
id int64 599M 3.26B | number int64 1 7.7k | title stringlengths 1 290 | body stringlengths 0 228k ⌀ | state stringclasses 2
values | html_url stringlengths 46 51 | created_at timestamp[s]date 2020-04-14 10:18:02 2025-07-23 08:04:53 | updated_at timestamp[s]date 2020-04-27 16:04:17 2025-07-23 18:53:44 | closed_at timestamp[s]date 2020-04-14 12:01:40 2025-07-23 16:44:42 ⌀ | user dict | labels listlengths 0 4 | is_pull_request bool 2
classes | comments listlengths 0 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
1,615,029,615 | 5,621 | Adding Oracle Cloud to docs | Adding Oracle Cloud's fsspec implementation to the list of supported cloud storage providers. | closed | https://github.com/huggingface/datasets/pull/5621 | 2023-03-08T10:22:50 | 2023-03-11T00:57:18 | 2023-03-11T00:49:56 | {
"login": "ahosler",
"id": 29129502,
"type": "User"
} | [] | true | [] |
1,613,460,520 | 5,620 | Bump pyarrow to 8.0.0 | Fix those for Pandas 2.0 (tested [here](https://github.com/huggingface/datasets/actions/runs/4346221280/jobs/7592010397) with pandas==2.0.0.rc0):
```python
=========================== short test summary info ============================
FAILED tests/test_arrow_dataset.py::BaseDatasetTest::test_to_parquet_in_memory... | closed | https://github.com/huggingface/datasets/pull/5620 | 2023-03-07T13:31:53 | 2023-03-08T14:01:27 | 2023-03-08T13:54:22 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,613,439,709 | 5,619 | unpin fsspec | close https://github.com/huggingface/datasets/issues/5618 | closed | https://github.com/huggingface/datasets/pull/5619 | 2023-03-07T13:22:41 | 2023-03-07T13:47:01 | 2023-03-07T13:39:02 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,612,977,934 | 5,618 | Unpin fsspec < 2023.3.0 once issue fixed | Unpin `fsspec` upper version once root cause of our CI break is fixed.
See:
- #5614 | closed | https://github.com/huggingface/datasets/issues/5618 | 2023-03-07T08:41:51 | 2023-03-07T13:39:03 | 2023-03-07T13:39:03 | {
"login": "albertvillanova",
"id": 8515462,
"type": "User"
} | [] | false | [] |
1,612,947,422 | 5,617 | Fix CI by temporarily pinning fsspec < 2023.3.0 | As a hotfix for our CI, temporarily pin `fsspec`:
Fix #5616.
Until root cause is fixed, see:
- #5614 | closed | https://github.com/huggingface/datasets/pull/5617 | 2023-03-07T08:18:20 | 2023-03-07T08:44:55 | 2023-03-07T08:37:28 | {
"login": "albertvillanova",
"id": 8515462,
"type": "User"
} | [] | true | [] |
1,612,932,508 | 5,616 | CI is broken after fsspec-2023.3.0 release | As reported by @lhoestq, our CI is broken after `fsspec` 2023.3.0 release:
```
FAILED tests/test_filesystem.py::test_compression_filesystems[Bz2FileSystem] - AssertionError: assert [{'created': ...: False, ...}] == ['file.txt']
At index 0 diff: {'name': 'file.txt', 'size': 70, 'type': 'file', 'created': 1678175677... | closed | https://github.com/huggingface/datasets/issues/5616 | 2023-03-07T08:06:39 | 2023-03-07T08:37:29 | 2023-03-07T08:37:29 | {
"login": "albertvillanova",
"id": 8515462,
"type": "User"
} | [
{
"name": "bug",
"color": "d73a4a"
}
] | false | [] |
1,612,552,653 | 5,615 | IterableDataset.add_column is unable to accept another IterableDataset as a parameter. | ### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
... | closed | https://github.com/huggingface/datasets/issues/5615 | 2023-03-07T01:52:00 | 2023-03-09T15:24:05 | 2023-03-09T15:23:54 | {
"login": "zsaladin",
"id": 6466389,
"type": "User"
} | [
{
"name": "wontfix",
"color": "ffffff"
}
] | false | [] |
1,611,896,357 | 5,614 | Fix archive fs test | null | closed | https://github.com/huggingface/datasets/pull/5614 | 2023-03-06T17:28:09 | 2023-03-07T13:27:50 | 2023-03-07T13:20:57 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,611,875,473 | 5,613 | Version mismatch with multiprocess and dill on Python 3.10 | ### Describe the bug
Grabbing the latest version of `datasets` and `apache-beam` with `poetry` using Python 3.10 gives a crash at runtime. The crash is
```
File "/Users/adpauls/sc/git/DSI-transformers/data/NQ/create_NQ_train_vali.py", line 1, in <module>
import datasets
File "/Users/adpauls/Library/Caches/... | open | https://github.com/huggingface/datasets/issues/5613 | 2023-03-06T17:14:41 | 2024-04-05T20:13:52 | null | {
"login": "adampauls",
"id": 1243668,
"type": "User"
} | [] | false | [] |
1,611,262,510 | 5,612 | Arrow map type in parquet files unsupported | ### Describe the bug
When I try to load parquet files that were processed with Spark, I get the following issue:
`ValueError: Arrow type map<string, string ('warc_headers')> does not have a datasets dtype equivalent.`
Strangely, loading the dataset with `streaming=True` solves the issue.
### Steps to reproduce ... | open | https://github.com/huggingface/datasets/issues/5612 | 2023-03-06T12:03:24 | 2024-03-15T18:56:12 | null | {
"login": "TevenLeScao",
"id": 26709476,
"type": "User"
} | [] | false | [] |
1,611,197,906 | 5,611 | add Dataset.to_list | close https://github.com/huggingface/datasets/issues/5606
This PR is for adding the `Dataset.to_list` method.
Thank you in advance.
| closed | https://github.com/huggingface/datasets/pull/5611 | 2023-03-06T11:21:57 | 2023-03-27T13:34:19 | 2023-03-27T13:26:38 | {
"login": "kyoto7250",
"id": 50972773,
"type": "User"
} | [] | true | [] |
1,610,698,006 | 5,610 | use datasets streaming mode in trainer ddp mode cause memory leak | ### Describe the bug
use datasets streaming mode in trainer ddp mode cause memory leak
### Steps to reproduce the bug
import os
import time
import datetime
import sys
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader, random_split, RandomSampler, Sequenti... | open | https://github.com/huggingface/datasets/issues/5610 | 2023-03-06T05:26:49 | 2024-03-07T01:11:32 | null | {
"login": "gromzhu",
"id": 15223544,
"type": "User"
} | [] | false | [] |
1,610,062,862 | 5,609 | `load_from_disk` vs `load_dataset` performance. | ### Describe the bug
I have downloaded `openwebtext` (~12GB) and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_di... | open | https://github.com/huggingface/datasets/issues/5609 | 2023-03-05T05:27:15 | 2023-07-13T18:48:05 | null | {
"login": "davidgilbertson",
"id": 4443482,
"type": "User"
} | [] | false | [] |
1,609,996,563 | 5,608 | audiofolder only creates dataset of 13 rows (files) when the data folder it's reading from has 20,000 mp3 files. | ### Describe the bug
x = load_dataset("audiofolder", data_dir="x")
When running this, x is a dataset of 13 rows (files) when it should be 20,000 rows (files) as the data_dir "x" has 20,000 mp3 files. Does anyone know what could possibly cause this (naming convention of mp3 files, etc.)
