
url stringlengths 61 61 | repository_url stringclasses 1
value | labels_url stringlengths 75 75 | comments_url stringlengths 70 70 | events_url stringlengths 68 68 | html_url stringlengths 49 51 | id int64 1.6B 1.71B | node_id stringlengths 18 19 | number int64 5.58k 5.87k | title stringlengths 9 113 | user dict | labels list | state stringclasses 1
value | locked bool 1
class | assignee dict | assignees list | milestone null | comments list | created_at timestamp[s] | updated_at timestamp[s] | closed_at timestamp[s] | author_association stringclasses 3
values | active_lock_reason null | draft bool 2
classes | pull_request dict | body stringlengths 3 19.9k ⌀ | reactions dict | timeline_url stringlengths 70 70 | performed_via_github_app null | state_reason stringclasses 1
value | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5751 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5751/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5751/comments | https://api.github.com/repos/huggingface/datasets/issues/5751/events | https://github.com/huggingface/datasets/pull/5751 | 1,668,333,316 | PR_kwDODunzps5OVMuT | 5,751 | Consistent ArrayXD Python formatting + better NumPy/Pandas formatting | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-04-14T14:13:59 | 2023-04-20T14:43:20 | 2023-04-20T14:40:34 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5751",
"html_url": "https://github.com/huggingface/datasets/pull/5751",
"diff_url": "https://github.com/huggingface/datasets/pull/5751.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5751.patch",
"merged_at": "2023-04-20T14:40... | Return a list of lists instead of a list of NumPy arrays when converting the variable-shaped `ArrayXD` to Python. Additionally, improve the NumPy conversion by returning a numeric NumPy array when the offsets are equal or a NumPy object array when they aren't, and allow converting the variable-shaped `ArrayXD` to Panda... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5751/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5751/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5750 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5750/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5750/comments | https://api.github.com/repos/huggingface/datasets/issues/5750/events | https://github.com/huggingface/datasets/issues/5750 | 1,668,289,067 | I_kwDODunzps5jcBIr | 5,750 | Fail to create datasets from a generator when using Google Big Query | {
"login": "ivanprado",
"id": 895720,
"node_id": "MDQ6VXNlcjg5NTcyMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/895720?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ivanprado",
"html_url": "https://github.com/ivanprado",
"followers_url": "https://api.github.com/users/ivan... | [] | closed | false | null | [] | null | [
"`from_generator` expects a generator function, not a generator object, so this should work:\r\n```python\r\nfrom datasets import Dataset\r\nfrom google.cloud import bigquery\r\n\r\nclient = bigquery.Client()\r\n\r\ndef gen()\r\n # Perform a query.\r\n QUERY = (\r\n 'SELECT name FROM `bigquery-public-d... | 2023-04-14T13:50:59 | 2023-04-17T12:20:43 | 2023-04-17T12:20:43 | NONE | null | null | null | ### Describe the bug
Creating a dataset from a generator using `Dataset.from_generator()` fails if the generator is the [Google Big Query Python client](https://cloud.google.com/python/docs/reference/bigquery/latest). The problem is that the Big Query client is not pickable. And the function `create_config_id` tries t... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5750/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5750/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5749 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5749/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5749/comments | https://api.github.com/repos/huggingface/datasets/issues/5749/events | https://github.com/huggingface/datasets/issues/5749 | 1,668,016,321 | I_kwDODunzps5ja-jB | 5,749 | AttributeError: 'Version' object has no attribute 'match' | {
"login": "gulnaz-zh",
"id": 54584290,
"node_id": "MDQ6VXNlcjU0NTg0Mjkw",
"avatar_url": "https://avatars.githubusercontent.com/u/54584290?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gulnaz-zh",
"html_url": "https://github.com/gulnaz-zh",
"followers_url": "https://api.github.com/users/... | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"I got the same error, and the official website for visual genome is down. Did you solve this problem? ",
"I am in the same situation now :( ",
"Thanks for reporting, @gulnaz-zh.\r\n\r\nI am investigating it.",
"The host server is down: https://visualgenome.org/\r\n\r\nWe are contacting the dataset authors.",... | 2023-04-14T10:48:06 | 2023-04-18T12:58:01 | 2023-04-18T12:57:08 | NONE | null | null | null | ### Describe the bug
When I run
from datasets import load_dataset
data = load_dataset("visual_genome", 'region_descriptions_v1.2.0')
AttributeError: 'Version' object has no attribute 'match'
### Steps to reproduce the bug
from datasets import load_dataset
data = load_dataset("visual_genome", 'region_descripti... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5749/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5749/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5746 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5746/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5746/comments | https://api.github.com/repos/huggingface/datasets/issues/5746/events | https://github.com/huggingface/datasets/pull/5746 | 1,667,102,459 | PR_kwDODunzps5ORIUU | 5,746 | Fix link in docs | {
"login": "bbbxyz",
"id": 7485661,
"node_id": "MDQ6VXNlcjc0ODU2NjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/7485661?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bbbxyz",
"html_url": "https://github.com/bbbxyz",
"followers_url": "https://api.github.com/users/bbbxyz/foll... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-04-13T20:45:19 | 2023-04-14T13:15:38 | 2023-04-14T13:08:42 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5746",
"html_url": "https://github.com/huggingface/datasets/pull/5746",
"diff_url": "https://github.com/huggingface/datasets/pull/5746.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5746.patch",
"merged_at": "2023-04-14T13:08... | Fixes a broken link in the use_with_pytorch docs | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5746/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5746/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5743/comments | https://api.github.com/repos/huggingface/datasets/issues/5743/events | https://github.com/huggingface/datasets/issues/5743 | 1,666,843,832 | I_kwDODunzps5jWgS4 | 5,743 | dataclass.py in virtual environment is overriding the stdlib module "dataclasses" | {
"login": "syedabdullahhassan",
"id": 71216295,
"node_id": "MDQ6VXNlcjcxMjE2Mjk1",
"avatar_url": "https://avatars.githubusercontent.com/u/71216295?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/syedabdullahhassan",
"html_url": "https://github.com/syedabdullahhassan",
"followers_url": "ht... | [] | closed | false | null | [] | null | [
"We no longer depend on `dataclasses` (for almost a year), so I don't think our package is the problematic one. \r\n\r\nI think it makes more sense to raise this issue in the `dataclasses` repo: https://github.com/ericvsmith/dataclasses."
] | 2023-04-13T17:28:33 | 2023-04-17T12:23:18 | 2023-04-17T12:23:18 | NONE | null | null | null | ### Describe the bug
"e:\Krish_naik\FSDSRegression\venv\Lib\dataclasses.py" is overriding the stdlib module "dataclasses"
### Steps to reproduce the bug
module issue
### Expected behavior
overriding the stdlib module "dataclasses"
### Environment info
VS code | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5743/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5743/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5742 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5742/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5742/comments | https://api.github.com/repos/huggingface/datasets/issues/5742/events | https://github.com/huggingface/datasets/pull/5742 | 1,666,209,738 | PR_kwDODunzps5OOH-W | 5,742 | Warning specifying future change in to_tf_dataset behaviour | {
"login": "amyeroberts",
"id": 22614925,
"node_id": "MDQ6VXNlcjIyNjE0OTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amyeroberts",
"html_url": "https://github.com/amyeroberts",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-04-13T11:10:00 | 2023-04-21T13:18:14 | 2023-04-21T13:11:09 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5742",
"html_url": "https://github.com/huggingface/datasets/pull/5742",
"diff_url": "https://github.com/huggingface/datasets/pull/5742.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5742.patch",
"merged_at": "2023-04-21T13:11... | Warning specifying future changes happening to `to_tf_dataset` behaviour when #5602 is merged in | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5742/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5742/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5741 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5741/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5741/comments | https://api.github.com/repos/huggingface/datasets/issues/5741/events | https://github.com/huggingface/datasets/pull/5741 | 1,665,860,919 | PR_kwDODunzps5OM9nZ | 5,741 | Fix CI warnings | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-04-13T07:17:02 | 2023-04-13T09:48:10 | 2023-04-13T09:40:50 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5741",
"html_url": "https://github.com/huggingface/datasets/pull/5741",
"diff_url": "https://github.com/huggingface/datasets/pull/5741.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5741.patch",
"merged_at": "2023-04-13T09:40... | Fix warnings in our CI tests. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5741/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5741/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5740 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5740/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5740/comments | https://api.github.com/repos/huggingface/datasets/issues/5740/events | https://github.com/huggingface/datasets/pull/5740 | 1,664,132,130 | PR_kwDODunzps5OHI08 | 5,740 | Fix CI mock filesystem fixtures | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-04-12T08:52:35 | 2023-04-13T11:01:24 | 2023-04-13T10:54:13 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5740",
"html_url": "https://github.com/huggingface/datasets/pull/5740",
"diff_url": "https://github.com/huggingface/datasets/pull/5740.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5740.patch",
"merged_at": "2023-04-13T10:54... | This PR fixes the fixtures of our CI mock filesystems.
Before, we had to pass `clobber=True` to `fsspec.register_implementation` to overwrite the still present previously added "mock" filesystem. That meant that the mock filesystem fixture was not working properly, because the previously added "mock" filesystem, sho... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5740/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5740/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5738 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5738/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5738/comments | https://api.github.com/repos/huggingface/datasets/issues/5738/events | https://github.com/huggingface/datasets/issues/5738 | 1,663,477,690 | I_kwDODunzps5jJqe6 | 5,738 | load_dataset("text","dataset.txt") loads the wrong dataset! | {
"login": "Tylersuard",
"id": 41713505,
"node_id": "MDQ6VXNlcjQxNzEzNTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/41713505?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Tylersuard",
"html_url": "https://github.com/Tylersuard",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"You need to provide a text file as `data_files`, not as a configuration:\r\n\r\n```python\r\nmy_dataset = load_dataset(\"text\", data_files=\"TextFile.txt\")\r\n```\r\n\r\nOtherwise, since `data_files` is `None`, it picks up Colab's sample datasets from the `content` dir."
] | 2023-04-12T01:07:46 | 2023-04-19T12:08:27 | 2023-04-19T12:08:27 | NONE | null | null | null | ### Describe the bug
I am trying to load my own custom text dataset using the load_dataset function. My dataset is a bunch of ordered text, think along the lines of shakespeare plays. However, after I load the dataset and I inspect it, the dataset is a table with a bunch of latitude and longitude values! What in th... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5738/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5738/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5737 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5737/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5737/comments | https://api.github.com/repos/huggingface/datasets/issues/5737/events | https://github.com/huggingface/datasets/issues/5737 | 1,662,919,811 | I_kwDODunzps5jHiSD | 5,737 | ClassLabel Error | {
"login": "mrcaelumn",
"id": 10896776,
"node_id": "MDQ6VXNlcjEwODk2Nzc2",
"avatar_url": "https://avatars.githubusercontent.com/u/10896776?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mrcaelumn",
"html_url": "https://github.com/mrcaelumn",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | [
"Hi, you can use the `cast_column` function to change the feature type from a `Value(int64)` to `ClassLabel`:\r\n\r\n```py\r\ndataset = dataset.cast_column(\"label\", ClassLabel(names=[\"label_1\", \"label_2\", \"label_3\"]))\r\nprint(dataset.features)\r\n{'text': Value(dtype='string', id=None),\r\n 'label': ClassL... | 2023-04-11T17:14:13 | 2023-04-13T16:49:57 | 2023-04-13T16:49:57 | NONE | null | null | null | ### Describe the bug
I still getting the error "call() takes 1 positional argument but 2 were given" even after ensuring that the value being passed to the label object is a single value and that the ClassLabel object has been created with the correct number of label classes
### Steps to reproduce the bug
from... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5737/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5737/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5735 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5735/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5735/comments | https://api.github.com/repos/huggingface/datasets/issues/5735/events | https://github.com/huggingface/datasets/pull/5735 | 1,662,150,903 | PR_kwDODunzps5OAY3A | 5,735 | Implement sharding on merged iterable datasets | {
"login": "Hubert-Bonisseur",
"id": 48770768,
"node_id": "MDQ6VXNlcjQ4NzcwNzY4",
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Hubert-Bonisseur",
"html_url": "https://github.com/Hubert-Bonisseur",
"followers_url": "https://... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi ! What if one of the sub-iterables only has one shard ? In that case I don't think we'd end up with a correctly interleaved dataset, since only rank 0 would yield examples from this sub-iterable",
"Hi ! \r\nI just tested this ou... | 2023-04-11T10:02:25 | 2023-04-27T16:39:04 | 2023-04-27T16:32:09 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5735",
"html_url": "https://github.com/huggingface/datasets/pull/5735",
"diff_url": "https://github.com/huggingface/datasets/pull/5735.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5735.patch",
"merged_at": "2023-04-27T16:32... | This PR allows sharding of merged iterable datasets.
