
status stringclasses 1
value | repo_name stringclasses 31
values | repo_url stringclasses 31
values | issue_id int64 1 104k | title stringlengths 4 233 | body stringlengths 0 186k ⌀ | issue_url stringlengths 38 56 | pull_url stringlengths 37 54 | before_fix_sha stringlengths 40 40 | after_fix_sha stringlengths 40 40 | report_datetime timestamp[us, tz=UTC] | language stringclasses 5
values | commit_datetime timestamp[us, tz=UTC] | updated_file stringlengths 7 188 | chunk_content stringlengths 1 1.03M |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54 | python | 2023-01-22T00:08:14 | langchain/vectorstores/faiss.py | """Wrapper around FAISS vector database."""
from __future__ import annotations
import uuid
from typing import Any, Callable, Dict, Iterable, List, Optional, Tuple
import numpy as np
from langchain.docstore.base import AddableMixin, Docstore
from langchain.docstore.document import Document
from langchain.docstore.in_mem... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54 | python | 2023-01-22T00:08:14 | langchain/vectorstores/faiss.py | """Wrapper around FAISS vector database.
To use, you should have the ``faiss`` python package installed.
Example:
.. code-block:: python
from langchain import FAISS
faiss = FAISS(embedding_function, index, docstore)
"""
def __init__(
self,
embedding_functi... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54 | python | 2023-01-22T00:08:14 | langchain/vectorstores/faiss.py | self, texts: Iterable[str], metadatas: Optional[List[dict]] = None
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54 | python | 2023-01-22T00:08:14 | langchain/vectorstores/faiss.py | ]
self.docstore.add({_id: doc for _, _id, doc in full_info})
index_to_id = {index: _id for index, _id, _ in full_info}
self.index_to_docstore_id.update(index_to_id)
return [_id for _, _id, _ in full_info]
def similarity_search_with_score(
self, query: str, k: int = 4... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54 | python | 2023-01-22T00:08:14 | langchain/vectorstores/faiss.py | self, query: str, k: int = 4, **kwargs: Any
) -> List[Document]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query.... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54 | python | 2023-01-22T00:08:14 | langchain/vectorstores/faiss.py | self, query: str, k: int = 4, fetch_k: int = 20
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
query: Text to look up documents s... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54 | python | 2023-01-22T00:08:14 | langchain/vectorstores/faiss.py | cls,
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> FAISS:
"""Construct FAISS wrapper from raw documents.
This is a user friendly interface that:
1. Embeds documents.
2. Creates an in memory... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54 | python | 2023-01-22T00:08:14 | langchain/vectorstores/faiss.py | 3. Initializes the FAISS database
This is intended to be a quick way to get started.
Example:
.. code-block:: python
from langchain import FAISS
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
f... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54 | python | 2023-01-22T00:08:14 | tests/integration_tests/vectorstores/test_faiss.py | """Test FAISS functionality."""
from typing import List
import pytest
from langchain.docstore.document import Document
from langchain.docstore.in_memory import InMemoryDocstore
from langchain.docstore.wikipedia import Wikipedia
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.faiss import FA... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54 | python | 2023-01-22T00:08:14 | tests/integration_tests/vectorstores/test_faiss.py | """Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
index_to_id = docsearch.index_to_docstore_id
expected_docstore = InMemoryDocstore(
{
index_to_id[0]: Document(page_content="foo"),
index_to_i... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54 | python | 2023-01-22T00:08:14 | tests/integration_tests/vectorstores/test_faiss.py | """Test what happens when document is not found."""
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
docsearch.docstore = InMemoryDocstore({})
with pytest.raises(ValueError):
docsearch.similarity_search("foo")
def test_faiss_add_texts() -> None:
"""Tes... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 906 | Error in Pinecone batch selection logic | Current implementation of pinecone vec db finds the batches using:
```
# set end position of batch
i_end = min(i + batch_size, len(texts))
```
[link](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/pinecone.py#L199)
But the following lines then go on to use a mix of `[i : i + batch_s... | https://github.com/langchain-ai/langchain/issues/906 | https://github.com/langchain-ai/langchain/pull/907 | 82c080c6e617d4959fb4ee808deeba075f361702 | 3aa53b44dd5f013e35c316d110d340a630b0abd1 | 2023-02-06T07:52:59 | python | 2023-02-06T20:45:56 | langchain/vectorstores/pinecone.py | """Wrapper around Pinecone vector database."""
from __future__ import annotations
import uuid
from typing import Any, Callable, Iterable, List, Optional, Tuple
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.base import VectorStore
class Pine... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 906 | Error in Pinecone batch selection logic | Current implementation of pinecone vec db finds the batches using:
```
# set end position of batch
i_end = min(i + batch_size, len(texts))
```
[link](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/pinecone.py#L199)
But the following lines then go on to use a mix of `[i : i + batch_s... | https://github.com/langchain-ai/langchain/issues/906 | https://github.com/langchain-ai/langchain/pull/907 | 82c080c6e617d4959fb4ee808deeba075f361702 | 3aa53b44dd5f013e35c316d110d340a630b0abd1 | 2023-02-06T07:52:59 | python | 2023-02-06T20:45:56 | langchain/vectorstores/pinecone.py | self,
index: Any,
embedding_function: Callable,
text_key: str,
):
"""Initialize with Pinecone client."""
