
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 48 51 | id int64 600M 3.43B | node_id stringlengths 18 24 | number int64 2 7.78k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at stringdate 2020-04-14 18:18:51 2025-09-18 08:25:34 | updated_at stringdate 2020-04-29 09:23:05 2025-09-22 08:47:53 | closed_at stringlengths 20 20 ⌀ | author_association stringclasses 4
values | type null | active_lock_reason null | draft bool 0
classes | pull_request dict | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 4
values | sub_issues_summary dict | issue_dependencies_summary dict | is_pull_request bool 1
class |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3656/comments | https://api.github.com/repos/huggingface/datasets/issues/3656/events | https://github.com/huggingface/datasets/issues/3656 | 1,120,510,823 | I_kwDODunzps5CyaNn | 3,656 | checksum error subjqa dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/9828683?v=4",
"events_url": "https://api.github.com/users/RensDimmendaal/events{/privacy}",
"followers_url": "https://api.github.com/users/RensDimmendaal/followers",
"following_url": "https://api.github.com/users/RensDimmendaal/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @RensDimmendaal, \r\n\r\nI'm sorry but I can't reproduce your bug:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n ...: ds = load_dataset(\"subjqa\", \"electronics\")\r\nDownloading builder script: 9.15kB [00:00, 4.10MB/s] ... | 2022-02-01T10:53:33Z | 2022-02-10T10:56:59Z | 2022-02-10T10:56:38Z | NONE | null | null | null | null | ## Describe the bug
I get a checksum error when loading the `subjqa` dataset (used in the transformers book).
## Steps to reproduce the bug
```python
from datasets import load_dataset
subjqa = load_dataset("subjqa","electronics")
```
## Expected results
Loading the dataset
## Actual results
```
---... | {
"avatar_url": "https://avatars.githubusercontent.com/u/9828683?v=4",
"events_url": "https://api.github.com/users/RensDimmendaal/events{/privacy}",
"followers_url": "https://api.github.com/users/RensDimmendaal/followers",
"following_url": "https://api.github.com/users/RensDimmendaal/following{/other_user}",
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3656/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3656/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3655/comments | https://api.github.com/repos/huggingface/datasets/issues/3655/events | https://github.com/huggingface/datasets/issues/3655 | 1,119,801,077 | I_kwDODunzps5Cvs71 | 3,655 | Pubmed dataset not reachable | {
"avatar_url": "https://avatars.githubusercontent.com/u/77638579?v=4",
"events_url": "https://api.github.com/users/abhi-mosaic/events{/privacy}",
"followers_url": "https://api.github.com/users/abhi-mosaic/followers",
"following_url": "https://api.github.com/users/abhi-mosaic/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @abhi-mosaic, thanks for reporting.\r\n\r\nI'm looking at it... ",
"also hitting this issue",
"Hey @albertvillanova, sorry to reopen this... I can confirm that on `master` branch the dataset is downloadable now but it is still broken in streaming mode:\r\n\r\n```python\r\n >>> import datasets\r\n >>> pubmed... | 2022-01-31T18:45:47Z | 2022-12-19T19:18:10Z | 2022-02-14T14:15:41Z | CONTRIBUTOR | null | null | null | null | ## Describe the bug
Trying to use the `pubmed` dataset fails to reach / download the source files.
## Steps to reproduce the bug
```python
pubmed_train = datasets.load_dataset('pubmed', split='train')
```
## Expected results
Should begin downloading the pubmed dataset.
## Actual results
```
ConnectionEr... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3655/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3655/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3653/comments | https://api.github.com/repos/huggingface/datasets/issues/3653/events | https://github.com/huggingface/datasets/issues/3653 | 1,119,186,952 | I_kwDODunzps5CtXAI | 3,653 | `to_json` in multiprocessing fashion sometimes deadlock | {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [] | 2022-01-31T09:35:07Z | 2022-01-31T09:35:07Z | null | CONTRIBUTOR | null | null | null | null | ## Describe the bug
`to_json` in multiprocessing fashion sometimes deadlock, instead of raising exceptions. Temporary solution is to see that it deadlocks, and then reduce the number of processes or batch size in order to reduce the memory footprint.
As @lhoestq pointed out, this might be related to https://bugs.... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3653/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3653/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3649/comments | https://api.github.com/repos/huggingface/datasets/issues/3649/events | https://github.com/huggingface/datasets/issues/3649 | 1,117,502,250 | I_kwDODunzps5Cm7sq | 3,649 | Add IGLUE dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "19E633",... | open | false | null | [] | null | [] | 2022-01-28T14:59:41Z | 2022-01-28T15:02:35Z | null | MEMBER | null | null | null | null | ## Adding a Dataset
- **Name:** IGLUE
- **Description:** IGLUE brings together 4 vision-and-language tasks across 20 languages (Twitter [thread](https://twitter.com/ebugliarello/status/1487045497583976455?s=20&t=SB4LZGDhhkUW83ugcX_m5w))
- **Paper:** https://arxiv.org/abs/2201.11732
- **Data:** https://github.com/e-... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3649/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3649/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3645/comments | https://api.github.com/repos/huggingface/datasets/issues/3645/events | https://github.com/huggingface/datasets/issues/3645 | 1,116,541,298 | I_kwDODunzps5CjRFy | 3,645 | Streaming dataset based on dl_manager.iter_archive/iter_files are not reset correctly | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2022-01-27T17:17:41Z | 2022-01-28T16:34:28Z | 2022-01-28T16:34:28Z | MEMBER | null | null | null | null | Hi ! When iterating over a streaming dataset once, it's not reset correctly because of some issues with `dl_manager.iter_archive` and `dl_manager.iter_files`. Indeed they are generator functions (so the iterator that is returned can be exhausted). They should be iterables instead, and be reset if we do a for loop again... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3645/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3645/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3644/comments | https://api.github.com/repos/huggingface/datasets/issues/3644/events | https://github.com/huggingface/datasets/issues/3644 | 1,116,519,670 | I_kwDODunzps5CjLz2 | 3,644 | Add a GROUP BY operator | {
"avatar_url": "https://avatars.githubusercontent.com/u/208336?v=4",
"events_url": "https://api.github.com/users/felix-schneider/events{/privacy}",
"followers_url": "https://api.github.com/users/felix-schneider/followers",
"following_url": "https://api.github.com/users/felix-schneider/following{/other_user}",
... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! At the moment you can use `to_pandas()` to get a pandas DataFrame that supports `group_by` operations (make sure your dataset fits in memory though)\r\n\r\nWe use Arrow as a back-end for `datasets` and it doesn't have native group by (see https://github.com/apache/arrow/issues/2189) unfortunately.\r\n\r\nI ju... | 2022-01-27T16:57:54Z | 2025-01-28T11:39:48Z | null | NONE | null | null | null | null | **Is your feature request related to a problem? Please describe.**
Using batch mapping, we can easily split examples. However, we lack an appropriate option for merging them back together by some key. Consider this example:
```python
# features:
# {
# "example_id": datasets.Value("int32"),
# "text": datas... | null | {
"+1": 8,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 8,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3644/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3644/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3640/comments | https://api.github.com/repos/huggingface/datasets/issues/3640/events | https://github.com/huggingface/datasets/issues/3640 | 1,116,133,769 | I_kwDODunzps5ChtmJ | 3,640 | Issues with custom dataset in Wav2Vec2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/9079808?v=4",
"events_url": "https://api.github.com/users/peregilk/events{/privacy}",
"followers_url": "https://api.github.com/users/peregilk/followers",
"following_url": "https://api.github.com/users/peregilk/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Closed and moved to transformers."
] | 2022-01-27T12:09:05Z | 2022-01-27T12:29:48Z | 2022-01-27T12:29:48Z | NONE | null | null | null | null | We are training Vav2Vec using the run_speech_recognition_ctc_bnb.py-script.
This is working fine with Common Voice, however using our custom dataset and data loader at [NbAiLab/NPSC]( https://huggingface.co/datasets/NbAiLab/NPSC) it crashes after roughly 1 epoch with the following stack trace:
:\r\n```\r\n- ... | 2022-01-27T03:19:03Z | 2024-03-11T13:56:15Z | null | NONE | null | null | null | null | ## Describe the bug
AutoTokenizer hash value got change after datasets.map
## Steps to reproduce the bug
1. trash huggingface datasets cache
2. run the following code:
```python
from transformers import AutoTokenizer, BertTokenizer
from datasets import load_dataset
from datasets.fingerprint import Hasher
tok... | null | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3638/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3638/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3637/comments | https://api.github.com/repos/huggingface/datasets/issues/3637/events | https://github.com/huggingface/datasets/issues/3637 | 1,115,526,438 | I_kwDODunzps5CfZUm | 3,637 | [TypeError: Couldn't cast array of type] Cannot load dataset in v1.18 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @lewtun!\r\n \r\nThis one was tricky to debug. Initially, I tought there is a bug in the recently-added (by @lhoestq ) `cast_array_to_feature` function because `git bisect` points to the https://github.com/huggingface/datasets/commit/6ca96c707502e0689f9b58d94f46d871fa5a3c9c commit. Then, I noticed that the feat... | 2022-01-26T21:38:02Z | 2022-02-09T16:15:53Z | 2022-02-09T16:15:53Z | MEMBER | null | null | null | null | ## Describe the bug
I am trying to load the [`GEM/RiSAWOZ` dataset](https://huggingface.co/datasets/GEM/RiSAWOZ) in `datasets` v1.18.1 and am running into a type error when casting the features. The strange thing is that I can load the dataset with v1.17.0. Note that the error is also present if I install from `master... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3637/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3637/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3634/comments | https://api.github.com/repos/huggingface/datasets/issues/3634/events | https://github.com/huggingface/datasets/issues/3634 | 1,115,133,279 | I_kwDODunzps5Cd5Vf | 3,634 | Dataset.shuffle(seed=None) gives fixed row permutation | {
"avatar_url": "https://avatars.githubusercontent.com/u/18127060?v=4",
"events_url": "https://api.github.com/users/elisno/events{/privacy}",
"followers_url": "https://api.github.com/users/elisno/followers",
"following_url": "https://api.github.com/users/elisno/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"I'm not sure if this is expected behavior.\r\n\r\nAm I supposed to work with a copy of the dataset, i.e. `shuffled_dataset = data.shuffle(seed=None)`?\r\n\r\n```diff\r\nimport datasets\r\n\r\n# Some toy example\r\ndata = datasets.Dataset.from_dict(\r\n {\"feature\": [1, 2, 3, 4, 5], \"label\": [\"a\", \"b\", \"... | 2022-01-26T15:13:08Z | 2022-01-27T18:16:07Z | 2022-01-27T18:16:07Z | NONE | null | null | null | null | ## Describe the bug
Repeated attempts to `shuffle` a dataset without specifying a seed give the same results.
## Steps to reproduce the bug
```python
import datasets
# Some toy example
data = datasets.Dataset.from_dict(
{"feature": [1, 2, 3, 4, 5], "label": ["a", "b", "c", "d", "e"]}
)
# Doesn't work... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3634/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3634/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3632/comments | https://api.github.com/repos/huggingface/datasets/issues/3632/events | https://github.com/huggingface/datasets/issues/3632 | 1,115,027,185 | I_kwDODunzps5Cdfbx | 3,632 | Adding CC-100: Monolingual Datasets from Web Crawl Data (Datasets links are invalid) | {
"avatar_url": "https://avatars.githubusercontent.com/u/55232459?v=4",
"events_url": "https://api.github.com/users/AnzorGozalishvili/events{/privacy}",
"followers_url": "https://api.github.com/users/AnzorGozalishvili/followers",
"following_url": "https://api.github.com/users/AnzorGozalishvili/following{/other_... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @AnzorGozalishvili,\r\n\r\nMaybe their site was temporarily down, but it seems to work fine now.\r\n\r\nCould you please try again and confirm if the problem persists? ",
"Hi @albertvillanova \r\nI checked and it works. \r\nIt seems that it was really temporarily down.\r\nThanks!"
] | 2022-01-26T13:35:37Z | 2022-02-10T06:58:11Z | 2022-02-10T06:58:11Z | CONTRIBUTOR | null | null | null | null | ## Describe the bug
The dataset links are no longer valid for CC-100. It seems that the website which was keeping these files are no longer accessible and therefore this dataset became unusable.
Check out the dataset [homepage](http://data.statmt.org/cc-100/) which isn't accessible.
