
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 1.83B | node_id stringlengths 18 32 | number int64 1 6.09k | title stringlengths 1 290 | labels list | state stringclasses 2
values | locked bool 1
class | milestone dict | comments int64 0 54 | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | closed_at stringlengths 20 20 ⌀ | active_lock_reason null | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 3
values | draft bool 2
classes | pull_request dict | is_pull_request bool 2
classes | comments_text list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/4553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4553/comments | https://api.github.com/repos/huggingface/datasets/issues/4553/events | https://github.com/huggingface/datasets/pull/4553 | 1,282,779,560 | PR_kwDODunzps46Q1q7 | 4,553 | Stop dropping columns in to_tf_dataset() before we load batches | [] | closed | false | null | 4 | 2022-06-23T18:21:05Z | 2022-07-04T19:00:13Z | 2022-07-04T18:49:01Z | null | `to_tf_dataset()` dropped unnecessary columns before loading batches from the dataset, but this is causing problems when using a transform, because the dropped columns might be needed to compute the transform. Since there's no real way to check which columns the transform might need, we skip dropping columns and instea... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4553/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4553/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4553.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4553",
"merged_at": "2022-07-04T18:49:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4553.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq Rebasing fixed the test failures, so this should be ready to review now! There's still a failure on Win but it seems unrelated.",
"Gentle ping @lhoestq ! This is a simple fix (dropping columns after loading a batch from th... |
https://api.github.com/repos/huggingface/datasets/issues/5024 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5024/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5024/comments | https://api.github.com/repos/huggingface/datasets/issues/5024/events | https://github.com/huggingface/datasets/pull/5024 | 1,385,947,624 | PR_kwDODunzps4_mZ3J | 5,024 | Fix string features of xcsr dataset | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 1 | 2022-09-26T11:55:36Z | 2022-09-28T07:56:18Z | 2022-09-28T07:54:19Z | null | This PR fixes string features of `xcsr` dataset to avoid character splitting.
Fix #5023.
CC: @yangxqiao, @yuchenlin | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5024/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5024/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5024.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5024",
"merged_at": "2022-09-28T07:54:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5024.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5804 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5804/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5804/comments | https://api.github.com/repos/huggingface/datasets/issues/5804/events | https://github.com/huggingface/datasets/pull/5804 | 1,688,285,666 | PR_kwDODunzps5PX0Dk | 5,804 | Set dev version | [] | closed | false | null | 3 | 2023-04-28T10:10:01Z | 2023-04-28T10:18:51Z | 2023-04-28T10:10:29Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5804/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5804/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5804.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5804",
"merged_at": "2023-04-28T10:10:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5804.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5804). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... |
https://api.github.com/repos/huggingface/datasets/issues/1124 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1124/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1124/comments | https://api.github.com/repos/huggingface/datasets/issues/1124/events | https://github.com/huggingface/datasets/pull/1124 | 757,186,983 | MDExOlB1bGxSZXF1ZXN0NTMyNjA0NzY3 | 1,124 | Add Xitsonga Ner | [] | closed | false | null | 1 | 2020-12-04T15:27:44Z | 2020-12-06T18:31:35Z | 2020-12-06T18:31:35Z | null | Clean Xitsonga Ner PR | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1124/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1124/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1124.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1124",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1124.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1124"
} | true | [
"looks like this PR includes changes about many files other than the ones related to xitsonga NER\r\n\r\ncould you create another branch and another PR please ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/952 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/952/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/952/comments | https://api.github.com/repos/huggingface/datasets/issues/952/events | https://github.com/huggingface/datasets/pull/952 | 754,357,270 | MDExOlB1bGxSZXF1ZXN0NTMwMjcxMTQz | 952 | Add orange sum | [] | closed | false | null | 0 | 2020-12-01T12:33:34Z | 2020-12-01T15:44:00Z | 2020-12-01T15:44:00Z | null | Add OrangeSum a french abstractive summarization dataset.
Paper: [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/952/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/952/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/952.diff",
"html_url": "https://github.com/huggingface/datasets/pull/952",
"merged_at": "2020-12-01T15:44:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/952.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/952... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4597/comments | https://api.github.com/repos/huggingface/datasets/issues/4597/events | https://github.com/huggingface/datasets/issues/4597 | 1,288,672,007 | I_kwDODunzps5Mz5MH | 4,597 | Streaming issue for financial_phrasebank | [
{
"color": "8B51EF",
"default": false,
"description": "",
"id": 4069435429,
"name": "hosted-on-google-drive",
"node_id": "LA_kwDODunzps7yjqgl",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hosted-on-google-drive"
}
] | closed | false | null | 3 | 2022-06-29T12:45:43Z | 2022-07-01T09:29:36Z | 2022-07-01T09:29:36Z | null | ### Link
https://huggingface.co/datasets/financial_phrasebank/viewer/sentences_allagree/train
### Description
As reported by a community member using [AutoTrain Evaluate](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions/5#62bc217436d0e5d316a768f0), there seems to be a problem streaming this dat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4597/timeline | null | completed | null | null | false | [
"cc @huggingface/datasets: it seems like https://www.researchgate.net/ is flaky for datasets hosting (I put the \"hosted-on-google-drive\" tag since it's the same kind of issue I think)",
"Let's see if their license allows hosting their data on the Hub.",
"License is Creative Commons Attribution-NonCommercial-S... |
https://api.github.com/repos/huggingface/datasets/issues/5361 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5361/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5361/comments | https://api.github.com/repos/huggingface/datasets/issues/5361/events | https://github.com/huggingface/datasets/issues/5361 | 1,497,153,889 | I_kwDODunzps5ZPMFh | 5,361 | How concatenate `Audio` elements using batch mapping | [] | closed | false | null | 3 | 2022-12-14T18:13:55Z | 2023-07-21T14:30:51Z | 2023-07-21T14:30:51Z | null | ### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.concatnate(audios[i: i+3]) for i in range(i, len(batc... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5361/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5361/timeline | null | completed | null | null | false | [
"You can try something like this ?\r\n```python\r\ndef mapper_function(batch):\r\n return {\"concatenated_audio\": [np.concatenate([audio[\"array\"] for audio in batch[\"audio\"]])]}\r\n\r\ndataset = dataset.map(\r\n mapper_function,\r\n batched=True,\r\n batch_size=3,\r\n remove_columns=list(dataset.... |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | [] | closed | false | null | 6 | 2023-03-03T09:52:08Z | 2023-03-29T01:44:05Z | 2023-03-24T12:44:25Z | null | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
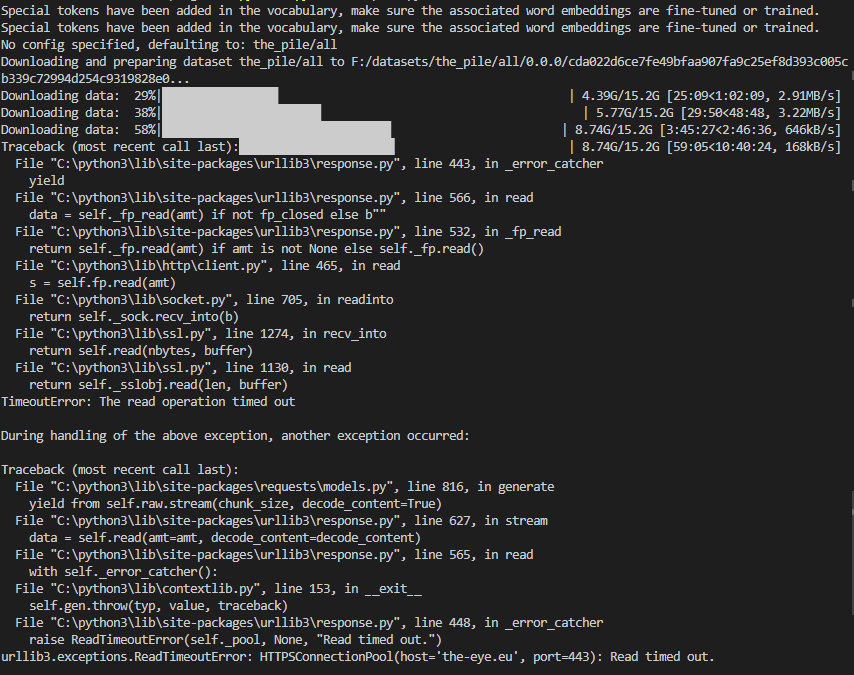
Here are the downloaded files:
)` in `load_dataset` to resume the download when re-running the code after the timeout error:\r\n```python\r\nfrom datasets import load_dataset, DownloadConfig\r\ndataset = load_dataset('the_pile', split='train', cache_dir='F:\\da... |
https://api.github.com/repos/huggingface/datasets/issues/2418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2418/comments | https://api.github.com/repos/huggingface/datasets/issues/2418/events | https://github.com/huggingface/datasets/pull/2418 | 904,051,497 | MDExOlB1bGxSZXF1ZXN0NjU1MjM2OTEz | 2,418 | add utf-8 while reading README | [] | closed | false | null | 2 | 2021-05-27T18:12:28Z | 2021-06-04T09:55:01Z | 2021-06-04T09:55:00Z | null | It was causing tests to fail in Windows (see #2416). In Windows, the default encoding is CP1252 which is unable to decode the character byte 0x9d | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2418/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2418/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2418.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2418",
"merged_at": "2021-06-04T09:55:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2418.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Can you please add encoding to this line as well to fix the issue (and maybe replace `path.open(...)` with `open(path, ...)`)?\r\nhttps://github.com/huggingface/datasets/blob/7bee4be44706a59b084b9b69c4cd00f73ee72f76/src/datasets/utils/metadata.py#L58",
"Sure, in fact even I was thinking of adding this in order t... |
https://api.github.com/repos/huggingface/datasets/issues/2977 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2977/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2977/comments | https://api.github.com/repos/huggingface/datasets/issues/2977/events | https://github.com/huggingface/datasets/issues/2977 | 1,009,378,692 | I_kwDODunzps48KeWE | 2,977 | Impossible to load compressed csv | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-09-28T07:18:54Z | 2021-10-01T15:53:16Z | 2021-10-01T15:53:15Z | null | ## Describe the bug
It is not possible to load from a compressed csv anymore.
## Steps to reproduce the bug
```python
load_dataset('csv', data_files=['/path/to/csv.bz2'])
```
## Problem and possible solution
This used to work, but the commit that broke it is [this one](https://github.com/huggingface/datasets... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2977/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2977/timeline | null | completed | null | null | false | [
"Hi @Valahaar, thanks for reporting and for your investigation about the source cause.\r\n\r\nYou are right and that commit prevents `pandas` from inferring the compression. On the other hand, @lhoestq did that change to support loading that dataset in streaming mode. \r\n\r\nI'm fixing it."