try:
import pinecone
except ImportError:
raise ValueError(
"Could not import pinecone python package. "
"Pl... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 906 | Error in Pinecone batch selection logic | Current implementation of pinecone vec db finds the batches using:
```
# set end position of batch
i_end = min(i + batch_size, len(texts))
```
[link](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/pinecone.py#L199)
But the following lines then go on to use a mix of `[i : i + batch_s... | https://github.com/langchain-ai/langchain/issues/906 | https://github.com/langchain-ai/langchain/pull/907 | 82c080c6e617d4959fb4ee808deeba075f361702 | 3aa53b44dd5f013e35c316d110d340a630b0abd1 | 2023-02-06T07:52:59 | python | 2023-02-06T20:45:56 | langchain/vectorstores/pinecone.py | self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
namespace: Optional[str] = None,
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to a... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 906 | Error in Pinecone batch selection logic | Current implementation of pinecone vec db finds the batches using:
```
# set end position of batch
i_end = min(i + batch_size, len(texts))
```
[link](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/pinecone.py#L199)
But the following lines then go on to use a mix of `[i : i + batch_s... | https://github.com/langchain-ai/langchain/issues/906 | https://github.com/langchain-ai/langchain/pull/907 | 82c080c6e617d4959fb4ee808deeba075f361702 | 3aa53b44dd5f013e35c316d110d340a630b0abd1 | 2023-02-06T07:52:59 | python | 2023-02-06T20:45:56 | langchain/vectorstores/pinecone.py | self,
query: str,
k: int = 5,
filter: Optional[dict] = None,
namespace: Optional[str] = None,
) -> List[Tuple[Document, float]]:
"""Return pinecone documents most similar to query, along with scores.
Args:
query: Text to look up documents similar to.
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 906 | Error in Pinecone batch selection logic | Current implementation of pinecone vec db finds the batches using:
```
# set end position of batch
i_end = min(i + batch_size, len(texts))
```
[link](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/pinecone.py#L199)
But the following lines then go on to use a mix of `[i : i + batch_s... | https://github.com/langchain-ai/langchain/issues/906 | https://github.com/langchain-ai/langchain/pull/907 | 82c080c6e617d4959fb4ee808deeba075f361702 | 3aa53b44dd5f013e35c316d110d340a630b0abd1 | 2023-02-06T07:52:59 | python | 2023-02-06T20:45:56 | langchain/vectorstores/pinecone.py | self,
query: str,
k: int = 5,
filter: Optional[dict] = None,
namespace: Optional[str] = None,
**kwargs: Any,
) -> List[Document]:
"""Return pinecone documents most similar to query.
Args:
query: Text to look up documents similar to.
k: ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 906 | Error in Pinecone batch selection logic | Current implementation of pinecone vec db finds the batches using:
```
# set end position of batch
i_end = min(i + batch_size, len(texts))
```
[link](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/pinecone.py#L199)
But the following lines then go on to use a mix of `[i : i + batch_s... | https://github.com/langchain-ai/langchain/issues/906 | https://github.com/langchain-ai/langchain/pull/907 | 82c080c6e617d4959fb4ee808deeba075f361702 | 3aa53b44dd5f013e35c316d110d340a630b0abd1 | 2023-02-06T07:52:59 | python | 2023-02-06T20:45:56 | langchain/vectorstores/pinecone.py | return docs
@classmethod
def from_texts(
cls,
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
batch_size: int = 32,
text_key: str = "text",
index_name: Optional[str] = None,
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 906 | Error in Pinecone batch selection logic | Current implementation of pinecone vec db finds the batches using:
```
# set end position of batch
i_end = min(i + batch_size, len(texts))
```
[link](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/pinecone.py#L199)
But the following lines then go on to use a mix of `[i : i + batch_s... | https://github.com/langchain-ai/langchain/issues/906 | https://github.com/langchain-ai/langchain/pull/907 | 82c080c6e617d4959fb4ee808deeba075f361702 | 3aa53b44dd5f013e35c316d110d340a630b0abd1 | 2023-02-06T07:52:59 | python | 2023-02-06T20:45:56 | langchain/vectorstores/pinecone.py | try:
import pinecone
except ImportError:
raise ValueError(
"Could not import pinecone python package. "
"Please install it with `pip install pinecone-client`."
