
title stringlengths 1 100 | titleSlug stringlengths 3 77 | Java int64 0 1 | Python3 int64 1 1 | content stringlengths 28 44.4k | voteCount int64 0 3.67k | question_content stringlengths 65 5k | question_hints stringclasses 970
values |
|---|---|---|---|---|---|---|---|
Simple Python 🐍 solution using deque (BFS) | employee-importance | 0 | 1 | ```\nclass Solution:\n def getImportance(self, employees: List[\'Employee\'], id: int) -> int:\n emap = {e.id: e for e in employees}\n\n q=deque([id])\n ans=0\n \n while q:\n emp_id=q.popleft()\n ans+=emap[emp_id].importance\n \n for sub ... | 4 | You have a data structure of employee information, including the employee's unique ID, importance value, and direct subordinates' IDs.
You are given an array of employees `employees` where:
* `employees[i].id` is the ID of the `ith` employee.
* `employees[i].importance` is the importance value of the `ith` employ... | null |
75% TC and 62% SC easy python solution | employee-importance | 0 | 1 | ```\ndef getImportance(self, employees: List[\'Employee\'], id: int) -> int:\n\td = {j.id:i for i, j in enumerate(employees)}\n\ts = [id]\n\tans = 0\n\twhile(s):\n\t\tcurr = s.pop()\n\t\tans += employees[d[curr]].importance\n\t\tfor child in employees[d[curr]].subordinates: \n\t\t\ts.append(child)\n\treturn... | 1 | You have a data structure of employee information, including the employee's unique ID, importance value, and direct subordinates' IDs.
You are given an array of employees `employees` where:
* `employees[i].id` is the ID of the `ith` employee.
* `employees[i].importance` is the importance value of the `ith` employ... | null |
Solution | employee-importance | 1 | 1 | ```C++ []\nclass Solution {\n void dfs(int id,vector<Employee*> employees, unordered_map<int,int>&mp,int& ans){\n ans += employees[mp[id]]->importance;\n for(auto it:employees[mp[id]]->subordinates)\n dfs(it,employees,mp,ans);\n }\npublic:\n int getImportance(vector<Employee*> employee... | 2 | You have a data structure of employee information, including the employee's unique ID, importance value, and direct subordinates' IDs.
You are given an array of employees `employees` where:
* `employees[i].id` is the ID of the `ith` employee.
* `employees[i].importance` is the importance value of the `ith` employ... | null |
✔ Python3 Solution | DFS | O(n) | employee-importance | 0 | 1 | # Complexity\n- Time complexity: $$O(n)$$\n- Space complexity: $$O(n)$$\n\n# Code\n```\nclass Solution:\n def getImportance(self, employees: List[\'Employee\'], id: int) -> int:\n D = {i.id : e for e, i in enumerate(employees)}\n def dfs(id):\n ans = employees[D[id]].importance\n ... | 2 | You have a data structure of employee information, including the employee's unique ID, importance value, and direct subordinates' IDs.
You are given an array of employees `employees` where:
* `employees[i].id` is the ID of the `ith` employee.
* `employees[i].importance` is the importance value of the `ith` employ... | null |
✅ Simple Python DFS Solution | Beats 97% | hashtable | employee-importance | 0 | 1 | 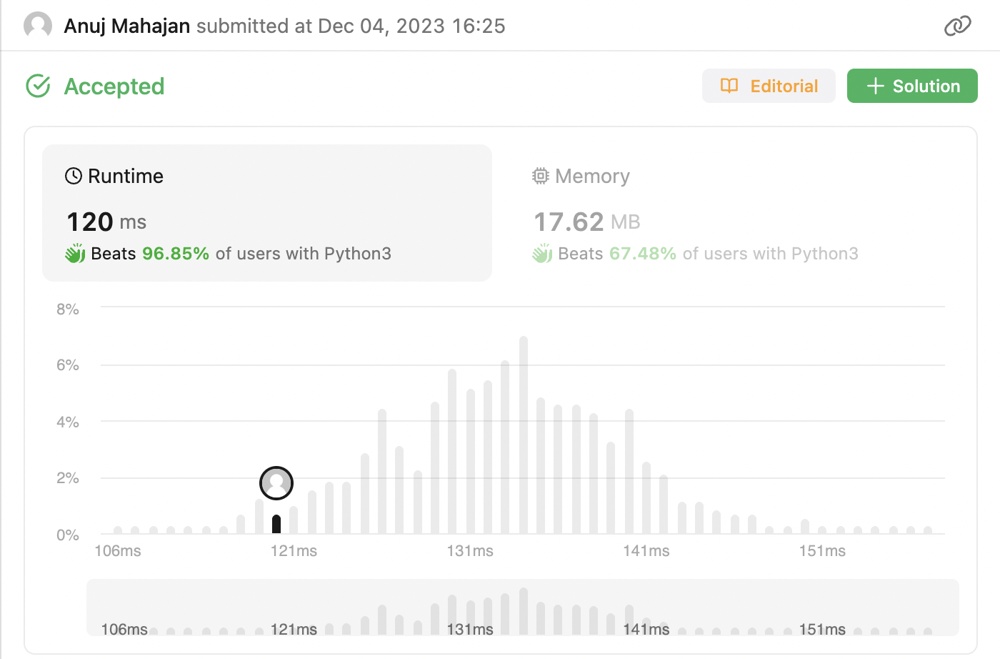\n\n# Code\n```\n"""\n# Definition for Employee.\nclass Employee:\n def __init__(self, id: int, importance: int, subordinates: List[int]):\n self.id = id\n se... | 0 | You have a data structure of employee information, including the employee's unique ID, importance value, and direct subordinates' IDs.
You are given an array of employees `employees` where:
* `employees[i].id` is the ID of the `ith` employee.