Merged iterable datasets with for instance the `interleave_datasets` command are comprised of multiple sub-iterable, one for each dataset that has been merged.
With this PR, sharding a merged iterable will result in multiple merged datasets each comprised of sh... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5735/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5735/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5734 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5734/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5734/comments | https://api.github.com/repos/huggingface/datasets/issues/5734/events | https://github.com/huggingface/datasets/issues/5734 | 1,662,058,028 | I_kwDODunzps5jEP4s | 5,734 | Remove temporary pin of fsspec | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2023-04-11T09:04:17 | 2023-04-11T11:04:52 | 2023-04-11T11:04:52 | MEMBER | null | null | null | Once root cause is found and fixed, remove the temporary pin introduced by:
- #5731 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5734/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5734/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5733 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5733/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5733/comments | https://api.github.com/repos/huggingface/datasets/issues/5733/events | https://github.com/huggingface/datasets/pull/5733 | 1,662,039,191 | PR_kwDODunzps5OAA04 | 5,733 | Unpin fsspec | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-04-11T08:52:12 | 2023-04-11T11:11:45 | 2023-04-11T11:04:51 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5733",
"html_url": "https://github.com/huggingface/datasets/pull/5733",
"diff_url": "https://github.com/huggingface/datasets/pull/5733.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5733.patch",
"merged_at": "2023-04-11T11:04... | In `fsspec--2023.4.0` default value for clobber when registering an implementation was changed from True to False. See:
- https://github.com/fsspec/filesystem_spec/pull/1237
This PR recovers previous behavior by passing clobber True when registering mock implementations.
This PR also removes the temporary pin in... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5733/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5733/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5732 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5732/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5732/comments | https://api.github.com/repos/huggingface/datasets/issues/5732/events | https://github.com/huggingface/datasets/issues/5732 | 1,662,020,571 | I_kwDODunzps5jEGvb | 5,732 | Enwik8 should support the standard split | {
"login": "lucaslingle",
"id": 10287371,
"node_id": "MDQ6VXNlcjEwMjg3Mzcx",
"avatar_url": "https://avatars.githubusercontent.com/u/10287371?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lucaslingle",
"html_url": "https://github.com/lucaslingle",
"followers_url": "https://api.github.com/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "lucaslingle",
"id": 10287371,
"node_id": "MDQ6VXNlcjEwMjg3Mzcx",
"avatar_url": "https://avatars.githubusercontent.com/u/10287371?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lucaslingle",
"html_url": "https://github.com/lucaslingle",
"followers_url": "https://api.github.com/... | [
{
"login": "lucaslingle",
"id": 10287371,
"node_id": "MDQ6VXNlcjEwMjg3Mzcx",
"avatar_url": "https://avatars.githubusercontent.com/u/10287371?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lucaslingle",
"html_url": "https://github.com/lucaslingle",
"followers_url": "htt... | null | [
"#self-assign",
"The Enwik8 pipeline is not present in this codebase, and is hosted elsewhere. I have opened a PR [there](https://huggingface.co/datasets/enwik8/discussions/4) instead. "
] | 2023-04-11T08:38:53 | 2023-04-11T09:28:17 | 2023-04-11T09:28:16 | NONE | null | null | null | ### Feature request
The HuggingFace Datasets library currently supports two BuilderConfigs for Enwik8. One config yields individual lines as examples, while the other config yields the entire dataset as a single example. Both support only a monolithic split: it is all grouped as "train".
The HuggingFace Datasets l... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5732/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5732/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5731 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5731/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5731/comments | https://api.github.com/repos/huggingface/datasets/issues/5731/events | https://github.com/huggingface/datasets/pull/5731 | 1,662,012,913 | PR_kwDODunzps5N_7Un | 5,731 | Temporarily pin fsspec | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-04-11T08:33:15 | 2023-04-11T08:57:45 | 2023-04-11T08:47:55 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5731",
"html_url": "https://github.com/huggingface/datasets/pull/5731",
"diff_url": "https://github.com/huggingface/datasets/pull/5731.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5731.patch",
"merged_at": "2023-04-11T08:47... | Fix #5730. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5731/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5731/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5730/comments | https://api.github.com/repos/huggingface/datasets/issues/5730/events | https://github.com/huggingface/datasets/issues/5730 | 1,662,007,926 | I_kwDODunzps5jEDp2 | 5,730 | CI is broken: ValueError: Name (mock) already in the registry and clobber is False | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2023-04-11T08:29:46 | 2023-04-11T08:47:56 | 2023-04-11T08:47:56 | MEMBER | null | null | null | CI is broken for `test_py310`.
See: https://github.com/huggingface/datasets/actions/runs/4665326892/jobs/8258580948
```
=========================== short test summary info ============================
ERROR tests/test_builder.py::test_builder_with_filesystem_download_and_prepare - ValueError: Name (mock) already ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5730/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5730/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5729 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5729/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5729/comments | https://api.github.com/repos/huggingface/datasets/issues/5729/events | https://github.com/huggingface/datasets/pull/5729 | 1,661,929,923 | PR_kwDODunzps5N_pvI | 5,729 | Fix nondeterministic sharded data split order | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The error in the CI was unrelated to this PR. I have merged main branch once that has been fixed.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### B... | 2023-04-11T07:34:20 | 2023-04-26T15:12:25 | 2023-04-26T15:05:12 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5729",
"html_url": "https://github.com/huggingface/datasets/pull/5729",
"diff_url": "https://github.com/huggingface/datasets/pull/5729.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5729.patch",
"merged_at": "2023-04-26T15:05... | This PR makes the order of the split names deterministic. Before it was nondeterministic because we were iterating over `set` elements.
Fix #5728. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5729/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5729/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5728 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5728/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5728/comments | https://api.github.com/repos/huggingface/datasets/issues/5728/events | https://github.com/huggingface/datasets/issues/5728 | 1,661,925,932 | I_kwDODunzps5jDvos | 5,728 | The order of data split names is nondeterministic | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2023-04-11T07:31:25 | 2023-04-26T15:05:13 | 2023-04-26T15:05:13 | MEMBER | null | null | null | After this CI error: https://github.com/huggingface/datasets/actions/runs/4639528358/jobs/8210492953?pr=5718
```
FAILED tests/test_data_files.py::test_get_data_files_patterns[data_file_per_split4] - AssertionError: assert ['random', 'train'] == ['train', 'random']
At index 0 diff: 'random' != 'train'
Full diff:... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5728/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5728/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5726 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5726/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5726/comments | https://api.github.com/repos/huggingface/datasets/issues/5726/events | https://github.com/huggingface/datasets/issues/5726 | 1,660,944,807 | I_kwDODunzps5jAAGn | 5,726 | Fallback JSON Dataset loading does not load all values when features specified manually | {
"login": "myluki2000",
"id": 3610788,
"node_id": "MDQ6VXNlcjM2MTA3ODg=",
"avatar_url": "https://avatars.githubusercontent.com/u/3610788?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/myluki2000",
"html_url": "https://github.com/myluki2000",
"followers_url": "https://api.github.com/users... | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Thanks for reporting, @myluki2000.\r\n\r\nI am working on a fix."
] | 2023-04-10T15:22:14 | 2023-04-21T06:35:28 | 2023-04-21T06:35:28 | NONE | null | null | null | ### Describe the bug
The fallback JSON dataset loader located here:
https://github.com/huggingface/datasets/blob/1c4ec00511868bd881e84a6f7e0333648d833b8e/src/datasets/packaged_modules/json/json.py#L130-L153
does not load the values of features correctly when features are specified manually and not all features... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5726/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5726/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5725/comments | https://api.github.com/repos/huggingface/datasets/issues/5725/events | https://github.com/huggingface/datasets/issues/5725 | 1,660,455,202 | I_kwDODunzps5i-Iki | 5,725 | How to limit the number of examples in dataset, for testing? | {
"login": "ndvbd",
"id": 845175,
"node_id": "MDQ6VXNlcjg0NTE3NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/845175?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ndvbd",
"html_url": "https://github.com/ndvbd",
"followers_url": "https://api.github.com/users/ndvbd/followers"... | [] | closed | false | null | [] | null | [
"Hi! You can use the `nrows` parameter for this:\r\n```python\r\ndata = load_dataset(\"json\", data_files=data_path, nrows=10)\r\n```",
"@mariosasko I get:\r\n\r\n`TypeError: __init__() got an unexpected keyword argument 'nrows'`",
"I misread the format in which the dataset is stored - the `nrows` parameter wo... | 2023-04-10T08:41:43 | 2023-04-21T06:16:24 | 2023-04-21T06:16:24 | NONE | null | null | null | ### Describe the bug
I am using this command:
`data = load_dataset("json", data_files=data_path)`
However, I want to add a parameter, to limit the number of loaded examples to be 10, for development purposes, but can't find this simple parameter.
### Steps to reproduce the bug
In the description.
### Expected beh... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5725/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5725/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5724/comments | https://api.github.com/repos/huggingface/datasets/issues/5724/events | https://github.com/huggingface/datasets/issues/5724 | 1,659,938,135 | I_kwDODunzps5i8KVX | 5,724 | Error after shuffling streaming IterableDatasets with downloaded dataset | {
"login": "szxiangjn",
"id": 41177966,
"node_id": "MDQ6VXNlcjQxMTc3OTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/41177966?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/szxiangjn",
"html_url": "https://github.com/szxiangjn",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | [
"Moving `\"en\"` to the end of the path instead of passing it as a config name should fix the error:\r\n```python\r\nimport datasets\r\ndataset = datasets.load_dataset('/path/to/your/data/dir/en', streaming=True, split='train')\r\ndataset = dataset.shuffle(buffer_size=10_000, seed=42)\r\nnext(iter(dataset))\r\n```\... | 2023-04-09T16:58:44 | 2023-04-20T20:37:30 | 2023-04-20T20:37:30 | NONE | null | null | null | ### Describe the bug
I downloaded the C4 dataset, and used streaming IterableDatasets to read it. Everything went normal until I used `dataset = dataset.shuffle(seed=42, buffer_size=10_000)` to shuffle the dataset. Shuffled dataset will throw the following error when it is used by `next(iter(dataset))`:
```
File "/d... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5724/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5724/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5719 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5719/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5719/comments | https://api.github.com/repos/huggingface/datasets/issues/5719/events | https://github.com/huggingface/datasets/issues/5719 | 1,659,203,222 | I_kwDODunzps5i5W6W | 5,719 | Array2D feature creates a list of list instead of a numpy array | {
"login": "off99555",
"id": 15215732,
"node_id": "MDQ6VXNlcjE1MjE1NzMy",
"avatar_url": "https://avatars.githubusercontent.com/u/15215732?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/off99555",
"html_url": "https://github.com/off99555",
"followers_url": "https://api.github.com/users/off... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\nYou need to set the format to `np` before indexing the dataset to get NumPy arrays:\r\n```python\r\nfeatures = Features(dict(seq=Array2D((2,2), 'float32'))) \r\nds = Dataset.from_dict(dict(seq=[np.random.rand(2,2)]), features=features)\r\nds.set_format(\"np\")\r\na = ds[0]['seq']\r\n```\r\n\r\n> I th... | 2023-04-07T21:04:08 | 2023-04-20T15:34:41 | 2023-04-20T15:34:41 | NONE | null | null | null | ### Describe the bug
I'm not sure if this is expected behavior or not. When I create a 2D array using `Array2D`, the data has list type instead of numpy array. I think it should not be the expected behavior especially when I feed a numpy array as input to the data creation function. Why is it converting my array int... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5719/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5719/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5718 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5718/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5718/comments | https://api.github.com/repos/huggingface/datasets/issues/5718/events | https://github.com/huggingface/datasets/pull/5718 | 1,658,958,406 | PR_kwDODunzps5N2IZC | 5,718 | Reorder default data splits to have validation before test | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"After this CI error: https://github.com/huggingface/datasets/actions/runs/4639528358/jobs/8210492953?pr=5718\r\n```\r\nFAILED tests/test_data_files.py::test_get_data_files_patterns[data_file_per_split4] - AssertionError: assert ['ran... | 2023-04-07T16:01:26 | 2023-04-27T14:43:13 | 2023-04-27T14:35:52 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5718",
"html_url": "https://github.com/huggingface/datasets/pull/5718",
"diff_url": "https://github.com/huggingface/datasets/pull/5718.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5718.patch",
"merged_at": "2023-04-27T14:35... | This PR reorders data splits, so that by default validation appears before test.