)
_index_name = index_name or str(uuid.uuid4())
indexes = pinecone.l... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 906 | Error in Pinecone batch selection logic | Current implementation of pinecone vec db finds the batches using:
```
# set end position of batch
i_end = min(i + batch_size, len(texts))
```
[link](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/pinecone.py#L199)
But the following lines then go on to use a mix of `[i : i + batch_s... | https://github.com/langchain-ai/langchain/issues/906 | https://github.com/langchain-ai/langchain/pull/907 | 82c080c6e617d4959fb4ee808deeba075f361702 | 3aa53b44dd5f013e35c316d110d340a630b0abd1 | 2023-02-06T07:52:59 | python | 2023-02-06T20:45:56 | langchain/vectorstores/pinecone.py | for j, line in enumerate(lines_batch):
metadata[j][text_key] = line
to_upsert = zip(ids_batch, embeds, metadata)
if index is None:
pinecone.create_index(_index_name, dimension=len(embeds[0]))
index = pinecone.Index(_index_name)
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,087 | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | 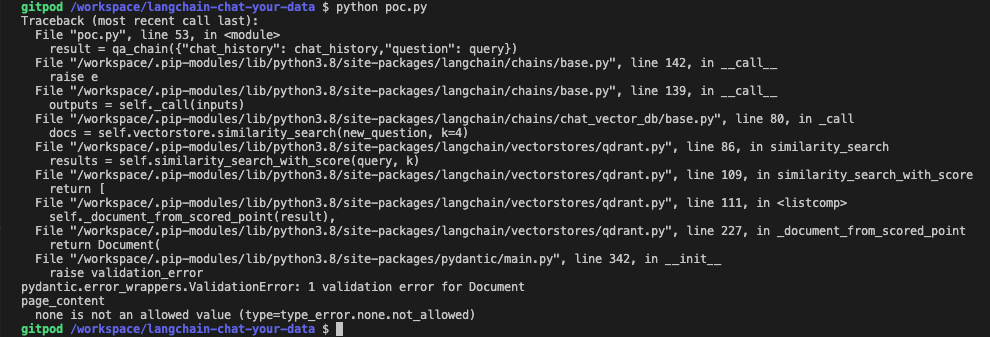
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | https://github.com/langchain-ai/langchain/issues/1087 | https://github.com/langchain-ai/langchain/pull/1088 | 774550548242f44df9b219595cd46d9e238351e5 | 5d11e5da4077ad123bfff9f153f577fb5885af53 | 2023-02-16T13:18:41 | python | 2023-02-16T15:06:02 | langchain/vectorstores/qdrant.py | """Wrapper around Qdrant vector database."""
import uuid
from operator import itemgetter
from typing import Any, Callable, Iterable, List, Optional, Tuple
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.utils import get_from_dict_or_env
from langchain.vec... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,087 | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | 
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | https://github.com/langchain-ai/langchain/issues/1087 | https://github.com/langchain-ai/langchain/pull/1088 | 774550548242f44df9b219595cd46d9e238351e5 | 5d11e5da4077ad123bfff9f153f577fb5885af53 | 2023-02-16T13:18:41 | python | 2023-02-16T15:06:02 | langchain/vectorstores/qdrant.py | """Wrapper around Qdrant vector database.
To use you should have the ``qdrant-client`` package installed.
Example:
.. code-block:: python
from langchain import Qdrant
client = QdrantClient()
collection_name = "MyCollection"
qdrant = Qdrant(client, collecti... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,087 | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | 
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | https://github.com/langchain-ai/langchain/issues/1087 | https://github.com/langchain-ai/langchain/pull/1088 | 774550548242f44df9b219595cd46d9e238351e5 | 5d11e5da4077ad123bfff9f153f577fb5885af53 | 2023-02-16T13:18:41 | python | 2023-02-16T15:06:02 | langchain/vectorstores/qdrant.py | self, texts: Iterable[str], metadatas: Optional[List[dict]] = None
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,087 | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | 
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | https://github.com/langchain-ai/langchain/issues/1087 | https://github.com/langchain-ai/langchain/pull/1088 | 774550548242f44df9b219595cd46d9e238351e5 | 5d11e5da4077ad123bfff9f153f577fb5885af53 | 2023-02-16T13:18:41 | python | 2023-02-16T15:06:02 | langchain/vectorstores/qdrant.py | self, query: str, k: int = 4, **kwargs: Any
) -> List[Document]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query.... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,087 | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | 
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | https://github.com/langchain-ai/langchain/issues/1087 | https://github.com/langchain-ai/langchain/pull/1088 | 774550548242f44df9b219595cd46d9e238351e5 | 5d11e5da4077ad123bfff9f153f577fb5885af53 | 2023-02-16T13:18:41 | python | 2023-02-16T15:06:02 | langchain/vectorstores/qdrant.py | self, query: str, k: int = 4
) -> List[Tuple[Document, float]]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query a... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,087 | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | 
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | https://github.com/langchain-ai/langchain/issues/1087 | https://github.com/langchain-ai/langchain/pull/1088 | 774550548242f44df9b219595cd46d9e238351e5 | 5d11e5da4077ad123bfff9f153f577fb5885af53 | 2023-02-16T13:18:41 | python | 2023-02-16T15:06:02 | langchain/vectorstores/qdrant.py | self, query: str, k: int = 4, fetch_k: int = 20
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
query: Text to look up documents s... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,087 | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | 
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | https://github.com/langchain-ai/langchain/issues/1087 | https://github.com/langchain-ai/langchain/pull/1088 | 774550548242f44df9b219595cd46d9e238351e5 | 5d11e5da4077ad123bfff9f153f577fb5885af53 | 2023-02-16T13:18:41 | python | 2023-02-16T15:06:02 | langchain/vectorstores/qdrant.py | cls,
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> "Qdrant":
"""Construct Qdrant wrapper from raw documents.