] |
https://api.github.com/repos/huggingface/datasets/issues/784 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/784/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/784/comments | https://api.github.com/repos/huggingface/datasets/issues/784/events | https://github.com/huggingface/datasets/issues/784 | 733,700,463 | MDU6SXNzdWU3MzM3MDA0NjM= | 784 | Issue with downloading Wikipedia data for low resource language | [] | closed | false | null | 5 | 2020-10-31T11:40:00Z | 2022-02-09T17:50:16Z | 2020-11-25T15:42:13Z | null | Hi, I tried to download Sundanese and Javanese wikipedia data with the following snippet
```
jv_wiki = datasets.load_dataset('wikipedia', '20200501.jv', beam_runner='DirectRunner')
su_wiki = datasets.load_dataset('wikipedia', '20200501.su', beam_runner='DirectRunner')
```
And I get the following error for these tw... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/784/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/784/timeline | null | completed | null | null | false | [
"Hello, maybe you could ty to use another date for the wikipedia dump (see the available [dates](https://dumps.wikimedia.org/jvwiki) here for `jv`) ?",
"@lhoestq\r\n\r\nI've tried `load_dataset('wikipedia', '20200501.zh', beam_runner='DirectRunner')` and got the same `FileNotFoundError` as @SamuelCahyawijaya.\r\n... |
https://api.github.com/repos/huggingface/datasets/issues/3382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3382/comments | https://api.github.com/repos/huggingface/datasets/issues/3382/events | https://github.com/huggingface/datasets/pull/3382 | 1,071,293,299 | PR_kwDODunzps4vZT2K | 3,382 | #3337 Add typing overloads to Dataset.__getitem__ for mypy | [] | closed | false | null | 2 | 2021-12-04T20:54:49Z | 2021-12-14T10:28:55Z | 2021-12-14T10:28:55Z | null | Add typing overloads to Dataset.__getitem__ for mypy
Fixes #3337
**Iterable**
Iterable from `collections` cannot have a type, so you can't do `Iterable[int]` for example. `typing` has a Generic version that builds upon the one from `collections`.
**Flake8**
I had to add `# noqa: F811`, this is a bug from Fl... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3382/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3382/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3382.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3382",
"merged_at": "2021-12-14T10:28:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3382.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Locally the `make quality` passes with the same dependencies. I would suggest upgrading flake8. (I can take care of it in another PR)\r\ncc @lhoestq ",
"Thank you for fixing flake8! I think we are ready to merge then. "
] |
https://api.github.com/repos/huggingface/datasets/issues/788 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/788/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/788/comments | https://api.github.com/repos/huggingface/datasets/issues/788/events | https://github.com/huggingface/datasets/issues/788 | 734,136,124 | MDU6SXNzdWU3MzQxMzYxMjQ= | 788 | failed to reuse cache | [] | closed | false | null | 0 | 2020-11-02T02:42:36Z | 2020-11-02T12:26:15Z | 2020-11-02T12:26:15Z | null | I packed the `load_dataset ` in a function of class, and cached data in a directory. But when I import the class and use the function, the data still have to be downloaded again. The information (Downloading and preparing dataset cnn_dailymail/3.0.0 (download: 558.32 MiB, generated: 1.28 GiB, post-processed: Unknown si... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/788/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/788/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/3786 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3786/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3786/comments | https://api.github.com/repos/huggingface/datasets/issues/3786/events | https://github.com/huggingface/datasets/issues/3786 | 1,150,233,067 | I_kwDODunzps5Ejynr | 3,786 | Bug downloading Virus scan warning page from Google Drive URLs | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-02-25T09:32:23Z | 2022-03-03T09:25:59Z | 2022-02-25T11:56:35Z | null | ## Describe the bug
Recently, some issues were reported with URLs from Google Drive, where we were downloading the Virus scan warning page instead of the data file itself.
See:
- #3758
- #3773
- #3784
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3786/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3786/timeline | null | completed | null | null | false | [
"Once the PR merged into master and until our next `datasets` library release, you can get this fix by installing our library from the GitHub master branch:\r\n```shell\r\npip install git+https://github.com/huggingface/datasets#egg=datasets\r\n```\r\nThen, if you had previously tried to load the data and got the ch... |
https://api.github.com/repos/huggingface/datasets/issues/4781 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4781/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4781/comments | https://api.github.com/repos/huggingface/datasets/issues/4781/events | https://github.com/huggingface/datasets/pull/4781 | 1,326,114,161 | PR_kwDODunzps48hOie | 4,781 | Fix label renaming and add a battery of tests | [] | closed | false | null | 12 | 2022-08-02T16:42:07Z | 2022-09-12T11:27:06Z | 2022-09-12T11:24:45Z | null | This PR makes some changes to label renaming in `to_tf_dataset()`, both to fix some issues when users input something we weren't expecting, and also to make it easier to deprecate label renaming in future, if/when we want to move this special-casing logic to a function in `transformers`.
The main changes are:
- Lab... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4781/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4781/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4781.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4781",
"merged_at": "2022-09-12T11:24:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4781.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Why don't we deprecate label renaming already instead ?",
"I think it'll break a lot of workflows if we deprecate it now! There isn't really a non-deprecated workflow yet - once we've added the `auto_rename_labels` option, then we ... |
https://api.github.com/repos/huggingface/datasets/issues/3461 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3461/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3461/comments | https://api.github.com/repos/huggingface/datasets/issues/3461/events | https://github.com/huggingface/datasets/pull/3461 | 1,085,007,346 | PR_kwDODunzps4wFzDP | 3,461 | Fix links in metrics description | [] | closed | false | null | 0 | 2021-12-20T16:56:19Z | 2021-12-20T17:14:52Z | 2021-12-20T17:14:51Z | null | Remove Markdown syntax for links in metrics description, as it is not properly rendered.
Related to #3437. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3461/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3461/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3461.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3461",
"merged_at": "2021-12-20T17:14:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3461.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1031 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1031/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1031/comments | https://api.github.com/repos/huggingface/datasets/issues/1031/events | https://github.com/huggingface/datasets/pull/1031 | 755,844,004 | MDExOlB1bGxSZXF1ZXN0NTMxNDgyMzEy | 1,031 | add crows_pairs | [] | closed | false | null | 2 | 2020-12-03T05:05:11Z | 2020-12-03T18:29:52Z | 2020-12-03T18:29:39Z | null | This PR adds CrowS-Pairs datasets.
More info:
https://github.com/nyu-mll/crows-pairs/
https://arxiv.org/pdf/2010.00133.pdf | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1031/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1031/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1031.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1031",
"merged_at": "2020-12-03T18:29:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1031.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"looks good now :) wdyt @yjernite ?",
"Looks good to merge for me, can edit the dataset card later if required. Merging"
] |
https://api.github.com/repos/huggingface/datasets/issues/5509 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5509/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5509/comments | https://api.github.com/repos/huggingface/datasets/issues/5509/events | https://github.com/huggingface/datasets/pull/5509 | 1,574,177,320 | PR_kwDODunzps5JbH-u | 5,509 | Add a static `__all__` to `__init__.py` for typecheckers | [] | open | false | null | 2 | 2023-02-07T11:42:40Z | 2023-02-08T17:48:24Z | null | null | This adds a static `__all__` field to `__init__.py`, allowing typecheckers to know which symbols are accessible from `datasets` at runtime. In particular [Pyright](https://github.com/microsoft/pylance-release/issues/2328#issuecomment-1029381258) seems to rely on this. At this point I have added all (modulo oversight) t... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5509/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5509/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5509.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5509",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5509.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5509"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5509). All of your documentation changes will be reflected on that endpoint.",
"Hi! I've commented on the original issue to provide some context. Feel free to share your opinion there."
] |
https://api.github.com/repos/huggingface/datasets/issues/5807 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5807/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5807/comments | https://api.github.com/repos/huggingface/datasets/issues/5807/events | https://github.com/huggingface/datasets/pull/5807 | 1,688,977,237 | PR_kwDODunzps5PaKRE | 5,807 | Support parallelized downloading in load_dataset with Spark | [] | closed | false | null | 3 | 2023-04-28T18:34:32Z | 2023-05-25T16:54:14Z | 2023-05-25T16:54:14Z | null | As proposed in https://github.com/huggingface/datasets/issues/5798, this adds support to parallelized downloading in `load_dataset` with Spark, which can speed up the process by distributing the workload to worker nodes.
Parallelizing dataset processing is not supported in this PR. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5807/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5807/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5807.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5807",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5807.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5807"
} | true | [
"Hi @lhoestq or other maintainers, this is ready for review, could you please take a look?",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5807). All of your documentation changes will be reflected on that endpoint.",
"Per the discussion in #5798, will implement with `jo... |
https://api.github.com/repos/huggingface/datasets/issues/290 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/290/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/290/comments | https://api.github.com/repos/huggingface/datasets/issues/290/events | https://github.com/huggingface/datasets/issues/290 | 641,978,286 | MDU6SXNzdWU2NDE5NzgyODY= | 290 | ConnectionError - Eli5 dataset download | [] | closed | false | null | 2 | 2020-06-19T13:40:33Z | 2020-06-20T13:22:24Z | 2020-06-20T13:22:24Z | null | Hi, I have a problem with downloading Eli5 dataset. When typing `nlp.load_dataset('eli5')`, I get ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/eli5/LFQA_reddit/1.0.0/explain_like_im_five-train_eli5.arrow
I would appreciate if you could help me with this issue. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/290/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/290/timeline | null | completed | null | null | false | [
"It should ne fixed now, thanks for reporting this one :)\r\nIt was an issue on our google storage.\r\n\r\nLet me now if you're still facing this issue.",
"It works now, thanks for prompt help!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5893 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5893/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5893/comments | https://api.github.com/repos/huggingface/datasets/issues/5893/events | https://github.com/huggingface/datasets/pull/5893 | 1,722,519,056 | PR_kwDODunzps5RK40K | 5,893 | Load cached dataset as iterable | [] | closed | false | null | 8 | 2023-05-23T17:40:35Z | 2023-06-01T11:58:24Z | 2023-06-01T11:51:29Z | null | To be used to train models it allows to load an IterableDataset from the cached Arrow file.
See https://github.com/huggingface/datasets/issues/5481 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5893/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5893/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5893.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5893",
"merged_at": "2023-06-01T11:51:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5893.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"@lhoestq Could you please look into that and review?",
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq I refactored the code. Could you please check is it what you requested?",
"@lhoestq Thanks for a review. Excellent tips. All tips applied. ",
"I think there is j... |
https://api.github.com/repos/huggingface/datasets/issues/5489 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5489/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5489/comments | https://api.github.com/repos/huggingface/datasets/issues/5489/events | https://github.com/huggingface/datasets/pull/5489 | 1,565,761,705 | PR_kwDODunzps5I_WPH | 5,489 | Pin dill lower version | [] | closed | false | null | 2 | 2023-02-01T09:33:42Z | 2023-02-02T07:48:09Z | 2023-02-02T07:40:43Z | null | Pin `dill` lower version compatible with `datasets`.
Related to:
- #5487
- #288
Note that the required `dill._dill` module was introduced in dill-2.8.0, however we have heuristically tested that datasets can only be installed with dill>=3.0.0 (otherwise pip hangs indefinitely while preparing metadata for multip... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5489/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5489/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5489.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5489",
"merged_at": "2023-02-02T07:40:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5489.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/3885 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3885/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3885/comments | https://api.github.com/repos/huggingface/datasets/issues/3885/events | https://github.com/huggingface/datasets/pull/3885 | 1,165,102,209 | PR_kwDODunzps40O00Z | 3,885 | Fix some shuffle docs | [] | closed | false | null | 1 | 2022-03-10T11:29:15Z | 2022-03-10T14:16:29Z | 2022-03-10T14:16:28Z | null | Following #3842 some docs were still outdated (with `buffer_size` as the first argument) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3885/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3885/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3885.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3885",
"merged_at": "2022-03-10T14:16:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3885.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3885). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/5238 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5238/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5238/comments | https://api.github.com/repos/huggingface/datasets/issues/5238/events | https://github.com/huggingface/datasets/pull/5238 | 1,448,211,251 | PR_kwDODunzps5C2L9h | 5,238 | Make `Version` hashable | [] | closed | false | null | 1 | 2022-11-14T14:52:55Z | 2022-11-14T15:30:02Z | 2022-11-14T15:27:35Z | null | Add `__hash__` to the `Version` class to make it hashable (and remove the unneeded methods), as `Version("0.0.0")` is the default value of `BuilderConfig.version` and the default fields of a dataclass need to be hashable in Python 3.11.