The default order becomes: [train, validation, test] instead of [train, test, validation]. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5718/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5718/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5715 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5715/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5715/comments | https://api.github.com/repos/huggingface/datasets/issues/5715/events | https://github.com/huggingface/datasets/issues/5715 | 1,657,479,788 | I_kwDODunzps5iyyJs | 5,715 | Return Numpy Array (fixed length) Mode, in __get_item__, Instead of List | {
"login": "jungbaepark",
"id": 34066771,
"node_id": "MDQ6VXNlcjM0MDY2Nzcx",
"avatar_url": "https://avatars.githubusercontent.com/u/34066771?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jungbaepark",
"html_url": "https://github.com/jungbaepark",
"followers_url": "https://api.github.com/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"Hi! \r\n\r\nYou can use [`.set_format(\"np\")`](https://huggingface.co/docs/datasets/process#format) to get NumPy arrays (or Pytorch tensors with `.set_format(\"torch\")`) in `__getitem__`.\r\n\r\nAlso, have you been able to reproduce the linked PyTorch issue with a HF dataset?\r\n "
] | 2023-04-06T13:57:48 | 2023-04-20T17:16:26 | 2023-04-20T17:16:26 | NONE | null | null | null | ### Feature request
There are old known issues, but they can be easily forgettable problems in multiprocessing with pytorch-dataloader:
Too high usage of RAM or shared-memory in pytorch when we set num workers > 1 and returning type of dataset or dataloader is "List" or "Dict".
https://github.com/pytorch/pytorch... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5715/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5715/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5714 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5714/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5714/comments | https://api.github.com/repos/huggingface/datasets/issues/5714/events | https://github.com/huggingface/datasets/pull/5714 | 1,657,388,033 | PR_kwDODunzps5NxIOc | 5,714 | Fix xnumpy_load for .npz files | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-04-06T13:01:45 | 2023-04-07T09:23:54 | 2023-04-07T09:16:57 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5714",
"html_url": "https://github.com/huggingface/datasets/pull/5714",
"diff_url": "https://github.com/huggingface/datasets/pull/5714.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5714.patch",
"merged_at": "2023-04-07T09:16... | PR:
- #5626
implemented support for streaming `.npy` files by using `numpy.load`.
However, it introduced a bug when used with `.npz` files, within a context manager:
```
ValueError: seek of closed file
```
or in streaming mode:
```
ValueError: I/O operation on closed file.
```
This PR fixes the bug an... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5714/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5714/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5713 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5713/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5713/comments | https://api.github.com/repos/huggingface/datasets/issues/5713/events | https://github.com/huggingface/datasets/issues/5713 | 1,657,141,251 | I_kwDODunzps5ixfgD | 5,713 | ArrowNotImplementedError when loading dataset from the hub | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [
"Hi Julien ! This sounds related to https://github.com/huggingface/datasets/issues/5695 - TL;DR: you need to have shards smaller than 2GB to avoid this issue\r\n\r\nThe number of rows per shard is computed using an estimated size of the full dataset, which can sometimes lead to shards bigger than `max_shard_size`. ... | 2023-04-06T10:27:22 | 2023-04-06T13:06:22 | 2023-04-06T13:06:21 | CONTRIBUTOR | null | null | null | ### Describe the bug
Hello,
I have created a dataset by using the image loader. Once the dataset is created I try to download it and I get the error:
```
Traceback (most recent call last):
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 1860, in _prepare_split_... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5713/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5713/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5712 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5712/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5712/comments | https://api.github.com/repos/huggingface/datasets/issues/5712/events | https://github.com/huggingface/datasets/issues/5712 | 1,655,972,106 | I_kwDODunzps5itCEK | 5,712 | load_dataset in v2.11.0 raises "ValueError: seek of closed file" in np.load() | {
"login": "rcasero",
"id": 1219084,
"node_id": "MDQ6VXNlcjEyMTkwODQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1219084?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rcasero",
"html_url": "https://github.com/rcasero",
"followers_url": "https://api.github.com/users/rcasero/... | [] | closed | false | null | [] | null | [
"Closing since this is a duplicate of #5711",
"> Closing since this is a duplicate of #5711\r\n\r\nSorry @mariosasko , my internet went down went submitting the issue, and somehow it ended up creating a duplicate"
] | 2023-04-05T16:47:10 | 2023-04-06T08:32:37 | 2023-04-05T17:17:44 | NONE | null | null | null | ### Describe the bug
Hi,
I have some `dataset_load()` code of a custom offline dataset that works with datasets v2.10.1.
```python
ds = datasets.load_dataset(path=dataset_dir,
name=configuration,
data_dir=dataset_dir,
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5712/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5712/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5711 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5711/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5711/comments | https://api.github.com/repos/huggingface/datasets/issues/5711/events | https://github.com/huggingface/datasets/issues/5711 | 1,655,971,647 | I_kwDODunzps5itB8_ | 5,711 | load_dataset in v2.11.0 raises "ValueError: seek of closed file" in np.load() | {
"login": "rcasero",
"id": 1219084,
"node_id": "MDQ6VXNlcjEyMTkwODQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1219084?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rcasero",
"html_url": "https://github.com/rcasero",
"followers_url": "https://api.github.com/users/rcasero/... | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"It seems like https://github.com/huggingface/datasets/pull/5626 has introduced this error. \r\n\r\ncc @albertvillanova \r\n\r\nI think replacing:\r\nhttps://github.com/huggingface/datasets/blob/0803a006db1c395ac715662cc6079651f77c11ea/src/datasets/download/streaming_download_manager.py#L777-L778\r\nwith:\r\n```pyt... | 2023-04-05T16:46:49 | 2023-04-07T09:16:59 | 2023-04-07T09:16:59 | NONE | null | null | null | ### Describe the bug
Hi,
I have some `dataset_load()` code of a custom offline dataset that works with datasets v2.10.1.
```python
ds = datasets.load_dataset(path=dataset_dir,
name=configuration,
data_dir=dataset_dir,
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5711/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5711/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5710 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5710/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5710/comments | https://api.github.com/repos/huggingface/datasets/issues/5710/events | https://github.com/huggingface/datasets/issues/5710 | 1,655,703,534 | I_kwDODunzps5isAfu | 5,710 | OSError: Memory mapping file failed: Cannot allocate memory | {
"login": "Saibo-creator",
"id": 53392976,
"node_id": "MDQ6VXNlcjUzMzkyOTc2",
"avatar_url": "https://avatars.githubusercontent.com/u/53392976?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Saibo-creator",
"html_url": "https://github.com/Saibo-creator",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | null | [
"Hi! This error means that PyArrow's internal [`mmap`](https://man7.org/linux/man-pages/man2/mmap.2.html) call failed to allocate memory, which can be tricky to debug. Since this error is more related to PyArrow than us, I think it's best to report this issue in their [repo](https://github.com/apache/arrow) (they a... | 2023-04-05T14:11:26 | 2023-04-20T17:16:40 | 2023-04-20T17:16:40 | NONE | null | null | null | ### Describe the bug
Hello, I have a series of datasets each of 5 GB, 600 datasets in total. So together this makes 3TB.
When I trying to load all the 600 datasets into memory, I get the above error message.
Is this normal because I'm hitting the max size of memory mapping of the OS?
Thank you
```te... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5710/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5710/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5709/comments | https://api.github.com/repos/huggingface/datasets/issues/5709/events | https://github.com/huggingface/datasets/issues/5709 | 1,655,423,503 | I_kwDODunzps5iq8IP | 5,709 | Manually dataset info made not taken into account | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | null | [
"hi @jplu ! Did I understand you correctly that you create the dataset, push it to the Hub with `.push_to_hub` and you see a `dataset_infos.json` file there, then you edit this file, load the dataset with `load_dataset` and you don't see any changes in `.info` attribute of a dataset object? \r\n\r\nThis is actually... | 2023-04-05T11:15:17 | 2023-04-06T08:52:20 | 2023-04-06T08:52:19 | CONTRIBUTOR | null | null | null | ### Describe the bug
Hello,
I'm manually building an image dataset with the `from_dict` approach. I also build the features with the `cast_features` methods. Once the dataset is created I push it on the hub, and a default `dataset_infos.json` file seems to have been automatically added to the repo in same time. Hen... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5709/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5709/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5705/comments | https://api.github.com/repos/huggingface/datasets/issues/5705/events | https://github.com/huggingface/datasets/issues/5705 | 1,653,500,383 | I_kwDODunzps5ijmnf | 5,705 | Getting next item from IterableDataset took forever. | {
"login": "HongtaoYang",
"id": 16588434,
"node_id": "MDQ6VXNlcjE2NTg4NDM0",
"avatar_url": "https://avatars.githubusercontent.com/u/16588434?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HongtaoYang",
"html_url": "https://github.com/HongtaoYang",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | [
"Hi! It can take some time to iterate over Parquet files as big as yours, convert the samples to Python, and find the first one that matches a filter predicate before yielding it...",
"Thanks @mariosasko, I figured it was the filter operation. I'm closing this issue because it is not a bug, it is the expected beh... | 2023-04-04T09:16:17 | 2023-04-05T23:35:41 | 2023-04-05T23:35:41 | NONE | null | null | null | ### Describe the bug
I have a large dataset, about 500GB. The format of the dataset is parquet.
I then load the dataset and try to get the first item
```python
def get_one_item():
dataset = load_dataset("path/to/datafiles", split="train", cache_dir=".", streaming=True)
dataset = dataset.filter(lambda... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5705/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5705/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5703/comments | https://api.github.com/repos/huggingface/datasets/issues/5703/events | https://github.com/huggingface/datasets/pull/5703 | 1,653,158,955 | PR_kwDODunzps5NjCCV | 5,703 | [WIP][Test, Please ignore] Investigate performance impact of using multiprocessing only | {
"login": "hvaara",
"id": 1535968,
"node_id": "MDQ6VXNlcjE1MzU5Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1535968?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hvaara",
"html_url": "https://github.com/hvaara",
"followers_url": "https://api.github.com/users/hvaara/foll... | [] | closed | false | null | [] | null | [
"`multiprocess` uses `dill` instead of `pickle` for pickling shared objects and, as such, can pickle more types than `multiprocessing`. And I don't think this is something we want to change :).",
"That makes sense to me, and I don't think you should merge this change. I was only curious about the performance impa... | 2023-04-04T04:37:49 | 2023-04-20T03:17:37 | 2023-04-20T03:17:32 | NONE | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5703",
"html_url": "https://github.com/huggingface/datasets/pull/5703",
"diff_url": "https://github.com/huggingface/datasets/pull/5703.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5703.patch",
"merged_at": null
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5703/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5703/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5702 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5702/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5702/comments | https://api.github.com/repos/huggingface/datasets/issues/5702/events | https://github.com/huggingface/datasets/issues/5702 | 1,653,104,720 | I_kwDODunzps5iiGBQ | 5,702 | Is it possible or how to define a `datasets.Sequence` that could potentially be either a dict, a str, or None? | {
"login": "gitforziio",
"id": 10508116,
"node_id": "MDQ6VXNlcjEwNTA4MTE2",
"avatar_url": "https://avatars.githubusercontent.com/u/10508116?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gitforziio",
"html_url": "https://github.com/gitforziio",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"Hi ! `datasets` uses Apache Arrow as backend to store the data, and it requires each column to have a fixed type. Therefore a column can't have a mix of dicts/lists/strings.\r\n\r\nThough it's possible to have one (nullable) field for each type:\r\n```python\r\nfeatures = Features({\r\n \"text_alone\": Value(\"... | 2023-04-04T03:20:43 | 2023-04-05T14:15:18 | 2023-04-05T14:15:17 | NONE | null | null | null | ### Feature request
Hello! Apologies if my question sounds naive:
I was wondering if it’s possible, or how one would go about defining a 'datasets.Sequence' element in datasets.Features that could potentially be either a dict, a str, or None?