### Steps to reproduce the b... | closed | https://github.com/huggingface/datasets/issues/5608 | 2023-03-05T00:14:45 | 2023-03-12T00:02:57 | 2023-03-12T00:02:57 | {
"login": "jcho19",
"id": 107211437,
"type": "User"
} | [] | false | [] |
1,609,166,035 | 5,607 | Fix outdated `verification_mode` values | ~I think it makes sense not to save `dataset_info.json` file to a dataset cache directory when loading dataset with `verification_mode="no_checks"` because otherwise when next time the dataset is loaded **without** `verification_mode="no_checks"`, it will be loaded successfully, despite some values in info might not co... | closed | https://github.com/huggingface/datasets/pull/5607 | 2023-03-03T19:50:29 | 2023-03-09T17:34:13 | 2023-03-09T17:27:07 | {
"login": "polinaeterna",
"id": 16348744,
"type": "User"
} | [] | true | [] |
1,608,911,632 | 5,606 | Add `Dataset.to_list` to the API | Since there is `Dataset.from_list` in the API, we should also add `Dataset.to_list` to be consistent.
Regarding the implementation, we can re-use `Dataset.to_dict`'s code and replace the `to_pydict` calls with `to_pylist`. | closed | https://github.com/huggingface/datasets/issues/5606 | 2023-03-03T16:17:10 | 2023-03-27T13:26:40 | 2023-03-27T13:26:40 | {
"login": "mariosasko",
"id": 47462742,
"type": "User"
} | [
{
"name": "enhancement",
"color": "a2eeef"
},
{
"name": "good first issue",
"color": "7057ff"
}
] | false | [] |
1,608,865,460 | 5,605 | Update README logo | null | closed | https://github.com/huggingface/datasets/pull/5605 | 2023-03-03T15:46:31 | 2023-03-03T21:57:18 | 2023-03-03T21:50:17 | {
"login": "gary149",
"id": 3841370,
"type": "User"
} | [] | true | [] |
1,608,304,775 | 5,604 | Problems with downloading The Pile | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
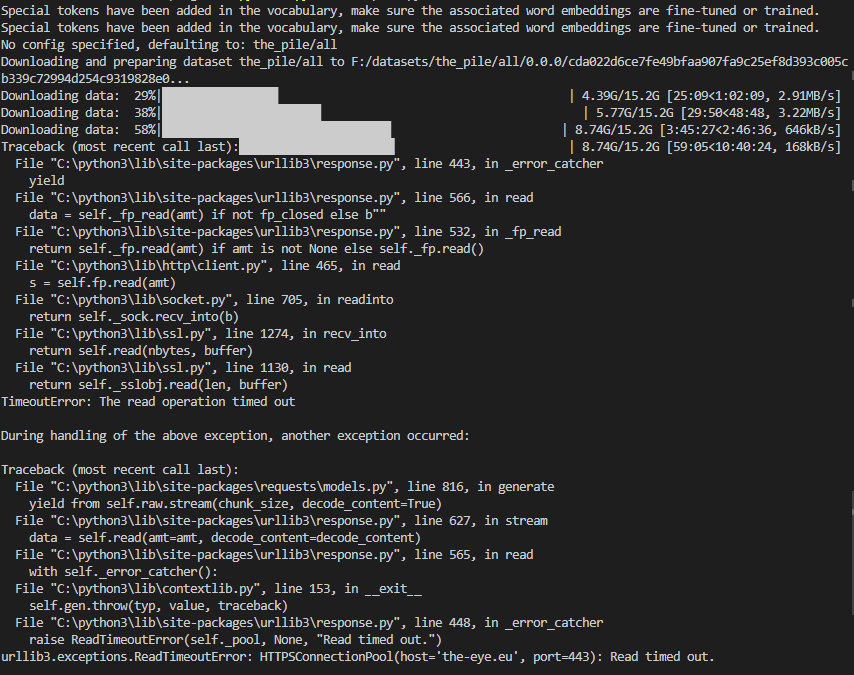
Here are the downloaded files:
,
1. `huggingface-cli login` with WRITE token
2. `git lfs install`
3. `git clone https://huggingfa... | closed | https://github.com/huggingface/datasets/issues/5601 | 2023-03-02T12:08:39 | 2023-03-14T16:55:35 | 2023-03-14T16:55:34 | {
"login": "OleksandrKorovii",
"id": 107404835,
"type": "User"
} | [] | false | [] |
1,606,585,596 | 5,600 | Dataloader getitem not working for DreamboothDatasets | ### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset ... | closed | https://github.com/huggingface/datasets/issues/5600 | 2023-03-02T11:00:27 | 2023-03-13T17:59:35 | 2023-03-13T17:59:35 | {
"login": "salahiguiliz",
"id": 76955987,
"type": "User"
} | [] | false | [] |
1,605,018,478 | 5,598 | Fix push_to_hub with no dataset_infos | As reported in https://github.com/vijaydwivedi75/lrgb/issues/10, `push_to_hub` fails if the remote repository already exists and has a README.md without `dataset_info` in the YAML tags
cc @clefourrier | closed | https://github.com/huggingface/datasets/pull/5598 | 2023-03-01T13:54:06 | 2023-03-02T13:47:13 | 2023-03-02T13:40:17 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,604,928,721 | 5,597 | in-place dataset update | ### Motivation
For the circumstance that I creat an empty `Dataset` and keep appending new rows into it, I found that it leads to creating a new dataset at each call. It looks quite memory-consuming. I just wonder if there is any more efficient way to do this.