Fix https://github.com/huggingface/datasets/issues/5230 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5238/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5238/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5238.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5238",
"merged_at": "2022-11-14T15:27:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5238.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/75 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/75/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/75/comments | https://api.github.com/repos/huggingface/datasets/issues/75/events | https://github.com/huggingface/datasets/pull/75 | 616,520,163 | MDExOlB1bGxSZXF1ZXN0NDE2NjE0MzU1 | 75 | WIP adding metrics | [] | closed | false | null | 1 | 2020-05-12T09:52:00Z | 2020-05-13T07:44:12Z | 2020-05-13T07:44:10Z | null | Adding the following metrics as identified by @mariamabarham:
1. BLEU: BiLingual Evaluation Understudy: https://github.com/tensorflow/nmt/blob/master/nmt/scripts/bleu.py, https://github.com/chakki-works/sumeval/blob/master/sumeval/metrics/bleu.py (multilingual)
2. GLEU: Google-BLEU: https://github.com/cnap/gec-... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/75/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/75/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/75.diff",
"html_url": "https://github.com/huggingface/datasets/pull/75",
"merged_at": "2020-05-13T07:44:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/75.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/75"
} | true | [
"It's all about my metric stuff so I'll probably merge it unless you want to have a look.\r\n\r\nTook the occasion to remove the old doc and requirements.txt"
] |
https://api.github.com/repos/huggingface/datasets/issues/647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/647/comments | https://api.github.com/repos/huggingface/datasets/issues/647/events | https://github.com/huggingface/datasets/issues/647 | 704,734,764 | MDU6SXNzdWU3MDQ3MzQ3NjQ= | 647 | Cannot download dataset_info.json | [] | closed | false | null | 4 | 2020-09-19T01:35:15Z | 2020-09-21T08:28:42Z | 2020-09-21T08:28:42Z | null | I am running my job on a cloud server where does not provide for connections from the standard compute nodes to outside resources. Hence, when I use `dataset.load_dataset()` to load data, I got an error like this:
```
ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/text... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/647/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/647/timeline | null | completed | null | null | false | [
"Thanks for reporting !\r\nWe should add support for servers without internet connection indeed\r\nI'll do that early next week",
"Thanks, @lhoestq !\r\nPlease let me know when it is available. ",
"Right now the recommended way is to create the dataset on a server with internet connection and then to save it an... |
https://api.github.com/repos/huggingface/datasets/issues/904 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/904/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/904/comments | https://api.github.com/repos/huggingface/datasets/issues/904/events | https://github.com/huggingface/datasets/pull/904 | 752,372,743 | MDExOlB1bGxSZXF1ZXN0NTI4NzA5NTUx | 904 | Very detailed step-by-step on how to add a dataset | [] | closed | false | null | 1 | 2020-11-27T16:45:21Z | 2020-11-30T09:56:27Z | 2020-11-30T09:56:26Z | null | Add very detailed step-by-step instructions to add a new dataset to the library. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/904/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/904/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/904.diff",
"html_url": "https://github.com/huggingface/datasets/pull/904",
"merged_at": "2020-11-30T09:56:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/904.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/904... | true | [
"Awesome! Thanks @lhoestq "
] |
https://api.github.com/repos/huggingface/datasets/issues/2518 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2518/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2518/comments | https://api.github.com/repos/huggingface/datasets/issues/2518/events | https://github.com/huggingface/datasets/pull/2518 | 924,654,100 | MDExOlB1bGxSZXF1ZXN0NjczMjU5Nzg1 | 2,518 | Add task templates for tydiqa and xquad | [] | closed | false | null | 1 | 2021-06-18T08:06:34Z | 2021-06-18T15:01:17Z | 2021-06-18T14:50:33Z | null | This PR adds question-answering templates to the remaining datasets that are linked to a model on the Hub.
Notes:
* I could not test the tydiqa implementation since I don't have enough disk space 😢 . But I am confident the template works :)
* there exist other datasets like `fquad` and `mlqa` which are candida... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2518/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2518/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2518.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2518",
"merged_at": "2021-06-18T14:50:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2518.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Just tested TydiQA and it works fine :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/3090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3090/comments | https://api.github.com/repos/huggingface/datasets/issues/3090/events | https://github.com/huggingface/datasets/pull/3090 | 1,027,100,371 | PR_kwDODunzps4tPEtH | 3,090 | Update BibTeX entry | [] | closed | false | null | 0 | 2021-10-15T05:39:27Z | 2021-10-15T07:35:57Z | 2021-10-15T07:35:57Z | null | Update BibTeX entry. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3090/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3090/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3090.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3090",
"merged_at": "2021-10-15T07:35:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3090.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/179 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/179/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/179/comments | https://api.github.com/repos/huggingface/datasets/issues/179/events | https://github.com/huggingface/datasets/issues/179 | 622,525,410 | MDU6SXNzdWU2MjI1MjU0MTA= | 179 | [Feature request] separate split name and split instructions | [] | closed | false | null | 2 | 2020-05-21T14:10:51Z | 2020-05-22T13:31:08Z | 2020-05-22T13:31:07Z | null | Currently, the name of an nlp.NamedSplit is parsed in arrow_reader.py and used as the instruction.
This makes it impossible to have several training sets, which can occur when:
- A dataset corresponds to a collection of sub-datasets
- A dataset was built in stages, adding new examples at each stage
Would it be ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/179/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/179/timeline | null | completed | null | null | false | [
"If your dataset is a collection of sub-datasets, you should probably consider having one config per sub-dataset. For example for Glue, we have sst2, mnli etc.\r\nIf you want to have multiple train sets (for example one per stage). The easiest solution would be to name them `nlp.Split(\"train_stage1\")`, `nlp.Split... |
https://api.github.com/repos/huggingface/datasets/issues/1182 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1182/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1182/comments | https://api.github.com/repos/huggingface/datasets/issues/1182/events | https://github.com/huggingface/datasets/pull/1182 | 757,804,877 | MDExOlB1bGxSZXF1ZXN0NTMzMTA5Nzgx | 1,182 | ADD COVID-QA dataset | [] | closed | false | null | 2 | 2020-12-05T23:31:56Z | 2020-12-28T13:23:14Z | 2020-12-07T14:23:27Z | null | This PR adds the COVID-QA dataset, a question answering dataset consisting of 2,019 question/answer pairs annotated by volunteer biomedical experts on scientific articles related to COVID-19
Link to the paper: https://openreview.net/forum?id=JENSKEEzsoU
Link to the dataset/repo: https://github.com/deepset-ai/COVID-... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1182/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1182/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1182.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1182",
"merged_at": "2020-12-07T14:23:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1182.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"merging since the CI is fixed on master",
"Wow, thanks for including this dataset from my side as well!"
] |
https://api.github.com/repos/huggingface/datasets/issues/917 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/917/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/917/comments | https://api.github.com/repos/huggingface/datasets/issues/917/events | https://github.com/huggingface/datasets/pull/917 | 753,391,591 | MDExOlB1bGxSZXF1ZXN0NTI5NDc5MTIy | 917 | Addition of Concode Dataset | [] | closed | false | null | 8 | 2020-11-30T11:20:59Z | 2020-12-29T02:55:36Z | 2020-12-29T02:55:36Z | null | ##Overview
Concode Dataset contains pairs of Nl Queries and the corresponding Code.(Contextual Code Generation)
Reference Links
Paper Link = https://arxiv.org/pdf/1904.09086.pdf
Github Link =https://github.com/microsoft/CodeXGLUE/tree/main/Text-Code/text-to-code | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/917/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/917/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/917.diff",
"html_url": "https://github.com/huggingface/datasets/pull/917",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/917.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/917"
} | true | [
"Testing command doesn't work\r\n###trace\r\n-- Docs: https://docs.pytest.org/en/stable/warnings.html\r\n========================================================= short test summary info ========================================================== \r\nERROR tests/test_dataset_common.py - absl.testing.parameterized.No... |
https://api.github.com/repos/huggingface/datasets/issues/2340 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2340/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2340/comments | https://api.github.com/repos/huggingface/datasets/issues/2340/events | https://github.com/huggingface/datasets/pull/2340 | 882,370,824 | MDExOlB1bGxSZXF1ZXN0NjM1OTExNzIx | 2,340 | More consistent copy logic | [] | closed | false | null | 0 | 2021-05-09T14:17:33Z | 2021-05-11T08:58:33Z | 2021-05-11T08:58:33Z | null | Use `info.copy()` instead of `copy.deepcopy(info)`.
`Features.copy` now creates a deep copy. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2340/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2340/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2340.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2340",
"merged_at": "2021-05-11T08:58:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2340.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/57 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/57/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/57/comments | https://api.github.com/repos/huggingface/datasets/issues/57/events | https://github.com/huggingface/datasets/pull/57 | 614,261,638 | MDExOlB1bGxSZXF1ZXN0NDE0ODUzMDM5 | 57 | Better cached path | [] | closed | false | null | 2 | 2020-05-07T18:36:00Z | 2020-05-08T13:20:30Z | 2020-05-08T13:20:28Z | null | ### Changes:
- The `cached_path` no longer returns None if the file is missing/the url doesn't work. Instead, it can raise `FileNotFoundError` (missing file), `ConnectionError` (no cache and unreachable url) or `ValueError` (parsing error)
- Fix requests to firebase API that doesn't handle HEAD requests...
- Allow c... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/57/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/57/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/57.diff",
"html_url": "https://github.com/huggingface/datasets/pull/57",
"merged_at": "2020-05-08T13:20:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/57.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/57"
} | true | [
"I should have read this PR before doing my own: https://github.com/huggingface/nlp/pull/62 :D \r\nwill close mine. Looks great :-) ",
"> Awesome, this is really nice!\r\n> \r\n> By the way, we should improve the `cached_path` method of the `transformers` repo similarly, don't you think (@patrickvonplaten in part... |
https://api.github.com/repos/huggingface/datasets/issues/381 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/381/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/381/comments | https://api.github.com/repos/huggingface/datasets/issues/381/events | https://github.com/huggingface/datasets/issues/381 | 655,277,119 | MDU6SXNzdWU2NTUyNzcxMTk= | 381 | NLp | [] | closed | false | null | 0 | 2020-07-11T20:50:14Z | 2020-07-11T20:50:39Z | 2020-07-11T20:50:39Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/381/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/381/timeline | null | completed | null | null | false | [] | |
https://api.github.com/repos/huggingface/datasets/issues/1803 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1803/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1803/comments | https://api.github.com/repos/huggingface/datasets/issues/1803/events | https://github.com/huggingface/datasets/issues/1803 | 798,243,904 | MDU6SXNzdWU3OTgyNDM5MDQ= | 1,803 | Querying examples from big datasets is slower than small datasets | [] | closed | false | null | 8 | 2021-02-01T11:08:23Z | 2021-08-04T18:11:01Z | 2021-08-04T18:10:42Z | null | After some experiments with bookcorpus I noticed that querying examples from big datasets is slower than small datasets.