Also the URLs for dataset file ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3632/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3632/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3631/comments | https://api.github.com/repos/huggingface/datasets/issues/3631/events | https://github.com/huggingface/datasets/issues/3631 | 1,114,833,662 | I_kwDODunzps5CcwL- | 3,631 | Labels conflict when loading a local CSV file. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8571301?v=4",
"events_url": "https://api.github.com/users/pichljan/events{/privacy}",
"followers_url": "https://api.github.com/users/pichljan/followers",
"following_url": "https://api.github.com/users/pichljan/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @pichljan, thanks for reporting.\r\n\r\nThis should be fixed. I'm looking at it. "
] | 2022-01-26T10:00:33Z | 2022-02-11T23:02:31Z | 2022-02-11T23:02:31Z | NONE | null | null | null | null | ## Describe the bug
I am trying to load a local CSV file with a separate file containing label names. It is successfully loaded for the first time, but when I try to load it again, there is a conflict between provided labels and the cached dataset info. Disabling caching globally and/or using `download_mode="force_red... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3631/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3631/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3630/comments | https://api.github.com/repos/huggingface/datasets/issues/3630/events | https://github.com/huggingface/datasets/issues/3630 | 1,114,578,625 | I_kwDODunzps5Cbx7B | 3,630 | DuplicatedKeysError of NewsQA dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/37647985?v=4",
"events_url": "https://api.github.com/users/StevenTang1998/events{/privacy}",
"followers_url": "https://api.github.com/users/StevenTang1998/followers",
"following_url": "https://api.github.com/users/StevenTang1998/following{/other_user}",
... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @StevenTang1998.\r\n\r\nI'm fixing it. "
] | 2022-01-26T03:05:49Z | 2022-02-14T08:37:19Z | 2022-02-14T08:37:19Z | NONE | null | null | null | null | After processing the dataset following official [NewsQA](https://github.com/Maluuba/newsqa), I used datasets to load it:
```
a = load_dataset('newsqa', data_dir='news')
```
and the following error occurred:
```
Using custom data configuration default-data_dir=news
Downloading and preparing dataset newsqa/defaul... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3630/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3630/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3628 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3628/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3628/comments | https://api.github.com/repos/huggingface/datasets/issues/3628/events | https://github.com/huggingface/datasets/issues/3628 | 1,113,930,644 | I_kwDODunzps5CZTuU | 3,628 | Dataset Card Creator drops information for "Additional Information" Section | {
"avatar_url": "https://avatars.githubusercontent.com/u/26013491?v=4",
"events_url": "https://api.github.com/users/dennlinger/events{/privacy}",
"followers_url": "https://api.github.com/users/dennlinger/followers",
"following_url": "https://api.github.com/users/dennlinger/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [] | 2022-01-25T14:06:17Z | 2022-01-25T14:09:01Z | null | NONE | null | null | null | null | First of all, the card creator is a great addition and really helpful for streamlining dataset cards!
## Describe the bug
I encountered an inconvenient bug when entering "Additional Information" in the react app, which drops already entered text when switching to a previous section, and then back again to "Addition... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3628/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3628/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3626/comments | https://api.github.com/repos/huggingface/datasets/issues/3626/events | https://github.com/huggingface/datasets/issues/3626 | 1,113,534,436 | I_kwDODunzps5CXy_k | 3,626 | The Pile cannot connect to host | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2022-01-25T07:43:33Z | 2022-02-14T08:40:58Z | 2022-02-14T08:40:58Z | MEMBER | null | null | null | null | ## Describe the bug
The Pile had issues with their previous host server and have mirrored its content to another server.
The new URL server should be updated.
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3626/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3626/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3625/comments | https://api.github.com/repos/huggingface/datasets/issues/3625/events | https://github.com/huggingface/datasets/issues/3625 | 1,113,017,522 | I_kwDODunzps5CV0yy | 3,625 | Add a metadata field for when source data was produced | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_ur... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"A question to the datasets maintainers: is there a policy about how the set of allowed metadata fields is maintained and expanded?\r\n\r\nMetadata are very important, but defining the standard is always a struggle between allowing exhaustivity without being too complex. Archivists have Dublin Core, open data has h... | 2022-01-24T18:52:39Z | 2022-06-28T13:54:49Z | null | MEMBER | null | null | null | null | **Is your feature request related to a problem? Please describe.**
The current problem is that information about when source data was produced is not easily visible. Though there are a variety of metadata fields available in the dataset viewer, time period information is not included. This feature request suggests mak... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3625/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3625/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3622/comments | https://api.github.com/repos/huggingface/datasets/issues/3622/events | https://github.com/huggingface/datasets/issues/3622 | 1,112,831,661 | I_kwDODunzps5CVHat | 3,622 | Extend support for streaming datasets that use os.path.relpath | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2022-01-24T15:58:23Z | 2022-02-04T14:03:54Z | 2022-02-04T14:03:54Z | MEMBER | null | null | null | null | Extend support for streaming datasets that use `os.path.relpath`.
This feature will also be useful to yield the relative path of audio or image files.
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3622/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3622/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3621/comments | https://api.github.com/repos/huggingface/datasets/issues/3621/events | https://github.com/huggingface/datasets/issues/3621 | 1,112,720,434 | I_kwDODunzps5CUsQy | 3,621 | Consider adding `ipywidgets` as a dependency. | {
"avatar_url": "https://avatars.githubusercontent.com/u/1019791?v=4",
"events_url": "https://api.github.com/users/koaning/events{/privacy}",
"followers_url": "https://api.github.com/users/koaning/followers",
"following_url": "https://api.github.com/users/koaning/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi! We use `tqdm` to display progress bars, so I suggest you open this issue in their repo.",
"It depends on how you use `tqdm`, no? \r\n\r\nDoesn't this library import via; \r\n\r\n```\r\nfrom tqdm.notebook import tqdm\r\n```",
"Hi! Sorry for the late reply. We import `tqdm` as `from tqdm.auto import tqdm`, w... | 2022-01-24T14:27:11Z | 2022-02-24T09:04:36Z | 2022-02-24T09:04:36Z | NONE | null | null | null | null | When I install `datasets` in a fresh virtualenv with jupyterlab I always see this error.
```
ImportError: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
```
It's a bit of a nuisance, because I need to run shut down the jupyterlab ser... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3621/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3621/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3618/comments | https://api.github.com/repos/huggingface/datasets/issues/3618/events | https://github.com/huggingface/datasets/issues/3618 | 1,112,123,365 | I_kwDODunzps5CSafl | 3,618 | TIMIT Dataset not working with GPU | {
"avatar_url": "https://avatars.githubusercontent.com/u/3227869?v=4",
"events_url": "https://api.github.com/users/TheSeamau5/events{/privacy}",
"followers_url": "https://api.github.com/users/TheSeamau5/followers",
"following_url": "https://api.github.com/users/TheSeamau5/following{/other_user}",
"gists_url":... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! I think you should avoid calling `timit_train['audio']`. Indeed by doing so you're **loading all the audio column in memory**. This is problematic in your case because the TIMIT dataset is huge.\r\n\r\nIf you want to access the audio data of some samples, you should do this instead `timit_train[:10][\"train\"... | 2022-01-24T03:26:03Z | 2023-07-25T15:20:20Z | 2023-07-25T15:20:20Z | NONE | null | null | null | null | ## Describe the bug
I am working trying to use the TIMIT dataset in order to fine-tune Wav2Vec2 model and I am unable to load the "audio" column from the dataset when working with a GPU.
I am working on Amazon Sagemaker Studio, on the Python 3 (PyTorch 1.8 Python 3.6 GPU Optimized) environment, with a single ml.g4... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3618/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3618/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3615/comments | https://api.github.com/repos/huggingface/datasets/issues/3615/events | https://github.com/huggingface/datasets/issues/3615 | 1,111,576,876 | I_kwDODunzps5CQVEs | 3,615 | Dataset BnL Historical Newspapers does not work in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"@albertvillanova let me know if there is anything I can do to help with this. I had a quick look at the code again and though I could try the following changes:\r\n- use `download` instead of `download_and_extract`\r\nhttps://github.com/huggingface/datasets/blob/d3d339fb86d378f4cb3c5d1de423315c07a466c6/datasets/bn... | 2022-01-22T14:12:59Z | 2022-02-04T14:05:21Z | 2022-02-04T14:05:21Z | MEMBER | null | null | null | null | ## Describe the bug
When trying to load in streaming mode, it "hangs"...
## Steps to reproduce the bug
```python
ds = load_dataset("bnl_newspapers", split="train", streaming=True)
```
## Expected results
The code should be optimized, so that it works fast in streaming mode.
CC: @davanstrien
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3615/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3613/comments | https://api.github.com/repos/huggingface/datasets/issues/3613/events | https://github.com/huggingface/datasets/issues/3613 | 1,110,684,015 | I_kwDODunzps5CM7Fv | 3,613 | Files not updating in dataset viewer | {
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "http... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"Yes. The jobs queue is full right now, following an upgrade... Back to normality in the next hours hopefully. I'll look at your datasets to be sure the dataset viewer works as expected on them.",
"Should have been fixed now."
] | 2022-01-21T16:47:20Z | 2022-01-22T08:13:13Z | 2022-01-22T08:13:13Z | MEMBER | null | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:**
Some examples:
* https://huggingface.co/datasets/abidlabs/crowdsourced-speech4
* https://huggingface.co/datasets/abidlabs/test-audio-13
*short description of the issue*
It seems that the dataset viewer is reading a cached version of the dataset and... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3613/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3613/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3611/comments | https://api.github.com/repos/huggingface/datasets/issues/3611/events | https://github.com/huggingface/datasets/issues/3611 | 1,110,399,096 | I_kwDODunzps5CL1h4 | 3,611 | Indexing bug after dataset.select() | {
"avatar_url": "https://avatars.githubusercontent.com/u/17096858?v=4",
"events_url": "https://api.github.com/users/kamalkraj/events{/privacy}",
"followers_url": "https://api.github.com/users/kamalkraj/followers",
"following_url": "https://api.github.com/users/kamalkraj/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Hi! Thanks for reporting! I've opened a PR with the fix."
] | 2022-01-21T12:09:30Z | 2022-01-27T18:16:22Z | 2022-01-27T18:16:22Z | NONE | null | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
Dataset indexing is not working as expected after `dataset.select(range(100))`
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
import datasets
task_to_keys = {
"cola": ("sentence", None),
"mnli":... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3611/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3611/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3610/comments | https://api.github.com/repos/huggingface/datasets/issues/3610/events | https://github.com/huggingface/datasets/issues/3610 | 1,109,777,314 | I_kwDODunzps5CJdui | 3,610 | Checksum error when trying to load amazon_review dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.git... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"It is solved now"
] | 2022-01-20T21:20:32Z | 2022-01-21T13:22:31Z | 2022-01-21T13:22:31Z | NONE | null | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
I am getting the issue when trying to load dataset using
```
dataset = load_dataset("amazon_polarity")
```
## Expected results
dataset loaded
## Actual results
```
-------------------------------------... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3610/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3610/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3608/comments | https://api.github.com/repos/huggingface/datasets/issues/3608/events | https://github.com/huggingface/datasets/issues/3608 | 1,109,310,981 | I_kwDODunzps5CHr4F | 3,608 | Add support for continuous metrics (RMSE, MAE) | {
"avatar_url": "https://avatars.githubusercontent.com/u/50770?v=4",
"events_url": "https://api.github.com/users/ck37/events{/privacy}",
"followers_url": "https://api.github.com/users/ck37/followers",
"following_url": "https://api.github.com/users/ck37/following{/other_user}",
"gists_url": "https://api.github... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | null | [] | null | [
"Hey @ck37 \r\n\r\nYou can always use a custom metric as explained [in this guide from HF](https://huggingface.co/docs/datasets/master/loading_metrics.html#using-a-custom-metric-script).\r\n\r\nIf this issue needs to be contributed to (for enhancing the metric API) I think [this link](https://scikit-learn.org/stabl... | 2022-01-20T13:35:36Z | 2022-03-09T17:18:20Z | 2022-03-09T17:18:20Z | NONE | null | null | null | null | **Is your feature request related to a problem? Please describe.**
I am uploading our dataset and models for the "Constructing interval measures" method we've developed, which uses item response theory to convert multiple discrete labels into a continuous spectrum for hate speech. Once we have this outcome our NLP m... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3608/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3608/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3606/comments | https://api.github.com/repos/huggingface/datasets/issues/3606/events | https://github.com/huggingface/datasets/issues/3606 | 1,108,918,701 | I_kwDODunzps5CGMGt | 3,606 | audio column not saved correctly after resampling | {
"avatar_url": "https://avatars.githubusercontent.com/u/24724502?v=4",
"events_url": "https://api.github.com/users/laphang/events{/privacy}",
"followers_url": "https://api.github.com/users/laphang/followers",
"following_url": "https://api.github.com/users/laphang/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! We just released a new version of `datasets` that should fix this.\r\n\r\nI tested resampling and using save/load_from_disk afterwards and it seems to be fixed now",
"Hi @lhoestq, \r\n\r\nJust tested the latest datasets version, and confirming that this is fixed for me. \r\n\r\nThanks!",
"Also, just an FY... | 2022-01-20T06:37:10Z | 2022-01-23T01:41:01Z | 2022-01-23T01:24:14Z | NONE | null | null | null | null | ## Describe the bug
After resampling the audio column, saving with save_to_disk doesn't seem to save with the correct type.
## Steps to reproduce the bug
- load a subset of common voice dataset (48Khz)
- resample audio column to 16Khz
- save with save_to_disk()
- load with load_from_disk()
## Expected resul... | {
"avatar_url": "https://avatars.githubusercontent.com/u/24724502?v=4",
"events_url": "https://api.github.com/users/laphang/events{/privacy}",
"followers_url": "https://api.github.com/users/laphang/followers",
"following_url": "https://api.github.com/users/laphang/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3606/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3606/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3604/comments | https://api.github.com/repos/huggingface/datasets/issues/3604/events | https://github.com/huggingface/datasets/issues/3604 | 1,108,477,316 | I_kwDODunzps5CEgWE | 3,604 | Dataset Viewer not showing Previews for Private Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "http... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "E5583E",
"default": fals... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | null | [
"Sure, it's on the roadmap.",
"Closing in favor of https://github.com/huggingface/datasets-server/issues/39."