Specifically, I’d like to define a feature for a list that contains 18... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5702/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5702/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5701 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5701/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5701/comments | https://api.github.com/repos/huggingface/datasets/issues/5701/events | https://github.com/huggingface/datasets/pull/5701 | 1,652,931,399 | PR_kwDODunzps5NiSCy | 5,701 | Add Dataset.from_spark | {
"login": "maddiedawson",
"id": 106995444,
"node_id": "U_kgDOBmCe9A",
"avatar_url": "https://avatars.githubusercontent.com/u/106995444?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maddiedawson",
"html_url": "https://github.com/maddiedawson",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@mariosasko Would you or another HF datasets maintainer be able to review this, please?",
"Amazing ! Great job @maddiedawson \r\n\r\nDo you know if it's possible to also support writing to Parquet using the HF ParquetWriter if `fil... | 2023-04-03T23:51:29 | 2023-04-27T17:26:53 | 2023-04-26T15:43:39 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5701",
"html_url": "https://github.com/huggingface/datasets/pull/5701",
"diff_url": "https://github.com/huggingface/datasets/pull/5701.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5701.patch",
"merged_at": "2023-04-26T15:43... | Adds static method Dataset.from_spark to create datasets from Spark DataFrames.
This approach alleviates users of the need to materialize their dataframe---a common use case is that the user loads their dataset into a dataframe, uses Spark to apply some transformation to some of the columns, and then wants to train ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5701/reactions",
"total_count": 6,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 4,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5701/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5697 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5697/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5697/comments | https://api.github.com/repos/huggingface/datasets/issues/5697/events | https://github.com/huggingface/datasets/pull/5697 | 1,651,812,614 | PR_kwDODunzps5NefxZ | 5,697 | Raise an error on missing distributed seed | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-04-03T10:44:58 | 2023-04-04T15:05:24 | 2023-04-04T14:58:16 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5697",
"html_url": "https://github.com/huggingface/datasets/pull/5697",
"diff_url": "https://github.com/huggingface/datasets/pull/5697.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5697.patch",
"merged_at": "2023-04-04T14:58... | close https://github.com/huggingface/datasets/issues/5696 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5697/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5697/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5696 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5696/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5696/comments | https://api.github.com/repos/huggingface/datasets/issues/5696/events | https://github.com/huggingface/datasets/issues/5696 | 1,651,707,008 | I_kwDODunzps5icwyA | 5,696 | Shuffle a sharded iterable dataset without seed can lead to duplicate data | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [] | 2023-04-03T09:40:03 | 2023-04-04T14:58:18 | 2023-04-04T14:58:18 | MEMBER | null | null | null | As reported in https://github.com/huggingface/datasets/issues/5360
If `seed=None` in `.shuffle()`, shuffled datasets don't use the same shuffling seed across nodes.
Because of that, the lists of shards is not shuffled the same way across nodes, and therefore some shards may be assigned to multiple nodes instead o... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5696/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5696/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5695 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5695/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5695/comments | https://api.github.com/repos/huggingface/datasets/issues/5695/events | https://github.com/huggingface/datasets/issues/5695 | 1,650,974,156 | I_kwDODunzps5iZ93M | 5,695 | Loading big dataset raises pyarrow.lib.ArrowNotImplementedError | {
"login": "amariucaitheodor",
"id": 32778667,
"node_id": "MDQ6VXNlcjMyNzc4NjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/32778667?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amariucaitheodor",
"html_url": "https://github.com/amariucaitheodor",
"followers_url": "https://... | [] | closed | false | null | [] | null | [
"Hi ! It looks like an issue with PyArrow: https://issues.apache.org/jira/browse/ARROW-5030\r\n\r\nIt appears it can happen when you have parquet files with row groups larger than 2GB.\r\nI can see that your parquet files are around 10GB. It is usually advised to keep a value around the default value 500MB to avoid... | 2023-04-02T14:42:44 | 2023-04-11T09:17:54 | 2023-04-10T08:04:04 | NONE | null | null | null | ### Describe the bug
Calling `datasets.load_dataset` to load the (publicly available) dataset `theodor1289/wit` fails with `pyarrow.lib.ArrowNotImplementedError`.
### Steps to reproduce the bug
Steps to reproduce this behavior:
1. `!pip install datasets`
2. `!huggingface-cli login`
3. This step will throw the e... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5695/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5695/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5693 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5693/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5693/comments | https://api.github.com/repos/huggingface/datasets/issues/5693/events | https://github.com/huggingface/datasets/pull/5693 | 1,649,934,749 | PR_kwDODunzps5NYdPS | 5,693 | [docs] Split pattern search order | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-31T19:51:38 | 2023-04-03T18:43:30 | 2023-04-03T18:29:58 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5693",
"html_url": "https://github.com/huggingface/datasets/pull/5693",
"diff_url": "https://github.com/huggingface/datasets/pull/5693.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5693.patch",
"merged_at": "2023-04-03T18:29... | This PR addresses #5681 about the order of split patterns 🤗 Datasets searches for when generating dataset splits. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5693/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5693/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5691 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5691/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5691/comments | https://api.github.com/repos/huggingface/datasets/issues/5691/events | https://github.com/huggingface/datasets/pull/5691 | 1,649,737,526 | PR_kwDODunzps5NX08d | 5,691 | [docs] Compress data files | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"[Confirmed](https://huggingface.slack.com/archives/C02EMARJ65P/p1680541667004199) with the Hub team the file size limit for the Hugging Face Hub is 10MB :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<deta... | 2023-03-31T17:17:26 | 2023-04-19T13:37:32 | 2023-04-19T07:25:58 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5691",
"html_url": "https://github.com/huggingface/datasets/pull/5691",
"diff_url": "https://github.com/huggingface/datasets/pull/5691.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5691.patch",
"merged_at": "2023-04-19T07:25... | This PR addresses the comments in #5687 about compressing text file extensions before uploading to the Hub. Also clarified what "too large" means based on the GitLFS [docs](https://docs.github.com/en/repositories/working-with-files/managing-large-files/about-git-large-file-storage). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5691/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5691/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5689 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5689/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5689/comments | https://api.github.com/repos/huggingface/datasets/issues/5689/events | https://github.com/huggingface/datasets/pull/5689 | 1,648,956,349 | PR_kwDODunzps5NVMuI | 5,689 | Support streaming Beam datasets from HF GCS preprocessed data | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"```python\r\nIn [1]: from datasets import load_dataset\r\n\r\nIn [2]: ds = load_dataset(\"wikipedia\", \"20220301.en\", split=\"train\", streaming=True); item = next(iter(ds)); item\r\nOut[2]: \r\n{'id': '12',\r\n 'url': 'https://en.... | 2023-03-31T08:44:24 | 2023-04-12T05:57:55 | 2023-04-12T05:50:31 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5689",
"html_url": "https://github.com/huggingface/datasets/pull/5689",
"diff_url": "https://github.com/huggingface/datasets/pull/5689.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5689.patch",
"merged_at": "2023-04-12T05:50... | This PR implements streaming Apache Beam datasets that are already preprocessed by us and stored in the HF Google Cloud Storage:
- natural_questions
- wiki40b
- wikipedia
This is done by streaming from the prepared Arrow files in HF Google Cloud Storage.
This will fix their corresponding dataset viewers. Relat... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5689/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5689/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5687 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5687/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5687/comments | https://api.github.com/repos/huggingface/datasets/issues/5687/events | https://github.com/huggingface/datasets/issues/5687 | 1,647,009,018 | I_kwDODunzps5iK1z6 | 5,687 | Document to compress data files before uploading | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | closed | false | null | [] | null | [
"Great idea!\r\n\r\nShould we also take this opportunity to include some audio/image file formats? Currently, it still reads very text heavy. Something like:\r\n\r\n> We support many text, audio, and image data extensions such as `.zip`, `.rar`, `.mp3`, and `.jpg` among many others. For data extensions like `.csv`,... | 2023-03-30T06:41:07 | 2023-04-19T07:25:59 | 2023-04-19T07:25:59 | MEMBER | null | null | null | In our docs to [Share a dataset to the Hub](https://huggingface.co/docs/datasets/upload_dataset), we tell users to upload directly their data files, like CSV, JSON, JSON-Lines, text,... However, these extensions are not tracked by Git LFS by default, as they are not in the `.giattributes` file. Therefore, if they are t... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5687/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5687/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5686/comments | https://api.github.com/repos/huggingface/datasets/issues/5686/events | https://github.com/huggingface/datasets/pull/5686 | 1,646,308,228 | PR_kwDODunzps5NMXdu | 5,686 | set dev version | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5686). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... | 2023-03-29T18:24:13 | 2023-03-29T18:33:49 | 2023-03-29T18:24:22 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5686",
"html_url": "https://github.com/huggingface/datasets/pull/5686",
"diff_url": "https://github.com/huggingface/datasets/pull/5686.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5686.patch",
"merged_at": "2023-03-29T18:24... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5686/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5686/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5685 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5685/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5685/comments | https://api.github.com/repos/huggingface/datasets/issues/5685/events | https://github.com/huggingface/datasets/issues/5685 | 1,646,048,667 | I_kwDODunzps5iHLWb | 5,685 | Broken Image render on the hub website | {
"login": "FrancescoSaverioZuppichini",
"id": 15908060,
"node_id": "MDQ6VXNlcjE1OTA4MDYw",
"avatar_url": "https://avatars.githubusercontent.com/u/15908060?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FrancescoSaverioZuppichini",
"html_url": "https://github.com/FrancescoSaverioZuppichini"... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\nYou can fix the viewer by adding the `dataset_info` YAML field deleted in https://huggingface.co/datasets/Francesco/cell-towers/commit/b95b59ddd91ebe9c12920f0efe0ed415cd0d4298 back to the metadata section of the card. \r\n\r\nTo avoid this issue in the feature, you can use `huggingface_hub`'s [RepoCard... | 2023-03-29T15:25:30 | 2023-03-30T07:54:25 | 2023-03-30T07:54:25 | NONE | null | null | null | ### Describe the bug
Hi :wave:
Not sure if this is the right place to ask, but I am trying to load a huge amount of datasets on the hub (:partying_face: ) but I am facing a little issue with the `image` type
",
"Closed in #5693 "
] | 2023-03-29T11:44:49 | 2023-04-03T18:31:11 | 2023-04-03T18:31:11 | CONTRIBUTOR | null | null | null | Following [this](https://github.com/huggingface/datasets/issues/5650) issue I think we should add a note about the order of patterns that is used to find splits, see [my comment](https://github.com/huggingface/datasets/issues/5650#issuecomment-1488412527). Also we should reference this page in pages about packaged load... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5681/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5681/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5680 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5680/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5680/comments | https://api.github.com/repos/huggingface/datasets/issues/5680/events | https://github.com/huggingface/datasets/pull/5680 | 1,645,430,103 | PR_kwDODunzps5NJYNz | 5,680 | Fix a description error for interleave_datasets. | {
"login": "QizhiPei",
"id": 55624066,
"node_id": "MDQ6VXNlcjU1NjI0MDY2",
"avatar_url": "https://avatars.githubusercontent.com/u/55624066?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/QizhiPei",
"html_url": "https://github.com/QizhiPei",
"followers_url": "https://api.github.com/users/Qiz... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_a... | 2023-03-29T09:50:23 | 2023-03-30T13:14:19 | 2023-03-30T13:07:18 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5680",
"html_url": "https://github.com/huggingface/datasets/pull/5680",
"diff_url": "https://github.com/huggingface/datasets/pull/5680.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5680.patch",
"merged_at": "2023-03-30T13:07... | There is a description mistake in the annotation of interleave_dataset with "all_exhausted" stopping_strategy.
``` python
d1 = Dataset.from_dict({"a": [0, 1, 2]})
d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
d3 = Dataset.from_dict({"a": [20, 21, 22, 23, 24]})
dataset = interleave_datasets([d1, d2, d3], stopping... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5680/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5680/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5675/comments | https://api.github.com/repos/huggingface/datasets/issues/5675/events | https://github.com/huggingface/datasets/issues/5675 | 1,641,763,478 | I_kwDODunzps5h21KW | 5,675 | Filter datasets by language code | {
"login": "named-entity",
"id": 5658496,
"node_id": "MDQ6VXNlcjU2NTg0OTY=",
"avatar_url": "https://avatars.githubusercontent.com/u/5658496?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/named-entity",
"html_url": "https://github.com/named-entity",
"followers_url": "https://api.github.com... | [] | closed | false | null | [] | null | [
"The dataset still can be found, if instead of using the search form you just enter the language code in the url, like https://huggingface.co/datasets?language=language:myv. \r\n\r\nBut of course having a more complete list of languages in the search form (or just a fallback to the language codes, if they are missi... | 2023-03-27T09:42:28 | 2023-03-30T08:08:15 | 2023-03-30T08:08:15 | NONE | null | null | null | Hi! I use the language search field on https://huggingface.co/datasets
However, some of the datasets tagged by ISO language code are not accessible by this search form.