For example
```python
from datasets import load_dataset
b1 = load_dataset("bookcorpus", split="train[:1%]")
b50 = load_dataset("bookcorpus", split="train[:50%]")
b100 = load_dataset("bookcorp... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1803/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1803/timeline | null | completed | null | null | false | [
"Hello, @lhoestq / @gaceladri : We have been seeing similar behavior with bigger datasets, where querying time increases. Are you folks aware of any solution that fixes this problem yet? ",
"Hi ! I'm pretty sure that it can be fixed by using the Arrow IPC file format instead of the raw streaming format but I ha... |
https://api.github.com/repos/huggingface/datasets/issues/38 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/38/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/38/comments | https://api.github.com/repos/huggingface/datasets/issues/38/events | https://github.com/huggingface/datasets/issues/38 | 611,677,656 | MDU6SXNzdWU2MTE2Nzc2NTY= | 38 | [Checksums] Error for some datasets | [] | closed | false | null | 3 | 2020-05-04T08:00:16Z | 2020-05-04T09:48:20Z | 2020-05-04T09:48:20Z | null | The checksums command works very nicely for `squad`. But for `crime_and_punish` and `xnli`,
the same bug happens:
When running:
```
python nlp-cli nlp-cli test xnli --save_checksums
```
leads to:
```
File "nlp-cli", line 33, in <module>
service.run()
File "/home/patrick/python_bin/nlp/commands... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/38/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/38/timeline | null | completed | null | null | false | [
"@lhoestq - could you take a look? It's not very urgent though!",
"Fixed with 06882b4\r\n\r\nNow your command works :)\r\nNote that you can also do\r\n```\r\nnlp-cli test datasets/nlp/xnli --save_checksums\r\n```\r\nSo that it will save the checksums directly in the right directory.",
"Awesome!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2707/comments | https://api.github.com/repos/huggingface/datasets/issues/2707/events | https://github.com/huggingface/datasets/issues/2707 | 950,812,945 | MDU6SXNzdWU5NTA4MTI5NDU= | 2,707 | 404 Not Found Error when loading LAMA dataset | [] | closed | false | null | 3 | 2021-07-22T15:52:33Z | 2021-07-26T14:29:07Z | 2021-07-26T14:29:07Z | null | The [LAMA](https://huggingface.co/datasets/viewer/?dataset=lama) probing dataset is not available for download:
Steps to Reproduce:
1. `from datasets import load_dataset`
2. `dataset = load_dataset('lama', 'trex')`.
Results:
`FileNotFoundError: Couldn't find file locally at lama/lama.py, or remotely ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2707/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2707/timeline | null | completed | null | null | false | [
"Hi @dwil2444! I was able to reproduce your error when I downgraded to v1.1.2. Updating to the latest version of Datasets fixed the error for me :)",
"Hi @dwil2444, thanks for reporting.\r\n\r\nCould you please confirm which `datasets` version you were using and if the problem persists after you update it to the ... |
https://api.github.com/repos/huggingface/datasets/issues/2476 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2476/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2476/comments | https://api.github.com/repos/huggingface/datasets/issues/2476/events | https://github.com/huggingface/datasets/pull/2476 | 917,686,662 | MDExOlB1bGxSZXF1ZXN0NjY3MTg3OTk1 | 2,476 | Add TimeDial | [] | closed | false | null | 1 | 2021-06-10T18:33:07Z | 2021-07-30T12:57:54Z | 2021-07-30T12:57:54Z | null | Dataset: https://github.com/google-research-datasets/TimeDial
To-Do: Update README.md and add YAML tags | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2476/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2476/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2476.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2476",
"merged_at": "2021-07-30T12:57:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2476.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Hi @lhoestq,\r\nI've pushed the updated README and tags. Let me know if anything is missing/needs some improvement!\r\n\r\n~PS. I don't know why it's not triggering the build~"
] |
https://api.github.com/repos/huggingface/datasets/issues/4423 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4423/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4423/comments | https://api.github.com/repos/huggingface/datasets/issues/4423/events | https://github.com/huggingface/datasets/pull/4423 | 1,253,326,023 | PR_kwDODunzps44trdP | 4,423 | Add new dataset MMChat | [] | closed | false | null | 2 | 2022-05-31T04:45:07Z | 2022-06-11T12:40:52Z | 2022-06-11T12:31:42Z | null | Hi, I am adding a new dataset MMChat.
It seems that all tests are passed | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4423/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4423/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4423.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4423",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4423.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4423"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks ! As for https://github.com/huggingface/datasets/pull/4431 please also update the licensing section in https://huggingface.co/datasets/silver/mmchat ;)\r\n\r\nThen if it's fine for you feel free to close this PR"
] |
https://api.github.com/repos/huggingface/datasets/issues/2480 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2480/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2480/comments | https://api.github.com/repos/huggingface/datasets/issues/2480/events | https://github.com/huggingface/datasets/issues/2480 | 918,678,578 | MDU6SXNzdWU5MTg2Nzg1Nzg= | 2,480 | Set download/extracted paths configurable | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2021-06-11T12:20:24Z | 2021-06-15T14:23:49Z | null | null | As discussed with @stas00 and @lhoestq, setting these paths configurable may allow to overcome disk space limitation on different partitions/drives.
TODO:
- [x] Set configurable extracted datasets path: #2487
- [x] Set configurable downloaded datasets path: #2488
- [ ] Set configurable "incomplete" datasets path? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2480/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2480/timeline | null | null | null | null | false | [
"For example to be able to send uncompressed and temp build files to another volume/partition, so that the user gets the minimal disk usage on their primary setup - and ends up with just the downloaded compressed data + arrow files, but outsourcing the huge files and building to another partition. e.g. on JZ there... |
https://api.github.com/repos/huggingface/datasets/issues/4789 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4789/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4789/comments | https://api.github.com/repos/huggingface/datasets/issues/4789/events | https://github.com/huggingface/datasets/pull/4789 | 1,328,409,253 | PR_kwDODunzps48o3Kk | 4,789 | Update doc upload_dataset.mdx | [] | closed | false | null | 1 | 2022-08-04T10:24:00Z | 2022-09-09T16:37:10Z | 2022-09-09T16:34:58Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4789/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4789/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4789.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4789",
"merged_at": "2022-09-09T16:34:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4789.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/292 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/292/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/292/comments | https://api.github.com/repos/huggingface/datasets/issues/292/events | https://github.com/huggingface/datasets/pull/292 | 642,897,797 | MDExOlB1bGxSZXF1ZXN0NDM3Nzk4NTM2 | 292 | Update metadata for x_stance dataset | [] | closed | false | null | 3 | 2020-06-22T09:13:26Z | 2020-06-23T08:07:24Z | 2020-06-23T08:07:24Z | null | Thank you for featuring the x_stance dataset in your library. This PR updates some metadata:
- Citation: Replace preprint with proceedings
- URL: Use a URL with long-term availability
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/292/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/292/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/292.diff",
"html_url": "https://github.com/huggingface/datasets/pull/292",
"merged_at": "2020-06-23T08:07:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/292.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/292... | true | [
"Great! Thanks @jvamvas for these updates.\r\n",
"I have fixed a warning. The remaining test failure is due to an unrelated dataset.",
"We just fixed the other dataset on master. Could you rebase from master and push to rerun the CI ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/4481 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4481/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4481/comments | https://api.github.com/repos/huggingface/datasets/issues/4481/events | https://github.com/huggingface/datasets/pull/4481 | 1,269,187,792 | PR_kwDODunzps45jIRi | 4,481 | Fix iwslt2017 | [] | closed | false | null | 4 | 2022-06-13T09:51:21Z | 2022-10-26T09:09:31Z | 2022-06-13T10:40:18Z | null | The files were moved to google drive, I hosted them on the Hub instead (ok according to the license)
I also updated the `datasets_infos.json` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4481/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4481/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4481.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4481",
"merged_at": "2022-06-13T10:40:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4481.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"CI fails are just abut missing tags in the dataset card, merging !",
"FYI, \r\n\r\nThe checksums have not been edited from the changes of .tgz to .zip files, and as a result a `ExpectedMoreDownloadedFiles` error occurs. Updating th... |
https://api.github.com/repos/huggingface/datasets/issues/2580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2580/comments | https://api.github.com/repos/huggingface/datasets/issues/2580/events | https://github.com/huggingface/datasets/pull/2580 | 935,767,421 | MDExOlB1bGxSZXF1ZXN0NjgyNjI2MTkz | 2,580 | Fix Counter import | [] | closed | false | null | 0 | 2021-07-02T13:21:48Z | 2021-07-02T14:37:47Z | 2021-07-02T14:37:46Z | null | Import from `collections` instead of `typing`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2580/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2580/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2580.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2580",
"merged_at": "2021-07-02T14:37:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2580.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1553/comments | https://api.github.com/repos/huggingface/datasets/issues/1553/events | https://github.com/huggingface/datasets/pull/1553 | 765,670,083 | MDExOlB1bGxSZXF1ZXN0NTM5MDI4MzM3 | 1,553 | added air_dialogue | [] | closed | false | null | 0 | 2020-12-13T21:59:02Z | 2020-12-23T11:20:40Z | 2020-12-23T11:20:39Z | null | UPDATE2 (3797ce5): Updated for multi-configs
UPDATE (7018082): manually created the dummy_datasets. All tests were cleared locally. Pushed it to origin/master
DRAFT VERSION (57fdb20): (_no longer draft_)
Uploaded the air_dialogue database.
dummy_data creation was failing in local, since the original download... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1553/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1553/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1553.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1553",
"merged_at": "2020-12-23T11:20:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1553.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/723 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/723/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/723/comments | https://api.github.com/repos/huggingface/datasets/issues/723/events | https://github.com/huggingface/datasets/issues/723 | 718,926,723 | MDU6SXNzdWU3MTg5MjY3MjM= | 723 | Adding pseudo-labels to datasets | [] | closed | false | null | 8 | 2020-10-11T21:05:45Z | 2021-08-03T05:11:51Z | 2021-08-03T05:11:51Z | null | I recently [uploaded pseudo-labels](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/precomputed_pseudo_labels.md) for CNN/DM, XSUM and WMT16-en-ro to s3, and thom mentioned I should add them to this repo.
Since pseudo-labels are just a large model's generations on an existing dataset, what is ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/723/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/723/timeline | null | completed | null | null | false | [
"Nice ! :)\r\nIt's indeed the first time we have such contributions so we'll have to figure out the appropriate way to integrate them.\r\nCould you add details on what they could be used for ?\r\n",
"They can be used as training data for a smaller model.",
"Sounds just like a regular dataset to me then, no?",
... |
https://api.github.com/repos/huggingface/datasets/issues/693 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/693/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/693/comments | https://api.github.com/repos/huggingface/datasets/issues/693/events | https://github.com/huggingface/datasets/pull/693 | 712,822,200 | MDExOlB1bGxSZXF1ZXN0NDk2MjQxMjUw | 693 | Rachel ker add dataset/mlsum | [] | closed | false | null | 1 | 2020-10-01T13:01:10Z | 2020-10-01T17:01:13Z | 2020-10-01T17:01:13Z | null | . | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/693/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/693/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/693.diff",
"html_url": "https://github.com/huggingface/datasets/pull/693",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/693.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/693"
} | true | [
"It looks like an outdated PR (we've already added mlsum). Closing it"
] |
https://api.github.com/repos/huggingface/datasets/issues/5793 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5793/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5793/comments | https://api.github.com/repos/huggingface/datasets/issues/5793/events | https://github.com/huggingface/datasets/issues/5793 | 1,684,777,320 | I_kwDODunzps5ka6lo | 5,793 | IterableDataset.with_format("torch") not working | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "a2eeef",
"default": true,
"descript... | closed | false | null | 1 | 2023-04-26T10:50:23Z | 2023-06-13T15:57:06Z | 2023-06-13T15:57:06Z | null | ### Describe the bug
After calling the with_format("torch") method on an IterableDataset instance, the data format is unchanged.