* `employees[i].importance` is the importance value of the `ith` employ... | null |
Solution | stickers-to-spell-word | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int minStickers(vector<string>& stickers, string target) {\n constexpr int invalid = -1;\n const int n_stickers = static_cast<int>(stickers.size());\n const int n_target = static_cast<int>(target.size());\n const int n_layouts = (1 << n_target);\n ... | 1 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
Solution | stickers-to-spell-word | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int minStickers(vector<string>& stickers, string target) {\n constexpr int invalid = -1;\n const int n_stickers = static_cast<int>(stickers.size());\n const int n_target = static_cast<int>(target.size());\n const int n_layouts = (1 << n_target);\n ... | 1 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
Python Accepted DFS + Memo Solution (With Explanation, Easy to Understand) | stickers-to-spell-word | 0 | 1 | \n# Approach\n<!-- Describe your approach to solving the problem. -->\nDisclaimer: I\'m aware that there are much more optimized solutions for this problem, but I wanted to provide a simple solution for those trying to understand this.\n\nThe main idea behind this solution is that at each point in time, we have two cho... | 15 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
Python Accepted DFS + Memo Solution (With Explanation, Easy to Understand) | stickers-to-spell-word | 0 | 1 | \n# Approach\n<!-- Describe your approach to solving the problem. -->\nDisclaimer: I\'m aware that there are much more optimized solutions for this problem, but I wanted to provide a simple solution for those trying to understand this.\n\nThe main idea behind this solution is that at each point in time, we have two cho... | 15 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
Fast Python solution | stickers-to-spell-word | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nMy first thoughts on how to solve this problem is to use dynamic programming to find the minimum number of stickers needed to spell out the target string.\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThe approach ... | 2 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
Fast Python solution | stickers-to-spell-word | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nMy first thoughts on how to solve this problem is to use dynamic programming to find the minimum number of stickers needed to spell out the target string.\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThe approach ... | 2 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
Python 3 || 12 lines, dfs || T/S: 75% / 95% | stickers-to-spell-word | 0 | 1 | \n```\nclass Solution:\n def minStickers(self, stickers: List[str], target: str) -> int:\n\n @lru_cache(None)\n def dfs(target):\n\n if not target: return 0\n tCtr, res = Counter(target), inf\n mn = min(tuple(tCtr), key= lambda x: tCtr[x] )\n\n for sCtr in sC... | 4 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
Python 3 || 12 lines, dfs || T/S: 75% / 95% | stickers-to-spell-word | 0 | 1 | \n```\nclass Solution:\n def minStickers(self, stickers: List[str], target: str) -> int:\n\n @lru_cache(None)\n def dfs(target):\n\n if not target: return 0\n tCtr, res = Counter(target), inf\n mn = min(tuple(tCtr), key= lambda x: tCtr[x] )\n\n for sCtr in sC... | 4 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
O(2^m * n) time | O(2^m) space | solution explained | stickers-to-spell-word | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nTo find the minimum stickers required to spell the target string, we need to find the minimum stickers required for the substrings (subsets).\n\nUse dynamic programming.\n\n# Approach\n<!-- Describe your approach to solving the problem. -... | 1 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
O(2^m * n) time | O(2^m) space | solution explained | stickers-to-spell-word | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nTo find the minimum stickers required to spell the target string, we need to find the minimum stickers required for the substrings (subsets).\n\nUse dynamic programming.\n\n# Approach\n<!-- Describe your approach to solving the problem. -... | 1 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
Python with Counter and LRU cache memoization | stickers-to-spell-word | 0 | 1 | # Intuition\nWe can observe that any string target can be reduced into a smaller problem after applying some stickers.\n\nNow, what would be the resulting string given "thehat" if we use the sticker "with"?\n\nWe would remove "th" and the resulting string would be something like "ehat"\n\nOk, now we see that the string... | 2 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
Python with Counter and LRU cache memoization | stickers-to-spell-word | 0 | 1 | # Intuition\nWe can observe that any string target can be reduced into a smaller problem after applying some stickers.\n\nNow, what would be the resulting string given "thehat" if we use the sticker "with"?\n\nWe would remove "th" and the resulting string would be something like "ehat"\n\nOk, now we see that the string... | 2 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
691: Solution with step by step explanation | stickers-to-spell-word | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Compute the length of target and create a bitmask maxMask that has a 1 in each position that corresponds to a character in target.\n2. Create a list dp of length maxMask to store the minimum number of stickers required to... | 3 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
691: Solution with step by step explanation | stickers-to-spell-word | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Compute the length of target and create a bitmask maxMask that has a 1 in each position that corresponds to a character in target.\n2. Create a list dp of length maxMask to store the minimum number of stickers required to... | 3 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
Python | BFS solution | stickers-to-spell-word | 0 | 1 | I need to say that this is not the fastest or smartes way to solve this problem, however, this is also can be interesting. \nP.S. For those who are interested, the solution is faster than 25% of other solutions. But perhaps it can be optimized a bit.\n\n```\nclass Solution:\n \n @staticmethod\n def substract(... | 1 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
Python | BFS solution | stickers-to-spell-word | 0 | 1 | I need to say that this is not the fastest or smartes way to solve this problem, however, this is also can be interesting. \nP.S. For those who are interested, the solution is faster than 25% of other solutions. But perhaps it can be optimized a bit.\n\n```\nclass Solution:\n \n @staticmethod\n def substract(... | 1 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
From recursion to memoized | stickers-to-spell-word | 0 | 1 | # Intuition\nTry all stickers.\n\n# Approach 1 (Recursive TLE\'D)\n1. For each sticker, make a counter only for those which have letters that overlap with the target letters. Eg. `target = "hello"` and `stickers = ["help","me"]`. Here `help` overlaps with our target `hello` but `me` does not so we wont make a counter f... | 5 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
From recursion to memoized | stickers-to-spell-word | 0 | 1 | # Intuition\nTry all stickers.\n\n# Approach 1 (Recursive TLE\'D)\n1. For each sticker, make a counter only for those which have letters that overlap with the target letters. Eg. `target = "hello"` and `stickers = ["help","me"]`. Here `help` overlaps with our target `hello` but `me` does not so we wont make a counter f... | 5 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
Python | Easy to Understand | Kinda like coin change problem | stickers-to-spell-word | 0 | 1 | \n# Code\n```\n\nclass Solution:\n def minStickers(self, stickers: List[str], target: str) -> int:\n\n def remove_chars(sticker, target):\n for ch in sticker:\n target = target.replace(ch, \'\', 1)\n return target\n\n memo = {}\n\n def dfs(remaining_target):\... | 0 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
Python | Easy to Understand | Kinda like coin change problem | stickers-to-spell-word | 0 | 1 | \n# Code\n```\n\nclass Solution:\n def minStickers(self, stickers: List[str], target: str) -> int:\n\n def remove_chars(sticker, target):\n for ch in sticker:\n target = target.replace(ch, \'\', 1)\n return target\n\n memo = {}\n\n def dfs(remaining_target):\... | 0 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
DP solution | stickers-to-spell-word | 0 | 1 | # Intuition\nAfter using a sticker, we recursively have to decide which sticker to use next until we build the target. We have to try all combinations to find the minimum. Hence DP.\n\n# Approach\nFor each sticker, see how much of target is still left after using it. Recursively call the procedure on this new target.\n... | 0 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
DP solution | stickers-to-spell-word | 0 | 1 | # Intuition\nAfter using a sticker, we recursively have to decide which sticker to use next until we build the target. We have to try all combinations to find the minimum. Hence DP.\n\n# Approach\nFor each sticker, see how much of target is still left after using it. Recursively call the procedure on this new target.\n... | 0 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
Using DFS to explore each sticker subtraction to remove first letter from target | stickers-to-spell-word | 0 | 1 | # Code\n```\nclass Solution:\n # https://leetcode.com/problems/stickers-to-spell-word/solutions/233915/python-12-lines-solution/\n def minStickers(self, stickers: List[str], target: str) -> int:\n counts = [Counter(s) for s in stickers]\n # T = O(N * W * N) - N is letters in target and S = number of... | 0 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
Using DFS to explore each sticker subtraction to remove first letter from target | stickers-to-spell-word | 0 | 1 | # Code\n```\nclass Solution:\n # https://leetcode.com/problems/stickers-to-spell-word/solutions/233915/python-12-lines-solution/\n def minStickers(self, stickers: List[str], target: str) -> int:\n counts = [Counter(s) for s in stickers]\n # T = O(N * W * N) - N is letters in target and S = number of... | 0 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
inspired by other's solution | stickers-to-spell-word | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
inspired by other's solution | stickers-to-spell-word | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
I want to discuss how to improve the time complexity of my solution to avoid timeout in the last 3. | stickers-to-spell-word | 0 | 1 | # Intuition\nThe idea is to turn strings into counters so that each counter stores the number of each letters in the string.\n\nFor some letters in the target string, we can only find one sticker that has that letter, so these can be handled first.\n\nThen for the rest of the string, I am doing BFS so that once a solut... | 0 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a s... |
I want to discuss how to improve the time complexity of my solution to avoid timeout in the last 3. | stickers-to-spell-word | 0 | 1 | # Intuition\nThe idea is to turn strings into counters so that each counter stores the number of each letters in the string.\n\nFor some letters in the target string, we can only find one sticker that has that letter, so these can be handled first.\n\nThen for the rest of the string, I am doing BFS so that once a solut... | 0 | We are given `n` different types of `stickers`. Each sticker has a lowercase English word on it.
You would like to spell out the given string `target` by cutting individual letters from your collection of stickers and rearranging them. You can use each sticker more than once if you want, and you have infinite quantiti... | We want to perform an exhaustive search, but we need to speed it up based on the input data being random.
For all stickers, we can ignore any letters that are not in the target word.
When our candidate answer won't be smaller than an answer we have already found, we can stop searching this path.
When a sticker... |
python3, collections.Counter() and sort list with a tuple as key | top-k-frequent-words | 0 | 1 | **Solution 1: Counter() and sort()** \nhttps://leetcode.com/submissions/detail/875157545/\nRuntime: **57 ms**, faster than 88.57% of Python3 online submissions for Top K Frequent Words. \nMemory Usage: 13.9 MB, less than 94.23% of Python3 online submissions for Top K Frequent Words. \n```\nclass Solution:\n def t... | 3 | Given an array of strings `words` and an integer `k`, return _the_ `k` _most frequent strings_.