This is a user friendly interface that:
1. Embeds documents.
2. Creates an in me... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,087 | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | 
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | https://github.com/langchain-ai/langchain/issues/1087 | https://github.com/langchain-ai/langchain/pull/1088 | 774550548242f44df9b219595cd46d9e238351e5 | 5d11e5da4077ad123bfff9f153f577fb5885af53 | 2023-02-16T13:18:41 | python | 2023-02-16T15:06:02 | langchain/vectorstores/qdrant.py | )
from qdrant_client.http import models as rest
partial_embeddings = embedding.embed_documents(texts[:1])
vector_size = len(partial_embeddings[0])
qdrant_host = get_from_dict_or_env(kwargs, "host", "QDRANT_HOST")
kwargs.pop("host")
collection_name = kwargs.pop("c... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,087 | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | 
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | https://github.com/langchain-ai/langchain/issues/1087 | https://github.com/langchain-ai/langchain/pull/1088 | 774550548242f44df9b219595cd46d9e238351e5 | 5d11e5da4077ad123bfff9f153f577fb5885af53 | 2023-02-16T13:18:41 | python | 2023-02-16T15:06:02 | langchain/vectorstores/qdrant.py | cls, texts: Iterable[str], metadatas: Optional[List[dict]]
) -> List[dict]:
return [
{
"page_content": text,
"metadata": metadatas[i] if metadatas is not None else None,
}
for i, text in enumerate(texts)
]
@classmethod
def _... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,103 | SQLDatabase chain having issue running queries on the database after connecting | Langchain SQLDatabase and using SQL chain is giving me issues in the recent versions. My goal has been this:
- Connect to a sql server (say, Azure SQL server) using mssql+pyodbc driver (also tried mssql+pymssql driver)
`connection_url = URL.create(
"mssql+pyodbc",
query={"odbc_connect": co... | https://github.com/langchain-ai/langchain/issues/1103 | https://github.com/langchain-ai/langchain/pull/1129 | 1ed708391e80a4de83e859b8364a32cc222df9ef | c39ef70aa457dcfcf8ddcf61f89dd69d55307744 | 2023-02-17T04:18:02 | python | 2023-02-17T21:39:44 | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
import ast
from typing import Any, Iterable, List, Optional
from sqlalchemy import create_engine, inspect
from sqlalchemy.engine import Engine
_TEMPLATE_PREFIX = """Table data will be described in the following format:
Table 'table name' has... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,103 | SQLDatabase chain having issue running queries on the database after connecting | Langchain SQLDatabase and using SQL chain is giving me issues in the recent versions. My goal has been this:
- Connect to a sql server (say, Azure SQL server) using mssql+pyodbc driver (also tried mssql+pymssql driver)
`connection_url = URL.create(
"mssql+pyodbc",
query={"odbc_connect": co... | https://github.com/langchain-ai/langchain/issues/1103 | https://github.com/langchain-ai/langchain/pull/1129 | 1ed708391e80a4de83e859b8364a32cc222df9ef | c39ef70aa457dcfcf8ddcf61f89dd69d55307744 | 2023-02-17T04:18:02 | python | 2023-02-17T21:39:44 | langchain/sql_database.py | self._engine = engine
self._schema = schema
if include_tables and ignore_tables:
raise ValueError("Cannot specify both include_tables and ignore_tables")
self._inspector = inspect(self._engine)
self._all_tables = set(self._inspector.get_table_names(schema=schema))
sel... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,103 | SQLDatabase chain having issue running queries on the database after connecting | Langchain SQLDatabase and using SQL chain is giving me issues in the recent versions. My goal has been this:
- Connect to a sql server (say, Azure SQL server) using mssql+pyodbc driver (also tried mssql+pymssql driver)
`connection_url = URL.create(
"mssql+pyodbc",
query={"odbc_connect": co... | https://github.com/langchain-ai/langchain/issues/1103 | https://github.com/langchain-ai/langchain/pull/1129 | 1ed708391e80a4de83e859b8364a32cc222df9ef | c39ef70aa457dcfcf8ddcf61f89dd69d55307744 | 2023-02-17T04:18:02 | python | 2023-02-17T21:39:44 | langchain/sql_database.py | """Get names of tables available."""
if self._include_tables:
return self._include_tables
return self._all_tables - self._ignore_tables
@property
def table_info(self) -> str:
"""Information about all tables in the database."""
return self.get_table_info()
def get_... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,103 | SQLDatabase chain having issue running queries on the database after connecting | Langchain SQLDatabase and using SQL chain is giving me issues in the recent versions. My goal has been this:
- Connect to a sql server (say, Azure SQL server) using mssql+pyodbc driver (also tried mssql+pymssql driver)
`connection_url = URL.create(
"mssql+pyodbc",
query={"odbc_connect": co... | https://github.com/langchain-ai/langchain/issues/1103 | https://github.com/langchain-ai/langchain/pull/1129 | 1ed708391e80a4de83e859b8364a32cc222df9ef | c39ef70aa457dcfcf8ddcf61f89dd69d55307744 | 2023-02-17T04:18:02 | python | 2023-02-17T21:39:44 | langchain/sql_database.py | fetch="one",
)
for column in self._inspector.get_columns(table_name, schema=self._schema):
columns.append(column["name"])
if self._sample_rows_in_table_info:
select_star = (
f"SELECT * FROM '{table_name}' LIMIT "
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,103 | SQLDatabase chain having issue running queries on the database after connecting | Langchain SQLDatabase and using SQL chain is giving me issues in the recent versions. My goal has been this:
- Connect to a sql server (say, Azure SQL server) using mssql+pyodbc driver (also tried mssql+pymssql driver)
`connection_url = URL.create(
"mssql+pyodbc",
query={"odbc_connect": co... | https://github.com/langchain-ai/langchain/issues/1103 | https://github.com/langchain-ai/langchain/pull/1129 | 1ed708391e80a4de83e859b8364a32cc222df9ef | c39ef70aa457dcfcf8ddcf61f89dd69d55307744 | 2023-02-17T04:18:02 | python | 2023-02-17T21:39:44 | langchain/sql_database.py | """Execute a SQL command and return a string representing the results.
