmail.com |
8252567d9a62b4688bd1e0d9909847736b2f41e4 | 02338bb8111fc1aa88e830ac09a11664720eb2d4 | /tmp/azure_rm_diagnosticsettingscategory.py | 81e867b980ec07f78f416b811e20a8757ce96ad7 | [] | no_license | Fred-sun/fred_yaml | a49977b0e8505c7447df23dd80c7fef1be70e6bc | 295ca4cd2b59b8d2758f06eb7fd79920327ea524 | refs/heads/master | 2023-04-28T05:51:56.599488 | 2023-04-25T13:52:10 | 2023-04-25T13:52:10 | 131,376,340 | 0 | 1 | null | 2020-07-06T14:22:46 | 2018-04-28T05:34:49 | TSQL | UTF-8 | Python | false | false | 6,634 | py | #!/usr/bin/python
#
# Copyright (c) 2020 GuopengLin, (@t-glin)
#
# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)
from __future__ import absolute_import, division, print_function
__metaclass__ = type
ANSIBLE_METADATA = {'metadata_version': '1.1',
'status': ['preview'],
'supported_by': 'community'}
DOCUMENTATION = '''
---
module: azure_rm_diagnosticsettingscategory
version_added: '2.9'
short_description: Manage Azure DiagnosticSettingsCategory instance.
description:
- 'Create, update and delete instance of Azure DiagnosticSettingsCategory.'
options:
resource_uri:
description:
- The identifier of the resource.
required: true
type: str
name:
description:
- The name of the diagnostic setting.
required: true
type: str
state:
description:
- Assert the state of the DiagnosticSettingsCategory.
- >-
Use C(present) to create or update an DiagnosticSettingsCategory and
C(absent) to delete it.
default: present
choices:
- absent
- present
extends_documentation_fragment:
- azure
author:
- GuopengLin (@t-glin)
'''
EXAMPLES = '''
'''
RETURN = '''
id:
description:
- Azure resource Id
returned: always
type: str
sample: null
name:
description:
- Azure resource name
returned: always
type: str
sample: null
type:
description:
- Azure resource type
returned: always
type: str
sample: null
category_type:
description:
- The type of the diagnostic settings category.
returned: always
type: sealed-choice
sample: null
'''
import time
import json
import re
from ansible.module_utils.azure_rm_common_ext import AzureRMModuleBaseExt
from copy import deepcopy
try:
from msrestazure.azure_exceptions import CloudError
from azure.mgmt.monitor import MonitorClient
from msrestazure.azure_operation import AzureOperationPoller
from msrest.polling import LROPoller
except ImportError:
# This is handled in azure_rm_common
pass
class Actions:
NoAction, Create, Update, Delete = range(4)
class AzureRMDiagnosticSettingsCategory(AzureRMModuleBaseExt):
def __init__(self):
self.module_arg_spec = dict(
resource_uri=dict(
type='str',
required=True
),
name=dict(
type='str',
required=True
),
state=dict(
type='str',
default='present',
choices=['present', 'absent']
)
)
self.resource_uri = None
self.name = None
self.body = {}
self.results = dict(changed=False)
self.mgmt_client = None
self.state = None
self.to_do = Actions.NoAction
super(AzureRMDiagnosticSettingsCategory, self).__init__(derived_arg_spec=self.module_arg_spec,
supports_check_mode=True,
supports_tags=True)
def exec_module(self, **kwargs):
for key in list(self.module_arg_spec.keys()):
if hasattr(self, key):
setattr(self, key, kwargs[key])
elif kwargs[key] is not None:
self.body[key] = kwargs[key]
self.inflate_parameters(self.module_arg_spec, self.body, 0)
old_response = None
response = None
self.mgmt_client = self.get_mgmt_svc_client(MonitorClient,
base_url=self._cloud_environment.endpoints.resource_manager,
api_version='2017-05-01-preview')
old_response = self.get_resource()
if not old_response:
if self.state == 'present':
self.to_do = Actions.Create
else:
if self.state == 'absent':
self.to_do = Actions.Delete
else:
modifiers = {}
self.create_compare_modifiers(self.module_arg_spec, '', modifiers)
self.results['modifiers'] = modifiers
self.results['compare'] = []
if not self.default_compare(modifiers, self.body, old_response, '', self.results):
self.to_do = Actions.Update
if (self.to_do == Actions.Create) or (self.to_do == Actions.Update):
self.results['changed'] = True
if self.check_mode:
return self.results
response = self.create_update_resource()
elif self.to_do == Actions.Delete:
self.results['changed'] = True
if self.check_mode:
return self.results
self.delete_resource()
else:
self.results['changed'] = False
response = old_response
return self.results
def create_update_resource(self):
try:
if self.to_do == Actions.Create:
response = self.mgmt_client.diagnostic_settings_category.create()
else:
response = self.mgmt_client.diagnostic_settings_category.update()
if isinstance(response, AzureOperationPoller) or isinstance(response, LROPoller):
response = self.get_poller_result(response)
except CloudError as exc:
self.log('Error attempting to create the DiagnosticSettingsCategory instance.')
self.fail('Error creating the DiagnosticSettingsCategory instance: {0}'.format(str(exc)))
return response.as_dict()
def delete_resource(self):
try:
response = self.mgmt_client.diagnostic_settings_category.delete()
except CloudError as e:
self.log('Error attempting to delete the DiagnosticSettingsCategory instance.')
self.fail('Error deleting the DiagnosticSettingsCategory instance: {0}'.format(str(e)))
return True
def get_resource(self):
try:
response = self.mgmt_client.diagnostic_settings_category.get(resource_uri=self.resource_uri,
name=self.name)
except CloudError as e:
return False
return response.as_dict()
def main():
AzureRMDiagnosticSettingsCategory()
if __name__ == '__main__':
main()
| [
"xiuxi.sun@qq.com"
] | xiuxi.sun@qq.com |
9222db26105e569fbad307f258bb1299d5225365 | 663c108dca9c4a30b7dfdc825a8f147ba873da52 | /venv/functions/25VariableLengthArgv.py | b5824e86a2958cb40b1f05bc9bf98f85d3963f09 | [] | no_license | ksrntheja/08-Python-Core | 54c5a1e6e42548c10914f747ef64e61335e5f428 | b5fe25eead8a0fcbab0757b118d15eba09b891ba | refs/heads/master | 2022-10-02T04:11:07.845269 | 2020-06-02T15:23:18 | 2020-06-02T15:23:18 | 261,644,116 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 506 | py | def f01(*n, x):
print('x :', x, type(x))
print('n :', n, type(n))
# f01(1)
# Traceback (most recent call last):
# File "/Code/venv/functions/25VariableLengthArgv.py", line <>, in <module>
# f01(1)
# TypeError: f01() missing 1 required keyword-only argument: 'x'
# f01(1, 2)
# TypeError: f01() missing 1 required keyword-only argument: 'x'
# f01(1, 2, 3)
# TypeError: f01() missing 1 required keyword-only argument: 'x'
f01()
# TypeError: f01() missing 1 required keyword-only argument: 'x'
| [
"srntkolla@gmail.com"
] | srntkolla@gmail.com |
7751ad4bdeec9135090e42680ec1598b9710257c | 9844294a93eef781f8cc2473abb0046f8a416966 | /xpdan/tests/test_io.py | e98861be36cd90a551663017f2f9d0ac133f5b9c | [] | no_license | sbillinge/xpdAn | b5decca72d1539e10a6920df5c75cc0374486687 | 0fc91ea7a26e505ff65e58b08b17b145f3e8e7d8 | refs/heads/master | 2021-01-01T18:49:49.964014 | 2017-07-26T15:42:18 | 2017-07-26T15:42:18 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,091 | py | ##############################################################################
#
# xpdan by Billinge Group
# Simon J. L. Billinge sb2896@columbia.edu
# (c) 2016 trustees of Columbia University in the City of
# New York.
# All rights reserved
#
# File coded by: Christopher J. Wright
#
# See AUTHORS.txt for a list of people who contributed.
# See LICENSE.txt for license information.
#
##############################################################################
import numpy as np
import os
from xpdan.io import fit2d_save, read_fit2d_msk
from numpy.testing import assert_array_equal
def test_save_output_fit2d(mk_glbl):
filename = os.path.join(mk_glbl['base_dir'], "function_values")
msk = np.random.random_integers(
0, 1, (np.random.random_integers(0, 200),
np.random.random_integers(0, 200))).astype(bool)
fit2d_save(msk, filename, dir_path=None)
msk2 = read_fit2d_msk(filename+'.msk')
assert_array_equal(msk2, msk)
os.remove(filename+'.msk')
| [
"cjwright4242@gmail.com"
] | cjwright4242@gmail.com |
c308f33845f5ac2ca3beaf0b4d9efb85dad9b9c6 | fd83af9e6348eddae2f4bfeeb1760048763e857b | /OsSearch/src/search_files.py | ca688ca06b42139934e87294770f837ac754d35b | [] | no_license | rduvalwa5/NewPythonOsLevel | 6f41f4c4934a0f3a016b435acbc4bbc5e2d057c5 | 44a434ace6a21ea27dfffd14a4b1f55931907673 | refs/heads/master | 2020-04-13T01:18:38.451607 | 2019-03-08T05:26:12 | 2019-03-08T05:26:12 | 162,870,765 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 6,108 | py | '''
Created on Jul 16, 2016
purpose search for files
@author: rduvalwa2
'''
import glob
import os
from os.path import join, getsize
import string
class find_file:
def __init__(self):
self.allFoundFiles = []
self.constrainedFiles = []
self.allDirectories = []
self.artist = []
def find(self,myFile, path = '.'):
for root, dirs, files in os.walk(path):
print(dirs)
for name in files:
foundFile = {}
if name == myFile:
file_info = os.stat(join(root, name))
# foundFile['Dir'] = dirs
foundFile['file_size'] = file_info.st_size
foundFile['file_access_time'] = file_info.st_atime
foundFile['file_path'] = os.path.abspath(path)
foundFile['name'] = name
self.allFoundFiles.append(foundFile)
def findAll(self,path = '.'):
for root, dirs, files in os.walk(path):
print(dirs)
for name in files:
foundFile = {}
file_info = os.stat(join(root, name))
# foundFile['Dir'] = dirs
foundFile['file_size'] = file_info.st_size
foundFile['file_access_time'] = file_info.st_atime
foundFile['file_path'] = os.path.abspath(path)
foundFile['name'] = name
self.allFoundFiles.append(foundFile)
def findConstrained(self,myConstraint, path = '.'):
# dirCount = 0
for root, dirs, files in os.walk(path):
self.allDirectories = dirs
print('directories ',dirs)
# print('files ',files)
for name in files:
if myConstraint in name:
foundFile = {}
file_info = os.stat(join(root, name))
# foundFile['Dir'] = dirs
foundFile['file_path'] = os.path.abspath(path)
foundFile['name'] = name
self.constrainedFiles.append(foundFile)
# dirCount = dirCount + 1
def find_file(self,myFile, path = '.'):
self.find(myFile, path)
if self.allFoundFiles != []:
return self.allFoundFiles
else:
return myFile + " Not found"
def find_fileAll(self,path = '.'):
self.findAll(path)
if self.allFoundFiles != []:
return self.allFoundFiles
else:
return "No Files found"
def find_fileConstraint(self,constraint,path = os.path.abspath('.')):
self.findConstrained(constraint, path)
if self.constrainedFiles != []:
return self.constrainedFiles
else:
return "No Files found"