Return the answer **sorted** by **the frequency** from highest to lowest. Sort the words with the same frequency by their **lexicographical order**.
**Example 1:**
**Input:** words = \[ "i ", "love ", "leetcode ", "i ", "... | null |
Python | 1 line Solution | Easy to Understand | top-k-frequent-words | 0 | 1 | # One Line\n```\nclass Solution:\n def topKFrequent(self, words: List[str], k: int) -> List[str]:\n return [x[0] for x in sorted(Counter(words).items(), key=lambda x:(-x[1], x[0]))][0:k]\n```\n\n# Three Lines (more understandable)\n```\nfrom collections import Counter\n\nclass Solution:\n def topKFrequent(... | 1 | Given an array of strings `words` and an integer `k`, return _the_ `k` _most frequent strings_.
Return the answer **sorted** by **the frequency** from highest to lowest. Sort the words with the same frequency by their **lexicographical order**.
**Example 1:**
**Input:** words = \[ "i ", "love ", "leetcode ", "i ", "... | null |
Top K Frequent Words | top-k-frequent-words | 0 | 1 | Arranging count of each word and returning ***k*** words\n\n# Steps \n - Getting Unique Words in list: words: List[str]\n - Creating Dictionary dict initialized with key as unique list and value as 0 \n - Traversing through list: words: List[str] and counting # of words and storing in Dictionary dict\n - So... | 1 | Given an array of strings `words` and an integer `k`, return _the_ `k` _most frequent strings_.
Return the answer **sorted** by **the frequency** from highest to lowest. Sort the words with the same frequency by their **lexicographical order**.
**Example 1:**
**Input:** words = \[ "i ", "love ", "leetcode ", "i ", "... | null |
Short and sweet solution. Beats 97% space, 82% time | top-k-frequent-words | 0 | 1 | ```\nclass Solution:\n def topKFrequent(self, words: List[str], k: int) -> List[str]:\n d = {}\n for word in words:\n d[word] = d.get(word, 0) + 1\n \n res = sorted(d, key=lambda word: (-d[word], word))\n return res[:k]\n```\nIf it helped or you learned a new way, kindly... | 4 | Given an array of strings `words` and an integer `k`, return _the_ `k` _most frequent strings_.
Return the answer **sorted** by **the frequency** from highest to lowest. Sort the words with the same frequency by their **lexicographical order**.
**Example 1:**
**Input:** words = \[ "i ", "love ", "leetcode ", "i ", "... | null |
Correct time complexity: O(n log(k)) | top-k-frequent-words | 0 | 1 | # Complexity\n- Time complexity: `O(n log(k))`\n\n- Space complexity: `O(k)`\n\n# Code\n```py\nclass HeapWord:\n def __init__(self, word):\n self.word = word\n\n def __gt__(self, other):\n return self.word < other.word\n \n def __repr__(self):\n return self.word\n\n\nclass Solution:\n ... | 0 | Given an array of strings `words` and an integer `k`, return _the_ `k` _most frequent strings_.
Return the answer **sorted** by **the frequency** from highest to lowest. Sort the words with the same frequency by their **lexicographical order**.
**Example 1:**
**Input:** words = \[ "i ", "love ", "leetcode ", "i ", "... | null |
No Need to explain.py | top-k-frequent-words | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nOnly this line confuse you:\nlet me expain \nl.sort(key=lambda x: (-x[0], x[1]))\n\nI use -x[0] because it sort the list in decending order and x[1] is used to sort in... | 1 | Given an array of strings `words` and an integer `k`, return _the_ `k` _most frequent strings_.
Return the answer **sorted** by **the frequency** from highest to lowest. Sort the words with the same frequency by their **lexicographical order**.
**Example 1:**
**Input:** words = \[ "i ", "love ", "leetcode ", "i ", "... | null |
python3 code | binary-number-with-alternating-bits | 0 | 1 | # Intuition\nThe function first converts n to its binary representation using the built-in bin() function, and then converts the resulting binary string to a regular string. It then extracts two substrings from this string, one containing all the even-indexed bits and the other containing all the odd-indexed bits.\n\nF... | 1 | Given a positive integer, check whether it has alternating bits: namely, if two adjacent bits will always have different values.
**Example 1:**
**Input:** n = 5
**Output:** true
**Explanation:** The binary representation of 5 is: 101
**Example 2:**
**Input:** n = 7
**Output:** false
**Explanation:** The binary repr... | null |
Solution | binary-number-with-alternating-bits | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n bool hasAlternatingBits(int n) {\n int pre = n&0x1;\n n>>=1; \n while(n!=0)\n {\n if((n&0x1) == pre)\n return false;\n \n pre = n&0x1;\n n>>=1;\n }\n return true;\n }\... | 2 | Given a positive integer, check whether it has alternating bits: namely, if two adjacent bits will always have different values.
**Example 1:**
**Input:** n = 5
**Output:** true
**Explanation:** The binary representation of 5 is: 101
**Example 2:**
**Input:** n = 7
**Output:** false
**Explanation:** The binary repr... | null |
Easy Solution | Java | Python | binary-number-with-alternating-bits | 1 | 1 | # Python\n```\nclass Solution:\n def hasAlternatingBits(self, n: int) -> bool:\n num = str(bin(n).split(\'b\')[1])\n prev = num[0]\n for i in range(1, len(num)):\n if num[i] == prev:\n return False\n prev = num[i] \n return True\n```\n# ... | 2 | Given a positive integer, check whether it has alternating bits: namely, if two adjacent bits will always have different values.
**Example 1:**
**Input:** n = 5
**Output:** true
**Explanation:** The binary representation of 5 is: 101
**Example 2:**
**Input:** n = 7
**Output:** false
**Explanation:** The binary repr... | null |
693: Space 91.89%, Solution with step by step explanation | binary-number-with-alternating-bits | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Convert the input integer n to its binary representation using the built-in bin() function. This will return a string of 0s and 1s representing the binary representation of n.\n\n2. Iterate over the binary string from ind... | 4 | Given a positive integer, check whether it has alternating bits: namely, if two adjacent bits will always have different values.
**Example 1:**
**Input:** n = 5
**Output:** true
**Explanation:** The binary representation of 5 is: 101
**Example 2:**
**Input:** n = 7
**Output:** false
**Explanation:** The binary repr... | null |
2 O(1) UNIQUE SOLUTION WITH EXPLANATION | binary-number-with-alternating-bits | 0 | 1 | \n\n## Approach 1\n- ``` 0x55555555 ``` = 1010101010101010101010101010101 (32 bits)\n- The Q asked if n = ```...101``` or ```...1010``` which is literally a part of ```0x55555555```. \n```\nSuppose n = 21 = 10101 which has 5 digits\nNow lets extract last 5 digits from 0x55555555, 10101\n 1 0 1 0 1\n... | 3 | Given a positive integer, check whether it has alternating bits: namely, if two adjacent bits will always have different values.
**Example 1:**
**Input:** n = 5
**Output:** true
**Explanation:** The binary representation of 5 is: 101
**Example 2:**
**Input:** n = 7
**Output:** false
**Explanation:** The binary repr... | null |
Simplest one-liner Python | binary-number-with-alternating-bits | 0 | 1 | \n# Code\n```\nclass Solution:\n def hasAlternatingBits(self, n: int) -> bool:\n return \'11\' not in bin(n) and \'00\' not in bin(n)\n``` | 3 | Given a positive integer, check whether it has alternating bits: namely, if two adjacent bits will always have different values.
**Example 1:**
**Input:** n = 5
**Output:** true
**Explanation:** The binary representation of 5 is: 101
**Example 2:**
**Input:** n = 7
**Output:** false
**Explanation:** The binary repr... | null |
Python 3 | binary-number-with-alternating-bits | 0 | 1 | \n# Complexity\n- Time complexity: O(n logn)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def hasAlternatingBits(self, n: int) -> bool:\n a = list(str(bin(n)[2:]))\n for i in r... | 2 | Given a positive integer, check whether it has alternating bits: namely, if two adjacent bits will always have different values.