```python
from datasets import Dataset
ds = Datas... | closed | https://github.com/huggingface/datasets/issues/5597 | 2023-03-01T12:58:18 | 2023-03-02T13:30:41 | 2023-03-02T03:47:00 | {
"login": "speedcell4",
"id": 3585459,
"type": "User"
} | [
{
"name": "wontfix",
"color": "ffffff"
}
] | false | [] |
1,604,919,993 | 5,596 | [TypeError: Couldn't cast array of type] Can only load a subset of the dataset | ### Describe the bug
I'm trying to load this [dataset](https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues) which consists of jsonl files and I get the following error:
```
casted_values = _c(array.values, feature[0])
File "/opt/conda/lib/python3.7/site-packages/datasets/table.py", line 1839, in wr... | closed | https://github.com/huggingface/datasets/issues/5596 | 2023-03-01T12:53:08 | 2023-12-05T03:22:00 | 2023-03-02T11:12:11 | {
"login": "loubnabnl",
"id": 44069155,
"type": "User"
} | [] | false | [] |
1,604,070,629 | 5,595 | Unpins sqlAlchemy | Closes #5477 | closed | https://github.com/huggingface/datasets/pull/5595 | 2023-03-01T01:33:45 | 2023-04-04T08:20:19 | 2023-04-04T08:19:14 | {
"login": "lazarust",
"id": 46943923,
"type": "User"
} | [] | true | [] |
1,603,980,995 | 5,594 | Error while downloading the xtreme udpos dataset | ### Describe the bug
Hi,
I am facing an error while downloading the xtreme udpos dataset using load_dataset. I have datasets 2.10.1 installed
```Downloading and preparing dataset xtreme/udpos.Arabic to /compute/tir-1-18/skhanuja/multilingual_ft/cache/data/xtreme/udpos.Arabic/1.0.0/29f5d57a48779f37ccb75cb8708d1... | closed | https://github.com/huggingface/datasets/issues/5594 | 2023-02-28T23:40:53 | 2023-11-04T20:45:56 | 2023-07-24T14:22:18 | {
"login": "simran-khanuja",
"id": 24687672,
"type": "User"
} | [] | false | [] |
1,603,619,124 | 5,592 | Fix docstring example | Fixes #5581 to use the correct output for the `set_format` method. | closed | https://github.com/huggingface/datasets/pull/5592 | 2023-02-28T18:42:37 | 2023-02-28T19:26:33 | 2023-02-28T19:19:15 | {
"login": "stevhliu",
"id": 59462357,
"type": "User"
} | [] | true | [] |
1,603,571,407 | 5,591 | set dev version | null | closed | https://github.com/huggingface/datasets/pull/5591 | 2023-02-28T18:09:05 | 2023-02-28T18:16:31 | 2023-02-28T18:09:15 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,603,549,504 | 5,590 | Release: 2.10.1 | null | closed | https://github.com/huggingface/datasets/pull/5590 | 2023-02-28T17:58:11 | 2023-02-28T18:16:27 | 2023-02-28T18:06:08 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,603,535,704 | 5,589 | Revert "pass the dataset features to the IterableDataset.from_generator" | This reverts commit b91070b9c09673e2e148eec458036ab6a62ac042 (temporarily)
It hurts iterable dataset performance a lot (e.g. x4 slower because it encodes+decodes images unnecessarily). I think we need to fix this before re-adding it
cc @mariosasko @Hubert-Bonisseur | closed | https://github.com/huggingface/datasets/pull/5589 | 2023-02-28T17:52:04 | 2023-09-24T10:07:33 | 2023-03-21T14:18:18 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,603,304,766 | 5,588 | Flatten dataset on the fly in `save_to_disk` | Flatten a dataset on the fly in `save_to_disk` instead of doing it with `flatten_indices` to avoid creating an additional cache file.
(this is one of the sub-tasks in https://github.com/huggingface/datasets/issues/5507) | closed | https://github.com/huggingface/datasets/pull/5588 | 2023-02-28T15:37:46 | 2023-02-28T17:28:35 | 2023-02-28T17:21:17 | {
"login": "mariosasko",
"id": 47462742,
"type": "User"
} | [] | true | [] |
1,603,139,420 | 5,587 | Fix `sort` with indices mapping | Fixes the `key` range in the `query_table` call in `sort` to account for an indices mapping
Fix #5586 | closed | https://github.com/huggingface/datasets/pull/5587 | 2023-02-28T14:05:08 | 2023-02-28T17:28:57 | 2023-02-28T17:21:58 | {
"login": "mariosasko",
"id": 47462742,
"type": "User"
} | [] | true | [] |
1,602,961,544 | 5,586 | .sort() is broken when used after .filter(), only in 2.10.0 | ### Describe the bug
Hi, thank you for your support!
It seems like the addition of multiple key sort (#5502) in 2.10.0 broke the `.sort()` method.
After filtering a dataset with `.filter()`, the `.sort()` seems to refer to the query_table index of the previous unfiltered dataset, resulting in an IndexError.
... | closed | https://github.com/huggingface/datasets/issues/5586 | 2023-02-28T12:18:09 | 2023-02-28T18:17:26 | 2023-02-28T17:21:59 | {
"login": "MattYoon",
"id": 57797966,
"type": "User"
} | [
{
"name": "bug",
"color": "d73a4a"
}
] | false | [] |
1,602,190,030 | 5,585 | Cache is not transportable | ### Describe the bug
I would like to share cache between two machines (a Windows host machine and a WSL instance).
I run most my code in WSL. I have just run out of space in the virtual drive. Rather than expand the drive size, I plan to move to cache to the host Windows machine, thereby sharing the downloads.