def all_files(self,constr,path = os.path.abspath('./')):
if len(constr) == 1:
if constr[0] == '*':
# print("find_fileAll")
return self.find_fileAll(path)
if len(constr) > 1:
if constr[0] == '*':
# print("all_files find_fileConstraint")
constraint = constr[1:]
# print('constraint ', constraint)
return self.find_fileConstraint(constraint, path)
else:
return self.find_file(constr,path)
else:
return "Input makes no sense"
def get_directories(self, path = os.path.abspath('./')):
for root, dirs, files in os.walk(path):
if dirs != []:
self.allDirectories.append(dirs)
return self.allDirectories
def get_roots(self, path = os.path.abspath('./')):
for root, dirs, files in os.walk(path):
if root != []:
self.artist.append(root)
return self.artist
def get_count(self, result):
if isinstance(result,str):
return(result)
else:
return len(result)
def printResult(self,result):
print("**************")
if isinstance(result,str):
print(result)
else:
print(self.get_count(result))
for item in result:
print(item)
if __name__ == "__main__":
'''
print("F1_____")
f1 = find_file()
result = f1.all_files('*','../')
f1.printResult(result)
print("F2_____")
f2 = find_file()
result2 = f2.all_files('*.py','./')
f2.printResult(result2)
print("F3_____")
f3 = find_file()
result3 = f3.all_files('test_file.txt','../')
f3.printResult(result3)
print("F4_____")
f4 = find_file()
result4 = f4.all_files('*.jpg','../../')
print("result is ", result4)
f4.printResult(result4)
print("F5_____")
f5 = find_file()
result5 = f5.all_files('*test','../../')
f5.printResult(result5)
print(len(result5))
'''
songPath = '/Users/rduvalwa2/Music/iTunes/iTunes Music/Music'
allSongNames = []
print("F6_____")
f6 = find_file()
result6 = f6.all_files('*.m4p',songPath)
for name in result6:
allSongNames.append(name['name'])
# f6.printResult(result5)
print(len(result6))
for item in allSongNames:
print(item)
fdir = find_file()
result6 = f6.all_files('*.m4p',songPath)
di = f6.get_directories(songPath)
print(len(di))
for directory in di:
print(directory)
rot = f6.get_roots(songPath)
print(rot)
'''
f7 = find_file()
result7 = f7.all_files('*.m4a',songPath)
# print(result7)
print(len(result7))
for name in result7:
print(os.path.abspath(songPath + '/' + name['name']))
# allSongNames.append(name[name])
f8 = find_file()
result8 = f8.all_files('*.m4p','/Users/rduvalwa2/Music/iTunes/iTunes Music/Music')
print(len(result8))
for name in result8:
allSongNames.append(name['name'])
'''
print(len(allSongNames))
| [
"rduvalwa5@hotmail.com"
] | rduvalwa5@hotmail.com |
854b0ae1add69f394aaa72b8c9bce2cc76f4601c | 288a00d2ab34cba6c389b8c2444455aee55a8a95 | /tests/data23/recipe-302262.py | a3a3ff5f7bf6d86259b10c3c2216689e4f7f3c66 | [
"BSD-2-Clause"
] | permissive | JohannesBuchner/pystrict3 | ffd77b7bbc378bd4d8f21b5c6bd69a0d64a52ddb | 18b0dd369082422f9bf0f89c72e7acb53a49849c | refs/heads/master | 2023-08-14T06:37:37.954880 | 2023-07-13T11:16:38 | 2023-07-13T11:16:38 | 268,571,175 | 1 | 1 | null | null | null | null | UTF-8 | Python | false | false | 4,727 | py | # -*- coding: iso-8859-1 -*-
"""
Handling of arguments: options, arguments, file(s) content iterator
For small scripts that:
- read some command line options
- read some command line positional arguments
- iterate over all lines of some files given on the command line, or stdin if none given
- give usage message if positional arguments are missing
- give usage message if input files are missing and stdin is not redirected
"""
__author__ = 'Peter Kleiweg'
__version__ = '0.2'
__date__ = '2004/08/28'
import os, sys, getopt
class Args:
"""
Perform common tasks on command line arguments
Instance data:
progname (string) -- name of program
opt (dictionary) -- options with values
infile (string) -- name of current file being processed
lineno (int) -- line number of last line read in current file
linesum (int) -- total of lines read
"""
def __init__(self, usage='Usage: %(progname)s [opt...] [file...]'):
"init, usage string: embed program name as %(progname)s"
self.progname = os.path.basename(sys.argv[0])
self.opt = {}
self.infile = None
self.lineno = 0
self.linesum = 0
self._argv = sys.argv[1:]
self._usage = usage
def __iter__(self):
"iterator: set-up"
if self._argv:
self.infile = self._argv.pop(0)
self._in = open(self.infile, 'r')
self._stdin = False
else:
if sys.stdin.isatty():
self.usage() # Doesn't return
self.infile = '<stdin>'
self._in = sys.stdin
self._stdin = True
return self
def __next__(self):
"iterator: get next line, possibly from next file"
while True:
line = self._in.readline()
if line:
self.lineno += 1
self.linesum += 1
return line
if self._stdin:
break
self._in.close()
try:
self.infile = self._argv.pop(0)
except IndexError:
break
self.lineno = 0
self._in = open(self.infile, 'r')
self.lineno = -1
self.infile = None
raise StopIteration
def getopt(self, shortopts, longopts=[]):
"get options and merge into dict 'opt'"
try:
options, self._argv = getopt.getopt(self._argv, shortopts, longopts)
except getopt.GetoptError:
self.usage()
self.opt.update(dict(options))
def shift(self):
"pop first of remaining arguments (shift)"
try:
return self._argv.pop(0)
except IndexError:
self.usage()
def pop(self):
"pop last of remaining arguments"
try:
return self._argv.pop()
except IndexError:
self.usage()
def warning(self, text):
"print warning message to stderr, possibly with filename and lineno"
if self.lineno > 0:
print('%s:%i: warning: %s' % (self.infile, self.lineno, text), file=sys.stderr)
else:
print('\nWarning %s: %s\n' % (self.progname, text), file=sys.stderr)
def error(self, text):
"print error message to stderr, possibly with filename and lineno, and exit"
if self.lineno > 0:
print('%s:%i: %s' % (self.infile, self.lineno, text), file=sys.stderr)
else:
print('\nError %s: %s\n' % (self.progname, text), file=sys.stderr)
sys.exit(1)
def usage(self):
"print usage message, and exit"
print(file=sys.stderr)
print(self._usage % {'progname': self.progname}, file=sys.stderr)
print(file=sys.stderr)
sys.exit(1)
if __name__ == '__main__':
a = Args('Usage: %(progname)s [-a value] [-b value] [-c] word [file...]')
a.opt['-a'] = 'option a' # set some default option values
a.opt['-b'] = 'option b' #
a.getopt('a:b:c') # get user supplied option values
word = a.shift() # get the first of the remaining arguments
# use a.pop() to get the last instead
for line in a: # iterate over the contents of all remaining arguments (file names)
if a.lineno == 1:
print('starting new file:', a.infile)
a.warning(line.rstrip())
print('Options:', a.opt)
print('Word:', word)
print('Total number of lines:', a.linesum)
print('Command line:', sys.argv) # unchanged
a.warning('warn 1') # print a warning
a.error('error') # print an error message and exit
a.warning('warn 2') # this won't show
| [
"johannes.buchner.acad@gmx.com"
] | johannes.buchner.acad@gmx.com |
13bc41ea13c609620e4b5eccc6962fa2e0a7aa90 | a0500eec8e656301d3e71f4ea240ddabd2994107 | /student/forms.py | e718c658f3efffcd83b3d15cb3e17a47e5b6889d | [] | no_license | abhinavsharma629/Stalk-Site | bc80aaf7ecc91f7b09e64173b351101a41253adf | 37564018543dfb2d0e439a4ee6933477958fca48 | refs/heads/master | 2020-04-19T13:08:28.544661 | 2019-01-30T23:50:26 | 2019-01-30T23:50:26 | 168,210,403 | 7 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,018 | py | from django import forms
from .models import StudentData
class StudentSubmit(forms.ModelForm):
er_no=forms.CharField(widget=forms.TextInput(attrs={'class':'form-group'}),required=True,max_length=100)
name=forms.CharField(widget=forms.TextInput(),required=True,max_length=150)
college_name=forms.CharField(widget=forms.TextInput(),required=True,max_length=250)
codeforces=forms.CharField(widget=forms.TextInput(),required=False,max_length=100)
codechef=forms.CharField(widget=forms.TextInput(),required=True,max_length=100)
spoj=forms.CharField(widget=forms.TextInput(),required=False,max_length=100)
hackerrank=forms.CharField(widget=forms.TextInput(),required=False,max_length=100)
hackerearth=forms.CharField(widget=forms.TextInput(),required=False,max_length=100)
github=forms.CharField(widget=forms.TextInput(), required=False, max_length=100)
class Meta:
model= StudentData
fields=['er_no','name','college_name','codeforces', 'codechef','spoj','hackerrank','hackerearth', 'github']
| [
"abhinavsharma629@gmail.com"
] | abhinavsharma629@gmail.com |
0e02b9d97b66a81201874125f05af122a2bdf46f | 761a3c37621b2daae06d9fe29c93e4d9a8bf5a95 | /policy/networks/fixed_actor_network.py | a269867bb588716baf82eb8a034559e15f03d784 | [] | no_license | matthewzhang1998/ecco | 486dd37e3b2038b0d3f4d9f40de094f64b6a0679 | b25b6d6d4d815e716c19aa53010e70583fbe5686 | refs/heads/master | 2020-03-26T19:36:55.511529 | 2018-09-17T04:53:52 | 2018-09-17T04:53:52 | 145,275,328 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 257 | py | #!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 14 14:21:09 2018
@author: matthewszhang
"""
from policy.networks import base_network
class network(base_network.base_network):
def __init__(self, *args, **kwargs):
pass
| [
"matthew.zhang@mail.utoronto.ca"
] | matthew.zhang@mail.utoronto.ca |
dbbe212390f1fa211ad11556a684327f80674fe8 | 366d50ddb1ae1c20f2e8bcbc1b6cde58996ac24a | /Python-02网络数据采集/Reference/chapter6-数据读取/2-getUtf8Text.py | d76ea93faa287090d1058be700deefa0793c77f0 | [] | no_license | luilui163/PythonBook | fe7796ca26842f07d3baa5d754f79cda5fd2b18f | f81585479fb3859dfd818fccd43a64e50f6f81dc | refs/heads/master | 2020-04-06T12:59:10.949209 | 2017-11-09T10:43:36 | 2017-11-09T10:43:36 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 726 | py | # 使用BeautifulSoup模块对txt格式文本进行UTF-8编码再提取
# 解决:Python把文本读成ASCII编码格式,而浏览器把文本读成 ISO-8859-1 编码格式
from urllib.request import urlopen
from bs4 import BeautifulSoup
# 使用BeautifulSoup获取网页源代码
html = urlopen("http://en.wikipedia.org/wiki/Python_(programming_language)")
bsObj = BeautifulSoup(html, "lxml")
content = bsObj.find("div", {"id": "mw-content-text"}).get_text() # bsObj.find():寻找第一个符合条件的div;.get_text():获取当前标签的内容
content = bytes(content, "UTF-8") # 对标签内容用utf-8格式转换成bytes
content = content.decode("UTF-8") # 对bytes内容用utf-8格式编码
print(content) | [
"lafitehhq@126.com"
] | lafitehhq@126.com |
e0b09cdc02c1147f7eebd503a05959609d961462 | fab15f0e35d3196b9e486d1d3e4f42b22f326817 | /scripts/ugm/52_create_curation.py | 73348c37c05695f765891d9bb8382f70a2424de0 | [] | no_license | nakamura196/genji | 4511c9d297b97697cad87f570085ac865ca0f750 | e1079ad2839772fca4c93657d96e6bee14957b68 | refs/heads/master | 2022-06-03T01:18:37.789217 | 2020-05-01T11:44:44 | 2020-05-01T11:44:44 | 194,894,216 | 0 | 0 | null | 2019-08-28T23:44:12 | 2019-07-02T15:56:09 | CSS | UTF-8 | Python | false | false | 2,515 | py | import pandas as pd