**Example 1:**
**Input:** n = 5
**Output:** true
**Explanation:** The binary representation of 5 is: 101
**Example 2:**
**Input:** n = 7
**Output:** false
**Explanation:** The binary repr... | null |
Binbin's another phenomenal idea | max-area-of-island | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 1 | You are given an `m x n` binary matrix `grid`. An island is a group of `1`'s (representing land) connected **4-directionally** (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.
The **area** of an island is the number of cells with a value `1` in the island.
Return _the maxim... | null |
Python Iterative Solution | max-area-of-island | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nWe want to traverse through the grid until we find some non-visited land. When we find some land, we want to call bfs to find all the neighboring land and calculate the area of the island. Every node that is visited can be added to a visi... | 5 | You are given an `m x n` binary matrix `grid`. An island is a group of `1`'s (representing land) connected **4-directionally** (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.
The **area** of an island is the number of cells with a value `1` in the island.
Return _the maxim... | null |
Click here if you're confused. | max-area-of-island | 0 | 1 | # Intuition\nTreat adjacent 1s as nodes in a graph that are connected. Each island is a subgraph and islands are disconnected. Traversing such a graph of 1 nodes is equivalent to exploring the island, each node is +1 area.\n\nWe mark already explored 1s as 0 to prevent re-exploring or infinite loops. Our traversal algo... | 2 | You are given an `m x n` binary matrix `grid`. An island is a group of `1`'s (representing land) connected **4-directionally** (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.
The **area** of an island is the number of cells with a value `1` in the island.
Return _the maxim... | null |
Python | Sets | BFS | Iterative | Easy | max-area-of-island | 0 | 1 | \n\n# Complexity\n- Time complexity:\nO($n^2$) where **n** is the total number of `vertices`\n\n- Space complexity:\nO($n$)\n\n# Code\n```\nclass GridType:\n def __init__(self):\n self.land = 1\n self.water = 0\n\nclass Solution:\n def maxAreaOfIsland(self, grid: List[List[int]]) -> int:\n if... | 1 | You are given an `m x n` binary matrix `grid`. An island is a group of `1`'s (representing land) connected **4-directionally** (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.
The **area** of an island is the number of cells with a value `1` in the island.
Return _the maxim... | null |
Simple 🐍 solution using DFS algo😎 | max-area-of-island | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def maxAreaOfIsland(self, grid: List[List[int]]) -> int:\n rows, cols = len(grid), len(grid[0])\n visited = set()\n\n def dfs(r, c):\n if(r<0 or r==rows or c<0 or c==cols or grid[r][c]==0 or (r,c) in visited):\n return 0\n v... | 2 | You are given an `m x n` binary matrix `grid`. An island is a group of `1`'s (representing land) connected **4-directionally** (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.
The **area** of an island is the number of cells with a value `1` in the island.
Return _the maxim... | null |
696: Solution with step by step explanation | count-binary-substrings | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize variables pre_len, cur_len, and count to 0.\n2. Traverse through the string using a for loop that starts at index 1 and ends at the length of the string.\n3. Check if the current character is the same as the pr... | 8 | Given a binary string `s`, return the number of non-empty substrings that have the same number of `0`'s and `1`'s, and all the `0`'s and all the `1`'s in these substrings are grouped consecutively.
Substrings that occur multiple times are counted the number of times they occur.
**Example 1:**
**Input:** s = "001100... | How many valid binary substrings exist in "000111", and how many in "11100"? What about "00011100"? |
💣Binary Substrings || 🔥Beats 75%🔥 || 😎Enjoy LeetCode... | count-binary-substrings | 0 | 1 | # KARRAR\n>Counting binary substrings...\n>>Using only MIN built-in function...\n>>>Most optimized...\n>>>>Easily Understand able...\n>>>>>Similar to the original solution...\n- PLEASE UPVOTE...\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach:\n Take three variables a... | 2 | Given a binary string `s`, return the number of non-empty substrings that have the same number of `0`'s and `1`'s, and all the `0`'s and all the `1`'s in these substrings are grouped consecutively.
Substrings that occur multiple times are counted the number of times they occur.
**Example 1:**
**Input:** s = "001100... | How many valid binary substrings exist in "000111", and how many in "11100"? What about "00011100"? |
Python | Two Pointer Approach | O(N) Time Complexity | O(1) Space Complexity | count-binary-substrings | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. --> Using two pointer approach \n\n# Approach\n<!-- Describe your approach to solving the problem. --> Two Pointers. I also defined a list with just two elements. I keep the number of 0\'s in our window (defined by using two pointers) in the f... | 2 | Given a binary string `s`, return the number of non-empty substrings that have the same number of `0`'s and `1`'s, and all the `0`'s and all the `1`'s in these substrings are grouped consecutively.
Substrings that occur multiple times are counted the number of times they occur.
**Example 1:**
**Input:** s = "001100... | How many valid binary substrings exist in "000111", and how many in "11100"? What about "00011100"? |
Minimal complexity answer (one pass, O(n)), beats 99.9% on time complexity. | count-binary-substrings | 0 | 1 | # Intuition\nSee the approach below, the main intuitive leap is to realize that once the string is arranged in "groups" of consecutive 0\'s and 1\'s, you only need information about the lengths of pairs of consecutive groups to count the number of desired substrings. \n\n# Approach\nFor a consecutive string of 0\'s and... | 2 | Given a binary string `s`, return the number of non-empty substrings that have the same number of `0`'s and `1`'s, and all the `0`'s and all the `1`'s in these substrings are grouped consecutively.
Substrings that occur multiple times are counted the number of times they occur.
**Example 1:**
**Input:** s = "001100... | How many valid binary substrings exist in "000111", and how many in "11100"? What about "00011100"? |
Solution | count-binary-substrings | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int countBinarySubstrings(string s) {\n char anchor;\n int sums = 0, i = 0, j = 0, numa = 0, total = 0, next = 0;\n\n while (i < s.length()){\n anchor = s[i];\n total = 0;\n\n numa = 1;\n for (j = i + 1; j < s.len... | 2 | Given a binary string `s`, return the number of non-empty substrings that have the same number of `0`'s and `1`'s, and all the `0`'s and all the `1`'s in these substrings are grouped consecutively.
Substrings that occur multiple times are counted the number of times they occur.
**Example 1:**
**Input:** s = "001100... | How many valid binary substrings exist in "000111", and how many in "11100"? What about "00011100"? |
Python/C++/Java/Go O(n) by character grouping [w/ Hint] | count-binary-substrings | 1 | 1 | **Hint**:\n\nbinary substring of equal 0s and 1s is **decided** by the **minimal continuous occurrence** between character groups\n\nExample:\n\nGiven s = **000**11111\n\n0\'s continuous occurrence = 3\n1\'s continuous occurrence = 5\n\nmin(3, 5) = 3\n\nThere are 3 binary substrings of equal 0s and 1s as following:\n\n... | 16 | Given a binary string `s`, return the number of non-empty substrings that have the same number of `0`'s and `1`'s, and all the `0`'s and all the `1`'s in these substrings are grouped consecutively.
Substrings that occur multiple times are counted the number of times they occur.
**Example 1:**
**Input:** s = "001100... | How many valid binary substrings exist in "000111", and how many in "11100"? What about "00011100"? |
python 3 || O(n) || O(1) | count-binary-substrings | 0 | 1 | ```\nclass Solution:\n def countBinarySubstrings(self, s: str) -> int:\n prev, cur = 0, 1\n res = 0\n for i in range(1, len(s)):\n if s[i] == s[i - 1]:\n cur += 1\n else:\n prev, cur = cur, 1\n\n if cur <= prev:\n res ... | 3 | Given a binary string `s`, return the number of non-empty substrings that have the same number of `0`'s and `1`'s, and all the `0`'s and all the `1`'s in these substrings are grouped consecutively.
Substrings that occur multiple times are counted the number of times they occur.