I... | closed | https://github.com/huggingface/datasets/issues/5585 | 2023-02-28T00:53:06 | 2023-02-28T21:26:52 | 2023-02-28T21:26:52 | {
"login": "davidgilbertson",
"id": 4443482,
"type": "User"
} | [] | false | [] |
1,601,821,808 | 5,584 | Unable to load coyo700M dataset | ### Describe the bug
Seeing this error when downloading https://huggingface.co/datasets/kakaobrain/coyo-700m:
```ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.```
Full stack trace
```Downloading and preparing dataset parquet/kakaobrain--coy... | closed | https://github.com/huggingface/datasets/issues/5584 | 2023-02-27T19:35:03 | 2023-02-28T07:27:59 | 2023-02-28T07:27:58 | {
"login": "manuaero",
"id": 3059998,
"type": "User"
} | [] | false | [] |
1,601,583,625 | 5,583 | Do no write index by default when exporting a dataset | Ensures all the writers that use Pandas for conversion (JSON, CSV, SQL) do not export `index` by default (https://github.com/huggingface/datasets/pull/5490 only did this for CSV) | closed | https://github.com/huggingface/datasets/pull/5583 | 2023-02-27T17:04:46 | 2023-02-28T13:52:15 | 2023-02-28T13:44:04 | {
"login": "mariosasko",
"id": 47462742,
"type": "User"
} | [] | true | [] |
1,600,932,092 | 5,582 | Add column_names to IterableDataset | This PR closes #5383
* Add column_names property to IterableDataset
* Add multiple tests for this new property | closed | https://github.com/huggingface/datasets/pull/5582 | 2023-02-27T10:50:07 | 2023-03-13T19:10:22 | 2023-03-13T19:03:32 | {
"login": "patrickloeber",
"id": 50772274,
"type": "User"
} | [] | true | [] |
1,600,675,489 | 5,581 | [DOC] Mistaken docs on set_format | ### Describe the bug
https://huggingface.co/docs/datasets/v2.10.0/en/package_reference/main_classes#datasets.Dataset.set_format
<img width="700" alt="image" src="https://user-images.githubusercontent.com/36224762/221506973-ae2e3991-60a7-4d4e-99f8-965c6eb61e59.png">
While actually running it will result in:
<img w... | closed | https://github.com/huggingface/datasets/issues/5581 | 2023-02-27T08:03:09 | 2023-02-28T19:19:17 | 2023-02-28T19:19:17 | {
"login": "NightMachinery",
"id": 36224762,
"type": "User"
} | [
{
"name": "good first issue",
"color": "7057ff"
}
] | false | [] |
1,600,431,792 | 5,580 | Support cloud storage in load_dataset via fsspec | Closes https://github.com/huggingface/datasets/issues/5281
This PR uses fsspec to support datasets on cloud storage (tested manually with GCS). ETags are currently unsupported for cloud storage. In general, a much larger refactor could be done to just use fsspec for all schemes (ftp, http/s, s3, gcs) to unify the in... | closed | https://github.com/huggingface/datasets/pull/5580 | 2023-02-27T04:06:05 | 2024-11-27T01:25:39 | 2023-03-11T00:55:40 | {
"login": "dwyatte",
"id": 2512762,
"type": "User"
} | [] | true | [] |
1,599,732,211 | 5,579 | Add instructions to create `DataLoader` from augmented dataset in object detection guide | The following adds instructions on how to create a `DataLoader` from the guide on how to use object detection with augmentations (#4710). I am open to hearing any suggestions for improvement ! | closed | https://github.com/huggingface/datasets/pull/5579 | 2023-02-25T14:53:17 | 2023-03-23T19:24:59 | 2023-03-23T19:24:50 | {
"login": "Laurent2916",
"id": 21087104,
"type": "User"
} | [] | true | [] |
1,598,863,119 | 5,578 | Add `huggingface_hub` version to env cli command | Add the `huggingface_hub` version to the `env` command's output. | closed | https://github.com/huggingface/datasets/pull/5578 | 2023-02-24T15:37:43 | 2023-02-27T17:28:25 | 2023-02-27T17:21:09 | {
"login": "mariosasko",
"id": 47462742,
"type": "User"
} | [] | true | [] |
1,598,587,665 | 5,577 | Cannot load `the_pile_openwebtext2` | ### Describe the bug
I met the same bug mentioned in #3053 which is never fixed. Because several `reddit_scores` are larger than `int8` even `int16`. https://huggingface.co/datasets/the_pile_openwebtext2/blob/main/the_pile_openwebtext2.py#L62
### Steps to reproduce the bug
```python3
from datasets import load... | closed | https://github.com/huggingface/datasets/issues/5577 | 2023-02-24T13:01:48 | 2023-02-24T14:01:09 | 2023-02-24T14:01:09 | {
"login": "wjfwzzc",
"id": 5126316,
"type": "User"
} | [] | false | [] |
1,598,582,744 | 5,576 | I was getting a similar error `pyarrow.lib.ArrowInvalid: Integer value 528 not in range: -128 to 127` - AFAICT, this is because the type specified for `reddit_scores` is `datasets.Sequence(datasets.Value("int8"))`, but the actual values can be well outside the max range for 8-bit integers. | I was getting a similar error `pyarrow.lib.ArrowInvalid: Integer value 528 not in range: -128 to 127` - AFAICT, this is because the type specified for `reddit_scores` is `datasets.Sequence(datasets.Value("int8"))`, but the actual values can be well outside the max range for 8-bit integers.
I worked aro... | closed | https://github.com/huggingface/datasets/issues/5576 | 2023-02-24T12:57:49 | 2023-02-24T12:58:31 | 2023-02-24T12:58:18 | {
"login": "wjfwzzc",
"id": 5126316,
"type": "User"
} | [] | false | [] |
1,598,396,552 | 5,575 | Metadata for each column | ### Feature request
Being able to put some metadata for each column as a string or any other type.
### Motivation
I will bring the motivation by an example, lets say we are experimenting with embedding produced by some image encoder network, and we want to iterate through a couple of preprocessing and see which on... | open | https://github.com/huggingface/datasets/issues/5575 | 2023-02-24T10:53:44 | 2024-01-05T21:48:35 | null | {
"login": "parsa-ra",
"id": 11356471,
"type": "User"
} | [
{
"name": "enhancement",
"color": "a2eeef"
}
] | false | [] |
1,598,104,691 | 5,574 | c4 dataset streaming fails with `FileNotFoundError` | ### Describe the bug
Loading the `c4` dataset in streaming mode with `load_dataset("c4", "en", split="validation", streaming=True)` and then using it fails with a `FileNotFoundException`.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("c4", "en", split="train", ... | closed | https://github.com/huggingface/datasets/issues/5574 | 2023-02-24T07:57:32 | 2023-12-18T07:32:32 | 2023-02-27T04:03:38 | {
"login": "krasserm",
"id": 202907,
"type": "User"
} | [] | false | [] |
1,597,400,836 | 5,573 | Use soundfile for mp3 decoding instead of torchaudio | I've removed `torchaudio` completely and switched to use `soundfile` for everything. With the new version of `soundfile` package this should work smoothly because the `libsndfile` C library is bundled, in Linux wheels too.
Let me know if you think it's too harsh and we should continue to support `torchaudio` decodi... | closed | https://github.com/huggingface/datasets/pull/5573 | 2023-02-23T19:19:44 | 2023-02-28T20:25:14 | 2023-02-28T20:16:02 | {
"login": "polinaeterna",
"id": 16348744,
"type": "User"
} | [] | true | [] |
1,597,257,624 | 5,572 | Datasets 2.10.0 does not reuse the dataset cache | ### Describe the bug
download_mode="reuse_dataset_if_exists" will always consider that a dataset doesn't exist.