from rdflib import URIRef, BNode, Literal, Graph
from rdflib.namespace import RDF, RDFS, FOAF, XSD
from rdflib import Namespace
import numpy as np
import math
import sys
import argparse
import json
import urllib.request
import os
import csv
import glob
import requests
import csv
map = {}
label_map = {
"https://nakamura196.github.io/genji/ugm/ndl/manifest/3437686.json": "校異源氏物語",
"https://nakamura196.github.io/genji/ugm/utokyo/manifest/01.json": "東大本",
"https://nakamura196.github.io/genji/ugm/kyushu/manifest/01.json": "九大本(古活字版)",
"https://nakamura196.github.io/genji/ugm/kyushu2/manifest/01.json": "九大本(無跋無刊記整版本)"
}
with open('curation_merged.csv', 'r') as f:
reader = csv.reader(f)
header = next(reader) # ヘッダーを読み飛ばしたい時
for row in reader:
manifest = row[0]
member_id = row[1]
label = row[2]
line_id = row[3]
sort = row[4]
if manifest not in map:
map[manifest] = {}
map[manifest][sort] = {
"label": label,
"line_id": line_id,
"member_id": member_id
}
selections = []
for manifest in map:
members = []
for sort in sorted(map[manifest]):
obj = map[manifest][sort]
member = {
"@id": obj["member_id"],
"@type": "sc:Canvas",
"label": obj["label"]
}
members.append(member)
if "line_id" in obj and obj["line_id"] != "":
member["line_id"] = obj["line_id"]
selection = {
"@id": "http://mp.ex.nii.ac.jp/api/curation/json/9ab5cac5-78e6-41b8-9d8f-ab00f57d7b64/range1",
"@type": "sc:Range",
"label": "Manual curation by IIIF Curation Viewer",
"members": members,
"within": {
"@id": manifest,
"@type": "sc:Manifest",
"label": label_map[manifest]
}
}
selections.append(selection)
curation_data = {
"@context": [
"http://iiif.io/api/presentation/2/context.json",
"http://codh.rois.ac.jp/iiif/curation/1/context.json"
],
"@type": "cr:Curation",
"@id": "http://mp.ex.nii.ac.jp/api/curation/json/9ab5cac5-78e6-41b8-9d8f-ab00f57d7b64",
"label": "Curating list",
"selections": selections
}
fw2 = open("curation.json", 'w')
json.dump(curation_data, fw2, ensure_ascii=False, indent=4,
sort_keys=True, separators=(',', ': '))
| [
"na.kamura.1263@gmail.com"
] | na.kamura.1263@gmail.com |
b1b319ea7e1a3d520dec06505878bcb419be66fd | 35429631806692df957bd74a77e5c97db7d5db1e | /05_Themenmodellierung/project.py | 10cbef9bdc4818d3982ef4ad3a87f94bd1b66503 | [
"MIT"
] | permissive | felixdittrich92/NLP | f135f4390a3d76676dbd28fda11fad49c68ae8a5 | 1097d43dd1c99762b6a909a876a765bc79245471 | refs/heads/master | 2020-10-01T14:32:14.389080 | 2020-09-18T11:33:23 | 2020-09-18T11:33:23 | 227,556,715 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 683 | py | import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import NMF
questions = pd.read_csv('./TextFiles/quora_questions.csv')
print(questions.head())
tfidf = TfidfVectorizer(max_df=0.95, min_df=2, stop_words='english')
dtm = tfidf.fit_transform(questions['Question'])
nmf = NMF(n_components=20, random_state=42)
nmf.fit(dtm)
for index, topic in enumerate(nmf.components_):
print(f'Die TOP-15 Wörter für das Thema #{index}')
print([tfidf.get_feature_names()[i] for i in topic.argsort()[-15:]])
print('\n')
topic_results = nmf.transform(dtm)
questions['Topic'] = topic_results.argmax(axis=1)
print(questions.head()) | [
"felixdittrich92@gmail.com"
] | felixdittrich92@gmail.com |
e941491f6ee750b1d448382918e1e2807a6dd007 | b53e3d57d31a47a98d87141e44a5f8940ee15bca | /src/programy/utils/license/keys.py | 65a5dc3d00fa025f122135206e067f668429418a | [
"MIT"
] | permissive | Chrissimple/program-y | 52177fcc17e75fb97ab3993a4652bcbe7906bd58 | 80d80f0783120c2341e6fc57e7716bbbf28a8b3f | refs/heads/master | 2020-03-29T13:20:08.162177 | 2018-09-26T19:09:20 | 2018-09-26T19:09:20 | 149,952,995 | 1 | 0 | null | 2018-09-23T06:11:04 | 2018-09-23T06:11:04 | null | UTF-8 | Python | false | false | 3,057 | py | """
Copyright (c) 2016-17 Keith Sterling http://www.keithsterling.com
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated
documentation files (the "Software"), to deal in the Software without restriction, including without limitation
the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software,
and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions
of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO
THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
"""
import logging
class LicenseKeys(object):
def __init__(self):
self._keys = {}
def add_key(self, name, value):
if name in self._keys:
if logging.getLogger().isEnabledFor(logging.WARNING):
logging.warning("License key [%s], already exists", name)
self._keys[name] = value
def has_key(self, name):
return bool(name in self._keys)
def get_key(self, name):
if name in self._keys:
return self._keys[name]
else:
raise ValueError("No license key named [%s]"%name)
def load_license_key_data(self, license_key_data):
lines = license_key_data.split('\n')
for line in lines:
self._process_license_key_line(line)
def load_license_key_file(self, license_key_filename):
try:
if logging.getLogger().isEnabledFor(logging.INFO):
logging.info("Loading license key file: [%s]", license_key_filename)
with open(license_key_filename, "r", encoding="utf-8") as license_file:
for line in license_file:
self._process_license_key_line(line)
except Exception:
if logging.getLogger().isEnabledFor(logging.ERROR):
logging.error("Invalid license key file [%s]", license_key_filename)
def _process_license_key_line(self, line):
line = line.strip()
if line:
if line.startswith('#') is False:
splits = line.split("=")
if len(splits) > 1:
key_name = splits[0].strip()
# If key has = signs in it, then combine all elements past the first
key = "".join(splits[1:]).strip()
self._keys[key_name] = key
else:
if logging.getLogger().isEnabledFor(logging.WARNING):
logging.warning("Invalid license key [%s]", line)
| [
"keith@keithsterling.com"
] | keith@keithsterling.com |
fe30adbedfb9ded1a2bbaa6ae520a3830eb00f32 | dfcb65de02953afaac24cc926ee32fcdede1ac21 | /src/pyrin/utils/custom_print.py | 589ac02c3990c2630664b441e021a3eab0f9f5b6 | [
"BSD-3-Clause"
] | permissive | mononobi/pyrin | 031d0c38da945b76b07ea100554ffc7f8081b05e | 9d4776498225de4f3d16a4600b5b19212abe8562 | refs/heads/master | 2023-08-31T03:56:44.700142 | 2023-08-20T22:20:06 | 2023-08-20T22:20:06 | 185,481,041 | 20 | 8 | null | null | null | null | UTF-8 | Python | false | false | 2,928 | py | # -*- coding: utf-8 -*-
"""
utils custom_print module.
"""
import colorama
import pyrin.application.services as application_services
def print_colorful(value, color, force=False):
"""
prints the given value into stdout using the given color.
if the application has been started in scripting mode
it does not print the value.
:param object value: value to be printed.
:param int color: color of text to be printed.
it should be from `colorama.Fore` colors.
:param bool force: forces the printing, even if application
has been started in scripting mode.
defaults to False if not provided.
"""
if force is True or application_services.is_scripting_mode() is False:
try:
if not isinstance(value, str):
value = str(value)
colorama.init(autoreset=True)
print(str(color) + value)
finally:
colorama.deinit()
def print_warning(value, force=False):
"""
prints the given value into stdout as a warning.
if the application has been started in scripting mode
it does not print the value.
:param object value: value to be printed.
:param bool force: forces the printing, even if application
has been started in scripting mode.
defaults to False if not provided.
"""
print_colorful(value, colorama.Fore.YELLOW, force)
def print_error(value, force=False):
"""
prints the given value into stdout as an error.
if the application has been started in scripting mode
it does not print the value.
:param object value: value to be printed.
:param bool force: forces the printing, even if application
has been started in scripting mode.
defaults to False if not provided.
"""
print_colorful(value, colorama.Fore.RED, force)
def print_info(value, force=False):
"""
prints the given value into stdout as an info.
if the application has been started in scripting mode
it does not print the value.
:param object value: value to be printed.
:param bool force: forces the printing, even if application
has been started in scripting mode.
defaults to False if not provided.
"""
print_colorful(value, colorama.Fore.BLUE, force)
def print_default(value, force=False):
"""
prints the given value into stdout with default color.
if the application has been started in scripting mode
it does not print the value.
:param object value: value to be printed.
:param bool force: forces the printing, even if application
has been started in scripting mode.
defaults to False if not provided.
"""
print_colorful(value, colorama.Fore.RESET, force)
| [
"mohamadnobakht@gmail.com"
] | mohamadnobakht@gmail.com |
a04e9f18fb32c8d4bac7255f10399e78f854df1c | 54e3397609cc31b9142d483a29a9a3854800a620 | /create/factoryMethod2.py | 6b56640fb0915d08428d7528383759fbf17c12b3 | [] | no_license | qiangayz/DesignPatterns | 1ac2ee51e2a176910bc19520dcb6ebb9914e0a36 | 527a0ffe59e5fd980ba6b4387d422d6c96fe1623 | refs/heads/master | 2020-03-23T22:34:21.040915 | 2018-07-24T16:10:22 | 2018-07-24T16:10:22 | 142,183,151 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,958 | py | # _*_coding:utf-8_*_
'''
工厂方法模式是简单工厂模式的衍生,解决了许多简单工厂模式的问题。
首先完全实现‘开-闭 原则’,实现了可扩展。其次更复杂的层次结构,可以应用于产品结果复杂的场合。
工厂方法模式的对简单工厂模式进行了抽象。有一个抽象的Factory类(可以是抽象类和接口),这个类将不在负责具体的产品生产,
而是只制定一些规范(接口作用),具体的生产工作由其子类去完成。在这个模式中,工厂类和产品类往往可以依次对应。即一个抽象工厂对应一个抽象产品,一个具体工厂对应一个具体产品,这个具体的工厂就负责生产对应的产品。
工厂方法模式(Factory Method pattern)是最典型的模板方法模式(Templete Method pattern)应用。
'''
class AbstractSchool(object):
name = ''
addr = ''
principal = ''
def enroll(self, name, course):
pass
def info(self):
pass
class AbstractCourse(object):
def __init__(self, name, time_range, study_type, fee):
self.name = name
self.time_range = time_range
self.study_type = study_type
self.fee = fee
def enroll_test(self):
'''
参加这门课程前需要进行的测试
:return:
'''
print("课程[%s]测试中..." % self.name)
def print_course_outline(self):
'''打印课程大纲'''
pass
class LinuxOPSCourse(AbstractCourse):
'''
运维课程
'''
def print_course_outline(self):
outline = '''
Linux 基础
Linux 基本服务使用
Linux 高级服务篇
Linux Shell编程
'''
print(outline)
def enroll_test(self):
print("不用测试,是个人就能学...")