**Example 1:**
**Input:** s = "001100... | How many valid binary substrings exist in "000111", and how many in "11100"? What about "00011100"? |
Solution in Python 3 (beats ~98%) | degree-of-an-array | 0 | 1 | ```\nclass Solution:\n def findShortestSubArray(self, nums: List[int]) -> int:\n \tC = {}\n \tfor i, n in enumerate(nums):\n \t\tif n in C: C[n].append(i)\n \t\telse: C[n] = [i]\n \tM = max([len(i) for i in C.values()])\n \treturn min([i[-1]-i[0] for i in C.values() if len(i) == M]) + 1\n\t\t\n\t\t... | 49 | Given a non-empty array of non-negative integers `nums`, the **degree** of this array is defined as the maximum frequency of any one of its elements.
Your task is to find the smallest possible length of a (contiguous) subarray of `nums`, that has the same degree as `nums`.
**Example 1:**
**Input:** nums = \[1,2,2,3,... | Say 5 is the only element that occurs the most number of times - for example, nums = [1, 5, 2, 3, 5, 4, 5, 6]. What is the answer? |
Easy Python | One-Pass | 3 Approaches | Top Speed | degree-of-an-array | 0 | 1 | **Easy Python | One-Pass | 3 Approaches | Top Speed**\n\n**A) Classic Version**\n\nTypical algorithm:\n\n1. Group elements by label/value. \n2. Find the highest degree, which is the maximum length of each sub-array per label.\n3. Find the shortest span for each sub-array at maximum degree (this is enough to contain the... | 24 | Given a non-empty array of non-negative integers `nums`, the **degree** of this array is defined as the maximum frequency of any one of its elements.
Your task is to find the smallest possible length of a (contiguous) subarray of `nums`, that has the same degree as `nums`.
**Example 1:**
**Input:** nums = \[1,2,2,3,... | Say 5 is the only element that occurs the most number of times - for example, nums = [1, 5, 2, 3, 5, 4, 5, 6]. What is the answer? |
Solution | degree-of-an-array | 1 | 1 | ```C++ []\n#include <tuple>\n\nclass Solution {\n struct Info {\n int count;\n int startIdx;\n int endIdx;\n\n void updateEnd(int end) {\n endIdx = end;\n ++count;\n }\n int range() const {\n return endIdx - startIdx + 1;\n }\n };\n... | 3 | Given a non-empty array of non-negative integers `nums`, the **degree** of this array is defined as the maximum frequency of any one of its elements.
Your task is to find the smallest possible length of a (contiguous) subarray of `nums`, that has the same degree as `nums`.
**Example 1:**
**Input:** nums = \[1,2,2,3,... | Say 5 is the only element that occurs the most number of times - for example, nums = [1, 5, 2, 3, 5, 4, 5, 6]. What is the answer? |
697: Solution with step by step explanation | degree-of-an-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize variables:\n- degree to 0\n- degree_nums dictionary to track the frequency of each number in nums\n- left dictionary to track the leftmost index of each number in nums\n- right dictionary to track the rightmost... | 5 | Given a non-empty array of non-negative integers `nums`, the **degree** of this array is defined as the maximum frequency of any one of its elements.
Your task is to find the smallest possible length of a (contiguous) subarray of `nums`, that has the same degree as `nums`.
**Example 1:**
**Input:** nums = \[1,2,2,3,... | Say 5 is the only element that occurs the most number of times - for example, nums = [1, 5, 2, 3, 5, 4, 5, 6]. What is the answer? |
Simple Python Solution with explanation - O(n) | degree-of-an-array | 0 | 1 | ```\nclass Solution:\n def findShortestSubArray(self, nums: List[int]) -> int:\n \'\'\'\n step 1: find the degree\n - create a hashmap of a number and value as list of occurance indices\n - the largest indices array in the hashmap gives us the degree\n step 2: find the mini... | 14 | Given a non-empty array of non-negative integers `nums`, the **degree** of this array is defined as the maximum frequency of any one of its elements.
Your task is to find the smallest possible length of a (contiguous) subarray of `nums`, that has the same degree as `nums`.
**Example 1:**
**Input:** nums = \[1,2,2,3,... | Say 5 is the only element that occurs the most number of times - for example, nums = [1, 5, 2, 3, 5, 4, 5, 6]. What is the answer? |
Backtrack | partition-to-k-equal-sum-subsets | 0 | 1 | \u5176\u5B9E\u6211\u66F4\u80FD\u7406\u89E3\u4ECE\u6570\u5B57\u6765\u770B\uFF0C\u4F46\u662F\u6570\u5B57\u7684\u65F6\u95F4\u8D85\u65F6\u4E86\u3002\u6876\u6709\u70B9\u4E00\u77E5\u534A\u89E3\u7684\u611F\u89C9\n\n# Code\n```\nclass Solution:\n def canPartitionKSubsets(self, nums: List[int], k: int) -> bool:\n memo... | 1 | Given an integer array `nums` and an integer `k`, return `true` if it is possible to divide this array into `k` non-empty subsets whose sums are all equal.
**Example 1:**
**Input:** nums = \[4,3,2,3,5,2,1\], k = 4
**Output:** true
**Explanation:** It is possible to divide it into 4 subsets (5), (1, 4), (2,3), (2,3) w... | We can figure out what target each subset must sum to. Then, let's recursively search, where at each call to our function, we choose which of k subsets the next value will join. |
Python | 90ms Faster than 92% | 95% Less Memory | partition-to-k-equal-sum-subsets | 0 | 1 | ```\ndef canPartitionKSubsets(self, nums: List[int], k: int) -> bool:\n\ttotal = sum(nums)\n\n\tif total % k:\n\t\treturn False\n\n\treqSum = total // k\n\tsubSets = [0] * k\n\tnums.sort(reverse = True)\n\n\tdef recurse(i):\n\t\tif i == len(nums): \n\t\t\treturn True\n\n\t\tfor j in range(k):\n\t\t\tif subSets[j] + ... | 67 | Given an integer array `nums` and an integer `k`, return `true` if it is possible to divide this array into `k` non-empty subsets whose sums are all equal.
**Example 1:**
**Input:** nums = \[4,3,2,3,5,2,1\], k = 4
**Output:** true
**Explanation:** It is possible to divide it into 4 subsets (5), (1, 4), (2,3), (2,3) w... | We can figure out what target each subset must sum to. Then, let's recursively search, where at each call to our function, we choose which of k subsets the next value will join. |
Fully explained Backtracking + DFS in Python | partition-to-k-equal-sum-subsets | 0 | 1 | # Intuition\nTo determine if it\'s possible to divide an array into `k` subsets with equal sums, we can use a depth-first search (DFS) approach. The idea is to find `k` subsets that have a sum of `target_sum`, where `target_sum` is equal to the total sum of the array divided by `k`.\n\n# Approach\n1. Calculate the sum ... | 1 | Given an integer array `nums` and an integer `k`, return `true` if it is possible to divide this array into `k` non-empty subsets whose sums are all equal.
**Example 1:**
**Input:** nums = \[4,3,2,3,5,2,1\], k = 4
**Output:** true
**Explanation:** It is possible to divide it into 4 subsets (5), (1, 4), (2,3), (2,3) w... | We can figure out what target each subset must sum to. Then, let's recursively search, where at each call to our function, we choose which of k subsets the next value will join. |
[Python3] - Two solutions, DP with Bit mask(48ms), DFS+backtracking with detailed explanations | partition-to-k-equal-sum-subsets | 0 | 1 | Very classic question. Most of the answers in Leetcode discuss use DFS+backtracking (see solution2), but we can optimize the solution with DP and bit mask to O(2^N) time. Still exponential time, but faster. Good luck with your interviews and upvote if you found this useful :)\n\n**Explanations:**\n[1]. If input array h... | 36 | Given an integer array `nums` and an integer `k`, return `true` if it is possible to divide this array into `k` non-empty subsets whose sums are all equal.