For example, [myv_ru_2022](https://huggingface.co/datasets/slone/myv_ru_2022) is has `myv` language tag but it is not included in Languages search fo... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5675/reactions",
"total_count": 6,
"+1": 6,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5675/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5674/comments | https://api.github.com/repos/huggingface/datasets/issues/5674/events | https://github.com/huggingface/datasets/issues/5674 | 1,641,084,105 | I_kwDODunzps5h0PTJ | 5,674 | Stored XSS | {
"login": "Fadavvi",
"id": 21213484,
"node_id": "MDQ6VXNlcjIxMjEzNDg0",
"avatar_url": "https://avatars.githubusercontent.com/u/21213484?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Fadavvi",
"html_url": "https://github.com/Fadavvi",
"followers_url": "https://api.github.com/users/Fadavv... | [] | closed | false | null | [] | null | [
"Hi! You can contact `security@huggingface.co` to report this vulnerability."
] | 2023-03-26T20:55:58 | 2023-03-27T21:01:55 | 2023-03-27T21:01:55 | NONE | null | null | null | ### Describe the bug
I found a Stored XSS on a page that can be publicly accessible to all visitors. But I didn't find a suitable place to report.
Please guide me on this.
### Steps to reproduce the bug
Due to security restrictions, I don't want to publish it publicly.
### Expected behavior
User inputs must be ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5674/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5674/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5673/comments | https://api.github.com/repos/huggingface/datasets/issues/5673/events | https://github.com/huggingface/datasets/pull/5673 | 1,641,066,352 | PR_kwDODunzps5M6wc3 | 5,673 | Pass down storage options | {
"login": "dwyatte",
"id": 2512762,
"node_id": "MDQ6VXNlcjI1MTI3NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/2512762?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dwyatte",
"html_url": "https://github.com/dwyatte",
"followers_url": "https://api.github.com/users/dwyatte/... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> download_and_prepare is not called when streaming a dataset, so we may need to have storage_options in the DatasetBuilder.__init__ ? This way it could also be passed later to as_streaming_dataset and the StreamingDownloadManager\r\... | 2023-03-26T20:09:37 | 2023-03-28T15:03:38 | 2023-03-28T14:54:17 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5673",
"html_url": "https://github.com/huggingface/datasets/pull/5673",
"diff_url": "https://github.com/huggingface/datasets/pull/5673.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5673.patch",
"merged_at": "2023-03-28T14:54... | Remove implementation-specific kwargs from `file_utils.fsspec_get` and `file_utils.fsspec_head`, instead allowing them to be passed down via `storage_options`. This fixes an issue where s3fs did not recognize a timeout arg as well as fixes an issue mentioned in https://github.com/huggingface/datasets/issues/5281 by all... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5673/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5673/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5672/comments | https://api.github.com/repos/huggingface/datasets/issues/5672/events | https://github.com/huggingface/datasets/issues/5672 | 1,641,005,322 | I_kwDODunzps5hz8EK | 5,672 | Pushing dataset to hub crash | {
"login": "tzvc",
"id": 14275989,
"node_id": "MDQ6VXNlcjE0Mjc1OTg5",
"avatar_url": "https://avatars.githubusercontent.com/u/14275989?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tzvc",
"html_url": "https://github.com/tzvc",
"followers_url": "https://api.github.com/users/tzvc/followers"... | [] | closed | false | null | [] | null | [
"Hi ! It's been fixed by https://github.com/huggingface/datasets/pull/5598. We're doing a new release tomorrow with the fix and you'll be able to push your 100k images ;)\r\n\r\nBasically `push_to_hub` used to fail if the remote repository already exists and has a README.md without dataset_info in the YAML tags.\r\... | 2023-03-26T17:42:13 | 2023-03-30T08:11:05 | 2023-03-30T08:11:05 | NONE | null | null | null | ### Describe the bug
Uploading a dataset with `push_to_hub()` fails without error description.
### Steps to reproduce the bug
Hey there,
I've built a image dataset of 100k images + text pair as described here https://huggingface.co/docs/datasets/image_dataset#imagefolder
Now I'm trying to push it to the hub b... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5672/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5672/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5671 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5671/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5671/comments | https://api.github.com/repos/huggingface/datasets/issues/5671/events | https://github.com/huggingface/datasets/issues/5671 | 1,640,840,012 | I_kwDODunzps5hzTtM | 5,671 | How to use `load_dataset('glue', 'cola')` | {
"login": "makinzm",
"id": 40193664,
"node_id": "MDQ6VXNlcjQwMTkzNjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/40193664?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/makinzm",
"html_url": "https://github.com/makinzm",
"followers_url": "https://api.github.com/users/makinz... | [] | closed | false | null | [] | null | [
"Sounds like an issue with incompatible `transformers` dependencies versions.\r\n\r\nCan you try to update `transformers` ?\r\n\r\nEDIT: I checked the `transformers` dependencies and it seems like you need `tokenizers>=0.10.1,<0.11` with `transformers==4.5.1`\r\n\r\nEDIT2: this old version of `datasets` seems to im... | 2023-03-26T09:40:34 | 2023-03-28T07:43:44 | 2023-03-28T07:43:43 | NONE | null | null | null | ### Describe the bug
I'm new to use HuggingFace datasets but I cannot use `load_dataset('glue', 'cola')`.
- I was stacked by the following problem:
```python
from datasets import load_dataset
cola_dataset = load_dataset('glue', 'cola')
------------------------------------------------------------------------... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5671/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5671/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5670/comments | https://api.github.com/repos/huggingface/datasets/issues/5670/events | https://github.com/huggingface/datasets/issues/5670 | 1,640,607,045 | I_kwDODunzps5hya1F | 5,670 | Unable to load multi class classification datasets | {
"login": "ysahil97",
"id": 19690506,
"node_id": "MDQ6VXNlcjE5NjkwNTA2",
"avatar_url": "https://avatars.githubusercontent.com/u/19690506?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ysahil97",
"html_url": "https://github.com/ysahil97",
"followers_url": "https://api.github.com/users/ysa... | [] | closed | false | null | [] | null | [
"Hi ! This sounds related to https://github.com/huggingface/datasets/issues/5406\r\n\r\nUpdating `datasets` fixes the issue ;)",
"Thanks @lhoestq!\r\n\r\nI'll close this issue now."
] | 2023-03-25T18:06:15 | 2023-03-27T22:54:56 | 2023-03-27T22:54:56 | NONE | null | null | null | ### Describe the bug
I've been playing around with huggingface library, mostly with `datasets` and wanted to download the multi class classification datasets to fine tune BERT on this task. ([link](https://huggingface.co/docs/transformers/training#train-with-pytorch-trainer)).
While loading the dataset, I'm getting... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5670/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5670/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5667/comments | https://api.github.com/repos/huggingface/datasets/issues/5667/events | https://github.com/huggingface/datasets/pull/5667 | 1,637,789,361 | PR_kwDODunzps5Mv8Im | 5,667 | Jax requires jaxlib | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-23T15:41:09 | 2023-03-23T16:23:11 | 2023-03-23T16:14:52 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5667",
"html_url": "https://github.com/huggingface/datasets/pull/5667",
"diff_url": "https://github.com/huggingface/datasets/pull/5667.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5667.patch",
"merged_at": "2023-03-23T16:14... | close https://github.com/huggingface/datasets/issues/5666 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5667/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5667/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5666/comments | https://api.github.com/repos/huggingface/datasets/issues/5666/events | https://github.com/huggingface/datasets/issues/5666 | 1,637,675,062 | I_kwDODunzps5hnPA2 | 5,666 | Support tensorflow 2.12.0 in CI | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2023-03-23T14:37:51 | 2023-03-23T16:14:54 | 2023-03-23T16:14:54 | MEMBER | null | null | null | Once we find out the root cause of:
- #5663
we should revert the temporary pin on tensorflow introduced by:
- #5664 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5666/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5666/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5664 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5664/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5664/comments | https://api.github.com/repos/huggingface/datasets/issues/5664/events | https://github.com/huggingface/datasets/pull/5664 | 1,637,192,684 | PR_kwDODunzps5Mt6vp | 5,664 | Fix CI by temporarily pinning tensorflow < 2.12.0 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-23T09:52:26 | 2023-03-23T10:17:11 | 2023-03-23T10:09:54 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5664",
"html_url": "https://github.com/huggingface/datasets/pull/5664",
"diff_url": "https://github.com/huggingface/datasets/pull/5664.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5664.patch",
"merged_at": "2023-03-23T10:09... | As a hotfix for our CI, temporarily pin `tensorflow` upper version:
- In Python 3.10, tensorflow-2.12.0 also installs `jax`
Fix #5663
Until root cause is fixed. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5664/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5664/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5663/comments | https://api.github.com/repos/huggingface/datasets/issues/5663/events | https://github.com/huggingface/datasets/issues/5663 | 1,637,173,248 | I_kwDODunzps5hlUgA | 5,663 | CI is broken: ModuleNotFoundError: jax requires jaxlib to be installed | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2023-03-23T09:39:43 | 2023-03-23T10:09:55 | 2023-03-23T10:09:55 | MEMBER | null | null | null | CI test_py310 is broken: see https://github.com/huggingface/datasets/actions/runs/4498945505/jobs/7916194236?pr=5662
```
FAILED tests/test_arrow_dataset.py::BaseDatasetTest::test_map_jax_in_memory - ModuleNotFoundError: jax requires jaxlib to be installed. See https://github.com/google/jax#installation for installati... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5663/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5663/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5662/comments | https://api.github.com/repos/huggingface/datasets/issues/5662/events | https://github.com/huggingface/datasets/pull/5662 | 1,637,140,813 | PR_kwDODunzps5MtvsM | 5,662 | Fix unnecessary dict comprehension | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I am merging because the CI error is unrelated.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | re... | 2023-03-23T09:18:58 | 2023-03-23T09:46:59 | 2023-03-23T09:37:49 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5662",
"html_url": "https://github.com/huggingface/datasets/pull/5662",
"diff_url": "https://github.com/huggingface/datasets/pull/5662.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5662.patch",
"merged_at": "2023-03-23T09:37... | After ruff-0.0.258 release, the C416 rule was updated with unnecessary dict comprehensions. See:
- https://github.com/charliermarsh/ruff/releases/tag/v0.0.258
- https://github.com/charliermarsh/ruff/pull/3605
This PR fixes one unnecessary dict comprehension in our code: no need to unpack and re-pack the tuple valu... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5662/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5662/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5661 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5661/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5661/comments | https://api.github.com/repos/huggingface/datasets/issues/5661/events | https://github.com/huggingface/datasets/issues/5661 | 1,637,129,445 | I_kwDODunzps5hlJzl | 5,661 | CI is broken: Unnecessary `dict` comprehension | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2023-03-23T09:13:01 | 2023-03-23T09:37:51 | 2023-03-23T09:37:51 | MEMBER | null | null | null | CI check_code_quality is broken:
```
src/datasets/arrow_dataset.py:3267:35: C416 [*] Unnecessary `dict` comprehension (rewrite using `dict()`)
Found 1 error.
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5661/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5661/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5659/comments | https://api.github.com/repos/huggingface/datasets/issues/5659/events | https://github.com/huggingface/datasets/issues/5659 | 1,635,447,540 | I_kwDODunzps5hevL0 | 5,659 | [Audio] Soundfile/libsndfile requirements too stringent for decoding mp3 files | {
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com... | [] | closed | false | null | [] | null | [
"cc @polinaeterna @lhoestq ",
"@sanchit-gandhi can you please also post the logs of `pip install soundfile==0.12.1`? To check what wheel is being installed or if it's being built from source (I think it's the latter case). \r\nRequired `libsndfile` binary **should** be bundeled with `soundfile` wheel but I assume... | 2023-03-22T10:07:33 | 2023-04-28T03:25:39 | 2023-04-07T08:51:28 | CONTRIBUTOR | null | null | null | ### Describe the bug
I'm encountering several issues trying to load mp3 audio files using `datasets` on a TPU v4.