class PythonCourse(AbstractCourse):
'''python自动化开发课程'''
def print_course_outline(self):
outline = '''
python 介绍
python 基础语法
python 函数式编程
python 面向对象
python 网络编程
python web开发基础
'''
print(outline)
def enroll_test(self):
print("-------python入学测试-------")
print("-------500道题答完了-------")
print("-------通过了-------")
class BJSchool(AbstractSchool):
name = "北京校区"
def create_course(self, course_type):
if course_type == 'py_ops':
course = PythonCourse("Python自动化开发",
7, '面授', 11000)
elif course_type == 'linux':
course = LinuxOPSCourse("Linux运维课程",
5, '面授', 12800)
return course
def enroll(self, name, course):
print("开始为新学员[%s]办入学手续... " % name)
print("帮学员[%s]注册课程[%s]..." % (name, course))
course.enroll_test()
def info(self):
print("------[%s]-----" % self.name)
class SHSchool(AbstractSchool):
name = "上海分校"
def create_course(self, course_type):
if course_type == 'py_ops':
course = PythonCourse("Python自动化开发",
8, '在线', 6500)
elif course_type == 'linux':
course = LinuxOPSCourse("Linux运维课程",
6, '在线', 8000)
return course
def enroll(self, name, course):
print("开始为新学员[%s]办入学手续... " % name)
print("帮学员[%s]注册课程[%s]..." % (name, course))
# course.level_test()
def info(self):
print("--------[%s]-----" % self.name)
school1 = BJSchool()
school2 = SHSchool()
school1.info()
c1 = school1.create_course("py_ops")
school1.enroll("张三", c1)
school2.info()
c2 = school1.create_course("py_ops")
school2.enroll("李四", c2) | [
"38162672+qiangayz@users.noreply.github.com"
] | 38162672+qiangayz@users.noreply.github.com |
986ae54cc208bb5b8f14735de120a47266e6fe9f | 9c5f36b72323090b9f0254938923a04b436fd3be | /scripts/test_image_contrast.py | 81fd44194ba9ab7620bb56b92c03da263360a07a | [] | no_license | mdlaskey/IL_ROS_HSR | 7c7233905e6a1fc8388661236bade3862da0fc90 | d12f8397249acea4fae71d12c74074314a8a005e | refs/heads/master | 2021-01-20T18:30:11.815581 | 2018-04-07T01:14:41 | 2018-04-07T01:14:41 | 90,918,344 | 2 | 1 | null | null | null | null | UTF-8 | Python | false | false | 1,392 | py | import numpy as np
import cPickle as pickle
import matplotlib.pyplot as plt
import IPython
import sys
sys.path.append('/home/autolab/Workspaces/michael_working/yolo_tensorflow/')
import configs.config_bed as cfg
import cv2
if __name__ == "__main__":
#-----Reading the image-----------------------------------------------------
img = cv2.imread(cfg.IMAGE_PATH+'frame_0.png', 1)
cv2.imshow("img",img)
cv2.waitKey(30)
#-----Converting image to LAB Color model-----------------------------------
lab= cv2.cvtColor(img, cv2.COLOR_BGR2LAB)
# cv2.imshow("lab",lab)
# cv2.waitKey(30)
#-----Splitting the LAB image to different channels-------------------------
l, a, b = cv2.split(lab)
# cv2.imshow('l_channel', l)
# cv2.waitKey(30)
# cv2.imshow('a_channel', a)
# cv2.waitKey(30)
# cv2.imshow('b_channel', b)
# cv2.waitKey(30)
#-----Applying CLAHE to L-channel-------------------------------------------
clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
cl = clahe.apply(l)
# cv2.imshow('CLAHE output', cl)
# cv2.waitKey(30)
#-----Merge the CLAHE enhanced L-channel with the a and b channel-----------
limg = cv2.merge((cl,a,b))
# cv2.imshow('limg', limg)
# cv2.waitKey(30)
#-----Converting image from LAB Color model to RGB model--------------------
final = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
cv2.imshow('final', final)
cv2.waitKey(30)
IPython.embed() | [
"mdlaskey@umich.edu"
] | mdlaskey@umich.edu |
bed356639866f41e11f0b2455c985aa120917362 | ee803c29e9c5216a16a2699854b98c8a6d9760b8 | /dataServer/FlaskDataServer/app/test.py | 6dd9b65ccf3c7303b2957ba3d976bab84c9c4f92 | [] | no_license | algo2019/algorithm | c160e19b453bc979853caf903ad96c2fa8078b69 | 3b5f016d13f26acab89b4a177c95a4f5d2dc1ba1 | refs/heads/master | 2022-12-12T17:59:57.342665 | 2019-02-23T07:45:39 | 2019-02-23T07:45:39 | 162,404,028 | 0 | 0 | null | 2022-12-08T01:29:20 | 2018-12-19T08:08:13 | Python | UTF-8 | Python | false | false | 204 | py | import urllib2
import cPickle as pickle
import json
r = urllib2.urlopen('http://127.0.0.1:5001/api/v1.0/dom_info?symbol=a&&start=20100101')
res = r.read()
print pickle.loads(str(json.loads(res)['res'])) | [
"xingwang.zhang@renren-inc.com"
] | xingwang.zhang@renren-inc.com |
2af4aa1e5d0238e05026c8ffb75754f820cc2f9a | 253089ef4ee99c50cdaa23fde4d789794789e2e9 | /15/enumerate_data.py | a77262511b818966d3f7f2bb7417e4e4ee3d2f3a | [] | no_license | Zaubeerer/bitesofpy | 194b61c5be79c528cce3c14b9e2c5c4c37059259 | e5647a8a7a28a212cf822abfb3a8936763cd6b81 | refs/heads/master | 2021-01-01T15:01:21.088411 | 2020-11-08T19:56:30 | 2020-11-08T19:56:30 | 239,328,990 | 1 | 0 | null | null | null | null | UTF-8 | Python | false | false | 368 | py | names = 'Julian Bob PyBites Dante Martin Rodolfo'.split()
countries = 'Australia Spain Global Argentina USA Mexico'.split()
def enumerate_names_countries():
"""Outputs:
1. Julian Australia
2. Bob Spain
3. PyBites Global
4. Dante Argentina
5. Martin USA
6. Rodolfo Mexico"""
pass | [
"r.beer@outlook.de"
] | r.beer@outlook.de |
6fbb0dabca820df63974542daab4cc8236741723 | 208446b30b8c4a479ed414376453c4edbab5053b | /python_space/Atest/duoxiancheng/1.py | b161562b65506e220985a498fba9628eda000dea | [] | no_license | fengyu0712/myclone | 6e0bcb0e4b4f5919c4cabb1eb1be49afa7e68ba2 | d4e47adf81b3ced0f433d5e261989b0bbb457fa4 | refs/heads/master | 2023-02-10T06:50:43.349167 | 2021-01-05T08:38:35 | 2021-01-05T08:38:35 | 316,674,323 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 724 | py | import threading
import time
import random
start_time =time.time()
def do_something():
print ("{thread_name} start at {now}\n".format(thread_name=threading.currentThread().name,now=time.time()))
time.sleep(1)
print ("{thread_name} stop at {now}".format(thread_name=threading.currentThread().name,now=time.time()))
if __name__== "__main__":
threads = []
# start all threading.
for i in range(1,8):
t = threading.Thread(target=do_something)
t.start()
threads.append(t)
#wait until all the threads terminnates.
for thread in threads:
thread.join()
print ("all threads deid.")
print ("this run take {t} seconds".format(t = (time.time()-start_time))) | [
"121193252@qq.com"
] | 121193252@qq.com |
6e9bb166100ed8ecfed7b6e5acfac458e92d0fab | ab65fa746dafd99873d4fd0a1576469809db162c | /django/apps/stories/migrations/0012_auto_20150527_0113.py | f3ab04d2999839499ee31db58ce176f33729546d | [] | no_license | haakenlid/tassen-dockerize | 27dfb13a05925e2570949ad6337379fe6bc8d452 | c867c36c1330db60acfc6aba980e021585fbcb98 | refs/heads/master | 2021-01-22T03:14:05.219508 | 2017-03-23T12:57:54 | 2017-03-23T12:57:54 | 81,106,809 | 2 | 1 | null | null | null | null | UTF-8 | Python | false | false | 1,157 | py | # -*- coding: utf-8 -*-
from __future__ import unicode_literals
from django.db import models, migrations
class Migration(migrations.Migration):
dependencies = [
('stories', '0011_auto_20150527_0050'),
]
operations = [
migrations.AlterField(
model_name='storyimage',
name='aspect_ratio',
field=models.FloatField(verbose_name='aspect ratio', choices=[(0.0, 'auto'), (0.5, '1:2 landscape'), (0.6666666666666666, '2:3 landscape'), (0.75, '3:4 landscape'), (1.0, 'square'), (1.3333333333333333, '4:3 portrait'), (1.5, '3:2 portrait'), (2.0, '2:1 portrait'), (100.0, 'original')], default=0.0, help_text='height / width'),
),
migrations.AlterField(
model_name='storyvideo',
name='aspect_ratio',
field=models.FloatField(verbose_name='aspect ratio', choices=[(0.0, 'auto'), (0.5, '1:2 landscape'), (0.6666666666666666, '2:3 landscape'), (0.75, '3:4 landscape'), (1.0, 'square'), (1.3333333333333333, '4:3 portrait'), (1.5, '3:2 portrait'), (2.0, '2:1 portrait'), (100.0, 'original')], default=0.0, help_text='height / width'),
),
]
| [
"haakenlid@gmail.com"
] | haakenlid@gmail.com |
3312a1191c10cb37edbb6e8c7a0bd3feb12e7e8b | eec9299fd80ed057585e84e0f0e5b4d82b1ed9a7 | /blog/views.py | ada404e5e604dbf81ca51b66062ae71c9a74efc4 | [] | no_license | aimiliya/mysite | f51967f35c0297be7051d9f485dd0e59b8bb60c2 | b8e3b639de6c89fb8e6af7ee0092ee744a75be41 | refs/heads/master | 2020-04-08T19:06:36.539404 | 2018-12-01T08:05:18 | 2018-12-01T08:05:18 | 159,640,181 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 4,284 | py | from django.core.paginator import Paginator
from django.db.models import Count
from django.shortcuts import render, get_object_or_404
from read_statistic.utils import read_statisitcs_once_read
from .models import Blog, BlogType
EACH_PAGE_BLOGS_NUMBER = 10
def get_blog_list_common_data(request, blog_all_list):
paginator = Paginator(blog_all_list, EACH_PAGE_BLOGS_NUMBER)
page_num = request.GET.get('page', 1) # 获取页码参数,如果没有,返回1
page_of_blogs = paginator.get_page(page_num)
currentr_page = page_of_blogs.number # 获取当前页码
# 实现只显示当前页但后个两页,且不超出页码范围。
page_range = list(range(max(currentr_page - 2, 1), currentr_page)) + list(
range(currentr_page, min(currentr_page + 2, paginator.num_pages) + 1))
# 加上省略标记
if page_range[0] - 1 >= 2:
page_range.insert(0, '...')
if paginator.num_pages - page_range[-1] >= 2:
page_range.append('...')