If the statement returns rows, a string of the results is returned.
If the statement returns no rows, an empty string is returned.
"""
with self._engine.begin() as connection:
if self._schema is not None:
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | langchain/vectorstores/faiss.py | """Wrapper around FAISS vector database."""
from __future__ import annotations
import pickle
import uuid
from pathlib import Path
from typing import Any, Callable, Dict, Iterable, List, Optional, Tuple
import numpy as np
from langchain.docstore.base import AddableMixin, Docstore
from langchain.docstore.document import ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | langchain/vectorstores/faiss.py | """Wrapper around FAISS vector database.
To use, you should have the ``faiss`` python package installed.
Example:
.. code-block:: python
from langchain import FAISS
faiss = FAISS(embedding_function, index, docstore)
"""
def __init__(
self,
embedding_functi... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | langchain/vectorstores/faiss.py | self, texts: Iterable[str], metadatas: Optional[List[dict]] = None
) -> List[str]:
"""Run more texts through the embeddings and add to the vectorstore.
Args:
texts: Iterable of strings to add to the vectorstore.
metadatas: Optional list of metadatas associated with the texts.... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | langchain/vectorstores/faiss.py | for i, doc in enumerate(documents)
]
self.docstore.add({_id: doc for _, _id, doc in full_info})
index_to_id = {index: _id for index, _id, _ in full_info}
self.index_to_docstore_id.update(index_to_id)
return [_id for _, _id, _ in full_info]
def similarity_search_with_... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | langchain/vectorstores/faiss.py | self, query: str, k: int = 4
) -> List[Tuple[Document, float]]:
"""Return docs most similar to query.
Args:
query: Text to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Documents most similar to the query a... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | langchain/vectorstores/faiss.py | self, embedding: List[float], k: int = 4, **kwargs: Any
) -> List[Document]:
"""Return docs most similar to embedding vector.
Args:
embedding: Embedding to look up documents similar to.
k: Number of Documents to return. Defaults to 4.
Returns:
List of Docu... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | langchain/vectorstores/faiss.py | self, embedding: List[float], k: int = 4, fetch_k: int = 20
) -> List[Document]:
"""Return docs selected using the maximal marginal relevance.
Maximal marginal relevance optimizes for similarity to query AND diversity
among selected documents.
Args:
embedding: Embedding t... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | langchain/vectorstores/faiss.py | _id = self.index_to_docstore_id[i]
if _id == -1:
continue
doc = self.docstore.search(_id)
if not isinstance(doc, Document):
raise ValueError(f"Could not find document for id {_id}, got {doc}")
docs.append(doc)
retur... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | langchain/vectorstores/faiss.py | metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> FAISS:
"""Construct FAISS wrapper from raw documents.
This is a user friendly interface that:
1. Embeds documents.
2. Creates an in memory docstore
3. Initializes the FAISS database
This i... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | langchain/vectorstores/faiss.py | """Save FAISS index, docstore, and index_to_docstore_id to disk.
Args:
folder_path: folder path to save index, docstore,
and index_to_docstore_id to.
"""
path = Path(folder_path)
path.mkdir(exist_ok=True, parents=True)
faiss = dependable_faiss... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | tests/integration_tests/vectorstores/test_faiss.py | """Test FAISS functionality."""
import tempfile
import pytest
from langchain.docstore.document import Document
from langchain.docstore.in_memory import InMemoryDocstore
from langchain.docstore.wikipedia import Wikipedia
from langchain.vectorstores.faiss import FAISS
from tests.integration_tests.vectorstores.fake_embedd... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | tests/integration_tests/vectorstores/test_faiss.py | """Test vector similarity."""
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
index_to_id = docsearch.index_to_docstore_id
expected_docstore = InMemoryDocstore(
{
index_to_id[0]: Document(page_content="foo"),
index_to_id[1]: Document(pa... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | tests/integration_tests/vectorstores/test_faiss.py | """Test end to end construction and search."""
texts = ["foo", "bar", "baz"]
metadatas = [{"page": i} for i in range(len(texts))]
docsearch = FAISS.from_texts(texts, FakeEmbeddings(), metadatas=metadatas)
expected_docstore = InMemoryDocstore(
{
docsearch.index_to_docstore_id[0]: Docu... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29 | python | 2023-02-21T00:39:13 | tests/integration_tests/vectorstores/test_faiss.py | """Test what happens when document is not found."""
texts = ["foo", "bar", "baz"]
docsearch = FAISS.from_texts(texts, FakeEmbeddings())
docsearch.docstore = InMemoryDocstore({})
with pytest.raises(ValueError):
docsearch.similarity_search("foo")
def test_faiss_add_texts() -> None:
"""Tes... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 983 | SQLite Cache memory for async agent runs fails in concurrent calls | I have a slack bot using slack bolt for python to handle various request for certain topics.