Specifically, upon losing an internet connection trying to load a dataset for a second time in ten seconds, a connection error results, showing a breakpoint of:
```
File ~/jupyterlab/.direnv/python-... | closed | https://github.com/huggingface/datasets/issues/5572 | 2023-02-23T17:28:11 | 2023-02-23T18:03:55 | 2023-02-23T18:03:55 | {
"login": "lsb",
"id": 45281,
"type": "User"
} | [] | false | [] |
1,597,198,953 | 5,571 | load_dataset fails for JSON in windows | ### Describe the bug
Steps:
1. Created a dataset in a Linux VM and created a small sample using dataset.to_json() method.
2. Downloaded the JSON file to my local Windows machine for working and saved in say - r"C:\Users\name\file.json"
3. I am reading the file in my local PyCharm - the location of python file is di... | closed | https://github.com/huggingface/datasets/issues/5571 | 2023-02-23T16:50:11 | 2023-02-24T13:21:47 | 2023-02-24T13:21:47 | {
"login": "abinashsahu",
"id": 11876897,
"type": "User"
} | [] | false | [] |
1,597,190,926 | 5,570 | load_dataset gives FileNotFoundError on imagenet-1k if license is not accepted on the hub | ### Describe the bug
When calling ```load_dataset('imagenet-1k')``` FileNotFoundError is raised, if not logged in and if logged in with huggingface-cli but not having accepted the licence on the hub. There is no error once accepting.
### Steps to reproduce the bug
```
from datasets import load_dataset
imagenet =... | closed | https://github.com/huggingface/datasets/issues/5570 | 2023-02-23T16:44:32 | 2023-07-24T15:18:50 | 2023-07-24T15:18:50 | {
"login": "buoi",
"id": 38630200,
"type": "User"
} | [] | false | [] |
1,597,132,383 | 5,569 | pass the dataset features to the IterableDataset.from_generator function | [5558](https://github.com/huggingface/datasets/issues/5568) | closed | https://github.com/huggingface/datasets/pull/5569 | 2023-02-23T16:06:04 | 2023-02-24T14:06:37 | 2023-02-23T18:15:16 | {
"login": "bruno-hays",
"id": 48770768,
"type": "User"
} | [] | true | [] |
1,596,900,532 | 5,568 | dataset.to_iterable_dataset() loses useful info like dataset features | ### Describe the bug
Hello,
I like the new `to_iterable_dataset` feature but I noticed something that seems to be missing.
When using `to_iterable_dataset` to transform your map style dataset into iterable dataset, you lose valuable metadata like the features.
These metadata are useful if you want to interleav... | closed | https://github.com/huggingface/datasets/issues/5568 | 2023-02-23T13:45:33 | 2023-02-24T13:22:36 | 2023-02-24T13:22:36 | {
"login": "bruno-hays",
"id": 48770768,
"type": "User"
} | [
{
"name": "enhancement",
"color": "a2eeef"
},
{
"name": "good first issue",
"color": "7057ff"
}
] | false | [] |
1,595,916,674 | 5,566 | Directly reading parquet files in a s3 bucket from the load_dataset method | ### Feature request
Right now, we have to read the get the parquet file to the local storage. So having ability to read given the bucket directly address would be benificial
### Motivation
In a production set up, this feature can help us a lot. So we do not need move training datafiles in between storage.
### Yo... | open | https://github.com/huggingface/datasets/issues/5566 | 2023-02-22T22:13:40 | 2023-02-23T11:03:29 | null | {
"login": "shamanez",
"id": 16892570,
"type": "User"
} | [
{
"name": "duplicate",
"color": "cfd3d7"
},
{
"name": "enhancement",
"color": "a2eeef"
}
] | false | [] |
1,595,281,752 | 5,565 | Add writer_batch_size for ArrowBasedBuilder | This way we can control the size of the record_batches/row_groups of arrow/parquet files.
This can be useful for `datasets-server` to keep control of the row groups size which can affect random access performance for audio/image/video datasets
Right now having 1,000 examples per row group cause some image dataset... | closed | https://github.com/huggingface/datasets/pull/5565 | 2023-02-22T15:09:30 | 2023-03-10T13:53:03 | 2023-03-10T13:45:43 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,595,064,698 | 5,564 | Set dev version | null | closed | https://github.com/huggingface/datasets/pull/5564 | 2023-02-22T13:00:09 | 2023-02-22T13:09:26 | 2023-02-22T13:00:25 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,595,049,025 | 5,563 | Release: 2.10.0 | null | closed | https://github.com/huggingface/datasets/pull/5563 | 2023-02-22T12:48:52 | 2023-02-22T13:05:55 | 2023-02-22T12:56:48 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,594,625,539 | 5,562 | Update csv.py | Removed mangle_dup_cols=True from BuilderConfig.
It triggered following deprecation warning:
/usr/local/lib/python3.8/dist-packages/datasets/download/streaming_download_manager.py:776: FutureWarning: the 'mangle_dupe_cols' keyword is deprecated and will be removed in a future version. Please take steps to stop the ... | closed | https://github.com/huggingface/datasets/pull/5562 | 2023-02-22T07:56:10 | 2023-02-23T11:07:49 | 2023-02-23T11:00:58 | {
"login": "xdoubleu",
"id": 54279069,
"type": "User"
} | [] | true | [] |
1,593,862,388 | 5,561 | Add pre-commit config yaml file to enable automatic code formatting | @huggingface/datasets do you think it would be useful? Motivation - sometimes PRs are like 30% "fix: style" commits :)
If so - I need to double check the config but for me locally it works as expected. | closed | https://github.com/huggingface/datasets/pull/5561 | 2023-02-21T17:35:07 | 2023-02-28T15:37:22 | 2023-02-23T18:23:29 | {
"login": "polinaeterna",
"id": 16348744,
"type": "User"
} | [] | true | [] |
1,593,809,978 | 5,560 | Ensure last tqdm update in `map` | This PR modifies `map` to:
* ensure the TQDM bar gets the last progress update
* when a map function fails, avoid throwing a chained exception in the single-proc mode | closed | https://github.com/huggingface/datasets/pull/5560 | 2023-02-21T16:56:17 | 2023-02-21T18:26:23 | 2023-02-21T18:19:09 | {
"login": "mariosasko",
"id": 47462742,
"type": "User"
} | [] | true | [] |
1,593,676,489 | 5,559 | Fix map suffix_template | #5455 introduced a small bug that lead `map` to ignore the `suffix_template` argument and not put suffixes to cached files in multiprocessing.