# 实现显示第一页和最后一页
if page_range[0] != 1:
page_range.insert(0, 1)
if page_range[-1] != paginator.num_pages:
page_range.append(paginator.num_pages)
# 获取某类型博客的数量
# 方法1 原理: 直接引用数据到内存中使用
# blog_types = BlogType.objects.all()
# blog_types_list = []
# for blog_type in blog_types:
# blog_type.blog_count = Blog.objects.filter(blog_type=blog_type).count()
# blog_types_list.append(blog_type)
# 方法2 annotate 拓展查询字段,转化为sql语句,当用到时才引用到内存。
# blog_count是自己写的名,不是特殊值
blog_types_list = BlogType.objects.annotate(blog_count=Count('blog'))
# 获取日期归档应用的博客数量
# 方法一
blog_dates = Blog.objects.dates('create_time', 'month', order="DESC")
blog_date_dict = {}
for blog_date in blog_dates:
blog_count = Blog.objects.filter(create_time__year=blog_date.year,
create_time__month=blog_date.month).count()
blog_date_dict[blog_date] = blog_count
# 方法二 不方便
# blog_dates = Blog.objects.dates('create_time', 'month', order="DESC").annotate(blog_counts=Count('create_time__month'))
context = {'blogs': page_of_blogs.object_list,
'blog_types': blog_types_list, 'page_of_blogs': page_of_blogs,
'page_range': page_range, 'blog_dates': blog_date_dict, }
return context
def blog_list(request):
blog_all_list = Blog.objects.all()
context = get_blog_list_common_data(request, blog_all_list)
return render(request, 'blog/blog_list.html', context)
def blog_detail(request, blog_pk):
blog = get_object_or_404(Blog, pk=blog_pk)
read_cookie_key = read_statisitcs_once_read(request, blog)
context = {}
context['blog'] = blog
# 双下划线添加比较条件。__gt大于。__gte大于等于。.last()返回满足条件的最后一条
context['previous_blog'] = Blog.objects.filter(
create_time__gt=blog.create_time).last()
# 返回下一条博客,__lt 小于,first()取第一个。
# 字符串用 包含:__contains(加 i 忽略大小写);=>不等于
# __startwith, __endwith, 其中之一:__in ; range(范围)
context['next_blog'] = Blog.objects.filter(
create_time__lt=blog.create_time).first()
response = render(request, 'blog/blog_detail.html', context) # 响应
response.set_cookie(read_cookie_key, 'true') # 标记阅读
return response
def blog_with_type(request, blog_type_pk):
blog_type = get_object_or_404(BlogType, pk=blog_type_pk)
blog_all_list = Blog.objects.filter(blog_type=blog_type)
context = get_blog_list_common_data(request, blog_all_list)
context['blog_type'] = blog_type
return render(request, 'blog/blogs_with_type.html', context)
def blogs_with_date(request, year, month):
blog_all_list = Blog.objects.filter(create_time__year=year,
create_time__month=month)
context = get_blog_list_common_data(request, blog_all_list)
context['blogs_with_date'] = '%s年%s月' % (year, month)
return render(request, 'blog/blogs_with_date.html', context)
| [
"951416267@qq.com"
] | 951416267@qq.com |
ce31f2005a4906c1d8266048483b4c20e17a7f1c | 969fed6b9f4c0daa728bda52fea73d94bda6faad | /fakeTempControl/oxford/MercurySCPI.py | d2e94fb25e63fcbc0fd4c62448f863e23a7df451 | [] | no_license | ess-dmsc/essiip-fakesinqhw | 7d4c0cb3e412a510db02f011fb9c20edfbd8a84f | ad65844c99e64692f07e7ea04d624154a92d57cd | refs/heads/master | 2021-01-18T22:50:50.182268 | 2020-10-01T08:39:30 | 2020-10-01T08:39:30 | 87,077,121 | 0 | 0 | null | 2018-12-07T08:43:00 | 2017-04-03T13:28:23 | Python | UTF-8 | Python | false | false | 5,980 | py | # vim: ft=python ts=8 sts=4 sw=4 expandtab autoindent smartindent nocindent
# Fake Mercury Temperature Controller
#
# Author: Douglas Clowes 2014
#
from MercuryDevice import MercuryDevice
import random
import re
import os
import sys
import time
sys.path.insert(0, os.path.realpath(os.path.abspath(os.path.join(os.path.dirname(sys.argv[0]),"../../util"))))
from fopdt import fopdt, fopdt_sink
from pid import PID
class Loop(fopdt):
def __init__(self, the_temp, the_nick):
fopdt.__init__(self, the_temp)
self.setpoint = the_temp
self.sensor = the_temp
# P, I, D
self.pid = PID(0.05, 0.02, 1.2)
self.pid.setPoint(the_temp)
# Value, Kp, Tp, Td, Absolute
self.AddSource(fopdt_sink(0, 2, 13, 10, True))
self.AddSink(fopdt_sink(the_temp, 1, 30, 1, False))
self.power = 0
self.nick = the_nick
self.count = 0
def Setpoint(self, the_sp):
self.setpoint = the_sp
self.pid.setPoint(the_sp)
def doIteration(self):
self.pid_delta = self.pid.update(self.pv)
self.sources[0].value = self.pid_delta
if self.sources[0].value > 100.0:
self.sources[0].value = 100.0
if self.sources[0].value < 0.0:
self.sources[0].value = 0.0
self.count += 1
self.iterate(self.count)
self.sensor = 0.9 * self.sensor + 0.1 * self.setpoint
class MercurySCPI(MercuryDevice):
"""Mercury SCPI temperature controller object - simulates the device"""
def __init__(self):
MercuryDevice.__init__(self)
print MercurySCPI.__name__, "ctor"
self.RANDOM = 0.0
self.IDN = "Simulated Mercury SCPI"
self.CONFIG_LOOPS = [1, 2, 3, 4]
self.CONFIG_SNSRS = [1, 2, 3, 4]
self.Loops = {}
self.Loops[1] = self.Loops['MB0'] = self.Loops['MB1'] = Loop(270, "VTI_STD")
self.Loops[2] = self.Loops['DB1'] = self.Loops['DB6'] = Loop(270, "Sample_1")
self.Loops[3] = self.Loops['DB2'] = self.Loops['DB7'] = Loop(270, "Sample_2")
self.Loops[4] = self.Loops['DB3'] = self.Loops['DB8'] = Loop(270, "VTI")
self.valve_open = 0.0
self.hlev = 92.0
self.nlev = 87.6
self.reset_powerup()
def doCommand(self, command, params):
print MercurySCPI.__name__, "Command:", command, params
return MercuryDevice.doCommand(self, command, params)
def doQuery(self, command, params):
print MercurySCPI.__name__, "Query:", command, params
return MercuryDevice.doQuery(self, command, params)
def reset_powerup(self):
print MercurySCPI.__name__, "reset_powerup"
self.LAST_ITERATION = 0
def doIteration(self):
delta_time = time.time() - self.LAST_ITERATION
if delta_time < 1:
return
#print "DoIteration:", delta_time
self.LAST_ITERATION = time.time()
for idx in self.CONFIG_LOOPS:
self.Loops[idx].doIteration()
def doCommandSET(self, cmd, args):
if args[0] != "DEV":
return
key = args[1].split(".")[0]
if key == "DB4":
# Valve
self.valve_open = float(args[5])
self.write("STAT:SET:" + ":".join(args) + ":VALID")
return
if key in self.Loops:
if args[4] == "TSET":
self.Loops[key].Setpoint(float(args[5]))
self.write("STAT:SET:" + ":".join(args) + ":VALID")
return
self.write("STAT:SET:" + ":".join(args) + ":INVALID")
def doQueryREAD(self, cmd, args):
if args[0] != "DEV":
return
key = args[1].split(".")[0]
if key == "DB4":
# Valve
self.write("STAT:DEV:DB4.G1:AUX:SIG:OPEN:%7.4f%%" % self.valve_open)
return
if key == "DB5":
# Level
if args[4] == "HEL":
self.write("STAT:DEV:DB5.L1:LVL:SIG:HEL:LEV:%7.4f%%" % self.hlev)
return
if args[4] == "NIT":
self.write("STAT:DEV:DB5.L1:LVL:SIG:NIT:LEV:%7.4f%%" % self.nlev)
return
return
if key in self.Loops:
if args[3] == "NICK":
self.write("STAT:DEV:"+args[1]+":TEMP:NICK:%s" % self.Loops[key].nick)
return
if args[4] == "TSET":
self.write("STAT:DEV:"+args[1]+":TEMP:LOOP:TSET:%g" % self.Loops[key].setpoint)
return
if args[4] == "TEMP":
self.write("STAT:DEV:"+args[1]+":TEMP:SIG:TEMP:%7.4fK" % self.Loops[key].sensor)
return
if args[4] == "POWR":
self.write("STAT:DEV:"+args[1]+":HTR:SIG:POWR:%.4fW" % self.Loops[key].power)
return
self.write("STAT:" + ":".join(args) + ":INVALID")
print "TODO implement Query: \"READ\" in \"" + cmd + ":" + ":".join(args) + "\""
if __name__ == '__main__':
from MercuryProtocol import MercuryProtocol
class TestFactory:
def __init__(self):
print self.__class__.__name__, "ctor"
self.numProtocols = 0
def write(self, data):
print "test write:", data,
def loseConnection(self):
print "test lose connection"
test_factory = TestFactory()
test_device = MercurySCPI()
test_protocol = MercuryProtocol(test_device, "\r\n")
test_protocol.factory = test_factory
test_protocol.transport = test_factory
test_device.protocol = test_protocol
test_device.protocol.connectionMade()
commands = ["READ:DEV:MB1.T1:TEMP:SIG:TEMP",
"READ:DEV:MB1.T1:TEMP:NICK",
"SET:DEV:MB1.T1:TEMP:LOOP:TSET:274",
"READ:DEV:MB1.T1:TEMP:LOOP:TSET",
"READ:DEV:MB0.H1:HTR:SIG:POWR"]
for cmd in commands:
test_device.protocol.dataReceived(cmd)
test_device.protocol.dataReceived(test_protocol.term)
test_device.protocol.connectionLost("Dunno")
| [
"mark.koennecke@psi.ch"
] | mark.koennecke@psi.ch |
95a422e8dee940a9edc01bbbe8a0d875f40c8fe1 | 817588295567c6ea114e5a25abfb9aabc9b6b312 | /planetary_system_stacker/planetary_system_stacker_windows.spec | 6a20795833d229c8aa878d72ad907a502dedc9d1 | [] | no_license | Flashy-GER/PlanetarySystemStacker | 72037bcbfd0bbd184d06c997ccbcac991c60c03f | bae9191746b0456fa97a68a70b52a38750bf8ee0 | refs/heads/master | 2023-02-13T03:46:00.808743 | 2021-01-05T19:19:45 | 2021-01-05T19:19:45 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 2,133 | spec | # -*- mode: python -*-
block_cipher = None
# Integrate astropy as data directory instead of module:
import astropy
astropy_path, = astropy.__path__
a = Analysis(['planetary_system_stacker.py'],
pathex=['D:\\SW-Development\\Python\\PlanetarySystemStacker\\planetary_system_stacker'],
binaries=[('C:\Python35\Lib\site-packages\opencv_ffmpeg342_64.dll', '.'),
('D:\SW-Development\Python\PlanetarySystemStacker\planetary_system_stacker\Binaries\Api-ms-win-core-xstate-l2-1-0.dll', '.'),
('D:\SW-Development\Python\PlanetarySystemStacker\planetary_system_stacker\Binaries\Api-ms-win-crt-private-l1-1-0.dll', '.'),
('C:\Windows\System32\downlevel\API-MS-Win-Eventing-Provider-L1-1-0.dll', '.'),
('D:\SW-Development\Python\PlanetarySystemStacker\planetary_system_stacker\Binaries\\api-ms-win-downlevel-shlwapi-l1-1-0.dll', '.')],
datas=[( 'D:\\SW-Development\\Python\\PlanetarySystemStacker\\Documentation\\Icon\\PSS-Icon-64.ico', '.' ),
( 'D:\\SW-Development\\Python\\PlanetarySystemStacker\\Documentation\\Icon\\PSS-Icon-64.png', '.' ),
(astropy_path, 'astropy')],
hiddenimports=['pywt._extensions._cwt', 'scipy._lib.messagestream', 'shelve', 'csv', 'pkg_resources.py2_warn'],
hookspath=[],
runtime_hooks=[],
excludes=['astropy'],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
pyz = PYZ(a.pure, a.zipped_data,
cipher=block_cipher)
exe = EXE(pyz,
a.scripts,
[],
exclude_binaries=True,
name='planetary_system_stacker',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
console=True ) # To display a console window, change value to True.