] | 2022-01-19T19:29:26Z | 2022-09-26T08:04:43Z | 2022-09-26T08:04:43Z | MEMBER | null | null | null | null | ## Dataset viewer issue for 'abidlabs/test-audio-13'
It seems that the dataset viewer does not show previews for `private` datasets, even for the user who's private dataset it is. See [1] for example. If I change the visibility to public, then it does show, but it would be useful to have the viewer even for private ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3604/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3604/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3599/comments | https://api.github.com/repos/huggingface/datasets/issues/3599/events | https://github.com/huggingface/datasets/issues/3599 | 1,108,111,607 | I_kwDODunzps5CDHD3 | 3,599 | The `add_column()` method does not work if used on dataset sliced with `select()` | {
"avatar_url": "https://avatars.githubusercontent.com/u/59422506?v=4",
"events_url": "https://api.github.com/users/ThGouzias/events{/privacy}",
"followers_url": "https://api.github.com/users/ThGouzias/followers",
"following_url": "https://api.github.com/users/ThGouzias/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"similar #3611 "
] | 2022-01-19T13:36:50Z | 2022-01-28T15:35:57Z | 2022-01-28T15:35:57Z | NONE | null | null | null | null | Hello, I posted this as a question on the forums ([here](https://discuss.huggingface.co/t/add-column-does-not-work-if-used-on-dataset-sliced-with-select/13893)):
I have a dataset with 2000 entries
> dataset = Dataset.from_dict({'colA': list(range(2000))})
and from which I want to extract the first one thousan... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3599/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3599/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3598 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3598/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3598/comments | https://api.github.com/repos/huggingface/datasets/issues/3598/events | https://github.com/huggingface/datasets/issues/3598 | 1,108,107,199 | I_kwDODunzps5CDF-_ | 3,598 | Readme info not being parsed to show on Dataset card page | {
"avatar_url": "https://avatars.githubusercontent.com/u/79796807?v=4",
"events_url": "https://api.github.com/users/davidcanovas/events{/privacy}",
"followers_url": "https://api.github.com/users/davidcanovas/followers",
"following_url": "https://api.github.com/users/davidcanovas/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"i suspect a markdown parsing error, @severo do you want to take a quick look at it when you have some time?",
"# Problem\r\nThe issue seems to coming from the front matter of the README\r\n```---\r\nannotations_creators:\r\n- no-annotation\r\nlanguage_creators:\r\n- machine-generated\r\nlanguages:\r\n- 'ca'\r\n-... | 2022-01-19T13:32:29Z | 2022-01-21T10:20:01Z | 2022-01-21T10:20:01Z | NONE | null | null | null | null | ## Describe the bug
The info contained in the README.md file is not being shown in the dataset main page. Basic info and table of contents are properly formatted in the README.
## Steps to reproduce the bug
# Sample code to reproduce the bug
The README file is this one: https://huggingface.co/datasets/softcatal... | {
"avatar_url": "https://avatars.githubusercontent.com/u/79796807?v=4",
"events_url": "https://api.github.com/users/davidcanovas/events{/privacy}",
"followers_url": "https://api.github.com/users/davidcanovas/followers",
"following_url": "https://api.github.com/users/davidcanovas/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3598/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3598/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3597/comments | https://api.github.com/repos/huggingface/datasets/issues/3597/events | https://github.com/huggingface/datasets/issues/3597 | 1,108,092,864 | I_kwDODunzps5CDCfA | 3,597 | ERROR: File "setup.py" or "setup.cfg" not found. Directory cannot be installed in editable mode: /content | {
"avatar_url": "https://avatars.githubusercontent.com/u/49492030?v=4",
"events_url": "https://api.github.com/users/amitkml/events{/privacy}",
"followers_url": "https://api.github.com/users/amitkml/followers",
"following_url": "https://api.github.com/users/amitkml/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi! The `cd` command in Jupyer/Colab needs to start with `%`, so this should work:\r\n```\r\n!git clone https://github.com/huggingface/datasets.git\r\n%cd datasets\r\n!pip install -e \".[streaming]\"\r\n```",
"thanks @mariosasko i had the same mistake and your solution is what was needed"
] | 2022-01-19T13:19:28Z | 2022-08-05T12:35:51Z | 2022-02-14T08:46:34Z | NONE | null | null | null | null | ## Bug
The install of streaming dataset is giving following error.
## Steps to reproduce the bug
```python
! git clone https://github.com/huggingface/datasets.git
! cd datasets
! pip install -e ".[streaming]"
```
## Actual results
Cloning into 'datasets'...
remote: Enumerating objects: 50816, done.
remot... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3597/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3596/comments | https://api.github.com/repos/huggingface/datasets/issues/3596/events | https://github.com/huggingface/datasets/issues/3596 | 1,107,345,338 | I_kwDODunzps5CAL-6 | 3,596 | Loss of cast `Image` feature on certain dataset method | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_ur... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi! Thanks for reporting! The issue with `cast_column` should be fixed by #3575 and after we merge that PR I'll start working on the `push_to_hub` support for the `Image`/`Audio` feature.",
"> Hi! Thanks for reporting! The issue with `cast_column` should be fixed by #3575 and after we merge that PR I'll start wo... | 2022-01-18T20:44:01Z | 2022-01-21T18:07:28Z | 2022-01-21T18:07:28Z | MEMBER | null | null | null | null | ## Describe the bug
When an a column is cast to an `Image` feature, the cast type appears to be lost during certain operations. I first noticed this when using the `push_to_hub` method on a dataset that contained urls pointing to images which had been cast to an `image`. This also happens when using select on a data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3596/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3596/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3587 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3587/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3587/comments | https://api.github.com/repos/huggingface/datasets/issues/3587/events | https://github.com/huggingface/datasets/issues/3587 | 1,106,719,182 | I_kwDODunzps5B9zHO | 3,587 | No module named 'fsspec.archive' | {
"avatar_url": "https://avatars.githubusercontent.com/u/13246825?v=4",
"events_url": "https://api.github.com/users/shuuchen/events{/privacy}",
"followers_url": "https://api.github.com/users/shuuchen/followers",
"following_url": "https://api.github.com/users/shuuchen/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [] | 2022-01-18T10:17:01Z | 2022-08-11T09:57:54Z | 2022-01-18T10:33:10Z | NONE | null | null | null | null | ## Describe the bug
Cannot import datasets after installation.
## Steps to reproduce the bug
```shell
$ python
Python 3.9.7 (default, Sep 16 2021, 13:09:58)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import datasets
Traceback (most recent... | {
"avatar_url": "https://avatars.githubusercontent.com/u/13246825?v=4",
"events_url": "https://api.github.com/users/shuuchen/events{/privacy}",
"followers_url": "https://api.github.com/users/shuuchen/followers",
"following_url": "https://api.github.com/users/shuuchen/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3587/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3587/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3586/comments | https://api.github.com/repos/huggingface/datasets/issues/3586/events | https://github.com/huggingface/datasets/issues/3586 | 1,106,455,672 | I_kwDODunzps5B8yx4 | 3,586 | Revisit `enable/disable_` toggle function prefix | {
"avatar_url": "https://avatars.githubusercontent.com/u/25360440?v=4",
"events_url": "https://api.github.com/users/jaketae/events{/privacy}",
"followers_url": "https://api.github.com/users/jaketae/followers",
"following_url": "https://api.github.com/users/jaketae/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [] | 2022-01-18T04:09:55Z | 2022-03-14T15:01:08Z | 2022-03-14T15:01:08Z | CONTRIBUTOR | null | null | null | null | As discussed in https://github.com/huggingface/transformers/pull/15167, we should revisit the `enable/disable_` toggle function prefix, potentially in favor of `set_enabled_`. Concretely, this translates to
- De-deprecating `disable_progress_bar()`
- Adding `enable_progress_bar()`
- On the caching side, adding `en... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3586/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3586/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3585/comments | https://api.github.com/repos/huggingface/datasets/issues/3585/events | https://github.com/huggingface/datasets/issues/3585 | 1,105,821,470 | I_kwDODunzps5B6X8e | 3,585 | Datasets streaming + map doesn't work for `Audio` | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "cfd3d7",
"default": true,
"descript... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"This seems related to https://github.com/huggingface/datasets/issues/3505."
] | 2022-01-17T12:55:42Z | 2022-01-20T13:28:00Z | 2022-01-20T13:28:00Z | CONTRIBUTOR | null | null | null | null | ## Describe the bug
When using audio datasets in streaming mode, applying a `map(...)` before iterating leads to an error as the key `array` does not exist anymore.
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "en", streaming=True, split="train")... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3585/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3585/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3584/comments | https://api.github.com/repos/huggingface/datasets/issues/3584/events | https://github.com/huggingface/datasets/issues/3584 | 1,105,231,768 | I_kwDODunzps5B4H-Y | 3,584 | https://huggingface.co/datasets/huggingface/transformers-metadata | {
"avatar_url": "https://avatars.githubusercontent.com/u/37082592?v=4",
"events_url": "https://api.github.com/users/ecankirkic/events{/privacy}",
"followers_url": "https://api.github.com/users/ecankirkic/followers",
"following_url": "https://api.github.com/users/ecankirkic/following{/other_user}",
"gists_url"... | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
},
{
"color": "E5583E",
"default": false,
... | closed | false | null | [] | null | [] | 2022-01-17T00:18:14Z | 2022-02-14T08:51:27Z | 2022-02-14T08:51:27Z | NONE | null | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3584/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3584/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3583/comments | https://api.github.com/repos/huggingface/datasets/issues/3583/events | https://github.com/huggingface/datasets/issues/3583 | 1,105,195,144 | I_kwDODunzps5B3_CI | 3,583 | Add The Medical Segmentation Decathlon Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",... | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/64613009?v=4",
"events_url": "https://api.github.com/users/pri1311/events{/privacy}",
"followers_url": "https://api.github.com/users/pri1311/followers",
"following_url": "https://api.github.com/users/pri1311/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/64613009?v=4",
"events_url": "https://api.github.com/users/pri1311/events{/privacy}",
"followers_url": "https://api.github.com/users/pri1311/followers",
"following_url": "https://api.github.com/users/pri1311/following{/other_user}",
"gists... | null | [
"Hello! I have recently been involved with a medical image segmentation project myself and was going through the `The Medical Segmentation Decathlon Dataset` as well. \r\nI haven't yet had experience adding datasets to this repository yet but would love to get started. Should I take this issue?\r\nIf yes, I've got ... | 2022-01-16T21:42:25Z | 2022-03-18T10:44:42Z | null | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *The Medical Segmentation Decathlon Dataset*
- **Description:** The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data, and small objects.
- **Paper:*... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3583/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3582/comments | https://api.github.com/repos/huggingface/datasets/issues/3582/events | https://github.com/huggingface/datasets/issues/3582 | 1,104,877,303 | I_kwDODunzps5B2xb3 | 3,582 | conll 2003 dataset source url is no longer valid | {
"avatar_url": "https://avatars.githubusercontent.com/u/303900?v=4",
"events_url": "https://api.github.com/users/rcanand/events{/privacy}",
"followers_url": "https://api.github.com/users/rcanand/followers",
"following_url": "https://api.github.com/users/rcanand/following{/other_user}",
"gists_url": "https://... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"descrip... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"I came to open the same issue.",
"Thanks for reporting !\r\n\r\nI pushed a temporary fix on `master` that uses an URL from a previous commit to access the dataset for now, until we have a better solution",
"I changed the URL again to use another host, the fix is available on `master` and we'll probably do a ne... | 2022-01-15T23:04:17Z | 2022-07-20T13:06:40Z | 2022-01-21T16:57:32Z | NONE | null | null | null | null | ## Describe the bug
Loading `conll2003` dataset fails because it was removed (just yesterday 1/14/2022) from the location it is looking for.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("conll2003")
```
## Expected results
The dataset should load.
## Actual r... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 5,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3582/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3582/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3581/comments | https://api.github.com/repos/huggingface/datasets/issues/3581/events | https://github.com/huggingface/datasets/issues/3581 | 1,104,857,822 | I_kwDODunzps5B2sre | 3,581 | Unable to create a dataset from a parquet file in S3 | {
"avatar_url": "https://avatars.githubusercontent.com/u/18012903?v=4",
"events_url": "https://api.github.com/users/regCode/events{/privacy}",
"followers_url": "https://api.github.com/users/regCode/followers",
"following_url": "https://api.github.com/users/regCode/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "a2eeef",
"default": true,
"descript... | open | false | null | [] | null | [
"Hi ! Currently it only works with local paths, file-like objects are not supported yet"
] | 2022-01-15T21:34:16Z | 2022-02-14T08:52:57Z | null | NONE | null | null | null | null | ## Describe the bug
Trying to create a dataset from a parquet file in S3.
## Steps to reproduce the bug
```python
import s3fs
from datasets import Dataset
s3 = s3fs.S3FileSystem(anon=False)
with s3.open(PATH_LTR_TOY_CLEAN_DATASET, 'rb') as s3file:
dataset = Dataset.from_parquet(s3file)
```
## Expe... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3581/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3581/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3580/comments | https://api.github.com/repos/huggingface/datasets/issues/3580/events | https://github.com/huggingface/datasets/issues/3580 | 1,104,663,242 | I_kwDODunzps5B19LK | 3,580 | Bug in wiki bio load | {
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"events_url": "https://api.github.com/users/tuhinjubcse/events{/privacy}",
"followers_url": "https://api.github.com/users/tuhinjubcse/followers",
"following_url": "https://api.github.com/users/tuhinjubcse/following{/other_user}",
"gists_ur... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [
"+1, here's the error I got: \r\n\r\n```\r\n>>> from datasets import load_dataset\r\n>>>\r\n>>> load_dataset(\"wiki_bio\")\r\nDownloading: 7.58kB [00:00, 4.42MB/s]\r\nDownloading: 2.71kB [00:00, 1.30MB/s]\r\nUsing custom data configuration default\r\nDownloading and preparing dataset wiki_bio/default (download: 318... | 2022-01-15T10:04:33Z | 2022-01-31T08:38:09Z | 2022-01-31T08:38:09Z | NONE | null | null | null | null |
wiki_bio is failing to load because of a failing drive link . Can someone fix this ?