I fixed this and also improved a few things:
- regarding logging: "Loading cached processed dataset" is now logged only once even in multiprocessing (it used to be logged ... | closed | https://github.com/huggingface/datasets/pull/5559 | 2023-02-21T15:26:26 | 2023-02-21T17:21:37 | 2023-02-21T17:14:29 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,593,655,815 | 5,558 | Remove instructions for `ffmpeg` system package installation on Colab | Colab now has Ubuntu 20.04 which already has `ffmpeg` of required (>4) version. | closed | https://github.com/huggingface/datasets/pull/5558 | 2023-02-21T15:13:36 | 2023-03-01T13:46:04 | 2023-02-23T13:50:27 | {
"login": "polinaeterna",
"id": 16348744,
"type": "User"
} | [] | true | [] |
1,593,545,324 | 5,557 | Add filter desc | Otherwise it would show a `Map` progress bar, since it uses `map` under the hood | closed | https://github.com/huggingface/datasets/pull/5557 | 2023-02-21T14:04:42 | 2023-02-21T14:19:54 | 2023-02-21T14:12:39 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,593,246,936 | 5,556 | Use default audio resampling type | ...instead of relying on the optional librosa dependency `resampy`.
It was only used for `_decode_non_mp3_file_like` anyway and not for the other ones - removing it fixes consistency between decoding methods (except torchaudio decoding)
Therefore I think it is a better solution than adding `resampy` as a dependen... | closed | https://github.com/huggingface/datasets/pull/5556 | 2023-02-21T10:45:50 | 2023-02-21T12:49:50 | 2023-02-21T12:42:52 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,592,469,938 | 5,555 | `.shuffle` throwing error `ValueError: Protocol not known: parent` | ### Describe the bug
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In [16], line 1
----> 1 train_dataset = train_dataset.shuffle()
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/dataset... | open | https://github.com/huggingface/datasets/issues/5555 | 2023-02-20T21:33:45 | 2023-02-27T09:23:34 | null | {
"login": "prabhakar267",
"id": 10768588,
"type": "User"
} | [] | false | [] |
1,592,285,062 | 5,554 | Add resampy dep | In librosa 0.10 they removed the `resmpy` dependency and set it to optional.
However it is necessary for resampling. I added it to the "audio" extra dependencies. | closed | https://github.com/huggingface/datasets/pull/5554 | 2023-02-20T18:15:43 | 2023-09-24T10:07:29 | 2023-02-21T12:43:38 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,592,236,998 | 5,553 | improved message error row formatting | Solves #5539 | closed | https://github.com/huggingface/datasets/pull/5553 | 2023-02-20T17:29:14 | 2023-02-21T13:08:25 | 2023-02-21T12:58:12 | {
"login": "Plutone11011",
"id": 26489385,
"type": "User"
} | [] | true | [] |
1,592,186,703 | 5,552 | Make tiktoken tokenizers hashable | Fix for https://discord.com/channels/879548962464493619/1075729627546406912/1075729627546406912
| closed | https://github.com/huggingface/datasets/pull/5552 | 2023-02-20T16:50:09 | 2023-02-21T13:20:42 | 2023-02-21T13:13:05 | {
"login": "mariosasko",
"id": 47462742,
"type": "User"
} | [] | true | [] |
1,592,140,836 | 5,551 | Suggest scikit-learn instead of sklearn | This is kinda unimportant fix but, the suggested `pip install sklearn` does not work.
The current error message if sklearn is not installed:
```
ImportError: To be able to use [dataset name], you need to install the following dependency: sklearn.
Please install it using 'pip install sklearn' for instance.
```
... | closed | https://github.com/huggingface/datasets/pull/5551 | 2023-02-20T16:16:57 | 2023-02-21T13:27:57 | 2023-02-21T13:21:07 | {
"login": "osbm",
"id": 74963545,
"type": "User"
} | [] | true | [] |
1,591,409,475 | 5,550 | Resolve four broken refs in the docs | Hello!
## Pull Request overview
* Resolve 4 broken references in the docs
## The problems
Two broken references [here](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.class_encode_column):
 it said that if we set HF_HOME, downloaded datasets would be cached at specified address but it does not. downloaded models from checkpoint names are downloaded and cached at HF_HOME but this is not the case for datasets, t... | closed | https://github.com/huggingface/datasets/issues/5546 | 2023-02-18T13:30:35 | 2023-07-24T14:22:43 | 2023-07-24T14:22:43 | {
"login": "ErfanMoosaviMonazzah",
"id": 79091831,
"type": "User"
} | [] | false | [] |
1,590,315,972 | 5,545 | Added return methods for URL-references to the pushed dataset | Hi,
I was missing the ability to easily open the pushed dataset and it seemed like a quick fix.
Maybe we also want to log this info somewhere, but let me know if I need to add that too.
Cheers,
David | open | https://github.com/huggingface/datasets/pull/5545 | 2023-02-18T11:26:25 | 2023-12-18T16:57:56 | null | {
"login": "davidberenstein1957",
"id": 25269220,
"type": "User"
} | [] | true | [] |
1,588,951,379 | 5,543 | the pile datasets url seems to change back | ### Describe the bug
in #3627, the host url of the pile dataset became `https://mystic.the-eye.eu`. Now the new url is broken, but `https://the-eye.eu` seems to work again.
### Steps to reproduce the bug
```python3
from datasets import load_dataset
dataset = load_dataset("bookcorpusopen")
```
shows
```python3
... | closed | https://github.com/huggingface/datasets/issues/5543 | 2023-02-17T08:40:11 | 2023-02-21T06:37:00 | 2023-02-20T08:41:33 | {
"login": "wjfwzzc",
"id": 5126316,
"type": "User"
} | [] | false | [] |
1,588,633,724 | 5,542 | Avoid saving sparse ChunkedArrays in pyarrow tables | Fixes https://github.com/huggingface/datasets/issues/5541 | closed | https://github.com/huggingface/datasets/pull/5542 | 2023-02-17T01:52:38 | 2023-02-17T19:20:49 | 2023-02-17T11:12:32 | {
"login": "marioga",
"id": 6591505,
"type": "User"
} | [] | true | [] |
1,588,633,555 | 5,541 | Flattening indices in selected datasets is extremely inefficient | ### Describe the bug
If we perform a `select` (or `shuffle`, `train_test_split`, etc.) operation on a dataset , we end up with a dataset with an `indices_table`. Currently, flattening such dataset consumes a lot of memory and the resulting flat dataset contains ChunkedArrays with as many chunks as there are rows. Thi... | closed | https://github.com/huggingface/datasets/issues/5541 | 2023-02-17T01:52:24 | 2023-02-22T13:15:20 | 2023-02-17T11:12:33 | {
"login": "marioga",
"id": 6591505,
"type": "User"
} | [] | false | [] |
1,588,438,344 | 5,540 | Tutorial for creating a dataset | A tutorial for creating datasets based on the folder-based builders and `from_dict` and `from_generator` methods. I've also mentioned loading scripts as a next step, but I think we should keep the tutorial focused on the low-code methods. Let me know what you think! 🙂 | closed | https://github.com/huggingface/datasets/pull/5540 | 2023-02-16T22:09:35 | 2023-02-17T18:50:46 | 2023-02-17T18:41:28 | {
"login": "stevhliu",
"id": 59462357,
"type": "User"
} | [] | true | [] |
1,587,970,083 | 5,539 | IndexError: invalid index of a 0-dim tensor. Use `tensor.item()` in Python or `tensor.item<T>()` in C++ to convert a 0-dim tensor to a number | ### Describe the bug
When dataset contains a 0-dim tensor, formatting.py raises a following error and fails.