### Steps to reproduce the bug
```python
from datasets import IterableDataset
def gen():
for i in range(4):
yield {"a": [i] * 4}
dataset = IterableDataset.from_generator(g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5793/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5793/timeline | null | completed | null | null | false | [
"Hi ! Thanks for reporting, I'm working on it ;)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5019 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5019/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5019/comments | https://api.github.com/repos/huggingface/datasets/issues/5019/events | https://github.com/huggingface/datasets/pull/5019 | 1,384,673,718 | PR_kwDODunzps4_iq9b | 5,019 | Update swiss judgment prediction | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 4 | 2022-09-24T13:28:57Z | 2022-09-28T07:13:39Z | 2022-09-28T05:48:50Z | null | Hi,
I updated the dataset to include additional data made available recently. When I test it locally, it seems to work. However, I get the following error with the dummy data creation:
`Dummy data generation done but dummy data test failed since splits ['train', 'validation', 'test'] have 0 examples for config 'fr... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5019/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5019/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5019.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5019",
"merged_at": "2022-09-28T05:48:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5019.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Thank you very much for the detailed review @albertvillanova!\r\n\r\nI updated the PR with the requested changes. ",
"At the end, I had to manually fix the conflict, so that CI tests are launched.\r\n\r\nPLEASE NOTE: you should first pull to incorporate the previous commit\r\n```shell\r\ngit pull\r\n```",
"_Th... |
https://api.github.com/repos/huggingface/datasets/issues/1998 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1998/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1998/comments | https://api.github.com/repos/huggingface/datasets/issues/1998/events | https://github.com/huggingface/datasets/pull/1998 | 823,723,960 | MDExOlB1bGxSZXF1ZXN0NTg2MTE4NTQ4 | 1,998 | Add -DOCSTART- note to dataset card of conll-like datasets | [] | closed | false | null | 1 | 2021-03-06T19:08:29Z | 2021-03-11T02:20:07Z | 2021-03-11T02:20:07Z | null | Closes #1983 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1998/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1998/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1998.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1998",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1998.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1998"
} | true | [
"Nice catch! Yes I didn't check the actual data, instead I was just looking for the `if line.startswith(\"-DOCSTART-\")` pattern."
] |
https://api.github.com/repos/huggingface/datasets/issues/1231 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1231/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1231/comments | https://api.github.com/repos/huggingface/datasets/issues/1231/events | https://github.com/huggingface/datasets/pull/1231 | 758,121,398 | MDExOlB1bGxSZXF1ZXN0NTMzMzQzMzAz | 1,231 | Add Urdu Sentiment Corpus (USC) | [] | closed | false | null | 0 | 2020-12-07T03:25:20Z | 2020-12-07T18:05:16Z | 2020-12-07T16:43:23Z | null | @lhoestq opened a clean PR containing only relevant files.
old PR #1140 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1231/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1231/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1231.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1231",
"merged_at": "2020-12-07T16:43:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1231.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5824 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5824/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5824/comments | https://api.github.com/repos/huggingface/datasets/issues/5824/events | https://github.com/huggingface/datasets/pull/5824 | 1,697,152,148 | PR_kwDODunzps5P1rIZ | 5,824 | Fix incomplete docstring for `BuilderConfig` | [] | closed | false | null | 2 | 2023-05-05T07:34:28Z | 2023-05-05T12:39:14Z | 2023-05-05T12:31:54Z | null | Fixes #5820
Also fixed a couple of typos I spotted | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5824/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5824/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5824.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5824",
"merged_at": "2023-05-05T12:31:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5824.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/1690 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1690/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1690/comments | https://api.github.com/repos/huggingface/datasets/issues/1690/events | https://github.com/huggingface/datasets/pull/1690 | 779,441,631 | MDExOlB1bGxSZXF1ZXN0NTQ5NDEwOTgw | 1,690 | Fast start up | [] | closed | false | null | 0 | 2021-01-05T19:07:53Z | 2021-01-06T14:20:59Z | 2021-01-06T14:20:58Z | null | Currently if optional dependencies such as tensorflow, torch, apache_beam, faiss and elasticsearch are installed, then it takes a long time to do `import datasets` since it imports all of these heavy dependencies.
To make a fast start up for `datasets` I changed that so that they are not imported when `datasets` is ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 3,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1690/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1690/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1690.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1690",
"merged_at": "2021-01-06T14:20:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1690.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1061 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1061/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1061/comments | https://api.github.com/repos/huggingface/datasets/issues/1061/events | https://github.com/huggingface/datasets/pull/1061 | 756,362,661 | MDExOlB1bGxSZXF1ZXN0NTMxOTE5ODA0 | 1,061 | add labr dataset | [] | closed | false | null | 0 | 2020-12-03T16:38:57Z | 2020-12-03T18:25:44Z | 2020-12-03T18:25:44Z | null | Arabic Book Reviews dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1061/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1061/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1061.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1061",
"merged_at": "2020-12-03T18:25:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1061.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2355 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2355/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2355/comments | https://api.github.com/repos/huggingface/datasets/issues/2355/events | https://github.com/huggingface/datasets/pull/2355 | 890,484,408 | MDExOlB1bGxSZXF1ZXN0NjQzNDk5NTIz | 2,355 | normalized TOCs and titles in data cards | [] | closed | false | null | 3 | 2021-05-12T20:59:59Z | 2021-05-14T13:23:12Z | 2021-05-14T13:23:12Z | null | I started fixing some of the READMEs that were failing the tests introduced by @gchhablani but then realized that there were some consistent differences between earlier and newer versions of some of the titles (e.g. Data Splits vs Data Splits Sample Size, Supported Tasks vs Supported Tasks and Leaderboards). We also ha... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2355/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2355/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2355.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2355",
"merged_at": "2021-05-14T13:23:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2355.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Oh right! I'd be in favor of still having the same TOC across the board, we can either leave it as is or add a `[More Info Needed]` `Contributions` Section wherever it's currently missing, wdyt?",
"(I thought those were programmatically updated based on git history :D )",
"Merging for now to avoid conflict sin... |
https://api.github.com/repos/huggingface/datasets/issues/3503 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3503/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3503/comments | https://api.github.com/repos/huggingface/datasets/issues/3503/events | https://github.com/huggingface/datasets/issues/3503 | 1,090,472,735 | I_kwDODunzps5A_0sf | 3,503 | Batched in filter throws error | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2021-12-29T12:01:04Z | 2022-01-04T10:24:27Z | 2022-01-04T10:24:27Z | null | I hope this is really a bug, I could not find it among the open issues
## Describe the bug
using `batched=False` in DataSet.filter throws error
```python
TypeError: filter() got an unexpected keyword argument 'batched'
```
but in the docs it is lister as an argument.
## Steps to reproduce the bug
```python
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3503/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3503/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4375/comments | https://api.github.com/repos/huggingface/datasets/issues/4375/events | https://github.com/huggingface/datasets/pull/4375 | 1,241,921,147 | PR_kwDODunzps44IMCS | 4,375 | Support DataLoader with num_workers > 0 in streaming mode | [] | closed | false | null | 7 | 2022-05-19T15:00:31Z | 2022-07-04T16:05:14Z | 2022-06-10T20:47:27Z | null | ### Issue
It's currently not possible to properly stream a dataset using multiple `torch.utils.data.DataLoader` workers:
- the `TorchIterableDataset` can't be pickled and passed to the subprocesses: https://github.com/huggingface/datasets/issues/3950
- streaming extension is failing: https://github.com/huggingfa... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4375/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4375/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4375",
"merged_at": "2022-06-10T20:47:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Alright this is finally ready for review ! It's quite long I'm sorry, but it's not easy to disentangle everything ^^'\r\n\r\nThe main additions are in\r\n- src/datasets/formatting/dataset_wrappers/torch_iterable_dataset.py\r\n- src/d... |
https://api.github.com/repos/huggingface/datasets/issues/639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/639/comments | https://api.github.com/repos/huggingface/datasets/issues/639/events | https://github.com/huggingface/datasets/pull/639 | 704,217,963 | MDExOlB1bGxSZXF1ZXN0NDg5MTgxOTY3 | 639 | Update glue QQP checksum | [] | closed | false | null | 0 | 2020-09-18T09:08:15Z | 2020-09-18T11:37:08Z | 2020-09-18T11:37:07Z | null | Fix #638 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/639/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/639/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/639.diff",
"html_url": "https://github.com/huggingface/datasets/pull/639",
"merged_at": "2020-09-18T11:37:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/639.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/639... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/533 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/533/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/533/comments | https://api.github.com/repos/huggingface/datasets/issues/533/events | https://github.com/huggingface/datasets/pull/533 | 685,585,914 | MDExOlB1bGxSZXF1ZXN0NDczMjg4OTgx | 533 | Fix ArrayXD for pyarrow 0.17.1 by using non fixed length list arrays | [] | closed | false | null | 0 | 2020-08-25T15:32:44Z | 2020-08-26T08:02:24Z | 2020-08-26T08:02:23Z | null | It should fix the CI problems in #513 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/533/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/533/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/533.diff",
"html_url": "https://github.com/huggingface/datasets/pull/533",
"merged_at": "2020-08-26T08:02:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/533.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/533... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5856 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5856/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5856/comments | https://api.github.com/repos/huggingface/datasets/issues/5856/events | https://github.com/huggingface/datasets/issues/5856 | 1,709,218,242 | I_kwDODunzps5l4JnC | 5,856 | Error loading natural_questions | [] | closed | false | null | 2 | 2023-05-15T02:46:04Z | 2023-06-05T09:11:19Z | 2023-06-05T09:11:18Z | null | ### Describe the bug
When try to load natural_questions through datasets == 2.12.0 with python == 3.8.9:
```python
import datasets
datasets.load_dataset('natural_questions',beam_runner='DirectRunner')
```
It failed with following info:
`pyarrow.lib.ArrowNotImplementedError: Nested data conversions not impl... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5856/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5856/timeline | null | completed | null | null | false | [
"Hi! You can avoid this error by using the preprocessed version:\r\n```python\r\nimport datasets\r\nds = datasets.load_dataset('natural_questions')\r\n```\r\n\r\nPS: Once we finish https://github.com/huggingface/datasets/pull/5364, this error will no longer be a problem.",
"> Hi! You can avoid this error by using... |
https://api.github.com/repos/huggingface/datasets/issues/4899 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4899/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4899/comments | https://api.github.com/repos/huggingface/datasets/issues/4899/events | https://github.com/huggingface/datasets/pull/4899 | 1,352,031,286 | PR_kwDODunzps492uTO | 4,899 | Re-add code and und language tags | [] | closed | false | null | 1 | 2022-08-26T09:48:57Z | 2022-08-26T10:27:18Z | 2022-08-26T10:24:20Z | null | This PR fixes the removal of 2 language tags done by:
- #4882
The tags are:
- "code": this is not a IANA tag but needed
- "und": this is one of the special scoped tags removed by 0d53202b9abce6fd0358cb00d06fcfd904b875af
- used in "mc4" and "udhr" datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4899/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4899/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4899.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4899",
"merged_at": "2022-08-26T10:24:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4899.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5625/comments | https://api.github.com/repos/huggingface/datasets/issues/5625/events | https://github.com/huggingface/datasets/issues/5625 | 1,618,971,855 | I_kwDODunzps5gf4zP | 5,625 | Allow "jsonl" data type signifier | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 2 | 2023-03-10T13:21:48Z | 2023-03-11T10:35:39Z | null | null | ### Feature request
`load_dataset` currently does not accept `jsonl` as type but only `json`.