Using the SQLite Cache as described in here
https://langchain.readthedocs.io/en/latest/modules/llms/examples/llm_caching.html
Fails when asking the same question mutiple times for the first time with error
> (sqlite3... | https://github.com/langchain-ai/langchain/issues/983 | https://github.com/langchain-ai/langchain/pull/1286 | 81abcae91a3bbd3c90ac9644d232509b3094b54d | 42b892c21be7278689cabdb83101631f286ffc34 | 2023-02-10T19:30:13 | python | 2023-02-27T01:54:43 | langchain/cache.py | """Beta Feature: base interface for cache."""
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Tuple
from sqlalchemy import Column, Integer, String, create_engine, select
from sqlalchemy.engine.base import Engine
from sqlalchemy.orm import Session
try:
from sqlalchemy.orm import dec... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 983 | SQLite Cache memory for async agent runs fails in concurrent calls | I have a slack bot using slack bolt for python to handle various request for certain topics.
Using the SQLite Cache as described in here
https://langchain.readthedocs.io/en/latest/modules/llms/examples/llm_caching.html
Fails when asking the same question mutiple times for the first time with error
> (sqlite3... | https://github.com/langchain-ai/langchain/issues/983 | https://github.com/langchain-ai/langchain/pull/1286 | 81abcae91a3bbd3c90ac9644d232509b3094b54d | 42b892c21be7278689cabdb83101631f286ffc34 | 2023-02-10T19:30:13 | python | 2023-02-27T01:54:43 | langchain/cache.py | """Base interface for cache."""
@abstractmethod
def lookup(self, prompt: str, llm_string: str) -> Optional[RETURN_VAL_TYPE]:
"""Look up based on prompt and llm_string."""
@abstractmethod
def update(self, prompt: str, llm_string: str, return_val: RETURN_VAL_TYPE) -> None:
"""Update cache ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 983 | SQLite Cache memory for async agent runs fails in concurrent calls | I have a slack bot using slack bolt for python to handle various request for certain topics.
Using the SQLite Cache as described in here
https://langchain.readthedocs.io/en/latest/modules/llms/examples/llm_caching.html
Fails when asking the same question mutiple times for the first time with error
> (sqlite3... | https://github.com/langchain-ai/langchain/issues/983 | https://github.com/langchain-ai/langchain/pull/1286 | 81abcae91a3bbd3c90ac9644d232509b3094b54d | 42b892c21be7278689cabdb83101631f286ffc34 | 2023-02-10T19:30:13 | python | 2023-02-27T01:54:43 | langchain/cache.py | """Cache that uses SQAlchemy as a backend."""
def __init__(self, engine: Engine, cache_schema: Any = FullLLMCache):
"""Initialize by creating all tables."""
self.engine = engine
self.cache_schema = cache_schema
self.cache_schema.metadata.create_all(self.engine)
def lookup(self, p... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 983 | SQLite Cache memory for async agent runs fails in concurrent calls | I have a slack bot using slack bolt for python to handle various request for certain topics.
Using the SQLite Cache as described in here
https://langchain.readthedocs.io/en/latest/modules/llms/examples/llm_caching.html
Fails when asking the same question mutiple times for the first time with error
> (sqlite3... | https://github.com/langchain-ai/langchain/issues/983 | https://github.com/langchain-ai/langchain/pull/1286 | 81abcae91a3bbd3c90ac9644d232509b3094b54d | 42b892c21be7278689cabdb83101631f286ffc34 | 2023-02-10T19:30:13 | python | 2023-02-27T01:54:43 | langchain/cache.py | """Cache that uses SQLite as a backend."""
def __init__(self, database_path: str = ".langchain.db"):
"""Initialize by creating the engine and all tables."""
engine = create_engine(f"sqlite:///{database_path}")
super().__init__(engine)
class RedisCache(BaseCache):
"""Cache that uses Redis... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 983 | SQLite Cache memory for async agent runs fails in concurrent calls | I have a slack bot using slack bolt for python to handle various request for certain topics.
Using the SQLite Cache as described in here
https://langchain.readthedocs.io/en/latest/modules/llms/examples/llm_caching.html
Fails when asking the same question mutiple times for the first time with error
> (sqlite3... | https://github.com/langchain-ai/langchain/issues/983 | https://github.com/langchain-ai/langchain/pull/1286 | 81abcae91a3bbd3c90ac9644d232509b3094b54d | 42b892c21be7278689cabdb83101631f286ffc34 | 2023-02-10T19:30:13 | python | 2023-02-27T01:54:43 | langchain/cache.py | """Compute key from prompt, llm_string, and idx."""
return str(hash(prompt + llm_string)) + "_" + str(idx)
def lookup(self, prompt: str, llm_string: str) -> Optional[RETURN_VAL_TYPE]:
"""Look up based on prompt and llm_string."""