```bash
Traceback (most recent call last):
File "<path>/lib/python3.8/site-packages/datasets/formatting/formatting.py", line 501, in format_row
return _unnest(formatted_batch)
File "<path>/lib/py... | closed | https://github.com/huggingface/datasets/issues/5539 | 2023-02-16T16:08:51 | 2023-02-22T10:30:30 | 2023-02-21T13:03:57 | {
"login": "aalbersk",
"id": 41912135,
"type": "User"
} | [
{
"name": "good first issue",
"color": "7057ff"
}
] | false | [] |
1,587,732,596 | 5,538 | load_dataset in seaborn is not working for me. getting this error. | TimeoutError Traceback (most recent call last)
~\anaconda3\lib\urllib\request.py in do_open(self, http_class, req, **http_conn_args)
1345 try:
-> 1346 h.request(req.get_method(), req.selector, req.data, headers,
1347 encode_chu... | closed | https://github.com/huggingface/datasets/issues/5538 | 2023-02-16T14:01:58 | 2023-02-16T14:44:36 | 2023-02-16T14:44:36 | {
"login": "reemaranibarik",
"id": 125575109,
"type": "User"
} | [] | false | [] |
1,587,567,464 | 5,537 | Increase speed of data files resolution | Certain datasets like `bigcode/the-stack-dedup` have so many files that loading them takes forever right from the data files resolution step.
`datasets` uses file patterns to check the structure of the repository but it takes too much time to iterate over and over again on all the data files.
This comes from `res... | closed | https://github.com/huggingface/datasets/issues/5537 | 2023-02-16T12:11:45 | 2023-12-15T13:12:31 | 2023-12-15T13:12:31 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [
{
"name": "enhancement",
"color": "a2eeef"
},
{
"name": "good second issue",
"color": "BDE59C"
}
] | false | [] |
1,586,930,643 | 5,536 | Failure to hash function when using .map() | ### Describe the bug
_Parameter 'function'=<function process at 0x7f1ec4388af0> of the transform datasets.arrow_dataset.Dataset.\_map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and ca... | closed | https://github.com/huggingface/datasets/issues/5536 | 2023-02-16T03:12:07 | 2023-09-08T21:06:01 | 2023-02-16T14:56:41 | {
"login": "venzen",
"id": 6916056,
"type": "User"
} | [] | false | [] |
1,586,520,369 | 5,535 | Add JAX-formatting documentation | ## What's in this PR?
As a follow-up of #5522, I've created this entry in the documentation to explain how to use `.with_format("jax")` and why is it useful.
@lhoestq Feel free to drop any feedback and/or suggestion, as probably more useful features can be included there! | closed | https://github.com/huggingface/datasets/pull/5535 | 2023-02-15T20:35:11 | 2023-02-20T10:39:42 | 2023-02-20T10:32:39 | {
"login": "alvarobartt",
"id": 36760800,
"type": "User"
} | [] | true | [] |
1,586,177,862 | 5,534 | map() breaks at certain dataset size when using Array3D | ### Describe the bug
`map()` magically breaks when using a `Array3D` feature and mapping it. I created a very simple dummy dataset (see below). When filtering it down to 95 elements I can apply map, but it breaks when filtering it down to just 96 entries with the following exception:
```
Traceback (most recent cal... | open | https://github.com/huggingface/datasets/issues/5534 | 2023-02-15T16:34:25 | 2023-03-03T16:31:33 | null | {
"login": "ArneBinder",
"id": 3375489,
"type": "User"
} | [] | false | [] |
1,585,885,871 | 5,533 | Add reduce function | This PR closes #5496 .
I tried to imitate the `reduce`-method from `functools`, i.e. the function input must be a binary operation. I assume that the input type has an empty element, i.e. `input_type()` is defined, as the acumulant is instantiated as this object - im not sure that is this a reasonable assumption?
... | closed | https://github.com/huggingface/datasets/pull/5533 | 2023-02-15T13:44:01 | 2024-11-25T14:33:27 | 2023-02-28T14:46:12 | {
"login": "AJDERS",
"id": 38854604,
"type": "User"
} | [] | true | [] |
1,584,505,128 | 5,532 | train_test_split in arrow_dataset does not ensure to keep single classes in test set | ### Describe the bug
When I have a dataset with very few (e.g. 1) examples per class and I call the train_test_split function on it, sometimes the single class will be in the test set. thus will never be considered for training.
### Steps to reproduce the bug
```
import numpy as np
from datasets import Dataset
... | closed | https://github.com/huggingface/datasets/issues/5532 | 2023-02-14T16:52:29 | 2023-02-15T16:09:19 | 2023-02-15T16:09:19 | {
"login": "Ulipenitz",
"id": 37191008,
"type": "User"
} | [] | false | [] |
1,584,387,276 | 5,531 | Invalid Arrow data from JSONL | This code fails:
```python
from datasets import Dataset
ds = Dataset.from_json(path_to_file)
ds.data.validate()
```
raises
```python
ArrowInvalid: Column 2: In chunk 1: Invalid: Struct child array #3 invalid: Invalid: Length spanned by list offsets (4064) larger than values array (length 4063)
```
This ... | open | https://github.com/huggingface/datasets/issues/5531 | 2023-02-14T15:39:49 | 2023-02-14T15:46:09 | null | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [
{
"name": "bug",
"color": "d73a4a"
}
] | false | [] |
1,582,938,241 | 5,530 | Add missing license in `NumpyFormatter` | ## What's in this PR?
As discussed with @lhoestq in https://github.com/huggingface/datasets/pull/5522, the license for `NumpyFormatter` at `datasets/formatting/np_formatter.py` was missing, but present on the rest of the `formatting/*.py` files. So this PR is basically to include it there. | closed | https://github.com/huggingface/datasets/pull/5530 | 2023-02-13T19:33:23 | 2023-02-14T14:40:41 | 2023-02-14T12:23:58 | {
"login": "alvarobartt",
"id": 36760800,
"type": "User"
} | [] | true | [] |
1,582,501,233 | 5,529 | Fix `datasets.load_from_disk`, `DatasetDict.load_from_disk` and `Dataset.load_from_disk` | ## What's in this PR?