The PR https://github.com/huggingface/datasets/pull/5573 updated the audio loading logic to rely solely on the `soundfile`/`libsndfile` libraries for loading audio samples, regardless of their file t... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5659/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5659/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5658/comments | https://api.github.com/repos/huggingface/datasets/issues/5658/events | https://github.com/huggingface/datasets/pull/5658 | 1,634,867,204 | PR_kwDODunzps5MmJe0 | 5,658 | docs: Update num_shards docs to mention num_proc on Dataset and DatasetDict | {
"login": "connor-henderson",
"id": 78612354,
"node_id": "MDQ6VXNlcjc4NjEyMzU0",
"avatar_url": "https://avatars.githubusercontent.com/u/78612354?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/connor-henderson",
"html_url": "https://github.com/connor-henderson",
"followers_url": "https://... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-22T00:12:18 | 2023-03-24T16:43:34 | 2023-03-24T16:36:21 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5658",
"html_url": "https://github.com/huggingface/datasets/pull/5658",
"diff_url": "https://github.com/huggingface/datasets/pull/5658.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5658.patch",
"merged_at": "2023-03-24T16:36... | Closes #5653
@mariosasko | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5658/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5658/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5656/comments | https://api.github.com/repos/huggingface/datasets/issues/5656/events | https://github.com/huggingface/datasets/pull/5656 | 1,634,156,563 | PR_kwDODunzps5Mjxoo | 5,656 | Fix `fsspec.open` when using an HTTP proxy | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-21T15:23:29 | 2023-03-23T14:14:50 | 2023-03-23T13:15:46 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5656",
"html_url": "https://github.com/huggingface/datasets/pull/5656",
"diff_url": "https://github.com/huggingface/datasets/pull/5656.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5656.patch",
"merged_at": "2023-03-23T13:15... | Most HTTP(S) downloads from this library support proxy automatically by reading the `HTTP_PROXY` environment variable (et al.) because `requests` is widely used. However, in some parts of the code, `fsspec` is used, which in turn uses `aiohttp` for HTTP(S) requests (as opposed to `requests`), which in turn doesn't supp... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5656/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5656/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5655/comments | https://api.github.com/repos/huggingface/datasets/issues/5655/events | https://github.com/huggingface/datasets/pull/5655 | 1,634,030,017 | PR_kwDODunzps5MjWYy | 5,655 | Improve features decoding in to_iterable_dataset | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-21T14:18:09 | 2023-03-23T13:19:27 | 2023-03-23T13:12:25 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5655",
"html_url": "https://github.com/huggingface/datasets/pull/5655",
"diff_url": "https://github.com/huggingface/datasets/pull/5655.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5655.patch",
"merged_at": "2023-03-23T13:12... | Following discussion at https://github.com/huggingface/datasets/pull/5589
Right now `to_iterable_dataset` on images/audio hurts iterable dataset performance a lot (e.g. x4 slower because it encodes+decodes images/audios unnecessarily).
I fixed it by providing a generator that yields undecoded examples | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5655/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5655/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5653/comments | https://api.github.com/repos/huggingface/datasets/issues/5653/events | https://github.com/huggingface/datasets/issues/5653 | 1,633,254,159 | I_kwDODunzps5hWXsP | 5,653 | Doc: save_to_disk, `num_proc` will affect `num_shards`, but it's not documented | {
"login": "RmZeta2718",
"id": 42400165,
"node_id": "MDQ6VXNlcjQyNDAwMTY1",
"avatar_url": "https://avatars.githubusercontent.com/u/42400165?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RmZeta2718",
"html_url": "https://github.com/RmZeta2718",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
},
{
"id": 19358928... | closed | false | null | [] | null | [
"I agree this should be documented"
] | 2023-03-21T05:25:35 | 2023-03-24T16:36:23 | 2023-03-24T16:36:23 | NONE | null | null | null | ### Describe the bug
[`num_proc`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict.save_to_disk.num_proc) will affect `num_shards`, but it's not documented
### Steps to reproduce the bug
Nothing to reproduce
### Expected behavior
[document of `num_shards`](https://... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5653/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5653/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5652/comments | https://api.github.com/repos/huggingface/datasets/issues/5652/events | https://github.com/huggingface/datasets/pull/5652 | 1,632,546,073 | PR_kwDODunzps5MeVUR | 5,652 | Copy features | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-20T17:17:23 | 2023-03-23T13:19:19 | 2023-03-23T13:12:08 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5652",
"html_url": "https://github.com/huggingface/datasets/pull/5652",
"diff_url": "https://github.com/huggingface/datasets/pull/5652.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5652.patch",
"merged_at": "2023-03-23T13:12... | Some users (even internally at HF) are doing
```python
dset_features = dset.features
dset_features.pop(col_to_remove)
dset = dset.map(..., features=dset_features)
```
Right now this causes issues because it modifies the features dict in place before the map.
In this PR I modified `dset.features` to return a ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5652/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5652/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5646/comments | https://api.github.com/repos/huggingface/datasets/issues/5646/events | https://github.com/huggingface/datasets/pull/5646 | 1,627,838,762 | PR_kwDODunzps5MOqjj | 5,646 | Allow self as key in `Features` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-16T16:17:03 | 2023-03-16T17:21:58 | 2023-03-16T17:14:50 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5646",
"html_url": "https://github.com/huggingface/datasets/pull/5646",
"diff_url": "https://github.com/huggingface/datasets/pull/5646.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5646.patch",
"merged_at": "2023-03-16T17:14... | Fix #5641 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5646/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5646/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5645/comments | https://api.github.com/repos/huggingface/datasets/issues/5645/events | https://github.com/huggingface/datasets/issues/5645 | 1,627,108,278 | I_kwDODunzps5g-7O2 | 5,645 | Datasets map and select(range()) is giving dill error | {
"login": "Tanya-11",
"id": 90728105,
"node_id": "MDQ6VXNlcjkwNzI4MTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/90728105?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Tanya-11",
"html_url": "https://github.com/Tanya-11",
"followers_url": "https://api.github.com/users/Tan... | [] | closed | false | null | [] | null | [
"It looks like an error that we observed once in https://github.com/huggingface/datasets/pull/5166\r\n\r\nCan you try to update `datasets` ?\r\n\r\n```\r\npip install -U datasets\r\n```\r\n\r\nif it doesn't work, can you make sure you don't have packages installed that may modify `dill`'s behavior, such as `apache-... | 2023-03-16T10:01:28 | 2023-03-17T04:24:51 | 2023-03-17T04:24:51 | NONE | null | null | null | ### Describe the bug
I'm using Huggingface Datasets library to load the dataset in google colab
When I do,
> data = train_dataset.select(range(10))
or
> train_datasets = train_dataset.map(
> process_data_to_model_inputs,
> batched=True,
> batch_size=batch_size,
> remove_columns... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5645/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5645/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5644/comments | https://api.github.com/repos/huggingface/datasets/issues/5644/events | https://github.com/huggingface/datasets/pull/5644 | 1,626,204,046 | PR_kwDODunzps5MJHUi | 5,644 | Allow direct cast from binary to Audio/Image | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-15T20:02:54 | 2023-03-16T14:20:44 | 2023-03-16T14:12:55 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5644",
"html_url": "https://github.com/huggingface/datasets/pull/5644",
"diff_url": "https://github.com/huggingface/datasets/pull/5644.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5644.patch",
"merged_at": "2023-03-16T14:12... | To address https://github.com/huggingface/datasets/discussions/5593.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5644/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5644/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5643/comments | https://api.github.com/repos/huggingface/datasets/issues/5643/events | https://github.com/huggingface/datasets/pull/5643 | 1,626,160,220 | PR_kwDODunzps5MI9zO | 5,643 | Support PyArrow arrays as column values in `from_dict` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-15T19:32:40 | 2023-03-16T17:23:06 | 2023-03-16T17:15:40 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5643",
"html_url": "https://github.com/huggingface/datasets/pull/5643",
"diff_url": "https://github.com/huggingface/datasets/pull/5643.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5643.patch",
"merged_at": "2023-03-16T17:15... | For consistency with `pa.Table.from_pydict`, which supports both Python lists and PyArrow arrays as column values.
"Fixes" https://discuss.huggingface.co/t/pyarrow-lib-floatarray-did-not-recognize-python-value-type-when-inferring-an-arrow-data-type/33417 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5643/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5643/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5642 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5642/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5642/comments | https://api.github.com/repos/huggingface/datasets/issues/5642/events | https://github.com/huggingface/datasets/pull/5642 | 1,626,043,177 | PR_kwDODunzps5MIjw9 | 5,642 | Bump hfh to 0.11.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-15T18:26:07 | 2023-03-20T12:34:09 | 2023-03-20T12:26:58 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5642",
"html_url": "https://github.com/huggingface/datasets/pull/5642",
"diff_url": "https://github.com/huggingface/datasets/pull/5642.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5642.patch",
"merged_at": "2023-03-20T12:26... | to fix errors like
```
requests.exceptions.HTTPError: 400 Client Error: Bad Request for url: https://hub-ci.huggingface.co/api/datasets/__DUMMY_TRANSFORMERS_USER__/...
```
(e.g. from this [failing CI](https://github.com/huggingface/datasets/actions/runs/4428956210/jobs/7769160997))
0.11.0 is the current mini... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5642/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5642/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5641/comments | https://api.github.com/repos/huggingface/datasets/issues/5641/events | https://github.com/huggingface/datasets/issues/5641 | 1,625,942,730 | I_kwDODunzps5g6erK | 5,641 | Features cannot be named "self" | {
"login": "alialamiidrissi",
"id": 14365168,
"node_id": "MDQ6VXNlcjE0MzY1MTY4",
"avatar_url": "https://avatars.githubusercontent.com/u/14365168?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alialamiidrissi",
"html_url": "https://github.com/alialamiidrissi",
"followers_url": "https://api... | [] | closed | false | null | [] | null | [] | 2023-03-15T17:16:40 | 2023-03-16T17:14:51 | 2023-03-16T17:14:51 | NONE | null | null | null | ### Describe the bug
Hi,
I noticed that we cannot create a HuggingFace dataset from Pandas DataFrame with a column named `self`.
The error seems to be coming from arguments validation in the `Features.from_dict` function.
### Steps to reproduce the bug
```python
import datasets
dummy_pandas = pd.DataFrame([0... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5641/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5641/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5640/comments | https://api.github.com/repos/huggingface/datasets/issues/5640/events | https://github.com/huggingface/datasets/pull/5640 | 1,625,896,057 | PR_kwDODunzps5MID3I | 5,640 | Less zip false positives | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-03-15T16:48:59 | 2023-03-16T13:47:37 | 2023-03-16T13:40:12 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5640",
"html_url": "https://github.com/huggingface/datasets/pull/5640",
"diff_url": "https://github.com/huggingface/datasets/pull/5640.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5640.patch",
"merged_at": "2023-03-16T13:40... | `zipfile.is_zipfile` return false positives for some Parquet files. It causes errors when loading certain parquet datasets, where some files are considered ZIP files by `zipfile.is_zipfile`
This is a known issue: https://github.com/python/cpython/issues/72680
At first I wanted to rely only on magic numbers, but t... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5640/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5640/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5639/comments | https://api.github.com/repos/huggingface/datasets/issues/5639/events | https://github.com/huggingface/datasets/issues/5639 | 1,625,737,098 | I_kwDODunzps5g5seK | 5,639 | Parquet file wrongly recognized as zip prevents loading a dataset | {
"login": "clefourrier",
"id": 22726840,
"node_id": "MDQ6VXNlcjIyNzI2ODQw",
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/clefourrier",
"html_url": "https://github.com/clefourrier",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | [] | 2023-03-15T15:20:45 | 2023-03-16T13:40:14 | 2023-03-16T13:40:14 | CONTRIBUTOR | null | null | null | ### Describe the bug
When trying to `load_dataset_builder` for `HuggingFaceGECLM/StackExchange_Mar2023`, extraction fails, because parquet file [devops-00000-of-00001-22fe902fd8702892.parquet](https://huggingface.co/datasets/HuggingFaceGECLM/StackExchange_Mar2023/resolve/1f8c9a2ab6f7d0f9ae904b8b922e4384592ae1a5/data... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5639/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5639/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5638 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5638/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5638/comments | https://api.github.com/repos/huggingface/datasets/issues/5638/events | https://github.com/huggingface/datasets/issues/5638 | 1,625,564,471 | I_kwDODunzps5g5CU3 | 5,638 | xPath to implement all operations for Path | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
" I think https://github.com/fsspec/universal_pathlib is the project you are looking for.\r\n\r\n`xPath` has the methods often used in dataset scripts, and `mkdir` is not one of them (`dl_manager`'s role is to \"interact\" with the file system, so using `mkdir` is discouraged).",
"Right is there a difference betw... | 2023-03-15T13:47:11 | 2023-03-17T13:21:12 | 2023-03-17T13:21:12 | MEMBER | null | null | null | ### Feature request
Current xPath implementation is a great extension of Path in order to work with remote objects. However some methods such as `mkdir` are not implemented correctly. It should instead rely on `fsspec` methods, instead of defaulting do `Path` methods which only work locally.