**Example 1:**
**Input:** nums = \[4,3,2,3,5,2,1\], k = 4
**Output:** true
**Explanation:** It is possible to divide it into 4 subsets (5), (1, 4), (2,3), (2,3) w... | We can figure out what target each subset must sum to. Then, let's recursively search, where at each call to our function, we choose which of k subsets the next value will join. |
Solution | partition-to-k-equal-sum-subsets | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int len;\n vector<int> nums;\n vector<bool> st;\n\n bool dfs(int start, int cur, int k) {\n if (!k) return true;\n if (cur == len) return dfs(0, 0, k - 1);\n for (int i = start; i < nums.size(); i ++ ) {\n if (st[i]) continue;\n ... | 3 | Given an integer array `nums` and an integer `k`, return `true` if it is possible to divide this array into `k` non-empty subsets whose sums are all equal.
**Example 1:**
**Input:** nums = \[4,3,2,3,5,2,1\], k = 4
**Output:** true
**Explanation:** It is possible to divide it into 4 subsets (5), (1, 4), (2,3), (2,3) w... | We can figure out what target each subset must sum to. Then, let's recursively search, where at each call to our function, we choose which of k subsets the next value will join. |
Solution | falling-squares | 1 | 1 | ```C++ []\n#include <vector>\n#include <algorithm>\n#include <iterator>\n\nstruct SegmentTree {\n\n SegmentTree(int n) : n(n) {\n size = 1;\n while (size < n) {\n size <<= 1;\n }\n tree.resize(2*size);\n lazy.resize(2*size);\n }\n\n void add_range(int l, int r, int... | 2 | There are several squares being dropped onto the X-axis of a 2D plane.
You are given a 2D integer array `positions` where `positions[i] = [lefti, sideLengthi]` represents the `ith` square with a side length of `sideLengthi` that is dropped with its left edge aligned with X-coordinate `lefti`.
Each square is dropped o... | If positions = [[10, 20], [20, 30]], this is the same as [[1, 2], [2, 3]]. Currently, the values of positions are very large. Can you generalize this approach so as to make the values in positions manageable? |
Python 3 || 9 lines, bisect || T/S: 98% / 91% | falling-squares | 0 | 1 | ```\nclass Solution:\n def fallingSquares(self, positions: List[List[int]]) -> List[int]:\n\n def helper(box: List[int])->int:\n\n l, h = box\n r = l + h\n \n i, j = bisect_right(pos, l), bisect_left (pos, r)\n\n res = h + max(hgt[i-1:j], default = 0)\n ... | 3 | There are several squares being dropped onto the X-axis of a 2D plane.
You are given a 2D integer array `positions` where `positions[i] = [lefti, sideLengthi]` represents the `ith` square with a side length of `sideLengthi` that is dropped with its left edge aligned with X-coordinate `lefti`.
Each square is dropped o... | If positions = [[10, 20], [20, 30]], this is the same as [[1, 2], [2, 3]]. Currently, the values of positions are very large. Can you generalize this approach so as to make the values in positions manageable? |
LazySegmentTree python3 | falling-squares | 0 | 1 | # Intuition\nLazySegmentTree with max query and set_value to range.\nhttps://cp-algorithms.com/data_structures/segment_tree.html#assignment-on-segments\n# Approach\nWe normalize the points while dividing them into left and right parts.\nusing (point,0) #left and (point,1) #right to handle the "brushing the left/right s... | 0 | There are several squares being dropped onto the X-axis of a 2D plane.
You are given a 2D integer array `positions` where `positions[i] = [lefti, sideLengthi]` represents the `ith` square with a side length of `sideLengthi` that is dropped with its left edge aligned with X-coordinate `lefti`.
Each square is dropped o... | If positions = [[10, 20], [20, 30]], this is the same as [[1, 2], [2, 3]]. Currently, the values of positions are very large. Can you generalize this approach so as to make the values in positions manageable? |
✅bruet force || python | falling-squares | 0 | 1 | \n# Code\n```\nclass Solution:\n def fallingSquares(self, positions: List[List[int]]) -> List[int]:\n ans=[]\n maxi=0\n arr=[]\n n=len(positions)\n for i in range(n):\n ch=0\n l=positions[i][0]\n r=positions[i][0]+positions[i][1]\n for j ... | 0 | There are several squares being dropped onto the X-axis of a 2D plane.
You are given a 2D integer array `positions` where `positions[i] = [lefti, sideLengthi]` represents the `ith` square with a side length of `sideLengthi` that is dropped with its left edge aligned with X-coordinate `lefti`.
Each square is dropped o... | If positions = [[10, 20], [20, 30]], this is the same as [[1, 2], [2, 3]]. Currently, the values of positions are very large. Can you generalize this approach so as to make the values in positions manageable? |
Short Python O(n^2) | falling-squares | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nBecause the size of the input is lower than 1000, we can free ourselves to use an $$O(n^2)$$ algorithm. we see that at any square we only need to look at previous ones, but we have to keep track of the highest each square can reach in ano... | 0 | There are several squares being dropped onto the X-axis of a 2D plane.
You are given a 2D integer array `positions` where `positions[i] = [lefti, sideLengthi]` represents the `ith` square with a side length of `sideLengthi` that is dropped with its left edge aligned with X-coordinate `lefti`.
Each square is dropped o... | If positions = [[10, 20], [20, 30]], this is the same as [[1, 2], [2, 3]]. Currently, the values of positions are very large. Can you generalize this approach so as to make the values in positions manageable? |
Python (Simple Maths) | falling-squares | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | There are several squares being dropped onto the X-axis of a 2D plane.
You are given a 2D integer array `positions` where `positions[i] = [lefti, sideLengthi]` represents the `ith` square with a side length of `sideLengthi` that is dropped with its left edge aligned with X-coordinate `lefti`.
Each square is dropped o... | If positions = [[10, 20], [20, 30]], this is the same as [[1, 2], [2, 3]]. Currently, the values of positions are very large. Can you generalize this approach so as to make the values in positions manageable? |
699: Solution with step by step explanation | falling-squares | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize an empty list called "heights" to store the heights of each column, and initialize the maximum height to 0.\n2. Initialize an empty list called "ans" to store the answer.\n3. Iterate through each square in the ... | 0 | There are several squares being dropped onto the X-axis of a 2D plane.
You are given a 2D integer array `positions` where `positions[i] = [lefti, sideLengthi]` represents the `ith` square with a side length of `sideLengthi` that is dropped with its left edge aligned with X-coordinate `lefti`.
Each square is dropped o... | If positions = [[10, 20], [20, 30]], this is the same as [[1, 2], [2, 3]]. Currently, the values of positions are very large. Can you generalize this approach so as to make the values in positions manageable? |
Python Simple Bottom Up DP | falling-squares | 0 | 1 | # Intuition\nFind best from previously computed values, check edges and add on top if valid else continue.\n\n# Approach\nSimple Bottom up DP\n\n# Complexity\n- Time complexity:\nO(N^2)\n\n- Space complexity:\nO(N)\n\n# Code\n```\nclass Solution:\n def fallingSquares(self, arr: List[List[int]]) -> List[int]:\n ... | 0 | There are several squares being dropped onto the X-axis of a 2D plane.
You are given a 2D integer array `positions` where `positions[i] = [lefti, sideLengthi]` represents the `ith` square with a side length of `sideLengthi` that is dropped with its left edge aligned with X-coordinate `lefti`.
Each square is dropped o... | If positions = [[10, 20], [20, 30]], this is the same as [[1, 2], [2, 3]]. Currently, the values of positions are very large. Can you generalize this approach so as to make the values in positions manageable? |
2 approach with great explanation. Beats 84% user. Recursive and Looping | search-in-a-binary-search-tree | 1 | 1 | 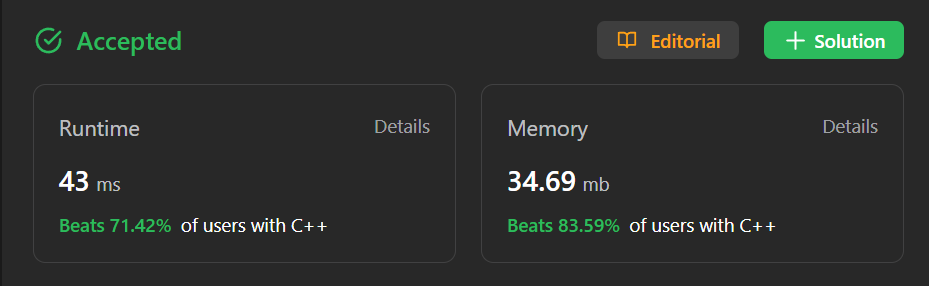\n\n# \u2705 \u2B06\uFE0F --- Soln - 1 --- \u2B06 \u267B\uFE0F\n# \uD83E\uDD29 Intuition and Approach - Recursive \uD83E\uDD73\n\nthe searchBST function is a recursive function that... | 41 | You are given the `root` of a binary search tree (BST) and an integer `val`.