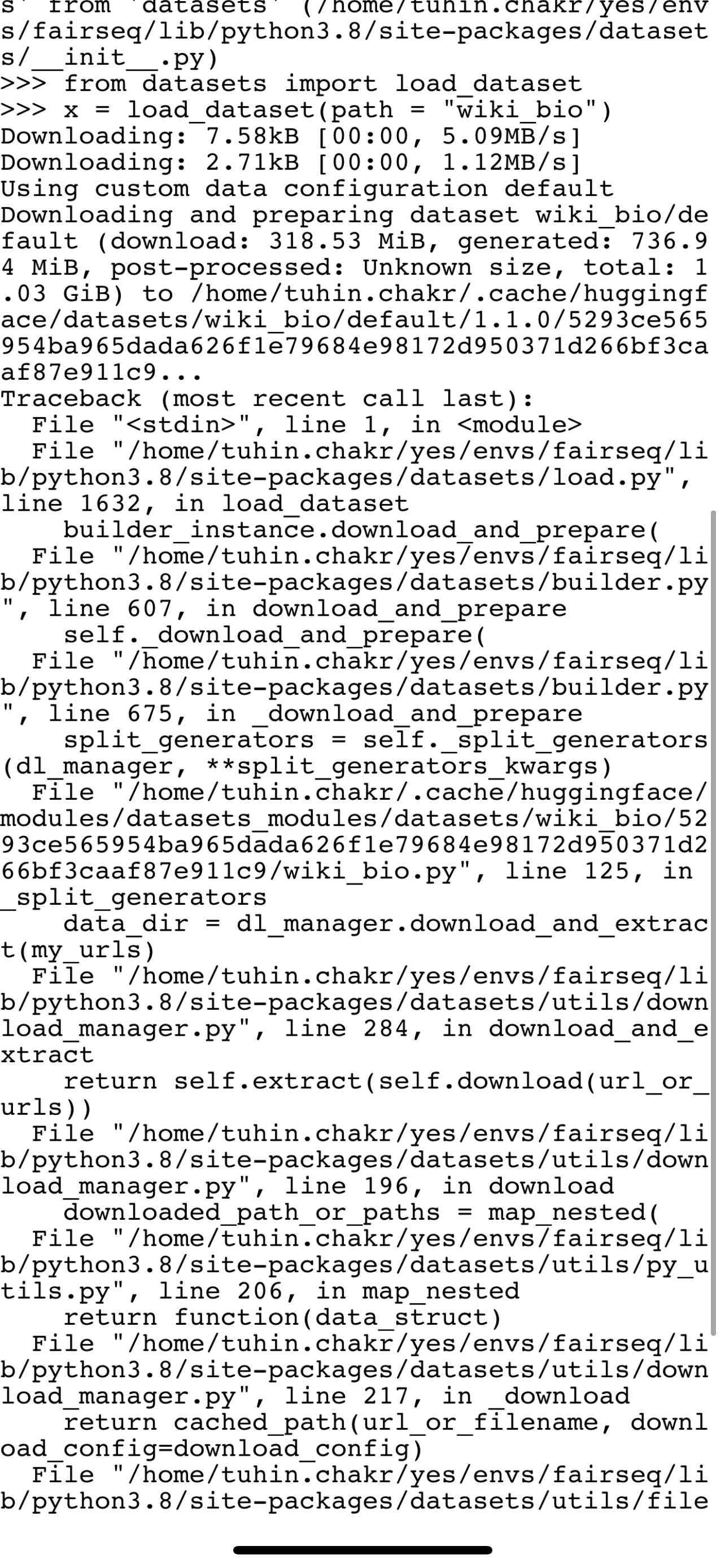

dataset.save_to_disk("normal_save")
# save ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3578/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3578/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3577 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3577/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3577/comments | https://api.github.com/repos/huggingface/datasets/issues/3577/events | https://github.com/huggingface/datasets/issues/3577 | 1,102,598,241 | I_kwDODunzps5BuFBh | 3,577 | Add The Mexican Emotional Speech Database (MESD) | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",... | open | false | null | [] | null | [] | 2022-01-13T23:49:36Z | 2022-01-27T14:14:38Z | null | NONE | null | null | null | null | ## Adding a Dataset
- **Name:** *The Mexican Emotional Speech Database (MESD)*
- **Description:** *Contains 864 voice recordings with six different prosodies: anger, disgust, fear, happiness, neutral, and sadness. Furthermore, three voice categories are included: female adult, male adult, and child. *
- **Paper:** *... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3577/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3577/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3572 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3572/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3572/comments | https://api.github.com/repos/huggingface/datasets/issues/3572/events | https://github.com/huggingface/datasets/issues/3572 | 1,100,634,244 | I_kwDODunzps5BmliE | 3,572 | ConnectionError in IndicGLUE dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/79107194?v=4",
"events_url": "https://api.github.com/users/sahoodib/events{/privacy}",
"followers_url": "https://api.github.com/users/sahoodib/followers",
"following_url": "https://api.github.com/users/sahoodib/following{/other_user}",
"gists_url": "htt... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"@sahoodib, thanks for reporting.\r\n\r\nIndeed, none of the data links appearing in the IndicGLUE website are working, e.g.: https://storage.googleapis.com/ai4bharat-public-indic-nlp-corpora/evaluations/soham-articles.tar.gz\r\n```\r\n<Error>\r\n<Code>UserProjectAccountProblem</Code>\r\n<Message>User project billi... | 2022-01-12T17:59:36Z | 2022-09-15T21:57:34Z | 2022-09-15T21:57:34Z | NONE | null | null | null | null | While I am trying to load IndicGLUE dataset (https://huggingface.co/datasets/indic_glue) it is giving me with the error:
```
ConnectionError: Couldn't reach https://storage.googleapis.com/ai4bharat-public-indic-nlp-corpora/evaluations/wikiann-ner.tar.gz (error 403) | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3572/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3572/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3568 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3568/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3568/comments | https://api.github.com/repos/huggingface/datasets/issues/3568/events | https://github.com/huggingface/datasets/issues/3568 | 1,100,380,631 | I_kwDODunzps5BlnnX | 3,568 | Downloading Hugging Face Medical Dialog Dataset NonMatchingSplitsSizesError | {
"avatar_url": "https://avatars.githubusercontent.com/u/49265757?v=4",
"events_url": "https://api.github.com/users/fabianslife/events{/privacy}",
"followers_url": "https://api.github.com/users/fabianslife/followers",
"following_url": "https://api.github.com/users/fabianslife/following{/other_user}",
"gists_u... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @fabianslife, thanks for reporting.\r\n\r\nI think you were using an old version of `datasets` because this bug was already fixed in version `1.13.0` (13 Oct 2021):\r\n- Fix: 55fd140a63b8f03a0e72985647e498f1fc799d3f\r\n- PR: #3046\r\n- Issue: #2969 \r\n\r\nPlease, feel free to update the library: `pip install -... | 2022-01-12T14:03:44Z | 2022-02-14T09:32:34Z | 2022-02-14T09:32:34Z | NONE | null | null | null | null | I wanted to download the Nedical Dialog Dataset from huggingface, using this github link:
https://github.com/huggingface/datasets/tree/master/datasets/medical_dialog
After downloading the raw datasets from google drive, i unpacked everything and put it in the same folder as the medical_dialog.py which is:
```
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3568/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3568/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3563 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3563/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3563/comments | https://api.github.com/repos/huggingface/datasets/issues/3563/events | https://github.com/huggingface/datasets/issues/3563 | 1,099,070,368 | I_kwDODunzps5Bgnug | 3,563 | Dataset.from_pandas preserves useless index | {
"avatar_url": "https://avatars.githubusercontent.com/u/20703486?v=4",
"events_url": "https://api.github.com/users/Sorrow321/events{/privacy}",
"followers_url": "https://api.github.com/users/Sorrow321/followers",
"following_url": "https://api.github.com/users/Sorrow321/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi! That makes sense. Sure, feel free to open a PR! Just a small suggestion: let's make `preserve_index` a parameter of `Dataset.from_pandas` (which we then pass to `InMemoryTable.from_pandas`) with `None` as a default value to not have this as a breaking change. "
] | 2022-01-11T12:07:07Z | 2022-01-12T16:11:27Z | 2022-01-12T16:11:27Z | CONTRIBUTOR | null | null | null | null | ## Describe the bug
Let's say that you want to create a Dataset object from pandas dataframe. Most likely you will write something like this:
```
import pandas as pd
from datasets import Dataset
df = pd.read_csv('some_dataset.csv')
# Some DataFrame preprocessing code...
dataset = Dataset.from_pandas(df)
`... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3563/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3563/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3561 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3561/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3561/comments | https://api.github.com/repos/huggingface/datasets/issues/3561/events | https://github.com/huggingface/datasets/issues/3561 | 1,098,328,870 | I_kwDODunzps5Bdysm | 3,561 | Cannot load ‘bookcorpusopen’ | {
"avatar_url": "https://avatars.githubusercontent.com/u/54684403?v=4",
"events_url": "https://api.github.com/users/HUIYINXUE/events{/privacy}",
"followers_url": "https://api.github.com/users/HUIYINXUE/followers",
"following_url": "https://api.github.com/users/HUIYINXUE/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"descrip... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"The host of this copy of the dataset (https://the-eye.eu) is down and has been down for a good amount of time ([potentially months](https://www.reddit.com/r/Roms/comments/q82s15/theeye_downdied/))\r\n\r\nFinding this dataset is a little esoteric, as the original authors took down the official BookCorpus dataset so... | 2022-01-10T20:17:18Z | 2022-02-14T09:19:27Z | 2022-02-14T09:18:47Z | NONE | null | null | null | null | ## Describe the bug
Cannot load 'bookcorpusopen'
## Steps to reproduce the bug
```python
dataset = load_dataset('bookcorpusopen')
```
or
```python
dataset = load_dataset('bookcorpusopen',script_version='master')
```
## Actual results
ConnectionError: Couldn't reach https://the-eye.eu/public/AI/pile_pre... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3561/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3561/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3558 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3558/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3558/comments | https://api.github.com/repos/huggingface/datasets/issues/3558/events | https://github.com/huggingface/datasets/issues/3558 | 1,098,025,866 | I_kwDODunzps5BcouK | 3,558 | Integrate Milvus (pymilvus) library | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/83447078?v=4",
"events_url": "https://api.github.com/users/xiaofan-luan/events{/privacy}",
"followers_url": "https://api.github.com/users/xiaofan-luan/followers",
"following_url": "https://api.github.com/users/xiaofan-luan/following{/other_user}",
"gist... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/83447078?v=4",
"events_url": "https://api.github.com/users/xiaofan-luan/events{/privacy}",
"followers_url": "https://api.github.com/users/xiaofan-luan/followers",
"following_url": "https://api.github.com/users/xiaofan-luan/following{/other_use... | null | [
"Hi @mariosasko,Just search randomly and I found this issue~ I'm the tech lead of Milvus and we are looking forward to integrate milvus together with huggingface datasets.\r\n\r\nAny suggestion on how we could start?\r\n",
"Feel free to assign to me and we probably need some guide on it",
"@mariosasko any updat... | 2022-01-10T15:20:29Z | 2022-03-05T12:28:36Z | null | COLLABORATOR | null | null | null | null | Milvus is a popular open-source vector database. We should add a new vector index to support this project. | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3558/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3558/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3555 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3555/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3555/comments | https://api.github.com/repos/huggingface/datasets/issues/3555/events | https://github.com/huggingface/datasets/issues/3555 | 1,097,736,982 | I_kwDODunzps5BbiMW | 3,555 | DuplicatedKeysError when loading tweet_qa dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/30300891?v=4",
"events_url": "https://api.github.com/users/LeonieWeissweiler/events{/privacy}",
"followers_url": "https://api.github.com/users/LeonieWeissweiler/followers",
"following_url": "https://api.github.com/users/LeonieWeissweiler/following{/other_... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Hi, we've just merged the PR with the fix. The fixed version of the dataset can be downloaded as follows:\r\n```python\r\nimport datasets\r\ndset = datasets.load_dataset(\"tweet_qa\", revision=\"master\")\r\n```"
] | 2022-01-10T10:53:11Z | 2022-01-12T15:17:33Z | 2022-01-12T15:13:56Z | NONE | null | null | null | null | When loading the tweet_qa dataset with `load_dataset('tweet_qa')`, the following error occurs:
`DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: 2a167f9e016ba338e1813fed275a6a1e
Keys should be unique and deterministic in nature
`
Might be related to issues #2433 and #2333
- `datasets` ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3555/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3555/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3554 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3554/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3554/comments | https://api.github.com/repos/huggingface/datasets/issues/3554/events | https://github.com/huggingface/datasets/issues/3554 | 1,097,711,367 | I_kwDODunzps5Bbb8H | 3,554 | ImportError: cannot import name 'is_valid_waiter_error' | {
"avatar_url": "https://avatars.githubusercontent.com/u/84714841?v=4",
"events_url": "https://api.github.com/users/danielbellhv/events{/privacy}",
"followers_url": "https://api.github.com/users/danielbellhv/followers",
"following_url": "https://api.github.com/users/danielbellhv/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi! I can't reproduce this error in Colab, but I'm assuming you are using Amazon SageMaker Studio Notebooks (you mention the `conda_pytorch_p36` kernel), so maybe @philschmid knows more about what might be causing this issue? ",
"Hey @mariosasko. Yes, I am using **Amazon SageMaker Studio Jupyter Labs**. However,... | 2022-01-10T10:32:04Z | 2022-02-14T09:35:57Z | 2022-02-14T09:35:57Z | NONE | null | null | null | null | Based on [SO post](https://stackoverflow.com/q/70606147/17840900).
I'm following along to this [Notebook][1], cell "**Loading the dataset**".
Kernel: `conda_pytorch_p36`.