### Motivation
I was working with one of the `run_translation` scripts and used my own datasets (`.jsonl`) as train_dataset. But the default code did not work because
```
FileNotFoundError: Couldn't find a dataset scri... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5625/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5625/timeline | null | null | null | null | false | [
"You can use \"json\" instead. It doesn't work by extension names, but rather by dataset builder names, e.g. \"text\", \"imagefolder\", etc. I don't think the example in `transformers` is correct because of that",
"Yes, I understand the reasoning but this issue is to propose that the example in transformers (whil... |
https://api.github.com/repos/huggingface/datasets/issues/3305 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3305/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3305/comments | https://api.github.com/repos/huggingface/datasets/issues/3305/events | https://github.com/huggingface/datasets/pull/3305 | 1,059,161,000 | PR_kwDODunzps4uzZWv | 3,305 | asserts replaced with exception for ``fingerprint.py``, ``search.py``, ``arrow_writer.py`` and ``metric.py`` | [] | closed | false | null | 0 | 2021-11-20T14:51:23Z | 2021-11-22T18:24:32Z | 2021-11-22T17:08:13Z | null | Addresses #3171
Fixes exception for ``fingerprint.py``, ``search.py``, ``arrow_writer.py`` and ``metric.py`` and modified tests | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3305/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3305/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3305.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3305",
"merged_at": "2021-11-22T17:08:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3305.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2696 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2696/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2696/comments | https://api.github.com/repos/huggingface/datasets/issues/2696/events | https://github.com/huggingface/datasets/pull/2696 | 949,901,726 | MDExOlB1bGxSZXF1ZXN0Njk0NTMwODg3 | 2,696 | Add support for disable_progress_bar on Windows | [] | closed | false | null | 1 | 2021-07-21T16:34:53Z | 2021-07-26T13:31:14Z | 2021-07-26T09:38:37Z | null | This PR is a continuation of #2667 and adds support for `utils.disable_progress_bar()` on Windows when using multiprocessing. This [answer](https://stackoverflow.com/a/6596695/14095927) on SO explains it nicely why the current approach (with calling `utils.is_progress_bar_enabled()` inside `Dataset._map_single`) would ... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2696/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2696/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2696.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2696",
"merged_at": "2021-07-26T09:38:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2696.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"The CI failure seems unrelated to this PR (probably has something to do with Transformers)."
] |
https://api.github.com/repos/huggingface/datasets/issues/5466 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5466/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5466/comments | https://api.github.com/repos/huggingface/datasets/issues/5466/events | https://github.com/huggingface/datasets/pull/5466 | 1,557,584,845 | PR_kwDODunzps5Ij-z1 | 5,466 | remove pathlib.Path with URIs | [] | closed | false | null | 5 | 2023-01-26T03:25:45Z | 2023-01-26T17:08:57Z | 2023-01-26T16:59:11Z | null | Pathlib will convert "//" to "/" which causes retry errors when downloading from cloud storage | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5466/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5466/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5466.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5466",
"merged_at": "2023-01-26T16:59:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5466.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Thanks !\r\n`os.path.join` will use a backslash `\\` on windows which will also fail. You can use this instead in `load_from_disk`:\r\n```python\r\nfrom .filesystems import is_remote_filesystem\r\n\r\nis_local = not is_remote_filesystem(fs)\r\npath_join = os.path.join if is_local else posixpath.join\r\n```",
"Th... |
https://api.github.com/repos/huggingface/datasets/issues/3724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3724/comments | https://api.github.com/repos/huggingface/datasets/issues/3724/events | https://github.com/huggingface/datasets/issues/3724 | 1,138,827,681 | I_kwDODunzps5D4SGh | 3,724 | Bug while streaming CSV dataset with pandas 1.4 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-02-15T15:16:19Z | 2022-02-15T16:55:44Z | 2022-02-15T16:55:44Z | null | ## Describe the bug
If we upgrade to pandas `1.4`, the patching of the pandas module is no longer working
```
AttributeError: '_PatchedModuleObj' object has no attribute '__version__'
```
## Steps to reproduce the bug
```
pip install pandas==1.4
```
```python
from datasets import load_dataset
ds = load_dat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3724/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3724/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/3209 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3209/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3209/comments | https://api.github.com/repos/huggingface/datasets/issues/3209/events | https://github.com/huggingface/datasets/issues/3209 | 1,044,505,771 | I_kwDODunzps4-QeSr | 3,209 | Unpin keras once TF fixes its release | [] | closed | false | null | 0 | 2021-11-04T09:15:32Z | 2021-11-05T10:57:37Z | 2021-11-05T10:57:37Z | null | Related to:
- #3208 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3209/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3209/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/2834 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2834/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2834/comments | https://api.github.com/repos/huggingface/datasets/issues/2834/events | https://github.com/huggingface/datasets/pull/2834 | 978,309,749 | MDExOlB1bGxSZXF1ZXN0NzE4OTE5NjQ0 | 2,834 | Fix IndexError by ignoring empty RecordBatch | [] | closed | false | null | 0 | 2021-08-24T17:06:13Z | 2021-08-24T17:21:18Z | 2021-08-24T17:21:18Z | null | We need to ignore the empty record batches for the interpolation search to work correctly when querying arrow tables
Close #2833
cc @SaulLu | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2834/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2834/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2834.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2834",
"merged_at": "2021-08-24T17:21:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2834.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4974 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4974/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4974/comments | https://api.github.com/repos/huggingface/datasets/issues/4974/events | https://github.com/huggingface/datasets/pull/4974 | 1,371,682,020 | PR_kwDODunzps4-4Iri | 4,974 | [GH->HF] Part 2: Remove all dataset scripts from github | [] | closed | false | null | 6 | 2022-09-13T16:01:12Z | 2022-10-03T17:09:39Z | 2022-10-03T17:07:32Z | null | Now that all the datasets live on the Hub we can remove the /datasets directory that contains all the dataset scripts of this repository
- [x] Needs https://github.com/huggingface/datasets/pull/4973 to be merged first
- [x] and PR to be enabled on the Hub for non-namespaced datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4974/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4974/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4974.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4974",
"merged_at": "2022-10-03T17:07:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4974.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"So this means metrics will be deleted from this repo in favor of the \"evaluate\" library? Maybe you guys could just redirect metrics to that library.",
"We are deprecating the metrics in `datasets` indeed and suggest users to swit... |
https://api.github.com/repos/huggingface/datasets/issues/5829 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5829/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5829/comments | https://api.github.com/repos/huggingface/datasets/issues/5829/events | https://github.com/huggingface/datasets/issues/5829 | 1,699,958,189 | I_kwDODunzps5lU02t | 5,829 | (mach-o file, but is an incompatible architecture (have 'arm64', need 'x86_64')) | [] | closed | false | null | 2 | 2023-05-08T10:07:14Z | 2023-06-30T11:39:14Z | 2023-05-09T00:46:42Z | null | ### Describe the bug
M2 MBP can't run
```python
from datasets import load_dataset
jazzy = load_dataset("nomic-ai/gpt4all-j-prompt-generations", revision='v1.2-jazzy')
```
### Steps to reproduce the bug
1. Use M2 MBP
2. Python 3.10.10 from pyenv
3. Run
```
from datasets import load_dataset
jazzy = load_... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5829/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5829/timeline | null | completed | null | null | false | [
"Can you paste the error stack trace?",
"That is weird. I can't reproduce it again after reboot.\r\n```python\r\nIn [2]: import platform\r\n\r\nIn [3]: platform.platform()\r\nOut[3]: 'macOS-13.2-arm64-arm-64bit'\r\n\r\nIn [4]: from datasets import load_dataset\r\n ...:\r\n ...: jazzy = load_dataset(\"nomic-ai... |
https://api.github.com/repos/huggingface/datasets/issues/2789 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2789/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2789/comments | https://api.github.com/repos/huggingface/datasets/issues/2789/events | https://github.com/huggingface/datasets/pull/2789 | 967,361,934 | MDExOlB1bGxSZXF1ZXN0NzA5NTQwMzY5 | 2,789 | Updated dataset description of DaNE | [] | closed | false | null | 1 | 2021-08-11T19:58:48Z | 2021-08-12T16:10:59Z | 2021-08-12T16:06:01Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2789/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2789/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2789.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2789",
"merged_at": "2021-08-12T16:06:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2789.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Thanks for finishing it @albertvillanova "
] |
https://api.github.com/repos/huggingface/datasets/issues/5542 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5542/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5542/comments | https://api.github.com/repos/huggingface/datasets/issues/5542/events | https://github.com/huggingface/datasets/pull/5542 | 1,588,633,724 | PR_kwDODunzps5KLjMl | 5,542 | Avoid saving sparse ChunkedArrays in pyarrow tables | [] | closed | false | null | 2 | 2023-02-17T01:52:38Z | 2023-02-17T19:20:49Z | 2023-02-17T11:12:32Z | null | Fixes https://github.com/huggingface/datasets/issues/5541 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5542/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5542/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5542.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5542",
"merged_at": "2023-02-17T11:12:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5542.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/4703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4703/comments | https://api.github.com/repos/huggingface/datasets/issues/4703/events | https://github.com/huggingface/datasets/pull/4703 | 1,307,844,097 | PR_kwDODunzps47kABf | 4,703 | Make cast in `from_pandas` more robust | [] | closed | false | null | 1 | 2022-07-18T11:55:49Z | 2022-07-22T11:17:42Z | 2022-07-22T11:05:24Z | null | Make the cast in `from_pandas` more robust (as it was done for the packaged modules in https://github.com/huggingface/datasets/pull/4364)
This should be useful in situations like [this one](https://discuss.huggingface.co/t/loading-custom-audio-dataset-and-fine-tuning-model/8836/4). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4703/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4703/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4703.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4703",
"merged_at": "2022-07-22T11:05:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4703.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2294 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2294/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2294/comments | https://api.github.com/repos/huggingface/datasets/issues/2294/events | https://github.com/huggingface/datasets/issues/2294 | 872,136,075 | MDU6SXNzdWU4NzIxMzYwNzU= | 2,294 | Slow #0 when using map to tokenize. | [] | open | false | null | 3 | 2021-04-30T08:00:33Z | 2021-05-04T11:00:11Z | null | null | Hi, _datasets_ is really amazing! I am following [run_mlm_no_trainer.py](url) to pre-train BERT, and it uses `tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
loa... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2294/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2294/timeline | null | null | null | null | false | [
"Hi ! Have you tried other values for `preprocessing_num_workers` ? Is it always process 0 that is slower ?\r\nThere are no difference between process 0 and the others except that it processes the first shard of the dataset.",
"Hi, I have found the reason of it. Before using the map function to tokenize the data,... |
https://api.github.com/repos/huggingface/datasets/issues/1274 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1274/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1274/comments | https://api.github.com/repos/huggingface/datasets/issues/1274/events | https://github.com/huggingface/datasets/pull/1274 | 758,943,174 | MDExOlB1bGxSZXF1ZXN0NTM0MDI0MTQx | 1,274 | oclar-dataset | [] | closed | false | null | 1 | 2020-12-07T23:56:45Z | 2020-12-09T15:36:08Z | 2020-12-09T15:36:08Z | null | Opinion Corpus for Lebanese Arabic Reviews (OCLAR) corpus is utilizable for Arabic sentiment classification on reviews, including hotels, restaurants, shops, and others. : [homepage](http://archive.ics.uci.edu/ml/datasets/Opinion+Corpus+for+Lebanese+Arabic+Reviews+%28OCLAR%29#) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1274/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1274/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1274.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1274",
"merged_at": "2020-12-09T15:36:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1274.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/3682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3682/comments | https://api.github.com/repos/huggingface/datasets/issues/3682/events | https://github.com/huggingface/datasets/pull/3682 | 1,124,434,330 | PR_kwDODunzps4yGFml | 3,682 | adding told-br for toxic/abusive hatespeech detection | [] | closed | false | null | 2 | 2022-02-04T17:18:29Z | 2022-02-07T03:23:24Z | 2022-02-04T17:36:40Z | null | Hey,
I'm adding our dataset from our paper published at AACL 2020. Feel free to ask for modifications.