coll = COLLECT(exe,
a.binaries,
a.zipfiles,
a.datas,
strip=False,
upx=True,
name='PlanetarySystemStacker')
| [
"rolf6419@gmx.de"
] | rolf6419@gmx.de |
c782987ab7f5eb6736b6b9063fcbb3c8fbb6fa90 | d38a2f807138232165fd665fd74231df942efc8d | /exercises/21_jinja2/conftest.py | 2b59c73af8fd796c19bf8fb37e3f98571a465c85 | [] | no_license | maximacgfx/work | b2537381916fe92c6267302375e49809cf7f327b | 84a3da63b65a9883febd5191ca9d759c43a15bfa | refs/heads/master | 2022-11-22T06:14:21.593468 | 2019-09-04T19:25:53 | 2019-09-04T19:25:53 | 25,587,765 | 0 | 1 | null | 2022-11-15T11:25:46 | 2014-10-22T15:03:24 | Python | UTF-8 | Python | false | false | 260 | py | import re
import yaml
import pytest
def strip_empty_lines(output):
lines = []
for line in output.strip().split('\n'):
line = line.strip()
if line:
lines.append(re.sub(' +', ' ', line.strip()))
return '\n'.join(lines)
| [
"vagrant@stretch.localdomain"
] | vagrant@stretch.localdomain |
7e2280a0a8cc80790caebdbd2dcdd8770668b623 | b8faf65ea23a2d8b119b9522a0aa182e9f51d8b1 | /vmraid/desk/doctype/notification_settings/test_notification_settings.py | ed60aac3c067eff22a0a8bb529d0d61175255e1b | [
"MIT"
] | permissive | vmraid/vmraid | a52868c57b1999a8d648441eb9cd05815204345d | 3c2e2a952003ba7ea2cf13673b9e79e127f4166e | refs/heads/main | 2022-07-29T18:59:28.585133 | 2022-04-22T08:02:52 | 2022-04-22T08:02:52 | 372,473,120 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 169 | py | # Copyright (c) 2021, VMRaid Technologies and Contributors
# See license.txt
# import vmraid
import unittest
class TestNotificationSettings(unittest.TestCase):
pass
| [
"sowrisurya@outlook.com"
] | sowrisurya@outlook.com |
50f230ad7fe45a58dc789e52770f1670d7cca518 | 2ce3ef971a6d3e14db6615aa4da747474d87cc5d | /练习/Python基础/工具组件/时间处理/datetime_test.py | aea34308073615d9f580245e46ef6834e2d5eee7 | [] | no_license | JarvanIV4/pytest_hogwarts | 40604245807a4da5dbec2cb189b57d5f76f5ede3 | 37d4bae23c030480620897583f9f5dd69463a60c | refs/heads/master | 2023-01-07T09:56:33.472233 | 2020-11-10T15:06:13 | 2020-11-10T15:06:13 | 304,325,109 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 747 | py | import datetime
class DatetimeTest:
def start_date(self, current_date, delta_date):
"""
计算执行时间前N天的日期
:param current_date: 执行时间
:param delta_date: 当前日期偏差天数
:return: 返回当前日期前N天的日期
"""
current_date = datetime.datetime.strptime(current_date, "%Y-%m-%d") # 将字符串转换为时间格式
delta = datetime.timedelta(days=delta_date) # 当前日期前29天的日期偏差值
start_date = (current_date + delta).strftime("%Y-%m-%d") # 计算当前日期前N天的日期
return start_date
if __name__ == '__main__':
t = DatetimeTest()
print(t.start_date("2020-02-07", 5)) # 2020-02-12 | [
"2268035948@qq.com"
] | 2268035948@qq.com |
632157ea55bfbdc2a50330d4b79d18c9094b58c7 | d7663e323e2b48ad094e0ab7454ab0bed73aafd1 | /pychzrm course/Django/day_01/code/mywebsite1/mywebsite1/views.py | a0ed194f3f17e5a79bebfa79a6e5dc5d3653c2c6 | [] | no_license | Jack-HFK/hfklswn | f9b775567d5cdbea099ec81e135a86915ab13a90 | f125671a6c07e35f67b49013c492d76c31e3219f | refs/heads/master | 2021-06-19T05:58:54.699104 | 2019-08-09T10:12:22 | 2019-08-09T10:12:22 | 201,442,926 | 7 | 0 | null | 2021-04-20T18:26:03 | 2019-08-09T10:07:20 | HTML | UTF-8 | Python | false | false | 3,682 | py | """
视图处理函数 : request接受请求:代表的浏览器给我们的数据
return 响应内容
一个视图处理函数可以对应多个url路由
一个utl路由只能对应一个视图处理函数
"""
from django.http import HttpResponse
# 视图处理函数
def index_view(request):
html = "欢迎来到主页面"
html += "<a href='/page1'> 第一页 </a>"
html += "<a href='/page2'> 第二页 </a>"
html += "<a href='/page3'> 第三页 </a>"
return HttpResponse(html)
def page1_view(request):
html = "欢迎来到第一个页面"
html += "<a href='http://www.tmooc.cn'> 达内 </a>"
html += "<a href='/page2'> 第二页 </a>"
html += "<a href='/page3'> 第三页 </a>"
return HttpResponse(html)
def page2_view(request):
html = "欢迎来到第二个页面"
html += "<a href='/'> 返回首页 </a>"
html += "<a href='/page1'> 第一页 </a>"
html += "<a href='/page3'> 第三页 </a>"
return HttpResponse(html)
def page3_view(request):
html = "欢迎来到第三个页面"
html += "<a href='/'> 返回首页 </a>"
html += "<a href='/page1'> 第一页 </a>"
html += "<a href='/page2'> 第二页 </a>"
return HttpResponse(html)
# 在视图函数内,可以用正则表达式分组 () 提取参数后用函数位置传参传递给视图函数
def year_view(request,y):
html = "year中的年份是" + y
html += "URL路由字符串" + request.path_info
return HttpResponse(html)
def cal_view(request,a,op,b):
html = "欢迎来到cal页面"
a = int(a)
b = int(b)
if op == "add":
ab = a+b
elif op == "sub":
ab = a - b
elif op == "mul":
ab = a * b
else:
return HttpResponse("不能运算")
return HttpResponse(ab)
def date_viem(request,y,m,d):
""" y,m,d : 年 月 日"""
html = y + "年" + m + "月" + d + "日"
return HttpResponse(html)
# def date_viem(request,**kwargs):
# """ y,m,d : 年 月 日"""
# html = y + "年" + m + "月" + d + "日"
# return HttpResponse(html)
def show_info_view(request):
html = "request.path=" + request.path # path:只代表URL中的路由
if request.method == "GET": #字符串,表示HTTP请求方法,常用值: 'GET' 、 'POST'
html += "<h4>您正在进行GET请求</h4>"
elif request.metchod == "POST":
html += "<h4>您正在进行POST请求</h4>"
html += "<h5> 您的IP地址是" + request.META["REMOTE_ADDR"] #客户端IP地址
html += "<h5> 请求源IP地址是" + request.META['HTTP_REFERER'] #请求源地址
return HttpResponse(html)
def page_view(request):
html = ""
# 字符串,表示 HTTP 请求方法,常用值: 'GET' 、 'POST'
if request.method == "GET":
dic = dict(request.GET) # request.GET获取请求内容
s = str(dic)
html = "GET请求:" + s
get_one = request.GET.get("某个请求值") # request.GET.get获取GET请求内容中具体某一个请求数据
gets = request.GET.getlist("请求列表") # request.GET.getlist 获取GET请求列表:列表中可以有一个或多个请求
elif request.method == "POST":
pass
return HttpResponse(html)
def sum_view(request,):
html = ""
if request.method == "GET":
start = int(request.GET.get("start")) # request.GET.get获取GET请求内容中具体某个请求数据
stop = int(request.GET.get("stop"))
step = int(request.GET.get("step"))
html += str(sum(range(start,stop,step)))
elif request.method == "POST":
html = "没法计算"
return HttpResponse(html)
| [
"88888888@qq.com"
] | 88888888@qq.com |
cf03c0cf829ae23af046854d5a4f1118d9e1b1ef | e2f7c64ea3674033c44fa4488e6479d21c86ce54 | /mkoenig/python/database/wholecellkb/wsgi.py | e9dcdff586b7e2867b033b48f36fe50fe2a43870 | [] | no_license | dagwa/wholecell-metabolism | f87c6105c420ebb83f7bfd19a44cd59df2b60414 | aa0c3c04680f56e0676b034eed92c34fd87b9234 | refs/heads/master | 2021-01-17T13:05:18.679605 | 2016-10-19T08:39:19 | 2016-10-19T08:39:19 | 31,332,881 | 3 | 0 | null | null | null | null | UTF-8 | Python | false | false | 397 | py | """
WSGI config for wholecellkb project.
It exposes the WSGI callable as a module-level variable named ``application``.
For more information on this file, see
https://docs.djangoproject.com/en/1.6/howto/deployment/wsgi/
"""
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "wholecellkb.settings")
from django.core.wsgi import get_wsgi_application
application = get_wsgi_application()
| [
"konigmatt@googlemail.com"
] | konigmatt@googlemail.com |
b81c75bb9187cf61314bd837262eea0add8331fb | ba766731ae8132a14460dc3b92bc73cb951a5612 | /header/lobby.py | 43ec541c23a7b3a0dcb9e9141b6ec254fd12da8b | [] | no_license | Jineapple/aoc-mgz | 566318dc96b8a19dac7a03c450ec112fa9a421a8 | bc263ac3728a714c670d6120b9fae952f60818a2 | refs/heads/master | 2021-01-15T12:25:25.211495 | 2015-05-17T04:27:34 | 2015-05-17T04:27:34 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 615 | py | from construct import *
from aoc.mgz.enums import *
"""Player inputs in the lobby, and several host settings"""
lobby = Struct("lobby",
Array(8, Byte("teams")), # team number selected by each player
Padding(1),
RevealMapEnum(ULInt32("reveal_map")),
Padding(8),
ULInt32("population_limit"), # multiply by 25 for UserPatch 1.4
GameTypeEnum(Byte("game_type")),
Flag("lock_teams"),
ULInt32("num_chat"),
Array(lambda ctx: ctx.num_chat, # pre-game chat messages
Struct("messages",
ULInt32("message_length"),
String("message", lambda ctx: ctx.message_length, padchar = '\x00', trimdir = 'right')
)
)
) | [
"happyleaves.tfr@gmail.com"
] | happyleaves.tfr@gmail.com |
70030042ac847cb5174a253c07fa9f9c635f637f | f87f51ec4d9353bc3836e22ac4a944951f9c45c0 | /.history/HW06_20210719110929.py | 20b3509b7524593d8999e837b41f92d3b9ffb6f9 | [] | no_license | sanjayMamidipaka/cs1301 | deaffee3847519eb85030d1bd82ae11e734bc1b7 | 9ddb66596497382d807673eba96853a17884d67b | refs/heads/main | 2023-06-25T04:52:28.153535 | 2021-07-26T16:42:44 | 2021-07-26T16:42:44 | 389,703,530 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 7,463 | py | """
Georgia Institute of Technology - CS1301
HW06 - Text Files & CSV
Collaboration Statement:
"""
#########################################
"""
Function Name: findCuisine()
Parameters: filename (str), cuisine (str)
Returns: list of restaurants (list)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def findCuisine(filename, cuisine):
file = open(filename,'r')
content = file.readlines()
listOfRestaurants = []
for i in range(len(content)):
if content[i].strip() == cuisine:
listOfRestaurants.append(content[i-1].strip()) #add the name of the restaurant, which is the previous line
file.close()
return listOfRestaurants
"""
Function Name: restaurantFilter()
Parameters: filename (str)
Returns: dictionary that maps cuisine type (str)
to a list of restaurants of the same cuisine type (list)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def restaurantFilter(filename):
dict = {}
file = open(filename,'r')
content = file.readlines()
cuisines = []
for i in range(1,len(content),4):
line = content[i].strip()
if line not in cuisines:
cuisines.append(line)
for i in range(len(cuisines)):
dict[cuisines[i]] = []
for i in range(0,len(content),4):
line = content[i].strip()
lineBelow = content[i+1].strip()
dict[lineBelow].append(line)
return dict
"""
Function Name: createDirectory()
Parameters: filename (str), output filename (str)
Returns: None (NoneType)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def createDirectory(filename, outputFilename):
readFile = open(filename, 'r')
writeFile = open(outputFilename, 'w')
content = readFile.readlines()
fastfood = []
sitdown = []
fastfoodcounter = 1
sitdowncounter = 1
for i in range(2,len(content), 4):
restaurant = content[i-2].strip()
cuisine = content[i-1].strip()
group = content[i].strip()
if group == 'Fast Food':
fastfood.append(restaurant + ' - ' + cuisine)
else:
sitdown.append(restaurant + ' - ' + cuisine)
fastfood = sorted(fastfood)
sitdown = sorted(sitdown)
for i in range(len(fastfood)):
fastfood[i] = str(fastfoodcounter) + '. ' + fastfood[i] + '\n'
fastfoodcounter += 1
for i in range(len(sitdown)):
sitdown[i] = str(sitdowncounter) + '. ' + sitdown[i]
sitdowncounter += 1
writeFile.write('Restaurant Directory' + '\n')
writeFile.write('Fast Food' + '\n')
writeFile.writelines(fastfood)
writeFile.write('Sit-down' + '\n')
for i in range(len(sitdown)):
if i != len(sitdown)-1:
writeFile.write(sitdown[i] + '\n')
else:
writeFile.write(sitdown[i])
"""
Function Name: extraHours()
Parameters: filename (str), hour (int)
Returns: list of (person, extra money) tuples (tuple)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def extraHours(filename, hour):
overtime = []
file = open(filename, 'r')
header = file.readline()
content = file.readlines()
for i in content:
line = i.strip().split(',')
name = line[0]
wage = int(line[2])
hoursWorked = int(line[4])
if hoursWorked > hour:
compensation = (hoursWorked - hour) * wage
overtime.append((name, compensation))
return overtime
"""
Function Name: seniorStaffAverage()
Parameters: filename (str), year (int)
Returns: average age of senior staff members (float)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def seniorStaffAverage(filename, year):
averageAge = 0.0
employeeCount = 0.0
file = open(filename, 'r')
header = file.readline()
content = file.readlines()
for i in content:
line = i.strip().split(',')
age = int(line[1])
yearHired = int(line[3])
if yearHired < year:
averageAge += age
employeeCount += 1
if averageAge == 0 or employeeCount == 0:
return 0
averageAge /= employeeCount
return round(averageAge,2)
"""
Function Name: ageDict()
Parameters: filename (str), list of age ranges represented by strings (list)
Returns: dictionary (dict) that maps each age range (str) to a list of employees (list)
"""
#########################################
########## WRITE FUNCTION HERE ##########
#########################################
def ageDict(filename, ageRangeList):
employeeAgeDictionary = {}
newDict = {}
ageRangesFormatted = []
for i in ageRangeList:
employeeAgeDictionary[i] = []
# print(employeeAgeDictionary)
for i in ageRangeList:
ageRangesFormatted.append(i.split('-'))
# print(ageRangesFormatted)
file = open(filename, 'r')
header = file.readline()
content = file.readlines()
for i in content:
line = i.strip().split(',')
age = int(line[1])
name = line[0]
for j in ageRangesFormatted:
if age >= int(j[0]) and age <= int(j[1]):
employeeAgeDictionary[j[0] + '-' + j[1]].append(name)
for i in employeeAgeDictionary:
if employeeAgeDictionary[i] != []:
newDict[i] = employeeAgeDictionary[i]
return newDict
# print(findCuisine('restaurants.txt', 'Mexican'))
# print(restaurantFilter('restaurants.txt'))
# print(createDirectory('restaurants.txt','directory.txt'))
# print(extraHours('employees.csv', 40))
# print(seniorStaffAverage('employees.csv', 2001))
# rangeList = ["20-29", "30-39"]
# print(ageDict('employees.csv', rangeList))
# print(ageDict('employees.csv', ['0-18', '18-19']))
a_list = ['a', 'b', [2,4]]
b_list = a_list[:]
my_list = b_list
print('a_list', a_list, 'b_list', b_list)
a_list[2].append(4)
print('a_list', a_list, 'b_list', b_list)
a_list[1] = 'c'
print('a_list', a_list, 'b_list', b_list)
b_list[0] = 'z'
print('a_list', a_list, 'b_list', b_list)
array = [[1, 'a'],[0, 'b']]
array.sort()
print(array)
num = 0
tupList = [(8,6,7,5),(3,0,9)]
for x in range(len(tupList)):
if x%2==0:
print(x)
num += 1
tupList[x] = num
print(tupList)
sentence = 'i love doggos !!'