Find the node in the BST that the node's value equals `val` and return the subtree rooted with that node. If such a node does not exist, return `null`.
**Example 1:**
**Input:** root = \[4,2,7,1,3\], val = 2
**Output:** \[2,1,3\]
**Example... | null |
2 approach with great explanation. Beats 84% user. Recursive and Looping | search-in-a-binary-search-tree | 1 | 1 | \n\n# \u2705 \u2B06\uFE0F --- Soln - 1 --- \u2B06 \u267B\uFE0F\n# \uD83E\uDD29 Intuition and Approach - Recursive \uD83E\uDD73\n\nthe searchBST function is a recursive function that... | 41 | Given the `root` of a Binary Search Tree (BST), return _the minimum difference between the values of any two different nodes in the tree_.
**Example 1:**
**Input:** root = \[4,2,6,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,0,48,null,null,12,49\]
**Output:** 1
**Constraints:**
* The number of nodes... | null |
Easy to Understand | BFS | search-in-a-binary-search-tree | 0 | 1 | # Intuition\nThis is similar to Level Order Traversal\n\n# Approach\nUsed the Level Order Traversal approach to find the search value leve; by level. if serach val is found just return that node, else return Null. \n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(n)\n\n# Code\n```\n# Definition for a ... | 0 | You are given the `root` of a binary search tree (BST) and an integer `val`.
Find the node in the BST that the node's value equals `val` and return the subtree rooted with that node. If such a node does not exist, return `null`.
**Example 1:**
**Input:** root = \[4,2,7,1,3\], val = 2
**Output:** \[2,1,3\]
**Example... | null |
Easy to Understand | BFS | search-in-a-binary-search-tree | 0 | 1 | # Intuition\nThis is similar to Level Order Traversal\n\n# Approach\nUsed the Level Order Traversal approach to find the search value leve; by level. if serach val is found just return that node, else return Null. \n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(n)\n\n# Code\n```\n# Definition for a ... | 0 | Given the `root` of a Binary Search Tree (BST), return _the minimum difference between the values of any two different nodes in the tree_.
**Example 1:**
**Input:** root = \[4,2,6,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,0,48,null,null,12,49\]
**Output:** 1
**Constraints:**
* The number of nodes... | null |
Solution | search-in-a-binary-search-tree | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n TreeNode* searchBST(TreeNode* root, int val) {\n if(root==NULL) return root;\n if(root->val==val) return root;\n if(root->val>val) return searchBST(root->left,val);\n else return searchBST(root->right,val);\n }\n};\n```\n\n```Python3 []\nclass Sol... | 4 | You are given the `root` of a binary search tree (BST) and an integer `val`.
Find the node in the BST that the node's value equals `val` and return the subtree rooted with that node. If such a node does not exist, return `null`.
**Example 1:**
**Input:** root = \[4,2,7,1,3\], val = 2
**Output:** \[2,1,3\]
**Example... | null |
Solution | search-in-a-binary-search-tree | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n TreeNode* searchBST(TreeNode* root, int val) {\n if(root==NULL) return root;\n if(root->val==val) return root;\n if(root->val>val) return searchBST(root->left,val);\n else return searchBST(root->right,val);\n }\n};\n```\n\n```Python3 []\nclass Sol... | 4 | Given the `root` of a Binary Search Tree (BST), return _the minimum difference between the values of any two different nodes in the tree_.
**Example 1:**
**Input:** root = \[4,2,6,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,0,48,null,null,12,49\]
**Output:** 1
**Constraints:**
* The number of nodes... | null |
Python beats 90% (Simple iterative approach) | search-in-a-binary-search-tree | 0 | 1 | ```\nstack, subtree = [], None\nwhile True:\n\twhile root:\n\t\tif root.val == val: subtree = root\n\t\tstack.append(root)\n\t\troot = root.left\n\n\tif subtree: return subtree\n\t\n\tif not stack: return None\n\n\troot = stack.pop().right\n``` | 2 | You are given the `root` of a binary search tree (BST) and an integer `val`.
Find the node in the BST that the node's value equals `val` and return the subtree rooted with that node. If such a node does not exist, return `null`.
**Example 1:**
**Input:** root = \[4,2,7,1,3\], val = 2
**Output:** \[2,1,3\]
**Example... | null |
Python beats 90% (Simple iterative approach) | search-in-a-binary-search-tree | 0 | 1 | ```\nstack, subtree = [], None\nwhile True:\n\twhile root:\n\t\tif root.val == val: subtree = root\n\t\tstack.append(root)\n\t\troot = root.left\n\n\tif subtree: return subtree\n\t\n\tif not stack: return None\n\n\troot = stack.pop().right\n``` | 2 | Given the `root` of a Binary Search Tree (BST), return _the minimum difference between the values of any two different nodes in the tree_.
**Example 1:**
**Input:** root = \[4,2,6,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,0,48,null,null,12,49\]
**Output:** 1
**Constraints:**
* The number of nodes... | null |
Easy python solution | insert-into-a-binary-search-tree | 0 | 1 | ```\nclass Solution:\n def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:\n node = TreeNode(val)\n if not root:\n root = node\n return root\n if not root.left and val < root.val:\n root.left = node\n elif not root.right and ... | 3 | You are given the `root` node of a binary search tree (BST) and a `value` to insert into the tree. Return _the root node of the BST after the insertion_. It is **guaranteed** that the new value does not exist in the original BST.
**Notice** that there may exist multiple valid ways for the insertion, as long as the tre... | null |
Easy python solution | insert-into-a-binary-search-tree | 0 | 1 | ```\nclass Solution:\n def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:\n node = TreeNode(val)\n if not root:\n root = node\n return root\n if not root.left and val < root.val:\n root.left = node\n elif not root.right and ... | 3 | Given a string `s`, you can transform every letter individually to be lowercase or uppercase to create another string.
Return _a list of all possible strings we could create_. Return the output in **any order**.
**Example 1:**
**Input:** s = "a1b2 "
**Output:** \[ "a1b2 ", "a1B2 ", "A1b2 ", "A1B2 "\]
**Example 2:*... | null |
Beginner-friendly || Simple Depth-First Search in Python3 | insert-into-a-binary-search-tree | 0 | 1 | # Intuition\nThe problem description is the following:\n- there\'s a **Binary Search Tree (BST)**\n- and our goal is to **insert** the new value\n\nThere\'re some methods to insert a new value, and all of these representations **will(could?)** be valid.\nWe\'ll focus on the straightforward solution as the next one:\n``... | 1 | You are given the `root` node of a binary search tree (BST) and a `value` to insert into the tree. Return _the root node of the BST after the insertion_. It is **guaranteed** that the new value does not exist in the original BST.
**Notice** that there may exist multiple valid ways for the insertion, as long as the tre... | null |
Beginner-friendly || Simple Depth-First Search in Python3 | insert-into-a-binary-search-tree | 0 | 1 | # Intuition\nThe problem description is the following:\n- there\'s a **Binary Search Tree (BST)**\n- and our goal is to **insert** the new value\n\nThere\'re some methods to insert a new value, and all of these representations **will(could?)** be valid.\nWe\'ll focus on the straightforward solution as the next one:\n``... | 1 | Given a string `s`, you can transform every letter individually to be lowercase or uppercase to create another string.
Return _a list of all possible strings we could create_. Return the output in **any order**.