idx = 0
generations = []
while self.redis.get(... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,383 | ValueError: unsupported format character 'b' (0x62) at index 52 | python version 3.9.12, langchain version 0.0.98
Using this code
```
db = SQLDatabase.from_uri(DATABSE_URI, include_tables=['tbl_abc'])
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("search for th... | https://github.com/langchain-ai/langchain/issues/1383 | https://github.com/langchain-ai/langchain/pull/1408 | 443992c4d58dcb168a21c0f45afb36b84fbdd46a | 882f7964fb0c5364bce0dcfb73abacd8ece525e4 | 2023-03-02T07:22:39 | python | 2023-03-03T00:03:16 | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
from typing import Any, Iterable, List, Optional
from sqlalchemy import MetaData, create_engine, inspect, select
from sqlalchemy.engine import Engine
from sqlalchemy.exc import ProgrammingError, SQLAlchemyError
from sqlalchemy.schema import ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,383 | ValueError: unsupported format character 'b' (0x62) at index 52 | python version 3.9.12, langchain version 0.0.98
Using this code
```
db = SQLDatabase.from_uri(DATABSE_URI, include_tables=['tbl_abc'])
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("search for th... | https://github.com/langchain-ai/langchain/issues/1383 | https://github.com/langchain-ai/langchain/pull/1408 | 443992c4d58dcb168a21c0f45afb36b84fbdd46a | 882f7964fb0c5364bce0dcfb73abacd8ece525e4 | 2023-03-02T07:22:39 | python | 2023-03-03T00:03:16 | langchain/sql_database.py | self,
engine: Engine,
schema: Optional[str] = None,
metadata: Optional[MetaData] = None,
ignore_tables: Optional[List[str]] = None,
include_tables: Optional[List[str]] = None,
sample_rows_in_table_info: int = 3,
custom_table_info: Optional[dict] = None,
):
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,383 | ValueError: unsupported format character 'b' (0x62) at index 52 | python version 3.9.12, langchain version 0.0.98
Using this code
```
db = SQLDatabase.from_uri(DATABSE_URI, include_tables=['tbl_abc'])
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("search for th... | https://github.com/langchain-ai/langchain/issues/1383 | https://github.com/langchain-ai/langchain/pull/1408 | 443992c4d58dcb168a21c0f45afb36b84fbdd46a | 882f7964fb0c5364bce0dcfb73abacd8ece525e4 | 2023-03-02T07:22:39 | python | 2023-03-03T00:03:16 | langchain/sql_database.py | f"include_tables {missing_tables} not found in database"
)
self._ignore_tables = set(ignore_tables) if ignore_tables else set()
if self._ignore_tables:
missing_tables = self._ignore_tables - self._all_tables
if missing_tables:
raise ValueError(
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,383 | ValueError: unsupported format character 'b' (0x62) at index 52 | python version 3.9.12, langchain version 0.0.98
Using this code
```
db = SQLDatabase.from_uri(DATABSE_URI, include_tables=['tbl_abc'])
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("search for th... | https://github.com/langchain-ai/langchain/issues/1383 | https://github.com/langchain-ai/langchain/pull/1408 | 443992c4d58dcb168a21c0f45afb36b84fbdd46a | 882f7964fb0c5364bce0dcfb73abacd8ece525e4 | 2023-03-02T07:22:39 | python | 2023-03-03T00:03:16 | langchain/sql_database.py | """Construct a SQLAlchemy engine from URI."""
return cls(create_engine(database_uri), **kwargs)
@property
def dialect(self) -> str:
"""Return string representation of dialect to use."""
return self._engine.dialect.name
def get_table_names(self) -> Iterable[str]:
"""Get names ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,383 | ValueError: unsupported format character 'b' (0x62) at index 52 | python version 3.9.12, langchain version 0.0.98
Using this code
```
db = SQLDatabase.from_uri(DATABSE_URI, include_tables=['tbl_abc'])
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("search for th... | https://github.com/langchain-ai/langchain/issues/1383 | https://github.com/langchain-ai/langchain/pull/1408 | 443992c4d58dcb168a21c0f45afb36b84fbdd46a | 882f7964fb0c5364bce0dcfb73abacd8ece525e4 | 2023-03-02T07:22:39 | python | 2023-03-03T00:03:16 | langchain/sql_database.py | """Information about all tables in the database."""
return self.get_table_info()
def get_table_info(self, table_names: Optional[List[str]] = None) -> str:
"""Get information about specified tables.