sentence = sentence.split()
newSentence = []
count = 0
for word in sentence:
if count % 2 == 1:
newSentence.append(word)
count += 1
print(newSentence)
mydict = {}
sand = ('pb', 'and', 'jelly')
alist = [1,2,3]
del alist[1]
print(alist)
aList = [1, 2, 3, [4, 5]]
bList = aList
cList = bList[:]
aList.append('hello!')
cList[3] *= 2
del bList[1]
bList[2] = ':)'
print(aList, '\n', bList, '\n', cList)
dict1 = {1:5, 1:9, 1:15}
#print(dict1[1])
#print(('sweet', '', 'treat')+('',))
alist = [6,12]
blist = [1,3]
clist = blist
for i,j in enumerate(alist):
if alist[i] % 3 == 0:
clist.append(j)
alist[i] = ['candy']
alist[i].append('boo')
print(alist, blist)
#print('merry' + 5)
list2 = ['1']
list2[0].append(4)
print(list2)
| [
"sanjay.mamidipaka@gmail.com"
] | sanjay.mamidipaka@gmail.com |
04346790cd9cf5310fb94eba427a9102cf59e99d | 5ed2d0e107e4cdcd8129f418fdc40f1f50267514 | /AAlgorithms/LongestWordInDictionary/test.py | 68b3f9841632adcbba727c63a7beed0329f2636f | [] | no_license | tliu57/Leetcode | 6cdc3caa460a75c804870f6615653f335fc97de1 | c480697d174d33219b513a0b670bc82b17c91ce1 | refs/heads/master | 2020-05-21T03:14:07.399407 | 2018-07-08T18:50:01 | 2018-07-08T18:50:01 | 31,505,035 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 985 | py | class Node(object):
def __init__(self):
self.children = {}
self.end = 0
self.word = ""
class Trie(object):
def __init__(self):
self.root = Node()
def insert(self, word, index):
curr = self.root
for c in word:
if not c in curr.children:
curr.children[c] = Node()
curr = curr.children.get(c)
curr.end = index
curr.word = word
def dfs(self, words):
ans = ""
stack = []
stack.append(self.root)
while stack:
node = stack.pop()
if node.end > 0 or node == self.root:
if node != self.root > 0:
word = words[node.end - 1]
if len(word) > len(ans) or (len(word) == len(ans) and word < ans):
ans = word
for n in node.children.values():
stack.append(n)
return ans
class Solution(object):
def longestWord(self, words):
root = Trie()
index = 1
for word in words:
root.insert(word, index)
index += 1
return root.dfs(words)
sol = Solution()
print sol.longestWord(["w","wo","wor","worl", "world"])
| [
"tliu57@asu.edu"
] | tliu57@asu.edu |
fb82eb83ed7a0670cab22075f2c7c1d27231a585 | 48a647031af30b93b332001544b258a787542c6f | /venv/chapter_20/spider/data_storage.py | f5f27694d9569870052315a462ac75977a203333 | [] | no_license | Adminsys-debug/xdclass_python | 3d3f37f7812336aa79bf9dc0d990658c67156057 | c2e82b750c5337045b07c19a0c9ead5c3752b3a7 | refs/heads/master | 2022-05-20T07:10:33.396655 | 2020-04-18T05:40:48 | 2020-04-18T05:40:48 | 256,659,175 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 418 | py | #!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/4/11 13:17
# @Author : mr.chen
# @File : data_storage
# @Software: PyCharm
# @Email : 794281961@qq.com
from product import Product
# 数据存储器
class DataStorage:
def storage(self, products):
"""
数据存储
:param products:set结构
:return:
"""
for i in products:
print(i)
| [
"a794281961@126.com"
] | a794281961@126.com |
74605f100f294cbdb2fd6b1603fc54e1b2f208bf | 0fccee4c738449f5e0a8f52ea5acabf51db0e910 | /genfragments/EightTeV/VH_TTH/WH_ZH_HToZG_M_145_TuneZ2star_8TeV_pythia6_tauola_cff.py | 4d683cb2a41735d37ed09f293c40900ce5814b99 | [] | no_license | cms-sw/genproductions | f308ffaf3586c19b29853db40e6d662e937940ff | dd3d3a3826343d4f75ec36b4662b6e9ff1f270f4 | refs/heads/master | 2023-08-30T17:26:02.581596 | 2023-08-29T14:53:43 | 2023-08-29T14:53:43 | 11,424,867 | 69 | 987 | null | 2023-09-14T12:41:28 | 2013-07-15T14:18:33 | Python | UTF-8 | Python | false | false | 3,034 | py | import FWCore.ParameterSet.Config as cms
from Configuration.Generator.PythiaUEZ2starSettings_cfi import *
from GeneratorInterface.ExternalDecays.TauolaSettings_cff import *
generator = cms.EDFilter("Pythia6GeneratorFilter",
pythiaPylistVerbosity = cms.untracked.int32(1),
# put here the efficiency of your filter (1. if no filter)
filterEfficiency = cms.untracked.double(1.0),
pythiaHepMCVerbosity = cms.untracked.bool(False),
# put here the cross section of your process (in pb)
crossSection = cms.untracked.double(1.0),
maxEventsToPrint = cms.untracked.int32(1),
comEnergy = cms.double(8000.0),
ExternalDecays = cms.PSet(
Tauola = cms.untracked.PSet(
TauolaPolar,
TauolaDefaultInputCards
),
parameterSets = cms.vstring('Tauola')
),
PythiaParameters = cms.PSet(
pythiaUESettingsBlock,
processParameters = cms.vstring('PMAS(25,1)=145.0 !mass of Higgs',
'MSEL=0 ! user selection for process',
'MSUB(102)=0 !ggH',
'MSUB(123)=0 !ZZ fusion to H',
'MSUB(124)=0 !WW fusion to H',
'MSUB(24)=1 !ZH production',
'MSUB(26)=1 !WH production',
'MSUB(121)=0 !gg to ttH',
'MSUB(122)=0 !qq to ttH',
'MDME(210,1)=0 !Higgs decay into dd',
'MDME(211,1)=0 !Higgs decay into uu',
'MDME(212,1)=0 !Higgs decay into ss',
'MDME(213,1)=0 !Higgs decay into cc',
'MDME(214,1)=0 !Higgs decay into bb',
'MDME(215,1)=0 !Higgs decay into tt',
'MDME(216,1)=0 !Higgs decay into',
'MDME(217,1)=0 !Higgs decay into Higgs decay',
'MDME(218,1)=0 !Higgs decay into e nu e',
'MDME(219,1)=0 !Higgs decay into mu nu mu',
'MDME(220,1)=0 !Higgs decay into tau nu tau',
'MDME(221,1)=0 !Higgs decay into Higgs decay',
'MDME(222,1)=0 !Higgs decay into g g',
'MDME(223,1)=0 !Higgs decay into gam gam',
'MDME(224,1)=1 !Higgs decay into gam Z',
'MDME(225,1)=0 !Higgs decay into Z Z',
'MDME(226,1)=0 !Higgs decay into W W'),
# This is a vector of ParameterSet names to be read, in this order
parameterSets = cms.vstring('pythiaUESettings',
'processParameters')
)
)
configurationMetadata = cms.untracked.PSet(
version = cms.untracked.string('$Revision: 1.1 $'),
name = cms.untracked.string('$Source: /cvs/CMSSW/CMSSW/Configuration/GenProduction/python/EightTeV/WH_ZH_HToZG_M_145_TuneZ2star_8TeV_pythia6_tauola_cff.py,v $'),
annotation = cms.untracked.string('PYTHIA6 WH/ZH, H->Zgamma mH=145GeV with TAUOLA at 8TeV')
)
| [
"sha1-dc1081d72f70055f90623ceb19c685a609c9cac9@cern.ch"
] | sha1-dc1081d72f70055f90623ceb19c685a609c9cac9@cern.ch |
0ddf55572f09ed16988fcd1aa1f47e8401d8b4f8 | fac51719e067ee2a70934e3bffdc98802d6dbb35 | /src/textbook/rosalind_ba6i.py | 3097321406cca35d9f4218a69ee6417dcadcbe36 | [
"MIT"
] | permissive | cowboysmall-comp/rosalind | 37730abdd03e86a2106ef39b39cdbae908f29e6e | 021e4392a8fc946b97bbf86bbb8227b28bb5e462 | refs/heads/master | 2022-03-05T14:30:21.020376 | 2019-11-20T02:03:09 | 2019-11-20T02:03:09 | 29,898,979 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 472 | py | import os
import sys
sys.path.append(os.path.join(os.path.dirname(__file__), '../tools'))
import files
import genetics
def main(argv):
line = files.read_line(argv[0])
edges = [tuple(int(node) for node in edge.split(', ')) for edge in line[1:-1].split('), (')]
genome = genetics.graph_to_genome(edges)
print ''.join('(%s)' % (' '.join('+%s' % p if p > 0 else '%s' % p for p in g)) for g in genome)
if __name__ == "__main__":
main(sys.argv[1:])
| [
"jerry@cowboysmall.com"
] | jerry@cowboysmall.com |
fa43b38cc8c680ff7d76c83a79980ff488fd793b | f0d713996eb095bcdc701f3fab0a8110b8541cbb | /s89T6kpDGf8Pc6mzf_16.py | 0ae192e947c37b17c83cb839b9559d913bf5a661 | [] | no_license | daniel-reich/turbo-robot | feda6c0523bb83ab8954b6d06302bfec5b16ebdf | a7a25c63097674c0a81675eed7e6b763785f1c41 | refs/heads/main | 2023-03-26T01:55:14.210264 | 2021-03-23T16:08:01 | 2021-03-23T16:08:01 | 350,773,815 | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 1,893 | py | """
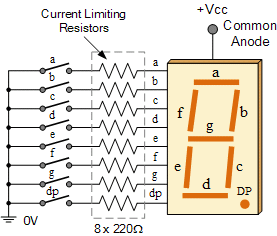
The table below shows which of the segments `a` through `g` are illuminated on
the seven segment display for the digits `0` through `9`. When the number on
the display changes, some of the segments may stay on, some may stay off, and
others change state (on to off, or off to on).