**Example 1:**
**Input:** s = "a1b2 "
**Output:** \[ "a1b2 ", "a1B2 ", "A1b2 ", "A1B2 "\]
**Example 2:*... | null |
✅ Well Detailed Explanation [Java , C++, Python] 🧠 Beats around 100% users. | insert-into-a-binary-search-tree | 1 | 1 | \n\n# \u2705 \u2B06\uFE0F Approach 1 - iterative method \u2B06 \u267B\uFE0F\n\nIn **CPP** or **JAVA** or **PYTHON**, the main difference is nothing. Only have to change 1-2 **word** in **syntax**. Otherwis... | 35 | You are given the `root` node of a binary search tree (BST) and a `value` to insert into the tree. Return _the root node of the BST after the insertion_. It is **guaranteed** that the new value does not exist in the original BST.
**Notice** that there may exist multiple valid ways for the insertion, as long as the tre... | null |
✅ Well Detailed Explanation [Java , C++, Python] 🧠 Beats around 100% users. | insert-into-a-binary-search-tree | 1 | 1 | \n\n# \u2705 \u2B06\uFE0F Approach 1 - iterative method \u2B06 \u267B\uFE0F\n\nIn **CPP** or **JAVA** or **PYTHON**, the main difference is nothing. Only have to change 1-2 **word** in **syntax**. Otherwis... | 35 | Given a string `s`, you can transform every letter individually to be lowercase or uppercase to create another string.
Return _a list of all possible strings we could create_. Return the output in **any order**.
**Example 1:**
**Input:** s = "a1b2 "
**Output:** \[ "a1b2 ", "a1B2 ", "A1b2 ", "A1B2 "\]
**Example 2:*... | null |
Python || Easy || Iterative || Recursive || Two Solutions | insert-into-a-binary-search-tree | 0 | 1 | **Recursive Solution:**\n```\nclass Solution:\n def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:\n if root==None:\n return TreeNode(val)\n else:\n if root.val<val:\n root.right=self.insertIntoBST(root.right,val)\n else:\n... | 1 | You are given the `root` node of a binary search tree (BST) and a `value` to insert into the tree. Return _the root node of the BST after the insertion_. It is **guaranteed** that the new value does not exist in the original BST.
**Notice** that there may exist multiple valid ways for the insertion, as long as the tre... | null |
Python || Easy || Iterative || Recursive || Two Solutions | insert-into-a-binary-search-tree | 0 | 1 | **Recursive Solution:**\n```\nclass Solution:\n def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:\n if root==None:\n return TreeNode(val)\n else:\n if root.val<val:\n root.right=self.insertIntoBST(root.right,val)\n else:\n... | 1 | Given a string `s`, you can transform every letter individually to be lowercase or uppercase to create another string.
Return _a list of all possible strings we could create_. Return the output in **any order**.
**Example 1:**
**Input:** s = "a1b2 "
**Output:** \[ "a1b2 ", "a1B2 ", "A1b2 ", "A1B2 "\]
**Example 2:*... | null |
Best and Efficient recursive solution in python 🐍✔✔ | insert-into-a-binary-search-tree | 0 | 1 | \n\n# Code\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:\n... | 2 | You are given the `root` node of a binary search tree (BST) and a `value` to insert into the tree. Return _the root node of the BST after the insertion_. It is **guaranteed** that the new value does not exist in the original BST.
**Notice** that there may exist multiple valid ways for the insertion, as long as the tre... | null |
Best and Efficient recursive solution in python 🐍✔✔ | insert-into-a-binary-search-tree | 0 | 1 | \n\n# Code\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def insertIntoBST(self, root: Optional[TreeNode], val: int) -> Optional[TreeNode]:\n... | 2 | Given a string `s`, you can transform every letter individually to be lowercase or uppercase to create another string.
Return _a list of all possible strings we could create_. Return the output in **any order**.
**Example 1:**
**Input:** s = "a1b2 "
**Output:** \[ "a1b2 ", "a1B2 ", "A1b2 ", "A1B2 "\]
**Example 2:*... | null |
Solution | insert-into-a-binary-search-tree | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n TreeNode* insertIntoBST(TreeNode* root, int val) {\n if(root==NULL){\n return new TreeNode(val);\n }\n if(val < root->val){\n root->left=insertIntoBST(root->left,val);\n }\n else{\n root->right=insertIntoBST(roo... | 2 | You are given the `root` node of a binary search tree (BST) and a `value` to insert into the tree. Return _the root node of the BST after the insertion_. It is **guaranteed** that the new value does not exist in the original BST.
**Notice** that there may exist multiple valid ways for the insertion, as long as the tre... | null |
Solution | insert-into-a-binary-search-tree | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n TreeNode* insertIntoBST(TreeNode* root, int val) {\n if(root==NULL){\n return new TreeNode(val);\n }\n if(val < root->val){\n root->left=insertIntoBST(root->left,val);\n }\n else{\n root->right=insertIntoBST(roo... | 2 | Given a string `s`, you can transform every letter individually to be lowercase or uppercase to create another string.
Return _a list of all possible strings we could create_. Return the output in **any order**.
**Example 1:**
**Input:** s = "a1b2 "
**Output:** \[ "a1b2 ", "a1B2 ", "A1b2 ", "A1B2 "\]
**Example 2:*... | null |
Solution | kth-largest-element-in-a-stream | 1 | 1 | ```C++ []\nclass KthLargest {\npublic:\nstruct A\n{\nbool operator()(int a, int b)\n{\n return a<b;\n}\n};\n KthLargest(int k, vector<int>& nums) {\n K =k;\n for(int i=0;i<nums.size();i++)\n {\n pq.push(nums[i]);\n }\n while(pq.size() > k)\n pq.pop();\n ... | 2 | Design a class to find the `kth` largest element in a stream. Note that it is the `kth` largest element in the sorted order, not the `kth` distinct element.
Implement `KthLargest` class:
* `KthLargest(int k, int[] nums)` Initializes the object with the integer `k` and the stream of integers `nums`.
* `int add(int... | null |
Solution | kth-largest-element-in-a-stream | 1 | 1 | ```C++ []\nclass KthLargest {\npublic:\nstruct A\n{\nbool operator()(int a, int b)\n{\n return a<b;\n}\n};\n KthLargest(int k, vector<int>& nums) {\n K =k;\n for(int i=0;i<nums.size();i++)\n {\n pq.push(nums[i]);\n }\n while(pq.size() > k)\n pq.pop();\n ... | 2 | You are playing a simplified PAC-MAN game on an infinite 2-D grid. You start at the point `[0, 0]`, and you are given a destination point `target = [xtarget, ytarget]` that you are trying to get to. There are several ghosts on the map with their starting positions given as a 2D array `ghosts`, where `ghosts[i] = [xi, y... | null |
Python🔥Java🔥C++🔥Simple Solution🔥Easy to Understand | kth-largest-element-in-a-stream | 1 | 1 | **!! BIG ANNOUNCEMENT !!**\nI am currently Giving away my premium content well-structured assignments and study materials to clear interviews at top companies related to computer science and data science to my current Subscribers. This is only for first 10,000 Subscribers. **DON\'T FORGET** to Subscribe\n\n# Search \u... | 14 | Design a class to find the `kth` largest element in a stream. Note that it is the `kth` largest element in the sorted order, not the `kth` distinct element.
Implement `KthLargest` class:
* `KthLargest(int k, int[] nums)` Initializes the object with the integer `k` and the stream of integers `nums`.
* `int add(int... | null |
Python🔥Java🔥C++🔥Simple Solution🔥Easy to Understand | kth-largest-element-in-a-stream | 1 | 1 | **!! BIG ANNOUNCEMENT !!**\nI am currently Giving away my premium content well-structured assignments and study materials to clear interviews at top companies related to computer science and data science to my current Subscribers. This is only for first 10,000 Subscribers. **DON\'T FORGET** to Subscribe\n\n# Search \u... | 14 | You are playing a simplified PAC-MAN game on an infinite 2-D grid. You start at the point `[0, 0]`, and you are given a destination point `target = [xtarget, ytarget]` that you are trying to get to. There are several ghosts on the map with their starting positions given as a 2D array `ghosts`, where `ghosts[i] = [xi, y... | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.