### Motivation
I'm using... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5638/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5638/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5636/comments | https://api.github.com/repos/huggingface/datasets/issues/5636/events | https://github.com/huggingface/datasets/pull/5636 | 1,623,721,577 | PR_kwDODunzps5MAunR | 5,636 | Fix CI: ignore C901 ("some_func" is to complex) in `ruff` | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-14T15:29:11 | 2023-03-14T16:37:06 | 2023-03-14T16:29:52 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5636",
"html_url": "https://github.com/huggingface/datasets/pull/5636",
"diff_url": "https://github.com/huggingface/datasets/pull/5636.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5636.patch",
"merged_at": "2023-03-14T16:29... | idk if I should have added this ignore to `ruff` too, but I added :) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5636/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5636/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5633/comments | https://api.github.com/repos/huggingface/datasets/issues/5633/events | https://github.com/huggingface/datasets/issues/5633 | 1,621,469,970 | I_kwDODunzps5gpasS | 5,633 | Cannot import datasets | {
"login": "eerio",
"id": 11250555,
"node_id": "MDQ6VXNlcjExMjUwNTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/11250555?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eerio",
"html_url": "https://github.com/eerio",
"followers_url": "https://api.github.com/users/eerio/follow... | [] | closed | false | null | [] | null | [
"Okay, the issue was likely caused by mixing `conda` and `pip` usage - I forgot that I have already used `pip` in this environment previously and that it was 'spoiled' because of it. Creating another environment and installing `datasets` by pip with other packages from the `requirements.txt` file solved the problem... | 2023-03-13T13:14:44 | 2023-03-13T17:54:19 | 2023-03-13T17:54:19 | NONE | null | null | null | ### Describe the bug
Hi,
I cannot even import the library :( I installed it by running:
```
$ conda install datasets
```
Then I realized I should maybe use the huggingface channel, because I encountered the error below, so I ran:
```
$ conda remove datasets
$ conda install -c huggingface datasets
```
Pl... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5633/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5633/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5631/comments | https://api.github.com/repos/huggingface/datasets/issues/5631/events | https://github.com/huggingface/datasets/issues/5631 | 1,620,442,854 | I_kwDODunzps5glf7m | 5,631 | Custom split names | {
"login": "ErfanMoosaviMonazzah",
"id": 79091831,
"node_id": "MDQ6VXNlcjc5MDkxODMx",
"avatar_url": "https://avatars.githubusercontent.com/u/79091831?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ErfanMoosaviMonazzah",
"html_url": "https://github.com/ErfanMoosaviMonazzah",
"followers_url... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"Hi!\r\n\r\nYou can also use names other than \"train\", \"validation\" and \"test\". As an example, check the [script](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/blob/e095840f23f3dffc1056c078c2f9320dad9ca74d/common_voice_11_0.py#L139) of the Common Voice 11 dataset. "
] | 2023-03-12T17:21:43 | 2023-03-24T14:13:00 | 2023-03-24T14:13:00 | NONE | null | null | null | ### Feature request
Hi,
I participated in multiple NLP tasks where there are more than just train, test, validation splits, there could be multiple validation sets or test sets. But it seems currently only those mentioned three splits supported. It would be nice to have the support for more splits on the hub. (curren... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5631/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5631/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5628 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5628/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5628/comments | https://api.github.com/repos/huggingface/datasets/issues/5628/events | https://github.com/huggingface/datasets/pull/5628 | 1,619,641,810 | PR_kwDODunzps5LzVKi | 5,628 | add kwargs to index search | {
"login": "SaulLu",
"id": 55560583,
"node_id": "MDQ6VXNlcjU1NTYwNTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SaulLu",
"html_url": "https://github.com/SaulLu",
"followers_url": "https://api.github.com/users/SaulLu/fo... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2023-03-10T21:24:58 | 2023-03-15T14:48:47 | 2023-03-15T14:46:04 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5628",
"html_url": "https://github.com/huggingface/datasets/pull/5628",
"diff_url": "https://github.com/huggingface/datasets/pull/5628.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5628.patch",
"merged_at": "2023-03-15T14:46... | This PR proposes to add kwargs to index search methods.
This is particularly useful for setting the timeout of a query on elasticsearch.
A typical use case would be:
```python
dset.add_elasticsearch_index("filename", es_client=es_client)
scores, examples = dset.get_nearest_examples("filename", "my_name-train_2... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5628/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5628/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5626/comments | https://api.github.com/repos/huggingface/datasets/issues/5626/events | https://github.com/huggingface/datasets/pull/5626 | 1,619,252,984 | PR_kwDODunzps5LyBT4 | 5,626 | Support streaming datasets with numpy.load | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-10T16:33:39 | 2023-03-21T06:36:05 | 2023-03-21T06:28:54 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5626",
"html_url": "https://github.com/huggingface/datasets/pull/5626",
"diff_url": "https://github.com/huggingface/datasets/pull/5626.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5626.patch",
"merged_at": "2023-03-21T06:28... | Support streaming datasets with `numpy.load`.
See: https://huggingface.co/datasets/qgallouedec/gia_dataset/discussions/1 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5626/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5626/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5624 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5624/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5624/comments | https://api.github.com/repos/huggingface/datasets/issues/5624/events | https://github.com/huggingface/datasets/issues/5624 | 1,617,400,192 | I_kwDODunzps5gZ5GA | 5,624 | glue datasets returning -1 for test split | {
"login": "lithafnium",
"id": 8939967,
"node_id": "MDQ6VXNlcjg5Mzk5Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8939967?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lithafnium",
"html_url": "https://github.com/lithafnium",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | null | [
"Hi @lithafnium, thanks for reporting.\r\n\r\nPlease note that you can use the \"Community\" tab in the corresponding dataset page to start any discussion: https://huggingface.co/datasets/glue/discussions\r\n\r\nIndeed this issue was already raised there (https://huggingface.co/datasets/glue/discussions/5) and answ... | 2023-03-09T14:47:18 | 2023-03-09T16:49:29 | 2023-03-09T16:49:29 | NONE | null | null | null | ### Describe the bug
Downloading any dataset from GLUE has -1 as class labels for test split. Train and validation have regular 0/1 class labels. This is also present in the dataset card online.
### Steps to reproduce the bug
```
dataset = load_dataset("glue", "sst2")
for d in dataset:
# prints out -1
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5624/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5624/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5623/comments | https://api.github.com/repos/huggingface/datasets/issues/5623/events | https://github.com/huggingface/datasets/pull/5623 | 1,616,712,665 | PR_kwDODunzps5Lpb4q | 5,623 | Remove set_access_token usage + fail tests if FutureWarning | {
"login": "Wauplin",
"id": 11801849,
"node_id": "MDQ6VXNlcjExODAxODQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Wauplin",
"html_url": "https://github.com/Wauplin",
"followers_url": "https://api.github.com/users/Waupli... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-03-09T08:46:01 | 2023-03-09T15:39:00 | 2023-03-09T15:31:59 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5623",
"html_url": "https://github.com/huggingface/datasets/pull/5623",
"diff_url": "https://github.com/huggingface/datasets/pull/5623.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5623.patch",
"merged_at": "2023-03-09T15:31... | `set_access_token` is deprecated and will be removed in `huggingface_hub>=0.14`.
This PR removes it from the tests (it was not used in `datasets` source code itself). FYI, it was not needed since `set_access_token` was just setting git credentials and `datasets` doesn't seem to use git anywhere.
In the future, us... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5623/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5623/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5622/comments | https://api.github.com/repos/huggingface/datasets/issues/5622/events | https://github.com/huggingface/datasets/pull/5622 | 1,615,190,942 | PR_kwDODunzps5LkSj8 | 5,622 | Update README template to better template | {
"login": "emiltj",
"id": 54767532,
"node_id": "MDQ6VXNlcjU0NzY3NTMy",
"avatar_url": "https://avatars.githubusercontent.com/u/54767532?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/emiltj",
"html_url": "https://github.com/emiltj",
"followers_url": "https://api.github.com/users/emiltj/fo... | [] | closed | false | null | [] | null | [
"IMO this template should stay generic.\r\n\r\nAlso, we now use [the card template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md) from `hugginface_hub` as the source of truth on the Hub (you now have the option to import it into the dataset card/READ... | 2023-03-08T12:30:23 | 2023-03-11T05:07:38 | 2023-03-11T05:07:38 | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5622",
"html_url": "https://github.com/huggingface/datasets/pull/5622",
"diff_url": "https://github.com/huggingface/datasets/pull/5622.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5622.patch",
"merged_at": null
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5622/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5622/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5621/comments | https://api.github.com/repos/huggingface/datasets/issues/5621/events | https://github.com/huggingface/datasets/pull/5621 | 1,615,029,615 | PR_kwDODunzps5LjwD8 | 5,621 | Adding Oracle Cloud to docs | {
"login": "ahosler",
"id": 29129502,
"node_id": "MDQ6VXNlcjI5MTI5NTAy",
"avatar_url": "https://avatars.githubusercontent.com/u/29129502?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ahosler",
"html_url": "https://github.com/ahosler",
"followers_url": "https://api.github.com/users/ahosle... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-08T10:22:50 | 2023-03-11T00:57:18 | 2023-03-11T00:49:56 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5621",
"html_url": "https://github.com/huggingface/datasets/pull/5621",
"diff_url": "https://github.com/huggingface/datasets/pull/5621.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5621.patch",
"merged_at": "2023-03-11T00:49... | Adding Oracle Cloud's fsspec implementation to the list of supported cloud storage providers. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5621/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5621/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5620/comments | https://api.github.com/repos/huggingface/datasets/issues/5620/events | https://github.com/huggingface/datasets/pull/5620 | 1,613,460,520 | PR_kwDODunzps5LefAf | 5,620 | Bump pyarrow to 8.0.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-07T13:31:53 | 2023-03-08T14:01:27 | 2023-03-08T13:54:22 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5620",
"html_url": "https://github.com/huggingface/datasets/pull/5620",
"diff_url": "https://github.com/huggingface/datasets/pull/5620.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5620.patch",
"merged_at": "2023-03-08T13:54... | Fix those for Pandas 2.0 (tested [here](https://github.com/huggingface/datasets/actions/runs/4346221280/jobs/7592010397) with pandas==2.0.0.rc0):
```python
=========================== short test summary info ============================
FAILED tests/test_arrow_dataset.py::BaseDatasetTest::test_to_parquet_in_memory... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5620/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5620/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5619/comments | https://api.github.com/repos/huggingface/datasets/issues/5619/events | https://github.com/huggingface/datasets/pull/5619 | 1,613,439,709 | PR_kwDODunzps5LeaYP | 5,619 | unpin fsspec | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-07T13:22:41 | 2023-03-07T13:47:01 | 2023-03-07T13:39:02 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5619",
"html_url": "https://github.com/huggingface/datasets/pull/5619",
"diff_url": "https://github.com/huggingface/datasets/pull/5619.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5619.patch",
"merged_at": "2023-03-07T13:39... | close https://github.com/huggingface/datasets/issues/5618 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5619/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5619/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5618/comments | https://api.github.com/repos/huggingface/datasets/issues/5618/events | https://github.com/huggingface/datasets/issues/5618 | 1,612,977,934 | I_kwDODunzps5gJBcO | 5,618 | Unpin fsspec < 2023.3.0 once issue fixed | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [] | 2023-03-07T08:41:51 | 2023-03-07T13:39:03 | 2023-03-07T13:39:03 | MEMBER | null | null | null | Unpin `fsspec` upper version once root cause of our CI break is fixed.