After playing around a little bit with 🤗`datasets` in Google Cloud Storage (GCS), I found out some things that should be fixed IMO in the code:
* `datasets.load_from_disk` is not checking whether `state.json` is there too when trying to load a `Dataset`, just `dataset_info.json` is checked
... | closed | https://github.com/huggingface/datasets/pull/5529 | 2023-02-13T14:54:55 | 2023-02-23T18:14:32 | 2023-02-23T18:05:26 | {
"login": "alvarobartt",
"id": 36760800,
"type": "User"
} | [] | true | [] |
1,582,195,085 | 5,528 | Push to hub in a pull request | Fixes #5492.
Introduce new kwarg `create_pr` in `push_to_hub`, which is passed to `HFapi.upload_file`. | open | https://github.com/huggingface/datasets/pull/5528 | 2023-02-13T11:43:47 | 2023-10-06T21:58:02 | null | {
"login": "AJDERS",
"id": 38854604,
"type": "User"
} | [] | true | [] |
1,581,228,531 | 5,527 | Fix benchmarks CI - pin protobuf | fix https://github.com/huggingface/datasets/actions/runs/4156059127/jobs/7189576331 | closed | https://github.com/huggingface/datasets/pull/5527 | 2023-02-12T11:51:25 | 2023-02-13T10:29:03 | 2023-02-13T09:24:16 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
1,580,488,133 | 5,526 | Allow loading/saving of FAISS index using fsspec | Fixes #5428
Allow loading/saving of FAISS index using fsspec:
1. Simply use BufferedIOWriter/Reader to Read/Write indices on fsspec stream.
2. Needed `mockfs` in the test, so I took it out of the `TestCase`. Let me know if that makes sense.
I can work on the documentation once the code changes are approved.
| closed | https://github.com/huggingface/datasets/pull/5526 | 2023-02-10T23:37:14 | 2023-03-27T15:26:46 | 2023-03-27T15:18:20 | {
"login": "Dref360",
"id": 8976546,
"type": "User"
} | [] | true | [] |
1,580,342,729 | 5,525 | TypeError: Couldn't cast array of type string to null | ### Describe the bug
Processing a dataset I alredy uploaded to the Hub (https://huggingface.co/datasets/tj-solergibert/Europarl-ST) I found that for some splits and some languages (test split, source_lang = "nl") after applying a map function I get the mentioned error.
I alredy tried reseting the shorter strings... | closed | https://github.com/huggingface/datasets/issues/5525 | 2023-02-10T21:12:36 | 2023-02-14T17:41:08 | 2023-02-14T09:35:49 | {
"login": "TJ-Solergibert",
"id": 74564958,
"type": "User"
} | [] | false | [] |
1,580,219,454 | 5,524 | [INVALID PR] | Hi to whoever is reading this! 🤗
## What's in this PR?
~~Basically, I've removed the 🤗`datasets` installation as `python -m pip install ".[quality]" in the `check_code_quality` job in `.github/workflows/ci.yaml`, as we don't need to install the whole package to run the CI, unless that's done on purpose e.g. to ... | closed | https://github.com/huggingface/datasets/pull/5524 | 2023-02-10T19:35:50 | 2023-02-10T19:51:45 | 2023-02-10T19:49:12 | {
"login": "alvarobartt",
"id": 36760800,
"type": "User"
} | [] | true | [] |
1,580,193,015 | 5,523 | Checking that split name is correct happens only after the data is downloaded | ### Describe the bug
Verification of split names (=indexing data by split) happens after downloading the data. So when the split name is incorrect, users learn about that only after the data is fully downloaded, for large datasets it might take a lot of time.
### Steps to reproduce the bug
Load any dataset with rand... | open | https://github.com/huggingface/datasets/issues/5523 | 2023-02-10T19:13:03 | 2023-02-10T19:14:50 | null | {
"login": "polinaeterna",
"id": 16348744,
"type": "User"
} | [
{
"name": "bug",
"color": "d73a4a"
}
] | false | [] |
1,580,183,124 | 5,522 | Minor changes in JAX-formatting docstrings & type-hints | Hi to whoever is reading this! 🤗
## What's in this PR?
I was exploring the code regarding the `JaxFormatter` implemented in 🤗`datasets`, and found some things that IMO could be changed. Those are mainly regarding the docstrings and the type-hints based on `jax`'s 0.4.1 release where `jax.Array` was introduced a... | closed | https://github.com/huggingface/datasets/pull/5522 | 2023-02-10T19:05:00 | 2023-02-15T14:48:27 | 2023-02-15T13:19:06 | {
"login": "alvarobartt",
"id": 36760800,
"type": "User"
} | [] | true | [] |
1,578,418,289 | 5,521 | Fix bug when casting empty array to class labels | Fix https://github.com/huggingface/datasets/issues/5520. | closed | https://github.com/huggingface/datasets/pull/5521 | 2023-02-09T18:47:59 | 2023-02-13T20:40:48 | 2023-02-12T11:17:17 | {
"login": "marioga",
"id": 6591505,
"type": "User"
} | [] | true | [] |
1,578,417,074 | 5,520 | ClassLabel.cast_storage raises TypeError when called on an empty IntegerArray | ### Describe the bug
`ClassLabel.cast_storage` raises `TypeError` when called on an empty `IntegerArray`.
### Steps to reproduce the bug
Minimal steps:
```python
import pyarrow as pa
from datasets import ClassLabel
ClassLabel(names=['foo', 'bar']).cast_storage(pa.array([], pa.int64()))
```
In practice, thi... | closed | https://github.com/huggingface/datasets/issues/5520 | 2023-02-09T18:46:52 | 2023-02-12T11:17:18 | 2023-02-12T11:17:18 | {
"login": "marioga",
"id": 6591505,
"type": "User"
} | [] | false | [] |
1,578,341,785 | 5,519 | Lint code with `ruff` | EDIT:
Use `ruff` for linting instead of `isort` and `flake8` ~~`black`~~ to be consistent with [`transformers`](https://github.com/huggingface/transformers/pull/21480) and [`hfh`](https://github.com/huggingface/huggingface_hub/pull/1323).
TODO:
- [x] ~Merge the community contributors' PR to avoid having to run `ma... | closed | https://github.com/huggingface/datasets/pull/5519 | 2023-02-09T17:50:21 | 2024-06-01T15:35:02 | 2023-02-14T16:18:38 | {
"login": "mariosasko",
"id": 47462742,
"type": "User"
} | [] | true | [] |
1,578,203,962 | 5,518 | Remove py.typed | Fix https://github.com/huggingface/datasets/issues/3841 | closed | https://github.com/huggingface/datasets/pull/5518 | 2023-02-09T16:22:29 | 2023-02-13T13:55:49 | 2023-02-13T13:48:40 | {
"login": "mariosasko",
"id": 47462742,
"type": "User"
} | [] | true | [] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.