Create a function that accepts a string of digits, and for each transition of
one digit to the next, returns a list of the segments that change state.
Designate the segments that turn on as uppercase and those that turn off as
lowercase. Sort the lists in alphabetical order.
For example:
seven_segment("805") ➞ [["g"], ["b", "e", "G"]]
In the transition from `8` to `0`, the `g` segment turns off. Others are
unchanged. In the transition from `0` to `5`, `b` and `e` turn off and `G`
turns on. Others are unchanged.
Digit| Lit Segments
---|---
0| abcdef
1| bc
2| abdeg
3| abcdg
4| bcfg
5| acdfg
6| acdefg
7| abc
8| abcdefg
9| abcfg
### Examples
seven_segment("02") ➞ [["c", "f", "G"]]
seven_segment("08555") ➞ [["G"], ["b", "e"], [], []]
# Empty lists designate no change.
seven_segment("321") ➞ [["c", "E"], ["a", "C", "d", "e", "g"]]
seven_segment("123") ➞ [["A", "c", "D", "E", "G"], ["C", "e"]]
seven_segment("3") ➞ []
seven_segment("33") ➞ [[]]
### Notes
N/A
"""
def seven_segment(txt):
guide = {'0':'abcdef','1':'bc','2':'abdeg','3':'abcdg','4':'bcfg','5':'acdfg',
'6':'acdefg','7':'abc','8':'abcdefg','9':'abcfg'}
changes, temp = [], []
for i in range(1,len(txt)):
for j in 'abcdefg':
if j in guide[txt[i]] and j not in guide[txt[i-1]]:
temp.append(j.upper())
elif j in guide[txt[i-1]] and j not in guide[txt[i]]:
temp.append(j)
changes.append(temp)
temp = []
return changes
| [
"daniel.reich@danielreichs-MacBook-Pro.local"
] | daniel.reich@danielreichs-MacBook-Pro.local |
18b7335146eec47a871a0deced551625885c4dcb | d0f11aa36b8c594a09aa06ff15080d508e2f294c | /leecode/1-500/301-400/391-完美矩形.py | d16f82be1881abf68bae10af5492ab41a8008a61 | [] | no_license | saycmily/vtk-and-python | 153c1fe9953fce685903f938e174d3719eada0f5 | 5045d7c44a5af5c16df5a3b72c157e9a2928a563 | refs/heads/master | 2023-01-28T14:02:59.970115 | 2021-04-28T09:03:32 | 2021-04-28T09:03:32 | 161,468,316 | 1 | 1 | null | 2023-01-12T05:59:39 | 2018-12-12T10:00:08 | Python | UTF-8 | Python | false | false | 1,067 | py | class Solution:
def isRectangleCover(self, rectangles: list[list[int]]) -> bool:
# 保存所有矩形的四个点
lookup = set()
# 最大矩形的 左下角 右上角
x1 = float("inf")
y1 = float("inf")
x2 = float("-inf")
y2 = float("-inf")
area = 0
for x, y, s, t in rectangles:
x1 = min(x1, x)
y1 = min(y1, y)
x2 = max(x2, s)
y2 = max(y2, t)
area += (t - y) * (s - x)
# 每个矩形的四个点
for item in [(x, y), (x, t), (s, y), (s, t)]:
if item not in lookup:
lookup.add(item)
else:
lookup.remove(item)
# 只剩下四个点并且是最大矩形的左下角和右上角
if len(lookup) != 4 or \
(x1, y1) not in lookup or (x1, y2) not in lookup or (x2, y1) not in lookup or (x2, y2) not in lookup:
return False
# 面积是否满足
return (x2 - x1) * (y2 - y1) == area
| [
"1786386686@qq.com"
] | 1786386686@qq.com |
81c6fedb138c99e3a0488312702050b36f603ddb | 5439a18b31ac213b16306c9eeacadadfc38cdfb8 | /examples/base_demo.py | bf3e2a354aeb01de311246c14f74ca03912f415e | [
"Apache-2.0"
] | permissive | DaoCalendar/text2vec | 459767e49295c17838179264516e3aa7873ecd11 | c5822a66dfb36623079196d0d0a5f717a829715a | refs/heads/master | 2022-12-30T12:30:13.658052 | 2020-10-22T04:08:06 | 2020-10-22T04:08:06 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 726 | py | # -*- coding: utf-8 -*-
"""
@author:XuMing<xuming624@qq.com>
@description:
"""
import numpy as np
import text2vec
text2vec.set_log_level('DEBUG')
char = '我'
result = text2vec.encode(char)
print(type(result))
print(char, result)
word = '如何'
print(word, text2vec.encode(word))
a = '如何更换花呗绑定银行卡'
emb = text2vec.encode(a)
print(a, emb)
b = ['我',
'如何',
'如何更换花呗绑定银行卡',
'如何更换花呗绑定银行卡,如何更换花呗绑定银行卡。如何更换花呗绑定银行卡?。。。这个,如何更换花呗绑定银行卡!']
result = []
for i in b:
r = text2vec.encode(i)
result.append(r)
print(b, result)
print(np.array(result).shape)
| [
"xuming624@qq.com"
] | xuming624@qq.com |
23754283199886f836e1f45d13b736c23b777186 | a37b756e34fc39c1237fc68997dbef77df9fa6fc | /keras/keras34-44/keras44_8_cifar10_Conv1D.py | ee930cb705b6fa2be595a7c93d86b5b8f8520fae | [] | no_license | jvd2n/ai-study | e20e38493ad295940a3201fc0cc8061ca9052607 | a82f7c6d89db532f881c76b553b5ab3eea0bdd59 | refs/heads/main | 2023-08-06T03:24:39.182686 | 2021-10-06T14:41:01 | 2021-10-06T14:41:01 | null | 0 | 0 | null | null | null | null | UTF-8 | Python | false | false | 3,032 | py | import time
from icecream import ic
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import cifar10
from keras.utils import np_utils
#1. Data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
ic('********* raw data **********')
ic(x_train.shape, x_test.shape)
ic(y_train.shape, y_test.shape)
# Data preprocessing
x_train = x_train.reshape(x_train.shape[0], x_train.shape[1] * x_train.shape[2] * x_train.shape[3])
x_test = x_test.reshape(x_test.shape[0], x_test.shape[1] * x_test.shape[2] * x_test.shape[3])
y_train = y_train.reshape(-1,1)
y_test = y_test.reshape(-1,1)
ic('********* 1st reshape **********')
ic(x_train.shape, x_test.shape)
ic(y_train.shape, y_test.shape)
from sklearn.preprocessing import StandardScaler, MinMaxScaler, MaxAbsScaler, RobustScaler, QuantileTransformer, PowerTransformer
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
ic('********* Scaling **********')
ic(x_train.shape, x_test.shape)
x_train = x_train.reshape(-1, 32 * 32, 3)
x_test = x_test.reshape(-1, 32 * 32, 3)
ic('********* 2nd reshape **********')
ic(x_train.shape, x_test.shape)
from sklearn.preprocessing import OneHotEncoder
oneEnc = OneHotEncoder()
y_train = oneEnc.fit_transform(y_train).toarray()
y_test = oneEnc.transform(y_test).toarray()
ic('********** OneHotEnc **********')
ic(y_train.shape, y_test.shape)
#2. Model
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Input, Conv1D, Flatten, Dropout, GlobalAveragePooling1D, MaxPooling1D
model = Sequential()
model.add(Conv1D(filters=32, kernel_size=2, padding='same', activation='relu', input_shape=(32 * 32, 3)))
model.add(Dropout(0.2))
model.add(Conv1D(32, 2, padding='same', activation='relu'))
model.add(MaxPooling1D())
model.add(Conv1D(64, 2, padding='same', activation='relu'))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(10, activation='softmax'))
#3 Compile, Train
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
from tensorflow.keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss', patience=10, mode='min', verbose=1)
start_time = time.time()
model.fit(x_train, y_train, epochs=10, batch_size=512, verbose=2,
validation_split=0.15, callbacks=[es])
duration_time = time.time() - start_time
#4 Evaluate
loss = model.evaluate(x_test, y_test) # evaluate -> return loss, metrics
ic(duration_time)
ic(loss[0])
ic(loss[1])
'''
CNN
loss: 0.05057989060878754
accuracy: 0.9922999739646912
DNN
loss: 0.17536625266075134
accuracy: 0.9753999710083008
DNN + GAP
loss: 1.7715743780136108
accuracy: 0.35740000009536743
LSTM
ic| duration_time: 3403.9552216529846
loss: 2.045886754989624
accuracy: 0.26010000705718994
StandardScaler Conv1D
ic| duration_time: 317.79892349243164
ic| loss[0]: 1.2282058000564575
ic| loss[1]: 0.585099995136261
'''
| [
"juhnmayer@gmail.com"
] | juhnmayer@gmail.com |
5343dfd6363f61f125f0bb08022f46540282dba2 | f6e83bc298b24bfec278683341b2629388b22e6c | /sonic_cli_gen/main.py | bfcd301aedea983579ed265c5c2cdd1c57149398 | [
"LicenseRef-scancode-generic-cla",
"Apache-2.0"
] | permissive | noaOrMlnx/sonic-utilities | 8d8ee86a9c258b4a5f37af69359ce100c29ad99c | 9881f3edaa136233456408190367a09e53386376 | refs/heads/master | 2022-08-17T23:15:57.577454 | 2022-05-18T21:49:32 | 2022-05-18T21:49:32 | 225,886,772 | 1 | 0 | NOASSERTION | 2022-07-19T08:49:40 | 2019-12-04T14:31:32 | Python | UTF-8 | Python | false | false | 1,385 | py | #!/usr/bin/env python
import sys
import click
import logging
from sonic_cli_gen.generator import CliGenerator
logger = logging.getLogger('sonic-cli-gen')
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
@click.group()
@click.pass_context
def cli(ctx):
""" SONiC CLI Auto-generator tool.\r
Generate click CLI plugin for 'config' or 'show' CLI groups.\r
CLI plugin will be generated from the YANG model, which should be in:\r\n
/usr/local/yang-models/ \n
Generated CLI plugin will be placed in: \r\n
/usr/local/lib/python3.7/dist-packages/<CLI group>/plugins/auto/
"""
context = {
'gen': CliGenerator(logger)
}
ctx.obj = context
@cli.command()
@click.argument('cli_group', type=click.Choice(['config', 'show']))
@click.argument('yang_model_name', type=click.STRING)
@click.pass_context
def generate(ctx, cli_group, yang_model_name):
""" Generate click CLI plugin. """
ctx.obj['gen'].generate_cli_plugin(cli_group, yang_model_name)
@cli.command()
@click.argument('cli_group', type=click.Choice(['config', 'show']))
@click.argument('yang_model_name', type=click.STRING)
@click.pass_context
def remove(ctx, cli_group, yang_model_name):
""" Remove generated click CLI plugin from. """
ctx.obj['gen'].remove_cli_plugin(cli_group, yang_model_name)
if __name__ == '__main__':
cli()
| [
"noreply@github.com"
] | noaOrMlnx.noreply@github.com |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.