See:
- #5614 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5618/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5618/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5617 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5617/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5617/comments | https://api.github.com/repos/huggingface/datasets/issues/5617/events | https://github.com/huggingface/datasets/pull/5617 | 1,612,947,422 | PR_kwDODunzps5LcvI- | 5,617 | Fix CI by temporarily pinning fsspec < 2023.3.0 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-07T08:18:20 | 2023-03-07T08:44:55 | 2023-03-07T08:37:28 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5617",
"html_url": "https://github.com/huggingface/datasets/pull/5617",
"diff_url": "https://github.com/huggingface/datasets/pull/5617.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5617.patch",
"merged_at": "2023-03-07T08:37... | As a hotfix for our CI, temporarily pin `fsspec`:
Fix #5616.
Until root cause is fixed, see:
- #5614 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5617/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5617/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5616/comments | https://api.github.com/repos/huggingface/datasets/issues/5616/events | https://github.com/huggingface/datasets/issues/5616 | 1,612,932,508 | I_kwDODunzps5gI2Wc | 5,616 | CI is broken after fsspec-2023.3.0 release | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [] | 2023-03-07T08:06:39 | 2023-03-07T08:37:29 | 2023-03-07T08:37:29 | MEMBER | null | null | null | As reported by @lhoestq, our CI is broken after `fsspec` 2023.3.0 release:
```
FAILED tests/test_filesystem.py::test_compression_filesystems[Bz2FileSystem] - AssertionError: assert [{'created': ...: False, ...}] == ['file.txt']
At index 0 diff: {'name': 'file.txt', 'size': 70, 'type': 'file', 'created': 1678175677... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5616/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5616/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5615/comments | https://api.github.com/repos/huggingface/datasets/issues/5615/events | https://github.com/huggingface/datasets/issues/5615 | 1,612,552,653 | I_kwDODunzps5gHZnN | 5,615 | IterableDataset.add_column is unable to accept another IterableDataset as a parameter. | {
"login": "zsaladin",
"id": 6466389,
"node_id": "MDQ6VXNlcjY0NjYzODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6466389?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zsaladin",
"html_url": "https://github.com/zsaladin",
"followers_url": "https://api.github.com/users/zsala... | [
{
"id": 1935892913,
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": "This will not be worked on"
}
] | closed | false | null | [] | null | [
"Hi! You can use `concatenate_datasets([ids1, ids2], axis=1)` to do this."
] | 2023-03-07T01:52:00 | 2023-03-09T15:24:05 | 2023-03-09T15:23:54 | NONE | null | null | null | ### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5615/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5615/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5614 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5614/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5614/comments | https://api.github.com/repos/huggingface/datasets/issues/5614/events | https://github.com/huggingface/datasets/pull/5614 | 1,611,896,357 | PR_kwDODunzps5LZOTd | 5,614 | Fix archive fs test | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-06T17:28:09 | 2023-03-07T13:27:50 | 2023-03-07T13:20:57 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5614",
"html_url": "https://github.com/huggingface/datasets/pull/5614",
"diff_url": "https://github.com/huggingface/datasets/pull/5614.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5614.patch",
"merged_at": "2023-03-07T13:20... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5614/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5614/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5611/comments | https://api.github.com/repos/huggingface/datasets/issues/5611/events | https://github.com/huggingface/datasets/pull/5611 | 1,611,197,906 | PR_kwDODunzps5LW2Lx | 5,611 | add Dataset.to_list | {
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi, thanks for working on this! `Table.to_pylist` requires PyArrow 7.0+, and our minimal version requirement is 6.0, so we need to bump the version requirement to avoid CI failure. I'll do this in a separate PR.",
"<details>\n<summ... | 2023-03-06T11:21:57 | 2023-03-27T13:34:19 | 2023-03-27T13:26:38 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5611",
"html_url": "https://github.com/huggingface/datasets/pull/5611",
"diff_url": "https://github.com/huggingface/datasets/pull/5611.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5611.patch",
"merged_at": "2023-03-27T13:26... | close https://github.com/huggingface/datasets/issues/5606
This PR is for adding the `Dataset.to_list` method.
Thank you in advance.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5611/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5611/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5608/comments | https://api.github.com/repos/huggingface/datasets/issues/5608/events | https://github.com/huggingface/datasets/issues/5608 | 1,609,996,563 | I_kwDODunzps5f9pkT | 5,608 | audiofolder only creates dataset of 13 rows (files) when the data folder it's reading from has 20,000 mp3 files. | {
"login": "jcho19",
"id": 107211437,
"node_id": "U_kgDOBmPqrQ",
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jcho19",
"html_url": "https://github.com/jcho19",
"followers_url": "https://api.github.com/users/jcho19/follower... | [] | closed | false | null | [] | null | [
"Hi!\r\n\r\n> naming convention of mp3 files\r\n\r\nYes, this could be the problem. MP3 files should end with `.mp3`/`.MP3` to be recognized as audio files.\r\n\r\nIf the file names are not the culprit, can you paste the audio folder's directory structure to help us reproduce the error (e.g., by running the `tree ... | 2023-03-05T00:14:45 | 2023-03-12T00:02:57 | 2023-03-12T00:02:57 | NONE | null | null | null | ### Describe the bug
x = load_dataset("audiofolder", data_dir="x")
When running this, x is a dataset of 13 rows (files) when it should be 20,000 rows (files) as the data_dir "x" has 20,000 mp3 files. Does anyone know what could possibly cause this (naming convention of mp3 files, etc.)
### Steps to reproduce the b... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5608/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5608/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5607/comments | https://api.github.com/repos/huggingface/datasets/issues/5607/events | https://github.com/huggingface/datasets/pull/5607 | 1,609,166,035 | PR_kwDODunzps5LQPbG | 5,607 | Fix outdated `verification_mode` values | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-03T19:50:29 | 2023-03-09T17:34:13 | 2023-03-09T17:27:07 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5607",
"html_url": "https://github.com/huggingface/datasets/pull/5607",
"diff_url": "https://github.com/huggingface/datasets/pull/5607.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5607.patch",
"merged_at": "2023-03-09T17:27... | ~I think it makes sense not to save `dataset_info.json` file to a dataset cache directory when loading dataset with `verification_mode="no_checks"` because otherwise when next time the dataset is loaded **without** `verification_mode="no_checks"`, it will be loaded successfully, despite some values in info might not co... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5607/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5607/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5606/comments | https://api.github.com/repos/huggingface/datasets/issues/5606/events | https://github.com/huggingface/datasets/issues/5606 | 1,608,911,632 | I_kwDODunzps5f5gsQ | 5,606 | Add `Dataset.to_list` to the API | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | closed | false | {
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://api.github.com/users/... | [
{
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://a... | null | [
"Hello, I have an interest in this issue.\r\nIs the `Dataset.to_dict` you are describing correct in the code here?\r\n\r\nhttps://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/arrow_dataset.py#L4633-L4667",
"Yes, this is where `Dataset.to_dict` is defined.",
"#self-a... | 2023-03-03T16:17:10 | 2023-03-27T13:26:40 | 2023-03-27T13:26:40 | CONTRIBUTOR | null | null | null | Since there is `Dataset.from_list` in the API, we should also add `Dataset.to_list` to be consistent.
Regarding the implementation, we can re-use `Dataset.to_dict`'s code and replace the `to_pydict` calls with `to_pylist`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5606/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5606/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5605/comments | https://api.github.com/repos/huggingface/datasets/issues/5605/events | https://github.com/huggingface/datasets/pull/5605 | 1,608,865,460 | PR_kwDODunzps5LPPf5 | 5,605 | Update README logo | {
"login": "gary149",
"id": 3841370,
"node_id": "MDQ6VXNlcjM4NDEzNzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3841370?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gary149",
"html_url": "https://github.com/gary149",
"followers_url": "https://api.github.com/users/gary149/... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Are you sure it's safe to remove? https://github.com/huggingface/datasets/pull/3866",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benc... | 2023-03-03T15:46:31 | 2023-03-03T21:57:18 | 2023-03-03T21:50:17 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5605",
"html_url": "https://github.com/huggingface/datasets/pull/5605",
"diff_url": "https://github.com/huggingface/datasets/pull/5605.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5605.patch",
"merged_at": "2023-03-03T21:50... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5605/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5605/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | {
"login": "sentialx",
"id": 11065386,
"node_id": "MDQ6VXNlcjExMDY1Mzg2",
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sentialx",
"html_url": "https://github.com/sentialx",
"followers_url": "https://api.github.com/users/sen... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\n\r\nYou can specify `download_config=DownloadConfig(resume_download=True))` in `load_dataset` to resume the download when re-running the code after the timeout error:\r\n```python\r\nfrom datasets import load_dataset, DownloadConfig\r\ndataset = load_dataset('the_pile', split='train', cache_dir='F:\\da... | 2023-03-03T09:52:08 | 2023-03-29T01:44:05 | 2023-03-24T12:44:25 | NONE | null | null | null | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
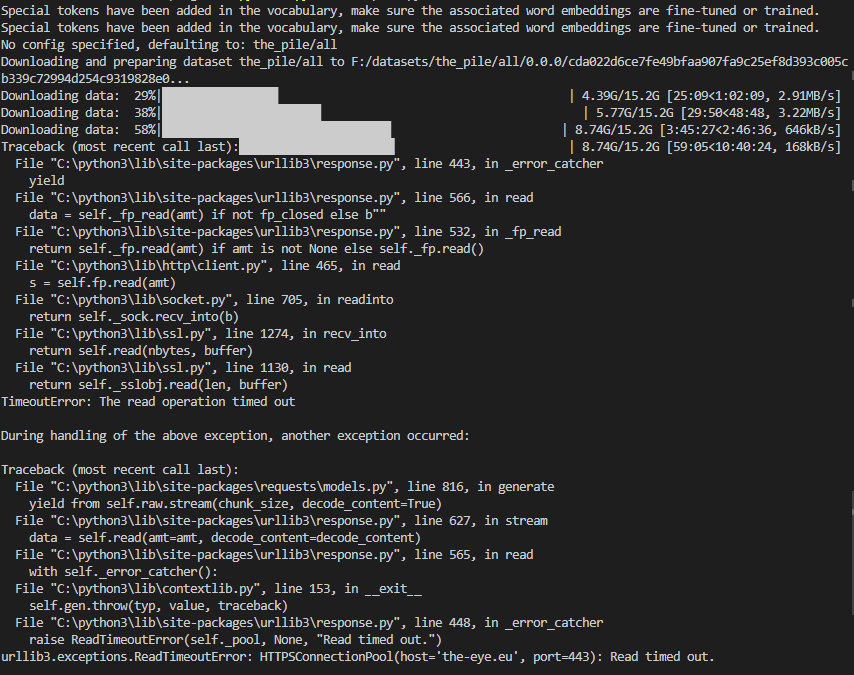
Here are the downloaded files:
`hg_user` but my repo cont... | 2023-03-02T12:08:39 | 2023-03-14T16:55:35 | 2023-03-14T16:55:34 | NONE | null | null | null | ### Describe the bug
Get `Authorization error` when try to push data into hugginface datasets hub.
### Steps to reproduce the bug
I did all steps in the [tutorial](https://huggingface.co/docs/datasets/share),
1. `huggingface-cli login` with WRITE token
2. `git lfs install`
3. `git clone https://huggingfa... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5601/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5601/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5600/comments | https://api.github.com/repos/huggingface/datasets/issues/5600/events | https://github.com/huggingface/datasets/issues/5600 | 1,606,585,596 | I_kwDODunzps5fwoz8 | 5,600 | Dataloader getitem not working for DreamboothDatasets | {
"login": "salahiguiliz",
"id": 76955987,
"node_id": "MDQ6VXNlcjc2OTU1OTg3",
"avatar_url": "https://avatars.githubusercontent.com/u/76955987?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/salahiguiliz",
"html_url": "https://github.com/salahiguiliz",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\n> (see example of DreamboothDatasets)\r\n\r\n\r\nCould you please provide a link to it? If you are referring to the example in the `diffusers` repo, your issue is unrelated to `datasets` as that example uses `Dataset` from PyTorch to load data."
] | 2023-03-02T11:00:27 | 2023-03-13T17:59:35 | 2023-03-13T17:59:35 | NONE | null | null | null | ### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5600/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5600/timeline | null | completed | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.