I run:
```
! pip install datasets transformers optimum[intel]
```
Output:
```
Requirement already satisfied: datasets in /home/ec2-u... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3554/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3554/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3553/comments | https://api.github.com/repos/huggingface/datasets/issues/3553/events | https://github.com/huggingface/datasets/issues/3553 | 1,097,252,275 | I_kwDODunzps5BZr2z | 3,553 | set_format("np") no longer works for Image data | {
"avatar_url": "https://avatars.githubusercontent.com/u/5862228?v=4",
"events_url": "https://api.github.com/users/cgarciae/events{/privacy}",
"followers_url": "https://api.github.com/users/cgarciae/followers",
"following_url": "https://api.github.com/users/cgarciae/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"A quick fix for now is doing this:\r\n\r\n```python\r\nX_train = np.stack(dataset[\"train\"][\"image\"])[..., None]",
"This error also propagates to jax and is even trickier to fix, since `.with_format(type='jax')` will use numpy conversion internally (and fail). For a three line failure:\r\n\r\n```python\r\ndat... | 2022-01-09T17:18:13Z | 2022-10-14T12:03:55Z | 2022-10-14T12:03:54Z | NONE | null | null | null | null | ## Describe the bug
`dataset.set_format("np")` no longer works for image data, previously you could load the MNIST like this:
```python
dataset = load_dataset("mnist")
dataset.set_format("np")
X_train = dataset["train"]["image"][..., None] # <== No longer a numpy array
```
but now it doesn't work, `set_format(... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3553/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3553/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3550/comments | https://api.github.com/repos/huggingface/datasets/issues/3550/events | https://github.com/huggingface/datasets/issues/3550 | 1,096,522,377 | I_kwDODunzps5BW5qJ | 3,550 | Bug in `openbookqa` dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/23355969?v=4",
"events_url": "https://api.github.com/users/lucadiliello/events{/privacy}",
"followers_url": "https://api.github.com/users/lucadiliello/followers",
"following_url": "https://api.github.com/users/lucadiliello/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"descrip... | closed | false | null | [] | null | [
"Closed by:\r\n- #4259"
] | 2022-01-07T17:32:57Z | 2022-05-04T06:33:00Z | 2022-05-04T06:32:19Z | CONTRIBUTOR | null | null | null | null | ## Describe the bug
Dataset entries contains a typo.
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> obqa = load_dataset('openbookqa', 'main')
>>> obqa['train'][0]
```
## Expected results
```python
{'id': '7-980', 'question_stem': 'The sun is responsible for', 'choices'... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3550/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3550/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3548 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3548/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3548/comments | https://api.github.com/repos/huggingface/datasets/issues/3548/events | https://github.com/huggingface/datasets/issues/3548 | 1,096,409,512 | I_kwDODunzps5BWeGo | 3,548 | Specify the feature types of a dataset on the Hub without needing a dataset script | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "http... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gis... | null | [
"After looking into this, discovered that this is already supported if the `dataset_infos.json` file is configured correctly! Here is a working example: https://huggingface.co/datasets/abidlabs/test-audio-13\r\n\r\nThis should be probably be documented, though. "
] | 2022-01-07T15:17:06Z | 2022-01-20T14:48:38Z | 2022-01-20T14:48:38Z | MEMBER | null | null | null | null | **Is your feature request related to a problem? Please describe.**
Currently if I upload a CSV with paths to audio files, the column type is string instead of Audio.
**Describe the solution you'd like**
I'd like to be able to specify the types of the column, so that when loading the dataset I directly get the feat... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"events_url": "https://api.github.com/users/abidlabs/events{/privacy}",
"followers_url": "https://api.github.com/users/abidlabs/followers",
"following_url": "https://api.github.com/users/abidlabs/following{/other_user}",
"gists_url": "http... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3548/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3548/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3547 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3547/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3547/comments | https://api.github.com/repos/huggingface/datasets/issues/3547/events | https://github.com/huggingface/datasets/issues/3547 | 1,096,405,515 | I_kwDODunzps5BWdIL | 3,547 | Datasets created with `push_to_hub` can't be accessed in offline mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Thanks for reporting. I think this can be fixed by improving the `CachedDatasetModuleFactory` and making it look into the `parquet` cache directory (datasets from push_to_hub are loaded with the parquet dataset builder). I'll look into it",
"Hi, I'm having the same issue. Is there any update on this?",
"We hav... | 2022-01-07T15:12:25Z | 2024-02-15T17:41:24Z | 2023-12-21T15:13:12Z | CONTRIBUTOR | null | null | null | null | ## Describe the bug
In offline mode, one can still access previously-cached datasets. This fails with datasets created with `push_to_hub`.
## Steps to reproduce the bug
in Python:
```
import datasets
mpwiki = datasets.load_dataset("teven/matched_passages_wikidata")
```
in bash:
```
export HF_DATASETS_OFFLIN... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 4,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 7,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3547/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3547/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3544 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3544/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3544/comments | https://api.github.com/repos/huggingface/datasets/issues/3544/events | https://github.com/huggingface/datasets/issues/3544 | 1,095,784,681 | I_kwDODunzps5BUFjp | 3,544 | Ability to split a dataset in multiple files. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2022-01-06T23:02:25Z | 2022-01-06T23:02:25Z | null | CONTRIBUTOR | null | null | null | null | Hello,
**Is your feature request related to a problem? Please describe.**
My use case is that I have one writer that adds columns and multiple workers reading the same `Dataset`. Each worker should have access to columns added by the writer when they reload the dataset.
I understand that we shouldn't overwrite... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3544/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3544/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3543 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3543/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3543/comments | https://api.github.com/repos/huggingface/datasets/issues/3543/events | https://github.com/huggingface/datasets/issues/3543 | 1,095,226,438 | I_kwDODunzps5BR9RG | 3,543 | Allow loading community metrics from the hub, just like datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"events_url": "https://api.github.com/users/eladsegal/events{/privacy}",
"followers_url": "https://api.github.com/users/eladsegal/followers",
"following_url": "https://api.github.com/users/eladsegal/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | closed | false | null | [] | null | [
"Hi ! Thanks for your message :) This is a great idea indeed. We haven't started working on this yet though. For now I guess you can host your metric on the Hub (either with your model or your dataset) and use `hf_hub_download` to download it (docs [here](https://github.com/huggingface/huggingface_hub/blob/main/doc... | 2022-01-06T11:26:26Z | 2022-05-31T20:59:14Z | 2022-05-31T20:53:37Z | CONTRIBUTOR | null | null | null | null | **Is your feature request related to a problem? Please describe.**
Currently, I can load a metric implemented by me by providing the local path to the file in `load_metric`.
However, there is no option to do it with the metric uploaded to the hub.
This means that if I want to allow other users to use it, they must d... | {
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"events_url": "https://api.github.com/users/eladsegal/events{/privacy}",
"followers_url": "https://api.github.com/users/eladsegal/followers",
"following_url": "https://api.github.com/users/eladsegal/following{/other_user}",
"gists_url": "... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3543/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3543/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3541 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3541/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3541/comments | https://api.github.com/repos/huggingface/datasets/issues/3541/events | https://github.com/huggingface/datasets/issues/3541 | 1,095,033,828 | I_kwDODunzps5BROPk | 3,541 | Support 7-zip compressed data files | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"This should also resolve: https://github.com/huggingface/datasets/issues/3185."
] | 2022-01-06T07:11:03Z | 2022-07-19T10:18:30Z | null | MEMBER | null | null | null | null | **Is your feature request related to a problem? Please describe.**
We should support 7-zip compressed data files:
- [x] in `extract`:
- #4672
- [ ] in `iter_archive`: for streaming mode
both in streaming and non-streaming modes.
| null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3541/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3541/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3540 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3540/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3540/comments | https://api.github.com/repos/huggingface/datasets/issues/3540/events | https://github.com/huggingface/datasets/issues/3540 | 1,094,900,336 | I_kwDODunzps5BQtpw | 3,540 | How to convert torch.utils.data.Dataset to datasets.arrow_dataset.Dataset? | {
"avatar_url": "https://avatars.githubusercontent.com/u/35062414?v=4",
"events_url": "https://api.github.com/users/CindyTing/events{/privacy}",
"followers_url": "https://api.github.com/users/CindyTing/followers",
"following_url": "https://api.github.com/users/CindyTing/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2022-01-06T02:13:42Z | 2022-01-06T02:17:39Z | null | NONE | null | null | null | null | Hi,
I use torch.utils.data.Dataset to define my own data, but I need to use the 'map' function of datasets.arrow_dataset.Dataset later, so I hope to convert torch.utils.data.Dataset to datasets.arrow_dataset.Dataset.
Here is an example.
```
from torch.utils.data import Dataset
from datasets.arrow_dataset import ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3540/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3540/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3533 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3533/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3533/comments | https://api.github.com/repos/huggingface/datasets/issues/3533/events | https://github.com/huggingface/datasets/issues/3533 | 1,094,156,147 | I_kwDODunzps5BN39z | 3,533 | Task search function on hub not working correctly | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"known issue due to https://github.com/huggingface/datasets/pull/2362 (and [internal](https://github.com/huggingface/moon-landing/issues/946)) , will be solved soon",
"hmm actually i have no recollection of why I said that",
"Because it has dots in some YAML keys, it can't be parsed and indexed by the back-end"... | 2022-01-05T09:36:30Z | 2022-05-12T14:45:57Z | null | CONTRIBUTOR | null | null | null | null | When I want to look at all datasets of the category: `speech-processing` *i.e.* https://huggingface.co/datasets?task_categories=task_categories:speech-processing&sort=downloads , then the following dataset doesn't show up for some reason:
- https://huggingface.co/datasets/speech_commands
even thought it's task t... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3533/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3533/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3531 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3531/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3531/comments | https://api.github.com/repos/huggingface/datasets/issues/3531/events | https://github.com/huggingface/datasets/issues/3531 | 1,094,033,280 | I_kwDODunzps5BNZ-A | 3,531 | Give clearer instructions to add the YAML tags | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2022-01-05T06:44:20Z | 2022-01-17T15:54:36Z | 2022-01-17T15:54:36Z | MEMBER | null | null | null | null | ## Describe the bug
As reported by @julien-c, many community datasets contain the line `YAML tags:` at the top of the YAML section in the header of the README file. See e.g.: https://huggingface.co/datasets/bigscience/P3/commit/a03bea08cf4d58f268b469593069af6aeb15de32
Maybe we should give clearer instruction/hints... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3531/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3531/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3522 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3522/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3522/comments | https://api.github.com/repos/huggingface/datasets/issues/3522/events | https://github.com/huggingface/datasets/issues/3522 | 1,093,807,586 | I_kwDODunzps5BMi3i | 3,522 | wmt19 is broken (zh-en) | {
"avatar_url": "https://avatars.githubusercontent.com/u/5404177?v=4",
"events_url": "https://api.github.com/users/AjayP13/events{/privacy}",
"followers_url": "https://api.github.com/users/AjayP13/followers",
"following_url": "https://api.github.com/users/AjayP13/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"descrip... | closed | false | null | [] | null | [
"This issue is not reproducible."
] | 2022-01-04T22:33:45Z | 2022-05-06T16:27:37Z | 2022-05-06T16:27:37Z | NONE | null | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("wmt19", 'zh-en')
```
## Expected results
The dataset should download.
## Actual results
`ConnectionError: Couldn't reach ftp://cwmt-wm... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3522/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3522/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3518 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3518/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3518/comments | https://api.github.com/repos/huggingface/datasets/issues/3518/events | https://github.com/huggingface/datasets/issues/3518 | 1,093,063,455 | I_kwDODunzps5BJtMf | 3,518 | Add PubMed Central Open Access dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"In the framework of BigScience:\r\n- bigscience-workshop/data_tooling#121\r\n\r\nI have created this dataset as a community dataset: https://huggingface.co/datasets/albertvillanova/pmc_open_access\r\n\r\nHowever, I was wondering that it may be more appropriate to move it under an org namespace: `pubmed_central` or... | 2022-01-04T06:54:35Z | 2022-01-17T15:25:57Z | 2022-01-17T15:25:57Z | MEMBER | null | null | null | null | ## Adding a Dataset
- **Name:** PubMed Central Open Access
- **Description:** The PMC Open Access Subset includes more than 3.4 million journal articles and preprints that are made available under license terms that allow reuse.
- **Paper:** *link to the dataset paper if available*
- **Data:** https://www.ncbi.nlm.... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3518/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3518/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3515 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3515/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3515/comments | https://api.github.com/repos/huggingface/datasets/issues/3515/events | https://github.com/huggingface/datasets/issues/3515 | 1,092,624,695 | I_kwDODunzps5BICE3 | 3,515 | `ExpectedMoreDownloadedFiles` for `evidence_infer_treatment` | {
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"descrip... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting @VictorSanh.\r\n\r\nI'm looking at it... "
] | 2022-01-03T15:58:38Z | 2022-02-14T13:21:43Z | 2022-02-14T13:21:43Z | CONTRIBUTOR | null | null | null | null | ## Describe the bug
I am trying to load a dataset called `evidence_infer_treatment`. The first subset (`1.1`) works fine but the second returns an error (`2.0`). It downloads a file but crashes during the checksums.
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> load_dataset("e... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3515/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3515/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3512 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3512/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3512/comments | https://api.github.com/repos/huggingface/datasets/issues/3512/events | https://github.com/huggingface/datasets/issues/3512 | 1,092,359,973 | I_kwDODunzps5BHBcl | 3,512 | No Data format found | {
"avatar_url": "https://avatars.githubusercontent.com/u/57741378?v=4",
"events_url": "https://api.github.com/users/shazzad47/events{/privacy}",
"followers_url": "https://api.github.com/users/shazzad47/followers",
"following_url": "https://api.github.com/users/shazzad47/following{/other_user}",
"gists_url": "... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"Hi, which dataset is giving you an error?"