Follows best practices as specified in: Rajkumar et al, 2022
(https://arxiv.org/abs/22... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,383 | ValueError: unsupported format character 'b' (0x62) at index 52 | python version 3.9.12, langchain version 0.0.98
Using this code
```
db = SQLDatabase.from_uri(DATABSE_URI, include_tables=['tbl_abc'])
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("search for th... | https://github.com/langchain-ai/langchain/issues/1383 | https://github.com/langchain-ai/langchain/pull/1408 | 443992c4d58dcb168a21c0f45afb36b84fbdd46a | 882f7964fb0c5364bce0dcfb73abacd8ece525e4 | 2023-03-02T07:22:39 | python | 2023-03-03T00:03:16 | langchain/sql_database.py | tables.append(self._custom_table_info[table.name])
continue
create_table = str(CreateTable(table).compile(self._engine))
if self._sample_rows_in_table_info:
command = select(table).limit(self._sample_rows_in_table_info)
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,383 | ValueError: unsupported format character 'b' (0x62) at index 52 | python version 3.9.12, langchain version 0.0.98
Using this code
```
db = SQLDatabase.from_uri(DATABSE_URI, include_tables=['tbl_abc'])
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("search for th... | https://github.com/langchain-ai/langchain/issues/1383 | https://github.com/langchain-ai/langchain/pull/1408 | 443992c4d58dcb168a21c0f45afb36b84fbdd46a | 882f7964fb0c5364bce0dcfb73abacd8ece525e4 | 2023-03-02T07:22:39 | python | 2023-03-03T00:03:16 | langchain/sql_database.py | create_table
+ select_star
+ ";\n"
+ columns_str
+ "\n"
+ sample_rows_str
)
else:
tables.append(create_table)
final_str = "\n\n".join(tables)
return final_str
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,383 | ValueError: unsupported format character 'b' (0x62) at index 52 | python version 3.9.12, langchain version 0.0.98
Using this code
```
db = SQLDatabase.from_uri(DATABSE_URI, include_tables=['tbl_abc'])
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("search for th... | https://github.com/langchain-ai/langchain/issues/1383 | https://github.com/langchain-ai/langchain/pull/1408 | 443992c4d58dcb168a21c0f45afb36b84fbdd46a | 882f7964fb0c5364bce0dcfb73abacd8ece525e4 | 2023-03-02T07:22:39 | python | 2023-03-03T00:03:16 | langchain/sql_database.py | """Get information about specified tables.
Follows best practices as specified in: Rajkumar et al, 2022
(https://arxiv.org/abs/2204.00498)
If `sample_rows_in_table_info`, the specified number of sample rows will be
appended to each table description. This can increase performance as
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,489 | LLM making its own observation when a tool should be used | I'm playing with the [CSV agent example](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/csv.html) and notice something strange. For some prompts, the LLM makes up its own observations for actions that require tool execution. For example:
```
agent.run("Summarize the data in one sentence")
... | https://github.com/langchain-ai/langchain/issues/1489 | https://github.com/langchain-ai/langchain/pull/1566 | 30383abb127d7687a82df6593dd74329d00db730 | a9502872069409039c69b41d4857b2c7791c3752 | 2023-03-07T06:41:07 | python | 2023-03-10T00:36:15 | langchain/agents/agent.py | """Chain that takes in an input and produces an action and action input."""
from __future__ import annotations
import json
import logging
from abc import abstractmethod
from pathlib import Path
from typing import Any, Dict, List, Optional, Sequence, Tuple, Union
import yaml
from pydantic import BaseModel, root_validato... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,489 | LLM making its own observation when a tool should be used | I'm playing with the [CSV agent example](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/csv.html) and notice something strange. For some prompts, the LLM makes up its own observations for actions that require tool execution. For example:
```
agent.run("Summarize the data in one sentence")
... | https://github.com/langchain-ai/langchain/issues/1489 | https://github.com/langchain-ai/langchain/pull/1566 | 30383abb127d7687a82df6593dd74329d00db730 | a9502872069409039c69b41d4857b2c7791c3752 | 2023-03-07T06:41:07 | python | 2023-03-10T00:36:15 | langchain/agents/agent.py | """Class responsible for calling the language model and deciding the action.
This is driven by an LLMChain. The prompt in the LLMChain MUST include
a variable called "agent_scratchpad" where the agent can put its
intermediary work.
"""
llm_chain: LLMChain
allowed_tools: Optional[List[str]] = Non... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,489 | LLM making its own observation when a tool should be used | I'm playing with the [CSV agent example](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/csv.html) and notice something strange. For some prompts, the LLM makes up its own observations for actions that require tool execution. For example:
```
agent.run("Summarize the data in one sentence")
... | https://github.com/langchain-ai/langchain/issues/1489 | https://github.com/langchain-ai/langchain/pull/1566 | 30383abb127d7687a82df6593dd74329d00db730 | a9502872069409039c69b41d4857b2c7791c3752 | 2023-03-07T06:41:07 | python | 2023-03-10T00:36:15 | langchain/agents/agent.py | """Extract tool and tool input from llm output."""
def _fix_text(self, text: str) -> str:
"""Fix the text."""
raise ValueError("fix_text not implemented for this agent.")
@property
def _stop(self) -> List[str]:
return [f"\n{self.observation_prefix}", f"\n\t{self.observation_prefix}"]... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,489 | LLM making its own observation when a tool should be used | I'm playing with the [CSV agent example](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/csv.html) and notice something strange. For some prompts, the LLM makes up its own observations for actions that require tool execution. For example:
```
agent.run("Summarize the data in one sentence")
... | https://github.com/langchain-ai/langchain/issues/1489 | https://github.com/langchain-ai/langchain/pull/1566 | 30383abb127d7687a82df6593dd74329d00db730 | a9502872069409039c69b41d4857b2c7791c3752 | 2023-03-07T06:41:07 | python | 2023-03-10T00:36:15 | langchain/agents/agent.py | full_output = await self.llm_chain.apredict(**full_inputs)
parsed_output = self._extract_tool_and_input(full_output)
while parsed_output is None:
full_output = self._fix_text(full_output)
full_inputs["agent_scratchpad"] += full_output
output = await self.llm_chain.apr... |
End of preview. Expand in Data Studio
README.md exists but content is empty.
- Downloads last month
- 5