Thanks! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3682/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3682/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3682.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3682",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3682.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3682"
} | true | [
"Sorry for using multiple github accounts, I didn't notice I was using my professional account to commit/push. Please consider this @JAugusto97 account as the correct one.",
"Will remake the PR with the correct github account."
] |
https://api.github.com/repos/huggingface/datasets/issues/862 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/862/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/862/comments | https://api.github.com/repos/huggingface/datasets/issues/862/events | https://github.com/huggingface/datasets/pull/862 | 744,906,131 | MDExOlB1bGxSZXF1ZXN0NTIyNTUzMzY1 | 862 | Update head requests | [] | closed | false | null | 0 | 2020-11-17T16:49:06Z | 2020-11-18T14:43:53Z | 2020-11-18T14:43:50Z | null | Get requests and Head requests didn't have the same parameters. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/862/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/862/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/862.diff",
"html_url": "https://github.com/huggingface/datasets/pull/862",
"merged_at": "2020-11-18T14:43:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/862.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/862... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4805 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4805/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4805/comments | https://api.github.com/repos/huggingface/datasets/issues/4805/events | https://github.com/huggingface/datasets/issues/4805 | 1,332,653,531 | I_kwDODunzps5Pbq3b | 4,805 | Wrong example in opus_gnome dataset card | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-08-09T03:21:27Z | 2022-08-09T11:52:05Z | 2022-08-09T11:52:05Z | null | ## Describe the bug
I found that [the example on opus_gone dataset ](https://github.com/huggingface/datasets/tree/main/datasets/opus_gnome#dataset-summary) doesn't work.
## Steps to reproduce the bug
```python
load_dataset("gnome", lang1="it", lang2="pl")
```
`"gnome"` should be `"opus_gnome"`
## Expected r... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4805/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4805/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/348 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/348/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/348/comments | https://api.github.com/repos/huggingface/datasets/issues/348/events | https://github.com/huggingface/datasets/pull/348 | 652,158,308 | MDExOlB1bGxSZXF1ZXN0NDQ1MjgwNjk3 | 348 | Add OSCAR dataset | [] | closed | false | null | 20 | 2020-07-07T09:22:07Z | 2021-05-03T22:07:08Z | 2021-02-09T10:19:19Z | null | I don't know if tests pass, when I run them it tries to download the whole corpus which is around 3.5TB compressed and I don't have that kind of space. I'll really need some help with it 😅
Thanks! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 4,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/348/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/348/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/348.diff",
"html_url": "https://github.com/huggingface/datasets/pull/348",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/348.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/348"
} | true | [
"@pjox I think the tests don't pass because you haven't provided any dummy data (`dummy_data.zip`).\r\n\r\n ",
"> @pjox I think the tests don't pass because you haven't provided any dummy data (`dummy_data.zip`).\r\n\r\nBut can I do the dummy data without running `python nlp-cli test datasets/<your-dataset-folder... |
https://api.github.com/repos/huggingface/datasets/issues/3248 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3248/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3248/comments | https://api.github.com/repos/huggingface/datasets/issues/3248/events | https://github.com/huggingface/datasets/pull/3248 | 1,050,171,082 | PR_kwDODunzps4uXZzU | 3,248 | Stream from Google Drive and other hosts | [] | closed | false | null | 3 | 2021-11-10T18:32:32Z | 2021-11-30T16:03:43Z | 2021-11-12T17:18:11Z | null | Streaming from Google Drive is a bit more challenging than the other host we've been supporting:
- the download URL must be updated to add the confirm token obtained by HEAD request
- it requires to use cookies to keep the connection alive
- the URL doesn't tell any information about whether the file is compressed o... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3248/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3248/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3248.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3248",
"merged_at": "2021-11-12T17:18:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3248.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"I just tried some datasets and noticed that `spider` is not working for some reason (the compression type is not recognized), resulting in FileNotFoundError. I can take a look tomorrow",
"I'm fixing the remaining files based on TAR archives",
"THANKS A LOT"
] |
https://api.github.com/repos/huggingface/datasets/issues/5196 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5196/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5196/comments | https://api.github.com/repos/huggingface/datasets/issues/5196/events | https://github.com/huggingface/datasets/pull/5196 | 1,434,401,646 | PR_kwDODunzps5CH439 | 5,196 | Use hfh hf_hub_url function | [] | closed | false | null | 9 | 2022-11-03T10:08:09Z | 2022-12-06T11:38:17Z | 2022-11-09T07:15:12Z | null | Small refactoring to use `hf_hub_url` function from `huggingface_hub`.
This PR also creates the `hub` module that will contain all `huggingface_hub` functionalities relevant to `datasets`.
This is a necessary stage before implementing the use of the `hfh` caching system (which uses its `hf_hub_url` under the hood... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5196/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5196/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5196.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5196",
"merged_at": "2022-11-09T07:15:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5196.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5196). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq I think we should first agree if `datasets` can introduce the breaking change of ignoring `config.HUB_DATASETS_URL`: some users may have o... |
https://api.github.com/repos/huggingface/datasets/issues/4450 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4450/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4450/comments | https://api.github.com/repos/huggingface/datasets/issues/4450/events | https://github.com/huggingface/datasets/pull/4450 | 1,261,878,324 | PR_kwDODunzps45Kzwh | 4,450 | Update README.md of fquad | [] | closed | false | null | 1 | 2022-06-06T13:52:41Z | 2022-06-06T14:51:49Z | 2022-06-06T14:43:03Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4450/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4450/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4450.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4450",
"merged_at": "2022-06-06T14:43:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4450.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1586/comments | https://api.github.com/repos/huggingface/datasets/issues/1586/events | https://github.com/huggingface/datasets/pull/1586 | 768,864,502 | MDExOlB1bGxSZXF1ZXN0NTQxMTY0MDc2 | 1,586 | added irc disentangle dataset | [] | closed | false | null | 5 | 2020-12-16T13:25:58Z | 2021-01-29T10:28:53Z | 2021-01-29T10:28:53Z | null | added irc disentanglement dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1586/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1586/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1586.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1586",
"merged_at": "2021-01-29T10:28:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1586.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"@lhoestq sorry, this was the only way I was able to fix the pull request ",
"@lhoestq Thank you for the feedback. I wondering whether I should be passing an 'id' field in the dictionary since the 'connections' reference the 'id' of the linked messages. This 'id' would just be the same as the id_ that is in the y... |
https://api.github.com/repos/huggingface/datasets/issues/4902 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4902/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4902/comments | https://api.github.com/repos/huggingface/datasets/issues/4902/events | https://github.com/huggingface/datasets/issues/4902 | 1,352,469,196 | I_kwDODunzps5QnQrM | 4,902 | Name the default config `default` | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "d876e3",
"default": true... | closed | false | null | 1 | 2022-08-26T16:16:22Z | 2023-07-24T21:15:31Z | 2023-07-24T21:15:31Z | null | Currently, if a dataset has no configuration, a default configuration is created from the dataset name.
For example, for a dataset loaded from the hub repository, such as https://huggingface.co/datasets/user/dataset (repo id is `user/dataset`), the default configuration will be `user--dataset`.
It might be easier... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4902/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4902/timeline | null | completed | null | null | false | [
"Addressed in #5331."
] |
https://api.github.com/repos/huggingface/datasets/issues/4989 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4989/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4989/comments | https://api.github.com/repos/huggingface/datasets/issues/4989/events | https://github.com/huggingface/datasets/issues/4989 | 1,376,832,233 | I_kwDODunzps5SEMrp | 4,989 | Running add_column() seems to corrupt existing sequence-type column info | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-09-17T17:42:05Z | 2022-09-19T12:54:54Z | 2022-09-19T12:54:54Z | null | I have a dataset that contains a column ("foo") that is a sequence type of length 4. So when I run .to_pandas() on it, the resulting dataframe correctly contains 4 columns - foo_0, foo_1, foo_2, foo_3. So the 1st row of the dataframe might look like:
ds = load_dataset(...)
df = ds.to_pandas()
df:
foo_0 | foo_1 ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4989/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4989/timeline | null | completed | null | null | false | [
"Nevermind, I was incorrect."
] |
https://api.github.com/repos/huggingface/datasets/issues/5083 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5083/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5083/comments | https://api.github.com/repos/huggingface/datasets/issues/5083/events | https://github.com/huggingface/datasets/issues/5083 | 1,399,842,514 | I_kwDODunzps5Tb-bS | 5,083 | Support numpy/torch/tf/jax formatting for IterableDataset | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "fef2c0",
"default": fals... | open | false | null | 0 | 2022-10-06T15:14:58Z | 2023-02-17T14:10:01Z | null | null | Right now `IterableDataset` doesn't do any formatting.
In particular this code should return a numpy array:
```python
from datasets import load_dataset
ds = load_dataset("imagenet-1k", split="train", streaming=True).with_format("np")
print(next(iter(ds))["image"])
```
Right now it returns a PIL.Image.
S... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5083/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5083/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4915 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4915/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4915/comments | https://api.github.com/repos/huggingface/datasets/issues/4915/events | https://github.com/huggingface/datasets/issues/4915 | 1,356,009,042 | I_kwDODunzps5Q0w5S | 4,915 | FileNotFoundError while downloading wikipedia dataset for any language | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 5 | 2022-08-30T16:15:46Z | 2022-12-04T22:20:33Z | null | null | ## Describe the bug
Hi, I am currently trying to download wikipedia dataset using
load_dataset("wikipedia", language="aa", date="20220401", split="train",beam_runner='DirectRunner'). However, I end up in getting filenotfound error. I get this error for any language I try to download.