] | 2022-01-03T09:41:11Z | 2022-01-17T13:26:05Z | 2022-01-17T13:26:05Z | NONE | null | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3512/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3512/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3511 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3511/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3511/comments | https://api.github.com/repos/huggingface/datasets/issues/3511/events | https://github.com/huggingface/datasets/issues/3511 | 1,092,170,411 | I_kwDODunzps5BGTKr | 3,511 | Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/92849978?v=4",
"events_url": "https://api.github.com/users/MIKURI0114/events{/privacy}",
"followers_url": "https://api.github.com/users/MIKURI0114/followers",
"following_url": "https://api.github.com/users/MIKURI0114/following{/other_user}",
"gists_url"... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"Can you reopen with the correct dataset name (if relevant)?\r\n\r\nThanks",
"The dataset viewer was down tonight. It works again."
] | 2022-01-03T02:03:23Z | 2022-01-03T08:41:26Z | 2022-01-03T08:23:07Z | NONE | null | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3511/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3511/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3510 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3510/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3510/comments | https://api.github.com/repos/huggingface/datasets/issues/3510/events | https://github.com/huggingface/datasets/issues/3510 | 1,091,997,004 | I_kwDODunzps5BFo1M | 3,510 | `wiki_dpr` details for Open Domain Question Answering tasks | {
"avatar_url": "https://avatars.githubusercontent.com/u/40918514?v=4",
"events_url": "https://api.github.com/users/pk1130/events{/privacy}",
"followers_url": "https://api.github.com/users/pk1130/followers",
"following_url": "https://api.github.com/users/pk1130/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Hi ! According to the DPR paper, the wikipedia dump is the one from Dec. 20, 2018.\r\nEach instance contains a paragraph of at most 100 word, as well as the title of the wikipedia page it comes from and the DPR embedding (a 768-d vector).",
"Closed by:\r\n- #3534"
] | 2022-01-02T11:04:01Z | 2022-02-17T13:46:20Z | 2022-02-17T13:46:20Z | NONE | null | null | null | null | Hey guys!
Thanks for creating the `wiki_dpr` dataset!
I am currently trying to use the dataset for context retrieval using DPR on NQ questions and need details about what each of the files and data instances mean, which version of the Wikipedia dump it uses, etc. Please respond at your earliest convenience regard... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3510/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3510/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3507 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3507/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3507/comments | https://api.github.com/repos/huggingface/datasets/issues/3507/events | https://github.com/huggingface/datasets/issues/3507 | 1,091,214,808 | I_kwDODunzps5BCp3Y | 3,507 | Discuss whether support canonical datasets w/o dataset_infos.json and/or dummy data | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | closed | false | null | [] | null | [
"IMO, the data streaming test is good enough of a test that the dataset works correctly (assuming that we can more or less ensure that if streaming works then the non-streaming case will also work), so that for datasets that have a working dataset preview, we can remove the dummy data IMO. On the other hand, it see... | 2021-12-30T17:04:25Z | 2022-11-04T15:31:38Z | 2022-11-04T15:31:37Z | MEMBER | null | null | null | null | I open this PR to have a public discussion about this topic and make a decision.
As previously discussed, once we have the metadata in the dataset card (README file, containing both Markdown info and YAML tags), what is the point of having also the JSON metadata (dataset_infos.json file)?
On the other hand, the d... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3507/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3507/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3505 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3505/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3505/comments | https://api.github.com/repos/huggingface/datasets/issues/3505/events | https://github.com/huggingface/datasets/issues/3505 | 1,091,150,820 | I_kwDODunzps5BCaPk | 3,505 | cast_column function not working with map function in streaming mode for Audio features | {
"avatar_url": "https://avatars.githubusercontent.com/u/8268102?v=4",
"events_url": "https://api.github.com/users/ashu5644/events{/privacy}",
"followers_url": "https://api.github.com/users/ashu5644/followers",
"following_url": "https://api.github.com/users/ashu5644/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Hi! This is probably due to the fact that `IterableDataset.map` sets `features` to `None` before mapping examples. We can fix the issue by passing the old `features` dict to the map generator and performing encoding/decoding there (before calling the map transform function)."
] | 2021-12-30T14:52:01Z | 2022-01-18T19:54:07Z | 2022-01-18T19:54:07Z | NONE | null | null | null | null | ## Describe the bug
I am trying to use Audio class for loading audio features using custom dataset. I am able to cast 'audio' feature into 'Audio' format with cast_column function. On using map function, I am not getting 'Audio' casted feature but getting path of audio file only.
I am getting features of 'audio' of s... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3505/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3505/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3504 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3504/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3504/comments | https://api.github.com/repos/huggingface/datasets/issues/3504/events | https://github.com/huggingface/datasets/issues/3504 | 1,090,682,230 | I_kwDODunzps5BAn12 | 3,504 | Unable to download PUBMED_title_abstracts_2019_baseline.jsonl.zst | {
"avatar_url": "https://avatars.githubusercontent.com/u/12600692?v=4",
"events_url": "https://api.github.com/users/ToddMorrill/events{/privacy}",
"followers_url": "https://api.github.com/users/ToddMorrill/followers",
"following_url": "https://api.github.com/users/ToddMorrill/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"descrip... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @ToddMorrill, thanks for reporting.\r\n\r\nThree weeks ago I contacted the team who created the Pile dataset to report this issue with their data host server: https://the-eye.eu\r\n\r\nThey told me that unfortunately, the-eye was heavily affected by the recent tornado catastrophe in the US. They hope to have th... | 2021-12-29T18:23:20Z | 2024-05-20T09:44:59Z | 2022-02-17T15:04:25Z | NONE | null | null | null | null | ## Describe the bug
I am unable to download the PubMed dataset from the link provided in the [Hugging Face Course (Chapter 5 Section 4)](https://huggingface.co/course/chapter5/4?fw=pt).
https://the-eye.eu/public/AI/pile_preliminary_components/PUBMED_title_abstracts_2019_baseline.jsonl.zst
## Steps to reproduce ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3504/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3504/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3503 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3503/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3503/comments | https://api.github.com/repos/huggingface/datasets/issues/3503/events | https://github.com/huggingface/datasets/issues/3503 | 1,090,472,735 | I_kwDODunzps5A_0sf | 3,503 | Batched in filter throws error | {
"avatar_url": "https://avatars.githubusercontent.com/u/32967787?v=4",
"events_url": "https://api.github.com/users/gpucce/events{/privacy}",
"followers_url": "https://api.github.com/users/gpucce/followers",
"following_url": "https://api.github.com/users/gpucce/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
... | null | [] | 2021-12-29T12:01:04Z | 2022-01-04T10:24:27Z | 2022-01-04T10:24:27Z | CONTRIBUTOR | null | null | null | null | I hope this is really a bug, I could not find it among the open issues
## Describe the bug
using `batched=False` in DataSet.filter throws error
```python
TypeError: filter() got an unexpected keyword argument 'batched'
```
but in the docs it is lister as an argument.
## Steps to reproduce the bug
```python
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3503/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3503/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3499 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3499/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3499/comments | https://api.github.com/repos/huggingface/datasets/issues/3499/events | https://github.com/huggingface/datasets/issues/3499 | 1,090,132,618 | I_kwDODunzps5A-hqK | 3,499 | Adjusting chunk size for streaming datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/3775944?v=4",
"events_url": "https://api.github.com/users/JoelNiklaus/events{/privacy}",
"followers_url": "https://api.github.com/users/JoelNiklaus/followers",
"following_url": "https://api.github.com/users/JoelNiklaus/following{/other_user}",
"gists_ur... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi ! Data streaming uses `fsspec` to read the data files progressively. IIRC the block size for buffering is 5MiB by default. So every time you finish iterating over a block, it downloads the next one. You can still try to increase the `fsspec` block size for buffering if it can help. To do so you just need to inc... | 2021-12-28T21:17:53Z | 2022-05-06T16:29:05Z | 2022-05-06T16:29:05Z | CONTRIBUTOR | null | null | null | null | **Is your feature request related to a problem? Please describe.**
I want to use mc4 which I cannot save locally, so I stream it. However, I want to process the entire dataset and filter some documents from it. With the current chunk size of around 1000 documents (right?) I hit a performance bottleneck because of the ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3499/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3499/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3497 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3497/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3497/comments | https://api.github.com/repos/huggingface/datasets/issues/3497/events | https://github.com/huggingface/datasets/issues/3497 | 1,090,050,148 | I_kwDODunzps5A-Nhk | 3,497 | Changing sampling rate in audio dataset and subsequently mapping with `num_proc > 1` leads to weird bug | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Same error occures when using max samples with https://github.com/huggingface/transformers/blob/master/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py",
"I'm seeing this too, when using preprocessing_num_workers with \r\nhttps://github.com/huggingface/transformers/blob/master/examples/pytor... | 2021-12-28T18:03:49Z | 2022-01-21T13:22:27Z | 2022-01-21T13:22:27Z | CONTRIBUTOR | null | null | null | null | Running:
```python
from datasets import load_dataset, DatasetDict
import datasets
from transformers import AutoFeatureExtractor
raw_datasets = DatasetDict()
raw_datasets["train"] = load_dataset("common_voice", "ab", split="train")
feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2ve... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3497/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3497/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3495 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3495/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3495/comments | https://api.github.com/repos/huggingface/datasets/issues/3495/events | https://github.com/huggingface/datasets/issues/3495 | 1,089,983,632 | I_kwDODunzps5A99SQ | 3,495 | Add VoxLingua107 | {
"avatar_url": "https://avatars.githubusercontent.com/u/25360440?v=4",
"events_url": "https://api.github.com/users/jaketae/events{/privacy}",
"followers_url": "https://api.github.com/users/jaketae/followers",
"following_url": "https://api.github.com/users/jaketae/following{/other_user}",
"gists_url": "https:... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | null | [] | 2021-12-28T15:51:43Z | 2021-12-28T15:51:43Z | null | CONTRIBUTOR | null | null | null | null | ## Adding a Dataset
- **Name:** VoxLingua107
- **Description:** VoxLingua107 is a speech dataset for training spoken language identification models.
- **Paper:** https://arxiv.org/abs/2011.12998
- **Data:** http://bark.phon.ioc.ee/voxlingua107/
- **Motivation:** 107 languages, totaling 6628 hours for the train sp... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3495/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3495/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3491 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3491/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3491/comments | https://api.github.com/repos/huggingface/datasets/issues/3491/events | https://github.com/huggingface/datasets/issues/3491 | 1,089,918,018 | I_kwDODunzps5A9tRC | 3,491 | Update version of pib dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2021-12-28T14:03:58Z | 2021-12-29T08:42:57Z | 2021-12-29T08:42:57Z | MEMBER | null | null | null | null | On the Hub we have v0, while there exists v1.3.
Related to bigscience-workshop/data_tooling#130
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3491/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3491/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3490 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3490/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3490/comments | https://api.github.com/repos/huggingface/datasets/issues/3490/events | https://github.com/huggingface/datasets/issues/3490 | 1,089,730,181 | I_kwDODunzps5A8_aF | 3,490 | Does datasets support load text from HDFS? | {
"avatar_url": "https://avatars.githubusercontent.com/u/20511825?v=4",
"events_url": "https://api.github.com/users/dancingpipi/events{/privacy}",
"followers_url": "https://api.github.com/users/dancingpipi/followers",
"following_url": "https://api.github.com/users/dancingpipi/following{/other_user}",
"gists_u... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! `datasets` currently supports reading local files or files over HTTP. We may add support for other filesystems (cloud storages, hdfs...) at one point though :)"
] | 2021-12-28T08:56:02Z | 2022-02-14T14:00:51Z | null | NONE | null | null | null | null | The raw text data is stored on HDFS due to the dataset's size is too large to store on my develop machine,
so I wander does datasets support read data from hdfs? | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3490/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3490/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3488 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3488/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3488/comments | https://api.github.com/repos/huggingface/datasets/issues/3488/events | https://github.com/huggingface/datasets/issues/3488 | 1,089,345,653 | I_kwDODunzps5A7hh1 | 3,488 | URL query parameters are set as path in the compression hop for fsspec | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"I think the test passes because it simply ignore what's after `gzip://`.\r\n\r\nThe returned urlpath is expected to look like `gzip://filename::url`, and the filename is currently considered to be what's after the final `/`, hence the result.\r\n\r\nWe can decide to change this and simply have `gzip://::url`, this... | 2021-12-27T16:29:00Z | 2022-01-05T15:15:25Z | null | MEMBER | null | null | null | null | ## Describe the bug
There is an ssue with `StreamingDownloadManager._extract`.
I don't know how the test `test_streaming_gg_drive_gzipped` passes:
For
```python
TEST_GG_DRIVE_GZIPPED_URL = "https://drive.google.com/uc?export=download&id=1Bt4Garpf0QLiwkJhHJzXaVa0I0H5Qhwz"
urlpath = StreamingDownloadManager().... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3488/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3488/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3485 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3485/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3485/comments | https://api.github.com/repos/huggingface/datasets/issues/3485/events | https://github.com/huggingface/datasets/issues/3485 | 1,089,027,581 | I_kwDODunzps5A6T39 | 3,485 | skip columns which cannot set to specific format when set_format | {
"avatar_url": "https://avatars.githubusercontent.com/u/13161779?v=4",
"events_url": "https://api.github.com/users/tshu-w/events{/privacy}",
"followers_url": "https://api.github.com/users/tshu-w/followers",
"following_url": "https://api.github.com/users/tshu-w/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"You can add columns that you wish to set into `torch` format using `dataset.set_format(\"torch\", ['id', 'abc'])` so that input batch of the transform only contains those columns",
"Sorry, I miss `output_all_columns` args and thought after `dataset.set_format(\"torch\", columns=columns)` I can only get specific ... | 2021-12-27T07:19:55Z | 2021-12-27T09:07:07Z | 2021-12-27T09:07:07Z | NONE | null | null | null | null | **Is your feature request related to a problem? Please describe.**
When using `dataset.set_format("torch")`, I must make sure every columns in datasets can convert to `torch`, however, sometimes I want to keep some string columns.