Environment:
## Step... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4915/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4915/timeline | null | reopened | null | null | false | [
"Hi @Shilpac20,\r\n\r\nAs explained in the Wikipedia dataset card: https://huggingface.co/datasets/wikipedia\r\n> You can find the full list of languages and dates [here](https://dumps.wikimedia.org/backup-index.html).\r\n\r\nThis means that, before passing a specific date, you should first make sure it is availabl... |
https://api.github.com/repos/huggingface/datasets/issues/5028 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5028/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5028/comments | https://api.github.com/repos/huggingface/datasets/issues/5028/events | https://github.com/huggingface/datasets/issues/5028 | 1,386,272,533 | I_kwDODunzps5SoNcV | 5,028 | passing parameters to the method passed to Dataset.from_generator() | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 1 | 2022-09-26T15:20:06Z | 2022-10-03T13:00:00Z | 2022-10-03T13:00:00Z | null | Big thanks for providing dataset creation via a generator.
I want to ask whether there is any way that parameters can be passed to the method Dataset.from_generator() method, like as follows.
```
from datasets import Dataset
def gen(param1):
for idx in len(custom_dataset):
yield custom_dataset[id... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5028/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5028/timeline | null | completed | null | null | false | [
"Hi! Yes, you can either use the `gen_kwargs` param in `Dataset.from_generator` (`ds = Dataset.from_generator(gen, gen_kwargs={\"param1\": val})`) or wrap the generator function with `functools.partial`\r\n(`ds = Dataset.from_generator(functools.partial(gen, param1=\"val\"))`) to pass custom parameters to it.\r\n"
... |
https://api.github.com/repos/huggingface/datasets/issues/4652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4652/comments | https://api.github.com/repos/huggingface/datasets/issues/4652/events | https://github.com/huggingface/datasets/issues/4652 | 1,296,697,498 | I_kwDODunzps5NSgia | 4,652 | Add Sentence Compression Dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 1 | 2022-07-07T02:13:46Z | 2022-07-14T02:11:48Z | 2022-07-14T02:11:48Z | null | ## Adding a Dataset
- **Name:** *Sentence Compression*
- **Description:** *Large corpus of uncompressed and compressed sentences from news articles.*
- **Paper:** *https://www.aclweb.org/anthology/D13-1155/*
- **Data:** *https://github.com/google-research-datasets/sentence-compression/tree/master/data*
- **Motivat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4652/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4652/timeline | null | completed | null | null | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/sentence-compression)."
] |
https://api.github.com/repos/huggingface/datasets/issues/3440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3440/comments | https://api.github.com/repos/huggingface/datasets/issues/3440/events | https://github.com/huggingface/datasets/issues/3440 | 1,081,528,426 | I_kwDODunzps5AdtBq | 3,440 | datasets keeps reading from cached files, although I disabled it | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-12-15T21:26:22Z | 2022-02-24T09:12:22Z | 2022-02-24T09:12:22Z | null | ## Describe the bug
Hi,
I am trying to avoid dataset library using cached files, I get the following bug when this tried to read the cached files. I tried to do the followings:
```
from datasets import set_caching_enabled
set_caching_enabled(False)
```
also force redownlaod:
```
download_mode='force_redownloa... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3440/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3440/timeline | null | completed | null | null | false | [
"Hi ! What version of `datasets` are you using ? Can you also provide the logs you get before it raises the error ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/6083 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6083/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6083/comments | https://api.github.com/repos/huggingface/datasets/issues/6083/events | https://github.com/huggingface/datasets/pull/6083 | 1,824,832,348 | PR_kwDODunzps5WkgAI | 6,083 | set dev version | [] | closed | false | null | 3 | 2023-07-27T17:10:41Z | 2023-07-27T17:22:05Z | 2023-07-27T17:11:01Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6083/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6083/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6083.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6083",
"merged_at": "2023-07-27T17:11:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6083.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6083). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... |
https://api.github.com/repos/huggingface/datasets/issues/4521 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4521/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4521/comments | https://api.github.com/repos/huggingface/datasets/issues/4521/events | https://github.com/huggingface/datasets/issues/4521 | 1,274,919,437 | I_kwDODunzps5L_boN | 4,521 | Datasets method `.map` not hashing | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2022-06-17T11:31:10Z | 2022-08-04T12:08:16Z | 2022-06-28T13:23:05Z | null | ## Describe the bug
Datasets method `.map` not hashing, even with an empty no-op function
## Steps to reproduce the bug
```python
from datasets import load_dataset
# download 9MB dummy dataset
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean")
def prepare_dataset(batch):
return(b... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4521/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4521/timeline | null | completed | null | null | false | [
"Fix posted: https://github.com/huggingface/datasets/issues/4506#issuecomment-1157417219",
"Didn't realize it's a bug when I asked the question yesterday! Free free to post an answer if you are sure the cause has been addressed.\r\n\r\nhttps://stackoverflow.com/questions/72664827/can-pickle-dill-foo-but-not-lambd... |
https://api.github.com/repos/huggingface/datasets/issues/1562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1562/comments | https://api.github.com/repos/huggingface/datasets/issues/1562/events | https://github.com/huggingface/datasets/pull/1562 | 765,981,749 | MDExOlB1bGxSZXF1ZXN0NTM5MTc5ODc3 | 1,562 | Add dataset COrpus of Urdu News TExt Reuse (COUNTER). | [] | closed | false | null | 3 | 2020-12-14T06:32:48Z | 2020-12-21T13:14:46Z | 2020-12-21T13:14:46Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1562/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1562/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1562.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1562",
"merged_at": "2020-12-21T13:14:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1562.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Just a small revision from simon's review: 20KB for the dummy_data.zip is fine, you can keep them this way.",
"Also the CI is failing because of an error `tests/test_file_utils.py::TempSeedTest::test_tensorflow` that is not related to your dataset and is fixed on master. You can ignore it",
"merging since the ... | |
https://api.github.com/repos/huggingface/datasets/issues/2644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2644/comments | https://api.github.com/repos/huggingface/datasets/issues/2644/events | https://github.com/huggingface/datasets/issues/2644 | 944,254,748 | MDU6SXNzdWU5NDQyNTQ3NDg= | 2,644 | Batched `map` not allowed to return 0 items | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 6 | 2021-07-14T09:58:19Z | 2021-07-26T14:55:15Z | 2021-07-26T14:55:15Z | null | ## Describe the bug
I'm trying to use `map` to filter a large dataset by selecting rows that match an expensive condition (files referenced by one of the columns need to exist in the filesystem, so we have to `stat` them). According to [the documentation](https://huggingface.co/docs/datasets/processing.html#augmenting... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2644/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2644/timeline | null | completed | null | null | false | [
"Hi ! Thanks for reporting. Indeed it looks like type inference makes it fail. We should probably just ignore this step until a non-empty batch is passed.",
"Sounds good! Do you want me to propose a PR? I'm quite busy right now, but if it's not too urgent I could take a look next week.",
"Sure if you're interes... |
https://api.github.com/repos/huggingface/datasets/issues/916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/916/comments | https://api.github.com/repos/huggingface/datasets/issues/916/events | https://github.com/huggingface/datasets/pull/916 | 753,376,643 | MDExOlB1bGxSZXF1ZXN0NTI5NDY3MTkx | 916 | Add Swedish NER Corpus | [] | closed | false | null | 2 | 2020-11-30T10:59:51Z | 2020-12-02T03:10:50Z | 2020-12-02T03:10:49Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/916/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/916.diff",
"html_url": "https://github.com/huggingface/datasets/pull/916",
"merged_at": "2020-12-02T03:10:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/916.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/916... | true | [
"Yes the use of configs is optional",
"@abhishekkrthakur we want to keep track of the information that is and isn't in the dataset cards so we're asking everyone to use the full template :) If there is some information in there that you really can't find or don't feel qualified to add, you can just leave the `[Mo... | |
https://api.github.com/repos/huggingface/datasets/issues/5090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5090/comments | https://api.github.com/repos/huggingface/datasets/issues/5090/events | https://github.com/huggingface/datasets/issues/5090 | 1,401,102,407 | I_kwDODunzps5TgyBH | 5,090 | Review sync issues from GitHub to Hub | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-10-07T12:31:56Z | 2022-10-08T07:07:36Z | 2022-10-08T07:07:36Z | null | ## Describe the bug
We have discovered that sometimes there were sync issues between GitHub and Hub datasets, after a merge commit to main branch.
For example:
- this merge commit: https://github.com/huggingface/datasets/commit/d74a9e8e4bfff1fed03a4cab99180a841d7caf4b
- was not properly synced with the Hub: https... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5090/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5090/timeline | null | completed | null | null | false | [
"Nice!!"
] |
https://api.github.com/repos/huggingface/datasets/issues/1748 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1748/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1748/comments | https://api.github.com/repos/huggingface/datasets/issues/1748/events | https://github.com/huggingface/datasets/pull/1748 | 788,431,642 | MDExOlB1bGxSZXF1ZXN0NTU2OTQ0NDEx | 1,748 | add Stuctured Argument Extraction for Korean dataset | [] | closed | false | null | 0 | 2021-01-18T17:14:19Z | 2021-09-17T16:53:18Z | 2021-01-19T11:26:58Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1748/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1748/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1748.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1748",
"merged_at": "2021-01-19T11:26:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1748.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] | |
https://api.github.com/repos/huggingface/datasets/issues/4946 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4946/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4946/comments | https://api.github.com/repos/huggingface/datasets/issues/4946/events | https://github.com/huggingface/datasets/pull/4946 | 1,364,692,069 | PR_kwDODunzps4-g0Hz | 4,946 | Introduce regex check when pushing as well | [] | closed | false | null | 2 | 2022-09-07T13:45:58Z | 2022-09-13T10:19:01Z | 2022-09-13T10:16:34Z | null | Closes https://github.com/huggingface/datasets/issues/4945 by adding a regex check when pushing to hub.
Let me know if this is helpful and if it's the fix you would have in mind for the issue and I'm happy to contribute tests. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4946/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4946/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4946.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4946",
"merged_at": "2022-09-13T10:16:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4946.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Let me take over this PR if you don't mind"
] |
https://api.github.com/repos/huggingface/datasets/issues/889 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/889/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/889/comments | https://api.github.com/repos/huggingface/datasets/issues/889/events | https://github.com/huggingface/datasets/pull/889 | 751,115,691 | MDExOlB1bGxSZXF1ZXN0NTI3NjkwODE2 | 889 | Optional per-dataset default config name | [] | closed | false | null | 3 | 2020-11-25T21:02:30Z | 2020-11-30T17:27:33Z | 2020-11-30T17:27:27Z | null | This PR adds a `DEFAULT_CONFIG_NAME` class attribute to `DatasetBuilder`. This allows a dataset to have a specified default config name when a dataset has more than one config but the user does not specify it. For example, after defining `DEFAULT_CONFIG_NAME = "combined"` in PolyglotNER, a user can now do the following... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/889/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/889/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/889.diff",
"html_url": "https://github.com/huggingface/datasets/pull/889",
"merged_at": "2020-11-30T17:27:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/889.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/889... | true | [
"I like the idea ! And the approach is right imo\r\n\r\nNote that by changing this we will have to add a way for users to get the config lists of a dataset. In the current user workflow, the user could see the list of the config when the missing config error is raised but now it won't be the case because of the def... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.