**Describe the solution you'd like**
skip columns which cannot set to specific forma... | {
"avatar_url": "https://avatars.githubusercontent.com/u/13161779?v=4",
"events_url": "https://api.github.com/users/tshu-w/events{/privacy}",
"followers_url": "https://api.github.com/users/tshu-w/followers",
"following_url": "https://api.github.com/users/tshu-w/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3485/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3485/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3484 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3484/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3484/comments | https://api.github.com/repos/huggingface/datasets/issues/3484/events | https://github.com/huggingface/datasets/issues/3484 | 1,088,910,402 | I_kwDODunzps5A53RC | 3,484 | make shape verification to use ArrayXD instead of nested lists for map | {
"avatar_url": "https://avatars.githubusercontent.com/u/13161779?v=4",
"events_url": "https://api.github.com/users/tshu-w/events{/privacy}",
"followers_url": "https://api.github.com/users/tshu-w/followers",
"following_url": "https://api.github.com/users/tshu-w/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi! \r\n\r\nYes, this makes sense for numeric values, but first I have to finish https://github.com/huggingface/datasets/pull/3336 because currently ArrayXD only allows the first dimension to be dynamic."
] | 2021-12-27T02:16:02Z | 2022-01-05T13:54:03Z | null | NONE | null | null | null | null | As describe in https://github.com/huggingface/datasets/issues/2005#issuecomment-793716753 and mentioned by @mariosasko in [image feature example](https://colab.research.google.com/drive/1mIrTnqTVkWLJWoBzT1ABSe-LFelIep1c#scrollTo=ow3XHDvf2I0B&line=1&uniqifier=1), IMO make shape verifcaiton to use ArrayXD instead of nest... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3484/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3484/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3480 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3480/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3480/comments | https://api.github.com/repos/huggingface/datasets/issues/3480/events | https://github.com/huggingface/datasets/issues/3480 | 1,088,267,110 | I_kwDODunzps5A3aNm | 3,480 | the compression format requested when saving a dataset in json format is not respected | {
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"events_url": "https://api.github.com/users/SaulLu/events{/privacy}",
"followers_url": "https://api.github.com/users/SaulLu/followers",
"following_url": "https://api.github.com/users/SaulLu/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Thanks for reporting @SaulLu.\r\n\r\nAt first sight I think the problem is caused because `pandas` only takes into account the `compression` parameter if called with a non-null file path or buffer. And in our implementation, we call pandas `to_json` with `None` `path_or_buf`.\r\n\r\nWe should fix this:\r\n- either... | 2021-12-24T09:23:51Z | 2022-01-05T13:03:35Z | 2022-01-05T13:03:35Z | CONTRIBUTOR | null | null | null | null | ## Describe the bug
In the documentation of the `to_json` method, it is stated in the parameters that
> **to_json_kwargs – Parameters to pass to pandas’s pandas.DataFrame.to_json.
however when we pass for example `compression="gzip"`, the saved file is not compressed.
Would you also have expected compression t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3480/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3480/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3479 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3479/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3479/comments | https://api.github.com/repos/huggingface/datasets/issues/3479/events | https://github.com/huggingface/datasets/issues/3479 | 1,088,232,880 | I_kwDODunzps5A3R2w | 3,479 | Dataset preview is not available (I think for all Hugging Face datasets) | {
"avatar_url": "https://avatars.githubusercontent.com/u/66887439?v=4",
"events_url": "https://api.github.com/users/Abirate/events{/privacy}",
"followers_url": "https://api.github.com/users/Abirate/followers",
"following_url": "https://api.github.com/users/Abirate/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "E5583E",
"default": false,
"descrip... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | null | [
"You're right, we have an issue today with the datasets preview. We're investigating.",
"It should be fixed now. Thanks for reporting.",
"Down again. ",
"Fixed for good."
] | 2021-12-24T08:18:48Z | 2021-12-24T14:27:46Z | 2021-12-24T14:27:46Z | NONE | null | null | null | null | ## Dataset viewer issue for '*french_book_reviews*'
**Link:** https://huggingface.co/datasets/Abirate/french_book_reviews
**short description of the issue**
For my dataset, the dataset preview is no longer functional (it used to work: The dataset had been added the day before and it was fine...)
And, after lo... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3479/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3479/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3475 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3475/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3475/comments | https://api.github.com/repos/huggingface/datasets/issues/3475/events | https://github.com/huggingface/datasets/issues/3475 | 1,087,352,041 | I_kwDODunzps5Az6zp | 3,475 | The rotten_tomatoes dataset of movie reviews contains some reviews in Spanish | {
"avatar_url": "https://avatars.githubusercontent.com/u/17426779?v=4",
"events_url": "https://api.github.com/users/puzzler10/events{/privacy}",
"followers_url": "https://api.github.com/users/puzzler10/followers",
"following_url": "https://api.github.com/users/puzzler10/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Hi @puzzler10, thanks for reporting.\r\n\r\nPlease note this dataset is not hosted on Hugging Face Hub. See: \r\nhttps://github.com/huggingface/datasets/blob/c8f914473b041833fd47178fa4373cdcb56ac522/datasets/rotten_tomatoes/rotten_tomatoes.py#L42\r\n\r\nIf there are issues with the source data of a dataset, you sh... | 2021-12-23T03:56:43Z | 2021-12-24T00:23:03Z | null | NONE | null | null | null | null | ## Describe the bug
See title. I don't think this is intentional and they probably should be removed. If they stay the dataset description should be at least updated to make it clear to the user.
## Steps to reproduce the bug
Go to the [dataset viewer](https://huggingface.co/datasets/viewer/?dataset=rotten_tomato... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3475/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3475/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3473 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3473/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3473/comments | https://api.github.com/repos/huggingface/datasets/issues/3473/events | https://github.com/huggingface/datasets/issues/3473 | 1,086,937,610 | I_kwDODunzps5AyVoK | 3,473 | Iterating over a vision dataset doesn't decode the images | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "bfdadc",
"default": false,
"descrip... | closed | false | null | [] | null | [
"As discussed, I remember I set `decoded=False` here to avoid decoding just by iterating over examples of dataset. We wanted to decode only if the \"audio\" field (for Audio feature) was accessed.",
"> I set decoded=False here to avoid decoding just by iterating over examples of dataset. We wanted to decode only ... | 2021-12-22T15:26:32Z | 2021-12-27T14:13:21Z | 2021-12-23T15:21:57Z | MEMBER | null | null | null | null | ## Describe the bug
If I load `mnist` and I iterate over the dataset, the images are not decoded, and the dictionary with the bytes is returned.
## Steps to reproduce the bug
```python
from datasets import load_dataset
import PIL
mnist = load_dataset("mnist", split="train")
first_image = mnist[0]["image"... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3473/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3473/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3465 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3465/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3465/comments | https://api.github.com/repos/huggingface/datasets/issues/3465/events | https://github.com/huggingface/datasets/issues/3465 | 1,085,400,432 | I_kwDODunzps5AseVw | 3,465 | Unable to load 'cnn_dailymail' dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42352729?v=4",
"events_url": "https://api.github.com/users/talha1503/events{/privacy}",
"followers_url": "https://api.github.com/users/talha1503/followers",
"following_url": "https://api.github.com/users/talha1503/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "cfd3d7",
"default": true,
"descript... | closed | false | null | [] | null | [
"Hi @talha1503, thanks for reporting.\r\n\r\nIt seems there is an issue with one of the data files hosted at Google Drive:\r\n```\r\nGoogle Drive - Quota exceeded\r\n\r\nSorry, you can't view or download this file at this time.\r\n\r\nToo many users have viewed or downloaded this file recently. Please try accessing... | 2021-12-21T03:32:21Z | 2024-06-12T14:41:17Z | 2022-02-17T14:13:57Z | NONE | null | null | null | null | ## Describe the bug
I wanted to load cnn_dailymail dataset from huggingface datasets on Google Colab, but I am getting an error while loading it.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset('cnn_dailymail', '3.0.0', ignore_verifications = True)
```
## Expe... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3465/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3465/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3464 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3464/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3464/comments | https://api.github.com/repos/huggingface/datasets/issues/3464/events | https://github.com/huggingface/datasets/issues/3464 | 1,085,399,097 | I_kwDODunzps5AseA5 | 3,464 | struct.error: 'i' format requires -2147483648 <= number <= 2147483647 | {
"avatar_url": "https://avatars.githubusercontent.com/u/30341159?v=4",
"events_url": "https://api.github.com/users/koukoulala/events{/privacy}",
"followers_url": "https://api.github.com/users/koukoulala/followers",
"following_url": "https://api.github.com/users/koukoulala/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Hi ! Can you try setting `datasets.config.MAX_TABLE_NBYTES_FOR_PICKLING` to a smaller value than `4 << 30` (4GiB), for example `500 << 20` (500MiB) ? It should reduce the maximum size of the arrow table being pickled during multiprocessing.\r\n\r\nIf it fixes the issue, we can consider lowering the default value f... | 2021-12-21T03:29:01Z | 2022-11-21T19:55:11Z | null | NONE | null | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
using latest datasets=datasets-1.16.1-py3-none-any.whl
process my own multilingual dataset by following codes, and the number of rows in all dataset is 306000, the max_length of each sentence is 256:
?",
"Upgrading the datasets version as per #3190 fixes this bug. \r\nI'm Marking as closed."
] | 2021-12-20T16:16:49Z | 2021-12-20T16:34:57Z | 2021-12-20T16:34:57Z | NONE | null | null | null | null | ## Describe the bug
When using dataset.select to select a subset of a dataset, dataset._indices are set to indicate which elements are now considered in the dataset.
The same thing happens when you shuffle the dataset; dataset._indices are set to indicate what the new order of the data is.
However, if you then use a... | {
"avatar_url": "https://avatars.githubusercontent.com/u/9354454?v=4",
"events_url": "https://api.github.com/users/mmajurski/events{/privacy}",
"followers_url": "https://api.github.com/users/mmajurski/followers",
"following_url": "https://api.github.com/users/mmajurski/following{/other_user}",
"gists_url": "h... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3459/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3459/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3457 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3457/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3457/comments | https://api.github.com/repos/huggingface/datasets/issues/3457/events | https://github.com/huggingface/datasets/issues/3457 | 1,084,862,121 | I_kwDODunzps5Aqa6p | 3,457 | Add CMU Graphics Lab Motion Capture dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",... | open | false | null | [] | null | [
"This dataset has files in ASF/AMC format. [ The skeleton file is the ASF file (Acclaim Skeleton File). The motion file is the AMC file (Acclaim Motion Capture data). ] \r\n\r\nSome questions : \r\n1. How do we go about representing these features using datasets.Features and generate examples ?\r\n2. The dataset d... | 2021-12-20T14:34:39Z | 2022-03-16T16:53:09Z | null | CONTRIBUTOR | null | null | null | null | ## Adding a Dataset
- **Name:** CMU Graphics Lab Motion Capture database
- **Description:** The database contains free motions which you can download and use.
- **Data:** http://mocap.cs.cmu.edu/
- **Motivation:** Nice motion capture dataset
Instructions to add a new dataset can be found [here](https://github.c... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3457/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3457/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3455 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3455/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3455/comments | https://api.github.com/repos/huggingface/datasets/issues/3455/events | https://github.com/huggingface/datasets/issues/3455 | 1,084,599,650 | I_kwDODunzps5Apa1i | 3,455 | Easier information editing | {
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"events_url": "https://api.github.com/users/borgr/events{/privacy}",
"followers_url": "https://api.github.com/users/borgr/followers",
"following_url": "https://api.github.com/users/borgr/following{/other_user}",
"gists_url": "https://api.g... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | closed | false | null | [] | null | [
"Hi ! I guess you are talking about the dataset cards that are in this repository on github ?\r\n\r\nI think github allows to submit a PR even for 1 line though the `Edit file` button on the page of the dataset card.\r\n\r\nMaybe let's mention this in `CONTRIBUTING.md` ?",
"We now host all the datasets on the HF ... | 2021-12-20T10:10:43Z | 2023-07-25T15:36:14Z | 2023-07-25T15:36:14Z | CONTRIBUTOR | null | null | null | null | **Is your feature request related to a problem? Please describe.**
It requires a lot of effort to improve a datasheet.
**Describe the solution you'd like**
UI or at least a link to the place where the code that needs to be edited is (and an easy way to edit this code directly from the site, without cloning, branc... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3455/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3455/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3453 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3453/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3453/comments | https://api.github.com/repos/huggingface/datasets/issues/3453/events | https://github.com/huggingface/datasets/issues/3453 | 1,084,515,911 | I_kwDODunzps5ApGZH | 3,453 | ValueError while iter_archive | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2021-12-20T08:46:18Z | 2021-12-20T10:04:59Z | 2021-12-20T10:04:59Z | MEMBER | null | null | null | null | ## Describe the bug
After the merge of:
- #3443
the method `iter_archive` throws a ValueError:
```
ValueError: read of closed file
```
## Steps to reproduce the bug
```python
for path, file in dl_manager.iter_archive(archive_path):
pass
```
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3453/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3453/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3452 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3452/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3452/comments | https://api.github.com/repos/huggingface/datasets/issues/3452/events | https://github.com/huggingface/datasets/issues/3452 | 1,083,803,178 | I_kwDODunzps5AmYYq | 3,452 | why the stratify option is omitted from test_train_split function? | {
"avatar_url": "https://avatars.githubusercontent.com/u/9985334?v=4",
"events_url": "https://api.github.com/users/j-sieger/events{/privacy}",
"followers_url": "https://api.github.com/users/j-sieger/followers",
"following_url": "https://api.github.com/users/j-sieger/following{/other_user}",
"gists_url": "http... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "BDE59C",
"default": fals... | closed | false | null | [] | null | [
"Hi ! It's simply not added yet :)\r\n\r\nIf someone wants to contribute to add the `stratify` parameter I'd be happy to give some pointers.\r\n\r\nIn the meantime, I guess you can use `sklearn` or other tools to do a stratified train/test split over the **indices** of your dataset and then do\r\n```\r\ntrain_datas... | 2021-12-18T10:37:47Z | 2022-05-25T20:43:51Z | 2022-05-25T20:43:51Z | NONE | null | null | null | null | why the stratify option is omitted from test_train_split function?
is there any other way implement the stratify option while splitting the dataset? as it is important point to be considered while splitting the dataset. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 6,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3452/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3452/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3450 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3450/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3450/comments | https://api.github.com/repos/huggingface/datasets/issues/3450/events | https://github.com/huggingface/datasets/issues/3450 | 1,083,450,158 | I_kwDODunzps5AlCMu | 3,450 | Unexpected behavior doing Split + Filter | {
"avatar_url": "https://avatars.githubusercontent.com/u/26432605?v=4",
"events_url": "https://api.github.com/users/jbrachat/events{/privacy}",
"followers_url": "https://api.github.com/users/jbrachat/followers",
"following_url": "https://api.github.com/users/jbrachat/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! This is an issue with `datasets` 1.12. Sorry for the inconvenience. Can you update to `>=1.13` ?\r\nsee https://github.com/huggingface/datasets/issues/3190\r\n\r\nMaybe we should also backport the bug fix to `1.12` (in a new version `1.12.2`)"
] | 2021-12-17T17:00:39Z | 2023-07-25T15:38:47Z | 2023-07-25T15:38:47Z | NONE | null | null | null | null | ## Describe the bug
I observed unexpected behavior when applying 'train_test_split' followed by 'filter' on dataset. Elements of the training dataset eventually end up in the test dataset (after applying the 'filter')
## Steps to reproduce the bug
```
from datasets import Dataset
import pandas as pd
dic = {'x'... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3450/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3450/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3449 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3449/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3449/comments | https://api.github.com/repos/huggingface/datasets/issues/3449/events | https://github.com/huggingface/datasets/issues/3449 | 1,083,373,018 | I_kwDODunzps5AkvXa | 3,449 | Add `__add__()`, `__iadd__()` and similar to `Dataset` class | {
"avatar_url": "https://avatars.githubusercontent.com/u/8904453?v=4",
"events_url": "https://api.github.com/users/sgraaf/events{/privacy}",
"followers_url": "https://api.github.com/users/sgraaf/followers",
"following_url": "https://api.github.com/users/sgraaf/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | closed | false | null | [] | null | [
"I was going through the codebase, and I believe the implementation of __add__() and __iadd__() will be similar to concatenate_datasets() after the elimination of code for arguments other than the list of datasets (info, split, axis). \r\n(Assuming elimination of axis means concatenating over axis 1.)",
"Most dat... | 2021-12-17T15:29:11Z | 2024-02-29T16:47:56Z | 2023-07-25T15:33:56Z | NONE | null | null | null | null | **Is your feature request related to a problem? Please describe.**
No.
**Describe the solution you'd like**
I would like to be able to concatenate datasets as follows:
```python
>>> dataset["train"] += dataset["validation"]
```
... instead of using `concatenate_datasets()`:
```python
>>> raw_datasets["trai... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3449/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3449/timeline | null | not_planned | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3448 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3448/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3448/comments | https://api.github.com/repos/huggingface/datasets/issues/3448/events | https://github.com/huggingface/datasets/issues/3448 | 1,083,231,080 | I_kwDODunzps5AkMto | 3,448 | JSONDecodeError with HuggingFace dataset viewer | {
"avatar_url": "https://avatars.githubusercontent.com/u/57716109?v=4",
"events_url": "https://api.github.com/users/kathrynchapman/events{/privacy}",
"followers_url": "https://api.github.com/users/kathrynchapman/followers",
"following_url": "https://api.github.com/users/kathrynchapman/following{/other_user}",
... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"Hi ! I think the issue comes from the dataset_infos.json file: it has the \"flat\" field twice.\r\n\r\nCan you try deleting this file and regenerating it please ?",
"Thanks! That fixed that, but now I am getting:\r\nServer Error\r\nStatus code: 400\r\nException: KeyError\r\nMessage: 'feature'\r\n\r\n... | 2021-12-17T12:52:41Z | 2022-02-24T09:10:26Z | 2022-02-24T09:10:26Z | NONE | null | null | null | null | ## Dataset viewer issue for 'pubmed_neg'
**Link:** https://huggingface.co/datasets/IGESML/pubmed_neg
I am getting the error:
Status code: 400
Exception: JSONDecodeError
Message: Expecting property name enclosed in double quotes: line 61 column 2 (char 1202)
I have checked all files - I am not u... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3448/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3448/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3447 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3447/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3447/comments | https://api.github.com/repos/huggingface/datasets/issues/3447/events | https://github.com/huggingface/datasets/issues/3447 | 1,082,539,790 | I_kwDODunzps5Ahj8O | 3,447 | HF_DATASETS_OFFLINE=1 didn't stop datasets.builder from downloading | {
"avatar_url": "https://avatars.githubusercontent.com/u/51274745?v=4",
"events_url": "https://api.github.com/users/dunalduck0/events{/privacy}",
"followers_url": "https://api.github.com/users/dunalduck0/followers",
"following_url": "https://api.github.com/users/dunalduck0/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! Indeed it says \"downloading and preparing\" but in your case it didn't need to download anything since you used local files (it would have thrown an error otherwise). I think we can improve the logging to make it clearer in this case",
"@lhoestq Thank you for explaining. I am sorry but I was not clear abou... | 2021-12-16T18:51:13Z | 2022-02-17T14:16:27Z | 2022-02-17T14:16:27Z | NONE | null | null | null | null | ## Describe the bug
According to https://huggingface.co/docs/datasets/loading_datasets.html#loading-a-dataset-builder, setting HF_DATASETS_OFFLINE to 1 should make datasets to "run in full offline mode". It didn't work for me. At the very beginning, datasets still tried to download "custom data configuration" for JSON... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3447/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3447/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3445 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3445/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3445/comments | https://api.github.com/repos/huggingface/datasets/issues/3445/events | https://github.com/huggingface/datasets/issues/3445 | 1,082,370,968 | I_kwDODunzps5Ag6uY | 3,445 | question | {
"avatar_url": "https://avatars.githubusercontent.com/u/38075175?v=4",
"events_url": "https://api.github.com/users/BAKAYOKO0232/events{/privacy}",
"followers_url": "https://api.github.com/users/BAKAYOKO0232/followers",
"following_url": "https://api.github.com/users/BAKAYOKO0232/following{/other_user}",
"gist... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"Hi ! What's your question ?"
] | 2021-12-16T15:57:00Z | 2022-01-03T10:09:00Z | 2022-01-03T10:09:00Z | NONE | null | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3445/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3445/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3444 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3444/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3444/comments | https://api.github.com/repos/huggingface/datasets/issues/3444/events | https://github.com/huggingface/datasets/issues/3444 | 1,082,078,961 | I_kwDODunzps5Afzbx | 3,444 | Align the Dataset and IterableDataset processing API | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Yes I agree, these should be as aligned as possible. Maybe we can also check the feedback in the survey at http://hf.co/oss-survey and see if people mentioned related things on the API (in particular if we go the breaking change way, it would be good to be sure we are taking the right direction for the community).... | 2021-12-16T11:26:11Z | 2025-01-31T11:07:07Z | null | MEMBER | null | null | null | null | ## Intro
items marked like <s>this</s> are done already :)
Currently the two classes have two distinct API for processing:
### The `.map()` method
Both have those parameters in common: function, batched, batch_size
- IterableDataset is missing those parameters:
<s>with_indices</s>, with_rank, <s>input_columns</s>,... | null | {
"+1": 14,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 14,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3444/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3444/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3441 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3441/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3441/comments | https://api.github.com/repos/huggingface/datasets/issues/3441/events | https://github.com/huggingface/datasets/issues/3441 | 1,081,571,784 | I_kwDODunzps5Ad3nI | 3,441 | Add QuALITY dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | null | [
"I'll take this one if no one hasn't yet!"
] | 2021-12-15T22:26:19Z | 2021-12-28T15:17:05Z | null | MEMBER | null | null | null | null | ## Adding a Dataset
- **Name:** QuALITY
- **Description:** A challenging question answering with very long contexts (Twitter [thread](https://twitter.com/sleepinyourhat/status/1471225421794529281?s=20))
- **Paper:** No ArXiv link yet, but draft is [here](https://github.com/nyu-mll/quality/blob/main/quality_preprint.... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3441/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3441/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3440/comments | https://api.github.com/repos/huggingface/datasets/issues/3440/events | https://github.com/huggingface/datasets/issues/3440 | 1,081,528,426 | I_kwDODunzps5AdtBq | 3,440 | datasets keeps reading from cached files, although I disabled it | {
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! What version of `datasets` are you using ? Can you also provide the logs you get before it raises the error ?"
] | 2021-12-15T21:26:22Z | 2022-02-24T09:12:22Z | 2022-02-24T09:12:22Z | NONE | null | null | null | null | ## Describe the bug
Hi,
I am trying to avoid dataset library using cached files, I get the following bug when this tried to read the cached files. I tried to do the followings:
```
from datasets import set_caching_enabled
set_caching_enabled(False)
```
also force redownlaod:
```
download_mode='force_redownloa... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3440/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3440/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3434 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3434/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3434/comments | https://api.github.com/repos/huggingface/datasets/issues/3434/events | https://github.com/huggingface/datasets/issues/3434 | 1,080,917,446 | I_kwDODunzps5AbX3G | 3,434 | Add The People's Speech | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",... | closed | false | null | [] | null | [
"This dataset is now available on the Hub here: https://huggingface.co/datasets/MLCommons/peoples_speech"
] | 2021-12-15T11:21:21Z | 2023-02-28T16:22:29Z | 2023-02-28T16:22:28Z | COLLABORATOR | null | null | null | null | ## Adding a Dataset
- **Name:** The People's Speech
- **Description:** a massive English-language dataset of audio transcriptions of full sentences.
- **Paper:** https://openreview.net/pdf?id=R8CwidgJ0yT
- **Data:** https://mlcommons.org/en/peoples-speech/
- **Motivation:** With over 30,000 hours of speech, this ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3434/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3434/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3433 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3433/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3433/comments | https://api.github.com/repos/huggingface/datasets/issues/3433/events | https://github.com/huggingface/datasets/issues/3433 | 1,080,910,724 | I_kwDODunzps5AbWOE | 3,433 | Add Multilingual Spoken Words dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",... | closed | false | null | [] | null | [] | 2021-12-15T11:14:44Z | 2022-02-22T10:03:53Z | 2022-02-22T10:03:53Z | MEMBER | null | null | null | null | ## Adding a Dataset
- **Name:** Multilingual Spoken Words
- **Description:** Multilingual Spoken Words Corpus is a large and growing audio dataset of spoken words in 50 languages for academic research and commercial applications in keyword spotting and spoken term search, licensed under CC-BY 4.0. The dataset contain... | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3433/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3433/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3431/comments | https://api.github.com/repos/huggingface/datasets/issues/3431/events | https://github.com/huggingface/datasets/issues/3431 | 1,079,866,083 | I_kwDODunzps5AXXLj | 3,431 | Unable to resolve any data file after loading once | {
"avatar_url": "https://avatars.githubusercontent.com/u/84694183?v=4",
"events_url": "https://api.github.com/users/LzyFischer/events{/privacy}",
"followers_url": "https://api.github.com/users/LzyFischer/followers",
"following_url": "https://api.github.com/users/LzyFischer/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Hi ! `load_dataset` accepts as input either a local dataset directory or a dataset name from the Hugging Face Hub.\r\n\r\nSo here you are getting this error the second time because it tries to load the local `wiki_dpr` directory, instead of `wiki_dpr` from the Hub. It doesn't work since it's a **cache** directory,... | 2021-12-14T15:02:15Z | 2022-12-11T10:53:04Z | 2022-02-24T09:13:52Z | NONE | null | null | null | null | when I rerun my program, it occurs this error
" Unable to resolve any data file that matches '['**train*']' at /data2/whr/lzy/open_domain_data/retrieval/wiki_dpr with any supported extension ['csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'zip']", so how could i deal with this problem?
thx.
And below is my code .
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3431/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3431/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/3425 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3425/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3425/comments | https://api.github.com/repos/huggingface/datasets/issues/3425/events | https://github.com/huggingface/datasets/issues/3425 | 1,078,598,140 | I_kwDODunzps5AShn8 | 3,425 | Getting configs names takes too long | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"maybe related to https://github.com/huggingface/datasets/issues/2859\r\n",
"It looks like it's currently calling `HfFileSystem.ls()` ~8 times at the root and for each subdirectory:\r\n- \"\"\r\n- \"en.noblocklist\"\r\n- \"en.noclean\"\r\n- \"en\"\r\n- \"multilingual\"\r\n- \"realnewslike\"\r\n\r\nCurrently `ls` ... | 2021-12-13T14:27:57Z | 2021-12-13T14:53:33Z | null | COLLABORATOR | null | null | null | null |
## Steps to reproduce the bug
```python
from datasets import get_dataset_config_names
get_dataset_config_names("allenai/c4")
```
## Expected results
I would expect to get the answer quickly, at least in less than 10s
## Actual results
It takes about 45s on my environment
## Environment info
- `d... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3425/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3425/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.